<<
2408.06345v2.pdf

---
## Page 1
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p001.png)
### 和訳
ディープラーニングを使った業務文書からの重要情報抽出:体系的文献レビュー
ALEXANDER MICHAEL ROMBACH、ザールラント大学(ドイツ)およびドイツ人工知能研究センター(DFKI)
PETER FETTKE、ザールラント大学(ドイツ)およびドイツ人工知能研究センター(DFKI)
---
書類から大事な情報を抜き出す作業ってな、ビジネスの現場でめっちゃ大きな割合を占めてるねん。せやから、これを効率化したり自動化したりできたら、ほんまにえらい効果があるわけよ。最近ディープラーニングがめっちゃ進歩してきたおかげで、「ドキュメント・アンダースタンディング」っていう大きな傘の下で、重要情報抽出のためのディープラーニング手法がわんさか提案されてきてん。複雑な業務文書もバリバリ処理できるようになってきたってわけや。この体系的文献レビューの目的はな、この分野の既存手法をガッツリ深掘りして分析して、今後の研究でどこにチャンスがあるか見つけ出すことやねん。そのために、2017年から2024年の間に発表された130件の手法を分析したで。
CCS概念:・応用コンピューティング → 文書分析;ビジネスプロセス管理システム;・コンピューティング手法 → 情報抽出;ニューラルネットワーク
追加キーワード:重要情報抽出、ドキュメント・アンダースタンディング、業務文書、ディープラーニング、体系的文献レビュー
---
**1 はじめに**
「ペーパーレスオフィス」、まあ完全に紙をなくすとまではいかんでも「紙を減らしたオフィス」っていうアイデア、実はもう50年も前に出てきてたんよ [50]。せやけどな、今でも紙の書類ってビジネスの現場でめっちゃ重要な役割を果たしてるねん。なんでかっていうと、組織の中でも組織同士の間でも、取引に関するコミュニケーションの主要な手段になってるからや [146]。こういう書類の処理ってな、めっちゃ必要不可欠やけど、同時にめっちゃ時間かかる作業やねん。作業量がハンパないし、異なる情報システム間で情報をやりとりするっていう重要な役割もあるから、自動化できたらめっちゃポテンシャルあるわけよ [22, 161]。それと同時に、ビジネスのデジタル化がどんどん進んでるせいで、書類もデジタルで処理されることが増えてきてるんよな。この流れがまた、自動文書処理の必要性と可能性を強めてるわけや。デジタル形式で手に入る書類がどんどん増えてきてるからな [137]。
---
著者連絡先:Alexander Michael Rombach、ザールラント大学 情報システム研究所(ドイツ・ザールブリュッケン)およびドイツ人工知能研究センター(DFKI)情報システム研究所、alexander_michael.rombach@uni-saarland.de;Peter Fettke、ザールラント大学 情報システム研究所(ドイツ・ザールブリュッケン)およびドイツ人工知能研究センター(DFKI)情報システム研究所、peter.fettke@dfki.de
この論文の全部または一部を個人利用や教育目的でデジタルまたは紙でコピーすることは、営利目的や商業的優位性のために配布されない限り、また最初のページにこの通知と完全な引用が記載されている限り、無料で許可されます。サードパーティコンポーネントの著作権は尊重されなければなりません。その他の使用については、所有者/著者に連絡してください。
© 2025 著作権は所有者/著者に帰属
ACMに投稿された原稿
---
## Page 2
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p002.png)
### 和訳
2
Alexander Michael RombachとPeter Fettke
文書処理の研究って、べつに新しい話ちゃうねん。もう何十年も前からやってることやで[80]。「文書分析」っていう言葉自体、1980年代までさかのぼれるんやって[176]。せやけどな、ここ数年でめっちゃ研究が盛り上がってきてんねん。なんでかっていうと、ディープラーニング(DL)がめちゃくちゃ進歩したおかげで、見た目がリッチな文書(VRDs)とかビジネス文書を処理する研究がガンガン進んどるからや。この分野で一番研究されとるタスクの一つが「キー情報抽出」(KIE)[114]やねん。これ何かっていうと、文書から特定の名前付きエンティティ(人名とか会社名とか金額とか、そういう意味のある情報のことやな)を構造化した形で抜き出すことなんや[146]。
複雑なビジネス文書って、KIEシステムにとってほんまに厄介な相手やねん。なんでかっていうと、従来のKIEアプリケーションみたいに、文書を一本の直線的なテキストとして読んでいくやり方が通用せえへんからや[15]。こういう文書には、暗黙的なヒントとか明示的なヒントがあったり、テキストの部分部分の間に複雑な位置関係があったりするんや。せやから関連する研究では、そういうヒントをモデルの構造にどうやって組み込んだら、もっとええ抽出結果が出せるかを調べとるわけや。ビジネス文書には、業務プロセスと結びついとることから来る特別な性質もあんねん。例えばな、同じプロセスの中で処理される複数の文書には、だいたい同じ情報が繰り返し出てくるやろ。こういう側面とか、それをどうやってKIEシステムの改善に活かせるかって話は、調べる価値があるねん。全体的に言うて、現実世界でKIEの課題にちゃんと取り組むには、プロセス志向の理解がめっちゃ大事やねん。
DLベースのKIEアプローチはVRDs向けにいっぱい提案されてきたんやけど、最新の研究を網羅的にまとめたものがないんや。特に、根底にあるDLの概念とか技術的な特徴に焦点を当てつつ、ビジネスプロセスの観点も取り入れたやつがな。この系統的文献レビュー(SLR)の目的は、まさにその穴を埋めて、この研究分野の詳しい概要と最先端の状況を示すことやねん。この研究の貢献は3つあるで:
(1) 130のアプローチに基づくSLRで、ビジネス文書向けのDLベースKIE手法の簡潔な概要を提供すること
(2) さまざまな特徴に基づいて、対応する手法を分類して詳細に比較すること
(3) 結果、研究のギャップ、そして将来の研究への可能性を広めること
この論文の残りの構成はこんな感じや:第2章では、このSLRに関連する重要な概念と用語の背景情報を説明するで。第3章では、既存の調査論文という観点から関連研究を議論して、この研究がどう違うかを示すねん。第4章では、このSLRに使った方法論、特にどうやって関連文献を特定したかを説明する。第5章では、詳細な分析の結果の概要を示すで。第6章は主要な発見の議論に充てて、特定された文献の具体的な側面について掘り下げるねん。前の2章を踏まえて、第7章では研究アジェンダとフォローアップ研究の出発点を提案するで。第8章でまとめて論文を締めくくるわ。
2 背景
2.1 ビジネスプロセスの観点から
ビジネス文書ってそれ自体に価値があるんやけど、一番よく理解できるのは、お互いの関係性の中で見たときやねん。同じプロセスの実行に属しとる文書同士は、含まれとる情報も密接に関係しとるんや。例えばな、同じ購買プロセスの実行に関連するすべての文書には、たいてい同じ注文IDが入っとるやろ。特定のプロセスに組み込まれとって、どの情報が関係あるかが指定されとるから、ビジネス文書には必ず決まったエンティティのセットが含まれとるんや[21]。例えば請求書やったら、いろんな種類の金額とか、請求書番号みたいな一意の識別子がいっぱい入っとって、それを特定せなあかんわけや。
ビジネスプロセスにおける時間的な関係を理解することも大事やで。簡略化した購買プロセスの例を考えてみてや。まず、お客さんが物理的な商品の注文を出すやろ。ほんで会社がその注文を処理するわけや。
Manuscript submitted to ACM
---
## Page 3
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p003.png)
### 和訳
ディープラーニングを使ったビジネス文書からの重要情報抽出:システマティック文献レビュー
3
注文が来たら、会社は注文確認を送って、そのあとに実際のモノを発送するやん?で、納品書と請求書も送るわけや。電子付録の図SF1には、このプロセスの流れの例が載ってて、顧客とか取引先みたいな社内外の関係者とのやり取りも含まれとるねん。赤でハイライトされてるとこが、ビジネス文書が関わってくる部分で、ここが「文書理解」のアプローチがめっちゃ重要になってくるポイントやな。見たらわかるけど、特に外部のパートナーとのやり取りは、文書ベースのコミュニケーションで行われてるんよ。
あらかじめ決まってるエンティティ(要は情報の種類のことな)についての暗黙知に加えて、関連するビジネスプロセスを考慮するのも実は役立つねん。なんでかっていうと、個々のプロセスステップ間の情報の流れを考慮できるからや。例えば、ビジネス文書から抽出したデータが、次のプロセスステップでどう処理されるかを考えられるやん。そこから、対応するビジネス文書をどう処理すべきかの結論が導き出せるわけや。あと、文書そのものに加えて、文書処理のステップ間に追加のデータフローがあるかどうかも分析できて、それが文書の理解を助けてくれる可能性もあるんよ。
2.2 文書理解
文書理解(DU)っていうのは、自然言語処理(NLP)とコンピュータビジョン(CV)の概念をベースにした包括的な用語で、めっちゃ幅広い文書処理タスクをカバーしてるねん。具体的には、重要情報抽出(KIE)、表の理解、文書レイアウト分析(DLA)、文書分類、視覚的質問応答(VQA)とかがあるで[15]。最近では新しいタスクも提案されてて、「重要情報の位置特定と抽出」っていうのがあるんやけど、これはKIEの拡張版で、重要情報の位置を特定する必要性を強調してるねん。例えばバウンディングボックス(文書画像内の要素の位置を、左上の座標と幅・高さで示すやつな)を識別するとかや[146]。このレビューでカバーしてないKIE以外のDUタスクについて簡単に知りたかったら、[22]を見てな。あと、この研究分野には別の呼び方もあって、文書分析、ドキュメントAI、ドキュメントインテリジェンスとか言われたりもするで[22, 116]。
DUはタスクの複雑さによっても分類できるねん。[37]が提案してるんやけど、知覚タスクは文書の記述的要素(テキストとか表全体とか)の認識を扱うもんで、帰納タスクは知覚された文書に基づいて、もっと豊かな情報(文書クラスとか固有表現とか)の抽出を目指すもんや。そして推論が一番複雑なサブタスクで、知覚と帰納を組み合わせて、文書に明示的に含まれてる情報を超えた理解を可能にするねん。これは主にVQAの文脈で使われるな。推論タスクの例としては、文書内の図やダイアグラムを自然言語で説明するとかがあるで[146]。
2.3 重要情報抽出
KIEっていうのは、文書から固有表現を自動で抽出して、構造化されたフォーマットにするための手法を研究する分野や[146]。さらに個別の研究領域に細分化できて、固有表現認識(NER)、固有表現リンキング、照応解決、関係抽出(RE)、イベント検出、テンプレート穴埋めとかがあるねん[38, 122]。この中でNERとREが一番メジャーやな。NERの目標は、テキスト内のエンティティを検出して、あらかじめ定義されたラベルを割り当てることで、普通は系列ラベリングタスクとして解かれるで[8]。図1には、DUとその下位の研究領域(KIEとか)の階層構造が視覚化されとるわ。
KIEのアプローチは、基礎となる文書をどう表現するかによって、3つの主要なサブグループに分けられるねん。グラフベース、グリッドベース、シーケンス(系列)ベースの手法や。グラフベースのシステムは、文書ページをグラフ構造に変換して、ページのレイアウトと内容を表現するねん。こういうグラフは柔軟な構造を持てて、いろんな方法で構築できるんよ。例えば、文書画像内の各単語、場合によっては各文字をグラフの要素として考えることができるで。
(注:この階層構造は本研究の結果やなくて、文献での理解を反映したもんやで)
ACMに投稿された原稿
---
## Page 4
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p004.png)
### 和訳
図1. 文書理解と重要情報抽出の全体像
グラフの中のノードとして扱うわけやねん。エッジの定義についてもいろんなやり方があってな、例えば全結合グラフっていって、全部のノードが他の全部のノードと繋がってるような構造も作れるんよ。
グラフを作る代わりに、グリッドベースのアプローチっていうのは、もっと整理された格子状の構造を作ろうとするねん。直線的なリンクが主な特徴で、ちゃんと定義された接続関係を持ってるんや。これは文書画像のピクセルをベースにしてることが多いわ。グリッドは普通、いろんな粒度レベルで定義されてて、これによって個々のグリッド要素にどんな特徴が割り当てられるかが変わってくるねん。例えばな、文字レベルでグリッドを定義した場合、文書画像内のある文字のバウンディングボックス(囲み枠みたいなもんや)と重なってるグリッド要素には、その文字から導き出された値(例えば固定の文字インデックスとか)が入るんよ。
一方で、シーケンスベースの手法っていうのは、文書を線形の入力列に変換するねん。理想的には文書のレイアウトとか他の視覚的な手がかりもちゃんと保持して取り込むんや。この入力列は普通、シーケンスラベリングっていう方法で処理されて、各要素が特定のクラスに割り当てられるわけ。詳しくは参考文献[140]を見てな。次の図2で、さっき説明したパラダイムと、サンプル文書の一部をどう表現するかを示してるで。
(a) グラフベース(単語レベル)
(b) グリッドベース(文字レベル)
(c) シーケンスベース(単語レベル)
図2. 重要情報抽出手法における主な文書表現方法(カラーで見るとわかりやすいで)
2.4 入力文書
文書理解の研究では、入力文書のことを「視覚的にリッチな文書」って呼ぶことが多いねん。普遍的に受け入れられてる定義はないんやけど、まとめるとこんな感じで理解できるわ:VRD(視覚的にリッチな文書)っていうのは、要するに見た目の情報がめっちゃ重要な文書のことやねん。
Manuscript submitted to ACM
---
## Page 5
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p005.png)
### 和訳
ディープラーニングを使ったビジネス文書からの重要情報抽出:体系的文献レビュー
5
複雑な文書っていうのはな、テキストとレイアウトと見た目の情報を同時に考えなあかんねん。これ全部まとめて見ないと、文書の意味がちゃんと捉えられへんのよ[22, 42, 74, 180]。視覚的な特徴って何かっていうと、例えばフォントの性質やな。太字でフォントサイズがデカい部分は文書のタイトルやったり、特定のキーワードが「ここの情報抽出してや!」って教えてくれたりするわけ[22]。せやから、KIE(重要情報抽出)には全部のモダリティ(情報の種類)が大事やねん。VRDsを一列のテキストに変換してもうたら、めっちゃ情報が失われてまうんよ。これはニュース記事みたいな「シンプルな」文書とは違うところやな。ニュース記事やったら一列のテキスト表現で十分やからな。ディープラーニングが進歩したおかげで、こういう複雑な入力文書も処理できるようになったんや。なんでかっていうと、いろんな入力モダリティをうまく統合して適切に処理できるからやねん。
「ビジネス文書」っていう言葉は関連する文献ではあんまり頻繁には出てこーへんし、普遍的な定義もないんよ[21]。一般的に言うと、ビジネス文書には組織の内部・外部の業務に関係するプロセスに関わる詳細が含まれてるねん。これらの文書はコミュニケーションの中心的な手段やからな[22, 146]。ビジネス文書はVRDsと同じように、自動化された文書理解システムにとってはなかなかの難題なんや。[116]が議論してるように、いろんな理由があるねん。例えば、対応する文書はめっちゃいろんなフォーマットで存在するし、紙ベースで配布されてるせいでスキャンされた形でしか手に入らんことも多いんよ。スキャンされた文書は画像データに落とし込まれるから、内容を機械が読めるようにするにはOCR(光学文字認識)みたいな技術が必要になるんや[124]。ビジネス文書のレイアウトと全体的な内容は、めっちゃ構造化されてるものからめっちゃ非構造化されてるものまでいろいろあるねん。さらに、ビジネス文書は他の文書と関係があったり、階層的に複数の文書で構成されてたりすることもあるんよ。ビジネス文書を理解するには、こういう相互関係を観察して、プロセスにおける時間的な関係も理解せなあかんねん。
最初に言うたように、文書処理はビジネスの文脈では中心的な活動やねん。せやから、ビジネスプロセスの観点からKIEを研究して、この課題に直接取り組む手法を調査するのは有望なんよ。この研究で扱う入力文書の範囲は、VRDsとビジネス文書の交差する部分やねん。せやから、ビジネスの文脈に普通は組み込まれてないVRDsは考慮せーへんし、同時に、VRDsの特性を持ってないビジネス文書も考慮せーへんねん。後者の例としては会社の一般取引条件があるな。ビジネス文書とみなせるかもしれんけど、普通は視覚的な要素で装飾されてないシンプルなテキスト文書として出てくるからな。この交差部分を扱うときは、VRDsとビジネス文書って言葉を同じ意味で使うで。
3 重要情報抽出に関する既存のレビュー
多くのサーベイは、ドメイン特化型(例えば医療分野[171])やったり、一列のテキスト入力だけを扱うアプローチをカバーしてたりするんよ[94]。最近何年かで、VRDsも扱いながらディープラーニングベースの文書理解手法をカバーするサーベイがいくつか出版されてるねん。でもな、全部がKIEのタスクに焦点を当ててるわけちゃうねん(例えば[14]はDLA(文書レイアウト分析)をカバーしてる)。
以下では、最も密接に関連する研究について議論するで。[148]は簡単なKIEのセクションを提供してるけど、いくつかの関連する側面についての議論に限定されてるねん。このサーベイはアプローチの詳細な分析も含んでへんのよ。[9]では、著者らが多くの異なる側面を持つ文書処理の包括的な概要を提供してるねん。でも、KIEについての議論は限られてるんよ。多くはNER(固有表現認識)に特化して言及してて、全体的なワークフローと前処理や特徴抽出に関するいろんな手法が議論されてるねん。著者らはいくつかのモデルアーキテクチャについて議論してるで。彼らが選んだ検索期間には2010年から2020年の間の研究が含まれてるから、分析された論文の多くも必ずしもディープラーニング手法を使ってへんかったり、VRDsを考慮してへんかったりするんよ。[22]は広範囲のディープラーニングベースの文書理解トピックをカバーしてるねん。一方で、KIEは比較的簡潔に議論されてるんよ。このサーベイはTransformerベースの文書処理手法に関連する側面を一般的な観点から議論してるねん。でもな、使用されてるモデルアーキテクチャや他のKIEパラダイムについての詳細は
(ACMに投稿された原稿)
---
## Page 6
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p006.png)
### 和訳
6
Alexander Michael Rombach と Peter Fettke
細かいところまでは説明されてへんねん。[4]のサーベイはな、文書理解の前段階みたいなタスク、つまりテキストを見つけるやつとテキストを読み取るやつに焦点当ててるんや。
KIE(重要情報抽出)も一応カバーしてるんやけど、紹介されてる手法の数がちょっと少ないねん。著者らはいくつかの手法を詳しく説明してくれてはるんやけど、全体像をばーっと見渡せるような整理が足りてないんやな。[114]ではな、文書処理をRPA(ロボットによる業務自動化)の文脈で位置づけてるんや。めっちゃ広範囲に文献調査はしてるんやけど、視覚的にリッチな文書向けのKIE手法についての技術的な深掘りがないねん。[99]ではKIEの主要な手法の概要を示してくれてるんやけど、結構ざっくりした感じやな。ただ著者らは今後の研究の方向性についてはめっちゃ充実した展望を示してくれてるで。[140]はKIEだけやなくて、VQA(画像に対する質問応答)と文書分類もカバーしてるんや。著者らは文書理解のための分類体系をいろんな観点から提案してて、KIEのベンチマークデータセットに重点置いてるねん。課題と今後の研究についてもいくつか議論されてるわ。[1]は文書理解タスク向けのトランスフォーマーベースの手法をレビューしてるんや。対応するモデルの主要なパラダイムを強調して、いくつかの手法を詳しく紹介してはるねん。このレビューの大きな焦点はベンチマークデータセットの説明とそれに関連する性能比較やな。全体的に見ると、このサーベイはいくつかのトランスフォーマーベースの手法を詳しく議論することを選んでるんやけど、KIEに関する深層学習ベースの手法を幅広く概観する形にはなってへんねん。
全体として、既存のサーベイはな、KIEをめっちゃ広い視点から見てるか、少数の手法だけを詳しくカバーしてるか、あるいは多くの発表された研究を含めてるけどその分手法の詳細な議論が犠牲になってるか、のどれかやねん。一方でこの研究はな、量的にも質的にも深い分析を提供してるんや。もう一つの大きな違いは、ビジネスプロセスの視点を取り入れてることやな。セクション2.1で議論したように、ビジネスプロセスと一般的なドメイン知識の考慮は、KIEシステムにとってめっちゃ重要なんや。この点で、[114]のレビューだけが分析の際に実務志向の視点も採用してるんやな。表1は、前述した関連研究をいくつかの区別要因に沿って比較したものやで。
表1. 既存のレビューとの比較
| 区別要因 | [148] | [9] | [22] | [4] | [114] | [99] | [140] | [1] | 我々の研究 |
|---|---|---|---|---|---|---|---|---|---|
| 検索期間 | n/a | 2010-2020 | n/a | n/a | 2017-2022 | n/a | n/a | 2014-2023 | 2017-2024 |
| 詳細な検索戦略 | | ★★★★★ | | | ★★★★★ | | | ★★★★ | ★★★★★ |
| KIEタスクへの焦点 | ★★ | ★★★ | ★★★ | ★★★ | ★★ | ★★★★★ | ★★★ | ★★★ | ★★★★★ |
| ビジネスプロセスの視点 | ★ | ★★ | ★ | | ★★★★ | | | | ★★★★★ |
| DL概念の分析 | ★★ | ★★★ | ★★ | ★★ | ★ | ★★ | ★★ | ★★★★ | ★★★★★ |
| 主要特性の分析 | ★ | ★★★ | ★★★★ | ★★★ | ★★★ | ★★★★ | ★★★★ | ★★★ | ★★★★★ |
| KIEデータセットの分析 | | ★ | ★★★ | ★ | ★ | ★★★★ | ★★★ | ★★★★★ | ★★★★★ |
| 性能比較 | | ★★ | | ★★ | ★ | ★★ | | ★★★★ | ★★★★★ |
| 今後の研究への言及 | | ★★★ | ★★ | ★ | ★★ | ★★★ | ★★★ | ★ | ★★★★★ |
4 方法論
4.1 リサーチクエスチョン
このシステマティック文献レビューで答えなあかん全体的なリサーチクエスチョンはこれや:「ビジネス文書からの深層学習ベースの重要情報抽出における最先端技術はどないなっとるんや?」。ほんで、さらに8つのリサーチクエスチョンを設定してるんや:
- RQ1:どんな入力モダリティ(情報の種類)が考慮されてて、それらはどうやって統合されとるんや?
- RQ2:どんな深層学習アーキテクチャが使われとるんや?
- RQ3:既存の手法はどんな基準で分類できるんや?
- RQ4:どんな入力文書が対象になっとるんや?
Manuscript submitted to ACM
---
## Page 7
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p007.png)
### 和訳
# ビジネス文書からのディープラーニングを使った重要情報抽出:系統的文献レビュー
## 7ページ目
ほな、研究で調べたい質問を紹介していくで!
- **RQ5**: 実際の使い道とか、その分野の専門知識ってどれくらい議論されとるん?
- **RQ6**: 一番ええ感じに動いてる方法ってどれなん?
- **RQ7**: 提案されてる方法とかモデルの設計に、なんか目立った流行りとかあるん?
- **RQ8**: これからの研究で「ここ改善できるやん!」ってとこ、どんなんがあるん?
最初の5つの質問はな、見つけた方法をめっちゃ深掘りして分析するためのもんやねん。提案されてる手法がどんなんで、お互いどう違うんかを調べるんや。入力データの種類とか、モデルの設計とか、使ってるデータベースとか、そういう大事なポイントを見ていくわけ。ほんで6番目から8番目の質問は、もうちょい引いた目線で全体を見渡して、「今一番イケてる技術ってどれ?」っていうのを特定したり、これから研究する人への「こうしたらええで」っていうアドバイスを出すのが目的やねん。
## 4.2 文献の探し方
関係ありそうな論文を探すのに、以下の6つのデータベースを使ったで:ACM Digital Library(ACM)、ACL Anthology(ACL)、AIS eLibrary(AIS)、IEEE Xplore(IEEE)、ScienceDirect(SD)、それとSpringerLink(SL)や。
検索に使う文字列はめっちゃ慎重に考えて作ったんや。なんでかっていうと、この研究分野でよく使われる用語と、対象にしてる領域(VRD、つまり視覚的にリッチな文書のことやな)に関係するキーワード、あとディープラーニングの設計に関する言葉を全部入れたかったからやねん。検索エンジンが対応してたら、「この言葉は入ってたらあかん」っていう除外ワードも設定して、この研究の範囲外の論文を弾くようにしたで。検索期間は2017年から2024年に限定したんや。2017年を下限にしたんは、めっちゃ助かるポイントでな。なんでかっていうと、重要情報抽出に関する論文って、2017年より前はディープラーニングの手法使ってへんかったからや。各データベースの最終的な検索文字列と、その時に出てきた結果の数は、電子付録の表ST1に載せてあるで。
論文をふるいにかけるための「入れる基準」と「外す基準」を以下のように決めたんや。まず、タイトル、要約、結論を分析して、この基準に引っかからへんかったら、次に全文を分析する流れやねん。
**【入れる基準】**
- **IN1**: その研究が査読済みで、重要情報抽出の分野に関係してること
- **IN2**: ディープラーニングの考え方を使ってて、そのモデルの設計をちゃんと説明してること
- **IN3**: その方法がどれくらい効果的か、数字で評価するか、質的に評価するか、どっちかでちゃんと検証してること
**【外す基準】**
- **EX1**: 英語で書かれてへん、または決めた検索期間の外に出版されてる
- **EX2**: 重要情報抽出の新しい方法を提案してるんやなくて、既存の方法を別の用途に使ってるだけやったり、既存の方法のまとめをしてるだけやったり、新しいデータセットを提案してるだけやったりする
- **EX3**: VRD(視覚的にリッチな文書)に適用してへんくて、別の分野に使ってたり、テキストだけの入力しか考えてへん
- **EX4**: 重要情報抽出に焦点当ててへんくて、他の文書理解タスクをやってたり、画像の前処理だけに集中してる
- **EX5**: 表みたいな、めっちゃ特定の文書要素から情報抽出することだけに焦点当ててる
全体の検索プロセスは、PRISMA[125]っていう方法に沿って進めてて、電子付録の図SF2で図解してあるで。この系統的文献レビューでは、合計130個の関連する方法が見つかったんや。見つけた方法のリストと、この論文の中で参照用に使う番号は、電子付録の表ST2に載せてあるで。
## 5 結果
### 5.1 概要
まずは、分析した研究の全体像をざっくり見ていこか。電子付録の表ST3に、いろんな性質に沿った分析結果を載せてあるねん。それぞれの性質は違う側面を見てて、実際の応用も念頭に置いてるで。図3aは、重要情報抽出のパラダイム(考え方のタイプ)がどんな割合で分布してるかを視覚化したもんや。ほぼ半分の
---
*ACMに提出された原稿*
---
## Page 8
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p008.png)
### 和訳
8
Alexander Michael RombachとPeter Fettkeの研究やねんけど
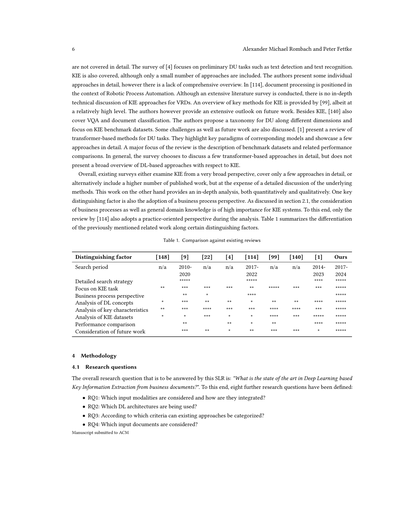
ここで紹介してるアプローチっていうのは、「シーケンスベース」っていうグループに入るもんやねん。ほんで、よく使われるカテゴリーとしてはあと2つあって、「グラフベース」のシステムと、グラフベースとシーケンスベースを組み合わせたアプローチがあるんよ。グリッド表現っていうのは、グラフ表現ほどメジャーやないねん。なんでかっていうと、純粋にこのやり方だけでやってるのは9個しかないからや。大規模言語モデル(LLM)ベースのシステムは新しく出てきたカテゴリーで、11個のアプローチが見つかっとる。あと、分析した論文のうち7つだけはどのグループにも当てはまらへんかってんけど、これって逆に言うたら、さっき挙げたパラダイムがKIE(重要情報抽出)システムでめっちゃ支配的やってことを裏付けてるわけやな。おもろいことに、[169]の研究だけがグリッドベースとシーケンスベースの概念を1つのKIEアプローチに組み合わせてるんよ。
図3bで見える時系列での手法の分布を見てみると、特に2021年以降、KIE研究への関心がめっちゃ高まってるのがわかるねん。あと注目すべきは、シーケンスベースのアプローチが優勢になり始めたんは2021年からで、それ以前はグラフベースの手法が一番多かったっていうことや。この時期にシーケンスベースの手法が人気出た理由は、おそらく[178]の影響力のある研究のおかげやと思うわ。この研究は、トランスフォーマーアーキテクチャと大規模な事前学習を使って最先端の結果を出した最初の研究の一つやってん。ほんで、これがきっかけでこの方向での後続研究がめっちゃ増えたんよ。2023年には、前年や他のカテゴリーと比べてグラフベースの手法も大幅に増加しとる。つまり、このカテゴリーは時間が経っても比較的人気を維持してるってことやな。全体的に見ると、2024年が一番論文の発表数が多くて、この研究分野への関心がまだまだ高いことを示してるわ。せやけど、2022年はKIE関連のアプローチの数がかなり減少してん。これの理由の一つは、さっき言うたシーケンスベースの手法への関心が高まったことかもしれへん。シーケンスベースの手法は普通、大規模な事前学習が必要やからな。やから、多くの研究者が2022年は対応する手法の開発と論文執筆に費やして、2023年か2024年に発表したんやろうな。LLMの登場を考えると、KIE研究にも2023年から現れ始めて、2024年には大幅に増加して、すでに2番目に多いカテゴリーになっとる。
(a) 全体の分布
(b) 時系列での分布
図3. カテゴリーの分布
統合された入力モダリティの分析を見ると、大多数のアプローチが少なくともテキストとレイアウト関連の特徴を統合してるねん。これは当たり前っちゃ当たり前やな、だってこれらの要素が文書処理にとって一番関連性の高い情報を含んでるからや。レイアウトモダリティは通常、バウンディングボックス、つまり文書画像内の単語の座標から導き出されるんよ。分析したアプローチの約60%が、文書画像から得られる視覚的特徴を統合しとる。セクション2.4で議論したように、こういう視覚的な手がかりをKIEシステムに統合することは、複雑なVRD(視覚的にリッチな文書)をちゃんと理解するためにめっちゃ重要になりうるねん。この重要性を考えたら、視覚的特徴を使ってるアプローチが比較的少ないんちゃうか、って議論もできるわな。
Manuscript submitted to ACM
---
## Page 9
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p009.png)
### 和訳
ディープラーニング使ったビジネス文書からの重要情報抽出:研究論文の系統的レビュー
9
画像モダリティを統合するやつの話やねんけど、結果見てみたら、2021年以降めっちゃ視覚的な手がかりをモデルに組み込む傾向が増えてきてんねん。この点について、[123]の研究がKIEシステムに視覚モダリティをどう取得して融合するかっていう様々な方法をがっつり調べてくれてんねん。で、わかったんは、視覚情報をどう表現するかは元になるVRD(視覚的にリッチな文書)次第やし、アテンションベースの融合メカニズムは、特徴ベクトルを単純にくっつけるだけみたいな基本的な方法より性能ええってことやねん。一般的に、複数のモダリティを統合するんは文書理解システムにとってめっちゃ重要な役割果たすねん。なんでかっていうと、お互いを補い合う異なる側面からの手がかりを取り込めるからやねん。例えば、画像モダリティはテキストやバウンディングボックスが少ない文書に対して関連する洞察を与えてくれるし、レイアウトモダリティはめっちゃ複雑なレイアウトと独特な構造を持つ文書には欠かせへんねん[181]。手作りの入力モダリティを使うアプローチもあるねん。ほとんどの場合、カスタム入力特徴として統合されてて、例えば文書内の単語が日付とか金額みたいな特定のエンティティを表してるかどうかのブーリアンフラグとかやな。もう一つの特徴タイプは、全体の読み順に対する特定の単語の位置情報やねん。いくつかの論文では、手作り入力は単語の文字数とか、フォントの詳細とか、エンコードされた文字表現みたいな構文的特徴に基づいてるねん。手作り特徴の使用はグリッドベースのアプローチとセットになることも多いねん。そういう方法は通常、グリッドの各要素に特定の値を割り当てるカスタムエンコーディング関数を定義するねん。例えば、[127]は文書画像の各ピクセルに定数値を割り当ててて、各位置の文字の整数インデックスとか、文書画像の空白部分には0の値を使うねん。どのアプローチもセクション2.1で議論したような関連ビジネスワークフローから得られるメタデータは統合してへんから、この点では実務志向の視点が欠けてるねん。全体的に見て、手作り特徴は文書に明示的に含まれてるデータ以上の追加情報を提供するから、KIEシステムを改善できるねん。ただし言うとかなあかんのは、手作り入力特徴は労働集約的なデータアノテーションという点でかなりの追加作業につながる可能性があるってことやねん[137]、これがこの特徴タイプがあんまり使われへん理由かもしれへんな。あと、そういう手作り特徴を含めると、訓練文書のドメインに過学習してまう可能性があって、異なるドメインへの汎化能力が下がるって議論もできるねん。せやけど、手作り入力特徴の統合と異なるドメインへの汎化能力のトレードオフを分析した研究は今のところないねん。
基礎となるデータに関しては、使用文書数の中央値は2,172やねん。これ、特にデータを訓練用と評価用に分けなあかんこと考えたら、結構少ない量やねん。結果として、多くのアプローチは小さな文書コーパスでしか訓練されてへんくて、つまりレイアウトのバリエーションも少ないってことやろな。DLベースの文書理解モデルは通常訓練に大量のデータが必要やから[137]、提案されたアプローチがほんまに全力出せてるかは疑問やねん。この観察には事前学習目的で使われるデータは含まれてへんことに注意してな、それについてはセクション5.2.1の系列ベースアプローチのところで議論するわ。平均とは違って、[79, 126, 139]はKIEシステムの実装に100万以上の文書を使ってるねん。一方で、199文書しか使ってへんのにええ抽出結果出してるケースもあるねん。これは個々のアプローチのデータ要件にめっちゃ大きな違いがあって、一部のアーキテクチャは大幅に少ないデータでもやっていけるってことを示してるねん。考慮されてる文書タイプの大多数はレシートとフォームで、少なくとも半分のアプローチで使われてるねん。主な理由は、最もよく使われるベンチマークデータセットがこれらの文書タイプに基づいてるからやねん。それ以外では、著者が公開ベンチマークやなくて非公開の社内データセットを使う場合に、請求書が最もよく考慮されてるねん。
再現性の観点では、50のアプローチで実装コードが利用可能やねん。ほとんどの場合、著者が直接コードを共有してるんやけど、外部ソースが再実装して公開してる例外もあるねん。モデルの重みはさらに共有されることが少ないんやけど、事前学習モデルにとってはほんまは特に役立つはずやねん。なんでかっていうと、それをベースに外部の人らが改善や最適化できるからやねん。
ACMに提出された原稿
---
## Page 10
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p010.png)
### 和訳
10
Alexander Michael RombachとPeter Fettke
コードかモデルの重み、どっちかを公開するときは、だいたい商用利用OKなライセンスつけてることが多いねん。これってめっちゃええことやねん。なんでかっていうと、自分とこの業務プロセスにKIEシステム組み込みたい組織にとってはありがたい話やし、そうすることで研究の成果がどんどん広まっていくわけや。
いくつかのアプローチは外部のOCRエンジンに頼らんでもええようになってて、やから文字読み取りと情報抽出の両方を自分でやるタイプ(エンドツーエンド)か、もしくはそもそも文字読み取り自体が要らんくて、見た目豊かな文書(VRD)をそのまま欲しい出力に変換するタイプ(OCRフリー)かのどっちかやねん[140]。[5]のシステムは事前学習のときだけエンドツーエンドやねん。あと[79]が提案してるシステムもエンドツーエンドで設計できるんやけど、著者らは結局外部のOCRエンジン使う方選んでるねん。こういうアプローチは2019年に初めて出てきて、2022年以降はもっと増えてきてるねん。23個見つかった生成型KIE手法についても同じことが言えて、2021年に初めて登場したんやけど、今は注目度上がってきてるねん。特に生成型の大規模言語モデル(LLM)が盛り上がってきてるからな。このカテゴリのKIE手法は、自己回帰的なデコードの仕組みを使って、どんなテキストでも出力できるのが特徴やねん。めっちゃええ点として、OCRがミスっても影響受けにくいことがあるねん。なんでかっていうと、目的の単語をOCRなしの表現で生成できるからや[17]。あと、いろんな文書理解タスクにも適応しやすいねん。例えば、テキストのプロンプトを変えるだけでええとかな[26, 77]。一方で、分類ヘッドを使う従来型のKIE手法やと、文書分類みたいな別のタスクをやりたかったら、分類層を変えて再学習せなあかんねん[26]。
ドメイン知識を明示的に使ってるのは10本の論文だけやねん。ドメイン知識の組み込み方は、さっき話した通り、だいたい手作業で設計した入力特徴量を使うパターンが多いねん。これってやっぱり関連文献に実務的な視点が欠けてることを示してるわけや。対応するKIEシステムが、実際の現場のワークフローから得られる知見を考慮してないってことやからな。あと、実際の産業現場で評価されてるアプローチはたった3つだけやねん。そういうケースでは、著者らが開発したKIE手法が実際の文書処理タスクにどんなインパクトがあるか、例えば効率がどんだけ上がったかとかを示してるねん。やから、研究の進歩と実際の応用の間にはめっちゃ大きなギャップがあるわけや。提案されてるモデルのほとんどが実際の現場で評価されてへんからな。せやから、ベンチマークでスコア上がる改良でも、実際の現場ではすぐには使えへん可能性があるねん。例えば、めっちゃ大量のデータが必要やったりとかな。分析した論文のうち16本は、既存アプローチの発展版やねん。代表的な例がLayoutLMファミリーやな。元祖のLayoutLM [178]をベースに、いろんな面で改良・改善した後継版がいっぱい提案されてきたわけや。もう一つの例はChargrid [74]で、これがグリッドベースの多くのアプローチの土台になってるねん(5.2.3節参照)。分析したアプローチのうちいくつかは、弱いアノテーションのデータで実装されてるねん。だいたいの場合、文書画像の他に必要なのはテキストの目標値だけってことやな。他のアプローチではセグメントレベルか単語レベルのアノテーションだけでええものもあるねん。こういうアプローチは完全にアノテーションされた文書で学習せんでもええねん。普通は各単語にラベル付けして、その境界ボックスとエンティティも全部付けなあかんのやけどな。こういうアプローチは、データのアノテーションにコストかかる実際の現場では使いやすいかもしれんな。
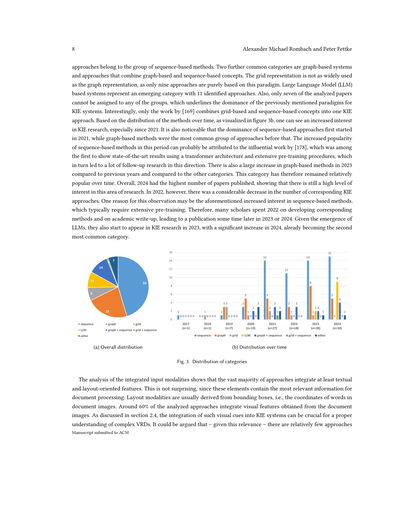
モデルサイズの推移(パラメータ数、単位は百万)を図4に示してるで。[60]のアプローチはGPT3ベースで1750億パラメータもあるから、y軸は対数スケールにせなあかんかったことに注意してな。オレンジの線が時間経過に伴うトレンドを示してるねん。分析したアプローチに基づくと、学習可能なパラメータ数の中央値は1億7000万やねん。ほとんどのアプローチは2000万から5億パラメータの範囲に収まってて、これは時間が経ってもあんまり変わってへんねん。せやけど、LLMの登場で、数十億パラメータのアプローチがどんどん提案されるようになってきてて、図にも示されてる通りやねん。
5.2 カテゴリ
**シーケンスベースの手法。** 電子補足資料の表ST4に、シーケンスベースアプローチの分析結果を示してるで。複数のパラダイムに基づくハイブリッドKIEアプローチも含めてるねん
Manuscript submitted to ACM
---
## Page 11
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p011.png)
### 和訳
# ディープラーニングを使った、ビジネス文書からの重要情報抽出:研究論文まとめ
11
図4. パラメータ数の変遷
(例えば、グラフベースとシーケンスベースを組み合わせた方法とか)をこの分析では扱ってて、シーケンスベースのサブシステムに関する発見を紹介するで。ほとんどの手法は「単語レベル」で定義されとって、つまり文書画像の各単語がシーケンスの1つの要素になるっちゅうことやな。場合によっては、セグメント(区切り)とか文レベルの粒度が選ばれることもあって、これは文を意味のまとまりとして扱って、その後に集約した埋め込みベクトルを計算するっちゅうやり方やねん。他にもあんまり使われへんけど、文字レベル、トークンレベル、セルレベルとかの粒度もあるで。単語レベルが人気なんは、意味の豊かさと計算効率のバランスがええからやねん。それにOCR(文字認識)の出力とか、LayoutLMみたいな事前学習済みのTransformerとも相性がええねん。もっと細かい粒度やと構造の理解は良くなるかもしれんけど、複雑になるし位置合わせが難しなるから、あんまり使われへんのが現状やな。著者によっては複数の粒度を同時に使うこともあって、細かい特徴と粗い特徴の両方を見ることで、お互いを補い合えるっちゅうわけや。
シーケンスベースのアプローチの約半分は、モデルの事前学習とその後のKIE(重要情報抽出)タスク向けファインチューニングをやってへんねん。これはちょっと意外やな、なんでかっていうと、事前学習で文書の一般的な理解を獲得するんが有望な研究方向やって示されとるからや。事前学習をやる場合、使われる文書の平均数は約500万件やで。これ見たら、事前学習にどんだけ大量のデータが必要かわかるやろ。事前学習用の最大の文書コーパスは[16]が使ったやつで、4300万件の文書からできとる。これとは違って[119]のアプローチは、事前学習にたった5,170件の文書しか使ってへんのに、それでも競争力のあるベンチマーク結果を出しとるんやで。事前学習はめっちゃリソース食うねん。例えば[178]によると、彼らの最大モデルは600万件の文書データセットの1エポック学習するのに170時間かかったって報告しとる。約半分のケースではIIT-CDIPデータセットが使われとる。このデータセットは[91]で提案されたやつで、Legacy Tobacco Document Library(タバコ文書ライブラリ)³の文書が含まれとって、1990年代のタバコ産業に対する訴訟関連の文書やねん。もう一つよく使われるデータセットはRVL-CDIPやけど、これはIIT-CDIPの一部やから追加の文書は含まれてへん。あと、7つのケースでは非公開の文書コレクションが事前学習に使われとる。これらのよく使われるデータセット以外にも、DocBankみたいな大規模データセットはあるんやけど、あんまり使われてへんな。表ST4には使われた事前学習タスクもリストアップされとって、一番よく使われるんは[178]が提案したMVLM(Masked Visual-Language Modeling:マスク付き視覚言語モデリング)やねん。このタスクは、もっと一般的なMasked Language Modeling(マスク付き言語モデリング)と強く関連しとって、これは元々BERT[32]で導入されたもんや。MVLMでは、入力シーケンスのランダムなトークンをマスク(隠す)して、モデルの目標は周りの文脈から隠されたトークンを予測することやねん。ほんまに大事なんは、位置情報はマスクされへんから、モデルの復元を助けてくれるっちゅうことや。こうやって、モデルは言語の文脈を学びながら、位置情報も活用できるようになるんや。著者によってはこのアイデアを画像モダリティにも転用して、
³https://www.industrydocuments.ucsf.edu/tobacco/
ACMに投稿された原稿
---
## Page 12
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p012.png)
### 和訳
12
Alexander Michael RombachとPeter Fettkeの研究やな
**Masked Image Modeling(マスク画像モデリング)**っていう手法があってな、これはモデルに「隠された画像トークンを復元させる」っていうタスクをやらせるんや。でもこれ、ちょっと問題があってな。文書画像って大部分が白い背景やろ?せやから、モデルが周りのテキストとか画像トークンのこと全然考えんと、「とりあえず白いピクセル予測しとけばええやん」ってなりがちなんよ[145]。時間が経つにつれて、他にもいろんな関連タスクが提案されてきてな、画像の情報も明示的に含むようになったんや。これでKIE(キー情報抽出)モデルは、事前学習のときにテキスト・位置・視覚情報をフルに活用できるようになったわけ。研究者がエンドツーエンドとか生成型のKIE手法を提案するときは、テキストを読んで出力を順番に生成する(自己回帰的に)やり方を学習させるために、特別な事前学習の目的を設定するんやで。詳しくは6.2章も見てな。
エンコーダとデコーダのアーキテクチャの分布についてやけど、12個のアプローチは専用のテキストエンコーダを全く使ってへんし、25個は視覚エンコーダを使ってへん。[60, 127]の研究では、どっちのエンコーダも使ってへんねん。ほとんどの場合、テキストエンコーディングにはBERTか、RoBERTA[106]やSBERT[134]みたいな派生バージョンが使われてるわ。これはまあ当然やな、BERTベースのモデルがNLP(自然言語処理)でめっちゃ人気やからな。もう一つよく使われるエンコーディング手法は、LayoutLMファミリーや。具体的にはLayoutXLM、LayoutLM、LayoutLMv2とかな。なんでかっていうと、これらのモデルがDU(文書理解)の分野でめっちゃ人気あるし、大規模な事前学習がされてるから、表現力豊かな埋め込みを活用できるねん。せやから、系列ベースのアプローチの多くが専用の事前学習ステージを設けへんのも説明つくわ。すでに事前学習済みのモデルを使えるからな。一部の研究者は、N-gramモデルとかWord2Vec、FastTextみたいな、もっと伝統的な埋め込み手法を使ってるで。視覚エンコーダについては、特定のモデルが圧倒的に優勢ってわけちゃうけど、一番よく使われる視覚のバックボーンはResNetモデル[59]やな。これは関連するCV(コンピュータビジョン)タスクでも人気あるねん。ResNet50とResNet18が一番よく使われるバリエーションやけど、改良版として提案されたResNeXt101-FPNとかConvNeXt-FPNも使われてるで。あと、最近のSwin Transformer[107]を視覚エンコーダとして組み込んでる研究者もおる。これは重ならない画像パッチを順番に処理して、シフトウィンドウの自己注意機構を使って、局所的・大域的な画像特徴を捉えるんや。面白いことに、Vision Transformer(ViT)を組み込んでるのは[56]のアプローチだけやねん。このモデルも視覚タスクにTransformerを活用するんやけど、Swin Transformerと違って、入力画像を階層的な分割なしにパッチの系列として処理するんや。Document Image Transformer(DiT)[95]っていう、ViTを自己教師あり学習で改良したやつも、[68]のアプローチでしか使われてへん。Transformerベースの視覚エンコーダがあんまり使われへん理由は、CNNベースのモデルより豊かな視覚特徴を捉えられる可能性があるのに、計算コストと学習の複雑さが高いからかもしれんな。デコーダの選択の分布を見ると、大多数のアプローチが系列ラベリング層をデコーディングに使ってるわ。これは普通、線形層とSoftmax層で構成されてて、系列中の各トークンに対して、可能なすべてのフィールドの確率分布を割り当てるんや。KIEのタスクは、その確率分布に従って最も確率の高いフィールドを選ぶことで実行されるねん。それ以外に、LSTM[61]、BiLSTM[141]、条件付き確率場(CRF)[87]、またはこれらの組み合わせを使うアプローチもあるで。BiLSTMがよく使われるのは、双方向で文脈情報を効果的に捉えられるからや。CRFが便利なんは、系列中のラベル間の依存関係をモデル化して、大域的な文脈を取り込めるからやな。こういうより複雑なモデルは、単純なSoftmax層と比べて追加の情報を提供できるから、抽出性能を向上させられる可能性があるんや。デコーダの選択を時系列で見ると、前述の2つのバリエーションは2022年以降あんまり頻繁には使われてへんのがわかるわ。あと、特に2023年以降は、新しいデコーディング手法が検討されてる。それでも、系列ラベリング層は時間が経っても人気を保ってるな。一部の研究者は、既存のKIEアプローチをデコーディングに使ってる。例えば、[30]は[77]のモデルをデコーディングステップに使ってるで。
全体的に言えることは、エンコーダとデコーダの仕組みにはめっちゃいろんなアプローチがあって、圧倒的に優勢なアプローチはないってことやな。テキストエンコーディングにはBERTモデルとLayoutLMみたいなレイアウト対応バリエーションが一番よく使われてて、視覚バックボーンにはResNetベースのモデルが使われてる。デコーディングステップは普通、
Manuscript submitted to ACM
---
## Page 13
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p013.png)
### 和訳
ディープラーニングによるビジネス文書からのキー情報抽出:系統的文献レビュー
13
シンプルな系列ラベリング層使うか、もうちょい複雑なアーキテクチャ使ってトークン系列の中の依存関係を取り込むかの違いがあんねん。
5.2.2 グラフベースの手法。分析したグラフベースのアプローチについての結果は、電子補足資料の表ST5に載せてるで。これらのアプローチで一番違うポイントは、ベースになるグラフ表現をどうやって作るかってとこやねん。ほとんどのアプローチは完全連結グラフっていうの使ってて、これはグラフの全部のノードが他の全ノードと繋がってるってことや。せやから、できあがるグラフはめっちゃエッジの数が多くなんねん。あとよう使われるんがk近傍法で、各ノードがk個の隣接ノード持つやつやな。アプローチによってkの値は4から100までいろいろあんねん。このkの値選ぶんがなかなか難しくて、いろんなバイアスが入り込む可能性があんねん[13]。それにkを大きくしたら、必然的にグラフ構造が複雑になりすぎてエッジが多くなりすぎるんよ[177]。そうなると、KIEのアプローチが文書内の実際の関係性をちゃんと認識でけへんくなることがあんねん。せやけど、この辺を深く調べた研究はまだないんよな。他によう使われる方法としては、上下左右の4方向の隣接ノードを見る方法とか、β-スケルトングラフアルゴリズムっていうのがあって、これはパラメータβに応じて幾何学的な近さでノードを繋ぐやつや。ちなみに全部のアプローチでβ=1を選んでるで。何人かの研究者は、各ノードから出発して文書を別々のエリアに分けて(例えば45度の角度で)、各セグメントで一番近い隣接ノードを特定してんねん。[20]では各ノードから36本の光線を出して、その光線がバウンディングボックスを横切る他のノードを全部隣接ノードとして扱ってんねん。一部のKIEシステムでは、グラフ作成をヒューリスティックなアルゴリズムで決めるんやなくて、ニューラルネットワークで繰り返し学習して決めてんねん。なんでかっていうと、さっき言うたヒューリスティックなアルゴリズムやと、VRD(視覚的にリッチな文書)のレイアウトをちゃんと表現でけへんことがあるからやねん。
グラフを通じて情報を伝播させる方法についてやけど、ほとんどの場合はグラフ畳み込みネットワーク(GCN)が使われてんねん。GCNはグラフノード間で情報を伝播させて、局所的なコンテキストと大域的なコンテキストの両方を捉える表現を繰り返し学習していくんや。各イテレーション(つまりグラフ畳み込み)で、ノードとエッジの新しい埋め込みを計算すんねん。いくつかの論文では、ノード-エッジ-ノードの3つ組で定義されたGCNのバリエーションを多層パーセプトロン(MLP)と組み合わせて使ってんねん。この設定やと、ノード自体の特徴量、そのエッジ、全部の隣接ノードの特徴量を融合して新しいノードの埋め込みを得んねん。グラフ伝播のもう一つのよく使われる方法として、グラフアテンションネットワーク(GAT)があって、マルチヘッドアテンションありなしの両方があんねん。このアーキテクチャはトランスフォーマーベースのアテンション機構を使って、各隣接ノードに対して異なる重み係数を計算すんねん。そうすることでモデルがグラフ伝播の際に一番関連性の高い情報に集中できて、全体的なノード表現が改善されんねん[159]。せやけど、GCNほどは使われてへんねん。それはたぶん、アテンション機構の複雑さと計算コストが増えるからやと思うわ、特に大きなグラフ扱う時はな。グラフ伝播に関しては、伝播層の数も分析できんねん。層の数はシステム全体の複雑さだけやなく、各ノードの受容野も決めんねん。受容野っていうのは、隣接ノードからどこまで情報を集約できるかってことや。各層で受容野の深さが1つずつ増えんねん。平均すると、これらのアプローチは3.7層で構成されてんねん。[105]は層の数について消去法的な研究をして、GCN層の最適な数は2やって結論出したんやけど、これはタスクによるから、ケースバイケースで考えなあかんで。GATベースのアプローチについては、アテンションヘッドの数を決めなあかんねん。[12]がいろんなアテンションヘッド数で研究して、彼らのケースでは26個のアテンションヘッドが一番ええ結果出したって結論づけてんねん。著者らはアテンションヘッドの数と抽出するフィールドの数の間に相関関係があるかもしれんとも言うてんねん。ここでも、個々のケースでどのバリエーションが一番うまくいくか調べる必要があんねん。
最終的にKIEをどうやって実行するかって点でもアプローチは違ってんねん。ほとんどのアプローチはシンプルなノード分類を使ってて、つまり各グラフノードの埋め込みが得られたら、それを使って各ノードを
Manuscript submitted to ACM
---
## Page 14
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p014.png)
### 和訳
14
Alexander Michael RombachとPeter Fettke
抽出したいフィールドを特定するのに、分類層っていうのを使うねん。あと、BiLSTMとかCRF、それからこの2つを組み合わせたBiLSTM-CRFもよく使われとるで。他にもいろんな方法があって、たとえば[88]の研究ではビタビアルゴリズムっていうのを使っとるんや。これ何かっていうと、確率を順番に計算していって、グラフを逆向きにたどることで「一番ありそうな状態の並び」を見つけ出すっちゅう賢い方法やねん。
ほとんどの場合、グラフは単語レベルで定義されとって、文書画像上の各単語が、作られるグラフの1つのノード(点みたいなもんやな)になるわけや(図2a参照)。これはシーケンスベースの方法での粒度とも一致しとるで。グラフを定義するもう1つのよくあるやり方は、文全体とかセグメント(かたまり)全体を考えるパターンやな。そうすると、できあがるグラフはけっこう大雑把な感じになるわけや。テキスト行全体を1つのノードとして扱うアプローチもあって、その行の中のテキスト要素が互いに関係あるかどうかは気にせえへんねん。一部の研究者は、細かい粒度(単語とか)と粗い粒度(テキストのかたまりとか)の両方を同時に使って、複数の粒度でグラフを定義しとるで。
グラフベースの方法のもう1つの重要な要素が、ノード特徴量の定義やねん。この特徴量によって、KIE(重要情報抽出)にどんなタイプの情報を使えるかが決まってくるんや。一般的に、ノード特徴量には位置に関する値が入っとって、たとえば文書画像内でのノードの正規化座標とかやな。近くのノードとの相対的な距離が入っとることもあるで。もう1つよくある特徴量のタイプは、そのノードが表すテキスト内容に関するもの、つまり単語埋め込みやな。どの埋め込みモデルを使うかはアプローチによって違うねん。BERTベースの埋め込みがよく使われとって、これはシーケンスベースのアプローチでテキストエンコーダーを見たときの観察結果とも一致しとるわ。他の方法としては、Byte Pair Encoding [143]、BiLSTM、LayoutLMなんかがあるで。複数のテキスト埋め込みを同時に使うケースもあって、たとえば[195]はWord2Vec、BERT、LayoutLMを単語埋め込みに使っとるんや。位置とテキストの埋め込みに加えて、多くのアプローチは視覚的な特徴量も統合しとって、これはResNetとかLayoutLMみたいなモデルから得られることが多いな。手作りの雑多な特徴量を考慮する研究者も多いで。こういう特徴量の目的は、特定のノードの特性とか、ノード間の関係性を取り込んで、モデルがKIEをうまくやれるように助けることやねん。たとえば[108]では、グラフノードが日付を表すか、郵便番号を表すか、既知の都市名を表すか、などのいろんな真偽値の特徴量を入れとるで。ノード特徴量ベクトルのサイズもアプローチによって違うな。論文に具体的な数字が明示されてへんことも多いけど、平均すると特徴量ベクトルの長さは500くらいやで。全般的に、関連研究ではノード特徴量の埋め込みサイズについてあんまり議論されてへんから、これがKIEシステムの性能にそんなに大きな影響を与えへんっていう結論になるわな。それよりも、どんなタイプの特徴量を統合するかの方がずっと重要みたいやで。グラフベースのアプローチを区別するもう1つの要因は、定義されたグラフ表現にグローバルノードを組み込んどるかどうかやねん。このグローバルノードには文書画像全体についての情報を入れられて、グラフの個々のノードと接続できるんや。これに関しては、[67, 196]のアプローチだけがそういうグローバルノードを使っとるな。[101]もグローバルノードを構築しとるけど、情報を運ぶためやなくて、文書レイアウトツリーに基づいた概念を採用したから形式的に必要やっただけやねん。
エッジ(辺、ノードをつなぐ線のことやな)がグラフ構造の2番目の重要な部分やで。注目すべきは、かなり多くの研究がエッジ特徴量をまったく使ってへんっていうことやねん。結果として、ノード埋め込みに比べて、このタイプの特徴量にはあんまり注意が払われてへんわけや。せやけど、[13]が示しとるのは、エッジ特徴量、特に幾何学的なデータに関するものは、KIEの性能を向上させられるっていうことやねん。ノード特徴量から得られる幾何学的情報よりもさらに効果的で、周囲の空間情報を統合できるからやで。エッジ特徴量は通常、接続されたノード間のペアごとの位置関係から導出されるんや。水平方向と垂直方向の距離が、絶対値でも相対値でも、一番よく考慮されとるな。この点について、[105]は2つのノード間の視覚的な距離の重要性を強調しとるで。グラフノードを囲むバウンディングボックス(ノードを囲む四角形やな)のアスペクト比(縦横比)もエッジ特徴量としてよく含まれとるわ。グラフベースのアプローチのうち、視覚的な埋め込みをエッジ特徴量の一部として使っとるのは3つだけやで。エッジの方向性の分布、つまりエッジが
Manuscript submitted to ACM
---
## Page 15
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p015.png)
### 和訳
ビジネス文書からのディープラーニングを使ったキー情報抽出:体系的文献レビュー
15
グラフの辺が向きありか向きなしかって話やけど、どっちが優勢かはっきりせーへんねん。まあ大体の場合は向きなしの辺使うことが多いけどな。辺の向きとかが抽出の性能にどんだけ影響するかは、もっと研究せなあかんとこやねん。これに関して[47]の研究では、向きありの辺を使うのと、辺に重みをつけるのと、両方とも抽出結果を良くできるって示してるで。まあせやけど、さっきも言うたように、こういう話は結局どんな場面で使うかによって変わってくるから、「これが絶対正解や!」みたいな一般化はなかなかでけへんねん。
5.2.3 グリッドベースの手法。セクション5.1でも触れたけど、このやり方は論文の中ではあんまり人気ないねん。10個のアプローチだけがこのグリッド構造使ってるんや。これが何を意味するかっていうと、グリッドって文書を直感的に表現できてええ感じなんやけど、いろんな複雑なレイアウトの見た目重視の文書(VRDsって呼ぶねん)に対して、柔軟に対応したり汎用的に使うのが難しいってことやな。各アプローチの分析は電子付録の表ST6に載せてるで。おもろい発見やったんは、ほとんどのアプローチが既存のグリッドベースのシステムの進化版やってことやねん。特にChargrid[74]のやつな。つまり関連する研究って、めっちゃ狭い範囲の中でしか進んでへんってことや。グリッドの細かさについては、大多数のシステムが単語レベルで定義してて、3つが文字レベル、1つはトークンレベルで定義してるで。
表ST6にはグリッドの次元についての調査結果も載ってんねん。ほぼ全部の手法が、入力画像のピクセル数に基づいてグリッドの高さと幅を決めてるんや。やからグリッドは長方形になんねん。これは見た目重視の文書自体が長方形やから当然やな。[43]と[186]は高さと幅に固定値を使ってて、それぞれ512と336やから、正方形のグリッドになってるわけや。[75]は入力の次元を8分の1に縮小して、モデル全体の複雑さを減らしてるで。[169]はちょっと違うアプローチで、動的なグリッド構造を使ってんねん。これは高さと幅を、バウンディングボックス(文字とかの位置を囲む箱やな)の縦方向と横方向の最大座標と最小座標の距離で決めるんや。つまり実際に文書のコンテンツがある範囲やな。もう一つの違いは特徴ベクトルの長さや。ここは割と似たような値が選ばれてて、256と768が一番よく使われてるで。[43]のアプローチが一番シンプルで、ベクトルの長さが35しかないねん。一番複雑な特徴ベクトルは[126]が定義してて、これは4×128×103っていう次元になってるで。
グリッドの各要素にどんな特徴を選ぶかっていう話やけど、大多数のアプローチはいろんなモデルから得たテキストの埋め込み表現を使ってるねん。ほとんどがBERTベースのアーキテクチャやな。もう一つよくある特徴の種類は、文字の1-hotエンコーディングってやつや。これは単語コーパス(文字の集まりやな)の各文字に特定のインデックス番号を割り当てるっていう方法やねん。ピクセルごとのRGB値とか、ResNet18とか、Swin Transformerの埋め込みを使って、視覚的な特徴を取り入れてるアプローチもいくつかあるで。もう一つの違いは、グリッドの背景要素に対する特徴をどうするかや。背景要素っていうのは、文書画像のコンテンツに重なってない部分のことやな。これについては、ほぼ全部のアプローチが全部ゼロの特徴ベクトルを使ってるねん。実際のコンテンツと背景をはっきり区別するのが目的やからな。[126]はスパーステンソル(疎なテンソル)を使って、背景要素を完全に捨ててしまうねん。[75]だけが背景要素にも特徴を取り入れてて、対応する座標のRGBチャンネルを使って、視覚情報をアーキテクチャに融合させてるんや。
ほとんどの手法は、キー情報抽出タスクをやるのにセマンティックセグメンテーション(意味的分割って意味やな)を使ってるねん。これは文書画像の各要素を意味的なカテゴリ(つまり抽出したいフィールドやな)に割り当てて、元の文書画像のセグメンテーションマスクを作るっていうやり方や。他の選択肢としてはバウンディングボックス回帰があるで。これは意味的なエンティティのバウンディングボックスを予測するのが目標で、個々のオブジェクトをうまく区別するのに役立つねん。例えば請求書を処理する時、各明細行を分けられると便利やろ?やからいくつかのアプローチは、セマンティックセグメンテーションとバウンディングボックス回帰(または一般的な明細行検出)を組み合わせてるんや[31, 74, 186]。
5.2.4 LLMベースの手法。いろんな研究分野で大規模言語モデル(LLM)が出てきたことで、キー情報抽出への応用も最近研究されてきてるねん。特にマルチモーダルLLM(複数の情報形式を扱えるやつな)がこの流れを加速させてて、なんでかっていうと、いろんなモダリティ(情報の形式やな)に基づいて見た目重視の文書をちゃんと処理できるからやねん。こういうモデルの特性上、キー情報抽出は通常VQA(視覚的質問応答)タスクとして定式化されるで。
ACMに投稿された原稿
---
## Page 16
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p016.png)
### 和訳
16
Alexander Michael RombachとPeter Fettke
つまりな、LLM(大規模言語モデル)にOCRで読み取ったテキストを渡して、「この{キー}の値って何なん?」みたいな質問をぶつけるわけやねん。
LLMベースのアプローチはぜんぶ生成型になっとるんやけど、これのめっちゃええとこは何かっていうとな、LLMってもうめちゃくちゃ大量のデータで事前学習されとるねん。KIE(重要情報抽出)専門のシーケンスベースモデル(5.2.1節も見てな)で使われるデータよりもはるかに多いんや。せやから、めっちゃ広い世界の知識を持っとって、従来のKIE手法と比べて汎化能力が高くなる可能性があるってことやねん。LLMベースのアプローチの分析は、電子付録の表ST7に載せとるで。
半分以上のアプローチが外部のOCRエンジンを使っとるんや。これ見たらわかるやろ、ちゃんとしたテキスト認識がまだまだ大事で、LLMだけに任せたらあかんってことやねん。ほんまにその通りで、[39, 104, 185]だけが画像だけで動いとるんや。ほとんどの手法がオープンソースのLLMをバックボーンに使っとって、特にLLama2がよう使われとるわ。たいていの場合、視覚情報を取り込むために視覚エンコーダーを使うんやけど、そのうち3つのアプローチはLayoutLMv3を画像エンコーディングに使っとるねん。画像解像度もいろいろあって、2560×2560みたいな高解像度を使うやつもおれば、224×224みたいな低解像度やけど、その代わりに最大20枚の画像クロップを切り出して、文書の各部分を細かく捉えようとするやつもおるんや。ここはな、計算コストと抽出品質のトレードオフを考えなあかんねん。
一部のアプローチは、バックボーンのLLMを視覚的にリッチな文書(VRD)にもっと適応させるために、継続的な事前学習をやっとるんや。このフェーズで使われるタスクには、テキスト認識、テキストスポッティング、表の理解とかがあるねん。この継続的事前学習は、IIT-CDIPみたいな既存のKIEデータセットでよくやられとるわ。[58]を除いて、全部のアプローチがKIE用の教師ありファインチューニング(SFT)もやっとるから、モデルの重みを調整するんやな。目標は、基盤モデルがVRDを処理してKIEをこなす能力を向上させることやねん。そのために、対応する指示チューニング用のデータセットを作るんやけど、CORDみたいな人気のベンチマークデータセットをベースにすることが多いんや。具体的には、文書のアノテーションを、さっき言うたVQAスタイルの質問みたいに、質問と回答のペアに変換するねん。それ以外にも、画像キャプショニング(LLMに入力文書のテキストキャプションを生成させる)みたいな、いろんなSFTタスクを入れとる著者もおるで。ちなみに、LoRAみたいなパラメータ効率の良いファインチューニング手法を使っとるアプローチはほんまに少なくて、たいていはSFT中にLLMの全パラメータを学習させとるんや。これが意味するのはな、基盤モデルをVRDとKIEにちゃんと適応させるには、アーキテクチャの大部分の重みを更新せなあかんってことやねん。ただ、この点を深く分析した研究はまだないんやけどな。
各アプローチは、異なるモダリティ(テキストとか画像とか)をどうやってLLMに渡すかも違うんや。例えば、[58]はOCRデータをLLMに渡して、対応するクラスを取得するようにプロンプトするねん。フォーマットの例はこんな感じや:「Q3:{text: 'TO:', Box:[102 345 129 359]}...、これらのテキストのラベルは何ですか?」みたいな。こうやってバウンディングボックスのリスト表現をプロンプトに入れてレイアウト情報を明示的に組み込むのは、シンプルでよう使われる方法やねん。でもな、限界もあるんや。この方法使うと、入力シーケンスの大部分がこれらのトークンで埋まってしまうから、実際のVRDコンテンツに使えるコンテキスト長が減ってまうねん。あと、バックボーンのLLMは普通こういうプロンプト形式で(事前)学習されてへんから、レイアウト情報についてうまく推論できへん可能性があるんや。
[115]は違うアプローチを取っとって、文書をHTML構造に変換してLLMに渡して、抽出した情報を構造化されたJSONで出力させるねん。著者らの主張によると、LLMは事前学習データの大部分がHTMLやから、HTMLの処理が得意なんやって。それ以外やと、LLMベースのアプローチの一般的なやり方は、画像エンコーディングを取得して、テキストプロンプトと一緒にLLMに渡して、それぞれのフィールドの抽出値を得ることやねん。一部の研究(例えば[115])は抽出すべき全フィールドを1つのプロンプトに含めるけど、他の研究(例えば[185])は1回の呼び出しで1つのフィールドだけを扱うんや。後者は1文書あたり複数回の呼び出しが必要やから実行時間が増えるかもしれんけど、LLMが1つのフィールドに集中できて、フィールドごとの抽出品質が上がるかもしれへんねん。著者らはいろんなプロンプトテンプレートも試しとるわ。例えば、KIEを選択式の問題として設定することもあるんや:
原稿はACMに提出済み
---
## Page 17
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p017.png)
### 和訳
ディープラーニングによるビジネス文書からの重要情報抽出:系統的文献レビュー
17
「{document} この文書の中で '{value}' って何なん?選択肢はこれやで:{keys}」みたいな形式で、{keys}にはデータセットからランダムに選んだ項目名のサブセットが入るねん[187]。要するに、LLM(大規模言語モデル)が元々知ってるフィールド名の知識を活かして、正しい値をうまいこと見つけ出そうっていう作戦やな。だいたいの研究は似たようなプロンプトの書き方してるんやけど、[197]の研究によると、いろんなパターンのプロンプトを混ぜた学習データセットを作った方がええらしいねん。なんでかっていうと、視覚的にリッチな文書(VRD)のレイアウトがいろいろ違っても、ちゃんと対応できる頑丈さが増すからやねん。
5.2.5 その他の手法。分析した130本の論文のうち7本は、これまで紹介してきた重要情報抽出(KIE)のどのパラダイムにも当てはまらへんかってん。ここでは、そういう変わり種のアプローチの大事なコンセプトをざっくり紹介するで。
[113]のアプローチは、文書の断片の表現を学習して、抽出すべきフィールドに分類するっていう方法やねん。まず、データの型に基づいて各フィールドの候補を洗い出すねん。次のステップは、各フィールドに対して正しい候補を選ぶこと。そのために、候補それぞれと、抽出すべきフィールドそれぞれの表現(ベクトル)を作るねん。候補の表現は、その候補自体と周りのセグメントの情報を使って作られてて、テキスト情報と位置情報をセルフアテンション機構で処理してるわけや。最後に、候補の埋め込みベクトルとフィールドの埋め込みベクトルの各ペアについて類似度スコアを計算するねん。その類似度スコアを別のモジュールで使って、各エンティティにふさわしい候補を選ぶんやけど、選び方はいろいろ定義できるで。一番シンプルなんは、各エンティティに対して類似度スコアが一番高い候補を選ぶ方法やな。
[172]は、グラフベースの手法と似てるんやけど、文書ページの断片を階層的なツリー構造で表現してるねん。普通のツリー構造と違うところは、同じ階層レベルのノード同士も繋がれるっていうとこやな。このツリーの親ノードと子ノードがキーと値のペアを表してるねん。KIEのタスクは、個々の断片間の関係、つまりエッジの向きを予測することでやるわけや。各断片の一番ありそうな親要素を見つけることで、最終的に抽出すべきフィールドを特定できるっていう仕組みやねん。
[193]はエンドツーエンドのKIEシステムを提案してて、テキスト読み取りとテキスト理解を組み合わせてるねん。テキスト読み取りのステップには、検出モデルとLSTMベースの認識モデルが含まれてて、文書画像の中のテキストを見つけ出すねん。このアプローチには、異なる入力モダリティ(テキストとか画像とか)を融合させる専用モジュールもあって、それを最終的なKIEモジュールが使うわけや。関心のあるフィールドに関連するエンティティを予測するデコーディング機構として、BiLSTMと全結合ネットワークを組み合わせて使ってるねん。だから、このアプローチはシーケンスベースのKIE手法とめっちゃ近い親戚みたいなもんやな。
[139]は[113]のコンセプトを踏襲してて、抽出すべき各フィールドに対して、まず候補となるスパン(テキストの範囲)を特定するっていうやり方やねん。名前付きエンティティの候補スパンを特定するために、複数の検出関数を実装してて、ある程度はドメイン知識に基づいてるねん。そんで著者らは、特定した視覚的スパンのローカルコンテキスト(局所的な文脈)を見つけるために敵対的ニューラルネットワークを使ってるねん。このローカルコンテキストっていうのは、そのスパンと関連する重要なコンテキスト(例えば、大きめの段落とか)を含む文書画像の特定の断片を表してるわけや。これらの特定されたセグメントに基づいて、テキスト特徴と視覚特徴の両方を使ってグローバルコンテキストベクトルとローカルコンテキストベクトルを構築するねん。そんでこれらの特徴を二値分類モデルで使って、ある視覚的スパンが特定の抽出すべきフィールドを含んでるかどうかを予測するっていう仕組みやねん。
[152]のアプローチも、各フィールドの候補を生成してから、それらにスコアを付けていくっていう方法やねん。文書画像と、抽出すべきフィールド(データ型含む)が与えられたら、システムはまずサードパーティの検出関数を使ってOCR出力の中から候補を特定するねん。特定された候補は、二値分類の設定で、特定の関心フィールドを正しく表してる可能性に応じてスコア付けされるわけや。[113]と似てて、スコアは候補の埋め込みベクトルと関心フィールドの埋め込みベクトルの類似度に依存してるねん。いろんなスコアリング関数を組み込めるんやけど、著者らは各フィールドに対して類似度スコアが一番高い候補を割り当てる関数を選んでるな。
[151]は新しい文書表現構造を提案してて、これをセルベースって呼んでるねん。この表現はグリッドベースの手法と似てるんやけど、セルベースの方法論では要素の配置が
原稿はACMに投稿済み
---
## Page 18
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p018.png)
### 和訳
18ページ目
Alexander Michael RombachとPeter Fettkeの論文やで
高さと幅だけで決めるんちゃうくて、セルは実際の文書の中身によって定義されるねん。例えばな、セル構造の中の異なる行や列は、それぞれ違う数の要素で構成されてることがあるわけや。で、個々のセルは行インデックスと列インデックスでちゃんとソートされてて、これがKIE(重要情報抽出)システムにとって追加の手がかりになるねん。こうやって得られたセルベースのレイアウトは、LayoutLMみたいなシーケンスベースの手法で処理されて、だからそういうモデルがKIEをやる時の典型的なシーケンスラベリングのやり方に沿ってるわけや。
[103]のアプローチはな、要素を順番に処理したり複雑なグラフ構造を作ったりせんと、事前学習済みエンコーダーから得た複数のモダリティの特徴を使って、トークンペア表現の行列を作るねん。ほんで3つの関係行列を同時に生成するんや:行抽出(テキスト行の境界を決める用)、行グルーピング(複数行にまたがるエンティティを形成する関連行をまとめる用)、そしてエンティティリンキング(キーと対応する値を結びつける用)。これらの予測を組み合わせて、最終的にキーと値のペアを抽出するっちゅう仕組みやねん。
**5.3 評価**
**5.3.1 方法論とセットアップ** 電子補足資料の表ST8に、提示された評価セットアップに関する調査結果が載ってるで。全体的に一貫して言えることは、著者さんらが評価手順をめっちゃ詳しく説明してへんことが多くて、論文自体からも明らかやないことがあるねん。これは分析した論文の約半分で見られる状況や。該当する項目は「n/a(該当なし)」として扱ったで。分析した論文のうち19本では、要素ベースの評価方法が採用されてて、これはシーケンスベースのアプローチの場合、トークンの予測クラスみたいな要素を正解クラスと比較するっちゅうことやねん。もう一つよくある要素ベースの評価は、予測した境界ボックスと実際の境界ボックスを比較して、それぞれの座標の重なり具合でマッチかミスマッチかを判定するやつや。分析したアプローチのうち45本が文字列ベースの評価設定を採用してるねん。こういう場合は、抽出されたテキスト値を正解文字列と比較して、特定のフィールドの予測が正しかったかどうかを判断するわけや。文字列ベースの評価は、抽出したテキストがさらに次の処理(例えば他の情報システムへの転送とか)に使われる実世界のアプリケーションへの適合性を評価するのにめっちゃ重要やねん。
ほぼ全ての論文で、著者さんらは全体パフォーマンス、つまりテストセットの全文書の全対象フィールドにわたって集計された結果を提示してるねん。せやけど、各フィールド個別のパフォーマンスを示すフィールドレベルのパフォーマンスは、分析した論文の約30%でしか採用されてへんねや。ほぼ絶対に提示されへんのが、Unknown(未知)クラスのパフォーマンスや。KIEの文脈では、Unknownは抽出対象のどのフィールドにも属さない文書内の全要素を表すねん。これは、そのアプローチが文書画像の関係ない内容と関係ある部分をどれだけちゃんと区別できるかを判断するのに役立つんやけどな。ほとんどの場合、提案手法は既存のKIEシステムと比較されてて、それぞれの論文で示された評価指標と自分の結果を比較するか、再実装して比較するかのどっちかやねん。せやから、全体的な比較可能性と自分のアプローチの正当化にめっちゃ重点が置かれてるって言えるわな。せやけど、特に著者さんらが既存のアプローチを再実装することにした場合、評価結果の比較が必ずしも適切とは限らへんねん。なんでかっていうと、他者のアプローチの学習には普通あんまり労力をかけへんからや。
使用されてる評価指標を見てみると、F1スコアがほとんどの場合使われてるのがわかるわ。適合率(Precision)と再現率(Recall)—F1スコアはこの2つの指標の調和平均やねんけど—は約25%のケースでしか明示的に報告されてへんねん。面白いことに、普段めっちゃよく使われる正解率(Accuracy)指標はごく一部の著者しか提示してへんのや。この理由の一つは、KIEデータセットはラベル分布の点で通常めっちゃ偏ってて、それが全体の正解率指標を大きく歪めるからやねん[44]—せやからこういうシナリオではあんまり代表的な指標にならへんわけや。とはいえ、KIEは通常マルチクラス分類問題として見なされるから、著者さんらがそういうタスクでめっちゃ一般的な適合率、再現率、F1みたいな指標を採用するのは驚くことやないわな。さっきも言うたように、多くの著者が文字列ベースの評価を提示してるねん。そのために、
Manuscript submitted to ACM(ACMに投稿された原稿)
---
## Page 19
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p019.png)
### 和訳
ディープラーニングを使ったビジネス文書からの重要情報抽出:体系的な文献レビュー
19
評価の指標にもいろんなもんが使われてんねん。例えば「単語正解率」っていうのがあって、これは正解データと予測結果の間で、どんだけ単語が入れ替わったか、追加されたか、削除されたかをカウントするんや[75]。ほんで気づくんやけど、見つかった評価指標のめっちゃ大部分が、その論文だけで独自に定義されて使われとる「オレオレ指標」やねん。これがあるせいで、既存の重要情報抽出手法とちゃんと比較できへんっていう問題があんねんな。
分析した論文のうち54本では、独自のデータセットが使われとって、これは大抵その会社の内部で持っとる文書コレクションで、一般公開されてへんねん。せやけど、独自データセット使っとる論文の約8割は、公開されてるベンチマーク用データセットでも結果を出してくれとるから、他の重要情報抽出システムとの比較はできるようになっとるわ。あと、個々の論文で提案されたデータセットはいっぱいあんねんけど、その後どこの研究でも採用されへんかったやつも多いねん。これもまた、重要情報抽出の研究界隈が、限られた少数のベンチマークデータセットに集中しとるっていうことを示しとるわな。
表2. 重要情報抽出研究でよく使われるデータセット
| データセット | 文書タイプ | 文書数 | クラス数a | 言語 | 使用回数b | 事前学習用? |
|---|---|---|---|---|---|---|
| FUNSD | フォーム | 199 | 4 | 英語 | 61 | ✗ |
| CORD | レシート | 1,000 | 30 | 英語 | 52 | ✗ |
| SROIE | レシート | 973 | 4 | 英語 | 45 | ✗ |
| IIT-CDIP | 訴訟文書 | 6,000,000 | / | 英語 | 24 | ✓ |
| XFUND | フォーム | 1,393 | 4 | 中,日,西,仏,伊,独,葡 | 15 | ✗ |
| EPHOIE | 試験 | 1,494 | 10 | 中国語 | 9 | ✗ |
| RVL-CDIP | 訴訟文書 | 400,000 | / | 英語 | 7 | ✓ |
| Kleister-NDA | 秘密保持契約 | 540 | 4 | 英語 | 6 | ✗ |
| Kleister-Charity | 報告書 | 2,778 | 8 | 英語 | 6 | ✗ |
a 抽出する項目(エンティティ)の数
b 分析した論文での使用回数
表2に、重要情報抽出研究でよう使われとるデータセットの一覧をまとめたで。ベンチマーク用データセットと事前学習用データセットの両方が載っとるわ。ダントツでよく使われとるんはFUNSD[73]、CORD[128]、SROIE[69]の3つで、これらは全部、分析した論文の少なくとも3分の1で使われとるねん。FUNSDはいろんな分野のフォーム(申請書とか)が入っとる。一方でCORDとSROIEは、主にスーパーとかレストランで撮影されたレシートの写真やねん。データセットの大きさも、抽出するキー(項目)の数もバラバラや。何十万件もあるような大規模データセットは、モデルの事前学習によく使われるんであって、評価のベンチマークとしてはあんま使われへんねん。せやから、そういうデータセットは文書理解の他のタスクでもよう使われとるわ。
よく使われとる3つのデータセットのうち2つは、抽出する項目がたった4つだけやねん。普通こういう文書にはもっといろんな情報が載っとるのに、4つってのはかなり少ないで。一方、CORDは30項目も抽出せなあかんから、この表の中では一番多いわ。CORDとSROIEの決定的な違いは何かっていうと、CORDの場合は個々の商品の明細、つまり数量とか単価みたいな詳細情報まで抽出せなあかんねん。でもSROIEは合計金額みたいな集計された情報だけ抽出すればええねん。
ほとんどのデータセットは英語の文書やねんけど、例外もあるで。XFUND[179]は、重要情報抽出手法の多言語対応能力を調べるために特別に作られたもんや。中国語のデータセットとしてはEPHOIEとTicketが有名やねんけど、まあ当然っちゃ当然やけど、国際的な研究コミュニティが使う英語のデータセットほどは広く採用されてへんわな。
5.3.2 定量的な比較. 意味のある代表的な定量比較をするために、ここからはダントツでよく使われとるCORD、FUNSD、SROIEの3つのデータセットに絞って話すわ。指標もF1スコアだけに限定して見ていくで。
ACMに投稿された原稿
---
## Page 20
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p020.png)
### 和訳
ほな、この論文の内容を説明していくで!
---
評価には一番よく使われとるF1スコアっていう指標を使ってん。これ選んだ理由は、サンプルサイズを最大限確保できるし、いろんな手法を比較しやすいからやねん。ちなみに、マイクロ平均とかマクロ平均とか加重平均とか、F1スコアの計算方法にはいくつか種類があるんやけど、論文によっては明記されてへんことも多いから、今回はそこは区別してへんねん。せやから、結果はちょっと注意して見てな。
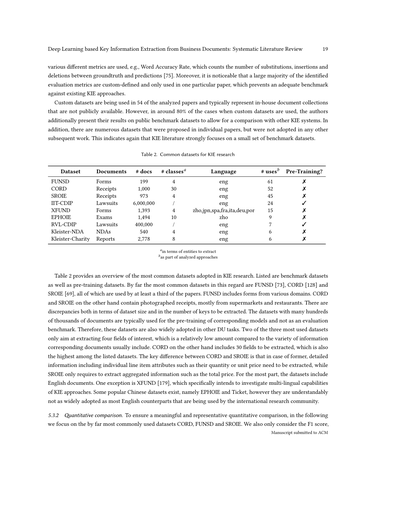
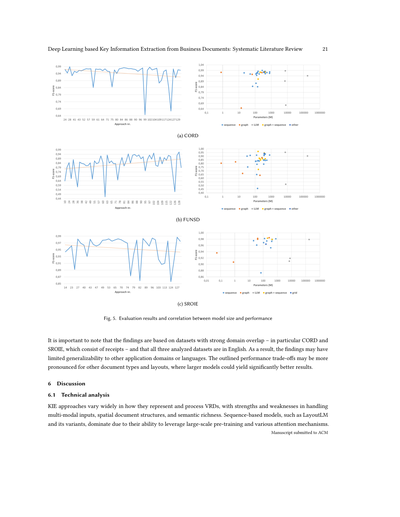
で、図5を見てみ。FUNSD、CORD、SROIEっていう3つのデータセットでの結果を、これまでの論文から集めてプロットしてるねん。トレンドライン(傾向線)も引いてあるで。面白いことに、FUNSDだけは時間とともに性能が上がってるんやけど、他の2つは逆に下がってきてるねん。でもな、どのグラフにも、前後の研究よりめっちゃ悪い結果出してる「外れ値」がいくつかあるんよ。
なんでこんな外れ値が出るんかっていうと、F1スコアの計算方法が違う可能性があるねん。例えば、マイクロ平均やなくてマクロ平均使ってるとか。あとは、そのモデルがタスクの特性にちゃんと合ってへん可能性もあるな。データセットの空間的な配置とか意味的な特徴を考慮してへんモデルは、パラメータ数がめっちゃ多くても性能悪なるんよ。こういう外れ値があるから、トレンドラインにも悪影響出てまうねん。
ちなみに、各データセットで一番ええ成績出したんは、CORDは[51]の手法、FUNSDは[177]の手法、SROIEは[167]の手法やで。平均的にはCORDとSROIEはめっちゃ似た結果になってて、F1スコアの平均がそれぞれ0.94と0.95やねん。これは両方とも構造化されたレシートのデータやから、レイアウトとか空間的な情報の扱いが性能にめっちゃ効いてくるからやな。一方でFUNSDは平均F1スコアが0.83しかなくて、だいぶ悪いねん。FUNSDがなんでこんな難しいかっていうと、そもそもこのデータセット、KIE(キー情報抽出)タスク用に作られたもんちゃうねん。抽出したいフィールドが複数行にまたがってることが多くて、普通のKIEデータセットみたいに「この日付を取り出す」みたいな単純な話とちゃうんよ。
図5ではパラメータ数と性能の関係も見れるで。横軸は対数スケールになってるねん。どのデータセットでも、はっきりしたクラスター(まとまり)があって、そっから外れてるやつもおるな。相関係数を計算したら、CORDは-0.02(p=0.90)、FUNSDは0.08(p=0.60)、SROIEは0.11(p=0.63)やった。つまり、モデルの大きさと性能の間には統計的に意味のある相関はないねん。おもろいことに、CORDではちょっとマイナスの相関があるから、小さいモデルの方が大きいモデルより性能ええこともあるってことやな。
図では、KIEの手法を色分けしてパラダイム(アプローチの種類)ごとに区別してあるで。注目すべきは、グラフベースの手法がよく外れ値として出てくることやな。特にFUNSDでは、エンティティ(抽出対象)が複数行にまたがることが多い独特のレイアウトやから、グラフで表現するには向いてへんねん。グラフベースとシーケンスベース(順序処理)を組み合わせたハイブリッドモデルの方が、特にこういう場面では純粋なグラフベースのモデルより性能ええ傾向があるで。
この分析からわかるんは、モデルをある程度以上大きくしても、性能の伸びは頭打ちになるってことやな。つまり、モデルをただデカくするより、タスクに合った設計をする方がめっちゃ大事やねん。これ、計算リソースが限られてる環境やと特に役立つ知見やで。小さくてもタスクに合ったモデルなら、競争力のある、場合によってはそれ以上の結果出せるからな。
FUNSDでは性能のバラつきがCORDやSROIEより大きくて、小さいモデルの中には苦戦してるやつもおるねん。これはFUNSDの複雑なレイアウトと意味的な要求のせいやろな。興味深いことに、LLM(大規模言語モデル)ベースのアプローチは、競争力のある結果を出せてへんことが多くて、場合によっては最悪の部類に入ってまうこともあるねん。唯一、[41]のLLMベースの手法だけがCORDとFUNSDでほぼ最先端に近い結果を出してるで。これもまた、アーキテクチャが適切やなかったら、モデルがデカくても性能良くなるとは限らへんってことを示してるな。逆に、[48]の手法はたった80万パラメータしかないのに、ええ結果出してて、CORDでは最高レベルのシステムの一つになってるねん。
結論としては、この分析が強調してるのは、モデルの大きさよりも設計とタスクへの適合が大事やってことやな。CORDやSROIEみたいな構造化された文書には、レイアウトをちゃんと理解できるシンプルなモデルが効果的やし、FUNSDみたいな複雑なKIE設定には、シーケンスベースとグラフベースの特徴を組み合わせたハイブリッドモデルが一番ええねん。意味的な複雑さとレイアウト構造のバランスを取るようにアーキテクチャを選ぶことが、KIEの性能を最適化するには大事やで。
---
---
## Page 21
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p021.png)
### 和訳
ディープラーニングを使ったビジネス書類からの重要情報抽出:系統的文献レビュー
21ページ
(a) CORD
(b) FUNSD
(c) SROIE
図5. 評価結果とモデルサイズ・性能の相関関係
ここでめっちゃ大事なポイント言うとくな。この結果は、ドメイン(分野)がかなり被ってるデータセットに基づいてるねん。特にCORDとSROIEは両方ともレシートのデータやし、しかも分析した3つのデータセット全部が英語やねん。せやから、他の用途とか他の言語にそのまま当てはまるかっていうと、ちょっと限界あるかもしれへんで。ここで説明した性能のトレードオフ(つまり「こっち良くなったらあっちは悪くなる」みたいな話な)は、他のタイプの書類とかレイアウトやともっとハッキリ出てくる可能性があって、そういう場合はでっかいモデルの方がめっちゃええ結果出すかもしれへんねん。
6 議論
6.1 技術的分析
KIE(Key Information Extraction、重要情報抽出のことな)のアプローチって、VRD(Visually Rich Documents、見た目がリッチな書類のことやで)をどう表現して処理するかでめっちゃバラバラやねん。それぞれに得意・不得意があって、マルチモーダル入力(テキストと画像とか、複数の種類の情報を一緒に扱うことな)、書類の空間的構造(どこに何があるかっていうレイアウトのこと)、あと意味的な豊かさをどう扱うかが違うねん。シーケンスベースのモデル、例えばLayoutLMとかその派生版が今のところ主流やねんけど、なんでかっていうと、大規模な事前学習ができることと、いろんな種類のアテンション機構(モデルが「どこに注目するか」を学習する仕組みな)をうまく使えるからやねん。
Manuscript submitted to ACM(ACMに投稿された原稿)
---
## Page 22
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p022.png)
### 和訳
22ページ目やで!
Alexander Michael RombachとPeter Fettkeの研究な。
このへんのモデルは、位置の情報を「位置埋め込み」っていう技術で取り込んで、固有表現抽出(NER)には線形分類層っていうのをよく使うねん。でもな、こういう分類層には弱点があってな、文章の中でラベル同士がどう関係してるかをうまく捉えられへんのよ — CRF(条件付き確率場)とは違ってな。それに「飛び飛びのエンティティ」っていう、実際の文書でめっちゃよく出てくるやつにも苦戦するねん[158]。あと、エンドツーエンドモデル(最初から最後まで一気にやるタイプ)は統一された抽出パイプラインを提供してくれるんやけど、ベンチマークではOCR依存のシステムのほうがまだ性能ええねん。なんでかっていうと、文字認識とエンティティ抽出っていう複雑なタスクを分けて処理できるからやな[142]。
グラフベースのモデルは、空間的にも意味的にも定義されたグラフ構造を通じて文書の構造を捉えるのがめっちゃ得意やねん。GCN(グラフ畳み込みネットワーク)やGAT(グラフアテンションネットワーク)を使うと、レイアウトを意識した情報の伝播が効果的にできるんや。でもな、多くのアプローチがヒューリスティック(経験則的な)グラフ構築に頼ってて、これがノイズやバイアスを持ち込む原因になることもあるねん。一方で、グラフ構造を学習させる方法やと、モデルが複雑になる代わりに頑健性と汎化性能が上がることが分かってるで[177]。エッジの特徴量はまだあんまり活用されてへんねんけど、空間的な推論を改善する可能性があるっていう証拠はあるんやで。
グリッドベースのアプローチは、文書をグリッド(格子)として扱って、セグメンテーション(領域分割)みたいな技術をKIE(重要情報抽出)に適用するねん。この方法は特に、めっちゃ構造化されたVRD(視覚的にリッチな文書)には向いてるんやけど、いろんなレイアウトに適応する柔軟性は低めやな。それに意味的なエンコーディングも限定的で、[74]が提案した初期の設計選択からあんまり進歩してへん感じやねん。これは、グリッドベースのアプローチの研究がほとんど2022年以前に行われてたことにも表れてるわな。
新しいLLM(大規模言語モデル)ベースの方法は、KIEに生成的で指示駆動型のパラダイムを導入してるねん。こういうモデルは大規模な基盤モデルを使うことで、めっちゃ強い汎化能力とタスクの柔軟性を持ってるんやけど、実用面での限界もあるんよ。レイアウト情報は単純なプロンプトエンジニアリングで注入されることが多くて、これはLLMの学習手順にネイティブなもんちゃうから効率に影響することがあるねん。さらに、推論時間がめっちゃ長くて — 条件によっては同等のハードウェアで他のアプローチの最大120倍もかかることがあるねん[130] — これはスケーラビリティの課題になるわな。ハルシネーション(元の文書にないテキストを生成してまうこと)は珍しくて、ケースによっては1%未満なんやけど[130]、それでも防ぐための専用の仕組みが必要かもしれんな。
ほぼすべてのKIEアプローチは、長い文書や複数ページのVRDを扱う能力が限られてるねん。これは主にアーキテクチャ上の制約が原因で、例えばTransformerは入力シーケンスの長さが固定で、普通は512トークンなんやけど、これはVRDの1ページ分を捉えるのにも足りへんことが多いねん。グラフベースやグリッドベースの方法は、文書表現がページごとに定義されてるから、複数ページにまたがる依存関係を捉えられへんのよ。LLMベースのアプローチはこの問題をある程度克服できるねん、なんでかっていうとバックボーンのLLMは普通もっと長いコンテキスト長(例えば4,096トークン)を提供してくれるからな。この点は、単語数が少ないVRD(CORDやSROIEに見られるレシートとか)を処理する時はあんまり問題にならへんけど、フォーム(FUNSDを参照)みたいなコンテンツが多い文書では影響してくる可能性があるな。結局のところ、長いVRDを適切に理解して、長いシーケンスにわたってコンテキストを維持するのは依然として課題やねん。
全体的に見ると、それぞれのカテゴリは意味的な表現力、空間的推論、実用的な制約の間でトレードオフが必要やねん。Transformerは強力な文脈理解を提供するけど、シーケンスモデリングとレイアウト認識の改善が必要やな。グラフベースの方法は文書構造を明示的に捉えられて、ヒューリスティックなアルゴリズムに頼るんやなくてグラフの接続性を学習することで恩恵を受けられるねん。グリッドベースのモデルはレイアウトをうまく扱えるけど、意味的な柔軟性に欠けるわ。LLMベースのアプローチは幅広い適応性を持ってるけど、計算コストが高くて、精密な空間推論にはあんまり効果的やないねん。
**6.2 事前学習とファインチューニングの手順**
KIE研究でますます人気になってるアプローチ、特にシーケンスベースの方法を扱う時にな、モデルの学習を自己教師あり事前学習と教師ありファインチューニングのステップに分けるやり方があるねん。前者の目的は、まずモデルに一般的な文書理解を獲得させることやねん。そうすると、その後のファインチューニングステップの一部として、KIEみたいないろんな下流タスクに活用できるようになるんや。一般的に、事前学習の手順には大量のデータが必要やねん。モデルに対応する文書表現をちゃんと学習させるためにな。やから、ほとんどの著者は以下のような大規模データセットを使うんや...
---
ACMに投稿された原稿やで
---
## Page 23
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p023.png)
### 和訳
ディープラーニングを使ってビジネス文書から重要な情報を抜き出す研究:論文レビュー
23ページ目
さて、IIT-CDIPっていうデータセットの話やねんけど(第5.2.1章でも触れたやつな)、これがまた問題ありでさ。なんでかっていうと、このデータセットに入ってる文書って1990年代のもんばっかりやねん。せやから画像の質がめっちゃ悪いし、スキャンがうまいこといってへんノイズも入ってるし、そもそも解像度が低いんよ。これが何を意味するかっていうと、提案されてる手法のかなりの部分が古い文書で事前学習されてるってことやねん。せやから、実際に使おうとして新しい文書でファインチューニング(微調整のことな)しても、うまいこといかへん可能性があるんよ。
もう一個考えなあかんのは、IIT-CDIPの文書が全部タバコ業界への訴訟に関係してるってことやねん。これって何を意味するかっていうと、モデルが事前学習の段階でめっちゃ偏った知識を身につけてまうってことや。そう考えると、もっと色んな種類の文書が入ったデータセットで事前学習した方がええんちゃう?って話になるわな(第7章も見てや)。
第5.2.1章で話したけど、ほとんどの研究者がMVLM(マスク付き視覚言語モデリング)っていう手法を事前学習で使ってんねん。場合によってはこれだけを事前学習の目的にしてることもあるくらいや。自然言語処理の世界でMLM(マスク言語モデリング)がめっちゃ人気やから、そこから派生したMVLMがKIE(重要情報抽出)の研究でも人気なんは当然やな。この手法は、周りのテキストとか位置の情報を手がかりにして、モデルに役立つ表現を学ばせるのにめっちゃ効果的やねん。
ただ、視覚的にリッチな文書をちゃんと処理するには、見た目の手がかりも考慮せなあかんやん。せやから、視覚情報をKIEシステムに取り込むための新しい事前学習の目的が提案されてきてんねん。これにはいろんなやり方があってな、例えば文書画像の一部分とか全体をモデルに再構成させる方法[5, 157]とか、画像の一部分の長さを予測させる方法[100]とかがあるねん。
他にも、テキストと文書画像の間でいろんなマッチング課題を与える方法もあるで。例えば、ある文章がその文書画像を説明してるかどうかをモデルに予測させたり[5]、与えられた画像とテキストが同じページのもんかどうかを当てさせたり[180]、単語の画像パッチがマスクされてるかどうかを判断させたり[68]するわけや。
位置情報をもっとうまく使うための事前学習の目的を設定してる研究者もおるで。例えば、トークン(テキストの最小単位のことな)が文書画像のどのエリアに置かれてるかを分類問題として推定させたり[92, 166]、ある要素の周りの要素との相対的な位置関係の方向を推定させたり[100]するんや。
ビジネス文書に出てくる数値とその関係性をもっとよう理解するための研究もされてるで[36]。これは請求書みたいな文書を処理するときにめっちゃ役立つねん。なんでかっていうと、請求書には金額がいっぱい出てきて、それらがお互いに密接に関係してるからや。
まとめると、提案されてる事前学習の目的っていうのは、テキスト・位置・視覚の情報をうまいこと融合させるように慎重に設計されてんねん。これによってモデルは文書を理解する力を身につけて、その力をKIEみたいな後続のタスクで発揮できるようになるわけや。
事前学習の目的にはもう一つのカテゴリがあってな、それが生成型KIE手法から来てるやつやねん。これらのモデルは自然言語理解と自然言語生成(入力に応じて出力を生成する能力のことな)の両方を学ばなあかんねん。このために、[16, 17]の研究では[35]が定義した事前学習タスクを採用してんねん。具体的には、単方向LM、双方向LM、Sequence-to-Sequence LMの3つや。重要なんは、共有されたTransformerネットワークを使って、この3つの目的を同時に学習させるってとこやねん。モデルは3つの目的を切り替えながら学習できるんや。
[157]の研究では、タスクのプロンプト(指示文のことな)とテキスト形式の目標出力に基づいた、自己教師あり学習と教師あり学習による生成的な事前学習の目的をいろいろ提案してんねん。例えば、欠けてるテキストを予測して、それが文書画像のどこにあるかを構造化された目標シーケンスとして特定させたりするんや。
[26]のアプローチは、テキスト認識、文書理解、生成能力を学習するための独自の戦略を持ってんねん。この研究は事前学習のセットアップがほんまに目立ってて、異なる文書タイプにまたがる25種類以上の目的を使ってるんや。とはいえ、MLM関連のタスクに重点が置かれてるけどな。
一つの重要な事前学習タスクは、与えられた文書に対してモデルが構造化されたJSON出力を予測するってやつやねん。これは最終的にKIEにも使われるんや。この戦略は実際のビジネスの場面でめっちゃ役立つで。なんでかっていうと、入力文書の詳細な階層構造の出力が必要な場合があるからや。例えば、請求書の個々の明細行をちゃんと区別するとかな。
シーケンスラベリング層で出力をデコードするような非生成型KIE手法は、こういう階層構造を再構成するのが苦手で、追加の後処理ステップが必要になることが多いねん。モデルにテキスト認識を学習させるために、
ACMに投稿された原稿
---
## Page 24
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p024.png)
### 和訳
24ページ目
Alexander Michael RombachとPeter Fettkeの論文やで
[33, 77]の研究では、事前学習のタスクとして、前のトークンと文書の画像を両方考慮しながら次のトークンを予測するっていう方法を使ってんねん。
**6.3 実務的な視点**
分析してみたらな、関連研究で実務寄りの視点がめっちゃ足りてへんことがはっきりしたわ。実際のところ、分析した手法の中でドメイン知識(その業界特有の専門知識のことな)を組み込んでるのはほんの一部だけやねん。しかもな、そういうケースでも、せいぜい手作業で作った入力特徴量にドメイン知識をくっつけてるくらいやねん。あと、提案されてるKIE(Key Information Extraction:重要情報抽出のことな)の手法が実際の現場でどんだけ役立つかっていう評価も全然足りてへんねん。この問題は[114]の研究でも指摘されとるで。
ドメイン知識をちゃんと考慮してる点で目立ってるのは[6]の研究やな。この人らは、ディープラーニングモデルとルールベースの手法を組み合わせたハイブリッドなKIEシステムを提案してて、抽出結果を良くするための後処理ステップもいくつか入れとるねん。例えば、自動で抽出された商品コードや商品価格の修正とかな。ただし、この後処理はあくまでDLモデルが間違えた時の補助として使われてて、アーキテクチャ自体を変えてるわけちゃうねん。もう一つの例は[126]の研究で、請求書に関するドメイン特有のルールを組み込んどるねん。例えば「合計金額は小計と税額の合計やで」とか「税額は小計×税率で計算できるで」とかな。これを学習時の損失計算を調整することで実現してんねんけど、残念ながら大きな性能向上は見られへんかったって報告してるわ。でもこれは逆に言うたら、この分野でもっと研究が必要やってことを示してるねん(7章も見てな)。直接こういう要素を手法に組み込んでへんくても、ドメイン知識を統合できるように設計してる研究者もおるで。例えば[152]の研究では、まず抽出したいフィールドの候補を特定して、その後スコアリングするっていう方法を取ってんねん。著者らが挙げてる例としては、「請求書の日付は支払期限より前やないとあかん」みたいな制約を組み込んだスコアリング関数を定義できるようにしてるねん。
セクション2.1で議論したように、実務的な視点を取り入れてドメイン知識を考慮することは、自動抽出システムにいろんな面で価値ある洞察をもたらす可能性があるねん。でもこの側面は、過去にDocument Understanding(文書理解)の重要な課題として挙げられてたにもかかわらず[116]、文献でちゃんと探求されてへんのが現状やねん。せやから、今後の研究ではビジネスプロセスの視点を取り入れて、この未開拓のポテンシャルを活用するアプローチを開発すべきやと思うわ。これによって、現在の研究ではまだ考慮されてへんKIEシステムの全く新しい可能性が見つかるかもしれへんねん。なんでかっていうと、今の研究って既存のベンチマークデータセットでの性能向上ばっかりに焦点当てがちやからな。こういう考察には関連するビジネスプロセスの深い理解が必要になるかもしれへんけど、それはデータ、動作、制御フローを含むコンピュータ統合システムをモデリングすることで達成できるねん[40]。文脈を考慮したDLシステムのポテンシャルは他の研究分野で調査されとるで。例えば[175]では、ビジネス文書から抽出した情報と従来のイベントログデータを融合させて、予測的プロセスモニタリングの能力を強化することを提案してるねん。でもな、逆方向、つまりプロセスマイニング技術から得られた文脈を考慮したデータをKIEシステムに入力するっていうアプローチは、まだ検討されてへんねん。
**6.4 トレンド**
2017年以降のKIE研究では、いろんな側面でいくつかのトレンドが観察できるで。一つの側面は、特定のKIEシステムのパラダイム(考え方の枠組みな)が優勢になってることやねん。特に目立つのがシーケンスベースの手法で、2021年以降は主流のアプローチになっとるわ。逆に、グリッドベースの手法は、最初から人気のあったグラフベースのアプローチと比較可能やったにもかかわらず、結局定着できへんかったねん。同時にこれは、通常複雑なレイアウトを持つVRD(Visually Rich Documents:視覚的にリッチな文書のことな)は、きっちり定義された構造を持つグリッドとして適切に表現でけへんってことを示してるわけやな。
Manuscript submitted to ACM
---
## Page 25
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p025.png)
### 和訳
ディープラーニングを使ったビジネス文書からの重要情報抽出:システマティック・レビュー
25ページ目
静的グラフは動的グラフと比べて柔軟性が低いねん。で、予想通りやけど、LLMベースのシステムは2023年に登場してから、あっという間に人気になったわ。あと、シーケンスベースとグラフベースみたいに異なるパラダイムを組み合わせて使うアプローチは、一つのパラダイムに集中するやり方ほど広まってへんねんな。
2022年からは、OCRに依存せえへんアプローチと、生成型のKIEアプローチを作ることにめっちゃ注目が集まるようになってん。後者は、最近LLMみたいな生成AIの手法がどんどん人気になってきて、それが文書理解の分野にも影響を与えてきた結果やねん。OCRに依存せえへんシステムへのシフトが増えてる理由はな、外部のOCRエンジンを使わなあかんと、そいつがエラー起こしやすくて、特に実際の現場で使うときに間違った情報を抽出してまう可能性があるからやねん。
それとな、時間が経つにつれてKIEシステムを開発・改善するための戦略もいろいろ変わってきてん。最初の頃は、異なる入力モダリティ(テキストとか画像とかレイアウトとか)をどうやってうまく統合するかに研究の力が注がれてたんやけど、最近は別の戦略も出てきてるわ。例えばな、読み取り順序がめっちゃ重要やっていうことを強調して調べてる論文もあるねん。従来の方法やと、外部OCRエンジンに頼ってた影響もあって、単純に上から下、左から右っていう読み取り順序を使うのが普通やってん。でもこれやと、複雑な視覚的にリッチな文書をええ感じに分割でけへんことがあるんよ。そこで、[129、151、190]みたいなアプローチでは、実際の文書レイアウトにもっとマッチした最適な読み取り順序を得るための、より洗練された方法を調べてるねん。[160]も、読み取り順序から来るバイアスを克服するための評価指標を提案してるで。ただな、KIEの性能を上げるためのレバーとして、学習可能なパラメータの数、つまりモデルサイズはほとんど考慮されてこんかってん。2017年から2024年の間、LLMをより頻繁に使うようになった以外には、モデルサイズの大幅な増加はなかったんよ。
ええニュースとしては、最近コードやモデルの重みを公開することが増えてきてるってことやな。共有された実装の絶対数はまだ比較的少ないんやけど、特に2021年以降、どんどん増えてきてるねん。これはめっちゃええ流れやで、なんでかっていうと研究の進歩と普及を加速させることができるからな。この観察は、HuggingFace(https://huggingface.co/)の人気上昇とも連動してるねん。HuggingFaceってのは、自然言語処理とコンピュータビジョンの研究を促進するためのツール、データセット、事前学習済みモデルを提供してるプラットフォームやねん。前に議論したKIEアプローチのいくつかも利用可能で、例えばLayoutLMv3(https://huggingface.co/microsoft/layoutlmv3-base)とかがあるで。
こういうトレンドや観察は、今後のKIE研究でも続くと考えられるわ。特に生成型KIEシステムへのシフトは明らかやな、なんでかっていうと対応するモデルが複数の分野でどんどん人気になってきてるからや。強力なLLMを使った初期のアプローチは存在するんやけど、専門的な文書理解手法と比べて、まだ一貫して競争力のある結果を出せてへんねん。この点については、このパフォーマンスギャップをどうやって埋めるか、そしてそういったアプローチをより実用的にするか、特にセクション5.3.2で議論したモデルサイズ(つまりハードウェア要件)と抽出性能のトレードオフに関して、追加の研究が必要やねん。
7 研究アジェンダ
今後の研究で考慮すべきいくつかの側面を特定したで。これらは研究成果を良くするだけやなくて、KIEシステムを実際の現場でもっと使えるようにすることにもつながるはずや。
**新しいデータセット**。一般的に使われてる公開データセットはほんまに少ないねん。例えば、シーケンスベースのアプローチの半分以上が、IIT-CDIPの(サブセットを使って)事前学習されてるんよ。このデータセット特有の問題としては、画像品質が比較的低くて、今の基準を満たしてへんってことやねん。これらの特性は、対応するアプローチを実際の現場で使うときに直接影響するんよ。なんでかっていうと、実際の現場では普通もっと画像品質のええ文書を扱うからな。
---
ACMに投稿された原稿
---
## Page 26
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p026.png)
### 和訳
事前学習データセット以外にも、新しいベンチマーク用のデータセットも作らなあかんねん。理想を言うたら、よくあるレシートとちゃう種類の文書をベースにしたやつがええな——これは[99, 146]でも言われとることやねん。ドメイン(分野)を変えるだけやなくて、新しく作るデータセットは、現実世界で実際に使われとる文書にもっと近いもんにせなあかんのよ。[173, 185, 190]の研究で、今主流になっとるデータセットにはこの点でめっちゃ問題があるって示されとるねん。あと、アノテーション(ラベル付け)が間違っとったり、ラベル付けのやり方が一貫してへんデータセットもあるんよ[103]。さらにな、SROIEとかFUNSDみたいなよう使われるベンチマークは、訓練用と評価用のデータでレイアウトがめっちゃ似てもうてるから[86]、報告されとる評価結果の信頼性がちょっと怪しなってまうねん。新しいデータセット作る方法として合成文書(コンピュータで作った架空の文書)を生成するっていう手もあるんやけど、これには「レイアウトの多様性とか複雑さが現実の文書と違うかもしれへん」っていうリスクがあるんよ[146]。
**一貫した評価について** セクション5.3の分析で分かったんやけど、論文ごとに評価のやり方がバラバラやねん。しかも著者さんらが評価方法を詳しく書いてへんことも多いから、「この評価結果、実際どうやって出したん?」ってなってまうわけよ。せやから、いろんなアプローチを定量的に(数字で)比較するんが意味あるとは限らへんのよ。これ特にやばいのは、この研究分野で「最先端を更新した!」って言うとき、だいたい「既存の研究と比べてベンチマークの数字が上がったかどうか」で判断されるからやねん。SROIEみたいな公開コンペでは、手法を一貫してランキングするための専用の評価プロトコルが用意されとる。^7 でもな、これは例外中の例外で、普通はそんなんないねん。
やから、統一されたアプローチで合意するか、いろんなベンチマークデータセットに使える集中管理型の評価ツールキットを作るんが理想やねん。その中で特定の指標セット(例えばPrecision(適合率)、Recall(再現率)、F1スコアとか)が実装されとるやつな。[15]がDU(文書理解)ベンチマーク用のリファレンス実装を提案しとるんやけど、まだあんまり使われてへんのよ。あとワイらは、文字列ベースの評価指標(実際に抽出した文字列がどれだけ正しいか見るやつ)をもっと使うべきやと思っとる。なんでかっていうと、現実のアプリケーションでの性能をより正確に評価できるからやねん。でもな、分析した論文のうち3分の1しかこういう文字列ベースの評価をしてへんかったんよ。あと驚くことに、フィールドレベル(項目ごと)の結果を出しとる論文も3分の1くらいしかないねん。この点についてはな、今後の研究ではもっと頻繁にこういう評価を載せるべきやと思っとる。なんでかっていうと、あるアプローチが特定のフィールドで問題抱えてへんかどうかがよう分かるし、それによってより深い分析ができるからやねん——これは[121]でも議論されとることや。最後にもう一個、著者さんらはエンティティレベル(抽出した情報のかたまり単位)の性能指標を採用すべきやねん。なんでかっていうと、実際のアプリケーションでは抽出した情報をひとまとまりとして処理するから、こっちの方が実用的な性能を評価するのに向いとるんよ[190]。現実世界での性能をもっとちゃんと示せる指標が必要や、っていうのは[76]でも言われとって、前に述べた問題点を軽減するための新しい指標を提案しとるねん。
**前処理手法について** 文書画像の前処理技術を研究する専門分野があるねん。高度なアプローチの例としては[138]が提案しとるやつがあるで。この文脈で、この研究分野とのシナジー効果(相乗効果)を活かすべきやねん、特にKIE(重要情報抽出)システムへの対応する技術の統合についてな[9]。関連研究では前処理技術が含まれてへんことも多いし、使われとっても傾き補正(Deskewing)みたいな単純な方法だけやったりするんよ。現実世界での文書のライフサイクル(作成から保管まで)の中で、画像品質が劣化するポイントがいくつもあるねん。例えば、デジタル化するときにスキャンのアーティファクト(ノイズとか歪み)が入ったり、何回も圧縮したり送信したりする過程で劣化したりするんよ[2]。[181]の研究では、画像ノイズとかフォントみたいな品質の側面が、DU(文書理解)システムの性能にめっちゃ大きな影響を与えることが示されとる。せやから、DUパイプライン(処理の流れ)にそういう手法をもっと積極的に取り入れるべきやねん。
**トークン化について** 特にシーケンスベース(系列ベース)のKIEアプローチでは、入力文書をトークン列(単語や文字の並び)にエンコードするためにトークナイザーを使うねん。そのトークン列にはその後、視覚的な埋め込み(画像情報)と位置的な埋め込み(レイアウト情報)が追加されるんよ。KIEの
^7 KIEタスクのリーダーボードはこちらで見れるで:https://rrc.cvc.uab.es/?ch=13&com=evaluation&task=3
---
## Page 27
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p027.png)
### 和訳
ディープラーニングを使ったビジネス文書からの重要情報抽出:体系的な文献レビュー
27
ほんでな、こういうシステムって大体BERTみたいな事前学習済みの言語モデルをエンコーダーの土台として使うんやけど、だいたいそのモデルに付属してるトークナイザー(文章を細かく分割するやつやな)をそのまんま使うことが多いねん。でもな、いくつかの研究で「違うジャンルのデータにそのまま持ってきたらちょっと問題あるで」って指摘されとるんよ[118]。せやから、トークナイザーを新しいジャンルに合わせて調整する方法がいろいろ提案されてきてん。ほんなら下流タスクの性能がアップするっちゅうわけや。具体例としては、元のトークナイザーの語彙にジャンル特有の単語を追加したり[135, 149]、学習データとか前処理の設定とか語彙のいじり方を丁寧に検討したり[23]する方法があるねん。
今んとこ、KIE(重要情報抽出)の文脈でトークナイザーの役割をめっちゃ深く調べた研究はあんまりないねん。[154]は医学系のテキストから固有表現を抜き出すときのトークン化の影響を分析しとるけど、視覚的にリッチな文書(VRD)を扱う複雑な文書理解タスクに関しては研究が足りてへんのよ。せやから今後の研究では、既存のトークナイザーをKIEにうまく適用させるための洗練された方法を探ったり、複雑な文書をもっとしっかりトークン化できる新しい手法を開発したりすることを考えるべきやな。まず手始めとしては、既存のKIEアプローチをそのまんまのトークナイザーで使ってみて、トークナイザーの調整だけに集中して、オリジナルの実装と比較するベンチマークをやってみるのがええかもしれん。
**汎化性能について。** [57]の研究で、既存のKIE手法には汎化能力(色んな状況に対応できる力やな)がちゃんと備わってへんって示されとるねん。これはさっき言うたデータセットの限界も原因かもしれん。ほんで、汎化性能のことってあんまり詳しく考慮されてへんのよ。大体は、複数のベンチマークデータセット(文書タイプが違うやつ)で評価するときに、なんとなく暗黙的に考慮されるだけやねん。
今後の研究では、色んな文書のレイアウトやタイプ、ジャンルに対してもっと高い汎化性能を実現するために、モデルのアーキテクチャや新しい(事前)学習タスクをどう効果的に設計するかに注目すべきやな。あと、KIEシステムのモジュール化をもっとちゃんと調べて、個々のコンポーネント同士の依存関係を減らして、より汎用的なアプローチを作り出すっていう可能性もあるで[126]。歯科画像分析とか他の分野ではそういう取り組みがあるねん[82]。文書レイアウト分析(DLA)の文脈でも研究されとって、そこでは新しいモデルと整備された(合成)データセットを組み合わせて汎化性能の課題に取り組むことを推奨しとる[117]。でもな、KIEの文脈ではそんなに多くの取り組みはないんよ。
**ドメイン知識について。** 6.3章で議論したように、提案されたアプローチにドメイン知識(その分野特有の知識やな)を組み込んだり、そもそも実践寄りの視点を持ったりしてる著者はほんま少ないねん。でもな、既存のドメイン知識をKIEシステムに組み込むのは有望やと思うで。これは[22]でも議論されとるんやけど、なんでかっていうと、そこには対応するビジネスプロセスとか、その文書とか、それらを全体としてどう理解すべきかっていう貴重な情報が含まれとるからやねん。新しい事前学習タスクを設計するときに、こういう側面を組み込むのが一つの可能性やな。
**実世界での使いやすさについて。** 実世界のシナリオで自動文書処理が重要やってことは議論の余地ないで([114]のレビューも見てな)。めっちゃ重要やからこそ、KIEアプローチ全体の実用性を向上させるためにもっと努力すべきやねん。さっき言うた研究の方向性はすでにこの問題に取り組んどる。例えば、実世界特有の文書画像のノイズ(印鑑を消すとか[183])を除去する前処理技術を考慮することもできるやん。さっき言うた汎化能力への注力も、KIEシステムの実用性にプラスの影響を与えられるで。なんでかっていうと、色んな種類の文書を同時にちゃんと処理できるシステムを導入したら、コストが下がってメンテナンスも減るかもしれんからやねん。
それに加えて、追加の側面も考慮できるで。例えば、[78]は抽出されたデータの信頼度推定を提供する方法を提案しとる。著者らが強調しとるのは、産業の現場では、生の抽出データそのものよりも、モデルの予測に基づいて意思決定することが主な目標やってことやねん。この方向の研究は、文書処理タスクにおけるKIEシステムと人間の管理者との協働をめっちゃ助けるやろうな。なんでかっていうと、実世界の現場では自動抽出されたデータを検証することが必須やからやねん[64]。[140]も産業応用におけるリアルタイムKIEの重要性を強調しとる。この点に関しては、軽量なKIEソリューションに焦点を当てることを考慮すべきやな。これは例えば
Manuscript submitted to ACM
---
## Page 28
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p028.png)
### 和訳
28ページ
Alexander Michael RombachとPeter Fettke
例えばな、モデルのサイズと抽出性能のトレードオフについて、もっと詳しく調べるっていうのがあんねん。[58]の研究で分かったんやけど、だいたい5万パラメータくらいの比較的小さいモデルでも、数億パラメータもあるシステムと張り合えるくらいの結果出せるって証明されてんねん。
**エンドツーエンド性能について。** 評価の結果分かったんやけど、エンドツーエンド方式って、外部のOCRエンジン使うシステムと比べると、たいてい抽出結果がイマイチやねん。せやから、テキスト認識のステップをどうやって改善するか、もっと研究せなあかんねん。なんでかっていうと、エンドツーエンドシステムってOCRエンジンに頼らんでええから、めっちゃポテンシャル高いねん。これは[140]も強調してるところやな。エンドツーエンド方式って今までそんなに注目されてこんかって、見つかったアプローチの数見ても分かるやろ。けどな、特に2022年以降は、この手の手法がかなり増えてきてんねん。
## 8 結論
重要情報抽出(Key Information Extraction)の研究分野って、ここ数年でめっちゃ注目されるようになってん。主な理由は、ディープラーニングの分野でごっつい進歩があったからやねん。今の時代、めっちゃ複雑なレイアウトで情報てんこ盛りのビジネス文書でも、対応するシステムで自動処理できるようになってん。そういうわけで、この論文は2017年から2024年までの重要情報抽出の研究について、130個の提案されたアプローチを含む系統的な文献レビューをまとめたもんやねん。目的は、この分野の最先端技術を特定して、今後の研究の可能性を見つけることや。見つかった手法は、いろんな特徴に基づいて定性的にも定量的にも比較したで。
分析して分かったんやけど、関連研究ってめっちゃ狭い範囲で進んでて、すでに実績のあるコンセプトをちょっとずつ改良して良くしていく、っていうパターンが多いねん。基本的に、どのアプローチも文書画像を表現するのに同じパラダイム使ってて、シーケンス(連続データ)、グラフ、グリッドのどれかやねん。細かいとこ見ると、入力文書をエンコード・デコードするのに使うアーキテクチャの選び方は違うんやけど、特定のモデルがよく使われる傾向もあんねん(例えば、テキスト入力にはBERTベースのモデルとかな)。それに加えて、新しいコンセプトも時間とともに探求されてきて、OCR不要の手法とか自己回帰的な手法とかがあんねん。前者はテキストを事前に読み取るための外部OCRエンジンがいらんし、後者は任意のテキストを出力できるから、対応できる下流タスクの面でより柔軟やねん。研究者たちは、複雑な文書に暗黙的・明示的に含まれてる異なる入力モダリティ(情報の種類)を、どうやったらモデルアーキテクチャに最適に統合できるか調べてんねん。特に、文書画像からの視覚的な手がかりをモデルにどんどん組み込むようになってて、より複雑なユースケースでの性能向上を目指してんねん。ディープラーニングモデルを使って汎用的な文書理解を学習させることにも、めっちゃ力入れてて、それを重要情報抽出に活用してんねん。これは普通、大規模で革新的な事前学習タスクをやってから、特定のファインチューニングをするっていう流れやな。あと、全般的に分かったのは、モデルの複雑さ(パラメータ数)ってそんなに重要やないってことで、軽量なモデルでも期待できる抽出結果を出せるねん。
この研究分野の特徴として、確立されたベンチマークデータセットでより良い抽出結果を出すことで最先端を更新していく、っていうのがあんねん。けどな、発表された結果を定量的に比較するのが必ずしも意味あるとは限らへんねん。なんでかっていうと、著者らが使う評価セットアップがバラバラすぎるからや。それに、ほとんどのベンチマークで、もうめっちゃ良い結果出てもうてんねん(F1スコア0.97以上とか)。せやから、この研究分野はベンチマーク結果の改善にこだわるのはもうやめて、他の側面での革新を調べるべきやと思うねん。今後の研究では、実用性を高めるためにもっと軽量なモデルに焦点当てたらええんちゃうかな。あとは、学習に必要なデータ量を減らせるようなモデル設計についても調べる価値あるで。この調査結果に基づいて、今後の研究の出発点になりそうなポイントをいくつか特定したで。
Manuscript submitted to ACM
---
## Page 29
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p029.png)
### 和訳
【ビジネス文書からのディープラーニングベース重要情報抽出:システマティック文献レビュー】
29ページ目
ここで言うてんのは、新しくてもっとバラエティ豊かなデータセットを提案せなあかんってことと、ちゃんと定量的に比較できるような一貫した評価の仕組みを作らなあかんってことやねん。あと、実際に現場で使えるかどうかっちゅうことにもっと注目すべきやって言うてるんや。これには専門分野の知識を取り込むことも含まれとるんやけど、なんでかっていうと、一方では文書処理タスクって日々の業務で超重要な役割果たしてるし、もう一方では重要情報抽出に対して独特の要件と可能性を持った特別な視点を提供してくれるからやねん。
**参考文献**
[1] アブデルラーマン・アブダラー、ダニエル・エーベルハーター、ゾエ・フィスター、アダム・ヤトヴト。2024年。フォーム理解におけるTransformerと言語モデル:スキャン文書分析の包括的レビュー。arXiv:2403.04080 http://arxiv.org/abs/2403.04080
[2] アリレザ・アライー、ヴィン・ブイ、デビッド・ドーマン、ウマパダ・パル。2023年。文書画像品質評価:サーベイ。Comput. Surveys 56巻2号(2023年2月)、1-36ページ。doi:10.1145/3606692
[3] トフィク・アリ、パルタ・プラティム・ロイ。2024年。マルチタスク事前学習による文書情報分析の強化:視覚的にリッチな文書における情報抽出のためのロバストなアプローチ。2024年国際ニューラルネットワーク合同会議(IJCNN)にて。IEEE、1-10ページ。doi:10.1109/IJCNN60899.2024.10651151
[4] ジェイソン・アントニオ、アディティア・ラクマン・プトラ、ハリッツ・アブドゥロマン、モッフ・シャンディ・ツァラサ・プトラ。2022年。スキャンレシートOCRと情報抽出に関するサーベイ。0-26ページ。doi:10.13140/RG.2.2.24735.84643
[5] スリカール・アッパラージュ、バーヴァン・ジャサニ、バルガヴァ・ウラーラ・コータ、ユシェン・シエ、R.マンマタ。2021年。DocFormer:文書理解のためのエンドツーエンドTransformer。IEEE国際コンピュータビジョン会議論文集。IEEE、973-983ページ。doi:10.1109/ICCV48922.2021.00103
[6] ロベルト・アロヨ、ハビエル・イェベス、エレナ・マルティネス、エクトル・コラーレス、ハビエル・ロレンソ。2022年。ディープラーニングとルールベース補正を用いた購買文書における重要情報抽出。ディープラーニング時代のNLPにおけるパターンベースアプローチに関する第1回ワークショップ論文集。計算言語学国際会議、韓国・慶州、11-20ページ。arXiv:2210.03453 http://arxiv.org/abs/2210.03453
[7] シーチン・バイ、イー・チン、ペイセン・ワン。2024年。AIE-KB:中国のアーカイブシナリオ向け知識ベース付き情報抽出技術。パターン認識とコンピュータビジョン、チンシャン・リウ、ハンジ・ワン、ザンユー・マー、ウェイシー・ジェン、ホンビン・ジャー、シーリン・チェン、リャン・ワン、ロンロン・ジー(編)。Springer Nature Singapore、シンガポール、52-64ページ。doi:10.1007/978-981-99-8540-1_5
[8] クリスティアン・バログ。2018年。エンティティ指向検索。情報検索シリーズ第39巻。Springer International Publishing、チャム。doi:10.1007/978-3-319-93935-3
[9] ディパリ・バヴィスカル、スワティ・アヒラオ、ヴィドヤサガール・ポトダール、ケタン・コテチャ。2021年。人工知能を用いた非構造化文書の効率的自動処理:システマティック文献レビューと今後の方向性。IEEE Access 9巻(2021年)、72894-72936ページ。doi:10.1109/ACCESS.2021.3072900
[10] ジェジガ・ベルハジ、アブデル・ベライド、ヨランデ・ベライド。2023年。アテンションベース半変分グラフオートエンコーダを用いた半構造化文書からの情報抽出改善。Lecture Notes in Computer Science(人工知能とバイオインフォマティクス分野のLecture Notes含む)、ゲルノート・A・フィンク、ラジーヴ・ジェイン、小瀬康一、リチャード・ザニッビ(編)、14188巻LNCS。Springer Nature Switzerland、チャム、113-129ページ。doi:10.1007/978-3-031-41679-8_7
[11] ジェジガ・ベルハジ、アブデル・ベライド、ヨランデ・ベライド。2023年。半構造化文書のための低次元情報抽出モデル。Lecture Notes in Computer Science(人工知能とバイオインフォマティクス分野のLecture Notes含む)、ニコラス・ツァパツーリス、アンドレアス・ラニティス、マリオス・パティキス、コンスタンティノス・パティキス、クリストス・キルコウ、エフティヴォウロス・キリアコウ、ゼノナス・セオドシウ、アンドレアス・パナイデス(編)、14184巻LNCS。Springer Nature Switzerland、チャム、76-85ページ。doi:10.1007/978-3-031-44237-7_8
[12] ジェジガ・ベルハジ、ヨランデ・ベライド、アブデル・ベライド。2021年。半構造化文書における情報抽出のためのGATにおける単語の近傍考慮。Lecture Notes in Computer Science(人工知能とバイオインフォマティクス分野のLecture Notes含む)、ジョゼップ・ヤドス、ダニエル・ロプレスティ、内田誠一(編)、12822巻LNCS。Springer International Publishing、チャム、854-869ページ。doi:10.1007/978-3-030-86331-9_55
[13] ニル・ビエスカス、カルロス・ボネッド、ジョゼップ・ヤドス、サンケット・ビスワス。2024年。GeoContrastNet:言語非依存文書理解のための対照的キーバリューエッジ学習。文書分析と認識 - ICDAR 2024、エリザ・H・バーニー・スミス、マーカス・リウィッキ、リャングルイ・ペン(編)。Springer Nature Switzerland、チャム、294-310ページ。doi:10.1007/978-3-031-70533-5_18
[14] ガラル・M・ビンマクハシェン、サブリ・A・マフムード。2019年。文書レイアウト分析:包括的サーベイ。Comput. Surveys 52巻6号(2019年11月)、1-36ページ。doi:10.1145/3355610
[15] ウカシュ・ボルフマン、ミハウ・ピエトルシュカ、トマシュ・スタニスワヴェク、ダヴィド・ユルキェヴィチ、ミハウ・P・トゥルスキ、カロリナ・シンドレル、フィリップ・グラリンスキ。2021年。DUE:エンドツーエンド文書理解ベンチマーク。NeurIPS Datasets and Benchmarks。https://openreview.net/forum?id=rNs2FvJGDK
[16] ハオユー・ツァオ、シン・リー、ジエフェン・マー、デチャン・ジャン、アンタイ・グオ、イーチン・フー、ハオ・リウ、インソン・リウ、ボー・レン。2022年。実環境における文書情報抽出のためのクエリ駆動生成ネットワーク。MM 2022 - 第30回ACM国際マルチメディア会議論文集(MM '22)。ACM、ニューヨーク、NY、USA、4261-4271ページ。doi:10.1145/3503161.3547877
[17] ハオユー・ツァオ、ジエフェン・マー、アンタイ・グオ、イーチン・フー、ハオ・リウ、デチャン・ジャン、インソン・リウ、ボー・レン。2022年。GMN:実用的文書情報抽出のための生成マルチモーダルネットワーク。2022年北米計算言語学会会議:人間言語技術論文集。計算言語学会、ペンシルベニア州ストラウズバーグ、3768-3778ページ。arXiv:2207.04713
ACMに投稿された原稿
---
## Page 30
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p030.png)
### 和訳
30ページ目
Alexander Michael RombachとPeter Fettke
doi:10.18653/v1/2022.naacl-main.276
[18] Panfeng Caoら、2023年。GenKIE:頑丈な生成型マルチモーダル文書キー情報抽出やねん。
EMNLP 2023の学会論文集に載っとるで。これな、いろんな種類のデータ(テキストとか画像とか)を組み合わせて、文書から大事な情報をバシッと抜き出す手法やねん。めっちゃ頑丈に作ってあるから、ちょっとやそっとじゃブレへんのよ。pp.14702-14713
[19] Manuel Carbonellら、2020年。グラフニューラルネットワーク使って半構造化文書から固有表現認識と関係抽出やるで。
パターン認識の国際会議に出とる論文やな。半構造化文書っていうのは、完全にキッチリ決まった形式でもないけど、ある程度パターンがある文書のことやねん。そこからグラフ(点と線の繋がり)で表現して、人名とか組織名とか抜き出して、それらの関係性も見つけるっちゅう話や。pp.9622-9627
[20] Mengli Chengら、2020年。ワンショットテキストフィールドラベリング:アテンションと信念伝播使った構造情報抽出やで。
ACMマルチメディア会議の論文やな。「ワンショット」ってのがミソでな、たった1個の例を見せるだけで、「あ、ここがこういう項目やな」って学習できるねん。アテンション(注目する仕組み)と信念伝播(情報をグラフ上で伝える技術)を組み合わせとるんや。pp.340-348
[21] Matteo Cristaniら、2018年。ビジネス文書の自動処理における未来のパラダイムについて。
国際情報管理ジャーナルの論文やで。これから先、ビジネス文書の処理がどないなっていくか、っていう将来展望を語っとる論文やな。pp.67-75
[22] Lei Cuiら、2021年。ドキュメントAI:ベンチマーク、モデル、応用について。
ICDAR 2021のワークショップ論文やねん。ドキュメントAIっていう分野全体をまとめて、どんなベンチマーク(性能比較の基準)があって、どんなモデルがあって、どこに使えるかを整理しとる論文や。
[23] Gautier Daganら、2024年。事前学習とドメイン適応のためにトークナイザーを最大限活用する方法。
ICML 2024の論文やで。トークナイザーってのは、文章を機械が扱いやすい単位(トークン)に分割する仕組みやねん。これをうまく使いこなして、AIの事前学習とか特定分野への適応をもっと効率よくやろうって話や。
[24] He-Sen Daiら、2024年。GraphMLLM:グラフベースの多層レイアウト言語非依存モデルで文書理解するで。
ICDAR 2024の論文やな。文書のレイアウト(配置)をグラフで表現して、しかも言語に依存せん形で文書を理解するモデルやねん。多層構造になっとるから、いろんなレベルで文書を捉えられるんや。pp.227-243
[25] Tuan Anh Nguyen Dangら、2020年。文字レベル埋め込みと多段階アテンションU-Netによるエンドツーエンド情報抽出。
BMVC 2019の論文やで。文字単位で埋め込み(ベクトル表現)を作って、U-Net(画像処理でよく使うネットワーク構造)にアテンションを何段階も組み込んで、最初から最後まで一気に情報抽出するんや。
[26] Brian Davisら、2023年。Dessurtでエンドツーエンドの文書認識と理解やるで。
Lecture Notes in Computer Scienceに載っとる論文やな。Dessurtっていうモデルで、文書の認識から理解まで全部通しでやってまうねん。途中で切れへんから効率ええんよ。pp.280-296
[27] Brian Davisら、2021年。Visual FUDGE:動的グラフ編集によるフォーム理解。
これもLecture Notesの論文やで。フォーム(申込書とか入力用紙とか)を理解するのに、グラフをリアルタイムで編集しながら処理していくっちゅうアプローチやねん。FUDGEって名前がオモロいやろ。pp.416-431
[28] Charles De Trogoffら、2022年。見た目リッチな文書からの自動キー情報抽出。
IEEE ICMLA 2022の論文やな。「見た目リッチ」ってのは、レイアウトとか色とかフォントとか、視覚的な情報がいっぱい詰まった文書のことやねん。そこから大事な情報を自動で抜き出すんや。pp.89-96
[29] Jiyao Dengら、2023年。文書帰納バイアスに基づく反復グラフ学習畳み込みネットワークでキー情報抽出。
Lecture Notesの論文やで。「帰納バイアス」ってのは、モデルが持っとる前提知識みたいなもんやねん。文書特有の性質を事前に組み込んで、グラフ学習を繰り返しながらキー情報を抽出するアプローチや。pp.84-97
[30] Xinrui Dengら、2023年。GenTC:対照学習使った生成型Transformerでレシート情報抽出。
これもLecture Notesに載っとる論文やな。対照学習ってのは、「似てるもの同士は近づけて、違うもの同士は遠ざける」っていう学習方法やねん。それをTransformer(最近のAIの主流アーキテクチャ)と組み合わせて、レシートから情報抜き出すんや。pp.394-406
[31] Timo I. DenkとChristian Reisswig、2019年。BERTgrid:2次元文書表現と理解のための文脈化埋め込み。
NeurIPS 2019のワークショップ論文やで。BERT(有名な言語モデル)の考え方を2次元に拡張して、文書の空間的な配置も考慮した埋め込みを作るねん。gridってのは格子状ってことやな。
[32] Jacob Devlinら、2019年。BERT:言語理解のための深い双方向Transformer事前学習。
NAACL 2019の論文やけど、これはめっちゃ有名やで!BERTってのは、文章を前からも後ろからも両方向で読んで学習するTransformerモデルやねん。これが出てから自然言語処理の世界がガラッと変わったんや。pp.4171-4186
[33] Mohamed Dhouibら、2023年。DocParser:見た目リッチな文書からのOCRフリーなエンドツーエンド情報抽出。
Lecture Notesの論文やな。OCRフリーってのがポイントでな、普通は文字認識(OCR)してからテキスト処理するんやけど、このDocParserはOCRなしで直接情報を抽出できるねん。一石二鳥やろ。pp.155-172
[34] Xuan Cuong Doら、2023年。ベトナムの処方箋画像からキー情報抽出する新しいアプローチ。
SOICT 2023の論文やで。ベトナムの処方箋に特化した情報抽出やねん。国や言語によって処方箋の形式って違うから、こういう地域特化の研究も大事なんよ。pp.539-545
[35] Li Dongら、2019年。自然言語理解と生成のための統合言語モデル事前学習。
NeurIPS 2019の論文やな。言語の「理解」と「生成」って別々に学習することが多いんやけど、これを統合して一緒に事前学習しようっていうアプローチやねん。両方できたら便利やもんな。
ACMに投稿された原稿やで
---
## Page 31
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p031.png)
### 和訳
ディープラーニングを使ったビジネス文書からの重要情報抽出:システマティック文献レビュー
31ページ
[36] Thibault Douzonら、2022年。ビジネス文書向けの特別な事前学習タスクで情報抽出を改善するって話やねん。ようはな、普通の事前学習だけやのうて、ビジネス文書に特化した学習をさせたら、もっと上手く情報取れるようになるでって研究や。Lecture Notes in Computer Scienceに載っとるで。
[37] Qinyi Duら、2022年。CALMっていう、常識知識を文書画像理解に組み込むシステムの話やな。なんでかっていうと、AIって意外と常識ないねん。せやから「これ普通こうやろ」っていう知識を入れてあげると、文書の理解がめっちゃ良くなるってことや。ACM国際マルチメディア会議で発表されとる。
[38] Jacob Eisenstein、2019年。自然言語処理入門の教科書やな。MITプレスから出とって519ページもある分厚いやつや。基礎からしっかり学びたい人向けやで。
[39] Hao Fengら、2024年。DocPediaっていうシステムで、めっちゃでかいマルチモーダルモデル(画像もテキストも両方扱えるやつ)のパワーを周波数領域で解き放つって話やねん。周波数領域っていうのは、画像を波の重ね合わせとして見る手法のことや。これで色んな文書を理解できるようになるねん。Science China Information Sciencesに載っとる。
[40] Peter FettkeとWolfgang Reisig、2021年。Heraklitっていうツールでサービス指向システムとクラウドサービスをモデル化する話や。これは情報抽出とはちょっと違う分野で、システム設計寄りの内容やな。
[41] Masato Fujitake、2024年。LayoutLLMっていう、大規模言語モデルを視覚的にリッチな文書理解のために命令チューニングする研究や。要するにな、ChatGPTみたいなでかいAIに「このレイアウトの文書はこう読むんやで」って教え込む話やねん。LREC-COLING 2024で発表されとる。
[42] Rinon Galら、2020年。Cardinal Graph Convolutionっていうフレームワークで文書から情報抽出する話や。グラフっていうのは、点と線で繋がりを表すやつな。文書の中の要素同士の関係をグラフで表現して、そこから情報取り出すんや。
[43] Rinon Galら、2019年。レシートの項目を認識するための視覚-言語的手法の研究やな。レシートって見た目も大事やし、書いてある内容も大事やろ?その両方を使って「これは金額」「これは商品名」とか認識するんや。
[44] Mikel Galarら、2012年。クラス不均衡問題に対するアンサンブル手法のレビューやな。クラス不均衡っていうのは、例えば1000枚の画像のうち「異常」が10枚しかないみたいな偏りのことや。バギング、ブースティング、ハイブリッドとか色んな対策があるねん。IEEE Transactionsに載っとる。
[45] Łukasz Garncarekら、2021年。LAMBERTっていう、レイアウトを意識した言語モデルで情報抽出する研究や。BERTって有名なAIモデルあるやろ?あれをレイアウトも理解できるように改良したやつやと思ってくれたらええわ。
[46] Hamza Gbadaら、2023年。VisualIEっていう、レシートから情報抽出するための新しい視覚とテキスト両方使うアプローチや。国際サイバーワールド会議で発表されとる。
[47] Hamza Gbadaら、2024年。方向付き重み付きグラフニューラルネットワークを使って、見た目がリッチな文書から情報抽出する話やな。グラフに方向と重みをつけることで、要素同士の関係性をより細かく表現できるようになるねん。ICDAR 2024で発表。
[48] Hamza Gbadaら、2024年。マルチモーダル(複数の情報源を使う)重み付きグラフ表現で、見た目がリッチな文書から情報抽出する研究や。Neurocomputingっていうジャーナルに載っとる。
[49] Andrea Gemelliら、2023年。Doc2Graphっていう、タスクに依存しない文書理解フレームワークの話や。グラフニューラルネットワークベースで、どんなタスクにも使えるように汎用的に作ってあるのがポイントやな。
[50] Vincent E. Giuliano、1975年。「未来のオフィス」っていう記事やな。Business Weekに載った古い記事で、当時の人らが未来のオフィスどうなるか予想しとったんやな。
[51] Jiuxiang Guら、2021年。文書理解のための統合事前学習フレームワークの話や。色んなタスクで使える共通の事前学習方法を作ろうっていう研究やな。arXivに論文あるで。
[52] Zhangxuan Guら、2022年。XYLayoutLMっていう、レイアウトを意識したマルチモーダルネットワークや。XY座標の情報をしっかり使って、見た目がリッチな文書を理解しようって話やな。CVPRっていうめっちゃ有名な学会で発表されとる。
[53] He Guoら、2019年。EATENっていう、エンティティを意識したアテンションで一発撮りの視覚テキスト抽出をするシステムや。一発撮りっていうのは、何回も処理せんでも一回で結果出せるってことやな。ICDARで発表されとる。
[54] Pengcheng Guoら、2024年。DCMAIっていう、動的クロスモーダルアライメントインタラクションフレームワークや。文書のキー情報抽出のために、視覚情報とテキスト情報を動的にうまく合わせていく仕組みやな。IEEE Transactionsに載っとる。
[55] Ahmed Hamdiら、2021年。請求書からの情報抽出についての研究や。請求書ってフォーマットバラバラやのに、必要な情報ちゃんと取り出さなあかんから、結構難しい問題やねん。
原稿はACMに提出済みやで。
---
## Page 32
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p032.png)
### 和訳
32
Alexander Michael RombachとPeter Fettke
[56] Mouad Hamriさん、Maxime Devanneさん、Jonathan Weberさん、Michel Hassenforderさんが2023年に発表した研究やねん。これ何かっていうと、文書から情報抜き出すときに、GNN(グラフニューラルネットワーク)っていう技術の性能をTransformerっていう別の技術使ってめっちゃ強化しましたよって話やねん。Lecture Notes in Computer Scienceっていう本に載ってて、Bertrand Kerautretさんとか色んな人が編集してはって、Vol. 14068 LNCSの25〜39ページに収録されとるで。Springer Nature Switzerlandから出とるやつな。doi:10.1007/978-3-031-40773-4_2
[57] Jiabang Heさん、Yi Huさん、Lei Wangさん、Xing Xuさん、Ning Liuさん、Hui Liuさん、Heng Tao Shenさんが2023年に出した論文やねん。Do-GOODっていうタイトルでな、事前学習済みのビジュアル文書理解モデルがデータの分布がズレたときにどんだけ頑張れるかを評価しようやって話や。第46回のACM SIGIRカンファレンス(情報検索の研究開発に関する国際会議やで)で発表されて、New Yorkで開かれたやつやな。569〜579ページに載っとる。doi:10.1145/3539618.3591670
[58] 同じJiabang Heさんたちが2023年にもう一個出してて、ICL-D3IEっていうやつやねん。これはIn-Context Learning、つまり文脈の中で学習する方法を使って、いろんな例を見せながら文書から情報抜き出す精度を上げていこうって研究や。IEEE International Conference on Computer Vision(コンピュータビジョンの国際会議やで)で10月に発表されて、19428〜19437ページやな。doi:10.1109/ICCV51070.2023.01785
[59] Kaiming Heさん、Xiangyu Zhangさん、Shaoqing Renさん、Jian Sunさんが2016年に出した超有名な論文やで。Deep Residual Learning、つまり深層残差学習で画像認識しようって話や。これめっちゃ画期的やってん。IEEE Conference on Computer Vision and Pattern Recognition(CVPR)で発表されて、770〜778ページに載っとる。doi:10.1109/CVPR.2016.90
[60] Shaojie Heさん、Tianshu Wangさん、Yaojie Luさん、Hongyu Linさん、Xianpei Hanさん、Yingfei Sunさん、Le Sunさんが2023年に出した研究やねん。文書から情報抜き出すのに、Global Taggingっていうグローバルなタグ付け手法を使おうやって話や。Lecture Notes in Computer Scienceに載ってて、Maosong Sunさんたちが編集したVol. 14232 LNAIの145〜158ページやで。doi:10.1007/978-981-99-6207-5_9
[61] Sepp HochreiterさんとJürgen Schmidhuberさんが1997年に発表したLong Short-Term Memory、略してLSTMや。これほんまに歴史的な論文でな、ニューラルネットワークが長い系列のデータを覚えとくのがめっちゃ苦手やった問題を解決したんや。Neural Computationっていう雑誌の第9巻8号、1735〜1780ページに載っとるで。doi:10.1162/neco.1997.9.8.1735
[62] Martin Holečekさんが2021年に出した論文や。類似性から学習することと、構造化された文書から情報抜き出すことについて研究してはるねん。International Journal on Document Analysis and Recognition(文書解析・認識の国際ジャーナル)の第24巻3号、149〜165ページやで。doi:10.1007/s10032-021-00375-3
[63] Teakgyu Hongさん、Donghyun Kimさん、Mingi Jiさん、Wonseok Hwangさん、Daehyun Namさん、Sungrae Parkさんが2022年に発表したBROSっていうモデルやねん。これな、テキストとレイアウトの両方に注目した事前学習済み言語モデルで、文書から重要な情報をもっとうまく抜き出せるようにしたんや。第36回AAAI Conference on Artificial Intelligenceで発表されて、Vol. 36の10767〜10775ページに載っとる。doi:10.1609/aaai.v36i10.21322
[64] Constantin Houyさん、Maarten Hambergさん、Peter Fettkeさんが2019年に出した研究で、公共行政におけるRPA(ロボティック・プロセス・オートメーション)についてやねん。要するに、お役所の仕事をロボットで自動化しようやって話や。「Digitalisierung von Staat und Verwaltung」(国家と行政のデジタル化)っていう本の62〜74ページに載っとるで。
[65] Anwen Huさん、Haiyang Xuさん、Jiabo Yeさん、Ming Yanさん、Liang Zhangさん、Bo Zhangさん、Ji Zhangさん、Qin Jinさん、Fei Huangさん、Jingren Zhouさんが2024年に出したmPLUG-DocOwl 1.5や。これめっちゃすごくて、OCRなしで文書理解できる統一的な構造学習モデルやねん。Association for Computational LinguisticsのEMNLP 2024のFindingsに載ってて、3096〜3120ページやで。doi:10.18653/v1/2024.findings-emnlp.175
[66] Kai Huさん、Jiawei Wangさん、Weihong Linさん、Zhuoyao Zhongさん、Lei Sunさん、Qiang Huoさんが2024年に発表したUniVIEっていう研究やねん。フォームみたいな文書から視覚的な情報を抜き出すのに、統一されたラベル空間を使うアプローチやって。Document Analysis and Recognition - ICDAR 2024で発表されて、77〜96ページやな。doi:10.1007/978-3-031-70552-6_5
[67] Yuan Huaさん、Zheng Huangさん、Jie Guoさん、Weidong Qiuさんが2020年に出した研究や。文書理解のために、グローバルな文脈を意識したAttentionベースのグラフニューラルネットワークを提案してはるねん。中国情報処理学会が海口で開催した会議で発表されて、Lecture Notes in Computer ScienceのVol. 12522 LNAIの45〜56ページに載っとる。doi:10.1007/978-3-030-63031-7_4
[68] Yupan Huangさん、Tengchao Lvさん、Lei Cuiさん、Yutong Luさん、Furu Weiさんが2022年に発表したLayoutLMv3やで。これDocument AI(文書AI)のための事前学習モデルで、テキストと画像の両方をマスクして統一的に学習させるっていう手法やねん。第30回ACM International Conference on Multimedia(MM 2022)で発表されて、4083〜4091ページやな。doi:10.1145/3503161.3548112
[69] Zheng Huangさん、Kai Chenさん、Jianhua Heさん、Xiang Baiさん、Dimosthenis Karatzasさん、Shijian Luさん、C V Jawaharさんが2019年に開催したICDAR2019のコンペティションについてやねん。スキャンしたレシートのOCRと情報抽出に関するコンペや。2019 International Conference on Document Analysis and Recognitionで発表されて、1516〜1520ページに載っとる。doi:10.1109/ICDAR.2019.00244
[70] Zhicai Huangさん、Shunxin Xiaoさん、Da-Han Wangさん、Shunzhi Zhuさんが2024年に出したMCKIEっていう研究やねん。複雑な文書から複数クラスの重要情報を抜き出すのに、グラフ畳み込みネットワーク(GCN)を使う手法や。Pattern Recognition and Computer Visionの会議で発表されて、89〜100ページやで。doi:10.1007/978-981-99-8540-1_8
[71] Wonseok Hwangさん、Hyunji Leeさん、Jinyeong Yimさん、Geewook Kimさん、Minjoon Seoさんが2021年に出した研究や。半構造化された文書画像から、コスト効率よくエンドツーエンドで情報抽出しようって話やねん。EMNLP 2021(自然言語処理における経験的手法に関する会議)で発表されて、3375〜3383ページやで。doi:10.18653/v1/2021.emnlp-main.271
[72] 同じWonseok Hwangさんたちが2021年にもう一個出してて、これは空間的な依存関係をパースして半構造化文書から情報抜き出そうやって話やねん。Association for Computational LinguisticsのACL-IJCNLP 2021のFindingsで発表されて、330〜343ページに載っとる。doi:10.18653/v1/2021.findings-acl.28
[73] Guillaume Jaumeさん、Hazim Kemal Ekenelさん、Jean-Philippe Thiranさんが2019年に作ったFUNSDっていうデータセットについてやねん。ノイズの多いスキャン文書でフォームを理解するためのデータセットや。2019 International Conference on Document Analysis and Recognition Workshops(ICDARW)で発表されて、Vol. 2の1〜6ページやで。doi:10.1109/ICDARW.2019.10029
[74] Anoop R. Kattiさん、Christian Reisswigさん、Cordula Guderさん、Sebastian Brardaさん、Steffen Bickelさん、Johannes Höhneさん、Jean Baptiste Faddoulさんが2018年に発表したChargridやねん。2次元の文書を理解しようとする試みで、EMNLP 2018(自然言語処理における経験的手法に関する2018年会議)のProceedingsに載っとるで。
Manuscript submitted to ACM(ACMに投稿された原稿やで)
---
## Page 33
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p033.png)
### 和訳
ディープラーニング使ったビジネス文書からの重要情報抽出:体系的な文献レビュー
33
Association for Computational Linguistics, Stroudsburg, PA, USA, 4459–4469. doi:10.18653/v1/d18-1476
[75] Mohamed Kerroumi, Othmane Sayem, Aymen Shabou. 2021年。VisualWordGrid:マルチモーダルアプローチ使ったスキャン文書からの情報抽出やねん。Lecture Notes in Computer Science(AI関連のサブシリーズとかバイオインフォマティクス関連のやつも入ってるで)、Elisa H Barney SmithとUmapada Pal編。Vol. 12917 LNCS。Springer International Publishing, Cham, 389–402。doi:10.1007/978-3-030-86159-9_28
[76] Minsoo Khang, Sang Chul Jung, Sungrae Park, Teakgyu Hong. 2025年。KIEval:文書の重要情報抽出の評価指標っちゅうやつやな。arXiv:2503.05488 [cs.CL] https://arxiv.org/abs/2503.05488
[77] Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeong Yeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park. 2022年。OCR使わんでも文書理解できるTransformerやで。Lecture Notes in Computer Science(AI関連のサブシリーズとかバイオインフォマティクス関連のやつも入ってるで)、Shai Avidan, Gabriel Brostow, Moustapha Cissé, Giovanni Maria Farinella, Tal Hassner編、Vol. 13688 LNCS。Springer Nature Switzerland, Cham, 498–517。doi:10.1007/978-3-031-19815-1_29
[78] Juhani Kivimäki, Aleksey Lebedev, Jukka K Nurminen. 2023年。2D文書情報抽出における失敗予測、キャリブレーションされた信頼スコア使うてやるやつやねん。2023 IEEE 47th Annual Computers, Software, and Applications Conference (COMPSAC)。IEEE, 193–202。doi:10.1109/COMPSAC57700.2023.00033
[79] Shachar Klaiman, Marius Lehne. 2021年。DocReader:バウンディングボックスなしで学習できる文書情報抽出モデルやで。なんでかっていうと、枠で囲まんでもええってめっちゃ楽やん。Lecture Notes in Computer Science(AI関連のサブシリーズとかバイオインフォマティクス関連のやつも入ってるで)、Josep Lladós, Daniel Lopresti, Seiichi Uchida編、Vol. 12821 LNCS。Springer International Publishing, Cham, 451–465。doi:10.1007/978-3-030-86549-8_29
[80] Bertin Klein, Stevan Agne, Andreas Dengel. 2004年。ドイツでの請求書読み取りシステムの研究結果やねん。Lecture Notes in Computer Science(AI関連のサブシリーズとかバイオインフォマティクス関連のやつも入ってるで)、Marinai SimoneとAndreas R Dengel編。Vol. 3163。Springer Berlin Heidelberg, Berlin, Heidelberg, 451–462。doi:10.1007/978-3-540-28640-0_43
[81] Felix Krieger, Paul Drews, Burkhardt Funk, Till Wobbe. 2021年。請求書からの情報抽出:レイアウトがめっちゃバラバラなデータセットに対するグラフニューラルネットワークのアプローチやで。Lecture Notes in Information Systems and Organisation、Frederik Ahlemann, Reinhard Schütte, Stefan Stieglitz編。Vol. 47。Springer International Publishing, Cham, 5–20。doi:10.1007/978-3-030-86797-3_1
[82] Joachim Krois, Anselmo Garcia Cantu, Akhilanand Chaurasia, Ranjitkumar Patil, Prabhat Kumar Chaudhari, Robert Gaudin, Sascha Gehrung, Falk Schwendicke. 2021年。歯科画像分析におけるディープラーニングモデルの汎化性能についてやな。ほんまに他のデータでも使えるんかって話や。Scientific Reports 11, 1 (2021年3月), 6102。doi:10.1038/s41598-021-85454-5
[83] Jianfeng Kuang, Wei Hua, Dingkang Liang, Mingkun Yang, Deqiang Jiang, Bo Ren, Xiang Bai. 2023年。実世界での視覚情報抽出:実践的なデータセットとエンドツーエンドのソリューションやねん。Lecture Notes in Computer Science(AI関連のサブシリーズとかバイオインフォマティクス関連のやつも入ってるで)、Gernot A Fink, Rajiv Jain, Koichi Kise, Richard Zanibbi編、Vol. 14192 LNCS。Springer Nature Switzerland, Cham, 36–53。doi:10.1007/978-3-031-41731-3_3
[84] Ashish Kubade, Prathyusha Akundi, Bilal Arif Syed Mohd. 2024年。階層的データに対する重要情報抽出を次文予測として再定式化するやつやで。Document Analysis and Recognition – ICDAR 2024 Workshops、Harold MouchèreとAnna Zhu編。Springer Nature Switzerland, Cham, 175–183。doi:10.1007/978-3-031-70642-4_11
[85] Ritesh Kumar, Saurabh Goyal, Ashish Verma, Vatche Isahagian. 2024年。ProtoNER:プロトタイピカルネットワーク使った固有表現認識のための少数ショット増分学習やねん。めっちゃ少ないデータでも学習できるって話や。Business Process Management Workshops、Jochen De WeerdtとLuise Pufahl編。Springer Nature Switzerland, Cham, 70–82。doi:10.1007/978-3-031-50974-2_6
[86] Seif Laatiri, Pirashanth Ratnamogan, Joël Tang, Laurent Lam, William Vanhuffel, Fabien Caspani. 2023年。公開文書情報抽出ベンチマークにおける情報の冗長性とバイアスの話やで。ほんまにこのベンチマーク大丈夫なん?ってツッコミや。Document Analysis and Recognition - ICDAR 2023、Gernot A Fink, Rajiv Jain, Koichi Kise, Richard Zanibbi編。Springer Nature Switzerland, Cham, 280–294。doi:10.1007/978-3-031-41682-8_18
[87] John D Lafferty, Andrew McCallum, Fernando C N Pereira. 2001年。条件付き確率場:系列データのセグメンテーションとラベリングのための確率モデルやねん。これがCRFってやつの元祖やで。Proceedings of the Eighteenth International Conference on Machine Learning (ICML '01)。Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 282–289。
[88] Chen Yu Lee, Chun Liang Li, Timothy Dozat, Vincent Perot, Guolong Su, Nan Hua, Joshua Ainslie, Renshen Wang, Yasuhisa Fujii, Tomas Pfister. 2022年。FormNet:フォーム文書情報抽出における系列モデリングを超えた構造エンコーディングやで。Proceedings of the Annual Meeting of the Association for Computational Linguistics、Vol. 1。Association for Computational Linguistics, Dublin, Ireland, 3735–3754。doi:10.18653/v1/2022.acl-long.260
[89] Chen Yu Lee, Chun Liang Li, Chu Wang, Renshen Wang, Yasuhisa Fujii, Siyang Qin, Ashok Popat, Tomas Pfister. 2021年。ROPE:グラフベースの文書情報抽出のための読み順序等変位置エンコーディングやねん。読む順番をちゃんと考慮するってことやな。ACL-IJCNLP 2021 - 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Proceedings of the Conference、Vol. 2。Association for Computational Linguistics, Online, 314–321。doi:10.18653/v1/2021.acl-short.41
[90] Chen Yu Lee, Chun Liang Li, Hao Zhang, Timothy Dozat, Vincent Perot, Guolong Su, Xiang Zhang, Kihyuk Sohn, Nikolai Glushnev, Renshen Wang, Joshua Ainslie, Shangbang Long, Siyang Qin, Yasuhisa Fujii, Nan Hua, Tomas Pfister. 2023年。FormNetV2:フォーム文書情報抽出のためのマルチモーダルグラフ対照学習やで。FormNetの進化版やな。Proceedings of the Annual Meeting of the Association for Computational Linguistics、Vol. 1。Association for Computational Linguistics, Toronto, Canada, 9011–9026。doi:10.18653/v1/2023.acl-long.501
[91] D Lewis, G Agam, S Argamon, O Frieder, D Grossman, J Heard. 2006年。複雑な文書情報処理のためのテストコレクション構築についてやねん。Proceedings of the 29th annual international ACM SIGIR conference on Research and development in information retrieval (SIGIR '06)。ACM, New
Manuscript submitted to ACM
---
## Page 34
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p034.png)
### 和訳
Alexander Michael RombachとPeter Fettkeの参考文献リストやな!
[92] Chenliang Liらが2021年に発表した「StructuralLM」っていう研究があるねん。これ何かっていうと、フォーム(申込書とか入力画面みたいなやつ)を理解するための構造的な事前学習の手法やねん。ACL-IJCNLPっていう自然言語処理のめっちゃ大きい国際学会で発表されとるで。
[93] Haipeng Liらが2024年に出した「DocPointer」は、少ないパラメータで効率よく重要な情報を抜き出すポインターネットワークやねん。マルチメディアアジアっていう学会で発表されとるわ。
[94] Jing Liらの2022年の論文は、固有表現認識(人名とか地名とか組織名を見つける技術やな)のディープラーニング手法をまとめたサーベイ論文やで。IEEE Transactions on Knowledge and Data Engineeringっていう一流ジャーナルに載っとる。
[95] Junlong Liらが2022年に発表した「DiT」は、文書画像用のTransformerを自己教師あり学習で事前学習する手法やねん。ACMのマルチメディア国際会議で発表されとるで。
[96] Peizhao Liらの2021年の「SelfDoc」は、文書の表現学習を自己教師ありでやる手法やな。CVPRっていうコンピュータビジョンの超有名学会で発表されとるわ。
[97] Qiwei Liらが2023年に出した論文は、レイアウト構造をモデリングすることで視覚的にリッチな文書の理解を強化する手法やねん。
[98] Xin Liらの2022年の研究は、視覚的にリッチな文書における関係表現学習についてやで。文書の中の要素同士の関係をうまく学習しようっていう話やな。
[99] Yangchun Liらが2023年に出したのは、ディープラーニングベースの半構造化文書からの情報抽出技術のレビュー論文やねん。これまでの手法をまとめて整理しとるわ。
[100] Yulin Liらの2021年の「StrucTexT」は、マルチモーダルTransformerを使って構造化されたテキストを理解する手法やで。
[101] Haofu Liaoらが2023年に発表した「DocTr」は、文書から構造化された情報を抽出するためのDocument Transformerやねん。ICCVっていうコンピュータビジョンの大きい学会で発表されとる。
[102] Weihong Linらの2021年の「ViBERTgrid」は、文書からの重要情報抽出のために、複数のモダリティを一緒に学習した2D文書表現やねん。
[103] Zening Linらが2024年に出した「PEneo」は、行の抽出、行のグルーピング、エンティティのリンキングを統一して、文書のペア抽出をエンドツーエンドでやる手法やで。
[104] Chaohu Liuらの2024年の「HRVDA」は、高解像度の視覚文書アシスタントやねん。CVPRで発表されとるで。
[105] Xiaojing Liuらが2019年に出した論文は、視覚的にリッチな文書からマルチモーダル情報を抽出するためにグラフ畳み込みを使う手法やな。
[106] Yinhan Liuらの2019年の「RoBERTa」は、BERTの事前学習をロバストに最適化したアプローチやねん。これめっちゃ有名で、自然言語処理でよく使われとるで。
[107] Ze Liuらが2021年に発表した「Swin Transformer」は、シフトウィンドウを使った階層的なVision Transformerやねん。ICCVで発表されて、画像認識の分野でめっちゃ影響力あるわ。
[108] D Lohaniらの2019年の論文は、グラフ畳み込みネットワークを使った請求書読み取りシステムやで。
[109] Chuwei Luoらが2023年に出した「GeoLayoutLM」は、視覚情報抽出のための幾何学的な事前学習手法やねん。CVPRで発表されとる。
[110] Chuwei Luoらの2024年の「LayoutLLM」は、大規模言語モデルを使ったレイアウト指示チューニングで文書理解する手法やで。CVPRで発表されとるわ。
---
## Page 35
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p035.png)
### 和訳
ディープラーニングを使ったビジネス文書からの重要情報抽出:系統的な文献レビュー
35ページ
[111] Chuwei Luoらの2020年の研究やねんけど、これがめっちゃおもろいねん。「Merge and Recognize」っていうモデルで、文書の見た目から名前付きエンティティ(人名とか会社名とか、そういう固有名詞的なやつやな)を認識するんやけど、幾何学的な情報と2Dの文脈を考慮したグラフモデルを使ってんねん。COLING 2020のTextGraphsワークショップで発表されてるで。
[112] Shun Luoらの2024年の論文は、マルチモーダルネットワーク(画像とかテキストとか、いろんな種類のデータを一緒に扱うやつな)に「多変量意味連想グラフ」っていうのを組み込んで、文書から情報抽出する話やねん。The Journal of Supercomputingに載ってるで。
[113] Bodhisattwa Prasad Majumderらの2020年の研究は、フォームみたいな文書から情報抽出するための「表現学習」についてやねん。なんでかっていうと、フォームって決まったレイアウトがあるから、その構造をうまく学習できたら情報取り出しやすいやろ?っていう発想やな。ACLの年次大会で発表されてるで。
[114] A. Martínez-Rojasらの2023年の論文は、RPA(ロボティック・プロセス・オートメーション、要は業務自動化のことやな)の文脈での知的文書処理についての系統的な文献レビューやねん。エンドツーエンド、つまり最初から最後まで全部自動でやるRPAの中で、文書処理がどう使われてるかをまとめてくれてるわけや。
[115] Mohammad Minoueiらの2024年の研究は、大規模言語モデル(LLM、ChatGPTみたいなやつやな)を使って文書を理解するために、レイアウト情報をテキストに埋め込むっていうアプローチやねん。ICDAR 2024で発表されてるで。ほんまに最新の研究やな。
[116] Hamid Motahariらの2021年の報告は、NeurIPS 2019で開催された最初の「Document Intelligence(文書知能)」ワークショップについてのレポートやねん。このワークショップがきっかけで、この分野がめっちゃ盛り上がってきたんやで。
[117] Jill P Naimanの2023年の論文は、科学論文から図とキャプションを抽出するための文書レイアウト分析の「汎化性能」について研究してるねん。汎化性能っていうのは、いろんな種類の文書にも対応できるかどうかってことやな。arXivのプレプリントやで。
[118] Anmol Nayakらの2020年の研究は、BERTっていう有名な言語モデルが、トークン化(文章を単語とかに分割すること)とサブワード表現で、学習データになかった単語(OOV: Out-of-Vocabulary)にうまく対応できへんっていう課題について書いてるねん。ドメイン適応の難しさを指摘してる重要な論文やで。
[119] Tuan Anh D. Nguyenらの2021年の研究は、見た目がリッチな文書から情報抽出するための「スパン抽出アプローチ」についてやねん。スパンっていうのは、文章の中の連続した部分のことやな。その範囲を特定して情報を取り出すわけや。
[120] Maizhen Ningらの2021年の論文は、文書画像から情報抽出するための「セグメントベースのレイアウト考慮モデル」についてやねん。文書をセグメント(部分)に分けて、そのレイアウトを考慮しながら処理するんやな。
[121] Armineh Nourbakhshらの2024年の論文は、マルチモーダルな企業文書理解について、「今の研究で何が足りてへんのか?」っていう新しい研究課題を提案してるねん。ACL 2024のFindingsに載ってて、これからの研究の方向性を示してくれてるわけや。
[122] Berke Oralらの2020年の研究は、銀行の文書からの情報抽出についてやねん。銀行の文書ってテキストがめっちゃ多くて、しかも見た目もリッチやから、両方うまく扱わなあかんねん。Information Processing and Managementに載ってるで。
[123] 同じくBerke Oralらの2022年の研究は、構造化されてない取引文書からマルチモーダル情報抽出するために、視覚的な表現を融合させるアプローチについてやねん。International Journal on Document Analysis and Recognitionに載ってるで。
[124] Ismail Oussaidらの2022年の研究は、見た目がリッチな文書から情報抽出するときに、「フォントスタイルの埋め込み」を使うっていうアイデアやねん。太字とか斜体とか、そういうフォントの情報も大事やろ?っていう発想やな。ICPR 2022で発表されてるで。
[125] Matthew J Pageらの2021年の論文は、PRISMA 2020っていう系統的レビューを報告するためのガイドラインの更新版やねん。これ自体は機械学習の話やないんやけど、系統的文献レビューをちゃんとやるための重要な指針やから参照されてるんやな。BMJに載ってる有名な論文やで。
[126] Rasmus Berg Palmらの2019年の研究は、「Attend, Copy, Parse」っていう、文書からエンドツーエンドで情報抽出するシステムについてやねん。注意機構を使って、必要な部分をコピーして、パースする(構造化する)っていう流れやな。ICDARで発表されてるで。
[127] 同じくRasmus Berg Palmらの2017年の研究は、「CloudScan」っていう、設定不要で請求書を分析できるシステムについてやねん。リカレントニューラルネットワーク(RNN)を使ってて、2017年の時点でこれができてたんは結構すごいことやねん。
[128] Seunghyun Parkらの2019年の研究は、「CORD」っていうレシートのデータセットを作った話やねん。OCR後のパース(構造化)のために統合されたレシートデータセットで、この分野の研究に広く使われてるで。NeurIPS 2019のDocument Intelligenceワークショップで発表されてるわ。
[129] Qiming Pengらの2022年の研究は、「ERNIE-Layout」っていうモデルについてやねん。レイアウトの知識を使って事前学習を強化して、見た目がリッチな文書の理解を改善するっていうアプローチやな。ERNIEシリーズはBaidu(百度)が作ってる中国発の有名なモデルやで。EMNLP 2022のFindingsに載ってるわ。
[130] Vincent Perotらの2024年の研究は、「LMDX」っていう、言語モデルベースの文書情報抽出と位置特定のシステムについてやねん。ACL 2024のFindingsで発表されてて、最新のLLMを使った文書処理の研究やな。
---
## Page 36
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p036.png)
### 和訳
ほな、この参考文献リストを説明していくで!
---
36ページ目
Alexander Michael RombachとPeter Fettkeの論文やな
---
[131] Powalskiらの2021年の研究やねん。「Full-TILT Boogie」っていうめっちゃカッコええ名前のシステムで、これは文書理解のためのText-Image-Layout Transformer(テキストと画像とレイアウトを全部まとめて処理するやつ)の話や。コンピュータサイエンスの講義ノートシリーズに載ってて、Josep Lladósらが編集してはるやつの732-747ページに収録されとるで。
[132] Qiらの2024年の研究やな。「GVDIE」っていう、大規模言語モデルを使って視覚的な文書から情報を抽出する手法やねん。しかもゼロショット(事前に例を見せんでもいける)っていうのがすごいとこや。アジア太平洋の信号処理学会の年次会議で発表されとるで。
[133] Qianらの2019年の研究や。「GraphIE」っていうグラフベースの情報抽出フレームワークやねん。要するに、データをグラフ構造(点と線でつないだやつ)で表現して、そこから情報を引っ張り出す方法やな。北米の計算言語学会の会議で発表されとるで。
[134] ReimersとGurevychの2019年の研究やな。「Sentence-BERT」っていう、シャム(双子の)BERTネットワークを使って文章の埋め込み表現を作る方法やねん。なんでかっていうと、文章同士の意味的な類似度を効率よく計算できるようになるからめっちゃ便利なんや。
[135] Sachidanandaらの2021年の研究や。言語モデルを新しい分野に効率よく適応させるための「適応的トークン化」っていう手法やねん。トークン化っていうのは文章を小さい単位に分ける処理のことやで。
[136] Sageらの2020年の研究やな。ビジネス文書から構造化された情報をエンドツーエンド(最初から最後まで一気に)で抽出する方法で、Pointer-Generator Networksっていう技術を使っとるねん。
[137] Saifullahらの2023年の研究や。文書画像の分類にアクティブラーニング(能動学習)がどれだけ使えるか分析した論文やねん。アクティブラーニングっていうのは、AIが「これ教えて」って自分で学習データを選ぶ賢い学習方法のことやで。
[138] 同じSaifullahらの2023年の別の研究やな。「ColDBin」っていう、Cold Diffusion(冷拡散)を使って文書画像を二値化(白黒にする)する方法やねん。ICDAR 2023(文書解析と認識の国際会議)で発表されとるで。
[139] SarkhelとNandiの2021年の研究や。視覚的にリッチな文書から情報抽出するのを、視覚的スパン表現っていうのを使って改善する方法やねん。VLDBっていうデータベース系のめっちゃ権威ある学会の論文誌に載っとるで。
[140] Sassiouiらの2023年の研究やな。視覚的にリッチな文書理解について、概念とか分類体系とか課題をまとめた論文やねん。全体像を把握するのにええ論文やで。
[141] SchusterとPaliwalの1997年の研究や。双方向リカレントニューラルネットワーク(Bidirectional RNN)の論文やねん。これはめっちゃ基礎的で重要な研究で、前からも後ろからも情報を処理できるニューラルネットの仕組みを提案したんや。
[142] Scius-Bertrandらの2024年の研究やな。ファウンデーションモデル(基盤モデル)を使った文書情報抽出において、レイアウト解析とOCRがまだ役に立つんかどうかを調べた論文やねん。ほんまに興味深い問いかけやで。
[143] Sennrichらの2016年の研究や。ニューラル機械翻訳で珍しい単語をサブワード単位(単語をさらに小さく分けたやつ)で処理する方法やねん。これがあとで出てくるBPE(Byte Pair Encoding)の元になった重要な研究やで。
[144] Shiらの2023年の研究やな。文書理解のためのマルチスケールなセルベースのレイアウト表現の話や。WACVっていうコンピュータビジョンの冬の会議で発表されとるで。
[145] Siyuanらの2024年の研究や。「LayoutPointer」っていう、空間的なコンテキストに適応するポインターネットワークで視覚情報を抽出する方法やねん。NAACLっていう北米の計算言語学会で発表されとるで。
[146] Skalickýらの2022年の研究やな。ビジネス文書の情報抽出について、実用的なベンチマーク(性能評価の基準)を目指した研究やねん。
[147] SokolovaとLapalmeの2009年の研究や。分類タスクのパフォーマンス評価指標を体系的に分析した論文やねん。精度とか再現率とかF値とか、そういう評価方法を整理してくれとるで。
[148] Subramaniらの2020年の研究やな。OCRと文書理解のための深層学習アプローチについてのサーベイ(調査論文)やねん。この分野の全体像を知りたいときにめっちゃ便利な論文やで。
---
---
## Page 37
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p037.png)
### 和訳
**ビジネス文書からのディープラーニングベース重要情報抽出:システマティック・レビュー**
37
[149] Wen Taiさんたちが2020年に発表したexBERTっていう研究があんねん。これ何かっていうと、学習リソースが限られとる状況でも、特定の専門分野の語彙を追加して事前学習済みモデルを拡張する方法やねん。コンピュータ言語学会のEMNLP 2020で発表されとって、1433〜1439ページに載っとるで。doi:10.18653/v1/2020.findings-emnlp.129
[150] 2021年にGuozhi Tangさんたちが出したMatchVIEっていうのがあってな、これめっちゃおもろいねん。エンティティ同士の「マッチング関連度」をうまいこと活用して、視覚的な情報を抽出する手法やねん。国際人工知能会議(IJCAI)の1039〜1045ページに載っとるで。doi:10.24963/ijcai.2021/144
[151] Zineng Tangさんたちが2023年に発表した研究は、視覚・テキスト・レイアウトを全部統合して、どんな文書でも処理できるユニバーサルな手法を提案しとるねん。IEEE/CVFのコンピュータビジョン会議(CVPR 2023)の19254〜19264ページに掲載されとる。doi:10.1109/CVPR52729.2023.01845
[152] Sandeep Tataさんたちが2021年に発表したGleanっていうシステムがあんねんけど、これはテンプレート型の文書から構造化された情報を抽出するやつやねん。VLDB Endowmentの14巻6号、997〜1005ページに載っとるで。doi:10.14778/3447689.3447703
[153] 2024年にHuynh Vu Theさんたちが出した研究は、視覚的にリッチな文書を理解するためのワンショット(一発学習)Transformerフレームワークやねん。ICDAR 2024の244〜261ページに掲載されとる。doi:10.1007/978-3-031-70533-5_15
[154] Christos Theodoropolousさんたちが2023年に出した研究で、めっちゃ大事なこと言うてんねん。「情報抽出するとき、トークン化のこと忘れたらあかんで!」っていう話やねん。トークン化っていうのは、テキストを細かい単位に分割する処理のことや。593〜606ページに載っとる。doi:10.1007/978-3-031-39965-7_49
[155] An C Tranさんたちが2024年に発表した研究は、レシートから情報抽出するときに使うグラフ畳み込みニューラルネットワーク(要するにグラフ構造を使ったAI)のフィルターサイズがどれくらい効率に影響するかを評価したもんやねん。doi:10.1007/s41870-024-02089-1
[156] Akkshita Trivediさんたちが2024年に出したGDPっていう研究があんねん。これ「汎用文書事前学習」の略で、いろんな種類の文書理解を改善するための手法やねん。ICDAR 2024の208〜226ページに載っとる。doi:10.1007/978-3-031-70533-5_13
[157] Yi Tuさんたちが2023年に発表したLayoutMaskは、文書理解のためのマルチモーダル(複数の情報源を使う)事前学習で、テキストとレイアウトの相互作用を強化する手法やねん。コンピュータ言語学会の年次大会の15200〜15212ページに掲載されとる。doi:10.18653/v1/2023.acl-long.847
[158] 同じくYi Tuさんたちが2024年に出したUNERは、視覚的にリッチな文書における固有表現認識(人名とか会社名とかを見つける処理)のための統一予測ヘッドやねん。ACM Multimedia 2024の4890〜4898ページに載っとる。doi:10.1145/3664647.3681473
[159] Petar Veličkovićさんたちが2018年に発表したGraph Attention Networks(グラフ注意ネットワーク)は、めっちゃ有名な研究やねん。グラフ構造のデータを扱うときに、どこに注目すべきかをAIが学習する仕組みやな。ICLRで発表されとる。https://openreview.net/forum?id=rJXMpikCZ
[160] David Villanova-Aparisiさんたちが2024年に出した研究は、手書き文書の情報抽出を評価するときに、読み順に依存せん評価指標を提案しとるねん。ICDAR 2024の191〜215ページに載っとる。doi:10.1007/978-3-031-70536-6_12
[161] Joris Voermanさんたちが2021年に発表した研究は、文書ストリーム(次々流れてくる文書)を段階的に分類していくシステムやねん。複数のシステムをカスケード(連鎖)させて処理する方法を提案しとる。ICDAR 2021ワークショップの240〜254ページに掲載。doi:10.1007/978-3-030-86159-9_16
[162] Jianqiang Wanさんたちが2024年に発表したOMNIPARSERは、ほんまにすごい統合フレームワークやねん。テキスト検出、重要情報抽出、表認識を全部まとめて1つのシステムでできるようにしたんや。CVPR 2024の15641〜15653ページに載っとる。doi:10.1109/CVPR52733.2024.01481
[163] Bowen Wangさんたちが2024年に出したRobustLayoutLMは、最適化されたレイアウト情報と追加のモダリティ(情報源)を活用して、文書理解を改善する手法やねん。IEEE SMC 2024の3167〜3174ページに掲載。doi:10.1109/SMC54092.2024.10831373
[164] Dongsheng Wangさんたちが2023年に発表したDocGraphLMは、文書のグラフ言語モデルやねん。情報抽出のために文書をグラフ構造として捉えるアプローチや。SIGIR 2023の1944〜1948ページに載っとる。doi:10.1145/3539618.3591975
[165] 同じくDongsheng Wangさんたちが2024年に出したDocLLMは、レイアウトを意識した生成言語モデルやねん。マルチモーダルな文書理解のために設計されとって、ACL 2024の8529〜8548ページに掲載されとる。doi:10.18653/v1/2024.acl-long.463
[166] Jiapeng Wangさんたちが2022年に発表したLiLT(Language-Independent Layout Transformer)は、シンプルやけどめっちゃ効果的な言語非依存のレイアウトTransformerやねん。つまり、どの言語の文書でも使えるっていう優れもんや。ACL 2022の7747〜7757ページに載っとる。doi:10.18653/v1/2022.acl-long.534
[167] 同じくJiapeng Wangさんたちが2024年に出したLiLTv2は、言語を入れ替え可能なレイアウト・画像Transformerで、視覚的情報抽出のための進化版やねん。ACM Transactions on Multimedia Computing, Communications, and Applicationsに掲載。doi:10.1145/3708351
[168] またまたJiapeng Wangさんたちが2021年に発表した研究は、実世界での頑健な視覚的情報抽出に向けたもんやねん。新しいデータセットと新しい解決策を両方提案しとる。AAAI 2021の2738〜2745ページに掲載されとる。doi:10.1609/aaai.v35i4.16378
ACMに投稿された原稿
---
## Page 38
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p038.png)
### 和訳
38
Alexander Michael RombachとPeter Fettke
[169] Jiapeng Wangさんたちが2021年に発表した研究やねんけど、「タグ付け、コピー、予測」っていう3つの方法を使った弱教師あり学習の統合フレームワークを作ったんや。これは連続データを使って視覚的な情報を抜き出すためのもんで、IJCAIっていう人工知能の国際会議で発表されたんよ。1082-1090ページに載ってて、doi:10.24963/ijcai.2021/150やで。
[170] Wenjin Wangさんたちが2022年に出したMmLayoutっていうのは、めっちゃ細かいレベルからざっくりしたレベルまで対応できるマルチモーダルTransformerなんや。これ使ったら文書をうまいこと理解できるようになるねん。ACMのマルチメディア国際会議で発表されて、4877-4886ページ、doi:10.1145/3503161.3548406やで。
[171] Yanshan Wangさんたちが2018年に出した論文は、医療情報を抜き出すアプリケーションの文献レビューやねん。要するに、これまでの研究を全部まとめてくれてんのや。Journal of Biomedical Informaticsの77巻、34-49ページに載ってて、doi:10.1016/j.jbi.2017.11.011やで。
[172] Zilong Wangさんたちが2020年に発表したDocStructっていうのは、マルチモーダルな手法を使って文書の階層構造を抜き出すもんやねん。これで一般的なフォームの理解がめっちゃやりやすくなるんや。ACLのEMNLP 2020で発表されて、898-908ページ、doi:10.18653/v1/2020.findings-emnlp.80やで。
[173] Zilong Wangさんたちが2023年に出したVRDUっていうのは、視覚的にリッチな文書を理解するためのベンチマークやねん。要するに「この手法、ほんまにええの?」って比較評価するための基準を作ったんや。KDD 2023で発表されて、5184-5193ページ、doi:10.1145/3580305.3599929やで。
[174] Mengxi Weiさんたちが2020年に発表した研究は、事前学習済み言語モデルを使って、視覚的にリッチな文書からレイアウトを考慮しながらロバストに情報抽出するもんやねん。SIGIR 2020で発表されて、2367-2376ページ、doi:10.1145/3397271.3401442やで。
[175] Sven Weinzierlさんたちが2019年に出した研究は、文書からのコンテキスト情報を使って予測的ビジネスプロセスモニタリングをするっていうもんや。ECISっていうヨーロッパの情報システム会議で発表されたんやで。
[176] K Y Wongさんたちが1982年に出した論文は、文書分析システムについてやねん。IBMの研究開発ジャーナルの26巻6号、647-656ページに載ってて、doi:10.1147/rd.266.0647やで。めっちゃ昔の研究やけど、この分野の基礎になってるんや。
[177] Chun-Bo Xuさんたちが2024年に発表したEntityLayoutっていうのは、エンティティレベルで事前学習する言語モデルやねん。これ使ったら意味的なエンティティの認識とか関係抽出がうまいことできるようになるんや。ICDAR 2024で発表されて、262-279ページ、doi:10.1007/978-3-031-70533-5_16やで。
[178] Yiheng Xuさんたちが2020年に発表したLayoutLMは、めっちゃ有名な研究やねん。テキストとレイアウトを一緒に事前学習させて、文書画像の理解に使うっていう画期的なアプローチなんや。KDDで発表されて、1192-1200ページ、doi:10.1145/3394486.3403172やで。
[179] Yiheng Xuさんたちが2022年に出したXFUNDっていうのは、多言語対応の視覚的にリッチなフォーム理解のためのベンチマークデータセットやねん。いろんな言語でテストできるようになったんや。ACLで発表されて、3214-3224ページ、doi:10.18653/v1/2022.findings-acl.253やで。
[180] Yang Xuさんたちが2021年に発表したLayoutLMv2は、LayoutLMの進化版やねん。マルチモーダルな事前学習で視覚的にリッチな文書をもっとよく理解できるようになったんや。ACL-IJCNLP 2021で発表されて、2579-2591ページ、doi:10.18653/v1/2021.acl-long.201やで。
[181] Hsiu-Wei Yangさんたちが2024年に出した研究は、めっちゃおもろい視点やねん。AIモデルが文書の見た目の美しさを理解できるんか?っていう疑問に答えようとしてて、読みやすさとかレイアウトの質と予測の確信度の関係を調べてるんや。arXiv:2403.18183、http://arxiv.org/abs/2403.18183で見れるで。
[182] Jeff Yangさんたちが2024年に発表した研究は、視覚的にリッチな文書を理解するための軽量なマルチモーダル特徴融合ネットワークやねん。軽いのにちゃんと性能出るっていうのがポイントや。ICDAR 2024で発表されて、191-207ページ、doi:10.1007/978-3-031-70533-5_12やで。
[183] Xinye Yangさんたちが2023年に出した研究は、実際の文書画像からスタンプを消すためのマスクガイド手法やねん。印鑑とか邪魔なもんを消して、下の文字を読めるようにするんや。IEEE ICMEで発表されて、1631-1636ページ、doi:10.1109/ICME55011.2023.00281やで。
[184] Zhibo Yangさんたちが2023年に発表した研究は、エンティティを意味的なポイントとしてモデリングして、実世界の視覚的情報抽出をするもんやねん。CVPRで発表されて、15358-15367ページ、doi:10.1109/CVPR52729.2023.01474やで。
[185] Jiabo Yeさんたちが2023年に出したUReaderっていうのは、OCRなしで視覚的に配置された言語を理解できる普遍的なマルチモーダル大規模言語モデルやねん。OCR使わんでも文書が読めるようになるんや、すごいやろ?EMNLP 2023で発表されて、2841-2858ページ、doi:10.18653/v1/2023.findings-emnlp.187やで。
[186] Arsen Yeghiazaryanさんたちが2022年に発表したTokengridっていうのは、非構造化文書からもっと効率的にデータを抽出するためのもんやねん。IEEE Accessの10巻、39261-39268ページに載ってて、doi:10.1109/ACCESS.2022.3164674やで。
[187] Chang Oh Yoonさんたちが2024年に出したLOFIパイプラインっていうのは、言語にもOCRにもフォームにも依存せんで産業文書から情報を抽出できるっていうめっちゃ便利なもんやねん。いろんな種類の文書に対応できるのがポイントや。EMNLP 2024のIndustry Trackで発表されて、1056-1067ページ、doi:10.18653/v1/2024.emnlp-industry.79やで。
ACMに投稿された原稿
---
## Page 39
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p039.png)
### 和訳
ディープラーニングを使ったビジネス文書からの重要情報抽出:系統的文献レビュー
39ページ目
[188] Wenwen Yuさんらが2020年に発表した研究やねんけど、これは「PICK」っていう手法で、グラフ学習と畳み込みニューラルネットワークを改良したやつを使って、文書から大事な情報を引っ張り出すっていう話や。パターン認識の国際学会で発表されてん。要するに、文書の中の関係性をグラフで表現して、そこから必要な情報をうまいこと取り出す技術やな。
[189] Yuechen Yuさんらの2023年の研究は「StrucTexTv2」っていうやつで、文書画像の事前学習のために、視覚情報とテキスト情報を隠して予測させるっていうアプローチやねん。めっちゃ有名なICLRっていう学会で発表されとる。文書の見た目と文字の両方を理解させるための学習方法ってことやな。
[190] Chong Zhangさんらの2023年の研究は「読む順番が大事やで!」っていう話。見た目がリッチな文書から情報を抽出する時に、トークンの経路を予測するっていうアイデアや。EMNLP 2023で発表されてん。なんでかっていうと、文書って見た目はごちゃごちゃしてても、人間が読む順番があるやろ?その順番を考慮すると、もっとうまく情報が取れるっていう発見やな。
[191] Chao Zhangさんらの2022年の研究は、請求書からデータポイントを抽出するのに、多層グラフアテンションネットワークと固有表現認識を組み合わせた手法や。IEEE ICAICA 2022で発表されとる。請求書みたいな定型的な文書から、金額とか日付とかを自動で取り出す技術やねん。
[192] Junwei Zhangさんらの2022年の研究は「Dual-VIE」っていうやつで、2段階のグラフアテンションネットワークを使って視覚情報を抽出するんや。ほんまに、文書の構造を2つのレベルで見ることで、より精度よく情報が取れるようになるってことやな。
[193] Peng Zhangさんらの2020年の研究は「TRIE」っていう手法で、テキストの読み取りと情報抽出を一気通貫でやっちゃおうっていうアプローチやねん。ACM MMで発表されとる。従来は文字認識と情報抽出を別々にやってたんやけど、これを一緒にやることで文書理解の精度が上がるっていう話や。
[194] Xinpeng Zhangさんらの2023年の研究は、文字レベルで文書の重要情報を抽出する方法で、対照学習っていう技術を使ってるねん。細かい文字単位で見ることで、より正確に情報が取れるようになるってことやな。
[195] Yue Zhangさんらの2021年の研究は、見た目がリッチな文書での実体関係抽出を、依存構文解析みたいにやっちゃおうっていうアイデアや。EMNLP 2021で発表されとる。文書内の要素同士の関係を、文法の解析みたいな手法で取り出すってことやな。
[196] Zhenrong Zhangさんらの2023年の研究は、グラフアテンションネットワークを使ったマルチモーダル事前学習で、文書理解のための手法や。IEEE Transactions on Multimediaに載っとる。画像とテキストの両方をグラフで表現して、その関係性を学習させるっていう話やねん。
[197] Ran Zmigrodさんらの2024年の研究は「テンプレートの価値って何やねん?」っていう問いかけから始まる研究で、大規模言語モデル(LLM)のための文書情報抽出データセットを見直そうっていう提案や。EMNLP 2024のFindingsで発表されとる。今までのデータセットがLLMの評価に本当に適してるんか?っていう根本的な疑問を投げかけてる、めっちゃ重要な論文やな。
ACMに投稿された原稿
---
## Page 40
[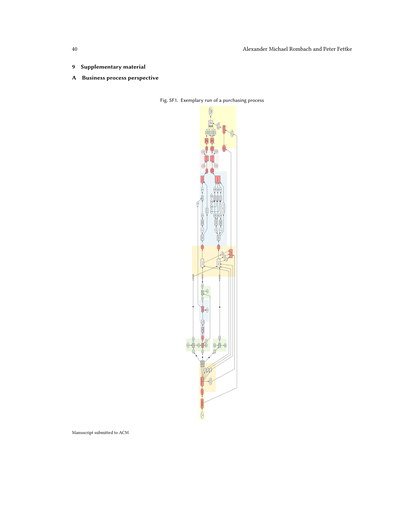](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p040.png)
### 和訳
40
Alexander Michael RombachとPeter Fettke
9 補足資料
A ビジネスプロセスの見方
図SF1. 購買プロセスの実行例やで
ACMに投稿された原稿やねん
---
## Page 41
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p041.png)
### 和訳
ビジネス文書からのディープラーニングによる重要情報抽出:システマティック文献レビュー
41
付録B 検索手順の詳細
B.1 データベース検索文字列
表ST1. 定義した検索文字列
| 検索文字列 | ヒット数 | DB |
|---|---|---|
| intitle:((information AND extract*) OR "entity extraction" OR "entity recognition" OR document* OR "visually rich") AND (intitle:("visually?rich" OR modal* OR image* OR invoice* OR receipt*) OR abstract:("visually?rich" OR modal* OR image* OR invoice* OR receipt*) OR keywords:("visually?rich" OR modal* OR image* OR invoice* OR receipt*)) | 100 | ACL |
| Title:((information AND extract*) OR "entity extraction" OR "entity recognition" OR document* OR "visually?rich") AND ( Title:("visually?rich" OR modal* OR image OR invoice OR receipt) OR Abstract:("visually?rich" OR modal* OR image OR invoice OR receipt) OR Keyword:("visually?rich" OR modal* OR image OR invoice OR receipt) ) AND NOT (Title:(handwrit*) OR Title:(histor*) OR Title:(table) OR Title:(web)) | 300 | ACM |
| ((title:information AND title:extract*) OR title:"entity extraction" OR title:"entity recognition" OR title:document* OR title:"visually rich") AND ("deep learning" OR "artificial intelligence" OR "neural network*") &start_date=01/01/2017&end_date=12/31/2023 | 35 | AIS |
| ((("Document Title":information AND "Document Title":extract*) OR "Document Title":"entity extraction" OR "Document Title":"entity recognition" OR "Document Title":document* OR "Document Title":"visually rich") AND ( ("Document Title":"visually rich" OR "Document Title":modal* OR "Document Title":invoice OR "Document Title":receipt) OR ("Abstract":"visually rich" OR "Abstract":modal* OR "Abstract":invoice OR "Abstract":receipt) OR ("Author Keywords":"visually rich" OR "Author Keywords":modal* OR "Author Keywords":invoice OR "Author Keywords":receipt) ) NOT ("Document Title":handwrit* OR "Document Title":histor* OR "Document Title":table)) | 152 | IEEE |
| Year: 2017-2023; Title, abstract, keywords: "visually rich" OR modal OR image OR invoice OR receipt; Title: (information AND extract) OR document OR "visually rich" ; "deep learning" OR "artificial intelligence" OR cognitive OR intelligent OR "neural network" | 198 | SD |
| query="visually+rich"+OR+modal*+OR+image+OR+invoice+OR+receipt & dc.title=information+extract* & date-facet-mode=between&facet-start-year=2017 & facet-end-year=2023 | 348 | SL |
| **合計** | **1133** | |
タイトルにはDU(文書理解)のサブタスクの名前、つまりKIE(重要情報抽出)とその言い換え表現、あと「entity extraction」みたいなよう使われる用語を入れとかなあかんねん。それに加えて「document*」もタイトル検索に入れたんやけど、これがまあ関係ない論文もめっちゃ引っかかる原因になってもうたわ。でもこれ大事やねん。なんでかっていうと、さっきも言うたけど、この研究分野って色んな呼び方されとるからな。
そのせいで手作業でフィルタリングする手間はめっちゃ増えたんやけど、その分「再現率」、つまり取りこぼしを減らせて網羅性が上がったから、まあトレードオフやな。ほんでタイトル、要旨、キーワード、メタデータには「visually rich」とか「image」みたいな用語を入れて、この研究の範囲に合うようにVRD(見た目がリッチな文書)を扱っとる文献を見つけられるようにしたんや。「invoice」とか「receipt」も入れたで。これが文書タイプでいちばんよう使われる用語やからな。ただな、これらの用語はOR演算子でつないどるから、結果に必ず含まれとる必要はないねん。ディープラーニングの手法使っとるアプローチを特定するために、「deep learning」「artificial intelligence」「neural network*」も追加したで。これらのうち最低1個がテキストかメタデータのどっかに出てきたらOKって設定や。この研究の範囲外の論文をフィルタリングするために、
Manuscript submitted to ACM
---
## Page 42
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p042.png)
### 和訳
図 SF2. PRISMAのフロー図(文献検索の流れを示す図)
**同定(Identification)**
データベース検索で見つかった文献の数:
- ACM: 300件
- ACL: 100件
- AIS: 35件
- IEEE: 152件
- ScienceDirect: 198件
- SpringerLink: 348件
- **合計: 1133件**
**スクリーニング(Screening)**
スクリーニング前に除外された文献:
- 重複していた文献を削除: 22件
スクリーニングにかけた文献数: 1111件
除外された文献:
- IN1に該当せず: 601件
- IN2に該当せず: 32件
- EX1に該当: 6件
- EX2に該当: 97件
- EX3に該当: 141件
- EX4に該当: 126件
- EX5に該当: 17件
- **合計除外: 1020件**
**適格性評価(Eligibility)**
適格性評価にかけた文献数: 1099件
別途除外された文献: 12件
**採用(Included)**
採用された研究: 79件
後方引用追跡で追加: 51件
**レビューに含まれた研究の合計: 130件**
---
ほんで、検索する時の条件の話やねんけど、タイトルに「handwrit*」(手書き系)とか「histor*」(歴史系)とか「table」とか「web」って入ってる論文は、検索エンジンが対応してたら除外するようにしたんや。あと、ワイルドカード(*)っていう便利なやつを使って、ちょっと違う言い回しでも引っかかるようにしたんやで。例えば「information AND extract*」って検索したら、「extraction」でも「extracting」でも両方ヒットするようになるねん。めっちゃ効率的やろ?
---
## Page 43
[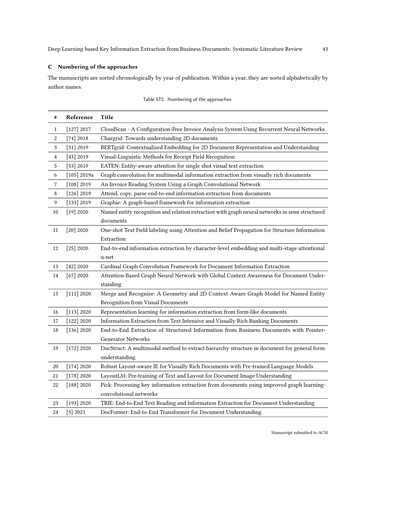](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p043.png)
### 和訳
ディープラーニングによるビジネス文書からの重要情報抽出:系統的文献レビュー
43ページ
付録C 各手法の番号付け
論文は発表年で時系列順に並べてるねん。同じ年の中では、著者名のアルファベット順にソートしてあるで。
表ST2. 各手法の番号付け
| # | 参考文献 | タイトル |
|---|----------|----------|
| 1 | [127] 2017年 | CloudScan - 設定いらずの請求書解析システム、リカレントニューラルネットワーク使ってるやつ |
| 2 | [74] 2018年 | Chargrid: 2次元の文書を理解しようって話 |
| 3 | [31] 2019年 | BERTgrid: 2次元文書の表現と理解のための文脈を考慮した埋め込み |
| 4 | [43] 2019年 | レシートの項目認識のための視覚・言語手法 |
| 5 | [53] 2019年 | EATEN: 一発撮りで視覚的なテキスト抽出するための、エンティティを意識したアテンション機構 |
| 6 | [105] 2019年a | 見た目リッチな文書からマルチモーダル情報抽出するためのグラフ畳み込み |
| 7 | [108] 2019年 | グラフ畳み込みネットワーク使った請求書読み取りシステム |
| 8 | [126] 2019年 | Attend, Copy, Parse - 文書から情報をエンドツーエンドで抽出するやつ |
| 9 | [133] 2019年 | Graphie: 情報抽出のためのグラフベースのフレームワーク |
| 10 | [19] 2020年 | 半構造化文書でグラフニューラルネットワーク使った固有表現認識と関係抽出 |
| 11 | [20] 2020年 | ワンショットのテキストフィールドラベリング - アテンションと確率伝播で構造情報抽出するやつ |
| 12 | [25] 2020年 | 文字レベル埋め込みと多段階アテンションU-Netによるエンドツーエンド情報抽出 |
| 13 | [42] 2020年 | Cardinal Graph Convolution Framework - 文書情報抽出用のやつ |
| 14 | [67] 2020年 | 文書理解のための、グローバルな文脈を意識したアテンションベースのグラフニューラルネットワーク |
| 15 | [111] 2020年 | Merge and Recognize: 視覚的文書から固有表現認識するための、幾何学と2D文脈を考慮したグラフモデル |
| 16 | [113] 2020年 | フォームみたいな文書からの情報抽出のための表現学習 |
| 17 | [122] 2020年 | 文字がめっちゃ多くて見た目もリッチな銀行文書からの情報抽出 |
| 18 | [136] 2020年 | ポインタ生成ネットワーク使ったビジネス文書からの構造化情報のエンドツーエンド抽出 |
| 19 | [172] 2020年 | DocStruct: 汎用フォーム理解のために文書の階層構造を抽出するマルチモーダル手法 |
| 20 | [174] 2020年 | 事前学習済み言語モデル使った、見た目リッチな文書のための頑健なレイアウト考慮型情報抽出 |
| 21 | [178] 2020年 | LayoutLM: 文書画像理解のためのテキストとレイアウトの事前学習 |
| 22 | [188] 2020年 | PICK: 改良版グラフ学習畳み込みネットワーク使った文書からの重要情報抽出 |
| 23 | [193] 2020年 | TRIE: 文書理解のためのエンドツーエンドのテキスト読み取りと情報抽出 |
| 24 | [5] 2021年 | DocFormer: 文書理解のためのエンドツーエンドTransformer |
ACMに投稿された原稿やで
---
## Page 44
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p044.png)
### 和訳
44
Alexander Michael RombachとPeter Fettke
25
[12] 2021年
半構造化文書から情報抽出するときにGAT(グラフアテンションネットワーク)で単語の近所関係も考慮しようって話
26
27
28
29
30
31
32
33
34
35
[27] 2021年
Visual FUDGE:動的にグラフを編集してフォームを理解しようってやつ
[45] 2021年
LAMBERT:レイアウトをちゃんと意識した言語モデルで情報抽出するねん
[51] 2021年
文書理解のための統一された事前学習フレームワークやで
[55] 2021年
請求書から情報を抜き出す研究
[62] 2021年
類似性から学習して、構造化された文書から情報を抜き出す方法
[71] 2021年a
半構造化文書の画像からコスパよくエンドツーエンドで情報抽出する話
[72] 2021年b
半構造化文書の情報抽出を空間的な依存関係のパース(構文解析みたいなもんやな)でやろうって研究
[75] 2021年
VisualWordGrid:スキャンした文書からマルチモーダル(複数の情報源を組み合わせるってことやで)なアプローチで情報抽出する方法
[79] 2021年
DocReader:バウンディングボックス(囲み枠のことな)なしで文書の情報抽出モデルを学習させる方法
[81] 2021年
請求書からの情報抽出:レイアウトがめっちゃバラバラなデータセットに対してグラフニューラルネットワークでアプローチする研究
36
[89] 2021年
ROPE:グラフベースの文書情報抽出のための読み順が入れ替わっても大丈夫な位置エンコーディング
[92] 2021年a
StructuralLM:フォーム理解のための構造的な事前学習
[96] 2021年b
SelfDoc:自己教師あり学習で文書の表現を学ぶ方法
[100] 2021年c
StrucTexT:マルチモーダルなTransformerで構造化されたテキストを理解する
[102] 2021年
ViBERTgrid:文書から重要な情報を抽出するための、一緒に学習させたマルチモーダルな2D文書表現
[119] 2021年
視覚的にリッチな文書の情報抽出にスパン抽出(テキストの範囲を取り出すってことやな)アプローチを使う研究
[120] 2021年
文書画像の情報抽出でセグメントベースのレイアウト認識モデルを使う方法
[131] 2021年
Full-TILT Boogie:テキスト・画像・レイアウトのTransformerで文書理解をめっちゃパワーアップさせる話
[139] 2021年
視覚的にリッチな文書からの情報抽出を、視覚的スパン表現を使って改善する研究
[150] 2021年
MatchVIE:エンティティ(抽出したい項目のことやで)間のマッチング関連性を活用した視覚的情報抽出
[152] 2021年
Glean:テンプレート的な文書から構造化された抽出をする方法
[168] 2021年a
実世界でちゃんと使える頑健な視覚的情報抽出を目指して:新しいデータセットと新しい解決策
[169] 2021年b
タグ付け・コピー・予測:シーケンスを使った視覚的情報抽出のための統一的な弱教師あり学習(ラベルが少なくてもいける学習方法やねん)フレームワーク
[180] 2021年
LayoutLMv2:視覚的にリッチな文書理解のためのマルチモーダル事前学習
[195] 2021年
視覚的にリッチな文書でのエンティティ関係抽出を依存構造解析としてやる研究
[6] 2022年
購買文書からの重要情報抽出:ディープラーニングとルールベースの修正を組み合わせる方法
[16] 2022年a
実環境の文書情報抽出のためのクエリ駆動型生成ネットワーク
[17] 2022年b
GMN:実用的な文書情報抽出のための生成マルチモーダルネットワーク
[28] 2022年
視覚的にリッチな文書からの自動キー情報抽出
[37] 2022年
CALM:文書画像理解のための常識知識を補強する方法
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
Manuscript submitted to ACM(ACMに投稿された原稿やで)
---
## Page 45
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p045.png)
### 和訳
深層学習を使ったビジネス文書からの重要情報抽出:システマティック文献レビュー
45〜83番の論文リストやで
[52] 2022年
**XYLayoutLM: 見た目リッチな文書を理解するための、レイアウトを意識したマルチモーダルネットワークを目指して**
[63] 2022年
**BROS: 文書からのキー情報抽出をもっとうまくやるために、テキストとレイアウトに注目した事前学習言語モデル**
[68] 2022年
**LayoutLMv3: テキストと画像の両方をマスキングして統一的にやる、文書AI向けの事前学習**
[77] 2022年
**OCR-Free Document Understanding Transformer: OCRなしで文書を理解できるTransformerやで**
[88] 2022年
**FormNet: フォーム文書の情報抽出で、ただの順番に並べる以上の構造的エンコーディングをやってみた**
[98] 2022年c
**見た目リッチな文書における関係性の表現学習**
[123] 2022年
**構造化されてない取引文書から情報抽出するための、マルチモーダル視覚表現の融合**
[129] 2022年
**ERNIE-Layout: 見た目リッチな文書理解のための、レイアウト知識を強化した事前学習**
[166] 2022年b
**LiLT: 構造化文書理解のための、シンプルやけどめっちゃ効く言語非依存レイアウトTransformer**
[170] 2022年a
**MmLayout: 文書理解のための細かい粒度と粗い粒度両方扱うマルチモーダルTransformer**
[186] 2022年
**Tokengrid: 構造化されてない文書からもっと効率よくデータ抽出しようや**
[191] 2022年a
**多層グラフアテンションネットワークと固有表現認識を使って、請求書からデータポイントを抽出する話**
[192] 2022年b
**Dual-VIE: 視覚情報抽出のための2レベルグラフアテンションネットワーク**
[11] 2023年b
**半構造化文書のための低次元情報抽出モデル**
[10] 2023年a
**アテンションベースの半変分グラフオートエンコーダを使って、半構造化文書からの情報抽出を改善する話**
[18] 2023年
**GenKIE: 頑健な生成型マルチモーダル文書キー情報抽出**
[26] 2023年
**Dessurtを使った、エンドツーエンドの文書認識と理解**
[29] 2023年b
**文書の帰納的バイアスに基づいた、キー情報抽出のための反復グラフ学習畳み込みネットワーク**
[30] 2023年a
**GenTC: レシート情報抽出のための、対照学習を使った生成型Transformer**
[33] 2023年
**DocParser: 見た目リッチな文書からOCRなしでエンドツーエンドに情報抽出するやつ**
[34] 2023年
**ベトナム語の処方箋画像からキー情報を抽出する新しいアプローチ**
[46] 2023年
**VisualIE: 新しい視覚・テキストアプローチを使ったレシートベースの情報抽出**
[49] 2023年
**Doc2Graph: グラフニューラルネットワークベースの、タスクに依存しない文書理解フレームワーク**
[56] 2023年
**Transformerを使って、文書情報抽出のGNN特徴モデリングを強化する話**
[58] 2023年b
**ICL-D3IE: 文書情報抽出のための、多様なデモンストレーションを更新しながらやるインコンテキスト学習**
[60] 2023年c
**グローバルタギングによる文書情報抽出**
[83] 2023年
**実世界での視覚情報抽出:実用的なデータセットとエンドツーエンドのソリューション**
[90] 2023年
**FormNetV2: フォーム文書情報抽出のためのマルチモーダルグラフ対照学習**
ACMに投稿された原稿やで
---
## Page 46
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p046.png)
### 和訳
46ページ目
Alexander Michael RombachさんとPeter Fettkeさんの論文やで
84から109番までの研究論文リストやねん。これ全部、書類とか文書から情報を自動で引っ張り出す技術に関する論文やで。
[97] 2023b年
「レイアウト構造モデリングで見た目リッチな文書理解をパワーアップさせる研究」
→ 要はな、PDFとか請求書みたいな見た目がゴチャゴチャした書類を、AIがもっと賢く読めるようにする技術やねん
[101] 2023年
「DocTr:構造化された情報抽出のための文書トランスフォーマー」
→ Transformerっていう最新のAI技術を使って、書類から情報を整理して抜き出す方法やで
[109] 2023年
「GeoLayoutLM:視覚的情報抽出のための幾何学的事前学習」
→ 文書の「どこに何があるか」っていう位置関係をめっちゃ重視して学習させる手法やねん
[144] 2023年
「マルチスケールのセルベースレイアウト表現で文書を理解する研究」
→ 表とかのセル(マス目)を色んなサイズで見ることで、文書の構造をうまく捉えようっていう話やで
[151] 2023年
「視覚・テキスト・レイアウトを統一した万能文書処理」
→ 見た目も文字も配置も、全部まとめて処理できる最強のモデルを作ったでっていう研究やな
[157] 2023年
「LayoutMask:文書理解のためのマルチモーダル事前学習でテキストとレイアウトの相互作用を強化」
→ 文字と配置の関係性をもっと深く学習させる新しい方法やねん
[164] 2023a年
「DocGraphLM:情報抽出のための文書グラフ言語モデル」
→ 文書をグラフ(点と線のネットワーク)として表現して、そこから情報を引っ張り出す技術やで
[184] 2023a年
「野生環境での視覚的情報抽出:エンティティをセマンティックポイントとしてモデル化」
→ 「野生」ってのは現実世界のグチャグチャな状況のことやねん。そういう厳しい条件でも情報抽出できるようにする研究やで
[185] 2023年
「UReader:マルチモーダル大規模言語モデルを使ったOCR不要の視覚言語理解」
→ OCR(文字認識)を別途やらんでも、大規模言語モデルが直接画像から文字を読み取れるようにした研究やねん。めっちゃ画期的やで
[189] 2023年
「StrucTexTv2:文書画像の事前学習のためのマスク付き視覚テキスト予測」
→ 一部を隠して「ここ何やと思う?」って当てさせる学習法で、文書理解の精度を上げる研究やな
[190] 2023b年
「読み順が大事やで:トークンパス予測による視覚リッチ文書からの情報抽出」
→ 人間が文書を読む順番をAIにも教え込むことで、もっと賢く情報を抜き出せるようにする話やねん
[194] 2023a年
「対照学習を使った文字レベルの文書キー情報抽出手法」
→ 単語単位じゃなくて1文字1文字のレベルで処理する方法やで。対照学習っていうのは「これとこれは似てる、これは違う」って学ばせる手法やねん
[196] 2023c年
「グラフアテンションネットワークを使った文書理解のためのマルチモーダル事前学習」
→ グラフの構造に注目しながら、画像とテキストの両方を学習させる研究やで
[3] 2024年
「マルチタスク事前学習で文書情報分析を強化:視覚リッチ文書の情報抽出への堅牢なアプローチ」
→ 複数のタスクを同時に学習させることで、もっとタフで使えるモデルを作ろうっていう研究やねん
[7] 2024年
「AIE-KB:中国の公文書シナリオ向け知識ベース付き情報抽出技術」
→ 中国のお役所文書に特化した情報抽出システムで、知識ベースっていう「物知り辞書」を組み合わせてるねん
[13] 2024年
「GeoContrastNet:言語に依存しない文書理解のための対照的キーバリューエッジ学習」
→ どの言語でも使える文書理解モデルやで。キーと値のペア(例えば「名前:田中」みたいな)の関係を学習するねん
[24] 2024年
「GraphMLLM:文書理解のためのグラフベースのマルチレベルレイアウト言語非依存モデル」
→ これも言語に関係なく使えて、グラフ構造を活用した文書理解モデルやな
[39] 2024年
「DocPedia:周波数領域で大規模マルチモーダルモデルのパワーを解き放つ汎用文書理解」
→ 周波数領域っていうのは、画像を波の形で分析する方法やねん。それを使って色んな種類の文書に対応できるようにしたんやで
[41] 2024年
「LayoutLLM:視覚リッチ文書理解のための大規模言語モデル命令チューニング」
→ ChatGPTみたいな大規模言語モデルを、文書理解に特化させるためにチューニングした研究やねん
[47] 2024a年
「有向重み付きグラフニューラルネットワークを使った視覚リッチ文書からの情報抽出」
→ 矢印の向きと重みがついたグラフを使って、より賢く情報を抜き出す手法やで
[48] 2024b年
「視覚リッチ文書からの情報抽出のためのマルチモーダル重み付きグラフ表現」
→ 上の研究の続きみたいなもんで、画像とテキスト両方使ってグラフを作る方法やねん
[54] 2024年
「DCMAI:文書キー情報抽出のための動的クロスモーダルアライメント相互作用フレームワーク」
→ 画像とテキストの対応関係を動的に(状況に応じて)調整しながら、重要な情報を抜き出す仕組みやで
[65] 2024b年
「mPLUG-DocOwl 1.5:OCR不要の文書理解のための統一構造学習」
→ またOCRなしで文書を理解できるモデルやけど、構造を統一的に学習するのがウリやねん
[66] 2024a年
「UniVIE:フォーム型文書からの視覚情報抽出への統一ラベル空間アプローチ」
→ 申請書とかフォーム形式の書類から情報を抜き出すとき、ラベルの付け方を統一して効率化する研究やで
[70] 2024年
「MCKIE:グラフ畳み込みネットワークベースの複雑な文書からの多クラスキー情報抽出」
→ 色んな種類の重要情報を同時に抜き出せるモデルで、グラフ畳み込みっていう技術を使ってるねん
[84] 2024年
「階層データの次文予測としてキー情報抽出を再定式化」
→ 「次に来る文は何?」って予測するタスクに置き換えることで、入れ子構造のデータもうまく処理できるようにした研究やで
ACMに投稿された原稿やねん
---
## Page 47
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p047.png)
### 和訳
ディープラーニング使ったビジネス文書からの重要情報抽出:体系的な文献レビュー
47ページ
110番
[85] 2024年
ProtoNER:プロトタイプネットワーク使った固有表現認識のためのフューショット増分学習
→ ようは、ちょっとの例だけで新しい名前とか組織名とかをどんどん覚えていけるシステムやねん
111番、112番
[93] 2024年
DocPointer:パラメータ効率のええポインタネットワークで重要情報抽出するやつ
→ めっちゃ少ないパラメータで大事な情報ピンポイントで取ってこれるんやで
113番、114番
[103] 2024年
PEneo:行の抽出、行のグループ化、エンティティのリンク付けを一気通貫でやって文書ペア抽出するやつ
→ 文書の中の行を見つけて、関連あるやつをまとめて、意味のある情報同士をつなげる、これ全部一発でできるシステムやねん
[104] 2024年
HRVDA:高解像度ビジュアル文書アシスタント
→ めっちゃ細かい画像の文書もバッチリ理解できるAIアシスタントやな
[110] 2024年a
LayoutLLM:大規模言語モデルにレイアウト指示を学習させて文書理解するやつ
→ ChatGPTみたいな賢いAIに「この文書のどこに何があるか」っていうレイアウト情報も教え込むんやで
115番
[112] 2024年b
多変量意味関連グラフをマルチモーダルネットワークに組み込んで文書から情報抽出するやつ
→ 色んな情報のつながりをグラフで表して、それを画像とテキスト両方扱えるAIに食わせるってことやねん
[115] 2024年
大規模言語モデル使った文書理解のためにレイアウトをテキストに埋め込むやつ
→ 「この文字は左上にある」みたいな位置情報もテキストとして一緒に入れちゃうんやで
[130] 2024年
LMDX:言語モデルベースの文書情報抽出と位置特定
→ 賢いAIで文書から情報抜き出して、それがどこにあったかまで教えてくれるやつやな
[132] 2024年
GVDIE:大規模言語モデルベースのゼロショット生成型視覚文書情報抽出手法
→ 事前に例を見せんでも、いきなり文書の画像見せたら情報取ってこれるすごいやつやねん
[145] 2024年
LayoutPointer:空間的文脈に適応するポインタネットワークで視覚情報抽出するやつ
→ 文書の中で「どこに何がある」っていう位置関係をうまく使って、欲しい情報をピンポイントで指し示すシステムやで
[153] 2024年
見た目リッチな文書理解のためのワンショット Transformer フレームワーク
→ たった1個の例見せるだけで、複雑なデザインの文書も理解できるようになるやつやねん
[155] 2024年
レシートからの情報抽出におけるグラフ畳み込みニューラルネットワークのフィルタサイズ効率評価
→ レシート読み取るAIで、どのサイズのフィルタが一番ええか調べたって話やな
[156] 2024年
GDP:汎用文書事前学習で文書理解を改善するやつ
→ 色んな文書をめっちゃ読ませて下準備しとくと、後で何でも理解できるようになるってことやねん
[158] 2024年
UNER:見た目リッチな文書の固有表現認識のための統一予測ヘッド
→ 人名とか会社名とか認識する部分を、一個の仕組みにまとめて効率よくしたやつやで
[162] 2024年
OMNIPARSER:テキスト検出、重要情報抽出、表認識を統一的にやるフレームワーク
→ 文字見つける、大事な情報取る、表を理解する、これ全部一つのシステムでできちゃうんやな
125番
[163] 2024年
RobustLayoutLM:追加のモダリティと最適化されたレイアウトを活用して文書理解を改善するやつ
→ レイアウト情報をうまく調整して、画像とかも一緒に使ってより強力な文書理解を実現したやつやねん
126番
[165] 2024年b
DocLLM:マルチモーダル文書理解のためのレイアウト対応生成型言語モデル
→ 文書のレイアウトがわかる、めっちゃ賢い文章生成AIやで
127番、128番
[167] 2024年a
LiLTv2:視覚情報抽出のための言語交換可能なレイアウト画像Transformer
→ どの言語でも使えるように、言語部分だけ差し替え可能にした画像とレイアウト理解するAIやねん
[177] 2024年
EntityLayout:意味エンティティ認識と関係抽出のためのエンティティレベル事前学習言語モデル
→ 「これは会社名」「これは金額」みたいな意味のある塊単位で学習させて、それらの関係も理解できるようにしたやつやな
129番
[182] 2024年b
軽量マルチモダリティ特徴融合ネットワークで見た目リッチな文書理解するやつ
→ テキストと画像の情報をうまいこと混ぜ合わせるんやけど、めっちゃ軽くて速いモデルやねん
130番
[187] 2024年
LOFI:言語・OCR・フォーマットに依存しない産業文書情報抽出パイプライン
→ 何語でも、どんなOCRソフト使っても、どんな書式の文書でも対応できる産業向けの情報抽出システムやで。ほんまに汎用性高いやつやな
Manuscript submitted to ACM(ACMに投稿済みの原稿)
---
## Page 48
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p048.png)
### 和訳
48
D 概要
Alexander Michael Rombach と Peter Fettke
ほな、それぞれの論文をどんな観点で調べたかっていうのを説明するわな。これ、実際に使うことも考えて、いろんな角度から見てるねん。
• カテゴリ:これはな、KIE(文書から情報抜き出すタスクのことな)に使われてる大きな手法の分類のことやねん(セクション2.3見てな)。複数の手法を組み合わせてる場合もあるで。
• 入力モダリティ:入力する文書からどんな種類の情報を使ったかってことやな。テキストとか、見た目(画像)とか、レイアウト(配置)とか、あと研究者が独自に作った特徴量とかも含めて分析してるねん。ちなみにLLM(大規模言語モデル)を使うアプローチの場合、そもそもプロンプト(指示文)は設計上必要なもんやから、それはテキストモダリティとしてはカウントしてへんで。
• データ基盤:どんだけの量で、どんな種類の文書を使って実装・評価したかっていうのを調べてるねん。これ見たら、どれくらいのデータが土台にあって、どれくらいのデータが必要かわかるやろ。
• 再現性とデプロイ可能性:これめっちゃ大事やねんけど、実装したコードとかモデルの重み(学習済みのパラメータな)が公開されてるかどうか、あと商用で使ってもええかどうかってことやな。
• 外部OCRに依存せえへんか:そのKIEアプローチが、外部のOCRエンジン(文字認識システムな)なしで動くかどうかってことやで。
• パラメータ数:著者が書いてたら、モデル全体のパラメータ数(百万単位で)を載せてるねん。これでモデルがどんだけ複雑かわかるわな。複数のバリエーションがある場合は、一番でかいやつを載せてるで。
• ドメイン知識の統合:業務プロセスとか、抜き出したい値についての知識とか、そういうドメイン(専門領域)の知識を何らかの形で組み込んでるかどうかやな。
• 既存KIEアプローチの進化版か:すでにあるKIE手法をベースにして、はっきりした改良を加えた後継アプローチかどうかってことやで。
• 産業現場での評価:ほんまの現場、つまり実際のビジネス環境で評価されてるかどうかやな。定量的(数字で)でも定性的(感想とか)でもええねんけど、単に「処理時間これくらいでした」って報告してるだけのはカウントしてへんで。
• 弱いアノテーションでOKか:学習に必要なアノテーション(正解ラベル付け)について、単語レベルの詳細なラベルとバウンディングボックス(位置の四角枠な)まで全部いるんか、それともそこまでガチガチじゃなくてもええんかってことやねん。これ見たら、そのアプローチを学習させるのにどんだけ手間かかるかわかるやろ。
• 生成型か:そのKIEシステムが自己回帰型(前の出力を見ながら次を予測するタイプな)で、デコード(出力生成)のステップで自由に何でも出力できるかどうかってことやで。
Manuscript submitted to ACM
---
## Page 49
[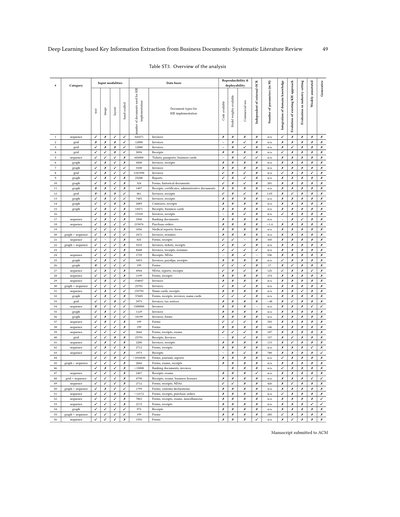](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p049.png)
### 和訳
ビジネス文書からのディープラーニングによる重要情報抽出:系統的文献レビュー
49ページ
表ST3. 分析の概要
この表がめっちゃ大事なとこやねん。ざっくり説明するとな、56本の研究論文を色んな角度から分析した結果をまとめてるんや。
**入力モダリティ**ってのは、要するに「AIにどんな情報を食わせるか」ってことやな。テキスト、画像、レイアウト(配置情報)の3種類があって、ほとんどの研究がこの3つ全部使ってるんや。なんでかっていうと、請求書とか領収書って、文字だけじゃなくて「どこに何が書いてあるか」も超重要やからな。
**手作り vs 学習済み**ってのは、特徴量を人間が設計したか、AIに自動で学習させたかの違いや。最近の研究はほぼ全部「学習済み」を使ってる。人間がチマチマ設計するより、AIに任せた方がええってことがわかってきたんやな。
**データ構造**のとこ見てみ?シーケンス(順番に並べる)、グリッド(格子状)、グラフ(ネットワーク状)の3パターンがあるんや。シーケンスが一番多いけど、最近はグラフ構造を組み合わせる研究が増えてきてるんやで。
**データ数**がほんまにバラバラやねん。199件しかないのもあれば、118万件とか60万件とかめっちゃ大規模なのもある。一般的に言うて、データは多い方がAIの精度上がるから、この差は結構デカいで。
**文書タイプ**は、請求書(Invoices)と領収書(Receipts)がダントツで多いな。あとはフォーム、名刺、チケット、契約書、医療レポートとか色々や。ビジネスで一番よく使う書類から攻めてるってことやな。
**再現性と展開可能性**のとこ、これめっちゃ重要やねん。コードが公開されてるか、学習済みモデルが使えるか、商用利用できるか、外部のOCR(文字認識)に依存してないか、とかを調べてる。正直、コード公開してへん研究が結構あるのは残念やな。再現できへんと検証もできんからな。
**パラメータ数**は、AIモデルのサイズを表してるんや。n/a(データなし)が多いけど、わかってるやつだと数百万から数億パラメータまで幅があるな。でかけりゃええってもんでもないけど、最近は大規模モデルが主流やな。
**ドメイン知識の統合**ってのは、その業界特有の知識をAIに教え込んでるかどうかや。例えば「請求書には必ず合計金額がある」みたいなルールな。これやってる研究は意外と少ないんや。
**既存手法の発展**は、前の研究を改良したかどうか。**産業環境での評価**は、実際のビジネス現場でテストしたかどうかや。これもあんまりやってへんのが現状やな。学術的な実験だけで終わってる研究が多いってことや。
**弱アノテーション**と**生成型**は、最新のトレンドや。弱アノテーションは、完璧なラベル付けなしでも学習できる手法。生成型は、ChatGPTみたいに文章を生成するタイプのAIを使う手法やな。まだ数は少ないけど、これから増えてくると思うで。
ACM投稿原稿
---
## Page 50
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p050.png)
### 和訳
50
Alexander Michael RombachとPeter Fettke
57から125行目まで、めっちゃでかい表があるんやけど、ちょっと説明させてな!
この表、要するに色んな文書処理システムを比較してるねん。左側のカラムから順番に見ていこか。
**データの形式**についてやけど、「sequence」っていうのは文字を一列に並べて処理するやり方で、「graph」っていうのは文書の構造を網目みたいなグラフで表現するやり方やな。「graph + sequence」は両方使うハイブリッド型。「grid」は格子状に処理するやつで、「LLM」っていうのは最近流行りの大規模言語モデル(ChatGPTみたいなやつ)を使ってるってことやねん。
ほんで、✓と✗がいっぱい並んでる列があるやろ?これは各システムがどんな機能を持ってるかを表してるねん。✓があったら「その機能あり」、✗は「なし」ってことや。
**数字の列**は主にサンプル数とか性能指標やな。1825とか65500とかの数字は、学習に使った文書の数を表してることが多いねん。めっちゃ差があるやろ?65500使ってるやつもあれば、199しか使ってへんやつもあるわけや。
**文書タイプの列**を見てみ。「Forms, receipts」(フォームとレシート)が一番多いねんけど、他にも「Invoices」(請求書)、「Banking documents」(銀行書類)、「Prescriptions」(処方箋)、「Contracts」(契約書)、「Purchase orders」(発注書)とか、いろんな種類の書類を扱えるシステムがあるってことがわかるな。
最後の方の数字、340とか368とか、あと7000とか0.8みたいな値は処理速度とか精度の指標やと思われるわ。「n/a」は「データなし」やな。∼9.5みたいな∼(にょろ)がついてるやつは「だいたいこれくらい」って意味や。
一番下の方、また✓と✗が並んでる列があるけど、これはさらに細かい機能の有無を示してるねん。見てわかる通り、ほとんど✗やから、まだまだ発展途上の機能が多いってことやな。
最後に「Manuscript submitted to ACM」って書いてあるけど、これは「この論文はACM(コンピュータ学会)に投稿しましたで」っていう意味やねん。学術論文のお決まりの表記やな。
---
## Page 51
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p051.png)
### 和訳
ビジネス文書からの重要情報抽出における深層学習:系統的文献レビュー
51番から130番までの研究についてまとめた表があるんやけど、ちょっと見てってや。
126番、127番、128番、129番、130番の研究があってな、モデルの種類でいうと、126番はLLM(大規模言語モデル)使っとって、残りは127番がグラフと系列の組み合わせで、128番、129番、130番は系列ベースのアプローチやねん。
全部の研究で最初のチェック項目(おそらく何かの機能や特徴やな)はクリアしとるんやけど、2番目の項目は126番と128番だけがあかんくて、127番と129番と130番はOKやねん。3番目の項目は全部OKで、4番目は全滅でどれもあかんかったわ。
データセットのサイズでいうと、126番がめっちゃでかくて約10,582件、対象はフォームとか領収書とかレポートやな。127番は3,666件でフォーム・領収書・試験問題、128番は1,199件でフォームと領収書、129番は4,224件で領収書だけ、130番は3,226件でフォームと領収書を扱っとるで。
で、残りのチェック項目がずらーっと並んどるんやけど、ほとんど全部バツで「対応してへん」状態やねん。126番だけが約7,853件(n/aの記載もあり)で一個だけマルがあって、154番と21番と131番っていう関連研究も載っとるけど、これらもほぼ全部バツやな。
最後にちょこっとだけマルがついとる項目もあるんやけど、全体的に見たら「まだまだ課題だらけやな〜」っていう感じの表やわ。
(この原稿はACMに投稿されたものやで)
---
## Page 52
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p052.png)
### 和訳
52
Alexander Michael RombachとPeter Fettke
**表ST4. シーケンスベースのアプローチの分析**
| # | シーケンスベースアプローチ | ビジュアルエンコーダー | テキストエンコーダー | デコーダー | 特殊アテンション機構 | 事前学習タスク | 事前学習用データセット | 使用ドキュメント数 | 粒度 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | Inceptionv3 | BiLSTM+CRF | LSTM | グローバルアテンション | / | / | / | 単語 |
| 5 | FastText, ELMo, BERT | BiLSTM | LSTM | エンティティ認識アテンション機構 | / | / | / | 単語 |
| 17 | Faster RCNN (ResNet101) | DocBERT | 2D絶対位置付きセルフアテンション | シーケンスラベリング層 | マスク付きビジュアル言語モデリング, マルチラベル分類 | IIT-CDIP | 600,000 | 単語 |
| 18 | RoBERTa | / | / | シーケンスラベリング層 | 事前学習 | / | / | 文字 |
| 20 | ResNet50 | / | BiLSTM+CRF | ゲーテッドクロスアテンション | / | / | / | 単語+文字 |
| 21 | ResNet50 | / | BiLSTM+CRF | ゲーテッドクロスアテンション | / | / | / | 文字 |
| 22 | ResNet50 | LSTM | CRF | トランスフォーマー+ゲーテッドコピー機構+パーサー | シーケンスラベリング層 | / | / | / | 単語 |
| 24 | / | CharGrid OCR | / | シーケンスラベリング層 | / | / | / | 文字 |
| 27 | CNN | LSTM | Transformer | 画像がテキストを記述、テキストが再構成、ドキュメント分類 | / | / | / | 文字 |
| 28 | LayoutLM | / | / | シーケンスラベリング層 | マスク付き言語モデリング, マルチモーダル学習 | IIT-CDIP* | 5,000,000 | 単語 |
| 29 | RoBERTa | / | / | シーケンスラベリング層 | マスク付き言語モデリング, ビジョン言語アライメント学習 | CommonCrawl* | 315,000 | 単語 |
| 30 | SBERT | / | / | シーケンスラベリング層 | マスク付き文モデリング, ビジュアルコントラスティブ | IIT-CDIP* | 1,000,000 | 文 |
| 31 | CamemBERT | BERT | / | / | / | / | / | n/a |
| 34 | / | / | 位置特徴付きBiLSTM+CRF | マルチモーダルセルフアテンション | シーケンスラベリング層 | / | カスタム | 600,000 | / |
| 37 | BERT | / | シーケンスラベリング層 | マスク付きビジュアル言語モデリング, セル位置分類 | IIT-CDIP | 600,000 | 単語 |
| 38 | Faster RCNN | ResNet50 | SBERT | モダリティ適応型アテンション | シーケンスラベリング層 | マスク付きビジュアル言語モデリング, セグメント長 | RVLCDIP, DocBank | 32,000 | セル |
| 39 | ERNIE | / | シーケンスラベリング層 | マスク付きビジュアル言語モデリング | RVLCDIP | 90,000 | 文 |
| 41 | T5 | UNet | BiLSTM+CRF | 相対アテンションバイアス付き文脈化画像埋め込み | シーケンスラベリング層 | / | / | / | 文 |
| 42 | Mask RCNN (ResNet50) | / | BiLSTM+CRF | 2つのマルチレイヤーマルチヘッドセルフアテンションモジュール | シーケンスラベリング層 | / | / | / | 単語 |
| 43 | ResNet34 | MLP+CRF | 空間認識セルフアテンション | シーケンスラベリング層 | / | / | / | 単語 |
| 45 | UNet, ResNet18 | BiLSTM | MLP+BiLSTM | / | / | / | / | 単語 |
| 47 | ResNeXt101FPN | Transformer | n/a | / | / | / | / | 単語 |
| 48 | CNN | n/a | / | / | / | / | / | 単語 |
| 49 | MDBERT | ResNet18 | MDBERT | モーダル認識マルチヘッドアテンション | MLP | 単方向LM, 双方向LM, シーケンスtoUni LM | IIT-CDIP | 600,000 | 単語 |
| 50 | LayoutLMv2 | LayoutLMv2 | / | シーケンスラベリング層 | シーケンスLM, NER LM | / | / | 単語 |
| 51 | LayoutXLM | / | / | シーケンスラベリング層 | 単方向LM, 双方向LM, シーケンスtoUni LM, シーケンスLM | IIT-CDIP*, カスタム | 43,000,000 | 単語 |
| 52 | LayoutLM | Transformer | BiLSTM | 意味抽出スパン事前学習 | / | ドキュメントライブラリ, CommonCrawl* | 5,170 | 単語 |
| 53 | BERT | T5 | BERT | ペアボックス方向予測, マスク付きビジュアル言語モデリング | RVLCDIP*, UCSF, IndustryDoc | 1,105,000 | 単語 |
| 55 | UniLMv2 | / | シーケンスラベリング層 | テキスト画像アライメント, テキスト画像マッチング, マスク付きビジュアル言語モデリング | IIT-CDIP | 600,000 | セグメント |
| | | | | | | | | | セグメント+トークン |
| | | | | | | | | | 単語 |
| | | | | | | | | | 単語 |
| | | | | | | | | | 単語 |
| | | | | | | | | | 単語 |
| | | | | | | | | | 単語 |
---
ほな、この表の内容を噛み砕いて説明するで!
これはな、**書類から情報を自動で抜き出すAI**の技術を比較した表やねん。めっちゃたくさんの研究があって、それぞれどんな仕組みで動いてるかをまとめてあるんや。
**主なポイントを解説するで:**
- **ビジュアルエンコーダー**:これは画像を理解するための部品やな。ResNetとかCNNっていうのは、画像認識でめっちゃ有名な技術やで。
- **テキストエンコーダー**:文字を理解する部品や。BERTとかRoBERTaっていうのは、人間の言葉をAIに理解させるためのすごい技術やねん。
- **デコーダー**:理解した情報から最終的な答えを出す部品や。
- **事前学習タスク**:本番の仕事をする前に、AIに予習させる課題みたいなもんやな。「マスク付き言語モデリング」っていうのは、文章の一部を隠して当てさせる練習やで。
- **粒度**:どれくらい細かく情報を見るかってことや。「文字」単位で見るか、「単語」単位で見るか、「文」単位で見るかの違いやな。
なんでかっていうと、請求書とか契約書みたいな書類って、ただの文字だけやなくて、どこに何が書いてあるかっていう**レイアウト**もめっちゃ大事やねん。せやから、画像も文字も両方理解できるモデルが必要になるわけや。
ほんまにすごい数の研究があって、どんどん進化してるのがわかるやろ?
Manuscript submitted to ACM(ACMに投稿された原稿)
---
## Page 53
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p053.png)
### 和訳
ディープラーニングを使ったビジネス文書からの重要情報抽出:体系的文献レビュー
53ページ
ほんで、これ表やねんけど、めっちゃいろんなモデルとか手法が並んでるやつやな。ちょっと整理して説明するわ。
この表は、文書から情報を抜き出す(Key Information Extraction)ための深層学習モデルをずらーっと比較してるねん。各行が一つの研究で、番号で言うと56番から98番まであるな。
**見るポイントとしては**
- **使ってるデータセット**:IIT-CDIP(めっちゃでかい文書画像のデータセット、60万〜100万枚レベル)、DocBank、RVLCDIP、FUNSD、CORD、SROIEとか色々あるねん。訓練に使うデータの量も70万とか80万とか100万超えとか、まあまあエグい量やで。
- **テキストの単位**:「word」(単語ごと)か「text line」(テキスト行ごと)か「word + segment」(単語+セグメント)かで処理の粒度が違うねん。
- **画像の特徴抽出**:ResNet50、ResNet101、ConvNeXt、Swin Transformer、VGG16とか、画像認識でお馴染みのモデルを使って画像から特徴を取り出してるんや。FPN(Feature Pyramid Network)っていう、いろんなサイズのものを検出しやすくする仕組みも組み合わせてるな。
- **テキストの特徴抽出**:BERT、RoBERTa、LayoutLM(レイアウト考慮したやつ)、LayoutLMv2、LayoutLMv3、XLM、InfoXLMとか使ってる。Transformerベースの言語モデルが主流やな。
- **事前学習のタスク**:これがキモやねん。
- Masked Language Modeling(MLM):文章の一部を隠して当てさせる
- Masked Visual Language Modeling:画像とテキスト両方考慮して隠したとこ当てる
- Token masked MLM、Area masked MLM:隠し方にもバリエーションある
- Text-Image Alignment:テキストと画像の対応を学ぶ
- Reading Order Prediction:読む順番を予測
- Word-Patch Alignment:単語と画像のパッチを対応づける
- Masked Image Model:画像の一部隠して復元
- **アテンション機構**:Self-Attention、Cross-Attention、Spatial-Aware Self-Attention(空間も考慮)、Disentangled Spatial-Aware Attention(空間情報を分離)、Rich Attention(距離も考慮)とか、どうやって「どこに注目するか」を決めるかの違いやな。
- **最終的な分類方法**:Sequence labeling(系列ラベリング)が多いけど、Biaffine classifier、Greedy search decoding、CRF(条件付き確率場)、カスタムのデコーダーとか色々あるで。
**具体的なモデル名でいうと**
- **LayoutLM系**(56, 64, 77, 81, 82など):文書のレイアウト(位置情報)とテキストを一緒に学習する代表格やな
- **Donut**(62, 63):OCRなしで画像から直接テキスト理解するやつ。「pseudo OCR」って書いてあるのは、OCRを使わんでも擬似的にOCR的なことができるって意味やで
- **BROS**(86):文書の方向とか関係性を予測するタスクで事前学習
- **LayoutLMv3**(85):Word-Patch Alignmentとかいう、単語と画像パッチの対応を学ぶやつ追加
- **DocFormer**(88):マルチモーダル(画像もテキストも)扱うやつで、画像再構成とかレイアウト再構成もやる
- **PubLayNet**(95):レイアウトセグメントの識別、関係抽出、読み順予測とかやってる
**データセット補足**
- IIT-CDIP:タバコ訴訟の文書画像600万〜1000万枚
- DocBank:50万ページの文書、きれいにアノテーションされてる
- RVLCDIP:分類とか情報抽出用
- FUNSD、CORD、SROIE:フォーム理解とかレシート情報抽出用のベンチマーク
なんでかっていうと、ビジネス文書って請求書とか領収書とかフォームとか、テキストだけちゃうくて「どこに何が書いてあるか」っていうレイアウトがめっちゃ大事やねん。せやから画像の情報とテキストの情報を両方うまいこと使うマルチモーダルなモデルが主流になってきてるってわけや。
ACMに投稿された原稿やで。
---
## Page 54
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p054.png)
### 和訳
[翻訳エラー: ]
---
## Page 55
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p055.png)
### 和訳
# ビジネス文書からのディープラーニングによる重要情報抽出:系統的文献レビュー
## 表ST5. グラフベースアプローチの分析
ほな、この表について説明するで!これはな、文書から重要な情報を取り出すときに使う「グラフベースのアプローチ」っていう手法をまとめたもんやねん。
### グラフベースアプローチって何やねん?
なんでかっていうと、文書の中の文字とか単語って、バラバラに存在してるわけちゃうやろ?「この単語の右にはあの単語がある」とか「この文はあの文の下にある」とか、位置関係があるわけや。それをグラフ(点と線でつないだネットワーク)として表現して、AIに学習させる方法やねん。
### 表の見方
この表にはめっちゃいろんな項目があるんやけど、主なポイントを説明するわ:
**ノード(節点)の粒度**
- 「word(単語)」単位で扱うか、「sentence(文)」単位で扱うか、「segment(セグメント)」単位で扱うかってことや
- 細かく単語ごとにするか、ざっくり文ごとにするかで、精度とか計算量が変わってくるねん
**エッジ(辺)の作り方**
- 「kNN」:近くにあるk個の要素とつなぐ方法(k=5とかk=10とか)
- 「Fully connected」:全部の要素を互いにつなぐ方法
- 「Nearest neighbors in 4 major directions」:上下左右の4方向で一番近いやつとつなぐ方法
- 学習で自動的にどこをつなぐか決める方法もあるで
**特徴量(Features)**
- 各ノードに持たせる情報のことや
- BERTとかFastTextとかの「埋め込み(embeddings)」:単語の意味を数値ベクトルで表したもん
- 座標情報(coordinates):文書のどこにあるかって位置情報
- ResNetの埋め込み:画像としての見た目の特徴
- Boolean features:「数字が含まれてるか」とかのYes/No情報
**特徴ベクトルのサイズ**
96から1024まで、いろんなサイズがあるで。大きいほど情報量は多いけど、計算も重くなるねん。
**グラフの伝播タイプ**
- 「directed(有向)」:A→Bみたいに方向がある
- 「undirected(無向)」:AとBがつながってる、って感じで方向なし
**グラフニューラルネットワークの種類**
- GCN(Graph Convolutional Network):グラフ畳み込みネットワーク
- GAT(Graph Attention Network):注意機構付きのグラフネットワーク、どのつながりが重要かを自動で判断するねん
**グローバルノード**
ほとんどのアプローチでは使ってへん(✗マーク)けど、1つだけ使ってるやつ(✓マーク)があるで。これは文書全体の情報をまとめる特別なノードのことや。
**KIE(Key Information Extraction)の方法**
最終的に情報を抽出する部分やな:
- BiLSTM-CRF:双方向LSTMと条件付き確率場の組み合わせ、めっちゃ定番の組み合わせや
- Softmax layer:分類に使う層
- MLP(多層パーセプトロン):シンプルなニューラルネット
- Node classification:各ノードがどのカテゴリかを分類する
- Sequence labeling:系列ラベリング、順番に並んだデータにラベルをつけていく方法
**レイヤー数**
1層から5層まで、いろいろあるで。深ければええってもんでもないんや。
ほんまに、この分野はめっちゃ発展してて、いろんなアプローチが試されてるのがこの表からわかるやろ?それぞれ一長一短があって、どれがベストかは扱う文書の種類とかによって変わってくるねん。
---
## Page 56
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p056.png)
### 和訳
56
Alexander Michael RombachとPeter Fettke
ほな、この表の説明するわな。めっちゃ色んな技術の比較表やねん。縦に並んどるんやけど、読みにくいから整理して説明するで。
**シーケンスラベリング層**
- 「n/a」って書いてあるやつは「該当なし」ってことやな
- ビタビアルゴリズム、Softmax層(ノード分類用)、BiLSTM CRF、MLP、グリーディサーチとか色々使われとるわ
- ETCとか、ノードとエッジの予測器とか、トークンパスの予測(二値分類)なんかもあるで
**タイプ**
- GCN(グラフ畳み込みネットワーク)が色んな種類あるねん
- 細粒度、粗粒度、交差粒度、空間認識付きセルフアテンション型とか
- GAT(グラフアテンションネットワーク)も多いわ
- マルチヘッドアテンション付き、サーキットブレーキングアテンション付きとかな
- 変形版GraphSAGE、グラフトランスフォーマー、ChebConv GCNとかもあるで
**方向性**
- 有向(directed)か無向(undirected)かってことやな
- ほとんどが無向グラフを使っとるけど、有向のもちょこちょこあるわ
**エッジの特徴量**
- 相対距離+最短距離+アスペクト比とか
- ユークリッド距離の正規化、チェビシェフ距離の正規化、マンハッタン距離の正規化
- 水平・垂直距離、角度、画像セグメント間の相互情報量
- テキストセグメント間のコサイン類似度と相関係数とかな
**ノードの埋め込み(特徴量)**
- BERTの埋め込み+正規化座標+ワンホットエンコーディングとか
- LayoutLMv2/v3の埋め込み+常識推論とか
- バイトペアエンコーディング+正規化座標+ラベル埋め込み(NERカテゴリ)
- Word2Vec+ResNet50+UNet埋め込みとか
- SpaCy+UNet埋め込み+正規化座標とかな
- SwinTransformer埋め込み、SBERT埋め込み+正規化座標とかもあるで
**グラフ構造**
- kNN(k近傍法)がめっちゃ多いねん。kの値は4、6、8、12、15、36、50、100とか色々や
- 完全連結グラフ、スケルトングラフ(β=1)
- カスタムレイアウトツリー(4方向の最近傍)
- 同一バウンディングボックス内で完全連結、同カテゴリ内で完全連結とかな
- 3行以内のkNN(同一行、上の行、下の行があれば)ってのも多いわ
**ノード数**
- 最大で256、337、512、777ノードとか
- 24&1465とか99とか192とか、データセットによって全然ちゃうねん
**事前学習済み**
- ✓(あり)と✗(なし)があって、ほとんどが✗やな
- 事前学習してるのは少数派やねん
参考文献番号も右端に書いてあって、65、67、68、69、70、73、77、78、79、83、84、90、94、96、99、100、103、104、108、115、121とかやな。
原稿はACMに投稿されたもんやで。
---
## Page 57
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p057.png)
### 和訳
# ビジネス文書からのディープラーニングベースの重要情報抽出:体系的文献レビュー
57ページ
---
**表の説明(関西弁で)**
ほな、この表の内容説明するわな!
これ、グラフニューラルネットワーク(GCN)使った手法の比較表やねん。
**ノードの分類方法について**
- 「token」っていうのは、文字とか単語の単位でノード(点)を作るってことやで
- 「text box」は、テキストボックス単位でノード作る方法やな
**リンクの種類**
- 「directed」は一方向の矢印みたいなつながり
- 「undirected」は双方向のつながりやな
- 「×」になってるとこは、その機能使ってへんってことや
**つなぎ方(エッジの作り方)**
- 「Fully connected within」っていうのは、テキストボックスの中で全部のノードをつなぐってことやねん
- 「Fully connected & learned relation」は、全部つないだ上に、関係性も学習させるってめっちゃ賢い方法やで
**ノードの数**
- 125個とか128個とか、実験で使ったノードの数やな
- 「n/a」は「データないで〜」って意味や
**ノードの特徴量**
これがめっちゃ大事なとこやねんけど:
- 「BERT embeddings」っていうのは、言語モデルBERTで文字や単語の意味を数値化したもんや
- 「normalized coordinates」は位置情報を0〜1の範囲に正規化したやつ
- 「center coordinates + width + height」は、テキストボックスの中心座標と幅と高さの情報やな
- 「relationship matrix」は、ノード同士の関係を行列で表したもんや
**タスクの種類**
- 「Token classification」は、各トークン(文字・単語)を分類する問題
- 「Node classification + segment」は、ノードの分類とセグメント(かたまり)の特定を両方やるってことやで
なんでこんな細かく比較してるかっていうと、どの設定が一番ええ結果出すか調べたいからやねん!
---
## Page 58
[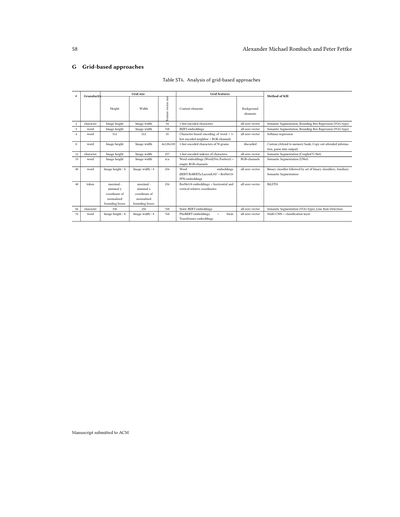](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p058.png)
### 和訳
## グリッドベースのアプローチについて
**表ST6. グリッドベースアプローチの分析**
ほな、この表の説明していくで!
まずグリッドサイズやねんけど、これは画像をどう区切るかって話や。縦(Height)と横(Width)があって、それぞれ「画像の高さそのまま」とか「512ピクセルで固定」とか、いろんなパターンがあんねん。
で、粒度(Granularity)っていうのは、どれくらい細かく見るかってことやな。「文字単位」で見るか「単語単位」で見るか、っちゅう違いがある。
**特徴ベクトルのサイズ**は54から768まで色々あって、これはデータをどれだけ詳しく表現するかの数字やと思ってくれたらええわ。
**中身の要素(Content elements)の特徴量**としては:
- ワンホットエンコードした文字(要は文字を0と1の並びに変換したやつ)
- BERTっていう賢いAIが作った埋め込み表現
- 単語ベース+隣の情報+RGB色チャンネル
- N-gramっていう連続した文字の塊をエンコードしたやつ
- Word2VecとかFasttextとかいう単語の意味を数値化したやつ
- ResNet18っていう画像認識AIの特徴量に座標情報足したやつ
**背景要素(Background elements)の特徴量**は、ほとんど「全部ゼロのベクトル」か「空っぽのRGBチャンネル」やねん。なんでかっていうと、背景には特に情報ないから「何もない」って表現してるわけや。
**情報抽出の方法(Method of KIE)**もめっちゃいろいろあって:
- セマンティックセグメンテーション(画像のどこが何かを塗り分ける)+バウンディングボックス回帰(VGG型)
- Softmax回帰(確率的に分類するやつ)
- カスタム方式(メモリバンクに注目して、情報コピーして、出力にパースする)
- U-NetとかCoupled U-Netっていうネットワーク使ったセグメンテーション
- 二値分類器を連続で使うやつ+補助的なセグメンテーション
- BiLSTM(双方向の長期記憶ネットワーク)
- 複数のCNN+分類層
番号で言うと、2, 3, 4, 8, 12, 33, 40, 48, 66, 76番の手法が紹介されてて、それぞれ違うアプローチ取ってんねん。
48番なんかおもろくて、バウンディングボックス(囲み枠)の正規化された座標の最小・最大値をグリッドサイズに使ってるし、FPN埋め込みっていう特徴ピラミッドネットワークの出力使ってるねん。
76番は最新っぽくて、PhoBERTの埋め込み+Swin Transformerの埋め込みを組み合わせてて、めっちゃ豪華な構成やな。
---
*原稿はACMに提出済み*
---
## Page 59
[](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p059.png)
### 和訳
**ディープラーニングでビジネス文書から重要情報を抜き出す技術:これまでの研究まとめ**
59
**表7. LLM(大規模言語モデル)ベースのアプローチの分析**
LLMベースのアプローチっていうのはな、めっちゃでっかいAIモデルを使って文書から情報を取り出す方法のことやねん。
この表見てもらったらわかるんやけど、いろんな研究が並んでるわけ。番号でいうと86、92、101、102、106、113、114、116、117、118、126って感じやな。
**主なポイントをかいつまんで説明するで:**
- **バックボーン(土台となるモデル)**: LayoutLMv3とかSwinTransformerとか使ってるところが多いねん。これらは画像とテキストを一緒に理解できる賢いやつらや。
- **画像エンコーディング**: 文書を画像として読み込むときの解像度は224×224から2560×2560までいろいろあるねん。大きいほど細かいとこまで見えるけど、その分計算も重くなるわけや。
- **事前学習**: ほとんどの研究でやってるな。テキスト検出とか認識とか、文章のキャプション作成とか、いろんなタスクで先に勉強させといて、それから本番の情報抽出に使うってわけ。
- **ファインチューニング(微調整)**: LoRAっていう効率的な調整方法使ってるとこもあるし、使ってないとこもあるな。
- **使ってるLLM**: Vicuna 7B、LLaMA 7B、LLaMA2 27B、CodeLlama、Falcon、PaLM2、Geminiとか、まあいろんな種類の大規模言語モデル使われてるねん。
- **オープンソースかどうか**: ✓がついてるのは公開されてて使えるやつ、✗は非公開ってことや。
- **データセット**: CORD、SROIE、DocILE、FUNSD、Kleister、DeepForm、VRDU、DocBank、PWCとかが使われてるな。これらは請求書とか領収書とかフォームとかの文書データセットやねん。
- **タスクの種類**: 情報抽出、文書分類、テーブル解析、Visual QA(画像見ながら質問に答えるやつ)、文書要約とかいろいろやってるわ。
- **学習パラメータ数**: 数百万から数十億までめっちゃ幅があるな。でかいほど賢いことできる可能性あるけど、計算資源もめっちゃいるってわけや。
要するにな、この表は「最近のAI技術使って文書から情報取り出す研究、どんなんあるねん」ってのを一覧にしたもんやねん。大規模言語モデルと画像認識を組み合わせて、請求書から金額読み取ったり、フォームの項目分類したり、そういうことを自動でやらせようとしてる研究がようさんあるってことがわかるやろ。
論文はACMに投稿中やで。
---
## Page 60
[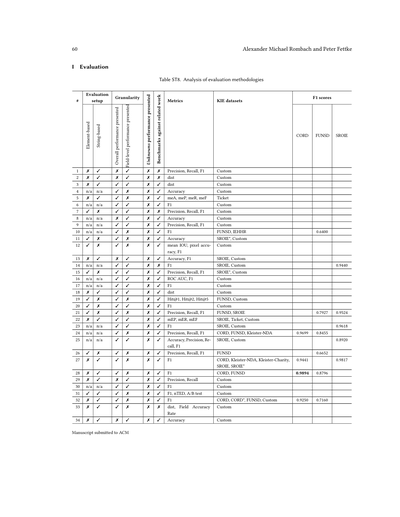](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p060.png)
### 和訳
60
# I 評価のところ
Alexander Michael RombachとPeter Fettkeさんの研究やで
**表ST8. 評価方法の分析**
ほな、この表なんやけど、めっちゃいろんな研究の評価方法を比較してるんやな。
**メトリクス(評価指標)のところ**
左側の列は「どんな細かさで評価してるか」っちゅう話やねん:
- **エレメントベース**:要素ごとに見てる
- **ストリングベース**:文字列単位で見てる
ほんで、**どんな性能を報告してるか**も見てるで:
- 全体的なパフォーマンス出してるか
- フィールドレベル(項目ごと)のパフォーマンス出してるか
- 未知のデータに対するパフォーマンス出してるか
- 他の研究とちゃんとベンチマーク比較してるか
✓が「やってる」、✗が「やってない」、n/aは「該当なし」やな。
**F1スコア**のところでは、各研究が使ってる具体的な指標が書いてあるで。Precision(精度)、Recall(再現率)、F1、Accuracy(正解率)とか、研究によってバラバラやねん。なかには「dist」っていう距離ベースの指標使ってるとこもあるし、「mean IOU」とか「pixel accuracy」みたいな画像系の指標使ってるとこもある。
**KIEデータセット**のところは、どのデータセットで評価してるかやな。CORD、FUNSD、SROIEっていうのが有名なベンチマークデータセットやねん。数字が書いてあるとこは、そのデータセットでのスコアやで。たとえば0.9894とかめっちゃ高いスコア出してる研究もあれば、0.6400くらいのもある。
「Custom」って書いてあるのは、その研究独自のデータセット使ってるってことや。TicketとかKleister-NDA、Kleister-Charityとかも特定のタスク用のデータセットやな。
**評価セットアップ**は、どんなデータセットの組み合わせで実験したかっちゅうことやで。
まあ要するに、この表全体で言いたいんは「みんな評価方法バラバラやから比較難しいで」っちゅうことやな。統一されたベンチマークの重要性を示してるんやと思うわ。
---
Manuscript submitted to ACM(ACMに投稿された原稿やで)
---
## Page 61
[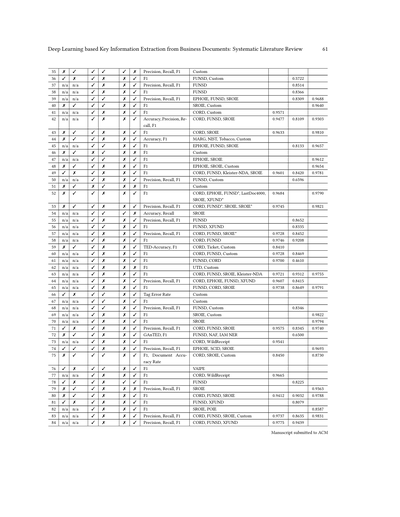](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p061.png)
### 和訳
ディープラーニングを使ったビジネス文書からの重要情報抽出:体系的文献レビュー
61ページ
ほな、この表見てってな。チェックマーク(✓)とバツ(✗)がいっぱい並んどるやろ?これ何かっていうと、35番から84番までの研究論文それぞれが、どんな条件満たしてるか一覧にしたもんやねん。「n/a」っていうのは「該当なし」とか「データなし」って意味やで。
で、右の方に「評価指標」っていう列があるやん。ここに書いてあるのは、それぞれの研究がどうやって性能を測ったかってことやねん。
- **Precision(精度)**:予測した中でどんだけ正解やったか
- **Recall(再現率)**:正解の中でどんだけ見つけられたか
- **F1**:精度と再現率のバランス取った総合点みたいなもん
- **Accuracy(正解率)**:全体でどんだけ当たったか
- **TED-Accuracy**:表構造の編集距離に基づく精度
- **GAnTED**:グラフの編集距離に基づくやつ
- **Tag Error Rate**:タグの間違い率
- **Document Accuracy Rate**:文書全体の正解率
次に「データセット」の列やけど、これが研究で使われたテスト用のデータやねん。よう出てくるやつ説明するで:
- **FUNSD**:フォームの理解用データセット
- **CORD**:レシート(領収書)のデータセット
- **SROIE**:これもレシート関連
- **EPHOIE**:中国語の試験解答用紙のデータ
- **XFUND**:多言語のフォームデータセット
- **Kleister-NDA**:秘密保持契約書のデータ
- **Custom**:研究者が独自に作ったデータセット
アスタリスク(*)付いてるやつは、そのデータセットの特別バージョン使ったってことやな。
一番右の数字の列2つは、それぞれのデータセットでの**F1スコア**やねん。0.8335から0.9831くらいの範囲に収まっとるで。0.98超えとるやつはめっちゃ優秀ってことや。例えば0.9831とか0.9821とかあるやろ?これほんまにすごい精度やで。
一方で0.4610とか0.5722みたいな低いスコアもあるけど、これは難しいタスクやったか、まだ発展途上の手法やったんやろな。
---
Manuscript submitted to ACM(ACM(コンピュータ学会)に投稿された原稿)
---
## Page 62
[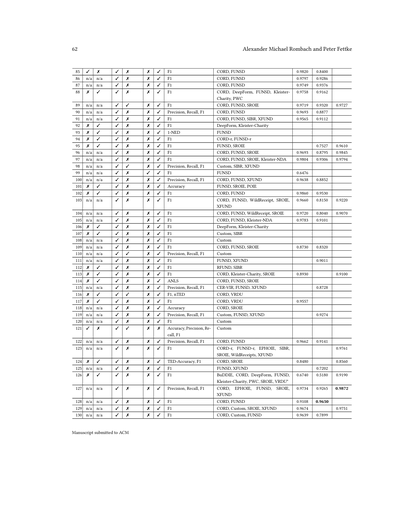](/attach/a4a0359e459c36b6c2c17dbf08eaa4be2e21a1ce20df89c0b1bcb681c51bf4c3_p062.png)
### 和訳
62
Alexander Michael RombachとPeter Fettkeの論文やねん
✗
85 ✓
86
87
88
該当なし 該当なし
該当なし 該当なし
✗
✓
✓
✓
✓
✓
該当なし 該当なし
89
該当なし 該当なし
90
該当なし 該当なし
91
✗
92
✗
93
✗
94
✗
95
該当なし 該当なし
96
該当なし 該当なし
97
該当なし 該当なし
98
99
該当なし 該当なし
100 該当なし 該当なし
101 ✗
102 ✗
103 該当なし 該当なし
✓
✓
✓
✓
104 該当なし 該当なし
105 該当なし 該当なし
106 ✗
107 ✗
108 該当なし 該当なし
109 該当なし 該当なし
110 該当なし 該当なし
111 該当なし 該当なし
112 ✗
113 ✗
114 ✗
115 該当なし 該当なし
116 ✗
117 ✗
118 該当なし 該当なし
119 該当なし 該当なし
120 該当なし 該当なし
121 ✓
✓
✓
✓
✓
✓
✗
122 該当なし 該当なし
123 該当なし 該当なし
✓
124 ✗
125 該当なし 該当なし
126 ✗
✓
127 該当なし 該当なし
128 該当なし 該当なし
129 該当なし 該当なし
130 該当なし 該当なし
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✗
✗
✗
✗
✓
✗
✗
✗
✗
✗
✗
✗
✗
✓
✗
✗
✗
✗
✗
✗
✗
✗
✗
✗
✗
✓
✗
✗
✗
✗
✗
✓
✗
✗
✗
✗
✓
✗
✗
✗
✗
✗
✗
✗
✗
✗
✗
✗
✗
✗
✗
✗
✗
✗
✗
✗
✗
✗
✗
✗
✓
✗
✗
✗
✗
✗
✗
✗
✗
✗
✗
✗
✗
✗
✗
✗
✗
✗
✗
✗
✗
✗
✗
✗
✗
✗
✗
✗
✗
✗
✗
✗
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✗
✓
✓
✓
✓
✓
✓
✓
✓
✓
F1値
F1値
F1値
F1値
F1値
適合率、再現率、F1値
F1値
F1値
1-NED(正規化編集距離)
F1値
F1値
F1値
F1値
適合率、再現率、F1値
F1値
適合率、再現率、F1値
正解率
F1値
F1値
F1値
F1値
F1値
F1値
F1値
F1値
適合率、再現率、F1値
F1値
F1値
F1値
ANLS(平均正規化レーベンシュタイン類似度)
適合率、再現率、F1値
F1値、nTED
F1値
正解率
適合率、再現率、F1値
F1値
正解率、適合率、再現率、F1値
適合率、再現率、F1値
F1値
TED正解率、F1値
F1値
F1値
適合率、再現率、F1値
F1値
F1値
F1値
CORD、FUNSDデータセット
CORD、FUNSDデータセット
CORD、FUNSDデータセット
CORD、DeepForm、FUNSD、KleisterCharity、PWCデータセット
CORD、FUNSD、SROIEデータセット
CORD、FUNSDデータセット
CORD、FUNSD、SIBR、XFUNDデータセット
DeepForm、Kleister-Charityデータセット
FUNSDデータセット
CORD-r、FUNSD-rデータセット
FUNSD、SROIEデータセット
CORD、FUNSD、SROIEデータセット
CORD、FUNSD、SROIE、Kleister-NDAデータセット
独自、SIBR、XFUNDデータセット
FUNSDデータセット
CORD、FUNSD、XFUNDデータセット
FUNSD、SROIE、POIEデータセット
CORD、FUNSDデータセット
CORD、FUNSD、WildReceipt、SROIE、XFUNDデータセット
CORD、FUNSD、WildReceipt、SROIEデータセット
CORD、FUNSD、Kleister-NDAデータセット
DeepForm、Kleister-Charityデータセット
独自、SIBRデータセット
独自データセット
CORD、FUNSD、SROIEデータセット
独自データセット
FUNSD、XFUNDデータセット
RFUND、SIBRデータセット
CORD、Kleister-Charity、SROIEデータセット
CORD、FUNSD、SROIEデータセット
CER-VIR、FUNSD、XFUNDデータセット
CORD、VRDUデータセット
CORD、VRDUデータセット
CORD、SROIEデータセット
独自、FUNSD、XFUNDデータセット
独自データセット
独自データセット
0.9820
0.9797
0.9749
0.9758
0.9719
0.9693
0.9565
0.9693
0.9804
0.6476
0.9638
0.8400
0.9286
0.9376
0.9162
0.9320
0.8877
0.9112
0.9727
0.7527
0.8795
0.9306
0.9610
0.9845
0.9794
0.8852
0.9860
0.9660
0.9530
0.8150
0.9720
0.9783
0.8040
0.9101
0.9220
0.9070
0.8730
0.8320
0.9011
0.8930
0.9100
0.9557
0.8728
0.9274
CORD、FUNSDデータセット
CORD-r、FUNSD-r、EPHOIE、SIBR、SROIE、WildReceipts、XFUNDデータセット
CORD、SROIEデータセット
FUNSD、XFUNDデータセット
BuDDIE、CORD、DeepForm、FUNSD、Kleister-Charity、PWC、SROIE、VRDU*データセット
CORD、EPHOIE、FUNSD、SROIE、XFUNDデータセット
CORD、FUNSDデータセット
CORD、独自、SROIE、XFUNDデータセット
CORD、独自、FUNSDデータセット
0.9662
0.9141
0.8480
0.6740
0.7202
0.5180
0.9761
0.8560
0.9190
0.9734
0.9265
0.9872
0.9108
0.9674
0.9639
0.9650
0.7899
0.9751
ACMに投稿された原稿やで
---
![]()
1 / 1
100%