<<
fcomp-7-1590632.pdf

---
## Page 1
[](/attach/be35480839ed8df24385cd047d83444c3a9842de8dfb102c573c6610802d06cc_p001.png)
### 和訳
オープンアクセス
**編集者**
Xinqing Xiao
中国農業大学(中国)
**査読者**
Leonardo Nascimento
リオグランデ・ド・スル連邦研究所(ブラジル)
Joel Oduro-Afriyie
OriGen AI(アメリカ)
**連絡先**
Yong Zhao
yong.zhao@scupi.cn
受付日:2025年3月10日
承認日:2025年6月25日
公開日:2025年7月16日
**引用情報**
Cai L, Yu C, Kang Y, Fu Y, Zhang H and Zhao Y (2025) ナレッジグラフと大規模言語モデルの融合における実践、機会、課題。Front. Comput. Sci. 7:1590632. doi: 10.3389/fcomp.2025.1590632
**著作権**
© 2025 Cai, Yu, Kang, Fu, Zhang and Zhao.
本論文はクリエイティブ・コモンズ表示ライセンス(CC BY)の下で配布されるオープンアクセス論文やねん。他のフォーラムでの使用、配布、複製は、原著者と著作権者がクレジットされ、本誌の原出版物が学術的慣行に従って引用される場合に限り許可されるで。これらの条項に準拠しない使用、配布、複製は認められへんからな。
種別:レビュー
公開日:2025年7月16日
DOI: 10.3389/fcomp.2025.1590632
---
# ナレッジグラフと大規模言語モデルの融合における実践、機会、課題
Linyue Cai¹, Chaojia Yu¹, Yongqi Kang¹, Yu Fu¹, Heng Zhang², Yong Zhao¹*
¹四川大学ピッツバーグ学院コンピュータサイエンス学部(中国・成都)
²浙江財経大学東方学院情報・人工知能研究所コンピュータサイエンス学部(中国・嘉興)
---
## 要旨
ナレッジグラフ(KG)と大規模言語モデル(LLM)を組み合わせるっちゅうのは、それぞれの強みをうまいこと活かして、両方の技術が抱えとる弱点をカバーしようって話やねん。この論文では、統合の実践方法とか、チャンスとか、課題について掘り下げていくで。特に3つの戦略に注目しとって、まずKGでLLMをパワーアップさせる方法(KEL)、次にLLMでKGを強化する方法(LEK)、ほんで両方を協力させる方法(LKC)やな。この研究では、これらの方法論をレビューして、知識の表現とか推論とか質問応答をどんだけ良くできるかっていうポテンシャルを明らかにしとるで。知識の獲得とかリアルタイム更新みたいな重要な課題を網羅的にまとめて分類して、将来の研究に役立つ方向性を示しとるねん。新しい技術とかアプリケーションについても議論して、KGとLLMの相乗効果をもっと高めようって話もしとるで。全体的に見て、この論文は今のKGとLLM融合の全体像と、いろんな分野でどんだけ革新的な可能性があるかをバッチリまとめた内容になっとるわ。
**キーワード**:大規模言語モデル、ナレッジグラフ、KEL、LEK、LKC
---
## 1. はじめに
大規模言語モデル(LLM)っちゅうのは、めっちゃ大量のデータで学習されとって、いろんな自然言語処理(NLP)タスクでえげつない進歩を見せとんねん。モデルのサイズが爆発的にデカくなったおかげで、LLMは「創発能力」っていう新しい力を手に入れて、どんどん複雑な問題にも対応できるようになってきたわけや。何十億ものパラメータを持つめっちゃ洗練されたLLMは、教育支援とかコード生成とかレコメンドシステムとか、現実世界の複雑なタスクをこなす力を見せつけとるねん。
せやけど、どんだけ成功してきたとはいえ、LLMにはまだ結構な批判があるんよな。特に事実に関する情報の扱いがイマイチっていう点でな。
LLMは学習データから事実を記憶することにめっちゃ頼っとるんやけど、研究によると、これらの事実を正確に引き出すのに苦労することが多いって分かっとんねん。これが「ハルシネーション(幻覚)」って呼ばれる現象につながるわけや。なんでかっていうと、LLMがもっともらしく聞こえる回答を生成するんやけど、実は事実と違うことを言うてしまうことがあんねん。Zhang et al.(2024b)はCoderEvalデータセットで6つの主要なLLMを使って実験して、このハルシネーション現象を詳しく説明して、いろんなモデルでどう分布しとるかを分析しとるで。
この事実の不整合問題は、デリケートなアプリケーションではほんまに困るねん。しかもLLMは「ブラックボックス」やから、中身が見えへんって批判されることも多いんよな(Liao and Vaughan, 2023)。何十億ものパラメータの中にエンコードされた知識は暗黙的で、解釈したり検証したりするのがめっちゃ難しいねん。
---
Frontiers in Computer Science 01 frontiersin.org
---
## Page 2
[](/attach/be35480839ed8df24385cd047d83444c3a9842de8dfb102c573c6610802d06cc_p002.png)
### 和訳
Cai et al.
10.3389/fcomp.2025.1590632
こういう問題をなんとかするええ方法があってな、それがナレッジグラフ(KG)と大規模言語モデル(LLM)を組み合わせるっていう戦略やねん。KGっていうのは事実に基づく知識をきっちり整理して保存してくれるもんで、普通は「頭の実体」「関係」「尻尾の実体」っていう3つ組の形で情報持ってんねん。で、昔からその正確さと「なんでそうなったか」がわかりやすいところが重宝されてきたんや。このKGを取り入れることで、LLMは信頼できてかつ理解しやすい明確な知識っていう土台の恩恵を受けられるわけ。それに加えて、KGは記号を使った推論がめっちゃ得意で、新しい知識が見つかったら進化していくから、特定の分野に特化した情報を提供するのにぴったりなんよ。
ここ数年、LLMとKGを一緒に使おうっていう動きにめっちゃ注目が集まってきてんねん。なんでかっていうと、研究者とか実務家の人らが、この2つがお互いの弱点を補い合える関係やって気づいたからや。一方では、KGを使ってLLMの事前学習とか推論の段階で外部知識を注入できて、事実に基づいた土台を追加して解釈しやすさも上がるんや。もう一方では、LLMがKGにとって重要な作業、例えばKGの埋め込み、補完、構築、質問応答とかをこなせることが証明されてて、KG全体の品質と使い勝手を向上させてくれるんよ。LLMとKGがお互いを強化し合う協力アプローチは、データ駆動型の学習と構造化された知識の両方のええとこ取りして、知識表現と推論を進歩させるめっちゃ大きな可能性を秘めてるんや。既存のサーベイ論文のほとんどは、KGでLLMを強化する(KEL)ことに主に焦点当ててるって俺らは気づいたんよ。やから、この2つを統合する他の可能性も探ってみようと思ったんや。LLMがKG関連のタスクにどう貢献できるかとか、両者のコラボレーションとかな。
俺らの主な貢献をまとめるとこんな感じや:
1. 分類とレビュー。LLMとKGを統合する研究について、詳細な分類と新しい体系を提示するで。各カテゴリーで、異なる統合戦略とタスクの観点から研究をレビューして、それぞれのフレームワークについてより深い洞察を提供するんや。
2. 最新の進歩のカバー。LLMとKG両方の先進的な技術をカバーしてるで。
3. 課題と将来の方向性のまとめ:既存研究の課題を浮き彫りにして、将来有望な研究の方向性をいくつか提示するわ。
この論文の残りはこんな構成になってるで。セクションIIでまずLLMとKGの背景を説明するわ。セクションIIIではLLM強化KGの分類と課題を提示するで。セクションIVではKG強化LLMアプローチの分類と課題を提示するんや。セクションVではLLMとKGの協調の分類を提示するで。セクションVIIではいくつかのアプリケーションについて議論するわ。最後に、セクションVIIIでこの論文を締めくくるで。
LLMはトランスフォーマー(Vaswani, 2017)みたいなアーキテクチャを使ってて、これが文脈を処理して長距離の依存関係を捉えてくれるから、人間っぽいテキストの生成ができるようになってんねん。LLMの発展は、昔ながらのルールベースとか統計モデル、例えばn-gram(Brown et al., 1992)とか隠れマルコフモデル(HMM)(Rabiner and Juang, 1986)から始まって、リカレントニューラルネットワーク(RNN)とか長短期記憶(LSTM)ネットワーク(Sherstinsky, 2020)を経て進化してきたんや。RNNとLSTMは連続データの処理には役立ったんやけど、長距離の依存関係を扱うのに限界があったから、トランスフォーマーアーキテクチャが生まれて、今ではほとんどの最新LLMの基盤になってるんよ。
2.1.1 エンコーダーのみのモデル
エンコーダーのみのモデルは、双方向アテンションを使って入力を理解することに主に焦点当ててて、テキストの深い理解が必要なタスク、例えば分類とか固有表現認識とか読解とかにぴったりなんや。例えば、BERT、RoBERTa、ALBERTみたいなモデルは、マスク言語モデリングと次文予測に頼ってて、質問応答、感情分析、固有表現認識とか色んなNLPタスクに広く使われてるで。
2.1.2 デコーダーのみのモデル
デコーダーのみのモデルは、単方向アテンションを使って文とか段落みたいなシーケンスを生成するのがめっちゃ得意なんや。これらのモデルは自己回帰型であることが多くて、以前に生成したトークンに基づいて次のトークンを予測するんよ。GPT、OPT、LLaMAみたいなトランスフォーマーモデルはデコーダーのみのアーキテクチャを採用してて、チャットボット、テキスト要約、コード生成みたいなテキスト生成タスクで高いパフォーマンスを発揮してるわ。
2.1.3 エンコーダー・デコーダーモデル
エンコーダー・デコーダーモデル(シーケンス・トゥ・シーケンスモデルとも呼ばれるで)は、あるシーケンスを別のシーケンスに変換するように設計されてて、翻訳、要約、言い換えみたいなタスクに特に効果的なんや。これらのモデルはエンコーダーで入力シーケンスを処理して、デコーダーで出力シーケンスを生成するんやけど、この2つを繋ぐためにクロスアテンションを使うことが多いで。T5とかBARTみたいなエンコーダー・デコーダーモデルは、機械翻訳、テキスト要約、質問応答、対話システムみたいなタスクに広く使われてるんや。
2 背景
2.1 大規模言語モデル
大規模言語モデル(LLM)は、自然言語処理(NLP)の分野でめっちゃ大きな飛躍を表してて、主にディープラーニング技術のおかげなんや。これらのモデルは膨大な量のテキストデータで訓練されてて、様々なタスクで人間の言語を理解して、生成して、操作できるようになってるんよ。
2.2 ナレッジグラフ
ナレッジグラフ(KG)は知識の構造化された表現で、実体間の関係を浮き彫りにするように情報を整理するもんや。この構造のおかげで、機械がデータ間のつながりを理解して活用しやすくなるんよ。KGは、より良いセマンティック検索、データ統合、質問応答や推薦システムみたいなAIアプリケーションを実現するのに重要な役割を果たしてるで。
Frontiers in Computer Science
02
frontiersin.org
---
## Page 3
[](/attach/be35480839ed8df24385cd047d83444c3a9842de8dfb102c573c6610802d06cc_p003.png)
### 和訳
Caiらの研究やな
10.3389/fcomp.2025.1590632
2.2.1 知識グラフの分類について
知識グラフ(KG)っていうのは、中身のパターンによっていろんな種類に分けられるねん。百科事典タイプ、常識タイプ、特定分野タイプ、それからマルチモーダルタイプがあるで。
百科事典タイプの知識グラフは、まさに百科事典みたいに、いろんな分野の一般的な知識を幅広くカバーしてるやつやねん。
常識タイプの知識グラフは、日常生活で使う「当たり前の知識」を集めたもんで、AIが人間みたいに考えられるようになるために、めっちゃ大事な役割を果たしてるんや。
特定分野タイプの知識グラフは、医療とか金融とか法律とか、特定の専門分野に特化した知識をガッツリ集めたもんやな。
マルチモーダルタイプの知識グラフは、テキストだけやなくて画像とか動画とか、いろんな種類のデータを組み合わせてて、複数のメディアにまたがる知識を総合的に理解できるようになってるねん。
2.2.2 知識グラフの仕組み
知識グラフの重要な概念をざっくり説明するで:
1. エンティティ(ノード):人とか場所とか組織とかイベントとか、主要な「モノ」や「概念」のことで、図でいうと「点」として表されるやつやな。
2. リレーションシップ(エッジ):エンティティ同士の「つながり」を表すもんで、どういう関係があるかを示してるねん。
3. 属性:エンティティの特徴とか性質のことで、追加情報を教えてくれるもんや。
4. トリプル:知識グラフの中の「事実」を表す形式で、「主語-述語-目的語」の3つ組で表現するねん。例えば「バラク・オバマはハワイで生まれた」みたいな感じや。
5. オントロジー:知識グラフの設計図みたいなもんで、エンティティとかリレーションシップとか属性をきちんと整理して、一貫性を保つための枠組みやねん。
2.3 大規模言語モデルと知識グラフの長所と短所
大規模言語モデル(LLM)の良いところ:
- いろんなタスクに対応できる(文章生成、要約、質問応答とかな)
- 文脈をしっかり理解して、まとまりのある自然な文章を作れる
- スケーラブルで、いろんな種類の入力に対応できる
- ゼロショット学習とかフューショット学習ができる(つまり、例が少なくても学習できるってことや)
大規模言語モデルの悪いところ:
- 明確な知識構造がないから、ハルシネーション(でっち上げ)とか事実と違うこと言うてまうことがある
- データも計算パワーもめっちゃ必要で、コストかかるし環境にも負担かかる
- 中身がどうなってるかわかりにくい「ブラックボックス」問題がある
- 何段階もの論理が必要な複雑な推論は苦手
- バイアスとか倫理的な問題が出てくる可能性もある
知識グラフ(KG)の良いところ:
- 知識を構造化してはっきり表現できるから、機械が理解しやすい
- 推論とかクエリ(検索)の能力が高くて、何段階も経由する複雑な質問とか論理的推論にも対応できる
- 専門分野での精度がめっちゃ高い
- 一貫性があって、いろんなアプリケーションで使い回せる
- 説明しやすいから、透明性が大事な意思決定にはほんまに向いてる
知識グラフの悪いところ:
- 作るのがめっちゃ大変で、人の手で整理せなあかんし専門知識も必要
- 大きくなるとスケーラビリティ(拡張性)の問題が出てくる
- 構造化されてないデータと組み合わせるのが難しい
- カバーできる知識に限界がある
2.4 LLMが知識グラフの限界をどう補うか
1. 知識のカバー範囲を広げる:大規模モデルは意味を理解する力とか文章を生成する力を使って知識を抽出して、知識抽出の精度とカバー範囲を向上させるねん。
2. 構築コストを下げる:大規模モデルはテキストや基本的な知識をより深く理解できるから、暗黙的な知識とか複雑な知識、マルチモーダルな知識も抽出できて、グラフを作るコストを減らせるんや。
3. 出力の質と種類を改善:大規模モデルは知識グラフの出力を改善して、より合理的で、まとまりがあって、創造的な内容を生成する手助けをしてくれる。
4. 理解を促進:大規模モデルは知識グラフの出力が、構造化されてないデータや情報をうまく統合・分類できるように助けてくれるねん。
2.5 知識グラフベースのレトロフィッティングがLLMの限界をどう直すか
1. ハルシネーションを減らす:KGR(知識グラフベースのレトロフィッティング)は知識グラフを使って、LLMが出した回答を検証して修正するねん。LLMの出力を知識グラフのデータと照らし合わせることで、回答が検証済みの知識とちゃんと一致してるか確認するんや。
2. 推論能力を向上:KGRはLLMの最初の下書きから主張を抽出して、連鎖的な検証を行うねん。これによって、LLMが構造化された知識を使って自分の推論プロセスを検証できるようになるんや。
3. リアルタイムの知識統合:KGRは知識グラフから最新の知識を自動的に取り込んでくれて、LLMが最新の事実情報にアクセスできるようになるねん。これで回答の信頼性と関連性がグッと上がるんや。
4. 一貫性と正確性の向上:KGRは構造化された検証プロセスを通じて、回答を生成するときに文脈に合った事実を確保して、全体的なまとまりと正確性を改善するねん。
5. 客観的な事実検証:KGRは知識グラフを使ってより客観的な事実の情報源を提供して、LLMの学習データに含まれるバイアスを相殺する手助けをしてくれるんや。
Frontiers in Computer Science
03
frontiersin.org
---
## Page 4
[](/attach/be35480839ed8df24385cd047d83444c3a9842de8dfb102c573c6610802d06cc_p004.png)
### 和訳
Caiたちの研究な。
10.3389/fcomp.2025.1590632
データセットの話やねんけど、オープンソースで使えるかどうかも選ぶ時の基準にしてん。これ、今後の研究がしやすくなるようにっていう配慮やな。図4見てもらったら、いろんなタスクごとの重要な研究を発表年順に整理してあるで。
3.1 LLMでナレッジグラフを作る話
ナレッジグラフ構築っていうのは何かっていうとな、整理されたデータとかバラバラのデータから、エンティティ(実体)とか関係性とかイベントを引っ張り出して、ちゃんと構造化された知識のネットワークを作ることやねん。
図5見たらわかるけど、LLMがナレッジグラフ構築でどんな役割果たしてるか示してあるで。エンティティとか関係性とかイベントの抽出・生成、あとエンティティリンキングとか共参照解決みたいなタスクも含まれてるねん。抽出と生成のプロセスでは、LLMはプロンプトとしても生成器としても働いて、構造化された知識を作るのを手伝ってくれるわけや。エンティティリンキングでは、LLMがプロンプトとカテゴライザーの役割して、エンティティを外部の知識ソースとつなげてくれる。共参照解決では、LLMがセレクターとサマライザーとして機能して、いろんな文脈で同じエンティティを指してる参照を解決してくれんねん。こういう統合によって、ナレッジグラフ構築の精度と効率がめっちゃ上がって、包括的で相互につながったナレッジグラフが作れるようになるんや。
3.1.1 固有表現認識
固有表現認識(NER)っていうのはな、整理されてないデータの中からエンティティを見つけ出して分類する作業やねん。LLMは言語と文脈をめっちゃ深く理解してるから、難しい場面でもエンティティの認識と分類がうまくできるようになってNERが改善されるんや。GPT-NER(Wang S.たち、2023)は、LLMとNERの間のギャップを埋めるために、シーケンスラベリングタスクをテキスト生成タスクに変換して、特別なマーカー使ってエンティティを特定してるねん。TOPT(Zhangたち、2024a)はタスク指向の事前学習モデルで、LLM使ってタスクに特化した知識コーパスを生成して、ドメインへの適応力とNERの感度を上げてるんや。Graphusion(Yangたち、2024d)はエンティティのマージとか衝突解決とか新しいトリプルの発見を組み合わせて、エンティティ抽出にグローバルな視点を提供してて、フリーテキスト入力を使う時の課題に対処してるで。SF-GPT(Sunたち、2025)は知識トリプル抽出に3つのモジュール使ってて、結果をフィルタリングするEntity Extraction Filter、意味の豊かさを高めるEntity Alignment Generator、ノイズを減らすSelf-Fusion Subgraph戦略があるねん。
3.1.2 関係抽出と生成
関係抽出っていうのは、テキストの中のエンティティ間の意味的な関係を特定して分類するプロセスやねん。もうすでにいろんな研究がLLM使ってこのプロセスを強化してるで。BertNet(Haoたち、2022)は検索と再スコアリングの仕組みを作って、最小限の関係定義で広いエンティティペアの空間を効果的に検索できるようにして、効率と精度の両方を上げてるねん。CDLM(Cacialurたち、2021)は動的なグローバルアテンション機構を使って、長距離トランスフォーマーを改良して、マスクされたトークンを予測する時に入力全体にアクセスできるようにしてるんや。DREEAM(Maたち、2023)はメモリ効率のええアプローチを導入して、エビデンス情報を監督信号として使って、アテンションモジュールがエビデンスに高い重みを割り当てるように誘導してるで。
図1
LLMとナレッジグラフの相補的な関係
LLMとナレッジグラフの相補的な関係が図1に示されてて、この2つを統合したらAIシステムがどう強化されるかがわかるようになってるで。
2.6 ナレッジグラフとLLMの融合のロードマップ
図2で示されてる技術的アプローチは、ナレッジグラフとLLMの統合を説明してて、構造化された情報とLLMの推論・言語生成能力を組み合わせることでシステム全体が強化されるんや。この統合によって、いろんなタスクで精度とか文脈認識とか推論効率が向上するねん。システムが進化していくにつれて、ナレッジグラフとLLMの相乗効果で継続的に改善されて、複雑なマルチモーダルアプリケーションもより効果的に扱えるようになるんや。
この統合をさらに進めるために、3つの融合戦略があるで:LLM強化ナレッジグラフ(LEK)、ナレッジグラフ強化LLM(KEL)、LLMとナレッジグラフの協調(LKC)や。
3 LLM強化ナレッジグラフ
ナレッジグラフはエンティティと関係を構造化されたフォーマットでつなげて、質問応答とかレコメンデーションシステムとかウェブ検索みたいなアプリケーションをサポートしてるねん。でもな、従来のナレッジグラフには不完全さとかテキストデータの活用不足みたいな課題があったんや。最近の研究ではLLMを統合して、テキストデータを取り込んでいろんなタスクでナレッジグラフのパフォーマンスを改善することで、これらの問題に対処してるで。図3に示されてる通りやな。
こういうタスク特化の進歩を踏まえて、このセクションで調査した文献は、2019年以降のLLM強化ナレッジグラフ技術の急速な進化を反映してて、特に2023〜2025年のブレイクスルーに重点置いてるねん。ナレッジグラフの構築、埋め込み、推論における根本的な課題にLLMの革新的な統合で取り組んでる研究を優先してて、ハイブリッドアーキテクチャとかプロンプトベースの技術の導入みたいな方法論的な新規性と、標準データセットでのベンチマークを通じて実証されたインパクトに基づいて論文を評価してるんや。
Frontiers in Computer Science
04
frontiersin.org
---
## Page 5
[](/attach/be35480839ed8df24385cd047d83444c3a9842de8dfb102c573c6610802d06cc_p005.png)
### 和訳
Caiさんらの研究やで。
10.3389/fcomp.2025.1590632
**図2**
知識グラフ(KG)と大規模言語モデル(LLM)を融合させるまでのロードマップやねん。
**図3**
LLMで強化された知識グラフ(LEK)のロードマップやで。
## 3.1.3 イベント抽出と生成
イベント抽出っちゅうのは、テキストからイベントとそれに関連する情報を自動的に見つけ出す作業のことやねん。具体的には、トリガー(きっかけとなる言葉)、エンティティ(登場人物や組織など)、それから時間や場所みたいな重要な詳細情報を引っ張ってくるんや。これがEventKG(Gottschalk and Demidova, 2018)みたいなイベント知識グラフを作る土台になるわけやな。
EvIT(Tao et al., 2024)は、イベントに特化した指示チューニングでLLMを訓練して、ヒューリスティック(経験則ベース)な教師なし手法を使って、大規模なテキストデータからイベントの4つ組(イベント・主体・客体・関係みたいなセット)を掘り起こすんや。Chen R.ら(2024)は、LLMを専門家のアノテーター(ラベル付け係)として使って、文章からイベント情報を抽出して、ベースラインの分布に合わせた拡張データセットを作成してるで。STAR(Ma M. D. et al., 2024)は、めっちゃ少ない種データだけでLLMを使ってデータを合成する生成手法を提案してんねん。詳細な指示に従って目標構造(Y)と段落(X)を生成して、その後エラーを見つけ出して繰り返し改善することでデータの品質を上げていくっちゅうやり方やな。
## 3.1.4 エンティティリンキング
エンティティリンキング(EL)っていうのは、テキスト中の言及(メンション)を知識ベースの中の特定のエンティティと結びつける作業やねん。これやることで、テキストの理解や情報検索がめっちゃ強化されるんや。
ReFinED(Ayoola et al., 2022)は、きめ細かいエンティティタイプとエンティティの説明文を使って、効率的なエンドツーエンドのエンティティリンキングモデルを構築してて、他の大規模知識ベースにも汎用化できるようになってるで。ChatEL(Ding Y. et al., 2024)は、LLMを活用した3ステップのフレームワークを提案してんねん。候補エンティティを生成して、文脈情報を強化して、選択式フォーマットを取り入れることで効率的なエンティティリンキングを実現してるんや。UniMEL(Liu Q. et al., 2024)は、LLMを使ったマルチモーダル(テキストと画像の両方を扱える)エンティティリンキングのフレームワークを提案してるで。テキスト情報と視覚情報を統合してメンションとエンティティの表現を強化して、埋め込みベースの検索と候補の再ランキングでリンキング性能を向上させてんねん。
## 3.1.5 共参照解決
共参照解決っちゅうのは、テキスト中で同じエンティティを指してる異なる表現を特定して結びつける自然言語処理のタスクやねん。例えば「田中さん」と「彼」が同じ人を指してるって認識するようなもんや。
Zheng L.ら(2024)は、マルチモーダル共参照解決(MCR)におけるデータ不足と活用不足の問題に取り組むために、適応型マルチモーダルデータ拡張フレームワークを提案してるで。Minら(2024)は、文書横断イベント共参照解決(CDECR)のための協調的アプローチを提示してんねん。汎用LLMがイベントを要約して、タスク特化型の小規模言語モデルがイベント表現学習をさらに改善するっちゅう組み合わせや。Nathら(2024)は、イベントクラスタリングと知識精緻化のための原則ベースの手法を提案してて、現代の自己回帰型LLMが生成する自由テキスト推論(FTR)を活用してイベント共参照解決を改善してるんやで。
## 3.2 知識グラフ埋め込みにおけるLLM
知識グラフ埋め込み(KGE)っちゅうのは、知識グラフ内のエンティティと関係の低次元表現を学習することやねん。なんでかっていうと、元々のグラフ構造のままやと計算が大変やから、コンパクトなベクトル(数値の並び)に変換して扱いやすくするんや。このプロセスは...
Frontiers in Computer Science
05
frontiersin.org
---
## Page 6
[](/attach/be35480839ed8df24385cd047d83444c3a9842de8dfb102c573c6610802d06cc_p006.png)
### 和訳
Caiさんたちの研究やねん。
10.3389/fcomp.2025.1590632
**図4**
LEK(LLMで知識グラフを強化する研究)の主要な研究をタスク別と発表年でまとめた図やで。
kNN-KGE(Wang P.さんたち、2023年)っていうのは、事前学習済みの言語モデルを使って、k個の最近傍(一番近いやつら)で実体の分布を線形補間するんや。これ、実体の埋め込み表現と知識ストレージの間の距離をもとに計算してんねん。
### 3.3 LLMを使った知識グラフの整列
実体の整列っていうのは、要するに別々の知識グラフにある「同じものを表してるノード」を見つけてマッチングさせる作業のことやねん。
AutoAlign(Zhang R.さんたち、2023年)は、述語近接グラフっていうのを作って、知識グラフ間の述語(関係を表す部分やな)の類似性を捉えるんや。ほんでTransE(Bordesさんたち、2013年)を使って実体の埋め込みを計算して、違うグラフの実体を同じベクトル空間に整列させるわけや。
LLM-Align(Chen X.さんたち、2024年)は、ヒューリスティックな方法(経験則に基づくやり方やな)で重要な実体の属性と関係を選んで、実体のトリプル(主語-述語-目的語の3つ組)をLLMに入力して整列結果を推論するんや。ほんで複数回投票する仕組みを使って、ハルシネーション(LLMが嘘つくやつ)と位置バイアスを軽減してんねん。
あと、LLMEA(Yangさんたち、2024b)っていう方法もあって、これは実体埋め込みの類似性と編集距離を組み合わせて候補の整列を特定して、LLMの推論能力で整列結果を最適化するんやで。
### 3.4 LLMを使った知識グラフの補完
#### 3.4.1 プロンプトエンジニアリング
知識グラフ補完のためのプロンプトエンジニアリングっていうのは、入力するプロンプト(指示文)をうまく設計して、LLMに欠けてる情報を推論させて埋めさせることやねん。
**図5**
LLMがどうやって知識グラフの構築を強化するかの図やで。
まず実体と関係の表現から始まって、次にスコアリング関数の定義があって、最後に表現学習で締めくくるんや。埋め込みには主に2つのアプローチがあんねん:構造ベースと説明文ベースや。下の図6がLLMが知識グラフの埋め込みプロセスをどう強化するか示してるで。
Pretrain-KGE(Zhang Z.さんたち、2020年)は、どんな知識グラフ埋め込みモデルにも使える訓練フレームワークやねん。事前学習モデルからの世界知識を実体と関係の埋め込みに組み込んで、知識グラフ埋め込みモデルの性能を上げるんや。
LMKE(Wang X.さんたち、2022年)とzrLLM(Ding Z.さんたち、2024年)は、言語モデルを使って知識埋め込みを導出するんやけど、これによってロングテール実体(あんまり出てこないレアな実体やな)の表現を豊かにして、説明文ベースの方法の問題点に対処してんねん。
Frontiers in Computer Science
06
frontiersin.org
---
## Page 7
[](/attach/be35480839ed8df24385cd047d83444c3a9842de8dfb102c573c6610802d06cc_p007.png)
### 和訳
Cai et al.
10.3389/fcomp.2025.1590632
**図6**
LLMがどうやってKG(知識グラフ)の埋め込みをパワーアップさせるか、っていう話やねん。
知識グラフの一部分だけを使うアプローチがあってな、これがマルチホップ(何段階もジャンプする)リンク予測をめっちゃ強化してくれるねん。しかも、ゼロショット(学習データなしの)シナリオで、見たことないヒントにLLMがどう対応できるかっていう可能性も探ってるんや(例えば Shu et al., 2024)。これをベースにして、ProLINK(Wang K. et al., 2024)っていうのが出てきてん。これ、新しい事前学習とヒンティングのフレームワークで、追加の学習なしでどんな知識グラフでも少ないデータで帰納的推論ができるように設計されてるんや。同時に、TAGREAL(Jiang P. et al., 2023)は高品質なクエリヒントを自動で生成できて、大規模テキストコーパスから補助情報を引っ張ってきて、事前学習済み言語モデル(PLM)の中の知識を検出できるねん。PPTベースのTKGCモデル(Xu et al., 2023)はプロンプトベースの事前学習済み言語モデルを使ってて、マスキング戦略で学習することで、TKGC(時間的知識グラフ補完)タスクをマスクトークン予測に変換して、事前学習モデルの意味情報を活用してるんや。
**3.4.2 マスキング手法**
マスク言語モデル(MLM)っていうのは事前学習タスクの一種でな、テキスト中のいくつかの単語を[MASK]に置き換えて、モデルが文脈から一番ありそうな単語を予測する、っていうやつやねん。MEM-KGC(Choi et al., 2021)はこのプロセスを採用してて、尾部エンティティをマスクして、頭部エンティティと関係を文脈として使って、欠けてる尾部エンティティを予測するんや。これ、モデルが与えられた文脈からマスクされたトークンを予測するMLMとめっちゃ似てるやろ?これをさらに発展させて、Choi and Ko(2023)はマスクされた位置に適切なエンティティや関係を予測するようにしたんや。さらに、オープンワールドKGC(知識グラフ補完)での新しいエンティティ問題に対処するために、Choi and Ko(2023)は統一学習手法を提案してて、新しいエンティティのトークン埋め込みを置き換える埋め込みを生成するんや。
**3.4.3 マルチタスク学習**
マルチタスク学習っていうのは、リンク予測の性能を上げるのにめっちゃ効果的な方法で、すでにかなりの研究で関連モデルが構築されてるねん。Choi and Ko(2023)はマルチタスク学習ネットワーク(MT-DNN)アーキテクチャを提案してて、エンティティ説明予測(EDP)とエンティティタイプ予測(ITP)タスクを組み合わせて、同じ事前学習済み言語モデルとネットワーク層を共有して一緒に学習させるんや。同様に、LP-BERT(Li et al., 2023)モデルは3つのタスク、マスク言語モデル(MLM)、マスクエンティティモデル(MEM)、マスク関係モデル(MRM)でマルチタスク学習アプローチを採用してて、同じ入力フォーマットを共有して文脈情報と意味情報を同時に学習するねん。Kim et al.(2020)は関係予測と関連性ランキングタスクをリンク予測と統合して、モデルがKGの関係属性をより良く学習できるようにしてるんや。
**3.4.4 テキスト表現とグラフ埋め込みの統合**
ここ数年、テキストエンコーディングとグラフ埋め込みを組み合わせるのが、知識グラフ補完の有望なアプローチとして注目されてるねん。KG-BERT(Yao et al., 2019)は知識グラフのトリプル(三つ組)をテキストシーケンスとして扱って、BERTスタイルのアーキテクチャでエンコードするんや。同様に、SimKGC(Wang L. et al., 2022)はバッチ内、バッチ前、自己ネガティブを使った対照学習でエンティティ表現を強化してるねん。Shen et al.(2022)は言語モデルからの意味表現と構造的知識を確率的損失で最適化してるんや。別のアプローチとしてアテンション機構を統合するものがあって、MADLINK(Biswas et al., 2024)はアテンションベースのエンコーダ・デコーダを使ってKG構造とテキストエンティティ説明を組み合わせてるねん。Wang B. et al.(2021)はシャムネットワークを使って、組み合わせ爆発を避けながら構造化表現を学習してるんや。
**3.4.5 系列から系列への手法**
KG補完タスクの最近の進歩で、系列から系列(sequence-to-sequence)モデルを活用するのもめっちゃ有望やってわかってきてん。Saxena et al.(2022)はKGリンク予測を系列から系列タスクに変換して、従来のトリプルスコアリング手法を自己回帰デコーディングに置き換えることを提案してるんや。同様に、GenKGC(Xie et al., 2022)は事前学習済み言語モデルを活用して、KG補完タスクを系列から系列の生成タスクに変換してるねん。
**3.4.6 パス学習**
パス学習の核心的なアイデアは、エンティティ間の接続パスを基盤として扱うことで、明示的な
Frontiers in Computer Science
07
frontiersin.org
---
## Page 8
[](/attach/be35480839ed8df24385cd047d83444c3a9842de8dfb102c573c6610802d06cc_p008.png)
### 和訳
Caiさんたちの研究やねん。
10.3389/fcomp.2025.1590632
構造化されたナレッジグラフ(KG)の中にある情報とか、暗黙の関係性を扱う話やな。BERTRL(Zhaさんら、2022年)は事前学習済みの言語モデルを使って、関係のインスタンスと推論パスを訓練サンプルにしてファインチューニングするんや。KRST(Suさんら、2023年)はKGの中の信頼できるパスをエンコードして、正確なパスのクラスタリングができるようにして、帰納的な関係を予測するための多面的な説明を提供してくれるねん。
あと、KGの線形化のためにBFS戦略っていう幅優先探索を関係性バイアス付きで導入したり、KG再構築でマルチタスク学習を使うっていう貢献もあるねん。BDMG(Duさんら、2024年)は双方向マルチ粒度生成フレームワークを使って、対応する三項成分に基づいて文レベルの生成を何回もやって、最終的にグラフレベルのテキストを生成するんや。
### 3.5 LLMを使ったKGのエラー検証
KGのエラー検証っていうのは、KGの中のデータをチェックして、正確性と一貫性を確認するプロセスのことやねん。よくある方法の一つは、外部の知識ベースに対してLLMを使って検証することや。Zhang M.さんたち(2024年)はLLM強化埋め込みフレームワークを提案してて、まずグラフ構造の情報を使ってトリプレット(三つ組)の関係が成り立つかどうかを判定して、怪しいやつを選び出して、最後に言語モデルと組み合わせて検証するんや。KGValidator(Boylanさんら、2024年)は生成モデルを使ってKGを検証するための一貫性・検証フレームワークで、どんな外部知識ソースでも対応できるねん。
モデル自体を調整することでエラーを検証・修正する研究もあるで。KC-GenRe(Wang Y.さんら、2024年)はKGC(ナレッジグラフ補完)の再ランキングタスクを、生成型LLMで解く候補ランキング問題に変換するねん。あと、知識強化制約推論っていう方法で欠損問題にも対処してるんや。Mouさんたち(2024年)は自己省察モデルを提案してて、GPT-4が与えられた例で犯したエラーを振り返って、KGCの時に似たようなミスを避けるように言語的フィードバックを生成してモデルを導くねん。
### 3.6 LLMを使ったKGの推論
KGの推論っていうのは、グラフ構造と論理ルールを活用して、既存の知識から新しい情報や関係を推測することやねん。ReLMKG(CaoとLiu、2023年)は言語モデルを使って複雑な質問をエンコードして、異なる層からの出力を通じてグラフニューラルネットワーク(GNN)のメッセージ伝播と集約を導くんや。KG-Agent(Jiang J.さんら、2024年)はプログラミング言語を使ってKG上でのマルチホップ推論プロセスを設計して、ベースのLLMをファインチューニングするためのコードベースの指示データセットを合成するねん。KG-CoT(Zhaoさんら、2024年)は小規模な増分グラフ推論モデルをKG上での推論に使うんや。推論パスを生成する方法を使って、大規模LLM向けの高信頼度知識チェーンを作り出すねん。
### 3.7 LLMを使ったKGからテキストへの変換
KG-to-textっていうのは、構造化されたKGから自然言語テキストを生成する方法で、モデルを活用してグラフデータを一貫性のある情報豊かな文章にマッピングするんや。GAP(Colasさんら、2022年)はマスキング構造を使って近傍情報をキャプチャして、接続タイプに基づいてグラフアテンションの重みにバイアスをかける新しいタイプエンコーダを導入してるねん。KGPT(Chenさんら、2020年)は知識が豊富なテキストを生成する生成モデルと、ウェブからクロールした大規模な知識テキストコーパスでの事前学習パラダイムで構成されてて、タスクを実現するんや。Liさんたち(2021年)は、関係性バイアス付きのBFS戦略をKG線形化に導入したり、KG再構築でマルチタスク学習を採用したりして、めっちゃ大きな貢献をしたんや。
### 3.8 LLMを使ったKGの質問応答
ナレッジグラフ質問応答(KGQA)システムは、自然言語処理技術を活用して自然言語のクエリを構造化されたグラフクエリに変換するねん。Lukovnikovさんたち(2019年)のモデルやReLMKG(CaoとLiu、2023年)みたいな事前学習済みトランスフォーマーベースの方法は、言語モデルを使って質問とKG構造の間の意味的ギャップを埋めるんや。ReLMKG(CaoとLiu、2023年)はさらにGNNを使って明示的な知識伝播もやってるで。ChatKBQA(Luo H.さんら、2023年)やGoG(Xuさんら、2024年)みたいな生成-検索フレームワークは二段階アプローチを採用してて、まず論理形式や新しいトリプルを生成してから、関連するKG要素を検索するんや。DRLK(Zhang M.さんら、2022年)みたいな動的推論システムは階層的なQAコンテキスト特徴を抽出するし、QA-GNN(Yasunagaさんら、2021年)はKGの関連性をスコアリングしてGNNを通じて表現を更新することで、共同推論を行うねん。データセット構築については、ConvKGYarn(Pradeepさんら、2024年)がLLMを使って設定可能な会話型KGQAデータセットを生成するスケーラブルな方法を提供してるで。
## 4 LLMでKGを強化する際の課題
近年、LLMでKGを強化する研究がめっちゃ増えてきてるけど、まだいくつかの課題が残ってるねん。図7がこれらの課題をまとめてて、将来の研究の方向性を示してくれてるで。
### 4.1 ナレッジグラフ構築における課題
1. **情報融合の難しさ**: LLMとKGの融合では、LLMの暗黙的な統計パターンとKGの明示的なシンボリック構造の間で、根本的な表現の衝突が起こるねん。このミスマッチがエンティティリンキングの一貫性を体系的に乱すんや。現在のハイブリッドアプローチには3つの核心的な限界があるで:コンテキスト拡張時に意味的ノイズを導入してしまう(Ayoolaさんら、2022年; Xinさんら、2024年)、候補生成でLLMの訓練バイアスに制約される(Ding Y.さんら、2024年)、マルチモーダル融合で新しいモダリティ特有の依存性を生み出してしまう(Liu Q.さんら、2024年)っていう問題やな。なんでかっていうと、これはLLMを周辺的なツールとして扱ってて、核心となるシンボリック-ニューラルインターフェースを再設計してへんからやねん。将来の解決策は拡張パラダイムを超えて、パラダイム間での動的でリアルタイムな知識変換を可能にせなあかんねん。
2. **データ品質への依存**: LLMベースのナレッジグラフ構築の有効性は、入力データの品質にめっちゃ依存するんや。分析を通じて、3つの普遍的な
Frontiers in Computer Science
08
frontiersin.org
---
## Page 9
[](/attach/be35480839ed8df24385cd047d83444c3a9842de8dfb102c573c6610802d06cc_p009.png)
### 和訳
Cai et al.
10.3389/fcomp.2025.1590632
図7
LLMでナレッジグラフ強化するときの課題やで
ほんでな、LLMをこういう場面で使うときの限界についてちょっと説明するわ。まず、トレーニングデータに元々入ってるバイアスがあって、それが知識抽出のパイプライン全体に広がっていくねん(Zhang et al., 2024a)。専門的な知識に対応させようとしたときのドメイン適応の問題もめっちゃ根本的な課題やし、レアな関係性——特に複数の文書をまたぐようなケースやと顕著なんやけど——そういうのをカバーしきれへん問題もあるねん(Caciularu et al., 2021; Min et al., 2024)。こういう問題が全部合わさって、作ったナレッジグラフの信頼性がガタ落ちするんよ。特に正確さがめっちゃ大事な専門分野やとキツいわな。今んとこの対策としては、人が手作業でチェックしたり、専門分野向けの知識ベースを使ったりしてるんやけど、これがまたスケールさせようとするとボトルネックになって、実際に使おうとしたら制限がかかってまうねん(Fan et al., 2007)。
4.2 ナレッジグラフ補完の課題
1. 記憶と推論の区別がめっちゃ難しい:LLMってな、ナレッジグラフの補完するときに、覚えてる知識と推測した予測をごっちゃにしてまうねん。これがなんで問題かっていうと、ベンチマーク用のデータセットが事前学習で使ったデータと被ってると、評価するときにややこしくなるんよ。LLMが予測を出しても、それが「事実を思い出した」のか「統計的に推測した」のか「ハルシネーション(幻覚)」なのか区別つかへんねん。ProLINK(Wang K. et al., 2024)やTAGREAL(Jiang P. et al., 2023)みたいなプロンプトベースの手法でLLMの推論をガイドしようとしてるんやけど、事実の想起と本物の推論の間のこの根本的なあいまいさは完全には解決でけへんねん。これは特に医療分野みたいに「その情報どっから来たん?」が重要な場面ではほんまに問題やで(Waldock et al., 2024)。この課題はプロンプティング、マスキング、seq2seqとか、どのLLMベースの補完方式でも、意味的な豊かさがあるにもかかわらず消えへんねん。
2. ナレッジグラフ補完の計算コストがえげつない:LLMベースの補完——例えばseq2seq型のGenKGC(Xie et al., 2022)とか、テキストとグラフのハイブリッド型のMADLINK(Biswas et al., 2024)とか——これらはテキスト処理と候補のスコアリングをめっちゃ大量にやらなあかんから、大きいナレッジグラフやと計算コストがヤバいことになるねん(Wang B. et al., 2021; Ren et al., 2024)。MT-DNN(Choi and Ko, 2023)やLP-BERT(Li et al., 2023)みたいなマルチタスク学習のアプローチで計算の負担をタスク間で分け合おうとしてるんやけど、根本的なスケーラビリティのギャップは残ったままやねん。特に大規模なナレッジグラフやと、グラフの密度に応じてレイテンシが多項式的に増えていくから余計にキツいんよ(Heim et al., 2025)。これによって、LLMの意味的な豊かさと従来手法の運用効率の間に、解決でけへんトレードオフが生まれてるわけや。
3. プロンプトエンジニアリングの課題:今のナレッジグラフ補完向けのプロンプトエンジニアリング手法——ProLINK(Wang K. et al., 2024)やTAGREAL(Jiang P. et al., 2023)とか——にはいくつか重要な限界があんねん。複雑なエンティティ名を表現するとき、プロンプト手法やと長い名前をサブワードの断片に分割せなあかんから情報が欠落してまうねん。一方でMEM-KGC(Choi et al., 2021)みたいなマスキング技術は[MASK]トークンを使ってエンティティの完全性を保てるんよ。関係性の理解についても、プロンプト手法は人が手作業で作ったテンプレートに頼るから結果が不安定になりがちやねん。それに対してBERTRL(Zha et al., 2022)みたいなパスベースのアプローチは、エンティティ間の経路を自動的に分析してより信頼性の高い予測ができるんよ。こういう制約があるから、プロンプト手法は新しいドメインに適応したり知識を更新したりするときにめっちゃ手作業のメンテナンスが必要になって、スケーラビリティがかなり制限されてまうねん(Choi and Ko, 2023; Li H. et al., 2024)。
Frontiers in Computer Science
09
frontiersin.org
---
## Page 10
[](/attach/be35480839ed8df24385cd047d83444c3a9842de8dfb102c573c6610802d06cc_p010.png)
### 和訳
Caiさんらの研究やねんけど、
## 4.3 ナレッジグラフのアラインメントとエラー検証の課題
1. **LLMとKGの表現のズレ問題**: LLM(大規模言語モデル)とKG(ナレッジグラフ)の埋め込みで、トークン化の仕方が違うから、アラインメント(うまく対応づけること)するときに情報が抜け落ちてまうことがあんねん。LLM-Alignっていう手法(Chenさんら、2024年)みたいに、何回も投票して補おうとする混合手法もあるんやけど、複雑な文脈やとまだまだ限界あるし、コストもめっちゃかかんねんな。この断片化のせいで、人間と機械のインターフェース(HMI)の信頼性が下がってまうねん。なんでかっていうと、解釈がバラバラになって、曖昧さとか混乱が起きるからやな。今後の研究では、意味をちゃんと保ちつつ(LLM向け)、構造の整合性も維持できる(KG向け)ような、統一された新しいトークン化の仕組みを開発することを考えたほうがええかもな。
2. **マルチモーダルアラインメント**: ナレッジグラフのアラインメントをうまくやるには、構造的な特徴と意味的な特徴を統合せなあかんねん。AutoAlign(Zhangさんら、2023年)みたいな手法やと、複数の特徴を融合することでクロスナレッジグラフのアラインメントがええ感じになるって示されてんねんけど、グラフのサイズが大きくなると計算コストが指数関数的に増えてまうねん。マルチモーダル領域やと、マルチモーダル統合で精度は上がるけど、リソースもめっちゃ食うから、これが課題になってるわけや。今後は、価値の高い融合処理を優先して、無駄な計算はスキップするような動的な特徴選択の戦略を探っていくのがええかもしれんな。
3. **意味評価の限界**: ナレッジグラフの補完に使われてる既存の評価指標って、論理的な一貫性よりも表面的な正しさを重視しがちやねん。例えばな、「(アインシュタイン、受賞した、ノーベル化学賞)」みたいなトリプルが生成されたとするやん。埋め込みベースの指標やと高い信頼スコアが出るかもしれんけど、実際の事実とは矛盾してるやろ(アインシュタインは物理学賞やからな)。AMIE(Galárragaさんら、2013年)みたいなルールベースのシステムやと、事前に決めた制約でこういうエラーを見つけられるんやけど、ルールが不完全なオープンドメインのシナリオやと苦労すんねん。もっと有望な方向としては、リスクの高い予測だけに厳密な記号的検証を適用するみたいな、階層的な評価フレームワークがあるかもしれんな。
## 4.4 ナレッジグラフ推論の課題
1. **ルールベース推論の難しさ**: LLMベースのKG推論における核心的な課題は、確率的な推論と決定論的な記号ルールの間に本質的な矛盾があることやねん。現在の手法は、論理タスクでのLLMの性能を上げるためにいろんな戦略を試してんねんけど、それぞれ根本的な限界があるんよ。ReLMKG(CaoさんとLiuさん、2023年)は動的なマルチホップ推論が苦手で解釈可能性に欠けてるし、KG-Agent(Jiangさんら、2024年)は事前定義されたルールに依存してるから汎化能力が限られてて維持コストも高いねん。KG-CoT(Zhaoさんら、2024年)はナレッジグラフの完全性に制約されてて、局所的に正しくてもグローバルな論理的一貫性は保証できひんねん。3つとも、静的な知識への依存とエラー伝播の問題があって、記号システムみたいな複雑なロジックのモジュール処理能力が欠けてるわけや。今後は、ニューラルの柔軟性と記号の厳密性を動的に切り替えられるようなハイブリッドアーキテクチャを優先的に研究すべきやな。
2. **不透明さと説明可能性の課題**: LLMの確率的な性質のせいで、KG推論タスクでは根本的に説明可能性の壁があんねん。入力の前提から最終予測までの論理チェーンを明確に再構成できる記号システムと違って、LLMはそれを確実に再構成できひんのや。これは、監査可能性が求められるHMIアプリケーション(例えば、医師が診断経路を検証せなあかん臨床意思決定支援とか)にとっては致命的な欠点やねん。この不透明さは、KG-CoT(Zhaoさんら、2024年)みたいな進んだCoT(思考連鎖)フレームワークでも続いてて、生成された根拠が本物の推論と後付けの正当化をごっちゃにしてることが多いねん。将来の解決策としては、ニューラル計算と人間が解釈できるステップごとの検証を同時にサポートする「ホワイトボックス」的な中間表現が必要かもしれんな。
## 4.5 KGからテキスト生成の課題
1. **評価の主観性**: BLEU(Papineniさんら、2002年)やROUGE(Lin、2004年)みたいな現在の評価指標は、主に表面的なテキストの類似性を測るもんやから、生成されたテキストとKGの内容の間の意味的な一貫性を効果的に捉えられへんねん。最近の研究(Luoさんら、2024年;Honovichさんら、2022年)では、LLMベースの事実整合性評価を探り始めてるんやけど、計算コストがかなり増えてもうてるんよ。
2. **既存パターンへの依存**: 生成されるテキストの記述が、既存のテンプレートや構文構造に過度に依存しがちで、言語表現の革新性に欠けてんねん。この依存のせいで、生成テキストが新しい視点やユニークな言語スタイルを提供しにくくなって、ナレッジグラフの内容を表現する上での創造性が制限されてまうわけや。
## 4.6 ナレッジグラフ質問応答の課題
1. **クエリ変換における意味の忠実性**: LLMを使ったKGQA(ナレッジグラフ質問応答)システムでの重大な課題は、自然言語からKGクエリへの変換時に意味がズレてしまうことやねん(Liさんら、2024年)。ChatKBQA(Luoさんら、2023年)みたいな現在のLLM駆動の検索強化手法は、複雑なクエリを扱うときに意味の忠実性の問題に直面するねん。暗黙の制約を含むクエリを処理するとき、LLMが生成したクエリは時間範囲とか比較ロジックみたいな重要な要素を失ってしまうことが多いんよ。GoG(Xuさんら、2024年)は生成-検索フレームワークでこの問題を部分的に軽減してるんやけど、生成フェーズでの意味のズレが、検索結果をユーザーの意図から逸らす直接的な原因になってんねん。今後は、言語の解析とグラフ構造の制約を同時に処理できるエンドツーエンドのコンテキスト対応アーキテクチャが必要やな。
2. **会話型QAにおける動的コンテキスト**: 現在のKGQAシステムは、マルチターンの対話における文脈の連続性をうまく扱えへんことが多くて、重要な制約を落としてしまったりするねん(例えば...
---
## Page 11
[](/attach/be35480839ed8df24385cd047d83444c3a9842de8dfb102c573c6610802d06cc_p011.png)
### 和訳
Caiさんたちの研究やねんけど、
10.3389/fcomp.2025.1590632
図8
KGで強化されたLLM(KEL)のロードマップやで。
時間フィルターとかの制約条件を見落としたり、間違って使ってまうことがあるんよな。ConvKGYarn(Pradeepさんたち、2024年)みたいなフレームワークは、一つ一つの質問に対してはちゃんとした回答を生成できるんやけど、会話のターンをまたいでKGと照らし合わせてチェックする機能がないから、矛盾した答えを出してまうことがあるねん。これが人と機械のやりとり(HMI)にめっちゃ影響するんよ。なんでかっていうと、説明もなしに矛盾したこと言われたら、ユーザーの信頼がガタ落ちになるからやな。これからの解決策としては、会話の履歴とKGの制約を同時に監視できる、統合されたコンテキスト追跡が必要になってくるで。
教師ありファインチューニング、アラインメントファインチューニング、あと解釈可能性とかも含めてな。評価するときは、これらのカテゴリーの中で革新的な手法を提案しただけやなくて、知識集約型タスクで一貫してパフォーマンスが上がることを示した研究を優先したで。特に、主流のLLMアーキテクチャと互換性があって、複数の分野でちゃんと検証されてる技術を重視したんや。これらの手法の発展を年代と手法タイプ別にまとめたのが図9やで。
5 KGで強化されたLLM
自然言語処理(NLP)の世界では、LLMがテキストの理解と生成にめっちゃ強力なツールとして登場してきたんよ。せやけど、内部の知識ベースに限界があるから、深い知識と複雑な推論が必要なタスクには苦戦することが多いねん。KGは構造化された知識を持ってるから、このギャップを埋められるんや。KGをLLMに統合することで、いろんなNLPタスク、特に複雑な知識と推論が絡むタスクでパフォーマンスをめっちゃ向上させられるで。このセクションでは、KGを活用してLLMの能力を高める革新的な手法を探っていくで。事前学習の目的関数から推論テクニックまで、この統合がLLMをより高度なタスクに対応させる可能性を強調するんや。図8は大規模LLMのワークフローを示してて、KGがLLMの各ステップをどう強化するかを表してるで。
これらの進歩を調査するにあたって、特に2019年から2025年の研究で、KG統合によってLLMの能力が測定可能な形で向上したものに注目したで。このプロセスはKG強化の効果に基づいて3タイプに分類できるんや:事前学習、推論手法、
5.1 KG埋め込みLLM事前学習手法
5.1.1 学習目的関数の統合
KGを大規模LLMに統合するのは、NLPタスクでモデルの性能を高めるためのめっちゃ重要な課題やねん。一部のモデルはKGを使って事前学習データをより構造化して、LLMの性能を上げようとしてるで。
KEPLER(Wangさんたち、2021年)の研究では、テキストの説明文をエンコードしてエンティティ埋め込みを生成して、知識埋め込みとマスク言語モデルの目的関数を同時に最適化してるんや。これは知識グラフのリンク予測でええ結果出してるで。WKLM(Xiongさんたち、2019年)は弱教師あり事前学習の目的関数を使ってて、文書中のエンティティの言及を置き換えて、モデルに正しい知識表現と間違った知識表現を区別させるように訓練してるんや。ERNIE(Zhangさんたち、2019年)は知識グラフでNLPを強化してて、E-BERT(Zhangさんたち、2020年)はハイブリッドマスキングでEコマースタスクを最適化してる。KEPLER(Wangさんたち、
Frontiers in Computer Science
11
frontiersin.org
---
## Page 12
[](/attach/be35480839ed8df24385cd047d83444c3a9842de8dfb102c573c6610802d06cc_p012.png)
### 和訳
Cai et al.
10.3389/fcomp.2025.1590632
図9
LEKに関する主要研究を、タスク別・発表年別にまとめたやつやで。
2021年のモデル(Unifies knowledge embedding and language modeling)は、知識の埋め込みと言語モデリングを一緒にやって、めっちゃええ結果(SOTA)出したんや。Multi-task QA Model(Su et al., 2019)は、XLNetっていうのを使って、いろんな問題に対応できる汎化性能を上げとる。KALA(Kang et al., 2022)は、エンティティ(実体)を意識したチューニングで、特定の分野への適応力をブーストしてんねん。Knowledge-enhanced Pre-training(Xiong et al., 2019)は、弱教師あり学習っていう手法で事実の理解力を強化しとる。これらのモデル全部に共通してるのは、専門的な知識とか特殊なトレーニング戦略を使って、普通のモデルより性能がええっていう点やな。
5.1.2 入力表現の強化
LLMs(大規模言語モデル)の入力表現をKGs(知識グラフ)でどう強化するかって話やねんけど、いくつかの重要な研究が、モデルの理解力と生成能力を上げるいろんな方法を示してくれてんねん。
CoLAKE(Sun et al., 2020)は、言語と知識を「word-knowledge graph」っていう共有構造に統合して、両方の文脈に応じた表現を一緒に学習する事前学習フレームワークを提案してんねん。ERNIE 3.0(Sun et al., 2021b)は、ハイブリッドなアーキテクチャで中国語の54個のNLPタスクでSOTA達成しとる。DKPLM(Zhang T. et al., 2022)は、あんまり出てこないレアなエンティティ(ロングテール)の処理を、分解可能な知識注入で効率よくやってんねん。JAKET(Yu et al., 2022)は、知識グラフと言語の間で双方向の強化ができるようにしとる。KG-T5(Moiseev et al., 2022)は、KGのトリプル(主語-述語-目的語の3つ組)で直接事前学習して、性能が3倍になったんやで。SACKG(Chen S. et al., 2024)は、LLMsを活用して百万規模の高精度な知識グラフを構築してんねん。GNP(Tian et al., 2024)は、グラフニューラルプロンプティングでLLMsとKGsの橋渡しをしとる。K-BERT(Liu et al., 2020)は、ノイズ制御しながら効率的にドメイン知識を注入できるようにしてんねん。これらのモデルは、共同学習からモジュール方式まで、いろんなアプローチで知識強化型言語モデルを進化させてんねんな。
5.1.3 マルチモーダル学習
マルチモーダルKGs(複数の情報形式を扱う知識グラフ)で言語モデルの能力をどう強化するかって話やねんけど、マルチモーダルデータを扱うときのモデル性能を上げる革新的な方法とフレームワークが提案されてんねん。MRMKG(Lee et al., 2024)は、RGAT(関係グラフアテンションネットワーク)でMMKG(マルチモーダル知識グラフ)をエンコードして、画像とテキストを揃えるためのクロスモーダルモジュールを設計してんねん。VQA(視覚的質問応答)のインスタンスとMMKGsをマッチングしたデータセットで事前学習されてんねんで。KGEMT(Zheng J. et al., 2024)フレームワークは、粗い学習と細かい学習を組み合わせて、マルチモーダルの整合性を取るためのグローバルな意味グラフを構築してんねん。双方向の細かいマッチングで画像とテキストの要素をフィルタリングして、画像-テキスト検索の性能をめっちゃ上げとる。KG-Retrieval NLU(Huang et al., 2022)は、マルチモーダルKG(VisualSem)の検索を活用して、パラメータ効率のええやり方でNLU(自然言語理解)を強化するフレームワークやねん。
5.2 KGガイド付きLLM推論手法
5.2.1 プロンプトエンジニアリング
知識グラフガイド付きLLMs推論手法において、プロンプトエンジニアリングはめっちゃ重要な役割を果たしてんねん。ここからは、この分野でのプロンプトエンジニアリングの応用についてまとめていくで。いくつかの手法は、知識グラフ(KGs)からの構造化された手がかりをプロンプト空間に明示的に注入することで、LLMsの推論能力を強化することに焦点を当ててんねん。LPAQA(Jiang et al., 2020)は、ラベルを意識したプロンプティングを導入してんねんな。
Frontiers in Computer Science
12
frontiersin.org
---
## Page 13
[](/attach/be35480839ed8df24385cd047d83444c3a9842de8dfb102c573c6610802d06cc_p013.png)
### 和訳
Caiら
10.3389/fcomp.2025.1590632
知識グラフ(KG)のエンティティを、めっちゃ丁寧に設計されたテンプレートと合わせることで、モデルが事実に関する質問に正確に答えられるようにガイドしてんねん[1]。同じように、Mindmap(Wenら、2023年)とかChatRule(Luoら、2023a)とかCOK(Wangら、2023a)みたいなアプローチは、構造化された知識とか人間が決めたルールをプロンプト表現として外に出すことを目指してんねん。これによってLLM(大規模言語モデル)が複雑なグラフベースの状況で推論できるようになって、文脈の理解が良くなって、ハルシネーション(でたらめな回答)も減るんやで。これらの手法は、プロンプト設計がKGとLLMの間の軽量やけどめっちゃ強力なインターフェースになれるってことを示してんねん。
5.2.2 動的な知識検索
LLMが複雑なタスクを征服しようとしてる今の時代、KGからの動的な知識回復がめっちゃ強力なソリューションとして登場してきてん。これによってLLMがリアルタイムで関連する知識にアクセスして統合できるようになって、パフォーマンスが上がるんやな。このカテゴリは、検索強化アーキテクチャを通じて、クエリ固有の情報をリアルタイムでLLMに注入することを目指してんねん。REALM(Lewisら、2020年)とRAG(Guuら、2020年)が、ニューラル検索器と生成型トランスフォーマーの統合を先駆けてやったんや。大きなコーパスとか知識ベースから関連する文書とか知識の一節を検索して、下流の予測をサポートするんやで。KGLM(YounとTagkopoulos、2022年)はこのコンセプトを拡張して、知識エンティティを生成プロセスに直接埋め込んでん。これでモデルがデコード中にエンティティ固有の情報を動的に参照できるようになるんやな。さらに、EMAT(Mirkhaniら、2004年)はエンティティマッチングを意識した注意機構を導入して、検索の整合性を改善してんねん[8]。これらの基礎の上に、GraphRAG(Edgeら、2024年)、KG-RAG(Sanmartin、2024年)、ToG(Sunら、2023年)、ToG2.0(Ma S.ら、2024年)、FMEA-RAG(Razoukら、2023年)みたいな新しい手法が、構造化されたグラフ推論とマルチホップ検索をRAGフレームワークに組み込んでんねん。これでLLMがグラフ構造のエビデンスに基づいて推論できるようになって、産業用の故障診断とか、知識ベースの要約とか、ドメイン固有の意思決定みたいな技術的なタスクにめっちゃ役立つんやで。
5.2.3 文脈の強化
自然言語処理の領域で、KGによって強化された文脈エンハンスメントは、LLMの知識のボトルネックを突破して、複雑なタスクをより効果的に処理できるようにするための必須戦略になってきてんねん。
QA-GNN(Yasunagaら、2021年)はGNN推論とLMを使ったKGスコアリングを組み合わせて、常識的な質問応答と医療質問応答で最先端のパフォーマンスを達成してんねん。しかも解釈可能な推論ができるんやで。KoPA(Zhang Y.ら、2023年)は構造的埋め込みを仮想知識トークンに投影することで、KGタスク向けにLLMを強化してんねん。KGL-LLM(Guoら、2025年)は、精密なLLM-KG統合のための専用の知識グラフ言語を導入して、リアルタイム文脈検索によって補完エラーを減らしてんねん。KP-PLM(Wang J.ら、2022年)は動的サブグラフ変換と二重自己教師あり学習タスクによって知識プロンプティングを進歩させて、フルリソースでも少ないリソースでも自然言語理解でめっちゃ優秀やねん。SPINACH(Liu S.ら、2024年)は専門家がアノテーションしたKBQAデータセットをインコンテキスト学習で提供して、複雑なクエリでGPT-4を大幅に上回ってんねん。これらのモデルは全部まとめて、構造化された知識と言語モデルを統合するための多様なアプローチを示してんねん。グラフベースの推論(QA-GNN)からプロンプトエンジニアリング(KP-PLM)、専用の言語インターフェース(KGL-LLM)まで幅広くカバーしてるんやで。
5.2.4 知識駆動型のファインチューニング
自然言語処理の分野でLLMが広く応用されるようになって、特定のタスクでのパフォーマンス向上が研究の焦点になってきてんねん。KGはLLMに外部知識を提供して、理解・推論・生成を助けてくれるんやで。
知識駆動型ファインチューニングは、モデル適応中に構造化された知識を組み込むアプローチを含んでて、より良い汎化と知識認識につながるんやな。KP-LLM(Wang J.ら、2022年)とOntoPrompt(Yeら、2022年)は、オントロジーパスとスキーマ制約でLLMをファインチューニングして、モデルの出力を構造化された知識ルールに合わせてんねん。KG-FIT(Jiang P.ら、2024年)とGraphEval(Sansfordら、2024年)は、ファインチューニングや評価中にKG由来のシグナルを注入する汎用的でモジュラーなフレームワークを提供してて、モデルが知識集約型タスクでより頑健で、検証可能で、説明可能になるようにしてんねん。一方、ChatKBQA(Luo H.ら、2023年)とRoG(Luoら、2023b)は知識グラフ推論を対話型質問応答システムに統合して、事実の正確さと談話の一貫性の両方を向上させてんねん。GenTKG(Liaoら、2023年)とDIFT(Liu Y.ら、2024年)はこの方向性を生成型KG補完とドメイン転移設定に拡張して、モデルがスパースな監督信号や進化するオントロジーの下で適応して動作できるようにしてんねん。
5.3 KG支援によるLLMの解釈可能性手法
5.3.1 知識トレーシング
LLMが様々なシナリオで高品質なパフォーマンスを維持しようとする中で、KGによって強化された知識トレーシングが、知識の進化を正確に追跡して、知識のギャップを埋めて、回答の精度を向上させることを可能にしてんねん。KELP(Liu H.ら、2024年)は3段階のプロセスを通じてLLMの出力の事実精度を向上させてんねん。このプロセスは、入力テキストに意味的に関連する知識グラフのパスを抽出して選択するんやで。LAMA(Petroniら、2019年)は知識を穴埋め形式の質問に変換して、事前学習モデルの関係知識と想起能力を評価してんねん。Knowledge-neurons(Daiら、2021年)は特定の事実に対応するニューロンを特定して活性化させて、事前学習されたトランスフォーマーにおける事実知識の保存と、内部知識の編集・更新を探求してんねん。MedLAMA(Mengら、2021年)はUMLに基づいたベンチマークを作成して、Contrastive-Probeという自己教師あり対照的プローブ手法を導入してんねん。これはタスク固有のデータなしで、基盤となる事前学習モデルの表現空間を調整できるんやで。GenTKGQA(Gaoら、2024年)は2段階の時間的質問応答フレームワークを提示してて、まずLLM由来の制約を使って関連するサブグラフを検索して、次にグラフ情報とテキスト情報の共同表現を通じて回答を生成するんやな。
Frontiers in Computer Science
13
frontiersin.org
---
## Page 14
[](/attach/be35480839ed8df24385cd047d83444c3a9842de8dfb102c573c6610802d06cc_p014.png)
### 和訳
Caiさんたちの研究やねん。
10.3389/fcomp.2025.1590632
**図10**
LLM(大規模言語モデル)をKG(ナレッジグラフ)で強化するときの課題やで。
## 5.3.2 エンティティの関連性分析
LLMが複雑な知識ベースのタスクをこなそうとするとき、KGを使った**エンティティの関連性分析**がめっちゃ強力な武器になるねん。これ使うと、エンティティ同士のつながりを見つけて活用できるから、知識のスキマを埋めて、もっと正確で賢い回答ができるようになるわけや。
**KGFlex**(Anelliさんたち、2021年)は、KGとスパース因数分解っていう手法を組み合わせて、ユーザーがどういう基準で決断してるかの次元を分析して、ユーザーとアイテムの関係をモデル化してるねん。**KagNet**(Linさんたち、2019年)は、知識を意識したグラフネットワークでパターングラフを作って、グラフ畳み込みネットワーク、LSTM、階層的パスアテンション機構を使って常識的な推論問題を解いてるで。**AUTOPROMPT**(Shinさんたち、2020年)は、勾配ベースの探索で自動的にプロンプトを生成して、事前学習済みモデルがタスクをこなすのを助けてくれるねん。**BioLAMA**(Sungさんたち、2021年)は、バイオメディカル分野の知識探査ベンチマークを導入して、言語モデルが構造化されたファクトトリプル(事実の三つ組)を使って専門分野のナレッジベースとして使えるかどうかを評価してるで。**LLM-facteval**(Luoさんたち、2023c)は、KGベースのフレームワークを提案して、KGの事実から一般的なものと専門的なものの両方の文脈で質問を生成して、LLMを体系的に評価できるようにしてるねん。**LLM4EA**(Chen S.さんたち、2024年)は、LLMが生成したアノテーションを使ってKGをアラインメント(整列)して、能動学習でアノテーション空間を減らしつつ、ラベル精製器でノイズの多いラベルを修正してるで。
## 6 LLMをKGで強化する際の課題
LLMをKGで強化する研究はかなり進んできたんやけど、まだまだ重要な課題が残ってるねん。図10でこれらの課題をまとめて、今後の探求の道筋を示してるで。
### 6.1 知識獲得の限界
**1. 知識カバレッジの不足とスパース性(まばらさ)の問題:**
大規模なKGは一般的な知識をかなり広くカバーできるようになったんやけど、医学とか法律みたいな専門分野ではまだまだ表現が限られてることが多いねん。こういう分野では、多くのエンティティや関係が欠けてたり、つながりが弱かったりするわけや。このカバレッジのギャップと構造的なスパース性のせいで、細かいドメイン固有の推論が必要なタスクではKGの有用性が制限されてまうねん。結果として、KGで強化したLLMは、新興の病気、珍しい出来事、複雑な手続きを扱うときに、包括的な構造化サポートにアクセスできへんことがあるんや。ドメイン固有のKGがこの問題を部分的に解決してくれるんやけど、異質性(バラバラな形式)やスケールの制限のせいでLLMとの統合はまだ難しいねん(Panさんたち、2024年)。
**2. KG構築の高コストとスケーラビリティの問題:**
高品質なKGを構築・維持するには、めっちゃ人手がかかるねん。データのクリーニング、エンティティのアラインメント、関係のラベリング、専門家による検証とか、いろいろあるわけや。特に専門知識が必要な分野では、これらのプロセスがほんまに手間かかるねん。自動化や半自動化のKG構築手法、遠隔教師あり学習、ニューラルトリプル抽出とかは進歩してきたんやけど、ノイズの多いトリプルや冗長なトリプルが入り込みやすくて、複雑な文脈では精度が低くなりがちなんや。こういう問題はKG自体の信頼性を下げるだけやなくて、下流のKG強化LLMの効果も下げてまうねん。推論のときにエラーが伝播してまうこともあるんや(Yangさんたち、2024a)。
**3. マルチモーダル知識統合の不足:**
既存のKGのほとんどは主にテキストデータから構築されてて、構造化されたトリプルで情報をエンコードしてるねん。でも実世界の知識は、画像、音声、動画みたいなマルチモーダル(複数の形式)で存在することが多いんや。特にヘルスケア、自動運転、ロボティクスみたいな分野ではそうやね。統合されたマルチモーダル知識がないと、KG強化LLMはクロスモーダルな理解が必要なタスクをこなすのが難しくなるねん。マルチモーダルなナレッジグラフを構築する初期の試みは有望な結果を見せてるんやけど、まだまだ発展途上で、モダリティのアラインメント、意味的な一貫性、大規模展開に課題があるで(Chenさんたち、2023年)。
Frontiers in Computer Science
14
frontiersin.org
---
## Page 15
[](/attach/be35480839ed8df24385cd047d83444c3a9842de8dfb102c573c6610802d06cc_p015.png)
### 和訳
Cai et al.
10.3389/fcomp.2025.1590632
6.2 知識理解の限界
1. 自然言語の意味とのズレ:KG(ナレッジグラフ)ってカチッとした構造になってるやん?でもな、自然言語のしなやかさとか豊かさをうまく捉えられへんねん。KGで強化したLLMは、ふわっとした言葉をこのガチガチのグラフ構造にうまく落とし込むのにめっちゃ苦労するわけよ。この意味のギャップのせいで、関連する知識をちゃんと引っ張ってこれへんし、KG上での推論もうまいこといかへんねん。最近はグラフとテキストを一緒に埋め込む方法とか、プロンプトベースでスキーマを合わせる方法とか、一緒に学習するフレームワークとかが提案されてるけど、めっちゃチューニングせなあかんし、特定のタスク向けで汎用性に欠けるっていう問題があるんよ(Peng et al., 2024)。
2. 知識の矛盾と重複:いろんなソースから作ったKGには、矛盾したファクトとか重複したファクトが含まれてることがようあるねん。例えば医療分野やと、同じ病気に対して違うデータセットが全然違う治療法を提案してたり、症状と病態の因果関係について意見が割れてたりするわけ。この不整合は、そういう知識で強化されたLLMにとってめっちゃやっかいな課題やねん。どのファクトを信じるか、どれを優先するか決めるのがむずいからな。トリプルの信頼度スコアリングとか、矛盾検出とか、信頼度を考慮したグラフフィルタリングとかの技術が提案されてるけど、今の方法はヒューリスティック(経験則)ベースで、いろんなドメインやタスクに汎用的に使えへんのが現状や(Wang et al., 2023)。
3. 時間的・動的な知識のモデリングの難しさ:現実世界の知識って静的ちゃうやん?新しい情報が入ってきたら変わっていくもんやろ。従来のKGは静的なスナップショットで、時間的な依存関係を表現したり動的な更新をモデル化したりする仕組みがないねん。その結果、KGで強化されたLLMは、イベントの連続とか因果関係とか時間に敏感な情報についての推論がうまくできへんのよ。時間的KGはグラフ構造に時間を組み込もうとしてるけど、スケーラビリティの問題とか複雑なモデリング要件のせいで、大規模言語モデルと組み合わせられることはほとんどないんや(Wang et al., 2023b)。
6.3 知識活用の限界
1. タスク適応性の限界:KGで強化されたLLMアーキテクチャのほとんどは、特定のタスクを念頭に設計されてるねん。違うタスクに適用すると、特に異なる推論パスとかドメイン固有のロジックが必要なタスクやと、パフォーマンスが落ちることが多いんよ。なんでかっていうと、統合メカニズムが基本的に固定で、タスク間で適応するようにチューニングされてへんからや。マルチタスクグラフエンコーダとかタスク固有のアダプタを探求した研究もあるけど、多様なLLMタスクに柔軟に知識を統合できる統一的で汎用的なフレームワークがまだないんよ(Ibrahim et al., 2024)。
2. リアルタイム推論効率の低さ:KGで強化されたLLMは、推論中にグラフ探索、エンティティリンキング、動的検索が必要やから、計算コストがめっちゃ高くなりがちやねん。これらの処理がレイテンシ(遅延)を生んで、対話システムとか自律エージェントとかオンラインレコメンデーションみたいなリアルタイムアプリケーションへのデプロイを妨げるわけよ。グラフの枝刈りとかキャッシュとか近似検索みたいな最適化手法が導入されてるけど、精度を犠牲にするか、大規模グラフとかマルチユーザー環境でうまくスケールせえへんかのどっちかやねん(Guo et al., 2022)。
6.4 知識説明可能性の限界
1. 不透明な推論チェーンと意思決定ロジック:KGは構造化された性質のおかげで本来は解釈しやすいはずやねんけど、LLMと統合すると推論パスがわかりにくくなることが多いんよ。記号論理とディープニューラルネットワークの融合によってハイブリッドモデルができるわけやけど、その意思決定は絡み合ったアテンション重みとベクトル演算から生まれるから、追跡するのがめっちゃ難しいねん。既存の説明可能性技術が適用されてるけど、表面的な洞察しか提供できへんことが多くて、ユーザー中心の解釈可能性に欠けてるんよ(Yinxin et al., 2024)。
2. 知識の出所が不明確:KGで強化されたLLMシステムでは、特定の予測や生成された出力にどの知識ソースやKGトリプルが寄与したかがわからへんことが多いねん。これは信頼性を損なうし、医療とか法律とか金融みたいな、検証可能性とソースの追跡可能性がめっちゃ重要なハイステークスな領域での使用を妨げるんよ。出力に出所メタデータとかグラフノード識別子をタグ付けする最近の取り組みはあるけど、これらの機能がスケーラブルでユーザーがアクセスしやすい形でモデルアーキテクチャに統合されてることはほとんどないんや(Pan et al., 2023)。
7 LLMとKGの協調(LKC)フレームワーク
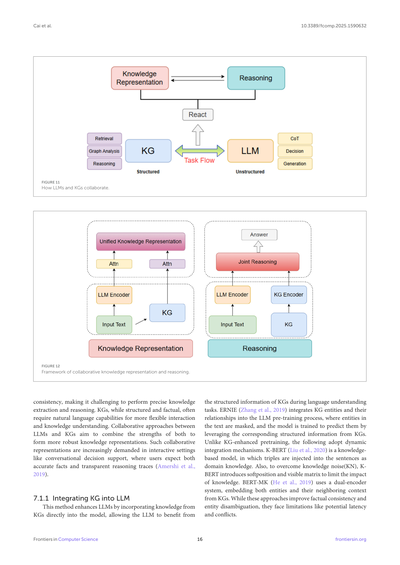
LLMとKGはそれぞれ単独でも様々な領域で強みを発揮してきたんよ。LLMは推論と推論(reasoning and inference)に優れてて、KGは構造化された性質のおかげで知識表現に対して堅牢なサポートを提供するねん。LLMとKGの協調的アプローチは、両方の利点を組み合わせて、知識表現と推論の両方でうまく機能する統一モデルを提供することを目指してるんよ。図11と図12はLLMとKGの協調メカニズムを示してて、最初の図はどう相互作用するかを、2番目の図は協調的な知識表現と推論のフレームワークを示してるで。
このセクションでは、知識表現と推論における最先端の協調モデルを検討して、2019年から2025年の研究の中から双方向LLM-KG協調で大きな進歩を示したものに焦点を当てるで。
俺らの選定では、ニューラルシステムとシンボリックシステム間の知識交換のための新しいメカニズムを確立するアプローチを優先してて、標準ベンチマークでスタンドアロンシステムを上回る測定可能なパフォーマンス改善が求められるんよ。さらに、実世界へのデプロイをサポートする実用的な実装を提供する方法を重視してるで。これらの基準を満たす代表的な方法とその主要な技術的貢献は図13で体系的に比較されてて、選定された研究が発表年とイノベーションタイプ別に整理されてるんや。
7.1 協調的知識表現
テキストコーパスとKGの両方が価値ある情報を持ってるけど、それぞれ限界があるねん。テキストコーパスは構造が欠けてたり事実が
Frontiers in Computer Science
15
frontiersin.org
---
## Page 16
[](/attach/be35480839ed8df24385cd047d83444c3a9842de8dfb102c573c6610802d06cc_p016.png)
### 和訳
Cai et al.
10.3389/fcomp.2025.1590632
**図11**
LLM(大規模言語モデル)とKG(知識グラフ)がどうやって協力するかの図やで。
**図12**
知識の表現と推論を一緒にやるフレームワークの図やな。
---
LLMっていうのは、めっちゃ賢い言葉のAIやねんけど、実は弱点があんねん。言うてることがコロコロ変わったり、一貫性がなかったりして、ちゃんとした知識を引っ張り出したり、論理的に考えたりするのが難しいことがあるんよ。一方でKG(知識グラフ)っていうのは、情報がきっちり整理されてて事実に基づいてるんやけど、自然な言葉でやり取りしたり、知識を柔軟に理解したりするには、やっぱり言語能力が必要やねん。
せやから、LLMとKGを一緒に使う協力アプローチが注目されてんねん。両方のええとこ取りして、もっとしっかりした知識表現ができるようになるっちゅう話や。特に、会話しながら意思決定をサポートするような場面では、ユーザーさんは正確な事実だけやなくて、「なんでそう考えたん?」っていう推論の過程も見せてほしいって思うやろ?そういうニーズがめっちゃ高まってきてるんや(Amershi et al., 2019)。
### 7.1.1 KGをLLMに組み込む方法
この方法は、KGの知識をLLMに直接取り込んで、LLMが言葉を理解するときにKGの整理された情報を活用できるようにするもんやねん。
**ERNIE**(Zhang et al., 2019)っていうモデルは、KGに入ってるエンティティ(まあ「モノ」とか「概念」のことやな)とその関係性を、LLMの事前学習に組み込んでるんや。文章の中のエンティティを隠して、KGの構造化された情報を使ってそれを予測させるっていう訓練をするわけや。
ERNIEみたいに事前学習に組み込む方法もあるんやけど、以下のやつらはもっと動的に、その場その場で統合するメカニズムを使ってるで。
**K-BERT**(Liu et al., 2020)は知識ベースのモデルで、文章にトリプル(「AはBとCという関係」みたいな3つ組の知識)を専門知識として注入するんや。ただな、知識ノイズ(KN)っていう問題があって、余計な知識が邪魔することがあるんよ。それを解決するために、K-BERTはソフトポジションとビジブルマトリックスっていう仕組みを導入して、知識の影響を制限してるんや。
**BERT-MK**(He et al., 2019)は、デュアルエンコーダシステムっていう2つのエンコーダを使う仕組みで、エンティティとそのKG上での周辺コンテキストを両方とも埋め込み表現にするんや。
これらのアプローチは、事実の一貫性を上げたり、同じ名前でも違う意味のエンティティを区別したりするのに役立つんやけど、処理が遅くなる可能性があったり、知識同士が矛盾することがあったりっていう限界もあるんやで。
---
Frontiers in Computer Science
16
frontiersin.org
---
## Page 17
[](/attach/be35480839ed8df24385cd047d83444c3a9842de8dfb102c573c6610802d06cc_p017.png)
### 和訳
Caiたちの研究やで。
10.3389/fcomp.2025.1590632
図13
LKC(言語知識協調)の研究をタスク別・発表年別にまとめたやつやな。
7.1.2 一緒に訓練したり最適化したりする方法
ほんで、一緒に訓練したり最適化したりする方法っていうのは、LLM(大規模言語モデル)とKG(知識グラフ)を同時に学習させて、両方を一つの統一された表現空間にまとめるっていうやり方やねん。そうすることで、言語と構造化された知識がお互いに補強し合えるようになるんやな。JointGT(Keたちが2021年に発表したやつ)は、グラフとテキストの表現を一緒に学習するフレームワークを提案してて、グラフベースのデータとテキストベースのデータの表現を揃えることを目指してるねん。グラフとテキストのアラインメント、ノードとテキストのマッチング、グラフベースの言語モデリングみたいなタスクを横断的に最適化することで、JointGTは知識と言語の能力をめっちゃ深いレベルで融合させてるわけや。一方、KEPLER(Wang X.たちが2021年に発表)は、知識の埋め込みと言語モデリングを統一してて、エンティティ(実体)のテキスト説明をLLMでエンコードしながら、知識埋め込みと言語モデリングの両方の目的を同時に最適化してるんや。比較してみると、JointGTはマルチタスク学習のスキームを採用して構造的な意味とテキスト的な意味を橋渡ししてる一方で、KEPLERはテキスト化された知識に頼ってて、マスク言語モデリングと知識埋め込みの目的を一緒に最適化してるねん。JointGTはグラフと言語のアラインメントを細かくコントロールできるんやけど、KEPLERはスケーラブルでテキスト中心のソリューションを提供してくれるっていう違いがあるんやな。
7.1.3 その他の方法
ここでは他に2つの戦略を紹介するで。CokeBERT(Suたちが2021年に発表)は、テキストの文脈に基づいて最も関連性の高いKGのサブグラフを動的に選んで統合するんやけど、これは学習された関連性スコアラーを使ってやってるねん。これで、冗長な知識や関係ない知識を取り込んでまう問題に対処してるわけや。HKLM(Zhuたちが2023年に発表)は、複数フォーマットの知識表現アプローチを導入してて、モデルが非構造化、半構造化、構造化されたテキストを同時に扱えるようにしてるんや。このマルチフォーマット戦略のおかげで、いろんな形式の知識表現に対応できる柔軟性がめっちゃ上がるねん。こういう代替戦略は、注入することからアダプテーションやフォーマットの一般化へと焦点をシフトさせてて、スケーラブルでユーザーに合わせた知識推論への新しい道を切り開いてるんやな。ただし、制御性や透明性にはまだ課題があって、特にインタラクティブな設定で使う時には注意が必要やで。
7.2 協調的な推論
協調的な推論っていうのは、LLMとKGの両方を使って効果的に推論できる協調モデルを設計することを目指してるんや。こういうモデルは、KGの持つ構造化された事実に基づく性質と、LLMの持つ深い文脈理解を活用して、もっと頑丈な推論能力を実現するねん。
7.2.1 KGベースの共同推論
KGベースの共同推論は、知識グラフの構造化された関係論理を明示的に活用することが中心になってて、典型的なパラダイムとしてはGNN(グラフニューラルネットワーク)で強化されたモデルやクロスアテンションメカニズムがあるねん。例えば、QA-GNN(Yasunagaたちが
Frontiers in Computer Science
17
frontiersin.org
---
## Page 18
[](/attach/be35480839ed8df24385cd047d83444c3a9842de8dfb102c573c6610802d06cc_p018.png)
### 和訳
Caiさんたちの研究やねん。
10.3389/fcomp.2025.1590632
**図14**
LLM(大規模言語モデル)とKG(知識グラフ)を一緒に使うときの課題やで。
2021年のやつ(QA-GNN)は、GNN(グラフニューラルネットワーク)っていう知識グラフを解析する技術と、LLMの言葉の意味を理解する力を組み合わせてるねん。ここでめっちゃ大事なんが「関連性スコアリング」っていう技術で、質問に対して知識グラフのどのノード(情報のかたまりみたいなもんやな)が重要かを見積もって、それをGNNで処理してLLMの回答生成に組み込むわけや。GreaseLM(Zhangさんたち、2022年)は、言語モデルとGNNをレイヤーごとにガッチリ連携させて、テキストと構造化された知識の間を行ったり来たりしながら推論できるようにしてるねん。JointLK(Sunさんたち、2021a)は、質問の単語と知識グラフのノードを密に双方向アテンション(お互いに注目し合う仕組みやな)でつないで、両方が同時にやり取りできるようにしてるわけや。知識グラフのノードが質問の単語に注目して、逆もまた然り、みたいな感じで、LLMが作った表現と知識グラフの構造を一緒に推論できるんやで。LKPNR(Runfengさんたち、2023年)は、知識グラフを何段階もたどる推論とLLMの文脈理解を組み合わせてるねん。Think-on-Graph(Sunさんたち、2023年)は、LLMを「エージェント」として扱って、知識グラフ上でビームサーチ(複数の可能性を並行して探索するやつやな)を繰り返し実行して、推論の道筋を見つけて評価していくんや。このエージェント的なアプローチは、人間が問題を解くみたいに、解釈しやすくて段階的な推論を目指す方向に進んでるってことやねん。
**7.2.2 エージェントと知識グラフの両方の役割を担う**
このパラダイムは、推論をコントロールする側と外部の知識ソースっていう従来の役割分担をぶち壊すねん。LLMが両方の役割を担って、事前学習で得た知識を使って新しい事実を生成しながら、追加情報のために知識グラフにも問い合わせるわけや。典型的なんがGenerate-on-Graph(Xuさんたち、2024年)で、LLMをこういうパラダイムで扱ってるねん。LLMが不完全な知識グラフを探索して、その場のグラフの文脈に応じて新しい事実のトリプル(「AはBである」みたいな3つ組の関係やな)を動的に生成するんや。これらの生成されたトリプルが推論の道筋に組み込まれて、モデルが推論しながら「グラフを成長させる」ことができる——まるで建設的な推論エージェントみたいやな。このアプローチは、知識グラフがスカスカな状況でもうまいこといくねん。KD-CoT(Wangさんたち、2023年)は、Chain-of-Thought(CoT)推論——要は段階的に考えを連鎖させていくやつやな——と、知識に基づいた検証を統合してるねん。LLMが推論の過程を一歩ずつ出力して、各ステップの後に関連する知識グラフの事実を取ってきて、途中の結論を検証したり修正したりするわけや。
**7.2.3 知識グラフとの動的なやり取り**
これは主に、LLMがリアルタイムで知識グラフと動的にやり取りして、推論中に知識を取得したり更新したりできるようにすることに焦点当ててるねん。KSL(Fengさんたち、2023年)は、LLMが外部の知識グラフから必要な知識を検索できるようにして、検索を多段階の意思決定プロセスに変えてるんや。構造化データ用のAPIを作るっていう方法もあるで。StructGPT(Jiangさんたち、2023年)は、構造化データにアクセスするためのAPIを作って、LLMが推論中に構造化されたデータベースと直接やり取りできるようにしてるねん。
**7.2.4 エージェント機能の強化**
LLMにエージェント的な能力を持たせるんが、今めっちゃ熱いトレンドになってるねん。AgentTuning(Zengさんたち、2023年)は、LLMのエージェントっぽい能力を強化することに特化してるんや。構造化されたデモンストレーションとやり取りの履歴を使ってLLMをファインチューニングすることで、もっと高度な推論タスクができるようになるねん。AgentTuningによって、LLMは知識グラフを単なるメモリ(記憶の倉庫)としてだけやなく、アクティブな環境として扱えるようになるんや。知識グラフ検索タスクで実証されてるように、AgentTuningで訓練されたモデルは、タスクに関連する知識の構造を特定して、複数ステップのアクションを計画して、知識グラフのAPIに動的にクエリを投げることができる——これがまさにきめ細かいコラボレーションってやつやねん。
**8 LLMと知識グラフを協調させる際の課題**
有望な進歩があるにもかかわらず、LLMと知識グラフを協調的に統合するには、まだまだ大きな課題が残ってるねん。図14がこれらの課題を特定して、今後の発展に向けた解決策を提案してるで。
Frontiers in Computer Science
18
frontiersin.org
---
## Page 19
[](/attach/be35480839ed8df24385cd047d83444c3a9842de8dfb102c573c6610802d06cc_p019.png)
### 和訳
Caiらの論文やねん。
10.3389/fcomp.2025.1590632
## 8.1 知識の統一的な表現について
1. **いろんな種類のデータを混ぜ合わせるのがめっちゃ難しい問題**: KG(ナレッジグラフ)とLLM(大規模言語モデル)って、知識の出どころとか構造がぜんぜん違うねん。KGの知識って基本的に構造化されたデータから来てて、エンティティ(モノとか概念のこと)、関係性、属性っていう形でハッキリ表現されてるわけ。人間が設計したパターンとかルールに頼ってるねんな。一方でLLMの知識は主にめっちゃでかいテキストの集まりから来てて、教師なし学習っていう方法で暗黙的な意味の関係性を捉えて、高次元の連続的なベクトル空間として表現してるわけや。せやからKGとLLMは、知識の粒度(どれくらい細かいか)、形式、意味の面で揃えるのがほんまに難しいねん。例えばな、KGは連続的な空間とは相性悪くて、LLMのベクトル化された表現に埋め込むのが大変やねん。逆にLLMの知識はKGの離散的な構造にマッピングしにくいわけ。この問題で一番重要なサブ問題の一つが、エンティティリンキングパイプラインをちゃんと確保することやねん(Shenらが2021年に言うてる)。このプロセスが簡単やないのは、言葉の曖昧さ、ロングテールエンティティ(あんまり出てこないレアなやつ)、文脈が不完全な問題があるからで、特にオープンドメインとか複数ターンの対話的な設定やとキツいねん。アライメントに失敗すると説明可能性が下がってまうし、この不確実性がユーザーの信頼にマイナスの影響を与えるわけや。
2. **意味表現の一貫性問題**: KGの関係性は離散的でハッキリ定義されてるけど、LLMの意味的関係性は暗黙的で分散してるねん。KGには曖昧やったり不完全な知識があったりする(一つのエンティティが矛盾する複数の属性を持ってたりするからな)。LLMが捉えた知識は文脈に依存してて、訓練コーパスとかモデルアーキテクチャの違いによって曖昧になることがあるねん。例えばな、KGには「りんごは果物の一種」って記録されてるかもしれんけど、LLMは「りんごはテクノロジー企業のことかもしれん」って推論するかもしれへん。これが意味の違いによって統一表現の難易度を上げてまうわけや。マルチホップ推論(複数のステップを踏む推論のこと)では、システムがリンクされたKGの事実に頼るか、LLM内部の推論チェーンに頼るか決めなあかんねん。知識の矛盾や食い違いは、推論経路やQA(質問応答)の回答で不安定な振る舞いにつながることがあるわけや(Zhang X.らが2022年に指摘してる)。もしユーザーが、どっちのコンポーネントに問い合わせたかによって微妙に違う答えを受け取ったら、システムの一貫性があるように見えへんくなってまうねん。これは医療とか金融みたいなセンシティブなアプリケーションでは特にヤバい問題やで。
## 8.2 リアルタイム性の問題
1. **KGの遅延**: KGは普通、静的な構造化データとして存在してて、更新や拡張は手作業の設計とルール駆動のプロセスに頼ってるから、更新サイクルが長いねん。KGの知識更新はオフラインでバッチ処理されることが多くて、新しい知識がモデルにタイムリーに取り込まれへんことになるわけ。特に金融、ニュース、感染症みたいに急速に変化する分野では、静的なKGはリアルタイムの意思決定のニーズを満たせへんねん。あとスケールの制限もあるで。データサイズと複雑さが増すと、KGのリアルタイム更新には相当な計算リソースとストレージリソースが必要になって、動的な能力がさらに制限されてまうわけや。
2. **LLMの遅延**: LLMのリアルタイム性能にもかなりの欠点があるねん。一つの例はオフライン訓練や。ほとんどのLLMは事前訓練が完了した後は凍結されて、実行時に新しい知識を動的に学習できへんねん(Gao P.らが2023年に言うてる)。もう一つは推論が過去の知識に頼ってることや。LLMの推論は訓練中にモデルが捉えたコーパス知識に基づいてて、リアルタイムの動的情報に対する感度が欠けてるねん。
3. **リアルタイムデータ融合の難しさ**: KGとLLMの知識ソースと融合メカニズムが、リアルタイム性能不足の課題をさらに悪化させてるねん。
**非同期更新**: KGとLLMの更新メカニズムを調整するのが難しいねん。例えば、リアルタイムのデータストリーム(センサーデータ、ソーシャルメディアデータとか)は即座に生成できるけど、KGとLLMで同期的に更新して一貫性を維持するのは複雑なタスクやねん。
**リアルタイム推論のボトルネック**: リアルタイムデータをKGとLLMの融合システムに動的に注入するには、複雑な前処理、関係抽出、文脈モデリングの操作が必要になることが多くて、推論時間がめっちゃ増えてまうねん。
4. **消費とコストと制約**: KGの更新コストは高いで。KG内のエンティティと関係をリアルタイムで更新するには、埋め込みと接続を再計算する必要があるかもしれんくて、大規模グラフではかなりの計算負荷がかかることがあるねん(Liu J.らが2024年に指摘してる)。
LLMの推論コストも高いで。生成型言語モデルは動的な文脈入力をサポートしてるけど、リアルタイムのシナリオで長いテキストや複雑な回答を生成する計算コストはまだ高くて、本当のリアルタイムレスポンスを達成するのは難しいねん。
変化の速い分野のユーザーの視点から見ると、回答が古い、または安全やないと感じたら、意思決定支援システムへの信頼は急速に失われていくわけや。一方で、リアルタイム性能を追求するとレイテンシスパイク(遅延の急上昇)が起きて、会話の流れが悪くなる。結果として、ユーザーがやり取りを諦めてまうかもしれへんねん。
## 8.3 オーバーヘッドと時間計算量
1. **双方向フローの問題**: KGとLLMを協調させる上での主な課題の一つは、KGとLLM間の双方向の情報フローを管理するオーバーヘッドと時間計算量やねん。特に動的なやり取りの場合な。LLMの推論に情報を与えるためにKGから知識を動的に取得しながら、同時にLLMが生成した新しい洞察や関係でKGを充実させるプロセスは、めっちゃ複雑やねん。この双方向のやり取りは計算オーバーヘッドと複雑さを増加させるわけで、特にLLMが推論中に大規模なKGを頻繁にクエリする必要がある場合はキツいねん。
## 8.4 矛盾の解決とエラーの伝播
1. **矛盾する知識の解決**: KGとLLMが提供する知識の間に矛盾がある場合、矛盾解決メカニズムを確立する必要があるねん。これには知識の優先順位ルールとか信頼度計算が含まれるかもしれへんで。
Frontiers in Computer Science
19
frontiersin.org
---
## Page 20
[](/attach/be35480839ed8df24385cd047d83444c3a9842de8dfb102c573c6610802d06cc_p020.png)
### 和訳
Cai et al.
10.3389/fcomp.2025.1590632
こういうメカニズムって、だいたいハイブリッドなスコアリング戦略に頼ってんねん。
せやけどな、このスコアがモダリティ(データの種類)とかソースによっては、そのまま比較できへんこともあるわけ。バージョン管理がまさにその典型例やな。
動的なやりとりの中では、KG(ナレッジグラフ)とLLM(大規模言語モデル)が同時に更新されることがあって、そうなると知識の変更を追跡して、双方向のやりとりでも結果に一貫性を持たせるための、ちゃんとしたバージョン管理の仕組みが必要になってくるねん。
2. エラーの伝播をどう管理するか:
双方向のやりとりをしてると、循環依存っていう厄介な問題が起きることがあんねん。
どういうことかっていうと、KGがLLMに注入する情報を更新して、そのLLMがその情報を元に知識を生成してKGに書き戻す、みたいなことをやってると、ちゃんとした検証とか制限の仕組みがないと、フィードバックループができてまうわけ。そうなるとエラーがどんどん伝播していくことになるねん。
KGかLLMのどっちかで入り込んだ知識の間違いが、ちゃんとフィルタリングされへんかったら、それが何回も繰り返し伝播されて、知識のドリフト(ズレ)とか事実の不正確さにつながってまうねん。生成された知識があたかも確かな事実みたいに後から検索されて、さらなる生成に影響を与えるようになると、このエラー伝播の問題はめっちゃ深刻になるわけ(Saparov and He, 2022)。これが示してるのは、因果関係でフィルタリングしたり、知識の出所を追跡したりする仕組みが必要やってことで、自己強化ループを抑えるために強化学習を使うっていうアプローチもあり得るねん。
8.5 人間中心の評価
KGとLLMを協調させたシステムを評価するのは、ユーザー体験への影響を確保するためにめっちゃ重要やねん。効果的な評価っていうのは、単に技術的な性能(精度とか効率とか)を検証するだけやなくて、動的で人間が関わるシナリオでユーザーの期待に応えられてるかどうか、つまり実際の場面での使いやすさと有効性を捉えることも含むねん。従来のタスクと違って、こういうシステムはインタラクティブな環境で動くことが多くて、説明可能性、信頼性、認知的な整合性、追跡可能性がめっちゃ重要になってくるわけ。例えばな、ユーザーは生成された事実がKGから取ってきたものなのか、それともLLMが幻覚(ハルシネーション)で作り出したものなのか、透明性を求めるかもしれへんし、対話の文脈が変わっていくにつれてシステムが推論を適応させることを期待するかもしれへん。こういう期待に応えるには、静的なベンチマークを超えて、タスク成功率、インタラクション満足度、リアルタイム制約下でのレイテンシ(応答遅延)みたいなユーザー中心の指標を取り入れた評価プロトコルが必要やねん。せやけど、こういう人間中心の評価はまだ発展途上で、実世界のインタラクティブな環境での協調的な推論の質を測るための標準化されたフレームワークが限られてるのが現状やねん。(Kaur et al., 2022)
この必要性を示す典型的な課題の一つがバイアス(偏り)の伝播やねん。偏った情報とか間違った情報がKGかLLMのどっちかから入り込んで、繰り返しの推論を通じて強化されると、システムが気づかんうちに誤解を招くコンテンツを増幅してまうことがあるねん(Bender et al., 2021)。これは事実の正確さを損なうだけやなくて、特に医療、教育、法律みたいな分野でユーザーの信頼を損なうことにもなるわけ。例えばな、ナレッジグラフが「CEO—典型的には男性」みたいな歴史的な関連性を符号化してるとするやん。この歴史データに基づくパターンをLLMに統合すると、LLMは「彼は生まれながらのリーダーで、CEOとして活躍するやろう」みたいな内容を出力することがあるねん。
これがジェンダー役割バイアスの循環的な拡散につながって、モデル内で「職業のジェンダーステレオタイプ」の構造的な固定化をさらに悪化させることすらあるわけ。そうなるとユーザーがシステムの公正さを疑うようになるやん。やから、評価プロトコルには公平性とバイアス追跡の次元を組み込んで、協調的な推論システムが人間に与える長期的な影響を評価せなあかんねん。
9 統合パラダイム全体にわたる包括的議論
LLM強化型KG(セクション4)、KG強化型LLM(セクション6)、KG-LLMシナジー(セクション8)の課題を詳しく分析してきた上で、全てのパラダイムに共通するいくつかの重要な課題を特定したで。ニューラル(神経回路網的)な知識システムとシンボリック(記号的)な知識システムの間にある表現ギャップが、それぞれ異なるけど同じくらい問題になる形で現れてんねん:KG構築では情報融合の障壁を生み出し、LLM強化では意味的なミスアラインメント(不整合)を引き起こし、協調システムでは統合の困難さをもたらすわけ。2つ目の普遍的な課題は動的な知識のメンテナンスに関するもので、KG更新のタイムリーさと、LLMの時間的推論の限界の両方を含んでて、リアルタイム処理の制約によってさらに複雑になってんねん。さらに、システム性能と解釈可能性の間には本質的なトレードオフがあって、これが常に説明可能性と信頼性のジレンマを生み出してるのも観察されたで。これが最も顕著に現れるのは、不透明な推論プロセス、曖昧な知識の出所、そして人間中心の評価フレームワークへの高まる需要やねん。
これらの共通課題が示唆してるのは、将来の進歩には、共有されたアーキテクチャ上の制約に対処しつつ、各パラダイム固有の要件にも対応できる包括的なソリューションが必要やってことやねん。これらの根本的な課題を特定することで、KG-LLM統合への3つのアプローチ全てを同時に前進させることができる統合的な研究方向を開発するための基盤を確立したわけや。
10 今後の方向性
10.1 知識リフレクションと動的更新
知識リフレクションと動的更新は、動的ナレッジグラフ研究における重要な方向性で、知識の適時性、正確性、適応性を確保することを目指してんねん。知識リフレクションっていうのは、古くなった情報、矛盾する情報、不完全な情報を特定して修正し、既存の知識を継続的に洗練していくものやねん。動的更新は、複数のソースからのデータから新しい知識をリアルタイムで抽出・統合して、KGの継続的な進化を促進することに焦点を当ててるわけ。今後の研究では、LLMの文脈学習能力を活用して、リフレクションと更新のフィードバックループを確立し、推論と更新のプロセスを最適化できる可能性があるねん。Mou et al.(2024)みたいな既存の研究は、リフレクションメカニズムがナレッジグラフ構築のダイナミズムと正確性を高めることを示してて、適応型KGの開発に新しい知見を提供してるで。
Frontiers in Computer Science
20
frontiersin.org
---
## Page 21
[](/attach/be35480839ed8df24385cd047d83444c3a9842de8dfb102c573c6610802d06cc_p021.png)
### 和訳
Cai et al.
10.3389/fcomp.2025.1590632
5つの重要な分野で使われてんねん:(1) 医療、(2) 産業、(3) 教育、(4) 金融、(5) 法律やな。
### 11.1 医療分野
医療の分野では、KG(知識グラフっていう、情報を網目みたいに整理したやつ)とLLM(ChatGPTみたいな大規模言語モデルのこと)を組み合わせることで、めっちゃいろんな医療アプリケーションが良くなる可能性見せてんねん。特に目立ってるのが、KGで強化したLLMを使った医療の質問応答システムやな(Yang et al., 2024c; Cabello et al., 2024)。KGに入ってる整理された医療知識とLLMを合体させることで、複雑な医療の質問にもっと正確で文脈に合った答えを返せるようになるわけや。例えばな、MEG(Cabello et al., 2024)とLLM-KGMQA(Wang F. et al., 2024)は、それぞれ事前学習済みのKGエンコーダーからグラフ埋め込み(知識を数字の羅列に変換したやつ)をLLMに統合して、LLMの推論能力を活かしてクエリの解釈を洗練させることで、知識グラフベースの質問応答を強化してんねん。それに加えて、KGで強化したLLMは会話エージェント(チャットボットみたいなやつ)も改善して、患者とのやり取りの時にもっと情報に基づいた返答ができるようにしてくれるんや(Varshney et al., 2023)。
バイオメディカル(生物医学)の分野では、CancerKG(Gubanov et al., 2024)みたいなプロジェクトが、複数のソースからがん関連データを集めた大規模なKGを活用してるで。さらに、DALK(LLMとKGの動的共同拡張)みたいなLLMとKGの組み合わせ(Li D. et al., 2024)は、病気に関する複雑な質問に答えることで研究者をサポートして、発見のプロセスを加速させてんねん。
### 11.2 産業分野
産業の分野では、KGとLLMの統合によって、品質テストやメンテナンス(Zhou et al., 2024; Su et al., 2024)、故障診断(Peifeng et al., 2024; Meng et al., 2022)、プロセス最適化とかのタスクをこなすインテリジェントシステムが進化してんねん。例えばな、BERT–BiLSTM–CRF(Meng et al., 2022)は、BERT、BiLSTM、CRFっていうモジュールを統合して、中国語の技術文書から電力機器のエンティティ(要素)を特定して、エンティティ間の意味的な関係を抽出してるんや。Su et al.(2024)は、LLMベースのchain-of-thought(CoT:段階的に考えていく推論方法)とKGを組み合わせて、めっちゃ実現可能で一貫性のあるテストシナリオを生成して、探索的テストをサポートしつつ、エラーレポートの品質がバラバラな問題とか実現不可能なテストシナリオみたいな課題に対処してんねん。
### 11.3 教育分野
教育の分野では、KGが複雑な学習コンテンツを整理して可視化するのに役立って、学生がより良く知識を理解して身につけられるようにしてんねん。LLMの自然言語処理能力と組み合わせることで、インテリジェントシステムは正確な学習ガイダンスと個人に合わせたおすすめを提供できるようになるんや。Jhajj et al.(2024)はGPT-4を使って教育用知識グラフ(EduKG)の構築を支援して、学習目標とカリキュラム構造を統合してグラフを検証したで。Abu-Rasheed et al.(2024)は、KGをLLMのための事実に基づく背景プロンプトとして使うことを提案して、LLMが埋めるテキストテンプレートを設計することで、正確でわかりやすい学習アドバイスを提供してんねん。
**図15**
LLMとKGの融合の応用分野
### 10.2 マルチモーダル知識グラフと言語モデルの統合
マルチモーダルKG(テキストだけやなくて画像とか音声とか、いろんな種類のデータを扱える知識グラフ)と言語モデル(LM)の統合は、人工知能分野のめっちゃ重要な最先端テーマやねん。テキスト、画像、音声、センサーデータとか、いろんなモダリティ(データの種類)をまたいで理解して推論できるインテリジェントシステムを構築することを目指してるんや。将来の研究は、統一表現学習の実現に焦点を当てていって、言語モデルがマルチモーダルKG内の構造化された多様なデータをフル活用できるようにするで。さらに、動的なマルチモーダルKGの構築が重要な方向性になって、システムは異なるデータストリームから継続的に新しい知識を抽出、更新、統合することが求められるんや。
### 10.3 時間的推論
時間的推論は、AIの推論においてめっちゃ重要な課題やねん。時間的な論理、因果関係、動的な知識の理解と予測に関わってくるんや。近年、LLMの発展によって新しいアプローチが出てきてんねん。現在の研究は主に、検索拡張生成フレームワーク(例えばGenTKG(Liao et al., 2024))を通じて時間的知識グラフ(TKG)とLLMのギャップに対処してて、few-shot学習(少ない例から学ぶやつ)と指示チューニングを統合することで計算コストを削減してんねん。それに加えて、TG-LLM(Xiong et al., 2024)やchain-of-thought(CoT)推論みたいなモデルが、複雑な時間的論理を理解するLLMの能力を強化してるで。さらに、生成型時間的質問応答フレームワーク(GenTKGQA)(Gao et al., 2024)は、サブグラフ検索と仮想知識統合を組み合わせることで効率的な推論を実現してんねん。将来の研究は、時間データ表現の最適化、クロスドメイン汎化(異なる分野でも使えるようにすること)の改善、時間的論理と因果関係の深いモデリングに焦点を当てて、AIにおける時間的推論の知能と効率を進歩させていくで。
### 11 応用
図15に示すように、知識グラフ(KG)と大規模言語モデル(LLM)の統合は、うまいこと成功してんねん。
Frontiers in Computer Science
21
frontiersin.org
---
## Page 22
[](/attach/be35480839ed8df24385cd047d83444c3a9842de8dfb102c573c6610802d06cc_p022.png)
### 和訳
Caiさんたちの研究やねん。
10.3389/fcomp.2025.1590632
## 11.4 金融分野
金融の世界では、ナレッジグラフ(KG)と大規模言語モデル(LLM)を組み合わせることで、金融リスクの管理とか、詐欺の検出とか、賢い投資アドバイスサービスにめっちゃ強力な技術的サポートができるようになってんねん。金融用のナレッジグラフを作ることで、会社とか個人とか取引みたいなもんを全部つなげて、「ここヤバいかも」っていうリスク要因を見つけられるようになるわけや。ほんで、LLMがめっちゃ大量の財務報告書とかニュースとか取引記録から情報を引っ張り出してきて、リスク評価とか意思決定のヒントをくれるねん。FinDKG(Li, 2023)がええ例やな。さらに、LLMで強化されたナレッジグラフの質問応答システムを使えば、金融相談もできて、個人も企業もちゃんと情報に基づいた投資判断ができるようになるんや。
## 11.5 法律分野
法律の分野では、ナレッジグラフとLLMを組み合わせることで、法律の質問応答(Shiさんたち、2024)とか、裁判の予測(Liu, 2024; Gao S.さんたち、2023)とか、法律文書の自動生成みたいな賢いアプリケーションが進んでるねん。法律用のナレッジグラフを作ると、法律とか判例とか過去の事例を整理できて、裁判官とか弁護士とか一般の人にも、ちゃんと構造化された法律知識を提供できるようになるわけや。LLMは言語生成とか推論がめっちゃ得意やから、このナレッジグラフを活用して、法律相談とか裁判予測とか法律文書の自動生成サービスを提供してくれるんやで。
## 12 結論
この研究では、ナレッジグラフとLLMを統合する3つのアプローチを体系的に分析してんねん:KEL(ナレッジグラフで強化したLLM)、LEK(LLMで強化したナレッジグラフ)、そしてLKC(LLMとナレッジグラフの協調)の3つや。これまでの研究を包括的にレビューした結果、こういう統合によって、構造化された知識と言語モデルそれぞれの強みをうまく組み合わせられることがわかったんや。質問応答システムとか意思決定支援みたいな具体的なタスクで、ほんまに実用的な価値があることが示されてるで。せやけど、知識の表現方法とか処理の仕方に根本的な違いがあるから、実際に統合しようとすると、リアルタイムで知識を更新するときの効率の問題とか、異なるモダリティ(形式)をまたいで学習するときの表現の一貫性みたいな、いくつかの重要な課題がまだ残ってるんやな。
この研究では、こういう技術的課題を体系的に検討することで、将来の研究の方向性を示す参考になるもんを提供してるんやで。
## 参考文献
Abu-Rasheed, H., Weber, C., and Fathi, M. (2024). 学習推薦の説明のためのLLMの文脈ソースとしてのナレッジグラフ。arXivプレプリント arXiv:2403.03008.
Amershi, S., Weld, D., Vorvoreanu, M., Fourney, A., Nushi, B., Collisson, P., et al. (2019). 「人間とAIのインタラクションのためのガイドライン」、2019 Chi Conference on Human Factors in Computing Systems論文集、1–13. doi: 10.1145/3290605.3300233
Anelli, V. W., Di Noia, T., Di Sciascio, E., Ferrara, A., and Mancino, A. C. M. (2021). 「ナレッジグラフを使った推薦システムのためのスパース特徴量分解」、第15回ACM Conference on Recommender Systems論文集、154–165. doi: 10.1145/3460231.3474243
## 著者の貢献
LC:原稿執筆。CY:原稿執筆。YK:原稿執筆。YF:原稿執筆。HZ:原稿執筆。YZ:執筆 – レビューと編集。
## 資金提供
著者らは、この研究および/または論文の出版に対して資金援助を受けたことを宣言するで。この研究は中国国家自然科学基金(NSFC)の助成金[No.62177007]によって支援されてんねん。
## 利益相反
著者らは、潜在的な利益相反と解釈される可能性のある商業的または金銭的関係がない状態でこの研究が行われたことを宣言するで。
## 生成AIに関する声明
著者らは、この原稿の作成に生成AIを使用したことを宣言するで。テキストの明確さと一貫性を改善するための提案を提供し、別の言い回しや表現を提案することで改訂プロセスを支援するために使ってんねん。
## 出版社からの注記
この論文で述べられているすべての主張は著者らのみのもんであり、必ずしも所属組織、出版社、編集者、査読者の見解を代表するもんやないで。この論文で評価される可能性のある製品、またはその製造者によってなされる可能性のある主張は、出版社によって保証または承認されたもんやないで。
Ayoola, T., Tyagi, S., Fisher, J., Christodoulopoulos, C., and Pierleoni, A. (2022). Refined:エンドツーエンドのエンティティリンキングへの効率的なゼロショット対応アプローチ。arXivプレプリント arXiv:2207.04108.
Bender, E. M., Gebru, T., McMillan-Major, A., and Shmitchell, S. (2021). 「確率的オウムの危険性について:言語モデルは大きすぎることがあるのか?」、2021 ACM Conference on Fairness, Accountability, and Transparency論文集、610–623. doi: 10.1145/3442188.3445922
Biswas, R., Sack, H., and Alam, M. (2024). Madlink:ナレッジグラフにおけるリンク予測のための注意機構を用いたマルチホップとエンティティ記述。Semant. Web 15, 83–106. doi: 10.3233/SW-222960
Bordes, A., Usunier, N., Garcia-Duran, A., Weston, J., and Yakhnenko, O. (2013). 「多関係データのモデリングのための埋め込み変換」、Advances in Neural Information Processing Systems, 26.
Boylan, J., Mangla, S., Thorn, D., Ghalandari, D. G., Ghaffari, P., and Hokamp, C. (2024). KGValidator:ナレッジグラフ構築の自動検証フレームワーク。arXivプレプリント arXiv:2404.15923.
Frontiers in Computer Science
22
frontiersin.org
---
## Page 23
[](/attach/be35480839ed8df24385cd047d83444c3a9842de8dfb102c573c6610802d06cc_p023.png)
### 和訳
Cai et al.
10.3389/fcomp.2025.1590632
Brown, P. F., Della Pietra, V. J., Desouza, P. V., Lai, J. C., and Mercer, R. L. (1992).
「クラスベースのn-gramモデルで自然言語を扱う話」っていう研究やな。これ何かっていうと、言葉をグループ分けして、次にどんな言葉が来るか予測する手法やねん。Comput. Linguist. 18, 467–480に載ってるで。
Cabello, L., Martin-Turrero, C., Akujuobi, U., Søgaard, A., and Bobed, C. (2024).
Megっていう、医療知識をめっちゃ詰め込んだ大規模言語モデルで質問に答えるシステムの論文や。arXiv preprint arXiv:2411.03883に出てるで。
Caciularu, A., Cohan, A., Beltagy, I., Peters, M. E., Cattan, A., and Dagan, I. (2021).
CDLMっていうのは、複数の文書をまたいで言語をモデル化する手法やねん。一個の文書だけやなくて、いろんな文書の関係性を理解できるようになるんや。arXiv preprint arXiv:2101.00406やで。
Cao, X., and Liu, Y. (2023).
RelMKGっていう研究で、事前学習した言語モデルと知識グラフを組み合わせて、めっちゃ複雑な質問にも答えられるようにしたんや。知識グラフって何かっていうと、「誰が」「何を」「どうした」みたいな情報をネットワーク状につなげたデータベースみたいなもんやな。Appl. Intell. 53, 12032–12046に載ってるで。doi: 10.1007/s10489-022-04123-w
Chen, R., Qin, C., Jiang, W., and Choi, D. (2024).
「大規模言語モデルって、イベント抽出のアノテーター(データにラベル付けする人)としてイケてるん?」っていう研究やな。AAAI Conference on Artificial Intelligenceで発表されて、17772–17780ページに載ってる。doi: 10.1609/aaai.v38i16.29730
Chen, S., Zhang, Q., Dong, J., Hua, W., Li, Q., and Huang, X. (2024).
大規模言語モデルからのノイズ混じりのアノテーション(ちょっと間違いが入ってるラベル付け)を使ってエンティティアライメント(異なるデータベース間で同じものを対応付ける作業)する研究やで。arXiv preprint arXiv:2405.16806
Chen, W., Su, Y., Yan, X., and Wang, W. Y. (2020).
KGPTっていうのは、知識を土台にした事前学習で、データから文章を生成する手法やねん。arXiv preprint arXiv:2010.02307
Chen, X., Lu, T., and Wang, Z. (2024).
LLM-Alignは、大規模言語モデルを使って知識グラフ同士のエンティティを対応付ける研究や。arXiv preprint arXiv:2412.04690
Chen, X., Zhang, J., Wang, X., Zhang, N., Wu, T., Wang, Y., et al. (2023).
マルチモーダル(テキストだけやなくて画像とかも含む)な知識グラフを継続的に作っていく研究やで。arXiv preprint arXiv:2305.08698
Choi, B., Jang, D., and Ko, Y. (2021).
Mem-KGCっていうのは、事前学習済み言語モデルを使ってマスク(隠した)エンティティモデルで知識グラフを補完する手法や。知識グラフって穴だらけのことが多いから、その穴を埋めるんやな。IEEE Access 9, 132025–132032に載ってる。doi: 10.1109/ACCESS.2021.3113329
Choi, B., and Ko, Y. (2023).
事前学習済み言語モデルを使って、統一的な学習方法で知識グラフを拡張する研究やで。Knowl.-Based Syst. 262:110245に載ってる。doi: 10.1016/j.knosys.2022.110245
Colas, A., Alvandipour, M., and Wang, D. Z. (2022).
GAPっていうのは、グラフを理解できる言語モデルのフレームワークで、知識グラフから文章を生成するんや。arXiv preprint arXiv:2204.06674
Dai, D., Dong, L., Hao, Y., Sui, Z., Chang, B., and Wei, F. (2021).
事前学習済みTransformerの中にある「知識ニューロン」っていう研究やな。モデルの中のどのニューロンが知識を持ってるか調べたんや。めっちゃ面白いで。arXiv preprint arXiv:2104.08696
Ding, Y., Zeng, Q., and Weninger, T. (2024).
ChatELは、チャットボットを使ってエンティティリンキング(テキスト中の言葉を知識ベースの項目に紐付ける作業)する研究や。arXiv preprint arXiv:2402.14858
Ding, Z., Cai, H., Wu, J., Ma, Y., Liao, R., Xiong, B., et al. (2024).
ZRLLMっていうのは、時間的な知識グラフ(いつ何が起きたかも含む知識グラフ)に対して、大規模言語モデルを使ってゼロショット(事前に例を見せずに)で関係を学習する手法やねん。NAACL 2024で発表されて、1877–1895ページに載ってる。doi: 10.18653/v1/2024.naacl-long.104
Du, H., Li, C., Zhang, D., and Zhao, D. (2024).
知識グラフから文章を生成するための双方向マルチ粒度生成フレームワークっていう研究で、大規模言語モデルを使うんや。ACL 2024で発表されて、147–152ページに載ってる。doi: 10.18653/v1/2024.acl-short.14
Edge, D., Trinh, H., Cheng, N., Bradley, J., Chao, A., Mody, A., et al. (2024).
「ローカルからグローバルへ:クエリに特化した要約のためのグラフRAGアプローチ」っていう研究やな。RAGってのは、検索で情報を取ってきて、それを使って回答を生成する手法やねん。arXiv preprint arXiv:2404.16130
Fan, W., Geerts, F., and Jia, X. (2007).
データ品質を改善する話で、一貫性と正確性についての本や。ACMから出版されてるで。
Feng, C., Zhang, X., and Fei, Z. (2023).
Knowledge Solverは、大規模言語モデルに知識グラフからドメイン知識を検索させる方法を教える研究やな。arXiv preprint arXiv:2309.03118
Galárraga, L. A., Teflioudi, C., Hose, K., and Suchanek, F. (2013).
AMIEっていうのは、不完全な証拠しかないオントロジカルな知識ベースで関連ルールをマイニングする手法や。WWW 2013で発表されて、413–422ページに載ってる。doi: 10.1145/2488388.2488425
Gao, P., Han, J., Zhang, R., Lin, Z., Geng, S., Zhou, A., et al. (2023).
LLaMA-Adapter v2は、パラメータ効率のいい視覚的な指示モデルやねん。少ないパラメータの調整だけで、画像も理解できるようになるんや。arXiv preprint arXiv:2304.15010
Gao, S., Sa, R., Li, Y., Ge, F., Yu, H., Wang, S., et al. (2023).
法律の知識グラフが法的テキストの罪状予測にどう役立つかっていう研究やで。ICONIP 2023で発表されて、408–420ページに載ってる。doi: 10.1007/978-981-99-8076-5_30
Gao, Y., Qiao, L., Kan, Z., Wen, Z., He, Y., and Li, D. (2024).
時間的知識グラフに対して、大規模言語モデルを使った2段階生成型質問応答の研究やな。arXiv preprint arXiv:2402.16568。doi: 10.18653/v1/2024.findings-acl.401
Gottschalk, S., and Demidova, E. (2018).
EventKGっていうのは、多言語対応のイベント中心の時間的知識グラフやねん。「いつ」「どこで」「何が起きた」っていうイベント情報をまとめたデータベースや。ESWC 2018で発表されて、272–287ページに載ってる。doi: 10.1007/978-3-319-93417-4_18
Gubanov, M., Pyayt, A., and Karolak, A. (2024).
CancerKG.orgは、Webスケールでインタラクティブで検証可能な知識グラフとLLMのハイブリッドシステムで、最適ながん治療とケアを支援するんや。CIKM 2024で発表されて、4497–4505ページに載ってる。doi: 10.1145/3627673.3680094
Guo, L., Bo, Z., Chen, Z., Zhang, Y., Chen, J., Yarong, L., et al. (2025).
MKGLは「3単語言語のマスタリー」っていう研究で、NeurIPS 2025で発表されて、140509–140534ページに載ってるで。
Guo, Q., Cao, S., and Yi, Z. (2022).
大規模言語モデルと知識グラフを使った医療質問応答システムの研究やな。Int. J. Intell. Syst. 37, 8548–8564に載ってる。doi: 10.1002/int.22955
Guu, K., Lee, K., Tung, Z., Pasupat, P., and Chang, M. (2020).
検索で情報を補強した言語モデルの事前学習っていう研究で、ICML 2020で発表されて、3929–3938ページに載ってるで。
Hao, S., Tan, B., Tang, K., Ni, B., Shao, X., Zhang, H., et al. (2022).
BertNetは、事前学習済み言語モデルから任意の関係を持つ知識グラフを収穫する研究やねん。arXiv preprint arXiv:2206.14268
He, B., Zhou, D., Xiao, J., Liu, Q., Yuan, N. J., Xu, T., et al. (2019).
グラフの文脈化された知識を事前学習済み言語モデルに統合する研究やで。arXiv preprint arXiv:1912.00147
Heim, D., Meyer, L.-P., Schröder, M., Frey, J., and Dengel, A. (2025).
「スケーリング則って知識グラフエンジニアリングのタスクにどう適用されるん?モデルサイズが大規模言語モデルのパフォーマンスに与える影響」っていう研究やな。arXiv preprint arXiv:2505.16276
Honovich, O., Aharoni, R., Herzig, J., Taitelbaum, H., Kukliansy, D., Cohen, V., et al. (2022).
TRUEは、事実の一貫性評価を再評価する研究やねん。AIが嘘ついてないかチェックする方法を見直してるんや。arXiv preprint arXiv:2204.04991
Huang, N., Deshpande, Y. R., Liu, Y., Alberts, H., Cho, K., Vania, C., et al. (2022).
言語モデルにマルチモーダルな知識グラフ表現を持たせる研究やで。arXiv preprint arXiv:2206.13163
Ibrahim, N., Aboulela, S., Ibrahim, A., and Kashef, R. (2024).
大規模言語モデルで知識グラフを拡張することに関するサーベイ論文やな。モデル、評価指標、ベンチマーク、課題についてまとめてるで。Disc. Artif. Intell. 4:76に載ってる。doi: 10.1007/s44163-024-00175-8
Jhajj, G., Zhang, X., Gustafson, J. R., Lin, F., and Lin, M. P.-C. (2024).
LLMを使った教育用知識グラフの作成と拡張の研究やねん。ITS 2024で発表されて、292–304ページに載ってる。doi: 10.1007/978-3-031-63031-6_25
Jiang, J., Zhou, K., Dong, Z., Ye, K., Zhao, W. X., and Wen, J.-R. (2023).
StructGPTは、大規模言語モデルが構造化データに対して推論するための汎用フレームワークやで。arXiv preprint arXiv:2305.09645
Jiang, J., Zhou, K., Zhao, W. X., Song, Y., Zhu, C., Zhu, H., et al. (2024).
KG-Agentは、知識グラフ上での複雑な推論のための効率的な自律エージェントフレームワークやねん。arXiv preprint arXiv:2402.11163
Jiang, P., Agarwal, S., Jin, B., Wang, X., Sun, J., and Han, J. (2023).
事前学習済み言語モデルを使って、テキストで補強したオープン知識グラフ補完の研究やで。arXiv preprint arXiv:2305.15597
Jiang, P., Cao, L., Xiao, C. D., Bhatia, P., Sun, J., and Han, J. (2024).
KG-FITは、オープンワールドの知識に対する知識グラフのファインチューニングの研究で、NeurIPS 2024で発表されてるで。
[...テキスト省略...]
---
## Page 24
[](/attach/be35480839ed8df24385cd047d83444c3a9842de8dfb102c573c6610802d06cc_p024.png)
### 和訳
Cai et al.
10.3389/fcomp.2025.1590632
Li, X. V. (2023). Findkg: 大規模言語モデルを使ったグローバル金融向けの動的ナレッジグラフ。SSRN 4608445で公開中やで。doi: 10.2139/ssrn.4608445
Liao, Q. V., and Vaughan, J. W. (2023). LLM時代のAI透明性:人間中心の研究ロードマップ。arXiv プレプリント arXiv:2306.01941,01910.
Mirkhani, K., Chaggares, C., Masterson, C., Jastrzebski, M., Dusatko, T., Sinclair, A., et al. (2004). EMAT送信機の最適設計。これ何かっていうと、電磁超音波トランスデューサーっていう非接触で材料検査できるやつの送信部分をどう設計したら一番ええかって話やねん。NDT e Int. 37, 181–193. doi: 10.1016/j.ndteint.2003.09.005
Moiseev, F., Dong, Z., Alfonseca, E., and Jaggi, M. (2022). SKILL: 大規模言語モデルへの構造化された知識注入。要するにLLMに知識グラフとかの構造化データをうまいこと教え込む方法やねん。arXiv プレプリント arXiv:2205.08184.
Liao, R., Jia, X., Li, Y., Ma, Y., and Tresp, V. (2023). GenTKG: 大規模言語モデルを使った時間的ナレッジグラフでの生成的予測。時間とともに変化するナレッジグラフで「次に何が起こるか」をLLMで予測しようって研究やな。arXiv プレプリント arXiv:2310.07793.
Liao, R., Jia, X., Li, Y., Ma, Y., and Tresp, V. (2024). "GenTKG: 大規模言語モデルを使った時間的ナレッジグラフでの生成的予測," Findings of the Association for Computational Linguistics: NAACL 2024, 4303–4317. doi: 10.18653/v1/2024.findings-naacl.268
Lin, B. Y., Chen, X., Chen, J., and Ren, X. (2019). KagNet: 常識推論のための知識認識グラフネットワーク。これめっちゃおもろくて、人間の常識をグラフにして推論に使うんやで。arXiv プレプリント arXiv:1909.02151.
Lin, C.-Y. (2004). "ROUGE: 要約の自動評価のためのパッケージ," Text Summarization Branches Out, 74–81. 機械が作った要約がどれくらいええかを自動で測るツールやねん。
Liu, F. (2024). "ナレッジグラフとディープラーニングによる法的判決予測の設計," 2024 IEEE 2nd International Conference on Image Processing and Computer Applications (ICIPCA) (IEEE), 1192–1195. doi: 10.1109/ICIPCA61593.2024.10709293 裁判の結果をAIで予測しようっていう研究やで。
Liu, H., Wang, S., Zhu, Y., Dong, Y., and Li, J. (2024). パス選択によるナレッジグラフ強化大規模言語モデル。ナレッジグラフの中から関連する経路を選んでLLMの回答を良くしようって話やな。arXiv プレプリント arXiv:2406.13862.
Liu, J., Ke, W., Wang, P., Shang, Z., Gao, J., Li, G., et al. (2024). "増分蒸留による継続的ナレッジグラフ埋め込みに向けて," Proceedings of the AAAI Conference on Artificial Intelligence, 8759–8768. doi: 10.1609/aaai.v38i8.28722 新しい知識が追加されても前の知識を忘れへんように学習する方法やねん。
Liu, Q., He, Y., Xu, T., Lian, D., Liu, C., Zheng, Z., et al. (2024). "UniMEL: 大規模言語モデルを使ったマルチモーダルエンティティリンキングの統一フレームワーク," Proceedings of the 33rd ACM International Conference on Information and Knowledge Management, 1909–1919. doi: 10.1145/3627673.3679793 画像とテキストの両方を使ってエンティティを結びつけるやつやで。
Liu, S., Semnani, S. J., Triedman, H., Xu, J., Zhao, I. D., and Lam, M. S. (2024). SPINACH: 難しい現実世界の質問に対するSPARQLベースの情報ナビゲーション。SPARQLっていうのはナレッジグラフを検索するための言語やねん。arXiv プレプリント arXiv:2407.11417.
Liu, W., Zhou, P., Zhao, Z., Wang, Z., Ju, Q., Deng, H., et al. (2020). "K-BERT: ナレッジグラフによる言語表現の実現," Proceedings of the AAAI Conference on Artificial Intelligence, 2901–2908. doi: 10.1609/aaai.v34i03.5681 BERTにナレッジグラフの知識を組み込んだやつやで。めっちゃ賢くなるねん。
Liu, Y., Tian, X., Sun, Z., and Hu, W. (2024). "ナレッジグラフ補完のための識別命令による生成的大規模言語モデルのファインチューニング," International Semantic Web Conference (Springer), 199–217. doi: 10.1007/978-3-031-77844-5_11 ナレッジグラフの欠けてる部分をLLMで埋める方法やな。
Lukovnikov, D., Fischer, A., and Lehmann, J. (2019). "ナレッジグラフ上の単純な質問応答のための事前学習済みトランスフォーマー," The Semantic Web-ISWC 2019, (Springer), 470–486. doi: 10.1007/978-3-030-30793-6_27
Luo, H., Tang, Z., Peng, S., Guo, Y., Zhang, W., Ma, C., et al. (2023). ChatKBQA: ファインチューニングした大規模言語モデルによるナレッジベース質問応答のための生成→検索フレームワーク。まず答えを生成してから検索で確認するっていう二段構えやねん。arXiv プレプリント arXiv:2310.08975.
Luo, L., Ju, J., Xiong, B., Li, Y.-F., Haffari, G., and Pan, S. (2023a). ChatRule: ナレッジグラフ推論のための大規模言語モデルによる論理ルールマイニング。LLMを使ってナレッジグラフから論理的なルールを見つけ出すんやで。arXiv プレプリント arXiv:2309.01538.
Mou, Y., Liu, L., Sowe, S., Collarana, D., and Decker, S. (2024). "命令駆動型ナレッジグラフ構築を改善するためのLLMの少数ショット学習の活用," Proceedings of the VLDB Endowment. ISSN 2150, 8097. 少ない例示だけでナレッジグラフを作れるようにする研究やな。
Nath, A., Manafi, S., Chelle, A., and Krishnaswamy, N. (2024). よっしゃ、やったろか!生成された根拠と知識蒸留によるイベント共参照モデリング。違う表現で書かれてても同じ出来事を指してるって認識する研究やねん。arXiv プレプリント arXiv:2404.03196.
Pan, J. Z., Razniewski, S., Kalo, J.-C., Singhania, S., Chen, J., Dietze, S., et al. (2023). 大規模言語モデルとナレッジグラフ:機会と課題。LLMとKGを組み合わせたら何ができるか、何が難しいかをまとめたサーベイ論文やで。arXiv プレプリント arXiv:2308.06374.
Pan, S., Luo, L., Wang, Y., Chen, C., Wang, J., and Wu, X. (2024). 大規模言語モデルとナレッジグラフの統合:ロードマップ。この分野の今後の方向性を示した重要な論文やな。IEEE Trans. Knowl. Data Eng. 36, 3580–3599. doi: 10.1109/TKDE.2024.3352100
Papineni, K., Roukos, S., Ward, T., and Zhu, W.-J. (2002). "BLEU: 機械翻訳の自動評価手法," Proceedings of the 40th annual meeting of the Association for Computational Linguistics, 311–318. doi: 10.3115/1073083.1073135 翻訳の品質を自動で測る超有名な指標やで。今でもめっちゃ使われとるねん。
Peifeng, L., Qian, L., Zhao, X., and Tao, B. (2024). ナレッジグラフと大規模言語モデルの統合による故障診断と航空組立への応用。飛行機の組み立て工程で不具合を見つけるのに使うねん。IEEE Trans. Ind. Inform. 20, 8160–8169. doi: 10.1109/TII.2024.3366977
Peng, B., Zhu, Y., Liu, Y., Bo, X., Shi, H., Hong, C., et al. (2024). グラフ検索拡張生成:サーベイ。GraphRAGって呼ばれる、グラフを使ってLLMの回答を良くする手法のまとめやで。arXiv プレプリント arXiv:2408.08921.
Petroni, F., Rocktäschel, T., Lewis, P., Bakhtin, A., Wu, Y., Miller, A. H., et al. (2019). 言語モデルはナレッジベースになれるか?LLMの中に知識がどれくらい入ってるかを調べた有名な研究やねん。arXiv プレプリント arXiv:1909.01066.
Pradeep, R., Lee, D., Mousavi, A., Pound, J., Sang, Y., Lin, J., et al. (2024). ConvKGYarn: 大規模言語モデルを使った設定可能でスケーラブルな会話型ナレッジグラフQAデータセットの生成。対話形式のQAデータセットを自動で作る方法やで。arXiv プレプリント arXiv:2408.05948.
Rabiner, L., and Juang, B. (1986). 隠れマルコフモデル入門。これ古典的やけどめっちゃ重要な論文やねん。音声認識とかの基礎になっとる。IEEE Assp Magaz. 3, 4–16. doi: 10.1109/MASSP.1986.1165342
Razouk, H., Liu, X. L., and Kern, R. (2023). 常識ナレッジグラフ補完技術によるFMEA理解可能性の改善。FMEAっていうのは故障モード影響解析のことで、製品の不具合を予測する手法やねん。IEEE Access 11, 127974–127986. doi: 10.1109/ACCESS.2023.3331585
Ren, X., Tang, J., Yin, D., Chawla, N., and Huang, C. (2024). "グラフのための大規模言語モデルのサーベイ," Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 6616–6626. doi: 10.1145/3637528.3671460
Runfeng, X., Xiangyang, C., Zhou, Y., Xin, W., Zhanwei, X., Kai, Z., et al. (2023). LKPNR: LLMとKGによるパーソナライズドニュース推薦フレームワーク。あんたの好みに合ったニュースを勧めてくれるシステムやで。arXiv プレプリント arXiv:2308.12028.
Sanmartin, D. (2024). KG-RAG: 知識と創造性のギャップを埋める。ナレッジグラフを使ったRAGの研究やな。arXiv プレプリント arXiv:2405.12035.
Sansford, H., Richardson, N., Maretic, H. P., and Saada, J. N. (2024). GraphEval: ナレッジグラフベースのLLMハルシネーション評価フレームワーク。LLMが嘘ついてないかをナレッジグラフで確認する方法やねん。arXiv プレプリント arXiv:2407.10793.
Saparov, A., and He, H. (2022). 言語モデルは貪欲な推論者である:Chain-of-Thoughtの体系的形式分析。LLMの推論能力を細かく分析した研究で、実は結構限界があることを示したんやで。arXiv プレプリント arXiv:2210.01240.
Luo, L., Li, Y.-F., Haffari, G., and Pan, S. (2023b). グラフ上の推論:忠実で解釈可能な大規模言語モデル推論。LLMがちゃんと根拠に基づいて推論できるようにする研究やな。arXiv プレプリント arXiv:2310.01061.
Saxena, A., Kochsiek, A., and Gemulla, R. (2022). シーケンス-to-シーケンスによるナレッジグラフ補完と質問応答。系列変換モデルを使ってナレッジグラフの欠けてる部分を埋めたり質問に答えたりするねん。arXiv プレプリント arXiv:2203.10321.
Luo, L., Vu, T.-T., Phung, D., and Haffari, G. (2023c). 大規模言語モデルにおける事実知識の体系的評価。LLMがほんまに正しい知識持ってるかを徹底的に調べた研究やで。arXiv プレプリント arXiv:2310.11638.
Luo, Z., Xie, Q., and Ananiadou, S. (2024). 大規模言語モデル時代における要約の事実整合性評価。LLMが作った要約が元の文章とちゃんと合ってるかを評価する方法やねん。Expert Syst. Appl. 254:124456. doi: 10.1016/j.eswa.2024.124456
Ma, M. D., Wang, X., Kung, P.-N., Brantingham, P. J., Peng, N., and Wang, W. (2024). "STAR: 大規模言語モデルによる構造-to-テキストデータ生成で低リソース情報抽出を強化," Proceedings of the AAAI Conference on Artificial Intelligence, 18751–18759. doi: 10.1609/aaai.v38i17.29839 データが少ない状況でも情報抽出できるようにする研究やな。
Ma, S., Xu, C., Jiang, X., Li, M., Qu, H., and Guo, J. (2024). Think-on-Graph 2.0: 深く解釈可...
[...テキスト省略...]
---
## Page 25
[](/attach/be35480839ed8df24385cd047d83444c3a9842de8dfb102c573c6610802d06cc_p025.png)
### 和訳
Cai らの研究やねん。
10.3389/fcomp.2025.1590632
Su, Y., Han, X., Zhang, Z., Lin, Y., Li, P., Liu, Z., ら(2021)。Cokebert:文脈に合わせた知識の選び方と埋め込みで、事前学習した言語モデルをもっとパワーアップさせる方法やねん。AI Open 2, 127–134。doi: 10.1016/j.aiopen.2021.06.004
Wang, Y., Feng, S., Wang, H., Shi, W., Balachandran, V., He, T., ら(2023)。大規模言語モデルの中で起こる知識のケンカを解決する方法やで。arXiv プレプリント arXiv:2310.00935。
Su, Y., Liao, D., Xing, Z., Huang, Q., Xie, M., Lu, Q., ら(2024)。「大規模言語モデルとナレッジグラフを使って探索的テストをめっちゃ強化する話」、IEEE/ACM 第46回国際ソフトウェア工学会議の論文集、1–12。doi: 10.1145/3597503.3639157
Su, Z., Wang, D., Miao, C., and Cui, L.(2023)。「センテンストランスフォーマーを使った多角的に説明できる帰納的関係予測」、AAAI人工知能会議論文集、6533–6540。doi: 10.1609/aaai.v37i5.25803
Sun, J., Xu, C., Tang, L., Wang, S., Lin, C., Gong, Y., ら(2023)。Think-on-graph:ナレッジグラフ上で大規模言語モデルが深くて責任ある推論をする仕組みやねん。arXiv プレプリント arXiv:2307.07697。
Sun, L., Zhang, P., Gao, F., An, Y., Li, Z., and Zhao, Y.(2025)。SF-GPT:大規模言語モデルでナレッジグラフを作る能力を、追加学習なしでパワーアップさせる方法やで。Neurocomputing 613:128726。doi: 10.1016/j.neucom.2024.128726
Sun, T., Shao, Y., Qiu, X., Guo, Q., Hu, Y., Huang, X., ら(2020)。Colake:文脈を考慮した言語と知識の埋め込みやねん。arXiv プレプリント arXiv:2010.00309。
Sun, Y., Shi, Q., Qi, L., and Zhang, Y.(2021a)。Jointlk:常識的な質問応答のために言語モデルとナレッジグラフを一緒に使って推論する方法やで。arXiv プレプリント arXiv:2112.02732。
Sun, Y., Wang, S., Feng, S., Ding, S., Pang, C., Shang, J., ら(2021b)。Ernie 3.0:言語の理解と生成のために知識をめっちゃ取り入れた大規模事前学習モデルやねん。arXiv プレプリント arXiv:2107.02137。
Sung, M., Lee, J., Yi, S., Jeon, M., Kim, S., and Kang, J.(2021)。言語モデルって生物医学の知識ベースになれるんかな?っていう研究やで。arXiv プレプリント arXiv:2109.07154。
Tao, Z., Chen, X., Jin, Z., Bai, X., Zhao, H., and Lou, Y.(2024)。Evit:イベント推論のためのイベント指向インストラクションチューニングやねん。arXiv プレプリント arXiv:2404.11978。
Tian, Y., Song, H., Wang, Z., Wang, H., Hu, Z., Wang, F., ら(2024)。「大規模言語モデルを使ったグラフニューラルプロンプティング」、AAAI人工知能会議論文集、19080–19088。doi: 10.1609/aaai.v38i17.29875
Varshney, D., Zafar, A., Behera, N. K., and Ekbal, A.(2023)。ナレッジグラフを使った端から端までの医療対話生成やで。Artif. Intell. Med. 139:102535。doi: 10.1016/j.artmed.2023.102535
Vaswani, A.(2017)。「Attention is all you need(アテンション機構だけでいけるで)」、神経情報処理システム学会の発展論文集。
Waldock, W. J., Zhang, J., Guni, A., Nabeel, A., Darzi, A., and Ashrafian, H.(2024)。医療の試験や資格認定でAIソリューションがどんだけ正確で使えるか:システマティックレビューとメタ分析やねん。J. Med. Internet Res. 26:e56532。doi: 10.2196/56532
Wang, B., Shen, T., Long, G., Zhou, T., Wang, Y., and Chang, Y.(2021)。「効率的なナレッジグラフ補完のための構造で強化されたテキスト表現学習」、2021年ウェブ会議論文集、1737–1748。doi: 10.1145/3442381.3450043
Wang, F., Shi, D., Aguilar, J., Cui, X., Jiang, J., Shen, L., ら(2024)。Llmkg-mqa:医療分野のナレッジグラフをベースにした大規模言語モデル強化型マルチホップ質問応答システムやで。Knowl. Inf. Syst. 2025:s1115。doi: 10.1007/s10115-025-02399-1
Wang, J., Huang, W., Shi, Q., Wang, H., Qiu, M., Li, X., ら(2022)。自然言語理解のための事前学習言語モデルにおける知識プロンプティングやねん。arXiv プレプリント arXiv:2210.08536。
Wang, J., Sun, Q., Li, X., and Gao, M.(2023a)。知識の連鎖プロンプティングで言語モデルの推論をブーストする方法やで。arXiv プレプリント arXiv:2306.06427。
Wang, J., Wang, B., Qiu, M., Pan, S., Xiong, B., Liu, H., ら(2023b)。時間的ナレッジグラフ補完に関するサーベイ:分類・進捗・今後の展望やねん。arXiv プレプリント arXiv:2308.02457。
Wang, K., Duan, F., Wang, S., Li, P., Xian, Y., Yin, C., ら(2023)。Knowledge-driven cot:知識集約型質問応答のために大規模言語モデルで忠実な推論を探る方法やで。arXiv プレプリント arXiv:2308.13259。
Wang, K., Xu, Y., Wu, Z., and Luo, S.(2024)。LLM as prompter:少ないリソースで任意のナレッジグラフ上で帰納的推論をする方法やねん。arXiv プレプリント arXiv:2402.11804。
Wang, L., Zhao, W., Wei, Z., and Liu, J.(2022)。SIMKGC:事前学習言語モデルを使ったシンプルな対照学習でナレッジグラフ補完する方法やで。arXiv プレプリント arXiv:2203.02167。
Wang, P., Xie, X., Wang, X., and Zhang, N.(2023)。「記憶を通じた推論:最近傍ナレッジグラフ埋め込み」、CCF自然言語処理・中国語コンピューティング国際会議(Springer)、111–122。doi: 10.1007/978-3-031-44693-1_9
Wang, S., Sun, X., Li, X., Ouyang, R., Wu, F., Zhang, T., ら(2023)。GPT-ner:大規模言語モデルを使った固有表現認識やねん。arXiv プレプリント arXiv:2304.10428。
Wang, X., Gao, T., Zhu, Z., Zhang, Z., Liu, Z., Li, J., ら(2021)。Kepler:知識埋め込みと事前学習言語表現を統合したモデルやで。Trans. Assoc. Comput. Linguist. 9, 176–194。doi: 10.1162/tacl_a_00360
Wang, X., He, Q., Liang, J., and Xiao, Y.(2022)。言語モデルを知識埋め込みとして使う方法やねん。arXiv プレプリント arXiv:2206.12617。
Wang, Y., Hu, M., Huang, Z., Li, D., Yang, D., and Lu, X.(2024)。Kc-genre:ナレッジグラフ補完のための大規模言語モデルベースの知識制約付き生成再ランキング手法やで。arXiv プレプリント arXiv:2403.17532。
Wen, Y., Wang, Z., and Sun, J.(2023)。Mindmap:ナレッジグラフプロンプティングが大規模言語モデルの中で思考のグラフを生み出すねん。arXiv プレプリント arXiv:2308.09729。
Xie, X., Zhang, N., Li, Z., Deng, S., Chen, H., Xiong, F., ら(2022)。「識別から生成へ:生成トランスフォーマーを使ったナレッジグラフ補完」、2022年ウェブ会議併設論文集、162–165。doi: 10.1145/3487553.3524238
Xin, A., Qi, Y., Yao, Z., Zhu, F., Zeng, K., Bin, X., ら(2024)。LLMAEL:大規模言語モデルはエンティティリンキングにおけるええ文脈補強役やで。arXiv:2407.04020。
Xiong, S., Payani, A., Kompella, R., and Fekri, F.(2024)。大規模言語モデルは時間推論を学べるで。arXiv プレプリント arXiv:2401.06853。
Xiong, W., Du, J., Wang, W. Y., and Stoyanov, V.(2019)。事前学習百科事典:弱教師あり知識事前学習言語モデルやねん。arXiv プレプリント arXiv:1912.09637。
Xu, W., Liu, B., Peng, M., Jia, X., and Peng, M.(2023)。時間的ナレッジグラフ補完のためのプロンプト付き事前学習言語モデルやで。arXiv プレプリント arXiv:2305.07912。
Xu, Y., He, S., Chen, J., Wang, Z., Song, Y., Tong, H., ら(2024)。Generate-on-graph:不完全なナレッジグラフ質問応答でLLMをエージェントとKGの両方として扱う方法やねん。arXiv プレプリント arXiv:2404.14741。
Yang, L., Chen, H., Li, Z., Ding, X., and Wu, X.(2024a)。事実をちょうだい:事実を意識した言語モデリングのためにナレッジグラフで大規模言語モデルを強化する方法やで。IEEE Trans. Knowl. Data Eng. 36, 3091–3110。doi: 10.1109/TKDE.2024.3360454
Yang, L., Chen, H., Wang, X., Yang, J., Wang, F.-Y., and Liu, H.(2024b)。二つの頭は一つよりええで:エンティティアライメントのためにナレッジグラフと大規模言語モデルの知識を統合する方法やねん。arXiv プレプリント arXiv:2401.16960。
Yang, R., Liu, H., Marrese-Taylor, E., Zeng, Q., Ke, Y. H., Li, W., ら(2024c)。Kg-rank:ナレッジグラフとランキング技術で医療QAのための大規模言語モデルを強化する方法やで。arXiv プレプリント arXiv:2403.05881。
Yang, R., Yang, B., Ouyang, S., She, T., Feng, A., Jiang, Y., ら(2024d)。Graphusion:NLP教育における科学的ナレッジグラフの融合と構築に大規模言語モデルを活用する方法やねん。arXiv プレプリント arXiv:2407.10794。
Yao, L., Mao, C., and Luo, Y.(2019)。Kg-bert:ナレッジグラフ補完のためのBERTやで。arXiv プレプリント arXiv:1909.03193。
Yasunaga, M., Ren, H., Bos
[...テキスト省略...]
---
## Page 26
[](/attach/be35480839ed8df24385cd047d83444c3a9842de8dfb102c573c6610802d06cc_p026.png)
### 和訳
Cai et al.
10.3389/fcomp.2025.1590632
Zhang, T., Wang, C., Hu, N., Qiu, M., Tang, C., He, X., et al. (2022). 「DKPLM: 自然言語理解のための分解可能な知識強化型事前学習言語モデル」、AAAI人工知能学会の論文集、11703–11711ページ。doi: 10.1609/aaai.v36i10.21425
→ これな、言語モデルに知識をバラバラにして組み込むっちゅう話やねん。自然言語を理解させるのに、知識を分解して入れたろうっていう賢いやり方やで。
Zhang, X., Bosselut, A., Yasunaga, M., Ren, H., Liang, P., Manning, C. D., et al. (2022). Greaselm: 質問応答のためのグラフ推論強化型言語モデル。arXivプレプリント arXiv:2201.08860。
→ 質問に答えるとき、グラフみたいな構造で推論させたら言語モデルがもっと賢なるんちゃう?っていう研究やねん。
Zhang, Y., Chen, Z., Guo, L., Xu, Y., Zhang, W., and Chen, H. (2023). 大規模言語モデルに知識グラフ補完をもっとうまくやらせる方法。arXivプレプリント arXiv:2310.06671。
→ 知識グラフって穴あきのところあるやん?それを大規模言語モデルに埋めさせたろうっていう話やな。
Zhang, Z., Han, X., Liu, Z., Jiang, X., Sun, M., and Liu, Q. (2019). Ernie: 情報量のあるエンティティで強化された言語表現。arXivプレプリント arXiv:1905.07129。
→ 「エンティティ」ってのは固有名詞とか概念のことやねんけど、それを賢く使って言語の表現力をめっちゃ上げたろうっていうモデルやで。
Zhang, Z., Lee, S., Wu, J., Zhang, D., Li, S., Cambria, E., et al. (2024a). 「タスク指向の生成知識を使ったクロスドメイン固有表現抽出:情報密度の観点からの実証研究」、2024年自然言語処理における経験的手法会議(EMNLP)論文集、1595–1609ページ。doi: 10.18653/v1/2024.emnlp-main.95
→ 違う分野のデータでも固有表現(人名とか地名とか)をちゃんと見つけられるようにしたいねん。そのために「情報がどんだけギュッと詰まってるか」っていう視点から研究したんやって。
Zhang, Z., Liu, X., Zhang, Y., Su, Q., Sun, X., and He, B. (2020). 「Pretrainkge: 事前学習済み言語モデルから知識表現を学習する」、計算言語学会論文集:EMNLP 2020、259–266ページ。doi: 10.18653/v1/2020.findings-emnlp.25
→ 事前学習済みのモデルから知識の表現を引っ張り出してこようっていう研究やな。もう学習しとるもんから賢く再利用するわけや。
Zhang, Z., Wang, Y., Wang, C., Chen, J., and Zheng, Z. (2024b). 実用的なコード生成におけるLLMの幻覚:現象、メカニズム、軽減策。arXivプレプリント arXiv:2409.20550。
→ 「幻覚」ってのは、AIがもっともらしいけど嘘のこと言うやつやねん。コード書かせたときにそれがどう起きるか、なんでそうなるか、どうやったら減らせるかを調べとるで。
Zhao, R., Zhao, F., Wang, L., Wang, X., and Xu, G. (2024). 「KG-CoT: 知識認識型質問応答のための知識グラフ上での大規模言語モデルの連鎖思考プロンプティング」、第33回国際人工知能合同会議(IJCAI-24)論文集(国際人工知能合同会議)、6642–6650ページ。doi: 10.24963/ijcai.2024/734
→ 「連鎖思考」っていうのは、AIに「こう考えて、次こう考えて…」って段階的に考えさせる技やねん。それを知識グラフと組み合わせて質問応答をもっと賢くしたろうっていう研究やで。
Zheng, J., Liang, M., Yu, Y., Li, Y., and Xue, Z. (2024). 「画像-テキストマルチモーダル検索のための知識グラフ強化型トランスフォーマー」、2024 IEEE第40回国際データエンジニアリング会議(ICDE)論文集(IEEE)、70–82ページ。doi: 10.1109/ICDE60146.2024.00013
→ 画像とテキスト両方を使って検索するとき、知識グラフで補強したトランスフォーマー使ったらめっちゃ精度上がるんちゃう?っていう話やな。
Zheng, L., Chen, B., Fei, H., Li, F., Wu, S., Liao, L., et al. (2024). 「半教師ありマルチモーダル共参照解決のための自己適応型きめ細かいマルチモーダルデータ拡張」、第32回ACMマルチメディア国際会議論文集、8576–8585ページ。doi: 10.1145/3664647.3680966
→ 「共参照解決」ってのは「この"彼"は誰のこと?」みたいなのを解くやつやねん。画像とテキスト両方使って、しかもラベル付きデータが少なくてもうまくやれるように、データを賢く増やす方法を考えたんやって。
Zhou, B., Li, X., Liu, T., Xu, K., Liu, W., and Bao, J. (2024). Causalkgpt: 航空宇宙製品製造における品質問題の原因分析のための産業構造因果知識強化型大規模言語モデル。Advanced Engineering Informatics 59巻:102333。doi: 10.1016/j.aei.2023.102333
→ 航空宇宙の製品作るとき、なんで品質問題が起きたんかを分析したいやん?そのために因果関係の知識をぶち込んだ大規模言語モデルを作ったっていう、めっちゃ実践的な研究やで。
Zhu, H., Peng, H., Lyu, Z., Hou, L., Li, J., and Xiao, J. (2023). ドメイン固有の異種知識を統一表現として言語モデルに組み込む事前学習。Expert Systems with Applications 215巻:119369。doi: 10.1016/j.eswa.2022.119369
→ 特定の分野のいろんな種類の知識を、一つにまとめて言語モデルに覚えさせる方法やねん。バラバラやった知識を統一的に扱えるようにしたのがポイントやで。
Frontiers in Computer Science
26
frontiersin.org
---
![]()
1 / 1
100%