<<
Attention Is All You Need.pdf

---
## Page 1
[](/attach/bdfaa68d8984f0dc02beaca527b76f207d99b666d31d1da728ee0728182df697_p001.png)
### 和訳
# Attention Is All You Need(注意機構がすべてや)
Ashish Vaswani∗ / Noam Shazeer∗ / Niki Parmar∗ / Jakob Uszkoreit∗ / Llion Jones∗ / Aidan N. Gomez∗ † / Łukasz Kaiser∗ / Illia Polosukhin∗ ‡
Google Brain、Google Research、トロント大学
## 概要
なぁ、今までの系列変換モデル——ようするに文章を別の言語に変えたりするやつな——これがめっちゃ複雑な再帰型ニューラルネットワーク(RNN)とか畳み込みニューラルネットワーク(CNN)使っとってん。エンコーダとデコーダっていう2つの部品が入っとるんやけど、一番ええ感じに動くモデルは、この2つをアテンション機構——つまり「どこに注目すべきか」を学習する仕組みやな——でつないどるねん。
ほんで俺らが提案するんは、**Transformer(トランスフォーマー)**っていう新しいシンプルなネットワーク構造や。これがめっちゃ革命的でな、アテンション機構だけで全部やってまうねん。再帰も畳み込みも完全に捨ててもうたんや。
「ほんまにそれでいけるん?」って思うやろ?なんでかっていうと、2つの機械翻訳タスクで実験したら、品質がめっちゃ上がっただけやなくて、並列計算しやすくなって学習時間も大幅に短縮できたんや。
具体的な数字言うたらな、WMT 2014の英語→ドイツ語翻訳タスクで28.4 BLEUスコア達成したんや。これ、複数モデルを組み合わせたアンサンブル含めて過去最高記録を2 BLEU以上ぶっちぎっとる。
英語→フランス語翻訳タスクでは、8個のGPUで3.5日学習しただけで41.8 BLEUっていう単一モデルの新記録叩き出したんや。これ、今まで一番ええとされとったモデルの学習コストのほんの一部やで。
しかもTransformerは他のタスクにも応用できることを示したで。英語の構文解析——文の構造を分析するやつな——に適用したら、学習データが多くても少なくてもちゃんと動いたんや。
---
∗全員が同等に貢献。名前の順番はランダムや。Jakobが「RNNをセルフアテンションに置き換えたらどうや」って提案して、このアイデアの評価を始めた。AshishはIlliaと一緒に最初のTransformerモデルを設計・実装して、この研究のあらゆる側面に深く関わっとる。Noamはスケールドドット積アテンション、マルチヘッドアテンション、パラメータ不要の位置表現を提案して、ほぼすべての詳細に関わるもう一人の人物になった。Nikiは元々のコードベースとtensor2tensorで数え切れんほどのモデル変種を設計・実装・調整・評価した。Llionも新しいモデル変種の実験をして、最初のコードベースと効率的な推論・可視化を担当した。LukaszとAidanはtensor2tensorの様々な部分の設計と実装に何日も費やして、以前のコードベースを置き換え、結果を大幅に改善し、研究をめっちゃ加速させた。
†Google Brain在籍時の研究成果。
‡Google Research在籍時の研究成果。
第31回ニューラル情報処理システム会議(NIPS 2017)、カリフォルニア州ロングビーチ
---
## Page 2
[](/attach/bdfaa68d8984f0dc02beaca527b76f207d99b666d31d1da728ee0728182df697_p002.png)
### 和訳
1
はじめに
リカレントニューラルネットワーク、特にLSTM(長短期記憶)[13]とGRU(ゲート付きリカレントユニット)[7]っていうのがあんねんけど、これがもう系列モデリングとか変換問題、例えば言語モデリングとか機械翻訳[35, 2, 5]の分野でめっちゃ最先端のアプローチとして確立されとるんよ。ほんで、その後もリカレント言語モデルとかエンコーダー・デコーダーアーキテクチャの限界を押し広げようとする取り組みがようさん続いとるわけ[38, 24, 15]。
リカレントモデルってのは普通、入力と出力の系列のシンボル位置に沿って計算を分解していくねん。位置を計算時間のステップに対応させて、隠れ状態htっていうのを生成していくんやけど、これは一つ前の隠れ状態ht−1と位置tの入力を使って計算するんよ。なんでかっていうと、この本質的に逐次的な性質があるせいで、訓練サンプル内での並列化ができへんのよ。これが特に長い系列になるとほんまにキツくなるねん。メモリの制約でサンプル間のバッチ処理も制限されるしな。最近の研究では、分解のトリック[21]とか条件付き計算[32]で計算効率をめっちゃ改善することに成功しとって、後者については性能も上がっとるんや。せやけど、逐次計算っていう根本的な制約はまだ残ったままなんよな。
アテンション機構ってのは、いろんなタスクで系列モデリングとか変換モデルの重要な部分になっとって、入力や出力系列内の距離に関係なく依存関係をモデル化できるようにしてくれるんよ[2, 19]。ただな、ごく一部の例外[27]を除いて、こういうアテンション機構はリカレントネットワークと一緒に使われとるんやわ。
この論文では、Transformerっていうのを提案するで。これはリカレンスを捨てて、入力と出力の間のグローバルな依存関係を引き出すのに完全にアテンション機構だけに頼るモデルアーキテクチャやねん。Transformerを使うとめっちゃ並列化できるようになって、8台のP100 GPUでたった12時間訓練しただけで翻訳品質の新しい最先端を達成できるんよ。
2 背景
逐次計算を減らすっていう目標は、Extended Neural GPU[16]、ByteNet[18]、ConvS2S[9]の基盤にもなっとって、これら全部が畳み込みニューラルネットワークを基本的な構成要素として使って、全ての入力・出力位置の隠れ表現を並列に計算するんや。これらのモデルでは、任意の2つの入力または出力位置からの信号を関連付けるのに必要な演算回数が、位置間の距離に応じて増えていくねん。ConvS2Sやと線形に、ByteNetやと対数的に増えるんよ。これのせいで、離れた位置間の依存関係を学習するのがめっちゃ難しくなるんや[12]。Transformerではこれが定数回の演算に減るんやけど、ただしアテンション重み付き位置を平均化することで実効解像度が下がるっていうコストはあるねん。このeffectに対抗するために、セクション3.2で説明するマルチヘッドアテンションを使うんよ。
自己アテンション、イントラアテンションとも呼ばれるんやけど、これは単一の系列の異なる位置を関連付けて、その系列の表現を計算するアテンション機構やねん。自己アテンションは、読解、抽象要約、テキスト含意、タスク非依存の文表現学習とか、いろんなタスクでうまく使われとるんよ[4, 27, 28, 22]。
エンドツーエンドのメモリネットワークは、系列に沿ったリカレンスの代わりにリカレントアテンション機構に基づいとって、シンプルな言語での質問応答とか言語モデリングタスクでええ性能を出すことが示されとるんや[34]。
せやけどな、ウチらが知る限り、Transformerは系列に沿ったRNNや畳み込みを使わずに、完全に自己アテンションだけで入力と出力の表現を計算する最初の変換モデルなんよ。以下のセクションでは、Transformerについて説明して、自己アテンションの動機付けをして、[17, 18]とか[9]みたいなモデルに対する利点を議論するで。
3 モデルアーキテクチャ
競争力のあるニューラル系列変換モデルのほとんどは、エンコーダー・デコーダー構造を持っとるんよ[5, 2, 35]。ここでは、エンコーダーがシンボル表現の入力系列(x1, ..., xn)を連続表現の系列z = (z1, ..., zn)にマッピングするねん。zが与えられると、デコーダーは出力系列(y1, ..., ym)のシンボルを一つずつ生成していくんや。各ステップでモデルは自己回帰的[10]で、次を生成するときに前に生成したシンボルを追加の入力として消費するんよ。
2
---
## Page 3
[](/attach/bdfaa68d8984f0dc02beaca527b76f207d99b666d31d1da728ee0728182df697_p003.png)
### 和訳
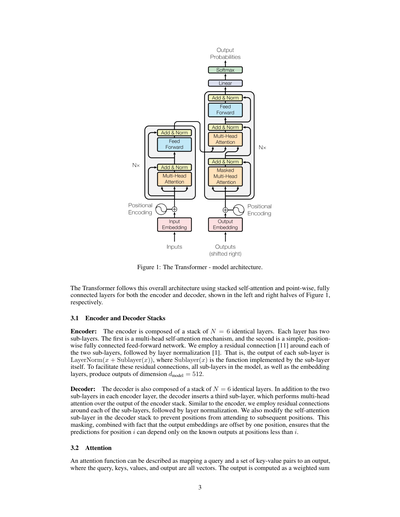
図1:Transformerのモデル構造やで。
Transformerってのは、こういう全体的な構造になっててな、エンコーダーとデコーダーの両方で「セルフアテンション」っていう仕組みを積み重ねて、あとは「ポイントワイズ」って呼ばれる各位置ごとの全結合層を使ってるねん。図1の左半分がエンコーダーで、右半分がデコーダーやで。
3.1 エンコーダーとデコーダーの積み重ね構造
**エンコーダー**:エンコーダーはな、N=6個の同じ層を積み重ねてできてるねん。で、各層には2つのサブ層があるわけよ。1つ目は「マルチヘッド・セルフアテンション」っていう仕組みで、2つ目はシンプルな「位置ごとの全結合フィードフォワードネットワーク」やねん。ほんで、この2つのサブ層それぞれの周りに「残差接続」っていうショートカットみたいなもんを入れて、そのあとに「レイヤー正規化」をかけてるんや。つまりな、各サブ層の出力は「LayerNorm(x + Sublayer(x))」ってなるねん。Sublayer(x)ってのはそのサブ層自体がやる処理のことやで。この残差接続をうまく機能させるために、モデル内の全サブ層とエンベディング層は、全部 dmodel = 512 っていう次元の出力を出すようになってるんや。
**デコーダー**:デコーダーもな、同じくN=6個の同じ層を積み重ねてできてるねん。でもエンコーダーの各層にある2つのサブ層に加えて、デコーダーは3つ目のサブ層を追加してるんや。この3つ目は何するかっていうと、エンコーダーの出力に対して「マルチヘッドアテンション」をかけるねん。エンコーダーと同じように、各サブ層の周りに残差接続入れて、そのあとレイヤー正規化やで。あとな、デコーダーのセルフアテンション層はちょっと改造されてて、ある位置がそれより後ろの位置を見れないようにしてるねん。なんでかっていうと、このマスキングと、出力エンベディングが1つずつずれてる仕組みを組み合わせることで、位置iの予測は、iより前の位置の既知の出力だけに依存するようになるからやねん。めっちゃ大事なポイントやで。
3.2 アテンション
アテンション関数ってのはな、簡単に言うと「クエリ」と「キーと値のペアのセット」を入力として、出力を返す仕組みやねん。クエリもキーも値も出力も、全部ベクトルやで。で、出力がどう計算されるかっていうと、重み付きの合計として計算されるんや。
3
---
## Page 4
[](/attach/bdfaa68d8984f0dc02beaca527b76f207d99b666d31d1da728ee0728182df697_p004.png)
### 和訳
スケールド・ドットプロダクト・アテンション
マルチヘッド・アテンション
図2:(左)スケールド・ドットプロダクト・アテンション。(右)マルチヘッド・アテンションは複数のアテンション層が並列で動いてるやつやねん。
各valueに割り当てられる重みっていうのは、queryと対応するkeyの相性を計算する関数で決まるんやで。
3.2.1 スケールド・ドットプロダクト・アテンション
うちらの提案するアテンションは「スケールド・ドットプロダクト・アテンション」って呼んでんねん(図2見てな)。入力はdk次元のqueriesとkeys、それとdv次元のvaluesやな。queryと全部のkeysの内積を計算して、それを√dkで割ってから、softmax関数をかけてvaluesの重みを出すんや。
実際の処理では、複数のqueriesをまとめて行列Qにパックして、一気にアテンション関数を計算するんやで。keysとvaluesも同じように行列KとVにまとめるねん。出力の行列はこうやって計算すんねん:
Attention(Q, K, V) = softmax(QK^T / √dk)V (1)
よう使われるアテンション関数は2種類あってな、加法的アテンション[2]と、内積(乗法的)アテンションやねん。内積アテンションはうちらのアルゴリズムとほぼ一緒なんやけど、1/√dkっていうスケーリング係数が違うだけや。加法的アテンションの方は、隠れ層1個のフィードフォワードネットワークを使って相性関数を計算するんやな。理論的な計算量は似たようなもんなんやけど、内積アテンションの方がめっちゃ速くてメモリ効率もええねん。なんでかっていうと、超最適化された行列積のコードが使えるからやで。
dkが小さいときは両方とも同じくらいの性能なんやけど、dkがデカくなると、スケーリングせん内積アテンションより加法的アテンションの方が性能ええねん[3]。ほんまにdkが大きいとき、内積の値がめっちゃデカくなって、softmax関数が勾配がほぼゼロになる領域に押し込まれてまうんちゃうかって思うねん⁴。この問題を防ぐために、内積を1/√dkでスケーリングしてるわけや。
3.2.2 マルチヘッド・アテンション
dmodel次元のkeys、values、queriesで1回だけアテンション関数を実行するんやなくて、queries、keys、valuesをそれぞれ違う学習済みの線形射影でh回変換して、dk、dk、dv次元にするんがええって分かったんや。この射影されたqueries、keys、valuesそれぞれに対してアテンション関数を並列で実行して、dv次元の
⁴なんで内積がデカくなるか説明するとな、qとkの各成分が平均0、分散1の独立な確率変数やとするやん。そしたらその内積 q·k = Σ(i=1からdk)qiki は、平均0で分散dkになるんや。
---
## Page 5
[](/attach/bdfaa68d8984f0dc02beaca527b76f207d99b666d31d1da728ee0728182df697_p005.png)
### 和訳
出力の値たちを全部くっつけて、もっぺん投影したら最終的な値が出てくるねん。図2見てもろたらわかるで。
マルチヘッドアテンションってのがめっちゃ優秀でな、モデルが違う位置にある違う表現の部分空間から情報をいっぺんに見れるようになるねん。アテンションヘッドが1個だけやったら、平均取ってまうから、この能力が台無しになってまうんよ。
MultiHead(Q, K, V) = Concat(head₁, ..., headₕ)Wᴼ
ここで headᵢ = Attention(QWᵢᵠ, KWᵢᴷ, VWᵢⱽ)
投影ってのはパラメータの行列で、Wᵢᵠ ∈ ℝᵈᵐᵒᵈᵉˡˣᵈᵏ、Wᵢᴷ ∈ ℝᵈᵐᵒᵈᵉˡˣᵈᵏ、Wᵢⱽ ∈ ℝᵈᵐᵒᵈᵉˡˣᵈᵛ、あとWᴼ ∈ ℝʰᵈᵛˣᵈᵐᵒᵈᵉˡ やねん。
今回の研究ではな、h = 8個の並列アテンション層、つまりヘッドを使ってるねん。それぞれのヘッドで dₖ = dᵥ = dₘₒₐₑₗ/h = 64 にしてるわけ。なんでかっていうと、各ヘッドの次元を小さくしてるから、全部合わせた計算コストは、フル次元の1個のアテンションヘッド使うのとだいたい同じになるねん。お得やろ?
### 3.2.3 このモデルでアテンションどう使ってるか
Transformerはマルチヘッドアテンションを3通りの方法で使ってるねん:
- 「エンコーダ・デコーダアテンション」の層ではな、クエリは1個前のデコーダ層から来て、メモリのキーとバリューはエンコーダの出力から来るねん。こうすることで、デコーダのどの位置からでも入力シーケンスの全部の位置を見れるようになるわけ。これって[38, 2, 9]みたいな配列から配列への変換モデルでよくあるエンコーダ・デコーダアテンションの仕組みをマネしてるねん。
- エンコーダにはセルフアテンション層が入ってるねん。セルフアテンション層ではな、キーもバリューもクエリも全部同じとこから来るんよ。この場合は、エンコーダの1個前の層の出力やな。エンコーダのどの位置でも、1個前の層の全部の位置を見れるってわけ。
- 同じようにな、デコーダのセルフアテンション層でも、デコーダの各位置がその位置までの全部の位置を見れるねん。でもな、デコーダでは左方向への情報の流れを止めなあかんねん。なんでかっていうと、自己回帰っていう性質を守らなあかんからや。これをどうやって実現してるかっていうと、スケール付きドット積アテンションの中で、違法な接続に当たるソフトマックスの入力の値を全部マスクして(−∞に設定して)るねん。図2見てな。
### 3.3 位置ごとのフィードフォワードネットワーク
アテンションのサブ層に加えてな、エンコーダとデコーダの各層には全結合のフィードフォワードネットワークも入ってるねん。これは各位置に対して別々に、でも同じやり方で適用されるんよ。中身は2つの線形変換で、間にReLU活性化関数が挟まってるねん。
FFN(x) = max(0, xW₁ + b₁)W₂ + b₂ (2)
線形変換自体は違う位置でも同じやねんけど、層が違ったらパラメータは別のもん使うねん。別の言い方したら、カーネルサイズ1の畳み込みを2回やってるようなもんやな。入力と出力の次元は dₘₒₐₑₗ = 512 で、中間層の次元は dff = 2048 やねん。
### 3.4 埋め込みとソフトマックス
他の配列変換モデルと同じようにな、学習可能な埋め込みを使って入力トークンと出力トークンを dₘₒₐₑₗ 次元のベクトルに変換してるねん。あとは普通に学習可能な線形変換とソフトマックス関数使って、デコーダの出力を次のトークンの予測確率に変換してるわけ。このモデルではな、[30]と同じように、2つの埋め込み層とソフトマックス前の線形変換で同じ重み行列を共有してるねん。埋め込み層では、その重みに√dₘₒₐₑₗ をかけてるで。
---
## Page 6
[](/attach/bdfaa68d8984f0dc02beaca527b76f207d99b666d31d1da728ee0728182df697_p006.png)
### 和訳
表1: いろんなレイヤータイプの最大パス長、1レイヤーあたりの計算量、最小の連続処理回数やで。nは系列の長さ、dは表現の次元数、kは畳み込みのカーネルサイズ、rは制限付きセルフアテンションの近傍のサイズやねん。
| レイヤーの種類 | 1レイヤーあたりの計算量 | 連続処理の回数 | 最大パス長 |
|---|---|---|---|
| セルフアテンション | O(n² · d) | O(1) | O(1) |
| リカレント(再帰型) | O(n · d²) | O(n) | O(n) |
| 畳み込み | O(k · n · d²) | O(1) | O(log_k(n)) |
| セルフアテンション(制限付き) | O(r · n · d) | O(1) | O(n/r) |
### 3.5 位置エンコーディング
うちのモデルには再帰も畳み込みも入ってへんから、系列の順番をモデルに理解させるには、トークンの相対的な位置とか絶対的な位置の情報をなんかの方法で注入せなあかんのよ。そこでな、エンコーダとデコーダのスタックの一番下で、入力の埋め込みに「位置エンコーディング」を足すことにしたんや。位置エンコーディングは埋め込みと同じ次元数dmodelにしてあるから、そのまま足し算できるねん。位置エンコーディングには学習するタイプと固定のタイプ、いろんな選択肢があるんやけど[9]。
この研究では、周波数の違うサインとコサイン関数を使ってるで:
PE(pos,2i) = sin(pos/10000^(2i/dmodel))
PE(pos,2i+1) = cos(pos/10000^(2i/dmodel))
ここでposは位置、iは次元やねん。つまりな、位置エンコーディングの各次元が正弦波に対応してるってことや。波長は2πから10000·2πまで等比数列で増えていくんや。なんでこの関数にしたかっていうと、固定のオフセットkに対して、PE(pos+k)がPE(pos)の線形関数として表現できるから、相対位置で注目する(アテンドする)のをモデルが簡単に学習できるんちゃうかって仮説を立てたからやねん。
学習する位置埋め込み[9]も試してみたんやけど、2つのバージョンでほぼ同じ結果が出たんよ(表3の行(E)参照)。正弦波バージョンを選んだのは、学習時に見た系列長より長い系列にも外挿できる可能性があるからやねん。
## 4 なんでセルフアテンションなん?
このセクションでは、セルフアテンション層を、可変長のシンボル表現の系列(x1, ..., xn)を同じ長さの別の系列(z1, ..., zn)に写像するためによく使われる再帰層や畳み込み層と、いろんな観点から比較するで。xi, zi ∈ R^dで、これは典型的な系列変換エンコーダやデコーダの隠れ層みたいなもんや。セルフアテンションを使う動機として、3つの要件を考えてるんよ。
1つ目は、1レイヤーあたりの総計算量やな。2つ目は、どんだけの計算を並列化できるか、これは最小の連続処理回数で測るんや。
3つ目は、ネットワーク内の長距離依存関係のパス長やねん。長距離依存関係を学習するのは、多くの系列変換タスクでめっちゃ重要な課題やねん。そういう依存関係を学習する能力に影響する重要な要因の1つが、順方向と逆方向の信号がネットワーク内を通る経路の長さなんや。入力と出力の系列のどの位置の組み合わせ間でも、この経路が短ければ短いほど、長距離依存関係を学習しやすくなるんよ[12]。せやから、異なるレイヤータイプで構成されたネットワークにおける、任意の2つの入出力位置間の最大パス長も比較してるで。
表1で見たように、セルフアテンション層はすべての位置を一定回数の連続処理で接続できるんやけど、再帰層はO(n)回の連続処理が必要やねん。計算量の観点では、系列の長さが
6
---
## Page 7
[](/attach/bdfaa68d8984f0dc02beaca527b76f207d99b666d31d1da728ee0728182df697_p007.png)
### 和訳
ほんでな、たいていの場合、文の長さnは表現の次元数dより小さいねん。機械翻訳で最先端のモデルが使うてる word-piece [38] とか byte-pair [31] みたいな文の表現やとそうなるわけや。めっちゃ長いシーケンスを扱うタスクで計算をもっと速くしたいんやったら、self-attention(自己注意機構)を、出力位置を中心にした入力シーケンスの近所r個だけに限定するっていう手があるねん。そうすると最長パス長はO(n/r)に増えるんやけどな。これは今後の研究でもっと調べていくつもりやで。
カーネル幅kがnより小さい畳み込み層1個だけやと、入力と出力の全部のペアをつなげられへんねん。全部つなげようと思ったら、普通の連続カーネルやったらO(n/k)層の畳み込み層を積み重ねなあかんし、dilated convolution(拡張畳み込み)[18]やったらO(logk(n))層いるねん。そうするとネットワーク内の任意の2点間の最長パスが長くなってまうわけや。畳み込み層は一般的にリカレント層よりk倍くらいコストかかるねん。でもな、separable convolution(分離可能畳み込み)[6]を使うと複雑さがめっちゃ下がって、O(k·n·d + n·d²)になるねん。ただな、k=nにしても、separable convolutionの複雑さはself-attention層とpoint-wise feed-forward層の組み合わせと同じになんねん。これがまさにうちらのモデルで採用してるアプローチやで。
おまけの利点としてな、self-attentionは解釈しやすいモデルを作れる可能性があるねん。うちらのモデルのattention分布を調べて、付録で例を示して議論してるで。個々のattentionヘッドがはっきり別々のタスクを学習してるだけやなくて、多くのヘッドが文の構文的・意味的な構造に関連した振る舞いを見せてるように見えるんや。
## 5 トレーニング
このセクションでは、うちらのモデルのトレーニング方法について説明するで。
### 5.1 トレーニングデータとバッチング
トレーニングには標準的なWMT 2014の英語-ドイツ語データセットを使ったんや。約450万の文ペアが入っとるで。文はbyte-pair encoding [3]でエンコードしてな、ソースとターゲットで共有の約37000トークンのボキャブラリーを使ったんや。英語-フランス語にはもっとでかいWMT 2014の英語-フランス語データセットを使って、これは3600万文あるねん。トークンは32000のword-pieceボキャブラリー[38]に分割したで。文ペアは大体の長さが同じくらいのもの同士でバッチにまとめたんや。各トレーニングバッチには、ソーストークン約25000個とターゲットトークン約25000個を含む文ペアのセットが入っとったで。
### 5.2 ハードウェアとスケジュール
モデルのトレーニングは、NVIDIA P100 GPU 8枚を積んだマシン1台でやったんや。論文全体で説明してるハイパーパラメータを使ったベースモデルやと、各トレーニングステップは約0.4秒かかったで。ベースモデルは合計100,000ステップ、つまり12時間トレーニングしたんや。ビッグモデル(表3の一番下の行に書いてあるやつ)やと、ステップ時間は1.0秒やったで。ビッグモデルは300,000ステップ(3.5日)トレーニングしたんや。
### 5.3 オプティマイザ
Adamオプティマイザ [20]を使ったで。パラメータはβ1 = 0.9、β2 = 0.98、ε = 10⁻⁹や。学習率はトレーニング中に以下の式に従って変化させたんや:
lrate = d_model^(-0.5) · min(step_num^(-0.5), step_num · warmup_steps^(-1.5)) (3)
これはな、最初のwarmup_stepsのトレーニングステップでは学習率を線形に上げていって、その後はステップ数の平方根の逆数に比例して下げていくってことやねん。warmup_stepsは4000にしたで。
### 5.4 正則化
トレーニング中に3種類の正則化を使ってるで:
---
## Page 8
[](/attach/bdfaa68d8984f0dc02beaca527b76f207d99b666d31d1da728ee0728182df697_p008.png)
### 和訳
表2:Transformerは、英語→ドイツ語と英語→フランス語のnewstest2014テストで、これまでの最先端モデルよりええBLEUスコアを叩き出してん。しかも学習コストはめっちゃ安いんやで。
| モデル | BLEUスコア | | 学習コスト(FLOPS) | |
|--------|-----------|--------|---------------------|--------|
| | 英→独 | 英→仏 | 英→独 | 英→仏 |
| ByteNet [18] | 23.75 | | | |
| Deep-Att + PosUnk [39] | | 39.2 | | 1.0 · 10¹⁹ |
| GNMT + RL [38] | 24.6 | 39.92 | 2.3 · 10¹⁹ | 1.4 · 10²⁰ |
| ConvS2S [9] | 25.16 | 40.46 | 9.6 · 10¹⁸ | 1.5 · 10²⁰ |
| MoE [32] | 26.03 | 40.56 | 2.0 · 10¹⁹ | 1.2 · 10²⁰ |
| Deep-Att + PosUnk アンサンブル [39] | | 40.4 | | 8.0 · 10²⁰ |
| GNMT + RL アンサンブル [38] | 26.30 | 41.16 | 1.8 · 10²⁰ | 1.1 · 10²¹ |
| ConvS2S アンサンブル [9] | 26.36 | 41.29 | 7.7 · 10¹⁹ | 1.2 · 10²¹ |
| Transformer(ベースモデル) | 27.3 | 38.1 | 3.3 · 10¹⁸ | |
| Transformer(でかいやつ) | 28.4 | 41.8 | 2.3 · 10¹⁹ | |
**残差ドロップアウト**
ドロップアウト[33]っていう技術を使ってんねんけど、これは各サブレイヤーの出力に適用してるんや。サブレイヤーの入力と足し算して正規化する前にな。それと、エンコーダとデコーダ両方で、埋め込みベクトルと位置エンコーディングを足したとこにもドロップアウトかけてるで。ベースモデルでは Pdrop = 0.1 の確率使ってんねん。
**ラベル平滑化**
学習中は ϵls = 0.1 のラベル平滑化[36]っていうのも使ってん。これな、パープレキシティ(モデルの自信度みたいなもん)は悪なんねん、なんでかっていうとモデルが「ちょっと自信ないなあ」って学習するからやねんけど、そのかわり精度とBLEUスコアはめっちゃ上がるんやで。
## 6 結果
### 6.1 機械翻訳
WMT 2014の英語→ドイツ語翻訳タスクでな、でかいTransformerモデル(表2のTransformer (big)ってやつ)は、それまでの最強モデル(アンサンブルも含めてやで)をBLEUで2.0以上ぶっちぎって、新記録の28.4を樹立したんや。このモデルの設定は表3の一番下に書いてあるで。学習時間は8台のP100 GPUで3.5日やった。ほんでな、ベースモデルでさえ、これまで発表されたモデルやアンサンブル全部超えてもうてん。しかも学習コストはライバルモデルのほんの一部やで。
WMT 2014の英語→フランス語翻訳タスクでは、うちのでかいモデルはBLEUスコア41.0を達成して、これまで発表された単体モデル全部に勝ったんや。学習コストは前の最先端モデルの4分の1以下やで。英語→フランス語用のTransformer (big)はドロップアウト率 Pdrop = 0.1 使ってん、0.3じゃなくてな。
ベースモデルでは、10分間隔で保存した最後の5個のチェックポイントを平均した単一モデルを使ってん。でかいモデルでは最後の20個のチェックポイントを平均したで。推論にはビームサーチっていうのを使って、ビームサイズは4、長さペナルティ α = 0.6 や[38]。このハイパーパラメータは開発用データセットで実験して決めたんや。推論時の最大出力長は入力長+50に設定してるけど、できるときは早めに終わらせるようにしてるで[38]。
表2に結果まとめてあるから見てな。翻訳品質と学習コストを他のモデルと比較してるで。モデルの学習に使った浮動小数点演算の回数は、学習時間×GPU数×各GPUの持続的な単精度浮動小数点演算能力で推定してん⁵。
### 6.2 モデルのバリエーション
Transformerの各部品がどんだけ大事かを調べるために、ベースモデルをいろいろいじって、英語→ドイツ語翻訳の
---
⁵ K80は2.8、K40は3.7、M40は6.0、P100は9.5 TFLOPSの値を使ったで。
---
## Page 9
[](/attach/bdfaa68d8984f0dc02beaca527b76f207d99b666d31d1da728ee0728182df697_p009.png)
### 和訳
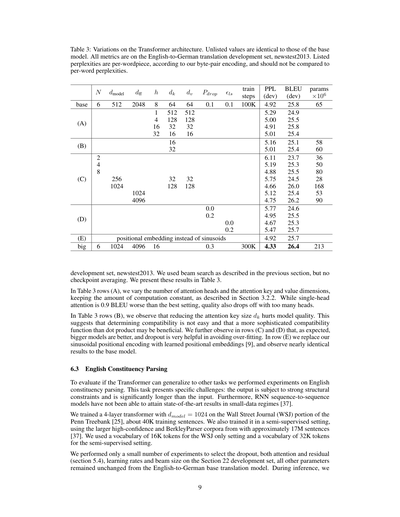
表3:Transformerアーキテクチャのいろんなバリエーションやねん。書いてないとこはベースモデルと一緒やで。評価は全部、英語からドイツ語への翻訳の開発セット(newstest2013)でやっとるねん。載ってるパープレキシティ(困惑度みたいなもんや)は単語の断片ごとの値で、うちらが使ったバイトペアエンコーディングってやつで計算しとるから、普通の単語単位のパープレキシティとは比べたらあかんで。
| | N | d_model | d_ff | h | d_k | d_v | P_drop | ε_ls | 訓練ステップ | PPL(dev) | BLEU(dev) | パラメータ×10^6 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| base | 6 | 512 | 2048 | 8 | 64 | 64 | 0.1 | 0.1 | 100K | 4.92 | 25.8 | 65 |
| (A) | | | | 1 | 512 | 512 | | | | 5.29 | 24.9 | |
| | | | | 4 | 128 | 128 | | | | 5.00 | 25.5 | |
| | | | | 16 | 32 | 32 | | | | 4.91 | 25.8 | |
| | | | | 32 | 16 | 16 | | | | 5.01 | 25.4 | |
| (B) | | | | | 16 | | | | | 5.16 | 25.1 | 58 |
| | | | | | 32 | | | | | 5.01 | 25.4 | 60 |
| (C) | | | | 2 | | | | | | 6.11 | 23.7 | 36 |
| | | | | 4 | | | | | | 5.19 | 25.3 | 50 |
| | | | | 8 | | | | | | 4.88 | 25.5 | 80 |
| | | 256 | 32 | | | | | | | 5.75 | 24.5 | 28 |
| | | 1024 | 128 | | | | | | | 4.66 | 26.0 | 168 |
| (D) | | | | | | | 0.0 | | | 5.12 | 25.4 | 53 |
| | | | | | | | 0.2 | | | 4.88 | 25.5 | 90 |
| | | | | | | | | 0.0 | | 5.75 | 24.6 | |
| | | | | | | | | 0.2 | | 4.95 | 25.5 | |
| (E) | サイン波の代わりに位置埋め込みを使用 | | | | | | | | | 4.67 | 25.3 | |
| big | 6 | 1024 | 4096 | 16 | | | 0.3 | | | 5.47 | 25.7 | |
| | | | | | 32 | 32 | | | | 4.92 | 25.7 | |
| | | | | | 128 | 128 | | | 300K | 4.33 | 26.4 | 213 |
開発セットのnewstest2013で、前のセクションで説明したビームサーチっていう手法を使って評価したんやけど、チェックポイントの平均化はやっとらんねん。その結果を表3にまとめとるで。
表3の(A)の行では、アテンションヘッドの数と、アテンションのキーとバリューの次元数をいろいろ変えてみたんやけど、計算量は一定に保っとるねん(セクション3.2.2で説明した通りや)。ヘッドが1個だけやと、一番ええ設定より0.9 BLEUも下がってまうんやけど、逆にヘッドが多すぎても品質落ちるねん。なかなか難しいとこやな。
表3の(B)の行では、アテンションのキーサイズd_kを小さくしたら、モデルの品質が下がることがわかったんや。これが何を意味しとるかっていうと、「この単語とこの単語は関係あるで!」っていう相性を判断するのは簡単やないってことやねん。内積(ドットプロダクト)よりもっと賢い相性判定の仕組みがあった方がええかもしれへんってことや。ほんで(C)と(D)の行を見てみると、予想通りやけど、モデルがでかいほど性能ええし、ドロップアウト(学習中にランダムに一部の接続を切って過学習を防ぐテクニックやで)がめっちゃ効果あるってわかるねん。(E)の行では、うちらが使っとるサイン波ベースの位置エンコーディングを、学習で獲得する位置埋め込み[9]に変えてみたんやけど、ベースモデルとほぼ同じ結果やったわ。
6.3 英語の構文解析
Transformerが他のタスクにも使えるか確かめるために、英語の構文解析(文の構造を木みたいに分析するやつや)で実験したんや。このタスク、なかなか難しいねん。なんでかっていうと、出力に強い構造的な制約があって、しかも入力よりかなり長くなるからや。さらに言うと、RNN(リカレントニューラルネットワーク)ベースのSequence-to-Sequenceモデルは、データが少ない状況では最先端の結果を出せへんかったんよ[37]。
ワイらは、Penn Treebank[25]のWall Street Journal(WSJ)部分、だいたい4万文くらいで、d_model=1024の4層Transformerを訓練したんや。あと半教師あり学習っていうやり方でも試してみて、そのときはBerkleyParserコーパスとかのもっとでかいデータ、約1700万文を使ったんや[37]。語彙サイズは、WSJだけのときは1万6千トークン、半教師ありのときは3万2千トークンにしたで。
実験の数はそんなに多くやってへんくて、ドロップアウト(アテンションと残差接続の両方、セクション5.4参照)、学習率、ビームサイズをSection 22の開発セットで選んだだけで、他のパラメータは英独翻訳のベースモデルからそのまま変えへんかったんや。推論のときは、
---
## Page 10
[](/attach/bdfaa68d8984f0dc02beaca527b76f207d99b666d31d1da728ee0728182df697_p010.png)
### 和訳
表4:Transformerは英語の構文解析にもめっちゃええ感じに汎化するで(結果はWSJのセクション23のやつな)
| 解析器 | 訓練方法 | WSJ 23 F1 |
|--------|----------|-----------|
| Vinyals & Kaiser el al. (2014) [37] | WSJだけ、識別的 | 88.3 |
| Petrov et al. (2006) [29] | WSJだけ、識別的 | 90.4 |
| Zhu et al. (2013) [40] | WSJだけ、識別的 | 90.4 |
| Dyer et al. (2016) [8] | WSJだけ、識別的 | 91.7 |
| Transformer (4層) | WSJだけ、識別的 | 91.3 |
| Zhu et al. (2013) [40] | 半教師あり | 91.3 |
| Huang & Harper (2009) [14] | 半教師あり | 91.3 |
| McClosky et al. (2006) [26] | 半教師あり | 92.1 |
| Vinyals & Kaiser el al. (2014) [37] | 半教師あり | 92.1 |
| Transformer (4層) | 半教師あり | 92.7 |
| Luong et al. (2015) [23] | マルチタスク | 93.0 |
| Dyer et al. (2016) [8] | 生成的 | 93.3 |
最大出力長は入力長+300に増やしたで。ビームサイズは21で、αは0.3にしたんやけど、これはWSJだけの設定でも半教師ありの設定でも同じやねん。
表4の結果見てもろたらわかるけど、タスク特化のチューニングしてへんのに、うちのモデルめっちゃええ感じやねん。Recurrent Neural Network Grammar [8]以外の今まで報告されたモデル全部に勝っとるで。
RNNのsequence-to-sequenceモデル [37] と比べたら、Transformerは4万文のWSJ訓練セットだけで訓練しても、BerkeleyParser [29] より上の性能出せるんやで。
## 7 結論
今回の研究では、Transformerっていう、完全にアテンションだけで作った初めてのsequence transductionモデルを紹介したで。エンコーダ・デコーダ構造でよう使われとったリカレント層を、マルチヘッドのセルフアテンションに置き換えたんや。
翻訳タスクでは、Transformerはリカレント層とか畳み込み層ベースのアーキテクチャよりめっちゃ速く訓練できるねん。WMT 2014の英語→ドイツ語と英語→フランス語の両方の翻訳タスクで、最新の記録を更新したで。英語→ドイツ語のタスクでは、うちの最強モデルは今まで報告されたアンサンブルモデル全部より上の性能やねん。
アテンションベースのモデルの未来にめっちゃワクワクしとって、他のタスクにも使っていきたいと思っとるで。Transformerをテキスト以外の入出力モダリティにも拡張したいし、画像とか音声とか動画みたいな大きい入出力を効率よく扱うための、局所的で制限されたアテンション機構も調べたいんや。生成をもっと並列化できるようにするんも、うちらの研究目標やで。
モデルの訓練と評価に使ったコードは https://github.com/tensorflow/tensor2tensor で公開しとるで。
## 謝辞
Nal KalchbrennerさんとStephan Gouwsさんには、めっちゃ参考になるコメントと修正とインスピレーションもろたから、ほんまに感謝しとるで。
## 参考文献
[1] Jimmy Lei Ba, Jamie Ryan Kiros, Geoffrey E Hinton. Layer normalization(レイヤー正規化). arXiv preprint arXiv:1607.06450, 2016.
[2] Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio. Neural machine translation by jointly learning to align and translate(アラインと翻訳を同時に学習するニューラル機械翻訳). CoRR, abs/1409.0473, 2014.
[3] Denny Britz, Anna Goldie, Minh-Thang Luong, Quoc V. Le. Massive exploration of neural machine translation architectures(ニューラル機械翻訳アーキテクチャの大規模探索). CoRR, abs/1703.03906, 2017.
[4] Jianpeng Cheng, Li Dong, Mirella Lapata. Long short-term memory-networks for machine reading(機械読解のためのLSTMネットワーク). arXiv preprint arXiv:1601.06733, 2016.
---
## Page 11
[](/attach/bdfaa68d8984f0dc02beaca527b76f207d99b666d31d1da728ee0728182df697_p011.png)
### 和訳
[5] Kyunghyun Choさんたち(Bart van Merrienboer、Caglar Gulcehre、Fethi Bougares、Holger Schwenk、Yoshua Bengioも一緒やで)。RNNのエンコーダー・デコーダーっていう仕組み使って、フレーズの表現を学習する方法について書いてはるねん。統計的な機械翻訳向けの話やな。CoRR、abs/1406.1078、2014年。
[6] Francois Cholletさん。Xceptionっていう深層学習の話やねん。depthwise separable convolutions、つまり「奥行き方向に分離できる畳み込み」っていうめっちゃ賢いやり方使ってんねん。普通の畳み込みより計算効率がええんやで。arXivプレプリント arXiv:1610.02357、2016年。
[7] Junyoung Chungさんたち(Çaglar Gülçehre、Kyunghyun Cho、Yoshua Bengioも)。ゲート付きリカレントニューラルネットワーク、略してGRUやな、これが系列モデリングでどんだけ使えるか実験で評価してはるねん。CoRR、abs/1412.3555、2014年。
[8] Chris Dyerさんたち(Adhiguna Kuncoro、Miguel Ballesteros、Noah A. Smithも)。リカレントニューラルネットワーク文法っていう、文法構造をRNNで扱う方法やねん。NAACLの論文集に載ってるで、2016年。
[9] Jonas Gehringさんたち(Michael Auli、David Grangier、Denis Yarats、Yann N. Dauphinも)。畳み込みを使った系列から系列への学習やねん。普通はRNN使うとこを、CNNでやったろうって話。arXivプレプリント arXiv:1705.03122v2、2017年。
[10] Alex Gravesさん。リカレントニューラルネットワークで系列を生成する話やねん。手書き文字とか作れるようになるやつや。arXivプレプリント arXiv:1308.0850、2013年。
[11] Kaiming Heさんたち(Xiangyu Zhang、Shaoqing Ren、Jian Sunも)。Deep Residual Learning、いわゆるResNetやな。画像認識のためのめっちゃ深いネットワークの学習方法やねん。なんでかっていうと、残差接続っていう仕組み入れたら、めっちゃ深くしても学習できるようになったんや。IEEE Conference on Computer Vision and Pattern Recognition論文集、770-778ページ、2016年。
[12] Sepp Hochreiterさんたち(Yoshua Bengio、Paolo Frasconi、Jürgen Schmidhuberも)。リカレントネットにおける勾配の流れの話やねん。長期的な依存関係を学習するんがなんでそんな難しいんかを説明してはる。2001年。
[13] Sepp HochreiterさんとJürgen Schmidhuberさん。Long Short-Term Memory、LSTMやな!これはほんまに革命的やったで。長い系列でも情報を保持できるようになったんや。Neural computation、9巻8号、1735-1780ページ、1997年。
[14] Zhongqiang HuangさんとMary Harperさん。潜在的なアノテーション付きPCFG文法を複数言語にまたがって自己学習させる方法やねん。2009年のEmpirical Methods in Natural Language Processing会議論文集、832-841ページ。ACL、2009年8月。
[15] Rafal Jozefowiczさんたち(Oriol Vinyals、Mike Schuster、Noam Shazeer、Yonghui Wuも)。言語モデリングの限界を探る研究やねん。どこまでいけるんかチャレンジしてはる。arXivプレプリント arXiv:1602.02410、2016年。
[16] Łukasz KaiserさんとSamy Bengioさん。アクティブメモリでアテンションの代わりになれるんか?っていう問いかけやねん。Advances in Neural Information Processing Systems (NIPS)、2016年。
[17] Łukasz KaiserさんとIlya Sutskeverさん。Neural GPUがアルゴリズムを学習するって話やねん。International Conference on Learning Representations (ICLR)、2016年。
[18] Nal Kalchbrennerさんたち(Lasse Espeholt、Karen Simonyan、Aaron van den Oord、Alex Graves、Koray Kavukcuogluも)。線形時間でのニューラル機械翻訳やねん。計算時間が入力の長さに比例するだけで済むっていうめっちゃ効率ええ方法や。arXivプレプリント arXiv:1610.10099v2、2017年。
[19] Yoon Kimさんたち(Carl Denton、Luong Hoang、Alexander M. Rushも)。構造化アテンションネットワークやねん。アテンションに構造を持たせたろうって発想や。International Conference on Learning Representations、2017年。
[20] Diederik KingmaさんとJimmy Baさん。Adam、確率的最適化の手法やねん。これほんまによう使われてるで、学習を効率よく進められるんや。ICLR、2015年。
[21] Oleksii KuchaievさんとBoris Ginsburgさん。LSTMネットワークの因数分解トリックやねん。LSTMをもっと効率よくする工夫の話や。arXivプレプリント arXiv:1703.10722、2017年。
[22] Zhouhan Linさんたち(Minwei Feng、Cicero Nogueira dos Santos、Mo Yu、Bing Xiang、Bowen Zhou、Yoshua Bengioも)。構造化された自己アテンション型の文埋め込みやねん。文をベクトルにするときに自己アテンション使うとええ感じになるって話や。arXivプレプリント arXiv:1703.03130、2017年。
[23] Minh-Thang Luongさんたち(Quoc V. Le、Ilya Sutskever、Oriol Vinyals、Lukasz Kaiserも)。マルチタスク系列から系列への学習やねん。複数のタスクを同時に学習させたろうって話や。arXivプレプリント arXiv:1511.06114、2015年。
[24] Minh-Thang Luongさんたち(Hieu Pham、Christopher D Manningも)。アテンションベースのニューラル機械翻訳の効果的なアプローチやねん。アテンションをどう使ったらうまくいくかをいろいろ試してはるで。arXivプレプリント arXiv:1508.04025、2015年。
11
---
## Page 12
[](/attach/bdfaa68d8984f0dc02beaca527b76f207d99b666d31d1da728ee0728182df697_p012.png)
### 和訳
[25] Mitchell P Marcusさんら。「でっかい英語コーパス作ったったで:ペンツリーバンクの話」これな、英語の文を解析するためのめっちゃデカいデータセット作った研究やねん。Computational linguistics、19巻2号、313-330ページ、1993年。
[26] David McCloskyさんら。「構文解析に効くセルフトレーニングの話」これ何かっていうと、自分で予測したデータを使ってまた学習するっていう、自己学習みたいな手法やねんけど、それがめっちゃ効果あったっていう研究やで。人間言語技術カンファレンス、152-159ページ、ACL、2006年6月。
[27] Ankur Parikhさんら。「分解可能なアテンションモデル」アテンションっていう「どこに注目するか」を学習する仕組みを、パーツに分解してうまいこと使う手法やねん。自然言語処理の実証的手法、2016年。
[28] Romain Paulusさんら。「要約のための深層強化学習モデル」長い文章をギュッとまとめる要約タスクに、強化学習っていうご褒美ベースの学習方法を使った研究やで。arXivプレプリント arXiv:1705.04304、2017年。
[29] Slav Petrovさんら。「正確でコンパクトで解釈しやすい木構造アノテーションの学習」文の構造を木みたいな形で表すんやけど、それをうまいことキレイに学習する方法の研究やな。計算言語学国際会議、433-440ページ、ACL、2006年7月。
[30] Ofir Pressさんら。「出力の埋め込みを使って言語モデルを改善する話」ニューラルネットの出力側で使う変換を入力側でも使い回したら、性能上がったで!っていう研究やねん。arXivプレプリント arXiv:1608.05859、2016年。
[31] Rico Sennrichさんら。「レアな単語をサブワード単位で扱う機械翻訳」知らん単語が出てきても、細かいパーツに分解したら対応できるやん!っていうアイデアの研究やで。arXivプレプリント arXiv:1508.07909、2015年。
[32] Noam Shazeerさんら。「とんでもなくデカいニューラルネット:スパースゲートMixture-of-Experts層」めっちゃデカいネットワーク作るんやけど、全部使わんと必要なとこだけ使う賢い仕組みの研究やねん。arXivプレプリント arXiv:1701.06538、2017年。
[33] Nitish Srivastavaさんら。「ドロップアウト:ニューラルネットの過学習をシンプルに防ぐ方法」学習中にランダムにニューロン消すっていう、めっちゃシンプルやけどめっちゃ効く手法の研究やで。Journal of Machine Learning Research、15巻1号、1929-1958ページ、2014年。
[34] Sainbayar Sukhbaatarさんら。「エンドツーエンドメモリネットワーク」記憶を持てるニューラルネットで、入力から出力まで一気通貫で学習できるやつの研究やねん。神経情報処理システム学会28、2440-2448ページ、Curran Associates, Inc.、2015年。
[35] Ilya Sutskeverさんら。「ニューラルネットでシーケンスをシーケンスに変換する学習」入力の列を出力の列に変換する、翻訳とかに使える基本的な枠組みの研究やで。これほんまに重要な論文やねん。神経情報処理システム学会、3104-3112ページ、2014年。
[36] Christian Szegedyさんら。「コンピュータビジョンのためのInceptionアーキテクチャの再考」画像認識で有名なInceptionっていうネットワークをもっと良くする方法の研究やな。CoRR, abs/1512.00567、2015年。
[37] Vinyalsさんら。「文法を外国語みたいに扱う」文法解析を、あたかも翻訳みたいに扱うっていう発想の転換がおもろい研究やねん。神経情報処理システム学会、2015年。
[38] Yonghui Wuさんら。「Googleのニューラル機械翻訳システム:人間と機械の翻訳の差を埋める」Googleが本気出して作った翻訳システムの論文やで。ほんまに人間に近づいてきたって話やねん。arXivプレプリント arXiv:1609.08144、2016年。
[39] Jie Zhouさんら。「ニューラル機械翻訳のための高速フォワード接続付き深層再帰モデル」翻訳モデルにショートカット的な接続を入れて性能上げた研究やな。CoRR, abs/1606.04199、2016年。
[40] Muhua Zhuさんら。「高速で正確なシフトリデュース構文解析」文の構造を解析するのを、めっちゃ速くてめっちゃ正確にした研究やで。ACL年次会議51、434-443ページ、ACL、2013年8月。
---
## Page 13
[](/attach/bdfaa68d8984f0dc02beaca527b76f207d99b666d31d1da728ee0728182df697_p013.png)
### 和訳
アテンションの可視化
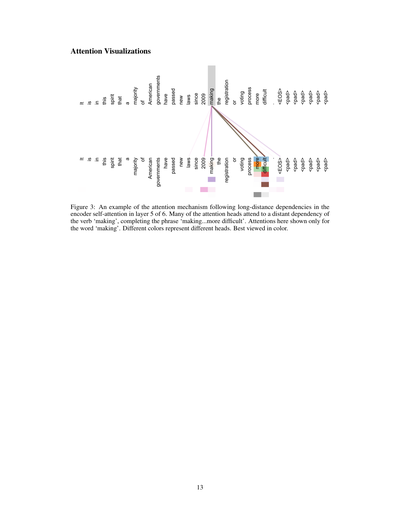
図3:これ見てや、エンコーダーの自己アテンション(6層のうちの5層目)で、めっちゃ離れた単語同士の関係をどうやって追跡してるかの例やねん。アテンションヘッドってやつの多くが、「making」っていう動詞の遠く離れた依存関係に注目してて、「making...more difficult」(〜をより難しくしている)っていうフレーズを完成させとるわけや。ここで見せてるアテンションは「making」って単語に対するものだけやで。色が違うのは別々のヘッドを表してるねん。カラーで見るのが一番ええで。
13ページ
入力-入力 レイヤー5
「この精神に基づいて、アメリカの大多数の政府は2009年以降、登録や投票のプロセスをより困難にする新しい法律を可決してきた。」
要するにな、「making」って単語がめっちゃ後ろにある「more difficult」とつながってるってことを、このモデルはちゃんと理解できてるってことやねん。普通に読んだら間に色んな単語挟まってるから関係性わかりにくいやろ?でもこのアテンションの仕組みのおかげで、離れた単語同士のつながりもバッチリ捉えられるようになっとるんや。ほんまにすごい仕組みやで!
---
## Page 14
[](/attach/bdfaa68d8984f0dc02beaca527b76f207d99b666d31d1da728ee0728182df697_p014.png)
### 和訳
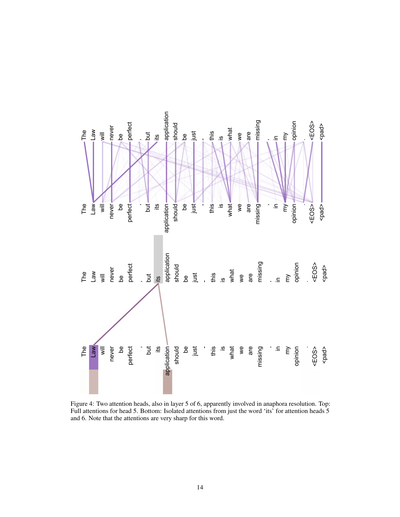
図4:6層中の第5層にある2つのアテンションヘッドで、こいつらはどうやら「照応解析」っていう処理に関わってるみたいやねん。上の図:ヘッド5の全アテンションを見せてるで。下の図:「its」っていう単語だけに注目したときの、ヘッド5とヘッド6のアテンションを分離して表示してるねん。ほんまに注目してほしいのは、この「its」って単語に対するアテンションがめっちゃシャープになってるとこやな。
14
---
## Page 15
[](/attach/bdfaa68d8984f0dc02beaca527b76f207d99b666d31d1da728ee0728182df697_p015.png)
### 和訳
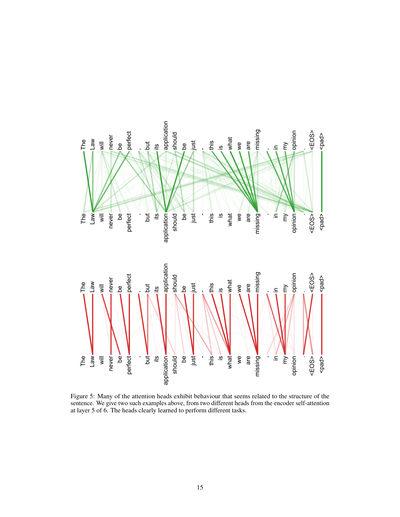
図5:アテンションヘッドの多くが、文の構造に関係してそうな動きをしてるんよ。上の図は、6層あるエンコーダの5層目にある、自己アテンションの別々の2つのヘッドから取ってきた例やねん。見たらわかるけど、それぞれのヘッドがちゃんと違う仕事をするように学習してるんやな。
15
入力-入力 レイヤー5「法律は完璧にはなれへんけど、その適用は公正であるべきや—私の意見では、これが欠けてるもんやねん。」<EOS><pad>「法律は完璧にはなれへんけど、その適用は公正であるべきや—私の意見では、これが欠けてるもんやねん。」<EOS><pad>入力-入力 レイヤー5「法律は完璧にはなれへんけど、その適用は公正であるべきや—私の意見では、これが欠けてるもんやねん。」<EOS><pad>「法律は完璧にはなれへんけど、その適用は公正であるべきや—私の意見では、これが欠けてるもんやねん。」<EOS><pad>
---
![]()
1 / 1
100%