<<
2404.16130v2.pdf

---
## Page 1
[](/attach/730f1a9f38d16689900969a3eeeb1b31e45eda1dcc1f37a043afa90aff76c867_p001.png)
### 和訳
ローカルからグローバルへ:クエリ特化型要約のためのGraphRAGアプローチ
Darren Edge1† Ha Trinh1† Newman Cheng2 Joshua Bradley2 Alex Chao3 Apurva Mody3 Steven Truitt2 Dasha Metropolitansky1 Robert Osazuwa Ness1 Jonathan Larson1
1Microsoft Research
2Microsoft Strategic Missions and Technologies
3Microsoft Office of the CTO
{daedge,trinhha,newmancheng,joshbradley,achao,moapurva,
steventruitt,dasham,robertness,jolarso}@microsoft.com
†この2人、同じくらい貢献してくれてんねん
要約
ほな説明するで!RAG(検索拡張生成)っていう技術があんねんけど、これ何かっていうと、外部の知識ソースから関連情報を引っ張ってきて、大規模言語モデル(LLM)がプライベートなデータとか、今まで見たことないドキュメントの山に対して質問に答えられるようにする仕組みやねん。
せやけどな、RAGにも弱点があって、テキスト全体に向けた「グローバルな質問」には対応できひんねん。例えば「このデータセットの主なテーマって何?」みたいな質問な。なんでかっていうと、これって単なる検索タスクやなくて、本質的には「クエリ特化型要約(QFS)」っていうタスクやからやねん。一方で、従来のQFS手法は、普通のRAGシステムが扱うような大量のテキストにはスケールせえへんねん。
そこでワイらが提案するんが「GraphRAG」や!これ、グラフベースのアプローチで、プライベートなテキストコーパスに対する質問応答を実現するんやけど、ユーザーの質問の一般性と、ソーステキストの量、両方にスケールできるようになってんねん。
ワイらのアプローチは、LLMを使って2段階でグラフインデックスを構築するんや。まず第1段階で、ソースドキュメントからエンティティ(固有名詞とか重要な概念とかな)のナレッジグラフを抽出すんねん。ほんで第2段階で、密接に関連するエンティティのグループ全部に対して、コミュニティ要約を事前生成しとくねん。
質問が来たら、各コミュニティ要約を使って部分的な回答を生成して、最後にそれら全部の部分回答をまとめて、ユーザーへの最終回答を作るっちゅう流れや。
100万トークン規模のデータセットに対するグローバルなセンスメイキング質問(全体像を把握するような質問やな)について実験したところ、GraphRAGは従来のRAGベースラインと比べて、生成される回答の「網羅性」と「多様性」の両方でめっちゃ大幅な改善が見られたで!
1 はじめに
検索拡張生成(RAG)(Lewisら、2020)っちゅうのは、言語モデルのコンテキストウィンドウに収まりきらんほどでっかいデータに基づいて、LLMに質問に答えさせるための確立されたアプローチやねん。コンテキストウィンドウっていうのは、LLMが一度に処理できるトークン(テキストの単位やな)の最大数のことや(Kuratovら、2024;Liuら、2023)。
標準的なRAGのセットアップでは、システムは外部のでっかいテキストレコードのコーパスにアクセスできて、クエリに個別に関連していて、かつ全部合わせてもLLMのコンテキストウィンドウに収まるサイズのレコードのサブセットを検索してくるねん。ほんでLLMが...
プレプリント。査読中やで。
---
## Page 2
[](/attach/730f1a9f38d16689900969a3eeeb1b31e45eda1dcc1f37a043afa90aff76c867_p002.png)
### 和訳
クエリと検索してきたレコードの両方を使うて回答を生成するんやな(Baumelら、2018年;Dang、2006年;Laskarら、2020年;Yaoら、2017年)。この従来からあるアプローチ、まとめて「ベクトルRAG」って呼ぶんやけど、これは少数のレコードの中にある情報だけで答えられるようなクエリにはめっちゃうまいこといくねん。せやけどな、ベクトルRAGはセンスメイキングクエリ、つまりデータセット全体をグローバルに理解せなあかんようなクエリには対応でけへんのよ。例えば「過去10年間で、学際的研究が科学的発見にどう影響してきたか、その主要なトレンドは何やろ?」みたいな質問やな。
センスメイキングタスクっちゅうんは、「人とか場所とかイベントの間のつながりを推論して、それらがこれからどう展開していくか予測して、効果的に行動する」ことが必要やねん(Kleinら、2006年)。GPT(Achiamら、2023年;Brownら、2020年)、Llama(Touvronら、2023年)、Gemini(Anilら、2023年)みたいな大規模言語モデル(LLM)は、科学的発見(Microsoft、2023年)とかインテリジェンス分析(RanadeとJoshi、2023年)みたいな複雑な領域でのセンスメイキングがめっちゃ得意やねん。センスメイキングのクエリと、暗黙的につながり合った概念を含むテキストを渡したら、LLMはそのクエリに答えるような要約を生成できるんや。せやけどな、問題はデータの量がめっちゃ多くてRAGアプローチが必要な時に起こるねん。なんでかっていうと、ベクトルRAGはコーパス全体にわたるセンスメイキングに対応でけへんからや。
この論文では、GraphRAGを提案するで。これはグラフベースのRAGアプローチで、大規模テキストコーパス全体にわたるセンスメイキングを可能にするんや。GraphRAGはまずLLMを使うて知識グラフを構築するねん。ノードはコーパス内の重要なエンティティに対応してて、エッジはそれらエンティティ間の関係を表すんや。次に、そのグラフを密接に関連したエンティティのコミュニティの階層構造に分割して、LLMを使うてコミュニティレベルの要約を生成するんや。この要約は、抽出されたコミュニティの階層構造に沿ってボトムアップ方式で生成されるねん。階層の上位レベルの要約は、下位レベルの要約を再帰的に取り込んでいくんや。これらのコミュニティ要約が合わさって、コーパス全体についてのグローバルな説明と洞察を提供してくれるっちゅうわけや。最後に、GraphRAGはコミュニティ要約のマップリデュース処理を通じてクエリに答えるねん。マップステップでは、各要約が独立に並列で部分的な回答を提供して、リデュースステップでは、それらの部分的な回答を組み合わせて最終的なグローバルな回答を生成するんや。
GraphRAGの手法と、コーパス全体にわたるグローバルなセンスメイキングを実行する能力が、この研究の主要な貢献やねん。この能力を実証するために、LLM審判員技術(Zhengら、2024年)の新しい応用を開発したで。これは正解がない、広範な問題やテーマを対象とした質問に適してるんや。このアプローチでは、まず1つ目のLLMがコーパス固有のユースケースに基づいて多様なグローバルセンスメイキング質問のセットを生成して、次に2つ目のLLMが事前定義された基準(セクション3.3で定義)を使って2つの異なるRAGシステムの回答を判定するんや。このアプローチを使うて、GraphRAGとベクトルRAGを2つの代表的な実世界テキストデータセットで比較したで。結果を見たら、LLMとしてGPT-4を使った時、GraphRAGはベクトルRAGをめっちゃ大きく上回ったんや。
GraphRAGはオープンソースソフトウェアとしてhttps://github.com/microsoft/graphragで公開されてるで。さらに、GraphRAGアプローチの各種バージョンは、LangChain(LangChain、2024年)、LlamaIndex(LlamaIndex、2024年)、NebulaGraph(NebulaGraph、2024年)、Neo4J(Neo4J、2024年)を含む複数のオープンソースライブラリの拡張機能としても利用可能やで。
## 2 背景
### 2.1 RAGのアプローチとシステム
RAGっちゅうんは一般的に、ユーザーのクエリを使って外部データソースから関連情報を検索して、その情報をLLM(または他の生成AIモデル、例えばマルチメディアモデルとか)によるクエリへの応答生成に組み込むシステム全般のことを指すねん(Ramら、2023年)。クエリと検索されたレコードでプロンプトテンプレートを埋めて、それをLLMに渡すんや。RAGは、データソース内のレコード総数がLLMへの1回のプロンプトに含めるには多すぎる場合、つまりデータソース内のテキスト量がLLMのコンテキストウィンドウを超える場合にほんまに理想的やねん。
標準的なRAGアプローチでは、検索プロセスはクエリに意味的に類似した一定数のレコードを返して、生成される回答はそれら検索されたレコード内の情報だけを使うねん。従来のRAGでよく使われるアプローチは、テキスト埋め込みを使うことで、ベクトル空間内でクエリに最も近いレコードを検索するんや。ここでの「近さ」は意味的類似性に対応してるんやで(Gaoら、2023年)。一部のRAGアプローチは別の検索メカニズムを使うかもしれんけど、この従来型アプローチのファミリーをまとめてベクトルRAGと呼ぶことにするわ。GraphRAGがベクトルRAGと違うんは、データコーパス全体にわたるグローバルなセンスメイキングを必要とするクエリに答える能力があるところやねん。
---
## Page 3
[](/attach/730f1a9f38d16689900969a3eeeb1b31e45eda1dcc1f37a043afa90aff76c867_p003.png)
### 和訳
GraphRAGってのは、前からあったちょっと進んだRAG戦略の上に作られてんねん。GraphRAGはデータソースの大きな部分の要約を「セルフメモリー」(Chengらが2024年に説明してるやつ)みたいな形で使ってて、これを後からクエリに答えるときに活用してんねん(Maoらの2020年の研究みたいに)。この要約は並列で生成されて、繰り返しグローバルな要約に集約されていくんやけど、これは前からあるテクニックと似てるな(Fengら2023年、Gaoら2023年、Khattabら2022年、Shaoら2023年、Suら2020年、Trivediら2022年、Wangら2024年)。特にGraphRAGは、階層的なインデックスを使って要約を作る他のアプローチと似てるねん(Kimらの2023年やSarthiらの2024年みたいな)。でもGraphRAGがこれらと違うのは、元データからグラフインデックスを生成して、そこにグラフベースのコミュニティ検出を適用してデータをテーマ別に分けるところやねん。
2.2 ナレッジグラフをLLMとRAGで使う話
自然言語のテキストからナレッジグラフを抽出するアプローチには、ルールマッチング、統計的パターン認識、クラスタリング、埋め込みとかがあるんやで(Etzioniら2004年、Kimら2016年、MooneyとBunescu 2005年、Yatesら2007年)。GraphRAGは最近の研究の流れに入ってて、LLMをナレッジグラフ抽出に使うやつやな(Banら2023年、Melnykら2022年、OpenAI 2023年、Tanら2017年、Trajanoskaら2023年、Yaoら2023年、Yatesら2007年、Zhangら2024a年)。さらにナレッジグラフをインデックスとして使うRAGアプローチの仲間入りもしてるねん(Gaoら2023年)。いくつかのテクニックはサブグラフとかグラフの要素、グラフ構造の特性を直接プロンプトに使ったり(Baekら2023年、Heら2024年、Zhang 2023年)、生成された出力の事実的な裏付けとして使ったりしてるねん(KangとRanade and Joshi 2023年)。他のテクニック(Wangら2023b年)はナレッジグラフを検索強化に使ってて、クエリ時にLLMベースのエージェントがドキュメント要素(パッセージやテーブルとか)を表すノードと、語彙的・意味的な類似性や構造的関係をエンコードしたエッジを持つグラフを動的にたどっていくねん。GraphRAGがこれらと違うのは、このコンテキストでまだ探索されてなかったグラフの特性に注目してるところやねん:グラフの固有のモジュール性(Newman 2006年)と、グラフを密接に関連したノードのネストしたモジュラーコミュニティに分割できる能力(例えばLouvain、Blondelら2008年、Leiden、Traagら2019年)やな。具体的には、GraphRAGはこのコミュニティ階層をまたいでLLMを使って要約を作ることで、どんどんグローバルな要約を再帰的に作っていくねん。
2.3 RAG評価のための適応型ベンチマーク
オープンドメインの質問応答のベンチマークデータセットはめっちゃあんねん、HotPotQA(Yangら2018年)、MultiHop-RAG(TangとYang 2024年)、MT-Bench(Zhengら2024年)とかな。でもこれらのベンチマークはベクトルRAGの性能向けやねん、つまり明示的な事実の検索の性能を評価してるわけや。この研究では、コーパス全体のグローバルなセンスメイキング(意味理解)を評価するための質問セットを生成するアプローチを提案してるねん。うちらのアプローチは、コーパスを使ってその要約が答えになるような質問を生成するLLM手法に関連してるで、XuとLapata(2021年)みたいな。でも公平な評価をするために、うちらの方法はコーパス自体から直接質問を生成することを避けてるねん(別の実装として、後続のグラフ抽出と回答評価のステップから除外したコーパスのサブセットを使うこともできるで)。
適応型ベンチマークっていうのは、特定のドメインやユースケースに合わせた評価ベンチマークを動的に生成するプロセスのことやねん。最近の研究ではLLMを適応型ベンチマークに使って、対象のアプリケーションやタスクとの関連性、多様性、整合性を確保してるねん(Yuanら2024年、Zhangら2024b年)。この研究では、LLM向けのグローバルなセンスメイキングクエリを生成するための適応型ベンチマークアプローチを提案してるねん。うちらのアプローチは、LLMベースのペルソナ生成の先行研究に基づいてて、LLMを使って多様で本物っぽいペルソナのセットを生成するやつやな(Kosinski 2024年、Salminenら2024年、Shinら2024年)。うちらの適応型ベンチマーク手順はペルソナ生成を使って、実際のRAGシステム利用を代表するクエリを作るねん。具体的には、うちらのアプローチはLLMを使ってRAGシステムを使う可能性のあるユーザーとそのユースケースを推測して、それがコーパス固有のセンスメイキングクエリの生成をガイドするねん。
2.4 RAG評価基準
うちらの評価は、RAGシステムが生成された質問にどれだけうまく答えられるかをLLMに評価させることに頼ってるねん。先行研究では、LLMが自然言語生成の良い評価者であることが示されてて、LLMの評価が人間の評価と競争できるレベルやったという研究もあるで(Wangら2023a年、Zhengら2024年)。いくつかの先行研究はLLMに品質を定量化させるための基準を提案してて...
---
## Page 4
[](/attach/730f1a9f38d16689900969a3eeeb1b31e45eda1dcc1f37a043afa90aff76c867_p004.png)
### 和訳
# Graph RAGのパイプライン(LLMで作った文書のグラフインデックスを使うやつ)
## 図1の説明
これな、元の文書からどうやってうまいこと答えを出すかっていう流れを示してんねん。
### インデックス作成のとき
1. **元の文書** → **テキストの切り出しとチャンク分け**
2. そっから **テキストチャンク** ができる
3. このチャンクを **ドメイン特化の要約** にかけると、**エンティティと関係性** が抽出される
4. それが **知識グラフ** になる
5. **コミュニティ検出** っていう処理で、グラフを **グラフコミュニティ** に分ける
6. またドメイン特化の要約で **コミュニティの要約** を作る
### 質問されたとき
1. **コミュニティの要約** に対して **クエリ重視の要約** をかける
2. **コミュニティごとの回答** が出てくる
3. 最後にまた **クエリ重視の要約** をやって **グローバルな回答** を出す
このグラフインデックスにはな、ノード(エンティティのことやね)、エッジ(関係性のこと)、あとコベリエイト(主張とか)が入ってて、これ全部LLMのプロンプトで検出・抽出・要約してんねん。しかもそのプロンプトはデータセットのドメインに合わせてチューニングしてあるんよ。
コミュニティ検出(例えばLeidenアルゴリズムとか、Traagらが2019年に出したやつ)を使って、グラフインデックスを要素のグループに分けるんや。ほんでLLMがインデックス作成時と質問時の両方で並列に要約できるようにしてんねん。質問に対する「グローバルな回答」は、その質問に関連するって判定された全部のコミュニティ要約を、最後にもう一回クエリ重視で要約して作るんやで。
---
生成されたテキストの評価基準としては「流暢さ」とか(Wangら、2023a)があるんやけど、これらの基準の中にはベクトルRAGシステム向けの一般的なやつもあって、グローバルな意味理解には関係ないのもあんねん。例えば「文脈の関連性」とか「忠実さ」とか「回答の関連性」とか(RAGAS、Esら、2023)。
正解データがない場合にどうするかっていうとな、LLMに2つの違うモデルが生成したもんを比較させて、相対的な性能を測るんや(LLM-as-judge、Zhengら、2024)。この研究では、グローバルな意味理解の質問に対するRAG生成回答を評価する基準を設計して、この比較アプローチで結果を評価してんねん。あと、LLMが抽出した検証可能な事実の記述、つまり「クレーム」から導き出した統計でも結果を検証してるで。
---
## 3 方法
### 3.1 GraphRAGのワークフロー
図1がGraphRAGアプローチとパイプラインの大まかなデータの流れを示してるわ。このセクションでは、各ステップの重要な設計パラメータ、テクニック、実装の詳細を説明するで。
#### 3.1.1 元文書 → テキストチャンク
まずな、コーパス内の文書をテキストチャンクに分割するんや。LLMが各チャンクから情報を抽出して、後続の処理に使うねん。
チャンクのサイズをどうするかっていうのはめっちゃ基本的な設計判断やで。長いチャンクにしたら抽出に必要なLLMの呼び出し回数が減る(つまりコスト削減や)けど、チャンクの最初の方に出てくる情報の再現率が落ちるっていうデメリットがあんねん(Kuratovら、2024; Liuら、2023)。プロンプトの例と再現率・精度のトレードオフについてはセクションA.1を見てな。
#### 3.1.2 テキストチャンク → エンティティと関係性
このステップではな、LLMにプロンプトを投げて、与えられたチャンクから重要なエンティティのインスタンスと、エンティティ間の関係性を抽出させるんや。さらに、LLMがエンティティと関係性の短い説明文も生成してくれる。
例を挙げるとな、チャンクに以下のようなテキストが含まれてたとするやん:
---
## Page 5
[](/attach/730f1a9f38d16689900969a3eeeb1b31e45eda1dcc1f37a043afa90aff76c867_p005.png)
### 和訳
NeoChip(NC)の株が、NewTech取引所で取引始まってから最初の1週間でめっちゃ跳ね上がったんやで。せやけど、市場のアナリストらは「この半導体メーカーの上場デビューが他のテック企業のIPOのトレンドを表してるとは限らんで」って警告しとるわ。NeoChipはもともと非公開企業やったんやけど、2016年にQuantum Systemsに買収されたんやな。この革新的な半導体会社は、ウェアラブル端末とかIoTデバイス向けの省電力プロセッサを専門にしとるねん。
LLMには、こういう情報を抽出するようにプロンプトで指示するんやで:
・NeoChipっていうエンティティ。説明は「NeoChipはウェアラブルとIoTデバイス向けの省電力プロセッサを専門とする上場企業」ってな感じ。
・Quantum Systemsっていうエンティティ。説明は「Quantum SystemsはかつてNeoChipを所有してた会社」や。
・NeoChipとQuantum Systemsの関係性。説明は「Quantum Systemsは2016年からNeoChipが上場するまでNeoChipを所有してた」ってこと。
これらのプロンプトは、文書コーパスの分野に合わせてカスタマイズできるんやで。なんでかっていうと、文脈内学習(Brown et al., 2020)のために、その分野に適した少数ショットの例を選べるからなんや。例えば、うちらのデフォルトプロンプトは人名・地名・組織名みたいな幅広い「固有表現」を抽出して汎用的に使えるんやけど、専門知識がいる分野(科学とか医療とか法律とか)では、その分野に特化した少数ショット例があった方がええ結果出るんよ。
LLMには、検出したエンティティについての「クレーム」も抽出するように指示できるんや。クレームっていうのは、エンティティに関する重要な事実の記述のことで、日付とかイベントとか他のエンティティとの関わりとかやな。エンティティと関係性と同じで、文脈内学習の例を使ってドメイン固有のガイダンスを与えられるんや。上の例文から抽出されたクレームの説明はこんな感じやで:
・NeoChipの株はNewTech取引所での取引初週に急騰した。
・NeoChipはNewTech取引所に上場企業としてデビューした。
・Quantum Systemsは2016年にNeoChipを買収し、NeoChipが上場するまで所有権を持ってた。
エンティティとクレーム抽出の実装についてのプロンプトと詳細は付録Aを見てな。
3.1.3 エンティティと関係性 → ナレッジグラフ
LLMを使ってエンティティ・関係性・クレームを抽出するっていうのは、抽象的な要約の一種なんやで。これらは概念の意味のある要約やねんけど、関係性とクレームの場合は、テキストに明示的に書かれてないこともあるんや。エンティティ・関係性・クレームの抽出プロセスでは、一つの要素に対して複数のインスタンスができるんやけど、なんでかっていうと、通常は一つの要素が文書全体で何回も検出・抽出されるからなんよ。
ナレッジグラフ抽出の最終ステップでは、これらのエンティティと関係性のインスタンスがグラフの個々のノードとエッジになるんや。エンティティの説明は各ノードとエッジごとに集約されて要約されるで。関係性はグラフのエッジに集約されて、ある関係性の重複数がエッジの重みになるんや。クレームも同じように集約されるで。
この論文では、うちらの分析ではエンティティマッチング(同じエンティティに対する異なる抽出名を照合するタスク)に完全一致の文字列マッチングを使ってるんや(Barlaug and Gulla, 2021; Christen and Christen, 2012; Elmagarmid et al., 2006)。せやけど、プロンプトやコードをちょっと調整すれば、もっと緩いマッチング手法も使えるで。それに、GraphRAGは重複エンティティにも概ね強いんや。なんでかっていうと、重複は通常、後続のステップで要約のために一緒にクラスタリングされるからなんよ。
3.1.4 ナレッジグラフ → グラフコミュニティ
前のステップで作ったグラフインデックスがあれば、いろんなコミュニティ検出アルゴリズムを使って、グラフを強く繋がったノードのコミュニティに分割できるんや(例えばFortunato (2010)とJin et al. (2021)のサーベイを見てな)。うちらのパイプラインでは、Leidenコミュニティ検出(Traag et al., 2019)を階層的に使ってるんやで。どういうことかっていうと、検出した各コミュニティの中でサブコミュニティを再帰的に検出して、これ以上分割できない葉っぱのコミュニティに到達するまで続けるんや。
---
## Page 6
[](/attach/730f1a9f38d16689900969a3eeeb1b31e45eda1dcc1f37a043afa90aff76c867_p006.png)
### 和訳
この階層構造の各レベルってな、グラフのノード(点)をコミュニティごとにきれいに分けてくれるねん。しかも、どのノードも必ずどっかのコミュニティに入ってて、かつ複数のコミュニティに重複して入ることもないっていう完璧な分け方やねん。これがあるから、めっちゃでかいデータでも「分割して攻略する」方式でグローバルな要約ができるんやで。実際にどんな感じで階層的に分かれるかは、付録Bにサンプルデータでの例を載せとるから見てみてな。
### 3.1.5 グラフコミュニティ → コミュニティ要約
次のステップでは、この階層構造の各コミュニティについて、レポートみたいな要約を作るねん。このやり方は、めっちゃ巨大なデータセットでもスケールできるように設計されとるで。この要約、実は単独でもかなり使えるもんでな、データセット全体の構造とか意味を理解するのにめっちゃ役立つねん。特定の質問がなくても、コーパス(文書の集まり)を把握するのに使えるんや。例えばな、ユーザーがあるレベルのコミュニティ要約をざーっと眺めて「お、このテーマ気になるな」って見つけたら、その下の階層のレポートを読んでサブトピックの詳細を深掘りする、みたいな使い方ができるわけや。ただ、ここではグローバルな質問に答えるためのグラフベースのインデックスの一部として使う場合に焦点を当てとるで。
GraphRAGがコミュニティ要約を作る方法はこうや。まず色んな要素の要約(ノード、エッジ、関連するクレーム)をコミュニティ要約のテンプレートに追加していくねん。下の階層のコミュニティ要約を使って、上の階層のコミュニティ要約を作っていくんやけど、具体的にはこんな感じや:
**● 末端レベル(葉っぱ)のコミュニティの場合**
要素の要約に優先順位をつけてな、LLMのコンテキストウィンドウ(一度に処理できるテキスト量)がいっぱいになるまで順番に追加していくねん。優先順位の付け方はこうや:コミュニティ内の各エッジについて、その両端のノード(ソースとターゲット)の次数(つながってる数)の合計が多い順、つまり目立ち度が高い順に並べる。ほんで、ソースノードの説明、ターゲットノードの説明、エッジ自体の説明、関連するクレームの順で追加していくねん。
**● より上位のコミュニティの場合**
もし全部の要素要約がコンテキストウィンドウに収まるんやったら、末端レベルと同じやり方で全部まとめて要約するで。収まらへん場合は、サブコミュニティを要素要約のトークン数が多い順にランク付けしてな、サブコミュニティの要約(短い)で元の要素要約(長い)を置き換えていって、コンテキストウィンドウに収まるまで調整するねん。
### 3.1.6 コミュニティ要約 → コミュニティ回答 → グローバル回答
ユーザーから質問が来たら、さっき作ったコミュニティ要約を使って、何段階かのプロセスを経て最終的な答えを生成するねん。コミュニティ構造が階層的になっとるから、質問に答えるのに色んなレベルのコミュニティ要約を使えるわけや。ほんなら「どのレベルの要約を使うのがベストなん?」って疑問が出てくるやろ?要約の詳しさとカバー範囲のバランスがええのはどこか、っていう話やな。これについてはセクション4で評価しとるで。
あるコミュニティレベルでグローバルな回答を生成する流れはこうや:
**● コミュニティ要約の準備**
コミュニティ要約をランダムにシャッフルして、あらかじめ決めたトークンサイズのチャンク(塊)に分けるねん。なんでかっていうと、関連する情報をチャンク全体に分散させるためや。一箇所に集中させてしもたら、一つのコンテキストウィンドウで処理しきれへんくて情報が失われる可能性があるからな。
**● コミュニティ回答のマップ処理**
中間的な回答を並列で生成するねん。それと同時に、LLMに「この回答が質問に答えるのにどんだけ役立つか」を0〜100点で採点してもらうねん。0点の回答はフィルターで除外するで。
**● グローバル回答へのリデュース処理**
中間的なコミュニティ回答を役立ち度スコアの高い順に並べ替えてな、新しいコンテキストウィンドウがいっぱいになるまで順番に追加していくねん。この最終的なコンテキストを使って、ユーザーに返すグローバル回答を生成するわけや。
### 3.2 グローバルなセンスメイキング質問の生成
RAGシステムがグローバルなセンスメイキング(全体を理解して意味を見出す作業)にどんだけ効果的かを評価するために、LLMを使ってコーパス固有の質問セットを生成するねん。この質問は、特定の細かい事実を検索せんでも、コーパス全体の高レベルな理解を評価できるように設計されとるで。
具体的にはこうや。まず、コーパスの概要とその目的をLLMに渡して、「このRAGシステムを使いそうな架空のユーザー像(ペルソナ)」を考えてもらうねん。次に、それぞれの架空ユーザーについて「このユーザーがRAGシステムで達成したいタスク」を具体的に挙げてもらう。最後に、ユーザーとタスクの各組み合わせについて「コーパス全体を理解せんと答えられへん質問」を生成してもらうねん。このアプローチの詳細はアルゴリズム1に書いとるで。
---
## Page 7
[](/attach/730f1a9f38d16689900969a3eeeb1b31e45eda1dcc1f37a043afa90aff76c867_p007.png)
### 和訳
**アルゴリズム1:質問生成のためのプロンプト手順**
1: **入力**: コーパス(テキストデータの集まり)の説明、ユーザー数K人、ユーザーごとのタスク数N個、(ユーザー、タスク)の組み合わせごとの質問数M個
2: **出力**: K × N × M個の、コーパス全体の理解が必要なハイレベルな質問セット
3: **手順** GENERATEQUESTIONS(質問生成)
4: コーパスの説明をもとに、LLM(大規模言語モデル)に以下をやってもらうねん:
1. そのデータセットを使いそうなK人分のユーザー像(ペルソナ)を描写する
2. 各ユーザーに関連するN個のタスクを特定する
3. ユーザーとタスクのペアごとに、M個のハイレベルな質問を生成する。その質問は:
- コーパス全体の理解が必要なやつ
- 細かい事実をピンポイントで探すようなやつはアカン
5: 生成された質問を集めて、そのデータセット用のK × N × M個のテスト質問を作るわけや
6: **手順おわり**
ワイらの評価では、K = M = N = 5に設定して、データセットごとに合計125個のテスト質問を用意したで。表1に、2つの評価用データセットそれぞれの質問例を載せてるわ。
---
**3.3 グローバルセンスメイキング(全体像把握)の評価基準**
ワイらの活動ベースのセンスメイキング質問には「正解」がないねん。せやから、LLM評価者を使った一対一比較アプローチを採用して、特定の基準に従って相対的なパフォーマンスを判定するようにしたで。グローバルセンスメイキング活動にとって望ましい3つの目標基準を設計したんや。
付録FにLLM評価者を使った一対一評価のプロンプトを載せてるけど、ざっくりまとめるとこんな感じや:
- **包括性(Comprehensiveness)**: 質問のあらゆる側面と詳細をカバーするのに、どれだけ詳しく答えてるか?
- **多様性(Diversity)**: 質問に対して、どれだけいろんな視点や洞察を豊かに提供できてるか?
- **エンパワーメント(Empowerment)**: そのトピックについて読み手が理解して、ちゃんと判断できるようになるのにどれだけ役立ってるか?
---
**表1**: ターゲットデータセットの短い説明をもとにLLMが生成した、潜在的なユーザー、タスク、質問の例。質問は細かい詳細やなくて、全体的な理解を狙ったもんやで。
| データセット | 活動フレーミングとグローバルセンスメイキング質問の生成例 |
|---|---|
| **ポッドキャスト文字起こし** | **ユーザー**: テック業界のトレンドや洞察を探してるテックジャーナリスト<br>**タスク**: テックリーダーが政策と規制の役割をどう見てるか理解する<br>**質問**:<br>1. テック政策と政府規制を主に扱ってるエピソードはどれ?<br>2. ゲストはプライバシー法が技術発展に与える影響をどう捉えてる?<br>3. イノベーションと倫理的配慮のバランスについて議論してるゲストはおる?<br>4. ゲストが言うてる現行政策への変更提案って何?<br>5. テック企業と政府の協力について議論されてる?どんな風に? |
| **ニュース記事** | **ユーザー**: 時事問題をカリキュラムに取り入れたい教育者<br>**タスク**: 健康とウェルネスについて教える<br>**質問**:<br>1. 健康教育のカリキュラムに組み込める今の健康トピックって何がある?<br>2. ニュース記事は予防医学やウェルネスの概念をどう扱ってる?<br>3. 互いに矛盾する健康記事の例はある?あるならなんで?<br>4. ニュース報道から公衆衛生の優先事項についてどんな洞察が得られる?<br>5. ヘルスリテラシーの重要性を強調するために、教育者はこのデータセットをどう使える? |
7
---
## Page 8
[](/attach/730f1a9f38d16689900969a3eeeb1b31e45eda1dcc1f37a043afa90aff76c867_p008.png)
### 和訳
それとな、「Directness(直接性)」っていう「コントロール基準」も使ってんねん。これ何かっていうと、「その答えが質問にどんだけ具体的にビシッと答えてるか?」を見るもんやねん。要するに、LLMが作った要約がどんだけ簡潔かを汎用的に評価するもんやな。なんでこれ入れてるかっていうと、他の基準の結果がちゃんとしてるかどうかを判断するための参照ポイントにしたいからやねん。で、この直接性ってやつ、網羅性とか多様性とは基本的に反対の性質やから、全部の4つの基準で勝つ方法なんてあるわけないやろ、って話やねん。
評価のやり方やけど、LLMに質問と、2つの競合システムが出した答えを見せて、「この基準に沿ってどっちがええか比べてや」って指示して、最終的にどっちが好みか判定させんねん。LLMは勝者を決めるか、もしくはほぼ同じやったら引き分けって返すねん。LLMの生成って本質的にランダム性あるやん?やからそれを考慮して、各比較を複数回やって、その結果を複製間と質問間で平均取んねん。サンプル質問に対する答えをLLMがどう評価するかの具体例は付録Dに載ってるで。
## 4 分析
### 4.1 実験1
#### 4.1.1 データセット
100万トークン規模のデータセットを2つ選んだで。どっちもユーザーが実際の活動で出くわしそうなコーパスの代表例やねん:
**ポッドキャストの文字起こし。** 「Behind the Tech with Kevin Scott」っていう公開ポッドキャストの文字起こしやねん。MicrosoftのCTOであるKevin Scottが科学とかテクノロジーの色んな著名人と対談する番組やで(Scott, 2024)。このコーパスは600トークンのテキストチャンク1669個に分割されてて、チャンク間で100トークンの重複があんねん(約100万トークン)。
**ニュース記事。** 2013年9月から2023年12月に公開されたニュース記事で構成されたベンチマークデータセットやねん。エンタメ、ビジネス、スポーツ、テクノロジー、健康、科学とか色んなカテゴリーがあるで(Tang and Yang, 2024)。コーパスは600トークンのテキストチャンク3197個に分割されてて、チャンク間で100トークンの重複があんねん(約170万トークン)。
#### 4.1.2 条件
6つの条件を比較したで。GraphRAGの4つの異なるグラフコミュニティレベル(C0、C1、C2、C3)、ソーステキストに直接map-reduceアプローチを適用するテキスト要約手法(TS)、そしてベクトルRAGの「意味検索」アプローチ(SS)やねん:
- **C0。** ルートレベルのコミュニティ要約(数が一番少ない)を使ってユーザーのクエリに答えるやつ。
- **C1。** 高レベルのコミュニティ要約を使ってクエリに答えるやつ。これらはC0のサブコミュニティやねんけど、もしなかったらC0コミュニティを下に投影したもんを使うねん。
- **C2。** 中間レベルのコミュニティ要約を使ってクエリに答えるやつ。これらはC1のサブコミュニティやねんけど、もしなかったらC1コミュニティを下に投影したもんを使うねん。
- **C3。** 低レベルのコミュニティ要約(数が一番多い)を使ってクエリに答えるやつ。これらはC2のサブコミュニティやねんけど、もしなかったらC2コミュニティを下に投影したもんを使うねん。
- **TS。** セクション3.1.6と同じ手法やねんけど、コミュニティ要約やなくてソーステキストをシャッフルしてチャンク化して、map-reduce要約ステージに使うねん。
- **SS。** ベクトルRAGの実装で、テキストチャンクを取り出して、指定されたトークン上限に達するまで利用可能なコンテキストウィンドウに追加していくやつやねん。
コンテキストウィンドウのサイズと回答生成に使うプロンプトは、6つの条件全部で同じやねん(使うコンテキスト情報の種類に合わせて参照スタイルをちょっと変えてるくらいの違いはあるけどな)。条件の違いは、コンテキストウィンドウの中身をどう作るかだけやねん。
C0からC3の条件を支えるグラフインデックスは、エンティティと関係性の抽出用の汎用プロンプトを使って作ったんやけど、エンティティの種類とfew-shotの例はデータのドメインに合わせてカスタマイズしてあるで。
---
## Page 9
[](/attach/730f1a9f38d16689900969a3eeeb1b31e45eda1dcc1f37a043afa90aff76c867_p009.png)
### 和訳
4.1.3 設定のこと
コミュニティの要約とか、コミュニティからの回答、それからグローバルな回答を作るときに使うコンテキストウィンドウ、これ8,000トークンで固定してん。詳しいことは付録Cに書いてあるで。グラフのインデックス作成は600トークンのウィンドウでやって(これは付録A.2で説明しとる)、Podcastのデータセットで281分かかったわ。使ったマシンは仮想マシンで、RAMが16GB、CPUはIntel(R) Xeon(R) Platinum 8171Mの2.60GHzのやつ。OpenAIの公開エンドポイントでgpt-4-turbo使って、1分あたり200万トークン、1分あたり1万リクエストの制限やったな。
Leidenコミュニティ検出っていう、ネットワークの中でどのノードがまとまってるか見つける方法やねんけど、これはgraspologicっていうライブラリ使って実装したで(Chungらが2019年に作ったやつ)。グラフのインデックスとグローバル回答を作るときのプロンプトは付録E、LLMの回答を評価基準に照らしてチェックするときのプロンプトは付録Fに載せてる。次のセクションで出てくる結果の統計分析は全部付録Gにあるから、気になったら見てな。
4.2 実験2
実験1で出た「網羅性」と「多様性」の結果がほんまに正しいか確かめるために、主張ベースの測定ってのをやってん。「事実に関する主張」の定義はNiらが2024年に言うたやつを使ってて、これは「検証可能な事実を明確に示す文」のことや。例えばな、「カリフォルニア州とニューヨーク州は再生可能エネルギー導入のインセンティブを実施して、政策決定における持続可能性の重要性を広く示した」っていう文があるとするやろ。これには事実の主張が2つ入ってんねん。(1)カリフォルニア州が再生可能エネルギー導入のインセンティブを実施した、と(2)ニューヨーク州が再生可能エネルギー導入のインセンティブを実施した、ってな。
事実の主張を抜き出すのに、Claimifyっていうツール使ったで(Metropolitanskyと Larsonが2025年に作ったやつ)。これはLLMを使った方法で、答えの中から少なくとも1つの事実主張が入ってる文を見つけて、その文をシンプルで独立した事実の主張に分解してくれんねん。実験1の条件で生成された回答にClaimify適用して、重複する主張を取り除いたら、47,075個のユニークな主張が出てきたわ。1つの回答あたり平均31個の主張やな。
2つの指標を定義したで。数値が高いほどええ結果ってことな:
1. 網羅性:各条件で生成された回答から抽出された主張の平均数で測定
2. 多様性:各回答の主張をクラスタリングして、平均クラスター数で測定
クラスタリングはPadmakumarとHeが2024年に説明した方法に従ったで。Scikit-learnの凝集型クラスタリングってやつを使ってん(Pedregosaらが2011年に作ったやつ)。クラスターは「完全連結法」でマージしていくねんけど、これはどういうことかっていうと、一番遠い点同士の距離が事前に決めたしきい値以下のときだけクラスターをくっつけるってことや。距離の計算には1からROUGE-Lを引いた値を使ってる。しきい値によってクラスター数が変わるから、いろんなしきい値での結果を報告してるで。
5 結果
5.1 実験1
インデックス作成の結果、Podcastデータセットでは8,564ノードと20,691エッジのグラフができて、Newsデータセットではもっと大きくて15,754ノードと19,520エッジのグラフになったわ。表2に、各グラフのコミュニティ階層の異なるレベルでのコミュニティ要約の数を載せてる。
グローバルアプローチ vs ベクトルRAG。図2と表6見てもらったらわかるけど、グローバルアプローチは従来のベクトルRAG(SS)を網羅性と多様性の両方でめっちゃ上回ってん、両方のデータセットでな。具体的に言うと、グローバルアプローチの網羅性の勝率は、Podcast書き起こしで72-83%(p<.001)、ニュース記事で72-80%(p<.001)やった。多様性の勝率はそれぞれ75-82%(p<.001)と62-71%(p<.01)やったな。「直接性」を妥当性の検証として使ったら、ベクトルRAGがすべての比較で一番直接的な回答を出すことが確認できたで。
エンパワーメント。エンパワーメントの比較では、グローバルアプローチ対ベクトルRAG(SS)でも、GraphRAGアプローチ対ソーステキスト要約(TS)でも、結果がまちまちやったわ。この指標でLLMの推論をLLMで分析してみたら、具体例を挙げる能力が
---
## Page 10
[](/attach/730f1a9f38d16689900969a3eeeb1b31e45eda1dcc1f37a043afa90aff76c867_p010.png)
### 和訳
ポッドキャストの書き起こしデータ
SS TS C0 C1 C2 C3
SS TS C0 C1 C2 C3
SS TS C0 C1 C2 C3
SS TS C0 C1 C2 C3
SS
50 17 28 25 22 21
SS
50 18 23 25 19 19
SS
50 42 57 52 49 51
SS
50 56 65 60 60 60
TS
83 50 50 48 43 44
TS
82 50 50 50 43 46
TS
58 50 59 55 52 51
TS
44 50 55 52 51 52
C0
72 50 50 53 50 49
C0
77 50 50 50 46 44
C0
43 41 50 49 47 48
C0
35 45 50 47 48 48
C1
75 52 47 50 52 50
C1
75 50 50 50 44 45
C1
48 45 51 50 49 50
C1
40 48 53 50 50 50
C2
78 57 50 48 50 52
C2
81 57 54 56 50 48
C2
51 48 53 51 50 51
C2
40 49 52 50 50 50
C3
79 56 51 50 48 50
C3
81 54 56 55 52 50
C3
49 49 52 50 49 50
C3
40 48 52 50 50 50
網羅性
多様性
ユーザーの理解促進度
直接性
ニュース記事データ
SS TS C0 C1 C2 C3
SS TS C0 C1 C2 C3
SS TS C0 C1 C2 C3
SS TS C0 C1 C2 C3
SS
50 20 28 25 21 21
SS
50 33 38 35 29 31
SS
50 47 57 49 50 50
SS
50 54 59 55 55 54
TS
80 50 44 41 38 36
TS
67 50 53 45 44 40
TS
53 50 58 50 50 48
TS
46 50 55 53 52 52
C0
72 56 50 52 54 52
C0
62 47 50 40 41 41
C0
43 42 50 42 45 44
C0
41 45 50 48 48 47
C1
75 59 48 50 58 55
C1
65 55 60 50 50 50
C1
51 50 58 50 52 51
C1
45 47 52 50 49 49
C2
79 62 46 42 50 59
C2
71 56 59 50 50 51
C2
50 50 55 48 50 50
C2
45 48 52 51 50 49
C3
79 64 48 45 41 50
C3
69 60 59 50 49 50
C3
50 52 56 49 50 50
C3
46 48 53 51 51 50
網羅性
多様性
ユーザーの理解促進度
直接性
図2:これな、(行の条件)が(列の条件)に対してどんだけ勝ったかっていうパーセンテージを示してんねん。2つのデータセット、4つの評価指標、比較ごとに125問(それぞれ5回繰り返して平均とってる)で計算してるで。データセットと評価指標ごとの総合優勝者は太字で書いてある。自分対自分の勝率は計算してへんけど、参考値として期待される50%を載せてるわ。全部のGraph RAGの条件が、普通のRAG(ナイーブRAG)に対して網羅性と多様性で勝ってんねん。C1からC3の条件は、TS(グラフインデックスなしのグローバルテキスト要約)と比べても、回答の網羅性と多様性でちょっとだけ改善が見られたで。
表2:コンテキストの単位数(C0からC3はコミュニティ要約の数、TSはテキストチャンクの数)、それに対応するトークン数、最大トークン数に対するパーセンテージを示してるで。元テキストのマップリデュース要約が一番リソース食う方法で、最大のコンテキストトークンが必要やねん。ルートレベルのコミュニティ要約(C0)は、クエリあたりのトークン数がめっちゃ少なくて済むねん(9倍から43倍も少ない)。
ポッドキャスト書き起こし
C3
C1
C0
367
34
1310
225756 565720 746100 1014611 39770
26657
73.5
22.2
2.6
TS
1669
C2
969
55.8
100
2.3
ニュース記事
C0
55
C3
2142
C2
1797
C1
555
352641 980898 1140266 1707694
20.7
TS
3197
66.8
57.4
100
単位数
トークン数
最大比(%)
具体例とか引用、出典をちゃんと残すことが、ユーザーがしっかり理解するのにめっちゃ重要やって判定されてん。要素抽出のプロンプトをチューニングしたら、GraphRAGのインデックスにこういう詳細をもっと残せるかもしれへんで。
**コミュニティ要約 vs 元テキスト**
GraphRAGでコミュニティ要約と元テキストを比較したらな、コミュニティ要約の方が回答の網羅性と多様性でちょっとやけど一貫した改善があったんや。ただし、ルートレベルの要約は別やで。ポッドキャストデータセットの中間レベル要約と、ニュースデータセットの低レベルコミュニティ要約が、それぞれ網羅性で57%(p<.001)と64%(p<.001)の勝率を達成してん。多様性の勝率は、ポッドキャストの中間レベル要約で57%(p=.036)、ニュースの低レベルコミュニティ要約で60%(p<.001)やったで。表2見たらGraphRAGのスケーラビリティの優位性もわかるねん:低レベルコミュニティ要約(C3)では、GraphRAGは元テキスト要約より26〜33%少ないコンテキストトークンで済んで、ルートレベルコミュニティ要約(C0)では97%以上も少なくて済むんや。他のグローバル手法と比べてちょっとだけ性能落ちるけど、ルートレベルGraphRAGはセンスメイキング活動(情報を理解して意味を見出す作業やな)に特徴的な繰り返し質問応答に対して、めっちゃ効率的な方法を提供してくれんねん。しかも網羅性(勝率72%)と多様性(勝率62%)でベクトルRAGより優れてるっていう利点も残してるで。
---
## Page 11
[](/attach/730f1a9f38d16689900969a3eeeb1b31e45eda1dcc1f37a043afa90aff76c867_p011.png)
### 和訳
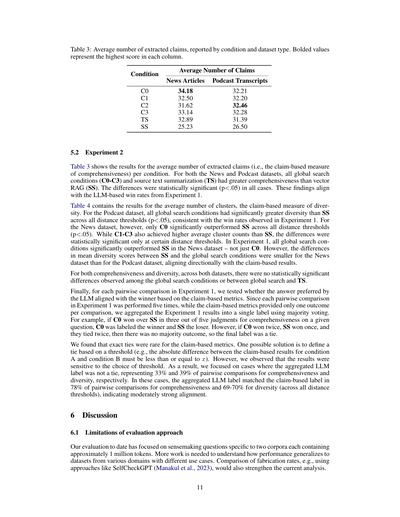
表3: 抽出されたクレーム(主張)の平均数やねん。条件別とデータセット種類別で報告してるで。太字になってるのは各列で一番高いスコアや。
条件 | クレームの平均数
--- | ---
| ニュース記事 | ポッドキャスト文字起こし
C0 | 34.18 | 32.21
C1 | 32.50 | 32.20
C2 | 31.62 | 32.46
C3 | 33.14 | 32.28
TS | 32.89 | 31.39
SS | 25.23 | 26.50
5.2 実験2
表3は抽出されたクレームの平均数(つまり、クレームベースの網羅性の指標やな)を条件別に示してるねん。ニュースデータセットとポッドキャストデータセットの両方で、グローバル検索の条件(C0からC3まで)とソーステキスト要約(TS)は、ベクトルRAG(SS)よりも網羅性がめっちゃ高かったんよ。この差は全部のケースで統計的に有意やった(p<.05)。この結果は実験1のLLMベースの勝率とバッチリ一致してるで。
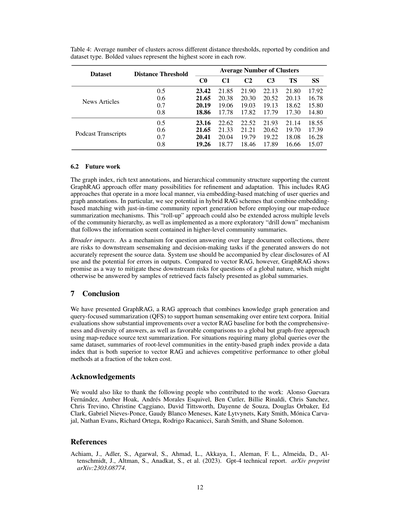
表4にはクラスター数の平均、つまりクレームベースの多様性の指標が載ってるねん。ポッドキャストデータセットでは、グローバル検索の全条件が全部の距離閾値でSSよりも有意に多様性が高かった(p<.05)。これも実験1で観察された勝率と一致してるな。ところがやで、ニュースデータセットでは、全部の距離閾値でSSを有意に上回ったのはC0だけやってん(p<.05)。C1からC3もSSより高い平均クラスター数を達成してたけど、統計的に有意な差があったのは特定の距離閾値だけやったんよ。実験1では、ニュースデータセットでグローバル検索の全条件がSSを有意に上回ってた、C0だけやなくてな。せやけど、SSとグローバル検索条件の間の多様性スコアの平均差は、ニュースデータセットの方がポッドキャストデータセットより小さかってん。これはクレームベースの結果と方向性としては合ってるな。
網羅性と多様性の両方で、両データセットにおいて、グローバル検索条件同士の間やグローバル検索とTSの間には統計的に有意な差は見られへんかったで。
最後に、実験1の各ペアワイズ比較について、LLMが好んだ回答がクレームベースの指標に基づく勝者と一致してるかテストしたんよ。実験1の各ペアワイズ比較は5回ずつ行われたんやけど、クレームベースの指標は比較ごとに1つの結果しか出さへんから、実験1の結果を多数決で1つのラベルに集約したねん。例えば、ある質問の網羅性でC0がSSに5回中3回勝ったら、C0が勝者でSSが敗者とラベル付けされるわけや。せやけど、C0が2回勝って、SSが1回勝って、2回引き分けやったら、多数決の結果が出えへんから、最終ラベルは引き分けになるねん。
クレームベースの指標では完全な引き分けはめっちゃ珍しかってん。一つの解決策として、閾値に基づいて引き分けを定義する方法があるな(例えば、条件Aと条件Bのクレームベース結果の絶対差がx以下やないとアカンとか)。せやけど、結果は閾値の選び方にめっちゃ敏感やったんよ。そんなわけで、集約されたLLMラベルが引き分けやなかったケースに焦点を当てたねん。これは網羅性で33%、多様性で39%のペアワイズ比較に相当するで。これらのケースでは、集約されたLLMラベルとクレームベースのラベルが一致したのは、網羅性で78%、多様性で69-70%(全距離閾値にわたって)やった。これはまあまあ強い一致を示してるな。
6 考察
6.1 評価アプローチの限界
今回の評価は、それぞれ約100万トークンを含む2つのコーパスに特化したセンスメイキング(意味理解)の質問に焦点を当ててきたんよ。様々なドメインの異なるユースケースを持つデータセットに対して、パフォーマンスがどう一般化するかを理解するには、もっと研究が必要やねん。例えばSelfCheckGPT(Manakulら、2023年)みたいなアプローチを使った捏造率の比較も、現在の分析をもっと強化してくれるやろな。
---
## Page 12
[](/attach/730f1a9f38d16689900969a3eeeb1b31e45eda1dcc1f37a043afa90aff76c867_p012.png)
### 和訳
表4:距離の閾値ごとの平均クラスター数やねん。条件別とデータセットの種類別で分けて報告してるで。太字になってるのは、各行で一番高いスコアってことや。
| データセット | 距離の閾値 | 平均クラスター数 |||||
|---|---|---|---|---|---|---|
| | | C0 | C1 | C2 | C3 | TS | SS |
| ニュース記事 | 0.5 | 23.42 | 21.85 | 21.90 | 22.13 | 21.80 | **17.92** |
| | 0.6 | 21.65 | 20.38 | 20.30 | 20.52 | 20.13 | **16.78** |
| | 0.7 | 20.19 | 19.06 | 19.03 | 19.13 | 18.62 | **15.80** |
| | 0.8 | 18.86 | 17.78 | 17.82 | 17.79 | 17.30 | **14.80** |
| ポッドキャスト文字起こし | 0.5 | 23.16 | 22.62 | 22.52 | 21.93 | 21.14 | **18.55** |
| | 0.6 | 21.65 | 21.33 | 21.21 | 20.62 | 19.70 | **17.39** |
| | 0.7 | 20.41 | 20.04 | 19.79 | 19.22 | 18.08 | **16.28** |
| | 0.8 | 19.26 | 18.77 | 18.46 | 17.89 | 16.66 | **15.07** |
6.2 今後の研究について
今のGraphRAGのやり方を支えてるグラフインデックス、リッチテキストのアノテーション、階層的なコミュニティ構造、これらにはめっちゃいろんな改良や応用の可能性があるんよ。例えば、ユーザーの質問とグラフのアノテーションを埋め込みベースでマッチングさせて、もっとローカルな感じで動くRAGのアプローチとかな。特にワイらが注目してるんは、埋め込みベースのマッチングと「その場でコミュニティレポートを生成する」やり方を組み合わせてから、ワイらのmap-reduce要約の仕組みを使うっていうハイブリッドRAGやねん。この「ロールアップ」的なアプローチは、コミュニティ階層の複数レベルにまたがって拡張することもできるし、上位レベルのコミュニティ要約に含まれる「情報の手がかり」を追いかけていく「ドリルダウン」みたいな探索的なメカニズムとしても実装できるんやで。
**社会への広い影響について。** 大量の文書コレクションに対する質問応答の仕組みとして、生成された回答がソースデータを正確に表現してへんかったら、その後の意思決定とか分析作業にリスクがあるんよな。システムを使う時は、AIを使ってるってことと、出力に間違いがある可能性があるってことをちゃんと開示せなあかんねん。でもな、ベクトルRAGと比べたら、GraphRAGはグローバルな性質の質問に対するこういう下流リスクを軽減できる可能性があるんや。なんでかっていうと、普通やったら取得した事実のサンプルをあたかもグローバルな要約みたいに偽って答えてまうところを、ちゃんとできるからやねん。
7 結論
ワイらはGraphRAGを提案したんや。これは知識グラフ生成とクエリ重視の要約(QFS)を組み合わせて、テキストコーパス全体に対する人間の理解・分析をサポートするRAGアプローチやねん。初期評価では、回答の網羅性と多様性の両方で、ベクトルRAGのベースラインに対してめっちゃ大幅な改善が見られたんよ。それと、map-reduceでソーステキストを要約するグラフなしのグローバルアプローチと比較しても、ええ感じの結果やったで。同じデータセットに対してグローバルな質問をいっぱいせなあかん状況では、エンティティベースのグラフインデックスのルートレベルコミュニティの要約が、ベクトルRAGより優れたデータインデックスを提供するし、他のグローバル手法と同等の性能を、トークンコストのほんの一部で達成できるんや。
謝辞
以下の方々にも研究に貢献していただいたことを感謝したいと思います:Alonso Guevara Fernández、Amber Hoak、Andrés Morales Esquivel、Ben Cutler、Billie Rinaldi、Chris Sanchez、Chris Trevino、Christine Caggiano、David Tittsworth、Dayenne de Souza、Douglas Orbaker、Ed Clark、Gabriel Nieves-Ponce、Gaudy Blanco Meneses、Kate Lytvynets、Katy Smith、Mónica Carvajal、Nathan Evans、Richard Ortega、Rodrigo Racanicci、Sarah Smith、Shane Solomon。
参考文献
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., 他 (2023). GPT-4テクニカルレポート。arXivプレプリント arXiv:2303.08774.
---
## Page 13
[](/attach/730f1a9f38d16689900969a3eeeb1b31e45eda1dcc1f37a043afa90aff76c867_p013.png)
### 和訳
Anilさんたちが2023年に出したんやけど、Geminiっていうめっちゃすごいマルチモーダルモデル(テキストも画像も扱えるやつな)のファミリーを発表したんや。
Baekさんたちは2023年に、知識グラフの質問応答をゼロショット(事前に学習なしで)でやるための知識を付け加えた言語モデルのプロンプティング手法を提案してるねん。
Banさんたちは2023年に、大規模言語モデルを単なる質問ツールやなくて、データから因果関係を見つけ出す「因果発見の設計者」として使う方法を研究してはるんや。
Barlaugさんとこは2021年に、エンティティマッチング(似たもん同士を見つける技術やな)にニューラルネットワーク使う研究のサーベイ論文を書いてはる。ACM TKDDに載ってて、かなり網羅的やで。
Baumelさんたちは2018年に、クエリに焦点当てた要約をやる研究してんねん。seq2seqモデルに、クエリとの関連性とか、複数文書のカバレッジとか、要約の長さの制限とかを組み込む方法を提案してはる。
Blondelさんたちは2008年の論文で、でっかいネットワークの中からコミュニティ(グループみたいなもんやな)を素早く見つけ出すアルゴリズムを発表したんや。統計力学のジャーナルに載ってるで。
Brownさんたちは2020年に超有名な論文出してん。言語モデルは少ないサンプルでも学習できるっていう「few-shot learners」の研究や。NeurIPSに載って、もうめっちゃ引用されまくりやで。
Chengさんたちは2024年に、自分自身の記憶を使って検索強化型のテキスト生成をする「セルフメモリー」っていう手法をNeurIPSで発表してはる。自分で自分を引き上げるような賢い方法やねん。
Christenさんは2012年にデータマッチングのプロセスについての本をSpringerから出してはる。
Chungさんたちは2019年に、GraSpyっていうPythonでグラフ統計をやるためのライブラリを作って、JMLRに論文載せてはる。
Dangさんは2006年に、質問に焦点当てた要約システムの評価についてDUC 2005のワークショップで発表してはる。
Elmagarmidさんたちは2006年に、重複レコード検出についてのサーベイ論文をIEEE TKDEに出してはる。データベースの中から同じもん見つける研究の定番論文やな。
Esさんたちは2023年に、RAG(検索強化型生成)を自動で評価するRAGASっていう手法を提案してはる。RAGの評価ってめっちゃ難しいんやけど、それを自動化しようとしてんねん。
Etzioniさんたちは2004年に、KnowItAllっていうWeb規模で情報抽出するシステムの初期成果をWWW学会で発表してはる。Webからデータ集めるパイオニア的研究やな。
Fengさんたちは2023年に、検索と生成を相乗効果的に組み合わせて大規模言語モデルを強化する研究を発表してはる。
Fortunatoさんは2010年に、グラフの中のコミュニティ検出についてのめっちゃ詳しいレビュー論文をPhysics Reportsに出してはる。この分野の教科書みたいな論文やで。
Gaoさんたちは2023年に、大規模言語モデルのための検索強化型生成(RAG)についての包括的なサーベイ論文を出してはる。RAG勉強するならまずこれ読んどきって感じやな。
Heさんたちは2024年に、G-retrieverっていうテキスト形式のグラフを理解して質問に答えるための検索強化型生成システムを提案してはる。グラフデータ×LLMの最先端研究やで。
Huangさんたちは2023年に、大規模言語モデルはまだ自分で推論の間違いを直せへんっていう結構衝撃的な研究を発表してはる。LLMの自己修正能力の限界を示した重要な論文やねん。
---
## Page 14
[](/attach/730f1a9f38d16689900969a3eeeb1b31e45eda1dcc1f37a043afa90aff76c867_p014.png)
### 和訳
ForceAtlas2っていうのは、ネットワークを見やすく配置するためのアルゴリズムなんやけど、Gephiっていうソフト用に作られてて、ずっと動き続けながらグラフをええ感じに並べてくれるやつやねん。これJacomyさんらが2014年にPLoS ONEで発表してはるわ。
コミュニティ検出、つまりグラフの中で仲良しグループを見つける方法についてのめっちゃ網羅的なレビューがあって、統計モデルから深層学習まで全部カバーしてるねん。Jinさんらが2021年にIEEEの論文誌に出してはる。
知識グラフで強化した言語モデルっていう話もあって、これは会話を生成するときに、ちゃんと知識に基づいた返答ができるようにするやつやねん。Kangさんらが2023年にarXivで発表してはる。
Khattabさんらの「見せて・探して・予測する」っていう研究は、検索システムと言語モデルを組み合わせて、知識がめっちゃ必要なNLPタスクをやる方法やねん。2022年のarXiv論文やで。
確率的な知識グラフの構築について、段階的に組み立てていく方法をKimさんらが2016年のCIKMで発表してはる。
曖昧な質問に答えるときの「明確化の木」っていうアプローチもあって、これは検索で強化した大規模言語モデルを使うやつやねん。別のKimさんらが2023年にarXiv出してはる。
センスメイキング、つまり状況を理解するってどういうことやねん?っていう話を、いろんな視点から解説した論文もあるで。Kleinさんらが2006年にIEEEの雑誌で書いてはる。
大規模言語モデルが「心の理論」、つまり他人の気持ちを推測できるかどうかを評価した研究もあって、Kosinskiさんが2024年にPNASで発表してはる。
「1100万個の干し草の山から針を探す」っていうおもろいタイトルの論文があって、再帰的なメモリを使うと、普通のLLMが見逃すもんも見つけられるって話やねん。Kuratovさんらの2024年の研究や。
LangChainがGraphRAGの実装を2024年に公開してて、ドキュメントがreadthedocsにあるで。
質問に焦点を当てた要約を、クエリの関連性を考慮しながらTransformerモデルで転移学習する方法をLaskarさんらが2020年のカナダAI会議で発表してはる。
RAG、つまり検索で強化した生成っていうのは、知識がいっぱい必要なNLPタスクのためのやつで、Lewisさんらが2020年にNeurIPSで発表しためっちゃ有名な論文やねん。
「真ん中で迷子になる」っていう面白い現象があって、言語モデルが長い文脈を使うとき、真ん中の情報を見落としがちやっていう話やねん。Liuさんらが2023年にarXivで出してはる。
LlamaIndexがGraphRAGの実装をGitHubで2024年に公開してるで。v2のやつや。
Self-Refineっていうのは、自分で自分にフィードバックして繰り返し改善していく方法やねん。Madaanさんらが2024年のNeurIPSで発表してはる。
SelfCheckGPTっていうのは、外部リソース使わんと、生成型の大規模言語モデルがハルシネーション(嘘ついてるか)を検出する方法やねん。Manakulさんらが2023年にarXivで出してはる。
オープンドメインの質問応答のために、生成で検索を強化するアプローチをMaoさんらが2020年にarXivで発表してはる。
OpenORDっていうのは、でっかいグラフをレイアウトするためのオープンソースのツールボックスやねん。Martinさんらが2011年のSPIEの可視化会議で発表してはる。
テキストから知識グラフを生成する研究もあって、Melnykさんらが2022年に発表してはる。
---
## Page 15
[](/attach/730f1a9f38d16689900969a3eeeb1b31e45eda1dcc1f37a043afa90aff76c867_p015.png)
### 和訳
Metropolitanskyさんとかが2025年に出した論文は、事実かどうかの主張をうまく抽出して評価する方法についてやねん。
で、Microsoft(2023年)は、GPT-4使って科学的発見にでっかい言語モデルがどんだけ影響与えるかっていう予備的な研究やってん。
MooneyさんとBunescuさん(2005年)は、情報抽出使ってテキストから知識をマイニングする方法について書いてて、これSIGKDD Explor. Newsl.っていう雑誌の7巻1号の3〜10ページに載ってるで。
NebulaGraph(2024年)は、業界初のグラフRAGっていうのを発表したんやけど、これ何かっていうと、知識グラフベースの大規模言語モデルを使った検索拡張生成ってやつやねん。めっちゃ画期的やで。URLはhttps://www.nebula-graph.io/posts/graph-RAGや。
Neo4J(2024年)もGraphRAGを始めよう、Neo4Jのエコシステムツールについてって記事出してて、https://neo4j.com/developer-blog/graphrag-ecosystem-tools/で見れるで。
Newmanさん(2006年)は、ネットワークにおけるモジュラリティとコミュニティ構造についての論文を米国科学アカデミー紀要の103巻23号、8577〜8582ページに載せてるねん。要はネットワークの中でグループがどうやってできるかって話やな。
Niさんたち(2024年)は、AFaCTAっていうのを作ったんやけど、これは信頼できる大規模言語モデルのアノテーターを使って、事実主張の検出のアノテーション作業を手助けするシステムやねん。Kuさん、Martinsさん、Srikumarさんが編集した、計算言語学会第62回年次大会の議事録(第1巻:長編論文)の1890〜1912ページに載ってて、タイで開催されたやつや。
OpenAI(2023年)はChatGPT、つまりGPT-4言語モデルを出したんやで。みんな知ってるやつやな。
PadmakumarさんとHeさん(2024年)は、言語モデル使って文章書いたら内容の多様性が減るんちゃうか?っていう問題をICLRで発表してん。ほんまに興味深いテーマやな。
Pedregosaさんたち(2011年)は、Scikit-learnっていうPythonで機械学習するためのライブラリについての論文をJournal of Machine Learning Researchの12巻2825〜2830ページに出してん。これめっちゃ有名なライブラリやで。
Ramさんたち(2023年)は、文脈内検索で拡張された言語モデルについて、Transactions of the Association for Computational Linguisticsの11巻1316〜1331ページに載せてるねん。要は、モデルが必要な情報をその場で取ってきて賢く答えるって話や。
RanadeさんとJoshiさん(2023年)は、Fabulaっていう、検索拡張型の物語構築を使ったインテリジェンスレポート生成システムについてarXivのプレプリント(arXiv:2310.13848)で発表してん。
Salminenさんたち(2024年)は、「機械仕掛けの神と大規模言語モデルから生まれるペルソナ:AI生成ペルソナ記述の構成を調査する」っていう論文を、CHI Conference on Human Factors in Computing Systemsの議事録の1〜20ページに載せてん。AIがどんなキャラ設定を作るかって話やな。
Sarthiさんたち(2024年)は、RAPTORっていうのを作ったんやけど、これは木構造で整理された検索のための再帰的抽象処理ってやつで、arXivのプレプリント(arXiv:2401.18059)で出してるで。
Scottさん(2024年)は、Behind the Techっていうのを出してて、https://www.microsoft.com/en-us/behind-the-techで見れるで。
Shaoさんたち(2023年)は、反復的な検索と生成の相乗効果で検索拡張型の大規模言語モデルを強化する方法について、arXivのプレプリント(arXiv:2305.15294)で発表してん。何回も検索と生成を繰り返してどんどん良くなるって仕組みやな。
Shinさんたち(2024年)は、ペルソナ生成における人間とAIのワークフローを理解するっていう論文を、2024 ACM Designing Interactive Systems Conferenceの議事録の757〜781ページに載せてるで。
Shinnさんたち(2024年)は、Reflexionっていうのを作ったんやけど、これは言葉による強化学習を使う言語エージェントやねん。Advances in Neural Information Processing Systemsの36巻に載ってるで。要はAIが自分の間違いを言葉で振り返って学習するって仕組みで、めっちゃ賢いやり方やな。
---
## Page 16
[](/attach/730f1a9f38d16689900969a3eeeb1b31e45eda1dcc1f37a043afa90aff76c867_p016.png)
### 和訳
Su, D.らの研究チーム(2020年)がCAIRE-COVIDっていうシステム作ってん。これ何かっていうと、COVID-19関連の学術情報を管理するためのシステムで、質問に答えてくれたり、複数の文書から要点まとめて要約してくれたりするんよ。arXivのプレプリントで発表されてるわ。
Tan, Z.らのグループ(2017年)は、めっちゃでっかいナレッジグラフ(知識のネットワーク図みたいなもんやな)をどう表現するかっていう研究してん。エンティティ(データの中の「もの」や「人」みたいな要素やな)の特徴を組み合わせて学習させる方法を提案してて、ニューヨークで開かれたCIKM '17っていう情報管理の学会で発表してるで。
Tang, Y.とYang, Y.(2024年)はMultiHop-RAGっていうベンチマーク作ってん。これ何かっていうと、RAG(検索で情報取ってきてAIに答えさせるやつ)が、複数のステップ踏まなあかん複雑な質問にどれくらい対応できるか測るためのもんやねん。
Touvron, H.ら(2023年)がLlama 2を発表してん。これはオープンソースの基盤モデルで、チャット用にファインチューニングもされてるやつやな。
Traag, V. A.ら(2019年)はLouvainからLeidenへっていう論文書いてて、コミュニティ検出アルゴリズム(ネットワークの中でつながりの強いグループを見つける手法やな)がちゃんとつながったコミュニティを保証できるように改良したんよ。Scientific Reportsに載ってるで。
Trajanoska, M.ら(2023年)は大規模言語モデル使ってナレッジグラフの構築を強化する方法を研究してん。
Trivedi, H.ら(2022年)はめっちゃ面白い研究してて、情報検索とChain-of-Thought推論(段階的に考えていく方法やな)を交互にやることで、知識がいっぱい必要な複数ステップの質問に答えられるようにしたんよ。
Wang, J.らのチーム(2023a)はChatGPTがNLG(自然言語生成)の評価者として使えるかどうか予備的に調べてるで。
Wang, S.ら(2024年)はFEB4RAGっていう研究で、RAGの文脈での連合検索(複数のデータソースをまたいで検索するやつ)を評価してるんよ。
Wang, X.ら(2022年)はセルフコンシステンシーっていう手法を提案してて、これ使うと言語モデルのChain-of-Thought推論がめっちゃ良くなるねん。
Wang, Y.ら(2023b)は複数文書にまたがる質問応答のために、ナレッジグラフを使ったプロンプティング手法を研究してるで。
Xu, Y.とLapata, M.(2021年)は潜在的なクエリ(隠れた質問みたいなもん)を使ったテキスト要約の研究してん。
Yang, Z.ら(2018年)がHotpotQAっていうデータセット作ってん。これは多様で説明可能なマルチホップ質問応答(複数の情報をつなげて答えを出す必要がある質問やな)のためのもんで、EMNLP学会で発表されてるわ。
Yao, J.-g.ら(2017年)は文書要約の最近の進展についてまとめた論文書いてて、Knowledge and Information Systemsに載ってるで。
Yao, L.ら(2023年)は大規模言語モデルをナレッジグラフの補完(欠けてる情報を埋めるやつ)に使う研究を探ってるんよ。
Yates, A.ら(2007年)がTextRunnerっていうシステム作ってん。これウェブ上でオープン情報抽出(構造化されてないテキストから情報を自動で引っ張り出すやつ)をやるためのもんで、NAACL-HLT学会で発表されてるわ。
Yuan, X.ら(2024年)はS-evalっていうの開発してて、大規模言語モデルの安全性評価のためのテストを自動で適応的に生成するシステムやねん。
Zhang, J.(2023年)はGraph-ToolFormerっていう研究してて、ChatGPTでプロンプトを強化することで、大規模言語モデルにグラフ推論(ネットワーク構造を使った推論)の能力を持たせようとしてるんよ。
---
## Page 17
[](/attach/730f1a9f38d16689900969a3eeeb1b31e45eda1dcc1f37a043afa90aff76c867_p017.png)
### 和訳
Zhang, Y., Zhang, Y., Gan, Y., Yao, L., and Wang, C. (2024a). 「検索拡張生成(RAG)ベースの大規模言語モデルを使った因果グラフの発見」やねん。arXiv プレプリント arXiv:2402.15301。
Zhang, Z., Chen, J., and Yang, D. (2024b). 「DARG:適応的推論グラフによる大規模言語モデルの動的評価」っちゅう論文や。arXiv プレプリント arXiv:2406.17271。
Zheng, L., Chiang, W.-L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E., ほか (2024). 「MT-benchとChatbotアリーナを使ってLLM審判官を審判する」っていう研究やな。Advances in Neural Information Processing Systems, 36に載っとるで。
Zhu, Y., Wang, X., Chen, J., Qiao, S., Ou, Y., Yao, Y., Deng, S., Chen, H., and Zhang, N. (2024). 「知識グラフの構築と推論のためのLLM:最近の能力と今後のチャンス」についてまとめた論文やねん。
17
---
## Page 18
[](/attach/730f1a9f38d16689900969a3eeeb1b31e45eda1dcc1f37a043afa90aff76c867_p018.png)
### 和訳
エンティティと関係性の抽出アプローチについて説明するわな
以下のプロンプトはGPT-4用に作られてて、デフォルトのGraphRAG初期化パイプラインで使われとるんや:
・デフォルトのグラフ抽出プロンプト
・クレーム抽出プロンプト
**A.1 エンティティ抽出**
これ何やってるかっていうと、複数パートからなるLLMプロンプトを使ってんねん。まず最初にテキストの中にあるエンティティ(要は「もの」とか「人」とか「概念」とかのことやな)を全部見つけ出すわけ。名前、タイプ、説明も含めてな。その次に、明らかに関連してるエンティティ同士の関係性を全部特定すんねん。どっちがソース(元)でどっちがターゲット(先)かっていうのと、その関係の説明も含めてな。で、両方の要素は区切り文字で分けられたタプル(組み合わせデータのことやで)のリストとして一気に出力されんねん。
**A.2 自己反省(セルフリフレクション)**
プロンプトエンジニアリングの技術をどう選ぶかで、ナレッジグラフの抽出品質がめっちゃ変わってくんねん(Zhuさんらの2024年の研究)。しかも技術によって、モデルが消費したり生成したりするトークンのコストも全然ちゃうんやで。
自己反省っていうのはな、プロンプトエンジニアリングの技術の一つで、LLMがまず答えを出して、その後で自分の出力が正しいか、わかりやすいか、漏れがないかを評価させて、最後にその評価に基づいてより良い回答を生成させるっちゅうやり方やねん(Huangさんら2023年、Madaanさんら2024年、Shinnさんら2024年、Wangさんら2022年の研究)。わいらはこの自己反省をナレッジグラフ抽出に活用してて、自己反省を外したらパフォーマンスとコストにどう影響するかも調べとるんや。
チャンクサイズ(一度に処理するテキストの塊のことな)を大きくすると、LLMへの呼び出し回数的にはコストが下がるんやけど、でもな、LLMは大きいチャンクからエンティティをあんまり抽出せえへん傾向があんねん。例えばな、サンプルデータセット(HotPotQA、Yangさんら2018年)で試したら、チャンクサイズが600トークンの時は2400トークンの時の約2倍のエンティティ参照を抽出できたんやで、GPT-4使ってな。
この問題に対処するために、自己反省のプロンプトエンジニアリングアプローチを導入してんねん。チャンクからエンティティを抽出した後、抽出したエンティティをLLMに戻して、「見落としたエンティティがないか拾い集めて(gleam)」って促すんや。これは複数段階のプロセスでな、まずLLMに「全部のエンティティ抽出できた?」って聞くんやけど、その時にlogit biasを100に設定して強制的にYes/Noの二択で答えさせんねん。もしLLMが「エンティティ見落としあったわ」って答えたら、「さっきの抽出でめっちゃたくさんエンティティ見落としとったで」っていう続きを入れて、LLMにその見落としエンティティを検出するよう促すんや。このアプローチのおかげで、品質を落とさず(図3参照)、余計なノイズも入れずに、大きなチャンクサイズが使えるようになるんやで。自己反省のステップは指定した最大回数まで繰り返すようになっとるんや。
[図3の説明]
HotPotQAデータセット(Yangさんら2018年)で検出されたエンティティ参照が、チャンクサイズと自己反省の繰り返し回数によってどう変わるかを示したグラフやな。汎用エンティティ抽出プロンプトとgpt-4-turboを使った結果やで。
グラフ見たらわかるけど、600トークンのチャンクサイズやと自己反省0回でも結構な数のエンティティ参照(約2万件)検出できとるんや。でも1200や2400トークンやと自己反省0回の時点ではめっちゃ少ないねん。そこから自己反省を1回、2回、3回と重ねていくと、どのチャンクサイズでもだんだん検出数が増えていって、最終的には3万件近くまで行くんやな。つまり、自己反省めっちゃ大事ってことやで!
**B コミュニティ検出の例**
---
## Page 19
[](/attach/730f1a9f38d16689900969a3eeeb1b31e45eda1dcc1f37a043afa90aff76c867_p019.png)
### 和訳
(a) レベル0のルートコミュニティ
(b) レベル1のサブコミュニティ
図4:MultiHop-RAGデータセット(Tang and Yang, 2024)をインデックス化したものに対して、Leidenアルゴリズム(Traag et al., 2019)を使って検出したグラフコミュニティやねん。丸印はエンティティノードを表してて、サイズは次数に比例してるんや。ノードの配置はOpenORD(Martin et al., 2011)とForce Atlas 2(Jacomy et al., 2014)でやったで。ノードの色はエンティティコミュニティを表してて、階層的クラスタリングの2つのレベルで示してるんや:(a) レベル0は、モジュラリティが最大になる階層的分割に対応してて、(b) レベル1は、このルートレベルのコミュニティの内部構造を明らかにしてるねん。
C コンテキストウィンドウの選択
コンテキストウィンドウのサイズが特定のタスクにどう影響するかって、実はよくわかってへんねん。特に128kトークンっていうめっちゃでかいコンテキストサイズを持つgpt-4-turboみたいなモデルやとなおさらや。長いコンテキストやと情報が「真ん中で迷子になる」可能性があるから(Kuratov et al., 2024; Liu et al., 2023)、ワイらはデータセット、質問、評価指標の組み合わせに対して、コンテキストウィンドウのサイズを変えたらどうなるか調べたかったんや。特にワイらの目標は、ベースライン条件(SS)に最適なコンテキストサイズを決めて、それをクエリ時のLLM使用全部に統一的に使うことやったんや。そのために、4つのコンテキストウィンドウサイズ:8k、16k、32k、64kをテストしたで。びっくりしたことに、テストした中で一番小さいコンテキストウィンドウサイズ(8k)が、包括性に関するすべての比較でダントツによかったんや(平均勝率58.1%)。一方で、多様性(平均勝率52.4%)とエンパワメント(平均勝率51.3%)については、もっと大きいコンテキストサイズと同程度のパフォーマンスやったで。ワイらはより包括的で多様な回答を好むから、最終評価には8kトークンの固定コンテキストウィンドウサイズを使うことにしたんや。
19
---
## Page 20
[](/attach/730f1a9f38d16689900969a3eeeb1b31e45eda1dcc1f37a043afa90aff76c867_p020.png)
### 和訳
ほな聞いてや!この表5はな、Newsっていう記事データセットを使って「どんな質問」「どんな回答が出たか」「AIがどう評価したか」を比べてるもんやねん。
**質問**:いろんな芸能記事に何回も出てくる有名人って誰がおる?
**Graph RAGの回答**
芸能界ってめっちゃ広いやん?映画、テレビ、音楽、スポーツ、ネットメディアとか色々あるやろ。その中で特に目立ってる人らがおるねん。ほんで、芸能記事で何回も名前が出てくる人らをまとめたったで。その人らがどんだけ影響力あるかがわかるわ。俳優と監督[...]、スキャンダルになった人ら[...]、ミュージシャンと業界のエライ人ら[...]、スポーツ選手とコーチ[...]、インフルエンサーと起業家[...]
この人らが何回も記事に出てくるってことは、今もバリバリ注目されてるってことやし、みんなこの人らの活動に興味津々ってことやねん。映画とかテレビで文化を作っていったり、音楽とかネットのトレンドを引っ張っていったり、その影響力はほんまに幅広いで。この人らは自分の専門分野だけちゃうて、世の中全体の文化にも影響与えてて、よく社会的な議論とか世間話の中心になってるねん。
**Na¨ıve RAGの回答**
いろんな芸能記事によう名前が出てくる有名人っていうたら、テイラー・スウィフト、トラビス・ケルシー、ブリトニー・スピアーズ、ジャスティン・ティンバーレイクらへんやな。この人らは仕事の実績からプライベートなことまで、色んな理由で注目されてるねん。
テイラー・スウィフト[...]、トラビス・ケルシー[...]、ブリトニー・スピアーズ[...]、ジャスティン・ティンバーレイク[...]
この人らがしょっちゅう取り上げられるのは、めっちゃ有名やからやし、みんなこの人らの仕事とかプライベートに興味あるからやねん。音楽にしろスポーツにしろ恋愛にしろ、この人らがやることは文化的にも経済的にもデカい影響があるねん。メディアの報道とか世間の反応見たらようわかるわ。
**AIの判定結果**
**網羅性**:勝者=1(Graph RAG)。なんでかっていうと、回答1のほうがめっちゃ詳しくて、芸能界のいろんな分野から幅広く有名人リストアップしてるねん。映画、テレビ、音楽、スポーツ、ゲーム、ネットメディアとかな。しかもその人らがどんな貢献したかとか、どんな影響与えたかとか、スキャンダルとその意味まで書いてある。回答2は数人について詳しく書いてるけど、人数少ないし、仕事の影響力より主にプライベートな話ばっかりになってるねん。
**多様性**:勝者=1(Graph RAG)。回答1のほうが色んな角度から書いてて内容が豊富やねん。芸能界のいろんな分野から幅広く有名人取り上げてて、映画、テレビ、音楽、スポーツ、ゲーム、ネットメディアまでカバーしてる。この人らの貢献とか影響力、スキャンダル、世間への影響まで書いてあるで。しかも名前挙げた人それぞれにちゃんとデータの出典も書いてあるから、根拠のバリエーションも豊富やねん。それに比べて回答2は、主に音楽とスポーツの少人数に絞ってて、データも一つの情報源に頼りがちやから、視点とか考察の幅が狭いねん。
**理解促進力**:勝者=1(Graph RAG)。回答1のほうがええのは、芸能界のいろんな分野の有名人について、きれいに整理された概要を出してるからやねん。映画、テレビ、音楽、スポーツ、ネットメディアとか全部含めて、何人も名前挙げて、具体的な貢献例とか、なんで芸能記事で取り上げられてるかの文脈も書いてある。しかも各情報にデータレポートの参照も付けてる。こういうアプローチやと、読む人がトピックの広がりを理解できて、誤解なく自分で判断できるようになるねん。それに対して回答2は、少人数に絞ってて主にプライベートな話と人間関係中心やから、トピックを幅広く理解するには物足りないわ。回答2も出典は書いてるけど、回答1ほど深くて多様な内容には及ばへんねん。
**直接性**:勝者=2(Na¨ıve RAG)。回答2のほうがええのは、芸能記事によう出てくる有名人を直球でリストアップしてるからやねん。テイラー・スウィフト、トラビス・ケルシー、ブリトニー・スピアーズ、ジャスティン・ティンバーレイクって具体的に名前出して、なんでよく取り上げられるか簡潔に説明してる。回答1は網羅的やけど、芸能界の色んな分野の色んな人について詳しい情報がいっぱい入ってて、情報としてはええけど、回答2ほど簡潔でピンポイントな回答にはなってへんねん。
---
## Page 21
[](/attach/730f1a9f38d16689900969a3eeeb1b31e45eda1dcc1f37a043afa90aff76c867_p021.png)
### 和訳
---ゴール---
テキストドキュメントがあるやん、これが今やってる作業に関係ありそうな内容で、さらにエンティティタイプのリストも渡されるねん。そしたら、そのテキストからそれらのタイプに当てはまるエンティティ(実体)を全部見つけ出して、さらにそれらのエンティティ同士の関係性も全部洗い出してほしいねん。
---ステップ---
1. まず全部のエンティティを特定してな。
- エンティティ名:そのエンティティの名前、大文字で書いてな
- エンティティタイプ:以下のタイプのどれかから選んでな
- エンティティの説明:そのエンティティの属性とか活動内容をめっちゃ詳しく書いてな
特定したエンティティごとに、以下の情報を抽出してな:
[{entity types}]
各エンティティはこんなフォーマットで書いてな:("entity"{tuple delimiter}<エンティティ名>{tuple delimiter}<エンティティタイプ>{tuple delimiter}<エンティティの説明>
2. ステップ1で見つけたエンティティの中から、*明らかに関係がある*ペア(ソースエンティティ、ターゲットエンティティ)を全部見つけてな
関係があるエンティティのペアごとに、以下の情報を抽出してな:
- ソースエンティティ:ステップ1で特定したソースエンティティの名前
- ターゲットエンティティ:ステップ1で特定したターゲットエンティティの名前
- 関係性の説明:なんでソースエンティティとターゲットエンティティが関係あると思ったか、その理由を説明してな
- 関係性の強さ:ソースエンティティとターゲットエンティティの関係がどんだけ強いか、数値スコアで示してな
各関係性はこんなフォーマットで書いてな:("relationship"{tuple delimiter}<ソースエンティティ>{tuple delimiter}<ターゲットエンティティ>{tuple delimiter}<関係性の説明>{tuple delimiter}<関係性の強さ>)
3. 出力は英語で返してな、ステップ1と2で特定した全部のエンティティと関係性を1つのリストにまとめるねん。
リストの区切りには**{record delimiter}**を使ってな。
4. 全部終わったら、{completion delimiter}を出力してな
---例---
エンティティタイプ:ORGANIZATION, PERSON
入力:
FRB(連邦準備制度理事会)は火曜と水曜に会合を予定してて、中央銀行は水曜の午後2時(東部時間)に最新の政策決定を発表する予定やねん。その後、FRB議長のジェローム・パウエルが質問に答える記者会見があるで。投資家たちは、連邦公開市場委員会がベンチマーク金利を5.25%〜5.5%の範囲で据え置くと予想してるねん。
出力:
("entity"{tuple delimiter}FED{tuple delimiter}ORGANIZATION{tuple delimiter}FEDっていうのは連邦準備制度のことで、火曜と水曜に金利を決めるねん)
{record delimiter}
("entity"{tuple delimiter}JEROME POWELL{tuple delimiter}PERSON{tuple delimiter}ジェローム・パウエルは連邦準備制度の議長やで)
{record delimiter}
("entity"{tuple delimiter}FEDERAL OPEN MARKET COMMITTEE{tuple delimiter}ORGANIZATION{tuple delimiter}連邦準備制度の委員会で、金利とかアメリカのマネーサプライ(通貨供給量)の成長に関する重要な決定を下すところやねん)
{record delimiter}
("relationship"{tuple delimiter}JEROME POWELL{tuple delimiter}FED{tuple delimiter}ジェローム・パウエルは連邦準備制度の議長で、記者会見で質問に答えるねん{tuple delimiter}9)
{completion delimiter}
...もっと例あるで...
---実際のデータ---
エンティティタイプ:{entity types}
入力:
{input text}
出力:
E.2 コミュニティ要約の生成
---役割---
あんたはAIアシスタントで、人間のアナリストが一般的な情報発見をするのを手伝う役目やねん。情報発見っていうのは、ネットワーク内の特定のエンティティ(組織とか個人とか)に関連する重要な情報を特定して評価するプロセスのことやで。
---
## Page 22
[](/attach/730f1a9f38d16689900969a3eeeb1b31e45eda1dcc1f37a043afa90aff76c867_p022.png)
### 和訳
「コミュニティのレポートを書いてや」っていう指示書やねん
---目的---
コミュニティに属するエンティティ(まぁ、「登場人物」とか「組織」みたいなもんやな)のリストと、それらの関係性、あと任意で関連するクレーム(主張とか申し立てのことやで)があったら、そのコミュニティについてめっちゃ詳しいレポートを書いてな、っていう話や。このレポートは意思決定者が「このコミュニティってどんなんやろ?どんな影響あるんやろ?」って判断するために使われるねん。レポートの中身としては、コミュニティの主要エンティティの概要、法令遵守の状況、技術的な能力、評判、それから注目すべきクレームなんかを含めるんやで。
---レポートの構成---
レポートには以下のセクションを入れてな:
- タイトル:コミュニティの主要エンティティを表す名前や。短くてもええけど具体的にしてな。できるんやったら、代表的な固有名詞をタイトルに入れるとええで。
- サマリー:コミュニティ全体の構造、エンティティ同士がどう関係してるか、エンティティに関連する重要な情報をまとめた要約やな。いわゆるエグゼクティブサマリーってやつや。
- インパクト重大度評価:0から10の間の小数点付きスコアで、コミュニティ内のエンティティがもたらすインパクトの重大さを表すねん。インパクトってのは、そのコミュニティがどれだけ重要かをスコア化したもんや。
- 評価の説明:なんでそのインパクト重大度評価にしたか、一文で説明してな。
- 詳細な発見事項:コミュニティについての重要な洞察を5〜10個リストアップするねん。各洞察は短い要約と、その後に続く複数段落の説明文で構成してな。説明文は下に書いてある「根拠ルール」に従って、ちゃんとデータの裏付けを示すんやで。網羅的に書いてな。
出力は以下の形式でちゃんと整ったJSONフォーマットの文字列で返してな:
{{
"title": <レポートのタイトル>,
"summary": <エグゼクティブサマリー>,
"rating": <インパクト重大度評価>,
"rating explanation": <評価の説明>,
"findings": [
{{
"summary":<洞察1の要約>,
"explanation": <洞察1の説明>
}},
{{
"summary":<洞察2の要約>,
"explanation": <洞察2の説明>
}}
]
}}
---根拠ルール---
データで裏付けられてるポイントは、こんな感じでデータ参照を列挙してな:
「これはデータで裏付けられた例文やで [Data: <データセット名> (レコードID); <データセット名> (レコードID)]。」
1つの参照で5個以上のレコードIDは書かんといてな。その代わり、最も関連性の高い上位5つのIDを書いて、「+more」って付けて「まだあるで」って示すんや。
例えば:
「人物Xは会社Yのオーナーで、めっちゃいろんな不正行為の申し立てを受けてるねん [Data: Reports (1), Entities (5, 7); Relationships (23); Claims (7, 2, 34, 64, 46, +more)]。」
ここで1, 5, 7, 23, 2, 34, 46, 64っていうのは、関連するデータレコードのID(インデックスちゃうで、IDやで)を表してるんや。
裏付けとなる証拠が提供されてへん情報は含めたらあかんで。
---例---
入力:
エンティティ
id,entity,description
5,VERDANT OASIS PLAZA,Verdant Oasis Plazaはユニティ・マーチの開催場所や
6,HARMONY ASSEMBLY,Harmony AssemblyはVerdant Oasis Plazaでマーチを開催してる組織やねん
関係性
id,source,target,description
37,VERDANT OASIS PLAZA,UNITY MARCH,Verdant Oasis Plazaはユニティ・マーチの開催場所や
38,VERDANT OASIS PLAZA,HARMONY ASSEMBLY,Harmony AssemblyはVerdant Oasis Plazaでマーチを開催してるで
39,VERDANT OASIS PLAZA,UNITY MARCH,ユニティ・マーチはVerdant Oasis Plazaで行われるねん
40,VERDANT OASIS PLAZA,TRIBUNE SPOTLIGHT,Tribune SpotlightはVerdant Oasis Plazaで行われるユニティ・マーチについて報道してるで
41,VERDANT OASIS PLAZA,BAILEY ASADI,Bailey AsadiはVerdant Oasis Plazaでマーチについてスピーチしてるねん
43,HARMONY ASSEMBLY,UNITY MARCH,Harmony Assemblyがユニティ・マーチを主催してるんや
出力:
22
---
---
## Page 23
[](/attach/730f1a9f38d16689900969a3eeeb1b31e45eda1dcc1f37a043afa90aff76c867_p023.png)
### 和訳
ほな、これ翻訳していくで!
---
Verdant Oasis Plaza(緑豊かなオアシス広場)っていうのが、このコミュニティの中心的な存在やねん。
{{
"title": "Verdant Oasis Plazaとユニティ・マーチ",
"summary": "このコミュニティはVerdant Oasis Plazaを中心に回ってて、ここでユニティ・マーチ(団結の行進)が開催されるんやで。この広場はHarmony Assembly(調和の会)、ユニティ・マーチ、Tribune Spotlight(トリビューン・スポットライト)っていうメディアと関係があって、全部この行進イベントに絡んでるわけや。",
"rating": 5.0,
"rating explanation": "影響の深刻度は中程度やな。なんでかっていうと、ユニティ・マーチの最中に不穏な空気とか対立が起きる可能性があるからやねん。",
"findings": [
{{
"summary": "Verdant Oasis Plazaが中心的な場所やで",
"explanation": "ユニティ・マーチの開催地としてVerdant Oasis Plazaがこのコミュニティの中心的存在になっとるんや。この広場が他の全部の関係者をつなぐ共通点になってて、めっちゃ重要な場所やっていうことがわかるやろ。この広場と行進の関係性は、行進の性質とか周りの反応によっては、公共の秩序を乱すとか対立を引き起こす可能性もあるんやで。[Data: Entities (5), Relationships (37, 38, 39, 40, 41,+more)]"
}},
{{
"summary": "Harmony Assemblyのコミュニティでの役割",
"explanation": "Harmony AssemblyはVerdant Oasis Plazaでの行進を企画してる団体やねん。彼らの目的とか、それに対する周りの反応によっては、潜在的な脅威になる可能性もあるんや。Harmony Assemblyと広場の関係を理解することが、このコミュニティの力学を把握する上でめっちゃ重要やで。[Data: Entities(6), Relationships (38, 43)]"
}},
{{
"summary": "ユニティ・マーチっていう重要イベント",
"explanation": "ユニティ・マーチはVerdant Oasis Plazaで開催される重要なイベントやねん。これがコミュニティの動きを左右する大きな要因で、行進の性質とか周りの反応によっては潜在的な脅威の源になる可能性もあるんや。行進と広場の関係を理解することが、このコミュニティの力学を把握するのにほんまに大事やで。[Data: Relationships (39)]"
}},
{{
"summary": "Tribune Spotlightの役割",
"explanation": "Tribune SpotlightっていうのはVerdant Oasis Plazaで行われるユニティ・マーチを報道してるメディアやねん。これってつまり、このイベントがメディアの注目を集めてるっていうことで、コミュニティへの影響がさらに大きくなる可能性があるわけや。Tribune Spotlightの役割は、このイベントとか関係者に対する世間の見方を形作る上でめっちゃ重要かもしれへんで。[Data: Relationships (40)]"
}}
]
}}
---実際のデータ---
回答には以下のテキストを使ってな。
回答で何も作り話したらあかんで。
入力:
{input text}
...レポートの構造とグラウンディングルールの繰り返し...
出力:
E.3 コミュニティ回答の生成
---役割---
あんたは複数のアナリストの視点を統合して、データセットに関する質問に答える便利なアシスタントやで。
---目標---
ユーザーの質問に対して、指定された長さと形式で回答を生成してな。データセットの異なる部分に焦点を当てた複数のアナリストからのレポートを全部まとめて、関連する一般的な知識も組み込むんやで。
ちなみに、下に示すアナリストのレポートは**役立つ順に降順**でランク付けされとるからな。
答えがわからへんかったら、正直にわからへんって言うてな。何も作り話したらあかんで。
最終的な回答では、アナリストのレポートから関係ない情報は全部取り除いて、きれいにした情報を統合して、回答の長さと形式に適した全ての重要ポイントと意味合いの説明を含む包括的な回答にまとめるんやで。
長さと形式に応じて、適切にセクションとコメントを回答に追加してな。回答はマークダウン形式でスタイリングするんやで。
回答では「shall」「may」「will」みたいな法助動詞の元の意味と使い方を保持せなあかんで。
回答では、アナリストのレポートに含まれていた全てのデータ参照も保持するんやで。
---
## Page 24
[](/attach/730f1a9f38d16689900969a3eeeb1b31e45eda1dcc1f37a043afa90aff76c867_p024.png)
### 和訳
けど、分析の途中で何人かのアナリストが関わってることは言わんといてな。
参考文献には5個以上のレコードIDを並べたらあかんねん。一番関係ありそうなやつを5個だけ挙げて、まだあるでって時は「+more」って付けといてな。
例えばこんな感じや:
「Xさんは会社Yのオーナーで、なんか色々と不正の疑惑がかけられとるねん [データ: レポート (2, 7, 34, 46, 64, +more)]。あと会社Xの社長もやっとるんやで [データ: レポート (1, 3)]」
ここで出てくる1、2、3、7、34、46、64っていう数字は、関連するデータレコードのID(インデックスとちゃうで)を表しとるねん。
裏付けとなる証拠が示されてへん情報は入れたらあかんで。
---目標とする回答の長さとフォーマット---
{response type}
---アナリストレポート---
{report data}
...目標と回答の長さ・フォーマットがまた繰り返されるで...
回答の長さとフォーマットに合わせて、適切にセクション分けしたりコメント入れたりしてな。マークダウン形式でスタイリングしてや。
出力:
E.4 グローバル回答生成
---役割---
あんたは、提供されたテーブルのデータに関する質問に答える親切なアシスタントやで。
---目標---
ユーザーの質問に答える形で、指定された長さとフォーマットの回答を作ってな。入力データテーブルの中の関連情報を、回答の長さとフォーマットに合わせてまとめて、あと関係ありそうな一般知識も盛り込んでや。
答えがわからへんかったら、正直にわからんって言うてな。でっち上げは絶対あかんで。
回答では「shall」「may」「will」みたいな法助動詞の元々の意味と使い方をちゃんと保ってな。
データに裏付けられとるポイントは、こんな感じで関連レポートを参照として挙げてや:
「これはデータ参照に裏付けられた例文やねん [データ: レポート (レポートID)]」
注意:SS(意味検索)とTS(テキスト要約)条件のプロンプトでは、上の「レポート」の代わりに「ソース」を使うで。
参考文献には5個以上のレコードIDを並べたらあかんねん。一番関係ありそうなやつを5個だけ挙げて、まだあるでって時は「+more」って付けといてな。
例えばこんな感じや:
「Xさんは会社Yのオーナーで、なんか色々と不正の疑惑がかけられとるねん [データ: レポート (2, 7, 64, 46, 34, +more)]。あと会社Xの社長もやっとるんやで [データ: レポート (1, 3)]」
ここで出てくる1、2、3、7、34、46、64っていう数字は、提供されたテーブルの中の関連データレポートのID(インデックスとちゃうで)を表しとるねん。
裏付けとなる証拠が示されてへん情報は入れたらあかんで。
回答の最初に、0から100までの整数スコアを生成してな。これはユーザーの質問に答える上で、この回答がどれだけ**役に立つか**を示すもんやねん。
スコアはこのフォーマットで返してな:<ANSWER HELPFULNESS> スコア値 </ANSWER HELPFULNESS>
---目標とする回答の長さとフォーマット---
{response type}
---データテーブル---
{context data}
...目標と回答の長さ・フォーマットがまた繰り返されるで...
出力:
24
---
## Page 25
[](/attach/730f1a9f38d16689900969a3eeeb1b31e45eda1dcc1f37a043afa90aff76c867_p025.png)
### 和訳
F 評価用プロンプト
F.1 相対評価プロンプト
---役割--
あんたは2人の別々の人が出した答えを採点する、めっちゃ頼りになるアシスタントやで。
---目標--
質問と2つの答え(答え1と答え2)があるから、どっちの答えがええかを以下の基準で判断してな:
{criteria}
あんたの評価には2つの部分を入れてな:
- 勝者:1(答え1の方がええ場合)か2(答え2の方がええ場合)、もしくは根本的に似てて違いがどうでもええレベルやったら0や。
- 理由:上に書いた基準に対して、なんでその勝者を選んだか短く説明してな。
回答はこんな感じのJSON形式でフォーマットしてや:
{{
"winner": <1, 2, もしくは 0>,
"reasoning": "答え1の方がええで、なんでかっていうと<あんたの理由>やからや。"
}}
---質問--
{question}
---答え1--
{answer1}
---答え2--
{answer2}
以下の基準でどっちの答えがええか評価してな:
{criteria}
出力:
F.2 相対評価の指標
CRITERIA = {
"comprehensiveness(網羅性)": "その答えが質問のあらゆる側面と詳細をカバーするのに、どんだけ詳しいかってことやな。網羅的な答えっちゅうのは、冗長やったり的外れにならんと、徹底的で完璧なもんやねん。例えば、質問が『原子力エネルギーのメリットとデメリットは何?』やったとするやろ。網羅的な答えは原子力のええとこも悪いとこも両方出すねん。効率とか環境への影響とか安全性とかコストとかな。網羅的な答えは重要なポイントを抜かしたり、関係ない情報を入れたらあかんねん。例えば、不完全な答えやったらデメリット抜きでメリットだけ言うやろ、冗長な答えやったら同じ情報を何回も繰り返すやろ。",
"diversity(多様性)": "その答えが質問に対していろんな視点や洞察をどんだけ多彩に豊かに提供してるかやな。多様な答えっちゅうのは、多面的で多次元的で、質問に対していろんな見方や角度を提供するもんやねん。例えば、質問が『気候変動の原因と影響は何?』やったら、多様な答えは気候変動のいろんな原因と影響を出すねん。温室効果ガスの排出とか森林伐採とか自然災害とか生物多様性の喪失とかな。多様な答えは、答えを裏付けるいろんな情報源や証拠も出さなあかんねん。例えば、情報源が1つだけの答えは1つの出典や証拠しか引用せんし、偏った答えは1つの視点や意見しか出さんやろ。",
"directness(直接性)": "その答えがどんだけ具体的にはっきりと質問に答えてるかやな。直接的な答えっちゅうのは、質問に対して明確で簡潔な答えを出すもんやねん。例えば、質問が『フランスの首都は何?』やったら、直接的な答えは『パリ』やな。直接的な答えは、質問に答えてない関係ない情報や不要な情報を入れたらあかんねん。例えば、間接的な答えやったら『フランスの首都はセーヌ川沿いにある』みたいになるやろ。",
"empowerment(理解促進力)": "その答えが、読者が誤解したり間違った思い込みをせんと、そのトピックを理解して適切な判断ができるようにどんだけ助けてくれるかやな。それぞれの答えを、答えの中の主張の背後にある説明や理由付けや出典をどんだけちゃんと示してるかっていう観点で評価してな。"
}
25
---
## Page 26
[](/attach/730f1a9f38d16689900969a3eeeb1b31e45eda1dcc1f37a043afa90aff76c867_p026.png)
### 和訳
# G 統計分析
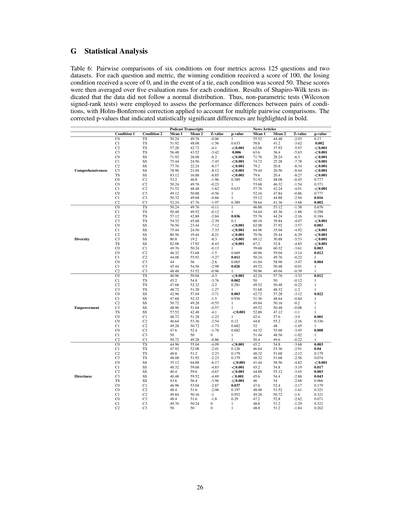
**表6:125個の質問と2つのデータセットについて、4つの評価指標で6条件をペアごとに比較した結果**
これ何やってるかっていうとな、各質問・各評価指標ごとに、勝った条件には100点、負けた条件には0点、引き分けやったら両方50点つけてるねん。ほんでこのスコアを各条件で5回評価した平均値を出してるわけや。
シャピロ・ウィルク検定っていう「データが正規分布してるかどうか調べるテスト」やったら、データが正規分布に従ってへんかったんよ。せやから、正規分布を仮定せんでもええノンパラメトリック検定(ウィルコクソンの符号順位検定っていうやつ)を使って、条件ペア間の性能差を評価してるねん。ほんで、何回も比較したらどうしても偶然ヒットする確率上がるやん?それを補正するためにホルム・ボンフェローニ補正っちゅうのをかけてるんや。**太字になってるp値が統計的に有意な差があった**ってことやで。
| | | **ポッドキャスト文字起こし** | | | **ニュース記事** | | |
|---|---|---|---|---|---|---|---|
| **条件1** | **条件2** | **平均1** | **平均2** | **Z値** | **p値** | **平均1** | **平均2** | **Z値** | **p値** |
### 網羅性(Comprehensiveness)
めっちゃざっくり言うと「どんだけ幅広くカバーできてるか」やな。
ポッドキャストのデータ見たら、C0〜C3とTSを比べると、TSの方がだいたい強いんやけど、C2とC3との差だけ統計的に有意(p<0.001とp=0.006)やねん。一方でSS(シングルソース)と比べたらC0〜TSまで全部めっちゃ有意差出とる(全部p<0.001)。つまり複数ソース使った方がええってことやな。
ニュース記事の方はもっとはっきりしてて、TS・SSどっちと比べてもほぼ全部有意差出とるで。
### 多様性(Diversity)
「どんだけいろんな視点入っとるか」やな。
ポッドキャストやと、SSとの比較は全部有意差出とる(p<0.001ばっかり)。でもTS(トピックサマリーっぽいやつ)との比較やC0〜C3同士の比較はあんまり有意差出てへん。C2-TSとC3-TSだけp=0.036とp=0.1で、C2-TSだけギリ有意やな。
ニュース記事の方がパターンはっきりしてて、SS比較は軒並み有意、あとC1-C2(p<0.001)とかC2-C3(p=0.002)とか条件間でも差出とる。
### エンパワーメント(Empowerment)
これは「ユーザーが自分で判断できるようになるか」みたいな指標やな。
ポッドキャストのデータ、これがおもろくてな、SSの方が勝ってるケースもあるねん。平均見たらC0-SSでC0が40.96でSSが59.04やったりして、SSの方が高いこともある。有意差出てるのはC0-TS(p<0.001)、C1-TS(p=0.002)あたりやな。
ニュース記事やと逆転してて、C0-SSでC0が42.72、SSが57.28でSS優位やけど、p=0.022で有意。条件同士の比較はほぼ有意差なしや。
### 直接性(Directness)
「ストレートに答えてるか」ってことやな。
ポッドキャストやと、TSとの比較でC0-TSがp<0.001で有意、SSとの比較も全部有意(p<0.001〜p=0.037)。でも条件同士(C0-C1とか)はほぼ有意差なしやな。
ニュース記事も似たような傾向で、SSとの比較でC0-SS(p<0.001)、C1-SS(p=0.017)、C2-SS(p=0.003)、C3-SS(p=0.043)と軒並み有意やけど、TS-SSは有意差なし(p=0.066)。条件同士の比較もC0-C3(p=0.008)以外はほぼ差なしや。
---
要するにな、この表が言いたいんは「どの条件の組み合わせで統計的に意味のある差があったか」ってことで、太字のp値のとこだけ「これはたまたまちゃうで、ほんまに差があるんや」って解釈してええってことやねん。
---
![]()
1 / 1
100%