<<
AGENTIC RETRIEVAL-AUGMENTED GENERATION: A SURVEY ON AGENTIC RAG

---
## Page 1
[](/attach/b637a8052912693dd5bbde5e61e2ab9b7076bc2f57fabee16ca001dd0352d404_p001.png)
### 和訳
# エージェンティック検索拡張生成:Agentic RAGのサーベイ
Aditi Singh
コンピュータサイエンス学部
クリーブランド州立大学
オハイオ州クリーブランド、アメリカ
a.singh22@csuohio.edu
Abul Ehtesham
The Davey Tree Expert Company
オハイオ州ケント、アメリカ
abul.ehtesham@davey.com
Saket Kumar
The MathWorks Inc
マサチューセッツ州ネイティック、アメリカ
saketk@mathworks.com
Tala Talaei Khoei
Khoury College of Computer Science
ノースイースタン大学 Roux Institute
メイン州ポートランド、アメリカ
t.talaeikhoei@northeastern.edu
## 概要
大規模言語モデル(LLM)ってやつがな、人工知能(AI)の世界をめっちゃ変えてもうたんよ。人間みたいに文章書いたり、自然言語を理解したりできるようになったわけや。せやけどな、こいつらには弱点があってな、学習に使ったデータが固定されてるから、リアルタイムで変わっていく質問にうまく答えられへんねん。結果として、古い情報とか間違った回答が出てきてまうことがあるんよ。
そこで登場したんが検索拡張生成(RAG)やねん。これはLLMにリアルタイムのデータ検索機能をくっつけることで、その場の文脈に合った最新の回答ができるようにしたんや。ええ感じやん?って思うやろ?せやけどな、従来のRAGシステムには限界があってな、ワークフローが固定的で、何段階もの推論が必要な複雑なタスクには対応しにくかったんよ。
ほんで、その限界を突破したんがエージェンティック検索拡張生成(Agentic RAG)やねん。これ何がすごいかっていうと、RAGのパイプラインの中に自律型AIエージェントを組み込んだんよ。このエージェントたちはな、「リフレクション(振り返り)」「プランニング(計画立て)」「ツール使用」「マルチエージェント協調」っていうエージェント的な設計パターンを活用して、検索戦略を動的に管理したり、文脈の理解を繰り返し改善したり、順番に進める方式から柔軟に協力する方式まで、明確に定義された運用構造を通じてワークフローを適応させたりできるんや。この統合によって、Agentic RAGシステムはこれまでにない柔軟性、拡張性、そして文脈への対応力をいろんな用途で発揮できるようになったんよ。
このサーベイではな、Agentic RAGについて徹底的に掘り下げていくで。まず基礎となる原理とRAGパラダイムの進化から始めて、Agentic RAGアーキテクチャの詳細な分類法を示すんや。ほんで、ヘルスケア、金融、教育なんかの業界での主要な応用例を紹介して、実際の実装戦略も検討するで。さらに、これらのシステムをスケールさせる際の課題、倫理的な意思決定の確保、実際のアプリケーション向けの性能最適化についても取り上げて、Agentic RAGを実装するためのフレームワークやツールについても詳しく解説するで。このサーベイのGitHubリンクはここや:https://github.com/asinghcsu/AgenticRAG-Survey
**キーワード** 大規模言語モデル(LLM)・人工知能(AI)・自然言語理解・検索拡張生成(RAG)・Agentic RAG・自律型AIエージェント・リフレクション・プランニング・ツール使用・マルチエージェント協調・エージェントパターン・文脈理解・動的適応性・スケーラビリティ・リアルタイムデータ検索・Agentic RAGの分類法・ヘルスケア応用・金融応用・教育応用・倫理的AI意思決定・性能最適化・多段階推論
---
## Page 2
[](/attach/b637a8052912693dd5bbde5e61e2ab9b7076bc2f57fabee16ca001dd0352d404_p002.png)
### 和訳
# 1章 はじめに
大規模言語モデル(LLMs)[1, 2, 3]、たとえばOpenAIのGPT-4とかGoogleのPaLM、MetaのLLaMAとかな、これらがAI(人工知能)の世界をめっちゃ変えてもうたんよ。なんでかっていうと、人間みたいな文章を作り出せるし、複雑な言葉の処理もこなせるからやねん。おかげで会話できるAI[4]とか、自動で記事書いてくれるやつとか、リアルタイム翻訳とか、いろんな分野でイノベーションが起きとるんや。最近はさらに進化して、マルチモーダルっていう、文章から画像作ったり動画作ったり[5]もできるようになってきてん[6]。詳しい説明文から映像や写真を生み出したり編集したりできるから、生成AIの可能性がほんまに広がっとるんやで。
けどな、LLMsにも大きな弱点があんねん。学習したときのデータに縛られてまうっていう問題や。せやから情報が古くなったり、嘘っぽい回答(ハルシネーション)が出てきたり[7]、リアルタイムで変化する現実世界についていけへんのよ。こういう課題があるから、最新のデータを取り込んで、その場その場で回答を調整できるシステムが必要やねんな。
そこで登場したんが、検索拡張生成(RAG)[8, 9]っていう技術や。LLMの文章生成能力と、外部から情報を引っ張ってくる仕組み[10]を組み合わせることで、回答の関連性とか新鮮さをグッと上げられるんよ。知識ベース[11]とかAPI、ウェブから最新情報をリアルタイムで取ってきて、学習時の古いデータと実際に必要な動的なアプリとの溝を埋めてくれるわけや。ただな、従来のRAGは一本道で固定的な設計やったから、複雑な多段階の推論とか、深い文脈理解とか、繰り返し回答を磨いていくとか、そういうんはちょっと苦手やってん。
ほんで、エージェント[12]っていう概念が進化してきて、AIシステムの能力がめっちゃ上がったんや。最新のエージェント、LLMを搭載したやつとかモバイルエージェント[13]とかは、周りを認識して、考えて、自分で判断して動ける賢い存在なんよ。こいつらは「エージェント的パターン」っていうのを使ってて、たとえば振り返り(リフレクション)[14]、計画立て[15]、ツール使い、複数エージェントでの協力[16]とかで、意思決定力と柔軟性を高めとるんや。
さらにこのエージェントたち、「エージェント的ワークフローパターン」[12, 13]も活用しとってな。プロンプトチェーニング(指示の連鎖)とか、ルーティング(振り分け)、パラレル処理(並列化)、オーケストレーター・ワーカーモデル(指揮者と作業者みたいな構造)、エバリュエーター・オプティマイザー(評価して最適化するやつ)とか、タスクの実行を整理して最適化するパターンやな。こういうパターンを組み込むことで、Agentic RAGシステムは動的なワークフローを効率よく管理して、複雑な問題解決にも対応できるようになったんや。RAGとエージェント的知能が合体して生まれたんが、Agentic RAG(エージェント型検索拡張生成)[14]っていう新しいパラダイムやねん。RAGのパイプラインにエージェントを組み込んだやつや。Agentic RAGは動的な検索戦略、文脈理解、繰り返しの改善[15]ができて、柔軟で効率的な情報処理を実現するんよ。従来のRAGと違って、Agentic RAGは自律的なエージェントが検索を指揮して、関連情報をフィルタリングして、回答を磨いていくから、精度と適応力が求められる場面でめっちゃ活躍するんや。Agentic RAGの全体像は図1を見てな。
この調査論文では、Agentic RAGの基礎原理、分類体系、応用について掘り下げていくで。RAGのパラダイム、たとえばナイーブRAG、モジュラーRAG、グラフRAG[16]とか、それらがAgentic RAGシステムへと進化していく流れを包括的に概観するんや。主な貢献としては、Agentic RAGフレームワークの詳細な分類体系、医療[17, 18]、金融、教育[19]といった分野での応用、実装戦略やベンチマーク、倫理的考慮についての知見をまとめとるで。
この論文の構成はこんな感じや:第2章ではRAGとその進化を紹介して、従来手法の限界を明らかにするで。第3章ではエージェント的知能とエージェント的パターンの原理を詳しく説明するわ。第4章ではエージェント的ワークフローパターンを掘り下げるで。第5章ではAgentic RAGシステムの分類体系、シングルエージェント、マルチエージェント、グラフベースのフレームワークを含めて紹介するんや。第6章ではAgentic RAGフレームワークの比較分析をするで。第7章ではAgentic RAGの応用を検討して、第8章では実装ツールとフレームワークについて議論するわ。第9章ではベンチマークとデータセットに焦点当てて、第10章でAgentic RAGシステムの今後の方向性をまとめて締めくくるで。
# 2章 検索拡張生成の基礎
## 2.1 検索拡張生成(RAG)の概要
検索拡張生成(RAG)っていうのは、人工知能の分野でめっちゃ大きな進歩を表してるんや。大規模言語モデル(LLMs)の文章生成能力と、リアルタイムのデータ検索を組み合わせた技術やねん。LLMsは自然言語処理ですごい能力を見せてくれるんやけど、学習時点で固定されたデータに頼っとるから、古くなった情報や不完全な回答を出してまうことがよくあるんよ。RAGはこの弱点を解決するために、外部ソースから関連情報を動的に取ってきて、生成プロセスに組み込むんや。そうすることで、文脈的に正確で最新の出力ができるようになるんやで。
---
## Page 3
[](/attach/b637a8052912693dd5bbde5e61e2ab9b7076bc2f57fabee16ca001dd0352d404_p003.png)
### 和訳
図1:エージェント型RAGの全体像
## 2.2 RAGのコアコンポーネント
RAGシステムのアーキテクチャは、3つの主要コンポーネントで構成されてるねん(図2参照):
• **検索(Retrieval)**:ナレッジベースとかAPI、ベクトルデータベースみたいな外部データソースにクエリ投げる役割やな。最先端の検索システムは、密ベクトル検索とかTransformerベースのモデル使って、検索精度と意味的な関連性をめっちゃ高めてんねん。
• **拡張(Augmentation)**:取ってきたデータを処理して、クエリの文脈に合う一番関連性の高い情報を抽出・要約するパートやで。
• **生成(Generation)**:検索で得た情報とLLMが元々持ってる事前学習済みの知識を組み合わせて、まとまりのある、文脈に適した応答を作り出すとこやな。
## 2.3 RAGパラダイムの進化
検索拡張生成(RAG)の分野はめっちゃ進化してきてん。なんでかっていうと、現実世界のアプリケーションがどんどん複雑になってきて、文脈の正確さ、スケーラビリティ、複数ステップの推論が超重要になってきたからやねん。最初は単純なキーワードベースの検索やったのが、今や色んなデータソースを統合できて、自律的に意思決定できるような、洗練されたモジュール式で適応型のシステムに変わってきたんや。この進化は、RAGシステムが複雑なクエリを効率的かつ効果的に処理せなあかんっていうニーズがほんまに高まってることを示してるんやで。
このセクションでは、RAGパラダイムの発展を見ていくで。主な開発段階として、ナイーブRAG、アドバンストRAG、モジュラーRAG、グラフRAG、そしてエージェント型RAGを、それぞれの特徴、強み、そして
3
---
## Page 4
[](/attach/b637a8052912693dd5bbde5e61e2ab9b7076bc2f57fabee16ca001dd0352d404_p004.png)
### 和訳
図2: RAGの主要コンポーネント
限界があるんよな。このパラダイムがどう進化してきたかを理解することで、検索と生成の技術がどんだけ進歩してきたか、ほんでいろんな分野でどう使われてるかがわかるようになるねん。
2.3.1 ナイーブRAG
ナイーブRAG [20]っていうんは、検索拡張生成の一番基本的なやつやねん。図3を見てもらったらわかるけど、シンプルに「検索して読む」っていうワークフローになってて、キーワードベースの検索と固定のデータセットを使うんや。このシステムは、TF-IDFとかBM25みたいなシンプルなキーワードベースの検索技術を使って、固定のデータセットから文書を取ってくるねん。ほんで、その取ってきた文書を使って言語モデルの生成能力をパワーアップさせるっちゅうわけや。
図3: ナイーブRAGの概要
ナイーブRAGの特徴は、シンプルで実装が簡単なことやねん。せやから、事実を聞くような質問で、文脈がそんな複雑やないタスクには向いてるんや。でもな、いくつか問題点もあるねん:
• 文脈を理解でけへん:取ってきた文書が、質問の意味的なニュアンスをちゃんと捉えられへんことが多いねん。なんでかっていうと、意味を理解するんやなくて、単語の一致だけで検索してるからやねん。
• バラバラな出力:高度な前処理とか文脈の統合がないから、つながりのない回答とか、めっちゃ一般的すぎる回答になりがちやねん。
• スケーラビリティの問題:キーワードベースの検索技術は、でっかいデータセットやと苦戦するねん。一番関係ある情報を見つけられへんことが多いんや。
こういう限界はあるけど、ナイーブRAGシステムは「検索と生成を組み合わせる」っていう概念を実証する重要な役割を果たしたんや。これがあったから、もっと洗練されたパラダイムの土台ができたんやで。
2.3.2 アドバンストRAG
アドバンストRAG [20]は、ナイーブRAGの限界を克服するために、意味理解と強化された検索技術を取り入れたシステムやねん。図4を見たら、検索における意味的な改善と、繰り返し処理ができて文脈を意識したパイプラインがわかるで。このシステムは、Dense Passage Retrieval(DPR)みたいな密ベクトル検索モデルとか、ニューラルランキングアルゴリズムを使って、検索の精度をめっちゃ上げてるねん。
アドバンストRAGの主な特徴はこんな感じや:
---
## Page 5
[](/attach/b637a8052912693dd5bbde5e61e2ab9b7076bc2f57fabee16ca001dd0352d404_p005.png)
### 和訳
**図4:Advanced RAGの全体像**
• **Dense Vector Search(密ベクトル検索)**:クエリ(検索したいこと)とドキュメント(文書)を高次元のベクトル空間で表現するねん。これで何がええかっていうと、ユーザーが探してる内容と取ってきた文書の「意味的なマッチング」がめっちゃ良くなるんよ。
• **Contextual Re-Ranking(文脈に基づく再ランキング)**:ニューラルモデルが取ってきた文書を再ランキングして、「文脈的に一番関係ありそうな情報」を優先的に上に持ってくるんやで。
• **Iterative Retrieval(反復検索)**:Advanced RAGではマルチホップ検索っていう仕組みが入ってきてな、複雑な質問に対して複数の文書をまたいで推論できるようになったんや。
こういう進化のおかげで、Advanced RAGは高い精度と繊細な理解が必要なアプリケーション、例えば研究の統合とかパーソナライズされたレコメンデーションとかにめっちゃ向いてるねん。せやけど、計算コストがかかるとか、スケーラビリティに限界があるとかの課題もまだ残ってて、特に大規模データセットや複数ステップのクエリを扱うときには悩ましいところやな。
**2.3.3 Modular RAG**
Modular RAG [20]は、RAGパラダイムの最新の進化形やねん。柔軟性とカスタマイズ性を重視してるのが特徴や。このシステムは、検索と生成のパイプラインを独立した再利用可能なコンポーネントに分解することで、ドメイン固有の最適化やタスクへの適応を可能にしてるんよ。図5ではモジュラーアーキテクチャを示してて、ハイブリッド検索戦略、組み合わせ自由なパイプライン、外部ツールとの統合なんかが見れるで。
Modular RAGの主な革新点はこんな感じや:
• **Hybrid Retrieval Strategies(ハイブリッド検索戦略)**:スパース検索手法(例えばスパースエンコーダーのBM25みたいなやつ)と密検索技術 [21](例えばDPR - Dense Passage Retrieval)を組み合わせることで、いろんなタイプのクエリに対して精度を最大化するねん。
• **Tool Integration(ツール統合)**:外部のAPI、データベース、計算ツールなんかを組み込んで、リアルタイムデータ分析とかドメイン固有の計算みたいな専門的なタスクを処理できるようにしてるんや。
• **Composable Pipelines(組み合わせ可能なパイプライン)**:Modular RAGでは、検索器、生成器、その他のコンポーネントを独立して置き換えたり、強化したり、再構成したりできるから、特定のユースケースへの適応力がめっちゃ高いねん。
例えばな、金融分析用に設計されたModular RAGシステムやったら、APIを使ってリアルタイムの株価を取得して、密検索を使って過去のトレンドを分析して、カスタマイズされた言語モデルを通じて実行可能な投資インサイトを生成する、みたいなことができるわけや。このモジュール性とカスタマイズ性のおかげで、Modular RAGは複雑でマルチドメインなタスクにほんまに最適で、スケーラビリティと精度の両方を実現できるんやで。
---
## Page 6
[](/attach/b637a8052912693dd5bbde5e61e2ab9b7076bc2f57fabee16ca001dd0352d404_p006.png)
### 和訳
[翻訳エラー: 実行エラー: [Errno 2] No such file or directory: 'claude']
---
## Page 7
[](/attach/b637a8052912693dd5bbde5e61e2ab9b7076bc2f57fabee16ca001dd0352d404_p007.png)
### 和訳
[翻訳エラー: 実行エラー: [Errno 2] No such file or directory: 'claude']
---
## Page 8
[](/attach/b637a8052912693dd5bbde5e61e2ab9b7076bc2f57fabee16ca001dd0352d404_p008.png)
### 和訳
**表1: RAGパラダイムの比較分析**
| パラダイム | 主な特徴 | 強み |
|---|---|---|
| **ナイーブRAG** | ・キーワードベースの検索(TF-IDFとかBM25とか使うやつやな) | ・シンプルで実装が楽やねん<br>・事実を聞くような質問には向いてるで |
| **アドバンストRAG** | ・密ベクトル検索モデル(DPRとかな)<br>・ニューラルネットでランキングしたり再ランキングしたり<br>・マルチホップ検索(何段階も情報たどっていくやつ) | ・めっちゃ精度高い検索ができるねん<br>・文脈の関連性もかなり改善されるで |
| **モジュラーRAG** | ・ハイブリッド検索(スパースと密ベクトル両方使う)<br>・ツールとかAPIとも連携できる<br>・組み合わせ自由で、業界特化のパイプラインも作れる | ・柔軟性めっちゃ高いねん<br>・いろんな用途に使えるで<br>・スケールもしやすい |
| **グラフRAG** | ・グラフ構造を取り入れてるねん<br>・マルチホップ推論(複数の情報を渡り歩いて考える)<br>・ノード経由で文脈を豊かにしていく | ・関係性を考えた推論ができるんや<br>・嘘つき(ハルシネーション)を減らせる<br>・構造化されたデータには最適やで |
| **エージェンティックRAG** | ・自律的なエージェントが動く<br>・状況に応じて動的に判断する<br>・繰り返し改善しながらワークフローを最適化 | ・リアルタイムの変化にも対応できるねん<br>・複数の分野にまたがるタスクもスケールする<br>・精度もめっちゃ高いで |
---
**2.4.2 マルチステップ推論**
現実の質問って、一発で答え出せへんことが多いねん。何段階もかけて情報を取ってきて、それを組み合わせて考えなあかん「マルチホップ推論」ってやつが必要になるんや。でも従来のRAGシステムは、途中で得た知見とかユーザーからのフィードバックを元に検索を調整するのが苦手やねん。せやから、答えが中途半端やったり、バラバラでまとまりのない回答になりがちなんよ。
**例えばな:** 「ヨーロッパの再生可能エネルギー政策から学べることで、発展途上国に活かせるもんは何や?ほんで経済的にどんな影響があるん?」みたいな複雑な質問あるやん。これ答えるには、政策のデータと、発展途上国向けの文脈への落とし込みと、経済分析っていう全然違う種類の情報をうまいこと組み合わせなあかんねん。従来のRAGシステムは、こういうバラバラな要素を一つのまとまった回答にするんがほんまに苦手なんや。
---
**2.4.3 スケーラビリティとレイテンシの問題**
外部のデータソースがどんどん増えてくると、大量のデータセットにクエリ投げてランキングするのに、計算パワーがめっちゃ必要になってくるねん。そうなると遅延(レイテンシ)がえらいことになって、リアルタイムで素早く返事せなあかんアプリケーションでは使いもんにならんくなるんや。
**例えばな:** 金融分析とかライブのカスタマーサポートみたいな、時間との勝負な場面あるやん。複数のデータベースに問い合わせたり、大量の文書を処理したりするのに時間かかると、システム全体の使い勝手がガタ落ちやねん。たとえば高頻度取引(めっちゃ速いスピードで売買するやつ)やってる時に、市場のトレンド情報取ってくるのが遅れたら、儲けるチャンス逃してまうやろ?
---
**2.5 エージェンティックRAG:パラダイムシフトや**
従来のRAGシステムは、ワークフローが固定されてて柔軟性に欠けるから、動的に変化する状況とか、マルチステップの推論とか、複雑な現実世界のタスクにうまく対応でけへんことが多いねん。こういう限界があったからこそ、「エージェンティックな知性」を組み込もうって流れが出てきたんや。
---
## Page 9
[](/attach/b637a8052912693dd5bbde5e61e2ab9b7076bc2f57fabee16ca001dd0352d404_p009.png)
### 和訳
そんでこれがAgentic RAGっちゅうもんになるわけやねん。自分で判断できて、何回も考え直せて、しかも情報の取り方も臨機応変に変えられる自律型エージェントっていうやつを組み込むことで、Agentic RAGは前のやり方のモジュール性っていう良いとこは活かしながら、限界も突破できるようになったんや。この進化のおかげで、もっと複雑で、いろんな分野にまたがるようなタスクも、めっちゃ正確に、しかも文脈もちゃんと理解して処理できるようになってん。せやからAgentic RAGは次世代AIの基盤になるって言われてるんやな。特にな、Agentic RAGシステムは作業の流れを最適化して待ち時間も減らせるし、出力も何回も磨き上げていくから、昔から従来のRAGの拡張性とか効果を邪魔してた問題にも対処できるようになってん。
## 3 Agentic Intelligenceの基本原則と背景
Agentic Intelligence(エージェント型知能)っていうのは、Agentic RAGシステムの土台になっとるもんで、これがあるから従来のRAGみたいな固定的で受け身なやり方を超えられるんや。自分で判断して動けて、何回も論理的に考え直せて、しかもチームワークで作業できる自律型エージェントを組み込むことで、Agentic RAGシステムはめっちゃ柔軟で正確になるんやな。このセクションでは、エージェント型知能を支えとる基本原則について説明するで。
**AIエージェントの構成要素**
ぶっちゃけて言うと、AIエージェントは以下のもんで出来とる(図7参照):
• **LLM(役割とタスクが決められとるやつ)**:エージェントのメインの考えるエンジンで、対話の窓口みたいなもんや。ユーザーの質問を理解して、答えを作って、話の筋を通すのが仕事やねん。
• **メモリ(短期と長期)**:やり取りの中での文脈とか関係するデータを覚えとくんや。短期メモリ[22]は今の会話の状態を追跡して、長期メモリ[22]は蓄積された知識とかエージェントの経験を保存しとくんやで。
• **計画(振り返りと自己批評)**:振り返りとか、問い合わせの振り分けとか、自己批評[23]を通じて、エージェントが何回も考え直すプロセスを導くんや。これで複雑なタスクも効果的に分解できるようになる[24]。
• **ツール(ベクトル検索、ウェブ検索、APIとか)**:エージェントの能力をテキスト生成以外にも広げるもんで、外部のリソースとか、リアルタイムのデータとか、専門的な計算にアクセスできるようにするんやで。
図7:AIエージェントの全体像
**Agenticパターン**[25, 26]っていうのは、Agentic RAGシステムでエージェントがどう動くかを導く体系的な方法論やねん。このパターンのおかげでエージェントは動的に適応したり、計画したり、協力したりできて、複雑で現実世界のタスクも正確に、しかもスケールできる形で処理できるんや。エージェント型ワークフローを支える4つの重要なパターンがあるで:
### 3.1 振り返り(Reflection)
振り返りっていうのは、エージェント型ワークフローの基本的なデザインパターンで、エージェントが自分の出力を繰り返し評価して改善できるようにするもんやねん。自分自身へのフィードバックの仕組みを取り入れることで、エージェントは間違いとか、矛盾しとるとことか、改善すべきとこを見つけて対処できるから、コード生成とか、文章作成とか、質問回答とかのタスクのパフォーマンスがグンと上がるんやで。
---
## Page 10
[](/attach/b637a8052912693dd5bbde5e61e2ab9b7076bc2f57fabee16ca001dd0352d404_p010.png)
### 和訳
図8に示してるみたいに、実際の使い方としては、Reflection(振り返り)ってのはな、エージェントに自分のアウトプットを「これ正しいか?」「スタイルええ感じか?」「効率的か?」ってツッコませて、そのフィードバックを次のイテレーションに活かすっていうやり方やねん。ユニットテストとかWeb検索みたいな外部ツールも使えて、結果の検証とか足りへんとこの発見とかにめっちゃ役立つで。
マルチエージェントシステムでは、Reflectionは役割分担もできるねん。例えば、あるエージェントがアウトプット作って、別のエージェントがそれにダメ出しするみたいな感じで、お互い切磋琢磨して良くしていくわけや。法律リサーチで言うたら、判例を取ってきて「これほんまに合うてるか?」って何回も見直して、正確で漏れのない回答に仕上げていくイメージやな。Self-Refine、Reflexion、CRITICみたいな研究で、Reflectionがめっちゃパフォーマンス上げるって実証されてるで。
図8:エージェントの自己振り返りの概要
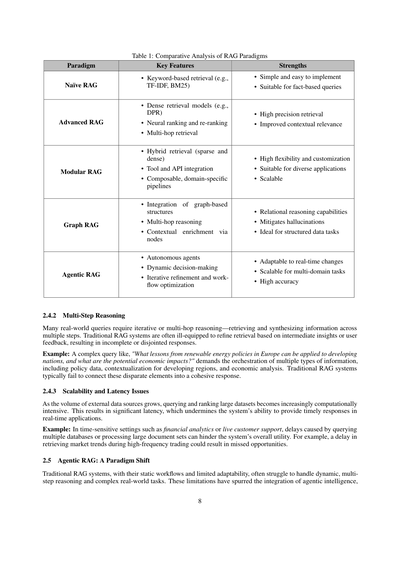
3.2 計画(Planning)
計画(Planning)ってのはな、エージェントのワークフロー設計でめっちゃ大事なパターンで、複雑なタスクを自動で小さい管理しやすいサブタスクに分解できるようにするもんやねん。図9aに示してるみたいに、状況がコロコロ変わったり不確実やったりする場面で、何段階もの推論とか繰り返し問題解決するのに欠かせへんねん。
計画を使うことで、エージェントは大きな目標を達成するために必要なステップの順番を動的に決められるようになるんや。この適応力のおかげで、事前に決められへんようなタスクにも対応できて、意思決定に柔軟性が出るわけやな。ただな、計画はReflectionみたいな決まったワークフローに比べると、結果の予測がちょっとしにくいっていう面もあるで。計画が特に向いてるのは、事前に決めたワークフローじゃ対応しきれへん、動的な適応が必要なタスクやな。技術が成熟していくにつれて、いろんな分野で革新的なアプリケーションを生み出す可能性はどんどん広がっていくで。
3.3 ツール利用(Tool Use)
ツール利用ってのはな、図9bに示してるみたいに、エージェントが外部のツールとかAPIとか計算リソースとやり取りすることで、自分の能力を拡張できるようにするもんやねん。このパターンのおかげで、エージェントは事前に学習した知識の範囲を超えて、情報を集めたり、計算したり、データを操作したりできるようになるんや。ツールをワークフローに動的に組み込むことで、複雑なタスクにも適応できて、より正確で文脈に合ったアウトプットが出せるようになるで。
最近のエージェントワークフローでは、情報検索とか計算推論とか外部システムとの連携とか、いろんな用途でツール利用が取り入れられてるねん。このパターンの実装は、GPT-4の関数呼び出し機能とか、めっちゃたくさんのツールへのアクセスを管理できるシステムとかの進歩で、だいぶ進化してきたんや。こういう発展のおかげで、エージェントが与えられたタスクに一番適したツールを自分で選んで実行するような、高度なワークフローができるようになってきたで。
ツール利用はエージェントワークフローをめっちゃ強化してくれるんやけど、課題も残ってるねん。特に選択肢がめっちゃ多い時に、どのツールを選ぶか最適化するのが難しいんや。RAG(検索拡張生成)にヒントを得た、ヒューリスティックベースの選択みたいな手法がこの問題に対処するために提案されてるで。
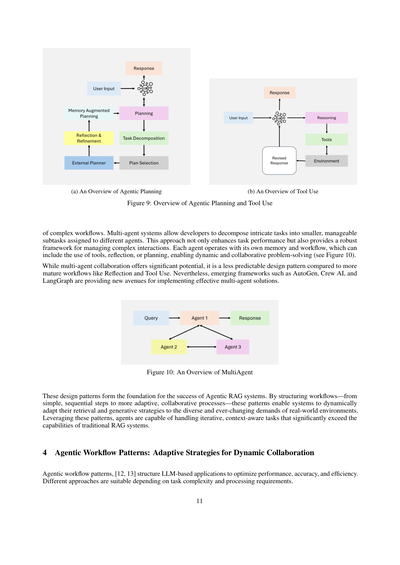
3.4 マルチエージェント
マルチエージェント協調ってのはな、エージェントワークフローの設計パターンでめっちゃ重要なやつで、タスクの専門分化と並列処理を可能にするもんやねん。エージェント同士がコミュニケーションして中間結果を共有することで、全体のワークフローが効率的で一貫性のあるものになるんや。専門化したエージェントにサブタスクを分散させることで、このパターンはスケーラビリティと適応性を向上させるわけやな。
---
## Page 11
[](/attach/b637a8052912693dd5bbde5e61e2ab9b7076bc2f57fabee16ca001dd0352d404_p011.png)
### 和訳
(a) エージェント的プランニングの全体像
(b) ツール使用の全体像
図9:エージェント的プランニングとツール使用の概要
複雑なワークフローを実現するための仕組みについて説明するで。マルチエージェントシステムってのはな、開発者が複雑なタスクを細かい扱いやすいサブタスクに分解して、それぞれ別のエージェントに割り当てられるようにしたもんやねん。このアプローチのええところは、タスクのパフォーマンスが上がるだけやなくて、複雑なやりとりを管理するためのしっかりした枠組みも提供してくれるところやな。各エージェントは自分専用のメモリとワークフローを持ってて、ツールを使ったり、リフレクション(自分の出力を振り返って改善すること)したり、プランニングしたりできるから、動的で協調的な問題解決ができるんや(図10を見てな)。
マルチエージェントの協調にはめっちゃ可能性があるんやけど、リフレクションやツール使用みたいな成熟したワークフローと比べると、予測しにくい設計パターンではあるねん。それでも、AutoGen、Crew AI、LangGraphみたいな新しいフレームワークが出てきて、効果的なマルチエージェントソリューションを実装するための新しい道を切り開いてくれてるで。
図10:マルチエージェントの概要
これらの設計パターンが、エージェント型RAGシステムの成功の土台になってるんや。シンプルな順次処理から、もっと適応的で協調的なプロセスまで、ワークフローを構造化することで、システムが現実世界の多様で常に変化する要求に合わせて、検索戦略と生成戦略を動的に適応させられるようになるねん。これらのパターンを活用することで、エージェントは従来のRAGシステムの能力をはるかに超える、繰り返し処理や文脈を考慮したタスクを処理できるようになるんやで。
4 エージェント的ワークフローパターン:動的協調のための適応戦略
エージェント的ワークフローパターン[12, 13]は、LLMベースのアプリケーションを構造化して、パフォーマンス、精度、効率を最適化するもんやねん。タスクの複雑さや処理要件によって、適切なアプローチは変わってくるで。
11
---
## Page 12
[](/attach/b637a8052912693dd5bbde5e61e2ab9b7076bc2f57fabee16ca001dd0352d404_p012.png)
### 和訳
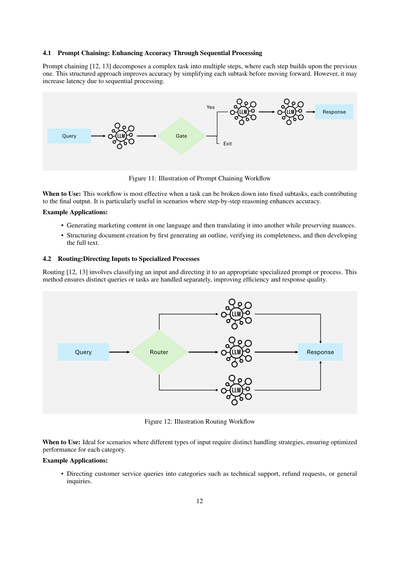
4.1 プロンプトチェーン:順番に処理して精度上げていく方法やで
プロンプトチェーン[12, 13]っていうのはな、めっちゃ複雑なタスクを何個かのステップに分けて、前のステップの結果を次に活かしていくやり方やねん。こうやって構造的にやると、一個一個のサブタスクがシンプルになるから精度が上がるんよ。ただな、順番に処理せなあかんから、ちょっと時間かかるっていうデメリットもあるで。
図11:プロンプトチェーンのワークフローのイメージ図
いつ使うんがええか:タスクを決まった手順のサブタスクに分けられて、それぞれが最終的なアウトプットに貢献するような時にめっちゃ効果的やねん。特に、ステップバイステップで考えた方が精度上がるような場面でバッチリやで。
使用例:
• マーケティングのコンテンツをまず一個の言語で作って、そのニュアンスを残しながら別の言語に翻訳するとか。
• ドキュメント作成を段階的にやる時、まずアウトラインを作って、それがちゃんとカバーできてるか確認して、それから本文を書いていくとか。
4.2 ルーティング:入力を専門の処理に振り分ける方法やで
ルーティング[12, 13]っていうのはな、入力を分類して、それに合った専門的なプロンプトとか処理に振り分けるやり方やねん。なんでこれがええかっていうと、違う種類のクエリとかタスクを別々に処理できるから、効率も上がるし回答の質もようなるんよ。
図12:ルーティングのワークフローのイメージ図
いつ使うんがええか:入力のタイプによって違う対応せなあかん時にめっちゃ向いてるで。それぞれのカテゴリに最適化されたパフォーマンスが出せるんや。
使用例:
• カスタマーサービスの問い合わせを、技術サポートとか、返金リクエストとか、一般的な質問とかのカテゴリに振り分けるとか。
---
## Page 13
[](/attach/b637a8052912693dd5bbde5e61e2ab9b7076bc2f57fabee16ca001dd0352d404_p013.png)
### 和訳
シンプルなやつは小っちゃいモデルに任せてコスト抑えて、難しいやつは賢いモデルに回すってわけや。
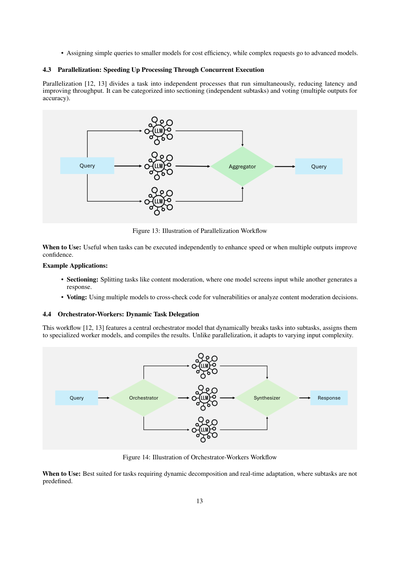
**4.3 並列化:同時実行で処理をめっちゃ速くする方法**
並列化[12, 13]ってのは、タスクを独立したプロセスに分けて同時に動かすことで、待ち時間減らしてスループット(処理量)上げるやり方やねん。大きく分けて「セクショニング」(独立したサブタスク)と「投票」(精度上げるために複数の出力を出す)の2種類があるで。
図13:並列化ワークフローのイメージ図
**いつ使うん?**:タスクが独立して実行できてスピードアップしたいとき、あるいは複数の出力があった方が確信持てるときに使うとええで。
**具体的な使い方の例:**
- **セクショニング**:例えばコンテンツモデレーション(不適切な内容のチェック)みたいなタスクを分割するんや。一個のモデルが入力をスクリーニングしてる間に、別のモデルがレスポンス生成する、みたいな感じやな。
- **投票**:複数のモデル使ってコードの脆弱性をクロスチェックしたり、コンテンツモデレーションの判断を分析したりするんや。
**4.4 オーケストレーター・ワーカー:動的にタスク振り分けるやつ**
このワークフロー[12, 13]は、中央にオーケストレーター(指揮者)モデルがおって、そいつがタスクを動的にサブタスクに分解して、専門のワーカーモデルたちに割り振って、最後に結果をまとめるっていう仕組みやねん。さっきの並列化と違うのは、入力の複雑さによって柔軟に対応できるところやな。
図14:オーケストレーター・ワーカーワークフローのイメージ図
**いつ使うん?**:サブタスクが事前に決まってなくて、動的に分解せなあかんとき、リアルタイムで適応する必要があるときにめっちゃ向いてるで。
---
## Page 14
[](/attach/b637a8052912693dd5bbde5e61e2ab9b7076bc2f57fabee16ca001dd0352d404_p014.png)
### 和訳
使用例はこんな感じやで:
• コードベースの複数ファイルを、リクエストされた変更の内容に応じて自動で修正してくれるんやわ。
• リアルタイムで調べもんして、複数のソースから関連情報をかき集めてまとめてくれるんや。
### 4.5 評価者-最適化者: 繰り返しでアウトプットを磨き上げる
評価者-最適化者[12, 13]っていうワークフローは、まず最初にアウトプットを作って、それを評価モデルからのフィードバックに基づいて何回も磨き上げていく仕組みやねん。
図15: 評価者-最適化者ワークフローのイメージ図
いつ使うん?: 繰り返し改善することでレスポンスの質がめっちゃ上がる時に効果的やで。特に「こういう基準で評価する」っていうのがはっきりしてる時にええわ。
使用例はこんな感じ:
• 文学作品の翻訳を、何回も評価と修正のサイクル回してええ感じに仕上げるんや。
• 調査クエリを何ラウンドもかけて、追加で回すたびに検索結果をどんどん洗練させていくんやわ。
## 5 エージェント型RAGシステムの分類
エージェント型の検索拡張生成(RAG)システムっていうのは、複雑さとか設計思想によっていくつかの構造パターンに分けられるんや。単一エージェント構造、マルチエージェントシステム、それと階層型エージェント構造があるで。それぞれの構造は特定の課題に対応するために作られてて、いろんなアプリケーションで性能を最適化できるようになってるんやわ。このセクションでは、これらの構造の詳しい分類を紹介して、それぞれの特徴、強み、弱みを説明していくで。
### 5.1 単一エージェント型エージェントRAG: ルーター
単一エージェント型エージェントRAG[30]っていうのは、1つのエージェントが情報の検索、振り分け、統合を全部管理する、いわば司令塔みたいなシステムやねん(図16を見てな)。この構造はこれらのタスクを1つのエージェントにまとめることでシステムをシンプルにしてるから、ツールやデータソースが限られてる環境では特に効果的やで。
**ワークフロー**
1. **クエリの送信と評価**: まずユーザーがクエリを投げるところから始まるんや。調整役のエージェント(マスター検索エージェントって呼ぶこともある)がそのクエリを受け取って、どの情報源が一番ええか分析するんやわ。
2. **知識ソースの選択**: クエリの種類に応じて、調整役エージェントがいろんな検索オプションの中から選ぶんや:
---
## Page 15
[](/attach/b637a8052912693dd5bbde5e61e2ab9b7076bc2f57fabee16ca001dd0352d404_p015.png)
### 和訳
• **構造化データベース**:表形式のデータにアクセスせなあかんクエリの場合は、Text-to-SQLエンジンっちゅうもんを使って、PostgreSQLとかMySQLみたいなデータベースとやり取りするねん。
• **セマンティック検索**:構造化されてへん情報を扱うときは、ベクトルベースの検索を使って関連するドキュメント(PDFとか本とか組織の記録とか)を引っ張ってくるんや。
• **Web検索**:リアルタイムの情報とか幅広い文脈の情報が必要なときは、Web検索ツールを使って最新のオンラインデータにアクセスするで。
• **レコメンデーションシステム**:パーソナライズされた質問とか文脈に応じた質問には、レコメンデーションエンジンにアクセスして、その人に合った提案をしてくれるねん。
3. **データ統合とLLMによる合成**:選んだソースから関連データを取ってきたら、それを大規模言語モデル(LLM)に渡すねん。LLMは集めた情報を合成して、複数のソースからの知見をまとめて、一貫性があって文脈に合った回答を作り上げるんや。
4. **出力生成**:最後に、元の質問に答える包括的でユーザー向けの回答を出すねん。この回答はすぐ使えて簡潔な形式で提示されて、オプションで使った情報源への参照や引用も含められるで。
図16:シングルエージェンティックRAGの概要
**主な特徴と利点**
• **一元化されたシンプルさ**:1つのエージェントが全部の検索とルーティングのタスクを担当するから、設計も実装もメンテナンスもめっちゃシンプルになるねん。
• **効率性とリソースの最適化**:エージェントが少なくて調整もシンプルやから、必要な計算リソースが少なくて済むし、クエリもサクサク処理できるで。
• **動的ルーティング**:エージェントが各クエリをリアルタイムで評価して、一番適切な知識ソース(構造化DB、セマンティック検索、Web検索とか)を選ぶんや。
• **ツール横断の汎用性**:いろんなデータソースや外部APIに対応してるから、構造化されたワークフローも非構造化のワークフローも両方いけるで。
• **シンプルなシステムに最適**:タスクがはっきり決まってたり、統合要件が限られてるアプリケーション(ドキュメント検索とかSQLベースのワークフローとか)にめっちゃ向いてるねん。
---
## Page 16
[](/attach/b637a8052912693dd5bbde5e61e2ab9b7076bc2f57fabee16ca001dd0352d404_p016.png)
### 和訳
使用例:カスタマーサポート
プロンプト:「注文した商品、今どこにあるか教えてくれへん?」
システムの処理(シングルエージェント方式):
1. 問い合わせの受付と評価:
・お客さんからの問い合わせが来たら、まず司令塔みたいな役割のコーディネーターエージェントが受け取るねん。
・このコーディネーターエージェントが「この質問にはどの情報源を使ったらええかな」って分析して判断するんやで。
2. 情報源の選択:
・注文管理のデータベースから追跡情報を引っ張ってくる。
・配送業者のAPIからリアルタイムの最新情報をゲットする。
・必要やったら、天気とか物流の遅延みたいな、配達に影響しそうな地域の状況をウェブ検索で調べることもあるんや。
3. データの統合とLLMによる合成:
・集めてきた関連データをLLM(大規模言語モデル)に渡して、バラバラの情報をまとまった回答に仕上げてもらうねん。
4. 出力の生成:
・システムが、すぐ行動に移せるような簡潔な回答を作り出すんや。リアルタイムの追跡情報とか、他の選択肢なんかも提示してくれるで。
回答例:
統合された回答:「お客様の荷物は現在配送中で、明日の夕方に届く予定やで。UPSのリアルタイム追跡によると、今は地域の配送センターにあるみたいやな。」
5.2 マルチエージェント型のAgentic RAGシステム:
マルチエージェントRAG[30]っていうのは、シングルエージェント構成からめっちゃ進化した、モジュール式でスケーラブルな仕組みやねん(図17参照)。複雑なワークフローとか、いろんな種類の問い合わせに対応できるように、複数の専門エージェントを活用するんや。一人のエージェントに全部任せる——推論も検索も回答生成も——んじゃなくて、複数のエージェントに仕事を分担させて、それぞれが得意分野に特化した役割を担うっていう設計やな。
ワークフロー
1. 問い合わせの受付:まずユーザーからの問い合わせをコーディネーターエージェント(マスター検索エージェントとも言うで)が受け取るところから始まるんや。このエージェントが全体の司令塔として、問い合わせの内容に応じて専門の検索エージェントに仕事を振り分けるねん。
2. 専門検索エージェントたち:問い合わせは複数の検索エージェントに分配されて、それぞれが特定のデータソースやタスクに集中するんや。例えばこんな感じ:
・エージェント1:PostgreSQLとかMySQLみたいなSQLベースのデータベースに対する構造化クエリを担当。
・エージェント2:PDFとか本とか社内記録みたいな非構造化データから、意味的に関連する情報を検索するのが専門。
・エージェント3:ウェブ検索とかAPIを使って、リアルタイムの公開情報を取ってくるのが仕事。
・エージェント4:レコメンドシステムに特化してて、ユーザーの行動履歴とかプロフィールに基づいた文脈に沿った提案をしてくれるんや。
3. ツールへのアクセスとデータ取得:各エージェントは、自分の担当領域内で適切なツールやデータソースに問い合わせをルーティングするねん。例えば:
・ベクトル検索:意味的な関連性を見つけるため。
・Text-to-SQL:構造化データにアクセスするため。
・ウェブ検索:リアルタイムの公開情報を得るため。
・API:外部サービスとか独自システムにアクセスするため。
ほんでな、この検索処理は並列で実行されるから、いろんな種類の問い合わせを効率よく処理できるんやで。
---
## Page 17
[](/attach/b637a8052912693dd5bbde5e61e2ab9b7076bc2f57fabee16ca001dd0352d404_p017.png)
### 和訳
図17: マルチエージェント型Agentic RAGシステムの全体像
4. データ統合とLLMによる合成:検索が終わったら、全部のエージェントから集めたデータを大規模言語モデル(LLM)に渡すねん。LLMがその検索で集めた情報をうまいことまとめて、文脈に合った一貫性のある回答を作ってくれるわけや。複数のソースからの知見をめっちゃスムーズに統合してくれるんやで。
5. 出力生成:システムが包括的な回答を生成して、ユーザーに返すねん。すぐ行動に移せるような、簡潔なフォーマットでな。
主な特徴とメリット
• モジュール性:各エージェントが独立して動くから、システムの要件に応じてエージェントの追加とか削除がめっちゃ簡単にできるねん。
• スケーラビリティ:複数のエージェントが並列で処理するから、大量のクエリもサクサク効率よく捌けるんやで。
• タスクの専門化:各エージェントが特定のクエリタイプとかデータソースに最適化されてるから、精度と検索の的確さがグッと上がるねん。
• 効率性:専門化されたエージェントにタスクを分散させることで、ボトルネックを最小限に抑えて、複雑なワークフローでもパフォーマンス出せるようになってるんや。
• 汎用性:研究、分析、意思決定、カスタマーサポートとか、いろんな分野のアプリケーションに対応できるねん。
課題
• 連携の複雑さ:エージェント間のコミュニケーションとかタスクの割り振りを管理するには、めっちゃ高度なオーケストレーション(指揮・調整)の仕組みが必要になるねん。
• 計算リソースのオーバーヘッド:複数のエージェントを並列処理させると、リソースの使用量が増えてまうんや。
• データ統合の難しさ:いろんなソースからの出力を一つのまとまった回答に合成するんは、なかなか一筋縄ではいかへんねん。高度なLLMの能力が求められるところやな。
---
## Page 18
[](/attach/b637a8052912693dd5bbde5e61e2ab9b7076bc2f57fabee16ca001dd0352d404_p018.png)
### 和訳
ほな説明していくで!
---
**使用例:いろんな分野またいで調べてくれるリサーチアシスタント**
**プロンプト:** ヨーロッパで再生可能エネルギーが広まったら、経済と環境にどんな影響あるん?
**システムの処理(複数のエージェントが連携して動く仕組み):**
- **エージェント1:** SQLっていうデータベース検索の言語使って、経済関連のデータベースから統計データ引っ張ってくるねん
- **エージェント2:** セマンティック検索っていう、意味を理解して探す賢い検索で、関連する学術論文探してくれるわけや
- **エージェント3:** ウェブ検索して、再生可能エネルギーに関する最新ニュースとか政策の動きとかチェックしてくれんねん
- **エージェント4:** レコメンドシステムに相談して、関連するレポートとか専門家のコメントとか、「これも見といたら?」って提案してくれるんやで
**回答:**
**統合された回答:** 「ヨーロッパで再生可能エネルギー導入したことで、この10年で温室効果ガスが20%も減ったんやって。これEUの政策レポートに書いてあるねん。経済面で言うたら、再生可能エネルギーへの投資でだいたい120万人分の雇用が生まれてて、特に太陽光と風力のとこがめっちゃ伸びてるんや。ほんで最近の学術研究やと、送電網の安定性とかエネルギー貯める時のコストとか、そういうトレードオフもあるでって指摘されてるわ。」
---
**5.3 階層型のエージェンティックRAGシステム**
階層型エージェンティックRAG:[14] これ何かっていうと、情報を取ってきて処理する時に、段階的に構造化されたやり方を使うシステムやねん。図18に示してある通り、効率も戦略的な判断力もめっちゃ上がるんよ。エージェントたちが階層構造になってて、上のレベルのエージェントが下のレベルのエージェントを監督したり指示したりしてんねん。この構造のおかげで、何段階にも分けて意思決定できるから、クエリ(検索したいこと)を一番ふさわしいリソースに任せられるっちゅうわけや。
**図18:階層型エージェンティックRAGのイメージ図**
---
**ワークフロー(処理の流れ)**
1. **クエリの受付:** ユーザーが質問投げかけたら、まずトップレベルのエージェントが受け取るねん。こいつが最初の評価と、どこに振り分けるか決める役や。
2. **戦略的な判断:** トップのエージェントが「このクエリどんだけ複雑なん?」って評価して、どの部下エージェントとかデータソースを優先するか決めるんや。クエリの分野によって、「このデータベースの方が信頼できるな」とか「このAPIの方が関連性高いわ」とか判断してくれるねん。
3. **部下エージェントへの割り振り:** トップのエージェントが、それぞれの検索方法を専門にしてる下位エージェントにタスク振り分けるんよ。例えばSQLデータベース担当とか、ウェブ検索担当とか、自社専用システム担当とかな。ほんで各エージェントは割り当てられたタスクを独立して実行するんやで。
---
## Page 19
[](/attach/b637a8052912693dd5bbde5e61e2ab9b7076bc2f57fabee16ca001dd0352d404_p019.png)
### 和訳
4. 集約と統合:部下みたいなエージェントから集まった結果を、上のレベルのエージェントがまとめて、ちゃんと筋の通った回答に仕上げるねん。
5. 回答のお届け:最終的にまとまった答えをユーザーに返すんやけど、ちゃんと網羅的で文脈にも合った回答になってるのがポイントやで。
**主な特徴とメリット**
・戦略的な優先順位付け:トップレベルのエージェントが、質問の複雑さとか信頼性、文脈に応じてデータソースやタスクの優先順位を決められるねん。
・スケーラビリティ:タスクを複数の階層に分散させることで、めっちゃ複雑な質問とか色んな側面がある質問にも対応できるようになるんや。
・意思決定の強化:上位のエージェントが戦略的に全体を見渡すから、回答の正確さとか一貫性がグッと上がるねん。
**課題**
・調整の複雑さ:複数の階層間でエージェント同士がちゃんと連携するの、オーケストレーションの負担が増えてまうねん。
・リソース配分:ボトルネックを避けながら各階層にタスクをうまく割り振るのは、簡単な話ちゃうねん。
**ユースケース:金融分析システム**
プロンプト:再生可能エネルギーの今の市場トレンドを踏まえて、一番ええ投資先はどこ?
システムの処理(階層型エージェントワークフロー):
1. トップ階層のエージェント:質問の複雑さを見極めて、信頼性の低いデータソースより、ちゃんとした金融データベースとか経済指標を優先するねん。
2. 中間階層のエージェント:専用のAPIとか構造化されたSQLデータベースから、リアルタイムの市場データ(株価とかセクターのパフォーマンスとか)を引っ張ってくるんや。
3. 下位階層のエージェント:最近の政策発表をウェブ検索したり、専門家の意見やニュース分析を追ってるレコメンドシステムに聞いたりするねん。
4. 集約と統合:トップ階層のエージェントが結果をまとめて、数字のデータと政策の洞察を組み合わせるんや。
回答:
統合された回答:「今の市場データによると、再生可能エネルギー株は過去四半期で15%成長してるねん。なんでかっていうと、政府の支援政策と投資家の関心の高まりがあるからや。アナリストによると、特に風力と太陽光セクターは勢いが続きそうで、グリーン水素みたいな新しい技術はリスクはそこそこあるけど、リターンは高くなる可能性があるってことやで。」
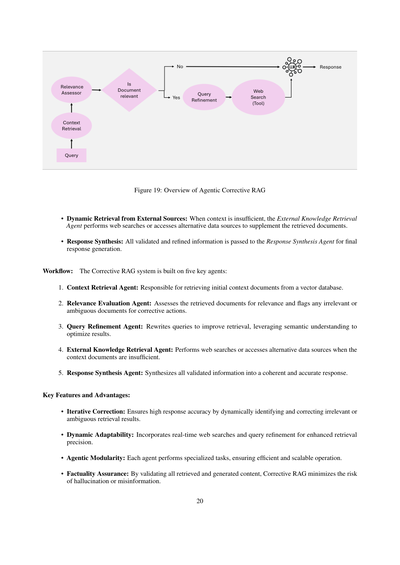
**5.4 エージェント型コレクティブRAG**
コレクティブRAG:図19に示されてるように、検索結果を自己修正する仕組みを導入して、文書の活用度を高めて、回答生成の質を上げるもんやねん。賢いエージェントをワークフローに組み込むことで、コレクティブRAG[31][32]はコンテキスト文書と回答を繰り返し改善して、エラーを最小限に抑えながら関連性を最大化するんや。
**コレクティブRAGのキモとなるアイデア**:コレクティブRAGの核心は、取得した文書をダイナミックに評価して、修正アクションを実行して、クエリを洗練させて、生成される回答の質を高める能力にあるねん。コレクティブRAGは以下のようにアプローチを調整するんや:
・文書の関連性評価:取得した文書は関連性評価エージェントによって関連性をチェックされるねん。関連性の閾値を下回る文書があったら、修正ステップが発動するんや。
・クエリの洗練と拡張:クエリ洗練エージェントがクエリを磨き上げるねん。意味的な理解を活用して、もっとええ結果が得られるように検索を最適化するんや。
---
## Page 20
[](/attach/b637a8052912693dd5bbde5e61e2ab9b7076bc2f57fabee16ca001dd0352d404_p020.png)
### 和訳
図19:エージェント型修正RAGの全体像
**・外部ソースからの動的検索**:コンテキストが足りひん時は、外部知識検索エージェントがウェブ検索したり他のデータソースにアクセスしたりして、取ってきた文書を補強してくれるねん。
**・回答の合成**:検証して磨き上げた情報は全部、回答合成エージェントに渡されて、最終的な回答が作られるんやで。
**ワークフロー**:修正RAGシステムは5つの主要なエージェントで構成されてるねん:
1. **コンテキスト検索エージェント**:ベクトルデータベースから最初のコンテキスト文書を取ってくる係や。
2. **関連性評価エージェント**:取ってきた文書がほんまに関係あるか評価して、関係ないやつとか曖昧なやつには「修正せなあかん」ってフラグ立てるねん。
3. **クエリ改良エージェント**:検索結果を良くするためにクエリを書き直してくれるやつ。意味をちゃんと理解して最適化してくれるんや。
4. **外部知識検索エージェント**:コンテキスト文書だけじゃ足りひん時に、ウェブ検索したり別のデータソースにアクセスしたりする係やな。
5. **回答合成エージェント**:検証された情報を全部まとめて、筋の通った正確な回答を作り上げてくれるねん。
**主な特徴とメリット**:
**・反復的な修正**:関係ない検索結果とか曖昧な結果を動的に見つけて直すから、めっちゃ正確な回答が出せるんやで。
**・動的な適応力**:リアルタイムでウェブ検索したりクエリ改良したりするから、検索の精度がバチバチに上がるねん。
**・エージェントのモジュール性**:それぞれのエージェントが専門の仕事をするから、効率良くてスケールもしやすいんや。
**・事実の正確さを保証**:取ってきた情報も生成した情報も全部検証するから、ハルシネーション(でたらめ)とか誤情報のリスクをめっちゃ抑えられるんやで。
---
## Page 21
[](/attach/b637a8052912693dd5bbde5e61e2ab9b7076bc2f57fabee16ca001dd0352d404_p021.png)
### 和訳
**ユースケース:学術研究アシスタント**
**プロンプト:** 生成AIの研究で最新の発見ってなんなん?
**システムの処理フロー(補正型RAGのワークフロー):**
1. **クエリの送信:** ユーザーがシステムに質問を投げるわけや。
2. **コンテキストの取得:**
- 「コンテキスト取得エージェント」ってやつが、生成AIについて書かれた論文のデータベースから、最初のドキュメントを引っ張ってくるねん。
- で、取ってきたドキュメントは次のステップに渡されて評価されるんやで。
3. **関連性の評価:**
- 「関連性評価エージェント」が、取ってきたドキュメントが質問とちゃんと合ってるかどうかをチェックするねん。
- ドキュメントは「関連あり」「微妙」「関係なし」の3つに分類されるんや。関係ないドキュメントは補正対象としてマークされるで。
4. **補正アクション(必要な場合):**
- 「クエリ改善エージェント」が、質問をもっと具体的で的確なものに書き直すねん。
- 「外部知識取得エージェント」が、ウェブ検索して外部ソースから追加の論文やレポートを取ってくるんやで。
5. **回答の合成:**
- 「回答合成エージェント」が、検証済みのドキュメントをうまいことまとめて、わかりやすくて包括的なサマリーを作るねん。
**回答:**
統合された回答:「生成AIの最近の発見では、拡散モデルの進歩、テキストから動画を作るタスクでの強化学習、あと大規模モデルの学習を効率化するテクニックなんかが注目されてるで。もっと詳しく知りたかったら、NeurIPS 2024とかAAAI 2025で発表された研究を見てみてな。」
---
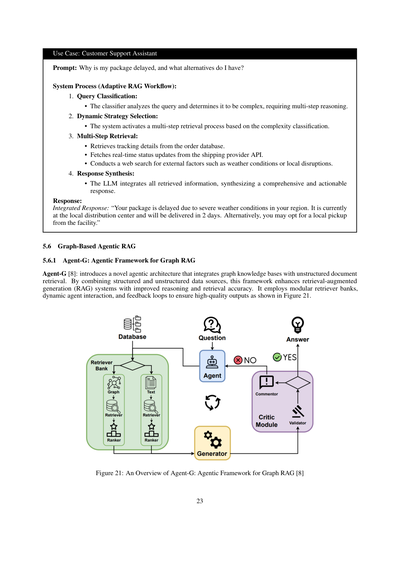
**5.5 適応型エージェンティックRAG**
適応型RAG(Adaptive RAG)[33]っていうのは、めっちゃ柔軟で効率的に大規模言語モデル(LLM)を使えるようにした仕組みやねん。なんでかっていうと、入ってきた質問の難しさに応じて、クエリの処理方法を動的に変えるからなんや。従来の固定的な取得ワークフローとは違って、適応型RAG[34]は分類器を使って質問の複雑さを判断して、一番ええアプローチを選ぶねん。1回で取得して終わりのパターンから、何段階にも分けて推論するパターン、あるいは簡単な質問やったらそもそも取得をスキップするパターンまであるんや(図20参照)。
**図20:適応型エージェンティックRAGの概要**
**適応型RAGのキーアイデア**
適応型RAGの核心は、質問の複雑さに応じて取得戦略を動的にカスタマイズできるところにあるねん。適応型RAGは以下のようにアプローチを調整するんやで:
---
## Page 22
[](/attach/b637a8052912693dd5bbde5e61e2ab9b7076bc2f57fabee16ca001dd0352d404_p022.png)
### 和訳
**シンプルな質問**:事実ベースの質問で追加の情報取得がいらんやつ(例えば「水の沸点って何度?」みたいなん)は、システムが元々持ってる知識だけでパパッと答えを出すねん。
**ちょいムズの質問**:ちょっとだけ複雑で、最低限の情報が必要なやつ(例えば「ワイの最新の電気代の支払い状況どうなってる?」みたいなん)は、1回だけ情報を取りに行って、必要な詳細をゲットするんや。
**めっちゃ複雑な質問**:何層にもなってる質問で、段階的に考えなあかんやつ(例えば「X市の人口がこの10年でどう変わって、その要因は何やねん?」みたいなん)は、何回も情報取りに行く多段階検索ってやつを使って、中間結果をどんどん磨き上げて、ちゃんとした答えを出すねん。
**仕組み**:このAdaptive RAGシステムは3つの主要パーツでできてるで:
1. **分類器の役割**:
- ちっちゃい言語モデルが質問を分析して、どれくらい複雑かを予測するねん。
- この分類器は、過去のモデルの結果とか質問のパターンから自動でラベル付けされたデータセットを使って学習してるんや。
2. **動的な戦略選択**:
- シンプルな質問やったら、わざわざ情報取りに行かんと、LLM(大規模言語モデル)が直接答えを作るねん。
- ちょいムズの質問やったら、1回だけ検索して関連する情報を持ってくるんや。
- めっちゃ複雑な質問やったら、多段階検索を発動して、繰り返し磨き上げながら推論を強化するで。
3. **LLMとの連携**:
- LLMが取ってきた情報をまとめて、ちゃんとした答えに仕上げるねん。
- 複雑な質問の場合は、LLMと分類器が何回もやり取りして、答えをブラッシュアップしていくんや。
**主な特徴とええとこ**
- **動的な適応力**:質問の複雑さに応じて検索戦略を調整するから、計算効率と回答の正確さの両方を最適化できるねん。
- **リソースの効率化**:シンプルな質問には無駄な処理をせんようにして、複雑なやつにはしっかり処理するっていう、メリハリのある使い方ができるんや。
- **精度アップ**:繰り返しの改善があるから、複雑な質問でもめっちゃ高い精度で解決できるで。
- **柔軟性**:専門分野用のツールとか外部APIとか、追加の経路を組み込めるように拡張できるんや。
---
## Page 23
[](/attach/b637a8052912693dd5bbde5e61e2ab9b7076bc2f57fabee16ca001dd0352d404_p023.png)
### 和訳
**使用例:カスタマーサポートのアシスタント**
**プロンプト:** 「なんで荷物届くの遅れてんの?他になんか方法ないん?」
**システムの処理(適応型RAGワークフロー):**
1. **クエリの分類:**
まず分類器がクエリを分析して、「これ複雑な質問やな、何段階かに分けて考えなあかんわ」って判断するねん。
2. **戦略の動的選択:**
複雑やって分かったから、システムは「よっしゃ、マルチステップ検索でいこか」って検索プロセスを起動するんよ。
3. **マルチステップ検索:**
ここがめっちゃ大事なとこやねんけど、いろんなところから情報かき集めてくるねん。
- 注文データベースから追跡情報を引っ張ってくる
- 配送業者のAPIからリアルタイムの状況を取得する
- ウェブ検索で天気とか地域の交通障害とか外部要因も調べる
4. **レスポンスの統合:**
LLM(大規模言語モデルのことやで)が集めた情報を全部まとめて、包括的でちゃんと役立つ回答を作り上げるねん。
**回答:**
統合されたレスポンス:「お客様の荷物は、お住まいの地域の悪天候で遅れてますわ。今、地元の配送センターにあって、2日後にはお届けできる予定です。もしお急ぎやったら、その施設に直接取りに来てもらうこともできますよ。」
---
**5.6 グラフベースのエージェント型RAG**
**5.6.1 Agent-G:グラフRAGのためのエージェントフレームワーク**
Agent-G [8]っていうのはな、めっちゃ画期的なエージェント型のアーキテクチャやねん。何がすごいかっていうと、グラフ型のナレッジベース(知識を整理したデータベースみたいなもんや)と、構造化されてへんドキュメントの検索をうまいこと組み合わせてるとこやな。
なんでこれがええかっていうと、構造化データ(きっちり整理された情報)と非構造化データ(バラバラな文書とか)の両方から情報取ってこれるから、RAGシステムの推論能力と検索精度がグーンと上がるねん。
仕組みとしては、モジュール式のリトリーバーバンク(検索器を複数用意しといて使い分けるやつ)、エージェント同士の動的なやり取り、フィードバックループ(結果を見て改善していくサイクル)を使って、質の高いアウトプットを保証してるんよ。図21見てみてな。
**図21:Agent-Gの概要:グラフRAGのためのエージェントフレームワーク [8]**
---
## Page 24
[](/attach/b637a8052912693dd5bbde5e61e2ab9b7076bc2f57fabee16ca001dd0352d404_p024.png)
### 和訳
Agent-Gの基本的な考え方
Agent-Gのキモは何かっていうと、検索タスクを専門のエージェントたちにええ感じに振り分けられるところやねん。グラフ知識ベースとテキスト文書の両方をうまいこと使い分けるんや。Agent-Gは検索のやり方をこんな風に調整しとるで:
• グラフ知識ベース:構造化されたデータから、関係性とか階層とかつながりを引っ張ってくるんや(例えば医療分野やったら、病気と症状の対応関係とかな)。
• 非構造化文書:昔ながらのテキスト検索システムで、グラフデータを補うための文脈情報を持ってくるわけや。
• 批評モジュール:取ってきた情報がほんまに関係あるか、質はどうかをチェックして、クエリ(質問)とちゃんと合ってるか確認するんや。
• フィードバックループ:何回も検証したり再検索したりして、検索結果と統合の精度をどんどん上げていくんやで。
ワークフロー:Agent-Gシステムは4つの主要コンポーネントで構成されとるで:
1. リトリーバーバンク(検索エージェント集団):
• グラフベースのデータか非構造化データを取ってくることに特化したエージェントがモジュール式で揃っとる。
• クエリの要件に応じて、エージェントたちが動的に関連するソースを選ぶんや。
2. 批評モジュール:
• 取ってきたデータが関係あるか、質がええかを検証するんや。
• 自信度が低い結果には「もっかい取ってきて」とか「精度上げて」ってフラグ立てるねん。
3. 動的エージェント連携:
• タスクごとに専門のエージェントたちが協力して、いろんな種類のデータを統合するんや。
• グラフとテキストの両方のソースからまとまりのある検索と統合ができるようにしとるで。
4. LLM統合:
• 検証済みのデータを一貫性のある回答にまとめ上げるんや。
• 批評モジュールからの繰り返しフィードバックで、クエリの意図とちゃんと合ってるか確認するねん。
主な特徴とメリット
• 推論能力がめっちゃ上がる:グラフからの構造化された関係性と、非構造化文書からの文脈情報を組み合わせられるんや。
• 動的に適応できる:クエリの要件に応じて検索戦略をその場で調整するで。
• 精度が向上する:批評モジュールのおかげで、関係ない情報とか質の低いデータが回答に混ざるリスクを減らせるんや。
• スケーラブルなモジュール性:専門タスク用の新しいエージェントを追加できるから、拡張性もバッチリやで。
---
## Page 25
[](/attach/b637a8052912693dd5bbde5e61e2ab9b7076bc2f57fabee16ca001dd0352d404_p025.png)
### 和訳
**ユースケース:医療診断**
**プロンプト:** 2型糖尿病の一般的な症状ってなに?あと、心臓病とどう関係してるん?
**システムの処理(Agent-Gのワークフロー):**
1. **クエリの受け取りと振り分け:** システムがこの質問を受け取って、「あ、これちゃんと答えるには、グラフ構造のデータと普通の文書データの両方いるな」って判断するねん。
2. **グラフ検索くん:**
- 医療用のナレッジグラフ(知識がつながったネットワークみたいなもんやな)から、2型糖尿病と心臓病の関係性を引っ張り出してくるねん。
- グラフの階層とか関係性をたどって、肥満とか高血圧みたいな共通のリスク要因も見つけてくれるんや。
3. **文書検索くん:**
- 医学文献から2型糖尿病の症状(のどがめっちゃ乾く、しょっちゅうトイレ行きたくなる、だるいとか)の説明を取ってくるねん。
- グラフから得た情報を補完する追加の文脈情報も加えてくれるんや。
4. **批評モジュール:**
- 取ってきたグラフデータと文書データが、ほんまに関連あるか、質ええか評価するねん。
- 「これちょっと自信ないわ〜」ってやつには印つけて、もっかい検索し直すか改善するように促すんや。
5. **回答の統合:** LLM(大規模言語モデルな)が、グラフ検索くんと文書検索くんから来た検証済みデータをまとめて、質問の意図にちゃんと沿った一貫性ある回答にしてくれるねん。
**回答:**
統合された回答:「2型糖尿病の症状には、のどの渇きがひどくなる、頻尿、疲労感があるで。研究によると、糖尿病と心臓病には50%の相関があって、主な原因は肥満と高血圧っていう共通のリスク要因やねん。」
---
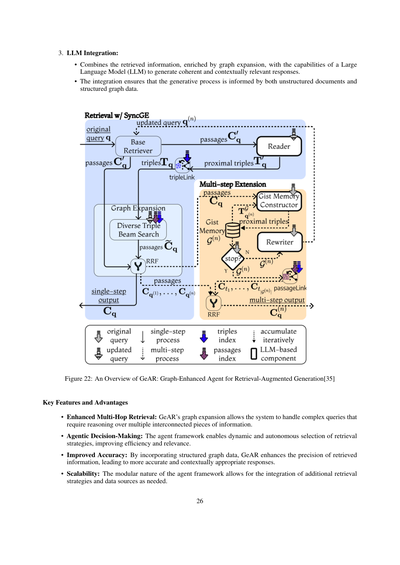
**5.6.2 GeAR:グラフ強化エージェントによる検索拡張生成**
**GeAR [35]:** これはな、従来のRAG(検索拡張生成)システムにグラフベースの検索機能を組み込んだエージェントフレームワークやねん。グラフ拡張技術とエージェントベースのアーキテクチャを使うことで、GeARはマルチホップ検索(複数ステップの検索が必要なやつな)のシナリオでの課題に対処して、図22に示すように複雑なクエリを処理する能力をめっちゃ向上させてるんや。
**GeARのキーアイデア** GeARは主に2つの革新でRAGのパフォーマンスを進化させてるねん:
- **グラフ拡張:** 従来のベース検索器(BM25とかな)を強化して、検索プロセスにグラフ構造データを組み込むねん。これで、エンティティ(モノとか概念とか)間の複雑な関係や依存性を捉えられるようになるんや。
- **エージェントフレームワーク:** エージェントベースのアーキテクチャを取り入れて、グラフ拡張を活用しながら検索タスクをもっと効果的に管理するねん。検索プロセスで動的かつ自律的な意思決定ができるようになるんやで。
**ワークフロー:** GeARシステムは以下のコンポーネントで動いてるねん:
1. **グラフ拡張モジュール:**
- グラフベースのデータを検索プロセスに統合して、検索中にエンティティ間の関係を考慮できるようにするねん。
- 検索範囲を関連するエンティティにまで広げることで、ベース検索器のマルチホップクエリ処理能力を強化するんや。
2. **エージェントベースの検索:**
- 検索プロセスを管理するためにエージェントフレームワークを使って、クエリの複雑さに応じて検索戦略を動的に選んだり組み合わせたりできるようにしてるねん。
- エージェントは自分で判断して、グラフ拡張された検索パスを使うことで、取ってくる情報の関連性と正確性を上げることができるんやで。
---
## Page 26
[](/attach/b637a8052912693dd5bbde5e61e2ab9b7076bc2f57fabee16ca001dd0352d404_p026.png)
### 和訳
3. LLMとの連携:
• 取ってきた情報(グラフ拡張で強化されたやつな)と、大規模言語モデル(LLM)の能力を組み合わせて、ちゃんとつじつまの合った、文脈に沿った回答を生成するねん。
• この連携のおかげで、文章みたいな非構造化データとグラフみたいな構造化データの両方を活かした生成ができるわけや。
図22:GeARの全体像:検索拡張生成のためのグラフ強化エージェント[35]
主な特徴とええとこ
• マルチホップ検索がめっちゃ強化される:GeARのグラフ拡張のおかげで、いろんな情報をつなげて考えなあかんような複雑な質問にも対応できるようになるねん。
• エージェントが自分で判断してくれる:エージェントの仕組みがあることで、「どの検索方法使おかな」っていうのを動的に、しかも自律的に選んでくれるから、効率もええし、的確な結果が返ってくるんや。
• 精度がアップする:構造化されたグラフデータを取り入れることで、取ってくる情報の正確さがグンと上がって、結果的にもっと正確で文脈にピッタリな回答ができるようになるで。
• スケーラビリティがある:エージェントの仕組みがモジュール式になってるから、必要に応じて検索の方法やデータソースをどんどん追加していけるんや。
26
---
## Page 27
[](/attach/b637a8052912693dd5bbde5e61e2ab9b7076bc2f57fabee16ca001dd0352d404_p027.png)
### 和訳
使用例:マルチホップ質問応答
プロンプト:J.K.ローリングの師匠に影響を与えた作家って誰なん?
システムの処理(GeAR ワークフロー):
1. トップ階層のエージェント:このクエリが「マルチホップ」、つまり何段階もたどらなあかんやつやって判断して、グラフの展開と文書検索を両方使わなあかんって決めるねん。
2. グラフ展開モジュール:
• まず「J.K.ローリングの師匠」がこの質問のキーになる人物やって特定するねん。
• ほんで文学的な関係性をグラフ構造のデータで探っていって、その師匠に影響を与えた人を追跡していくわけや。
3. エージェントベースの検索:
• エージェントが自分で判断して、グラフ展開した検索パスを選んで、師匠に影響を与えた人の情報をかき集めてくるねん。
• さらに、師匠とその影響元について書かれたテキストデータも引っ張ってきて、文脈をもっと補強するんや。
4. レスポンスの合成:グラフ検索と文書検索で得た情報を、LLM(大規模言語モデル)がええ感じに組み合わせて、この複雑な関係性をちゃんと反映した回答を生成するんやで。
回答:
統合レスポンス:「J.K.ローリングの師匠である【師匠の名前】は、【作家の名前】からめっちゃ影響を受けてたんやって。その人は【代表作やジャンル】で有名な作家やねん。この繋がりを見ると、文学の歴史って何層にも重なった関係性があって、影響力のあるアイデアが何世代もの作家を通じて受け継がれていくんやなぁってわかるわ。」
5.7 エージェンティック RAG における エージェンティック・ドキュメント・ワークフロー
エージェンティック・ドキュメント・ワークフロー(ADW)[36]っていうのは、従来の RAG(検索拡張生成)の仕組みをめっちゃパワーアップさせたやつやねん。なんでかっていうと、これを使うと知識を使った仕事を端から端まで自動化できるからなんや。このワークフローは複雑な文書中心の処理を取りまとめてくれて、文書の解析、検索、推論、それに構造化された出力を賢いエージェントたちと連携させるんや(図23を見てな)。ADWシステムは、インテリジェント文書処理(IDP)や RAG の弱点を克服してて、状態を保持しながら、複数ステップのワークフローを調整して、ドメイン固有のロジックを文書に適用できるんやで。
ワークフロー
1. 文書の解析と情報の構造化:
• 企業向けのちゃんとしたツール(LlamaParseとか)を使って文書を解析して、請求書番号、日付、取引先情報、明細項目、支払条件みたいな関連データを抜き出すねん。
• 抽出したデータは後の処理がしやすいように整理しておくんや。
2. プロセス間での状態維持:
• システムは文書のコンテキスト(文脈情報)についての状態を保持してて、複数ステップのワークフローを通じて一貫性と関連性を保つようにしてるねん。
• 文書がいろんな処理段階を通過していく進捗も追跡するで。
3. 知識の検索:
• 外部のナレッジベース(LlamaCloudとか)やベクトルインデックスから関連する参照情報を取ってくるねん。
• リアルタイムで、そのドメイン専用のガイドラインを取得して、より良い意思決定ができるようにするんや。
4. エージェンティックなオーケストレーション(指揮・調整):
• 賢いエージェントたちがビジネスルールを適用して、マルチホップの推論(何段階もたどる推論)をやって、実際に使える提案を生成するねん。
• パーサー(解析器)、検索器、外部APIなんかのコンポーネントをスムーズに連携させるように指揮するんやで。
5. アクション可能な出力の生成:
• 出力は構造化されたフォーマットで、それぞれのユースケースに合わせた形で提示されるねん。
• 提案と抽出されたインサイト(洞察)は、簡潔で実際に行動に移せるレポートにまとめられるんやで。
---
## Page 28
[](/attach/b637a8052912693dd5bbde5e61e2ab9b7076bc2f57fabee16ca001dd0352d404_p028.png)
### 和訳
図23:エージェント型ドキュメントワークフロー(ADW)の全体像
[36]
**使用例:請求書の支払いワークフロー**
プロンプト:提出された請求書と、それに関連するベンダーとの契約条件をもとに、支払いの推奨レポートを作成してや。
システムの処理(ADWワークフロー):
1. まず請求書を解析して、請求書番号、日付、ベンダー情報、明細項目、支払い条件みたいな重要な情報を抜き出すねん。
2. 次に、該当するベンダーとの契約書を引っ張ってきて、支払い条件を確認したり、使える割引とかコンプライアンス要件がないかチェックするわけや。
3. ほんで、支払い推奨レポートを作成するんやけど、ここには元々の請求額、早期支払い割引がどれくらいあるか、予算への影響分析、それから戦略的にどう支払うべきかっていうアクションを含めるねん。
レスポンス:統合レスポンス:「請求書INV-2025-045、15,000ドルの処理が完了しましたで。2025年4月10日までに支払ったら2%の早期支払い割引が使えるから、支払額が14,700ドルに減るねん。あと、小計が10,000ドル超えてたから5%の大口注文割引も適用されてるで。早期支払いを承認して2%節約しつつ、今後のプロジェクトフェーズに向けて予算をしっかり確保しとくのがおすすめやな。」
**主な特徴とメリット**
• **状態の維持**:ドキュメントの文脈とワークフローがどの段階にあるかをちゃんと追跡してくれるから、プロセス全体で一貫性が保たれるねん。
• **マルチステップのオーケストレーション**:複数のコンポーネントとか外部ツールが絡む複雑なワークフローも、まとめて面倒見てくれるんや。
• **ドメイン特化型のインテリジェンス**:その業界専用のビジネスルールやガイドラインを適用して、めっちゃ的確な推奨を出してくれるで。
• **スケーラビリティ**:モジュール式で動的にエージェントを組み込めるから、大規模なドキュメント処理にも対応できるんや。
• **生産性の向上**:繰り返しの作業は自動化しつつ、人間の専門知識を活かした意思決定をサポートしてくれるっていう、ほんまにええとこ取りやねん。
28
---
## Page 29
[](/attach/b637a8052912693dd5bbde5e61e2ab9b7076bc2f57fabee16ca001dd0352d404_p029.png)
### 和訳
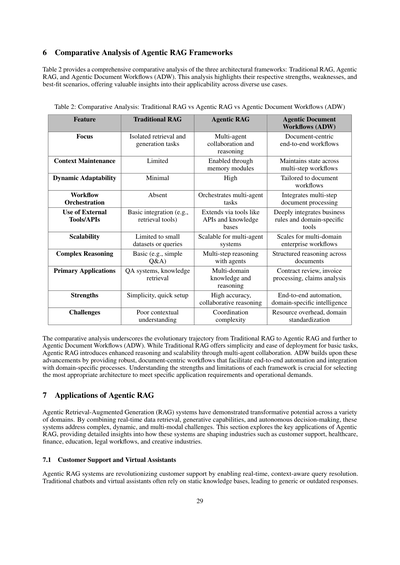
6 Agentic RAGフレームワークの比較分析
表2は3つのアーキテクチャフレームワーク(従来型RAG、Agentic RAG、Agentic Document Workflows(ADW))の包括的な比較分析を示してるねん。この分析では、それぞれの強み、弱み、どんな場面に向いてるかをハイライトしてて、いろんなユースケースでの適用可能性について、めっちゃ有益な洞察を提供してくれてるわけやな。
表2:比較分析 - 従来型RAG vs Agentic RAG vs Agentic Document Workflows(ADW)
| 特徴 | 従来型RAG | Agentic RAG | Agentic Document Workflows(ADW) |
|------|-----------|-------------|-----------------------------------|
| フォーカス | 単独の検索と生成タスク | マルチエージェントの協調と推論 | ドキュメント中心のエンドツーエンドワークフロー |
| コンテキスト維持 | 限定的 | メモリモジュールで実現 | 複数ステップのワークフロー全体で状態を維持 |
| 動的適応性 | ほぼない | 高い | ドキュメントワークフローに特化 |
| ワークフロー調整 | なし | マルチエージェントタスクを調整 | 複数ステップのドキュメント処理を統合 |
| 外部ツール/APIの利用 | 基本的な連携(検索ツールとか) | APIや知識ベースなどのツールで拡張 | ビジネスルールやドメイン特化ツールと深く統合 |
| スケーラビリティ | 小規模データセットやクエリに限定 | マルチエージェントシステムとしてスケール可能 | マルチドメインの企業向けワークフローにスケール |
| 複雑な推論 | 基本的(単純なQ&Aとか) | エージェントによる複数ステップ推論 | ドキュメント横断の構造化された推論 |
| 主な用途 | Q&Aシステム、知識検索 | マルチドメインの知識と推論 | 契約書レビュー、請求書処理、クレーム分析 |
| 強み | シンプル、すぐセットアップできる | 高精度、協調的推論 | エンドツーエンド自動化、ドメイン特化のインテリジェンス |
| 課題 | コンテキスト理解が弱い | 調整の複雑さ | リソースのオーバーヘッド、ドメインの標準化 |
この比較分析で見えてくるのは、従来型RAGからAgentic RAG、そしてさらにAgentic Document Workflows(ADW)への進化の流れやねん。従来型RAGは基本的なタスクにはシンプルでデプロイしやすいっていうメリットがあるんやけど、Agentic RAGはマルチエージェントの協調を通じて推論能力とスケーラビリティを強化してるわけ。ADWはこれらの進歩の上に構築されてて、堅牢でドキュメント中心のワークフローを提供して、エンドツーエンドの自動化とドメイン特化プロセスとの統合を実現してるねん。それぞれのフレームワークの強みと限界を理解することが、特定のアプリケーション要件や運用上のニーズに合った最適なアーキテクチャを選ぶためにめっちゃ重要なんやで。
7 Agentic RAGの応用分野
Agentic Retrieval-Augmented Generation(RAG)システムは、いろんな分野で変革をもたらす可能性を見せてるねん。リアルタイムのデータ検索、生成能力、そして自律的な意思決定を組み合わせることで、これらのシステムは複雑で動的でマルチモーダルな課題に対応してるわけや。このセクションでは、Agentic RAGの主要な応用分野を探って、カスタマーサポート、ヘルスケア、金融、教育、法務ワークフロー、クリエイティブ産業といった業界をどう変えていってるか、詳しく見ていくで。
7.1 カスタマーサポートとバーチャルアシスタント
Agentic RAGシステムは、リアルタイムでコンテキストを理解したクエリ解決を可能にすることで、カスタマーサポートに革命を起こしてるねん。なんでかっていうと、従来のチャットボットやバーチャルアシスタントは静的な知識ベースに頼ってることが多くて、そうするとありきたりな回答や古い情報の回答になってしまうからやねん。
---
## Page 30
[](/attach/b637a8052912693dd5bbde5e61e2ab9b7076bc2f57fabee16ca001dd0352d404_p030.png)
### 和訳
それに対して、Agentic RAGシステムは動的に一番関連性の高い情報を取ってきて、ユーザーの状況に合わせて適応して、パーソナライズされた回答を生成するねん。
**事例:Twitchの広告営業強化 [37]**
例えばな、TwitchがAmazon Bedrock上でRAGを使ったエージェント型ワークフローを活用して、広告営業をめっちゃ効率化したんよ。このシステムは広告主のデータとか、過去のキャンペーン実績、視聴者の属性データを動的に取ってきて、詳細な広告提案書を自動生成して、業務効率がごっつ上がったんやで。
**主なメリット:**
• **回答品質の向上**:パーソナライズされた、文脈を理解した返答でユーザーのエンゲージメントがアップするねん。
• **業務効率化**:複雑な問い合わせを自動化することで、人間のサポート担当者の負担を減らせるんや。
• **リアルタイムの適応力**:サービス障害とか料金改定みたいな、刻々と変わるデータをその場で取り込めるんやで。
**7.2 ヘルスケアと個別化医療**
医療の現場では、患者ごとのデータと最新の医学研究を統合することが、ちゃんとした意思決定にめっちゃ重要やねん。Agentic RAGシステムは、リアルタイムの診療ガイドライン、医学文献、患者の病歴を取得して、医師の診断や治療計画を支援できるんや。
**事例:患者症例サマリー [38]**
Agentic RAGシステムは患者の症例サマリー作成に活用されてるんよ。例えば、電子カルテ(EHR)と最新の医学文献を統合することで、医師がより早く、より的確な判断を下せるような包括的なサマリーを生成するんや。
**主なメリット:**
• **個別化されたケア**:一人ひとりの患者のニーズに合わせた推奨ができるねん。
• **時間効率**:関連する研究の検索がスムーズになって、医療従事者の貴重な時間を節約できるんや。
• **正確性**:最新のエビデンスと患者固有のパラメータに基づいた推奨ができるんやで。
**7.3 法務・契約分析**
Agentic RAGシステムは、法務のワークフローのあり方を根本から変えつつあって、迅速な文書分析と意思決定のためのツールを提供してるんや。
**事例:契約書レビュー [39]**
法務向けのAgentic RAGシステムは、契約書を分析して、重要な条項を抽出して、潜在的なリスクを特定できるんよ。セマンティック検索の機能と法務ナレッジグラフを組み合わせることで、めんどくさい契約書レビューのプロセスを自動化して、コンプライアンスを確保しながらリスクを軽減するんや。
**主なメリット:**
• **リスクの特定**:標準的な条件から外れてる条項を自動的にフラグ立てしてくれるねん。
• **効率性**:契約書レビューにかかる時間を大幅に削減できるんや。
• **スケーラビリティ**:大量の契約書を同時に処理できるんやで。
**7.4 金融・リスク分析**
Agentic RAGシステムは、投資判断、市場分析、リスク管理のためのリアルタイムな洞察を提供することで、金融業界を変革しつつあるんや。これらのシステムは、ライブデータストリーム、過去のトレンド、予測モデリングを統合して、実際に行動に移せるアウトプットを生成するねん。
**事例:自動車保険の保険金請求処理 [40]**
自動車保険では、Agentic RAGが保険金請求処理を自動化できるんよ。例えば、保険契約の詳細を取得して、事故データと組み合わせることで、規制要件へのコンプライアンスを確保しながら、保険金支払いの推奨を生成するんや。
**主なメリット:**
• **リアルタイム分析**:ライブの市場データに基づいたインサイトを提供してくれるんやで。
---
## Page 31
[](/attach/b637a8052912693dd5bbde5e61e2ab9b7076bc2f57fabee16ca001dd0352d404_p031.png)
### 和訳
**リスク軽減**: 予測分析と多段階推論を使って、起こりそうなリスクを見つけ出すねん。
**意思決定の強化**: 過去のデータとリアルタイムのデータを組み合わせて、めっちゃ総合的な戦略を立てられるようになるんや。
## 7.5 教育とパーソナライズ学習
教育分野もな、Agentic RAGシステムがめっちゃ活躍してるとこやねん。このシステムは、学習者の進み具合や好みに合わせて、説明とか教材、フィードバックを自動で作ってくれる「適応型学習」ってやつを実現してくれるんや。
**活用例: 研究論文の作成 [41]**
大学とかの高等教育でな、Agentic RAGが研究者のサポートに使われてて、いろんな文献から重要な発見をまとめてくれんねん。例えば「量子コンピューティングの最新の進歩って何?」って聞いたら、参考文献付きのコンパクトな要約を返してくれて、研究の質も効率もめっちゃ上がるってわけや。
**主なメリット:**
- **オーダーメイドの学習ルート**: 生徒一人ひとりのニーズや習熟度に合わせてコンテンツを変えてくれる。
- **ワクワクするやり取り**: インタラクティブな説明と個人に合わせたフィードバックがもらえる。
- **スケーラビリティ**: いろんな教育環境で、大規模に展開できるんや。
## 7.6 マルチモーダルワークフローにおけるグラフ強化型アプリケーション
グラフ強化型Agentic RAG(GEAR)っていうのはな、グラフ構造と検索の仕組みを組み合わせたやつで、いろんなデータソースがつながってる必要があるマルチモーダル(テキストも画像も動画も全部扱う)ワークフローでめっちゃ効果的やねん。
**活用例: 市場調査レポートの作成**
GEARを使うと、マーケティングキャンペーン用にテキストと画像と動画を組み合わせた資料が作れるんや。例えば「エコフレンドリーな製品の新しいトレンドって何?」って聞いたら、お客さんの好み、競合分析、マルチメディアコンテンツが全部入った詳細レポートを生成してくれるねん。
**主なメリット:**
- **マルチモーダル対応**: テキスト、画像、動画のデータを統合して、総合的なアウトプットが出せる。
- **クリエイティビティの向上**: マーケティングとかエンタメ向けに、革新的なアイデアや解決策を生み出してくれる。
- **動的な適応力**: 市場のトレンドやお客さんのニーズの変化に合わせて対応できる。
Agentic RAGシステムの活用範囲はほんまに幅広い業界に及んでて、その汎用性と変革の可能性がよう分かるわ。パーソナライズされたカスタマーサポートから適応型教育、グラフ強化型のマルチモーダルワークフローまで、複雑で動的な、知識をめっちゃ使う課題に対応してくれるんや。検索、生成、エージェント的な知能を統合することで、Agentic RAGシステムは次世代AIアプリケーションへの道を切り開いてるってことやな。
# 8 Agentic RAGのためのツールとフレームワーク
Agentic検索拡張生成(RAG)システムってのはな、検索と生成とエージェント的知能を組み合わせた、めっちゃ大きな進化なんや。従来のRAGの機能を拡張して、意思決定、クエリの再構成、適応型ワークフローを統合してるねん。以下のツールとフレームワークは、Agentic RAGシステムを開発するためのしっかりしたサポートを提供してて、現実世界のアプリケーションの複雑な要件に対応してくれるんや。
**主なツールとフレームワーク:**
- **LangChainとLangGraph**: LangChain [42] は、RAGパイプラインを構築するためのモジュール式コンポーネントを提供してて、リトリーバー(検索器)、ジェネレーター(生成器)、外部ツールをスムーズに統合できるんや。LangGraphはこれを補完するもんで、ループ、状態の保持、人間が介入できるインタラクションをサポートするグラフベースのワークフローを導入してて、エージェント型システムでの高度なオーケストレーションと自己修正機能を実現してくれるねん。
- **LlamaIndex**: LlamaIndex [43] の「Agentic Document Workflows(ADW)」は、ドキュメントの処理から検索、構造化された推論までをエンドツーエンドで自動化してくれるんや。メタエージェントっていうアーキテクチャを導入してて、サブエージェントがそれぞれ小さいドキュメントセットを管理して、トップレベルのエージェントを通じて連携することで、コンプライアンス分析とか文脈の理解みたいなタスクをこなすねん。
- **Hugging Face TransformersとQdrant**: Hugging Face [44] は埋め込みと生成タスク用の学習済みモデルを提供してて、Qdrant [45] は適応型ベクトル検索機能で検索ワークフローを強化してくれるんや。エージェントがスパースベクトルとデンスベクトルの手法を動的に切り替えることで、パフォーマンスを最適化できるようになってるねん。
---
## Page 32
[](/attach/b637a8052912693dd5bbde5e61e2ab9b7076bc2f57fabee16ca001dd0352d404_p032.png)
### 和訳
• CrewAIとAutoGen:こいつらはマルチエージェントアーキテクチャ、つまり複数のAIが協力して動く仕組みを推してるフレームワークやねん。CrewAI [46]は階層的な処理とか順番に処理する方式に対応してて、しっかりしたメモリシステムと外部ツールとの連携もバッチリや。AG2 [47](昔はAutoGen [48, 49]って呼ばれてた)は複数エージェントの連携がめっちゃ得意で、コード生成とかツール実行、意思決定のサポートがほんまに充実してるで。
• OpenAI Swarmフレームワーク:これは教育目的で作られたフレームワークで、使いやすくて軽量なマルチエージェントのオーケストレーション(複数のAIをうまく調整する仕組みな)ができるんや [50]。エージェントが自律的に動けることと、ちゃんと構造化された協力体制を大事にしてるねん。
• Agentic RAG with Vertex AI:Googleが開発したVertex AI [51]は、Agentic RAG(エージェント型の検索拡張生成)とめっちゃスムーズに連携できるんや。機械学習モデルを作って、デプロイして、スケールさせるためのプラットフォームで、高度なAI機能を活用して、文脈をちゃんと理解した検索と意思決定のワークフローを実現できるで。
• Semantic Kernel:Semantic Kernel [52, 53]はMicrosoftが作ったオープンソースのSDKで、大規模言語モデル(LLM)をアプリに組み込めるようにしてくれるんや。エージェント的なパターンに対応してて、自然言語の理解とかタスクの自動化、意思決定ができる自律型AIエージェントを作れるねん。ServiceNowのP1インシデント管理みたいな場面で使われてて、リアルタイムの協力作業とかタスクの自動実行、文脈に合った情報の取得をスムーズにやってくれるで。
• Amazon Bedrock for Agentic RAG:Amazon Bedrock [37]はAgentic RAGのワークフローを実装するためのしっかりしたプラットフォームを提供してるんや。
• IBM WatsonとAgentic RAG:IBMのwatsonx.ai [54]はAgentic RAGシステムの構築をサポートしてて、Granite-3-8B-Instructモデルを使って外部情報を統合しながら複雑な質問に答えて、回答の精度を上げる例なんかがあるで。
• Neo4jとベクトルデータベース:Neo4jは有名なオープンソースのグラフデータベースで、複雑な関係性とかセマンティッククエリ(意味を理解した検索のことな)を扱うのがめっちゃ得意やねん。Neo4jと一緒に、WeaviateとかPinecone、Milvus、Qdrantみたいなベクトルデータベースが効率的な類似検索と情報取得の機能を提供してて、高性能なAgentic RAGワークフローの基盤になってるんや。
9 ベンチマークとデータセット
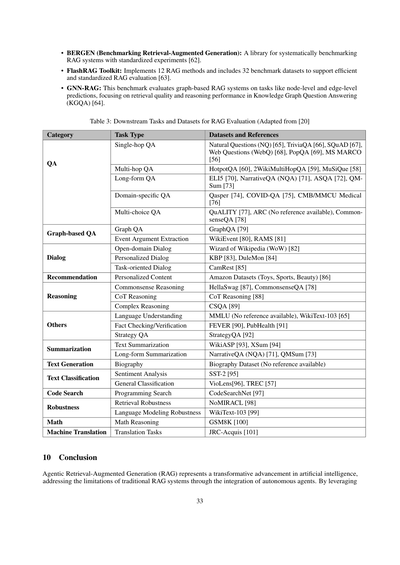
今あるベンチマークとデータセットは、RAG(検索拡張生成)システムの評価についてめっちゃ貴重な知見を提供してくれてるんや。エージェント型とかグラフベースの拡張を含むやつもあるで。RAG専用に設計されたものもあれば、いろんなシナリオで検索・推論・生成の能力をテストするために応用されてるものもあるねん。データセットはRAGシステムの検索、推論、生成の各コンポーネントをテストするのにめっちゃ重要や。表3ではRAG評価のための下流タスクに基づいた主要なデータセットについて説明してるで。
ベンチマークは構造化されたタスクと評価指標を提供することで、RAGシステムの評価を標準化する上でほんまに大事な役割を果たしてるんや。以下のベンチマークが特に関連性が高いで:
• BEIR(Benchmarking Information Retrieval):埋め込みモデルをいろんな情報検索タスクで評価するための汎用的なベンチマークで、バイオインフォマティクスとか金融、質問応答みたいな多様なドメインにまたがる17個のデータセットを含んでるねん [55]。
• MS MARCO(Microsoft Machine Reading Comprehension):パッセージランキング(文章の順位付け)と質問応答に特化してて、RAGシステムの密な検索タスクでめっちゃよく使われてるベンチマークや [56]。
• TREC(Text REtrieval Conference, Deep Learning Track):パッセージとドキュメントの検索用データセットを提供してて、検索パイプラインにおけるランキングモデルの品質を重視してるんや [57]。
• MuSiQue(Multihop Sequential Questioning):複数の文書をまたいだマルチホップ推論(何段階もの情報をつなげて考えること)のためのベンチマークで、バラバラの文脈から情報を取得して統合することの重要性を強調してるで [58]。
• 2WikiMultihopQA:2つのWikipedia記事をまたいだマルチホップQAタスク用に設計されたデータセットで、複数の情報源の知識をつなげる能力に焦点を当ててるねん [59]。
• AgentG(Agentic RAG for Knowledge Fusion):エージェント型RAGタスク専用に作られたベンチマークで、複数の知識ベースをまたいだ動的な情報統合を評価するんや [8]。
• HotpotQA:つながりのある文脈から検索と推論が必要なマルチホップQAベンチマークで、複雑なRAGワークフローの評価にめっちゃ向いてるで [60]。
• RAGBench:産業ドメインにまたがる10万件の例を含む大規模で説明可能なベンチマークで、実用的なRAG評価指標のためのTRACe評価フレームワークがついてるんや [61]。
---
## Page 33
[](/attach/b637a8052912693dd5bbde5e61e2ab9b7076bc2f57fabee16ca001dd0352d404_p033.png)
### 和訳
• BERGEN(Retrieval-Augmented Generationのベンチマーキング):RAGシステムを標準化された実験で体系的にベンチマークするためのライブラリやねん[62]。
• FlashRAGツールキット:12種類のRAG手法を実装してて、32個のベンチマークデータセットが入ってるから、効率的で標準化されたRAG評価ができるようになってるで[63]。
• GNN-RAG:グラフベースのRAGシステムを評価するベンチマークやねん。ノードレベルとかエッジレベルの予測タスクで評価して、特にナレッジグラフ質問応答(KGQA)における検索の質と推論性能に焦点当ててるんやで[64]。
表3:RAG評価のための下流タスクとデータセット([20]より改変)
| カテゴリ | タスクの種類 | データセットと参考文献 |
|---------|------------|---------------------|
| 質問応答 | シングルホップQA | Natural Questions (NQ) [65], TriviaQA [66], SQuAD [67], Web Questions (WebQ) [68], PopQA [69], MS MARCO [56] |
| | マルチホップQA | HotpotQA [60], 2WikiMultiHopQA [59], MuSiQue [58] |
| | 長文形式QA | ELI5 [70], NarrativeQA (NQA) [71], ASQA [72], QMSum [73] |
| | ドメイン特化QA | Qasper [74], COVID-QA [75], CMB/MMCU Medical [76] |
| | 多肢選択QA | QuALITY [77], ARC(参考文献なし), CommonsenseQA [78] |
| グラフベースQA | グラフQA | GraphQA [79] |
| | イベント引数抽出 | WikiEvent [80], RAMS [81] |
| 対話 | オープンドメイン対話 | Wizard of Wikipedia (WoW) [82] |
| | パーソナライズド対話 | KBP [83], DuleMon [84] |
| | タスク指向対話 | CamRest [85] |
| レコメンデーション | パーソナライズドコンテンツ | Amazon Datasets (Toys, Sports, Beauty) [86] |
| 推論 | 常識推論 | HellaSwag [87], CommonsenseQA [78] |
| | CoT推論 | CoT Reasoning [88] |
| | 複雑な推論 | CSQA [89] |
| その他 | 言語理解 | MMLU(参考文献なし), WikiText-103 [65] |
| | 事実確認/検証 | FEVER [90], PubHealth [91] |
| | 戦略QA | StrategyQA [92] |
| 要約 | テキスト要約 | WikiASP [93], XSum [94] |
| | 長文形式要約 | NarrativeQA (NQA) [71], QMSum [73] |
| テキスト生成 | 伝記 | Biography Dataset(参考文献なし) |
| テキスト分類 | 感情分析 | SST-2 [95] |
| | 一般分類 | VioLens[96], TREC [57] |
| コード検索 | プログラミング検索 | CodeSearchNet [97] |
| ロバスト性 | 検索のロバスト性 | NoMIRACL [98] |
| | 言語モデリングのロバスト性 | WikiText-103 [99] |
| 数学 | 数学推論 | GSM8K [100] |
| 機械翻訳 | 翻訳タスク | JRC-Acquis [101] |
## 10 結論
エージェンティックRAG(Retrieval-Augmented Generation)っていうのは、AIにおけるめっちゃ革新的な進歩やねん。なんでかっていうと、従来のRAGシステムの限界を、自律型エージェントを組み込むことで解決してるからやで。
---
## Page 34
[](/attach/b637a8052912693dd5bbde5e61e2ab9b7076bc2f57fabee16ca001dd0352d404_p034.png)
### 和訳
エージェント的な知能っちゅうもんを使うことで、こういうシステムには動的な意思決定とか、繰り返し考えるやつとか、みんなで協力して仕事するワークフローみたいな能力が加わって、複雑な現実世界の問題にめっちゃ正確に、しかも柔軟に対応できるようになってきてんねん。
このサーベイでは、RAGシステムがどう進化してきたかを探ってきたわ。最初の実装から、モジュラーRAGみたいな進んだパラダイムまで、それぞれの貢献と限界を見てきたで。エージェントをRAGのパイプラインに組み込むっていうのが重要な発展になってて、その結果生まれたのがエージェンティックRAGシステムやねん。これのおかげで、固定的なワークフローとか、文脈への適応力が限られてた問題を克服できるようになったんや。医療、金融、教育、クリエイティブ産業とかいろんな分野での応用を見ると、このシステムの変革的なポテンシャルがようわかるで。パーソナライズされた、リアルタイムで、文脈をちゃんとわかった解決策を提供できるっちゅうことを示してくれてんねん。
とはいえ、エージェンティックRAGシステムにはまだ課題があって、もっと研究とイノベーションが必要やで。マルチエージェントアーキテクチャでの調整の複雑さ、スケーラビリティ、レイテンシの問題、それから倫理的な考慮事項なんかは、しっかりした責任ある展開のために解決せなあかん。あと、エージェント的な能力を評価するための専門的なベンチマークやデータセットがないっていうのも大きなハードルやな。マルチエージェントの協調とか動的な適応性みたいな、エージェンティックRAG特有の側面を捉える評価手法を開発することが、この分野を前に進めるのにめっちゃ重要になってくるで。
これからを見据えると、検索拡張生成とエージェント的知能の融合は、動的で複雑な環境におけるAIの役割を再定義する可能性を秘めてんねん。これらの課題に取り組んで将来の方向性を探ることで、研究者や実務家はエージェンティックRAGシステムの完全なポテンシャルを解き放って、様々な産業やドメインにおける変革的な応用への道を切り開けるはずや。AIシステムが進化し続ける中で、エージェンティックRAGは、急速に変化する世界の要求に応える適応的で文脈認識能力のある、インパクトのあるソリューションを作るための礎石として立っとるんやで。
参考文献
[1] Shervin Minaee, Tomas Mikolov, Narjes Nikzad, Meysam Chenaghlu, Richard Socher, Xavier Amatriain, and Jianfeng Gao. Large language models: A survey, 2024.
[2] Aditi Singh. Exploring language models: A comprehensive survey and analysis. In 2023 International Conference on Research Methodologies in Knowledge Management, Artificial Intelligence and Telecommunication Engineering (RMKMATE), pages 1–4, 2023.
[3] Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie, and Ji-Rong Wen. A survey of large language models, 2024.
[4] Sumit Kumar Dam, Choong Seon Hong, Yu Qiao, and Chaoning Zhang. A complete survey on llm-based ai chatbots, 2024.
[5] Aditi Singh. A survey of ai text-to-image and ai text-to-video generators. In 2023 4th International Conference on Artificial Intelligence, Robotics and Control (AIRC), pages 32–36, 2023.
[6] Aditi Singh, Abul Ehtesham, Gaurav Kumar Gupta, Nikhil Kumar Chatta, Saket Kumar, and Tala Talaei Khoei. Exploring prompt engineering: A systematic review with swot analysis, 2024.
[7] Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, and Ting Liu. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. ACM Transactions on Information Systems, November 2024.
[8] Meng-Chieh Lee, Qi Zhu, Costas Mavromatis, Zhen Han, Soji Adeshina, Vassilis N. Ioannidis, Huzefa Rangwala, and Christos Faloutsos. Agent-g: An agentic framework for graph retrieval augmented generation, 2024.
[9] Penghao Zhao, Hailin Zhang, Qinhan Yu, Zhengren Wang, Yunteng Geng, Fangcheng Fu, Ling Yang, Wentao Zhang, Jie Jiang, and Bin Cui. Retrieval-augmented generation for ai-generated content: A survey, 2024.
[10] Zhengbao Jiang, Frank F. Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. Active retrieval augmented generation, 2023.
[11] Yikun Han, Chunjiang Liu, and Pengfei Wang. A comprehensive survey on vector database: Storage and retrieval technique, challenge, 2023.
[12] Anthropic. Building effective agents, 2024. https://www.anthropic.com/research/building-effective-agents. Accessed: February 2, 2025.
[13] LangChain. Langgraph workflows tutorial, 2025. https://langchain-ai.github.io/langgraph/tutorials/workflows/. Accessed: February 2, 2025.
34
---
## Page 35
[](/attach/b637a8052912693dd5bbde5e61e2ab9b7076bc2f57fabee16ca001dd0352d404_p035.png)
### 和訳
[14] Ravuru、Sakhinana、Runkanaの3人組が時系列分析のための「エージェンティック検索拡張生成」っていう研究を2024年に出しとんねん。
[15] Huang先生とChang先生が2023年に「大規模言語モデルで推論できるようになるんか?」っていうテーマでサーベイ論文書いてはるわ。
[16] Peng先生らが2024年に「グラフ検索拡張生成」のサーベイを出してん。グラフっていうのは、データ同士のつながりを網の目みたいに表現したやつやな。それをRAGに組み込もうって話やねん。
[17] Singh先生たちが2024年のIEEEの学会で発表した研究やねんけど、LangChainっていうツールを使って大規模言語モデルでメンタルヘルスのケアを革命的に変えようって話やねん。めっちゃ画期的やで。
[18] Gupta先生らが2025年のAI誌に出した「デジタル診断」の論文。大規模言語モデルで一般的な病気の症状を認識できるポテンシャルについて書いてはるわ。
[19] またSingh先生たちやねんけど、2025年にシンガポールのSpringerから出た本の中で、教育現場での生成AIの責任ある使い方を促す報酬ベースの学習アプローチについて書いてはんねん。要は「ちゃんと使おうや」って話やな。
[20] Gao先生らが2024年に出した「大規模言語モデルのための検索拡張生成」のサーベイ論文。RAGの全体像をまとめてくれてるやつやで。
[21] Karpukhin先生たちが2020年に出した「密ベクトル検索」の論文。オープンドメインの質問応答、つまりなんでも聞いてOKな質問に答えるシステムのための技術やねん。
[22] Zhang先生らが2024年に出した「大規模言語モデルベースのエージェントの記憶メカニズム」のサーベイ。AIエージェントがどうやって物事を覚えとくかって話やな。
[23] Gou先生たちの2024年の「CRITIC」っていう研究。大規模言語モデルがツールを使いながら自分で自分を批評して修正できるっていうやつやねん。自己修正できるってすごない?
[24] Huang先生らが2024年に出した「LLMエージェントの計画立案を理解する」サーベイ。AIがどうやって物事を計画するかを調べた研究やで。
[25] Singh先生たちが2024年のIEEE World AI IoT Congressで発表した論文。大規模言語モデルでエージェンティックなワークフローパターンを使ってAIシステムを強化しようって内容やねん。
[26] DeepLearning.AIが2024年に出した記事で「エージェントがどうやってLLMの性能を向上させるか」について解説してはるわ。2025年1月13日にアクセスしたURLも載ってるで。
[27] Madaan先生らが2023年に出した「Self-Refine」の研究。自分自身でフィードバックしながら繰り返し改善していくっていう方法やねん。めっちゃ賢いやろ。
[28] Shinn先生たちの2023年の「Reflexion」論文。言語エージェントに言葉による強化学習をさせるっていう研究やで。失敗から言葉で学ぶって面白いアプローチやな。
[29] Guo先生らが2024年に出した大規模言語モデルベースのマルチエージェントのサーベイ。進展と課題についてまとめてくれてるわ。複数のAIが協力する話やねん。
[30] Weaviateのブログで「エージェンティックRAGって何やねん?」を解説してる記事。2025年1月14日にアクセスしたURLやで。
[31] Yan先生らが2024年に出した「Corrective Retrieval Augmented Generation」の研究。検索結果を修正しながらRAGするっていう賢いアプローチやねん。
[32] LangGraphのCRAGチュートリアル。文脈化された検索拡張生成のやり方を教えてくれるページやで。2025年1月14日にアクセス。
[33] Jeong先生たちが2024年に出した「Adaptive-RAG」の研究。質問の複雑さに応じて検索拡張型の大規模言語モデルを適応させる方法を学習するっていう話やねん。簡単な質問と難しい質問で対応変えるってことや。
[34] LangGraphのAdaptive RAGチュートリアル。適応型RAGのやり方を解説してるページ。2025年1月14日にアクセスしたで。
[35] Shen先生らが2024年に出した「GEAR」の研究。Graph-Enhanced Agent for Retrieval-Augmented Generationの略で、グラフで強化したエージェントでRAGするって話やねん。
[36] LlamaIndexが2025年に出したブログ記事「エージェンティック文書ワークフローの紹介」。2025年1月13日にアクセス。文書を扱うワークフローをAIエージェントでやろうって内容やで。
---
## Page 36
[](/attach/b637a8052912693dd5bbde5e61e2ab9b7076bc2f57fabee16ca001dd0352d404_p036.png)
### 和訳
[翻訳エラー: 実行エラー: [Errno 2] No such file or directory: 'claude']
---
## Page 37
[](/attach/b637a8052912693dd5bbde5e61e2ab9b7076bc2f57fabee16ca001dd0352d404_p037.png)
### 和訳
[58] Harsh Trivediさんたち。Musique:シングルホップの質問を組み合わせてマルチホップの質問作るで、2022年。
→ これ何かっていうとな、簡単な質問をいくつか組み合わせて、複雑な質問を作るっていうデータセットやねん。
[59] Xanh Hoさんたち。推論のステップをちゃんと評価できるマルチホップQAデータセット作ったで、2020年。
→ 要は、AIが答えにたどり着くまでの考える過程もしっかりチェックできるようにしたやつやな。
[60] Zhilin Yangさんたち。HotpotQA:いろんなパターンがあって、なんでその答えになったか説明できるマルチホップ質問応答のデータセットや、2018年。
→ めっちゃ多様な質問があって、しかも「なんでそうなるん?」って説明もできるのがポイントやで。
[61] Robert Frielさんたち。RAGBench:検索して文章生成するシステム(RAG)のベンチマークで、なんでその結果になったか説明もできるやつ、2024年。
[62] David Rauさんたち。Bergen:RAGのベンチマーク用ライブラリやで、2024年。
→ RAGシステムを比較評価するための便利なツールやねん。
[63] Jiajie Jinさんたち。FlashRAG:RAG研究を効率よくやるためのモジュール式ツールキット、2024年。
→ 部品みたいに組み合わせて使えるから、研究しやすいんやで。
[64] Costas Mavromatisさんたち。GNN-RAG:大規模言語モデルの推論にグラフニューラルネットワークを使った検索するやつ、2024年。
→ グラフ(ネットワーク構造)を使って情報探してくるっていう、ちょっとおしゃれなアプローチやな。
[65] Tom Kwiatkowskiさんたち。Natural Questions:質問応答研究のためのベンチマーク。Transactions of the Association for Computational Linguistics、7巻452-466ページ、2019年。
→ Googleの検索クエリから作った、めっちゃリアルな質問のデータセットやねん。
[66] Mandar Joshiさんたち。TriviaQA:読解力テストのための大規模なデータセットで、遠隔教師あり学習で作ったやつ、2017年。
→ トリビアクイズみたいな質問がいっぱい入ってるで。
[67] Pranav Rajpurkarさんたち。SQuAD:テキスト読解のための10万問以上の質問集、2016年。
→ これ、めっちゃ有名なやつやで。読解力を測るスタンダードになってるねん。
[68] Jonathan Berantさんたち。Freebaseで質問と答えのペアから意味解析するやつ。自然言語処理の実証的手法に関する会議、2013年。
→ 知識ベース(Freebase)を使って、質問の意味を理解して答え見つけるっていう研究やな。
[69] Alex Mallenさんたち。言語モデルを信用したらあかん時:パラメトリックメモリとノンパラメトリックメモリの効果を調べたで。ACL会議の論文集(長い論文の部)、9802-9822ページ、2023年7月、トロント。
→ AIが自分の頭の中(パラメータ)に持ってる知識と、外から持ってくる知識、どっちがええか調べたんやで。ほんまに大事な研究やねん。
[70] Angela Fanさんたち。ELI5:長文で答える質問応答、2019年。
→ 「5歳児に説明するように(Explain Like I'm 5)」っていう名前で、詳しく説明する回答を生成するデータセットやねん。
[71] Tomáš Kočiskýさんたち。NarrativeQA読解チャレンジ、2017年。
→ 本や映画のあらすじを読んで質問に答えるっていう、物語理解のデータセットやで。
[72] Ivan Stelmakhさんたち。ASQA:事実を聞く質問に長文で答えるやつ、2023年。
→ 短い答えじゃなくて、ちゃんと説明しながら答えるっていうタスクやねん。
[73] Ming Zhongさんたち。QMSum:クエリベースで複数ドメインの会議を要約する新しいベンチマーク、5905-5921ページ、2021年6月。
→ 会議の内容を「この部分について要約して」って聞いたら答えてくれるようなタスクやで。
[74] Pradeep Dasigiさんたち。研究論文に基づいた情報探索型の質問と回答のデータセット。NAACL-HLT 2021の論文集、4599-4610ページ、2021年6月。
→ 論文読んで「これどういう意味?」って聞くような質問に答えるデータセットやねん。研究者には嬉しいやつやで。
[75] Timo Möllerさんたち。COVID-QA:COVID-19についての質問応答データセット。ACL 2020のCOVID-19自然言語処理ワークショップ、2020年。
→ コロナ禍で作られた、コロナに関する質問に答えるためのデータセットやな。
[76] Xidong Wangさんたち。CMB:中国語の総合的な医療ベンチマーク、2024年。
→ 中国語で医療の質問に答えられるかテストするやつやで。
[77] Richard Yuanzhe Pangさんたち。QuALITY:長い文章を入力にした質問応答、できるで!、2022年。
→ 名前が「Quality」と「Yes!」をかけてるんやな。めっちゃ長い文章読んで質問に答えるタスクやで。
---
## Page 38
[](/attach/b637a8052912693dd5bbde5e61e2ab9b7076bc2f57fabee16ca001dd0352d404_p038.png)
### 和訳
[78] Alon Talmorさんら。CommonsenseQA:常識的な知識を問う質問応答チャレンジやねん。2019年6月にミネアポリスで開催された北米計算言語学会の会議論文集、4149〜4158ページに載ってるで。
[79] Xiaoxin Heさんら。G-retriever:テキストグラフの理解と質問応答のための検索拡張生成についての研究やねん、2024年。
[80] Sha Liさんら。条件付き生成による文書レベルのイベント引数抽出、2021年。これ何かっていうと、文書の中から「誰が」「何を」「どこで」みたいなイベントの要素を抜き出す技術やな。
[81] Seth Ebnerさんら。複数文にまたがる引数リンキング、2020年。一文だけやなくて、いくつもの文をまたいで情報をつなげる研究やで。
[82] Emily Dinanさんら。Wizard of Wikipedia:知識でパワーアップした対話エージェント、2019年。Wikipediaの知識使ってめっちゃ賢く会話できるシステムやねん。
[83] Hongru Wangさんら。大規模言語モデルをソースプランナーとして使う、個人に合わせた知識ベース対話の研究、2023年。ユーザーごとにカスタマイズされた会話ができるようになるってわけや。
[84] Xinchao Xuさんら。久しぶりやな!長期的なペルソナ記憶を持つオープンドメイン対話、2022年。AIが「この人前にこんなこと言うてたな」って覚えてて、それに基づいて話してくれるシステムやねん。
[85] Tsung-Hsien Wenさんら。ニューラル対話システムにおける条件付き生成とスナップショット学習。2016年11月にテキサス州オースティンで開催されたEMNLP会議の論文集、2153〜2162ページや。
[86] Ruining Heさんら。アップダウン:ワンクラス協調フィルタリングでファッショントレンドの視覚的な変化をモデル化する研究。2016年のWWW会議、507〜517ページやで。ファッションの流行がどう変わっていくか、AIで追跡する研究やな。
[87] Rowan Zellersさんら。HellaSwag:機械はほんまにあなたの文を完成させられるんか?2019年7月にイタリアのフィレンツェで開催されたACL会議の論文集、4791〜4800ページ。文の続きを予測させて、AIの常識的な理解力をテストするベンチマークやねん。
[88] Seungone Kimさんら。The CoT Collection:Chain-of-Thought(思考の連鎖)でファインチューニングして、言語モデルのゼロショット・フューショット学習を改善する研究、2023年。要は「考える過程」を学習させたら賢くなるってことやな。
[89] Amrita Sahaさんら。複雑な連続質問応答:知識グラフと連携した質問応答ペアで会話できるようになるための学習、2018年。
[90] James Thorneさんら。FEVER:事実抽出と検証のための大規模データセット。2018年6月にニューオーリンズで開催されたNAACL-HLT会議の論文集、809〜819ページやで。これめっちゃ有名なファクトチェック用のデータセットやねん。
[91] Neema Kotonyaさんら。公衆衛生に関する主張の説明可能な自動ファクトチェック、2020年。健康関連の情報が正しいかどうか、AIが根拠付きで判定してくれる研究やな。
[92] Mor Gevaさんら。アリストテレスはノートパソコン使ってたん?暗黙の推論戦略を必要とする質問応答ベンチマーク、2021年。ほんまにおもろいタイトルやけど、直接書いてないことを推論できるかテストする研究やねん。
[93] Hiroaki Hayashiさんら。WikiAsp:マルチドメインのアスペクトベース要約のためのデータセット、2020年。いろんな分野の文書を、観点ごとにまとめる研究やで。
[94] Shashi Narayanさんら。詳細はええから要約だけちょうだい!トピックを意識した畳み込みニューラルネットワークによる超要約、2018年。めっちゃ短くまとめる技術の研究やな。
[95] Richard Socherさんら。感情ツリーバンク上の意味的構成性のための再帰的深層モデル。2013年10月にシアトルで開催されたEMNLP会議の論文集、1631〜1642ページ。文の感情を細かく分析できるモデルとデータセットを作った研究やで。
---
## Page 39
[](/attach/b637a8052912693dd5bbde5e61e2ab9b7076bc2f57fabee16ca001dd0352d404_p039.png)
### 和訳
[96] Sourav Sahaさんらの研究やねんけど、Vio-lensっていう新しいデータセット作ったんよ。これ何かっていうと、SNSの投稿で「コミュニティ間の暴力」につながるようなやつを集めてアノテーション(ラベル付け)したもんやねん。いろんな形の暴力に発展するパターンがあるから、それを分類して評価もしてるで。2023年12月にシンガポールで開催されたバングラ語処理ワークショップ(BLP-2023)の論文集72〜84ページに載っとるわ。
[97] Hamel Husainさんらが2020年に出したCodeSearchNetチャレンジの話やで。これ、「意味的なコード検索」がどれくらいイケてるか評価するためのもんやねん。つまり、プログラムのコードを意味で探す技術の実力テストみたいなもんや。
[98] Nandan Thakurさんらの2024年の研究で、タイトルがめっちゃ面白いねん。「自分がわからんことをわかってる」っていう。何の話かっていうと、多言語の関連性評価データセット作って、RAG(検索して情報持ってきてから回答生成するやつ)をもっと頑丈にするためのもんやねん。AIが「これ知らんわ」ってちゃんと言えるようにする研究やな。
[99] Stephen Merityさんらの2016年の論文で、Pointer Sentinel Mixture Modelsっていう手法の提案やで。ポインターとセンチネルを混ぜたモデルやねん。
[100] Karl Cobbeさんらの2021年の研究やけど、これめっちゃ大事なやつやで。数学の文章問題を解くために「検証器(verifier)」を訓練するっていう話やねん。なんでかっていうと、AIに答え出させるだけじゃなくて、その答えが合ってるかチェックする仕組みも一緒に育てたら精度上がるやろって発想やな。
[101] Ralf Steinbergerさんらが2006年5月にイタリアのジェノバで発表した研究やで。JRC-Acquisっていう多言語の対訳コーパス(翻訳文のペアを大量に集めたもん)を作ったんや。これがほんまにすごくて、20言語以上が揃ってて、全部きれいに対応付けされてんねん。言語資源評価の国際会議(LREC'06)で発表されたやつやで。
---
![]()
1 / 1
100%