<<
Large Language Models for Generative Information Extraction: A Survey

---
## Page 1
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p001.png)
### 和訳
【総説論文】
---
生成型情報抽出のための大規模言語モデル:サーベイ
Derong Xu†1,2, Wei Chen†1, Wenjun Peng1, Chao Zhang1,2, Tong Xu((cid:66))1, Xiangyu Zhao((cid:66))2, Xian Wu((cid:66))3, Yefeng Zheng3, Yang Wang4, Enhong Chen((cid:66))1
1 認知知能国家重点実験室 & 中国科学技術大学(中国・合肥)
2 香港城市大学 データサイエンス学科(香港)
3 テンセントYouTuラボ Jarvis研究センター(中国・北京)
4 安徽海螺情報技術工程有限公司(中国・蕪湖)
© Higher Education Press 2024
---
**要旨**
情報抽出(IE)っていうのはな、普通の自然言語テキストから構造化された知識を引っ張り出す技術のことやねん。最近な、生成型の大規模言語モデル(LLM)がテキストの理解と生成においてめっちゃすごい能力を見せつけてきてんねん。そんなわけで、この生成パラダイムをベースにしてLLMをIEタスクに組み込もうっていう研究がめっちゃたくさん出てきたわけや。この研究ではな、IEタスクにおけるLLMの取り組みについて、包括的かつ体系的なレビューと探索をやっていくで。まず、いろんなIEのサブタスクとテクニックの観点からこれらの研究を分類して、幅広い概観を示すねん。ほんで、最先端の手法を実験的に分析して、LLMを使ったIEタスクの新たなトレンドを発見していくで。徹底的なレビューを踏まえてな、技術面でのいくつかの知見と、今後の研究でもっと掘り下げる価値のある有望な研究方向を特定したで。関連する研究とリソースはGitHubの公開リポジトリ(LLM4IE repository)で継続的に更新していくから、チェックしてみてな。
---
**キーワード**
情報抽出、大規模言語モデル、レビュー
---
## Page 2
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p002.png)
### 和訳
2
Front. Comput. Sci., 2024, 0(0): 1–47
1
はじめに
情報抽出(IE)っていうのは、自然言語処理(NLP)の中でもめっちゃ大事な分野でな、普通のテキストを構造化された知識(エンティティとか関係性とかイベントとか)に変換するんや。これが知識グラフの構築[1]とか、知識推論[2]、質問応答[3]みたいな下流タスクの土台になってるわけやねん。代表的なIEタスクには、固有表現認識(NER)、関係抽出(RE)、イベント抽出(EE)があるんや[4, 5, 6, 7]。せやけど、IEタスクをやるのはほんまに難しいねん。なんでかっていうと、IEはいろんなソースから情報を抜き出さなあかんし、複雑でコロコロ変わるドメインの要件に対応せなあかんからや[8]。従来のNLPタスクと違って、IEはエンティティ抽出とか関係抽出とか、めっちゃ幅広い目的を含んでんねん。IEでは、抽出対象が複雑な構造をしてて、エンティティはスパン構造(文字列構造)で表されるし、関係性はトリプル構造で表現されんねん[4]。さらに、いろんな情報抽出タスクを効果的に処理するには、複数の独立したモデルを使わなあかん。これらのモデルは各タスクごとに別々に学習されて、リソースを共有せえへんのや。せやけど、このアプローチには欠点があってな、大量の情報抽出モデルを管理するのは、アノテーション付きコーパスみたいな構築や学習に必要なリソースの面でコストがかかるんや。
GPT-4[9]みたいな大規模言語モデル(LLMs)が登場したことで、NLP分野はめっちゃ進歩したんや。テキストの理解と生成において驚異的な能力を持ってるからな[10, 11, 12]。自己回帰予測を使ってLLMsを事前学習することで、テキストコーパスに含まれる固有のパターンと意味的な知識を捉えられるようになったんや[13, 14, 15, 16, 17, 18, 19]。これによってLLMsはゼロショット学習やフューショット学習ができるようになって、いろんなタスクを一貫してモデル化できるし、データ拡張のツールとしても使えるようになったんや[20, 21, 22]。さらに、LLMsは複雑なタスクの計画と実行のためのインテリジェントエージェントとして機能して、メモリ検索や様々なツールを使って効率を上げて、タスクをうまいことやり遂げられるんや[23, 24, 25, 26, 27]。そういうわけで、最近は生成型IE手法[28]への関心がめっちゃ高まってて、プレーンテキストから構造的情報を抽出するんやなくて、LLMsを使って構造的情報を生成するアプローチが注目されてんねん。これらの手法は、識別型手法[29, 30]と比べて実世界のシナリオでより実用的やって証明されてて、何百万ものエンティティを含むスキーマでも大きな性能低下なしに扱えるんや[31]。
一方で、LLMsは研究者からめっちゃ注目されてて、IEの様々なシナリオやタスクでの可能性が探られてんねん。個々のIEタスクで優れた性能を発揮するだけやなくて、LLMsにはすべてのIEタスクを統一フォーマットで効果的にモデル化するすごい能力があるんや。これは指示的なプロンプトでタスク間の依存関係を捉えることで実現されて、一貫した性能を達成してるんや[4, 5, 32, 33, 34, 35, 36]。もう一方では、最近の研究でLLMsの優れた汎化能力が示されてて、ファインチューニングを通じてIEの学習データから学ぶだけやなくて[33, 33, 37, 38, 39]、インコンテキスト例や指示だけを頼りにフューショットやゼロショットのシナリオでも情報抽出ができるんや[40, 41, 42, 43, 44]。
せやけど、既存のサーベイ[8, 45, 46]は、上記の2つの研究グループについて包括的な探求を提供してへんのや:1)複数タスクに対応する統一フレームワークと、2)学習データが限られたシナリオ向けの最先端学習技術や。コミュニティは強く
---
## Page 3
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p003.png)
### 和訳
図1 LLMって生成型情報抽出にめっちゃ研究されてんねん。これらの研究は、いろんな情報抽出テクニックとか、特定のサブタスク専用に作られたフレームワークとか、複数のサブタスクを一気に処理できる万能フレームワークとか、ほんまにいろいろカバーしてんねん。
ここでな、LLMをどうやったら情報抽出タスクにもっとうまく適用できるか、もっと深く分析せなあかんねん。なんでかっていうと、LLMを情報抽出に適用する時に、知識の学習とか理解の面でまだまだ課題とか問題があるからやねん。具体的にどんな課題があるかっていうと、自然言語の出力と構造化された形式の間のズレとか、LLMの「幻覚」問題(嘘つくやつな)、文脈への依存性、計算リソースがめっちゃ必要なこと、内部知識の更新がむずいこととか、いろいろあんねん。
この調査ではな、図1に示してる通り、生成型情報抽出向けのLLMについて包括的に探ってんねん。そのために、既存の手法を主に2つの分類法で整理してんねん:(1) 情報抽出のサブタスクの分類法 - これは個別にも統一的にも抽出できる様々な情報タイプを分類するもんやねん、(2) 情報抽出テクニックの分類法 - これはLLMを生成型情報抽出に使う様々な新しいアプローチを分類するもんで、特にデータが少ない状況向けやねん。さらに、情報抽出テクニックの様々な分野での応用に焦点を当てた研究も包括的にレビューしてんねん。ほんで、情報抽出向けLLMの性能を評価・分析しようとする研究についても議論してんねん。この分類に基づいて、図2に示すような関連研究の分類体系を作ったんや。代表的な手法もいくつか比較して、その可能性と限界をより深く理解し、将来の方向性について洞察に満ちた分析も提供してんねん。俺らの知る限り、これがLLMを使った生成型情報抽出に関する初めての調査やで。
この調査の残りの部分はこんな構成になってんねん:まずセクション2で生成型情報抽出の定義と全サブタスクの目標を紹介するで。ほんでセクション3では、各タスクと汎用情報抽出の代表的なモデルを紹介して、それらの性能を比較すんねん。セクション4では、情報抽出向けLLMの様々な学習テクニックをまとめてんねん。さらに、セクション5では特定ドメイン向けに提案された研究を紹介し、セクション6では情報抽出タスクにおけるLLMの能力を評価・分析した最近の研究を紹介するで。最後に、今後の研究の
---
## Page 4
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p004.png)
### 和訳
4
Front. Comput. Sci., 2024, 0(0): 1–47
今後の研究の方向性についてはセクション7で議論して、セクション8では研究者向けのリファレンスとして、よう使われるLLMとデータセットの統計を網羅的にまとめてるで。
## 2 生成型情報抽出の基礎知識
このセクションでは、識別型と生成型の情報抽出の正式な定義を説明して、[46]で概説されてるIEのサブタスクをまとめていくで。このサーベイでは主に固有表現認識(NER)、関係抽出(RE)、イベント抽出(EE)[5, 32]に焦点当ててんねん。なんでかっていうと、これらがIE論文でめっちゃ注目されてるタスクやからやな。例は図3に載せてるで。
(1) 識別モデルの場合、目的はデータの尤度を最大化することやねん。これはアノテーションされた文xと、重複する可能性のある三つ組の集合を考慮するっちゅうことや。t j = (s, r, o)やで:
$$p_{cls}(t|x) = \prod_{(s,r,o) \in t_j} p((s, r, o)|x_j)$$ (1)
識別のもう一つの方法は、各位置iに対してシーケンシャルタギングでタグを生成することやねん。n個の単語からなる文xに対して、「BIESO」(Begin=始まり、Inside=内部、End=終わり、Single=単独、Outside=外部)っていう表記スキーマに基づいてn個の異なるタグ系列がアノテーションされるわけや。モデルの学習時には、各位置iの隠れベクトルh_iを使って、ターゲットのタグ系列の対数尤度を最大化するのが目的やで:
$$p_{tag}(y|x) = \frac{\exp(h_i, y_i)}{\exp(\exp(h_i, y'_i))}$$ (2)
(2) 3種類のIEタスクは生成的な方式で定式化できるねん。入力テキスト(文とかドキュメントとか)がn個のトークンの系列X = [x₁, ..., xₙ]で、プロンプトP、そしてターゲット抽出系列Y = [y₁, ..., yₘ]があるとするやん。目的は自己回帰的な定式化で条件付き確率を最大化することやで:
$$p_\theta(Y|X, P) = \prod_{i=1}^{m} p_\theta(y_i|X, P, y_{<i})$$ (3)
ここでθはLLMのパラメータを表してて、凍結することも学習可能にすることもできるねん。LLMの時代には、LLMにとってタスクをわかりやすくするために、追加のプロンプトや指示PをXに付け加えることを提案した研究がいくつもあるで[5]。入力テキストXは同じままやけど、ターゲット系列はタスクごとに変わってくるんや:
- **固有表現認識(NER)**には2つのタスクがあるねん:エンティティ識別とエンティティタイピングや。前者はエンティティのスパン(範囲)を特定することに関係してて、後者は特定されたエンティティにタイプを割り当てることに焦点当ててるで。
- **関係抽出(RE)**は論文によって設定が違うことがあるねん。文献[4, 5]に従って3つの用語で分類してるで:(1) 関係分類は、与えられた2つのエンティティ間の関係タイプを分類することや;(2) 関係三つ組は、関係タイプと対応する主語と目的語のエンティティスパンを特定することや;(3) 関係厳密は、正しい関係タイプ、スパン、そして主語と目的語のエンティティのタイプを与えることやで。
- **イベント抽出(EE)**は2つのサブタスクに分けられるねん[151]:(1) イベント検出(一部の研究ではイベントトリガー抽出とも呼ばれてる)は、イベントの発生を最も明確に表すトリガーワードとタイプを特定して分類することが目的や。(2) イベント引数抽出は、文からイベント内で特定の役割を持つ引数を特定して分類することが目的やで。
---
## Page 5
[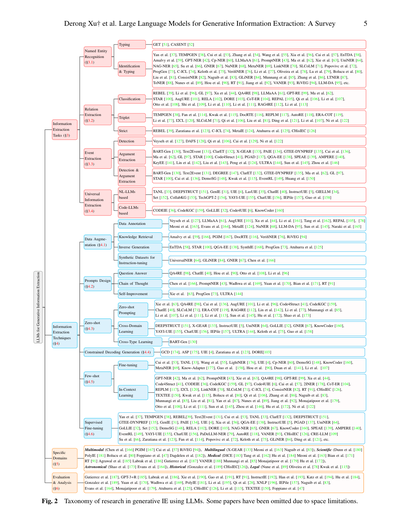](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p005.png)
### 和訳
Derong Xuさんらの論文「大規模言語モデルを使った生成型情報抽出:サーベイ」
5ページ目
**情報抽出タスク(§3)**
**固有表現認識(§3.1)**
「固有表現認識」っちゅうのはな、テキストの中から「人名」とか「地名」とか「組織名」みたいな固有名詞を見つけ出すタスクやねん。
- **タイピング(型付け)**: GET [51]、CASENT [52]
- これは見つけた固有表現が「何の種類か」を判定するやつやな
- **識別&タイピング**: めっちゃたくさんの研究があってな、Yanさんら [37]、TEMPGEN [38]、Cuiさんら [53]、Zhangさんら [54]、Wangさんら [55]、Xiaさんら [56]、Caiさんら [57]、EnTDA [58]、Amalvyさんら [59]、GPT-NER [42]、Cp-NER [60]、LLMaAA [61]、PromptNER [43]、Maさんら [62]、Xieさんら [63]、UniNER [64]、NAG-NER [65]、Suさんら [66]、GNER [67]、NuNER [68]、MetaNER [69]、LinkNER [70]、SLCoLM [71]、Popovicさんら [72]、ProgGen [73]、C-ICL [74]、Kelothさんら [75]、VerifiNER [76]、Liさんら [77]、Oliveiraさんら [78]、Luさんら [79]、Bolucuさんら [80]、Liuさんら [81]、ConsistNER [82]、Naguibさんら [83]、GLiNER [84]、Munnangさんら [85]、Zhangさんら [86]、LTNER [87]、ToNER [88]、Nunesさんら [89]、Houさんら [90]、RT [91]、Jiangさんら [92]、VANER [93]、RiVEG [94]、LLM-DA [95]とか、ほんまにぎょうさんあるわ
**関係抽出(§3.2)**
「関係抽出」っていうのはな、2つのエンティティ(実体)の間にどんな関係があるかを見つけ出すタスクやねん。
- **分類**: REBEL [39]、Liさんら [96]、GL [97]、Xuさんら [44]、QA4RE [98]、LLMaAA [61]、GPT-RE [99]、Maさんら [62]、STAR [100]、AugURE [101]、RELA [102]、DORE [103]、CoT-ER [104]、REPAL [105]、Qiさんら [106]、Liさんら [107]、Ottoさんら [108]、Shiさんら [109]、Liさんら [110]、Liさんら [111]、RAG4RE [112]、Liさんら [113]
- 関係の「種類」を分類するアプローチやな
- **トリプレット(三つ組)**: TEMPGEN [38]、Fanさんら [114]、Kwakさんら [115]、DocRTE [116]、REPLM [117]、AutoRE [118]、ERA-COT [119]、Liさんら [77]、I2CL [120]、SLCoLM [71]、Qiさんら [106]、Liuさんら [81]、Dingさんら [121]、Liさんら [107]、Niさんら [122]
- 「主語-関係-目的語」みたいな三つ組で抽出するやつやで
- **厳密型**: REBEL [39]、Zaratianaさんら [123]、C-ICL [74]、MetaIE [124]、Atuhurraさんら [125]、CHisIEC [126]
**イベント抽出(§3.3)**
「イベント抽出」はな、テキストの中から「何が起こったか」っていう出来事を見つけ出すタスクやねん。
- **検出**: Veysehさんら [127]、DAFS [128]、Qiさんら [106]、Caiさんら [129]、Niさんら [122]
- まずイベントがあるかどうかを検出するやつやな
- **引数抽出**: BART-Gen [130]、Text2Event [131]、ClarET [132]、X-GEAR [133]、PAIE [134]、GTEE-DYNPREF [135]、Caiさんら [136]、Maさんら [62]、GL [97]、STAR [100]、Code4Struct [41]、PGAD [137]、QGA-EE [138]、SPEAE [139]、AMPERE [140]、KeyEE [141]、Linさんら [142]、Liuさんら [143]、Pengさんら [124]、ULTRA [144]、Sunさんら [145]、Zhouさんら [146]
- イベントの「誰が」「いつ」「どこで」みたいな引数(パラメータ)を抽出するやつやで
- **検出&引数抽出**: BART-Gen [130]、Text2Event [131]、DEGREE [147]、ClarET [132]、GTEE-DYNPREF [135]、Maさんら [62]、GL [97]、STAR [100]、Caiさんら [136]、DemoSG [148]、Kwakさんら [115]、EventRL [149]、Huangさんら [150]
- 検出と引数抽出を両方やるやつやな
**統合情報抽出(§3.4)**
「統合情報抽出」っていうのはな、上の固有表現認識・関係抽出・イベント抽出を全部まとめて一気にやろうっちゅう欲張りなアプローチやねん。
- **自然言語LLMベース**: TANL [33]、DEEPSTRUCT [151]、GenIE [31]、UIE [4]、LasUIE [35]、ChatIE [40]、InstructUIE [5]、GIELLM [34]、Set [152]、CollabKG [153]、TechGPT-2 [154]、YAYI-UIE [155]、ChatUIE [156]、IEPile [157]、Guoさんら [158]
- **コードLLMベース**: CODEIE [36]、CodeKGC [159]、GoLLIE [32]、Code4UIE [6]、KnowCoder [160]
- プログラミング言語っぽい形式で抽出するアプローチやな
---
**情報抽出テクニック(§4)**
**データ拡張(§4.1)**
「データ拡張」っていうのはな、学習データを増やすためのテクニックやねん。なんでかっていうと、機械学習はデータが多いほど性能上がるからやで。
- **データアノテーション(ラベル付け)**: Veysehさんら [127]、LLMaAA [61]、AugURE [101]、Xuさんら [44]、Liさんら [161]、Tangさんら [162]、REPAL [105]、Meoniさんら [163]、Evansさんら [164]、MetaIE [124]、NuNER [68]、LLM-DA [95]、Sunさんら [145]、Narakiさんら [165] [78]
- **知識検索**: Amalvyさんら [59]、[166]、PGIM [167]、DocRTE [116]、VerifiNER [76]、RiVEG [94]
- 外部の知識ベースから情報を引っ張ってくるやつやな
- **逆生成**: EnTDA [58]、STAR [100]、QGA-EE [138]、SynthIE [168]、ProgGen [73]、Atuhurraさんら [125]
- 答えから問題を作るみたいな逆転の発想やで
- **インストラクションチューニング用合成データセット**: UniversalNER [64]、GLiNER [84]、GNER [67]、Chenさんら [166]
**プロンプト設計(§4.2)**
「プロンプト設計」はな、LLMにどうやって指示を出すかっていう技術やねん。
- **質問応答形式**: QA4RE [98]、ChatIE [40]、Houさんら [90]、Ottoさんら [108]、Liさんら [96]
- 「〇〇は何ですか?」みたいな質問形式で抽出させるやつやな
- **思考の連鎖(Chain of Thought)**: Chenさんら [166]、PromptNER [43]、Wadhwaさんら [169]、Yuanさんら [170]、Bianさんら [171]、RT [91]
- ステップバイステップで考えさせるテクニックやで。めっちゃ効果あるらしいわ
- **自己改善**: Xieさんら [63]、ProgGen [73]、ULTRA [144]
**ゼロショット(§4.3)**
「ゼロショット」っていうのはな、そのタスク専用の学習データなしで、いきなり本番やらせるアプローチやねん。
- **ゼロショットプロンプティング**: Xieさんら [63]、QA4RE [98]、Caiさんら [136]、AugURE [101]、Liさんら [96]、Code4Struct [41]、CodeKGC [159]、ChatIE [40]、SLCoLM [71]、ERA-COT [119]、RAG4RE [112]、Linさんら [142]、Liさんら [77]、Munnangiさんら [85]、Liさんら [107]、Liさんら [111]、Liさんら [113]、Sunさんら [145]、Huさんら [172]、Shaoさんら [173]
- **クロスドメイン学習**: DEEPSTRUCT [151]、X-GEAR [133]、InstructUIE [5]、UniNER [64]、GoLLIE [32]、GNER [67]、KnowCoder [160]、YAYI-UIE [155]、ChatUIE [156]、IEPile [157]、ULTRA [144]、Kelothさんら [75]、Guoさんら [158]
- ある分野で学習したモデルを別の分野に適用するやつやな
- **クロスタイプ学習**: BART-Gen [130]
**制約付きデコード生成(§4.4)**
GCD [174]、ASP [175]、UIE [4]、Zaratianaさんら [123]、DORE [103]
- 出力を特定のフォーマットに制約するテクニックやで
**フューショット(§4.5)**
「フューショット」はな、ちょっとだけ例を見せて学習させるアプローチやねん。
- **ファインチューニング**: Cuiさんら [53]、TANL [33]、Wangさんら [55]、LightNER [176]、UIE [4]、Cp-NER [60]、DemoSG [148]、KnowCoder [160]、MetaNER [69]、Know-Adapter [177]、Guoさんら [158]、Houさんら [90]、Duanさんら [141]、Liさんら [107]
- **インコンテキスト学習(文脈内学習)**: GPT-NER [42]、Maさんら [62]、PromptNER [43]、Xieさんら [63]、QA4RE [98]、GPT-RE [99]、Xuさんら [44]、Code4Struct [41]、CODEIE [36]、CodeKGC [159]、GL [97]、Code4UIE [6]、Caiさんら [57]、2INER [178]、CoT-ER [104]、REPLM [117]、I2CL [120]、LinkNER [70]、SLCoLM [71]、C-ICL [74]、ConsistNER [82]、RT [91]、CHisIEC [126]、TEXTEE [150]、Kwakさんら [115]、Bolucuさんら [80]、Qiさんら [106]、Zhangさんら [86]、Naguibさんら [83]、Munnangiさんら [85]、Liuさんら [81]、Yanさんら [87]、Nunesさんら [89]、Jiangさんら [92]、Monajatipoorさんら [179]、Ottoさんら [108]、Liさんら [111]、Sunさんら [145]、Zhouさんら [146]、Huさんら [172]、Niさんら [122]
- 例をプロンプトに含めて、その場で学習させるやつやで。めっちゃ便利やねん
**教師ありファインチューニング(§4.6)**
Yanさんら [37]、TEMPGEN [38]、REBEL [39]、Text2Event [131]、Cuiさんら [53]、TANL [33]、ClarET [132]、DEEPSTRUCT [151]、GTEE-DYNPREF [135]、GenIE [31]、PAIE [134]、UIE [4]、Xiaさんら [56]、QGA-EE [138]、InstructUIE [5]、PGAD [137]、UniNER [64]、GoLLIE [32]、Set [152]、DemoSG [148]、RELA [102]、DORE [103]、NAG-NER [65]、GNER [67]、KnowCoder [160]、SPEAE [139]、AMPERE [140]、EventRL [149]、YAYI-UIE [155]、ChatUIE [156]、PaDeLLM-NER [79]、AutoRE [118]、VANER [93]、CHisIEC [126]、CRE-LLM [109]、Suさんら [66]、Zaratianaさんら [123]、Fanさんら [114]、Popovicさんら [72]、Kelothさんら [75]、GLiNER [84]、Dingさんら [121]とか、ほんまにいっぱいあるわ
---
**特定ドメイン(§5)**
色んな専門分野向けの研究もあるねんで:
- **マルチモーダル(複数メディア)**: Chenさんら [166]、PGIM [167]、Caiさんら [57]、RiVEG [94]
- テキストだけやなくて画像とかも使うやつやな
- **多言語**: X-GEAR [133]、Meoniさんら [163]、Naguibさんら [83]
- **科学論文**: Dunnさんら [180]、PolyIE [181]、Bolucuさんら [80]、Foppianoさんら [47]、Dagdelenさんら [182]
- **医療**: DICE [183]、Tangさんら [162]、Huさんら [184]、Meoniさんら [163]、Bianさんら [171]、RT [91]、Agrawalさんら [185]、Labrakさんら [186]、Gutierrezさんら [187]、VANER [188]、Munnangiさんら [85]、Monajatipoorさんら [179]、Huさんら [172]
- **天文学**: Shaoさんら [173]、Evansさんら [164]
- **歴史**: Gonzalezさんら [189]、CHisIEC [126]
- **法律**: Nuneさんら [89]、Oliveiraさんら [78]、Kwakさんら [115]
---
**評価と分析(§6)**
Gutierrezさんら [187]、GPT-3+R [185]、Labrakさんら [186]、Xieさんら [190]、Gaoさんら [191]、RT [91]、InstructIE [192]、Hanさんら [193]、Katzさんら [194]、Huさんら [184]、Gonzalezさんら [189]、Yuanさんら [170]、Wadhwaさんら [169]、PolyIE [181]、Liさんら [195]、Qiさんら [28]、XNLP [196]、IEPile [157]、Naguibさんら [83]、Evansさんら [164]、Monajatipoorさんら [179]、Atuhurraさんら [125]、CHisIEC [126]、Liさんら [113]、TEXTEE [150]、Foppianoさんら [47]
---
**図2**: LLMを使った生成型情報抽出研究の分類体系やで。スペースの都合で省略した論文もあるから、全部じゃないねん。
---
## Page 6
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p006.png)
### 和訳
6
Front. Comput. Sci., 2024, 0(0): 1–47
デモンストレーション使って、LLMのゼロショットNERの性能めっちゃ上げられるんやで。
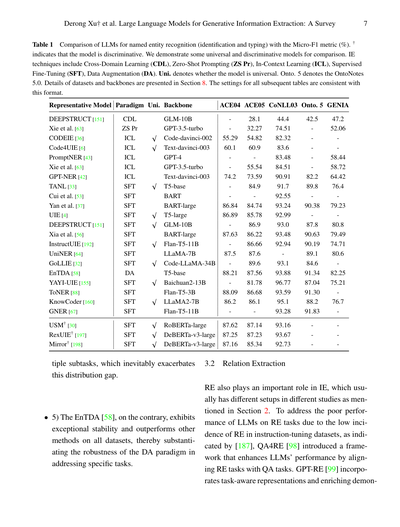
表1は5つの主要なデータセットでのNERの比較やねんけど、元の論文から持ってきたデータやな。ほんで、見てみるとこんなことがわかるねん:
• 1) few-shot(少数例学習)とzero-shot(ゼロショット)の設定のモデルは、SFT(教師ありファインチューニング)とDA(データ拡張)と比べたら、まだまだ性能に大きな差があるねん。
• 2) バックボーン(基盤モデル)にはそんな大きな違いないのに、ICL(文脈内学習)パラダイムの下では手法によって性能がめっちゃ変わるんよ。例えばGPT-NERは各データセットで他の手法より最低でも6%のF1値の差つけてて、最大で約19%も高いねん。
• 3) ICLと比べて、SFT後は異なるモデル間の性能差はちょっとしかないねん。バックボーンのパラメータ数が数百倍も違っててもやで。
• 4) SFTパラダイムで訓練されたモデルの性能は、データセット間でばらつきが大きいねん、特に汎用モデルでな。例えば、YAYI-UIE [155]とKnowCoder [160]はCoNLL03で他のモデルより少なくとも2.89%と1.22%それぞれ上回ってるんやけど、GENIAでは最良モデルと比べて7.04%と5.55%もそれぞれ下がってんねん。なんでかっていうと、これらのモデルは主にニュースとかSNSドメインから集めた多様なデータセットで訓練されてるんやけど、GENIAは生物医学ドメインやから訓練セットの中で占める割合が小さいねん。そやから分野間の分布ギャップがめっちゃでかくなって、最終的な性能に影響してまうんちゃうかなって仮説立ててるわ。さらに、汎用モデルは複数
図3 異なるIEタスクの例
3 情報抽出タスクにおけるLLM
このセクションでは、まずIEのサブタスクに関連するLLM技術の紹介をするで。NER(§3.1)、RE(§3.2)、EE(§3.3)を含むねん。さらに、代表的なデータセットで3つのサブタスクの様々な手法の性能を評価する実験分析もやるで。ほんで、汎用IEフレームワークを2つのカテゴリに分類するねん:自然言語(NL-LLMs)とコード言語(Code-LLMs)や。これらが3つの異なるタスクを統一パラダイムでどうモデル化してるか議論するで(§3.4)。
3.1 固有表現認識
NERはIEのめっちゃ重要な要素で、REとEEの前段階またはサブタスクとして見ることができるねん。他のNLPタスクの基本タスクでもあるから、LLM時代の新しい可能性を探る研究者からめっちゃ注目されてるんよ [47, 90, 91, 92, 93, 94, 95, 108, 122, 124, 125, 126, 164, 165, 172, 173, 177, 179, 182]。系列ラベリングと生成モデルの間のギャップを考慮して、GPT-NER [42]はNERを生成タスクに変換して、NULL入力をエンティティとして誤ってラベル付けするのを修正する自己検証戦略を提案したんや。Xieら [63]は訓練不要の自己改善フレームワークを提案して、LLMを使ってラベルなしコーパスで予測して疑似
| タスク | 入力 | 出力 |
|--------|------|------|
| NER | In 1997, Steve Jobs returned as CEO of Apple. | {(Steve Jobs:PER),(Apple:ORG)} |
| RE | In 1997, Steve Jobs returned as CEO of Apple. | {(SteveJobs,WorkFor,Apple)} |
| EE | In 1997, Steve Jobs returned as CEO of Apple. | {startposition:returned,employee:SteveJobs,employer:Apple,organization:Apple} |
---
## Page 7
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p007.png)
### 和訳
表1 固有表現認識(特定と分類)におけるLLMの比較、Micro-F1指標(%)で測っとるで。†がついてるやつは識別型モデルやねん。汎用モデルと識別型モデルを比較用にいくつか載せとるで。IE技術には、クロスドメイン学習(CDL)、ゼロショットプロンプティング(ZS Pr)、文脈内学習(ICL)、教師ありファインチューニング(SFT)、データ拡張(DA)があるねん。Uni.は汎用モデルかどうか、Onto. 5はOntoNotes 5.0のことや。データセットとベースモデルの詳細はセクション8に書いてあるで。これ以降の表も全部同じフォーマットやからな。
[表の内容は代表的なモデル、パラダイム、汎用性、ベースモデル、各データセット(ACE04、ACE05、CoNLL03、Onto. 5、GENIA)でのスコアを示しとる]
ほんで、複数のサブタスクを同時にやろうとすると、この分布のズレがめっちゃ悪化してまうねん。これが問題やな。
**3.2 関係抽出**
- 5番目やけど、EnTDA [58]はな、逆にめっちゃ安定しとって、全部のデータセットで他の手法より優れた結果出しとんねん。これで何がわかるかっていうと、特定のタスクに取り組むときにデータ拡張(DA)のやり方がほんまに頑丈やってことが証明されたわけや。
関係抽出(RE)もIEの中でめっちゃ重要な役割を果たしとって、セクション2で触れたように研究によって色々な設定があるねん。なんでかっていうと、[187]で指摘されとるように、LLMが関係抽出タスクで成績悪いのは、指示チューニング用のデータセットに関係抽出のサンプルがあんまり入ってへんからやねん。そこでQA4RE [98]っていうフレームワークが登場して、関係抽出タスクを質問応答(QA)タスクに合わせることでLLMの性能をアップさせるようにしたんや。GPT-RE [99]はタスクを意識した表現を取り入れて、デモンストレーションを...
---
## Page 8
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p008.png)
### 和訳
8
Front. Comput. Sci., 2024, 0(0): 1–47
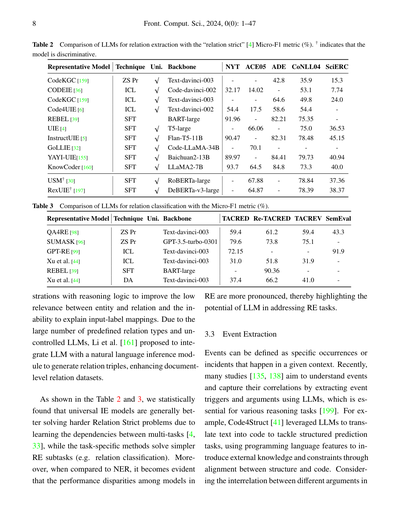
表2 「relation strict」[4] のMicro-F1指標(%)を使った関係抽出向けLLMの比較やで。†がついてるモデルは識別型ってことな。
| 代表的なモデル | 手法 | 統一型 | ベースモデル | NYT | ACE05 | ADE | CoNLL04 | SciERC |
|---|---|---|---|---|---|---|---|---|
| CodeKGC [159] | ZS Pr | | Text-davinci-003 | | | | 42.8 | 15.3 |
| CODEIE [36] | ICL | √ | Code-davinci-002 | 32.17 | 14.02 | | 64.6 | 7.74 |
| CodeKGC [159] | ICL | √ | Text-davinci-003 | 54.4 | 17.5 | | 58.6 | 24.0 |
| Code4UIE [6] | ICL | √ | Text-davinci-002 | 91.96 | 66.06 | | 82.21 | 36.53 |
| REBEL [39] | SFT | | BART-large | 90.47 | 70.1 | 35.9 | 82.31 | 45.15 |
| UIE [4] | SFT | √ | T5-large | 89.97 | 64.5 | 53.1 | 84.41 | 40.94 |
| InstructUIE [5] | SFT | SFT | Flan-T5-11B | | | 49.8 | 84.8 | 40.0 |
| GoLLIE [32] | SFT | √ | Code-LLaMA-34B | 93.7 | | 54.4 | | |
| YAYI-UIE[155] | SFT | √ | Baichuan2-13B | | 67.88 | 75.35 | | 37.36 |
| KnowCoder [160] | SFT | √ | LLaMA2-7B | | 64.87 | 75.0 | 78.48 | 38.37 |
| USM† [30] | SFT | √ | RoBERTa-large | | | | 79.73 | |
| RexUIE† [197] | SFT | √ | DeBERTa-v3-large | | | | 73.3 | |
表3 Micro-F1指標(%)を使った関係分類向けLLMの比較やで。
| 代表的なモデル | 手法 | 統一型 | ベースモデル | TACRED | Re-TACRED | TACREV | SemEval |
|---|---|---|---|---|---|---|---|
| QA4RE [98] | ZS Pr | | Text-davinci-003 | 59.4 | 61.2 | 59.4 | 43.3 |
| SUMASK [96] | ZS Pr | | GPT-3.5-turbo-0301 | 79.6 | 73.8 | 75.1 | |
| GPT-RE [99] | ICL | | Text-davinci-003 | 72.15 | 51.8 | | 91.9 |
| Xu et al. [44] | ICL | | Text-davinci-003 | 31.0 | 90.36 | 31.9 | |
| REBEL [39] | SFT | | BART-large | 37.4 | 66.2 | 41.0 | |
| Xu et al. [44] | DA | | Text-davinci-003 | | | | |
ほんでな、推論のロジックを含んだデモンストレーション(お手本みたいなやつ)を使って、エンティティと関係の関連性が低い問題とか、入力とラベルの対応関係をうまく説明できへん問題を改善しようとしてるねん。あらかじめ定義された関係タイプがめっちゃ多くて、LLMを制御しにくいっていう問題があるから、Li et al. [161]は自然言語推論モジュールとLLMを組み合わせて関係トリプル(主語-関係-目的語みたいなセット)を生成する方法を提案して、文書レベルの関係データセットを強化したんやで。
表2と表3を見てもらったらわかるけど、統計的に調べたら、統一型の情報抽出モデルは複数タスク間の依存関係を学習できるから[4, 33]、より難しいRelation Strict問題を解くのが得意やってわかったんや。一方で、タスク特化型の手法は関係分類みたいな比較的シンプルな関係抽出のサブタスクを解く感じやな。それとな、固有表現認識(NER)と比べると、関係抽出(RE)ではモデル間の性能差がめっちゃはっきり出てて、REタスクにおけるLLMの可能性がよう見えてくるねん。
3.3 イベント抽出
イベントっていうのは、ある文脈の中で起こる特定の出来事とか事件のことやねん。最近の研究[135, 138]では、LLMを使ってイベントのトリガー(きっかけとなる言葉)と引数(関係する情報)を抽出して、イベントを理解してそれらの相関関係を捉えようとしてるんや。これがいろんな推論タスク[199]にめっちゃ大事やねん。例えばな、Code4Struct [41]はLLMを使ってテキストをコードに変換して、構造化予測タスクに取り組んでるんやけど、構造とコードを対応させることで、プログラミング言語の特徴を活かして外部知識や制約を取り入れてるんや。異なる引数間の相互関係を考慮して
---
## Page 9
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p009.png)
### 和訳
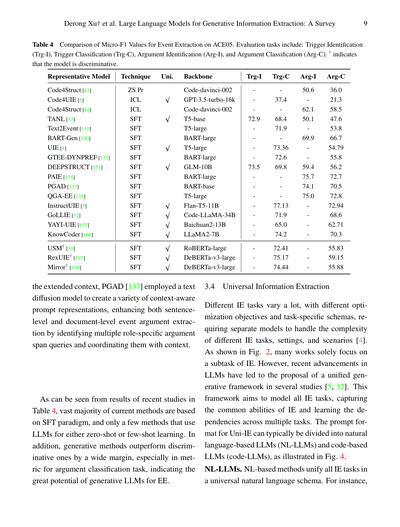
**表4:ACE05データセットでのイベント抽出におけるMicro-F1値の比較**
評価タスクの内容はこんな感じやで:トリガー特定(Trg-I)、トリガー分類(Trg-C)、引数特定(Arg-I)、引数分類(Arg-C)の4つや。†マークついてるモデルは識別型、つまり「これかな?あれかな?」って選ぶタイプのモデルやねん。
[表4の内容は数値データのため省略]
拡張されたコンテキスト、つまり文脈情報をもっとうまく活用するためにな、PGAD [137]ってやつはテキスト拡散モデルを使って、文脈を意識したいろんなプロンプト表現を作り出したんや。これで何ができるかっていうと、文レベルでも文書レベルでもイベントの引数抽出がめっちゃ上手くなんねん。具体的には、役割ごとの引数スパンクエリ(どこからどこまでが引数かっていう質問みたいなもんや)を複数見つけ出して、それを文脈とうまく連携させてるわけや。
表4の最近の研究結果を見てみるとな、今あるほとんどの手法はSFT(教師ありファインチューニング)っていうパラダイムをベースにしてて、LLM(大規模言語モデル)をゼロショットとかフューショット学習で使ってる手法はほんまに少ないねん。それとな、生成型の手法は識別型の手法をめっちゃ大差で上回ってるんや。特に引数分類タスクの指標でその差がはっきり出てて、イベント抽出における生成型LLMのポテンシャルがほんまにすごいってことがわかるわ。
---
**3.4 ユニバーサル情報抽出**
情報抽出のタスクってな、それぞれめっちゃ違うねん。最適化の目標も違えば、タスク固有のスキーマ(データの構造みたいなもんや)も違う。せやから、いろんなIEタスクや設定、シナリオの複雑さに対応するには、別々のモデルが必要やったんや [4]。図2を見てもろたらわかるけど、多くの研究がIEの一部のサブタスクだけに集中してるやろ?
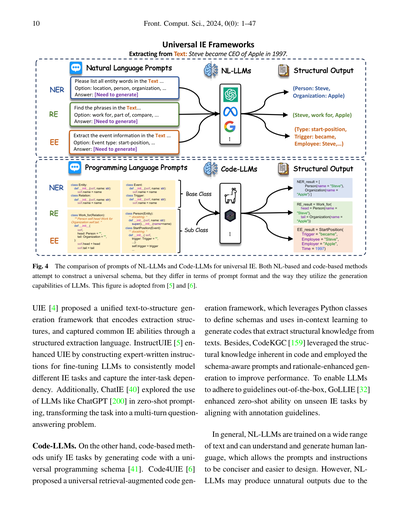
でもな、最近のLLMの進歩によって、いくつかの研究で統一的な生成フレームワークが提案されてきてん [5, 32]。このフレームワークの狙いは何かっていうと、全部のIEタスクをモデル化して、IE共通の能力を捉えつつ、複数タスク間の依存関係も学習しようっていう野心的なもんや。Uni-IE(ユニバーサル情報抽出)のプロンプト形式は、大きく分けて自然言語ベースのLLM(NL-LLMs)とコードベースのLLM(code-LLMs)の2種類があんねん。図4に図解してあるで。
**NL-LLMs(自然言語ベースの大規模言語モデル)**
自然言語ベースの手法はな、全部のIEタスクを統一的な自然言語スキーマにまとめるアプローチや。例えばな...
---
## Page 10
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p010.png)
### 和訳
10
Front. Comput. Sci., 2024, 0(0): 1–47
図4 ユニバーサル情報抽出における自然言語LLMとコードLLMのプロンプト比較やねん。自然言語ベースとコードベース、どっちの方法も統一的なスキーマ作ろうとしてるんやけど、プロンプトのフォーマットとかLLMの生成能力の使い方がちゃうねん。この図は[5]と[6]から持ってきたやつやで。
UIE [4]っていうのは、抽出の構造を統一されたテキストから構造への生成フレームワークでエンコードして、構造化抽出言語っていうもんを使って共通の情報抽出能力をキャッチできるようにしたんや。InstructUIE [5]はUIEをパワーアップさせたやつで、専門家が書いた指示文を作って、LLMをファインチューニングすることで、いろんな情報抽出タスクを一貫してモデル化できるようにして、タスク間の依存関係もちゃんと捉えられるようにしたんやで。それに加えて、ChatIE [40]はChatGPT [200]みたいなLLMをゼロショットプロンプティングで使う方法を探って、タスクを複数ターンの質問応答問題に変換するっていうアプローチを試したんや。
**コードLLM** 一方で、コードベースの方法は、ユニバーサルなプログラミングスキーマでコードを生成することで情報抽出タスクを統一してるんやで [41]。Code4UIE [6]は、Pythonのクラスを使ってスキーマを定義して、文脈内学習を使ってテキストから構造化知識を抽出するコードを生成する、ユニバーサルな検索拡張コード生成フレームワークを提案したんや。それから、CodeKGC [159]はコードに本来備わってる構造化知識を活用して、スキーマを意識したプロンプトと理論的根拠を強化した生成を使ってパフォーマンスを上げたんやで。LLMが最初からガイドラインに従えるようにするために、GoLLIE [32]はアノテーションガイドラインに沿わせることで、未知の情報抽出タスクに対するゼロショット能力を強化したんや。
全体的に言うと、自然言語LLMは幅広いテキストで訓練されてて、人間の言葉を理解して生成できるから、プロンプトや指示をより簡潔で設計しやすくできるねん。せやけど、自然言語LLMは不自然な出力を生成してまうことがあるんやな。なんでかっていうと...
[図の説明]
- 左側:自然言語プロンプト - NER(固有表現認識)、RE(関係抽出)、EE(イベント抽出)それぞれに対して「Textの中の全てのエンティティ単語をリストアップしてください...」みたいな自然言語の指示を出して、構造化出力として(Person: Steve, Organization: Apple)とか(Steve, work for, Apple)みたいな結果を得るんや。
- 右側:プログラミング言語プロンプト - Entity、Relation、Eventみたいな基底クラスを定義して、Person、Work_for、StartPositionみたいなサブクラスを作って、コードの形式で構造化出力を生成するんやで。
- 抽出対象のテキスト:「Steve became CEO of Apple in 1997.」(スティーブは1997年にAppleのCEOになった)
---
## Page 11
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p011.png)
### 和訳
Derong Xu†ら「大規模言語モデルを使った生成的情報抽出:サーベイ」
11ページ
IEタスク特有の文法とか構造[159]は、学習データとはだいぶ違うもんやねん。コードっていうのは形式化された言語やから、いろんなスキーマにまたがる知識を正確に表現する能力がもともと備わってて、それが構造的な予測にめっちゃ向いてるんや[6]。せやけど、コードベースの手法はPythonクラスを定義するのにかなりの量のテキストが必要になることが多くて(図4見てな)、その結果コンテキストに入れられるサンプル数が制限されてまうねん。表1、2、4の実験比較を見たら分かるように、SFT(教師あり微調整)を施したUni-IEモデルは、NER、RE、EEタスクにおいてほとんどのデータセットでタスク特化型モデルを上回ってるで。
3.5 タスクのまとめ
このセクションでは、IE内の3つの主要タスクとそれに関連するサブタスク、そしてこれらのタスクを統一するフレームワーク[4]について探ってきたわけや。重要な発見としては、生成型LLMをNER[67, 178]に応用するケースが増えてきてて、これがめっちゃ進歩してて、IE研究の中でもほんまに活発な領域のままやということやな。それに対して、関係抽出とかイベント抽出みたいなタスクは応用がちょっと少なめで、特に厳密な関係抽出[39]と検出のみのイベント抽出[128]はその傾向が顕著やねん。なんでこんな差があるかっていうと、NERがめっちゃ重要で、いろんな下流タスクに使えて、出力の構造が比較的シンプルやから大規模な教師あり微調整がやりやすいからやと思うで[1]。
あと、注目すべきトレンドとしては、IEタスクのための統一モデルが登場してきてることやな。これは現代の大規模モデルが持つ一般的なテキスト理解能力を活用したものや[4, 6, 156]。いくつかの研究では、IEタスク間で共通する能力を捉えて、タスク間の依存関係を学習する統一的な生成フレームワークが提案されてるねん。こういう統一的なアプローチは、大きく分けて自然言語ベースとコードベースの手法に分類できて、それぞれに独自のメリットとデメリットがあるんや。
表1、2、3、4にまとめた実験結果を見ると、ユニバーサルIEモデルは複数タスク間の依存関係を学習できるから、より複雑な厳密関係抽出タスクで一般的に性能がええことが分かるで。さらに、生成的手法はイベント抽出タスク、特に引数分類において識別的手法をめっちゃ上回ってて、この領域での生成型LLMのポテンシャルがほんまにすごいことが浮き彫りになってるわ。
4 生成的IEのためのLLM技術
このセクションでは、最近の手法を技術ごとに分類していくで。データ拡張(§4.1、LLMを使って既存データにいろんな変換を適用して情報を増強すること)、プロンプト設計(§4.2、タスク固有の指示やプロンプトを使ってモデルの動作を誘導すること)、ゼロショット学習(§4.3、特定のIEタスク用の学習例なしで答えを生成すること)、制約付きデコード生成(§4.4、特定の制約やルールに従いながらテキストを生成するプロセス)、フューショット学習(§4.5、学習やインコンテキスト学習によって少数のラベル付き例から汎化すること)、教師あり微調整(§4.6、ラベル付きデータを使ってIEタスクでLLMをさらに学習させること)、これらを取り上げて、LLMをIEに適応させるためによく使われるアプローチを紹介するで。
4.1 データ拡張
データ拡張っていうのは、意味のある多様なデータを生成して、学習を効果的に強化することやねん。
---
## Page 12
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p012.png)
### 和訳
12
Front. Comput. Sci., 2024, 0(0): 1–47
図5 データ拡張手法の比較やで
サンプルデータを増やしながら、現実離れしたやつとか、勘違いさせるようなパターン、あと方向性がズレたパターンを入れへんようにせなあかんねん。最近のめっちゃ賢いLLM(大規模言語モデル)は、データ生成タスクでもすごい性能を見せとるんよ [201, 202, 203, 204, 205]。せやから、情報抽出(IE)用の合成データを作るのにLLMを使おうっていう研究者がめっちゃ増えてきてるねん [44, 61, 101, 127, 161, 162, 163]。技術的なアプローチでざっくり4つの戦略に分けられるで、図5を見てな。
**データアノテーション** この戦略は、LLMを使って直接ラベル付きの構造化データを生成するやり方やねん。例えばな、Zhangらの研究 [61] ではLLMaAAっていうのを提案しとって、アクティブラーニング(能動学習)のループの中でLLMをアノテーター(ラベル付けする人)として使うことで、精度とデータ効率を上げてんねん。要はアノテーションと学習プロセスの両方を最適化するってことやな。AugURE [101] は、教師なし関係抽出でポジティブペア(正例のペア)の多様性を高めるために、文内ペア拡張と文間ペア抽出を使って、さらにセンテンスペア用のマージン損失っていうのも導入したんやで。Liらの研究 [161] は、長いコンテキストから文書レベルの関係抽出をするっていう難しい課題に取り組んでて、LLMと自然言語推論モジュールを組み合わせて関係トリプル(3つ組の関係データ)を生成する、DocRE用の自動アノテーション手法を提案してるねん。
**知識検索** この戦略は、LLMから情報抽出に関連する情報を効果的に取り出すやり方で、RAG(検索拡張生成)[206] に似とるねん。PGIM [167] はマルチモーダルNER(複数の情報形式を扱う固有表現認識)用の2段階フレームワークを提案しとって、ChatGPTを暗黙の知識ベースとして使って、エンティティ予測をもっと効率よくするための補助知識をヒューリスティックに(経験則的に)取り出してくるんやで。Amalvyらの研究 [59] は、合成的なコンテキスト検索用の訓練データセットを生成して、ニューラルコンテキスト検索器を学習させることで、長い文書でのNER性能を上げようとしてるねん。Chenらの研究 [166] はマルチモーダルNERとREのタスクに焦点を当てとって、名詞、文、マルチモーダル入力っていう異なる観点を網羅したいろんなCoT(思考の連鎖)プロンプトを使って、常識推論スキルを強化するアプローチを披露してるんや。さらに、スタイル、エンティティ、画像の操作みたいなデータ拡張テクニックも使って、もっと性能を上げようとしてるで。
[図の説明]
知識検索 | データアノテーション | 逆生成
「スティーブ・ジョブズはアメリカの実業家、工業デザイナー、発明家やった。生まれは…」
「スティーブ・ジョブズは実業家、発明家、投資家で、Apple Inc.を共同創業したんやで。」
自然言語テキスト
(スティーブ・ジョブズ、だった、実業家)(スティーブ・ジョブズ、共同創業した、Apple)…
関連知識 | 構造化トリプレット
指示:バーチャルアシスタントが質問に答える… 会話:エンティティを抽出する…
指示チューニング
[大規模言語モデルからのデータ構築]
会話データの蒸留
[小規模言語モデルでのファインチューニング]
---
## Page 13
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p013.png)
### 和訳
**逆生成(Inverse Generation)**
この方法はな、LLM(大規模言語モデル)に構造化されたデータを入力として渡して、そこから自然な文章とか質問を生成させるっていうもんやねん。これがめっちゃええのは、LLMがもともと学習してきたやり方とバッチリ合ってるからなんよ。例えばな、SynthIE [168]っていう研究では、タスクの方向を逆にするだけで、LLMが複雑なタスク用の高品質な合成データを作れることを示したんや。で、そのデータで新しいモデルを訓練したら、これまでのベンチマークを超える性能が出たんやで。STAR [100]は、正解データに頼るんやなくて(そうすると汎用性とかスケーラビリティが制限されてまうからな)、有効なトリガーと引数から構造を生成して、さらに細かい指示とかエラー特定、繰り返し修正を設計することでLLMに文章を生成させたんや。あと、テキストの一貫性を保ちながらエンティティ(固有名詞とか実体のこと)も維持するっていう難しい課題に対して、EnTDA [58]は元のテキストのエンティティリストをいじるっていう方法を提案したんや。具体的には、エンティティを追加したり、削除したり、置き換えたり、入れ替えたりするんやな。さらに「多様性ビームサーチ」っていうのを導入して、エンティティからテキストを生成するときの多様性を高めたんやで。
**ファインチューニング用の合成データセット**
この戦略はな、LLMに問い合わせることで、指示チューニング用のデータをいくつか生成するっていうもんやねん。普通は、より強力なモデルが対話の中で指示をファインチューニングするためのデータを生成して、それを小さいモデルに蒸留(知識を移す)することで、小さいモデルでも強力なゼロショット能力(見たことないタスクでもできる力)を獲得できるようにするんや [64, 67, 84]。例えばな、UniversalNER [64]は、オープンNER(固有表現認識)に優れた生徒モデルを訓練するために、ミッションに特化した指示チューニングを使った目的指向の蒸留を探求したんや。ChatGPTを先生モデルとして使って、それを小さいUniversalNERモデルに蒸留したわけやな。GNER [67]は、文脈情報を導入してラベルの境界を改善することで、既存の手法を強化するためにネガティブインスタンス(「これは違う」っていう例)を統合することを提案したんや。著者らは、約13Kの異なるエンティティカテゴリにわたる約24万のエンティティを含むPile-NERっていうデータセットを使ってモデルを訓練したんやけど、これはPile Corpus [207]からサンプリングして、ChatGPTを使ってエンティティを生成する処理をしたもんなんや。結果として、未知のエンティティドメインでもゼロショット性能が向上したことが示されたんやで。
**4.2 プロンプト設計**
プロンプトエンジニアリングっていうのは、LLMのネットワークパラメータをいじらんと性能を向上させる技術やねん [49, 208, 209, 210, 211, 212]。タスクに特化した指示、つまりプロンプトを使って、モデルの振る舞いをガイドするんや [13, 213, 214]。このプロンプト設計っていう実践は、いろんなアプリケーションで成功を収めてきたんやで [215, 216, 217, 218]。もちろん、効果的なプロンプト設計は、IEタスク(情報抽出タスク)でLLMの性能を向上させる上でもめっちゃ重要な役割を果たすんや。このセクションでは、プロンプト設計のアプローチを異なる戦略に基づいて分類して、これらの技術の背後にある動機について詳しく説明するで。
**質問応答(QA)**
LLMは対話ベースの方法を使って指示チューニングされとるんやけど [219, 220]、これがIEタスクの構造化予測の要件と比べるとギャップがあるんや。なんでかっていうと、IEタスクって決まった形式で情報を抽出せなあかんからやねん。そこで最近は、LLMを強化して望ましい結果をよりスムーズに生成できるようにするために、QAプロンプトのアプローチを採用する取り組みがなされとるんや [40, 90, 96, 98, 108]。例えばな、QA4RE [98]は、LLMがRE(関係抽出)でパフォーマンスが悪くなりがちなのは、訓練に使われる指示チューニングデータセットにREタスクがあんまり含まれてへんからやと発見したんや。そこで、指示チューニングデータセットにはQAタスクがもっと多く含まれてることを利用するために、REを多肢選択式のQAに再定式化することを提案したんやで。Li ら [96]は、既存のREプロンプトの限界を分析して、「summarize-and-ask prompting」っていう新しいアプローチを提案したんや。これはゼロショットREの入力を、LLMを再帰的に使って効果的なQA形式に変換するっていうもんなんやで。これは過剰な...(続きがあるみたいやな)
---
## Page 14
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p014.png)
### 和訳
14
Front. Comput. Sci., 2024, 0(0): 1–47
重複する関係もうまく扱えて、「該当なし」っていう厄介な関係もちゃんと処理できるんやで。ChatIE [40]っていうのは、ゼロショットIE(情報抽出)タスクを、何回もやりとりするQ&A問題に変換する2段階のフレームワークを提案したんや。最初の段階では、いろんな種類の要素を見つけ出して、その後、見つけた要素タイプごとに順番に情報抽出していくねん。各段階では、テンプレートと前に抽出した情報を使ってプロンプトを作って、マルチターンQ&Aをやるわけや。
**思考の連鎖(CoT)。** CoT [221]っていうのは、LLM(大規模言語モデル)の性能を上げるためのプロンプト戦略やねん。なんでかっていうと、段階を踏んで筋の通った推論の流れをプロンプトとして与えることで、モデルの回答生成をガイドできるからや。このCoTプロンプティングは最近めっちゃ注目されてて [222]、IEタスクでの効果を調べる研究が今も続いてるんや [43, 91, 166, 169, 170, 171]。PromptNER [43]は、LLMとプロンプトベースのヒューリスティック(経験則)、それからエンティティ(固有表現)の定義を組み合わせたんや。エンティティタイプの定義を与えて、LLMに候補となるエンティティのリストとその説明を生成させるねん。Bianら [171]は、LLMを使ってバイオメディカル(生命医学)のNER(固有表現認識)を改善する2段階アプローチを提案したで。彼らのアプローチは、CoTを使ってLLMがバイオメディカルNERタスクをステップバイステップで取り組めるようにして、エンティティのスパン(範囲)抽出とエンティティタイプの判定に分けるんや。Yuanら [170]も、時間的RE(関係抽出)タスクで時間関係の推論をChatGPTにやらせるために、2段階アプローチとしてCoTプロンプトを提案してるで。
**自己改善。** COT技術でLLMの推論能力をある程度引き出せるんやけど、それでもLLMが事実と違うエラーを出してまうのは避けられへんねん。そやから、LLMに繰り返し自己検証と自己改善させて、結果を修正しようっていう取り組みがあるんや [63, 73, 144]。例えば、Xieら [63]は、学習なしで自己改善するフレームワークを提案してて、これは主に3つのステップで構成されてるんや。まず、LLMがラベルなしのコーパス(文章集)に対して予測を行って、自己一貫性を使って自己アノテーション(自動ラベル付け)したデータセットを作る。次に、信頼できるアノテーションを選ぶためのいろんな戦略を検討する。最後に、推論時に、信頼できる自己アノテーションデータセットからデモンストレーション(例示)を取ってきて、インコンテキスト学習に使うんや。ProgGen [73]は、LLMに特定のドメインで自己省察させて、その結果、ドメインに関連した属性を生成させるねん。これで属性が豊富な学習データを作れるんや。さらに、ProgGenは先にエンティティ用語を生成して、それを中心にNERのコンテキストデータを構築するっていうプロアクティブ(先回り的)な戦略を使ってて、これでLLMが複雑な構造を扱うときの課題を回避できるんやで。
**4.3 ゼロショット学習**
ゼロショット学習の主な課題は、モデルが訓練されてないタスクやドメインにもちゃんと汎化できるようにすること、それからLLMの事前学習のやり方をこういう新しいタスクに合わせることやねん。LLMは中に大量の知識を持ってるから、見たことないタスクのゼロショットシナリオでもほんまにすごい能力を見せるんや [40, 223]。IEタスクでLLMのゼロショットクロスドメイン汎化を実現するために、いくつかの研究が提案されてるで [5, 32, 64]。これらの研究は、いろんなIEタスクとドメインをモデル化するための普遍的なフレームワークを提供してて、インストラクション(指示)[5]やガイドライン [32]みたいな革新的な学習プロンプトを導入して、既知のタスク間の依存関係を学習・把握して、それを見たことないタスクやドメインに汎化できるようにしてるんや。クロスタイプ汎化については、BART-Gen [130]が文書レベルのニューラルモデルを導入してて、EE(イベント抽出)タスクを条件付き生成として捉えることで、性能を
---
## Page 15
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p015.png)
### 和訳
ほな翻訳していくで!
---
めっちゃ性能ええし、見たことないイベントタイプにもバッチリ対応できる移植性の高さがあるねん。
一方で、LLMをゼロショットプロンプト(ファインチューニングせんでええやつ)で使えるようにしたいってことで、QA4RE [98]とChatIE [40]ってのが、情報抽出をマルチターンの質問応答問題に変換するって方法を提案したんや。なんでかっていうと、質問応答タスクって、インストラクション・チューニングのデータセットでめっちゃメインのタスクやから、それに合わせたろってことやねん。Liらの研究 [96]では、チェーン・オブ・ソート(思考の連鎖)っていうアプローチを取り入れて、「まず要約して、それから質問する」っていうプロンプト手法を提案して、ブラックボックスなLLMの出力の信頼性をどう担保するかって課題 [62]に取り組んだんや。
**4.4 制約付きデコード生成**
LLMってのは、もともと「次のトークン(言葉の断片みたいなもん)を予測する」ってタスクで事前学習されたモデルなんや。この事前学習のおかげで、研究者はいろんなNLPタスクにこのモデルの強みを活かせるようになったんやで [8, 224]。せやけど、LLMって基本的に自由形式のテキストを生成するように作られてるから、「この選択肢しかあかん」みたいな限られた出力しか許されへん構造化予測タスクには、あんまり向いてへんのや。
この課題を解決するために、研究者らは制約付き生成を使ってデコードをうまいことやる方法を模索してきたんや [4, 123, 174, 175]。自己回帰型LLMでの制約付きデコード生成っていうのは、特定の制約やルールを守りながらテキストを生成するプロセスのことやで [225, 226, 227]。例えばGengらの研究 [174]では、文法制約付きデコードを使って言語モデルの生成をコントロールして、出力が決まった構造に従うようにする方法を提案したんや。著者らは入力依存の文法っていうのを導入して柔軟性を高めて、入力によって文法が変わって、入力ごとに違う出力構造を生成できるようにしたんや。
これまでの方法はトークンを1個ずつ生成していくスタイルやったんやけど、Zaratianaらの研究 [123]では、エンティティ(実体)とリレーション(関係)を抽出するのに、線形化されたグラフを生成するっていう新しいアプローチを導入したんや。このグラフでは、ノードがテキストのスパン(範囲)を表して、エッジが関係トリプレット(主語-関係-目的語みたいなやつ)を表すねん。トランスフォーマーのエンコーダ・デコーダ構造に、ポインティング機構とスパン・関係タイプの動的語彙を組み合わせて使うことで、構造的な特徴と境界を捉えつつ、元のテキストにちゃんと紐づけた出力ができるようになったんや。
**4.5 少数ショット学習**
少数ショット学習っていうのは、ラベル付きの例がほんまに少ない状態でしかアクセスできへんから、過学習(データに過剰に適合しすぎること)とか、複雑な関係をうまく捉えられへんとか、そういう課題があるんや [228]。せやけどありがたいことに、LLMのパラメータをでっかくスケールアップしたら、小さい事前学習モデルと比べてびっくりするくらいの汎化能力が得られて、少数ショットの設定でもめっちゃええ性能が出せるようになったんや [43, 91]。Paoliniらの研究 [33]は「拡張自然言語間の翻訳」っていうフレームワークを提案して、Luらの研究 [4]はテキストから構造への生成フレームワークを提案して、Chenらの研究 [60]は固有表現認識(NER)のための協調的ドメイン・プレフィックス・チューニングを提案したんや。これらの方法は最先端の性能を達成して、少数ショット設定での有効性を実証したんやで。LLMの成功にもかかわらず、学習なしの情報抽出には課題があるんや。なんでかっていうと、系列ラベリング(文の各要素にタグを付けていくやつ)とテキスト生成モデルの間に違いがあるからやねん [187]。この限界を乗り越えるために、GPT-NER [42]は自己検証戦略を導入して、GPT-RE [99]はタスク認識表現を強化して、推論ロジックをリッチなデモンストレーションに組み込んだんや。これらの方法は、GPTを文脈内学習(in-context learning)にどう活用できるかをうまいこと示してるで。CODEIE [36]とCodeKGC [159]は、情報抽出タスクをコードスタイルのプロンプトと文脈内の例を使ったコード生成タスクに変換したら、自然言語LLMより優れた性能が出ることを示したんや。なんでかっていうと、コードスタイルのプロンプトは構造化された出力をより効果的に表現できるから、効率よく
---
## Page 16
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p016.png)
### 和訳
16
Front. Comput. Sci., 2024, 0(0): 1–47
自然言語の複雑な依存関係をうまいこと処理できるようになるねん。
4.6 教師あり微調整
全部の訓練データ使ってLLM(大規模言語モデル)を微調整するんが、一番よく使われるし期待できる方法やねん [88, 110, 111, 113, 129, 141, 143, 229, 230, 231, 232, 233]。これやったらモデルがデータの中に隠れてる構造パターンをちゃんと捉えられて、見たことない新しいサンプルにも対応できるようになるんや。例えばな、DEEPSTRUCT [151]っていうのは、タスクに依存せんコーパス(テキストの集まりやな)を使って構造の事前学習を導入して、言語モデルの構造理解力をアップさせたんや。UniNER [64]は、ターゲット絞った蒸留と、ミッション重視の指示チューニングを探求して、NER(固有表現認識のことやで)みたいな幅広い用途に使える生徒モデルを訓練したんや。GIELLM [34]は、複数タスクで相乗効果が出るように集めた混合データセットでLLMを微調整して、パフォーマンスを上げたんやで。
4.7 技術のまとめ
データ拡張 [61, 101]は、モデルの性能アップに効きそうやから、めっちゃ研究されとる分野やねん。LLMは膨大な暗黙知を持っとるし、テキスト生成もめっちゃ得意やから、データのアノテーション(ラベル付けのことやな)タスクにはほんまにぴったりなんや [222]。せやけどな、データ拡張で訓練データセット増やして汎化性能上げられる一方で、ノイズが入ってまう可能性もあるねん。例えばな、知識検索の手法使ったら、エンティティ(実体)や関係についての追加コンテキストを供給できて、抽出プロセスがもっとリッチになるんや。でもな、そのノイズのせいで抽出した情報の全体的な品質が落ちることもあるんやで [94, 167]。
一方でな、GPT-4 [9]みたいなLLMを活用するには、効果的なプロンプトを設計するんがまだまだ大きな課題やねん。QA対話とかCoT(Chain-of-Thought、思考の連鎖ってやつや)[104]みたいなアプローチでLLMのIE(情報抽出)能力を上げられるんやけど、プロンプトだけに頼る方法は、小さいモデルを教師あり微調整するのにはまだ及ばんのや。教師あり微調整 [5, 64, 67]、クロスドメインとかfew-shot学習(少ないサンプルで学習するやつな)含めて、だいたいより良いパフォーマンス出せるねん。これが示唆しとるのは、大規模LLMでデータアノテーションして、その追加データで教師あり微調整を組み合わせたら、パフォーマンス最適化できるし、手作業でのアノテーションコストも減らせるってことやな [68, 95, 164]。
まとめるとな、LLM使ったIEの色んな技術にはそれぞれの強みがあるんやけど、課題もあるねん。これらの戦略をうまいこと組み合わせて考えたら、IEタスクでめっちゃすごい改善が得られるんやで。
5 特定ドメインへの応用
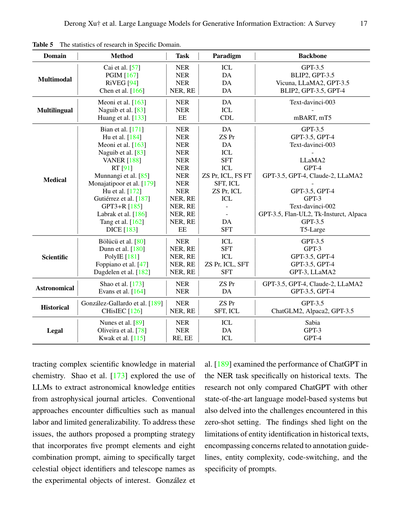
見逃したらあかんのが、LLMには特定のドメインから情報を抽出するのにめっちゃ大きなポテンシャルがあるってことやねん。例えばマルチモーダル(複数の情報形式を扱うやつな)[57, 94, 166, 167]、多言語 [83, 133, 163]、医療 [85, 91, 162, 163, 171, 172, 179, 183, 184, 185, 186, 187, 188, 234, 235]、科学 [47, 80, 180, 181, 182]、天文学 [164, 173]、歴史 [126, 189]、法律 [78, 89, 115]とかな。あと、表5に統計データも載せとるで。
例を挙げるとな、Chenら [166]は条件付きプロンプト蒸留っていう手法を導入したんや。これはテキストと画像のペアをLLMからのChain-of-Thought知識と組み合わせることでモデルの推論能力を高めるもんで、マルチモーダルNERとマルチモーダルRE(関係抽出のことやで)でめっちゃパフォーマンス上がったんや。Tangら [162]は臨床テキストマイニングの分野でLLMのポテンシャルを探って、新しい訓練アプローチを提案したんや。これは合成データを活用してパフォーマンス上げながら、プライバシーの問題にも対処できるやつやねん。Dunnら [180]は、GPT-3使って複雑な科学テキストから固有表現認識と関係抽出を同時にやるsequence-to-sequence(系列から系列へ変換する)アプローチを発表して、その有効性を実証したんやで。
---
## Page 17
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p017.png)
### 和訳
特定ドメインの研究に関する統計データ(表5)
| ドメイン | 手法 | タスク | パラダイム | ベースモデル | マルチモーダル | 多言語対応 |
|----------|------|--------|------------|--------------|----------------|------------|
**マルチモーダル対応**
- Cai ら [57] | NER | ICL | GPT-3.5
- PGIM [167] | NER | DA | BLIP2, GPT-3.5
- RiVEG [94] | NER | DA | Vicuna, LLaMA2, GPT-3.5
- Chen ら [166] | NER, RE | DA | BLIP2, GPT-3.5, GPT-4
**多言語対応**
- Meoni ら [163] | NER | DA | Text-davinci-003
- Naguib ら [83] | NER | ICL | mBART, mT5
- Huang ら [133] | EE | CDL | ―
**医療分野**
- Bian ら [171] | NER | DA | GPT-3.5
- Hu ら [184] | NER | ZS Pr | GPT-3.5, GPT-4
- Meoni ら [163] | NER | DA | Text-davinci-003
- Naguib ら [83] | NER | ICL | LLaMA2
- VANER [188] | NER | SFT | GPT-4
- RT [91] | NER | ICL | GPT-3.5, GPT-4, Claude-2, LLaMA2
- Munnangi ら [85] | NER | ZS Pr, ICL, FS FT | GPT-3.5, GPT-4
- Monajatipoor ら [179] | NER | SFT, ICL | GPT-3
- Hu ら [172] | NER | ZS Pr, ICL | Text-davinci-002
- Gutiérrez ら [187] | NER, RE | ICL | GPT-3.5, Flan-UL2, Tk-Instruct, Alpaca
- GPT3+R [185] | NER, RE | DA | GPT-3.5
- Labrak ら [186] | NER, RE | SFT | T5-Large
- Tang ら [162] | NER, RE | ― | ―
- DICE [183] | EE | ― | ―
**科学分野**
- Bölücü ら [80] | NER | ICL | GPT-3.5
- Dunn ら [180] | NER, RE | SFT | GPT-3
- PolyIE [181] | NER, RE | ICL | GPT-3.5, GPT-4
- Foppiano ら [47] | NER, RE | ZS Pr, ICL, SFT | GPT-3.5, GPT-4
- Dagdelen ら [182] | NER, RE | SFT | GPT-3, LLaMA2
**天文学分野**
- Shao ら [173] | NER | ZS Pr | GPT-3.5, GPT-4, Claude-2, LLaMA2
- Evans ら [164] | NER | DA | GPT-3.5, GPT-4
**歴史分野**
- González-Gallardo ら [189] | NER | ZS Pr | GPT-3.5
- CHisIEC [126] | NER, RE | SFT, ICL | ChatGLM2, Alpaca2, GPT-3.5
**法律分野**
- Nunes ら [89] | NER | ICL | Sabia
- Oliveira ら [78] | NER | DA | GPT-3
- Kwak ら [115] | RE, EE | ICL | GPT-4
---
ほんでな、材料化学の分野で複雑な科学知識を引っ張り出すって話やねんけど、Shaoらの研究[173]では、天文学の論文から知識のカタマリを抜き出すのにLLMが使えへんか試してみてん。従来のやり方やと、めっちゃ手作業が必要やし、汎用性も低いっていう問題があってんな。
そこでこの問題解決するために、5つのプロンプト要素と8つの組み合わせプロンプトを取り入れた戦略を提案してん。特に「天体の識別子」と「望遠鏡の名前」をターゲットにして実験したわけや。
Gonzálezらの研究[189]では、歴史的なテキストのNERタスク(固有表現認識っていって、文章から人名とか地名とか特定の情報を見つけ出す作業のことやで)において、ChatGPTがどんだけ使えるか調べてん。この研究、ただChatGPTと他の最新の言語モデルベースのシステムを比較しただけやなくて、ゼロショット設定(事前に例を見せへんで、いきなり本番やらせるやつな)でどんな課題があるかも深掘りしてん。
で、結果としてわかったんは、歴史テキストで固有表現を見つけるのには限界があるってことやねん。なんでかっていうと、アノテーションガイドライン(ラベル付けのルールのことな)の問題とか、固有表現自体がめっちゃ複雑やったり、コードスイッチング(一つの文章の中で言語が切り替わることやで)があったり、プロンプトの具体性が足りへんかったりするからやねん。ほんま、歴史テキスト相手やと一筋縄ではいかへんってことが明らかになったわけや。
---
## Page 18
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p018.png)
### 和訳
18
Front. Comput. Sci., 2024, 0(0): 1–47
## 6章 評価と分析
LLMって色んな自然言語処理のタスクでめっちゃ成功してるやん[236, 237]。でもな、情報抽出の分野ではまだまだ改善の余地があんねん[193]。この問題をなんとかしよう思て、最近の研究ではLLMの能力を情報抽出の主要なサブタスクごとに調べてんねん。つまり、固有表現認識(NER)[83, 190]、関係抽出(RE)[169, 170]、イベント抽出(EE)[191]やな。
LLMの推論能力がめっちゃ優れてるやろ、そこに注目してXieらの研究チーム[190]がNER用の推論戦略を4つ提案してん。これはChatGPTがゼロショットNER(事前に例を見せんでもできるやつ)でどれくらいいけるか試すためのもんやねん。Wadhwaらのチーム[169]は関係抽出にLLMを使う方法を調べて、GPT-3に数個の例を見せてプロンプトするだけで、ほぼ最先端の性能出せることがわかってん。しかもFlan-T5っていうモデルは、GPT-3で作った思考の連鎖スタイルの説明を使うとさらに良くなんねん。イベント抽出については、Gaoらのチーム[191]が調べたところ、ChatGPTはまだ苦戦してるって判明したわ。なんでかっていうと、複雑な指示が必要やし、頑健性も足りひんからやねん。
この流れで、もっと総合的にLLMを分析した研究者もおるで。複数の情報抽出サブタスクを同時に評価するやつな。Liらのチーム[195]はChatGPTの情報抽出における総合力を評価してん。具体的には、性能、説明可能性、キャリブレーション(確信度の正確さ)、忠実性を見たんや。結果わかったんは、通常の情報抽出設定ではChatGPTはBERTベースのモデルより大体パフォーマンス悪いねん。せやけどOpenIE(オープン情報抽出)の設定ではめっちゃ優秀やったわ。さらにHanらのチーム[193]は、より正確な評価のためにソフトマッチング戦略っていうのを導入してん。これで「アノテーションされてないスパン」が主要なエラータイプやって特定できて、データのアノテーション品質に問題ある可能性を浮き彫りにしたんや。
## 7章 今後の研究の方向性
生成的な情報抽出のためのLLM開発はまだ始まったばっかりで、改善のチャンスがめっちゃようさんあんねん。
**汎用的な情報抽出** これまでの生成的情報抽出の手法とかベンチマークって、特定のドメインとかタスク向けに作られてることが多くて、汎用性に限界があんねん[51]。最近LLMを使った統一的な手法[4]も提案されとるけど、まだ課題があんねん(例えば、入力が長すぎる問題とか、構造化された出力がズレる問題とかな)。やから、色んなドメインやタスクに柔軟に対応できる汎用的な情報抽出フレームワークを開発するんは、ほんまに有望な研究方向やで(例えば、タスク特化型モデルの知見を取り入れて、汎用モデルの構築に活かすとかな)。
**低リソース環境での情報抽出** LLMを使った生成的情報抽出システムは、リソースが限られた状況ではまだ苦戦してんねん[195]。LLMのインコンテキスト学習(文脈から学ぶやつ)について、特に例の選び方を改善するところでもっと探求が必要やな。今後の研究では、頑健なクロスドメイン学習技術の開発を優先すべきやで[5]。例えば、ドメイン適応とかマルチタスク学習とかで、リソース豊富なドメインから知識を活用するんや。あと、LLMを使った効率的なデータアノテーション戦略も探求すべきやな。
**情報抽出のためのプロンプト設計** 効果的な指示を設計するんは、LLMの性能にめっちゃ大きな影響あると考えられてんねん[224, 238]。プロンプト設計の一つの側面は、LLMの事前学習段階(例えばコード生成とか)とうまく合致する入出力ペアを作ることやねん[6]。もう一つの側面は、モデルの理解と推論を良くするためにプロンプトを最適化することや(例えばChain-of-Thought、思考の連鎖ってやつ)[96]。これはLLMに論理的な推論とか説明可能な生成をさせるように促すんや。さらに、研究者たちは対話型のプロンプト設計も探求できるで(マルチターンのQ&Aとか)[98]。これやったらLLMが抽出結果を自動的に繰り返し改善したり、フィードバックを提供したりできるようになんねん。
---
## Page 19
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p019.png)
### 和訳
Open IE(オープンIE)の話やけどな、これがまたむっちゃ難しいねん。なんでかっていうと、普通のIEやったら「こっから選んでな」って候補ラベルが用意されてるんやけど、Open IEはそれがないねん。モデルが自分でタスクを理解せなあかんわけや。ほんで、LLM(大規模言語モデル)はめっちゃ知識持ってるし理解力もあるから、一部のOpen IEタスクではかなりええ感じやねん[64]。せやけどな、もっと難しいタスクになるとまだまだアカン結果も出てるんよ[28]。研究者の皆さん、もうちょい頑張ってな、って感じやな。
## 8 ベンチマークとバックボーン
### 8.1 代表的なデータセット
**表6 代表的なIEデータセットのまとめ**
| データセット | 概要 |
|------------|------|
| CoNLL03 [239] | 対象:NER(固有表現認識);ロイターの英語ニュース記事1,393本;ドイツ語ニュース記事909本;4種類のエンティティタイプにアノテーション付き |
| CoNLL04 [240] | 対象:RE(関係抽出);ニュース文からのエンティティ-関係トリプル;4種類のエンティティタイプ;5種類の関係タイプ |
| ACE05 [241] | 対象:NER、RE、EE(イベント抽出);いろんなテキストタイプとジャンル;7種類のエンティティタイプ;7種類の関係タイプ;33種類のイベントタイプと22種類の引数ロール |
このセクションではな、NER、RE、EEそれぞれの代表的なデータセットを紹介するで。表6に各データセットの簡単なまとめを載せてるから、これ見たらタスクのことがもっとわかりやすくなると思うわ。
**CoNLL03**
CoNLL03 [239]はNERの代表的なデータセットやねん。英語のニュース記事1,393本とドイツ語のニュース記事909本が入ってるで。英語の部分はロイターが作った共有タスクデータセットから取ってきてるんや。このデータセットには4種類のエンティティタイプがアノテーションされてて、PER(人物)、LOC(場所)、ORG(組織)、MISC(その他全部のエンティティ)があるねん。
**CoNLL04**
CoNLL04 [240]はRE(関係抽出)タスクでめっちゃ有名なベンチマークデータセットやで。ニュース記事から抜き出した文で構成されてて、各文には最低1つのエンティティ-関係トリプルが含まれてるんや。エンティティは4種類(PER、ORG、LOC、OTH)、関係は5種類(Kill、Work For、Live In、OrgBased In、Located In)あるねん。
**ACE05**
Automatic Content Extraction 05 [241]は、IEタスクでめっちゃ広く認知されて使われてるデータセットやねん。自動システムがいろんなテキストソース(ニュース記事、インタビュー、レポートとか)から構造化された情報をうまく抽出できるかどうかを評価するんに使える貴重なリソースなんや。しかもこのデータセット、政治、経済、スポーツとか、いろんなジャンルをカバーしてるねん。具体的にACE05のEE(イベント抽出)タスクについて言うと、599個のニュース文書が入ってて、33種類のイベントタイプと22種類の引数ロールが含まれてるで。
### 8.2 ベンチマーク
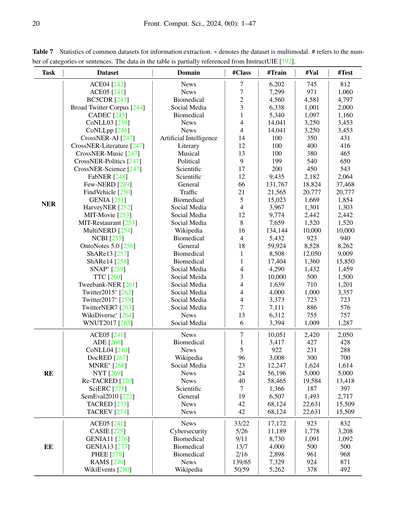
表7に載せてるけどな、いろんなドメインとタスクをカバーする包括的なベンチマークコレクションをまとめたで。研究者の皆さんが必要に応じて調べたり参照したりできる貴重なリソースになると思うわ。あと、各データセットのダウンロードリンクもオープンソースリポジトリ(LLM4IE repository)にまとめてあるから、そっちも見てみてな。
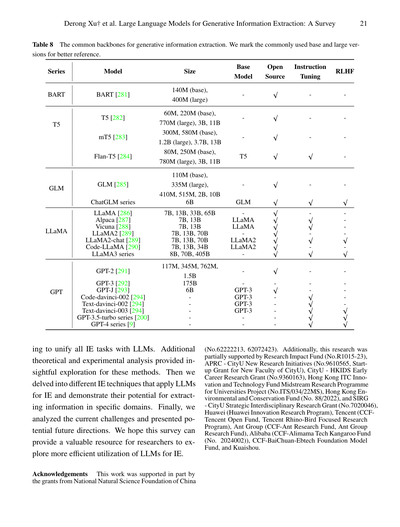
### 8.3 バックボーン
生成的情報抽出の分野でよう使われるバックボーンをざっくり紹介するで。表8に載せてるから見てみてな。
## 9 結論
このサーベイではな、まずIEのサブタスクを紹介して、それから汎用的なフレームワークについて議論したで...
---
## Page 20
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p020.png)
### 和訳
# よく使われるデータセットの統計情報やで〜情報抽出用のやつな
**表7** 情報抽出でよく使われるデータセットの統計やで。※印がついてるのはマルチモーダル(画像とかテキストとか複数の種類のデータが入ってるやつ)やねん。#ってのはカテゴリーの数とか文の数を表してるで。このテーブルのデータは一部InstructUIE[192]から引っ張ってきてるわ。
---
めっちゃざっくり説明すると、この表は3つの大きなタスクに分かれてんねん:
## NER(固有表現認識)
人名とか地名とか組織名とか、そういう「特定の名前」を見つけ出すタスクやな
ニュース系、医療系、SNS系、科学系とかいろんなドメイン(分野)のデータセットがあんねん。例えばCoNLL03とかACE05はニュース記事から作られてて、BC5CDRとかGENIAは医療・バイオ系、Twitterなんちゃらってやつはソーシャルメディアからのデータやで。
クラス数(#Class)ってのは「何種類の固有表現を見分けるか」ってことで、少ないやつは1〜4種類、多いのはFew-NERDみたいに66種類もあったりするねん。
トレーニングデータ(#Train)の量もピンキリで、100件くらいのちっちゃいやつから、Few-NERDの13万件超えのデカいやつまであるわ。
## RE(関係抽出)
「AさんとBさんはどういう関係?」みたいな、エンティティ同士の関係性を見つけるタスクやねん
NYTとかTACREDは6〜7万件もあってめっちゃデカいけど、ADEとかCoNLL04は数百〜数千件くらいでコンパクトやな。関係の種類も1種類から96種類(DocRED)まで様々やで。
## EE(イベント抽出)
「いつ、どこで、誰が、何をした」みたいなイベント情報を抜き出すタスクや
これが一番複雑でな、クラス数のとこに「33/22」みたいにスラッシュで区切られてるのは、イベントタイプの数とイベントの引数(役割)の数を別々に示してるねん。RAMSなんか139種類のイベントタイプに65種類の引数があるとか、めっちゃ細かく分類されとるわ。
---
ほんまにいろんなドメインのデータがあるから、自分のやりたいタスクに合ったやつを選べるようになってるってわけや!
---
## Page 21
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p021.png)
### 和訳
表8 生成系の情報抽出で使われる定番のバックボーン(基盤モデル)一覧やで。参考にしやすいように、よう使われるbaseサイズとlargeサイズにはマークつけといたで。
| シリーズ | モデル | サイズ | ベースモデル | オープンソース | 命令チューニング | RLHF |
|---------|--------|--------|-------------|---------------|-----------------|------|
| BART | BART [281] | 140M (base), 400M (large) | ー | ✓ | ー | ー |
| T5 | T5 [282] | 60M, 220M (base), 770M (large), 3B, 11B | ー | ✓ | ー | ー |
| | mT5 [283] | 300M, 580M (base), 1.2B (large), 3.7B, 13B | T5 | ✓ | ー | ー |
| | Flan-T5 [284] | 80M, 250M (base), 780M (large), 3B, 11B | T5 | ✓ | ✓ | ー |
| GLM | GLM [285] | 110M (base), 335M (large), 410M, 515M, 2B, 10B | ー | ✓ | ー | ー |
| | ChatGLMシリーズ | 6B | GLM | ✓ | ✓ | ✓ |
| LLaMA | LLaMA [286] | 7B, 13B, 33B, 65B | ー | ✓ | ー | ー |
| | Alpaca [287] | 7B, 13B | LLaMA | ✓ | ✓ | ー |
| | Vicuna [288] | 7B, 13B | LLaMA | ✓ | ✓ | ー |
| | LLaMA2 [289] | 7B, 13B, 70B | ー | ✓ | ー | ー |
| | LLaMA2-chat [289] | 7B, 13B, 70B | LLaMA2 | ✓ | ✓ | ✓ |
| | Code-LLaMA [290] | 7B, 13B, 34B | LLaMA2 | ✓ | ー | ー |
| | LLaMA3シリーズ | 8B, 70B, 405B | ー | ✓ | ✓ | ✓ |
| GPT | GPT-2 [291] | 117M, 345M, 762M, 1.5B | ー | ✓ | ー | ー |
| | GPT-3 [292] | 175B | ー | ー | ー | ー |
| | GPT-J [293] | 6B | ー | ✓ | ー | ー |
| | Code-davinci-002 [294] | ー | GPT-3 | ー | ー | ー |
| | Text-davinci-002 [294] | ー | GPT-3 | ー | ✓ | ー |
| | Text-davinci-003 [294] | ー | GPT-3 | ー | ✓ | ✓ |
| | GPT-3.5-turboシリーズ [200] | ー | GPT-3 | ー | ✓ | ✓ |
| | GPT-4シリーズ [9] | ー | ー | ー | ✓ | ✓ |
---
ほんで、ここまでワシらは大規模言語モデル(LLM)使って全部の情報抽出タスクを統一的にやろうとする研究について見てきたわけや。理論面でも実験面でもめっちゃ深い分析があって、これらの手法についてええ洞察が得られたで。そっからさらに、LLMを情報抽出に応用する色んなテクニックに踏み込んで、特定の分野で情報を引っ張り出すポテンシャルを見せてもらったわ。最後に、今ある課題を整理して、これからの将来の方向性を示したで。このサーベイ論文が、研究者のみんなにとってLLMを情報抽出にもっと効率よく使うための貴重な参考資料になったらええなと思っとるで。
## 謝辞
この研究は中国国家自然科学基金(No.62222213, 62072423)から一部支援受けとるで。あと、Research Impact Fund(No.R1015-23)、APRC - CityU New Research Initiatives(No.9610565、CityU新任教員スタートアップ助成金)、CityU - HKIDS Early Career Research Grant(No.9360163)、香港ITC Innovation and Technology Fund Midstream Research Programme for Universities Project(No.ITS/034/22MS)、香港環境保全基金(No. 88/2022)、SIRG - CityU Strategic Interdisciplinary Research Grant(No.7020046)からも支援もらっとるんや。ほんで、Huawei(Huawei Innovation Research Program)、Tencent(CCF-Tencent Open Fund、Tencent Rhino-Bird Focused Research Program)、Ant Group(CCF-Ant Research Fund、Ant Group Research Fund)、Alibaba(CCF-Alimama Tech Kangaroo Fund(No. 2024002))、CCF-BaiChuan-Ebtech Foundation Model Fund、それからKuaishouからも支援してもろとるで。ほんまに感謝やな!
---
## Page 22
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p022.png)
### 和訳
[翻訳エラー: 実行エラー: [Errno 2] No such file or directory: 'claude']
---
## Page 23
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p023.png)
### 和訳
[14] Lyu Yら。CRUD-RAG: 中国語のための包括的な検索拡張生成ベンチマーク。arXivプレプリント、2024年
これな、大規模言語モデル(LLM)の「検索して答え生成する」っていう仕組み、いわゆるRAGってやつの性能を測るための中国語ベンチマークやねん。
[15] Lyu Yら。Retrieve-Plan-Generation: 知識集約型LLM生成のための反復的な計画・回答フレームワーク。arXivプレプリント、2024年
これはな、情報いっぱい必要な質問に答えるとき、「検索して→計画立てて→生成する」っていうサイクルを繰り返すことで、ええ回答出そうってアプローチやで。
[16] Jia Pら。MILL: ゼロショットクエリ拡張のための大規模言語モデルを使った相互検証。NAACL-HLT 2024、2498-2518頁
ゼロショットっていうのは事前に例を見せへんでやるってことな。検索クエリを広げるときに、複数のLLMで互いにチェックさせて精度上げようって話やねん。
[17] Wang Mら。大規模マルチモーダルモデルの圧縮:反復的な効率的プルーニングと蒸留による手法。ACM Web Conference 2024、235-244頁
でっかいマルチモーダル(画像とかテキストとか複数扱える)モデルをな、「枝刈り」と「蒸留」っていう技術で小さくして軽くしようって研究やで。
[18] Fu Zら。大規模言語モデルによるマルチドメインCTR予測の統一フレームワーク。arXivプレプリント、2023年
CTRって「クリック率」のことな。いろんな分野のクリック率予測を、LLM使って一つのフレームワークでまとめてやろうって試みやねん。
[19] Jia Pら。G3: 大規模マルチモダリティモデルを使った世界規模の位置特定のための効果的で適応的なフレームワーク。arXivプレプリント、2024年
写真とか見て「これどこで撮ったん?」って世界中のどこかを当てるタスクな。マルチモーダルモデル使って、めっちゃ精度よく場所特定しようって研究やで。
[20] Zhang Cら。NoteLLM: ノート推薦のための検索可能な大規模言語モデル。ACM Web Conference 2024、170-179頁
メモとかノートをおすすめする(レコメンドする)ためのLLMやな。欲しい情報にたどり着きやすくする仕組みやねん。
[21] Wang Xら。In-context Former: 大規模言語モデルのためのコンテキスト高速圧縮。arXivプレプリント、2024年
LLMに渡す文脈(コンテキスト)をめっちゃ速く圧縮して、効率よく処理できるようにしようって話やで。
[22] Zhu Jら。FastMem: プロンプトの高速記憶化による大規模言語モデルの文脈認識向上。arXivプレプリント、2024年
プロンプト(指示文)を素早く覚えさせることで、LLMが文脈をもっとちゃんと理解できるようにしようって研究やねん。
[23] Wang Lら。大規模言語モデルベースの自律エージェントに関するサーベイ。Frontiers of Computer Science、2024年、18(6): 186345
LLMを頭脳にした「自分で考えて動くエージェント」についての総まとめ論文やな。めっちゃ注目されてる分野やで。
[24] Guan Zら。グラフ認識学習による言語モデル駆動レコメンデーションの協調的意味の強化。arXivプレプリント、2024年
おすすめシステムで、グラフ(つながりの構造)を理解させることで、言語モデルベースのレコメンドをもっと賢くしようって話やねん。
[25] Huang Jら。QDMR ベースの計画・解決プロンプティング:複雑な推論タスク向け。LREC-COLING 2024、13395-13406頁
QDMRっていうのは質問を細かく分解する手法な。複雑な問題を「計画立てて→解く」っていう流れでLLMに解かせようってアプローチやで。
[26] Fu Cら。Video-MME: マルチモーダルモデルの初の包括的動画評価ベンチマーク(続く)
動画を理解できるマルチモーダルモデルの性能を測る、史上初の本格的なベンチマークやねん。これほんまに画期的やで。
---
## Page 24
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p024.png)
### 和訳
24ページ目やで〜
Front. Comput. Sci., 2024, 0(0): 1–47
動画分析におけるマルチモーダルLLM(大規模言語モデル)についての論文やな。arXiv:2405.21075、2024年のやつ。
[27] Li Xさんらの研究で、「Agent4ranking」っちゅうのがあんねん。これ何かっていうと、複数のAIエージェント使って検索クエリ(検索ワードみたいなもんやな)を書き換えて、意味的にしっかりしたランキングを作るっちゅう話や。めっちゃパーソナライズされた検索ができるようになるってことやな。arXiv:2312.15450、2023年の論文やで。
[28] Qi Jさんらは「知識の不変性を守る」っちゅうテーマで研究してんねん。オープン情報抽出(文章から情報を自動で引っ張り出す技術やな)の頑健性評価を見直そうって話や。要するに、ちょっと文章変えられても正しく情報取れるかどうかをちゃんと評価しようやってことやねん。2023年の自然言語処理の学会(EMNLP)で発表されとって、5876〜5890ページに載っとるで。
[29] Chen Wさんらの「HEProto」っちゅうのは、めっちゃ賢いプロトタイプネットワークやねん。マルチタスク学習(複数のことを同時に学ぶやつ)を使って、データが少ない状況でも固有表現認識(人名とか地名とか見つけるやつ)ができるようにしたんや。階層構造になっててパワーアップしとるんやな。2023年のCIKMっていう情報・知識管理の国際会議で発表されて、296〜305ページに載っとるで。
[30] Lou Jさんらは「ユニバーサル情報抽出」を「統一的な意味マッチング」として捉える研究をしてんねん。どういうことかっていうと、いろんな種類の情報抽出タスクを一つの枠組みでまとめてやっちゃおうってことや。2023年のAAAI(めっちゃ有名なAIの学会やで)で発表されて、13318〜13326ページやな。
[31] Josifoski Mさんらの「GenIE」は生成型の情報抽出システムやねん。従来のやり方とちゃうて、テキストを生成する形で情報を抽出するっちゅう新しいアプローチや。2022年のNAACL-HLT(北米の計算言語学会)で発表されて、4626〜4643ページに載っとるで。
[32] Sainz Oさんらの「GoLLIE」はめっちゃおもろい研究やねん。なんでかっていうと、アノテーションガイドライン(データにラベル付けするときのルールみたいなもん)をうまく使うことで、学習データなしでも情報抽出できるようになるって発見したんや!2024年のICLR(機械学習のトップ会議やで)で発表されとるな。
[33] Paolini Gさんらは「構造化予測」を「拡張された自然言語間の翻訳」として捉える研究をしてんねん。複雑な構造を持った出力を、言語の翻訳みたいに扱うっちゅう発想やな。2021年のICLR(9回目)で発表されとるで。
[34] Gan Cさんらの「GIELLM」は日本語に特化した情報抽出用の大規模言語モデルやねん!相互強化効果っちゅうのを活用してるんやって。日本語処理に興味ある人は要チェックやな。arXiv:2311.06838、2023年の論文や。
[35] Fei Hさんらの「LasUIE」は、潜在的で適応的な構造認識型の生成言語モデルを使って情報抽出を統一するっちゅう研究やねん。ちょっと難しいけど、要するにモデルが自動的に文章の構造を理解して、それを活かして情報抽出するってことや。2022年のNeurIPS(これもめっちゃ有名な機械学習の学会)で発表されて、35巻の15460〜15475ページに載っとるで。
[36] Li Pさんらの「CodeIE」はめっちゃおもろい発見してんねん。大規模なコード生成モデル(プログラムを自動で書くAIやな)が、実は少ないデータでの情報抽出もめっちゃ上手いってことがわかったんや!2023年のACL(計算言語学のトップ会議)で発表されて、第1巻の15339〜15353ページに載っとるで。
[37] Yan Hさんらは固有表現認識(NER)のいろんなサブタスクを統一的な生成フレームワークでまとめる研究をしてんねん。これ一個のモデルでいろんなNERタスクに対応できるようになるっちゅう話や。2021年のACL-IJCNLPで発表されて、第1巻の5808〜5822ページに載っとるで。
---
## Page 25
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p025.png)
### 和訳
[翻訳エラー: 実行エラー: [Errno 2] No such file or directory: 'claude']
---
## Page 26
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p026.png)
### 和訳
[52] Feng Y, Pratapa A, Mortensen D R. 効率的で汎用性のある超細粒度エンティティタイピングのためのキャリブレーション済みseq2seqモデル。In: Findings of the Association for Computational Linguistics. 2023, 15550–15560
要はな、これ「超細かいエンティティタイピング」ってやつに取り組んでる研究やねん。エンティティタイピングってのは、テキストの中の単語が「人物」なのか「場所」なのか「組織」なのかを判定する技術やけど、「超細粒度」ってことはもっとめっちゃ細かく分類するってことや。seq2seqモデルをキャリブレーション(調整)することで、効率よくて色んな場面で使える手法を提案してるんやで。
[53] Cui L, Wu Y, Liu J, Yang S, Zhang Y. BARTを使ったテンプレートベースの固有表現認識。In: Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. 2021, 1835–1845
これはな、BARTっていう言語モデルを使って固有表現認識(NER)をやる研究や。テンプレートベースってことは、「〇〇は人物である」みたいな型にはめて予測させるアプローチやねん。従来の方法とはちょっと違う発想でおもろいで。
[54] Zhang S, Shen Y, Tan Z, Wu Y, Lu W. 統合NERタスクにおける生成的抽出のバイアス除去。In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022, 808–818
生成モデルでNERをやると、どうしてもバイアス(偏り)が出てきてまうんやけど、この研究はそのバイアスを取り除く方法を提案してるんや。なんでかっていうと、生成モデルって学習データに引っ張られやすいから、特定のパターンばっかり出力しがちになるねん。それを直そうってことやな。
[55] Wang L, Li R, Yan Y, Yan Y, Wang S, Wu W, Xu W. InstructionNER:少数ショットNERのためのマルチタスク指示ベース生成フレームワーク。arXiv preprint arXiv:2203.03903, 2022
少数ショット(few-shot)ってのは、学習データがめっちゃ少ない状況のことやねん。この研究は「指示」を使って複数のタスクを同時にこなせるフレームワークを作ってるんや。例えば「この文から人物名を抜き出して」みたいな指示を与えると、少ないデータでもNERができるようになるってわけや。
[56] Xia Y, Zhao Y, Wu W, Li S. 系列尤度のキャリブレーションによる生成的固有表現認識のバイアス除去。In: Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2023, 1137–1148
[54]と似た話やけど、こっちは「系列尤度」っていう確率的な値を調整することでバイアスを除去しようとしてるんや。尤度ってのは「どれくらいありそうか」を表す数値やねん。これをキャリブレーション(較正)することで、モデルの出力がより正確になるってことやな。
[57] Cai C, Wang Q, Liang B, Qin B, Yang M, Wong K F, Xu R. 少数ショットマルチモーダル固有表現認識のための文脈内学習。In: Findings of the Association for Computational Linguistics: EMNLP 2023. 2023, 2969–2979
マルチモーダルってのは、テキストだけやなくて画像とかも一緒に扱うってことやねん。で、文脈内学習(in-context learning)っていうのは、例を見せるだけでモデルがタスクを学習するやつや。ほんまに便利な技術で、これを使って画像とテキスト両方からエンティティを認識できるようにしてるんやで。
[58] Hu X, Jiang Y, Liu A, Huang Z, Xie P, Huang F, Wen L, Philip S Y. 様々な固有表現認識タスクのためのエンティティからテキストへのデータ拡張。In: Findings of the Association for Computational Linguistics: ACL 2023. 2023, 9072–9087
データ拡張ってのは、学習データを人工的に増やす技術やねん。この研究では、エンティティ(固有表現)からテキストを生成して、それをデータ拡張に使ってるんや。例えば「トヨタ」っていうエンティティから「トヨタは日本の自動車メーカーです」みたいな文を作って、学習データを増やすってことやな。
[59] Amalvy A, Labatut V, Dufour R. 合成データセットを使った固有表現認識のための文脈ランキング学習。In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023, 10372–10382
合成データセット、つまり人工的に作ったデータを使って、NERに役立つ文脈をランク付けする方法を学習させてるんや。どの文脈が固有表現を認識するのに一番役立つか、それをモデルに教えるってことやな。
[60] Chen X, Li L, Qiao S, Zhang N, Tan C, Jiang Y, Huang F, Chen H. 全ドメイン対応の単一モデル:クロスドメインNERのための協調的ドメインプレフィックスチューニング。In: Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence. 2023, 5030–5038
普通、NERモデルって特定の分野(ドメイン)でしか使えへんことが多いねん。医療用のモデルはニュースには使いにくい、みたいな。でもこの研究は、一つのモデルで色んなドメインに対応できるようにする方法を提案してるんや。「プレフィックスチューニング」っていう技術を使って、ドメインごとの特徴をうまく扱えるようにしてるねん。
[61] Zhang R, Li Y, Ma Y, Zhou M, Zou L. LLMaAA:大規模言語モデルをアクティブアノテーターとして活用する。In: Findings of the Association for Computational Linguistics: EMNLP 2023. 2023, 13088–13103
アノテーションってのは、データにラベルを付ける作業やねん。普通は人間がやるんやけど、めっちゃ大変やし金もかかる。この研究は、大規模言語モデル(LLM)にそのアノテーション作業をやらせようっていうアイデアや。しかも「アクティブ」ってことは、どのデータにラベル付けするかを賢く選ぶってことやな。
[62] Ma Y, Cao Y, Hong Y, Sun A. 大規模言語モデルは少数ショット情報抽出器としては優秀やないけど、難しいサンプルのリランカーとしてはめっちゃ優秀!In: Findings of the Association for Computational Linguistics: EMNLP 2023. 2023, 10572–10601
これ、ほんまにおもろい発見やねん。LLMって万能やと思われがちやけど、実は少数ショットで情報を抽出するのはそんなに得意やないらしい。でもな、難しいサンプルを「リランク」する、つまり順位付けし直すのにはめっちゃ使えるんやて。適材適所ってことやな。
[63] Xie T, Li Q, Zhang Y, Liu Z, Wang H. 大規模言語モデルを用いたゼロショット固有表現認識の自己改善。In: Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers). 2024, 583–593
ゼロショットってのは、学習データが全くない状態でタスクをこなすことやねん。この研究は、LLMが自分で自分を改善しながらNERをやる方法を提案してるんや。最初はそこそこの結果でも、自己改善を繰り返すことでどんどん精度が上がっていくってわけやな。めっちゃ賢いやん。
---
## Page 27
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p027.png)
### 和訳
[64] Zhou Wら。UniversalNER:オープン固有表現認識のための大規模言語モデルからの狙い撃ち蒸留。発表:第12回学習表現に関する国際会議。2024年
これな、めっちゃでかい言語モデルから知識を「蒸留」するっていう技術の話やねん。蒸留ってのは、賢いモデルの知識をコンパクトなモデルに移し替える技術のことやで。「オープン固有表現認識」っていうのは、人名とか地名とか組織名みたいな「固有名詞」を文章から見つけ出す作業のことで、それを色んな分野に対応できるようにしたってことやな。
[65] Zhang Xら。NAGNER:様々なNERタスク向けの統一的な非自己回帰生成フレームワーク。発表:計算言語学会第61回年次総会産業トラック論文集。2023年、676-686頁
「非自己回帰」ってちょっと難しそうやけど、要するに「一個ずつ順番に出力するんやなくて、まとめてドーンと出力する」方式のことやねん。普通の生成モデルは「一文字ずつ」とか「一単語ずつ」出していくんやけど、この方式やと速いんよ。それを固有表現認識(NER)の色んなパターンに使えるように統一したフレームワークを作ったってことやな。
[66] Su J、Yu H。マルチラベル系列生成としての統一的固有表現認識。発表:ニューラルネットワーク国際合同会議。2023年、1-8頁
これは固有表現認識を「複数のラベルを同時に付けられる系列生成」として捉え直そうっていう研究やねん。例えば「田中太郎」っていう単語に「人名」と「日本人名」みたいに複数のタグを付けられるようにしたってことやな。
[67] Ding Yら。生成的固有表現認識における負例の再考。発表:計算言語学会ACL 2024研究発見論文集。2024年、3461-3475頁
「負例」っていうのは、「これは固有表現やないで」っていう例のことやねん。モデルを訓練するときに「これは正解」だけやなくて「これは不正解」も教えるんやけど、その不正解の扱い方をもっかい考え直そうっていう研究や。なんでかっていうと、負例の選び方でモデルの性能がめっちゃ変わるからやねん。
[68] Bogdanov Sら。NuNER:LLMでアノテーションしたデータによる固有表現認識エンコーダの事前学習。arXivプレプリント arXiv:2402.15343、2024年
これはほんまに賢いアイデアやねん。大規模言語モデル(LLM)に大量のデータをラベル付けさせて、そのデータで別のもっとコンパクトなモデル(エンコーダ)を事前学習させるっていう話や。人間がラベル付けするよりめっちゃ速いし安いやろ?
[69] Chen Jら。固有表現認識のための文脈内学習の学習。発表:計算言語学会第61回年次総会論文集(第1巻:長編論文)。2023年、13661-13675頁
「文脈内学習(in-context learning)」っていうのは、モデルに「こういう例があるで、じゃあこれはどうや?」って聞くだけで新しいタスクができるようになる能力のことやねん。この研究はその文脈内学習を「学習する」っていう、ちょっとメタな話やな。つまり、より上手に文脈内学習できるようにモデルを訓練したってことや。
[70] Zhang Zら。LinkNER:不確実性を使ってローカルな固有表現認識モデルを大規模言語モデルに接続する。発表:ACMウェブ会議2024論文集。2024年、4047-4058頁
これめっちゃ実用的な研究やで。ローカルで動く小さいNERモデルと、でっかいLLMを「不確実性」っていう指標で繋ぐ話やねん。小さいモデルが「うーん、これ自信ないわ」ってなったときだけLLMに聞きに行くっていう仕組みや。効率ええやろ?
[71] Tang Xら。小規模言語モデルは中国語エンティティ関係抽出において大規模言語モデルの良いガイドになる。arXivプレプリント arXiv:2402.14373、2024年
中国語の関係抽出タスクで、小さいモデルがでかいモデルの「ガイド役」になれるっていう発見やねん。小さいモデルが道案内して、でかいモデルがそれに従って作業するイメージやな。意外と小さいモデルも役に立つんやで。
[72] Popovič N、Färber M。プローブ分類器を使った埋め込み型固有表現認識。arXivプレプリント arXiv:2403.11747、2024年
「プローブ分類器」っていうのは、モデルの内部表現を調べるための小さい分類器のことやねん。モデルの中間層に「お前、固有表現のこと分かってる?」って聞くみたいな感じで、それを使って固有表現認識をやろうっていう研究や。
[73] Heng Yら。ProgGen:自己反省する大規模言語モデルでステップバイステップに固有表現認識データセットを生成する。発表:計算言語学会ACL 2024研究発見論文集。2024年、15992-16030頁
これめっちゃおもろい研究やねん。LLMに自分で反省させながら、段階的にNER用のデータセットを作らせるっていう話や。「このラベル付け、ほんまに合ってるか?」って自分で確認しながら作業させるんやな。自己反省型AIや!
[74] Mo Yら。C-ICL:情報抽出のための対照的文脈内学習。arXivプレプリント arXiv:2402.11254、2024年
「対照的(Contrastive)」っていうのは、「これとこれは似てる」「これとこれは違う」っていう対比を使って学習する方法やねん。それを文脈内学習と組み合わせて、情報抽出をより賢くやろうっていう研究や。
[75] Keloth V Kら。大規模言語モデルのインストラクションチューニングによるバイオメディカル分野のエンティティ認識の進歩。Bioinformatics誌、2024年、btae163
バイオメディカル、つまり医学・生物学分野の固有表現認識をLLMの「インストラクションチューニング」で改善したっていう研究やねん。インストラクションチューニングっていうのは、「こういう指示に従ってこうしてな」っていう形式でモデルを訓練する方法のことや。タンパク質名とか遺伝子名とか、専門用語を見つけるのがめっちゃ上手くなったらしいで。
[76] Kim Sら。VerifiNER:大規模言語モデルによる知識に基づく推論を使った検証強化型NER。発表:計算言語学会第62回年次総会論文集
これは固有表現認識の結果を「検証」するっていうアイデアやねん。ただラベル付けするだけやなくて、「ほんまにこれ合ってるか?」って知識ベースを使って確認するステップを入れることで、精度を上げようっていう研究や。二重チェックは大事やな!
---
## Page 28
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p028.png)
### 和訳
# 28
Front. Comput. Sci., 2024, 0(0): 1–47
Computational Linguistics (Volume 1: Long Papers). 2024, 2441–2461
[77] Li Y, Ramprasad R, Zhang C. シンプルやけどめっちゃ効くやつ:情報抽出のための構造化言語モデル出力を改善する手法やねん。arXiv プレプリント arXiv:2402.13364, 2024
[78] Oliveira V, Nogueira G, Faleiros T, Marcacini R. プロンプトベースの言語モデルと弱教師あり学習を組み合わせて、法律文書の固有表現認識にラベル付けするっちゅう話や。Artificial Intelligence and Law, 2024, 1–21
[79] Lu J, Yang Z, Wang Y, Liu X, Huang C. PadeLLM-NER:大規模言語モデルで固有表現認識を並列デコードするやつやねん。arXiv プレプリント arXiv:2402.04838, 2024
[80] Bölücü N, Rybinski M, Wan S. 科学論文からエンティティ抽出するときの文脈内学習で、サンプル選択がどんだけ影響するかって研究や。In: Findings of the Association for Computational Linguistics: EMNLP 2023. 2023, 5090–5107
[81] Liu J, Wang J, Huang H, Zhang R, Yang M, Zhao T. 文脈内学習使ってLLMベースの健康情報抽出をパワーアップさせるで。In: China Health Information Processing Conference. 2023, 49–59
[82] Wu C, Ke W, Wang P, Luo Z, Li G, Chen W. ConsistNER:オントロジーと文脈の一貫性を活かして、LLM向けのええ感じのNERデモンストレーション作るやつや。In: Thirty-Eighth AAAI Conference on Artificial Intelligence. 2024, 19234–19242
[83] Naguib M, Tannier X, Névéol A. 3言語での少数ショット臨床エンティティ認識:マスク言語モデルがLLMプロンプティングより強いんやで。arXiv プレプリント arXiv:2402.12801, 2024
[84] Zaratiana U, Tomeh N, Holat P, Charnois T. GLiNER:双方向トランスフォーマー使った汎用固有表現認識モデルやねん。arXiv プレプリント arXiv:2311.08526, 2023
[85] Munnangi M, Feldman S, Wallace BC, Amir S, Hope T, Naik A. バイオメディカルNERのためにLLMの定義をその場で拡張するっちゅうやつや。In: Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2024, 3833–3854
[86] Zhang M, Wang B, Fei H, Zhang M. 入れ子になった固有表現認識のための文脈内学習やで。arXiv プレプリント arXiv:2402.01182, 2024
[87] Yan F, Yu P, Chen X. LTNER:文脈化されたエンティティマーキングで大規模言語モデルにタグ付けさせる固有表現認識やねん。arXiv プレプリント arXiv:2404.05624, 2024
[88] Jiang G, Luo Z, Shi Y, Wang D, Liang J, Yang D. ToNER:生成言語モデル使ったタイプ指向の固有表現認識やで。In: Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation. 2024, 16251–16262
[89] Nunes RO, Spritzer AS, Freitas CMDS, Balreira DG. セサミストリートの外へ:研究やで
---
## Page 29
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p029.png)
### 和訳
ポルトガル語の法律文書に出てくる固有表現認識を、文脈内学習のプロンプトで改善したって話やねん。
[90] Hou W, Zhao W, Liu X, Guo W. 知識をめっちゃ詰め込んだ低リソース言語向けの固有表現認識。ACM Transactions on Asian and Low-Resource Language Information Processing, 2024, 23(5): 1–15
これ何かっていうと、あんまりデータがない言語でも固有表現をうまく見つけられるように、外部の知識をプロンプトに入れ込んでるねん。
[91] Li M, Zhou H, Yang H, Zhang R. RT: 医療分野の固有表現認識を少ないデータでやるための、検索と思考の連鎖を組み合わせたフレームワーク。Journal of the American Medical Informatics Association, 2024, ocae095
医療用語ってめっちゃ専門的やろ?でも関連する情報を検索してきて、それを段階的に考える仕組みを作ったら、少ないデータでもうまくいくようになったんやって。
[92] Jiang G, Ding Z, Shi Y, Yang D. P-ICL: 大規模言語モデルを使った固有表現認識のための「ポイント」文脈内学習。arXiv preprint arXiv:2405.04960, 2024
ポイントっていうのは、テキストの中で「ここが大事やで」って場所を指し示す方法のことやな。
[93] Biana J, Zhai W, Huang X, Zheng J, Zhu S. VANER: 大規模言語モデルを活用した、バイオ医学分野の固有表現認識を柔軟にこなすシステム。arXiv preprint arXiv:2404.17835, 2024
バイオ系って遺伝子名とかタンパク質名とかめっちゃややこしいやん?それを汎用的に認識できるようにしたんやで。
[94] Li J, Li H, Sun D, Wang J, Zhang W, Wang Z, Pan G. LLMを橋渡しに使う: マルチモーダルな固有表現認識の新しいアプローチ。In: Findings of the Association for Computational Linguistics ACL 2024. 2024, 1302–1318
画像とテキストの両方を見て固有表現を見つけるとき、LLMがその間を繋ぐ役割を果たすっていう発想やねん。
[95] Ye J, Xu N, Wang Y, Zhou J, Zhang Q, Gui T, Huang X. LLM-DA: 少ないデータでの固有表現認識のために、大規模言語モデルでデータを水増しする方法。arXiv preprint arXiv:2402.14568, 2024
データが少ないなら作ったらええやん!って発想で、LLMに似たようなデータを生成させてるんやな。
[96] Li G, Wang P, Ke W. 大規模言語モデルをゼロショット関係抽出器として使うことを再検討。In: Findings of the Association for Computational Linguistics: EMNLP 2023. 2023, 6877–6892
ゼロショットって何かというと、例を全く見せへんでもタスクをこなすことやねん。関係抽出っていうのは「AとBの関係は何?」を見つける作業のことやで。
[97] Pang C, Cao Y, Ding Q, Luo P. 文脈内の情報抽出のためのガイドライン学習。In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023, 15372–15389
「こういうルールで抽出してな」っていうガイドラインを、モデルが自分で学習するっていう賢い方法やで。
[98] Zhang K, Gutierrez B J, Su Y. 指示タスクを揃えたら、大規模言語モデルがゼロショット関係抽出器になるで。In: Findings of the Association for Computational Linguistics: ACL 2023. 2023, 794–812
指示の出し方を工夫するだけで、追加学習なしでも関係抽出ができるようになるっていう話やな。
[99] Wan Z, Cheng F, Mao Z, Liu Q, Song H, Li J, Kurohashi S. GPT-RE: 大規模言語モデルを使った文脈内学習による関係抽出。In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023, 3534–3547
GPT系のモデルに例をいくつか見せて、関係抽出させるっていうシンプルやけど効果的な方法やで。
[100] Ma M D, Wang X, Kung P N, Brantingham P J, Peng N, Wang W. STAR: 大規模言語モデルで「構造からテキスト」へのデータ生成をして、低リソースなイベント抽出を強化する方法。In: Proceedings of the AAAI Conference on Artificial Intelligence. 2024, 18751–18759
イベント抽出っていうのは「いつ、どこで、誰が、何をした」を見つけることやねん。データが少ないときに、LLMに構造化されたデータからテキストを生成させて、それを学習に使うっていうトリックやな。
[101] Wang Q, Zhou K, Qiao Q, Li Y, Li Q. 多様な文ペアを増やして教師なし関係抽出を改善する方法。In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023, 12136–12147
教師なしってことは正解データなしでやるってことやねん。いろんなパターンの文を増やしたら、関係のパターンも見つけやすくなるって話やで。
---
## Page 30
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p030.png)
### 和訳
30
Front. Comput. Sci., 2024, 0(0): 1–47
[102] Li Bらの研究(2023)は「ラベル拡張を使った系列生成で関係抽出やってみた」っていう話やねん。第37回AAAI人工知能会議で発表されとって、13043〜13050ページに載ってるで。要するに、関係を抽出するときにラベルの情報をうまいこと増やして、文章を生成する形でやってみましたって研究やな。
[103] Guoらの研究(2022)は「DORE」っていうシステムの話で、文書の中の順序を考慮した関係抽出を生成フレームワークでやるっていうもんやねん。計算言語学会のEMNLP 2022のFindingsに載ってて、3463〜3474ページや。文書の流れを意識しながら関係を抜き出すってところがミソやな。
[104] Maらの研究(2023)はめっちゃおもろくて、「明示的な証拠推論を使ったChain of Thought」で少数ショット関係抽出やってるねん。EMNLP 2023のFindingsの2334〜2352ページや。なんでかっていうと、普通のChain of Thought(段階的に考えていく手法やな)に加えて、「なんでそう判断したか」っていう証拠をちゃんと示しながら推論することで、少ないデータでも関係抽出がうまくいくようになるんやって。
[105] Zhouらの研究(2024)は「大規模言語モデルでゼロショット関係抽出するときに、本質をつかむのが大事やで」っていう内容やねん。arXivのプレプリント(arXiv:2402.11142)で公開されとる。ゼロショットっていうのは、その関係の例を一切見せずにいきなり抽出させることやで。大規模言語モデルをうまく調整して、それを可能にしようっていう研究や。
[106] Qiらの研究(2023)は、大規模言語モデルと一貫した推論環境を使って「オープン情報抽出」をマスターしようっていう話やねん。arXiv:2310.10590で公開されとるで。オープン情報抽出っていうのは、あらかじめ決まった関係タイプじゃなくて、どんな関係でも抜き出せるようにする技術のことや。
[107] Liらの研究(2024)は「メタ・イン・コンテキスト学習」っていう手法で、大規模言語モデルをゼロショットや少数ショットの関係抽出でもっと賢くしようっていうもんやねん。arXiv:2404.17807で見れるで。イン・コンテキスト学習(プロンプトに例を入れて学習させる方法やな)をさらにメタレベルで工夫してるってことや。
[108] Ottoらの研究(2024)は、ソフトウェア関連の情報抽出を生成言語モデルでパワーアップさせる話で、単一選択の質問応答形式を使ってるねん。arXiv:2404.05587で公開中や。ソフトウェアの情報を抜き出すのに、「これはAですか?Bですか?」みたいな形式にしてモデルに答えさせる工夫をしてるんやな。
[109] ShiとLuoの研究(2024)は「CRE-LLM」っていう、中国語に特化した関係抽出フレームワークの話やねん。大規模言語モデルをファインチューニング(特定のタスク向けに追加学習すること)して作ってるで。arXiv:2404.18085で見れるわ。
[110] Liらの研究(2024)は「Recall, Retrieve and Reason」(思い出して、取ってきて、推論する)っていうアプローチで、イン・コンテキスト関係抽出をもっとええ感じにしようっていうもんやねん。第33回IJCAI(国際人工知能合同会議)で発表されとるで。
[111] 同じくLiらの別の研究(2024)は、対話文からの関係抽出を大規模言語モデルでやったときの実証分析やねん。これも第33回IJCAIで発表されとる。会話のやりとりから関係を抜き出すのは、普通の文章とはまた違った難しさがあるんやけど、それを詳しく調べた研究や。
[112] EfeogluとPaschkeの研究(2024)は「RAGベースの関係抽出」やねん。arXiv:2404.13397で公開されとるで。RAG(Retrieval-Augmented Generation)っていうのは、関連する情報を検索で取ってきてから生成するっていう手法で、それを関係抽出に応用したってわけや。
[113] Liらの研究(2024)は、大規模言語モデルを使った関係抽出の事例研究で、なんと鍼灸のツボの位置情報を対象にしてるねん!arXiv:2404.05415で見れるで。医療分野、特に東洋医学の知識抽出に応用した珍しい研究やな。
[114] FanとHeの研究(2023)は、事前学習済み言語モデルを使ってオープン情報抽出を効率的に学習させる方法の話やねん。EMNLP 2023のFindingsの13056〜13063ページに載ってるで。データを効率よく使って学習させるところがポイントや。
[115] Kwakらの研究(2023)は、法律の遺言書からの情報抽出で「GPT-4はどんだけできるん?」っていう検証やねん。EMNLP 2023のFindingsの4336〜4353ページや。法律文書っていう専門的な分野で、GPT-4の実力を試してみたっていうほんまに実用的な研究やで。
---
## Page 31
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p031.png)
### 和訳
[116] Sun Q, Huang K, Yang X, Tong R, Zhang K, Poria S. 「LLMでのゼロショット文書レベル関係トリプレット抽出における、一貫性ガイド付き知識検索とノイズ除去」 In: Proceedings of the ACM on Web Conference 2024. 2024, 4407–4416
これな、めっちゃ面白い研究やねん。LLM(大規模言語モデル)使って、文書から「誰が誰とどういう関係なん?」っていうのを抜き出すタスクがあるんやけど、普通は学習データなしでやる(ゼロショット)と精度がガタガタになるやん。そこでこの研究は、知識を取ってくる時に「一貫性あるかどうか」をちゃんとチェックして、ノイズ(邪魔な情報)を取り除く仕組みを作ったんや。
[117] Ozyurt Y, Feuerriegel S, Zhang C. 「事前学習済み言語モデルによるインコンテキスト少数ショット関係抽出」 arXiv preprint arXiv:2310.11085, 2023
インコンテキスト学習って知ってる?例をちょっと見せるだけで、モデルがタスクのやり方を理解してくれるやつやねん。この研究は、その仕組みを使って、少ない例だけで関係抽出(AとBはこういう関係やで、って見つけるやつ)をやろうとしてるんや。
[118] Xue L, Zhang D, Dong Y, Tang J. 「AutoRE: 大規模言語モデルによる文書レベル関係抽出」 In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations). 2024, 211–220
AutoREってシステムの話やな。文書全体から関係を自動で抜き出すんやけど、LLMをうまいこと使ってるんや。文書レベルっていうのがポイントで、文単位やなくて長い文書全体を見て関係を見つけるから、もっと複雑な関係もわかるようになるんやで。
[119] Liu Y, Peng X, Du T, Yin J, Liu W, Zhang X. 「ERA-CoT: エンティティ関係分析による思考の連鎖の改善」 In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024, 8780–8794
Chain-of-Thought(思考の連鎖)って、AIに「ステップバイステップで考えてや」って言うと精度上がるテクニックやねんけど、この研究はそれをさらに進化させてるんや。エンティティ(人とか物とか)の関係を分析することで、推論の質をめっちゃ上げてるんやで。
[120] Li G, Ke W, Wang P, Xu Z, Ji K, Liu J, Shang Z, Luo Q. 「関係トリプレット抽出のための表形式プロンプトによる指示的インコンテキスト学習の解放」 arXiv preprint arXiv:2402.13741, 2024
これめっちゃ賢いアイデアやねん。プロンプト(AIへの指示)を表形式にしてあげることで、インコンテキスト学習の力をフルに引き出そうとしてるんや。関係トリプレットって「主語-関係-目的語」みたいな3つ組のことやねんけど、それを抽出する時に表形式が効くんやって。
[121] Ding Z, Huang W, Liang J, Xiao Y, Yang D. 「大規模言語モデルの再現率向上: 関係トリプレット抽出のためのモデル協調アプローチ」 In: Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation. 2024, 8890–8901
再現率(Recall)ってな、「見つけるべきもんをどれだけ見つけられたか」っていう指標やねん。LLMって精度は高いけど、見逃しも多いのが問題やったんや。この研究は複数のモデルを協力させることで、見逃しを減らそうとしてるんやで。チームワークは大事やな!
[122] Ni X, Li P, Li H. 「指示チューニング言語モデルによる統一テキスト構造化」 arXiv preprint arXiv:2303.14956, 2023
テキストを構造化するって、バラバラの文章を整理整頓して使いやすくすることやねん。この研究は、指示チューニング(特定の指示に従うように学習させること)したモデルを使って、いろんな種類のテキスト構造化を統一的にやろうとしてるんや。
[123] Zaratiana U, Tomeh N, Holat P, Charnois T. 「エンティティと関係の同時抽出のための自己回帰型テキストからグラフへのフレームワーク」 In: Thirty-Eighth AAAI Conference on Artificial Intelligence. 2024, 19477–19487
自己回帰型っていうのは、前に出した答えを使って次の答えを出す方式やねん。テキストをグラフ(ノードとエッジでできた図)に変換するんやけど、エンティティ(ノード)と関係(エッジ)を一緒に抽出できるのがポイントや。めっちゃ効率ええやん。
[124] Peng L, Wang Z, Yao F, Wang Z, Shang J. 「MetaIE: あらゆる情報抽出タスクのためのLLMからのメタモデル蒸留」 arXiv preprint arXiv:2404.00457, 2024
蒸留(Distillation)ってな、でっかいモデルの知識を小さいモデルに移す技術やねん。この研究は、LLMからメタモデル(いろんなタスクに対応できる汎用モデル)を蒸留して、情報抽出のあらゆるタスクに使えるようにしようとしてるんや。一個作ったら全部いけるって最高やん。
[125] Atuhurra J, Dujohn S C, Kamigaito H, Shindo H, Watanabe T. 「絶滅危惧種のための固有表現認識モデルの大規模言語モデルからの蒸留」 arXiv preprint arXiv:2403.15430, 2024
これめっちゃええ研究やな。絶滅危惧種に関するテキストから固有表現(種の名前とか)を見つけるモデルを、LLMから蒸留して作ってるんや。環境保護にAI使うって素敵やん。
[126] Tang X, Su Q, Wang J, Deng Z. 「ChiSIEC: 中国古代史のための情報抽出コーパス」 In: Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation. 2024, 3192–3202
古代中国の歴史文書から情報を抽出するためのデータセットを作ったって話やな。コーパスっていうのは、研究用に集めた大量のテキストデータのことや。歴史研究にもAI使えるようになってきてるんやで。
[127] Veyseh A P B, Lai V, Dernoncourt F, Nguyen T H. 「イベント検出のためのGPT-2パワーの解放」 In: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021, 6271–6282
GPT-2って、ChatGPTの先祖みたいなモデルやねん。この研究は、そのGPT-2をイベント検出(テキストの中から「何が起きた」を見つけるタスク)に使おうとしてるんや。タイトルがかっこええな、「パワーを解放する」って。
[128] Xia N, Yu H, Wang Y, Xuan J, Luo X. 「DAFS: イベント検出のためのドメイン認識型少数ショット生成モデル」 Machine Learning, 2023, 112(3): 1011–1031
ドメイン認識型っていうのは、分野(医療とか金融とか)の特徴をちゃんと理解してるってことやねん。少数ショットやから、少ない例でも学習できる。つまり、新しい分野でも少ないデータでイベント検出できるようになるんや。これめっちゃ実用的やな!
---
## Page 32
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p032.png)
### 和訳
ほな、イベント抽出の研究についてめっちゃわかりやすく説明していくで!
[129] Caiさんたちの研究やねんけど、「ゼロショットイベント検出」っていう、学習データなしでイベント見つける技術があんねん。これ、イベントの定義をAIにちゃんと理解させるんがポイントやねんけど、そこを改善したって話や。2024年のarXivで発表されとるで。
[130] Liさんたちは文書全体からイベントの「引数」(誰が、何を、どこで、みたいな情報やな)を抜き出す方法を考えたんや。「条件付き生成」っていう技術使っとって、これがなかなかかしこいねん。2021年のNAACL会議で発表されたやつや。
[131] Luさんたちの「Text2Event」はめっちゃ面白いで!テキストから構造化されたイベント情報を端から端まで一気に抽出できんねん。「制御可能な系列-構造生成」って呼んどって、要するにテキストをきれいに整理された形に変換するシステムやな。2021年のACL会議での発表や。
[132] Zhouさんたちの「CLARET」はTransformerっていうAIモデルを事前学習させる方法やねん。イベントを中心に据えて、文脈からイベントへの変換を学習させるんや。「相関認識型」って言うとって、関連性をちゃんと理解させるのがミソやな。2022年のACL会議で発表されとるで。
[133] Huangさんたちは多言語対応の話や。学習データがない言語でもイベントの引数を抽出できる「ゼロショット・クロスリンガル」技術を開発したんや。生成型言語モデルを使っとって、これがほんまにすごいねん。2022年のACL会議での発表や。
[134] Maさんたちの「PAIE」はプロンプト(AIへの指示文)を使ってイベント引数を抽出する方法やねん。「引数間の相互作用」を促すプロンプト設計がポイントで、引数同士の関係を考慮して抽出精度上げとるんや。2022年のACL会議で発表されたで。
[135] Liuさんたちは「動的プレフィックスチューニング」っていう方法を提案しとって、テンプレートベースのイベント抽出を生成型でやるんやけど、そのチューニング方法を動的に変えるのが新しいところやな。2022年のACL会議での発表や。
[136] Caiさんたちは「モンテカルロ言語モデルパイプライン」を使って、社会政治的なイベントをゼロショットで抽出する研究やねん。モンテカルロっていうのは確率的なサンプリング手法のことで、それを言語モデルに組み込んどるんや。2023年のNeurIPSワークショップでの発表やで。
[137] LuoさんとXuさんは「拡散モデル」を使ったイベント引数抽出やねん。文脈を意識したプロンプトと、画像生成で有名な拡散モデルを組み合わせとって、なかなか斬新なアプローチやな。2023年のACM CIKM会議で発表されとるで。
[138] Luさんたちはイベント抽出を「質問生成と回答」の問題として捉え直したんや。つまり「何が起きた?」「誰がやった?」みたいな質問を自動で作って、それに答える形でイベント情報を抽出するっていう発想やねん。2023年のACL会議での発表や。
[139] Nguyenさんたちは「文脈化されたソフトプロンプト」を使ってイベント引数を抽出する方法を提案しとるねん。ソフトプロンプトっていうのは、人間が書く指示文じゃなくて、AIが学習する数値ベクトルのプロンプトのことや。2023年のACL Findingsで発表されたで。
---
## Page 33
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p033.png)
### 和訳
[140] Hsu Iら (2023) - AMPERE: AMR対応プレフィックスを使った生成ベースのイベント引数抽出モデル
ほな説明するで!これはな、AMR(抽象的意味表現)っていうのを上手いこと使って、文章の中から「誰が」「何を」「どこで」みたいなイベントの詳細情報を引っ張り出すモデルやねん。ACL 2023で発表されとるで。
[141] Duan Jら (2024) - Keyee: キーワード補助サブプロンプトで低リソース生成型イベント抽出を強化する方法
これめっちゃ面白くてな、データが少ない状況でもイベント抽出できるように、キーワードを補助的に使うプロンプトの工夫をしてんねん。Big Data Mining and Analyticsの論文やで。
[142] Lin Zら (2023) - プロンプトを使ったグローバル制約でゼロショットイベント引数分類
なんでこれがすごいかっていうと、学習データなしでイベントの引数を分類できるようにしてんねん。プロンプトに全体的な制約をかけることで実現しとるわ。EACL 2023のFindingsに載っとる。
[143] Liu Wら (2024) - 単一イベント抽出を超えて:効率的な文書レベル複数イベント引数抽出に向けて
ほんまにこれ大事でな、今までは1つのイベントだけ見とったんやけど、長い文書から複数のイベントの情報をまとめて効率よく取り出す手法やねん。ACL 2024のFindingsで発表されとるで。
[144] Zhang X Fら (2024) - ULTRA: 階層的モデリングとペアワイズ精緻化でLLMのイベント引数抽出の可能性を解き放つ
これはな、大規模言語モデルの力を最大限引き出すために、階層的に情報を整理して、ペア単位で細かく調整していく手法やねん。まだarXivのプレプリントやけど、めっちゃ期待できるわ。
[145] Sun Zら (2024) - 医薬品安全性監視イベント抽出でChatGPTを活用する:実証研究
これ実用的な話でな、薬の副作用とかの報告からイベント情報を抽出するのにChatGPT使ってみたらどうなるか実験しとるんや。EACL 2024で発表されとるで。
[146] Zhou Hら (2024) - LLMはデモンストレーションからタスクのヒューリスティックを学ぶ:文書レベルイベント引数抽出のためのヒューリスティック駆動プロンプト戦略
これめっちゃ賢い方法でな、LLMに例を見せることで「こういうパターンで情報取ればええねんな」っていうコツを学ばせる手法やねん。ACL 2024で発表されとるわ。
[147] Hsu Iら (2021) - DEGREE: データ効率の良い生成ベースイベント抽出モデル
少ないデータでも上手いことイベント抽出できるモデルやで。NAACL 2022で発表されとるけど、この分野ではほんまに重要な研究やねん。
[148] Zhao Gら (2023) - DemoSG: 低リソースイベント抽出のためのデモンストレーション強化スキーマガイド生成
これもデータ少ない状況向けやねんけど、スキーマ(イベントの構造定義)をガイドにして、さらにデモンストレーションで強化する手法や。EMNLP 2023のFindingsに載っとるで。
[149] Gao Jら (2024) - Event-RL: 大規模言語モデルのための結果監視によるイベント抽出強化
これ面白いアプローチでな、強化学習の考え方を使って、抽出結果がええかどうかを監視しながらモデルを改善していくんや。arXivのプレプリントやで。
[150] Huang K Hら (2024) - TEXTEE: イベント抽出のベンチマーク、再評価、考察、そして今後の課題
これはな、イベント抽出の分野全体を見直して、「ほんまに今までの評価方法でよかったんか?」「これからどうしていくべきか?」を整理した重要な論文やねん。ACL 2024のFindingsに載っとるわ。
[151] Wang Cら - DeepStruct: 構造予測のための言語モデル事前学習
言語モデルを構造予測に特化して事前学習させる手法やな。文章の中の構造的な情報を理解するのに役立つ基盤技術やで。
---
## Page 34
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p034.png)
### 和訳
ほな、この参考文献リストの内容を説明していくで!
---
34ページ目
Front. Comput. Sci., 2024, 0(0): 1–47
計算言語学会:ACL 2022の研究成果集、2022年、803〜823ページ
[152] Li Jらの研究チームが「集合学習を使った生成型の情報抽出」っていうのを発表してんねん。2023年の自然言語処理の実証手法に関する学会(EMNLP)で出した論文で、13043〜13052ページに載ってるで。要するに、テキストから情報を引っ張り出すのに新しいアプローチ使ってみたっちゅう話やな。
[153] Wei Xらが「CollabKG」っていうめっちゃ便利なツール作ってん。これ何かっていうと、人間と機械が協力して情報を抽出して、知識グラフ(いろんな情報のつながりを図にしたやつやな)を作れるシステムやねん。2023年にarXivっていう論文投稿サイトで公開されてるで。
[154] Wang Jらが「TechGPT-2.0」っていう大規模言語モデルのプロジェクトを発表してん。知識グラフを自動で作るタスクを解決しようっていう野心的な取り組みやで。2024年のarXiv論文や。
[155] Xiao Xらの「Yayi-UIE」は、チャット機能を強化した指示チューニングのフレームワークで、あらゆる種類の情報抽出に使えるように作られてんねん。つまり、AIにいろんな指示の仕方を教え込んで、どんな情報でもうまく引っ張り出せるようにしたっちゅうことや。2023年のarXiv論文やで。
[156] Xu Jらの「ChatUIE」は、チャット形式で統一的な情報抽出ができへんかって探ってみた研究やねん。大規模言語モデル使ってな。2024年の計算言語学とか言語資源評価の国際会議で発表されて、3146〜3152ページに載ってるで。
[157] Gui Hらが「IEPile」っていう、めっちゃでかいスキーマ条件付き情報抽出用のデータセットを掘り起こしてきたんや。スキーマっていうのは、どんな種類の情報をどういう形式で抽出するかの設計図みたいなもんやな。2024年のACL(計算言語学会の年次大会)の短い論文部門で発表されて、127〜146ページに載ってるで。
[158] Guo Qらの「DiluIE」は、大規模言語モデルを使ったインコンテキスト学習(文脈の中で学ぶやつやな)で、いろんなパターンの例を作って統一的な情報抽出に使おうっていう研究やねん。Neural Computing and Applicationsっていうジャーナルの2024年号、1〜22ページに載ってるで。
[159] Bi Zらの「CodeKGC」は、コード言語モデルを使って知識グラフを生成的に構築しようっていう面白いアプローチやねん。プログラミングコードの知識を活用して知識グラフ作るんや。アジアや少資源言語の情報処理に関するACMのジャーナル2024年23巻3号、1〜16ページに載ってるで。
[160] Li Zらが作った「KnowCoder」はめっちゃ注目の研究やで。構造化された知識をLLM(大規模言語モデル)にコーディングして、どんな情報抽出にも使えるようにしようっていう話やねん。2024年のACL年次大会の長い論文部門で発表されて、8758〜8779ページに載ってるで。
[161] Li Jらの研究は、大規模言語モデルからの遠隔監視(直接的なラベルなしで学習させる手法やな)を使って、文書レベルの関係抽出のためのデータを半自動で増やす方法を提案してんねん。2023年のEMNLP学会で発表されて、5495〜5505ページに載ってるで。
[162] Tang Rらは「LLMで作った合成データって、臨床テキストマイニング(医療関係のテキスト分析やな)の役に立つんやろか?」っていう疑問に答えようとした研究やねん。2023年のarXiv論文で公開されてるで。
---
---
## Page 35
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p035.png)
### 和訳
[163] Meoni S, Clergerie D. l E, Ryffel T.「大規模言語モデルを先生役にしてみた:多言語の臨床エンティティ抽出の研究」In: The 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks. 2023, 178–190
これな、LLM(大規模言語モデル)を"インストラクター"として使うっていう発想やねん。医療分野で、いろんな言語から病名とか症状とかの専門用語を抜き出す作業あるやん?それをLLMに教師役やらせてみたらどうなるかって研究や。
[164] Evans J, Sadruddin S, D'Souza J.「AstroNER - 天文学の固有表現認識:GPTはええ感じの専門アノテーターになれるんか?」arXiv preprint arXiv:2405.02602, 2024
天文学の論文から星の名前とか天体現象とかを自動で見つけ出すタスクがあるねんけど、GPTにそれやらせたらプロの天文学者並みにちゃんとできるんかな?っていう素朴な疑問を検証した研究やで。
[165] Naraki Y, Yamaki R, Ikeda Y, Horie T, Naganuma H.「LLMでNERデータセットを増やしてみた:自動で精度の高いアノテーションを目指して」arXiv preprint arXiv:2404.01334, 2024
NER(固有表現認識)って、人名とか地名とかを文章から見つけ出すタスクやねんけど、そのための学習データを作るのがめっちゃ大変やねん。なんでかっていうと、人間が一個一個「これは人名」「これは地名」ってラベル付けせなあかんから。この研究は、その作業をLLMに自動でやらせて、しかも精度も上げようっていう試みやな。
[166] Chen F, Feng Y.「Chain-of-Thoughtプロンプトの蒸留:マルチモーダルな固有表現認識と関係抽出のために」arXiv preprint arXiv:2306.14122, 2023
Chain-of-Thought(思考の連鎖)っていうのは、AIに「順を追って考えさせる」テクニックやねん。これを画像とテキストの両方を扱うタスクに応用して、その知識を小さいモデルに移す(蒸留する)って研究や。固有表現を見つけたり、モノとモノの関係を抜き出したりするのに使えるで。
[167] Li J, Li H, Pan Z, Sun D, Wang J, Zhang W, Pan G.「MNERでChatGPTを使いこなす:補助的な洗練された知識でマルチモーダル固有表現認識を強化」In: Findings of the Association for Computational Linguistics: EMNLP 2023. 2023, 2787–2802
MNER(マルチモーダル固有表現認識)っていうのは、テキストだけやなくて画像も一緒に見て固有表現を見つけるタスクやねん。この研究では、ChatGPTに追加の知識を与えてプロンプトを工夫することで、精度をグンと上げたんやって。
[168] Josifoski M, Sakota M, Peyrard M, West R.「非対称性を利用した合成学習データの生成:SynthIEと情報抽出の事例」In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023, 1555–1574
ほんまにおもろい発想やねんけど、「生成は簡単やけど検証は難しい」っていう非対称性を逆手に取って、情報抽出用の学習データを自動生成するSynthIEっていうシステムを作った研究や。要は、人工的にデータを作り出すことで、学習データ不足問題を解決しようとしてるねん。
[169] Wadhwa S, Amir S, Wallace B C.「大規模言語モデル時代の関係抽出を再考する」In: Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023, 15566–15589
関係抽出っていうのは、「AさんはB社のCEOや」みたいな文から「Aさん-CEO-B社」っていう関係を抜き出すタスクやねん。LLMがめっちゃ賢くなった今、従来のやり方を見直そうやないかって話や。
[170] Yuan C, Xie Q, Ananiadou S.「ChatGPTでゼロショット時間関係抽出」In: The 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks. 2023, 92–102
時間関係抽出っていうのは、「手術の後に熱が出た」みたいな文から「手術→熱」っていう時系列の関係を見つけ出すタスクや。ゼロショットっていうのは、事前に例を見せんでもいきなりできるかってことやね。ChatGPTでそれを試してみた研究やで。
[171] Bian J, Zheng J, Zhang Y, Zhu S.「外部知識で大規模言語モデルを刺激する:バイオ医学固有表現認識のために」arXiv preprint arXiv:2309.12278, 2023
バイオ医学の分野って専門用語がめっちゃ多いやん?LLMだけやと限界があるから、外部のデータベースとかの知識を与えて「刺激(inspire)」してあげることで、より正確に専門用語を見つけ出せるようにしようって研究や。
[172] Hu Y, Chen Q, Du J, Peng X, Keloth V K, Zuo X, Zhou Y, Li Z, Jiang X, Lu Z, others.「プロンプトエンジニアリングで大規模言語モデルの臨床固有表現認識を改善する」Journal of the American Medical Informatics Association, 2024, ocad259
臨床現場の文章から病名とか薬の名前とかを抜き出すタスクやねんけど、LLMへの指示の仕方(プロンプト)を工夫するだけで精度がめっちゃ上がるって話や。どんな聞き方するかで答えの質が変わるって、人間と一緒やな。
[173] Shao W, Zhang R, Ji P, Fan D, Hu Y, Yan X, Cui C, Tao Y, Mi L, Chen L.「大規模言語モデルによる天体物理学ジャーナル論文からの天文学知識エンティティ抽出」Research in Astronomy and Astrophysics, 2024, 24(6): 065012
天体物理学の論文から、星の名前とか観測装置の名前とか天文学的な概念を自動で抜き出すのにLLMを使ってみた研究や。宇宙の研究にもAIが役立つ時代やな。
[174] Geng S, Josifosky M, Peyrard M, West R.「言語モデルのための柔軟な文法ベース制約付きデコーディング」arXiv preprint arXiv:2305.13971, 2023
LLMって自由に文章生成できるのがええとこやけど、たまに変な形式で出力してくることあるやん?この研究は、「こういう文法に従って出力してな」っていう制約をかけながらも柔軟に生成できるようにする技術や。情報抽出で決まった形式で出力してほしいときにめっちゃ便利やで。
[175] Liu T, Jiang Y E, Monath N, Cotterell R, Sachan M.「言語モデルによる自己回帰的構造予測」In: Findings of the Association for Computational Linguistics: EMNLP 2022. 2022, 993–1005
自己回帰っていうのは、前に出力したものを見ながら次を予測するってことやねん。言語モデルでこのアプローチを使って、構造化された出力(木構造とかグラフとか)を予測する研究や。情報抽出の結果をきれいな形で出すのに使えるテクニックやな。
---
## Page 36
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p036.png)
### 和訳
[176] Chen X, Li L, Deng S, Tan C, Xu C, Huang F, Si L, Chen H, Zhang N. LightNER:少ないリソースでも固有表現認識できるように、プラグイン式のプロンプトを使っためっちゃ軽量なチューニング手法やねん。第29回国際計算言語学会議論文集。2022, 2374–2387
[177] Nie B, Shao Y, Wang Y. Know-adapter:データがちょびっとしかない状況での固有表現認識のために、知識を活用しながらパラメータも節約できる転移学習の仕組みやで。2024年計算言語学・言語資源評価合同国際会議論文集。2024, 9777–9786
[178] Zhang J, Liu X, Lai X, Gao Y, Wang S, Hu Y, Lin Y. Instructive and in2iner:少ないデータで固有表現認識するときの文脈学習の話やねん。計算言語学会:EMNLP 2023 Findings。2023, 3940–3951
[179] Monajatipoor M, Yang J, Stremmel J, Emami M, Mohaghegh F, Rouhsedaghat M, Chang K W. 大規模言語モデルを医療分野で使う研究で、臨床の固有表現認識について調べてるやつやで。arXivプレプリント arXiv:2404.07376, 2024
[180] Dunn A, Dagdelen J, Walker N, Lee S, Rosen A S, Ceder G, Persson K, Jain A. ファインチューニングした大規模言語モデルで、めっちゃ複雑な科学論文から構造化された情報を抜き出す話やねん。arXivプレプリント arXiv:2212.05238, 2022
[181] Cheung J J, Zhuang Y, Li Y, Shetty P, Zhao W, Grampurohit S, Ramprasad R, Zhang C. PolyIE:高分子材料の科学論文から情報抽出するためのデータセットやで。arXivプレプリント arXiv:2311.07715, 2023
[182] Dagdelen J, Dunn A, Lee S, Walker N, Rosen A S, Ceder G, Persson K A, Jain A. 大規模言語モデル使って科学論文から構造化された情報を抜き出すやつやねん。Nature Communications, 2024, 15(1): 1418
[183] Ma M D, Taylor A, Wang W, Peng N. DICE:生成モデル使ってデータ効率よく臨床イベント抽出する手法やで。第61回計算言語学会年次大会論文集(第1巻:長編論文)。2023, 15898–15917
[184] Hu Y, Ameer I, Zuo X, Peng X, Zhou Y, Li Z, Li Y, Li J, Jiang X, Xu H. ChatGPT使ってゼロショット、つまり事前学習なしで臨床の固有表現を認識する話やねん。arXivプレプリント arXiv:2303.16416, 2023
[185] Agrawal M, Hegselmann S, Lang H, Kim Y, Sontag D. 大規模言語モデルはちょっとの例示だけで臨床情報を抽出できるっちゅう話やで。2022年自然言語処理における経験的手法会議論文集。2022, 1998–2022
[186] Labrak Y, Rouvier M, Dufour R. 指示でファインチューニングした大規模言語モデルを臨床・医療タスクに使ったときの、ゼロショットと少数ショットの研究やねん。arXivプレプリント arXiv:2307.12114, 2023
[187] Gutiérrez B J, McNeal N, Washington C, Chen Y, Li L, Sun H, Su Y. GPT-3の文脈内学習を医療情報抽出に使おうって思ってる?ちょっと待ちいな、もう一回考え直しや。計算言語学会:EMNLP 2022 Findings。2022, 4497–4512
[188] Biana J, Zhai W, Huang X, Zheng J, Zhu S. Vaner:大規模言語モデルを活用した...
---
## Page 37
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p037.png)
### 和訳
Derong Xu†ら「生成型情報抽出のための大規模言語モデル:サーベイ」
37
いろんな生物医学の固有表現認識に使える、万能で適応力のあるモデルや。arXiv プレプリント arXiv:2404.17835, 2024
性能とか説明可能性、キャリブレーション、それに忠実性の評価についての話やで。arXiv プレプリント arXiv:2304.11633, 2023
[189] González-Gallardo C, Boros E, Girdhar N, Hamdi A, Moreno J G, Doucet A. 「せやけど...ChatGPTって歴史的な文書から固有表現見つけられるん?」In: ACM/IEEE デジタルライブラリ合同会議. 2023, 184–189
[190] Xie T, Li Q, Zhang J, Zhang Y, Liu Z, Wang H. ゼロショット固有表現認識でのChatGPTの実証研究やねん。In: 2023年自然言語処理における経験的手法に関する会議論文集. 2023, 7935–7956
[191] Gao J, Zhao H, Yu C, Xu R. ChatGPTでイベント抽出できるかどうか試してみた話や。arXiv プレプリント arXiv:2303.03836, 2023
[192] Gui H, Zhang J, Ye H, Zhang N. InstructIE:中国語の指示ベース情報抽出データセットやで。arXiv プレプリント arXiv:2305.11527, 2023
[196] Fei H, Zhang M, Zhang M, Chua T S. XNLP:めっちゃ汎用的な構造化NLPのためのインタラクティブなデモシステムや。arXiv プレプリント arXiv:2308.01846, 2023
[197] Liu C, Zhao F, Kang Y, Zhang J, Zhou X, Sun C, Kuang K, Wu F. RexUIE:明示的なスキーマ指示器を使った再帰的手法で、なんでも情報抽出できるんや。In: 計算言語学会発表論文集:EMNLP 2023. 2023, 15342–15359
[198] Zhu T, Ren J, Yu Z, Wu M, Zhang G, Qu X, Chen W, Wang Z, Huai B, Zhang M. Mirror:いろんな情報抽出タスクに使える万能フレームワークやねん。In: 2023年自然言語処理における経験的手法に関する会議論文集. 2023, 8861–8876
[193] Han R, Peng T, Yang C, Wang B, Liu L, Wan X. 情報抽出ってChatGPTで解決したん?性能とか評価基準、頑健性、エラーについて分析してみたで。arXiv プレプリント arXiv:2305.14450, 2023
[199] Bhagavatula C, Bras R L, Malaviya C, Sakaguchi K, Holtzman A, Rashkin H, Downey D, Yih t W, Choi Y. アブダクティブ常識推論の話や。なんでかっていうと、観察された事実から一番もっともらしい説明を導き出す推論のことやねん。In: 第8回国際学習表現会議. 2020
[194] Katz U, Vetzler M, Cohen A D N, Goldberg Y. NERetrieve:次世代の固有表現認識と検索のためのデータセットやで。In: 計算言語学会発表論文集:EMNLP 2023. 2023, 3340–3354
[195] Li B, Fang G, Yang Y, Wang Q, Ye W, Zhao W, Zhang S. ChatGPTの情報抽出能力を評価してみた:性能、説明可能性、キャリブレーション、忠実性についての評価やねん。
[200] OpenAI. ChatGPTの紹介や。OpenAI ブログ, 2023
[201] Whitehouse C, Choudhury M, Aji A F. LLMを使ったデータ拡張で言語間のパフォーマンスをめっちゃ上げる話やで。In: 2023年自然言語処理における経験的手法に関する会議. 2023
[202] Wu L, Zheng Z, Qiu Z, Wang H, Gu H, Shen T, Qin C, Zhu C, Zhu H, Liu Q, ほか.
---
## Page 38
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p038.png)
### 和訳
よっしゃ、ほな説明していくで!
---
38ページ目
Front. Comput. Sci., 2024, 0(0): 1–47
レコメンデーション向け大規模言語モデルのサーベイやねん。World Wide Web, 2024, 27(5): 60
大規模言語モデルとオンラインレコメンデーションシステムを組み合わせて、「なんでこれをおすすめしたか」っていう説明を自動で作る研究や。arXiv preprint arXiv:2407.02833, 2024
[203] Chen Yら. Tomgpt: テキストだけで学習できる、コスパ最強のマルチモーダル大規模言語モデルの話やねん。要するに、画像とか動画とか使わんでも、文字情報だけでちゃんと学習できるようにした手法や。ACM Transactions on Knowledge Discovery from Data, 2024
[204] Luo Pら. コンテンツと知識のギャップを埋めるマルチモーダルエンティティリンキングの研究や。これ何かっていうと、文章と画像みたいな違う種類の情報を、ちゃんと正しい実体(人とか物とか)に結びつける技術のことやで。In: ACM Multimedia. 2024
[205] Yang Hら. Latex-gcl: 大規模言語モデル(LLM)を使ったデータ増強で、テキスト付きグラフの対照学習をめっちゃ強化する手法や。グラフっていうのはノード(点)とエッジ(線)でできたネットワーク構造のことで、それにテキスト情報がくっついてるやつを上手く学習させるんやな。arXiv preprint arXiv:2409.01145, 2024
[206] Gao Yら. 検索拡張生成(RAG)を大規模言語モデルに適用した研究のサーベイやねん。RAGってのは、AIが答えを生成する前に外部のデータベースから関連情報を検索してきて、それを参考にしながら回答作る仕組みのことや。めっちゃ賢いやろ? arXiv preprint arXiv:2312.10997, 2023
[207] Gao Lら. The Pile: 言語モデルの学習用に作った、800GBもある超巨大な多様なテキストデータセットの話や。800GBやで!?ほんまにえげつない量やな。arXiv preprint arXiv:2101.00027, 2020
[210] Zheng Zら. 大規模言語モデルを使った求人レコメンデーションの生成についての研究や。「あなたにはこの仕事がええんちゃう?」って自動で提案してくれるシステムやな。arXiv preprint arXiv:2307.02157, 2023
[211] Wu Lら. オンライン求人レコメンデーションで、グラフデータを理解するために大規模言語モデルを活用する研究や。求職者と求人情報の関係をグラフ構造で表現して、それをLLMに理解させようとしてるわけやな。In: Proceedings of the AAAI Conference on Artificial Intelligence. 2024, 9178–9186
[212] Zheng Zら. テキストがめっちゃ多い逐次レコメンデーションに大規模言語モデルを活用する研究や。逐次レコメンデーションっていうのは、ユーザーの過去の行動履歴を順番に見て、次に何をおすすめするか決める手法のことやで。In: Proceedings of the ACM on Web Conference 2024. 2024, 3207–3216
[213] Chen Bら. 大規模言語モデルにおけるプロンプトエンジニアリングの可能性を徹底的に引き出す包括的レビューやねん。プロンプトエンジニアリングっていうのは、AIに指示を出すときの文章の書き方を工夫して、もっとええ回答を引き出す技術のことや。arXiv preprint arXiv:2310.14735, 2023
[214] Zhao Zら. Dynllm: 動的グラフレコメンデーションと大規模言語モデルが出会ったらどうなるか、っていう研究や。動的グラフっていうのは、時間とともに変化するネットワーク構造のことで、それを使ったレコメンデーションにLLMを組み合わせてるんやな。arXiv preprint arXiv:2405.07580, 2024
[208] Marvin Gら. 大規模言語モデルにおけるプロンプトエンジニアリングの話や。In: International Conference on Data Intelligence and Cognitive Informatics. 2023, 387–402
[215] Wang Jら. 医療分野向けのプロンプトエンジニアリング:手法と応用についてまとめた論文やで。病院とか医療現場でAIを使うときに、どうやってプロンプト書いたらええか、っていう実践的な話やな。arXiv preprint arXiv:2304.14670, 2023
[209] Zhao Hら. Lane: チューニングせんでも使える大規模言語モデルの論理的な整合性を取る手法や。
[216] Xu Dら.(続く)
---
## Page 39
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p039.png)
### 和訳
【参考文献リスト(関西弁版)】
39ページ目やで〜
大規模言語モデル使って知識グラフの補完をいろんな角度から良くしよう、っていう研究や。2024年の計算言語学・言語資源・評価に関する合同国際会議で発表されとって、11956-11968ページに載ってるで。
[217] Li X、Zhou J、Chen W、Xu D、Xu T、Chen Eの論文やねん。大規模言語モデルをプロンプトベースで再プログラミングして可視化のおすすめする、っちゅう内容や。要するにAIに「こういう風にグラフ作ってや」って指示したら、ええ感じの可視化を提案してくれるようにする研究やな。2024年の計算言語学会の第62回年次大会(第1巻:長論文)で発表されて、13250-13262ページや。
[218] Liu C、Xie Z、Zhao S、Zhou J、Xu T、Li M、Chen Eの論文。「心から話す」っちゅうタイトルで、感情に導かれた大規模言語モデルベースのマルチモーダル手法で感情的な対話を生成するっていう研究やねん。マルチモーダルっていうのは、テキストだけやなくて画像とか音声とかいろんな情報を組み合わせて使うことやで。2024年のマルチメディア検索国際会議で発表、533-542ページや。
[219] Peng W、Xu D、Xu T、Zhang J、Chen Eの論文やな。GPTの埋め込み(文章を数字の列に変換したやつ)って広告とかレコメンドに使えるん?っていう研究や。2023年の知識科学・工学・マネジメント国際会議で発表されて、151-162ページに載ってるで。
[220] Peng W、Yi J、Wu F、Wu S、Zhu B B、Lyu L、Jiao B、Xu T、Sun G、Xie Xの論文。「あんた、ワイのモデルパクってへん?」みたいなタイトルで、EaaS(サービスとしてのエンジンを提供するやつ)向けの大規模言語モデルの著作権を、バックドア透かしで守る方法についての研究やねん。めっちゃ大事な問題やで、AIモデルは作るのにコストかかるからな。2023年の計算言語学会第61回年次大会(第1巻:長論文)で発表、7653-7668ページや。
[221] Wei J、Wang X、Schuurmans D、Bosma M、Xia F、Chi E、Le Q V、Zhou Dらの論文やで。Chain-of-thought(思考の連鎖)プロンプティングで大規模言語モデルの推論能力を引き出す、っていうめっちゃ有名な研究や。AIに「考える過程を見せてや」って言うと、ほんまに賢く答えられるようになるねん。2022年のニューラル情報処理システム学会誌35巻、24824-24837ページや。
[222] Chu Z、Chen J、Chen Q、Yu W、He T、Wang H、Peng W、Liu M、Qin B、Liu Tの論文。Chain-of-thought推論のサーベイ(まとめ論文)で、進歩・最前線・将来についてまとめてるで。arXivプレプリント、arXiv:2309.15402、2023年や。
[223] Kojima T、Gu S S、Reid M、Matsuo Y、Iwasawa Yの論文やねん。大規模言語モデルはゼロショット推論者や、っていう研究。ゼロショットっていうのは、例題を見せんでもいきなり問題解けるっちゅうことやで。ほんまにすごいやろ?2022年のニューラル情報処理システム学会第35回年次大会、22199-22213ページや。
[224] Yin S、Fu C、Zhao S、Li K、Sun X、Xu T、Chen Eの論文。マルチモーダル大規模言語モデルについてのサーベイやな。テキストだけやなくて画像とかも理解できるAIについてのまとめやで。arXivプレプリント、arXiv:2306.13549、2023年。
[225] Willard B T、Louf Rの論文。大規模言語モデルの効率的なガイド付き生成についてや。AIの出力をうまくコントロールする方法やな。arXiv e-prints、2023年、arXiv-2307。
[226] Beurer-Kellner L、Müller M N、Fischer M、Vechev Mの論文。大規模言語モデル向けのプロンプトスケッチングっていう技術や。スケッチみたいにざっくり指示出して、AIに細部を埋めてもらう感じやな。arXivプレプリント、arXiv:2311.04954、2023年。
[227] Zheng L、Yin L、Xie Z、Huang J、Sun C、Yu C H、Cao S、Kozyrakis C、Stoica I、Gonzalez J Eらの論文やで。SGLangを使って大規模言語モデルを効率的にプログラミングする方法についてや。AIをもっと使いやすくする道具を作ったってことやな。arXivプレプリント、arXiv:2312.07104、2023年。
[228] Huang J、Li C、Subudhi K、Jose D、Balakrishnan S、Chen W、Peng B、Gao J、Han Jの論文。Few-shot(少数例)固有表現認識の実証的ベースライン研究や。固有表現認識っていうのは、文章から人名とか地名とか組織名とかを見つけ出す技術のことやで。ちょっとの例だけ見せて、どこまでできるか調べた研究やな。2021年の自然言語処理の実証的方法に関する会議で発表されとるで。
---
## Page 40
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p040.png)
### 和訳
なぁなぁ、ここからは参考文献のリストやねん!ちょっと聞いてな。
[229] Liuさんらが2024年に出した論文で、「Dr. e」っていうのがグラフとでっかい言語モデルを言葉を通じてつなぐ方法について書いてはるねん。arXivっていう論文サイトで読めるで。
[230] Guanさんらも2024年に、「LangTopo」っていう、グラフの言葉での説明とトポロジー(つながり方の構造みたいなもんやな)のモデリングをうまいこと合わせる方法を発表してはるわ。
[231] Zhaさんらは2024年のICDEっていうデータエンジニアリングの国際会議で、時系列データ(時間とともに変わるデータのことやな)の事前学習を、空間と時間の表現を分けてスケールアップする方法を発表してんねん。667ページから678ページに載ってるで。
[232] Zhaoさんらは2024年のSIGIRっていう情報検索の会議で、ディープニューラルネットワーク(めっちゃ深い人工知能のことやな)がショートカット学習(ズルして近道で学ぶ悪いクセみたいなもん)しちゃう問題を直したり軽減したりする「COMI」っていう方法を発表してはるわ。218ページから228ページやで。
[233] Linさんらは2024年のKDDっていうデータマイニングの会議で、タグを使ったレコメンデーション(おすすめ機能やな)において、Boxっていう手法とグラフニューラルネットワークを組み合わせる方法を発表してんねん。1770ページから1780ページに載ってるで。
[234] Liuさんらは2024年のSIGIRで、MOE(専門家の混合モデルっていう技術やな)とLLM(でっかい言語モデル)を組み合わせて、医療分野の複数タスクに効率よく対応するファインチューニング方法を発表してはるわ。1104ページから1114ページやで。
[235] Liuさんらが2024年に出したやつで、でっかい言語モデルを使って薬の推薦モデルを蒸留(大きいモデルの知識を小さいモデルに移すことやな)する方法についての論文やねん。
[236] Wangさんらは2024年に、「LLM4MSR」っていう、LLMを使って複数のシナリオでのレコメンデーションを強化するパラダイム(新しい考え方の枠組みやな)を発表してはるで。
[237] Zhaoさんらは2024年にIEEE Transactions on Knowledge & Data Engineeringっていう雑誌で、でっかい言語モデル時代のレコメンダーシステムについてのサーベイ論文を書いてはるねん。1ページから20ページやで。
[238] Qiaoさんらは2023年のACL(計算言語学会の年次総会やな)で、言語モデルのプロンプティング(言語モデルへの指示の出し方やな)を使った推論についてのサーベイを発表してはるわ。5368ページから5393ページに載ってるで。
[239] SangさんとDe Mulderさんは2003年のCoNLL(自然言語学習の会議やな)で、言語に依存しない固有表現認識(人名とか地名とかを見つける技術のことやな)の共有タスクを紹介してはるねん。142ページから147ページやで。
[240] RothさんとYihさんは2004年のCoNLLで、自然言語タスクにおけるグローバル推論(全体を見渡した推論のことやな)を線形計画法で定式化する方法を発表してはるわ。1ページから8ページやで。
[241] Walkerさんらは2006年に、ACE 2005っていう多言語のトレーニング用コーパス(学習用のテキストデータ集みたいなもんやな)を作ってはるねん。
---
## Page 41
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p041.png)
### 和訳
[242] Doddington G Rら「自動コンテンツ抽出(ACE)プログラム - タスク、データ、評価について」第4回言語リソース・評価国際会議論文集、2004年、837-840ページ
[243] Li Jら「Biocreative V CDRタスクコーパス:化学物質と病気の関係を抽出するためのリソース」Database J. Biol. Databases Curation、2016年
[244] Derczynski L、Bontcheva K、Roberts I「Broad Twitterコーパス:多様な固有表現認識のためのリソース」第26回計算言語学国際会議、2016年、1169-1179ページ
[245] Karimi S、Metke-Jimenez A、Kemp M、Wang C「Cadec:薬の副作用イベントのアノテーションコーパス」J. Biomed. Informatics、2015年、55巻、73-81ページ
[246] Wang Zら「CrossWeigh:不完全なアノテーションから固有表現タガーを訓練する方法」自然言語処理における経験的手法に関する2019年会議および第9回自然言語処理国際合同会議論文集、2019年、5153-5162ページ
[247] Liu Zら「CrossNER:クロスドメイン固有表現認識の評価」第35回AAAI人工知能会議、2021年、13452-13460ページ
[248] Kumar A、Starly B「FabNER:固有表現認識を使った製造プロセス科学分野の文献からの情報抽出」J. Intell. Manuf.、2022年、33巻8号、2393-2407ページ
[249] Ding Nら「Few-NERD:少数ショット固有表現認識データセット」計算言語学協会第59回年次大会および第11回自然言語処理国際合同会議論文集、2021年、3198-3213ページ
[250] Guan Rら「FindVehicleとVehicleFinder:自然言語ベースの車両検索のためのNERデータセットと、キーワードベースのクロスモーダル車両検索システム」Multimedia Tools and Applications、2023年
[251] Kim J、Ohta T、Tateisi Y、Tsujii J「GENIAコーパス - バイオテキストマイニングのための意味的にアノテーションされたコーパス」分子生物学のためのインテリジェントシステムに関する第11回国際会議論文集、2003年、180-182ページ
[252] Chen P、Xu H、Zhang C、Huang R「交差点、建物、近隣地域:きめ細かい位置認識のためのデータセット」北米計算言語学協会2022年会議:人間言語技術論文集、2022年、3329-3339ページ
[253] Liu J、Pasupat P、Cyphers S、Glass J R「Asgard:多言語対応のポータブルアーキテクチャ」
---
あ、ちょっと待って!これ参考文献リストやから、関西弁で説明するっていうよりは、正確に翻訳した方がええやつやな。
ほな改めて、カジュアルに説明する感じでいくで!
---
[242] これはDoddingtonらが2004年に発表したやつで、「ACE(自動コンテンツ抽出)プログラム」について書いてんねん。タスクとかデータとか評価方法について説明してる論文やで。
[243] Li Jらが2016年に出した「Biocreative V CDRタスクコーパス」っていうのは、化学物質と病気の関係を引っ張り出すためのデータセットやねん。めっちゃ医療系の研究に役立つやつや。
[244] Derczynski Lらの2016年の論文で、「Broad Twitterコーパス」っていう、Twitterのデータを使った固有表現認識(人名とか地名とか見つけるやつな)のためのリソースを紹介してんねん。多様なデータが入ってるのがポイントやで。
[245] Karimi Sらが2015年に作った「Cadec」っていうのは、薬の副作用に関するアノテーション(ラベル付け)されたコーパスやねん。薬飲んで「うわ、調子悪なった」みたいな情報を集めたデータセットや。
[246] Wang Zらが2019年に発表した「CrossWeigh」は、ちょっと不完全なアノテーションデータからでも固有表現タガー(名前とか場所を見つけるAI)を訓練できる方法を提案してんねん。完璧なデータがなくてもいけるってのがすごいとこやな。
[247] Liu Zらが2021年に出した「CrossNER」は、違うドメイン間での固有表現認識がどんだけできるか評価するためのやつやねん。例えば医療分野で訓練したモデルが、政治の分野でも使えるんかな?みたいな話や。
[248] Kumar AとStarly Bが2022年に発表した「FabNER」は、製造業の文献から情報を抽出するために固有表現認識を使うっていう研究やねん。工場とかモノづくりの専門用語を見つけ出すためのやつや。
[249] Ding Nらが2021年に出した「Few-NERD」は、少ないデータ(Few-shot)で固有表現認識をやるためのデータセットやねん。データが少なくてもなんとかしたいって時に使えるやつや。
[250] Guan Rらが2023年に発表した「FindVehicle」と「VehicleFinder」は、自然言語で車を検索するためのNERデータセットと、キーワードベースで車を見つけるシステムやねん。「赤いスポーツカー」って言ったら見つけてくれるみたいなやつやな。
[251] Kim Jらが2003年に作った「GENIAコーパス」は、バイオ系のテキストマイニングのために意味的なラベルがついたコーパスやねん。生物学とか医学の論文を解析するときにめっちゃ使われてる有名なやつや。
[252] Chen Pらが2022年に出したやつは、交差点とか建物とか近隣地域みたいな、細かい位置情報を認識するためのデータセットやねん。「駅の近くのコンビニ」みたいな表現を理解するのに使えるわけや。
[253] Liu Jらの「Asgard」は、多言語に対応できるポータブルなアーキテクチャについての論文やねん。(続きが切れてるみたいやけど)
---
## Page 42
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p042.png)
### 和訳
42ページ目
Front. Comput. Sci., 2024, 0(0): 1–47
In: IEEE International Conference on Acoustics, Speech and Signal Processing(音響・音声・信号処理に関する国際会議). 2013, 8386–8390
[254] Tedeschi S, Navigli R. MultiNERD: 固有表現認識(あと曖昧性解消もできる)のための多言語・多ジャンル・きめ細かいデータセットやで。In: Findings of the Association for Computational Linguistics: NAACL 2022. 2022, 801–812
→ これな、いろんな言語といろんなジャンルに対応した、めっちゃ細かく分類されたデータセットやねん。固有表現認識っていうのは、文章の中から人名とか地名とか組織名とかを見つけ出す技術のことやで。
[255] Doğan R I, Leaman R, Lu Z. NCBIの病気コーパス:病名の認識と概念の正規化のためのリソースやで。Journal of Biomedical Informatics, 2014, 47: 1–10
→ 病気の名前を見つけ出して、それを統一された形に整理するためのデータセットやねん。医療系のAI開発にはほんまに必須やで。
[256] Pradhan S, Moschitti A, Xue N, Ng H T, Björkelund A, Uryupina O, Zhang Y, Zhong Z. OntoNotesを使ってもっと頑丈な言語分析を目指そうやないかって話。In: Proceedings of the Seventeenth Conference on Computational Natural Language Learning, CoNLL 2013. 2013, 143–152
→ OntoNotesっていうのは、めっちゃでかい言語データセットやねん。これ使って、いろんな条件でもちゃんと動く言語解析システムを作ろうっていう研究やで。
[257] Pradhan S, Elhadad N, South B R, Martínez D, Christensen L M, Vogel A, Suominen H, Chapman W W, Savova G K. タスク1:ShARe/CLEF eHealth評価ラボ2013。In: Working Notes for CLEF 2013 Conference. 2013
→ 医療テキストから情報抽出する技術のコンペティションやねん。eHealthっていうのは電子医療情報のことで、それを賢く処理できるか競い合う場やで。
[258] Mowery D L, Velupillai S, South B R, Christensen L M, Martínez D, Kelly L, Goeuriot L, Elhadad N, Pradhan S, Savova G K, Chapman W W. タスク2:ShARe/CLEF eHealth評価ラボ2014。In: Working Notes for CLEF 2014 Conference. 2014, 31–42
→ 上の2013年版の続きで、2014年バージョンやな。毎年改良されてより難しい課題に挑戦してるねん。
[259] Lu D, Neves L, Carvalho V, Zhang N, Ji H. マルチモーダルなソーシャルメディアで名前タグ付けするための視覚的注意モデルやで。In: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018, 1990–1999
→ マルチモーダルっていうのは、テキストだけやなくて画像とかも一緒に見るってことやねん。SNSの投稿から人名とか見つけ出すときに、添付されてる画像も参考にしたら精度上がるんちゃうかって研究やで。
[260] Rijhwani S, Preotiuc-Pietro D. 固有表現認識の時間的な変化を分析したで。In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020, 7605–7617
→ なんでかっていうと、新しい言葉とか名前って時代とともに変わるやん?その変化がAIの性能にどう影響するか調べた研究やねん。
[261] Jiang H, Hua Y, Beeferman D, Roy D. Tweebankコーパスに固有表現のアノテーションつけて、SNS分析用のNLPモデル作ったで。In: Proceedings of the Thirteenth Language Resources and Evaluation Conference. 2022, 7199–7208
→ Tweebankっていうのはツイッター(今のX)のデータを集めたやつで、そこに「これは人名」「これは場所」みたいなラベルをつけて、SNS専用のAIを作れるようにしたんやで。
[262] Zhang Q, Fu J, Liu X, Huang X. ツイートの固有表現認識のための適応型共注意ネットワークやで。In: Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence. 2018, 5674–5681
→ 共注意(co-attention)っていうのは、複数の情報源を同時に見て、どこに注目すべきか一緒に学習する仕組みやねん。ツイートみたいな短い文でもうまく動くように工夫してるで。
[263] Ushio A, Barbieri F, Silva V, Neves L, Camacho-Collados J. ツイッターの固有表現認識:データセットと短期的な時間変化の分析やで。In: Proceedings of the 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing, AACL/IJCNLP 2022 - Volume 1: Long Papers. 2022, 309–319
→ ツイッターって流行り廃りが激しいやん?数ヶ月で全然違う言葉が使われるようになるから、その変化にAIがどれだけついていけるか調べた研究やねん。
[264] Wang X, Tian J, Gui M, Li Z, Wang R, Yan M, Chen L, Xiao Y. WikiDiverse:いろんな文脈のトピックとエンティティタイプが入ったマルチモーダルなエンティティリンキングのデータセットやで。In: Proceedings of the 60th Annual Meeting of
→ エンティティリンキングっていうのは、文章中の「田中さん」が具体的にどの田中さんのことを指してるか、Wikipediaとかの知識ベースと紐付ける技術やねん。このデータセットは画像も含めていろんなパターンを網羅してるから、めっちゃ実用的やで。
---
## Page 43
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p043.png)
### 和訳
[265] Derczynski L, Nichols E, Erp v M, Limsopatham N. WNUT2017共有タスクの結果報告:新しく出てきたエンティティ認識についてやねん。掲載先:第3回ノイジーなユーザー生成テキストに関するワークショップ論文集。2017年、140-147ページ
[266] Gurulingappa H, Rajput A M, Roberts A, Fluck J, Hofmann-Apitius M, Toldo L. 医療症例報告から薬関連の副作用を自動で抜き出すためのベンチマークコーパス開発したで。J. Biomed. Informatics誌、2012年、45巻5号:885-892ページ
[267] Yao Y, Ye D, Li P, Han X, Lin Y, Liu Z, Liu Z, Huang L, Zhou J, Sun M. DocRED:めっちゃデカい文書レベルの関係抽出データセットやねん。掲載先:第57回計算言語学会年次大会論文集。2019年、764-777ページ
[268] Zheng C, Wu Z, Feng J, Fu Z, Cai Y. MNRE:SNS投稿の画像を証拠として使うニューラル関係抽出のための、なかなか手強いマルチモーダルデータセットや。掲載先:IEEE国際マルチメディアエキスポ会議。2021年、1-6ページ
[269] Riedel S, Yao L, McCallum A. ラベル付きテキストなしで関係とその言及をモデル化する方法やで。掲載先:機械学習とデータベースからの知識発見。2010年、148-163ページ
[270] Stoica G, Platanios E A, Pόczos B. Re-TACRED:TACREDデータセットの問題点に対処したやつや。掲載先:第35回AAAI人工知能会議。2021年、13843-13850ページ
[271] Luan Y, He L, Ostendorf M, Hajishirzi H. 科学知識グラフ構築のためのエンティティ・関係・共参照のマルチタスク識別やねん。掲載先:2018年自然言語処理における経験的手法会議論文集。2018年、3219-3232ページ
[272] Hendrickx I, Kim S N, Kozareva Z, Nakov P, Séaghdha D Ó, Padó S, Pennacchiotti M, Romano L, Szpakowicz S. SemEval-2010タスク8:名詞ペア間の意味関係の多方向分類やで。掲載先:第5回意味評価国際ワークショップ論文集。2010年、33-38ページ
[273] Zhang Y, Zhong V, Chen D, Angeli G, Manning C D. 位置を意識したアテンションと教師ありデータでスロットフィリングが改善するって話や。掲載先:2017年自然言語処理における経験的手法会議論文集。2017年、35-45ページ
[274] Alt C, Gabryszak A, Hennig L. TACRED再検証:TACRED関係抽出タスクのめっちゃ徹底的な評価やねん。掲載先:第58回計算言語学会年次大会論文集。2020年、1558-1569ページ
[275] Satyapanich T, Ferraro F, Finin T. CASIE:テキストからサイバーセキュリティのイベント情報を抜き出すやつや。掲載先:第34回AAAI人工知能会議。2020年、8749-8757ページ
[276] Kim J, Wang Y, Takagi T, Yonezawa A. BioNLPにおけるGeniaイベントタスクの概要やで
---
## Page 44
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p044.png)
### 和訳
44
Front. Comput. Sci., 2024, 0(0): 1–47
In: Proceedings of BioNLP Shared Task 2011 Workshop. 2011, 7–15
転移学習の限界を探るっていう研究やねん。テキストをテキストに変換する統一型トランスフォーマーを使ってな。J. Mach. Learn. Res., 2020, 21: 140:1–140:67
[277] Kim J, Wang Y, Yamamoto Y. Geniaイベント抽出共有タスク、2013年版の概要やで。In: Proceedings of the BioNLP Shared Task 2013 Workshop. 2013, 8–15
[278] Sun Z, Li J, Pergola G, Wallace B C, John B, Greene N, Kim J, He Y. PHEE:テキストから薬の副作用とかを見つけ出すためのデータセットやねん。要するに、薬を飲んでなんか起きた時の報告文から、何が起きたかを自動で抜き出す研究用のデータやな。In: Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022, 5571–5587
[279] Ebner S, Xia P, Culkin R, Rawlins K, Durme B V. 複数の文にまたがる引数リンキングっていう話やねん。なんでかっていうと、一つの文だけやなくて、いくつかの文を見て「誰が」「何を」「どうした」を繋げなあかんからな。In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020, 8057–8077
[280] Li S, Ji H, Han J. 文書レベルのイベント引数抽出を条件付き生成でやるっていう研究やで。文書全体を見て、イベントに関係する要素を生成する形で取り出すんやな。In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2021. 2021, 894–908
[281] Lewis M, Liu Y, Goyal N, Ghazvininejad M, Mohamed A, Levy O, Stoyanov V, Zettlemoyer L. Bart:ノイズ除去を使った系列変換の事前学習やねん。自然言語の生成、翻訳、理解に使えるやつや。めっちゃざっくり言うと、わざと文を壊して元に戻す訓練をさせることで、言語をよう理解できるようになるモデルやな。In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020, 7871–7880
[282] Raffel C, Shazeer N, Roberts A, Lee K, Narang S, Matena M, Zhou Y, Li W, Liu P J.
[283] Xue L, Constant N, Roberts A, Kale M, Al-Rfou R, Siddhant A, Barua A, Raffel C. mT5:めっちゃ多言語に対応した事前学習済みテキスト変換トランスフォーマーやで。要するに、いろんな言語で使えるT5モデルってことやな。In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021, 483–498
[284] Chung H W, Hou L, Longpre S, Zoph B, Tay Y, Fedus W, Li Y, Wang X, Dehghani M, Brahma S, others. 指示でファインチューニングした言語モデルのスケーリングについてやねん。ほんまにでっかいモデルを「こうしてな」って指示で調整したらどうなるか、っていう研究や。arXiv preprint arXiv:2210.11416, 2022
[285] Du Z, Qian Y, Liu X, Ding M, Qiu J, Yang Z, Tang J. GLM:自己回帰的な空白埋めで汎用言語モデルを事前学習するっていう話やで。文の一部を空白にして、それを予測させながら学習させるんやな。In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022, 320–335
[286] Touvron H, Lavril T, Izacard G, Martinet X, Lachaux M A, Lacroix T, Rozière B, Goyal N, Hambro E, Azhar e aF. LLaMA:オープンで効率的な基盤言語モデルやねん。誰でも使えて、しかも軽いのにめっちゃ賢いモデルを目指したやつや。arXiv preprint arXiv:2302.13971, 2023
[287] Taori R, Gulrajani I, Zhang T, Dubois Y, Li X, Guestrin C, Liang P, Hashimoto T B. Stanford Alpaca:指示に従うLLaMAモデルやで、2023
[288] Chiang W L, Li Z, Lin Z, Sheng Y, Wu Z, Zhang H, Zheng L, Zhuang S, Zhuang Y, Gonzalez J E, others. Vicuna:
---
## Page 45
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p045.png)
### 和訳
Derong Xuくんは今、中国科学技術大学と香港城市大学の両方で博士課程やっとんねん。研究テーマはマルチモーダル知識グラフと大規模言語モデルやで。
Wei Chenくんは中国科学技術大学で博士課程の学生さんや。データマイニングとか情報抽出、あと大規模言語モデルに興味持って研究しとるんやて。
Wenjun Pengくんは中国科学技術大学のコンピュータ科学技術学院で修士号取ったんや。学部は2021年に四川大学卒業やな。データマイニングとかマルチモーダル学習、あと人物再同定(要は「この人さっきの人と同じ人?」って判定する技術やな)が主な研究分野やねん。
Chao Zhangくんは2022年に山東大学でソフトウェア工学の学士号取って、今は中国科学技術大学と香港城市大学で博士号目指して頑張っとる。データマイニングとかマルチモーダル学習、大規模言語モデルが研究テーマやで。
---
## Page 46
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p046.png)
### 和訳
46
Front. Comput. Sci., 2024, 0(0): 1–47
Tong Xuさんは今、中国の合肥にある中国科学技術大学(USTC)で教授やってはるんやで。この人、めっちゃすごくて、関連分野のトップクラスのジャーナルや学会で100本以上も論文出してはんねん。TKDE、TMC、TMM、TOMM、KDD、SIGIR、WWW、ACM MMとか、まあ名だたる学会ばっかりやな。2020年のKSEMっていう学会でベストペーパー賞もらってるし、2023年のACL(言語処理の超有名な学会やで)では自然言語処理応用トラックのエリアチェア賞も受賞してはるんや。
Xian Wuさんは今テンセントでプリンシパルリサーチャーやってはるんやけど、テンセント入る前はマイクロソフトとかIBMリサーチでシニアサイエンティストマネージャーとかスタッフリサーチャーとして働いてはってん。上海交通大学で博士号取ってはるんや。研究分野は医療AI、自然言語処理(まあコンピュータに人間の言葉を理解させる技術やな)、それからマルチモーダルモデリング(画像とかテキストとか、いろんな種類のデータを組み合わせて処理する技術のことや)。Nature Computational Science、NPJ digital medicine、T-PAMI、CVPR、NeurIPS、ACL、WWW、KDD、AAAI、IJCAIとか、ほんまにすごい学会やジャーナルに論文出してはるし、BMJ、T-PAMI、TKDE、TKDD、TOIS、TIST、CVPR、ICCV、AAAIとかのプログラム委員もやってはるんやで。
Xiangyu Zhaoさんは香港城市大学(CityU)のデータサイエンス学部で助教授やってはるんや。今の研究はデータマイニング(大量のデータから価値ある情報を掘り出す技術やな)と機械学習が中心やで。トップクラスの学会やジャーナルに100本以上論文出してはるし、研究成果もめっちゃ認められてて、ICDM'22とICDM'21でベストランク論文に選ばれてるし、「AIにおける中国の新星トップ100」にも選ばれてるんや。それだけやのうて、Huaweiのイノベーション研究プログラム、CCF-テンセントオープンファンド(これ2回もらってるんやで)、CCF-Ant研究ファンド、Antグループ研究ファンド、テンセントフォーカスド研究ファンドとか、いろんな助成金ももらってるし、AAAI/ACM SIGAIの博士論文賞にもノミネートされてるんや。データサイエンスのトップ学会では(シニア)プログラム委員とかセッションチェアもやってるし、ジャーナルのゲストエディターとかレビュアーとしても活躍してはるんやで。
Yefeng Zhengさんは、1998年と2001年に中国の北京にある清華大学で学士と修士を取って、2005年にはアメリカのメリーランド大学カレッジパーク校で博士号を取ってはるんや。卒業後は、アメリカのニュージャージー州プリンストンにあるシーメンスの研究所で医療画像解析の仕事してはって、2018年に中国の深センにあるテンセントに入社したんやで。今はテンセントJarvis研究センターのディスティングイッシュドサイエンティスト兼ディレクターとして、会社の医療人工知能プロジェクトを引っ張ってはるんや。論文は300本以上出してるし、アメリカの特許も80件以上持ってはるんやで。研究は22,000回以上引用されてて、h-indexは74もあるんや(h-indexっていうのは研究者の影響力を測る指標で、74はめっちゃ高いんやで)。IEEEのフェロー、AIMBEのフェローでもあるし、IEEE Transactions on Medical Imagingっていう医療画像のトップジャーナルの副編集長もやってはるんや。
---
## Page 47
[](/attach/a20d379d59deef5835a5074156aab0ac59f431f20321854729a0531e02bc031d_p047.png)
### 和訳
楊王さんは今、中国の蕪湖にある安徽海螺情報技術工程っていう会社でエンジニアとして働いてはるねん。
この人、建材業界でITプロジェクトを10年以上もやってきた超ベテランやねん。発明特許を11件も申請してるし、技術論文も2本出してるし、さらに国の大規模な科学技術プロジェクトにも3つも参加してるんやで。めっちゃすごない?
---
陳恩紅さん(CCFフェロー、IEEEフェローっていう、学会のめっちゃ偉い称号を2つも持ってはる人やで)は、中国科学技術大学の教授さんやねん。
研究分野としては、データマイニングとか機械学習(コンピュータにデータから賢くパターンを見つけさせる技術やな)、ソーシャルネットワーク分析(SNSとかの人間関係を分析するやつ)、あとレコメンダーシステム(「あなたへのおすすめ」を出すやつやな)とかをやってはるねん。
論文の数がほんまにエグくて、300本以上も査読付きの学会や論文誌に出してはるんやで。しかもNature Communicationsとか、IEEE/ACMのTransactionsとか、KDD、NIPS、IJCAI、AAAIとか、AI・データサイエンス界隈では超一流のとこばっかりやねん。
さらにKDD、ICDM、SDMみたいな有名学会のプログラム委員(どの論文を採択するか決める偉い人たち)もやってはるし、受賞歴もめっちゃすごいねん。KDD-2008で最優秀応用論文賞、ICDM-2011で最優秀研究論文賞、SDM-2015でもベスト論文に選ばれてるんやで。
研究費は中国の国家傑出青年科学基金っていう、若手研究者向けのめっちゃ名誉ある助成金からもらってはるねん。要するに、この人ほんまに中国のAI・データサイエンス界のトップ中のトップってことやな。
---
![]()
1 / 1
100%