<<
Long-context LLMs Struggle with Long In-context Learning
・Claudeでロングコンテキストが特に注目されているけど、ロングコンテキストの学習を計った研究。2024年。
・結果は自明で、長いと学習に支障がでるということなのだけど、定量的に結果を明示していることが良い。
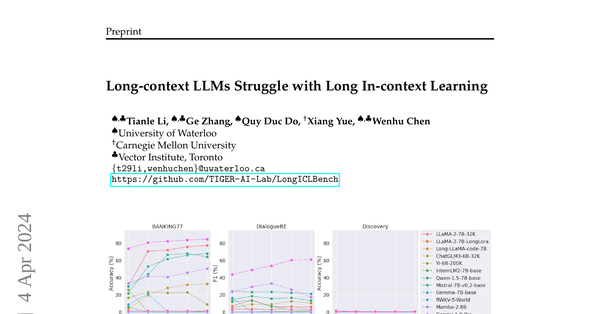
・QwenやMistralなど一部のLLMは、入力の長さに対してほぼ線形に性能が低下したって書いてある。モノによってそういうふうな因果関係があったりもするのね。
・プロンプトの入力例の配置が性能に影響することも分かったと書いてある。経験則的にそんなこともあるのかなぁと思っていたけど、これからLLMを使う際にはその点意識するようにしよう。Long-context LLMs Struggle with Long In-context Learning
・Claudeでロングコンテキストが特に注目されているけど、ロングコンテキストの学習を計った研究。2024年。
・結果は自明で、長いと学習に支障がでるということなのだけど、定量的に結果を明示していることが良い。
・QwenやMistralなど一部のLLMは、入力の長さに対してほぼ線形に性能が低下したって書いてある。モノによってそういうふうな因果関係があったりもするのね。
・プロンプトの入力例の配置が性能に影響することも分かったと書いてある。経験則的にそんなこともあるのかなぁと思っていたけど、これからLLMを使う際にはその点意識するようにしよう。
---
```mermaid
graph LR
A[長文コンテキストLLMの長文in-context学習に関する研究] --> B1(導入)
A --> B2(長文in-contextベンチマークLongICLBench)
A --> B3(長文in-context評価実験)
A --> B4(位置分布の影響に関する分析実験)
A --> B5(結論)
B1 --> C1[長文コンテキストLLMの登場と評価の課題]
C1 --> D1[言語モデルの長期記憶、情報検索、質問応答タスクでは全文読解が不要な場合がある。極端なラベル数のin-context学習では全体を理解する必要がある。]
B1 --> C2[極端なラベル数を持つ分類タスクとin-context学習の組み合わせによる長文理解能力の評価]
C2 --> D2[大規模なラベル空間を持つ分類タスクは自然な長文理解の評価となる。本研究ではその能力を体系的に評価するためのベンチマークを構築する。]
B2 --> C3[異なる難易度の6つのデータセットから構成されるLongICLBench]
C3 --> D3[コンテキスト長とラベル数の観点で難易度の異なるタスクを選定。ラベルを均等にサンプリングし、1~5ラウンドのデモを作成。]
B3 --> C4[13の長文コンテキストLLMを評価]
C4 --> D4[タスクが難しくなるにつれ全モデルのパフォーマンスが低下。Discovery 174ラベル ではゼロに近い精度。]
C4 --> D5[一定の長さまでは長いデモから学習できるが、あまりに長いと悪影響。QwenとMistralは線形に低下。]
B4 --> C5[TacREDデータセットでラベル位置の分布を変化させて分析]
C5 --> D6[ランダムに配置した場合、一部のラベルのみ60%の精度。GPT4-turboは80%以上を安定して達成。]
C5 --> D7[同じラベルを近くに配置すると、ほとんどのモデルでパフォーマンスが大きく低下。GPT4-turboも20.3%低下。]
B5 --> C6[長文コンテキストLLMの限界と今後の研究の必要性]
C6 --> D8[既存のLLMは20Kトークン程度までは長文理解が可能だが、それ以上は難しい。デモ内のラベル分布の影響も大きい。]
C6 --> D9[LongICLBenchによって長文理解能力をより現実的に評価できる。今後の長文コンテキストLLMの発展に貢献することを期待。]
```
![]()
1 / 1
100%