<<
2601.21912v1_ProRAG_Process-Supervised_Reinforcement_Learning_f.pdf

---
## Page 1
[](/attach/c6e9c1e9c6079bbbbe6a151c39c28b1066ea8d5729dc904c2543a0645c2ba8a8_p001.png)
### 和訳
ProRAG:検索拡張生成のためのプロセス監視型強化学習
Zhao Wang
中国人民大学 高齢人工知能学院、北京、中国
lilin22wz@gmail.com
Ziliang Zhao
中国人民大学 高齢人工知能学院、北京、中国
zhaoziliang@ruc.edu.cn
Zhicheng Dou*
中国人民大学 高齢人工知能学院、北京、中国
dou@ruc.edu.cn
## 概要
強化学習(RL)ってのが、複雑な推論タスクでRAG(検索拡張生成)を最適化するのにめっちゃええ方法として注目されとるんよ。せやけどな、従来の結果ベースのRLアプローチって、報酬がスカスカすぎたり、クレジット割り当てがうまいこといかんって問題があるねん。なんでかっていうと、ざっくりしたスカラー報酬やと、長い軌道の中でどのステップがアカンかったんか特定でけへんからやねん。この曖昧さが「プロセス幻覚」っちゅう厄介な現象を引き起こすことが多いんよ。これ何かっていうと、モデルが間違った論理とか余計な検索ステップ踏んでても、最終的に正解にたどり着いてまうってやつやな。
最近のプロセス認識型アプローチは、静的な選好学習とかヒューリスティックな報酬形成でこの問題を何とかしようとしてんねんけど、ステップレベルのクレジットをグローバルな結果から切り離すのに必要なオンポリシー探索の能力が足りてへんことが多いんや。
こういう課題を解決するために、ワイらはProRAGっちゅうプロセス監視型強化学習フレームワークを提案するで。学習したステップレベルの監視をオンライン最適化ループに組み込む設計になっとるんよ。このフレームワークは4つのステージで構成されとる:
1. **教師あり政策ウォームアップ**:構造化された推論フォーマットでモデルを初期化するやつ
2. **MCTSベースのプロセス報酬モデル(PRM)の構築**:中間推論の品質を定量化するやつ
3. **PRMガイド付き推論の洗練**:ポリシーを細かいプロセス選好に合わせるやつ
4. **プロセス監視型強化学習**:二重粒度のアドバンテージ機構を使うやつ
ステップレベルのプロセス報酬とグローバルな結果シグナルを集約することで、ProRAGはすべてのアクションに対して正確なフィードバックを提供できるんよ。
5つのマルチホップ推論ベンチマークで徹底的に実験したんやけど、ProRAGは強力な結果ベースやプロセス認識型RLのベースラインと比べて、全体的に優れた性能を達成したで。特に複雑な長期タスクで顕著やったんは、細かいプロセス監視の有効性を証明しとるな。コードとモデルはhttps://github.com/lilinwz/ProRAGで公開しとるで。
## CCS概念
• コンピューティング手法 → 自然言語生成; 強化学習; • 情報システム → 質問応答
## キーワード
検索拡張生成、強化学習、質問応答、大規模言語モデル
## 1 はじめに
最近の大規模言語モデル(LLM)は、めっちゃすごい推論能力を見せとって [4, 16]、複雑で知識集約型のタスクでのパフォーマンスがガッツリ向上しとるんよ。こういう進歩のおかげで、RAGは静的なパイプラインからエージェント型システムへと進化してきたんや。モデルが自律的な意思決定者として、検索戦略を能動的に計画したり、外部ツールと対話したり、フィードバックに基づいて反復的に推論を洗練したりするようになったんやな [3, 14]。
せやけどな、こういう動的なワークフローを標準的な教師あり学習で最適化するのはなかなか難しいんよ。効果的な推論と検索の軌道って、オープンエンドなことが多くて、中間的な決定に対する細かい正解データが手に入らんか、めっちゃコストかかるんや。このギャップを埋めるために、最終的な結果シグナルからモデルポリシーを最適化する強化学習(RL)がどんどん採用されるようになってきとる [9, 21]。
ただな、従来の結果ベースの強化学習は、報酬のスパース性とクレジット割り当て問題に悩まされることが多くて、複雑なマルチホップRAGタスクには効果的やないねん。こういう長い軌道のタスクでは、最終回答の正確さに基づくざっくりしたスカラー報酬だと、中間アクションそれぞれの具体的な貢献を区別でけへんことが多いんよ。この曖昧さが「プロセス幻覚」を引き起こしがちで、モデルが正解にたどり着いたからって報酬もらえても、実は途中の論理がおかしかったりするんや。
---
**図1:最適化パラダイムの比較**
(a) **結果ベースRL**:スパースなグローバルシグナルのせいで見せかけの相関に悩まされるんよ。
(b) **オフラインDPO**:静的データセットによる分布シフトに制限されるんや。
(c) **ProRAG(ワイらの提案)**:正確なクレジット割り当てと動的なエラー修正のために、密なステップレベルの監視を活用するで。
---
*Zhicheng Douが責任著者や。
---
## Page 2
[](/attach/c6e9c1e9c6079bbbbe6a151c39c28b1066ea8d5729dc904c2543a0645c2ba8a8_p002.png)
### 和訳
ほな、正解にたどり着いたとしても、おかしな推論とか、要らん情報の取得とか、ちゃんと確認してない思い込みに頼ってることがあるねん。結果として、こういう「結果だけ見てフィードバックするやり方」は、ほんまの推論能力やなくて、たまたまの相関関係を強化してまうことがあるわけや。しかも、どこが具体的に間違ってるか細かく指摘する仕組みがないから、モデルは学習の初期段階でズレてもうても修正しにくくて、効率悪い最適化になってまうねん。
こういう課題を解決するために、最近の研究ではプロセスレベルの信号を取り入れる最適化戦略が探られてて、大きく分けてオフラインとオンラインの2つのアプローチがあるねん。オフラインの方法[12, 22, 37]は、MCTSみたいな探索アルゴリズムを使って、Direct Preference Optimization (DPO)用の好みの軌跡を合成するんやけど、静的なデータに頼ってるから、学習中の分布の変化に適応するのが苦手やねん。逆にオンラインの方法は、ヒューリスティックな報酬の調整[6, 31]とか、ステップごとの正規化[28, 32]とか、複数エージェントの相互作用[26]とかで学習を安定させようとしてるねん。でもな、これらのアプローチは主に報酬の大きさを調整したり、コストの高いLLMの審査員に頼ったりしてて、中間ステップの論理的な正しさをちゃんと検証してるわけちゃうねん。さらに、木構造の探索[36]とか推論時の修正モジュール[29]でエラーを減らせることもあるんやけど、めっちゃ時間かかるし、推論能力をモデル自体に内在化できへんねん。やから、オンライン学習中に直接、探索から得られる細かいプロセス監督を提供するのは、まだまだ難しい課題やねん。
この論文では、ProRAGっていう、プロセス監督型の強化学習フレームワークを提案するで。これは、マルチホップRAGタスクにおける「貢献度割り当て問題」を解決するためのもんやねん。従来みたいに、まばらな結果信号とか、静的なオフラインの好みとか、ヒューリスティックなルールに頼るんやなくて、ProRAGは学習したステップレベルの監督を直接オンライン最適化のループに組み込むねん。具体的には、まず「教師あり方策ウォームアップ」で、構造化された推論フォーマットでモデルを初期化するんや。この方策を事前知識として活用して、モンテカルロ木探索(MCTS)で構築した多様な推論パスを使ってProcess Reward Model (PRM)っていう細かい評価器を訓練するねん。初期方策とこの評価器の間のギャップを埋めるために、「推論リファインメント」段階を導入してて、PRMでフィルタリングした高品質な軌跡を使ってモデルを効果的にウォームアップするんや。最後に、二重粒度メカニズムを備えた「プロセス監督強化学習」段階を実装するで。PRMからのステップレベルのプロセスアドバンテージと、グローバルな結果報酬を組み合わせることで、ProRAGは各アクションに対して即座で正確なフィードバックを提供できるねん。このメカニズムのおかげで、モデルは中間エラーを動的に特定して修正できて、最終的な答えに過学習するんやなくて、「正しく推論する方法」を学べるわけや。
5つの難しいマルチホップ推論ベンチマークで大規模な実験をやったで。PopQA[15]、HotpotQA[34]、2WikiMultihopQA[7]、MuSiQue[23]、Bamboogle[17]やな。実験結果から、ProRAGは結果ベースやプロセス認識型の強力なベースラインと比べて優れた性能を達成してて、特に複雑な長期タスクでその効果が顕著やねん。これは、細かいプロセス監督が、まばらな結果報酬やオフライン好み学習よりも効果的な最適化信号を提供することを実証してるわけや。さらに、包括的なアブレーション研究で、フレームワークの各コンポーネントの本質的な貢献を確認してて、PRMガイドのリファインメントと二重粒度アドバンテージメカニズムが、観察された性能向上に不可欠やってことがわかったで。加えて、分析によると、ProRAGは検索プロセスを効果的に制御してて、無関係な文書に対してもロバストやし、タスクの複雑さに応じて適応的に推論ステップを計画できるねん。効率性の評価でも、推論能力を内在化することで、ProRAGは高いデータ効率と低い推論レイテンシを達成してて、実世界での展開がしやすいことが示されてるで。
この論文の主な貢献は以下の通りやで:
(1) ProRAGを提案したで。これは、学習したステップレベルのプロセス報酬と結果信号を組み合わせた二重粒度アドバンテージメカニズムによって、マルチホップRAGタスクの貢献度割り当て問題を解決するプロセス監督強化学習フレームワークやねん。
(2) MCTSベースのProcess Reward Modelを導入したで。これは木探索による探索を活用して、中間推論の品質を定量化して、プロセスのハルシネーション(幻覚)を効果的に特定できるねん。
(3) PRMガイドの推論リファインメント戦略を設計したで。これで方策を細かいプロセスの好みに合わせて、安定した収束を確保して、強化学習のコールドスタート問題を軽減できるんや。
2 関連研究
2.1 検索拡張生成(RAG)
検索拡張生成(RAG)は、外部の知識源から関連情報を動的に取り込むことで、LLMのハルシネーションと知識の陳腐化を軽減する重要なパラダイムとして登場したで[13, 38]。RAGの初期研究は主に標準的な「検索してから生成」フレームワークに焦点を当ててて、検索器が入力クエリに基づいて関連文書を特定して、生成器が最終的な回答を合成するっていう流れやった[5, 10]。複数の検索ステップが必要なより複雑なマルチホップクエリに対応するために、その後の研究では反復的な検索メカニズムが導入されたで。Iter-RetGen[19]やIRCoT[24]みたいな手法は、検索と生成のステップを交互に行って、文脈を段階的に洗練させるんや。さらに、FLARE[8]やSelf-RAG[1]みたいなアクティブ戦略は、低確信度の生成やトークンレベルの信号によってトリガーされる動的検索で効率を改善してるで。
でもな、これらのパイプラインは通常、事前定義されたワークフローに従ってるから、オープンエンドで複雑な推論タスクへの適応性が制限されてまうねん。これに対処するために、最近の研究ではAgentic RAGが探索されてて、LLMが検索と推論プロセスを統括する自律エージェントとして機能するんや[2]。このパラダイムでは、モデルが明示的に検索クエリを計画して、検索エンジンと対話して、取得した証拠を評価するねん。ReAct[35]みたいな基礎的な研究は、推論の軌跡と外部ツールのアクションを交互に配置する可能性を示したで。これをベースにして、Search-o1[14]やDeepRAG[3]みたいな最近の高度なシステムは、RAGプロセスを多段階の意思決定タスクとしてモデル化して、長期クエリに対応してるねん。でも、これらのアーキテクチャの進歩にもかかわらず、既存のほとんどのagentic RAGシステムは主に教師ありファインチューニングや複雑なプロンプトエンジニアリングに頼ってて、最適な推論軌跡が利用できない新しいシナリオへの汎化能力が根本的に制限されてまうねん。
2.2 RAGのための強化学習
強化学習(RL)は、タスク固有の報酬を最大化することで静的な監督の限界を克服して、RAGシステムを最適化するための有望なパラダイムになってきてるで。Search-R1[9]やR1-Searcher[21]みたいな最近の進歩は、その可能性を示してるねん。
---
## Page 3
[](/attach/c6e9c1e9c6079bbbbe6a151c39c28b1066ea8d5729dc904c2543a0645c2ba8a8_p003.png)
### 和訳
ProRAG:検索拡張生成のためのプロセス教師付き強化学習
図2:左側のパネルはワイらのモデルの推論フォーマットを示してて、右側はプロセス報酬モデルを訓練するために使うモンテカルロ木探索(MCTS)の仕組みを図解してんねん。
結果教師付き強化学習(outcome-supervised RL)を使うと、モデルが検索ツールを呼び出す能力とか、取得したコンテンツを使って推論する能力がめっちゃ向上するってことがわかってんねん。せやけど、最近の研究[12, 37]で指摘されてるように、結果ベースのアプローチには長期的なタスクで報酬がスカスカになる問題とか、勾配が衝突する問題があんねん。最終的な答えが合ってるからって、推論の過程が正しいとは限らへんねん。これが「プロセス幻覚」って呼ばれる現象を引き起こすことがあって、モデルが間違った論理とか無駄な検索を使っても、たまたま正解にたどり着いたら強化されてまうんよ[31]。
この「功績の帰属問題」(どのステップが正解に貢献したかわからへん問題)に対処するために、最近の研究ではプロセスレベルの監督を統合する方法が探られてて、大きく分けてオフラインとオンラインのアプローチがあんねん。オフライン手法[12, 22, 37]はMCTSみたいな探索アルゴリズムとか、切り離して実行する方法を使って、DPO(直接選好最適化)用の高品質な選好データセットを合成すんねん。せやけど、これらの手法は静的なデータセットに頼ってるから、モデルがオンポリシーの分布シフト(学習中に自分の行動パターンが変わること)に適応する能力が制限されてまうんよ。
逆に、オンライン手法は訓練中により密なフィードバックを提供しようとすんねん。いくつかのアプローチ[28, 31, 32]は、ステップごとのヒューリスティックな報酬整形とか正規化戦略を導入してんねん。もっと最近のフレームワーク[6, 26]は、マルチエージェントの相互作用とか多次元の報酬関数を活用して推論をガイドしてんねん。これらは効果的やけど、普通は高価な外部LLMの審判とか手作業でルール設計が必要やから、学習された検証器の効率性に欠けてんねん。さらに、木ベースの探索[36]とか推論時の改良モジュール[29]はエラーを軽減するのに役立つけど、訓練や推論の際にかなりの計算遅延が発生して、推論能力をポリシーモデルに効率的に内在化できへんことが多いねん。
それに対して、ワイらのProRAGは、学習されたMCTSベースのプロセス報酬モデルをオンライン強化学習ループに直接統合してんねん。二重粒度のアドバンテージ機構を採用することで、ProRAGはより正確で、密度が高くて、効率的な監督を提供すんねん。
3 ProRAG
RAG向けの既存の強化学習アプローチは、複雑なマルチステップ推論において報酬のスパース性(まばらさ)と非効率な功績帰属に苦しんでることが多いねん。これらの課題に対処するために、ワイらはProRAGを提案すんねん。これはステップレベルの細かい最適化のためにプロセス報酬を導入して、RAGモデルの推論能力を向上させるもんやねん。ワイらのフレームワークは4つのステージで構成されてんねん:(1) **教師ありポリシーウォームアップ**でモデルをマルチステップ推論フォーマットに合わせる、(2) **MCTSベースのプロセス報酬モデリング**でステップレベルのプロセス報酬モデルを構築する、(3) **PRM誘導推論改良**でモデルポリシーを急速に向上させる、(4) **プロセス教師付き強化学習**で細かい報酬による最終最適化を行う。
3.1 教師ありポリシーウォームアップ
LLMに複雑なマルチホップ推論と自律的な検索の能力を身につけさせるために、まず教師ありポリシーウォームアップから始めんねん。このステージでは、構造化された推論-行動フォーマットに従って構築されたデータセットを使ってモデルをファインチューニングして、後続の訓練のための安定した参照ポリシー𝜋sftを確立すんねん。
標準的なQAベンチマークは通常、サブクエリのチェーンと対応する検索ドキュメントを提供するけど、明示的な推論プロセスは含まれてへんから、ワイらはモデルにこの能力を教えるための高品質なデータセットを構築すんねん。これを達成するために、優れたLLM(例えばGPT-4o)を活用して詳細な思考連鎖の軌跡を合成すんねん。提供されたサブクエリとドキュメントに基づいて各ステップの推論プロセスを生成するように教師モデルにプロンプトを与えることで、初期クエリと最終回答の間のギャップを埋める多様な推論パスを得られんねん。
細かいプロセス監督を可能にするために、合成された軌跡を構造化されたスキーマに整理してんねん。図に示されてる通りやで。
---
【図の説明部分】
ユーザークエリ...…正しい/信頼性なし/間違い
アクション1、アクション2、アクション3
ユーザークエリ:
現在のプレミアリーグ首位のチームは、これまでにチャンピオンズリーグで優勝したことあるん?
モデル出力:
<step>まず、現在プレミアリーグの順位表で首位にいるチームを特定せなあかんな。</step>
<subquery>現在のプレミアリーグ順位表 1位</subquery>
<retrieval>本日時点で、アーセナルがプレミアリーグ順位表の首位におるで。</retrieval>
<step>まず検索した記事をチェックして、プレミアリーグの現在の首位を確認したら、アーセナルが1位やってことがわかったわ。</step>
<subanswer>現在のプレミアリーグ首位はアーセナルやで。</subanswer>
……
<step>現在の首位(アーセナル)はタイトルを獲得したことがあるから、答えは「はい」やな。</step>
<answer>はい</answer>
却下/採用
---
## Page 4
[](/attach/c6e9c1e9c6079bbbbe6a151c39c28b1066ea8d5729dc904c2543a0645c2ba8a8_p004.png)
### 和訳
ほな、図2の左側のパネルを説明していくで。推論の軌跡っちゅうのは、特別な制御トークンで囲まれた一連のステップでできてるねん。`<step>`は計画立てるための内部思考プロセスをマークしてて、`<subquery>`は検索システムに投げるキーワードを示してるんや。`<retrieval>`は外部の環境から返ってきた証拠を包んでて、`<subanswer>`は途中の結論を示してる。ほんで`<answer>`が最終的な答えやな。この構造化されたフォーマットのおかげで、ぐちゃぐちゃした推論を離散的で評価できるアクションの列に変換できるわけや。
この構造化された軌跡を活用して、教師ありファインチューニングをやって参照ポリシー𝜋SFTを確立するねん。長い推論プロセスや検索ドキュメントで学習シグナルが埋もれてまう連続シーケンスで訓練するんやなくて、訓練データを特定の入力-ターゲットのペアとして定式化するんや。入力には過去のコンテキスト(凍結された検索コンテンツも含む)が入ってて、ターゲット出力は現在の推論とアクションブロック(つまり`<step>`と`<subquery>`)で構成されてる。このアプローチによって、モデルの注意を目の前の生成タスクに完全に向けさせることができるんやで。
構造フォーマットをさらにしっかり守らせるために、フォーマットを意識した訓練目的を採用してる:
LSFT = −∑(t∉Tctrl) log P(yt | c, y<t) − λ∑(t∈Tctrl) log P(yt | c, y<t) (1)
ここでTctrlは特別な制御トークン(`<step>`とか`<subquery>`とか)の集合やねん。λを1より大きく設定することで、この段階でモデルがフォーマットスキーマをちゃんと守るようにしてるんや。
## 3.2 MCTSベースのプロセス報酬モデリング
SFTフェーズでモデルに基本的な推論フォーマットを身につけさせても、最終的な答えの正しさだけで監督するのはまだ不十分やねん。この粗い粒度のフィードバックは「プロセスハルシネーション」を引き起こしがちで、これはモデルが間違った論理や冗長な検索アクションで正解にたどり着いてまう現象のことや。これを軽減するために、中間推論ステップの妥当性を評価するプロセス報酬モデル(PRM)を導入するで。
これを実現するために、モンテカルロ木探索(MCTS)を使って、ステップレベルのラベル付きの多様な推論パスのデータセットを構築するんや。具体的には、推論プロセスを木探索問題として定式化して、SFTポリシー𝜋sftを事前分布として利用する。ここで状態stは蓄積された推論履歴(検索コンテキスト含む)を表してて、アクションatは生成された推論ステップに対応してるねん。
選択フェーズでは、木を走査して、高い価値のパスの活用と不確実なパスの探索のバランスを取るためにPredictor Upper Confidence Bound(PUCT)を最大化する子ノードを選ぶんや:
at = arg max_a (Q(st, a) + cpuct · πSFT(a|st) · √(Σa' N(st, a')) / (1 + N(st, a))) (2)
葉ノードに到達したら、高い温度で𝜋sftから候補ステップをサンプリングして新しい候補ステップを展開するねん。ほんでシミュレーションを実行して完全な軌跡を生成し、終端状態を正解と比較して二値の正解スコアv ∈ {0, 1}を得る。これを探索パスに沿ってバックプロパゲーションして、訪問回数と平均アクション値を更新するんや。ステップt ≤ Tに対応するノードについて、アクション値を次のように更新する:
Q(st, at) ← (Q(st, at) · N(st, at) + γ^(T-t) · v) / (N(st, at) + 1) (3)
ここでγは減衰係数で、冗長な軌跡への報酬を割り引いて、より直接的な解を促進するんやで。
反復的なシミュレーションを通じて、MCTSは解空間を効果的に探索して、妥当な推論パスとエラーに至るパスを区別できる豊富な軌跡のセットを蓄積するねん。
MCTSは効率的な探索を可能にして推論軌跡に値を割り当てるけど、得られるQ値は主に結果志向のままやねん。推論ステップが高い値を受け取るのは、単にそれが正解につながるからかもしれんくて、そのステップ自体に論理的エラーや裏付けのない仮定が含まれてても関係ないんや。せやから、そういう結果ベースのシグナルは、きめ細かい推論の質を確実に監督するには不十分やねん。
きめ細かいプロセスレベルの監督を得るために、MCTS探索木から対照的なステップレベルの選好ペアをさらに構築するんや。具体的には、同じ親コンテキストを共有するけど現在の推論ステップで異なる兄弟ノードを選んで、GPT-4oを論理的な審判として使って推論の質を比較するねん。モデルは厳密な論理的妥当性に基づいて各ペアを「選択」(y+)または「棄却」(y−)とラベル付けする。これらのラベルの信頼性を検証するために、ランダムにサンプリングした50ペアを手動で評価したところ、GPT-4oと人間のアノテーターの間で96%の一致率が観察されて、高いラベルの信頼性を示してるで。これらの対照ペアは結果ベースのシグナルからノイズをフィルタリングして、PRMに直接的な監督を提供するんや。これによって、同一のコンテキストの下で論理的に妥当なステップと欠陥のある代替案を区別できるようになるねん。
最後に、これらの構築された対照ペアでプロセス報酬モデルR𝜙を訓練して、中間推論の質を定量化するんや。モデルはクエリコンテキストと特定の推論ステップを入力として受け取り、スカラースコアを出力する。選択されたステップと棄却されたステップの間のスコアマージンを最大化するために、ペアワイズランキング損失を使ってR𝜙を最適化するで:
LPRM = −E(x,y+,y−)∼D [log σ(R𝜙(x, y+) − R𝜙(x, y−))] (4)
ここでσはシグモイド関数で、Dは収集された選好データセットを表してる。この損失を最小化することで、R𝜙は後続の段階でステップレベルのフィードバックを提供する密な検証器として機能するんやで。
## 3.3 PRMガイドによる推論の洗練
強化学習フェーズの前に、初期のSFTポリシーとPRMのきめ細かい選好との間のアライメントギャップを埋めることがめっちゃ重要やねん。𝜋sftはSFTを通じて望ましい構造フォーマットを学習するけど、その出力分布は質の面でまだ幅広くて、PRMにエンコードされた論理基準からしばしば逸脱してまうんや。このようにアライメントされてないポリシーを直接RLで最適化すると、初期の探索空間で高報酬の軌跡がスパースであるために、深刻なコールドスタート問題に悩まされることが多いねん。
これに対処するために、SFTと強化学習の間の中間ステップとして推論洗練ステージを提案するで。PRMでフィルタリングされた高品質な推論軌跡でポリシーモデルをファインチューニングすることで、ステップレベルのプロセスの正確性を向上させて、SFTポリシーとPRMの間の分布ミスマッチを減らすんや。その結果、洗練されたポリシーは後続の強化学習のための、よくアライメントされた安定した初期化を提供してくれるっちゅうわけや。
---
## Page 5
[](/attach/c6e9c1e9c6079bbbbe6a151c39c28b1066ea8d5729dc904c2543a0645c2ba8a8_p005.png)
### 和訳
ProRAG:プロセス監督型強化学習でRAGをめっちゃ強化する話
図3:プロセス監督型強化学習のフレームワークやで
これを実現するために、ステップレベルのRejection Sampling ファインチューニング(RFT)っていう戦略を使って、洗練用のデータセットを作るねん。具体的に言うと、SFTポリシー𝜋sftを使って、各クエリに対してN個の候補となる軌道(trajectory)を生成するわけや。ポリシーモデルには最適な推論パスだけを学習してほしいから、2段階のフィルタリングをかけるねん。まず1つ目は、結果の正しさを厳しくチェックして、正解にたどり着いた軌道だけを残すねん。2つ目は、プロセスの妥当性をチェックするために、訓練済みのPRM(プロセス報酬モデル)R𝜙を使って中間ステップを全部評価するわけや。特定の(コンテキスト、アクション)ペアは、報酬スコアが設定した閾値を超えた場合(例えば R𝜙(𝑠𝑡) > 0)だけ訓練用に残すねん。この選択的なメカニズムのおかげで、高品質な推論セグメントを集められて、PRMが「ここ価値高いで!」って言ってる領域にポリシーを選択的にアラインできるってわけや。
最後に、こうやって厳選した軌道で初期ポリシー𝜋SFTをファインチューニングするねん。(コンテキスト、アクション)ペアを高品質なお手本として扱って、標準的な次トークン予測の目的関数でモデルを最適化するわけや。このプロセスで、PRMからのスパースで価値の高いシグナルを、洗練されたポリシーモデル𝜋RFTのパラメータに効果的に蒸留できるねん。その結果、𝜋rftは初期ポリシー𝜋sftよりめっちゃ強い推論能力を発揮して、次の強化学習ステージでのコールドスタート問題を効果的に緩和できるんや。
3.4 プロセス監督型強化学習
推論の洗練ステージの後は、強化学習(RL)を使ってモデルの能力をさらに高めるねん。でもな、PPO [18] とか GRPO [20] みたいな従来のRLアルゴリズムは、スパースな結果報酬に頼りがちで、マルチホップRAGタスクでは「クレジット割り当て問題」に悩まされるんや。つまり、ポリシーモデルが「どのステップがあかんかったんや?」とか「中間の推論は合ってたんか?」を特定できへんのや。これを解決するために、ProRAGっていう二重粒度アドバンテージ機構を持つ強化学習フレームワークを提案するで。図3に示すように、ステップレベルのプロセスシグナルと最終結果報酬の両方からグループ正規化されたアドバンテージを集約して、推論プロセス全体にわたって細かくて密な監督を提供するねん。
3.4.1 グループ軌道サンプリング
ポリシーの分散を推定するために、現在のポリシー𝜋𝜃から軌道のグループをサンプリングするねん。このポリシーは洗練モデル𝜋rftで初期化されてるで。具体的には、与えられたクエリ𝑞に対して、𝜋𝜃からG個の独立した軌道 Y = {𝑦1, 𝑦2, . . . , 𝑦𝐺} をサンプリングするわけや。各軌道𝑦𝑖は離散的な推論ステップの列 𝑦𝑖 = (𝑠𝑖,1, 𝑠𝑖,2, . . . , 𝑠𝑖,𝑇) として定式化されて、各ステップ 𝑠𝑖,𝑡 = (𝑜𝑖,𝑡,1, . . . , 𝑜𝑖,𝑡,𝑙𝑖,𝑡) はポリシーが生成したトークンのサブシーケンスに対応するねん。
3.4.2 報酬の定式化
これらの生成を評価するために、密なステップレベル監督とスパースな軌道レベル検証から、2種類の報酬シグナルを導出するで。
まず、軌道𝑦𝑖内の各中間推論ステップ𝑠𝑖,𝑡に対して、ステップレベルのプロセス報酬 𝑟^step_𝑖,𝑡 を計算するねん。この報酬は、ローカルなフォーマット制約と、凍結したPRM R𝜙からの確率スコアに基づいてアクションの品質を評価するわけや。形式的には、履歴コンテキスト𝒄𝑖,𝑡が与えられたとき、プロセス報酬は以下のように定義されるで:
𝑟^step_𝑖,𝑡 = R𝜙(𝒄𝑖,𝑡, 𝑠𝑖,𝑡) + 𝜈1 · I^step(𝑠𝑖,𝑡) (5)
ここで I^step(·) は指示関数で、現在のステップ𝑠𝑖,𝑡が指定されたタグスキーマ(例えば<step>とか<subquery>の正しい使い方)に厳密に従ってたら1を返して、そうでなければ0を返すねん。𝜈1はこのフォーマットボーナスの係数や。
次に、軌道が完了した後に終端結果報酬 𝑟^out_𝑖 を割り当てて、グローバルな有用性を評価するねん。この報酬は最終回答の正しさと、完全な推論チェーンのフォーマット整合性で決まるで:
𝑟^out_𝑖 = F1(ˆ𝑎𝑖, 𝑎∗) + 𝜈2 · I^traj(𝑦𝑖) (6)
ここで、ˆ𝑎𝑖は𝑦𝑖から抽出した予測回答で、𝑎∗は正解やねん。関数F1(·)は予測と正解の間のトークンレベルの精度を計算するで。指示関数 I^traj(𝑦𝑖) は軌道𝑦𝑖全体が完全な推論-アクションワークフローに従ってるかを評価して、ポリシーが必要な検索とか中間推論ステップをスキップすることを抑制するねん。𝜈2はこのフォーマットボーナスの係数や。
3.4.3 二重粒度アドバンテージ推定
マルチターン軌道でのクレジット割り当て問題に対処するために、密なステップレベル監督とスパースな結果報酬を集約する二重粒度アドバンテージ推定戦略を提案するで。
生成された軌道𝑦𝑖に対して、報酬をトークンレベルにブロードキャストして、ステップ𝑠𝑖,𝑡内のk番目のトークンに対するプロセスアドバンテージ 𝐴^proc_𝑖,𝑡,𝑘 と結果アドバンテージ 𝐴^out_𝑖,𝑡,𝑘 を以下のように定義するねん:
𝐴^proc_𝑖,𝑡,𝑘 = (𝑟^step_𝑖,𝑡 − 𝜇^step) / 𝜎^step, 𝐴^out_𝑖,𝑡,𝑘 = (𝑟^out_𝑖 − 𝜇^out) / 𝜎^out (7)
---
## Page 6
[](/attach/c6e9c1e9c6079bbbbe6a151c39c28b1066ea8d5729dc904c2543a0645c2ba8a8_p006.png)
### 和訳
ここで μ と σ は、それぞれの報酬のグループごとの平均と標準偏差を表してるねん。このメカニズムによって、報酬シグナルが各ステップ s_{i,t} 内のすべてのトークン k にブロードキャストされるわけや。これで最適化のための密な(細かい)監督が得られるっちゅうことやな。
プロセスアドバンテージとアウトカムアドバンテージを重み付けして集約することで、トータルのアドバンテージ A_{i,t,k} が得られるんやけど、式はこうなるで:
A_{i,t,k} = A^{out}_{i,t,k} + β · A^{proc}_{i,t,k} (8)
この二つの粒度のアドバンテージ推定は、単一ソースの監督の限界を補ってくれるねん。なんでかっていうと、スパースな(まばらな)アウトカム報酬だけやと、途中の推論ステップに対するクレジット割り当て(どのステップがどれだけ貢献したかの評価)が不十分になってまうからや。逆に、ステップレベルのプロセス報酬だけに頼ると、局所的なシグナルの最適化に走ってしまって、全体的な正解にたどり着けへんリスクがあるんよ。アウトカムアドバンテージと重み付けしたプロセスアドバンテージを組み合わせることで、ProRAG は密なトークンレベルの監督を実現しつつ、最終的な推論目標との整合性も保てるっちゅうわけや。
**3.4.4 ポリシー最適化** 最後に、軌跡グループ全体のトータルアドバンテージを最大化することでポリシー π_θ を最適化するで。GRPO [20] と同じく、バリューネットワークの代わりに式8のグループ統計を使ってベースラインを計算するから、メモリ効率もええねん。損失関数はこうなるで:
L(θ) = -E_{q∼D,Y∼π_{old}} [1/G ∑_{i=1}^{G} ∑_{t=1}^{T_i} ∑_{k=1}^{l_{i,t}} min(ρ_{i,t,k} A_{i,t,k}, clip(ρ_{i,t,k}, 1-ε, 1+ε) A_{i,t,k})] (9)
ここで ρ_{i,t,k} = π_θ(o_{i,t,k}|h_{i,t,k}) / π_{old}(o_{i,t,k}|h_{i,t,k}) は現在のポリシーと参照ポリシーの確率比を表してるねん。h_{i,t,k} はトークン o_{i,t,k} より前のすべてのコンテキストで、ε はクリッピング係数やで。
## 4 実験
### 4.1 データセットと評価指標
ProRAG と全ベースラインモデルを5つの多様なベンチマークで評価したで。一般的なQAデータセットの PopQA [15] と、4つのマルチホップQAデータセット:HotpotQA [34]、2WikiMultiHopQA [7]、MuSiQue [23]、Bamboogle [17] や。これらのデータセットは、ロングテール知識の検索から複雑な多段階演繹推論まで、幅広い課題をカバーしてるねん。これで、難易度や分布シフトの異なる条件下で、モデルが計画・検索・推論する能力を包括的に評価できるってわけや。これらのベンチマークでは、回答精度を評価するために Exact Match(EM)と F1スコア を報告してるで。さらに、性能向上の統計的有意性を検証するために、ProRAG と最強ベースラインの間で対応のあるt検定を有意水準 p < 0.05 で実施したんや。
### 4.2 ベースライン
ProRAG を包括的なベースラインセットと比較したで。以下の3タイプに分類できるねん:
**(1) 標準ベースライン** これには Naïve Generation と Standard RAG が含まれてて、性能の下限を表してるわ。Naïve Generation は外部検索なしで、事前学習済みLLMのパラメトリック知識だけに頼るやつや。Standard RAG [13] は従来の「検索してから生成」フレームワークを代表してて、最初のクエリに基づいて1回だけ検索してから最終回答を生成するねん。
**(2) 発展的ベースライン** このカテゴリには、推論時に検索プロセスを動的に調整したり、エージェント的な計画を採用する手法が含まれるで。Iter-RetGen [19] と IRCoT [24] を評価したんやけど、これらは検索と推論ステップを反復ループで交互に行って、段階的に証拠を集めていくやつや。それから FLARE [8] も含めてるで。これは生成の確信度に基づいて検索アクションをトリガーするアクティブ検索戦略やねん。さらに、Search-o1 [14] っていう強力なエージェント的ベースラインもベンチマークに入れてるで。これはLLMを自律エージェントとして扱って、多段階計画、タスク分解、振り返りを通じて検索ワークフローを明示的に制御できるやつや。
**(3) 強化学習ベースライン** 最後に、強化学習を通じてポリシーを最適化する最先端手法と比較したで。アウトカムベースのRLでは、Search-R1 [9] を主要ベースラインとして選んだんや。これはPPOを使って最終回答に基づいてポリシーを最適化するねん。オフラインのプロセス監督では、ReasonRAG [37] を含めたで。これはMCTSを使って静的な選好データを合成し、DPO用のステップレベルシグナルを提供するやつや。オンラインのプロセス認識RLでは、HiPRAG [31] と比較したで。これはサブゴールヒューリスティクスを通じて報酬を形成する最近の手法やねん。
### 4.3 実装の詳細
HuggingFace Transformers [30] と TRL [25] ライブラリをベースにフレームワークを実装して、Qwen3-8B [33] を我々の手法と全ベースラインのバックボーンとして使ったで。検索環境には、2018年のWikipediaダンプ [11] を知識ソースとして、E5-base [27] をリトリーバーとして使用し、各クエリに対してトップ3のドキュメントを検索してるねん。
すべての実験は NVIDIA A100(80GB)GPU 4台で実施したで。**教師あり政策ウォームアップ段階**では、109kのMuSiQueコンテキスト-アクションペアで1エポックの全パラメータファインチューニングを行って、モデルの推論能力を初期化したんや。**プロセス報酬モデリング段階**では、HotpotQAとMuSiQueから728クエリをサンプリングして、200シミュレーション、展開幅 K=5、最大深度10、探索定数 c_{puct}=2.5、割引率 γ=0.99 でMCTSを実行したで。これらの木に対して、GPT-4oでラベル付けした8,255の対照ペアを収集して、SFTチェックポイントからスカラー回帰ヘッドを3エポック訓練したんや。次に、**推論改良段階**では、訓練したPRMでフィルタリングした2つのデータセットから105kの高品質軌跡を選択して、ポリシーモデルをさらに1エポックファインチューニングして推論能力を強化したで。最後に、**プロセス監督RL段階**では、両データセットから抽出した10kのホールドアウトクエリに対してLoRAファインチューニングを1エポック適用して、生成グループサイズ G=8、二重粒度重み β=0.3 でポリシーを最適化したんや。
### 4.4 主要な結果
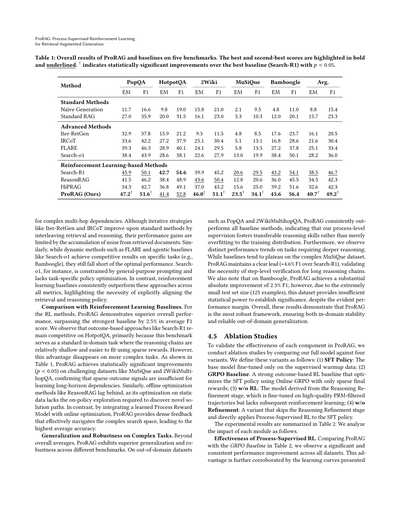
ProRAG とベースラインモデルの5つのベンチマーク全体での性能は表1に示してるで。
**標準・発展的ベースラインとの比較** 表に示されてる通り、標準・発展的ベースラインはRLベースの手法と比べて高い精度を達成するのにめっちゃ苦戦してるねん。具体的には、Naïve Generation は内部知識の限界のせいで最悪の性能やったし、Standard RAG も控えめな改善しか得られへんかった。これは1回だけの検索じゃ不十分やっていうことを示唆してるわな。
---
## Page 7
[](/attach/c6e9c1e9c6079bbbbe6a151c39c28b1066ea8d5729dc904c2543a0645c2ba8a8_p007.png)
### 和訳
ProRAG:プロセス監視型強化学習でRAGをパワーアップさせる話
表1:ProRAGと他の手法を5つのベンチマークで比較した総合結果やねん。一番ええスコアは太字、二番目はアンダーラインで示してるで。†がついてるのは、一番強かったベースライン(Search-R1)と比べて統計的にめっちゃ有意な改善があったってこと(p < 0.05)やな。
[表の内容は数値データなのでそのまま]
複雑なマルチホップの依存関係、つまり何段階も情報をたどらなあかん問題には弱いねん。Iter-RetGenとかIRCoTみたいな繰り返し型の戦略は、検索と推論を交互にやることで基本的な方法よりはマシになるんやけど、取ってきた文書からノイズがどんどん溜まっていくから、性能の伸びには限界があるんよ。同じように、FLAREみたいな動的な方法とか、Search-o1みたいなエージェント型のベースラインも、特定のタスク(たとえばBamboogle)ではええ勝負するんやけど、最高性能にはまだ届かへんねん。Search-o1なんかは、汎用的なプロンプトに縛られてて、タスクに特化した方策の最適化ができてへんのが原因やな。それに対して、強化学習ベースのベースラインはどの指標でも一貫してこれらの手法を上回ってて、検索と推論の方策をちゃんと揃えることがめっちゃ大事やってことがわかるわ。
**強化学習ベースラインとの比較**
強化学習の手法の中でも、ProRAGは全体的にめっちゃ優秀な性能を見せてて、平均F1スコアで最強のベースラインを2.5%も上回ってるねん。Search-R1みたいな結果ベースのアプローチは、HotpotQAではまだまだ戦えるんやけど、なんでかっていうと、このベンチマークは推論の連鎖が比較的浅くて、スパースな報酬でもフィットしやすい標準的なドメイン内タスクやからなんよ。でもな、もっと複雑なタスクになると、この優位性は消えてまうねん。表1を見てもらったらわかるように、ProRAGはMuSiQueとか2WikiMultihopQAみたいな難しいデータセットで統計的に有意な改善(p < 0.05)を達成してて、スパースな結果シグナルだけじゃ長期的な依存関係を学習するには足りひんってことが確認できるわ。同様に、ReasonRAGみたいなオフライン最適化手法も遅れをとってるんやけど、これは静的なデータでの最適化では、新しい解決経路を発見するのに必要なオンポリシーの探索ができへんからやねん。それに対して、ProRAGは学習済みのプロセス報酬モデルとオンライン最適化を組み合わせることで、複雑な探索空間をうまくナビゲートできる密なフィードバックを提供して、結果として最高の平均精度を叩き出してるんや。
**複雑なタスクでの汎化性能と頑健性**
全体の平均だけやなくて、ProRAGは異なるベンチマーク間でも優れた汎化性能と頑健性を見せてるねん。PopQAとか2WikiMultihopQAみたいなドメイン外のデータセットでも、ProRAGは全てのベースライン手法を一貫して上回ってて、これはつまり、うちらのプロセスレベルの監視が、訓練データに過学習するんやなくて、ちゃんと転用できる推論スキルを育ててるってことを示してるんや。さらに、より深い推論が必要なタスクでは、はっきりとした性能の傾向が見られるねん。ベースラインは複雑なMuSiQueデータセットで頭打ちになりがちやけど、ProRAGははっきりとしたリード(Search-R1より+4.6% F1)を維持してて、長い推論チェーンにはステップレベルの検証が必要やってことを証明してるわ。Bamboogleでも、ProRAGは2.3% F1という大きな絶対的改善を達成してるんやけど、テストセットがめっちゃ小さい(125例だけ)から、明らかな性能差があるにもかかわらず、統計的有意性を確立するには検出力が足りひんねん。全体として、これらの結果はProRAGが最も頑健なフレームワークで、ドメイン内での安定性とドメイン外での信頼できる汎化の両方を保証してることを示してるんや。
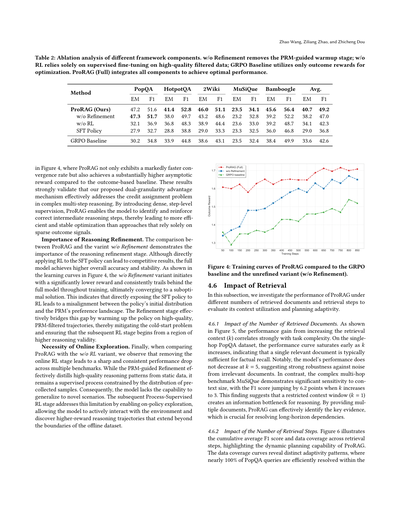
**4.5 アブレーション研究**
ProRAGの各コンポーネントの有効性を検証するために、完全版モデルと4つの変種を比較するアブレーション研究をやったで。変種の定義はこんな感じや:(1) SFT Policy:教師あり学習のウォームアップデータだけでファインチューニングしたベースモデル、(2) GRPO Baseline:スパースな最終報酬だけを使ってOnline GRPOでSFTポリシーを最適化した、結果ベースの強力なRLベースライン、(3) w/o RL:推論リファインメント段階から得られたモデルで、高品質なPRMでフィルタリングした軌跡でファインチューニングしてるけど、その後の強化学習はやってへんやつ、(4) w/o Refinement:推論リファインメント段階をスキップして、SFTポリシーに直接プロセス監視型RLを適用した変種や。
実験結果は表2にまとめてあるで。各モジュールの影響を分析していくな。
**プロセス監視型RLの有効性**
表2でProRAGとGRPO Baselineを比較すると、全てのデータセットで有意かつ一貫した性能改善が見られるねん。この優位性は、提示された学習曲線でもさらに裏付けられてるわ。
---
## Page 8
[](/attach/c6e9c1e9c6079bbbbe6a151c39c28b1066ea8d5729dc904c2543a0645c2ba8a8_p008.png)
### 和訳
表2:フレームワークの各コンポーネントを抜いたときにどうなるか分析したやつやねん。「w/o Refinement」っていうのはPRMで導いてあげるウォームアップ段階を取っ払ったバージョン、「w/o RL」は強化学習なしで高品質なデータだけでファインチューニングしたやつ、「GRPO Baseline」は最終結果の報酬だけで最適化したやつやな。んで「ProRAG (Full)」が全部入りで、これが一番ええ性能出るねん。
Zhao Wang, Ziliang Zhao, and Zhicheng Dou
PopQA
HotpotQA
2Wiki
MuSiQue
Bamboogle
平均
手法
ProRAG(ウチらの)
w/o Refinement
w/o RL
SFTポリシー
EM
47.2
47.3
32.1
27.9
F1
51.6
51.7
36.9
32.7
EM
41.4
38.0
36.8
28.8
F1
52.8
49.7
48.3
38.8
EM
46.0
43.2
38.9
29.0
F1
51.1
48.6
44.4
33.3
EM
23.5
23.2
23.6
23.3
F1
34.1
32.8
33.0
32.5
EM
45.6
39.2
39.2
36.0
GRPO Baseline
30.2
34.8
33.9
44.8
38.6
43.1
23.5
32.4
38.4
F1
56.4
52.2
48.7
46.8
49.9
EM
40.7
38.2
34.1
29.0
F1
49.2
47.0
42.3
36.8
33.6
42.6
図4見てみてや、ProRAGは収束するスピードがめっちゃ速いし、最終的に到達する報酬もベースラインと比べてかなり高いんよ。この結果が何を示してるかっていうと、ウチらが提案した「二段階の粒度で有利さを測る仕組み」が、複雑な多段階推論での「どのステップが良かったか問題」をちゃんと解決してるってことやねん。ステップごとに細かく監督入れることで、モデルが「この途中の推論ステップ、合ってるな」って見分けて強化できるようになるから、最終結果だけ見るスカスカな信号に頼る方法より、効率よく安定した最適化ができるわけや。
**推論の洗練がめっちゃ大事な理由。** ProRAGと「w/o Refinement」を比べたら、推論を洗練する段階がいかに大事かようわかるで。SFTポリシーに直接強化学習かけてもそこそこの結果は出るんやけど、全部入りモデルの方が精度も安定性も上なんよ。図4の学習曲線見たらわかるけど、「w/o Refinement」バージョンは最初の報酬がめっちゃ低くて、訓練中ずっとフルモデルに追いつかれへんまま、結局イマイチな解に収束してまうねん。これが意味するのは、SFTポリシーにいきなり強化学習かますと、ポリシーの最初の分布とPRMが「こっちがええで」って思ってる好み空間がズレてまうってことや。洗練段階を入れることで、PRMでフィルターした高品質な軌跡でポリシーをウォーミングアップできるから、「コールドスタート問題」を緩和して、次の強化学習段階がちゃんと推論の質が高いところからスタートできるようになるんやな。
**オンライン探索が絶対必要な理由。** 最後に、ProRAGと「w/o RL」を比べると、オンライン強化学習の段階を抜いたら複数のベンチマークでガクッと一貫して性能が落ちるのがわかるで。PRMで導く洗練は、固定データから高品質な推論パターンをうまく抽出してくれるんやけど、結局それは事前に集めたサンプルの分布に縛られた教師あり学習なんよ。せやから、モデルが新しい状況に対応する力が足りひんねん。その後のプロセス監督付き強化学習段階がこの弱点を補ってくれて、オンポリシーで探索できるようになるから、モデルが環境と積極的にやりとりして、オフラインデータセットの範囲を超えた高報酬の推論軌跡を自分で見つけられるようになるんや。
図4:ProRAGの学習曲線をGRPOベースラインと洗練なしバージョン(w/o Refinement)と比較したやつやで。
### 4.6 検索の影響
このセクションでは、検索するドキュメントの数と検索ステップの数を変えたときにProRAGがどう変わるか調べて、コンテキストの使い方と計画の適応力を評価したで。
#### 4.6.1 検索ドキュメント数の影響
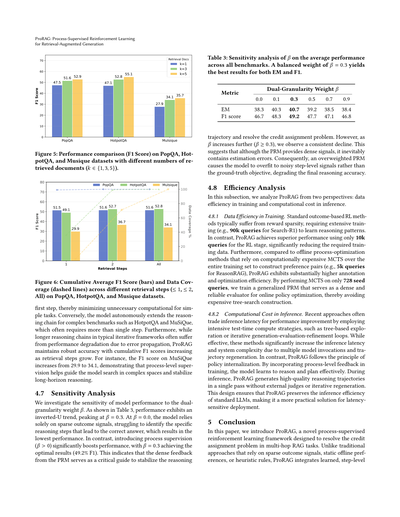
図5見てみ、検索コンテキスト(k)を増やしたときの性能アップは、タスクの複雑さとめっちゃ相関してるんよ。単発の質問に答えるPopQAデータセットでは、kを増やしても性能曲線が早めに頭打ちになるねん。これは事実を思い出すだけなら、だいたい関連文書1個あれば十分ってことやな。注目すべきは、k=5にしても性能が下がらへんこと。これは関係ない文書のノイズに対してめっちゃ頑丈やってことを示してるで。逆に、複雑なマルチホップベンチマークのMuSiQueはコンテキストサイズにかなり敏感で、kを3に増やしたらF1スコアが6.2ポイントも跳ね上がるんや。これが示唆してるのは、コンテキストウィンドウを狭くしすぎる(k=1)と、推論に必要な情報が足りへんボトルネックになってまうってことやな。複数のドキュメント渡すことで、ProRAGは重要な証拠をうまく見つけられるようになって、長い依存関係を解決するのに超大事なんや。
#### 4.6.2 検索ステップ数の影響
図6は検索ステップごとの累積平均F1スコアとデータカバレッジを示してて、ProRAGの動的な計画能力がようわかるで。データカバレッジの曲線見たら、適応パターンがはっきり違うのがわかるねん。PopQAのクエリはほぼ100%が最初の
訓練ステップ 結果報酬 ProRAG(フル) w/o Refinement GRPOベースライン
---
## Page 9
[](/attach/c6e9c1e9c6079bbbbe6a151c39c28b1066ea8d5729dc904c2543a0645c2ba8a8_p009.png)
### 和訳
ProRAG: プロセス監視型強化学習を使った
検索拡張生成の話
図5: PopQA、HotpotQA、Musiqueっていうデータセットで、取ってくる文書の数(k=1、3、5)を変えたときのF1スコアの比較やで。
図6: PopQA、HotpotQA、Musiqueで、検索ステップごと(1回以下、2回以下、全部)の累積平均F1スコア(棒グラフ)とデータカバレッジ(点線)を見せとるで。
最初の1ステップ目で済ますことで、簡単なタスクには余計な計算せんで済むようになっとるねん。逆に、HotpotQAとかMuSiQueみたいな難しいベンチマークやと、モデルが自分で判断して推論のチェーンを長くしていくんよ。普通は1回じゃ足りひんからな。ほんで、普通の繰り返し型フレームワークやと、推論チェーンが長なったらエラーが伝播して性能落ちがちやねんけど、ProRAGはめっちゃ安定した精度を保っとって、検索ステップが増えるほど累積F1スコアが上がっていくねん。例えばMuSiQueやと、F1スコアが29.9から34.1まで上がるんよ。これって、プロセスレベルの監視がモデルの探索をうまいこと導いて、長い推論でも安定させてくれとるってことやな。
4.7 感度分析
二重粒度の重み𝛽に対してモデルの性能がどんだけ敏感かを調べたで。表3見てもらったらわかるけど、性能は逆U字型のトレンドを示して、𝛽=0.3でピークになるねん。𝛽=0.0のときは、モデルは疎な結果シグナルだけに頼ることになって、どの推論ステップが正解に繋がったんか特定するのに苦労するから、一番低い性能になってまうねん。それに対して、プロセス監視を入れる(𝛽>0)と性能がめっちゃ上がって、𝛽=0.3で最高の結果(F1が49.2%)になるんよ。これはPRM(プロセス報酬モデル)からの密なフィードバックが、推論の軌道を安定させて、どのステップが効いたんかっていう貢献度割り当て問題を解決する重要なガイドになっとるってことやねん。でもな、𝛽がもっと上がっていく(𝛽≥0.3)と、一貫して性能が下がっていくのが見られるんよ。これが何を意味するかっていうと、PRMは密なシグナルを出してくれるけど、どうしても推定誤差が含まれてまうねん。せやから、PRMの重みを大きくしすぎると、モデルがノイズの多いステップレベルのシグナルに過学習してもうて、本来の正解目標じゃなくて、最終的な推論精度が落ちてまうってわけや。
表3: 全ベンチマークの平均性能に対する𝛽の感度分析やで。バランスのとれた重み𝛽=0.3がEMとF1の両方で一番ええ結果出すねん。
| 指標 | 二重粒度の重み𝛽 |
|------|----------------|
| | 0.0 | 0.1 | 0.3 | 0.5 | 0.7 | 0.9 |
| EM | 38.3 | 40.3 | 40.7 | 39.2 | 38.5 | 38.4 |
| F1スコア | 46.7 | 48.3 | 49.2 | 47.7 | 47.1 | 46.8 |
4.8 効率性分析
このセクションでは、ProRAGを2つの観点から分析するで:訓練時のデータ効率と推論時の計算コストや。
4.8.1 訓練時のデータ効率
標準的な結果ベースのRL手法は、報酬が疎やから、推論パターンを学ぶのにめっちゃ大量の訓練が必要になるねん(例えばSearch-R1は9万クエリとか)。それに対してProRAGは、RLステージでたった1万クエリで優れた性能を達成して、必要な訓練データを大幅に減らしとるんよ。さらに、オフラインのプロセス最適化手法みたいに、訓練セット全体にわたって計算コストの高いMCTS(モンテカルロ木探索)を実行して選好ペアを作る方法(例えばReasonRAGは5千クエリ使う)と比べると、ProRAGはアノテーションと最適化の効率がめっちゃ高いねん。たった728個のシードクエリでMCTSをやるだけで、汎化されたPRMを訓練できて、それがオンラインのポリシー最適化のための密で信頼性の高い評価器として機能するから、高コストな木探索の構築を避けられるってわけや。
4.8.2 推論時の計算コスト
最近のアプローチは、木ベースの探索とか、生成→評価→改良を繰り返すループみたいな、テスト時の計算をめっちゃ使う戦略で性能向上を狙うことが多いねん。効果はあるんやけど、モデルを何回も呼び出したり軌道を再生成したりするから、推論の遅延とシステムの複雑さがめっちゃ増えてまうんよ。それに対してProRAGは、ポリシーの内在化っていう原則に従っとるねん。訓練時にプロセスレベルのフィードバックを取り入れることで、モデルが効果的に推論して計画する方法を学ぶんよ。推論時には、ProRAGは外部の判定器も繰り返しの再生成もなしに、1回のパスで高品質な推論軌道を生成するねん。この設計のおかげで、ProRAGは標準的なLLMの推論効率を保ちつつ、遅延に敏感なデプロイメントにも実用的な解決策になっとるわけや。
5 結論
この論文では、マルチホップRAGタスクにおける貢献度割り当て問題を解決するために設計された、新しいプロセス監視型強化学習フレームワークのProRAGを紹介したで。疎な結果シグナルとか、静的なオフライン選好とか、ヒューリスティックなルールに頼る従来のアプローチとは違って、ProRAGは学習されたステップレベルの
---
## Page 10
[](/attach/c6e9c1e9c6079bbbbe6a151c39c28b1066ea8d5729dc904c2543a0645c2ba8a8_p010.png)
### 和訳
オンラインの最適化ループに直接プロセス監視を組み込むんや。これがめっちゃ効くねん。「プロセス幻覚」っていう、モデルが間違った推論とか無駄な検索しながらもなぜか正解にたどり着いちゃう現象があるんやけど、これを効果的に抑え込めるわけや。
モンテカルロ木探索っていう手法を使って、質の高いプロセス報酬モデルを作るねん。で、二段階の粒度でアドバンテージを測る仕組みを使うことで、途中の一つ一つの行動に対してめっちゃ細かいフィードバックができるようになるんや。これでモデルが「ちゃんとした論理的な推論」と「たまたまうまくいっただけの見せかけの相関」を見分けられるようになるってわけやな。
5つの違うベンチマークで徹底的に実験したんやけど、ProRAGは全体的にめっちゃええ性能出してん。特に複雑で長い推論が必要なタスクでは抜群やったわ。さらに分析してわかったんは、ProRAGはデータ効率がめっちゃ高いってことと、推論能力をポリシー自体に内蔵させることで推論の遅延を低く抑えられるってこと。つまり実際に使うときも効率ええねん。
今後は、このプロセス監視のやり方をもっとダイナミックでオープンエンドな環境にも広げていって、自律システムの信頼性をさらに高めていきたいと思ってるで。
**参考文献**
[1] Akari Asaiら(2023年)Self-RAG:自己反省を通じて検索・生成・批評を学習する手法や。arXiv:2310.11511
[2] Yunfan Gaoら(2024年)大規模言語モデルのための検索拡張生成のサーベイ論文やで。arXiv:2312.10997
[3] Xinyan Guanら(2025年)DeepRAG:大規模言語モデルがステップバイステップで検索しながら考える手法や。arXiv:2502.01142
[4] Daya Guoら(2025年)DeepSeek-R1:強化学習で大規模言語モデルの推論を促進する研究やな。Nature誌に載っとる。doi:10.1038/s41586-025-09422-z
[5] Kelvin Guuら(2020年)REALM:検索拡張型言語モデルの事前学習についてや。arXiv:2002.08909
[6] Jie Heら(2025年)十分性から反省へ:大規模言語モデルの検索拡張推論における思考品質の強化学習ガイドやで。arXiv:2507.22716
[7] Xanh Hoら(2020年)推論ステップを包括的に評価するためのマルチホップQAデータセット構築についてや。arXiv:2011.01060
[8] Zhengbao Jiangら(2023年)能動的検索拡張生成の研究やな。arXiv:2305.06983
[9] Bowen Jinら(2025年)Search-R1:強化学習で大規模言語モデルに推論と検索エンジン活用を学習させる手法や。arXiv:2503.09516
[10][11] Vladimir Karpukhinら(2020年)オープンドメイン質問応答のための密検索パッセージについての論文や。arXiv:2004.04906
[12] Yongqi Lengら(2025年)DecEx-RAG:プロセス監視による意思決定と実行の最適化でエージェント型検索拡張生成を強化する研究やで。arXiv:2510.05691
[13] Patrick Lewisら(2020年)知識集約型NLPタスクのための検索拡張生成。NeurIPSの論文やな。
[14] Xiaoxi Liら(2025年)Search-o1:エージェント型検索で強化された大規模推論モデルや。arXiv:2501.05366
[15] Alex Mallenら(2023年)言語モデルを信用したらあかん時:パラメトリックメモリと非パラメトリックメモリの有効性調査やで。arXiv:2212.10511
[16] OpenAIら(2024年)GPT-4のテクニカルレポートや。arXiv:2303.08774
[17] Ofir Pressら(2023年)言語モデルにおける構成性ギャップの測定と縮小についてやな。arXiv:2210.03350
[18] John Schulmanら(2017年)PPO(近接方策最適化)アルゴリズムの論文や。強化学習の基本やで。arXiv:1707.06347
[19] Zhihong Shaoら(2023年)反復的な検索-生成シナジーで検索拡張型大規模言語モデルを強化する研究や。arXiv:2305.15294
[20] Zhihong Shaoら(2024年)DeepSeekMath:オープン言語モデルで数学的推論の限界を押し広げる研究やで。arXiv:2402.03300
[21] Huatong Songら(2025年)R1-Searcher:強化学習で大規模言語モデルの検索能力を引き出す手法や。arXiv:2503.05592
[22] Zhongxiang Sunら(2025年)ReARTeR:信頼できるプロセス報酬による検索拡張推論やな。arXiv:2501.07861
[23] Harsh Trivediら(2022年)MuSiQue:単一ホップ質問の組み合わせでマルチホップ質問を作るデータセットや。arXiv:2108.00573
[24] Harsh Trivediら(2023年)知識集約型マルチステップ質問のための検索とChain-of-Thought推論の交互実行についてやで。arXiv:2212.10509
[25] Leandro von Werraら(2020年)TRL:Transformer強化学習ライブラリや。GitHubで公開されとる。
[26] Junlin Wangら(2025年)SIRAG:プロセス監視型マルチエージェントフレームワークで安定的かつ解釈可能なRAGを目指す研究や。arXiv:2509.18167
[27] Liang Wangら(2022年)弱教師あり対照学習による事前学習でテキスト埋め込みを作る研究やな。arXiv:2212.03533
[28] Ziliang Wangら(2025年)StepSearch:ステップごとの近接方策最適化で大規模言語モデルの検索能力を発火させる手法や。arXiv:2505.15107
[29] Tongyu Wenら(2026年)SmartSearch:検索エージェントのためのプロセス報酬ガイド付きクエリ改善についてやで。arXiv:2601.04888
---
## Page 11
[](/attach/c6e9c1e9c6079bbbbe6a151c39c28b1066ea8d5729dc904c2543a0645c2ba8a8_p011.png)
### 和訳
ProRAG:検索強化生成のための
プロセス教師あり強化学習
[34] Zhilin Yangさんたち。2018年。HotpotQA:いろんなタイプの説明できるマルチホップ質問応答のためのデータセットやねん。これな、複数の情報源をたどって答えを導き出すような、ちょっと複雑な質問に答えるためのデータセットなんよ。arXiv:1809.09600 [cs.CL] https://arxiv.org/abs/1809.09600
[35] Shunyu Yaoさんたち。2023年。ReAct:言語モデルで推論と行動をうまいこと組み合わせる手法やで。なんでかっていうと、AIが考えるだけやなくて、実際にアクション起こしながら問題解決できるようにしたってわけやな。めっちゃ画期的やねん。arXiv:2210.03629 [cs.CL] https://arxiv.org/abs/2210.03629
[36] Tianhua Zhangさんたち。2026年。TreePS-RAG:エージェント型RAGの強化学習に木構造ベースのプロセス教師を使う手法やねん。木みたいに枝分かれする構造で、AIの学習過程をしっかり監督するっちゅう話やな。arXiv:2601.06922 [cs.CL] https://arxiv.org/abs/2601.06922
[37] Wenlin Zhangさんたち。2025年。プロセス報酬と結果報酬:エージェント型RAGの強化学習にはどっちがええんやろ?っていう研究やねん。ほんまに、途中経過を褒めるんがええのか、最終結果だけ見て褒めるんがええのか、めっちゃ大事な問いかけやで。arXiv:2505.14069 [cs.IR] https://arxiv.org/abs/2505.14069
[38] Penghao Zhaoさんたち。2024年。AI生成コンテンツのための検索強化生成:サーベイ論文やねん。RAGっちゅう技術の全体像をまとめてくれてる、めっちゃありがたい総説やで。arXiv preprint arXiv:2402.19473 (2024).
---
![]()
1 / 1
100%