<<
2212.05767v7.pdf

---
## Page 1
[](/attach/69b2fea2270e9023fdc9fc71de7508b0c86499993250984e243c1a8429a487fe_p001.png)
### 和訳
ナレッジグラフ推論のサーベイ:グラフの種類別に見てみよう
〜静的・動的・マルチモーダル〜
Ke Liang, Lingyuan Meng, Meng Liu, Yue Liu, Wenxuan Tu, Siwei Wang, Sihang Zhou, Xinwang Liu†(IEEE シニアメンバー), Fuchun Sun(IEEE フェロー)
**概要** — ナレッジグラフ推論(KGR)っちゅうのは、ナレッジグラフ(KG)の中にある既存の事実から、隠れた論理ルールを掘り出して新しい事実を導き出す技術のことやねん。これがめっちゃ勢いよく伸びてる研究分野でな。質問応答とかレコメンドシステムとか、いろんなAIアプリでKGを使うときにめちゃくちゃ役立つことが証明されとるんよ。グラフの種類で分けると、今あるKGRモデルはざっくり3つに分類できるわ。つまり、静的モデル、時系列モデル、マルチモーダルモデルの3つやな。初期の研究は主に静的KGRに集中しとったんやけど、最近の研究は時間的な情報とかマルチモーダルな情報も活用しようとしてて、こっちの方がより実用的で現実世界に近いわけや。せやけど、この重要な分野のモデルを網羅的にまとめて議論したサーベイ論文やオープンソースのリポジトリがなかってん。そのギャップを埋めるために、わいらは静的KGから時系列KG、さらにマルチモーダルKGまでを追跡する初めてのサーベイをやったんよ。具体的には、二段階の分類体系でモデルをレビューしとる。上位レベル(グラフの種類)と基礎レベル(技術とシナリオ)や。さらに、性能とデータセットもまとめて紹介しとるで。ほんで、課題と将来の可能性も指摘して、読者のヒントになるようにしたわ。対応するオープンソースのリポジトリはGitHubで公開しとるで:https://github.com/LIANGKE23/Awesome-Knowledge-Graph-Reasoning
**キーワード** — ナレッジグラフ推論、ナレッジグラフ、時系列ナレッジグラフ、マルチモーダルナレッジグラフ
---
## 1 はじめに
人間がスキルを身につけるソースは大きく2つあんねん。専門書と実務経験や。たとえば、ええ医者になるには学校で知識を学んで、病院で実践経験を積まなあかんよな。せやけど、今のAIモデルのほとんどは経験からの学習プロセスだけを真似しとって、前者(つまり知識からの学習)を無視しとるんよ [1], [2], [3], [4]。そのせいで説明可能性が低くなったり、性能も落ちたりするわけや。ナレッジグラフ(KG)[5] っちゅうのは、人間の知識事実を直感的なグラフ構造で保存したもんで [6]、ここ数年、この問題の解決策として注目されとるんよ。ただな、KGの構築っちゅうのは動的で継続的なプロセスやから、ほとんどのKGは不完全やねん。これが質問応答 [7] やレコメンドシステム [8] みたいなKG活用アプリケーションの足を引っ張っとるわけや。この問題を緩和するために、ナレッジグラフ推論(KGR)がここ数年めっちゃ注目を集めとるんよ。KGRの目的は、KGの中にある既存の事実から欠けてる事実を推論することや。図1(a)を対象KGとして例を挙げると、KGRモデルは「(A, 〜の父, B) かつ (A, 〜の夫, C) ならば (C, 〜の母, B)」っちゅう論理ルールを導き出して、そこから欠けてる事実「(サバンナ, 〜の母, ブロニー)」を推論することが期待されとるんやな。
KGに含まれる情報の種類によって、現在のKGはざっくり3つに分けられるんよ。静的KG、時系列KG、マルチモーダルKGの3つで、図1に示しとる通りや。従来のKGは静的でユニモーダル(単一の情報形式)の事実しか含んでへんかった。シンプルやけど、一般的な基本のKGRモデルを開発するには十分有効やったんよ。せやけど、現実世界はいろんなソースからの情報で構成されとるから、静的KGだけでは現実のシナリオを完全に表現できへんのや。そこで最近のKG(つまり時系列KGとマルチモーダルKG)は、静的KGをベースにして時間的な情報やマルチモーダルな情報を統合して構築されるようになってん。こっちの方がより実用的で現実世界に近いわけやな。ただし、どの種類のKGであっても不完全性の問題はつきまとうんよ。やから、より良い推論性能を目指して、さまざまな高度なKGRモデルが継続的に開発・研究されとるんや。もちろん注意しとかなあかんのは、KGの種類によってKGRモデルのコアとなる課題が違うっちゅうことや。具体的に言うと、静的KGRモデルは汎用的な表現学習の能力に焦点を当てとる。一方で、時系列やマルチモーダルのKGRモデルでは、追加情報をうまく融合することがカギになるんよ。さらに、より包括的で体系的なレビューのために、各グラフ種類の中でさらに2つのサブ分類、つまり推論技術と推論シナリオについても議論しとるで。
KGRに関するサーベイ論文はいくつかあるんやけど、そのほとんどは静的KGRだけに焦点を当てとって、他のKG(時系列KGやマルチモーダルKG)の最近の進展を見落としとるんよ。[9] は最初にKGRを
**図1**: ナレッジグラフの3カテゴリの例やで。静的ナレッジグラフ、時系列ナレッジグラフ、マルチモーダルナレッジグラフの3つや。
(図の説明)
- (a) 静的ナレッジグラフ:レブロン、サバンナ、デイビス、ブロニー、レイカーズ、L.A.の関係が「〜の父」「〜の夫」「〜の母」「〜に住んでる」「チームメイト」「〜の一部」「〜に位置する」とかで繋がっとる
- (b) 時系列ナレッジグラフ:ボルト、ホリー、ジャマイカスプリントチーム、ドルトムントチーム、キャシー・ベネットの関係が時間情報付きで表現されとる(「〜に所属」「〜の配偶者」「〜を受賞」とか、それぞれにタイムスタンプ付き)
- (c) マルチモーダルナレッジグラフ:西安、陝西省、中国(中華人民共和国)の関係が、テキスト情報だけやなくて画像情報も含めて表現されとる(「〜に位置する」「〜の省」「〜の画像」「〜のテキスト」「同じ場面」とか)
---
## Page 2
[](/attach/69b2fea2270e9023fdc9fc71de7508b0c86499993250984e243c1a8429a487fe_p002.png)
### 和訳
2
図2:このサーベイ論文の全体フレームワークやで。
表1:他のKGR(ナレッジグラフ推論)サーベイとの比較表やで。
サーベイ
静的KGR
[9]
✓
埋め込みベースのモデル ✓
✓
✓
パスベースのモデル
ルールベースのモデル
トランスダクティブシナリオ(既知のノードだけで推論するやつ)
インダクティブシナリオ(未知のノードにも対応するやつ)
時系列KGR
RNNベースのモデル
RNN使わんモデル
補間シナリオ(過去の時間範囲内を埋めるやつ)
外挿シナリオ(未来を予測するやつ)
マルチモーダルKGR
Transformer使わんモデル
Transformerモデル
[10]
✓
✓
✓
✓
[11]
✓
✓
✓
✓
[12]
✓
✓
✓
✓
[13]
✓
✓
✓
[14]
[15] ウチら
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
✓
まず[9]の研究やけど、KGRのタスクを「記号的推論」と「統計的推論」に分けてんねん。ほんで[10]は、KGRモデルを「記号的」「ニューラル」「ハイブリッド」の3タイプに分類してるわけや。そのあと[11]と[12]が、ロジックベースと埋め込みベースのKGRモデルをもっと細かく分類してんねんな。最近やと[13]が、まだ見たことないデータに対するKGRモデルの汎化能力、つまり「知らんもんにもちゃんと対応できるか」を分析してるで。時系列KGRについては、[14]が事実のタイムスタンプをどう使って時間の変化を捉えるかっていう観点で既存モデルをレビューしてるんやけど、時系列KGRの「補間」と「外挿」のシナリオをちゃんと区別できてへんねん。マルチモーダルKGのサーベイで一番影響力あるのは[15]やけど、これは推論よりもKGの構築とか応用に重点置いてるんよな。それに対してウチらのサーベイは、もっと包括的にナレッジグラフ推論をカバーしてんねん(表1見てな)。静的→時系列→マルチモーダルっていう流れで追っていくで。もっと具体的に言うと、2段階の分類体系を使ってレビューしてんねん。トップレベルが「グラフの種類」、ベースレベルが「技術とシナリオ」や。特に、レビュー対象のモデルの推論シナリオについてはめっちゃ丁寧に議論してるで。静的KGRやったら「トランスダクティブ」と「インダクティブ」のシナリオ、時系列KGRやったら「補間」と「外挿」のシナリオ、っちゅう感じやな。
まとめると、ウチらが初めて、異なるグラフタイプにまたがる既存のKGRモデルをガッツリ網羅的にサーベイしたっちゅうことやねん。従来のKG(静的KG)だけやなくて、追加情報付きのKG(時系列KGとマルチモーダルKG)も含めてな。具体的には、まず予備知識を紹介して(第2章)、次に最新のKGRモデルを第3章から第5章で2段階分類とパフォーマンスに基づいてシステマティックにレビューするで。そのあと第6章で代表的なKGRデータセットを整理・収集して、第7章で課題と今後のチャンスを指摘して、最後に第8章で論文をまとめるっちゅう構成や。このサーベイの価値をもっと高めるために、主な貢献をまとめとくで:
• **包括的なレビュー**。2段階の分類体系、つまりトップレベル(グラフの種類)とベースレベル(技術、シナリオ)に基づいて、代表的なKGRモデルをめっちゃ包括的に調べ上げたで。3種類のグラフタイプ(静的・時系列・マルチモーダルKG)、14の技術、4つの推論シナリオを含んでて、KGRの体系的なレビューを提供してるねん。
• **洞察に満ちた分析**。既存のKGRモデルの強みと弱み、それぞれどんな場面に向いてるかを分析してるで。
表2:記号の一覧やで
| 記号 | 説明 |
|---|---|
| SKG | 静的ナレッジグラフ |
| TKG | 時系列ナレッジグラフ |
| MKG | マルチモーダルナレッジグラフ |
| E | エンティティ(実体)の集合 |
| R | リレーション(関係)の集合 |
| F | ファクト(事実)の集合、つまりエッジのことやな |
| T | タイムスタンプの集合 |
| Ft | 時刻tにおけるファクトの集合 |
| (eh, r, et) | ファクトの三つ組(ヘッド、リレーション、テイル) |
| (eh, r, et, t) | ファクトの四つ組(ヘッド、リレーション、テイル、タイムスタンプ) |
| h, rq, eq(et q) | クエリされたファクトの三つ組(ヘッド、リレーション、テイル) |
| e | エンティティの埋め込みベクトル |
| r | リレーションの埋め込みベクトル |
| t | タイムスタンプの埋め込みベクトル |
これは読者がベースライン(比較対象のモデル)を選ぶときにめっちゃ役立つガイドになるはずやで。
• **今後のチャンス**。ナレッジグラフ推論の課題をまとめて、今後の可能性をいくつか指摘してるから、読者にとってええヒントになると思うで。
• **オープンソースのリソース**。180の最新KGRモデル(論文とコード)と67の代表的なデータセットのコレクションをGitHub¹で公開してるで。
## 2 予備知識
このセクションでは、まず静的・時系列・マルチモーダルのナレッジグラフを正式に定義するで。ほんで、それぞれのKGタイプとシナリオに対する推論タスクを定式化するわ。最後に、KGRモデルの分類基準を紹介するで。
### 2.1 定義と記号
ナレッジグラフ(KG)っちゅうのは、グラフ形式のナレッジベース(知識データベース)みたいなもんやと思ったらええで。せやから従来のナレッジベース[16]のほとんどの機能、例えば保存とかインデックス付けとかを引き継いでるんやけど、もっと直感的にわかりやすい形になってんねん。既存のKGはだいたい3種類に分けられるで。静的、時系列、マルチモーダルKGや。先行研究にならって、以下でそれぞれの定義を宣言するで。記号は表2にまとめてあるからな。
**定義1. 静的ナレッジグラフ。** 静的ナレッジグラフ(KG)は SKG = {E, R, F} って定義されるで。ここで E はエンティティ(実体)の集合、R はリレーション(関係)の集合、F はファクト(事実)の集合やな。ファクトは三つ組の形式 (eh, r, et) ∈ F で表されるねん。eh と et は E に含まれるエンティティで、r は R に含まれるそれらの間の関係や。ちなみに静的KGは[9]では「従来のKG」って呼ばれてるけど、「静的」っていう名前は他のKGタイプと区別するために付けてるだけやで。
**定義2. 時系列ナレッジグラフ。** 時系列ナレッジグラフ(KG)は、異なるタイムスタンプにおける静的KGの列として定義されるねん。TKG={SKG1, SKG2, SKG3, · · · , SKGt} っちゅう形やな。タイムスタンプ t におけるKGのスナップショットは SKGt={E, R, Ft} って定義されるで。
¹ https://github.com/LIANGKE23/Awesome-Knowledge-Graph-Reasoning
---
## Page 3
[](/attach/69b2fea2270e9023fdc9fc71de7508b0c86499993250984e243c1a8429a487fe_p003.png)
### 和訳
3
**図4:トランスダクティブ推論とインダクティブ推論のイメージ図やで。** トランスダクティブのパターンやと、テストで使うグラフに出てくるエンティティ(まあ「もの」とか「人」みたいなやつやな)は、全部トレーニングの時に見たことあるやつばっかりやねん。せやけどインダクティブのパターンやと、テストのグラフに「初めまして」のエンティティが出てくることがあんねん。
**図5:補間(内挿)と外挿の推論のイメージ図やで。** 補間のパターンでは、ナレッジグラフの推論に使うタイムスタンプtは過去に見たことある範囲内(0 ≤ t ≤ T)やねん。せやけど外挿のパターンやと、未来の事実(t ≥ T)について聞かれるわけや。
候補となるeq_hとかeq_tとかrqが、与えられたナレッジグラフの範囲超えてまうこともあんねん。この2つのシナリオは、だいたい静的なKGR(ナレッジグラフ推論)で議論されるパターンやな。
**補間と外挿の推論シナリオについて。** 聞かれてる事実のタイミングtqがいつかによって、時間軸付きKGRは2つのカテゴリに分けられんねん(図5見てな)。つまり補間と外挿のシナリオやな。具体的に言うと、タイムスタンプが時刻0から時刻Tまであるテンポラルなナレッジグラフがあったとして、補間推論は0 ≤ t ≤ Tの範囲、つまり「もう知ってる時間帯」の事実を推論すんねん。それに対して外挿推論は t ≥ T、つまり「まだ来てへん未来」の事実を推論すんねん。この2つのシナリオは、だいたいテンポラルKGRで議論されるやつやな。
### 2.3 分類体系のデザイン
ワイらは、いろんなナレッジグラフに対する既存のKGRモデルを体系的にレビューするために、2段階の分類体系を設計したで。具体的には、レビューしたKGRモデルを分類するのに3つの基準を使ってんねん。グラフの種類、テクニック、そしてシナリオの3つや。図6に示してるように、グラフの種類がトップレベルの分類で、ここには3種類のナレッジグラフが入ってんねん。静的、テンポラル(時間軸付き)、マルチモーダル(複数の情報形態を扱う)KGの3つやな。ほんで、ベースレベルの分類はテクニック(14種類)とシナリオ(4種類)で構成されてんねん。あるKGRモデルを分類するときは、まずトップレベルの分類で振り分けて、その後さらに具体的なテクニックとシナリオで細かく分類していく流れやで。
**図6:レビューしたKGRモデルの2段階分類体系やで。**
**図3:2種類のマルチモーダルナレッジグラフの比較やで。** N-MMKGはマルチモーダルデータ(画像とかテキストとか色んな種類のデータやな)をエンティティとして表現すんねん。一方でA-MMKGはマルチモーダルデータを新しい属性として表現すんねん。
E、Rはそれぞれエンティティと関係の集合で、Ftはタイムスタンプt ∈ Tにおける事実の集合やねん。四つ組の事実 (eh, r, et, t) は、タイムスタンプtの時点でヘッド(頭)ehとテイル(尻尾)etの間に関係rが存在してるっちゅうことを表してんねん。
**定義3. マルチモーダルナレッジグラフ。** マルチモーダルナレッジグラフ(KG)MKGは、2つ以上のモダリティ(情報の種類、例えばテキストとか画像とかやな)が存在する知識事実で構成されてんねん。他のモーダルデータの表現方法によって、マルチモーダルKGには2種類あんねん[17]。N-MMKGとA-MMKGや(図3見てな)。
### 2.2 タスクの定式化
ナレッジグラフ推論(KGR)っちゅうのは、既存の事実から導き出された根底にある論理ルールに基づいて、新しい事実を推論することを目指すもんやねん。グラフの種類によって、KGRは3つのタスクに分けられんねん。静的、テンポラル、マルチモーダルのKGRやな。この中で、テンポラルとマルチモーダルのKGにはそれぞれ時間情報と視覚情報っちゅう追加の情報が入ってくるから、静的KGRとはタスクの定式化にちょっとした違いがあんねん。それと、分類体系をもっとわかりやすくするために、推論シナリオに関する2組の用語も紹介するで。トランスダクティブ&インダクティブのシナリオと、補間&外挿のシナリオやな。
**静的ナレッジグラフ推論。** 静的KG SKG = {E, R, F}が与えられたとき、KGRはスコアリング関数で計算された尤もらしさに基づいて、既存の事実を使って問い合わせ事実 (eq_h, rq, eq_t) を推論することを目指すねん。欠けてる要素のタイプによって、3つのサブタスクがあんねん。ヘッド推論 (?, rq, eq_t)、テイル推論 (eq_h, rq, ?)、そして関係推論 (eq_h, ?, eq_t) の3つやな。
**テンポラルナレッジグラフ推論。** テンポラルKG TKG = {SKG1, SKG2, ···, SKGt}(ここでSKGt = {E, R, Ft}でタイムスタンプt ∈ T)が与えられたとき、KGRは四つ組の事実 (eq_h, rq, eq_t, tq) を推論することを目指すねん。静的KGRと同じように、特定のタイムスタンプtqにおいて3つのサブタスクが存在すんねん。
**マルチモーダルナレッジグラフ推論。** マルチモーダルKGRは他の2つのKGRタイプと似てて、つまり欠けてる事実を推論するっちゅうことやねん。それに加えて、マルチモーダル情報を活用してもっとええ推論性能を出すために、追加の融合モジュールがだいたい必要になんねん。
**トランスダクティブとインダクティブの推論シナリオ。** 問い合わせるエンティティと関係がトレーニング中に見えてるかどうかによって、2種類の推論シナリオがあんねん(図4見てな)。トランスダクティブとインダクティブのシナリオやな。トランスダクティブのシナリオでは、問い合わせ事実に出てくるエンティティと関係は全部、与えられたKGの中で見たことあるやつやねん。つまりeq_h, eq_t ∈ E で rq ∈ R っちゅうことや。インダクティブのシナリオやと、
---
## Page 4
[](/attach/69b2fea2270e9023fdc9fc71de7508b0c86499993250984e243c1a8429a487fe_p004.png)
### 和訳
前も言うたけどな、KGR(ナレッジグラフ推論)っていうのは、グラフの種類によって使う技術とかシナリオが全然ちゃうねん。具体的に言うとな、(1) 技術面では、静的KGRには埋め込みベース(5つのサブタイプあるで)、パスベース、ルールベースっていう代表的な手法があんねん(図7見てな)。ほんで、時間的KGR(時系列を扱うやつ)にはRNNベース(3つのサブタイプ)とRNN使わへんやつ(2つのサブタイプ)があって(図9参照)、マルチモーダルKGR(いろんな種類のデータ混ぜるやつ)にはTransformerベースとTransformer使わへんやつがあんねん(図10参照)。(2) 推論シナリオについては、静的KGRと時間的KGRだけで議論してんねんけど、静的KGRではトランスダクティブ(学習時に見たデータ内での推論)とインダクティブ(未知のデータにも対応する推論)、時間的KGRでは内挿(既知の時間範囲内の推論)と外挿(未来の予測みたいなやつ)っていうシナリオに分けてるで。
# 3 静的KGRモデル
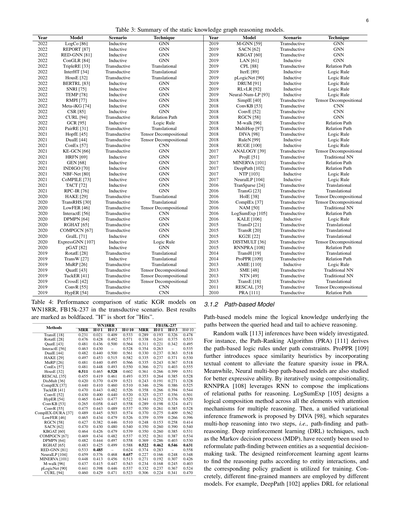
静的KGRモデル90個を、技術とシナリオに基づいて体系的に紹介するで(表3見てな)。
## 3.1 推論技術のレビュー
静的KGRモデルは大きく分けて、埋め込みベース、パスベース、ルールベースの3種類や。詳しく説明するわ。
### 3.1.1 埋め込みベースモデル
埋め込みベースモデルっていうのはな、既存の事実トリプレット(「AはBとCの関係がある」みたいな3つ組のデータ)から埋め込みベクトル(数値に変換したやつ)を学習して、スコアリング関数で計算した尤もらしさに基づいて、上位k個の候補事実をランキングするっていうもんや。基本的に3タイプあって、翻訳型、テンソル分解型、ニューラルネットワーク型やねん。数がめっちゃ多いから、埋め込みベースモデルの時系列は図8にまとめてあるで。
**翻訳型モデル。** 翻訳型モデルっていうのは、関係rをエンティティ(実体)eを潜在空間に射影するための「翻訳変換」として扱うもんやねん。TransE [18]が最初の翻訳型モデルで、関係を単純な平行移動として扱ってん。つまり「頭のエンティティの埋め込み+関係 ≈ 尾のエンティティの埋め込み」(eh+r ≈ et)っていうシンプルな式や。効果的やって証明されたんやけど、一対多、多対一、対称、推移的な関係みたいな特殊な関係をうまく扱えへんかってん。この限界を克服するために、いろんな翻訳型モデルが開発されたんや。TransH [19]はエンティティを関係ごとの超平面に射影することで、一対多・多対一の関係でええ推論性能を出したで。ほんで、TransR [20]はエンティティと関係に別々の潜在空間を使うことで、推移的な関係の推論がうまいこといくようになってん。さらに、TransD [21]は大規模なナレッジグラフ向けに、エンティティと関係それぞれに独立した射影ベクトルを使うことで、初めてスケーラビリティ(規模が大きくなっても大丈夫か)の問題に取り組んだんや。その後は、KGRの不確実性をモデル化するために確率的な原理が導入されてん。例えば、KG2E [22]はガウス分布の共分散を使って、TransG [23]はベイズ技術を一対多の関係事実に活用してるで。同時に、データの異質性と不均衡の問題を軽減するために、TranSparse [24]が適応的に疎な転送行列を設計することで効率的な解決策を提供して、表現力がアップしたんや。その後、TorusE [25]はコンパクトなリー群トーラス上に埋め込みを射影して、MuRP [26]はメビウス行列-ベクトル積とメビウス加算をエンティティ埋め込みの射影に設計して、どっちも精度とスケーラビリティが向上したで。同時に、TransW [27]は初めてエンティティと関係の埋め込みを単語埋め込みで豊かにして、未知のエンティティや関係を含む事実の推論性能が良くなったんや。さらに、RotatE [28]は複素数値の埋め込みを使った回転ベースの翻訳手法を提案して、対称、反対称、逆、合成の事実をよりうまく推論できるようになってん。あと、HAKE [29]は関係パターンやなくて意味的な階層構造を極座標空間でモデル化してるで。ほんで、TransRHS [30]は初めて関係階層構造(RHS)を考慮して、RHSを埋め込みにシームレスに組み込んだんや。さらに、複雑な関係事実を統一モデルで扱うために、PairRE [31]は各関係表現をペアベクトルでモデル化して複雑な関係に適応的に調整できるようにして、HousE [32]は回転と射影のためにハウスホルダー変換に基づく新しいパラメータ化を導入してるで。最近では、翻訳型モデルでもっと十分な相互作用を実現しようとする面白い試みもあって、TripleRE [33]とInterHT [34]がそうやねん。TripleREは関係ベクトルを3つの部分に創造的に分割して、残差の概念を活用することでええ性能を出してるし、InterHTは尾と頭の情報の相互作用を強化してモデルの能力を向上させてるで。
**テンソル分解型モデル。** テンソル分解型モデルっていうのは、ナレッジグラフを3次元テンソル(でっかい多次元配列みたいなもんや)としてエンコードして、それをエンティティと関係の低次元ベクトルの組み合わせに分解するもんやねん。
最初のテンソル分解型モデルであるRESCAL [35]は、各エンティティの潜在的な意味をベクトルで捉えて、さらに行列を使って潜在因子間のペアワイズ相互作用をモデル化してるんやけど、パラメータがO(d²)もあってモデルが複雑やったんや。それを簡単にするために、DistMult [36]は双線形の対角行列を使って関係ごとのパラメータをO(d)に削減したで。ほんで、ComplEx [37]は複素数値の埋め込みを使ってDistMultを一般化して、非対称関係のモデリングが改善されてん。同時に、HolE [38]はホログラフィック縮約表現と循環相関をモデル化して、Analogy [39]は類推構造制約付きの双線形スコアリング関数を設計して類推推論に使ってて、どっちもエンティティ間の豊かな相互作用を捉えようとしてるんや。その後、分解操作を置き換えるモデルが出てきてん。SimplE [40]は2つの独立したエンティティ埋め込みのための正準多項式(CP)分解を強化して、Tucker分解はTucker [41]が初めて使ったで。同時に、CrossE [42]は関係固有の相互作用行列を介してエンティティ間のクロスオーバー相互作用を考慮してるし、QuatE [43]は関係回転四元数表現に基づいて頭と尾の意味的マッチングを強化してるんや。これに触発されて、DualE [44]は双対四元数空間に埋め込みを射影して、翻訳と回転の両方の操作を統一的なフレームワークで実現してるで。あと、HopfE [45]は4次元超球面空間で構造的・意味的属性の両方を活用しつつ、解釈可能性も失わへんようにしてるんや。表現力だけやなくて、効率性もここ数年めっちゃ注目されてきてるで。Tucker分解に基づく因子化双線形プーリングモデルがLowFER [46]として提案されて、より効率的で軽量になってん。さらに、QuatRE [47]は2つの新しい操作で四元数埋め込みを学習してて、ハミルトン積でエンティティ埋め込み間の相関を強化しつつ、計算を簡略化して計算量を削減してるで。
---
## Page 5
[](/attach/69b2fea2270e9023fdc9fc71de7508b0c86499993250984e243c1a8429a487fe_p005.png)
### 和訳
図8:静的KGR(ナレッジグラフ推論)のための埋め込みベースモデルの年表やで。
翻訳行列についてな。
**ニューラルネットワークモデル**。ニューラルネットワーク(NN)モデルはここ数年、KG推論でめっちゃすごい性能を叩き出してんねん。NNの技術によって3つのサブタイプに分けられるで。つまり、従来型ニューラルネットワーク(NN)、畳み込みニューラルネットワーク(CNN)、ほんでグラフニューラルネットワーク(GNN)モデルの3つやな。
**1) 従来型NNモデル:** SME [48]が最初にニューラルネットワークを使ってエンティティ(実体)とリレーション(関係)を潜在空間にエンコード(変換)したんや。それと同時に、NTN [49]ではニューラルテンソルネットワークっちゅうのをKGの関係推論に使ってんねん。ほんで、NAM [50]がリレーション変調型ニューラルネットワーク(RMNN)ちゅうのを提案して、ProjE [51]では変数を共有するNNモデルで、標準的な損失関数を使ってエンティティとリレーションの埋め込みを同時に学習するようになったんや。こういう従来型NNモデルは静的KGRでかなりのポテンシャルを見せてんねんけど、浅くて表現力の乏しい特徴しか学習できひんっちゅう弱点があんねん。
**2) CNNモデル:** もっと深い特徴を学習するために、畳み込みニューラルネットワーク(CNN)がKGRモデルに組み込まれるようになったんや。ConvE [52]が最初に2D畳み込み層をKGRに使ったんやで。ConvKB [53]はConvEを発展させて、形状変換の操作を取っ払って、事実の中にあるグローバルな特徴と推移的な特徴を捉えて、より情報量の多い表現ができるようにしたんや。その後、HypER [54]は全結合層と関係ごとの畳み込みフィルターを使ってもっとええ性能を出してんねん。それに加えて、ConvR [55]はエンティティとリレーションの表現にまたがって畳み込みフィルターを構成することで、エンティティとリレーションのやり取りを最大限に引き出す適応型畳み込みネットワークを設計したんや。さらに、InteractE [56]では特徴の形状変換、特徴の並び替え、循環畳み込みっちゅう新しい操作を設計して、複雑なやり取りに対応できるようにしてんねん。一方、ConEx [57]はアフィン変換とエルミート内積を複素数値の埋め込みに対して畳み込み操作と統合してて、ええ表現力を見せてるんや。CNNモデルは全般的に従来型NNモデルよりええ性能を出すんやけど、なんでかっていうと、グラフ構造の裏にある情報をうまく学習でけへんちゅう問題があんねん。
**3) GNNモデル:** グラフニューラルネットワークはグラフ系のタスクで広く使われてて、KG推論にもめっちゃ速く応用されるようになってきてんねん。RGCN [58]は関係ごとの変換を使って近隣の情報を集約するんや。ほんで、各エンティティをベクトルにエンコードして、デコーダ、つまりスコアリング関数で、エンティティの表現を元に事実を復元すんねん。ただ、RGCNはエンティティ間のばらつきを無視してしまうから、表現力が制限されてまうんや。この問題を軽減するために、M-GNN [59]、KBGAT [60]、[61]みたいなたくさんのモデルにアテンション機構(注意機構)が組み込まれたんやで。特にKBGAT [60]はアテンションベースの特徴埋め込みを活用して、推論性能をアップさせてんねん。一方、SACN [62]は重み付きグラフ畳み込みネットワーク(WGCN)をエンコーダに、Conv-TransEっちゅう畳み込みネットワークをデコーダに使ってて、これがなかなか効果的やねん。その後、TransGCN [63]はリレーション用の変換演算子を使って、リレーションとエンティティの埋め込みを同時に学習するようにしたんや。さらに、DPMPN [64]とRGHAT [65]は2つのGNNを使うフレームワークを設計して、異なるレベルの情報を同時に別々にエンコードするようにしたんやで。つまり、DPMPNはグローバルとローカルの情報、RGHATはリレーションとエンティティの情報をそれぞれ扱うんや。その後、KE-GCN [66]はエンティティとエッジの両方の埋め込みを同時に伝播・更新するようにしたんや。同様に、COMPGCN [67]もいろんなエンティティ・リレーション合成操作を使って表現を同時に学習するんやで。最近は、ナレッジグラフの外の未知のシナリオに対応しようっちゅう研究者がどんどん増えてきてんねん。GEN [68]とHRFN [69]はメタ学習を使って、既知→未知と未知→未知の両方の事実に対するエンティティ埋め込みを学習するんや。ほんで、INDIGO [70]がペアワイズエンコーディングを使ったGNNベースで提案されたんや。それ以外にも、GraILベースのモデルっちゅうのは帰納的シナリオ向けの典型的なGNNモデル群やねん。プロトタイプのGraIL [71]は、画期的なGNNベースモデルとして初めてRGCNを活用して、ローカルな包囲部分グラフに基づいて推論を行ったんや。これをベースにして、TACT [72]、CoMPILE [73]、Meta-iKG [74]、SNRI [75]、RPC-IR [76]とか、ぎょうさんの発展的な研究が生まれたんやで。これらのGraILベースのモデルはみんな、帰納的推論でええ成績を収めてんねん。その中でも、TACT [72]とCoMPILE [73]はどっちもタスクにおけるリレーション埋め込みの重要性を強調してるんや。具体的に言うと、TACT [72]はリレーション間のトポロジー(構造的な繋がり)を考慮した相関関係を使ってトリプレット(三つ組)のスコアリング用の表現を生成してて、これがRMPI [77]やTEMP [78]にもインスピレーションを与えてんねん。それに加えて、CoMPILEは新しいメカニズムを使ってリレーションとエンティティ間のメッセージのやり取りを強化したんや。その後、コントラスティブ学習(対照学習)の大成功 [6], [79]に触発されて、コントラスティブ学習モデルがどんどん提案されるようになったんやで。例えばRPC-IR [76]やSNRI [75]とかな。それに、Meta-iKG [74]はKGRタスクにおけるメタ学習の有効性を実証してんねん。その後、研究者たちは推論をもっと効率的にしようとしてんねん。NBF-net [80]とRED-GNN [81]は、ベルマン・フォードアルゴリズムや動的計画法っちゅう伝統的なアルゴリズムを活用して、従来のGNNモデルの伝播戦略を最適化することで、より高い効率を達成してんねん。それに、pGAT [82]はEMアルゴリズムを使って効率的な学習を実現してるんや。さらに、BERTRL [83]とConGLR [84]は各エンティティのコンテキスト(文脈情報)を統合してKG上の推論を強化してんねん。特にBERTRL [83]は未知の関係的事実も扱えるんやで。それに関連して、CSR [85]はパス(経路)やなくて、構造パターンの裏にある論理ルールを深く掘り下げてんねん。
---
## Page 6
[](/attach/69b2fea2270e9023fdc9fc71de7508b0c86499993250984e243c1a8429a487fe_p006.png)
### 和訳
表3:静的知識グラフ推論モデルのまとめやで。
| 年 | モデル | シナリオ | 手法 |
|------|--------|----------|------|
| 2022 | LogCo [86] | 帰納的 | GNN |
| 2022 | REPORT [87] | 帰納的 | GNN |
| 2022 | RED-GNN [81] | 帰納的 | GNN |
| 2022 | ConGLR [84] | 帰納的 | GNN |
| 2022 | TripleRE [33] | 転導的 | 平行移動系 |
| 2022 | InterHT [34] | 転導的 | 平行移動系 |
| 2022 | HousE [32] | 転導的 | 平行移動系 |
| 2022 | BERTRL [83] | 帰納的 | GNN |
| 2022 | SNRI [75] | 帰納的 | GNN |
| 2022 | TEMP [78] | 帰納的 | GNN |
| 2022 | RMPI [77] | 帰納的 | GNN |
| 2022 | Meta-iKG [74] | 帰納的 | GNN |
| 2022 | CSR [85] | 帰納的 | GNN |
| 2022 | CURL [94] | 転導的 | 関係パス系 |
| 2022 | GCR [95] | 帰納的 | 論理ルール系 |
| 2021 | PairRE [31] | 転導的 | 平行移動系 |
| 2021 | HopfE [45] | 転導的 | テンソル分解系 |
| 2021 | DualE [44] | 転導的 | テンソル分解系 |
| 2021 | ConEx [57] | 転導的 | CNN |
| 2021 | KE-GCN [66] | 転導的 | GNN |
| 2021 | HRFN [69] | 帰納的 | GNN |
| 2021 | GEN [68] | 帰納的 | GNN |
| 2021 | INDIGO [70] | 帰納的 | GNN |
| 2021 | NBF-Net [80] | 帰納的 | GNN |
| 2021 | CoMPILE [73] | 帰納的 | GNN |
| 2021 | TACT [72] | 帰納的 | GNN |
| 2021 | RPC-IR [76] | 帰納的 | GNN |
| 2020 | HAKE [29] | 転導的 | 平行移動系 |
| 2020 | TransRHS [30] | 転導的 | 平行移動系 |
| 2020 | LowFER [46] | 転導的 | テンソル分解系 |
| 2020 | InteractE [56] | 転導的 | CNN |
| 2020 | DPMPN [64] | 転導的 | GNN |
| 2020 | RGHAT [65] | 転導的 | GNN |
| 2020 | COMPGCN [67] | 転導的 | GNN |
| 2020 | GraIL [71] | 帰納的 | GNN |
| 2020 | ExpressGNN [107] | 帰納的 | 論理ルール系 |
| 2020 | pGAT [82] | 帰納的 | GNN |
| 2019 | RotatE [28] | 転導的 | 平行移動系 |
| 2019 | TransW [27] | 帰納的 | 平行移動系 |
| 2019 | MuRP [26] | 転導的 | 平行移動系 |
| 2019 | QuatE [43] | 転導的 | テンソル分解系 |
| 2019 | TuckER [41] | 転導的 | テンソル分解系 |
| 2019 | CrossE [42] | 転導的 | テンソル分解系 |
| 2019 | ConvR [55] | 転導的 | CNN |
| 2019 | HypER [54] | 転導的 | CNN |
| 2019 | M-GNN [59] | 転導的 | GNN |
| 2019 | SACN [62] | 転導的 | GNN |
| 2019 | KBGAT [60] | 転導的 | GNN |
| 2019 | LAN [61] | 帰納的 | GNN |
| 2019 | CPL [88] | 転導的 | 関係パス系 |
| 2019 | IterE [89] | 帰納的 | 論理ルール系 |
| 2019 | pLogicNet [90] | 帰納的 | 論理ルール系 |
| 2019 | DRUM [91] | 帰納的 | 論理ルール系 |
| 2019 | RLvLR [92] | 帰納的 | 論理ルール系 |
| 2019 | Neural-Num-LP [93] | 帰納的 | 論理ルール系 |
| 2018 | SimplE [40] | 転導的 | テンソル分解系 |
| 2018 | ConvKB [53] | 転導的 | CNN |
| 2018 | ConvE [52] | 転導的 | CNN |
| 2018 | RGCN [58] | 転導的 | GNN |
| 2018 | M-walk [96] | 転導的 | 関係パス系 |
| 2018 | MultiHop [97] | 転導的 | 関係パス系 |
| 2018 | DIVA [98] | 転導的 | 論理ルール系 |
| 2018 | RuleN [99] | 帰納的 | 論理ルール系 |
| 2018 | RUGE [100] | 帰納的 | 論理ルール系 |
| 2017 | ANALOGY [39] | 転導的 | テンソル分解系 |
| 2017 | ProjE [51] | 転導的 | 従来型NN |
| 2017 | MINERVA [101] | 転導的 | 関係パス系 |
| 2017 | DeepPath [102] | 転導的 | 関係パス系 |
| 2017 | NTP [103] | 帰納的 | 論理ルール系 |
| 2017 | NeuralLP [104] | 帰納的 | 論理ルール系 |
| 2016 | TranSparse [24] | 転導的 | 平行移動系 |
| 2016 | TransG [23] | 転導的 | 平行移動系 |
| 2016 | HolE [38] | 転導的 | テンソル分解系 |
| 2016 | ComplEx [37] | 転導的 | テンソル分解系 |
| 2016 | NAM [50] | 転導的 | 従来型NN |
| 2016 | LogSumExp [105] | 転導的 | 関係パス系 |
| 2016 | KALE [106] | 帰納的 | 論理ルール系 |
| 2015 | TransD [21] | 転導的 | 平行移動系 |
| 2015 | TransR [20] | 転導的 | 平行移動系 |
| 2015 | KG2E [22] | 転導的 | 平行移動系 |
| 2015 | DISTMULT [36] | 転導的 | テンソル分解系 |
| 2015 | RNNPRA [108] | 転導的 | 関係パス系 |
| 2014 | TransH [19] | 転導的 | 平行移動系 |
| 2014 | ProPPR [109] | 転導的 | 関係パス系 |
| 2013 | AMIE [110] | 帰納的 | 論理ルール系 |
| 2013 | SME [48] | 転導的 | 従来型NN |
| 2013 | NTN [49] | 転導的 | 従来型NN |
| 2013 | TransE [18] | 転導的 | 平行移動系 |
| 2011 | RESCAL [35] | 転導的 | テンソル分解系 |
| 2010 | PRA [111] | 転導的 | 関係パス系 |
---
表4:静的KGRモデルの性能比較やで。WN18RRとFB15k-237での転導的シナリオの結果をまとめとるねん。一番ええ結果は太字にしとるで。「H」は「Hits」の略やな。
| モデル | WN18RR |||| FB15K-237 ||||
|--------|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| | MRR | H@1 | H@3 | H@10 | MRR | H@1 | H@3 | H@10 |
| TransE [18] | 0.226 | 0.021 | 0.409 | 0.533 | 0.293 | 0.193 | 0.326 | 0.478 |
| RotatE [28] | 0.476 | 0.428 | 0.492 | 0.571 | 0.338 | 0.241 | 0.375 | 0.533 |
| QuatE [43] | 0.481 | 0.436 | 0.500 | 0.564 | 0.311 | 0.221 | 0.342 | 0.476 |
| InteractE [56] | 0.463 | 0.430 | – | 0.528 | 0.354 | 0.263 | – | 0.495 |
| DualE [44] | 0.482 | 0.440 | 0.500 | 0.561 | 0.330 | 0.237 | 0.363 | 0.481 |
| HAKE [29] | 0.497 | 0.453 | 0.515 | 0.582 | 0.335 | 0.237 | 0.371 | 0.535 |
| MuRP [26] | 0.481 | 0.440 | 0.495 | 0.566 | 0.335 | 0.243 | 0.367 | 0.463 |
| ConEx [57] | 0.481 | 0.448 | 0.493 | 0.550 | 0.366 | 0.271 | 0.403 | 0.518 |
| HousE [32] | 0.511 | 0.465 | 0.528 | 0.602 | 0.361 | 0.266 | 0.399 | 0.482 |
| RESCAL [35] | 0.455 | 0.419 | 0.461 | 0.493 | 0.353 | 0.264 | 0.385 | 0.530 |
| DisMult [36] | 0.430 | 0.370 | 0.439 | 0.521 | 0.271 | 0.191 | 0.271 | 0.497 |
| ComplEX [37] | 0.460 | 0.410 | 0.460 | 0.510 | 0.346 | 0.256 | 0.386 | 0.518 |
| TuckER [41] | 0.470 | 0.443 | 0.482 | 0.526 | 0.358 | 0.266 | 0.394 | 0.481 |
| ConvE [52] | 0.460 | 0.400 | 0.440 | 0.520 | 0.325 | 0.237 | 0.356 | 0.530 |
| HypER [54] | 0.465 | 0.443 | 0.477 | 0.522 | 0.341 | 0.252 | 0.376 | 0.482 |
| ConvKB [53] | 0.265 | 0.058 | 0.445 | 0.558 | 0.289 | 0.198 | 0.324 | 0.421 |
| ConvR [55] | 0.475 | 0.443 | 0.489 | 0.537 | 0.350 | 0.261 | 0.385 | 0.528 |
| ComplEX-DURA [37] | 0.489 | 0.445 | 0.503 | 0.574 | 0.370 | 0.275 | 0.409 | 0.562 |
| LowFER [46] | 0.465 | 0.434 | 0.479 | 0.526 | 0.359 | 0.266 | 0.396 | 0.489 |
| RGCN [58] | 0.440 | 0.382 | 0.446 | 0.510 | 0.248 | 0.153 | 0.258 | 0.414 |
| SACN [62] | 0.470 | 0.430 | 0.480 | 0.540 | 0.350 | 0.260 | 0.390 | 0.540 |
| KBGAT [60] | 0.412 | 0.426 | 0.479 | 0.539 | 0.350 | 0.260 | 0.385 | 0.531 |
| COMPGCN [67] | 0.479 | 0.434 | 0.482 | 0.537 | 0.352 | 0.261 | 0.387 | 0.530 |
| DPMPN [64] | 0.482 | 0.444 | 0.497 | 0.558 | 0.369 | 0.286 | 0.403 | 0.534 |
| RGHAT [65] | 0.483 | 0.425 | 0.499 | 0.588 | 0.462 | 0.522 | 0.546 | 0.631 |
| RED-GNN [81] | 0.533 | 0.485 | – | 0.624 | 0.374 | 0.283 | – | 0.558 |
| NeuralLP [104] | 0.435 | 0.376 | 0.468 | 0.657 | 0.227 | 0.166 | 0.248 | 0.348 |
| MINERVA [101] | 0.448 | 0.413 | 0.456 | 0.513 | 0.271 | 0.192 | 0.307 | 0.459 |
| M-walk [96] | 0.437 | 0.415 | 0.447 | 0.543 | 0.234 | 0.168 | 0.245 | 0.426 |
| pLogicNet [90] | 0.441 | 0.398 | 0.446 | 0.537 | 0.332 | 0.237 | 0.367 | 0.524 |
| CURL [94] | 0.471 | 0.429 | 0.471 | 0.523 | 0.306 | 0.224 | 0.341 | 0.470 |
---
### 3.1.2 パスベースモデル
パスベースモデルっちゅうのは、質問されてる頭のエンティティと尻尾のエンティティの間にあるパス(経路)の中に隠れとる論理的な知識を掘り出して、推論に使うモデルやねん。
ランダムウォーク [113] を使った推論はめっちゃ研究されとるで。例えばな、PRA(パスランキングアルゴリズム)[111] は、パスの制約条件のもとでパスベースの論理ルールを導き出すやつやねん。ほんでProPPR [109] はさらに一歩進んで、テキストの中身を取り入れることで空間的な類似性のヒューリスティクス(経験則みたいなもんやな)を導入して、PRAで問題やった特徴量がスカスカになる問題を和らげとるんよ。
一方で、ニューラルネットワークを使ったマルチホップ(何段階もジャンプする)パスベースモデルも、もっと表現力を上げるために研究されとるで。RNNPRA [108] は構成性を繰り返し使うことで、RNNっちゅうリカレントニューラルネットワークを活用して、関係パスの意味合いを組み立てて推論するやつやねん。LogSumExp [105] は、アテンション機構(どこに注目するか自動で決める仕組みや)を使って、全要素にわたる論理的な合成方法を設計して、複数の推論をこなすモデルやで。
ほんで、DIVA [98] が提案した統一的な変分推論フレームワークっちゅうのがおもろくてな。マルチホップ推論を「パスを見つける」と「パスで推論する」の2ステップにきれいに分けとるねん。
最近はな、深層強化学習(DRL)の技術、特にマルコフ決定過程(MDP)っちゅうのが使われるようになってきとるで。なんでかっていうと、エンティティ間のパスを見つけるっちゅう作業を「順番に意思決定していくタスク」として捉え直せるからやねん。設計された強化学習エージェントが、エンティティ同士のやり取りを見ながら推論パスを見つけることを学習して、対応するポリシー勾配っちゅう手法で訓練するんよ。
具体的にはな、モデルによってちょっとずつ細かいやり方が違うねん。例えば、DeepPath [102] はDRLを関係推論に適用して──
---
## Page 7
[](/attach/69b2fea2270e9023fdc9fc71de7508b0c86499993250984e243c1a8429a487fe_p007.png)
### 和訳
表5:静的KGR(知識グラフ推論)モデルのHits@10の性能比較(パーセント)やで。WN18RR、FB15k-237、NELL-995っていうデータセットで、帰納的シナリオでの結果やねん。一番ええ結果は太字にしてあるで。
手法
Neural-LP [104]
DRUM [91]
RuleN [99]
GraIL [71]
TACT [72]
CoMPILE [73]
Meta-iKG [74]
RPC-IR [76]
SNRI [75]
RMPI [77]
REPORT [87]
ConGLR [112]
LogCo [86]
v1
74.37
74.37
80.85
82.45
83.24
83.60
–
85.11
87.23
82.45
88.03
85.64
90.16
WN18RR
FB15K-237
NELL-995
v2
68.93
68.93
78.23
78.68
81.63
79.82
–
81.63
83.10
78.68
85.83
92.93
84.69
v3
46.18
46.18
53.39
58.43
62.73
60.69
–
62.40
67.31
58.68
72.31
70.74
68.68
v4
67.13
67.13
71.59
73.41
76.27
75.49
–
76.35
83.32
73.41
81.46
92.90
79.08
v1
52.92
52.92
49.76
64.15
65.61
67.64
66.52
67.56
71.79
65.37
71.69
68.29
73.90
v2
58.94
58.73
77.82
81.80
83.05
82.98
72.37
82.53
86.50
81.80
88.91
85.98
81.91
v3
52.90
52.90
87.69
82.83
87.28
84.67
68.81
84.39
89.59
81.10
91.62
88.61
80.64
v4
55.88
55.88
85.60
89.29
91.33
87.44
74.32
89.22
89.39
87.25
92.28
89.31
84.20
v1
40.78
19.42
53.50
59.50
55.00
58.38
60.49
59.75
–
59.50
–
–
61.75
v2
78.73
78.55
81.75
93.25
88.97
93.87
74.07
93.28
–
92.23
–
–
93.48
v3
82.71
82.71
77.26
91.41
91.35
92.77
77.99
94.01
–
93.57
–
–
94.19
v4
80.58
80.58
61.35
73.19
74.69
75.19
71.63
71.82
–
87.62
–
–
80.82
7
**パスの学習**のとこやけどな、新しいタイプの報酬と関係アクション空間を使って、モデルの性能と効率の両方をアップさせてんねん。ほんで、MINERVA [101]はエンティティ間のパス探索を逐次最適化問題として捉えてて、期待報酬を最大化する[7]んやけど、ここがミソで、ターゲットの答えとなるエンティティを除外することで、もっと賢い推論ができるようにしてんねん。そのあとMultiHop [97]が出てきて、0か1かの二値報酬だけに頼るんやなくて、ソフト報酬っていう柔軟な仕組みと、ドロップアウトアクションを考案して、もっと効果的にパスを探索できるようにしたんやで。さらにな、モンテカルロ木探索(MCTS)をM-Walk [96]がパス生成に使ってて、CPL [88]はパス探索と事実抽出のための協調的な方策学習を提案してんねん。エンティティに対応するテキストコーパスをうまいこと活用するっちゅうわけや。ほんで、CURL [94]では2つのレベルのエージェント、つまりエンティティレベルのDWARF AGENTとクラスタレベルのGIANT AGENTっちゅう2人組が協力して、最適な推論パフォーマンスを叩き出すねん。
### 3.1.3 ルールベースモデル
ルールベースモデルっちゅうのはな、論理ルールの裏にある記号的な特徴をめっちゃうまいこと使おうとするモデルやねん。論理ルールは一般的にB → Aっていう形で定義されてて、Aが事実で、Bは事実の集合になれるんやで。知識グラフからルールマイニングツール、例えばAMIE [110]やRuleN [99]なんかを使って論理ルールを抽出して推論に使えんねん。ほんで、RLvLR [92]がルール探索と枝刈りの技術を使って、もっとスケーラブルなルールマイニングのアプローチを設計したんや。そのあと、論理ルールを埋め込みに注入して推論性能をもっと上げるにはどうしたらええかっちゅう研究がめっちゃ注目されるようになってん[7]。基本的に2つのやり方があって、同時学習と反復学習やな。例えば、KALE [106]は、互換性のある事実とルール埋め込みの間のt-ノルムファジィ論理結合子っちゅうもんを活用した統合的な同時学習モデルやねん。あとRUGE [100]はソフトルールを使って埋め込みを修正する反復モデルやで。これに触発されて、IterE [89]では埋め込み学習、公理帰納、公理注入の3ステップからなる反復学習戦略が設計されてん。そのあと、研究者たちは従来のルールベースモデルが抱えてた表現力の限界と膨大な空間消費の問題を緩和するために、ニューラルネットワークの技術をルールベースモデルに統合し始めたんや。Neural Theorem Provers (NTP) [103]は設計されたラジアルカーネルで論理ルールをマイニングするし、NeuralLP [104]はアテンション機構と補助メモリを使ってルールマイニングの勾配を最適化するんやで。ほんで、Neural-Num-LP [93]はNeuralLPに累積和演算と動的計画法をさらに統合して数値ルールを学習できるようにしたんや。同時に、DRUM [91]ではエンドツーエンドで微分可能なルールベースモデルが提案されてん。そしたら、pLogicNet [90]で確率論理ニューラルネットワークが設計されて、一階述語論理のマイニングでめっちゃええ性能を見せたんやで。ExpressGNN [107]はこれをさらに一般化して、GNNモデルをファインチューニングすることで、もっと効率的な推論ができるようにしてん。さらに、GCR [95]はクエリされた事実の周辺の近傍情報をマイニングすることで、推論と推薦の両方でええ結果を出してんねん。
### 3.2 推論シナリオに関するレビュー
観察に基づくとな、トランスダクティブ(転導的)モデルが56個、インダクティブ(帰納的)モデルが34個あんねん(表3参照)。帰納的モデルのうち56.25%がGNNモデルで、37.5%がルールベースモデルやねん。特筆すべきは、パスベースモデルで帰納的推論にめっちゃ強いやつは一個もないっちゅうことやな。一方で、ルールベースモデルのほとんどは帰納的シナリオが得意で、これは理にかなってんねん。なんでかっていうと、パスベースモデルは特定のパスを探索することをベースに開発されてるから、そうやって学習したモデルは未知の要素が出てきたときに適用しにくいねん。一方でルールベースモデルのほとんどは知識グラフからエンティティに依存せん論理ルールを導き出せるし、ルールがもたらす不変性は帰納的シナリオにも簡単に適用できるっちゅうわけや。さらに、代表的な最新の静的KGRモデルについて、転導的シナリオと帰納的シナリオを別々に公平な性能比較をしてるで(表4と表5参照)。結果は上の分析を裏付けてんねん。加えて、埋め込みベースモデル、特にGNNモデルは両方のシナリオに対してええ能力と互換性を示してて、最近の研究のほとんどもこのタイプに集中してんで。
### 3.3 考察と議論
上のレビューに基づいて、以下のことが観察できんねん。これは静的KGRモデルの適用範囲を示して、将来のトレンドを明らかにしてくれるもんやで。
**(1)** 埋め込みベースモデルは一般的に表現力がめっちゃ高いけど、説明可能性に欠けるんやな。ほんで今はGNNベースモデルの開発にめっちゃ注目が集まってんねん。なんでかっていうと、KGRモデルには関係事実とグラフ構造の高品質な表現が必要で、これが一番GNNモデルに向いてるからやねん。
**(2)** パスベースとルールベースのモデルは埋め込みベースモデルよりも説明しやすいんやけど、表現力の限界と時間・空間の膨大な計算量に悩まされがちやねん。
**(3)** パスベースモデルのほとんどはパス探索の仕組みのせいで転導的推論に向いてて、ルールベースモデルはルールパラダイムの汎化性のおかげで自然と帰納的な能力を持ってんねん。
**(4)** 長いこと転導的推論モデルが次々と登場して、学術研究にも産業応用にもめっちゃ大きなインパクトを与えてきてん。せやけど、スケーラビリティと表現力の問題があるせいで、最近の研究者は帰納的推論モデルの開発に注力するようになってきてんねん。
ざっくりまとめるとな、GNNベースモデルをもっと研究することをおすすめするで。静的KGRにおいて一番有望なモデルタイプやと考えられてるからな。
---
## Page 8
[](/attach/69b2fea2270e9023fdc9fc71de7508b0c86499993250984e243c1a8429a487fe_p008.png)
### 和訳
8
関係の埋め込みと時間の埋め込みを、活性化関数っていう仕組みを通して環境に取り込むねん。ExKGR [150]は時間的KGでの推論にLSTMを導入して、推論の道筋もちゃんと示してくれるモデルやで。
**GRUを使ったモデルたち。** GRUベースのモデルはここ数年めっちゃ注目されとるねん。最近やとTeMP [153]が提案されてて、これはメッセージパッシング型のグラフニューラルネットワーク(MPNN)を使って、各タイムスタンプでの構造ベースのエンティティ表現を学習して、全タイムスタンプの表現をエンコーダで統合するっちゅう仕組みや。RE-GCN [125]は時間的KGの中の進化的なダイナミクス――つまり時間と共にグラフがどう変わっていくかに注目してて、直近の数タイムスタンプ分の固定長KG系列をモデル化してエンティティの埋め込みを生成するねん。TPmod [156]はエンティティと関係の属性を集約して、いろんなイベントに対する動的な重みを学習するモデルや。HIPネットワーク [129]は、時間的・構造的・反復的っていう3つの視点から情報を伝達するねん。それぞれ、グラフの動的進化を掘り下げる、同じ時間ステップでのイベント間の相互作用を捉える、既知のイベントを活用する、っていう役割があるわけや。TRHyTE [152]はまずGRUでエンティティを潜在空間に変換して、その後で事実を時間-関係ハイパー平面にエンコードして、時間と関係を意識した表現を生成するねん。TiRGN [147]は2つのエンコーダを使って、ローカルレベルとグローバルレベルの両方の情報を掘り出すモデルや。HiSMatch [122]は、過去のクエリ構造と候補エンティティの意味情報をそれぞれ別のエンコーダで掘り下げる方法を提案しとるで。
**4.1.2 RNNを使わないモデル**
RNN非依存モデルっていうのは、もともとの静的KGR(知識グラフ推論)モデルを拡張して、RNNのフレームワークを使わずに時間情報を取り込むタイプのモデルやねん。時間情報がモデルをどうガイドするかによって、大きく2種類に分けられるで。「時間ベクトルガイド型」と「時間操作ガイド型」や。
**時間ベクトルガイド型モデル。** このタイプは、追加の時間的埋め込み **t** をそのまま生成して、それを事実の埋め込みとくっつけるっちゅうシンプルなアプローチやねん。
TComplExとTNTComplEx [139]はどっちもComplExから派生したモデルで、時間情報を追加で考慮した4階テンソル空間をモデル化するねん。xERTE [115]では、サブグラフを構築する過程で時間埋め込みを使って重み付き確率を計算するで。ほんで、T-GAP [167]は時間的KGのクエリ固有の構造パターンをエンコードして、それに基づいてパスベースの推論をやるモデルや。CyGNet [117]は、各クエリの主語エンティティに関連する過去の事実をエンコードして、時間インデックスベクトルを生成することでエンティティ予測タスクを解こうとするねん。ChronoR [123]はRotatEをベースにしてて、関係と時間の埋め込みをつなげて全体の回転埋め込みを作り、最終的なエンティティ埋め込みに適用するっちゅう仕組みや。さらに、DBKGE [164]はノードの表現ベクトルを時間的に滑らかにするオンライン推論アルゴリズムを提案しとる。BoxTE [138]は静的KGR手法のBoxEをベースに、時間的KGRのための新しいボックス表現手法を導入したモデルやで。TuckERTNT [141]は、時間埋め込みを追加した4階テンソルのタッカー分解にヒントを得た、時間的KG向けの新しいテンソル分解モデルを提案しとる。TempoQR [140]は質問固有の時間ベクトルを生成して、そのベクトルを使って特定のエンティティとそのタイムスタンプを集約するねん。TLT-KGE [134]は意味情報と時間情報を複素空間の異なる軸として捉えるモデルや。RotateQVS [148]は潜在空間での回転操作で時間情報の変化を考慮しようとするアプローチやで。
**時間操作ガイド型モデル。** このタイプは、事実を特定の操作でエンコードするとか、
図9:時間的KGRモデルの分類体系。
**4 時間的KGRモデル**
ここでは58個の時間的KGRモデルを、技術面――つまり時間情報をどう統合するか――とシナリオに基づいて体系的に紹介するで(表6参照)。
**4.1 推論技術のレビュー**
時間的KGRモデルは、RNNベースのモデルとRNN非依存モデルに分類できるねん。詳しくは以下の通りや。
**4.1.1 RNNベースのモデル**
リカレントニューラルネットワーク(RNN)っていうのは、時間とともに変化するパターンを捉えるのにめっちゃ向いてるネットワークやねん。せやから、時間的KGRモデルの多くがRNNを直接使って時間情報をモデル化してて、これらをRNNベースモデルって呼ぶわけや。RNNにもいろんなバリエーションがあって、モデルは大きく3タイプに分けられるで。基本的なRNN強化モデル、LSTM強化モデル、GRU強化モデルの3つや。
**基本的なRNN強化モデル。** 時間的KGRモデルの中には、基本的なRNNモデルで効果的に時間情報をモデル化できるものがあるねん。例を挙げると、Know-Evolve [168]は古典的な時間的KGRモデルで、時間の経過とともに非線形にエンティティの埋め込みを生成するやつや。RE-NET [155]はGCNとRNNモデルを組み合わせて、時間的KGにおける進化的ダイナミクスを捉えて、時間に沿ったクエリに対応するねん。EvoKG [154]はRNNモデルを導入して動的に変化する構造情報を掘り出し、近傍情報を組み合わせることでエンティティ間の相互作用をモデル化するで。
**LSTM強化モデル。** ロング・ショート・ターム・メモリ(LSTM)ネットワークも、時間的KGRモデルで時間的特徴を掘り出すのにめっちゃよう使われとるねん。例えば、TTransE [159]はTransEを拡張したもので、時間的制約を追加して、RNNで関係と同じように時間情報を「移動(トランスレーション)」としてエンコードすることで、埋め込み空間の中でヘッダーの表現を動かすねん。TA-TransEとTA-DistMult [165]もそれぞれTransEとDistMultを拡張したバージョンで、時間的埋め込みを組み込んどるで。さらに、EvolveGCN [151]はグラフ畳み込みネットワーク(GCN)で各静的スナップショットのグラフ構造をモデル化して、LSTMモデル(GRUモデルも使える)でGCNのパラメータを時間とともに進化させるっちゅう手法や。CluSTeR [160]は強化学習を使って、LSTMとGRUの両方のモデルで時間的KGにおける進化パターンを発見するアプローチやねん。DacKGR [137]は、時間情報を使って動的予測を行いながら、スパースな(データがまばらな)時間的KG上でマルチホップのパスベース推論をやるモデルや。時間幅の情報を捉えてモデルの学習をガイドするために、TimeTraveler [158]はディリクレ分布に基づく新しい相対時間エンコーディングモジュールと時間整形報酬モジュールを提案しとるで。TPath [131]もLSTMモデルを導入して現在の環境情報を掘り出して、ほんでそこから
時間的KGR → 補間モデル / 外挿モデル → 技術面 / シナリオ / グラフタイプ → 時間ベクトルガイド型モデル / RNNベースモデル(LSTM強化モデル / GRU強化モデル / 基本RNN強化モデル) / 時間操作ガイド型モデル / RNN非依存モデル
---
## Page 9
[](/attach/69b2fea2270e9023fdc9fc71de7508b0c86499993250984e243c1a8429a487fe_p009.png)
### 和訳
表6:時間的ナレッジグラフ推論モデルのまとめやで。
| 年 | モデル | シナリオ | テクニック | | 年 | モデル | シナリオ | テクニック |
|---|---|---|---|---|---|---|---|---|
| 2023 | RETIA [114] | 外挿 | GRU | | 2021 | xERTE [115] | 外挿 | Time-Vector |
| 2023 | RPC [116] | 外挿 | GRU | | 2021 | CyGNet [117] | 外挿 | Time-Vector |
| 2022 | CENET [118] | 外挿 | Time-Operation | | 2021 | TIE [119] | 内挿 | Time-Operation |
| 2022 | DA-Net [120] | 外挿 | Time-Operation | | 2021 | TeLM [121] | 内挿 | Time-Operation |
| 2022 | HiSMatch [122] | 外挿 | GRU | | 2021 | ChronoR [123] | 内挿 | Time-Vector |
| 2022 | rGalT [124] | 外挿 | Time-Operation | | 2021 | RE-GCN [125] | 外挿 | GRU |
| 2022 | MetaTKGR [126] | 外挿 | Time-Operation | | 2021 | RTFE [127] | 内挿 | Time-Operation |
| 2022 | FILT [128] | 内挿 | Time-Operation | | 2021 | HIP [129] | 外挿 | GRU |
| 2022 | TKGC-AGP [130] | 内挿 | Time-Operation | | 2021 | Tpath [131] | 内挿 | LSTM |
| 2022 | Tlogic [132] | 外挿 | Time-Operation | | 2020 | TIMEPLEX [133] | 内挿 | Time-Operation |
| 2022 | TLT-KGE [134] | 内挿 | Time-Vector | | 2020 | DyERNIE [135] | 内挿 | Time-Operation |
| 2022 | CEN [136] | 外挿 | Time-Operation | | 2020 | DacKGR [137] | 内挿 | RNN |
| 2022 | BoxTE [138] | 内挿 | Time-Vector | | 2020 | TNTComplEx [139] | 内挿 | Time-Vector |
| 2022 | TempoQR [140] | 内挿 | Time-Vector | | 2020 | TComplEx [139] | 内挿 | Time-Vector |
| 2022 | TuckERTNT [141] | 内挿 | Time-Vector | | 2020 | TDGNN [142] | 外挿 | Time-Operation |
| 2022 | GHT [143] | 外挿 | Time-Operation | | 2020 | ATiSE [144] | 内挿 | Time-Operation |
| 2022 | DKGE [145] | 内挿 | Time-Operation | | 2020 | Diachronic [146] | 内挿 | Time-Operation |
| 2022 | TiRGN [147] | 外挿 | GRU | | 2020 | DE-Simple [146] | 内挿 | Time-Operation |
| 2022 | RotateQVS [148] | 内挿 | Time-Vector | | 2020 | TeRo [149] | 内挿 | Time-Operation |
| 2022 | ExKGR [150] | 内挿 | LSTM | | 2020 | EvolveGCN [151] | 外挿 | LSTM+GRU |
| 2022 | TRHyTE [152] | 内挿 | GRU | | 2020 | TeMP [153] | 内挿 | GRU |
| 2022 | EvoKG [154] | 外挿 | RNN | | 2020 | RE-NET [155] | 外挿 | RNN |
| 2021 | TPmod [156] | 内挿 | GRU | | 2019 | DyRep [157] | 外挿 | Time-Operation |
| 2021 | TimeTraveler [158] | 外挿 | LSTM | | 2018 | TTransE [159] | 内挿 | LSTM |
| 2021 | CluSTeR [160] | 外挿 | LSTM+GRU | | 2018 | HyTE [161] | 内挿 | Time-Operation |
| 2021 | TPRec [162] | 外挿 | Time-Operation | | 2018 | ChronoTranslate [163] | 内挿 | Time-Operation |
| 2021 | DBKGE [164] | 内挿 | Time-Vector | | 2018 | TA-DISTMULT [165] | 内挿 | LSTM |
| 2021 | TANGO [166] | 外挿 | Time-Operation | | 2018 | TA-TransE [165] | 内挿 | LSTM |
| 2021 | T-GAP [167] | 内挿 | Time-Vector | | 2017 | Know-Evolve [168] | 外挿 | RNN |
---
表7:時間的ナレッジグラフ推論モデルのICEWS14とICEWS05-15での内挿シナリオのパフォーマンス比較(パーセント表記)やで。一番ええ結果は**太字**にしてるで。「H」は「Hits」の略やねん。
| モデル | ICEWS14 | | | | ICEWS05-15 | | | |
|---|---|---|---|---|---|---|---|---|
| | MRR | H@1 | H@3 | H@10 | MRR | H@1 | H@3 | H@10 |
| TA-TransE [165] | 27.50 | 9.50 | – | 62.50 | 29.90 | 9.60 | – | 66.80 |
| TA-DISTMULT [165] | 47.70 | 36.30 | – | 68.60 | 47.40 | 34.60 | – | 72.80 |
| HyTE [161] | 29.70 | 10.80 | 41.60 | 65.50 | 31.60 | 11.60 | 44.50 | 68.10 |
| TTransE [159] | 25.50 | 7.40 | 39.86 | 60.10 | 27.10 | 8.40 | 43.70 | 61.60 |
| RE-NET [155] | 60.10 | 47.80 | 68.10 | 82.80 | 69.10 | 56.60 | 78.20 | 91.70 |
| TeMP [78] | 56.20 | 46.80 | 62.10 | 73.20 | 58.60 | 46.90 | 66.80 | 79.50 |
| TeRo [149] | 52.60 | 41.80 | 59.20 | 72.50 | 51.30 | 39.20 | 57.80 | 74.80 |
| DE-SimplE [146] | 52.60 | 41.80 | 59.20 | 72.50 | 51.30 | 39.20 | 57.80 | 74.80 |
| Diachronic [146] | 55.00 | 43.60 | 62.90 | 75.00 | 51.90 | 37.80 | 60.60 | 79.40 |
| ATiSE [144] | 61.90 | 54.20 | 66.10 | 76.70 | 66.40 | 58.30 | 71.60 | 81.10 |
| TComplEx [139] | 62.00 | 52.00 | 66.00 | 76.00 | 67.00 | 59.00 | 71.00 | 81.00 |
| TNTComplEx [139] | 66.90 | 59.90 | 71.40 | 79.70 | 73.90 | 67.90 | 77.30 | 85.50 |
| DyERNIE [135] | 61.00 | 50.90 | 67.70 | 79.00 | 67.00 | 56.80 | 74.30 | 84.50 |
| T-GAP [167] | 60.40 | 51.50 | – | 77.10 | 64.00 | 54.50 | – | 81.80 |
| TIMEPLEX [133] | 59.20 | 50.30 | 64.60 | 75.80 | 64.50 | 55.30 | 70.60 | 81.10 |
| RTFE [127] | 62.53 | 54.67 | 66.88 | 77.31 | 68.41 | 61.06 | 73.01 | 82.13 |
| ChronoR [123] | 62.50 | 54.50 | 67.30 | 77.40 | 67.80 | 59.90 | 72.80 | 82.30 |
| TeLM [121] | 59.10 | 50.70 | 64.20 | 75.40 | 63.30 | 52.90 | 70.90 | 81.30 |
| RotateQVS [148] | – | – | – | – | – | – | – | – |
| TuckERTNT [141] | 63.40 | 55.10 | 68.40 | 78.60 | 67.50 | 59.30 | 72.50 | 81.90 |
| TLT-KGE [134] | 61.30 | 52.80 | 66.40 | 76.30 | 60.90 | 60.90 | 74.10 | 83.50 |
| BoxTE [138] | 56.10 | 45.80 | 63.10 | 73.80 | 66.70 | 58.20 | 71.90 | 82.00 |
| TKGC-AGP [130] | 53.20 | 39.80 | 62.10 | 62.72 | – | – | – | 79.70 |
---
ほな本文の解説いくで〜。
時間の情報をどう使うかっちゅう話やねんけど、時間ごとの特別なハイパー平面(超平面)を設計したり、時間に関連した報酬を生成したりして、時間の埋め込みベクトル**t**をそのまんま直接くっつけるんやなくて、もっと賢い方法で時間情報を活用してるんやな。
**ChronoTranslate** [163]はな、エンティティ(実体)の汎用的な表現と、時間ごとに変わる時間的ナレッジグラフの表現を別々に学習するモデルやねん。
**HyTE** [161]は各タイムスタンプを埋め込み空間の中で学習可能なハイパー平面として表現して、エンティティと関係の埋め込みをそのハイパー平面に射影してから、TransEっていうスコア関数で評価するっちゅうやつや。要するに、「この時間にはこの平面で考えましょう」っていう発想やな。
**DyRep** [157]はグラフ学習とナレッジグラフ推論のモデルとして、過去の履歴の中で入り組んだダイナミクス(動的な変化)を捉えるんやけど、それを時間に注目した注意機構付きの表現ネットワークでパラメータ化してるんや。めっちゃ賢いやろ。
**TeRo** [149]はRotatEっちゅうモデルにインスパイアされて、頭のエンティティと尻尾のエンティティの間に時間でガイドされた回転操作を導入して、与えられた事実の意味的なスコアを評価するんやで。回転で時間を表現するってのがミソやな。
**Diachronic embeddings**(通時的埋め込み)[146]は、エンティティと関係の埋め込みを時間情報とペアにして、ナレッジグラフ推論のモデル空間にマッピングするフレームワークやねん。これによってDE-TransEとかDE-SimplEみたいな具体的なモデルが生まれてくるわけや。
**ATiSE** [144]は、時間情報の不確実性があるやん?グラフが時間とともにどう変化するかって予測しにくいやろ。そこでエンティティと関係の埋め込みをタイムスタンプに応じてガウス空間(正規分布の空間)にマッピングするっちゅうアプローチやねん。不確実性を確率的に扱えるから賢いんよな。
**TDGNN** [142]は新しい時間的集約器(テンポラル・アグリゲータ)を導入して、近傍の特徴量とエッジからの時間情報を組み合わせて最終的な表現を計算するモデルや。
時間的ナレッジグラフの動的なグラフ進化を捉えるために、**DyERNIE** [135]は接線空間(タンジェント空間)の中で時間に沿った速度ベクトルを定義して、エンティティの埋め込みがそれに従って進化するように促すんやで。つまり「エンティティは時間とともにこの方向にこのスピードで動くで〜」っちゅう考え方やな。
**TPRec** [162]は興味のレコメンデーション手法やねんけど、効率的な時間認識型インタラクション関係抽出コンポーネントを使って、時間を考慮したインタラクション付きの協調ナレッジグラフを構築して、さらに時間認識型パスモジュールで推論するんや。
**TeLM** [121]は線形の時間的正則化器とマルチベクトルエンコーダーを活用して、4次のテンソル分解で推論を実現してるモデルやで。テンソル分解って要するに、めっちゃ高次元のデータを分解して扱いやすくする技術やな。
**RTFE** [127]は時間的ナレッジグラフをマルコフ連鎖として扱うんや。前の状態から次の状態に遷移するっちゅう考え方で、タイムスタンプ間でパラメータや特徴量を渡しながら、再帰的に状態遷移を追跡するモデルやねん。
ほんで**TIE** [119]は経験リプレイと時間正則化をナレッジグラフ推論に組み合わせて、時間を意識した増分的な埋め込みを学習するアプローチや。
**CEN** [136]は長さを意識したCNN(畳み込みニューラルネットワーク)を使って、時間に沿って「簡単なもんから難しいもんへ」っちゅうカリキュラム学習戦略で過去の事実を処理するんやで。人間の学習と一緒で、まず簡単な問題から解いていく感じやな。
**DKGE** [145]は各エンティティと各関係(時間情報含む)に対して2つの異なる表現を導入するモデルや。
**TLogic** [132]は時間的ランダムウォーク(グラフ上をランダムに歩き回る手法)を実行して、それに基づいて時間的な論理ルールを抽出するんやけど、これによって説明可能性がめっちゃ良くなるんや。「なんでその推論結果になったん?」って聞かれたときにちゃんと答えられるっちゅうことやで。
**TKGC-AGP** [130]は多変量の近似を活用するモデルやねん。
---
## Page 10
[](/attach/69b2fea2270e9023fdc9fc71de7508b0c86499993250984e243c1a8429a487fe_p010.png)
### 和訳
表8:時間的KGRモデルの性能比較(パーセント表示)。GDELT、ICEWS14、ICEWS05-15、ICEWS18、WIKI、YAGOの各データセットでの外挿シナリオの結果やねん。一番ええスコアは太字にしてるで。「H」は「Hits」の略な。
10
モデル名
GDELT
ICEWS14
ICEWS05-15
ICEWS18
WIKI
YAGO
MRR H@1 H@3 H@10 MRR H@1 H@3 H@10 MRR H@1 H@3 H@10 MRR H@1 H@3 H@10 MRR H@1 H@3 H@10 MRR H@1 H@3 H@10
RGCRN [169] 19.37 12.24 20.57 33.32 38.48 28.52 42.85 58.10 44.56 34.16 50.06 64.51 28.02 18.62 31.59 46.44 65.79 61.66 68.17 72.99 65.76 62.25 67.56 71.69
RE-NET [155] 19.55 12.38 20.80 34.00 39.86 30.11 44.02 58.21 43.67 33.55 48.83 62.72 29.78 19.73 32.55 48.46 58.32 50.01 61.23 73.57 66.93 58.59 71.48 86.84
CyGNet [117] 20.22 12.35 21.66 35.82 37.65 27.43 42.63 57.90 40.42 29.44 46.06 61.60 27.12 17.21 30.97 46.85 58.78 47.89 66.44 78.70 68.98 58.97 76.80 86.98
TANGO [166] 19.66 12.50 20.93 33.55
42.86 32.72 48.14 62.34 28.97 19.51 32.61 47.51 53.04 51.52 53.84 55.46 63.34 60.04 65.19 68.79
xERTE [115] 19.45 11.92 20.84 34.18 40.79 32.70 45.67 57.30 46.62 37.84 52.31 63.92 29.31 21.03 33.51 46.48 73.60 69.05 78.03 79.73 84.19 80.09 88.02 89.78
RE-GCN [125] 19.69 12.46 20.93 33.81 42.00 31.63 47.20 61.65 48.03 37.33 53.90 68.51 32.62 22.39 36.79 52.68 78.53 74.50 81.59 84.70 82.30 78.83 84.27 88.58
TLogic [132]
CEN [136]
TITer [158]
58.96 70.61
18.19 11.52 19.20 31.00 41.73 32.74 46.46 58.44 47.60 38.29 52.74 64.86 29.98 22.05 33.46 44.83 73.91 71.70 75.41 76.96 87.47 80.09 89.96 90.27
41.80 31.93 47.23 60.53 45.99 34.49 52.89 67.39 28.41 18.74 32.71 47.97
41.64 31.22 46.55 61.59 49.57 37.86 56.42 71.32 29.70 19.38 33.91 49.90 63.39
–
71.68 83.16 51.98
–
–
–
–
–
–
–
–
–
–
–
–
–
–
–
–
–
–
–
–
–
HisMatch [122] 22.01 14.45 23.80 36.61 46.42 35.91 51.63 66.84 52.85 42.01 59.05 73.28 33.99 23.91 37.90 53.94 78.07 73.89 81.32 84.65
EvoKG [154] 19.28
81.13 92.73
TiRGN [147] 21.67 13.63 23.27 37.60 43.81 33.49 48.90 63.50 49.84 39.07 55.75 70.11 33.58 23.10 37.90 54.20 80.05 75.15 84.35 87.56 87.95 84.34 91.37 92.92
22.41 14.42 24.36 38.33 44.55 34.87 49.90 65.08 51.14 39.47 57.11 71.75 34.91 24.34 38.74 55.89 81.18 76.28 85.43 88.71 88.87 85.10 92.57 94.04
33.94 50.09 68.03
20.55 34.44 27.18
79.60 85.91 68.59
30.84 47.67
29.28
–
–
–
–
–
–
–
–
–
–
–
–
–
–
–
–
–
–
–
–
46.00 33.80
–
45.29 34.60 50.88 66.06 52.17 40.21 59.42 73.98 34.16 22.97 39.27 55.96 67.58
63.00 32.30 20.60
71.20 44.60 34.90
55.90
–
–
–
–
–
–
78.42 88.06 70.11
–
–
–
–
–
78.30 84.77
RPC [116]
CluSTeR [160]
RETIA [114]
ほんで、ガウス過程(MGPs)っちゅうのを使って事実のエンコーディングをやるモデルもあるねん。それから、FILT [128]はメタ学習っちゅうフレームワークを使って、時間的KGRの中でまだ見たことない新しいエンティティを含む事実を推論するんやで。その後に出てきたrGalT [124]は、グラフの中とグラフ間の両方のレベルでアテンション機構っちゅう「どこに注目するか」を決める仕組みを初めて設計して、過去の意味情報をうまいこと活用してるねん。似たような感じで、DANet [120]も過去の異なるタイムスタンプで繰り返し出てくる事実に対するアテンションの重みを学習しようとしてるわ。MetaTKGR [126]は、未来の事実をリアルタイムのフィードバックとして使う「時間的な教師信号」を通じて、新しいエンティティに対する近接事実からのサンプリングと集約の戦略を動的に調整するっちゅう、めっちゃ賢い仕組みやねん。さらに、CENET [118]は過去に出てきた事実との依存関係と、過去に出てこなかった事実との依存関係の両方を学習して、一番ありそうな事実を推論するんやで。
4.2 推論シナリオのレビュー
結果を見てみると、内挿モデルが34個、外挿モデルが24個あるねん(表6参照)。その中で、外挿モデルの42.57%が時間操作系モデルで、47.62%がRNNベースのモデルやねん。特に注目してほしいんやけど、RNNベースのモデルの中では、内挿モデルと外挿モデルの比率がめっちゃ近くて10:8になってるんよ。同じような傾向は時間操作系モデルでも見られて、そっちは12:9やねん。これが何を意味してるかっちゅうと、RNNベースのモデルと時間操作系モデルは、内挿と外挿の両方のシナリオにうまく対応できる互換性の高さを持ってるっちゅうことやな。ほんで、最近の研究もこのタイプに集中してるわ。それに比べて、時間ベクトル系のモデルは内挿シナリオでしかうまくいかへんねん。なんでかっていうと、時間情報をそんな素朴なやり方では十分に扱いきれへんからやな。あと、代表的な最先端の時間的KGRモデルの公平な性能比較も載せてるで(表7と表8参照)。結果からも同じような結論が導き出せて、上の分析を裏付けてるわ。
4.3 考察とディスカッション
ここまでのレビューを踏まえて、さらに以下の知見が得られるねん。これらは異なる時間的KGRモデルの適用範囲を示してて、時間的KGRの今後のトレンドも見えてくるで。(1) RNNを使わへんモデル、つまり時間ベクトル誘導型と時間操作誘導型のモデルは、一般的に時間情報を追加の属性として扱って、それを既存の静的KGRモデルにいろんな技術で統合するんやな。このやり方はRNNベースのモデルに比べて柔軟性が高いねん。(2) 時間ベクトル誘導型モデルは、時間情報を追加の時間ベクトルtとしてエンコードするんやけど、こういうモデルはシンプルやねんけど、その性能は時間エンコーダと埋め込み融合モジュールが適切かどうかにめっちゃ左右されるんよ。それとは違って、時間操作誘導型モデルは特定の時間操作を設計するんやけど、これはタスクに特化したものになるねん。(3) RNNベースのモデルは、一般的に他のモデルよりも時間情報をうまくモデル化できて、外挿シナリオにも適用しやすいんやで。(4) 外挿推論はまだ初期段階で、時間的KGRモデル全体の約30%しか占めてへんから、まだまだ探求の余地がめっちゃあるっちゅうことやな。まとめると、RNNベースのモデルをもっと研究することをオススメするで。時間的KGRにとって一番将来有望なモデルタイプやと考えられてるからな。
5 マルチモーダルKGRモデル
ここでは、技術別に分類した32個のマルチモーダルKGRモデルを体系的に紹介するで(図11参照)。
5.1 推論技術のレビュー
静的KGRモデルをそのままマルチモーダルのシナリオに適用すると、テキストや画像みたいな追加のマルチモーダル情報を融合するモジュールがないから、だいたい中途半端な性能になってまうねん。そういうマルチモーダル情報をどうやって融合するかの技術に基づいて、マルチモーダルKGRモデルを大きく2タイプに分けたで。Transformerベースのモデルと、Transformerを使わへんモデルやな。
5.1.1 Transformerベースのモデル
Transformerベースのモデルは、いろんなモダリティ(テキストとか画像とか)にスケールできるめっちゃ優れた能力があるから、マルチモーダル問題の統一的なパラダイムとしてよう使われてるねん。
VisualBERT [170]やViLBERT [171]みたいな一般的なマルチモーダル事前学習TransformerモデルもマルチモーダルKGRに使えることは使えるんやけど、マルチモーダル知識グラフと他のマルチモーダルデータの間には違いがあるから、上で挙げたような一般的なMPTモデルをそのままマルチモーダル知識グラフに
マルチモーダルKGR → Transformerベースのモデル / Transformerを使わへんモデル → 技術 / グラフの種類
---
## Page 11
[](/attach/69b2fea2270e9023fdc9fc71de7508b0c86499993250984e243c1a8429a487fe_p011.png)
### 和訳
11
表9:マルチモーダルKGR(ナレッジグラフ推論)モデルの性能比較(パーセント)。FB15K-237-IMGとWN18-IMGっていうデータセットで比べてんねん。一番ええスコアは太字にしてるで。「H」は「Hits」の略やな。
| モデル | FB15k-237-IMG ||| WN18-IMG |||
|---|---|---|---|---|---|---|
| | H@1 | H@10 | MR | MR | H@1 | H@10 |
| IKRL [184] | 19.4 | 45.8 | 596 | 298 | 12.7 | 92.8 |
| TransAE [185] | 19.9 | 46.3 | 352 | 431 | 32.3 | 93.4 |
| MTRL [189] | 22.9 | 49.4 | – | 187 | – | – |
| MKBE [190] | 25.8 | 53.2 | – | 158 | – | – |
| RSME [199] | 24.2 | 46.7 | 223 | 417 | 94.3 | 95.7 |
| MoSE [198] | 28.1 | 56.5 | 7 | 117 | 94.8 | 97.4 |
| KBLRN [186] | 21.9 | 49.3 | – | 209 | – | – |
| VisualBERT [170] | 21.7 | 43.9 | 122 | 592 | 17.9 | 65.4 |
| ViLBERT [171] | 23.3 | 45.7 | 131 | 483 | 22.3 | 76.1 |
| VBKGC [172] | 21.3 | 47.8 | – | 156 | – | – |
| HRGAT [177] | 27.1 | 54.2 | – | 252 | – | – |
| MKGformer [176] | 24.3 | 49.9 | 25 | 134 | 93.5 | 97.0 |
| IMF [179] | 28.7 | 59.3 | – | – | – | – |
図12:いろんな種類のナレッジグラフでモデルを統計的に比較した図やで。
マルチホップ推論——つまりナレッジグラフの中をポンポンと何段階も辿って答えを導き出す推論やな——をゲートアテンションネットワークっていう統一的な仕組みでやるモデルがあんねん。MKGAT [193]はマルチモーダルなグラフアテンション技術を使って、レコメンドシステム(おすすめ機能)をもっと賢くしてんねん。いろんな種類のデータが混在するナレッジグラフの上で情報をうまく伝播させるわけやな。KBVQA [194]とVSUA [195]は画像と外部知識を組み合わせて推論するモデルで、「なんでこの答えになったん?」っていうのを直感的に説明できるのがええとこやねん。似たような感じで、KVQA [196]は常識的な知識と画像を統合して推論してんねん。MMEA [197]はマルチモーダルなデータをうまく揃えるための結合損失関数を設計してるで。ほんで、MoSE [198]は3つのアンサンブル推論テクニックを駆使して、各モダリティ(データの種類)ごとの予測を「どのデータが一番大事か」を評価しながら組み合わせてんねん。最近やと、RSME [199]がMRPメトリックっていう指標付きの忘却ゲートを設計して、マルチモーダルKGRに役立つ画像だけを選別するようにしてんねん。要するに、エンティティ(実体)と関係ない画像のノイズに引っ張られへんようにする工夫やな。HMEA [200]はマルチモーダルな特徴量をGCN(グラフ畳み込みネットワーク)を使って双曲空間に射影してんねん。一方で、OTKGE [201]はマルチモーダル融合のプロセスを「輸送計画」として捉えて、異なるモダリティの埋め込みをワッサースタイン距離を最小化しながら統一空間に移動させるっちゅうアプローチやねん。これ、めっちゃ数学的にエレガントやろ?ほかにも、MM-RNS [202]とCKGC [203]はコントラスティブ学習(対照学習)の戦略を活用してるし、MMKRL [204]は強化学習をマルチモーダルKGRに使ってるで。
5.2 観察と考察
上で見てきたレビューと性能比較(表9参照)を踏まえると、こんなことが見えてくんねん。(1) まず、マルチモーダルKGRモデルのほとんどは、パスベースやルールベースやなくて、埋め込みベースの静的KGRモデルをベースに開発されてきたんよ。なんでかっていうと、既存のマルチモーダルKGRモデルのほとんどが、潜在空間での特徴融合を通じてマルチモーダル情報を活用してるからやねん。具体的には、それぞれのモダリティ(テキスト、画像、数値とか)に合わせた別々のエンコーダーを設計してるわけや。(2) 最近は、事前学習済みのTransformerベースのモデルみたいな統一的な学習フレームワークを研究する方向に流れが来てんねん。マルチモーダル
図11:マルチモーダルKGRモデルの年表(タイムライン)やで。
推論(MKGR)の話やけど、ただマルチモーダルにしたからって、ええ推論性能が出るとは限らへんねん。そこにヒントを得て、研究者たちはここ2年くらいでTransformerベースのマルチモーダルKGRモデルの開発に取り組んできたんよ。VBKGC [172]は事前学習済みTransformerを使ってマルチモーダル特徴量をエンコードして、マルチモーダル用のスコアリング関数を設計して最適化してんねん。ほんで、Knowledge-CLIP [173]はCLIP [174]モデルを活用して、マルチモーダルな概念同士の意味的なつながりを考慮した、より良い事前学習モデルを実現してるで。一方、MarT [175]はアナロジー推論(類推による推論)のためのモデルに依存せん推論フレームワークをTransformerで初めて提案してんねん。さらに、MKGformer [176]ではマルチレベル融合を備えたハイブリッドTransformerが設計されてて、いろんな下流タスクの学習パラダイムを統一フレームワークにまとめてるんや。その後、HRGAT [177]はハイパーノードグラフを構築して、Transformerが生成したマルチモーダル特徴量を集約してんねん。ほかにも、MSNEA [178]とIMF [179]はマルチモーダルアラインメント(異なるモダリティの情報を揃えること)にコントラスティブ学習を活用してるで。さらに、MuKEA [180]は視覚の理解と推論にKGRを統合してて、DRAGON [181]はテキストとナレッジグラフの自己教師あり事前学習の手法も提供してんねん。ただまあ、TransformerベースのマルチモーダルKGRはまだまだ初期段階やけどな。
5.1.2 Transformerを使わないモデル
マルチモーダルKGRモデルの大半は、Transformerフレームワークを使わんと特徴量の生成と融合をやってんねん。代わりに、TransE [18]みたいな元々あったユニモーダル(単一モダリティ)のKGRモデルを拡張して、追加のモーダル情報をエンコードするためのいろんな仕組みを設計してるわけや。こういうモデルを「Transformer非依存モデル」って呼んでるで。
CKE [182]が推論と協調フィルタリング(ユーザーの好みを予測する手法やな)を同時にやる最初のモデルやねん。これによって、表現を生成しながらナレッジグラフに暗黙的に含まれるルールも同時に捉えられるようになったんよ。ほんで、DKRL [183]はナレッジグラフ内のエンティティの説明文を言語ニューラルネットワークで活用して、推論に使えるもっと表現力豊かな意味表現を獲得してんねん。これにインスパイアされて、IKRL [184]がアテンションベースのニューラルネットワークを初めて設計して、エンティティの画像に含まれる視覚情報を考慮するようにしたんや。このアテンション機構はTransAE [185]でも使われてるで。KBLRN [186]はエンドツーエンドの推論フレームワークを初めて提案したモデルで、ニューラルネットワーク技術と専門家モデルを組み合わせて、潜在的・関係的・数値的な特徴量を扱えるようにしてんねん。その後、KR-AMD [187]とMKRL [188]はテキストデータを補助データとして活用して推論性能を改善してるで。ほかにも、翻訳ベースの静的KGRモデルにインスパイアされたMTRL [189]は、視覚・言語・構造の3つの情報に対応する3つのエネルギー関数を持つ翻訳ベースのモデルやねん。さらに、MKBE [190]とMRCGN [191]はいろんなニューラルエンコーダーとデコーダーを関係モデルと統合して、埋め込み学習とマルチモーダルデータの推論をやってるで。MMKGR [192]は「マルチモーダルな補助特徴量をどうやったら効果的に活用してマルチホップ推論できるんやろ?」っていう問題を初めて本格的に調べたモデルやねん。
---
## Page 12
[](/attach/69b2fea2270e9023fdc9fc71de7508b0c86499993250984e243c1a8429a487fe_p012.png)
### 和訳
表10:静的トランスダクティブ知識グラフ推論の定番ベンチマークデータセットやで。
表11:静的インダクティブ知識グラフ推論の定番ベンチマークデータセットやな。
12
(※表10・表11の数値データ部分は原文のまま省略せず以下に記載)
---
ほな、データセットの説明いくで!
特徴量のことで言うと、特に大規模言語モデル(LLM)がバーッと花開いてからがすごいねん。こういうモデルは汎用人工知能に求められる条件をバッチリ満たしてて、今の時代ほんまに実用的でスケールしやすいんよ。(3)他の2種類の知識グラフ推論(KGR)と比べると、マルチモーダルKGRの研究はまだまだ初期段階やねん。つまり、マルチモーダル向けのモデルはたった18%しかないっちゅうこっちゃ。要するに、めっちゃ深掘りできる余地がまだまだあるっちゅうことで、詳しくはセクション7.4で課題とチャンスとして書いてるで。
# 6 データセット
ここでは、KGRのデータセットを網羅的にまとめてるで。特に時間的なやつとマルチモーダルな知識グラフに注目して、それぞれの説明と統計情報を載せてるねん。あと、データセットはうちらのGitHubリポジトリにまとめてあるから、コミュニティのみんなが使いやすいようになってるで。
## 6.1 静的KGRデータセット
静的KGRの定番データセット、つまりトランスダクティブ(既知のエンティティで推論するやつ)が38個、インダクティブ(未知のエンティティにも対応するやつ)が15個まとめてあるで。統計は表10と表11に載ってて、以下に各データセットの説明を書いていくな。
- **ATOMIC** [205] は日常の常識推論のための知識グラフやねん。人間の行動に対する反応、影響、意図、そしてそれぞれのエンティティの説明で構成されてるで。要は「こういうことしたら普通こうなるよな」っていう常識をまとめたもんや。
- **Countries** [206] は公開されてる地理データをもとに、国同士の関係をまとめたデータセットやで。
- **CoDEX** [207] はWikidataとWikipediaから抽出した補完用データセット(COmpletion Datasets EXtracted)のセットやねん。サイズ違いで3種類あって、CoDEX-S(小)、CoDEX-M(中)、CoDEX-L(大)があるで。
- **ConceptNet** [208] は単語やフレーズをラベル付きのエッジ(辺)でつないで、AIアプリが言葉の意味をもっとちゃんと理解できるようにするためのもんやねん。**ConceptNet100K** [209] は学習用トリプレット(主語-関係-目的語の3つ組)が10万個入ってるバージョンや。
- **DBpedia** [233] はWikipediaとかいろんなWikimediaプロジェクトから作られた構造化コンテンツで構成されてるで。エンティティの数によっていくつかのサブセットに分けられて、**DBpedia50** [210]、**DBpedia500** [210]、**DB100K** [211] があるねん。
- **FAMILY** [212] は家族メンバー間の関係をまとめたデータセットや。シンプルやけど、関係推論のテストにはええ感じやで。
- **FreeBASE** [234] はWikipedia、NNDB、ファッションモデルディレクトリとか、いろんなソースから作られた大規模知識ベースやねん。エンティティの数に応じてめっちゃいっぱいサブセットがあって、**FB13** [213]、**FB122** [214]、**FB15k** [215]、**FB20k** [210]、**FB24k** [216]、**FB5M** [19]、**FB15k-237** [217]、**FB60k-NYT10** [218] とか、もうバリエーション豊富やで。
- **Hetionet** [219] は公開リソースをもとにした生物医学研究から作られた知識グラフやねん。化合物、病気、遺伝子、解剖学的部位、経路(パスウェイ)、生物学的プロセス、分子機能、細胞成分、薬理学的分類、副作用、症状の間の関係を記述してるで。めっちゃ医学・生物系の情報が詰まっとるんよ。
- **Kinship** [212] はアリャワラ族 [235] っていうオーストラリアの先住民族の親族関係を記述したデータセットやで。
- **Nation** [212] は国家間の関係をまとめたもんや [221]。
- **NELL** [236] は「NeverEnding Language Learner(終わりなき言語学習者)」っちゅうシステムが作った知識ベースやねん。これ何がすごいかって、ウェブを読み続けて時間とともに学習していくっちゅう仕組みなんよ。エンティティの数に応じていくつかのサブセットがあって、**Location** [220]、**Sports** [220]、**NELL23k** [222]、**NELL-995** [223] とかあるで。
- **OpenBioLink** [224] は大規模で高品質、しかもめっちゃチャレンジングな生物医学系の知識グラフや。ガチで難しいやつやで。
- **Toy** [225] はテストとかデバッグ用の小さい知識グラフやねん。名前の通りおもちゃみたいなサイズやけど、動作確認には便利やで。
- **UMLS** [237] は「Unified Medical Language System(統合医学用語システム)」の知識グラフやで。医学用語を統一的に扱うためのもんやな。
---
## Page 13
[](/attach/69b2fea2270e9023fdc9fc71de7508b0c86499993250984e243c1a8429a487fe_p013.png)
### 和訳
表12:時間的ナレッジグラフ推論でよう使われるベンチマークデータセットまとめ
表13:マルチモーダルなナレッジグラフ推論でよう使われるベンチマークデータセットまとめ
13
| データセット | エンティティ数 | 関係数 | タイムスタンプ数 | 学習用ファクト数 | 検証用ファクト数 | テスト用ファクト数 |
|---|---|---|---|---|---|---|
| DBpedia-3SP [241] | 66,967 | 968 | 3 | 103,211 | 3,000 | 3,000 |
| GDELT [134] | 7,691 | 240 | 8,925 | 1,033,270 | 238,765 | 305,241 |
| GDELT-small [119] | 500 | 20 | 366 | 2,735,685 | 341,961 | 341,961 |
| GDELT-m10 [242] | 50 | 20 | 30 | 221,132 | 27,608 | 27,926 |
| IMDB-13-3SP [134] | 3,244,455 | 14 | 3 | 7,913,773 | 10,000 | 3,000 |
| IMDB-30SP [134] | 243,148 | 14 | 30 | 621,096 | 3,000 | 46,275 |
| ICEWS05-15 [243] | 10,488 | 251 | 4,017 | 386,962 | 46,092 | 46,275 |
| ICEWS11-14 [243] | 6,738 | 235 | 1,461 | 118,766 | 14,859 | 14,756 |
| ICEWS14 [115] | 7,128 | 230 | 365 | 63,685 | 13,823 | 13,222 |
| ICEWS14-Plus [242] | 7,128 | 230 | 365 | 72,826 | 8,941 | 8,963 |
| ICEWS18 [115] | 23,033 | 256 | 7,272 | 373,018 | 45,995 | 49,545 |
| YOGA11k/YOGA [161] | 10,623 | 10 | 189 | 161,540 | 19,523 | 20,026 |
| YOGA-3SP [241] | 27,009 | 37 | 3 | 124,757 | 3,000 | 3,000 |
| YOGA15k [243] | 15,403 | 34 | 198 | 110,441 | 13,815 | 13,800 |
| YOGA1830 [115] | 10,038 | 10 | 205 | 51,205 | 10,973 | 10,973 |
| WIKI/Wikidata12k [161] | 12,554 | 24 | 232 | 2,735,685 | 341,961 | 341,961 |
| Wikidata11k [167] | 11,134 | 95 | 328 | 242,844 | 28,748 | 14,283 |
| Wikidata-big [140] | 125,726 | 203 | 1,700 | 323,635 | 5,000 | 5,000 |
PubMedコーパスと組み合わせることで、UMLS-PubMed [218]に拡張されとるんやで。
- **WordNet** [238] っちゅうのは、単語同士の意味的な関係——たとえば類義語とか、上位概念・下位概念の関係とか、部分と全体の関係とか——をまとめたデータベースやねん。エンティティ(登録されてるモノ)の数によって、WN11 [213]、WN18 [227]、WN18RR [217]みたいなサブセットに分けられるで。
- **Wikidata** [239] はWikipediaの共通データソースを提供してるやつや。WD-singer [222] とか wikidata5m [228] はそこから切り出したサブセットやな。
- **YAGO** [240] は軽量で拡張しやすいオントロジー(知識の体系みたいなもんや)で、WikidataとWordNetを統合して作られとるねん。関係の数によって、YAGO3-10 [229]、YAGO37 [230]、YAGO39k [231] みたいなバリエーションがあるで。
## 6.2 時間的KGR(ナレッジグラフ推論)データセット
時間情報つきのKGR向けデータセット、代表的なやつを18個まとめたで。統計情報は表12にあって、以下がその説明やな。
- **DBpedia-3SP** [241] はDBpediaから3つの異なるタイムスタンプで切り出したサブセットやねん。
- **GDELT** [134] は「Global Database of Events, Language, and Tone」っちゅう、世界中のイベント・言語・論調をまとめたデータベースから作った、めっちゃ密度の高いナレッジグラフや。GDELT-m10 [242] とGDELT-small [119] はそこから抽出したもんやで。
- **IMDB** [244] は映画、テレビシリーズ、俳優、監督のエンティティで構成されたナレッジグラフやねん。あの有名なインターネット・ムービー・データベースのことや。IMDB-30SP [134] とIMDB-13-3SP [134] は、異なるタイムスタンプでそこから抽出してるで。
- **ICEWS** [245] は「Integrated Crisis Early Warning System(統合危機早期警戒システム)」の略で、具体的なタイムスタンプ付きの政治的イベントが入ったデータベースやねん。ここから作られた代表的な時間的KGとして、ICEWS05-15 [243]、ICEWS11-14 [243]、ICEWS14 [115]、ICEWS14-Plus [242]、ICEWS18 [115] があるで。
- **Wikidata** [239] の時間的KGR版は、静的なWikidataデータセットに時間情報をプラスしたやつや。WIKI/Wikidata12k [161]、Wikidata11k [167]、Wikidata-big [140] は異なる期間に基づいて生成されとるねん。
- **YAGO** [240] の時間的KGR版も同じく時間情報が追加されとる。YOGA11k/YOGA [161]、YOGA15k [243]、YOGA-3SP [241]、YOGA1830 [115] は異なる期間から生成されたもんやで。
## 6.3 マルチモーダルKGRデータセット
マルチモーダル(複数の情報の種類を扱う)KGRの代表的なデータセットを11個まとめたで。統計情報は表13にあって、以下がその説明や。
| データセット | モダリティ | エンティティ数 | 関係数 | 学習用ファクト数 | 検証用ファクト数 | テスト用ファクト数 |
|---|---|---|---|---|---|---|
| FB-IMG-TXT [189] | KG / TXT / IMG | 11,757 / 11,757 / 1,175,700 | 1,231 | 285,850 | 34,863 | 29,580 |
| FB15k-237-IMG [176] | KG / IMG | 14,541 / 145,410 | 237 | 272,115 | 17,535 | 20,466 |
| IMGpedia [247] | KG / IMG | 14,765,300 / 44,295,900 | — | 442,959,000 | 3,119,207,705 | — |
| MMKG-FB15k [249] | KG / Numeric / IMG | 14,951 / 29,395 / 13,444 | 1,345 | 592,213 | — | — |
| MMKG-DB15k [249] | KG / Numeric / IMG | 14,777 / 46,121 / 12,841 | 279 | — | — | — |
| MMKG-Yago15k [249] | KG / Numeric / IMG | 15,283 / 48,405 / 11,194 | 32 | — | — | — |
| MKG-Wikipedia [202] | KG / TXT / IMG | 14,463 / 15,000 / 12,305 | 169 | 34,196 | 4,274 | 4,276 |
| MKG-YAGO [202] | KG / TXT / IMG | 14,541 / 145,410 / — | 28 | 21,310 | 2,663 | 2,665 |
| RichPedia [250] | KG / IMG | — / — | 3 | 119,669,570 | — | — |
| WN9-IMG-TXT [189] | KG / TXT / IMG | 6,555 / 6,555 / 63,225 | 9 | 11,741 | 1,319 | 1,337 |
| WN18-IMG [176] | KG / IMG | 14,244 / 29,985 / 2,914,770 | 18 | 141,442 | 5,000 | 5,000 |
- **FB-IMG-TXT** [189] はテキストの説明文と画像を組み合わせたナレッジグラフやねん。トリプル(主語・述語・目的語の三つ組)の部分は、有名なKGデータセットFB15k [215] のサブセットで、画像はImageNet [246] から持ってきてるで。これと比較して、**FB15K-237-IMG** [176] はトリプルの範囲をFB15k-237 [217] に変更しとるんや。
- **IMGpedia** [247] はWikimedia Commonsデータセットの画像から視覚情報を取り込んだナレッジグラフやで。
- **MKG** [248] は2つのサブセットからなるねん。MKG-WikipediaとMKG-YAGOや。どっちもウェブ検索エンジンで生成した視覚的なエンティティを含んでるんやけど、トリプル部分はそれぞれWikipediaとYAGOから取ってるという違いがあるで。
- **MMKG** [249] は3つのサブセットを提供してるねん。MMKG-FB15k-IMG、MMKG-DB15k、Yago15k-IMG-TXTや。特定のKGに数値リテラル(数値データ)と画像を統合したもんやな。
- **RichPedia** [250] はトリプル、テキスト説明文、画像で構成されとるで。テキスト説明文はWikidataから取って、対応する画像リソースはウェブサイトからクロールして集めてるんや。
- **WN9-IMG-TXT** [184] はテキスト説明文と画像を組み合わせたナレッジグラフや。トリプル部分は古典的なKGデータセットWN18 [227] のサブセットで、画像はImageNet [246] から引っ張ってきてるで。これと比べて、**WN18-IMG** [176] はトリプルの範囲をWN18全体に広げてるんやな。
## 7 課題とチャンス
ここまでの既存KGRモデルの分析を踏まえて、今後の研究で「ここ攻めたらおもろいんちゃう?」っていう方向性をいくつか挙げるで。
### 7.1 分布外推論(Out-of-distribution Reasoning)
現実世界では、ナレッジグラフに新しいエンティティや関係がどんどん出てくるやんか。これって元のKGではあんまり探索されてへん部分やねん。こういう「まだよう調べられてへん要素」を含むファクトについて推論することを**分布外推論**って呼ぶんやけど、これはKGRモデルの設計にめっちゃ高い要求を突きつけてくるねん。なんでかっていうと、見たことないデータに対応せなあかんからや。最近の研究では、未知の要素を推論するための
---
## Page 14
[](/attach/69b2fea2270e9023fdc9fc71de7508b0c86499993250984e243c1a8429a487fe_p014.png)
### 和訳
図13:多関係・二関係・単関係のファクトの比較
---
エンティティが未知のケースに対応するモデル、いわゆる帰納的推論モデルってのがあんねん。[71]とか[72]、[73]、[75]みたいなやつやな。こいつらはエンティティの具体的な意味は気にせんと、グラフの構造に隠れてるロジックルールを掘り出すんよ。それでなかなかええ結果出してるわけ。ほんで未知の関係を推論するほうはっていうと、少数ショットKGRモデル [74]、[85]、[126] が、モデルの汎化能力を上げることで、ちょっとのデータだけで未知の関係にもうまく対応できるようにしてんねん。つまりな、前に学んだ似たような知識を使って、新しいタスクをパパッと覚えられるってことやで。あと、BERTRL [83] ってのは、言語モデルで計算したテキストの意味を使ってこの問題に対処しようとしてるんやけど、言語モデルがちゃんと学習されてへんかったら性能がガクッと落ちるのが弱点やねん。まとめると、分布外の推論タスクに対応するKGRモデルはまだまだ初期段階で、今後もっと深掘りする価値があるテーマやな。
## 7.2 大規模推論
産業界で使われるナレッジグラフはめっちゃデカいのが普通やから、もっと効率ええKGRモデルが必要になるわけよ。そこで、伝播の手順を段階的に最適化しようとする研究がいくつかあんねん [251]。例えばNBF-net [80] は、GNNベースのKGRモデルで使われてた元々のDFS(深さ優先探索)ベースの集約手順を、ベルマン-フォードアルゴリズムに置き換えてるんよ。さらにA\*Star [251] Netは、貪欲法を使って集約手順をもっと最適化してるわけ。それ以外にも、グラフクラスタリング [252]、[253]、[254] の考え方も使われてるで。例えばCURL [94] は、まずエンティティの意味に基づいてナレッジグラフをいくつかのクラスタに分けて、パス探索の手順をクラスタ内レベルとクラスタ間レベルの2段階に細分化するんよ。こうすることで、グラフ全体を無駄に探索せんで済むようになるねん。同じような発想で、完全なグラフやなくてサブグラフ上で推論する研究も多いで。GraIL [71] とかCSR [85] とかな。でもほとんどの場合、推論の精度を犠牲にしてもうてるから、もっとバランスのええモデルを探る余地はまだまだあるわけや。
## 7.3 多関係推論
図13 (a) に示すように、2つのエンティティの間に複数の関係があるっていう状況は、ナレッジグラフではよくあることやねん。ただし、図13 (b) と (c) に示す単関係や二関係のファクトと比べると、構造的にもっと多様で、意味的にもっと複雑やねん。せやから、既存のKGRモデルは主に単関係と二関係のファクトに焦点を当ててて、多関係のファクトも一部の関係を省略して単関係や二関係として扱ってしまうことが多いんよ。こんなやり方のKGRモデルは、現実の状況を正確にモデル化でけへんし、意味のある情報をごっそり失ってまうから、表現力が足りんくなるねん。将来的には、多関係のファクトをうまく活かして推論能力を高める方法を研究する必要があるで。
## 7.4 マルチモーダル推論
複数のソースからの情報を融合したナレッジ推論は、テキストコーパスとか他のモダリティの追加情報を組み合わせることで、ナレッジグラフの断絶やスパースさ(データがスカスカな状態)を軽減できるんよ。複数モダリティのデータを融合した推論は、お互いの強みを補完し合って、推論性能を向上させるわけやな。でもな、既存のマルチモーダルKGRモデルはまだ初期段階なんよ。異なるモダリティの埋め込みをそのままくっつけて最終スコアを計算するだけのものがほとんどやねん。こういうシンプルな融合でもそこそこの結果は出てるんやけど、もっと細かく制御できてスケーラブルな方式を開発する価値は十分あるで。例えば、各モダリティの重要度を重み付けするような適応的融合方式なんかは、探求する価値があるテーマやな。
## 7.5 説明可能な推論
説明可能性っちゅうのは、いろんな分野の深層学習モデルにとって共通の重要な課題やねん。KGRモデルは一般的に説明しやすいほうではあるんやけど、特に埋め込みベースのKGRモデルに関しては、もっと深掘りする価値があるんよ。最近はニューラルネットワーク、例えばGNN [255] をベースにしたKGRモデルがどんどん開発されてるやろ。こいつらは表現力はめっちゃ高いんやけど、説明可能性に難があるんよな。それに比べて、ルールベースやパスベースのKGRモデルは説明しやすいけど、計算コストが高くて表現力が弱い [256]。表現力と説明可能性のええバランスを取るために、埋め込みベースのモデルとルールベース・パスベースのモデルを統合しようっていう試みもあるで。例えばARGCN [232] がそうで、RGCN [58] で生成された埋め込みを使って報酬関数を構築することで、パスベースモデルの説明可能性を高めてるんよ。ただ、こういう試みのほとんどはまだ粗削りな段階やけどな。
## 7.6 ナレッジグラフ推論の応用
近年めっちゃたくさんのKGR手法が提案されて、理論分野でのKGRの大きな可能性が示されてきたわけやけど、KGRの応用についてはまだまだ研究が必要やねん [257]。今のところ、ナレッジグラフは医療、金融、盗作検出とか、いろんな下流のアプリケーションでよく使われてるで。医療のナレッジ推論モデルは、電子カルテから病気を診断するのを先生たちにサポートすることを目指してるんよ。例えば [258] と [259] はどっちも、電子カルテのデータベースから構築したナレッジグラフ上で推論を行ってるねん。BERTみたいな事前学習済み言語モデルを使ってエンティティのテキスト埋め込みを生成するんやけど、これが既存のマルチモーダルKGRモデルで効果的やと証明されてるんよ。それ以外にも、KGRモデルは不正検知にも役立つで。金融分野では重要なタスクやからな。例えば [260] は、事前に情報を検証して不正を見抜くための事例ベース推論手法を提案してるんよ。さらに [261] は、継続学習の方式でKGRアプローチを実行して盗作検出を行ってるわけや。
## 7.7 ナレッジグラフと大規模言語モデル
大規模言語モデル(LLM)[262]、つまりChatGPTとかGPT-4やな、これが今年ほんまに大人気で、推論能力と汎化性の高さからめっちゃインパクトがあるんよ [263]。でもな、こいつらにもまだ2つの課題があんねん。(1) 説明可能性が低いこと、(2) 新しいデータを扱うときのスケーラビリティが弱いこと。これらの問題は、KGRモデルとうまく連携できたら解決できるかもしれへんのよ。例えばQA-GNN [264] は、まずLLMをテキストの前処理に使って、その後ナレッジグラフ上での推論ステップをガイドするっていう試みを初めてやったんよ。あとDRAGON [181] は、マルチモーダルKGRのためのLLMガイド型論理推論手法やな。一方で、どんどん
---
Tom → Mary:友達、配偶者、愛してる
(a) 多関係ファクト
Tom → Mary:友達、配偶者、~~愛してる~~
(b) 二関係ファクト
Tom → Mary:友達、~~配偶者~~、~~愛してる~~
(c) 単関係ファクト
---
## Page 15
[](/attach/69b2fea2270e9023fdc9fc71de7508b0c86499993250984e243c1a8429a487fe_p015.png)
### 和訳
ほな、翻訳いくで〜!
---
今まさにデータを学習してる最中やけど、一部の研究者は「LLM(大規模言語モデル)って、将来的にはもっと汎用的なKG(知識グラフ)みたいなもんになるんちゃう?」って言うてんねん。インデックス作ったり、推論したり、情報保存したり、そういう機能もLLMでできるようになるんちゃうかって話やな。LLMとKGの関係性についてはいろんな仮説が出てて、どれもそれなりに筋が通ってるから、「これが一番正しい!」とは言い切れへんねん。せやけど、LLMとKGの関係を掘り下げて研究していくっていうのは、間違いなくこれからも熱いテーマになるっていうのは確かやで。
## 8 まとめ
このサーベイ(調査論文)では、知識グラフ推論(KGR)の既存モデルを**二段階の分類体系**でめっちゃ徹底的にレビューしたんよ。上のレベルが「グラフの種類」で、下のレベルが「使ってる技術とかシナリオ」やねん。具体的に言うたら、グラフの種類は3つ(静的KG、時間的KG、マルチモーダルKG)、技術は14種類、推論シナリオは4パターンをカバーしてて、KGRの全体像をしっかり見渡せるようなレビューになってるで。ほんで、知識グラフ推論の課題も整理して、「こっちの方向おもろいんちゃう?」っていう将来の可能性も示してるから、読者の皆さんにとってヒントになるはずやわ。あと、最先端のKGRモデル180本分(論文とコード付き)と、代表的なデータセット67個をまとめたオープンソースのリポジトリをGitHubで公開してるから、研究コミュニティのみんなに使ってもらえるようにしてるで!
## 参考文献
[1] H. Yuan, H. Yu, S. Gui, S. Ji「グラフニューラルネットワークの説明可能性:分類的サーベイ」IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022年。
[2] F.-A. Croitoru, V. Hondru, R. T. Ionescu, M. Shah「画像分野における拡散モデル:サーベイ」IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023年。
[3] Y. Zhang, B. Kang, B. Hooi, S. Yan, J. Feng「深層ロングテール学習:サーベイ」IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023年。
[4] P. Xu, X. Zhu, D. A. Clifton「Transformerを使ったマルチモーダル学習:サーベイ」IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023年。
[5] M. Ali, M. Berrendorf, C. T. Hoyt, L. Vermue, M. Galkin, S. Sharifzadeh, A. Fischer, V. Tresp, J. Lehmann「闇に光を照らす:統一フレームワークによる知識グラフ埋め込みモデルの大規模評価」IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 12, pp. 8825–8845, 2021年。
[6] K. Liang, Y. Liu, S. Zhou, X. Liu, W. Tu「関係対称性に基づく知識グラフ対照学習」2022年。
[7] S. Ji, S. Pan, E. Cambria, P. Marttinen, S. Y. Philip「知識グラフのサーベイ:表現・獲得・応用」IEEE Transactions on Neural Networks and Learning Systems, 2021年。
[8] C.-M. Wong, F. Feng, W. Zhang, C.-M. Vong, H. Chen, Y. Zhang, P. He, H. Chen, K. Zhao, H. Chen「数十億規模の知識グラフの事前学習による対話型推薦システムの改善」2021 IEEE 37th International Conference on Data Engineering (ICDE), 2021年。
[9] P. Hitzler, K. Janowicz, W. Li, G. Qi, Q. Ji「知識グラフにおけるハイブリッド推論:記号推論と統計推論の融合」Semant. Web, 2020年。
[10] J. Zhang, B. Chen, L. Zhang, X. Ke, H. Ding「知識グラフにおけるニューラル・記号・ニューラルシンボリック推論」AI Open, 2021年。
[11] W. Zhang, J. Chen, J. Li, Z. Xu, J. Z. Pan, H. Chen「論理と埋め込みによる知識グラフ推論:サーベイと展望」arXiv preprint arXiv:2202.07412, 2022年。
[12] Y. Chen, H. Li, H. Li, W. Liu, Y. Wu, Q. Huang, S. Wan「知識グラフ推論の概要:主要技術と応用」Journal of Sensor and Actuator Networks, 2022年。
[13] M. Chen, W. Zhang, Y. Geng, Z. Xu, J. Z. Pan, H. Chen「未知要素への汎化:知識グラフにおける知識外挿のサーベイ」arXiv preprint arXiv:2302.01859, 2023年。
[14] B. Cai, Y. Xiang, L. Gao, H. Zhang, Y. Li, J. Li「時間的知識グラフ補完:サーベイ」arXiv preprint arXiv:2201.08236, 2022年。
[15] X. Zhu, Z. Li, X. Wang, X. Jiang, P. Sun, X. Wang, Y. Xiao, N. J. Yuan「マルチモーダル知識グラフの構築と応用:サーベイ」arXiv preprint arXiv:2202.05786, 2022年。
[16] R. H. Richens「機械翻訳のための事前プログラミング」Mech. Transl. Comput. Linguistics, 1956年。
[17] X. Zhu, Z. Li, X. Wang, X. Jiang, P. Sun, X. Wang, Y. Xiao, N. J. Yuan「マルチモーダル知識グラフの構築と応用:サーベイ」ArXiv, 2022年。
[18] A. Bordes, N. Usunier, A. Garcia-Duran, J. Weston, O. Yakhnenko「多関係データのモデリングのための埋め込み変換」Proc. of NeurIPS, 2013年。 — これがTransEっていう、知識グラフ埋め込みの超有名なやつやねん。
[19] Z. Wang, J. Zhang, J. Feng, Z. Chen「超平面上での変換による知識グラフ埋め込み」Proc. of AAAI, 2014年。
[20] Y. Lin, Z. Liu, M. Sun, Y. Liu, X. Zhu「知識グラフ補完のためのエンティティ・関係埋め込みの学習」Proc. of AAAI, 2015年。
[21] G. Ji, S. He, L. Xu, K. Liu, J. Zhao「動的マッピング行列による知識グラフ埋め込み」Proc. of ACL, 2015年。
[22] S. He, K. Liu, G. Ji, J. Zhao「ガウス埋め込みによる知識グラフの表現学習」Proceedings of the 24th ACM International Conference on Information and Knowledge Management, 2015年。
[23] H. Xiao, M. Huang, Y. Hao, X. Zhu「TransG:知識グラフ埋め込みのための生成的混合モデル」arXiv preprint arXiv:1509.05488, 2015年。
[24] G. Ji, K. Liu, S. He, J. Zhao「適応的スパース転送行列による知識グラフ補完」Proc. of AAAI, 2016年。
[25] T. Ebisu, R. Ichise「TorusE:リー群上の知識グラフ埋め込み」Proc. of AAAI, 2018年。
[26] I. Balažević, C. Allen, T. Hospedales「多関係ポアンカレグラフ埋め込み」Proc. of NeurIPS, 2019年。
[27] L. Ma, P. Sun, Z. Lin, H. Wang「単語埋め込みを介した知識グラフ埋め込みの合成」arXiv preprint arXiv:1909.03794, 2019年。
[28] Z. Sun, Z.-H. Deng, J.-Y. Nie, J. Tang「RotatE:複素空間における関係回転による知識グラフ埋め込み」arXiv preprint arXiv:1902.10197, 2019年。
[29] Z. Zhang, J. Cai, Y. Zhang, J. Wang「リンク予測のための階層認識型知識グラフ埋め込みの学習」Proc. of AAAI, 2020年。
[30] F. Zhang, X. Wang, Z. Li, J. Li「TransRHS:関係階層構造を持つ知識グラフの表現学習手法」Proc. of IJCAI, 2021年。
[31] L. Chao, J. He, T. Wang, W. Chu「PairRE:ペア関係ベクトルによる知識グラフ埋め込み」ACL, 2021年。
[32] R. Li, J. Zhao, C. Li, D. He, Y. Wang, Y. Liu, H. Sun, S. Wang, W. Deng, Y. Shen ほか「HousE:ハウスホルダーパラメータ化による知識グラフ埋め込み」arXiv preprint arXiv:2202.07919, 2022年。
[33] L. Yu, Z. Luo, H. Liu, D. Lin, H. Li, Y. Deng「TripleRE:三重関係ベクトルによる知識グラフ埋め込み」arXiv preprint arXiv:2209.08271, 2022年。
[34] B. Wang, Q. Meng, Z. Wang, D. Wu, W. Che, S. Wang, Z. Chen, C. Liu「InterHT:ヘッドエンティティとテールエンティティ間のインタラクションによる知識グラフ埋め込み」ArXiv preprint, vol. abs/2202.04897, 2022年。
[35] M. Nickel, V. Tresp, H.-P. Kriegel「多関係データの集団学習のための三方向モデル」ICML, 2011年。
[36] B. Yang, W.-t. Yih, X. He, J. Gao, L. Deng「知識ベースにおける学習と推論のためのエンティティ・関係埋め込み」arXiv preprint arXiv:1412.6575, 2014年。
[37] T. Trouillon, J. Welbl, S. Riedel, É. Gaussier, G. Bouchard「シンプルなリンク予測のための複素埋め込み」Proc. of ICML, 2016年。
[38] M. Nickel, L. Rosasco, T. Poggio「知識グラフのホログラフィック埋め込み」Proc. of AAAI, 2016年。
[39] H. Liu, Y. Wu, Y. Yang「多関係埋め込みのためのアナロジカル推論」Proc. of ICML, 2017年。
[40] S. M. Kazemi, D. Poole「知識グラフにおけるリンク予測のためのシンプル埋め込み」Proc. of NeurIPS, 2018年。
[41] I. Balažević, C. Allen, T. M. Hospedales「TuckER:知識グラフ補完のためのテンソル分解」arXiv preprint arXiv:1901.09590, 2019年。
[42] W. Zhang, B. Paudel, W. Zhang, A. Bernstein, H. Chen「知識グラフにおける予測と説明のためのインタラクション埋め込み」Proc. of WSDM, 2019年。
---
## Page 16
[](/attach/69b2fea2270e9023fdc9fc71de7508b0c86499993250984e243c1a8429a487fe_p016.png)
### 和訳
[45] A. Bastos, K. Singh, A. Nadgeri, S. Shekarpour, I. O. Mulang, J. Hoffart, 「HopfE: 逆ホップファイブレーションを使った知識グラフの表現学習」 — ようするにな、ホップファイブレーションっていう数学のめっちゃ綺麗な構造を逆手にとって、知識グラフの埋め込みに使おうって話やねん。CIKM 2021で発表されとるで。
[46] S. Amin, S. Varanasi, K. A. Dunfield, G. Neumann, 「LowFER: リンク予測のための低ランク双線形プーリング」 — 双線形プーリングっていうのは、2つのベクトルを掛け合わせて特徴を取り出す手法やねんけど、それを低ランクにして計算を軽くしたろうって話や。ICML 2020。
[47] D. Q. Nguyen, T. Vu, T. D. Nguyen, D. Phung, 「QuatRE: 知識グラフ埋め込みのための関係考慮型四元数」 — 四元数って4次元の数やねんけど、それを使って関係の回転とかをうまく表現しようっちゅうモデルやな。WWW 2022。
[48] A. Bordes, X. Glorot, J. Weston, Y. Bengio, 「多関係データの学習のための意味マッチングエネルギー関数」 — エネルギー関数っていうのは「こいつらどれくらい相性ええか」をスコアで出す仕組みのことやで。Machine Learning誌、2014年。
[49] R. Socher, D. Chen, C. D. Manning, A. Ng, 「知識ベース補完のためのニューラルテンソルネットワークによる推論」 — テンソルネットワークっちゅうのは、行列のさらに上位版みたいなもんで、エンティティ間のめっちゃ複雑な関係も捉えられるんやで。NeurIPS 2013。
[50] Q. Liu, H. Jiang, A. Evdokimov, Z.-H. Ling, X. Zhu, S. Wei, Y. Hu, 「ディープラーニングによる確率的推論:ニューラル関連モデル」 — 深層学習で確率的な推論をやったろうっていう話やな。arXivプレプリント、2016年。
[51] B. Shi, T. Weninger, 「ProjE: 知識グラフ補完のための射影埋め込み」 — エンティティを射影(ある空間にぽーんと投げる変換みたいなもん)して、リンクの予測精度上げようって手法やで。AAAI 2017。
[52] T. Dettmers, P. Minervini, P. Stenetorp, S. Riedel, 「畳み込み2D知識グラフ埋め込み」 — 知識グラフの埋め込みに2次元の畳み込み(画像認識でよう使うやつ)を持ち込んだ画期的なやつやねん。ConvEって名前で有名や。AAAI 2018。
[53] D. Q. Nguyen, T. D. Nguyen, D. Q. Nguyen, D. Phung, 「畳み込みニューラルネットワークに基づく知識ベース補完のための新しい埋め込みモデル」 — CNNベースの埋め込みモデルの別バージョンやな。arXivプレプリント、2017年。
[54] I. Balažević, C. Allen, T. M. Hospedales, 「ハイパーネットワーク知識グラフ埋め込み」 — ハイパーネットワークってのは「ネットワークのパラメータを別のネットワークが生成する」っていうめっちゃ賢い仕組みで、それを知識グラフに適用したんやで。ICANN 2019。
[55] X. Jiang, Q. Wang, B. Wang, 「多関係学習のための適応的畳み込み」 — 関係ごとにフィルタを適応的に変えるっちゅう畳み込みの手法や。AACL 2019。
[56] S. Vashishth, S. Sanyal, V. Nitin, N. Agrawal, P. Talukdar, 「InteractE: 特徴交互作用を増やして畳み込みベースの知識グラフ埋め込みを改善する」 — なんでかっていうと、特徴同士のやり取り(インタラクション)が多いほど表現力上がるやん?そこを強化したモデルやねん。AAAI 2020。
[57] C. Demir, A.-C. N. Ngomo, 「畳み込み複素知識グラフ埋め込み」 — 複素数(虚数を含む数)と畳み込みを組み合わせて知識グラフを表現しようっていう話や。European Semantic Web Conference 2021。
[58] M. Schlichtkrull, T. N. Kipf, P. Bloem, R. v. d. Berg, I. Titov, M. Welling, 「グラフ畳み込みネットワークによる関係データのモデリング」 — R-GCNっていう超有名なモデルやで。グラフ畳み込みを関係データに拡張して、関係の種類ごとに別の変換を適用するんや。European Semantic Web Conference 2018。
[59] Z. Wang, Z. Ren, C. He, P. Zhang, Y. Hu, 「リンク予測のためのマルチレベル構造を用いたロバスト埋め込み」 — 複数の階層の構造情報を使って、ノイズに強い頑丈な埋め込みを作ろうっていう話やな。IJCAI 2019。
[60] D. Nathani, J. Chauhan, C. Sharma, M. Kaul, 「知識グラフにおける関係予測のための注意ベース埋め込みの学習」 — アテンション(注意機構)を使って「どの近傍ノードが大事か」を見極めながら埋め込みを学習するモデルやで。arXivプレプリント、2019年。
[61] P. Wang, J. Han, C. Li, R. Pan, 「帰納的知識グラフ埋め込みのための論理注意に基づく近傍集約」 — 論理的なルールの情報をアテンションに組み込んで近傍の情報を集めるっていう、論理と深層学習のいいとこ取りな手法やねん。AAAI 2019。
[62] C. Shang, Y. Tang, J. Huang, J. Bi, X. He, B. Zhou, 「知識ベース補完のためのエンドツーエンド構造考慮型畳み込みネットワーク」 — グラフの構造をちゃんと意識しながら、入力から出力まで一気通貫で学習するネットワークや。AAAI 2019。
[63] L. Cai, B. Yan, G. Mai, K. Janowicz, R. Zhu, 「TransGCN: 変換仮定とグラフ畳み込みネットワークの結合によるリンク予測」 — TransEみたいな変換ベースの考え方とGCNを合体させたモデルやで。Knowledge Capture 2019。
[64] X. Xu, W. Feng, Y. Jiang, X. Xie, Z. Sun, Z.-H. Deng, 「大規模知識グラフ推論のための動的枝刈りメッセージパッシングネットワーク」 — 大規模グラフやと計算がえげつないことになるから、要らんメッセージを動的にバッサリ切って効率化しようっていう話や。arXivプレプリント、2019年。
[65] Z. Zhang, F. Zhuang, H. Zhu, Z. Shi, H. Xiong, Q. He, 「知識グラフ補完のための階層的注意を持つ関係グラフニューラルネットワーク」 — 階層的なアテンションで、ノードレベルと関係レベルの両方で重要度を見分けるっちゅう仕組みやねん。AAAI 2020。
[66] D. Yu, Y. Yang, R. Zhang, Y. Wu, 「知識埋め込みベースのグラフ畳み込みネットワーク」 — 知識グラフの埋め込みとGCNをうまいこと融合させたモデルや。WWW 2021。
[67] S. Vashishth, S. Sanyal, V. Nitin, P. Talukdar, 「合成ベースの多関係グラフ畳み込みネットワーク」 — CompGCNって呼ばれとるやつやな。関係をノードと同じように埋め込んで、合成操作(足し算、掛け算、回転とか)で組み合わせるのがミソやで。arXivプレプリント、2019年。
[68] J. Baek, D. B. Lee, S. J. Hwang, 「知識を外挿する学習:トランスダクティブな少数ショットグラフ外リンク予測」 — 学習時に見たことないノードに対しても、少ないデータからリンク予測できるようにしようっていうめっちゃ実用的な研究やで。NeurIPS 2020。
[69] Y. Zhang, W. Wang, W. Chen, J. Xu, A. Liu, L. Zhao, 「知識ベース外埋め込みのためのメタ学習ベースのハイパー関係特徴モデリング」 — 知識グラフに載ってへん新しいエンティティに対して、メタ学習で素早く対応しようって話やな。CIKM 2021。
[70] S. Liu, B. Grau, I. Horrocks, E. Kostylev, 「IndiGO: ペアワイズエンコーディングを用いたGNNベースの帰納的知識グラフ補完」 — ペアワイズっていうのは2つ1組でエンコードするってことやねん。帰納的(未知のエンティティにも対応できる)な知識グラフ補完をGNNでやるモデルや。NeurIPS 2021。
[73] S. Mai, S. Zheng, Y. Yang, H. Hu, 「帰納的関係推論のための通信型メッセージパッシング」 — ノード同士が「通信」するみたいにメッセージをやり取りして、未知の関係も推論できるようにしたモデルやで。AAAI 2021。
[74] S. Zheng, S. Mai, Y. Sun, H. Hu, Y. Yang, 「メタ学習によるサブグラフ考慮型少数ショット帰納的リンク予測」 — サブグラフの情報を活かしつつ、メタ学習で少ないデータからでもリンク予測できるようにした手法やな。IEEE Transactions on Knowledge and Data Engineering 2022。
[75] X. Xu, P. Zhang, Y. He, C. Chao, C. Yan, 「知識グラフの帰納的リンク予測のためのサブグラフ近傍関係情報最大化」 — サブグラフの近傍にある関係の情報をめっちゃ最大限に活用して、帰納的なリンク予測の精度を上げようって研究や。arXivプレプリント、2022年。
[76] Y. Pan, J. Liu, L. Zhang, X. Hu, T. Zhao, Q. Lin, 「帰納的関係推論のための関係パスコントラストによる一階述語規則の学習」 — コントラスト学習(似てるもんは近づけて、違うもんは離す学習)を使って論理規則を学ぼうって話やねん。arXivプレプリント、2021年。
[77] Y. Geng, J. Chen, W. Zhang, J. Z. Pan, M. Chen, H. Chen, S. Jiang, 「完全帰納的知識グラフ補完のための関係メッセージパッシング」 — 「完全帰納的」っていうのは、学習時に見てないエンティティにも関係にも全部対応できるっちゅう意味で、ほんまに汎用性高いモデルやで。arXivプレプリント、2022年。
[78] Z. Hu, V. Gutiérrez-Basulto, Z. Xiang, X. Li, R. Li, J. Z. Pan, 「知識グラフ上のマルチホップ推論のための型考慮埋め込み」 — エンティティの「型」(人なのか、場所なのか、組織なのか)の情報を使って、複数ステップの推論精度を上げようっていう手法やな。arXivプレプリント、2022年。
[79] T. Chen, S. Kornblith, M. Norouzi, G. Hinton, 「視覚表現のコントラスト学習のためのシンプルなフレームワーク」 — SimCLRっていうめっちゃ有名なやつやで!画像を2通りにデータ拡張して、同じ画像から来たもんは近づけて、違う画像のもんは離すっていうシンプルやけど強力な手法や。ICML 2020。
[80] Z. Zhu, Z. Zhang, L.-P. Xhonneux, J. Tang, 「ニューラルベルマンフォードネットワーク:リンク予測のための汎用グラフニューラルネットワークフレームワーク」 — ベルマンフォード法っていう最短経路アルゴリズムをニューラルネットワーク化して、リンク予測全般に使えるフレームワークにしたんやで。NeurIPS 2021。
[81] Y. Zhang, Q. Yao, 「関係有向グラフによる知識グラフ推論」 — 関係を有向グラフ(矢印付きのグラフ)として表現して推論するモデルやな。ACM Web Conference 2022。
[82] L. V. Harsha Vardhan, G. Jia, S. Kok, 「推論のための確率的論理グラフアテンションネットワーク」 — 確率的な論理とグラフアテンションを組み合わせて推論するっていう、なかなか贅沢な組み合わせのモデルやで。WWW 2020。
[83] H. Zha, Z. Chen, X. Yan, 「BERTによる帰納的関係予測」 — あのBERT(自然言語処理の超有名モデル)を使って、未知のエンティティ間の関係を予測しようっていう発想やねん。AAAI 2022。
[84] Q. Lin, J. Liu, F. Xu, Y. Pan, Y. Zhu, L. Zhang, T. Zhao, 「帰納的関係予測のための論理推論を伴うコンテキストグラフの統合」 — コンテキスト(文脈)のグラフに論理推論を組み込んで、帰納的な関係予測をパワーアップさせた手法や。SIGIR 2022。
[85] Q. Huang, H. Ren, J. Leskovec, 「接続サブグラフ事前学習による少数ショット関係推論」 — サブグラフの接続パターンを事前学習しておいて、少ないデータでも関係を推論できるようにしたんやで。arXivプレプリント、2022年。
[86] Y. Pan, J. Liu, L. Zhang, T. Zhao, Q. Lin, X. Hu, Q. Wang, 「コントラスト表現を用いた論理推論による帰納的関係予測」 — コントラスト学習と論理推論をがっちゃんこして、帰納的な関係予測を強化した研究やな。EMNLP 2022、アブダビ開催。
[87] J. Li, Q. Wang, Z. Mao, 「階層的トランスフォーマーによる関係パスとコンテキストからの帰納的関係予測」 — 関係のパス(道筋)とコンテキストの両方を階層的なトランスフォーマーで処理して、帰納的な関係予測するっていう手法や。ICASSP 2023。
[88] C. Fu, T. Chen, M. Qu, W. Jin, X. Ren, 「オープン知識グラフ推論のための協調的方策学習」 — 複数のエージェントが協力しながら知識グラフ上を探索して、ええ推論経路を見つけようっていう強化学習ベースの手法やで。arXivプレプリント、2019年。
[89] W. Zhang, B. Paudel, L. Wang, J. Chen, H. Zhu, W. Zhang, A. Bernstein, H. Chen, 「知識グラフ推論のための埋め込みとルールの反復学習」 — 埋め込みとルールを交互に学習させて、お互いの弱点を補い合うっちゅう賢いやり方やねん。WWW 2019。
[90] M. Qu, J. Tang, 「推論のための確率的論理ニューラルネットワーク」 — 確率的な論理とニューラルネットワークを融合させて推論するモデルやで。NeurIPS 2019。
[91] A. Sadeghian, M. Armandpour, P. Ding, D. Z. Wang, 「DRUM: 知識グラフ上のエンドツーエンド微分可能ルールマイニング」 — ルールの発見を微分可能(つまり勾配降下法で学習できる)にしたのがほんまに画期的なポイントやねん。NeurIPS 2019。
[92] P. G. Omran, K. Wang, Z. Wang, 「知識グラフにおけるルール学習への埋め込みベースのアプローチ」 — 埋め込みの情報を手がかりにして論理ルールを学習しようっていう手法や。IEEE Transactions on Knowledge and Data Engineering 2019。
[93] P.-W. Wang, D. Stepanova, C. Domokos, J. Z. Kolter, 「知識グラフにおける数値ルールの微分可能学習」 — 数値を含むルール(例えば「体重が○○以上なら〜」みたいなん)も微分可能な形で学習できるようにした研究やで。ICLR 2019。
[94] D. Zhang, Z. Yuan, H. Liu, H. Xiong ほか, 「知識グラフ推論のためのデュアルエージェントによるウォーク学習」 — 2つのエージェントが知識グラフ上を「歩き回って」ええ推論経路を見つけるっていう、ほんまにおもろい強化学習の手法やな。
---
## Page 17
[](/attach/69b2fea2270e9023fdc9fc71de7508b0c86499993250984e243c1a8429a487fe_p017.png)
### 和訳
ほな、参考文献リスト17ページ目、いくで〜!
---
[100] S. Guoら、「ソフトルールからの反復的ガイダンスを使ったナレッジグラフ埋め込み」、AAAI、2018年。
→ ようするに、ふわっとしたルール(ソフトルール)を何回も繰り返し参考にしながら、ナレッジグラフ(知識のつながりを表すネットワークみたいなもんやな)をベクトル空間に落とし込む方法を提案してんねん。
[126] R. Wangら、「サンプリングと集約の学習:時間的ナレッジグラフに対する少数ショット推論」、arXivプレプリント arXiv:2210.08654、2022年。
→ 時間軸つきのナレッジグラフで、データがめっちゃ少ない状況でもうまいこと推論できるように、「どこからサンプル取ってくるか」と「どうまとめるか」を学習する手法やねん。
[101] R. Dasら、「散歩に出かけて答えにたどり着け:強化学習を使ったナレッジベース上のパス推論」、arXivプレプリント arXiv:1711.05851、2017年。
→ ナレッジベースの中を強化学習のエージェントがウロウロ歩き回って、正解の答えにたどり着くっていう、めっちゃ面白いアプローチやで。
[102] W. Xiongら、「DeepPath:ナレッジグラフ推論のための強化学習手法」、arXivプレプリント arXiv:1707.06690、2017年。
→ これも強化学習ベースやねんけど、ナレッジグラフの中で最適な推論パスを見つけ出す方法を提案してるんや。
[103] T. RocktäschelとS. Riedel、「エンドツーエンドで微分可能な証明」、NeurIPS、2017年。
→ 論理的な証明プロセスを、ニューラルネットワークで丸ごと微分可能にしてもうたっていう、なかなかぶっ飛んだ研究やな。つまり、論理推論を勾配降下法で学習できるようにしたんや。
[104] F. Yangら、「ナレッジベース推論のための論理ルールの微分可能学習」、NeurIPS、2017年。
→ [103]と似た発想で、論理ルール自体をニューラルネットで学習できるようにした研究やねん。
[105] R. Dasら、「リカレントニューラルネットワークを用いたエンティティ・関係・テキストに対する推論チェーン」、arXivプレプリント arXiv:1607.01426、2016年。
→ エンティティ(実体)、関係、テキスト情報をRNN(繰り返し型ニューラルネット)で連鎖的に推論していく手法やで。
[106] S. Guoら、「ナレッジグラフと論理ルールの同時埋め込み」、EMNLP、2016年。
→ ナレッジグラフの情報と論理ルールを一緒くたにベクトル空間に埋め込むことで、両方のええとこ取りしようって話やねん。
[107] Y. Zhangら、「グラフニューラルネットワークによる効率的な確率的論理推論」、arXivプレプリント arXiv:2001.11850、2020年。
→ 確率的な論理推論をグラフニューラルネットワーク(GNN)で効率よくやるで〜って研究や。
[108] A. Neelakantanら、「ナレッジベース補完のための構成的ベクトル空間モデル」、arXivプレプリント arXiv:1504.06662、2015年。
→ ベクトル空間モデルを組み合わせて(構成的に)使うことで、ナレッジベースの穴埋め(補完)をやろうっていう話やな。
[109] M. Gardnerら、「ナレッジベース上のランダムウォーク推論にベクトル空間類似度を組み込む」、EMNLP、2014年。
→ ランダムウォーク(ふらふら歩き回る手法)にベクトルの似とる度合いの情報を加えることで、推論の精度を上げようとしてんねん。
[110] L. A. Galárragaら、「AMIE:不完全なエビデンス下でのオントロジーナレッジベースにおける関連ルールマイニング」、WWW、2013年。
→ データが全部揃ってない状況でも、知識ベースから有用なルールを掘り出す(マイニングする)手法やで。AMIEっていう名前がついてるんやな。
[111] N. LaoとW. W. Cohen、「パス制約付きランダムウォークの組み合わせによる関係検索」、Machine Learning誌、2010年。
→ ランダムウォークに「こういうパスしか通ったらあかん」っていう制約をつけて、関係データの検索精度を上げるアプローチや。
[112] Q. Linら、「帰納的関係予測のための論理推論を用いたコンテキストグラフの導入」、SIGIR '22、2022年、893–903頁。
→ コンテキスト(文脈情報)のグラフと論理的な推論を組み合わせて、まだ見たことない関係を予測する(帰納的関係予測)手法やねん。
[113] G. F. LawlerとV. Limic、『ランダムウォーク:現代的入門』、ケンブリッジ大学出版、2010年。
→ ランダムウォークの理論をちゃんとまとめた教科書的な本やな。基礎をしっかり押さえたい人向けや。
[114] K. Liuら、「RETIA:時間的ナレッジグラフ外挿のための関係-エンティティ双方向対話的集約」、IEEE ICDE、2023年。
→ 関係とエンティティが双方向にやりとり(インタラクション)しながら情報を集約して、時間的ナレッジグラフの未来予測(外挿)をする手法やで。
[115] Z. Hanら、「時間的ナレッジグラフの予測のための説明可能なサブグラフ推論」、ICLR、2020年。
→ サブグラフ(部分グラフ)を使って推論することで、「なんでその予測になったんか」が説明できるようにしてんねん。ほんまに大事なことやで、説明可能性って。
[116] K. Liangら、「時間的ナレッジグラフ推論のための関係相関と周期的イベントからの学習」、SIGIR '23、2023年。
→ 関係同士の相関関係と、「毎年この時期にこれが起こるねん」みたいな周期的なパターンの両方から学習する手法やな。
[117] C. Zhuら、「歴史から学ぶ:逐次的コピー生成ネットワークによる時間的ナレッジグラフのモデリング」、AAAI、2021年。
→ 過去の出来事をコピーしたり新しく生成したりするネットワークを使って、時間的ナレッジグラフをモデル化するんや。歴史は繰り返すってやつやな。
[118] Y. Xuら、「歴史的対照学習を用いた時間的ナレッジグラフ推論」、AAAI、2022年。
→ 対照学習(似てるものと似てないものを比較して学ぶ手法)を過去のデータに適用して、時間的ナレッジグラフの推論精度を上げてるんや。
[119] J. Wuら、「TIE:埋め込みベースの増分的時間ナレッジグラフ補完フレームワーク」、SIGIR、2021年。
→ 時間が進むにつれて新しい情報が増えていくのに対応して、ちょっとずつ(増分的に)更新していけるフレームワークやねん。
[120] K. Liuら、「DA-Net:時間的ナレッジグラフ推論のための分散アテンションネットワーク」、CIKM、2022年。
→ アテンション(注意機構)を分散的に配置して、時間的ナレッジグラフの推論をやるネットワークや。
[121] C. Xuら、「線形時間正則化と多ベクトル埋め込みを用いた時間的ナレッジグラフ補完」、AACL、2021年。
→ 時間の情報を線形的な正則化で扱い、複数のベクトルで埋め込むことで、時間的ナレッジグラフの穴を埋める手法やで。
[122] Z. Liら、「HiSMatch:歴史的構造マッチングに基づく時間的ナレッジグラフ推論」、arXivプレプリント arXiv:2210.09708、2022年。
→ 過去のグラフ構造のパターンをマッチングさせることで、将来どうなるか推論するっていうアイデアやな。
[123] A. Sadeghianら、「ChronoR:回転ベースの時間的ナレッジグラフ埋め込み」、AAAI、2021年。
→ 回転(RotatE的な発想やな)を使って時間情報を表現するナレッジグラフ埋め込み手法やねん。
[124] Y. Gaoら、「オートエンコーダ構造による時間的ナレッジグラフ推論の前駆体モデリング」、IJCAI、2022年。
→ 「ある出来事の前にはこういうことが起こってた」っていう前駆体(先行事象)をオートエンコーダでモデル化して推論に活かすんや。
[127] Y. Xuら、「RTFE:時間的ナレッジグラフ補完のための再帰的時間事実埋め込みフレームワーク」、AACL、2021年。
→ 時間的な事実を再帰的に埋め込んでいくフレームワークやで。
[128] Z. Dingら、「概念認識情報を用いた時間的ナレッジグラフ上の少数ショット帰納的学習」、AKBC、2022年。
→ データが少ない状況で、概念レベルの情報を活用して時間的ナレッジグラフの帰納的学習をやる手法やな。
[129] Y. Heら、「HIPネットワーク:時間的ナレッジグラフの外挿推論のための歴史情報伝達ネットワーク」、IJCAI、2021年。
→ 歴史的な情報をうまいこと伝播させて、未来の出来事を予測するネットワークやねん。
[130] L. ZhangとD. Zhou、「近似ガウス過程埋め込みによる時間的ナレッジグラフ補完」、COLING、2022年。
→ ガウス過程(確率的なモデリング手法やな)を近似的に使って、時間的ナレッジグラフの補完をする研究や。
[131] L. Baiら、「強化学習を用いた時間的ナレッジグラフにおけるマルチホップ推論」、Applied Soft Computing、2021年。
→ 強化学習のエージェントが時間的ナレッジグラフの中を何ステップも飛び回って(マルチホップで)推論する手法やで。
[132] Y. Liuら、「TLogic:時間的ナレッジグラフ上の説明可能なリンク予測のための時間的論理ルール」、AAAI、2022年。
→ 時間的な論理ルールを使うことで、「なんでこのリンクを予測したんか」がちゃんと説明できるようにした研究やねん。めっちゃ実用的やと思うで。
[133] P. Jainら、「時間的ナレッジベース補完:新しいアルゴリズムと評価プロトコル」、arXivプレプリント arXiv:2005.05035、2020年。
→ 新しいアルゴリズムだけやなくて、どうやって評価するかっていうプロトコルも提案してるんや。ほんまに大事やで、評価基準って。
[134] F. Zhangら、「時間軸に沿って:時間的ナレッジグラフ補完のためのタイムライン追跡型埋め込み」、CIKM、2022年。
→ タイムライン(時間軸)をなぞるように埋め込みを行うことで、時間的な変化を捉える手法やな。
[135] Z. Hanら、「DyERNIE:時間的ナレッジグラフ補完のためのリーマン多様体埋め込みの動的進化」、EMNLP、2020年。
→ リーマン多様体(めっちゃざっくり言うと曲がった空間のことやな)の上で埋め込みを時間とともに動的に変化させる手法やねん。普通のユークリッド空間よりも表現力が高いんやで。
[136] Z. Liら、「時間的ナレッジグラフ推論のための複雑な進化パターン学習」、ACL、2022年。
→ 単純なパターンだけやなくて、複雑に進化していくパターンも学習できるようにした研究や。
[137] X. Lvら、「スパースなナレッジグラフ上のマルチホップ推論のための動的予測と補完」、EMNLP、2020年。
→ データがスカスカ(スパース)なナレッジグラフでも、動的に先を予測しながら穴を埋めて、マルチホップ推論をやれるようにしてるんや。
[138] J. Messnerら、「ボックス埋め込みを用いた時間的ナレッジグラフ補完」、AAAI、2022年。
→ ポイント(点)じゃなくてボックス(箱、つまり領域)として埋め込むことで、不確実性とか包含関係をうまく表現できるようにした手法やで。
[139] T. Lacroixら、「時間的ナレッジベース補完のためのテンソル分解」、ICLR、2019年。
→ テンソル分解(多次元配列を分解する数学的手法やな)を時間的ナレッジベースの補完に適用した研究やねん。
[140] C. Mavromatisら、「TempoQR:ナレッジグラフに対する時間的質問推論」、AAAI、2022年。
→ 「2020年にこの人がやってたことは何?」みたいな時間を含む質問に、ナレッジグラフを使って答える手法やで。
[141] P. Shaoら、「Tucker分解ベースの時間的ナレッジグラフ補完」、Knowledge-Based Systems、2022年。
→ Tucker分解っていうテンソル分解の一種を使って、時間的ナレッジグラフの補完をやる研究や。
[142] L. Quら、「時間依存グラフニューラルネットワークによる連続時間リンク予測」、WWW、2020年。
→ 離散的な時間ステップやなくて、連続的な時間の中でリンクを予測するGNNの手法やねん。
[143] H. Sunら、「Graph Hawkesトランスフォーマー:時間的ナレッジグラフの外挿推論」、EMNLP 2022、アブダビ、7481–7493頁。
→ Hawkes過程(「ある出来事が起こると、その後に関連する出来事が起こりやすくなる」っていう確率モデルやな)とトランスフォーマーを組み合わせて、グラフの未来を予測するんや。
[144] C. Xuら、「時系列ガウス埋め込みに基づく時間的ナレッジグラフ補完」、ISWC、2020年。
→ 時系列データとガウス分布の埋め込みを組み合わせた手法やで。
[145] T. Wuら、A. Khan、M. Yong、G. Qi、M. Wa...(以下テキスト省略)
---
## Page 18
[](/attach/69b2fea2270e9023fdc9fc71de7508b0c86499993250984e243c1a8429a487fe_p018.png)
### 和訳
[153] J. Wu, M. Cao, J. C. K. Cheung, W. L. Hamilton, "Temp: 時間的メッセージパッシングによる時間的知識グラフ補完," EMNLP会議録, 2020年.
要はな、知識グラフの中で「時間」っちゅう要素を使ってメッセージを受け渡しする仕組みを作って、抜けてる情報を補完しようって話やねん。
[154] N. Park, F. Liu, P. Mehta, D. Cristofor, C. Faloutsos, Y. Dong, "EvoKG: 時間的知識グラフの推論のためにイベント発生時刻とネットワーク構造を同時にモデル化する手法," WSDM会議録, 2022年.
イベントが「いつ起きたか」と「どんなつながりがあるか」を一緒にモデル化してんねん。両方同時に考えることで、時間軸のある知識グラフをうまく推論できるようにしてるわけやな。
[155] W. Jin, M. Qu, X. Jin, X. Ren, "Recurrent Event Network: 時間的知識グラフにおける自己回帰型の構造推論," EMNLP会議録, 2020年.
過去のイベントを再帰的に振り返って、次にどんな構造が出てくるか自動で推論するネットワークやねん。
[156] L. Bai, X. Ma, M. Zhang, W. Yu, "TPMoD: 時間的知識グラフ補完のための傾向ガイド型予測モデル," ACM Transactions on Knowledge Discovery from Data, 2021年.
データの「傾向」、つまりトレンドみたいなもんをガイドにして、時間的な知識グラフの欠けてる部分を予測するモデルやで。
[157] R. Trivedi, M. Farajtabar, P. Biswal, H. Zha, "DyRep: 動的グラフにおける表現学習," ICLR会議録, 2019年.
時間とともに変化するグラフ、つまり動的なグラフから、ええ感じの表現(ベクトル)を学習する手法やねん。
[158] H. Sun, J. Zhong, Y. Ma, Z. Han, K. He, "TimeTraveler: 時間的知識グラフ予測のための強化学習," EMNLP会議録, 2021年.
名前がめっちゃカッコええやろ?タイムトラベラーや。強化学習を使って、時間的な知識グラフの未来を予測するっちゅう話やねん。
[159] A. Garcia-Duran, S. Dumancic, M. Niepert, "時間的知識グラフ補完のための系列エンコーダの学習," EMNLP, 2018年.
時間の流れを「系列(シーケンス)」として捉えて、そのエンコーダを学習することで知識グラフの穴埋めをするアプローチやで。
[160] Z. Li, X. Jin, S. Guan, W. Li, J. Guo, Y. Wang, X. Cheng, "歴史から探して未来を推論する:時間的知識グラフにおける二段階推論," ACL, 2021年.
めっちゃ直感的な名前やな。まず過去のデータを「検索」して、それをもとに未来を「推論」するっちゅう二段構えの方法やねん。
[161] S. S. Dasgupta, S. N. Ray, P. Talukdar, "HyTE: 超平面ベースの時間対応知識グラフ埋め込み," EMNLP会議録, 2018年.
超平面(ハイパープレーン)を使って、時間の情報を知識グラフの埋め込みに組み込むやり方やねん。各時刻ごとに別の超平面を用意して、そこにエンティティを射影するイメージやな。
[162] Y. Zhao, X. Wang, J. Chen, Y. Wang, W. Tang, X. He, H. Xie, "推薦のための知識グラフ上の時間対応パス推論," ACM Transactions on Information Systems (TOIS), 2021年.
レコメンドシステムに使う話やねん。知識グラフの上で、時間を意識しながらパス(経路)をたどって推論することで、より良い推薦ができるようにしてるわけや。
[163] A. Sadeghian, M. Rodriguez, D. Z. Wang, A. Colas, "イベント知識グラフにおける時間的推論," Workshop on Knowledge Base Construction, Reasoning and Mining, 2016年.
イベントに焦点を当てた知識グラフで、時間をどう扱って推論するかっちゅうワークショップ論文やで。
[164] S. Liao, S. Liang, Z. Meng, Q. Zhang, "時間的知識グラフのための動的埋め込み学習," WSDM会議録, 2021年.
時間とともに変化するダイナミックな埋め込みを学習することで、時間的知識グラフをうまく扱おうって話やねん。
[165] A. García-Durán, S. Dumancic, M. Niepert, "時間的知識グラフ補完のための系列エンコーダの学習," EMNLP, 2018年.
[159]とほぼ同じ論文やな。系列エンコーダで時間的知識グラフの補完をするやつや。
[166] Z. Han, Z. Ding, Y. Ma, Y. Gu, V. Tresp, "時間的知識グラフにおける未来リンク予測のためのニューラル常微分方程式の学習," Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 2021年, pp. 8352–8364.
ニューラルODE(常微分方程式)っちゅう連続的な時間モデルを使って、時間的知識グラフの将来のリンクを予測する手法やねん。連続的に時間を扱えるのがめっちゃポイントやで。
[167] J. Jung, J. Jung, U. Kang, "解釈可能な時間的知識グラフ補完のための時間を横断する歩行学習," KDD会議録, 2021年.
グラフの上を「歩く」ように探索するんやけど、それを時間軸もまたいでやるねん。しかも解釈可能、つまり「なんでその答えになったか」が説明できるのがええとこやな。
[168] R. Trivedi, H. Dai, Y. Wang, L. Song, "Know-Evolve: 動的知識グラフのための深層時間的推論," ICML会議録, 2017年.
知識グラフが時間とともに「進化」していく過程を、深層学習で時間的に推論するモデルやねん。ほんまに先駆的な研究やで。
[169] Y. Seo, M. Defferrard, P. Vandergheynst, X. Bresson, "グラフ畳み込みリカレントネットワークによる構造化系列モデリング," International Conference on Neural Information Processing, Springer, 2018年, pp. 362–373.
グラフ畳み込みとリカレントネットワークを組み合わせて、構造を持った系列データをモデル化する方法やねん。グラフの構造と時間の流れ、両方いっぺんに扱えるのがミソやで。
[170] L. H. Li, M. Yatskar, D. Yin, C.-J. Hsieh, K.-W. Chang, "VisualBERT: 視覚と言語のためのシンプルで高性能なベースライン," arXivプレプリント arXiv:1908.03557, 2019年.
BERTに画像の情報もぶっ込んで、視覚と言語を一緒に扱えるようにしたモデルやねん。シンプルなのにめっちゃ性能ええのがウリやで。
[171] W. Su, X. Zhu, Y. Cao, B. Li, L. Lu, F. Wei, J. Dai, "VL-BERT: 汎用的な視覚言語表現の事前学習," arXivプレプリント arXiv:1908.08530, 2019年.
VisualBERTと似たコンセプトやけど、こっちはもっと汎用的な視覚と言語の表現を事前学習で獲得しようっちゅうアプローチやな。
[172] Y. Zhang, W. Zhang, "事前学習済みマルチモーダルTransformerとツインズ負例サンプリングによる知識グラフ補完," arXivプレプリント arXiv:2209.07084, 2022年.
マルチモーダル(テキストと画像とか複数の情報源)のTransformerを事前学習して、さらに「ツインズ負例サンプリング」っちゅう賢い負例の作り方を組み合わせて知識グラフを補完するやつやねん。
[173] X. Pan, T. Ye, D. Han, S. Song, G. Huang, "知識グラフを用いた対照的言語画像事前学習," NeurIPS会議録.
CLIPみたいな言語と画像の対照学習に、知識グラフの情報も加えたバージョンやな。知識グラフがあることで、より賢い表現が学べるっちゅうわけや。
[174] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark ほか, "自然言語の教師信号から転移可能な視覚モデルを学習する," ICML会議録, 2021年.
これがあの有名なCLIPの論文やねん!自然言語のテキストを使って画像のモデルを学習させたら、めっちゃいろんなタスクに転移できるようになったっちゅう画期的な研究や。
[175] N. Zhang, L. Li, X. Chen, X. Liang, S. Deng, H. Chen, "知識グラフにおけるマルチモーダル類推推論," arXivプレプリント arXiv:2210.00312, 2022年.
「AはBに対して、CはDに対して」みたいな類推推論を、画像とかテキストとか複数のモダリティを使って知識グラフ上でやるっちゅう話やで。
[176] X. Chen, N. Zhang, L. Li, S. Deng, C. Tan, C. Xu, F. Huang, L. Si, H. Chen, "マルチモーダル知識グラフ補完のためのマルチレベル融合ハイブリッドTransformer," SIGIR会議録, 2022年.
複数の階層レベルでマルチモーダルな情報を融合するハイブリッドTransformerを使って、知識グラフの穴埋めをする手法やねん。融合の仕方に工夫があるのがポイントやな。
[177] S. Liang, A. Zhu, J. Zhang, J. Shao, "マルチモーダル知識グラフ補完のためのハイパーノードリレーショナルグラフアテンションネットワーク," vol. 19, no. 2, 2023年2月. オンライン: https://doi.org/10.1145/3545573
ハイパーノード(複数のエンティティをまとめたノード)とリレーショナルなグラフアテンションを使って、マルチモーダルな知識グラフを補完する方法やで。
[178] L. Chen, Z. Li, T. Xu, H. Wu, Z. Wang, N. J. Yuan, E. Chen, "エンティティアライメントのためのマルチモーダルシャムネットワーク," Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD '22), ニューヨーク, USA: Association for Computing Machinery, 2022年, pp. 118–126. オンライン: https://doi.org/10.1145/3534678.3539244
異なる知識グラフ間で「こっちのエンティティとあっちのエンティティは同じもんやで」って対応付ける(アライメントする)のに、シャムネットワークっちゅう双子みたいなネットワーク構造を使うねん。しかもマルチモーダルやから、テキストも画像も使えるで。
[179] X. Li, X. Zhao, J. Xu, Y. Zhang, C. Xing, "IMF: リンク予測のためのインタラクティブマルチモーダル融合モデル," Proceedings of the ACM Web Conference 2023 (WWW '23), ニューヨーク, USA: Association for Computing Machinery, 2023年, pp. 2572–2580. オンライン: https://doi.org/10.1145/3543507.3583554
マルチモーダルな情報をインタラクティブに(お互いに影響し合いながら)融合して、リンク予測の精度を上げるモデルやねん。
[180] Y. Ding, J. Yu, B. Liu, Y. Hu, M. Cui, Q. Wu, "MUKEA: 知識ベース視覚質問応答のためのマルチモーダル知識抽出・蓄積," Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022年.
画像を見て質問に答えるタスク(VQA)に、知識グラフから引っ張ってきた知識を使うねんけど、その知識をマルチモーダルに抽出して蓄積する仕組みやで。
[181] M. Yasunaga, A. Bosselut, H. Ren, X. Zhang, C. D. Manning, P. Liang, J. Leskovec, "深層双方向言語・知識グラフ事前学習," NeurIPS会議録.
言語モデルと知識グラフを双方向に深く事前学習するっちゅう話やねん。言語から知識グラフへ、知識グラフから言語へ、両方向に情報が流れるのがミソや。
[182] F. Zhang, N. J. Yuan, D. Lian, X. Xie, W.-Y. Ma, "推薦システムのための協調的知識ベース埋め込み," KDD会議録, 2016年.
推薦システムに知識ベースの埋め込みを協調的に(ユーザーの行動データと知識グラフを一緒に)学習する手法やで。
[183] R. Xie, Z. Liu, J. Jia, H. Luan, M. Sun, "エンティティ記述文を用いた知識グラフの表現学習," AAAI会議録, 2016年.
知識グラフのエンティティに付いてるテキストの説明文を使って、より良い表現を学習しようって話やねん。
[184] R. Xie, Z. Liu, H. Luan, M. Sun, "画像を体現した知識表現学習," IJCAI会議録, 2017年.
知識グラフのエンティティに画像情報を組み込んで表現学習する手法やで。テキストだけちゃう、画像も使うねん。
[185] Z. Wang, L. Li, Q. Li, D. Zeng, "知識グラフのためのマルチモーダルデータ強化表現学習," IJCNN会議録, 2019年.
マルチモーダルなデータ(テキスト、画像など)を使って知識グラフの表現をパワーアップさせる学習方法やで。
[186] A. Garcia-Duran, M. Niepert, "KBLRN: 潜在的・関係的・数値的特徴を用いた知識ベース表現のエンドツーエンド学習," arXiv e-prints, 2017年.
潜在的な特徴、関係の特徴、数値的な特徴、この3つを全部まとめてエンドツーエンドで学習するっちゅう欲張りなアプローチやな。
[187] Y. Zuo, Q. Fang, S. Qian, X. Zhang, C. Xu, "エンティティ属性とマルチメディア記述を用いた知識グラフの表現学習," 2018 IEEE Fourth International Conference on Multimedia Big Data (BigMM), 2018年.
エンティティの属性情報とマルチメディア(画像や動画とか)の記述、両方使って知識グラフの表現を学習するやつやで。
[188] X. Tang, L. Chen, J. Cui, B. Wei, "エンティティ記述・階層型タイプ・テキスト関係を用いた知識表現学習," Information Processing & Management, 2019年.
記述文だけやなくて、エンティティの階層的なタイプ(例えば「犬→動物→生物」みたいな)とテキストで表現された関係も使って、知識表現を学習するアプローチやねん。
[189] H. Mousselly-Sergieh, T. Botschen, I. Gurevych, S. Roth, "知識グラフ表現学習のためのマルチモーダル翻訳ベースアプローチ," Proceedings of the Seventh Joint Conference on Lexical and Computational Semantics, 2018年.
翻訳ベース(TransEとかの系譜やな)のアプローチをマルチモーダルに拡張して知識グラフの表現を学習するやつやで。
[190] P. Pezeshkpour, L. Chen, S. Singh, "知識ベース補完のためのマルチモーダル関係データの埋め込み," EMNLP会議録, 2018年.
マルチモーダルな関係データを埋め込み空間にマッピングして、知識ベースの穴埋めをする手法やねん。
[191] W. Wilcke, P. Bloem, V. de Boer, R. van't Veer, F. van Harmelen, "マルチモーダル知識グラフにおけるエンドツーエンドエンティティ分類," arXivプレプリント arXiv:2003.12383, 2020年.
マルチモーダルな知識グラフの上で、エンティティを最初から最後まで一気通貫で分類するモデルやで。
[192] S. Zheng, W. Wang, J. Qu, H. Yin, W. Chen, L. Zhao, "MMKGR: マルチホップ・マルチモーダル知識グラフ推論," arXivプレプリント arXiv:2209.01416, 2022年.
複数ホップ(何段階もたどる)の推論を、マルチモーダルな情報を使いながら知識グラフ上でやる手法やねん。一段階やなくて、何段階も推論できるのがポイントやで。
[193] R. Sun, X. Cao, Y. Zhao, J. Wan, K. Zhou, F. Zhang, Z. Wang, K. Zheng, "推薦システムのためのマルチモーダル知識グラフ," CIKM会議録, 2020年.
推薦システムにマルチモーダルな知識グラフを使おうっちゅう話やな。テキストだけちゃう、画像とかの情報も入った知識グラフでレコメンドの精度を上げるわけや。
[194] P. Wang, Q. Wu, C. Shen, A. v. d. Hengel, A. Dick, "視覚質問応答のための明示的知識ベース推論," arXivプレプリント arXiv:1511.02570, 2015年.
画像に関する質問に答えるときに、知識ベースを明示的に使って推論するアプローチやねん。暗黙的にやなくて、はっきり知識を参照するのがポイントやで。
[195] L. Guo, J. Liu, J. Tang, J. Li, W. Luo, H. Lu, "画像キャプション生成のための言語的単語と視覚的意味ユニットの整合," Proceedings of the 27th ACM International Conference on Multimedia, 2019年, pp. 765–773.
画像キャプションを生成するときに、言葉の単位と画像の意味的な単位をうまく対応付ける(アライメントする)手法やねん。
[196] S. Shah, A. Mishra, N. Yadati, P. P. Talukdar, "KVQA: 知識を活用した視覚質問応答,"
[...以下テキスト省略...]
---
## Page 19
[](/attach/69b2fea2270e9023fdc9fc71de7508b0c86499993250984e243c1a8429a487fe_p019.png)
### 和訳
[翻訳エラー: ]
---
## Page 20
[](/attach/69b2fea2270e9023fdc9fc71de7508b0c86499993250984e243c1a8429a487fe_p020.png)
### 和訳
20
[258] Y. Lan, S. He, K. Liu, X. Zeng, S. Liu, J. Zhao「テキストの意味情報を使ったパスベースの知識推論で医療ナレッジグラフを完成させるで」っていう論文やねん。要するに、文章の意味をちゃんと読み取りながら、知識の道筋をたどって、医療系のナレッジグラフの足りんとこを埋めていこうって話やな。BMC Medical Informatics and Decision Making, 2021年。
[259] M. Rotmensch, Y. Halpern, A. Tlimat, S. Horng, D. Sontag「電子カルテから健康に関するナレッジグラフを学習するで」って研究やねん。ほんまに、病院の電子カルテのデータから、病気とか症状の関係をナレッジグラフとして自動で作り上げるっちゅうめっちゃ実用的な話や。Scientific reports, 2017年。
[260] S. Kapetanakis, G. Samakovitis, B. Gunasekara, M. Petridis「事例ベース推論を使って金融取引の不正を監視するで」っていう研究や。なんでかっていうと、過去の不正事例をベースにして「これ怪しいんちゃう?」って判断する仕組みやねん。2012年。
[261] M. Franco-Salvador, P. Gupta, P. Rosso, R. E. Banchs「連続空間とナレッジグラフベースの言語表現を使った多言語間の盗作検出」っていう論文やな。要は、違う言語で書かれとっても「これパクリちゃうん?」ってバレる仕組みを作ったっちゅうことやねん。めっちゃ賢いやろ。Knowledge-Based Systems, 2016年。
[262] Y. Liu, T. Han, S. Ma, J. Zhang, Y. Yang, J. Tian, H. He, A. Li, M. He, Z. Liu ほか「ChatGPT/GPT-4の研究まとめと、大規模言語モデルの将来に向けた展望」やな。これはほんまにそのまんまで、ChatGPTとかGPT-4がどんな研究されてきたかをバーッとまとめて、今後どうなっていくんやろなぁって考察した論文やねん。arXivプレプリント arXiv:2304.01852, 2023年。
[263] S. Pan, L. Luo, Y. Wang, C. Chen, J. Wang, X. Wu「大規模言語モデルとナレッジグラフを統合するで:ロードマップ」っていう論文や。これめっちゃ大事な話でな、LLM(大規模言語モデル)とナレッジグラフっていう2つの強力な技術をどうやって一緒に使っていくか、その道筋を示したロードマップ的な論文やねん。arXivプレプリント arXiv:2306.08302, 2023年。
[264] M. Yasunaga, H. Ren, A. Bosselut, P. Liang, J. Leskovec「QA-GNN:言語モデルとナレッジグラフを使った質問応答の推論」っていう研究や。これはな、質問に答えるときに言語モデルとナレッジグラフの両方を組み合わせて推論するGNN(グラフニューラルネットワーク)ベースのモデルやねん。両方のええとこ取りしてるから、めっちゃ賢く答えられるっちゅうわけや。arXivプレプリント arXiv:2104.06378, 2021年。
---
![]()
1 / 1
100%