<<
2601.21969v1_Token-Guard_Towards_Token-Level_Hallucination_Cont.pdf

---
## Page 1
[](/attach/601913d208e3b5340f2fdb02c3063a0234db92fc3c6600efb67482659c87755b_p001.png)
### 和訳
# TOKEN-GUARD: トークンレベルで「嘘」をコントロールする〜自己チェックしながら文章作る方法〜
Yifan Zhu1, Huiqiang Rong1, Haoran Luo2∗
1北京郵電大学 2南洋理工大学
## 要約
大規模言語モデル(LLM)ってな、めっちゃ賢いんやけど、よう嘘つくねん。入力された内容と全然違うこと平気で生成しよるんや。これを「ハルシネーション(幻覚)」って呼ぶんやけどな。
で、この嘘問題を解決する方法として、RAG(外部から情報引っ張ってくるやつ)とかRLHF(人間のフィードバックで学習させるやつ)があるんやけど、これがまためっちゃリソース食うねん。情報検索のシステム組んだり、大規模に再学習したりせなあかんから、正直しんどいわけや。一方で、デコーディング(文章生成のやり方)をいじる方法は軽いんやけど、嘘を明確にコントロールする仕組みがないねん。
そこで俺らが提案するのが**Token-Guard**や!これ、トークン(単語みたいなもん)レベルで嘘をコントロールする方法で、自己チェックしながら文章作るねん。Token-Guardはな、推論の各ステップで内部検証やって、嘘トークンが広がる前に検出するんや。候補となる文章の断片は「潜在空間」っていう特殊な場所で評価されて、嘘リスクのスコアがはっきり出るようになってる。で、繰り返し剪定と再生成をすることで、見つかったエラーを動的に修正していくんやで。
HALUデータセットで実験したら、Token-Guardは嘘をめっちゃ減らして、生成精度もかなり上がったんや。スケーラブル(規模に応じて対応できる)でモジュール式やから、信頼できるLLM出力のための実用的な解決策になるで!コードは公開しとるから見てや。
## 1 はじめに
大規模言語モデル(LLM)はな、自然言語処理のタスクでめっちゃ成功しとるねん。せやけど、専門知識が必要な場面とか、独自のデータを扱う場面では、まだハルシネーション問題に悩まされとるんや。要するに、不正確やったり誤解を招くような内容を平気で生成しよるってことやな。
事実との整合性を上げるために、RAG(検索拡張生成)やRLHF(人間フィードバックによる強化学習)みたいな戦略が提案されてきたんや。これらは確かに嘘を減らせるんやけど、外部の知識検索システムとか大規模な再学習にめっちゃ依存してて、リソースがかかりすぎるねん。この問題に対処するために、デコーディングベースの方法が採用されるようになって、モデルの生成プロセスを改善して、品質と出力の信頼性を高めようとしてるわけや。
**図1: Token-Guardの仕組みのイメージ図**
既存のデコーディング方法、例えばAuto-Regressive CoT(思考の連鎖を自動回帰で作るやつ)、Tree-of-Thought(思考の木構造)、ガイド付きデコーディング、予測デコーディングなんかには、主に3つの特徴があるねん:
1つ目は、出力がステップごとの推論で段階的に生成されること。モデルが多段階の思考の連鎖を組み立てられるようになるんや。
2つ目は、探索的な生成がよく採用されること。複数の推論経路を並行して展開して、正解にたどり着く確率を上げるんやな。
3つ目は、中間段階での自己評価があること。各推論ステップでフィードバックが得られて、先に進む前に一貫性や整合性を部分的に評価できるんや。
---
## Page 2
[](/attach/601913d208e3b5340f2fdb02c3063a0234db92fc3c6600efb67482659c87755b_p002.png)
### 和訳
ICLR 2026のカンファレンス論文として発表されたやつやで
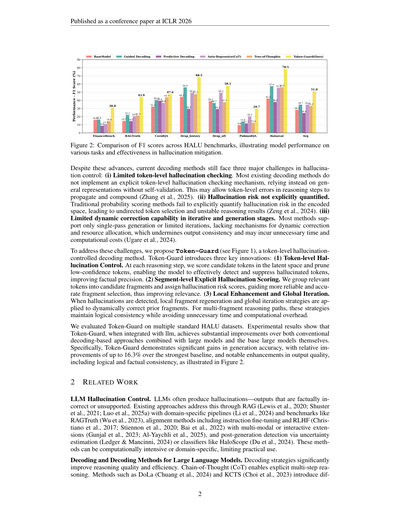
図2:HALUベンチマークでのF1スコアの比較やねん。いろんなタスクでモデルがどんだけ頑張れたか、あと幻覚(ハルシネーション)をどんだけ抑えられたかを見せてるグラフやで。
こんだけ進歩してきたのに、今のデコーディング手法(AIが文章を生成するときの方法のことな)には、幻覚を抑える上でまだ3つのデカい問題があんねん:(i) トークン単位での幻覚チェックが限定的やねん。今あるデコーディング手法のほとんどは、トークン(単語とか文字の単位やな)ごとにちゃんと幻覚かどうかチェックする仕組みがないねん。自分で検証せんと、なんとなくの表現に頼ってるだけやから、推論の途中でトークン単位のミスが起きたら、それがどんどん積み重なって大きな間違いになってまうんや(Zhang et al., 2025)。(ii) 幻覚リスクがちゃんと数値化されてへんねん。昔ながらの確率スコアリングやと、エンコード空間(AIの内部表現のことやな)で幻覚リスクをはっきり数字にできへんから、トークン選びに方向性がなくて、推論結果がブレブレになるんや(Zeng et al., 2024)。(iii) 繰り返し処理や生成段階での動的修正能力が限られてるねん。ほとんどの手法は一発勝負の生成か、ちょっとだけの繰り返ししかできへんくて、途中で動的に修正したりリソースを振り分けたりする仕組みがないから、出力の一貫性が崩れるし、無駄に時間と計算コストがかかってまうんや(Ugare et al., 2024)。
この問題を解決するために、ワイらはToken-Guard(図1見てな)っていうトークン単位で幻覚をコントロールするデコーディング手法を提案するで。Token-Guardには3つの革新的なポイントがあんねん:(1) トークン単位の幻覚コントロール。推論の各ステップで、候補となるトークンを潜在空間(AIの隠れた表現空間のことな)でスコアリングして、自信のないトークンを刈り取るねん。これでモデルが幻覚トークンをちゃんと見つけて抑えられるようになって、事実の正確さがアップするんや。(2) セグメント単位での明示的な幻覚スコアリング。関連するトークンをまとめて候補の断片(セグメント)にして、それぞれに幻覚リスクのスコアをつけるねん。これでより信頼できて正確な断片を選べるようになって、関連性が上がるんや。(3) ローカル強化とグローバル反復。幻覚が見つかったら、その部分の断片だけ再生成するローカル戦略と、全体を見直すグローバル反復戦略を使って、前の断片を動的に修正するねん。複数の断片からなる推論パスでも、この戦略で論理的な一貫性を保ちながら、無駄な時間と計算コストを避けられるんや。
ワイらは複数の標準的なHALUデータセットでToken-Guardを評価したで。実験結果を見ると、Token-Guardを大規模言語モデル(LLM)と組み合わせたら、従来のデコーディングベースのアプローチを大規模モデルと組み合わせたやつより、あと大規模モデル単体よりも、めっちゃ改善されとったんや。具体的に言うと、Token-Guardは生成精度でかなりの向上を見せて、一番強いベースラインと比べて最大16.3%も相対的に改善したんや。さらに出力の質、つまり論理的・事実的な一貫性もめっちゃ良くなっとって、それが図2に示されてるで。
2 関連研究
LLMの幻覚コントロール。LLMはよく幻覚を起こすねん—事実と違うとか、根拠のない出力をしてまうやつな。今ある対策としては、RAG(検索拡張生成)(Lewis et al., 2020; Shuster et al., 2021; Luo et al., 2025a)で、専門分野に特化したパイプライン(Li et al., 2024)やRAGTruthみたいなベンチマーク(Wu et al., 2023)を使うやつ、あとアラインメント手法として命令ファインチューニングやRLHF(人間のフィードバックからの強化学習)(Christiano et al., 2017; Stiennon et al., 2020; Bai et al., 2022)があって、マルチモーダルとかインタラクティブな拡張もあるねん(Gunjal et al., 2023; Al-Yaychli et al., 2025)。それと生成後の検出として、不確実性推定(Ledger & Mancinni, 2024)やHaloScopeみたいな分類器を使うやつもあるで(Du et al., 2024)。でもこれらの手法は計算コストが高かったり、特定の分野にしか使えなかったりして、実用的に使いにくいっていう限界があるねん。
大規模言語モデルのデコーディングとデコーディング手法。デコーディング戦略は推論の質と効率をめっちゃ上げてくれるで。Chain-of-Thought(CoT、思考の連鎖な)は明示的な多段階推論を可能にしてくれるねん。DoLa(Chuang et al., 2024)やKCTS(Choi et al., 2023)みたいな手法は差分を
---
## Page 3
[](/attach/601913d208e3b5340f2fdb02c3063a0234db92fc3c6600efb67482659c87755b_p003.png)
### 和訳
ICLR 2026の会議論文として発表されたで
トークンレベルで幻覚(ハルシネーション)を検出する方法はいろいろあんねんけど、これによってモデルが信用でけへんトークンをフィルタリングして、生成中の事実との整合性を高められるようになるねん。Phi-Decodingっていう手法(Xu et al., 2025)は、適応的な枝刈りと先読みサンプリングを使って計算効率を上げて、幻覚をもっとうまくコントロールするんや。マルチレベル制御(Hiriyanna & Zhao, 2025)と自己反省的デコーディング(Ji et al., 2023b)の研究を踏まえて、ワシらは「Token-Guard」っていうデコーディング手法を提案するで。これはLLMの推論プロセス全体を通じて、明確かつ頑健に幻覚を減らすように設計されとるんや。
3 準備知識
現代の自己回帰モデルの根底にある重要な概念と基本原理、つまりトークンレベルの生成、マルチレベル監視、そして反復検証プロセスについてまとめるで:
(a) トークンレベル自己回帰生成。トークン列 a1, . . . , aT は自己回帰的に生成されるねん。数式で言うと、入力 x が与えられたときの全体のシーケンスの確率はこう定義されるで:
P (a1, . . . , aT | x) =
T
∏
t=1
Pθ(at | x, a<t),
(1)
ここで T はシーケンスの長さ、a<t = {a1, . . . , at−1} はステップ t より前に生成されたトークンを表してて、Pθ は at のモデルが割り当てる条件付き確率やねん。
(b) マルチレベル監視。トークンの確率は階層的な信号で調整でけるんや:
Ct =
∑
l∈L
wl gl(at | x, a<t, Ct−1),
(2)
ここで L は監視レベルの集合、gl はレベル l での制御関数、wl はその重み、Ct−1 は前の複合スコアや。Ct は複合的なガイダンススコアを表しとるねん。
(c) 反復検証。生成されたシーケンスは反復的に改善でけるで:
K (t+1) =
{ K (t), S(K (t) | Q) ≥ τ のとき
{ R(K (t), S(K (t) | Q), Q), S(K (t) | Q) < τ のとき
(3)
ここで K (t) は反復 t でのシーケンス、Q は入力クエリ、S(· | Q) は正確さやら幻覚リスクを測定するスコア、τ は閾値、R(·) は低スコアのシーケンスに適用して精度を上げて潜在的な幻覚を減らすための改善関数やねん。
4 方法論:TOKEN-GUARD
このセクションでは、図3に示すように、Token-Guardを紹介するで。これにはトークンレベルの自己チェック初期化、反復的なトークンスコアリングと局所修正、枝刈りベースの候補選択、グローバルな反復、そして最終応答生成が含まれとって、デコーディング中の幻覚をコントロールするんや。
4.1 プロンプト自己チェック
Token-Guardパイプラインの前に、一般的なテンプレートとドメイン固有の制約を組み合わせた統一プロンプト戦略を使うねん。一般プロンプトは入力への依存と標準化された出力フォーマット(「Answer:[...]」)を強制して、ドメイン固有のプロンプトはPubMedQAでの「Yes/No/Maybe」みたいな制限、FinanceBenchでの財務報告、History・CovidQA・RagTruthでの入力依存の回答とかを追加するんや。詳細は付録A.1に載せとるで。
4.2 トークンレベル幻覚自己チェック
Token-Guardは制御可能な生成空間 S0 を確立して、トークンレベルの自己チェックを行って幻覚リスクを減らすんや。各トークン at は伝播される前に検証されて、局所的な幻覚を制限しながらマルチステップ推論をサポートするで。
潜在トークン環境の初期化。生成ステップ t で、潜在環境 St が構築されて、j < t の受理されたトークン aj の意味表現 sj とコンテキスト状態 hj を保存するんや。
3
---
## Page 4
[](/attach/601913d208e3b5340f2fdb02c3063a0234db92fc3c6600efb67482659c87755b_p004.png)
### 和訳
ICLR 2026で学会発表された論文やで
図3:Token-Guardフレームワークの全体像やねん。トークンレベルでの繰り返しデコーディング軌道があって、自己チェック、ハルシネーション(嘘っぽい出力)のスコアリング、ローカル修正、そして枝刈りをやることで、信頼できる出力を保証するっていう仕組みやな。
t=1のときの潜在環境の初期化問題に対応するために、入力コンテキストトークンの平均隠れ状態を最初のアンカー(基準点)として定義するねん:
h̄x := 1/|x| × Σ(i=1から|x|まで) LLM^(L-1)_hidden(x_i), h̄<1 := h_x (式4)
ここでx = (x_1, ..., x_{|x|})は入力コンテキストトークンのことで、LLM^(L-1)_hiddenっていうのはモデルが出す最後から2番目の層の隠れ表現のことやねん。なんでこうするかっていうと、最初の候補トークンに対する軌道の一貫性がちゃんと定義できて、ハルシネーションスコアリングが最初から適用できるようになるからやで。
**候補トークンと隠れ状態**
LLMは候補トークン集合A_t = {a_t^(1), ..., a_t^(M)}を生成するねん。それぞれに隠れ状態h_t^(i)があって、こう定義されるで:
h_t^(i) = LLM^(L-1)_hidden(a_t^(i), a_{<t}, x) (式5)
ここでa_{<t}は前に受け入れられたトークンの列で、xは入力コンテキストやな。
**ハイブリッドトークンレベルのハルシネーションスコアリング**
各候補トークンa_t^(i)に対して、まず前に受け入れられたトークンの平均隠れ状態を計算するねん:h̄_{<t} = 1/(t-1) × Σ(j=1からt-1まで)h_j(t>1のとき)。h_jはトークンa_jの隠れ状態やで。ほんで、ハイブリッドトークンレベルのハルシネーションスコアはこう定義されるねん:
F^token_halu(a_t^(i) | s_t) = λ · (h_t^(i) · h̄_{<t}) / (|h_t^(i)| |h̄_{<t}|) + (1-λ) · P(a_t^(i) | a_{<t}, x) (式6)
λは0から1の間の値で、意味的な一貫性とトークン確率のバランスを取るパラメータやねん。この重み付き組み合わせで解釈しやすいスコアが得られて、意味と確率のトレードオフを簡単に調整できるようになるわけや。実験ではλ=0.6に設定したで。
**候補トークンの選択と環境の更新**
候補集合A_tから次のトークンa_t^*を選ぶんやけど、こういう式になるねん:
a_t^* = arg max_{i∈A_t} 1{F^token_halu(a_t^(i) | s_t) ≥ τ_token}, s_{t+1} = s_t ∪ {h^t(a_t^*)} (式7)
トークンレベルの閾値を連続して通過したトークンは候補セグメントC_kを形成して、セグメントレベルのスコアリングのために意味的な一貫性を保持するねん。実験ではτ_token=0.4に設定したで。
**メモリの注意点**:スコアリングには移動平均h̄_{<t}だけを維持してるねん。トークンの隠れ状態はセグメントが形成されるまで一時的にバッファに保持されて、その後解放されるから、メモリはO(L_max · K_active · d)で、生成全体の長さTには依存せんようになってるわけや。
**命題1**:トークンレベルの自己チェックは、生成されるシーケンスの期待ハルシネーションを減少させるで。
*証明*:実験結果はセクション5.4に、理論的な証明は付録B.1にあるから見てな。
---
## Page 5
[](/attach/601913d208e3b5340f2fdb02c3063a0234db92fc3c6600efb67482659c87755b_p005.png)
### 和訳
4.3 候補セグメントの表現
候補セグメントCkってのは、セルフチェック済みのトークン{at1, . . . , atn}の並びやねん。それぞれのトークンatiには、トークンレベルのセルフチェックで出てきた隠れ状態h(i)tがくっついとるわけや。
で、セグメントレベルの表現Hkは、これらのトークンの隠れ状態を重み付き平均で作るんやけど、この重みwiはトークンレベルのハルシネーションスコアF token halu(ati | sti)からソフトマックス関数を使って出すねん。なんでかっていうと、信頼性の高いトークンをもっと重視したいからや:
wi = exp(F token halu(ati | sti)) / Σj=1からn exp(F token halu(atj | stj))、Hk = Σi=1からn wi h(i)t (式8)
これで、信頼性が高いトークンほどHkにめっちゃ貢献するようになって、一番信頼できる意味的な中身を捉えられるってわけや。ほんで各セグメントCkは3つの補完的な観点から評価するんやで。
まず1つ目は、重み付きトークンレベルのハルシネーションスコアで、個々のトークンの信頼性を集約するねん:
F token halu(Ck) = Σi=1からn wi F token halu(ati | sti) (式9)
2つ目はローカル一貫性で、これは隣り合うトークン間の意味的な遷移がどんだけスムーズかを測るんや。急激な変化があったらハルシネーションとか論理の飛躍を示唆してる可能性があるからな:
Consistency(Ck) = 1 - (1/(n-1)) Σi=1からn-1 |h(i)t - h(i+1)t| (式10)
3つ目はグローバル整合性で、セグメントが全体の入力コンテキスト表現Hxとどんだけ合ってるかを評価するねん。セグメント表現HkとHxのコサイン類似度として計算するんや:
Alignment(Ck) = (Hk · Hx) / (|Hk| |Hx|) (式11)
セグメントレベルのハルシネーションスコアは、この3つの要素の重み付き和で計算するで:
F seg halu(Ck) = αF token halu(Ck) + β Consistency(Ck) + γ Alignment(Ck) (式12)
ここでα、β、γ ∈ [0, 1]は3つのパーツの相対的な重要度を表してて、α + β + γ = 1を満たすねん。実験ではα = 0.5、β = 0.3、γ = 0.2に設定したわ。
τ high segより上のスコアのセグメントは洗練されて、τ low segより下のは捨てられるんや。τ low segとτ high segの間のスコアのセグメントは有効やから、保存されるか多段階推論に使われるで。こうすることで信頼性が高くて一貫性のある内容だけを残すわけやな。
ローカル洗練の時は、対象のセグメントCkだけを更新するねん。下流のセグメントCk+1、Ck+2、...の隠れ状態はそのまま保持して、グローバル構造を維持するんや。残りの系列を全部再生成せんでええから効率的やで。これは選択的ローカル洗練の原則に従ってて、Tang et al., 2025やLyu et al., 2025で実証されとるやつや。
ローカル洗練では、セグメント内で一番スコアが低いトークンalowを特定して、その直近の隣接トークンを含むローカルウィンドウW(l)k = {ai-1, alow i, ai+1}を形成するねん。このウィンドウを使ってセグメントの一番弱い部分を修正しつつ、周囲のコンテキストは保持するわけや。LLMは周囲のコンテキストa<i-1、a>i+1とセグメント表現Hkを条件として洗練されたトークンを生成して、元のウィンドウをセグメント内で置き換える洗練ウィンドウW(l)'kを作るんや:
W(l)'k = LLM_refine(W(l)k | a<i-1, a>i+1, Hk)、C'k = Ck \ W(l)k ∪ W(l)'k (式13)
洗練後、セグメントスコアF seg halu(C'k)を再計算するねん。τ high segに達したらセグメントは採用、そうでなければNmaxステップまで繰り返すんや。このプロセスでセグメントの信頼性を制御しながら段階的に改善できるってわけ。τ low seg = 0.55、τ high seg = 0.75、Nmax = 3に設定したで。
メモリに関する注意点:セグメント形成とローカル洗練の間、セグメント内のトークン隠れ状態は一時的にバッファリングされるねん。最終的なセグメント表現Hkが計算されたら、一時的な隠れ状態は解放されるんや。下流のセグメントベクトルはコンパクトな表現としてのみ保持されるから、メモリはO(Lmax · d + K · d)に抑えられて、総生成長Tに依存せえへんのがポイントやな。
命題2:ローカル洗練を伴うセグメントレベルの処理は、品質を向上させてハルシネーションを減少させる。
証明:実験結果はセクション5.5で、理論的証明は付録B.2で示すで。
---
## Page 6
[](/attach/601913d208e3b5340f2fdb02c3063a0234db92fc3c6600efb67482659c87755b_p006.png)
### 和訳
ICLR 2026の会議論文として発表されたやつやで
4.4 グローバルな反復と修正
ステージ3では、Token-Guardがステージ2から出てきた候補出力を全体的にもっかい評価し直すねん。信頼できるセグメントを推論チェーンR = {C1, C2, . . . , CK}として組み立てていくんやけど、ここがポイントで、元のセグメントの順番にはこだわらへんねん。なんでかっていうと、いろんな分岐を探索した方がグローバルな一貫性とか事実の正確さが上がるからや。これはSahaらの2024年の研究からヒントもらってるで。セグメントはTF-IDFとKMeansでクラスタリングして、各クラスタの重心に一番近いチェーンを選んで候補チェーンを作るんや。大規模データセットではクラスタ数K = 5にしてて、HaluEvalみたいな小さいデータセットでは計算量減らすためにK = 3にしてるで。各セグメントCkにはベクトル表現Hk、トークンレベルの信頼度ベクトルfk、それと生成された内容と関連する知識ソースを比較した知識検証スコアEkがあるねん。チェーンの事実整合性はこない計算するで:
Ffact(R) =
1
K
K
(cid:88)
k=1
wk Fseg(Ck), wk =
∥fk∥ · Ek
j=1 ∥fj∥ · Ej
(cid:80)K
,
(14)
ここでFseg(Ck)はセグメントレベルのハルシネーションスコアのことで、wkはトークンの信頼度とエビデンスの整合性を組み合わせて、長いセグメントを重視するようにしてるんや。論理的な一貫性は隣り合うセグメント間でHkとHk+1のコサイン類似度使って測るんやけど、文脈因子λkで重み付けしてるで:
Flogic(R) =
1
K − 1
K−1
(cid:88)
k=1
λk
Hk · Hk+1
∥Hk∥ ∥Hk+1∥
,
λk = simctx(Ck, Ck+1),
(15)
simctxは乗法的な文脈調整を提供するやつで、こう定義されてるねん:
simctx(Ck, Ck+1) =
1 + cos(˜ek, ˜ek+1)
2
,
˜ek =
1
nk
nk(cid:88)
i=1
ek,i,
(16)
ek,iはセグメントCkの入力トークン埋め込みのことや。この因子分解された定式化は、cos(Hk, Hk+1)による隠れ状態の連続性と、simctxによるセグメントテキスト間の意味的整合性を組み合わせてて、simctxはトークンIDから再構築した入力埋め込みだけ使ってるんや。
グローバルスコアFglobal(R)は事実と論理の両成分をソフト最小値で組み合わせるで:
Fglobal(R) =
Ffact(R) Flogic(R)
Ffact(R) + Flogic(R) − Ffact(R) Flogic(R)
,
(17)
Fglobal(R) < τglobalの場合は再生成をトリガーするんやけど、τglobalは0.7に設定してるで。FfactとFlogicの両方が0.5を下回ったら「回答できません」を返すねん。安定性を上げるために、セグメントの閾値は調整マージン∆τで動的に調整するんや:
τ adj
seg =
(cid:40)τ high
seg + ∆τ,
τ low
seg − ∆τ,
Ffactが低くてFlogicが高い場合、
Flogicが低くてFfactが高い場合。
(18)
τ adj
segが調整後の閾値やで。各イテレーションで候補チェーンR(i)を生成してF (i)
globalを再計算して、Mmax回のイテレーション前にF (i)
global ≥ τglobalになったらチェーンを採用、そうでなければシステムは「回答できません」を出力するねん。うちの経験ではτglobal = 0.7、∆τ = 0.1、Mmax = 2に設定してるで。
メモリに関する注記:グローバルな整合とスコアリングはコンパクトなセグメントベクトル{Hk}K
k=1とトークンレベル信頼度ベクトルfkだけで動いてるんや。完全なトークン隠れシーケンスは保存せえへんから、メモリ使用量はO(K · d)に抑えられて、総生成長Tには依存せえへんのがめっちゃええとこやねん。
命題3. 候補シーケンスに対するグローバルな反復的改良はハルシネーションを減らすで。
証明. 実験結果はセクション5.6で、理論的証明は付録B.3で示してるから見てな。
5 実験
このセクションでは実験のセットアップ、主な結果、分析を示すで。以下の研究課題(RQ)に答えていくで:RQ1:Token-Guardは他の手法より性能ええんか? RQ2:Token-Guardの主要コンポーネントはちゃんと機能してるんか、比較分析はどうなってるんか? RQ3–5:Token-Guardは生成全体の品質をどれくらい改善するんか、事実の精度と正確さ、クエリとの関連性、多段階推論における論理的一貫性と完全性の観点で見ていくで。RQ6:Token-Guardはデコード時の時間効率とメモリ消費にどう影響するんか?RQ7:Token-Guardは異なるスケールのバックボーンモデルでどう性能出るんか?
6
---
## Page 7
[](/attach/601913d208e3b5340f2fdb02c3063a0234db92fc3c6600efb67482659c87755b_p007.png)
### 和訳
ICLR 2026の学会論文として発表されたで
# 手法(Method)
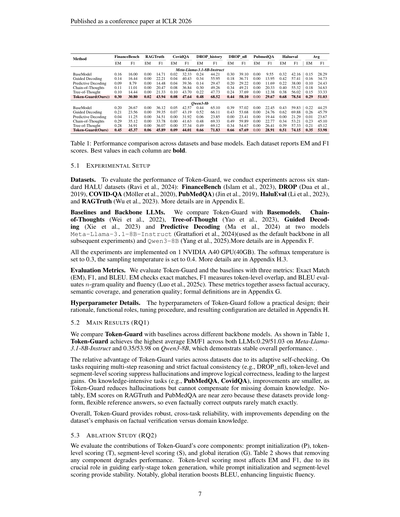
**表1:データセットと基盤モデルごとの性能比較やで。各データセットでEMとF1スコアを報告しとって、各列の最高値は太字にしてるで。**
| 手法 | FinanceBench | RAGTruth | CovidQA | DROP_history | DROP_nfl | PubmedQA | Halueval | 平均 |
|------|--------------|----------|---------|--------------|----------|----------|----------|------|
| | EM / F1 | EM / F1 | EM / F1 | EM / F1 | EM / F1 | EM / F1 | EM / F1 | EM / F1 |
**Meta-Llama-3.1-8B-Instruct**
| BaseModel | 0.16 / 16.00 | 0.00 / 14.71 | 0.24 / 44.21 | 0.02 / 32.33 | 0.30 / 39.10 | 0.00 / 9.55 | 0.32 / 42.16 | 0.15 / 28.29 |
| Guided Decoding | 0.14 / 16.44 | 0.00 / 22.21 | 0.34 / 55.95 | 0.04 / 40.43 | 0.18 / 36.71 | 0.00 / 13.95 | 0.42 / 57.41 | 0.16 / 34.73 |
| Predictive Decoding | 0.09 / 8.79 | 0.00 / 14.48 | 0.14 / 29.47 | 0.04 / 39.36 | 0.20 / 29.22 | 0.00 / 11.69 | 0.22 / 38.00 | 0.10 / 24.43 |
| Chain-of-Thoughts | 0.11 / 11.01 | 0.00 / 20.47 | 0.30 / 49.26 | 0.08 / 36.84 | 0.34 / 49.21 | 0.00 / 20.33 | 0.40 / 55.32 | 0.18 / 34.63 |
| Tree-of-Thought | 0.10 / 14.44 | 0.00 / 21.33 | 0.22 / 47.73 | 0.10 / 43.70 | 0.24 / 37.69 | 0.00 / 12.38 | 0.38 / 56.02 | 0.15 / 33.33 |
| **Token-Guard(Ours)** | **0.30 / 30.80** | **0.02 / 43.94** | **0.48 / 68.52** | **0.08 / 47.64** | **0.44 / 58.10** | **0.00 / 29.67** | **0.68 / 78.54** | **0.29 / 51.03** |
**Qwen3-8b**
| BaseModel | 0.20 / 26.67 | 0.00 / 36.12 | 0.44 / 65.10 | 0.05 / 42.57 | 0.39 / 57.02 | 0.00 / 22.45 | 0.43 / 59.83 | 0.22 / 44.25 |
| Guided Decoding | 0.21 / 23.56 | 0.00 / 39.35 | 0.52 / 66.11 | 0.07 / 43.19 | 0.43 / 53.68 | 0.00 / 24.76 | 0.62 / 69.88 | 0.26 / 45.79 |
| Predictive Decoding | 0.04 / 11.25 | 0.00 / 34.51 | 0.06 / 23.85 | 0.00 / 31.92 | 0.00 / 23.41 | 0.00 / 19.44 | 0.00 / 21.29 | 0.01 / 23.67 |
| Chain-of-Thoughts | 0.29 / 35.12 | 0.00 / 33.78 | 0.48 / 69.33 | 0.00 / 41.63 | 0.49 / 59.89 | 0.00 / 22.77 | 0.34 / 53.21 | 0.23 / 45.10 |
| Tree-of-Thought | 0.28 / 34.91 | 0.00 / 36.07 | 0.49 / 69.12 | 0.00 / 37.34 | 0.34 / 54.67 | 0.00 / 26.41 | 0.39 / 57.33 | 0.21 / 45.12 |
| **Token-Guard(Ours)** | **0.45 / 45.37** | **0.06 / 45.89** | **0.66 / 71.83** | **0.09 / 44.01** | **0.66 / 67.69** | **0.00 / 28.91** | **0.51 / 74.15** | **0.35 / 53.98** |
## 5.1 実験のセットアップ
**データセットについて。** Token-Guardの性能を評価するために、6つの標準的なHALU(ハルシネーション)データセットで実験したで(Ravi et al., 2024):FinanceBench(Islam et al., 2023)、DROP(Dua et al., 2019)、COVID-QA(Möller et al., 2020)、PubMedQA(Jin et al., 2019)、HaluEval(Li et al., 2023)、RAGTruth(Wu et al., 2023)や。詳しくは付録Eを見てな。
**ベースラインと基盤LLM。** Token-Guardを他の手法と比較したで。比較対象は、Basemodels、Chain-of-Thoughts(Wei et al., 2022)、Tree-of-Thought(Yao et al., 2023)、Guided Decoding(Xie et al., 2023)、Predictive Decoding(Ma et al., 2024)や。使ったモデルは2つあって、Meta-Llama-3.1-8B-Instruct(Grattafiori et al., 2024)(これが以降の全実験でデフォルトの基盤モデルやで)とQwen3-8B(Yang et al., 2025)や。詳しくは付録Fを見てな。
全部の実験はNVIDIA A40 GPU(40GB)1台で動かしたで。softmaxの温度は0.3、サンプリングの温度は0.4に設定してる。詳しくは付録H.3を見てな。
**評価指標について。** Token-Guardとベースラインの評価には3つの指標を使ったで:Exact Match(EM)、F1、BLEUや。EMは完全一致かどうかをチェックするやつ、F1はトークンレベルでどれくらい重なってるかを測るやつ、BLEUはn-gramの品質と流暢さを評価するやつや(Luo et al., 2025c)。これらの指標を組み合わせることで、事実の正確さ、意味的なカバー率、生成品質をまとめて評価できるねん。正式な定義は付録Gにあるで。
**ハイパーパラメータの詳細。** Token-Guardのハイパーパラメータは実用的な設計に基づいてるで。その根拠、機能的な役割、チューニング手順、最終的な設定については付録Hで詳しく説明してるわ。
## 5.2 メインの結果(RQ1)
Token-Guardを色んなベースラインと、異なる基盤モデルで比較したで。表1を見てもらったら分かるように、Token-Guardは両方のLLMで平均EM/F1が最高やねん:Meta-Llama-3.1-8B-Instructで0.29/51.03、Qwen3-8Bで0.35/53.98や。これで安定した全体的な性能を示してるで。
Token-Guardの相対的な優位性はデータセットによって変わるねん。なんでかっていうと、適応的なセルフチェック機能があるからや。複数ステップの推論と厳密な事実の一貫性が必要なタスク(例えばDROP_nfl)では、トークンレベルとセグメントレベルのスコアリングがハルシネーションを抑制して論理的な正確さを向上させるから、めっちゃ大きな改善が見られるねん。知識集約型のタスク(例えばPubMedQA、CovidQA)では、改善幅は小さめや。Token-Guardはハルシネーションを減らせるけど、足りない専門知識を補うことまではできひんからな。注目すべき点として、RAGTruthとPubMedQAのEMスコアがほぼゼロやねんけど、これはこれらのデータセットが長文で柔軟な参照回答を提供してるからで、事実的に正しい出力でも完全一致することはほとんどないねん。
全体的に見て、Token-Guardは頑健でタスクをまたいだ信頼性を提供してくれるで。改善の度合いは、そのデータセットが事実検証と専門知識のどっちを重視してるかによって変わってくるわ。
## 5.3 アブレーション研究(RQ2)
Token-Guardの主要コンポーネントがどれくらい貢献してるか評価したで:プロンプト初期化(P)、トークンレベルスコアリング(T)、セグメントレベルスコアリング(S)、グローバル反復(G)の4つや。表2を見ると、どのコンポーネントを外しても性能が落ちることが分かるで。トークンレベルスコアリングがEMとF1に一番影響するねん。なんでかっていうと、初期段階のトークン生成をガイドする上でめっちゃ重要な役割を果たしてるからや。一方、プロンプト初期化とセグメントレベルスコアリングは安定性を提供してくれる。注目すべきは、グローバル反復がBLEUを向上させて、言語的な流暢さを高めてくれることやな。
---
## Page 8
[](/attach/601913d208e3b5340f2fdb02c3063a0234db92fc3c6600efb67482659c87755b_p008.png)
### 和訳
ICLR 2026の学会論文として発表されたで
**手法のバリエーション**
| | DROP_history | | | RAGTruth | | | 平均 | | |
|---|---|---|---|---|---|---|---|---|---|
| | EM | F1 | BLEU | EM | F1 | BLEU | EM | F1 | BLEU |
| フルToken-Guard | 0.48 | 68.52 | 65.21 | 0.02 | 43.94 | 38.27 | 0.25 | 56.23 | 51.74 |
| プロンプトなし | 0.32 | 55.23 | 51.48 | 0.01 | 32.50 | 27.92 | 0.17 | 43.87 | 39.70 |
| トークンレベルスコアリングなし | 0.28 | 47.51 | 44.88 | 0.00 | 27.10 | 25.05 | 0.14 | 37.31 | 34.97 |
| セグメントレベルスコアリングなし | 0.43 | 60.10 | 59.55 | 0.01 | 39.20 | 33.08 | 0.22 | 49.65 | 46.32 |
| グローバル反復なし | 0.42 | 63.05 | 52.37 | 0.01 | 41.05 | 20.14 | 0.22 | 52.05 | 36.26 |
表2:代表的なデータセットでToken-Guardのアブレーション実験やってみた結果やで。
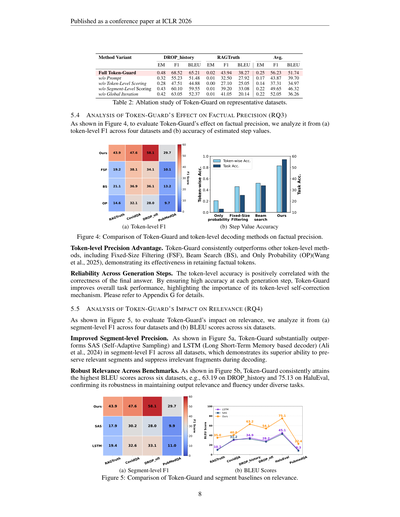
## 5.4 Token-Guardが事実の正確さにどう効くか分析したで(RQ3)
図4見てな、Token-Guardが事実の正確さにどう効いてるか、(a)4つのデータセットでのトークンレベルF1と(b)推定ステップ値の精度で分析しとるねん。
(a) トークンレベルF1
(b) ステップ値の精度
図4:Token-Guardと他のトークンレベルデコーディング手法を事実の正確さで比べてみたで。
**トークンレベルでの精度がめっちゃええねん。** Token-Guardは他のトークンレベル手法、つまり固定サイズフィルタリング(FSF)、ビームサーチ(BS)、確率だけ見るやつ(OP)(Wangら、2025)より一貫してええ成績出しとって、事実に合ったトークンをちゃんと残せてることがわかるねん。
**生成ステップ全体で安定しとるで。** トークンレベルの精度は最終的な答えが正しいかどうかとめっちゃ相関あんねん。各生成ステップで高い精度保つことで、Token-Guardは全体的なタスクの性能上げとるわけや。これがトークンレベル自己修正の仕組みがなんで大事かってことやな。詳しくは付録G見てな。
## 5.5 Token-Guardが関連性にどう効くか分析したで(RQ4)
図5見てな、Token-Guardが関連性にどう効いてるか、(a)4つのデータセットでのセグメントレベルF1と(b)6つのデータセットでのBLEUスコアで分析しとるで。
**セグメントレベルの精度がめっちゃ上がったで。** 図5a見たらわかるけど、Token-Guardは全データセットでSAS(自己適応サンプリング)とLSTM(長短期記憶ベースのデコーダー)(Aliら、2024)をセグメントレベルF1でごぼう抜きにしとんねん。なんでかっていうと、デコーディング中に関連あるセグメントはちゃんと残して、関係ないとこは抑え込む能力がほんまに優れとるからやねん。
**いろんなベンチマークで関連性が安定しとるで。** 図5b見たら、Token-Guardは6つのデータセット全部で一番高いBLEUスコア叩き出しとんねん。例えばDROP_historyで63.19、HaluEvalで75.13とかな。これで色んなタスクでも出力の関連性と流暢さをちゃんと保てるってことが確認できたわけや。
(a) セグメントレベルF1
(b) BLEUスコア
図5:Token-Guardとセグメントベースラインを関連性で比べてみたで。
8
---
## Page 9
[](/attach/601913d208e3b5340f2fdb02c3063a0234db92fc3c6600efb67482659c87755b_p009.png)
### 和訳
ICLR 2026の学会論文として発表
5.6 Token-Guardの論理一貫性と動的リソース管理における役割の分析(RQ5)
表3と図6に示すとおり、Token-Guardを「生成品質をどんだけ良くできるか」って観点から評価したんやけど、この多段階フィルタリングの仕組みが、事実の正確さをちゃんと守って、曖昧やったり情報が足りん文脈でも推論を安定させるってのがよう分かるねん。
**Token-Guardの各評価項目でのパフォーマンス**
Token-Guardは複数の評価項目でめっちゃ明らかな改善を見せとって、特に「事実精度」「論理一貫性」「関連性」でええ結果出とるんや。トークンレベルとセグメントレベルでチェックかけることで、ハルシネーション(AIが嘘つくやつな)を抑え込んで、より信頼できる断片を選べるようになっとる。ほんで反復的に改善していく仕組みのおかげで、推論プロセス全体で論理の一貫性がキープされるわけや。「簡潔さ」のスコアがちょっと低めなんは、簡潔に書くことより正確さと完全さを優先して、詳しめの説明をする傾向があるからやねん。詳細は付録Gを見てな。
**ケーススタディの説明**
表3はDROP_nflからの例を示しとるんやけど、ベースライン手法は「情報が足りません」って言うか、間違った値を報告してまうのに対して、Token-Guardは61ヤードの得点プレーをちゃんと正しく特定できとるんや。これは動的なローカル再生成によって、意味的にも事実的にも正確さを保っとるからやねん。文章は付録A.2を参照してな。
図6:生成評価
表3:DROP_nflのクエリに対する生成品質のケーススタディ(文章は付録にあるで)
5.7 Token-Guardの時間とメモリ消費の分析(RQ6)
ここではToken-Guardの計算効率を調べて、デコーディング段階ごとの時間オーバーヘッドとメモリ使用量を分析したんや。注目したんは2つの側面:(a)ランタイム、つまり1サンプルあたりのレイテンシとスループット、(b)トークンレベル、セグメントレベル、グローバルレベルの各段階でのメモリ使用量や。これらの測定で、Token-Guardがリソースにどんな影響与えるか分かるってわけや。
**時間とスループットの分析**
表4に示すとおり、Token-Guardはデータセットによって時間、トークン数、スループットのパターンがはっきり違うねん。動的に反復する仕組みのおかげで、PubMedQAとHaluEvalでは効率よく計算できる一方で、CovidQAとRAGTruthみたいな難しいデータセットにはより多くの実行時間と出力トークンを割り当てとるんや。注目すべきは、一部の設定でトークン予算が多めでも、
9
[図6と表3の説明]
図6は各評価指標(正確性、関連性、論理一貫性、事実精度、完全性、簡潔さ)でのスコアを示しとって、Tree-of-Thought、Chain-of-Thought、Basemodel、Guided Decoding、Predictive Decoding、Token-Guard(提案手法)を比較しとる。
表3のケーススタディ:
- **クエリ**:ゴアは前半で何ヤード得点した?
- **正解**:[61]
各手法の生成結果を見ると:
- **Tree-of-Thought、Basemodel、Chain-of-Thoughts**:全部「文章には十分な情報がありません」って答えて、F1もBLEUも0.00や
- **Guided Decoding、Predictive Decoding**:148ヤード(ラッシングヤード)って答えてもうて、得点ヤードを聞いとるのに間違えとる。これもF1、BLEU共に0.00
- **Token-Guard(提案手法)**:61ヤードの得点プレーを正しく特定して、F1が66.67、BLEUが50.00や
なんでかっていうと、Token-Guardは「得点ヤード」と「ラッシングヤード」の違いをちゃんと理解して、61ヤードランが唯一の得点プレーやって正確に判断できとるからやねん。
---
## Page 10
[](/attach/601913d208e3b5340f2fdb02c3063a0234db92fc3c6600efb67482659c87755b_p010.png)
### 和訳
ICLR 2026の学会論文として発表されたで
Token-Guardはな、ええ感じのスループット(処理速度みたいなもんや)を維持してるか、むしろ他より優れてるねん。これってつまり、何回も繰り返し改良するプロセスと、効率よくテキストを生成することをうまいことバランス取れてるってことやな。
| 手法 | RAGTruth | CovidQA | PubmedQA | HaluEval | 平均 |
|------|----------|---------|----------|----------|------|
| | 時間・トークン・秒速 | 時間・トークン・秒速 | 時間・トークン・秒速 | 時間・トークン・秒速 | 時間・トークン・秒速 |
| Chain-of-Thoughts | 11・899・80.71 | 9・670・73.14 | 11・998・88.45 | 7・543・77.33 | 9.65・777.08・79.41 |
| Tree-of-Thought | 57・3687・64.49 | 67・3423・51.09 | 58・4253・73.38 | 35・2786・79.49 | 54.29・3537.19・67.11 |
| Predictive Decoding | 107・12058・112.82 | 138・6473・47.07 | 79・8416・106.06 | 58・5954・102.20 | 95.50・8225.61・92.54 |
| Guided Decoding | 110・17234・155.96 | 189・13525・71.64 | 103・18733・182.05 | 77・11689・151.15 | 119.38・15295.41・140.20 |
| Token-Guard | 69・18024・262.81 | 301・17474・58.10 | 32・7699・240.58 | 54・5254・97.54 | 113.29・12112.95・164.76 |
表4:処理時間、出力トークンの消費量、あと正規化したスループット(1秒あたり何トークン出せるか)やで。
**メモリ消費量の分析**
HaluEvalデータセットで見てみるとな、Token-Guardは段階ごとにメモリの使い方が変わんねん。トークンレベル(単語一個一個みたいな細かい単位)の状態は効率よくバッファリング(一時保存みたいなもんや)されて1.2〜9.4%くらい。セグメントレベル(もうちょい大きなかたまり)では一瞬ピークが来て21.6〜19.6%。グローバルレベル(全体的なやつ)では10.3〜19.0%くらいで安定するわけや。トータルで見ると、ピークは21.6%、平均は約16.3%で、他の手法と比べても遜色ないレベルやねん。表5にToken-Guardと他の手法のピークメモリ、平均メモリ、実行時間をまとめといたで。
| 手法 | ピークメモリ(%) | 平均メモリ(%) | 実行時間(秒) |
|------|----------------|--------------|-------------|
| Guided Decoding | 21.4 | 15.0 | 77.31 |
| Chain-of-Thoughts | 21.3 | 14.5 | 7.02 |
| Tree-of-Thought | 21.4 | 17.8 | 35.04 |
| Predictive Decoding | 4.1 | 3.7 | 58.26 |
| Token-Guard | 21.6 | 16.3 | 53.89 |
表5:Token-Guardと他の手法のメモリと実行時間の比較やで。
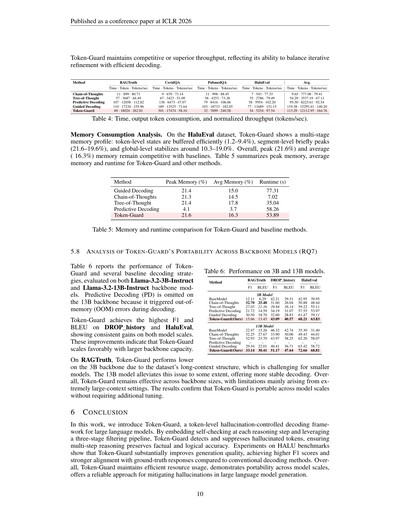
**5.8 Token-Guardが色んなバックボーンモデルでも使えるかの分析(RQ7)**
表6では、Token-Guardといくつかの比較対象の手法を、Llama-3.2-3B-InstructとLlama-3.2-13B-Instructっていう2つのバックボーンモデル(土台になるAIモデルのことや)で評価した結果を載せてるで。ちなみにPredictive Decoding(PD)は13Bモデルでやろうとしたらメモリ不足(OOM)エラーが出てもうたから省略してるわ。
Token-Guardはな、DROP_historyとHaluEvalでF1スコア(精度と再現率を合わせた指標やで)とBLEUスコア(生成文がどんだけ正解に近いかの指標)が一番高くて、3Bでも13Bでもちゃんと改善してるねん。これが何を意味するかっていうと、Token-Guardは大きいモデルになればなるほど、ええ感じにスケールするってことや。
| 手法 | RAGTruth | DROP_history | HaluEval |
|------|----------|--------------|----------|
| | F1 / BLEU | F1 / BLEU | F1 / BLEU |
| **3Bモデル** | | | |
| BaseModel | 12.11 / 6.29 | 42.21 / 39.31 | 42.95 / 39.95 |
| Chain-of-Thoughts | 32.70 / 25.48 | 31.60 / 26.04 | 50.88 / 48.44 |
| Tree-of-Thought | 27.05 / 21.16 | 39.84 / 36.14 | 59.22 / 55.11 |
| Predictive Decoding | 21.72 / 14.59 | 34.19 / 31.07 | 57.55 / 53.97 |
| Guided Decoding | 30.50 / 18.70 | 32.60 / 28.83 | 63.47 / 59.11 |
| Token-Guard(ウチの) | 15.66 / 13.45 | 43.09 / 40.57 | 68.21 / 63.83 |
| **13Bモデル** | | | |
| BaseModel | 22.47 / 15.26 | 46.32 / 42.74 | 35.30 / 31.40 |
| Chain-of-Thoughts | 32.25 / 27.67 | 33.90 / 30.06 | 49.43 / 44.01 |
| Tree-of-Thought | 32.93 / 23.70 | 43.97 / 38.25 | 62.20 / 58.07 |
| Predictive Decoding | – / – | – / – | – / – |
| Guided Decoding | 29.34 / 22.01 | 40.41 / 36.71 | 63.42 / 58.72 |
| Token-Guard(ウチの) | 33.14 / 30.41 | 51.17 / 47.64 | 72.66 / 68.81 |
表6:3Bモデルと13Bモデルでの性能比較やで。
RAGTruthでは、Token-Guardは3Bモデルやとちょっと成績が下がるねん。なんでかっていうと、このデータセットって長いコンテキスト(文脈)を扱う構造になってて、小さいモデルにはキツいからや。13Bモデルやとこの問題がある程度マシになって、もうちょい安定してデコードできるようになるわ。総じて言うとな、Token-Guardは色んなサイズのモデルで効果があって、めっちゃ長い文脈を扱う場面で限界があるくらいや。この結果から、Token-Guardは追加でチューニングせんでも色んなモデルサイズで使える、つまりポータビリティ(移植性)があるってことが確認できたわけやな。
**6 結論**
この研究ではな、Token-Guardっていうトークンレベルで幻覚(AIがでっち上げること)を制御するデコーディングフレームワークを紹介したで。推論の各ステップごとにセルフチェックを埋め込んで、3段階のフィルタリングパイプラインを活用することで、Token-Guardは幻覚トークンを検出して抑制すんねん。これによって、複数ステップの推論でも事実的・論理的な正確さが保たれるわけや。HALUベンチマークでの実験結果を見ると、Token-Guardは生成品質をめっちゃ改善してて、従来のデコーディング手法と比べてF1スコアが高いし、正解との一致度も強いねん。全体的に見て、Token-Guardは効率的なリソース使用を維持しつつ、色んなモデルサイズで使えるし、大規模言語モデルの生成における幻覚を軽減するための信頼できるアプローチを提供してるってことやな。
---
## Page 11
[](/attach/601913d208e3b5340f2fdb02c3063a0234db92fc3c6600efb67482659c87755b_p011.png)
### 和訳
ICLR 2026の学会論文として発表されたで
**謝辞**
この研究はな、中国の国家重点研究開発計画(助成番号2024YFC3308500)、北京市自然科学基金(助成番号L251042)、中国国家自然科学基金(助成番号62406036)、中国博士研究員科学基金(助成番号2025M781457)から支援もろうてんねん。ほんでさらに、ネットワーキング・スイッチング技術国家重点実験室(助成番号NST20250110)からもスポンサーしてもらっとるで。
**参考文献**
Borkan Ahmed Al-Yaychliら。RLHFベースのハルシネーション追跡の自動化について。Journal Européen des Systèmes Automatisés、58巻7号、1477-1483頁、2025年。doi: 10.18280/jesa.580715。URL https://doi.org/10.18280/jesa.580715。受付:2025年5月27日、修正:2025年6月30日、受理:2025年7月22日、オンライン公開:2025年7月31日。
Rizwan Aliら。データから意思決定へ:AIトークン価格予測をLSTMで強化する話やねん。Journal of Economic Studies、51巻8号、1677-1693頁、2024年。
Akari Asaiら。Self-RAG:自己反省を通じて検索・生成・批評を学習するっちゅう研究や。2024年。
Yuntao Baiら。人間のフィードバックからの強化学習(RLHF)を使って、役に立ってかつ無害なアシスタントを訓練する方法についてやねん。ArXiv、abs/2204.05862、2022年。URL https://api.semanticscholar.org/CorpusID:248118878。
Sehyun Choiら。KCTS:トークンレベルのハルシネーション検出を使った知識制約付き木探索デコーディングっちゅうもんや。2023年。URL https://arxiv.org/abs/2310.09044。
Paul Francis Christianoら。人間の好みからの深層強化学習についてやで。ArXiv、abs/1706.03741、2017年。URL https://api.semanticscholar.org/CorpusID:4787508。
Yung-Sung Chuangら。DoLA:レイヤー間の対比でデコードして大規模言語モデルの事実性を向上させるっちゅう話や。2024年。URL https://arxiv.org/abs/2309.03883。
Xuefeng Duら。HaloScope:ラベルなしのLLM生成物を活用してハルシネーションを検出する方法やねん。ArXiv、abs/2409.17504、2024年。URL https://api.semanticscholar.org/CorpusID:272910798。
Dheeru Duaら。DROP:段落に対する離散的推論を必要とする読解ベンチマークやで。Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies、第1巻(長編・短編論文)、2368-2378頁、ミネソタ州ミネアポリス、2019年6月。Association for Computational Linguistics。doi: 10.18653/v1/N19-1246。URL https://aclanthology.org/N19-1246/。
Mor Gevaら。アリストテレスはノートパソコン使ってたんか?暗黙の推論戦略を含む質問応答ベンチマークについてやねん。Transactions of the Association for Computational Linguistics、9巻、346-361頁、2021年。doi: 10.1162/tacl_a_00370。URL https://aclanthology.org/2021.tacl-1.21/。
11
---
## Page 12
[](/attach/601913d208e3b5340f2fdb02c3063a0234db92fc3c6600efb67482659c87755b_p012.png)
### 和訳
ICLR 2026の学会論文として発表されたで
Aaron Grattafioriさんをはじめ、Abhimanyu Dubeyさん、Abhinav Jauhriさん、Abhinav Pandeyさん、Abhishek Kadianさん、Ahmad Al-Dahleさん、Aiesha Letmanさん、Akhil Mathurさん、Alan Scheltenさん、Alex Vaughanさん、Amy Yangさん、Angela Fanさん、Anirudh Goyalさん、Anthony Hartshornさん、Aobo Yangさん、Archi Mitraさん、Archie Sravankumarさん、Artem Korenevさん、Arthur Hinsvarkさん、Arun Raoさん、Aston Zhangさん、Aurelien Rodriguezさん、Austen Gregersonさん、Ava Spataruさん、Baptiste Roziereさん、Bethany Bironさん、Binh Tangさん、Bobbie Chernさん、Charlotte Caucheteux さん、Chaya Nayakさん、Chloe Biさん、Chris Marraさん、Chris McConnellさん、Christian Kellerさん、Christophe Touretさん、Chunyang Wuさん、Corinne Wongさん、Cristian Canton Ferrerさん、Cyrus Nikolaidisさん、Damien Allonsiusさん、Daniel Songさん、Danielle Pintzさん、Danny Livshitsさん、Danny Wyattさん、David Esiobuさん、Dhruv Choudharyさん、Dhruv Mahajanさん、Diego Garcia-Olanoさん、Diego Perinoさん、Dieuwke Hupkesさん、Egor Lakomkinさん、Ehab Al-Badawyさん、Elina Lobanovaさん、Emily Dinanさん、Eric Michael Smithさん、Filip Radenovicさん、Francisco Guzmánさん、Frank Zhangさん、Gabriel Synnaeveさん、Gabrielle Leeさん、Georgia Lewis Andersonさん、その他大勢の共著者による「The llama 3 herd of models(Llama 3モデル群)」、2024年の論文や。URLはこちら:https://arxiv.org/abs/2407.21783
Anish Gunjalさん、Jihan Yinさん、Erhan Basさんの論文で、大規模視覚言語モデルにおけるハルシネーション(AIが事実と違うことをもっともらしく言うてまうやつやな)を検出して防ぐ方法について書いてあるねん。2023年のAAAI人工知能学会で発表されたで。URLはこちら:https://api.semanticscholar.org/CorpusID:260887222
Sachin Hiriyannaさんとwenbing Zhaoさんの論文は、めっちゃ重要な場面(医療とか法律とか、間違ったらアカンやつな)でLLMのハルシネーションを減らすための多層フレームワークについてのチュートリアルやねん。2025年のComputers誌、第14巻8号に載ってるで。ISSN 2073-431X、DOI: 10.3390/computers14080332。URLはこちら:https://www.mdpi.com/2073-431X/14/8/332
Pranab Islamさん、Anand Kannappanさん、Douwe Kielaさん、Rebecca Qianさん、Nino Scherrerさん、Bertie Vidgenさんの論文で、FinanceBenchっていう金融分野の質問応答用の新しいベンチマーク(要は性能を測るためのテスト問題集みたいなもんやな)を作ったって話や。2023年の論文で、URLはこちら:https://arxiv.org/abs/2311.11944
Ziwei Jiさん、Tiezheng Yuさん、Yan Xuさん、Nayeon Leeさん、Etsuko Ishiiさん、Pascale Fungさんの論文は、大規模言語モデルのハルシネーションを自己反省(AIが自分で「これほんまに合ってるか?」って確認するやつ)で減らそうっていう研究やねん。2023aの論文で、URLはこちら:https://arxiv.org/abs/2310.06271
同じ著者らの別バージョンの論文もあって、こっちはACL(計算言語学会)のEMNLP 2023のFindingsに載ったやつや。2023年12月にシンガポールで発表されて、Houda Bouamorさん、Juan Pinoさん、Kalika Baliさんが編集してはるねん。ページは1827〜1843で、DOI: 10.18653/v1/2023.findings-emnlp.123。URLはこちら:https://aclanthology.org/2023.findings-emnlp.123/
Qiao Jinさん、Bhuwan Dhingraさん、Zhengping Liuさん、William Cohenさん、Xinghua Luさんの論文は、PubMedQAっていう生物医学研究の質問応答用データセットを作った話やねん。2019年のEMNLP-IJCNLP(香港で開催された自然言語処理の学会や)で発表されて、Kentaro Inuiさん、Jing Jiangさん、Vincent Ngさん、Xiaojun Wanさんが編集してはる。ページは2567〜2577、DOI: 10.18653/v1/D19-1259。URLはこちら:https://aclanthology.org/D19-1259/
Grant Ledgerさん、Rafael Mancinniさんの論文は、トークン確率(AIが次の単語を選ぶときの確信度みたいなもんや)にモンテカルロシミュレーション(確率的なシミュレーション手法やな)を使ってLLMのハルシネーションを検出する方法についてやねん。2024年6月のTechRxivに載ってるで。URLはこちら:https://doi.org/10.36227/techrxiv.171822396.61518693/v1。引用するときは「Grant Ledger, Rafael Mancinni. TechRxiv. June 12, 2024.」って書いてな。
Patrick Lewisさん、Ethan Perezさん、Aleksandara Piktusさん、Fabio Petroniさん、Vladimir Karpukhinさん、Naman Goyalさん、Heinrich Kuttlerさん、Mike Lewisさん、Wen tau Yihさん、Tim Rocktäschelさん、Sebastian Riedelさん、Douwe Kielaさんの論文は、RAG(検索拡張生成)っていう、知識をめっちゃ使うNLPタスクのための手法についてやねん。なんでかっていうと、AIに外部の情報を検索させてから回答させることで、より正確な答えが出せるようになるからや。2020年のArXiv論文で、URLはこちら:https://api.semanticscholar.org/CorpusID:218869575
Jiarui Liさん、Ye Yuanさん、Zehua Zhangさんの論文は、RAGを使ってLLMの事実の正確さを上げて、ハルシネーションに対抗しようっていう話やねん。特定のドメイン(専門分野)のクエリをプライベートな知識ベースで処理するケーススタディになってるで。2024年のArXiv論文で、URLはこちら:https://api.semanticscholar.org/CorpusID:268510182
12
---
## Page 13
[](/attach/601913d208e3b5340f2fdb02c3063a0234db92fc3c6600efb67482659c87755b_p013.png)
### 和訳
ICLR 2026 会議論文として発表
Junyi Li、Xiaoxue Cheng、Xin Zhao、Jian-Yun Nie、Ji-Rong Wen。HaluEval:大規模言語モデル用のハルシネーション評価ベンチマーク。これな、めっちゃでかい規模のベンチマークやねん。Houda Bouamor、Juan Pino、Kalika Bali(編)、2023年自然言語処理における経験的手法会議(EMNLP)論文集、6449〜6464ページ、シンガポール、2023年12月。計算言語学協会。doi: 10.18653/v1/2023.emnlp-main.397。URL https://aclanthology.org/2023.emnlp-main.397/
Haoran Luo、Haihong E、Guanting Chen、Qika Lin、Yikai Guo、Fangzhi Xu、Zemin Kuang、Meina Song、Xiaobao Wu、Yifan Zhu、Luu Anh Tuan。Graph-r1:エンドツーエンドの強化学習を使ったエージェント型GraphRAGフレームワークへの道、2025a。URL https://arxiv.org/abs/2507.21892。これな、グラフ構造を使った検索拡張生成を強化学習で賢くしようって話やねん。
Haoran Luo、Haihong E、Guanting Chen、Yandan Zheng、Xiaobao Wu、Yikai Guo、Qika Lin、Yu Feng、Zemin Kuang、Meina Song、Yifan Zhu、Luu Anh Tuan。HypergraphRAG:ハイパーグラフ構造の知識表現による検索拡張生成、2025b。URL https://arxiv.org/abs/2503.21322。普通のグラフちゃうねん、ハイパーグラフっていう複数のノードを一度に繋げられるもっと複雑な構造使ってるのがポイントやな。
Haoran Luo、Haihong E、Yikai Guo、Qika Lin、Xiaobao Wu、Xinyu Mu、Wenhao Liu、Meina Song、Yifan Zhu、Luu Anh Tuan。KBQA-o1:モンテカルロ木探索を使ったエージェント型知識ベース質問応答、2025c。URL https://arxiv.org/abs/2501.18922。なんでかっていうと、モンテカルロ木探索っていうのは囲碁AIとかで使われてる賢い探索方法で、それを質問応答に応用してるんやで。
Zhiyi Lyu、Jianguo Huang、Yanchen Deng、Steven Hoi、Bo An。Let's revise step-by-step:LLMを使ったコード生成のための統一的なローカル探索フレームワーク、2025。URL https://arxiv.org/abs/2508.07434。コード生成を一歩ずつ見直して改善していこうって発想やな。
Chang Ma、Haiteng Zhao、Junlei Zhang、Junxian He、Lingpeng Kong。言語モデルの非近視眼的生成による推論と計画。ArXiv、abs/2410.17195、2024。URL https://api.semanticscholar.org/CorpusID:273507611。「非近視眼的」ってのはな、目先のことだけちゃうて、もっと先のことまで見据えて生成するってことやねん。
Aman Madaan、Niket Tandon、Prakhar Gupta、Skyler Hallinan、Luyu Gao、Sarah Wiegreffe、Uri Alon、Nouha Dziri、Shrimai Prabhumoye、Yiming Yang、Shashank Gupta、Bodhisattwa Prasad Majumder、Katherine Hermann、Sean Welleck、Amir Yazdanbakhsh、Peter Clark。Self-refine:自己フィードバックによる反復的改善。2023。URL https://arxiv.org/abs/2303.17651。自分で自分を直していくって、めっちゃ賢い仕組みやろ?
Timo Möller、Anthony Reina、Raghavan Jayakumar、Malte Pietsch。COVID-QA:COVID-19のための質問応答データセット。Karin Verspoor、Kevin Bretonnel Cohen、Mark Dredze、Emilio Ferrara、Jonathan May、Robert Munro、Cecile Paris、Byron Wallace(編)、ACL 2020 COVID-19のためのNLPワークショップ第1回論文集、オンライン、2020年7月。計算言語学協会。URL https://aclanthology.org/2020.nlpcovid19-acl.18/。コロナの時にほんまに必要やった研究やな。
Selvan Sunitha Ravi、Bartosz Mielczarek、Anand Kannappan、Douwe Kiela、Rebecca Qian。Lynx:オープンソースのハルシネーション評価モデル。2024。URL https://arxiv.org/abs/2407.08488。AIが嘘ついてへんか評価するためのモデルやで。
Swarnadeep Saha、Omer Levy、Asli Celikyilmaz、Mohit Bansal、Jason Weston、Xian Li。Branch-Solve-Merge:大規模言語モデルの評価と生成を改善する手法、2024。URL https://arxiv.org/abs/2310.15123。分岐して、解いて、統合する、っていう3ステップで精度上げていく方法やねん。
Kurt Shuster、Spencer Poff、Moya Chen、Douwe Kiela、Jason Weston。検索拡張で会話のハルシネーションを減らす。Marie-Francine Moens、Xuanjing Huang、Lucia Specia、Scott Wen-tau Yih(編)、計算言語学協会発見論文集:EMNLP 2021、3784〜3803ページ、プンタカナ、ドミニカ共和国、2021年11月。計算言語学協会。doi: 10.18653/v1/2021.findings-emnlp.320。URL https://aclanthology.org/2021.findings-emnlp.320/。外部の情報を検索して持ってくることで、AIが適当なこと言うのを減らせるって証明したんやな。
Nisan Stiennon、Long Ouyang、Jeff Wu、Daniel M. Ziegler、Ryan J. Lowe、Chelsea Voss、Alec Radford、Dario Amodei、Paul Christiano。人間のフィードバックから要約を学習する。ArXiv、abs/2009.01325、2020。URL https://api.semanticscholar.org/CorpusID:221665105。これがRLHF(人間のフィードバックからの強化学習)の元祖みたいな研究やねん。めっちゃ重要な論文やで。
13
---
## Page 14
[](/attach/601913d208e3b5340f2fdb02c3063a0234db92fc3c6600efb67482659c87755b_p014.png)
### 和訳
だいしろーさん!
---
ICLR 2026のカンファレンス論文として発表されたで
Zeyu Tangさんら。「Reflection-window decoding: Text generation with selective refinement」、2025年。これ何かっていうと、テキスト生成するときに「ここちょっと怪しいな」ってとこだけ選んで直す方法やねん。URL: https://arxiv.org/abs/2502.03678
Shubham Ugareさんら。「Itergen: バックトラッキング付きの反復的な意味認識構造化LLM生成」。International Conference on Learning Representations、2024年。要するに、LLMが文章作るとき、構造をちゃんと意識しながら「あ、ちゃうわ」って戻れる仕組みやねん。URL: https://api.semanticscholar.org/CorpusID:273233268
Haoran Wangさんら。「Beyond tokens: 大規模言語モデルと大規模視覚言語モデルのデコーディング手法に関するサーベイ」。Authorea Preprints、2025年。トークンだけ見てても分からへんで、もっと広い視点でデコーディング(文章の生成方法)を整理した総まとめ論文やな。
Jason Weiさんら。「Chain-of-thought prompting elicits reasoning in large language models」。Advances in Neural Information Processing Systems、第35巻、24824〜24837ページ、2022年。これめっちゃ有名やねん!「一歩ずつ考えてみて」って言うだけで、AIが賢く推論できるようになるっていう発見やで。URL: https://proceedings.neurips.cc/paper_files/paper/2022/file/9d5609613524ecf4f15af0f7b31abca4-Paper-Conference.pdf
Yuanhao Wuさんら。「RAGTruth: 信頼できる検索拡張型言語モデルを開発するためのハルシネーションコーパス」。Annual Meeting of the Association for Computational Linguistics、2023年。なんでかっていうと、AIが嘘ついちゃう(ハルシネーション)問題を解決するために、嘘のデータセット作って研究しようって話やねん。URL: https://api.semanticscholar.org/CorpusID:266693591
Yuxi Xieさんら。「Self-evaluation guided beam search for reasoning」。Advances in Neural Information Processing Systems、第36巻、41618〜41650ページ、2023年。AIが自分で「これでええんかな?」って評価しながら、ビームサーチ(複数の候補を探索する方法)で推論する手法やで。URL: https://proceedings.neurips.cc/paper_files/paper/2023/file/81fde95c4dc79188a69ce5b24d63010b-Paper-Conference.pdf
Fangzhi Xuさんら。「φ-decoding: 推論時の探索と活用のバランスを取る適応的先読みサンプリング」。ArXiv、abs/2503.13288、2025年。ほんまにバランス大事やねん。新しいこと試す(探索)のと、分かってること使う(活用)のをうまいこと両立させる方法やで。URL: https://api.semanticscholar.org/CorpusID:277104404
An Yangさんら(めっちゃ大人数やな!)。「Qwen3 technical report」、2025年。Qwen3っていう新しいAIモデルの技術レポートやで。URL: https://arxiv.org/abs/2505.09388
Shunyu Yaoさんら。「Tree of thoughts: 大規模言語モデルによる意図的な問題解決」。Advances in Neural Information Processing Systems、第36巻、11809〜11822ページ、2023年。Chain-of-thoughtをさらに進化させて、木構造で色んな考え方を試しながら問題解くっていうアイデアやねん。URL: https://proceedings.neurips.cc/paper_files/paper/2023/file/271db9922b8d1f4dd7aaef84ed5ac703-Paper-Conference.pdf
Yongcheng Zengさんら。「Token-level direct preference optimization」。ArXiv、abs/2404.11999、2024年。DPO(直接選好最適化)をトークンレベルでやるっていう話。要は、文章全体じゃなくて一つ一つの単語レベルで「こっちの方がええ」って学習させる方法やな。URL: https://api.semanticscholar.org/CorpusID:269214026
Muru Zhangさんら。「How language model hallucinations can snowball」。ArXiv、abs/2305.13534、2023年。これほんまに怖い話やねん。AIの嘘がどんどん雪だるま式に大きくなっていくっていう現象を研究した論文やで。URL: https://api.semanticscholar.org/CorpusID:258841857
14
---
## Page 15
[](/attach/601913d208e3b5340f2fdb02c3063a0234db92fc3c6600efb67482659c87755b_p015.png)
### 和訳
これはICLR 2026の学会論文として発表されたやつやねん。
Tunyu Zhang、Haizhou Shi、Yibin Wang、Hengyi Wang、Xiaoxiao He、Zhuowei Li、Haoxian Chen、Ligong Han、Kai Xu、Huan Zhang、Dimitris N. Metaxas、Hao Wang。「大規模言語モデルの推論におけるトークンレベルの不確実性推定」っていう論文やな。これ何かっていうと、AIが文章作るとき一個一個の単語(トークン)がどれくらい自信あるかを測る方法の研究やねん。ArXiv、abs/2505.11737、2025年。URLはこっち:https://api.semanticscholar.org/CorpusID:278740334
Wayne Xin Zhao、Kun Zhou、Junyi Li、Tianyi Tang、Xiaolei Wang、Yupeng Hou、Yingqian Min、Beichen Zhang、Junjie Zhang、Zican Dong、Yifan Du、Chen Yang、Yushuo Chen、Zhipeng Chen、Jinhao Jiang、Ruiyang Ren、Yifan Li、Xinyu Tang、Zikang Liu、Peiyu Liu、Jian-Yun Nie、Ji-Rong Wen。「大規模言語モデルのサーベイ」、2025年。これはめっちゃ有名なLLM(大規模言語モデル)についての総まとめ論文やで。URLはこっち:https://arxiv.org/abs/2303.18223
15ページ目
---
## Page 16
[](/attach/601913d208e3b5340f2fdb02c3063a0234db92fc3c6600efb67482659c87755b_p016.png)
### 和訳
よっしゃ、これ説明していくで!
ICLR 2026の学会論文として発表されたやつやねん
付録
A TOKEN-GUARDで使うインプットについて
A.1 TOKEN-GUARDのプロンプト
図8に載せてるけど、実験で使ったデータセットごとのプロンプトを詳しく説明するわな。
PubMedQAってやつでは、回答は絶対「Yes./No./Maybe.」から始めなあかんくて、大事な医学用語とか条件はちゃんと残したまま、簡潔に一文で結論まとめなあかんねん。FinanceBenchでは、出力は正解のフォーマットとピッタリ合わせなあかんねん(ドル金額とか、パーセンテージとか、比率とかな)。ほんで、与えられた財務データだけ使って、途中の計算とか勝手にやったらあかんで。Historyでは、文章に明確に書いてある数字と固有名詞だけ使わなあかんし、情報が足りひん時は決まった拒否文を返すルールやねん。RagTruthみたいな検索拡張QAでは、回答は与えられた文章だけに限定して、事実の詳細は全部含めるか、そうでなければ標準化された拒否文を返すんや。
なんでこうするかっていうと、ドメイン特有の制約と汎用的なフォールバックプロンプトを組み合わせることで、いろんな分野で回答の一貫性が上がって、ハルシネーション(AIが嘘つくこと)のリスクを減らせるからやねん。
図7: Token-Guardのプロンプト
A.2 ケーススタディの文章
図8: Token-Guardのプロンプト
16
```
prompt_map = {
'pubmedqa': (
"PubMedスタイルの文章とYes/No/Maybeの質問が出されるで。\n"
"回答ルール:\n"
"1. 必ず「Yes.」「No.」「Maybe.」のどれか一つから始めること。\n"
"2. 文章からのメインの結論を、25語以内の短い一文でまとめること。\n"
"3. 文章のキーフレーズや医学用語はそのまま残すこと。同義語に置き換えたらあかん。\n"
"4. 結論に明記されてる条件、サブグループ、制限事項は必ず含めること。\n"
"5. 推奨事項、説明、新しい情報は追加したらあかん。\n"
"回答:[Yes./No./Maybe. + 短い一文]"
),
'financebench': (
"あなたは株式リサーチアナリストや。**提供されたデータだけ**使って質問に答えてな。\n"
"1. 必ず一行で最終回答を出すこと。\n"
"2. 計算過程、推論、コメントは見せたらあかん。\n"
"3. 正解と全く同じフォーマットに合わせること(例:千ドル単位なら「$360000.00」、百万ドル単位なら「$7223.00」、十億ドル単位なら「$4.90」、パーセンテージなら「34.7%」、比率なら「1.08」)。\n"
"4. 財務諸表から直接答えが出せへん場合は「Unable to answer based on given data.」と出力すること。\n"
"例:Q: ボーイングの2017年度の支払利息(千ドル単位)はなんぼ?\n"
"A: Answer: $360000.00\n"
"最後に出力:Answer:[あなたの回答]"
),
'history': (
"質問が出されるで。\n"
"1. 質問分析:期待される回答タイプを判断すること(例:「いくつ」→数字、「何年」→年、「何/どれ/誰」→スパン、「いつ」→時間)。\n"
"2. 数字の扱い:文章に明記されてる数字だけ使うこと。推測したり作ったりしたらあかん。時間と組織の変更は慎重に扱うこと。\n"
"3. 情報抽出:名前、数字、出来事は文章に書いてある通りに正確に抽出すること。\n"
"4. 情報不足:文章に十分な情報がない場合は「The passage does not provide enough information to answer this question.」と答えること。\n"
"5. 選択式:質問に「or」が含まれてたら、与えられた選択肢だけで厳密に答えること。\n"
"最後に出力:Answer:[あなたの回答]"
),
'ragtruth': (
"文章と質問が与えられるで。以下の手順に従ってな:\n"
"与えられた文章の情報だけを使って質問に答えること。\n"
" - 言及されてたら具体例、数字、比較を含めること。\n"
" - 回答を裏付ける詳細は全部含めること。\n"
" - 外部情報は追加したらあかん。\n"
" - 文章に十分な情報がない場合は「Unable to answer based on given passages.」と答えること。\n"
"最後に出力:Answer:[あなたの回答]"
),
}
default_prompt = (
"質問が出されるで。\n"
"与えられた情報だけに基づいてユーザーの質問に答えること。\n"
"情報を作り上げたらあかん。\n"
"最後に出力:Answer:[あなたの回答]"
)
```
サンフランシスコはチャンスを逃しまくってデトロイトを試合に残らせてもうたけど、なんとかギリギリのプレーで珍しく2連勝を達成して、今シーズン初のアウェイ勝利を手に入れたんや。RBのフランク・ゴアは前半だけで148ヤードラッシングっていうフランチャイズ記録を打ち立てて、61ヤードのタッチダウンランも決めたんやけど、脳震盪で途中退場してもうたんや。サンフランシスコは最初の4ドライブのうち3回で得点して、ハーフタイムで13-3とリードしてたんやけど、ヤード数247対102と圧倒してファンブルリカバーもしてターンオーバーもなかったから、もっと点差つけたかったやろな。49ersは第3クォーターで大きくリードするチャンスがあったんや。なんでかっていうと、デトロイトが最初の3プレーで2回もターンオーバーしたからな。でも結局フィールドゴール1本だけで13点差のままやったんや。ほんでゴアは7ヤードのパスキャッチした後、フラフラしながらフィールドを出て、そのまま戻ってこれへんかった。第3クォーター中盤でQBアレックス・スミスがファンブルして、それがライオンズの得点につながって試合が接戦になってもうたんや。49ersはドライブでフィールドを進んでKジョー・ネドニーの4本目のフィールドゴールをセットアップしたんやけど、これがめっちゃ大事やったんや。なんでかっていうと、この得点のおかげでデトロイトは試合終盤に同点狙いのフィールドゴールじゃなくてタッチダウンを狙わなあかんくなったからな。Sキース・ルイスが残り2分半で49ersの2ヤード地点でQBジョン・キトナのパスをインターセプトして、4勝5敗になったサンフランシスコは試合を決めるのに必要なファーストダウンを1回取って、2003年以来2度目の連勝を飾ったんや。RBフランク・ゴアはキャリアハイの159ヤードラッシングで終えて、サンフランシスコのQBアレックス・スミスは20投中14回成功で136ヤード、ファンブル1回やった。WRアーナズ・バトルは6キャッチ55ヤードで、最後のドライブで3rd&4をコンバートして49ersが時間を使い切れるようにしたんや。49ersのディフェンスはまたもやめっちゃ活躍して、総オフェンスヤードをたった273ヤードに抑えて4ターンオーバーを強いたんや。LBブランドン・ムーアがまたしても大活躍で、チームトップの9タックル、2サック、2ターンオーバー誘発を記録したで。この勝利で49ersは4勝5敗になったんや。
---
## Page 17
[](/attach/601913d208e3b5340f2fdb02c3063a0234db92fc3c6600efb67482659c87755b_p017.png)
### 和訳
ICLR 2026で発表された会議論文やで
# B 理論の証明
## B.1 命題1の証明
**命題1.** トークン単位のセルフチェックをすると、生成された文章のハルシネーション(嘘つき度合い)の期待値が下がるねん。
**証明.** atはステップtで生成されたトークンで、モデルの確率pθ(at | st)で生成されるんや。stっていうのは今の状態(文脈とか、それまでに生成されたトークンとか全部含む)のことな。各トークンにはハルシネーションスコアFhalu(at) ∈ [0, 1]がついてて、これが「このトークン、事実と違う確率どんくらい?」っていう指標やねん。
Token-Guardっていう仕組みは、ハルシネーションにペナルティをかけるように生成確率をいじるんや:
pguard(at | st) = pθ(at | st) exp(−γFhalu(at)) / Zt
Zt = Σ_{a∈V} pθ(a | st) exp(−γFhalu(a)) (19)
ここで、γ > 0がハルシネーションへのペナルティの強さを調整するパラメータで、Ztは確率の合計を1にするための正規化定数、Vは語彙に入ってる全トークンの集合やな。
ステップtでの期待ハルシネーションをこう定義するで:
Epguard[Fhalu] = Σ_{at} pguard(at | st) Fhalu(at) (20)
**情報理論的な見方:** 元のモデルとToken-Guardでのトークンの条件付きエントロピーを定義するとな:
Hθ(At | st) = −Σ_{at} pθ(at | st) log pθ(at | st)
Hguard(At | st) = −Σ_{at} pguard(at | st) log pguard(at | st) (21)
ここで「Facts」っていうのは、生成タスクに関係する事実情報とか根拠のことや。生成されるトークンと事実的な根拠との間の条件付き相互情報量はこうなる:
I(At; Facts | st) = H(At | st) − H(At | Facts, st)
Token-Guardはハルシネーション高いトークンの重みを下げるから、こうなるねん:
Epguard[Fhalu] ≤ Epθ[Fhalu] (22)
I(At; Facts | st)guard ≥ I(At; Facts | st)θ (23)
つまりな、期待ハルシネーションは下がって、事実との相互情報量は上がるってことや。
**まとめ:** トークン単位のセルフチェックは、1トークンあたりの期待ハルシネーションを減らすだけやなくて、事実との整合性も上げるんや。これが後に続くセグメント単位とか軌跡単位の選択の理論的な土台になってて、結果的に生成時のモデルの事実精度がめっちゃ上がるってわけやな。
## B.2 命題2の証明
**命題2.** セグメント単位のスコアリングと局所的な改良を組み合わせると、生成品質が上がってハルシネーションも減るねん。
**証明.** 候補セグメントCkがトークン{at1, ..., atn}で構成されてて、各トークンにハルシネーションスコアFhalu(ati)と重みwi(全部足したらΣi wi = 1になる)がついてるとするで。セグメント単位のスコアをこう定義するんや:
Fseg(Ck) = Σ_{i=1}^{n} wi Fhalu(ati) + βHk (24)
ここで、Hkは構造的・意味的な一貫性を測る指標で、β > 0はハルシネーションと構造のバランスを取るパラメータやな。
17
---
## Page 18
[](/attach/601913d208e3b5340f2fdb02c3063a0234db92fc3c6600efb67482659c87755b_p018.png)
### 和訳
ICLR 2026での学会論文として発表されとるんやけど、
**セグメントレベルのハルシネーション(嘘っぱち生成)の期待値**について説明するな:
E[Fseg] =
n
(cid:88)
i=1
wiE[Fhalu(ati)] + βE[Hk].
これ何かっていうと、Fseg(Ck)っていうスコアがτsegっていう閾値を下回ったときに、ローカルな修正ウィンドウW (l) = {ai−1, alow
i
, ai+1}を取り出すねん。このalow
i
ってのは一番スコアがヤバい(低い)トークンのことや。んで、修正されたウィンドウはこうやって生成されるで:
W (l)′
= LLM_refine(W (l) | Ck \ W (l)),
(25)
これでセグメントが更新されて C ′
k = Ck \ W (l) ∪ W (l)′
になるわけや。
(26)
**情報理論的な見方**をすると、セグメントと事実ソースの間の相互情報量ってのはこうなるねん:
I(Ck; Facts) =
n
(cid:88)
i=1
wiI(ati; Facts) + I(Hk; Facts).
(27)
修正することで一番弱いサブウィンドウが改善されるから、
E[I(C ′
k; Facts)] ≥ E[I(Ck; Facts)],
(28)
つまり修正されたセグメントは事実とより整合性が取れるようになるっちゅうことや。
**まとめ**:セグメントレベルのスコアリングとローカル修正を組み合わせることで、信頼できへん部分を繰り返しブラッシュアップできるねん。これでハルシネーション(嘘っぱち)の期待値が減って、意味的なまとまり、事実との整合性、生成の関連性がアップして、結果的に生成品質全体がめっちゃ良くなるわけや。
B.3 命題3の証明
**命題3**:候補シーケンスに対する反復的な修正は、ハルシネーションを減らして、論理的整合性を高めることで最終レスポンスの信頼性を向上させるんや。
**証明**:{τi}N
i=1を候補の軌道(トラジェクトリー)として、それぞれがセグメント{C (i)
1 , . . . , C (i)
K }を持ってるとするわな。ほんで軌道レベルのスコアをこう定義するで:
Ffinal(τi) = λ
K
(cid:88)
k=1
Fseg(C (i)
k ) + (1 − λ)
T
(cid:88)
t=1
Fhalu(a(i)
t ),
λ ∈ [0, 1].
(29)
クラスタリングを使って階層的に最適な軌道を選ぶんやけど:
τ ∗
j = arg min
τi∈Cj
Ffinal(τi),
(30)
τfinal = arg min
j
Ffinal(τ ∗
j ).
(31)
**グローバルな整合性のための反復修正**:論理的なまとまりをもっと良くするために、グローバルな反復更新を導入するで:
F (t+1)(τi) = α F (t)
final(τi) + (1 − α)
1
N − 1
(cid:88)
j̸=i
Sim(τi, τj),
(32)
ここでSim(τi, τj)ってのは軌道同士の論理的な一致度を測るもんで、α ∈ (0, 1)はローカルの信頼性とグローバルなコンセンサスのバランスを取るパラメータやねん。収束した後の最終軌道は
τ ∗
final = arg min
τi∈R
F (T )(τi),
(33)
これでハルシネーションの最小化とグローバルな論理的整合性の両方を取り込んでるわけや。
**情報理論的な見方**:軌道と事実知識の間の相互情報量はこうなるで:
I(τi; Facts) =
K
(cid:88)
k=1
I(C (i)
k ; Facts) +
T
(cid:88)
t=1
I(a(i)
t
; Facts).
(34)
18
---
## Page 19
[](/attach/601913d208e3b5340f2fdb02c3063a0234db92fc3c6600efb67482659c87755b_p019.png)
### 和訳
ICLR 2026の学会論文として発表されたやつやで
反復的な改良っていうのはな、I(τi; Facts)を最大化するプロセスのことやねん。これ、合意制約のもとでやるんやけど、要するに選ばれた軌道が最大限の事実的な中身と一貫した論理的推論を持つようにするってことやな。
**まとめ**: グローバルな多段階選択と反復的改良を使うことで、ハルシネーション(AIが嘘ついちゃうやつやな)を減らして、論理の一貫性を守って、自信のない部分を動的に修正しつつ、計算リソースもちゃんとコントロールできるねん。
## C トークンガードのアルゴリズム詳細
Token-Guardの仕組みを説明するために、アルゴリズム1で全体のワークフローを見せるで。これは3つの重要なステージで構成されてて、反復的な自己チェックとグローバルな一貫性評価を通じてハルシネーションを軽減するように設計されてるねん。
**アルゴリズム1 Token-Guard: 多段階ハルシネーション制御生成**
必要なもの: 入力x、言語モデルLLM、閾値{τtoken, τ^low_seg, τ^high_seg, τglobal}、最大ステップ数Nmax
保証するもの: 最終的なハルシネーション制御済みの回答y
1: // フェーズ1: トークンレベルの生成と検証
2: 潜在環境s1を空で初期化、推論チェーンRも空で初期化
3: tが1からTまでの間、繰り返すで
4: 候補{a^(i)_t}と隠れ状態{h^(i)_t}をLLMからサンプリング
5: 意味的類似性と確率を使ってスコアF^token_halu(a^(i)_t)を計算
6: τtokenを満たすa*_tを選んで、現在のセグメントCkに追加; s_{t+1} ← s_t ∪ {h(a*_t)}
7: ループ終わり
8: // フェーズ2: セグメントレベルの評価とローカル改良
9: 完了した各セグメントCk = {a_{t1}, ..., a_{tn}}に対して
10: H_k = Σw_ih^(i)_{ti}を計算して、セグメントスコアF^seg_haluも計算
11: もしF^seg_halu(C_k) ≥ τ^high_segなら、C_kを有効プールに追加してRに追加
12: そうじゃなくて、もしτ^low_seg ≤ F^seg_halu(C_k) < τ^high_segなら
13: F^seg_halu(C_k) < τ^high_segかつr < Nmaxの間、繰り返すで
14: a_low ← arg min_i F^token_halu; W^(l)'_k ← LLM_refine(W^(l)_k | context, H_k)
15: C_kを更新 ← (C_k \ W^(l)_k) ∪ W^(l)'_k; H_kとF^seg_haluを再計算; r ← r + 1
16: ループ終わり
17: もしF^seg_halu(C_k) ≥ τ^high_haluなら、C_kを受け入れてRに追加、そうじゃなければC_kを破棄
18: そうじゃなければC_kを破棄
19: 条件分岐終わり
20: ループ終わり
21: // フェーズ3: グローバル再考とフィードバック修正
22: イテレーションi ← 1で初期化
23: i ≤ Nmaxの間、繰り返すで
24: セグメント表現{H_k}を使ってF_fact(R)と論理的整合性F_logic(R)を計算
25: グローバルスコアF_global(R) = (F_fact・F_logic) / (F_fact + F_logic - F_fact・F_logic)を計算
26: もしF_global(R) ≥ τglobalなら、回答y = Rを返す
27: そうじゃなければ、τ^adj_seg ← f(F_fact, F_logic)を調整; ステージ2のロジックでチェーンRを改良; i ← i + 1
28: 条件分岐終わり
29: ループ終わり
30: "回答できません"を返す ▷ Nmaxのグローバルイテレーション超えたで
## D 包括的な評価
TOKEN-GUARDのポテンシャルを色んなデータセットとタスクで評価するために、7つのQA・推論ベンチマークと、オープンドメインのStrategyQAデータセットで実験したんや。StrategyQA(Gevaら、2021年)については、LLaMA-7Bモデルを使って、Decoding by Contrasting Layers手法のDoLa(Chuangら、2024年)と比較したで。元のDoLa論文で報告されてる精度ベースの評価プロトコルに従ってやってんねん。
---
## Page 20
[](/attach/601913d208e3b5340f2fdb02c3063a0234db92fc3c6600efb67482659c87755b_p020.png)
### 和訳
ICLR 2026の学会論文として発表
方法
精度 (%) ベース精度 (%)
改善分 (%)
改善率 (%)
DOLA
TOKEN-GUARD
64.1
69.4
60.1
62.3
4.0
7.1
6.66
11.40
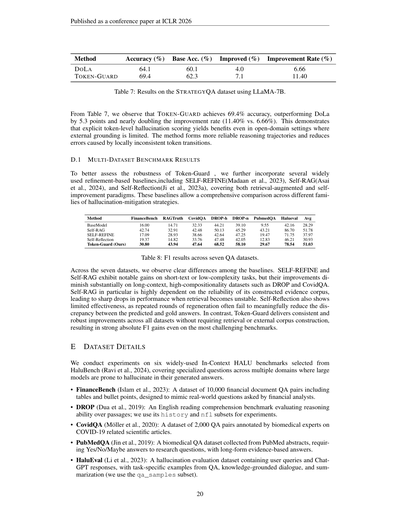
表7: LLaMA-7BでSTRATEGYQAデータセット使った結果やで。
表7見てみ、TOKEN-GUARDは69.4%の精度叩き出してて、DoLaより5.3ポイントも上回ってんねん。改善率に至ってはほぼ倍やで(11.40% vs. 6.66%)。これが何を意味してるかっていうと、外部の根拠が限られてるオープンドメインの設定でも、トークンレベルでハルシネーション(AIが嘘つく現象のこと)をガチで点数化してあげると、ちゃんと効果あるってことやねん。この手法使うと、もっと信頼できる推論の道筋が作れるし、局所的にトークンの繋がりがおかしくなって起きるエラーも減らせるんや。
D.1 複数データセットでのベンチマーク結果
Token-Guardの頑健性(どんな状況でもちゃんと動くか)をもっとしっかり評価するために、よく使われる改良系のベースラインもいくつか加えたで。SELF-REFINE(Madaanら、2023)、Self-RAG(Asaiら、2024)、Self-Reflection(Jiら、2023a)とかやな。これらは検索で補強するタイプと、自分で自分を良くしていくタイプの両方カバーしてて、ハルシネーション対策の色んな系統と包括的に比較できるようになってんねん。
方法
FinanceBench RAGTruth CovidQA DROP-h DROP-n PubmedQA Halueval
平均
BaseModel
Self-RAG
SELF-REFINE
Self-Reflection
Token-Guard (俺らの)
16.00
42.74
17.09
19.37
30.80
14.71
32.91
28.93
14.82
43.94
32.33
42.48
38.66
33.76
47.64
44.21
50.13
42.64
47.48
68.52
39.10
45.29
47.25
42.05
58.10
9.55
43.21
19.47
12.83
29.67
42.16
86.70
71.75
46.21
78.54
28.29
51.78
37.97
30.93
51.03
表8: 7つのQAデータセットでのF1スコアやで。
7つのデータセット全部見てみると、ベースライン同士でハッキリ差が出てんねん。SELF-REFINEとSelf-RAGは、短いテキストとか複雑さ低めのタスクではなかなかええ結果出してんねんけど、DROPとかCovidQAみたいに文脈長くて複合的な要素多いデータセットになると、改善がめっちゃしょぼくなるんよ。特にSelf-RAGは自分で作った証拠コーパス(根拠になる文書の集まり)がどんだけ信頼できるかにめっちゃ依存してて、検索が不安定になると性能がガクッと落ちるんや。Self-Reflectionも効果イマイチで、なんでかっていうと、何回も生成し直しても、予測した答えと正解との差を意味のある形で縮められへんことが多いねん。それに対してToken-Guardは、検索も外部コーパスの構築も要らんのに、全部のデータセットで安定してしっかり改善してて、一番難しいベンチマークでも高いF1スコアの絶対的な向上を達成してるんや。
E データセットの詳細
実験はHaluBench(Raviら、2024)から選んだ6つのよく使われるIn-Context HALUベンチマークで実施したで。これらは複数の専門分野にまたがる質問を含んでて、大規模モデルが生成した回答でハルシネーション(嘘つき)しやすいやつらやねん。
• FinanceBench(Islamら、2023): 10,000件の金融ドキュメントQ&Aペアのデータセットで、表とか箇条書きも含んでるで。金融アナリストが実際に聞きそうな質問を模倣して作られてんねん。
• DROP(Duaら、2019): 英語の読解力ベンチマークで、文章に対する推論能力を評価するやつや。実験ではhistoryとnflのサブセットを使ったで。
• CovidQA(Möllerら、2020): バイオメディカル(生物医学)の専門家がCOVID-19関連の科学論文にアノテーション(注釈付け)した2,000件のQ&Aペアのデータセットやねん。
• PubMedQA(Jinら、2019): PubMedの要約から集めたバイオメディカルQAデータセットで、研究上の質問に「はい/いいえ/多分」で答えなあかんねん。長い形式の根拠に基づいた回答も含まれてるで。
• HaluEval(Liら、2023): ハルシネーション評価用のデータセットで、ユーザーの質問とChatGPTの回答が入ってるねん。QA、知識に基づいた対話、要約のタスク別の例があって、俺らはqa_samplesのサブセットを使ったで。
20
---
## Page 21
[](/attach/601913d208e3b5340f2fdb02c3063a0234db92fc3c6600efb67482659c87755b_p021.png)
### 和訳
ICLR 2026の学会論文として発表されたで
• RAGTruth(Wu et al., 2023):LLMが生成したテキストの幻覚(ハルシネーション)を単語レベルで注釈つけたデータセットやねん。
F ベースラインの詳細
今回の実験では、Token-Guardと4つの代表的な推論ベースの手法を比較してるで:
• Auto-Regressive(CoT):(Wei et al., 2022)自己回帰的に言語生成しながら、思考の連鎖(chain-of-thought)による推論をするんやけど、自己修正の仕組みがないから幻覚が起きやすいんよな。
• Tree-of-Thought(ToT)(Yao et al., 2023):与えられた問題に対して木構造を作って、各ノードが推論のステップを表すねん。ワイらはBFS(幅優先探索)の実装を採用してて、これで探索がうまくいって局所的な幻覚が減るんや。
• Guided Decoding(Xie et al., 2023):各ステップで自己評価を使って確率的ビームサーチをやるんや。これでクオリティ低い推論経路をフィルタリングして、トークンレベルの幻覚を軽減できるねん。
• Predictive Decoding(Ma et al., 2024):モデル予測制御を活用した先読み戦略を提案してて、LLMの確率分布を重み付け直すことで、目先だけじゃない言語モデリングができて、長距離の幻覚を減らせるんや。
G 評価の詳細
Token-Guardの性能評価には、よく使われる4つの指標を使ってるで:
(i) Exact Match(EM、完全一致)。EMは予測した答えが正解とぴったり一致してるかを測るんや。norm(·)を正規化関数とすると:
EM = (1/N) Σ(i=1からN) I{norm(yi) = norm(y*i)} (35)
(ii) F1スコア。F1スコアは予測した答えyiと正解y*iのトークンレベルの重なり具合を、適合率と再現率の調和平均で測るんや:
F1 = (1/N) Σ(i=1からN) (2・|tokens(yi) ∩ tokens(y*i)|) / (|tokens(yi)| + |tokens(y*i)|) (36)
(iii) BLEU。BLEUは正解に対する予測答えのn-gram適合率を評価するんやけど、短すぎる出力にはペナルティ(BP)がかかるねん。n-gramの次数がKまでの場合:
BLEU = BP・exp(Σ(n=1からK) wn log pn) (37)
ここでpnは修正n-gram適合率、wnは重み(一様に1/K)、BPはmin(1, exp(1 - |y*|/|y|))やで。
(iv) 生成ステップごとのトークンレベル精度。Token-Guardが各生成ステップでどれだけ信頼できるか評価するために、ステップごとの正解率を計算するんや:
Acct = 1(at = a*t) (38)
ここでatは予測トークン、a*tはステップtの正解トークン、1(·)は指示関数やで。
長さTのシーケンス全体のトークンレベル精度は
トークンレベル精度 = (1/T) Σ(t=1からT) Acct (39)
H パラメータ最適化の詳細
H.1 コアプロセスパラメータの設定
表9に示すように、Token-Guardの各パラメータの効果をまとめてるで。λと∆τを大きくすると一般的にF1は上がるんやけど、サンプルあたりの処理時間(TPS)も増えるねん。
Token-Guardの各ハイパーパラメータにはちゃんとした役割があって:λと(α, β, γ)はトークンレベルの信頼度とセグメントレベルの意味的一貫性の相互作用を制御して、∆τ、Nmax、そして
21
---
## Page 22
[](/attach/601913d208e3b5340f2fdb02c3063a0234db92fc3c6600efb67482659c87755b_p022.png)
### 和訳
ICLR 2026のカンファレンス論文として発表
NmaxとMmaxっていうのは、ローカルな微調整をどこまでやるか、何回繰り返すかっていう範囲を決めるもんやねん。全部のベンチマークデータセットの学習データ全体を使ってグリッドサーチ(しらみつぶしに探す方法やな)やって、F1スコアとTPS(1秒あたりのトークン処理数)のバランスがええ、どのデータにも使える頑丈な設定を一個選んだんや。
ID
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
λ
0.40
0.40
0.40
0.50
0.50
0.50
0.60
0.60
0.60
0.70
0.70
0.70
0.80
0.80
0.80
∆τ
0.05
0.10
0.15
0.05
0.10
0.15
0.05
0.10
0.15
0.05
0.10
0.15
0.05
0.10
0.15
(α, β, γ)
Nmax Mmax
F1
TPS (秒)
(0.3,0.3,0.4)
(0.4,0.3,0.3)
(0.5,0.25,0.25)
(0.3,0.3,0.4)
(0.4,0.3,0.3)
(0.5,0.25,0.25)
(0.3,0.3,0.4)
(0.5,0.3,0.2)
(0.5,0.25,0.25)
(0.3,0.3,0.4)
(0.4,0.3,0.3)
(0.5,0.25,0.25)
(0.3,0.3,0.4)
(0.4,0.3,0.3)
(0.5,0.25,0.25)
2
2
2
3
3
3
3
3
2
3
3
3
2
2
3
2
3
4
2
3
4
2
2
4
2
3
4
2
3
4
45.32
48.76
50.21
49.12
52.45
55.03
50.12
51.03
53.87
51.56
54.12
56.78
48.92
50.67
57.34
95.21
142.35
187.64
110.87
156.78
201.95
122.56
113.29
180.12
131.45
165.88
198.45
104.36
148.72
205.89
表9:Token-Guardのグリッドサーチ結果やで。ハイライトしてある行が、性能高くてコスパもええ選ばれた設定やねん。
NmaxとMmaxを大きくすると、TPSがめっちゃ急激に、しかも掛け算的に増えていくねん。特に複雑なデータセットやとその傾向が顕著で、これって精度と効率のトレードオフ(あっちを立てればこっちが立たへん関係)をよう表してるわな。ウチらが選んだ設定(ID 8)は、λ=0.60、∆τ=0.10、(α, β, γ)=(0.5, 0.3, 0.2)、Nmax=3、Mmax=2で、F1=51.03をTPS=113.29で達成してて、めっちゃコスパええねん。
H.2 トークンレベルからセグメント・グローバルレベルへの閾値の伝播
Token-Guardの閾値っていうのは、お互いに関係し合ってるねん。トークンレベルの閾値τtokenを、セグメントレベルとグローバルレベルの閾値にシステマチックに伝播させて、意味の一貫性と事実の信頼性を担保してるわけや。
セグメントレベルの閾値 トークンレベルのチェックをパスしたn個のトークンを持つ候補セグメントCkについて、
¯F seg
token =
1
n
n
(cid:88)
i=1
F token
halu (ati | sti)
(40)
これはトークンレベルの幻覚スコア(AIが嘘ついてる度合いやな)の平均値を表してるねん。セグメントを受け入れるかどうかの閾値はこう定義されるで:
seg = ¯F seg
τ high
seg = ¯F seg
τ low
token + k1(Cseg − 0.5),
token − k2(1 − Cseg),
(41)
(42)
ここでk1とk2は[0.1, 0.2]の範囲の値で、閾値のマージン(余裕幅やな)をコントロールしてるねん。高閾値のセグメントはすぐにOK出して、中くらいのやつはローカルな微調整にかけることができるんや。
グローバル閾値 グローバルな閾値は、セグメントレベルの閾値と期待される一貫性に基づいて決まるで:
τglobal = max
seg − ∆1, F expected
τ high
fact
(cid:16)
(cid:17)
,
(43)
ここで∆1は[0.05, 0.1]の範囲で、F expected
fact
は大体0.7くらいやねん。
伝播アルゴリズム
1. トークンレベルの閾値τtokenを選ぶ。
2. セグメントの一貫性Csegは大体0.7くらいと仮定する。
3. セグメントの平均スコア¯F seg
4. セグメントレベルの閾値を計算する:
tokenを計算する(τtokenとほぼ同じくらいになるで)。
seg = ¯F seg
τ high
token + k1(Cseg − 0.5),
seg = ¯F seg
τ low
token − k2(1 − Cseg)
22
---
## Page 23
[](/attach/601913d208e3b5340f2fdb02c3063a0234db92fc3c6600efb67482659c87755b_p023.png)
### 和訳
ICLR 2026の学会論文として発表されたで
5. グローバル閾値を計算するんや:
τglobal = max(τ high
seg − ∆1, F expected
fact
)
6. あとはお好みで、k1、k2、∆1のパラメータを実験しながら微調整して、F1スコアと処理時間(TPS)のバランス取ったらええで。
ID
τtoken
τ low
seg
τ high
seg
τglobal
F1
TPS (秒)
1
2
3
4
5
6
7
8
9
0.30
0.30
0.30
0.40
0.40
0.40
0.50
0.50
0.50
0.52
0.54
0.55
0.55
0.57
0.58
0.60
0.62
0.63
0.70
0.72
0.74
0.75
0.77
0.79
0.80
0.82
0.84
0.68
0.70
0.71
0.70
0.72
0.73
0.74
0.75
0.76
42.17
43.89
44.36
51.03
49.03
50.21
52.45
53.18
54.09
125.34
132.58
138.45
113.29
110.87
118.46
140.12
148.77
156.92
表10:トークンレベルからセグメントレベル、ほんでグローバルレベルへの閾値の伝播を示した例やねん。F1スコアとTPSも一緒に載せとるで。4行目が高性能でコスパええ設定やから、ここ注目やで。
H.3 温度パラメータの選び方
Token-Guardでなんでソフトマックス温度を0.3、サンプリング温度を0.4にしたんか、ちょっと説明するわな。
Token-Guardってのは、トークンレベルの隠れ状態の軌跡が安定してへんと、ちゃんと自己検証できへんねん。温度が高すぎると、デコーディングのときにランダム性が強くなりすぎて、この軌跡がグチャグチャになってまうんや。そうなると、Token-Guardが頼りにしてる一貫性のシグナルが弱なってまうねん。逆に温度低めにすると、局所的な遷移のダイナミクスがなめらかになって、ハルシネーション(嘘をつくこと)を検出するのに必要な細かいパターンがちゃんと保たれるんや。
ワイらが選んだ0.3〜0.4ってのは、Li et al.(2025)の研究結果とも合ってんねん。彼らの研究やと、低温度(だいたい0.4くらい)でデコードすると、自己一貫性推論で分布の整合性がめっちゃ安定するって分かってんねん。温度上げすぎると回答の分布が歪んで、一貫性がガタ落ちするんやって。
さらにこの選択が正しいか確かめるために、5パターンの温度ペアで感度分析もやってみたで。結果、0.3と0.4の組み合わせが隠れ状態の安定性と出力の信頼性のバランスが一番ええかったんや。温度高くすると、Token-Guardが早期のハルシネーションのズレを検出する能力が一貫して落ちてしもたわ。
ソフトマックス / サンプリング HaluEval RAGTruth
0.15 / 0.25
0.30 / 0.40
0.50 / 0.60
0.80 / 0.80
75.63
79.56
73.34
67.05
41.94
43.60
43.31
42.30
表11:HaluEvalとRAGTruthでの温度設定ごとのF1性能やで。
理論的な考察と実験結果の両方に基づいて、ワイらはデフォルトの温度設定として0.3(ソフトマックス)/ 0.4(サンプリング)を採用することにしたんや。
I エラー事例研究
この付録では、文脈依存QAデータセットから代表的な失敗例を5つ紹介するで。トークンレベルの自己チェックと再生成をやっても、なんでまだ間違った答えが出てまうことがあんのか、それを説明する例やねん。各ケースには、データセットの出典、質問、文脈、Token-Guardの出力、正解、ほんで失敗の原因の簡単な分析を載せとるで。
ケース1 – CovidQA
質問:[口腔スワブ以外に、2019-nCOVウイルスの存在を検出したのはどの検査ですか?]
文脈:[血液中に検出可能な2019-nCoVウイルスRNAは、さらなる臨床
23
---
## Page 24
[](/attach/601913d208e3b5340f2fdb02c3063a0234db92fc3c6600efb67482659c87755b_p024.png)
### 和訳
ICLR 2026の学会論文として発表されてんで
重症度のことやねんけど。この研究は、2019-nCoV(新型コロナウイルスのことやな)に感染した患者さんの咽頭(口の奥)スワブ、血液、肛門スワブにウイルスがおるかどうかを後ろ向きに分析したんや。血液のグループでは、57人中6人からRNAが検出されて、その全員が重症化したんやで。肛門スワブのグループでは、28人中11人が陽性で、そのうち8人が重症になったんや。何人かの患者さんは何日間にもわたってサンプル取られてて、ウイルス量が上がったり下がったりしとったんやな。患者1さんは5日目、7日目、8日目、11日目に咽頭スワブからウイルスRNA検出されて、6日目には血液で弱陽性、13日目には肛門スワブで高かったんや。患者2さんは同じ日で比べたら、血液より肛門スワブのほうがウイルスRNA多かったんやで。患者3〜6さんも血液と肛門スワブでRNA検出のパターンがバラバラで、それが重症化と関係しとったんや。この研究で大事なんは、肺以外のところでウイルスRNAが見つかると重症度と関係あるってことで、血液と肛門サンプルをモニタリングしたら早期予測に役立つかもってことやねん。それに、肛門スワブでRNAが高いってことは、消化管でウイルスが増えとる可能性があるってことやな。限界としては、便サンプルが取れへんかったことと、気管支肺胞洗浄液は処置のリスクがあって測れへんかったことやねん。まあ全体的に、肺以外のところにもウイルスRNAがおることが確認されて、口のスワブだけやなくて早期からいろんなとこモニタリングしたほうがええっていう話を裏付けとるわけや。]
Token-Guardの出力:[血液と肛門スワブのサンプル]
正解:[2019-nCoVのRNAは血液(57人中6人)と肛門スワブ(28人中11人)から容易に検出された。]
分析:Token-Guardはサンプルの種類は正しく特定できとるけど、数値の詳細とか連続測定の情報が抜けとるんや。なんでかっていうと、長くて情報ぎっしりのテキストを完全な回答に要約するんがめっちゃ難しいからやねん。これ、長くて複雑な文脈に対して正確やけど省略しすぎた出力を生成してまうっていう、よくある失敗パターンを示しとるわけや。
ケース2 – DROP_nfl
質問:[ハーフタイム時点で各チーム何点やった?]
文脈:[レイダーズとの厳しいオーバータイムのアウェイ戦で負けた後、立て直しを図るジェッツは第8週、カンザスシティ・チーフスとのホーム戦に臨んだんや。第1クォーターでニューヨークは飛び立って、QBのブレット・ファーヴがRBのレオン・ワシントンに18ヤードのTDパスを決めたんや。第2クォーターでチーフスが追いついて、QBのタイラー・シグペンがTEのトニー・ゴンザレスに19ヤードのTDパスを通したんやな。ジェッツはワシントンの60ヤードTDランで勝ち越したんや。カンザスシティは前半終了間際、シグペンがWRのマーク・ブラッドリーに11ヤードTDパスを決めて締めくくったんやで。]
Token-Guardの出力:[ハーフタイム時点の各チームの得点についての明確な情報はないんやけど。ただ、最初の2クォーターで両チームとも2つのタッチダウン決めとるんや:ワシントンの18ヤードTDパスと60ヤードTDラン、ゴンザレスの19ヤードTDパスとブラッドリーの11ヤードTDパスやな。タッチダウンは1回6点やから、ハーフタイム時点でジェッツ14点、チーフス12点やな。]
正解:[14]
分析:この失敗は、文脈が複数ステップの推論を必要とする場合に正確な数値の答えを出すのがほんまに難しいってところから来とるんや。Token-Guardはタッチダウンは正しく特定できとるけど、正確な得点ルール(エクストラポイントとかやな)を適用して参照答案と一致させることができてへんのや。これ、長い文脈の中で算数的な推論を扱う限界を示しとるわけやな。
ケース3 – PubMedQA
質問:[小児の骨折診断で超音波はX線と同等か?]
文脈:[超音波は現在、骨折診断には確立されてへんのや。この研究の目的は、骨折の特定だけやなくて、骨折のタイプと転位の検出について、小児骨折診断における超音波とX線を比較することやったんや。死んだ子豚の四肢の骨を小児の骨のモデルとして使ったんやで。骨折した骨を超音波、X線、そしてゴールドスタンダードとしてのCTで検査したんや。248本中162本が骨折しとって、超音波では130件、X線では148件の骨折が特定されたんや。骨折タイプの検出ではX線のほうが超音波よりちょっと有利やった(X線で80件正解、超音波で66件正解)。でもな、転位の特定では超音波のほうがX線より優れとったんや(X線で41件正解、超音波で51件正解)。ただし、両方の結果とも多重検定の調整後は統計的に有意ではなかったんやで。]
Token-Guardの出力:[いいえ。超音波は骨折タイプの検出ではX線と同等ではなかったけど、小児骨折診断における転位の特定ではX線より優れとった。]
正解:[はい]
分析:この失敗は主に、文脈の中の証拠が不完全やったり曖昧やったりすることから来とるんや。超音波とX線の間に数値的な差はあるんやけど、統計的に有意ではないってことは、全体的には同等の効果があるってことを示しとるんやな。Token-Guardは骨折の
---
## Page 25
[](/attach/601913d208e3b5340f2fdb02c3063a0234db92fc3c6600efb67482659c87755b_p025.png)
### 和訳
Published as a conference paper at ICLR 2026
構造タイプの検出について、生物医学の文脈でのちょっとした解釈の違いが、再生成後でも食い違いを生む例を見せとるわけやな。
ケース4 – HaluEval
質問:[世界で7番目に大きい国にいる蛾の属で、1種類しか含まへん属はどれ?]
コンテキスト:[Indogrammodes(インドグラモデス)はツトガ科の蛾の属やねん。この属には1種類だけ、Indogrammodes pectinicornalisっていう種がおって、インドで見つかってるんや。インド、正式名称はインド共和国、南アジアにある国やで。面積では世界で7番目に大きくて、人口は12億人以上で世界第2位、民主主義国家としては世界一人口多いねん。]
Token-Guardの出力:[Indogrammodes]
正解:[Crambidae(ツトガ科)]
分析:これはな、コンテキストが曖昧やったから起きたエラーやねん。Indogrammodes属とツトガ科、両方とも文中に出てきてるから、どっちも答えとして成り立つんよ。Token-Guardは属名を出力したんやけど、これ自体は事実として正しいんやけどな、参照回答と違ってしまったんや。つまり、曖昧な根拠からエラーが生まれる典型例やな。
ケース5 – DROP_history
質問:[2008年に一番少なかった宗教は何?]
コンテキスト:[グレーター・マンチェスターは多様な人口を抱えてて、多文化が混ざり合った地域やねん。2001年時点で少数民族は全人口の8.5%やった。2008年には、この地域に66以上の難民の国籍の人らがおったんや。2001年の英国国勢調査では、グレーター・マンチェスターの住民の74.2%がキリスト教徒、5.0%がイスラム教徒、0.9%がユダヤ教徒、0.7%がヒンドゥー教徒、0.2%が仏教徒、0.1%がシク教徒やった。11.4%は無宗教で、0.2%が他の宗教、7.4%は宗教を回答せんかった。これは国全体とだいたい同じやけど、イスラム教徒とユダヤ教徒の割合は全国平均のほぼ2倍やねん。ここにはヒートン・パーク・ヘブライ会衆っていう、北マンチェスターにある大きなアシュケナジ正統派シナゴーグがあるんや。グレーター・マンチェスターはローマ・カトリックのソルフォード教区とシュルーズベリー教区、それにリバプール大司教区がカバーしてるで。グレーター・マンチェスターのほとんどは英国国教会のマンチェスター教区に入ってるけど、ウィガン大都市自治区だけはリバプール教区に入っとるんや。]
Token-Guardの出力:[仏教徒]
正解:[シク教徒]
分析:モデルは一番少ない宗教を間違えてしもたんや。なんでかっていうと、コンテキスト内の仏教徒0.2%とシク教徒0.1%の微妙な差を見落としたからやねん。これはな、細かい数値の推論が必要な場面で、トークンレベルの自己チェックだけでは小さな数量の違いを完全に見分けられへんっていう失敗パターンを示してるんや。
I.1 失敗パターンのまとめ
この5つの代表的なケースを通してわかるのは、よくある失敗はコンテキストの根拠が不完全やったり曖昧やったりするところから来てるってことやな。複数のもっともらしい答えがあったり、重要な情報がめっちゃ微妙やったりするねん。あとは、モデルの知識の限界からくるエラーもあるで、特に珍しい話題とか専門的なトピックでな。
他にも、幻覚(ハルシネーション)を抑えることと表現の完全さのトレードオフから生じる失敗もあるんや。詳細とか数値情報が省略されてしまうパターンやな。それから、複数ステップの推論とか長文の集約がトークンレベルの検証を超えてしまう場合もある。これらの例は、Token-Guardが幻覚を減らすのにめっちゃ効果的やってことと同時に、今のモデルとデータセットの制約下でコンテキスト依存の質問応答には実際的な限界があるってことも示してるんや。
J 限界と今後の課題
Token-Guardは様々なデータセットとバックボーンモデルで強い性能を見せとるんやけど、いくつか限界も残ってるねん。
まず1つ目、トークンレベルとセグメントレベルのスコアリングを使った多段階デコーディングは、無視できへん計算コストがかかるんや。特に長い文章やとな。これは小さいモデルとか、レイテンシ(遅延)に敏感なアプリケーションではスケーラビリティを制限する可能性があるで。
25
---
## Page 26
[](/attach/601913d208e3b5340f2fdb02c3063a0234db92fc3c6600efb67482659c87755b_p026.png)
### 和訳
まずな、Token-Guardは基本的にデコーディング(文章生成のプロセスやな)の時に起こる幻覚(ウソ情報のことやで)を抑える仕組みやねん。せやけど、足りん知識を補ってくれるわけやないんよ。やから、めっちゃ専門的な知識が必要なタスクやと、事実の正確さがどこまで上がるかは、ベースになってるLLM(大規模言語モデルのことな)の持ってる知識に縛られてまうねん。特にな、ベースのLLMが重要な知識をそもそも持ってへん時は、幻覚の原因がデコーディングのミスやなくて、「そもそも情報知らんやん」っていう問題になるんよ。
次にな、クラスタリング(似たもんをグループ分けする処理やな)と全体を繰り返し見ていく仕組みは、意味的にまとまりのある文章の塊を前提にしてるねん。せやから、めっちゃバラバラやったりノイズだらけの入力やと、セグメント(文章の区切りやな)ごとのスコアリングとか、推論チェーンの選び方がうまいこといかへんのよ。要するに、グチャグチャな入力にはセグメントスコアリングの効果が限定的やから、Token-Guardが幻覚を抑えられる範囲にも限界があるっちゅうことやな。
最後にな、Token-Guardは今んとこテキストの知識と構造化された推論チェーンに特化してるねん。せやから、マルチモーダル(画像とか音声とか、テキスト以外のデータも扱うやつな)への拡張は、これからの有望な研究テーマやで。
---
![]()
1 / 1
100%