<<
2509.19631v1.pdf

---
## Page 1
[](/attach/d8b29e3a0f021c27945a6d2282a71b221a90e9067ee80386fa6a5d879e69e8a9_p001.png)
### 和訳
# マルチモーダルLLMにおける音声要約の強化 〜強化学習でどこまでいけるか〜
Shaoshi Ling, Gang Liu, Guoli Ye, Jinyu Li
Microsoft CoreAI, USA
---
## 要旨(アブストラクト)
音声要約(SSum)っていうのはな、しゃべった内容をちゃんと理解するためのめっちゃ大事な技術やねん。特に今の時代、音声とか動画のデータがどんどん増えてるやろ? そこで最近注目されてるのが、マルチモーダル大規模言語モデル(MLLM)っていうやつで、LLMのパワーを活かして、音声からいきなりテキストの要約を作れるようになってきてん。途中で文字起こし挟まんでええし、出力スタイルも自由に変えられるし、初めて見るタスクにもゼロショットで対応できるっちゅうわけや。
せやけどな、オープンソースのMLLMは最先端のテキストベースLLMにまだまだ追いついてへんのが現状で、実際の音声要約に使うにはちょっと力不足やねん。
そこでワイらは、MLLMの音声要約能力をガツンと底上げするための、新しい多段階の強化学習(RL)トレーニングの仕組みを提案するで! このモデルはな、強力なベースラインをしっかり上回って、もっとデカいMLLMよりもええ成績叩き出して、最先端のテキストベースLLMとの差もめっちゃ縮めることに成功したんや。
**キーワード** — 音声要約、マルチモーダル大規模言語モデル、知識蒸留、強化学習
---
## 1. はじめに
今の時代、コミュニケーションもメディアも音声や動画がどんどん中心になってきてるやんか。そんな中で「音声要約(SSum)」——つまり、しゃべった内容からパッと簡潔でまとまりのあるテキスト要約を作る技術——がめっちゃ重要になってきてんねん。情報に素早くアクセスできるし、学校や仕事のワークフローにも役立つし、個人で使うにも便利やし、膨大な音声データとテキストの便利さの橋渡しをしてくれる、ほんまに大事な役割を担ってるわけや。会議、講義、ポッドキャスト、SNS……世の中にしゃべった系のデータがどんどん溢れてくる中で、この技術の重要性はますます高まる一方やで。
従来の音声要約はな、カスケード型パイプラインっていう方式でやってたんよ。どういうことかというと、まず自動音声認識(ASR)で音声をテキストに変換して、そのテキストを要約するっちゅう二段階構成やねん。これはこれでまあまあ使えるんやけど、ASRの段階でミスが出ると、それがそのまま要約にも伝播してまうっていう問題があるねん。しかも、話の構造とか、抑揚とか、強調みたいなニュアンスを拾いきれへんことも多い。
この弱点を克服するために提案されたんが、エンドツーエンドの音声要約手法[2, 3, 4, 5, 6, 7]やねん。これは途中の文字起こしなしで、音声からダイレクトに要約を生成するアプローチや。典型的には音声エンコーダと、別々に学習されたLLMとか要約専用モジュールを組み合わせて、ASRから来るエラーの伝播を減らそうとしてるんやな。ただな、各パーツがバラバラに学習されてて、ファインチューニングも限られたデータでやってるもんやから、指示に従う力とか、ゼロショット汎化、制御性がイマイチやねん[1]。
そこで登場するのが、大規模言語モデル(LLM)の成功をベースにしたマルチモーダル大規模言語モデル(MLLM)や。これはLLMをテキスト以外の入力——つまり複数のモダリティ——にも対応できるように拡張したもんやねん。音声要約にとってこれがなんで大事かっていうと、入力がそもそもマルチモーダルやからや。音声信号には言葉の内容だけやなくて、話者の強調、抑揚、感情みたいなパラ言語情報も入ってるやろ? こういう情報をうまく使えたら、テキストだけのモデルよりも正確で文脈に忠実な要約が作れる可能性があるわけやな。
商用モデルのGPT-4o-Audio [8]やGemini-2.5 [9]は、なかなか期待できる音声要約能力を見せてくれてるんやけど、サイズがデカいし、ソースは非公開やし、一般ユーザーが大規模に使うにはハードルが高いんよな。一方で、オープンソースのQwen2-Audio [10]はタスク専用の学習なしでゼロショット音声要約に使われてるし、Phi-4MM [11]は最大2時間の長い音声にも対応した汎用音声要約機能を持つ初のオープンソースモデルやねん。せやけど、これらのオープンソースモデルはGPT-4o [8]みたいな最先端の商用モデルと比べると、まだまだ差があるのが現実や。しかもな、今あるMLLM全般に言えることやけど、音声モダリティはテキストモダリティに比べてパフォーマンスが落ちるっていう「モダリティギャップ」がずっと存在してて、音声要約の実力を制限してしまってるねん。
というわけで、ワイらは以下のアプローチを提案するで。まず、大規模な合成データセットを作って、いろんな指示に対応できるようにモデルの指示追従能力を強化する。次に、大規模な強化学習(RL)でオンポリシー知識蒸留[12, 13, 14]を使って、強力なテキストベースLLMの知識を生徒側のMLLMに移植して、モダリティギャップを縮める。最後に、直接選好最適化(DPO)[15]っていう別のRL手法でモデルをさらに鍛えて、幻覚(ハルシネーション)みたいな問題を抑えつつ、頑健性を向上させるんや。
ワイらの貢献をまとめるとこんな感じや:
- **新しいトレーニングの枠組み:** MLLMの音声要約のために、指示追従・モダリティの整合性・言語横断的な汎化をまとめて改善する、新しい多段階RL学習フレームワークを提案したで。
- **オンポリシー知識蒸留:** 大きなテキストベースLLMから、音声対応のMLLMへ効果的に知識を移すオンポリシー知識蒸留手法を提案したんや。
- **ごっつい実験結果:** ワイらのモデルは、競争力のあるベースラインに対して最大28%の相対改善を達成し、GPT-4o-audioみたいなもっとデカいMLLMも超えて、最先端のテキストベースLLMとの差もグッと縮めることに成功したで!
---
## Page 2
[](/attach/d8b29e3a0f021c27945a6d2282a71b221a90e9067ee80386fa6a5d879e69e8a9_p002.png)
### 和訳
図1. 3段階トレーニングプロセスの全体像
## 2. やり方(METHOD)
ほな説明していくで!ここではな、音声をうまいこと要約できるようになるための、3段階のトレーニング方法を提案してんねん。マルチモーダル大規模言語モデル(MLLMs)っていう、音声もテキストも扱えるめっちゃ賢いAIの要約力をレベルアップさせるんが目的や。図1に示してる通り、フレームワークは以下の3つからできてるで:(1) 合成データを使った教師ありファインチューニング(SFT)、(2) オンポリシー知識蒸留(KD)で、テキストが得意な強いLLMから要約力を移植する、(3) 直接選好最適化(DPO)で、でたらめな内容(ハルシネーション)を抑える。
### 2.1. SFT用の合成データ
教師ありファインチューニング(SFT)はな、この多段階トレーニングの土台になるパートやねん。なんでかっていうと、「こう指示されたらこう答えてな」っていう基本的な能力を直接叩き込むところやからや。ちゃんと指示通りに動いて、ええ感じの要約を出せるようにするのがゴールやな。MLLMsの指示理解力をもっと強くするために、要約タスクに特化した、めっちゃでかくて多様な合成データセットを作ってん。
データの集め方はな、Phi-4MM [11]で紹介されたやり方をベースにしてんねん。匿名化された音声録音と、その文字起こし(トランスクリプト)をペアにして使うんや。音声の内容は日常会話から専門的な話題まで幅広くカバーしてるで。元のPhi-4MMのやり方では、1つの音声サンプルから1回のパスで10組の「質問と要約」ペアを作ってたんやけど、ワイらはこのプロセスをさらに拡張・改良して、多様性と品質を上げてんねん。
具体的にはな、まず各トランスクリプトに対してGPT-4.1を使って、複数の候補クエリ(質問文)を生成すんねん。それぞれに「要約タスクとしてどれくらいええか」っていう重要度スコアをつけるんや。スコアが低いやつはポイッと捨てて、質の高い指示だけ残すっちゅうわけ。そのフィルタリングされた中から、ランダムに1つのクエリを選んで対応する音声と紐づけるんや。多様性を重視しつつ、重複は避けるっていう作戦やな。出来上がるクエリはほんまにバラエティ豊かで、「短くまとめてや」みたいなシンプルなやつから、「箇条書きで」「JSON形式で」「メール風に書いて」みたいな構造化された出力を求めるものまであるで。
クエリと文字起こしが決まったら、GPT-4.1に参照用の要約を生成してもらうんや。この2段階設計 — まず重要度スコアリングして、それからクエリを選ぶ — のおかげで、データセットの多様性と一貫性と関連性のバランスがめっちゃええ感じになるんやで。Phi-4MM [11]のベースラインでは、GPT-4に1回で10組の質問・要約ペアを作らせてたんやけど、ワイらの方法やと要約がかなり長くなって、内容も豊富で、フォーマットも多彩になるんや。
### 2.2. オンポリシー知識蒸留
知識蒸留(KD)[16, 17]っていうのはな、めっちゃ強い先生モデルの振る舞いを、小さい生徒モデルに移すためによく使われるテクニックやねん。でもな、音声要約の場合、直接蒸留しようとすると問題が出てくんねん。なんでかっていうと、分布のミスマッチがめっちゃ強いからや。先生モデルはテキストの世界で出力するから、表現力がリッチなんやけど、音声を入力にしてる生徒モデルにはそこまで再現でけへんのよ。しかも生徒は先生が作った文章をただ真似するだけで、自分のミスを直す訓練をしてへんねん。このミスマッチのせいで、学習が不安定になって汎化性能も弱くなるんや。特に、先生の学習データとちゃう入力が来た時にアカンことになる。これは文献では「モード崩壊」ってよく言われてる現象やな [14]。
この問題を解決するためにな、オンポリシー蒸留っていう戦略を採用してん。これはな、先生の出力だけを真似するんやなくて、**生徒自身が生成した文章から学ぶ**っちゅうやり方や。トレーニング中に、生徒が音声入力をもとに自分で出力(ロールアウト)を生成するんや。ほんで先生がその文章に対して、トークン(単語みたいなもんや)レベルで「ここはこういう確率分布がええで」っていう指導をすんねん。
こうすることで、指導が生徒自身の軌道に基づいたものになりつつ、先生の豊かな言語知識の恩恵も受けられるっちゅうわけや。これで「エクスポージャーバイアス」(訓練時と推論時のズレ)が減って、生徒が推論時にやりがちなミスを改善できるようになんねん。結果として最適化がより安定して、モデルの能力と指導内容のアラインメントがぴったりになるんや。
ほんで大事なんが、この設計はクロスモダリティ転移(テキスト→音声への能力移植)もやりやすくしてくれるんよ。先生はテキストの世界で動いてるんやけど、生徒は先生の要約能力を吸収しつつ、それを音声にグラウンディング(定着)させることで、モダリティ間の性能ギャップを縮めるんや。さらに、オンポリシーデータを蒸留中に使うと、生徒が自分で生成した出力の中の間違ったトークンに対して、先生のロジット(確率出力)からトークン固有のフィードバックがもらえるんや。これは強化学習(RL)で見られるようなフィードバックループと似た効果があって、訓練時と推論時の分布のズレを最小化するのに役立つんやで。
数式でちゃんと書くとな、音声入力 x が与えられた時、生徒のMLLMs P_S^θ が出力系列 y ∼ p_S(·|x) を生成するんや。生成された系列の各トークンに対して、生徒は先生のLLMs P_T のトークンレベルの確率分布を真似しようとすんねん。トレーニングの目的関数はこう表されるで:
L(θ) = E_{x∼X} [ E_{y∼p_S(·|x)} [ D_KL( p_T ∥ p_S^θ )(y|x) ] ] …(1)
ここで重要なんがな、[13]の戦略に従って、サンプリング分布 p_S^θ(·|x) を通じた逆伝播はせえへんねん。これはな、勾配の分散がめっちゃ大きくなるのを避けるためで、安定して計算効率もええトレーニングができるんや。目的関数の勾配はこう書けるで:
∇_θ L(θ) = E_{x∼X} E_{y∼p_S(·|x)} [ Σ_z p_T(z|x,y) ∇_θ log p_S^θ(z|x,y) ] …(2)
ここで z はボキャブラリ(語彙)のトークンや。注目してほしいんやけど、この式は方策勾配法(ポリシーグラディエント)[18]と同じ形をしてんねん。ワイらの定式化では、報酬は p_T(z|x,y) で与えられてて、これが「文脈 x, y が与えられた時にトークン z がどれくらいええか」っていうフィードバックを提供してくれるんやで。
---
## Page 3
[](/attach/d8b29e3a0f021c27945a6d2282a71b221a90e9067ee80386fa6a5d879e69e8a9_p003.png)
### 和訳
従来の知識蒸留やと、先生モデルが文章を生成するやん?でもこの方法やと、生徒モデルが実際にやってる動きにもっと合った指導ができるねん。そのおかげで安定性がめっちゃ上がるし、自然な汎化もできるようになるし、モード崩壊っていう「同じようなことばっかり出力してまう現象」のリスクも減るんよ。実際のところ、このステージが俺らのフレームワークの中で一番デカい性能アップを叩き出してん。つまりな、オンポリシー蒸留っていうのは、テキストだけで学習した大規模言語モデル(LLM)の言語能力を、音声も扱えるマルチモーダルLLM(MLLM)に移すんにめっちゃ効果的やってことや。しかも同時に、テキストと音声の間の溝も埋められるし、頑健性も上がるっちゅうわけやな。
## 2.3. DPO
教師あり微調整とオンポリシー知識蒸留で、モデルの音声要約(SSum)性能はガッツリ上がるんやけど、困ったことに変なクセも一緒についてきてまうねん。具体的に言うとな、生徒のMLLMがたまに「壊れた出力」を出すことがあんねん。学習の目的関数の弱点を突くような感じで——例えば同じフレーズを繰り返したり、ありもせんことをでっち上げる「ハルシネーション」を起こしたりすんねん。しかもタチ悪いことに、そういう出力でも先生モデルからは高いスコアもらえてまうんよ。これ、強化学習の世界では「報酬ハッキング」[19]って呼ばれてる現象で、システムの信頼性をガタガタにしてまうやつやねん。
この問題に対処するために、最終段階として**DPO(Direct Preference Optimization:直接選好最適化)**[15]に基づく学習を導入してん。DPOは、ペアの選好データを使って、モデルを人間の品質判断にもっと近づけるようにするんや。入力音声xに対して、生徒モデルから2つの異なる仮説(出力候補)をサンプリングすんねん。ほんで、その2つをGPT-4.1に評価してもらって、「どっちがええか」を判定してもらうわけや。選ばれた方の応答をy+って書くんやけど、これは大体まとまりがあってちゃんと構造化された要約やねん。逆に選ばれへんかった方のy−は、繰り返しとかハルシネーションみたいな壊れた振る舞いが入ってることが多いんよ。GPT-4.1が「どっちも変わらんわ」って言うた場合は、そのデータは捨てるで。
DPOでは以下の目的関数を最適化すんねん:
L_DPO = E_{x〜X} [ log σ( β log π(y+|x)/π_ref(y+|x) − β log π(y−|x)/π_ref(y−|x) ) ] (3)
ここでπは現在のモデルのことで、参照モデルπ_refから初期化されてんねん。π_refはセクション2.2のオンポリシー知識蒸留で得られたチェックポイントやで。DPOを最終ステップとして適用することで、ハルシネーションを効果的に減らして、生成される要約の全体的な一貫性もアップさせてるっちゅうわけや。
## 3. 実験設定
### 3.1. ベースライン
ベースラインのモデルはPhi-4MM [11]をベースにしてんねん。これは50万件の要約サンプル——5万件の音声録音にそれぞれ10組のクエリと要約ペアがついたやつ——で学習されたモデルや。より分かりやすい分析と比較のために、最終的に公開されたモデルはあえて使ってへんねん。代わりに、事前学習段階のモデルを使ってんねん。これは大規模な自動音声認識(ASR)データで学習されてて、音声エンコーダとテキストベースのPhi-4Mini [11]を意味空間で揃えるところまでやったやつやな。
ほんで、生成される要約は中身がめっちゃ充実してんねん。平均するとベースラインのデータセットと比べて要約の長さが3倍になってて、より細かいディテールまで拾えてるんよ。
知識蒸留とDPOの段階では、同じプロセスでデータを作るんやけど、要約生成のステップは省いてんねん。学習用に3万5千件の高品質な音声とクエリのペアをサンプリングしてるで。上記のデータは全部英語のみや。
### 3.3. 学習設定
全ての学習段階で、音声エンコーダは凍結(固定)して、音声プロジェクターとLoRAモジュールだけを更新してんねん。LoRAの設定はα=32、ランク=16やで。SFT段階では、32台のA100 GPUで2エポック学習してんねん。知識蒸留の段階では、教師モデルとしてGPT-4oのテキストオンリーモード [8]を使ってんねん。学習はverlフレームワーク [20]で行って、ロールアウトにはvLLM [21]を使ってるで。生徒モデルは8台のA100 GPUで学習すんねんけど、教師モデルに割り当てられたGPUは別やで。DPO段階では、32台のA100 GPUで1エポック学習してんねん。全段階を通じて、最大30分の長さの音声入力(だいたい2万2500トークンに相当)で学習してるで。言語デコーダのコンテキスト長が12万8000トークンやから、推論時には最大2.8時間の音声まで対応できるっちゅうわけや。
### 3.4. 評価設定
音声要約の性能は、3つのベンチマークで評価してんねん:
- **Golden3**:社内の会議データセットで、108件の録音(平均6分)と321個の指示が入ってるで。英語のみで、いろんなトピックをカバーしてんねん。
- **AMI [22]**:公開されてる英語のみの会議コーパスで、約100時間分あんねん。マルチモーダルのストリームがついてるで。テスト分割(20会議、各32分)を近接マイク音声で評価してんねん。各会議に3つの要約指示があって、合計60個やな。
- **FLORAS [23]**:YouTubeの生の長時間会話音声でモデルの性能を測るための多言語ベンチマークやねん。5分から1時間の録音を548件選んでて、スペイン語、イタリア語、フランス語、ドイツ語、ポルトガル語、中国語、日本語とかの言語をカバーしてるで。
推論時には、俺らのモデルは長時間音声をセグメント分割なしで一発で処理すんねん。評価指標はPhi-4MM [11]と同じ設定をベースに、ちょっとだけ修正を加えてるで。出力はGPT-4.1が文字起こしと照らし合わせて全体的な品質をスコアリングすんねん。全体品質スコアは1から7の範囲で、詳細の正確さ、一貫性、文章スタイル、ハルシネーションの度合い、指示で求められたフォーマット・内容・長さへの準拠度を測ってんねん。
## 4. 実験結果
### 4.1. メイン結果
表1に、3つのベンチマークでの結果を載せてんねん。俺らが提案するPhiSSumモデルと、オープンソースのベースライン、そして最先端のテキストベースおよびマルチモーダルシステムを比較してるで。公平なベースラインを作るために、Phi-4MMの事前学習段階を50万件の要約サンプルで再現してんねんけど、要約専用のデータだけに限定してんねん。公開されたPhi-4MMは追加の音声
---
## Page 4
[](/attach/d8b29e3a0f021c27945a6d2282a71b221a90e9067ee80386fa6a5d879e69e8a9_p004.png)
### 和訳
## 4.2. アブレーション実験
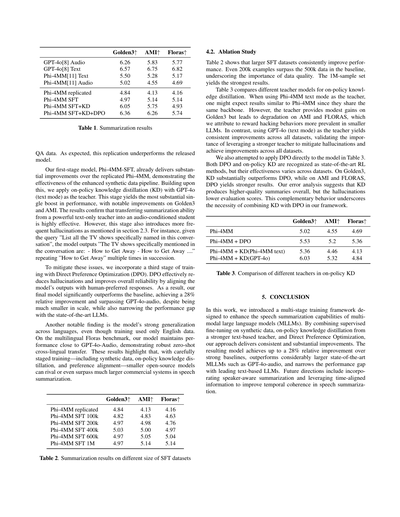
表2見てみ?SFTのデータセットでかくしたら、どんどん性能上がってくねん。200kのデータでも、ベースラインの500kデータ超えてまうんよ。これ、データの「量」より「質」がめっちゃ大事やってことを示してるわけ。で、100万サンプルが一番ええ結果出してんねん。
表3は、オンポリシー知識蒸留で使う「先生モデル」を比較してるで。Phi-4MMのテキストモードを先生にしたら、同じバックボーン使ってるんやから、Phi-4MMと似たような結果になるやろって思うやん?ところがどっこい、Golden3ではちょっとだけ良くなるんやけど、AMIとFLORASではむしろ悪なってまうねん。なんでかっていうと、小さいLLMって「報酬ハッキング」っていう、ズルいことしがちやからやと考えてるわ。一方で、GPT-4o(テキストモード)を先生にしたら、全部のデータセットで一貫して良くなってん。これ、ハルシネーション(でたらめ言うやつな)を減らして全体的に改善するには、強い先生モデル使うんが大事やってことを証明してるわけや。
DPOを表3のモデルに直接適用するんも試してみたで。DPOとオンポリシーKDは両方とも最先端のRL手法として認められてるんやけど、データセットによって効き目が違うねん。Golden3ではKDがDPOをめっちゃ上回るんやけど、AMIとFLORASではDPOの方がええ結果出すんよ。エラー分析してみたら、KDは全体的に質の高い要約作るんやけど、ハルシネーションのせいで評価スコア下がってまうみたいやねん。この補完的な関係があるからこそ、うちらのフレームワークではKDとDPOを組み合わせる必要があるってわけや。
**表3. オンポリシーKDにおける異なる先生モデルの比較**
| モデル | Golden3↑ | AMI↑ | Floras↑ |
|--------|----------|------|---------|
| Phi-4MM | 5.02 | 4.55 | 4.69 |
| Phi-4MM + DPO | 5.53 | 5.2 | 5.36 |
| Phi-4MM + KD(Phi-4MM text) | 5.36 | 4.46 | 4.13 |
| Phi-4MM + KD(GPT-4o) | 6.03 | 5.32 | 4.84 |
## 5. 結論
今回の研究では、マルチモーダル大規模言語モデル(MLLMs)の音声要約能力をパワーアップさせるための多段階トレーニングフレームワークを提案したで。合成データでの教師あり微調整、強力なテキストベースの先生モデルからのオンポリシー知識蒸留、そしてDirect Preference Optimizationを組み合わせることで、一貫してめっちゃ大きな改善を達成したんや。
できあがったモデルは、強力なベースラインと比べて最大28%の相対的改善を達成して、GPT-4o-audioみたいなめっちゃでかい最先端MLLMsを上回ってん。しかもテキストベースのトップLLMsとの性能差も縮めたで。今後は、話者を意識した要約を取り入れたり、時間的な整合性を改善するために時間情報を活用したりする方向で研究進めていく予定やわ。
**表1. 要約結果**
| モデル | Golden3↑ | AMI↑ | Floras↑ |
|--------|----------|------|---------|
| GPT-4o Audio | 6.26 | 5.83 | 5.77 |
| GPT-4o Text | 6.57 | 6.75 | 6.82 |
| Phi-4MM Text | 5.50 | 5.28 | 5.17 |
| Phi-4MM Audio | 5.02 | 4.55 | 4.69 |
| Phi-4MM replicated | 4.84 | 4.13 | 4.16 |
| Phi-4MM SFT | 4.97 | 5.14 | 5.14 |
| Phi-4MM SFT+KD | 6.05 | 5.75 | 4.93 |
| Phi-4MM SFT+KD+DPO | 6.36 | 6.26 | 5.74 |
QAデータ使ってるで。予想通り、この再現版はリリースされたモデルより性能低いねん。
うちらの第1段階モデル、Phi-4MM-SFTは、再現したPhi-4MMよりすでにめっちゃ改善されてて、強化した合成データパイプラインの効果を示してるわ。これをベースに、GPT-4o(テキストモード)を先生としたオンポリシー知識蒸留(KD)を適用したで。この段階が一番でかい性能向上をもたらして、Golden3とAMIで顕著な改善が見られたんや。強力なテキスト専用の先生から、音声を条件とする生徒モデルに要約能力を転移させるんがめっちゃ効果的やってことが確認できたわけ。ただ、この段階ではセクション2.3で述べたように、ハルシネーションも増えてまうねん。例えば「この会話で具体的に名前が出たテレビ番組を全部挙げて」って聞いたら、モデルは「この会話で具体的に言及されたテレビ番組は:- How to Get Away - How to Get Away ....」って、「How to Get Away」を何回も繰り返し出力してまうんよ。
こういう問題を軽減するために、Direct Preference Optimization(DPO)を使った第3段階のトレーニングを取り入れたで。DPOは、モデルの出力を人間が好む回答に合わせることで、ハルシネーションを効果的に減らして全体的な信頼性を向上させるねん。その結果、最終モデルはベースラインを大幅に上回って、28%の相対的改善を達成し、規模がずっと小さいにもかかわらずGPT-4o-audioを超えて、最先端LLMsとの性能差も縮めたんや。
もう一つ注目すべき発見は、トレーニングに英語データしか使ってへんのに、多言語に対してめっちゃ汎化性能が高いってことや。多言語のFlorasベンチマークで、うちらのモデルはGPT-4o-Audioに近い性能を維持してて、ゼロショットでの言語間転移がしっかりできてることを示してるわ。これらの結果から、合成データ、オンポリシー知識蒸留、選好アラインメントを含む段階的なトレーニングを丁寧にやれば、小さいオープンソースモデルでもずっとでかい商用システムに匹敵したり、音声要約で超えたりできるってことがわかったんや。
**表2. 異なるサイズのSFTデータセットでの要約結果**
| モデル | Golden3↑ | AMI↑ | Floras↑ |
|--------|----------|------|---------|
| Phi-4MM replicated | 4.84 | 4.13 | 4.16 |
| Phi-4MM SFT 100k | 4.82 | 4.83 | 4.63 |
| Phi-4MM SFT 200k | 4.97 | 4.98 | 4.76 |
| Phi-4MM SFT 400k | 5.03 | 5.00 | 4.97 |
| Phi-4MM SFT 600k | 4.97 | 5.05 | 5.04 |
| Phi-4MM SFT 1M | 4.97 | 5.14 | 5.14 |
---
## Page 5
[](/attach/d8b29e3a0f021c27945a6d2282a71b221a90e9067ee80386fa6a5d879e69e8a9_p005.png)
### 和訳
[17] Geoffrey Hinton、Oriol Vinyals、Jeff Dean、「ニューラルネットワークの中の知識を蒸留する」、arXiv プレプリント arXiv:1503.02531、2015年。
これな、めっちゃ有名な論文やねん。でっかいニューラルネットワークが持ってる「賢さ」を、ちっちゃいネットワークにギュッと詰め込む方法について書いてあるんや。
[18] Richard S Sutton、David McAllester、Satinder Singh、Yishay Mansour、「関数近似を使った強化学習のための方策勾配法」、Advances in neural information processing systems、vol. 12、1999年。
強化学習でな、AIが「こういう行動したらええんちゃう?」って決める方針(方策っていうねん)を、ちょっとずつ改善していく数学的なやり方を提案した論文やで。
[19] Lilian Weng、「強化学習における報酬ハッキング」、lilianweng.github.io、2024年11月。
これ面白いテーマやねん。AIに「これできたらご褒美あげるで」って設定したら、AIがズルして本来の目的と違う方法でご褒美だけゲットしよるっていう問題について解説してるブログ記事や。
[20] Guangming Sheng、Chi Zhang、Zilingfeng Ye、Xibin Wu、Wang Zhang、Ru Zhang、Yanghua Peng、Haibin Lin、Chuan Wu、「HybridFlow:柔軟で効率的なRLHFフレームワーク」、EuroSys、2025年、pp. 1279–1297。
RLHFっていうのは「人間のフィードバックを使った強化学習」のことやねんけど、それを効率よくやるための新しいシステムを提案してる論文やで。
[21] Woosuk Kwon、Zhuohan Li、Siyuan Zhuang、Sheng ら、「PagedAttentionを使った大規模言語モデル提供のための効率的なメモリ管理」、第29回オペレーティングシステム原理シンポジウム論文集、2023年、pp. 611–626。
でっかいAIモデルを動かす時な、メモリがめっちゃ必要やねん。この論文は、そのメモリを賢く使い回す方法を提案してて、vLLMっていう有名なシステムの基盤になってるんやで。
[22] Jean Carletta、Simone Ashby、Sebastien Bourban、Mike Flynn ら、「AMI会議コーパス:事前告知」、機械学習によるマルチモーダルインタラクション国際ワークショップ、Springer、2005年、pp. 28–39。
会議の録音と書き起こしを集めたデータセットの紹介やな。AIに会議の内容を理解させる研究でよく使われてるデータやで。
[23] William Chen、Brian Yan、Chih-Chen Chen、Shinji Watanabe、「FLORAS 50:長時間の会話音声のための超多言語マルチタスクベンチマーク」、2024 SLT、IEEE、2024年、pp. 891–898。
50言語もカバーしてる、長い会話音声を処理するAIの性能を測るためのテスト問題集みたいなもんやな。
6. 参考文献
[1] Fabian Retkowski、Maike Züfle、Andreas Sudmann、Dinah Pfau、Jan Niehues、Alexander Waibel、「音声から要約へ:音声要約の包括的サーベイ」、arXiv プレプリント arXiv:2504.08024、2025年。
音声を自動で要約する技術について、これまでの研究を全部まとめた総説論文やで。
[2] Kohei Matsuura、Takanori Ashihara、Takafumi Moriya、Tomohiro Tanaka ら、「エンドツーエンド音声要約のための大規模テキストコーパスの活用」、ICASSP、IEEE、2023年、pp. 1–5。
[3] Kohei Matsuura、Takanori Ashihara、Takafumi Moriya、Tomohiro Tanaka ら、「事前学習済み言語モデルからの転移学習がエンドツーエンド音声要約を改善する」、arXiv プレプリント arXiv:2306.04233、2023年。
この2つはな、音声を直接要約にする(エンドツーエンドっていうねん)システムで、すでに賢くなってるテキストAIの知識を活用する方法を提案してる論文や。
[4] Roshan Sharma、Shruti Palaskar、Alan W Black、Florian Metze、「制限付き自己注意を使ったエンドツーエンド音声要約」、ICASSP、IEEE、2022年、pp. 8072–8076。
音声要約で、AIが「どこに注目するか」を制限することで、より効率よく要約できるようにした研究やな。
[5] Hengchao Shang、Zongyao Li、Jiaxin Guo、Shaojun Li ら、「大規模言語モデルを使ったエンドツーエンド音声要約」、arXiv プレプリント arXiv:2407.02005、2024年。
[6] Wonjune Kang、Deb Roy、「汎用音声要約のための音声プロンプトによる大規模言語モデルの活用」、arXiv プレプリント arXiv:2406.05968、2024年。
この2つは、ChatGPTみたいな大規模言語モデルに音声を直接聞かせて要約させる方法の研究やで。
[7] SooHwan Eom、Jay Shim、Eunseop Yoon、Hee Suk Yoon、Hyeonmok Ko、Mark A Hasegawa-Johnson、Chang D Yoo、「SQUBA:効率的な要約のためのクエリ注意機構を備えた音声Mamba言語モデル」。
Mambaっていう新しいタイプのAIアーキテクチャを音声要約に使った研究やな。
[8] Aaron Hurst、Adam Lerer、Adam P Goucher、Adam Perelman ら、「GPT-4oシステムカード」、arXiv プレプリント arXiv:2410.21276、2024年。
OpenAIのGPT-4oっていうマルチモーダルAI(テキストも音声も画像も扱えるやつ)の技術仕様書やで。
[9] Gheorghe Comanici、Eric Bieber、Mike Schaekermann、Ice Pasupat ら、「Gemini 2.5:高度な推論、マルチモーダリティ、長いコンテキスト、次世代エージェント能力でフロンティアを押し広げる」、arXiv プレプリント arXiv:2507.06261、2025年。
GoogleのGemini 2.5の技術レポートや。めっちゃ賢いAIの最新版やな。
[10] Yunfei Chu、Jin Xu、Qian Yang、Haojie Wei、Xipin Wei、Zhifang Guo、Yichong Leng、Yuanjun Lv、Jinzheng He、Junyang Lin ら、「Qwen2-Audio技術レポート」、arXiv プレプリント arXiv:2407.10759、2024年。
アリババのQwenっていうAIの音声版の技術レポートやで。
[11] Abdelrahman Abouelenin、Atabak Ashfaq、Adam Atkinson、Hany Awadalla ら、「Phi-4-mini技術レポート:Mixture-of-LoRAsによるコンパクトで強力なマルチモーダル言語モデル」、arXiv プレプリント arXiv:2503.01743、2025年。
MicrosoftのPhi-4-miniっていう、小さいけどめっちゃ賢いAIの技術レポートや。LoRAっていう効率的な学習方法を組み合わせてるねん。
[12] Yuxian Gu、Li Dong、Furu Wei、Minlie Huang、「MiniLLM:大規模言語モデルの知識蒸留」、arXiv プレプリント arXiv:2306.08543、2023年。
でっかいAIの賢さを小さいAIに教え込む(蒸留っていうねん)方法の研究やで。
[13] Rishabh Agarwal、Nino Vieillard、Yongchao Zhou、Piotr Stanczyk、Sabela Ramos Garea、Matthieu Geist、Olivier Bachem、「言語モデルのオンポリシー蒸留:自分で作った間違いから学ぶ」、ICLR、2024年。
AIが自分で作った間違いから学習する蒸留方法やな。なんでかっていうと、他人の間違いより自分の間違いの方が学びやすいんやって。
[14] Yihan Cao、Yanbin Kang、「LLM知識蒸留について - 順方向KLと逆方向KLの比較」、The Fourth Blogpost Track at ICLR 2025。
知識蒸留でどっちの方向から学ばせるかで結果が変わるっていう比較研究やで。
[15] Rafael Rafailov、Archit Sharma、Eric Mitchell、Christopher D Manning、Stefano Ermon、Chelsea Finn、「直接選好最適化:あなたの言語モデルは実は報酬モデルや」、NeuIPS、vol. 36、pp. 53728–53741、2023年。
これめっちゃ有名な論文やねん!DPOって呼ばれてて、AIを人間の好みに合わせて調整する新しい方法を提案してるんや。従来より簡単でええ結果出るって話題になったで。
[16] Jinyu Li、Rui Zhao、Jui-Ting Huang、Yifan Gong、「出力分布ベースの基準を使った小さいDNNの学習」、Proc. Interspeech、2014年、pp. 1910–1914。
小さいニューラルネットワークを、でっかいやつの出力を真似させて賢くする方法の初期の研究やな。
---
![]()
1 / 1
100%