<<
2204.08387v3.pdf

---
## Page 1
[](/attach/bd5395610755a49e6419c406e651906e688e7a0cfe155b3c43566469dfd641fe_p001.png)
### 和訳
# LayoutLMv3:テキストと画像のマスキングを統一した文書AIの事前学習
Yupan Huang∗
中山大学
huangyp28@mail2.sysu.edu.cn
Tengchao Lv
Microsoft Research Asia
tengchaolv@microsoft.com
Lei Cui
Microsoft Research Asia
lecu@microsoft.com
Yutong Lu
中山大学
luyutong@mail.sysu.edu.cn
Furu Wei
Microsoft Research Asia
fuwei@microsoft.com
## 概要
自己教師あり学習っていう事前学習のテクニック、これがめっちゃ進歩してんねん、文書AIの分野で。マルチモーダル(テキストと画像の両方を扱うってことやな)の事前学習モデルのほとんどは、「マスク言語モデリング」っていう方法を使って、テキスト側の双方向の表現を学習してるんやけど、画像側の事前学習の目的関数がモデルによってバラバラやねん。これがマルチモーダルの表現学習をめっちゃややこしくしとるわけ。
ほんで、このペーパーではLayoutLMv3っていうのを提案してんねん。これは文書AIのためにマルチモーダルTransformerを事前学習するモデルなんやけど、テキストと画像のマスキングを統一してるのがポイントやねん。さらに、LayoutLMv3は「ワード・パッチアラインメント」っていう目的関数でも事前学習してて、テキストの単語に対応する画像パッチがマスクされてるかどうかを予測することで、テキストと画像のクロスモーダルな対応関係を学ぶようになっとるねん。
このシンプルで統一されたアーキテクチャと学習目的関数のおかげで、LayoutLMv3はテキスト中心の文書AIタスクにも画像中心の文書AIタスクにも使える汎用的な事前学習モデルになってるわけよ。実験結果を見ると、LayoutLMv3はテキスト中心のタスク——フォーム理解、レシート理解、文書の視覚的質問応答——だけやなくて、画像中心のタスク——文書画像分類とか文書レイアウト解析——でも最先端の性能を叩き出してんねん。コードとモデルは https://aka.ms/layoutlmv3 で公開されてるで。
## CCSコンセプト
• 応用コンピューティング → 文書解析; • コンピューティング手法 → 自然言語処理
## キーワード
文書AI、LayoutLM、マルチモーダル事前学習、視覚と言語
## ACM引用フォーマット:
Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, and Furu Wei. 2022. LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking. In Proceedings of the 30th ACM International Conference on Multimedia (MM '22), October 10–14, 2022, Lisboa, Portugal. ACM, New York, NY, USA, 10 pages. https://doi.org/10.1145/3503161.3548112
∗Microsoftリサーチでのインターン中の貢献。責任著者:Lei CuiとFuru Wei。
(a) テキスト中心のフォーム理解(FUNSDデータセット)
(b) 画像中心のレイアウト解析(PubLayNetデータセット)
図1:文書AIタスクの例
## 1 はじめに
ここ数年、事前学習のテクニックが文書AIの分野でめっちゃ話題になってんねん。文書理解タスクでごっつい成果を上げてるからやな [2, 13–15, 17, 25, 28, 31, 32, 40, 41, 50, 52, 54–56]。図1に示しとるように、事前学習された文書AIモデルを使えば、スキャンしたフォームとか学術論文とか、いろんな文書のレイアウトを解析して重要な情報を抽出できるんよ。これ、産業応用でも学術研究でもめっちゃ大事なことやねん [8]。
自己教師あり学習の事前学習テクニックは、「再構成型の事前学習目的関数」ってやつをうまいこと使って、表現学習でめっちゃ急速に進歩してきたんや。なんでかっていうと、自分自身のデータから勝手に学習できるからやねん。NLP(自然言語処理)の研究では、BERTっていうモデルが最初に「マスク言語モデリング」(MLM)っていう方法を提案したんよ。これは何かっていうと、ランダムにマスク(隠す)した単語を、周りの文脈から元の単語IDを予測することで、双方向の表現を学習するっていう仕組みやねん [9]。
ほんで、高性能なマルチモーダルの事前学習済み文書AIモデルのほとんどは、BERTが提案したMLMをテキスト側に使ってるんやけど、画像側の事前学習目的関数は図2に示すようにモデルによってバラバラやねん。
例えばDocFormerっていうモデルは、CNNデコーダを通して画像ピクセルを再構成しようとするんやけど [2]、これやと文書レイアウトみたいな高レベルの構造よりも、ノイズの多い細かいディテールばっかり学んでまう傾向があんねん [43, 45]。SelfDocっていうモデルは、マスクされた領域の特徴量を回帰(数値を予測)する方法を提案してるんやけど [31]、これは小さいボキャブラリの中で離散的な特徴を分類するよりもノイズが多くて学習がむずいんよ [6, 18]。画像(例えば密なピクセルとか連続的な領域特徴)とテキスト(つまり離散的な
---
## Page 2
[](/attach/bd5395610755a49e6419c406e651906e688e7a0cfe155b3c43566469dfd641fe_p002.png)
### 和訳
このモデルはな、画像の特徴を取り出すのにCNNを使わへんねん。これがめっちゃ大事なポイントで、パラメータをごっそり節約できるし、領域アノテーション(画像のどこに何があるか手作業でラベル付けするやつな)もいらんくなるねん。シンプルに統一されたアーキテクチャと学習目標のおかげで、LayoutLMv3はテキスト中心のタスクでも画像中心のDocument AIタスクでも使える、汎用的な事前学習モデルになっとるわけや。
事前学習したLayoutLMv3モデルを5つの公開ベンチマークで評価したで。テキスト中心のベンチマークとしては、フォーム理解のFUNSD [20]、レシート理解のCORD [39]、文書の視覚的質問応答のDocVQA [38]。画像中心のベンチマークとしては、文書画像分類のRVL-CDIP [16]、文書レイアウト解析のPubLayNet [59]や。実験結果を見たらな、LayoutLMv3はこれら全部のベンチマークで、パラメータ効率ええまま最高性能を叩き出しとるねん。しかもLayoutLMv3は、アーキテクチャも事前学習の目標もシンプルでスッキリしとるから、再現もめっちゃ簡単やで。
ワイらの貢献をまとめるとこんな感じや:
- LayoutLMv3は、Document AIの分野で初めて、視覚特徴を抽出するのに事前学習済みCNNやFaster R-CNNのバックボーンに頼らへんマルチモーダルモデルやねん。これでパラメータをごっそり節約できて、領域アノテーションもいらんくなるんや。
- LayoutLMv3は、テキストと画像のマルチモーダル表現学習の間にあったズレを、MLMとMIMっていう統一された離散トークン再構成の目標で解消しとるねん。つまりな、テキスト側も画像側も「マスクされた部分を当てる」っていう同じ方式で学習するから、足並みが揃うわけや。さらに、Word-Patch Alignment(WPA)っていう目標も提案して、テキストと画像の対応関係(クロスモーダルアライメント)の学習を促進しとるで。
- LayoutLMv3は、テキスト中心のタスクにも画像中心のDocument AIタスクにも使える汎用モデルやねん。Document AIの分野で、マルチモーダルTransformerが画像タスクにも通用するっていうのを示したんは、これが初めてやで。
- 実験結果から、LayoutLMv3はDocument AIのテキスト中心タスクでも画像中心タスクでも最高性能を達成しとることがわかったで。コードとモデルは https://aka.ms/layoutlmv3 で公開しとるから、誰でも使えるで。
## 2 LAYOUTLMV3
図3にLayoutLMv3の全体像を示しとるで。
### 2.1 モデルアーキテクチャ
LayoutLMv3は、テキストと画像を統一的に扱うマルチモーダルTransformerを使って、クロスモーダル表現(テキストと画像をまたいだ表現)を学習するねん。このTransformerは多層構造になっとって、各層は主にマルチヘッド自己注意機構と、位置ごとの全結合フィードフォワードネットワーク [49] で構成されとるんや。要するに、各層で「入力全体の中でどこに注目すべきか」を計算して、それを元に情報を変換していく仕組みやな。Transformerへの入力は、テキスト埋め込み Y = y1:L と画像埋め込み X = x1:M を連結したもので、LとMはそれぞれテキストと画像の系列長やで。Transformerを通すと、最終層からテキストと画像の文脈的な表現が出力されるんや。
**テキスト埋め込み。** テキスト埋め込みは、単語埋め込みと位置埋め込みを組み合わせたもんやねん。文書画像を既製のOCRツールで処理して、テキスト内容と対応する2D位置情報を取得するんや。単語埋め込みは、事前学習モデルRoBERTa [36] の単語埋め込み行列で初期化しとるで。位置埋め込みには1D位置と2Dレイアウト位置の埋め込みがあって、1D位置はテキスト系列内でのトークンのインデックス(何番目の単語かってこと)、2Dレイアウト位置はテキストトークンのバウンディングボックス座標(文書画像上でそのテキストがどこにあるかの四角い枠の座標やな)を指しとるで。
**図2:既存手法(DocFormer [2] やSelfDoc [31] など)との比較やで。** (1) 画像埋め込みについて:ワイらのLayoutLMv3は線形パッチを使うことで、CNNの計算ボトルネックを解消して、物体検出器の学習に必要な領域教師データもいらんくしとるねん。(2) 画像モダリティの事前学習目標について:ワイらのLayoutLMv3は、生のピクセルや領域特徴量やなくて、マスクされたパッチの離散画像トークンを再構成することを学習するんや。なんでかっていうと、ノイズまみれの細かいディテールよりも、高レベルのレイアウト構造を捉えたいからやねん。
...っていう目標がさらにクロスモーダルアライメント学習の難易度を上げとって、これはマルチモーダル表現学習にとってめっちゃ重要なポイントやねん。テキストと画像のモダリティで事前学習目標にズレがある問題を克服して、マルチモーダル表現学習を促進するために、ワイらはLayoutLMv3を提案したんや。Document AI向けに、テキストと画像の統一されたマスキング目標MLMとMIMでマルチモーダルTransformerを事前学習するねん。図3に示しとるように、LayoutLMv3はテキストモダリティのマスクされた単語トークンを再構成することを学習して、それと対称的に画像モダリティのマスクされたパッチトークンも再構成することを学習するんや。DALL-E [43] やBEiT [3] にインスパイアされて、ターゲットの画像トークンは離散VAE(変分オートエンコーダ)の潜在コードから取得しとるで。文書ではな、各テキスト単語が画像パッチに対応しとるんや。このクロスモーダルアライメントを学習するために、Word-Patch Alignment(WPA)っていう目標を提案して、テキスト単語に対応する画像パッチがマスクされとるかどうかを予測するようにしとるねん。ViT [11] やViLT [22] にインスパイアされて、LayoutLMv3はページ内の物体検出みたいな複雑な前処理なしに、文書画像から直接生の画像パッチを活用するんや。LayoutLMv3は、統一されたMLM・MIM・WPAの目標を持つTransformerモデルで、画像・テキスト・マルチモーダルの表現を一緒に学習するねん。これによってLayoutLMv3は、事前学習済みDocument AIマルチモーダルモデルとして初めてのもんになっとるわけや。
---
## Page 3
[](/attach/bd5395610755a49e6419c406e651906e688e7a0cfe155b3c43566469dfd641fe_p003.png)
### 和訳
図3:LayoutLMv3のアーキテクチャと事前学習の目的
LayoutLMv3っていうのは、ドキュメントAI向けに事前学習されたマルチモーダルTransformerでな、テキストと画像のマスキング(隠す処理)を統一的にやるんが特徴やねん。入力としてドキュメントの画像と、それに対応するテキスト、あとレイアウトの位置情報を受け取るんやけど、モデルは画像パッチ(画像を小さく区切ったやつ)の線形射影と単語トークンを入力にして、それを文脈を考慮したベクトル表現にエンコードするわけや。LayoutLMv3の事前学習には、離散トークンを復元する目的関数として、マスク言語モデリング(MLM)とマスク画像モデリング(MIM)を使ってんねん。さらに、単語-パッチアライメント(WPA)っていう目的関数もあって、テキストの単語に対応する画像パッチがマスクされてるかどうかを予測することで、テキストと画像のクロスモーダルな対応関係を学習するんや。「Seg」はセグメントレベルの位置を表してて、「[CLS]」「[MASK]」「[SEP]」「[SPE]」は特殊トークンやで。
LayoutLMに倣って、座標は全部画像サイズで正規化して、x軸・y軸・幅・高さの特徴量をそれぞれ別の埋め込み層で埋め込んでるねん[54]。LayoutLMとLayoutLMv2は単語レベルのレイアウト位置を使ってて、各単語がそれぞれ位置情報を持ってたんやけど、ウチらはセグメントレベルのレイアウト位置を採用してんねん。なんでかっていうと、同じセグメント内の単語は普通同じ意味を表してるから、同じ2D位置を共有させた方がええやろってことや[28]。
**画像の埋め込みについて。** ドキュメントAIの既存のマルチモーダルモデルは、CNNのグリッド特徴量を抽出するか[2, 56]、Faster R-CNN[44]みたいな物体検出器を使ってリージョン特徴量を抽出するか[14, 31, 40, 54]してたんやけど、これがめっちゃ計算コスト高いか、リージョンの教師データが必要やったんよな。そこでViT[11]とViLT[22]にインスパイアされて、ウチらはドキュメント画像を画像パッチの線形射影特徴量として表現してから、マルチモーダルTransformerに食わせることにしたんや。具体的に言うと、ドキュメント画像を𝐻×𝑊にリサイズして、画像をI ∈ R^{𝐶×𝐻×𝑊}って表すねん。ここで𝐶、𝐻、𝑊はそれぞれチャンネル数、幅、高さや。ほんで画像を均一な𝑃×𝑃のパッチに分割して、各パッチを線形射影で𝐷次元に変換して、平坦化してベクトルの列にするんやけど、その長さは𝑀 = 𝐻𝑊/𝑃²になるわけや。そこに学習可能な1D位置埋め込みを各パッチに足すんやけど、2D位置埋め込みを使っても予備実験で改善見られへんかったから1Dにしてんねん。LayoutLMv3は、ドキュメントAIで初めてCNNに頼らず画像特徴量を抽出するマルチモーダルモデルやねん。これがほんまに大事でな、パラメータ数を減らしたり、複雑な前処理のステップをなくしたりできるんや。
LayoutLMv2[56]に倣って、テキストと画像のモダリティ両方のセルフアテンションネットワークに、意味的な1D相対位置と空間的な2D相対位置をバイアス項として入れてるで。
**2.2 事前学習の目的関数**
LayoutLMv3は、MLM・MIM・WPAの目的関数を使って、自己教師あり学習でマルチモーダル表現を学習するんや。LayoutLMv3の事前学習の目的関数全体は 𝐿 = 𝐿_{MLM} + 𝐿_{MIM} + 𝐿_{WPA} って定義されてるで。
**目的関数その1:マスク言語モデリング(MLM)。** 言語側のMLMは、BERT[9]のマスク言語モデリングと、LayoutLM[54]やLayoutLMv2[56]のマスク視覚-言語モデリングからヒントもろてんねん。テキストトークンの30%をマスクして
---
## Page 4
[](/attach/bd5395610755a49e6419c406e651906e688e7a0cfe155b3c43566469dfd641fe_p004.png)
### 和訳
せやな、ほな説明していくで!
---
まず最初の仕組みは**スパンマスキング**っていう戦略やねん。ポアソン分布(λ = 3)っていう確率の法則に従って、マスクする長さを決めるんや [21, 27]。事前学習の目的はな、画像トークンX_M'とテキストトークンY_L'を壊した(マスクした)配列の文脈表現をもとに、正しいマスクされたテキストトークンy_lの対数尤度——まあ「どんだけ正解っぽいか」のスコアやな——を最大化することやねん。ここでM'とL'はマスクされた位置を表してるで。Transformerモデルのパラメータをθとして、こんなクロスエントロピー損失を最小化するんや:
$$L_{MLM}(\theta) = -\sum_{l=1}^{L'} \log p_\theta(y_l | X_{M'}, Y_{L'}) \quad (1)$$
レイアウト情報はそのまま変えへんから、この目的関数のおかげで、モデルは「レイアウト情報」と「テキスト・画像の文脈」の対応関係をちゃんと学べるようになるんやで。
**目的関数II:マスク画像モデリング(MIM)**。テキストと画像の文脈表現から視覚的な内容を読み取れるようにするために、BEiT [3] のMIM事前学習の目的関数を、このマルチモーダル(複数の情報を扱う)Transformerモデルに取り入れてるんや。MIMはMLMと対称的な関係にあってな、ブロック単位のマスキング戦略 [3] を使って、画像トークンの約40%をランダムにマスクするんや。MIMの目的関数はクロスエントロピー損失で動いてて、周りのテキストと画像トークンの文脈から、マスクされた画像トークンx_mを復元するっていう仕組みやねん。
$$L_{MIM}(\theta) = -\sum_{m=1}^{M'} \log p_\theta(x_m | X_{M'}, Y_{L'}) \quad (2)$$
画像トークンのラベル(正解)は画像トークナイザーから来るんやけど、こいつは密な画像ピクセルを視覚的な語彙に基づいて離散的なトークンに変換できるんや [43]。せやからMIMは、ノイズだらけの低レベルな細かいディテールやなくて、**高レベルなレイアウト構造**を学習するのに役立つっちゅうわけや。
**目的関数III:単語-パッチアライメント(WPA)**。文書ではな、テキストの各単語が画像のパッチ(区画)に対応してるんや。MLMとMIMでテキストと画像のトークンをそれぞれランダムにマスクしてるけど、テキストと画像のモダリティ間の**明示的なアライメント学習**——つまり「この文字とこの画像部分が対応してるで」っていう学習——がないんよな。そこで、テキスト単語と画像パッチの間の細かい対応関係を学ぶために、WPA目的関数を提案してるんや。WPAの目的はな、あるテキスト単語に対応する画像パッチがマスクされてるかどうかを予測することやねん。具体的には、マスクされてないテキストトークンに対して、それに対応する画像トークンもマスクされてなかったら「アライメントあり」のラベルを付けるんや。そうやなかったら「アライメントなし」のラベルを付ける。WPA損失を計算するときは、マスクされたテキストトークンは除外するで。なんでかっていうと、マスクされたテキスト単語と画像パッチの対応関係を学んでもうたら困るからやねん。2層のMLPヘッドを使って、テキストと画像の文脈表現を入力して、二値分類(アライメントあり/なし)のラベルをバイナリクロスエントロピー損失で出力するんや:
$$L_{WPA}(\theta) = -\sum_{l=1}^{L-L'} \log p_\theta(z_l | X_{M'}, Y_{L'}) \quad (3)$$
ここでL−L'はマスクされてないテキストトークンの数で、z_lはl番目の位置の言語トークンの二値ラベルやで。
## 3 実験
### 3.1 モデルの設定
LayoutLMv3のネットワーク構造は、公平に比較するためにLayoutLM [54] とLayoutLMv2 [56] に合わせてるんや。LayoutLMv3にはbaseとlargeの2つのサイズを用意してるで。**LayoutLMv3 BASE**は12層のTransformerエンコーダで、12ヘッドのセルフアテンション、隠れ層のサイズD = 768、フィードフォワードネットワークの中間サイズが3,072や。**LayoutLMv3 LARGE**は24層のTransformerエンコーダで、16ヘッドのセルフアテンション、隠れ層のサイズD = 1,024、フィードフォワードネットワークの中間サイズが4,096やで。テキスト入力の前処理には、Byte-Pair Encoding(BPE)[46] でテキスト列をトークン化して、最大系列長はL = 512にしてるんや。各テキスト列の最初と最後に[CLS]と[SEP]トークンを追加するで。テキスト列の長さがLより短いときは、[PAD]トークンで埋めるんや。これらの特殊トークンのバウンディングボックス座標は全部ゼロやで。画像埋め込みのパラメータは C × H × W = 3 × 224 × 224、P = 16、M = 196 や。
分散学習と混合精度学習を使って、メモリコストを減らしてトレーニングを速くしてるんや。あと、勾配蓄積メカニズムっていうのを使って、バッチ(まとめて処理するサンプルの塊)をいくつかのミニバッチに分割して、大きなバッチサイズでもメモリが足りんくならんようにしてるで。文書レイアウト解析では、さらに勾配チェックポイント技術を使ってメモリコストを抑えてるんや。学習を安定させるために、CogView [10] に倣ってアテンションの計算方法をこう変えてるで:
もともとの softmax(Q^T K / √d) を、softmax((Q^T K / √d − max(Q^T K / √d)) × α) / α に変更。ここで α は32やねん。
### 3.2 LayoutLMv3の事前学習
いろんな文書タスクに使えるユニバーサルな表現を学習するために、めっちゃでかいIIT-CDIPデータセットで事前学習してるんや。IIT-CDIP Test Collection 1.0は大規模なスキャン文書画像データセットで、約1,100万枚の文書画像が入ってて、4,200万ページに分割できるんや [26]。そのうち1,100万枚だけを使ってLayoutLMv3を学習してるで。LayoutLMモデル [54, 56] に従って、画像の拡張(データオーグメンテーション)はやってへんで。マルチモーダルTransformerエンコーダとテキスト埋め込み層は、事前学習済みのRoBERTa [36] の重みで初期化してるんや。画像トークナイザーは、DiTっていう自己教師あり事前学習済み文書画像Transformerモデル [30] の事前学習済み画像トークナイザーで初期化してるで。画像トークンの語彙サイズは8,192や。残りのモデルパラメータはランダムに初期化してるんやで。LayoutLMv3の事前学習には、Adamオプティマイザー [23] を使って、バッチサイズ2,048で500,000ステップ学習してるんや。重み減衰は1e-2、(β1, β2) = (0.9, 0.98)や。**LayoutLMv3 BASE**モデルでは学習率1e-4で、最初の4.8%のステップで線形ウォームアップしてるで。**LayoutLMv3 LARGE**では学習率5e-5、ウォームアップ率10%やねん。
### 3.3 マルチモーダルタスクでのファインチューニング
LayoutLMv3を、代表的な自己教師あり事前学習手法と比較してるんやけど、事前学習で使うモダリティ(情報の種類)で分類してるで。
- **[T] テキストモダリティ**:BERT [9] とRoBERTa [36] は、Transformerアーキテクチャでテキスト情報だけを使う代表的な事前学習済み言語モデルやな。FUNSDとRVL-CDIPの結果はLayoutLM [54] のRoBERTaから、BERTの結果はLayoutLMv2 [56] から引用してるで。CORDとDocVQAの結果はRoBERTaを再現して報告してるんや。
- **[T+L] テキスト+レイアウトモダリティ**:LayoutLMは、BERTの埋め込みに単語レベルの空間的な埋め込みを追加することでレイアウト情報を取り入れてるんや [54]。StructuralLMはセグメントレベルのレイアウト情報を活用してるで [28]。BROSは相対的なレイアウト情報をエンコードしてるんやな。
---
## Page 5
[](/attach/bd5395610755a49e6419c406e651906e688e7a0cfe155b3c43566469dfd641fe_p005.png)
### 和訳
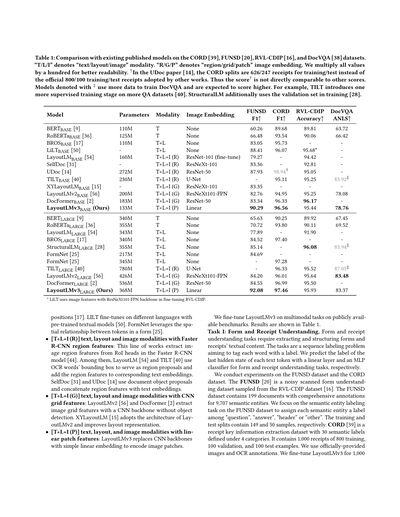
表1:CORD [39]、FUNSD [20]、RVL-CDIP [16]、DocVQA [38] のデータセットで、今まで出てきた既存モデルと比べてみた結果やで。
「T/L/I」っていうのは「テキスト/レイアウト/画像」のことで、どの情報を使ってるかってことやねん。「R/G/P」は「領域/グリッド/パッチ」っていう画像の取り込み方の違いやな。見やすいように数値は全部100倍にしてるで。†UDocの論文 [14] では、CORDのデータの分け方が訓練626枚/テスト247枚になってて、他のみんなが使ってる公式の訓練800枚/テスト100枚とちゃうねん。せやからこの†マーク付きのスコアは他とそのまま比べたらアカンで。‡マーク付きのモデルはDocVQAの学習にもっとぎょうさんデータ使ってるから、スコア高くなるのは当然やねん。例えばTILTはQAデータセットをもう1段階余分に教師あり学習させとるし [40]、StructuralLMは検証用データも訓練に突っ込んどる [28]。
[表1の内容はモデル名、パラメータ数、使ってるモダリティ、画像の埋め込み方法、そして各データセットでのスコアが並んどる。LayoutLMv3が提案手法(Ours)やで。]
* LiLTはRVL-CDIPのファインチューニング時にResNeXt101-FPNバックボーンの画像特徴量を使ってるで。
---
ほな、各モデルのアプローチをざっくり説明するで。
**[T+L]のやつら**:BROSはテキストとレイアウト情報を使って、トークンの相対位置をうまいこと活用してるねん [17]。LiLTは事前学習済みのテキストモデルを使って、いろんな言語でファインチューニングできるようにしてる [50]。FormNetはフォーム内のトークン同士の空間的な位置関係をうまく使ってるで [25]。
**[T+L+I (R)] テキスト+レイアウト+画像で、Faster R-CNNの領域特徴量を使うタイプ**:こいつらはFaster R-CNNモデル [44] のRoIヘッドから画像の領域特徴量を引っ張ってくるねん。LayoutLM [54] とTILT [40] はOCRで読み取った単語のバウンディングボックス(囲み枠のことやな)を領域の候補として使って、その特徴量を対応するテキストの埋め込みに足してる。SelfDoc [31] とUDoc [14] は文書オブジェクトの候補領域を使って、領域特徴量をテキスト埋め込みとくっつけてるで。
**[T+L+I (G)] テキスト+レイアウト+画像で、CNNのグリッド特徴量を使うタイプ**:LayoutLMv2 [56] とDocFormer [2] は物体検出なしで、CNNバックボーンから画像のグリッド特徴量を取り出してるねん。XYLayoutLM [15] はLayoutLMv2のアーキテクチャをベースにして、レイアウトの表現をもっとええ感じに改良したやつやで。
**[T+L+I (P)] テキスト+レイアウト+画像で、線形パッチ特徴量を使うタイプ**:LayoutLMv3はCNNバックボーンをやめて、シンプルな線形埋め込みで画像パッチをエンコードしてるねん。めっちゃシンプルやけど、ちゃんと強いんよこれが。
---
ほんで、LayoutLMv3を公開されてるベンチマークでマルチモーダルタスクにファインチューニングした結果が表1に載ってるで。
**タスクI:フォームとレシートの理解**。これはフォームやレシートに書いてあるテキストの中身を抜き出して、きれいに構造化するタスクやねん。要するに系列ラベリング問題で、各単語にラベルをペタペタ貼っていく感じやな。テキストトークンの最後の隠れ状態に線形層を使ってラベルを予測するんやけど、フォーム理解にはそのまま線形層、レシート理解にはMLPの分類器をそれぞれ使ってるで。
実験はFUNSDデータセットとCORDデータセットでやってるねん。FUNSD [20] はRVL-CDIPデータセット [16] からサンプリングした、ノイズの多いスキャンフォームの理解用データセットや。199文書あって、9,707個のセマンティックエンティティ(意味のあるまとまりやな)にちゃんとアノテーションが付いてる。FUNSDではセマンティックエンティティラベリングっていうタスクに取り組んでて、各エンティティに「質問」「回答」「ヘッダー」「その他」のどれかのラベルを振るねん。訓練が149サンプル、テストが50サンプルや。CORD [39] はレシートからキー情報を抜き出すデータセットで、4カテゴリの下に30個のセマンティックラベルが定義されてるで。レシート1,000枚あって、訓練800枚、検証100枚、テスト100枚に分かれとる。公式提供の画像とOCRアノテーションを使ってるで。LayoutLMv3は1,000
---
## Page 6
[](/attach/bd5395610755a49e6419c406e651906e688e7a0cfe155b3c43566469dfd641fe_p006.png)
### 和訳
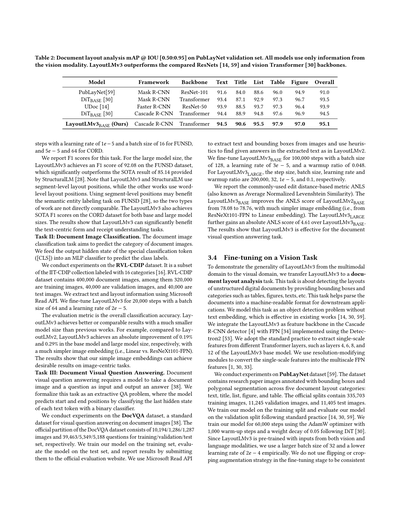
**表2:PubLayNetの検証セットでの文書レイアウト解析 mAP @ IOU [0.50:0.95] の結果やで。全モデルとも視覚の情報だけ使ってるねん。LayoutLMv3は、比較対象のResNetsとか視覚Transformerのバックボーンよりええ成績出してるで。**
| モデル | フレームワーク | バックボーン | テキスト | タイトル | リスト | 表 | 図 | 全体 |
|---|---|---|---|---|---|---|---|---|
| PubLayNet | Mask R-CNN | ResNet-101 | 91.6 | 84.0 | 88.6 | 96.0 | 94.9 | 91.0 |
| DiT_BASE | Mask R-CNN | Transformer | 93.4 | 87.1 | 92.9 | 97.3 | 96.7 | 93.5 |
| UDoc | Faster R-CNN | ResNet-50 | 93.9 | 88.5 | 93.7 | 97.3 | 96.4 | 93.9 |
| DiT_BASE | Cascade R-CNN | Transformer | 94.4 | 88.9 | 94.8 | 97.6 | 96.9 | 94.5 |
| **LayoutLMv3_BASE(ワイらの)** | Cascade R-CNN | Transformer | **94.5** | **90.6** | **95.5** | **97.9** | **97.0** | **95.1** |
---
学習率1e-5、バッチサイズ16でFUNSDは学習して、CORDの方は学習率5e-5、バッチサイズ64でやってるねん。
このタスクの評価にはF1スコアを使ってるで。ラージモデルのLayoutLMv3はFUNSDデータセットでF1スコア92.08を叩き出してて、これStructuralLMが出してた最高記録85.14をめっちゃ大幅に上回ってるねん。ただ注意してほしいんやけど、LayoutLMv3とStructuralLMは「セグメント単位」のレイアウト位置情報を使ってるのに対して、他の研究は「単語単位」の位置情報を使ってるねん。セグメント単位の方がFUNSDの意味エンティティラベリングタスクに有利に働く可能性があるから、この2種類の研究は単純に比べられへんのよな。LayoutLMv3はCORDデータセットでもベースモデル・ラージモデルの両方で最高F1スコアを達成してるで。要するに、LayoutLMv3はテキスト中心のフォームとかレシート読み取りタスクにめっちゃ効くってことやねん。
**タスクII:文書画像の分類やで。** これは文書画像のカテゴリを予測するタスクやねん。分類専用の特別なトークン([CLS])の出力隠れ状態をMLPっていう分類器に突っ込んで、クラスラベルを予測するっちゅう仕組みやで。
実験にはRVL-CDIPデータセットを使ってるねん。これはIIT-CDIPコレクションの一部で、16カテゴリのラベルが付いてるやつや。RVL-CDIPには全部で40万枚の文書画像があって、そのうち32万枚が学習用、4万枚が検証用、4万枚がテスト用やねん。テキストとレイアウト情報の抽出にはMicrosoftのRead APIを使ってるで。LayoutLMv3はバッチサイズ64、学習率2e-5で2万ステップのファインチューニングをやってるねん。
評価指標は全体の分類精度やで。LayoutLMv3は前の研究と比べて、めっちゃ小さいモデルサイズで同等かそれ以上の結果を出してるねん。例えばLayoutLMv2と比べると、ベースモデルで0.19%、ラージモデルで0.29%の絶対精度向上を達成してて、しかも画像の埋め込み方法がめっちゃシンプルになってるねん(ResNeXt101-FPNっていう複雑なやつからLinearっていうシンプルなやつに変わってるで)。つまりな、ワイらのシンプルな画像埋め込みでも、画像中心のタスクでちゃんとええ結果出せるってことやねん。
**タスクIII:文書のビジュアル質問応答やで。** これは文書画像と質問を入力として受け取って、答えを出力するっていうタスクやねん。このタスクを「抽出型QA問題」として扱ってて、つまりモデルが各テキストトークンの最終隠れ状態を二値分類器で判定して、答えの開始位置と終了位置を予測する仕組みやねん。
実験にはDocVQAデータセットを使ってるで。これは文書画像に対するビジュアル質問応答の標準的なデータセットやねん。DocVQAの公式データ分割は、学習/検証/テストセットがそれぞれ10,194/1,286/1,287枚の画像と39,463/5,349/5,188個の質問で構成されてるで。学習セットで訓練して、テストセットで評価して、公式の評価サイトに結果を提出して報告してるねん。テキストとバウンディングボックスの抽出にはMicrosoft Read APIを使ってて、LayoutLMv2と同じようにヒューリスティックス(経験則的な手法)で抽出テキストの中から正解を見つけてるで。LayoutLMv3_BASEは10万ステップ、バッチサイズ128、学習率3e-5、ウォームアップ比率0.048でファインチューニングしてるねん。LayoutLMv3_LARGEの方は、ステップ数20万、バッチサイズ32、学習率1e-5、ウォームアップ比率0.1やで。
評価指標にはよく使われる編集距離ベースのANLS(Average Normalized Levenshtein Similarityとも呼ばれるやつ)を使ってるねん。LayoutLMv3_BASEはLayoutLMv2_BASEのANLSスコアを78.08から78.76に改善してて、しかも画像埋め込みがめっちゃシンプルになってるねん(ResNeXt101-FPNからLinear埋め込みに変わってるで)。LayoutLMv3_LARGEはさらにLayoutLMv3_BASEから絶対ANLSスコアで4.61ポイントも上乗せしてるねん。これでLayoutLMv3が文書ビジュアル質問応答タスクにもめっちゃ有効やってことが分かるやろ。
**3.4 ビジョンタスクへのファインチューニングやで**
LayoutLMv3がマルチモーダル(複数の情報源を使う)領域だけやなくて、ビジュアル領域にも応用できるっていう汎用性を示すために、文書レイアウト解析タスクに転用してみたんやで。このタスクはな、構造化されてないデジタル文書のレイアウトを検出するもんで、表・図・テキストとかのカテゴリとバウンディングボックス(囲み枠)を出力するねん。文書を機械が読めるフォーマットに変換して、後続のアプリケーションで使えるようにするためのもんやで。このタスクはテキスト埋め込みなしのオブジェクト検出問題としてモデル化してて、既存の研究でも効果的やと分かってるアプローチやねん。
LayoutLMv3をCascade R-CNN検出器の特徴抽出バックボーンとして組み込んでて、FPNと一緒にDetectron2で実装してるねん。標準的なやり方に従って、Transformerの異なる層(ベースモデルやと4, 6, 8, 12層目)から単一スケールの特徴を抽出してるで。ほんで、解像度を変えるモジュールを使って、その単一スケール特徴をマルチスケールFPN特徴に変換してるねん。
実験にはPubLayNetデータセットを使ってるで。このデータセットには研究論文の画像が入ってて、テキスト・タイトル・リスト・図・表の5つの文書レイアウトカテゴリでバウンディングボックスとポリゴンセグメンテーション(多角形による領域分割)のアノテーションが付いてるねん。公式のデータ分割は学習画像335,703枚、検証画像11,245枚、テスト画像11,405枚やで。標準的なやり方に従って学習用データで訓練して、検証用データで評価してるねん。AdamWオプティマイザを使って6万ステップ学習してて、ウォームアップが1,000ステップ、重み減衰が0.05やで(DiTに倣ってるねん)。LayoutLMv3はもともと視覚と言語の両方の情報で事前学習されてるから、経験的にバッチサイズを32と大きめに、学習率を2e-4と低めに設定してるで。ファインチューニング段階では反転とかクロッピングのデータ拡張は使ってへんねん。これは
---
## Page 7
[](/attach/bd5395610755a49e6419c406e651906e688e7a0cfe155b3c43566469dfd641fe_p007.png)
### 和訳
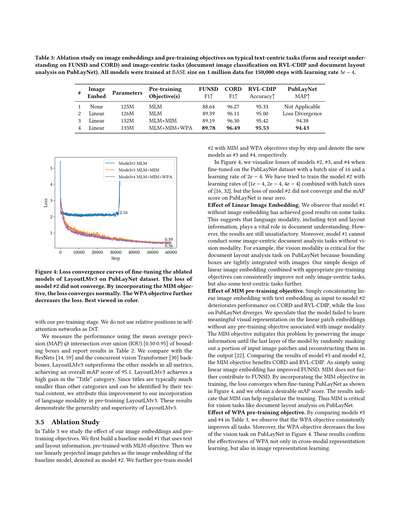
表3:画像埋め込みと事前学習の目的関数についてのアブレーション実験やで。テキスト中心のタスク(FUNSDとCORDでのフォームとレシート理解)と、画像中心のタスク(RVL-CDIPでの文書画像分類とPubLayNetでの文書レイアウト解析)で調べとるんや。モデルは全部BASEサイズで、100万データを使って15万ステップ、学習率3e-4で訓練しとるで。
| # | 画像埋め込み | パラメータ数 | 事前学習の目的関数 | FUNSD F1↑ | CORD F1↑ | RVL-CDIP 正解率↑ | PubLayNet MAP↑ |
|---|---|---|---|---|---|---|---|
| 1 | なし | 125M | MLM | 88.64 | 96.27 | 95.33 | 使えへん |
| 2 | 線形 | 126M | MLM | 89.39 | 96.11 | 95.00 | ロス発散 |
| 3 | 線形 | 132M | MLM+MIM | 89.19 | 96.30 | 95.42 | 94.38 |
| 4 | 線形 | 133M | MLM+MIM+WPA | 89.78 | 96.49 | 95.53 | 94.43 |
モデル#2にMIMとWPAの目的関数を段階的に追加していって、新しいモデルをそれぞれ#3と#4って呼んどるで。
図4では、モデル#2、#3、#4をPubLayNetデータセットでファインチューニングした時のロスを可視化しとる。バッチサイズ16、学習率2e-4でやっとるんや。モデル#2については学習率{1e-4, 2e-4, 4e-4}とバッチサイズ{16, 32}の組み合わせも試してみたんやけど、モデル#2のロスは収束せんくて、PubLayNetでのmAPスコアはほぼゼロやったんよ。
**線形画像埋め込みの効果について。** 画像埋め込みなしのモデル#1でもそこそこええ結果出とんのがわかるな。これが何を意味するかっていうと、テキストとレイアウト情報っていう言語系の情報が、文書理解にめっちゃ大事やってことやねん。せやけど、まだ満足できる結果とは言えへんのよ。しかもモデル#1は画像の情報を使ってへんから、画像中心の文書解析タスクがそもそもでけへんねん。例えばPubLayNetの文書レイアウト解析では、バウンディングボックスが画像とガッチリ結びついとるから、画像情報がめっちゃ重要なんや。うちらのシンプルな線形画像埋め込みの設計を適切な事前学習の目的関数と組み合わせたら、画像中心のタスクだけやなくて、テキスト中心のタスクもさらに改善できるんやで。
**MIM事前学習の目的関数の効果について。** 線形画像埋め込みをテキスト埋め込みとただ単にくっつけただけのモデル#2やと、CORDとRVL-CDIPの性能が下がってしもて、PubLayNetではロスが発散してまうんや。なんでかっていうと、画像に関連した事前学習の目的関数がないと、線形パッチ埋め込みからモデルが意味のある視覚表現を学習でけへんかったんちゃうかなって推測しとる。MIMの目的関数はこの問題を和らげてくれるんや。どうやるかっていうと、入力画像パッチの一部をランダムにマスクして、出力でそれを復元させることで、モデルの最後の層まで画像情報を保持させるんやで[22]。モデル#3と#2の結果を比べたら、MIMの目的関数はCORDとRVL-CDIPに効いとるのがわかるな。FUNSDは線形画像埋め込みだけですでに改善されとったから、MIMはFUNSDにはさらなる貢献はしてへんねん。MIMの目的関数を訓練に組み込むと、図4に示すようにPubLayNetのファインチューニング時にロスがちゃんと収束するようになって、ええ感じのmAPスコアが得られるんや。この結果は、MIMが訓練の正則化に役立つことを示しとる。つまりMIMは、PubLayNetの文書レイアウト解析みたいな画像タスクにはほんまに不可欠やねん。
**WPA事前学習の目的関数の効果について。** 表3でモデル#3と#4を比べてみたら、WPAの目的関数が全タスクで一貫して改善しとるのがわかるで。さらに、図4ではPubLayNetの画像タスクのロスもWPAで下がっとる。この結果から、WPAはクロスモーダル(異なるモダリティ間)の表現学習だけやなくて、画像表現の学習にも効果的やってことが確認できたんや。
**図4:** PubLayNetデータセットでLayoutLMv3のアブレーションモデルをファインチューニングした時のロス収束曲線やで。モデル#2のロスは収束せんかった。MIMの目的関数を入れたらロスがちゃんと収束するようになって、WPAの目的関数でさらにロスが下がっとる。カラーで見るのがおすすめやで。
うちらの事前学習段階と合わせて使っとるんやけど、DiTみたいにセルフアテンションネットワークで相対位置は使ってへんで。
性能の測定には、バウンディングボックスのIOU(重なり具合)[0.50:0.95]での平均適合率(MAP)を使って、結果を表2に載せとる。ResNets[14, 59]と同時期に出てきたビジョンTransformer[30]のバックボーンと比較しとるで。LayoutLMv3は全指標で他のモデルを上回って、全体のmAPスコア95.1を達成しとるんや。特に「タイトル」カテゴリでめっちゃ大きな改善が出とる。タイトルって他のカテゴリよりだいぶ小さくて、テキストの中身で識別できることが多いやろ?せやから、この改善はLayoutLMv3の事前学習で言語の情報を取り入れたことが効いとるんやと考えとる。この結果は、LayoutLMv3の汎用性と優れた性能を示しとるで。
**3.5 アブレーション実験**
表3では、うちらの画像埋め込みと事前学習の目的関数の効果を調べとる。まずテキストとレイアウト情報を使って、MLMの目的関数で事前学習したベースラインモデル#1を作ったんや。次に、線形射影した画像パッチを画像埋め込みとしてベースラインモデルに追加したのがモデル#2やで。さらにモデル
---
## Page 8
[](/attach/bd5395610755a49e6419c406e651906e688e7a0cfe155b3c43566469dfd641fe_p008.png)
### 和訳
パラメータの比較についてやけどな。表を見てもらったらわかるねんけど、16×16のパッチ投影に画像埋め込みを入れた場合(#1→#2)、増えるパラメータはたったの0.6Mやねん。これ、CNNのバックボーン(例えばResNet-101やったら44Mもあるで)と比べたら、ほんまに微々たるもんやな。事前学習の段階でMIMヘッドが6.9M、WPAヘッドが0.6Mのパラメータを追加するんやけど、MLMヘッドが語彙数50,265に対して39.2Mもパラメータ持ってることと比べたら、画像埋め込みによるパラメータの増加なんてほぼ誤差みたいなもんやで。ちなみに画像トークナイザーはパラメータの計算に入れてへんねん。なんでかっていうと、トークナイザーはMIMのラベルを生成するための独立したモジュールで、Transformerのバックボーンには組み込まれてへんからやな。
## 4 関連研究
マルチモーダルの自己教師あり事前学習っていう技術が、文書インテリジェンスの分野でめっちゃ急速に進歩してきてんねん。これは文書のレイアウトとか画像の表現学習がうまいこといったおかげやな [2, 13–15, 17, 25, 28, 31, 32, 40, 41, 50, 52, 54–56]。LayoutLMとその後続の研究では、テキストの空間座標をエンコードすることでレイアウトの表現学習を組み合わせてるねん [17, 25, 28, 54]。ほんで、いろんな研究がCNNとTransformer [49] の自己注意ネットワークを組み合わせて画像の表現学習も統合していったんや。こういう研究は、CNNのグリッド特徴を抽出するか [2, 56]、物体検出器を使ってリージョン特徴を抽出するか [14, 31, 40, 54] のどっちかやねんけど、これが計算のめっちゃ重いボトルネックになったり、リージョンのアノテーション(領域の教師データ)が必要になったりするわけやな。自然画像の視覚言語事前学習(VLP)の分野では、あらかじめ決めた物体クラスとかリージョンのアノテーションっていう制約を取っ払うために、リージョン特徴 [5, 47, 48] からグリッド特徴 [19] へとシフトしてきてんねん。Vision Transformer(ViT)[11] に触発されて、CNNの弱点を克服するためにCNNなしでVLPをやろうっていう動きも最近出てきとるんやけど、それでもたいていは視覚特徴を学習するのに別々の自己注意ネットワークを使ってるから、計算コストはあんまり減ってへんのが実情やねん [12, 29, 57]。例外がViLTで、こいつは軽量な線形層で視覚特徴を学習して、モデルサイズと実行時間をめっちゃ削減したんや [22]。ワイらのLayoutLMv3は、このViLTに触発されて、Document AIの分野でCNNなしの画像埋め込みを使った初めてのマルチモーダルモデルやねん。
再構成型の事前学習目的関数っていうのが、表現学習にめっちゃ革命を起こしてん。NLPの研究では、BERTが最初に「マスク言語モデリング」(MLM)っていうのを提案して、双方向の表現を学習できるようにして、幅広い言語理解タスクで最先端を更新したんや [9]。コンピュータビジョンの分野では、マスク画像モデリング(MIM)が、見えてる部分を手がかりにマスクされた内容を予測することで、リッチな視覚表現を学習しようとするもんやねん。例えば、ViTはマスクされたパッチの平均色を再構成することで、ImageNetの分類で性能向上を達成してるし [11]、BEiTは離散VAEっていうので学習した視覚トークンを再構成して、画像分類とセマンティックセグメンテーションで競争力のある結果を出してるんや [3]。DiTはBEiTを文書画像に拡張して、文書レイアウト解析に応用しとるで [30]。
MLMとMIMに触発されて、視覚言語の分野の研究者たちがマルチモーダル表現学習のための再構成型の目的関数をいろいろ探ってきてんねん。ほとんどの性能の高い視覚言語事前学習(VLP)モデルは、テキスト側にはBERTが提案したMLMを使ってるんやけど、画像側の事前学習目的関数についてはそれぞれ違うアプローチを取ってるわけや。画像埋め込みの種類に応じて、MIMには3つのバリエーションがあんねん:マスクリージョンモデリング(MRM)、マスクグリッドモデリング(MGM)、マスクパッチモデリング(MPM)の3つや。MRMは、マスクされた領域について元のリージョン特徴を回帰したり [5, 31, 48]、物体ラベルを分類したり [5, 37, 48] するのに効果的やって証明されてるで。MGMはSOHOっていう研究で探られていて、マスクされたグリッド特徴に対して視覚辞書の中のマッピングインデックスを予測するのが目的やねん [19]。パッチレベルの画像埋め込みについては、Visual Parsing [57] が自己注意型の画像エンコーダの注意重みに基づいて視覚トークンをマスクする方法を提案したんやけど、これはシンプルな線形画像エンコーダには使えへんのよな。ViLT [22] とMETER [12] はViT [11] やBEiT [3] みたいなMPMを活用しようとして、それぞれ画像パッチの平均色と視覚語彙の離散トークンを再構成しようとしたんやけど、下流タスクの性能が下がってしまうっていう結果になってもうたんや。ワイらのLayoutLMv3は、線形パッチ画像埋め込みに対してMIMが効果的やってことを初めて実証したモデルやねん。
マルチモーダルモデルにおける視覚と言語(VL)のアラインメント学習のために、いろんなクロスモーダルの目的関数も開発されてるで。画像テキストマッチングは、粗い粒度のVLアラインメント、つまり画像とテキストの大まかな対応関係を学習するのにめっちゃ広く使われてんねん [2, 5, 19, 22, 56]。もっと細かい粒度のVLアラインメントを学ぶために、UNITERは最適輸送に基づく単語リージョンアラインメント目的関数を提案してるんやけど、これは文脈化された画像埋め込みを単語埋め込みに輸送するための最小コストを計算するっていうもんやねん [5]。ViLTはこの目的関数をパッチレベルの画像埋め込みに拡張しとるで [22]。自然画像と違って、文書画像にはテキストの単語と画像の領域の間に明確で細かい粒度のアラインメント関係が暗黙的にあんねん。この関係を使って、UDocは対照学習と類似度蒸留で同じ領域に属する画像とテキストをアラインメントしてるし [14]、LayoutLMv2は生画像の一部のテキスト行を隠して、各テキストトークンが隠されてるかどうかを予測するっていう方法を取ってんねん [56]。それに対して、ワイらはMIMのマスク操作をそのまま自然に利用して、アラインメントされたペアとされてないペアを効果的かつ統一的な方法で構築してるんや。
## 5 結論と今後の研究
この論文では、Document AI向けのマルチモーダルTransformerを事前学習するLayoutLMv3を提案してん。LayoutLMのモデルアーキテクチャと事前学習の目的関数を再設計したもんやねん。Document AIの既存のマルチモーダルモデルと違って、LayoutLMv3は視覚特徴の抽出に事前学習済みのCNNやFaster R-CNNのバックボーンに頼ってへんから、パラメータをめっちゃ節約できるし、リージョンのアノテーションも不要になるんや。テキストと画像の統一的なマスキング事前学習目的関数、つまりマスク言語モデリング、マスク画像モデリング、単語パッチアラインメントを使って、マルチモーダル表現を学習するようにしてん。大規模な実験の結果、LayoutLMv3がシンプルなアーキテクチャと統一的な目的関数で、テキスト中心のDocument AIタスクと画像中心のDocument AIタスクの両方において、汎用性と優位性を持っていることが実証されたで。今後の研究では、事前学習モデルのスケールアップを調査して、もっと多くの訓練データを活用してさらに最先端の結果を推し進めていく予定やねん。さらに、Document AI業界のより多くの実際のビジネスシナリオに対応するために、Few-shot学習やZero-shot学習の能力も探っていくつもりやで。
## 6 謝辞
Yiheng Xuさんには実りある議論とインスピレーションをいただいて、ほんまに感謝しとります。本研究はNSFC(U1811461)と、広東省革新・起業チーム導入プログラム(助成番号 NO.2016ZT06D211)の支援を受けてるで。
---
## Page 9
[](/attach/bd5395610755a49e6419c406e651906e688e7a0cfe155b3c43566469dfd641fe_p009.png)
### 和訳
**表4:中国語の視覚情報抽出、EPHOIEテストセットでのF1スコア**
| モデル | 科目 | 試験日 | 名前 | 学校 | 受験番号 | 座席番号 | クラス | 学籍番号 | 学年 | 点数 | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| BiLSTM+CRF [24] | 98.51 | 100.0 | 98.87 | 98.80 | 75.86 | 72.73 | 94.04 | 84.44 | 98.18 | 69.57 | 89.10 |
| GCN-based [35] | 98.18 | 100.0 | 99.52 | 100.0 | 88.17 | 86.00 | 97.39 | 80.00 | 94.44 | 81.82 | 92.55 |
| GraphIE [42] | 94.00 | 100.0 | 95.84 | 97.06 | 82.19 | 84.44 | 93.07 | 85.33 | 94.44 | 76.19 | 90.26 |
| TRIE [58] | 98.79 | 100.0 | 99.46 | 99.64 | 88.64 | 85.92 | 97.94 | 84.32 | 97.02 | 80.39 | 93.21 |
| VIES [51] | 99.39 | 100.0 | 99.67 | 99.28 | 91.81 | 88.73 | 99.29 | 89.47 | 98.35 | 86.27 | 95.23 |
| StrucTexT [32] | 99.25 | 100.0 | 99.47 | 99.83 | 97.98 | 95.43 | 98.29 | 97.33 | 99.25 | 93.73 | 97.95 |
| **LayoutLMv3-Chinese BASE(ワイら)** | **98.99** | **100.0** | **99.78** | **100.0** | **100.0** | **98.82** | **99.78** | **98.31** | **97.27** | **99.21** | **99.21** |
---
## 付録A
### A.1 LayoutLMv3の中国語版
**中国語でLayoutLMv3を事前学習させた話やねん。** LayoutLMv3が英語だけやなくて、中国語でもちゃんと使えるっていうのを見せたろ思て、LayoutLMv3-Chineseっていうベースサイズのモデルを事前学習させたんよ。学習データは中国語の文書ページ5000万ページ分やで。めっちゃ多いやろ?大規模な中国語の文書は、ネット上で公開されてるデジタル生まれの文書をダウンロードして集めてん。ほんで、Common Crawl(https://commoncrawl.org/)っていうウェブデータの収集プロジェクトのやり方を参考にして処理したんや。
マルチモーダルTransformerエンコーダーとテキスト埋め込み層については、XLM-R [7]っていう多言語モデルの学習済みの重みを初期値として使ってん。残りのパラメーターはランダムに初期化したで。その他の学習設定はLayoutLMv3と一緒や。
**視覚情報抽出でのファインチューニングの話。** 視覚情報抽出(VIE)っちゅうのは、文書の画像からキーになる情報を抜き出すタスクのことやねん。要するに、系列ラベリング問題やから、各単語にあらかじめ決められたラベルをペタペタ貼っていく作業や。ワイらは各テキストトークンの最後の隠れ状態に対して線形層を使ってラベルを予測するようにしてん。
実験はEPHOIEデータセットで行ったで。EPHOIE [51]っちゅうのは、試験用紙のヘッダー部分を集めた視覚情報抽出データセットやねん。いろんなレイアウトや背景のやつが含まれてて、画像は1,494枚、中国語のテキストインスタンスは15,771個分のアノテーション付きっていう充実ぶりや。ワイらが取り組んだのは、EPHOIEデータセットでのトークンレベルのエンティティラベリングタスクで、各文字に10種類のカテゴリーの中からラベルを割り当てるっちゅうもんや。訓練セットは1,183枚、テストセットは311枚の画像やで。LayoutLMv3-Chineseは100エポックでファインチューニングしてん。バッチサイズは16、学習率は5e-5で、最初の1エポック分はリニアウォームアップを使ってるで。
F1スコアの結果は表4にまとめてあるわ。LayoutLMv3-Chineseはほとんどの指標でバリバリの性能を出してて、平均F1スコアは99.21%っちゅう最高記録(SOTA)を達成したんや!ほんまにすごない?この結果から、LayoutLMv3が中国語の視覚情報抽出タスクにもめっちゃ効果あるっていうのがわかるわけや。
---
## 参考文献
[1] Alaaeldin Aliら。2021年。Xcit: 交差共分散画像Transformer。NeurIPSにて発表。
[2] Srikar Appalarajuら。2021年。DocFormer: 文書理解のためのEnd-to-End Transformer。ICCVにて発表。
[3] Hangbo Baoら。2022年。BEiT: 画像TransformerのBERT事前学習。ICLRにて発表。
[4] Zhaowei CaiとNuno Vasconcelos。2018年。Cascade R-CNN: 高品質物体検出への探求。CVPRにて発表。
[5] Yen-Chun Chenら。2020年。UNITER: 汎用的な画像テキスト表現学習。ECCVにて発表。
[6] Jaemin Choら。2020年。X-LXMERT: マルチモーダルTransformerで描いて、説明して、質問に答える。EMNLPにて発表。
[7] Alexis Conneauら。2020年。教師なし大規模クロスリンガル表現学習。ACLにて発表。
[8] Lei Cuiら。2021年。Document AI: ベンチマーク、モデル、応用。arXivプレプリント arXiv:2111.08609。
[9] Jacob Devlinら。2019年。BERT: 言語理解のための深い双方向Transformerの事前学習。NAACLにて発表。
[10] Ming Dingら。2021年。CogView: Transformerでテキストから画像生成をマスターする。NeurIPSにて発表。
[11] Alexey Dosovitskiyら。2021年。1枚の画像は16×16個の単語に値する:画像認識のためのTransformer。ICLRにて発表。
[12] Zi-Yi Douら。2021年。End-to-End Vision-and-Language Transformerの学習に関する実証研究。arXivプレプリント arXiv:2111.02387。
[13] Łukasz Garncarekら。2021年。LAMBERT: 情報抽出のためのレイアウト認識型言語モデリング。ICDARにて発表。
[14] Jiuxiang Guら。2021年。UniDoc: 文書理解のための統合事前学習フレームワーク。NeurIPSにて発表。
[15] Zhangxuan Guら。2022年。XYLayoutLM: 視覚的にリッチな文書理解のためのレイアウト認識型マルチモーダルネットワークを目指して。CVPRにて発表。
[16] Adam W Harleyら。2015年。文書画像の分類と検索のための深層畳み込みネットの評価。ICDARにて発表。
[17] Teakgyu Hongら。2022年。BROS: テキストとレイアウトに着目した事前学習言語モデルでキー情報抽出を改善。AAAIにて発表。
[18] Yupan Huangら。2021年。双方向の画像・テキスト生成のためのマルチモーダルTransformerの統合。ACM Multimediaにて発表。
[19] Zhicheng Huangら。2021年。箱の外を見る:視覚言語表現学習のためのEnd-to-End事前学習。CVPRにて発表。
[20] Guillaume Jaumeら。2019年。FUNSD: ノイズのあるスキャン文書におけるフォーム理解データセット。ICDARワークショップにて発表。
[21] Mandar Joshiら。2020年。SpanBERT: スパンの表現と予測による事前学習の改善。Transactions of the Association for Computational Linguistics 8巻、64-77頁。
[22] Wonjae Kimら。2021年。ViLT: 畳み込みもリージョン監視も使わないVision-and-Language Transformer。ICMLにて発表。
[23] Diederik P KingmaとJimmy Ba。2014年。Adam: 確率的最適化のための手法。arXivプレプリント arXiv:1412.6980。
[24] Guillaume Lampleら。2016年。固有表現認識のためのニューラルアーキテクチャ。NAACL HLTにて発表。
[25] Chen-Yu Leeら。2022年。FormNet: フォーム文書の情報抽出における系列モデリングを超えた構造エンコーディング。ACLにて発表。
[26] D. Lewisら。2006年。複雑な文書情報処理のためのテストコレクション構築。SIGIRにて発表。
---
## Page 10
[](/attach/bd5395610755a49e6419c406e651906e688e7a0cfe155b3c43566469dfd641fe_p010.png)
### 和訳
[27] Mike Lewisら、2020年。「BART:自然言語の生成・翻訳・理解のためのノイズ除去型Sequence-to-Sequence事前学習」ACLで発表。
→ ざっくり言うと、文章をわざとぐちゃぐちゃに壊してから元に戻す訓練をさせて、文章作ったり翻訳したり理解したりするのがめっちゃうまくなるモデルを作ったっちゅう話やねん。
[28] Chenliang Liら、2021年。「StructuralLM:フォーム理解のための構造的事前学習」ACLで発表。
→ 書類とかフォームの「構造」——つまりどこに何が書いてあるかっていうレイアウト情報を使って事前学習させたモデルやな。申込書みたいなやつの理解がめっちゃ得意になるねん。
[29] Junnan Liら、2021年。「合体の前にまず揃えよう:運動量蒸留を使った視覚と言語の表現学習」NeurIPSで発表。
→ 画像と文章を合わせて学習するとき、いきなりくっつけるんやなくて、まず「揃える」ステップを入れたほうがええで、っていう研究やねん。「運動量蒸留」っちゅう、先生モデルをゆっくり更新するテクニックも使っとるで。
[30] Junlong Liら、2022年。「DiT:文書画像Transformerのための自己教師あり事前学習」arXivプレプリント。
→ 文書の画像を扱うTransformerを、ラベルなしのデータだけで事前学習させるやり方やねん。自分で自分を教えるっちゅう自己教師ありの仕組みがミソやで。
[31] Peizhao Liら、2021年。「SelfDoc:自己教師ありによる文書表現学習」CVPRで発表。
→ これも人がラベル付けせんでも、文書の特徴を自動で学習してくれるモデルやな。文書をうまく「ベクトル」——つまり数値の列で表現できるようになるねん。
[32] Yulin Liら、2021年。「StrucTexT:マルチモーダルTransformerによる構造化テキスト理解」ACM Multimediaで発表。
→ テキストの中身だけやなくて、見た目のレイアウトとか画像情報とか、いろんな情報(マルチモーダル)をまとめて使って文書を理解するTransformerやで。
[33] Yanghao Liら、2021年。「Vision Transformerを使った物体検出における転移学習のベンチマーク」arXivプレプリント。
→ 最近流行りのVision Transformer(画像をTransformerで処理するやつ)を物体検出に転用したとき、どんぐらい性能出るか徹底的に比較実験した研究やねん。
[34] Tsung-Yi Linら、2017年。「Feature Pyramid Networks:物体検出のための特徴ピラミッドネットワーク」CVPRで発表。
→ 画像の中で大きいもんも小さいもんも見つけられるように、いろんなスケールの特徴を「ピラミッド」みたいに積み上げて使う手法やで。物体検出のめっちゃ基本的な技術やな。
[35] Xiaojing Liuら、2019年。「見た目リッチな文書からのマルチモーダル情報抽出のためのグラフ畳み込み」NAACL HLTで発表。
→ 請求書とか領収書みたいな、見た目が凝った文書から情報を抜き出すのに、グラフ構造を使った畳み込みニューラルネットワークを適用した研究やで。
[36] Yinhan Liuら、2019年。「RoBERTa:頑健に最適化されたBERT事前学習アプローチ」arXivプレプリント。
→ あの有名なBERTの学習方法を徹底的に見直して、「もっとちゃんとチューニングしたらもっと強くなるやん!」って示した研究やねん。ほんまにBERTの改良版って感じやな。
[37] Jiasen Luら、2019年。「ViLBERT:視覚と言語のタスク非依存な事前学習表現」NeurIPSで発表。
→ 画像と言葉を両方理解できるBERTみたいなモデルやねん。特定のタスクに依存せん汎用的な表現を学習するのがポイントやで。
[38] Minesh Mathewら、2021年。「DocVQA:文書画像に対する視覚的質問応答データセット」WACVで発表。
→ 文書の画像を見せて「これなんて書いてある?」みたいな質問に答えさせるための、めっちゃちゃんとしたデータセットを作った研究やねん。
[39] Seunghyun Parkら、2019年。「CORD:OCR後のレシート解析のための統合レシートデータセット」NeurIPSのDocument Intelligenceワークショップで発表。
→ レシートをOCRで読み取った後に、店名とか金額とかを正しく分類するためのデータセットやで。レシート認識の研究にめっちゃ使われとるやつやな。
[40] Rafal Powalskiら、2021年。「Going Full-TILT Boogie:テキスト・画像・レイアウトTransformerによる文書理解」ICDARで発表。
→ テキストと画像とレイアウトの3つを全部まとめて扱うTransformerで文書理解をガッツリやったろうっちゅう研究やねん。タイトルのノリがめっちゃ陽気やな。
[41] Subhojeet Pramanikら、2020年。「文書表現学習のためのマルチモーダル・マルチタスク学習ベースの事前学習フレームワークに向けて」arXivプレプリント。
→ いろんな種類の情報(マルチモーダル)を使って、いろんなタスク(マルチタスク)を同時にこなせるように文書の表現を学習させるフレームワークの提案やで。
[42] Yujie Qian、2019年。「情報抽出のためのグラフベースフレームワーク」マサチューセッツ工科大学の博士論文。
→ MITの博士論文やで。文書から情報を抜き出すのにグラフ構造を使うアプローチを研究したやつやな。
[43] Aditya Rameshら、2021年。「ゼロショットのテキストから画像への生成」ICMLで発表。
→ これめっちゃ有名なやつやねん。文章を入れたら、見たことない組み合わせでも画像を作り出してくれるモデルや。DALL·Eの元になった研究やで。
[44] Shaoqing Renら、2015年。「Faster R-CNN:領域提案ネットワークによるリアルタイム物体検出に向けて」TPAMI。
→ 物体検出の超有名モデルやな。「ここに物体あるんちゃう?」って提案するネットワークを組み込んで、検出をめっちゃ速くしたやつやで。
[45] Tim Salimansら、2017年。「PixelCNN++:離散化ロジスティック混合尤度などの改良によるPixelCNNの改善」ICLRで発表。
→ 画像を1ピクセルずつ生成していくPixelCNNっちゅうモデルを、確率分布の扱い方とかを工夫してパワーアップさせた研究やねん。
[46] Rico Sennrichら、2016年。「サブワード単位による希少語のニューラル機械翻訳」ACLで発表。
→ 翻訳で知らん単語が出てきたときに、単語をもっと細かい「サブワード」に分割して対処しようっちゅうアイデアやねん。BPE(Byte Pair Encoding)っちゅう手法がここから広まったんやで。ほんまに影響力デカい論文やな。
[47] Weijie Suら、2019年。「VL-BERT:汎用的な視覚言語表現の事前学習」ICLRで発表。
→ BERTを画像と言語の両方で使えるように拡張したモデルやな。視覚と言語を一緒に扱う汎用的な表現を学習するのが目的やで。
[48] Hao TanとMohit Bansal、2019年。「LXMERT:Transformerによるクロスモダリティエンコーダ表現の学習」EMNLPで発表。
→ 言語と視覚のそれぞれのエンコーダと、両方をつなぐクロスモダリティのエンコーダを組み合わせたTransformerやねん。画像と文章の関係を学ぶのがめっちゃうまいモデルやで。
[49] Ashish Vaswaniら、2017年。「Attention Is All You Need(注意機構さえあればええねん)」NeurIPSで発表。
→ これはもう伝説の論文やで!!RNNとかCNNを使わんと、Attention(注意機構)だけで言語処理をやったろうっちゅう、Transformerを提案した論文やねん。今のAIブームの土台中の土台やな。
[50] Jiapeng Wangら、2022年。「LiLT:構造化文書理解のためのシンプルかつ効果的な言語非依存レイアウトTransformer」ACLで発表。
→ どの言語でも使えるように、レイアウト情報と言語情報を分離して学習するTransformerやねん。シンプルやけどめっちゃ効果的なんがポイントやで。
[51] Jiapeng Wangら、2021年。「実世界における頑健な視覚情報抽出に向けて:新データセットと新手法」AAAIで発表。
→ 現実の汚い画像とかからもちゃんと情報を抜き出せるように、新しいデータセットと手法を両方提案した研究やな。実用性重視でええ感じやで。
[52] Te-Lin Wuら、2021年。「LAMPRET:文書理解のためのレイアウト考慮型マルチモーダル事前学習」arXivプレプリント。
→ 文書のレイアウトをちゃんと考慮しながら、テキストと画像を合わせて事前学習するモデルやで。
[53] Yuxin Wuら、2019年。「Detectron2」
→ Facebookが作ったオープンソースの物体検出ライブラリやねん。研究者がめっちゃ使ってるツールキットやで。GitHubで公開されとるやつやな。
[54] Yiheng Xuら、2020年。「LayoutLM:文書画像理解のためのテキストとレイアウトの事前学習」KDDで発表。
→ 文書のテキスト情報だけやなくて、「どこに何が配置されてるか」っちゅうレイアウト情報も一緒に事前学習させたモデルやねん。文書理解の分野でめっちゃ画期的やったで。
[55] Yiheng Xuら、2021年。「LayoutXLM:多言語の視覚リッチ文書理解のためのマルチモーダル事前学習」arXivプレプリント。
→ LayoutLMを多言語対応にしたバージョンやな。日本語とか中国語とか、いろんな言語の文書でも使えるようになったやつやで。
[56] Yang Xuら、2021年。「LayoutLMv2:視覚リッチ文書理解のためのマルチモーダル事前学習」ACLで発表。
→ LayoutLMの進化版やな。テキスト、レイアウト、画像の3つの情報をもっとうまく統合して、文書理解の性能をガツンと上げた研究やで。
[57] Hongwei Xueら、2021年。「モダリティ間の探索:視覚と言語の事前学習のための自己注意による視覚解析」NeurIPSで発表。
→ 画像と言語を一緒に学習するときに、自己注意機構を使って画像の中身をもっと深く解析しようっちゅう研究やねん。モダリティ間の関係をしっかり捉えるのがポイントやで。
[58] Peng Zhangら、2020年。「TRIE:文書理解のためのエンドツーエンドのテキスト読み取りと情報抽出」ACM Multimediaで発表。
→ 文書の文字を読み取るのと情報を抽出するのを、バラバラにやるんやなくて一気通貫(エンドツーエンド)でやったろうっちゅう研究やねん。一体化させたほうが精度ええねんな。
[59] Xu Zhongら、2019年。「PubLayNet:文書レイアウト解析のための史上最大のデータセット」ICDARで発表。
→ 文書のレイアウト——つまり「ここがタイトル」「ここが図」「ここが本文」みたいな構造を認識するための、めっちゃデカいデータセットを作ったっちゅう研究やで。100万件以上あるらしいで、ほんまにスケールがエグいわ。
---
![]()
1 / 1
100%