<<
2312.10997v5.pdf

---
## Page 1
[](/attach/396a0fadeb4cd40f5c8ccc36b73a0815f6cb4d7f6bfa53b6c48c1f9aba7c7e02_p001.png)
### 和訳
# 大規模言語モデルのための検索拡張生成:サーベイ論文
## 要約
なぁなぁ、大規模言語モデル(LLM)ってめっちゃすごい能力持ってるんやけど、実は結構やっかいな問題も抱えてんねん。「ハルシネーション」って呼ばれる嘘つき現象とか、知識が古くなってまう問題とか、なんでそう答えたんかよう分からん不透明な推論とかな。そこで登場したんが**検索拡張生成(RAG)**っちゅう技術や!外部のデータベースから知識を引っ張ってくることで、これらの問題に対処しよるんやで。
RAGを使うと、生成される回答の正確さと信頼性がグンと上がるねん。特に知識をめっちゃ必要とするタスクには効果抜群や。しかも知識を継続的にアップデートしたり、特定の分野に特化した情報も組み込めるっちゅうわけ。要するにRAGは、LLMが元々持ってる知識と、外部データベースにある膨大で常に更新される情報をうまいこと融合させとるんやな。
この総合レビュー論文では、RAGのパラダイム(基本的な考え方のパターン)がどう進化してきたかを詳しく見ていくで。**ナイーブRAG**、**アドバンストRAG**、そして**モジュラーRAG**っちゅう3つの段階があんねん。ほんで、RAGフレームワークの三本柱、つまり**検索**、**生成**、**拡張**の技術についてもじっくり分析しとるわ。それぞれの重要なパーツに組み込まれてる最先端技術も紹介してるから、RAGシステムの進歩がよう分かるようになっとる。さらに、最新の評価フレームワークとベンチマークも紹介してるで。最後には、今どんな課題があって、これからどんな研究・開発の方向性があるんかも示しとるわ。
**キーワード:** 大規模言語モデル、検索拡張生成、自然言語処理、情報検索
---
## 1. はじめに
大規模言語モデル(LLM)はめっちゃ目覚ましい成功を収めてきたんやけど、まだまだ大きな限界もあんねん。特に専門分野とか、知識をごっつい必要とするタスクでは顕著やな [1]。学習データにない質問とか、最新の情報が必要な時には「ハルシネーション」っちゅう嘘をついてまう現象 [2] が起きやすいんや。
こういう課題を乗り越えるために、**検索拡張生成(RAG)** がLLMを強化しとるんやで。仕組みはこうや:外部の知識ベースから、意味の類似度を計算して関連する文書の断片を検索してくるねん。外部知識を参照することで、RAGは事実と違う内容を生成してまう問題を効果的に減らせるんや。RAGがLLMに統合されたことで、めっちゃ広く使われるようになって、チャットボットを進化させたり、LLMを実世界のアプリケーションに適用しやすくする重要技術として確立されたんやな。
RAG技術はここ数年でめっちゃ急速に発展してきて、関連研究をまとめた技術ツリーは図1に示しとるで。大規模モデル時代におけるRAGの発展の軌跡は、いくつかのはっきりした段階的特徴を示してんねん。
最初、RAGの誕生はTransformerアーキテクチャの台頭と同時期やった。**事前学習モデル(PTM)** を通じて追加の知識を取り込むことで言語モデルを強化することに焦点を当てとったんや。この初期段階は、事前学習技術を洗練させることを目指した基礎的な研究が特徴やったな [3]–[5]。
その後、**ChatGPT** [6] の登場が大きな転換点になったんや。LLMがめっちゃ強力な**インコンテキスト学習(ICL)** 能力を持ってることが示されてな。RAG研究は、推論段階でLLMがより複雑で知識集約的なタスクに答えられるように、より良い情報を提供する方向にシフトして、RAG研究が急速に発展したんや。研究が進むにつれて、RAGの強化は推論段階だけに限らず、LLMのファインチューニング技術とももっと統合されるようになってきたわ。
RAGの分野はめっちゃ急成長してるんやけど、全体の流れを明確にする体系的なまとめがまだなかったんや。このサーベイは、そのギャップを埋めようとしてんねん。RAGのプロセスをマッピングして、その進化と将来予測される道筋を描いとるで。LLM内でのRAGの統合に焦点を当ててな。
この論文では、技術的なパラダイムと研究手法の両方を考慮して、100以上のRAG研究から3つの主要な研究パラダイムをまとめ、「検索」「生成」「拡張」のコア段階における重要技術を分析しとる。一方で、現在の研究は手法に焦点を当てがちで、RAGをどう評価するかの分析やまとめが不足してんねん。この論文は、RAGに適用可能な下流タスク、データセット、ベンチマーク、評価方法を包括的にレビューしとるで。
全体として、この論文は、LLM以降に登場したRAGの基礎的な技術概念、歴史的な進展、そして様々な方法論とアプリケーションを丁寧にまとめて分類することを目指しとる。読者や専門家に、大規模モデルとRAGの両方について、詳細で構造化された理解を提供するように設計されとんねん。検索拡張技術の進化を明らかにし、各アプローチの長所と短所をそれぞれの文脈で評価し、今後のトレンドやイノベーションについても推測しとるわ。
### 貢献
僕らの貢献はこんな感じや:
- このサーベイでは、最先端のRAG手法について徹底的かつ体系的なレビューを行って、ナイーブRAG、アドバンストRAG、モジュラーRAGというパラダイムを通じてその進化を描いとるで。
---
## Page 2
[](/attach/396a0fadeb4cd40f5c8ccc36b73a0815f6cb4d7f6bfa53b6c48c1f9aba7c7e02_p002.png)
### 和訳
図1. RAG研究の技術ツリーやねん。RAGが関わるステージは大きく分けて「事前学習」「ファインチューニング」「推論」の3つがあるんよ。LLM(大規模言語モデル)が登場してからは、最初はLLMのめっちゃすごい「文脈内学習」の能力を活かすことに注目が集まって、主に推論のステージを研究しとったんや。その後、研究はどんどん深まっていって、だんだんLLMのファインチューニングとも融合するようになってきたんやな。ほんで、研究者たちは事前学習のステージでも、この検索で補強する技術を使って言語モデルをパワーアップさせる方法を探っとるんやで。
- Naive RAG(素朴なRAG)、Advanced RAG(進化版RAG)、Modular RAG(モジュール型RAG)っていう分類でRAGの発展を整理しとるねん。このレビューでは、LLMの世界全体の中でRAG研究がどういう位置づけにあるかっていう広い視点で見とるで。
- RAGのプロセスで核心となる技術、つまり「検索」「生成」「拡張」っていう3つの側面に焦点を当てて、それぞれの相乗効果について突っ込んで議論しとるんや。これらの要素がどうやって複雑に連携して、一つのまとまった効果的なRAGフレームワークを形成するか、わかりやすく説明しとるで。
- 現在のRAGの評価方法もまとめとって、26個のタスク、約50個のデータセットをカバーしとるんや。評価の目的と指標、それから今使われとる評価ベンチマークやツールについても概説しとるで。さらに、現在の課題を克服するための潜在的な改善点を強調しながら、RAGの今後の方向性も予測しとるんやで。
論文の構成はこんな感じや:セクションIIでRAGの主要な概念と現在のパラダイムを紹介するで。続く3つのセクションでは、「検索」「生成」「拡張」っていうコア要素をそれぞれ掘り下げとる。セクションIIIは検索の最適化手法に焦点を当てて、インデックス作成、クエリ、埋め込みの最適化を扱っとる。セクションIVは検索後の処理と生成におけるLLMのファインチューニングに集中しとるで。セクションVでは3つの拡張プロセスを分析しとる。セクションVIはRAGの下流タスクと評価システムに焦点を当てとって、セクションVIIでは主にRAGが現在直面しとる課題と今後の発展方向について議論しとる。最後にセクションVIIIで論文を締めくくっとるんや。
II. RAGの概要
RAGの典型的な応用例を図2に示しとるで。ここでは、ユーザーがChatGPTに最近話題になっとるニュースについて質問しとるんや。ChatGPTは事前学習データに依存しとるから、最初は最新の動向について答える能力がないねん。なんでかっていうと、学習時点より後の情報は持ってへんからやな。RAGはこの情報のギャップを埋める役割を果たして、外部のデータベースから知識を引っ張ってきて取り込むんや。この例では、ユーザーの質問に関連するニュース記事を集めとる。これらの記事を元の質問と組み合わせて、包括的なプロンプトを作るねん。そうすることでLLMがちゃんとした情報に基づいた回答を生成できるようになるんやで。
RAGの研究パラダイムはずっと進化し続けとって、図3に示すように、Naive RAG、Advanced RAG、Modular RAGっていう3つのステージに分類しとるんや。RAGの手法はコスパが良くて、素のLLMの性能を超えるんやけど、いくつかの限界もあるねん。Advanced RAGとModular RAGの開発は、Naive RAGのこういった特定の欠点に対応するために生まれたんやで。
A. Naive RAG
Naive RAGの研究パラダイムは最も初期の方法論を代表しとって、これが注目を集めたんは...
---
## Page 3
[](/attach/396a0fadeb4cd40f5c8ccc36b73a0815f6cb4d7f6bfa53b6c48c1f9aba7c7e02_p003.png)
### 和訳
図2やねん。これ、質問に答えるときのRAGプロセスの代表的な例を示してんねん。主に3つのステップがあんねん。1)インデキシング:ドキュメントをチャンク(かたまり)に分けて、ベクトルにエンコードして、ベクトルデータベースに保存すんねん。2)検索:意味的な類似度に基づいて、質問に一番関係あるTop kのチャンクを取ってくんねん。3)生成:元の質問と取ってきたチャンクを一緒にLLM(大規模言語モデル)に入力して、最終的な回答を作るってわけや。
ChatGPTがめっちゃ広まったことで、Naive RAG(素朴なRAG)っちゅうのが出てきてん。これは昔ながらのやり方で、インデキシング、検索、生成っていう流れを踏むねん。「検索して読む」フレームワーク[7]とも言われてるわ。
**インデキシング**は、PDF、HTML、Word、Markdownみたいないろんな形式の生データをきれいにして抽出するとこから始まんねん。ほんで、それを統一されたプレーンテキスト形式に変換すんねん。言語モデルには文脈の長さに制限があるから、テキストをもっと小さい、消化しやすいチャンクに分けなあかんねん。ほんでそのチャンクを埋め込みモデル使ってベクトル表現にエンコードして、ベクトルデータベースに保存すんねん。このステップがめっちゃ重要やねんで。なんでかっていうと、次の検索フェーズで効率よく類似検索できるようになるからや。
**検索**やけど、ユーザーからクエリ(質問)を受け取ったら、RAGシステムはインデキシングのときと同じエンコードモデルを使って、そのクエリをベクトル表現に変換すんねん。ほんで、クエリのベクトルとインデックス済みコーパス内のチャンクのベクトルとの類似度スコアを計算すんねん。システムは優先順位つけて、クエリに対して一番類似度が高いTop Kのチャンクを取ってくるわけや。これらのチャンクが、プロンプトの拡張コンテキストとして使われんねん。
**生成**では、投げかけられた質問と選ばれたドキュメントが一つのまとまったプロンプトに合成されて、大規模言語モデルがそれに対する回答を作る役目を担うねん。モデルの回答アプローチはタスク固有の基準によって変わることがあって、自分が持ってるパラメトリック知識(学習で身につけた知識)を使ってもええし、提供されたドキュメントに含まれる情報だけに限定して回答してもええねん。会話が続いてる場合は、既存の会話履歴をプロンプトに組み込めるから、モデルは複数ターンの対話のやり取りを効果的にできるようになるわけや。
せやけど、Naive RAGには目立つ欠点があんねん:
**検索の課題**。検索フェーズは精度と再現率に苦戦しがちで、ずれたチャンクや関係ないチャンクを選んでまうことがあんねん。ほんで重要な情報を取りこぼすこともあるわ。
**生成の難しさ**。回答を生成するとき、モデルはハルシネーション(幻覚)っちゅう問題に直面することがあんねん。これは、取ってきたコンテキストに裏付けられてない内容を作り出してまうことやねん。このフェーズでは、出力が的外れやったり、有害やったり、偏りがあったりする問題も起こりうるから、回答の品質と信頼性を損なってまうねん。
**拡張のハードル**。取ってきた情報を異なるタスクと統合するんはチャレンジングで、時々ばらばらでまとまりのない出力になってまうねん。複数のソースから似たような情報を取ってきたときに冗長になることもあって、繰り返しの多い回答になりがちやねん。様々な文章の重要性と関連性を判断して、文体とトーンの一貫性を確保するんも、さらに複雑さを増すポイントやねん。複雑な問題に直面したとき、元のクエリに基づく1回の検索だけでは十分なコンテキスト情報を得られへんかもしれんねん。さらに、生成モデルが拡張情報に頼りすぎて、洞察や統合された情報を加えずに、取ってきたコンテンツをただ繰り返すだけの出力になってまう懸念もあるわ。
## B. Advanced RAG(進化版RAG)
Advanced RAGは、Naive RAGの限界を克服するための具体的な改善を導入してんねん。検索品質の向上に焦点を当てて、検索前と検索後の戦略を採用してるわ。インデキシングの問題に取り組むために、Advanced RAGはスライディングウィンドウアプローチ、きめ細かいセグメンテーション、メタデータの組み込みを使って、インデキシング技術を洗練させてんねん。さらに、検索プロセスを効率化するためのいくつかの最適化手法も取り入れてるで[8]。
---
## Page 4
[](/attach/396a0fadeb4cd40f5c8ccc36b73a0815f6cb4d7f6bfa53b6c48c1f9aba7c7e02_p004.png)
### 和訳
図3. RAGの3つのパラダイムの比較やねん。(左)ナイーブRAGは主に3つのパートで構成されてんねん:インデックス作成、検索、そして生成や。(中央)アドバンストRAGは検索の前後でいろんな最適化戦略を提案してんねんけど、プロセス自体はナイーブRAGと似てて、まだチェーン(鎖)みたいな構造を保ってんねん。(右)モジュラーRAGは前のパラダイムを引き継ぎながら発展させてて、全体的にめっちゃ柔軟性が高いねん。これは複数の特定機能モジュールを導入したり、既存のモジュールを置き換えたりできるところに表れてんねん。全体のプロセスは順番に検索して生成するだけやなくて、繰り返し検索とか適応的な検索みたいな方法も含まれてんねん。
**検索前のプロセス**。この段階では、インデックス構造と元のクエリの最適化に主に焦点を当ててんねん。インデックス最適化の目標は、インデックスされるコンテンツの品質を上げることやねん。これにはいくつかの戦略があって:データの粒度を細かくしたり、インデックス構造を最適化したり、メタデータを追加したり、アライメント(整合性)の最適化をしたり、複合的な検索をしたりすんねん。一方、クエリ最適化の目標は、ユーザーの元の質問をより明確にして、検索タスクにより適したものにすることやねん。よく使われる方法には、クエリの書き換え、クエリの変換、クエリの拡張、その他のテクニックがあんねん [7], [9]–[11]。
**検索後のプロセス**。関連するコンテキストを取ってきたら、それをクエリとうまく統合することがめっちゃ重要やねん。検索後のプロセスの主な方法には、チャンク(文章の塊)の再ランキングとコンテキストの圧縮があんねん。取ってきた情報を再ランキングして、一番関連性の高いコンテンツをプロンプトの端っこに配置し直すのが重要な戦略やねん。このコンセプトはLlamaIndex、LangChain、HayStackみたいなフレームワークで実装されてんねん [12]。関連する文書を全部そのままLLMに突っ込むと、情報過多になって、関係ないコンテンツで重要な詳細への集中が薄まってまうねん。これを軽減するために、検索後の作業では本質的な情報を選び出して、重要なセクションを強調して、処理するコンテキストを短くすることに集中すんねん。
**C. モジュラーRAG**
モジュラーRAGのアーキテクチャは、前の2つのRAGパラダイムを超えて進化してて、適応性と汎用性がめっちゃ強化されてんねん。コンポーネントを改善するためのいろんな戦略を取り入れてて、例えば類似性検索のための検索モジュールを追加したり、ファインチューニングでリトリーバー(検索器)を改良したりすんねん。再構成されたRAGモジュール [13] や再編成されたRAGパイプライン [14] みたいな革新的なアイデアも、特定の課題に対処するために導入されてんねん。モジュラーRAGアプローチへの移行は主流になりつつあって、順次処理とコンポーネント全体にわたる統合されたエンドツーエンドのトレーニングの両方をサポートしてんねん。独自性はあるけど、モジュラーRAGはアドバンストRAGとナイーブRAGの基本原則の上に構築されてて、RAGファミリー内での進化と改良を示してんねん。
**1) 新しいモジュール**: モジュラーRAGフレームワークは、検索と処理能力を強化するために追加の専門コンポーネントを導入してんねん。検索モジュールは特定のシナリオに適応して、検索エンジン、データベース、ナレッジグラフみたいなさまざまなデータソースに対して、LLMが生成したコードやクエリ言語を使って直接検索できるようにしてんねん [15]。RAG-Fusionは従来の検索の限界に対処するために、マルチクエリ戦略を使ってんねん。これはユーザーのクエリを多様な視点に拡張して、並列ベクトル検索とインテリジェントな再ランキングを活用して、明示的な知識と変革的な知識の両方を発見すんねん [16]。メモリモジュールはLLMのメモリを活用して検索をガイドして、制限のないメモリプールを作り出すねん。
---
## Page 5
[](/attach/396a0fadeb4cd40f5c8ccc36b73a0815f6cb4d7f6bfa53b6c48c1f9aba7c7e02_p005.png)
### 和訳
RAGシステムにおけるテキスト整合っちゅうのは、繰り返し自己強化することでデータの分布にテキストをより近づけていく仕組みやねん。ルーティングってのは、色んなデータソースの中を縦横無尽に動き回って、そのクエリにとってベストな道筋を選んでくれるんや。要約が必要なんか、特定のデータベース検索がええんか、それとも複数の情報を混ぜ合わせるんがええんか、そういうのを判断してくれるわけやな。Predictモジュールは、LLMを使って直接コンテキストを生成することで、余計な重複やノイズを減らして、関連性と正確さを確保しようとするもんやねん。ほんで最後に、Task Adapterモジュールは、RAGを色んな下流タスクに合わせてカスタマイズしてくれるんや。ゼロショット入力に対しては自動でプロンプトを取ってきてくれるし、数ショットのクエリ生成を使ってタスク専用のレトリーバーも作れるんやで。この包括的なアプローチのおかげで、検索プロセスがスムーズになるだけやなくて、取ってくる情報の質と関連性がめっちゃ上がるから、幅広いタスクやクエリに対して精度も柔軟性も格段にアップするっちゅうわけや。
**2) 新しいパターン**: モジュラーRAGは、特定の課題に対応するためにモジュールを入れ替えたり再構成したりできるから、めっちゃ適応力が高いんや。これは、単純な「検索」して「読む」っていう固定の仕組みしかないナイーブRAGやアドバンストRAGとは全然違うねん。しかも、モジュラーRAGは新しいモジュールを追加したり、既存モジュール間のやり取りを調整したりすることで柔軟性を広げて、色んなタスクに使えるようになってるんやで。
Rewrite-Retrieve-Read(書き換え-検索-読み取り)モデルみたいな革新的な手法は、LLMの能力を活かして、書き換えモジュールと言語モデルのフィードバック機構を使って検索クエリを洗練させて、書き換えモデルを更新することでタスクのパフォーマンスを向上させてるんや。同じように、Generate-Read(生成-読み取り)っていうアプローチは従来の検索をLLMが生成したコンテンツで置き換えるし、Recite-Read(暗唱-読み取り)はモデルの重みから検索することを重視して、知識集約型タスクを処理する能力を強化してるんやで。ハイブリッド検索戦略は、キーワード検索、意味検索、ベクトル検索を組み合わせて、多様なクエリに対応してるねん。さらに、サブクエリや仮想ドキュメント埋め込み(HyDE)を使うことで、生成された回答と実際のドキュメント間の埋め込み類似度に着目して、検索の関連性を上げようとしてるんや。
Demonstrate-Search-Predict(DSP)フレームワークや、ITER-RETGENの繰り返しRetrieve-Read-Retrieve-Readフローみたいな、モジュールの配置と相互作用の調整は、あるモジュールの出力を使って別のモジュールの機能を強化するっていう動的な使い方を示してるんや。これはモジュール間のシナジーを高めることへの洗練された理解を物語ってるな。モジュラーRAGフローの柔軟なオーケストレーションは、FLAREやSelf-RAGみたいな技術を通じて適応的検索のメリットを見せてくれてるんや。このアプローチは、固定されたRAG検索プロセスを超えて、シナリオによって検索が必要かどうかを評価するんやで。柔軟なアーキテクチャのもう一つのメリットは、RAGシステムが他の技術(ファインチューニングや強化学習とか)とより簡単に統合できることやねん。例えば、より良い検索結果のためにレトリーバーをファインチューニングしたり、よりパーソナライズされた出力のためにジェネレーターをファインチューニングしたり、共同ファインチューニングに取り組んだりできるんや。
**D. RAG vs ファインチューニング**
LLMの拡張は、その普及が進むにつれてめっちゃ注目されるようになってきてん。LLMの最適化手法の中で、RAGはよくファインチューニング(FT)やプロンプトエンジニアリングと比較されるんや。それぞれの手法には図4に示されてるような異なる特徴があるで。4象限チャートを使って、外部知識の必要性とモデル適応の必要性っていう2つの軸で3つの手法の違いを示したんや。プロンプトエンジニアリングは、外部知識もモデル適応も最小限で、モデルが元々持ってる能力を活用するもんや。RAGは、情報検索用にカスタマイズされた教科書をモデルに渡すようなもんで、正確な情報検索タスクに最適やねん。一方、FTは学生が時間をかけて知識を内面化するようなもんで、特定の構造、スタイル、フォーマットを再現する必要があるシナリオに向いてるんや。
RAGは、リアルタイムの知識更新と外部知識ソースの効果的な活用ができて、解釈可能性も高いから、動的な環境でめっちゃ優れてるんや。せやけど、レイテンシ(遅延)が高くなることと、データ検索に関する倫理的な考慮事項があるんやで。一方、FTはより静的で、更新するには再訓練が必要やけど、モデルの振る舞いやスタイルを深くカスタマイズできるんや。データセットの準備と訓練にかなりの計算リソースが必要で、ハルシネーション(でたらめ)を減らせる一方で、見たことないデータには苦戦するかもしれへんねん。
様々なトピックにわたる知識集約型タスクでの性能を複数回評価した結果、教師なしファインチューニングはある程度の改善を示すものの、RAGは一貫してそれを上回ることがわかったんや。訓練中に遭遇した既存の知識に対しても、全く新しい知識に対してもな。さらに、LLMは教師なしファインチューニングを通じて新しい事実情報を学習するのが苦手やということもわかったんや。RAGとFTのどっちを選ぶかは、アプリケーションの文脈におけるデータの動的性、カスタマイズ性、計算能力への具体的なニーズによるんやで。RAGとFTは排他的なもんやなくて、異なるレベルでモデルの能力を強化するために補完し合えるんや。場合によっては、両方を組み合わせて使うことで最適なパフォーマンスが得られることもあるで。RAGとFTを含む最適化プロセスは、満足のいく結果を得るために複数回のイテレーションが必要になることもあるんや。
**III. 検索**
RAGの文脈では、データソースから関連するドキュメントを効率的に検索することがめっちゃ重要やねん。検索ソース、検索の粒度、検索の前処理、対応する埋め込みモデルの選択など、いくつかの重要な課題があるんや。
**A. 検索ソース**
RAGは外部知識を使ってLLMを強化するもんやけど、検索ソースの種類と検索単位の粒度の両方が、最終的な生成結果に影響するんやで。
**1) データ構造**: 最初は、テキストが検索の主流のソースやってん。その後、検索ソースは半構造化データ(PDF)や構造化データ(ナレッジグラフ、KG)も含むように拡大して、強化に使われるようになったんや。元々の外部ソースから検索するだけやなくて、最近の研究ではLLM自身が生成したコンテンツを検索と強化の目的で使う傾向も増えてきてるんやで。
---
## Page 6
[](/attach/396a0fadeb4cd40f5c8ccc36b73a0815f6cb4d7f6bfa53b6c48c1f9aba7c7e02_p006.png)
### 和訳
6
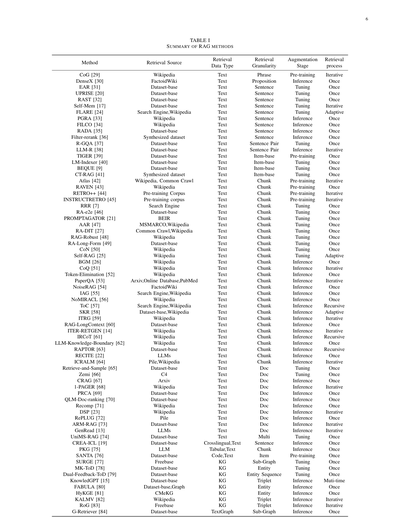
**表1**
**RAG手法のまとめ**
| 手法 | 検索元 | データの種類 | 検索の細かさ | どの段階で使うか | 検索のやり方 |
|------|--------|-------------|-------------|----------------|-------------|
| CoG [29] | Wikipedia | テキスト | フレーズ | 事前学習 | 繰り返し |
| DenseX [30] | FactoidWiki | テキスト | 命題 | 推論時 | 1回だけ |
| EAR [31] | データセット | テキスト | 文 | チューニング | 1回だけ |
| UPRISE [20] | データセット | テキスト | 文 | チューニング | 1回だけ |
| RAST [32] | データセット | テキスト | 文 | チューニング | 1回だけ |
| Self-Mem [17] | データセット | テキスト | 文 | チューニング | 繰り返し |
| FLARE [24] | 検索エンジン、Wikipedia | テキスト | 文 | チューニング | 状況に応じて |
| PGRA [33] | Wikipedia | テキスト | 文 | 推論時 | 1回だけ |
| FILCO [34] | Wikipedia | テキスト | 文 | 推論時 | 1回だけ |
| RADA [35] | データセット | テキスト | 文 | 推論時 | 1回だけ |
| Filter-rerank [36] | 合成データセット | テキスト | 文 | 推論時 | 1回だけ |
| R-GQA [37] | データセット | テキスト | 文ペア | チューニング | 1回だけ |
| LLM-R [38] | データセット | テキスト | 文ペア | 推論時 | 繰り返し |
| TIGER [39] | データセット | テキスト | アイテム単位 | 事前学習 | 1回だけ |
| LM-Indexer [40] | データセット | テキスト | アイテム単位 | チューニング | 1回だけ |
| BEQUE [9] | データセット | テキスト | アイテム単位 | チューニング | 1回だけ |
| CT-RAG [41] | 合成データセット | テキスト | アイテム単位 | チューニング | 1回だけ |
| Atlas [42] | Wikipedia、Common Crawl | テキスト | チャンク | 事前学習 | 繰り返し |
| RAVEN [43] | Wikipedia | テキスト | チャンク | 事前学習 | 1回だけ |
| RETRO++ [44] | 事前学習コーパス | テキスト | チャンク | 事前学習 | 繰り返し |
| INSTRUCTRETRO [45] | 事前学習コーパス | テキスト | チャンク | 事前学習 | 繰り返し |
| RRR [7] | 検索エンジン | テキスト | チャンク | チューニング | 1回だけ |
| RA-e2e [46] | データセット | テキスト | チャンク | チューニング | 1回だけ |
| PROMPTAGATOR [21] | BEIR | テキスト | チャンク | チューニング | 1回だけ |
| AAR [47] | MSMARCO、Wikipedia | テキスト | チャンク | チューニング | 1回だけ |
| RA-DIT [27] | Common Crawl、Wikipedia | テキスト | チャンク | チューニング | 1回だけ |
| RAG-Robust [48] | Wikipedia | テキスト | チャンク | チューニング | 1回だけ |
| RA-Long-Form [49] | データセット | テキスト | チャンク | チューニング | 1回だけ |
| CoN [50] | Wikipedia | テキスト | チャンク | チューニング | 1回だけ |
| Self-RAG [25] | Wikipedia | テキスト | チャンク | チューニング | 状況に応じて |
| BGM [26] | Wikipedia | テキスト | チャンク | 推論時 | 1回だけ |
| CoQ [51] | Wikipedia | テキスト | チャンク | 推論時 | 繰り返し |
| Token-Elimination [52] | Wikipedia | テキスト | チャンク | 推論時 | 1回だけ |
| PaperQA [53] | Arxiv、オンラインDB、PubMed | テキスト | チャンク | 推論時 | 繰り返し |
| NoiseRAG [54] | FactoidWiki | テキスト | チャンク | 推論時 | 1回だけ |
| IAG [55] | 検索エンジン、Wikipedia | テキスト | チャンク | 推論時 | 1回だけ |
| NoMIRACL [56] | Wikipedia | テキスト | チャンク | 推論時 | 1回だけ |
| ToC [57] | 検索エンジン、Wikipedia | テキスト | チャンク | 推論時 | 再帰的 |
| SKR [58] | データセット、Wikipedia | テキスト | チャンク | 推論時 | 状況に応じて |
| ITRG [59] | Wikipedia | テキスト | チャンク | 推論時 | 繰り返し |
| RAG-LongContext [60] | データセット | テキスト | チャンク | 推論時 | 1回だけ |
| ITER-RETGEN [14] | Wikipedia | テキスト | チャンク | 推論時 | 繰り返し |
| IRCoT [61] | Wikipedia | テキスト | チャンク | 推論時 | 再帰的 |
| LLM-Knowledge-Boundary [62] | Wikipedia | テキスト | チャンク | 推論時 | 1回だけ |
| RAPTOR [63] | データセット | テキスト | チャンク | 推論時 | 再帰的 |
| RECITE [22] | LLMs | テキスト | チャンク | 推論時 | 1回だけ |
| ICRALM [64] | Pile、Wikipedia | テキスト | チャンク | 推論時 | 繰り返し |
| Retrieve-and-Sample [65] | データセット | テキスト | 文書 | チューニング | 1回だけ |
| Zemi [66] | C4 | テキスト | 文書 | チューニング | 1回だけ |
| CRAG [67] | Arxiv | テキスト | 文書 | 推論時 | 1回だけ |
| 1-PAGER [68] | Wikipedia | テキスト | 文書 | 推論時 | 繰り返し |
| PRCA [69] | データセット | テキスト | 文書 | 推論時 | 1回だけ |
| QLM-Doc-ranking [70] | データセット | テキスト | 文書 | 推論時 | 1回だけ |
| Recomp [71] | Wikipedia | テキスト | 文書 | 推論時 | 1回だけ |
| DSP [23] | Wikipedia | テキスト | 文書 | 推論時 | 繰り返し |
| RePLUG [72] | Pile | テキスト | 文書 | 推論時 | 1回だけ |
| ARM-RAG [73] | データセット | テキスト | 文書 | 推論時 | 繰り返し |
| GenRead [13] | LLMs | テキスト | 文書 | 推論時 | 繰り返し |
| UniMS-RAG [74] | データセット | テキスト | 複数 | チューニング | 1回だけ |
| CREA-ICL [19] | データセット | 多言語、テキスト | 文 | 推論時 | 1回だけ |
| PKG [75] | LLM | 表データ、テキスト | チャンク | 推論時 | 1回だけ |
| SANTA [76] | データセット | コード、テキスト | アイテム単位 | 事前学習 | 1回だけ |
| SURGE [77] | Freebase | 知識グラフ | 部分グラフ | チューニング | 1回だけ |
| MK-ToD [78] | データセット | 知識グラフ | エンティティ | チューニング | 1回だけ |
| Dual-Feedback-ToD [79] | データセット | 知識グラフ | エンティティ列 | チューニング | 1回だけ |
| KnowledGPT [15] | データセット | 知識グラフ | トリプレット | 推論時 | 複数回 |
| FABULA [80] | データセット、グラフ | 知識グラフ | エンティティ | 推論時 | 1回だけ |
| HyKGE [81] | CMeKG | 知識グラフ | エンティティ | 推論時 | 1回だけ |
| KALMV [82] | Wikipedia | 知識グラフ | トリプレット | 推論時 | 繰り返し |
| RoG [83] | Freebase | 知識グラフ | トリプレット | 推論時 | 繰り返し |
| G-Retriever [84] | データセット | テキストグラフ | 部分グラフ | 推論時 | 1回だけ |
---
ほな、この表について説明するで!
これな、RAG(検索拡張生成)っていう技術の色んな手法をまとめた表やねん。RAGってのは、AIが答えを出すときに外部の情報を検索して持ってきて、それを参考にして回答を作るっていう仕組みのことやな。
表の各列の意味をざっくり説明すると:
- **検索元(Retrieval Source)**:どこから情報を取ってくるか、やな。Wikipediaが一番多いけど、データセットとか検索エンジンとか、LLM(大規模言語モデル)自体から引っ張ってくるやつもあるねん。
- **データの種類(Retrieval Data Type)**:何のタイプのデータを検索するか。ほとんどはテキストやけど、知識グラフ(KG)とかコード、表データを使うやつもあるで。
- **検索の細かさ(Retrieval Granularity)**:どのくらいの単位で情報を取ってくるか。フレーズ単位の細かいやつから、文、チャンク(かたまり)、文書全体まで色々あるねん。
- **どの段階で使うか(Augmentation Stage)**:いつ検索を使うか。事前学習の時、チューニングの時、推論(実際に使う時)の3パターンがあるで。
- **検索のやり方(Retrieval process)**:1回だけ検索するか、何回も繰り返すか、状況に応じて判断するか、とかやな。
めっちゃようけ手法があるやろ?これ全部、研究者たちが「もっとええ回答できるようにしたろ!」って工夫した結果やねん。ほんまに日進月歩で進化しとるんやで〜!
---
## Page 7
[](/attach/396a0fadeb4cd40f5c8ccc36b73a0815f6cb4d7f6bfa53b6c48c1f9aba7c7e02_p007.png)
### 和訳
7
図4. RAGを「外部知識が必要かどうか」と「モデルの調整が必要かどうか」って観点で、他のモデル最適化方法と比べてみたやつやねん。プロンプトエンジニアリングは、モデルいじったり外部知識持ってきたりする必要があんまりなくて、LLMそのものの力を引き出すことに集中してるんや。一方でファインチューニングは、モデルをさらに追加で訓練するやつやな。RAGの初期段階(ナイーブRAG)では、モデルをいじる必要はそんなになかったんやけど、研究が進んでくると、モジュラーRAGはファインチューニングの技術とめっちゃ融合するようになってきたんやで。
**非構造化データ**、つまりテキストみたいなやつが、一番よく使われる検索ソースやねん。主にコーパス(大量の文書の集まりのことな)から集めてくるんや。オープンドメイン質問応答(ODQA)タスクでは、主な検索ソースはWikipediaダンプで、今メインで使われてるバージョンはHotpotQA(2017年10月1日版)とDPR(2018年12月20日版)やな。百科事典的なデータ以外にも、よくある非構造化データには、多言語テキスト[19]とか、医療[67]や法律[29]みたいな特定分野のデータがあるで。
**半構造化データ**っていうのは、普通はテキストと表が混ざったデータのことを指すんや。PDFとかがそうやな。なんでかっていうと、従来のRAGシステムで半構造化データを扱うのは難しいんやけど、理由は主に2つあんねん。まず1つ目、テキストを分割する処理で、うっかり表がバラバラになってしもて、検索するときにデータが壊れてまうことがあるんや。2つ目、表をデータに入れると、意味的な類似性検索がややこしくなってまうねん。半構造化データを扱うときの1つのアプローチは、LLMのコード実行能力を活かして、データベース内の表に対してText-2-SQLクエリを実行する方法やな。TableGPT[85]みたいなやつや。もう1つの方法は、表をテキスト形式に変換して、テキストベースの手法でさらに分析するやつ[75]やねん。けどな、どっちの方法もベストな解決策とはいえへんから、この分野にはめっちゃ研究の余地があるってことやで。
**構造化データ**、例えば知識グラフ(KGs)[86]みたいなやつは、普通は検証済みやから、より正確な情報を提供できるんや。KnowledGPT[15]はKB(知識ベース)の検索クエリを生成して、知識を個人用のベースに保存することで、RAGモデルの知識の豊かさを強化してるねん。テキストグラフに対するLLMの理解や質問応答の限界に対応するために、G-Retriever[84]はグラフニューラルネットワーク(GNNs)、LLM、RAGを統合してるんや。LLMのソフトプロンプティングを通じてグラフの理解と質問応答能力を強化して、Prize-Collecting Steiner Tree(PCST)最適化問題を使ってターゲットを絞ったグラフ検索をやってるで。ただな、その反面、構造化データベースを構築したり、検証したり、メンテナンスしたりするのに、追加の手間がかかるんやで。
**LLMが生成したコンテンツ**。RAGにおける外部補助情報の限界に対処するために、LLMの内部知識を活用することに焦点を当てた研究もあるんや。SKR[58]は質問を「知ってる」か「知らん」かに分類して、検索強化を選択的に適用するねん。GenRead[13]は検索器をLLM生成器に置き換えてるんやけど、なんでかっていうと、LLMが生成したコンテキストの方が、因果言語モデリングの事前学習目標とよりうまく整合するから、正確な答えを含んでることが多いってわかったんや。Selfmem[17]は、検索強化された生成器で無限のメモリプールを繰り返し作成して、メモリセレクターを使って元の質問に対する双対問題として機能する出力を選ぶことで、生成モデルを自己強化してるねん。これらの方法論は、RAGにおける革新的なデータソース活用の幅広さを示してて、モデルのパフォーマンスとタスクの有効性を改善しようとしてるんやで。
**2) 検索の粒度**:検索ソースのデータ形式以外にも、もう1つ重要な要素があって、それは検索するデータの粒度(どれくらい細かくするか)やねん。粗い粒度の検索単位は、理論的には問題に関連する情報をより多く提供できるんやけど、余計な内容も含んでまう可能性があって、それが検索器や下流タスクの言語モデルの注意を散らしてまうかもしれへんねん[50][87]。一方で、細かい粒度の検索単位にすると、検索の負担が増えるし、意味的な完全性や必要な知識を満たせる保証もないんや。選ぶのが難しいところやな。
---
## Page 8
[](/attach/396a0fadeb4cd40f5c8ccc36b73a0815f6cb4d7f6bfa53b6c48c1f9aba7c7e02_p008.png)
### 和訳
ほな、検索の精度上げる話からいこか!
推論のときに、どれくらいの粒度で情報取ってくるか調整するだけで、密なリトリーバーの検索性能とかその後のタスクの成績がめっちゃ良くなるねん。シンプルやけど効果バツグンの戦略やで。
テキストの検索粒度って、細かいほうから粗いほうまであってな、トークン、フレーズ、文、命題、チャンク、ドキュメントって感じで分かれてんねん。この中で DenseX ってやつが「命題」を検索単位にしようって提案したんや。命題ってのは何かっていうと、テキストの中の「これ以上分けられへん表現」のことで、一個一個が独立した事実を含んでて、短くて完結した自然言語の形になってるねん。こうすることで検索の精度と関連性がグッと上がるわけや。ナレッジグラフ(KG)の場合は、エンティティ、トリプレット、サブグラフって粒度があるで。あと、検索粒度はタスクに合わせて変えることもできて、例えばレコメンドタスクやったらアイテムIDを取ってきたり、文のペアを取ってきたりするねん。詳しくは表Iを見てな。
## B. インデキシングの最適化
インデキシングの段階では、ドキュメントを処理して分割して、埋め込みベクトルに変換してベクトルデータベースに保存するねん。このインデックスの作り方の質が、検索のときにちゃんと正しい文脈を取ってこれるかどうかを決めるわけや。
### 1) チャンキング戦略
一番よくあるやり方は、ドキュメントを固定のトークン数(100とか256とか512とか)で分割する方法やねん。大きいチャンクにすると文脈をいっぱい取れるんやけど、ノイズも増えるし、処理時間もコストもかかるねん。逆に小さいチャンクやとノイズは少ないけど、必要な文脈を全部伝えられへんかもしれん。でもな、チャンクで切ると文の途中でブツ切りになる問題があるから、再帰的分割とかスライディングウィンドウって方法が考え出されて、複数の検索プロセスで全体的に関連する情報をマージして階層的に検索できるようになったんや。それでもまだ意味的な完全性と文脈の長さのバランスが難しいから、Small2Bigって方法が提案されてん。これは文(小さいやつ)を検索単位にして、その前後の文を(大きい)文脈としてLLMに渡すっていうやり方や。
### 2) メタデータの付与
チャンクにはメタデータを付けられるねん。ページ番号、ファイル名、著者、カテゴリ、タイムスタンプとかな。そしたら検索のときにこのメタデータでフィルタリングして、検索範囲を絞れるわけや。ドキュメントのタイムスタンプに重み付けすれば、時間を意識したRAGができて、知識の新鮮さを保って古い情報を避けられるねん。
元のドキュメントからメタデータ抽出するだけやなくて、人工的に作ることもできるで。例えば段落の要約を付けたり、仮想的な質問を導入したりな。これはReverse HyDEとも呼ばれてるねん。具体的には、LLMを使ってそのドキュメントで答えられる質問を生成して、検索のときに元の質問と仮想質問の類似度を計算するんや。こうすると質問と答えの間の意味的なギャップを減らせるねん。
### 3) 構造的インデックス
情報検索を強化する効果的な方法の一つが、ドキュメントに階層構造を作ることやねん。この構造を作ることで、RAGシステムは関連データの検索と処理をめっちゃ速くできるようになるんや。
**階層的インデックス構造**
ファイルは親子関係で配置されて、チャンクがそれにリンクしてるねん。各ノードにはデータの要約が保存されてて、データを素早くたどれるし、RAGシステムがどのチャンクを取り出すか決めるのを助けてくれるんや。このアプローチはブロック抽出の問題が原因で起こるハルシネーション(幻覚)を軽減することもできるで。
**ナレッジグラフインデックス**
ドキュメントの階層構造を作るときにナレッジグラフ(KG)を使うと、一貫性を保つのに役立つねん。異なる概念やエンティティ間のつながりを明確にして、ハルシネーションの可能性をめっちゃ減らすんや。もう一個のメリットは、情報検索プロセスをLLMが理解できる命令に変換できることで、これで知識検索の精度が上がって、LLMが文脈的に一貫した応答を生成できるようになって、RAGシステム全体の効率が向上するねん。ドキュメントの内容と構造の論理的関係を捉えるために、KGPってやつが複数ドキュメント間にKGを使ってインデックスを構築する方法を提案したんや。このKGはノード(ドキュメント内の段落や構造、例えばページとかテーブルを表す)とエッジ(段落間の意味的/字句的類似性やドキュメント構造内の関係を示す)で構成されてて、複数ドキュメント環境での知識検索と推論の問題に効果的に対処できるねん。
## C. クエリの最適化
ナイーブRAGの主な課題の一つは、ユーザーの元のクエリをそのまま検索の基準にしてまうことやねん。正確で明確な質問を作るのは難しいし、雑なクエリやと検索結果がイマイチになるんや。時には質問自体が複雑で、言葉遣いがちゃんと整理されてへんこともある。もう一つの難しさは言語の複雑さと曖昧さやな。言語モデルは専門用語とか、複数の意味を持つ曖昧な略語を扱うときによく苦戦するねん。例えば「LLM」が大規模言語モデルのことなのか、法律の分野での法学修士のことなのか、判断できへんかったりするんや。
### 1) クエリ拡張
一つのクエリを複数のクエリに拡張すると、クエリの内容が豊かになって、特定のニュアンスが足りへん部分を補う追加の文脈を提供できるから、生成される回答の関連性が最適になるねん。
**マルチクエリ**
プロンプトエンジニアリングを使ってLLMでクエリを拡張して、これらのクエリを並列で実行するんや。クエリの拡張はランダムちゃうくて、めっちゃ緻密に設計されてるねん。
**サブクエリ**
サブ質問の計画プロセスは、元の質問に完全に答えるために必要なサブ質問を生成して文脈化することやねん。この関連文脈を追加するプロセスは、原理的にはクエリ拡張と似てるで。具体的には、least-to-mostプロンプティング法を使って、複雑な質問をより単純なサブ質問の系列に分解するねん。
**Chain-of-Verification(CoVe)**
拡張されたクエリはLLMによって検証されて、ハルシネーションを減らす効果があるねん。検証された拡張クエリは通常、信頼性がより高いんや。
---
## Page 9
[](/attach/396a0fadeb4cd40f5c8ccc36b73a0815f6cb4d7f6bfa53b6c48c1f9aba7c7e02_p009.png)
### 和訳
2) クエリ変換:ここのキモはな、ユーザーが最初に入力したクエリそのまま使うんやなくて、変換したクエリでチャンク(文書の断片)を取ってくるっていう考え方やねん。
**クエリの書き換え**。ぶっちゃけな、ユーザーが入力したそのままのクエリって、LLM(大規模言語モデル)で検索するには最適やないことが多いねん。特に実際のサービスとかやとそうやな。せやから、LLMに「このクエリ、もうちょい検索しやすく書き換えてや」ってお願いするわけ。LLM使う以外にも、RRR(Rewrite-retrieve-read:書き換えて→検索して→読む)っていう専用の小さい言語モデルもあるで。タオバオ(中国の巨大ECサイト)ではBEQUEっていう実装があってな、あんまり検索されへんニッチなクエリ(ロングテールクエリって言うねん)の検索精度がめっちゃ上がって、売上(GMV)も伸びたんやて。
もう一つのクエリ変換のやり方は、プロンプトエンジニアリング(LLMへの指示の工夫)を使って、元のクエリから検索用の新しいクエリを作らせる方法やな。HyDEっていうのは、仮想的な文書(元のクエリに対する「こんな答えやろな」っていう想定回答)を作るねん。これのおもろいとこは、質問同士の類似度やなくて、答え同士の類似度で検索するっていう発想やねん。Step-back Promptingっていう方法もあってな、これは元のクエリを抽象化して、もうちょい上位概念の質問(ステップバック質問って呼ぶ)を作るねん。RAGシステムでは、このステップバック質問と元のクエリ両方で検索して、両方の結果を言語モデルの回答生成に使うわけや。
3) クエリルーティング:クエリの内容によって、別々のRAGパイプライン(処理の流れ)に振り分けるっていう話やな。これ、いろんなシナリオに対応できる万能型RAGシステム作りたいときにめっちゃ使えるで。
**メタデータルーター/フィルター**。まずクエリからキーワード(エンティティ)を抜き出すやん。ほんで、そのキーワードとチャンクに付いてるメタデータ(付加情報)でフィルタリングして、検索範囲を絞り込むねん。
**セマンティックルーター**はまた別のルーティング方法で、クエリの意味情報(セマンティック)を活用するやつやな。具体的なやり方はSemantic Routerのドキュメント見てな。もちろん、セマンティックとメタデータベースの両方を組み合わせたハイブリッドなルーティングもアリやで。
D. 埋め込み(Embedding)
RAGでは、質問と文書チャンクの埋め込みベクトル同士の類似度(コサイン類似度とか)を計算して検索するねん。せやから、埋め込みモデルがどんだけ意味をうまく表現できるかがめっちゃ重要やねん。主に2種類あって、スパースエンコーダー(BM25みたいなやつ)と、デンスリトリーバー(BERTみたいな事前学習済み言語モデル)があるで。最近の研究では、AngIE、Voyage、BGEとかの優秀な埋め込みモデルが出てきてな、これらはマルチタスク指示チューニングっていう訓練方法の恩恵を受けてるねん。Hugging FaceのMTEBリーダーボードっていうのがあって、8種類のタスク、58個のデータセットで埋め込みモデルを評価してるで。あと、C-MTEBっていうのは中国語に特化してて、6タスク35データセットをカバーしてるな。「どの埋め込みモデル使えばええの?」っていう万能の答えはないねんけど、特定のユースケースにはこのモデルがええで、みたいなのはあるわ。
1) ミックス/ハイブリッド検索:スパース(疎)とデンス(密)の埋め込みアプローチって、それぞれ違う関連性の特徴を捉えてるねん。せやから、お互いの補完的な情報を活かして助け合えるわけや。例えばな、スパース検索モデルで初期の検索結果を出して、それをデンス検索モデルの訓練データにするとかできるし。あと、事前学習済み言語モデル(PLM)を使って単語の重みを学習させて、スパース検索を強化することもできるで。具体的に言うと、スパース検索モデルがデンス検索モデルのゼロショット(訓練なしで使う)検索能力を高めたり、珍しいエンティティが含まれるクエリをデンスリトリーバーがうまく処理できるよう助けたりして、全体的にロバスト(頑健)になるねん。
2) 埋め込みモデルのファインチューニング:扱うコンテキストが事前学習に使われたデータとめっちゃ違う場合、例えば医療とか法律とか専門用語だらけの分野やと、自分のドメインのデータセットで埋め込みモデルをファインチューニングせなあかんねん。そうせんとギャップが埋まらへんからな。
ドメイン知識を補うだけやなくて、ファインチューニングには別の目的もあるで。それはリトリーバー(検索器)とジェネレーター(生成器)を揃えることやねん。例えば、LLMの出力をファインチューニングの教師信号として使う方法があって、これをLSR(LM-supervised Retriever:言語モデルで監督するリトリーバー)って呼ぶねん。PROMPTAGATORっていうのは、LLMをfew-shot(少数例から学習)クエリ生成器として使って、タスク専用のリトリーバーを作るねん。これ、データが少ない分野での教師あり学習の課題を解決するのに効くで。LLM-Embedderっていう別のアプローチは、複数の下流タスクにわたってLLMに報酬シグナルを生成させるねん。リトリーバーは、データセットのハードラベル(正解データ)とLLMからのソフト報酬っていう2種類の監督信号でファインチューニングされるわけや。この二重信号アプローチで、いろんな下流アプリケーションに合わせた埋め込みモデルを効果的に作れるねん。REPLUGっていうのは、リトリーバーとLLMを使って検索された文書の確率分布を計算して、KLダイバージェンス(2つの確率分布の違いを測る指標)を計算することで教師あり訓練をするねん。これめっちゃシンプルで効果的な訓練方法で、特別なクロスアテンション機構とか要らんと、言語モデルを教師信号として検索モデルの性能を上げられるねん。あと、RLHF(人間のフィードバックからの強化学習)にインスパイアされて、言語モデルベースのフィードバックで強化学習してリトリーバーを強化するアプローチもあるで。
E. アダプター
モデルのファインチューニングって、ちょっとハードル高いこともあるねん。例えばAPIでしか機能にアクセスできへん場合とか、手元のマシンの計算リソースが足りへん場合とかな。せやから、外部のアダプターを組み込んでアライメント(整合性合わせ)を助けるアプローチもあるわけや。
LLMのマルチタスク能力を最適化するために、UPRISEっていうのは軽量なプロンプトリトリーバーを訓練してな、ゼロショットのタスク入力に対して、事前に作っておいたプロンプトプールから適切なプロンプトを自動で取ってこれるようにしたねん。AAR(Augmentation-Adapted Retriever)っていうのは、複数の下流タスクに対応できるユニバーサルアダプターを導入してるで。PRCAは、特定タスクの性能を上げるために、プラグイン式の報酬駆動型コンテキストアダプターを追加するねん。BGMは、リトリーバーとLLMは固定したまま、その間にブリッジ用のSeq2Seq(系列変換)モデルを訓練するアプローチやな。このブリッジモデルの目的は、検索で取ってきた情報をLLMが効果的に扱える形式に変換することやねん。これでリランキング(順位付け直し)だけやなく、クエリごとに動的に文書を選んだり、繰り返し使うみたいなもっと高度な戦略も取れるようになるで。さらに、PKGっていうのは...
---
## Page 10
[](/attach/396a0fadeb4cd40f5c8ccc36b73a0815f6cb4d7f6bfa53b6c48c1f9aba7c7e02_p010.png)
### 和訳
ほな、この技術の話をわかりやすく説明していくで!
まずな、「directive fine-tuning」っていう新しい方法が出てきてん。これ何かっていうと、ホワイトボックスモデル(中身が見えるAIモデルのことやな)に知識を組み込む革新的なやり方やねん。この方法やと、検索モジュールを直接置き換えて、質問に合った文書を生成できるようになるんや。ファインチューニング(AIの追加学習みたいなもんや)するときの面倒な問題を解決してくれて、モデルの性能もアップするってわけ。
## IV. 生成
検索が終わったら、取ってきた情報を全部そのままAIにぶち込んで答えさせるのはあかんねん。ここからは2つの視点から調整する方法を紹介するで:取ってきた内容の調整と、AI自体の調整や。
### A. コンテキストの整理
余計な情報が多すぎると、AIの最終的な出力がおかしくなるし、文脈が長すぎると「真ん中で迷子になる問題」が起きるねん。人間と一緒で、AIも長い文章の最初と最後だけ注目して、真ん中の部分は忘れてまうんや。やから、RAGシステムでは取ってきた内容をさらに加工する必要があるねん。
#### 1) リランキング(並べ替え)
リランキングっていうのは、文書の断片を並べ替えて、一番関連性の高いやつを先頭に持ってくる作業やねん。これで全体の文書量を減らせるし、情報検索において「質を上げる役」と「フィルターの役」の一人二役をこなしてくれるんや。言語モデルがより正確に処理できるように、洗練された入力を渡せるってわけ。
リランキングのやり方は2種類あってな。ルールベースの方法は、多様性とか関連性とかMRR(検索の良さを測る指標や)みたいな、あらかじめ決めた基準で並べ替えるんや。もう一つはモデルベースの方法で、BERTシリーズのエンコーダー・デコーダーモデル(SpanBERTとか)、専用のリランキングモデル(Cohere rerankとかbge-reranker-largeとか)、それにGPTみたいな汎用の大規模言語モデルを使うやり方やな。
#### 2) コンテキストの選択・圧縮
RAGでよくある勘違いがあってな、「関連文書をできるだけたくさん取ってきて、全部つなげて長いプロンプトにしたら良くなる」って思ってる人が多いんや。でもこれ、逆効果やねん。文脈が多すぎるとノイズが増えて、AIが大事な情報を見つけにくくなるんや。
(Long) LLMLinguaっていう手法があってな、これはGPT-2 SmallとかLLaMA-7Bみたいな小さい言語モデル(SLM)を使って、重要じゃないトークン(言葉の断片みたいなもんや)を見つけて削除するんや。人間には「なんやこれ?」ってなる形に変換するんやけど、AIにはちゃんと理解できるんやで。これ、めっちゃ実用的なプロンプト圧縮の方法で、AIを追加で訓練する必要もないし、言葉の整合性と圧縮率のバランスもええねん。
PRCAっていう手法は、情報抽出器を訓練してこの問題に取り組んでん。RECOMPも似たようなアプローチで、対照学習っていう方法を使って情報圧縮器を訓練するんや。訓練データは、正解サンプル1個と不正解サンプル5個のセットになってて、エンコーダーは対照損失っていうもので訓練されるねん。
文脈を圧縮するだけじゃなくて、文書の数を減らすのもモデルの回答精度を上げるのに効くんや。Maさんたちは「Filter-Reranker」っていうパラダイムを提案してて、これは大規模言語モデル(LLM)と小規模言語モデル(SLM)のええとこ取りをする方法やねん。SLMがフィルター役で、LLMが並べ替え役を担当するんや。研究によると、SLMが「これ難しいな」って判断したサンプルをLLMに並べ替えさせると、いろんな情報抽出タスクでめっちゃ改善するらしいで。
もう一つのシンプルで効果的な方法は、最終回答を生成する前に、AIに取ってきた内容を評価させることやねん。これでAIが「この文書、関係ないな」って判断したやつをフィルターできるんや。例えばChatlawっていうシステムでは、参照した法律条文についてAI自身に「これ関係ある?」って自己チェックさせてるんや。
### B. LLMのファインチューニング
使う場面やデータの特性に合わせてAIをファインチューニング(追加訓練)すると、もっとええ結果が出るねん。これ、自社でAIを持つことの最大のメリットの一つやな。AIが特定の分野のデータを持ってへん場合、ファインチューニングで追加の知識を教えられるんや。Huggingfaceのファインチューニングデータを最初のステップとして使うのもアリやで。
ファインチューニングのもう一つのメリットは、モデルの入出力を調整できることやねん。例えば、特定のデータ形式に対応させたり、指示通りの特定のスタイルで回答を生成させたりできるんや。構造化データを扱う検索タスクには、SANTAフレームワークっていうのがあって、3段階の訓練方式で構造的な情報と意味的なニュアンスの両方をうまく取り込めるようになってるねん。最初の段階では検索器に焦点を当てて、対照学習を使ってクエリと文書の埋め込み表現(AIが理解しやすい数値表現のことや)を洗練させるんや。
強化学習を使って、AIの出力を人間や検索器の好みに合わせるのも有望なアプローチやな。例えば、最終的に生成された回答に人間が手動でアノテーション(注釈付け)して、それを強化学習でフィードバックするんや。人間の好みだけじゃなくて、ファインチューニングしたモデルや検索器の好みに合わせることもできるねん。
もし強力な商用モデルや大きなパラメータのオープンソースモデルにアクセスできへん状況なら、シンプルで効果的な方法として、より強力なモデル(GPT-4とか)を蒸留(知識を小さいモデルに移す技術や)するっていう手があるで。LLMのファインチューニングは、検索器のファインチューニングと連携させて好みを揃えることもできるんや。典型的なアプローチとしては、RA-DITっていう手法があって、KLダイバージェンス(確率分布の違いを測る指標や)を使って検索器と生成器のスコアリング関数を揃えるねん。
## V. RAGにおける拡張プロセス
RAGの世界では、普通は1回だけ検索してから生成するっていうのが標準的なやり方やねん。でもこれ、効率悪いこともあるし、複数ステップの推論が必要な複雑な問題には情報が足りひんことが多いんや。この問題に対応するために検索プロセスを最適化した研究がたくさんあって、それを図5にまとめてあるで。
### A. 反復的検索
反復的検索っていうのは、最初のクエリとそれまでに生成したテキストに基づいて、知識ベースを繰り返し検索するプロセスやねん。これで、より包括的な知識を得られるようになるんや。
---
## Page 11
[](/attach/396a0fadeb4cd40f5c8ccc36b73a0815f6cb4d7f6bfa53b6c48c1f9aba7c7e02_p011.png)
### 和訳
図5の説明
一番よくある「1回だけ検索」以外にも、RAGには3つの検索強化パターンがあんねん。(左)**反復検索**っていうのは、検索と生成を交互にやるやつで、毎ステップごとに知識ベースからもっとリッチで的を絞ったコンテキストが取れるようになるねん。(真ん中)**再帰検索**っていうのは、ユーザーのクエリをちょっとずつ洗練させて、問題を小問題に分解していって、検索と生成を繰り返しながら複雑な問題を解いていくやつやな。(右)**適応検索**っていうのは、外部知識の検索がそもそも必要かどうか、いつ検索と生成を止めるべきかをRAGシステムが自分で判断できるようにするやつで、たいていLLMが生成する特殊トークンで制御してんねん。
---
これでLLMの知識ベースができるわけや。このアプローチ使うと、何回も検索することで追加のコンテキスト参照が得られるから、その後の回答生成がより頑丈になることがわかってんねん。ただな、意味的な断絶とか、関係ない情報がどんどん溜まっていく問題が出ることもあるんや。ITER-RETGENっていうのは「検索で生成を強化」と「生成で検索を強化」を相乗的に使うアプローチで、特定の情報を再現せなあかんタスクに向いてんねん。このモデルは、入力タスクを解くのに必要な内容を、関連知識を検索するためのコンテキストとして活用して、それで次のイテレーションでより良い回答が生成できるようになるっちゅうわけや。
## B. 再帰検索
再帰検索は情報検索とかNLP(自然言語処理)でよく使われてて、検索結果の深さと関連性を上げるためのもんやねん。どういうことかっていうと、前の検索結果を元に検索クエリをどんどん洗練させていくプロセスなんや。再帰検索の狙いは、フィードバックループを通じてちょっとずつ一番ピッタリな情報に収束させていって、検索体験を良くすることやねん。IRCoTっていうのは、思考の連鎖(chain-of-thought)を使って検索プロセスをガイドして、取ってきた検索結果でその思考の連鎖をさらに洗練させるんや。ToCっていうのは「明確化ツリー」を作って、クエリの曖昧な部分をシステマチックに最適化していくやつやな。これがめっちゃ役立つのは、ユーザーが何を求めてるか最初からはっきりせえへん複雑な検索シナリオとか、探してる情報がめっちゃ専門的やったり微妙なニュアンスがある場合やねん。再帰的にやることでユーザーの要求に継続的に学習・適応できるから、たいてい検索結果への満足度が上がるっちゅうわけや。
特定のデータシナリオに対応するために、再帰検索とマルチホップ検索の技術を組み合わせて使うこともあるねん。再帰検索は構造化されたインデックスを使ってデータを階層的に処理・検索するもんで、例えば文書とか長いPDFのセクションをまず要約してから、その要約に基づいて検索するとかやな。その後、文書内で二次検索をかけて検索をさらに絞り込む——これが再帰的っていう所以やねん。一方、マルチホップ検索はグラフ構造のデータソースをもっと深く掘り下げて、相互につながった情報を抽出するように設計されてんねん。
## C. 適応検索
適応検索の手法、例えばFlareとかSelf-RAGとかは、LLMが検索の最適なタイミングと内容を自分で判断できるようにすることでRAGフレームワークを洗練させて、取ってくる情報の効率と関連性を高めてんねん。
これらの手法は、LLMが自分の動作において能動的に判断を下すっていう大きなトレンドの一部やねん。AutoGPTとかToolformerとかGraph-Toolformerみたいなモデルエージェントで見られるやつやな。例えばGraph-Toolformerは、検索プロセスを別々のステップに分けて、LLMが能動的に検索器を使ったり、Self-Askテクニックを適用したり、few-shotプロンプトで検索クエリを発動したりするねん。この能動的なスタンスのおかげで、LLMは必要な情報をいつ検索するか自分で決められるようになる——ちょうどエージェントがツールを使うみたいにな。
WebGPTは強化学習のフレームワークを組み込んで、GPT-3モデルがテキスト生成中に自律的に検索エンジンを使えるようにトレーニングしてんねん。検索エンジンへのクエリ、結果のブラウジング、参照の引用みたいなアクションを可能にする特殊トークンを使ってこのプロセスをナビゲートして、外部検索エンジンの活用でGPT-3の能力を拡張してるわけや。Flareは生成プロセスの信頼度をモニタリングすることで、検索のタイミングを自動化してんねん。
---
## Page 12
[](/attach/396a0fadeb4cd40f5c8ccc36b73a0815f6cb4d7f6bfa53b6c48c1f9aba7c7e02_p012.png)
### 和訳
ほな、生成した単語の確率について説明するで[24]。この確率がある閾値より下がったら、検索システムが起動して関連情報を集めてくるっていう仕組みやねん。これで検索サイクルがめっちゃ最適化されるわけや。Self-RAG[25]っていうのは「リフレクショントークン」っていうのを導入してて、これがあるとモデルが自分のアウトプットを振り返れるようになるねん。このトークンには2種類あって、「retrieve(検索せえ)」と「critic(批評せえ)」っていうやつや。モデルが自分で「今検索すべきやな」って判断することもできるし、あらかじめ決めた閾値で自動的に検索が走ることもあるで。検索するときは、生成器が複数の段落にまたがってフラグメントレベルのビームサーチっていうのをやって、一番筋の通った文章を導き出すねん。批評スコアを使って細分化スコアを更新していくんやけど、このウェイトは推論時に調整できるから、モデルの動きをカスタマイズできるっていう柔軟さがあるわけや。Self-RAGの設計のええとこは、追加の分類器とか自然言語推論(NLI)モデルに頼らんでもええところやねん。せやから、いつ検索メカニズムを使うかの意思決定がシンプルになるし、正確な回答を生成するためのモデルの自律的な判断能力がめっちゃ向上するで。
## VI. タスクと評価
RAGがNLP分野で急速に発展して、どんどん使われるようになってきたから、RAGモデルの評価がLLMコミュニティの研究で超重要なテーマになってきてるねん。この評価の一番の目的は、いろんな使用シーンでRAGモデルがどれくらいちゃんと動くか理解して、最適化することやで。この章では主にRAGの主要な下流タスク、データセット、あとRAGシステムをどう評価するかについて紹介していくで。
### A. 下流タスク
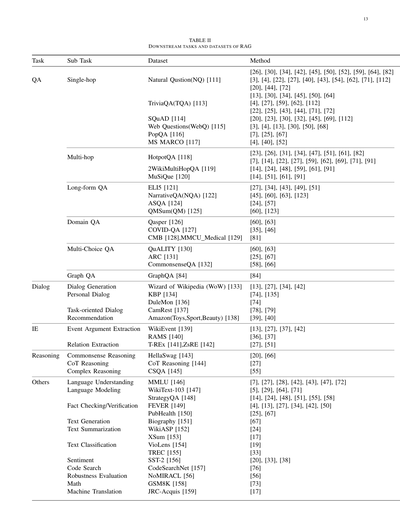
RAGのコアタスクは相変わらず質問応答(QA)やねん。これには従来のシングルホップ/マルチホップQA、選択式問題、特定分野向けQA、それからRAGに適した長文シナリオとかが含まれるで。QA以外にも、RAGはどんどん他の下流タスクに広がっていってて、情報抽出(IE)、対話生成、コード検索とかにも使われてるねん。RAGの主な下流タスクとそれに対応するデータセットは表IIにまとめてあるで。
### B. 評価対象
これまでのRAGモデルの評価は、特定の下流タスクでの実行性能に焦点当ててきたんや。そのタスクに合った確立された指標を使って評価するわけやな。例えば、質問応答の評価やったらEMとF1スコアを使うことが多いし[7]、[45]、[59]、[72]、ファクトチェックのタスクやったら精度(Accuracy)がメインの指標になることが多いねん[4]、[14]、[42]。BLEUとROUGE指標も回答の質を評価するのによう使われるで[26]、[32]、[52]、[78]。RAGアプリケーションの自動評価用に設計されたRALLEみたいなツールも、同じようにこういうタスク固有の指標に基づいて評価してるわけや[160]。とはいえ、RAGモデル特有の特性を評価するための研究はまだまだ少ないのが現状やねん。主な評価目標としては以下があるで:
**検索品質**。検索品質の評価は、検索コンポーネントが取ってきたコンテキストがどれだけ効果的かを判断するのにめっちゃ重要やねん。検索エンジン、レコメンドシステム、情報検索システムの分野で使われてる標準的な指標を使って、RAGの検索モジュールの性能を測るわけや。ヒット率、MRR、NDCGみたいな指標がよう使われるで[161]、[162]。
**生成品質**。生成品質の評価は、取得したコンテキストから一貫性があって関連性のある回答を生成器が作れるかどうかに焦点を当てるねん。この評価はコンテンツの目的によって分類できて、ラベルなしコンテンツとラベル付きコンテンツがあるで。ラベルなしコンテンツの場合は、生成された回答の忠実性、関連性、無害性を評価するねん。一方、ラベル付きコンテンツの場合は、モデルが生成した情報の正確性に焦点を当てるで[161]。あと、検索品質も生成品質も、手動評価と自動評価の両方で評価できるねん[29]、[161]、[163]。
### C. 評価の観点
今のRAGモデルの評価では、3つの主要な品質スコアと4つの必須能力が重視されてて、これらを総合してRAGモデルの2つの主要ターゲット(検索と生成)を評価するねん。
#### 1) 品質スコア
品質スコアには、コンテキスト関連性、回答忠実性、回答関連性が含まれるで。これらの品質スコアは、情報検索と生成のプロセスにおいてRAGモデルの効率をいろんな観点から評価するもんやねん[164]–[166]。
**コンテキスト関連性**は、取得したコンテキストの精度と具体性を評価して、関連性を確保しつつ、余計なコンテンツによる処理コストを最小限に抑えるためのもんやで。
**回答忠実性**は、生成された回答が取得したコンテキストに忠実であることを保証して、一貫性を維持して矛盾を避けるためのもんやねん。
**回答関連性**は、生成された回答が質問に直接関係していて、核心的な問いにちゃんと答えていることを求めるもんやで。
#### 2) 必要な能力
RAGの評価には、適応性と効率性を示す4つの能力も含まれるねん:ノイズ耐性、ネガティブリジェクション、情報統合、反事実耐性やで[167]、[168]。これらの能力は、いろんな課題や複雑なシナリオでのモデルのパフォーマンスにとってめっちゃ重要で、品質スコアに影響を与えるもんやねん。
**ノイズ耐性**は、質問に関連はあるけど実質的な情報を含んでへんノイズ文書をモデルがどれだけうまく処理できるかを評価するもんやで。
**ネガティブリジェクション**は、取得した文書に質問に答えるための必要な知識が含まれてへんときに、モデルが回答を控える判断力を評価するもんやねん。
**情報統合**は、複雑な質問に答えるために複数の文書から情報を統合するモデルの能力を評価するもんやで。
**反事実耐性**は、潜在的な誤情報について指示されたときでも、文書内の既知の不正確さを認識して無視する能力をテストするもんやねん。
コンテキスト関連性とノイズ耐性は検索品質の評価に重要で、回答忠実性、回答関連性、ネガティブリジェクション、情報統合、反事実耐性は生成品質の評価に重要やで。
---
## Page 13
[](/attach/396a0fadeb4cd40f5c8ccc36b73a0815f6cb4d7f6bfa53b6c48c1f9aba7c7e02_p013.png)
### 和訳
# TABLE II: RAGの下流タスクとデータセット
| タスク | サブタスク | データセット | 手法 |
|--------|------------|--------------|------|
| **QA(質問応答)** | **シングルホップ**(1回の検索で答えられるやつやな) | Natural Question(NQ) [111] | [26], [30], [34], [42], [45], [50], [52], [59], [64], [82] |
| | | TriviaQA(TQA) [113] | [3], [4], [22], [27], [40], [43], [54], [62], [71], [112] |
| | | SQuAD [114] | [20], [44], [72] |
| | | Web Questions(WebQ) [115] | [13], [30], [34], [45], [50], [64] |
| | | PopQA [116] | [4], [27], [59], [62], [112] |
| | | MS MARCO [117] | [22], [25], [43], [44], [71], [72] |
| | **マルチホップ**(何回も情報つなげなあかんやつ) | HotpotQA [118] | [20], [23], [30], [32], [45], [69], [112] |
| | | | [3], [4], [13], [30], [50], [68] |
| | | 2WikiMultiHopQA [119] | [7], [25], [67] |
| | | MuSiQue [120] | [4], [40], [52] |
| | **長文QA**(がっつり説明せなあかんやつ) | ELI5 [121] | [23], [26], [31], [34], [47], [51], [61], [82] |
| | | NarrativeQA(NQA) [122] | [7], [14], [22], [27], [59], [62], [69], [71], [91] |
| | | ASQA [124] | [14], [24], [48], [59], [61], [91] |
| | | QMSum(QM) [125] | [14], [51], [61], [91] |
| | **ドメイン特化QA**(専門分野のやつ) | Qasper [126] | [27], [34], [43], [49], [51] |
| | | COVID-QA [127] | [45], [60], [63], [123] |
| | | CMB [128], MMCU Medical [129] | [24], [57] |
| | | | [60], [123] |
| | **選択式QA**(4択みたいなやつやな) | QuALITY [130] | [60], [63] |
| | | ARC [131] | [35], [46] |
| | | CommonsenseQA [132] | [81] |
| | **グラフQA**(グラフ構造使うやつ) | GraphQA [84] | [84] |
| **対話** | **対話生成** | Wizard of Wikipedia (WoW) [133] | [13], [27], [34], [42] |
| | **パーソナル対話** | KBP [134] | [74], [135] |
| | | DuleMon [136] | [74] |
| | **タスク指向対話** | CamRest [137] | [78], [79] |
| | **レコメンデーション** | Amazon(Toys,Sport,Beauty) [138] | [39], [40] |
| **IE(情報抽出)** | **イベント引数抽出** | WikiEvent [139] | [13], [27], [37], [42] |
| | | RAMS [140] | [36], [37] |
| | **関係抽出** | T-REx [141], ZsRE [142] | [27], [51] |
| **推論** | **常識推論**(普通のこと推理するやつ) | HellaSwag [143] | [20], [66] |
| | **CoT推論**(思考の連鎖ってやつやな) | CoT Reasoning [144] | [27] |
| | **複雑推論** | CSQA [145] | [55] |
| **その他** | **言語理解** | MMLU [146] | [7], [27], [28], [42], [43], [47], [72] |
| | **言語モデリング** | WikiText-103 [147] | [5], [29], [64], [71] |
| | | StrategyQA [148] | [14], [24], [48], [51], [55], [58] |
| | **ファクトチェック/検証** | FEVER [149] | [4], [13], [27], [34], [42], [50] |
| | | PubHealth [150] | [25], [67] |
| | **テキスト生成** | Biography [151] | [67] |
| | **テキスト要約** | WikiASP [152] | [24] |
| | | XSum [153] | [17] |
| | **テキスト分類** | VioLens [154] | [19] |
| | | TREC [155] | [33] |
| | **感情分析** | SST-2 [156] | [20], [33], [38] |
| | **コード検索** | CodeSearchNet [157] | [76] |
| | **頑健性評価** | NoMIRACL [56] | [56] |
| | **数学** | GSM8K [158] | [73] |
| | **機械翻訳** | JRC-Acquis [159] | [17] |
---
ほんでな、この表が何言うてるかっていうと、RAG(検索拡張生成)っていう技術がどんなタスクに使われてるかをまとめたやつやねん。
めっちゃざっくり言うとな、**QA(質問応答)**がほんまに多いねん。シングルホップっていうのは「織田信長って誰?」みたいに1回調べたら答えられるやつ。マルチホップは「織田信長の奥さんの出身地は?」みたいに何個か情報つなげなあかんやつやな。
**対話**のとこは、Wikipediaの知識使ってしゃべるやつとか、ユーザーの好みに合わせたパーソナルな会話とか、Amazonのレコメンドに使うやつとかあるねん。
**IE(情報抽出)**は、文章から「誰が」「何を」「どこで」みたいな関係性を引っ張り出すやつやな。
**推論**のとこは、常識的なこと推理したり、CoT(Chain of Thought)っていう「考える過程を書き出す」やり方で複雑な問題解いたりするやつやで。
ほんで**その他**には、言語理解のベンチマークとか、フェイクニュース検出とか、要約とか、コード検索とか、数学の問題とか、めっちゃ色々入ってるわ。
要するにRAGって、「外部の情報を検索して、それを元に回答する」っていう仕組みやから、知識が必要なタスクにはめっちゃ幅広く使われてるってことやねん!
---
## Page 14
[](/attach/396a0fadeb4cd40f5c8ccc36b73a0815f6cb4d7f6bfa53b6c48c1f9aba7c7e02_p014.png)
### 和訳
表III
RAG評価の各側面に使えるメトリクスのまとめやで
| | コンテキスト関連性 | 忠実性 | 回答関連性 | ノイズ耐性 | ネガティブ拒否 | 情報統合 | 反事実耐性 |
|---|---|---|---|---|---|---|---|
| Accuracy(正確性) | | | ✓ | | | | |
| EM(完全一致) | | | ✓ | | | | |
| Recall(再現率) | ✓ | | ✓ | | | | |
| Precision(適合率) | ✓ | | | | | | |
| R-Rate | | | | ✓ | ✓ | ✓ | ✓ |
| Cosine Similarity(コサイン類似度) | ✓ | ✓ | | | | | |
| Hit Rate(ヒット率) | ✓ | | | | | | |
| MRR | ✓ | | | | | | |
| NDCG | ✓ | | | | | | |
| BLEU | | ✓ | ✓ | | | | |
| ROUGE/ROUGE-L | | ✓ | ✓ | | | | |
14
それぞれの評価側面に使うメトリクスは表IIIにまとめてあるで。ただな、ここで紹介してるメトリクスは先行研究から持ってきた昔ながらの指標やねん。RAGの評価をちゃんと数値化するための成熟した標準的なアプローチとしてはまだまだこれからや。ここには載せてへんけど、RAGモデル特有の細かいとこに合わせたカスタムメトリクスも、いくつかの評価研究で開発されとるで。
D. 評価用ベンチマークとツール
RAGの評価をやりやすくするために、いろんなベンチマークテストやツールが提案されてきたんや。これらの道具を使うと、RAGモデルの性能を測る定量的な指標が手に入るだけやなくて、いろんな評価側面でモデルがどんな能力持ってるかもよう分かるようになるねん。RGB、RECALL、CRUD[167]-[169]みたいな有名どころのベンチマークは、RAGモデルの基本的な能力を評価することに注力してるで。それと同時に、RAGAS[164]、ARES[165]、TruLens8みたいな最先端の自動化ツールは、LLMを使って品質スコアを判定してくれるんや。これらのツールとベンチマークが全部合わさって、RAGモデルを体系的に評価するためのしっかりした枠組みができてるんやな。表IVにまとめてあるで。
VII. 議論と今後の展望
RAG技術はめっちゃ進歩してきたんやけど、まだまだ深く掘り下げて研究せなあかん課題がいくつも残ってるねん。この章では、RAGが今直面してる課題と、これからの研究の方向性について主に紹介していくで。
A. RAG vs ロングコンテキスト
関連研究が深まっていくにつれて、LLMが扱えるコンテキストの長さはどんどん伸びてきてるんや[170]-[172]。今やLLMは20万トークン超えるコンテキストも余裕で処理できるようになってきてるねん9。これ何を意味するかっていうと、前はRAGに頼らなあかんかった長い文書への質問応答が、今やドキュメント丸ごとプロンプトに突っ込めるようになったってことや。そんで「コンテキストの制限がなくなったら、もうRAGいらんのちゃう?」って議論も出てきてるんやな。
でもな、実はRAGにはまだまだ替えのきかん役割があるねん。まず一つ目、LLMに一気に大量のコンテキストを与えると、推論速度がめっちゃ遅くなってまうんや。その点、チャンクに分けて検索して必要な時だけ入力する方式やと、運用効率がグンと上がるねん。二つ目、RAGベースの生成やと、生成された回答をユーザーが検証するために、LLMが参照した元ネタをすぐに特定できるんや。検索から推論までの全プロセスが見えるわけや。一方、ロングコンテキストだけに頼った生成は完全にブラックボックスのままやねん。
逆に言うと、コンテキストが長くなったことでRAGの発展にも新しいチャンスが生まれてるんや。もっと複雑な問題とか、大量の資料を読まなあかん統合的な質問や要約的な質問にも対応できるようになるってことやな[49]。超長文コンテキストの時代に合わせた新しいRAG手法を開発するんが、これからの研究トレンドの一つやで。
B. RAGの頑健性
検索の時にノイズとか矛盾した情報が混じってると、RAGの出力品質にめっちゃ悪影響が出るんや。これは比喩的に「間違った情報は、情報がないより悪いことがある」って言われてるねん。こういう敵対的な入力や反事実的な入力に対するRAGの耐性を上げることが研究の勢いを増してきてて、重要な性能指標にもなってきてるで[48]、[50]、[82]。Cuconasu et al.[54]は、どんな種類の文書を検索すべきか分析して、プロンプトとの関連性、文書の位置、コンテキストに含める数を評価したんや。研究結果でびっくりしたんが、関連性のない文書を含めると予想に反して正確性が30%以上も上がることがあるってことやねん。最初は「関連ないもん入れたら品質下がるやろ」って思っとったのに、逆やったんや。この結果から分かるのは、検索と言語生成モデルを統合するための専門的な戦略を開発することがめっちゃ大事やってことやな。RAGの頑健性についてはもっと研究と探索が必要やで。
C. ハイブリッドアプローチ
RAGとファインチューニングを組み合わせるんが、トップクラスの戦略として浮上してきてるんや。RAGとファインチューニングをどうやって最適に統合するか——順番にやるんか、交互にやるんか、それともエンドツーエンドで一緒に訓練するんか——それに両方の
---
## Page 15
[](/attach/396a0fadeb4cd40f5c8ccc36b73a0815f6cb4d7f6bfa53b6c48c1f9aba7c7e02_p015.png)
### 和訳
表IV
評価フレームワークのまとめ
| 評価フレームワーク | 評価対象 | 評価の観点 | 定量的な指標 |
|---|---|---|---|
| RGB† | 検索の質、生成の質 | ノイズへの強さ、ネガティブ拒否、情報統合、反事実への頑健性 | 正解率、EM、正解率、正解率 |
| RECALL† | 生成の質 | 反事実への頑健性 | R-Rate(再出現率) |
| RAGAS‡ | 検索の質、生成の質 | コンテキストの関連性、忠実性、回答の関連性 | *、*、コサイン類似度 |
| ARES‡ | 検索の質、生成の質 | コンテキストの関連性、忠実性、回答の関連性 | 正解率、正解率、正解率 |
| TruLens‡ | 検索の質、生成の質 | コンテキストの関連性、忠実性、回答の関連性 | *、*、* |
| CRUD† | 検索の質、生成の質 | 創造的生成、知識集約型QA、エラー修正、要約 | BLEU、ROUGE-L、BertScore、RAGQuestEval |
†はベンチマーク、‡はツールを表してるで。*は従来の指標とはちょっと違うカスタム定量指標のことや。具体的な計算式が知りたかったら、関連する論文を見てな。
---
ほんで、パラメータ化された利点と非パラメータ化された利点をうまいこと組み合わせるんは、これからめっちゃ研究の余地があるとこやねん[27]。もう一つのトレンドとしては、特定の機能を持ったSLM(小規模言語モデル)をRAGに導入して、RAGシステムの結果でファインチューニングするっていう方法があるんや。例えばCRAG[67]では、軽量な検索評価器を訓練して、クエリに対して取得したドキュメント全体の質を評価して、信頼度に応じて違う知識検索アクションを発動させるようにしてるねん。
**D. RAGのスケーリング則**
エンドツーエンドのRAGモデルとRAGベースの事前学習モデルは、今の研究者たちが注目してる分野の一つやねん[173]。これらのモデルのパラメータ数は重要な要素の一つや。LLMについてはスケーリング則[174]が確立されてるけど、RAGにも同じことが当てはまるかはまだわからんのよ。RETRO++[44]みたいな初期の研究がこの問題に取り組み始めてるけど、RAGモデルのパラメータ数はまだLLMには追いついてへんのが現状や。めっちゃ興味深いんは「逆スケーリング則」(注10)の可能性やねん。これは小さいモデルの方が大きいモデルより性能ええかもしれんっていう話で、もっと調べる価値あるで。
**E. 本番環境で使えるRAG**
RAGは実用性があってエンジニアリングの要件とも相性がええから、どんどん採用されてきてるねん。せやけど、検索効率を上げること、大規模な知識ベースでのドキュメント再現率を改善すること、あとデータセキュリティを確保すること——例えばLLMがうっかりドキュメントのソースやメタデータを漏らさんようにすること——これらは解決せなあかん重要なエンジニアリングの課題として残ってるんや[175]。
RAGエコシステムの発展は、技術スタックの進歩にめっちゃ影響されてるねん。LangChainとかLLamaIndexみたいな主要ツールは、ChatGPTの登場とともにすぐに人気出て、RAG関連のAPIをいっぱい提供して、LLM界隈では欠かせん存在になったんや。新しい技術スタックはLangChainやLLamaIndexほど機能豊富やないけど、専門化した製品で差別化してるねん。例えばFlowise AIはローコードアプローチを重視してて、ユーザーフレンドリーなドラッグ&ドロップのインターフェースでRAGを含むAIアプリをデプロイできるようにしてるんや。HayStack、Meltano、Cohere Coralみたいな他の技術も、この分野への独自の貢献で注目されてきてるで。
AI専門のベンダーだけやなくて、従来のソフトウェアやクラウドサービスのプロバイダーもRAG中心のサービスを拡充してきてるねん。Weaviateの Verba(注11)はパーソナルアシスタント用途向けに設計されてて、AmazonのKendra(注12)はインテリジェントな企業向け検索サービスを提供してて、組み込みのコネクタ使っていろんなコンテンツリポジトリを検索できるようになってるんや。
RAG技術の発展において、明らかに違う専門化の方向性へのトレンドがあるねん。例えば:1)**カスタマイズ**——特定の要件に合わせてRAGを調整すること。2)**シンプル化**——RAGを使いやすくして導入のハードルを下げること。
---
注10: https://github.com/inverse-scaling/prize
注11: https://github.com/weaviate/Verba
注12: https://aws.amazon.com/cn/kendra/
---
## Page 16
[](/attach/396a0fadeb4cd40f5c8ccc36b73a0815f6cb4d7f6bfa53b6c48c1f9aba7c7e02_p016.png)
### 和訳
16
Vid2Seqっちゅうのは、言語モデルに特別な時間マーカーを付け足すことで、イベントがいつ始まっていつ終わるか、あとそのテキストの説明を一つの出力シーケンスでまとめて予測できるようにしたやつやねん[181]。
**コード**。RBPS[182]は、小規模な学習タスクでめっちゃ力を発揮するんやけど、なんでかっていうと、開発者が「こういうのやりたいねん」っていう目的に合ったコード例を、エンコーディングと頻度分析使って引っ張ってくるからやねん。テストのアサーション生成とかプログラムの修復みたいなタスクでちゃんと効果出てるで。構造化された知識に関しては、CoK手法[106]がおもろくて、まず入力クエリに関係ある事実をナレッジグラフから抜き出して、その事実をヒントとして入力に混ぜ込むことで、ナレッジグラフの質問応答タスクの性能をグンと上げてるんや。
## VIII. 結論
この論文のまとめは図6に示してあるんやけど、RAGが言語モデルの能力をめっちゃ底上げしたことを強調してんねん。どうやってるかっていうと、言語モデルが持ってるパラメータ化された知識と、外部の知識ベースにある膨大なパラメータ化されてないデータをガッチャンコさせてるわけや。このサーベイでは、RAG技術がどう進化してきたか、あといろんなタスクにどう応用されてるかを見せてるで。分析では、RAGフレームワークの中で3つの発展パラダイムを整理してんねん:ナイーブRAG、アドバンスドRAG、モジュラーRAGや。それぞれが前のやつをパワーアップさせた感じやな。RAGがファインチューニングとか強化学習みたいな他のAI手法と技術的に統合されたことで、できることがさらに広がってんねん。RAG技術は進歩してきたけど、まだまだ研究のチャンスはあって、頑健性を上げたり、長いコンテキストをうまく扱えるようにしたりする余地があるんや。RAGの応用範囲はマルチモーダル領域にも広がってきてて、画像とか動画とかコードみたいな多様なデータ形式を解釈・処理するためにRAGの原理を適応させてるんや。この拡大は、AIを実際に使う上でRAGがほんまに重要やってことを示してて、学術界と産業界の両方から注目を集めてるで。
**図6. RAGエコシステムのまとめ**
最初の学習曲線やな。3) 専門化 - 本番環境でRAGがもっとええ感じに動くように最適化することや。
RAGモデルとその技術スタックの相互成長は明らかやねん。技術の進歩が既存のインフラに対して常に新しい基準を作り出してて、逆に技術スタックの強化がRAGの能力開発を後押ししてるんや。RAGツールキットは基盤となる技術スタックとして収束してきてて、高度なエンタープライズアプリケーションの土台を作ってるところやねん。せやけど、完全に統合された包括的なプラットフォームっていう概念はまだ先の話で、もっとイノベーションと開発が必要やな。
## F. マルチモーダルRAG
RAGは最初のテキストベースの質問応答の枠を超えて、いろんな種類のモーダルデータを受け入れるようになってきたんや。この拡大によって、RAGのコンセプトをいろんな領域に統合した革新的なマルチモーダルモデルが生まれてきたで:
**画像**。RA-CM3[176]は、テキストと画像の両方を検索したり生成したりできる先駆的なマルチモーダルモデルやねん。BLIP-2[177]は、凍結した画像エンコーダーとLLMを組み合わせて効率的な視覚言語の事前学習を実現してて、ゼロショットで画像からテキストへの変換ができるようになってるんや。「書く前に視覚化する」手法[178]は、画像生成を使って言語モデルのテキスト生成を導くやり方で、オープンエンドなテキスト生成タスクで有望な結果を見せてるで。
**音声と動画**。GSS手法は、音声クリップを検索してつなぎ合わせることで、機械翻訳データを音声翻訳データに変換するんや[179]。UEOPは、外部のオフライン戦略を取り入れて音声からテキストへの変換をすることで、エンドツーエンドの自動音声認識において大きな進歩を遂げたで[180]。さらに、KNNベースのアテンション融合は、音声の埋め込みと意味的に関連するテキストの埋め込みを活用してASRを洗練させて、ドメイン適応を加速させてるんや。
---
## Page 17
[](/attach/396a0fadeb4cd40f5c8ccc36b73a0815f6cb4d7f6bfa53b6c48c1f9aba7c7e02_p017.png)
### 和訳
RAGの世界がめっちゃ盛り上がってきてるんやで!RAGを中心としたAIアプリがバンバン出てきてるし、それを支えるツールもどんどん開発されとるんや。RAGの使い道がどんどん広がってきてるから、それに合わせて「ちゃんと性能を測る方法」もアップデートせなあかんねん。正確で実態に合った性能評価ができるようにならんと、RAGがAI研究や開発のコミュニティにどんだけ貢献しとるか、ちゃんと把握できへんからな。
## 参考文献
[1] Kandpalらの研究やねんけど、大規模言語モデルって「マイナーな知識」を学ぶのがめっちゃ苦手やっていう話や。なんでかっていうと、ネット上にあんまり出てこーへん情報は、学習データにも少ないからやねん。2023年の機械学習の国際会議で発表されたやつやで。
[2] Zhangらがまとめたサーベイ論文で、「AIの海でセイレーンの歌」っていうおもろいタイトルや。大規模言語モデルの「ハルシネーション」、つまり嘘つき問題についてまとめとるんや。モデルが自信満々でデタラメ言うやつな。
[3] Aroraらの研究で、「GARとRAGが出会うパラダイム」っていうやつ。ゼロショット、つまり事前に例を見せへんでも情報検索できるようにする方法を提案しとるんや。
[4] Lewisらの超有名な論文や!「知識集約型のNLPタスクのための検索拡張生成」っていうて、RAGの元祖みたいな論文やねん。外部の知識ベースから情報を取ってきて、それを使って回答を生成するっていう基本的なアイデアを提案したんや。
[5] Borgeaudらの研究で、「何兆トークンから検索することで言語モデルを改善する」っていうやつ。めっちゃデカいデータベースから関連情報を取ってくることで、モデルの性能がグンと上がるって示したんや。
[6] Ouyangらの論文で、人間のフィードバックを使って言語モデルに指示を従わせる訓練をする方法や。ChatGPTが賢くなった理由の一つがこれやねん。
[7] Maらの研究で、「検索拡張型の大規模言語モデルのためのクエリ書き換え」っていうやつ。ユーザーの質問をそのまま検索するんじゃなくて、検索しやすい形に書き換えてから検索するっていうテクニックやな。
[8] ILINさんが書いた「高度なRAGテクニック」の解説記事や。図解付きでわかりやすいやつやで。
[9] Pengらの研究で、タオバオ(中国の巨大ECサイト)の検索で、マイナーな検索クエリを大規模言語モデルで書き換える方法を提案しとる。
[10] Zhengらの「一歩下がって考える」っていう論文。抽象化を通じて推論を引き出すっていうアイデアで、具体的な問題をちょっと抽象的に考えることで、より良い答えが出せるようになるんや。
[11] Gaoらの研究で、関連性ラベルなしでも精密なゼロショット密ベクトル検索ができるっていうやつ。事前に「これが正解」っていうデータを用意せんでも検索できるようになる技術やな。
[12] Blagojevicさんの記事で、Haystackっていうツールでのパイプライン強化について。「多様性ランカー」と「真ん中で迷子ランカー」を導入する話や。長い文書の真ん中らへんの情報が見落とされがちっていう問題に対処するんやで。
[13] Yuらの「検索するより生成せよ」っていう論文。大規模言語モデルは強力な文脈生成器やっていうて、外部から検索してくるんじゃなくて、モデル自身に関連情報を生成させるアプローチを提案しとるんや。
[14] Shaoらの研究で、反復的な「検索→生成」の相乗効果で検索拡張型言語モデルを強化するっていうやつ。1回検索して終わりじゃなくて、何回か繰り返すことでどんどん良くなるんやで。
[15] Wangらの「KnowledGPT」っていうシステム。知識ベースへの検索とストレージアクセスで大規模言語モデルを強化するっていうやつや。
[16] Raudaschlさんの「RAGは忘れろ、未来はRAG-Fusionや」っていう記事。複数の検索結果を賢く融合させる手法を紹介しとるんや。
[17] Chengらの「自分で自分を持ち上げろ」っていう論文。セルフメモリを使った検索拡張型テキスト生成についてや。
[18] Wangらの研究で「訓練データは思っとるより価値があるで」っていうやつ。訓練データから検索するっていうシンプルやけど効果的な方法を提案しとる。
[19] Liらの研究で、分類から生成へのインサイト。言語をまたいだ検索拡張型の文脈内学習についてや。
[20] Chengらの「UPRISE」っていうシステム。ゼロショット評価を改善するためのユニバーサルなプロンプト検索や。
[21] Daiらの「Promptagator」っていう研究。たった8個の例から少数ショット密ベクトル検索ができるようになるっていうやつやで。
[22] Sunらの「暗唱拡張型言語モデル」の研究。モデルに情報を暗唱させるっていうおもろいアプローチや。
[23] Khattabらの「Demonstrate-Search-Predict」っていう有名なフレームワーク。検索と言語モデルを組み合わせて知識集約型NLPをやるっていうやつで、DSPyの元になった研究やな。
[24] Jiangらの「Active RAG」の研究。必要な時だけ能動的に検索するっていうアイデアやねん。毎回検索するんじゃなくて、「これは検索した方がええな」って判断してから検索するんや。
[25] Asaiらの「Self-RAG」っていうめっちゃ重要な研究。自己反省を通じて検索、生成、批評を学習するっていうやつや。モデルが自分で「検索必要かな?」「この回答ええかな?」って判断できるようになるんやで。
[26] Keらの研究で、検索器とLLMの間の好み(プレファレンス)のギャップを埋めるっていうやつ。検索器が「これええで」って持ってきたものと、LLMが「これ欲しかった」ってものが違う問題に対処するんや。
[27] Linらの「RA-DIT」っていう研究。検索拡張型の二重指示チューニングや。
[28] Ovadiaらの「ファインチューニングか検索か?」っていう比較研究。LLMへの知識注入の方法を比べとるんや。場合によってどっちがええか変わるんやで。
[29] Lanらの「コピーこそ全て」っていうおもろいタイトルの論文。学習表現の国際会議で発表されたやつや。
[30] Chenらの「Dense X検索」っていう研究。「どれくらいの粒度で検索すべきか?」っていう問いに答えようとしとる。文書まるごと?段落?文?っていう話やな。
[31] LuoとSurdeanの研究で、含意を意識したマルチホップ証拠検索のための「分割統治」アプローチや。
[32] Gouらの研究で、検索拡張型スタイル転送で質問生成を多様化するっていうやつ。
[33] Guoらの研究で、知識集約的じゃないタスクのためのプロンプトガイド検索拡張や。RAGは知識が必要なタスクだけじゃなくて、他のタスクにも使えるっていう話やな。
[34] Wangらの「検索拡張生成のための文脈フィルタリングを学習する」研究。取ってきた情報の中から本当に必要なものだけを選ぶ方法を学習するんや。
[35] Seoらの研究で、低リソースドメインタスクのための検索拡張型データ拡張や。データが少ない分野でも頑張れるようにする技術やな。
[36] Maらのおもろい研究で「大規模言語モデルは少数ショット情報抽出器としてはイマイチやけど、難しいサンプルの再ランク付けには最高やで!」っていうやつ。
[37] DuとJiの研究で、イベント引数抽出のための検索拡張型生成質問応答や。
[38] Wangらの「文脈内学習の例を検索することを学習する」研究。どんな例を持ってくればLLMが上手く動くか学習するんや。
[39] Rajputらの研究で、生成的検索を使ったレコメンダーシステムや。おすすめシステムにもRAGの考え方を使うっていうやつやな。
[40] Jinらの「言語モデルを意味的インデクサーとして使う」研究。
[41] Ananthaらの研究...(以下省略)
---
## Page 18
[](/attach/396a0fadeb4cd40f5c8ccc36b73a0815f6cb4d7f6bfa53b6c48c1f9aba7c7e02_p018.png)
### 和訳
[44] B. Wang, W. Ping, P. Xu, L. McAfee, Z. Liu, M. Shoeybi, Y. Dong, O. Kuchaiev, B. Li, C. Xiao ら「自己回帰型言語モデルって検索付きで事前学習したらええの? 徹底的に調べてみたで」arXiv プレプリント arXiv:2304.06762, 2023.
[45] B. Wang, W. Ping, L. McAfee, P. Xu, B. Li, M. Shoeybi, B. Catanzaro「InstructRetro: 検索付き事前学習の後に指示調整かますやつ」arXiv プレプリント arXiv:2310.07713, 2023.
[46] S. Siriwardhana, R. Weerasekera, E. Wen, T. Kaluarachchi, R. Rana, S. Nanayakkara「オープンドメインの質問応答で RAG モデルのドメイン適応をもっとええ感じにする方法」Transactions of the Association for Computational Linguistics, vol. 11, pp. 1–17, 2023.
[47] Z. Yu, C. Xiong, S. Yu, Z. Liu「拡張に適応したリトリーバーで言語モデルの汎用プラグインとしての汎化性能アップさせるで」arXiv プレプリント arXiv:2305.17331, 2023.
[48] O. Yoran, T. Wolfson, O. Ram, J. Berant「検索拡張型言語モデルを関係ない文脈にも強くするねん」arXiv プレプリント arXiv:2310.01558, 2023.
[49] H.-T. Chen, F. Xu, S. A. Arora, E. Choi「長文質問応答における検索拡張の仕組みを理解しよう」arXiv プレプリント arXiv:2310.12150, 2023.
[50] W. Yu, H. Zhang, X. Pan, K. Ma, H. Wang, D. Yu「Chain-of-Note: 検索拡張型言語モデルのロバスト性をめっちゃ高める方法」arXiv プレプリント arXiv:2311.09210, 2023.
[51] S. Xu, L. Pang, H. Shen, X. Cheng, T.-S. Chua「Search-in-the-Chain: 知識集約型タスクで正確で信頼できて追跡可能な大規模言語モデルを目指すねん」CoRR, vol. abs/2304.14732, 2023.
[52] M. Berchansky, P. Izsak, A. Caciularu, I. Dagan, M. Wasserblat「トークン削除で検索拡張リーダーモデルを最適化するで」arXiv プレプリント arXiv:2310.13682, 2023.
[53] J. Lála, O. O'Donoghue, A. Shtedritski, S. Cox, S. G. Rodriques, A. D. White「PaperQA: 科学研究向けの検索拡張生成エージェント」arXiv プレプリント arXiv:2312.07559, 2023.
[54] F. Cuconasu, G. Trappolini, F. Siciliano, S. Filice, C. Campagnano, Y. Maarek, N. Tonellotto, F. Silvestri「ノイズの力: RAGシステムの検索を再定義するで」arXiv プレプリント arXiv:2401.14887, 2024.
[55] Z. Zhang, X. Zhang, Y. Ren, S. Shi, M. Han, Y. Wu, R. Lai, Z. Cao「IAG: 推論質問に答えるための帰納拡張生成フレームワーク」Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023, pp. 1–14.
[56] N. Thakur, L. Bonifacio, X. Zhang, O. Ogundepo, E. Kamalloo, D. Alfonso-Hermelo, X. Li, Q. Liu, B. Chen, M. Rezagholizadeh ら「NoMIRACL: ロバストな多言語検索拡張生成のために『わからん』をちゃんと知る」arXiv プレプリント arXiv:2312.11361, 2023.
[57] G. Kim, S. Kim, B. Jeon, J. Park, J. Kang「Tree of Clarifications: 検索拡張型大規模言語モデルで曖昧な質問に答える」arXiv プレプリント arXiv:2310.14696, 2023.
[58] Y. Wang, P. Li, M. Sun, Y. Liu「大規模言語モデルのための自己知識ガイド検索拡張」arXiv プレプリント arXiv:2310.05002, 2023.
[59] Z. Feng, X. Feng, D. Zhao, M. Yang, B. Qin「検索と生成のシナジーで大規模言語モデルを拡張するで」arXiv プレプリント arXiv:2310.05149, 2023.
[60] P. Xu, W. Ping, X. Wu, L. McAfee, C. Zhu, Z. Liu, S. Subramanian, E. Bakhturina, M. Shoeybi, B. Catanzaro「検索と長いコンテキストの大規模言語モデルが出会うとき」arXiv プレプリント arXiv:2310.03025, 2023.
[61] H. Trivedi, N. Balasubramanian, T. Khot, A. Sabharwal「知識集約型の多段階質問に向けて検索とChain-of-Thought推論を交互にやるねん」arXiv プレプリント arXiv:2212.10509, 2022.
[62] R. Ren, Y. Wang, Y. Qu, W. X. Zhao, J. Liu, H. Tian, H. Wu, J.-R. Wen, H. Wang「検索拡張で大規模言語モデルの事実知識の境界を調べてみた」arXiv プレプリント arXiv:2307.11019, 2023.
[63] P. Sarthi, S. Abdullah, A. Tuli, S. Khanna, A. Goldie, C. D. Manning「RAPTOR: 木構造検索のための再帰的抽象処理」arXiv プレプリント arXiv:2401.18059, 2024.
[64] O. Ram, Y. Levine, I. Dalmedigos, D. Muhlgay, A. Shashua, K. Leyton-Brown, Y. Shoham「文脈内検索拡張型言語モデル」arXiv プレプリント arXiv:2302.00083, 2023.
[65] Y. Ren, Y. Cao, P. Guo, F. Fang, W. Ma, Z. Lin「Retrieve-and-Sample: ハイブリッド検索拡張による文書レベルのイベント引数抽出」Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2023, pp. 293–306.
[66] Z. Wang, X. Pan, D. Yu, D. Yu, J. Chen, H. Ji「Zemi: 複数タスクからゼロショット半パラメトリック言語モデルを学習する」arXiv プレプリント arXiv:2210.00185, 2022.
[67] S.-Q. Yan, J.-C. Gu, Y. Zhu, Z.-H. Ling「CRAG: 修正検索拡張生成」arXiv プレプリント arXiv:2401.15884, 2024.
[68] P. Jain, L. B. Soares, T. Kwiatkowski「1-Pager: ワンパスで回答生成と証拠検索」arXiv プレプリント arXiv:2310.16568, 2023.
[69] H. Yang, Z. Li, Y. Zhang, J. Wang, N. Cheng, M. Li, J. Xiao「PRCA: プラグイン型報酬駆動コンテキストアダプターでブラックボックス大規模言語モデルを検索質問応答に適合させる」arXiv プレプリント arXiv:2310.18347, 2023.
[70] S. Zhuang, B. Liu, B. Koopman, G. Zuccon「オープンソース大規模言語モデルは文書ランキングの強力なゼロショットクエリ尤度モデルやで」arXiv プレプリント arXiv:2310.13243, 2023.
[71] F. Xu, W. Shi, E. Choi「RECOMP: 圧縮と選択的拡張で検索拡張LMを改善する」arXiv プレプリント arXiv:2310.04408, 2023.
[72] W. Shi, S. Min, M. Yasunaga, M. Seo, R. James, M. Lewis, L. Zettlemoyer, W.-t. Yih「REPLUG: 検索拡張型ブラックボックス言語モデル」arXiv プレプリント arXiv:2301.12652, 2023.
[73] E. Melz「ARM-RAG: 補助的根拠メモリで検索拡張生成のLLM知能を強化する」arXiv プレプリント arXiv:2311.04177, 2023.
[74] H. Wang, W. Huang, Y. Deng, R. Wang, Z. Wang, Y. Wang, F. Mi, J. Z. Pan, K.-F. Wong「UniMS-RAG: パーソナライズド対話システムのための統合マルチソース検索拡張生成」arXiv プレプリント arXiv:2401.13256, 2024.
[75] Z. Luo, C. Xu, P. Zhao, X. Geng, C. Tao, J. Ma, Q. Lin, D. Jiang「パラメトリック知識ガイドで拡張された大規模言語モデル」arXiv プレプリント arXiv:2305.04757, 2023.
[76] X. Li, Z. Liu, C. Xiong, S. Yu, Y. Gu, Z. Liu, G. Yu「構造認識型言語モデル事前学習で構造化データの密検索を改善する」arXiv プレプリント arXiv:2305.19912, 2023.
[77] M. Kang, J. M. Kwak, J. Baek, S. J. Hwang「知識グラフ拡張型言語モデルによる知識に基づく対話生成」arXiv プレプリント arXiv:2305.18846, 2023.
[78] W. Shen, Y. Gao, C. Huang, F. Wan, X. Quan, W. Bi「エンドツーエンドのタスク指向対話システムのための検索-生成アラインメント」arXiv プレプリント arXiv:2310.08877, 2023.
[79] T. Shi, L. Li, Z. Lin, T. Yang, X. Quan, Q. Wang「タスク指向対話システムのためのデュアルフィードバック知識検索」arXiv プレプリント arXiv:2310.14528, 2023.
[80] P. Ranade, A. Joshi「Fabula: 検索拡張ナラティブ構築を使った諜報レポート生成」arXiv プレプリント arXiv:2310.13848, 2023.
[81] X. Jiang, R. Zhang, Y. Xu, R. Qiu, Y. Fang, Z. Wang, J. Tang, H. Ding, X. Chu, J. Zhao ら「Think and Retrieval: 仮説知識グラフで強化された医療大規模言語モデル」arXiv プレプリント arXiv:2312.15883, 2023.
[82] J. Baek, S. Jeong, M. Kang, J. C. Park, S. J. Hwang「知識拡張型言語モデル検証」arXiv プレプリント arXiv:2310.12836, 2023.
[83] L. Luo, Y.-F. Li, G. Haffari, S. Pan「グラフ上での推論: 忠実で解釈可能な大規模言語モデル推論」arXiv プレプリント arXiv:2310.01061, 2023.
[84] X. He, Y. Tian, Y. Sun, N. V. Chawla, T. Laurent, Y. LeCun, X. Bresson, B. Hooi「G-Retriever: テキストグラフ理解のための検索拡張生成」[...テキスト省略...]
---
## Page 19
[](/attach/396a0fadeb4cd40f5c8ccc36b73a0815f6cb4d7f6bfa53b6c48c1f9aba7c7e02_p019.png)
### 和訳
[89] Langchain、「文字で再帰的に分割する」、https://python.langchain.com/docs/modules/data_connection/document_transformers/recursive_text_splitter、2023年。
[90] S. Yang、「応用RAG 01: Small-to-big 検索」、https://towardsdatascience.com/advanced-rag-01-small-to-big-retrieval-172181b396d4、2023年。
→ これな、ちっちゃいチャンクで検索かけて、でもでっかいコンテキストを返すっちゅう技術やねん。めっちゃ賢いやろ?
[91] Y. Wang、N. Lipka、R. A. Rossi、A. Siu、R. Zhang、T. Derr、「複数文書の質問応答のためのナレッジグラフプロンプティング」、arXivプレプリント arXiv:2308.11730、2023年。
→ 複数の文書から答え探すときに、知識グラフっていう知識のネットワーク図みたいなもん使ってプロンプト作るんやで。
[92] D. Zhou、N. Schärli、L. Hou、J. Wei、N. Scales、X. Wang、D. Schuurmans、C. Cui、O. Bousquet、Q. Leら、「最小から最大へのプロンプティングで大規模言語モデルの複雑な推論を可能にする」、arXivプレプリント arXiv:2205.10625、2022年。
→ なんでかっていうと、難しい問題をいきなり解くんやなくて、簡単な問題から順番に解いていくことで、めっちゃ複雑な推論もできるようになるねん。
[93] S. Dhuliawala、M. Komeili、J. Xu、R. Raileanu、X. Li、A. Celikyilmaz、J. Weston、「検証の連鎖で大規模言語モデルの幻覚を減らす」、arXivプレプリント arXiv:2309.11495、2023年。
→ AIが嘘つくやつ、ハルシネーションっていうねんけど、それを減らすために自分で検証しながら答え出す仕組みやな。ほんまに賢いで。
[94] X. Li、J. Li、「角度最適化テキスト埋め込み」、arXivプレプリント arXiv:2309.12871、2023年。
→ テキストをベクトル(数字の羅列)に変換するとき、角度を最適化することでより良い表現ができるっちゅう研究やねん。
[95] VoyageAI、「Voyageの埋め込みモデル」、https://docs.voyageai.com/embeddings/、2023年。
[96] BAAI、「FlagEmbedding」、https://github.com/FlagOpen/FlagEmbedding、2023年。
[97] P. Zhang、S. Xiao、Z. Liu、Z. Dou、J.-Y. Nie、「大規模言語モデルを強化するためのなんでも検索」、arXivプレプリント arXiv:2310.07554、2023年。
→ Retrieve Anythingっていう名前通り、どんなもんでも検索してきてAIを賢くするっちゅうことやな。
[98] N. F. Liu、K. Lin、J. Hewitt、A. Paranjape、M. Bevilacqua、F. Petroni、P. Liang、「真ん中で迷子: 言語モデルは長いコンテキストをどう使うか」、arXivプレプリント arXiv:2307.03172、2023年。
→ これめっちゃ面白い研究でな、長い文章の真ん中あたりの情報を、AIが結構無視しがちやっていう発見やねん。最初と最後は覚えてるのに、真ん中忘れるって人間みたいやろ?
[99] Y. Gao、T. Sheng、Y. Xiang、Y. Xiong、H. Wang、J. Zhang、「Chat-Rec: インタラクティブで説明可能なLLM強化レコメンダーシステムに向けて」、arXivプレプリント arXiv:2303.14524、2023年。
→ おすすめシステムにLLM使って、なんでこれおすすめしたか説明もしてくれるようにする研究やで。
[100] N. Anderson、C. Wilson、S. D. Richardson、「Lingua: リアルタイム通訳と自動吹き替えのシナリオに対応」、機械翻訳協会南北アメリカ大陸第15回隔年会議議事録(第2巻: ユーザーおよびプロバイダートラックと政府トラック)、J. Campbell、S. Larocca、J. Marciano、K. Savenkov、A. Yanishevsky編、オーランド、アメリカ: 機械翻訳協会南北アメリカ大陸、2022年9月、pp. 202–209。https://aclanthology.org/2022.amta-upg.14 にてオンラインで閲覧可能。
→ ライブ通訳とか映画の自動吹き替えとかのシナリオに対応したシステムの話やな。
[101] H. Jiang、Q. Wu、X. Luo、D. Li、C.-Y. Lin、Y. Yang、L. Qiu、「LongLLMLingua: プロンプト圧縮による長いコンテキストシナリオでのLLMの高速化と強化」、arXivプレプリント arXiv:2310.06839、2023年。
→ めっちゃ長いプロンプトを圧縮して、AIの処理を速くしつつ性能も上げるっていう一石二鳥な技術やねん。
[102] V. Karpukhin、B. Oğuz、S. Min、P. Lewis、L. Wu、S. Edunov、D. Chen、W.-t. Yih、「オープンドメイン質問応答のための密な文章検索」、arXivプレプリント arXiv:2004.04906、2020年。
→ DPR(Dense Passage Retrieval)っていう有名なやつやで。ニューラルネットワーク使って関連する文章を検索する基礎的な研究やな。
[103] Y. Ma、Y. Cao、Y. Hong、A. Sun、「大規模言語モデルは少数ショット情報抽出には向いてへんけど、難しいサンプルのリランカーとしてはええで!」、ArXiv、vol. abs/2303.08559、2023年。https://api.semanticscholar.org/CorpusID:257532405 にてオンラインで閲覧可能。
→ これほんまにタイトルそのまんまやねん。LLMは少ない例で情報抽出するのは苦手やけど、検索結果の順位付け直すのはめっちゃ得意やっていう発見や。
[104] J. Cui、Z. Li、Y. Yan、B. Chen、L. Yuan、「ChatLaw: 外部知識ベース統合型オープンソース法律大規模言語モデル」、arXivプレプリント arXiv:2306.16092、2023年。
→ 法律専門のAIで、外部の法律データベースと連携して正確な回答出すようにしたやつやな。弁護士さんも安心やで。
[105] O. Yoran、T. Wolfson、O. Ram、J. Berant、「検索拡張言語モデルを無関係なコンテキストに対して頑健にする」、arXivプレプリント arXiv:2310.01558、2023年。
→ 検索で引っ張ってきた情報に関係ないゴミが混じってても、AIがちゃんと無視できるようにする研究やねん。
[106] X. Li、R. Zhao、Y. K. Chia、B. Ding、L. Bing、S. Joty、S. Poria、「知識の連鎖: 構造化知識ベースで大規模言語モデルを基盤づけるフレームワーク」、arXivプレプリント arXiv:2305.13269、2023年。
→ Chain of Knowledgeっていうて、知識ベース使ってAIの回答に根拠持たせるフレームワークやな。
[107] H. Yang、S. Yue、Y. He、「オンライン意思決定のためのAuto-GPT: ベンチマークと追加意見」、arXivプレプリント arXiv:2306.02224、2023年。
→ Auto-GPTっていう自律型AIエージェントがオンラインでどれだけうまく意思決定できるか調べた研究やで。
[108] T. Schick、J. Dwivedi-Yu、R. Dessì、R. Raileanu、M. Lomeli、L. Zettlemoyer、N. Cancedda、T. Scialom、「Toolformer: 言語モデルは自分でツールの使い方を学習できる」、arXivプレプリント arXiv:2302.04761、2023年。
→ これめっちゃ革新的でな、AIが勝手に「あ、ここ計算機使お」とか「ここ検索しよ」とか判断してツール使えるようになる研究やねん。
[109] J. Zhang、「Graph-ToolFormer: ChatGPTによるプロンプト拡張でLLMにグラフ推論能力を与える」、arXivプレプリント arXiv:2304.11116、2023年。
→ さっきのToolformerをグラフ(ネットワーク構造のデータ)にも対応させたバージョンやな。
[110] R. Nakano、J. Hilton、S. Balaji、J. Wu、L. Ouyang、C. Kim、C. Hesse、S. Jain、V. Kosaraju、W. Saundersら、「WebGPT: 人間のフィードバックによるブラウザ支援質問応答」、arXivプレプリント arXiv:2112.09332、2021年。
→ OpenAIの研究で、AIがブラウザ使ってネット検索しながら質問に答えるやつやな。人間のフィードバックで学習してるんやで。
[111] T. Kwiatkowski、J. Palomaki、O. Redfield、M. Collins、A. Parikh、C. Alberti、D. Epstein、I. Polosukhin、J. Devlin、K. Leeら、「Natural Questions: 質問応答研究のためのベンチマーク」、Transactions of the Association for Computational Linguistics、vol. 7、pp. 453–466、2019年。
→ Googleが作った質問応答のベンチマークデータセットやで。実際のGoogle検索クエリから作られてるから、めっちゃ実用的やねん。
[112] Y. Liu、S. Yavuz、R. Meng、M. Moorthy、S. Joty、C. Xiong、Y. Zhou、「リトリーバーと大規模言語モデルの統合戦略の探索」、arXivプレプリント arXiv:2308.12574、2023年。
→ 検索システムとLLMをどうやって組み合わせるのが一番ええか、いろんなやり方を試した研究やな。
[113] M. Joshi、E. Choi、D. S. Weld、L. Zettlemoyer、「TriviaQA: 読解力のための大規模遠隔監視チャレンジデータセット」、arXivプレプリント arXiv:1705.03551、2017年。
→ トリビアの質問と答えを集めた大規模データセットや。ウェブから自動収集してるから「遠隔監視」って呼ばれてるねん。
[114] P. Rajpurkar、J. Zhang、K. Lopyrev、P. Liang、「SQuAD: テキストの機械読解のための10万以上の質問」、arXivプレプリント arXiv:1606.05250、2016年。
→ スタンフォードが作った超有名なQAデータセットやで。Wikipediaの記事に対する質問と答えが入ってるねん。
[115] J. Berant、A. Chou、R. Frostig、P. Liang、「質問応答ペアからのFreebase上でのセマンティックパーシング」、2013年自然言語処理における経験的手法会議議事録、2013年、pp. 1533–1544。
→ Freebaseっていう知識ベースに対して、質問を論理的なクエリに変換する研究やな。
[116] A. Mallen、A. Asai、V. Zhong、R. Das、H. Hajishirzi、D. Khashabi、「言語モデルを信用したらあかん時: パラメトリックメモリと非パラメトリックメモリの効果と限界の調査」、arXivプレプリント arXiv:2212.10511、2022年。
→ これめっちゃ大事な研究でな、AIの頭の中の知識(パラメトリック)と外部から持ってくる知識(非パラメトリック)、どっちがどんな時に使えるか調べてるねん。
[117] T. Nguyen、M. Rosenberg、X. Song、J. Gao、S. Tiwary、R. Majumder、L. Deng、「MS MARCO: 人間が作成した機械読解データセット」、2016年。
→ Microsoftが作った有名な検索・読解データセットやで。実際のBing検索クエリから作られてるから超実用的やねん。
[118] Z. Yang、P. Qi、S. Zhang、Y. Bengio、W. W. Cohen、R. Salakhutdinov、C. D. Manning、「HotpotQA: 多様で説明可能なマルチホップ質問応答のデータセット」、arXivプレプリント arXiv:1809.09600、2018年。
→ マルチホップっていうのは、一つの質問に答えるのに複数の文書を渡り歩かなあかんやつやな。「AはBの何?で、Bは何年に生まれた?」みたいな質問に答えるには2回ジャンプせなあかんやろ?
[119] X. Ho、A.-K. D. Nguyen、S. Sugawara、A. Aizawa、「推論ステップの包括的評価のためのマルチホップQAデータセットの構築」、arXivプレプリント arXiv:2011.01060、2020年。
→ 2WikiMultiHopQAっていうデータセットやな。推論の各ステップをちゃんと評価できるように作られてるねん。
[120] H. Trivedi、N. Balasubramanian、T. Khot、A. Sabharwal、「MuSiQue: シングルホップ質問の合成によるマルチホップ質問」、Transactions of the Association for Computational Linguistics、vol. 10、pp. 539–554、2022年。
→ 簡単な質問を組み合わせて複雑なマルチホップ質問を作る方法を提案してるねん。質問の作り方が賢いんやで。
[121] A. Fan、Y. Jernite、E. Perez、D. Grangier、J. Weston、M. Auli、「ELI5: 長文回答の質問応答」、arXivプレプリント arXiv:1907.09190、2019年。
→ "Explain Like I'm 5"(5歳児に説明するように)っていうRedditのスレッドから作ったデータセットやな。長い説明的な回答が特徴やで。
[122] T. Kočiský、J. Schwarz、P. Blunsom、C. Dyer、K. M. Hermann、G. Melis、E. Grefenstette、「NarrativeQA読解チャレンジ」、Transactions of the Association for Computational Linguistics、vol. 6、pp. 317–328、2018年。
→ 本や映画のスクリプト全体を読んで質問に答えるデータセットやで。ほんまに長い文書を理解せなあかんから難しいねん。
[123] K.-H. Lee、X. Chen、H. Furuta、J. Canny、I. Fischer、「めっちゃ長いコンテキストの要点メモリを持つ人間に着想を得た読書エージェント」、arXivプレプリント arXiv:2402.09727、2024年。
→ 人間みたいに長い文章を読むとき、要点だけメモしながら読み進めるエージェントの研究やな。賢いやろ?
[124] I. Stelmakh、Y. Luan、B. Dhingra、M.-W. Chang、「ASQA: 事実質問と長文回答の出会い」、arXivプレプリント arXiv:2204.06092、2022年。
→ 事実を聞く質問やけど、長い説明的な回答が必要なデータセットやな。両方のいいとこ取りやで。
[125] M. Zhong、D. Yin、T. Yu、A. Zaidi、M. Mutuma、R. Jha、A. H. Awadallah、A. Celikyilmaz、Y. Liu、X. Qiuら、「QMSum: クエリベースのマルチドメイン会議要約のための新しいベンチマーク」、arXivプレプリント arXiv:2104.05938、2021年。
→ 会議の議事録を特定の観点から要約するデータセットやな。「技術的な議論だけまとめて」みたいなクエリに応じて要約するねん。
[126] P. Dasigi、K. Lo、I. Beltagy、A. Cohan、N. A. Smith、M. Gardner、「研究論文に基づく情報検索質問と回答のデータセット」、arXivプレプリント arXiv:2105.03011、2021年。
→ Qasperっていうデータセットやな。NLP論文に対する質問と回答が入ってるで。
[127] T. Möller、A. Reina、R. Jayakumar、M. Pietsch、「COVID-QA: COVID-19のための質問応答データセット」、ACL 2020 COVID-19のための自然言語処理ワークショップ(NLP-COVID)、2020年。
→ コロナ禍で作られた、COVID-19に関する質問応答データセットやな。
[128] X. Wang、G. H. Chen、D. Song、Z. Zhang、Z. Chen、Q. Xiao、F. Jiang、J. Li、X. Wan、B. Wangら、「CMB: 中国語の包括的医療ベンチマーク」、arXivプレプリント arXiv:2308.08833、2023年。
→ 中国語の医療分野に特化したベンチマークやで。AIの医療知識を測るのに使うねん。
[129] H. Zeng、「大規模マルチタスク中国語理解の測定」、arXivプレプリント arXiv:2304.12986、2023年。
→ C-Evalっていう中国語版の総合評価ベンチマークやな。いろんな分野の問題が入ってるで。
[130] R. Y. Pang、A. Parrish、N. Joshi [...テキスト省略...]
---
## Page 20
[](/attach/396a0fadeb4cd40f5c8ccc36b73a0815f6cb4d7f6bfa53b6c48c1f9aba7c7e02_p020.png)
### 和訳
[翻訳エラー: ]
---
## Page 21
[](/attach/396a0fadeb4cd40f5c8ccc36b73a0815f6cb4d7f6bfa53b6c48c1f9aba7c7e02_p021.png)
### 和訳
[翻訳エラー: ]
---
![]()
1 / 1
100%