<<
2401.15884v3.pdf

---
## Page 1
[](/attach/975aa1fd3c1b603126e93ff99d6504858b61301bf1d34c9df88ebe53a0b026cb_p001.png)
### 和訳
# 修正型検索拡張生成(CRAG)
Shi-Qi Yan、Jia-Chen Gu、Yun Zhu、Zhen-Hua Ling
中国科学技術大学、UCLA、Google DeepMind
---
## 概要
ほな聞いてや、大規模言語モデル(LLM)ってめっちゃ賢いねんけど、どうしても「ハルシネーション」っていう嘘つき問題が出てくるねん。なんでかっていうと、モデルが自分の頭の中に持ってる知識だけじゃ、生成するテキストの正確さを保証でけへんからやねん。検索拡張生成(RAG)っていう方法がLLMの補助としてええ感じに使えるんやけど、これって検索で引っ張ってきた文書がどんだけ関係あるかにめっちゃ依存してるから、検索がミスったらどうなるん?っていう心配があるわけや。
そこでワイらが提案するんが、**修正型検索拡張生成(CRAG)**やねん。これで生成の頑丈さをアップさせるんや。
具体的に言うとな、軽量な検索評価器っていうのを設計して、クエリに対して引っ張ってきた文書全体の質をチェックするねん。で、その確信度に応じて、違う知識検索アクションを発動させるっちゅう仕組みや。静的で限られたデータベースからの検索やと、どうしても最適とは言えん文書しか返ってこんことがあるやろ?せやから、大規模なウェブ検索を追加して検索結果を拡張するねん。さらに、「分解して再構成」っていうアルゴリズムを設計して、検索文書から重要な情報だけを選んで、いらん情報をフィルタリングするようにしたんや。
CRAGはプラグアンドプレイやから、いろんなRAGベースの手法にそのままくっつけて使えるで。短文生成と長文生成のタスクを含む4つのデータセットで実験したら、CRAGがRAGベースの手法の性能をめっちゃ向上させることがわかったんや。
---
## 1. はじめに
大規模言語モデル(LLM)ってほんまに注目されてて、指示を理解して流暢な文章を生成する能力がすごいねん(Brown et al., 2020; Ouyang et al., 2022; Touvron et al., 2023a)。せやけど、LLMはどうしてもハルシネーションを起こしてまうねん(Ji et al., 2023)。事実の間違いに苦労するし(Mallen et al., 2023; Min et al., 2023)、自分が持ってるパラメータの知識だけじゃ生成テキストの正確さを担保でけへんからや(Zhang et al., 2023b; Muhlgay et al., 2023)。
これまでの研究では、入力に関連する知識を取り込んで生成を強化する検索技術が導入されてきたんや。その代表例が検索拡張生成(RAG)やな(Lewis et al., 2020)。このフレームワークでは、外部の知識コーパスから検索した関連文書を前に付け加えて、モデルへの入力を拡張するねん(Guu et al., 2020)。RAGはLLMの実用的な補完手段として使えるんやけど、その効果は検索された文書の関連性と正確さに左右されるねん(Li et al., 2022; Tan et al., 2022)。生成が検索された知識にめっちゃ依存してるから、検索が失敗したり不正確な結果を返したりするシナリオで、モデルがどう振る舞うかっていう大きな懸念があるわけや(Shi et al., 2023)。
図1を見てもらったらわかるけど、質の低い検索器は大量の無関係な情報を持ってきがちで、生成器が正確な知識を得るのを邪魔するし、下手したら間違った方向に導いてまうこともあるねん。
---
**図1の説明**: 質の低い検索器が大量の無関係情報を持ち込んで、生成器が正確な知識を得るのを妨げたり、ミスリードしたりする例を示してるで。
---
## Page 2
[](/attach/975aa1fd3c1b603126e93ff99d6504858b61301bf1d34c9df88ebe53a0b026cb_p002.png)
### 和訳
めっちゃ関係ない情報がどっさり入ってきてしまうから、モデルがちゃんとした知識を身につけるのを邪魔してまうねん。しかも変な方向に誘導されて、「ハルシネーション」って呼ばれる嘘情報を生成してまう問題も出てくるわけや(Zhang et al., 2023b)。せやけどな、今までの普通のRAGのやり方は、取ってきた文書が関係あろうがなかろうが、お構いなしに全部突っ込んでまうねん(Rony et al., 2022)。それに加えて、今の方法はほとんど、文書まるごとを参照知識として扱ってるんやけど、実際には取ってきた文書の中のかなりの部分が、生成には全然必要ないテキストやったりするわけ。そんなん同じように参照してRAGに組み込むべきちゃうやろって話やねん。
こういう問題があるから、この論文では特に「検索器が不正確な結果を返してまう場面」に注目して研究してるねん。ほんで**Corrective Retrieval-Augmented Generation(CRAG)**っていう手法を提案してるんやけど、これは検索器の結果を自己修正して、文書の活用をもっとええ感じにして生成を強化するもんやねん。まず、軽量な検索評価器を設計して、クエリに対して取ってきた文書全体の品質を評価するようにしてるわ。これがRAGの中でめっちゃ重要な部品になってて、取ってきた文書の関連性と信頼性をちゃんとレビューして評価することで、ええ情報を使った生成に貢献するんや。ほんで信頼度を数値化して、それに基づいて{Correct(正しい)、Incorrect(間違い)、Ambiguous(曖昧)}の3つの知識検索アクションを発動させるようにしてるねん。後ろの2つのアクションの場合は、大規模なウェブ検索(Piktus et al., 2021; Komeili et al., 2022)を戦略的な拡張として組み込んでるわ。なんでかっていうと、静的で限られたコーパスからの検索だけやと、範囲も多様性も今ひとつな文書しか返せへんからやねん。この拡張は、取ってくる情報の幅を広げるために実装されてて、ウェブの広大でダイナミックな性質を活かして、最初に取得した文書を補完して充実させるようにしてるんや。さらに、RAGに役立たへん冗長な文脈を取ってきた文書から取り除くために、「分解してから再構成する」アルゴリズムを検索と活用のプロセス全体にわたって丁寧に作り込んでるねん。このアルゴリズムのおかげで、取ってきた情報を洗練して、重要なポイントの抽出を最適化しつつ、必要ない要素の混入を最小限に抑えて、データの活用効率をめっちゃ上げてるわけや。
CRAGはプラグアンドプレイで使えるから、RAG(Lewis et al., 2020)やSelf-RAG(Asai et al., 2024)に実験的に組み込んで、RAGベースのアプローチへの適応性を示してるで。PopQA(Mallen et al., 2023)、Biography(Min et al., 2023)、Pub Health(Zhang et al., 2023a)、Arc-Challenge(Bhakthavatsalam et al., 2021)の4つのデータセットでの結果を見たら、CRAGは標準的なRAGと最先端のSelf-RAGの性能をめっちゃ向上させられることがわかって、短文生成でも長文生成でも汎用性があることが実証されてるねん。他の人らが結果を再現できるように、ソースコード全部を後で公開する予定やで。
まとめると、この論文の貢献は3つあるねん:1)検索器が不正確な結果を返す場面を研究して、ワイらの知る限り、RAGのロバスト性を向上させるための修正戦略を設計した初めての試みやねん。2)CRAGっていうプラグアンドプレイの手法を提案して、自動的な自己修正と取ってきた文書の効率的な活用の能力を向上させてるで。3)実験結果でCRAGのRAGベースアプローチへの適応性と、短文・長文生成タスク両方への汎用性を幅広く実証してるわ。
## 2 関連研究
**LLMのハルシネーション** LLMは指示を理解して流暢な言語テキストを生成するめっちゃすごい能力を見せてきたんやけど(Bang et al., 2023; Qin et al., 2023; Zhong et al., 2023)、まだ苦しんでる一番深刻な問題の一つがハルシネーションやねん。いろんな研究でわかってきたように(Tonmoy et al., 2024; Zhang et al., 2023b; Shuster et al., 2021)、古くなった情報や間違った知識が活性化されると、ほんまに深刻なハルシネーションを引き起こしてまうねん。大規模で管理されてへんトレーニングデータの収集、高品質なサンプリングデータの割合が低いこと、入力空間でのデータ配分の不完全さ、その他いろんな現実的な要因がLLMに影響して、問題を悪化させる可能性があるわけや。せやから、正確で具体的な知識が不足してると、誤解を招くような、もしくは不正確な生成につながるのは明らかで、ほとんどの実用的なアプリケーションでユーザー体験をめっちゃ損なってまうねん。
**検索拡張生成(RAG)** RAG(Lewis et al., 2020; Guu et al., 2020)は上で述べた問題に対処する有効な方法とされてて、生成型言語モデルの入力質問を取ってきた文書で強化するもんやねん。通常、特定のコーパス、つまりWikipediaなんかから追加の知識ソースを提供してくれて、いろんなタスク、特に知識集約型のタスクで言語モデルの性能をめっちゃ向上させるねん。提案された
---
## Page 3
[](/attach/975aa1fd3c1b603126e93ff99d6504858b61301bf1d34c9df88ebe53a0b026cb_p003.png)
### 和訳
この手法はな、情報検索を使って生成AIに関連する知識が入った文書を渡すっていう仕組みやねん。初期の研究では、疎な検索器(キーワードベースみたいなやつ)か密な検索器(意味ベースのやつ)を、回答生成専門の事前学習済み言語モデルの前段に置いてたんや。せやけどな、これらの手法には見落としがあって、それが「検索がコケたらどないすんねん?」っていう問題やねん。そもそも検索を導入する目的は、生成AIが関連性あって正確な知識をちゃんとゲットできるようにすることやろ?せやから、もし取ってきた文書が的外れやったら、検索システムがむしろAIの事実誤認を悪化させてまうことすらあるんやで。
**発展型RAG** ここ数年で、オリジナルのRAGからめっちゃ進化したアプローチがいっぱい開発されてきてん(Zhang et al., 2024; Kim et al., 2024; Wang et al., 2024; Liu et al., 2024)。なんでかっていうと、クエリによっては検索せんでもええ場合もあるし、むしろ検索なしの回答の方が正確なケースも結構あるからやねん。Self-RAG(Asai et al., 2024)は、知識を選択的に検索して、検索するかどうかを判断する批評モデルを導入したやつや。Yoran et al.(2024)は、関係ない文脈を見分けてシステムの頑健性を上げるNLI(自然言語推論)モデルを設計したで。SAIL(Luo et al., 2023)は、指示文の前に検索文書を挿入するように調整されてるやつや。一方でToolformer(Schick et al., 2023)は、WikipediaみたいなAPIを呼び出せるように事前学習されとる。あと、長文生成タスクでは外部知識が何回も必要になることがあって、いつ検索するかも考えなあかんのや。Jiang et al.(2023)は、長文生成で将来の内容を予測して、いつ何を検索するか決める仕組みを作ったで。
最近の研究(Schick et al., 2023; Luo et al., 2023; Asai et al., 2024)でうちらの研究に一番近いやつと比べると、大事な違いがあるんや。これらのアプローチは、検索を生成を強化する便利なツールとして活用することや、そもそも検索が必要かどうかに焦点当ててるんやけど、うちらの研究は特に検索器が不正確な結果を返してまう場面を研究してるんや。うちらが知る限り、この論文はRAGの生成の頑健性を上げるための修正戦略を探求・設計した初めての試みやで。
## 3 タスクの定式化
先行研究(Lewis et al., 2020; Asai et al., 2024)に従って説明するとな、入力Xと、めっちゃ大量の知識文書が入ったアクセス可能なコーパスC = {d1, ..., dN}があるとき、システムは出力Yを生成することが期待されるんや。フレームワーク全体は普通、検索器Rと生成器Gに分かれとる。検索器Rは、コーパスCから入力Xに関連するトップK個の文書D = {dr1, ..., drk}を取ってくることが目的や。ほんで入力Xと検索結果Dに基づいて、生成器Gが出力Yを生成する責任を持つんや。このフレームワークは以下のように定式化できるで:
P(Y|X) = P(D|X)P(Y, D|X). (1)
これを見たらわかるように、検索器と生成器はがっちり結合してて、リスク許容度が低いんや。生成器がどんだけすごい能力持ってても、検索が失敗したら不満足な回答になってまう。まさにここが、この論文で生成の頑健性を上げようとしてるポイントやねん。
## 4 CRAG
### 4.1 モデル推論の概要
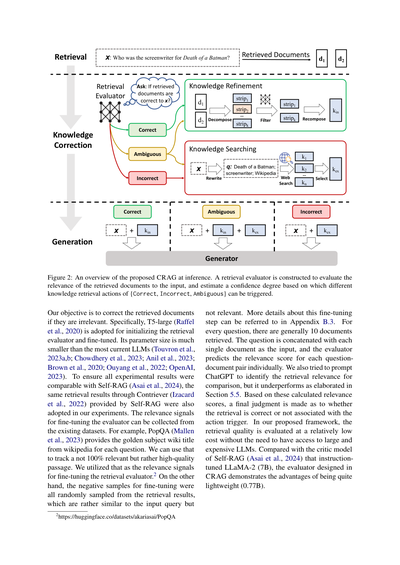
図2とアルゴリズム1に、推論時のCRAGの概要が示されてるで。これは生成の頑健性を上げるための修正戦略を設計したもんや。入力クエリと任意の検索器から取得した文書が与えられると、まず軽量な検索評価器を構築して、検索文書と入力クエリの関連度スコアを推定するんや(セクション4.2)。この関連度スコアは全部で3段階の確信度に量子化されて、それに対応するアクションが発動するんや:{Correct(正しい)、Incorrect(間違い)、Ambiguous(曖昧)}(セクション4.3)。Correctアクションが発動したら、検索文書はより精密な知識ストリップに精製されるで。この精製操作には、知識の分解、フィルタリング、再構成が含まれとる(セクション4.4)。Incorrectアクションが発動したら、検索文書は捨てられるんや。代わりにウェブ検索に頼って、修正用の補完的な知識源として使うんやで(セクション4.5)。最終的に、正しいか間違いかを自信持って判断できへん時は、両方を組み合わせたソフトでバランスの取れたAmbiguousアクションが発動するんや。検索結果を最適化した後は、任意の生成モデルを採用できるで。
### 4.2 検索評価器
検索した文書を使う前に、それがほんまに正確かどうか確認したいって思うのは当然やんな。これはめっちゃ重要やねん、なんでかっていうと関係ない情報や誤解を招くメッセージをこの段階で見分けられるからや。検索評価器の精度は、システム全体のパフォーマンスを形作る上で間違いなく重要な役割を果たしてるんや。後続のプロセスの結果に影響を与えるからな。
---
## Page 4
[](/attach/975aa1fd3c1b603126e93ff99d6504858b61301bf1d34c9df88ebe53a0b026cb_p004.png)
### 和訳
図2:推論時に提案するCRAGの全体像やで。取ってきた文書が入力とどれくらい関係あるか評価する「検索評価器」っていうのを作って、その確信度に応じて{正解、不正解、あいまい}っていう3種類の知識検索アクションを発動させる仕組みになってるねん。
ほんで、ワシらの目的は何かっていうと、取ってきた文書が的外れやったときにそれを修正することやねん。具体的にはな、T5-large(Raffelら、2020)っていうモデルを検索評価器の初期値として使って、それをファインチューニングしてるわけ。このモデルのパラメータサイズ、めっちゃ小さいねん。今どきの大規模言語モデル(Touvronら、2023a,b; Chowdheryら、2023; Anilら、2023; Brownら、2020; Ouyangら、2022; OpenAI、2023)と比べたら全然ちゃうで。Self-RAG(Asaiら、2024)と実験結果をちゃんと比較できるようにな、Self-RAGが提供してくれたContriever(Izacardら、2022)経由の検索結果を、うちの実験でもそのまま使わせてもらってん。評価器をファインチューニングするための「関連性あり」の信号は、既存のデータセットから集められるんよ。例えばPopQA(Mallenら、2023)っていうデータセットでは、各質問に対してWikipediaの正解サブジェクトのタイトルが付いてるやん。それを使えば、100%関連してるわけちゃうけど、まあまあ質の高いパッセージを追跡できるってわけ。これを関連性の信号としてファインチューニングに使ったんや。² 一方で、ファインチューニング用のネガティブサンプル(関係ない例)は、検索結果からランダムにサンプリングしてん。これらは入力クエリとけっこう似てるんやけど、実際には関連性がないやつやねん。このファインチューニングの詳しい話は付録B.3を見てな。各質問に対して、だいたい10個の文書が検索されるんやけど、質問と各文書を1つずつくっつけて入力にして、評価器が質問と文書のペアごとに関連スコアを予測するっていう仕組みや。ChatGPTに検索の関連性を判定させるプロンプトも試してみたんやけど、これがあかんかったわ。詳しくは5.5節で説明してるで。この計算された関連スコアに基づいて、検索が正しいか間違ってるか、アクショントリガーと紐づけて最終判定するねん。うちが提案したフレームワークでは、でかくて高いLLMにアクセスせんでも、比較的低コストで検索品質を評価できるのがミソやねん。Self-RAG(Asaiら、2024)の批評モデルがLLaMA-2(7B)を命令調整して使ってるのと比べたら、CRAGで設計した評価器はめっちゃ軽量(0.77B)っていうのが強みやで。
²https://huggingface.co/datasets/akariasai/PopQA
---
## Page 5
[](/attach/975aa1fd3c1b603126e93ff99d6504858b61301bf1d34c9df88ebe53a0b026cb_p005.png)
### 和訳
アルゴリズム1: CRAGの推論
必要なもん:E(検索評価くん)、W(クエリ書き換えくん)、G(生成くん)
入力:x(質問)、D = {d1, d2, ..., dk}(取ってきた文書たち)
出力:y(生成された回答)
1行目:scorei = Eが各ペア(x, di)の関連性を評価するねん、di ∈ D
2行目:Confidence = {score1, score2, ...scorek}を元に計算して最終判定を出すで
// Confidenceは3つの値があんねん:[CORRECT]、[INCORRECT]、[AMBIGUOUS]のどれか
3行目:もしConfidenceが[CORRECT]やったら
4行目:Internal_Knowledge = Knowledge_Refine(x, D)で内部知識を整理
5行目:k = Internal_Knowledge
6行目:そうやなくてConfidenceが[INCORRECT]やったら
7行目:External_Knowledge = Web_Search(Wがxを検索用に書き換えたやつ)で外から探してくる
8行目:k = External_Knowledge
9行目:そうやなくてConfidenceが[AMBIGUOUS]やったら
10行目:Internal_Knowledge = Knowledge_Refine(x, D)
11行目:External_Knowledge = Web_Search(Wがxを検索用に書き換えたやつ)
12行目:k = Internal_Knowledge + External_Knowledge(両方使うねん)
13行目:終わり
14行目:Gがxとkを使ってyを予測するで
4.3 アクションのきっかけ
関係ない文書を修正したり、ええ感じの文書を必要に応じて磨いたりするために、状況に応じてアクションを使い分けなあかんねん。さっき説明した各文書の信頼度スコアに基づいて、3種類のアクションを用意してて、上限と下限のしきい値を設定してんねん。
信頼度スコアが上限より高かったら、その文書は「Correct(正しい)」って判定されるし、下限より低かったら「Incorrect(間違い)」って判定されるわけや。どっちでもない場合は、もうちょいソフトで中間的なアクション、つまり「Ambiguous(曖昧)」が実行されるねん。各文書は個別に処理されて、最終的に統合されるで。
**Correct(正しい)について**
ここでは、少なくとも1つの文書の信頼度スコアが上限より高かったら、その検索は「Correct」やと判断するねん。そういう場合は、取ってきた結果の中に関連する文書があるってことやから、検索結果からの知識はより信頼できて正確やと考えられるわけや。でもな、関連する文書が見つかったとしても、その文書の中にはどうしてもノイズみたいな余計な情報が入ってまうねん。やから、その文書の中から一番大事な知識だけを抜き出すために、知識の精製メソッドをさらに設計してんねん。これについては4.4節で詳しく説明するで。
**Incorrect(間違い)について**
一方で、取ってきた全部の文書の信頼度スコアが下限より低かったら、その検索は「Incorrect」やと判断するねん。これは取ってきた文書が全部関係ないってことで、回答を生成するのに役立たへんってことや。検索結果からの知識が不正確やって判断されたら、それにしがみついとっても意味ないねん。なんでかっていうと、デタラメな情報を作り出してまう可能性が高いからや。やから、修正のために新しい知識源を探さなあかんねん。ここでウェブ検索を導入して、インターネットから探してくるわけや。これについては4.5節で詳しく説明するで。この修正アクションのおかげで、「頼れる知識が何もない」っていう困った状況を乗り越えられるようになるねん。
**Ambiguous(曖昧)について**
上の2つの状況以外は、中間的なアクションの「Ambiguous」に割り当てられるねん。これは一般的に、検索の正確さを判断するのが難しくて、評価くんが中途半端なスコアを出した時に起こるねん。検索評価くんが自分の判断に自信持ってへんから、「Correct」と「Incorrect」の両方で処理された知識を組み合わせてお互いを補完するようにすんねん。こういう穏やかでソフトな戦略を取ることで、システムの頑健性と回復力をめっちゃ強化できて、最適なパフォーマンスのためのより柔軟なフレームワークを育てられるっちゅうわけや。
**議論**
最初の実験で「Correct」と「Incorrect」のアクションだけを使ってみたら、CRAGの効果が検索評価くんの精度にめっちゃ左右されることがわかってん。なんでかっていうと、判断の確信度のレベルに関係なく、全部の入力ケースで知識をバッサリ切り替えてたからやと思われるねん。「Ambiguous」アクションの設計は
---
## Page 6
[](/attach/975aa1fd3c1b603126e93ff99d6504858b61301bf1d34c9df88ebe53a0b026cb_p006.png)
### 和訳
これめっちゃ大事なポイントやねんけど、検索の評価システムがどんだけ正確かってことに依存しすぎる問題を、かなり軽減してくれるんよ。
## 4.4 知識の精製
関連ありそうな文書を取ってきたら、次は「分解してから再構成する」っていう知識精製の方法を使って、その中から一番重要な知識の断片をさらに抽出していくねん。細かい粒度で検索結果を得るために、取ってきた結果を内部的な断片に分割するんよ。もし取ってきた結果が1〜2文くらいの短いもんやったら、それはそのまま1つの断片として扱うねん。そうじゃなくて長い場合は、全体の長さに応じてもっと小さい単位に分割せなあかんくて、だいたい数文ずつのまとまりになるんよ。このスケールは独立した情報の塊を含むって想定してて、フィルタリングはこの断片単位でやっていくねん。ほんで、セクション4.2でファインチューニングした検索評価器を使って、各知識断片の関連性スコアを計算するんよ。このスコアを基にして、関係ない知識断片は弾いて、関連あるやつは順番通りに連結して再構成する。これを「内部知識」って呼ぶねん。
## 4.5 ウェブ検索
システム自身が「あ、今持ってる知識だけじゃこの問題うまく解けへんな」って判断できて、追加の外部知識を探しに行けたら、めっちゃ賢いやんな。逆に考えてみ?システムが「今の知識じゃ解けへん」ってわかってるのに、それでも限られた知識にしがみついてたら、結局でっち上げた事実を出すしかなくなるんよ。これが「ハルシネーション」ってやつやねん。やから、取ってきた結果が全部関係なさそうって判断されたときに、補完的な外部知識を探しに行くのがめっちゃ重要なんよ。ほんで俺らは、「自分が知らんこと」「自分が答えられへんこと」をちゃんとわかってるシステムの方が、限られた知識にしがみついて外部の知識を探す能力がないシステムより賢いって考えてるねん。
なんでかっていうと、静的で限られたコーパスからの検索やと、範囲的にも多様性的にも最適とは言えへん文書しか返せへんからな。そこで大規模ウェブ検索(Piktus et al., 2021; Komeili et al., 2022)をRAGの戦略的拡張として組み込んでるんよ。具体的にはな、入力をChatGPTでキーワードで構成されたクエリに書き換えるねん。普段検索エンジン使うときみたいな感じを真似てな。書き換え用のプロンプトは付録Aに載せてるで。CRAGでは、公開されてて誰でもアクセスできる商用ウェブ検索APIを使って、各クエリに対して一連のURLリンクを生成するんよ。³ ただ、大規模ウェブ検索からの知識はバイアスとか信頼性の低い情報を持ち込む可能性があるから、Wikipediaみたいな権威があってちゃんと管理されてるウェブページを優先するようにしてて、これで問題をかなり軽減できるんよ。さらに、そのURLリンクを使ってウェブページに飛んで、中身を文字起こしして、セクション4.4と同じ知識精製の方法を使って関連するウェブ知識を抽出する。これを「外部知識」って呼ぶねん。
## 5 実験
CRAGがRAGベースのアプローチにどんだけ適応できるか、あと短文生成タスクと長文生成タスクの両方でどんだけ汎用的に使えるかを徹底的に示すために、実験やったで。
## 5.1 タスク、データセット、評価指標
CRAGは4つのデータセットで評価したんよ。PopQA(Mallen et al., 2023)は短文生成、Biography(Min et al., 2023)は長文生成、PubHealth(Zhang et al., 2023a)は真偽判定問題、Arc-Challenge(Bhakthavatsalam et al., 2021)は選択式問題やね。先行研究に従って、PopQA、PubHealth、Arc-Challengeには正解率を評価指標として使ったで。Biographyには FactScore(Min et al., 2023)を評価指標として使ったんよ。詳しくは付録B.1見てな。
同じ評価指標を使ってるのは、俺らの提案手法が先行研究と比較可能やからやねん。先行研究と同じ検索結果を使ってるしな。違いは何かっていうと、俺らのモチベーションは「システムが低品質って判断した検索結果を修正することで検索の質を上げる」ってとこにあるんよ。これはRAGが単体のパラメトリック言語モデルを強化するのに似てて、俺らはさらにRAGを修正戦略で強化してるってわけやね。
## 5.2 ベースライン
CRAGは主に、検索ありのアプローチと検索なしのアプローチの両方と比較したで。検索ありの方はさらに標準的なRAGと最新の高度なRAGに分けられるんよ。含まれるのは:
**検索なしのベースライン。** いくつかの公開LLMを評価したで。LLaMA2-7B、13B(Touvron et al., 2023b)、命令調整されたモデルのAlpaca-7B、13B(Dubois et al., 2023)、あと反復的なエンジニアリングを導入したCoVE65B(Dhuliawala et al., 2024)やね。
³ この研究ではGoogle Search APIを検索に使ってるで。
---
## Page 7
[](/attach/975aa1fd3c1b603126e93ff99d6504858b61301bf1d34c9df88ebe53a0b026cb_p007.png)
### 和訳
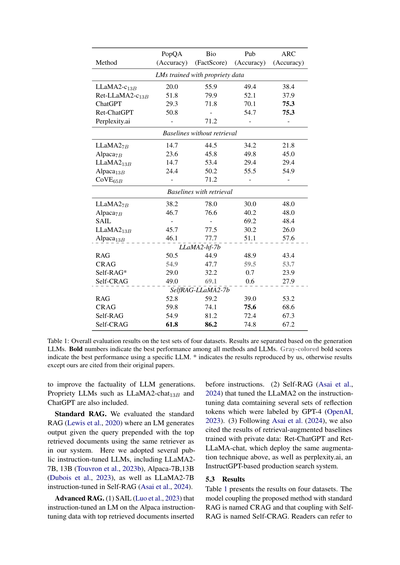
【方法】の表やな
PopQA(正答率)、Bio(FactScore)、Pub(正答率)、ARC(正答率)っていう4つのデータセットで評価した結果がこれやねん。
**企業秘密のデータで学習したLLMたち**
LLaMA2-chatの13Bとか、ChatGPT、Perplexity.aiみたいな大手のやつらの結果が上の方に載っとるで。検索機能つけたバージョン(Ret-ってついてるやつ)は、やっぱりスコア上がっとるな。
**検索なしのベースライン**
普通のLLaMA2の7Bと13B、あとAlpacaの7Bと13B、CoVEの65Bとかを検索機能なしで動かした結果やな。まあ、検索なしやとそこそこの成績やねん。
**検索ありのベースライン**
ここがおもろいとこやで!RAG、CRAG、Self-RAG、Self-CRAGって比較しとるんやけど、LLaMA2-hf-7bとSelfRAG-LLaMA2-7bで分けて見とる。Self-CRAGがめっちゃ強いのわかるやろ?Bioのデータセットでは86.2%とか叩き出しとるねん。
表1は、4つのデータセットのテストセットでの総合評価結果やな。生成に使ったLLMごとに分けて載せとるで。太字は全手法・全LLMの中で一番ええスコア、グレーの太字は特定のLLM使った中での最高スコアやねん。*がついとるのはワイらが再現実験したやつで、それ以外は元の論文から引用しとるで。
---
で、比較対象の説明やけど、まずLLMの事実性(ほんまのこと言うかどうか)を上げるための手法たちを見とるねん。LLaMA2-chatの13BとかChatGPTみたいな企業製のLLMも含めとるで。
**標準のRAG**やけど、これはLewisらが2020年に出したやつで、クエリの前に検索で取ってきた上位の文書をくっつけて、LMに出力させるんや。ワイらと同じ検索エンジン使っとるで。公開されとる指示チューニング済みLLMをいくつか使っとって、LLaMA2の7Bと13B、Alpacaの7Bと13B、あとSelf-RAGで指示チューニングしたLLaMA2-7Bも入れとるねん。
**進化版のRAG**はこんな感じや:
(1) SAILっていうのは、Alpacaの指示チューニングデータに検索結果を指示の前に挟み込んでLMをチューニングしたやつやねん。
(2) Self-RAGは、GPT-4がラベル付けした「振り返りトークン」っていうのを何セットか含んだ指示チューニングデータでLLaMA2をチューニングしたやつや。
(3) Asaiらの論文に従って、企業秘密データで学習した検索強化ベースラインの結果も引用しとるで。Ret-ChatGPTとRet-LLaMA-chat(上と同じ強化テクニック使っとる)、あとperplexity.ai(InstructGPTベースの本番検索システム)やな。
**5.3 結果**
表1が4つのデータセットでの結果やで。ワイらが提案した手法を標準RAGと組み合わせたのがCRAG、Self-RAGと組み合わせたのがSelf-CRAGって名前にしとるねん。詳しくは続きを見てな〜
---
## Page 8
[](/attach/975aa1fd3c1b603126e93ff99d6504858b61301bf1d34c9df88ebe53a0b026cb_p008.png)
### 和訳
ほな、付録B.3に提案した手法の実装の詳細が載ってるから、そっちも見てな。この結果から、こんなことがわかったんや:
**まず、提案した手法でRAGとSelf-RAGの性能がめっちゃ上がるっちゅうことやな。**
具体的に言うと、表1見てもらったらわかるけど、CRAGはRAGより全然ええ結果出したんや。SelfRAG-LLaMA2-7bベースやと、PopQAで7.0%、Biographyで14.9%のFactScore、PubHealthで36.6%、Arc-Challengeで15.4%も精度が上がってん。LLaMA2-hf-7bベースでも、PopQAで4.4%、Biographyで2.8%のFactScore、Arc-Challengeで10.3%アップや。
ほんで今一番イケてるSelf-RAGと比べても、Self-CRAGの方が上なんよ。LLaMA2-hf-7bベースやと、PopQAで20.0%、Biographyで36.9%のFactScore、Arc-Challengeで4.0%も勝ってる。SelfRAG-LLaMA2-7bベースでも、PopQAで6.9%、Biographyで5.0%のFactScore、PubHealthで2.4%上回ってんねん。この結果から何がわかるかっていうと、CRAGはプラグアンドプレイ、つまりポン付けできる柔軟さがあって、RAGベースのいろんな手法にサッと組み込めるっちゅうことやな。
**次に、提案した手法はいろんな生成タスクに対してめっちゃ汎用性が高いってことや。**
表1に載ってるベンチマークは、それぞれ違う実用シナリオを表してんねん。PopQAは短い文で実体を生成するやつ、Biographyは長文生成、PubHealthとArc-Challengeは選択肢から選ぶ閉じたタスクや。この結果でCRAGが一貫して効果的やってことが証明されたわけや。いろんなタスクでちゃんと使えるっていうのは、CRAGの頑健な能力と多様なシナリオへの汎用性を示してるんやで。
**ほんで三つ目、提案した手法は裏で動いてるLLM(大規模言語モデル)を別のに入れ替えるときの柔軟性がめっちゃ高いってことやな。**
見てみ、CRAGは裏のLLMをSelfRAG-LLaMA2-7bからLLaMA2-hf-7bに変えても、ちゃんとええ性能出してんねん。一方でSelf-RAGは性能がガクッと落ちて、いくつかのベンチマークでは普通のRAGにも負けてもうてる。
なんでこうなるかっていうとな、Self-RAGは人間やLLMがアノテーションしたデータを使って、特別な「批評トークン」っていうのを必要に応じて出力できるように命令調整せなあかんねん。でもこの能力は普通のLLMには備わってへんのよ。CRAGはそんな能力いらんから、その点で有利やねん。将来もっとすごいLLMが出てきたら、CRAGはすぐに組み合わせられるけど、Self-RAGは追加で命令調整せなあかんっちゅうことや。
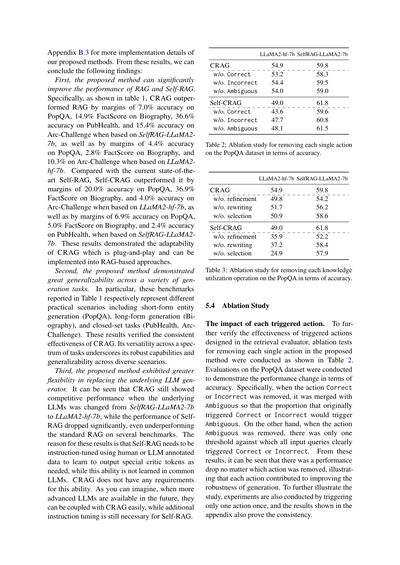
| | LLaMA2-hf-7b | SelfRAG-LLaMA2-7b |
|---|---|---|
| CRAG | 54.9 | 59.8 |
| Correct除去 | 53.2 | 58.3 |
| Incorrect除去 | 54.4 | 59.5 |
| Ambiguous除去 | 54.0 | 59.0 |
| Self-CRAG | 49.0 | 61.8 |
| Correct除去 | 43.6 | 59.6 |
| Incorrect除去 | 47.7 | 60.8 |
| Ambiguous除去 | 48.1 | 61.5 |
表2:PopQAデータセットでの各アクションを一つずつ除去したときのアブレーション実験(精度で評価)
| | LLaMA2-hf-7b | SelfRAG-LLaMA2-7b |
|---|---|---|
| CRAG | 54.9 | 59.8 |
| 精製除去 | 49.8 | 54.2 |
| 書き換え除去 | 51.7 | 56.2 |
| 選択除去 | 50.9 | 58.6 |
| Self-CRAG | 49.0 | 61.8 |
| 精製除去 | 35.9 | 52.2 |
| 書き換え除去 | 37.2 | 58.4 |
| 選択除去 | 24.9 | 57.9 |
表3:PopQAでの各知識活用操作を除去したときのアブレーション実験(精度で評価)
**5.4 アブレーション実験**
**各トリガーアクションの影響について**
検索評価器で設計したトリガーアクションがほんまに効いてるか確かめるために、提案手法から各アクションを一つずつ抜いたアブレーションテストをやったんが表2や。PopQAデータセットで精度の変化を見てみたで。
具体的にどうやったかっていうと、CorrectかIncorrectのアクションを除去したときは、それをAmbiguousと統合してん。つまり元々CorrectかIncorrectが発動するはずやったケースがAmbiguousになるようにしたんや。逆にAmbiguousを除去したときは、閾値を一個だけにして、全部の入力クエリがはっきりCorrectかIncorrectのどっちかになるようにしたんやな。
結果見たらわかるけど、どのアクションを除去しても性能が下がってんねん。つまり各アクションがそれぞれ生成の頑健性向上に貢献してるっちゅうことや。もっと詳しく調べるために、一回に一つのアクションだけ発動させる実験もやって、その結果は付録に載せてるけど、やっぱり一貫した結果が出てるで。
---
## Page 9
[](/attach/975aa1fd3c1b603126e93ff99d6504858b61301bf1d34c9df88ebe53a0b026cb_p009.png)
### 和訳
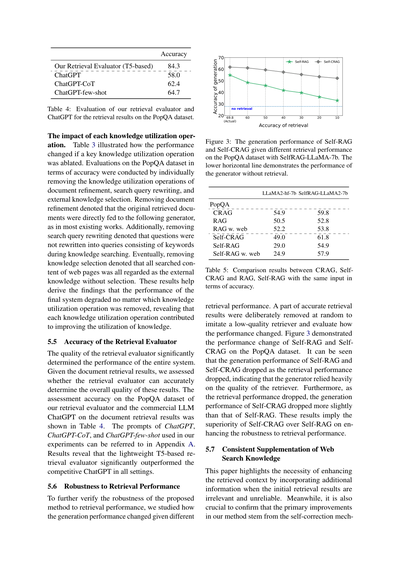
## 精度の話やで
| 手法 | 精度 |
|------|------|
| ウチらの検索評価器(T5ベース) | 84.3 |
| ChatGPT | 58.0 |
| ChatGPT-CoT(思考の連鎖ってやつ) | 62.4 |
| ChatGPT-few-shot(お手本ちょっと見せるやつ) | 64.7 |
表4:PopQAデータセットの検索結果に対して、ウチらの検索評価器とChatGPTがどんだけ正確に判断できるか比べてみた結果やで。
---
### それぞれの知識活用の操作がどんだけ効いてるか
表3見てもらったら、大事な知識活用の操作を一個ずつ外したらどうなるかがわかるねん。PopQAデータセットで精度を測って、「ドキュメントの整理」「検索クエリの書き換え」「外部知識の選別」をそれぞれ外して実験してん。
「ドキュメントの整理」を外すってことは、取ってきた文書をそのまんま次の生成器に渡すってことで、これは今までの研究でよくやってた方法やな。
「検索クエリの書き換え」を外すってことは、質問をキーワードだけのクエリに直さへんってことや。
最後に「知識の選別」を外すってことは、ウェブページから取ってきた内容を全部まるっと外部知識として使うってことやねん。選り好みせーへんってことやな。
結果見てわかったんは、**どれを外しても最終的なシステムの性能が落ちる**ってことやねん。つまり、それぞれの知識活用の操作がちゃんと知識をうまく使うのに貢献してるってことがわかったわけや。
---
### 5.5 検索評価器の精度について
検索評価器の質がシステム全体の性能をめっちゃ左右するねん。文書検索の結果が出たときに、その結果が全体的にええかどうかをちゃんと判断できるかどうかを評価してん。
PopQAデータセットでウチらの検索評価器と商用のChatGPTを比べた結果が表4やで。ChatGPT、ChatGPT-CoT、ChatGPT-few-shotで使ったプロンプトは付録Aを見てな。
結果やけど、**軽量なT5ベースの検索評価器が、どの設定でもChatGPTをめっちゃ上回ってる**ねん。すごない?
---
### 5.6 検索性能が悪くてもどんだけ頑張れるか
提案手法が検索性能が落ちてもどんだけ耐えられるか、もうちょい深掘りして調べてん。検索性能が変わったら生成性能がどう変わるか見たわけや。
図3:PopQAデータセットでSelfRAG-LLaMA-7bを使ったときの、Self-RAGとSelf-CRAGの生成性能やで。検索性能によってどう変わるか示してる。下の横線は検索なしで生成器だけ使ったときの性能やな。
| 手法 | LLaMA2-hf-7b | SelfRAG-LLaMA2-7b |
|------|--------------|-------------------|
| PopQA | - | - |
| CRAG | 54.9 | 59.8 |
| RAG | 50.5 | 52.8 |
| RAG + ウェブ検索 | 52.2 | 53.8 |
| Self-CRAG | 49.0 | 61.8 |
| Self-RAG | 29.0 | 54.9 |
| Self-RAG + ウェブ検索 | 24.9 | 57.9 |
表5:同じ入力でCRAG、Self-CRAGとRAG、Self-RAGを比べた精度の結果やで。
正確な検索結果の一部をわざとランダムに消して、質の悪い検索器を真似してみたねん。そんで性能がどう変わるか見たわけや。
図3がPopQAデータセットでのSelf-RAGとSelf-CRAGの性能変化を示してるで。見てわかるんは、**検索性能が落ちると生成性能も落ちる**ってことやな。つまり生成器は検索器の質にめっちゃ依存してるってことや。
ほんでな、検索性能が落ちたとき、**Self-CRAGの方がSelf-RAGより性能の落ち方がマシ**やねん。これが何を意味するかっていうと、Self-CRAGの方が検索性能が悪くても粘り強いってことや。Self-CRAGの方が優れてるってことやな。
---
### 5.7 ウェブ検索の知識を安定して補えるか
この論文で強調したいのは、最初の検索結果が的外れで信用でけへんときに、追加の情報を取り入れて検索結果を強化する必要があるってことやねん。
ほんでもう一個大事なのは、ウチらの手法の改善が主に**自己修正メカニズム**から来てるってことをちゃんと確認することや。ウェブ検索をただ足しただけで良くなったわけちゃうねん、ってことを示さなあかんわけや。
---
## Page 10
[](/attach/975aa1fd3c1b603126e93ff99d6504858b61301bf1d34c9df88ebe53a0b026cb_p010.png)
### 和訳
トークンあたりのTFLOPs
実行時間(秒)
RAG
CRAG
Self-RAG
Self-CRAG
26.5
27.2
26.5〜132.4
27.2〜80.2
0.363
0.512
0.741
0.908
表6:RAG、CRAG、Self-CRAG、Self-RAGの計算コストを比較したやつやねん。GPUでのトークンあたりのFLOPsと、1インスタンスあたりの実行時間を測ってみたんや。Self-CRAGの上限が低いんは、入力として3つの文章(正解、不正解、曖昧な内容)しか渡してへんからやねん。ちなみにこの表のデータは生成フェーズだけのざっくりした見積もりで、検索とかデータ処理の段階は含まれてへんで。
せやから、この改善はウェブ検索で追加情報ゲットしたからちゃうくて、ほんまに自己修正の仕組みのおかげやねんってことを示したいわけや。提案した自己修正の仕組みがほんまに効いてるんかをもっとはっきり見せるために、RAGもSelf-RAGも同じようにウェブ検索の知識を常に足して、取得できる知識の範囲を揃えたんや。
表5の結果見てみたら、RAGやSelf-RAGにウェブ検索の知識を常に足すと、ほとんどの場合で性能上がるんやけど(オリジナルのLLaMA2モデル使ったSelf-RAG w. webは別やけど)、その改善は限定的やねん。ほんでな、RAGやSelf-RAGに提案した自己修正の仕組みを加えたら、ウェブ検索の知識を常に足したモデルを全部のケースでめっちゃ上回ったんや。これで確認できたのは、観察された進歩は主に提案した自己修正の仕組みのおかげやってことやねん。
5.8 計算オーバーヘッドの分析
俺らの自己修正の仕組みが軽量でプラグアンドプレイ(差し込むだけで使える)なソリューションとして色んなRAGベースのフレームワークに使えるってことを示すために、計算コストを測ってみたで。Narayananらが2021年に出したFLOPs予測の計算式を使って、表6に結果を載せてんねん。GPUでのトークンあたりの予測FLOPsやな。Self-RAGは入力によって生成戦略がコロコロ変わるアダプティブな性質があるから、計算コストをピシッと決められへんのや。せやから範囲で示してんねん。
あと、PopQAで実験して、実際に1インスタンスあたりの平均実行時間も測ってみたで。それも表6に詳しく載ってるわ。結果から分かるんは、自己修正の仕組みは計算コストがちょっとしか増えへんのに、性能はめっちゃ上がるってことや。これで軽量やってことが証明できたな。
6 結論と限界
この論文では、RAGベースのアプローチが検索に失敗した時にどうなるかっていう問題を研究してんねん。検索がミスったら、生成型の言語モデルに不正確でミスリードな知識が渡されてまうやろ。そこでCorrective Retrieval Augmented Generation(訂正付き検索拡張生成)を提案して、生成の頑健性を改善しようとしてんねん。本質的には、軽量な検索評価器を使って、3つの知識検索アクションを判別してトリガーするんや。ウェブ検索もさらに活用して、知識の使い方も最適化することで、CRAGは自動的な自己修正能力と取得した文書の効率的な活用能力をめっちゃ改善したんやで。実験で、短文生成タスクにも長文生成タスクにも適応できることと、色んなRAGベースのアプローチに組み込める汎用性があることを広範囲に実証したで。
俺らは主に訂正の観点からRAGフレームワークを改善することを提案してて、CRAGは色んなRAGベースのアプローチとシームレスに組み合わせられるんやけど、外部の検索評価器をファインチューニングせなあかんのは避けられへんねん。この外部評価器をなくして、LLM自身にもっとええ検索評価能力を持たせる方法が今後の課題やな。
参考文献
Rohan Anil, Andrew M. Dai, Orhan Firat, Melvin Johnson, Dmitry Lepikhin, Alexandre Passos, Siamak Shakeri, Emanuel Taropa, Paige Bailey, Zhifeng Chen, Eric Chu, Jonathan H. Clark, Laurent El Shafey, Yanping Huang, Kathy Meier-Hellstern, Gaurav Mishra, Erica Moreira, Mark Omernick, Kevin Robinson, Sebastian Ruder, ほか. 2023. PaLM 2 技術レポート. CoRR, abs/2305.10403.
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, Hannaneh Hajishirzi. 2024. Self-rag: 自己反省を通じて検索、生成、批評を学習する. The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net.
Yejin Bang, Samuel Cahyawijaya, Nayeon Lee, Wenliang Dai, Dan Su, Bryan Wilie, Holy Lovenia, Ziwei Ji, Tiezheng Yu, Willy Chung, Quyet V. Do, Yan Xu, Pascale Fung. 2023. ChatGPTの推論、ハルシネーション、インタラクティビティに関するマルチタスク、多言語、マルチモーダル評価. pages 675–718.
Sumithra Bhakthavatsalam, Daniel Khashabi, Tushar Khot, Bhavana Dalvi Mishra, Kyle Richardson, Ashish Sabharwal, Carissa Schoenick, Oyvind
---
## Page 11
[](/attach/975aa1fd3c1b603126e93ff99d6504858b61301bf1d34c9df88ebe53a0b026cb_p011.png)
### 和訳
Tafjord, Peter Clark. 2021. 「直接回答型の質問応答、もう解決したと思ってへん?ARC-DA試してみいや、AI2の推論チャレンジの直接回答版やで」CoRR, abs/2102.03315.
Tom B Brown, Benjamin Mann, Nick Ryder, ほか. 2020. 「言語モデルって少数のサンプルで学習できんねん」Advances in neural information processing systems, 1877–1901ページ.
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, Parker Schuh, Kensen Shi, Sasha Tsvyashchenko, Joshua Maynez, Abhishek Rao, Parker Barnes, Yi Tay, Noam Shazeer, Vinodkumar Prabhakaran, Emily Reif, Nan Du, Ben Hutchinson, Reiner Pope, James Bradbury, Jacob Austin, Michael Isard, Guy Gur-Ari, Pengcheng Yin, Toju Duke, Anselm Levskaya, Sanjay Ghemawat, Sunipa Dev, Henryk Michalewski, Xavier Garcia, Vedant Misra, Kevin Robinson, Liam Fedus, Denny Zhou, Daphne Ippolito, David Luan, Hyeontaek Lim, Barret Zoph, Alexander Spiridonov, Ryan Sepassi, David Dohan, Shivani Agrawal, Mark Omernick, Andrew M. Dai, Thanumalayan Sankaranarayana Pillai, Marie Pellat, Aitor Lewkowycz, Erica Moreira, Rewon Child, Oleksandr Polozov, Katherine Lee, Zongwei Zhou, Xuezhi Wang, Brennan Saeta, Mark Diaz, Orhan Firat, Michele Catasta, Jason Wei, Kathy Meier-Hellstern, Douglas Eck, Jeff Dean, Slav Petrov, Noah Fiedel. 2023. 「PaLM: Pathwaysっちゅう仕組み使って言語モデルをめっちゃでっかくスケールさせたで」J. Mach. Learn. Res., 24:240:1–240:113.
Shehzaad Dhuliawala, Mojtaba Komeili, Jing Xu, Roberta Raileanu, Xian Li, Asli Celikyilmaz, Jason Weston. 2024. 「Chain-of-Verification(検証の連鎖)で大規模言語モデルの幻覚、つまり嘘っぱち生成を減らせんねん」3563–3578ページ.
Yann Dubois, Xuechen Li, Rohan Taori, Tianyi Zhang, Ishaan Gulrajani, Jimmy Ba, Carlos Guestrin, Percy Liang, Tatsunori B. Hashimoto. 2023. 「AlpacaFarm: 人間のフィードバックから学ぶ手法のためのシミュレーション環境作ったで」CoRR, abs/2305.14387.
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, Ming-Wei Chang. 2020. 「検索で補強した言語モデルの事前学習やで」Proceedings of the 37th International Conference on Machine Learning, ICML 2020, 2020年7月13-18日, バーチャル開催, volume 119 of Proceedings of Machine Learning Research, 3929–3938ページ. PMLR.
Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bojanowski, Armand Joulin, Edouard Grave. 2022. 「対照学習使った教師なし密検索やねん」Trans. Mach. Learn. Res., 2022.
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Yejin Bang, Andrea Madotto, Pascale Fung. 2023. 「自然言語生成における幻覚(ハルシネーション)のサーベイやで」なんでかっていうと、AIが事実と違うことをもっともらしく言うてまう問題があんねん。ACM Comput. Surv., 55(12):248:1–248:38.
Zhengbao Jiang, Frank F. Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, Graham Neubig. 2023. 「能動的検索拡張生成やで」つまり必要なときに自分で検索しにいくRAGやな。Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, シンガポール, 2023年12月6-10日, 7969–7992ページ. Association for Computational Linguistics.
Jaehyung Kim, Jaehyun Nam, Sangwoo Mo, Jongjin Park, Sang-Woo Lee, Minjoon Seo, Jung-Woo Ha, Jinwoo Shin. 2024. 「SURE: オープンドメイン質問応答で、回答候補使って検索結果を要約する方法やねん」The Twelfth International Conference on Learning Representations, ICLR 2024, ウィーン, オーストリア, 2024年5月7-11日. OpenReview.net.
Mojtaba Komeili, Kurt Shuster, Jason Weston. 2022. 「インターネットで補強した対話生成やで」Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2022, ダブリン, アイルランド, 2022年5月22-27日, 8460–8478ページ. Association for Computational Linguistics.
Patrick S. H. Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela. 2020. 「知識いっぱい必要なNLPタスクのための検索拡張生成(RAG)やで」めっちゃ有名な論文やな。Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, 2020年12月6-12日, バーチャル開催.
Huayang Li, Yixuan Su, Deng Cai, Yan Wang, Lemao Liu. 2022. 「検索拡張テキスト生成のサーベイやで」CoRR, abs/2202.01110.
Yanming Liu, Xinyue Peng, Xuhong Zhang, Weihao Liu, Jianwei Yin, Jiannan Cao, Tianyu Du. 2024. 「RA-ISF: 繰り返し自己フィードバックで検索拡張から回答と理解を学ぶ方法やねん」Findings of the Association for Computational Linguistics, ACL 2024, バンコク, タイ&オンライン, 2024年8月11-16日, 4730–4749ページ. Association for Computational Linguistics.
Hongyin Luo, Tianhua Zhang, Yung-Sung Chuang, Yuan Gong, Yoon Kim, Xixin Wu, Helen Meng, James R. Glass. 2023. 「検索で補強した指示学習やで」Findings of the Association for Computational Linguistics: EMNLP 2023, シンガポール, 2023年12月6-10日, 3717–3729ページ. Association for Computational Linguistics.
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, Hannaneh Hajishirzi. 2023. 「言語モデルをいつ信用したらあかんのか:パラメトリックメモリと非パラメトリックメモリの効果を調べてみたで」なんでかっていうと、モデルが自分の中に持ってる知識と、外から取ってくる知識、どっちがええか場合によるねん。Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, トロント, カナダ, 2023年7月9-14日, 9802–9822ページ. Association for Computational Linguistics.
---
## Page 12
[](/attach/975aa1fd3c1b603126e93ff99d6504858b61301bf1d34c9df88ebe53a0b026cb_p012.png)
### 和訳
Sewon Minさん、Kalpesh Krishnaさん、Xinxi Lyuさん、Mike Lewisさん、Wen-tau Yihさん、Pang Wei Kohさん、Mohit Iyyerさん、Luke Zettlemoyerさん、Hannaneh Hajishirziさん。2023年の論文やねん。「Factscore: 長文テキスト生成における事実の正確さを細かく評価する方法」っていうタイトルで、2023年12月6日から10日にシンガポールで開催されたEMNLP 2023っていう自然言語処理の学会で発表されて、12076ページから12100ページに載ってるねん。Association for Computational Linguisticsっていう学会が出版元やで。
Dor Muhlgayさん、Ori Ramさん、Inbal Magarさん、Yoav Levineさん、Nir Ratnerさん、Yonatan Belinkovさん、Omri Abendさん、Kevin Leyton-Brownさん、Amnon Shashuaさん、Yoav Shohamさん。2023年の論文で、「言語モデルの事実性を評価するためのベンチマーク生成」っていうやつやねん。CoRRっていうプレプリントサーバーに出てて、論文番号はabs/2307.06908やで。
Deepak Narayananさん、Mohammad Shoeybiさん、Jared Casperさん、Patrick Legresleyさん、Mostofa Patwaryさん、Vijay Korthikantiさん、Dmitri Vainbrandさん、Prethvi Kashinkuntiさん、Julie Bernauerさん、Bryan Catanzaroさん、Amar Phanishayeeさん、Matei Zahariaさん。2021年の論文やねん。「Megatron-LMを使ってGPUクラスタで効率よく大規模言語モデルを学習させる方法」っていう内容で、2021年11月14日から19日にアメリカのミズーリ州セントルイスで開催されたSC 2021(スーパーコンピューティングの国際学会)で発表されて、58ページに載ってるねん。ACMが出版元やで。
OpenAI。2023年の論文で、「GPT-4の技術レポート」やねん。CoRRに出てて、論文番号はabs/2303.08774やで。
Long Ouyangさん、Jeffrey Wuさん、Xu Jiangさん、Diogo Almeidaさん、Carroll L. Wainwrightさん、Pamela Mishkinさん、Chong Zhangさん、Sandhini Agarwalさん、Katarina Slamaさん、Alex Rayさん、John Schulmanさん、Jacob Hiltonさん、Fraser Keltonさん、Luke Millerさん、Maddie Simensさん、Amanda Askellさん、Peter Welinderさん、Paul F. Christianoさん、Jan Leikeさん、Ryan Loweさん。2022年の論文やねん。「人間のフィードバックを使って言語モデルに指示に従うように学習させる方法」っていう内容で、NeurIPSっていうめっちゃ有名な機械学習の学会で発表されたんやで。
Aleksandra Piktusさん、Fabio Petroniさん、Vladimir Karpukhinさん、Dmytro Okhonkoさん、Samuel Broscheitさん、Gautier Izacardさん、Patrick S. H. Lewisさん、Barlas Oguzさん、Edouard Graveさん、Wen-tau Yihさん、Sebastian Riedelさん。2021年の論文で、「ウェブはあなたの宝庫 - めっちゃ巨大なウェブコーパスに対する知識集約型NLP」っていうやつやねん。CoRRに出てて、論文番号はabs/2112.09924やで。
Chengwei Qinさん、Aston Zhangさん、Zhuosheng Zhangさん、Jiaao Chenさん、Michihiro Yasunagaさん、Diyi Yangさん。2023年の論文やねん。「ChatGPTって汎用的な自然言語処理タスクを解けるんやろか?」っていう問いを検証した研究で、2023年12月6日から10日にシンガポールで開催されたEMNLP 2023で発表されて、1339ページから1384ページに載ってるねん。Association for Computational Linguisticsが出版元やで。
Colin Raffelさん、Noam Shazeerさん、Adam Robertsさん、Katherine Leeさん、Sharan Narangさん、Michael Matenaさん、Yanqi Zhouさん、Wei Liさん、Peter J. Liuさん。2020年の論文やねん。「統一的なtext-to-text変換器を使った転移学習の限界を探る」っていう内容で、J. Mach. Learn. Res.(機械学習研究ジャーナル)の21巻、140:1から140:67に載ってるで。
Md. Rashad Al Hasan Ronyさん、Ricardo Usbeckさん、Jens Lehmannさん。2022年の論文やねん。「Dialokg: 知識構造を意識したタスク指向対話生成」っていう研究で、2022年7月10日から15日にアメリカのワシントン州シアトルで開催されたNAACL 2022のFindingsに載ってて、2557ページから2571ページやねん。Association for Computational Linguisticsが出版元やで。
Timo Schickさん、Jane Dwivedi-Yuさん、Roberto Dessìさん、Roberta Raileanuさん、Maria Lomeliさん、Eric Hambroさん、Luke Zettlemoyerさん、Nicola Canceddaさん、Thomas Scialomさん。2023年の論文で、「Toolformer: 言語モデルは自分でツールの使い方を学習できるんやで」っていう画期的な研究やねん。
Freda Shiさん、Xinyun Chenさん、Kanishka Misraさん、Nathan Scalesさん、David Dohanさん、Ed H. Chiさん、Nathanael Schärliさん、Denny Zhouさん。2023年の論文やねん。「大規模言語モデルは関係ない情報に簡単に気を取られてまうんやで」っていう内容で、第40回国際機械学習会議(ICML)で発表されて、Proceedings of Machine Learning Researchの202巻、31210ページから31227ページに載ってるねん。PMLRが出版元やで。
Kurt Shusterさん、Spencer Poffさん、Moya Chenさん、Douwe Kielaさん、Jason Westonさん。2021年の論文やねん。「検索で補強したら会話でのハルシネーション(嘘つき問題)が減るんやで」っていう研究で、2021年11月16日から20日にバーチャル開催されたEMNLP 2021のFindings(ドミニカ共和国のプンタカナとのハイブリッド開催)に載ってて、3784ページから3803ページやねん。Association for Computational Linguisticsが出版元やで。
Chao-Hong Tanさん、Jia-Chen Guさん、Chongyang Taoさん、Zhen-Hua Lingさん、Can Xuさん、Huang Huさん、Xiubo Gengさん、Daxin Jiangさん。2022年の論文やねん。「Tegtok: タスク特化型とオープンワールドの知識でテキスト生成を強化する」っていう研究で、2022年5月22日から27日にアイルランドのダブリンで開催されたACL 2022のFindingsに載ってて、1597ページから1609ページやねん。Association for Computational Linguisticsが出版元やで。
S. M. Towhidul Islam Tonmoyさん、S. M. Mehedi Zamanさん、Vinija Jainさん、Anku Raniさん、Vipula Rawteさん、Aman Chadhaさん、Amitava Dasさん。2024年の論文で、「大規模言語モデルのハルシネーション(嘘つき問題)を軽減する技術の包括的サーベイ」っていうめっちゃ網羅的なレビュー論文やねん。CoRRに出てて、論文番号はabs/2401.01313やで。
Hugo Touvronさん、Thibaut Lavrilさん、Gautier Izacardさん、Xavier Martinetさん、Marie-Anne Lachauxさん、Timothée Lacroixさん、Baptiste Rozièreさん、Naman Goyalさん、Eric Hambroさん、Faisal Azharさん、Aurélien Rodriguezさん、Armand Joulinさん、Edouard Graveさん、Guillaume Lampleさん。2023年aの論文やねん。「Llama: オープンで効率的な基盤言語モデル」っていう研究で、CoRRに出てて、論文番号はabs/2302.13971やで。
Hugo Touvronさん、Louis Martinさん、Kevin Stoneさん、Peter Albertさん、Amjad Almahairiさん、Yasmine Babaeiさん、Nikolay Bashlykovさん、Soumya Batraさん、Prajjwal Bhargavaさん、Shruti Bhosaleさん、Dan Bikelさん、Lukas Blecherさん、その他大勢。2023年bの論文やねん。「Llama 2: オープンな基盤モデルとファインチューニング済みチャットモデル」っていう研究で、CoRRに出てて、論文番号はabs/2307.09288やで。
Zihao Wangさん、Anji Liuさん、Haowei Linさん、Jiaqi Liさん、Xiaojian Maさん、Yitao Liangさん。2024年の論文やねん。「RAT: 検索で補強された思考が長期的な生成で文脈を意識した推論を引き出すんやで」っていう研究で、CoRRに出てて、論文番号はabs/2403.05313やで。
Ori Yoranさん、Tomer Wolfsonさん、Ori Ramさん、Jonathan Berantさん。2024年の論文で、「検索で補強した言語モデルを関係ない文脈に対して頑健にする方法」っていう研究やねん。
---
## Page 13
[](/attach/975aa1fd3c1b603126e93ff99d6504858b61301bf1d34c9df88ebe53a0b026cb_p013.png)
### 和訳
ほな、これらの参考文献を関西弁で説明していくで!
---
Tianhua Zhang、Hongyin Luo、Yung-Sung Chuang、Wei Fang、Luc Gaitskell、Thomas Hartvigsen、Xixin Wu、Danny Fox、Helen Meng、そしてJames R. Glass。2023a年の論文やねん。「解釈可能な統合言語チェック」っていうタイトルで、要するに言葉のチェックを一つにまとめて、しかもなんでそう判断したんかわかるようにしたシステムの話やな。CoRRっていうプレプリントサーバーに出とって、論文番号はabs/2304.03728や。
Tianjun Zhang、Shishir G. Patil、Naman Jain、Sheng Shen、Matei Zaharia、Ion Stoica、そしてJoseph E. Gonzalez。2024年の論文やで。「RAFT:言語モデルを特定分野のRAGに適応させる方法」っていう内容やねん。RAGっていうのは検索して情報引っ張ってきて回答する仕組みのことやけど、それを専門分野向けにチューニングする話やな。めっちゃ実用的やで。CoRRのabs/2403.10131に載っとるわ。
Yue Zhang、Yafu Li、Leyang Cui、Deng Cai、Lemao Liu、Tingchen Fu、Xinting Huang、Enbo Zhao、Yu Zhang、Yulong Chen、Longyue Wang、Anh Tuan Luu、Wei Bi、Freda Shi、そしてShuming Shi。2023b年の論文やねん。「AIの海に響くセイレーンの歌:大規模言語モデルにおけるハルシネーションの調査」っていうタイトルで、これがほんまにおもろいねん。ハルシネーションっていうのは、AIがもっともらしい嘘をつくことやねんけど、それについてめっちゃ網羅的に調べた総説論文や。セイレーンって昔のギリシャ神話で船乗りを歌で惑わす魔物のことやけど、AIの嘘もそれと似とるやろ?っていう洒落た例えやな。CoRRのabs/2309.01219にあるで。
Qihuang Zhong、Liang Ding、Juhua Liu、Bo Du、そしてDacheng Tao。2023年の論文や。「ChatGPTも理解できるんか?ChatGPTとファインチューニングしたBERTの比較研究」っていう内容やねん。なんでかっていうと、ChatGPTがめっちゃ流行ったけど、ほんまに言葉を「理解」しとるんか、それとも前からあるBERTを専用に訓練したやつのほうがええんか、ちゃんと比べてみましょうや、っていう研究やな。CoRRのabs/2302.10198に載っとるわ。
---
---
## Page 14
[](/attach/975aa1fd3c1b603126e93ff99d6504858b61301bf1d34c9df88ebe53a0b026cb_p014.png)
### 和訳
# 付録A:タスクのプロンプトたち
ウェブ検索のクエリに使う知識キーワードを生成するためのプロンプトは、表7に載せてるで。
**表7:GPT-3.5 Turboに知識キーワード(ウェブ検索クエリ用)を生成させるためのfew-shotプロンプト**
> 以下の対話と質問から、ウェブ検索のクエリとして使えるキーワードを最大3つ、カンマ区切りで抽出してな。対話の中の話題の背景と、質問の中の主な意図を含めてや。
>
> 質問:Henry Feildenの職業は何?
> クエリ:Henry Feilden, occupation
>
> 質問:Billy Carlsonはどの街で生まれた?
> クエリ:city, Billy Carlson, born
>
> 質問:John Gwynnの宗教は何?
> クエリ:religion of John Gwynn
>
> 質問:Kiribati男子バスケットボール代表チームは何のスポーツをしてる?
> クエリ:sport, Kiribati men's national basketball team play
>
> 質問:[質問]
> クエリ:
---
ChatGPTを評価者として使うときのプロンプトは、表8、表9、表10にそれぞれ載せてるで。
**表8:GPT-3.5 Turboを評価者として使うときのシンプルなプロンプト**
> 質問が与えられたとき、以下のドキュメントにはその質問に答えるための正確な情報が含まれてる?yesかnoだけで答えてな。
> 質問:[質問]
> ドキュメント:[ドキュメント]
**表9:GPT-3.5 TurboをChain-of-Thought(ステップバイステップ思考)付きで評価者として使うときのプロンプト**
> 質問が与えられたとき、以下のドキュメントにはその質問に答えるための正確な情報が含まれてる?
> 質問:[質問]
> ドキュメント:[ドキュメント]
> ステップバイステップで考えて、yesかnoだけで答えてな。
**表10:GPT-3.5 Turboを評価者として使うときのfew-shotプロンプト**
> 質問が与えられたとき、以下のドキュメントにはその質問に答えるための正確な情報が含まれてる?yesかnoだけで答えてな。
>
> 質問:Abraham Raimbachはどの街で生まれた?
> ドキュメント:Bancroftは1839年11月25日、ニューハンプシャー州New IpswichでJames BancroftとSarah Kimballの間に生まれた。幼い頃、隣町のマサチューセッツ州AshbyのPatch夫妻に育てられた。法的に養子縁組されたわけやないけど、Patch夫妻は最近亡くなった息子にちなんでCecil Franklin Patch Bancroftという名前をつけた。AshbyとNew IpswichのAppleton Academyの公立学校に通った。1856年に16歳でダートマス大学に入学し、1860年にクラスのトップ付近で卒業した。Bancroftは教職のキャリアを始めながら教育を続けた。1864-65年度にはニューヨーク市のUnion Theological Seminaryで授業を受けた。そこにいる間、United States Christian Commissionのメンバーとして南北戦争中に兵士を支援するために各地を回った。その後Andover Theological Seminaryに移り、1867年に卒業した。
> 答え:No.
>
> 質問:Wilcza Jama, Sokółka Countyはどの国にある?
> ドキュメント:Wilcza Jamaはポーランド北東部、ベラルーシとの国境近くのポドラシェ県Sokółka郡Gmina Sokółkaの行政区にある村や。
> 答え:Yes.
>
> 質問:2004 Legg Mason Tennis Classicは何のスポーツをしてる?
> ドキュメント:2004 Legg Mason Tennis Classicはこのテニストーナメントの36回目の大会で、屋外ハードコートで行われた。このトーナメントは2004 ATPツアーのInternational Seriesの一部やった。2004年8月16日から22日まで、ワシントンD.C.のWilliam H.G. FitzGerald Tennis Centerで開催された。
> 答え:Yes.
>
> 質問:Skinの著者は誰?
> ドキュメント:「The Skin We're In: A Year of Black Resistance and Power」はDesmond Coleが書いた本で、2020年にDoubleday Canadaから出版された。この本は2017年のカナダにおける人種差別との闻いを描いてて、反人種差別活動家としてのColeの役割とカナダ社会における制度的人種差別の影響を年代記として記録してる。2016年後半のDafonte Miller暴行事件の余波やCanada 150などの出来事を論じてる。この本はカナダもアメリカ社会を特徴づける反黒人人種差別と無縁ではないと主張してる。出版社のミスで、初版の表紙にはサブタイトルの「Black」という言葉が含まれてなかった。このミスは後に修正された。この本は2020年のToronto Book Awardを受賞した。2021年には政治著作部門のShaughnessy Cohen Prizeにノミネートされた。
> 答え:No.
>
> 質問:[質問]
> ドキュメント:[ドキュメント]
> 答え:
---
## Page 15
[](/attach/975aa1fd3c1b603126e93ff99d6504858b61301bf1d34c9df88ebe53a0b026cb_p015.png)
### 和訳
# B 実験
## B.1 タスク、データセットと評価指標
CRAGの評価には4つのデータセットを使ったんやけど、全部パブリックドメインで研究目的で使えるライセンスのもんやねん。ほな紹介していくで!
**PopQA**(Mallenら、2023)は短い文を生成するタスクやねん。基本的に、1つの質問に対して1つの事実知識を答えることが求められるわけや。今回の実験では、Self-RAG(Asaiら、2024)の設定をそのまま踏襲して、月間ウィキペディアの閲覧数が100回未満というレアな存在(エンティティ)に関する1,399件のクエリで評価したんや。要するにマイナーな知識をちゃんと答えられるか試したってことやな。評価指標は正解率(Accuracy)を使ったで。
**Biography**(Minら、2023)は長文生成のタスクやねん。ある人物について詳しい伝記を書くっていうお題や。先行研究に倣って、FactScore(Minら、2023)っていう指標で生成された伝記を評価したんやで。
**PubHealth**(Zhangら、2023a)は医療・健康分野の○×問題みたいなもんやねん。健康に関する事実情報を含む主張が提示されて、その真偽を判断するタスクや。これも正解率で評価したで。
**Arc-Challenge**(Bhakthavatsalamら、2021)は日常の科学現象に関する選択問題やねん。日常生活で起こる科学的な出来事について、3つか4つの選択肢から正しい説明を選ぶんや。これも正解率で評価したで。
## B.2 実験に使った計算リソース
実験にはNVIDIA A800 80GB GPUを使ったんや。LLaMA-2(70億パラメータ)で文章生成するときは、推論中に40GB以上のメモリを食うねん。めっちゃ重いやろ?T5-large(7.7億パラメータ)のファインチューニングはLLaMA-2に比べたらだいぶ軽かったけどな。
## B.3 実装の詳細
**検索評価器(Retrieval Evaluator)**:軽量なT5-large(Raffelら、2020)の事前学習モデルをベースにファインチューニングしたんや。使ったデータセットはSelf-RAG(Asaiら、2024)が提供してるバージョンやねん。具体的に言うと、元のPopQAデータセットは1万4千件のサンプルがあって、そのうち1,399件はSelf-RAGに倣ってテスト用に使って、残りはファインチューニングに回したんや。なんでかっていうと、情報漏れを防ぐためやねん。あと、このファインチューニングした評価器はBio、Pub、ARCのデータセットでも推論時に転用したで。正例のラベルは1、負例は-1に設定して、推論時には各文書の関連度を-1から1の間でスコアリングするんや。3つのアクションのどれを発動するかを決める2つの信頼度閾値は経験的に設定したで。具体的には、PopQAでは(0.59, -0.99)、PubQAとArc-Challengeでは(0.5, -0.91)、Biographyでは(0.95, -0.91)って感じや。
**内部知識(Internal Knowledge)**:きめ細かい検索結果を得るために、検索結果を内部ストリップ(小さな断片)に分割したんや。検索結果が1〜2文くらい短かったらそのまま1つのストリップとして扱うけど、長い文書は全体の長さに応じて数文からなる小さい単位に分割する必要があるねん。この規模感やと独立した1つの情報を含むと想定して、フィルタリングはこのセグメント単位でやるんや。知識ストリップのフィルタリングにも同じ評価器を使って、top-kは5、フィルタ閾値は-0.5に設定したで。
**外部知識(External Knowledge)**:関連URLの検索にはGoogle Search APIを使ったんや。top-kは5に設定して、ウィキペディアのページは優先的に追加するようにしたで。検索されたウェブページは大体HTMLファイルの形式で、`<p>`とか`</p>`みたいな特殊タグでコンテンツが区切られてるやん。せやから内部知識みたいに追加でセグメンテーションする必要はなくて、関連する知識の段落を内部知識と同じように評価器で直接選択できるんや。こうすることで、生成に使う情報の品質と関連性を損なわずに検索結果の精度を確保できるってわけやねん。
**生成器(Generator)**:CRAGはプラグアンドプレイ方式やから、RAGで使える生成モデルならなんでも使えるんや。ベースラインとの比較で一貫性を保つために、生成にはLLaMA2(Touvronら、2023b)を採用したで。まずHuggingfaceのLLaMA2-hf-7bで応答を生成したんやけど、Self-RAG(Asaiら、2024)がLLaMA2をファインチューニングしていくつかのタスクで最高性能を達成してたから、彼らの研究と整合性を取って手法の具体的な改善を調べるために、公開モデルのSelfRAG-LLaMA2-7bも新しい生成器として使ったんや。
**Self-CRAG**:うちのプラグアンドプレイ手法が他の同時期の研究でも使えることを示すために、CRAGをSelf-RAG(Asaiら、2024)のフレームワークに組み込んで、Self-CRAGって名付けたんや。
---
## Page 16
[](/attach/975aa1fd3c1b603126e93ff99d6504858b61301bf1d34c9df88ebe53a0b026cb_p016.png)
### 和訳
表11: PopQAデータセットで1つのアクションだけを取り除いた時の精度に関するアブレーション研究やで。
LLaMA2-hf-7b SelfRAG-LLaMA2-7b
CRAG
Correctだけの時
Incorrectだけの時
Ambiguousだけの時
Self-CRAG
Correctだけの時
Incorrectだけの時
Ambiguousだけの時
54.9
52.4
47.0
52.7
49.0
48.6
40.8
44.9
59.8
56.7
48.5
58.0
61.8
57.2
53.3
59.8
これはな、めっちゃ進化したRAGのやり方で、批評家モデルっていうのを導入してんねん。要は「情報取ってくるべきか?」「取ってきた文書のどれを参考にして回答作るべきか?」を判断してくれるやつや。ほんまにウチらが求めてた「どのアクションを発動させるか」を決める機能にピッタリやったから、Self-RAGの中の取得アイテムを入れ替えたんよ。具体的にはな、Correct(正解)の時は内部知識を処理したやつ、Incorrect(不正解)の時は外部知識、Ambiguous(あいまい)の時は両方を組み合わせた知識を使うようにしたんや。
B.4 もっと詳しい結果
アブレーション研究: 下の表11の結果は、全部のケースに対して1つのアクションだけを発動させた時のアブレーション研究を示してるで。
B.5 PubHealthとArc-Challengeでの結果
ここでちょっと言うとかなあかんのやけど、LLaMA2-hf-7bを使った時のPubHealthでの性能がな、他と比べてめっちゃ悪かってん。なんでかっていうと、このケースをよう調べたら、LLaMA2-hf-7bは指示の理解力がちょっと弱いことがわかったんや。二択で「True」か「False」って答えなあかんタスクやのに、ほとんどのケースでそれがちゃんと生成でけへんかって、評価の時に精度がガクッと下がってもうたんよ。同じような状況がArc-Challengeでもちょいちょい起きててな、モデルに「候補の番号を答えてや」って言うてるのに、うまいこといかへん時があるんや。
---
![]()
1 / 1
100%