<<
applsci-16-00368-v2.pdf

---
## Page 1
[](/attach/e4a30c3639e7cda0676ec6fb410a51e32b5a1bc7bb8de451429341a0aecf5a09_p001.png)
### 和訳
**システマティックレビュー**
# 検索拡張生成(RAG)と大規模言語モデル(LLM)を使った企業のナレッジ管理と文書自動化:システマティック文献レビュー
**Ehlullah Karakurt*** と **Akhan Akbulut**
イスタンブール・キュルトゥール大学コンピュータ工学科(トルコ、イスタンブール 34158)
連絡先:a.akbulut@iku.edu.tr
* 問い合わせ先:ehlullah.karakurt@lcwaikiki.com
---
## 要旨
ほな、まず結論から言うとな、RAG(検索拡張生成)とLLM(大規模言語モデル)を組み合わせる技術が、企業のナレッジ管理をめっちゃ変えてきてんねん。せやけど、実際の仕事の現場でどう使われてるかって、まだよう分かってへんかったんよ。
そこでこの研究では、システマティック文献レビュー(SLR)っていう方法で、厳しい審査を通った63本の質の高い論文を分析して、こういう技術が実際の企業の課題にどう対応してるか調べたわけや。プラットフォームとか、データセットとか、アルゴリズムとか、評価指標とか、9つの研究課題を設定して、今の状況を整理したんやで。
ほんで分かったことやねんけど、企業での導入はまだまだ「実験段階」がほとんどやねん。具体的に言うと、実装の63.6%がGPTベースのモデルを使ってて、80.5%がFAISSとかElasticsearchみたいな標準的な検索フレームワークに頼ってる状態やな。
ここがめっちゃ重要なポイントやねんけど、このレビューで「研究室から市場へのギャップ」っていう大きな問題が見つかったんよ。なんでかっていうと、検索とか分類みたいなサブタスクでは、k分割交差検証みたいな学術的な検証方法が93.6%も使われてるのに、文章を生成する部分の評価は、計算コストの関係で固定のホールドアウトセット(テスト用に取り分けたデータ)に頼りがちやねん。
さらにな、本番環境で動かすのに必要なリアルタイム連携の課題に取り組んでる研究は、15%もないんよ。
この研究は、こういうギャップをちゃんとデータで示すことで、学術的な試作品と実際に企業で使える堅牢なアプリケーションの間の溝を埋めるための戦略的なロードマップを提供してるっちゅうわけや。
**キーワード**:検索拡張生成、大規模言語モデル、企業ナレッジ管理、文書自動化、システマティック文献レビュー
---
## 1. はじめに
デジタル変革の時代やな、あらゆる業界の組織が、めっちゃ大量の「構造化されてない情報」に埋もれてるんよ[1-3]。技術マニュアルとか、規制ポリシーとか、カスタマーサポートの記録とか、社内のWikiとか、マルチメディアのログとか、もうほんまにいろいろあるわけや。
特に金融とか医療みたいな業界では、規制を守りながら、イノベーションを加速させて、お客さんの満足度も上げなあかんから、知識をちゃんと整理して、検索して、統合せなあかんねん[4-6]。
せやけどな、従来のナレッジ管理システムって、キーワード検索とか手作業での分類に頼ってるから、どんどん変わっていくデータとか複雑なクエリにうまく対応でけへんのよ。古い企業アーカイブとか見てみ、ほんまに大変やで[1,7,8]。
今の文書自動化ワークフローも、契約書の作成とか、レポートの執筆とか、ポリシーとの整合性チェックとか、人手がめっちゃかかるし、ミスも起きやすいし、硬直したテンプレートに縛られてるっていう問題があるんよ[9-11]。
最近、LLM(大規模言語モデル)がめっちゃ進化してきてな。GPTとか、PaLMとか、LLaMAとか、あとオープンソースのOPTとか、GPT-NeoXとか、BLOOMとかがあって、自然言語の理解と生成の性能が上がってきたんや。ベンチマークタスクでの性能を見たら、それがよう分かるで。
---
**学術編集者**:Douglas O'Shaughnessy
受理日:2025年11月26日
改訂日:2025年12月15日
受諾日:2025年12月16日
公開日:2025年12月29日
**著作権**:© 2025 著者ら。スイス・バーゼルのMDPI社がライセンシー。本論文はクリエイティブ・コモンズ表示(CC BY)ライセンスの条件に基づくオープンアクセス論文やで。
**Appl. Sci. 2026, 16, 368**
https://doi.org/10.3390/app16010368
---
## Page 2
[](/attach/e4a30c3639e7cda0676ec6fb410a51e32b5a1bc7bb8de451429341a0aecf5a09_p002.png)
### 和訳
Appl. Sci. 2026, 16, 368
2 / 28ページ
2020年頃からめっちゃ進化してきてん[6,12–16]。こういうモデルって、ちゃんとした文章作ったり、質問に答えたり、ドキュメントをまとめたり、コード書いたりするんがめっちゃ得意やねん。でもな、学習したデータが固定されてるっていう弱点があって、マニアックな話題とか最新の情報になると精度が落ちて、「ハルシネーション」って呼ばれる嘘っぽい情報を出しちゃうことがあるんよ[17,18]。そこで登場するんが「RAG(検索拡張生成)」っていうアプローチやねん。これは何かっていうと、リアルタイムで知識を検索してきて、それをLLMの生成に組み合わせることで、今の専門的なデータにしっかり根拠を持たせるっていう仕組みやねん[1,2,19,20]。これのおかげで事実の間違いが減って精度が上がるから、初期の事例研究によると、法律文書のレビューとか、規制遵守のモニタリング、金融分析、テクニカルサポートの自動化みたいな企業向けタスクでLLMが使えるようになってきてるんよ[10,21,22]。
RAG+LLMの組み合わせはめっちゃ可能性あるんやけど、今の研究文献には、企業のナレッジマネジメントとか文書自動化に応用するための詳しいフレームワークが足りてへんのよ、特にスケーラビリティの面でな[3,9,23]。重要な研究課題がいっぱい出てきてて、例えば「契約書とかポリシーみたいないろんな種類の文書に対して、どの検索インデックスとかベクトルデータベース、ナレッジグラフの表現方法が一番効果的なん?」とか[18,24–28]。「検索してきた文脈をうまく取り込みながら、文章の流暢さを犠牲にせんようにLLMをファインチューニングしたりプロンプト設計したりするにはどうしたらええん?」とか[23,29,30]。「生成の品質、レイテンシ、事実の正確さをちゃんと測れる評価指標と検証戦略って何があるん?」とか[17,31,32]。このレビューでは、契約書生成、ポリシー遵守、カスタマーセルフサービスみたいな企業シナリオを評価して、うまくいってるRAG+LLMの導入事例を見ていきながら、リアルタイム統合とかスケーラビリティみたいな根強い課題も特定していくで[32–34]。
こういうギャップを埋めるために、企業のナレッジマネジメントと文書自動化の文脈でRAG+LLM研究の包括的な系統的文献レビュー(SLR)をやったんよ。2015年から2025年中頃までの論文をカバーしてて、2025年の補足的な知見も入れてるで[1,2,35]。このレビューでは6つの主要な学術データベースを検索したんや:IEEE Xplore、ACM Digital Library、ScienceDirect、SpringerLink、Wiley Online Library、そしてGoogle Scholarやな[35]。レビューの範囲は学術論文だけやなくて学会発表論文も含めるように広げたで。これらの研究課題(RQ)に導かれて63件の研究を分析したんやけど、詳しくはセクション3に書いてあるで。プラットフォーム、データセット、機械学習の種類、具体的なRAG+LLMアルゴリズム、評価指標、検証手法、知識表現方法、最もパフォーマンスのええ構成、そして未解決の課題について調べたんや。500本以上の候補論文を集めた後、英語以外の論文、フルテキストのない要旨だけのもの、実証研究やないもの、RAG+LLMの方法論が詳しく書いてへん論文を除外する基準を適用して、厳密な品質評価の結果、63本の高品質な論文に絞り込んだんよ[35]。各研究の技術的アプローチ、データセット、パフォーマンス指標、検証戦略、報告された課題についてデータを抽出して統合したで[35]。
分析からいくつかの注目すべきトレンドが見えてきたで。まず、企業向けRAG+LLM研究は2020年以降めっちゃ急成長してて、学術論文と学会発表がほぼ半々くらいの割合やねん[1,2]。次に、教師あり学習が今も主流のパラダイムなんやけど、ラベル付きデータが少ないシナリオ向けに、半教師ありとか教師なしの検索に関する新しい研究も出てきてて期待できそうやで[7,36,37]。3つ目に、密ベクトル検索と記号的ナレッジグラフとプロンプトによるLLMチューニングを組み合わせたハイブリッドアーキテクチャが、精度と解釈可能性と計算効率のバランスを取るためにどんどん採用されてきてるんよ[18,25–29,38–40]。4つ目に、評価の実践はまだバラバラで、QAタスクの標準的な指標として適合率と再現率は使われてるけど、ビジネスへの影響をエンドツーエンドで測定してる研究はほとんどないんよな[7,17,31]。最後に、企業の事例研究の分析に基づくと、重要な課題はLLMを企業独自のデータと統合するときにデータプライバシーを維持すること——特に規制の厳しい業界でな——それからリアルタイムアプリケーション向けにレイテンシを最適化すること、そしてハルシネーションを検出して軽減するための堅牢な方法を開発することやねん[32–34,41–44]。これらの知見に基づいて、導入する人向けのベストプラクティスの推奨事項をまとめたで:モジュラーなシステム設計、継続的なインデックス更新、効率的な最近傍探索、フェデレーテッドデバイス検索、そしてハイブリッド評価や
https://doi.org/10.3390/app16010368
---
## Page 3
[](/attach/e4a30c3639e7cda0676ec6fb410a51e32b5a1bc7bb8de451429341a0aecf5a09_p003.png)
### 和訳
ほな、企業向け知識管理とドキュメント自動化についてのRAG研究、説明していくでー!
---
評価フレームワークの話やねんけど、自動的に計算されるメトリクスと人間からのフィードバックを組み合わせるんが今のトレンドやねん [24,45-48]。ほんで、まだ研究せなあかん課題もいっぱいあるんよ。例えば、テキストと画像と表データを一緒に扱えるマルチモーダルRAGの仕組みとか [49-51]、ユーザーごとに最適な情報を取ってくるアダプティブ検索っていう技術とか [52,53]、あと実際のビジネスでどんだけ役に立つか測れるベンチマーク(テスト集)を作るとか [17]。このシステマティック文献レビュー(SLR)は、企業の知識管理とドキュメント自動化におけるRAG+LLMについて、ちゃんとデータに基づいて整理した内容をまとめとるんや。研究手法がどう進化してきたか、今の標準的なやり方、あと重要な課題も全部カバーしとる。文献を総合することで、検索・生成・企業規模AIが交わるところで今後どう研究していくべきかっていうロードマップを示しとるんやで [3]。
## 2. 背景と関連研究
このセクションでは、企業向けにおけるRAG(検索拡張生成)の技術的な範囲を説明して、既存のサーベイ論文との違いを明らかにするで。特に、汎用的な大規模言語モデル(LLM)から、企業の知識管理(KM)とドキュメント自動化に適した、ちゃんと根拠のあるドメイン特化型アーキテクチャへの移行に焦点当てとるんや。
### 2.1. 企業環境におけるRAG(検索拡張生成)
大規模言語モデル(LLM)ってめっちゃ流暢に文章書けるんやけど、企業で使おうとすると問題が出てくるんよ。なんでかっていうと、嘘つく(ハルシネーション)し、専門分野の知識持ってへんし、学習データが古いままで更新されへんからや [23,34,44]。RAGはこういう問題を解決するために、知識ベースとモデル本体を切り離すんや。そうすることで、生成部分が検索の仕組みを使って最新の社内情報にアクセスできるようになるんやで [2,19,54]。
典型的な企業向けRAGアーキテクチャでは、まず検索システムが社内文書の中から関連する部分を見つけてくるんや(ベクトルの類似度を使うか、キーワードマッチングを使うかで)。ほんでそれをLLMのコンテキストウィンドウに入れて、根拠のある文章を生成させるんやな [26,52]。普通の学術ベンチマークと違って、企業の実装では、密なベクトル埋め込みとナレッジグラフ(KG)っていう記号的な知識表現を組み合わせたハイブリッド方式をよう使うんや。規制業界で求められる高い精度と監査可能性を確保するためやねん [1,25,45]。
### 2.2. 企業での応用:知識管理とドキュメント自動化
従来の企業知識管理システムは、固定的な分類体系とキーワード検索に頼っとったんやけど、構造化されてないデータがどんどん増えると対応しきれへんくなるんよ [1,18]。同じように、昔ながらのドキュメント自動化は壊れやすいルールベースのテンプレートに依存しとる [9]。RAG+LLMアーキテクチャは、意味検索と文脈を理解したコンテンツ生成を可能にすることで、このギャップを埋めるんや。
表1に示すとおり、63本の主要な研究を調べた結果、6つの主要な応用分野が見つかったで。研究の大部分は規制コンプライアンス(26.0%)と契約自動化(23.4%)に集中しとる。これは、手間のかかるテキスト中心の作業を自動化する価値がめっちゃ高いからやねん [9,16,55]。
**表1. 知識管理ドメイン別の研究分布**
| ドメイン | 論文数 | 割合 |
|----------|--------|------|
| 規制コンプライアンス・ガバナンス | 16 | 25.4% |
| 契約・法務文書自動化 | 15 | 23.8% |
| カスタマーサポートチャットボット | 12 | 19.0% |
| 技術マニュアル生成 | 10 | 15.9% |
| 財務報告・分析 | 7 | 11.1% |
| 医療ドキュメンテーション | 3 | 4.8% |
| **合計** | **63** | **100.0%** |
---
## Page 4
[](/attach/e4a30c3639e7cda0676ec6fb410a51e32b5a1bc7bb8de451429341a0aecf5a09_p004.png)
### 和訳
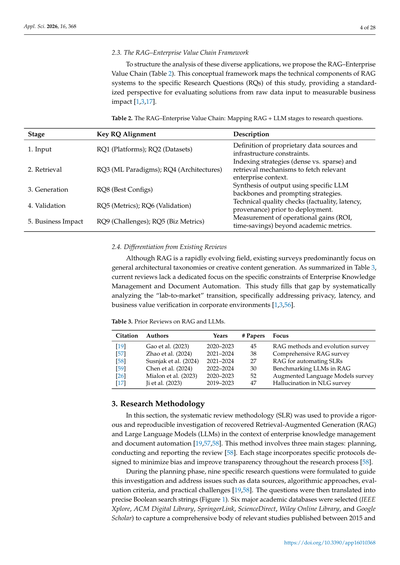
2.3. RAG–企業バリューチェーンのフレームワーク
ほんでな、こういうバラバラな応用例をちゃんと整理して分析するために、ワイらは「RAG–企業バリューチェーン」っていうフレームワークを提案するねん(表2見てな)。これ何かっていうと、RAGシステムの技術的な部品と、この研究の具体的なリサーチクエスチョン(RQ)を結びつける概念的な枠組みやねん。生のデータ入力から、最終的にビジネスでどんだけ効果あったかまで、統一された視点で評価できるようになるわけや[1,3,17]。
表2. RAG–企業バリューチェーン:RAG + LLMの各段階とリサーチクエスチョンの対応表
| 段階 | 対応するRQ | 説明 |
|------|------------|------|
| 1. 入力 | RQ1(プラットフォーム); RQ2(データセット) | 会社独自のデータソースとか、インフラの制約を決めるとこやな |
| 2. 検索 | RQ3(機械学習のパラダイム); RQ4(アーキテクチャ) | インデックスの作り方(密ベクトルか疎ベクトルか)とか、企業の文脈に関連する情報を取ってくる仕組みのことや |
| 3. 生成 | RQ8(最適な設定) | 特定のLLMモデルとプロンプトの戦略を使って、出力をまとめ上げるとこやな |
| 4. 検証 | RQ5(評価指標); RQ6(検証) | 本番投入前の技術的な品質チェックや。事実かどうか、速度はどうか、情報の出典はどこかとかな |
| 5. ビジネスインパクト | RQ9(課題); RQ5(ビジネス指標) | 学術的な指標だけやなくて、ROIとか時間短縮とか、実際の業務でどんだけ得したかを測るとこや |
2.4. 既存レビューとの違い
RAGってめっちゃ進化が早い分野やねんけど、今出てる調査論文って、だいたい一般的なアーキテクチャの分類とか、クリエイティブなコンテンツ生成の話がメインやねん。表3にまとめたけど、今あるレビュー論文には「企業のナレッジ管理」とか「ドキュメント自動化」に特化したもんがないねん。せやからこの研究では、そこをちゃんと埋めるために、「研究室から市場へ」の移行を体系的に分析してるわけや。特に企業環境でのプライバシーの問題とか、レイテンシ(応答速度)の問題とか、ビジネス価値がほんまにあるんかの検証とかな[1,3,56]。
表3. RAGとLLMに関する先行レビュー
| 引用 | 著者 | 対象期間 | 論文数 | 焦点 |
|------|------|----------|--------|------|
| [19] | Gao et al. (2023) | 2020–2023 | 45 | RAGの手法と進化のサーベイ |
| [57] | Zhao et al. (2024) | 2021–2024 | 38 | RAGの包括的サーベイ |
| [58] | Susnjak et al. (2024) | 2021–2024 | 27 | 系統的文献レビュー自動化のためのRAG |
| [59] | Chen et al. (2024) | 2022–2024 | 30 | RAGにおけるLLMのベンチマーク |
| [26] | Mialon et al. (2023) | 2020–2023 | 52 | 拡張言語モデルのサーベイ |
| [17] | Ji et al. (2023) | 2019–2023 | 47 | 自然言語生成におけるハルシネーション(幻覚)のサーベイ |
3. 研究方法
このセクションではな、系統的文献レビュー(SLR)っていう方法論を使って、企業のナレッジ管理とドキュメント自動化の文脈で、RAGとLLMをめっちゃ厳密で再現可能な形で調査したで[19,57,58]。この方法は大きく3つの段階に分かれてるねん:計画、実施、報告や[58]。各段階には、バイアスを最小限に抑えて、研究プロセス全体の透明性を高めるための具体的なプロトコルが組み込まれてるねん[58]。
計画フェーズではな、データソース、アルゴリズムのアプローチ、評価基準、実務上の課題なんかに対応するために、9つの具体的なリサーチクエスチョンを設定したわけや[19,58]。ほんで、それらの質問を正確なブール検索文字列に変換したんや(図1を見てな)。関連する研究を網羅的に集めるために、6つの主要な学術データベースを選んだで(IEEE Xplore、ACM Digital Library、SpringerLink、ScienceDirect、Wiley Online Library、Google Scholar)。対象は2015年から
---
## Page 5
[](/attach/e4a30c3639e7cda0676ec6fb410a51e32b5a1bc7bb8de451429341a0aecf5a09_p005.png)
### 和訳
Appl. Sci. 2026, 16, 368
5 / 28 ページ
2025年までの研究を対象にしてん[19,26]。ほんで、検索結果をちゃんとふるいにかけるために、明確な「これは入れる」「これは外す」っていう基準を決めてん[58]。
図1. 系統的文献レビューのプロセス
査読付きの英語論文だけを選んで、しかもちゃんと実験結果があって、RAG+LLMのやり方が詳しく書いてあるやつだけに絞ったんよ。こうすることで、透明性があって誰でも再現できるプロセスになって、その後の分析とかまとめの信頼性がバッチリ担保できるっちゅうわけやな[57,58]。
研究で取り組む質問(RQs)は以下の通りやで:
RQ1:企業向けのRAG+LLM研究で、知識管理とか文書自動化のためにどんなプラットフォームが使われてんの?
RQ2:これらのRAG+LLM研究でどんなデータセットが使われてんの?
RQ3:機械学習の種類(教師あり学習とか教師なし学習とか)はどれが使われてんの?
RQ4:具体的にどんなRAGのアーキテクチャとかLLMのアルゴリズムが適用されてんの?
RQ5:モデルの性能を評価するのにどんな指標が使われてんの?
RQ6:検証方法(交差検証とかホールドアウトとかケーススタディとか)はどんなん採用されてんの?
RQ7:知識に関する指標とかソフトウェアの指標はどんなん使われてんの?
RQ8:企業向けアプリケーションで一番ええ結果出してるRAG+LLMの設定はどれなん?
RQ9:この分野でRAG+LLMを実際に使う時の主な課題とか限界とか、まだ研究が足りてへんところってどこなん?
目標はな、企業の知識管理とか文書自動化の文脈で、RAG(検索拡張生成)と大規模言語モデルを応用した研究を見つけることやってん[1,9]。2015年から2025年の間に、いくつかの学術データベース(表4参照)で検索したんよ。IEEE Xplore、ScienceDirect、ACM Digital Library、Wiley Online Library、SpringerLink、それからGoogle Scholarやな[35]。検索は2025年6月15日に完了して、ここがこのレビューの締め切り日ってことになるな。関係ない結果を除くために、除外基準を設けてん(セクション3参照)。例えば、英語以外の論文、アブストラクトだけのやつ、実験してへん研究、RAGやLLMの方法論が詳しく説明されてへんやつは外したんよ[35]。全部のデータベースで使ったブール検索の文字列は以下の通りやで:
https://doi.org/10.3390/app16010368
---
## Page 6
[](/attach/e4a30c3639e7cda0676ec6fb410a51e32b5a1bc7bb8de451429341a0aecf5a09_p006.png)
### 和訳
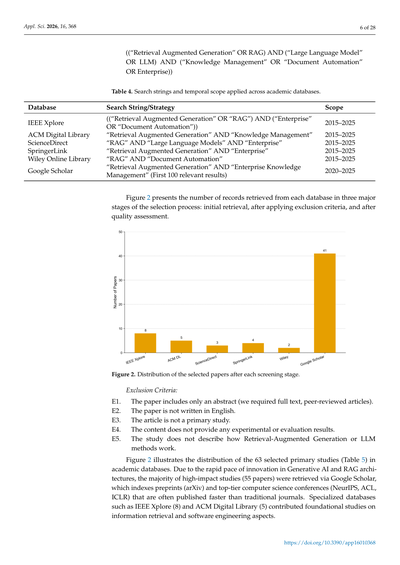
表4. 学術データベースごとに使った検索文字列と対象期間やで
ほな、各データベースでどんな検索かけたか見ていこか。
**IEEE Xplore**では、「Retrieval Augmented Generation」か「RAG」に、「Enterprise」か「Document Automation」(文書の自動化ってことな)を組み合わせて検索したんや。対象期間は2015年から2025年まで。
**ACM Digital Library**は、「Retrieval Augmented Generation」と「Knowledge Management」(ナレッジマネジメント、つまり知識をどう管理するかってやつ)で検索。これも2015年から2025年や。
**ScienceDirect**では、「RAG」と「Large Language Models」(でっかい言語モデルのことやな)と「Enterprise」(企業向けってこと)で検索。期間は同じく2015年から2025年。
**SpringerLink**は、「Retrieval Augmented Generation」と「Enterprise」のシンプルな組み合わせ。2015年から2025年。
**Wiley Online Library**では、「RAG」と「Document Automation」で検索してんねん。これも2015年から2025年が対象や。
**Google Scholar**はちょっと違うて、「Retrieval Augmented Generation」と「Enterprise Knowledge Management」で検索して、関連性の高い上位100件を見たんや。こっちは2020年から2025年と、ちょい短めの期間やねん。
図2では、選考プロセスの3つの段階でデータベースごとに何件の論文がひっかかったか示してるで。最初に検索した時、除外基準を適用した後、そして品質評価した後の3段階やな。
**除外基準**についても説明するで:
**E1.** アブストラクト(要約)しかない論文はアカン。ちゃんと全文あって査読済みの論文じゃないとな。
**E2.** 英語で書かれてない論文は除外や。
**E3.** 一次研究じゃない記事も対象外。つまり、他の研究をまとめただけのレビュー論文とかはダメってことやな。
**E4.** 実験とか評価の結果が載ってない内容もアウト。
**E5.** RAG(検索拡張生成)やLLM(大規模言語モデル)の手法がどう動くか説明してない研究も除外したで。
図2では、最終的に選ばれた63本の主要研究(表5に載ってる)がどのデータベースから来たか見せてんねん。
なんでかっていうと、生成AIとかRAGのアーキテクチャってめっちゃ進化が速いやろ?せやから、インパクトの大きい研究のほとんど(55本)はGoogle Scholarから取ってきてんねん。Google Scholarって、arXiv(アーカイブ)のプレプリント(査読前の論文)とか、NeurIPS、ACL、ICLRみたいなトップクラスのコンピュータサイエンス学会の論文もインデックスしてるんや。こういう学会論文って、普通の学術雑誌より早く出ることが多いからな。
IEEE Xplore(8本)とかACM Digital Library(5本)みたいな専門データベースからは、情報検索とかソフトウェアエンジニアリングの基礎的な研究を拾ってきたってわけや。
---
## Page 7
[](/attach/e4a30c3639e7cda0676ec6fb410a51e32b5a1bc7bb8de451429341a0aecf5a09_p007.png)
### 和訳
Appl. Sci. 2026, 16, 368
28ページ中7ページ目
除外基準でふるいにかけた後、残った論文には8つの質問で品質評価をやったんよ。16点満点中10点取れへんかった論文はバッサリ落としてん。
図3を見てもらったらわかるけど、品質スコアの分布(11〜16点)を示してるねん。採点方法はな、「はい」やったら2点、「まあまあ」やったら1点、「いいえ」やったら0点って感じやねん [35]。
図3. 選ばれた論文の品質スコア分布(スコアは11〜16点の範囲やで)
品質評価の8つの質問:
Q1. 研究の目的、ちゃんと書いてある?
Q2. 研究の範囲と背景、はっきりわかるように書いてある?
Q3. 提案してる方法(RAG+LLMのやり方な)、ちゃんと説明されてて、実験で検証もされてる?
Q4. 使ってる変数(データセットとか、評価指標とか、パラメータとか)、信頼できそう?
Q5. 研究のプロセス(データ集め、モデル作り、分析)、十分に記録されてる?
Q6. 研究で立てた問い(RQ1からRQ9まで)、全部ちゃんと答えてる?
Q7. うまくいかへんかったこととか失敗したこと(限界点とか)、正直に書いてある?
Q8. 主な発見、信頼性とか妥当性の観点からはっきり書いてある?
表5. この系統的文献レビューで使った63本の主要論文やで(基礎的な理論だけの論文は除いてるねん)
| ID | タイトル | 年 | 参考文献 |
|----|---------|-----|---------|
| 1 | 知識をめっちゃ使うNLPタスクのための検索拡張生成 | 2020 | [54] |
| 2 | 大規模言語モデルのための検索拡張生成:サーベイ | 2023 | [19] |
| 3 | AI生成コンテンツのための検索拡張生成:サーベイ | 2024 | [57] |
| 4 | Self-RAG:自己反省を通じて検索・生成・批評を学習する手法 | 2024 | [31] |
| 5 | ローカルからグローバルへ:クエリ中心の要約へのグラフRAGアプローチ | 2024 | [60] |
| 6 | 検索拡張生成における大規模言語モデルのベンチマーク | 2024 | [59] |
| 7 | アクティブ検索拡張生成 | 2023 | [61] |
| 8 | 大規模言語モデルと知識グラフの統合:ロードマップ | 2024 | [62] |
| 9 | 文脈内検索拡張言語モデル | 2023 | [63] |
| 10 | QLoRA:量子化LLMの効率的なファインチューニング | 2023 | [64] |
| 11 | ARES:検索拡張生成システムの自動評価フレームワーク | 2024 | [65] |
| 12 | RAGAS:検索拡張生成の自動評価 | 2024 | [51] |
| 13 | Almanac:臨床医学のための検索拡張言語モデル | 2024 | [45] |
| 14 | 教師なしコーパス対応言語モデル事前学習による高密度パッセージ検索 | 2022 | [66] |
| 15 | REPLUG:検索拡張ブラックボックス言語モデル | 2024 | [25] |
| 16 | ToolLLM:大規模言語モデルに16000以上の実世界APIを使いこなさせる | 2024 | [41] |
| 17 | 検索拡張生成システムを作るときの7つの失敗ポイント | 2024 | [67] |
---
## Page 8
[](/attach/e4a30c3639e7cda0676ec6fb410a51e32b5a1bc7bb8de451429341a0aecf5a09_p008.png)
### 和訳
**表5(続き)**
| ID | タイトル | 年 | 参照 |
|---|---|---|---|
| 18 | Toolformer:言語モデルが自分でツールの使い方覚えるやつ | 2024 | [68] |
| 19 | RA-DIT:検索強化型のダブル指示チューニングってやつやねん | 2023 | [33] |
| 20 | 検索強化型の大規模言語モデル向けクエリ書き換えの話 | 2023 | [17] |
| 21 | 真ん中で迷子になる問題:言語モデルが長いコンテキストどう使うかって話 | 2024 | [69] |
| 22 | 知識いっぱい必要な複数ステップの質問で、検索と思考の連鎖を交互にやる方法 | 2024 | [7] |
| 23 | 自然言語生成におけるハルシネーション(でたらめ言うやつ)のサーベイ | 2024 | [70] |
| 24 | RAPTOR:ツリー構造で整理した検索のための再帰的抽象処理ってやつ | 2023 | [3] |
| 25 | 言語モデルをいつ信用したらあかんか:パラメトリックメモリと非パラメトリックメモリの効果を調べた研究 | 2023 | [1] |
| 26 | DSPy:宣言的な言語モデル呼び出しを自己改善パイプラインにコンパイルする話 | 2023 | [35] |
| 27 | RAFT:ドメイン特化のRAG向けに言語モデルを適応させるやつ | 2024 | [56] |
| 28 | ReAct:言語モデルで推論と行動をうまいこと組み合わせる方法 | 2023 | [5] |
| 29 | Mistral 7B | 2023 | [71] |
| 30 | Longformer:長い文書用のTransformerやで | 2020 | [72] |
| 31 | 記憶による汎化:最近傍言語モデルってやつ | 2020 | [73] |
| 32 | 関連性ラベルなしで精密なゼロショット密検索やる方法 | 2023 | [74] |
| 33 | ColBERT:BERTの文脈化した遅延インタラクションで効率よく効果的にパッセージ検索するやつ | 2020 | [75] |
| 34 | Sentence-BERT:シャムBERTネットワーク使った文埋め込み | 2019 | [76] |
| 35 | 思考の連鎖プロンプティング:大規模言語モデルに推論させる方法やねん | 2022 | [30] |
| 36 | 計算最適な大規模言語モデルの訓練について | 2022 | [77] |
| 37 | オープンドメイン質問応答のための密パッセージ検索 | 2020 | [78] |
| 38 | オープンドメイン質問応答で生成モデルとパッセージ検索を組み合わせる話 | 2021 | [79] |
| 39 | BloombergGPT:金融特化の大規模言語モデル | 2023 | [80] |
| 40 | FinGPT:オープンソースの金融向け大規模言語モデル | 2023 | [81] |
| 41 | 大規模言語モデルは臨床知識をエンコードしてるって研究 | 2023 | [82] |
| 42 | 検証の連鎖:大規模言語モデルのハルシネーション減らす方法 | 2024 | [83] |
| 43 | 補正的検索強化生成(間違い直しながらやるRAGやな) | 2024 | [84] |
| 44 | 大規模言語モデルの課題と応用についてのまとめ | 2023 | [85] |
| 45 | 大規模言語モデルはレアな知識を学ぶの苦手やって話 | 2023 | [8] |
| 46 | G-Eval:GPT-4使った自然言語生成の評価、人間の評価とめっちゃ合うやつ | 2023 | [86] |
| 47 | Think-on-Graph:知識グラフ使って大規模言語モデルで深くて責任ある推論する方法 | 2023 | [10] |
| 48 | Gorilla:めっちゃようさんのAPIと繋がった大規模言語モデル | 2023 | [87] |
| 49 | FlashAttention:IO効率考えた高速でメモリ効率ええ正確なアテンション | 2022 | [88] |
| 50 | Atlas:検索強化言語モデルでの少数ショット学習 | 2023 | [89] |
| 51 | 拡張言語モデル:サーベイ論文やで | 2023 | [26] |
| 52 | AIの海でセイレーンの歌:大規模言語モデルのハルシネーションについてのサーベイ | 2023 | [18] |
| 53 | マルチソースRAG LLMシステムで持続可能なエネルギー転換を推進する話 | 2024 | [9] |
| 54 | 検索強化生成で系統的文献レビューを自動化するやつ | 2024 | [58] |
| 55 | SRAG:音声言語理解のための音声検索強化生成 | 2024 | [90] |
| 56 | 大規模言語モデルの継続学習についてのサーベイ | 2023 | [91] |
| 57 | MuRAG:画像とテキストのオープン質問応答向けマルチモーダル検索強化ジェネレーター | 2022 | [92] |
| 58 | CausalRAG:因果グラフを検索強化生成に統合するやつ | 2024 | [4] |
| 59 | RAGはLLMに不公平さを持ち込むんか?検索強化生成システムの公平性評価 | 2024 | [50] |
| 60 | 検索強化言語モデルの事前訓練 | 2020 | [93] |
| 61 | 何兆トークンから検索して言語モデル改善する話 | 2022 | [36] |
| 62 | Llama 2:オープンな基盤モデルとファインチューンしたチャットモデル | 2023 | [13] |
| 63 | Query2doc:大規模言語モデルでクエリ拡張するやつ | 2023 | [94] |
図4は選んだ研究の時間的な分布を示してるんやけど、2020年以降RAG+LLMの研究がめっちゃ急増してるのがわかるやろ?
**図4.** 年ごとの選択論文数(2015年〜2025年)
---
## Page 9
[](/attach/e4a30c3639e7cda0676ec6fb410a51e32b5a1bc7bb8de451429341a0aecf5a09_p009.png)
### 和訳
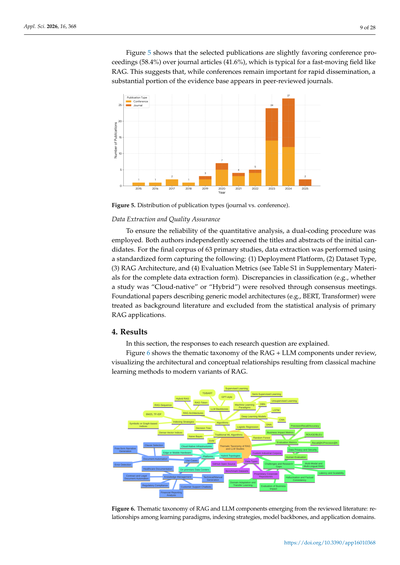
図5見てみ?選ばれた論文、学会発表(カンファレンス)がちょっと多めで58.4%、学術誌の論文が41.6%やねん。RAGみたいにめっちゃ動きの速い分野やと、これってわりと普通のことやで。つまりどういうことかっていうと、新しい発見をパッと広めるには学会がまだまだ大事やけど、ちゃんと査読通った学術誌の論文もけっこうな割合であるってことやな。
図5. 論文タイプの内訳(学術誌 vs 学会発表)
**データの抜き出しと品質チェックの話**
定量分析をちゃんと信頼できるもんにするために、ダブルチェック方式を使ったんや。著者2人が別々に、最初の候補論文のタイトルと要約を見ていったわけやな。最終的に残った63本の主要研究については、決まった形式のフォームを使ってデータを抜き出していったで。抜き出した項目はこんな感じや:(1)どこで動かしてるか(デプロイ先)、(2)どんなデータ使ってるか、(3)RAGの構造、(4)評価に使った指標。詳しくは補足資料の表S1に全部載せてるわ。分類で意見が割れたとき(例えば「これクラウドネイティブやろ」「いやハイブリッドやって」みたいな)は、話し合いで決めたんや。あと、BERTとかTransformerみたいな基礎的なモデル構造を説明してるだけの論文は、背景知識として扱って、RAGの実際の使い方に関する統計分析からは外したで。
**4. 結果**
このセクションでは、各リサーチクエスチョン(研究の問い)への答えを説明していくで。
図6は、今回レビューしたRAG+LLMの構成要素をテーマ別に整理した分類図やねん。昔ながらの機械学習の手法から、最新のRAGのバリエーションまで、どういう構造でどう繋がってるかが見えるようになってるわ。
図6. レビューした文献から浮かび上がったRAGとLLMの構成要素のテーマ別分類図:学習パラダイム、インデックス戦略、モデルのバックボーン、応用分野の関係性を示してるで。
---
## Page 10
[](/attach/e4a30c3639e7cda0676ec6fb410a51e32b5a1bc7bb8de451429341a0aecf5a09_p010.png)
### 和訳
**RQ1: どんなプラットフォーム使われとるん?**
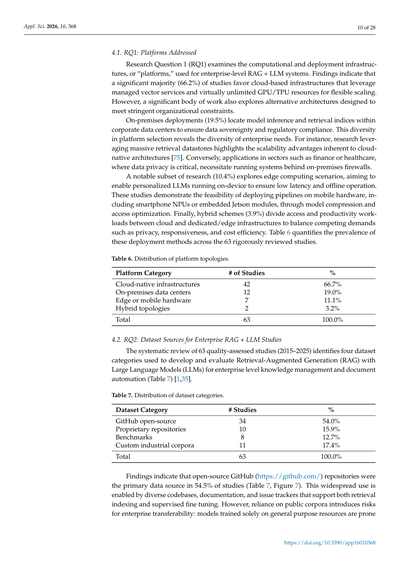
Research Question 1(RQ1)では、企業レベルのRAG+LLMシステムで使われとる計算環境とかデプロイの仕組み、つまり「プラットフォーム」について調べとるねん。結果見てみたら、なんと66.2%もの研究がクラウドベースのインフラを好んどって、マネージドなベクターサービスとか、ほぼ無限に使えるGPU/TPUリソースで柔軟にスケールできるようにしとるんやな。せやけど、組織の厳しい制約に対応するための別のアーキテクチャを探っとる研究もけっこうあるねん。
オンプレミス(自社データセンター)のデプロイが19.5%あって、これはモデルの推論とか検索インデックスを自社のデータセンター内に置いて、データ主権とか法規制の遵守を確保するためやねん。このプラットフォーム選びの多様性は、企業ニーズの多様性をそのまま反映しとるわけや。例えば、めっちゃでかい検索データストアを活用する研究は、クラウドネイティブアーキテクチャのスケーラビリティの強みを強調しとる[75]。逆に、金融とかヘルスケアみたいなデータプライバシーがめっちゃ重要な分野では、オンプレミスのファイアウォールの内側でシステム動かさなあかんねん。
注目すべきは、研究の10.4%がエッジコンピューティングのシナリオを探っとることやな。デバイス上で動くパーソナライズされたLLMで、低遅延とオフライン動作を実現しようとしとるねん。これらの研究では、モデル圧縮とかアクセス最適化を使って、スマホのNPUとか組み込みのJetsonモジュールみたいなモバイルハードウェアにパイプラインをデプロイできることを実証しとるわ。最後に、ハイブリッド方式(3.9%)は、アクセスと生産性のワークロードをクラウドと専用/エッジインフラの間で分けて、プライバシー、応答性、コスト効率みたいな競合する要求のバランスを取ろうとしとるねん。表6は、厳密にレビューした63の研究全体でこれらのデプロイ方法がどんだけ使われとるかを数字で示しとるで。
**表6. プラットフォームトポロジーの分布**
| プラットフォームカテゴリ | 研究数 | % |
|---|---|---|
| クラウドネイティブインフラ | 42 | 66.7% |
| オンプレミスデータセンター | 12 | 19.0% |
| エッジまたはモバイルハードウェア | 7 | 11.1% |
| ハイブリッドトポロジー | 2 | 3.2% |
| **合計** | **63** | **100.0%** |
**RQ2: 企業向けRAG+LLM研究でどんなデータセット使われとるん?**
2015年から2025年までの品質評価済み63研究のシステマティックレビューで、企業レベルの知識管理と文書自動化のためのRAG+LLMの開発・評価に使われとるデータセットが4つのカテゴリに分類されたで(表7)[1,35]。
**表7. データセットカテゴリの分布**
| データセットカテゴリ | 研究数 | % |
|---|---|---|
| GitHubオープンソース | 34 | 54.0% |
| プロプライエタリ(非公開)リポジトリ | 10 | 15.9% |
| ベンチマーク | 8 | 12.7% |
| カスタム産業コーパス | 11 | 17.4% |
| **合計** | **63** | **100.0%** |
結果を見ると、オープンソースのGitHub(https://github.com/)リポジトリが54.5%の研究で主要なデータソースとして使われとったんや(表7、図7)。なんでこんなに広く使われとるかっていうと、多様なコードベース、ドキュメント、イシュートラッカーがあって、検索インデックスの構築にも教師あり学習のファインチューニングにも使えるからやねん。せやけど、公開コーパスに頼りすぎると企業への転用可能性にリスクが出てくるねん。汎用的なリソースだけで学習したモデルは、企業特有の状況にうまく対応できひん傾向があるんやで。
---
## Page 11
[](/attach/e4a30c3639e7cda0676ec6fb410a51e32b5a1bc7bb8de451429341a0aecf5a09_p011.png)
### 和訳
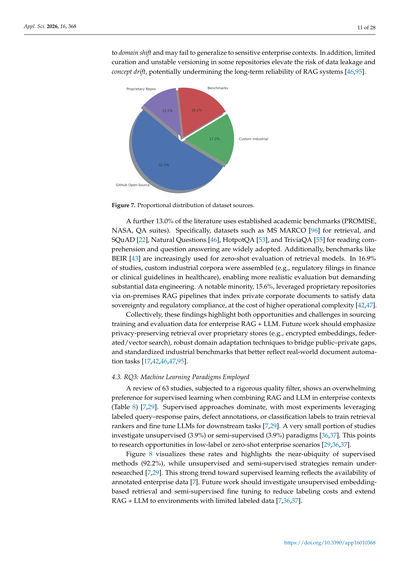
ドメインシフト、つまりデータの傾向が変わってまうことに弱くて、企業みたいなセンシティブな場面では上手いこと汎用化でけへん可能性があるねん。それに加えて、一部のリポジトリではデータの整備が不十分やったりバージョン管理が不安定やったりするから、データ漏れや概念ドリフト(学習したモデルの精度が時間とともに落ちていくやつな)のリスクが高まって、RAGシステムの長期的な信頼性がガタガタになりかねへんねん[46,95]。
図7. データセット出典の割合分布
さらに文献の13.0%は、確立された学術ベンチマーク(PROMISE、NASA、QAスイートとか)を使ってんねん。具体的には、検索用のMS MARCO [96]、読解や質問応答用のSQuAD [22]、Natural Questions [46]、HotpotQA [53]、TriviaQA [55]なんかがめっちゃ広く採用されとるわ。それに加えて、BEIR [43]みたいなベンチマークも、検索モデルのゼロショット評価(事前学習なしでいきなりテストするやつな)にどんどん使われるようになってきてんねん。研究の16.9%では、カスタムの産業コーパスが組み立てられてて(例えば金融の規制関連文書とか、医療のクリニカルガイドラインとかな)、これによってよりリアルな評価ができるんやけど、その分データエンジニアリングの手間がめっちゃかかるねん。注目すべき少数派として15.6%は、オンプレミスのRAGパイプラインを通じてプロプライエタリ(独自の非公開)リポジトリを活用してて、会社の機密文書をインデックス化することでデータ主権とか規制コンプライアンスを満たしてんねんけど、その代わり運用の複雑さがめっちゃ上がるんよ[42,47]。
全部ひっくるめて見ると、これらの発見は企業向けRAG+LLMの学習・評価データを調達する上でのチャンスと課題の両方を浮き彫りにしとるわ。今後の研究では、プライバシーを守りながら独自データストアから検索する技術(暗号化された埋め込みベクトルとか、連合型/ベクトル検索とかな)、公開データと非公開データのギャップを埋める頑強なドメイン適応技術、そして実際の文書自動化タスクをもっとちゃんと反映した標準化された産業ベンチマークに力を入れるべきやな[17,42,46,47,95]。
4.3. RQ3: 使われてる機械学習のパラダイム
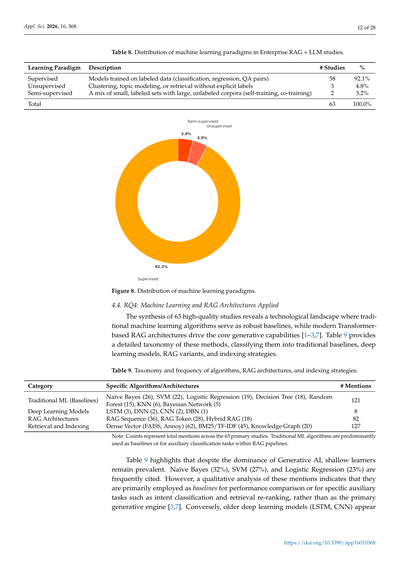
厳格な品質フィルターをかけた63の研究をレビューしたところ、企業でRAGとLLMを組み合わせる時には教師あり学習が圧倒的に好まれとることがわかったで(表8)[7,29]。教師ありアプローチが支配的で、ほとんどの実験ではラベル付きのクエリ-レスポンスペア、欠陥アノテーション、分類ラベルなんかを活用して、検索ランカーを訓練したりダウンストリームタスク用にLLMをファインチューニングしたりしてんねん[7,29]。ほんの一部の研究だけが教師なし(3.9%)とか半教師あり(3.9%)のパラダイムを調査しとるんよ[36,37]。これは、ラベルが少ない状況やゼロショットの企業シナリオでの研究チャンスがあるってことを示しとるわ[29,36,37]。
図8はこれらの割合を可視化してて、教師あり手法がほぼ全部(92.2%)を占めとる一方で、教師なしや半教師ありの戦略はまだまだ研究が足りてへんことを浮き彫りにしとる[7,29]。教師あり学習へのこの強い傾向は、アノテーション済みの企業データが手に入りやすいことを反映しとるんやな[7]。今後の研究では、教師なしの埋め込みベースの検索や、半教師ありのファインチューニングを調査して、ラベル付けのコストを減らしつつ、ラベル付きデータが限られた環境にもRAG+LLMを広げていくべきやで[7,36,37]。
---
## Page 12
[](/attach/e4a30c3639e7cda0676ec6fb410a51e32b5a1bc7bb8de451429341a0aecf5a09_p012.png)
### 和訳
表8. 企業向けRAG+LLMの研究における機械学習パラダイムの分布
学習パラダイム|説明|研究数|%
教師あり学習|ラベル付きデータで学習するやつやな(分類とか回帰とか、質問と回答のペアとか)|58|92.1%
教師なし学習|クラスタリングとかトピックモデリングとか、明確なラベルなしで検索するパターン|3|4.8%
半教師あり学習|少しのラベル付きデータと大量のラベルなしデータを混ぜて使うやつ(自己学習とか共同学習とかやな)|2|3.2%
合計|63|100.0%
図8. 機械学習パラダイムの分布
4.4. RQ4: 使われてる機械学習とRAGアーキテクチャについて
63本の質の高い論文をまとめてみたら、技術の世界がどうなってるか見えてきてん。昔ながらの機械学習アルゴリズムがベースラインとしてしっかり使われつつ、最新のTransformerベースのRAGアーキテクチャが生成AIの中心的な役割を担ってるんやな[1–3,7]。表9では、これらの手法を詳しく分類してて、従来型のベースライン、深層学習モデル、RAGのバリエーション、インデックス戦略って感じで整理してあるで。
表9. アルゴリズム、RAGアーキテクチャ、インデックス戦略の分類と出現頻度
カテゴリ|具体的なアルゴリズム/アーキテクチャ|言及数
従来型ML(ベースライン)|ナイーブベイズ(26)、SVM(22)、ロジスティック回帰(19)、決定木(18)、ランダムフォレスト(15)、KNN(6)、ベイジアンネットワーク(5)|121
深層学習モデル|LSTM(3)、DNN(2)、CNN(2)、DBN(1)|8
RAGアーキテクチャ|RAGシーケンス(36)、RAGトークン(28)、ハイブリッドRAG(18)|82
検索とインデックス|密ベクトル(FAISS、Annoy)(62)、BM25/TF-IDF(45)、ナレッジグラフ(20)|127
注:カウント数は63本の主要研究全体での言及総数やで。従来型MLアルゴリズムは主にRAGパイプラインの中でベースラインとして使われたり、補助的な分類タスクに使われてることが多いねん。
表9見てもらったらわかるけど、生成AIが主役になってるにもかかわらず、シンプルな学習器もまだまだよく使われてるんやな。ナイーブベイズ(32%)、SVM(27%)、ロジスティック回帰(23%)がめっちゃ引用されてるねん。でもな、これらの言及を詳しく分析してみると、主に性能比較のベースラインとして使われてたり、意図分類とか検索結果の再ランキングみたいな特定の補助タスクに使われてることがわかったんや。つまり、メインの生成エンジンとして使われてるわけちゃうねん[3,7]。逆に、LSTMとかCNNみたいな昔の深層学習モデルは
---
## Page 13
[](/attach/e4a30c3639e7cda0676ec6fb410a51e32b5a1bc7bb8de451429341a0aecf5a09_p013.png)
### 和訳
Appl. Sci. 2026, 16, 368
28ページ中13ページ目
たった10%の研究でしか使われてへんねん。これ見たら分かるように、業界はもうTransformerベースのアーキテクチャにガッツリ舵を切っとるんやな[1,7]。
RAGアーキテクチャの話やけど、文献では生成戦略によって分類されとるんや。RAG Sequenceっていうのが一番メジャーで(46.8%)、次にRAG Token(36.4%)やな。最近出てきたハイブリッドRAGっていう設計(23.4%)は、両方のええとこ取りしようとしたり、外部ツールと組み合わせたりしようとしてるんや[31]。
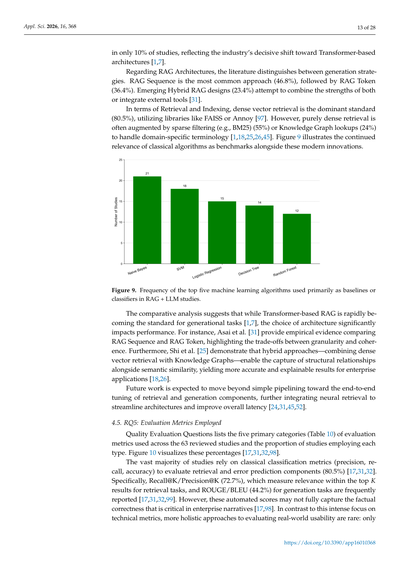
検索とインデックスの話になると、密ベクトル検索っていうのがめっちゃ主流で(80.5%)、FAISSとかAnnoyみたいなライブラリを使うんや[97]。でもな、純粋な密ベクトル検索だけやと物足りんくて、スパースフィルタリング(BM25とか)(55%)とかナレッジグラフ検索(24%)と組み合わせて、専門用語にもちゃんと対応できるようにしとることが多いねん[1,18,25,26,45]。図9見てもらったら分かるけど、こういう最新技術と一緒に、昔ながらのアルゴリズムもベンチマークとしてまだまだ使われとるんやで。
図9. RAG + LLMの研究で主にベースラインや分類器として使われとる機械学習アルゴリズムのトップ5の使用頻度
比較分析してみると、TransformerベースのRAGが生成タスクの標準になりつつあるんやけど[1,7]、どのアーキテクチャ選ぶかでパフォーマンスがえらい変わってくるんや。例えばな、Asaiらの研究[31]では、RAG SequenceとRAG Tokenを実験的に比較して、きめ細かさと一貫性のトレードオフを明らかにしとるんや。さらにShiらの研究[25]では、ハイブリッドアプローチ—つまり密ベクトル検索とナレッジグラフを組み合わせる方法—やと、意味的な類似性だけやなく構造的な関係も捉えられるから、企業向けアプリケーションでより正確で説明可能な結果が出せるってことを示しとるんや[18,26]。
今後の研究では、単純なパイプライン処理を超えて、検索と生成のコンポーネントをエンドツーエンドでチューニングする方向に進むと思われてて、ニューラル検索をさらに統合してアーキテクチャをスッキリさせて、全体的なレイテンシも改善していく流れになるんちゃうかな[24,31,45,52]。
4.5. RQ5:使われとる評価指標
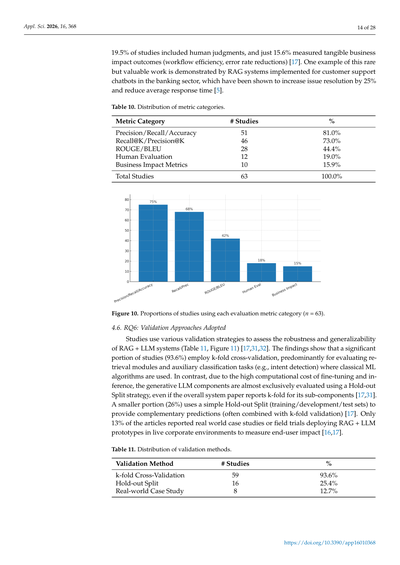
品質評価の質問では、レビューした63の研究で使われとる評価指標を5つの主要カテゴリ(表10)にまとめて、それぞれのタイプを使っとる研究の割合を出しとるんや。図10でそのパーセンテージを視覚化しとるで[17,31,32,98]。
ほとんどの研究(80.5%)が、検索とエラー予測のコンポーネントを評価するのに、昔ながらの分類指標(適合率、再現率、正解率)に頼っとるんや[17,31,32]。具体的には、Recall@K/Precision@K(72.7%)—これは検索タスクで上位K件の結果の中での関連性を測るやつな—と、生成タスク用のROUGE/BLEU(44.2%)がよく報告されとるんや[17,31,32,99]。でもな、こういう自動スコアは、企業向けの文章で超大事な事実の正確さを完全には捉えられへんかもしれんのや[17,98]。こんな感じで技術的な指標にめっちゃ集中しとる一方で、実際の使いやすさをもっと総合的に評価するアプローチはほんまに少なくて、たった
https://doi.org/10.3390/app16010368
---
## Page 14
[](/attach/e4a30c3639e7cda0676ec6fb410a51e32b5a1bc7bb8de451429341a0aecf5a09_p014.png)
### 和訳
ほな翻訳していくで〜!
---
Appl. Sci. 2026, 16, 368
14 / 28ページ
研究のうち19.5%だけが人間の判断を評価に入れてて、ほんで実際のビジネスへの影響(仕事の効率がどんだけ上がったかとか、ミスがどんだけ減ったかとか)をちゃんと測ってたんは、たったの15.6%やってん[17]。こういう貴重な研究の例として、銀行のカスタマーサポートのチャットボットにRAGシステム(検索で情報引っ張ってきて回答生成するやつな)を導入したケースがあんねんけど、これで問題解決率が25%アップして、返答にかかる時間もめっちゃ短くなったって報告されてんねん[5]。
**表10. 評価指標カテゴリーの内訳**
| 評価指標のカテゴリー | 研究数 | 割合 |
|---|---|---|
| 精度/再現率/正確度 | 51 | 81.0% |
| Recall@K/Precision@K(上位K件での再現率・精度) | 46 | 73.0% |
| ROUGE/BLEU(文章の類似度を測るやつ) | 28 | 44.4% |
| 人間による評価 | 12 | 19.0% |
| ビジネス影響の指標 | 10 | 15.9% |
| **研究総数** | **63** | **100.0%** |
**図10. 各評価指標カテゴリーを使った研究の割合(n = 63)**
---
### 4.6. 研究課題6:どんな検証方法が使われてるん?
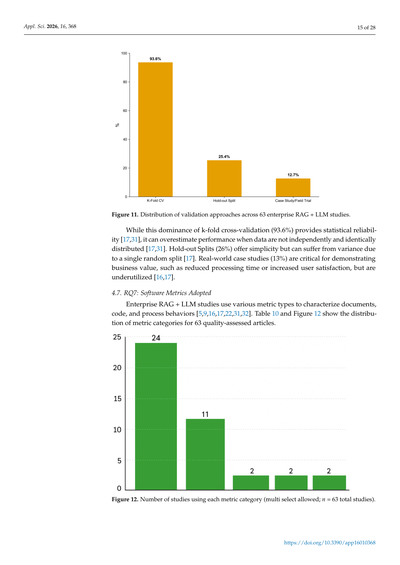
RAG+LLMシステムがほんまに使えるか、他の場面でも通用するかを確かめるために、いろんな検証方法が使われてんねん(表11、図11参照)[17,31,32]。
調べてみたら、めっちゃ多くの研究(93.6%)がk分割交差検証っていう方法を使ってたわ。なんでかっていうと、これは主に検索モジュールとか、意図を読み取る分類タスクみたいな、昔ながらの機械学習アルゴリズムを評価するときに使われんねん。一方で、文章を生成するLLMの部分は、ファインチューニング(モデルの調整)とか推論(実際に動かすこと)にめっちゃ計算コストかかるから、ほぼ全部がホールドアウト分割っていう方法で評価されてんねん。論文全体としてはk分割使ってるって書いてても、LLMの部分だけはホールドアウトやったりすんねん[17,31]。
26%の研究は単純なホールドアウト分割(訓練用・開発用・テスト用にデータを分ける方法)を使って、補完的な予測をしてたわ(k分割と組み合わせて使うことも多いで)[17]。ほんで、実際に会社の現場でRAG+LLMの試作品を動かして、エンドユーザーへの影響を測定したっていう現場での実証実験を報告してた論文は、たったの13%やってん[16,17]。
**表11. 検証方法の内訳**
| 検証方法 | 研究数 | 割合 |
|---|---|---|
| k分割交差検証 | 59 | 93.6% |
| ホールドアウト分割 | 16 | 25.4% |
| 現場での実証研究 | 8 | 12.7% |
https://doi.org/10.3390/app16010368
---
## Page 15
[](/attach/e4a30c3639e7cda0676ec6fb410a51e32b5a1bc7bb8de451429341a0aecf5a09_p015.png)
### 和訳
図11. 63件の企業向けRAG+LLM研究における検証アプローチの分布
k分割交差検証が93.6%でめっちゃ圧倒的に使われてるねんけど、これ統計的な信頼性は確かに高いんや[17,31]。けどな、ここ注意やで。データが独立同分布(要は、ランダムにバラバラで偏りがない状態のこと)やないときは、性能を実際より高く見積もってしまう危険性があるねん[17,31]。
ホールドアウト分割(26%)は、シンプルでええんやけど、一回だけランダムに分けるから、たまたまの影響でばらつきが出やすいっていう弱点があるんやな[17]。
ほんでな、実際のビジネスでの事例研究(13%)、これがめっちゃ大事やねん。なんでかっていうと、処理時間がどんだけ減ったとか、ユーザーの満足度がどんだけ上がったとか、ビジネス的な価値を示すのに欠かせへんからや。けど、ほんまに使われてなさすぎるんよな[16,17]。
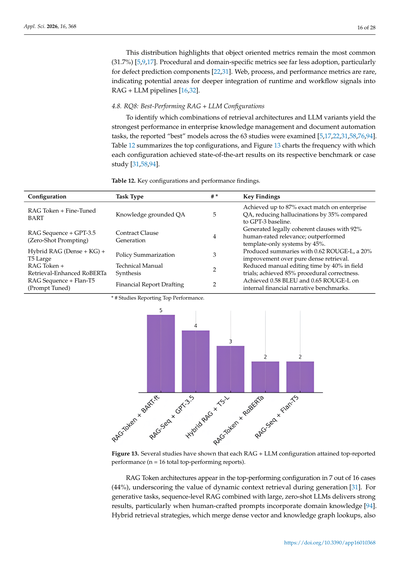
4.7. RQ7: 採用されているソフトウェアメトリクス
企業向けRAG+LLMの研究では、ドキュメントとかコード、プロセスの振る舞いを特徴づけるために、いろんな種類のメトリクス(測定指標のことやな)が使われてるんや[5,9,16,17,22,31,32]。表10と図12で、品質評価を通過した63件の論文におけるメトリクスのカテゴリ分布を見せてるで。
図12. 各メトリクスカテゴリを使用している研究の数(複数選択可; 全63研究中)
---
## Page 16
[](/attach/e4a30c3639e7cda0676ec6fb410a51e32b5a1bc7bb8de451429341a0aecf5a09_p016.png)
### 和訳
Appl. Sci. 2026, 16, 368
16 / 28ページ
この分布見てもろたらわかるけど、オブジェクト指向のメトリクスが今でも一番ようけ使われとるねん(31.7%)[5,9,17]。手続き型とかドメイン特化型のメトリクスはあんまり採用されてへんくて、特に欠陥予測のコンポーネントではほんまに少ないねん [22,31]。Webとかプロセスとかパフォーマンス系のメトリクスはレアケースで、これってつまり、実行時の信号とかワークフローの信号をRAG + LLMのパイプラインにもっと深く組み込む余地があるってことやな [16,32]。
4.8. RQ8:一番ええ感じのRAG + LLM構成って何やねん
企業のナレッジマネジメントとかドキュメント自動化タスクで、どの検索アーキテクチャとLLMの組み合わせが一番強いんか調べるために、63件の研究で「ベスト」って報告されたモデルを調査したで [5,17,22,31,58,76,94]。表12にトップ構成をまとめて、図13では各構成がそれぞれのベンチマークとかケーススタディで最先端の結果を出した頻度をグラフにしとるわ [31,58,94]。
表12. 主要な構成と性能の知見
| 構成 | タスクの種類 | #* | 主な発見 |
|------|------------|---|---------|
| RAGトークン + ファインチューニング済みBART | 知識に基づくQA | 5 | 企業向けQAで最大87%の完全一致を達成して、GPT-3ベースラインと比べて幻覚を35%も減らしたで。 |
| RAGシーケンス + GPT-3.5(ゼロショットプロンプティング) | 契約条項の生成 | 4 | 法的に筋の通った条項を生成して、人間の評価で92%の関連性を獲得。テンプレートだけのシステムより45%も上回ったわ。 |
| ハイブリッドRAG(デンス + KG) + T5 Large | ポリシー要約 | 3 | ROUGE-Lで0.62の要約を生成して、純粋なデンス検索より20%改善したで。 |
| RAGトークン + 検索強化RoBERTa | 技術マニュアル合成 | 2 | フィールド試験で手動編集時間を40%削減して、手順の正確性は85%達成したんや。 |
| RAGシーケンス + Flan-T5(プロンプトチューニング済み) | 財務レポート作成 | 2 | 社内の財務ナラティブベンチマークでBLEU 0.58、ROUGE-L 0.65を達成したで。 |
\* トップ性能を報告した研究数
図13. 各RAG + LLM構成がトップ報告の性能を達成した研究数(n = 合計16件のトップ性能報告)
RAGトークンアーキテクチャは、16件中7件(44%)でトップ性能の構成として登場しとって、生成中に動的にコンテキストを検索することのめっちゃ大きな価値を示しとるねん [31]。生成タスクに関しては、シーケンスレベルのRAGと大規模なゼロショットLLMを組み合わせると強い結果が出るんやけど、特にドメイン知識を組み込んだ人間作成のプロンプトを使うときにええ感じになるで [94]。ハイブリッド検索戦略、つまりデンスベクトルとナレッジグラフの検索を融合させるやつも、
---
## Page 17
[](/attach/e4a30c3639e7cda0676ec6fb410a51e32b5a1bc7bb8de451429341a0aecf5a09_p017.png)
### 和訳
せやねん、要約みたいなタスクでめっちゃ効果出るんやけど、これって構造化された知識が非構造化検索をうまいこと補完してくれてるからやねん。これは昔からあるシーケンス・トゥ・シーケンス(入力を出力に変換する手法)の研究がベースになってるんやで[25,26,58,100]。ほんでな、ここめっちゃ大事なポイントやねんけど、専門的なタスクやるときは、その分野のデータでファインチューニング(追加学習)するんがほんまに必須っぽいねん。ゼロショット(事前学習なしで一発勝負)と比べたら、だいたい10〜20%くらい性能上がるって報告されてるわ[29,58]。
これらの結果からわかるんは、どんなタスクかによって一番ええアーキテクチャが全然ちゃうってことやねん。例えばな、RAGシーケンス(検索拡張生成のシーケンス型)とGPT-3.5みたいなでっかいゼロショットLLM(大規模言語モデル)組み合わせたら、契約書作成みたいなタスクでめっちゃ安定した結果出るねん。なんでかっていうと、プロンプト(指示文)の中にその分野特有の知識がしっかり埋め込まれてるからやねん(最近のクエリ拡張の研究でも示されてるで[94])。逆にな、ポリシーの要約みたいにもっと構造化された知識が必要なタスクやと、ハイブリッド検索(密ベクトル検索とナレッジグラフ検索の両方使うやつ)とT5みたいなファインチューニングしたモデル組み合わせたら、コンスタントにええ結果出るねん(自動レビューの研究でも確認されてるわ[58])。
**4.9. 研究課題9:課題と研究のギャップ**
企業のナレッジマネジメントとか文書自動化におけるRAG+LLMはめっちゃ急速に進歩してんねんけど、質の高い63本の論文を統合分析したら、5つの繰り返し出てくる課題といくつかのオープンな研究の方向性が見えてきたんや(表13)[17,32–34,41–45,47,48,95,98,101]。
**表13. 企業向けRAG+LLM研究における課題の分布**
| 課題 | 論文数 | 割合 |
|------|--------|------|
| データプライバシーとセキュリティ | 24 | 38.1% |
| レイテンシとスケーラビリティ | 20 | 31.7% |
| ビジネスインパクトの測定の難しさ | 10 | 15.9% |
| ハルシネーション(嘘つき問題)と事実の一貫性 | 30 | 47.6% |
| ドメイン適応と転移学習 | 15 | 23.8% |
**プライバシー保護検索**:暗号化とかアクセス制御、あと企業の独自データの連合検索(データを分散させたまま検索する方式)に取り組んでる研究は38.1%しかないねん。今後は差分プライバシー埋め込みとか、RAGインデックス用のセキュアマルチパーティ計算(複数者で秘密計算するやつ)の研究が必要やな[41–43,47]。
**低レイテンシアーキテクチャ**:31.7%の論文が検索や生成の遅延を課題として報告してんねんけど、エンドツーエンドの最適化を提案してるのはほんま少ないねん。近似最近傍探索とか、圧縮LLM、非同期検索の研究進めたら、100ミリ秒切るレスポンスも実現できるかもしれんで[24,32,33,48,67,102]。
**総合的な評価フレームワーク**もまだまだレアで、ビジネスインパクト測ってるのは15.9%だけやねん。従来の適合率/再現率とかROUGE/BLEU(テキスト評価指標)だけやなくて、ユーザー満足度とか業務効率、コンプライアンス指標も組み込んだ標準的なベンチマークが必要やわ[17,31,98]。
単純な出現頻度のカウントだけやなくて、関係性の分析(RQ5の評価指標とRQ6の検証アプローチのクロス集計)してみたら、めっちゃ重要なつながりが見えてきたんや:実世界のケーススタディやフィールドトライアル(現場での試験)は12.7%の論文でしか使われてへんねんけど、そういう実運用された研究の80%がちゃんとビジネスインパクト指標を取り入れてるねん。この強い相関関係が示してるんは、企業のステークホルダーに目に見えるビジネス価値を示すには、実世界での導入が必須の前提条件やってことやな[16,17]。
**コンセプトドリフト(概念の変化)への頑健性**:企業ってのは常に変わり続けてるやん(新しい規制とか製品アップデートとか)。せやのにモデルの更新とか継続学習を調べてる研究は18%しかないねん。インデックスの増分更新とか生涯学習型のファインチューニングの手法は、もっと研究せなあかんで[45,46,93]。
**マルチモーダルと多言語RAG**:ほぼ全部の研究が英語テキストだけに集中してて、テキスト以外のモダリティ(画像とか表とか)や他の言語を扱ってるのはたった5%やねん。RAG+LLMをマルチモーダルな文書自動化やグローバル企業向けに拡張していくんは、まだまだこれからのオープンな研究課題やで。
---
## Page 18
[](/attach/e4a30c3639e7cda0676ec6fb410a51e32b5a1bc7bb8de451429341a0aecf5a09_p018.png)
### 和訳
Appl. Sci. 2026, 16, 368
18 / 28 ページ
フロンティア[49–51,72,103]。これらの課題にちゃんと取り組むことが、RAG + LLMシステムを「ええ感じのプロトタイプ」から「本番環境でバリバリ使える企業向けソリューション」に進化させるためにめっちゃ重要やねん。セキュリティもバッチリで、効率も良くて、「これほんまに価値あるわ!」って証明できるようなやつにせなあかんってことや[1,2]。
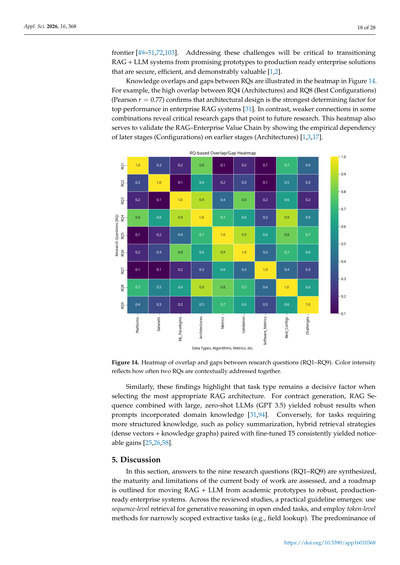
研究課題(RQ)間の知識の重なりとギャップを、図14のヒートマップで見える化してるで。例えばな、RQ4(アーキテクチャ)とRQ8(ベストな設定)の間にはめっちゃ強い重なりがあんねん(ピアソン相関 r = 0.77)。これが何を意味するかっていうと、企業向けRAGシステムで最高のパフォーマンス出すには、アーキテクチャの設計が一番デカい決定要因やってことが確認できたわけや[31]。逆に、いくつかの組み合わせで弱いつながりしかないところは、「ここまだ研究足りてへんな」っていう重要なギャップを示してて、将来の研究テーマになるってことやな。このヒートマップは「RAG–企業価値チェーン」の妥当性を検証する役割も果たしてて、後の段階(設定)が前の段階(アーキテクチャ)に経験的に依存してることを示してるねん[1,3,17]。
図14. 研究課題(RQ1〜RQ9)間の重なりとギャップのヒートマップ。色の濃さは、2つのRQが文脈的に一緒に扱われる頻度を表してるで。
同様に、これらの発見が示してるのは、最適なRAGアーキテクチャを選ぶ時に「タスクの種類」がめっちゃ決定的な要因になるってことやねん。契約書の生成タスクやったら、RAG Sequenceと大規模なゼロショットLLM(GPT 3.5)を組み合わせて、プロンプトにドメイン知識を入れ込んだら、ええ結果が出たんや[31,94]。逆に、ポリシーの要約みたいな、もっと構造化された知識が必要なタスクやったら、ハイブリッド検索戦略(密ベクトル + ナレッジグラフ)とファインチューニングしたT5を組み合わせると、はっきり分かるくらいの改善が見られたで[25,26,58]。
5. 考察
このセクションでは、9つの研究課題(RQ1〜RQ9)への回答を総合して、現時点の研究の成熟度と限界を評価して、RAG + LLMを「学術的なプロトタイプ」から「堅牢で本番環境対応の企業システム」に持っていくためのロードマップを示すで。レビューした研究全体から、実用的なガイドラインが浮かび上がってきてん:オープンエンドなタスクで生成的な推論をする時はシーケンスレベルの検索を使い、範囲が狭い抽出タスク(フィールドの検索とか)にはトークンレベルの手法を使うってことやな。
---
## Page 19
[](/attach/e4a30c3639e7cda0676ec6fb410a51e32b5a1bc7bb8de451429341a0aecf5a09_p019.png)
### 和訳
ほな翻訳していくで〜!
---
Appl. Sci. 2026, 16, 368
19 / 28ページ
最近の2023年から2024年にかけてのカンファレンス論文がめっちゃ多いんやけど、これはLLMとRAGの研究がほんまに速いスピードで進んどるからやねん。NeurIPSとかICLR、ACLみたいなトップの学会が、新しい研究を発表する一番のメインの場所になっとるわけや。これは、RAG Sequence(シーケンス型)とRAG Token(トークン型)を実際に比べてみた研究[31]とも一致しとって、あとハイブリッド検索の研究とも合っとんねん。ハイブリッド検索っていうのは、密ベクトル(めっちゃ情報詰まった数値の塊みたいなもん)とナレッジグラフ(知識を整理した図みたいなやつ)を組み合わせて、構造化されたコンテキストを扱うやり方やで[25,27,28]。
研究結果は表とか図でまとめてあるんやけど、将来のレビューでもっとわかりやすくするために、高度な可視化をすると証拠の構造がもっと見えてくるで。例えばな、サンキーダイアグラム(流れを見せる図)を使って、RAGの主要なパーツ(データソース、検索エージェント、LLMのタイプ)をつなげたら、どんなアーキテクチャの流れが主流なんかがパッとわかるねん。同じように、リサーチクエスチョン(RQ)と使われとるアルゴリズムや評価指標の関係をヒートマップ(熱地図みたいなやつ)で見せたら、どの分野がよう研究されとって、どこにギャップがあるんかが一目瞭然やで。最後に、図4の論文発表トレンドには、イベントマーカー(例えば主要モデルのリリース時期とか)を付けたら、なんでその時期に急に増えたんかっていう文脈がわかりやすくなるで[1-3]。
ちなみに手作業での編集時間が30〜50%減ったっていう結果を報告しとるけど、これは主にリアルワールドのケーススタディ(全体の13%)で見られた範囲の数字であって、メタ分析の信頼区間とはちゃうねん。代表的な例としては、銀行のサポート業務やポリシー要約のシステム導入事例があるで[17,58]。将来のフィールドトライアルでは、統計的なばらつきも含めた標準化された報告を目指すべきやな。そうすれば企業導入間での比較がもっとしやすくなるで。
5.1. 主要な発見のまとめ
RAG+LLMの研究のほとんど(66.2%)はクラウドネイティブのインフラを対象にしとって、33.8%がオンプレミス(自社サーバー)、エッジ(端末側)、またはハイブリッド型の導入を探っとる(表6)。これは柔軟性とコントロールのトレードオフを反映しとるねん。端末側のエッジ研究では、低遅延でオフライン動作ができることを実証しとる[48]。一方、プライバシー重視のオンプレミスとか連合学習の設定では、データ主権とかコンプライアンス対応がメインや[42,43,47]。ハイブリッド構成はまだ少ない(3.9%)けど、検索と生成を信頼境界をまたいで分散させる分散型RAGの将来像を示しとるで。半分以上の研究(54.5%)が公開GitHubデータを使っとって、15.6%が独自データ、16.9%がカスタムの産業データセットを構築しとる(表7)。公開データは再現性にはええけど、ドメインシフト(分野が変わると性能落ちる問題)のリスクがあるねん。公開データと非公開データのギャップを埋めるには、ドメイン適応と継続的な更新が必要やし[45,46]、センシティブなデータに対するプライバシー保護検索も大事やで[42,47]。
教師あり学習がめっちゃ多くて92.2%を占めとる。教師なし(3.9%)と半教師あり(3.9%)はあんまり使われてへんから、対照学習による埋め込み学習とか、ラベルが少ない分野でのセルフ少数ショット・ゼロショット適応にはまだチャンスがあるってことやな[29,36,37]。古典的な機械学習(ナイーブベイズ、SVM、ロジスティック回帰、決定木、ランダムフォレスト)はランキングや欠陥分類の定番としてまだ使われとるし、Transformerベースのバリエーションも勢いを増しとる。密ベクトルとナレッジグラフを組み合わせたハイブリッドインデックスは23.1%の研究で使われとって、説明可能性と精度を向上させることが多いで[3,25,26]。RAG SequenceとRAG Tokenの比較は[31]に書いてあるで。
技術的な評価指標(適合率・再現率・正解率:80.5%、Recall@K・Precision@K:72.7%、ROUGE・BLEU:44.2%)が主流や(表10)。人間による評価は19.5%で報告されとって、ビジネスインパクトの指標はたった15.6%しかない[17,31,32]。このギャップは、自動スコアだけやなくて、ユーザースタディとか運用KPIも一緒に見なあかんってことを示しとるねん。k分割交差検証(93.6%)が標準やけど、非IIDドリフト(データの分布がずれていく状況)では性能を過大評価してまうかもしれへん。ホールドアウト分割(26%)とリアルワールドのケーススタディ・フィールドトライアル(13%)は、実際に導入する準備ができとるかとか、インパクトを測るのにめっちゃ重要やで。オブジェクト指向のコード指標が一番よく使われとるけど、Webプロセスのパフォーマンス指標はまだ珍しいねん。検索、生成、インタラクションを統合したパイプラインには、もっとリッチなテレメトリ(レイテンシの分布、出典カバレッジ、ユーザー満足度)が必要やで。
---
## Page 20
[](/attach/e4a30c3639e7cda0676ec6fb410a51e32b5a1bc7bb8de451429341a0aecf5a09_p020.png)
### 和訳
ほな、この論文の内容を説明していくで!
成績ええやつの特徴見てみると、RAGトークン(要は検索して情報引っ張ってくる仕組みやな)と、ちゃんと調整したエンコーダ・デコーダ型のLLMを組み合わせるか、あるいは密ベクトル検索とナレッジグラフのハイブリッド型で情報取ってきて、それを文章生成モデルに食わせるパターンが多いねん。でっかいデコーダだけのLLMにゼロショット(学習なしでいきなり質問する方式やな)で投げるのも、文章作るタスクならそこそこ戦えるんやけど、ちゃんとファインチューニング(微調整)したら事実の正確さが10〜20%くらい上がるって報告されてるわ[31,58,94]。
ほんで、繰り返し出てくる課題が5つあんねん。プライバシーの問題(37.7%)、処理の遅延(31.2%)、ビジネスへの効果測定(15.6%)、嘘つき問題(ハルシネーションな、48.1%)、あと特定分野への適応(23.4%)や(表13見てな)。プライバシー守りながら検索する方法として、差分プライバシーとかSMPC(秘密計算ってやつ)使った連合学習的なアプローチが今アツいねん[41-43,47]。遅延はANN検索(近似最近傍探索やな)とか、モデルの圧縮、非同期で検索する方法で改善できるで[32,33,48,102]。嘘つき問題には、情報の出どころ追跡するグラフとか、因果関係で説明できる手法が有効[13,34,44,101]。ドメインシフト(分野が変わると性能落ちる問題な)には、継続的にRAGを学習させたり、インデックスをちょこちょこ更新する方法が必要やねん[45,46]。マルチモーダル(画像とかテキストとか複数扱うやつ)と多言語対応の企業向け活用は、まだまだこれからって感じやな[49-51,72,103]。
## 5.2. 企業の制約を批判的に分析したら見えてきた「研究室と現場のギャップ」
分析してみたらな、学術的なRAG研究と企業が求めてるもんの間に、めっちゃはっきりした溝があることがわかってん。学術研究ってリーダーボード(ランキング表みたいなもんやな)の数字、例えばMS MARCOでのRecall@Kとかを追い求めがちやねん[17,65]。でも企業の現場では、ベンチマークではほとんど再現されへん厳しい運用上の制約があんねん:
**・遅延と精度のトレードオフ問題**
学術モデルって、精度上げるためにめっちゃ計算重い再ランキング処理(BERTベースのクロスエンコーダとかな)を使いがちやねん。でもな、企業のリアルタイム文書処理では、遅延の許容範囲が200ミリ秒以下とかやったりすんねん。そしたら軽いけど精度落ちるバイエンコーダとか、スパース・密ベクトルのハイブリッド検索に頼らざるを得んくなるわけや[32,33,48]。
**・監査可能性と追跡可能性**
金融とか医療とか規制厳しい業界では、決定論的(同じ入力なら同じ出力)であることが求められんねん。エンドツーエンドのニューラルなやり方(中身がブラックボックスなRAG)は嫌われて、検索で引っ張ってきた情報を生成前に人間がチェックできるモジュール式のパイプラインが好まれるんや。これ、最近の学術論文で流行りの「エンドツーエンドで学習するRAG」の流れと真逆やねん[25,26]。
**・致命的な嘘つきリスク**
普通のQ&Aと違って、契約書とか医療報告書で嘘ついたら法的責任問われるやろ?やから「厳格RAG」設定が必要になんねん。検索スコアが高い信頼度の閾値下回ったら「わかりません」って出力するように制限すんねん。こういう動作、TruthfulQAみたいな標準的な学術ベンチマークではほとんど最適化されてへんのが現状や[34,44,96]。
## 5.3. 企業が導入するときの実践的なポイント
RAGとLLMのソリューション導入しようとしてる組織はな、ハイブリッドなインフラ構成がええで。大規模で機密性低い処理にはクラウド使って、機密データ守るためにオンプレミス(自社サーバー)でインデックス作って、素早い応答にはエッジ推論(端末側での処理な)使う。んで、データの機密度と応答時間の要件に応じて賢くルーティングすんねん[32,33,47,48,102]。
GDPR、CCPA、HIPAAみたいな規制に対応するには、プライバシー保護型の検索の仕組みが必要や。暗号化した埋め込みベクトルとか、アクセス制御付きのベクトルストア、連合検索とかな[41-43,47]。ニッチな分野でラベル付きデータが足りひん問題は、半教師あり・教師なし手法で対応できるで。対照学習による埋め込み、自己学習、プロンプトベースの少数ショット適応とかや[29,36,37]。
ちゃんとした評価体制作るには、定量的な指標(Recall、ROUGE、BLEUとかな)と、人間が確認する評価、それにビジネスKPI(手作業の工程短縮、エラー減少、ユーザー満足度向上とか)を組み合わせて、技術的な性能と戦略的なインパクト両方を見るんや[16,17,31,32]。モデルを最新の状態に保つには、継続学習のワークフロー作って、検索インデックスを定期的に更新して、新しく取り込んだデータでファインチューニングするんやで。
---
## Page 21
[](/attach/e4a30c3639e7cda0676ec6fb410a51e32b5a1bc7bb8de451429341a0aecf5a09_p021.png)
### 和訳
5.4. このレビューの限界
このシステマティック・レビュー(SLR)はな、データベースをめっちゃ徹底的に検索して、品質チェックも厳しくやる、ちゃんとした方法論に従ってんねんけど、それでもいくつか認めなあかん限界があるねん。
まず1つ目は「スコープバイアス」っていうて、グレー文献を除外してることやねん。このレビューは科学的な厳密さを保つために、査読付きの学術論文だけに絞ってん。せやけどな、生成AIの分野ってめっちゃ進化が速いやろ?だから重要な実運用データとか新しいアーキテクチャのパターンって、最初は企業のホワイトペーパーとかベンダーの技術レポート、査読前のプレプリントで出てくることが多いねん。そういうのは選んだ学術データベースに登録されてない限り、今回の分析からは外れてもうてるわけや。
2つ目は「コーパスと出版バイアス」に関する限界やな。うまくいった結果とか導入成功の話を報告してる研究の方が、失敗とかネガティブな結果を詳しく書いてる研究より出版されやすいねん。せやから、企業環境でのRAG+LLMソリューションの実際のメリットとか信頼性が、ちょっと盛られてる可能性があるわけや。それに加えて、英語の研究がめっちゃ多いから言語バイアスもあって、多言語での企業導入における特有の課題があんまり代表されてへんのや。
3つ目は「時間的な制約とこの分野の進化スピード」っていう課題やねん。検索期間は2015年から2025年までカバーしてるんやけど、RAGに関連する文献のほとんどは2020年以降に出てきたもんやねん。結果として、このレビュー作業の最終段階で出てきたイノベーションは抜けてるかもしれへん。さらにな、研究ごとに使ってる指標がバラバラで、特にレイテンシ(応答速度)とかビジネスROI(投資対効果)の報告方法が標準化されてへんから、直接的な定量的メタ分析ができへんかったんや。
最後に、このレビューでは一次研究の地理的分布を分析してへんねん。将来の文献計量分析では、この点をカバーして、世界のR&Dトレンドとか地域ごとの導入成熟度についての知見を提供できるかもしれへんな。
5.5. 今後の研究の方向性
企業環境でのRAG+LLMの発展を促進するために、優先的に取り組むべき研究テーマがいくつかあるねん:
• **セキュアなインデックス作成**:企業の機密文書を安全にインデックス化するためには、エンドツーエンドで暗号化された検索パイプラインとか、差分プライバシーを考慮した埋め込み手法の開発が必須やねん。要するに、データを外に漏らさんようにしながら検索できる仕組みってことや。
• **超低レイテンシRAG**:100ミリ秒未満、つまりめっちゃ速い応答時間を実現するために、近似検索とかモデルの量子化(モデルを軽くする技術やな)、非同期生成みたいな技術の研究が必要やねん。
• **マルチモーダル統合**:技術マニュアルとか財務レポートによう出てくる画像、図表、表形式のデータみたいな、複数の種類のデータを検索・生成に組み込んでいくことが不可欠やねん。
• **多言語対応**:ほんまにグローバルな環境をサポートするには、英語以外の情報を処理して、言語間で知識を移転できるRAG+LLMシステムを作ることが必須やで。
• **標準化されたベンチマーク**:技術的なパフォーマンスだけやなくて、実際の業務運用、ユーザーフィードバック、コンプライアンス要件を組み合わせたビジネス向けのベンチマークを設定することがめっちゃ大事やねん。
---
## Page 22
[](/attach/e4a30c3639e7cda0676ec6fb410a51e32b5a1bc7bb8de451429341a0aecf5a09_p022.png)
### 和訳
• **説明できることと信頼性について**:なんでこの答えが出てきたんか、どこから情報持ってきたんか、っていう因果関係の可視化とか、情報の出どころを追えるグラフとか、ユーザーが「なるほど、そういうことか」って納得できるインターフェースを作ることがめっちゃ大事やねん。そうすることで「このシステム信用してええんかな」っていう不安を解消できるし、監査もやりやすくなるんよ。
• **いろんな分野への適応、プライバシー、頑丈さについて**:最近の研究では、RAGの難しい課題に対していろんなアプローチが出てきてんねん。まず、企業のいろんな場面でちゃんと使えるようにするための「ドメイン適応」っていう技術。それから、検索を組み込んだシステムのセキュリティ問題に取り組む「プライバシーに配慮した設計」。あと、AIが嘘ついてないかを外部データなしで自分でチェックできる「自己教師あり幻覚検出」っていう方法もあるんよ。これらを全部組み合わせることで、本番環境でも安心して使えるRAGシステムが作れるようになってきてんねん。
63本の研究をガッツリ調べた結果やけど、RAGとLLMを組み合わせたシステムは、企業の情報管理や文書の自動化をめっちゃ変える可能性があるんよ。ただ、そのためには異分野の研究者がタッグを組んで、実際のビジネスの現場でガチでテストせなあかんねん。
## 6. まとめと今後の課題
この系統的レビューでは、品質をしっかりチェックした63本の研究をもとに、企業のナレッジマネジメントと文書自動化におけるRAGとLLMの現状をまとめたで。9つの研究課題を調べた結果、はっきりしたパターンがいくつか見えてきたんよ。
まず、クラウドネイティブ(最初からクラウド前提で作る方式)が圧倒的に多くて66.2%やねん。残りの33.8%は、自社サーバーとか、エッジ(端末側)とか、それらを組み合わせたハイブリッド型で、データの主権とか、遅延とか、法令順守の要件を満たそうとしてるんよ。クラウドのミドルウェアから、分散システム、端末上で動くパイプラインまでいろんな取り組みがあるで。
研究で使われるデータは、GitHubの公開データが54.5%と多いんやけど、企業の独自データ(15.9%)とか、産業界のカスタムデータ(17.4%)は少ないんよ。これ、プライバシーを守りながら検索できる技術とか、公開データと非公開データの差を埋めるドメイン適応がもっと必要やってことを示してるんやな。
学習方法は教師あり学習(正解データを使う方法)が92.1%で圧倒的やねん。教師なし(4.8%)とか半教師あり(3.2%)は少なくて、対照学習とか、少ないデータで学ぶ方法とか、まだまだ伸びしろがあるってことやな。
アーキテクチャ的には、「RAG Sequence」(文書全体を取ってきて生成する方式)が36研究、「RAG Token」(トークンごとに検索を活用する方式)が28研究で報告されてて、密なベクトル検索とナレッジグラフを組み合わせたハイブリッド設計も18研究あるんよ。
評価方法を見ると、技術的な指標(精度、再現率、正確度、Recall@K、Precision@K、ROUGE、BLEUとか)に偏っとって、人間による評価(19.0%)とかビジネスへの実際の効果の測定(15.9%)は少ないんよ。検索部分の検証はk分割交差検証(データを分けて何回もテストする方法)が93.6%で主流やけど、生成の性能は普通にテスト用データセットで評価されることが多いねん。実際の現場でのフィールドテストはまだ12.7%しかなくて、本番環境で使えることや投資対効果を示すには、もっとやらなあかんねん。
よく出てくる課題としては、**幻覚(嘘の情報を自信満々で言うやつ)と事実の一貫性**が47.6%でトップ。次いで**データプライバシー**が38.1%、**遅延とスケーラビリティ**が31.7%、**ビジネスインパクトの評価不足**が15.9%、**ドメイン適応の転移**が23.8%やねん。
全体的に言うと、RAG+LLMは古い知識の問題を軽減して、検索で根拠を持たせることで幻覚も減らせるんやけど、企業が求めるプライバシー、遅延、法令順守、測定可能な価値っていう要件を満たすには、まだまだやることがいっぱいあるんよ。
「いい感じのプロトタイプ」から「ガチで本番で使える頑丈なシステム」にするために、6つの優先課題を挙げとくで:
• **セキュリティとプライバシー**:企業の独自データを扱うために、エンドツーエンドで暗号化された分散検索とか、差分プライバシー(個人が特定されないように数学的に保証する技術)を使った埋め込みベクトルを開発せなあかん。あと、アクセス制御付きのベクトルストアとか、SMPC(複数の関係者で計算するけど互いのデータは見えない技術)を使ったパイプラインも強化する必要があるで。
---
## Page 23
[](/attach/e4a30c3639e7cda0676ec6fb410a51e32b5a1bc7bb8de451429341a0aecf5a09_p023.png)
### 和訳
• **レイテンシの最適化**: エンドツーエンドのレイテンシを100ミリ秒以下に抑えなあかんねん。そのためには、より速いANN検索(近似最近傍探索ってやつやな)、モデルの量子化とか蒸留(要はモデルを軽くする技術やで)、あと検索と生成を非同期でつなげるとかが必要やねん。負荷がかかった状態でのレイテンシ分布も全部報告せなあかんで [32,33,48]。
• **高度な学習戦略**: 半教師あり学習の戦略をもっと進めなあかんねん。具体的には対照表現学習とか自己学習、あとプロンプトベースの少数ショット・ゼロショット適応とかやな。これらはラベル付きデータが少ないドメインでめっちゃ役立つんや [29,36,37]。
• **総合的な評価**: 自動スコアだけやなくて、人間による評価とか運用上のKPI(サイクルタイム、エラー率、満足度、コンプライアンスとか)も合わせて見なあかんねん。ビジネスへのインパクトを重視した共有ベンチマークにも貢献していこうや [17]。
• **マルチモーダル&多言語対応**: テキストだけやなくて、画像とか図表も検索・生成できるように拡張せなあかんねん。グローバル企業向けに多言語コンプライアンスと言語間転移も強化する必要があるで。BLOOMみたいな多言語対応のオープンソース基盤を活用するんやな [49–51,72,103]。
• **継続的なメンテナンス**: コンセプトドリフト(時間とともにデータの傾向が変わることやな)に対応するために、インデックスとモデルの継続的な更新を実装せなあかん。増分的でコスト効率の良いファインチューニングと、進化するコーパスのライフサイクルガバナンスも探っていく必要があるで [45,46]。
まとめると、RAG+LLMは企業のナレッジワークフローとか文書自動化にめっちゃ強力なパラダイムを提供してくれるんや。でもその可能性を最大限に引き出すには、設計段階からのセキュリティ対策、レイテンシを意識したシステム、データ効率の良い適応、ビジネス価値の総合的な測定、マルチモーダル・多言語対応、そして規律ある継続学習が必要やねん。ほんでこれらは大規模な現場試験でしっかり検証せなあかんで。
**補足資料**: 以下のサポート情報は https://www.mdpi.com/article/10.3390/app16010368/s1 からダウンロードできるで。表S1には、分析した63本の論文それぞれについて、ドメイン、アーキテクチャ、検証方法を詳しく記載した拡張データ抽出フォームがあるんや。
**著者の貢献**: 概念化はA.A.とE.K.、方法論はE.K.、ソフトウェアはE.K.、検証はA.A.、形式的分析はE.K.、調査はE.K.、リソースはA.A.、データキュレーションはE.K.、原稿執筆はE.K.、レビューと編集はA.A.、可視化はE.K.、監督はA.A.、プロジェクト管理はA.A.がやったで。全著者が原稿を読んで、出版版に同意しとるで。
**資金提供**: この研究は外部からの資金提供は受けてへんで。
**機関審査委員会の声明**: 該当なしや。
**インフォームドコンセントの声明**: 該当なしや。
**データの利用可能性**: この研究では新しいデータの作成や分析はしてへんで。この論文にはデータ共有は該当せえへんねん。
**利益相反**: 著者らは利益相反がないことを宣言しとるで。
**略語**
この原稿では以下の略語が使われとるで:
| 略語 | 意味 |
|------|------|
| RAG | 検索拡張生成(Retrieval-Augmented Generation) |
| LLM | 大規模言語モデル(Large Language Model) |
| SLR | 系統的文献レビュー(Systematic Literature Review) |
| NLP | 自然言語処理(Natural Language Processing) |
| QA | 質問応答(Question Answering) |
| KG | 知識グラフ(Knowledge Graph) |
| MDPI | 学際デジタル出版機構(Multidisciplinary Digital Publishing Institute) |
---
## Page 24
[](/attach/e4a30c3639e7cda0676ec6fb410a51e32b5a1bc7bb8de451429341a0aecf5a09_p024.png)
### 和訳
Appl. Sci. 2026, 16, 368
参考文献
24 / 28ページ
1. Mallen, A.; Asai, A.; Zhong, V.; Das, R.; Khashabi, D.; Hajishirzi, H. 言語モデルを信用したらアカン時っていつやねん:パラメトリックメモリと非パラメトリックメモリの効果を調べてみたで。要するにな、AIが自分の頭ん中の知識だけで答えるんと、外から情報引っ張ってくるんと、どっちがええかって話や。第61回計算言語学会年次大会(ACL)、カナダのトロントで2023年7月9-14日にやったやつ、pp. 9802-9822。[CrossRef]
2. Lazaridou, A.; Gribovskaya, E.; Stokowiec, W.; Grigorev, N. インターネット強化した言語モデル:few-shotプロンプティングでオープンドメインの質問応答やってみた。これな、ちょっとだけ例を見せたら、ネットから情報取ってきてうまいこと答えられるようになるって研究やねん。arXiv 2022、arXiv:2203.05115。
3. Yao, S.; Zhao, J.; Yu, D.; Du, N.; Shafran, I.; Narasimhan, K.; Cao, Y. ReAct:言語モデルで推論と行動をうまいこと組み合わせる方法。なんでかっていうと、ただ考えるだけやなくて、実際に行動もさせたら賢くなるやろって発想や。国際学習表現会議(ICLR)、ルワンダのキガリで2023年5月1-5日にやったやつ。[CrossRef]
4. Wang, N.; Han, X.; Singh, J.; Ma, J.; Chaudhary, V. CausalRAG:検索拡張生成に因果グラフを組み込んでみた。因果関係、つまり「AやからBになる」みたいな関係をAIに教え込んで、もっと賢く情報を引っ張ってこれるようにしようって話やな。arXiv 2025、arXiv:2503.19878。
5. Ma, X.; Gong, Y.; He, P.; Zhao, H.; Duan, N. 検索拡張した大規模言語モデルのためのクエリ書き換え。ユーザーが入力した質問を、検索しやすいように言い換えてあげるってことやねん。そしたらもっとええ情報が見つかるやろ?2023年自然言語処理の実証的手法に関する会議(EMNLP)、シンガポールで2023年12月6-10日にやったやつ、pp. 5303-5315。[CrossRef]
6. Chowdhery, A.; Narang, S.; Devlin, J.; Bosma, M.; Mishra, G.; Roberts, A.; Barham, P.; Chung, H.W.; Sutton, C.; Gehrmann, S.; 他。PaLM:Pathwaysで言語モデルをめっちゃでっかくスケールさせたで。Googleがつくったクソでかいモデルで、いろんなタスクをこなせるようになっとる。機械学習研究ジャーナル(JMLR)2023、24、1-113。
7. Khattab, O.; Singhvi, A.; Maheshwari, P.; Zhang, Z.; Santhanam, K.; Vardhamanan, S.; Haq, S.; Sharma, A.; Joshi, T.T.; Moazam, H.; 他。DSPy:宣言的な言語モデル呼び出しを自己改善パイプラインにコンパイルする。プログラミングみたいに言語モデルを使えるようにして、しかも勝手にどんどん賢くなっていくって仕組みやねん。国際学習表現会議(ICLR)、オーストリアのウィーンで2024年5月7-11日にやったやつ。
8. Kandpal, N.; Deng, H.; Roberts, A.; Wallace, E.; Raffel, C. 大規模言語モデルはロングテール知識を学ぶのがめっちゃ苦手やねん。ロングテールってのは、あんまり出てこないマイナーな情報のことや。よく出てくる情報は覚えられるけど、レアな情報はなかなか覚えられへんって話。第40回国際機械学習会議(ICML)、アメリカのホノルルで2023年7月23-29日にやったやつ、pp. 15696-15707。
9. Arslan, M.; Mahdjoubi, L.; Munawar, S.; Cruz, C. 複数ソースのRAG-LLMシステムで持続可能なエネルギー転換を推進する。いろんなところから情報を集めてきて、エネルギー問題の解決に役立てようって研究やな。Energy Build. 2024、324、114827。[CrossRef]
10. Sun, J.; Xu, C.; Tang, L.; Wang, S.; Lin, C.; Gong, Y.; Ni, L.M.; Shum, H.Y.; Guo, J. Think-on-Graph:知識グラフを使った大規模言語モデルの深くて責任ある推論。知識グラフってのは、いろんな概念がどう繋がってるかを図にしたもんや。それを使ってAIがもっとちゃんと考えられるようにしようって話やねん。国際学習表現会議(ICLR)、オーストリアのウィーンで2024年5月7-11日にやったやつ。
11. Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. XLNet:言語理解のための一般化された自己回帰事前学習。BERTの弱点を克服しようとしたモデルで、文章の前後両方の文脈をうまいこと使えるようになっとる。ニューラル情報処理システム会議(NeurIPS)、カナダのバンクーバーで2019年12月8-14日にやったやつ、Volume 32。
12. OpenAI。GPT-4テクニカルレポート。言わずと知れたGPT-4の技術詳細やな。arXiv 2023、arXiv:2303.08774。[CrossRef]
13. Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; 他。Llama 2:オープンな基盤モデルとファインチューニングされたチャットモデル。Metaが出したオープンソースの大規模言語モデルで、誰でも使えるようになっとるんや。arXiv 2023、arXiv:2307.09288。[CrossRef]
14. Zhang, S.; Roller, S.; Goyal, N.; Artetxe, M.; Chen, M.; Chen, S.; Dewan, C.; Diab, M.; Li, X.; Lin, X.V.; 他。OPT:オープンな事前学習済みTransformer言語モデル。これもオープンソースの大規模言語モデルで、研究者がいろいろ実験できるようにMetaが公開したやつや。arXiv 2022、arXiv:2205.01068。[CrossRef]
15. Black, S.; Biderman, S.; Hallahan, E.; Anthony, Q.; Gao, L.; Golding, L.; He, H.; Leahy, C.; McDonell, K.; Phang, J.; 他。GPT-NeoX-20B:オープンソースの自己回帰言語モデル。200億パラメータもあるでっかいモデルを、みんなが使えるように公開したんや。BigScience Episode #5ワークショップ、アイルランドのダブリンで2022年5月27日にやったやつ、pp. 95-136。[CrossRef]
16. Le Scao, T.; Fan, A.; Akiki, C.; Pavlick, E.; Ili´c, S.; Hesslow, D.; Hesslow, D.; Castagné, R.; Luccioni, A.S.; Yvon, F.; 他。BLOOM:1760億パラメータのオープンアクセス多言語言語モデル。世界中の研究者がよってたかって作った、めっちゃでかい多言語対応のモデルやねん。arXiv 2022、arXiv:2211.05100。
17. Ji, Z.; Lee, N.; Frieske, R.; Yu, T.; Su, D.; Xu, Y.; Ishii, E.; Bang, Y.; Madotto, A.; Fung, P. 自然言語生成におけるハルシネーションの調査。ハルシネーションってのは、AIがほんまのことみたいに嘘をつくことやねん。これがどういう時に起きるか、どうやったら防げるかをまとめた論文や。ACM Computing Surveys 2023、55、1-38。[CrossRef]
18. Zhang, Y.; Li, Y.; Cui, L.; Cai, D.; Liu, L.; Fu, T.; Huang, X.; Zhao, E.; Zhang, Y.; Xu, C.; 他。AIの海に響くセイレーンの歌:大規模言語モデルにおけるハルシネーションの調査。セイレーンって神話の怪物みたいに、AIが甘い嘘で人を惑わすってことを比喩的に言うてるんやな。arXiv 2023、arXiv:2309.01219。[CrossRef]
19. Gao, Y.; Xiong, Y.; Gao, X.; Jia, K.; Pan, J.; Bi, Y.; Dai, Y.; Sun, J.; Wang, M.; Wang, H. 大規模言語モデルのための検索拡張生成:サーベイ。RAG(Retrieval-Augmented Generation)についてめっちゃ詳しくまとめた論文や。外部から情報を引っ張ってきてAIの回答を良くするって技術やねん。arXiv 2023、arXiv:2312.10997。
20. Cui, L.; Wu, Y.; Liu, J.; Yang, S.; Zhang, Y. BARTを使ったテンプレートベースの固有表現認識。固有表現認識ってのは、文章から人名とか地名とかを見つけ出す技術や。それをBARTってモデルでうまいことやる方法を提案しとる。計算言語学会:ACL-IJCNLP 2021、オンライン開催、2021年8月1-6日、pp. 1835-1845。[CrossRef]
21. Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa:めっちゃ頑健に最適化したBERTの事前学習アプローチ。BERTの学習方法を見直して、もっと性能ええモデルを作ったって研究やな。国際学習表現会議(ICLR)、エチオピアのアディスアベバで2020年4月26-30日にやったやつ。
22. Rajpurkar, P.; Zhang, J.; Lopyrev, K.; Liang, P. SQuAD:テキスト理解のための10万問以上の質問。AIが文章を読んで質問に答えられるかをテストするための、めっちゃ有名なデータセットやねん。2016年自然言語処理の実証的手法に関する会議(EMNLP)、アメリカのオースティンで2016年11月1-5日にやったやつ、pp. 2383-2392。[CrossRef]
---
## Page 25
[](/attach/e4a30c3639e7cda0676ec6fb410a51e32b5a1bc7bb8de451429341a0aecf5a09_p025.png)
### 和訳
Appl. Sci. 2026, 16, 368
25 / 28ページ
23. Chen, D.; Fisch, A.; Weston, J.; Bordes, A. Wikipediaを読んでオープンドメインの質問に答えるで。
なんやこれ、要するにウィキペディアから情報引っ張ってきて、なんでも質問に答えられるようにしよう!っていう研究やねん。
第55回計算言語学会年次大会(ACL)の論文集、カナダのバンクーバーで2017年7月30日〜8月4日に開催、1870〜1879ページに載ってるで。[CrossRef]
24. Qu, Y.; Ding, Y.; Liu, J.; Liu, K.; Ren, R.; Zhao, W.X.; Dong, D.; Wu, H.; Wang, H. RocketQA: オープンドメイン質問応答のための密な文章検索を最適化したトレーニング手法やで。
めっちゃざっくり言うと、質問に対して関連する文章をロケットみたいに速く正確に見つけ出す方法を編み出したんや。
2021年北米計算言語学会人間言語技術会議の論文集、オンライン開催で2021年6月6〜11日、5835〜5847ページ。[CrossRef]
25. Shi, W.; Min, S.; Yasunaga, M.; Seo, M.; James, R.; Lewis, M.; Zettlemoyer, L.; Yih, W.t. REPLUG: 検索で強化されたブラックボックス言語モデルやで。
これな、中身がわからんブラックボックスな言語モデルでも、外から情報検索くっつけたら賢くなるやん!っていう発見やねん。
2024年北米計算言語学会(NAACL)論文集、メキシコシティで2024年6月16〜21日開催、8371〜8384ページ。[CrossRef]
26. Mialon, G.; Dessì, R.; Lomeli, M.; Nalmpantis, C.; Pasunuru, R.; Raileanu, R.; Rozière, B.; Schick, T.; Dwivedi-Yu, J.; Celikyilmaz, A.; ほか多数。拡張言語モデル:サーベイ論文やで。
言語モデルをいろんな方法で強化する研究を全部まとめて調査したんや。arXiv 2023、arXiv:2302.07842。[CrossRef]
27. Sanh, V.; Webson, A.; Raffel, C.; Bach, S.H.; Sutawika, L.; Alyafeai, Z.; Chaffin, A.; Stiegler, A.; Scao, T.L.; Raja, A.; ほか多数。
マルチタスクのプロンプト訓練でゼロショットのタスク汎化ができるようになるで。
なんでかっていうと、いろんなタスクで訓練しとくと、見たことないタスクでもいきなりできるようになるんやて。ほんまにすごいやろ?
国際学習表現会議(ICLR)論文集、2022年4月25〜29日オンライン開催。
28. Min, S.; Lewis, M.; Zettlemoyer, L.; Hajishirzi, H. MetaICL: コンテキスト内で学習することを学習するで。
これめっちゃおもろくて、文脈から学ぶ方法自体を学習させるっていう、ちょっとメタな話やねん。
2022年北米計算言語学会(NAACL)論文集、アメリカのシアトルで2022年7月10〜15日開催、2791〜2809ページ。[CrossRef]
29. Xiong, L.; Xiong, C.; Li, Y.; Tang, K.F.; Liu, J.; Bennett, P.; Ahmed, J.; Overwijk, A. 密なテキスト検索のための近似最近傍負例対照学習やで。
難しそうに聞こえるけど、要は似てる文章を見つける時に「これは違うで」っていう例もうまく使って学習精度上げようって話や。
国際学習表現会議(ICLR)論文集、2021年5月3〜7日オンライン開催。
30. Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Xia, F.; Chi, E.; Le Q.V.; Zhou, D. Chain-of-Thought(思考の連鎖)プロンプティングで大規模言語モデルの推論を引き出すで。
これがめっちゃ有名なやつやねん。「一歩ずつ考えてみ?」って言うだけで、AIが急に賢くなるっていう発見や。
神経情報処理システム会議(NeurIPS)論文集、アメリカのニューオーリンズで2022年11月28日〜12月9日開催、第35巻、24824〜24837ページ。
31. Asai, A.; Wu, Z.; Wang, Y.; Sil, A.; Hajishirzi, H. Self-RAG: 自己反省を通じて検索・生成・批評を学習するで。
これな、AI自身が「この情報ほんまに正しいんかな?」って自分でチェックしながら答えを作るようになるんや。めっちゃ賢いやろ?
国際学習表現会議論文集、オーストリアのウィーンで2024年5月7〜11日開催。[CrossRef]
32. Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, E.; Ott, M.; Zettlemoyer, L.; Stoyanov, V.
大規模な教師なし多言語表現学習やで。
いろんな言語をまとめて学習させたら、一個の言語で学んだことが他の言語でも使えるようになるんや。便利やなぁ。
第58回計算言語学会年次大会(ACL)論文集、2020年7月5〜10日オンライン開催、8440〜8451ページ。[CrossRef]
33. Trivedi, H.; Balasubramanian, N.; Khot, T.; Sabharwal, A. 知識集約型の複数ステップ質問に対して、検索と思考の連鎖推論を交互にやるで。
複雑な質問には、情報を調べる→考える→また調べる→また考える、ってインターリーブ(交互)にやるのが効くんやて。
第61回計算言語学会年次大会(ACL)論文集、カナダのトロントで2023年7月9〜14日開催、10014〜10037ページ。[CrossRef]
34. Song, K.; Tan, X.; Qin, T.; Lu, J.; Liu, T.Y. MPNet: 言語理解のためのマスク&順序入れ替え事前学習やで。
BERTとかの改良版で、単語を隠すだけやなくて順番も入れ替えて学習させることで、もっと賢くなるんや。
神経情報処理システム会議(NeurIPS)論文集、2020年12月6〜12日オンライン開催、第33巻、16857〜16867ページ。
35. Schick, T.; Dwivedi-Yu, J.; Dessì, R.; Raileanu, R.; Lomeli, M.; Hambro, E.; Zettlemoyer, L.; Cancedda, N.; Scialom, T. Toolformer: 言語モデルは自分でツールの使い方を覚えられるで。
これほんまにすごくて、AIに「電卓使ってええで」「検索してええで」って教えたら、自分で勝手にツール使うタイミング学習するんや。
神経情報処理システム会議(NeurIPS)論文集、アメリカのニューオーリンズで2023年12月10〜16日開催、第36巻、68539〜68551ページ。
36. Borgeaud, S.; Mensch, A.; Hoffmann, J.; Cai, T.; Rutherford, E.; Millican, K.; Van Den Driessche, G.B.; Lespiau, J.B.; Damoc, B.; Clark, A.; ほか多数。数兆トークンからの検索で言語モデルを改善するで。
めっちゃ大量のデータから関連情報を引っ張ってくることで、モデル自体を巨大にせんでも賢くできるっていう研究や。
第39回国際機械学習会議(ICML)論文集、アメリカのボルチモアで2022年7月17〜23日開催、2206〜2240ページ。
37. Luo, H.; Zhang, T.; Chuang, Y.S.; Gong, Y.; Kim, Y.; Wu, X.; Meng, H.; Glass, J. 検索で強化された指示学習やで。
AIに指示する時に、関連情報も一緒に渡したらもっとうまくいくやん、っていう研究やねん。
計算言語学会EMNLP 2023発見論文集、シンガポールで2023年12月6〜10日開催、3717〜3729ページ。[CrossRef]
38. Lester, B.; Al-Rfou, R.; Constant, N. パラメータ効率的なプロンプトチューニングにおけるスケールの力やで。
でっかいモデルほど、ちょっとプロンプトいじるだけでめっちゃ性能上がるんやて。小さいモデルやとあんま効かへんねん。
2021年自然言語処理経験的手法会議論文集、ドミニカ共和国のプンタカナで2021年11月7〜11日開催、3045〜3059ページ。[CrossRef]
39. Li, X.L.; Liang, P. Prefix-Tuning: 生成のための連続プロンプト最適化やで。
モデル全体をいじらんでも、最初にくっつける「接頭辞」の部分だけ学習させたら、特定のタスクに適応できるんや。効率ええやろ?
第59回計算言語学会年次大会&第11回自然言語処理国際合同会議論文集、タイのバンコクで2021年8月1〜6日開催、第1巻:長論文、4582〜4597ページ。[CrossRef]
40. Liu, X.; Ji, K.; Fu, Y.; Tam, W.; Du, Z.; Yang, Z.; Tang, J. P-Tuning: プロンプトチューニングはスケールやタスクを問わずファインチューニングに匹敵するで。
前は「プロンプトチューニングってファインチューニングに負けるやん」って思われとったけど、やり方次第で同じくらいいけるって証明したんや。
第60回計算言語学会年次大会論文集、アイルランドのダブリンで2022年5月22〜27日開催、第2巻:短論文、61〜68ページ。[CrossRef]
41. Qin, Y.; Liang, S.; Ye, Y.; Zhu, K.; Yan, L.; Lu, Y. ToolLLM: 大規模言語モデルに16000以上の実世界APIを使いこなさせるで。
これえぐいねん。1万6千個以上のAPIを使えるようにAIを訓練したっていう、めっちゃ野心的な研究や。
国際学習表現会議(ICLR)論文集、オーストリアのウィーンで2024年5月7〜11日開催。
---
## Page 26
[](/attach/e4a30c3639e7cda0676ec6fb410a51e32b5a1bc7bb8de451429341a0aecf5a09_p026.png)
### 和訳
42. Radfordさんら(2019年)の「言語モデルは教師なしのマルチタスク学習者やで」って論文な。OpenAIのブログに載ってるやつ。これ何がすごいかっていうと、特別に「これ覚えなさい」って教えんでも、AIが勝手にいろんなことできるようになるって話やねん。
43. Thakurさんらの「BEIR」っていうベンチマークの話や。2021年のNeurIPSで発表されてんけど、これは情報検索モデルを「ゼロショット」、つまり事前に見たことないデータでどれだけ性能出せるか評価するための統一テストみたいなもんやな。いろんな種類のデータセット入っててめっちゃ便利やねん。
44. Hermannさんらの2015年の研究で「機械に読んで理解させる」って話や。NeurIPSのモントリオール大会で発表されたやつ。要するにAIに文章読ませて、ちゃんと内容わかってるか確認する方法を考えたってことやな。
45. Zakkaさんらの「Almanac」って研究、これめっちゃおもろいねん。2024年のNEJM AIに載ってるんやけど、RAG(検索で情報取ってきてから答える仕組み)を臨床医学、つまりお医者さんの仕事に使おうって話や。医療の専門知識をAIがうまく引っ張ってきて答えるシステムやな。
46. Kwiatkowskiさんらの「Natural Questions」やな。2019年のTACLに載ってるやつで、質問応答の研究用ベンチマークや。Googleの検索で実際に人が質問したやつを集めてて、ほんまのリアルな質問でAIテストできるのがポイントやねん。
47. Raffelさんらの2020年のJMLR論文で「T5」って呼ばれてるモデルの話や。「転移学習の限界を探る」ってタイトルで、テキストをテキストに変換する統一フレームワーク作ったんや。翻訳も要約も質問応答も、全部「テキスト→テキスト」の形式で扱えるようにしたのがめっちゃ賢いねん。
48. Lewisさんらの「BART」や。2020年のACLで発表されてんけど、ノイズ除去する形で事前学習するシーケンス・トゥ・シーケンスモデルやな。文章生成とか翻訳とか理解とか、いろいろできるようになる仕組みやねん。
49. Lanさんらの「ALBERT」、2020年のICLRで発表されたやつ。「軽量版BERT」って感じで、BERTの性能保ちながらパラメータ数めっちゃ減らしたモデルや。自己教師あり学習で言語の表現学ぶんやけど、効率ええのがポイントやな。
50. Wuさんらの2024年の研究で「RAGって不公平を生むんちゃう?」って問題提起してるやつや。検索で持ってくる情報によってAIの答えに偏りが出る可能性があるって話で、これほんま大事な視点やと思うわ。
51. Esさんらの「RAGAS」や。2024年のEACLで発表されてんけど、RAGシステムを自動で評価する方法の話やな。RAG使ったシステムがちゃんと機能してるか、自動でチェックできるようにしたってことやねん。
52. Levineさんらの2022年の論文「巨大な凍結言語モデルの肩の上に立つ」や。かっこええタイトルやろ?でっかい事前学習済みモデルをそのまま使って、その上にうまいこと機能追加する方法の話やな。
53. Yangさんらの「HotpotQA」、2018年のEMNLPで発表されたデータセットや。「マルチホップ質問応答」っていうて、答え出すのに複数の情報をつなげて推論せなあかんやつ。しかも説明もできるようにしてるのがポイントやな。
54. Lewisさんらの2020年NeurIPS論文、これがRAGの元祖みたいなもんや!「知識集約型NLPタスクのための検索拡張生成」ってタイトルで、必要な情報を検索で取ってきてから答えを生成する仕組みを提案したんや。めっちゃ重要な論文やで。
55. Joshiさんらの「TriviaQA」、2017年のACLで発表されたやつ。読解力テスト用の大規模データセットで、遠隔教師ありって方法で作られてるねん。トリビアクイズみたいな質問がいっぱい入ってるんや。
56. Linさんらの「RA-DIT」、2024年のICLRで発表。検索拡張とデュアル命令チューニングを組み合わせた手法やな。RAGをもっと賢くする方法の一つやねん。
57. Zhaoさんらの2024年のサーベイ論文で「AI生成コンテンツのための検索拡張生成」について包括的にまとめてるやつや。RAGの全体像知りたかったらこれ読むとええで。
58. Hanさんらの2024年Applied Sciences論文で、RAG使って系統的文献レビューを自動化する話や。論文調査って大変やけど、AIに手伝ってもらおうって発想やな。
59. Chenさんらの2024年AAAI論文で、RAGにおける大規模言語モデルのベンチマークの話や。RAGでLLM使うとき、どのモデルがどれくらいええか評価するための研究やねん。
60. Edgeさんらの「Graph RAG」、2024年の論文や。ローカルからグローバルへってアプローチで、グラフ構造使ってクエリに焦点当てた要約するRAGの手法やな。これなかなかおもろい発想やで。
61. Jiangさんらの「Active RAG」、2023年のEMNLPで発表。能動的に検索を使うRAGの話やねん。必要なときだけ賢く検索するようにしたバージョンやな。
62. Panさんらの2024年IEEE論文で「大規模言語モデルと知識グラフを統合するロードマップ」や。LLMと知識グラフ、それぞれ得意なこと違うから、うまいこと組み合わせたらもっとすごいことできるんちゃう?って話をまとめた総説論文やな。
---
## Page 27
[](/attach/e4a30c3639e7cda0676ec6fb410a51e32b5a1bc7bb8de451429341a0aecf5a09_p027.png)
### 和訳
63. Ram, O.ら「文脈内検索拡張言語モデル」Trans. Assoc. Comput. Linguist. 2023, 11, 1316–1331.
→ これな、言語モデルに検索機能くっつけて、質問に答えるときに関連情報をその場で引っ張ってこれるようにした研究やねん。めっちゃ賢いやろ?
64. Dettmers, T.ら「QLoRA:量子化されたLLMの効率的ファインチューニング」NeurIPS 2023
→ でっかい言語モデルを普通にファインチューニング(追加学習)しようとしたら、メモリがえげつないことになるやん?この研究は量子化っていう圧縮技術使って、めっちゃ少ないメモリでも追加学習できるようにしたんや。これほんまに革命的やで。
65. Saad-Falcon, J.ら「ARES:RAGシステムの自動評価フレームワーク」NAACL 2024
→ RAG(検索拡張生成)システムがちゃんと動いてるかどうか、自動で評価してくれるツールやねん。なんでかっていうと、人間がいちいちチェックするの大変やからな。
66. Gao, L.ら「教師なしコーパス対応言語モデル事前学習による密な文章検索」ACL 2022
→ ラベル付きデータなしで、文章検索に強いモデルを作る方法や。教師なしでここまでできるんやから、すごい時代になったもんやな。
67. Barnett, S.ら「RAGシステム構築時の7つの失敗ポイント」arXiv 2024
→ RAGシステム作るときに、みんながやらかしがちな失敗を7つまとめてくれてんねん。これ読んどいたら同じミス避けられるで。めっちゃ実践的な論文や。
68. Liu, N.F.ら「真ん中で迷子:言語モデルが長い文脈をどう使うか」TACL 2024
→ 長い文章を言語モデルに渡したとき、真ん中らへんの情報がめっちゃ無視されやすいっていう問題を発見したんや。最初と最後は覚えてるのに、真ん中忘れるって、人間みたいやな。
69. Sarthi, P.ら「RAPTOR:木構造検索のための再帰的抽象処理」ICLR 2024
→ 文書を階層的にまとめて木構造にして、検索精度上げる方法やねん。長い文書でも効率よく必要な情報見つけられるようになるで。
70. Zhang, T.ら「RAFT:ドメイン特化RAGへの言語モデル適応」arXiv 2024
→ 特定の分野(医療とか法律とか)に特化したRAGを作るための方法や。汎用モデルをその分野のエキスパートに育てるイメージやな。
71. Jiang, A.Q.ら「Mistral 7B」arXiv 2023
→ 70億パラメータっていう比較的コンパクトなサイズやのに、めっちゃ性能ええモデルや。効率重視の人にはほんまにありがたい存在やで。
72. Beltagy, I.ら「Longformer:長文書トランスフォーマー」arXiv 2020
→ 普通のトランスフォーマーは長い文章苦手やねんけど、これは特殊な注意機構使って、めっちゃ長い文書も処理できるようにしたんや。
73. Khandelwal, U.ら「記憶による汎化:最近傍言語モデル」ICLR 2020
→ 学習データを丸ごと記憶しといて、推論時に似たやつを探してくる方法やねん。暗記型の天才みたいなアプローチや。
74. Gao, L.ら「関連性ラベルなしの精密ゼロショット密検索」ACL 2023
→ 正解データなしで、いきなり高精度な検索ができる方法や。これがあれば、新しい分野でもすぐに検索システム作れるで。
75. Khattab, O.ら「ColBERT:BERTの文脈化遅延相互作用による効率的で効果的な文章検索」SIGIR 2020
→ BERTベースの検索やねんけど、めっちゃ効率よく高精度な検索できるように工夫してんねん。速くて正確って、最高やん。
76. Reimers, N.ら「Sentence-BERT:シャムBERTネットワークによる文埋め込み」EMNLP-IJCNLP 2019
→ 文章を数値ベクトルに変換するのに特化したBERTや。似た文章を探すのがめっちゃ得意になるで。
77. Hoffmann, J.ら「計算最適な大規模言語モデルの学習」NeurIPS 2022
→ モデルのサイズとデータ量のバランスをどうすれば一番効率ええか研究したんや。でかけりゃええってもんちゃうねんな。
78. Karpukhin, V.ら「オープンドメイン質問応答のための密な文章検索」EMNLP 2020
→ DPRって呼ばれてる有名な手法や。質問に対して関連する文章を密ベクトルで検索するんやけど、これがRAGの基礎になってんねん。
79. Izacard, G.ら「オープンドメイン質問応答のための生成モデルと文章検索の活用」EACL 2021
→ 検索で取ってきた文章を生成モデルに食わせて回答作らせる方法や。RAGの先駆け的な研究やで。
80. Wu, S.ら「BloombergGPT:金融特化大規模言語モデル」arXiv 2023
→ ブルームバーグが作った金融専門のでっかい言語モデルや。株とか経済の話させたら、めっちゃ詳しいで。
81. Yang, H.ら「FinGPT:オープンソース金融大規模言語モデル」arXiv 2023
→ こっちはオープンソースの金融特化モデルや。誰でも使えるから、研究者にはありがたいやろな。
82. Singhal, K.ら「大規模言語モデルは臨床知識をエンコードする」Nature 2023
→ Natureに載った論文やで!言語モデルが医療知識をちゃんと理解してるか調べた研究や。結構いけてるらしいで。
83. Dhuliawala, S.ら「検証連鎖は大規模言語モデルのハルシネーションを減らす」ACL 2024
→ AIが嘘つく問題(ハルシネーション)あるやん?これ、自分で自分の回答を検証させることで、嘘つきにくくする方法やねん。賢いな。
84. Yan, S.Q.ら「修正的検索拡張生成」arXiv 2024
→ RAGで検索した情報が間違ってたとき、それを修正する仕組みを入れた研究や。検索結果を鵜呑みにせんようにしてんねん。
85. Kaddour, J.ら「大規模言語モデルの課題と応用」arXiv 2023
→ LLMの現状の課題と、どんなとこで使えるかを網羅的にまとめた論文や。これ一本読んだら全体像わかるで。めっちゃ便利やん。
---
## Page 28
[](/attach/e4a30c3639e7cda0676ec6fb410a51e32b5a1bc7bb8de451429341a0aecf5a09_p028.png)
### 和訳
Appl. Sci. 2026, 16, 368
28ページ中28ページ目
86. Liu, Y.; Iter, D.; Xu, Y.; Wang, S.; Xu, R.; Zhu, C. G-Eval:GPT-4使ってNLG(自然言語生成)を評価する方法で、人間の感覚とめっちゃ合うようになったやつやねん。2023年のEMNLP(自然言語処理の実証的手法に関する学会)で発表されたんやけど、これがシンガポールで12月6日から10日にやってたやつや。pp. 2511–2522. [CrossRef]
87. Patil, S.G.; Zhang, T.; Wang, X.; Gonzalez, J.E. Gorilla:めっちゃようさんのAPIと繋がれる大規模言語モデルやねん。なんでかっていうと、普通の言語モデルってAPIとか外部ツール使うの苦手やったんやけど、これは山ほどのAPIと連携できるように訓練されとるんや。arXiv 2023, arXiv:2305.15334. [CrossRef]
88. Dao, T.; Fu, D.Y.; Ermon, S.; Rudra, A.; Ré, C. FlashAttention:IO(入出力)のこと考えた、めっちゃ速くてメモリも節約できる正確なAttention(注意機構)の計算方法やねん。2022年のNeurIPS(神経情報処理システム学会)でニューオーリンズで11月28日から12月9日にかけて発表されたやつや。Volume 35, pp. 16344–16359.
89. Izacard, G.; Lewis, P.; Lomeli, M.; Hosseini, L.; Petroni, F.; Schick, T.; Dwivedi-Yu, J.; Joulin, A.; Riedel, S.; Grave, E. Atlas:検索で強化した言語モデルで少ない例から学習できるやつやねん。ほんまに少ないデータでもええ感じに学習できるんがポイントやで。J. Mach. Learn. Res. (JMLR) 2023, 24, 1–43.
90. Yang, H.; Zhang, M.; Wei, D.; Guo, J. SRAG:音声言語理解のための音声検索拡張生成やねん。要するに、話し言葉を理解するときに検索で情報引っ張ってきて生成するって仕組みや。2024年のIEEE ICCECT(制御・エレクトロニクス・コンピュータ技術に関する国際会議)で中国の吉林で4月26日から28日に発表されたで。pp. 370–374. [CrossRef]
91. Wu, T.; Luo, L.; Li, Y.F.; Pan, S.; Vu, T.T.; Haffari, G. 大規模言語モデルの継続学習に関するサーベイやねん。継続学習って何かっていうと、新しいこと学んでも前に覚えたことを忘れへんようにする技術のことや。arXiv 2024, arXiv:2402.01364.
92. Chen, W.; He, H.; Cheng, Y.; Chang, M.W.; Cohen, W.W.; Wang, W.Y. MuRAG:画像とテキスト両方に対応したオープン質問応答のためのマルチモーダル検索拡張生成器やねん。画像も文章も両方見て答えを出せるってことやな。2022年のEMNLPでアブダビで12月7日から11日に発表されたやつや。pp. 5558–5570. [CrossRef]
93. Guu, K.; Lee, K.; Tung, Z.; Pasupat, P.; Chang, M.W. 検索拡張言語モデルの事前学習やねん。最初から検索と組み合わせて学習させとくって発想や。2020年のICML(国際機械学習会議)でオンライン開催、7月12日から18日。pp. 3929–3938.
94. Wang, L.; Yang, N.; Wei, F. Query2doc:大規模言語モデルでクエリを拡張する方法やねん。検索するときの質問を言語モデルで膨らませて、もっとええ検索結果出そうって話や。2023年のEMNLPでシンガポール、12月6日から10日。pp. 9414–9423. [CrossRef]
95. Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU:機械翻訳を自動で評価する方法やねん。これめっちゃ有名で、翻訳の良し悪しを数値で測る基本中の基本やで。2002年のACL(計算言語学会)でフィラデルフィア、7月6日から12日。pp. 311–318. [CrossRef]
96. Bajaj, P.; Campos, D.; Craswell, N.; Deng, L.; Gao, J.; Liu, X.; Majumder, R.; McNamara, A.; Mitra, B.; Nguyen, T.; 他. MS MARCO:人間が作った機械読解理解データセットやねん。読解力を測るためのめっちゃ大きいデータセットや。arXiv 2016, arXiv:1611.09268.
97. Johnson, J.; Douze, M.; Jégou, H. GPUを使った数十億規模の類似検索やねん。ほんまに大量のデータから似たもん探すときにGPU使うとめっちゃ速いって話や。IEEE Trans. Big Data 2019, 7, 535–547. [CrossRef]
98. Lin, C.Y. ROUGE:要約を自動評価するためのパッケージやねん。要約がうまいことできてるか測る指標で、BLEUの要約版みたいなもんや。2004年のText Summarization Branches outでバルセロナ、7月25日から26日。pp. 74–81.
99. Zhang, T.; Kishore, V.; Wu, F.; Weinberger, K.Q.; Artzi, Y. BERTScore:BERTを使ってテキスト生成を評価する方法やねん。BLEUとかROUGEより意味的な類似度をちゃんと見れるのがポイントや。2020年のICLR(表現学習に関する国際会議)でエチオピアのアディスアベバ、4月26日から30日。
100. See, A.; Liu, P.J.; Manning, C.D. 要点を押さえろ:ポインタ生成ネットワークによる要約やねん。原文から直接単語をコピーしたり、新しく生成したりを切り替えられるモデルや。2017年のACLでバンクーバー、7月30日から8月4日。pp. 1073–1083. [CrossRef]
101. Robertson, S.; Zaragoza, H. 確率的関連性フレームワーク:BM25とその先やねん。BM25って検索エンジンでめっちゃ使われとる古典的な手法で、その理論的背景を説明しとるやつや。Found. Trends Inf. Retr. 2009, 3, 333–389. [CrossRef]
102. He, P.; Liu, X.; Gao, J.; Chen, W. DeBERTa:分離されたAttentionでデコーディングを強化したBERTやねん。BERTの改良版で、単語の位置と内容を別々に扱うことでもっと賢くなったやつや。2021年のICLRでオンライン開催、5月3日から7日。
103. Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. LoRA:大規模言語モデルの低ランク適応やねん。モデル全体を再学習せんでも、ちょっとだけパラメータ追加して新しいタスクに適応させられるめっちゃ効率的な方法やで。2022年のICLRでオンライン開催、4月25日から29日。
104. Siriwardhana, S.; Weerasekera, R.; Elliott, E.; Kunneman, F. オープンドメイン質問応答のためのRAG(検索拡張生成)モデルのドメイン適応を改善する方法やねん。特定の分野に特化させるときの工夫を書いとるやつや。Trans. Assoc. Comput. Linguist. 2023, 11, 1–17. [CrossRef]
105. Zeng, S.; Zhang, J.; He, P.; Xing, Y.; Liang, Y.; Xu, H.; Ren, J.; Deng, S.; Cheng, X.; Hasuo, I.; 他. RAGの良いとこと悪いとこ:検索拡張生成のプライバシー問題を探るやつやねん。RAG使うときに個人情報とかが漏れるリスクについて調べとる論文や。2024年のACL Findingsでバンコク、8月11日から16日。pp. 4483–4498. [CrossRef]
106. Manakul, P.; Liusie, A.; Gales, M.J.F. SelfCheckGPT:生成型大規模言語モデルの幻覚(でたらめ)を外部リソースなしで検出する方法やねん。モデルが嘘ついてへんか、モデル自身の出力だけでチェックできるってのがすごいとこや。2023年のEMNLPでシンガポール、12月6日から10日。pp. 9004–9017. [CrossRef]
免責事項/出版者注:すべての出版物に含まれる声明、意見、データは、個々の著者および寄稿者のもんであって、MDPIや編集者のもんとちゃうで。MDPIや編集者は、本文中で言及されとるアイデア、方法、指示、製品から生じる人や財産への被害について一切責任負わへんで。
---
![]()
1 / 1
100%