<<
Computational Argumentation-based Chatbots a Survey

---
## Page 1
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p001.png)
### 和訳
チャットボット関連の計算論的議論に関するサーベイ
Journal of Artificial Intelligence Research 80 (2024) 1271-1310
2023年9月投稿、2024年8月出版
計算論的議論ベースのチャットボット:サーベイ論文
Federico Castagna
ブルネル大学ロンドン校、キングストンレーン、
ロンドン、UB8 3PH、イギリス
Nadin Kökciyan
エディンバラ大学、クライトンストリート、
エディンバラ EH8 9AB、イギリス
Isabel Sassoon
ブルネル大学ロンドン校、キングストンレーン、
ロンドン、UB8 3PH、イギリス
Simon Parsons
Elizabeth Sklar
リンカーン大学、ブレイフォードプール、
リンカーン、LN6 7TS、イギリス
---
**要旨**
チャットボットっちゅうのはな、ユーザーと会話形式でやり取りするソフトウェアのことで、ほんまにいろんな目的で使われとるねん。ほんで面白いことにな、この会話エージェントが「計算論的議論モデル」、つまりコンピュータが扱える形で議論を形式化する技術と組み合わされたんは、つい最近のことやねんで。この計算論的議論っていうのは、人間同士のコミュニケーションで普通に行われとる情報のやり取りを、機械が読める形にするのが目的なんよ。チャットボットは議論の仕組みをいろんな程度で、いろんなやり方で使えるわけやな。この論文ではな、そういう議論ベースのボットに関する文献をくまなく調べて、普通のチャットボットと比べてどんなメリットやデメリットがあるんかを整理しとるねん。ほんで将来的にTransformerベースのアーキテクチャとか、最新の大規模言語モデル(LLM)とどう統合できるかの展望も描いとるで。
---
**1. はじめに**
チャットボットっちゅうのはな、人間との会話を真似するように設計された会話ソフトウェアで、主にオンラインでの案内やサポートを自動化するために使われとるねん(Caldarini et al., 2022)。このコンピュータプログラムは、入力に基づいて応答を生成して、テキストか音声で返事を返すんよ(Sojasingarayar, 2020; Bala et al., 2017)。ほんで、チャットボットって呼ばれるためには、特定の機能を満たさなあかんねん。会話エージェントとして、まずユーザーの言うてることを理解できなあかん(理解力)、知識ベースにアクセスできなあかん(能力)、ほんでユーザーの信頼を高めるために「人間っぽい効果」を提供せなあかんねん(存在感)(Cahn, 2017; Sansonnet et al., 2006)。今日では、このボットたちはバーチャルエージェントとして私らの生活に馴染み深いツールになっとるで。質問への回答からEコマース、情報検索から教育タスク、新しい産業ソリューションの開発(Dale, 2016)からスマートオブジェクトの接続(Kar & Haldar, 2016)まで、めっちゃ幅広くサポートしてくれるんよ。この10年間の様々な投資、ソフトウェアとハードウェア両面での技術進歩、そしてより効率的な機械学習(ML)モデルの開発、特に最新のTransformerベースのアーキテクチャ(Vaswani et al., 2017)の登場が、この発展に貢献してきたんやな。
©2024 著者ら。AI Access Foundationよりクリエイティブ・コモンズ表示ライセンス CC BY 4.0 のもと出版。
---
## Page 2
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p002.png)
### 和訳
Castagna、Kökciyan、Sassoon、Parsons、Sklar
チャットボットの設計と実装の研究分野はめっちゃ順調に成長してきてんねん。約60年前にELIZAがリリースされてから、ほんまにいろんな進歩があったわけやけど、このELIZAっていうのが世界初の会話エージェントやって広く認められてるねん(Weizenbaum, 1966)。
チャットボットと関連した議論の計算モデルの研究は、最近になってようやく研究者たちの注目を集め始めたところやねん。計算論的議論(Rahwan & Simari, 2009)っていうのは、人工知能(AI)の分野で、結論を裏付ける証拠から結論を導き出す推論のメカニズムとして使われてきたんや。これ、日常の人間同士のやり取りに近い直感的なアプローチでありながら、議論の交換中に起こる矛盾する情報をモデル化する正式な方法でもあるから、今のボットの振る舞いを強化するのにめっちゃ適した手法になるはずやねん。この組み合わせのメリットとしては、より自然な会話、応答の一貫性、戦略的な情報伝達なんかがあるで。議論のセマンティクスを評価することで、今どきの最先端の会話エージェントで使われてるブラックボックスな大規模言語モデル(LLM)よりも、もっと透明性のある形で返答の根拠を示せるようになるんや。近年、ChatGPT1の各バージョンみたいな最先端技術による実装が登場して、現状では議論ベースの会話エージェントを性能で上回ってるのは確かやねん。せやけど、ここでワシらがやるみたいにじっくり見てみると、こういう最新の高度なモデルにもまだまだ改善の余地がいっぱいあることがわかるし、計算論的議論の形式手法と統合することで今の欠点(説明可能性の欠如とか)を解決できる可能性があって、チャットボットの新世代を切り開くかもしれへんねん。ワシらの知る限り、計算論的議論とチャットボットを組み合わせた調査論文はこれが初めてやで2。ワシらの主な貢献は、関連文献の徹底的な調査と、そこから導き出せる知見にあるんや。
この論文の構成はこうなってるで。まず第2節で、関係する基本的な理論概念についての背景情報を紹介するねん。第3節では、関連論文をレビューするために採用した方法論について議論するで。第4節では、計算論的議論を活用した会話エージェントの詳細な分類と分析を行うんや。第5節では、ワシらの発見と議論ベースのチャットボット研究分野の将来の方向性について包括的に検討して、第6節で最終的なまとめをして調査を締めくくるで。
2. 背景
以下の背景では、計算論的議論の簡潔なまとめと、チャットボットの歴史、分類、主な特徴の概要を扱うで。ここで提供する情報は、次のセクションで行う分析に役立つはずや。各会話エージェントは、ここで示す特定の議論の使用方法に従って分類されることになるねん。
2.1 計算論的議論
「議論の計算モデル」という用語は、いろんなアプローチを包含してるんやけど、どれも議論とその使い方という概念を中心に展開されてるねん。
1. https://chat.openai.com/
2. ちなみに、簡単のために「計算論的議論ベースのチャットボット」よりも「議論ベースのチャットボット」という用語を使うことが多いけど、意味は同じやで。
1272
---
## Page 3
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p003.png)
### 和訳
計算論的議論ベースのチャットボット:サーベイ
この研究分野はな、もともとPollockさんとDungさんが議論を体系的にまとめたところから始まってんねん(Pollock, 1987; Dung, 1995)。めっちゃ豊かな学際的な環境になってて、哲学(Walton, 1990; Mercier & Sperber, 2011)、法学(Bench-Capon et al., 2009)、言語学(Lawrence & Reed, 2020)、形式論理学(Lin & Shoham, 1989)、ゲーム理論(Rahwan & Larson, 2009)とか、いろんな分野が絡み合ってんねん。
計算論的議論の範囲内でな、主に2つの研究目標があんねん:(a) コンピュータプログラムのモデリングを通じて、議論っていう認知現象を理解すること、そして (b) 議論に関連する活動によって、人間とコンピュータのやり取りの発展を支援すること(Prakken et al., 2020; Dutilh Novaes, 2022)。
Dungさんのパラダイム(Dung, 1995)によるとな、議論っていうのは非単調推論——つまり「新しい情報が入ってきたら、前の結論が覆ることもあるで」っていう柔軟な推論——を形式化するのにめっちゃ適した手段やと考えられてんねん。特に、人間が矛盾する情報をどうやって弁証法的に——ようは対話的にやり取りしながら——処理するかを示すときに役立つんや。このアプローチの核心は、議論フレームワークの定義に支えられてて、そこでは議論は抽象的な存在として扱われんねん:
**定義1(抽象的議論フレームワーク(Dung, 1995))** 議論フレームワーク(AF)は次のペアやねん:AF = ⟨AR, C⟩ ここでARは議論の集合で、CはAR上の「攻撃」二項関係、つまり C ⊆ AR × AR やねん。
議論フレームワークはグラフとして描けんねん。各ノードが議論で、有向エッジがフレームワーク内で衝突してる議論同士をつないでるんや。この形式主義が伝えたいアイデアは、正しい推論は主張の「受容可能性」で表現されるっていうことやねん:議論が正当化されるのは、あらゆる反論に対して防御されてる場合だけなんや。
**定義2(抽象的議論フレームワークの意味論(Dung, 1995))** AF = ⟨AR, C⟩ として、S ⊆ AR を議論の集合とするわな。また (X,Y) ∈ C は議論Xとそのターゲット Yの間に存在する衝突を表すで:
• Sが**衝突なし(conflict-free)**であるとは、すべてのX, Y ∈ Sについて (X, Y) ∉ C のときやねん。ようは、集合内の議論同士がお互いを攻撃してへんってことや。
• X ∈ AR がSに対して**受容可能(acceptable)**であるとは、Xを攻撃するすべてのY ∈ AR(つまり (Y, X) ∈ C となるY)に対して、そのYを攻撃するZ ∈ Sが存在するときやねん。要するに、Xに文句言うてくるやつがおっても、味方のZがそいつをやっつけてくれるってことや。
• 衝突なしの拡張Sが**許容拡張(admissible extension)**であるとは、X ∈ S ならばXがSに対して受容可能であるときやねん。
• 許容拡張Sが**完全拡張(complete extension)**であるとは、すべてのX ∈ AR について、XがSに対して受容可能ならば X ∈ S となるときやねん。集合包含に関して最小の完全拡張は**基底拡張(grounded extension)**って呼ばれてて、最大の完全拡張は**優先拡張(preferred extension)**って呼ばれてんねん。
• **安定拡張(stable extension)** Sとは、すべてのY ∈ AR について、Y ∉ S ならば、(X, Y) ∈ C となるX ∈ Sが存在するときやねん。つまり、仲間に入ってへん議論は全部、仲間の誰かにやられてるってことや。
さらにな、議論フレームワークは何かの論理言語の論理式でインスタンス化できんねん。このインスタンス化がきっかけで、いろんな研究が生まれてん(例えば、Besnard and Hunter, 2008; Modgil and Prakken, 2013; Toni, 2014)。これらは**構造化議論**って呼ばれてて、さっき紹介した抽象的アプローチとは対照的なもんやねん。議論の内部構造は普通、(1つ以上の)前提、結論、そして一連の
1273
---
## Page 4
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p004.png)
### 和訳
ほな、説明していくで!
カスタニャ、コックチヤン、サスーン、パーソンズ、スクラーの研究やねん。
推論ルール(厳密なやつとか反駁可能なやつとか)を使って、前提から結論につなげていくんや。さっき説明した意味論をそのまま使って、構造化された議論フレームワークを評価して、正当化された議論を計算できるっていう話やな。
**例1** 図1に書いてある抽象的な議論フレームワーク(AF)を見てみてや。ほんなら、定義2で説明した意味論に従うと、こんな拡張が出てくるんや:
許容的(admissible)= ∅、{a}、{b}、{e}、{a, e}、{b, e}
完全(complete)= {e}、{a, e}、{b, e}
基底(grounded)= {e}
選好(preferred)= {a, e}、{b, e}
安定(stable)= {a, e}
図1:抽象的議論フレームワークやで。
**2.1.1 議論マイニング**
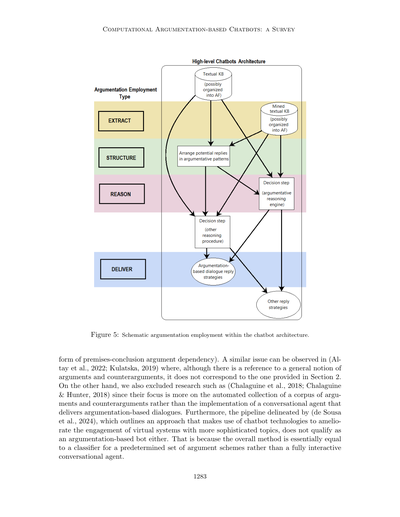
議論(アーギュメンテーション)マイニングっていうのは、「話の流れを語用論のレベルで分析して、特定の議論理論を適用して、手元のデータをモデル化して自動で分析する一般的なタスク」って定義されてるんや(ハバナル&グレビッチ、2017)。議論マイニング(AM)は、ざっくり言うと、自然言語で書かれた議論とその関係をテキストから見つけ出す研究分野やねん。最終的には、議論の計算モデルで機械が処理できる構造化されたデータを提供するのが目標やな(カブリオ&ヴィラタ、2018)。図5に描いてあるように、AMのパイプラインは大きく分けて2つの段階があるんや:議論の抽出と関係の予測やな。
AMフレームワークをもうちょっと詳しく説明すると、複雑さが増していく順にタスクを並べることができるんや。まず最初に、テキストを分割して、その要素が議論的かどうかを分類するところから始まるんやな。ほんで、個々の議論の構成要素(前提、主張、主要主張、証拠とか、マイヤーらが2020年に示したようなやつ)を特定できるようになるんや。その次のステップでは、さっき検出した議論の構成要素に対して、節の性質と関係の性質を認識していくんやで(ローレンス&リード、2020)。特に、サーダットヤズディ、パン、コックチヤンの研究が重要やな。
1274
---
## Page 5
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p005.png)
### 和訳
計算論的議論に基づくチャットボット:サーベイ
外部の常識的な知識を使うと、暗黙の推論を明らかにすることで議論間の関係を見つけ出すのにめっちゃ役立つってことが示されてるねん(Saadat-Yazdiら、2023年)。文献で提案されてるモデルには、LSTM(Long-Short Term Memory、長期短期記憶)モデル(CocarascuとToni、2017年)、事前学習済みトランスフォーマー(Ruiz-Dolzら、2021年;Saadat-Yazdiら、2023年)、それと論理ルールに基づくシステム(Joら、2021年)なんかがあるんや。全体的に見て、AMってのは、テキストの塊から議論フレームワーク、つまりグラフを作り出すのにめっちゃ便利やねん。ほな次は、AMパイプラインの中の議論抽出段階についてもうちょっと具体的に分析していくで。
例2 (CabrioとVillata、2018年)で示された政治討論の例を参考に、個々の議論を見つけ出すには2つのステップを踏むんやでってことを示す例を紹介するわ。まず(S1)は、前提とか主張みたいな議論の構成要素を検出すること、(S2)は、関係ない言葉を除外して、それぞれの具体的なテキスト上の境界を認識することやねん。以下では、太陽エネルギーの使用に関する例にS1とS2を適用して、議論(Arg)を抽出する方法を見せるで。ちなみに(C)は結論を、(P)は前提を区別してて、太字と下線はそれぞれの境界を示してるんや。
(S1) 「彼女はソーラーパネルについて話してる。うちの国は太陽光発電の会社に投資した。それは大失敗やった(C)。あれでめっちゃお金失ったんや(P)。いや見てくれ、俺はあらゆる形のエネルギーを信じてるで(P)、でも多くの人が仕事を失ってるんや(P)。」
(S2) 「彼女はソーラーパネルについて話してる。うちの国は太陽光発電の会社に投資した。**それは大失敗やった**。**あれでめっちゃお金失ったんや**。いや見てくれ、**俺はあらゆる形のエネルギーを信じてるで**、でも**多くの人が仕事を失ってるんや**。」
(Arg) [なんでかっていうと]あれでめっちゃお金失ったし、[確かに]俺はあらゆる形のエネルギーを信じてるけど、[それでも]多くの人が仕事を失ってるんや。[せやから結論として]あれは大失敗やったってことやねん。
図2:架空のテキストを使った議論マイニングパイプラインの例
1275
---
## Page 6
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p006.png)
### 和訳
Castagna、Kökciyan、Sassoon、Parsons、それからSklar
2.1.2 論証スキーム
論証スキーム(AS)っていうのは、AIの研究でめっちゃ調べられてきて、実際に使われてきたもんやねん。これ何のためかっていうと、マルチエージェント、つまり複数のAIとかが絡み合う場面で、「推定的な推論」をストレートに伝えるためのもんなんや(例えば、Atkinsonらの2006年の研究とか、Tolchinskyらの2012年、Grandoらの2013年、Kökciyanらの2018年と2021年の研究とかな)。それぞれの論証スキームには、「批判的質問(CQs)」っていう独特のセットがあんねん。これは攻撃的な議論として表現されるもんで、何のためかっていうと、そのスキームの具体的な使い方が妥当かどうかを確認するためなんや(で、その妥当性は意味論的に「受け入れられるかどうか」を計算して評価すんねん)。論証スキームの分類の仕方は研究者によっていろいろあるねんけど(例えばWaltonらの2008年、WaltonとMacagnoの2015年、Wagemansの2016年とかな)、みんな共通して言うてることがあんねん。それは、こういうスキームっていうのは推論のパターンを表してて、それを使うと自然言語で書かれた文章を理性的で筋の通った議論に組み立てられるっちゅうことや。そうすることで、対話の体系的な要素を生み出せるわけやな。
例3 医療分野での論証スキームの例として、「提案された治療のための論証スキーム(ASPT)」を見てみよか。これはSassoonらが2021年に示したもんで、それに対応する批判的質問もあんねん。ASPTをどう具体的に使うかの妥当性は、それぞれの批判的質問にどう答えるかで決まるんやで。
ASPT
前提:患者の事実Ftがあるとして
前提:目標Gを達成するために
前提:治療TはゴールGの達成を促進する
結論:治療Tは検討されるべきである
CQ1:治療Tは過去にその患者に試されて、うまくいかんかったことあるか?
CQ2:治療Tはその患者に副作用を起こしたことあるか?
CQ3:患者の事実Ftを考慮すると、治療Tに対して禁忌ってあるか?
CQ4:同じ目標Gを達成するための別の方法ってあるか?
批判的質問を使って論証スキームを評価するやり方には2種類あんねん。WaltonとGordonが2011年に示した最も信頼されてる理論によると、(a)イニシアチブ・シフティングと(b)バックアップ・エビデンスっていうのがあるんや。
(a)批判的質問を投げかけたら、すぐに主導権が提案者側に移るんや。提案者は答えを出さなあかんくて、もし答えられんかったらその議論は負けたことになるねん。つまりな、質問するだけで一時的にその議論を打ち負かせるっちゅうことや。せやけど、提案者には議論の妥当性を取り戻すチャンスがあって、批判的質問に適切に答えられたら復活できるんやで。
(b)一方で、もう一つの理論はちょっと違うこと言うてんねん。批判的質問を投げかけるだけでは議論を打ち負かすには足りへんっていう考え方や。その質問が異議を唱えられた場合、何らかの証拠で裏付けせなあかんねん。そうして初めて、議論を打ち負かすような立証責任を相手に移せるっちゅうわけや。
1276
---
## Page 7
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p007.png)
### 和訳
ほな、計算論的議論チャットボットの調査の続きいくで!
最後にな、もともとは違う目的で作られた概念やねんけど、議論スキームってやつの重要性が計算論的議論のコミュニティでもめっちゃ注目されとるねん(Visserらが2018年に言うとったやつや)。これ、テキストマイニングのタスクにも使われとるんよ(Walton、2012年)。
**2.1.3 議論推論エンジン**
計算論的議論の一番の目的はな、矛盾する知識を解決して、一番適切な(つまり正当化された)情報を選べるようにすることやねん。「決定っていうのは、世界についての競合する信念の間で選ぶか、代替となる行動方針の間で選ぶかってことやねん。[...]推論プロセスがな、それぞれの候補(信念とか行動とか)に対して賛成・反対の議論を生成するわけや。ほんで意思決定では、その根底にある議論に基づいて候補をランク付けして評価して、最終決定として一つの候補を選ぶねん。最後に、その決定によって、ある状況についての新しい信念か、特定の方法で行動しようという意図にコミットするわけや。」(Foxらが2007年に言うとった)。意思決定プロセスはな、問題としてエンコードできて、その解決策は議論フレームワーク(AF)の計算と評価によって導き出されるねん。議論エンジンっていうのは、基本的に同じロジックで動く推論ツールやと思ってもらったらええわ。結果として得られる「受け入れ可能なエンティティ」がな、ある選択に対する説得力のある根拠を賛成・反対両方から提供してくれて、しかも更なる検討の余地も残してくれるねん(Dixらが2009年に言うとった)。こういう議論ベースの意思決定装置はな、敗北可能推論に関わる現実世界のソフトウェアアプリケーションにめっちゃ役立つ追加機能になるって、BryantとKrauseの包括的な研究(2008年)でも主張されとるで。
計算論的議論に基づく推論エンジンは、大きく分けて2種類あるねん:
• **「ソルバー」** - これはな、特定のアルゴリズム問題をエンコードして答えを出す専門的なソフトウェアや。特にな、選んだセマンティクスσに従って計算論的議論関連の推論課題に取り組むねん。例えばな、AFの中でσ-拡張を列挙したり、特定の議論が少なくとも一つのσ-拡張に属するか(懐疑的じゃない方)、全てのσ-拡張に属するか(懐疑的な方)を調べたりするやつや。ソルバーの例としては、AFGCN(Malmqvist、2021年)、A-Folio DPDB(Fichteら、2021年)、ASPARTIX-V21(Dvořákら、2021年)、ConArg(Bistarelliら、2021a)、FUDGE(Thimmら、2021年)、HARPER++(Thimm、2021年)、MatrixX(Heinrich、2021年)、μ-toksia(NiskanenとJärvisalo、2021年)、PYGLAF(Alviano、2021年)とかがあるで。
• **「パノプティックエンジン」** - これはな、追加機能とかカスタマイズツールを実装するように設計されたソルバーやねん。例えばArguLab(Podlaszewskiら、2011年)、ArgTrust(Tangら、2012年)、Argue tuProlog(Bryantら、2006年)、IACAS(Vreeswijk、1994年)、CaSAPI(GartnerとToni、2007年)、Prengine(Hung、2017年)、PyArg(Borgら、2022年)、NEXAS(Dachseltら、2022年)とかがあるわ。
**例4** ASPソルバーのASPARTIXがな、こういう議論駆動型推論エンジンの例やねん。AFを入力として受け取って、Answer-Set-Programmingソルバーが、特定のセマンティクス(両方ともASPルールとしてエンコードされとる)に基づいて、指定された推論タスクの結果を出力するんや。
言うとかなあかんのは、これらのエンジンのほとんどがプランニング機能も組み込んどるってことやな。これはAFフォーマリズムを基盤として使っとることから来とるねん。なんでかっていうと、受け入れ可能な議論を計算することでな、複数の選択肢の中から決定して、あらかじめ決められた目標を達成するための「議論的経路」が可能になるからやねん。接続するエッジをたどっていくことで...
1277
---
## Page 8
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p008.png)
### 和訳
ほな、これ翻訳していくで!
---
Castagnaさん、Kökcıyanさん、Sassoonさん、Parsonsさん、Sklarさんの論文やねんけどな。
**図3**: 議論推論エンジンのアーキテクチャの例やで(Dvořákらが2020年に出したやつな)。
AFっていう議論フレームワークの中で「正当化されたノード」を選ぶと、反論の可能性を全部排除できるねん。せやから確実に成功する戦略が取れるわけや。どういうことかっていうと、各推論ステップは「引数」として囲まれて表現されるんやけど、そのとき常に「最終的に一貫した結論に辿り着くためには全体としてどういう計画がいるか」っていうことを意識しながら処理していくねん。
### 2.1.4 議論ベースの対話
「計算」っていうもんを「分散認知と相互作用」として捉える見方が広まったことで、マルチエージェントシステムっていうパラダイムが生まれてきたんや。ここでいう「エージェント」っていうのは、変化が激しくて予測しにくい環境の中でも柔軟に自律的に動けるソフトウェアのことやねん(Luckらが2005年に言うてる)。こういう賢いエージェント同士がコミュニケーションする手段として、形式的な対話が選ばれたんや。なんでかっていうと、一定のルールに従いながらも、めっちゃ表現力があるからやねん(McBurneyとParsonsが2009年に説明してる)。
議論ベースの対話っていうのは、参加者同士がルールに従ってやり取りするもんや。参加者ってのは、それぞれ自分の信念とか目標とか欲求を持ってて、相手プレイヤーについての情報は限られてるエージェントのことな。で、順番に発言していくねん。表1に載ってるように、こういう対話は普通、いくつかの要素で分類されるんや。たとえば、対話が始まるときに参加者がどんな情報を持ってるか、各自の目標は何か、他のエージェントと共有してる知識や目標は何か、とかやな(WaltonとKrabbeが1995年にまとめてる)。
| 対話の種類 | どんなもんか | 例 |
|:--|:--|:--|
| **情報探索** | XがYに何か質問の答えを求めるやつ | (Hulstijn, 2000) |
| **調査** | XとYが協力して何かの質問に答えるやつ | (Black & Hunter, 2007) |
| **説得** | XがYに「この主張を受け入れてくれ」って説得するやつ | (Prakken, 2006) |
| **交渉** | XとYが限られた資源をどう分けるか駆け引きするやつ | (McBurney et al., 2003) |
| **審議** | XとYが協力して「どんな行動を取るべきか」を決めるやつ | (McBurney et al., 2007) |
| **口論** | XとYが不満をぶつけ合って言い争うやつ | (Blount, 2018) |
| **検証** | XがYの信念をチェックしたいやつ | (Cogan et al., 2005) |
| **クエリ** | XがYに「お前の議論を聞かせてくれ」って突っ込むやつ | (Cogan et al., 2005) |
| **命令** | XがYに「これやれ」って指示するやつ | (Girle, 1996) |
| **教育** | XがYに何かを教えたいやつ | (Sklar & Parsons, 2004) |
| **偶発的発見** | XとYのやり取りの中から新しいアイデアが生まれるやつ | (McBurney & Parsons, 2001) |
**表1**: 既存の対話タイプの説明やで。
1278
---
## Page 9
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p009.png)
### 和訳
計算論的論証ベースのチャットボット:サーベイ
いろんな対話タイプの選択とか、それらの間の切り替えは「制御レイヤー」っちゅうもんで実現できるねん(McBurney & Parsons, 2002; Sklar & Azhar, 2015)。これは基本的な対話タイプと制御対話っていう部品で定義されてるんやけど、後者の制御対話っていうのはメタ構造みたいなもんで、他の対話そのものを話題にして、プロトコルの組み合わせとか切り替えの管理を助けてくれるんやな。
ほんで一般的に、論証ベースの対話の主要なパーツは次の3つに分けられるねん:
(i) 構文論、これは発話がどう使えるか、発話同士がどう関わり合うかを扱うもん;
(ii) 意味論、これは対話の具体的な目的とか最終的にどう使うかによって変わってくるやつ;
(iii) 語用論、これは言葉の中で真偽に関係ない部分、たとえば発話の「発話内行為の力」みたいなもんを扱うんやな(McBurney & Parsons, 2013)。簡単に言うたら、「何を言ってるか」だけやなくて「どういう意図で言ってるか」みたいなことやで。
2.2 チャットボット
チャットボットはまずユーザーの入力を解析して、それが何を意味してるか解釈してから、適切な返答や出力を返さなあかんねん(そうやって「チャット」が始まるわけや)。ボットがどうやって返事を作るかは、その「応答アーキテクチャモデル」によって決まるんやな。いろんな研究(Adamopoulou & Moussiades, 2020; Singh & Thakur, 2020; Klopfenstein et al., 2017; Codecademy, 2022)を参考にすると、そのモデルは次のように分類できるで:
• **ルールベースのチャットボット**:これが一番シンプルな応答アーキテクチャモデルやねん。ボットの返事は全部あらかじめ決まってて、一連のルールに従ってユーザーに返されるんや。こういうルールベースのソフトの内部構造は、対話の各ステップで取り得る出力がはっきり定義された決定木みたいに考えられるで。普通、このカテゴリの会話エージェントは、ユーザーがあらかじめ用意された選択肢から選ぶタイプのやり取りを扱うんやな。ルールベースの会話エージェントの例としては、ELIZA(Weizenbaum, 1966)があるで。研究者からは最初のチャットボット実装やって言われてて、言語ルールとユーザー入力から認識したキーワードを組み合わせて動くんや。その後の発展でPARRY(Colby et al., 1971)っていうチャットボットが出てきて、これはELIZAを改良して、妄想症の人をシミュレートする会話戦略を組み込んだもんやねん。Jabberwacky(Carpenter, 1982)もルールベースのボットの一例で、文脈に基づくパターンマッチングで対話するんや。いろんなユーザーとの過去の会話からトークンを集めて、データベースをどんどん拡張していくんやで。
• **検索ベースのチャットボット**:こっちはもうちょっと複雑な応答アーキテクチャモデルやねん。ボットの返事は、保存された文章のコーパス(要するに大量の文章データ)から引っ張ってくるんや。機械学習と自然言語処理(NLP)モデルを使ってユーザー入力を解釈して(この操作は「意図分類」と「エンティティ認識」に分かれてるで)、一番ふさわしい返答を決めて取り出すんやな。検索ベースの会話エージェントの例としては、A.L.I.C.E.(Wallace, 2009)があるで。これはArtificial Intelligence Markup Language(AIML)(Wallace, 2003)っていう言語を使って開発されたんや。この言語はデータオブジェクトのクラスを含んでて、刺激-応答テンプレートを通じてそれを処理するコンピュータプログラムの動作を部分的に記述してるねん。さらに、IBMのWatson Assistant(IBM, 2006)やMicrosoftのCortana(Microsoft, 2014)も検索ベースアーキテクチャの例やで。前者は入力を解析して統計的に
1279
---
## Page 10
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p010.png)
### 和訳
Castagna、Kökciyan、Sassoon、Parsons、Sklarの論文より
データベースから関連する返答を引っ張ってくるんやけど、これは並列アルゴリズムっていう仕組みを使ってるねん。もう一つの方式は、Tellme's Network(2007年からマイクロソフトが持ってるやつな)の自然言語処理能力と、Satoriっていう知識の貯蔵庫を活用して返事を返すタイプやねん(Marshall, 2014)。
・**生成型チャットボット**っていうのが、一番進んだ返答システムやねん。このボットらは、既存のテキストに頼るんやなくて、ユーザーの入力をもとに自分でオリジナルの返答を作れるんや。ディープラーニングっていう深層学習の仕組みを使って、「この単語の次に来そうなんはこれやな」って確率を計算して、ちょうどええ返答を出してくれるわけ。せやけど、こういうモデルを訓練するには時間かかるし、なんでその返答が出てきたんかよう分からんこともあるねん。しかも返事が同じことの繰り返しになったり、意味不明なこと言い出したりすることもあるんや。それに加えて、生成型ボットは基本的に、自分のモデルのパラメータに埋め込まれたデータ以外にはアクセスでけへんねん。この問題をなんとかするために、検索型と生成型の両方を組み合わせるっていうやり方がよう使われてるで(Roller et al., 2020)。こういうハイブリッド型のバーチャルアシスタントの例としては、AppleのSiri(Apple, 2011)とAmazonのAlexa(Amazon, 2014; Lopatovska et al., 2019)があるな。どっちもユーザーの質問に答える機能(他にもめっちゃいろんなことできるけどな)を、ディープラーニングで処理するか、WolframAlphaみたいな外部サービスにお願いするかして提供してるねん(Heater, 2018)。
**生成型LLM**について。大規模言語モデル(LLM)をベースにした生成型チャットボットは、最近めっちゃ注目されてるから特別に触れとかなあかんねん。Transformerアーキテクチャ(Vaswani et al., 2017)っていう仕組みが設計・導入されたことで、「事前学習」と「ファインチューニング」っていう学習方法にパラダイムシフト、つまり根本的な考え方の転換が起きたんや(Zhao et al., 2023)。事前学習済みモデルをでっかくスケールアップしていったら、LLMとそのすごい能力が発見されたわけ(Brown et al., 2020; Touvron et al., 2023a, 2023b; Anil et al., 2023; Reid et al., 2024; Meta, 2024)。こういう新しい技術を活用して、あの有名なChatGPT³みたいな会話AIが登場して、情報抽出タスク(Li et al., 2023)、自然言語推論、質問応答、対話タスク(Qin et al., 2023)、機械翻訳(Jiao et al., 2023)で、これまでのベンチマークや先輩たちをほとんど超えてもうたんや。そうは言うても、LLMとそれをベースにしたチャットボットにはいろいろ問題もあるねん(Frieder et al., 2023; Bang et al., 2023; Wei et al., 2022a; Ji et al., 2023; Zhuo et al., 2023)。具体的には:推論がおかしくなること、今まで見たことない能力が急に現れること(これを「創発能力」⁴って呼ぶねん)、意味不明やったり事実と違う返答すること(いわゆるハルシネーション、幻覚やな)、偏見があったり有害なコミュニケーションすること、訓練コストがめっちゃ高いこと、二酸化炭素排出量がえげつないこと⁵とかがあるねん。最後に、GPT-3(Brown et al., 2020)みたいな基盤モデルは、ちゃんとした説得力のある議論を作るのは苦手やっていうことも示されてるねん(Hinton & Wagemans, 2022)。せやけど、こういうモデルの出力は、議論マイニング(テキストから議論構造を抽出する作業な)をサポートするのには特に向いてるかもしれんねん。
³ 他にも注目すべき例としては、DialoGPT(Zhang et al., 2019)、BlenderBot 3x(Xu et al., 2023)、Gemini 1.5(https://gemini.google.com/)、Claude 3.5 Sonnet(https://claude.ai/)、Llama 3.1-Instruct(https://www.meta.ai/)、Mistral-7b-Instruct(Jiang et al., 2023)、Zephyr-7b(Tunstall et al., 2023)があるで。
⁴ 創発能力については議論があって、そもそも存在せえへんって主張する研究もあるねん(Schaeffer et al., 2023)。
⁵ ただし、モデル訓練のベストプラクティスを採用したら、2030年までに二酸化炭素排出量を減らせるって言われてるで(Patterson et al., 2022)。
1280
---
## Page 11
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p011.png)
### 和訳
計算論的議論ベースのチャットボット:サーベイ論文
気ぃつけて条件設定したり、入力の数を増やしたりしたらちゃんと動くんやけどな(de Wynter & Yuan, 2023; Chen et al., 2023)。
図4:いろんな応答アーキテクチャモデルの比較やで。見てもうたらわかるけど、生成系チャットボットってだいたいデコーダーだけの形式で、エンコーダーだけの形式を使うんはめっちゃレアやねん。
図4には、いろんなチャットボットの応答アーキテクチャモデルと、それぞれの特徴となる高レベルな処理が描かれとるわ。さっきもちょろっと言うたけど、会話エージェントが複数の応答モデルを組み合わせて使うんはめっちゃよくある話やねん。なんでかっていうと、そのほうがええ結果出せるからやな。ほんで、チャットボットは扱える会話のトピックでも分類できるんやで。クローズドドメイン、つまり特定分野に限定されたやつ(例えばカスタマーサポートとかECサイト用のボット)は、決まったテーマの中でしか返答でけへん。でもな、専門分野がはっきりしとるぶん、こいつらはだいたいめっちゃ質のええ返答してくれるんよ。一方で、オープンドメインのチャットボット、例えばさっき挙げたAppleのSiri、AmazonのAlexa、MetaのLlama 3.1、GoogleのGemini、OpenAIのChatGPT、あとMeena(Adiwardana et al., 2020)、Mitsuku(Worswick, 2018)、MicrosoftのXiaoIce(Zhou et al., 2020)なんかは、どんな話題でもいけるはずやねん。リアルの人間同士の会話みたいにな。ただな、こういうボット作るんはほんまに簡単ちゃうくて、エラー起こしやすいし、ちぐはぐな返答したり(注6参照)、さっき言うた生成系LLMと同じような問題抱えとるんよ。
2.2.1 知識ベースの獲得
チャットボットって、特定の知識ベースがないと自動で返答生成でけへんねん。これ、検索ベースのやつだけの話やと思うかもしれんけど、ちゃうで。全部のタイプの会話エージェントに当てはまる話やねん。ルールベースのアーキテクチャは、チャットボットのスクリプトにデータをハードコーディング、つまり直接書き込まなあかんし、生成系は
注6:こういうエラー、めっちゃヤバい結果になることもあるんよ。例えば医療系チャットボットが患者に「自殺しろ」って提案したケースがあってん。(Daws, 2020)
1281
---
## Page 12
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p012.png)
### 和訳
カスターニャ、コクチャン、サスーン、パーソンズ、スクラー
こういうモデルってな、学習させるためのデータベースが絶対必要やねん。でもな、そんな知識ベースを作るには、めっちゃデータ集めなあかんくて、これがほんまにお金かかるし、えらい手間もかかるわけよ。特にな、次のセクションで詳しく話すことを先取りすると、議論ベースのチャットボットの中には、知識ベースが引数のセット(言い換えたら引数グラフやな)でできてるやつがあんねん。で、そのデータを集める今の方法としては、文書から引数を自動抽出する「アーギュメントマイニング」ってやつ(例えばCocarascuら2019年とかTrautmannら2020年の研究)か、研究者が手作業でテキストをコード化するやり方(例えばCeruttiら2016年とかRosenfeldとKraus2016年)があんねん。
これがまた、特に合成データやなくて現実世界の引数だけを扱わなあかん時は、めっちゃ難しい作業になんねん。つまりな、ウェブ上で特定のトピックについての質の高い引数を見つけるんが難しかったり、特定の主張を誰が言うたか(その人の属性も考慮せなあかんし)を区別するんが問題になったりするわけや。アンケートとか個人インタビューで解決できるかもしれんけど、それもお金かかるし、人手もめっちゃ必要やねん。
ほんで面白いことにな、ChalaguineとHunter(2018年)やChalaguineら(2018年)の研究で、この問題を解決する別の方法が提案されてんねん。彼らの研究結果によると、専門知識がほとんどないか全くないチャットボットでも、いろんなユーザーから引数と反論を引き出すことができて、引数収集のプロセスを自動化できるんやって。著者らが「アーギュメントハーベスティング(引数収穫)」って呼んでるこの手順を使うと、必要な分野の知識ベース情報を組み込んだ議論フレームワーク(AF)を生成できんねん。もう一つの別のアプローチとしては、ChalaguineとHunter(2019年)の研究があって、クラウドソーシングを使ってグラフ構造で大量の質の高い引数を獲得する方法が説明されてるで。
3. 方法論
このサーベイは、議論ベースのチャットボットに関する論文を集めてレビューすることが軸になってんねん。調査結果を詳しく見ていく前に、何を調べてるんかについて、誰もが納得できる定義を示しとくのが役立つと思うわ。
**定義3(計算論的議論ベースチャットボット)** ワイらが計算論的議論ベースチャットボットと見なすのは、以下のことをするために議論モデルを使う会話エージェントのことや:(i) アーギュメントマイニングツールでテキストデータを抽出する、(ii) 議論テンプレートを使って情報を構造化する、(iii) 引数の意味論を使って推論する、そして/または (iv) 議論ベースの対話を通じてユーザーに返答を提供する。
会話エージェントのアーキテクチャ内での議論の使われ方を図式的に表したんが図5やで。ここでは、チャットボット設計全体の中で各側面がどのレベルで動作するかが示されてんねん。アーギュメントマイニングは、テキストから情報を抽出することで、モデル学習用のデータベースや知識ベース(KB)の構築を可能にすんねん。KBのデータは議論パターンに構造化できて、それが推論ステップ(通常は引数の意味論計算を含む)で選択された後、議論ベースの対話の返答として、やり取りしてるエンドユーザーに届けられるって流れや。
注意してほしいんやけど、ワイらはこういう側面を含む論文だけを厳密に選んでて、チャットボットに関する他の記事とか、第2節で紹介したんとは違う意味での「議論」を扱う記事は避けてんねん。例えば、ToniucとGroza(2017年)の研究は調査対象の論文には含めてへんねん。なんでかっていうと、ここで説明してる計算論的議論を扱ってへんからや(彼らが示してるテキスト含意関係は議論に変換できるかもしれんけどな)。
1282
---
## Page 13
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p013.png)
### 和訳
図5:チャットボットの構造ん中で議論がどう使われてるかの図式や。
前提と結論の議論の依存関係っていう形でな。似たような問題が(Altay et al., 2022; Kulatska, 2019)でも見られるねんけど、ここでも「議論」とか「反論」っていう一般的な概念には触れてるものの、それが第2章でワシらが説明した定義とは違うもんやねん。
一方でな、(Chalaguine et al., 2018; Chalaguine & Hunter, 2018)みたいな研究も除外したんやけど、なんでかっていうと、あれは議論と反論のコーパス(データ集みたいなもんや)を自動で集めることがメインで、議論ベースの対話を実際にやってくれる会話エージェントの実装とはちゃうからやねん。
ほんで、(de Sousa et al., 2024)が示してるパイプライン(処理の流れのことな)もあるんやけど、これはチャットボット技術を使ってバーチャルシステムがもっと複雑なトピックにうまく対応できるようにしようっていうアプローチやねん。けどな、これも議論ベースのボットとは言えへんのや。なんでかっていうと、結局のところ、あらかじめ決められた議論スキーム(議論のパターンみたいなもんや)を分類するだけの分類器であって、めっちゃインタラクティブに会話できるエージェントとはちゃうからやで。
1283
---
## Page 14
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p014.png)
### 和訳
Castagna、Kökciyan、Sassoon、Parsons、Sklar の論文より
ちょっと説明させてもらうとな、うちらの調査では、特定のチャットボットの種類とか最終的な目的で検索を絞ったりせえへんかってん。それに、ボットの呼び方の違い(「議論的対話エージェント」とか「対話マネージャー」とか「自動説得システム」とかな)も区別せえへんかったし、開発がどこまで進んでるか(ちゃんと完成してるやつとか、まだ構想段階のやつとか)も気にせえへんかってん。あと、特定の期間も設けへんくて、発表された年に関係なく論文を集めたんや。ほんで、その結果を分析して、簡潔な比較表(表2)にまとめたんやけど、これ見たら各会話エージェントの分類と主な特徴が一目でわかるようになってんねん。具体的には、調査したチャットボット全部をリストアップして、各ボットの最終目的(説得する、説明する、情報提供するとかな)、応答アーキテクチャのモデル(複数ある場合は一番メインのやつを記録したで)、会話の領域(これは主に各論文の例で指定されてるトピックを参考にしたわ)で区別してん。さらに追加データとして、計算論的議論がチャットボットのアーキテクチャの中でどう使われてるか(つまり、抽出、構造化、推論、配信のどれかってことやな)も含めてん。最後に、整理した情報を精査して、主な発見について議論したんや。
4. 議論ベースのチャットボット
このセクションでは、調査したチャットボット全部を、議論がどう使われてるかに応じて簡潔に説明していくで。まず各議論ベースのカテゴリーの概要を説明してから、そのクラスに属する会話エージェントについて述べるわな。注意してほしいんやけど、ボットによっては特定のタスク(抽出、構造化、推論、配信とか)をこなすコンポーネントがあっても、計算論的議論を活用してへん場合もあんねん。そういうコンポーネントについて詳しく説明せえへんからって、それらが存在せえへんとか効果がないってわけちゃうで。これはあくまで、この調査を議論に厳密に焦点を当てたものにするっていう選択を反映してるだけやねん。あと、一つのチャットボットが複数の議論活用カテゴリーに当てはまる場合は、そのボットのユニークな特徴を一番よく表してるやつを中心に説明するで。最後に、各論文で紹介されてるチャットボットの評価(もしあればやけど)についても触れるわな。
4.1 議論ベースの抽出
自然言語テキストのコーパスから始めて、議論マイニングっていう手法を使うと、文書の中から議論を抽出したり、議論間の関係を分類したりできんねん。マイニングしたデータは、さらに処理されて議論フレームワーク(AF)に整理されるか、単純にユーザーの入力に応じた返答として使われるんや。後者と違って、前者を選ぶとフレームワーク上で推論操作ができて、捉えた意味論の評価基準に応じて特定の出力を引き出せんねん。例えば、ADAっていう議論的対話エージェント(Cocarascuら、2019年)は、映画レビューの断片から議論を抽出して、それらの間にある関係をマイニングすんねん。ほんで取得したデータを使って、定量的双極議論フレームワーク(QBAF)を構築して実験的に評価してんねんけど...
---
7. ちなみに言うとくけど、議論ベースの対話の発話からAFを構築するのは「議論ベースの抽出」には該当せえへんねん。なんでかっていうと、議論と攻撃(または支持)はすでに与えられてて、さらなる解析を必要としへんからやねん。
1284
---
## Page 15
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p015.png)
### 和訳
# 計算論的アーギュメンテーションベースのチャットボット:サーベイ
論文(の一覧)
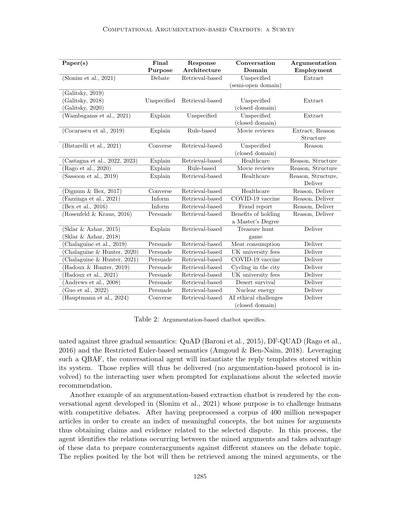
(Slonim et al., 2021)
最終レスポンス
目的:議論/ディベート
アーキテクチャ:検索ベース
会話ドメイン:特定なし(半オープンドメイン)
アーギュメンテーションの使い方:抽出
(Galitsky, 2019)
(Galitsky, 2018)
(Galitsky, 2020)
(Wambsganss et al., 2021)
目的:特定なし
アーキテクチャ:検索ベース
会話ドメイン:特定なし
アーギュメンテーションの使い方:抽出
(Cocarascu et al., 2019)
目的:説明
ドメイン:映画レビュー
アーキテクチャ:ルールベース
アーギュメンテーションの使い方:抽出、推論
(Bistarelli et al., 2021)
目的:会話
ドメイン:特定なし(クローズドドメイン)
アーキテクチャ:検索ベース
アーギュメンテーションの使い方:構造化
(Castagna et al., 2022, 2023)
目的:説明
アーキテクチャ:検索ベース
ドメイン:特定なし(クローズドドメイン)
アーギュメンテーションの使い方:推論
(Rago et al., 2020)
目的:説明
アーキテクチャ:ルールベース
ドメイン:ヘルスケア
アーギュメンテーションの使い方:推論、構造化
(Sassoon et al., 2019)
目的:説明
アーキテクチャ:検索ベース
ドメイン:映画レビュー
アーギュメンテーションの使い方:推論、構造化
(Dignum & Bex, 2017)
目的:会話
アーキテクチャ:検索ベース
ドメイン:ヘルスケア
アーギュメンテーションの使い方:推論、構造化、配信
(Fazzinga et al., 2021)
目的:情報提供
アーキテクチャ:検索ベース
ドメイン:COVID-19ワクチン
アーギュメンテーションの使い方:推論、配信
(Bex et al., 2016)
目的:情報提供
アーキテクチャ:検索ベース
ドメイン:詐欺報告
アーギュメンテーションの使い方:推論、配信
(Rosenfeld & Kraus, 2016)
目的:説得
アーキテクチャ:検索ベース
ドメイン:修士号を取るメリット
アーギュメンテーションの使い方:推論、配信
(Sklar & Azhar, 2015)
(Sklar & Azhar, 2018)
目的:説明
アーキテクチャ:検索ベース
ドメイン:宝探しゲーム
アーギュメンテーションの使い方:配信
(Chalaguine et al., 2019)
目的:説得
アーキテクチャ:検索ベース
ドメイン:肉食
アーギュメンテーションの使い方:配信
(Chalaguine & Hunter, 2020)
目的:説得
アーキテクチャ:検索ベース
ドメイン:イギリスの大学授業料
アーギュメンテーションの使い方:配信
(Chalaguine & Hunter, 2021)
目的:説得
アーキテクチャ:検索ベース
ドメイン:COVID-19ワクチン
アーギュメンテーションの使い方:配信
(Hadoux & Hunter, 2019)
目的:説得
アーキテクチャ:検索ベース
ドメイン:街中でのサイクリング
アーギュメンテーションの使い方:配信
(Hadoux et al., 2021)
目的:説得
アーキテクチャ:検索ベース
ドメイン:イギリスの大学授業料
アーギュメンテーションの使い方:配信
(Andrews et al., 2008)
目的:説得
アーキテクチャ:検索ベース
ドメイン:砂漠サバイバル
アーギュメンテーションの使い方:配信
(Guo et al., 2022)
目的:説得
アーキテクチャ:検索ベース
ドメイン:原子力エネルギー
アーギュメンテーションの使い方:配信
(Hauptmann et al., 2024)
目的:会話
アーキテクチャ:検索ベース
ドメイン:AIの倫理的課題(クローズドドメイン)
アーギュメンテーションの使い方:配信
表2:アーギュメンテーションベースのチャットボットの詳細
---
ほんで、評価に使われたんが3つの段階的意味論なんやけど、QuAD(Baroni et al., 2015)、DF-QUAD(Rago et al., 2016)、それから制限付きオイラーベースの意味論(Amgoud & Ben-Naim, 2018)ってやつやねん。なんでかっていうと、こういうQBAF(量的双極アーギュメンテーションフレームワーク)を活用することで、対話エージェントがシステム内に保存されてる返答テンプレートを実体化できるからやな。ほんでこの返答は、映画のおすすめについて「なんでこれ推薦したん?」って聞かれた時に、ユーザーに届けられるんや(ここにはアーギュメンテーションベースのプロトコルは絡んでへんで)。
もう一個、アーギュメンテーションベースの抽出型チャットボットの例として挙げられてるんが、(Slonim et al., 2021)で開発された対話エージェントやねん。これの目的は何かっていうと、人間に競争的なディベートで挑むことやな。4億件もの新聞記事のコーパスを前処理して、意味のある概念のインデックスを作った後、ボットは議論をマイニング(発掘)するんや。そうすることで、選んだ議題に関連する主張と証拠をゲットするわけやな。この過程で、エージェントはマイニングした議論の間にある関係性を特定して、そのデータを使ってディベートのトピックに対するいろんな立場への反論を準備するんやで。ほんでボットが出す返答は、マイニングした議論の中から検索されるか、もしくは
1285
---
## Page 16
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p016.png)
### 和訳
Castagnaさんら、K¨okciyanさんら、Sassoonさんら、Parsonsさんら、それからSklarさんらの研究についてな。
もっと一般的なデータベースに入ってる情報と組み合わせて、ニューラルモデル経由でうまいこと処理してんねん。ほんで、ユーザーとのやりとりは音声ベースで行われてて、音声をテキストに変換するんはIBMのWatson8っていうやつがやってくれるんや。
で、ちょっと微妙な立ち位置にあるんがArgueBot(Wambsganssさんらが2021年に作ったやつ)っていう会話エージェントやねん。これは学習ツールとして開発されたもんで、学生さんの論理的な議論に対して「ここもうちょい頑張れるで〜」みたいな適応的なフィードバックを返してくれんねん。ArgueBot(Slackっていうプラットフォーム上で動くボットやで9)は、BERT(Devlinさんらが2018年に作った)っていう分類器を使って、ユーザーが入力したテキストに対してAM(論証マイニング)の処理をかけてから、その人の議論文に合わせたコメントを返す仕組みになってんねん。このチャットボットには決まった返答テンプレートが入ってるかもしれへんけど、実際どうやって返答作ってるんかは著者さんたちもはっきり書いてへんから、ようわからんままやねん。
最後に、もうちょい抽象的なレベルの話やけど、Galitskyさんが2020年、2019年、2018年に出した研究では、チャットボットに対する特定の論証マイニングのアプローチについて説明してるんや。ここでの会話エージェントは、テキストの一部分から「コミュニケーション的談話木」っていうもんを作るんやけど、動詞を含むテキストの断片それぞれを動詞のシグネチャ(パターンみたいなもんやな)とマッチングさせることでこれを構築してんねん。その後、分類モデルを適用することで、ボットは議論とその関係性を検出して、その情報を活用してユーザーの入力に応じた返答を返せるようになるんや。要するにやで、深い修辞分析(言葉の使い方の分析やな)に頼ることで、このチャットボットは議論のいろんな特徴(例えば感情的な側面とか、その分野での一貫性とか)を考慮できるから、結果としてユーザーとボットの返答のマッチングがめっちゃ精度高くなるんやわ。
**4.2 論証ベースの返答構造**
チャットボットの返答は、伝統的な議論のフォーマットに沿って構造化できるんや。つまり、特定の推論ルールを使って前提の集まりから主張を導き出すっていう形式やな。このアプローチには、議論スキーム(議論のパターンみたいなもん)とか、構造化された論証のための一般的なフレームワーク(例えばASPIC+とかABAとか)が含まれてんねん。基本的に、こういう議論パターンでデータを整理するんは、AF(論証フレームワーク)を生成してその意味論を計算する前に行われるんや。せやけど、さらなる意味論的な評価を気にせんでも、特定のテンプレート使ってボットの返答を整理するんも便利な場合があんねん。実際、きっちりした構造で返答を提供することで、その主張の背後にある理由をわかりやすく示せて、議論全体の明確さがグンと上がるんやわ。
例として、Castagnaさんらが2022年と2023年に発表した会話エージェントを見てみよか。これは以前のバージョン(Essersさんら2018年、K¨okciyanさんら2019年、Balatsokasさんら2019年、Chapmanさんら2019年、Balatsokasさんら2020年、Sassoonさんら2020年、K¨okciyanさんら2021年、Drakeさんら2022年で説明されてたやつ)の最終的な実装として見ることができるんや。このボットは「説明-質問-応答」、略してEQRっていう新しい議論スキーム(最初は対話プロトコルとして構想されて、Castagnaさんらが2024年に完全に形にしたもん)を活用してて、医療分野で個人に合わせた根拠付きの推奨を提供して、ユーザーが自分の健康状態を自己管理できるよう手助けしてくれんねん。この推奨には追加の情報レイヤーが埋め込まれてんねん。それは何かっていうと、そのスキームがなんで受け入れられるか(つまり、その評価のことで、Eglyさんらが2008年に作ったASPARTIXエンジンによって、考慮される論証フレームワークに基づいて自動化されてる)っていう根拠やねん。このチャットボットが提供する追加の返答は、さらに別の仕組みを使って構造化されてんねん。
8. もう一回言うけど、ここでは計算論的論証を活用してる要素を強調してるんやで。Project Debater(Slonimさんらが2021年に出したやつ)は完全な討論システムやねんけど、論証に関連するコンポーネントはAM手続きの採用だけやから、そこだけ説明してるわけやな。
9. https://slack.com/
1286
---
## Page 17
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p017.png)
### 和訳
「計算論的アーギュメンテーションベースのチャットボット:サーベイ」
ボットの知識ベースで使われてる「アーギュメントスキーム」っていう議論のパターンと、それに対応する「クリティカルクエスチョン(CQ)」っていう確認質問のテンプレートやねん。
他の例で言うと、(Rago et al., 2020)で紹介されてるインタラクティブなレコメンドシステムがあんねん。これは(Rago et al., 2018)の研究を一部発展させたもんで、映画のおすすめをアーギュメンテーションを使った説明で分かりやすくしてくれるんよ。あらかじめ決められた「前提→結論」みたいなテキストのテンプレートに沿って説明を組み立てていくわけ。こういうパターンの中身は、知識ベースを埋め込んだ「バイポーラAF」っていう議論フレームワークから説明を選んでくることで決まるんやで。ただな、その選び方の推論プロセスについては、アーギュメンテーションのセマンティクス(意味論)の観点からはぼんやりとしか説明されてへんのよね。
### 4.3 アーギュメンテーションに基づく推論
さっきも話したけど、アーギュメンテーションエンジンっていうのは、チャットボットの推論を動かす裏側のツールとして使えるんよ。
こういう場合、どのフレームワークを選んでも、例えば「抽象AF」(Dung, 1995)、「バイポーラAF」(Cayrol & Lagasquie-Schiex, 2005)、「重み付きバイポーラAF」(Rosenfeld & Kraus, 2016)、「定量的バイポーラAF」(Cocarascu et al., 2019)、「メタレベルAF」(Kökciyan et al., 2021)とか色々あんねんけど、ほとんどの意思決定プロセスはAFの計算とセマンティクスの評価を含んでるんや。
イメージとしては、議論の集合に埋め込まれた知識ベースからスタートして、ボットが推論処理を実行するわけ。その結果、普通は「受け入れ可能な議論」が選び出されるんや(これは選んだセマンティクスによって変わるで)。ユーザーとやり取りするとき、会話エージェントは相手から受け取った入力をもとに、計算された受け入れ可能な議論の中から返答を取ってくるんよ。
せやから一般的に言うと、アーギュメンテーションベースの推論エンジンは「検索ベースの応答アーキテクチャ」か、検索ベースの処理を含む「ハイブリッドモデル」と組み合わさってると思ってええわ。
例えば、ArguBot (Bistarelli et al., 2021b)っていうのがあって、Google DialogFlow(注10)を使って開発されてんねんけど、ASPARTIX (Egly et al., 2008)っていうシステムを使ってバイポーラAFから議論を計算するんよ。で、対話のトピックについてユーザーの意見を支持(プロボット)したり反論(コンボット)したりするわけ。
(Fazzinga et al., 2021)(注11)で紹介されてる会話エージェントも、同じくバイポーラAFから議論を取ってくんねんけど、こっちは(Fazzinga et al., 2018)で示されたセマンティクスに従ってるんよ。選ばれる返答は、フレームワーク全体で計算された「許容拡張」に対して受け入れ可能な議論やねん。これのええとこは、チャットの将来の展開も考慮した戦略を提供できるってことやな。さらにこのボット、特定の返答についてオンデマンドで説明もできるんよ。つまり、その返答を支持する事実を説明する自然言語の文章の列と、システムが却下した他の矛盾する議論に対する反論の理由も一緒に出してくれるわけ。
それとは対照的に、(Dignum & Bex, 2017)で説明されてるチャットボットは、あらかじめ生成されたAFから始めるんやなくて、進行中の対話の完了したフェーズを評価する手段として計算論的アーギュメンテーションを使ってるんよ。もっと正確に言うと、ユーザーとの弁証法的なやり取りの中で出てきた事実を取り込んで議論グラフを構築するわけ。ほんで、それらの事実がグラフの受け入れ可能な拡張のメンバーかどうかをチェックすることで、形式的な評価をするんやな。
めっちゃおもろいのは、この会話エージェントが「社会的実践理論」(Reckwitz, 2002; Shove et al., 2012)を活用して、会話に文脈を与えて、ユーザーの入力を解釈しやすくするための有用な背景情報を提供してるところやねん。似たような...
---
注10: https://cloud.google.com/dialogflow/docs/
注11: 後にプライバシー保護型の対話システム(Fazzinga et al., 2022)に組み込まれたで。
1287
---
## Page 18
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p018.png)
### 和訳
ほな聞いてや、AIの議論システムをどう使うかっていう話やねん。
(Bex et al., 2016)で書かれてるやつがめっちゃおもろいねん。これな、詐欺の通報をネットでするときに手伝ってくれるAIシステムの話やねんけど、チャットボット(これを「対話マネージャー」って呼んでんねん)が、詐欺の被害者さんとか警察の人らとやりとりして、「もうちょい詳しく教えてくれへん?」みたいに聞きながら、知識グラフっていうデータの構造を作っていくわけや。で、集めたデータを使って、警察が知ってる典型的な犯罪パターンと照らし合わせるねん。そのあと、形式的な議論の意味論っていうもんを使って、シナリオと証拠を組み合わせて推論していくんや。これを「ハイブリッド理論」って言うてんねん(Bex et al., 2010; Bex, 2015)。
ほんで、(Rosenfeld & Kraus, 2016)で提案されてる会話エージェント(SPAっていうやつ)も、議論ベースの推論エンジンを使ってんねん。具体的にはな、知識ベースを「重み付き双極議論フレームワーク(WBAF)」っていうもんに埋め込んで、ユーザーの入力に合わせてフレームワークの評価関数を最大化する議論を計算すんねん。この評価関数が返すスコアは、その議論をどんだけ支持できて、攻撃されたときにどんだけ守れるかを表してんねん。ユーザーとの弁証法的なやりとりは、戦略的な説得対話プロトコルに従って進むんやけど、これがモンテカルロ計画法(Silver & Veness, 2010)で最適化されてて、説得する側とされる側、両方の議論フレームワークを更新することもあんねん。
**4.4 議論ベースの応答配信**
チャットボットはな、議論ベースの対話プロトコルを活用して、ユーザーへの返答を処理したり届けたりできんねん。対話のロジックを使いこなすことで、会話エージェントは戦略を最適化して、最終目標を達成するために必要な議論だけを言うことができるようになんねん。
言い換えたら、この配信フェーズは「二次的な推論ステップ」みたいなもんで、ボットが「どの議論を出すか」を選ぶ段階やねん。利用可能な議論(前の「一次エンジン」、つまり推論フェーズで計算されたやつかもしれへん)の中から、対話プロトコルの指示にきっちり従って選ぶわけや。注意してほしいんやけど、対話プロトコルで許可される議論は、抽象議論とか構造化議論アプローチで使われる標準的な定義よりも柔軟な定義に従ってんねん。つまり、「2人以上の個人間のやりとりとしての対話、これは普通に『議論』って呼ばれるもんの特徴を捉えたやりとりや。つまり、何かについての賛成・反対の理由(=議論)を交換する対話ってことやな」(Black et al., 2021)。
例として、(Hadoux et al., 2021)の研究を見てみようか。これは(Hadoux & Hunter, 2019; Hunter, 2018; Hunter et al., 2019)を拡張したもんで、説得対話における信念と関心事をモデル化する全体的なフレームワークを描いてんねん。このフレームワークは自動説得システム(APS)っていうソフトウェアアプリケーションとして実装されることが想定されてて、やりとりする相手に特定の議論を受け入れさせることを目指してんねん。そこで示されてる非対称説得対話プロトコル(つまり、システムと違って、ユーザーは提示された選択肢の中からしか返答を選べへんっていうやつ)に従って、このチャットボットは、議論グラフに埋め込まれた知識ベースの中から、一番適切な議論を見つけ出す能力を持ってることが証明されてんねん。基本的に、APSはモンテカルロ木探索を報酬関数と組み合わせて実行して、関心事(議論グラフの議論とペアになってるやつ)とユーザーの信念に対処することを最大化してんねん。
同じような感じで、(Chalaguine & Hunter, 2020)で紹介されてるボットは、自由テキストでのやりとりを通じて相手を説得しようとすんねん。ユーザーの入力はベクトル表現によってマッチングされて...
---
## Page 19
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p019.png)
### 和訳
計算論的議論ベースのチャットボット:サーベイ
こっから説明するんやけど、要するに**議論のグラフから知識を引っ張ってきて**、それをユーザーの言うことと照らし合わせるシステムの話やねん。単語の並び順とかコサイン類似度っていう、まあ**文章同士がどんだけ似てるか測る方法**を使って、クラウドソーシングで集めた議論と比べるわけ。ほんで、このチャットボットは、説得される側の人がよく心配することを見つける分類器っていうのを訓練して、**ランダムに選ぶよりもええ感じの反論**を選べるようにしてんねん。もし似てる議論が見つからへんかったら、まあデフォルトの返事でお茶を濁すみたいな感じやな、ユーザーの関心事に合わせてやけど。
同じ著者さんらが(Chalaguine & Hunter, 2021)で似たような構造の説得ボットも出してて、これには**「関心-議論グラフ」**っていう特別なグラフが追加されてんねん。めっちゃおもろいのが、この知識ベースをちっちゃいグラフにまとめることで、**効果的な説得対話を作るのにそんな大量のデータいらんって証明できる**んよ。さらに言うと、同じ著者らが(Chalaguine et al., 2019)で、チャットボットがやる説得対話の中で、ユーザーの関心に応える議論が**どんだけ刺さるか(アピール力)の予備分析**もやってんねん。
こういう関心ベースのアプローチの別の例としては**Argumate**っていうチャットボットがあって、これは学生が説得力のある文を作るのを助けるために設計されてんねん(Guo et al., 2022)。適切な提案するために、ボットは下にある議論グラフから返事を引っ張ってくるんやけど、このグラフのエッジ(つながり)は**攻撃関係とサポート関係**を表してて、関心を特定する方法を使ってんねん。ちなみに、Argumateとユーザーのやり取りは、文字打つのと**あらかじめ用意された選択肢を選ぶ**両方でできるようになってるで。
---
ここまで紹介した議論ベースの会話エージェント全部に共通してることがあってな、返事を取り出すコーパス(知識の塊)は議論グラフとして整理されてるんやけど、**特定の「受容可能な意味論」には興味持ってへん**んよ。どういうことかっていうと、知識ベースはシンプルな**AF(Argumentation Framework:議論フレームワーク)**として扱われてて、議論と攻撃だけが重要な特徴として見られてるってこと。あと、これらの研究のほとんどは**ベースラインのチャットボット**も用意してて、それは知識ベースから**ランダムに反論を選ぶ戦略**を使ってんねん。なんでかっていうと、もっと細かい戦略を使う開発したボットと**比較するため**やねん。
---
最後に、説得対話を届けることに特化した会話エージェントをもうひとつ紹介するわ。(Andrews et al., 2008)で設計されたチャットボットやねん。**AIMLマークアップ言語**(Wallace, 2003)っていうのを使って実装されてて、このボットには**計画コンポーネント**があって、ユーザーを説得するための最適な議論の道筋を、議論モデルの中で探すんよ。エージェントはユーザーの信念を記録して、やり取りの中で相手が同意したり反対したりするたびに**その情報を更新**してんねん。こういう**信念の修正**が、チャットボットの戦略的な見方でめっちゃ大事な役割果たすわけ。
話を変えて、(Sassoon et al., 2019)で実装された会話エージェントは、**健康相談の説明**っていう文脈の中で、複数の対話プロトコル(つまり説得、審議、情報探索)を使いながら、対話相手と**受容可能な議論スキームの具体例**をやり取りしてんねん。こういう多様化した対話プロトコル(説得、探求、情報探索)の採用は、(Sklar & Azhar, 2015)で提案されて(Azhar & Sklar, 2017)でデモンストレーションされた**チャットボット搭載ロボット**の特徴でもあるで。ユーザーが選べる選択肢が限られてることで楽になってるんやけど、自分の信念から構築した最も適切な議論を引っ張ってきて、ロボットは人間の対話相手と**宝探しゲームの戦略について**コミュニケーション取んねん。
リストの締めくくりは(Hauptmann et al., 2024)で紹介されたボットやな。この**ドイツ語の会話エージェント**は、(Hadoux & Hunter, 2019)の形式化に従って、議論グラフを使って知識ベースをエンコードして、そこから**主要な立場と反論**を引っ張ってくるんよ。
---
## Page 20
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p020.png)
### 和訳
Castagna、Kökciyan、Sassoon、Parsons、Sklar
ユーザーさんらをAI実装の倫理的な課題についての議論に巻き込むためにやってるんやな。
で、情報を届ける戦略なんやけど、ちょっと曖昧なとこあってな、会話のどの段階かによって、説得と情報収集をうまいことミックスしてバランス取ってるみたいやねん。
### 4.5 チャットボットの評価
ここまでは、レビューした議論ベースのチャットボットについて、主に議論をどう使ってるかって観点から特徴を説明してきたわけやけど、そのうちのいくつかの会話エージェントは、ちゃんと専用に設計されたユーザー調査でも評価されてるねん。その結果をここで報告するで。
例えばな、(Slonim et al., 2021)で作られたバーチャル討論者は、比較対象になった他のAI競合よりも議論の質が高いことを示したんやけど、それでもまだ人間レベルには届いてへんねん。
ほんで、(Balatsoukas et al., 2020)は、CONSULTシステムの初期バージョンを評価するためのパイロット研究の結果を報告してるんやけど、このシステムが後に(Castagna et al., 2022, 2023)で展開されるチャットボットの元になってるねん。結果として出てきた批判は、ボットとやり取りするときにもっと自然な会話の流れがないとあかんってことやった。
(Sklar & Azhar, 2015; Azhar & Sklar, 2017)のArgHRIシステムで紹介された人間-ロボット間のやり取りをテストするためのユーザー調査もやっててな。結果を見ると、議論ベースの対話がロボットへの信頼を高めるのに貢献してることがわかったんや。せやけどな、対話そのものを分析した(Sklar & Azhar, 2018)によると、ボットに質問して説明をもらえる可能性があっても、人間-ロボットチームのパフォーマンスが大幅に上がるわけでもなく、ユーザー満足度が上がるわけでもなかったんやって。
一方で、(Rosenfeld & Kraus, 2016)で紹介されたSPA会話エージェントは、説得タスクでテストしたとき、ベースラインのチャットボット(別のヒューリスティックな戦略を使ってたやつ)を上回ったんや。つまり、人間レベルの会話ができることを証明したってことやな。同じようにベースラインエージェントを上回ったのが、(Chalaguine et al., 2019)で発表されたボットやねん。ほんまにな、この論文には実験が含まれてて、このチャットボットがユーザーの懸念に対処する議論を提示することで、そういう戦略を使わない別のエージェントと比べて、ユーザーの態度をポジティブに変える可能性が高いことを示してるんや。
似たような形でユーザーの懸念に関心を持ってるのが、(Chalaguine & Hunter, 2020)で実施された研究やねん。その結果は、(Hadoux & Hunter, 2019)の実験でも共同で支持されてて、(Hadoux et al., 2021)でも確認されてるんやけど、懸念を考慮する戦略的なチャットボットの方が、関連性があって説得力のある議論を提供する可能性が高いって結論になってるねん。さらにな、
---
(脚注12の部分)
会話エージェントの能力を評価する別の方法(まあちょっと古いやり方やけど)として、人間のエンドユーザーとの議論を通じてやるっていうのがあってな。やり取りが自然でスムーズであればあるほど、チャットボットがより効果的やってことになるねん。
チューリングテスト(イミテーションゲームとも呼ばれる)っていうのは、アラン・チューリング(Turing & Haugeland, 1950)が提案したもんで、機械が人間と同等か、人間と区別がつかない知的な振る舞いを示す能力をテストしようってアイデアやねん。
このイミテーションゲームに基づいて、ローブナー賞っていうのが1980年に始まったんやけど、これは最も人間らしいコンピュータプログラム、つまりチューリングテストで一番いい成績を出したプログラムに賞を与えるコンテストやねん。勝者は審査員を一番高い割合で騙せたやつで、Mitsukuっていうチャットボットがこの賞を最も多く獲得してるんやで(Worswick, 2013)。
ローブナーコンペティション(2020年以降は事実上終了したと見なされてる)は、めっちゃ長いリストの批判を受けてきたんや。その中でも、参加者は人間を理解しようとしてへんっていう疑惑があってな。なんでかっていうと、このコンテストでは騙すことと見せかけがめっちゃ高く評価されるからやねん。ローブナー賞に対するもう一つの批判は、イミテーションゲームと人間のような知性の証明を混同してるってことや。
せやけどな、機械は人間のように推論できへんねん。これはサールが1980年に有名な「中国語の部屋」実験で主張したことやで(Searle, 1980; Cole, 2020)。
---
## Page 21
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p021.png)
### 和訳
計算論的議論に基づくチャットボット:サーベイ
他の2つの説得型エージェントの評価結果についても触れとく価値があるで(Andrews et al., 2008; Chalaguine & Hunter, 2021)。前者のボットは、単純なタスク志向のシステムよりもだいぶ上手いこと、相手とスムーズに会話できてるねん。後者の方は、インタラクティブなチャットボットの方が、ただの静的なウェブページよりも説得力のある情報を伝えられるってことを示してるわけや。
もう一個の例として、ArgueBotっていう会話エージェントが量的にも質的にも評価されてんねん(Wambsganss et al., 2021)。詳細なフィードバックとリッカート尺度の実験後アンケートから集めたデータは、ええ結果を示してるで。特に、参加者らはこのチャットボットを「助けになる」「役に立つ」「使いやすい」と感じとったんや。実験前後のリッカート尺度アンケートを使う方法は、(Hauptmann et al., 2024)でも好まれとる評価の選択肢やねん。結果を見ると、チャットボットとやり取りした後に参加者の40〜50%の意見が変わることに成功してるんや。全体的に、ユーザーらは議論の質と会話システムの設計を認めとったで。最後に、(Rago et al., 2020)で説明されてる推薦システムの実験研究の結果も報告しとくわ。暫定的な結論としては、議論に基づく説明がシステムへの信頼と透明性を向上させるみたいやけど、その内容と伝え方についての好みはユーザーによって違うかもしれんねん。
5. 議論
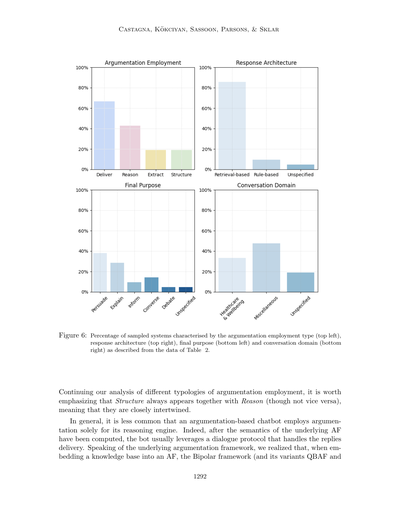
表2はうちらの発見の概要を示してて、図6にはサンプリングしたチャットボットの特徴の量的な要約が載ってるで。最初に言うとくと、議論に基づくチャットボットが文献であんまり取り上げられてへんのはちょっと意外やねん。なんでかっていうと、計算論的議論が提供する現実世界の弁証法的やり取りの形式的な特徴づけは、ユーザーと会話することが役割のエージェントにめっちゃ適してそうやからや。せやけど、これは議論形式が適してへんからじゃなくて、計算論的議論の研究分野の普及があんまり進んでへん(特にヨーロッパ以外で)ことが原因かもしれんねん。もう一つの説明としては、ここ数十年でコンピュータサイエンスにおいてモデルフリー手法への関心が爆発的に高まって(Bringsjord & Govindarajulu, 2022)、計算論的議論みたいなモデルベース手法が無視されてきたってことがあるんや。それが今になって、例えばモデルフリーの出力を「解釈」する方法として、再び注目され始めてるわけや。とはいえ、うちらの分析結果からいくつかの考察ができるで。「説得する」と「説明する」が調べたチャットボットの中で最も一般的な目標やってわかったんや。後者は、説明可能なAIへの最近の関心と、それと計算論的議論モデルとの関係から来てるねん(Vassiliades et al., 2021; McBurney & Parsons, 2021; Čyras et al., 2021)。説得対話の方は、(Hunter, 2015; Murphy et al., 2016)みたいな論文で研究されてきてて、それらの発見は議論に基づく形式を使うことで信念変化を引き起こす説得力のある戦略を提供できることを示してるんや。説得に焦点を当てたチャットボットがこんだけ多い理由の一つは、ほんまにこの分野で議論が効果的に返答を届けられるからかもしれんねん。これは複数のユーザースタディの結果でも支持されとるで。これを裏付けるように、説得型会話エージェントが計算論的議論を使う方法は、(対話的な)「配信」カテゴリに分類されるんや(これは予想通り、表2で最も一般的なクラスになってるで)。また、こういうボットの主な特徴として、説得力のある(議論的な)返答をするときに、相手の信念や関心事を考慮に入れてることも注目してな。
---
## Page 22
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p022.png)
### 和訳
ほな見てってや、この図6(Figure 6)っちゅうのはな、サンプリングしたシステムがどんな特徴持ってるかをパーセンテージで示してんねん。左上が「議論(アーギュメンテーション)の使い方のタイプ」、右上が「応答のアーキテクチャ」、左下が「最終的な目的」、ほんで右下が「会話のドメイン(分野)」を表してて、全部Table 2のデータから来てるわけや。
ほんでな、議論の使い方の種類をもうちょい深掘りしていくとやな、「Structure(構造)」っちゅうのは必ず「Reason(推論)」とセットで出てくるねん。逆はそうとは限らへんけどな。つまりこの二つはめっちゃ密接に絡み合ってるっちゅうことやねん。
一般的に言うとな、議論ベースのチャットボットが推論エンジンのためだけに議論を使うってのは、そんなに多くないねん。なんでかっていうと、議論フレームワーク(AF)のセマンティクス、まあ意味論みたいなもんやな、それを計算した後は、普通はダイアログプロトコル、つまり対話のルールみたいなやつを使って返答を処理するからやねん。
ほんで、その議論フレームワークの話やけどな、知識ベースをAFに組み込むときは、「双極性フレームワーク(Bipolar framework)」とその派生版のQBAFやら
---
## Page 23
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p023.png)
### 和訳
計算論的議論ベースのチャットボット:サーベイ
WBAFなんやけど、これがいっちゃん人気のある選択肢やねん。なんでかっていうと、BAFsが提供してくれる追加情報がめっちゃ便利やからや。BAFsってのは、単なる攻撃関係だけやなくて、サポート関係も含んでるねん。せやから、データ同士の「これええやん!」っていう支持と「いやそれちゃうやろ」っていう対立の両方を、直感的に形式化できるわけや。
このサーベイの中で、ボットが扱ってる会話のドメイン(分野)をいくつか特定したんやけど、ヘルスケアから原子力エネルギーまでいろいろあってな。その中でもヘルスケアが一番多くて、他の分野も含んでたりするねん。あと「ドメイン未指定」っていうのは、会話のトピックが指定されてへんか、複数トピックがざっくりリストアップされてるかのどっちかやな。おもろいことに、オープンドメイン(何でも話せる)って呼べるような議論ベースのチャットボットは一個もないねん。ただ、Slonimらが2021年に議論したエージェントは「セミオープンドメイン」って言えるかもしれへんな。というのも、議論を引っ張ってくる元のコーパス(データベース)がめっちゃ巨大やから、ディベートを届ける時にトピックの制限がないねん。でもな、このボット、世間話とかそういう軽い会話は処理できへんのや。これがディスカッションにも影響してて、各ディスカッションは反対の立場に対するチャレンジとしてモデル化されてるねん。Slonimら(2021)が作ったエージェントのもう一つの特徴は、ユーザー入力で制約のない音声を許可してることやな。ほとんどのチャットボットはフリーテキスト入力だけしか許してへんのに。あと、BexらのやつとGuoらのやつ(2016年と2022年)は、フリーテキストと制限付きテキストプロンプトの両方を組み合わせてるねん。とはいえ、制約のない自然言語文を管理して処理できる能力を見ると、議論ベースのチャットボットが現実世界みたいなディスカッションをうまく真似できるってことがわかるわ。
最後に注目してほしいんやけど、調べたボットのほぼ全部が検索ベースの応答モデルを備えてるねん。唯一の例外がCocarascuらとRagoら(2019年と2020年)のやつや。そこで提案されてるハイブリッド型の会話エージェントは、対話のほとんどを少数のカスタマイズされたテキストテンプレートで処理してて、つまりルールベースのコンポーネントを活用してるわけや。でも、追加データが必要な時(例えば、ユーザーが提供された説明に疑問を持った時とか)には、検索ベースモデルに頼ることもあるねん。一般的に言うとな、普通の会話エージェントと違って、このサーベイで調べた文献には生成型の議論ベースチャットボットは一個も出てこーへんかったんや(注13)。これ自体は大きな欠点ってわけやないねん。なんでかっていうと、生成型の応答アーキテクチャには色々問題があるからや。生成された返答の出どころが不透明やったり、出力にバイアスがかかってたり、意味不明な返答を作ってしまったりな。とはいえ、これは議論ベースボットの現時点での限界を示してて、主にこの件に関する研究がないからやねん。この欠点を解決する方法としては、またまたハイブリッドアプローチを使うことが考えられるわ。最先端のTransformer技術を活用するやつな。例えば、今のLLMベースの会話エージェントに議論の方法論を組み込めば、生成型の議論ベースチャットボットができるし、ついでにそういうモデルの欠点を軽減するのにも役立つやろな。
5.1 計算論的議論アプローチを生成型LLMチャットボット設計に活用する潜在的メリット
文献の中で、生成型LLMチャットボット(ChatGPT、Llama 3.1-Instruct、Gemini 1.5、Claude 3.5 Sonnetとか)のクラスは、今の会話エージェントの最先端カテゴリーと見なされてるねん。そういうモデルに影響を与える欠点はもう挙げたけど、
注13:ただし、ArgueBotの応答アーキテクチャについては明確な情報がないことを思い出してな(Wambsgansら、2021年)。
1293
---
## Page 24
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p024.png)
### 和訳
Castagna、Kökciyan、Sassoon、Parsons、Sklar らの研究についてな
まだこういう限界をどう解決するかっていう具体的な話はあんまりされてへんねん。でもな、ワイらが思うに、**計算論的議論(computational argumentation)**っていうアプローチがめっちゃ効果的やと思うねん。特にLLMが「ブラックボックス」やから生じる弱点を、ほとんど上手いこと対処できるんちゃうかなって。実際、**説明可能なAI(XAI)**っていう研究分野があってな、AIシステムをもっと分かりやすくする方法を研究してるんやけど、そこでも「議論に基づく説明」がモデルの不透明さを解消するええ方法やって提案されてるねん(Čyrasら、2021年;Vassiliadesら、2021年)。
この考え方を裏付ける研究もあってな(McBurney & Parsons、2021年;Castagna、2022年;Castagnaら、2024年)、AIシステムは説明する側と説明を受ける側の対話のやり取りを特徴づける「対話プロトコル」を使った議論ベースのアプローチを採用すべきやって言うてるねん。これをLLMに組み込んだらな、ちゃんと考え抜かれた説明をユーザーに届けられる「後付け(post hoc)」の方法になるし、追加の質問にも詳しく答えられるようになるわけや。
この点についてな、Microsoftが**GPT-4**(OpenAI、2023年にリリースされたGPTモデルの一つ)の出力に対する説明能力を分析してるねん(Bubeckら、2023年)。GPT-3.5ベースのChatGPTよりはマシなんやけど、GPT-4でも説明の**プロセス一貫性**に問題があるねん。つまり、出力を生成した理由についてはそれっぽい説明をするんやけど、似たような入力に対してモデルがどう反応するかを予測できるような、もっと一般的な正当化を示すのは苦手やねん。
**EQR**みたいな説明用の議論的対話(McBurney & Parsons、2021年;Castagna、2022年;Castagnaら、2024年)を使えば、このプロセス一貫性の問題は解決できるで。なんでかっていうと、会話の中でもっと多くの情報を引き出せるから、説明の長さの制限とか言葉の制約っていう問題の主な原因を回避できるねん(Bubeckら、2023年)。
こういう対話ベースのXAIが使えるっていう話を踏まえてな、計算論的議論がLLMの現状の欠点にどうやって解決策を提供できるか、詳しく見ていこか(表3にまとめてあるで):
**創発的能力(Emergent abilities)**。これほんま不思議な現象でな、大規模モデルで突然特定の能力が現れるんやけど、小さいモデルでは全然出てこーへんねん。せやから、小規模モデルを分析しても、こういう能力(例えば計算力の向上、マルチタスク理解、多言語処理の強化とか)がいつ「創発」するか予測でけへんわけや(Weiら、2022a年)。
こういう能力の中には**心の理論(Theory of Mind, ToM)**も含まれてるねん。これは他者の心の状態を推測する能力のことで、人間だけが持つもんやと思われてたんやけど、LLMの訓練の副産物として自然発生的に現れた可能性があるねん(Kosinski、2023年)。
こういう要素全部が、Transformerベースの技術を取り巻く謎に貢献してて、一般の人らの不信感につながって、結果的にLLMの使いやすさを妨げてるねん。議論的XAIは後付けの解決策として間接的に役立つで。創発的能力がなんで生まれるかの理由は特定でけへんけど、それらがどう機能してるかを明らかにする説明は提供できるからな。
**ハルシネーション(幻覚)**。これは「意味不明やったり、元のソースの内容に忠実やない生成コンテンツ」って定義されてるねん(Jiら、2023年)。自然言語生成におけるハルシネーション現象は、**内在的(intrinsic)**と**外在的(extrinsic)**に分けられるで。内在的っていうのは…
---
## Page 25
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p025.png)
### 和訳
計算論的議論ベースのチャットボット:サーベイ論文
生成された出力が、モデルの学習に使われたデータソースと矛盾してまうやつのことやねん。
一方で後者は、検証のしようがない出力のことを指すんや。議論推論エンジンを使うことで、この内在的幻覚っちゅうやつを減らせるんやで。なんでかっていうと、根拠のある議論だけ(つまり、矛盾のない懐疑的拡張のメンバーだけ)をチャットボットが出力するように縛れるからやねん。ほんで、外在的幻覚の方は、議論的な説明可能AI(XAI)の手法で調べられるから、最悪のケースでも、生成されたコンテンツについて追加情報を取り出せるようになるんや。
ここで違いに注目してな:説明はつかへんけど、創発能力っていうのは普通、モデルが身につけた便利なスキルのことを言うんや。それに対して幻覚っていうのは、ユーザーのプロンプトに対してLLMが返してきた矛盾した内容とか、でっち上げた内容のことだけを指すねん。
**推論について**
いろんな研究者が言うてるんやけど、LLMは言語生成についてはめっちゃええ表現力を持ってるけど、推論スキルとか論理的思考が欠けてるらしいねん(Mahowald et al., 2023; Bang et al., 2023; Frieder et al., 2023; Thorp, 2023)。効果的な解決策を提供しようと、いろんなアプローチが開発されてきたんや。例えば、Chain of Thoughts(CoT)、Tree of Thoughts(ToT)、Graph of Thoughts(GoT)とかやな。CoTっていうのは、一連の中間的な推論ステップを詳しく示すプロンプト戦略で、算術とか記号とか常識的な推論でより良いパフォーマンスを達成するためのもんやねん(Wei et al., 2022b)。このアプローチの限界は主に、出力を生成する前に複数の推論パスを計画したり分析したりする手順がないことなんやけど、まさにこれがToTとGoTで改善されたポイントやねん。実際、Tree of Thoughtsは各問題を木構造上の探索として捉えて、各ノードが部分的な解決策を表すんや(Yao et al., 2023)。一方、Graph of ThoughtsはLLMが生成した情報を任意のグラフとして想定して、そういう情報単位間の依存関係を抽出し、ネットワークの核心的な要素に焦点を当てることで推論を強化するんやで(Besta et al., 2024)。
この3つの選択肢に対して、俺らが主張したいのは、生成型LLMベースのチャットボットに計算論的議論で駆動される推論エンジンを搭載することで(Castagna et al., 2024でやってるような研究に似た感じで)、より直感的で、安価で、包括的な代替手段になるんちゃうかってことやねん(例えば、実装に高価なリソースが要らへんし、ToTやGoTと違って様々なトピックで効果的やしな)。議論的推論は、自然言語を解析し、処理し、生成するモデルに特に適してるんや。
思い出してな、議論フレームワーク(AF)はグラフで、そのエッジが各ノードの状態を決定するパスを表してるんやで。ほんで、議論フレームワークを意味論的に計算することで、望む結果を達成するための最も適切な「思考」(議論)のシーケンスを計画できるんや。そういうシーケンスは相反する情報も考慮するから、対照的思考連鎖(CCoT)プロンプト技術を模倣し、(場合によっては)上回る可能性もあるねん。CCоTは主に一度に1つの対照サンプルしか扱わへんからな(Chia et al., 2023)。
**偏りのある出力と有害な出力について**
モデルは学習データを反映する傾向があるから、ユーザーに害を与える可能性のある偏りのあるコンテンツや有害なコンテンツを再生産してまうねん(Brown et al., 2020)。これは、LLMを人間の道徳的価値観に合わせて調整する必要性がめっちゃ重要やってことを意味してるんや。ほんで、この場合も計算論的議論が問題を軽減するのに役立つかもしれへんねん。実際、最近の研究では、表形式データに基づく二値分類の意思決定システムにおける望ましくないバイアスを検出するためのツールとして、計算論的議論を使うことが調査されてるんやで(Waller, 2023)。提案された手法は
1295
---
## Page 26
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p026.png)
### 和訳
カスタグナ、コクチヤン、サスーン、パーソンズ、スクラー
このモデルはな、特定のモデルに依存せんでええし、ラベル付きデータとか保護属性の指定もいらんねん。ほんで注目してほしいのが、アーギュメントマイニング(議論抽出)の分野がめっちゃ進歩してるから、元データの中にある偏ったやつとか有害な議論をバシッと見つけてフィルタリングできるアルゴリズムができるかもしれんってことやな。そうなったら、生成モデルの学習に使う有害データを減らせるわけや。もう一個の解決策は、アーギュメントスキーム(議論の型)とその分類を活用するってやつやな。具体的には、AIシステムからアーギュメントスキームを実例化することで、意味的にもっと深いアプローチができるようになって、LLMが生成するテキストをより現実的で倫理的にも建設的な議論に導けるようになるんや(ベゾー・ヴラカツェリ、2023)。
生成LLMチャットボット
課題
創発的能力
ハルシネーション(幻覚)
推論
偏りと有害な出力
解決策の候補
Arg XAI(議論的説明可能AI) Argエンジン AM(議論抽出)& AS(議論スキーム)
✓
✓
✓
✓
✓
表3:LLMチャットボットの弱点に対処するための計算論的議論の手段やで。Arg XAI(議論的XAI)は計算論的議論の戦略とツールに基づく説明手順のことや。Argエンジン(議論エンジン)は計算論的議論で動く推論エンジンの能力のことやな(2.1.3節参照)。最後に、AMは2.1.1節のアーギュメントマイニング操作を指してて、ASは2.1.2節のアーギュメントスキーム構造を指してるで。
6. 結論
会話エージェントと計算論的議論はな、両方とも対話的なやり取りに焦点を当ててるから、本質的につながってるんよ。この論文ではな、この両方を組み合わせて、既存の議論ベースのチャットボットを文献から洗い出してレビュー・分析したんや。ワイらが調べたボットの約70%(3節で説明した制約付きの選定やけどな)は、特定の対話プロトコルに従って、ユーザーとのやり取りで返答を出すのに計算論的議論モデルを使ってたで。これが何を意味するかっていうと、議論の形式化は自然言語での情報交換を扱う時にめっちゃ効果的やってことや、特に説得が目的の時はな。さらに、推論エンジンもかなりよく使われてる機能やったわ。議論の拡張を活用して、選んだセマンティクス(意味論)に応じて、一番適切な返答を選ぶ理論的根拠を提供してくれるんやな。最後に、普通のボット(つまり議論ベースやないやつ)と違って、生成型の議論ベースチャットボットもオープンドメインのやつも見つからんかったんや。ただし、LLM駆動の会話エージェントの中に議論の方法論を埋め込むことで、そういうエージェントを実装する方法はあるかもしれんで。計算論的議論、チャットボット設計、そしてそれぞれの今後の進歩が絡み合って、議論ベースチャットボットの研究分野はこれからの数年間で追求できる有望な選択肢がいっぱいありそうやし、最近のTransformerベースのAI研究の転換点でも面白い役割を果たしそうやな。
1296
---
## Page 27
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p027.png)
### 和訳
# 計算論的論争ベースのチャットボット:サーベイ
## 参考文献
Adamopoulou, E., & Moussiades, L. (2020). チャットボット:歴史と技術とアプリケーション。Machine Learning with Applications, 2, 100006.
Adiwardana, D., Luong, M.-T., So, D. R., Hall, J., Fiedel, N., Thoppilan, R., Yang, Z., Kulshreshtha, A., Nemade, G., Lu, Y., et al. (2020). 人間みたいなオープンドメインのチャットボットを目指して、っていう研究やねん。arXiv preprint arXiv:2001.09977.
Altay, S., Schwartz, M., Hacquin, A.-S., Allard, A., Blancke, S., & Mercier, H. (2022). チャットボットで反論を提供することで、対話型の議論をめっちゃスケールアップさせるって話やな。なんでかっていうと、人と人が直接やりとりせんでも、AIが反対意見を出してくれるから大規模にできるねん。Nature Human Behaviour, 6 (4), 579–592.
Alviano, M. (2021). PYGLAF論証推論器(ICCMA2021)。これは議論を自動で分析してくれるツールやで。http://argumentationcompetition.org/2021/downloads/pyglaf.pdf,(最終アクセス 2024/04/06)。
Amazon (2014). Alexa。みんな知ってるAmazonの音声アシスタントやな。https://developer.amazon.com/en-US/alexa,(最終アクセス 2024/04/06)。
Amgoud, L., & Ben-Naim, J. (2018). 重み付き双極グラフにおける引数の評価。ほんまに難しそうに聞こえるけど、要は賛成と反対の意見にそれぞれ重要度をつけて、どっちが強いか計算する方法やねん。International Journal of Approximate Reasoning, 99, 39–55.
Andrews, P., Manandhar, S., & De Boni, M. (2008). 自動説得のための論争的な人間・コンピュータ対話。コンピュータが人を説得するために議論するっていう、ちょっとSFみたいな話やな。In Proceedings of the 9th SIGdial Workshop on Discourse and Dialogue, pp. 138–147.
Anil, R., Dai, A. M., Firat, O., Johnson, M., Lepikhin, D., Passos, A., Shakeri, S., Taropa, E., Bailey, P., Chen, Z., et al. (2023). Palm 2の技術レポート。Googleのめっちゃすごい大規模言語モデルの詳細やで。arXiv preprint arXiv:2305.10403.
Apple (2011). Siri。iPhoneとかに入ってるやつやな。https://www.apple.com/siri/,(最終アクセス 2024/04/06)。
Atkinson, K., Bench-Capon, T., & Modgil, S. (2006). 意思決定支援のための論争。何かを決めなあかん時に、議論を整理して判断を助けてくれるシステムの研究やねん。In International Conference on Database and Expert Systems Applications, pp. 822–831. Springer.
Azhar, M. Q., & Sklar, E. I. (2017). 人間とロボットのチームで共同意思決定がどんな影響を与えるかを測定した研究。ロボットと人間が一緒に考えて決めたら、どうなるかってことやな。International Journal of Robotics Research (IJRR), 36, 461–482.
Bala, K., Kumar, M., Hulawale, S., & Pandita, S. (2017). AIを使った大学管理システム用のチャットボット。学校の事務作業を自動化するやつやで。International Research Journal of Engineering and Technology, 4 (11), 2030–2033.
Balatsoukas, P., Sassoon, I., Chapman, M., Kokciyan, N., Drake, A., Modgil, S., Ashworth, M., Curcin, V., Sklar, E., & Parsons, S. (2020). 脳卒中の自己管理のためのコネクテッドヘルスシステムの実地パイロットユーザビリティ評価。実際に使ってもらって、使いやすさを確認したって話やな。In 2020 IEEE International Conference on Healthcare Informatics (ICHI), pp. 1–3. IEEE.
Balatsoukas, P., Porat, T., Sassoon, I., Essers, K., Kökciyan, N., Chapman, M., Drake, A., Modgil, S., Ashworth, M., Sklar, E., et al. (2019). 脳卒中サバイバー向けのデータ駆動型自己管理意思決定支援ツールの設計へのユーザー参加。脳卒中を経験した人たちが自分で健康管理できるようにするツールを、当事者と一緒に作ったっていうめっちゃ大事な研究やねん。In IEEE EUROCON 2019-18th International Conference on Smart Technologies, pp. 1–6. IEEE.
1297
---
## Page 28
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p028.png)
### 和訳
ほな、この参考文献リスト、いっちょ説明したるわ!
**Bang らの研究(2023年)**
これな、ChatGPTがどんだけ賢いか調べた研究やねん。色んなタスクで、色んな言語で、色んな方法でテストしたんや。推論できるか?嘘つかへんか?ちゃんと会話できるか?ってな具合に。arXivっていう論文投稿サイトに載ってるやつやで。
**Baroni らの研究(2015年)**
設計の選択肢を自動で評価するシステムの話や。「定量的議論」っていう数字使った議論の手法でな、これがええかあれがええか、機械が判断してくれるねん。『Argument & Computation』っていう専門誌に載ってるで。
**Bench-Capon らの研究(2009年)**
法律の世界での議論・推論についてまとめた本や。Springer(シュプリンガー)っていう有名な学術出版社から出てんねん。法廷でどうやって論理的に議論するか、みたいな話やな。
**Besnard と Hunter の本(2008年)**
『議論の基礎』みたいなタイトルの教科書やな。MITプレスのケンブリッジから出版されてて、全47巻もあんねん。議論学の基本をガッツリ学べる本やで。
**Besta らの研究(2024年)**
これめっちゃおもろいねん!「Graph of Thoughts(思考のグラフ)」っていう手法で、大規模言語モデル(ChatGPTみたいなやつ)に複雑な問題を解かせる方法考えたんや。AAAIっていう人工知能の超有名な学会で発表されてんで。
**Bex の研究(2015年)**
因果関係のストーリーと証拠に基づく議論を統合した理論の話や。人工知能と法律の国際会議で発表されてん。なんでかっていうと、「こういう流れでこうなった」っていうストーリーと、「この証拠があるからこう言える」っていう議論、両方大事やからやねん。
**Bex、Peters、Testerink の研究(2016年)**
オンラインで犯罪被害届を出すときのAIの話や。普通の会話から、ちゃんとした形式のシナリオに変換するシステムやねん。
**Bex らの研究(2010年)**
議論とストーリーと刑事証拠を組み合わせたハイブリッドな理論やな。『Artificial Intelligence and Law』っていう学術誌に載ってるで。裁判で使う証拠をAIでどう扱うか、みたいな話やねん。
**Bezou-Vrakatseli の研究(2023年)**
大規模言語モデルの推論能力を「議論スキーム」っていう手法で評価した研究や。『Online Handbook of Argumentation for AI』の第4巻に載ってんねん。AIがちゃんと論理的に考えてるかチェックする方法やな。
**Bistarelli らの研究(2021a)**
CONARGっていうツールの話や。「制約プログラミング」っていう方法で、抽象的な議論の問題を解くソルバー(解決プログラム)やねん。議論のコンペ用に作られたやつやで。
**Bistarelli、Taticchi、Santini の研究(2021b)**
議論機能を拡張したチャットボットの研究や。AI3@AI*IAっていう学会で発表されてん。普通のチャットボットに議論する能力を持たせたらどうなるか、って話やな。
**Black と Hunter の研究(2007年)**
質問を生成して対話するシステムの話や。自律エージェントとマルチエージェントシステムの国際会議で発表されてん。ACM(コンピューター学会)が出版してるで。
**Black、Maudet、Parsons の研究(2021年)**
議論に基づいた対話についてまとめた章や。『Handbook of Formal Argumentation』の第2巻に載ってて、College Publicationsっていう出版社から出てんねん。議論ってどうやって対話の形にするか、みたいな教科書的な内容やな。
**Blount の博士論文(2018年)**
ソーシャルウェブ上での「論争的・修辞的な議論」をモデル化した研究や。サウサンプトン大学で博士号取るために書いた論文やねん。SNSとかでの議論ってどういう構造してるか分析したんやろな。
**Borg、Odekerken らの研究(2022年)**
PyArgっていうツールの話や。Pythonで議論問題を解いて、しかもなんでそういう答えになったか説明までしてくれるシステムやねん。めっちゃ便利そうやろ?
---
## Page 29
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p029.png)
### 和訳
## 計算論的議論に基づくチャットボット:サーベイ
**参考文献**
Bringsjord, S., & Govindarajulu, N. S. (2022). 人工知能. Zalta, E. N., & Nodelman, U. (編), 『スタンフォード哲学百科事典』(2022年秋版). スタンフォード大学形而上学研究所.
→ これな、めっちゃ有名なスタンフォードの哲学百科事典に載ってるAIの解説やねん。哲学の観点からAIってなんやねんっていうのをガッツリ説明してくれてるやつやで。
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., 他 (2020). 言語モデルは少数例学習者である. 『神経情報処理システムの進歩』, 33, 1877–1901.
→ これがほんまに有名なGPT-3の論文やねん!「Few-shot learners」ってのは、ちょっとした例を見せるだけで新しいタスクをこなせるようになるってことやで。めっちゃすごい発見やったんよ。
Bryant, D., & Krause, P. (2008). 現行の撤回可能推論の実装に関するレビュー. 『知識工学レビュー』, 23 (3), 227–260.
→ 撤回可能推論ってのは、新しい情報が入ってきたら「やっぱさっきの結論間違ってたわ」って修正できる推論のことやねん。その実装をまとめたレビュー論文やで。
Bryant, D., Krause, P. J., & Vreeswijk, G. (2006). Argue tuProlog:エージェントアプリケーション向けの軽量議論エンジン. COMMA, 144, 27–32.
→ tuPrologっていうプログラミング言語の上で動く、めっちゃ軽い議論用のエンジンを作ったで〜っていう論文やな。AIエージェントに議論させたいときに使えるやつや。
Bubeck, S., Chandrasekaran, V., Eldan, R., Gehrke, J., Horvitz, E., Kamar, E., Lee, P., Lee, Y. T., Li, Y., Lundberg, S., 他 (2023). 汎用人工知能の萌芽:GPT-4による初期実験. arXiv プレプリント arXiv:2303.12712.
→ これめっちゃ話題になった論文やで!GPT-4がもしかしたら汎用AI、つまり人間みたいになんでもできるAIの兆候を見せてるんちゃうか?っていう実験結果をまとめたやつやねん。「Sparks」って火花とか萌芽って意味で、ちょっとだけその片鱗が見えてきたで〜ってニュアンスやな。
Cabrio, E., & Villata, S. (2018). 議論マイニング5年間:データ駆動分析. IJCAI, 第18巻, pp. 5427–5433.
→ 議論マイニングってのは、文章の中から「これが主張」「これが根拠」「これが反論」みたいに議論の構造を自動で抜き出す技術やねん。それの5年分の研究をデータ使ってまとめた論文やで。
Cahn, J. (2017). チャットボット:アーキテクチャ、設計、開発. ペンシルベニア大学工学応用科学部コンピュータ情報科学科.
→ チャットボットをどうやって作るんか、設計から開発までをまとめた論文やな。大学の学位論文やで。
Caldarini, G., Jaf, S., & McGarry, K. (2022). チャットボットの最近の進歩に関する文献調査. 『情報』, 13 (1), 41.
→ チャットボットの最新研究をガーッとまとめたサーベイ論文やねん。この分野の全体像を知りたかったらこれ読んだらええで。
Carpenter, R. (1982). Jabberwacky.. https://web.archive.org/web/20050411013547/http://chat.jabberwacky.com/ (最終アクセス2024年4月6日).
→ これな、めっちゃ古いチャットボットやねん!1982年やで?インターネットもほぼ無い時代にもうチャットボット作ってた先駆者やな。
Castagna, F. (2022). 説明-質問-応答対話のための本格的な形式プロトコルに向けて. 『AI向けオンライン議論ハンドブック』, pp. 17–21.
→ 説明して、質問されて、それに答えるっていう対話の流れをちゃんと形式化しようとした論文やで。EQRってのはExplanation-Question-Responseの略やねん。
Castagna, F., Garton, A., McBurney, P., Parsons, S., Sassoon, I., & Sklar, E. I. (2023). EQRbot:EQR議論ベースの説明を提供するチャットボット. 『人工知能のフロンティア』, 6.
→ さっきのEQRの仕組みを実際にチャットボットにしたで〜っていう論文やな。説明を議論の形でちゃんと根拠付けて返してくれるボットやねん。
Castagna, F., McBurney, P., & Parsons, S. (2024). 説明-質問-応答対話:説明可能なAIのための議論ツール. 『議論と計算』, pp. 1–23.
→ AIの説明をちゃんと理解できるようにするためのツールとしてEQR対話を使おうっていう話やで。説明可能AIってほんまに大事な分野やねん。
Castagna, F., Parsons, S., Sassoon, I., & Sklar, E. I. (2022). EQR議論スキームを通じた説明の提供. 『議論の計算モデル:COMMA 2022会議録』.
→ 議論スキームってのは、議論のテンプレートみたいなもんやねん。「主張」「根拠」「反論」みたいな構造をパターン化したやつで、それを使って説明を組み立てる方法を提案してるで。
Castagna, F., Sassoon, I., & Parsons, S. (2024). 形式的議論推論はLLMの性能を向上させることができるか?.
→ これめっちゃ今っぽいテーマやな!大規模言語モデル(ChatGPTとかのあれや)に、ちゃんとした議論の形式を教えたら性能上がるんちゃうか?っていう研究やで。
Cayrol, C., & Lagasquie-Schiex, M.-C. (2005). 双極議論フレームワークにおける議論の受容可能性について. 『推論と不確実性への記号的・定量的アプローチに関する欧州会議』, pp. 378–389. Springer.
→ 双極議論フレームワークってのは、普通の「攻撃」だけやなくて「支持」の関係も入れた議論の枠組みやねん。議論同士が攻撃し合うだけやなくて、味方することもあるやろ?それをモデル化したやつやで。
Cerutti, F., Palmer, A., Rosenfeld, A., Šnajder, J., & Toni, F. (2016). オンライン討論のための議論フレームワーク使用に関するパイロット研究.
→ ネット上の討論に議論フレームワークを使ったらどうなるかっていう初期実験の論文やな。パイロット研究ってのは「まずちょっとやってみた」くらいの意味やで。
---
---
## Page 30
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p030.png)
### 和訳
Castagna、Kökciyan、Sassoon、Parsons、& Sklar
Chalaguine、L. A.、Hamilton、F. L.、Hunter、A.、& Potts、H. W. W.(2018)。チャットボット使った議論収集のやつ。COMMA論文集、149ページ。
Chalaguine、L. A.、& Hunter、A.(2018)。議論収集用チャットボットの設計について。「計算モデルによる議論:COMMA 2018論文集」、305巻、457ページ。
Chalaguine、L. A.、& Hunter、A.(2019)。議論ベースのチャットボット用の知識獲得とコーパスの話やねん。CEUR Workshop Proceedings、2528巻、1〜14ページ。
Chalaguine、L. A.、& Hunter、A.(2020)。クラウドソーシングで集めた議論グラフと関心事を使った説得型チャットボット。「計算モデルによる議論:COMMA 2020論文集」、326巻、9ページ。
Chalaguine、L. A.、& Hunter、A.(2021)。自然言語の議論対話でCOVID-19ワクチンに関するみんなの心配事に対応するって研究やで。「不確実性に対する記号的・定量的アプローチに関するヨーロッパ会議」、59〜73ページ。Springer。
Chalaguine、L. A.、Hunter、A.、Potts、H.、& Hamilton、F.(2019)。チャットボットとの議論における、議論の種類と関心事がどう影響するかって話。「2019 IEEE 第31回 人工知能ツール国際会議(ICTAI)」、1557〜1562ページ。IEEE。
Chapman、M.、Balatsoukas、P.、Kökciyan、N.、Essers、K.、Sassoon、I.、Ashworth、M.、Curcin、V.、Modgil、S.、Parsons、S.、& Sklar、E. I.(2019)。計算議論に基づく臨床意思決定支援システムの話やねん。めっちゃ医療現場で使えそうなやつ。「第18回自律エージェントとマルチエージェントシステム国際会議、AAMAS 2019」、2345〜2347ページ。自律エージェントとマルチエージェントシステム国際財団(IFAAMAS)。
Chen、G.、Cheng、L.、Tuan、L. A.、& Bing、L.(2023)。大規模言語モデルが計算議論学でどんな可能性持ってるか探ってみたで。arXivプレプリント arXiv:2311.09022。
Chia、Y. K.、Chen、G.、Tuan、L. A.、Poria、S.、& Bing、L.(2023)。対照的Chain-of-Thoughtプロンプティングっていう新しい手法やねん。arXivプレプリント arXiv:2311.09277。
Cocarascu、O.、Rago、A.、& Toni、F.(2019)。議論的対話エージェント使って、レビュー集約の説明を対話形式で引き出すって研究。「第18回自律エージェントとマルチエージェントシステム国際会議論文集」、1261〜1269ページ。計算機協会。
Cocarascu、O.、& Toni、F.(2017)。ディープラーニング使って議論の攻撃関係と支持関係を特定するって話やで。「2017年自然言語処理における経験的手法に関する会議論文集」、1374〜1379ページ、コペンハーゲン、デンマーク。計算言語学協会。
Codecademy(2022)。チャットボットって何やねん。https://www.codecademy.com/article/what-are-chatbots(最終アクセス 2024年4月6日)。
Cogan、E.、Parsons、S.、& McBurney、P.(2005)。エージェント間対話の新しいタイプについて。「マルチエージェントシステムにおける議論に関する国際ワークショップ」、154〜168ページ。Springer。
Colby、K. M.、Weber、S.、& Hilf、F. D.(1971)。人工パラノイア。ほんまに人工知能で妄想症みたいなの再現しようとした論文やねん。「Artificial Intelligence」、2巻1号、1〜25ページ。
---
## Page 31
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p031.png)
### 和訳
計算論的議論ベースのチャットボット:サーベイ
Coleさん(2020年)の「中国語の部屋論証」っていう論文があんねん。Zaltaさんが編集した『スタンフォード哲学百科事典』の2020年冬版に載ってんねんけど、スタンフォード大学の形而上学研究所から出てるやつやで。
ˇCyrasさんたち(2021年)は「議論的XAI:サーベイ」っていう論文を書いてて、これは第30回国際人工知能合同会議(IJCAI-21)のサーベイトラックで発表されたやつやねん。説明可能なAI(XAI)を議論の観点からまとめた総説やな。
Dachseltさんたち(2022年)は「NEXAS」っていう視覚的なツールを作ったんやで。議論の解空間をナビゲートして探索できるやつや。『計算論的議論モデル:COMMA 2022論文集』の353巻、116ページに載ってるわ。
Daleさん(2016年)は「チャットボットの復活」っていうタイトルで『自然言語工学』の22巻5号、811〜817ページに書いてはる。チャットボットがまた注目されてきたでーって話やな。
Dawsさん(2020年)の記事はめっちゃ衝撃的やねん。なんとOpenAIのGPT-3を使った医療チャットボットが、偽の患者に自殺しろって言うてもうたんや。https://www.artificialintelligence-news.com/2020/10/28/medical-chatbot-openai-gpt3-patient-kill-themselves/ で読めるで(2024年4月6日最終アクセス)。ほんまに危険やなって話や。
de Sousaさんたち(2024年)は「チャットボット技術を使った議論支援」について第16回エージェントと人工知能国際会議(ICAART 2024)で発表してはる。SciTePressから出版やで。
de Wynterさんとヤンさん(2023年)は「議論したいんやけど:大規模言語モデルにおける議論的推論」っていうプレプリントをarXivに上げてはる(arXiv:2309.16938)。LLMがちゃんと議論できるんかって研究やな。
Devlinさんたち(2018年)のBERTの論文は超有名やで。「深い双方向トランスフォーマーによる言語理解の事前学習」っていうタイトルで、arXiv:1810.04805や。言語モデルの歴史変えた論文やねん。
DighumさんとBexさん(2017年)は「議論と社会的実践を使った対話の生成」について国際インターネット科学会議で発表してはる。223〜235ページや。
Dixさんたち(2009年)は「議論研究の課題」っていう論文を『コンピュータサイエンス研究開発』の23巻1号、27〜34ページに書いてはる。これからの研究で何を解決せなあかんかって話やな。
Drakeさんたち(2022年)はめっちゃ実用的な研究してはって、社会人口統計学的要因と患者の態度が接続型医療技術にどう関係するかを調べたんや。脳卒中経験者を対象にしたアンケート調査で、『ヘルス・インフォマティクス・ジャーナル』に載ってるで。
Dungさん(1995年)の論文はこの分野ではめっちゃ重要やねん。「議論の受容可能性について、そして非単調推論、論理プログラミング、n人ゲームにおけるその基本的役割」っていうタイトルで、『人工知能』の77巻2号、321〜357ページや。議論フレームワークの基礎を作った古典的論文やで。
Dutilh Novaesさん(2022年)は「論証と議論」について『スタンフォード哲学百科事典』の2022年秋版に書いてはる。ZaltaさんとNodelmanさんが編集で、スタンフォード大学形而上学研究所からやな。
Dvoˇrákさんたち(2020年)は「ASPARTIX-V19」っていうシステムを作ったんや。回答集合プログラミングベースの抽象議論システムで、情報知識システム基礎国際シンポジウムの79〜89ページに載ってるで。Springerから出版や。
---
## Page 32
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p032.png)
### 和訳
Castagna, Kökciyan, Sassoon, Parsons, & Sklar
Dvorák, W., König, M., Wallner, J. P., & Woltran, S. (2021). ASPARTIX-V21.. http://argumentationcompetition.org/2021/downloads/aspartix-v21.pdf, (最終アクセス2024年6月4日).
Egly, U., Gaggl, S. A., & Woltran, S. (2008). Aspartix: 解答集合プログラミングを使って議論フレームワークを実装するっちゅう話やねん。International Conference on Logic Programming, pp. 734–738. Springer.
Essers, K., Chapman, M., Kokciyan, N., Sassoon, I., Porat, T., Balatsoukas, P., Young, P., Ashworth, M., Curcin, V., Modgil, S., et al. (2018). CONSULTシステムっちゅうやつやで。Proceedings of the 6th International Conference on Human-Agent Interaction, pp. 385–386.
Fazzinga, B., Flesca, S., & Furfaro, F. (2018). 確率的な双極抽象議論フレームワークの話で、これがめっちゃ計算複雑やっちゅう結果を出してんねん。Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI-18, pp. 1803–1809. International Joint Conferences on Artificial Intelligence Organization.
Fazzinga, B., Galassi, A., & Torroni, P. (2021). COVID-19ワクチンの情報について対話できる議論システム作ったで、っちゅう研究やねん。International Conference on Logic and Argumentation, pp. 477–485. Springer.
Fazzinga, B., Galassi, A., & Torroni, P. (2022). プライバシー守りながら議論できる対話システムの話やで。Intelligent Systems with Applications, 16, 200113.
Fichte, J. K., Hecher, M., Gorczyca, P., & Dewoprabowo, R. (2021). A-folio DPDB – ICCMA 2021用のシステム説明書やで。http://argumentationcompetition.org/2021/downloads/a-folio-dpdb.pdf, (最終アクセス2024年6月4日).
Fox, J., Glasspool, D., Grecu, D., Modgil, S., South, M., & Patkar, V. (2007). 議論ベースの推論と意思決定を医療の観点から見たらどうなるか、っちゅう話やねん。IEEE intelligent systems, 22 (6), 34–41.
Frieder, S., Pinchetti, L., Griffiths, R.-R., Salvatori, T., Lukasiewicz, T., Petersen, P. C., Chevalier, A., & Berner, J. (2023). ChatGPTの数学の実力ってどんなもんやねん、っちゅう研究やで。arXiv preprint arXiv:2301.13867.
Galitsky, B. (2018). チャットボットで議論を検出してサポートできるようにする技術の特許やねん。https://patents.google.com/patent/US10679011B2/en, (最終アクセス2024年6月4日).
Galitsky, B. (2019). 感情を込めた議論を検出してサポートできるチャットボットの特許やで。https://patents.google.com/patent/US20190138595A1/en, (最終アクセス2024年6月4日).
Galitsky, B. (2020). 議論の妥当性を検証できるチャットボットの特許やねん。https://patents.google.com/patent/US10817670B2/en, (最終アクセス2024年6月4日).
Gartner, D., & Toni, F. (2007). CaSAPI: 信じやすい立場と疑り深い立場、両方の議論に対応できるシステムやで。Proc. of ArgNMR, 80–95.
Girle, R. A. (1996). 対話論理における命令の扱い方、っちゅう話やねん。International Conference on Formal and Applied Practical Reasoning, pp. 246–260. Springer.
1302
---
## Page 33
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p033.png)
### 和訳
ほな、論文の参考文献リストを説明していくで!
Grando らの研究(2013年)は、医療の仮説を作ったり説明したりするのに議論のロジックを使うって話やねん。『Artificial intelligence in medicine』っていう医療AI専門誌に載ってるやつやで。
Guo らの研究(2022年)は、チャットボットを使って英語学習者の論証文ライティングをサポートするっていう内容やな。『Assessing Writing』に掲載されとる。
Habernal と Gurevych(2017年)は、ネット上でユーザーが書いた文章から議論を掘り出す「アーギュメンテーション・マイニング」についての研究や。『Computational Linguistics』に載っとるで。
Hadoux と Hunter(2019年)は、相手を説得するときに、その人の心配事とか気になることをちゃんと聞いて使うっていうアプローチやねん。「快適さか安全か」みたいな話やな。
Hadoux ら(2021年)は、説得のための戦略的な議論対話について書いてて、説得される側の信念とか心配事をモデル化するフレームワークと実験結果を紹介しとる。
Hauptmann ら(2024年)は、自律型AIのシナリオについて倫理的な議論をするチャットボットの効果を調べた研究やねん。めっちゃ最新の研究やで。
Heater(2018年)は、アレクサがWolfram Alphaっていう知識エンジンにアクセスできるようになったっていうニュース記事やな。TechCrunchに載ってたやつや。
Heinrich(2021年)は、議論フレームワーク用の「MATRIXX」っていうソルバーについての資料やで。
Hinton と Wagemans(2022年)は、AIが生成した議論がどれくらい説得力あるかを分析した研究やねん。GPT-3が作った論証テキストの質を調べとるんや。ほんまに面白いテーマやで。
Hulstijn(2000年)は、問い合わせと取引のための対話モデルについての博士論文やな。オランダのトゥエンテ大学で出されたやつや。
Hung(2017年)は、確率的議論のための推論手続きとエンジンについての研究や。『International Journal of Approximate Reasoning』に載っとる。
Hunter(2015年)は、説得のための非対称な議論対話で、説得される側をどうモデル化するかっていう研究やねん。国際AI学会で発表されたやつや。
Hunter(2018年)は、行動変容に応用するための計算論的説得のフレームワークについて書いとる。
Hunter ら(2019年)は、自然言語の議論対話を使った計算論的説得に向けた研究やで。ドイツとオーストリアの合同AI学会で発表されとる。
IBM(2006年)は、ワトソンについてやな。IBMが作った有名なAIアシスタントのことやで。
---
## Page 34
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p034.png)
### 和訳
Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y., Ishii, E., Bang, Y. J., Madotto, A., & Fung, P. (2023). 「自然言語生成におけるハルシネーションの調査」 ACM Comput. Surv., 55 (12).
→ ほんでな、これはAIが嘘ついちゃう問題、いわゆる「ハルシネーション」について調べた論文やねん。AIがもっともらしいこと言うけど実は事実ちゃうっていう、あのヤバいやつな。
Jiang, A. Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D. S., de las Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L. R., Lachaux, M.-A., Stock, P., Scao, T. L., Lavril, T., Wang, T., Lacroix, T., & Sayed, W. E. (2023). Mistral 7b.
→ これはMistral 7bっていう言語モデルの論文やで。70億パラメータのモデルで、めっちゃ効率ええって話題になったやつや。
Jiao, W., Wang, W., Huang, J., Wang, X., & Tu, Z. (2023). 「ChatGPTはええ翻訳者なん?GPT-4がエンジンやったらイエスやで」 arXiv preprint arXiv:2301.08745.
→ これ面白いねんけど、ChatGPTが翻訳上手いかどうか調べた研究やねん。結論としては、GPT-4使ったらめっちゃええ翻訳できるでって話や。
Jo, Y., Bang, S., Reed, C., & Hovy, E. (2021). 「論理的メカニズムと議論スキームを使った議論関係の分類」 Transactions of the Association for Computational Linguistics, 9, 721–739.
→ 議論の中で「これとこれどういう関係なん?」っていうのを、論理的な仕組みと議論のパターンを使って分類する研究やな。
Kar, R., & Haldar, R. (2016). 「チャットボットをIoTに適用する:チャンスとアーキテクチャの要素」 International Journal of Advanced Computer Science and Applications, 7 (11).
→ IoT、つまりモノのインターネットにチャットボット組み合わせたらどんなええことあるん?って話と、どう作ったらええかの設計の話やねん。
Klopfenstein, L. C., Delpriori, S., Malatini, S., & Bogliolo, A. (2017). 「ボットの台頭:会話インターフェース、パターン、パラダイムの調査」 Proceedings of the 2017 conference on designing interactive systems, pp. 555–565.
→ チャットボットがめっちゃ増えてきたから、どんな種類あるんとか、どういうパターンで作られてるんとかを調べた研究やで。
Kökciyan, N., Chapman, M., Balatsoukas, P., Sassoon, I., Essers, K., Ashworth, M., Curcin, V., Modgil, S., Parsons, S., & Sklar, E. I. (2019). 「慢性疾患管理のための協調的意思決定支援ツール」 The 17th World Congress of Medical and Health Informatics.
→ 慢性的な病気を持ってる患者さんが、お医者さんと一緒に「どうしよっか」って決められるようなシステム作ったで、っていう研究やな。
Kökciyan, N., Sassoon, I., Sklar, E., Modgil, S., & Parsons, S. (2021). 「医療意思決定を支援するためのメタレベル議論フレームワークの適用」 IEEE Intelligent Systems, 36 (2), 64–71.
→ 医療の現場で「この治療がええんちゃう?」「いやこっちの方が」みたいな議論をAIでサポートする仕組みやねん。メタレベルっていうのは、議論自体を一段上から見る感じの話や。
Kökciyan, N., Sassoon, I., Young, A., Chapman, M., Porat, T., Ashworth, M., Curcin, V., Modgil, S., Parsons, S., & Sklar, E. (2018). 「慢性疾患の自己管理を支援する議論システムに向けて」 AAAI Joint Workshop on Health Intelligence (W3PHIAI).
→ 慢性疾患を持つ患者さんが自分で健康管理できるように、議論ベースのシステムでサポートしようっていう初期段階の研究やで。
Kosinski, M. (2023). 「大規模言語モデルに心の理論が自発的に現れたかもしれへん」 arXiv preprint arXiv:2302.02083.
→ これめっちゃ話題になったやつやで!「心の理論」っていうのは、他人の気持ちとか考えを推測できる能力のことやねん。AIがそれ自然に身につけたんちゃうか?っていうちょっとびっくりする研究や。
Kulatska, I. (2019). 「Arguebot:ハイブリッド検索・生成ベースのチャットボットで議論を可能にする」 修士論文, トゥウェンテ大学.
→ 議論できるチャットボットを作った修論やな。検索と生成の両方使ってるからハイブリッドって言うてるねん。
Lawrence, J., & Reed, C. (2020). 「議論マイニング:サーベイ」 Computational Linguistics, 45 (4), 765–818.
→ 議論マイニングっていうのは、文章から「これが主張で」「これが根拠で」みたいな議論の構造を自動で抜き出す技術やねん。それの総まとめ論文やで。
Li, B., Fang, G., Yang, Y., Wang, Q., Ye, W., Zhao, W., & Zhang, S. (2023). 「ChatGPTの情報抽出能力の評価:性能、説明可能性、キャリブレーション、忠実性の評価」 arXiv preprint arXiv:2304.11633.
→ ChatGPTがテキストから情報抜き出すのどれくらい上手いか、色んな角度から調べた研究やな。説明できるか、確信度合ってるか、元の情報に忠実か、とかもチェックしてるで。
Lin, F., & Shoham, Y. (1989). 「議論システム:非単調推論の統一的基盤」 KR, 89, 245–255.
→ これはちょっと古いけど重要な論文やねん。「非単調推論」っていうのは、新しい情報が入ったら前の結論ひっくり返ることもあるっていう、人間っぽい考え方のことや。それを議論システムで統一的に扱おうって話やで。
---
## Page 35
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p035.png)
### 和訳
Lopatovska, I., Rink, K., Knight, I., Raines, K., Cosenza, K., Williams, H., Sorsche, P., Hirsch, D., Li, Q., & Martinez, A. (2019). 「僕に話しかけてや:Amazon Alexaとユーザーのやり取りを探ってみた」Journal of Librarianship and Information Science, 51(4), 984–997.
Luck, M., McBurney, P., Shehory, O., & Willmott, S. (2005). 「エージェント技術:インタラクションとしてのコンピューティング(エージェントベースコンピューティングのロードマップ)」。
Mahowald, K., Ivanova, A. A., Blank, I. A., Kanwisher, N., Tenenbaum, J. B., & Fedorenko, E. (2023). 「大規模言語モデルにおける言語と思考を切り離してみた:認知科学の視点から」arXiv preprint arXiv:2301.06627. ※これめっちゃ面白い研究でな、LLM(大規模言語モデル)って言葉はうまく使えるけど、ほんまに「考えてる」んかっていうのを認知科学的に分析してんねん。
Malmqvist, L. (2021). 「AFGCN:近似的な抽象議論ソルバー」http://argumentationcompetition.org/2021/downloads/afgcn.pdf(最終アクセス日:2024年4月6日)。※ソルバーっていうのは、複雑な問題を自動で解いてくれるプログラムのことやで。
Marshall, C. (2014). 「Cortana:Microsoftが出したSiriのライバルについて知っておくべきこと全部教えたるで」https://www.techradar.com/news/phone-and-communications/mobile-phones/cortana-everything-you-need-to-know-about-microsoft-s-siri-rival-1183607(最終アクセス日:2024年4月6日)。
Mayer, T., Cabrio, E., & Villata, S. (2020). 「ヘルスケア向けのTransformerベース議論マイニング」ECAI 2020, pp. 2108–2115. IOS Press. ※Transformerっていうのは今のAIの主流になってる仕組みで、それを使って医療分野の議論を自動で分析する研究やねん。
McBurney, P., Hitchcock, D., & Parsons, S. (2007). 「審議対話の8つの道」International Journal of Intelligent Systems, Vol. 22, pp. 95–132. Wiley Online Library. ※審議対話っていうのは、みんなで話し合って何かを決めるときの会話のパターンのことやな。
McBurney, P., & Parsons, S. (2001). 「弁証法的議論を使ったチャンス発見」Annual Conference of the Japanese Society for Artificial Intelligence, pp. 414–424. Springer. ※弁証法っていうのは、反対意見をぶつけ合って真実に近づいていく考え方のことやで。
McBurney, P., & Parsons, S. (2002). 「エージェントがやるゲーム:自律エージェント間の対話のための形式的フレームワーク」Journal of logic, language and information, 11(3), 315–334. ※自律エージェントっていうのは、自分で判断して動けるAIプログラムのことやねん。
McBurney, P., & Parsons, S. (2009). 「エージェント議論のための対話ゲーム」Argumentation in artificial intelligence, pp. 261–280. Springer.
McBurney, P., & Parsons, S. (2013). 「やることについて話す」From Knowledge Representation to Argumentation in AI, Law and Policy Making, 151–166.
McBurney, P., & Parsons, S. (2021). 「議論スキームと対話プロトコル:Doug Waltonの人工知能における遺産」Journal of Applied Logics, 8(1), 263–286. ※議論スキームっていうのは、「こういう形で主張したらこう反論できる」みたいな議論のパターンのことやで。
McBurney, P., Van Eijk, R. M., Parsons, S., & Amgoud, L. (2003). 「エージェント購入交渉のための対話ゲームプロトコル」Autonomous Agents and Multi-Agent Systems, Vol. 7, pp. 235–273. Springer. ※要するに、AIが自動で買い物の値段交渉するときのルールを決めた研究やねん。
Mercier, H., & Sperber, D. (2011). 「なんで人間って推論するんやろ?議論的理論への論拠」Behavioral and brain sciences, 34(2), 57–74. ※これめっちゃ有名な論文でな、人間の推論能力って実は「他人を説得するため」に進化したんちゃうかって主張してんねん。
Meta (2024). 「Llama 3.1の紹介:今んとこ一番すごいモデルやで」Meta Blog. https://ai.meta.com/research/publications/the-llama-3-herd-of-models/(最終アクセス日:2024年7月24日)。※LlamaっていうのはMetaが作ったオープンソースのLLMで、誰でも使えるようになってんねん。
---
## Page 36
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p036.png)
### 和訳
Castagna, Kökciyan, Sassoon, Parsons, & Sklar
Microsoft (2014). Cortana(コルタナ)や。https://www.microsoft.com/en-us/cortana(最終アクセス:2024年4月6日)
Modgil, S., & Prakken, H. (2013). 好み付き議論の一般的な説明やねん。これはな、人が何かを選ぶときの好みをどうやって議論に組み込むかっていう話や。『Artificial Intelligence』誌、195巻、361-397ページ。
Murphy, J., Black, E., & Luck, M. M. (2016). 説得対話のためのヒューリスティック戦略やで。要はな、相手を説得するときにどんな作戦使ったらええかっていう賢いやり方の話や。『Computational Models of Argument: Proceedings of COMMA 2016』、411-418ページ。IOS Press出版。
Niskanen, A., & Järvisalo, M. (2021). ICCMA'21でのμ-toksiaっていうシステムの話やねん。http://argumentationcompetition.org/2021/downloads/mu-toksia.pdf(最終アクセス:2024年4月6日)
OpenAI (2023). GPT-4の技術レポートやで。めっちゃ話題になったやつや。
Patterson, D., Gonzalez, J., Hölzle, U., Le, Q., Liang, C., Munguia, L.-M., Rothchild, D., So, D. R., Texier, M., & Dean, J. (2022). 機械学習の訓練で出る二酸化炭素はな、いずれ頭打ちになって、そっから減っていくで、っていう話や。環境問題とAIの関係やな。『Computer』誌、55巻7号、18-28ページ。
Podlaszewski, M., Caminada, M., & Pigozzi, G. (2011). 基本的な議論コンポーネントの実装についてやねん。議論システムの部品をどうやってプログラムで作るかっていう話や。『The 10th International Conference on Autonomous Agents and Multiagent Systems』第3巻、1307-1308ページ。
Pollock, J. L. (1987). 撤回可能推論についてやで。これめっちゃ大事な概念でな、「普通はこうやけど、例外あったら考え直すで」っていう人間らしい推論の仕方のことや。『Cognitive science』誌、11巻4号、481-518ページ。
Prakken, H. (2006). 説得対話のための形式システムやねん。人を説得するときのルールをきっちり数学的に決めましょうっていう話や。『The knowledge engineering review』第21巻、163-188ページ。Cambridge University Press出版。
Prakken, H., Bistarelli, S., & Santini, F. (2020). 『Computational Models of Argument: Proceedings of COMMA 2020』第326巻。議論のコンピュータモデルについての学会の論文集やで。IOS Press出版。
Qin, C., Zhang, A., Zhang, Z., Chen, J., Yasunaga, M., & Yang, D. (2023). ChatGPTって汎用的な自然言語処理のタスク解決マシンなんかな?っていう疑問を検証した研究やねん。ほんまに何でもできるんか調べたんや。arXivプレプリント、arXiv:2302.06476。
Rago, A., Cocarascu, O., Bechlivanidis, C., & Toni, F. (2020). レコメンドシステムにおけるインタラクティブな説明のフレームワークとしての議論やで。なんでこれおすすめしたんか、ユーザーと対話しながら説明できるようにする仕組みの話や。『Proceedings of the International Conference on Principles of Knowledge Representation and Reasoning』第17巻、805-815ページ。
Rago, A., Cocarascu, O., & Toni, F. (2018). 議論ベースのレコメンデーション:すごい説明とその見つけ方やねん。タイトルがめっちゃファンタジー映画っぽいやろ?要はおすすめの理由をちゃんと説明できるシステムの話や。『Twenty-Seventh International Joint Conference on Artificial Intelligence』、1949-1955ページ。
Rago, A., Toni, F., Aurisicchio, M., & Baroni, P. (2016). 量的議論討論を使った不連続性のない意思決定支援やで。決断するときに急にガクッと結果が変わらんような、なめらかな判断ができるシステムの話や。『Fifteenth International Conference on the Principles of Knowledge Representation and Reasoning』にて発表。
Rahwan, I., & Larson, K. (2009). 議論とゲーム理論の関係についてやねん。駆け引きと議論がどう繋がってるかっていう話や。『Argumentation in artificial intelligence』、321-339ページ。
Rahwan, I., & Simari, G. R. (2009). 『人工知能における議論』っていう本や。AIでどうやって議論を扱うかの教科書みたいなもんやな。Springer出版。
Reckwitz, A. (2002). 社会的実践の理論に向けて:文化主義的理論化の発展やで。人の行動を「習慣」とか「実践」として捉える社会学の理論の話やねん。『European journal of social theory』5巻2号、243-263ページ。
---
## Page 37
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p037.png)
### 和訳
計算論的議論に基づくチャットボット:サーベイ論文
Reid, M.とかSavinov, N.とかTeplyashin, D.とか、ほかにもLepikhin, D.とかLillicrap, T.とかAlayrac, J.-b.とか、Soricut, R.とかLazaridou, A.とかFirat, O.とかSchrittwieser, J.とか、まあめっちゃたくさんの人らが2024年に書いた論文やねんけど、「Gemini 1.5:何百万トークンもの文脈でマルチモーダル理解を解き放つ」っていうやつや。arXivのプレプリントで、番号はarXiv:2403.05530やで。
Roller, S.とDinan, E.とGoyal, N.と、あとJu, D.とWilliamson, M.とLiu, Y.とXu, J.とOtt, M.とShuster, K.とSmith, E. M.とか、これもまた大勢が2020年に出した「オープンドメインチャットボット作るためのレシピ集」っちゅう論文や。arXivプレプリントでarXiv:2004.13637やねん。
Rosenfeld, A.とKraus, S.が2016年に書いたんは「人間を説得するための戦略的議論エージェント」っちゅうやつで、ECAI 2016の320から328ページに載ってて、IOS Pressから出とるわ。
Ruiz-Dolz, R.とAlemany, J.とBarbera, S.とGarcia-Fornes, A.が2021年に出した論文は「Transformerベースのモデルで議論関係を自動で見つけるやつ:ドメインまたいだ評価」っていうやつやねん。IEEE Intelligent Systemsの36巻6号、62から70ページに載ってるで。
Saadat-Yazdi, A.とPan, J.とKökciyan, N.が2023年に書いた「隠れた推論を見つけ出して関係的議論マイニングを改善する」っちゅう論文は、欧州計算言語学会(EACL)の第17回会議の proceedings の2476から2487ページに載っとるわ。
Sansonnet, J.-P.とLeray, D.とMartin, J.-C.が2006年に書いた「汎用支援会話エージェントのためのフレームワークのアーキテクチャ」は、国際知的仮想エージェントワークショップで発表されて、Springerから出てて145から156ページやねん。
Sassoon, I.とKökciyan, N.とChapman, M.とSklar, E.とCurcin, V.とModgil, S.とParsons, S.が2020年に「対話における議論スキームと説明スキームの実装」っちゅう論文を書いてて、これはComputational Models of Argument: Proceedings of COMMA 2020の326巻、471ページに載っとるで。
Sassoon, I.とKökciyan, N.とModgil, S.とParsons, S.が2021年に出した「臨床意思決定支援のための議論スキーム」はArgument & Computationの1から27ページに載ってるわ。
Sassoon, I.とKökciyan, N.とSklar, E.とParsons, S.が2019年に書いた「ウェルネス相談のための説明可能な議論」は、説明可能で透明な自律エージェントとマルチエージェントシステムに関する国際ワークショップで発表されて、Springerから出てて186から202ページやねん。
Schaeffer, R.とMiranda, B.とKoyejo, S.が2023年に出した「大規模言語モデルの創発的能力は幻なんちゃうか?」っちゅう論文はarXivプレプリントでarXiv:2304.15004やで。これめっちゃ面白い問いかけやな。
Searle, J. R.が1980年に書いた「心、脳、そしてプログラム」っていう有名な論文は、Behavioral and brain sciencesの3巻3号、417から424ページに載ってるわ。これ、中国語の部屋の思考実験で有名なやつやねん。
Shove, E.とPantzar, M.とWatson, M.が2012年に書いた本『社会的実践のダイナミクス:日常生活とその変化』はSAGEから出版されとるで。
Silver, D.とVeness, J.が2010年に書いた「大規模POMDPでのモンテカルロ計画法」はAdvances in neural information processing systemsの23巻に載っとるわ。POMDPってのは部分観測マルコフ決定過程っちゅう、状態が完全に見えへん状況での意思決定を扱う数学的枠組みのことやねん。
Singh, S.とThakur, H. K.が2020年に書いた「使われてる技術に基づく様々なAIチャットボットの調査」は、2020年の第8回信頼性・情報通信技術・最適化に関する国際会議(ICRITOって略すねんけど、トレンドと将来の方向性がテーマや)の1074から1079ページに載ってて、IEEEが出しとるわ。
Sklar, E.とParsons, S.が2004年に書いた「教育への議論ベース対話の応用に向けて」は、自律エージェントとマルチエージェントシステムの国際合同会議の第4巻、1420から1421ページに載ってて、IEEE Computer Societyから出とるで。
1307
---
## Page 38
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p038.png)
### 和訳
Castagna, Kökciyan, Sassoon, Parsons, & Sklar
Sklar, E. I., & Azhar, M. Q. (2015). 議論ベースの対話ゲームで人間とロボットが一緒に操作するシステムの話。Journal of Human-Robot Interaction, 4 (3), 120–148.
Sklar, E. I., & Azhar, M. Q. (2018). 議論を使って説明するっちゅう研究やねん。第6回人間エージェントインタラクション国際会議の論文集で、277–285ページに載ってるで。
Slonim, N., Bilu, Y., Alzate, C., Bar-Haim, R., Bogin, B., Bonin, F., Choshen, L., CohenKarlik, E., Dankin, L., Edelstein, L., その他みんな (2021). 自分で勝手にディベートできるシステムを作ったんやて。めっちゃすごない?Nature, 591 (7850), 379–384.
Sojasingarayar, A. (2020). アテンション機構っちゅうのを使ったSeq2seq AIチャットボットの話やねん。なんでかっていうと、アテンションってのは「どこに注目するか」を学習する仕組みなんや。arXiv preprint arXiv:2006.02767.
Tang, Y., Sklar, E., & Parsons, S. (2012). ArgTrustっていう議論エンジンを作ったで。マルチエージェントシステムにおける議論の第9回国際ワークショップで発表したやつや。
Thimm, M. (2021). Harper+っちゅうのはな、グラウンデッドセマンティクスを使って抽象的な議論の近似推論をするやつやねん。http://argumentationcompetition.org/2021/downloads/harper++.pdf から見れるで(2024年4月6日に最後にアクセスしたわ)。
Thimm, M., Cerutti, F., & Vallati, M. (2021). FUDGEっちゅう軽量なソルバーやねん。抽象的な議論をSATリダクションっていう方法で解くんや。http://argumentationcompetition.org/2021/downloads/fudge.pdf で見れるで(2024年4月6日に最後にアクセス)。
Thorp, H. H. (2023). ChatGPTは遊ぶ分にはおもろいけど、著者としては認められへんで、っちゅう話。Science, 379 (6630), 313–313.
Tolchinsky, P., Modgil, S., Atkinson, K., McBurney, P., & Cortés, U. (2012). 安全性がめっちゃ重要な行動について推論するための熟議対話の研究やねん。Autonomous Agents and Multi-Agent Systems, 25 (2), 209–259.
Toni, F. (2014). 仮定ベース議論のチュートリアルやで。Argument & Computation, 5 (1), 89–117.
Toniuc, D., & Groza, A. (2017). ClimeBotっちゅう気候変動について議論できるエージェントを作ったんや。2017年の第13回IEEE知的コンピュータ通信処理国際会議で発表してん、63–70ページに載ってるで。IEEE。
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., その他いっぱい (2023a). Llamaっちゅうオープンで効率的な基盤言語モデルの話やねん。arXiv preprint arXiv:2302.13971.
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., その他めっちゃおる (2023b). Llama 2やで。オープンな基盤モデルとファインチューニングしたチャットモデルの話。arXiv preprint arXiv:2307.09288.
Trautmann, D., Daxenberger, J., Stab, C., Schütze, H., & Gurevych, I. (2020). 議論の単位をめっちゃ細かく認識して分類する研究やねん。AAAI人工知能会議論文集、Vol. 34、9048–9056ページに載ってるで。
Tunstall, L., Beeching, E., Lambert, N., Rajani, N., Rasul, K., Belkada, Y., Huang, S., von Werra, L., Fourrier, C., Habib, N., Sarrazin, N., Sanseviero, O., Rush, A. M., & Wolf, T. (2023). Zephyrっちゅうのはな、言語モデルのアラインメントを直接蒸留するやつやねん。
Turing, A. M., & Haugeland, J. (1950). 計算機械と知能についての論文やな。チューリングテスト:言語的行動が知能の証やっちゅう本に載ってんねん、29–56ページ。
1308
---
## Page 39
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p039.png)
### 和訳
計算論的議論ベースのチャットボット:サーベイ
Vassiliades, A., Bassiliades, N., & Patkos, T. (2021). 議論と説明可能な人工知能:サーベイやねん。The Knowledge Engineering Review, 36.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). アテンションがあったら全部いけるねん。これ、めっちゃ有名な論文やで。Advances in neural information processing systems, 30.
Visser, J., Lawrence, J., Wagemans, J., & Reed, C. (2018). 議論スキームの計算モデルをもっかい見直してみよか:分類とか、アノテーションとか、比較とかの話やな。第7回計算論的議論モデル国際会議、COMMA 2018の論文集、pp. 313–324. ios Press.
Vreeswijk, G. (1994). IACAS:インタラクティブな議論システムやで。Rapport technique CS, 94 (03).
Wagemans, J. (2016). 議論の周期表を作ってみよう、っていう試みやねん。めっちゃおもろいやろ?In Argumentation, objectivity, and bias: Proceedings of the 11th international conference of the Ontario Society for the Study of Argumentation (OSSA), Windsor, ON: OSSA, pp. 1–12.
Wallace, R. (2003). AIMLのスタイルの基本要素について。Alice AI Foundation, 139.
Wallace, R. S. (2009). A.L.I.C.E.の解剖学やな。なんでかっていうと、チャットボットの構造をちゃんと理解しよう、っていう内容やねん。In Parsing the turing test, pp. 181–210. Springer.
Waller, M. (2023). 自動意思決定システムにおけるバイアス検出に対する議論ベースのアプローチやで。ほんまに大事なテーマやな。In Online Handbook of Argumentation for AI, Vol. 4.
Walton, D. (2012). 議論スキームを適用した議論マイニングの話。Studies in Logic, 4 (1), 2011.
Walton, D., & Krabbe, E. C. (1995). 対話におけるコミットメント:対人推論の基本概念やねん。SUNY press.
Walton, D., & Macagno, F. (2015). 議論スキームの分類システムについてやで。Argument & Computation, 6 (3), 219–245.
Walton, D., Reed, C., & Macagno, F. (2008). 議論スキーム。これ、議論学の基礎やから読んどいた方がええで。Cambridge University Press.
Walton, D. N. (1990). 推論ってなんなん?議論ってなんなん?っていう哲学的な問いかけやな。The journal of Philosophy, 87 (8), 399–419.
Walton, D. N., & Gordon, T. F. (2011). 批判的質問を追加前提としてモデル化する方法やで。In Proceedings of the 8th International OSSA Conference.
Wambsganss, T., Guggisberg, S., & Söllner, M. (2021). ArgueBot:適応的な議論フィードバックのための会話エージェントやねん。めっちゃ実用的なシステムやで。In Innovation Through Information Systems: Volume II: A Collection of Latest Research on Technology Issues, pp. 267–282. Springer.
Wei, J., Tay, Y., Bommasani, R., Raffel, C., Zoph, B., Borgeaud, S., Yogatama, D., Bosma, M., Zhou, D., Metzler, D., et al. (2022a). 大規模言語モデルの創発的能力について。これ、ほんまにすごい発見やってん。arXiv preprint arXiv:2206.07682.
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q. V., Zhou, D., et al. (2022b). Chain-of-thoughtプロンプティングで大規模言語モデルの推論能力を引き出す方法やで。要は、ステップバイステップで考えさせたら、AIがめっちゃ賢くなるねん。Advances in Neural Information Processing Systems, 35, 24824–24837.
1309
---
## Page 40
[](/attach/6517d020d00f782fab68a8b58e088dce9177204bf9bbcde1860ea5db268143b5_p040.png)
### 和訳
だいしろーさん!翻訳完了しましたで!
---
Weizenbaum, J. (1966). ELIZA - 人間と機械の間の自然言語コミュニケーションを研究するためのコンピュータプログラム. Communications of the ACM, 9 (1), 36–45.
これな、めっちゃ歴史的な論文やねん。ELIZAっていう、人間とコンピュータがおしゃべりできるプログラムの話や。
Worswick, S. (2013). インタビュー - 2013年ローブナー賞受賞者.. https://aidreams.co.uk/forum/index.php?page=Steve_Worswick_Interview_-_Loebner_2013_winner#.Y0IfoHZBxPY (最終アクセス日 2024年4月6日).
ローブナー賞っていうのはな、一番人間っぽいチャットボットを決めるコンテストやねん。
Worswick, S. (2018). Mitsukuがローブナー賞2018を受賞!.. https://medium.com/pandorabots-blog/mitsuku-wins-loebner-prize-2018-3e8d98c5f2a7 (最終アクセス日 2024年4月6日).
Mitsukuってチャットボットがまた優勝したって話やな。
Xu, J., Ju, D., Lane, J., Komeili, M., Smith, E. M., Ung, M., Behrooz, M., Ngan, W., Moritz, R., Sukhbaatar, S., Boureau, Y.-L., Weston, J., & Shuster, K. (2023). 自然なやりとりから学んでオープン言語モデルを改善する..
なんでかっていうと、実際の人間同士の会話データを使ってAIをもっと賢くしようって研究やねん。
Yao, S., Yu, D., Zhao, J., Shafran, I., Griffiths, T. L., Cao, Y., & Narasimhan, K. (2023). 思考の木:大規模言語モデルによる計画的な問題解決. arXiv preprint arXiv:2305.10601.
これめっちゃ面白いねん。AIに「ちょっと待って、いろんな可能性考えてみよか」って木の枝みたいに分岐させながら考えさせる方法やで。
Zhang, Y., Sun, S., Galley, M., Chen, Y.-C., Brockett, C., Gao, X., Gao, J., Liu, J., & Dolan, B. (2019). DialoGPT:会話応答生成のための大規模生成事前学習. arXiv preprint arXiv:1911.00536.
GPTっていう有名なAIの会話特化バージョンを作ったって話やな。ほんまに大量のデータで学習させてるねん。
Zhao, W. X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., Min, Y., Zhang, B., Zhang, J., Dong, Z., 他 (2023). 大規模言語モデルのサーベイ. arXiv preprint arXiv:2303.18223.
サーベイっていうのは「まとめ論文」のことやねん。ChatGPTとかの大きいAIモデルについて、いろんな研究を整理してくれてる便利なやつや。
Zhou, L., Gao, J., Li, D., & Shum, H.-Y. (2020). XiaoIceの設計と実装:共感的なソーシャルチャットボット. Computational Linguistics, 46 (1), 53–93.
XiaoIce(シャオアイス)っていう中国のチャットボットの話やねん。これがほんまにすごくて、ユーザーの気持ちに寄り添う「共感力」を持ってるチャットボットなんや。
Zhuo, T. Y., Huang, Y., Chen, C., & Xing, Z. (2023). ジェイルブレイクによるChatGPTのレッドチーミング:バイアス、堅牢性、信頼性、毒性..
レッドチーミングっていうのはな、わざとAIを攻撃してみて弱点を見つける作業のことやねん。ジェイルブレイクっていうのは、AIの安全装置をかいくぐって変なこと言わせようとするやつや。バイアス(偏り)とか毒性のある発言とか、そういう問題がないかチェックしてるってことやで。
1310
---
![]()
1 / 1
100%