<<
polat-et-al-2025-testing-prompt-engineering-methods-for-knowledge-extraction-from-text.pdf

---
## Page 1
[](/attach/8355017f6539389e244c8bf5b3ffbe25d00fc9b6ee5affae4d280c97300dd749_p001.png)
### 和訳
研究論文
**テキストから知識を引っ張り出すためのプロンプトエンジニアリング手法をテストしてみたで**
Semantic Web
Vol. 16(2) 1–32
© 2024 – 著者ら。IOS Press発行。
論文再利用ガイドライン:
sagepub.com/journals-permissions
DOI: 10.3233/SW-243719
journals.sagepub.com/home/swj
Fina Polat1, Ilaria Tiddi2, Paul Groth1
編集者:Sanju Tiwari(UAT、メキシコ)、Nandana Mihindukulasooriya(MIT-IBM Watson AI Lab、アメリカ)、Francesco Osborne(KMi、The Open University、イギリス)、Dimitris Kontokostas(Medidata、ギリシャ)、Jennifer D'Souza(TIB、ドイツ)、Mayank Kejriwal(南カリフォルニア大学、アメリカ)
査読者:Dimitris Kontokostas(Medidata Knowledge Graph、ギリシャ)、匿名査読者4名
**要約**
Mistral 7BとかLlama 3とかGPT-4みたいな大規模言語モデル(LLM)ってあるやん?あれがテキストから知識を引っ張り出す(知識抽出、KE)のにめっちゃ使えるチャンスがあんねん。せやけどな、LLMって文脈に敏感すぎるとこがあって、ちゃんと狙った通りの結果を出すんが難しいこともあんねん。そこで必要になんのがプロンプトエンジニアリングっちゅうやつや。
この研究ではな、5種類のプロンプト手法を、タスクの見本の出し方を変えながら、全部で17パターンのプロンプトテンプレートで試してみたんや。データセットには関係抽出用のRED-FMっていうやつを使って、さっき言うたLLMたちで実験したで。評価するために、Wikidata(ウィキデータ)のオントロジー(知識の体系みたいなもんや)をベースにした新しい評価フレームワークも作ったで。
結果どうやったかっていうとな、LLMはテキストからめっちゃいろんな事実を引っ張り出せることがわかったんや。特にすごかったんが、シンプルな指示に加えて、タスクの見本——検索メカニズムで選んだ3つの例——をつけたるやり方やねん。これがMistral 7B、Llama 3、GPT-4のどれでもめっちゃ性能アップしたんや。
一方で、Chain-of-Thought(思考の連鎖)とかReasoning and Acting(推論して行動する)みたいな、推論重視のプロンプト手法はどうやったかっていうとな、タスクの見本をつけたら確かに良くなったけど、他の手法を超えるまでにはいかんかったんや。これはつまり、知識抽出を「推論タスク」として扱う必要はないかもしれへんってことやな。ほんで注目すべきは、検索メカニズムで選んだ例をタスクの見本として使うやり方が、どのプロンプト戦略でも、どのLLMでも、効果的な知識抽出を実現できたっちゅうことやで。
**キーワード**
プロンプトエンジニアリング、生成型知識抽出、オントロジーベースの評価、GPT-4、Mistral 7B、Llama-3、Wikidata
**1 はじめに**
知識抽出(KE)、別名ナレッジトリプル抽出っていうんやけど、これはテキストの中からエンティティ(モノとか人とか概念とか)と、それらの間の意味的な関係を見つけ出すことやねん。大規模なナレッジグラフ(知識をネットワーク状に整理したデータベースみたいなもんや)を自動で作るためにめっちゃ重要なタスクなんや [20]。
大規模言語モデル(LLM)は、知識抽出タスクで最先端の性能を叩き出してきてんねん [12,15,32]。今の主流モデルは生成的なアプローチを使ってて、シーケンス・トゥ・シーケンス(入力を受けて出力を生成する)モデルを端から端まで一気に学習させて、生のテキストから〈主語–述語–目的語〉のトリプル(三つ組)を出力するようにしとんねん。生成型の知識抽出はモデルのファインチューニング(微調整)に頼ってきたんやけど、最近の研究 [17] で、インコンテキスト学習(ICL)[3] を使うのもイケるんちゃうかって言われ始めてんねん。
ICLっちゅうのは「見本から学ぶ」っていう考え方やねん。モデルに例を見せたって、「あぁ、こういうタスクね、こうやればええんやな」って理解させる方法や。モデルは見せられた例に合わせて、自分の出力を調整してくれんねん。どんなタスクでも、どのLLMでもこれが起きるんや。LLMみたいにパラメータがめっちゃ多いモデルやと、これがほんまにありがたいねん。なんでかっていうと、わざわざモデルを学習させたりファインチューニングしたりせんでもええからや。うまいこと作った入力(テキストのプロンプト)を渡すだけで、LLMに知識
1 Intelligent Data Engineering Lab(INDElab)、アムステルダム大学情報学研究所、オランダ
2 人工知能学科、アムステルダム自由大学理学部、オランダ
責任著者:
Fina Polat、Intelligent Data Engineering Lab(INDElab)、アムステルダム大学情報学研究所、オランダ
Email: f.yilmazpolat@uva.nl
クリエイティブ・コモンズ CC BY:これはオープンアクセスの論文で、クリエイティブ・コモンズ表示(CC BY 4.0)ライセンスの条件に基づいて配布されとるで。元の著作物をちゃんと引用すれば、どんな媒体でも制限なく使用・配布・複製してええっちゅうことや。
---
## Page 2
[](/attach/8355017f6539389e244c8bf5b3ffbe25d00fc9b6ee5affae4d280c97300dd749_p002.png)
### 和訳
2
Semantic Web 16(1)
図1. 知識抽出の例:RED-FMのターゲットグラフ vs. GPT-4が抽出したトリプル
抽出タスクにはめっちゃ使えるんやけど、問題は「ほなどうやっていい感じの入力プロンプトを作んねん?」ってとこやねん。ここで登場するんがプロンプトエンジニアリングっちゅうやつやな。
この疑問に答えるために、ワイらの研究では、知識抽出っていうタスクにおいて、最先端のプロンプトエンジニアリング手法のどれが一番ええ仕事するんかを調べたんや。具体的には、chain-of-thought(段階的に考えさせるやつ)[31]、reasoning and acting(考えながら行動させるやつ)[33]、self-consistency(何回もやらせて多数決取るやつ)[30]、generated knowledge(先に知識を生成させるやつ)[18]っていう手法を、いろんなタスクのお手本の見せ方と組み合わせて知識抽出向けにアレンジして、3つのイケてる生成系大規模言語モデル、つまりGPT-4 [22]、Mistral 7B [11]、Llama 3 [1]でそれぞれの性能をテストしたんや。評価には関係抽出データセットのRED-FM [10]を使って、オープン情報抽出っていうセットアップでやったで。もうちょっと具体的に言うと、テキストが与えられたら、そこから可能性のあるトリプル(要は関係性やな)を全部抜き出すんやけど、閉じた情報抽出 [17] みたいに「このラベルから選んでや」とか制約をプロンプトに入れたりはせーへんねん。
図1は、GPT-4 [22] モデルがこのタスクをやった例やねん。シンプルな指示の後に、検索メカニズムで選んだ3つの例をお手本として見せてるんや。入力テキストとターゲットのトリプルはどっちもRED-FMから取ってきたもんやで。古典的な厳密マッチベースの評価指標、つまり抽出されたトリプルとあらかじめ決められたターゲットのトリプルがぴったり一致してるかを測る指標によると、正解の抽出は1個だけ——図の中で黄色くハイライトしたやつだけやねん。せやけどな、LLMはもっと細かい粒度の関係を抽出できるんや。例えば、単なる「メンバー」やなくて「創設メンバー」っていう関係を引っ張り出してきたりするねん。さらに、図の中でオレンジにハイライトしてあるイベントに関する事実も抽出できるんやけど、これは元々のRED-FMタスクの範囲外のもんやねん。こういう厳密な評価指標と言語表現のバリエーションが、LLMの抽出結果を評価する上でボトルネックになってるんや。なんでかっていうと、いろんな文脈やアプリケーションに対して頑健かつ普遍的に使える評価基準を作るんがほんまに難しくなるからやねん [7]。
こういう限界を乗り越えるために、ワイらの研究ではWikidata [28] とWikidataのスキーマ(オントロジー、まあデータの構造定義みたいなもんや)の意味論に基づいた、新しい評価アプローチを提案してるんや。この方法では、抽出された全トリプルをWikidataと照らし合わせて徹底的にチェックするねん。知識抽出に一番効果的なプロンプトエンジニアリング手法を見つけるために、各手法で抽出されたトリプルの妥当性を、Wikidataから取得した知識と突き合わせて評価するんや。このベンチマーク作業によって、LLMが抽出した事実知識の正確さと信頼性を数値で測れるようになるっちゅうわけやな。
---
## Page 3
[](/attach/8355017f6539389e244c8bf5b3ffbe25d00fc9b6ee5affae4d280c97300dd749_p003.png)
### 和訳
ほな、まとめるで!この研究にはおっきい貢献が2つあんねん:
1. 最新のプロンプトエンジニアリング手法(AIへの指示の出し方を工夫するテクニックやな)を、いろんなタスクのお手本の見せ方と組み合わせて、知識抽出(KE)っていう分野で試してみたんや。使ったLLM(めっちゃ賢いAI)は3つで、Mistral 7B [11]、Llama 3 [1]、GPT-4 [22]やで。
2. Wikidata(ウィキペディアのデータベース版みたいなやつ)をベースにした評価のやり方を新しく提案したんや。これでオープン情報抽出がどれくらいちゃんとできてるか測れるようになったってわけ。
この研究で使ったデータとソースコードは全部GitHubのリポジトリ¹で公開してるから、誰でも見れるで。
## 2 背景
### 2.1 生成型の知識抽出
テキストから知識トリプル(「誰が」「何を」「どうした」みたいな3つ組の情報やな)を引っこ抜くっていうのは、自然言語処理(NLP)とセマンティックウェブ(SW)の研究者たちがずーっと取り組んできたテーマやねん [20]。昔ながらのやり方は2段階に分かれてたんや。まず第1段階で、テキストからエンティティ(固有名詞とか重要な単語)を見つけ出す。これが固有表現認識(NER)ってやつな。ほんで第2段階で、見つけたエンティティ同士にどんな関係があるか調べる。これが関係分類(RC)やねん [35,37]。でもなぁ、この2段階方式やと「どのエンティティ同士が関係あるんか」っていう追加のアノテーション(人間が手作業でラベル付けすること)が必要になるんよ。
最近のアプローチはもっと賢くて、この2つのタスクを同時にやってまうねん。系列から系列への学習問題として扱って、End-to-End関係抽出(RE)って呼ばれてるやつや。1つのモデルでNERとRCの両方を同時に学習させるんやな [9,12,13]。こうやってマルチタスクで同時に学習させると、追加のアノテーションなしでEnd-to-End REの性能が上がるんやけど、それでもけっこうな量の学習データが必要やねん。
ほんで、言語モデルをでっかくスケールアップしたら、特定のタスクに依存せんでも少ない例だけで色々できるようになってきたんや [3]。ICL(文脈内学習)っていうのは、LLMの中でも特にパラメータが何十億もあるようなデカいモデル、例えばGPT-3 [3]、LLaMDA [26]、PaLM [5]、LLaMA [27]、GPT-4 [22]とかに現れる能力やねん。特にGPT-3あたりからめっちゃ目立つようになったんや [3]。ICLの何がすごいかっていうと、追加の学習もファインチューニング(モデルの微調整)もなしで、ほんの数個の例を見せるだけでタスクをこなせるようになるってことや。パラメータを一切いじらんと、プロンプト(指示文)を与えるだけでタスクを実行してくれるんやで。ウチらのアプローチはこのICL(つまりプロンプティング、少数ショット学習)に焦点を当ててて、LLMの能力とテキスト中の文脈情報を組み合わせてるんや。
### 2.2 プロンプトエンジニアリング
プロンプトっていうのは、LLMに「こういう出力してな」って伝える指示のことやねん。シンプルに「EUの首都ってどこ?」って直接聞くパターンから、「EUの首都を一覧にして」みたいなちょっと丁寧な指示の出し方まで色々あるんや。ここで大事なんは、LLMっていうのはめっちゃ文脈に敏感やから、プロンプトの書き方がちょっと違うだけで返ってくる答えが変わることがあるってことやな。プロンプトエンジニアリングは、このプロンプトの開発と最適化に焦点を当てた分野やねん [19]。いろんなタスクやアプリケーションでLLMの効率を上げるのが目的や。プロンプトを丁寧に作り込んで磨き上げることで、研究者や実務家はLLMのポテンシャルをフルに引き出して、色んなタスクや目的にピッタリ合う応答を引き出そうとしてるんやで。
ちゃんとしたプロンプトにはいくつかの要素が含まれてて、タスクの説明、文脈、質問やリクエスト、そして例やな。タスクの説明みたいな部分は色んな書き方ができるから、そこに柔軟性があるんや。一方で、文脈や例の選び方はその都度変わるもんやから、最適なやつを引っ張ってくる仕組みが必要になるんやな。こういう色んな要素をうまくまとめるために、プロンプトテンプレートの設計が大事になってくるわけや [19]。プロンプティング戦略とかその仕組みについてもっと詳しく知りたい人は、Minらのサーベイ論文 [21] を見てみてな。
### 2.3 生成型アプローチにおける評価の難しさ
生成型アプローチを使ったオープン情報抽出は、その自由度の高さゆえに自動評価がめっちゃ難しいんやで [7]。図1で示されてるようなLLMの表現力の豊かさと、知識トリプル抽出のオープンエンドな性質が組み合わさって、評価が一筋縄ではいかへんねん。なんでかっていうと、生成されたテキストには表現のバリエーションがありすぎて、あらかじめ決めた正解と完全一致かどうかで判定するっていうのが現実的やないからや。これまでの研究では、生成されたトリプルと正解が完全に一致してるかどうかっていう厳密な評価方法が主に使われてきたんや。このやり方が有効な場面もあるんやけど、
¹ https://github.com/FinaPolat/Prompt-Engineering-for-KE
---
## Page 4
[](/attach/8355017f6539389e244c8bf5b3ffbe25d00fc9b6ee5affae4d280c97300dd749_p004.png)
### 和訳
4
Semantic Web 16(1)
REに特化した小さい条件付き生成モデル、たとえばBARTベースのREBEL [9]なんかを評価する話やねんけど [15]。こういうモデルはな、めっちゃでかいデータセットでガッツリfinetuningされとるから、いっつも決まったフォーマットで出力してくれるわけよ。
それに比べてな、Llama 3みたいなもっとデカくて表現力のあるモデルはどうかっていうと、Figure 1で見せとるように、ターゲットと似たような中身を伝えるんやけど、出力フォーマットがめっちゃバラエティ豊かやねん。従来のNERとかREのモデルは、入力のトークンを分類したりラベル貼ったりするやろ?でもMistral 7Bみたいな生成型の言語モデルは、あらかじめ決まったクラスの中から選ぶんやなくて、めっちゃでかい語彙の中から新しいトークンを生成するんよ [29]。こういうモデルの出力はオープンエンド、つまり何が出てくるかわからん性質があるし、事前に決めた基準と合わせるんがむずいから、実務ではよく人間が評価するパターンを選ぶねん。まあ時間もかかるし金もかかるんやけど、生成モデルの実力とか、出てきたトリプル(主語・述語・目的語のセット)の質と正確さをちゃんと見極められる定性的な評価ができるから、それはそれでええねんな [17,29]。
3 プロンプトエンジニアリングの手法
ワイらのアプローチはな、有名なプロンプトエンジニアリングの手法を知識抽出(KE)に適用して、「どのプロンプト戦略が一番効くねん?」っていうのを見つけることやねん。プロンプトエンジニアリングの手法は、基本的に似たようなパターンを踏むんよ。まずプロンプトのテンプレートを作って、構造とか入れる場所(プレースホルダー)を決めるやろ。ほんでエンジニアリングの方法に応じて、入力データとか例をそのテンプレートにぶち込むわけや。以下で、この研究で使ったプロンプトエンジニアリングの手法を説明するで。
3.1 シンプルな指示:ゼロショット、ワンショット、フューショットプロンプト
LLM(大規模言語モデル)はな、[23]で説明されとるように、訓練中にテキストのコーパス(大量の文章データ)から知識を身につけるねん。LLMの事前訓練の目的は、基本的にはめっちゃでかいコーパスで「次の単語を予測する」っていうタスクの誤差を小さくすることやねん。せやけどな、ユーザーが何をしたいか理解して、その指示にちゃんと従うっていうのは、もっと複雑な自然言語理解(NLU)のタスクやねん。このレベルの理解力は、モデルをデカくしたからって自動的に身につくもんやなくて、ユーザーの意図と意図的にすり合わせる作業(アラインメント)が必要やっていう話が [36] で指摘されとるわけよ。
タスクのお手本なしのシンプルな指示だけでプロンプトを投げるっていうのは、LLMが身につけたNLU能力と、ある程度は内部の知識を活用して、指定されたタスクをやらせるっていうことやねん。ワイらはこういう指示だけのプロンプトを「ゼロショット」プロンプトって呼んどる。普通、ゼロショットプロンプトは直接的な指示だけで構成されるんよ。せやけどな、ICL(In-Context Learning、文脈内学習)は、プロンプトにタスクの説明と、そのタスクを実行した例を一緒に入れるとめっちゃうまくいくねん。ICLではコンテキストウィンドウ(モデルが一度に見れる範囲)の制約の中で、例の数を増やせるんよ。このアプローチによって、与えられた文脈の中でタスクをこなすモデルの能力がアップするわけや。ワイらのゼロショットのテスト設定では、タスクの説明もお手本もプロンプトに入れへん。ただシンプルな直接指示のあとに入力テキストと、シグナルフレーズ、つまり「Your answer」っていうのを入れるだけやねん。このシグナルフレーズは「ここでプロンプト終わりやで」っていう区切りのために入れとるんよ。以下がゼロショットプロンプトの例や。
ほんで次に、プロンプトにタスクのお手本を追加して、使う例の数に応じてバージョンに名前をつけるねん。ワンショットプロンプトは指示と一緒にお手本が1個ついとるやつや。たとえば「Text: The Amazon River flows through Brazil and Peru. {"Triples": [["Amazon River", "country", "Brazil"], ["Amazon River", "country", "Peru"]]}」っていうお手本は、全部の入力に対して同じものを使うねん。以下がワンショットプロンプトの例やで。
---
## Page 5
[](/attach/8355017f6539389e244c8bf5b3ffbe25d00fc9b6ee5affae4d280c97300dd749_p005.png)
### 和訳
Polatらの研究についてな。
5
ワンショットプロンプティングっていうのは、1個だけ固定の例を見せるやり方やねん。これで「こういうタスクやで、こういう形式で出力してな」っていう基準点を示してあげるわけや。ほんで、フューショットプロンプトっていうのは、同じ指示と最初の例はそのまま残しつつ、例の数を3個(定番の例やな)に増やしたやつやねん。ワンショットと同じで、この例はどのデータに対しても全部同じもんを使うんよ。下の例がフューショットプロンプトの実例やで。
3.2 タスクのお手本にする例の選び方
LLM(大規模言語モデル)ってやつは、プロンプトの中にある文脈から学ぶ力がめっちゃすごいねん。せやから、関連性のある例を入れ込むのがほんまに大事なんよ。ワンショットとかフューショットのプロンプトは、どの入力に対しても関連性に関係なく同じ定番の例を使うやろ?でもな、関連性のある例を使った方が、ICL(文脈内学習)の能力をもっと引き出せるんや。ICLのめっちゃええとこは、大量のアノテーション(ラベル付け)済みデータにそこまで頼らんでもええっていう点やねん。ウチらのテスト設定みたいなケースでは、トレーニングデータは直接は使わへんのやけど、検索の仕組みを使えば、トレーニングデータから入力に合った文脈的に関連する例を引っ張ってこれるんよ。結果として、ICLの性能がアップするっちゅうわけや。
トレーニングセットから生成タスク用の例を持ってくるには、いろんな検索の仕組みが使えるで。どの検索手法を選ぶかっちゅうのは結構重要な話で、取ってくる例とそれがタスクにどう貢献するかに大きく影響するんや。ウチらの実験では、最大限界関連性(MMR)[34]に基づいた最先端の例検索メカニズムを使ってんねん。このMMR[4]っていうアプローチは、関連性が高くて、かつ多様性もある例を選んでくれるんよ。なんでMMRを選んだかっていうと、選んだ例同士が似たりよったりで冗長になるのを防ぎたかったからや。さらに、いろんなタイプの例があった方が、入力テキストから正確なトリプル(主語・述語・目的語の三つ組)を抽出するのに必要な、お互いを補い合うシグナルを示してくれる可能性が高いんやで。
以降のプロンプトエンジニアリング手法で使う例は、全部このMMR例検索器[34]で選んでるで。
3.2.1 取得した例をプロンプトに組み込む方法。LLMが知識にアクセスして正確に操作する能力って、まだまだ限界があるんよな。この問題に対処するために、明示的な非パラメトリックメモリ(モデルの外にある知識のことやな)に微分可能なアクセスの仕組みを使うことができるんや。RAG(検索拡張生成)っちゅうのは、LLMの汎用的なファインチューニング手法で、事前学習されたパラメトリックメモリ(モデルの中の知識)と非パラメトリックメモリ(外部の知識)を組み合わせて文章を生成するんや[16]。RAGの仕組みには、知識ベース(ドキュメント群)、エンベッダー(埋め込み器)、リトリーバー(検索器)、ジェネレーター(生成器)っていう重要なパーツが全部合わさってるねん。まず知識ベースをエンベッダーで埋め込み処理(ベクトル化みたいなもんやな)して、次にリトリーバーがその埋め込まれた知識ベースを検索して、入力クエリに似た文脈を引っ張ってくるんよ。最後に、取ってきた文脈と入力を合体させて生成モジュールに食わせるっちゅう流れやねん。
ウチらのアプローチは、RAGをそのまんまは使ってへんねん。その代わりに、トレーニングデータからランダムに選んだ一部の中から例を取ってきて、プロンプトの内容を充実させるっていうやり方やで。具体的には、トレーニングデータから300個のインスタンスをランダムにサンプリングするんよ。テスト入力と例を検索するためのトレーニングサンプルは、オープンソースの最先端の命令ファインチューニング済みテキスト埋め込みモデル[25]を使ってベクトル化してるで。ウチらは、検索メカニズムで選んだタスクのお手本を含むプロンプトと、定番の例を使ったプロンプトを区別するために、このタイプのプロンプトを「RAGプロンプト」って呼んでるんや。例えば、MMR[34]で検索された1個の例がワンショットRAGプロンプトのタスクのお手本として組み込まれるし、3個の例やったらフューショットRAGプロンプトになるっちゅうわけや。下の例がワンショットRAGプロンプトの実例やで。
---
## Page 6
[](/attach/8355017f6539389e244c8bf5b3ffbe25d00fc9b6ee5affae4d280c97300dd749_p006.png)
### 和訳
6
Semantic Web 16(1)
ワンショット/フューショットと、ワンショットRAG/フューショットRAGのプロンプトの違いはな、例文を組み込んどるかどうかっちゅうとこやねん。検索モジュールっていうやつが、サンプルの中から一番関係ありそうな例文をパパッと選んできてくれるんよ。次の例を見たら、フューショットRAGプロンプトでこの検索モジュールがどんだけ効くかわかるで。
3.3 Chain-of-thoughtプロンプト
Chain-of-thought(CoT)っちゅうのはな、最終的な答えにたどり着くまでの途中の考え方を、自然な言葉でひとつひとつ書き出していく方法のことやねん。これを「Chain-of-thoughtプロンプティング」って呼ぶんやけど、要するに「考える過程を見せろや」ってLLM(大規模言語モデル)にお願いする技やな。なんでこれがええかっていうと、途中の推論ステップを踏ませることで、LLMの複雑な推論能力をめっちゃ引き出せるからやねん。実験でも、算数の問題とか、常識的な推論とか、記号論理のタスクとか、いろんな分野でほんまにパフォーマンスが上がることが確認されとるんよ。CoTプロンプティングがLLMの推論力をどんだけアップさせるかは、最近の研究[31]でもしっかり調べられとるで。
知識抽出(KE)の場面でCoTプロンプティングを使うっちゅうのは、けっこう新しいアプローチでな、テキストから構造化された情報をうまいこと引っ張り出すLLMの能力を底上げしようっていう狙いがあるんよ。この方法の根っこにある考え方はこういうことや——LLMに「エンティティ(実体)はこれで、その種類はこうで、エンティティ同士の関係はこうやで」って明示的に考えさせることで、抽出される知識トリプルの質がグンと良くなるんちゃうか、っちゅうわけやな。
ゼロショットCoTの設定ではな、直接的な指示に加えて、知識抽出のタスク説明もセットで見せるんよ:「知識トリプルっちゅうのは3つの要素でできとるで——主語・述語・目的語や。主語と目的語はエンティティ(実体)で、述語はその間の関係を表すもんやで」ってな具合にな。
---
## Page 7
[](/attach/8355017f6539389e244c8bf5b3ffbe25d00fc9b6ee5affae4d280c97300dd749_p007.png)
### 和訳
Polatさんたちの論文の話やねんけどな。
7ページ目のとこ行くで。
「それらの間の関係」っていう部分な、これはいわゆる概念の定義みたいなもんで、「テキストから知識トリプルを抽出せえ」っていう直接的な指示とはちょっと違うねん。ほんで、LLM(大規模言語モデルっちゅうやつな)に「ステップバイステップで考えてみ」って指示するわけよ。そしたら、具体的なお手本を事前に見せんでも、順番に考えていくプロセスに入ってくれるねん。ワンショットとかフューショットの設定では、取ってきた(検索した)例だけを使って、タスクの実行を3つの中間ステップで見せるようにしてんねん。なんでかっていうと、実験してみたら、固定のお決まり例よりも検索で引っ張ってきた例の方がモデルの性能アップに効くっちゅうことがわかったからやねん。この3つのステップっていうのは、従来の知識抽出パイプラインでもめっちゃよく使われてるやつで、つまり「エンティティ抽出」「エンティティのタイプ分け」「関係抽出」の3つや。RED-FMっていうデータセットには、エンティティとか関係に加えて、エンティティのタイプ注釈も入ってんねん。で、テンプレートを使ってそのタイプ注釈を自然言語の説明文に変換してるわけや。知識抽出にCoT(Chain of Thought、思考の連鎖ってやつな)を適用した例は下に載せてるで。
**3.4 自己整合性プロンプト**
CoTの最初の実装な、素朴な貪欲デコーディング(要するに一番ありそうな答えを毎回選ぶだけの方法)に頼ってたから、別の推論の道筋を探ったり、途中で間違いを修正したりっていうのができへんかってん。これを改善するために出てきたんが「自己整合性プロンプティング」っちゅう考え方やねん[30]。自己整合性プロンプティングを使うと、LLMが複数の推論経路を検討できるようになって、エラーを見つけて直す仕組みも備わるねん。この方法の狙いは、もともとのCoTの単純なデコーディング戦略から、もっと包括的な推論アプローチに切り替えることで、LLMの意思決定プロセスをレベルアップさせることやねん。自己整合性プロンプティングのメリットとか影響についてはもっと詳しく[30]で掘り下げてるで。
知識抽出に自己整合性プロンプティングを適用する時はな、タスク実行の流れにもう一層「振り返り」のステップを追加してプロンプトを強化してんねん。ゼロショット設定では、こういう指示を使うねん:「まず、テキストから抽出したいエンティティと関係について考えてみ。次に、候補のトリプルを見てみ。ドメインの専門家になったつもりで、そのトリプルが妥当かどうかチェックしてみ。アカンやつはフィルタリングで外してな。ほんで、妥当なトリプルだけをJSON形式で返してくれ」って感じや。ワンショットとかフューショットの設定では、検索で取ってきた例を使ってタスクの実行方法をデモしてるで。
CoTと自己整合性プロンプトの一番大きな違いはな、まず候補リストを仮で作らせて、それからそのリストを批判的に評価させるっていうところやねん。ワンショット/フューショットの自己整合性プロンプトではな、わざと下書きの中に間違ったトリプルを入れとくねん。ほんで、その間違ったトリプルをLLMに見せて、「これはこういう理由でアカンねん」っていう説明もつけるわけや。自己整合性プロンプティングを知識抽出にフル適用した例は下に載せてるで。
---
## Page 8
[](/attach/8355017f6539389e244c8bf5b3ffbe25d00fc9b6ee5affae4d280c97300dd749_p008.png)
### 和訳
3.5 生成知識プロンプティング
生成知識プロンプティングっていうのはな、言語モデルに知識を作らせて、それを質問に答えるときの追加の文脈として使うっていう手法やねん。この方法のめっちゃええとこはな、知識を組み込むときにタスクごとの教師データがいらんし、ちゃんとした知識ベースにも頼らんでええっていうところやな。で、この生成知識プロンプティングを使うとな、最先端のデカいモデルがいろんな常識推論タスクでもっとええ感じに動くようになるって分かってん。特にすごいのがな、数値に関する常識(NumerSense)、一般的な常識(CommonsenseQA 2.0)、科学的な常識(QASC)っていうベンチマークでトップクラスの結果を叩き出してるとこやねん。つまりな、従来の知識ソースがなくても、モデルの推論力をガッツリ強化できるっていう証拠やで[18]。
で、このやり方を知識抽出(KE)に使う場合はな、実際に抽出する前に、LLMの中に埋め込まれてるエンティティ(要は「モノ」とか「人」とかの対象物やな)やその関係性についてのパラメトリック知識、つまりモデルが学習で覚えてる知識を活用しよう、っていう話やねん。なんでかっていうと、LLMがエンティティのタイプとか、ありそうな関係性とかについて元々持ってる知識を先に引き出しといたら、抽出される知識トリプル(「AはBとCの関係がある」みたいな3つ組の情報やな)の質がもっと良くなるやろ、っていう考え方が根っこにあるわけや。ゼロショット設定ではな、タスクの手順にまず「テキストに出てくるエンティティについての知識と、それらの間にありそうな関係性を先に生成してや」っていう指示を加えるねん。この事前に生成した知識が、そのあとの知識トリプル抽出の下準備になるっちゅうわけや。
ワンショットやフューショットの実験ではな、タスクのお手本に使う例はリトリーバー(検索して持ってくるやつやな)が選んでくるねん。データセットに入ってるエンティティタイプのアノテーション(「これは人名」とか「これは場所」みたいなラベルやな)をテンプレート使って文章にしたやつを、生成知識のお手本として使うんや。次の例がその全体の流れを見せてくれてるで。
---
## Page 9
[](/attach/8355017f6539389e244c8bf5b3ffbe25d00fc9b6ee5affae4d280c97300dd749_p009.png)
### 和訳
Polatさんたちの話やねんけどな。
**3.6 「考えて動く」プロンプトの話**
なぁ聞いてや、人間ってすごいやろ?何かやるときに、頭ん中でブツブツ考えながら(これを「内言」って言うねんけど)、同時に実際の行動もできるやん。これって人間の知能のめっちゃ特徴的なとこでな、自分をコントロールしたり、作戦立てたり、頭の中のメモ帳(ワーキングメモリってやつや)を維持するのにめっちゃ大事やって言われてんねん[33]。
ほんで、Yaoさんたちがこの人間の賢さにヒント得て何やったかっていうと、大規模言語モデル(LLM)に「考えること」と「実際にやること」を同時にやらせてみたんよ。この2つがええ感じに協力し合うようにしたんやな。これが**ReAct(リアクト)**っていうプロンプト技法やねん。名前の由来は「Reasoning(推論)and Acting(行動)」の略やで。
ReActのやり方はな、「考える→やることを決める→結果を観察する」っていうサイクルを、タスクが終わるまでグルグル繰り返すねん。せやから、対話しながら動くAIエージェントにはめっちゃ向いてるわけよ。「チェーン・オブ・ソート」とか「チェーン・オブ・ソート+自己整合性」みたいな手法は、ユーザーとのやり取りがないんやけど、ReActはちゃうねん。質問を途中のステップに分解して、考えや行動計画をユーザーと一緒にインタラクティブに進めていくんよ。こうやってユーザーが関わることで、もっと意味のあるやり取りができて、エージェントが目標達成したり、ユーザーの質問にええ感じに答えたりできるようになるわけや。
ただな、ぶっちゃけ言うと、ウチらの実験ではユーザーおらんかってん。せやから、ReActのほんまの実力を全部引き出せてるかっていうと、正直そうとは言い切れへんのよ。さっきも言うたけど、ReActの強みは「考える→やる→観察する」をユーザーと一緒にインタラクティブにグルグル回すとこやからな。ユーザーとのやり取りがない状態やと、目標達成とかクエリへの満足度の高い応答っていう面での効果を正確に測れてへんかもしれん。けどな、知識抽出っていう文脈でReActをどう使えるかはちゃんと見せたるで。ユーザーとのやり取りはなくても、「考える→やること決める→観察する」を繰り返し生成できるっていう、この手法の力はしっかり示しとるからな。
ReActのプロンプト手法を知識抽出(KE)に適用するにはな、追加の指示を組み込むねん。タスクの説明の後に、LLMに「考えて、行動計画を立てて、知識トリプル(主語・述語・目的語の3つ組のことやで)が抽出できるまで続けてな」ってお願いするわけや。ワンショット(1つだけ例を見せる)とかフューショット(数個の例を見せる)の実験では、取ってきた例を使って「こうやってやるんやで」ってLLMにお手本を見せるんよ。こんな感じでな↓
---
## Page 10
[](/attach/8355017f6539389e244c8bf5b3ffbe25d00fc9b6ee5affae4d280c97300dd749_p010.png)
### 和訳
4 評価
ほな、ワイらが提案する評価のやり方について説明するで!ベースになっとるんはWikidataっちゅうデータベースで、大きく2つのステップがあんねん。まず最初に、トリプル(主語・述語・目的語の3つセット)のそれぞれの部品と、Wikidataの識別子(IDみたいなもんやな)をちゃんと紐づけなあかん。これが前提条件や。ほんで次に、SPARQLクエリっちゅう問い合わせをバーンと実行して、エンティティ(モノとか概念のことやな)とリレーション(関係性)に関する意味的な情報をゲットすんねん。ここでめっちゃ大事なんが、エンティティの型が、述語で決められとる「主語の型の制約」(rdfs:domainっていうやつ)とか「値の型の制約」(rdfs:rangeっていうやつ)とちゃんと合っとるかチェックすることやねん。エンティティの型がdomainとrangeにバッチリ合致しとったら、「このトリプルは意味的に正しいで!」っちゅう確認になるわけや。
ほんで正しさの評価だけちゃうで!抽出されたトリプルがWikidataにもう存在しとるかどうかも調べて、「新しい発見かどうか」っちゅう新規性も判定するねん。つまりこの評価方法は、意味的な整合性だけやなくて、より広いナレッジベース(知識の集まり)の中でそのトリプルが新しいもんかどうかも考慮する、めっちゃ包括的なやり方やねん。
評価に使ったSPARQLクエリは全部付録Aに載せとるし、評価プロセスの出力結果の具体例は付録Bにバッチリまとめとるから、気になったら見てみてな。
4.1 データ
使ったデータセットはRED-FMっちゅうやつやねん。これは「Filtered and Multilingual Relation Extraction Dataset」の略で、要するにフィルタリング済みの多言語対応の関係抽出データセットや。Huguet Cabotさんらが2023年に詳しくまとめてくれたもんやで [10]。なんでかっていうと、このデータセットは人間がちゃんとレビューして精査しとって、7つの異なる言語にまたがる32種類の関係をカバーしとるっちゅう、めっちゃしっかりしたもんやからやねん。
---
## Page 11
[](/attach/8355017f6539389e244c8bf5b3ffbe25d00fc9b6ee5affae4d280c97300dd749_p011.png)
### 和訳
Polatらの研究チームの話やねんけどな、
11ページ目
ほんで、多言語の関係抽出(RE)システムをちゃんと評価できるように作られたもんやねん。RED-FMっていうデータセットは、WikipediaとWikidata [28]の両方から中身と構造を引っ張ってきてるんよ。もっと詳しいこと知りたかったら、元の論文 [10] を見てな。
で、ワイらが選んだプロンプトエンジニアリングの手法を評価するにあたって、RED-FMデータセットの中でも人間がアノテーション(ラベル付け)した部分、具体的にはRED-FMの英語版に絞って見てるんよ。このサブセットには全部で3,770個のデータポイントが入ってるねん。いろんなプロンプト手法を評価するときは、テスト用に分けてある446個のインスタンスを使ってるで。さらに、ワンショットとかフューショットプロンプトっていう「お手本見せてから本番やらせる」方式のために、トレーニングデータからランダムに300個のインスタンスを抜き出してきてん。この300個が「こういうふうにやるんやで」っていうお手本の役割を果たすわけやな。
4.2 大規模言語モデル(LLM)
ワイらが選んだプロンプトエンジニアリング戦略がほんまに効くんかどうか、最先端のLLM3つで試してみてん:GPT-4、Mistral 7B、Llama 3や。
4.2.1 Mistral 7B。Mistral 7B [11]っていうのは、自然言語処理(NLP)でめっちゃ高性能かつ効率的に動くように設計された言語モデルやねん。Apache 2.0ライセンスで公開されとるから、かなり自由に使えるで。モデルの構造はTransformerアーキテクチャがベースで、パラメータ数は70億個もあるんよ。Mistral 7Bにはスライディングウィンドウアテンション、ローリングバッファキャッシュ、プリフィル&チャンキングっていう機能が入ってて、要するに「めっちゃ賢く効率的に文章を処理する仕組み」が満載やねん。ほんで、Mistral 7B – Instructっていう特別バージョンがあって、これは指示に従うように追加学習(ファインチューニング)されてて、他のモデルよりベンチマークで好成績を出してるんよ。ワイらはこの特別バージョン²を使って実験してん。推論にはLangChainのHuggingFaceEndpoint³を使って、パラメータはTemperature 0.5、新しく生成するトークンの最大数は512に設定したで。
4.2.2 Llama 3。MetaがMeta Llama 3 [1]っていう大規模言語モデルファミリーを開発・公開してん。事前学習済みのやつと、指示に従うようチューニングしたやつがあって、パラメータサイズは80億(8B)と700億(70B)の2種類あるねん。Llama 3は自己回帰型の言語モデルで、最適化されたTransformerアーキテクチャを使ってるんよ。チューニング済みバージョンは、教師ありファインチューニング(SFT)と人間のフィードバックからの強化学習(RLHF)[6]を使って、人間が「これええな」って思う応答ができるように調整されてるねん。8Bも70Bもグループクエリアテンション(GQA)っていう仕組みを使ってて、推論のスケーラビリティ、つまり「大量の処理もサクサクこなせる力」が向上してるで。Llama 3はゲート付きモデルやから、使うにはアクセス申請が必要で、Meta Llama 3 Community License Agreementの下で公開されとるんよ。ワイらの実験では8B Instructモデル⁴を使って、LangChainのHuggingFaceEndpoint経由で推論を実行。パラメータはTemperature 0.5、新規トークン最大数512やで。
4.2.3 GPT-4。GPT-4 [22]は、Generative Pre-trained Transformerシリーズの最新版で、大規模マルチモーダルAIモデルとしてめっちゃ大きな進歩を遂げたもんやねん。大事なポイントやけど、GPT-4はプロプライエタリ(企業独自)の技術で、APIを通じてしかアクセスできひんのよ。性能の話をすると、GPT-4は模擬司法試験で受験者の上位10%と同等のパフォーマンスを発揮できるって報告されてるねん [22]。めっちゃすごない?先代モデルと同じように、インターネット上の公開データとサードパーティからライセンスを受けたデータを使って、文書中の次の単語を予測する事前学習をしてるんよ。その後、人間のフィードバックからの強化学習(RLHF)[6]でファインチューニングされとるねん。OpenAI(2023)[22]によると、学習後のアライメント(調整)プロセスを経て、事実に基づく正確さと望ましい振る舞いへの忠実さが向上したって報告されてるで。実験ではOpenAI APIを使って、Temperatureは0.5、トークンの最大数は2000に設定したんよ。
4.3 抽出されたトリプルの解析
この研究でわかったんやけど、抽出されたトリプル(主語・関係・目的語の3つ組)って、ほんまにいろんなフォーマットで出てくるんよ。リストのリスト、辞書のリスト、番号付き辞書、番号付きリスト、区切り文字(例えば「-」)付きの番号付き文字列、タプルのリスト、JSON文字列、トリプルの辞書…まあようけあるわ。このフォーマットのバラバラ具合のせいで、しっかりした後処理のアプローチが必要になるんよ。なんでかっていうと、使う手法によって結果のフォーマットが変わってくるからやねん。
² https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.3
³ https://python.langchain.com/v0.2/docs/integrations/llms/huggingface_endpoint/
⁴ https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct
---
## Page 12
[](/attach/8355017f6539389e244c8bf5b3ffbe25d00fc9b6ee5affae4d280c97300dd749_p012.png)
### 和訳
ほな、後処理のアプローチについて説明するで!これは抽出したトリプル(主語・述語・目的語の3つ組のことやな)を全部ちゃんとパースする、つまり解析するためのもんやねん。ここでは2つの大事な前提を置いてるで:
1. **直接構造の前提**:生成されたテキストが、もともと構造化されたフォーマットになってるやろ、って前提やねん。せやから、まずそのまま読み込もうとするわけや。ありえる構造としてはこんなんがあるで:
(a) リストのリスト(入れ子のリストやな)
(b) 辞書のリスト(キーと値のペアが並んだやつのリストや)
(c) 各キーが辞書のリストに対応してる辞書(トリプル辞書って呼んでるやつ)
(d) JSON文字列
2. **混在コンテンツの前提**:生成されたテキストの中に、構造化データと説明文がごちゃまぜになってたり、番号付きリストで書かれてたりするかもしれへん、って前提やねん。これに対処するために、正規表現を使って構造化データだけを抜き出してから読み込むようにしてるわけや。この抽出処理は、番号付きリスト・辞書・タプルみたいないろんな形に対応しとるで。
この2つの前提を組み合わせるアプローチのおかげで、生成テキストをめっちゃ幅広いフォーマットで漏れなくパースできるようになって、後処理の信頼性がグンと上がるっちゅうわけやな。
### 4.4 参照としてのWikidata
Wikidataっていうのは、Wikipediaの構造化データ版みたいなもんやねん。みんなで協力してナレッジグラフ(知識のつながりを表すネットワークやな)を作って管理する共同プラットフォームやで。Wikidataの知識はセマンティックWeb表現にきっちり変換されてて、いろんなWeb技術と統合したり相互運用したりできるような標準に準拠してるんや[28]。
この研究で使ったテストデータセットはWikipediaとWikidataから持ってきてて、エンティティ(実体)とリレーション(関係)のWikidata IDも含まれとるで。データセットはRED-FMで定義された特定のエンティティとリレーションに合わせて構造化されてるんやけど、入力テキストには意味的にいろんなトリプルが含まれてることがあるねん。例えば図1にあるようなイベントトリプルとかな。これらはRED-FMのスキーマには当てはまらへんやつや。つまり、入力テキストにはRED-FMのフレームワークで明示的に捉えたり分類したりしてへん余分な関係が含まれてる可能性があるっちゅうことやな。これによって、RED-FMで定義されたターゲットトリプルの範囲外のエンティティや関係も混在する環境ができるわけや。
この研究で使ってる評価プロトコルには、LLM(大規模言語モデル)がプロンプトに応じて生成した回答を後処理するフェーズがあるねん。セクション4.1で詳しく説明してるけど、PythonのJSONモジュールとREGEX(正規表現)モジュールを使って、回答をパースして線形化されたトリプルに対応する部分を特定するんや。ほんで、そのパーツをリストに変換して、主語・述語・目的語の3つからなる個別のトリプルに整理するわけやな。
パースが終わったら、トリプルの各要素をWikidata APIを使って検証するねん。ここではグリーディーキーワード検索っていう方法でエンティティリンキング(テキスト中の表現を知識ベースの実体に紐づけること)をやるで。エンティティリンキングは、この評価フレームワークを実装するための前提条件やねん。トリプルの主語・述語・目的語がそれぞれWikidataの対応するものにうまくリンクできたら、SPARQLの「ASK」クエリを実行するんや。このクエリは、そのトリプルがWikidata内に存在するかどうかを確認するためのもんやで。Trueが返ってきたら、LLMの出力が事実に基づいた知識やって検証されたことになるわけや。Falseが返ってきた場合は、新しく抽出された情報やから、Wikidataに追加できるかもしれへんっていう話やな。
### 4.5 オントロジーに基づくトリプル評価
オープン抽出の課題やLLMの表現力の豊かさにうまく対処するために、この研究ではオントロジー(知識の体系的な分類構造のことやな)に基づいたトリプル評価手法を提案してるで。オントロジーベースのトリプル評価は、人間による評価への依存を減らすことを目指してるんや。Wikidataに埋め込まれてるデータの意味論やプロパティの制約を活用することで、抽出されたトリプルの検証プロセスを自動化できるっちゅうわけやな。
評価プロセスはまず、Wikidataに述語を問い合わせて、ドメイン(定義域)とレンジ(値域)を取得するところから始まるで。ドメインは主語の型制約(Q21503250)で特定されて、レンジは値の型制約(Q21510865)で特定されるんや。さらに、エンティティの型情報もWikidataから抽出するんやけど、これは「instance of」(P31、~の一例)と「subclass of」(P279、~の下位クラス)っていうプロパティを使って、最大4階層分の情報を取ってくるで。
ほんで、述語のドメインとレンジが、抽出された階層のどのレベルでもええから、主語と目的語の型と一致するかどうかをチェックするんや。この検証によって、主語と目的語の型がWikidataの制約に基づいた述語のプロパティと矛盾してへんことを確認できるわけやな。
図2では、こんなトリプルの評価を具体的に見せてるで:「ポルシェ・パナメーラ」「製造者」「ポルシェ」。最初のステップは、Wikidataを調べてトリプルの各要素に対応するWikidata IDを見つけることや。この場合、全部の要素にWikidata IDがあるで:「Q501349」「P176」「Q40993」。次に、述語「P176」にドメインとレンジが定義されてるかどうかをWikidataに問い合わせるんや。「P176」はちゃんと定義された述語で、ドメインとレンジの両方の制約があるっちゅうことやな。
---
## Page 13
[](/attach/8355017f6539389e244c8bf5b3ffbe25d00fc9b6ee5affae4d280c97300dd749_p013.png)
### 和訳
Polatらの研究、13ページ目やな。
**図2. オントロジーベースのトリプル評価の例やで。**
トリプルの述語が「P176」のとき、主語は次のクラスのどれかに属してなあかんねん:「ソフトウェア」:「Q7397」、「物理的な物体」:「Q223557」、「モデルシリーズ」:「Q811701」、「具体的な物体」:「Q4406616」、「製品モデル」:「Q10929058」。ほんで、トリプルの目的語は次のクラスのどれかに属してなあかんで:「人間」:「Q5」、「動物」:「Q729」、「職業」:「Q28640」、「組織」:「Q43229」、「工場」:「Q83405」、「架空のキャラクター」:「Q95074」、「産業」:「Q268592」、「職人」:「Q1294787」、「架空のキャラクターのグループ」:「Q14514600」。3つ目のステップは、主語と目的語の型を4階層目まで遡ってチェックして、それらのクラスを述語のドメイン(定義域)とレンジ(値域)と比較するっちゅうことやねん。主語の「ポルシェ・パナメーラ」:「Q501349」は「モデルシリーズ」:「Q811701」に該当して、述語「P176」のドメインとバッチリ合ってるわけや。「モデルシリーズ」:「Q811701」までのプロパティパス(たどり方)はこうなってんねん:「自動車モデルシリーズ」:「Q59773381」→「車両モデルシリーズ」:「Q29048319」→「モデルシリーズ」:「Q811701」。目的語の「ポルシェ」:「Q40993」は「組織」:「Q43229」に該当して、述語のレンジとちゃんと一致してるで。「組織」:「Q43229」までのプロパティパスはこうや:「レースカーコンストラクター」:「Q15648574」→「組織」:「Q43229」。うちらのオントロジーベースの評価フレームワークによると、この抽出は正しいって判定されるわけやな。
## 5 結果
この研究では、RED-FMデータセットに対していろんなプロンプト戦略を適用して、抽出されたトリプルの正確さ・新規性・オントロジーとの整合性をガッツリ調べてんねん。5つのプロンプト手法にそれぞれ異なるタスクデモンストレーション戦略を組み合わせて、合計17パターンのプロンプトテンプレートを作ったんや。これを知識抽出(KE)に体系的に適用して、Mistral 7B、Llama 3、GPT-4の3つのモデルで、446件のテストデータを使って検証してんねん。使ったプロンプト手法は全部表1にまとめてあるで。この表では、うちらが名付けたプロンプトの種類ごとに分類してて、タスクデモンストレーションのやり方、方法論的な戦略、各手法で使った具体的な指示の詳細が書いてあんねん。各手法には、LLM(大規模言語モデル)に知識抽出タスクをやらせるための具体的な指示が含まれてて、そのタスクを効果的にこなすために必要なステップと注意点が、それぞれの方法論とアプローチに合わせて設計されてるわけや。この表は、うちらの研究で試したいろんなプロンプト手法を一覧にまとめて比較できるようにしたもんやねん。各プロンプト手法の有効性は、トリプルの抽出結果で測定してるで。うちらの評価プロトコルには以下の評価が含まれてんねん:
1. 標準的な評価指標、つまりRED-FMのゴールドスタンダード(正解データ)を基準にした適合率、再現率、F1スコアやな。
2. Wikidataオントロジーとの整合性チェック。
3. オントロジー整合性のさらに突っ込んだ分析。具体的には、Wikidataを基準にしたエンティティ(実体)と述語のリンク率、それからドメインとレンジが一致してるかどうかを確認するオントロジー整合性レベルのチェックや。
---
## Page 14
[](/attach/8355017f6539389e244c8bf5b3ffbe25d00fc9b6ee5affae4d280c97300dd749_p014.png)
### 和訳
14
Semantic Web 16(1)
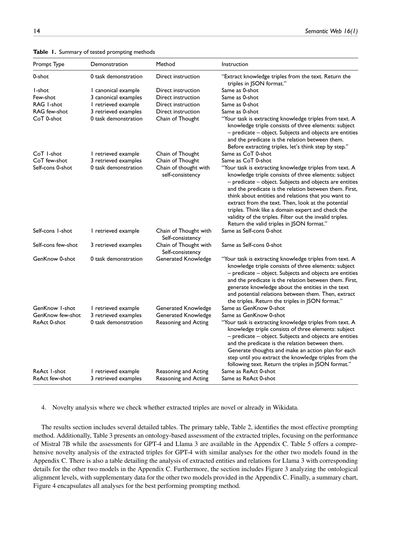
表1. テストしたプロンプト手法のまとめ
| プロンプトの種類 | デモンストレーション | 手法 | 指示内容 |
|---|---|---|---|
| 0-shot | タスクのデモなし | 直接指示 | 「テキストからナレッジトリプル(知識の三つ組)を抽出してな。JSON形式で返してや。」 |
| 1-shot | お手本1つ | 直接指示 | 0-shotと一緒やで |
| Few-shot | お手本3つ | 直接指示 | 0-shotと一緒やで |
| RAG 1-shot | 検索で引っ張ってきたお手本1つ | 直接指示 | 0-shotと一緒やで |
| RAG few-shot | 検索で引っ張ってきたお手本3つ | 直接指示 | 0-shotと一緒やで |
| CoT 0-shot | タスクのデモなし | 思考の連鎖(Chain of Thought) | 「あんたの仕事はテキストからナレッジトリプルを抜き出すことやねん。ナレッジトリプルっていうのは3つの要素でできてんねん:主語─述語─目的語や。主語と目的語はエンティティ(モノや概念のこと)で、述語はそいつらの関係性のことやな。トリプルを抽出する前に、まずステップバイステップで考えてみようや。」 |
| CoT 1-shot | 検索で引っ張ってきたお手本1つ | 思考の連鎖 | CoT 0-shotと一緒やで |
| CoT few-shot | 検索で引っ張ってきたお手本3つ | 思考の連鎖 | CoT 0-shotと一緒やで |
| Self-cons 0-shot | タスクのデモなし | 思考の連鎖+自己整合性チェック | 「あんたの仕事はテキストからナレッジトリプルを抜き出すことやねん。ナレッジトリプルっていうのは3つの要素でできてんねん:主語─述語─目的語や。主語と目的語はエンティティで、述語はそいつらの関係性のことやな。まず、テキストから抽出したいエンティティと関係性について考えてみてな。ほんで、候補のトリプルを見てみるねん。その分野の専門家になったつもりで、トリプルが正しいかチェックしてや。アカンやつはフィルタリングして弾いてな。正しいトリプルだけJSON形式で返してや。」 |
| Self-cons 1-shot | 検索で引っ張ってきたお手本1つ | 思考の連鎖+自己整合性チェック | Self-cons 0-shotと一緒やで |
| Self-cons few-shot | 検索で引っ張ってきたお手本3つ | 思考の連鎖+自己整合性チェック | Self-cons 0-shotと一緒やで |
| GenKnow 0-shot | タスクのデモなし | 知識生成(Generated Knowledge) | 「あんたの仕事はテキストからナレッジトリプルを抜き出すことやねん。ナレッジトリプルっていうのは3つの要素でできてんねん:主語─述語─目的語や。主語と目的語はエンティティで、述語はそいつらの関係性のことやな。まず、テキストに出てくるエンティティについての知識と、そいつらの間にありそうな関係性を生成してみてな。ほんでからトリプルを抽出するねん。JSON形式で返してや。」 |
| GenKnow 1-shot | 検索で引っ張ってきたお手本1つ | 知識生成 | GenKnow 0-shotと一緒やで |
| GenKnow few-shot | 検索で引っ張ってきたお手本3つ | 知識生成 | GenKnow 0-shotと一緒やで |
| ReAct 0-shot | タスクのデモなし | 推論と行動(Reasoning and Acting) | 「あんたの仕事はテキストからナレッジトリプルを抜き出すことやねん。ナレッジトリプルっていうのは3つの要素でできてんねん:主語─述語─目的語や。主語と目的語はエンティティで、述語はそいつらの関係性のことやな。テキストからナレッジトリプルを抽出するまで、各ステップごとに考えを出して行動計画を立ててみてや。JSON形式で返してな。」 |
| ReAct 1-shot | 検索で引っ張ってきたお手本1つ | 推論と行動 | ReAct 0-shotと一緒やで |
| ReAct few-shot | 検索で引っ張ってきたお手本3つ | 推論と行動 | ReAct 0-shotと一緒やで |
4. 新規性分析やねん。抽出したトリプルが新しいもんなんか、それともすでにWikidata(みんなで作るナレッジベースみたいなもんやな)に入ってるもんなんかをチェックするんやで。
結果セクションにはめっちゃ詳しい表がいくつか入ってるねん。メインの表は表2で、一番ええプロンプト手法がどれかを特定してるんや。ほんで表3は、抽出されたトリプルをオントロジー(知識の体系的な分類みたいなもんやな)ベースで評価したもんで、Mistral 7Bっていうモデルの性能に焦点当ててるねん。GPT-4とLlama 3の評価は付録Cに載ってるで。表5は、GPT-4で抽出されたトリプルの新規性をがっつり分析したもんで、他の2つのモデルの同じ分析も付録Cにあるわ。あと、Llama 3で抽出されたエンティティと関係性の分析を詳しく書いた表もあって、他の2つのモデルの対応する詳細も付録Cに載ってるんやで。さらに、図3ではオントロジーとの整合性レベルを分析してて、他の2つのモデルの補足データも付録Cに入ってるねん。最後に、まとめチャートの図4が、一番成績のええプロンプト手法についての全分析をギュッとまとめてくれてるんやで。
---
## Page 15
[](/attach/8355017f6539389e244c8bf5b3ffbe25d00fc9b6ee5affae4d280c97300dd749_p015.png)
### 和訳
Polatさんらの研究やねん。
15ページ目
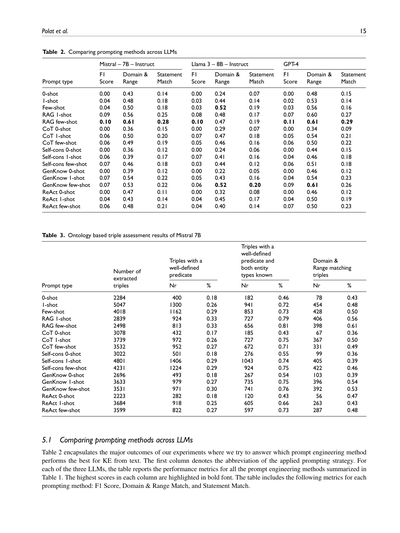
**表2. プロンプトの出し方をLLM(大規模言語モデル)ごとに比べてみた結果**
| プロンプトの種類 | Mistral – 7B – Instruct ||| Llama 3 – 8B – Instruct ||| GPT-4 |||
|---|---|---|---|---|---|---|---|---|---|
| | F1スコア | ドメイン&レンジ | 文マッチ | F1スコア | ドメイン&レンジ | 文マッチ | F1スコア | ドメイン&レンジ | 文マッチ |
| 0-shot | 0.00 | 0.43 | 0.14 | 0.00 | 0.24 | 0.07 | 0.00 | 0.48 | 0.15 |
| 1-shot | 0.04 | 0.48 | 0.18 | 0.03 | 0.44 | 0.14 | 0.02 | 0.53 | 0.14 |
| Few-shot | 0.04 | 0.50 | 0.18 | 0.03 | 0.52 | 0.19 | 0.03 | 0.56 | 0.16 |
| RAG 1-shot | 0.09 | 0.56 | 0.25 | 0.08 | 0.48 | 0.17 | 0.07 | 0.60 | 0.27 |
| RAG few-shot | 0.10 | 0.61 | 0.28 | 0.10 | 0.47 | 0.19 | 0.11 | 0.61 | 0.29 |
| CoT 0-shot | 0.00 | 0.36 | 0.15 | 0.00 | 0.29 | 0.07 | 0.00 | 0.34 | 0.09 |
| CoT 1-shot | 0.06 | 0.50 | 0.20 | 0.07 | 0.47 | 0.18 | 0.05 | 0.54 | 0.21 |
| CoT few-shot | 0.06 | 0.49 | 0.19 | 0.05 | 0.46 | 0.16 | 0.06 | 0.50 | 0.22 |
| Self-cons 0-shot | 0.00 | 0.36 | 0.12 | 0.00 | 0.24 | 0.06 | 0.00 | 0.44 | 0.15 |
| Self-cons 1-shot | 0.06 | 0.39 | 0.17 | 0.07 | 0.41 | 0.16 | 0.04 | 0.46 | 0.18 |
| Self-cons few-shot | 0.07 | 0.46 | 0.18 | 0.03 | 0.44 | 0.12 | 0.06 | 0.51 | 0.18 |
| GenKnow 0-shot | 0.00 | 0.39 | 0.12 | 0.00 | 0.22 | 0.05 | 0.00 | 0.46 | 0.12 |
| GenKnow 1-shot | 0.07 | 0.54 | 0.22 | 0.05 | 0.43 | 0.16 | 0.04 | 0.54 | 0.23 |
| GenKnow few-shot | 0.07 | 0.53 | 0.22 | 0.06 | 0.52 | 0.20 | 0.09 | 0.61 | 0.26 |
| ReAct 0-shot | 0.00 | 0.47 | 0.11 | 0.00 | 0.32 | 0.08 | 0.00 | 0.46 | 0.12 |
| ReAct 1-shot | 0.04 | 0.43 | 0.14 | 0.04 | 0.45 | 0.17 | 0.04 | 0.50 | 0.19 |
| ReAct few-shot | 0.06 | 0.48 | 0.21 | 0.04 | 0.40 | 0.14 | 0.07 | 0.50 | 0.23 |
**表3. Mistral 7Bのオントロジーベースでトリプル(三つ組)を評価した結果**
| プロンプトの種類 | 抽出されたトリプルの数 | ちゃんと定義された述語を持つトリプル || ちゃんと定義された述語+両方のエンティティ型がわかっとるトリプル || ドメイン&レンジが合致したトリプル ||
|---|---|---|---|---|---|---|---|
| | | 数 | % | 数 | % | 数 | % |
| 0-shot | 2284 | 400 | 0.18 | 182 | 0.46 | 78 | 0.43 |
| 1-shot | 5047 | 1300 | 0.26 | 941 | 0.72 | 454 | 0.48 |
| Few-shot | 4018 | 1162 | 0.29 | 853 | 0.73 | 428 | 0.50 |
| RAG 1-shot | 2839 | 924 | 0.33 | 727 | 0.79 | 406 | 0.56 |
| RAG few-shot | 2498 | 813 | 0.33 | 656 | 0.81 | 398 | 0.61 |
| CoT 0-shot | 3078 | 432 | 0.17 | 185 | 0.43 | 67 | 0.36 |
| CoT 1-shot | 3739 | 972 | 0.26 | 727 | 0.75 | 367 | 0.50 |
| CoT few-shot | 3532 | 952 | 0.27 | 672 | 0.71 | 331 | 0.49 |
| Self-cons 0-shot | 3022 | 501 | 0.18 | 276 | 0.55 | 99 | 0.36 |
| Self-cons 1-shot | 4801 | 1406 | 0.29 | 1043 | 0.74 | 405 | 0.39 |
| Self-cons few-shot | 4231 | 1224 | 0.29 | 924 | 0.75 | 422 | 0.46 |
| GenKnow 0-shot | 2696 | 493 | 0.18 | 267 | 0.54 | 103 | 0.39 |
| GenKnow 1-shot | 3633 | 979 | 0.27 | 735 | 0.75 | 396 | 0.54 |
| GenKnow few-shot | 3531 | 971 | 0.30 | 741 | 0.76 | 392 | 0.53 |
| ReAct 0-shot | 2223 | 282 | 0.18 | 120 | 0.43 | 56 | 0.47 |
| ReAct 1-shot | 3684 | 918 | 0.25 | 605 | 0.66 | 263 | 0.43 |
| ReAct few-shot | 3599 | 822 | 0.27 | 597 | 0.73 | 287 | 0.48 |
### 5.1 プロンプトの出し方をLLMごとに比べてみたで
表2がな、今回の実験のメインの結果をまとめたやつやねん。要するに「文章から知識を引っこ抜く(知識抽出)のに、どのプロンプトの出し方が一番ええねん?」っていう問いに答えようとしてるわけや。
最初の列がな、使ったプロンプト戦略の略称やねん。ほんで3つのLLMそれぞれについて、表1でまとめた全部のプロンプト手法の性能指標を載せとるで。各列で一番ええスコアは太字にしてあるからわかりやすいと思うわ。
で、この表に載っとる指標は何かっていうと、プロンプト手法ごとに**F1スコア**、**ドメイン&レンジマッチ**(述語の定義域と値域がちゃんと合っとるかっていう話やな)、それから**文マッチ**(ステートメントマッチ、つまり文の内容がどれだけ正解と一致しとるか)の3つやねん。
---
## Page 16
[](/attach/8355017f6539389e244c8bf5b3ffbe25d00fc9b6ee5affae4d280c97300dd749_p016.png)
### 和訳
16
Semantic Web 16(1)
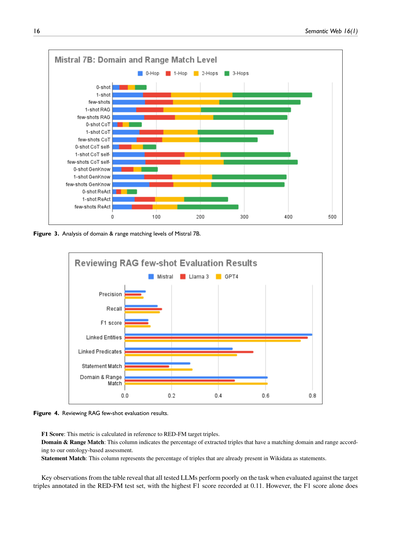
図3. Mistral 7Bのドメインとレンジのマッチングレベルの分析やで。
図4. RAGの少数ショット評価結果のレビューやな。
F1スコア:これはRED-FMのターゲットとなるトリプル(主語・述語・目的語の3つ組のことやで)を基準にして計算した指標やねん。
ドメイン&レンジ一致:この列はな、抽出されたトリプルのうち、ワイらが作ったオントロジー(知識の体系みたいなもんや)ベースの評価で、ドメイン(定義域)とレンジ(値域)がちゃんと合ってるやつの割合を示してるねん。
ステートメント一致:この列はな、抽出されたトリプルのうち、すでにWikidata(みんなで作る知識データベースやな)にステートメントとして登録されてるやつの割合やで。
ほんで表から見えてくる大事なポイントやねんけど、テストしたLLM(大規模言語モデルのことやな)は全部、RED-FMのテストセットにアノテーション(タグ付け)されたターゲットトリプルと比べると、めっちゃ成績悪いねん。一番高いF1スコアでも0.11しかないんやで。せやけどな、F1スコアだけで判断したらあかんねん——
---
## Page 17
[](/attach/8355017f6539389e244c8bf5b3ffbe25d00fc9b6ee5affae4d280c97300dd749_p017.png)
### 和訳
Polatらの研究、17ページ目やな。
オープン情報抽出っていう設定やと、生成系の言語モデルって言葉のバリエーションがめっちゃ出てくるねん。前のセクションでも詳しく話したし、図1でも見せた通りやな。せやから、F1スコアだけやと抽出の質をちゃんと測れへんのよ。ドメイン&レンジマッチとステートメントマッチっていう指標は、Wikidataを基準にして抽出結果がオントロジー的にどんだけ合ってるかを見るもんで、抽出の質とか正しさについてええ感じの洞察をくれるねん。この2つの指標はF1スコアよりもバラつきが大きくて、使ったプロンプト戦略がほんまに効いてるかどうか、もっと深く分かるようになってるわけや。
タスクのお手本(デモンストレーション)を入れたると、だいたい一貫してパフォーマンスが上がるねん。特にドメイン&レンジマッチとステートメントマッチでな。一番成績ええプロンプトは、検索メカニズムで選んだタスクのお手本を使うやつ(RAG few-shot)で、ほとんどのモデルでF1スコアもステートメントマッチ率もトップやねん。つまりこの方法が一番ええ抽出できるっちゅうことや。注目すべきは、ドメイン&レンジマッチのスコアがMistral 7Bで+0.5、GPT-4で+0.1改善してることやな。ただし、Llama 3はこの指標に関しては検索で持ってきたお手本を入れるとむしろ悪なってまうねん。Llama 3は標準的なお手本の方が相性ええみたいで、ドメイン&レンジとステートメントマッチの指標にそれが出とるわ。セルフコンシステンシーと生成知識っていう方法は、タスクのお手本をプロンプトに組み込んだら全部の指標でめっちゃ良くなるねん、特にLlama 3でな。けど、few-shotのシナリオやと改善が中くらいやったり、逆にちょっと悪なることもあって、例えばMistral 7Bで生成知識使った時とか、Llama 3でReasoning and Actingプロンプト使った時のドメイン&レンジマッチがそうやな。最後に、Reasoning and Actingプロンプトは、one-shotやfew-shotのアプローチやと、Chain of ThoughtやSelf-consistencyとええ勝負するパフォーマンスを見せてくれるねん。ゼロショットと比べたらの話やけどな。
**5.2 オントロジー的な整合性**
オントロジーっていうのは、ナレッジグラフの中で知識をどう表現するかの背骨みたいなもんやねん[8]。クラスとかプロパティとか、情報同士の関係性をちゃんと構造化したフレームワークを提供してくれるんや。これを踏まえて、抽出されたトリプル(主語・述語・目的語の3つ組)とエンティティ(実体)とリレーション(関係)を徹底的に分析したで。やり方としては、Wikidataの階層構造を活用して、エンティティの型を4階層目まで掘り下げて調べとるねん。リレーションのドメイン(定義域)とレンジ(値域)の指定も考慮して、ナレッジグラフの中でちゃんと正しい役割を果たしてるか確認しとるわけや。
結果は表3にまとめとるんやけど、Mistral 7Bが抽出したもんに対するオントロジーベースの評価の主な成果が書いてあるで。他の2つのLLMの結果は付録Cの表6と表7にあるわ。この2つのモデルも似たような傾向を見せとるねん。注目すべきは、GPT-4もMistralもドメイン&レンジのマッチング率が0.61で同じやっていうことやな。全体の結果を見ると、GPT-4がほんのちょっとだけ上やねん。けど、オントロジーベースのトリプル評価の全体像を見せるっていう目的では、Mistral 7Bに絞って説明することにしたで。
表3の最初の列「抽出されたトリプル数」は、各プロンプト戦略でMistral 7Bが抽出したトリプルの総数やねん。446個のテストインスタンスで計算しとるで。2番目の列「述語がちゃんと定義されたトリプル」は、Wikidataにリンクされてて、述語がちゃんと定義されとるトリプルの数や。つまりrdfs:domain(定義域)とrdfs:range(値域)がある述語のことやな。3番目の列は、そういうトリプルが全体の抽出セットに対してどんだけの割合かを示しとるで。さらに全体像を把握できるように追加の詳細もあるねん。4番目と5番目の列「述語がちゃんと定義されてて、かつ両方のエンティティ型が分かってるトリプル」は、述語がちゃんと定義されてて、主語も目的語もWikidataにリンクされてるトリプルの数と、述語がちゃんと定義されたトリプル全体に対する割合やで。最後の2つの列「ドメインとレンジがマッチするトリプル」は、ちゃんと定義された述語とそのトリプルを構成するエンティティの型がどんだけ合ってるかを見せてくれるねん。具体的には7番目の列で、主語の型が述語のドメインと一致し、かつ述語のレンジが目的語の型と一致するトリプルの数を示しとるわ。最後の列は、そういうドメイン&レンジがマッチしたトリプルの、述語がちゃんと定義された全トリプルに対する割合やねん。これらの統計で、抽出されたトリプルの意味的な整合性と構造的な一致度をもっと精密に評価できるっちゅうわけや。
表3を分析すると、表2での分析がさらに裏付けられるねん。ゼロショットプロンプトが一貫して最低のパフォーマンスやっていうのは、タスクのお手本なしで正確な抽出をするんがいかに難しいかを物語っとるわ。ゼロショットプロンプトっていうのは、「テキストから知識トリプルを抽出してや」っていう短い指示だけで構成されとるねん。おもろいことに、実験してみたら、このシンプルなプロンプトのアプローチが、セルフコンシステンシーっていうもっと手の込んだ方法と同じくらいの性能を出すんよ。セルフコンシステンシーは何回も出力生成して一番一貫性のある答えを選ぶっていう複雑な戦略やのにな。しかもこの直球ゼロショット技法は、他のゼロショット手法よりドメイン&レンジマッチで4〜6%も上回っとるねん。他の手法っていうのは、Chain of Thought(CoT、段階的に考えさせるやつ)とかSelf-consistency(セルフコンシステンシー)とかGenerated Knowledge(生成知識)とかで、言語モデルを導くために追加の文脈やステップを組み込むやつやな。ゼロショットプロンプトのストレートな指示がこんだけ効くっていうのは、最新の言語モデルが最小限の指示でもタスクをこなせる力を持っとることを示しとるわけや。
In-context Learning(ICL、文脈内学習)は「お手本見て学ぶ」っていう考え方を活用するもんやねん。この現象によって、LLMは示されたお手本に合わせて生成する回答を調整して、見せてもらったタスク特有の振る舞いを真似できるようになるんや。
---
## Page 18
[](/attach/8355017f6539389e244c8bf5b3ffbe25d00fc9b6ee5affae4d280c97300dd749_p018.png)
### 和訳
18
Semantic Web 16(1)
[14] ワイらの実験結果もこの現象をバッチリ裏付けとるねん。タスクのお手本(デモンストレーション)をプロンプトに入れたら、めっちゃパフォーマンスが上がるんよ。具体的に言うたら、表3に出とるように、ゼロショットのやり方と比べて36%(CoTゼロショット)から50%(CoT 1ショット)までドーンと跳ね上がるわけ。お手本を1個入れるだけで、モデルの性能がベースラインの0.43から0.48まで目に見えて良うなるねん。せやけどな、お手本をもう1ペア追加してフューショット学習にしても、性能の伸びはたったの2%でちょっとしか変わらへんのよ。つまりな、お手本を増やしてもモデルが吸収できる限界があるっちゅうことやねん。場合によってはお手本増やしすぎたら逆にパフォーマンス下がることもあって、Chain of ThoughtとGenerated Knowledgeプロンプトの結果にそれが出とるわ。
ICL(文脈内学習)でお手本をどう選ぶかっていうのは、モデルの性能にめっちゃ影響するからほんまに大事やねん。なんでかっていうと、お手本がモデルに「このタスクはこういうもんやで」って下地を作ってくれるからや。訓練データから引っ張ってきたお手本を入れたら、抽出されるトリプル(主語・述語・目的語の三つ組)の数が減るのが確認されとる。例えば表3で2839から2498に減っとるんやけど、その一方でRAGフューショットプロンプトではF1スコアは上がっとるねん。これが何を意味するかっていうと、選んだお手本が抽出プロセスに影響を与えとるっちゅうことや。モデルの焦点がシャープになったとか、お手本の特徴に合わせて抽出基準がチューニングされた結果、抽出されるトリプルの量が変わったんやないかと考えられるわけ。抽出されたトリプルの総数は減ったけど、Wikidataのオントロジー(ドメイン&レンジ一致)に沿ったトリプルは増えとるから、お手本を入れたことで抽出の質がグンと上がったっちゅうことやな。
おもろいことにな、Chain-of-Thought(CoT、段階的に考えさせるやつ)、Self-consistency(自己一貫性)、ReAct(推論して行動するやつ)みたいな、モデルの推論力を上げるために考えられたプロンプト手法を使っても、オープンな知識トリプル抽出の性能はたいして良うならへんのよ。これが何を示唆しとるかっていうと、プロンプトに推論を促すヒントを入れても、この実験の枠組みでは正しい答えを出す力とか複雑な問題に取り組む力がそこまで上がらへんっちゅうことやねん。まあでも、エンティティ(実体)のタイプについて推論すること自体は、人間がテキストからより正確なトリプルを抽出するのには役立つかもしれへんけどな。
この3つの推論系プロンプト手法を個別に見てみても、性能の数値はだいたい似たような範囲に固まっとるねん。どの手法を見ても、「これが圧倒的に優れとる!」って言えるほどの差は見当たらへん。この性能差がほとんどないっちゅう事実が、オープンな知識トリプル抽出の実験条件下では推論強化型プロンプトはモデルの出力にそこまで貢献せえへんっちゅう結論をさらに裏付けとるわけや。
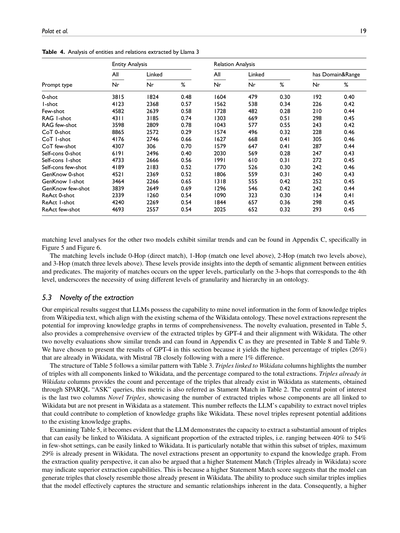
**5.2.1 抽出されたエンティティとリレーションの分析。** 抽出されたトリプルの評価プロセスは、Wikidataオントロジーが定義する意味論に基づいとるねん。抽出されたデータがWikidataの構造とちゃんと整合しとるかっていう意味的な整合性の確認が重要視されとるわけや。さらにワイらは、ユニーク(重複なし)な抽出結果を調べることが、抽出の質とプロンプト戦略の有効性を理解するのに大事やと考えとる。表3の結果に加えて、表4では各プロンプト戦略で抽出されたエンティティとリレーション(関係)を見ていくで。これによって、プロンプトエンジニアリングの手法がWikidataとの整合性に関する抽出性能にどう影響するか、もっと深く理解できるんや。
表4のエンティティ分析のセクションでは、Llama 3が抽出したユニークなエンティティの総数、そのうちWikidataにリンクできたもの、全体に対するリンク率を示しとる。GPT-4とMistral 7Bによるエンティティとリレーションの抽出分析は付録Cにあって、表10と表11に載っとるで。この2つのモデルもLlama 3と似たような傾向を示しとるんやけど、全体的なエンティティとリレーションのリンク分析を見せるにあたっては、リレーションのリンク率が一番ええLlama 3に焦点を当てることにしたんや。表4のリレーション分析のセクションでは、抽出されたユニークなリレーションの総数、Wikidataにリンクできた数とその割合を示しとる。さらに、リンクされたリレーションにドメイン(定義域)とレンジ(値域)の制約があるかどうかも評価しとって、データの意味論がどれだけ利用可能かをより深く理解できるようになっとるねん。
表4からエンティティとリレーションのリンク率についてわかることがあるんやけどな。リレーションと比べて、エンティティの方がどのプロンプト手法でもリンク率が高いねん。フューショット設定のRAGプロンプトではリンク率が最大78%まで行くんよ。一方でリレーションのリンク率はかなり低くて、同じくフューショット設定のRAGプロンプトでも最大55%止まりや。さらに統計を見ると、リンクされた述語のうちWikidataでちゃんと定義されとるのは40〜46%しかないっちゅうことで、まだまだ改善の余地があるっちゅうことがわかるわな。
**5.2.2 マッチングレベル。** 抽出結果のオントロジー的な整合性をもっと深く理解するために、ドメイン&レンジのマッチングレベルも調べたで。図3に示した分析では、各プロンプト手法ごとのドメインとレンジのマッチングレベルの分布を詳しく見とる。このセクションではMistral 7Bに焦点を当てることにしたんやけど、なんでかっていうと、前の表3でドメイン&レンジの一致率を示しとるから、それと一貫性を持たせて比較しやすくするためやねん。ドメイン&レンジの
---
## Page 19
[](/attach/8355017f6539389e244c8bf5b3ffbe25d00fc9b6ee5affae4d280c97300dd749_p019.png)
### 和訳
Polatらの論文、19ページ目やで。
**表4. Llama 3が抽出したエンティティとリレーションの分析**
| | | エンティティ分析 | | | リレーション分析 | | | | |
|---|---|---|---|---|---|---|---|---|---|
| プロンプトの種類 | 全部の数 | リンクできた数 | リンク率 | 全部の数 | リンクできた数 | リンク率 | ドメイン&レンジあり | その数 | その割合 |
| 0-shot | 3815 | 1824 | 0.48 | 1604 | 479 | 0.30 | 192 | 0.40 |
| 1-shot | 4123 | 2368 | 0.57 | 1562 | 538 | 0.34 | 226 | 0.42 |
| Few-shot | 4582 | 2639 | 0.58 | 1728 | 482 | 0.28 | 210 | 0.44 |
| RAG 1-shot | 4311 | 3185 | 0.74 | 1303 | 669 | 0.51 | 298 | 0.45 |
| RAG few-shot | 3598 | 2809 | 0.78 | 1043 | 577 | 0.55 | 243 | 0.42 |
| CoT 0-shot | 8865 | 2572 | 0.29 | 1574 | 496 | 0.32 | 228 | 0.46 |
| CoT 1-shot | 4176 | 2746 | 0.66 | 1627 | 668 | 0.41 | 305 | 0.46 |
| CoT few-shot | 4307 | 306 | 0.70 | 1579 | 647 | 0.41 | 287 | 0.44 |
| Self-cons 0-shot | 6191 | 2496 | 0.40 | 2030 | 569 | 0.28 | 247 | 0.43 |
| Self-cons 1-shot | 4733 | 2666 | 0.56 | 1991 | 610 | 0.31 | 272 | 0.45 |
| Self-cons few-shot | 4189 | 2183 | 0.52 | 1770 | 526 | 0.30 | 242 | 0.46 |
| GenKnow 0-shot | 4521 | 2369 | 0.52 | 1806 | 559 | 0.31 | 240 | 0.43 |
| GenKnow 1-shot | 3464 | 2266 | 0.65 | 1318 | 555 | 0.42 | 252 | 0.45 |
| GenKnow few-shot | 3839 | 2649 | 0.69 | 1296 | 546 | 0.42 | 242 | 0.44 |
| ReAct 0-shot | 2339 | 1260 | 0.54 | 1090 | 323 | 0.30 | 134 | 0.41 |
| ReAct 1-shot | 4240 | 2269 | 0.54 | 1844 | 657 | 0.36 | 298 | 0.45 |
| ReAct few-shot | 4693 | 2557 | 0.54 | 2025 | 652 | 0.32 | 293 | 0.45 |
残りの2つのモデルのマッチングレベル分析も似たような傾向を示してて、付録Cの図5と図6に載ってるで。
マッチングレベルっていうのは、0-Hop(直接一致)、1-Hop(1つ上の階層で一致)、2-Hop(2つ上の階層で一致)、3-Hop(3つ上の階層で一致)っていう段階があんねん。これらのレベルで、エンティティと述語の意味的な一致がどれくらい深いところで起きてるかがわかるわけや。大半のマッチングは上位レベル、特に4階層目にあたる3-Hopsで起きてて、これが何を意味するかっていうと、オントロジーでは粒度や階層構造を色々変えて使わなあかんってことやねん。
**5.3 抽出の新規性**
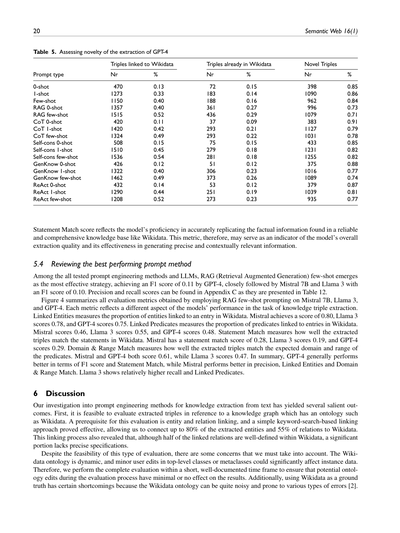
実験結果からわかったんやけど、LLM(大規模言語モデル)にはWikipediaのテキストから知識トリプルっていう形で新しい情報を掘り出す能力があって、しかもそれがWikidataのオントロジーの既存スキーマとちゃんと整合するねん。この新しく抽出されたやつは、ナレッジグラフの網羅性を向上させる可能性を示してるってことやな。新規性の評価は表5にまとめてあって、GPT-4が抽出したトリプルとWikidataとの整合性を包括的に示してるで。他の2つのモデルの新規性評価も似たような傾向やから、付録Cの表8と表9を見てな。このセクションでGPT-4の結果を紹介してるのは、なんでかっていうと、Wikidataに既に存在するトリプルの割合が26%と一番高かったからやねん。Mistral 7Bもほんまに僅差で、たった1%しか差がないで。
表5の構造は表3と似たパターンになってるわ。「Wikidataにリンクされたトリプル」の列は、全構成要素がWikidataにリンクできたトリプルの数と、全抽出数に対する割合を示してるねん。「Wikidataに既に存在するトリプル」の列は、SPARQLの「ASK」クエリで調べた結果、Wikidataにステートメントとして既に存在してるトリプルの数と割合を示してて、これは表2で「Statement Match」って呼ばれてるやつと同じやで。ほんで一番注目すべきポイントは最後の2列の「新規トリプル」やねん。これは、全構成要素がWikidataにリンクできるけど、Wikidataにはステートメントとして存在してへんトリプルの数を示してるわけや。この数字が、LLMがWikidataみたいなナレッジグラフの補完に貢献できる新しいトリプルを抽出する能力を反映してんねん。つまり、これらの新規トリプルは既存のナレッジグラフへの追加候補ってことやな。
表5を見たらめっちゃわかりやすいんやけど、LLMはWikidataに簡単にリンクできるトリプルをかなりの量抽出できることが明らかやねん。抽出されたトリプルのかなりの割合、具体的にはfew-shot設定で40%から54%がWikidataに簡単にリンクできるんや。特に注目すべきは、このリンクできたトリプルのうち、最大でも29%しかWikidataに既に存在してないってことやで。つまり、新規に抽出されたやつはナレッジグラフを拡張するチャンスやってことやな。抽出品質の観点から言うと、Statement Match(Wikidataに既に存在するトリプル)のスコアが高いほど、抽出能力が優れてるとも言えるねん。なんでかっていうと、Statement Matchのスコアが高いってことは、モデルがWikidataに既にあるトリプルとめっちゃ似たやつを生成できるってことやからな。そういう類似したトリプルを作れるってことは、データに内在する構造や意味的関係をモデルがしっかり捉えてるってことを意味するわけや。結果として、Statement Matchが高いほど
---
## Page 20
[](/attach/8355017f6539389e244c8bf5b3ffbe25d00fc9b6ee5affae4d280c97300dd749_p020.png)
### 和訳
表5. GPT-4が引っ張り出してきた情報の「新しさ」を調べてみた結果やで
Wikidataに紐づけできたトリプル / すでにWikidataにあったトリプル / 新しいトリプル
プロンプトの種類
| プロンプトの種類 | 紐づけ数 | 割合 | 既存数 | 割合 | 新規数 | 割合 |
|---|---|---|---|---|---|---|
| 0-shot | 470 | 0.13 | 72 | 0.15 | 398 | 0.85 |
| 1-shot | 1273 | 0.33 | 183 | 0.14 | 1090 | 0.86 |
| Few-shot | 1150 | 0.40 | 188 | 0.16 | 962 | 0.84 |
| RAG 0-shot | 1357 | 0.40 | 361 | 0.27 | 996 | 0.73 |
| RAG few-shot | 1515 | 0.52 | 436 | 0.29 | 1079 | 0.71 |
| CoT 0-shot | 420 | 0.11 | 37 | 0.09 | 383 | 0.91 |
| CoT 1-shot | 1420 | 0.42 | 293 | 0.21 | 1127 | 0.79 |
| CoT few-shot | 1324 | 0.49 | 293 | 0.22 | 1031 | 0.78 |
| Self-cons 0-shot | 508 | 0.15 | 75 | 0.15 | 433 | 0.85 |
| Self-cons 1-shot | 1510 | 0.45 | 279 | 0.18 | 1231 | 0.82 |
| Self-cons few-shot | 1536 | 0.54 | 281 | 0.18 | 1255 | 0.82 |
| GenKnow 0-shot | 426 | 0.12 | 51 | 0.12 | 375 | 0.88 |
| GenKnow 1-shot | 1322 | 0.40 | 306 | 0.23 | 1016 | 0.77 |
| GenKnow few-shot | 1462 | 0.49 | 373 | 0.26 | 1089 | 0.74 |
| ReAct 0-shot | 432 | 0.14 | 53 | 0.12 | 379 | 0.87 |
| ReAct 1-shot | 1290 | 0.44 | 251 | 0.19 | 1039 | 0.81 |
| ReAct few-shot | 1208 | 0.52 | 273 | 0.23 | 935 | 0.77 |
「ステートメント一致スコア」っちゅうのはな、Wikidataみたいな信頼できるデカい知識ベースにある事実情報を、モデルがどんだけ正確に再現できてるかを見る指標やねん。つまりこの数字を見れば、そのモデルが情報を引っ張り出す力がどんなもんか、的確で文脈に合った情報を出せてるかが分かるっちゅうわけやな。
### 5.4 一番成績よかったプロンプト手法を見てみよか
全部のプロンプト手法とLLMを試した中で、**RAG(検索拡張生成)のfew-shot**がぶっちぎりで一番優秀やったわ。GPT-4でF1スコア0.11を叩き出して、Mistral 7BとLlama 3がF1スコア0.10で僅差で追いかけとる感じやな。精度とか再現率の細かい数字は付録CのTable 12に載せてあるで。
図4は、RAG few-shotプロンプトをMistral 7B、Llama 3、GPT-4に使った時の評価指標を全部まとめたもんやねん。それぞれの指標がな、知識トリプル抽出っていう作業のどの側面を測ってるか説明するで。
**リンク済みエンティティ**は、抽出したエンティティ(要は「モノ」とか「概念」のことやな)のうち、Wikidataの項目に紐づけられた割合やねん。Mistralが0.80、Llama 3が0.78、GPT-4が0.75や。**リンク済み述語**は、述語(「関係性」を表す部分やな)がWikidataの項目に紐づけられた割合で、Mistralが0.46、Llama 3が0.55、GPT-4が0.48やで。**ステートメント一致**は、抽出したトリプルがWikidataの記述とどんだけ合ってるかを見るもんで、Mistralが0.28、Llama 3が0.19、GPT-4が0.29や。**ドメイン&レンジ一致**は、抽出したトリプルが述語に期待される定義域と値域にちゃんと合ってるかを測るんやけど、MistralとGPT-4が両方とも0.61で、Llama 3は0.47やったな。
まとめるとな、GPT-4はF1スコアとステートメント一致では全体的にええ感じで、Mistralは精度とリンク済みエンティティとドメイン&レンジ一致で強い。Llama 3は再現率とリンク済み述語が比較的高いっちゅう結果やな。それぞれ得意分野が違うんがおもろいところやわ。
## 6 議論
テキストから知識を引っ張り出すためのプロンプト工夫について調べてみたら、めっちゃ重要な発見がいくつかあったんよ。
まずな、**抽出したトリプルをWikidataみたいなオントロジー(知識の体系的な構造やな)を持つ知識グラフを基準にして評価できる**っちゅうことが分かったんや。この評価をするには、エンティティと関係性のリンキング(紐づけ)が前提条件になるんやけど、シンプルなキーワード検索ベースのリンキング方法でも十分いけて、抽出したエンティティの最大80%、関係性の55%をWikidataに紐づけできたんやで。このリンキングの過程で分かったんやけど、紐づけできた関係性の半分はWikidata内でちゃんと定義されてるものの、かなりの部分は正確な定義がないっちゅう状態やったわ。
ただな、この評価方法にはいくつか気をつけなアカンことがあるねん。Wikidataのオントロジーっちゅうのは常に変わり続けるもんで、上位クラスやメタクラスにちょっとした編集があっただけで、下にぶら下がってるインスタンスデータにめっちゃ影響が出る可能性があるんよ。やからな、評価は全部短い期間にまとめてやって、しっかり記録も残して、評価中にオントロジーが編集されても結果にほぼ影響が出ないようにしたんや。あとな、Wikidataを正解データとして使うこと自体にも限界があって、なんでかっていうと、Wikidataのオントロジーはノイズが多くて、いろんな種類のエラーが含まれてるからやねん [2]。
---
## Page 21
[](/attach/8355017f6539389e244c8bf5b3ffbe25d00fc9b6ee5affae4d280c97300dd749_p021.png)
### 和訳
Polatらの研究、21ページ目やな。
ほんで、今回やったエンティティとプロパティのリンキング(要するに、抽出した情報を既存のデータベースの項目と紐づける作業やな)は、正直かなり初歩的なやり方で、いくつか問題点があんねん。リンキングのミスがあるっちゅうことや。具体的に言うと、ほんまは一致するもんがあるのに見つけられへん場合(偽陰性っていうやつ)とか、間違ったエンティティや関係に紐づけてまう場合(偽陽性っていうやつ)があんねん。このミスが評価にめっちゃ影響して、知識抽出の手法をちゃんと評価できへんくなるわけや。この問題を解決するには、もっと賢いリンキングアルゴリズムを使えば、エンティティやプロパティのマッチング精度が上がるはずやねん。例えば、エンティティの文脈を考慮した埋め込みベースのリンキング手法(単語の意味をベクトルで表現して比較する方法やな)を使えば、偽陽性も偽陰性も減らせるやろうな。まあそういう弱点はあるけど、この研究は「こういう評価のやり方がイケるで!」っちゅうポテンシャルをちゃんと示せたと思うわ。
2つ目の発見やけど、LLM(大規模言語モデル)は1つのインスタンスから最大61個のトリプル(「主語・述語・目的語」のセットやな)を抽出できるっちゅうことで、めっちゃ抽出能力が高いねん。注目すべきは、プロンプトにタスクの例を1つ追加するだけで抽出性能がドカンと上がるっちゅうことや。ただし、例を増やしていくと効果はだんだん薄くなるんやけどな。おもろいことに、抽出されたトリプルのうちWikidata(ウィキペディアの構造化データベースみたいなもんや)に既に登録されてるもんは最大でも26%で、大半は新しく抽出された情報やねん。3つ目の発見として、いろんなプロンプト戦略を試した中で、推論に重点を置いた方法はシンプルなプロンプト設計より良くならへんかったんや。一方で、検索拡張(RAG、関連情報を事前に取ってきてプロンプトに足すやり方やな)を使うと、複雑な指示なしでもモデルが正確にトリプルを抽出できるようになったんやで。
RED-FMっちゅうのは関係抽出用に作られたデータセットで、32種類の関係に焦点を当ててるねん。今回の研究では、このデータセットをオープンな知識抽出タスクに使ったわけや。Mistral 7B、Llama 3、GPT-4のスコアは、完全教師あり学習のモデル、つまりmREBELとその派生モデル([10]で紹介されてるやつ)に比べると、かなり低いねん。一番ええ場合でも、GPT-4はF1スコア0.11なんやけど、mREBEL[10]は同じ英語のRED-FMテストセットで0.54のF1スコアを叩き出してるんや。あと大事なこととして、Mistral 7B、Llama 3、GPT-4はモデルのサイズが全然ちゃうねん。Mistralは70億パラメータ、今回使ったLlama 3は80億パラメータや。GPT-4はこのオープンソースモデルたちよりめっちゃデカくて、1.76兆パラメータもあるんやで。LLMのサイズっちゅうのは、パラメータにどんだけ情報を蓄えられるかを表してて、知識抽出みたいなタスクの性能に影響するわけやな。
最後に、今回調べたプロンプト設計手法を分析した結果、オープンな抽出設定での相対的な効果がわかったわけや。この調査から、LLMがナレッジグラフ(知識をグラフ構造で整理したデータベースやな)を充実させる可能性が見えた一方で、モデルの出力を外部の知識ベースと整合させるのがなかなか複雑やっちゅうこともわかったんや。ここで得られた洞察がめっちゃ面白くて、非構造化テキストを構造化された知識に変換するっちゅう作業は、推論タスクっちゅうよりも「フォーマット変換タスク」に近いんちゃうか、っちゅうことやねん。つまり、抽出プロセスを推論の練習みたいに捉えるのは、このタスクの本質やLLMの内部的な動き方と合ってへんかもしれんわけや。むしろ、抽出は「非構造化データから構造化データへの変換」として捉えた方がええし、この"翻訳"を最適化するには、よう練られた例を用意することが大事やっちゅうことが示されたんやな。
## 7 結論
この研究では、知識抽出(KE)タスクにおける最新のプロンプト設計手法の有効性を調べたんや。評価には標準的な指標に加えて、Wikidataベースの新しい評価プロトコルも使ったで。結果としては、Few-shot RAGプロンプト(少数の例と検索拡張を組み合わせた方法やな)が、複数のLLMにわたって一番ええ成績やったわ。今後の研究では、もっと多様なデータセットや、いろんなリンキング手法を使ってこのアプローチを検証すると、もっとええ知見が得られるはずや。そうすることで、今回提案したオントロジーベースの評価フレームワークの汎用性と有効性がしっかり確認できるし、もっと幅広くてバリエーション豊かな分野での知識抽出やグラフ充実化の戦略を洗練できるやろな。
## 謝辞
この研究は、欧州連合のHorizon Europeの研究・イノベーションプログラム内のENEXAプロジェクト(助成金契約番号101070305)から資金提供を受けてるで。
あと、Prompt Engineering Guide [24]には、今回のプロンプト設計手法の選択と適用にあたって、めっちゃ貴重な知見とインスピレーションをもろたんで、心から感謝申し上げますわ。
---
## Page 22
[](/attach/8355017f6539389e244c8bf5b3ffbe25d00fc9b6ee5affae4d280c97300dd749_p022.png)
### 和訳
22
Semantic Web 16巻1号
付録A. SPARQLクエリ集
A.1 ドメインクエリのテンプレート
A.2 レンジクエリのテンプレート
A.3 エンティティタイプのクエリテンプレート
A.3.1 インスタンスの所属(Instance of)
---
ちょっと補足しとくとな、これは目次みたいなもんやねん。SPARQLっていうのは、セマンティックウェブ(意味を理解できるウェブ)のデータを検索するための問い合わせ言語のことやで。ドメインは「主語側の型」、レンジは「目的語側の型」、エンティティタイプは「そのデータが何の種類か」ってことやな。「Instance of」は「これは〇〇の一種ですよ」っていう分類のことやで。
---
## Page 23
[](/attach/8355017f6539389e244c8bf5b3ffbe25d00fc9b6ee5affae4d280c97300dd749_p023.png)
### 和訳
Polat ら
A.3.2 のサブクラス
23
A.4 ステートメントチェッククエリのテンプレート
---
ちょっと待ってな、だいしろーさん!これ、論文の目次とか見出し部分やから、翻訳っていうよりそのまま項目名を訳した感じになるねん。
- **Polat ら** → 著者名やからそのままやで
- **A.3.2 〜のサブクラス** → 「あるもんの下位分類」って意味の章タイトルやな
- **A.4 ステートメントチェッククエリのテンプレート** → 要は「ある記述が正しいかどうかを確認するための問い合わせのひな型」ってことやねん
本文がもっとあったら、がっつり関西弁でおもろく訳せるから、続きあったら送ってな!
---
## Page 24
[](/attach/8355017f6539389e244c8bf5b3ffbe25d00fc9b6ee5affae4d280c97300dd749_p024.png)
### 和訳
付録B. 抜き出したトリプルに対して実施した分析の具体例をまるっと見せるで
「ポルシェ パナメーラ && メーカー && ポルシェ」っていうトリプルについてや:
**抜き出し元の文章:**
「ポルシェ パナメーラは、ドイツの自動車メーカーであるポルシェが製造しとる中型〜フルサイズの高級車やねん(ヨーロッパではEセグメントに分類されるやつや)。エンジンは前に積んどって、基本は後輪駆動なんやけど、四輪駆動バージョンもあるで。」
**文字列トリプル:**
- 「ポルシェ パナメーラ」
- 「メーカー」
- 「ポルシェ」
**Wikiデータのトリプル:**
- Q501349(パナメーラのID)
- P176(「メーカー」っていう関係のID)
- Q40993(ポルシェのID)
**ドメイン(主語がどんな種類のもんか)あるか?:** あるで
**ドメインの候補:**
- ソフトウェア (Q7397)
- 物理的なモノ (Q223557)
- モデルシリーズ (Q811701)
- 具体的なモノ (Q4406616)
- 製品モデル (Q10929058)
**レンジ(目的語がどんな種類のもんか)あるか?:** あるで
**レンジの候補:**
- 人間 (Q5)
- 動物 (Q729)
- 職業 (Q28640)
- 組織 (Q43229)
- 工場 (Q83405)
- 架空のキャラクター (Q95074)
- 産業 (Q268592)
- 職人 (Q1294787)
- 架空のキャラクターのグループ (Q14514600)
**述語にドメインとレンジ両方あるか?:** あるで
**主語の「〜のインスタンス」関係:**
ここがめっちゃおもろいとこやねん。ホップ数っていうのは、Wikiデータの階層をどれだけ辿ったかってことや。
- ゼロホップ(直接の分類):自動車モデルシリーズ (Q59773381)
- ワンホップ(1段階上):車両モデルシリーズ (Q29048319)
- ツーホップ(2段階上):モデルシリーズ (Q811701)
- スリーホップ(3段階上):シリーズ (Q20937557)
**主語の「〜のサブクラス」関係:**
- ゼロホップ:なし
- ワンホップ:なし
- ツーホップ:なし
- スリーホップ:なし
**ドメインとマッチしたか?:** したで!
**マッチしたレベル:** 2(つまりツーホップで一致したってことや)
**マッチしたラベル:** 「モデルシリーズ」
**マッチしたWikiデータID:** Q811701
なんでかっていうと、パナメーラは「自動車モデルシリーズ」で、2段階上の親カテゴリが「モデルシリーズ」やから、ドメインの候補にあった「モデルシリーズ」とバッチリ一致したってわけやな。
**目的語(ポルシェ)の「〜のインスタンス」関係:**
- ゼロホップ(直接の分類):
- 上場企業 (Q891723)
- 自動車メーカー (Q786820)
- レースカーコンストラクター (Q15648574)
- 自動車ブランド (Q10429667)
- ワンホップ(1段階上):
- 株式会社 (Q134161)
- 企業 (Q6881511)
- 組織 (Q43229)
- 自動車メーカー (Q786820)
- メーカー (Q13235160)
- ブランド (Q431289)
---
## Page 25
[](/attach/8355017f6539389e244c8bf5b3ffbe25d00fc9b6ee5affae4d280c97300dd749_p025.png)
### 和訳
Polat ら
25ページ目
"two_hop"(2ホップ先の関連概念):
ここにはな、Wikidataっていう知識ベースで「2段階たどった先」にある概念がズラーっと並んどるねん。
- "limited company"(有限会社): Q33685
- "juridical person"(法人): Q155076
- "operation"(事業活動): Q362482
- "social system"(社会システム): Q1639378
- "business"(ビジネス): Q4830453
- "enterprise"(企業体): Q6881511
- "manufacturer"(製造業者): Q13235160
- "provider"(提供者): Q13420330
- "group of humans"(人間の集まり): Q16334295
- "artificial object"(人工物): Q16686448
- "class"(クラス、分類のまとまりやな): Q16889133
- "person or organization"(個人または組織): Q106559804
"three_hop"(3ホップ先の関連概念):
ほんで次は3段階たどった先や。もっと抽象的な概念まで広がっとるで。
- "commercial company"(商業会社): Q567521
- "organization"(組織): Q43229
- "legal person"(法的な人格を持つもの): Q3778211
- "goods"(商品): Q28877
- "organizational unit"(組織単位): Q679206
- "economic agent"(経済主体、つまりお金のやり取りする存在やな): Q1415187
- "system"(システム): Q58778
- "juridical person"(法人): Q155076
- "economic entity"(経済的な存在): Q12569864
- "operation"(事業活動): Q362482
- "business"(ビジネス): Q4830453
- "provider"(提供者): Q13420330
- "group of living things"(生き物の集まり): Q16334298
- "object"(オブジェクト、モノのことやな): Q488383
- "abstract entity"(抽象的な存在): Q7048977
- "collective entity"(集合体): Q99527517
- "agent"(エージェント、何かしら行動する主体のことや): Q24229398
"Object subclassOf"(オブジェクト側の上位クラス階層):
ここはな、"zero_hop"から"three_hop"まで全部空っぽやねん。つまりオブジェクト側には上位クラスの該当がなかったっちゅうことやな。
ほんで最後にまとめの判定結果がバーンと出とるで:
- "Range match": true → レンジ(値域)が一致しとる!OKやで
- "Range matching level": 1 → レンジの一致は1ホップ先で見つかったっちゅうことや
- "Range matched label": "organization" → 一致したのは「組織(organization)」やな
- "Range matched wikiID": "Q43229" → WikidataのIDはQ43229や
- "All components in Wikidata": true → 全部の構成要素がWikidataに存在しとるで
- "Triple statement in Wikidata": true → トリプル(主語・述語・目的語の3つ組)もWikidataにちゃんとあるで
- "Domain&Range Match": true → ドメイン(定義域)とレンジ(値域)の両方が一致しとる!めっちゃええやん
- "Triple matching level": 2 → トリプル全体の一致レベルは2や。なんでかっていうと、ドメインとレンジそれぞれのホップ数を合わせた評価やねん
- "Both Statement and Domain&Range Match": true → トリプルの存在確認もドメイン&レンジの一致も両方クリアしとる!完璧やで
---
## Page 26
[](/attach/8355017f6539389e244c8bf5b3ffbe25d00fc9b6ee5affae4d280c97300dd749_p026.png)
### 和訳
Semantic Web 16(1)
付録C. 補足資料
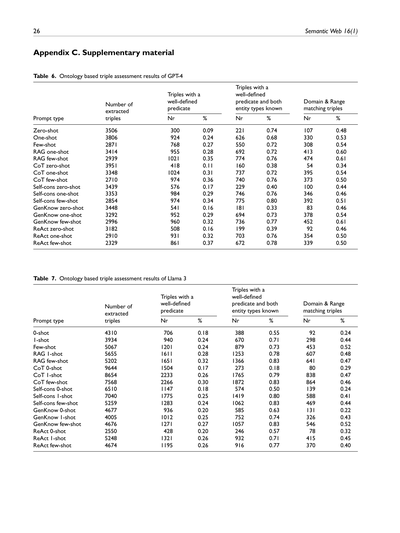
**表6. オントロジーベースのトリプル評価結果(GPT-4編)**
ほな説明するで!これはGPT-4っていうAIモデルが、文章から「主語・述語・目的語」みたいな3つ組(トリプルって呼ぶねん)をどんだけ正確に抜き出せたかを調べた結果やねん。
いろんなプロンプト(AIへの指示の仕方)を試してるんやけど、ゼロショットっていうのは「何も例を見せずにいきなりやらせる」パターンで、ワンショットは「1個だけ例を見せる」、フューショットは「何個か例を見せる」やつやな。RAGってのは関連する知識を検索して一緒に渡すやり方で、CoTは「順を追って考えてな」って指示するやつ。Self-consは同じ質問を何回もして多数決とるやつで、GenKnowは一般知識を活用させるパターン。ReActは考えて→行動して→観察してを繰り返すやつやで。
| プロンプトの種類 | 抽出されたトリプル数 | ちゃんと定義された述語を持つトリプル ||| ちゃんと定義された述語+両方のエンティティ型が既知のトリプル ||| ドメイン&レンジが一致するトリプル |||
|---|---|---|---|---|---|---|---|---|---|---|
| | | 件数 | 割合 | | 件数 | 割合 | | 件数 | 割合 |
| ゼロショット | 3506 | 300 | 0.09 | | 221 | 0.74 | | 107 | 0.48 |
| ワンショット | 3806 | 924 | 0.24 | | 626 | 0.68 | | 330 | 0.53 |
| フューショット | 2871 | 768 | 0.27 | | 550 | 0.72 | | 308 | 0.54 |
| RAGワンショット | 3414 | 955 | 0.28 | | 692 | 0.72 | | 413 | 0.60 |
| RAGフューショット | 2939 | 1021 | 0.35 | | 774 | 0.76 | | 474 | 0.61 |
| CoTゼロショット | 3951 | 418 | 0.11 | | 160 | 0.38 | | 54 | 0.34 |
| CoTワンショット | 3348 | 1024 | 0.31 | | 737 | 0.72 | | 395 | 0.54 |
| CoTフューショット | 2710 | 974 | 0.36 | | 740 | 0.76 | | 373 | 0.50 |
| Self-consゼロショット | 3439 | 576 | 0.17 | | 229 | 0.40 | | 100 | 0.44 |
| Self-consワンショット | 3353 | 984 | 0.29 | | 746 | 0.76 | | 346 | 0.46 |
| Self-consフューショット | 2854 | 974 | 0.34 | | 775 | 0.80 | | 392 | 0.51 |
| GenKnowゼロショット | 3448 | 541 | 0.16 | | 181 | 0.33 | | 83 | 0.46 |
| GenKnowワンショット | 3292 | 952 | 0.29 | | 694 | 0.73 | | 378 | 0.54 |
| GenKnowフューショット | 2996 | 960 | 0.32 | | 736 | 0.77 | | 452 | 0.61 |
| ReActゼロショット | 3182 | 508 | 0.16 | | 199 | 0.39 | | 92 | 0.46 |
| ReActワンショット | 2910 | 931 | 0.32 | | 703 | 0.76 | | 354 | 0.50 |
| ReActフューショット | 2329 | 861 | 0.37 | | 672 | 0.78 | | 339 | 0.50 |
ポイントとしてはやな、例を見せれば見せるほど(フューショット)、ちゃんと定義された述語を使えるようになるってことやねん。特にRAGフューショットがええ感じで、定義済み述語の割合が35%でトップクラスやし、ドメイン&レンジの一致率も61%でめっちゃ高いねん。逆にゼロショット系はどれもイマイチで、なんでかっていうと手本なしでやらせたら、AIが勝手な述語を作りがちやからやな。
---
**表7. オントロジーベースのトリプル評価結果(Llama 3編)**
お次はLlama 3っていうオープンソースのAIモデルの結果やで!
| プロンプトの種類 | 抽出されたトリプル数 | ちゃんと定義された述語を持つトリプル ||| ちゃんと定義された述語+両方のエンティティ型が既知のトリプル ||| ドメイン&レンジが一致するトリプル |||
|---|---|---|---|---|---|---|---|---|---|---|
| | | 件数 | 割合 | | 件数 | 割合 | | 件数 | 割合 |
| 0ショット | 4310 | 706 | 0.18 | | 388 | 0.55 | | 92 | 0.24 |
| 1ショット | 3934 | 940 | 0.24 | | 670 | 0.71 | | 298 | 0.44 |
| フューショット | 5067 | 1201 | 0.24 | | 879 | 0.73 | | 453 | 0.52 |
| RAG 1ショット | 5655 | 1611 | 0.28 | | 1253 | 0.78 | | 607 | 0.48 |
| RAGフューショット | 5202 | 1651 | 0.32 | | 1366 | 0.83 | | 641 | 0.47 |
| CoT 0ショット | 9644 | 1504 | 0.17 | | 273 | 0.18 | | 80 | 0.29 |
| CoT 1ショット | 8654 | 2233 | 0.26 | | 1765 | 0.79 | | 838 | 0.47 |
| CoTフューショット | 7568 | 2266 | 0.30 | | 1872 | 0.83 | | 864 | 0.46 |
| Self-cons 0ショット | 6510 | 1147 | 0.18 | | 574 | 0.50 | | 139 | 0.24 |
| Self-cons 1ショット | 7040 | 1775 | 0.25 | | 1419 | 0.80 | | 588 | 0.41 |
| Self-consフューショット | 5259 | 1283 | 0.24 | | 1062 | 0.83 | | 469 | 0.44 |
| GenKnow 0ショット | 4677 | 936 | 0.20 | | 585 | 0.63 | | 131 | 0.22 |
| GenKnow 1ショット | 4005 | 1012 | 0.25 | | 752 | 0.74 | | 326 | 0.43 |
| GenKnowフューショット | 4676 | 1271 | 0.27 | | 1057 | 0.83 | | 546 | 0.52 |
| ReAct 0ショット | 2550 | 428 | 0.20 | | 246 | 0.57 | | 78 | 0.32 |
| ReAct 1ショット | 5248 | 1321 | 0.26 | | 932 | 0.71 | | 415 | 0.45 |
| ReActフューショット | 4674 | 1195 | 0.26 | | 916 | 0.77 | | 370 | 0.40 |
Llama 3のおもろいところはやな、GPT-4と比べてめっちゃ大量にトリプルを抽出しがちやねん。特にCoTゼロショットなんか9644個も出してて、GPT-4の倍以上やで!でもな、数出せばええってもんちゃうねん。ほんまに大事なんは質の方で、定義済み述語の割合とかドメイン&レンジの一致率を見たら、GPT-4の方がだいぶ精度高いねん。
Llama 3でもフューショットの方がゼロショットよりええ結果出てるのはGPT-4と同じ傾向やな。RAGフューショットのエンティティ型既知率が83%でかなり優秀やけど、ドメイン&レンジの一致率は47%でGPT-4の61%にはちょっと及ばんかったわ。要するに、「量より質」でGPT-4に軍配が上がるって話やな。
---
## Page 27
[](/attach/8355017f6539389e244c8bf5b3ffbe25d00fc9b6ee5affae4d280c97300dd749_p027.png)
### 和訳
Polatらの研究やねん。
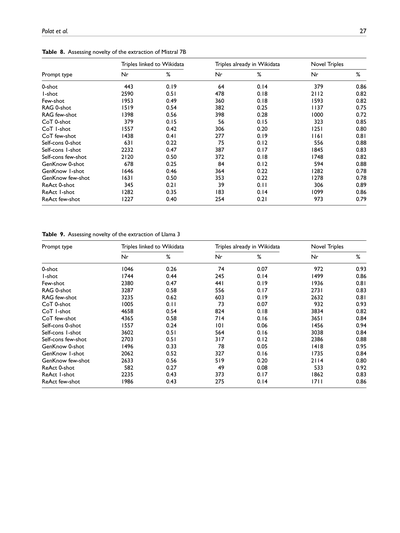
**表8. Mistral 7Bが抽出した情報のどれくらいが「新しい発見」なんか調べてみた結果**
ここでは3つの数字を見てるで:
- **Wikidataに紐づいたトリプル**(抽出した情報のうち、既存の知識ベースと照合できたやつ)
- **すでにWikidataにあったトリプル**(つまり既知の情報やな)
- **新規トリプル**(おお!これが新しく見つかった知識やで)
| プロンプトの種類 | Wikidata紐づき数 | 割合 | 既知の数 | 割合 | 新規の数 | 割合 |
|---|---|---|---|---|---|---|
| 0-shot | 443 | 0.19 | 64 | 0.14 | 379 | 0.86 |
| 1-shot | 2590 | 0.51 | 478 | 0.18 | 2112 | 0.82 |
| Few-shot | 1953 | 0.49 | 360 | 0.18 | 1593 | 0.82 |
| RAG 0-shot | 1519 | 0.54 | 382 | 0.25 | 1137 | 0.75 |
| RAG few-shot | 1398 | 0.56 | 398 | 0.28 | 1000 | 0.72 |
| CoT 0-shot | 379 | 0.15 | 56 | 0.15 | 323 | 0.85 |
| CoT 1-shot | 1557 | 0.42 | 306 | 0.20 | 1251 | 0.80 |
| CoT few-shot | 1438 | 0.41 | 277 | 0.19 | 1161 | 0.81 |
| Self-cons 0-shot | 631 | 0.22 | 75 | 0.12 | 556 | 0.88 |
| Self-cons 1-shot | 2232 | 0.47 | 387 | 0.17 | 1845 | 0.83 |
| Self-cons few-shot | 2120 | 0.50 | 372 | 0.18 | 1748 | 0.82 |
| GenKnow 0-shot | 678 | 0.25 | 84 | 0.12 | 594 | 0.88 |
| GenKnow 1-shot | 1646 | 0.46 | 364 | 0.22 | 1282 | 0.78 |
| GenKnow few-shot | 1631 | 0.50 | 353 | 0.22 | 1278 | 0.78 |
| ReAct 0-shot | 345 | 0.21 | 39 | 0.11 | 306 | 0.89 |
| ReAct 1-shot | 1282 | 0.35 | 183 | 0.14 | 1099 | 0.86 |
| ReAct few-shot | 1227 | 0.40 | 254 | 0.21 | 973 | 0.79 |
**表9. Llama 3が抽出した情報の「新しさ」を同じように調べた結果**
| プロンプトの種類 | Wikidata紐づき数 | 割合 | 既知の数 | 割合 | 新規の数 | 割合 |
|---|---|---|---|---|---|---|
| 0-shot | 1046 | 0.26 | 74 | 0.07 | 972 | 0.93 |
| 1-shot | 1744 | 0.44 | 245 | 0.14 | 1499 | 0.86 |
| Few-shot | 2380 | 0.47 | 441 | 0.19 | 1936 | 0.81 |
| RAG 0-shot | 3287 | 0.58 | 556 | 0.17 | 2731 | 0.83 |
| RAG few-shot | 3235 | 0.62 | 603 | 0.19 | 2632 | 0.81 |
| CoT 0-shot | 1005 | 0.11 | 73 | 0.07 | 932 | 0.93 |
| CoT 1-shot | 4658 | 0.54 | 824 | 0.18 | 3834 | 0.82 |
| CoT few-shot | 4365 | 0.58 | 714 | 0.16 | 3651 | 0.84 |
| Self-cons 0-shot | 1557 | 0.24 | 101 | 0.06 | 1456 | 0.94 |
| Self-cons 1-shot | 3602 | 0.51 | 564 | 0.16 | 3038 | 0.84 |
| Self-cons few-shot | 2703 | 0.51 | 317 | 0.12 | 2386 | 0.88 |
| GenKnow 0-shot | 1496 | 0.33 | 78 | 0.05 | 1418 | 0.95 |
| GenKnow 1-shot | 2062 | 0.52 | 327 | 0.16 | 1735 | 0.84 |
| GenKnow few-shot | 2633 | 0.56 | 519 | 0.20 | 2114 | 0.80 |
| ReAct 0-shot | 582 | 0.27 | 49 | 0.08 | 533 | 0.92 |
| ReAct 1-shot | 2235 | 0.43 | 373 | 0.17 | 1862 | 0.83 |
| ReAct few-shot | 1986 | 0.43 | 275 | 0.14 | 1711 | 0.86 |
ほな解説するで!この2つの表は、MistralとLlamaっていう2つのAIモデルが文章から「トリプル」——要するに「AはBとCの関係がある」みたいな知識の単位やな——をどんだけ引っ張り出せたか、そんでその中にどれだけ**新しい知識**が含まれてたかを見てるんや。
めっちゃ面白いのが、**新規トリプルの割合がどのパターンでもだいたい75〜95%くらいある**ってことやねん。つまり、AIが抽出した情報のほとんどが、Wikidataにまだ載ってへん新しい知識やったってわけや。ほんまにすごいやろ?
なんでかっていうと、Wikidataって世界最大級の知識ベースやけど、それでもまだまだカバーしきれてへん情報が山ほどあるってことやねん。AIがそこを補完できる可能性があるっていう、めっちゃワクワクする結果やで。
あと、Llama 3の方がMistral 7Bよりも全体的に新規率が高い傾向にあるな。特にSelf-cons 0-shotとかGenKnow 0-shotやと94〜95%が新規って、ほぼ全部が新しい発見みたいなもんやん。
---
## Page 28
[](/attach/8355017f6539389e244c8bf5b3ffbe25d00fc9b6ee5affae4d280c97300dd749_p028.png)
### 和訳
28
Semantic Web 16(1)
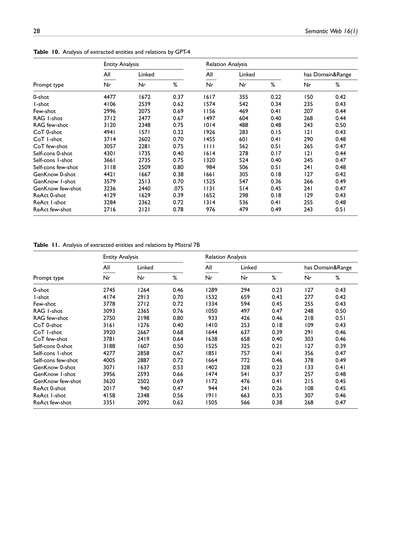
表10. GPT-4が抜き出したエンティティとリレーションの分析結果
エンティティの分析っていうのは、まあ「モノ」とか「概念」みたいなんを文章からどんだけ上手いこと見つけられたかって話やねん。リレーションの分析は、その見つけたモノ同士の「関係性」をどれだけちゃんと捉えられたかっていう話やな。
**エンティティ分析**と**リレーション分析**
| プロンプトの種類 | 全エンティティ数 | リンク済み数 | リンク率 | 全リレーション数 | リンク済み数 | リンク率 | ドメイン&レンジあり数 | その割合 |
|---|---|---|---|---|---|---|---|---|
| 0-shot(例なしでいきなり聞く) | 4477 | 1672 | 0.37 | 1617 | 355 | 0.22 | 150 | 0.42 |
| 1-shot(1個だけ例を見せる) | 4106 | 2539 | 0.62 | 1574 | 542 | 0.34 | 235 | 0.43 |
| Few-shot(何個か例を見せる) | 2996 | 2075 | 0.69 | 1156 | 469 | 0.41 | 207 | 0.44 |
| RAG 1-shot(知識検索+1例) | 3712 | 2477 | 0.67 | 1497 | 604 | 0.40 | 268 | 0.44 |
| RAG few-shot(知識検索+複数例) | 3120 | 2348 | 0.75 | 1014 | 488 | 0.48 | 243 | 0.50 |
| CoT 0-shot(考える過程を見せる・例なし) | 4941 | 1571 | 0.32 | 1926 | 283 | 0.15 | 121 | 0.43 |
| CoT 1-shot | 3714 | 2602 | 0.70 | 1455 | 601 | 0.41 | 290 | 0.48 |
| CoT few-shot | 3057 | 2281 | 0.75 | 1111 | 562 | 0.51 | 265 | 0.47 |
| Self-cons 0-shot(自己整合性チェック・例なし) | 4301 | 1735 | 0.40 | 1614 | 278 | 0.17 | 121 | 0.44 |
| Self-cons 1-shot | 3661 | 2735 | 0.75 | 1320 | 524 | 0.40 | 245 | 0.47 |
| Self-cons few-shot | 3118 | 2509 | 0.80 | 984 | 506 | 0.51 | 241 | 0.48 |
| GenKnow 0-shot(一般知識を活用・例なし) | 4421 | 1667 | 0.38 | 1661 | 305 | 0.18 | 127 | 0.42 |
| GenKnow 1-shot | 3579 | 2513 | 0.70 | 1525 | 547 | 0.36 | 266 | 0.49 |
| GenKnow few-shot | 3236 | 2440 | 0.75 | 1131 | 514 | 0.45 | 241 | 0.47 |
| ReAct 0-shot(考えて行動を繰り返す・例なし) | 4129 | 1629 | 0.39 | 1652 | 298 | 0.18 | 129 | 0.43 |
| ReAct 1-shot | 3284 | 2362 | 0.72 | 1314 | 536 | 0.41 | 255 | 0.48 |
| ReAct few-shot | 2716 | 2121 | 0.78 | 976 | 479 | 0.49 | 243 | 0.51 |
ざっくり言うとな、「リンク済み」っていうのは、抜き出したエンティティやリレーションが既存の知識ベースにちゃんと紐づけられたかってことやねん。「ドメイン&レンジあり」っていうのは、リレーションに「どこから(ドメイン)」と「どこへ(レンジ)」がちゃんと定義されてるかってことやな。
---
表11. Mistral 7B(もうちょい小さいモデルやな)が抜き出したエンティティとリレーションの分析結果
**エンティティ分析**と**リレーション分析**
| プロンプトの種類 | 全エンティティ数 | リンク済み数 | リンク率 | 全リレーション数 | リンク済み数 | リンク率 | ドメイン&レンジあり数 | その割合 |
|---|---|---|---|---|---|---|---|---|
| 0-shot | 2745 | 1264 | 0.46 | 1289 | 294 | 0.23 | 127 | 0.43 |
| 1-shot | 4174 | 2913 | 0.70 | 1532 | 659 | 0.43 | 277 | 0.42 |
| Few-shot | 3778 | 2712 | 0.72 | 1334 | 594 | 0.45 | 255 | 0.43 |
| RAG 1-shot | 3093 | 2365 | 0.76 | 1050 | 497 | 0.47 | 248 | 0.50 |
| RAG few-shot | 2750 | 2198 | 0.80 | 933 | 426 | 0.46 | 218 | 0.51 |
| CoT 0-shot | 3161 | 1276 | 0.40 | 1410 | 253 | 0.18 | 109 | 0.43 |
| CoT 1-shot | 3920 | 2667 | 0.68 | 1644 | 637 | 0.39 | 291 | 0.46 |
| CoT few-shot | 3781 | 2419 | 0.64 | 1638 | 658 | 0.40 | 303 | 0.46 |
| Self-cons 0-shot | 3188 | 1607 | 0.50 | 1525 | 325 | 0.21 | 127 | 0.39 |
| Self-cons 1-shot | 4277 | 2858 | 0.67 | 1851 | 757 | 0.41 | 356 | 0.47 |
| Self-cons few-shot | 4005 | 2887 | 0.72 | 1664 | 772 | 0.46 | 378 | 0.49 |
| GenKnow 0-shot | 3071 | 1637 | 0.53 | 1402 | 328 | 0.23 | 133 | 0.41 |
| GenKnow 1-shot | 3956 | 2593 | 0.66 | 1474 | 541 | 0.37 | 257 | 0.48 |
| GenKnow few-shot | 3620 | 2502 | 0.69 | 1172 | 476 | 0.41 | 215 | 0.45 |
| ReAct 0-shot | 2017 | 940 | 0.47 | 944 | 241 | 0.26 | 108 | 0.45 |
| ReAct 1-shot | 4158 | 2348 | 0.56 | 1911 | 663 | 0.35 | 307 | 0.46 |
| ReAct few-shot | 3351 | 2092 | 0.62 | 1505 | 566 | 0.38 | 268 | 0.47 |
ほんでな、この2つの表を見比べると面白いことがわかるねん。GPT-4もMistral 7Bも、例を多く見せる(few-shot)とかRAGを使うと、リンク率がめっちゃ上がるんよ。逆に0-shot(何も例を見せへん)やと、どっちのモデルもリンク率がガクッと下がるねん。あと、0-shotの時はCoTとかSelf-consistencyとか凝ったプロンプト手法を使っても、例がないとやっぱりキツいんやな。ドメイン&レンジの割合は、どのプロンプト手法でもだいたい0.4〜0.5くらいで安定してて、これはプロンプトの種類よりモデルの基本的な理解力に依存してる感じやな。
---
## Page 29
[](/attach/8355017f6539389e244c8bf5b3ffbe25d00fc9b6ee5affae4d280c97300dd749_p029.png)
### 和訳
だいしろーさん!翻訳しますね。
---
Polatら
29
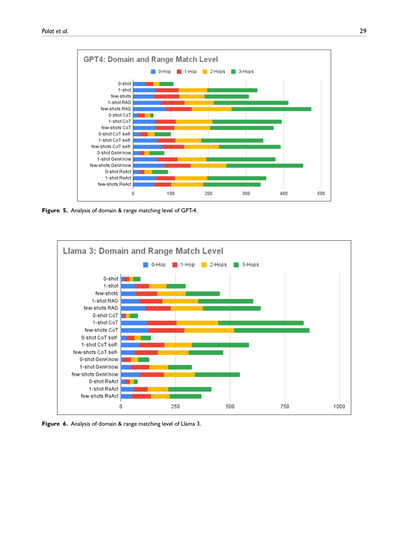
図5. GPT-4のドメインとレンジの一致レベルの分析やで。
図6. Llama 3のドメインとレンジの一致レベルの分析やで。
---
ちなみに「ドメインとレンジの一致レベル」ってのは、ざっくり言うと「入力と出力がどんだけちゃんと噛み合ってるか」を見てるもんやねん。GPT-4とLlama 3っていう2つのAIモデルで、それぞれどれくらいマッチしてるか比べてるんやな。
---
## Page 30
[](/attach/8355017f6539389e244c8bf5b3ffbe25d00fc9b6ee5affae4d280c97300dd749_p030.png)
### 和訳
30
Semantic Web 16(1)
表12. 適合率、再現率、F1スコア
適合率
プロンプトの種類
Mistral
Llama3
GPT-4
0-shot
1-shot
Few-shot
RAG 1-shot
RAG few-shot
CoT 0-shot
CoT 1-shot
CoT few-shot
Self-cons 0-shot
Self-cons 1-shot
Self-cons few-shot
GenKnow 0-shot
GenKnow 1-shot
GenKnow few-shot
ReAct 0-shot
ReAct 1-shot
ReAct few-shot
0.00
0.02
0.03
0.07
0.09
0.00
0.05
0.04
0.00
0.05
0.04
0.00
0.05
0.05
0.00
0.03
0.04
0.00
0.02
0.02
0.05
0.07
0.00
0.05
0.03
0.00
0.05
0.02
0.00
0.03
0.04
0.00
0.02
0.02
0.00
0.01
0.02
0.05
0.08
0.00
0.03
0.05
0.00
0.03
0.05
0.00
0.03
0.07
0.00
0.03
0.06
再現率
Mistral
0.00
0.08
0.08
0.12
0.14
0.00
0.10
0.09
0.00
0.10
0.13
0.00
0.12
0.12
0.00
0.07
0.09
F1スコア
Llama3
GPT-4
Mistral
Llama3
GPT-4
0.00
0.06
0.06
0.14
0.16
0.00
0.15
0.11
0.00
0.13
0.08
0.00
0.09
0.11
0.00
0.07
0.08
0.00
0.04
0.06
0.11
0.15
0.00
0.07
0.08
0.00
0.06
0.10
0.00
0.07
0.13
0.00
0.06
0.09
0.00
0.04
0.04
0.09
0.10
0.00
0.06
0.06
0.00
0.06
0.07
0.00
0.07
0.07
0.00
0.04
0.06
0.00
0.03
0.03
0.08
0.10
0.00
0.07
0.05
0.00
0.07
0.03
0.00
0.05
0.06
0.00
0.04
0.04
0.00
0.02
0.03
0.07
0.11
0.00
0.05
0.06
0.00
0.04
0.06
0.00
0.04
0.09
0.00
0.04
0.07
参考文献
[1] AI@Meta、Llama 3モデルカード、2024年、https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md.
[2] D. Ammalainen、2023年、https://upload.wikimedia.org/wikipedia/commons/1/1b/Wikidata_ontology_issues_—_suggestions_for_prioritisation_2023.pdf.
[3] T. Brownら、「言語モデルってなぁ、ちょっと例を見せたるだけでめっちゃ学習できるやつやねん(Few-shot学習者としての言語モデル)」。なんでかっていうと、大規模言語モデルに数個の例を与えるだけで、いろんなタスクをこなせるようになるっちゅう話やねん。Neural Information Processing Systems(NeurIPS)っていう超有名な学会の論文集、Vol. 33、2020年、pp. 1877–1901。
[4] J. CarbonellとJ. Goldstein、「MMRっていう手法を使って、文書の並べ替えと要約を作るっちゅう話やで」。要は、検索結果が似たようなもんばっかりにならんように、多様性を考慮してランキングし直す方法やねん。ACM SIGIRっていう情報検索の国際学会の論文集、1998年、pp. 335–336。
[5] A. Chowdheryら、「PaLM:Pathwaysっちゅう仕組みで言語モデルをめっちゃデカくスケールさせたで」。これはほんまにすごいやつで、Googleが作った超大規模言語モデルやねん。いろんなパラメータの組み合わせを試して、どうやったら言語モデルがもっと賢くなるかを研究した2022年の論文や。
[6] P.F. Christianoら、「人間の好みから深層強化学習するっちゅう方法やで」。これ何かっていうと、AIに「こっちの方がええで」って人間がフィードバックしてやることで、AIの行動をどんどん改善していく手法やねん。RLHF(人間のフィードバックからの強化学習)の基礎になった超重要な論文や。NeurIPS、Vol. 30、2017年。
[7] S. Gehrmannら、「GEMベンチマーク:自然言語生成とその評価・指標について」。これはな、AIが文章を生成する能力をどうやって評価するかっちゅうのをまとめたベンチマークやねん。いろんな研究者がめっちゃ集まって、自然言語生成の評価基準を標準化しようとした取り組みや。第1回自然言語生成・評価ワークショップの論文集より。
---
## Page 31
[](/attach/8355017f6539389e244c8bf5b3ffbe25d00fc9b6ee5affae4d280c97300dd749_p031.png)
### 和訳
Polat ら
31
and Metrics (GEM 2021)、A. Bosselut、E. Durmus、V.P. Gangal、S. Gehrmann、Y. Jernite、L. Perez-Beltrachini、S. Shaikh、W. Xu 編、Association for Computational Linguistics、オンライン、2021年、96–120頁。doi:10.18653/v1/2021.gem-1.10.
[8] A. Hogan、E. Blomqvist、M. Cochez、C. D'amato、G.D. Melo、C. Gutierrez、S. Kirrane、J.E.L. Gayo、R. Navigli、S. Neumaier、A.-C.N. Ngomo、A. Polleres、S.M. Rashid、A. Rula、L. Schmelzeisen、J. Sequeda、S. Staab、A. Zimmermann「ナレッジグラフ」っちゅう論文やねん。ナレッジグラフってのは、要するに知識をネットワークみたいにつなげて整理する仕組みのことやな。ACM Comput. Surv. 54(4)(2021年)。doi:10.1145/3447772.
[9] P.-L. Huguet Cabot、R. Navigli「REBEL:エンドツーエンドの言語生成による関係抽出」。これ何かっちゅうと、文章から「AとBはこういう関係やで」っていうのを、テキスト生成の仕組みで一気に抜き出す手法やねん。Findings of the Association for Computational Linguistics: EMNLP 2021、M.-F. Moens、X. Huang、L. Specia、S.W.-T. Yih 編、Association for Computational Linguistics、プンタカナ、ドミニカ共和国、2021年、2370–2381頁。doi:10.18653/v1/2021.findings-emnlp.204.
[10] P.-L. Huguet Cabot、S. Tedeschi、A.-C.N. Ngomo、R. Navigli「REDFM:フィルタリング済み多言語関係抽出データセット」。めっちゃいろんな言語に対応した、関係抽出のためのデータセットをキレイに整理して作りましたよ、っちゅう話やな。Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics(第1巻:長編論文)、A. Rogers、J. Boyd-Graber、N. Okazaki 編、Association for Computational Linguistics、トロント、カナダ、2023年、4326–4343頁。doi:10.18653/v1/2023.acl-long.237.
[11] A.Q. Jiang、A. Sablayrolles、A. Mensch、C. Bamford、D.S. Chaplot、D.D.L. Casas、F. Bressand、G. Lengyel、G. Lample、L. Saulnier ら「Mistral 7B」。これは70億パラメータの言語モデルやねんけど、そのサイズの割にめっちゃ性能ええっちゅうことで話題になったやつやな。2023年、arXiv プレプリント arXiv:2310.06825.
[12] M. Josifoski、N. De Cao、M. Peyrard、F. Petroni、R. West「GenIE:生成型情報抽出」。情報抽出を生成モデルでやってまおうっちゅうアプローチやねん。Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies、M. Carpuat、M.-C. de Marneffe、I.V. Meza Ruiz 編、Association for Computational Linguistics、シアトル、アメリカ、2022年、4626–4643頁。doi:10.18653/v1/2022.naacl-main.342.
[13] M. Josifoski、M. Sakota、M. Peyrard、R. West「非対称性を活用した合成学習データ生成:SynthIEと情報抽出の事例」。なんでかっていうと、学習データを人工的に作るときに、入力と出力の非対称性をうまいこと利用したら、もっと効率的にデータ作れるやん、っちゅう話やねん。2023年、arXiv プレプリント arXiv:2303.04132.
[14] M. Khalifa、L. Logeswaran、M. Lee、H. Lee、L. Wang「インコンテキスト学習における実例アンサンブルの探求」。インコンテキスト学習ってのは、モデルにお手本を見せてタスクをやらせる方法やねんけど、そのお手本の組み合わせ方をいろいろ工夫してみましたよ、っちゅうことやな。ICLR 2023 Workshop on Mathematical and Empirical Understanding of Foundation Models、2023年、https://openreview.net/forum?id=9kK4R_8nAsD.
[15] M. Lewis、Y. Liu、N. Goyal、M. Ghazvininejad、A. Mohamed、O. Levy、V. Stoyanov、L. Zettlemoyer「BART:自然言語の生成・翻訳・理解のためのノイズ除去型系列変換事前学習」。BARTっちゅうのは、文章をわざとぐちゃぐちゃにしたやつを元に戻す訓練をすることで、いろんな言語タスクがめっちゃ上手くなるモデルやねん。Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics、D. Jurafsky、J. Chai、N. Schluter、J. Tetreault 編、Association for Computational Linguistics、オンライン、2020年、7871–7880頁。doi:10.18653/v1/2020.acl-main.703.
[16] P. Lewis、E. Perez、A. Piktus、F. Petroni、V. Karpukhin、N. Goyal、H. Küttler、M. Lewis、W.-T. Yih、T. Rocktäschel、S. Riedel、D. Kiela「知識集約型NLPタスクのための検索拡張生成(RAG)」。これほんまに有名な論文でな、モデルが回答するときに外部のデータベースから関連情報を引っ張ってきて、それを参考にしながら答えを生成するっちゅう仕組みやねん。めっちゃ画期的やったで。Advances in Neural Information Processing Systems、H. Larochelle、M. Ranzato、R. Hadsell、M.F. Balcan、H. Lin 編、第33巻、Curran Associates, Inc.、2020年、9459–9474頁、https://proceedings.neurips.cc/paper_files/paper/2020/file/6b493230205f780e1bc26945df7481e5-Paper.pdf.
[17] B. Li、G. Fang、Y. Yang、Q. Wang、W. Ye、W. Zhao、S. Zhang「ChatGPTの情報抽出能力の評価:性能・説明可能性・キャリブレーション・忠実性の観点から」。要するにChatGPTに情報抽出やらせたらどれくらいイケるんか、いろんな角度からちゃんと調べてみましたっちゅう論文やな。(2023年)、arXiv:2304.11633. https://api.semanticscholar.org/CorpusID:258297899
[18] J. Liu、A. Liu、X. Lu、S. Welleck、P. West、R. Le Bras、Y. Choi、H. Hajishirzi「常識推論のための生成知識プロンプティング」。これ何かっちゅうと、まずモデルに関連する知識を生成させて、それをプロンプトに含めることで常識的な推論がめっちゃ上手くなるっちゅう手法やねん。Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics(第1巻:長編論文)、S. Muresan、P. Nakov、A. Villavicencio 編、Association for Computational Linguistics、ダブリン、アイルランド、2022年、3154–3169頁。doi:10.18653/v1/2022.acl-long.225.
[19] P. Liu、W. Yuan、J. Fu、Z. Jiang、H. Hayashi、G. Neubig「事前学習・プロンプト・予測:自然言語処理におけるプロンプティング手法の体系的サーベイ」。プロンプティングっちゅうのは、AIモデルに「こうやって答えてな」って指示する技術のことやねんけど、それを全部まとめて整理してくれたありがたいサーベイ論文やで。ACM Comput. Surv. 55(9)(2023年)。doi:10.1145/3560815.
[20] J.L. Martinez-Rodriguez、A. Hogan、I. Lopez-Arevalo「情報抽出とセマンティックWebの出会い:サーベイ」。テキストから情報を抜き出す技術と、Webの意味をコンピュータにわからせる技術、この二つがどう絡み合ってるかをまとめた論文やな。Semantic Web 11(2)(2020年)、255–335頁。doi:10.3233/SW-180333.
[21] B. Min、H. Ross、E. Sulem、A.P.B. Veyseh、T.H. Nguyen、O. Sainz、E. Agirre、I. Heintz、D. Roth「大規模事前学習言語モデルによる自然言語処理の最新動向:サーベイ」。でっかい言語モデルのおかげで自然言語処理がどないなったかを全部まとめてくれてる、めっちゃ助かるサーベイやねん。ACM Comput. Surv.、2023年、採択済み。doi:10.1145/3605943.
[22] OpenAI「GPT-4 技術レポート」。あのGPT-4の公式技術文書やで。2023年。
[23] F. Petroni、T. Rocktäschel、S. Riedel、P. Lewis、A. Bakhtin、Y. Wu、A. Miller「言語モデルは知識ベースとして使えるんちゃうか?」っちゅう論文やねん。ほんまに、モデルの中にどれだけ知識が詰まってるかを調べた研究やな。Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP)、K. Inui、J. Jiang、V. Ng、X. Wan 編、Association for Computational Linguistics、香港、中国、2019年、2463–2473頁。doi:10.18653/v1/D19-1250.
[24] E. Saravia、2022年、https://www.promptingguide.ai/. プロンプトエンジニアリングのガイドサイトやな。AIへの指示の出し方をまとめてくれてるで。
[25] H. Su、W. Shi、J. Kasai、Y. Wang、Y. Hu、M. Ostendorf、W.-T. Yih、N.A. Smith、L. Zettlemoyer、T. Yu「1つの埋め込みモデルであらゆるタスクに対応:指示ファインチューニングによるテキスト埋め込み」。埋め込みってのは文章を数値のベクトルに変換することやねんけど、指示を工夫してファインチューニングしたら、1個のモデルでいろんなタスクに使える埋め込みが作れるっちゅうことを示した論文やで。Findings of the Association for Computational Linguistics: ACL 2023、A. Rogers、J. Boyd-Graber、N. Okazaki 編、Association for Computational Linguistics、トロント、カナダ、2023年、1102–1121頁。doi:10.18653/v1/2023.findings-acl.71.
---
## Page 32
[](/attach/8355017f6539389e244c8bf5b3ffbe25d00fc9b6ee5affae4d280c97300dd749_p032.png)
### 和訳
[26] R. Thoppilan ら, LaMDA: 対話アプリケーションのための言語モデル, 2022.
→ これな、Googleが作った「LaMDA」っていう対話専用のAIモデルの論文やねん。めっちゃ大人数で開発しとって、要は「人間とちゃんと会話できるAI作ろうや」って話やな。2022年に発表されたやつやで。
[27] H. Touvron ら, LLaMA: オープンで効率的な基盤言語モデル, 2023.
→ これはMeta(元Facebook)が出した「LLaMA」っていうモデルやな。ポイントは「オープン」で「効率的」ってとこやねん。つまり、誰でも使えて、しかもそこそこ軽いのにめっちゃ賢いっていう、ほんまにありがたいモデルやで。2023年発表。
[28] D. Vrandečić と M. Krötzsch, Wikidata: 自由に共同編集できる知識ベース, Communications of the ACM 57(10) (2014), 78–85. doi:10.1145/2629489.
→ 「Wikidata」って知っとる? Wikipediaの裏側にある、みんなで作るデータベースやねん。人間だけやなくて、機械も読めるように構造化された知識がぎょうさん詰まっとるんよ。2014年の論文や。
[29] S. Wadhwa, S. Amir, B. Wallace, 大規模言語モデル時代における関係抽出の再考, ACL 2023 第61回年次大会論文集(第1巻:長編論文), トロント, カナダ, 2023, pp. 15566–15589. doi:10.18653/v1/2023.acl-long.868.
→ 「関係抽出」っていうのは、文章の中から「AとBはこういう関係やで」っていうのを自動で見つけ出す技術やねん。で、この論文は「最近のでっかいAIモデル使ったら、この関係抽出ってどうなるん?」ってもう一回ちゃんと検証し直した研究やな。
[30] X. Wang ら, 自己一貫性が言語モデルの連鎖思考推論を改善する, ICLR 2023.
→ これめっちゃおもろい話やねん。AIに「何回も同じ問題を解かせて、一番多い答えを採用する」っていうシンプルな方法で、推論の精度がグンと上がるっていう研究や。「自己一貫性」って名前がついとるけど、要は多数決みたいなもんやな。
[31] J. Wei ら, 連鎖思考プロンプティングが大規模言語モデルの推論を引き出す, NeurIPS 2022, Vol. 35, pp. 24824–24837.
→ これがあの有名な「Chain-of-Thought(CoT)」の元祖論文やで! AIに「ステップバイステップで考えてや」って指示するだけで、数学とかロジックの問題がめっちゃ解けるようになるっていう発見やねん。ほんまに革命的やったな。
[32] C. Whitehouse ら, WebIE: ウェブ上での忠実かつ頑健な情報抽出, ACL 2023 第61回年次大会論文集(第1巻:長編論文), トロント, カナダ, 2023, pp. 7734–7755. doi:10.18653/v1/2023.acl-long.428.
→ ウェブページから情報を正確に抜き出す技術の研究やな。ウェブって構造バラバラやし、ノイズだらけやから、そこから「忠実に」「頑健に」情報取るのってめっちゃ難しいねん。それをちゃんとやったろうっていう論文や。
[33] S. Yao ら, ReAct: 言語モデルにおける推論と行動の相乗効果, ICLR 2023.
→ 「ReAct」っていうのは、AIが「考える(Reasoning)」と「行動する(Acting)」を交互にやる仕組みやねん。普通のAIは考えるだけか行動するだけやけど、これを組み合わせたらめっちゃ賢くなるっていう話。なんでかっていうと、考えながら動いて、動きながら考えるから、人間に近い問題解決ができるようになるんやで。
[34] X. Ye ら, 効果的な文脈内学習のための相補的説明, ACL 2023 Findings, トロント, カナダ, 2023, pp. 4469–4484. doi:10.18653/v1/2023.findings-acl.273.
→ 「文脈内学習(in-context learning)」って、AIにお手本をいくつか見せるだけで新しいタスクを覚えさせる技術やねん。で、この論文は「どんなお手本の見せ方が一番効果的なん?」っていうのを研究して、「いろんなタイプの説明を組み合わせたら最強やで」って結論出しとるんや。
[35] D. Zeng ら, 畳み込み深層ニューラルネットワークによる関係分類, COLING 2014 第25回国際計算言語学会議論文集, ダブリン, アイルランド, 2014, pp. 2335–2344.
→ これはちょっと古い2014年の論文やけど、「畳み込みニューラルネットワーク(CNN)」っていう、元々は画像認識で使われてた技術を、文章の中の関係分類に応用したっていう先駆的な研究やねん。テキストの中から「この単語とこの単語はどういう関係?」を自動で分類するんや。
[36] S. Zhang ら, 大規模言語モデルのためのインストラクション・チューニング:サーベイ, 2023.
→ 「インストラクション・チューニング」っていうのは、AIに「こういう指示にはこう答えてや」って教え込む学習方法やねん。この論文はそれに関する研究を全部まとめた総まとめ(サーベイ)論文や。この分野の全体像をざっと把握したかったら、まずこれ読んどけって話やな。
[37] S. Zheng ら, ハイブリッドニューラルネットワークに基づく固有表現と関係の同時抽出, Neurocomputing 257 (2017), 59–66. doi:10.1016/j.neucom.2016.12.075.
→ 普通は「固有表現の抽出(人名とか地名を見つける)」と「関係の抽出(その人名同士の関係を見つける)」って別々にやるんやけど、この論文は「両方いっぺんにやったろうやないか!」ってハイブリッドなニューラルネットワークで同時にやる手法を提案しとるんや。一緒にやった方が精度上がるっていう、なるほどなぁって話やで。
---
![]()
1 / 1
100%