<<
Human-in-the-Loop Reinforcement Learning A Survey and Position on Requirements, Challenges, and Opportunities

---
## Page 1
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p001.png)
### 和訳
Journal of Artificial Intelligence Research 79 (2024) 359-415
2023年8月投稿、2024年1月出版
**人間参加型強化学習:要件・課題・可能性についてのサーベイと見解**
なあ聞いてくれや、これめっちゃ面白い論文やねん。「Human-in-the-Loop Reinforcement Learning」っていうのは、要するにAIが学習するときに人間も一緒に参加して教えたり修正したりする仕組みのことやで。普通の強化学習やったらAIが勝手に試行錯誤して学ぶんやけど、それだけやと危なかったり非効率やったりするやん?せやから人間がループの中に入って、ちょこちょこ指導したるわけや。
**著者陣**
カール・オルゲ・レッツラフ
ウィーン天然資源生命科学大学 人間中心AIラボ(オーストリア)
carl.retzlaff@human-centered.ai
スリジタ・ダス
アルバータ大学 コンピューティングサイエンス学部(カナダ)
srijita1@ualberta.ca
クリスタベル・ワイヤス
ニューメキシコ州立大学 コンピュータサイエンス学部(アメリカ)
cwayllac@nmsu.edu
パヤム・ムサヴィ
アルバータ機械知能研究所(Amii)(カナダ)
payam.mousavi@amii.ca
モハマド・アフシャリ
アルバータ大学 コンピューティングサイエンス学部(カナダ)
mafshari@ualberta.ca
ティエンペイ・ヤン
アルバータ大学 コンピューティングサイエンス学部(カナダ)
tianpei.yang@ualberta.ca
アンナ・サランティ
ウィーン天然資源生命科学大学 人間中心AIラボ(オーストリア)
anna.saranti@human-centered.ai
アレッサ・アンガーシュミット
ウィーン天然資源生命科学大学 人間中心AIラボ(オーストリア)
alessa.angerschmid@human-centered.ai
マシュー・E・テイラー
アルバータ大学 コンピューティングサイエンス学部 &
アルバータ機械知能研究所(Amii) &
AI Redefined(カナダ)
matthew.e.taylor@ualberta.ca
アンドレアス・ホルツィンガー
ウィーン天然資源生命科学大学 人間中心AIラボ(オーストリア) &
アルバータ大学 アルバータ機械知能研究所 説明可能AIラボ(カナダ)
andreas.holzinger@human-centered.ai
©2024 著者ら。AI Access Foundationより、クリエイティブ・コモンズ 表示ライセンス CC BY 4.0 のもとで出版。
---
## Page 2
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p002.png)
### 和訳
Retzlaffさんらの研究やで〜
**要約**
人工知能(AI)、特に強化学習(RL)っちゅうのはな、エージェントが自分で勝手にタスク学んで、人間超えるレベルでこなせるようになる可能性秘めてんねん。めっちゃすごいやろ?でもな、ワイらはこの強化学習を根本的には「Human-in-the-Loop(HITL)」、つまり人間がループの中に入ってるパラダイムやと考えてんねん。最終的にエージェントが自律的に動くようになったとしてもな。
なんでかっていうと、報酬関数ーーつまり「何がええ行動か」を数字で定義するのがむずかしい、もしくは無理な場合があんねん。そういうときにこそ、HITLアプローチがめっちゃ有利やと言われてるわけや。
ChatGPTみたいなシステムで使われてる「人間のフィードバックからの強化学習(RLHF)」っていう手法がな、ユーザー体験を最適化して、そのフィードバックを学習ループに組み込むのがいかに効果的かを証明してくれてんねん。HITL RLでは、エージェントが学習してる最中に人間の意見を取り入れて、繰り返し更新やチューニングをすることで、エージェントの性能がグンと上がんねん。人間がこのプロセスの欠かせない一部やからこそ、ワイらは「人間中心のアプローチこそが強化学習成功のカギや」って主張してんねん。これ、今までの文献ではあんまりちゃんと考慮されてこんかったポイントやで。
この論文の目的はな、HITL RLにおける今の説明可能性手法について読者に知ってもらうことや。ほんで、説明可能AI(xAI)を使うことや、既存の説明可能性アプローチを改善することで、HITL RLでの人間とエージェントのやりとりがもっとええもんになるってことを示すねん。一般の人でも、その分野の専門家でも、機械学習のスペシャリストでも、どんなユーザーにも対応できるようにな。
HITL RLのワークフローを考慮して、ソフトウェアや機械学習の方法論に基づいて、この論文ではHITL RLシステムを作るための人間の関与を4つのフェーズに分けてんねん:(1)エージェント開発、(2)エージェント学習、(3)エージェント評価、(4)エージェント展開や。各フェーズで人間がどう関わるか、どんな説明が必要か、新しい課題は何か、目標は何か、全部ハイライトしてるで。
さらにな、HITL RLの説明可能性研究で「リスク低いけどリターン高い」チャンスを特定して、この分野を前に進めるための長期的な研究目標も提示してんねん。最後に、人間とロボットがお互いの可能性を最大限に発揮して、効果的に協力できるような人間-ロボット協働のビジョンを提案してるで。
**1. はじめに**
強化学習(Sutton & Barto, 2018)(RL)っちゅうのはな、エージェントが自律的に行動を学んで、将来の報酬の割引合計——まあ簡単に言うと「長期的に見てどれだけええ結果になるか」っちゅうやつ——を最大化できるようになる汎用的なフレームワークやねん。これのおかげでエージェントは人間を超える性能を出せるようになって、時には誰も予想せんかった新しい戦略を生み出すこともあんねん。
強化学習エージェントはな、ボードゲーム、ビデオゲーム、ロボット工学、自然言語処理、その他いろんな分野でめっちゃすごい成功収めてきてん(Li, 2017)。産業界にもどんどん入ってきてて、世界最大級の企業で使われてんねん。たとえばNetflixやSpotifyのレコメンドシステム(Akanksha et al., 2021)、Metaでの動画最適化(Mao et al., 2020)、Covariantでのロボット自動化(Liu et al., 2022)とかな。
ChatGPTみたいなモデルの開発とインパクト、それから人間フィードバックからの強化学習(RLHF)の登場は、強化学習とHuman-in-the-Loop(HITL)アプローチを組み合わせることでどれだけすごい成功が得られるかを示す好例やねん。これらのモデルは人間みたいな高品質な応答を生成できることを証明してて、学習プロセス中の人間のフィードバックからめっちゃ恩恵受けてんねん。RLHFを使うことで、これらのモデルは人間のガイダンスから学んで、何回も改善を繰り返して、自然言語の理解や生成タスクで驚くほどの性能向上と能力アップを実現してんねん(Aiyappa et al., 2023)。強化学習とHuman-in-the-Loopのインタラクションの組み合わせは、ほんまにパワフルやって証明されてんで。
---
## Page 3
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p003.png)
### 和訳
ほな、AIを人間が教えるって話、聞いてってくれる?
これな、Human-in-the-Loop強化学習って呼ばれてるんやけど、めっちゃ画期的な方法やねん。AIモデルが特定の分野で人間超えるぐらいうまくなれるように訓練しながら、同時に人間の価値観とか専門知識もちゃんと学習に組み込めるっていう、ええとこ取りの仕組みなんよ(Choiらが2023年に言うてはったわ)。
でもな、AIとか強化学習システムが学んだ戦略って、確かにいろんな問題解くのに効果的やねんけど、人間が考えるやり方とはかなり違うことが多いねん(Lakeらの2017年の研究やな)。しかも頑丈さとか応用力に欠けるっていう問題もあるんよ(HolzingerとMüllerが2021年に指摘してはる)。モデルがどんどん複雑になってくると、大量の訓練データをきれいにするのが追いつかんくなって、モデルにバイアス入っちゃうリスクが高まるねん。そうなると変な動きするようになってまうわけや。さらにデータドリフトっていうて、時間とともにデータの性質が変わっちゃう問題もあって、これが再現性を下げてまうねん。大事な決定が同じように再現できへんようになるかもしれんのは困るやろ?(Banieckiらが2022年に言うてた)。特に失敗したら人間に直接害が及ぶようなヤバい状況では、AIの安全性と責任ってめっちゃ大事やねん。これは法律的な理由だけちゃうくて、倫理的にもそうやねん(Banieckiら2022年、Holzingerら2020年の話や)。
ほんで、説明可能性ってアプローチがこういう問題解決するのにめっちゃ重要な役割果たすねん。システムの安全性と責任を担保することで、医療とか金融とか防衛みたいな分野で「これ使ってもええな」って受け入れてもらえるようになるわけや(Banieckiら2022年、Heuilletら2021年)。それだけちゃうで、プログラマーが複雑なモデル作ってる時にバグ見つけて直すのにも役立つから、実際に使えるようにするまでのプロセスが速くなるっていうメリットもあんねん(Heuilletら2021年)。
人間からのフィードバックで学ぶっていう手法、これがChatGPTの成功の鍵の一つやったんよ。ChatGPTって、大規模言語モデル(LLM)の中で初めて一般の人にめっちゃ広まったやつやんな。でもな、このプロセスのせいでデータ汚染も起きてもうて、いろんな分野での頑丈さに疑問が出てきてるねん(Aiyappaらが2023年に言うてはる)。ワイらが主張したいのはな、説明可能性がこのインタラクティブなプロセスをもっと良くするための土台になるってことや。なんでかっていうと、根っこにあるアルゴリズムとその判断を、目的の違ういろんな人らが理解できるようにせなあかんのよ。そうせんと人間がエージェントの動きを理解して信頼できるようにならへんからな(Heuilletら2021年)。
人間とエージェントのやり取りがあんまりないケースでも、例えばソフトウェア開発とか工場での応用みたいな場合でも、HITLは役立つねん。こういう場面では、人間がエージェントのパフォーマンス見守って、判断の中の潜在的なエラーとかバイアスを直したりできるやろ。それでエージェントの頑丈さを上げられるわけや。あと環境の変化とか新しい要求に合わせてエージェントの動きを調整するために必要なインプットを提供することもできるねん(Husseinらが2017年に書いてはった)。人間のフィードバック取り入れた有名な例がChatGPTやな、2022年の強化学習アプリケーションで一番インパクトあったやつや。ChatGPTは人間のフィードバックから報酬モデルを学んで、その報酬モデルに対してポリシーを最適化するねん。これで、教師あり学習だけに頼る従来のやり方より優れた結果出せるってことを示したんよ(Stiennonらの2020年の研究やな)。
ワイらが言いたいのはな、今の強化学習の捉え方では、強化学習の問題に組み込まれとる重大な人間のインプットとバイアスが見落とされとるってことや。ほんで、こう主張するで:
1. 強化学習は根本的にHuman-in-the-Loop(人間参加型)のパラダイムやねん。
2. 現実世界の強化学習アプリケーションが成功するには、説明可能性がめっちゃ重要やねん。
まず一つ目やけど、強化学習は根本的にHITLパラダイムやって主張して、強化学習エージェントを実際に使えるようにするまでに人間の関与が欠かせない4つのフェーズを特定したんよ:エージェント開発、エージェント学習、エージェント評価、エージェント展開や(詳しくは次のサブセクション見てな)。
---
## Page 4
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p004.png)
### 和訳
Retzlaffらの研究やねんけど、
まず1.1のとこで言うてるんは、これらのフェーズは順番に進むけど、サイクル的に繰り返すもんやねん。つまり、全体のデプロイ(実際に使い始める)プロセスの中で、個々のフェーズは何回も繰り返されることがあるっちゅうことやな。
ほんで2つ目に、この論文は「ポジションペーパー」っていう立場表明の論文でもあるねん。僕らが言いたいのは、「強化学習(RL)を完全に自動で勝手に学ぶもんやと思って、人間を無視するのはアカン」っちゅうことやねん。めっちゃ近視眼的やで、それは。人間とAIエージェントが協力する4つのフェーズのどこで、どうやって「説明可能性」が重要な役割を果たすか、そこをハイライトしてるわけや。
3つ目に、この論文はRLにおける説明可能性のサーベイ(調査まとめ)でもあるねん。読者に今ある説明可能性の手法を教えて、それがHITL(Human-in-the-Loop、人間がループに入る)RLアプリケーションでどうやって人間とエージェントのやり取りをより良くできるかを説明して、この分野を前に進めるための長期的な研究目標も示してるわけや。
HITLパラダイムが機械学習全体にとってめっちゃ大事やと僕らは思ってるんやけど、この論文ではRL設定における人間とエージェントのやり取りに焦点を当ててるねん。なんでかっていうと、RLにはHITLパラダイムが特に適してるんや。人間の入力と監視を学習プロセスに組み込めるから、エージェントの行動をちゃんとコントロールできるようになるねん(Lee et al., 2021)。
ちょっと断っておくと、RLのHITLアプリケーションには、バイアス(偏り)、公平性、パーソナライゼーション(個人化)みたいなトピックも含まれるねん。でもこれらの問題は複雑で、もっと深くて専門的な分析が必要やから、他の人らの関連研究を参照してな。例えば欧州議会(2020)、Mehrabiら(2021)、Arrietaら(2019)とかや。僕らの研究は説明可能なRLに焦点を当てて、HITLの分野に貢献してるねん。なんで説明可能なRLが大事なんか、これらのシステムが透明で信頼できて、人間が理解できる意思決定プロセスを提供するためにどうすればええか、そこに光を当ててるわけや。
**1.1 HITL RLデプロイの4つのフェーズ**
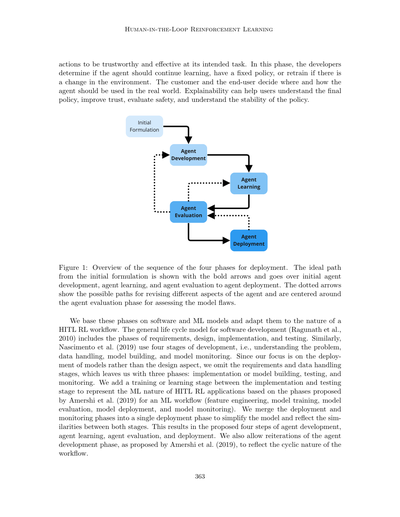
以下のステップには、RLのデプロイのために特定された、はっきり区別できるフェーズと、それぞれで人間がどう関わるかが書いてあるねん。図1はエージェントデプロイのフェーズの順序の概要やで。僕らの主張は、説明可能性はこの4つのフェーズ全部において、めっちゃ重要やのにまだ十分に開発されてへん技術やっちゅうことやねん。
**1. 初期エージェント開発**: 機械学習の専門家が、計画してるRLモデルの技術的な土台を作るねん。チームは解決すべき問題を定義して、エージェントの環境を定義して、ハイパーパラメータ(学習の設定値みたいなもん)についての決定をするわけや。ここで説明可能性が役立つのは、それらの決定がエージェントの学習プロセスにどう影響するかを示すことができるからやねん。
**2. エージェント学習**: モデルは対話的に訓練されて、人間の専門家がエージェントにフィードバックとガイダンスを提供するねん。専門家は学習プロセスにバイアスをかけたり、特定の行動を禁止したりして、モデルがより早く学習できるように手助けもできるんや。説明可能性は訓練中に使われて、現在のポリシー(方策、つまりエージェントの行動ルール)と、人間の専門家のガイダンスがモデルにどんな影響を与えてるかを示すねん。
**3. エージェント評価**: 評価フェーズでは、モデルがデプロイする準備ができてるかテストするねん。具体的には、このフェーズでドメイン専門家(その分野の専門家)が判断せなあかんねん。モデルをデプロイしてええか、もっと訓練が必要か、それとも問題定義自体を変える必要があるか、っちゅうことをな。ここで説明可能性が役立つのは、学習したポリシーと出てきた行動パターンを深く検査できるようにしてくれるからやねん。
**4. エージェントデプロイ**: エージェントが実際の稼働環境にデプロイされて、安全で、理解可能で、信頼できるものであるために説明可能性が必要やねん。それに加えて、スムーズなインター...
---
## Page 5
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p005.png)
### 和訳
ほな翻訳いくで!
---
人間参加型の強化学習
AIエージェントの行動が信頼できて、ちゃんと目的のタスクをこなせるようにせなあかんねん。この段階で、開発者はエージェントに学習を続けさせるか、ポリシー(行動の指針みたいなもんやな)を固定するか、それとも環境が変わったら再トレーニングするか決めるんや。お客さんとかエンドユーザーは、このエージェントを実際の世界でどこでどう使うか決めるねん。説明可能性っていうのがあると、ユーザーが最終的なポリシーを理解したり、信頼感が増したり、安全性を評価したり、ポリシーが安定してるかどうか分かるようになるんやで。
図1:導入までの4つのフェーズの流れを示した概要図やで。最初の設計から理想的に進む道筋は太い矢印で示してあって、最初のエージェント開発→エージェントの学習→エージェントの評価→エージェントの導入って順番で進むねん。点線の矢印は、エージェントのいろんな部分を見直すときの経路を示してて、モデルの欠点を見つけるためのエージェント評価フェーズを中心に回ってるんや。
これらのフェーズは、ソフトウェアとか機械学習モデルの考え方をベースにして、人間参加型の強化学習ワークフローの特性に合わせてアレンジしたもんやねん。ソフトウェア開発の一般的なライフサイクルモデル(Ragunathらが2010年に提唱したやつな)には、要件定義、設計、実装、テストっていうフェーズがあるんや。同じように、Nascimentoらは2019年に4つの段階を使ってて、問題の理解、データの取り扱い、モデル構築、モデルのモニタリングってなってるねん。ワイらは設計よりもモデルの導入に焦点を当ててるから、要件定義とデータ取り扱いの段階は省いて、実装またはモデル構築、テスト、モニタリングの3フェーズを残したんや。ほんで、Amershiらが2019年に機械学習ワークフロー用に提案したフェーズ(特徴量エンジニアリング、モデルトレーニング、モデル評価、モデル導入、モデルモニタリング)を参考にして、実装とテストの間にトレーニングまたは学習の段階を追加したんやで。なんでかっていうと、人間参加型強化学習アプリケーションの機械学習的な性質を表現したかったからやねん。導入とモニタリングのフェーズは、モデルをシンプルにするのと、両方の段階が似てるから、一つの導入フェーズにまとめたんや。これで、エージェント開発、エージェント学習、エージェント評価、導入っていう4つのステップができたわけや。Amershiらが提案したように、エージェント開発フェーズを繰り返せるようにもしてあって、ワークフローが循環的な性質を持ってることを反映してるんやで。
363
[図の説明]
エージェント開発 → エージェント学習 → エージェント評価 → エージェント導入
↑
最初の設計
---
## Page 6
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p006.png)
### 和訳
Retzlaffら
**1.2 概要と目標**
この論文でワシらがやりたいんは、強化学習(RL)の議論を「人間との関わり合い」とか「協力」っていう方向にシフトさせることやねん。それと、説明可能な強化学習っていう今めっちゃアツい研究分野への入り口を提供したいんよ。専門家じゃない人でも「HITL RL」(Human-in-the-Loop RL:人間が関与する強化学習)の研究に入りやすいようにな。
論文全体を通して、人間とエージェント(AIシステム)のやりとりに焦点当ててるから、「身体化された知能」っちゅうやつを中心に見ていくで。これ何かっていうと、AIに制御されたロボットみたいな物理的な存在のことやな。必要に応じて、人間とエージェントの関係の「より広い範囲」、つまりソフトウェアだけのアプリケーションについても触れるで。
正直に言うとな、HITL RLの分野ってまだめっちゃ若いから、改善の余地がだいぶあるんよ。この論文で紹介する技術が全部すぐ実用できるわけちゃうねん。むしろ、「こういう方向で研究進めたらええんちゃう?」っていう議論のきっかけにしたいんや。
**論文の構成**
イントロの後、セクション2で説明可能性とインタラクティブ学習の背景をおさらいするで。そこでは身体化された知能の基本的な課題と今の問題点をレビューするんや。
その後、HITL RLシステムを展開する4つのフェーズを探っていって、どこで説明可能性を適用すべきかを分析するで:
1. **エージェント開発**(セクション3)
2. **エージェント学習**(セクション4)
3. **エージェント評価**(セクション5)
4. **エージェント展開**(セクション6)
それぞれのフェーズで、人間がうまく参加するための特有の要件があるんよ。さらに、いろんなアプローチを探って、課題と今後の研究の方向性も議論するで。この4つのフェーズへの提言をわかりやすく説明するために、「林業でのロボット運用」っていうユースケースを追加したから、論文全体を通してこれ使って説明していくわ。
**なんで林業を例にしたん?**
林業をユースケースに選んだんは、HITLを適用できる可能性がめっちゃ幅広いからやねん。
森林ってほんまに経済的価値が高いんよ。なんでかっていうと、再生可能な原材料を提供してくれるだけやなくて、CO2を吸収してくれるから気候変動対策にも貢献してるやろ?せやから林業でロボット使うのは経済的にもめっちゃ重要なんや(Holzingerら、2022b; Holzingerら、2022d)。
実際、林業でのロボット運用は研究コミュニティからどんどん注目されてきてるんよ(Mikhaylov & Lositskii, 2018; Mowshowitzら, 2018; Zhangら, 2019a)。で、これが強化学習の適用にぴったりなんは、不確実で動的な環境の中で時間をかけて意思決定せなあかんからや。RLってこういう問題に向いてるんよ——エージェントが経験から学んで、変化する状況に適応できるからな。
森の中で自律的にナビゲーションできるようになったら、そこから草取り、樹種の識別、その他の森林管理アプリケーションみたいな、もっと高度なタスクへの土台になるんや。
ただな、ロボット運用はシミュレーションではめっちゃ研究されてるけど、実際の現場での応用は少ないんよ。なんでかっていうと、頑健性とセキュリティの問題があるからやねん(Surmannら、2020)。
---
1. 身体化された知能のアプローチの場合、これを「ヒューマン・ロボット・インタラクション」とも呼ぶで。
364
---
## Page 7
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p007.png)
### 和訳
人間参加型の強化学習
図2:森林でのロボット運用の活用シーンで、目的地まで移動する例を示してるねん。
ここでうまくいくために大事な課題が3つあるんよ:(1) 木の種類を見分けるみたいなメインの仕事をこなすこと、(2) ややこしい地形を乗り越えたりルートを変更したりすること、(3) オペレーターとか通りがかりの人とやり取りすること。
せやから、この使い方やと人間参加型アプローチの「頑丈さ」と「なんでそうなったか説明できる」っていうメリットがめっちゃ活きてくるわけや。
図2では、森林でロボット動かすときの大事な課題を3つ挙げてるねん:(1) 木の種類を特定するみたいなメインタスクをやり遂げること、(2) 厳しい地形を突破すること、(3) 指定された目的地に向かいながらオペレーターとか周りにおる人とコミュニケーション取ること。
各フェーズの最初のとこで、この課題がそのフェーズにどう関係してくるか書いてあるで。ほんで各フェーズの議論セクションでは、そのフェーズに合った具体的な方法を提案して、さっき言うた課題をどうやって乗り越えて、エージェントの性能・頑丈さ・信頼性をアップできるか説明してるわ。
セクション7では、全体通して見えてきた課題と、それを解決するための将来の方法がどんな形になりそうかを議論してるねん。最後のセクション8では、この分野全体の問題点と目標をまとめて、今後の研究の方向性を提案してるで。
365
!1.2.3.
---
## Page 8
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p008.png)
### 和訳
Retzlaffらの研究やで。
| フェーズ | 人間の関わり方 | 説明に求められること | 説明のしやすさ | 目標 | 評価の指標 |
|----------|----------------|---------------------|----------------|------|------------|
| **開発** | ・問題を決める<br>・状態空間、行動空間、報酬関数を設計する<br>・モデルを作る | ・他のバージョンと比較できること<br>・さらっと見るときは、早くてシンプルな説明<br>・じっくり調べるときは、複雑で網羅的な説明 | **注目ポイント:**<br>決定木とか因果モデルとか、組み合わせ言語みたいな「中身が見えるモデル」<br><br>**説明の方法:**<br>「もしこうやったらどうなってた?」っていう反実仮想、方策への質問、決定ルール<br><br>**使う人:**<br>強化学習の専門家 | ・しっかりした、比較できるモデルの要約を作る<br>・組み合わせて表現できる言葉を使う<br>・人間参加型のアプローチに因果学習をもっと取り入れる |
| **エージェント学習** | ・行動にフィードバックを返す<br>・アドバイスを与える<br>・行動の好みを選ぶ<br>・お手本を見せる | ・その分野の専門家が理解できること<br>・スムーズなやりとりができること | **注目ポイント:**<br>人間の好みを聞いたり、不確かなところを強調したりする人間参加型アプローチ<br><br>**説明の方法:**<br>反実仮想、ユーザーの言葉での文章説明、顕著性マップ<br><br>**使う人:**<br>ドメイン専門家、強化学習の専門家 | **忠実度**<br>**関連性**<br>・人間のフィードバック(タスクとの関連性についてユーザーアンケートで評価)<br><br>**性能**<br>・説明にかかる時間(ミリ秒単位) | ・模倣学習と好みベースの学習を補完的に使う<br>・xAI(説明可能AI)のアプローチを人間参加型の文脈に適応させる<br>・「人間が先生」アプローチを適用する<br>・人間とのやりとりで異なる種類のハイブリッド手法を見つける |
| **評価** | ・学習した方策をミクロとマクロの両方のレベルで理解・評価する<br>・モデルの限界と安全性をテストする<br>・モデルを実際に使っていいか判断する | ・学習した振る舞いを要約できること<br>・大きなモデルにもスケールすること<br>・学習前のモデルと比較できること<br>・その分野の専門家が理解できること | **注目ポイント:**<br>不確実性をモデル化したり、シールドベースの防御を使った安全性評価<br><br>**説明の方法:**<br>自然言語、ルール、コードでの方策要約、グラフベースの説明<br><br>**使う人:**<br>ドメイン専門家、強化学習の専門家 | **忠実度**<br>**関連性**<br>**認知負荷**<br>・コンパクトさ(特徴量の数、パスの長さ、完全データからの削減率での説明の絶対的な大きさ)<br>・冗長性(説明の各部分の重複) | ・ドメイン専門家が理解できるようにする<br>・モデルのサイズや複雑さに合わせてスケールする、しっかり比較できる説明を可能にする<br>・いろんな視点から方策を見れるダッシュボードをもっと開発する |
| **実運用** | ・エージェントを実際に動かす<br>・実際に動いてるエージェントとやりとりする<br>・エージェントの現実世界での目標と適用場面を決める | ・認知負荷を減らすために、早くて、明確で、簡潔であること<br>・エンドユーザーが理解できること<br>・ユーザーのパフォーマンスに悪影響を与えないように邪魔にならないこと | **注目ポイント:**<br>意図や不確実性を伝えたり、エラー修正を許可したりしてユーザーの信頼を築く<br><br>**説明の方法:**<br>顕著性マップ、樹形図、バウンディングボックス、文章での説明、視覚・聴覚的な合図<br><br>**使う人:**<br>エンドユーザー | **忠実度**<br>**関連性**<br>**認知負荷**<br>**性能** | ・画像とか自動運転ベースの説明だけやなくて、新しいアプローチを開発・適用する<br>・シンプルで速い説明を使う<br>・一貫したエラーと不確実性のハンドリングを実装する<br>・いろんな方法でエージェントの意図を伝える |
**忠実度**の評価方法
・正しさ(コントロールされた合成データや単一特徴量の削除での出力との相関)
・説明可能モデルの乖離(モデル予測間の誤差)
---
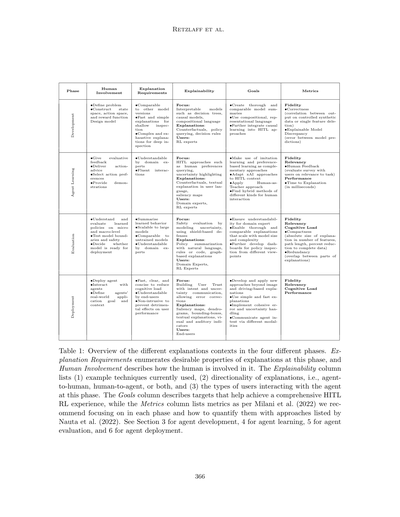
**表1**: 4つのフェーズにおける説明の文脈の概要やねん。「説明に求められること」ってのは、そのフェーズで説明に欲しい特性を列挙してて、「人間の関わり方」は人間がどう関係するかを説明してるで。「説明のしやすさ」の欄では (1) 今使われてる技術の例、(2) 説明の方向性(エージェントから人間へなのか、人間からエージェントへなのか、両方なのか)、(3) そのフェーズでエージェントとやりとりするユーザーのタイプを挙げてるわ。「目標」の欄は包括的な人間参加型強化学習の体験を実現するための目標を説明してて、「評価の指標」の欄はMilaniら(2022)による各フェーズで重視すべき指標と、Nautaら(2022)が挙げた定量化のアプローチを載せてるで。エージェント開発についてはセクション3、エージェント学習は4、エージェント評価は5、エージェント実運用は6を見てな。
366
---
## Page 9
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p009.png)
### 和訳
# 人間が一緒に手伝う強化学習
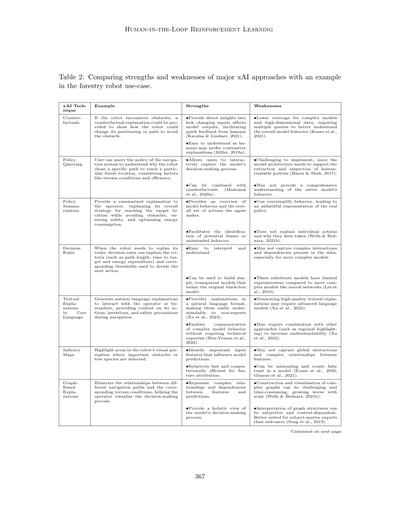
## 表2: 説明可能AIの主なアプローチの強みと弱みを、森林ロボットの使用例で比較したやつやで
| xAI手法 | 例 | ええとこ | あかんとこ |
|---------|-----|----------|------------|
| **反事実的説明(もしも〜やったら)** | ロボットが障害物にぶつかりそうな時、「こう動いたら避けられたで」って別の位置取りやルートを見せてくれるやつ。 | ・入力を変えたら出力がどう変わるかが直接わかるから、人間からのフィードバックがめっちゃ早くもらえるねん(Karalus & Lindner, 2021)。<br>・人間って「もしこうやったら」っていう対比的な説明が好きやから、理解しやすいねん(Miller, 2019a)。 | ・複雑なモデルとか高次元のデータやと、カバーできる範囲が狭くなってまうねん。全体の動きを理解するには何回も質問せなあかん(Keane et al., 2021)。 |
| **方針への問い合わせ** | ユーザーがナビシステムの方針に「なんでこのルート選んだん?」って聞けるやつ。地形の状態とか効率とかを考慮して、なんで特定の森の場所に行くのにそのルートにしたかがわかるねん。 | ・ユーザーがインタラクティブにモデルの意思決定プロセスを探っていけるんや。<br>・反事実的説明と組み合わせることもできるで(Madumal et al., 2020a)。 | ・実装がなかなか難しいねん。なんでかっていうと、モデルの構造が人間にわかる形で方針を取り出して見れるようになってないとあかんからや(Hayes & Shah, 2017)。<br>・モデル全体の動きを完全に理解できるわけちゃうねん。 |
| **方針の要約** | オペレーターに要約した説明を出すやつ。「目的地に着くために、障害物避けて、安全確保して、エネルギーも節約する」っていう全体的な戦略を説明してくれるねん。 | ・モデルの動きとエージェントがやる全体的なアクションの概要がわかるんや。<br>・潜在的なバイアスとか意図しない動きを見つけやすくなるで。 | ・動きを単純化しすぎて、ほんまの方針を忠実に表現できひんことがあるねん。<br>・個々のアクションとか、なんでそれをやったかは説明してくれへんねん(Wells & Bednarz, 2021b)。 |
| **決定ルール** | ロボットがルートを再計画する時、判断基準(経路の長さとか、目的地までの時間とか、エネルギー消費とか)と、次のアクションを決めるための閾値を説明してくれるやつ。 | ・解釈も理解もめっちゃ簡単やねん。<br>・元のブラックボックスモデルを真似した、シンプルで透明性のあるモデルを作るのに使えるで。 | ・データに含まれる複雑な相互作用や依存関係を捉えきれへんことがあるねん、特に複雑なモデルやと。<br>・ニューラルネットワークみたいな複雑なモデルと比べたら、この代替モデルは表現力が限られてまうんや(Liu et al., 2018)。 |
| **ユーザー言語でのテキスト説明** | 自然言語で説明を生成して、オペレーターとか周りの人とやり取りするやつ。ナビ中に自分のアクションとか意図とか安全対策とかを説明してくれるねん。 | ・自然言語形式で説明してくれるから、専門家じゃない人にもめっちゃわかりやすいんや(Xu et al., 2023)。<br>・技術的な専門知識がなくても、複雑なモデルの動きをコミュニケーションできるねん(Ben-Younes et al., 2022)。 | ・高品質なテキスト説明を生成するには、高度な言語モデルが必要かもしれへんねん(Xu et al., 2023)。<br>・理解度を上げるには、他のアプローチ(領域のハイライトとか)と組み合わせる必要があるかもしれんで(Xu et al., 2023)。 |
| **顕著性マップ** | ロボットの視覚で、重要な障害物とか木の種類が検出された場所をハイライトしてくれるやつ。 | ・モデルの予測に影響を与える重要な入力特徴を特定できるねん。<br>・特徴の帰属計算が比較的早くて、計算効率もええんや。 | ・特徴間のグローバルな相互作用とか複雑な関係を捉えられへんかもしれんねん。<br>・誤解を招いて、モデルへの偽りの信頼を作ってまうこともあるで(Evans et al., 2022; Glanois et al., 2021)。 |
| **グラフベースの説明** | 異なるナビルートと対応する地形条件の関係を図示して、オペレーターが意思決定プロセスを可視化しやすくするやつ。 | ・特徴と予測の間の複雑な関係や依存関係を表現できるんや。<br>・モデルの意思決定プロセスを全体的に見れるで。 | ・複雑なグラフの構築と可視化は難しくて時間がかかるねん、規模が大きくなるともっと大変や(Wells & Bednarz, 2021b)。<br>・グラフ構造の解釈は主観的で文脈依存になりがちやねん。エンドユーザーよりも専門家向けやな(Song et al., 2019)。 |
*次ページに続くで*
367
---
## Page 10
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p010.png)
### 和訳
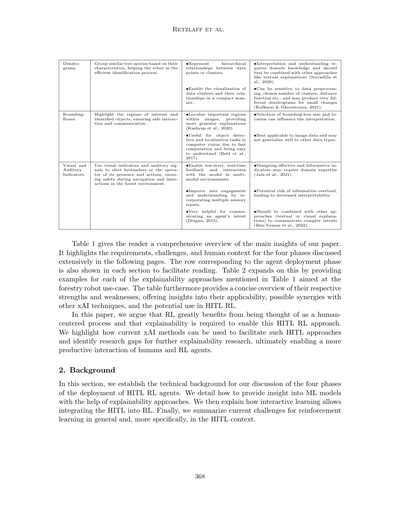
デンドログラム
似たような木の種類をその特徴に基づいてグループ分けして、ロボットが効率よく木を見分けられるようにサポートするんやで。
・データポイントやクラスターの間の階層的な関係性を表現するもんやねん。
バウンディングボックス
注目したい領域とか識別したオブジェクトをハイライトして、安全なやり取りとコミュニケーションを確保するためのもんやな。
視覚的・聴覚的インジケーター
視覚的なサインとか音のシグナルを使って、周りにおる人やオペレーターにロボットがおることとか、何しようとしてるかを知らせるんや。森の中でナビゲーションしたり何かするときの安全確保のためやで。
・データのクラスターとその関係性をコンパクトにわかりやすく見える化できるんやな。
・画像の中で重要な領域を特定して、もっと細かい説明ができるようになるんやで(Kashyapら、2020年)。
・計算が速くて理解しやすいから、コンピュータビジョンの物体検出とか位置特定のタスクにめっちゃ使えるんや(Behlら、2017年)。
・マルチモーダル環境でモデルとリアルタイムでやり取りしながら、ローレベルなフィードバックができるようになるんやで。
・いろんな感覚からの入力を取り入れることで、ユーザーの関わりとか理解度がアップするんや。
・エージェントが何しようとしてるか伝えるのにめっちゃ役立つで(Dragan、2015年)。
・解釈して理解するには専門知識がいるから、テキストでの説明みたいな他のアプローチと組み合わせるのがベストやねん(Serradillaら、2020年)。
・データの前処理とかクラスター数の選び方、距離関数なんかに敏感で、ちょっとした変更でもめっちゃ違うデンドログラムができることもあるんや(Kulkarni & Gkountouna、2021年)。
・バウンディングボックスのサイズとか配置の選び方で、解釈が変わってくることもあるんやな。
・画像データには一番向いてるけど、他のデータタイプにはそんなにうまく一般化できへんかもしれんで。
・効果的でわかりやすいインジケーターをデザインするには、その分野の専門知識がいるかもしれんのや(Jainら、2021年)。
・情報過多になるリスクがあって、そうなると逆に解釈しにくくなってまうこともあるで。
・複雑な意図を伝えるには、他のアプローチ(テキストとか視覚的な説明)と組み合わせた方がええんやな(Ben-Younesら、2022年)。
表1は、この論文のメインの知見を読者にわかりやすくまとめたもんやねん。これから詳しく説明する4つのフェーズについて、要件とか課題、人間の文脈をハイライトしてるんや。エージェント展開フェーズに対応する行は、読みやすいように各セクションにも載せてあるで。表2はこれをさらに発展させて、表1で触れた説明可能性アプローチそれぞれについて、森林ロボットのユースケースを想定した例を示してるんや。この表ではまた、それぞれの強みと弱みも簡潔にまとめてあって、どこで使えるか、他のxAI技術との相乗効果、HITL RLでの活用可能性についてもわかるようになってるで。
この論文でわしらが主張してるのは、RLは人間中心のプロセスとして考えた方がめっちゃメリットあるってことと、このHITL RLアプローチを実現するには説明可能性が必須やってことやねん。今あるxAI手法がこういうHITLアプローチをどうやって促進できるかを強調して、さらなる説明可能性研究のための研究ギャップも特定してるんや。最終的には、人間とRLエージェントのもっと生産的なやり取りを実現しようっていう話やで。
2. 背景
このセクションでは、HITL RLエージェント展開の4つのフェーズについて議論するための技術的な背景を整理するんや。説明可能性アプローチを使ってMLモデルの中身をどうやって見せるかを詳しく説明するで。ほんでから、インタラクティブ学習がどうやってHITLをRLに統合できるかを説明するんや。最後に、強化学習全般の現在の課題と、特にHITL文脈での課題をまとめるで。
368
---
## Page 11
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p011.png)
### 和訳
人間参加型の強化学習
2.1 説明可能性
説明可能な人工知能(xAI)っていうのはな、機械学習モデルがどういう処理をして、どんな結果を出してるかを、人間にわかりやすく伝えるための仕組みのことやねん。機械学習モデルって、今や農業とか医療とか、スマートホームみたいな暮らしに関わる場面でめっちゃ使われるようになってきてるやん?やからこそ、このxAIの仕組みがほんまに大事になってきてるわけや。それにな、人間とAIが一緒に協力して何かするシーンでは、AIが出した答えを理解して信頼できひんかったら使いようがないわけで、xAIのアプローチは絶対必要やねん(Holzinger, 2021)。
説明可能性の研究は1980年代から90年代に始まったんやけど、当時の研究者たちは知識ベースやルールベースのシステム、それからニューラルネットワークからルールを抽出しようとしてたんや(Buchanan & Shortliffe, 1984; Chandrasekaran et al., 1989; Tickle et al., 1998)。そっから発展して、今や専門の研究コミュニティがどんどん大きくなってきてるねん。DARPAっていうアメリカの研究機関が立ち上げたプロジェクトなんかがその代表例やな(Gunning & Aha, 2019)。xAIの取り組みのおかげで、うまくいってる手法もいくつか出てきてるで(Holzinger et al., 2022c; Zhou et al., 2021)。ただな、正直に言うと「説明可能性(explainability)」と「解釈可能性(interpretability)」っていう言葉は、論文によってバラバラに使われてて、同じ意味で使われることもあるんよ(Miller, 2019a)。やから、ここではHolzinger et al.(2022c)の定義に従うことにするわ。この定義によると、説明可能性っていうのは、機械の表現やモデルの中で「判断に関係する部分」を浮き彫りにする手法のことやねん。一方で解釈可能性は、Doran et al.(2017)によると、入力がどうやって数学的に出力に変換されるかを、ユーザーが見るだけやなくて理解できるシステムのことを指すんや。この解釈可能性の定義は、モデルの中身が透明で、技術的な変換の仕組みを理解する必要があるってことを意味してるんやけど、説明可能性と違って、判断に関係する側面とか外部要因は考慮に入れてへんねん。この理解の仕方は、Glanois et al.(2021)の考え方とも合ってて、彼らは解釈可能性を「受動的にモデルをわかりやすくする手法」、説明可能性を「能動的にモデルの説明を生成する手法」って定義してるんや。やから、ここでは解釈可能性をモデルの仕組みを機械的に理解できるようにする手法、説明可能性は判断に関係する要因を積極的に説明することも含む、っていう風に区別するで。
次の例は、xAIの仕組みと人間のユーザーがどんな風にやりとりできるかを示してるで:
1. 最終的な判断にデータソースがどう関わってるかを説明する。例えば、ある行動や判断にどのデータサンプルが使われたかを特定するみたいなことやな。これはな、データを作った人にちゃんと功績を認めて、場合によっては報酬を払うためにも大事なことやねん(Zanzotto, 2019)。
2. 人間のユーザーに信頼してもらうこと。これは安全性が関わる場面では特に重要やで。医療分野でAIを使う時なんか、人間のユーザーはAIエージェントが下した判断について、信頼できる説明を求めるやん。やから、透明性と説明責任がめっちゃ大事になってくるわけや(Schneeberger et al., 2020; Stoeger et al., 2021)。
3. 人間がもっと豊かなフィードバックを提供できるようにすること。「もしこうやったらどうなってた?」みたいな反事実的な例を追加で出せるようになるねん(Del Ser et al., 2024)。AIエージェントは人間が説明の形で提供するフィードバックを活用できて、それによってより正確で、頑丈で、透明性の高いモデルができるようになるんや(Karalus & Lindner, 2021; Puiutta & Veith, 2020)。
これらの例は、xAIの仕組みがいろんな場面で使えることを示してるな。特に人間と機械が協力する場面では、人間のオペレーターの認知能力と組み合わさって
369
---
## Page 12
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p012.png)
### 和訳
Retzlaffら
機械のめっちゃすごい計算パワーと人間を組み合わせたら、複雑なタスクも処理できる可能性があんねん(Bucheltら、2024年; Liangら、2017年)。ここで大事なんは、機械も人間のオペレーターも、両方とも環境に反応できなあかんし、オペレーターは機械がやってることをちゃんと理解して正しく解釈できなあかんってことやねん。せやから、アルゴリズムとその判断は、いろんな目的を持ったいろんな人らにとって分かりやすくないとあかんわけよ(Heuilletら、2021年)。これが人間と機械の協力において、説明可能性がめっちゃ重要やって示してるねん。
ここではGlanoisら(2021年)が提示した分類を使って、調査した解釈可能性のアプローチを分類していくで。彼らの分類を拡張して説明可能性のアプローチも含めた結果、以下の3つのカテゴリーになったわ:
1. 強化学習モデルの解釈可能/説明可能なインプット
2. 強化学習のための解釈可能/説明可能な遷移モデルと報酬モデル
3. 強化学習の解釈可能/説明可能な意思決定プロセス
最初のカテゴリーは、意思決定に使われる強化学習モデルへのインプットに焦点を当ててるねん。エージェントの状態だけやなくて、人間の専門家からの問題記述(Hasanbeigら、2021年)とか、問題の関係構造(Battagliaら、2018年; Martínezら、2017年)や階層構造(Andreasら、2017年; Lyuら、2019年)みたいな構造的な情報も含まれてるわ。こういう文脈情報があると、強化学習モデルが下した判断をもっとよう理解できるようになるねん。
モデルのインプットを説明するための大事な要素として、モデルがどう認識してるかを可視化することがあるねん。この可視化は、ある判断の関連性や重要性を示すことと組み合わされることが多くて、モデルがインプットの正しい部分に注目してるかどうかを評価するのに役立つんやけど、間違った使い方をするとユーザーを惑わせることもあるから気をつけてな。この問題についてはEvansら(2022年)がもっと詳しく議論してるで。顕著性マップ(サリエンシーマップ)は可視化アプローチの中でも一番よう使われる例の一つで、画像の重要な領域をハイライトする仕組みやねん。Liuら(2018年)は、特徴の影響が大きい連続した「スーパーピクセル」をハイライトする例を示してるわ。Bachら(2015年)は「層ごとの関連性伝播(Layer-Wise Relevance Propagation)」っていう技術を開発して、モデルのインプットを繰り返し変えながら、個々の(画像の)部分や特徴の相対的な重要性を見つけるようにしたんや。
2つ目のカテゴリーの説明可能な遷移モデルと報酬モデルは、タスクや環境の理解しやすいモデルを活用するねん。例えば、遷移モデル(Martínezら、2016年; Zhuら、2020年)とか嗜好モデル(Icarteら、2018年; Icarteら、2019年)とかやな。こういうモデルは、強化学習エージェントが意思決定についてどう推論してるかの説明と、人間が意思決定プロセスを理解することの両方を助けてくれるねん。
3つ目のカテゴリーは、強化学習エージェントの解釈可能/説明可能な意思決定や。これは意思決定の方針(ポリシー)を直感的に分かりやすい形で表現するアプローチで構成されてるねん。決定木(Likmetaら、2020年; Silvaら、2020年; Topinら、2021年)、数式(Heinら、2018年、2019年)、ファジィルール(Akrourら、2019年; Heinら、2017年; Zhangら、2021年)、論理ルール(Jiang & Luo、2019年)、あるいはプログラム(Sunら、2019年; Vermaら、2019年)の形で、そういう解釈可能なポリシーを学習するアプローチがあるわ。
一般的に、説明可能AIソリューションの品質と効果を確実に評価するんはなかなか難しいねん。なんでかっていうと、ユーザーコスト(つまり認知的負荷とかその他のユーザー要件)を客観的に測るんがほんまに難しいからやねん(Bruneauら、2002年)。ユーザーコストをもっとうまく評価するために、Milaniら(2022年)は4つの
370
---
## Page 13
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p013.png)
### 和訳
説明できるAI(xAI)の評価指標として、ワイらが使う大事なやつを紹介するで。まず**忠実度**、これはAIモデル自体に対して説明がどんだけ正直かってことやねん。次に**性能**、これはAIがちゃんと仕事できてるかの普通の評価基準や。それから**関連性**、説明がそのタスクにどんだけ関係あるかってこと。最後に**認知負荷**、説明を理解するのにどんだけ頭使わなアカンかってことやな。ここから、Milaniらの指標をどうやって数値化するか説明していくで。ちなみにNautaら(2022)も関連する論文出してて、xAIの色んな特性を定量的に測る方法をめっちゃ詳しく調査してるんや。
**モデルの忠実度**は、正確さで測れるねん。モデルがちゃんと動いて正しい出力出してるか確認するんが大事やからな(Nauta et al., 2022)。正確さを数値化するには、人工的にデータ作って、正解がわかってるデータでモデルをテストして、どんだけ正しい出力を再現できるか見るんや。もう一つの方法は、特徴を一個ずつ消したデータでモデルの性能をテストすることやねん。こうすると出力の変化とその特徴の重要度スコアの相関がわかるんや。説明可能なモデルやったら、モデルの判断と説明を比べて、平均二乗誤差(MSE)みたいな誤差指標で正確さを数値化できるで。MSEが低いほど、モデルと説明の意見が一致してるってことやな(Nauta et al., 2022)。
**計算性能**は直感的にわかりやすくて、説明を生成するのにどんだけ時間かかるか(ミリ秒とか秒とか)測ればええねん。
**関連性**と**認知負荷**は数値化がむずいねん。なんでかっていうと、ユーザーの専門知識とか周りの環境にめっちゃ左右されるからや(Milani et al., 2022)。せやから、関連性は定性的に測るのがベストやと思うわ。具体的には、説明に対する人間のフィードバックを評価して、その説明が人間にとって関係あるかどうか判断する方法が一番ええアプローチやな。
認知負荷は、Nautaら(2022)が調査した**コンパクトさ**でも評価できるで。コンパクトな説明っていうのは、サイズが小さい(情報のバイト数が少ない)とか、スパース(一番大事な情報だけ含んでる)ってことや。コンパクトさの測り方は、使ってるモデルとかデータの種類によって変わるねん。例えば、説明に含まれる特徴の数、決定木の経路の長さ、完全なデータと比べてどんだけサイズが減ったかとかで測れるわ。あと、説明の**冗長性**も計算できて、説明の各部分がどんだけ被ってるか評価して、それを最小化できるんや。
これらの指標で説明を数値化するだけやなくて、**一方向**か**双方向**かで分類もできるで。一方向の場合は、システムがユーザーに説明を出すだけや。双方向の場合は、ユーザーがフィードバックしたり追加の質問したりできて、それでモデルの精度が上がったり、システムが更新された説明を生成できたりするねん(Smith-Renner et al., 2020)。双方向のほうがより深くてインタラクティブな説明プロセスになるけど、このアプローチはまだ発展途上でな、技術的な実装とか適用規模の課題がまだ残ってるんや(Smith-Renner et al., 2020; Sreedharan et al., 2022)。ワイらはポジションペーパーの立場から言うてるんやけど、〇〇の段階からは双方向の説明を使うことをお勧めするで。
---
## Page 14
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p014.png)
### 和訳
Retzlaffさんらの話やねんけど、
エージェントの学習をさらに進めていくって話やな。ただ、双方向の説明(つまり、AIが人間に説明するだけやなくて、人間からのフィードバックも受け取るってこと)を実装するんは、技術的にめっちゃ複雑になるから、いつでもできるわけやないし、現実的やない場合もあるねん。
Glanoisさんらが2021年に出した説明可能性の大まかな分類の後、ここからの2つの段落では、学習した方策(ポリシー)によってパラメータ化されたモデルの意思決定を説明するアプローチに注目していくで。方策ってのはモデルの意思決定を決めるもんやから、Glanoisさんらの分類でいうところの「説明可能な意思決定」ってカテゴリに入るねん。方策の要約(ポリシー・サマライゼーション)では、一般的に、その裏にあるモデルと方策を分かりやすく見える化することが目的やねん。これを達成する方法としては、Liuさんらが2018年に出した線形モデルのU木みたいに、意思決定プロセスをルールとして書き出すやり方とか、Vermaさんらが2018年にやったみたいに、学習したモデルを生成されたコードブロックで表現するやり方があるねん。
モデルの意思決定を学習した方策で説明する2つ目のアプローチは、方策のクエリング(問い合わせ)やねん。方策クエリングでは、ある結果に至った意思決定プロセスを説明するねん。これは「どういうときにXをするの?」みたいな一般的なもんもあれば、特定のアクションに対する具体的なもんもあるで。具体的な説明の例としては、機械学習の分野での分類に対する自然言語での説明(Alonsoさんら、2018年)とか、エージェントの行動を説明するために「どういうときにXをするの?」タイプの質問の要約を自然言語で生成するやつ(HayesとShahさん、2017年)があるねん。
説明可能性アプローチの最後のサブセクションと同じように、因果モデルは説明可能性に対して根本的に違うアプローチを提供してくれるねん。この枠組みで使える手法は、だいたい「説明可能な遷移モデルと報酬モデル」と「意思決定」のカテゴリに分かれるねん。どっちもタスク、環境、または方策そのものに対する因果的な説明を提供してくれるで。
因果的アプローチの一つがグラフニューラルネットワーク(GNN)やねん(VuとThaiさん、2020年)。これは、予測に対して因果的に責任のある重要なグラフ要素(ノードとかエッジとか)を特定する確率的グラフィカルモデル(PGM)を使って、予測の説明を生成できるねん。同じような考え方で、Madumalさんら(2020b)は、因果モデルをアクション影響グラフを使ってエンコードして、因果連鎖を使って説明を生成してるねん。この因果的説明を加えると、ベースラインの説明モデルと比べて、より良い説明ができるだけやなくて、予測性能も向上するねん。
一方で、因果的模倣学習ってのを使うと、人間が行った方策から構造的因果モデル(SCM)を学習できるねん(Pearlさんら、2000年)。これは、実際の報酬が指定されてなくて、学習者と人間のエキスパートのデモンストレーターが環境を同じように認識してない場合でもできるねん。動的SCMは、エージェントが認識する部分観測マルコフ決定過程(POMDP)(SuttonとBartoさん、2018年)を形式化して、人間の介入とその影響を考慮に入れるために組み込まれてるねん。いわゆる反事実エージェントってやつは、人間のアドバイスを盲目的に受け取って実行するんやなくて、他の可能なアクションと比較して、それに応じて決定するねん。報酬関数と遷移関数が同じ場合は、指示が最適やなくても、人間のフィードバックは有益やねん。反事実的説明ってのは特に強力な説明アプローチやねん。なんでかっていうと、人間は対比的な説明を好むっていう事実を活用してるからやねん(もっと詳しい議論はMillerさん、2019aを見てな)。
**2.2 強化学習におけるインタラクティブ学習**
自然界での学習の基本的な方法の一つは、親が子供にインタラクティブに教えることやねん。同じような学習のダイナミクスは、先生と生徒の間にもあって、先生が
372
---
## Page 15
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p015.png)
### 和訳
人間参加型の強化学習
学生を自分の経験と知識で導いていく先生みたいな感じやねん。同じ考え方で、インタラクティブ学習(Arzate Cruz & Igarashi, 2020a)っていう強化学習は、人間を先生として参加させて、その専門知識とか豊富な人生経験を使ってAIエージェントを導こうとするもんなんや。
人間がおらんでも、強化学習はほんまに色んな現実の問題解決に使われてきてん。薬の発見(Popova et al., 2018)とか、成層圏の高気圧バルーンのナビゲーション(Bellemare et al., 2020)とか、ロボットに物を操作させるタスク(Nguyen & La, 2019)とかな。
これらはめっちゃワクワクする研究分野やねんけど、最近の深層強化学習システムはまだまだ課題が山積みなんや。サンプル効率の悪さとか、シミュレーションから現実への移行問題とか、汎化の問題とか、探索と活用のトレードオフとか、まあ色々あるねん(詳しくは2.3節見てな)(Ibarz et al., 2021)。こういう課題に対して、インタラクティブ強化学習は人間を巻き込むことで乗り越えようとしてんねん。学習の前に人間が関わる場合(Guo et al., 2022)、学習中に関わる場合(Knox & Stone, 2008)、あとは強化学習システムを実際に動かす段階で関わる場合(Guo et al., 2021)があるんや。で、やり取りの始め方も、先生側から始める場合(Torrey & Taylor, 2013)、生徒側から始める場合(Da Silva et al., 2020; Mandel et al., 2017)、両方から始める場合(Amir et al., 2016)があんねん。
インタラクティブ学習では、人間は先生として位置づけられることが多くて、教える過程には色んな種類の批評とかアドバイスの方法とかガイダンスが含まれてて、それが強化学習アルゴリズムにフィードバックされるんや。人間のアドバイスの形式も色々あって、二値の評価フィードバック[+1/-1](Knox & Stone, 2008)、行動アドバイス(Torrey & Taylor, 2013)、好み・選好ベースのフィードバック(Christiano et al., 2017; Lee et al., 2021)、サブゴールの指定(Le et al., 2018)とかな。深層強化学習における人間のガイダンスの種類については、Zhang et al.(2019b)に包括的なサーベイがあるで。Thomaz and Breazeal(2006)はインタラクティブ強化学習の最初期の研究の一つを提案してて、人間のトレーナーがエージェントの行動とかタスクに関連する特定のオブジェクトに対して二値フィードバックを与えられるようにしたんや。
報酬関数をいじる一般的なアプローチに「報酬シェイピング」っていうのがあんねん。報酬シェイピングでは、先生が有用な情報を提供して報酬関数を形作り、状態空間のええ部分を促進して、あかん部分にはペナルティを与えるんや(Ng et al., 1999)。報酬シェイピングは報酬がめっちゃまばらな環境で役立つし、複雑なドメインでの報酬設定を楽にしてくれるねん。TAMER(Knox & Stone, 2008; Knox et al., 2013)は有名な報酬シェイピングのフレームワークで、人間の専門家がエージェントの行動を観察しながら評価的な強化信号(ポジティブかネガティブなフィードバック)を与えて、エージェントは分類を使って人間のフィードバックを最大化しようとするんや。この手法の後続バリエーション(Knox & Stone, 2010, 2012)では、人間の強化信号と環境の報酬関数を最適化して報酬モデルを学習するようになったんや。
エージェントの方策そのものをいじる手法は「方策シェイピング」って呼ばれてんねん(Cederborg et al., 2015; Griffith et al., 2013; Wu et al., 2021a)。これらの手法は人間の知識を使ってエージェントの方策を直接補強するんや。この技術はちゃんと定式化された報酬関数は必要ないんやけど、トレーナーがエージェントを導くためのほぼ最適な方策を知っていることが前提になるねん。人間のアドバイスは探索フェーズでエージェントを導くのにも役立って、より少ない環境とのやり取りで高報酬の状態や軌道を見つけられるようになるんや(Amir et al., 2016)。行動の枝刈りも、人間参加型強化学習が探索を導いて学習を改善するもう一つの方法やで(Abel et al., 2017)。
最後に、人間のアドバイスに基づく価値関数をエージェントの価値関数と組み合わせることで、効果的にエージェントを導くことができるんや(Jiang et al., 2021; Kartoun et al., 2010; Taylor et al., 2011; Wu et al., 2021a)。人間のデモンストレーションも、専門家が取った行動に従って価値関数にバイアスをかけることで、価値関数を高めることができんねん(Hester et al., 2018; Nair et al., 2018;
---
## Page 16
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p016.png)
### 和訳
Retzlaff et al.
Vecerikら(2017年)の研究やねんけど、これらのアプローチは押したりスライドさせたりっていう複雑なロボット作業でめっちゃうまくいってんねん。こういうのって人間やったら簡単にお手本見せられるやんか。ただな、デモンストレーションってデフォルトで人間のバイアス(偏り)が入っちゃうことがあんねん。でもそれは専門家が後から取り除けるで(Wangら、2022年)。
人間が介入せなあかんサインの一番目は、モデルの性能がアカンときやな。なんでかっていうと、ダメなモデルは最適じゃない方策を出しやすいからやねん。けどな、ええモデルでも実際に使う場面では最適じゃない方策になることがあんねん。これ「sim-to-realギャップ」って言うねんけど、要はシミュレーションで学んだ行動を現実世界に持っていくときのズレのことや(Zagalら、2004年)。開発段階では、疑似エージェントを使って人間の介入をシミュレートすることが多いねん。このやり方やと、実際に使う前にモデルの良いとこも悪いとこも評価できるわけやな。あと、インタラクティブなフレームワークを設計する人は、人間の介入が必ずしも完璧とか有益とは限らへんってことも考えなあかんねん。ユーザーには特別なトレーニングとか、わかりやすいUI(ユーザーインターフェース)が必要かもしれへんで、RLアルゴリズムをちゃんと改善するためにはな。
ほんでな、UIのタイプ(ハードウェア駆動か自然なやりとりか)によって、必要な専門知識のレベルが変わるし、フィードバックの質にも影響すんねん(Linら、2020年)。キーボードのキー、スライダー付きのマウスクリック、ゲームコントローラーとかがハードウェア系のインタラクションのUIの例で、こういうのは専門家とか詳しいトレーナーが使うことが多いねん。一方で、可聴化とか音響化っていう技術を使った音声インターフェース(Hermannら、2011年; Kartounら、2010年; Sarantiら、2009年; Scurtoら、2021年)とか、顔の表情を撮るカメラ(Arakawaら、2018年)とかは自然なインタラクションのUIの例で、専門家じゃないユーザーはこっちの方を好むねん。
2.3 強化学習とHITLアプリケーションの課題
背景セクションの締めくくりとして、強化学習全般の根本的な課題と、HITLアプローチに特有の課題について話すわな。この分野の基本的な課題と今の課題をちゃんと理解するためにな。
強化学習の一番目の根本的な課題は「探索と活用のトレードオフ」やねん。これはな、今の選択肢を使い続けるか、新しい選択肢を探しにいくかっていう判断のことや。意思決定者は、最良のものを見つけるために未知の選択肢を調べる「探索」と、すでに見つけた最良の選択肢を使う「活用」のバランスを取らなあかんねん。この問題についてもっと詳しく知りたかったらAudibertら(2009年)を見てな。
二番目の重要な課題は「sim-to-realギャップ」やねん。これはシミュレーションが常にターゲットシステム(つまり現実世界)を完全にはモデル化できへんことから生じるもんやねん。現実のいろんな側面が抜け落ちとるわけや。そうするとエージェントは予期せぬ問題に直面して、最悪の場合シミュレーションで学んだ方策が現実世界に移せへんこともあんねん。でもな、現実世界でのサンプル取得はコスト、複雑さ、時間の面でめっちゃ高くつくから、課題はあってもモデリングの方が魅力的なんよな(Koberら、2013年)。
三番目の課題は、ピクセルベース学習の難しさに関することやねん。現実世界のアプリケーションでは、視覚がエージェントにとって中心的なモダリティ(感覚様式)になることが多いから、画像や動画から学習することがめっちゃ重要やねん。けど今の解決策は弱い仮定に頼っとることが多くて、その結果うまく汎化できへんねん(Tomarら、2021年)。もっと詳しくはIbarzら(2021年)を見てな。
2. 可聴化っていうのは既存の音を視覚化することで、音響化っていうのはデータや情報を表現するために音を作り出すことやねん。
374
---
## Page 17
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p017.png)
### 和訳
ほな、人間参加型の強化学習について話していくで!
まずな、強化学習の主な課題について、もうちょい詳しく見ていこか。具体的には、サンプル効率(どんだけ少ないデータで学習できるか)、シミュレーションと現実のギャップ、探索の難しさ、汎化の難しさ(新しい状況にも対応できるか)、目標と報酬の設計、それから安全性の問題やな。
で、こういう一般的な強化学習の課題に加えて、Royさんらが2021年に、ロボットみたいな「身体を持った知能」向けの強化学習特有の課題をまとめてくれてんねん。特に大事な5つの制約を紹介するわ:
- 現実世界で動くってことは、探索するときに安全上のリスクがあるし、エネルギーみたいなリソースにも限界があんねん。これめっちゃ重要やで。
- 学習したモデルが現実世界とうまく合わへん問題。シミュレーションで完璧でも、現実では全然あかんってことがよくあるんや。
- 普通のディープラーニングよりも、もっと強い汎化能力と適応力が必要やねん。なんでかっていうと、仕様とか目標とか報酬がコロコロ変わる可能性があるからや。
- 観測できるデータって今いる場所の局所的な分布からしか取れへんねんけど、汎化するためには今見てるもの以上の「世界モデル」を学習せなあかんのや。これがほんまに難しいところやな。
- エージェントの体の形(モルフォロジー)によって、環境から何を学べるかが決まってまうから、エージェント設計するときにちゃんと考えなあかんねん。
最後に、人間参加型(HITL)アプローチ特有の課題もあるで。まず最初の課題は、「どこまで上手い人間プレイヤーを真似すべきか」「いつ、どうやって強化学習で人間を超えていくか」っていう問題やな(Abelさんら、2017年)。さらにな、人間超えるためには、HITLの強化学習エージェントが新しいアクションの組み合わせを発見せなあかんねんけど、報酬関数を細かく複雑に設計しすぎると、それが邪魔になってまうんや(Liuさん&Abbeel、2020年)。人間の介入とエージェント自身の探索能力のバランスをどう取るかっていう課題は、さっき言うた「探索と活用のトレードオフ」の延長線上にあるんやな。
Glanoisさんらが2021年に、説明可能性に関する課題も議論してくれてんねん。HITLと説明可能性はめっちゃ密接に関係してるから、HITLの課題を考えるときに説明可能性の課題も含めとくで。Glanoisさんらが言うには、ニューラルネットワークがまだちゃんと学習し終わってないときは、説明が信頼できひんし、意味をなさへんねん。なんでかっていうと、ネットワークがまだ一貫した動きをしてへんから、説明しようがないんや。これは、学習不足、全体的なパフォーマンスの悪さ、汎化能力の欠如、間違った分類例、その他のエラーが原因になりうるで。やから、機械学習の専門家は、開発のどの時点で色んな説明手法を適用するのが適切で、モデルの理解に役立つかをちゃんと考えなあかんねん。Glanoisさんらはさらに、スケーラビリティ、パフォーマンス、強化学習のxAI(説明可能AI)手法で完全な解釈可能性を達成することを、未解決の課題として挙げてるわ。
説明可能性のもう一つの課題は、今あるほとんどのxAI手法がディープニューラルネットワーク向けに作られてて、強化学習の原理を念頭に置いて作られてへんってことやな。これらはニューラルネットワークの数学的原理に基づいてて、普通は「もっとシンプルで解釈可能なモデルを見つけ出す」か「入力のどの要素が重要かを特定する」ことを目的に開発されてんねん。例えば、Atariのゲーム画像を処理するのに使われた畳み込みニューラルネットワーク(CNN)の場合(Mnihさんら、2013年)、レイヤーごとの関連性伝播(LRP)っていう手法が使えるんや(Alberさんら、2019年;Bachさんら、2015年)。でもな、これやとユーザーには「ポジティブな予測かネガティブな予測かに対して、どこが重要か」っていうヒートマップしか提供できへんのや。つまり...
---
## Page 18
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p018.png)
### 和訳
Retzlaffらの話やねんけどな、
ヒートマップって強化学習(RL)で言うたら、ある一つの入力状態しか表現できへんねん。そのヒートマップは、その状態から取れるアクションとか、全体としての期待報酬と並べて見比べたり組み合わせたりできひんのよ。せやから人間からしたら、なんでRLアルゴリズムがそのアクションを選んだんか全然わからへんねん。モデルの戦略全体、つまりルールとか、全部の(少なくとも代表的な)状態-アクションのペアの背後にある目的をヒートマップだけから再構築するのは、めっちゃめんどくさい作業になるわけよ。
俺らが言いたいのは、ここで議論した課題を見たら、汎用的で性能の高いRLってのは根本的にムズい問題やってことやねん。これらの課題の多くは、HITL(Human-In-The-Loop:人間参加型)アプローチを使うことで乗り越えられるって主張してんねん。これはMathewsonとPilarski(2022)も支持してて、人間中心のインタラクティブなアプローチは機械学習システムの設計とデプロイに不可欠やって言うてはるわ。ただ、MathewsonとPilarski(2022)は機械学習システム全体を俯瞰して、人間中心設計のハイレベルなガイドラインを示してるんやけど、俺らはもっと絞って、インタラクティブなHITL RLシステムの設計・評価・デプロイと、それに関連する短期・長期の課題に特化して話してるねん。
この論文の二つ目の焦点として、説明可能AI(xAI)のアプローチがHITLアプローチの成功に不可欠やって主張してんねん。これは他の研究者(Heuillet et al., 2021; Milani et al., 2022)も支持してることやで。せやから、俺らが上で示した4つのデプロイフェーズそれぞれで、xAIが中心的な役割を果たすんや。これからのセクションでは、HITL RLエージェントのデプロイのどこでxAIが適用できるか、どんな解決策があるか、生産的なHITLインタラクションを可能にするためにどう適応させられるかを示していくで。さらに、各フェーズでの説明可能性がRLアプリケーションの安全性にどう影響するか、それがひいては信頼性とアカウンタビリティ(説明責任)の構築にどう役立つかも議論するわ。
このセクションは説明可能性、インタラクティブ学習、HITL RLの課題についての背景をまとめたもんやねん。次のセクションからは4つのデプロイフェーズに踏み込んでいくで。まずセクション3で、HITL RL開発の初期フェーズにxAI技術がどう適用できるか議論するわ。セクション4ではエージェントの学習フェーズに焦点当てて、その後セクション5と6でこれらのシステムの評価とデプロイについて議論するねん。
3. 初期エージェント開発
HITL RLモデルデプロイの最初のステップは、基盤となるモデル開発、問題の定式化、学習前の検討事項やねん。これらのステップで、自分のモデルの詳細を知りたい機械学習(ML)の専門家がモデルを理解できるようになるんや。開発フェーズの特徴は、MLの専門家が技術的な土台を作ることやねん。このフェーズでは、RLモデル自体に焦点が当たってるわけよ。
RLエージェント開発の全フェーズを通じて、3種類のユーザーを区別してんねん:機械学習の専門家、ドメインエキスパート、エンドユーザーや。MLの専門家、開発者とも呼ばれるんやけど、これはMLソリューションの開発と解釈に専門知識を持ってる人やねん。ドメインエキスパートは、AIソリューションが適用される分野での経験と権限を持ってるけど、AIモデルを完全に理解するための技術的バックグラウンドは持ってへん人やな。最後に、エンドユーザーは市場で入手可能な製品を購入して使う顧客を指してるねん。エンドユーザーはその分野のバックグラウンドは持ってるけど、与えられたポリシー(方策)が正しくて適切かどうかを判断する専門知識は持ってへんのや。
376
---
## Page 19
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p019.png)
### 和訳
人間が関わる強化学習の話
MLの専門家がな、エージェント(これが学習するやつやねん)に解かせたい問題を決めて、それに合った環境を選ぶわけや。そのために「マルコフ決定過程」っていうのを作るんやけど、これは要するに「今どんな状態か」「何ができるか」「どうしたらご褒美もらえるか」っていうルールを決めることやねん。この3つがめっちゃ大事で、学習の速さとか、最終的にどれくらい賢くなるかとか、どんな行動パターンを覚えるかに関わってくるんや。ほかにも専門家は、どのアルゴリズム使うか、ハイパーパラメータ(学習の微調整に使う設定値みたいなもん)をどうするか決めなあかんし、手作業で特徴量入れたり、既存のモデルから知識引き継いだりして、事前知識を活用するかどうかも考えなあかんねん。あと、すでにあるデータで事前学習させるかどうかも検討するんやで。
エージェント開発の初期段階でな、「説明可能性」っていうのがめっちゃ役立つんや。なんでかっていうと、アルゴリズムやハイパーパラメータの選び方がどう影響するか、事前知識がエージェントにどんなバイアス(偏り)を与えるか、事前学習が学習プロセスをどう変えるか、これらがわかるからやねん。この段階で説明可能性を意識しとくと、最初から正しい方向に進めるし、後になってから「やべ、直さなあかん」って高くつく修正をせんで済むんや。この段階で決めることは、強化学習のライフサイクル全体にでっかい影響を与えるし、後から変えるのがほんまに難しいねん。表4に、エージェント開発初期段階の重要ポイントをまとめてあるで。
| フェーズ | 人間の関わり | 説明に求められること | 説明可能性 | 目標 | 評価指標 |
|---------|------------|-------------------|-----------|------|---------|
| 開発 | ・問題を定義する<br>・状態空間、行動空間、報酬関数を作る<br>・モデルを設計する | ・他のモデルバージョンと比較できること<br>・ざっくり確認用にシンプルで速い説明<br>・じっくり調べる用に複雑で網羅的な説明 | **注力点:**<br>決定木とか因果モデルとか、構成的な言語みたいな解釈しやすいモデル<br>**説明の種類:**<br>反実仮想(「もしこうだったら」)、ポリシーへの問いかけ、決定ルール<br>**使う人:**<br>強化学習の専門家 | ・徹底的で比較可能なモデルの要約を作る<br>・構成的で表現しやすい言語を使う<br>・因果学習を人間参加型のアプローチにさらに統合する | **忠実度**<br>・正確さ(制御された合成データや単一特徴削除での出力の相関)<br>・説明可能モデルの不一致度(モデル予測間の誤差) |
表4:エージェント開発初期段階における、人間の関わり方の種類、説明に求められる具体的な要件、注力点、説明可能性のアプローチの種類をまとめたで。さらに、この段階での目標と、それを定量化するための評価指標やオプションも載せてるで。
ほんでな、めっちゃ大事なことを強調しときたいんやけど、開発者がモデルを理解できるようにすることがすごく重要やねん。自分で作ったモデルで基本的な仕組みはわかってても、やで。まず、説明可能性があると、モデルの裏にある仕組みとか、どうやって判断してるかを研究者が理解できるから、デバッグ(バグ取り)とか、問題点や改善点の発見に役立つんや。さらに、新しいモデルや手法を開発するのにも役立つねん。モデルがどう動いてるかわかれば、それを改良したり、能力を拡張した新しいモデルを作りやすくなるからな。
エージェント開発の段階で、理解しやすいモデルを使って作業すると、モデルが妥当な前提に基づいてて、一貫した結論を出せることを確認しやすいねん。訓練データのエラーとか、モデルの初期化ミスとか、最初の学習プロセスの問題とか、この段階で監視して抑えられるんや。この段階でモデルの適切な機能とアーキテクチャ(構造)を設計しとくと、学習済みモデルと比較するためのちゃんとしたベースラインができるんやで。
このエージェント開発段階は、インタラクティブ性(双方向のやりとり)が必須じゃない唯一の段階やと思ってるわ。専門家を巻き込むときには、双方向でインタラクティブな説明がほんまに大事になるんやけどな。
---
## Page 20
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p020.png)
### 和訳
よっしゃ、ほんなら翻訳していくで!
---
Retzlaffさんたちの研究やねんけど、
開発プロセスにエンドユーザーを巻き込むのは大事やねんけど、この最初の開発段階では、もっとシンプルな説明可能AI(xAI)の方法を使う方がええねん。なんでかっていうと、手間が少なくて済むからやで。
この段階では、主に「探索と活用のトレードオフ」と「シミュレーションと現実のギャップ」っていう課題が関係してくるねん(2.3節を見てな)。これらが学習アルゴリズムとかパラメータの選び方を制限してきて、その結果どんなタイプの説明がそのモデルに使えるかが決まってくるわけや。
森林作業の事例で言うとな、この段階で気づかんうちに根本的なエラーを入れてしまうリスクがめっちゃあるねん。例えば、報酬関数の設定を間違えてしまうと、エージェントが基本的なナビゲーションすらできひんようになる可能性があるんや。報酬関数っていうのはエージェントの行動を決める一番大事な土台やから、これをミスるとエージェント開発全体の進捗がガタガタになってまうねん。このフェーズの議論セクション(3.5節参照)で、説明可能性と「人間参加型」アプローチを使ってそういうリスクを最小限にする方法について話してるで。
3.1 要件
開発フェーズでの主な考慮事項を提案して、説明可能な開発プロセスのための2つのアプローチを特定したで。1つ目は、モデルの全体的な振る舞いをパパッと表面的に評価する方法で、モデルの動きを高いレベルでチェックできるねん。2つ目は、もっと詳しくて複雑な視点を提供する深掘り評価やで。
1つ目のケースでは、トレーニング中にフィードバックループを回せるように、説明を素早く計算せなあかんねん。Xinさんたちの2018年の研究では、フィードバックループが速くなるとどうなるかを調べてて、内省(自分のモデルの中身を素早く分析して、変更の影響を比較したり、途中の結果を再利用したりできること)みたいな側面を強調してるねん。フィードバックループが速いと、機械学習の専門家がエンドツーエンドの最適化をやりやすくなるってことも分かってるで。やから、Milaniさんたちの2022年の評価指標を使って、計算パフォーマンスを高くすることと、頭使う負担を減らすことを求めて、説明の幅を広げることを提案してるねん。
2つ目の深掘り評価のケースでは、説明を計算して、理解して、正しく解釈するのにもっと時間がかかるねん。やから、機械学習の専門家はこういう説明を使って、モデルのスナップショットを少数だけ深く分析できるわけや。これで複雑なモデルの振る舞いをもっとよく理解できるようになるねん。両方のアプローチはお互いを補完し合うべきやで。なんでかっていうと、モデルの振る舞いをちゃんと評価するには、深さと幅の両方が必要やからな。
エージェント開発の初期段階では、生成された説明が他のモデルバージョンのものと比較できるようにせなあかんねん。これは、異なる振る舞いとその説明を対比させて、開発の進捗を追跡するために必須やで。研究者がモデルの振る舞いがどう進化していくかを監視して、開発が望んでる方向に進んでるかどうかを評価できるようにするために、これがめっちゃ大事なんや。
複雑で詳細な説明は機械学習の専門家に一番向いてるねん。なんでかっていうと、モデルについての詳しい洞察が必要やし、それに必要な認知的負荷を引き受けられるからや。さらに、この段階では計算リソースの制約が一番少ないし、説明がまだ大きなモデルサイズに対応する必要もないねん。Milaniさんたちの2022年の評価指標で言うと、これらの要件は計算パフォーマンスと認知的負荷への要求は低めやけど、忠実度(モデルの実際の動きをどれだけ正確に反映してるか)は高くせなあかんってことになるねん。
378
---
## Page 21
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p021.png)
### 和訳
人間参加型強化学習
このセクションではな、このフェーズで役立つアプローチをいくつか紹介していくで。まず、事前学習っていうのがあって、これが賢い振る舞いの土台作りに効いてきて、デバッグもやりやすくなるねん。次に、解釈可能性のアプローチもこのフェーズで考えとくべきやな。最初から理解しやすい設計にしとくと、その後のフェーズ全部でめっちゃ恩恵があるんよ。ほんで、どんな種類の説明可能性アプローチがこのフェーズに向いてるかも議論していくわ。
3.2 アプローチ:事前学習
事前学習モデルっていうのは、強化学習のワークフローにめっちゃ役立つねん。なんでかっていうと、人間とロボットのやり取りの下地を整えてくれて、人間参加型のシステムにいろんな形で貢献するからや。事前学習すると、使える事前知識、多様な振る舞い、汎用的な方策やフィードバック、そして人間からの入力に対する効率的な初期フィードバックが身につくんよ(Daniel et al., 2016; Eysenbach et al., 2018; Florensa et al., 2017; Hazan et al., 2019; Lee et al., 2021)。最近やとな、Parisi et al.(2022)が、ロボット制御タスクとは全然関係ないコンピュータビジョンのデータセットで事前学習しても、下流のロボット制御にめっちゃ効くって示したんや。つまり、事前学習は専門外のデータからでも使える表現を学べるってことやねん。事前学習っていうのは、大規模なデータセットで教師なしでモデルを訓練して、一般的な言語表現を学ばせることや。この事前学習済みモデルを、転移学習で特定のタスクや領域向けに、もっと小さいデータセットでファインチューニングできるんよ(Taylor & Stone, 2009)。事前学習済みモデルが知識ベースとして機能して、一般的な言語理解を獲得しとって、ファインチューニングでその知識を目標タスクに適応させるから、効率的かつ効果的になるってわけや。
選好ベース学習っていうのは、事前学習からめっちゃ恩恵を受ける人間参加型の技術やねん。これはな、実体を持つエージェントが、2つ以上の振る舞いの選択肢(例えば、2種類の異なる動作方策とか)のうち、どっちが好みかを人間に決めてもらうやり方や。この選択によって、めんどくさい報酬設計のプロセスが簡単になる、つまり報酬関数を明示的に定義する必要がなくなるんよ。このアプローチでは、新しく作ったばっかりのモデルにありがちなガチャガチャした動きじゃなくて、ロボットが最初から2つの「意味のある」動作方策を見せてくれた方が有利やねん。最初のランダム初期化のノイズを過ぎた後やと、意味のある振る舞いを示すから、すでに学習済みのモデルの方策を判断する方が一般的に楽なんよ(Akrour et al., 2011)。Lee et al.(2021)は、内発的報酬を使った教師なし事前学習の重要性を示したんやけど、これでエージェントが多様なスキルを学んで、人間の選好を得るための有益なクエリを生成しやすくなるんや。一般的に、強化学習エージェント向けの転移学習や生涯学習みたいなアプローチは期待できるんよ。これらは強化学習のノイズだらけのウォームアップ段階の問題も軽減してくれるからな(Taylor & Stone, 2009; Yang et al., 2021)。
ChatGPTでの事前学習の応用は、大規模言語モデル(LLM)の初期化に大規模データセットを活用することの効果をほんまに見せつけたな。これによって妥当なパラメータ初期化ができて、その結果、下流タスクでの性能向上と効率的な学習が実現したんや(Zhou et al., 2023)。この成功は、事前学習が強化学習にもたらせるパラダイムシフトを示しとるわ。大量のラベルなしデータから有用な知識を獲得できるようになって、その後のファインチューニングや特定タスクからの学習のための強固な土台ができるってことやねん。
事前学習は開発段階だけやなくて、下流での性能が上がるから他の段階にも影響するんよ。学習段階では、事前学習が強化学習エージェントの初期化に役立って、収束が速くなるし、より良い
379
---
## Page 22
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p022.png)
### 和訳
Retzlaffら
サンプル効率のとこやねんけど、評価段階では事前学習のおかげでモデルの性能がめっちゃ上がるし、いろんなタスクにも対応できるようになんねん。ほんで最後のデプロイ段階では、事前学習しとくことでRLエージェントが基礎知識をバッチリ身につけとるから、現実世界のシナリオにもうまく適応できて、ちゃんと成果出せるようになるんやで(Yangら、2023)。
3.3 アプローチ:説明可能性
説明ってな、最初にRLモデル作る段階でめっちゃ役立つんよ。RLモデルにとって「ええ説明」って何やねんっていうのは、状況によって変わってくるねん。背景知識とか、説明聞く人の専門レベルとか、その人が何を求めてるかとかを考慮せなあかんわけや。説明の種類もいろいろあって、視覚的なやつ(Atreyら、2019;Guptaら、2019)、テキストベースのやつ(Fukuchiら、2017b;Hayes & Shah、2017)、因果関係を示すやつ(Madumalら、2020a、2020b)、決定木で説明するやつ(Bastaniら、2018)とかあんねん。Liuら(2018)のアプローチは、意思決定のプロセスをルールとして書き出すことで、ネットワークの影響とか学習をもっと見えるようにしてんねん。別のアプローチとしては、Vermaら(2018)が提案してるみたいに、学習したモデルをコードブロックで表現する方法もあるで。ニューラル方策ネットワークを学習して最適な方策を探索することで方策ネットワークをコード化するんやけど、これやと人間が読めるポリシーができて汎化性能も上がるんや。ただ、訓練中にパフォーマンスがちょっと落ちるっていうデメリットもあんねん。3つ目のアプローチは、ネットワークの方策を自然言語で表現するやり方で、Alonsoら(2018)なんかは決定木が選んだ理由をテキストで説明して分類を正当化する例を見せてくれてるで。
さらにな、「いつXをするん?」みたいな質問に答えられるポリシー照会アプローチの一部は、この段階で使えるねん。Hayes and Shah(2017)はそういう質問の例を出してて、「いつXするん?」タイプの質問の要約を自然言語で生成して、エージェントの行動を説明してんねん。このアプローチで重要な追加要素が反事実(counterfactuals)の使用やねん(反事実の重要性についてもっと詳しく知りたかったらEvansら(2022)見てな)。Madumalら(2020b)はRLエージェント用の構造的因果モデルを生成してて、これで取った行動の説明ができるようになるねん(2.2節参照)。このアプローチのええとこは、「なんでYせんかったん?」みたいな反事実的な質問にも答えられることやねん。著者らによると、こういう反事実を提供することで満足のいく説明ができて、ユーザーの信頼も上がることが示されとるで。
最後にな、因果学習戦略は基盤となるモデルの理解を助けて、単なる解釈可能性から完全な説明可能性へと進化させてくれるねん。なんでかっていうと、モデルを理解できるようにするだけやなくて、意思決定とその文脈を積極的に説明するからやねん。そういうxAI手法の例として確率的グラフィカルモデル(PGM)があって、これは因果モデルの構築を助けてくれて、グラフニューラルネットワーク(GNN)によく適用されてるんや(Sarantiら、2019)。グラフニューラルネットワークは、最初のエージェント開発段階での説明可能性手法にめっちゃ向いてんねん。なんでかっていうと、重要なコンポーネントを直感的にわかりやすく可視化できるからや。例えばVu and Thai(2020)は、重要なグラフコンポーネントを特定してから、その予測を近似するPGMを生成することで、因果モデルの作成を情報に基づいてサポートしてんねん。これらの重要なコンポーネントは、ニューラルネットワーク内の原因と結果を特定したり、因果関係を明らかにするのに役立つんやで。
380
---
## Page 23
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p023.png)
### 和訳
人間参加型の強化学習
3.4 焦点:解釈可能性
広い意味でのHITL(人間参加型学習)において説明可能性を付け加える中心的なアプローチは、モデルを解釈可能にすること、つまり本質的に理解しやすいAIソリューションを提供することやねん。解釈可能なモデルは、事前学習済みとか何らかの方法で初期化されたシステムと組み合わせることで、機械学習の専門家がモデルとその意思決定を判断しやすくなるんや。
Royらの研究(2021年)では、モデルをもっと解釈しやすくするためのいくつかのアプローチを挙げとるで。例えば、モデルにコアとなる知識(物理的な制約とか)を埋め込むことで、エージェントに生まれつきの推論能力を持たせられるんや。この推論する能力があることで、推論プロセス全体をチェックしたりデバッグしたりできるようになるわけやな(Ha & Schmidhuber, 2018)。2つ目の側面として、Royら(2021年)は構成的言語の使用を強調してて、これによってモデルが学んだ概念を高いレベルで理解しやすくなるんや。Koditschek(2021年)によると、モデルの構成、それに伴う構成的言語の使用が、身体化された知能の重要な要素やって言うとるで。
上で挙げたアプローチに加えて、代表的な言語を使うことで、厳密な一般化を伴う抽象的な推論ができるようになるんや(Roy et al., 2021)。これはグラフニューラルネットワーク、自然言語、あるいはシステム1/システム2の分離と組み合わせた注意機構によって実現でき、学習されたモデルの本質的な理解しやすさをさらに高めるんやで。生まれつきの推論と理解可能な言語を組み合わせる利点は、モデルを直感的に理解できるようになることやねん。モデルの振る舞いを直感的に理解できることは、例えば画像認識アプローチにおける敵対的攻撃という課題に取り組むための一つの土台になるんや。多くの画像認識モデルは人間とは全然違う側面に注目してて、根本的に違うレベルで画像を「理解」しとるんやな。せやから、人間の観察者には気づかへんような変更でも、画像の分類結果がガラッと変わってまうという攻撃に弱いんや(Chakraborty et al., 2021)。モデルが人間と同じやり方で画像を「理解」することを確保することで、この攻撃されやすい部分を減らせるっちゅうわけや。
3.5 議論、展望、およびユースケース
開発フェーズにおける現在の課題について見てみると、この設定向けに意図されたxAI(説明可能なAI)アプローチがめっちゃあるんやけど、説明のインタラクティブ性と比較可能性が不足しとって、このフェーズでモデルを徹底的に評価することの妨げになっとるんや。さらに、現在の説明可能性アプローチは、新しく開発されたモデルを徹底的に内省するために必要な因果関係と直感的な理解しやすさが欠けてることが多いんやで。
まず一つ目として、Royら(2021年)が言うとるように、説明可能性のために構成的で代表的な言語を使って、モデルの直感的な理解しやすさを高めることを提案するわ。モデルを階層的、グラフ的、あるいはトポロジー的な構造として表現すること(Battaglia et al., 2018; Lyu et al., 2019)は、従来のニューラルネットワークモデルよりも人間にとって理解しやすいんや。けど、こういう構造的モデルはニューラルネットワークモデルほど強力ちゃうねん。なんでかっていうと、表現能力と計算能力が限られとるからや。せやから、最適なアプローチは、説明可能性を失わずに構造的モデルをニューラルネットワークモデル自体と統合することやろな。
二つ目として、因果学習アプローチをHITLアプローチにもっとめっちゃ深く適応させて統合すべきやと思うわ。より良い説明を生成することに加えて、
381
---
## Page 24
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p024.png)
### 和訳
Retzlaffさんらの話やけど、
これな、予測性能もぐーんと良くなる可能性あるんよ。Madumalさんらが2020年に見せてくれた例がまさにそれやねん。
3つ目の話やけど、HayesとShahが2017年に発表した「ポリシー問い合わせ」っていうアプローチがあるんよ。これをちょっと改造したら、モデルの構造に対して「これどうなっとんの?」って具体的に質問できるようになるし、さらに「もしこうやったらどうなってた?」っていう反事実的な仕組みも追加できるんやって。最終的にはな、対話的で徹底的で、しかも比較しやすいモデルの要約を作りたいんよ。個々のパーツはもう存在してるんやけど、それを全部まとめたシンプルな解決策があったら、開発プロセスがめっちゃ捗るはずやねん。Royさんら(2021年)が言うてはるんやけど、他の種類のセンサーとか、センサーを組み合わせる技術とか、新しい部品が使えるようになったら、新しいインタラクションの方法とか、使える分野とか、学習のやり方とか、めっちゃ可能性広がるで、って(2.3節でその辺の課題について触れてるから見てみてな)。もう一つの方向性としては、人間が教える(Kulickさんら、2013年)とか、プログラムを使う(PenkovとRamamoorthy、2019年; Sunさんら、2019年)ことでAIエージェントがタスクの記号的な構造とか表現を学ぶのを手助けするっていうのがあって、これやるとタスクの複雑さがめっちゃ減るんよ。
森でロボット動かす例で言うとな、物理的な性質に関する基本知識があると、エージェントと環境のモデルがもっとしっかりしたもんになるんよ(HaとSchmidhuber、2018年)。モデルのポリシーは、例えばコードブロックで表現してテストできるんや(Vermaさんら、2018年)。なんでコードブロック使うかっていうと、この段階ではモデル開発者がメインやから、開発者の言葉で話そうってことやねん。モデルのデバッグをもっとええ感じにするためには、開発者がモデルのポリシーに質問できるようにして、「なんでロボット止まったん?」とか「何を障害物やと思ったん?」とか調べられるようにするとええねん(HayesとShah、2017年)。あとな、環境を興味のあるポイントを含んだグラフとして表現したら、開発者がエージェントが景色をどう認識してるか理解しやすくなるし(Lyuさんら、2019年)、その理解が現実の状況とちゃんと合ってるか確認できるんよ。
ここで強調しときたいんやけど、説明可能性っていうのは、エージェント開発の初期段階でモデルのエラーを見つけるためのめっちゃ大事なツールやねん。けどな、説明可能性だけで全部のエラーが見つかるわけちゃうねん。おすすめなのは、その分野の専門家とML(機械学習)のスペシャリストを連携させて、性能指標とか他の指標も見ながら、報酬関数が目指してるゴールとちゃんと合ってるか確認することやな。説明可能性はこのプロセスで価値あるツールになるんよ。なんでかっていうと、専門家とエージェントがHITL(Human-in-the-Loop:人間参加型)プロセスで協力するのを助けてくれて、エージェントがどこで間違った判断してるか教えてくれて、報酬関数がどういう影響持つか理解を深めるヒントをくれるからやねん(詳しくは5章見てな)。
**3.6 初期エージェント開発のまとめ**
開発フェーズをまとめると、表1を見てもらったらええんやけどな。モデルの説明は互いに比較できるようにしとくべきで、そうしたらユーザーがテストしたアーキテクチャ間の違いを理解できるようになるんよ。説明は、聞く人の認知リソースと目的に合わせて、広く浅くするか、詳しく複雑にするか、ちゃんと考えて設計せなあかんねん。この段階で人間が関わるのは、問題の定義、全体的なモデル設計、状態空間・行動空間・報酬関数の仕様決め、それからエージェントの評価指標を決めるところやな。
おすすめは、転移学習みたいな事前学習アプローチと、選好ベース学習を組み合わせて、人間の知識を効果的に活用することやで。この段階でのHITLに使えるxAI(説明可能AI)のアプローチは、基礎となるモデルをもっと理解しやす
382
---
## Page 25
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p025.png)
### 和訳
よっしゃ聞いてや!人間参加型の強化学習についてな。
まずモデルをわかりやすくする方法があんねん。例えば、モデルの方針を木構造とか因果モデルとか、組み合わせた言葉で表現して、人間が見てもパッと理解できるようにするんや。あと「後付け説明」っていうのもあってな、「もしこうやったらどうなってた?」みたいな反事実的な説明とか、ルールを抽出する方法とかで、この初期段階でも色々わかるようになるんやで。因果関係を見つけるアプローチも、この段階で原因と結果を特定するのにめっちゃ役立つし、後の段階でも使えるから考えとくべきやな。
ここまでが開発フェーズの話やったけど、HITL RLシステムを作る4つのフェーズのうちの最初のやつやねん。次は、エージェントを対話的に訓練するフェーズについて話すで。
## 4. エージェントの学習
開発が終わったら、エージェントの訓練や。自動でやるか、人間の助けを借りて対話的にやるかのどっちかやな。第3章では主に開発フェーズで使う説明技術について、開発者がガッツリ監督する前提で話したやろ。この章では、人間がトレーナーとか先生役(専門家として)になって、エージェントの学習をガイドするアプローチに焦点当てるで。
このフェーズでは、現場の専門家と対話しながらモデルを訓練するんやけど、機械学習の専門家もちゃんと見守ってる状態やな。ここで大事なのは、モデルが世界をどう認識してるかとか基本的なことを理解することと、エージェントがエンドユーザーとうまく協力できるかを評価することや。人間は「その行動はアカン」「それは微妙やで」ってエージェントに選ばせないようにもできるし、専門家のバイアスを加えて学習スピードを上げることもできるんや。さらに開発者は、人間のお手本を見せたり、フィードバックしたり、アドバイスしたり、その他いろんな協力方法を取り入れるかどうか決められるねん。
最終的には、現場の専門家が「学習うまいこといってるな」って判断するか、「MDP(とかエージェントの他の部品)を見直さなアカンな」って判断するかやな。見直しが必要になるのは、学習がめっちゃ遅いときとか、学習してる方針がその問題に合ってへんときとかや。最適な対話の仕組みを作るには、まずHITLがどういう役割を担うべきか見極めることが第一歩やで。ここで提案したいのは、この教える過程で人間に分かりやすい情報と明確な説明を提供して、お互いの間に透明性を持たせることに注力すべきやってことや。そうすれば、人間のトレーナーはエージェントが世界をどう見てるか理解できて、もっとええフィードバックができるようになるんや。説明可能性によって、既存のコントローラーや人間のアドバイスからくるバイアスの影響とか、学習がどこまで進んでるかとか、今の方針がどう機能してるかとかが見えるようになるねん。
第2.3節で挙げた課題の中で、このフェーズに関係あるのはこれらやな:(1) エージェントが人間のアドバイスにどこまで従うべきか、(2) 報酬シェーピングの最適化、(3) 先生の知識や専門性に合わせた説明方法と複雑さの選び方、(4) シミュレーションと現実のギャップを縮めること。表5にエージェント学習フェーズの重要なポイントをまとめてあるで。
森林作業のユースケースでいうとな、ここからは技術に詳しくない専門家とも関わり始めるねん。このフェーズでは、経験の浅いオペレーターとコミュニケーション取って対話するから、エージェントの汎化能力が試される想定外のシナリオが出てくるかもしれんな。あと、エージェントが環境と相互作用するときのリスクも考えなアカン。知らん障害物をよけたり、不安定な地面を進んだりすることも含めてな。せやから、このフェーズでは徹底的にテストして検証することがめっちゃ大事やねん。現場でちゃんと動けるようにするためにな。
---
## Page 26
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p026.png)
### 和訳
Retzlaffさんたちの研究やねんけど。
**フェーズ**
**人間の関わり方**
**説明に求められること**
**わかりやすさの目標**
**測る基準**
| 行動・評価的なやつ | •フィードバックあげる •アドバイスする •行動の好み選ぶ •お手本見せる |
|---|---|
**学習中のエージェント**
| •その分野の専門家がわかるように •スムーズなやり取りができるように | **注目ポイント:** 人間が一緒に学習に参加する(HITL)やり方、例えば人間の好みを聞いたり、よくわからんとこを目立たせたりするやつやな **説明の仕方:** 「もしこうやったらどうなる?」っていう反実仮想、言葉での説明、ユーザー向けの重要なとこマップで見せるやつ **使う人:** その分野の専門家、強化学習の専門家 | •好み学習とか真似っこ学習を補い合うように使う •わかりやすくする技術をHITLに合わせる •「人間が先生」っていう考え方を使う •いろんな種類の人間との関わり方をうまいこと組み合わせた方法見つける | **忠実さ** **関連性** •人間からのフィードバック(タスクに関係あるかどうかユーザーに評価してもらう) **パフォーマンス** •説明するまでの時間(ミリ秒単位で測るで) |
|---|---|---|---|
**表5:** エージェントの学習フェーズにおける、人間の関わり方の種類、説明に必要なこと、わかりやすさのアプローチの焦点と種類、目標、あと測る基準をまとめたやつやで。
## 4.1 必要なこと
このフェーズはな、初心者のユーザーが初めて強化学習エージェントとやり取りするかもしれん段階やねん。せやから、説明をあんまり複雑にせんようにせなあかんねん。あと、スムーズにやり取りするためには、パパッと説明できることも大事やねん。ほんまにインタラクティブなトレーニングをするためにな。記号で問題の構造を表したり、エージェントが何を見てるか可視化したりっていう、わかりやすいインプットがええねん。なんでかっていうと、エージェントが何を認識して、何を基準に判断してるかがすぐわかるからやな(Glanoisさんたち、2021年)。でもな、パパッとわかる分、深いとこまでは見れへんのよ。その辺は開発フェーズと評価フェーズでしっかりテストすることでカバーするねん。モデルの根本的なエラーは開発フェーズで考慮して、トレーニング中に入り込む隠れたバイアスは評価フェーズで注目するっちゅうことやな。
ここで強調したいんやけど、人間の先生による説明がちょっと完璧じゃなくても、何もないよりはマシやねん。今の研究では、学習フェーズで人間のアドバイスを使うエージェントに注目してて、人間が最初から持ってる知識を活用するんやな。でもな、人間の判断がちょっと的外れやったとしても、ZhangさんとBareinboimさん(2020年)の研究によると、人間のアドバイスを無視したエージェントの方が、うまくない方策を学んでまう可能性が高いんやて。Milaniさんたち(2022年)の基準を参考にすると、モデルがちゃんと学習できて、ユーザーとうまくやり取りできるように、**高い忠実さ**、**関連性**、**パフォーマンス**が必要やと提案するで。
## 4.2 アプローチ:わかりやすさ
2.2節で言うたように、インタラクティブ強化学習は人間のフィードバックを使って、サンプル効率(データをどれだけ効率よく使えるか)とか、シミュレーションから現実への移行の問題とか、汎化(新しい状況にも対応できるか)とかの課題を減らすんやな。どんなやり取りでもそうやけど、インタラクティブ強化学習には、エージェントと人間がお互いをある程度理解せなあかんねん。コミュニケーションを良くする効果的な方法のひとつは、自分や相手の行動を説明することやねん(De GraafさんとMalleさん、2017年)。せやから、最近はインタラクティブ強化学習にわかりやすくする技術を組み合わせるアプローチがめっちゃ増えてきてるねん。例えば、研究者によると、AIエージェントをトレーニングしてる人のほとんどは、自分の行動が自分の知識を表してるって思い込んでるんやて(Habibianさんたち、2021年)。
---
## Page 27
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p027.png)
### 和訳
人間参加型の強化学習
福地らのチーム(2017b)がおもろいこと考えてん。AIエージェントが「これからこうするで〜」って自分の行動を説明する時に、トレーナーさんが使ってた言葉をそのまま使うねん。なんでかっていうと、ちゃんとアドバイス通りにできたら報酬が高くなるはずやから、エージェントは「この言い方で説明したら伝わるやろ」って考えてフレーズを選ぶわけや。その後の研究(福地ら、2017a)では、ポリシーをコロコロ変えるタイプのエージェントにもこの方法を応用してるで。
あと、シンプルな可視化テクニックも使えるねん。「サリエンシーマップ」とか「レイヤーごとの関連性伝播」っていうやつやな。これ使うと、エージェントが世界をどう見てるかパッと一目でわかるようになるねん。それぞれメリット・デメリットがあって、詳しくはLiuらのチーム(2018)とBachらのチーム(2015)が突っ込んで議論してるから、気になる人はそっち見てな。
4.3 アプローチ:インタラクティブ学習
説明って普通は人間に向けてするもんやけど、インタラクティブ強化学習やと逆に人間からエージェントにフィードバックとか説明を与えることもできるねん。よくあるやり方は、エージェントの行動に「それええで!」とか「あかんやろ」ってポジティブ・ネガティブの評価をつけるパターンや(荒川ら、2018年;Knox & Stone、2008年;Knoxら、2013年;MacGlashanら、2017年)。でもこれだけやと情報量少ないやん?だから「なんでその行動があかんのか」を説明したらもっと良くなるはずやねん。Guanらのチーム(2020)は、人間からのサリエンシーマップ(どこ見てるか的な視覚的説明)を使って、単なる良し悪しの評価をパワーアップさせてん。これでサンプル効率が上がるだけやなくて、人間が入力せなあかん量も減るねん。一石二鳥やな。同じように、KaralusとLindner(2021)は反実仮想的な説明(「もしこうやったら〜」っていうやつ)を使って評価フィードバックを強化してんねん。これがめっちゃ効いて、収束速度がグンと上がったで。ネガティブなフィードバックの時、人間がエージェントに「別の状態s′で行動aをやってたらポジティブやったのにな〜」って伝えられるねん。著者らはこの反実仮想フィードバックをネガティブ報酬の時だけに限定してるんやけど、それが一番効果でかいからやねん。
反実仮想のもう一つの応用例はPearl(2009)が出してて、動的構造因果モデル(DSCM)っていうのを使ってるねん。世界の状態が変わっていく中で、エージェントと人間オペレーターの能力の違いを明示的にモデル化するやつや。この枠組みやと、エージェントは人間のフィードバックを「こうしたかったんやな」って意図された行動として受け取って、もしその行動がイマイチやったら反実仮想的推論を使って調整するねん。ここでおもろい話があってな、自律性と最適性のトレードオフが示されてるねん。つまり完全に自律的なエージェントは最適にはなりにくくて、人間オペレーターから重要なフィードバックもらわんと最適にならへんってことや。この反実仮想アプローチ、人間のアドバイスが完璧やなくても標準的な方法より良い結果出せるねん。
あと知っといてほしいんやけど、人間のトレーナーってポジティブなフィードバックを多めに出す傾向があるねん。だから学習エージェントはこのバイアスに対応できるようになっとかなあかん。エージェントが「自分はこう思ってるで」って前提を透明にトレーナーに見せることで、全体のプロセスが良くなるねん。それから、人間のデモンストレーションを見て学んだり、模倣したり、トレーナーの好みを聞いて学習するタイプのRLエージェントは、人間のバイアスをそのまま受け継いでまうことがあるねん。そういう時、説明可能AIを使えばデプロイ前にモデルのバイアスを明らかにできるわけや。ロボットがいろんな行動を見せて「どれが好み?」って人に聞くパターンもあるで。Habibianらのチーム(2021)は、ロボットの質問がトレーナーからどう見られるかに与える影響を研究してん。彼らのアプローチでは、ロボットが情報量の多い質問を選びながら、同時に自分の学習状況も明かすようになってるねん。人間の認知を考慮してない他のアプローチと比べて、Habibianらの研究(2021)では、人間は学習状況が見えて情報量のある
385
---
## Page 28
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p028.png)
### 和訳
Retzlaffさんらの研究についてな。
質問についてはな、こういう質問の方が答えやすいし、ロボットがどう学習してるかようわかるし、タスクの「ここがまだ自信ないねん」っていう部分にちゃんとフォーカスできるから、そっちの方がええって感じてるみたいやねん。
**4.4 注目ポイント:インタラクションデザイン**
エージェント学習ステップってのは、専門知識持ってない一般ユーザー、つまりその分野の専門家と初めてやり取りする段階やねん。せやから、この段階でユーザーとエージェントのやり取りにめっちゃ注目して、スムーズで協力的なワークフローを作ることをおすすめするで。Wuさんらが2021年に言うてるんやけど、人間はRLエージェント(強化学習エージェント)とやり取りするとき、いろんな役割を演じられるんやって。監督役、コントローラー、アシスタント、協力者、あと影響を与える要因みたいな感じでな。これ聞くと、効率的な教え方を開発するときに、コラボレーションをどうフレーミングするか、何が必要かをちゃんと考えなあかんなって思うやろ。学習エージェントは、設計者、トレーナー、最終ユーザーといろいろやり取りする可能性があんねん。せやから、専門家から素人まで幅広い人を考慮することが大事やねん。例えばな、よくあるデータ可視化のテクニック、棒グラフとかを使った視覚的な説明ツールは、科学系のバックグラウンドある人には便利やけど、そうじゃない人には頭の負担になってまうんや(Andersonさんら、2020年)。
Wuさんらが言うには、HITL(Human-in-the-Loop、人間参加型学習)の理想的なやり取りは、スムーズで、パフォーマンス高くて、信頼できるもんやって。パフォーマンス重視のシステムやと、やり取りは普通「コラボレーション」として捉えられるし、信頼性重視やと人間に「監督役」をやってもらう感じになるねん。でもな、スムーズさを追求するとなると、新しいやり取りの役割が提案されて議論されてて、それには新しい種類のインターフェースも必要になってくるんや。Cuiさんらが2020年に見せてくれたように、エージェントが人間からのジェスチャーとか声とか表情みたいな暗黙の共感的フィードバックを取り込めるようになったら、もっと直感的なやり取りができて、人間から学習エージェントへのフィードバックもめっちゃ豊かになるんやって。こういうフィードバックをうまく活用するには、適切なユーザーインターフェースを開発せなあかんし、ベースになるモデルも音声とか画像みたいなマルチモーダル(複数の形式)のデータを処理できるようにならなあかんねん。あとな、暗黙的にフィードバックを改善するもう一つのやり方として、Pengさんらが2016年に発表したアプローチがあんねん。これはエージェントが自信ないときはゆっくり動くようにするんや。そしたら人間は直感的にわかる合図で、一番役立つところでフィードバックできるってわけ。人間からの役立つ暗黙フィードバックを見つけて活用できたら、人間が先生として明示的に言うこと以上のものを引き出せて、エージェントの学習がめっちゃ進むんやで。
最終的には、エージェント学習のアプローチは、一つの特定のテクニックを押し付けるんやなくて、HITLフレームワークの中でいろんなアプローチを考慮すべきやと提案するで。そうすることで、さっき言うた「ちょうどええ塩梅」のインタラクションをもっとうまく見つけられるようになるんや。
**4.5 議論、今後の展望、ユースケース**
エージェント学習フェーズについてはな、「人間が先生役」っていうパラダイム自体をサポートするアプローチはたくさんあるんやけど、このやり取りをスムーズにするための説明可能性(なんでそうなるか説明できる仕組み)のアプローチが足りてへんことがわかったんや。もっと一般的に言うと、このフェーズでのxAI(説明可能なAI)アプローチは、HITL設定でのインタラクティブ性をサポートできるように進化せなあかんねんけど、今のところまだまだ発展途上やねん。
先に進むには、今あるいろんなアプローチをHITLとRL(強化学習)の文脈にもっと適応させなあかんねん。大事な適応の一つは、いろんなアプローチを系統的に導入して比較して、「ちょうどええ組み合わせ」を見つけるためのツール一式を開発することやな。効果的な組み合わせの例としては、まず模倣学習で基本的な行動を構築して、その後好み基準の学習でアクションを微調整して、最後にクエリ(質問)アプローチで弱点を特定して解決する、みたいな感じやな。こういう方向を目指していくべきやって提案するで。
386
---
## Page 29
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p029.png)
### 和訳
人間参加型の強化学習
現場でドメイン専門家と一緒に効率よくHITLトレーニングができる解決策を探してんねんけど、これがあったらユーザーがエージェントの行動をめっちゃ素早く立ち上げられるようになるし、再計画とか修正でさらにサポートもできるようになるわけや。こういうアプローチを組み合わせたら、実世界で使える頑丈なエージェントをめっちゃ効率よく、しかも速く作れるんとちゃうかな。
で、うちらのユースケースについてやけど、これからはドメイン専門家と一緒に実世界でのテストに移っていくで。この段階ではモデルの頑丈さとパフォーマンスを上げることが目標やから、とにかく「なんでそうなるん?」っていう説明をしっかりすることが大事やねん。おすすめはな、ロボットが何を見てどう判断してるかを視覚的に説明することや(Glanoisさんらが2021年に言うてはった)。例えば、画像のどの部分が重要かをハイライトする「顕著性マップ」っていうわかりやすいやつを付け加えるとええで(Liuさんらの2018年の研究な)。この段階では、人間からのフィードバックを取り入れ始めることもおすすめやねん。これ使ったら、環境の中の要素を分類できるようになるで。例えば「この道、通れるんか通れへんのか」みたいなことを判断するのに使えるわけや(Guanさんらの2020年の研究参照な)。もしロボットが「うーん、よーわからんな」ってなったら、ゆっくり動きながら視覚出力で問題点をハイライトして、ユーザーに「ここちょっと困ってんねん」って伝えることができるんや(Pengさんらの2016年の研究な)。あとな、模倣学習っていうのを組み込むのもええで。これやとロボットがユーザーの通った道をそのまま追いかけて、安全に環境のことをもっと学べるようになるんや(Pearlさんらの2000年の研究参照)。
4.6 エージェント学習のまとめ
表1に沿ってエージェント学習フェーズをまとめると、説明機能はユーザーに「わかりやすいインプット」を提供して、モデルの行動をもっとよく理解するための豊かなやり取りができるようにせなあかんねん。これにはな、説明がドメイン専門家の言葉で書かれてることも必要で、そうすることで「人間が先生役」っていう生産的なやり取りがしやすくなるんや。おすすめはな、人間とエージェントの間の最適なやり取りをデザインしてテストすること。フィードバックと説明可能性と「邪魔にならへん」ことのバランスを取るのがポイントやで。この段階で人間が関わる目的は、評価的なフィードバックを提供したり、エージェントにアドバイスや好みを伝えたり、難しいタスクのお手本を見せたりすることや。主な説明可能性の技術は、エージェントの知覚を説明するものと、行動を評価するもの、例えば「もしこうやったらどうなってた?」っていう反実仮想とか、テキストでの説明とかやな。
さらにな、エージェントが人間の好みを聞いてくるようにしたり、人間の先生からの指示にインタラクティブにフィードバックを返したりできる技術がおすすめやで。顕著性マップみたいな可視化のアプローチは、頭の負担も計算の負担も少ないからええで。この段階では説明可能性はインタラクティブで、強化学習の専門家もドメイン専門家も両方関わるんや。これはエージェント開発フェーズとは違うところがあってな、ドメイン専門家がプロセスに参加するし、説明可能性は「やり取りしやすさ」と「効率よくエージェントを学習させること」に向けられるべきやねん。一方で開発フェーズの方は、モデルのアーキテクチャについての洞察を得ることにもっと重点置いてたんや。
このセクションでは開発の第2フェーズ、つまりHITL強化学習エージェントのトレーニングについて話してきたで。次のセクションでは、その次のフェーズ、学習したポリシーと出てきたエージェントの行動をしっかり評価することについて話すわ。
5. エージェントの評価
このセクションではな、エージェント評価フェーズで何が求められるか、そして説明可能性のアプローチと安全性への配慮がどうやって学習したモデルへの信頼を築くのに役立つかを詳しく説明するで。人間とロボットのチームワークがうまくいくためには、安全性がめっちゃ大事やねん。ロボットは人間が本能的に持ってる
387
---
## Page 30
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p030.png)
### 和訳
Retzlaffさんたちの話やねんけど、
人間からしたら、AIには「予測できる動きしてくれや」「安全に動いてくれや」「何しようとしてるか教えてくれや」っていう期待があるわけ(Ederさんたちが2014年に言うてはるで)。
ほんで3番目のフェーズは何かっていうと、訓練したモデルの動きをテストする段階やねん。ここで必要なんは、比較できるようにするツール、学習の進み具合を数字で見れるようにするツール、あとでっかいモデルもちゃんと評価できるようにスケールアップできるツールやな。MLの専門家とその分野の専門家が、学習したモデルをめっちゃ徹底的にテストするわけ。開発者は「訓練中に変なバグとか間違った動きが出てへんか」をチェックせなあかんねんけど、これはどっちかいうと文法レベルの話やな。一方で、その分野の専門家は「学習した方策が細かいレベルでも大きいレベルでもちゃんと意味のある動きしてるか」を理解して評価せなあかんから、こっちは意味的な動きの評価が中心になるわけや。
「よっしゃ、市場に出すで!」って判断するか、「もう一回開発→学習→評価のサイクル回そか」って判断するか、これを決めるのがこのフェーズやねん。決めるのは開発者とプロジェクトのオーナーや。その分野の専門家は、「学習した方策、もうデプロイしてええわ」なのか、「もうちょい訓練いるな」なのか、「そもそも問題の定義変えなあかんな」を判断せなあかん。この評価フェーズでは、説明可能性(なんでそういう判断したか分かること)があると、学習した方策とか出てきた動きを深掘りして調べるのに役立つねん。
これをちゃんとやるために、訓練したシステムはめっちゃしっかりテストせなあかん。ここで大事なんは、「元のモデル自体のエラー」と「訓練中に学習してしもたエラー」を区別することやで。セクション6で説明してる「エージェントのデプロイフェーズ」では、モデルのアーキテクチャ自体の根本的なエラーは見つけて直しとくべきやねん。やから、このエージェント評価フェーズでは、訓練中に身についてしもたエラーを見つけることと、最終的に安全な意思決定ができるようにすることに集中できるわけや。
この「訓練中に身についたエラー」っていうのは、いろんな形で現れるねん。一つは「ショートカット学習」っていうやつで、モデルが本来学んでほしいことやなくて、訓練データの中の変なショートカットを見つけてまうことやな。これやと大体うまく一般化できへんねん。なんでかっていうと、そのショートカットは実際に使う場面では存在せえへんことがほとんどやからや。例えばな、肺炎のサインをレントゲン写真から見つけてほしいのに、「病院の名前が画像に埋め込まれてる」っていうトークンの方を学習してまうアルゴリズムとか、これがまさに「身についてしもたエラー」の例やな(Geirhosさんたちが2020年に言うてはる)。
あと、訓練中に身についたエラーの症状としては「敵対的攻撃」っていうのもあるねん。これは何かっていうと、モデルが本来学んでほしい概念やなくて、画像の中の人間には見えへんパターンを学習してもうてることを示してるねん(Goodfellowさんたちが2014年に言うてはる)。訓練プロセスを最適化して敵対的攻撃の攻撃対象を減らすアプローチはいろいろあるんやけど、ここでは「モデルが概念をちゃんと学習できてへん」っていう根本的な問題に焦点当てるわ。この問題は、セクション2.3で特定した「学習したモデルと現実世界のアラインメント(整合性)」の課題の一部でもあって、Royさんたちが2021年に議論してはるで。
この二つの問題を見たら、訓練したモデルの動きをちゃんと調べることがなんで大事か分かるやろ?ワイらが提案してるのは、開発のこのフェーズでは安全面の評価に焦点当てるべきやってことやねん。具体的には、モデルの意思決定プロセスを評価するってことで、これが学習した動きを反映してるからな。この意思決定プロセスを目に見える形にするには、「方策の要約」とか「グラフベースの説明」とか「因果モデル」みたいなアプローチが使えるねん。さらに、エージェントが許可された行動だけを取るようにしたり、自分の不確実性のレベルについて透明にしたりする、いろんな安全アプローチも考慮してるで。表6に、エージェント評価フェーズの重要なポイントをまとめてあるわ。
ワイらの森林作業のユースケースでは、このエージェント評価フェーズがめっちゃ重要やねん。起こりうる落とし穴を発見するためにな。一つの落とし穴は、モデルに出てきたエラーを見つけられへんことで、これやとパフォーマンスが落ちたり、現場で使えへんようになったりするわ。考慮し損ねると
388
---
## Page 31
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p031.png)
### 和訳
ほんなら、人間がAI学習に関わるときの話、めっちゃわかりやすく説明していくで!
---
**人間参加型の強化学習**
| フェーズ | 人間の関わり方 | 説明に求められること | 説明のしやすさって何? | 目標 | 評価の基準 |
|---------|--------------|-------------------|-------------------|------|-----------|
| **評価段階** | ・学習したAIの動き方を細かいとこも全体像も理解して評価すること<br>・モデルの限界とか安全性をテストすること<br>・実際に使えるレベルかどうか判断すること | ・学習した振る舞いをまとめられること<br>・でっかいモデルにも対応できること<br>・学習前のモデルと比較できること<br>・その分野の専門家が理解できること | ・専門家がちゃんとわかるようにすること<br>・モデルが大きくなっても複雑になっても、しっかり比較できる説明ができるようにすること<br>・いろんな角度からAIの方針を見れるダッシュボードをもっと開発すること | **注目ポイント**: 不確実性をモデル化したり、ルールベースの防御を使って安全性を評価すること<br><br>**説明の方法**: 自然言語とか、ルールとか、コードとか、グラフを使った説明でAIの方針をまとめること<br><br>**使う人**: その分野の専門家、強化学習の専門家 | ・忠実度(どれだけ正確か)<br>・関連性<br>・認知負荷(頭にどれだけ負担かかるか)<br>・コンパクトさ(説明の絶対的な大きさ、使う特徴の数とか、パスの長さとか、全データからどれだけ減らせたかとか)<br>・冗長性(説明の各部分がどれだけ被ってるか) |
**表6**: AIエージェント評価段階における、人間の関わり方の種類、説明に求められる具体的な要件、説明可能性アプローチの焦点と種類、目標、そして評価指標のまとめやで。
---
なんでかっていうとな、AIエージェントの性能がタスクの複雑さや大きさに応じてどう変わるかをちゃんと見とかんと、理論上はめっちゃええ結果出てても、実際使ってみたら「あれ?」ってなることがあるねん。例えばな、訓練された連続10個のタスクまではうまいことこなせるのに、その後からミスったり変な動きし始めるAIエージェントとかな、そういうことが起こりうるわけや。
もう一個大事なんは、エージェントをいろんなエッジケース(極端な状況)やシナリオでしっかりテストして、いろんな運用条件に対応できるか確認することやねん。いろんなタスクをこなせへん、いろんな条件でうまく動けへんエージェントは、めっちゃ狭い範囲でしか使えへんし、条件が悪くなったら失敗する可能性があるわけや。例えばな、訓練したときと違うバイオーム(生態系)の森とか、地形のデコボコ具合とか、天候条件が違う場合とかやな。せやから、エージェントの信頼性と安全性をちゃんと評価することがほんまに大事やねん。これには、障害物とか不安定な地面みたいな危険を検知して避けられるかどうかと、エンドユーザーや他のスタッフが怪我するリスクを最小限にしながら汎用的で信頼できる動きができるかどうか、両方含まれるで。
---
**5.1 要件**
評価フェーズでは、説明可能なAI(xAI)のアプローチは、でっかいモデルと複雑な意思決定プロセスを扱わなあかんねん。この要件があるから、例えばテキストベースとかルールベースのアプローチ(Hayes & Shah, 2017; Tabrez & Hayes, 2019)を使うのがなかなか難しくなってくるねん。なんでかっていうと、1ページ分の出力を作るときは役立つかもしれんけど、何ページもあるモデルの方針説明を読んで理解するのは、もう現実的ちゃうからな。同じようにな、ツリー(木構造)とかDAG(有向非巡回グラフ)みたいな視覚的なアプローチも、基本的にはある程度のサイズを超えたら使いもんにならへんねん。
この要件については、Wells and Bednarz (2021a)も指摘してて、いくつかのxAIアプローチの著者らが「自分らのアプローチをスケールアップ(大規模化)するのが大きな課題や」って認めてるって見つけてんねん。これ見たら、なんで多くのxAIアプローチがおもちゃみたいな簡単な例にしか適用されへんのか、よくわかるやろ。特にテキストベースとかグラフベースの説明は、あっという間に手に負えへんくらい膨れ上がるからな。
---
---
## Page 32
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p032.png)
### 和訳
Retzlaff らの研究やねんけど、聞いてや。
ほんで、モデルが出す説明ってのは、その分野の専門家が「なるほど、わかるわ」って言えるもんじゃないとあかんねん。なんでかっていうと、学習したポリシーがちゃんと筋通ってるかどうかを判断できるんは、開発者やなくてその分野のプロだけってことが多いからな。せやから、専門家がちゃんと評価できる形になってることがめっちゃ大事なわけや。
あと最後に考えなあかんことがあってな、新しく初期化したモデルとか、事前学習だけ済んでるモデルと比べて、「ここが違うで!」って見せられる説明じゃないとあかんねん。そうすることで、トレーニングの各段階でエージェントが実際に何を学んだんか、ちゃんとわかるようになるからな。
Milani らが言うてた評価基準の話に戻るとな、ワイらは前の段階で求められてた「忠実さ」と「関連性」に加えて、「認知的負荷」も考慮すべきやって提案しとるねん。認知的負荷を入れるんは、フルサイズのモデルにもちゃんと対応できる説明にするためや。視覚的なまとめとか文章でのまとめに頼る方法やと、ここがめっちゃ難しくなるねん(Vu & Thai, 2020)。
**5.2 アプローチ:説明可能性について**
ポリシー要約っていうアプローチはな、モデルのポリシー(方針)をユーザーに見せて説明することに焦点当ててんねん。モデルの意思決定プロセスを具体的に示す例として、ルールとして書いたり(Liu ら、2018)、コードブロックとして書いたり(Verma ら、2018)、あるいは自然言語で説明したりするやり方があるねん。Alonso ら(2018)が見せてくれた例やと、決定木が選んだ選択を文章で説明して分類を正当化してんねん。これは強化学習にも応用できるわな。大規模言語モデル(LLM)の中身を文章で説明する他の例としては、Zini & Awad(2022)とか Xu ら(2023)があるで。
ポリシー要約はな、学習済みモデルを評価して、予想外やったりあかん行動がないかポリシーをチェックするのにめっちゃ向いてんねん。どの専門家を巻き込むかによって、おすすめの要約方法も変わってくるで。モデルのポリシーをコードブロックでまとめるんは、コンピュータサイエンスとかその周辺分野の人にはわかりやすいかもしれへんけど、技術的な背景がない専門家にはあんまり向いてへんな。ここで気をつけなあかんのは、説明の対象となる人が直感的にわかるように、どうやってモデルをまとめるのがベストか見極めることやねん。説明の仕方を理解するための余計な頭の負担は、最小限に抑えなあかんからな。もう一つのポイントは、モデルの規模を考慮することや。10個のコードブロックやったら簡単に評価できるけど、100個もコードブロックがあったら、理解してちゃんと精査するのはほんまに難しいで。こういうときは、グラフベースの説明アプローチが役に立つかもしれへんな。
グラフベースの説明はな、モデルの振る舞いを素早く直感的に把握するのにめっちゃ便利やねん。Holzinger ら(2021)は、人間参加型(HITL)システムにはグラフベースの説明を使うことをおすすめしとる。なんでかっていうと、専門家の持ってるドメイン知識と、モデルが学習した振る舞いを直感的に比較できるからや。Song ら(2019)は、レコメンダーシステムでグラフベースの説明をどう使えるか見せてくれてん。レコメンダーシステムっていうのは、よく知識グラフが使われる分野やねんな。彼らが提案したシステムでは、どうやってその推薦が形成されたか、グラフ内の意味のある経路をユーザーに見せんねん。そうすることで、効果的な推薦とええ説明の両方ができるわけや。ただな、グラフベースの説明も、モデルの振る舞いとか説明対象の判断が複雑になりすぎると、ユーザーがパンクしてまうことがあんねん。PGExplainer(Vu & Thai, 2020)みたいなアプローチは、決定グラフの中の関連する部分に絞って説明グラフを作ることで、この問題を軽減しとるで。
---
## Page 33
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p033.png)
### 和訳
人間参加型の強化学習
**5.3 メインテーマ:安全性の評価**
強化学習のシステムってな、めっちゃ複雑で中身が見えへんことが多いねん。せやから、どうやって判断してるかとか、どこに危ない問題が潜んでるかとか、なかなか分かりにくいわけ。せやから、作ったアプリケーションの安全性をちゃんと先回りして評価せなあかんねん。そうすることで、AIエージェント自身も他の人も、リスク最小限で設計・導入できるようになるんよ。ここで紹介するアプローチは、エージェントの動きをチェックして、予想外のことやアカンことせえへんか確認するのに役立つで。
せやけど、モデルをテストするのは訓練のサイクルの中で大事なパーツやけど、安全な動作を保証するのにそれだけに頼ったらあかんねん。安全性を確保する例として、Xiongさんらの2020年の研究があるんやけど、これは「シールドベースの防御」っていうのを使うねん。どういうことかっていうと、訓練中も実際に使う時も、AIエージェントがあらかじめ決められた安全な範囲の中にいるように学習させるんよ。そうすることで頑丈さがアップするってわけ。
あと、いろんな場面でモデルがどれくらい自信持ってるか(不確実性)を推定するアプローチも役立つで。Lutjensさんらの2018年の研究では、ナビゲーションタスクで衝突回避のポリシーを提案してんねん。これ、計算もしやすいし並列処理もできる不確実性の推定ができるんよ。これを使えば、開発者が用意したテストシナリオでモデルがちゃんと自信持って動いてるか確認できるし、しかも「盲点」も見つけられるねん。その盲点を使って、モデルがそういう状況に出くわした時どう動くかテストできるってわけ。
**5.4 議論、今後の展望、そしてユースケース**
エージェントの評価フェーズでな、めっちゃ大きい課題見つけてん。それは説明可能AI(xAI)のスケーラビリティの問題やねん。小さいモデルには向いてるんやけど、大きく訓練されたモデルとそれが学習したポリシーを説明するってなると、うまくいかへんことが多いねん。あと、訓練済みモデルの異なるバージョン間の違いを特定できるアプローチがほとんどないってことも分かってん。これ、このフェーズではめっちゃ大事な機能やと思うねん。学習したポリシーを徹底的に評価するためにな。サリエンシーマップみたいな視覚的なアプローチはモデルの動きを評価するのに使えるんやけど、注意して使わなあかんで。なんでかっていうと、「どこ」に注目してるかっていう表面的な洞察しか得られへんし、「どうやって」判断してるかは分からへん。しかも確証バイアスにも影響されやすいんよ(Evansらの2022年の研究によると)。
開発・学習フェーズでは十分やった説明可能性のアプローチも、評価フェーズではモデルのサイズと複雑さのせいで調整が必要になるってことを強調したいねん。例えばVermaさんらの2018年の研究で提案されたコードブロック要約みたいなアプローチは、VuさんとThaiさんの2020年の研究で示されたように、説明の関連する部分だけに焦点を当てるように拡張できるかもしれへん。さらに、専門家が読みやすいようにせなあかんねん。そうすることで、その分野の専門家が学習したポリシーが理にかなってるかテストして評価する手助けができるやろ。その上、事後的な説明として視覚的なやつ(Atreyさんらの2019年、Guptaさんらの2019年)やテキストベースのやつ(Fukuchiさんらの2017b、HayesさんとShahさんの2017年)があれば、全体的な説明可能性がもっと上がるで。
いろんなツールを統合して、モデルをいろんな視点から評価して精査することをおすすめするわ。このプロセスには、モデルの判断についての詳細な説明が不可欠やと提案してんねん。さらに、モデルの安全性評価に焦点当てるべきで、その分野の専門家が理解できるような形で説明を提供することが大事やねん。そうすることで、表面的なモデルの動きをデバッグするだけやなくて、学習したルーティンが意味的にちゃんと筋が通ってるかチェックできるようになるんよ。これはその分野の専門家の知識も必要とするタスクやからな。
---
## Page 34
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p034.png)
### 和訳
ほな、いくで!
---
Retzlaffさんらの話
僕らが言いたいのはな、ここで紹介した「説明できる化」の方法をうまいこと組み合わせたら、モデルがちゃんと狙った通りの動きだけ学習してるかどうか、めっちゃ確認しやすくなるっちゅうことやねん。グラフ使った説明は、「ポリシーの要約」っていう方法と一緒に使うのがオススメやで。なんでかっていうと、要約の方でモデルの方針をざっくり全体像として見せてくれるから、それを見て「ここもうちょい詳しく知りたいな」ってところをグラフで掘り下げられるわけや。グラフの説明ってパパッと出せるし直感的でわかりやすいから、その道のプロ(ドメインエキスパート)と一緒に「このモデル、こういう判断してるんやな」って確認できるねん。ほんで、安全対策とか「どれくらい自信あるか」の見積もりも組み合わせたら、ユーザーに「ここまではできるけど、ここから先は限界やで」ってちゃんと教えてくれる信頼できるモデルが作れるっちゅうわけや。こういうの全部踏まえて、開発者とか専門家とかプロジェクトのオーナーが「よっしゃ、本番で使おう!」なのか「いや、もうちょい開発せなあかんな」って判断するんやな。
森林作業のロボットの例に戻るとな、僕らはエージェントが「いろんな環境で自分で動き回れる」「ユーザーがミスっても安全に対応できる」っていう信頼できるモデルに基づいてることを確認したいわけや。信頼性を担保するには、いろんな環境でテストせなあかん。さらに、わざとユーザーのミス(たとえば行けへん場所に行けって言うとか、めちゃくちゃなデータ入力するとか)を再現して、そういうレアケースでエージェントがどう振る舞うか見るのも大事やねん(Xiongさんらが2020年に言うてた話や)。ほんで、モデルの方針は要約して、ポリシーグラフみたいな形で見せたらええで。そしたら開発者とか専門家が「このロボット、こういう動きするんやな」ってパッと理解できるし、学習した方針がどう機能してるか見えるからな(VuさんとThaiさんが2020年に提案してた方法や)。これ、違うバージョンのモデル同士を比べて「新しいやつは何を新しく学んだんやろ」って見るのにも使えるで。最後に、森の中を移動するときに出くわすかもしれん「よくわからんとこ」とか「苦手なとこ」について、モデル自身が「ここはちょっと自信ないねん」って教えてくれる仕組みがあった方がええな。たとえば不確実性の推定値を使うとか(Lutjensさんらが2018年に言うてたやつやな)。
**5.5 エージェント評価のまとめ**
表1に沿ってエージェント評価フェーズをまとめるとな、このフェーズでの説明機能は、でっかい学習済みモデルにも対応できるスケーラビリティがあって、前のバージョンのエージェントと比較できなあかんねん。ほんで、専門家が理解できるもんじゃないとあかん。そうせんと、学習したモデルの動きを徹底的に比較できへんからな。あと、システム全体の安全性と、動きの頑健さ(ちょっとやそっとじゃブレへん強さ)の評価に力入れるのをオススメするわ。人間がこういう方針と結果の動きを、ミクロレベル(一個一個の判断がまともかどうか)とマクロレベル(全体としてまとまりのある動きしてるか)の両方で理解して評価して、「よっしゃ、現実世界で使おう」って判断するわけやな。
役に立つ「説明できる化」のテクニックとしては、ポリシーの要約、グラフベースの説明、それから決定木(判断の分かれ道を木の枝みたいに図にしたやつ)とか論理ルール(「もしAならB」みたいなルール)を抽出する解釈しやすい意思決定のアプローチがあるねん。専門家と強化学習のプロが双方向でやりとりしながら進めるのが大事やで。このフェーズでは、因果モデル(原因と結果の関係を整理したモデル)を使うとモデルの動きが内側からスッと説明できるようになるっていうメリットもあるんや。ほんで、ユーザーにずっと信頼してもらうために、安全面での評価も忘れたらあかんで。他のフェーズと比べると、最初のエージェント開発フェーズと使う「説明できる化」の技術は似てるところが多いんやけど、このフェーズではさらに「専門家が理解できること」と「複雑な方針にも対応できるスケーラビリティ」が求められるっちゅうわけや。
このセクションでは、HITL(Human-in-the-Loop、つまり人間が関わる)強化学習システムの評価について考えてきたで。次のセクションでは、いよいよ最後のステップ、現実世界でエージェントを実際に動かす「デプロイ」について話していくわな。
392
---
## Page 35
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p035.png)
### 和訳
# 人間参加型強化学習
## フェーズまとめ表(エージェント展開フェーズ)
| フェーズ | 人間の関わり方 | 説明に求められること | 説明可能性のポイント | 目標 | 評価指標 |
|---------|--------------|-------------------|-------------------|------|---------|
| **展開(エンドユーザー向け)** | ・エージェントをデプロイする<br>・エージェントと対話する<br>・実世界でのアプリの目的と状況を決める | ・認知負荷を減らすために、速くてわかりやすくて簡潔に<br>・ユーザーが理解できるように<br>・ユーザーの作業を邪魔せんように | **フォーカス:**<br>意図と不確実性のコミュニケーションでユーザーの信頼を構築、エラー修正も可能に<br><br>**説明の種類:**<br>顕著性マップ、デンドログラム、バウンディングボックス、テキスト説明、視覚・聴覚インジケーター<br><br>**ユーザー:** エンドユーザー | ・画像と運転ベース以外の新しいアプローチを開発・適用<br>・シンプルで速い説明を使う<br>・一貫したエラー処理と不確実性ハンドリングを実装<br>・色んなモダリティでエージェントの意図を伝える | 忠実度<br>関連性<br>認知負荷<br>パフォーマンス |
## 6. エージェント展開
ほんで、いよいよエージェントが実世界にデプロイされて、エンドユーザーと実際にやり取りするフェーズや。ここでは色んなユーザーに対して効率よく対話しながら、自分の行動に対する説明をちゃんと提供して信頼を勝ち取らなあかんねん。
普通はな、ベンダー側の立場から見て「このエージェントは安全やから実世界に出しても大丈夫やで」って説明できる人間が必要やねん。開発者は、エージェントを継続的に学習させ続けるんか、ポリシーを固定するんか、それとも環境が変わったら再学習させるんか、決めなあかんのや。ほんで最終的には、お客さんとエンドユーザーがデプロイを決定して、現場でどういう状況でどう使うかを決めるわけや。ここで説明可能性があると、ユーザーが最終的なポリシーを理解したり、信頼が高まったり、安全性を評価したり、ポリシーの安定性を把握したりできるようになるんやで。
このセクションでは、学習済みエージェントと人間ユーザーの間で効率的なやり取りを実現するアプローチに焦点を当ててるで。頻繁に繰り返されるやり取りやから、説明を適切に見せることと、今やってるタスクの邪魔にならんようにすることのバランスが大事なんや。これはAndersonとBischof(2013)も強調してることで、最初はガイドがあると助かるけど、長期的なパフォーマンスと学習にはむしろ悪影響になることもあるって言うてんねん。あと、安全性とか、予期せん状況への汎化とかいう課題も出てくるで(Royら(2021)とセクション2.3を見てな)。表7にエージェント展開フェーズの重要ポイントをまとめてあるで。
ワイらの提案としてはな、HITL(人間参加型)エージェントを使うことで、開発・学習・評価・展開の4つのフェーズで大幅なパフォーマンス向上が期待できるっちゅうことや。このセクションでは、そのメリットを実際にエンドユーザーに届けるためのアプローチに注目してて、精神的な負荷とか不信感みたいな問題も考慮してるで。
森林作業のユースケースでエージェント展開フェーズを考えると、いくつか気をつけなあかん課題があるんや。一番大きい課題の一つはコミュニケーションやな。エージェントの行動や意図がオペレーターにちゃんと伝わらんかったり、オペレーターがエージェントにコマンドやフィードバックを送れんかったりしたら、現場でうまく機能せえへんかもしれんねん。あと、エージェントはできるだけ自律的に動いて、ほんまに必要な時だけ人間に助けを求めるようにせなあかん。なんでかっていうと、人間参加型に頼りすぎると、エージェントの自律性が下がって、実世界で使う上で実用的やなくなってしまうからや。さらに、安全性は常に最優先やで。なんせエージェントは
---
## Page 36
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p036.png)
### 和訳
Retzlaffさんたちの研究やけど、
ここで大事なんは、このシステムが上手くいくには、人にケガさせたり、自分自身壊れて動けんようになったりしたらアカンってことやねん。
**6.1 必要な条件**
エンドユーザーが使うxAIシステムは、HCI(人とコンピュータのやりとり)のユーザビリティ研究っていう膨大な知見を活用できんねん。せやから、めっちゃ有名な「インターフェースデザインの黄金ルール」(Shneidermanさんたちが2016年にまとめたやつ)から考え方とか要件を引っ張ってきてるわけや。ただし、対話型の強化学習システムをデザインするには特別な要件があるって点には注意が必要やで(Arzate CruzとIgarashiが2020年に言うてる)。まあ、HCIデザインの基本ルールはそのまま使えるんやけどな。
記憶の負担を減らすためには、説明はシンプルでパッと理解できるもんやないとアカン。難しいタスクを楽にするのが目的やのに、ややこしすぎる説明で人とロボットのやりとりを余計に複雑にしてどないすんねんって話や。操作する人はコロコロ変わる視点とか環境で作業することが多いから、説明は今の状況にちゃんと対応するようにリアルタイムで計算せなあかん。例えば自動運転車やな。もし説明が数秒遅れて出てきたら、介入が必要やったかもしれん行動はもう起こってしもてるわけや。
「慣れたユーザーにはショートカットを使わせたれ」っていうガイドラインに関しては、エージェントは必要な時だけ説明を出して、いらん時は切れるようにすべきやねん。AndersonとBischofが2013年に議論してるとおりや。このオプションは情報疲れを防ぐためにも、人とロボットが自然にスムーズに協力するためにもめっちゃ大事やで。
3つ目の考慮点は、エラー処理を簡単にして、ユーザーに「自分がコントロールしてる」って感覚を持たせることや。ワイらが提案するのは、HITLモデル(Human-in-the-loop、つまり人間が介在するモデル)がある状況とか判断について「自信ないわー」ってことを示す手段を持つべきってこと。例えば車についてる警告ランプみたいなやつやな。こういう仕組みがあれば、「なんかおかしいで」とか「ここ不確かやで」ってユーザーに知らせられるし、原因を調べることもできるわけや。同じ考え方で、スタートアップチェックのシーケンスも提案してる。これも車の警告ランプが起動時に順番に点灯するやつをベースにしてて、ユーザーがシステムがちゃんと動いてるか、状況を正しく理解してるかを確認できるようにするんや。
HITL強化学習の導入における他の3つのフェーズとは違って、このフェーズでは主要な要件を緩和できるとは思ってへん。むしろ、このフェーズが4つの中で一番大変やと考えてんねん。なんでかっていうと、計算能力と認知能力の両方に制約があって、高い忠実度、関連性、パフォーマンス、そして低い認知負荷(Milaniさんたちが2022年に言うてる)が全部必要やからや。現実世界でモデルがちゃんと動いて、いろんな入力に対応できるようにせなあかんねん。
**6.2 アプローチ:説明可能性**
リアルタイムの説明がいろんなユースケースでどんな感じになるか、何人かの研究者が例を示してくれてるで。Rodriguezさんたちは2021年にCOVID-19の症例予測に対する特徴量ベースの説明を提供してるし、KulkarniとGkountounaは2021年に教室用のダッシュボードを開発して、樹形図(デンドログラム)とテキストベースの説明で生徒の成績を一覧できるようにしてんねん。もう一個の例は、産業用機械の残りの使用可能寿命を推定するのに樹形図を使うやつで、機械学習と専門知識を組み合わせてる(Serradillaさんたちが2020年に発表)。こういうリアルタイム説明可能性システムの大半はデータとかソフトウェアベースやねんけど、ロボットシステム向けの説明っていう分野になると、まだまだ
394
---
## Page 37
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p037.png)
### 和訳
人間参加型の強化学習
学習に必要なサンプル数をめっちゃ減らせるんやで。ほとんどの自動運転システムって、認識した物体に四角い枠(バウンディングボックス)とラベルをつける形で説明してくれるねん。これって、モデルが何を見てるかを説明するのにめっちゃ適してて、画像のどこが大事なんかを特定するのに役立つんや(Behlら、2017年;Kashyapら、2020年)。
次のステップは「判断の説明」やな。ここでBen-Younesら(2022年)が面白い方法を提案してるねん。物体の重要度(サリエンシー)と、行動のテキスト説明を組み合わせる方法や。例えばな、認識した信号機をハイライトしながら、「止まれ」って行動をテキストで説明するねん。こういうアプローチはめっちゃ便利やし、使う人もパッと評価できるんや。ただな、テキストの代わりに既知のシンボルや標識を使って、注目すべき場所をハイライトしたら、もっと良くなる可能性もあるで。Xuら(2023年)は、人間の判断基準に合ったテキスト説明を作る方法を示してて、これで理解しやすさがアップするんや。
AIエージェントを信頼する上でめっちゃ大事なんは、エージェントの行動が予測可能かどうかやねん。やから俺らとしては、実世界で使う説明可能AI(xAI)のアプローチは、エージェントがこれから何をしようとしてるかを見せることで、判断や計画をユーザーに透明化することに集中すべきやと提案するで。厳密に言うとな、行動を「説明」する必要はなくて、「予告」するだけでええねん。せやからこのアプローチは「解釈可能性」の領域に属するんや。これは「説明可能性」の一部やな(Dragan、2015年)。説明可能性まで求めずに解釈可能性だけでOKにすると、要件がシンプルになるねん。もちろん、人間とコンピュータのインタラクション(HCI)の原則は守らなあかんで。頭への負担がかかりすぎたらあかんからな。Caltagironeら(2017年)は例えば、自動運転で予測軌道を表示する方法を示してて、これは他の移動系のドメインにも簡単に応用できるはずや。まだ課題として残ってるんは、こういう予測を自動車以外の状況で、他のモダリティ(表示方法)でどう伝えるかやな。スマートウォッチとか、ヘッドホンとか、シンプルな視覚インジケーターとかが、馴染みやすくて柔軟なインターフェースになる可能性があるで。
6.3 フォーカス:ユーザーの信頼を築く
AIの発展にとって信頼ってほんまに大事やねん。なんでかっていうと、信頼があってこそAIシステムをちゃんと展開・普及できるからや。信頼がなかったら、人はAIシステムを使ったり頼ったりするのをためらってしまって、せっかくのメリットが活かせへんくなるねん(2.1節参照)。せやから、エージェントを実際に使う段階では、エンドユーザーとの信頼構築に集中することをおすすめするで。そのために色んな説明可能性アプローチがどう使えるかも説明したんや。
さらに提案したいんは、「警告ライト」みたいなアラートを使うことやな。エージェントが判断に自信がない時に、それを認識してユーザーに知らせるんや。これには二つの効果があるで。まず、エージェントの判断の堅牢性が全体的に上がる。それから、ユーザーがエージェントの判断への信頼も深まるねん。なんでかっていうと、ユーザーがエージェントがその判断に自信があるかどうかを推測できるようになるからや。
こういう警告ライトは、不確実性の推定に基づいて作れるで。不確実性が一定の閾値を超えたら発動する仕組みや。Jainら(2021年)は、認識論的不確実性(モデル自体の知識不足による不確実性)をある程度推定する方法の例を示してるで。こういうアプローチを導入したら、ユーザーは目の前のタスクやロボットとのやり取りに集中できるようになるねん。それでいて、必要な時には介入できるコントロールも保てるんや。
395
---
## Page 38
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p038.png)
### 和訳
Retzlaffさんたちの研究やねんけどな。
こういう介入アプローチについて、Wuさんたちが2021年に実際にやってみせてくれてんねん。どういうことかっていうと、HITLのオペレーター(人間が監視する人な)がエージェントが変な判断したときに介入できるようにしてて、さらにめっちゃええのが、その介入からモデルが学習できるようにしてるんやで。
起動シーケンスっていうアプローチは、このエラー処理の考え方とめっちゃ相性ええねん。Liuさんたちが2021年に提案したのは、エラー検出のフレームワークやねんけど、HITLオペレーターに一番関係ありそうで説明もちゃんとできる特徴のリストを見せるんや。おかしな動きとか意味不明な行動を見つけるためやな。このリストを起動時にパッと見るだけでチェックできて、信頼感がめっちゃ上がるっていうメリットがあんねん。
**6.4 議論と今後の展望、ユースケース**
エージェントを実際に動かす段階では、ほんまに使えるxAI(説明可能なAI)のアプローチってあんまりないねん。今あるアプローチがなんで使いにくいかっていうと、ユーザーにわかる言葉で説明できへんとか、計算パワーが足りひんとか、複雑すぎてリアルタイムで使われへんとかいう問題があんねん。それに加えて、HITLの強化学習アプローチの多くは、ユーザーの信頼を勝ち取れてへんし(まあ勝ち取る価値もないものが多いんやけど)、「ここ自信ないわ」って伝えるべきときにそれができてへんねん。
ワシらが提案したいのは、今あるアプローチが自動運転の視覚的な部分ばっかり見てるんやけど、他のモダリティ(情報の形式)も考えてほしいってことやな。たとえばローンの審査とか保険の計算みたいな場面では、テキストの事実を説明せなあかんやん。あと、グラフィカルなダッシュボード以外にも、音とか触覚とかの視点も考えなあかんねん。さらに、視覚的な面でもスマートウォッチとかLEDインジケーターとか画像投影とか、いろんな形を探っていくべきやと思うわ。
シンプルで速い説明がほんまに必要やって強調したいんや。今そういうアプローチがめっちゃ少ないからな。あと、エージェントの行動を説明するのに、視覚的なインジケーターだけやなくて、触覚とか聴覚のシグナルみたいな違うモダリティも検討してほしいねん。このへんはまだほとんど研究されてへんからな。最終的にワシらが思い描いてるのは、警告インジケーター付きのツール一式やねん。エージェントが難しい状況に遭遇したときに教えてくれて、エージェントがちゃんと対応できる範囲内やったら信頼してええし、そうやなかったらユーザーに知らせてくれるっていう。究極的には、起動時にいろんなチェックをするシーケンスがあれば、ユーザーはエージェントがちゃんと初期化されてて信頼できるって確認できるんやで。
ワシらのユースケースに関しては、同じようにシンプルで堅牢で邪魔にならへんインジケーターを使って、エージェントの状態をユーザーに伝えることを推奨するわ。たとえばロボットやったら、動こうとしてる意図を視覚的な合図で示しながら、不確かなときは警告ランプとか警告音で伝えるとかな(Jainさんたち2021年の研究)。あと、機械につなげるディスプレイを使えば、モデルがどう認識してるかをユーザーが見て理解できるようになるねん(Glanoisさんたち2021年)。これでユーザーに簡単で素早い説明ができて、途中の障害物を見つけて避けるのに役立つんや。さらに、行動をテキストで説明することもできるし(Ben-Younesさんたち2022年)、理想的にはユーザーがフィードバックして間違いを直せるようにもなるんやで(Wuさんたち2021年)。
**6.5 エージェント展開のまとめ**
まとめるとな、表1にあるエージェント展開フェーズでは、一番大事な要件は説明がエンドユーザーにわかるものであることやねん。あと、実際の現場で使われるから、認知的な負担が大きすぎたらあかんし、
396
---
## Page 39
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p039.png)
### 和訳
人間参加型強化学習
モデルの読み込みとか、めっちゃ時間かかる計算とかあるやん?そこで大事なんは、エラーが起きた時にどうするかとか、モデルがどれくらい自信ないかをユーザーにちゃんと伝えることやねん。人間はエンドユーザーとして、エージェントを実際に使う場面で関わってくるわけや。使う状況を決めたり、具体的なタスクを設定したりするのも人間の役目やな。
説明のしやすさっていうのは、いろんな情報をまとめたダッシュボードみたいな形で提供できるねん。エージェントが「何をしたいか」「何をしてるか」「不確かなこととかエラーをどう処理してるか」を、双方向でやり取りできるようにするわけや。説明の方法としては、エージェントがどこを見てるかを可視化したり、なんでそう決めたかをテキストとかで説明したりできるで。
可視化でよく使われてる技術は、サリエンシーマップ(どこに注目してるかを示すやつ)とか、デンドログラム(樹形図みたいなやつ)とか、バウンディングボックス(物体を四角で囲むやつ)やな。これらをテキストの説明とか、目で見える・音で聞こえるインジケーターと組み合わせて、エージェントが何しようとしてるか伝えられるねん。このフェーズは完全にエンドユーザー向けで、システムを信頼してもらうことに集中してるんや。エージェントの強みと弱みをちゃんと理解してもらって、実際の現場でうまく協力できるようにするわけや。これには、開発・デプロイ段階みたいにモデルの中身を見せる必要はなくて、学習段階みたいにエージェントが何を見て何を考えてるかの重要なところを強調すればええねん。
ここまでで、人間参加型強化学習システムをデプロイするまでの4つのフェーズを見てきたで。次のセクションでは、この論文から出てきた今後の研究の方向性について議論していくわ。
7. 研究の方向性
2.3節でも言うたけど、強化学習ってめっちゃ難しい問題設定やねん。せやからこそ、人間参加型のアプローチがほんまに役立つと思うわけや。説明可能性には「これさえあればOK」みたいな万能の解決策はないし、フェーズごとに必要とされる人間参加型の説明可能AI(xAI)も違うっていうことを強調しときたいねん。
各フェーズで使う説明技術を厳密に分けろって言うてるわけやないで。ただ、フェーズごとに向いてるxAIの種類があるってことを認識しようや。それは、人間がどう関わるか、エージェントのどこに注目するか(モデルの構造なのか、意思決定プロセスなのか、世界の認識なのか)、そしてどんなタスクに取り組むかによって変わってくるねん。
ワイらがオススメするxAIのタイプは、表1に書いてある説明の要件、表2にまとめたxAI手法の長所短所、それから人間の参加の仕方、ユーザーのタイプ、人間とエージェント間のやり取りの方向性を踏まえて選んでるんや。説明可能性はエージェントをデプロイするまでの全フェーズで中心的な役割を果たしてて、各ステップで安全性と信頼にどう影響するかも議論したで。
ワイらのもっと大きなビジョンは、ここで紹介した人間参加型強化学習のアプローチが、将来的には人間とロボットのチームの生産性を上げてくれることやねん。Khatibさんたちが1999年に言うてたんやけど、人間は経験と専門知識を持ってて、タスクがちゃんと実行されてるか確認できるっていう強みがあるねん。一方でロボットは、力とか速さとか精度の面で人間の能力を拡張できるわけや。しかも、危険な状況に人間がさらされるリスクを減らしてくれるしな。
ただし、めっちゃ大事なことがあるねん。機械も人間のオペレーターも両方が環境に反応できて、人間が機械の行動をちゃんと理解・解釈できるようにせなあかんってことや。なんでかっていうと、中で動いてるアルゴリズムとその判断は、目的の違ういろんな人たちに理解できるものじゃないとあかんからやねん(Heuillet et al., 2021)。せやから、人間参加型強化学習における説明可能性の重要さを強調しとくで。
397
---
## Page 40
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p040.png)
### 和訳
Retzlaffさんたちの研究やねんけど
人間のフィードバックをうまく活用した例として、ChatGPTのRLHF(人間のフィードバックを使った強化学習)がめっちゃ有名やねん。これ、モデルを微調整するときに人間のフィードバックを取り入れるんやけど、これがほんまに成功の鍵になってるんよ(Liさんたち、2023年)。RLHFを使うと、モデルが人間とのやり取りやフィードバックから学習できるようになって、性能がグンと上がるし、より自然な会話ができるようになるねん。実際、文脈に合った一貫性のある返答を生成する能力がすごいんよ。
それだけやなくて、RLHFはサンプル効率もめっちゃ良くできるねん。だいたい5万サンプルくらいのラベル付きデータがあれば十分やから、トレーニング時間も短縮できる可能性があるんよ(Lambertさんたち、2022年)。これ、なんでそんなにありがたいかっていうと、有名な強化学習モデルって訓練にめちゃくちゃ時間かかるからやねん。例えば、AlphaGoは1ヶ月、OpenAI Fiveなんか10ヶ月もかかったんやで(OpenAIさんたち、2019年;Silverさんたち、2017年)。こういう事例見ると、トレーニング時間とサンプル効率、両方ともまだまだ改善の余地がいっぱいあるってわかるやろ?
ただな、人間のフィードバックを取り入れることの限界も考えなあかんねん。訓練データに含まれるバイアスとか、人間のフィードバックを通じて入ってくるバイアスがあると、間違った回答や偏った回答が出てきてしまうことがあるんよ。実際、ChatGPTモデルは「ハルシネーション」って呼ばれる、もっともらしいけど嘘の情報を生成したり、事実と違う情報を出したりすることがあって、これが実用面でかなりのネックになってるねん(Pengさんたち、2023年)。
こういう限界を和らげるのに役立つのが「説明可能性」の技術やねん。モデルがどうやって判断してるかを明らかにすることで、ユーザーが問題を見つけて対処できるようになるんよ。HITL(人間参加型)と説明可能性を組み合わせることで、人間が監視したり介入したりできるから、偏った出力や間違った出力のリスクを軽減できるねん(Pengさんたち、2023年)。これ見ても、大規模言語モデルの意思決定プロセスを理解するために説明可能性がどれだけ大事かわかるやろ?あと、透明性がないことと訓練データのバイアスが合わさると、ユーザーが不正確な情報や有害なコンテンツを拡散してしまう可能性もあるねん(Rayさん、2023年)。
説明のアプローチにはいろんなもんがあるんよ。
自然言語処理で使われる古典的なアテンション機構(Glanoisさんたち、2021年)、大規模言語モデルによるテキストベースの説明(Xuさんたち、2023年;ZiniさんとAwadさん、2022年)、記号的表現(Sabaさん、2023年)とかがあって、これらを使えばユーザーがモデルの推論を理解して、潜在的な欠陥を見つけられるようになるねん。特に最近注目されてるのが、大規模言語モデル自体を使って説明を生成するやり方やねん。例えば、ZiniさんとAwadさん(2022年)は、モデル自身に自分の意思決定を透明に説明させるアプローチを取ってるんよ。同じように、Xuさんたち(2023年)は、人間の指示とGPTの暗黙の知識を組み合わせた説明可能な指標を提案してて、出力に対して人間の判断に沿った説明を提供してるねん。
説明可能性にはもう一つ注意点があってな。xAI(説明可能なAI)の研究の大部分は、研究者が「こういう説明がええやろ」って勝手に想定したもんに偏ってるねん(Millerさん、2019年b)。実際に使う人間のエンドユーザーの好みや専門知識を考慮してないことが多いんよ。オペレーターからのフィードバックに基づいて、モデルやアプローチは言葉遣いや表現方法を適応させていかなあかんし、そのためにはもっと人間中心の開発が必要やねん(PuiuttaさんとVeithさん、2020年)。説明可能性の手法がほんまにユーザーの期待に合ってるかを確認するために、xAIシステムを開発するための包括的なガイドラインと要件が必要やと訴えたいねん。
でもな、人間とロボットの協働には説明可能性以外にも課題があるんよ。エージェントを実際に配備するとき、信頼の要件がめっちゃ重要やねん。信頼がなかったら、そのエージェントは使われへんからな。De Santisさんたち(2008年)によると、信頼できるロボットだけがチームで働けるんやって。人間はロボットを擬人化しがちで(DamianoさんとDumouchelさん、2018年)、ロボットの認知能力を過大評価してしまう傾向があるねん。De Santisさんたち(2008年)は、ユーザーのメンタルモデルが「偽物のロボット信頼性」を生み出すかもしれんって指摘してて、これが人間とロボットの協働における安全性の問題をさらに深刻にしてるんよ。
---
## Page 41
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p041.png)
### 和訳
ロボットとの協力作業についてやねんけど、この協力がうまいこといくためには、ロボットの動きが予測できること、ちゃんとテストできること、なんでそういう判断したんかが説明できること、それとパフォーマンスが上がっていくこと、これらが大事やねん。せやから俺らは、長期的には「人間参加型の強化学習」(HITL RL)における信頼と安全の問題に研究の焦点を当てていこう言うてるわけや。
ほんで最後に、安全性における説明可能なAI(xAI)の活用について、今後の研究を提案するで。興味深いのは、説明可能なAIの手法を組み込んだ安全が超重要なシステムの開発やねん。これによって、AIエージェントがどうやって判断してるかが透明で、解釈しやすくて、人間の意思決定者にもすぐ理解できるようになるねん。具体的な技術としては、「反実仮想」っていうのがあって、これは「もしこの条件が違ってたら結果どうなってたん?」みたいに、特定の判断に至った要因を検証できる方法やねん。あと、自然言語での説明を使って、AIがどう判断したかを人間ユーザーに伝える方法もあるで。他の研究分野としては、AIエージェントの安全性と頑健性を評価・テストする方法の開発やな。例えば、データの分布が変わった時にもちゃんと動くかとか、わざと騙そうとする攻撃(敵対的攻撃)に耐えられるかのテスト、それからAIの判断過程におけるバイアスを検出して軽減する方法とかやな。
それと強調しときたいんやけど、信頼とユーザー体験、この両方がAIアプリケーションの成功を決める上でめっちゃ重要な役割を果たすねん。安全性と信頼が特に大事な分野もあるんやけど、医療、教育、エンターテイメントみたいな分野では、その効果と受け入れられ方がユーザー体験にかかってるわけや。ユーザーがAIシステムに対して快適で、自信を持てて、満足できひんかったら、ちゃんと使ってもらえへんし、恩恵も受けられへんねん(Holzinger, 2021; Holzinger et al., 2022a)。信頼を築くには、判断過程の透明性、説明可能性、説明責任を確保して、ユーザーの信頼感を高める必要があるねん。同時に、直感的なインターフェース、個人に合わせたやり取り、問題解決能力を通じて、ポジティブでスムーズなユーザー体験を提供することが、ユーザーの満足度と普及に不可欠やねん(Arzate Cruz & Igarashi, 2020b)。信頼と素晴らしいユーザー体験の両方を確立するバランスを取ることが、様々な分野でAIアプリケーションの成功と広範な受け入れを推進する上でめっちゃ重要やねん。今後の研究では、信頼構築の取り組みがスムーズなユーザー体験を邪魔したり(あるいはユーザー体験のために犠牲にされたり)せんように、両方の目標を効果的に両立させる方法を探る必要があるわ。このセクションでは、いろんな研究の方向性を提案してきたで。次のセクションでは、この論文の内容と核心的な洞察をまとめて、HITL RLの将来に対する俺らのビジョンで締めくくるで。
## 8. 結論と将来の展望
まとめると、強化学習(RL)っていうのは根本的にめっちゃ難しい問題設定やから、人間参加型のやり取りからものすごい恩恵を受けられるってことを俺らは強調するわ。人間の専門家は、その課題に関して長年の経験で培った概念的な理解を貢献できるから、頑健性と説明可能性が大幅に向上するねん(Holzinger, 2021)。たくさんのアプローチが、RLが人間中心のアプローチから恩恵を受けることを示してきたで(Li et al., 2019; Mathewson & Pilarski, 2022)。
さらに俺らは、特にHITL RLがxAI(説明可能なAI)アプローチからめっちゃ恩恵を受けるって主張するわ。なんでかっていうと、これらは根本的に人間のためのアプローチやから、結果として、成功するやり取り、受け入れ、信頼、それにエージェントの限界についての概念的な知識を確保できるねん(Heuillet et al., 2021; Milani et al., 2022)。
HITL RLソリューションを展開するための以下のフェーズを俺らは特定したで:(1) 初期エージェント開発、(2) エージェント学習、(3) エージェント評価、(4) エージェント展開。俺らの研究では、xAIがこれらの各フェーズをどうサポートできるか、そしてどんな考慮事項があるかを議論してるねん。
---
## Page 42
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p042.png)
### 和訳
Retzlaffらの研究やねん。
うまいことロボット動かすにはどうしたらええか、っていうとな、結局HITL(人間がループの中に入る方式)を組み合わせることで、人間とロボットの協力がめっちゃうまくいくようになって、仕事の生産性も効率もグンと上がんねん。
導入フェーズではな、インタラクティブで、しっかりしてて、筋の通ったモデルの要約があると、柔軟で透明性のある作業の流れができるんやわ。エージェントがインタラクティブに学習してる間は、xAI(説明可能なAI)のアプローチを使うと、現場での再計画とか模倣学習を通じて、もっと効率的にトレーニングできるようになるねん。評価フェーズでは、モデルがどんな判断したかを詳しく説明してくれることで、訓練されたモデルの中身がよう分かるようになって、「このまま導入してええんか、それともまた開発サイクル回した方がええんか」っていう判断が、ちゃんと情報に基づいてできるようになるんや。導入フェーズでは、行動についてシンプルで素早い説明があったり、エラー対応についていろんな説明があったりすると、ユーザーがエージェントを信頼する気持ちがめっちゃ高まって、より効率的な協力ができるようになるんやで。
最後にめっちゃ大事なこと言うとな、ワシらはインタラクティブな人間とロボットの協力っていうビジョンを提案してんねん。これがあると、強化学習の新しい使い道が開けて、人間もロボットもそれぞれの力を最大限に発揮できるようになるんや。こういう協力関係を築くには、両者の間にしっかりしたやり取りと信頼関係が必要やねんけど、それは包括的な説明と、エージェントが作り出すメンタルモデル(頭の中の理解の仕方みたいなもんや)を深くて直感的に理解することでしか実現できひんのや。
**謝辞**
この研究の一部は、オーストリア科学基金(FWF)のプロジェクト:P-32554「説明可能な人工知能」から資金提供を受けてんねん。また、この研究の一部はアルバータ大学のIntelligent Robot Learning(IRL)Labで行われたんやけど、ここはAlberta Machine Intelligence Institute(Amii)からの研究助成金、Canada CIFAR AI Chair、Amii、Compute Canada、Huawei、Mitacs、NSERCの支援を一部受けてるんや。あと、Antonie Bodley博士には編集と校正でお世話になったことも感謝してるで。
**参考文献**
Abel, D., Salvatier, J., Stuhlmüller, A., & Evans, O. (2017). Agent-agnostic human-in-the loop reinforcement learning(エージェントに依存しない人間参加型強化学習). arXiv preprint arXiv:1701.04079.
Aiyappa, R., An, J., Kwak, H., & Ahn, Y.-Y. (2023, March). Can we trust the evaluation on ChatGPT?(ChatGPTの評価って信用してええんか?)[arXiv:2303.12767 [cs]]. https://doi.org/10.48550/arXiv.2303.12767
Akanksha, E., Jyoti, Sharma, N., & Gulati, K. Review on Reinforcement Learning, Research Evolution and Scope of Application(強化学習のレビュー、研究の進化と応用範囲). In: In 2021 5th International Conference on Computing Methodologies and Communication (ICCMC). 2021, April, 1416–1423. https://doi.org/10.1109/ICCMC51019.2021.9418283.
Akrour, R., Schoenauer, M., & Sebag, M. Preference-based policy learning(好みに基づく方策学習)(D. Gunopulos, T. Hofmann, D. Malerba, & M. Vazirgiannis, Eds.). In: Machine learning and knowledge discovery in databases. Ed. by Gunopulos, D., Hofmann, T., Malerba, D., & Vazirgiannis, M. Berlin, Heidelberg: Springer Berlin Heidelberg, 2011, 12–27. https://doi.org/978-3-642-23780-5.
Akrour, R., Tateo, D., & Peters, J. Towards reinforcement learning of human readable policies(人間が読める方策の強化学習に向けて). In: In Workshop on deep continuous-discrete machine learning. 2019.
400
---
## Page 43
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p043.png)
### 和訳
# Human-in-the-Loop 強化学習(参考文献)
Alber, M., Lapuschkin, S., Seegerer, P., Hägele, M., Schütt, K. T., Montavon, G., Samek, W., Müller, K.-R., Dähne, S., & Kindermans, P.-J.(2019)。ニューラルネットワークを調査せよ!Journal of Machine Learning Research、20巻93号、1-8ページ。
Alonso, J. M., Ramos-Soto, A., Castiello, C., & Mencar, C.「説明できるAIビール分類器」。Sicsa realxにて発表。2018年。https://ceur-ws.org/Vol-2151/Paper_S1.pdf
Amershi, S., Begel, A., Bird, C., DeLine, R., Gall, H., Kamar, E., Nagappan, N., Nushi, B., & Zimmermann, T.「機械学習のためのソフトウェアエンジニアリング:ケーススタディ」。2019年IEEE/ACM第41回国際ソフトウェアエンジニアリング会議:ソフトウェアエンジニアリング実践編(ICSE-SEIP)にて発表。カナダ、ケベック州モントリオール:IEEE、2019年5月、291-300ページ。ISBN:978-1-72811-760-7。https://doi.org/10.1109/ICSE-SEIP.2019.00042
これな、機械学習のソフト開発ってどうやってんの?っていう実際の現場の話やねん。
Amir, O., Kamar, E., Kolobov, A., & Grosz, B.「エージェント訓練のためのインタラクティブな教え方」。IJCAI 2016にて発表。2016年。
要するにAIに「こうやってやるんやで~」って対話的に教える方法の話やな。
Anderson, A., Dodge, J., Sadarangani, A., Juozapaitis, Z., Newman, E., Irvine, J., Chattopadhyay, S., Olson, M., Fern, A., & Burnett, M.(2020)。強化学習の説明に対する普通の人々のメンタルモデル。ACM Transactions on Interactive Intelligent Systems(TiiS)、10巻2号、1-37ページ。https://doi.org/10.1145/3366485
これめっちゃ面白いねん。普通の人がAIの説明聞いて、頭の中でどう理解してるか調べた研究やで。
Anderson, F., & Bischof, W. F.「ジェスチャーガイドを使った学習とパフォーマンス」。SIGCHI会議(CHI '13)にて発表。フランス、パリ:Association for Computing Machinery、2013年、1109-1118ページ。ISBN:9781450318990。https://doi.org/10.1145/2470654.2466143
Andreas, J., Klein, D., & Levine, S.「ポリシースケッチを使ったモジュール式マルチタスク強化学習」。第34回機械学習国際会議にて発表。70巻。Proceedings of Machine Learning Research。PMLR。2017年、166-175ページ。
なんでかっていうと、複数のタスクを同時にこなせるようにするために、タスクをモジュール(部品)みたいに分けて学習させるっていうアイデアやねん。めっちゃ効率的やで。
Arakawa, R., Kobayashi, S., Unno, Y., Tsuboi, Y., & Maeda, S.-i.(2018)。DQN-TAMER:扱いにくいフィードバックを使った人間参加型強化学習。arXivプレプリント arXiv:1810.11748。
これほんまに画期的でな、人間が「ええやん」「あかんやん」ってフィードバックするのを、DQN(ディープQネットワーク)っていう強化学習と組み合わせた手法やねん。
Arrieta, A. B., Díaz-Rodríguez, N., Del Ser, J., Bennetot, A., Tabik, S., Barbado, A., García, S., Gil-López, S., Molina, D., Benjamins, R., Chatila, R., & Herrera, F.(2019)。説明可能な人工知能(XAI):責任あるAIに向けた概念、分類、機会と課題。arXiv:1910.10045 [cs]。2022年1月5日取得、http://arxiv.org/abs/1910.10045
XAIっていうのは「なんでそうなったん?」ってAIに説明させる技術のことやねん。ブラックボックスやったらあかんから、ちゃんと説明できるようにしようって話や。
Arzate Cruz, C., & Igarashi, T.「インタラクティブ強化学習のサーベイ:設計原則と未解決の課題」。2020年ACM Designing Interactive Systems会議(DIS '20)にて発表。ニューヨーク、NY、USA:Association for Computing Machinery、2020年7月、1195-1209ページ。ISBN:978-1-4503-6974-9。https://doi.org/10.1145/3357236.3395525
これ同じ著者が同じ年に同じ会議で発表してるから、重複してるみたいやな。人間とAIが一緒になって学習を進めていく「インタラクティブ強化学習」の全体像をまとめたサーベイ論文やで。
Atrey, A., Clary, K., & Jensen, D. D.(2019)。深層強化学習における顕著性マップの反事実分析:説明的ではなく探索的。arXivプレプリント arXiv:1912.05743。http://arxiv.org/abs/1912.05743
「顕著性マップ」っていうのは、AIがどこ見て判断したかを可視化したもんやねん。でもこの論文、それが説明として使えるんか?って疑問を投げかけてるんや。「探索的には使えるけど、ほんまの説明にはなってへんで」って主張してるわけやな。
---
## Page 44
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p044.png)
### 和訳
Retzlaff ら
Audibert, J.-Y., Munos, R., & Szepesvári, C. (2009). マルチアームバンディット問題における分散推定を使った探索と活用のトレードオフ。Theoretical Computer Science, 410 (19), 1876–1902. https://doi.org/10.1016/j.tcs.2009.01.016
→ これな、要するに「どのスロットマシン回したら一番儲かるかわからんけど、色々試しながら(探索)、ええやつに集中する(活用)、このバランスどうとるねん?」って話やねん。分散、つまりバラつき具合を見て判断しよう、っちゅう研究やな。
Bach, S., Binder, A., Montavon, G., Klauschen, F., Müller, K.-R., & Samek, W. (2015). 非線形分類器の判断に対するピクセル単位の説明:レイヤー単位の関連性伝播法について。PloS one, 10 (7), e0130140. https://doi.org/10.1371/journal.pone.0130140
→ AIが画像見て「これ猫やわ」って判断したとき、「どのピクセル見て猫って思ったん?」を逆算して説明できるようにする技術やねん。めっちゃ複雑な判断でも、どこ見てたか可視化できるんやで。
Baniecki, H., Kretowicz, W., Piatyszek, P., Wisniewski, J., & Biecek, P. (2022). Dalex:Pythonで使える対話型の説明可能性と公平性を備えた責任ある機械学習。The Journal of Machine Learning Research, 22 (1), 214:9759–214:9765. https://doi.org/10.5555/3546258.3546472
→ Pythonで動くツールの話や。AIの判断を「なんでそうなったん?」って説明できるようにしたり、「えこひいきしてへん?」ってチェックできるようにするやつやな。責任持ってAI使おうぜ、ってコンセプトやねん。
Bastani, O., Pu, Y., & Solar-Lezama, A. 方策抽出による検証可能な強化学習 (S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, & R. Garnett 編). In: Advances in neural information processing systems. 31. Curran Associates, Inc., 2018.
→ 強化学習っていう、AIが試行錯誤で学ぶやつあるやろ?あれの判断ルールを取り出して「ほんまにこれで大丈夫か」って検証できるようにする研究やねん。ブラックボックスやと怖いからな。
Battaglia, P. W., Hamrick, J. B., Bapst, V., Sanchez-Gonzalez, A., Zambaldi, V., Malinowski, M., Tacchetti, A., Raposo, D., Santoro, A., Faulkner, R., Gulcehre, C., Song, F., Ballard, A., Gilmer, J., Dahl, G., Vaswani, A., Allen, K., Nash, C., Langston, V., . . . Pascanu, R. (2018). 関係的帰納バイアス、ディープラーニング、グラフネットワーク。arXiv preprint arXiv:1806.01261.
→ めっちゃ著者多いな!これはな、「モノとモノの関係性」をAIに上手く学ばせる方法についての論文やねん。グラフネットワークっていう、点と線で繋がりを表すやつがディープラーニングとどう相性ええか、みたいな話や。
Behl, A., Hosseini Jafari, O., Karthik Mustikovela, S., Abu Alhaija, H., Rother, C., & Geiger, A. バウンディングボックス、セグメンテーション、物体座標:自動運転シナリオでの3Dシーンフロー推定において認識はどれくらい重要か? In: In Proceedings of the IEEE International Conference on Computer Vision. 2017, 2574–2583.
→ 自動運転の話やで。「この物体なんや?」って認識することと、「この物体どう動いてる?」って3Dで追跡すること、どっちがどんだけ大事なん?ってのを調べた研究や。四角い枠(バウンディングボックス)で囲むんと、輪郭くっきり切り取る(セグメンテーション)のと、どっちがええねん、みたいな比較もしてるで。
Bellemare, M. G., Candido, S., Castro, P. S., Gong, J., Machado, M. C., Moitra, S., Ponda, S. S., & Wang, Z. (2020). 強化学習を使った成層圏気球の自律航行。Nature, 588 (7836), 77–82. https://doi.org/10.1038/s41586-020-2939-8
→ これめっちゃおもろいねん!成層圏、つまり空のめっちゃ高いとこ飛んでる気球を、AIが勝手に操縦できるようにしたって話や。強化学習で風の流れ読んで、うまいこと目的地に向かうんやで。Natureに載ってるから、ほんまにすごい研究やな。
Ben-Younes, H., Zablocki, É., Pérez, P., & Cord, M. (2022). マルチレベル融合による運転行動の説明。Pattern Recognition, 123, 108421. https://doi.org/10.1016/j.patcog.2021.108421
→ 自動運転のAIが「なんでブレーキ踏んだん?」とか「なんで右に曲がったん?」を説明できるようにする研究やねん。いろんなレベルの情報を組み合わせて(マルチレベル融合)、人間にわかりやすく説明するんや。
Bruneau, D., Sasse, M. A., & McCarthy, J. 目は絶対嘘つかへん:HCI研究におけるアイトラッキングデータの活用。In: CHI 2002: Conference on Human Factors in Computing Systems. University College London, 2002.
→ アイトラッキング、つまり「人がどこ見てるか」を追跡する技術の話や。人間とコンピュータのやりとり(HCI)の研究で、目の動き見たら本音がわかるやろ?ってことやねん。タイトルがええな、「目は嘘つかへん」って。
Buchanan, B. G., & Shortliffe, E. H. (1984). ルールベースエキスパートシステム:スタンフォード・ヒューリスティック・プログラミング・プロジェクトのMYCIN実験。Artificial Intelligence. https://doi.org/10.1016/0004-3702(85)90067-0
→ これは歴史的に重要な研究やで。MYCINっていう、「もし〜やったら〜する」ってルールで動く医療診断AIの話や。1980年代やから、今のディープラーニングとか全然ない時代やねん。AIの説明可能性の原点みたいなもんやな。
Buchelt, A., Adrowitzer, A., Kieseberg, P., Gollob, C., Nothdurft, A., Eresheim, S., Tschiatschek, S., Stampfer, K., & Holzinger, A. (2024). 人工知能の探求
→ これは途中で切れてるな。2024年の論文で、AIの探求についての研究っぽいけど、続きがないとなんとも言えへんわ。
---
## Page 45
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p045.png)
### 和訳
人間参加型の強化学習
森林の生態学と管理にドローンを応用するための研究やで。これ、Forest Ecology and Managementっていう雑誌の551巻、121530ページに載ってんねん。(https://doi.org/10.1016/j.foreco.2023.121530)
Caltagirone, L.らの研究。LiDAR(レーザーで距離測るセンサーやな)を使って、完全畳み込みニューラルネットワークっていうAIで走行経路を作り出す話やねん。2017年のIEEEの知的交通システムに関する国際会議で発表されたやつや。1〜6ページ。(https://doi.org/10.1109/ITSC.2017.8317618)
Cederborg, T.らの研究。人間の先生と一緒にAIの方針を形作っていくっていう話やねん。2015年の第24回人工知能に関する国際会議で発表されて、3366〜3372ページや。
Chakraborty, A.らの研究(2021年)。敵対的攻撃とその防御についてのまとめ論文やで。敵対的攻撃っていうのは、AIをだまそうとする攻撃のことやねん。CAAI Transactions on Intelligence Technologyの6巻1号、25〜45ページ。(https://doi.org/10.1049/cit2.12028)
Chandrasekaran, B.らの研究(1989年)。問題解決における制御戦略の説明についてや。IEEE Intelligent Systemsの4巻1号、9〜15ページと19ページ。出版はIEEE Computer Societyやで。(https://doi.org/10.1109/64.21896)
Choi, J. H.らの研究(2023年1月)。「ChatGPTがロースクールに行く」っていうタイトルや。ChatGPTが法律の試験受けたらどうなるかって話やねん。めっちゃ面白そうやろ?(https://doi.org/10.2139/ssrn.4335905)
Christiano, P.らの研究(2017年)。人間の好みから学ぶ深層強化学習やで。なんでかっていうと、AIに「こっちの方がええで」って人間が教えてあげることで、AIがもっと賢くなれるねん。arXivプレプリント、arXiv:1706.03741。
Cui, Y.らの研究(2020年)。EMPATHICフレームワークっていうやつで、人間の暗黙的なフィードバックからタスクを学習する話や。暗黙的っていうのは、はっきり言葉にせんでも態度とかで伝わるやつやな。arXivプレプリント、arXiv:2009.13649。
Da Silva, F. L.らの研究。深層強化学習エージェントのための不確実性を考慮した行動アドバイスや。「これ自信ないわ」ってAIが分かるようにして、そういう時にアドバイスもらえるようにするねん。2020年のAAAI人工知能会議の議事録、34巻、5792〜5799ページ。(https://doi.org/10.1609/aaai.v34i04.6036)
Damiano, L.とDumouchel, P.の研究(2018年)。人間とロボットが一緒に進化していく中での擬人化についてや。擬人化っていうのは、ロボットを人間みたいに感じることやねん。Frontiers in Psychologyの9巻、468ページ。(https://doi.org/10.3389/fpsyg.2018.00468)
Daniel, C.らの研究(2016年)。階層的相対エントロピー方策探索や。これ、めっちゃ数学的な話やけど、AIが効率よく学習するための方法やねん。Journal of Machine Learning Researchの17巻、1〜50ページ。
De Graaf, M. M.とMalle, B. F.の研究。人間がどうやって行動を説明するか、そして自律的な知的システムもそうすべきやっていう話や。2017年のAAAI秋季シンポジウムシリーズで発表されたで。
De Santis, A.らの研究(2008年)。人間とロボットの物理的なやり取りについてのアトラス(地図帳みたいなまとめ)やねん。Mechanism and Machine Theoryの43巻3号、253〜270ページ。(https://doi.org/10.1016/j.mechmachtheory.2007.03.003)
Del Ser, J.らの研究(2024年)。信頼できる反事実的説明を生成する方法についてや。反事実的説明っていうのは「もしこうやったら結果変わってたで」っていう説明のことやねん。ほんまに大事な話や。Information Sciencesの655巻、119898ページ。(https://doi.org/10.1016/j.ins.2023.119898)
Doran, D.らの研究(2017年10月)。説明可能なAIって実際どういう意味なん?っていう新しい概念化の話や。arXiv:1710.00794 [cs]。(https://doi.org/10.48550/arXiv.1710.00794)
Dragan, A. D.の研究(2015年7月)。読みやすいロボットの動作計画についての博士論文やで。カーネギーメロン大学で取った学位論文やねん。(https://doi.org/10.1184/R1/6720419.v1)
Eder, K.、Harper, C.、Leonards, U.の研究。人間参加型ロボットの安全性に向けて:ロボットの同僚の安全保証における課題と機会っていう話や。一緒に働くロボットをどうやって安全にするかっていう、めっちゃ実践的な話やねん。
403
---
## Page 46
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p046.png)
### 和訳
Retzlaff et al.
第23回 IEEE 国際ロボットと人間のインタラクティブコミュニケーションシンポジウム。
IEEE、2014年、660-665頁。https://doi.org/10.1109/ROMAN.2014.6926328
欧州議会。(2020). 2020年10月20日の欧州議会決議。これな、AIとかロボット工学とかそれに関連する技術の倫理面をどう扱うか、欧州委員会に「こうしたらええんちゃう?」っていう提案を出したやつやねん。https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX:52020IP0275
Evans, T., Retzlaff, C. O., Geißler, C., Kargl, M., Plass, M., Müller, H., Kiehl, T.-R., Zerbe, N., & Holzinger, A. (2022). 説明可能性のパラドックス:デジタル病理学におけるXAIの課題。これ、めっちゃおもろい話やねんけど、「AIの判断を説明できるようにしよう」ってXAI(説明可能なAI)を病理診断の分野で使おうとしたら、逆に難しい問題がいっぱい出てきたって話やねん。Future Generation Computer Systems、133巻(8号)、281-296頁。https://doi.org/10.1016/j.future.2022.03.009
Eysenbach, B., Gupta, A., Ibarz, J., & Levine, S. (2018). 多様性こそ全てや:報酬関数なしでスキルを学習する。なんでかっていうと、普通の強化学習って「これやったらご褒美もらえる」って報酬を設定せなあかんねんけど、この研究では報酬なしでもAIが勝手にいろんなスキルを身につける方法を提案してんねん。arXivプレプリント arXiv:1802.06070。
Florensa, C., Duan, Y., & Abbeel, P. (2017). 階層的強化学習のための確率的ニューラルネットワーク。これは、AIが大きな問題を小さく分けて段階的に学んでいく「階層的強化学習」のための手法やで。arXivプレプリント arXiv:1704.03012。
Fukuchi, Y., Osawa, M., Yamakawa, H., & Imai, M. 方策が変わる強化学習エージェントへの指示ベースの行動説明の適用(D. Liu, S. Xie, Y. Li, D. Zhao, & E.-S. M. El-Alfy編)。ニューラル情報処理国際会議。Springer、2017年、100-108頁。https://doi.org/10.1007/978-3-319-70087-8_11。ほんまに、AIの行動が途中で変わっても「なんでそうしたん?」って説明できるようにする研究やねん。
Fukuchi, Y., Osawa, M., Yamakawa, H., & Imai, M. 対話的強化学習エージェントのための自律的自己説明。第5回人間エージェントインタラクション国際会議。ニューヨーク:Association for Computing Machinery、2017年、97-101頁。https://doi.org/10.1145/3125739.3125746。これ、AIが人間に教えてもらいながら学ぶときに、自分で「俺、今こういう理由でこうしてんねん」って説明できるようにする研究やで。
Geirhos, R., Jacobsen, J.-H., Michaelis, C., Zemel, R., Brendel, W., Bethge, M., & Wichmann, F. A. (2020). ディープニューラルネットワークにおけるショートカット学習。Nature Machine Intelligence、2巻(11号)、665-673頁。https://doi.org/10.1038/s42256-020-00257-z。これめっちゃ重要な話やねんけど、AIって本質を理解せんと「近道」で問題解いちゃうことがあんねん。例えば、「牛の写真」を見分けるAIが、実は牛やなくて背景の草原を見て判断してた、みたいなことが起こるねん。
Glanois, C., Weng, P., Zimmer, M., Li, D., Yang, T., Hao, J., & Liu, W. (2021). 解釈可能な強化学習に関するサーベイ。強化学習の判断を人間が理解できるようにする研究をまとめた総説やで。arXivプレプリント arXiv:2112.13112。
Goodfellow, I. J., Shlens, J., & Szegedy, C. (2014). 敵対的サンプルの説明と活用。これ有名な話やねんけど、人間には分からんような微妙な変化を画像に加えるだけで、AIがめっちゃ間違えるようになる「敵対的サンプル」について、なんでそうなるか説明して、逆に利用する方法も提案してんねん。arXivプレプリント arXiv:1412.6572。
Griffith, S., Subramanian, K., Scholz, J., Isbell, C. L., & Thomaz, A. L. ポリシーシェイピング:人間のフィードバックと強化学習の統合(C. Burges, L. Bottou, M. Welling, Z. Ghahramani, & K. Weinberger編)。Advances in Neural Information Processing Systems、26巻、2013年。人間が「それええやん」「それあかんで」ってAIに教えながら学習させる方法やねん。
Guan, L., Verma, M., Guo, S., Zhang, R., & Kambhampati, S. (2020). 人間参加型強化学習における説明で補強されたフィードバック。人間がAIに教えるとき、ただ「正解・不正解」だけやなくて、「なんでそうなるか」って説明も一緒に渡したらもっとええ学習できるんちゃう?って研究やで。arXivプレプリント arXiv:2006.14804v3。
Gunning, D., & Aha, D. W. (2019). DARPAの説明可能な人工知能プログラム。AI Magazine、40巻(2号)、44-58頁。https://doi.org/10.1609/aimag.v40i2.2850。DARPAってアメリカの国防総省の研究機関やねんけど、そこが「AIの判断を人間に分かるように説明できるようにしよう」って大規模なプロジェクトをやってんねん。
Guo, W., Wu, X., Khan, U., & Xing, X. EDGE:深層強化学習の方策を説明する(M. Ranzato, A. Beygelzimer, Y. Dauphin, P. Liang, & J. W. Vaughan編)。Advances in Neural Information Processing Systems(M. Ranzato, A. Beygelzimer,
404
---
## Page 47
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p047.png)
### 和訳
**Human-in-the-Loop 強化学習**
Y. Dauphin, P. Liang, & J. W. Vaughan 編). Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P., & Vaughan, J. W. 編集. 34. 2021, 12222–12236.
Guo, Z., Yao, C., Feng, Y., & Xu, Y. (2022). 人間の事前知識を使った強化学習のサーベイ論文やねん。Journal of Uncertain Systems, 15 (01), 2230001. https://doi.org/10.1142/S1752890922300011
Gupta, P., Puri, N., Verma, S., Kayastha, D., Deshmukh, S., Krishnamurthy, B., & Singh, S. (2019). 「お前の動き、説明してみぃ」っていう論文で、AIエージェントが何をしとるんか、大事な部分だけピックアップして見せてくれる「フォーカス特徴顕著性」っていう手法の話やねん。arXiv preprint arXiv:1912.12191v2.
Ha, D., & Schmidhuber, J. (2018). ワールドモデルっていう、AIが頭の中で世界をシミュレーションする仕組みの論文やで。arXiv preprint arXiv:1803.10122. https://doi.org/10.5281/ZENODO.1207631
Habibian, S., Jonnavittula, A., & Losey, D. P. (2021). 「ほな、これ教えてもらったで」っていう論文で、AIが報酬を学習するために、うまいこと質問を投げかける方法について書いてあるねん。arXiv preprint arXiv:2107.01995.
Hasanbeig, M., Jeppu, N. Y., Abate, A., Melham, T., & Kroening, D. DeepSynth:深層強化学習でタスクを自動的に分割するためのオートマタ合成の話やねん。AAAI人工知能会議にて発表。2. 2021, 36.
Hayes, B., & Shah, J. A. ロボットのコントローラーをもっと分かりやすくしよう、自動で方策を説明してくれるようにする話やで。2017年のACM/IEEE人間-ロボットインタラクション国際会議にて発表。IEEE. 2017, 303–312. https://doi.org/10.1145/2909824.3020233.
Hazan, E., Kakade, S., Singh, K., & Van Soest, A. 最大エントロピー探索を数学的に効率よくやる方法の証明付き論文やねん(K. Chaudhuri & R. Salakhutdinov 編)。第36回国際機械学習会議論文集。97. Proceedings of Machine Learning Research. PMLR. 2019, 2681–2691.
Hein, D., Hentschel, A., Runkler, T., & Udluft, S. (2017). 粒子群最適化っていう手法を使って、人間が読んで分かるファジィ強化学習の方策を作る話やで。めっちゃ実用的なAI応用の話やねん。Engineering Applications of Artificial Intelligence, 65, 87–98. https://doi.org/10.1016/j.engappai.2017.07.005
Hein, D., Udluft, S., & Runkler, T. A. (2018). 遺伝的プログラミングで解釈可能な強化学習方策を作る話やねん。なんでかっていうと、AIの判断を人間が理解できるようにしたいからやで。Engineering Applications of Artificial Intelligence, 76, 158–169. https://doi.org/10.1016/j.engappai.2018.09.007
Hein, D., Udluft, S., & Runkler, T. A. 遺伝的プログラミングで解釈可能な強化学習方策を生成する話の続きやねん。遺伝的・進化的計算会議コンパニオンにて発表。Association for Computing Machinery, 2019, 23–24. https://doi.org/10.1145/3319619.3326755.
Hermann, T., Hunt, A., & Neuhoff, J. G. (2011). ソニフィケーション・ハンドブック。これは何かっていうと、データを音に変換する技術のことやねん。耳で情報を理解するっていう、めっちゃユニークなアプローチやで。Logos Verlag Berlin.
Hester, T., Vecerik, M., Pietquin, O., Lanctot, M., Schaul, T., Piot, B., Horgan, D., Quan, J., Sendonaris, A., Osband, I., Dulac-Arnold, G., Agapiou, J., Leibo, J., & Gruslys, A. デモンストレーションから深層Q学習する話やねん。ほんまに画期的で、人間のお手本を見せたらAIがそこから学習するっていう仕組みやで。AAAI人工知能会議論文集にて発表。32. 2018. https://doi.org/10.1609/aaai.v32i1.11757.
Heuillet, A., Couthouis, F., & Díaz-Rodríguez, N. (2021). 深層強化学習における説明可能性の話やねん。AIがなんでその判断をしたんか、ちゃんと説明できるようにしようっていう、めっちゃ大事なテーマやで。Knowledge-Based Systems, 214, 106685. https://doi.org/10.1016/j.knosys.2020.106685
405
---
## Page 48
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p048.png)
### 和訳
Retzlaffらの研究やねんけど、まあ見ていってや。
Holzingerさんの「次のフロンティア:ほんまに信頼できるAI」(Kampさんが編集した2021年のECML PKDD会議の論文集に入ってるやつやねん)。これ、427ページから440ページに載ってて、めっちゃ大事な話しとるわ。
Holzinger、Carrington、Muellerの3人が2020年に出した論文があんねんけど、これは「説明の質をどう測るか」っていう話や。「システム因果理解度スケール(SCS)」っていうのを提案してて、人間の説明と機械の説明を比べとるわけや。ドイツのAI学術誌『KI - Künstliche Intelligenz』のインタラクティブ機械学習特集号に載っとって、ダルムシュタット工科大学のKersting先生が編集しとるやつやねん。34巻2号の193〜198ページやで。
で、2022年にはHolzingerさんがDehmer、Emmert-Streib、Cucchiara、Augenstein、Del Ser、Samek、Jurisica、Díaz-Rodríguezっていうめっちゃ豪華なメンバーと一緒に論文出しとるねん。「情報融合」がキーワードで、これが分野横断的な技術として、頑健で説明可能で信頼できる医療AIを実現するための要になるって話や。『Information Fusion』誌の79巻3号、263〜278ページに載っとるで。
同じくHolzingerさんが2021年にMalle、Saranti、Pfeiferと出した論文もあって、これはグラフニューラルネットワークを使ってマルチモーダルな因果理解性を目指すっていう研究やねん。情報融合を使って説明可能AIを実現しようっていう話で、『Information Fusion』の71巻7号、28〜37ページや。
HolzingerとMüllerが2021年に『Computer』誌に出した論文は、医療AIにおける説明可能性と因果理解性をサポートするための人間とAIのインターフェースについて書いとるわ。54巻10号の78〜86ページやで。
2022年にはHolzingerさんがSaranti、Angerschmid、Retzlaff、Gronauer、Pejakovic、Medel、Krexner、Gollob、Stampferっていうメンバーと一緒に「スマート農場と林業のデジタル変革には人間中心のAIが必要やで」っていう論文出しとるねん。課題と今後の方向性について『Sensors』誌の22巻8号、論文番号3043で発表しとるわ。
Holzingerさんらが2022年に出した「説明可能AIの手法 - 簡単な概要」っていう論文は、XXAI講義ノート(人工知能シリーズLNAI 13200)に収録されとるで。Springerから出とって、Saranti、Molnar、Biececk、Samekとの共著やねん。
同じく2022年にHolzinger、Stampfer、Nothdurft、Gollob、Kiesbergが「スマート林業におけるAIの課題」っていう論文を出しとって、これはヨーロッパ情報学研究コンソーシアム(ERCIM)のニュースの130号(7月号)40〜41ページに載っとるわ。
Hussein、Gaber、Elyan、Jayneが2017年に出した「模倣学習:学習手法のサーベイ」はACM Computing Surveys誌の50巻2号に載っとるで。ニューヨークのACM(米国計算機学会)が出版しとるやつやねん。
2021年にIbarz、Tan、Finn、Kalakrishnan、Pastor、Levineが「深層強化学習でロボットを訓練する方法:我々が学んだ教訓」っていう論文出しとって、これがめっちゃ実践的でええ論文やねん。『International Journal of Robotics Research』の40巻4-5号、698〜721ページや。
Icarte、Klassen、Valenzano、McIlraithが2018年に出した論文は、「リワードマシン」を使って強化学習における高レベルのタスク指定と分解をやろうっていう話や。DyとKrauseが編集した第35回国際機械学習会議(ICML)の予稿集に入っとって、機械学習研究予稿集の80巻、2107〜2116ページやで。
同じくIcarteらが出した「部分観測強化学習のためのリワードマシン学習」っていう論文は、Wallach、Larochelle、Beygelzimer、d'Alché-Buc、Fox、Garnettが編集したNeural Information Processing Systems(NeurIPS)の予稿集に載っとるねん。
406ページ目やで。
---
## Page 49
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p049.png)
### 和訳
人間が関わる強化学習
Beygelzimer、F. d'Alché-Buc、E. Fox、& R. Garnett編集)。Wallach, H.、Larochelle, H.、Beygelzimer, A.、d'Alché-Buc, F.、Fox, E.、& Garnett, R.が編集。32巻。2019年。
Jain, M.、Lahlou, S.、Nekoei, H.、Butoi, V.、Bertin, P.、Rector-Brooks, J.、Korablyov, M.、& Bengio, Y.(2021年)。DEUP:直接的な認識論的不確実性予測。arXivプレプリント arXiv:2102.08501。
Jiang, Y.、Bharadwaj, S.、Wu, B.、Shah, R.、Topcu, U.、& Stone, P. 継続的な強化学習タスクのための時間論理ベースの報酬整形。第35回AAAI人工知能学会会議論文集にて発表。2021年。
→ これな、ずーっと続く強化学習のタスクで、時間の論理を使って報酬をうまいこと整えるって話やねん。
Jiang, Z.、& Luo, S. ニューラル論理強化学習(K. Chaudhuri & R. Salakhutdinov編集)。第36回国際機械学習会議論文集。97巻。機械学習研究論文集。PMLR。2019年、3110-3119ページ。
→ ニューラルネットワークと論理をくっつけた強化学習の新しいアプローチやで。めっちゃ賢いやつや。
Karalus, J.、& Lindner, F.(2021年)。反実仮想説明による人間参加型強化学習の収束加速。arXivプレプリント arXiv:2108.01358。
→ なんでかっていうと、「もしこうしてたらどうなってた?」っていう説明を使うことで、人間が教える強化学習がもっと早くうまくいくようになるって研究やねん。ほんまに便利な考え方やで。
Kartoun, U.、Stern, H.、& Edan, Y.(2010年)。人間とロボットの協調強化学習アルゴリズム。Journal of Intelligent & Robotic Systems、60巻2号、217-239ページ。https://doi.org/10.1007/s10846-010-9422-y
→ 人間とロボットが一緒に学んでいくアルゴリズムの話やな。お互い協力しながら賢くなっていくってわけや。
Kashyap, S.、Karargyris, A.、Wu, J.、Gur, Y.、Sharma, A.、Wong, K. C. L.、Moradi, M.、& Syeda-Mahmood, T. 異常を見つけるのに正しい場所を見る:自動位置学習による説明可能なAI[ISSN: 1945-8452]。2020 IEEE第17回国際バイオメディカルイメージングシンポジウム(ISBI)にて発表。2020年4月、1125-1129ページ。https://doi.org/10.1109/ISBI45749.2020.9098370
→ 医療画像で異常を探すとき、AIが「ここを見てるで」って説明できるようにする研究やねん。めっちゃ大事やで、医者さんが「なんでそう判断したん?」って聞けるようになるからな。
Keane, M. T.、Kenny, E. M.、Delaney, E.、& Smyth, B.(2021年2月)。もっとええ反実仮想説明があったらなぁ:反実仮想XAI技術の評価における5つの主要な欠点を正す[arXiv:2103.01035 [cs]]。https://doi.org/10.48550/arXiv.2103.01035
→ 「もしこうやったらこうなってた」っていう説明(反実仮想説明って呼ぶねん)の評価方法に5つの問題点があるって指摘してる論文や。説明可能なAIをもっとちゃんと評価せなあかんって話やな。
Khatib, O.、Yokoi, K.、Brock, O.、Chang, K.、& Casal, A. 人間の環境におけるロボット。第1回ロボットモーション制御ワークショップ論文集。RoMoCo'99(カタログNo.99EX353)。IEEE、1999年、213-221ページ。https://doi.org/10.1109/ROMOCO.1999.791078
→ ロボットが人間のおる環境でどう動くかって話やな。家とかオフィスとか、人がおるところでロボットが安全に動けるようにする研究の走りみたいなもんや。
Knox, W. B.、& Stone, P. TAMER:評価的強化によるエージェントの手動訓練。2008 IEEE第7回国際発達学習会議。IEEE、2008年、292-297ページ。https://doi.org/10.1109/DEVLRN.2008.4640845
→ TAMERってのはめっちゃ有名な手法でな、人間が「それええで!」「あかんあかん!」ってフィードバックを直接AIに教えてあげるシステムやねん。強化学習の基礎的な研究や。
Knox, W. B.、& Stone, P. 手動フィードバックとその後のMDP報酬信号を組み合わせた強化学習。第9回自律エージェントとマルチエージェントシステム国際会議(AAMAS)2010。2010年、5-12ページ。
→ 人間からのフィードバックと、普通の強化学習の報酬を両方使うって話やな。両方のええとこ取りしようってわけや。
Knox, W. B.、& Stone, P. 人間とMDPの同時報酬からの強化学習。第11回自律エージェントとマルチエージェントシステム国際会議(AAMAS)2012。1004巻。バレンシア。2012年、475-482ページ。
→ さっきの発展版で、人間の評価とコンピュータが計算する報酬を同時に使って学習するってやつやな。リアルタイムでどっちも使えるようにしたんや。
Knox, W. B.、Stone, P.、& Breazeal, C. 人間のフィードバックによるロボット訓練:ケーススタディ(G. Herrmann、M. J. Pearson、A. Lenz、P. Bremner、A. Spiers、& U. Leonards編集)。国際社会ロボティクス会議。Herrmann, G.、Pearson,
407ページ
---
## Page 50
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p050.png)
### 和訳
Retzlaffさんらの研究やけどな、
Koberさんら(2013年)は「ロボット工学における強化学習:サーベイ」っていう論文出してはんねん。International Journal of Robotics Research、32巻11号の1238〜1274ページに載ってるで。これな、ロボットに強化学習っていう「試行錯誤で賢くなる学習法」を使うとどないなるかをまとめた総説論文やねん。
Koditschekさん(2021年)は「ロボット工学って何?なんで必要で、どうやって実現すんの?」っていう根本的な問いかけをしてはるわ。Annual Review of Control, Robotics, and Autonomous Systemsの4巻1号、1〜33ページや。ロボット工学の本質を問う、めっちゃ哲学的な論文やな。
Kulickさんら(2013年)は、ロボットに「関係を表すシンボル」を教えるための能動学習について研究してはんねん。なんでかっていうと、ロボットが「これとあれの関係は〇〇やで」みたいな概念を理解できるようにしたいからや。IJCAI(国際人工知能会議)'13で発表されて、北京で行われた会議の1451〜1457ページに載ってるで。
KulkarniさんとGkountounaさん(2021年)は「REACT」っていうもんを発表してはる。これな、リアルタイムでAIが教育を支援する教室ツールのデモンストレーションやねん。arXivっていう論文の事前公開サイトで読めるわ。
Lakeさんら(2017年)は「人間みたいに学んで考える機械を作ろうや」っていう論文を書いてはる。Behavioral and Brain Sciencesの40巻e253に載ってるねん。ほんまに、人間の思考プロセスをAIで再現しようっていう野心的な研究やで。
Lambertさんら(2022年)は「人間のフィードバックからの強化学習(RLHF)を図解する」っていう記事をHugging Faceのブログに書いてはる。RLHFって何かっていうとな、AIが出した結果に人間が「これええな」「これあかんわ」って評価して、それを元にAIを賢くしていく方法やねん。ChatGPTとかで使われとる技術や。
Leさんら(2018年)は「階層的な模倣学習と強化学習」について研究してはる。ICMLっていう機械学習のめっちゃ有名な国際会議の35回目で発表されて、80巻の2917〜2926ページに載ってるわ。
Leeさんら(2021年)は「PEBBLE」っていうシステムを提案してはんねん。これな、フィードバックを効率よく使うインタラクティブな強化学習の方法や。経験のラベルを付け直したり、教師なし事前学習を使ったりして、少ないフィードバックでも賢く学べるようにしてはるねん。
Liさんら(2023年4月)は「ChatGPTの情報抽出能力を評価する」っていう論文出してはる。性能、説明可能性、キャリブレーション(確信度の正確さ)、忠実性を評価してはんねん。arXivで公開されとるわ。
Liさんら(2019年)は「人間中心の強化学習:サーベイ」を書いてはる。IEEE Transactions on Human-Machine Systemsの49巻4号、337〜349ページや。人間を中心に据えた強化学習の研究をまとめた総説やで。
Li(2017年)は「深層強化学習:概説」を書いてはる。深層学習と強化学習を組み合わせた技術の全体像をまとめた論文やな。
Liangさんら(2017年)は「人間参加型強化学習」について発表してはる。中国自動化会議(CAC)2017の4511〜4518ページに載ってるで。人間がループに入って学習を助ける手法やねん。
Likmetaさんら(2020年)は「自動運転における透明で汎用的な意思決定のための、強化学習とルールベースコントローラの組み合わせ」っていう研究してはる。Robotics and Autonomous Systemsの131巻、103568やで。なんでこれ大事かっていうと、自動運転って命に関わるから、AIの判断が透明でわかりやすいことがめっちゃ重要やからな。
Linさんら(2020年)は「人間の社会的フィードバックからのインタラクティブ強化学習のレビュー」を書いてはる。IEEE Accessの8巻、120757〜120765ページや。人間が「ええやん」「あかんで」って言うフィードバックを使ってAIを学習させる研究のまとめやねん。
---
## Page 51
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p051.png)
### 和訳
人間参加型強化学習
Liuさんら(2018)は、解釈しやすい深層強化学習を目指して、線形モデルU木っていうのを使った研究をやってはるねん。機械学習とデータマイニングのヨーロッパ合同会議で発表されたやつやな。要するに、ディープラーニングってブラックボックスで何やってるかわかりにくいやん?それを木構造使って「ここでこう判断してるんや」って見えるようにしようって話やねん。
Liu & Abbeel(2020)は、強化学習のための教師なし能動的事前学習っていうのを提案したんやけど、これはICLR 2021で「新規性が足りひん」って理由でリジェクトされてもうたらしいわ。残念やな。
Liuさんら(2022年10月)は、3Dバウンディングボックス予測のための自己回帰型不確実性モデリングっていうのをやってはるねん。3次元の物体を四角い箱で囲む予測をするときに、「どれくらい自信あるか」も一緒に出力できるようにする手法やな。
Liuさんら(2021)は、感情分析でモデルがいつ・なぜ失敗するかを検出するフレームワークを作ったんや。これがまさに人間参加型のエラー検出やねん。AIが「この文章はポジティブ」とか判断するときに、人間が「いや、それ間違うてるで」ってフィードバックできる仕組みやな。
Lutjensさんら(2018)は、モデルの不確実性推定を使った安全な強化学習について書いてはるわ。「自分がどれくらい自信ないか」をAIが把握して、危ないことはせんようにするって発想やねん。
Lyuさんら(2019)は、SDRLっていう解釈可能でデータ効率のええ深層強化学習を提案してはるねん。記号的プランニング、つまり論理的な計画立案を組み合わせることで、少ないデータでも学習できて、しかも何やってるか説明もできるっていうめっちゃ欲張りなアプローチやな。
MacGlashanさんら(2017)は、ポリシー依存の人間フィードバックからのインタラクティブ学習について研究してはるねん。なんでかっていうと、AIの行動方針(ポリシー)が変わると、人間からのフィードバックの意味も変わってくるやん?そこをちゃんと考慮しようって話やな。
Madumalさんら(2020a)は、モデルフリーな説明可能強化学習のための遠位説明っていうのを提案してはるわ。「なんでその行動したん?」って聞かれたときに、直接の理由だけやなくて、もっと大きな目標との関係で説明できるようにするってことやねん。
同じMadumalさんら(2020)は、因果的なレンズを通した説明可能強化学習もやってはるねん。因果関係、つまり「AしたからBになった」っていう関係を使って、AIの判断を説明しようっていうアプローチやな。めっちゃわかりやすくなるで。
Mandelさんら(2017)は、人間参加型強化学習でどこにアクションを追加すべきかっていう問題に取り組んではるわ。人間が「ここでこういう選択肢も考えたらええんちゃう?」ってAIに教えるときに、どこで介入するのが一番効果的かって話やな。
Maoさんら(2020年8月)は、強化学習を使った実世界のビデオ適応について研究してはるねん。YouTubeとか見るときに、回線の状況に応じて画質を自動調整するやつ、あれを強化学習で最適化しようって話や。実際に使える技術やで。
Martínezさんら(2017)は、ガイド付きデモンストレーションを使った関係強化学習について書いてはるわ。AIとロボティクスの特集号に載った論文やねん。人間が「こうやるんやで」ってお手本見せながら、物体同士の関係性も学習させる手法やな。
同じMartínezさんら(2016)は、プランニングのための確率的ドメインの関係ダイナミクス学習について研究してはるねん。ランダム性がある環境で、「こうしたらこうなりやすい」っていう関係を学習して計画に活かすって話やな。
Mathewson & Pilarski(2022)は、人間中心のインタラクティブ機械学習を設計・評価するための簡単なガイドを書いてはるわ。人間とAIが協力するシステムを作るときに、「こういうとこ気をつけなあかんで」っていうポイントをまとめてくれてるねん。めっちゃ実用的やな。
Mehrabiさんら(2021)は、機械学習におけるバイアスと公平性についてのサーベイ論文を書いてはるねん。AIが特定の人種や性別に対して不公平な判断せんように、どうしたらええかっていうのを網羅的にまとめてくれてる重要な論文やわ。ACMから出てるやつやな。
---
## Page 52
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p052.png)
### 和訳
Mikhaylovさんとか Lositskiiさんらの研究やねんけど、森林ロボットの制御と誘導についての話や。2018年のサンクトペテルブルグで開かれた国際会議で発表されてん。
Milaniらは2022年に「説明できる強化学習」についてのまとめ論文(サーベイ)を出しとるねん。強化学習ってのは、AIがゲームみたいに試行錯誤して学ぶやつやけど、それをどうやって人間に説明するかって話や。
Millerさん(2019年)は、人工知能における「説明」についてめっちゃ詳しく書いとるねん。なんでかっていうと、AIの判断を人間にわかってもらうには、社会科学からヒントをもらうのがええって話や。同じ論文が2回引用されとるな。
Mnihさんらの2013年の論文は、ほんまに有名なやつやで!「深層強化学習でAtari(昔のゲーム機)をプレイする」ってやつや。これがDQNの始まりで、AIがゲームうまくなる研究のきっかけになってん。
Mowshowitzらは2018年に「森林管理におけるロボットナビゲーション」について書いとる。森の中でロボットをどう動かすかって実用的な研究やな。
Nairさんらの2018年の研究はめっちゃ面白いねん。強化学習で「探索」ってのがあんねんけど、これがなかなか難しいわけ。ほんで、お手本(デモンストレーション)を見せてその問題を乗り越えようって話や。
Nascimentoさんらは2019年に、機械学習システムの開発プロセスを理解しようとしたんや。開発する時にどんな課題があって、どう解決したらええかってのをまとめとるねん。
Nautaさんらは2022年に、説明可能なAI(XAI)の評価方法についてめっちゃ網羅的にレビューしとるねん。今まで「なんとなくこれでええやろ」って感じやったのを、ちゃんと数字で評価しようぜって話や。
Ngさんらの1999年の古典的な論文は、「報酬の変換」についてや。強化学習では報酬ってのを設定するねんけど、それをどう変換しても学習結果が変わらへん条件があるんや。これを「報酬シェーピング」に応用する理論やな。
NguyenさんとLaさんは2019年に、ロボットのマニピュレーション(物をつかんだり動かしたりする動作)に深層強化学習を使う研究をレビューしとるわ。
OpenAIの2019年の論文はほんまにすごいで!Dota 2っていうめっちゃ複雑なゲームを、大規模な深層強化学習で攻略したんや。人間のプロチームにも勝ったりしてん。著者がめっちゃおるけど、大きいプロジェクトやったんやろな。
Parisiさんらの2022年の研究は、「事前学習した画像認識モデルが制御にも意外と使えるで」って話や。画像を認識するために学習したモデルを、ロボットの制御にそのまま流用できるって、なんか得した気分になるやろ?
---
## Page 53
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p053.png)
### 和訳
人間参加型強化学習
ほな参考文献いくで!
Pearl, J.(2009年)。『因果関係:モデル、推論、それに推測について』(第2版)。ケンブリッジ大学出版。
- これ、因果関係についてめっちゃ詳しく書いてある本やねん。「AがBの原因なんちゃうか?」みたいなんを科学的にちゃんと調べる方法について書いてあるんや。
Pearl, J., ほか(2000年)。『モデル、推論、それに推測』。イギリスのケンブリッジ大学出版から出とるやつ。
Peng, B., Galley, M., He, P., Cheng, H., Xie, Y., Hu, Y., Huang, Q., Liden, L., Yu, Z., Chen, W., & Gao, J.(2023年3月)。「ファクトチェックしてもっかいやってみ:外部知識と自動フィードバックで大規模言語モデルを改善する話」
- これなにかっていうと、ChatGPTみたいな大規模言語モデルがたまに嘘つくやん?それを外部の知識とか使ってちゃんと事実確認させて、間違ってたらやり直させるっていう研究やねん。
Peng, B., MacGlashan, J., Loftin, R., Littman, M. L., Roberts, D. L., & Taylor, M. E.「スピード調整せなあかん:素人から学ぶときにAIエージェントの動く速さを調整してうまく学習させる話」2016年の自律エージェントとマルチエージェントシステムの国際会議で発表されたやつ。
- なんでかっていうと、普通の人がAIに教えようとするとき、AIが速すぎたら「ちょ、待って!」ってなるやろ?だからAIの動く速さを調整したら、素人でもうまく教えられるようになるで、っていう研究なんや。
Penkov, S., & Ramamoorthy, S.「パーセプター勾配を使ってプログラム的に構造化された表現を学習する話」2019年の国際学習表現会議(ICLR)で発表。
- これはAIが物事をプログラムみたいにきっちり構造化して理解できるようにする方法についての研究やな。
Popova, M., Isayev, O., & Tropsha, A.(2018年)。「深層強化学習で新しい薬を一から設計する話」Science advances誌に載ったやつ。
- これめっちゃすごいねん!AIに強化学習っていう「うまくいったらご褒美あげる」方式で学習させて、全く新しい薬の候補を自動で考えさせるっていう研究やねん。
Puiutta, E., & Veith, E. M.「説明可能な強化学習:サーベイ論文」2020年の機械学習と知識抽出の国際会議で発表。
- 強化学習って「なんでその行動したん?」って聞いてもAIが説明できへんことが多いやん?それをちゃんと説明できるようにしようっていう研究を全部まとめた総説論文やな。
Ragunath, P., Velmourougan, S., Davachelvan, P., Kayalvizhi, S., & Ravimohan, R.(2010年)。「ソフトウェア開発ライフサイクルの新しいモデル(SDLCモデル-2010)を進化させる」International Journal of Computer Science and Network Security誌。
- ソフトウェア作るときの流れ(企画→設計→開発→テスト→リリースみたいなやつ)の新しいモデルを提案した論文やねん。
Ray, P. P.(2023年)。「ChatGPT徹底レビュー:背景、応用、主な課題、バイアス、倫理、限界、それに今後の展望」Internet of Things and Cyber-Physical Systems誌。
- ChatGPTについてほんまに全部まとめた総説やな。すごいとこも問題点も全部書いてあるで。
Rodriguez, A., Tabassum, A., Cui, J., Xie, J., Ho, J., Agarwal, P., Adhikari, B., & Prakash, B. A.(2021年)。「DeepCOVID:説明可能なリアルタイムコロナ予測のための実用的な深層学習フレームワーク」
- コロナの感染者数とかをAIで予測するシステムやねん。しかも「なんでそう予測したか」も説明できるようになってて、実際に使えるレベルで作ったやつやで。
Roy, N., Posner, I., Barfoot, T., Beaudoin, P., Bengio, Y., Bohg, J., Brock, O., Depatie, I., Fox, D., Koditschek, D., ほか(2021年)。「機械学習からロボティクスへ:身体を持った知能の課題と可能性」
- 機械学習ってパソコンの中だけの話やったけど、それをロボットみたいに実際に体を持って動くものに応用するときの課題と可能性についてまとめた論文やな。
Saba, W. S.(2023年5月)。「説明可能で言語に依存しないLLMを目指して:言語の大規模なシンボリック逆エンジニアリング」
- 今のLLM(大規模言語モデル)って中身がブラックボックスで何やってるかわからへんやん?それを記号的に逆解析して、説明できるようにしようっていう研究やねん。
Saranti, A., Eckel, G., & Pirró, D.「量子調和振動子の可聴化」2009年の聴覚ディスプレイに関する書籍の中の一章。
- 量子力学の調和振動子っていう物理現象を音にして聞けるようにしたっていう研究やな。目に見えへん物理現象を耳で理解しようっていう面白いアプローチやで。
Saranti, A., Taraghi, B., Ebner, M., & Holzinger, A.「確率的グラフィカルモデルを通じた学習能力への洞察」
411ページ
---
## Page 54
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p054.png)
### 和訳
Retzlaffらの文献やねん。
E. Weipplとかが編集しとる国際的なクロスドメイン・カンファレンス、機械学習とナレッジ抽出についての本やな(A. Holzinger、P. Kieseberg、A. M. Tjoa、E. Weipplが編集しとって)。Springerから2019年に出てて、250-271ページに載っとるで。https://doi.org/10.1007/978-3-030-29726-8_16
Schneeberger、D.とStoeger、K.とHolzinger、A.の論文は医療AIのヨーロッパ法的枠組みについて書いとるねん。同じく国際クロスドメイン・カンファレンスの論文集で、Springer LNCS 12279に収録されとって、2020年出版で209-226ページやな。https://doi.org/10.1007/978-3-030-57321-8_12
Scurto、H.とKerrebroeck、B. V.とCaramiaux、B.とBevilacqua、F.(2021年)の論文は、人間がパラメータ探索するための深層強化学習をどう設計するかっていう話や。ACM Transactions on Computer-Human Interaction(TOCHI)っていう学術誌の28巻1号、1-35ページに載っとるで。https://doi.org/10.1145/3414472
Serradilla、O.とZugasti、E.とCernuda、C.とAranburu、A.とde Okariz、J. R.とZurutuza、U.の論文は、産業機械の残存耐用寿命(あとどんだけ使えるかってこと)の推定を、説明可能AI(XAIって呼ばれとるやつやな)と専門知識を組み合わせて解釈するっていう研究やねん。2020年7月のIEEE International Conference on Fuzzy Systems(FUZZ-IEEE)で発表されとって、1-8ページや。https://doi.org/10.1109/FUZZ48607.2020.9177537
Shneiderman、B.とPlaisant、C.とCohen、M. S.とJacobs、S.とElmqvist、N.とDiakopoulos、N.(2016年)は「ユーザーインターフェースのデザイン:効果的な人間とコンピュータのやりとりの戦略」っていう本をPearsonから出しとるで。ほんまに基本的な教科書やな。
Silva、A.とGombolay、M.とKillian、T.とJimenez、I.とSon、S.-H.の論文は、強化学習に適用できる解釈可能な微分可能決定木(ようするに、なんでその判断したかがわかりやすい木構造のAIってことや)の最適化手法についてやねん。S. ChiappaとR. Calandraが編集した第23回人工知能と統計に関する国際会議の論文集に入っとって、PMLRから2020年に出版、1855-1865ページやで。
Silver、D.とSchrittwieser、J.とSimonyan、K.とAntonoglou、I.とHuang、A.とGuez、A.とHubert、T.とBaker、L.とLai、M.とBolton、A.とChen、Y.とLillicrap、T.とHui、F.とSifre、L.とvan den Driessche、G.とGraepel、T.とHassabis、D.(2017年)の論文は、めっちゃ有名なやつやねん。「人間の知識なしで囲碁をマスターする」っていうタイトルで、Nature Publishing Groupから出とる。Natureの550巻7676号、354-359ページや。AlphaGo Zeroの論文やな。https://doi.org/10.1038/nature24270
Smith-Renner、A.とFan、R.とBirchfield、M.とWu、T.とBoyd-Graber、J.とWeld、D. S.とFindlater、L.の論文は「説明責任なくして説明可能性なし:インタラクティブ機械学習における説明とフィードバックの実証研究」っていうタイトルやねん。なんでかっていうと、AIがどう動いてるか説明するだけやなくて、ちゃんと責任持てる仕組みが必要やでって言うてるわけや。2020年4月のCHI Conferenceで発表されて、Association for Computing Machineryから出とる。1-13ページや。https://doi.org/10.1145/3313831.3376624
Song、W.とDuan、Z.とYang、Z.とZhu、H.とZhang、M.とTang、J.(2019年)は、知識グラフ(いろんな情報がつながったネットワークみたいなやつや)を使った説明可能な推薦システムを深層強化学習でやるっていう論文で、arXivのプレプリントとして出とるで。arXiv:1906.09506やな。
Sreedharan、S.とKulkarni、A.とKambhampati、S.(2022年)の「説明可能な人間-AI相互作用:計画の視点から」っていう本は、Morgan & Claypool Publishersから出とる。Synthesis Lectures on Artificial Intelligence and Machine Learningの16巻1号で、1-184ページとめっちゃ充実しとるわ。https://doi.org/10.2200/S01152ED1V01Y202111AIM050
Stiennon、N.とOuyang、L.とWu、J.とZiegler、D.とLowe、R.とVoss、C.とRadford、A.とAmodei、D.とChristiano、P. F.の論文は「人間のフィードバックを使って要約を学習する」っていう研究で、H. Larochelleとか M.が編集しとるやつや。
---
## Page 55
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p055.png)
### 和訳
人間参加型強化学習
Ranzato, R. Hadsell, M. F. Balcan, & H. Linが編集した『神経情報処理システムの進歩』(H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, & H. Linも編集に参加)っていう学会論文集があんねんけど、33巻でCurran Associates社から2020年に出とって、3008から3021ページに載ってるやつやな。https://proceedings.neurips.cc/paper/2020/file/1f89885d556929e98d3ef9b86448f951-Paper.pdf で見れるで。
Stoeger, K., Schneeberger, D., & Holzinger, A. (2021)。医療用人工知能:ヨーロッパの法的な視点からの話やねん。『Communications of the ACM』の64巻11号で、34から36ページに載ってるわ。https://doi.org/10.1145/3458652 これ、要するにヨーロッパでAIを医療に使うときの法律的なことをどう考えたらええかって話やな。
Sun, S.-H., Wu, T.-L., & Lim, J. J.。プログラムで誘導するエージェントっていう研究やねん。2019年の国際学習表現会議で発表されとったやつや。
Surmann, H., Jestel, C., Marchel, R., Musberg, F., Elhadj, H., & Ardani, M. (2020年5月)。室内環境での本物の自律移動ロボットのナビゲーションに深層強化学習を使うっていう研究やで[arXiv:2005.13857 [cs]]。https://doi.org/10.48550/arXiv.2005.13857 めっちゃ簡単に言うと、ロボットが建物の中を自分で動き回れるようになるための学習方法の話やな。
Sutton, R. S., & Barto, A. G. (2018)。『強化学習:入門編』。MIT出版から出とる。これは強化学習っていう、AIが試行錯誤しながら学ぶ方法の基本書やねん。めっちゃ有名な本やで。
Tabrez, A., & Hayes, B.。説明できる強化学習で人間とロボットのやりとりを改善するって話。2019年の第14回ACM/IEEE人間ロボットインタラクション国際会議でIEEEが出しとって、751から753ページやな。https://doi.org/10.1109/HRI.2019.8673198 なんでかっていうと、ロボットが「なんでそうしたん?」って聞かれたときにちゃんと説明できたら、人間との協力がうまくいくやろってことやねん。
Taylor, M. E., & Stone, P. (2009)。強化学習の分野における転移学習のサーベイ論文や。『Journal of Machine Learning Research』の10巻7号で、1633から1685ページ。転移学習ってのは、ある場面で学んだことを別の場面でも使えるようにするっていう、ほんまに賢い学び方やねん。
Taylor, M. E., Suay, H. B., & Chernova, S.。いろんなレベルの人間のデモンストレーションと強化学習を組み合わせる研究や。2011年の第10回自律エージェント・マルチエージェントシステム国際会議の第2巻に載っとる。AAMAS '11でCiteseerで出とって、サウスカロライナ州リッチランドの国際自律エージェント・マルチエージェントシステム財団から出版されてて、617から624ページやな。上手い人も下手な人もおるお手本を、AIがどう活かすかって話や。
Thomaz, A. L., & Breazeal, C.。人間の先生がおる強化学習:フィードバックとガイダンスが学習パフォーマンスにどう影響するかの証拠って研究や。2006年のAAAI会議の6巻、マサチューセッツ州ボストンで開催されて、1000から1005ページに載っとる。人間が「それええで!」とか「あかんあかん」って教えたら、AIの学習がめっちゃ良くなるってことを示した研究やねん。
Tickle, A., Andrews, R., Golea, M., & Diederich, J. (1998)。真実は明らかになる:訓練されたニューラルネットワークの中に埋め込まれた知識を取り出すための方向性と課題って論文や。『IEEE Transactions on Neural Networks』の9巻6号で、1057から1068ページ。https://doi.org/10.1109/72.728352 これ、AIが何を学んだのかをどうやって人間にわかる形で引っ張り出すかって話やねん。ブラックボックスを開けようとする挑戦やな。
Tomar, M., Mishra, U. A., Zhang, A., & Taylor, M. E. (2021)。ピクセルベースの制御のための表現学習:何が大事でなんでそうなんか?っていう論文。arXivのプレプリントでarXiv:2111.07775や。画像から直接ロボットを操作するとき、どんな情報をどう学ぶのが一番ええんかを調べた研究やで。
Topin, N., Milani, S., Fang, F., & Veloso, M.。反復的に境界をつけるMDP:解釈できない方法で解釈できる方策を学ぶって研究。2021年のAAAI人工知能会議の論文集の35巻で、9923から9931ページに載っとる。難しい方法で学んでも、最終的には人間が「なるほど」って理解できるような判断ルールを作ろうっていうアプローチやな。
Torrey, L., & Taylor, M.。予算内で教える:強化学習でエージェントがエージェントにアドバイスするっていう研究。2013年の自律エージェント・マルチエージェントシステム国際会議で発表されとって、サウスカロライナ州リッチランドの国際自律エージェント・マルチエージェントシステム財団から出とる。1053から1060ページ。https://doi.org/10.5555/2484920.2485086 これ、教える側のAIも無限にアドバイスできるわけちゃうから、限られた「予算」の中でどう効率よく教えるかって話やねん。
Vecerik, M., Hester, T., Scholz, J., Wang, F., Pietquin, O., Piot, B., Heess, N., Rothörl, T., Lampe, T., & Riedmiller, M. (2017)。報酬がめっちゃ少ないロボット工学の問題で、デモンストレーションを活用して深層強化学習するっていう論文や。arXivのプレプリントでarXiv:1707.08817。ロボットってさ、成功したときだけ「よっしゃ!」って報酬もらえることが多いねんけど、そしたらなかなか学べへんやん?せやから人間のお手本を見せて、それをヒントにして学習効率を上げようっていう賢い方法やねん。
413
---
---
## Page 56
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p056.png)
### 和訳
Retzlaff ら
Verma, A., Le, H., Yue, Y., & Chaudhuri, S. 模倣射影型プログラム強化学習(H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, & R. Garnett 編)。掲載誌:ニューラル情報処理システムの進歩。Curran Associates, Inc., 2019, 第32巻。
---
ほんでな、これなんの話かっていうと、Vermaさんたちが「模倣射影型プログラム強化学習」っていう手法を提案してんねん。強化学習って、AIがゲームとかで試行錯誤しながら上手くなっていく仕組みやねんけど、それに「模倣」と「プログラム」の要素を組み合わせてるんやな。めっちゃざっくり言うと、AIが学んだことをプログラムの形で書き出せるようにしてるから、「なんでそう動いたん?」がわかりやすくなるねん。
---
Verma, A., Murali, V., Singh, R., Kohli, P., & Chaudhuri, S. プログラム的に解釈可能な強化学習(J. Dy & A. Krause 編)。掲載誌:第35回機械学習国際会議論文集。PMLR, 2018, 5045-5054。https://proceedings.mlr.press/v80/verma18a.html
---
これも同じVermaさんたちの研究やねんけど、2018年のやつやな。「プログラム的に解釈可能な強化学習」って、要はAIの判断をプログラムのコードみたいに見える化できるようにしようって話やねん。普通の深層強化学習って、ニューラルネットワークの中で何やってるかブラックボックスで全然わからへんやん?それを「こういうルールで動いてますよ」ってプログラムとして出力できたら、人間が理解しやすいやろ?っていう発想やな。
---
Vu, M. N., & Thai, M. T. (2020). PGM-Explainer:グラフニューラルネットワークのための確率的グラフィカルモデル説明器。arXiv プレプリント arXiv:2010.05788。
---
これはグラフニューラルネットワーク(GNN)の説明手法やねん。GNNって、SNSの友達関係とか、分子の構造とか、「つながり」があるデータを扱うのが得意なAIやねんけど、これまた中で何してるかわかりにくいんよ。そこでPGM-Explainerっていうのを使って、「この予測結果は、このつながりのパターンが重要やったからやで」って説明できるようにしてるねん。
---
Wang, X., Lee, K., Hakhamaneshi, K., Abbeel, P., & Laskin, M. スキル優先度:人間のフィードバックからロボットスキルを抽出・実行することを学習する。掲載誌:ロボット学習会議論文集。PMLR. 2022, 1259-1268。
---
これめっちゃおもろい研究やで!ロボットに「こうやって動いてほしい」って人間がフィードバックするやん?そしたらロボットが「あ、この動き大事なんやな」って学習して、色んなスキルを身につけていくねん。「スキル優先度」っていうのは、どのスキルをどんな時に使うかの優先順位を学ぶってことやな。人間の好みを反映したロボット制御ができるようになるんやで。
---
Wells, L., & Bednarz, T. (2021a). 説明可能なAIと強化学習 — 現在のアプローチと傾向の体系的レビュー。Frontiers in Artificial Intelligence, 4, 48。https://doi.org/10.3389/frai.2021.550030
Wells, L., & Bednarz, T. (2021b). 説明可能なAIと強化学習 — 現在のアプローチと傾向の体系的レビュー。Frontiers in Artificial Intelligence, 4。2023年7月15日取得、https://www.frontiersin.org/articles/10.3389/frai.2021.550030
---
これ同じ論文が2回載ってるんやけど、「説明可能なAI(XAI)と強化学習」についての総まとめレビュー論文やねん。「今どんな研究があるんやろ?」「どういう方向に進んでるんやろ?」っていうのを体系的に整理してくれてるから、この分野を勉強したい人にはめっちゃありがたい論文やな。
---
Wu, J., Huang, Z., Huang, C., Hu, Z., Hang, P., Xing, Y., & Lv, C. (2021a). 自動運転への応用を伴う人間参加型深層強化学習。arXiv プレプリント arXiv:2104.07246。
---
自動運転に人間参加型の深層強化学習を使おうって研究やねん。なんでかっていうと、AIだけで運転任せるのってまだ怖いやん?だから人間が「そこ危ないで!」とか「もうちょいスムーズに曲がってや」ってフィードバックしながら、AIの運転スキルを鍛えていくねん。人間とAIの協力プレイで安全な自動運転を目指してるんやな。
---
Wu, X., Xiao, L., Sun, Y., Zhang, J., Ma, T., & He, L. (2021b). 機械学習における人間参加型のサーベイ。arXiv プレプリント arXiv:2108.00941。
---
これは「人間参加型機械学習」全般についてのサーベイ(調査論文)やな。機械学習って全部自動でやるイメージあるかもしれんけど、実は人間が途中で介入したほうが上手くいくことも多いねん。どういう場面で人間が入るべきか、どうやって効率よく人間の知恵を取り入れるか、そういう研究をまとめてくれてるんやで。
---
Xin, D., Ma, L., Liu, J., Macke, S., Song, S., & Parameswaran, A. 人間参加型機械学習の加速:課題と機会。掲載誌:エンドツーエンド機械学習のためのデータ管理に関する第2回ワークショップ論文集。ニューヨーク:Association for Computing Machinery, 2018, 1-4。https://doi.org/10.1145/3209889.3209897
---
これは人間参加型機械学習をもっと速くするにはどうしたらええか?っていう課題と、「こういうチャンスあるんちゃう?」っていう可能性を議論してる論文やねん。人間が関わると時間かかるやん?でもそこをうまいことデータ管理とかの工夫で効率化できたら、もっとええ機械学習システムが作れるよねって話やな。
---
Xiong, Z., Eappen, J., Zhu, H., & Jagannathan, S. (2020). 学習対応型コントローラにおける敵対的攻撃への頑健性。arXiv プレプリント arXiv:2006.06861。
---
これはセキュリティ的な話やねん。学習で作ったコントローラって、わざと変なデータ入れられたら騙されることがあるんよ。それを「敵対的攻撃」って言うねんけど、そういう攻撃に対して強い(頑健な)コントローラをどうやって作るかって研究やな。ロボットとか自動運転みたいな安全が大事なところで、ほんまに重要な話やで。
---
Xu, W., Wang, D., Pan, L., Song, Z., Freitag, M., Wang, W. Y., & Li, L. (2023年5月). INSTRUCTSCORE:自動フィードバックによる説明可能なテキスト生成評価に向けて [arXiv:2305.14282 [cs]]。https://doi.org/10.48550/arXiv.2305.14282
---
これ最近のホットな研究やで!AIが文章を生成した時に、「この文章ええの?あかんの?」を評価するシステムやねん。しかも「なんでこの点数なん?」って理由も説明してくれるのがポイントやな。INSTRUCTSCOREっていう名前の通り、指示(INSTRUCT)に基づいてスコアリングして、フィードバックも自動で出してくれるねん。ChatGPTとか使ってる人には身近な話題やな。
---
Yang, S., Nachum, O., Du, Y., Wei, J., Abbeel, P., & Schuurmans, D. (2023年3月). 意思決定のための基盤モデル:問題、手法、機会 [arXiv:2303.04129 [cs]]。https://doi.org/10.48550/arXiv.2303.04129
---
これめっちゃ大事な論文やで!「基盤モデル」っていうのは、GPTとかの超でかいAIモデルのことやねんけど、それを「意思決定」に使おうって話やねん。今まで基盤モデルって文章生成とか画像認識に使われてきたけど、ロボットの制御とか、ゲームの戦略とか、「何をするか決める」タスクにも使えるんちゃう?っていう可能性を探ってるんやな。問題点、手法、これからのチャンスを整理してくれてるから、この分野に興味ある人は必読やで。
---
Yang, T., Hao, J., Meng, Z., Zhang, Z., Hu, Y., Chen, Y., Fan, C., Wang, W., Liu, W., Wang, Z., & Peng, J. 適応的方策転移による効率的な深層強化学習。掲載誌:第29回人工知能国際合同会議論文集。
---
これは深層強化学習を効率的にやる方法についての研究やな。「方策転移」っていうのは、ある問題で学んだ知識を別の問題にも使い回すことやねん。人間も「自転車乗れたらバイクも乗りやすい」みたいに、似たスキルを転用するやん?AIにもそれをさせて、学習時間を短縮しようっていう発想やな。「適応的」っていうのは、転移先の問題に合わせてうまいこと調整するってことやで。
---
## Page 57
[](/attach/79c9b5351795635b15806edaa55b105c637acdefdea299db4f1a74dbf53ee0f9_p057.png)
### 和訳
ほな、この参考文献リストを関西弁で説明していくで〜!
---
人間参加型の強化学習
人工知能の国際会議。2021年、3094-3100ページ。https://doi.org/10.24963/ijcai.2020/428
Zagal, J. C., del Solar, J. R., & Vallejos, P.(2004年)。「現実に戻ろうや:進化型ロボット工学における現実とのギャップを埋める話」[IFAC/EURON 知的自律移動体シンポジウム、ポルトガルのリスボン、2004年7月5-7日]。IFACプロシーディングス・ボリュームズ、37(8)、834-839。https://doi.org/10.1016/S1474-6670(17)32084-0
これな、シミュレーションで学習したロボットを実際の世界で動かそうとしたら「あれ?全然ちゃうやん!」ってなる問題のことやねん。めっちゃ大事な課題やで。
Zanzotto, F. M.(2019年)。「視点:人間参加型の人工知能」。人工知能研究ジャーナル、64、243-252。https://doi.org/10.1613/jair.1.11345
要するに、AIに全部任せんと人間も一緒に関わっていこうや〜っていう考え方についての論文やな。
Zhang, C., Yong, L., Chen, Y., Zhang, S., Ge, L., Wang, S., & Li, W.(2019a)。「2D LiDARとジャイロスコープを使ったゴム採取ロボットの森林ナビゲーションと情報収集システム」[第9号、Multidisciplinary Digital Publishing Institute発行]。センサーズ、19(9)、2136。https://doi.org/10.3390/s19092136
これはな、森の中でゴムの木から樹液採るロボットの話やねん。LiDARっていうレーザーセンサーとジャイロスコープ(傾きとか回転を検知するやつ)を使って、森の中を迷わんように動くシステム作ったんやで。
Zhang, J., & Bareinboim, E.「人間ってループから外れてもええんかな?」:因果学習・推論に関する第1回会議(CLEAR 2022)にて。2020年。https://openreview.net/forum?id=P0f91v5fTK
ほんまに人間抜きでAIだけでいけるんかな?っていう根本的な問いかけをしてる論文やな。なかなか哲学的やで。
Zhang, P., Hao, J., Wang, W., Tang, H., Ma, Y., Duan, Y., & Zheng, Y.「Kogun:人間の"まあまあな"知識を取り入れて深層強化学習を加速させる方法」:第29回人工知能国際合同会議論文集にて。2021年、2291-2297。
これめっちゃおもろいねん。人間の知識って完璧じゃなくても「まあまあ使える」レベルでも、それをAIに教えたらめっちゃ学習が速くなるっていう話やで。完璧じゃなくてええんや!
Zhang, R., Torabi, F., Guan, L., Ballard, D. H., & Stone, P.「深層強化学習タスクで人間のガイダンスを活用する方法」:第28回人工知能国際合同会議(IJCAI-19)にて。人工知能国際合同会議機構、2019年、6339-6346。https://doi.org/10.24963/ijcai.2019/884
人間が「こっちやで〜」ってヒント出しながらAIを学習させたらええ感じになるっていう研究やな。
Zhou, C., Li, Q., Li, C., Yu, J., Liu, Y., Wang, G., Zhang, K., Ji, C., Yan, Q., He, L., Peng, H., Li, J., Wu, J., Liu, Z., Xie, P., Xiong, C., Pei, J., Yu, P. S., & Sun, L.(2023年5月)。「事前学習済み基盤モデルの包括的サーベイ:BERTからChatGPTまでの歴史」[arXiv:2302.09419 [cs]]。https://doi.org/10.48550/arXiv.2302.09419
これはな、BERTっていう昔のすごいAIからChatGPTまで、どうやって進化してきたかを全部まとめた論文やねん。めっちゃ分厚いサーベイ(調査論文)やで。基盤モデルっていうのは、いろんなタスクに使える土台になるでっかいAIモデルのことやな。
Zhou, J., Gandomi, A. H., Chen, F., & Holzinger, A.(2021年)。「機械学習の説明の品質を評価する:手法と指標のサーベイ」。エレクトロニクス、10(5)、593。https://doi.org/10.3390/electronics10050593
AIが「なんでそう判断したん?」って聞かれた時の説明、それがほんまにええ説明なんかどうかを測る方法についてまとめた論文やな。説明できるAI、めっちゃ大事やで。
Zhu, G., Wang, J., Ren, Z., Lin, Z., & Zhang, C.「マルチレベル抽象化を通じたオブジェクト指向のダイナミクス学習」:AAAI人工知能会議論文集にて。34巻。2020年、6989-6998。https://doi.org/10.1609/aaai.v34i04.6183
これはな、AIが物事を理解する時に、細かいレベルから大きなレベルまで段階的に抽象化して学ぶっていう方法やねん。人間も「これはリンゴ」→「これは果物」→「これは食べ物」みたいに段階的に理解するやん?それと似たようなことをAIにさせてるんやで。
Zini, J. E., & Awad, M.(2022年)。「自然言語処理の深層モデルの説明可能性について」。ACMコンピューティングサーベイズ、55(5)、103:1-103:31。https://doi.org/10.1145/3529755
ChatGPTみたいな言葉を扱うAI、なんでそう言うたんかを説明できるようにしようっていう研究のまとめやな。ブラックボックス(中身がわからん箱)じゃアカンやろ?っていう話やで。
415
---
![]()
1 / 1
100%