<<
Enhanced Recommendation Systems with Retrieval-Augmented Large Language Model

---
## Page 1
[](/attach/763a5542ddd3604fde1a7208d671f458ec383a8c07d1e347e704416e4a8bd776_p001.png)
### 和訳
Journal of Artificial Intelligence Research 82 (2025) 1147-1173
2024年12月投稿、2025年2月掲載
検索拡張型の大規模言語モデルを使った
レコメンドシステムの強化について
著者のみなさん:
Chuyuan Wei - 北京建築大学 電気情報工学部(北京)
Ke Duan - 北京建築大学 機械電子・車両工学部(北京)
Shengda Zhuo(責任著者)- 暨南大学 サイバーセキュリティ学部(広州)
Hongchun Wang - 北京建築大学 都市経済経営学部(北京)
Shuqiang Huang(責任著者)- 暨南大学 サイバーセキュリティ学部(広州)
Jie Liu - 北方工業大学(北京)
---
**要旨**
レコメンドシステムってな、昔からめっちゃ困った問題抱えてんねん。「コールドスタート」と「データのスパース性」っていうやつやな。コールドスタートっていうのは、新しいユーザーとか新商品が来た時に、過去のデータがないからおすすめしようがないって問題やねん。スパース性は、データがスカスカで全然足りひんって話や。こういうのがあると、おすすめの精度がガクッと落ちてまうんよ。
今までの研究では、この問題を解決しようと「補助情報」、つまりユーザーの属性とか商品の詳細みたいな追加データを入れてみたんやけど、これがまた問題でな。ノイズ(要らん情報)が入ってきたり、データを増やすのが柔軟にできひんかったり、データの質がバラバラやったりして、結局ユーザーが何を好んでるか正確に読み取れへんくて、おすすめの性能が上がらへんかってん。
ほんで、大規模言語モデル(LLM)の登場や!こいつらは膨大な知識を持ってて、めっちゃ賢い推論もできるから、補助情報を補ったり、ユーザーが表に出さへん「隠れた意図」を読み取るのにピッタリやねん。
そこでワイらが提案するのが「ER2ALM」っていう新しいフレームワークや。これは検索拡張生成(RAG)で強化したLLMの力を使って、レコメンドの結果を良くしようっていうもんやねん。RAGっていうのは、LLMが回答する時に外部のデータベースから関連情報を引っ張ってきて、それを参考にしながら答えを出す仕組みのことや。
ワイらのフレームワークの特徴はな、補助情報を柔軟かつ正確に増やせることと、ユーザーの隠れた好みや興味をしっかり捉えられることやねん。さらに、ノイズが入ってくるリスクを減らすために、ノイズ除去の戦略も組み込んでて、増やした情報の信頼性をちゃんと確保してるんや。
実際に2つの実世界データセットで実験して検証したら、ワイらのアプローチはめっちゃ効果的で、精度が大幅にアップしたんやで!
---
©2025 著者ら。AI Access Foundationより、クリエイティブ・コモンズ 表示ライセンス CC BY 4.0 のもとで公開。
---
## Page 2
[](/attach/763a5542ddd3604fde1a7208d671f458ec383a8c07d1e347e704416e4a8bd776_p002.png)
### 和訳
Wei、Duan、Zhuo、Wang、Huang、Liu
最先端の手法と比べて、レコメンドの精度とロバスト性がめっちゃ向上したんよ。これで、ワイらのフレームワークがレコメンドシステムでユーザーの好みを掘り起こす新しいパラダイムとして使えるってことが証明されたわけやな。
## 1. はじめに
インターネットがめっちゃ急成長したせいで、情報過多の問題(Zhuo et al., 2024b; Chen et al., 2022a; Tian et al., 2022; Wei et al., 2022; Zhou et al., 2023)がどんどん深刻になってきとるんよ。レコメンダーシステムっていうのは、ユーザーが過去にどんなもん見たり買ったりしたかっていう履歴を使って、膨大なデータの中からその人に合ったおすすめを的確に出してくれるから、この問題をうまいこと解決できるんやな。ユーザーが「ほんまに何を求めてるんか」っていう本当の意図(好みとか興味とか)を理解することがレコメンドの精度にはめっちゃ大事やねん。なんでかっていうと、ユーザーって普通、自分のニーズとか好みに基づいてアイテムを選ぶからな。こういう隠れたユーザーの意図を過去のインタラクションデータからさらに深掘りしていくと、レコメンドの関連性がグッと上がるんよ。
ユーザーのインタラクション履歴っていうのは、過去の行動の記録やから、そこにはユーザー固有の情報がめっちゃたくさん詰まっとるわけや。履歴に含まれるアイテムには、ユーザーが興味があって自分から探したものもあれば、特定のニーズを満たすために意図的に選んだものもあるんよ。この情報を他の関連データと照らし合わせると、ユーザー分析の基盤になるんやな。例えば映画のレコメンドシステムやったら、ユーザーは観た映画に評価やレビューをつけることが多いやろ。高い評価とポジティブなレビューは、ユーザーの暗黙の好みを知る最初の手がかりになるんよ。いくつかの研究では、ユーザーの好み分析を強化するために、まばらな暗黙のフィードバック信号を抽出する手段としてサイド情報を使うことが探求されてきたんや。この問題に対処するために、いくつかのアプローチでは協調フィルタリング(CF)フレームワークにグラフニューラルネットワーク(GNN)を統合しとる(例えば、NGCF(Wang et al., 2019)とかLightGCN(He et al., 2020)とかな)。せやけど、これらの手法は教師信号が足りへんっていう問題によくぶち当たるんよ。この問題を軽減するために、最近の研究(Ren et al., 2024b)では自己教師あり信号を強化するためにコントラスト学習(例えば、SGL(Wu et al., 2021)とかSimGCL(Yu et al., 2022))の技術を使っとるんや。NetflixとかMovieLensみたいな実際のオンラインプラットフォームは、ユーザー体験を向上させるためにマルチモーダルコンテンツをうまいこと活用しとるんよ。こういう背景があって、最近の手法は従来の協調フィルタリング(CF)アプローチ(Le & Lauw, 2021)とは違って、レコメンドシステムを改善するために補助的なサイド情報を統合することに焦点を当てとるんや。例えば、MMGCN(Wei et al., 2019)とGRCN(Wei et al., 2020)は、コンテンツに基づいた高次の関係を明らかにするために、アイテム側のコンテンツをGNNに組み込んどる。同様に、LATTICE(Zhang et al., 2021)は、アイテム間の関係を確立することでデータ拡張を行うために補助コンテンツを使っとるんよ。最近の革新的な手法、例えばMMSSL(Wei et al., 2023)とかMICRO(Zhang et al., 2022)は、様々なコンテンツ拡張ビュー間の相互情報量を最大化する自己教師ありタスクを実装することで、データのスパース性(まばらさ)の問題に取り組んどるんや。メインのデータが不完全な場合、補助情報の統合がユーザー特性を推測するのに適さへんこともあるんよ。補助データを導入する主な意図は商品情報を豊かにすることやけど、ユーザー固有の特性を記述するシステムの能力を向上させることにはうまくいかへんことが多いんや。その結果、このアプローチはユーザーとアイテムのインタラクション分析の精度を下げるだけやなく、ユーザーの好みを効果的に抽出することも妨げてまうかもしれへんのよ。
レコメンドシステムにおけるユーザーのインタラクションは、普通は意図に基づいとって、ユーザーの興味や好みを反映しとることが多いんや。そういう興味を理解することは、
1148
---
## Page 3
[](/attach/763a5542ddd3604fde1a7208d671f458ec383a8c07d1e347e704416e4a8bd776_p003.png)
### 和訳
検索拡張型大規模言語モデルを使った推薦システムの強化版
ユーザーの好みを理解するための情報源って、いろんな種類のフィードバックから取れるねん。過去にどんなアイテムとやり取りしたかっていう履歴、アイテムの属性、それからユーザーのレビューとかな(Caro-Martínez et al., 2021)。でもな、この情報が全部同じくらい推薦に役立つかっていうと、そうでもないねん。(1) アイテムの属性って、ユーザーの好みを正確に読み取るには浅すぎるんよ。アイテムのことをいろんな角度からざっくり説明はしてくれるけど、その人が「これのここが好き!」っていう具体的なツボまでは捉えられへんねん。(2) ユーザーレビューも、本当の好みをぼやかしてまうことがあるんよ。不完全やったり、的外れなフィードバックが混じってると、分析がややこしなってまうからな。せやから、過去のやり取りの流れから「この人、ほんまはこういうの求めてるんちゃう?」っていう隠れた意図をうまいこと読み取ることが、パーソナライズされた推薦を出すためにめっちゃ大事になってくるねん。最近の研究(He et al., 2024; Zhuo et al., 2024a; Chen et al., 2022b; Tanjim et al., 2020)では、高度なディープラーニングの手法を使って、ユーザーの行動の裏に隠れてる意図を探ろうとしてるんや。他の最近の取り組み(Wu et al., 2023; Wei et al., 2024; Zheng et al., 2024)では、大規模言語モデル(LLM)を使ってユーザーの好みをもっと効果的に引き出そうとしてるねん。補助的な情報を足すと、ユーザーの好みを掘り下げる精度は上がるんやけど、情報を増やしすぎると逆に、意味のある好みを捉える精度が落ちてまうこともあるんよ。
アイテムの基本情報に外部の知識をプラスして、その強化されたデータを分析するっていうアプローチは、隠れた内容を捉えるのにめっちゃ効果的やねん。追加の属性を提供することで、外部知識がアイテムについての情報を豊かにしてくれて、結果としてユーザーの意図をより正確に分析できるようになるんや。図1を見てもらったらわかるけど、映画の基本データが少なすぎると、システムが意味のある洞察を導き出すのに限界があるんよ。でもな、映画の基本情報をベースに補助情報を足してやると、システムは3つの視聴履歴の中から「同じ言語」とか「同じ監督」みたいな共通の特徴を見つけられるようになるねん。補助情報を広げることで、ユーザーの好みやニーズを推測する力がめっちゃ上がるんや。さらに言うと、ユーザーのレビューと評価だけに頼ってたら、ユーザーニーズの複雑さを完全には捉えきれへんのよ。LLMがどんだけ高度な言語理解と推論能力を持ってても、レビューデータから本当のユーザーニーズを正確に見抜くのはなかなか難しくて、そういう情報をうまく活用するのがほんまに大変なんや。補助情報を統合することで、使えるデータが豊かになるだけやなく、ユーザー行動を分析して的確な推薦をするための基盤も強化されるねん。でもな、推薦プロセスの効果は、この拡張された情報の質にかかってるんよ。拡張する時に低品質なデータが混じるとノイズになってまうから、それをどう抑えるかっていうのが大きな課題として残ってて、そういうデータをどう効果的に使うかはまだ解決されてへん問題なんや。
上で挙げた課題に取り組むために、ワイらは推薦向けにカスタマイズした「検索拡張型大規模言語モデルによる強化推薦システム(ER2ALM)」っていうアプローチを提案するで。この問題には、ユーザーがアイテムとやり取りした信頼できる履歴を活用して対処するねん。高評価をつけたアイテムをユーザーの好みを示す重要な指標として使うんや。ユーザーが気に入ったコンテンツに焦点を当てることで、あんまり好きやなかったアイテムから来るノイズを減らせるねん。ここで大事なのが、ユーザーレビューって感情的な反応を反映してることが多くて、本当のニーズとは違うことがあるってことや。誤解を招く可能性があるから、レビューはその後の分析からは除外してるねん。ユーザーのやり取り履歴に含まれる各アイテムの属性を拡張することで、その人の選択行動の中にあるパターンとか隠れたつながりを見つけ出すことに集中するんや。LLMを使うことで、もっと微妙な関連性を特定して、ユーザーの好みについてより深い洞察を引き出すねん。アイテムの補助情報を拡張するプロセスでは、RAG(検索拡張生成)を統合して
1149
---
## Page 4
[](/attach/763a5542ddd3604fde1a7208d671f458ec383a8c07d1e347e704416e4a8bd776_p004.png)
### 和訳
図1の説明やで:
視聴履歴見たら、拡張情報使って隠れたつながりとか発見できるんよな。でも評価とかレビューだけに頼っとったら、ほんまに価値ある情報集めるんがめっちゃ難しなるし、ユーザーが何好きかっていう理解も限られてまうねん。下の枠にある質問にちゃんと答えられへんかったら、レビューの評価も信用でけへんようになるんよ。
追加データがちゃんと関連性あって正確やってことを保証するんが大事やねん。この手法とLLM(大規模言語モデルっていう賢いAIのことや)を組み合わせることで、ユーザーのプロフィール分析とおすすめ生成の土台がめっちゃ強化されるわけや。なんでかっていうと、LLMが作るコンテンツって間違いとか不安定なとこがある可能性あるやん?せやからノイズ除去の仕組みを使うねん。この仕組みはグラフベースの相関関係を活用して、生成されたコンテンツがどんだけ信頼できるか評価するんや。で、一番信頼できる埋め込み表現だけを学習に使って、ノイズ混じりのデータはフィルターで弾いてまうってわけ。
まとめると、ワイらの貢献はこんな感じや:
• ER2ALMはRAG(検索拡張生成っていう情報引っ張ってくる技術や)とLLMを統合して、アイテムの補助情報をめっちゃ効果的に増強するねん。結果としてユーザーモデリングがより正確になるんよ。
• ER2ALMはLLM使ってパーソナライズされたユーザープロフィールをゼロから生成するねん。これでパーソナライズがめっちゃ強化されて、モデルの性能もアップするわけや。
• 実世界のデータセットで徹底的に評価した結果、ER2ALMは最先端のベースライン手法を上回る性能を示して、その優位性を確立したで。
この論文の残りはこんな構成になっとるで:セクション2で関連研究をレビューして、セクション3で提案手法の詳細を説明するねん。セクション4では大規模な実験を行って、その結果を分析するで。最後にセクション5で論文のまとめと、将来の研究の可能性について議論するんや。
1150
2010年、インセプション 4.5点 英語 アクション ノーラン監督 「映画ってほんまに魔法みたいな世界観持っとるな!!!」 拡張情報 評価とレビュー 2014年、インターステラー 3.5点 英語 SF ノーラン監督 「宇宙船めっちゃかっこええやん!」 2020年、テネット 2点 英語 相関関係 スリラー ノーラン監督 「意味わからん。退屈やわ。」 監督:ノーラン 言語:英語 「ユーザーは高評価の映画の何が気に入っとるん?」「ユーザーはファンタジージャンル楽しんどる?」「ユーザーは宇宙船好きなん?」「どんなタイプの宇宙船が好みなん?」「何がユーザーを退屈にさせとるん?」
---
## Page 5
[](/attach/763a5542ddd3604fde1a7208d671f458ec383a8c07d1e347e704416e4a8bd776_p005.png)
### 和訳
# 検索拡張型大規模言語モデルを使った、めっちゃパワーアップしたレコメンドシステム
**図2**: 提案してるER2ALMっていうシステムの全体像やねん。4つのパーツでできてるで:
(a) 補助情報の追加、(b) ユーザー分析、(c) ノイズ制御、(d) 強化表現学習。RAGっていうのは「検索で情報引っ張ってきて文章生成する技術」のことで、LLMは「でっかい言語モデル」のことやな。(Transf.とかAtt.とかEmb.とかは、変換とか属性とか埋め込みとかの略語やで)
## 2. 関連研究
### 2.1 レコメンドに使う大規模言語モデル
LLMっちゅうのは、昔からあった事前学習済みの言語モデルを、モデルのサイズもデータ量もめっちゃデカくしたバージョンやねん。いろんな研究で、このLLMをレコメンドのアルゴリズムの一部として取り入れてきてるんよ。
例えば、UniSRec(Houさんたちが2022年に発表)では、固定したBERTモデルでアイテムの表現を学習して、それを軽量なMoE(専門家の混合)ベースのネットワークでパワーアップさせて、いろんなドメインをまたいだ連続的なレコメンドをできるようにしてるねん。
で、UniSRecをさらに発展させたVQ-Rec(2023年)では、ベクトル量子化っていう技術を導入して、LLMが作るテキストの埋め込みをレコメンド用の空間にうまく合わせられるようにしてるんや。
Uni-CTR(Fuさんたち、2023年)は、共有LLMの中の階層的な意味表現を活用して、いろんなドメインに共通する特徴を捉えて、マルチドメインのレコメンド性能を上げてるで。
Zhiyuliさんたちは、LLMがテキストベースでユーザーの評価を予測する方法を提案してるし、Chat-REC(Gaoさんたち、2023年)は、ChatGPTを使って会話インターフェースと従来のレコメンドシステムの橋渡しをして、ユーザーに見せる前に返ってきたアイテム候補をいじってるんや。
LLaRA(Liaoさんたち、2024年)は、LLMの入力プロンプトでアイテムを表現するのに、ちょっと変わったハイブリッドなやり方を使ってて、従来のトークナイザーからのIDベースのアイテム埋め込みと、テキストのアイテム特徴を組み合わせてるねん。
SINGLE(Liuさんたち、2024b)は、LLMを使ってユーザーの過去の行動履歴から「ずっと変わらん好み」を捉えつつ、対照学習っていう技術で「その瞬間の好み」も捉えてるんや。
CLLM4Rec(Zhuさんたち、2024年)は、事前学習の時にソフト+ハードプロンプティングを使った相互正則化戦略で、言語モデリングを通じてユーザーとアイテムの協調フィルタリング情報とコンテンツベースの情報の両方をうまく捉えてるで。
それと比べて、うちのモデルは、LLMの「文章生成能力」と「頑丈なテキスト理解能力」を推論に活かしながら、LLMを使う時によく起こる「次元数が爆発的に増えすぎる問題」を軽減してるんや。
---
【図の説明部分】
**(a) 補助情報の追加**
- 映画の基本情報(タイトル:タイタニック、評価:IMDb 7.8、監督:ジェームズ・キャメロン、ジャンル:ドラマ・ロマンス、上映時間:195分...)
- RAGとLLMで情報生成
- 拡張された映画情報(あらすじとテーマ:〜を探求...、映像と音響のクオリティ:この映画は...、文化的影響:社会的・歴史的背景が...、観客の反応:レビューの感情分析...)
**(b) ユーザー分析**
- 視聴履歴から分析
- 家族のダイナミクス、喪失と癒し
- フランス語&英語
- ドラマ、ロマンス
**(c) ノイズ制御**
- 関連性のある属性の埋め込み、タイトルの埋め込み、その他の属性の埋め込み
- コサイン類似度で判断(0〜1)
- 残すか捨てるか決める
- アニメーション、コメディ、95-150分、ソフィア・コッポラとかの重み付け
**(d) 強化表現学習**
- フィルタリングされた映画の埋め込み
- ユーザーの埋め込み
- GNNで重み付けされたユーザー埋め込み
- ポジティブ・ネガティブのサンプル
---
## Page 6
[](/attach/763a5542ddd3604fde1a7208d671f458ec383a8c07d1e347e704416e4a8bd776_p006.png)
### 和訳
Wei、Duan、Zhuo、Wang、Huang、Liu
純粋にエンコーダーとしてだけ使うねん。レコメンデーションの意思決定プロセスでLLMを直接使わんことで、レコメンデーションタスクとLLMの特性の間にあるズレを軽減できるってわけや。
2.2 レコメンデーションのための検索拡張生成(RAG)
RAGっていうのは、外部データベースから正確で包括的な情報を引っ張ってきて、それを下流のタスクに適用することでテキスト生成の品質をめっちゃ上げる技術やねん。最近、検索拡張型の大規模言語モデル(RA-LLMs)が、検索と生成のプロセスをうまいこと統合することで、パーソナライズされた文脈に合った推薦を提供するのにめっちゃ有望やってことが分かってきてん(Di Palma, 2023; Wu et al., 2024)。例えばな、Di Palma(Di Palma, 2023)は、映画と本のデータセットから知識を活用して推薦品質を向上させる、シンプルな検索拡張型推薦モデルを提案してるねん。あと、Lu et al.(Lu et al., 2021)はユーザーレビューを取り入れて検索プロセスを改善して、推薦システム内のアイテム情報をより豊かにしてるんや。CoRAL(Wu et al., 2024)は強化学習を使ってデータセットから協調情報を抽出して、それを意味情報と整合させることでより精度の高い推薦を実現してるねん。RaSeRec(Zhao et al., 2025)はメモリ検索を使って対象ユーザーの協調記憶を抽出して、リアルタイムで更新されるメモリバンクを通じて動的な好みの変化にうまく適応してるんや。ユーザーの潜在的な好みを理解して発見するっていう観点から、ワイらはLLMの高度なテキスト生成能力を活用して、専門データベースからより複雑で包括的な情報を取得して、それによってモデルに追加の多次元的な文脈情報を与えてるわけやねん。
2.3 大規模言語モデルのためのデータ拡張
LLMは、そのオープンワールドな知識を持ってるから、柔軟な知識リポジトリとして見ることができて、ユーザーの好みモデリングやアイテムコンテンツの理解に補助的な機能を提供してくれるねん。例えばな、KAR(Xi et al., 2024)はLLMを使ってユーザー側の好み知識とアイテム側の事実知識を生成して、それを下流の推薦モデルの追加特徴として使ってるんや。SAGCN(Liu et al., 2024a)はチェーンベースのプロンプティング手法を導入して、意味的に認識されたインタラクションを発見して、ユーザー行動についてより明確な洞察を提供してるねん。CUP(Torbati et al., 2023)はChatGPTを使ってユーザーレビューテキストを分析して、各ユーザーの興味を簡潔なキーワードでまとめてるんや。あと、LLaMA-E(Shi et al., 2024)とEcomGPT(Li et al., 2024)は大規模言語モデルを使って、商品分類や意図推論みたいなEコマースシナリオでの様々な下流生成タスクを強化してるねん。他の研究もさらにLLMを使って、属性生成(Brinkmann et al., 2023; Li et al., 2023; Yin et al., 2023)やユーザー興味モデリング(Christakopoulou et al., 2023; Doddapaneni et al., 2024; Lyu et al., 2024; Ren et al., 2024a)みたいな色んな視点から訓練データを豊かにしてるんや。ほんで、上で述べた手法を踏まえて、ワイらはLLMの柔軟性と便利さを活用して利用可能な情報を拡張したんや。さらに、RAGを取り入れることで、信頼性があって関連性の高い情報の取得を確保して、それによって生成された補助データの信頼性を高めてるってわけやねん。
1152
---
## Page 7
[](/attach/763a5542ddd3604fde1a7208d671f458ec383a8c07d1e347e704416e4a8bd776_p007.png)
### 和訳
検索拡張型の大規模言語モデルを使ったレコメンドシステムの強化版やで
表1:ハードプロンプトの構造と中身の説明
| プロンプトのセクション | 内容 |
|---|---|
| タスクの説明 | タスクがどんなもんか簡潔に説明して、目標とか期待される結果をはっきりさせるとこやねん |
| タスクの指示 | 具体的に何を入力せなあかんか、どんな手順でやったらええかを示すパートやで |
| 詳細要件 | 出力の形式とか、回答で絶対押さえなあかん重要ポイントを指定するとこやな |
| 出力フォーマットの仕様 | 入力と出力のデータ項目を定義して、それぞれの意味とか使い道を明確にするんや |
| 詳細への注意喚起 | ミスとか誤解を防ぐための重要な注意点とか指示を強調するパートやで |
## 3. 提案するアプローチ
このセクションでは、レコメンド問題の正式な定義と、ワイが提案するER2ALMっていう手法を紹介するで。これは5つのコアモジュールで構成されてんねん:
**(1) 補助情報の補完**:RAG(検索拡張生成)とLLM(大規模言語モデル)を組み合わせて、関連する補助データを引っ張ってきて、レコメンドの精度を上げるんや。
**(2) ユーザー分析**:LLMを使ってユーザーの行動を分析して、その人専用のプロフィールを作るわけやな。
**(3) 埋め込み生成**:RoBERTaモデルを使って、テキストを質の高い埋め込みベクトルに変換するんやで。
**(4) ノイズ制御**:ノイズを減らして、埋め込みの品質と信頼性を守るっちゅうことや。
**(5) 強化された表現学習**:きれいにしたデータを処理して、効果的にモデルを学習させるんや。
ユーザーの好みと詳細な過去のデータを組み合わせることで、うちのモデルはレコメンドの裏にある論理をめっちゃ上手くキャッチできるようになるんやで。図2に全体のフレームワークの概要を載せとるわ。
**問題の定義**
U = {u₁, u₂, ..., u|U|} をユーザーの集合、I = {i₁, i₂, ..., i|I|} をアイテムの集合とするで。|U|と|I|はそれぞれユーザー数とアイテム数を表してんねん。
具体的に言うと、iₙ = {basicᵢ,ₙ | iₙ ∈ I, n = 1, 2, ..., |I|} が各アイテムの基本属性を表すんや。
ほんで、iₙᴬ = {(basicᵢ,ₙ, auxilᵢ,ₙ) | iₙᴬ ∈ Iᴬ, n = 1, 2, ..., |I|} が各アイテムの補助情報の拡張を表してて、Iᴬは補助情報で強化されたアイテムの集合やねん。
あるユーザー uₘ ∈ U に対して、hₘ = {iₘ,₁ᴬ, iₘ,₂ᴬ, ..., iₘ,|hₘ|ᴬ} がそのユーザーの履歴シーケンスを表すで。|hₘ|はシーケンスの長さで、hₘ ∈ Hᵤ はユーザーのインタラクション履歴の集合を表してんねん。
ユーザープロフィール qₘ = {prefe.analy.ₘ,ₖ | uₘ ∈ U, m = 1, 2, ..., |U|} で、qₘ ∈ Qᵤ がユーザープロフィールの集合、対応する好みの重み wₘ,ₖ ∈ Wᵤ がプロフィールの重みの集合を表すんや。これらはインタラクション履歴シーケンス hₘ を分析して導き出されるんやで。k は分析プロセスでのカテゴリ数を表してんねん。
ユーザープロフィールの埋め込みとアイテムの埋め込みは、それぞれ eₘᵍ と eₙⁱ で表すで。正例(E⁺ᵢ)はユーザーが興味持ちそうなアイテムを表して、負例(E⁻ᵢ)は興味持たへんやろうなっていうアイテムを表すんや。モデルは学習後に、インタラクションスコアを r̂(u, i) として予測するっちゅうわけやな。
---
## Page 8
[](/attach/763a5542ddd3604fde1a7208d671f458ec383a8c07d1e347e704416e4a8bd776_p008.png)
### 和訳
3.1 補助情報の補足
ユーザーの好みを推測するにはな、まずアイテムの属性を集めて分析せなあかんのやけど、そのためには足りてない属性情報を補完する必要があるねん。正確で信頼できて、しかも中身の濃い補助情報をゲットするために、俺らはRAG(検索拡張生成)とLLM(大規模言語モデル)を組み合わせた戦略を提案してるんや。
RAGの技術を使うとな、アイテムの名前やカテゴリーをもとに、もっと詳しい情報を引っ張ってこれるねん。in = {basici,n | in ∈ I, n = 1, 2, . . . , |I|} っていうのは各アイテムの基本属性を表してるんや。外部からアイテム情報を取ってきた後、LLMを使って生成プロセスをやるわけや:
iA
n = L(PI (in, A[R(in)])), n = 1, 2, ..., |I|,
(1)
ここでL(·)はLLMのことで、R(·)とA(·)はそれぞれRAGフレームワークの検索部分と拡張部分を表してるねん。PIは出力を生成するためのプロンプト(指示文)のことで、その構造は表1に詳しく書いてあるで。
取ってきた情報は3種類に分けられるねん:そのまま使える本質的な情報、いらん情報や関係ない情報、そして整理や要約が必要な複雑でバラバラな情報や。LLMのめっちゃ優れた言語理解能力とテキスト生成能力を活用して、取得したデータから価値ある洞察をさらに引き出して、補助情報をピンポイントで補強できるようにしてるんや。
iA
n = {(basici,n, auxil.i,n) | iA
n ∈ I A, n = 1, 2, . . . , |I|} は各アイテムの補助情報の拡張を表してて、I Aは補助情報で強化されたアイテムの集合やねん。basici,nの値は基本アイテム情報と同じままやで。
この方法はな、LLMの限界、特に不完全な内容や間違った内容を生成してまう問題を軽減してくれるねん。信頼性の低い「幻覚」応答(AIが事実と違うことをでっち上げてまうやつ)が出るリスクも最小限に抑えられるんや。LLMを使ったコンテンツ生成は、シンプルなだけやなくて、めっちゃ柔軟性も高いから、補足情報をサクッと作れるのがええとこやな。
3.2 ユーザー分析
次にな、アイテムに関連する補助情報を戦略的に拡張して、アイテムをより深く理解できるようにして、アイテム関連のデータを使ってユーザーの好みを推測するためのしっかりした基盤を作るねん。ユーザーのやり取り履歴はその人の好みを反映してるって仮定してるんや。なんでかっていうと、その履歴は特に満足したアイテムで構成されてるからやねん。この強化されたやり取り履歴を分析することで、ユーザーのアイテム選択を導いてる根底にある意図や好みを推測できるってわけや。包括的な購入履歴と事前に設計されたプロンプトテンプレートを組み合わせることで、モデルは精密な推論ができるようになるねん。このプロセスで重要な判断ポイントを特定して、論理的な関係性を明らかにして、暗黙のユーザー意図や興味を引き出して、詳細で正確なユーザープロファイルを構築できるんや。
俺らはハードプロンプト(固定テンプレート)の形でLLMに送る固定テンプレートのプロンプトを使ってるねん。(Fatemi et al., 2024)で提示されたアイデアにインスパイアされて、ユーザーのやり取り記録と関連商品情報のデータ内容と解釈アプローチを詳細化して、LLMの生成能力をさらに強化してるんや。
qm = L{PU [hm,
S(iA
n )
(cid:124) (cid:123)(cid:122) (cid:125)
n∈hm,1,hm,2,...,hm,|hm|
, T emp]},
(2)
1154
---
## Page 9
[](/attach/763a5542ddd3604fde1a7208d671f458ec383a8c07d1e347e704416e4a8bd776_p009.png)
### 和訳
検索強化型大規模言語モデル使ったレコメンドシステムの性能アップの話やで
T emp = {(Tdata), Des, Ins, Det, Out, Emp},
(3)
ここでな、qm ∈ QU ってのはユーザープロフィールの集まりのことやねん。hmは「このユーザーさん、過去にどんな商品見たり買ったりしてきたか」っていう履歴のことや。S(·)は、その履歴に関連する商品情報をくっつけて情報マシマシにしたやつを集めたもんやな。Tempってのはハードプロンプトテンプレート、要するにAIに「こういう感じで考えてな」って指示出すための雛形みたいなもんや。PUはユーザープロフィールを分析して生成するためのハードプロンプトで、L(·)は大規模言語モデル(LLM)のことやで。これら全部合わせて、ユーザーの好みを分析するためのヒント情報になるわけや。で、それをLLMがガーッと処理して「このユーザーさん、こういうの好きそうやな」って興味を推測するんやな。ハードプロンプトテンプレートTempの中身は表1に詳しく載ってるで。この構造があることで、LLMがよくやらかすミスを減らせるねん。このメソッドのプロンプト構造もこのフォーマットに従っとるで。
次にな、ユーザープロフィールは色んな角度からユーザーを分析して作るねん。それぞれの角度は、補助情報を生成するときに使う分類とめっちゃ密接に関係してるんや。これらの視点で「ユーザーがアイテム選ぶとき、何を重視してるか」っていう重要ポイントを浮き彫りにするわけや。ほんでな、どの視点をどんだけ重視するかは、ユーザーによって全然ちゃうねん。このバラつきを捉えるために、それぞれの視点がどれくらい影響するかを表す重みを別々に割り当てるんや。こうすることで、ユーザーごとのパーソナライズされた表現がもっと最適化されるってわけやな。ユーザーの行動履歴と好みの分析をベースにして、さらにLLMを使って各ユーザーのパーソナライズされた好みの重みを分析・導出するんや。この詳細な分析のおかげで、ユーザーの行動をより深く理解できるようになって、隠れた意図とか興味を引っ張り出せるから、パーソナライズされたユーザーモデリングをサポートできるんやで。図3には、ユーザープロフィール生成に使うプロンプトと、その出力結果が載っとるで。
図3:上の部分はプロンプトPromptUとPromptWへの入力を示してて、下の部分はその出力に対応しとるで。< · >は「ここに具体的なデータ入るけど省略してるで」って意味やな。
1155
(1)ユーザーの興味と好みを、行動履歴とアイテムの詳細からJSON形式でまとめるんや。(2)めっちゃエンゲージメント高いアイテムを分析して、論理的に整理して、潜在的なニーズを推測するんやで。(3)各アイテムに<重要なデータフィールド>を含めて、好みを論理的に分類するんや。(4)入力フィールドと出力フィールドを定義して、それぞれの役割と目的を明確にするんやで。(5)JSON出力は正確で、漏れなく、ちゃんと構造化されてることを確認するんやで。
プロット:複雑でサスペンスフルな映画がめっちゃ好き
テーマ:戦争もん
監督:ジョン・ラセター、ティム・バートン
ジャンル:アクション、ドラマ、戦争
映像と音質:実写とCGIのミックス
文化・言語:英語
上映時間:90〜120分
重み
0.15, 0.20, 0.10, 0.12, 0.08, 0.13, 0.22
(1)ユーザーの行動履歴とアイテム関連データを分析して、各要素の影響度の重みをJSON形式で生成するんや。(2)各レコードについて:<重要なデータフィールド>。ユーザープロフィールの内容を論理的に整理して、各要素に重みスコアを割り当てるんやで。(3)入力フィールドと出力フィールドを定義して、それぞれの役割と目的を明確にするんや。(4)JSON出力は正確で、漏れなく、指定された構造に従ってることを確認するんやで。(5)分析は包括的で、理にかなったもんにせなあかんで。
---
## Page 10
[](/attach/763a5542ddd3604fde1a7208d671f458ec383a8c07d1e347e704416e4a8bd776_p010.png)
### 和訳
3.3 エンベディング生成
ほんで次はな、RoBERTaっていうモデルを使って、テキストの情報(生成したテキストとかユーザープロフィールとか)をエンベディングに変換するんや。エンベディングってのは、要するに文章を数字の列に変えることやねん。アイテム関連のデータについては、それぞれの属性を個別にエンベディングするで。
ユーザープロフィールは複合エンベディングとして表現されるんやけど、これはいろんな側面を重要度の重みに応じて組み合わせて作るんや。つまり、ユーザーがどのコンテンツ要素を重視してるかを反映させてるわけやな。具体的に言うと、エンベディングのプロセスで、複数の情報を一つにまとめる時にこの重みを適用するんや。それぞれの情報が相対的な重要度に基づいて貢献するようになってるんやで。
なんでこんなことするかっていうと、重要なデータほど全体の表現にめっちゃ影響を与えるようにしたいからやねん。これで関連する情報を保持しながら、重要度の違いもちゃんと強調できるっちゅうわけや。ユーザーの好みの幅と深さの両方を捉えることで、ユーザー行動の微妙なニュアンスを反映する能力がグンと上がるんやで。
ユーザープロフィールベクトル eq_m は、いくつかの側面の重み付き和として表されるんや:
n = {ei_1, ei_2, . . . , ei_k′}、n ∈ [1, |I|]、(4)
eq_m = Σ(i=1からk) qm,k・wm,k、wm,k ∈ (0, 1)、m ∈ [1, |M|]、(5)
ここで ei_k′ はアイテム ei_n の k′番目の側面を表してて、qm,k はユーザープロフィール qm の k番目の側面、wm,k は対応する重みやねん。具体的には、ユーザープロフィールとアイテムのエンベディングをそれぞれ eq_m と ei_n で表すで。eq_m, ei_n ∈ R^(1×d) で、d はユーザープロフィールエンベディングとアイテムエンベディングの次元数や。|M| と |I| はそれぞれユーザー数とアイテム数を表してるんやで。
もしLLM(大規模言語モデル)でエンベディングを生成したら、いくつか問題が出てくることがあるねん。エンベディングの長さが長すぎたり、テキストごとに次元数がバラバラになったりするんや。従来のテキスト変換アプローチを使えば、エンベディングの長さをうまくコントロールしながら、コンテンツ要素の区別も維持できるんや。次元削減のプロセスで大事な情報が失われへんようにできるっちゅうことやな。
3.4 ノイズ制御
LLMで補助情報を充実させる時、どうしても間違った情報とか関係ない文章が生成されてまうことがあるねん。これがノイズとして後の学習に入り込んでしまうわけや。これを防ぐために、エンベディングプロセスの後に補助情報を検証する効率的な方法を採用してるで。
まず、基本的な属性を1つか複数選んで「信頼できるマーカー」として設定するんや。これが評価の信頼できる基準になるねん。そして、このマーカーのエンベディングと他のエンベディングの相関を、類似度指標を使って計算するんやで。
これを実現するために、グラフ破壊法(Wang et al., 2023)を使って、選んだマーカーのエンベディングと生成された各情報との相関を計算するんや。結果の相関値は0から1の範囲で、値が高いほど信頼性が高いっちゅうことやな。この値に基づいて、補助情報を残すか捨てるかを決めるんや。こうすることで、信頼できるデータだけが後の分析に使われるようにしてるんやで。
wiA_n,k′ = MLP [Wr (basici | iA_n,k′)]、n ∈ (1, 2, ..., |I|)、(6)
---
## Page 11
[](/attach/763a5542ddd3604fde1a7208d671f458ec383a8c07d1e347e704416e4a8bd776_p011.png)
### 和訳
ほな、めっちゃわかりやすく説明していくで!
ここで$w_{n,k'}^{iA}$っていうのは、2つの属性間のエッジの重みを表してんねん。$i \in I$、$iA \in I^A$で、MLP(・)っていうのはマルチレイヤーパーセプトロン(多層パーセプトロン)の略やねん。要するに何層も重なったニューラルネットワークのことやな。$W_r(・)$は関係$r$の変換行列やで。あと、$basic_i$と$i_{n,k'}^A$はそれぞれ各アイテムの基本属性と、それ以外の生成された属性の埋め込みベクトルを示してんねん。$k'$はアイテム$i_n^A$の$k'$番目の側面を表してるわ。$I$はアイテムの集合で、$I^A$は拡張されたアイテムの集合やねん。$|I|$はアイテムの数を意味してるで。
$$\epsilon = (2 \times bias - 1) \times rand(d) + (1 - bias) \tag{7}$$
ここで$\epsilon$はランダムに生成されたオフセット値を表してんねん。biasっていうのは小さい値で、なんでこれ入れてるかっていうと、完全に丸められたり全部そのまま残っちゃったりする問題を防ぐためやねん。計算の数値的な安定性を確保するためってわけや。$d$はアイテム埋め込みの次元数やで。
$$J_{n,k'}^{iA} = \sigma\left(\left(\log(\epsilon) - \log(1-\epsilon) + w_{n,k'}^{iA}\right)/\tau_{mA}\right), \quad iA \in I^A, n \in (1,2,...,|I^A|), \epsilon \in (0,1) \tag{8}$$
ランダム変数$\epsilon$は(0,1)の範囲から引っ張ってきてんねん。$\sigma(・)$はシグモイド関数を表してて、温度ハイパーパラメータ$\tau_{mA}$が近似をコントロールしてるわけや。$\tau_{mA}$が0に近づくと、$J_{n,k'}^{iA}$は2値(0か1)に近い値になっていくねん。$\theta$は正確か不正確かを判定するための閾値やで。$J_{n,k'}^{iA} > \theta$のとき、その埋め込みは信頼できる生成結果として残されるし、そうやなかったら低品質な情報として捨てられるってことやな。
上で説明した分類方法をベースにすると、正しい分類結果と間違った分類結果の両方を集められるねん。この分類された結果は後の評価のために保存しとくわけや。信頼できる結果と信頼できない結果が十分な数だけ分類されたら、新しいコンテンツをこれらの保存された埋め込みと比較するねん。コサイン類似度を計算することで、新しいコンテンツが信頼できる結果に近いんか、信頼できない結果に近いんかを評価できて、それが残すか捨てるかの判断のガイドになるってわけやな。
ワイらは2セットの埋め込みを維持してんねん:信頼できるデータ用と信頼できないデータ用や。埋め込みの信頼度スコアが信頼できない閾値と信頼できる閾値の間にあるとき、コサイン類似度を使って両方のセットの埋め込みと比較するねん。最も高い類似度スコアを持つカテゴリが最終的な分類結果として選ばれるわけや。2つのカテゴリの埋め込み数が一定の閾値に達したら、判定対象の拡張属性埋め込み$E_A^J$は以下のように表せるで:
$$E_A^J = \begin{cases} Emb_{n,k'}^{iA}, & J_{n,k'}^{iA} >> \theta_{reliable} \\ Emb_{n,k'}^{iA}, & J_{n,k'}^{iA} >= \theta_{reliable} \text{ かつ } \Delta > 0 \\ 0, & J_{i,k'}^{iA} < \theta_{reliable} \text{ または } \Delta < 0 \end{cases}$$
$$iA \in I^A, n \in (1,2,...,|I^A|), \epsilon \in (0,1) \tag{9}$$
$J_{n,k'}^{iA}$の値がめっちゃ高いときは、情報の品質が信頼できると判断するねん。スコアが低いときは、コサイン類似度を使って信頼性を評価するわけや。$\theta_{reliable}$は信頼性の閾値を表してるで。$k'$はアイテム$i_n^A$の$k'$番目の側面を表してんねん。
$$\Delta = sim(E_{retain}, Emb^A) - sim(E_{abandon}, Emb^A) \tag{10}$$
変数$\Delta$は、残す用の埋め込み$E_{retain}$と捨てる用の埋め込み$E_{abandon}$それぞれとの類似度の差を表してんねん。$Emb^A$は埋め込みを示してるで。
---
## Page 12
[](/attach/763a5542ddd3604fde1a7208d671f458ec383a8c07d1e347e704416e4a8bd776_p012.png)
### 和訳
ほな、このアルゴリズム説明するで〜!
---
**アルゴリズム1:ER2ALMの学習手順**
**入力するもん:** アイテムの集合I、ユーザーの集合U、過去のやりとり履歴HU
**出てくるもん:** トップkのおすすめリスト
---
まず最初にな、アイテムごとにループ回すねん(1〜3行目):
- 各アイテムiに対して、RAGっていう検索拡張生成とLLM(大規模言語モデル)を使って、アイテムの属性情報iAを作るんや。式1を使うで。
次にユーザーごとにループや(4〜11行目):
- ユーザーuの過去の履歴huを取ってくる
- その履歴とさっき作ったアイテム属性を分析して、ユーザープロファイルを作成するねん(式2使用)
- ほんで、そのプロファイルをRoBERTaっていう言語モデルに食わせて、ユーザーの埋め込みベクトルeuを生成(式5)
- さらにLLMを使って、ユーザーが「ええな〜」って思ったアイテム(ポジティブ)と「いらんわ」って思ったアイテム(ネガティブ)の情報ui+とui-を作る
- それらもRoBERTaで埋め込みベクトルE+とE-に変換するんや
ここからがめっちゃ大事なとこやねん!拡張されたアイテムごとにループ(12〜31行目):
- 各拡張アイテムiAをRoBERTaで属性埋め込みei_k'に変換
- ほんで、その埋め込みが信頼できるかどうかを判定するねん(式8で信頼性JAを計算)
- もし信頼できる情報と信頼できへん情報のストック(EretainとEabandon)がまだN個溜まってへんかったら:
- JAがしきい値θreliable以上やったら「信頼できる」としてEretainに追加
- そうやなかったら「信頼できへん」としてEabandonに追加
- もう両方ともN個溜まってたら:
- 式10で類似度の差分Δを計算する
- JAがしきい値以上でΔも0より大きかったら、信頼できる情報として確定して残す
- そうやなかったら、信頼できへん情報として捨てる
なんでこんなことすんのかっていうと、LLMが生成した情報って時々でたらめなこともあるから、ちゃんと信頼性チェックして使えるもんだけ残すっていう仕組みやねん。
最後に(32〜34行目):
- 全ユーザーと全アイテムの組み合わせについて、インタラクションスコア(どんだけ相性ええか)を式13で計算
- 各ユーザーに対して、スコアr̂(u,i)が一番高いk個のアイテムを選ぶ
- それをおすすめリストRu(i)として返す
---
ほんで、信頼性を判断する時に使うコサイン類似度の計算式はこれや(式11):
sim(u, v) = (u・v) / (∥u∥∥v∥)
要するに、2つのベクトルuとvがどんだけ同じ方向向いてるかを測る計算式やな。内積を各ベクトルの長さで割るだけや。1に近いほど似てて、0に近いほど関係ないってことやで〜。
---
## Page 13
[](/attach/763a5542ddd3604fde1a7208d671f458ec383a8c07d1e347e704416e4a8bd776_p013.png)
### 和訳
ほな説明していくで!
---
ここでの ∥u∥ と ∥v∥ っていうのは、ベクトル u と v のノルム(まあ簡単に言うたら「大きさ」みたいなもんやな)のことやねん。で、新しいコンテンツが「これ信頼できるわ」ってなったら、その埋め込みベクトルを今ある埋め込み行列にポンって追加するんや。
商品情報が正確か不正確かを見分けるための損失関数 Loss はこんな感じで計算するんやで:
Loss = −∑(i∈|E|) log σ(EmbA · E) (12)
ここで σ(·) ってのはシグモイド関数や(0から1の間に値をギュッと押し込む便利なやつやな)。EmbA は「これどうなん?」って評価したい補助的な商品情報の埋め込みベクトルで、E は比較の基準になる「信頼できるで」って選ばれた属性の埋め込みベクトルやねん。
**3.5 強化された表現学習**
従来のレコメンドモデルって、ユーザーが過去に見たもんの履歴と、それで学習した結果をベースにおすすめリストを作ってたんや(Caro-Martínezら、2021年;Burashnikovaら、2021年;Kotoら、2022年)。でもな、LLM(大規模言語モデル)の判断力と理解力を使ったら、このプロセスをもっとパワーアップできるんやで。生成された限られたおすすめリストの中から、LLMが「このユーザー、これめっちゃ興味ありそうやな」ってアイテムと「これはあんまり興味なさそうやな」ってアイテムを選び出して、それぞれ正例(E⁺ᵢ)と負例(E⁻ᵢ)として使うんや。学習のときにこういう少数の正例・負例を使うことで、インタラクション情報が増えて、ある程度の比較ができるようになるんやな。
最後に、生成されたユーザープロファイルと、フィルタリングされた補助情報の埋め込み、それから選ばれた正例・負例の一部を、GNN(グラフニューラルネットワーク)モデルに突っ込んで学習させるんや。このプロセスで最終的な予測モデルができて、より正確でパーソナライズされたおすすめができるように最適化されるってわけ。あと、ユーザー u がアイテム i とインタラクションする確率は、内積を使ってこんな風に計算するで:
ˆr(u, i) = eᵤᵀ eᵢ (13)
ここで eᵤ と eᵢ はそれぞれユーザーとアイテムの埋め込みやな。ほんで、タスクの損失を計算するために BPR損失関数を採用してて、その式はこうなるで:
Loss = ∑((i,i')∈S) − log σ(ˆr(u, i) − ˆr(u, i')) (14)
ここで σ(·) はシグモイド関数、S はテストセット、i はインタラクション履歴にあるアイテム、i' はユーザーの履歴にないアイテムのことやねん。なんでかっていうと、「履歴にあるアイテムの方が履歴にないアイテムより好まれるはずや」っていう考え方で学習してるからやな。
**4. 実験**
このセクションでは、提案した ER²ALM アルゴリズムがパーソナライズドレコメンドシステムでほんまに使えるし効果的やっていう実証的な証拠を示すで。このアルゴリズムは補助データをうまく活用してユーザーの好みを掘り出して、その情報をレコメンドのプロセスにスムーズに組み込めるんや。性能を検証するために、映画レコメンドの分野で実験をやって、広く使われてる2つの...
---
## Page 14
[](/attach/763a5542ddd3604fde1a7208d671f458ec383a8c07d1e347e704416e4a8bd776_p014.png)
### 和訳
Wei、Duan、Zhuo、Wang、Huang、Liu
表2:元のデータセットと拡張後のデータセットの統計
| データセット | Netflix | MovieLens |
|---|---|---|
| | 元データ | グラフ | 元データ | グラフ |
| ユーザー数(#U) | 13,187 | | 12,237 | |
| アイテム数(#I) | 17,366 | | 10,681 | |
| エッジ数(#E) | 68,933 | | 78,880 | |
| 拡張後 | #E: ⌈26,374 × η⌉ | | #E: ⌈24,474 × η⌉ | |
| 元のスパース率 | 99.970% | | 99.930% | |
| 元の属性 | U: なし | | U: なし | |
| | I: 公開年、タイトル | | I: タイトル、公開年、ジャンル | |
| 拡張後の属性 | I[1024]: あらすじとテーマ、ジャンル、映像音響特性、文化と言語、上映時間、監督 | | |
| | U[1024]: あらすじ、テーマ、ジャンル、映像音響特性、文化と言語、上映時間、監督、重み | | |
| モダリティ | テキスト[768]、視覚[512] | | テキスト[768]、視覚[512] | |
※Att.は属性、Ori.は元データ、Aug.は拡張を表すで。[X]の数字は特徴量の次元数やねん。⌈x⌉は天井関数で、ηは係数のことやで。
ほな本題いくで!ここでは2つの映画データセットを使って評価してんねん。セクション4.1では実験の全体設定を説明して、4.2から4.4では結果と発見について書いてるわ。ほんで4.5ではケーススタディの詳しい分析を紹介するで。この実験で明らかにしたい研究課題(RQs)はこんな感じや:
- **RQ1**: ワイらのLLM強化レコメンダー、この分野のトップクラスのベースラインと比べてどうなん?
- **RQ2**: モデルの主要な部品それぞれが、全体の性能にどんな影響与えてんの?
- **RQ3**: 重要なパラメータをいじったら、モデルの性能どれくらい変わんねん?
- **RQ4**: ワイらのモデル、予測結果に対して直感的に分かる説明できんの?
### 4.1 実験設定
このパートでは、実験の全体設定をざっくり説明するで。データセット、評価方法、比較用のベースライン、あと実装の詳細についてや。
**データセット**。公開されてるデータセット、NetflixとMovieLens10M(ML-10M)を使って実験したで。どっちも映画の基本情報が入ってんねん。Netflix¹はNetflixがリリースしたやつで、ユーザーから集めた1億件以上の匿名映画評価データが入ってるわ。
---
¹ https://www.kaggle.com/datasets/netflix-inc/netflix-prize-data
1160
---
## Page 15
[](/attach/763a5542ddd3604fde1a7208d671f458ec383a8c07d1e347e704416e4a8bd776_p015.png)
### 和訳
表3:いろんなデータセットでの性能比較やねん。Recall@10/20/50、NDCG@10/20/50、Precision@20っていう指標で見てるで
ベースライン
R@10 N@10 R@20 N@20 R@50 N@50 P@20
R@10 N@10 R@20 N@20 R@50 N@50 P@20
Netflix
MovieLens
BPR-MF
0.0282 0.0140 0.0542 0.0205 0.0932 0.0281 0.0027
0.1890
0.0815
0.2564 0.0985
0.3442
0.1161
0.0128
NGCF
CF
0.0347 0.0161 0.0699 0.0235 0.1092 0.0336 0.0032
0.2084
0.0886
0.2926 0.1100
0.4262
0.1362
0.0146
LightGCN
0.0352 0.0160 0.0701 0.0238 0.1125 0.0339 0.0032
0.1994
0.0837
0.2660 0.1005
0.3692
0.1209
0.0133
VBPR
0.0325 0.0142 0.0553 0.0199 0.1024 0.0291 0.0028
0.2144
0.0929
0.2980 0.1142
0.4076
0.1361
0.0149
MMGCN
SI
0.0363 0.0174 0.0699 0.0249 0.1164 0.0342 0.0033
0.2314
0.1097
0.2856 0.1233
0.4282
0.1514
0.0147
GRCN
0.0379 0.0192 0.0706 0.0257 0.1148 0.0358 0.0035
0.2384
0.1040
0.3130 0.1236
0.4532
0.1516
0.0150
DA
LATTICE
LLMRec
MICRO
0.0433 0.0181 0.0737 0.0259 0.1301 0.0370 0.0036
0.2116
0.0955
0.3454 0.1268
0.4667
0.1479
0.0167
0.0531 0.0272 0.0829 0.0347 0.1382 0.0456 0.0041
0.2603
0.1250
0.3643 0.1628
0.5281
0.1901
0.0186
0.0466 0.0196 0.0764 0.0271 0.1306 0.0378 0.0038
0.2150
0.1131
0.3461 0.1468
0.4898
0.1743
0.0175
CLCRec
SSL
0.0428 0.0217 0.0607 0.0262 0.0981 0.0335 0.0030
0.2266
0.0971
0.3164 0.1198
0.4488
0.1459
0.0158
MMSSL
0.0455 0.0224 0.0743 0.0287 0.1257 0.0383 0.0037
0.2482
0.1113
0.3354 0.1310
0.4814
0.1616
0.0170
ER2ALM 0.0566 0.0283 0.0840 0.0367 0.1469 0.0482 0.0042
0.2645 0.1376 0.3891 0.1767 0.6036 0.2165 0.0210
改善率
6.60% 4.04% 1.31% 5.76% 6.29% 5.70% 2.38% 1.61% 10.08% 6.81% 8.54% 14.30% 16.01% 12.09%
ほんで、1999年から2005年の間のデータを使ってるねん。MovieLensっていうのは、レコメンドシステムの研究でめっちゃよく使われるベンチマークデータセットのシリーズやねん。ML-10Mっていうやつには、1000万件の評価データと、72,000人のユーザーが10,000本の映画につけた10万件のタグ情報が入ってるんや。両方のデータセットとも、映画のタイトル、ジャンル、公開年みたいなメタデータだけを使って、属性情報がない状況をシミュレーションしてるわけやな。表2には、ユーザーとアイテムそれぞれについて、元のデータセットと拡張後のデータセットの統計的な詳細を載せてるで。
**評価の仕方について。** ワイらのアプローチがどれくらいイケてるか評価するために、3つの標準的な指標を使ってるねん:
• Recall@Nっていうのは、トップKのおすすめの中から、実際に関連するアイテムをどれだけ取ってこれたかの割合やねん。要するに「欲しいもんをちゃんと見つけられたか」ってことや。
• NDCG@Nっていうのは、トップKの中で関連アイテムが何位に来てるかを考慮する指標やねん。上の方に来てるほど高得点になるから、ランキングの質がわかるってわけや。
• Precision@Nっていうのは、トップKのおすすめの中に関連アイテムがどれくらいの割合で入ってるかを示すもんやねん。「おすすめした中でどれだけ当たりがあったか」ってことやな。
テストのサンプリングで偏りが出んように、全ランキング評価戦略(Wei et al., 2021a, 2020)を採用してるで。結果は5回独立して実験した平均値で、Kは10、20、50に設定してるねん。Recall@Kの値が高いほど検索がうまくいってるってことやし、NDCG@Kは上位に関連アイテムが来てるほど重み付けされるからランキングの質がわかるし、Precision@KはトップKの中にどれだけ関連アイテムが集中してるかがわかるってことや。
**比較対象のベースラインについて。** ワイらのアプローチの性能をちゃんと評価するために、4つの異なるカテゴリのベースライン手法と比較してるねん。それぞれが違う課題に取り組んでて、レコメンドタスクについていろんな視点を提供してくれるんや。
2. https://grouplens.org/datasets/movielens/10m/
1161
---
## Page 16
[](/attach/763a5542ddd3604fde1a7208d671f458ec383a8c07d1e347e704416e4a8bd776_p016.png)
### 和訳
【協調フィルタリング系の手法】
まず**一般的な協調フィルタリング(CF)**からいこか。これはな、ユーザーとアイテムのやりとりデータだけを使ってオススメを出す、めっちゃ基本的なやり方やねん。要は「この人、前にこれ買ったな」っていう履歴からユーザーとアイテムの特徴を学習するんやけど、他の追加情報は一切使わへんのがポイントやな。
代表的な手法でいうと:
- **BPR-MF**(Rendleら、2012年):行列分解っていう手法を使って、ベイズ流のランキング最適化でオススメを出すやつ
- **NGCF**(Wangら、2019年):グラフニューラルネットワークっていう技術を使って、ユーザーとアイテムの複雑な関係性をうまいこと捉えるモデルやねん
- **LightGCN**(Heら、2020年):NGCFをシンプルにして、いらん層とか変換を削って効率よくしたバージョンや。軽いのに精度ええから人気あるで
【サイド情報を使う手法(SI)】
次は**サイド情報**を活用するやり方やな。アイテムの属性とか、画像・テキストみたいなマルチモーダルデータっていう補助情報を使うねん。なんでかっていうと、やりとりデータだけやとスカスカ(データが少ない)問題があるから、それを補うためや。
主な手法はこんな感じ:
- **VBPR**(He & McAuley、2016年):見た目の特徴を協調フィルタリングと組み合わせるやつ。「この商品、見た目ええやん」っていう視覚的な魅力も考慮してオススメしてくれるねん
- **MMGCN**(Weiら、2019年):画像とかテキストとか、いろんな種類の情報をグラフ畳み込みネットワークに統合して、ユーザーをより深く理解しようとするモデルや
- **GRCN**(Weiら、2020年):タグとかジャンルみたいなコンテンツベースの特徴を取り入れて、アイテム同士の意味的なつながりを捉えるやつやな
【データ拡張系の手法(DA)】
**データ拡張**っていうのは、追加の学習データを作ったり、既存のデータを強化してモデルを頑丈にするアプローチやねん。データがスカスカな問題に対処して、ユーザーとアイテムの表現をもっと多様にするのが目的や。
注目の手法:
- **LATTICE**(Zhangら、2021年):隠れたアイテム同士の関係を発見してデータを豊かにするねん。データが少ない状況でもええオススメができるようになるで
- **LLMRec**(Weiら、2024年):大規模言語モデル、つまりChatGPTみたいなやつを使ってデータを充実させるアプローチや。文脈とか追加の説明情報を付けてくれるから、テキストが多い分野でめっちゃ役立つねん
【自己教師あり学習(SSL)】
最後に**自己教師あり学習**やな。これはほんまに賢いやり方で、やりとりデータから疑似的なラベルを自動生成して、人手でラベル付けせんでも学習できるようにするねん。対照学習っていう目的関数を使って、より表現力豊かな特徴を学習するんや。
主なアプローチ:
- **CLCRec**(Weiら、2021b):協調フィルタリングに対照学習を適用するやつ。拡張サンプルを作って、ユーザーとアイテムの埋め込みをより頑丈にするねん
- **MMSSL**(Weiら、2023年):マルチモーダルデータの異なる見方(ビュー)間で相互情報量を最大化するモデルや。いろんな種類のコンテンツを活用してユーザー表現を強化するで
- **MICRO**(Zhangら、2022年):ユーザーとアイテムのやりとりの複数の拡張ビューを揃えることで、特にデータがスカスカな環境でもオススメの質を上げるやつやな
【実装の詳細】
この研究では、ローカルにデプロイした**ChatGLM3-6B**っていうモデルを使って、LLMが生成した対話でデータを強化してるねん。最適化には**AdamW**っていうオプティマイザを使ってるで。
---
## Page 17
[](/attach/763a5542ddd3604fde1a7208d671f458ec383a8c07d1e347e704416e4a8bd776_p017.png)
### 和訳
検索拡張型大規模言語モデルを使った推薦システムの強化
2019年のやつを学習に使ったんやけど、学習率はNetflixデータセットで[5×10⁻⁵から1×10⁻³]、MovieLensデータセットで[2.5×10⁻⁴から9.5×10⁻⁴]の範囲で設定したで。LLMのパラメータについては、温度パラメータを{0.4, 0.8, 1}から選んでな、これは生成する内容の正確さと豊かさのバランスを取るためやねん。top-pっていう生成の精度を制御する値は{0.6, 0.8, 1}から選んだで。応答の完全性を保つために、データフローは無効にしてん。埋め込み生成には1024次元のRoBERTaモデルを使って、より詳細なコンテンツを捉えられるようにしたんや。ノイズ除去については、閾値を0.4に設定して、信頼できる埋め込みの数が500に達したら類似性判定を追加するようにしてん。
4.2 性能比較(RQ1)
表3に、ワイらが提案したER2ALM手法といろんなベースラインモデルとの比較を示してるで。Netflixデータセットでは、ワイらのモデルはPrecision@20が0.0042を達成して、最高性能のベースラインより2.38%改善してんねん。NDCG@10、20、50については、それぞれ0.0283、0.0367、0.0482を達成して、4.04%、5.76%、5.70%向上してるで。さらに、Recall@10、20、50は0.0566、0.0840、0.1469に達して、それぞれ6.60%、1.31%、6.29%改善してんねん。MovieLensデータセットでは、ワイらのモデルはPrecision@20が0.0210で、最高のベースラインを12.09%上回ったで。NDCG@10、20、50のスコアは0.1376、0.1767、0.2165で、それぞれ10.08%、8.54%、16.01%の向上やな。Recall@10、20、50については、0.2645、0.3891、0.6036で、対応する改善率は1.61%、6.81%、14.30%やで。以下の3つの観点から、より包括的な分析と洞察を導き出したんや。
• **補助情報の正確な強化**。RAGとLLMを通じて補助情報を強化することで、正確で柔軟で意味的に豊かな情報統合ができるようになるんや。VBPR(He & McAuley, 2016)は画像データだけを取り入れてるし、NGCF(Wang et al., 2019)は補助情報を活用してへんねん。MMSSL(Wei et al., 2023)やMICRO(Zhang et al., 2022)みたいなモデルは複数種類の補助情報を使ってるで。ワイらの手法は検索ベースのアプローチで追加情報を取得して、豊富なテキストデータを抽出・精製して正確な補助情報を導き出すんや。
• **補助情報とユーザーの関連付け**。ワイらのアプローチはNetflixとMovieLensデータセットでRecall@10指標をそれぞれ6.60%と1.61%改善したで。LATTICE(Zhang et al., 2021)やLLMRec(Wei et al., 2024)みたいな手法はサイド情報を組み込んで推薦システムを強化してるけど、拡張された情報とユーザーとの繋がりを見落としがちやねん。商品情報とユーザー情報を複数の次元で統合することで、ユーザーの意図をより完全に捉えられるんや。ワイらは多次元の映画情報を統合して、ユーザーの好みをより正確に表現することで、補助情報の効果を最大化してるで。めっちゃすごいのが、基本的なユーザー情報がなくても、ワイらのモデルはユーザーの好みを効果的に抽出できるんや。
• **ユーザー嗜好のマイニング**。ユーザーの好みを効果的にマイニングすることは、推薦性能を向上させるためにほんまに重要やねん。ワイらのアプローチは精度とNDCG指標で大幅な改善を示してるで。例えば、MMSSL(Weiとか)みたいな手法と比べると
1163
---
## Page 18
[](/attach/763a5542ddd3604fde1a7208d671f458ec383a8c07d1e347e704416e4a8bd776_p018.png)
### 和訳
ほな説明していくで!
Wei、Duan、Zhuo、Wang、Huang、Liuらの研究チームの話やねんけど、
他の手法(2023年のやつとか)は「自己教師あり信号」っていう、データが足りん問題をなんとかする技術を使ってるんやけど、ワイらの方法はそれよりもええ結果出とるねん。具体的に言うたら、NetflixのデータセットではNDCG@10っていう評価指標が0.0059も上がって、MovieLensのデータセットでは精度@20が0.0040も改善したんや。
なんでこんなに良くなったかっていうと、ワイらのアプローチは補助的な情報をめっちゃうまく使ってるんやけど、ユーザーの基本情報に頼ってへんねん。その代わりに、拡張された情報から直接ユーザーの好みの特徴を生成してるんや。LLMRec(Wei et al., 2024)みたいに、大規模言語モデルを二次的に使うことで生じるノイズ(余計なデータの汚れみたいなもんやな)を避けられるってわけや。
まとめると、ワイらのER2ALMモデルはめっちゃ大きな改善を達成してんねん。その理由は3つあるで:(1)豊富な補助情報を正確に統合してること、(2)それをユーザープロファイルとうまく関連付けてること、(3)拡張データから直接ユーザーの好みを掘り出してること。この3つの戦略が全部合わさって、レコメンデーションの精度がバチバチに上がって、NetflixとMovieLens両方のデータセットで他の手法を上回る結果になったんやで!
図4:4つのパラメータの性能結果やで。温度ハイパーパラメータτmA、候補判定数N、信頼度しきい値θ、強化係数η。3列の画像はそれぞれRecall@20、NDCG@20、Precision@20の評価指標に対応しとるで。左側と右側の縦軸は、それぞれMovieLensとNetflixのデータセットの結果を表しとるんや。
---
## Page 19
[](/attach/763a5542ddd3604fde1a7208d671f458ec383a8c07d1e347e704416e4a8bd776_p019.png)
### 和訳
検索拡張型の大規模言語モデルを使った推薦システムの強化版について
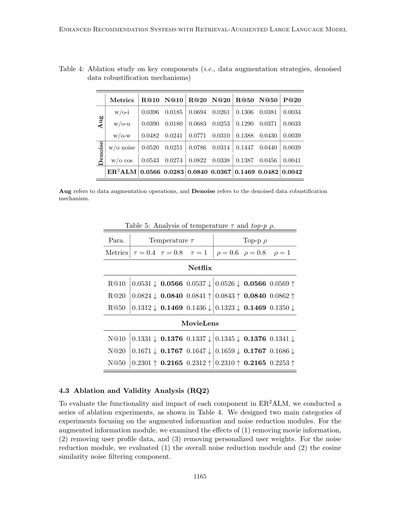
**表4:主要コンポーネントのアブレーション実験(データ拡張戦略とノイズ除去によるデータ堅牢化メカニズム)**
| 指標 | R@10 | N@10 | R@20 | N@20 | R@50 | N@50 | P@20 |
|------|------|------|------|------|------|------|------|
| w/o-i(映画情報なし) | 0.0396 | 0.0185 | 0.0694 | 0.0261 | 0.1306 | 0.0381 | 0.0034 |
| w/o-u(ユーザー情報なし) | 0.0390 | 0.0180 | 0.0683 | 0.0253 | 0.1290 | 0.0371 | 0.0033 |
| w/o-w(重み付けなし) | 0.0482 | 0.0241 | 0.0771 | 0.0310 | 0.1388 | 0.0430 | 0.0039 |
| w/o noise(ノイズ除去なし) | 0.0520 | 0.0251 | 0.0786 | 0.0314 | 0.1447 | 0.0440 | 0.0039 |
| w/o cos(コサイン類似度フィルタなし) | 0.0543 | 0.0274 | 0.0822 | 0.0338 | 0.1387 | 0.0456 | 0.0041 |
| ER2ALM(フル版) | **0.0566** | **0.0283** | **0.0840** | **0.0367** | **0.1469** | **0.0482** | **0.0042** |
※Augはデータ拡張の操作のことで、Denoiseはノイズ除去してデータを頑丈にするメカニズムのことやで。
**表5:温度τとトップpρのパラメータ分析**
| パラメータ | 温度τ | | | トップpρ | | |
|------------|--------|--------|--------|----------|----------|----------|
| 指標 | τ=0.4 | τ=0.8 | τ=1 | ρ=0.6 | ρ=0.8 | ρ=1 |
| **Netflix** | | | | | | |
| R@10 | 0.0531↓ | 0.0566 | 0.0537↓ | 0.0526↓ | 0.0566 | 0.0569↑ |
| R@20 | 0.0824↓ | 0.0840 | 0.0841↑ | 0.0843↑ | 0.0840 | 0.0862↑ |
| R@50 | 0.1312↓ | 0.1469 | 0.1436↓ | 0.1323↓ | 0.1469 | 0.1350↓ |
| **MovieLens** | | | | | | |
| N@10 | 0.1331↓ | 0.1376 | 0.1337↓ | 0.1345↓ | 0.1376 | 0.1341↓ |
| N@20 | 0.1671↓ | 0.1767 | 0.1647↓ | 0.1659↓ | 0.1767 | 0.1686↓ |
| N@50 | 0.2301↑ | 0.2165 | 0.2312↑ | 0.2310↑ | 0.2165 | 0.2253↑ |
## 4.3 アブレーション実験と妥当性の分析(RQ2)
ほな、ER2ALMの各パーツがどんな働きしてるか、どれくらい効いてるかを調べるために、アブレーション実験っていうのをやったんやわ。結果は表4に載せてるで。
アブレーション実験ってなんやねんって思うやろ?要するに「このパーツ外したらどうなる?」って一個ずつ取っ払って効果を確かめる実験のことやねん。めっちゃシンプルやけど、どのパーツが大事かがはっきりわかるんよ。
実験は大きく2つのカテゴリに分けてやったんや。1つ目は**情報を増やす(拡張する)モジュール**で、2つ目は**ノイズを減らすモジュール**やな。
まず情報拡張モジュールの方では、こんな感じで調べたで:
1. 映画の情報を抜いたらどうなるか
2. ユーザーのプロフィールデータを抜いたらどうなるか
3. ユーザーごとにパーソナライズした重み付けを抜いたらどうなるか
次にノイズ除去モジュールの方では:
1. ノイズ除去モジュール全体を外したらどうなるか
2. コサイン類似度を使ったノイズフィルタリングの部分だけ外したらどうなるか
っていう風に評価したんやで。なんでかっていうと、こうやって一個ずつ外すことで「ほんまにこのパーツ必要なん?」っていうのがわかるからやねん。結果見たらわかるけど、全部入りのER2ALMが一番成績ええから、各パーツちゃんと貢献してるってことやな!
---
## Page 20
[](/attach/763a5542ddd3604fde1a7208d671f458ec383a8c07d1e347e704416e4a8bd776_p020.png)
### 和訳
Netflixのデータセットで見てみると、映画情報がないとパフォーマンスがめっちゃ落ちるんよ。例えばやな、Recall@10は0.0396まで下がるし、Precision@20も0.0034まで減ってまうねん。ほんでユーザー情報がない場合はもっとひどくて、NDCG@20が0.0253まで落ちて、Precision@20なんか0.0033っていう最低レベルまでいってまうんや。あと、ユーザーごとの重み付けがない場合もあかん結果になって、Recall@50が0.1388、Precision@20が0.0039まで下がるねん。なんでこうなるかっていうと、補助的な情報がないと基本的な映画情報だけじゃユーザーの好みをちゃんと分析できへんからやねん。そしたらユーザーの設定情報の効果も落ちて、モデル全体のパフォーマンスに悪影響出るっちゅうわけや。逆に、しっかり分析された包括的なユーザー情報を取り除くと、モデルがユーザーの好みを感知して解釈する能力にめっちゃ影響出て、さらにパフォーマンス落ちるねん。最後に、ユーザーごとの重みの違いを省略すると、ユーザー固有の詳細をキャッチする能力が弱くなってイマイチな結果になるんやけど、基本的なユーザー情報は残ってるから、モデルの基本的な性能はまあ確保できるっちゅうことやな。
ノイズ除去モジュールがないとモデルのパフォーマンスが落ちて、NDCG@10が0.0251に、NDCG@50が0.0440になるんや。ノイズ除去モジュールから二次判定ステップ(これはノイズの蓄積を再評価するためのもんやねん)だけを取り除いた場合は、パフォーマンスがちょっと改善して、NDCG@10が0.0274、NDCG@50が0.0456になって、モデルの最適な結果にほぼ近づくねん。この分析から何がわかるかっていうと、生成された情報をフィルタリングするモジュールがないと、低品質な補助データがノイズになって、結局学習後のモデルのパフォーマンスが悪化するっちゅうことや。さらに、蓄積されたノイズの類似度評価モジュールが曖昧な埋め込みに対して二次評価をせえへんかったら、残ったノイズが最終結果に影響してまうねん。これらの結果が、ワイらのノイズ除去モジュールの有効性を証明してるっちゅうわけや。
**4.4 ハイパーパラメータ分析(RQ3)**
このパートでは、モデル内のいくつかのパラメータを分析して、実験観察を通じていろんなパラメータ値の影響を調べて評価するで。分析するパラメータは以下の通りや:LLMの温度τとトップpのρは表5に、温度ハイパーパラメータτmA、候補判定の数N、信頼度しきい値θ、強化係数ηは図4に示してるで。
・**LLMの温度τ**:温度パラメータτを0.4から上げていくと、両方のデータセットで結果が最初は良くなっていって、ピークに達した後、τ=1.0でちょっと下がるんがわかったで。なんでこうなるかっていうと、温度τは生成されるテキストのランダム性をコントロールする役割があるからやねん。τの値が高い(例えばτ=1.0)と、出力の多様性と創造性が促進されるけど、値が低い(0<τ<0.1)と、より決定論的で焦点が絞られた結果になるんや。
・**LLMのトップpのρ**:ρの値が低いと最も可能性の高いトークンを優先的に選ぶけど、値が高いとより広い範囲の選択肢からサンプリングするから多様性が高まるねん。ワイらはρの値を{0.6, 0.8, 1}で実験してみたんやけど、結果としてトップpの値が高いほど良いパフォーマンスが出る傾向があったんや。これはたぶん、RAGが多様で正確な補助情報を生成できるからやろな。この多様性のおかげで、ユーザーの好みをより包括的に多次元から分析できて、結果としてより頑健なユーザー嗜好モデルができるっちゅうわけやな。
---
## Page 21
[](/attach/763a5542ddd3604fde1a7208d671f458ec383a8c07d1e347e704416e4a8bd776_p021.png)
### 和訳
# 大規模言語モデル使った検索強化型レコメンドシステムの話
## ハイパーパラメータτmAについて
まずな、信頼度の閾値っちゅうのがあんねん。これがめっちゃ大事で、質の低い生成情報がモデルの性能に悪影響与えんようにするためのもんやねん。{0.2, 0.35, 0.5, 0.65, 0.8}の範囲で試してみたら、0.4が一番ええ結果出たわ。なんでかっていうと、閾値が高すぎても低すぎてもアカンねん。低すぎたら質の悪い情報がフィルタリングされへんから性能落ちるし、高すぎたら情報捨てすぎて、その後の処理の効果が薄れてまうねん。
## 候補判定数Nについて
Nの値はな、ノイズ除去の信頼性判定プロセスで、コサイン類似度ベースの介入がいつ入るかに影響すんねん。{200, 350, 500, 650, 800}で試したところ、両方のセットが500に達した時に二次コサイン類似度判定するんが、介入タイミングと判定の蓄積のバランスが一番ええことがわかったわ。Nが大きいと判定結果がもっと貯まるの待たなアカンから、曖昧閾値Jに基づく補助判断が遅れんねんけど、その分判定の根拠がしっかりするっちゅうメリットもあんねん。
## 信頼度閾値θについて
信頼度閾値θはな、生成された埋め込みのフィルタリング品質を決めるもんやねん。θが高いと質の高い生成情報だけ残るけど、補助データのサイズは小さくなるわ。{0.2, 0.35, 0.5, 0.65, 0.8}で試したら、低すぎても高すぎてもベストな結果にならへんかったわ。なんでかっていうと、閾値低いとノイズの多い情報まで含んでまうからフィルタリングが不十分になるし、高すぎたら情報足りんくなって論理的なつながりが不完全になってまうねん。
## 強化係数ηについて
強化係数ηはな、対照学習での追加の正例・負例サンプルの数をコントロールすんねん。適度に拡張したら、インタラクションデータがスカスカな問題を緩和できるわ。ηを{0.04, 0.08, 0.12, 0.16, 0.2}で試したところ、インタラクション増やすと性能上がるけど、増やしすぎたら効果が頭打ちになんねん。これはおそらく、新しいインタラクションが異なるユーザーの動機から生まれてて、ユーザー分析の精度を狂わせてまうからやと思うわ。
ちなみにな、うちのモデルには複数のパラメータがあんねんけど、それぞれの変動範囲内では性能への影響は比較的小さいねん。全部合わせても、モデル全体の効果への影響は限定的やで。
## 4.5 ケーススタディ(RQ4)
図5はな、ユーザーと映画に対するいろんな予測結果を示してんねん。LLMの分析から導き出されたユーザープロファイルを使うことで、ユーザーの好みとその優先順位の違いを正確に捉えられんねん。この好みと優先順位を活用したら、商品の属性をレコメンドに効果的にマッチングできるっちゅうわけや。
左側にはユーザーのプロファイル情報と好みの重みがあって、右側には映画の属性情報が表示されてんねん。つながってる線は、ユーザーの好みと映画属性の一致度を示してるわ。値が高いほど、その映画がユーザーの好みをより満たしてるっちゅうことやねん。図5(a)ではな、映画の属性がユーザーの多様な好みとめっちゃマッチしてて、結果的に
1167
---
## Page 22
[](/attach/763a5542ddd3604fde1a7208d671f458ec383a8c07d1e347e704416e4a8bd776_p022.png)
### 和訳
図5:ユーザーへの映画おすすめが成功したパターンと失敗したパターンの例やで。(a)と(b)が成功例で、(c)と(d)が失敗例やな。
おすすめスコアがめっちゃ高いケースを見てみよか。図5(b)の場合、監督とか文化・言語みたいな映画の属性がユーザーの好みと完全には合ってへんねんけど、それでもプロットとかテーマみたいな、もっと重要度の高い部分でユーザーのニーズを満たしてるから、予測スコアがそこそこ高くなってんねん。
逆に、図5(c)は映画の属性がユーザーの大事にしてるポイントをうまくカバーでけへんかった例やな。プロット、文化・言語、ジャンルはユーザーの好みと合ってるんやけど、好みの重み付けを見てみると、このユーザーは映像や音響の特徴、監督、それに映画のテーマをもっと重視してるんよ。そういうほんまに大事なところが満たされてへんから、この映画はおすすめ成功とは言えへんわけや。
最後に図5(d)やけど、これは映画の属性がどれもユーザーの好みとマッチしてへんパターンやな。結果としておすすめスコアが一番低くなってる。この映画、明らかにユーザーの興味と合ってへんわ。
## 5. 結論
この論文では、「検索拡張型大規模言語モデルを使った強化おすすめシステム」、略してER2ALMっていうアプローチを提案してんねん。これ何かっていうと、RAG(検索拡張生成)っていう戦略を使って、大規模言語モデル(LLM)の表現力をパワーアップさせて、ユーザーの好みとか興味をもっとうまく捉えようっていうもんやねん。
具体的にはな、RAG用にチューニングしたノイズ除去戦略を取り入れて、LLMの検索能力と生成能力を強化してんねん。これでユーザーが心の中で「こういうの欲しいねんけどな〜」って思ってる暗黙の意図を効果的にキャッチできるようになるわけや。
実際の2つのデータセットでがっつり実験したんやけど、うちらが提案した手法がめっちゃ効果的で、精度も高くて、しかもロバスト(頑丈)やってことが証明されたで。
今後の研究ではな、ドメイン知識とかコンテキストの認識を統合して、いろんなシナリオでフレームワークがもっと柔軟に対応できるようにしたいと思ってんねん。特にコールドスタート(新規ユーザーとか新しいアイテムでデータが全然ない状態)とか、データがスカスカな状況でのおすすめ性能をもっと向上させたいんよ。LLMには
1168ページ
---
## Page 23
[](/attach/763a5542ddd3604fde1a7208d671f458ec383a8c07d1e347e704416e4a8bd776_p023.png)
### 和訳
大規模言語モデルと検索拡張を組み合わせた進化型レコメンドシステムの話やねんけど
ユーザーの行動記録を処理してるんやけど、満足いく行動データがもっと増えてきたら、ユーザーの好みをもっとうまく抽出できるようになる余地があるねん。それとな、商品の属性情報がめっちゃ増えてくると、ユーザーの好みを正確に読み取るんがどんどん難しなってくるっていう課題もあるんよ。要するに、情報が増えれば増えるほど好みの抽出がややこしなって、精度が落ちてまうねん。これはほんまに今後もっと研究せなあかん問題やな。
**謝辞**
この研究は色んなところから支援受けてんねん。国の重点研究開発プログラム「産業ソフトウェア」の特別プロジェクト「部品サプライチェーンの製品サービスライフサイクルプロセスにおける協調最適化と動的ゲーム意思決定」(助成番号2022YFB3305602)、中国国家自然科学基金(助成番号62272198)、教育部の人文社会科学計画基金(助成番号22YJAZH110)、中国国家自然科学基金(No.62272198、62276277)、広東省データセキュリティとプライバシー保護重点実験室(No.2023B1212060036)、広東・香港合同データセキュリティ・プライバシー保護実験室(No.2023B1212120007)、広東省基礎・応用基礎研究基金(No.2024A1515010121)、暨南大学博士課程の優秀革新人材育成プログラム(No.2023CXB022)、それと暨南大学からの支援を受けとるで。
**参考文献**
Brinkmann, A., Shraga, R., Der, R. C., & Bizer, C. (2023). ChatGPTを使った商品情報抽出の研究や。
Burashnikova, A., Maximov, Y., Clausel, M., Laclau, C., Iutzeler, F., & Amini, M.-R. (2021). 好みのある・なしのアイテム順序からの学習で、頑健なレコメンドを実現する話。Journal of Artificial Intelligence Research, 71, 121–142.
Caro-Martínez, M., Jiménez-Díaz, G., & Recio-García, J. A. (2021). 説明可能なレコメンドシステムの概念モデリング:設計・開発をガイドするためのオントロジー形式化やねん。Journal of Artificial Intelligence Research, 71, 557–589.
Chen, H., Li, Y., Shi, S., Liu, S., Zhu, H., & Zhang, Y. (2022a). グラフ協調推論の研究。Proceedings of WSDM, pp. 75–84.
Chen, Y., Liu, Z., Li, J., McAuley, J., & Xiong, C. (2022b). 逐次レコメンデーションのための意図対照学習。Proceedings of Web Conference, pp. 2172–2182.
Christakopoulou, K., Lalama, A., Adams, C., Qu, I., Amir, Y., Chucri, S., Vollucci, P., Soldo, F., Bseiso, D., Scodel, S., Dixon, L., Chi, E. H., & Chen, M. (2023). ユーザーの興味の旅路を追うための大規模言語モデルの研究や。
Di Palma, D. (2023). 検索拡張型レコメンドシステム:大規模言語モデルでレコメンドシステムをパワーアップさせる話。Proceedings of RecSys, pp. 1369–1373.
Doddapaneni, S., Sayana, K., Jash, A., Sodhi, S., & Kuzmin, D. (2024). パーソナライズされた言語プロンプトのためのユーザー埋め込みモデルの研究やで。
---
## Page 24
[](/attach/763a5542ddd3604fde1a7208d671f458ec383a8c07d1e347e704416e4a8bd776_p024.png)
### 和訳
ほな、この参考文献リストを説明していくで!
Wei、Duan、Zhuo、Wang、Huang & Liu
Fatemiさんたちが2024年に出した論文やねんけど、「グラフみたいに喋ろう」っていうタイトルで、めっちゃでっかい言語モデル(LLMっていうやつな)にグラフの情報をどうやって教え込むかって話をICLRっていう学会で発表してんねん。
Fuさんたちの2023年の研究は、いろんな分野のCTR予測(これは「クリック率予測」のことやで、広告とかでよう使うやつ)を大規模言語モデルで一気にまとめてやろうっていう統一フレームワークの話や。Web Conferenceで発表されてんねん。
Gaoさんたちも2023年に「Chat-rec」っていうシステムを提案してて、これはLLMを使ったレコメンドシステムなんやけど、対話できて、なんでこれをおすすめしたかも説明してくれるっていう賢いやつやねん。
Heさんたち(2024年)はAI Research誌に論文出してて、58巻の112-134ページに載ってるで。
別のHeさんとMcAuleyさん(2016年)は「VBPR」っていう手法を提案してんねん。これは画像情報を使ったベイズ流のパーソナライズドランキングってやつで、ユーザーが「いいね」とか「買った」とかの暗黙的なフィードバックから学習するんや。AAAIの30巻で発表されとる。
またHeさんたち(2020年)は「LightGCN」っていうのを作ってて、これがめっちゃ画期的やねん。グラフ畳み込みネットワーク(難しそうに聞こえるけど、要はユーザーとアイテムの関係をネットワークで学習するやつ)をシンプルにして、レコメンドに使いやすくしたんや。SIGIRで発表されて639-648ページに載ってるで。
Houさんたち(2023年)は「ベクトル量子化」っていう技術を使ったアイテム表現の学習法を提案してて、これのええとこは、一つのレコメンダーで学んだことを別のとこでも使い回せる(転移できる)ってことやねん。ACM Webの1162-1171ページや。
同じHouさんたち(2022年)は、レコメンドシステムで使える「ユニバーサルな系列表現学習」を目指した研究もしてて、SIGKDDの585-593ページに載ってるで。
Kotoさんたち(2022年)は、要約の自動評価を解釈可能にするフレームワーク「FFCI」を提案してて、Journal of Artificial Intelligence Researchの73巻、1553-1607ページや。
LeさんとLauwさん(2021年)は、行列分解ベースのトップKレコメンデーション(上位K個のおすすめを出すやつな)を効率よく取り出す方法についてのサーベイ論文を書いてて、同じジャーナルの70巻、1441-1479ページやで。
Liさんたち(2023年)は「TagGPT」っていうのを発表してて、大規模言語モデルが学習なしで(ゼロショットって言うんやけど)いろんな種類のタグ付けができるって示してんねん。
別のLiさんたち(2024年)は「EcomGPT」っていうEC(ネット通販)向けの大規模言語モデルを作ってて、「chain-of-task」っていう連鎖的なタスクで指示調整(インストラクション・チューニング)してんねん。AAAIの38巻、18582-18590ページや。
Liaoさんたち(2024年)は「LLaRA」っていう、大規模言語モデルをレコメンドのアシスタントとして使うシステムを提案してるで。
Liuさんたち(2024a)は、レコメンドする前にまず理解しようやってコンセプトで、レビューの意味的な側面を大規模言語モデルで活用する研究をしてんねん。
もう一人のLiuさんたち(2024b)は、ユーザーが記事をどういう流れで見ていくかを大規模言語モデルでモデル化して、記事のレコメンドに使う研究をWeb Conferenceの83-92ページで発表してるで。
1170
---
## Page 25
[](/attach/763a5542ddd3604fde1a7208d671f458ec383a8c07d1e347e704416e4a8bd776_p025.png)
### 和訳
Luさんらがやった「Revcore」っていう研究やねんけど、これは会話型のレコメンドシステムにレビュー情報を足して強化するやつやねん。2021年の研究やで。
Lyuさんらの「LLM-Rec」(2024年)は、大規模言語モデル(めっちゃ賢いAIのことやな)にプロンプト(指示文みたいなもん)を使って、個人に合わせたおすすめを出す仕組みを作ったんや。
Paszkeさんらは「PyTorch」っていう深層学習ライブラリを2019年に発表してん。これ、命令型のスタイルでめっちゃ高性能なやつで、NeurIPSっていう学会で発表されたんやで。
Renさんらは2024年に2本論文出してて、1本目(Ren et al., 2024a)はWeb Conferenceで発表された「大規模言語モデルを使った表現学習でレコメンドする」やつ。2本目(Ren et al., 2024b)は「SSLRec」っていう自己教師あり学習のフレームワークをWSDMで発表してん。自己教師あり学習っていうのは、ラベル付きデータなしでAIが自分で学習する賢い方法やねん。
Rendleさんらの「BPR」(2012年)は、暗黙的フィードバック(ユーザーが「いいね」とか押さんでも、クリックとか閲覧履歴から好みを推測するやつな)からベイズ的にパーソナライズドランキングを作る手法やねん。
Shiさんらの「Llama-E」(2024年)は、ECサイト向けのコンテンツ作成を強化するやつで、商品画像とかを織り交ぜた指示に従えるようにしたんや。
Tanjimさんらは2020年のWeb Conferenceで、次に何をおすすめするか予測するために、ユーザーの隠れた意図をアテンション付きの系列モデルで捉える研究を発表してん。
Tianさんらの2022年のSIGIRの論文は、グラフ協調フィルタリング(ユーザーと商品の関係をグラフで表現して分析するやつな)で、信頼できひん相互作用のノイズを取り除く学習方法を提案してん。
Torbatiさんら(2023年)は、レビューテキストから簡潔なユーザープロファイルを作っておすすめに使う研究やねん。
Wangさんらは何本か論文出してて、2023年のWSDMでは知識適応型のコントラスト学習(似てるもんと似てないもんを区別する学習法やな)をレコメンドに使う研究。2019年のSIGIRでは「Neural Graph Collaborative Filtering」っていうニューラルネットワークとグラフを組み合わせた協調フィルタリングを発表してん。
Weiさんらはめっちゃ精力的で、2022年のWSDMではユーザーの色んな行動パターンを使ったコントラストメタ学習、2023年のWeb Conferenceではマルチモーダル(画像とかテキストとか複数の種類のデータを使うやつな)の自己教師あり学習、2024年のWSDMでは「LLMRec」っていう大規模言語モデルとグラフを組み合わせたレコメンド手法を発表してん。
Weiさん(別の人やで)らは2021年にIEEE Transactions on Multimediaで、マルチメディアレコメンド向けの階層的ユーザー意図グラフネットワークを発表してん。ユーザーが何を求めてるかを階層的に理解する仕組みやな。
---
## Page 26
[](/attach/763a5542ddd3604fde1a7208d671f458ec383a8c07d1e347e704416e4a8bd776_p026.png)
### 和訳
Wei, Duan, Zhuo, Wang, Huang & Liu
Wei, Y., Wang, X., Li, Q., Nie, L., Li, Y., Li, X., & Chua, T.-S. (2021b). コールドスタートのレコメンドに対比学習を使おう、って話やねん。ACM MMの論文集に載っとって、5382〜5390ページにあるで。
Wei, Y., Wang, X., Nie, L., He, X., & Chua, T.-S. (2020). 暗黙的フィードバック使ったマルチメディアレコメンドのための、グラフで洗練された畳み込みネットワークの話や。ACM MMの論文集、3541〜3549ページに載っとるわ。
Wei, Y., Wang, X., Nie, L., He, X., Hong, R., & Chua, T.-S. (2019). MMGCN:マイクロビデオのパーソナライズドレコメンドのためのマルチモーダルグラフ畳み込みネットワークやねん。要するに、いろんな種類のデータ使って、あんたにぴったりの短い動画おすすめしたろって話や。ACM MMの論文集、1437〜1445ページやで。
Wu, D., Zhuo, S., Wang, Y., Chen, Z., & He, Y. (2023). 色んな種類のデータがリアルタイムで流れてくる時のオンライン半教師あり学習についての研究やねん。AAAIの論文集、4720〜4728ページ、AAAI Pressから出とるで。
Wu, J., Wang, X., Feng, F., He, X., Chen, L., Lian, J., & Xie, X. (2021). レコメンドのための自己教師ありグラフ学習や。ラベルなしでもグラフの構造から勝手に学習してくれるっちゅう賢い仕組みやねん。SIGIRの論文集、726〜735ページやで。
Wu, J., Chang, C.-C., Yu, T., He, Z., Wang, J., Hou, Y., & McAuley, J. (2024). CORAL:協調型検索拡張の大規模言語モデルでロングテールレコメンドを改善する話や。ほら、あんまり人気ないけどニッチなアイテムをちゃんとおすすめできるようにしたろって研究やねん。SIGKDDの論文集、3391〜3401ページやで。
Xi, Y., Liu, W., Lin, J., Cai, X., Zhu, H., Zhu, J., Chen, B., Tang, R., Zhang, W., & Yu, Y. (2024). 大規模言語モデルからの知識で補強して、オープンワールドレコメンドを目指そうっていう話やねん。今まで見たことないような新しいアイテムにも対応できるようにしたいっちゅうことやな。RecSysの論文集、12〜22ページやで。
Yin, B., Xie, J., Qin, Y., Ding, Z., Feng, Z., Li, X., & Lin, W. (2023). 異種知識融合:LLM使ったパーソナライズドレコメンドの新しいアプローチやねん。いろんな種類の知識をうまいこと混ぜ合わせて、あんたにぴったりのおすすめ作ろうって話や。第17回ACMレコメンダーシステム会議の論文集、599〜601ページやで。
Yu, J., Yin, H., Xia, X., Chen, T., Cui, L., & Nguyen, Q. V. H. (2022). グラフの拡張って本当に必要なん?レコメンドのためのシンプルなグラフ対比学習、っていうちょっと挑戦的なタイトルの論文やねん。複雑にせんでもシンプルでええやんって主張しとるわ。SIGIRの論文集、1294〜1303ページやで。
Zhang, J., Zhu, Y., Liu, Q., Wu, S., Wang, S., & Wang, L. (2021). マルチメディアレコメンドのための潜在構造マイニングの話や。データの中に隠れとるパターンを見つけ出そうっちゅうことやねん。ACM MMの論文集、3872〜3880ページやで。
Zhang, J., Zhu, Y., Liu, Q., Zhang, M., Wu, S., & Wang, L. (2022). マルチメディアレコメンドのための、対比的なモダリティ融合を使った潜在構造マイニングや。IEEE Transactions on Knowledge and Data Engineering、第35巻9号、9154〜9167ページに載っとるで。
Zhao, X., Hu, B., Zhong, Y., Huang, S., Zheng, Z., Wang, M., & Wang, H. (2025). RASERec:検索拡張型シーケンシャルレコメンデーションやねん。ユーザーの過去の行動の流れを見て、外部情報も引っ張ってきて、次に何おすすめするか決めるっちゅう話や。Web Conferenceの論文集に載る予定で、ページはまだ未定やで。
Zheng, Z., Chao, W., Qiu, Z., Zhu, H., & Xiong, H. (2024). テキストリッチなシーケンシャルレコメンドに大規模言語モデルを活用する話やねん。文章いっぱいあるデータをLLMでうまいこと処理しようっちゅうことや。Web Conferenceの論文集、3207〜3216ページやで。
Zhou, X., Hu, Z., Huang, J., & Chen, J. (2023). プライバシー守りながら高速にPOI(場所)レコメンドするための、分散型勾配量子化ベースの行列分解の話やねん。Journal of Artificial Intelligence Research、第76巻、1019〜1041ページやで。
Zhu, Y., Wu, L., Guo, Q., Hong, L., & Li, J. (2024). レコメンダーシステムのための協調型大規模言語モデルやねん。みんなで協力してええおすすめ作ろうって発想やな。Web Conferenceの論文集、3162〜3172ページやで。
1172
---
## Page 27
[](/attach/763a5542ddd3604fde1a7208d671f458ec383a8c07d1e347e704416e4a8bd776_p027.png)
### 和訳
検索拡張型大規模言語モデルを使った、もっとええ感じのレコメンドシステム
Zhuo, S., Qiu, J.-J., Wang, C.-D., & Huang, S.-Q. (2024a). 特徴空間がコロコロ変わる状況でのオンライン特徴選択。IEEE国際知識・データエンジニアリング会議の論文集、4806–4819ページ。
これ何かっていうとな、データの特徴(つまり分析に使う項目みたいなもんやな)がリアルタイムで増えたり減ったりする状況でも、ちゃんとええ特徴を選び出す方法の話やねん。
Zhuo, S., Wu, D., Hu, X., & Wang, Y. (2024b). ARDST:敵対的学習に強い深層シンボリックツリー。International Journal of Intelligent Systems誌、2024年(1)号、2767008。
こっちはな、悪意ある攻撃(敵対的攻撃って言うんやけど)に対してめっちゃ強いAIモデルの話やで。「シンボリックツリー」っていうのは、AIの判断過程を人間にもわかりやすい木構造で表現する手法のことやねん。それを敵対的な攻撃にも耐えられるように強化したってわけや。
1173
---
![]()
1 / 1
100%