<<
2409.08596v2.pdf

---
## Page 1
[](/attach/facc6b2ed129d77b5b070815067f506239bb44c555500e6e617d993a9d16c24f_p001.png)
### 和訳
# 大規模言語モデルって、いろんな指示出したら複数人がしゃべってる場面でも文字起こしできるねん
Lingwei Meng*, Shujie Hu*, Jiawen Kang, Zhaoqing Li, Yuejiao Wang, Wenxuan Wu, Xixin Wu, Xunying Liu, Helen Meng
香港中文大学、中国香港特別行政区
---
**概要** — 最近の大規模言語モデル(LLM)の進化ってほんまにすごくて、いろんな分野をガラッと変えてもうてん。めっちゃ進歩して新しいチャンスもバンバン生まれとるわけや。音声関連のタスクでもそこそこ進んではおるんやけど、複数人が同時にしゃべっとるような場面でのLLMの使い方って、まだ全然掘り下げられてへんかったんよな。ほんで今回のこの研究では、LLMが複数人おるカオスな環境で音声を文字に起こす力をガチで調べた先駆的な取り組みを紹介するで。具体的にどんな指示に対応できるかっていうと、複数話者の自動音声認識(ASR)、特定の話者を狙ったASR、あと話者の性別・発話の順番・言語・しゃべった特定のキーワードみたいな属性に基づいたASRとか、めっちゃ多彩な指示に従えるねん。やり方としては、WavLMとWhisperエンコーダを使って、話者の特徴と意味的な文脈の両方に敏感な多面的な音声表現を抽出すんねん。そんでその表現をLoRAでファインチューニングしたLLMに突っ込んで、音声の理解と文字起こしができるようにしとるわけや。がっつり実験した結果、提案したシステム「MT-LLM」がカクテルパーティーみたいな場面でなかなかええ性能を見せてくれて、こういう複雑な状況でもユーザーの指示に基づいて音声タスクをこなせるLLMのポテンシャルが見えてきたで。
**キーワード** — 大規模言語モデル、カクテルパーティー問題、複数話者音声認識、マルチモーダル
## I. はじめに
大規模言語モデル(LLM)ってここ最近ほんまに急激に進化しとって、いろんな自然言語処理(NLP)のタスクで人間レベルに達したり、場合によっては超えてもうたりしとるんよ [1]–[3]。この進歩がきっかけで、LLMのマルチモーダル知覚の能力——つまり音声 [5]–[7] とか視覚 [1], [8], [9] とかコンテンツ生成 [10]–[12] とか——を探ろうっていう動きがめっちゃ活発になってきてん [4]。音声関連のLLMを調べた研究もいくつかあって、だいたいテキストベースのLLMを音声関連の指示でファインチューニングして、補助的な音響エンコーダと組み合わせるっていうやり方やねん [5]–[7]。音響エンコーダが音響的な表現を取り出して、それをLLMの入力特徴空間に合わせることで、LLMに自動音声認識(ASR)、音声翻訳(ST)、話者照合(SV)、音声質問応答(SQA)とか、いろんな音声タスクをやらせるわけや。せやけど、ここまで進歩してもなお、カクテルパーティー場面——つまり複数の人が同時にしゃべって音声が重なりまくるような状況——での音声LLMの可能性って、まだまだ十分に活かしきれてへんかったんよな。
ここ最近、複数話者ASRタスク、つまり複数の話者の音声を同時に文字起こしするタスクに取り組むために、いろんなエンドツーエンドのアプローチが注目されて開発されてきてん。これらの研究は、Permutation Invariant Training(PIT:順列不変学習)[13]–[15]、Heuristic Error Assignment Training(HEAT:ヒューリスティック誤差割当学習)[16], [17]、またはSerialized Output Training(SOT:直列化出力学習)[18]–[22] をベースにしとって、予測と対応する正解ラベルをマッチングさせてロス計算するんやな。でもな、こういうアプローチは基本的に全話者の音声をまとめて区別なく文字起こしするだけで、外部モデル [23], [24] か内部モデル [25]–[27] を別途使わへん限り、文字起こし結果を特定の話者と紐づけることができへんねん。いくつかの研究 [28], [29] では複数話者ASRを他のタスクと一緒に一つのモデルで処理しようとしたんやけど、対応できるタスクがまだまだ限定的で、「"ストロベリー"って言った話者の音声を文字起こしして」みたいな、話者の属性を細かく指定するユーザーの多様な要求に柔軟に応える力が足りてへんかったんよ。
そんな中、大規模言語モデルの台頭が、こういう問題を一つの統合モデルで解決する新しい可能性を照らし出してくれたわけや。この研究では、LLMの強力な理解力と指示追従能力を活かして、複数話者がおる場面でいろんな指示に基づいた音声認識をやるで。具体的には、基盤となるLLMとしてLlama 2 [3] を使って、意味的な文脈を抽出するためにWhisper [30] エンコーダ、話者特性を示す音響情報を捉えるためにWavLM [31] の多層特徴量を組み合わせとるんや。これはWavLLM [5] やSALMONN [6] を参考にしとるで。音声の埋め込みをLLMの入力空間に変換するための専用アダプタも設計しとる。提案モデルのことをMT-LLM(Multi-Talker LLM)と名付けたで。多彩な指示を使ってMT-LLMに以下のタスクをやらせるねん:(i) 複数話者の音声を同時にテキストに文字起こしする、(ii) 参照音声クリップが与えられた特定の話者の音声を文字起こしする、(iii) 話者の性別に基づいて音声を文字起こしする、(iv) 発話の出現順に基づいて指定された話者の音声を文字起こしする、(v) 指定されたキーワードが含まれる話者の音声を文字起こしする、(vi) 特定の言語をしゃべっとる話者の音声を文字起こしする。がっつり実験した結果、MT-LLMは話者の属性を指定する指示に基づいて複数話者の文字起こしに関するユーザーの多様な要求に効果的に応えられることが実証されたで。主な貢献は3つあるで:
- 複数話者がおる場面で指示ベースの音声認識を探求する先駆的な取り組みを提案したで。LLMの強力な理解力と生成能力を活かしとるんや。
- 複数話者ASRだけやなくて、MT-LLMは6種類の多彩な指示に従って特定の話者の音声を文字起こしでき、なかなかええ性能を示したで。
- 音声LLMがパラメータ効率の良い学習で、複雑な音声環境においてもっと自然で効果的な人間とコンピュータのやり取りを実現できることを明らかにしたで。
## II. 手法
テキストベースのLLMを、複数話者がおる音声場面で音声認識するための多目的な指示追従モデルとして強化する方法を提案するで。提案手法は3つの主要コンポーネントで構成されとる:低ランク適応(LoRA)[32] でファインチューニングした大規模言語モデルを基盤モデルとして使うこと、デュアル音声エンコーダとそれぞれ対応するアダプタ、ほんで学習データの構築や。以降のセクションでは、提案モデルをMT-LLMと呼ぶことにするで。
---
## Page 2
[](/attach/facc6b2ed129d77b5b070815067f506239bb44c555500e6e617d993a9d16c24f_p002.png)
### 和訳
図1. MT-LLMは複数人が同時にしゃべってる場面で、いろんな音声認識の指示に対応できるねん。複数人の声が重なった音声入力(a)とテキストの指示プロンプト(b)が与えられたら、提案するMT-LLM(c)が自己回帰的に対応する書き起こしテキスト(d)を生成してくれるっちゅうわけや。複数の話者が関わるタスクでは、MT-LLMはSOTスタイルの出力に従って、しゃべり始めた順番に各話者の発話を書き起こして、「<sc>」っていう「話者が変わったで」マークで区切るねん。
A. 問題の定式化
この研究では、複数人がしゃべってる場面での音声認識を、次のトークンを予測する言語モデリングのタスクとして扱ってるねん。入力の音声波形Xとテキスト指示Iを条件にして、MT-LLMは目的のテキスト出力Y = [y0, y1, ..., yN-1]を自己回帰的に生成するように最適化されるんや。要するに以下の確率分布を最大化するっちゅうことやな:
p(Y | X, I; θ) = ∏(t=0からT-1) p(yt | X, I, Y<t; θ) (1)
ここでθはMT-LLMのパラメータを表してるで。
Yの中で、複数の話者の書き起こしには順列の割り当てが必要になるねん。なんでかっていうと、誰の発話がどれかっていうラベルの曖昧さの問題[33]があるからや。先行研究[18][20]の経験を踏まえて、わいらはシンプルなSerialized Output Training(SOT)っていう方法でこの問題に対処したんや。図1(d)に示してるように、SOTは話者がしゃべり始めた順番に書き起こしを並べて、その間にプレーンテキストの「<sc>」を挟んで話者の交代を示すっちゅう仕組みやねん。
B. モデルのアーキテクチャ
図2に示してるように、2つの音声エンコーダが合成した音声の表現を融合して、バックボーンのLLMの特徴空間に射影するんや。ほんで、LLMがその音声入力とテキスト指示の両方を活用して、目的の書き起こしを予測するわけやな。バックボーンのLLMと音声エンコーダは凍結したまま(つまりパラメータ更新せーへん)で、パラメータ効率の良いアダプターを使ってファインチューニングすることで、音声の処理と理解の能力を身につけさせてるねん。
**2つの音声エンコーダとそれぞれのアダプター** [5][6]を参考にして、わいらは事前学習済みの2つの音声エンコーダ、WhisperエンコーダとWavLMを使って、音声の多面的な情報を捉えてるねん。Whisper[30]はウェブ規模の弱教師ありデータで学習された音声認識・翻訳モデルで、そのエンコーダは音声の意味的な文脈にめっちゃ敏感やねん[34]。わいらはその最終層の出力埋め込みを使って、豊富な意味情報を捉えてるんや。一方でWavLM[31]は、マスクされた音声予測っちゅうアプローチで学習された自己教師あり学習モデルで、各層がいろんな下流の音声タスクに敏感な音響情報をエンコードしてくれるんや。WavLMが抽出するマルチスケールの音響情報をうまく活用するために、各層に学習可能な重みをつけて、複数層の隠れ状態を足し合わせて集約してるで。2つの音声エンコーダ用のモダリティアダプターと線形プロジェクターは、音声表現をLLMの特徴空間にうまくアライメントするために設計されてるんや。
図2. MT-LLMのモデルアーキテクチャ。2つの音声エンコーダを使って多面的な音声表現を抽出して、LLMの特徴空間に射影するねん。LoRAでファインチューニングすることで、LLMがテキスト指示に基づいて複数人がしゃべってる場面の音声を理解して書き起こす能力を獲得するっちゅうわけや。
**バックボーンLLMとLoRA** わいらはMeta AIが開発したLlama-2-7b-chat²[3]を基盤のバックボーンとして使ってるねん。このモデルは大規模で多様な学習データで鍛えられてるんや。Llama 2は幅広いNLPタスクでめっちゃ優秀な性能を発揮して、文脈理解とテキスト生成で卓越した能力を見せてくれるで。音声モダリティをLLMに組み込むために、パラメータ効率の良いファインチューニング技術であるLoRA[32]を使ってるねん。LoRAはLlamaのアテンションモジュール内のキー、クエリ、バリュー、出力の重み行列に適用されて、モデルが音声モダリティの入力を処理・理解できるようにしてるんや。
C. タスクの説明
複数人がしゃべってる場面で指示に基づく音声認識のMT-LLMの性能を検証するために、単一話者の音声コーパスから複数人の重なった音声をシミュレーションで作って、6つのタスクとそれに対応する指示を設計して、それぞれの目的テキストラベルを生成したんや。図1(b)に示してるように、テキスト指示は以下のタスクに関するもんやで:
**マルチトーカー(MT) ASR** 複数の話者の音声を同時にテキストに書き起こすタスクや。この基本タスクは、1つの音声ストリームの中で声の重なりを処理して、異なる話者の声を区別するモデルの能力が試されるっちゅうことやな。ほんまにチャレンジングなタスクやで。
²https://llama.meta.com/llama2
---
## Page 3
[](/attach/facc6b2ed129d77b5b070815067f506239bb44c555500e6e617d993a9d16c24f_p003.png)
### 和訳
**ターゲット話者(TT)音声認識**
ランダムに1人の話者をターゲットとして選ぶねん。ほんで、そのターゲット話者の3秒間の音声クリップと3秒間の無音をくっつけて、複数人がしゃべってる音声の前にポンと付け足すわけや。モデルには「この人の声だけ文字起こししてな」って指示を出すねん。要するに、「この声のサンプル聞いて、同じ人の発言だけ重なった音声から抜き出してや」っていうタスクやな。特定の人の声を手がかりの音声クリップから聞き分けて、ちゃんと分離できるかを試すテストやねん。
**キーワード追跡(KT)音声認識**
複数人の音声サンプルごとに、まず全話者の発言内容の中で1回しか出てこーへんユニークな単語を集めるねん。しかも6文字以上の単語だけな。その中からランダムにキーワードを1つ選んで、「この単語を言うた人の発言だけ文字起こししてな」ってモデルに指示するわけや。このタスクは、モデルが特定の単語を追跡して、「これ誰が言うたんや?」っていうのを正しく特定できるかを見るもんやねん。
**性別指定(SS)音声認識**
モデルに「男性の声だけ文字起こしして」とか「女性の声だけ文字起こしして」ってランダムに指示するタスクやな。声の性別的な特徴を聞き分けて、それに合わせてフィルタリングできるかを評価するもんやで。
**順番指定(OS)音声認識**
「○番目にしゃべり始めた人の発言を文字起こしして」ってランダムに指示するタスクやねん。モデルが話者の登場順をちゃんと把握して、指定された順番の人の発言を正確に抜き出せるかを見るわけや。
**言語指定(TL)音声認識**
「英語しゃべってる人だけ文字起こしして」とか「ドイツ語しゃべってる人だけ文字起こしして」ってランダムに指示するタスクやな。モデルが言語を聞き分けて、指定された言語の発言だけを文字起こしできるかを評価するもんやで。
---
モデルのパラメータは凍結(固定)した状態で使うねん。LLM(大規模言語モデル)の方はLoRAっていう効率的な微調整手法を使って、ランク32でファインチューニングするんや。2つの音声エンコーダ用のアダプタは、まず畳み込み層2つでダウンサンプリングして時間方向の表現を揃えて、その後にボトルネックアダプタ[39]と線形層を通すっていう構成やな。両方のアダプタの出力は、時間の刻み幅が80ミリ秒で、次元数は2,048やで。MT-LLMの総パラメータ数は75.5億個で、そのうち学習可能なんはたった1%(7,660万個)だけやねん。めっちゃ効率的やろ?
MT-LLMの学習にはNVIDIA A100-40GのGPUを32台使ってるねん。バッチサイズはGPU1台あたり60秒分の音声に相当する量で、15万回の更新を行うんや。最適化にはAdamWオプティマイザを使って、最初の10%の更新で学習率を1e-4のピークまでウォームアップして、その後は線形に減衰させるっていうスケジュールやな。全タスクをまとめて混ぜて学習させることで、統一モデルを作るわけやで。
**表I:英語・ドイツ語テストセットにおける単一話者・複数話者の音声認識性能。WER(%)で評価。**
(表の内容はそのまま)
---
**III. 実験セットアップ**
**A. 学習データの構築**
多様なタスク指示に対応するために、単一話者の音声コーパスから複数話者の音声をシミュレーションで作ったんや。[18]のプロトコルに従ってな。具体的には、960時間のLibriSpeech [35]の学習セットから、2人または3人の話者の混合音声を主に作成してるねん。各話者の開始タイミングはランダムにサンプリングするから、音声が重なった混合音声ができるわけや。さらに、言語指定ASRタスクをサポートするために、CoVoST 2 [36]の180時間分のドイツ語サブセットとその対応するドイツ語テキストも使って、LibriSpeechの発話と混ぜてるねん。
元の単一話者コーパスと合わせると、学習用の音声データは合計約6,300時間で、そのうち約10%がドイツ語を含んでるで。
**B. 評価と指標**
MT-LLMの性能は、多様な指示ベースのタスクで評価するねん。公式の2話者・3話者のLibriSpeechMixテストセットと、言語指定ASRタスク用に自前で作った英独混合テストセットを使うんや。評価セットに含まれる話者が学習データに入ってへんことはちゃんと確認済みやで。単一話者のASR性能は、LibriSpeechのtest-cleanセットとCoVoST 2のドイツ語テストセットでも検証してるねん。
単語誤り率(WER)は、予測テキストとターゲットラベルの間で計算するんや。複数話者の音声認識タスクでは、先行研究[20][37][38]に倣って、最小誤りとなる順列を使ってWERを算出してるで。
**C. モデル設定と学習の詳細**
提案するMT-LLMは、音声の特徴を抽出するのにWhisper-large-v2のエンコーダとWavLM-baseを使って、バックボーンのLLMにはLlama-2-chat-7bを採用してるねん。これらのモデルのパラメータは全部凍結してるで。
(注:CoVoST 2はもともと音声翻訳用のデータセットやけど、この研究ではドイツ語サブセットをASR用に使ってるねん。)
---
**IV. 結果と考察**
**A. 複数話者ASRの結果**
LibriSpeechとCoVoST 2ドイツ語テストセットで単一話者ASRの性能を、2話者・3話者のLibriSpeechMixと自前の英独混合テストセットで複数話者ASRの性能を評価したで。表Iを見てもらったらわかるけど、提案したMT-LLMは全データセットでなかなかええ結果を出してて、PIT(順列不変学習)を使った最近の代表的な手法であるD2V-Sidecar-DB [28]を上回ってるねん。
SOT-Conformer [25]はLibriSpeechMixデータセットの複数話者ASRに特化して設計・大規模学習された最先端モデルやねん。2話者のLibriSpeechMixではMT-LLMはSOT-Conformerと同等の結果を出してるけど、3話者のセットではちょっと負けてるな。ただな、MT-LLMは複数話者ASRの限界を押し上げることだけが目的やなくて、LLMを使った多様な指示ベースの音声認識の可能性を探る探索的な研究やねんから、この差は理解できる範囲やと思うで。
めっちゃおもろいのが、SOT-Conformerは単一話者と複数話者の両方のデータで学習してるにもかかわらず、単一話者のシナリオでは性能が落ちてるねん。つまり複数話者に特化しすぎて、単一話者の性能が犠牲になってるわけや。一方、MT-LLMは単一話者ASRでも安定してええ性能を出してて、指示理解能力のおかげでシンプルな単一話者の場面でも高い性能を維持できてるんやで。
SALMONN [6]は重なった音声の認識を含む様々な音声関連タスクで学習された音声LLMやねんけど、公式のプロンプトを使ったら、表Iの通りうちのアプローチに比べてめっちゃ性能が劣ってたわ。
ドイツ語についてはwav2vec2-Large-XLSR-53-Germanモデルの性能を参考として載せてるで。ドイツ語を含む音声サンプルはLibriSpeechに比べて量も限られてるしノイズも多いけど、MT-LLMはドイツ語テストセットと英独混合テストセットでも満足のいく結果を出してるねん。これはこのモデルが複数話者の音声から複数言語を同時に聞き分けて文字起こしできる能力を持ってることを示してるんや。ほんまにすごいことやで。
---
## Page 4
[](/attach/facc6b2ed129d77b5b070815067f506239bb44c555500e6e617d993a9d16c24f_p004.png)
### 和訳
B. 指示ベースのいろんなタスクでの結果
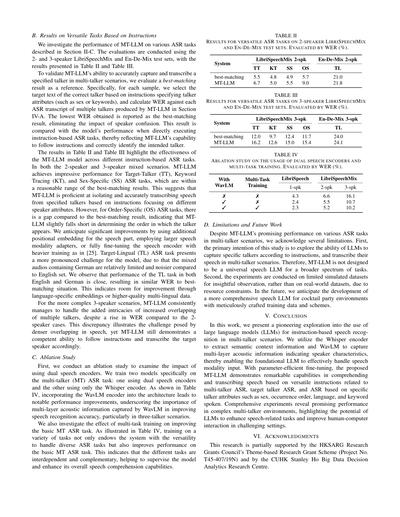
ほな、セクションII-Cで説明したいろんなASR(音声認識)タスクで、MT-LLMがどれくらいやれるか見ていくで。評価には、話者が2人と3人のLibriSpeechMixと、英語-ドイツ語ミックス(En-De-Mix)のテストセットを使ってて、結果は表IIと表IIIにまとめてあるわ。
MT-LLMが「複数人がしゃべってる中から、指定した人の声をちゃんと拾って文字起こしできるか」を確かめるために、ベストマッチング結果っていう基準を用意してんねん。具体的に言うと、各サンプルに対して、話者の属性(性別とかキーワードとか)を指定する指示に基づいて正解の話者のテキストを選んで、セクションIV-AでMT-LLMが出した複数話者のASR結果それぞれとのWER(単語誤り率)を計算すんねん。ほんで、一番低いWERを「ベストマッチング結果」として報告するわけ。こうすると話者の取り違えの影響を排除できるねんな。この結果と、指示ベースのASRタスクを直接実行したときの性能を比べることで、MT-LLMが指示にちゃんと従えてるか、狙った話者を正しく特定できてるかがわかるっちゅうわけや。
表IIと表IIIの結果を見ると、MT-LLMはいろんな指示ベースASRタスクでめっちゃええ感じに動いてんねん。2人混合でも3人混合でも、ターゲット話者(TT)、キーワード追跡(KT)、性別指定(SS)のASRタスクでは、ベストマッチング結果と比べてもまあ妥当な範囲の性能を出してるわ。つまり、いろんな話者の特徴に着目した指示をもとに、特定の話者の声をうまく分離して正確に文字起こしできてるっちゅうことやな。ただな、発話順序指定(OS)のASRタスクでは、ベストマッチング結果とちょっと差があって、「誰が何番目にしゃべり始めたか」を判断するのはまだちょい苦手みたいやねん。これについては、音声部分に位置エンベディングを追加したり、もっとデカい音声モダリティアダプタを使ったり、[25]みたいにがっつり音声エンコーダを全部ファインチューニングしたりすれば、かなり良くなるやろうと期待してるで。ターゲット言語(TL)のASRタスクはもうちょい手強くて、なんでかっていうと、ドイツ語が入った混合音声は英語セットに比べてデータが少ないし、ノイズも多いからやねん。英語とドイツ語のTLタスクの性能がだいたい近くて、WERもベストマッチングとそんなに変わらへんことがわかったわ。言語別のエンベディングとか、もっと質の高い多言語データがあれば、まだまだ伸びしろあるっちゅうことやな。
もっと複雑な3人混合のシナリオでも、MT-LLMは2人の場合と比べてWERは上がるものの、複数話者のオーバーラップが増える難しさにちゃんと対応できてるねん。この差は、音声の重なりが密になるとやっぱり大変やっちゅうことを示してるけど、それでもMT-LLMは指示に従ってターゲット話者をちゃんと文字起こしする力を見せてくれてるわ。
C. アブレーション研究
まず、2つの音声エンコーダを使うことの効果を調べるアブレーション研究をやったで。マルチ話者(MT)ASRタスクに特化して、2つの音声エンコーダを使うモデルと、Whisperエンコーダだけを使うモデルの2つを学習させてん。表IVを見てもらったらわかるけど、WavLMエンコーダを組み込むとめっちゃ性能が上がるねん。これは、WavLMが捉える多層の音響情報が音声認識の精度向上にほんまに大事やっちゅうことを裏付けてるわ。特に3人が同時にしゃべるシナリオで効果がデカいねん。
あと、マルチタスク学習が基本のMT ASRタスクの改善にどう効くかも調べてん。表IVに示してある通り、いろんなタスクで一緒に学習させると、多様なASRタスクに対応できる万能性が身につくだけやなくて、基本のMT ASRタスク自体の性能も上がるねん。つまり、それぞれのタスクがお互いに関連し合って補い合ってて、モデルの監督になって、全体的な音声理解力を底上げしてくれるっちゅうことやな。
表II
2話者のLIBRISPEECHMIXおよびEN-DE-MIXテストセットでの各種ASRタスクの結果。WER(%)で評価。
| システム | LibriSpeechMix 2話者 | | | En-De-Mix 2話者 | |
|---|---|---|---|---|---|
| | TT | KT | SS | OS | TL |
| ベストマッチング | 5.5 | 4.8 | 4.9 | 5.7 | 21.0 |
| MT-LLM | 6.7 | 5.0 | 5.5 | 9.0 | 21.8 |
表III
3話者のLIBRISPEECHMIXおよびEN-DE-MIXテストセットでの各種ASRタスクの結果。WER(%)で評価。
| システム | LibriSpeechMix 3話者 | | | En-De-Mix 3話者 | |
|---|---|---|---|---|---|
| | TT | KT | SS | OS | TL |
| ベストマッチング | 12.0 | 9.7 | 12.4 | 11.7 | 24.0 |
| MT-LLM | 16.2 | 12.6 | 15.0 | 15.4 | 24.1 |
表IV
2つの音声エンコーダの使用とマルチタスク学習に関するアブレーション研究。WER(%)で評価。
| WavLMあり | マルチタスク学習 | LibriSpeech 1話者 | LibriSpeechMix 2話者 | LibriSpeechMix 3話者 |
|---|---|---|---|---|
| ✗ | ✗ | 4.3 | 6.6 | 16.1 |
| ✓ | ✗ | 2.4 | 5.5 | 10.7 |
| ✓ | ✓ | 2.3 | 5.2 | 10.2 |
D. 限界と今後の課題
MT-LLMは複数人がしゃべってるシナリオでいろんなASRタスクをなかなかええ感じにこなしてくれるんやけど、いくつか限界もあるのは正直に認めなあかんな。まず、この研究の主な目的は「LLMが指示に従って特定の話者を捉えて、複数人がしゃべってる中からその人の音声を文字起こしできるか」を探ることやねん。せやから、MT-LLMはもっと幅広いタスクに対応するような汎用的な音声LLMとして設計されてるわけやないねん。次に、リソースの制約もあって、実験はシミュレーションで作ったデータセットでやってて、実世界のデータセットではやれてないねん。将来的には、カクテルパーティー環境(みんながガヤガヤしゃべってる中から聞きたい声を拾うっていう、あの有名な問題やな)に対応できるもっと本格的な音声LLMを、しっかり作り込んだ学習データと学習方法で開発したいと思ってるで。
V. 結論
この研究では、複数人がしゃべってるシナリオでの指示ベース音声認識に大規模言語モデル(LLM)を使うっていう、先駆的な挑戦をしたで。Whisperエンコーダで意味的な文脈情報を抽出して、WavLMで話者の特徴を示す多層の音響情報を捉えることで、ベースとなるLLMが音声モダリティの入力をうまく処理できるようにしてん。パラメータ効率の良いファインチューニングを使って、提案したMT-LLMは、マルチ話者ASR、ターゲット話者ASR、そして性別・発話順序・言語・発話キーワードといった話者属性に基づくASRなど、いろんな指示に基づいた音声の理解と文字起こしでめっちゃええ能力を発揮してくれたわ。包括的な実験の結果、複雑な複数話者環境でも期待できる性能が示されて、LLMが音声関連タスクを強化して、難しい環境での人間とコンピュータのやり取りを改善するポテンシャルがほんまにあるっちゅうことが浮き彫りになったで。
VI. 謝辞
この研究は、香港特別行政区研究助成評議会のテーマベース研究助成スキーム(プロジェクト番号:T45-407/19N)と、香港中文大学スタンレー・ホー ビッグデータ意思決定分析研究センターから一部支援を受けてるで。おおきにな。
---
## Page 5
[](/attach/facc6b2ed129d77b5b070815067f506239bb44c555500e6e617d993a9d16c24f_p005.png)
### 和訳
## 参考文献
[1] OpenAI、「GPT-4のテクニカルレポート」、arXivプレプリント arXiv:2303.08774、2023年。
→ これはな、OpenAIが出したGPT-4っていうめっちゃ賢いAIの技術的な詳細を書いた論文やねん。
[2] Hugo Touvronら、「LLaMA:オープンで効率的な基盤言語モデル」、arXivプレプリント arXiv:2302.13971、2023年。
→ Meta(旧Facebook)が作ったLLaMAっていう、誰でも使えるオープンソースの大規模言語モデルの論文やで。効率がめっちゃええのがウリやねん。
[3] Hugo Touvronら、「Llama 2:オープンな基盤モデルとファインチューニング済みチャットモデル」、arXivプレプリント arXiv:2307.09288、2023年。
→ LLaMAの進化版で、チャット用に調整されたモデルも一緒に公開してんねん。ほんまに太っ腹やな。
[4] Liang Chenら、「次トークン予測からマルチモーダル知能へ:包括的サーベイ」、arXivプレプリント arXiv:2412.18619、2024年。
→ AIが「次の言葉を予測する」っていう仕組みから、画像とか音声とかいろんな情報を扱える知能にどう進化してきたかを全部まとめた調査論文やで。
[5] Shujie Huら、「WavLLM:頑健で適応的な音声大規模言語モデルに向けて」、計算言語学会:EMNLP 2024、2024年11月、pp. 4552–4572。
→ 音声を理解できるLLMを作ろうっていう研究やねん。雑音があっても負けへん頑丈なモデルを目指してるんやで。
[6] Changli Tangら、「SALMONN:大規模言語モデルに汎用的な聴覚能力を」、第12回国際学習表現会議(ICLR)、2024年。
→ LLMに「耳」を付けたろうっていう研究や。音声だけやなくて、いろんな音を聞き分けられる能力をLLMに持たせようとしてんねん。
[7] Yunfei Chuら、「Qwen2-Audioテクニカルレポート」、arXivプレプリント arXiv:2407.10759、2024年。
→ アリババが作ったQwen2-Audioっていう音声対応AIモデルの技術レポートやで。
[8] Shaohan Huangら、「言語だけでは不十分:知覚を言語モデルに整合させる」、第37回神経情報処理システム会議(NeurIPS)、2023年。
→ テキストだけやなくて、見たり聞いたりする「知覚」もAIに教えなあかんっていう話やねん。なんでかっていうと、言語だけやと世界の理解が片手落ちになるからやで。
[9] Zhiliang Pengら、「マルチモーダル大規模言語モデルを現実世界に接地させる」、第12回国際学習表現会議(ICLR)、2024年。
→ AIが言葉で説明するだけやなくて、実際の世界の物体とか場所を正しく認識して紐づけられるようにする研究やで。
[10] Xichen Panら、「Kosmos-G:マルチモーダル大規模言語モデルによる文脈に応じた画像生成」、第12回国際学習表現会議(ICLR)、2024年。
→ 会話の流れに沿って画像を生成できるAIの研究やねん。めっちゃ賢い画像生成や。
[11] Tim Brooksら、「世界シミュレータとしての動画生成モデル」、2024年。
→ OpenAIのSoraみたいな動画生成AIは、実は世界をシミュレーションしてるんちゃうかっていう論文やで。
[12] Lingwei Mengら、「ベクトル量子化なしの自己回帰音声合成」、arXivプレプリント arXiv:2407.08551、2024年。
→ 従来は音声を細かいコードに変換(ベクトル量子化)してから合成してたんやけど、それなしで直接音声を作れるようにした研究やねん。
[13] Wangyou Zhangら、「エンドツーエンド単一チャンネル複数話者音声認識の改善」、IEEE/ACMオーディオ・音声・言語処理論文誌、vol. 28、pp. 1385–1394、2020年。
→ マイク1本で複数人が同時にしゃべってる音声を聞き分けて文字起こしする技術の改善やで。
[14] Xuankai Changら、「Transformerを用いたエンドツーエンド複数話者音声認識」、ICASSP 2020、2020年。
→ Transformerっていう今のAIの中核技術を使って、複数人の発話を一気に認識する方法やねん。
[15] Lingwei Mengら、「サイドカーセパレータで単一話者音声認識システムを複数話者対応に変換」、ICASSP 2023、2023年。
→ 1人用の音声認識システムに「サイドカー」っていう追加モジュールをくっつけるだけで、複数人対応にできるっていうめっちゃ便利な手法やで。
[16] Liang Luら、「話者識別と連携したストリーミング複数話者音声認識」、Interspeech 2021、2021年、pp. 1782–1786。
→ リアルタイムで複数人の声を聞き分けながら、「誰が言うたか」も同時に判定する技術やねん。
[17] Desh Rajら、「SURT 2.0:トランスデューサベース複数話者音声認識の進展」、IEEE/ACMオーディオ・音声・言語処理論文誌、vol. 31、pp. 3800–3813、2023年。
→ SURTっていう複数話者認識モデルの改良版やで。トランスデューサっていう仕組みを使ってるんや。
[18] Naoyuki Kandaら、「重なり合った音声認識のための直列化出力学習」、Interspeech 2020、2020年、pp. 2797–2801。
→ 複数人が同時にしゃべってる音声を、順番に並べて出力する学習方法やねん。SOT(Serialized Output Training)って呼ばれてるで。
[19] Naoyuki Kandaら、「トークンレベルの直列化出力学習によるストリーミング複数話者ASR」、Interspeech 2022、2022年、pp. 3774–3778。
→ さっきのSOTをリアルタイム処理(ストリーミング)でもできるようにした進化版やで。
[20] Ying Shiら、「学習された優位性による直列化出力学習」、Interspeech 2024、2024年、pp. 712–716。
→ 複数人の音声を並べる順番を、AIに自動で学習させるっていうアプローチやねん。
[21] Jiawen Kangら、「話者認識CTC を用いた複数話者音声認識における話者の分離」、arXivプレプリント arXiv:2409.12388、2024年。
→ CTC(Connectionist Temporal Classification)っていう技術に話者情報を組み込んで、誰が何を言うたかを解きほぐす研究やで。
[22] Lin Zhengら、「エンドツーエンド複数話者重複音声認識における教師なしドメイン適応」、IEEE信号処理レターズ、vol. 31、pp. 3119–3123、2024年。
→ 学習データと実際の使用環境が違っても、ラベルなしデータだけで適応できるようにする手法やねん。
[23] Zili Huangら、「話者埋め込みを用いた自己教師ありモデルの複数話者音声認識への適応」、ICASSP 2023、2023年。
→ 自己教師あり学習で事前学習したモデルに、話者の特徴(埋め込み)を加えて複数話者対応にする研究やで。
[24] Ryo Masumuraら、「エンドツーエンドのターゲット話者・非ターゲット話者ASR」、Interspeech 2023、2023年、pp. 2903–2907。
→ 聞きたい人の声だけやなくて、周りの人の声もちゃんと認識しようっていう研究やねん。
[25] Naoyuki Kandaら、「Transformerによるエンドツーエンド話者帰属ASR」、Interspeech 2021、2021年、pp. 4413–4417。
→ 「この発言は誰のもんか」を自動で紐づける音声認識システムやで。
[26] Yang Zhangら、「単一チャンネル音声のためのConformerベースのターゲット話者自動音声認識」、ICASSP 2023、2023年。
→ Conformerっていうモデルを使って、特定の人の声だけを狙い撃ちで認識する技術やねん。
[27] Ryo Masumuraら、「ターゲット話者登録あり・なしの統合的複数話者ASR」、Interspeech 2024、2024年、pp. 727–731。
→ 事前に声を登録してても、してへんくても、どっちでもいける統合型の複数話者認識システムやで。めっちゃ柔軟やな。
[28] Lingwei Mengら、「サイドカーセパレータによる複数話者重複音声認識とダイアライゼーションの統合モデリング」、Interspeech 2023、2023年、pp. 3467–3471。
→ 音声認識と「誰がいつしゃべったか」の判定(ダイアライゼーション)を一つのモデルでまとめてやる研究やで。
[29] Lingwei Mengら、「Whisperを複数話者・ターゲット話者音声認識の統合システムとして強化」、Interspeech 2024、2024年、pp. 4653–4657。
→ OpenAIのWhisperっていう音声認識モデルをパワーアップして、複数人対応にも特定の人だけ認識にも使えるようにした研究やねん。
[30] Alec Radfordら、「大規模弱教師あり学習による頑健な音声認識」、第40回国際機械学習会議、2023年、vol. 202、pp. 28492–28518。
→ これがWhisperの元論文やで。ネットから集めた大量の音声データ(正確なラベルがないから「弱教師あり」って言うねん)で学習して、めっちゃ頑丈な音声認識を実現したんや。
[31] Sanyuan Chenら、「WavLM:フルスタック音声処理のための大規模自己教師あり事前学習」、IEEE信号処理選択トピックス誌、vol. 16、no. 6、pp. 1505–1518、2022年。
→ 音声処理のあらゆるタスクに使える万能な事前学習モデルやで。ラベルなしの音声データだけで学習してるのがポイントやねん。
[32] Edward J Huら、「LoRA:大規模言語モデルの低ランク適応」、国際学習表現会議(ICLR)、2022年。
→ LoRAってめっちゃ有名な手法やで。巨大なモデルを少ないパラメータでチューニングできるようにした論文やねん。なんでかっていうと、全パラメータを更新するのはコスト的にしんどいからや。
[33] Dong Yuら、「話者非依存の複数話者音声分離のための順列不変学習」、ICASSP 2017、2017年。
→ PIT(Permutation Invariant Training)っていう超重要な手法の論文やで。複数話者の音声を分離するとき、「どの出力がどの話者に対応するか」の順番問題を解決した画期的な研究やねん。
[34] Yuan Gongら、「Whisper-AT:ノイズに頑健な音声認識器は優秀な汎用音声イベントタガーでもある」、Interspeech 2023、2023年、pp. 2798–2802。
→ Whisperは音声認識だけやなくて、犬の鳴き声とかドアの音とか、一般的な音のイベントも認識できるんやでっていう発見の論文や。
[35] Vassil Panayotovら、「LibriSpeech:パブリックドメインのオーディオブックに基づくASRコーパス」、ICASSP 2015、2015年。
→ LibriSpeechっていう音声認識研究でめっちゃよく使われるデータセットの論文やで。無料のオーディオブックから作られてんねん。
[36] Changhan Wangら、「CoVoST 2と大規模多言語音声翻訳」、Interspeech 2021、2021年。
→ いろんな言語の音声を別の言語に翻訳するためのデータセットの論文やで。多言語対応がめっちゃ充実してるのがウリやねん。
---
![]()
1 / 1
100%