---
## Page 1
[](/attach/aad405958c8b29883ce2a1f90e6b2e95208226d0a9d4ee37fb94e1a62fd01be1_p001.png)
### 和訳
FineInstructions: 事前学習レベルまで合成インストラクションをスケールアップさせる話やで
Ajay Patel 1 Colin Raffel 2 3 4 Chris Callison-Burch 1
## 要約
なあなあ、ちょっと聞いてや。大規模言語モデル(LLM)ってあるやん?あれな、教師ありの学習データが限られてるから、普通は「次の単語を予測する」っていう自己教師あり学習で、めっちゃ大量の構造化されてないテキストデータを使って事前学習するんよ。ほんで、できあがったモデルをユーザーさんにとって使いやすくするために、「インストラクションチューニング」っていうのをやるねん。これは指示と回答のペアからなる教師ありデータを使うんやけど、量的にはかなり少ないんよな。
この教師ありデータの少なさを克服するために、わいらはインターネット規模の事前学習文書に入ってる知識を、何十億っていう合成的な指示と回答のペアに変換する手法を提案するで!できあがったデータセット「FineInstructions」は、実際のユーザーが書いたクエリやプロンプトから作った約1800万個のインストラクションテンプレートを使うてんねん。これらのテンプレートを、構造化されてない事前学習コーパスの人間が書いたソース文書とマッチングして、インスタンス化するんや。
このスケールで「教師あり」の合成学習データを生成できたら、LLMをゼロからインストラクションチューニングの目的関数だけで事前学習できるようになるんよ。これ、めっちゃ大事やねん。なんでかっていうと、LLMの想定される使われ方(ユーザーのプロンプトに応答する)とめっちゃ近い分布になるからな。
わいらがトークン数を揃えた比較実験をしたところ、FineInstructionsで事前学習すると、標準的な事前学習や他の提案されてる合成事前学習手法よりも、自由形式の回答品質を測るベンチマークでええ結果が出たで!リソースはhttps://huggingface.co/fineinstructionsにあるから見てや。
## 1. はじめに
自己教師あり事前学習の時ってな、LLMは大量のテキストデータを使って次トークン予測みたいな言語モデリングタスクで学習するやん。この学習段階が、モデルが知識のほとんどを獲得するところで、計算資源もリソースも時間も一番かかるとこなんよ(Raffel et al., 2020; Brown et al., 2020; Kaplan et al., 2020)。
事前学習されたLLMはその後、指示に従う能力を高めるために、比較的少量の教師あり指示-回答ペアでさらに学習されるねん。これがインストラクションチューニングって呼ばれるやつな(Ouyang et al., 2022; Wei et al., 2021; Sanh et al., 2021; Mishra et al., 2022)。
でもな、既存のインストラクションチューニングデータセットにはいろんな問題があんねん。多くは数千例くらいしかなくてめっちゃ少ないし(Conover et al., 2023; Rajani et al., 2023)。他のやつは狭くて現実的やなくて、学術的なNLPタスクをインストラクションチューニング形式に変換しただけで、タスクテンプレートの数も比較的少ないんよ(Sanh et al., 2021; Wei et al., 2021; Mishra et al., 2022)。最先端の言語モデルを使ってもっと多様な指示-回答ペアを大量生成する手法もあるけど、これは結局、蒸留を通じてそのモデルを表面的に真似するだけになるってことがわかってるんや(Taori et al., 2023; Mukherjee et al., 2023; Honovich et al., 2022; Gudibande et al., 2023)。
こういう問題があるから、インストラクションチューニング段階は、モデルが指示に従うことと回答スタイルを学ぶのに主に役立つくらいに限られてしまうんよ。結果として、自己教師あり事前学習の段階がモデルの重みに知識のほとんどをエンコードする責任を負うことになるねん(Zhou et al., 2023; Ghosh et al., 2024; Hewitt et al., 2024)。
知識をエンコードするだけやなくて、事前学習コーパスは、事前学習文書に現れるタスクの例からの間接的な監督を通じて、モデルがタスクを実行するのを助けることも示されてるんや(Chen et al., 2024)。ただな、事前学習文書の次トークンを予測することが、モデルがそういう能力を吸収する最も最適で効率的な方法かどうかは、まだようわからんのよ。最近提案された合成的な...
---
## Page 2
[](/attach/aad405958c8b29883ce2a1f90e6b2e95208226d0a9d4ee37fb94e1a62fd01be1_p002.png)
### 和訳
# FineInstructions: 合成指示を事前学習スケールまで拡大するで
**図2. FineInstructionsのパイプライン。多様で事前学習スケールの合成「指示-回答」ペアを効率よく生成する仕組みやねん。**
---
言い換えや変換のパイプライン(Mainiらのやつとか、Suらの2024年の研究とか)見てみると、もともとの事前学習用ドキュメントを別のフォーマットに変換したら、事前学習中の知識吸収効率がめっちゃ上がるし、学習したモデルの性能や能力もアップするってことがわかっとるんよ。
この論文ではな、**FineInstructions**っていう手法を紹介するで(図2に図解しとるから見てみて)。これ何かっていうと、事前学習用のテキストコーパスを、多様でリアルな「指示と回答」のペアの大規模コレクションに変換するやつやねん。うちらのパイプラインでは、ドキュメントに対して「このドキュメントの知識について、ユーザーが聞きそうな指示や質問」をペアリングして、ほんでそのドキュメントに基づいた回答やレスポンスを抽出するんよ。
指示の作り方やけど、実際のユーザーが書いた約1800万件のクエリをテンプレート化して、それをドキュメントごとに具体化していくねん。事前学習用ドキュメントをこういう合成の指示と回答ペアに変換することで、事前学習スケールで効果的に教師ありの指示チューニングができるようになるわけや。
なんでこういうデータの再構成がええかっていうとな、これまでの研究でマルチタスクデータセットとか「指示-回答」フォーマットが汎化能力と指示に従う能力を引き出すって示されとるからやねん(Raffelらの2020年とか、Ouyangらの2022年とか、Hewittらの2024年の研究な)。
あとな、こういう再構成をすると、事前学習の計算リソースを低品質なノイズ(フッターとかヘッダーとか、あんまり教育的やない部分とかな)に無駄遣いせんで済むし、もっと高品質で教育的なドキュメントの部分にちゃんと使えるようになるんよ。ほんで最後に、ユーザーが実際に使う時の期待される使い方に、事前学習データをもっと近づけられるっていうメリットもあるで。
結局のところ、うちらの手法で生成した合成の「指示-回答」ペアは、これまでのアプローチと比べて多様性、複雑さ、品質の面でめっちゃ違うってことを実証したんや。
まとめると、うちらの貢献はこんな感じや:
1. **約1800万件の指示テンプレートの大規模データセットを作ったで。** このテンプレートは、実際のユーザーが書いたクエリやタスクをマイニングして、それを汎用的なテンプレートに変換して作ったんよ。この大量のテンプレートセットがあるからこそ、めっちゃ多様で、実際のユーザータスクを代表するような分布に沿った合成データを生成できるんやで。
2. **FineInstructionsっていう手順を導入したで。** これで事前学習用ドキュメントを大規模に合成の指示と回答に変換できるんや。
3. **FineInstructionsだけで事前学習したら、標準的な事前学習とか他の提案されてる合成変換パイプラインよりも性能がええことを実証したで。** 人間の判断と相関のある3つのLLM評価ベンチマークで検証したんやで。
---
**[図の説明]**
**1. 約1800万件のユーザーが書いたクエリ**
「リオネル・メッシとクリスティアーノ・ロナウド、どっちがより影響力あるん?」
↓ クエリ汎用化モデル(Query Genericizer Model)で汎用テンプレートに変換
**2. 約1800万件の指示テンプレート**
「<fi>エンティティA</fi>と<fi>エンティティB</fi>、どっちがより<fi>特性</fi>なん?」
↓ テンプレートを埋め込んで、指示テンプレート埋め込みのFAISS検索インデックスを構築
**3. 約3000億トークンの事前学習用ドキュメント**
例:GadgetBlog.com 2023年9月30日 スマートウォッチレビュー
「AppleとGarmin両方試してみたで。Apple Watch Ultraは新しい頑丈なデザインが特徴やけど、極限のアクティビティには、Garmin Fenixの方が対応しやすいで…」
↓ ドキュメントを埋め込んで、テンプレート⇔ドキュメント照合埋め込みモデルで互換性のある指示テンプレートを検索
**4. 合成指示(テンプレートとドキュメントで具体化)**
「Apple Watch UltraとGarmin Fenix、どっちがより頑丈なん?」
↓ インスタンス化モデル(Instantiator Model)で指示と回答を生成
**5. 合成回答(ドキュメントからの抜粋に基づく)**
「Apple Watch Ultraは新しい頑丈なデザインが特徴やけど、極限のアクティビティには、Garmin Fenixの方が対応しやすいで…」
↓ 判定モデル(Judge Model)でフィルタリング
**6. 合成の指示と回答**
**7. FineInstructions(約10億以上の指示-回答ペア)**
**8. 指示と回答で学習!**
---
**モデルについて**
各「モデル」は効率的に蒸留された専門モデルやで:
- テンプレート⇔ドキュメント照合埋め込みモデル
- クエリ汎用化モデル
- インスタンス化モデル
- 判定モデル
LLM + タスク特化プロンプト(ラベル付け、生成、改良用)→ 入力とラベル&出力で蒸留 → 10億〜30億パラメータの専門的で効率的なモデル(繰り返し改良)
---
## Page 3
[](/attach/aad405958c8b29883ce2a1f90e6b2e95208226d0a9d4ee37fb94e1a62fd01be1_p003.png)
### 和訳
**FineInstructions: 合成データを事前学習レベルまでスケールさせる話**
モデルの回答品質を測る基準として、学術的なタスクからもっと現実的なユーザータスクまで幅広くカバーしとるんや。
4. ワイらのコードと学習済みモデル、それから**FineInstructions**っていう10億件以上の合成された質問と回答のペアのデータセットを公開するで。LLMの学習にめっちゃ役立つやつやねん。
## 2. 関連研究
LLMって基本的にはウェブページとか本とか、そういう自然に存在する構造化されてないテキストで学習されとるんやけど、これまでいろんな研究で「LLM自身が生成した合成データを事前学習に組み込んだらどうなるん?」っていうのが試されてきたんや(Gunasekarら, 2023; Ben Allalら, 2024; Abdinら, 2024; Teamら, 2025; Yangら, 2025)。他のアプローチとしては、LLMに「この文書、質ええな」って判断させてフィルタリングしたり(Penedoら, 2023; 2024; Liら, 2024b; Suら, 2024)、文書の混合比率を重み付けし直したり再サンプリングしたり(Yadlowskyら, 2023; Albalakら, 2023; Xieら, 2023; Liら, 2024b; Yeら, 2025; Wettigら, 2025)するのもあるんや。
最近のアプローチはもっと洗練されてきてな、生の事前学習用文書を質問-回答ペアとか他のタスク形式に変換したり(Chengら, 2024; Suら, 2024; Yuan & Liu, 2022)、質の低い文書をもっとキレイで質の高い文書に言い換えたり(Mainiら, 2024; Suら, 2024; Nguyenら, 2025)するんや。ワイらの研究では、**指示テンプレートを自動で作って、それを実体化することで合成学習データを生成する**っていうやり方をしとるんや。
他にも、LLMとプロンプティングを使って指示チューニング用データや推論データを合成的に生成する研究もいっぱいあるで(Honovichら, 2022; Wangら, 2022a; Taoriら, 2023; Liら, 2024c;a; Lambertら, 2024b; Mukherjeeら, 2023; Lianら, 2023; Wangら, 2023a; Jaechら, 2024; Guoら, 2025)。Köksalら(2024)は長文生成用の質問-回答ペアを生成してて、事前学習用の文書と「この文書を生成するのにありそうな質問」を合成的に作ってペアリングしとるんや。
指示テンプレートを使うやり方は、指示チューニング用データセットを作るときの定番でもあるんや(Bachら, 2022; Sanhら, 2021; Weiら, 2021; Mishraら, 2022; Wangら, 2022b; Narayanら, 2024)。ただな、テンプレート使わんと単純にLLMに「この文書を変換して」「言い換えて」ってプロンプトするだけやと、合成データの多様性が足りんくなるっていう課題があるんや(Geら, 2024; Yuら, 2023)。既存の指示テンプレート使うアプローチは、だいたい手作りかクラウドソーシングで作ったテンプレートを使っとって、そうすると**テンプレートの数が少なく**(数百から数千くらい)なるし、**多様性も低い**し、**学習インスタンスの数もワイらに比べたらずっと少ない**んや。
## 3. FineInstructions
このセクションでは、図2に示したFineInstructionsパイプラインの実装を詳しく説明するで。生成された出力の例は付録Aにあるから見てな。
FineInstructionsパイプラインはまず、**ユーザーが書いたクエリ**(質問とか指示とかタスクのリクエストとか)を入力として受け取るんや。これらのクエリは**汎用的で再利用可能な指示テンプレート**に変換されて、いろんな主題、トピック、ドメイン向けのクエリとして実体化できるようになるんや。事前学習用の文書セットがあったら、それと互換性のある指示テンプレートをマッチングさせるんや。文書が「マッチする」って判定されるのは、**クエリを現実的に実体化できるだけの情報**と、**根拠のある回答を提供できるだけの情報**の両方が含まれてる場合やな。最後に、**審判モデル**を使ってこれらの質問-回答ペアの品質を測定して、高品質なサブセットにフィルタリングするんや。
ワイらのパイプラインを使うと、**主に人間が書いた質問-回答ペアの大規模なセット**が作れて、各指示に対する回答生成を条件付けて教師あり事前学習を行えるんや。この手順は**弱教師あり**の手法にめっちゃ似てて、大規模なラベルなしコーパスをプログラム的なラベリングで大規模な教師ありデータセットに変換するやつや(Ratnerら, 2017)。この場合、ワイらは**大規模な指示テンプレートのバンク**と、ある程度の教師ありデータで学習された**既存のモデル**を使って、より大量の教師ありデータを抽出する手助けをさせとるんや。
ワイらは**DataDreamer**(Patelら, 2024)っていう合成データ生成と学習のためのフレームワークを使って、タスク固有のプロンプトで**シルバースタンダードデータ**(完璧じゃないけどまあまあ良いデータ)を生成して、パイプラインの各ステップを事前学習規模で実行できる効率的な**蒸留モデル**を学習させとるんや。タスク固有のプロンプトの例は付録Cにあるで。パイプライン、プロンプト、学習、ハイパーパラメータの詳細は補足資料のコードに全部書いてあるから見てな。シルバースタンダードデータの生成に使ったLLMは**Llama-3.3 70B Instruct**(AI, 2024b)やで。
このパイプラインの各段階の実装については、以下のセクションでもっと詳しく説明するわ。
### 3.1. 指示テンプレートの生成
まず、現実のユーザーがLLMにクエリ投げてる例とか、オンライン(フォーラムとか)で他の人に質問してる例とか、検索エンジンで質問してる例を集めるんや。あと、プロンプトライブラリから人間が書いたプロンプトテンプレートも集めるで。
ユーザーが書いたクエリは以下のデータセットから集めてきたんや:
- **WildChat**(65.7万クエリ)(Zhaoら, 2024)
- **LMSys Chat**(55.9万クエリ)(Zhengら, 2023a)
- **LMSys Chatbot Arena Conversations**(2.65万クエリ)(Zhengら, 2023b)
- **OAsst1**(3,920クエリ)(Köpfら, 2023)
- **HuggingFace NoRobots**(9,490クエリ)(Rajaniら, 2023)
- **HelpSteer**(1万クエリ)(Wangら, 2023b)
- **Dolly**(1.47万クエリ)(Conoverら, 2023)
- **Reddit QA**(747万クエリ)
- **GooAQ**(301万クエリ)(Kashabiら, 2021)
- **ShareLM**(264クエリ)(Don-Yehiyaら, 2025)
- **ExpertQA**(1,730クエリ)(Malaviyaら, 2023)
- **ChatDoctor iCliniq**(7,320クエリ)(Liら, 2023b)
- **ChatDoctor HealthcareMagic**(11.2万クエリ)(Liら, 2023b)
- **Awesome ChatGPT Prompts**(203クエリ)
- **Anthropic Prompt Li**...
---
## Page 4
[](/attach/aad405958c8b29883ce2a1f90e6b2e95208226d0a9d4ee37fb94e1a62fd01be1_p004.png)
### 和訳
---
## Page 5
[](/attach/aad405958c8b29883ce2a1f90e6b2e95208226d0a9d4ee37fb94e1a62fd01be1_p005.png)
### 和訳
ほな翻訳していくで!
---
**改善:チャンクのインデックスに合わせて直線的に増えるようになっとるねん。**
**検索のとこ** 検索するときな、ある文書に対してテンプレートがマッチするかどうかは、埋め込みベクトルのコサイン類似度が手動で設定した閾値(0.865)を超えるかどうかで判断するんや。マッチする候補がいくつかあったら、多様性を出すために重み付きランダムサンプリングっちゅうのをやるねん。なんでかっていうと、うちらの指示テンプレートのセットには、シンプルで短いやつ(`<fi></fi>`タグが1個か2個だけのやつ)もあれば、めっちゃ複雑で長いやつ(`<fi></fi>`タグが10個以上あるやつ)もあるからや。ほんで、WildChat、LMSys*、OAsst1、ShareLMっていう実際の大規模言語モデルへのクエリデータセットから導出したテンプレートの複雑さの分布に合わせるように、サンプリングの重みを計算してるんやで。
**3.3. 指示と回答の生成**
ほんで最終的に、6個ずつ互換性のある指示テンプレートがついた約10万件の事前学習用文書のサンプルを使って、大規模言語モデルに指示テンプレートを具体化させて、そのクエリに対する適切な回答になりそうな文書の抜粋を特定させるんや。ほとんどの文書はクエリに対する回答みたいなスタイルで書かれてへんから、言語モデルには抜粋をちょっとだけ言い換えたり、文書からの抜粋で詳しい文脈や詳細を示す前に、クエリや指示にもっと直接的に答えるような言葉を冒頭にちょっと足すことを許可してるんや。合成で生成されたトークンよりも文書に基づいた回答の方がええから(Shumailovさんらの2023年の研究)、生成された回答に含まれる抜粋テキストの割合が80%以上になるようにしてるで。
あとな、この段階で長い回答を生成するんはめっちゃコストかかるねん。トークンを1個ずつ生成せなあかんし、GPUメモリのボトルネックの問題もあるしな。さらに言うと、1) うちらの回答は基本的に文書からの直接抜粋やし、2) 指示テンプレートの変数も基本的に文書からの直接抜粋で埋まるんや。これを活かして、合成データ生成時の計算量を減らすために、「テキストを直接コピーしてくれ」って指定するタグを導入したんや。例えばな、「It is known that no preferred inertial frame exists according to the principle of relativity」っていうテキストは、単に「`<excerpt>It is known that<...>the principle of relativity.</excerpt>`」って生成するだけでええねん。こうすることで、モデルは長いテキストを抜粋するのに省略記号(`<...>`)付きの`<excerpt>`タグだけ生成すればよくなって、生成するトークン数を減らせるんや。生成されたこれらのタグは、デコード後に安いコストでプログラム的に展開できるで。
約10万件のシルバースタンダード(まあまあの品質)の例を作って、Llama-3.2 3B Instructをファインチューニングすることで、指示テンプレートを具体化して回答を生成する蒸留モデルを訓練するねん。この効率的な蒸留モデルを使って、大量の文書に対してたくさんの指示-回答ペアを生成して、大規模言語モデルのジャッジプロンプトを使って高品質な具体化と回答をフィルタリングして、約10万件の新しい高品質な具体化済み指示と回答の例を作れるようにするんや。
言語モデルが「取得した指示テンプレートがこの文書と互換性ないわ」って判断したケースの一部は、低品質な生成を無理やり出力するんやなくてnull(何も出さない)を出力すべき例として残してあるで(全例の約5%くらいやな)。これらの新しい例を使って、2回目のラウンドで最終的なInstantiatorモデルを訓練するんや。この約10万件の新しい例は、長さ、複雑さ(テンプレート変数の数)、トピックの面でもちゃんと層化されてるようにしてて、キーワードベースのフィルターを使って数学やコードに関連する指示-回答ペアを特定して、蒸留例の中でバランスよく表現されるようにしてるで。
**3.4. 指示と回答の判定とフィルタリング**
事前学習データを独立した指示-回答ペアのフォーマットにすることで、うちらの生成データは既製の報酬モデルやジャッジモデルと一緒に使いやすくなるねん。合成で作った指示と回答に対して判定とフィルタリングの段階を設けて、より高品質なセットを作るんや。具体的には、既製のFlow Judgeモデルっていう蒸留された38億パラメータのジャッジモデル(AI, 2024a)を使って、1(関係ないか的外れ)から5(余計なこと、曖昧なこと、繰り返しなしでクエリにちゃんと答えてる)までの5段階リッカート尺度の評価基準で評価して、4点以上の指示-回答ペアだけを残すんや。
**4. 実験設定**
このセクションでは、FineInstructionsパイプラインからの合成指示と回答ペアをゼロから学習させることで、知識の吸収とモデルの性能が向上するかどうかを検証するための実験設定について説明するで。
**4.1. ベースライン**
公平に比較するために、評価するすべての手法は同じ非構造化文書ソースコーパスを使って、比較するすべてのモデルは同じトークン数で訓練されてるで。最初のベースラインとして、標準的な事前学習パイプラインでやるように、元の文書そのもので訓練することを考えるねん。また、事前学習文書を合成変換や言い換えで変換する類似の手順を提案した先行研究からも、関連するベースラインをいくつか選んでるで。これらの先行研究の著者らは、実験で使ったバニラ(標準的な)事前学習コーパスと、コーパスに対する事前計算済みの合成変換を公開してくれてるんや。以下で説明するで。
**Instruction Pre-Training (IPT)** 「Instruction Pre-Training」手法(Chengさんらの2024年の研究)は、文書を指示-回答ペアに変換するための指示・応答シンセサイザーモデルを訓練することを提案してるねん。シンセサイザーモデルは、学術的なNLP Q&Aデータセットからの指示と応答で訓練されてるで。うちらは、RefinedWeb(Penedoさんらの2023年の研究)からの約230億トークンで構成されるIPTのバニラ事前学習コーパスと、事前計算済みの合成
---
## Page 6
[](/attach/aad405958c8b29883ce2a1f90e6b2e95208226d0a9d4ee37fb94e1a62fd01be1_p006.png)
### 和訳
FineInstructions:合成インストラクションを事前学習スケールまで拡大する話やねん
このデータセットっていうのは、元のコーパスをIPTっていう「指示と応答を作り出すモデル」で変換したバージョンなんよ。
ほんで、うちらのFineInstructionsデータセットについてやけど、Nemotron-CCから派生したデータセットは1エポック(1周)だけ学習して、IPTから派生したやつは4エポック回すねん。
**Nemotron-CCについて**
Nemotron-CCの手法(Suさんたちが2024年に発表したやつ)は、CommonCrawl(2025年のFoundationのやつ)からフィルタリングした高品質な文書を、LLMにいろんなタスクの組み合わせで処理させて合成事前学習データを作るんや。このタスクっていうのは、文書を言い換えたり、合成のQ&Aペアを作ったり、文書から核心となる知識を抽出・蒸留・リスト化したりすることやねん。うちらは、Nemotron-CCのバニラ(素の)事前学習コーパス(約3000億トークン)と、彼らのタスクミックスで作られた事前計算済みのNemotron-CC合成事前学習データを使うで。それに加えて、彼らの多様なQ&A生成手法だけで作られた約3000億トークンの事前学習データを単独のベースラインとして選んでるねん。これがIPTとFineInstructionsと一番直接比較しやすいからや。最後に、WRAPテクニック(Web Rephrase Augmented Pre-training、Mainiさんたちが2024年に発表)を実装した、事前計算済みの合成言い換え事前学習データから約3000億トークンを選んで、強力な言い換えベースラインと比較するで。
**4.2. 事前学習**
両方のデータセットの元の非構造化文書を使って、うちらのパイプラインで6つのインストラクションテンプレートを取得するねん(K=5のガウシアンプーリングチャンクで文書をカバーするように)。ほんで、1文書あたり6つの「指示-回答」ペアを生成するんや。各事前学習文書について、元文書のトークン数を超えない範囲で、ランダムに「指示-回答」ペアを残すねん¹。平均すると、1文書あたり約3つの「指示-回答」ペアになるわけや。これらの指示と回答のペアは、他の合成ベースラインと似たシンプルなチャットテンプレートでフォーマットするで:「Instruction: {{instruction}}\n\nAnswer: {{answer}}」って感じ(これもトークン数にカウントされる)。こうすることで、データセットを制御した、トークン対トークンで等価なFineInstructions事前学習データが作れて、IPTとNemotron-CCデータセットでそれぞれ約230億トークンと約3000億トークンになるねん。FineInstructionsと違って、ベースラインの手法は独立した質問-回答ペアを生成せんくて、代わりに元文書が文脈として与えられないと意味が通じない質問を作るんや(例えば「ヘレンはどのクラブが好き?」みたいな)。彼らは通常、質問-回答ペアを文書の最後に追加する(読解問題スタイルのQ&A)から、うちらはそのネイティブなフォーマットのまま事前学習するで。事前学習の実験はLinguaフレームワーク(Videauさんたちが2024年に発表)を使ってやってん。これは8台のH100 GPUで制御された事前学習のアブレーション(要因分析)用に設計されてて、各バニラ事前学習データセット、各ベースライン
¹ もし「指示-回答」ペアが元の事前学習文書のトークン数をピッタリ埋められへんくて余りが出たら、その余ったトークン予算は将来の事前学習文書の「指示-回答」ペアに繰り越すで。
データセット、そしてうちらのFineInstructionsデータセットそれぞれについて、Llama-3トークナイザー(AI、2024b)を使った18億パラメータのモデルを事前学習するんや。
**4.3. ベンチマーク**
以下で説明する3つのLLM評価ベンチマークを選んだで。これらは人間がモデルの応答品質を判断する感覚と相関することを目指してるねん。これらのベンチマークは、知識の吸収だけやなくて、おすすめとかアドバイスとか提案とかについての現実的なユーザークエリに応答する能力も評価するんや。各手法を評価するときは、ベンチマークの質問と指示をその手法の学習テンプレートに合わせたチャットテンプレートにフォーマットして、バニラ事前学習データで学習したモデルには標準テンプレート(「Instruction:」と「Answer:」)を使うで。応答生成にはグリーディサンプリング(貪欲法)を使うねん。各手法の応答を手動で確認したところ、どの手法もプロンプトに対してそこそこちゃんと応答してフォーマットできてて、おかしな応答もほとんどなく、正確に判定できる状態やったで。
**MixEval**
MixEvalベンチマーク(Niさんたちが2024年に発表)は、TriviaQA(Joshiさんたち2017年)、MMLU(Hendrycksさんたち2020年)、HellaSwag(Zellersさんたち2019年)、CommonsenseQA(Talmorさんたち2019年)とかの様々な学術的LLMベンチマークからタスクインスタンスを選んだサブセットやねん。MixEvalは、これらの各データセットから人間の応答品質判断と一番相関する例だけを残すことを目指してて、参照回答を与えてLLM-as-judge(LLMを審判にする方式)で応答を採点するで。うちらはGPT-5 miniを審判に使って(OpenAI、2025年)、「2024-08-11」バージョンで「Standard」と「Hard」の両方の分割で評価してん。
**MT-Bench-101**
MT-Bench-101は、意見とかアドバイスとか文章作成とかの現実的で主観的なユーザークエリを含むマルチターン(複数回やり取りする)ベンチマークで、10点満点のルーブリック(評価基準)でLLM-as-judgeによって採点されるねん(Baiさんたちが2024年に発表)。マルチターンのベンチマークやけど、マルチターンチャット用にチューニングされてないモデルについては、シングルターン方式で評価するのが一般的やで。うちらはGPT-5 miniを審判に使ってん(OpenAI、2025年)。
**AlpacaEval**
AlpacaEvalベンチマークは、ユーザーがLLMに聞きそうな現実的なクエリやタスクで評価して、2つのモデルからの応答を直接対決させるLLM-as-judgeで勝率を出すねん(Liさんたちが2023aに発表)。長さバイアス(長い回答を好んでしまう傾向)の補正もしてるで(Duboisさんたち2024年)。うちらはサポートされてるGPT-4-Turboモデルを審判モデルとして使ってん(OpenAI、2023年)。
**5. 結果**
事前学習実験の結果は表1にあるで。FineInstructionsパイプラインからのデータで事前学習すると、標準的な事前学習も
6
---
## Page 7
[](/attach/aad405958c8b29883ce2a1f90e6b2e95208226d0a9d4ee37fb94e1a62fd01be1_p007.png)
### 和訳
FineInstructions: 合成インストラクションを事前学習スケールまでスケールアップする話やで
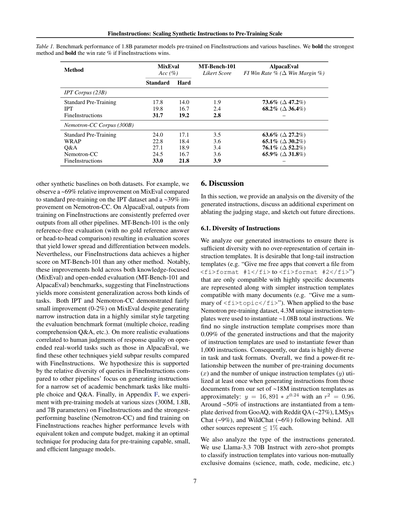
表1. FineInstructionsと色んなベースライン手法で事前学習した18億パラメータモデルのベンチマーク性能やねん。一番強かった手法は太字にしてあって、FineInstructionsが勝った時の勝率%も太字にしてあるで。
| 手法 | MixEval 正解率(%) | MT-Bench-101 リカート尺度 | AlpacaEval 標準 | 難しいやつ | FI勝率%(勝利マージン差%) |
|------|-------------------|--------------------------|----------------|-----------|------------------------|
| **IPTコーパス(230億トークン)** | | | | | |
| 普通の事前学習 | 17.8 | 14.0 | 1.9 | | 73.6%(差47.2%) |
| IPT | 19.8 | 16.7 | 2.4 | | 68.2%(差36.4%) |
| FineInstructions | **31.7** | **19.2** | **2.8** | | – |
| **Nemotron-CCコーパス(3000億トークン)** | | | | | |
| 普通の事前学習 | 24.0 | 17.1 | 3.5 | | 63.6%(差27.2%) |
| WRAP | 22.8 | 18.4 | 3.6 | | 65.1%(差30.2%) |
| Q&A | 27.1 | 18.9 | 3.4 | | 76.1%(差52.2%) |
| Nemotron-CC | 24.5 | 16.7 | 3.6 | | 65.9%(差31.8%) |
| FineInstructions | **33.0** | **21.8** | **3.9** | | – |
ほんでな、他の合成データ使ったベースラインと比べても、どっちのデータセットでもFineInstructionsがめっちゃ強いねん。例えばな、IPTデータセットのMixEvalでは普通の事前学習と比べて約69%も相対的に改善しとるし、Nemotron-CCでも約39%改善しとるんや。AlpacaEvalでもな、FineInstructionsで学習したモデルの出力は他のどの手法の出力よりも一貫して好まれとるねん。
MT-Bench-101だけは参照なし評価(正解となる参照回答も一対一比較もない評価方法)やから、モデル間のスコアの差があんまり開きにくいねん。それでもな、FineInstructionsのデータは他のどの手法よりもMT-Bench-101で高いスコア叩き出しとるんやで。特筆すべきはな、この改善は知識重視のベンチマーク(MixEval)でも自由形式の評価(MT-Bench-101とAlpacaEval)でも両方で成り立っとるっていうことやねん。つまりFineInstructionsはどっちの種類のタスクでもより一貫した汎化性能を発揮するっちゅうことや。
IPTもNemotron-CCも、評価ベンチマークのフォーマット(選択式とか読解Q&Aとか)にめっちゃ似たスタイルで狭い範囲のインストラクションデータ生成しとるのにな、MixEvalではたった0〜2%しか改善せえへんかったんや。でもな、AlpacaEvalみたいな現実世界の自由形式タスクで人間の品質判断と相関するもっとリアルな評価やとな、他の手法はFineInstructionsと比べてパッとせえへん結果になっとるねん。
なんでかっていうとな、これはFineInstructionsのクエリの多様性が他の手法より高いからやと俺らは考えとるねん。他の手法は選択式とかQ&Aみたいな狭い範囲の学術ベンチマークタスク向けのインストラクション生成に集中しとるからな。最後にな、付録Fでは色んなサイズ(3億、18億、70億パラメータ)のモデルをFineInstructionsと一番強かったベースライン(Nemotron-CC)で事前学習する実験もしとるんやけどな、同じトークン数と計算量の予算でFineInstructionsの方がより高い性能レベルに到達することがわかったんや。つまり、能力が高くて小さくて効率的な言語モデルを事前学習するためのデータ作成には最適な手法やっちゅうことやな。
## 6. 議論
このセクションではな、生成したインストラクションの多様性の分析と、判定ステージを除外した追加実験の議論と、今後の方向性についてざっくり説明するで。
### 6.1. インストラクションの多様性
生成したインストラクションを分析して、十分な多様性があって特定のインストラクションテンプレートに偏りすぎてへんか確認したんや。ロングテールのインストラクションテンプレート(例えば「<fi>フォーマット#1</fi>から<fi>フォーマット#2</fi>に変換できる無料アプリ教えて」みたいな、めっちゃ特定の文書としか相性良くないやつ)も、シンプルなインストラクションテンプレート(例えば「<fi>トピック</fi>の要約ちょうだい」みたいな、色んな文書と相性ええやつ)と一緒に表現されとることが望ましいねん。
ベースのNemotron事前学習データセットに適用した結果、430万個のユニークなインストラクションテンプレートを使って、合計約10.8億個のインストラクションを生成したんや。ほんでな、単一のインストラクションテンプレートが生成されたインストラクション全体の0.09%以上を占めることはなくて、大多数のインストラクションテンプレートは1,000個未満のインストラクションを生成するのに使われただけやったんや。つまりな、うちらのデータはタスクの種類もタスクのフォーマットもめっちゃ多様やっちゅうことや。
全体的にな、事前学習文書の数(x)と、その文書からインストラクション生成する時に少なくとも1回は使われたユニークなインストラクションテンプレートの数(y)の関係は、約1800万個のインストラクションテンプレートのセットから、だいたいこんな感じのべき乗則に従うことがわかったんや:y = 16,891 × x^0.24(r²=0.96)。
インストラクションの約50%はGooAQ由来のテンプレートからインスタンス化されとって、その後にReddit QA(約27%)、LMSys Chat(約9%)、WildChat(約6%)が続いとるねん。他のソースは全部1%以下やで。
生成されたインストラクションのタイプも分析したで。Llama-3.3 70B Instructをゼロショットプロンプトで使って、インストラクションテンプレートを色んな重複ありのドメイン(科学、数学、コード、医療とかな)に分類したんや。
---
## Page 8
[](/attach/aad405958c8b29883ce2a1f90e6b2e95208226d0a9d4ee37fb94e1a62fd01be1_p008.png)
### 和訳
FineInstructions: 合成インストラクションを事前学習スケールまで拡大する話
(a) FineInstructions(一部抜粋)
(b) FineInstructions(医療分野の一部)
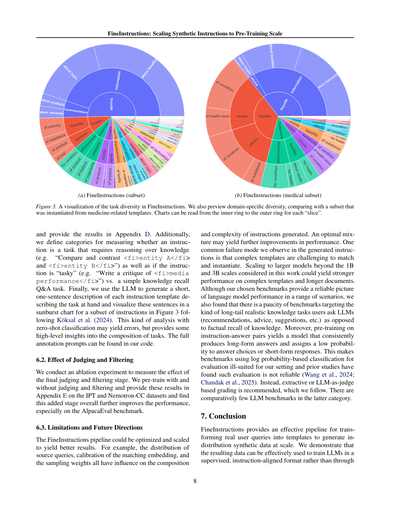
図3. FineInstructionsのタスク多様性を可視化したやつやねん。ドメイン特化の多様性もプレビューしてて、医療関連のテンプレートから生成したサブセットと比較してるで。チャートは各「スライス」について内側のリングから外側のリングに向かって読んでいくんやで。
で、結果は付録Dに載せてるねん。それと、インストラクションが知識を使って推論せなあかんタスクかどうかを測るためのカテゴリも定義してるで(例えば「<fi>エンティティA</fi>と<fi>エンティティB</fi>を比較対照して」みたいなやつやな)。あと、そのインストラクションが「タスクっぽい」かどうか(例えば「<fi>メディアパフォーマンス</fi>の批評を書いて」みたいな)と、単純な知識を思い出すだけのQ&Aタスクかどうかも分類してるねん。最後に、LLMを使って各インストラクションテンプレートについて、どんなタスクかを説明する短い一文を生成して、Köksalら(2024)のやり方に従って、インストラクションの一部をサンバーストチャートで可視化してるで(図3参照)。このゼロショット分類による分析はエラーも出るかもしれんけど、タスクの構成についてざっくりした洞察は得られるねん。完全なアノテーションプロンプトはワイらのコードに入ってるで。
6.2. 審査とフィルタリングの効果
最終段階の審査とフィルタリングがどんだけ効くかを測るためにアブレーション実験やったで。審査とフィルタリングありとなしで事前学習して、IPTとNemotron-CCデータセットでの結果を付録Eに載せてるねん。で、この追加ステージによって全体的にパフォーマンスがさらに上がることがわかったで、特にAlpacaEvalベンチマークではめっちゃ効いてるねん。
6.3. 限界と今後の方向性
FineInstructionsのパイプラインは最適化してスケールアップすれば、もっとええ結果出せるはずやねん。例えば、ソースクエリの分布、マッチング埋め込みのキャリブレーション、サンプリングの重み付け、これら全部が生成されるインストラクションの構成と複雑さに影響するんよ。最適な配合見つけたら、さらにパフォーマンス向上するかもしれへんで。ワイらが観察した一つのよくある失敗モードは、複雑なテンプレートはマッチングしてインスタンス化するのがめっちゃ難しいってことやねん。今回考えた1Bと3Bスケールより大きいモデルにスケールアップしたら、複雑なテンプレートと長い文書でもっと強いパフォーマンス出せるかもしれへんで。
ワイらが選んだベンチマークは様々なシナリオでの言語モデルの性能について信頼できる全体像を提供してくれるんやけど、ユーザーがLLMに実際に聞くようなロングテールの現実的な知識タスク(おすすめとか、アドバイスとか、提案とかな)をターゲットにしたベンチマークが少ないっていう問題も見つかってん。事実の想起とかじゃなくてな。さらに、インストラクションと回答のペアで事前学習すると、長文の回答を一貫して生成するモデルになって、選択肢や短い回答には低い確率を割り当てるようになるねん。これやと、対数確率ベースの分類を使った評価のベンチマークはワイらの設定には向いてへんし、先行研究でもそういう評価は信頼性に欠けるって言われてるんよ(Wangら、2024; Chandakら、2025)。代わりに、抽出ベースかLLMを審査員として使うグレーディングが推奨されてて、ワイらもそれに従ってるで。後者のカテゴリのLLMベンチマークは比較的少ないんよな。
7. 結論
FineInstructionsは、実際のユーザークエリをテンプレートに変換して、大規模に分布内の合成データを生成するための効果的なパイプラインを提供するねん。その結果のデータは、従来のやり方じゃなくて、教師あり学習でインストラクションに沿った形式でLLMを訓練するのにめっちゃ効果的に使えることを示したで。
8
---
## Page 9
[](/attach/aad405958c8b29883ce2a1f90e6b2e95208226d0a9d4ee37fb94e1a62fd01be1_p009.png)
### 和訳
FineInstructions:合成インストラクションを事前学習スケールまで拡大する話
普通の事前学習って、ドキュメント見ながら「次のトークン何やろ?」って予測する自己教師あり学習やねん。でもこのアプローチはな、学習の目的自体と事前学習データの構造をガラッと変えてしもうてんねん。そうすることで、実際に使われる場面にもっと近いデータでモデルを訓練できるし、知識を吸収する効率もめっちゃ上がるんやで。
**謝辞**
Hugging Faceの組織とチームには感謝せなあかんわ。この研究の実験に必要な計算資源とストレージを提供してくれて、手順のスケールアップについてもフィードバックくれたからな。特にLewis Tunstall、Hynek Kydlíček、Joel Niklausには評価とか関連研究についてめっちゃ議論してもろて、ほんまにありがとうやで。
この研究はDARPA(米国国防高等研究計画局)のSciFyプログラム(契約番号HR00112520300)から資金提供受けて進められたんや。ここで述べてる見解は著者個人のもんであって、国防総省やアメリカ政府の公式見解とちゃうからな。
**影響に関する声明**
この論文はな、合成データを使って大規模言語モデルの訓練を進化させることを目指してんねん。ええ影響としては、合成コーパスを一回だけ変換・生成したら、その後の訓練でより良い結果が出て収束も速くなるから、効率的な訓練ができるようになることやな。ただ、合成データで訓練すると、生成モデルが持ってるバイアスとかエラーが増幅される可能性もあるんや。これを軽減するために、元ドキュメントからほぼそのまま抜粋して、生成モデルは主に自然に存在するテキストデータを望みの形式に変換するだけに使ってるねん。ハルシネーション(でたらめな内容を作り出すこと)を含む新しいコンテンツは生成せんようにしてるわけや。せやけど、この研究は生成規模がめっちゃでかいから、データの系統的なバイアスのリスクが多少残る可能性はあるかもしれへんな。
**参考文献**
Abdin, M., Aneja, J., Behl, H., Bubeck, S., Eldan, R., Gunasekar, S., Harrison, M., Hewett, R. J., Javaheripi, M., Kauffmann, P., 他。Phi-4テクニカルレポート。arXivプレプリント arXiv:2412.08905, 2024.
AI, F. Flow Judge:LLMシステム評価のためのオープンな小規模言語モデル。テクニカルレポート、Flow AI、2024a。URL https://www.flow-ai.com/blog/flow-judge モデル:Flow-Judge v0.1(38億パラメータ); Apache 2.0ライセンス。
AI, M. The llama 3 herd of models. arXivプレプリント arXiv:2407.21783, 2024b.
Albalak, A., Pan, L., Raffel, C., Wang, W. Y. 言語モデル事前学習のための効率的なオンラインデータミキシング。R0FoMo: 大規模基盤モデルにおけるフューショット・ゼロショット学習のロバスト性、2023.
Bach, S. H., Sanh, V., Yong, Z.-X., Webson, A., Raffel, C., Nayak, N. V., Sharma, A., Kim, T., Bari, M. S., Fevry, T., Alyafeai, Z., Dey, M., Santilli, A., Sun, Z., Ben-David, S., Xu, C., Chhablani, G., Wang, H., Fries, J. A., Al-shaibani, M. S., Sharma, S., Thakker, U., Almubarak, K., Tang, X., Tang, X., Jiang, M. T.-J., Rush, A. M. Promptsource:自然言語プロンプトのための統合開発環境とリポジトリ、2022.
Bai, G., Liu, J., Bu, X., He, Y., Liu, J., Zhou, Z., Lin, Z., Su, W., Ge, T., Zheng, B., 他。MT-Bench-101:マルチターン対話における大規模言語モデル評価のための細粒度ベンチマーク。第62回計算言語学会年次大会論文集(第1巻:長論文)、pp. 7421–7454, 2024.
Ben Allal, L., Lozhkov, A., Penedo, G., Wolf, T., von Werra, L. Cosmopedia. テクニカルレポート、HuggingFace、2024年2月。URL https://huggingface.co/datasets/HuggingFaceTB/cosmopedia
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford, A., Sutskever, I., Amodei, D. 言語モデルはフューショット学習者である。Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M. F., Lin, H.(編)、Advances in Neural Information Processing Systems、第33巻、pp. 1877–1901. Curran Associates, Inc., 2020. URL https://proceedings.neurips.cc/paper/2020/file/1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf
Chandak, N., Goel, S., Prabhu, A., Hardt, M., Geiping, J. 言語モデル評価において回答マッチングは多肢選択式を上回る。arXivプレプリント arXiv:2507.02856, 2025.
Chase, H. LangChain. テクニカルレポート、LangChain、2022年10月。URL https://github.com/langchain-ai/langchain
Chen, Y., Zhao, C., Yu, Z., McKeown, K., He, H. 事前学習データにおける並列構造がインコンテキスト学習を生み出す。Ku, L.-W., Martins, A., Srikumar, V.(編)、第62回計算言語学会年次大会論文集(第1巻:
9
---
## Page 10
[](/attach/aad405958c8b29883ce2a1f90e6b2e95208226d0a9d4ee37fb94e1a62fd01be1_p010.png)
### 和訳
FineInstructions: Synthetic Instructionsを事前学習スケールにまでスケールさせる話
Long Papers), pp. 8582–8592、バンコク(タイ)、2024年8月。Association for Computational Linguistics。
doi: 10.18653/v1/2024.acl-long.465. URL https:
//aclanthology.org/2024.acl-long.465/.
Cheng, D., Gu, Y., Huang, S., Bi, J., Huang, M., and Wei, F.
Instruction pre-training: Language models are supervised
multitask learners(事前学習における指示学習:言語モデルは教師ありマルチタスク学習者やねん)。Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing、pp. 2529–2550、2024年。
Conover, M., Hayes, M., Mathur, A., Xie, J., Wan, J., Shah,
S., Ghodsi, A., Wendell, P., Zaharia, M., and Xin, R. Free
dolly: Introducing the world's first truly open instruction-tuned llm(Free dolly:世界初のほんまにオープンな指示チューニング済みLLMを紹介するで)。Technical report、Databricks、2023年。URL
https://www.databricks.com/blog/2023
/04/12/dolly-first-open-commerciall
y-viable-instruction-tuned-llm.
Don-Yehiya, S., Choshen, L., and Abend, O. The ShareLM
collection and plugin: Contributing human-model chats
for the benefit of the community(ShareLMコレクションとプラグイン:コミュニティのために人間とモデルのチャットを貢献する仕組みやな)。Mishra, P., Muresan,
S., and Yu, T.編、Proceedings of the 63rd Annual
Meeting of the Association for Computational Linguistics
(Volume 3: System Demonstrations)、pp. 167–177、ウィーン(オーストリア)、2025年7月。Association for Computational Linguistics。ISBN 979-8-89176-253-4。URL https:
//aclanthology.org/2025.acl-demo.17/.
Douze, M., Guzhva, A., Deng, C., Johnson, J., Szilvasy, G.,
Mazaré, P.-E., Lomeli, M., Hosseini, L., and Jégou, H.
The faiss library(faissライブラリの話やで)。IEEE Transactions on Big Data、2025年。
Dubois, Y., Galambosi, B., Liang, P., and Hashimoto, T. B.
Length-controlled alpacaeval: A simple way to debias automatic evaluators(長さ制御付きalpacaeval:自動評価器のバイアスを取り除くシンプルな方法やねん)。arXiv preprint arXiv:2404.04475、2024年。
Foundation, C. C. Common crawl web corpus(Common Crawlウェブコーパス)。https:
//commoncrawl.org/、2025年。アクセス日:2025年10月26日;データセットリリース CC-MAIN-2025-08。
Ge, T., Chan, X., Wang, X., Yu, D., Mi, H., and Yu, D. Scaling synthetic data creation with 1,000,000,000 personas(10億のペルソナで合成データ作成をスケールさせる話や)。arXiv preprint arXiv:2406.20094、2024年。
Ghosh, S., Evuru, C. K. R., Kumar, S., S, R., Aneja, D., Jin,
Z., Duraiswami, R., and Manocha, D. A closer look at
the limitations of instruction tuning(指示チューニングの限界をもっと詳しく見てみよか)。Proceedings of the 41st International Conference on Machine Learning、pp. 15559–15589、2024年。
Gudibande, A., Wallace, E., Snell, C., Geng, X., Liu,
H., Abbeel, P., Levine, S., and Song, D. The false
promise of imitating proprietary llms(プロプライエタリなLLMを真似することの偽りの約束について)。arXiv preprint
arXiv:2305.15717、2023年。
Gunasekar, S., Zhang, Y., Aneja, J., Mendes, C. C. T.,
Giorno, A. D., Gopi, S., Javaheripi, M., Kauffmann, P.,
de Rosa, G., Saarikivi, O., Salim, A., Shah, S., Behl,
H. S., Wang, X., Bubeck, S., Eldan, R., Kalai, A. T., Lee,
Y. T., and Li, Y. Textbooks are all you need(教科書だけあればええねん)、2023年。
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R.,
Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning(Deepseek-r1:強化学習でLLMの推論能力にインセンティブ与えるで)。arXiv preprint arXiv:2501.12948、2025年。
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M.,
Song, D., and Steinhardt, J. Measuring massive multitask language understanding(超大規模マルチタスク言語理解を測定するで)。International Conference on Learning Representations、2020年。
Hewitt, J., Liu, N. F., Liang, P., and Manning, C. D. Instruction following without instruction tuning(指示チューニングなしで指示に従う方法)。arXiv preprint arXiv:2409.14254、2024年。
Honovich, O., Scialom, T., Levy, O., and Schick, T. Unnatural instructions: Tuning language models with (almost) no human labor(不自然な指示:ほぼ人間の労力なしで言語モデルをチューニングする方法やで)、2022年。URL https://arxiv.org/
abs/2212.09689.
Jaech, A., Kalai, A., Lerer, A., Richardson, A., El-Kishky,
A., Low, A., Helyar, A., Madry, A., Beutel, A., Carney, A., et al. Openai o1 system card(OpenAI o1システムカード)。arXiv preprint arXiv:2412.16720、2024年。
Jang, J., Kim, S., Ye, S., Kim, D., Logeswaran, L., Lee, M.,
Lee, K., and Seo, M. Exploring the benefits of training expert language models over instruction tuning(指示チューニングよりも専門家言語モデルを訓練するメリットを探るで)。ICML 2023、pp. 14702–14729。International Machine Learning Society (IMLS)、2023年。
Joshi, M., Choi, E., Weld, D. S., and Zettlemoyer, L. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension(TriviaQA:読解のための大規模な遠隔教師ありチャレンジデータセットやな)。Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)、pp. 1601–1611、2017年。
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B.,
Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and
Amodei, D. Scaling laws for neural language models(ニューラル言語モデルのスケーリング則やで)、2020年。URL https://arxiv.org/abs/2001.0
8361.
Khashabi, D., Ng, A., Khot, T., Sabharwal, A., Hajishirzi,
H., and Callison-Burch, C. Gooaq: Open question answering with diverse answer types(Gooaq:多様な回答タイプでのオープンな質問応答やな)。Findings of the Association for Computational Linguistics: EMNLP 2021、pp. 421–433、2021年。
Köpf, A., Kilcher, Y., von Rütte, D., Anagnostidis, S., Tam,
Z. R., Stevens, K., Barhoum, A., Nguyen, D. M., Stanley,
10
---
## Page 11
[](/attach/aad405958c8b29883ce2a1f90e6b2e95208226d0a9d4ee37fb94e1a62fd01be1_p011.png)
### 和訳
FineInstructions:合成インストラクションを事前学習スケールまでスケールする
O., Nagyfi, R., ES, S., Suri, S., Glushkov, D. A., Dantuluri, A. V., Maguire, A., Schuhmann, C., Nguyen, H., and
Mattick, A. J. Openassistant conversations - democratizing large language model alignment(OpenAssistantの会話 - でっかい言語モデルのアライメントをみんなのもんにするで)。第37回Neural Information Processing Systemsカンファレンス、データセットとベンチマークトラック、2023年。URL https://openreview.net/forum?id=VSJotgbPHF.
Köksal, A., Schick, T., Korhonen, A., and Schütze, H. Longform: Effective instruction tuning with reverse instructions(ロングフォーム:逆インストラクションで効果的にインストラクションチューニングするやつ), 2024.
Lambert, N., Morrison, J., Pyatkin, V., Huang, S., Ivison,
H., Brahman, F., Miranda, L. J. V., Liu, A., Dziri, N.,
Lyu, S., et al. Tülu 3: Pushing frontiers in open language model post-training(Tülu 3:オープンな言語モデルの後学習の限界をめっちゃ押し広げるで)。CoRR, 2024a.
Lambert, N., Morrison, J., Pyatkin, V., Huang, S., Ivison,
H., Brahman, F., Miranda, L. J. V., Lyu, A. L. N. D. X.,
Graf, Y. G. S. M. V., Hwang, J. D., et al. Tülu 3: Pushing frontiers in open language model post-training(Tülu 3:オープンな言語モデルの後学習の最前線をガンガン攻めるで)。arXiv preprint arXiv:2411.15124, 2024b.
Li, H., Dong, Q., Tang, Z., Wang, C., Zhang, X., Huang,
H., Huang, S., Huang, X., Huang, Z., Zhang, D., et al.
Synthetic data (almost) from scratch: Generalized instruction tuning for language models(ほぼゼロから作る合成データ:言語モデルのための汎用インストラクションチューニングやで)。arXiv preprint arXiv:2402.13064, 2024a.
Li, J., Fang, A., Smyrnis, G., Ivgi, M., Jordan, M., Gadre,
S. Y., Bansal, H., Guha, E., Keh, S. S., Arora, K., et al.
Datacomp-lm: In search of the next generation of training sets for language models(Datacomp-lm:言語モデル用の次世代トレーニングセットを探す旅やな)。Advances in Neural Information Processing Systems, 37:14200–14282, 2024b.
Li, X., Zhang, T., Dubois, Y., Taori, R., Gulrajani, I.,
Guestrin, C., Liang, P., and Hashimoto, T. B. Alpacaeval: An automatic evaluator of instruction-following models(Alpacaeval:インストラクションに従うモデルを自動で評価してくれるやつ)。https://github.com/tatsu-lab/alpaca_eval, 5 2023a.
Li, X., Yu, P., Zhou, C., Schick, T., Levy, O., Zettlemoyer,
L., Weston, J. E., and Lewis, M. Self-alignment with instruction backtranslation(インストラクションの逆翻訳で自己アライメントするねん)。第12回International Conference on Learning Representations, 2024c.
Li, Y., Zihan, L., Zhang, K., Ruilong, D., Jiang, S., and
Zhang, Y. Chatdoctor: A medical chat model fine-tuned on a large language model meta-ai (llama) using medical domain knowledge(チャットドクター:医療の専門知識使ってLLaMAをファインチューニングした医療チャットモデルやで)。Cureus, 15(6), 2023b.
Maini, P., Seto, S., Bai, R., Grangier, D., Zhang, Y., and
Jaitly, N. Rephrasing the web: A recipe for compute and data-efficient language modeling(ウェブを言い換える:計算もデータも効率的に使う言語モデリングのレシピやで)。Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 14044–14072, 2024.
Malaviya, C., Lee, S., Chen, S., Sieber, E., Yatskar, M.,
and Roth, D. Expertqa: Expert-curated questions and attributed answers(ExpertQA:専門家が厳選した質問と出典付きの回答やな)。arXiv, 09 2023. URL https://arxiv.org/abs/2309.07852.
Markov, T., Zhang, C., Agarwal, S., Nekoul, F. E., Lee,
T., Adler, S., Jiang, A., and Weng, L. A holistic approach to undesired content detection in the real world(実世界で望ましくないコンテンツを検出するための総合的なアプローチやで)。Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence and Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence and Thirteenth Symposium on Educational Advances in Artificial Intelligence, pp. 15009–15018, 2023.
Mishra, S., Khashabi, D., Baral, C., and Hajishirzi, H. Cross-task generalization via natural language crowdsourcing instructions(自然言語のクラウドソーシングインストラクションでタスク間の汎化をするねん)。ACL, 2022.
Mukherjee, S., Mitra, A., Jawahar, G., Agarwal, S., Palangi,
H., and Awadallah, A. Orca: Progressive learning from complex explanation traces of gpt-4(Orca:GPT-4の複雑な説明の軌跡から段階的に学習するやつ), 2023.
Narayan, A., Chen, M. F., Bhatia, K., and Re, C. Cookbook: A framework for improving llm generative abilities via programmatic data generating templates(Cookbook:プログラムでデータ生成するテンプレート使ってLLMの生成能力を向上させるフレームワークやで)。arXiv preprint arXiv:2410.05224, 2024.
Nguyen, T., Li, Y., Golovneva, O., Zettlemoyer, L., Oh, S.,
Schmidt, L., and Li, X. Recycling the web: A method to enhance pre-training data quality and quantity for language models(ウェブをリサイクル:言語モデルの事前学習データの質と量を向上させる方法やな)。arXiv preprint arXiv:2506.04689, 2025.
Ni, J., Xue, F., Yue, X., Deng, Y., Shah, M., Jain, K., Neubig, G., and You, Y. Mixeval: Deriving wisdom of the crowd from llm benchmark mixtures(Mixeval:LLMベンチマークの組み合わせから群衆の知恵を引き出すで)。arXiv preprint arXiv:2406.06565, 2024.
OpenAI. GPT-4 technical report(GPT-4の技術レポート)。arXiv preprint arXiv:2303.08774, 2023.
OpenAI. Gpt-5 system card(GPT-5のシステムカード)。Technical report, OpenAI, August 2025. URL https://cdn.openai.com/gpt-5-system-card.pdf.
Lian, W., Goodson, B., Pentland, E., Cook, A., Vong, C.,
and "Teknium". Openorca: An open dataset of gpt augmented flan reasoning traces(OpenOrca:GPTで強化したFLANの推論トレースのオープンデータセットやで)。https://huggingface.co/Open-Orca/OpenOrca, 2023.
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C.,
Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A.,
et al. Training language models to follow instructions with human feedback(人間のフィードバック使って言語モデルにインストラクションに従うよう訓練するやつやな)。Advances in Neural Information Processing Systems, 35:27730–27744, 2022.
11
---
## Page 12
[](/attach/aad405958c8b29883ce2a1f90e6b2e95208226d0a9d4ee37fb94e1a62fd01be1_p012.png)
### 和訳
FineInstructions: 合成命令を事前学習スケールまでスケールさせるで
Patel, A., Raffel, C., and Callison-Burch, C. DataDreamer: 合成データ生成と再現可能なLLMワークフローのためのツールやねん。Ku, L.-W., Martins, A., and Srikumar, V.(編)、計算言語学会第62回年次大会論文集(第1巻:ロングペーパー)、pp. 3781–3799、バンコク、タイ、2024年8月。計算言語学会。doi: 10.18653/v1/2024.acl-long.208。URL https://aclanthology.org/2024.acl-long.208.
Penedo, G., Malartic, Q., Hesslow, D., Cojocaru, R., Cappelli, A., Alobeidli, H., Pannier, B., Almazrouei, E., and Launay, J. Falcon LLM用のRefinedWebデータセット:キュレーションされたコーパスを、ウェブデータだけで、しかもウェブデータだけで上回るっちゅう話やで。CoRR, 2023.
Penedo, G., Kydlíček, H., Lozhkov, A., Mitchell, M., Raffel, C. A., Von Werra, L., Wolf, T., et al. FineWebデータセット:ウェブから最高品質のテキストデータを大規模に蒸留するっちゅうやつやねん。Advances in Neural Information Processing Systems, 37: 30811–30849, 2024.
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., and Liu, P. J. 統一されたテキスト-to-テキスト変換器を使った転移学習の限界を探るで。The Journal of Machine Learning Research, 21(1):5485–5551, 2020.
Rajani, N., Tunstall, L., Beeching, E., Lambert, N., Rush, A. M., and Wolf, T. No robots(ロボットなし)やで。https://huggingface.co/datasets/HuggingFaceH4/no_robots, 2023.
Ratner, A., Bach, S. H., Ehrenberg, H., Fries, J., Wu, S., and Ré, C. Snorkel:弱教師あり学習で高速に学習データを作成するやつやねん。Proceedings of the VLDB endowment. International conference on very large data bases, volume 11, pp. 269, 2017.
Reimers, N. and Gurevych, I. Sentence-BERT:シャムBERTネットワークを使った文埋め込みやで。2019年自然言語処理における経験的手法に関する会議論文集。計算言語学会、2019年11月。URL http://arxiv.org/abs/1908.10084.
Sanh, V., Webson, A., Raffel, C., Bach, S. H., Sutawika, L., Alyafeai, Z., Chaffin, A., Stiegler, A., Scao, T. L., Raja, A., Dey, M., Bari, M. S., Xu, C., Thakker, U., Sharma, S. S., Szczechla, E., Kim, T., Chhablani, G., Nayak, N. V., Datta, D., Chang, J. D., Jiang, M. T.-J., Wang, H., Manica, M., Shen, S., Yong, Z.-X., Pandey, H., Bawden, R., Wang, T., Neeraj, T., Rozen, J., Sharma, A., Santilli, A., Févry, T., Fries, J. A., Teehan, R., Biderman, S., Gao, L., Bers, T., Wolf, T., and Rush, A. M. マルチタスクプロンプト学習でゼロショットのタスク汎化ができるようになるっちゅう話やねん。ArXiv, abs/2110.08207, 2021. URL https://api.semanticscholar.org/CorpusID:239009562.
Shi, C., Su, Y., Yang, C., Yang, Y., and Cai, D. スペシャリストかジェネラリストか?特定のNLPタスク向けの命令チューニングやで。Bouamor, H., Pino, J., and Bali, K.(編)、2023年自然言語処理における経験的手法に関する会議論文集、pp. 15336–15348、シンガポール、2023年12月。計算言語学会。doi: 10.18653/v1/2023.emnlp-main.947. URL https://aclanthology.org/2023.emnlp-main.947/.
Shumailov, I., Shumaylov, Z., Zhao, Y., Gal, Y., Papernot, N., and Anderson, R. 再帰の呪い:生成されたデータで学習するとモデルが忘れてまうっちゅう話やで、2023.
Su, D., Kong, K., Lin, Y., Jennings, J., Norick, B., Kliegl, M., Patwary, M., Shoeybi, M., and Catanzaro, B. Nemotron-CC:Common Crawlを洗練された長期間事前学習データセットに変換するやつやねん。arXiv preprint arXiv:2412.02595, 2024.
Talmor, A., Herzig, J., Lourie, N., and Berant, J. CommonsenseQA:常識知識をターゲットにした質問応答チャレンジやで。Burstein, J., Doran, C., and Solorio, T.(編)、2019年北米計算言語学会:人間言語技術論文集、第1巻(ロングペーパーとショートペーパー)、pp. 4149–4158、ミネアポリス、ミネソタ、2019年6月。計算言語学会。doi: 10.18653/v1/N19-1421. URL https://aclanthology.org/N19-1421/.
Taori, R., Gulrajani, I., Zhang, T., Dubois, Y., Li, X., Guestrin, C., Liang, P., and Hashimoto, T. B. Stanford Alpaca:命令に従うLlamaモデルやで。https://github.com/tatsu-lab/stanford_alpaca, 2023.
Team, K., Bai, Y., Bao, Y., Chen, G., Chen, J., Chen, N., Chen, R., Chen, Y., Chen, Y., Chen, Y., et al. Kimi K2:オープンなエージェント型知能やねん。arXiv preprint arXiv:2507.20534, 2025.
Videau, M., Idrissi, B. Y., Haziza, D., Wehrstedt, L., Copet, J., Teytaud, O., and Lopez-Paz, D. Meta Lingua:最小限のPyTorch LLM学習ライブラリやで、2024. URL https://github.com/facebookresearch/lingua.
Wang, X., Wei, J., Schuurmans, D., Le, Q. V., Chi, E. H., Narang, S., Chowdhery, A., and Zhou, D. 自己整合性で言語モデルのチェーン・オブ・ソート推論が改善されるっちゅう話やねん。The Eleventh International Conference on Learning Representations, 2023a.
12
---
## Page 13
[](/attach/aad405958c8b29883ce2a1f90e6b2e95208226d0a9d4ee37fb94e1a62fd01be1_p013.png)
### 和訳
FineInstructions:合成インストラクションを事前学習レベルまでスケールアップさせる話
---
Ye, J., Liu, P., Sun, T., Zhan, J., Zhou, Y., and Qiu, X.
データ混合の法則:言語モデルの性能予測でデータの混ぜ方を最適化するで。第13回学習表現国際会議、2025年。
Yu, Y., Zhuang, Y., Zhang, J., Meng, Y., Ratner, A., Krishna, R., Shen, J., and Zhang, C.
大規模言語モデルを属性付き学習データ生成器として使う話:多様性とバイアスの物語やな。第37回ニューラル情報処理システム会議 データセット&ベンチマークトラック、2023年。
Yuan, W. and Liu, P.
再構造化した事前学習について。arXiv プレプリント arXiv:2206.11147、2022年。
Zellers, R., Holtzman, A., Bisk, Y., Farhadi, A., and Choi, Y.
HellaSwag:機械ってほんまに文章完成できるん?っていう話やねん。Korhonen, A., Traum, D., and Màrquez, L.(編)、計算言語学会第57回年次大会論文集、4791–4800ページ、イタリアのフィレンツェ、2019年7月。計算言語学会。doi: 10.18653/v1/P19-1472。URL https://aclanthology.org/P19-1472/。
Zhao, W., Ren, X., Hessel, J., Cardie, C., Choi, Y., and Deng, Y.
WildChat:100万件のChatGPTとのやり取りログを野生で集めたったで。第12回学習表現国際会議、2024年。URL https://openreview.net/forum?id=Bl8u7ZRlbM。
Zheng, L., Chiang, W.-L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E. P., Zhang, H., Gonzalez, J. E., and Stoica, I.
LLMを審判として使うってどうなん?MT-benchとChatbotアリーナで検証したで、2023a。
Zheng, L., Chiang, W.-L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E. P., Zhang, H., Gonzalez, J. E., and Stoica, I.
LLMを審判として使うってどうなん?MT-benchとChatbotアリーナで検証したで、2023b。
Zhou, C., Liu, P., Xu, P., Iyer, S., Sun, J., Mao, Y., Ma, X., Efrat, A., Yu, P., Yu, L., et al.
LIMA:アライメントは少ないほうがええねん。ニューラル情報処理システムの進歩、36巻:55006–55021ページ、2023年。
Wang, X., Ma, B., Hu, C., Weber-Genzel, L., Röttger, P., Kreuter, F., Hovy, D., and Plank, B.
「ワイの答えはCや」:インストラクションチューニングした言語モデルって、最初のトークンの確率とテキストの答えが一致せんねん。Ku, L.-W., Martins, A., and Srikumar, V.(編)、計算言語学会ACL 2024発見論文集、7407–7416ページ、タイのバンコク、2024年8月。計算言語学会。doi: 10.18653/v1/2024.findings-acl.441。URL https://aclanthology.org/2024.findings-acl.441/。
Wang, Y., Kordi, Y., Mishra, S., Liu, A., Smith, N. A., Khashabi, D., and Hajishirzi, H.
Self-Instruct:言語モデルを自分で生成したインストラクションでアライメントさせるんや。arXiv プレプリント arXiv:2212.10560、2022a。
Wang, Y., Mishra, S., Alipoormolabashi, P., Kordi, Y., Mirzaei, A., Arunkumar, A., Ashok, A., Dhanasekaran, A. S., Naik, A., Stap, D., et al.
Super-NaturalInstructions:1600以上のタスクで宣言的インストラクションによる汎化を実現したで。EMNLP、2022b。
Wang, Z., Dong, Y., Zeng, J., Adams, V., Sreedhar, M. N., Egert, D., Delalleau, O., Scowcroft, J. P., Kant, N., Swope, A., and Kuchaiev, O.
HelpSteer:SteerLM用のマルチ属性ヘルプフルネスデータセットや、2023b。
Wei, J., Bosma, M., Zhao, V. Y., Guu, K., Yu, A. W., Lester, B., Du, N., Dai, A. M., and Le, Q. V.
ファインチューニングした言語モデルってゼロショット学習者なんやで。arXiv プレプリント arXiv:2109.01652、2021年。
Wettig, A., Lo, K., Min, S., Hajishirzi, H., Chen, D., and Soldaini, L.
ウェブを整理せえ:ドメインを構築したら事前学習データのキュレーションがめっちゃ良くなるねん。arXiv プレプリント arXiv:2502.10341、2025年。
Xiao, S., Liu, Z., Zhang, P., and Muennighoff, N.
C-Pack:一般的な中国語埋め込みを進歩させるためのパッケージリソースや、2023年。
Xie, S. M., Pham, H., Dong, X., Du, N., Liu, H., Lu, Y., Liang, P. S., Le, Q. V., Ma, T., and Yu, A. W.
DoReMi:データの混ぜ方を最適化したら言語モデルの事前学習がめっちゃ速なるねん。ニューラル情報処理システムの進歩、36巻:69798–69818ページ、2023年。
Yadlowsky, S., Doshi, L., and Tripuraneni, N.
事前学習データの混合で、Transformerモデルに狭いモデル選択能力を持たせられるって話や。arXiv プレプリント arXiv:2311.00871、2023年。
Yang, Z., Band, N., Li, S., Candes, E., and Hashimoto, T.
合成データで継続事前学習するやつや。第13回学習表現国際会議、2025年。
13ページ
---
## Page 14
[](/attach/aad405958c8b29883ce2a1f90e6b2e95208226d0a9d4ee37fb94e1a62fd01be1_p014.png)
### 和訳
FineInstructions:事前学習スケールまで合成指示をスケールアップする話
A. FineInstructionsの例
普通の事前学習ドキュメント:
より良いカルテ作成のための構造と同期性
カルテにな、自分がやったことだけやなくて、「何を考えてたか」もちゃんと伝えるための2つの大事なポイントがあるねん。
Fam Pract Manag. 2011 Jul-Aug;18(4):15-17.
なあ、診断とか治療の選択がなんでそうなったんか、全然わからん医療記録を読んだことあるやろ?自分が書いたカルテを医療訴訟の通知もらってから読み返して、「うわ、矛盾だらけやん...」って冷や汗かいた経験とかない?ちゃんと書けてないカルテってめっちゃ多いねん。俺は医学生とか研修医のカルテをレビューしてきたんやけど、標準治療にちゃんと沿ってて医療過誤のリスクがないかチェックする仕事でな、そこでこの問題をめっちゃ見てきたわ。ほとんどの医者は病歴とか身体所見をCPT(診療報酬コード)に必要な項目数はちゃんと記録してるんやけど、自分の臨床的な思考プロセス、つまり「なんでこう考えたか」っていう筋道をはっきり伝えられてる人はほとんどおらんねん。詳細な病歴と中程度に複雑な意思決定を記録してるカルテでも、なんでその決断に至ったんか、なんでその治療が正当化されるんかが見えてこーへんねん。
ほんで俺、「一体どの教育段階でこの重要な文書作成の概念を学生は学ぶんやろ?」って調べたくなってな。うちの研修プログラムに来てた複数の医学部の学生に非公式にヒアリングする調査もやったんや。そしたら誰一人として、アセスメントとプランを書くための正式な構造を学んだって言われへんかったわ。これ、ある研究で「標準化された診療場面を正確に記録できてた医学生はたった4%だけやった」っていう結果と一致してるんよな。あと2010年の米国医師免許試験(USMLE)の臨床技能試験ガイドも調べたんやけど、そこには「学生は鑑別診断リストを可能性の高い順に並べて、やりたい検査とかも提示することが期待される」って書いてあったんやけど、臨床的な根拠を議論する要件はなかったんよ。こういう発見を踏まえて、俺は研修医と学生にちゃんとしたカルテの書き方を教えるための正式なフレームワークを開発したんや。この記事で説明するやつやな。初期の反応はめっちゃ好評やったで。
確定診断の文書化
まず、確定診断を記録するときに何を含めるべきかを確認しとこか。一般的に、6つの要素が必要やねん...
指示テンプレート
合成された指示
合成された回答
<fi>文書の種類、例えば
技術レポート、研究論文
など</fi>の書き方のテンプレートやガイドラインを探してるんやけど。
その<fi>文書の種類</fi>は<fi>文脈や研究分野</fi>関連で、<fi>役職やポジション</fi>が<fi>分野や業界</fi>に関する<fi>問題やイシューの種類</fi>の<fi>タスクや調査</fi>の作業をレビューするためのものやねん。
医療記録の書き方のテンプレートやガイドラインを探してるんやけど。
その医療記録はヘルスケア関連で、医師が患者ケアに関する医療問題の臨床調査の作業をレビューするためのものやねん。
医療記録を書くには、以下のガイドラインを参考にしてな。まず、確定診断を記録するときに何を含めるべきかを確認しとこか。一般的に、6つの要素が必要やねん...
普通の事前学習ドキュメント:
Spotが書いてる:「あんたの歯医者さん正しいで、糖尿病は重度の歯周病を伴うことが多くて、口腔乾燥症(xerostomia、ドライマウスのことな)で複雑になるんや。その結果、虫歯の発生率が上がって歯を失うことになるんや。あと感染症も」>> Jackが書いてる:「」>> SpotとJackよ、そんなん全部知っとるわ!いやJack、彼女は歯周病の兆候なんか見てへんで、フルチェック受けたけど全く兆候なしやったんや。フロスをする箇所に虫歯が1本あってな、それで「もっとフロスしろ」ってアドバイスされたんよ。俺が言いたかったんは、忙しい生活+糖尿病の中で、追加でフロスすることは優先順位低いやろってことや。
俺もう毎日フロスしてるで、ただ1日3-4回とか毎食後にやってないだけや。ところでJack、俺のフロス時間は2-3分よりずっと長いからな。まあそういうわけで、非糖尿病の人よりもっと頻繁にフロスせーへんことの危険性は理解してるし、50年後の80歳で全部歯が抜けたら、JackとSpotは「ほら言うたやん」って言えるな。(vbg) Jill(1日5回フロスはまだしてないJillより)
———————————————— Yahoo!使ってる? Yahoo!オークション - 欲しいものをお得な価格で。 ————————————————
— ヘルプや購読/解除はこちら: HELP@insulin-pumpers.org 寄付もお願いします
指示テンプレート
合成された指示
合成された回答
<fi>医学的または心理学的な状態</fi>にはどんな影響があるん?
糖尿病にはどんな影響があるん?
糖尿病にはいくつかの影響があるんやけど、重度の歯周病を伴うことが多くて、口腔乾燥症(xerostomia、ドライマウスな)で複雑になるんや。その結果、虫歯の発生率が上がって歯を失うことになるで。
普通の事前学習ドキュメント:
次のページに続く...
14
---
## Page 15
[](/attach/aad405958c8b29883ce2a1f90e6b2e95208226d0a9d4ee37fb94e1a62fd01be1_p015.png)
### 和訳
FineInstructions: 事前学習スケールまで合成命令をスケールアップする話
この記事はな、本番レベルのNode.js、GraphQL、TypeScriptサーバーを自動デプロイパイプライン付きで作るシリーズの第1弾やねん。スケーラブルなバックエンドソリューションの作り方を説明する記事やチュートリアルはめっちゃいっぱいあるんやけど、ワイが「これ足りてへんな〜」って思ったんは、シンプルで適切なユースケースで全部の点を繋げてくれる解説やねん。大抵の場合、いきなりコード書き始めたりせえへんやろ?まずはアプリケーションの要件に基づいてバックエンドをどう設計するか考えるところから始めるやん。そのやり方を知ってることの方が、なんとかフレームワークの構文知ってるより大事なスキルやと思うねん。
コード書く前に、概念を学ぶために何を作るか見てみよか。画像管理アプリケーションを作るで〜。ユーザーが画像リソースを管理できるやつやな。主にログイン、サインアップ、メインアプリケーションで構成されてんねん。メインアプリでは、ユーザーが画像をアップロードして、アップロードした全画像を見れるようになるで。シンプルなユースケースやけど、このシンプルなユースケースで全部の概念が理解できるっちゅうわけや。
ログイン画面
メインアプリ画面
さて、何を作るかわかったところで、Node.js、GraphQL、TypeScriptサーバーを作るためのベストプラクティス全部適用していこか。
このパートでは、アプリケーションのセットアップ方法と、GraphQLとTypeScriptを使ってクエリとミューテーションを作る方法を説明するで。アプリケーションにはtypegraphqlを使うねん。必要な依存関係をインストールしよか、npm i apollo-server-express express graphql reflect-metadata type-graphql mongoose....
命令テンプレート
合成命令
合成回答
<fi>実行するアクションの数語での説明</fi>を<fi>サービス、システム、またはプラットフォームの名前</fi>でどうやるん?
type-graphqlを使ってGraphQLスキーマを作成してMongoDBデータベースに接続するにはどうすればええの?
type-graphqlを使ってGraphQLスキーマを作成してMongoDBデータベースに接続する手順はこうやで:
アプリケーションにはtype-graphqlを使うねん。必要な依存関係をインストールしよか、1npm i apollo-server-express express graphql reflect-metadata type-graphql mongoose...
B. テンプレート⇔ドキュメントマッチング埋め込みモデル用のガウシアンプーリング層
なんでかっていうと、これはトークンの埋め込みをうまいことまとめる数学的な仕組みやねん。
入力トークン埋め込みとアテンションマスク:
H = [h1, . . . , hT ]、ht ∈ Rd、mt ∈ {0, 1}
(要するに、各トークンのベクトル表現とどのトークンを見るかのマスクやな)
グローバル埋め込み:
(全体の平均的な表現を計算する式やで)
¯h = (Σt=1からTまで mtht) / (Σt=1からTまで mt)
K個のチャンク用のガウシアン中心:
(文書をK個の部分に分けて、それぞれの中心位置を決めるんやな)
ck = ρkT、ρk = k / (K + 1)、k = 1, . . . , K
ガウシアン重み:
(各位置のトークンにどれだけ重みをつけるか、釣鐘型の分布で決めるねん)
wk,t = mt exp(-1/2 × ((t - ck) / σT)²) / Σt'=1からTまで mt' exp(-1/2 × ((t' - ck) / σT)²)
チャンクローカル埋め込み:
(各チャンクの局所的な表現を計算するで)
˜hk = Σt=1からTまで wk,tht
チャンクローカル埋め込みとグローバル埋め込みをブレンド:
(全体の情報と局所の情報をええ感じに混ぜ合わせるんや)
h*k = (1 − α)¯h + α˜hk
最終的なグローバルとK個のチャンクローカル埋め込み:
(全部まとめて最終的な表現ベクトルの出来上がりや!)
E = [ ¯h, h*1, . . . , h*K ] ∈ Rd(K+1)
---
## Page 16
[](/attach/aad405958c8b29883ce2a1f90e6b2e95208226d0a9d4ee37fb94e1a62fd01be1_p016.png)
### 和訳
FineInstructions:合成命令を事前学習規模までスケールさせる話やで
C. FineInstructionsパイプラインで使うプロンプトの例
下に載せてるんは、LLMを命令チューニングするときに使える汎用的なクエリテンプレートやねん。自然言語でユーザーが聞くような質問のテンプレートになってて、<fi></fi>っていうタグで「ここにこういう内容入れてや」っていうテンプレート変数が入ってるねん。
{{テンプレートの例...}}
で、このテンプレートは*相性のええ*ドキュメント(ウェブページとか記事とか本とかエッセイとかそういうやつな)から実体化できるねん。そのドキュメントには、テンプレート変数を全部埋められるだけの情報があって、しかもそのクエリの答えも書いてあるやつを使うんよ。そしたら、テンプレートとドキュメントを組み合わせて、ちゃんと根拠があって、現実的で、いろんなバリエーションのある命令チューニング用の質問と回答が作れるっちゅうわけやな。
テンプレートと、それに合う相性ええドキュメントがあるとして:
1. **やること:** <fi></fi>のテンプレート変数を埋めて、そのドキュメントに書いてある内容とかトピックとか主題について、「これ実際に聞かれそうやな」っていう現実的な命令を作ってくれへん?
2. **答えられるかどうかとテンプレートの相性問題:** ...
{{その他の要件...}}
<<<命令テンプレート:
{{template}}
>>>
<<<相性ええドキュメント:
{{document}}
>>>
D. FineInstructionsのカテゴリ的な多様性
表4. FineInstructionsの10億件以上の命令を色んなカテゴリに分類してみた結果やで。
ドメイン/カテゴリ
割合(%)
科学
数学
コード
医療
日常生活
推論タスク
タスク系 vs 質疑応答系
36.61%
0.58%
0.25%
10.40%
14.74%
10.99%
6.42%
FineInstructionsみたいなデータセットは、特定のタスクとか特定のドメインに特化した命令を大量に掘り出すのに使えるんやで。例えばな、10億件以上の命令があったら、たった0.58%が数学の命令やったとしても、600万件以上の数学命令がゲットできるわけやねん。これ使ったら、トピックとかタスクの種類の配合を変えて学習する実験とか、特定のタスクの事前学習データの割合増やしてドメイン専門家LLMを作る実験とかができるようになるんよ。先行研究でもこういうのが下流タスクの性能にめっちゃ大事やって分かってるしな(Jangら、2023;Shiら、2023)。
16
---
## Page 17
[](/attach/aad405958c8b29883ce2a1f90e6b2e95208226d0a9d4ee37fb94e1a62fd01be1_p017.png)
### 和訳
E. 判定・フィルタリング段階のアブレーション実験
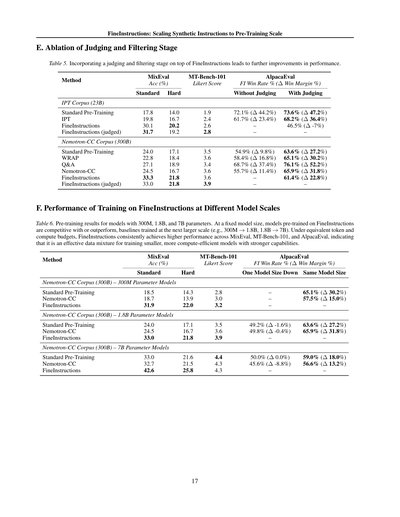
表5. FineInstructionsに判定・フィルタリングの段階を追加したら、さらに性能がアップするんやで。
要は何が言いたいかっていうと、データをただ作るだけやなくて、ちゃんと「これ使えるデータやな」って判定してフィルターかけると、もっとええ結果が出るっちゅうことやねん。
表の見方やけど、MixEvalってのは全体的な精度、MT-Bench-101はリッカート尺度っていう評価スコア、AlpacaEvalは勝率みたいなもんやな。
IPTコーパス(230億トークン)で見てみると、普通の事前学習が17.8%やったのが、FineInstructionsで30.1%まで上がって、さらに判定付きやと31.7%になるんや。めっちゃ伸びてるやろ?
Nemotron-CCコーパス(3000億トークン)でも同じ傾向で、普通の事前学習24.0%から、FineInstructionsで33.3%、判定付きでも33.0%とほぼ維持できてるねん。
F. FineInstructionsでの学習、モデルサイズ別の性能
表6. 3億、18億、70億パラメータのモデルで事前学習した結果やで。
ここがほんまにすごいとこやねんけど、同じモデルサイズで比べたら、FineInstructionsで学習したモデルは、なんと一つ上のサイズのベースラインモデルと同等かそれ以上の性能出すんや!つまり、3億パラメータのFineInstructionsモデルが18億パラメータの普通のモデルに勝てるし、18億が70億に勝てるってことやねん。
同じトークン数と計算量の予算やったら、FineInstructionsはMixEval、MT-Bench-101、AlpacaEvalのどれでも一貫して高い性能を達成するんや。
なんでかっていうと、これって要するに「質のええデータで学習したら、小さいモデルでもでかいモデル並みに賢くなれる」ってことを証明してるわけや。計算コスト抑えながら強いモデル作りたい人には、めっちゃ朗報やで!
具体的な数字見てみ。70億パラメータで普通の事前学習やと33.0%やけど、FineInstructionsやと42.6%まで跳ね上がるねん。これはほんまにえげつない差やで。
---
