<<
2311.07919v2.pdf

---
## Page 1
[](/attach/ec2582e1767927a67bc68db1fa9324c3a7839b8d2efa348ac6c76c57f5b44fae_p001.png)
### 和訳
# Qwen-Audio:統一された大規模音声言語モデルで汎用オーディオ理解を前進させる話
Yunfei Chu∗、Jin Xu∗、Xiaohuan Zhou∗、Qian Yang、
Shiliang Zhang、Zhijie Yan、Chang Zhou†、Jingren Zhou
Alibaba Group
コードとデモとモデルはここにあるで:https://github.com/QwenLM/Qwen-Audio
## 要約
最近な、人間と音声でやり取りできる「指示に従う音声言語モデル」ってやつがめっちゃ注目されとるんや。でもな、いろんな種類の音声とかタスクを扱える事前学習済みの音声モデルがなかったせいで、この分野の進歩がちょっと足踏みしとったんよ。せやから、今まであったやつらは、できることが限られとったわけ。
この論文でな、ワイらはQwen-Audioモデルを開発して、この問題をバシッと解決したんや。どうやったかっていうと、音声と言語の事前学習をめっちゃスケールアップして、30種類以上のタスクと、人の声、自然の音、音楽、歌とかいろんな種類の音声をカバーできるようにしたんや。これで汎用的な音声理解能力がつくようになったわけ。
でもな、全部のタスクとデータセットをそのまま一緒に学習させると、干渉問題が起きるんよ。なんでかっていうと、それぞれのデータセットについてるテキストラベルがバラバラやからや。タスクの目的とか、言語とか、アノテーションの細かさとか、テキストの構造とかが全然違うねん。
この「一対多」の干渉問題を乗り越えるためにな、ワイらは階層的なタグの並びをデコーダーに条件付けするっていうマルチタスク学習フレームワークを丁寧に設計したんや。共有タグで知識の共有を促して、専用タグで干渉を避けるって仕組みやな。
ほんで驚くべきことにな、Qwen-Audioはタスク固有のファインチューニングなしで、いろんなベンチマークタスクでめっちゃすごい性能を叩き出して、ライバルたちをぶっちぎったんや。
このQwen-Audioの能力をベースにして、さらにQwen-Audio-Chatっていうのも開発したで。これはいろんな音声とテキスト入力を受け付けて、複数ターンの対話ができて、音声中心のいろんなシナリオに対応できるんや。
## 1 はじめに
大規模言語モデル(LLM)(Brown et al., 2020; OpenAI, 2022, 2023; Chowdhery et al., 2022; Anil et al., 2023; Touvron et al., 2023a,c; Qwen, 2023)っていうのはな、知識をしっかり覚えとく力、複雑な推論力、問題解決能力がすごいから、汎用人工知能(AGI)の分野をめっちゃ前に進めてきたんや。
でもな、言語モデルには弱点があってな、人間みたいに画像とか音声みたいなテキスト以外のものを感じ取る能力がないんよ。音声っていう情報の形式はめっちゃ大事でな、テキスト以上に多様で複雑な信号を伝えてくれるんや。例えば、人の声に含まれる感情、トーン、意図とか、電車の汽笛、時計のチャイム、雷みたいな自然の音とか、音楽のメロディとかな。
LLMにこういう豊かな音声信号を感じ取って理解させて、音声でやり取りできるようにするっていうのが、めっちゃ注目されとるんや(Huang et al., 2023; Shen et al., 2023; Wang et al., 2023a; Lyu et al., 2023; Wu et al., 2023b; Gong et al., 2023b; Wang et al., 2023c; Shu et al., 2023)。
これまでの指示に従うモデルの研究はな、大規模(マルチモーダル)LLMの能力を引き継いで、軽めの教師ありファインチューニングでモデルがユーザーの意図に合うように能力を活性化させるっていうやり方やったんや(Ouyang et al., 2022; Wang et al., 2023a; Gong et al., 2023b)。せやけどな、ほとんどの研究は制約があってな、
∗同等の貢献、†責任著者
---
## Page 2
[](/attach/ec2582e1767927a67bc68db1fa9324c3a7839b8d2efa348ac6c76c57f5b44fae_p002.png)
### 和訳
図1:Qwen-Audioと、これまでトップクラスやった音声テキストのマルチタスク学習モデルたちの性能比較やねん。SpeechT5(Aoら、2021)、SpeechNet(Chenら、2021)、SpeechLLaMA(Wuら、2023a)、SALMONN(Anonymous、2023)、Pengi(Deshmukhら、2023)とかが比較対象やな。ここでは12個のデータセットのテスト結果を見せてんねん。カバーしてるタスクは、自動音声認識(ASR)、音声からテキストへの翻訳(S2TT)、音声の自動キャプション生成(AAC)、音響シーン分類(ASC)、音声感情認識(SER)、音声に関する質問応答(AQA)、人の声の分類(VSC)、音楽の音符分析(MNA)やで。ASRのデータセット、たとえばLibrispeech、Aishell1、Aishell2の結果は「1マイナス単語誤り率(WER)」のパーセントで表してんねん。CoVoST2の結果は、7つの翻訳方向(英語→ドイツ語、ドイツ語→英語、英語→中国語、中国語→英語、スペイン語→英語、フランス語→英語、イタリア語→英語)の平均BLEUスコアやねん。Qwen-Audioはな、タスクごとの専用ファインチューニングなしでめっちゃすごい性能出してて、他のモデルを圧倒してんねん。
音声インタラクション機能がなかなか発展せえへん原因はな、いろんな種類の音声とタスクを扱える事前学習済みの音声言語モデルがなかったからやねん。今まで代表的やった音声言語のマルチタスク言語モデル、たとえばSpeechNet(Chenら、2021)、SpeechT5(Aoら、2021)、VIOLA(Wangら、2023d)、Whisper(Radfordら、2023)、Pengi(Deshmukhら、2023)とかは、人の声とか自然音とか、特定の種類の音声しか処理できへんかってん。
ほんでな、音声テキストのマルチモーダルコミュニティの成長と発展を後押しするために、ワイらはQwen-Audioっていう大規模な音声言語モデルを紹介すんねん。Qwen-Audioは、音声とテキストの入力を条件にしたマルチタスク言語モデルでな、Qwen-7B(Baiら、2023a)っていう言語モデルを拡張して、1つの音声エンコーダーをつなぐことで音声信号をちゃんと認識できるようにしたんや。これまでの研究は、人の声みたいな1種類の音声だけ扱うとか、音声認識やキャプション生成みたいな特定のタスクに絞るとか、1つの言語だけに限定するとか(Wangら、2023a; Lyuら、2023; Wuら、2023b; Gongら、2023b; Shuら、2023)やったんやけど、ワイらは訓練を数十個のデータセットに拡大してな、30以上のタスク、8つの言語、いろんな種類の音声をカバーして、汎用的な音声理解能力を進化させたんや。マルチタスク
2
LibrispeechAishell1Aishell2CoVoST2ClothoCochlSceneTUT2017MeldClothoAQAVocalSoundNS.QualitiesNS.Instrucment91.593.094.597.4497.8898.3191.7593.595.258.7517.526.2511.523.034.565.070.075.017.535.052.537.044.051.020.040.060.046.2562.578.7512.525.037.520.040.060.0N/A以前のトップモデルQwen-Audio
---
## Page 3
[](/attach/ec2582e1767927a67bc68db1fa9324c3a7839b8d2efa348ac6c76c57f5b44fae_p003.png)
### 和訳
図2:Qwen-Audioがいろんな種類の音声をどんだけうまく認識して理解できるかっていう例やねん。Qwen-Audioは複数の音声を同時に分析したり、音の理解と推論、音楽の鑑賞、それから音声編集のツール使用なんかもできるんやで。デモは https://qwen-audio.github.io/Qwen-Audio/ で見れるから、チェックしてみてな。
ほんで、複数のデータセットを一緒に学習させるときの問題点なんやけど、それぞれのデータセットについてるテキストラベルがめっちゃバラバラやねん。なんでかっていうと、タスクの目的とか、言語とか、どこまで細かくアノテーションするかとか、テキストの構造(整理されてるか散らかってるか)とかが全然違うからやねん。この「一つの入力に対して複数の正解がある」っていう難しい問題に対処するために、デコーダーに階層的なタグの列を条件として与えるマルチタスク学習の枠組みをめっちゃ丁寧に設計したんやで。この設計のおかげで、共通のタグで知識を共有しつつ、専用のタグで干渉を減らせるようになっとるねん。
さらにな、単語レベルのタイムスタンプ予測付き音声認識(SRWT)っていうタスクも学習に取り入れたんやけど、これ今までのマルチタスク学習の研究ではあんまり注目されてなかったんよ。このタスク入れてみたら、音声だけやなくて音や音楽のグラウンディング(音と時間の紐付け)とか、それに基づく質問応答タスクがめっちゃ良くなったし、なんと音声認識(ASR)の性能まで上がったんやで。図1に示してる通り、いろんなタスクで広範囲に評価した結果、Qwen-Audioはタスク専用のファインチューニングなしで、これまでのマルチタスク学習モデルを超えるパフォーマンスを叩き出したんや。特にすごいのが、Aishell1、cochlscene、ClothoAQA、VocalSoundのテストセットで最先端の性能を達成したことやな。このQwen-Audioの能力を活かして、教師ありの指示ファインチューニングでQwen-Audio-Chatっていうのも作ったんやけど、これは複数回のやり取りで音声とテキスト両方から柔軟に入力できて、人間の指示に従って効果的にやり取りできるようになっとるねん。
この論文の貢献をまとめると以下の通りやで:
・Qwen-Audioっていう、いろんなタスクに対応できる基本的な音声-言語マルチタスクモデルを紹介したで
3
(a) 多言語音声認識と翻訳 (f) SWRTを使った音声編集 (d) 音声からインスピレーションを受けた創作文章 (e) 音楽鑑賞 (c) 音の理解と推論 (b) 複数音声の分析
「OK、"大家好我们来讨论一下公司周末团建的地点吧大家有什么意见呢"を英語に翻訳すると"Hello, let's discuss the location for our company's weekend team building. What are your opinions?"やで」音声を認識して英語に翻訳して「OK、"I think we can go to the countryside and find a beautiful natural area."を英語に翻訳すると"I think we can go to the countryside and find a beautiful natural area."やで」音声を認識して英語に翻訳して「OK、"わかりました。田舎に行くことに同意します。田舎暮らしを体験してみるのもいいかもしれません。"を英語に翻訳すると"I understand. I agree to go to the countryside. It's also good to experience country life."やで」
音声1と音声2の感情はそれぞれ何?「音声1の女性の声は明るくて、なんか楽しいこと話してる感じやな。音声2の女性の声は怖がってて、なんか恐ろしいこと話してるみたいやで」
音声1と音声2の質問にどう答えたらええ?「音声1では、女性が大丈夫?って聞いてるから、"心配してくれてありがとう、もう大丈夫やで、ちょっと急に気分悪くなっただけやから"って答えたらええで。音声2では、女性が怖がってて恐ろしいこと話してるから、"怖いわ、どうしたらええかわからん"とか"ほんまにつらい、この状況どう向き合ったらええかわからん"って返したらええで」
音の情報を認識して、その音がユーザーの周りで起きてるって仮定して、対処法をアドバイスして「ガラスが割れる音やな。対処法はこんな感じやで:1. 音の元を止める:割れたガラス製品から音がしてるなら、これ以上の被害を防ぐためにすぐ音の元を止めや。2. 割れたガラスを片付ける:手袋してほうきか掃除機で割れたガラスを片付けや。切らんように気をつけてな。3. 被害を確認する:割れたガラスが手の届きにくい場所にあったり、安全上の問題があったりしたら、専門家に連絡しや。4. その場所を覆う:割れたガラスがある場所を覆って、怪我やさらなる被害を防ぎや。5. 割れたガラスの上を歩かん:床に割れたガラスがあったら、その上を歩いたらあかんで。ほうきか掃除機で片付けるか、段ボールやテープで覆いや」
これ何?「ソロピアノの曲やで」
この音楽を詳しく説明して「これはソロピアノの曲やねん。テンポが速くて、遊び心があってユーモラスな雰囲気やな。ハ長調で4/4拍子やで。右手でメロディを弾いて、左手でコードを弾いとるねん。クラシックなラグタイム様式の曲やで」
似たような音楽をおすすめして「"ソロピアノラグタイム"に似た音楽やったら:1. スコット・ジョプリンの"The Entertainer" 2. スコット・ジョプリンの"Maple Leaf Rag" 3. フランツ・シューベルトの"Ave Maria" 4. ルートヴィヒ・ヴァン・ベートーヴェンの"Für Elise" 5. ヨハン・シュトラウス2世の"The Blue Danube"とかどうやろ」
上の音声について詩を書いて「鳥たちが木々でさえずって、優しい風が自由に吹いとる、葉のざわめきは音楽やで、自然の交響曲が続いていく。太陽が明るく暖かく輝いて、平和な雰囲気が広がっとる、自然の美しさの中で、安らぎと使命を見つけられるねん。鳥たちは軽やかに飛び立って、そのさえずりが木々を満たす、自然の恵みの交響曲、立ち止まって抱きしめる瞬間やで。風が枝の間でささやいて、葉っぱが枝の中で踊っとる、時の中の平和なひととき、手放してリラックスするチャンスやな。ここで少し立ち止まろうや、この大切な美しさを味わうために、自然の不思議の中で、驚きの感覚を見つけられるねん」
"joyful"を"interesting"に変えて「OK、編集した音声やで」
"what"っていう単語を削除して、ミームにしたいねん「"what"は3.04秒から始まって3.23秒で終わっとるで」
人の名前を"John"に変えて「OK、編集した音声やで」
---
## Page 4
[](/attach/ec2582e1767927a67bc68db1fa9324c3a7839b8d2efa348ac6c76c57f5b44fae_p004.png)
### 和訳
よっしゃ、聞いてや!これな、Qwen-Audioってモデルの話やねん。いろんなタスクとか言語とか音声の種類に対応できる、まあ言うたら「なんでもわかる音声AIモデル」みたいなもんやな。で、このQwen-Audioをベースにして、Qwen-Audio-Chatっていうのを作ったんやけど、これは指示に合わせて細かくチューニングしてあんねん。そしたら何ができるようになったかっていうと、何回もやり取りできる会話ができて、音声を使ったいろんな場面に対応できるようになったわけや。両方のモデルとも、オープンソースで公開してるから、音声とテキストを組み合わせた研究のコミュニティがどんどん盛り上がってくれたらええなーと思ってんねん。
ほんで、音声と言語を一緒に学習させる規模をでっかくしようとしたときに、データセットごとにラベルの付け方がバラバラやっていう問題があってん。これどないしたかっていうと、マルチタスク学習っていうやり方を提案したんや。これでな、知識を共有できて、しかも「一つの入力に対して複数の答えがある」みたいな干渉を避けられんねん。うちのモデルは30以上のタスクを取り込んでて、めっちゃたくさん実験した結果、ほんまにええ性能出とるで。
で、音声と言語の事前学習をもっと進めるためにな、SRWTっていうタスクを入れることにしてん。これ、音声関連のマルチモーダル研究界隈ではけっこう見落とされがちやったんやけど、実はめっちゃ重要やねん。なんでかっていうと、音声信号だけやなくて、「この部分がどこに対応してるか」を見つけるグラウンディングタスクとか、それをベースにした質問応答タスク、それに音声認識(ASR)の性能も上がることがわかったんや。
実験結果やけどな、Qwen-Audioはいろんなベンチマークテストで、タスクごとの特別なファインチューニングなしでめっちゃええ成績出してん。他のモデルより上やで。具体的に言うと、Aishell1、cochlscene、ClothoAQA、VocalSoundのテストセットで最先端の結果を叩き出したんや。
## 2 関連研究
**マルチタスク音声テキスト学習**
マルチタスク学習の目的はな、統一されたモデル構造とデータ形式を使って、異なるタスク間で知識を移し替えることやねん(Raffelら2020年、Aoら2021年、Chenら2021年の研究参照)。音声処理の分野では、全部の音声処理タスクを統一するんがめっちゃ難しいねん。なんでかっていうと、人間の声、自然の音、音楽、歌とか、いろんな種類の音声信号があって、しかもラベルの付け方が全然ちゃうからや。
SpeechNet(Chenら2021年)とSpeechT5(Aoら2021年)は、人間の音声タスクを「音声かテキストを入力して、音声かテキストを出力する」っていう形式にまとめて、共通のエンコーダー・デコーダー構造で事前学習してんねん。
他にもいろんな研究(Wangら2023d、Maitiら2023、Rubensteinら、Wangら2023e、Nachmaniら2023)があってな、データ形式とタスクを統一するために、音声の表現を直接入れたり(Nachmaniら2023)、連続的な音声信号を離散的なコードに変換したり(Défossézら2022、Zeghidourら2022、Zhangら2023c)して、いろんな人間の音声タスクを「条件付き生成タスク」として扱ってんねん。学習には、デコーダーだけのTransformerモデルをそのまま使ってる。VoiceBox(Leら2023)は、非自己回帰型の連続正規化フローモデルっていうのを使って、音声合成と音声編集タスクをやってる。
Whisper(Radfordら2023)は、マルチタスク学習用のテンプレートを提案してて、データセットのアノテーションの細かさ(文レベルのタイムスタンプありなし)とか、タスクの種類(音声認識と翻訳)を考慮して統一的に学習できるようにしてる。
でもな、今までの研究はほとんど人間の音声処理タスク、つまり音声認識とか翻訳ばっかりに注目してて、自然の音とか音楽みたいな他の音声タイプは無視されとったんや。Pengi(Deshmukhら2023)は自然音の理解タスクに焦点当てて、これらをテキスト生成タスクとして扱ってる。具体的には、テキストテンプレートでデータ形式を統一して、Transformerデコーダーモデルで全タスクを学習してる。
この研究では、Qwen-Audioが人間の音声、自然の音、音楽、歌みたいないろんな種類の音声を統合してんねん。バラバラなデータからきたデータセットとか、ラベルの細かさが全然違うやつも一緒に学習できるようにしたんや。これは統一学習フレームワークを導入することで実現してる。この共同学習が終わったら、モデルは音声の知覚、理解、認識タスクの全部に対応できる総合的な能力を持つようになって、タスクごとに特別な構造を追加する必要がなくなんねん。
**複数のモダリティでLLMとやり取りする**
最近な、ChatGPT(OpenAI 2022)みたいな大規模言語モデルが、人間の指示に従って知識を保持したり、推論したり、コーディングしたりする能力がめっちゃすごいってことがわかってきたんや。で、LLMの応用範囲を純粋なテキストタスク以外にも広げるために、LLMベースのマルチモーダルモデルがいっぱい開発されてんねん。視覚の分野では、GPT4(OpenAI 2023)、Flamingo(Alayracら2022)、Kosmos(Pengら2023)、BLIP(Liら2022)、Shikra(Chenら2023)、Emu(Sunら2023)とかがあるで。
---
## Page 5
[](/attach/ec2582e1767927a67bc68db1fa9324c3a7839b8d2efa348ac6c76c57f5b44fae_p005.png)
### 和訳
で、Qwen-VL(Bai et al., 2023b)とかは、LLMに画像を理解したり生成したりする能力を持たせるために、それぞれちゃう方法を提案してるんやで。
音声の方はな、AudioGPT(Huang et al., 2023)やHuggingGPT(Shen et al., 2023)みたいに、めっちゃ訓練された音声の基盤モデルをツールとして使おうって試みがあんねん。LLMを万能のインターフェースとして活用してるわけや。これらの取り組みでは、LLMに外部ツールを操作するコマンドを生成させたり、人間の話し声をテキストに変換してからLLMに入力したりしてるんやけどな。でもこのやり方やと、人間の声に含まれるプロソディ(抑揚とかリズムとかな)や感情みたいな大事な情報が抜け落ちてまうねん。それに場合によっては、自然の音みたいなテキストにならん音声を変換できひんこともあるんや。せやから、LLMの知識を音声の領域に持っていくのに壁があって、LLMには音声信号を感じ取って理解する能力が足りてへんかったわけや。
最近はな、直接音声でやり取りできるように、エンドツーエンドの音声テキストLLMを訓練する研究が進んでるで。SpeechGPT(Zhang et al., 2023a)は、まず人間の声を離散的なHuBERTトークン(Hsu et al., 2021)に変換して、それからペアの音声データ、音声指示データ、モダリティ連鎖の指示データに対応した3段階の訓練パイプラインを設計してるんや。BLSP(Wang et al., 2023a)は、人間の声とその書き起こしを与えたときにLLMが同じテキストの続きを生成するようにさせることで、表現の整合性を取ってるねん。LLaSM(Shu et al., 2023)は、MicrosoftのTTS APIを使って音声の質問を生成して大規模な音声指示データセットを作って、人間の声とテキストのエンドツーエンドのやり取りができるように訓練してるんや。
LTU(Gong et al., 2023b)は500万件の音声QAデータセットを作って、音声モジュールとLLaMA(Touvron et al., 2023b)のLoRAアダプター(Hu et al., 2021)に対して教師ありファインチューニング(SFT)をやって、音の認識と推論の間の整合性を高めてるで。SALMMON(Anonymous, 2023)は、テキストエンコーダと音声エンコーダの両方を使って、いろんな種類の音声とテキスト入力から表現を抽出して、それをQ-former(Li et al., 2023)スタイルのアテンションで訓練済みのLLMに繋いで応答を生成してるんや。
この研究でのQwen-Audioはな、音声入力を感じ取って理解できる統一された音声テキストのマルチタスク多言語LLMを訓練することを目指してるんやで。それでいてテキストでの会話能力もちゃんと保ってるねん。Qwen-Audioは全部の音声に対して単一のエンコーダを使ってて、大規模なエンドツーエンド訓練で音声とテキストのモダリティの溝を埋めてるから、自然音の検出、人間の音声認識とグラウンディング、音声キャプションのタスクみたいな色んなタスクに対応できるんや。できあがったモデルは、いろんな種類のタスクで前の研究よりめっちゃええ性能を出してるで。
## 3 手法
このセクションでは、Qwen-AudioとQwen-Audio-Chatの詳細を説明するで。これらは汎用的な音声理解と、人間の指示に基づく柔軟なやり取りのために設計されてるんや。Qwen-AudioとQwen-Audio-Chatのモデル構造はまずセクション3.1で説明するで。うちのモデルの訓練プロセスは2段階あるねん:マルチタスク事前訓練と教師ありファインチューニングや。セクション3.2ではマルチタスク学習によるQwen-Audioの訓練について説明して、セクション3.3では柔軟な人間とのやり取りを可能にする教師ありファインチューニングを使ったQwen-Audio-Chatについて説明するで。
### 3.1 モデルアーキテクチャ
Qwen-Audioモデルのアーキテクチャは図3に描かれてるで。Qwen-Audioは音声エンコーダと大規模言語モデルで構成されてるんや。ペアデータ(a, x)が与えられたとき(aは音声シーケンス、xはテキストシーケンスな)、訓練の目的は次のテキストトークンの確率を最大化することやねん:
Pθ(xt|x<t, Encoderϕ(a))
これは音声表現と前のテキストシーケンスx<tを条件にしてるで。θとϕはそれぞれLLMと音声エンコーダの訓練可能なパラメータを表してるんや。
**音声エンコーダ** Qwen-Audioは様々な種類の音声を処理するのに単一の音声エンコーダを使ってるねん。音声エンコーダの初期化はWhisper-large-v2モデル(Radford et al., 2023)に基づいてるで。これは
---
## Page 6
[](/attach/ec2582e1767927a67bc68db1fa9324c3a7839b8d2efa348ac6c76c57f5b44fae_p006.png)
### 和訳
図3:Qwen-Audioのアーキテクチャとマルチタスク事前学習の全体像やで
ほんでまず音声エンコーダーの話からするわ。これはWhisperっていう32層のTransformerモデルを使っててん。最初に2つの畳み込みダウンサンプリング層があって、これがいわば入り口みたいな役割やねん。音声エンコーダー全体で6億4000万個のパラメータがあるで。Whisperって元々は音声認識と翻訳用に教師あり学習されたモデルやねんけど、実はエンコードされた表現の中には背景ノイズみたいな豊富な情報も含まれてて(Gongらが2023年に報告してるで)、なんやったら元の音声を復元するのにも使えるらしいわ(Zhangらが2023年に示してる)。音声データの前処理としては、Whisperは音声を16kHzにリサンプリングして、生の波形を80チャンネルのメルスペクトログラム(要は音声を周波数ごとに分解した図みたいなもんや)に変換するねん。このとき窓サイズ25ミリ秒、ホップサイズ10ミリ秒を使ってる。さらにストライド2のプーリング層を入れて音声表現の長さを短くしてるから、エンコーダー出力の各フレームは元の音声信号のだいたい40ミリ秒分に対応するようになってるねん。あと学習時にはSpecAugmentっていうデータ拡張の手法も使ってるで。
次に大規模言語モデルの話や。Qwen-Audioは基盤コンポーネントとして大規模言語モデルを組み込んでるねん。このモデルはQwen-7Bっていう事前学習済みの重みで初期化されてる(Baiらが2023年に発表したやつや)。Qwen-7Bは32層のTransformerデコーダーモデルで、隠れ層のサイズが4096、全部で77億個のパラメータがあるめっちゃデカいモデルやで。
3.2 マルチタスク事前学習
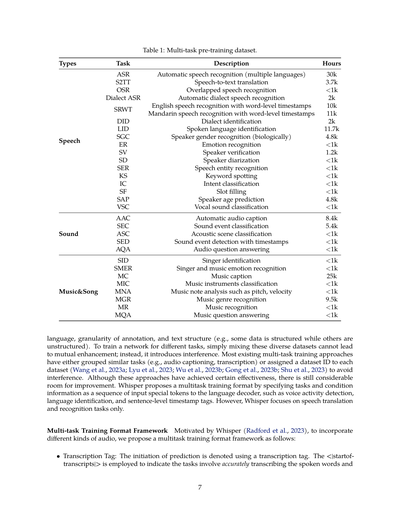
音声処理の分野では、表1に示すように特定のタスク向けにいろんな音声データセットが開発されてきたんや。Qwen-Audioが目指してるのは、こういう幅広い音声データセットを使って同時学習することやねん。目的は何かっていうと、全部の音声タスクに対応できる統一モデルを作ることや。そしたらタスクが変わるたびにいちいち面倒くさいモデルの切り替えせんでええようになるやろ。でもそれよりもっと大事なんは、同時学習することでタスク同士が助け合えるってことやねん。なんでかっていうと、1つ目は似たようなタスクは知識の共有と協調学習の恩恵を受けられるからや。だって音声信号に含まれる基本的な情報を扱うっていう共通の焦点があるやん。2つ目は、低レベルの知覚能力に頼るタスクが、より高レベルの理解や推論能力を必要とするタスクを助けられるからや。
せやけど、タスクの焦点が違うから、データセットによってテキストラベルにめっちゃ大きなバラつきがあるんやな。
---
## Page 7
[](/attach/ec2582e1767927a67bc68db1fa9324c3a7839b8d2efa348ac6c76c57f5b44fae_p007.png)
### 和訳
**タイプ**
**会話・言葉系**
**環境音**
**音楽・歌系**
**タスク**
ASR - 自動音声認識(いろんな言語に対応してるやつやな)
S2TT - 音声からテキストへの翻訳
OSR - 複数人が同時にしゃべってる音声の認識
Dialect ASR - 方言の自動音声認識
SRWT - 英語の音声認識で単語ごとにタイムスタンプつけるやつ
(下の行は)中国語(北京語)の音声認識で単語ごとにタイムスタンプつけるやつ
DID - 方言の識別
LID - しゃべってる言語の識別
SGC - 話者の性別認識(生物学的なやつやで)
ER - 感情認識
SV - 話者照合(この人ほんまにこの人か確認するやつ)
SD - 話者ダイアライゼーション(誰がいつしゃべったか分けるやつ)
SER - 音声からの固有表現認識
KS - キーワード検出
IC - 意図分類
SF - スロット埋め(会話の中から特定の情報抜き出すやつ)
SAP - 話者の年齢予測
VSC - 声の種類の分類
AAC - 音声の自動キャプション生成
SEC - 環境音のイベント分類
ASC - 音響シーン分類(どんな場所の音かってやつ)
SED - タイムスタンプ付きの音イベント検出
AQA - 音声に関する質問応答
SID - 歌手の識別
SMER - 歌手と音楽の感情認識
MC - 音楽のキャプション生成
MIC - 楽器の分類
MNA - 音楽のノート分析(音程とか強さとかやな)
MGR - 音楽ジャンル認識
MR - 音楽認識
MQA - 音楽に関する質問応答
**表1:マルチタスク事前学習用のデータセット**
| 説明 | 時間 |
|---|---|
| 自動音声認識(複数言語対応) | 3万時間 |
| 音声からテキストへの翻訳 | 3,700時間 |
| 複数人同時発話の音声認識 | 1,000時間未満 |
| 方言の自動音声認識 | 2,000時間 |
| 英語音声認識(単語レベルのタイムスタンプ付き) | 1万時間 |
| 中国語音声認識(単語レベルのタイムスタンプ付き) | 1.1万時間 |
| 方言識別 | 2,000時間 |
| 話されてる言語の識別 | 1.17万時間 |
| 話者の性別認識(生物学的に) | 4,800時間 |
| 感情認識 | 1,000時間未満 |
| 話者照合 | 1,200時間 |
| 話者ダイアライゼーション | 1,000時間未満 |
| 音声からの固有表現認識 | 1,000時間未満 |
| キーワード検出 | 1,000時間未満 |
| 意図分類 | 1,000時間未満 |
| スロット埋め | 1,000時間未満 |
| 話者の年齢予測 | 4,800時間 |
| 声の種類の分類 | 1,000時間未満 |
| 音声の自動キャプション | 8,400時間 |
| 環境音イベント分類 | 5,400時間 |
| 音響シーン分類 | 1,000時間未満 |
| タイムスタンプ付き音イベント検出 | 1,000時間未満 |
| 音声質問応答 | 1,000時間未満 |
| 歌手識別 | 1,000時間未満 |
| 歌手と音楽の感情認識 | 1,000時間未満 |
| 音楽キャプション | 2.5万時間 |
| 楽器分類 | 1,000時間未満 |
| 音楽ノート分析(音程、強さなど) | 1,000時間未満 |
| 音楽ジャンル認識 | 9,500時間 |
| 音楽認識 | 1,000時間未満 |
| 音楽質問応答 | 1,000時間未満 |
---
ほな本文いくで!
言語とか、アノテーション(ラベル付け)の細かさとか、テキストの構造とか(構造化されてるデータもあれば、されてないのもあるやん)、いろいろ違いがあんねん。で、いろんなタスク用にネットワークを学習させるとき、こういうバラバラのデータセットを単純にごちゃ混ぜにしても、お互いが高め合うどころか、逆に干渉し合って邪魔になってまうねんな。
今までのマルチタスク学習のやり方の多くは、似たようなタスクをグループ化したり(例えば音声キャプションと文字起こしを一緒にするとか)、各データセットにIDを振ったりして干渉を避けてきてん(Wang et al., 2023a; Lyu et al., 2023; Wu et al., 2023b; Gong et al., 2023b; Shu et al., 2023)。まあこれらのやり方もそれなりに効果あったんやけど、まだまだ改善の余地があるんよな。
Whisperってモデルは、マルチタスク学習のフォーマットを提案してて、タスクの種類とか条件の情報を、言語デコーダーへの入力として特別なトークンの列で指定するようにしてんねん。例えば音声活動検出とか、言語識別とか、文レベルのタイムスタンプタグとかな。でもWhisperは音声翻訳と音声認識のタスクだけに特化してるんよ。
**マルチタスク学習フォーマットのフレームワーク**
Whisper(Radford et al., 2023)に触発されて、いろんな種類の音声を扱えるように、こんなマルチタスク学習フォーマットのフレームワークを提案するで:
• **書き起こしタグ**:予測の開始は書き起こしタグで示すねん。`<|startoftranscripts|>`っていうのは、話されてる言葉を正確に文字起こしするタスクやでって示すために使うんや。ほんで...
---
## Page 8
[](/attach/ec2582e1767927a67bc68db1fa9324c3a7839b8d2efa348ac6c76c57f5b44fae_p008.png)
### 和訳
音声の録音から言葉の内容をキャッチするっていう話やねん。例えば音声認識とか音声翻訳みたいなタスクのことやな。他のタスクには`<|startofanalysis|>`っていうタグを使うんやで。
• **音声の言語タグ**: ほんで、音声の中で喋ってる言語を示すタグを入れるねん。このタグは、うちらのトレーニングセットに入ってる言語ごとにユニークなトークンを割り当ててて、全部で8言語あるんよ。もし音声に喋りが入ってへんかったら、例えば自然の音とか音楽とかの場合やな、モデルは`<|unknown|>`トークンを予測するように訓練されてるわけや。
• **タスクタグ**: 次のトークンでタスクを指定するんや。集めた音声タスクを5つのカテゴリに分けてんねん:`<|transcribe|>`(文字起こし)、`<|translate|>`(翻訳)、`<|caption|>`(キャプション)、`<|analysis|>`(分析)、ほんで`<|question-answer|>`(質疑応答)タスクや。質疑応答タスクの場合は、タグの後ろに対応する質問をくっつけるんやで。
• **テキスト言語タグ**: このタグトークンで出力テキストの言語を指定するんや。
• **タイムスタンプタグ**: `<|timestamps|>`か`<|notimestamps|>`のトークンがあるかどうかで、モデルがタイムスタンプを予測する必要があるかどうかが決まるねん。Whisperで使われてた文レベルのタイムスタンプとは違って、`<|timestamps|>`タグがあると、モデルはめっちゃ細かい単語レベルのタイムスタンプ予測をせなあかんのや。これをSRWT(単語レベルタイムスタンプ付き音声認識)って略すんやけどな。このタイムスタンプの予測は文字起こしの単語と交互に出てくるねん:開始時刻トークンは各文字起こしトークンの前に予測されて、終了時刻トークンはその後に予測されるっちゅう仕組みや。うちらの実験によると、SRWTはモデルが音声信号とタイムスタンプを合わせる能力を向上させるんやで。この改善されたアライメントのおかげで、モデルが音声信号をより包括的に理解できるようになって、音声認識とか音声QAタスクとか、いろんなタスクで目覚ましい進歩が見られたんや。
• **出力指示**: 最後に、いろんなサブタスクに対してタスクと望ましいフォーマットをさらに細かく指定するための出力指示を出して、そこからテキスト出力が始まるんやで。
うちらのフレームワークの基本的な考え方は、似たようなタスク同士でタグを共有することで知識の共有を最大化して、それによってパフォーマンスを向上させることなんや。同時に、異なるタスクと出力フォーマットをちゃんと区別できるようにして、モデルの「一対多」マッピング問題を避けるようにしてるんやで。Qwen-Audioのマルチタスクフォーマットの全体像は図3を見てな。
### 3.3 教師ありファインチューニング
マルチタスクモデルの大規模な事前学習によって、音声に対する幅広い理解力が身についたわけや。これをベースにして、うちらは指示ベースのファインチューニング技術を使って、モデルが人間の意図に沿う能力を向上させて、対話型チャットモデルを作ったんや。これをQwen-Audio-Chatって呼んでるで。
これを実現するために、各タスクのデモンストレーションを手作業で作成したんや。このデモンストレーションは、生のテキストラベル、質問、回答で構成されてるねん。ほんでGPT-3.5(OpenAI, 2022)を使って、提供された生のテキストラベルに基づいてさらなる質問と回答を生成したんや。さらに、手動アノテーション、モデル生成、戦略連結を使って音声対話データのデータセットも作ったで。このデータセットのおかげで、推論能力、ストーリー生成能力、複数画像理解能力をモデルに組み込むことができたんや。
複数の音声を使った対話と複数の音声入力を効果的に扱うために、異なる音声を「Audio id:」でラベル付けする規則を導入したんやで。idは音声入力対話の順番に対応してるねん。対話フォーマットに関しては、ChatML(Openai)フォーマットを使って指示チューニングデータセットを構築したんや。このフォーマットでは、各やり取りの発言が2つの特別なトークン(`<im_start>`と`<im_end>`)でマークされてて、対話の終了を簡単に処理できるようになってるんやで。
---
## Page 9
[](/attach/ec2582e1767927a67bc68db1fa9324c3a7839b8d2efa348ac6c76c57f5b44fae_p009.png)
### 和訳
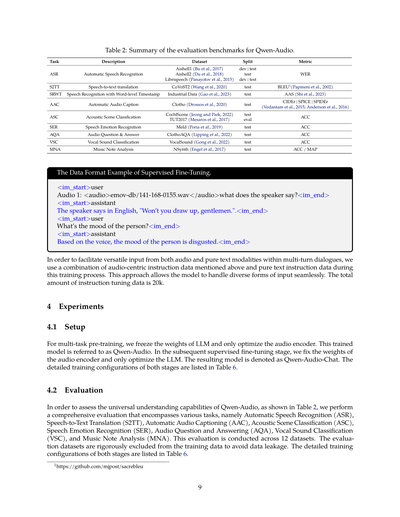
表2:Qwen-Audioの評価ベンチマークのまとめやで
| タスク | 説明 | データセット | 分割 | 評価指標 |
|--------|------|------------|------|----------|
| ASR | 自動音声認識(音声をテキストに変換するやつやな) | Aishell1 (Bu et al., 2017) | dev \| test | WER |
| | | Aishell2 (Du et al., 2018) | test | |
| | | Librispeech (Panayotov et al., 2015) | dev \| test | |
| S2TT | 音声からテキストへの翻訳 | CoVoST2 (Wang et al., 2020) | test | BLEU1(Papineni et al., 2002) |
| SRWT | 単語レベルのタイムスタンプ付き音声認識 | 産業データ (Gao et al., 2023) | test | AAS (Shi et al., 2023) |
| AAC | 自動音声キャプション生成(音が何かを説明文にするやつ) | Clotho (Drossos et al., 2020) | test | CIDEr \| SPICE \| SPIDEr (Vedantam et al., 2015; Anderson et al., 2016) |
| ASC | 音響シーン分類(どんな場所の音かを当てるやつ) | CochlScene (Jeong and Park, 2022) | test | ACC |
| | | TUT2017 (Mesaros et al., 2017) | eval | |
| SER | 音声感情認識(話してる人の気持ちを読み取るやつ) | Meld (Poria et al., 2019) | test | ACC |
| AQA | 音声に関する質問応答 | ClothoAQA (Lipping et al., 2022) | test | ACC |
| VSC | 声の音分類(咳とか笑い声とかを見分けるやつ) | VocalSound (Gong et al., 2022) | test | ACC |
| MNA | 音楽ノート分析 | NSynth (Engel et al., 2017) | test | ACC / MAP |
**教師ありファインチューニングのデータフォーマット例やで**
```
<im_start>user
Audio 1: <audio>emov-db/141-168-0155.wav</audio>話し手は何て言うてる?<im_end>
<im_start>assistant
話し手は英語で「Won't you draw up, gentlemen.」って言うてはるわ。<im_end>
<im_start>user
この人の気分はどんな感じ?<im_end>
<im_start>assistant
声から判断すると、この人の気分はめっちゃ嫌悪感を示してるな。<im_end>
```
複数回の対話の中で、音声と純粋なテキストの両方から柔軟に入力を受け付けられるようにするために、このトレーニングでは上で言うた音声中心の指示データと純粋なテキストの指示データを組み合わせて使ってんねん。このアプローチのおかげで、モデルがいろんな形式の入力をスムーズに処理できるようになるっちゅうわけや。指示チューニングデータの総量は2万件やで。
## 4 実験
### 4.1 セットアップ
マルチタスク事前学習では、LLM(大規模言語モデル)の重みは固定して、音声エンコーダだけを最適化するねん。このトレーニング済みモデルをQwen-Audioって呼ぶわけや。その後の教師ありファインチューニングの段階では、逆に音声エンコーダの重みを固定して、LLMだけを最適化すんねん。この結果できたモデルがQwen-Audio-Chatや。両方の段階の詳しいトレーニング設定は表6に載せてあるで。
### 4.2 評価
Qwen-Audioの汎用的な理解能力を評価するために、表2に示してある通り、いろんなタスクを網羅した総合評価をやってんねん。具体的には、自動音声認識(ASR)、音声からテキストへの翻訳(S2TT)、自動音声キャプション生成(AAC)、音響シーン分類(ASC)、音声感情認識(SER)、音声質問応答(AQA)、声の音分類(VSC)、そして音楽ノート分析(MNA)やな。この評価は12個のデータセットで実施してるで。なんでかっていうと、データリークを避けるために、評価用データセットはトレーニングデータからめっちゃ厳格に除外してあんねん。両方の段階の詳しいトレーニング設定は表6に載せてあるで。
1https://github.com/mjpost/sacrebleu
9
---
## Page 10
[](/attach/ec2582e1767927a67bc68db1fa9324c3a7839b8d2efa348ac6c76c57f5b44fae_p010.png)
### 和訳
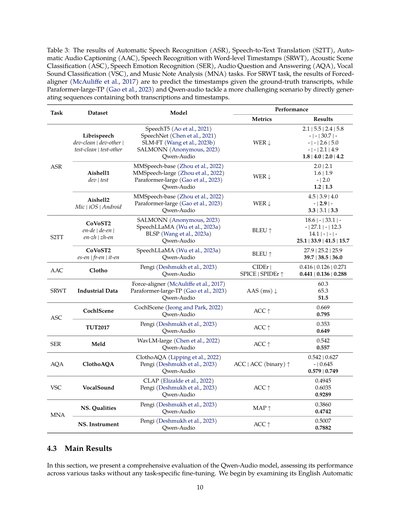
表3:自動音声認識(ASR)、音声からテキストへの翻訳(S2TT)、自動音声キャプション生成(AAC)、単語レベルタイムスタンプ付き音声認識(SRWT)、音響シーン分類(ASC)、音声感情認識(SER)、音声質問応答(AQA)、発声音分類(VSC)、音楽ノート分析(MNA)タスクの結果やで。SRWTタスクについては、Force-aligner(McAuliffeら、2017)の結果は正解の書き起こしをもとにタイムスタンプを予測するもんやねんけど、Paraformer-large-TP(Gaoら、2023)とQwen-audioはもっと難しいシナリオに挑戦してて、書き起こしとタイムスタンプの両方を含むシーケンスを直接生成してるんやで。
| タスク | データセット | モデル | 評価指標 | 結果 |
|--------|--------------|--------|----------|------|
| ASR | Librispeech dev-clean \| dev-other \| test-clean \| test-other | SpeechT5(Aoら、2021)<br>SpeechNet(Chenら、2021)<br>SLM-FT(Wangら、2023b)<br>SALMONN(Anonymous、2023)<br>Qwen-Audio | WER ↓ | 2.1 \| 5.5 \| 2.4 \| 5.8<br>- \| - \| 30.7 \| -<br>- \| 2.6 \| 5.0<br>- \| - \| 2.1 \| 4.9<br>1.8 \| 4.0 \| 2.0 \| 4.2 |
| ASR | Aishell1 dev \| test | MMSpeech-base(Zhouら、2022)<br>MMSpeech-large(Zhouら、2022)<br>Paraformer-large(Gaoら、2023)<br>Qwen-Audio | WER ↓ | 2.0 \| 2.1<br>1.6 \| 1.9<br>- \| 2.0<br>1.2 \| 1.3 |
| ASR | Aishell2 Mic \| iOS \| Android | MMSpeech-base(Zhouら、2022)<br>Paraformer-large(Gaoら、2023)<br>Qwen-Audio | WER ↓ | 4.5 \| 3.9 \| 4.0<br>- \| 2.9 \| 3.3<br>3.1 \| 3.3 |
| S2TT | CoVoST2 en-de \| de-en \| en-zh \| zh-en | SALMONN(Anonymous、2023)<br>SpeechLLaMA(Wuら、2023a)<br>BLSP(Wangら、2023a)<br>Qwen-Audio | BLEU ↑ | 18.6 \| - \| 33.1 \| -<br>27.1 \| - \| 12.3<br>14.1 \| - \| -<br>25.1 \| 33.9 \| 41.5 \| 15.7 |
| S2TT | CoVoST2 es-en \| fr-en \| it-en | SpeechLLaMA(Wuら、2023a)<br>Qwen-Audio | BLEU ↑ | 27.9 \| 25.2 \| 25.9<br>39.7 \| 38.5 \| 36.0 |
| AAC | Clotho | Pengi(Deshmukhら、2023)<br>Qwen-Audio | CIDEr \| SPICE \| SPIDEr ↑ | 0.416 \| 0.126 \| 0.271<br>0.441 \| 0.136 \| 0.288 |
| SRWT | 産業データ | Force-aligner(McAuliffeら、2017)<br>Paraformer-large-TP(Gaoら、2023)<br>Qwen-Audio | AAS(ms)↓ | 60.3<br>65.3<br>51.5 |
| ASC | CochlScene | CochlScene(JeongとPark、2022)<br>Qwen-Audio | ACC ↑ | 0.669<br>0.795 |
| ASC | TUT2017 | Pengi(Deshmukhら、2023)<br>Qwen-Audio | ACC ↑ | 0.353<br>0.649 |
| SER | Meld | WavLM-large(Chenら、2022)<br>Qwen-Audio | ACC ↑ | 0.542<br>0.557 |
| AQA | ClothoAQA | ClothoAQA(Lippingら、2022)<br>Pengi(Deshmukhら、2023)<br>Qwen-Audio | ACC \| ACC(バイナリ)↑ | 0.542 \| 0.627<br>- \| 0.645<br>0.579 \| 0.749 |
| VSC | VocalSound | CLAP(Elizaldeら、2022)<br>Pengi(Deshmukhら、2023)<br>Qwen-Audio | ACC ↑ | 0.4945<br>0.6035<br>0.9289 |
| MNA | NS. Qualities | Pengi(Deshmukhら、2023)<br>Qwen-Audio | MAP ↑ | 0.3860<br>0.4742 |
| MNA | NS. Instrument | Pengi(Deshmukhら、2023)<br>Qwen-Audio | ACC ↑ | 0.5007<br>0.7882 |
4.3 主な結果
このセクションでは、Qwen-Audioモデルの包括的な評価を見せたるで。なんでかっていうと、タスクごとの専用ファインチューニングなしで、いろんなタスクでどれくらいの性能が出るかを見るためやねん。まず最初に、英語の自動音声認識の性能を見ていくで。
---
## Page 11
[](/attach/ec2582e1767927a67bc68db1fa9324c3a7839b8d2efa348ac6c76c57f5b44fae_p011.png)
### 和訳
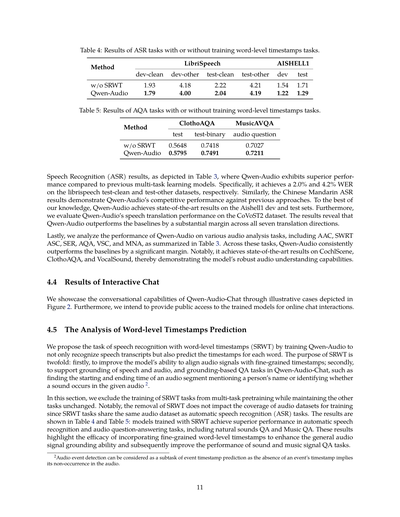
表4:単語レベルのタイムスタンプ予測タスクありなしでの音声認識(ASR)の結果やで
| 手法 | LibriSpeech | | | | AISHELL1 | |
|------|-------------|------------|------------|------------|----------|----------|
| | dev-clean | dev-other | test-clean | test-other | dev | test |
| SRWTなし | 1.93 | 4.18 | 2.22 | 4.21 | 1.54 | 1.71 |
| Qwen-Audio | 1.79 | 4.00 | 2.04 | 4.19 | 1.22 | 1.29 |
表5:単語レベルのタイムスタンプ予測タスクありなしでの音声質問応答(AQA)の結果やで
| 手法 | ClothoAQA | | MusicAVQA |
|------|-----------|-------------|-------------------|
| | test | test-binary | audio question |
| SRWTなし | 0.5648 | 0.7418 | 0.7027 |
| Qwen-Audio | 0.5795 | 0.7491 | 0.7211 |
音声認識(ASR)の結果は表3に載ってるんやけど、見てみたらQwen-Audioがこれまでのマルチタスク学習モデルよりめっちゃ優秀やねん。具体的に言うと、librispeechのtest-cleanとtest-otherっていうデータセットで、それぞれ2.0%と4.2%のWER(単語誤り率)を達成してんねん。中国語の普通話の音声認識でも、他の手法とええ勝負しとるで。ワイらが知る限り、Qwen-AudioはAishell1のdevセットとtestセットで最高記録を叩き出しとるんや。さらにな、CoVoST2っていうデータセットで音声翻訳の性能も評価したんやけど、7つの翻訳方向全部で、他の比較対象をぶっちぎりで上回っとるねん。
最後に、いろんな音声分析タスクでQwen-Audioがどんだけイケてるか分析したで。AAC(音声自動キャプショニング)、SWRT、ASC(音響シーン分類)、SER(音声感情認識)、AQA(音声質問応答)、VSC(発声音分類)、MNA(音楽分析)とかな。これらは表3にまとめてあるで。どのタスクでもQwen-Audioは他のモデルをめっちゃ大きく上回っとるねん。特にすごいのは、CochlScene、ClothoAQA、VocalSoundで最高記録を達成しとることや。これでこのモデルの音声理解能力がほんまにしっかりしとるってことがわかるやろ?
4.4 対話チャットの結果
Qwen-Audio-Chatの会話能力を、図2に載せた実例で見せとるで。あと、学習済みモデルをオンラインチャット用に一般公開する予定やから、楽しみにしといてな。
4.5 単語レベルのタイムスタンプ予測の分析
ワイらは「単語レベルタイムスタンプ付き音声認識」(SRWT)っていうタスクを提案したんや。これはQwen-Audioに音声の書き起こしだけやなくて、各単語のタイムスタンプも予測させるっちゅうもんやねん。なんでこれやるかっていうと、目的は2つあんねん。1つ目は、音声信号と細かいタイムスタンプをうまく合わせる能力を上げるため。2つ目は、Qwen-Audio-Chatで音声や音のグラウンディング(位置特定)とか、それに基づく質問応答タスクをサポートするためや。例えば「この人の名前が出てくる部分の開始時間と終了時間はどこ?」とか「この音声の中でこの音は鳴ってる?」みたいな質問に答えられるようになるねん。
このセクションでは、マルチタスク事前学習からSRWTタスクだけ外して、他は全部そのままにして実験したで。ポイントは、SRWTを外しても学習に使う音声データセットの範囲は変わらんっちゅうことや。なんでかっていうと、SRWTタスクは普通の音声認識(ASR)タスクと同じ音声データセットを使うからやねん。結果は表4と表5に載せとるで。SRWTを入れて学習したモデルの方が、音声認識でも音声質問応答でも成績がええねん。自然音のQAも音楽のQAもな。この結果から言えるんは、細かい単語レベルのタイムスタンプを入れることで、音声信号全般のグラウンディング能力が上がって、結果的に音や音楽の質問応答タスクの性能もアップするっちゅうことやな。
²音声イベント検出は、イベントのタイムスタンプ予測のサブタスクと考えられるねん。なんでかっていうと、タイムスタンプがないってことは、その音声の中でそのイベントが起きてないってことを意味するからや。
11
---
## Page 12
[](/attach/ec2582e1767927a67bc68db1fa9324c3a7839b8d2efa348ac6c76c57f5b44fae_p012.png)
### 和訳
# 5章 まとめ
この論文では、Qwen-Audioシリーズっていう、めっちゃすごい大規模な音声と言語を扱えるモデルを紹介してるねん。これ何がすごいかって、どんな種類の音声でも理解できる「ユニバーサルな音声理解能力」を持ってるとこやな。
いろんな種類の音声データを一緒に学習させるために、「統一マルチタスク学習フレームワーク」っていう新しい仕組みを提案してん。これのええとこは、似たようなタスク同士で知識を共有できるし、テキストのフォーマットが違うことで起きる「一対多マッピング問題」ってやつも回避できるねん。要するに、一つの入力に対して答えがバラバラになってまう問題を解決したってことや。
ほんで、特定のタスク用にファインチューニングせんでも、できあがったQwen-Audioモデルは、いろんなベンチマークテストで今までの研究を上回る結果を出してるねん。これがまさにユニバーサルな音声理解能力の証明やな。
さらに「教師あり指示ファインチューニング」ってやつをやることで、Qwen-Audio-Chatは人間の意図にバッチリ合わせられる能力を発揮してん。多言語対応やし、何回もやり取りする会話もできるし、音声入力でもテキスト入力でもOKっていう、ほんまに使い勝手ええやつになってるわ。
# 6章 謝辞
Jinze Bai、Shuai Bai、Peng Wang、Sinan Tan、Shijie Wangの皆さんには、めっちゃ参考になる議論してもらって感謝してるで。あとJuan Zhu、Junyang Lin、Siqi Zheng、Jiaming Wang、Zhihao Duの皆さんにも、このプロジェクトをサポートしてもらってほんまにありがとうございます。
# 参考文献
Jean-Baptiste Alayracらの研究(2022):Flamingoっていう視覚と言語のモデルで、少ないデータでも学習できるやつを発表してるねん。NeurIPSで発表されたやつや。
Peter Andersonらの研究(2016):SPICEっていう、画像のキャプションを意味的に評価する手法を提案してるねん。ヨーロッパのコンピュータビジョンの学会ECCVで発表されたやつや。
Rohan Anilらの研究(2023):PaLM 2の技術レポートや。arXivに載ってるで。
匿名の研究(2023):SALMONNっていう、大規模言語モデルに汎用的な聴覚能力を持たせようって研究や。ICLRに投稿されて、今審査中やねん。
Junyi Aoらの研究(2021):SpeechT5っていう、話し言葉処理のための統一的なエンコーダー・デコーダーの事前学習手法を提案してるねん。
Jinze Baiらの研究(2023a):Qwenの技術レポートや。arXivに載ってるで。
Jinze Baiらの研究(2023b):Qwen-VLっていう、めっちゃ多機能な大規模視覚言語モデルを発表してるねん。
Tom Brownらの研究(2020):「言語モデルは少数サンプル学習者や」って研究で、NeurIPSで発表されたやつや。これ、GPT-3の論文として有名やな。
Hui Buらの研究(2017):AISHELL-1っていうオープンソースの中国語音声コーパスと、音声認識のベースラインを発表してるねん。O-COCOSDA 2017でソウルで発表されたやつや。
---
## Page 13
[](/attach/ec2582e1767927a67bc68db1fa9324c3a7839b8d2efa348ac6c76c57f5b44fae_p013.png)
### 和訳
Keqin Chenさんたち、Zhao Zhangさんたち、Weili Zengさんたち、Richong Zhangさん、Feng Zhuさん、そしてRui Zhaoさんがな、2023年に出した「Shikra」っていう論文があるねん(arXiv:2306.15195)。これがめっちゃすごくてな、マルチモーダルな大規模言語モデルで「これ」とか「あれ」とか指し示しながら対話できる魔法みたいな機能を解き放ったんやで。
Sanyuan Chenさんを筆頭に、Chengyi Wangさん、Zhengyang Chenさん、Yu Wuさん、Shujie Liuさん、Zhuo Chenさん、Jinyu Liさん、Naoyuki Kandaさん、Takuya Yoshiokaさん、Xiong Xiaoさん、Jian Wuさん、Long Zhouさん、Shuo Renさん、Yanmin Qianさん、Yao Qianさん、もう一人のJian Wuさん、Michael Zengさん、Xiangzhan Yuさん、そしてFuru Weiさんがな、2022年に「WavLM」っていうのを発表してん(IEEE J. Sel. Top. Signal Process.に載ってるで)。これ何かっていうと、音声処理の全部の工程に使えるように、めっちゃ大規模な自己教師あり学習で事前学習させたモデルやねん。つまり、ラベル付きデータなしで音声の特徴をガッツリ学習させて、色んな音声タスクに応用できるようにしたんや。
Yi-Chen Chenさんたち、Po-Han Chiさん、Shu-wen Yangさん、Kai-Wei Changさん、Jheng-hao Linさん、Sung-Feng Huangさん、Da-Rong Liuさん、Chi-Liang Liuさん、Cheng-Kuang Leeさん、そしてHung-yi Leeさんが2021年に「SpeechNet」を出してん(arXiv:2105.03070)。これはな、音声処理のタスクならなんでもこなせる万能なモジュール型モデルやねん。部品を組み合わせるみたいにして、いろんな音声タスクに対応できるようになってるんやで。
Aakanksha Chowdheryさんを筆頭に、Sharan Narangさん、Jacob Devlinさん、Maarten Bosmaさん、Gaurav Mishraさん、Adam Robertsさん、Paul Barhamさん、Hyung Won Chungさん、Charles Suttonさん、Sebastian Gehrmannさんらが2022年に「PaLM」を発表してん(arXiv:2204.02311)。これはPathwaysっていう仕組みを使って言語モデルをめっちゃスケールアップさせた研究やねん。でっかくすればするほど賢くなるっていうのをガチで証明した論文やで。
Alexandre Défossezさん、Jade Copetさん、Gabriel Synnaaveさん、そしてYossi Adiさんが2022年に出したんが「高品質なニューラル音声圧縮」の論文やねん(arXiv:2210.13438)。音声をめっちゃ小さく圧縮しても、ほんまに高音質で再現できるっていう技術やで。
Soham Deshmukhさん、Benjamin Elizaldeさん、Rita Singhさん、そしてHuaming Wangさんが2023年に「Pengi」っていうのを発表してん(CoRRに載ってるで)。これは音声用の言語モデルで、いろんな音声タスクに対応できるやつやねん。
Konstantinos Drossosさん、Samuel Lippingさん、そしてTuomas Virtanenさんが2020年に「Clotho」っていうデータセットを発表したんや(2020年5月4日から8日にスペインのバルセロナでやったICASSP 2020で発表、IEEE主催やで)。これは音声キャプショニング用のデータセットでな、音を聞いてそれを文章で説明する研究に使えるやつやねん。
Jiayu Duさん、Xingyu Naさん、Xuechen Liuさん、そしてHui Buさんが2018年に「AISHELL-2」を発表してん(abs/1808.10583)。これは中国語の音声認識研究を産業レベルにまで引き上げたデータセットやねん。研究用やったのを、実際のビジネスで使えるレベルにしたってことやな。
Benjamin Elizaldeさん、Soham Deshmukhさん、Mahmoud Al Ismailさん、そしてHuaming Wangさんが2022年に「CLAP」を出してん(abs/2206.04769)。これがめっちゃ面白くてな、自然言語の説明を監督信号にして音声の概念を学習するっていうアプローチやねん。つまり「これはこういう音やで」っていう文章から、音の特徴を学習させるんや。
Jesse H. Engelさん、Cinjon Resnickさん、Adam Robertsさん、Sander Dielemanさん、Mohammad Norouziさん、Douglas Eckさん、そしてKaren Simonyanさんが2017年に発表したのが「WaveNetオートエンコーダで楽器の音をニューラルネットで合成する」っていう研究やねん(2017年8月6日から11日にオーストラリアのシドニーでやったICML 2017で発表、Proceedings of Machine Learning Researchに載ってるで、PMLRが出版元や)。楽器の音を人工的に作り出す技術やな。
Zhifu Gaoさんを筆頭に、Zerui Liさん、Jiaming Wangさん、Haoneng Luoさん、Xian Shiさん、Mengzhe Chenさん、Yabin Liさん、Lingyun Zuoさん、Zhihao Duさん、Zhangyu Xiaoさん、そしてShiliang Zhangさんが2023年に「FunASR」を発表してん(CoRR, abs/2305.11013)。これは音声認識の基本的なエンドツーエンドのツールキットやねん。最初から最後まで一貫して音声認識できる道具箱みたいなもんやで。
Yuan Gongさん、Jin Yuさん、そしてJames R. Glassさんが2022年に「VocalSound」っていうデータセットを発表したんや(2022年5月23日から27日にシンガポールでやったICASSP 2022で発表、IEEEの155ページ目らへんに載ってるで、doi: 10.1109/ICASSP43922.2022.9746828)。これは人間の声の音(咳とか笑い声とかそういうの)を認識する精度を上げるためのデータセットやねん。
同じYuan Gongさん、それからSameer Khuranaさん、Leonid Karlinskyさん、そしてJames R. Glassさんが2023年に「Whisper-AT」を出してん(CoRR, abs/2307.03183)。これがおもろい発見でな、ノイズに強い音声認識器は、実は一般的な音のイベントをタグ付けするのもめっちゃ得意やったっていう研究やねん。一石二鳥みたいな話やな。
またまたYuan Gongさん、今度はHongyin Luoさん、Alexander H. Liuさん、Leonid Karlinskyさん、そしてJames R. Glassさんと一緒に2023年に「Listen, Think, and Understand(聞いて、考えて、理解する)」を発表してん(CoRR, abs/2305.10790)。タイトル通り、音声を聞いて、それについて考えて、理解するっていうモデルの研究やで。
Wei-Ning Hsuさん、Benjamin Bolteさん、Yao-Hung Hubert Tsaiさん、Kushal Lakhotiaさん、Ruslan Salakhutdinovさん、そしてAbdelrahman Mohamedさんが2021年に「HuBERT」を発表してん(IEEE ACM Trans. Audio Speech Lang. Process.に載ってるで)。これは隠れたユニットのマスク予測っていう方法で、自己教師あり学習による音声表現学習をやったんやねん。つまり、一部を隠して「ここ何やったっけ?」って当てさせることで、音声の特徴を学習させる方法やな。
Edward J Huさん、Yelong Shenさん、Phillip Wallisさん、Zeyuan Allen-Zhuさん、Yuanzhi Liさん、Shean Wangさん、Lu Wangさん、そしてWeizhu Chenさんが2021年に「LoRA」を発表してん(arXiv:2106.09685)。これはめっちゃ有名になった技術でな、大規模言語モデルを低ランク適応するっていう方法やねん。なんでかっていうと、でっかいモデル全部を再学習させるとめっちゃ大変やから、一部だけを効率よく調整する方法を考えたんや。これのおかげで、少ない計算資源でもモデルをカスタマイズできるようになったんやで。
---
## Page 14
[](/attach/ec2582e1767927a67bc68db1fa9324c3a7839b8d2efa348ac6c76c57f5b44fae_p014.png)
### 和訳
Rongjie Huangさんとか、Mingze Liさんとか、めっちゃ大勢の研究者が集まって作った「Audiogpt」っていう研究があんねん。これ何かっていうと、音声とか音楽とか効果音、それに喋ってる人の顔映像まで、AIに理解させたり作らせたりできるっていうすごいやつやねん。2023年にCoRRっていう論文アーカイブに出してはるで。
Il-Young JeongさんとJeongsoo Parkさんが作った「Cochlscene」っていうのもあんねん。これはクラウドソーシング、つまり一般の人たちの協力を借りて、いろんな場所の音のデータを集めるっていうやつや。2022年に発表されてるで。
Matthew Leさんらが2023年に発表した「Voicebox」は、テキストで指示したら、いろんな言語の音声をめっちゃ大規模に作れるっていう、ほんまにすごいシステムやねん。
Junnan Liさんらの「BLIP」は2022年にICMLっていうトップの機械学習会議で発表されたやつで、言葉と画像を一緒に学習させて、両方理解したり生成したりできるようにする技術やねん。
で、その続編の「BLIP-2」は2023年のICML(ハワイのホノルルでやった会議やで)で発表されてん。これは画像を理解するモデルと大規模言語モデル、両方とも凍結したまま(つまり学習済みのを変えずに)使って、言葉と画像の事前学習をブートストラップするっていう賢いやり方やねん。
Samuel Lippingさんらが2022年にEUSIPCOっていうヨーロッパの信号処理の会議(ベオグラードでやったやつ)で発表した「Clotho-AQA」は、音声に関する質問応答のデータセットやねん。これもクラウドソーシングで集めたやつやで。
Chenyang Lyuさんらが2023年に出した「Macaw-LLM」は、画像、音声、動画、テキスト、全部まとめて扱えるマルチモーダルな言語モデルやねん。めっちゃ欲張りな設計やな。
Soumi Maitiさんらの「Voxtlm」は2023年の論文で、デコーダーだけのモデルで音声認識と音声合成、さらに音声とテキストの続きを生成するタスクを全部統一的にやっちゃおうっていうやつやねん。
Michael McAuliffeさんらが2017年のInterspeech(ストックホルムでやった音声の国際会議)で発表した「Montreal Forced Aligner」は、Kaldiっていうツールを使って、テキストと音声のタイミングを自動で合わせられる学習可能なアライナーやねん。
Annamaria Mesarosさんらが2017年にミュンヘンで開催されたDCASEワークショップで発表したのは、DCASE2017チャレンジのセットアップやねん。タスクとかデータセットとかベースラインシステムの説明やで。DCASEっていうのは、音のシーンやイベントを検出・分類するコンペやねん。
Eliya Nachmaniさんらが2023年に出した論文は「声を持つ言語モデル」っていうタイトルで、音声トークンだけじゃなくて、もっと広い意味での音声言語モデリングについて研究してはるねん。
OpenAIの「ChatML」っていうのは、チャット形式のプロンプトを記述するための文書フォーマットやねん。GitHubで公開されてるで。
OpenAIは2022年にChatGPTを発表したんや。ブログで紹介してはるで。
2023年にはOpenAIが「GPT-4」の技術レポートも出してるねん。
Long Ouyangさんらが2022年のNeurIPSで発表した研究は、人間のフィードバックを使って言語モデルに指示に従うよう訓練するっていう、めっちゃ重要な技術やねん。いわゆるRLHF(人間のフィードバックによる強化学習)の基礎的な論文やで。
Vassil Panayotovさんらが2015年のICASSP(オーストラリアのサウスブリスベンでやった音声の国際会議)で発表した「LibriSpeech」は、パブリックドメインのオーディオブックを使って作った音声認識用のコーパスやねん。今でもめっちゃ使われてる有名なデータセットやで。
---
## Page 15
[](/attach/ec2582e1767927a67bc68db1fa9324c3a7839b8d2efa348ac6c76c57f5b44fae_p015.png)
### 和訳
Kishore Papineni、Salim Roukos、Todd Ward、Wei-Jing Zhu。Bleu:機械翻訳を自動で評価する方法やねん。計算言語学会の40周年記念大会の論文集に載ってるで、2002年の話や。
Daniel S. Park、William Chan、Yu Zhang、Chung-Cheng Chiu、Barret Zoph、Ekin D. Cubuk、Quoc V. Le。SpecAugment:自動音声認識のためのめっちゃシンプルなデータ水増し手法やねん。Interspeech 2019、国際音声コミュニケーション学会の第20回年次大会で発表されてん、オーストリアのグラーツで2019年9月15日から19日にかけてやったやつやで。
Zhiliang Peng、Wenhui Wang、Li Dong、Yaru Hao、Shaohan Huang、Shuming Ma、Furu Wei。Kosmos-2:マルチモーダルな大規模言語モデルを現実世界に紐づけるっていう研究やねん。arXiv:2306.14824、2023年。
Soujanya Poria、Devamanyu Hazarika、Navonil Majumder、Gautam Naik、Erik Cambria、Rada Mihalcea。MELD:会話の中の感情認識のためのマルチモーダル・マルチパーティなデータセットやで。計算言語学会第57回大会の論文集、ACL 2019、イタリアのフィレンツェで2019年7月28日から8月2日にやったやつ、第1巻:長い論文のやつに載ってるねん。計算言語学会、2019年。
Qwen。Qwen-7Bのご紹介:オープンな基盤モデルで人間の価値観に沿うように調整された最先端のやつやで、2023年。URLはこれや https://github.com/QwenLM/Qwen-7B。
Alec Radford、Jong Wook Kim、Tao Xu、Greg Brockman、Christine McLeavey、Ilya Sutskever。大規模な弱教師あり学習で頑健な音声認識を実現するっていう研究やねん。国際機械学習会議、ICML 2023、2023年7月23日から29日、アメリカのハワイ・ホノルルでやったやつやで。
Colin Raffel、Noam Shazeer、Adam Roberts、Katherine Lee、Sharan Narang、Michael Matena、Yanqi Zhou、Wei Li、Peter J Liu。統一されたテキストからテキストへの変換器で転移学習の限界を探るっていう研究やねん。機械学習研究ジャーナル、2020年。
Paul K. Rubenstein、Chulayuth Asawaroengchai、Duc Dung Nguyen、Ankur Bapna、Zalán Borsos、Félix de Chaumont Quitry、Peter Chen、Dalia El Badawy、Wei Han、Eugene Kharitonov、Hannah Muckenhirn、Dirk Padfield、James Qin、Danny Rozenberg、Tara N. Sainath、Johan Schalkwyk、Matthew Sharifi、Michelle Tadmor Ramanovich、Marco Tagliasacchi、Alexandru Tudor、Mihajlo Velimirovic、Damien Vincent、Jiahui Yu、Yongqiang Wang、Vicky Zayats、Neil Zeghidour、Yu Zhang、Zhishuai Zhang、Lukas Zilka、Christian Havnø Frank。AudioPaLM:喋れて聞けるっていう大規模言語モデルやねん。CoRRに載ってるで。
Yongliang Shen、Kaitao Song、Xu Tan、Dongsheng Li、Weiming Lu、Yueting Zhuang。HuggingGPT:ChatGPTとHuggingFaceの仲間たちでAIタスクを解決するっていう研究やで。CoRR、abs/2303.17580、2023年。
Xian Shi、Yanni Chen、Shiliang Zhang、Zhijie Yan。非自己回帰型のエンドツーエンド音声認識モデルで認識しながらタイムスタンプ予測も達成するっていう研究やねん。人間と機械の音声コミュニケーションに関する国際会議、Springer、2023年。
Yu Shu、Siwei Dong、Guangyao Chen、Wenhao Huang、Ruihua Zhang、Daochen Shi、Qiqi Xiang、Yemin Shi。LLaSM:大規模言語・音声モデルやで。arXiv:2308.15930、2023年。
Quan Sun、Qiying Yu、Yufeng Cui、Fan Zhang、Xiaosong Zhang、Yueze Wang、Hongcheng Gao、Jingjing Liu、Tiejun Huang、Xinlong Wang。マルチモダリティにおける生成的事前学習っていう研究やねん。arXiv:2307.05222、2023年。
Hugo Touvron、Thibaut Lavril、Gautier Izacard、Xavier Martinet、Marie-Anne Lachaux、Timothée Lacroix、Baptiste Rozière、Naman Goyal、Eric Hambro、Faisal Azharら。LLaMA:オープンで効率的な基盤言語モデルやで。arXiv:2302.13971、2023a。
Hugo Touvron、Thibaut Lavril、Gautier Izacard、Xavier Martinet、Marie-Anne Lachaux、Timothée Lacroix、Baptiste Rozière、Naman Goyal、Eric Hambro、Faisal Azharら。Llama:オープンで効率的な基盤言語モデルやで。arXiv:2302.13971、2023b。
Hugo Touvron、Louis Martin、Kevin Stone、Peter Albert、Amjad Almahairi、Yasmine Babaei、Nikolay Bashlykov、Soumya Batra、Prajjwal Bhargava、Shruti Bhosale、Dan Bikel、Lukas Blecher、Cristian Canton-Ferrer、Moya Chen、Guillem Cucurull、David Esiobu、Jude Fernandes、Jeremy Fu、Wenyin Fu、Brian Fuller、Cynthia
15
---
## Page 16
[](/attach/ec2582e1767927a67bc68db1fa9324c3a7839b8d2efa348ac6c76c57f5b44fae_p016.png)
### 和訳
Gao、Vedanuj Goswami、Naman Goyal、Anthony Hartshorn、Saghar Hosseini、Rui Hou、Hakan Inan、Marcin Kardas、Viktor Kerkez、Madian Khabsa、Isabel Kloumann、Artem Korenev、Punit Singh Koura、Marie-Anne Lachaux、Thibaut Lavril、Jenya Lee、Diana Liskovich、Yinghai Lu、Yuning Mao、Xavier Martinet、Todor Mihaylov、Pushkar Mishra、Igor Molybog、Yixin Nie、Andrew Poulton、Jeremy Reizenstein、Rashi Rungta、Kalyan Saladi、Alan Schelten、Ruan Silva、Eric Michael Smith、Ranjan Subramanian、Xiaoqing Ellen Tan、Binh Tang、Ross Taylor、Adina Williams、Jian Xiang Kuan、Puxin Xu、Zheng Yan、Iliyan Zarov、Yuchen Zhang、Angela Fan、Melanie Kambadur、Sharan Narang、Aurélien Rodriguez、Robert Stojnic、Sergey Edunov、Thomas Scialom。Llama 2:オープンな基盤モデルとファインチューニングされたチャットモデルやねん。CoRR、abs/2307.09288、2023c。
Ashish Vaswani、Noam Shazeer、Niki Parmar、Jakob Uszkoreit、Llion Jones、Aidan N. Gomez、Lukasz Kaiser、Illia Polosukhin。「Attention is all you need(アテンションだけでええねん)」っていう論文やな。これめっちゃ有名でな、Transformerっていう今のAIの基盤になってるアーキテクチャを提案した歴史的な論文やねん。Isabelle Guyon、Ulrike von Luxburg、Samy Bengio、Hanna M. Wallach、Rob Fergus、S. V. N. Vishwanathan、Roman Garnettが編集した、Neural Information Processing Systems 30っていう2017年の学会で発表されたやつや。
Ramakrishna Vedantam、C Lawrence Zitnick、Devi Parikh。CIDer:合意ベースの画像説明評価やねん。なんでかっていうと、画像のキャプションがどれくらいええかを測る指標やからな。CVPR 2015で発表されとる。
Changhan Wang、Anne Wu、Juan Miguel Pino。CoVoST 2:めっちゃ大規模な多言語の音声からテキストへの翻訳コーパスやで。abs/2007.10310、2020年。URL: https://arxiv.org/abs/2007.10310
Chen Wang、Minpeng Liao、Zhongqiang Huang、Jinliang Lu、Junhong Wu、Yuchen Liu、Chengqing Zong、Jiajun Zhang。BLSP:続き書きの振る舞いを揃えることで言語と音声の事前学習をブートストラップする方法やねん。要するに、言語モデルと音声モデルをうまいこと連携させる技術やな。arXiv:2309.00916、2023a。
Mingqiu Wang、Wei Han、Izhak Shafran、Zelin Wu、Chung-Cheng Chiu、Yuan Cao、Yongqiang Wang、Nanxin Chen、Yu Zhang、Hagen Soltau、Paul K. Rubenstein、Lukas Zilka、Dian Yu、Zhong Meng、Golan Pundak、Nikhil Siddhartha、Johan Schalkwyk、Yonghui Wu。SLM:音声とテキストの基盤モデルの間にある薄いギャップを橋渡しするやつやねん。ほんまに音声とテキストをシームレスにつなぐ技術やで。abs/2310.00230、2023b。
Mingqiu Wang、Wei Han、Izhak Shafran、Zelin Wu、Chung-Cheng Chiu、Yuan Cao、Yongqiang Wang、Nanxin Chen、Yu Zhang、Hagen Soltau、他。SLM:音声とテキストの基盤モデル間の薄いギャップを橋渡しするやつ。arXiv:2310.00230、2023c。
Tianrui Wang、Long Zhou、Ziqiang Zhang、Yu Wu、Shujie Liu、Yashesh Gaur、Zhuo Chen、Jinyu Li、Furu Wei。VIOLA:音声認識、合成、翻訳のための統一コーデック言語モデルやねん。つまり、音声に関するいろんなタスクを一つのモデルでこなせるっちゅうことや。CoRR、2023d。
Xiaofei Wang、Manthan Thakker、Zhuo Chen、Naoyuki Kanda、Sefik Emre Eskimez、Sanyuan Chen、Min Tang、Shujie Liu、Jinyu Li、Takuya Yoshioka。SpeechX:万能な音声トランスフォーマーとしてのニューラルコーデック言語モデルやで。めっちゃ汎用性高いやつやねん。CoRR、2023e。
Jian Wu、Yashesh Gaur、Zhuo Chen、Long Zhou、Yimeng Zhu、Tianrui Wang、Jinyu Li、Shujie Liu、Bo Ren、Linquan Liu、Yu Wu。音声からテキストへの変換と大規模言語モデルの統合におけるデコーダーオンリーアーキテクチャについての研究やねん。デコーダーだけの構造でどこまでいけるか調べたやつや。abs/2307.03917、2023a。
Shengqiong Wu、Hao Fei、Leigang Qu、Wei Ji、Tat-Seng Chua。NExT-GPT:なんでもありのマルチモーダルLLMやで。どんな入力でもどんな出力でもいけるっていうめっちゃすごいやつやねん。CoRR、abs/2309.05519、2023b。
Neil Zeghidour、Alejandro Luebs、Ahmed Omran、Jan Skoglund、Marco Tagliasacchi。SoundStream:エンドツーエンドのニューラル音声コーデックやねん。音声を効率よく圧縮・復元できる技術や。IEEE ACM Trans. Audio Speech Lang. Process.、2022年。
Dong Zhang、Shimin Li、Xin Zhang、Jun Zhan、Pengyu Wang、Yaqian Zhou、Xipeng Qiu。SpeechGPT:大規模言語モデルに生まれつきのクロスモーダル会話能力を与えるやつやで。要するに、テキストだけやなくて音声でも自然に会話できるようにしたモデルやねん。CoRR、abs/2305.11000、2023a。
Xin Zhang、Dong Zhang、Shimin Li、Yaqian Zhou、Xipeng Qiu。SpeechTokenizer:音声大規模言語モデルのための統一音声トークナイザーやねん。音声をトークンに変換する標準的な方法を提案しとるんや。CoRR、abs/2308.16692、2023b。
16
---
## Page 17
[](/attach/ec2582e1767927a67bc68db1fa9324c3a7839b8d2efa348ac6c76c57f5b44fae_p017.png)
### 和訳
Yu Zhang、Wei Han、James Qin、Yongqiang Wang、Ankur Bapna、Zhehuai Chen、Nanxin Chen、Bo Li、Vera Axelrod、Gary Wang、Zhong Meng、Ke Hu、Andrew Rosenberg、Rohit Prabhavalkar、Daniel S. Park、Parisa Haghani、Jason Riesa、Ginger Perng、Hagen Soltau、Trevor Strohman、Bhuvana Ramabhadran、Tara N. Sainath、Pedro J. Moreno、Chung-Cheng Chiu、Johan Schalkwyk、Françoise Beaufays、Yonghui Wu。Google USM:100言語を超える自動音声認識のスケーリング。CoRR、2023c。
これな、Googleがめっちゃすごい音声認識システム作ったって話やねん。「USM」っていうのは「Universal Speech Model」の略で、要するに「なんでも聞き取れる万能音声モデル」みたいなもんや。100言語以上に対応できるようにスケールアップしたんやで。普通の音声認識って英語とか日本語とか限られた言語しかあかんかったりするやん?でもこれは世界中のいろんな言語をカバーしようとしてるねん。めっちゃ野心的な研究やな。
Xiaohuan Zhou、Jiaming Wang、Zeyu Cui、Shiliang Zhang、Zhijie Yan、Jingren Zhou、Chang Zhou。MMSpeech:音声認識のためのマルチモーダル・マルチタスク・エンコーダ・デコーダ事前学習。abs/2212.00500、2022。
こっちはな、「MMSpeech」っていうシステムの話やねん。「マルチモーダル」っていうのは、音声だけやなくて文字とか画像とか、いろんな種類の情報を一緒に扱えるってことや。「マルチタスク」は複数の仕事を同時にこなせるってこと。ほんで「エンコーダ・デコーダ」っていうのは、入ってきた情報を一回ギュッと圧縮して(エンコード)、それをまた展開して結果を出す(デコード)っていう仕組みやねん。「事前学習」っていうのは、本番の仕事させる前にめっちゃ大量のデータで下ごしらえしとくことや。これやっとくと、あとから少ないデータでも賢く動けるようになるねん。
---
## Page 18
[](/attach/ec2582e1767927a67bc68db1fa9324c3a7839b8d2efa348ac6c76c57f5b44fae_p018.png)
### 和訳
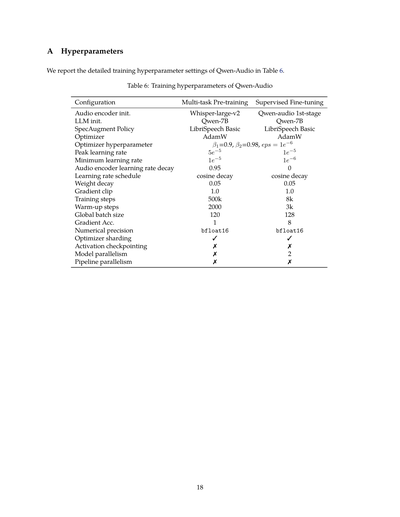
# 付録A ハイパーパラメータの話
さてさて、Qwen-Audioの学習設定について詳しく説明していくで!表6にまとめたから見てみてや。
## 表6:Qwen-Audioの学習ハイパーパラメータ
| 設定項目 | マルチタスク事前学習 | 教師ありファインチューニング |
|---------|---------------------|---------------------------|
| 音声エンコーダーの初期値 | Whisper-large-v2 | Qwen-audio 1st-stage |
| LLM(大規模言語モデル)の初期値 | Qwen-7B | Qwen-7B |
| SpecAugment(データ水増し)のやり方 | LibriSpeech Basic | LibriSpeech Basic |
| 最適化アルゴリズム | AdamW | AdamW |
| 最適化のこまかい設定 | β1=0.9, β2=0.98, eps = 1e−6 | β1=0.9, β2=0.98, eps = 1e−6 |
| 学習率のMAX | 1e−5 | 5e−5 |
| 学習率の最小値 | 1e−6 | 1e−5 |
| 音声エンコーダーの学習率減衰 | 0 | 0.95 |
| 学習率の変え方 | コサインで徐々に下げる | コサインで徐々に下げる |
| 重み減衰(正則化のやつな) | 0.05 | 0.05 |
| 勾配クリッピング | 1.0 | 1.0 |
| 学習ステップ数 | 8000回 | 50万回 |
| ウォームアップ期間 | 3000ステップ | 2000ステップ |
| グローバルバッチサイズ | 128 | 120 |
| 勾配の蓄積 | 8回 | 1回 |
| 計算精度 | bfloat16 | bfloat16 |
| オプティマイザのシャーディング | やってる✓ | やってる✓ |
| アクティベーションチェックポイント | やってない✗ | やってない✗ |
| モデル並列化 | 2分割 | なし✗ |
| パイプライン並列化 | なし✗ | なし✗ |
なんでこんな細かく書いてるかっていうとな、再現性ってめっちゃ大事やねん。他の研究者が「ほんまにそんな性能出るんか?」って思った時に、同じ設定で試せるようにしとかなあかんからな。事前学習とファインチューニングで設定ちょっと違うのも見どころやで!
---
![]()
1 / 1
100%