<<
2310.03668v5.pdf

---
## Page 1
[](/attach/2d6fc0f85a9a606ac0a2f5fd13c84a1cc99a56765017ca29e32217f9553543b4_p001.png)
### 和訳
ICLR 2024の学会論文として発表
# GoLLIE:アノテーションガイドラインでゼロショット情報抽出がめっちゃ良くなるって話
Oscar Sainz∗, Iker García-Ferrero∗
Rodrigo Agerri, Oier Lopez de Lacalle, German Rigau, Eneko Agirre
HiTZ バスク言語技術センター - Ixa NLPグループ
バスク大学 (UPV/EHU)
{oscar.sainz, iker.garciaf}@ehu.eus
## 概要
大規模言語モデル(LLM)に指示チューニングを組み合わせたら、見たことないタスクにもうまいこと対応できるようになってきたんよ。せやけどな、情報抽出(IE)の分野ではまだイマイチで、タスク専用に作られたモデルに負けてまうねん。そもそもIEタスクっていうのは、人間向けにめっちゃ細かいアノテーションガイドライン(「こういう風にラベル付けしてな」っていう説明書みたいなやつ)があるんやけど、今までこのガイドラインの情報を活かそうとしても、一番デカいモデルでもそのまんまじゃガイドラインに従えへんかったんよ。ほんなら今回、ワイらはGoLLIE(ガイドラインに従う大規模言語モデル for IE)ってのを提案するで。これはガイドラインに忠実に従うようにファインチューニングしたモデルで、見たことないIEタスクでもゼロショットでええ結果が出せるようになるねん。がっつり評価実験した結果、GoLLIEは初見のガイドラインにもちゃんと対応できて、今までのゼロショット情報抽出の手法を上回ることが実証されたで。さらにアブレーション実験(部品を一個ずつ外して効果を確かめるやつ)では、詳細なガイドラインがええ結果のカギやっていうことも分かったんや。コードもデータもモデルも全部公開してるから、ここから見てな:https://github.com/hitz-zentroa/GoLLIE
## 1 はじめに
情報抽出(IE)っていうタスクは、めっちゃムズいねん。なんでかっていうと、細かい定義とか例外がめちゃくちゃいっぱいある詳細なガイドラインに人間のアノテーター(ラベル付けする人)が従わなあかんからやねん。今の最強モデルの性能は、人間がラベル付けしたデータの量にめっちゃ左右されるんよ。モデルはそのラベル付き例からガイドラインを学ぶわけやけど、新しいアノテーション体系(ラベルの付け方のルール)でテストしたら、性能がガクッと下がってまうねん(Liu et al., 2021a)。IEでええ結果を出すための定番のやり方は、新しいドメインや体系ごとにイチから手作業でラベル付けし直すことやねんけど、ほぼ異なる応用分野間での転移(知識の使い回し)が効かへんからな。でもこれ、お金的にも人手的にも現実的ちゃうやろ。
最近の大規模言語モデル(LLM)の進歩(Min et al., 2023)のおかげで、見たことないタスクにも対応できるモデルが作れるようになってきたんや。ほんで、今のゼロショットIEシステムは——
∗同等の貢献
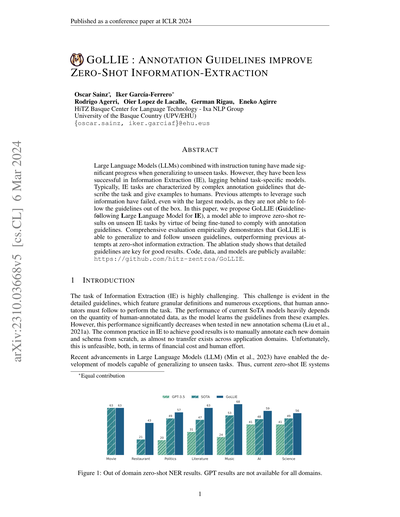
図1:ドメイン外のゼロショット固有表現認識(NER)の結果やで。GPTの結果は全ドメインでは出てへん。
---
## Page 2
[](/attach/2d6fc0f85a9a606ac0a2f5fd13c84a1cc99a56765017ca29e32217f9553543b4_p002.png)
### 和訳
ICLR 2024の学会論文として発表
LLM(大規模言語モデル)に詰まってる知識をうまいこと使って、新しいデータにアノテーション(ラベル付け)するっていう研究があんねん(Sainzら, 2022a; Wangら, 2023a)。事前学習のおかげで、モデルは「人」とか「組織」がどんなもんかめっちゃよう分かるようになっとるわけや。せやから、テキストからそういうカテゴリの言及を抜き出してくれって指示できるんやな。ただし、ここにはっきりした限界があんねん。どのアノテーションスキーマ*も「人」(とか他のラベル)を同じように定義してるわけちゃうねん。例えばな、ACE05(Walkerら, 2006)は代名詞も「人」としてアノテーションするけど、CoNLL03(Tjong Kim Sang & De Meulder, 2003)はせえへんねん。情報抽出(IE)タスクには、ラベル名だけやなくて、アノテーションガイドラインっちゅうもんが必要やねん。
今のLLMは指示に従うように訓練されとるけど、アノテーションガイドラインにそのまま従うのはまだ苦手やねん。例えば、図1を見てみてや。ドメイン特化のゼロショット固有表現認識の結果が出とるんやけど、gpt-3.5-turboにガイドラインを与えてプロンプトした場合(Zhangら, 2023a)の結果はめっちゃ低くて、音楽とか政治のドメインでF1スコアが20くらいしかないねん。人手のアノテーションっちゅうコストのかかる作業への依存を減らしつつ、高性能なゼロショット情報抽出を実現するシステムを作るっていうのは、まだまだ未解決の課題なんよ。
この論文では、GoLLIE(Guideline-following Large Language Model for IE、つまりガイドラインに従うIE向け大規模言語モデル)を提案しとんねん。これは、よく知られたIEタスクの小さなセットを使って、ガイドラインにちゃんと注意を払う方法を学習させたLLMや。包括的なゼロショット評価の結果、GoLLIEがゼロショット情報抽出で最先端手法(Wangら, 2023a)を上回ることが実証されたで(図1参照)。
2 関連研究
大規模言語モデル(LLM)は、未知のタスクにも汎化できるシステムの開発に向けて、めっちゃ大きな進歩を遂げてきたんや(Minら, 2023)。Radfordら(2019)は膨大なインターネットデータを使ってLLMを訓練して、事前学習済みモデルに自然言語でタスクの説明を与えたら、質問応答とか機械翻訳とか要約みたいなタスクを、明示的な教師なしでもこなせることを発見したんやな。この発見をベースにして、インストラクションチューニング——マルチタスクファインチューニングとも呼ばれるんやけど——が、未知のタスクへの汎化を実現する主要な手法として台頭してきたんや。これはどういうことかっていうと、まず大量のラベルなしデータでモデルを事前学習して、その後いろんなタスク(Wangら, 2022; Chungら, 2022)をテキスト同士の変換問題として表現したもの(Raffelら, 2020)でファインチューニングするっちゅうプロセスやねん。モデルがどのタスクを解くべきか識別するために、自然言語の指示やプロンプトが与えられるわけや(Schick & Schütze, 2021; Scao & Rush, 2021)。研究によると、言語モデルのパラメータ数を増やすこと(Brownら, 2020)と、インストラクションチューニング用データセットの規模と品質を向上させることを組み合わせると、汎化能力がグンと上がることが分かっとる(Chenら, 2023; Zhangら, 2022; Chowdheryら, 2022; Muennighoffら, 2023; Touvronら, 2023a;b)。LLMはいろんな難しいタスクでめっちゃすごいゼロショット汎化能力を見せとって、コーディング(Wang & Komatsuzaki, 2021; Blackら, 2022; Rozièreら, 2023)、常識推論(Touvronら, 2023a)、医療応用(Singhalら, 2023)とか、ほんまに幅広い分野で活躍しとんねん。
情報抽出(IE)の分野では、最近の共有タスク(Fetahuら, 2023)で、XLM-RoBERTa(Conneauら, 2020)やmDEBERTA(Heら, 2023)みたいなエンコーダオンリーの言語モデルがまだ一番強いっていう結果が出とんねん。LLMと自然言語の指示をIEに使おうとする試みは、あんまりうまくいってへんくて(Tanら, 2023; Zhouら, 2023; Zhangら, 2023a)、エンコーダオンリーモデルに性能で負けとる状況や。何十億パラメータのLLMが出てくる前は、テキスト含意(Sainzら, 2021; 2022a;b)や質問応答(Levyら, 2017)みたいなタスクで学んだ知識を活用する間接的な教師あり手法がゼロショットIEを改善しとったんや。Obeidatら(2019)は、Wikipediaのラベルの説明をLSTMで埋め込みにエンコードして、それを使って入力をスコアリングするエンティティタイピング手法を提案しとる。外部知識を活用する手法は、きめ細かいゼロショットNERでも成功しとったで(Chenら, 2021)。Luら(2022a)は、いろんなIEタスクを統一的にモデル化できるテキストから構造への統合生成を導入したんや。Louら(2023)は、IEタスクを意味マッチング問題に変換することを提案して、訓練時に見てへん新しいドメインやラベル体系にも汎化できるようにしたんやな。Wangら(2023a)は、IEタスクを自然言語の記述的指示として定式化して、多様なIEタスクにわたってLLMを訓練したんや。未知のラベル体系を持つタスクでの評価では、このモデルが他のインストラクションチューニング手法を上回ったんやで。
*スキーマっちゅうのは、ラベルの集合とその定義のことやで。
2
---
## Page 3
[](/attach/2d6fc0f85a9a606ac0a2f5fd13c84a1cc99a56765017ca29e32217f9553543b4_p003.png)
### 和訳
ほな訳していくで!
---
ICLR 2024の学会論文として発表されたやつやねん。
**図2:モデルに入れるもんと出てくるもんの例やで。**
情報抽出(IE)向けの指示チューニングって、ほとんどの試みに共通の弱点があんねん。プロンプトでラベルの名前しか使ってへんのよ(例えば「Personを全部リストアップして」みたいなやつな)。これやと大きく2つ困ることがあってな。まず、Personみたいなラベルの定義がデータセットによってバラバラやねん(架空のキャラとか代名詞を含めへんやつもある)。ほんで、ラベルの名前だけやと、ややこしいラベルとかマイナーなラベルをちゃんと説明しきれへんのよ。LLMにガイドラインを使ってプロンプトする試みもあるにはあんねん(Zhang et al., 2023a)けど、LLMがタスクのラベルについてめっちゃ強い事前知識持ってるもんやから(Blevins et al., 2023)、そのガイドラインをちゃんと守らへんっていう問題があんねん。
## 3 アプローチ
これまでのやり方とは違って、GoLLIEはモデルにガイドラインの細かいとこまでちゃんと注目させて、トレーニング中に見たことないスキーマに対してもしっかり動くようにしてんねん。このセクションでは、ワイらのアプローチの詳細に深く踏み込んで、入力と出力をどう表現したか、そしてモデルにガイドラインをちゃんと見させるための正則化テクニックについて説明するで。
### 3.1 入力と出力の表現方法
モデルの入力も出力も、Pythonコードベースの表現(Wang et al., 2023b; Li et al., 2023)を採用してん。このやり方のええとこは、見やすくて人間が読みやすい構造になるだけちゃうくて、自然言語の指示でありがちないろんな問題も解決できるとこやねん。どんな情報抽出タスクでも統一フォーマットで表現できるし、入力はBlackみたいなPythonコードフォーマッターで自動的にキレイに整えられるし、出力はちゃんと構造化されてるからパース(解析)もめっちゃ簡単やねん。しかも、今どきのLLMはほとんど事前学習データにコードが入ってるから、モデルはこの表現にもう慣れてるっちゅう話やねん。
図2では、フォーマットの3つの主要パーツを見せてるで:**スキーマ定義**、**入力テキスト**、**出力アノテーション**やな。
**スキーマ定義**は入力の最初の部分やねん。ここには、Pythonのクラスとして表現されたラベルの情報、docstringとして書かれたガイドライン、そしてコードコメントの形で示された代表的なアノテーション候補が入ってんねん。クラス定義の数はデータセットのラベルの数と一致するで。クラスはタスクごとに柔軟に変わんねん。例えば、固有表現認識(NER)のデータセットやったら、クラスに対応するテキスト範囲を指定する属性だけあればええねん。逆に、イベント引数抽出(EAE)とかスロットフィリング(SF)みたいな複雑なタスクやと、イベントの参加者リストみたいに、タスクを分類するためのクラス属性がもっとようけ必要になるんやで(付録Aの例を見てな)。
**入力テキスト**は入力の2番目の部分やねん。入力テキストはPythonの文字列変数として表現されるで。
**出力アノテーション**はモデルが生成する部分やねん。モデルは `result =` の後から生成を始めるんや。アノテーションは、スキーマ定義パートで定義されたクラスのインスタンスのリストとして表現されるで。出力のパースはめっちゃ簡単で、生成されたコードをPythonで実行したら結果を含むリストが得られんねん。この出力パースのしやすさが、ワイらのモデルのめっちゃ大きな利点やで。このアプローチの効率性についてのもっと詳しい分析は付録Eにあるから見てみてな。
---
**図2の中身の説明:**
| パーツ | 説明 |
|---|---|
| **スキーマ定義** | タスクの定義を記述する部分やで |
| ラベル | Pythonクラスとして定義されてんねん |
| ガイドライン | docstring(説明文)として導入されるで |
| 代表候補 | コメントとして導入されるんや |
| **入力テキスト** | 分析するテキストやで |
| **出力アノテーション** | クラスのインスタンスとして表現されるで |
```python
# 以下の行でタスク定義を記述してるで
@dataclass
class ProgrammingLanguage(Entity):
"""AIのアプリケーションや研究の開発に使われるプログラミング言語のことやで。
JavaとかPythonみたいなプログラミング言語の名前をアノテーションしてな。"""
span: str # 例えば: "Java", "R", "CLIPS", "Python", "C + +"
@dataclass
class Metric(Entity):
"""AIモデルやアルゴリズムの性能を評価するための評価指標のことやで。
F1スコアみたいな具体的な指標をアノテーションしてな。"""
span: str # 例えば: "mean squared error", "DCG", …
# これが分析するテキストやで
text = "Here , accuracy is measured by error rate , which is defined as..."
# 上のテキストに出てくるアノテーションのインスタンスをリストにしてんねん
result = [
Metric(span="accuracy"),
Metric(span="error rate"),
]
```
---
## Page 4
[](/attach/2d6fc0f85a9a606ac0a2f5fd13c84a1cc99a56765017ca29e32217f9553543b4_p004.png)
### 和訳
ICLR 2024の学会論文として発表
図3:入力の表し方の例やで。(左)ガイドライン情報なしのイベント定義の例。(右)同じ例やけど、ガイドライン情報をPythonのコメントとして入れたバージョンやな。
3.2 ガイドラインで強化した表現方法
この研究の一番のキモはな、推論のときにガイドラインを一緒に使うことで、ゼロショット——つまり一回も見たことないデータにも対応できる汎化性能をめっちゃ上げよう、ってとこやねん。ガイドラインありとなしのクラス定義の例は図3に載せとるで。データセットによってガイドラインの書き方はバラバラでな、ラベルの意味をめっちゃ複雑に定義して例外とか特殊ケースまで書いてるやつもあれば、そのラベルに当てはまる代表的な候補をちょろっと並べてるだけのやつもあるわけや。この入力形式を統一するために、ラベルの定義はクラスのdocstring(説明文みたいなやつ)として入れて、候補はメインの引数(だいたいmentionとかspanやな)のコメントとして入れたんや。イベント引数抽出(EAE)とかスロットフィリング(SF)みたいな複雑なタスクは、引数やスロットごとにも追加の説明がいるから、各クラス引数にちょっとした定義をコメントで付けたで。この論文では、ガイドラインなしのモデルを**Baseline**、ガイドラインありのモデルを**GoLLIE**と呼ぶことにするわ。
3.3 学習時の正則化
ここで大事なんは、モデルにちゃんとガイドラインに従わせることやねん。特定のデータセットを丸暗記して、それだけうまくいく、みたいなズルはさせたくないわけや。そこで学習中にいろんな種類のノイズを入れるようにしたんや。こうすると、モデルが特定のデータセットを見分けたり、特定のラベルを暗記したり、ガイドラインの中身を理解せんとラベル名だけ見て判断する、みたいなことを防げるねん。
具体的にやった正則化はこんな感じや。**クラス順序のシャッフル**——各サンプルごとに入力クラスの順番をランダムに入れ替えるねん。こうするとタスク定義全体を丸暗記するのがめっちゃ難しくなるわけや。**クラスのドロップアウト**——入力クラスの一部をランダムに消すねん。入力と出力の両方からいくつかクラスを消すことで、入力に定義されてるクラスのインスタンスだけを出力するように学習させるんや。これはスキーマ定義にちゃんと注目させるだけやなくて、推論時のハルシネーション(存在せんもんを作り出しちゃうやつ)も減らせるねん。**ガイドラインの言い換え**——ラベル定義のバリエーションを作って、モデルが定義を簡単に暗記できんようにしたんや。これで定義の書き方が多少変わっても頑健に対応できるようになると思うで。**代表候補のサンプリング**——言い換えと同じ考え方で、各入力に対して1クラスあたり10個の固定プールから5個の候補をランダムにサンプリングしたんや。**クラス名のマスキング**——ラベルのクラス名(例えばPERSON)をLABEL_1みたいなプレースホルダーに置き換えるねん。こうするとモデルが学習中にラベル名をズルに利用するのを防げて、ガイドラインの中身をちゃんと読んで理解するようになるわけや。
4 実験設定
4.1 データ
ゼロショットの能力を評価するには、データを学習用と評価用に分けなあかんねん。でもな、情報抽出のベンチマークって、同じドメインのデータに基づいてたり、スキーマの一部が被ってたりすることが多いんよ。ゼロショット評価が似たようなデータの影響を受けんように、ベンチマーク群をデータのドメインに基づいて分けたんや(関連する話題としてデータ汚染の問題もあるで、
4
---
## Page 5
[](/attach/2d6fc0f85a9a606ac0a2f5fd13c84a1cc99a56765017ca29e32217f9553543b4_p005.png)
### 和訳
ICLR 2024の会議論文として発表されたやつやねん
表1:実験で使ったデータセットやで。この表には、どの分野のデータか、どんなタスクに使うか、ほんで学習用なんか評価用なんか、それとも両方なんかが載ってるねん。
| データセット | 分野 | NER | RE | EE | EAE | SF | 学習 | 評価 |
|---|---|---|---|---|---|---|---|---|
| ACE05 (Walker et al., 2006) | ニュース | ✓ | ✓ | ✓ | ✓ | | ✓ | |
| BC5CDR (Wei et al., 2016) | 生物医学 | ✓ | | | | | ✓ | |
| CoNLL 2003 (Tjong Kim Sang & De Meulder, 2003) | ニュース | ✓ | | | | | ✓ | |
| DIANN (Fabregat et al., 2018) | 生物医学 | ✓ | | | | | ✓ | |
| NCBIDisease (Islamaj Doğan & Lu, 2012) | 生物医学 | ✓ | | | | | ✓ | |
| Ontonotes 5 (Pradhan et al., 2013) | ニュース | ✓ | | | | | ✓ | |
| RAMS (Ebner et al., 2020) | ニュース | | | | ✓ | | ✓ | |
| TACRED (Zhang et al., 2017) | ニュース | | | | | ✓ | ✓ | |
| WNUT 2017 (Derczynski et al., 2017) | ニュース | ✓ | | | | | ✓ | |
| BroadTwitter (Derczynski et al., 2016) | ツイッター | ✓ | | | | | | ✓ |
| CASIE (Satyapanich et al., 2020) | サイバー犯罪 | | | ✓ | ✓ | | | ✓ |
| CrossNER (Liu et al., 2021b) | いろいろ | ✓ | | | | | | ✓ |
| E3C (Magnini et al., 2021) | 生物医学 | ✓ | | | | | | ✓ |
| FabNER (Kumar & Starly, 2022) | 科学 | ✓ | | | | | | ✓ |
| HarveyNER (Chen et al., 2022) | ツイッター | ✓ | | | | | | ✓ |
| MIT Movie (Liu et al., 2013) | 検索クエリ | ✓ | | | | | | ✓ |
| MIT Restaurants (Liu et al., 2013) | 検索クエリ | ✓ | | | | | | ✓ |
| MultiNERD (Tedeschi & Navigli, 2022) | ウィキペディア | ✓ | | | | | | ✓ |
| WikiEvents (Li et al., 2021) | ウィキペディア | | | ✓ | ✓ | | | ✓ |
ほんで詳しい話(付録Gで議論してるやつ)やけど、学習にはだいたいニュースと生物医学の分野のデータセットを使ってん。一方で評価のほうは、めっちゃいろんな分野のデータセットを使ったんよ。なんでかっていうと、こうすることで評価の過程にノイズが入るのを避けられるからやねん。評価用データセットの中にはCrossNER(Liu et al., 2021b)っていうのがあって、これは複数の分野に分かれてるねんけど、わかりやすくするために各分野を別々のデータセットとして扱うことにしたで:AI、文学、音楽、政治、科学の5つや。あと、MIT MovieとMIT Restaurantはそれぞれ「Movie」と「Restaurant」って呼ぶことにするわ。表1に実験で使ったデータの情報がまとまってるで。
モデルの学習には5つの異なるタスクを使ったんや:固有表現認識(NER)、関係抽出(RE)、イベント抽出(EE)、イベント引数抽出(EAE)、ほんでスロットフィリング(SF)の5つやね。ただし、評価したのは主に興味のある3つのタスク、つまりNER、EE、EAEだけやねん。残りの2つのタスクは何のために入れたかっていうと、学習データの多様性を増やして、モデルの柔軟性を上げるためやで。
データセット2つにはちょっと手を加えてるねん、モデルの品質を上げるためにな。まず、Ontonotes 5の学習データはめっちゃガッツリ減らしたんよ。なんでかっていうと、もともと自動でアノテーション(ラベル付け)されたデータやったからやねん。次に、TACREDデータセットは関係抽出(RE)からスロットフィリング(SF)に変換して、タスクの難易度を上げたんや。こういう変更をしたから、これらのタスクについては既存の最先端手法とは直接比較できへんねん。でもな、わいらが本当に興味あるのはゼロショット評価(一回も見たことないデータでの評価)のほうやから、こっちのメリット(付録A参照)のほうが、教師あり設定で比較可能なポイントを2つ増やすよりもずっとおもろいってわけや。CASIEデータセットについては、アノテーションされたイベントの範囲(スパン)にバラつきがあることがわかってん。モデルは普通、全体のスパンやなくて部分的な文字列をアノテーションしがちやねん。せやから、全モデルの評価は予測されたイベントカテゴリに基づいてやって、テキストスパンが正確に一致してるかどうかは考慮せんことにしたわ。引数については部分一致で評価してるで。
各データセットの作者が公開してるガイドラインを使ったんや(詳しくは付録F参照)。そういうガイドラインが公開されてへん場合は、人間の専門家に頼んで、開発用データの分割からアノテーションを参考にして作ってもらったで。代表的な候補はガイドラインから抽出して、それがない場合は、学習用データから単語の出現頻度に基づいてサンプリングするか、ガイドラインを基に手作業で作成したんや。言い換え表現はVicuna 33B v1.3(Zheng et al., 2023)を使って自動生成したで。
4.2 言語モデルとベースライン
ベースとなるLLM(大規模言語モデル)の話やけどな:
GoLLIEっていうのは、Code-LLaMA(Rozière et al., 2023)をファインチューニング(微調整)したモデルやねん。開発段階では他のベースLLMも検討したで。例えばLLaMA(Touvron et al., 2023a)、LLaMA-2(Touvron et al., 2023b)、Falcon(Penedo et al., 2023)とかな。でもな、わいらのアプローチは入力と出力をコードで表現するっていう方法やから、予備実験ではCode-LLaMAモデルが一番よう働いてくれたんよ。公平に比較するために、この論文で開発したベースラインもCode-LLaMAベースにしてるで。論文の開発は基本的に70億パラメータ版のCode-LLaMAでやったんやけど、スケーリング分析(モデルの大きさを変えたらどうなるか調べるやつ)のために、130億パラメータと340億パラメータのモデルも学習させたで。
---
## Page 6
[](/attach/2d6fc0f85a9a606ac0a2f5fd13c84a1cc99a56765017ca29e32217f9553543b4_p006.png)
### 和訳
ICLR 2024の学会論文として発表されたで!
**表2:教師ありの評価結果やで。「*」がついてるやつは、そのまま比較するんはちょっと公平ちゃうで。**
データセット
ACE05NER
ACE05RE
ACE05EE
ACE05EAE
BC5CDR
CoNLL 2003
DIANN
NCBIDisease
Ontonotes 5
RAMS
TACRED
WNUT 2017
平均
最先端ベースライン
13B
34B
(Wang et al., 2023a) 86.6
(Lu et al., 2022b) 66.1
(Lu et al., 2022b) 73.4
(Lu et al., 2022b) *54.8
(Zhang et al., 2023b) 91.9
(Lu et al., 2022b) 93.0
(Zabala et al., 2018) 74.8
(Wang et al., 2023a) 90.2
(Li et al., 2021) 48.6
(Wang et al., 2021) 60.2
89.1±0.2
63.8±0.6
71.7±0.2
65.9±0.7
87.5±0.2
92.9±0.1
80.3±0.7
86.2±0.1
83.4±0.2
48.9±0.4
56.6±0.2
53.7±0.7
88.1±0.6
63.6±1.8
72.2±0.8
66.0±0.8
87.5±0.2
92.8±0.3
79.4±1.1
85.4±0.3
83.4±0.2
48.7±0.7
57.1±0.9
52.0±0.6
89.4±0.2
67.5±0.5
70.9±1.6
67.8±0.9
87.9±0.1
93.0±0.2
82.6±1.3
86.5±0.8
84.0±0.2
49.6±0.1
56.7±0.5
50.5±0.9
89.6±0.1
70.1±1.5
71.9±1.1
68.6±1.2
88.4±0.2
93.1±0.1
84.1±1.1
85.8±0.2
84.6±0.4
51.2±0.3
58.7±0.2
54.3±0.4
73.3±0.1
73.0±0.3
73.9±0.3
75.0±0.3
**学習のセットアップ:** モデルの学習にはQLoRA(Hu et al., 2022; Dettmers et al., 2023)を使ってるねん。LoRAっちゅうのは何かっていうと、事前学習済みのモデルの重みは凍結したまんまにしといて、Transformerの線形層に「学習可能な低ランク分解行列」っちゅうもんを差し込む技術やねん。要するに、モデル全体をいじらんでも効率よく学習できるっちゅうことやな。予備実験でこのやり方試したら、モデル全体をファインチューニングするよりもゼロショットタスクで成績よかったし、しかも学習めっちゃ速かったんよ(詳しくは付録D.4見てな)。Dettmers et al.(2023)がおすすめしとる通り、LoRAはTransformerブロックの全ての線形層に適用したで。学習は3エポック回して、実効バッチサイズは32、学習率は3e-4でコサインスケジューラー使ったんや。学習に使ったマシンはNVIDIAのA100(80GB)を2枚やで。もっと細かい話は付録Dに書いとるわ。
**比較対象のシステム:** 一番メインの比較対象はInstruct-UIE(Wang et al., 2023a)やねん。なんでかっていうと、ワイらのシステムに一番近いアプローチやからや。ただし向こうはガイドライン使ってへんねんな。もう一つ比較に入れたんがPromptNER(Zhang et al., 2023a)で、こっちはGPT-3.5とT5に定義文をプロンプトとして渡して、Chain-of-Thought(思考の連鎖)っちゅうテクニックで少数ショットの固有表現認識(NER)をやるっちゅうもんや。ワイらと違うのは、ガイドラインに注目するようにモデルをファインチューニングしてへんところやな。公平に比較するために、あっちの論文に載っとるゼロショットの結果だけを使ったで。あと、Instruct-UIEとPromptNERの結果がないデータセットについては、他の最先端システムも比較に加えとるわ。ワイらのシステムはゼロショット向けに設計しとるから、教師あり実験は「性能が落ちてへんか確認する」ためのもんやねん。せやから教師ありのシナリオでは、ワイらと一番設定が近いシステムを選んで比較しとるで。
**5 結果**
**5.1 教師ありの評価**
教師ありデータセットでの結果は表2に載っとるで。GoLLIEとベースラインを比べると、ほんまにめっちゃ似た結果になっとって、平均で絶対差0.3 F1ポイントしか変わらんのや。これは想定通りやねん。なんでかっていうと、ベースラインモデルはファインチューニング中にデータの分布から暗黙的にアノテーションのガイドラインを学習してまうからやな。それに加えて、GoLLIEはガイドラインから汎化するためにファインチューニングにノイズを入れとるんやけど、それでもベースラインに近い性能を出せとるっちゅうことや。
他のシステムと比べても、全体的に似たような結果出とるわ。ワイらのモデルが明らかに負けとるWNUTとNCBIDiseaseの2つのデータセットに注目すると、やっぱりタスク固有のテクニックがまだ必要やなってわかるねん。例えばWang et al.(2021)は外部知識を使って、新しく出てきた珍しいエンティティを検出しとるし、NCBIDiseaseデータセットでは生物医学分野のコーパスで事前学習したモデルが一番ええ結果出しとるんや(Kocaman & Talby, 2021)。Wang et al.(2023a)はFlan-T5を使っとるんやけど、これが生物医学分野のタスクにめっちゃ強いねん(Singhal et al., 2022)。ただ、こういう改善はワイらの提案と補完的な関係にあるから、組み合わせたらもっとええもんできるっちゅうことやな。
**5.2 ゼロショットの評価**
ゼロショットの結果は表3に載っとるで。全体的に見て、ベースラインと比べたら、ガイドラインを使うことでほぼ全てのデータセットで結果がめっちゃ改善されとって、絶対差で見ても
6
---
## Page 7
[](/attach/2d6fc0f85a9a606ac0a2f5fd13c84a1cc99a56765017ca29e32217f9553543b4_p007.png)
### 和訳
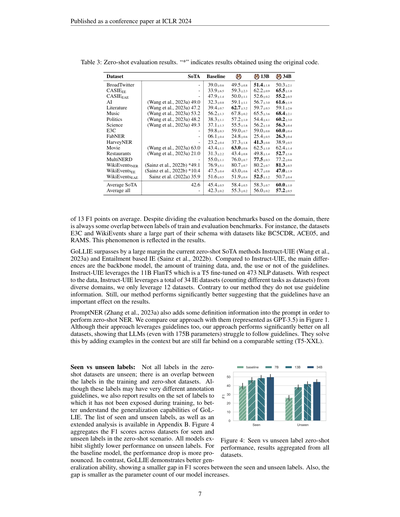
表3:ゼロショット評価の結果やで。「*」がついてるやつは、オリジナルのコードそのまま使って出した結果やねん。
データセット
BroadTwitter
CASIEEE
CASIEEAE
AI
Literature
Music
Politics
Science
E3C
FabNER
HarveyNER
Movie
Restaurants
MultiNERD
WikiEventsNER
WikiEventsEE
WikiEventsEAE
SoTA平均
全体平均
SoTAベースライン
13B
34B
(Wang et al., 2023a)49.0
(Wang et al., 2023a)47.2
(Wang et al., 2023a)53.2
(Wang et al., 2023a)48.2
(Wang et al., 2023a)49.3
(Wang et al., 2023a)63.0
(Wang et al., 2023a)21.0
(Sainz et al., 2022b)*49.1
(Sainz et al., 2022b)*10.4
Sainz et al.(2022a)35.9
42.6
39.0±0.6
33.9±6.5
47.9±1.4
32.3±0.8
39.4±0.7
56.2±1.3
38.3±1.1
37.1±1.3
59.8±0.3
06.1±0.4
23.2±0.4
43.4±1.1
31.3±2.2
55.0±1.1
76.9±5.1
47.5±0.4
51.6±0.5
45.4±0.5
42.3±0.2
49.5±0.8
59.3±2.3
50.0±1.1
59.1±1.1
62.7±3.2
67.8±0.2
57.2±1.0
55.5±1.6
59.0±0.7
24.8±0.6
37.3±1.8
63.0±0.6
43.4±0.8
76.0±0.7
80.7±0.7
43.0±0.6
51.9±0.4
58.4±0.5
55.3±0.2
51.4±1.8
62.2±0.9
52.6±0.2
56.7±3.0
59.7±0.3
65.5±3.6
54.4±4.1
56.2±1.0
59.0±0.8
25.4±0.5
41.3±0.8
62.5±1.0
49.8±1.4
77.5±0.3
80.2±0.7
45.7±0.8
52.5±1.2
58.3±0.7
56.0±0.2
50.3±2.1
65.5±1.8
55.2±0.5
61.6±1.9
59.1±2.6
68.4±2.1
60.2±3.0
56.3±0.4
60.0±0.4
26.3±0.4
38.9±0.5
62.4±1.4
52.7±1.6
77.2±0.6
81.3±0.5
47.0±1.9
50.7±0.4
60.0±1.0
57.2±0.5
平均でF1スコアが13ポイントも差がついとんねん。評価ベンチマークはドメインごとに分けてはいるんやけど、学習用と評価用のベンチマークのラベルってどうしてもちょっとかぶるところがあんねん。例えばな、E3CとWikiEventsっていうデータセットは、BC5CDRとかACE05、RAMSみたいなデータセットとスキーマ(データの構造みたいなもんやな)がかなり共通してるねん。その影響が結果にもしっかり出てるっちゅうわけや。
GoLLIEはな、今あるゼロショット(つまり一切学習なしでぶっつけ本番で挑む方式やな)の最強手法であるInstruct-UIE(Wang et al., 2023a)とEntailmentベースのIE(Sainz et al., 2022b)をめっちゃ大差で抜いとるんよ。Instruct-UIEと比べて何が違うかっていうと、ベースのモデル、学習データの量、ほんでガイドライン使うか使わんかっていう3つやねん。Instruct-UIEは11BパラメータのFlanT5っていうモデルを使ってて、これはT5を473個ものNLPデータセットでファインチューニング(追加学習みたいなもんや)したやつやねん。データに関してはな、Instruct-UIEは色んなドメインから合計34個のIE(情報抽出)データセットを使ってるんやけど(タスクが違えば別データセットとしてカウントしてるで)、ウチらはたった12個しか使ってへんのよ。ほんで向こうはガイドライン情報を使ってないんやけど、ウチの方法の方が断然ええ結果出してるっちゅうことは、ガイドラインがめっちゃ重要な役割果たしてるってことやな。
PromptNER(Zhang et al., 2023a)もな、ゼロショットのNER(固有表現認識、つまり文の中から人名とか地名とかを見つけ出すタスクやな)をやるために、プロンプトに定義情報をちょっと足してるねん。Figure 1でウチのアプローチと比較してるんやけど(GPT-3.5として載ってるやつがそれやで)、向こうもガイドラインは使ってるんやけど、ウチの方がどのデータセットでもめっちゃええ成績出してるんよ。これはつまり、大規模言語モデル(175Bパラメータっていうバケモンサイズでも!)がガイドラインにちゃんと従うのが苦手やってことを示してるねん。向こうはコンテキストに例を追加することで対処してるんやけど、それでも同じ条件(T5-XXL)で比べたらまだまだウチには全然届いてへんのよ。
学習済みラベル vs 未知のラベル:ゼロショット用のデータセットのラベルが全部未知ってわけちゃうねん。学習時のデータセットとゼロショット用のデータセットでかぶってるラベルがあるんよ。もちろんアノテーションのガイドライン(ラベルの付け方のルール)は全然ちゃうかもしれんけどな。ほんで、GoLLIEの汎化能力(初見のものにどれくらい対応できるか)をもっとちゃんと理解するために、学習中に一度も見たことないラベルだけに絞った結果も出してるで。学習済みと未知のラベルのリストと詳しい分析は付録Bに載ってるから見てみてな。Figure 4は、ゼロショットの場面で学習済みラベルと未知ラベルのF1スコアを全データセットでまとめたもんやねん。どのモデルも未知のラベルではちょっと性能落ちるんやけど、ベースラインモデルは落ち幅がかなりデカいねん。それに比べてGoLLIEはほんまに汎化能力が高くて、学習済みラベルと未知ラベルの間のF1スコアの差が小さいんよ。しかもな、モデルのパラメータ数が増えるほどその差がさらに縮まるっちゅうわけや。
Figure 4:学習済みラベル vs 未知ラベルのゼロショット性能。全データセットの結果をまとめたもんやで。
---
## Page 8
[](/attach/2d6fc0f85a9a606ac0a2f5fd13c84a1cc99a56765017ca29e32217f9553543b4_p008.png)
### 和訳
ICLR 2024の学会論文として発表
**モデルのスケーリングについて:** 最近の研究でな、言語モデルのパラメータ数を増やしたら汎化性能がめっちゃ良くなるっていうのが分かってきてん(Brown et al., 2020)。パラメータ数が多いほど、ゼロショット(一回も見たことないタスクをいきなりやる)の平均性能が上がるんやわ。せやけど、データセットやタスクによっては、でっかいLLM(大規模言語モデル)の恩恵をめちゃくちゃ受けるものもあれば、全然変わらんものもあるねん。なんでかっていうと、恩恵受けへんやつは、5.3節で話すガイドラインの問題が足引っ張ってるからやと思うねん。基本的には、でかいモデルの方が教師あり学習でもゼロショットでもええ結果出すんやけど、GoLLIEは70億パラメータのバックボーンでもう十分強いゼロショット性能を発揮してるんやで。
## 5.3 アブレーションスタディ(要素を一個ずつ抜いて効果を調べる実験)
ゼロショット評価で、どのパーツがどれだけ貢献してるか調べるために、アブレーション実験やったで。3.3節で提案した正則化テクニック(過学習を防ぐ仕組み)をそれぞれ分析してん。あと、ガイドラインも含めて全部取っ払ったベースラインを「w/o all(全部なし)」って表記してるわ。平均ゼロショットF1スコアと一緒に、GoLLIEに対する片側p値(統計的にどんだけ意味のある差かを示す数値)も載せてるで。
**表4:アブレーション結果**
| モデル | F1 | p値 |
|---|---|---|
| GoLLIE | 55.3±0.2 | — |
| シャッフルなし | 55.9±0.2 | 7.2e−2 |
| パラフレーズなし | 54.8±0.2 | 1.1e−1 |
| マスキングなし | 54.6±0.6 | 1.0e−1 |
| ドロップアウトなし | 54.0±0.2 | 4.0e−3 |
| 候補なし | 49.9±0.2 | 2.2e−10 |
| 全部なし(ベースライン) | 42.3±0.1 | 5.1e−13 |
クラスの順番シャッフル、ガイドラインの言い換え(パラフレーズ)、クラス名のマスキングは、最終結果にはそんな有意な貢献してへんみたいやねん。クラスドロップアウトは統計的に有意ではあるけど、改善幅はちっちゃいわ。付録Dでも詳しく説明してるけど、損失の計算は結果トークンだけで行われるから、モデルがガイドラインに過学習する余地が元々限られてるねん。それに対して、代表的なアノテーション項目(こういう例がありますよっていうやつ)はモデルにもっと強い手がかりを与えてくれるんや。定義と代表的な候補がお互い補い合って、一緒に使うことで性能が上がるっていうことが分かったで。
## 6 エラー分析
このセクションでは、ガイドラインをLLMにプロンプトとして与えた時の効果をもっと深く理解しようとしてるで。いろんなデータセットの特定のラベルに注目して、結果を表5にまとめてん。GoLLIEがうまくエンティティ(固有表現)をラベリングできたケースと、失敗したケースの両方を分析してるわ。失敗したやつについては、なんでモデルが正しくラベル付けできへんかったのか、その原因も探ってるで。出力がおかしくなったり、ハルシネーション(モデルが嘘つくやつ)の分析は付録Cで議論してるわ。
**表5:** この表は、いろんなデータセットの特定ラベルのF1スコアを示してるで。「ガイドライン」列は、モデルにプロンプトとして使った実際のガイドラインの要約やねん。
| データセット | ラベル | ガイドライン | ベースライン | GoLLIE |
|---|---|---|---|---|
| MultiNERD | メディア | 映画、本、歌、アルバム、架空のキャラクター、言語のタイトル | 13.6 | 69.1 |
| CASIE | 脆弱性パッチ | ソフトウェア会社がアップデートを出して脆弱性に対処した時のこと | 27.7 | 70.5 |
| Movie | トレイラー | 映画の短い宣伝動画やプレビューのこと | 00.0 | 76.4 |
| AI | タスク | 特定のAI研究分野における研究課題や問題のこと | 02.7 | 63.9 |
| MultiNERD | 時間 | 時代、歴史的な期間、世紀、年、重要な日みたいな、はっきりした時間の区切り | 01.4 | 03.5 |
| Movie | プロット | 映画の展開で重要な役割を果たす、繰り返し出てくるコンセプトや出来事やモチーフ | 00.4 | 05.1 |
| その他 | その他 | 他のどのカテゴリにも入らん固有表現 | 01.1 | 05.2 |
| その他 | その他 | 他のどのカテゴリにも入らん固有表現 | 03.7 | 30.8 |
| Literature | 作家 | 文学作品の創作に積極的に関わってる人 | 04.2 | 65.1 |
| Literature | 人物 | 作家以外の人名 | 33.5 | 49.4 |
| Science | 科学者 | 自然科学分野を研究してるか専門知識を持ってる人 | 02.1 | 05.8 |
| Science | 人物 | 科学者以外の人名 | 45.9 | — |
| Politics | 政党 | 特定の国の選挙に参加する組織 | 11.2 | 34.9 |
---
## Page 9
[](/attach/2d6fc0f85a9a606ac0a2f5fd13c84a1cc99a56765017ca29e32217f9553543b4_p009.png)
### 和訳
ICLR 2024の学会論文として発表されたで
細かいとこはガイドラインに書いてあんねん:MEDIAとかVULNERABILITYPATCH、TRAILER、TASKみたいなラベルって、もともと意味がいくつもある多義語やねん。せやから、ラベルの名前だけ見て「これはこのカテゴリやな」って判断するんがめっちゃ難しいわけ。その結果、ベースラインのモデルは情報が足りひんから、こういうラベルをうまく分類でけへんねん。一方でGoLLIEはガイドラインをちゃんと守って分類できてるから、ガイドラインがほんまに役に立つってことが証明されたわけや。
**アノテーションがガイドラインに従ってない場合:**
MultiNERDデータセットのTIMEラベルの話やねんけど、うちらのモデルは年号をTIMEエンティティとしてラベル付けしてるんよ。これ、アノテーションガイドラインに照らしたら正解やねん。ところがびっくりすることに、データセットの方では年号にエンティティのラベルが付いてないんよ。つまり、GoLLIEはガイドラインをちゃんと守ってるんやけど、残念なことにデータセットのアノテーションの方がガイドラインに従ってないっていう逆転現象が起きてるわけや。
**あいまいなラベルの問題:**
CoNLL03とCrossNERデータセットで使われてるMISCELLANEOUS(その他)カテゴリっていうんは、あらかじめ決められたカテゴリのどこにも入らん固有名詞を全部ぶっこむための受け皿みたいなもんやねん。この定義ってめっちゃあいまいで、どのカテゴリにもハマらんやつを全部まとめて放り込むゴミ箱みたいな存在やねん。同じように、Movieデータセットの「PLOT」カテゴリもいろんなもんをラベル付けするのに使われてて、例えば映画の中の出来事(殺人とか競馬とか)、キャラクター(吸血鬼とかゾンビとか)、それに出身国(イギリスとか)まで、なんでもかんでもPLOTに入れてるんよ。こんだけ具体性がないと、一貫したルールとかガイドラインを作るんがめっちゃ難しいわけで(Ratinov & Roth, 2009も言うてるけど)、これは人間にとってもAIにとっても同じ問題やねん。せやから、GoLLIEもこういうラベルは正確に付けられへんのよ。
**細かいエンティティと大雑把なエンティティの衝突:**
CrossNERデータセットは各ドメインで人名に2つのラベルを用意してるんよ。例えば科学ドメインやったらSCIENTISTとPERSONの2つがあって、PERSONの方は「科学者以外の人」に使うことになってるねん。同じように文学ドメインにはWRITERとPERSONがあるんよ。ガイドラインのおかげでGoLLIEはWRITERのラベル付けはちゃんとできてるねん。ところが、ガイドラインがあるにもかかわらず、科学者のことも「Person」って分類してまうことがあるんよ。まあ、よう考えたら科学者も人間やから、厳密に言えば間違いちゃうねんけどな。
**ラベルに対する先入観が強すぎる問題:**
CrossNERの政治ドメインにはPOLITICAL PARTY(政党)っていうラベルがあるんやけど、GoLLIEはベースラインよりええ成績出してて、ここでもガイドラインを使うことの効果が示されてるねん。ただ、モデルが政党を「組織(ORGANIZATION)」に分類してまうケースがよくあるんよ。なんでかっていうと、表1に載ってるように事前学習データのほとんどがニュースドメインのもんで、そこでは政党はよく出てくるエンティティやねん。でもファインチューニング用のデータセットにはPOLITICAL PARTYっていうエンティティが入ってなくて、代わりに全部ORGANIZATIONとして分類されてるんよ。せやから推論のときにも、モデルは政党を組織としてラベル付けしてまうわけや。この問題はファインチューニング用データセットの数と多様性を増やしたら解決できるんちゃうかって思ってるで。
**まとめると**、GoLLIEはガイドラインがしっかり定義されてて境界がはっきりしたラベルにはめっちゃ強いって期待できるんよ。逆に、あいまいなラベルとか大雑把すぎるラベルは苦手やねん。この点について言うと、「常に一番具体的なクラスをラベル付けせよ」とか「他に具体的なクラスがない場合にこのクラスでアノテーションせよ」みたいな指示を学習させたら、GoLLIEはもっと良くなるんちゃうかなと思ってるわ。あと、事前学習データセットの数と種類を増やすことも効果あるやろうと期待してるで。
## 7章 結論
この論文では**GoLLIE**を紹介したで。GoLLIEっていうんは、もともと人間がデータセットにアノテーションするために作られたガイドラインに従うように特別にファインチューニングされた大規模言語モデル(LLM)やねん。ゼロショット(一回も見たことないタスクで)の包括的な評価をやってみたら、アノテーションガイドラインがLLMにとってめっちゃ価値があるってことが実証されて、GoLLIEはそのガイドラインをしっかり活用できてるんよ。GoLLIEは、ガイドラインを使わへんとか、ガイドラインに従うようファインチューニングされてないモデルを使ってた過去のゼロショット情報抽出の試みよりもええ結果を叩き出したわけや。
GoLLIEは、まだ見たことないIE(情報抽出)タスクにも汎化できるモデルの開発に向けた大きな前進やねん。今後の展望としては、もっと大きくて多様な事前学習データセットを使ってGoLLIEを強化する予定やで。あと、あいまいなラベルとか大雑把なラベルに対する性能も、モデルが従える指示の種類を増やすことで改善していく計画や。
---
## Page 10
[](/attach/2d6fc0f85a9a606ac0a2f5fd13c84a1cc99a56765017ca29e32217f9553543b4_p010.png)
### 和訳
ICLR 2024の学会論文として発表
**謝辞**
この研究な、バスク政府からめっちゃ支援してもらってんねん(研究グループの資金IT1805-22とICL4LANGプロジェクト、助成番号KK-2023/00094)。それからMCIN/AEI/10.13039/501100011033の複数のプロジェクトにもほんまに感謝してるで:(i) DeepKnowledge(PID2021-127777OB-C21)、これはFEDERとEUからも支援もらってるやつ;(ii) Disargue(TED2021-130810B-C21)、これはEUのNextGenerationEU/PRTRからも;(iii) AWARE(TED2021-131617B-I00)、これもEUのNextGenerationEU/PRTRからや。あと、LUMINOUSプロジェクト(HORIZON-CL4-2023-HUMAN-01-21-101135724)からも一部資金もらってんねん。Oscar Sainzくんはバスク政府の博士課程向け助成金(PRE 2023 2 0137)で支援されてるし、Rodrigo Agerriさんは今RYC-2017-23647っていうフェローシップ(MCIN/AEI/10.13039/501100011033とESFの「あなたの未来に投資」プログラム)を持ってはるわ。
**参考文献**
Sidney Blackら。GPT-NeoX-20B:オープンソースの自己回帰型言語モデルやねん。なんでかっていうと、みんなが自由に使えるように公開された200億パラメータの言語モデルで、テキストを前から順番に予測していく仕組みのやつや。Angela Fanら(編)、BigScience Episode #5のワークショップ論文集 – 大規模言語モデルの構築における課題と展望、pp. 95-136、オンライン+ダブリン、2022年5月。計算言語学会。
Terra Blevinsら。言語モデルに言語構造を引き出すプロンプトの話やで。要するに、言語モデルにうまい聞き方(プロンプト)をすると、文法とか言語の構造をちゃんと理解してるってことを示せるっていう研究やねん。Anna Rogersら(編)、計算言語学会第61回年次大会論文集(Volume 1:長論文)、ACL 2023、カナダ・トロント、2023年7月9-14日、pp. 6649-6663。
Tom B. Brownら。言語モデルは少数事例学習者やで、っていうめっちゃ有名な論文やねん。これはな、GPT-3の論文で、ほんの数個の例を見せるだけで、言語モデルがいろんなタスクをこなせるようになるっていうことを示した画期的な研究や。Hugo Larochelleら(編)、NeurIPS 2020、2020年12月6-12日、オンライン開催。
Pei Chenら。交差点、建物、近隣地域:細かい位置認識のためのデータセットやねん。場所の情報をめっちゃ細かいレベルで認識するためのデータセットを作ったっていう研究やな。Marine Carputら(編)、NAACL 2022論文集、pp. 3329-3339、アメリカ・シアトル、2022年7月。
Yi Chenら。ゼロショットの細粒度エンティティタイピングにおける複数情報源の実証研究や。これはな、学習データなし(ゼロショット)で、エンティティ(人名とか地名とか)をめっちゃ細かいカテゴリに分類するときに、いろんな情報源を使ったらどうなるかを実験で調べた研究やねん。Marie-Francine Moensら(編)、EMNLP 2021論文集、pp. 2668-2678、オンライン+ドミニカ共和国プンタカナ、2021年11月。
Zekai Chenら。言語モデルは予後予測においても少数事例学習者やで、っていう論文や。医療分野で、患者の今後の経過(予後)を予測するのにも、少数の事例を見せるだけで言語モデルがそこそこやれるっちゅうことを示した研究やねん。CoRR, abs/2302.12692, 2023。
---
## Page 11
[](/attach/2d6fc0f85a9a606ac0a2f5fd13c84a1cc99a56765017ca29e32217f9553543b4_p011.png)
### 和訳
ICLR 2024の学会論文として発表
Aakanksha Chowdheryら(めっちゃ大人数やから名前は省略するで)。
**PaLM:Pathwaysを使って言語モデルをスケールさせたった話。** CoRR, abs/2204.02311, 2022年。doi: 10.48550/arXiv.2204.02311。URL: https://doi.org/10.48550/arXiv.2204.02311.
→ これはな、Googleが作った「PaLM」っていうめっちゃでかい言語モデルの論文やねん。「Pathways」っていう新しいシステムを使って、言語モデルをどこまででっかくできるかチャレンジしたやつやで。
Hyung Won Chungら。
**指示でファインチューニングした言語モデルをスケールさせる話。** CoRR, abs/2210.11416, 2022年。doi: 10.48550/arXiv.2210.11416。URL: https://doi.org/10.48550/arXiv.2210.11416.
→ なんでかっていうと、AIに「こうやってな」って指示(インストラクション)を出してチューニングする方法があるんやけど、それをどんどんデカいモデルに適用したらどうなるん?っていう研究やねん。
Alexis Conneauら。
**教師なしで多言語の表現学習をめっちゃスケールさせた話。** Dan Jurafskyら(編)、第58回計算言語学会(ACL 2020)の論文集、オンライン開催、2020年7月5-10日、pp. 8440–8451。計算言語学会、2020年。doi: 10.18653/v1/2020.acl-main.747。URL: https://doi.org/10.18653/v1/2020.acl-main.747.
→ これはほんまにすごくてな、ラベル付きデータなしで、いろんな言語をまたいで意味を理解できるモデルを大規模に作ったっちゅう話や。多言語AIの基盤になった重要な研究やで。
Leon Derczynskiら。
**Broad Twitterコーパス:いろんな種類の固有表現認識のためのリソース。** Yuji Matsumotoら(編)、COLING 2016の論文集(第26回国際計算言語学会議:技術論文)、pp. 1169–1179、大阪、日本、2016年12月。COLING 2016実行委員会。URL: https://aclanthology.org/C16-1111.
→ Twitterのツイートから人名とか地名とかの「固有表現」を見つけ出すためのデータセットを作ったで、っていう論文やな。いろんなジャンルのツイートが入ってるから、めっちゃ多様性があるのがポイントやねん。
Leon Derczynskiら。
**WNUT2017共有タスク:新しく出てきたエンティティの認識の結果報告。** Leon Derczynskiら(編)、第3回ノイジーなユーザー生成テキストワークショップの論文集、pp. 140–147、コペンハーゲン、デンマーク、2017年9月。計算言語学会。doi: 10.18653/v1/W17-4418。URL: https://aclanthology.org/W17-4418.
→ SNSとかで新しく出てきた言葉とか固有名詞をAIがちゃんと認識できるか、みんなで競争したコンペの結果報告やで。ノイズだらけのテキストが相手やから、なかなか大変やねん。
Tim Dettmersら。
**QLoRA:量子化したLLMを効率よくファインチューニングする方法。** CoRR, abs/2305.14314, 2023年。doi: 10.48550/arXiv.2305.14314。URL: https://doi.org/10.48550/arXiv.2305.14314.
→ これはな、めっちゃでかい言語モデル(LLM)を「量子化」っていうメモリ節約テクニックで圧縮した状態のまま、効率よくチューニングできるっていう画期的な手法やねん。お金もGPUメモリも節約できるから、ほんまにありがたい研究やで。
Jesse Dodgeら。
**でっかいウェブテキストのデータセットをちゃんと記録しようや:Colossal Clean Crawled Corpusのケーススタディ。** Marie-Francine Moensら(編)、2021年自然言語処理における経験的手法に関する会議(EMNLP)の論文集、pp. 1286–1305、オンラインおよびプンタカナ(ドミニカ共和国)、2021年11月。計算言語学会。doi: 10.18653/v1/2021.emnlp-main.98。URL: https://aclanthology.org/2021.emnlp-main.98.
→ AIの学習に使うウェブから集めたデータって、中身ちゃんと調べてへんやん?っていうツッコミから始まった研究や。めっちゃでかいデータセット「C4」の中身を詳しく調べて、どんなデータが入ってるか記録したったっていう話やな。
Seth Ebnerら。
**複数文にまたがる論点のリンキング。** Dan Jurafskyら(編)、第58回計算言語学会(ACL)年次大会の論文集、pp. 8057–8077、オンライン、2020年7月。計算言語学会。doi: 10.18653/v1/2020.acl-main.718。URL: https://aclanthology.org/2020.acl-main.718.
→ 一つの文だけやなくて、複数の文にまたがって「この話とあの話はつながってるで」っていう関係を見つけ出すタスクの研究やねん。文をまたいで意味をつなげるのって、ほんまに難しいんやで。
---
## Page 12
[](/attach/2d6fc0f85a9a606ac0a2f5fd13c84a1cc99a56765017ca29e32217f9553543b4_p012.png)
### 和訳
ICLR 2024の会議論文として発表されてんねん
Hermenegildo Fabregatさん、Juan Martínez-Romoさん、Lourdes Araujoさんの論文。「DIANNタスクの概要:障害アノテーションタスク」っていうやつやねん。これはIberEval 2018っていう、イベリア半島の言語向けの人間言語技術を評価するワークショップの第3回目で発表されたもんで、スペインのセビリアで2018年9月18日に開催されたんや。スペイン自然言語処理学会(SEPLN)の第34回大会と同時開催やったで。CEUR Workshop Proceedingsの第2150巻、pp. 1-14に載ってるわ。URL: https://ceur-ws.org/Vol-2150/overview-diann-task.pdf
Besnik Fetahuさん、Sudipta Karさん、Zhiyu Chenさん、Oleg Rokhlenkoさん、Shervin Malmasiさんの論文。「SemEval 2023 タスク2:きめ細かい多言語固有表現認識(MultiCoNER 2)」っていうタスクの話やねん。要するに、いろんな言語で人名とか地名とかを細かく見分けるコンペティションのことやな。第17回意味評価国際ワークショップ(SemEval@ACL 2023)で発表されて、2023年7月13-14日にカナダのトロントでやったんや。pp. 2247-2265。doi: 10.18653/v1/2023.semeval-1.310。URL: https://doi.org/10.18653/v1/2023.semeval-1.310
Pengcheng Heさん、Jianfeng Gaoさん、Weizhu Chenさんの論文。「DeBERTaV3:ELECTRAスタイルの事前学習で勾配分離した埋め込み共有を使ってDeBERTaを改良したで」っていう内容やねん。めっちゃざっくり言うと、言語モデルの学習方法を工夫して性能アップさせましたって話や。ICLR 2023(第11回国際学習表現会議)で発表されて、ルワンダのキガリで2023年5月1-5日に開催やったで。URL: https://openreview.net/pdf?id=sE7-XhLxHA
Edward J. Huさん、Yelong Shenさん、Phillip Wallisさん、Zeyuan Allen-Zhuさん、Yuanzhi Liさん、Shean Wangさん、Lu Wangさん、Weizhu Chenさんの論文。「LoRA:大規模言語モデルの低ランク適応」や。なんでかっていうと、でっかい言語モデルを全部一から学習し直すんはめっちゃ大変やから、低ランク行列で効率よく微調整しようぜっていうアイデアやねん。ほんまに画期的な手法やで。ICLR 2022(第10回国際学習表現会議)で発表、2022年4月25-29日のオンライン開催やったわ。URL: https://openreview.net/forum?id=nZeVKeeFYf9
Rezarta Islamaj Doğanさん、Zhiyong Luさんの論文。「PubMed引用文献における疾患メンションの改良コーパス」や。PubMedっていう医学論文のデータベースから、病気の名前がどこに書いてあるかをまとめたデータセットをもっとええ感じに作り直したって話やねん。BioNLP 2012ワークショップ(生物医学自然言語処理)で発表されて、カナダのモントリオールで2012年6月に開催やったで。pp. 91-99。URL: https://aclanthology.org/W12-2411
Veysel Kocamanさん、David Talbyさんの論文。「大規模な生物医学固有表現認識」っていうタイトルやねん。生物医学の分野で、めっちゃ大量のテキストから遺伝子名とか薬品名とかを自動で見つけ出す技術の話や。ICPR 2021の国際ワークショップで発表されて、Springer International Publishingから出版。pp. 635-646。ISBN 978-3-030-68763-2。
Aman Kumarさん、Binil Starlyさんの論文。「FabNER:固有表現認識を使った製造プロセス科学分野の文献からの情報抽出」や。製造業の論文から、材料名とかプロセス名とかを自動で抜き出す技術のことやねん。Journal of Intelligent Manufacturing、第33巻8号、pp. 2393-2407、2022年。doi: 10.1007/s10845-021-01807-x。URL: https://doi.org/10.1007/s10845-021-01807-x
Omer Levyさん、Minjoon Seoさん、Eunsol Choiさん、Luke Zettlemoyerさんの論文。「読解によるゼロショット関係抽出」や。これめっちゃおもろくて、関係抽出っていう「AとBの間にどんな関係があるか」を見つけるタスクを、読解問題として解いたろうっていうアプローチやねん。学習データが全くなくても(ゼロショットで)できるのがポイントや。CoNLL 2017(計算自然言語学習会議第21回)で発表、2017年8月にカナダのバンクーバーで開催。pp. 333-342。doi: 10.18653/v1/K17-1034。URL: https://aclanthology.org/K17-1034
Peng Liさん、Tianxiang Sunさん、Qiong Tangさん、Hang Yanさん、Yuanbin Wuさん、Xuanjing Huangさん、Xipeng Qiuさんの論文。「CodeIE:大規模コード生成モデルはもっとええ少数ショット情報抽出器になるで」っていうタイトルやねん。なんでかっていうと、プログラミングコードを生成するAIモデルを使って、少ない例示だけで情報抽出させたらめっちゃ性能良かったって話や。ACL 2023(計算言語学会第61回年次大会)の長論文セッションで発表、2023年7月にカナダのトロントで開催。pp. 15339-15353。doi: 10.18653/v1/2023.acl-long.855。URL: https://aclanthology.org/2023.acl-long.855
Sha Liさん、Heng Jiさん、Jiawei Hanさんの論文。「条件付き生成による文書レベルのイベント引数抽出」や。普通のイベント抽出って文単位でやるんやけど、この研究は文書全体を見てイベントの引数(誰が、どこで、何をしたか、みたいな情報)を抽出するんやで。条件付き生成っていうテクニックを使ってるのがミソやな。NAACL-HLT 2021(北米計算言語学会)で発表、2021年6月にオンラインで開催。pp. 894-908。doi: 10.18653/v1/2021.naacl-main.69。URL: https://aclanthology.org/2021.naacl-main.69
---
## Page 13
[](/attach/2d6fc0f85a9a606ac0a2f5fd13c84a1cc99a56765017ca29e32217f9553543b4_p013.png)
### 和訳
ICLR 2024の学会論文として発表
Ying Lin、Heng Ji、Fei Huang、Lingfei Wu。グローバル特徴量を使った情報抽出のための統合ニューラルモデルやねん。Dan Jurafsky、Joyce Chai、Natalie Schluter、Joel Tetreault(編)、第58回計算言語学会年次大会(ACL)の論文集、pp. 7999–8009、オンライン開催、2020年7月。計算言語学会。doi: 10.18653/v1/2020.acl-main.713. URL https://aclanthology.org/2020.acl-main.713. ようするに、情報抽出っていう「テキストから大事な情報を自動で引っこ抜く技術」を、全体の文脈も見ながらやるニューラルネットワークのモデルを作ったっちゅう話やな。
Xiao LingとDaniel S. Weld。きめ細かいエンティティ認識やで。Jörg HoffmannとBart Selman(編)、第26回AAAI人工知能学会の論文集、2012年7月22-26日、カナダのトロント、pp. 94–100。AAAI Press、2012年。doi: 10.1609/AAAI.V26I1.8122. URL https://doi.org/10.1609/aaai.v26i1.8122. これはな、エンティティ認識——つまり文章の中から「人名」とか「地名」とかを見つける技術を、もっと細かいカテゴリに分けて認識できるようにしたっちゅう研究やねん。
Jingjing Liu、Panupong Pasupat、Scott Cyphers、James R. Glass。Asgard:多言語対話システムのためのポータブルアーキテクチャやで。IEEE国際音響・音声・信号処理会議(ICASSP 2013)、カナダ・バンクーバー、2013年5月26-31日、pp. 8386–8390。IEEE、2013年。doi: 10.1109/ICASSP.2013.6639301. URL https://doi.org/10.1109/ICASSP.2013.6639301. なんでかっていうと、いろんな言語で動く対話システムを、持ち運びやすい設計で作りたかったんやな。
Zihan Liu、Yan Xu、Tiezheng Yu、Wenliang Dai、Ziwei Ji、Samuel Cahyawijaya、Andrea Madotto、Pascale Fung。CrossNER:ドメインをまたいだ固有表現認識の評価やねん。第35回AAAI人工知能学会(AAAI 2021)、第33回革新的AI応用学会(IAAI 2021)、第11回AI教育発展シンポジウム(EAAI 2021)、オンライン開催、2021年2月2-9日、pp. 13452–13460。AAAI Press、2021a。URL https://ojs.aaai.org/index.php/AAAI/article/view/17587. めっちゃざっくり言うと、ある分野で学習した固有表現認識(人名とか組織名とかを見つけるやつ)が、別の分野でもちゃんと使えるか評価するためのベンチマークを作ったっちゅうことやな。
Zihan Liu、Yan Xu、Tiezheng Yu、Wenliang Dai、Ziwei Ji、Samuel Cahyawijaya、Andrea Madotto、Pascale Fung。CrossNER:ドメインをまたいだ固有表現認識の評価。第35回AAAI人工知能学会(AAAI 2021)、第33回革新的AI応用学会(IAAI 2021)、第11回AI教育発展シンポジウム(EAAI 2021)、オンライン開催、2021年2月2-9日、pp. 13452–13460。AAAI Press、2021b。doi: 10.1609/aaai.v35i15.17587. URL https://doi.org/10.1609/aaai.v35i15.17587. 上と同じ論文の別引用形式やで。
Jie Lou、Yaojie Lu、Dai Dai、Wei Jia、Hongyu Lin、Xianpei Han、Le Sun、Hua Wu。統一的な意味マッチングとしてのユニバーサル情報抽出やねん。Brian Williams、Yiling Chen、Jennifer Neville(編)、第37回AAAI人工知能学会(AAAI 2023)、第35回革新的AI応用学会(IAAI 2023)、第13回AI教育発展シンポジウム(EAAI 2023)、アメリカ・ワシントンDC、2023年2月7-14日、pp. 13318–13326。AAAI Press、2023年。doi: 10.1609/aaai.v37i11.26563. URL https://doi.org/10.1609/aaai.v37i11.26563. ほんまにすごいのが、いろんな種類の情報抽出タスクを「意味のマッチング」っていう一つの枠組みで全部やっちゃおうっていう発想やねん。
Yaojie Lu、Qing Liu、Dai Dai、Xinyan Xiao、Hongyu Lin、Xianpei Han、Le Sun、Hua Wu。ユニバーサル情報抽出のための統一構造生成やで。Smaranda Muresan、Preslav Nakov、Aline Villavicencio(編)、第60回計算言語学会年次大会(第1巻:長編論文)、ACL 2022、アイルランド・ダブリン、2022年5月22-27日、pp. 5755–5772。計算言語学会、2022a。doi: 10.18653/v1/2022.acl-long.395. URL https://doi.org/10.18653/v1/2022.acl-long.395. これはな、情報抽出のいろんなタスク——固有表現認識とか関係抽出とかイベント抽出とか——を、全部「構造を生成する」っていう統一的なやり方で解くモデルを提案してるねん。めっちゃ画期的やで。
Yaojie Lu、Qing Liu、Dai Dai、Xinyan Xiao、Hongyu Lin、Xianpei Han、Le Sun、Hua Wu。ユニバーサル情報抽出のための統一構造生成。Smaranda Muresan、Preslav Nakov、Aline Villavicencio(編)、第60回計算言語学会年次大会(第1巻:長編論文)論文集、pp. 5755–5772、アイルランド・ダブリン、2022年5月、2022b。計算言語学会。doi: 10.18653/v1/2022.acl-long.395. URL https://aclanthology.org/2022.acl-long.395. さっきのと同じ論文の別引用形式やな。
Inbal MagarとRoy Schwartz。データ汚染:暗記から悪用までやねん。Smaranda Muresan、Preslav Nakov、Aline Villavicencio(編)、第60回計算言語学会年次大会(第2巻:短編論文)論文集、pp. 157–165、アイルランド・ダブリン、2022年5月。計算言語学会。doi: 10.18653/v1/2022.acl-short.18. URL https://aclanthology.org/2022.acl-short.18. これめっちゃ大事な話でな、AIモデルが学習データの中にテストデータが混ざってしまう「データ汚染」の問題を扱ってるねん。ただ丸暗記してるだけちゃうくて、それをうまいこと利用してしまうケースもあるっちゅう、なかなか怖い話やで。
---
## Page 14
[](/attach/2d6fc0f85a9a606ac0a2f5fd13c84a1cc99a56765017ca29e32217f9553543b4_p014.png)
### 和訳
ICLR 2024の学会論文として発表
Bernardo Magnini、Begoña Altuna、Alberto Lavelli、Manuela Speranza、Roberto Zanoli。E3Cプロジェクト:ヨーロッパの臨床症例コーパスっちゅうやつやねん。Jon Alkorta、Itziar Gonzalez-Dios、Aitziber Atutxa、Koldo Gojenola、Eugenio Martínez-Cámara、Álvaro Rodrigo、Paloma Martínez(編)、スペイン自然言語処理協会の年次大会:プロジェクトとデモ部門(SEPLN-PD 2021)の論文集に載ってるやつで、スペイン自然言語処理学会(SEPLN 2021)と同時開催やったんよ。2021年9月、スペインのマラガでやってん。CEUR Workshop Proceedings第2968巻、17〜20ページ。CEUR-WS.org、2021年。URL: https://ceur-ws.org/Vol-2968/paper5.pdf。
Bonan Min、Hayley Ross、Elior Sulem、Amir Pouran Ben Veyseh、Thien Huu Nguyen、Oscar Sainz、Eneko Agirre、Ilana Heintz、Dan Roth。めっちゃでっかい事前学習済み言語モデルを使った自然言語処理の最近の進歩:サーベイ論文やで。ACM Computing Surveys、第56巻第2号、2023年9月。ISSN 0360-0300。doi: 10.1145/3605943。URL: https://doi.org/10.1145/3605943。
Niklas Muennighoff、Thomas Wang、Lintang Sutawika、Adam Roberts、Stella Biderman、Teven Le Scao、M. Saiful Bari、Sheng Shen、Zheng Xin Yong、Hailey Schoelkopf、Xiangru Tang、Dragomir Radev、Alham Fikri Aji、Khalid Almubarak、Samuel Albanie、Zaid Alyafeai、Albert Webson、Edward Raff、Colin Raffel。マルチタスクのファインチューニングで言語の壁を超えるっちゅう話やねん。なんでかっていうと、いろんなタスクを同時に学習させたら他の言語にもうまく汎化できるようになるっていう研究なんよ。Anna Rogers、Jordan L. Boyd-Graber、Naoaki Okazaki(編)、計算言語学会第61回年次大会論文集(第1巻:長論文)、ACL 2023、カナダのトロントで2023年7月9〜14日に開催。15991〜16111ページ。計算言語学会、2023年。doi: 10.18653/v1/2023.acl-long.891。URL: https://doi.org/10.18653/v1/2023.acl-long.891。
Rasha Obeidat、Xiaoli Fern、Hamed Shahbazi、Prasad Tadepalli。説明文ベースのゼロショットで細かいエンティティタイピングをやる方法やねん。ほんまにざっくり言うと、事前に見たことないタイプのエンティティでも、その説明文を使ったらちゃんと分類できるっちゅう話や。Jill Burstein、Christy Doran、Thamar Solorio(編)、北米計算言語学会2019年大会論文集:人間言語技術、第1巻(長論文・短論文)、807〜814ページ。2019年6月、アメリカのミネソタ州ミネアポリスでやってん。計算言語学会。doi: 10.18653/v1/N19-1087。URL: https://aclanthology.org/N19-1087。
Guilherme Penedo、Quentin Malartic、Daniel Hesslow、Ruxandra Cojocaru、Alessandro Cappelli、Hamza Alobeidli、Baptiste Pannier、Ebtesam Almazrouei、Julien Launay。Falcon LLM用のRefinedWebデータセット:めっちゃすごいのが、人間が丁寧に選んだデータセットよりも、ウェブデータだけで性能を上回ったっちゅうことやねん。ウェブデータオンリーでいけるんやで!CoRR、abs/2306.01116、2023年。doi: 10.48550/arXiv.2306.01116。URL: https://doi.org/10.48550/arXiv.2306.01116。
Sameer Pradhan、Alessandro Moschitti、Nianwen Xue、Hwee Tou Ng、Anders Björkelund、Olga Uryupina、Yuchen Zhang、Zhi Zhong。OntoNotesを使ったロバストな言語分析に向けてっちゅう研究やな。要は、言語をしっかり分析するための頑丈な基盤を作ろうっちゅうことやねん。Julia Hockenmaier、Sebastian Riedel(編)、計算自然言語学習に関する第17回大会論文集、143〜152ページ。2013年8月、ブルガリアのソフィアで開催。計算言語学会。URL: https://aclanthology.org/W13-3516。
Ofir Press、Noah A. Smith、Mike Lewis。短く学習して、長くテストする:線形バイアス付きのAttentionで入力の長さをめっちゃ伸ばせるようになるっちゅう話やねん。なんでかっていうと、学習時より長い入力でもうまく対応できるAttentionの仕組みを提案してるんよ。第10回学習表現に関する国際会議(ICLR 2022)、2022年4月25〜29日、オンライン開催。OpenReview.net、2022年。URL: https://openreview.net/forum?id=R8sQPpGCv0。
Alec Radford、Jeffrey Wu、Rewon Child、David Luan、Dario Amodei、Ilya Sutskeverほか。言語モデルは教師なしのマルチタスク学習者やで、っちゅう有名な論文やな。OpenAIブログ、第1巻第8号、9ページ、2019年。
Colin Raffel、Noam Shazeer、Adam Roberts、Katherine Lee、Sharan Narang、Michael Matena、Yanqi Zhou、Wei Li、Peter J. Liu。テキストからテキストへの統一的な変換器を使って、転移学習の限界を探るっちゅう研究やねん。ほんまにいろんなタスクを全部「テキスト→テキスト」のフォーマットに統一して、めっちゃ効率よく学習させたんよ。Journal of Machine Learning Research、第21巻、140:1〜140:67、2020年。URL: http://jmlr.org/papers/v21/20-074.html。
Lev Ratinov、Dan Roth。固有表現認識における設計の課題と誤解について語ってる論文やな。固有表現認識っちゅうのは、文章の中から人名とか地名とかを見つけ出すタスクのことやねん。Suzanne Stevenson、Xavier Carreras(編)、計算自然言語学習に関する第13回大会(CoNLL-2009)論文集、147〜155ページ。2009年6月、アメリカのコロラド州ボルダーで開催。計算言語学会。URL: https://aclanthology.org/W09-1119。
14
---
## Page 15
[](/attach/2d6fc0f85a9a606ac0a2f5fd13c84a1cc99a56765017ca29e32217f9553543b4_p015.png)
### 和訳
ICLR 2024の会議論文として発表
Baptiste Rozière、Jonas Gehring、Fabian Gloeckle、Sten Sootla、Itai Gat、Xiaoqing Ellen Tan、Yossi Adi、Jingyu Liu、Tal Remez、Jérémy Rapin、Artyom Kozhevnikov、Ivan Evtimov、Joanna Bitton、Manish Bhatt、Cristian Canton-Ferrer、Aaron Grattafiori、Wenhan Xiong、Alexandre Défossez、Jade Copet、Faisal Azhar、Hugo Touvron、Louis Martin、Nicolas Usunier、Thomas Scialom、Gabriel Synnaeve。「Code Llama:コード向けのオープン基盤モデル」。これな、コード書くためのめっちゃすごいオープンな基盤モデルの話やねん。CoRR, abs/2308.12950, 2023年。doi: 10.48550/arXiv.2308.12950。URL https://doi.org/10.48550/arXiv.2308.12950.
Oscar Sainz、Oier Lopez de Lacalle、Gorka Labaka、Ander Barrena、Eneko Agirre。「ラベルの言語化と含意を使った、ゼロショット・少数ショット関係抽出の効率化」。要するにな、ラベルを自然な言葉に変換して、文の含意関係をうまく使うことで、学習データがほとんどなくても関係抽出ができるようになるっちゅう話やねん。Marie-Francine Moens、Xuanjing Huang、Lucia Specia、Scott Wen-tau Yih(編)、2021年自然言語処理の経験的手法に関する会議(EMNLP)論文集、pp. 1199–1212、オンラインおよびドミニカ共和国プンタカナ、2021年11月。計算言語学会。doi: 10.18653/v1/2021.emnlp-main.92。URL https://aclanthology.org/2021.emnlp-main.92.
Oscar Sainz、Itziar Gonzalez-Dios、Oier Lopez de Lacalle、Bonan Min、Eneko Agirre。「イベント引数抽出のためのテキスト含意:マルチソース学習によるゼロショット・少数ショット」。これはな、イベントの中の「誰が」「何を」みたいな引数を抜き出す話で、テキスト含意っていう仕組みを使って、いろんなデータソースから学習することで、データがめっちゃ少なくてもいけるようにしたんやで。Marine Carpuat、Marie-Catherine de Marneffe、Ivan Vladimir Meza Ruiz(編)、計算言語学会研究発表集:NAACL 2022、pp. 2439–2455、アメリカ・シアトル、2022年7月。計算言語学会。doi: 10.18653/v1/2022.findings-naacl.187。URL https://aclanthology.org/2022.findings-naacl.187.
Oscar Sainz、Haoling Qiu、Oier Lopez de Lacalle、Eneko Agirre、Bonan Min。「ZS4IE:シンプルな言語化によるゼロショット情報抽出ツールキット」。なんでかっていうと、情報抽出って普通は大量の学習データがいるんやけど、このツールキットはシンプルな言語化だけでゼロショット、つまり学習データなしで情報抽出できるっちゅうめっちゃ便利なやつやねん。Hannaneh Hajishirzi、Qiang Ning、Avi Sil(編)、北米計算言語学会2022年会議:人間言語技術:システムデモンストレーション論文集、pp. 27–38、ハイブリッド:シアトル+オンライン、2022年7月。計算言語学会。doi: 10.18653/v1/2022.naacl-demo.4。URL https://aclanthology.org/2022.naacl-demo.4.
Oscar Sainz、Jon Campos、Iker García-Ferrero、Julen Etxaniz、Oier Lopez de Lacalle、Eneko Agirre。「NLP評価がえらいことになってる:ベンチマークごとにLLMのデータ汚染を測る必要性について」。これほんまに大事な話でな、大規模言語モデル(LLM)がベンチマークのテストデータを学習データとして見てしもてる可能性があるから、ちゃんとそのデータ汚染を一個一個のベンチマークで測らなあかんっちゅうことを言うてるんや。Houda Bouamor、Juan Pino、Kalika Bali(編)、計算言語学会研究発表集:EMNLP 2023、pp. 10776–10787、シンガポール、2023年12月。計算言語学会。doi: 10.18653/v1/2023.findings-emnlp.722。URL https://aclanthology.org/2023.findings-emnlp.722.
Oscar Sainz、Jon Ander Campos、Iker García-Ferrero、Julen Etxaniz、Eneko Agirre。「ChatGPTはあんたのテストでカンニングしたんちゃう?」。これめっちゃおもろいタイトルやけど、要はChatGPTがテストの答えを事前に見て覚えてしもてるんちゃうかっちゅう問題提起やねん。2023年6月。URL https://hitz-zentroa.github.io/lm-contamination/blog/.
Taneeya Satyapanich、Francis Ferraro、Tim Finin。「CASIE:テキストからサイバーセキュリティイベント情報を抽出する」。サイバーセキュリティ関連のニュースとかの文章から、攻撃の種類とか被害とかのイベント情報を自動で引っ張ってくるシステムの話やで。AAAI人工知能会議論文集、34(05):8749–8757、2020年4月。doi: 10.1609/aaai.v34i05.6401。URL https://ojs.aaai.org/index.php/AAAI/article/view/6401.
Teven Le Scao、Alexander M. Rush。「プロンプト1個ってデータ何個分の価値があるん?」。ほんまにええ問いやろ?プロンプトエンジニアリングって、要は少ない指示で賢く動かす技術やけど、そのプロンプト1つが実際の学習データ何個分に相当するんかを定量的に調べた研究やねん。Kristina Toutanova、Anna Rumshisky、Luke Zettlemoyer、Dilek Hakkani-Tür、Iz Beltagy、Steven Bethard、Ryan Cotterell、Tanmoy Chakraborty、Yichao Zhou(編)、北米計算言語学会:人間言語技術会議(NAACL-HLT 2021)論文集、オンライン、2021年6月6-11日、pp. 2627–2636。計算言語学会、2021年。doi: 10.18653/v1/2021.naacl-main.208。URL https://doi.org/10.18653/v1/2021.naacl-main.208.
Timo Schick、Hinrich Schütze。「穴埋め問題を活用した少数ショットテキスト分類と自然言語推論」。穴埋め問題ってあるやん、「〇〇は__である」みたいなやつ。あれをうまく使って、ほんの数個の例だけでテキスト分類とか自然言語推論ができるようにした手法やねん。Paola Merlo、Jörg Tiedemann、Reut Tsarfaty(編)、欧州計算言語学会第16回会議:メインボリューム(EACL 2021)論文集、オンライン、2021年4月19-23日、pp. 255–269。計算言語学会、2021年。doi: 10.18653/v1/2021.eacl-main.20。URL https://doi.org/10.18653/v1/2021.eacl-main.20.
---
## Page 16
[](/attach/2d6fc0f85a9a606ac0a2f5fd13c84a1cc99a56765017ca29e32217f9553543b4_p016.png)
### 和訳
ICLR 2024の学会論文として発表されたで
Karan Singhalら。大規模言語モデルは臨床知識をちゃんと覚えとるねん。CoRR, abs/2212.13138, 2022. doi: 10.48550/ARXIV.2212.13138. URL https://doi.org/10.48550/arXiv.2212.13138.
→ これな、めっちゃでかい言語モデル(いわゆるLLMってやつ)が、お医者さんが使うような医療の知識をしっかり学習して持っとるっていう話やねん。
Karan Singhalら。大規模言語モデルは臨床知識をエンコードしとるで。Nature, pp. 1–9, 2023.
→ 上のやつがNatureっていうめっちゃ権威ある雑誌にも載ったバージョンやな。
Zeqi Tanら。DAMO-NLPチームのSemEval-2023タスク2への取り組み:多言語の固有表現認識のための統合型検索拡張システム。SemEval@ACL 2023の論文集、トロント、カナダ、2023年7月13-14日、pp. 2014–2028。計算言語学会、2023. doi: 10.18653/v1/2023.semeval-1.277. URL https://doi.org/10.18653/v1/2023.semeval-1.277.
→ 固有表現認識(NERって言うねんけど、文章の中から人名とか地名とかを見つけ出す技術やな)を、いろんな言語に対応できるように検索機能を組み合わせたシステムを作ったっていう研究やで。
Simone TedeschiとRoberto Navigli。MultiNERD:固有表現認識(ついでに曖昧性解消も)のための多言語・多ジャンル・きめ細かいデータセット。計算言語学会NAACL 2022 Findings、pp. 801–812、シアトル、アメリカ、2022年7月。doi: 10.18653/v1/2022.findings-naacl.60. URL https://aclanthology.org/2022.findings-naacl.60.
→ NERの研究に使えるめっちゃ充実したデータセットを作ったで、っていう論文やな。いろんな言語とジャンルに対応しとって、細かい分類もできるようになっとるねん。
Erik F. Tjong Kim SangとFien De Meulder。CoNLL-2003共有タスクの紹介:言語に依存せん固有表現認識やで。HLT-NAACL 2003での第7回自然言語学習カンファレンス論文集、pp. 142–147, 2003. URL https://aclanthology.org/W03-0419.
→ これはNERの分野ではほんまに有名な共有タスクの紹介論文やねん。「どの言語でも使えるNERを作ろうや!」っていうコンペの始まりの論文やな。
Hugo Touvronら。Llama:オープンで効率的な基盤言語モデル。CoRR, abs/2302.13971, 2023a. doi: 10.48550/arXiv.2302.13971. URL https://doi.org/10.48550/arXiv.2302.13971.
→ MetaがオープンソースでリリースしたLlamaっていう言語モデルの論文やで。効率よく動くように作られとって、研究者がみんな自由に使えるようにしたんがめっちゃ画期的やったんよ。
Hugo Touvronら。Llama 2:オープンな基盤モデルとファインチューニング済みチャットモデル。CoRR, abs/2307.09288, 2023b. doi: 10.48550/arXiv.2307.09288. URL https://doi.org/10.48550/arXiv.2307.09288.
→ Llamaの進化版やな。今回はチャット用にファインチューニング(要するに会話がうまくなるように追加学習させたってことやな)したモデルも一緒に公開しとるねん。めっちゃ大人数の著者が関わっとるのが見てわかるやろ、それだけ大規模なプロジェクトやったんや。
Christopher Walkerら。ACE 2005多言語トレーニングコーパス。Linguistic Data Consortium, Philadelphia, 57:45, 2006. URL https://catalog.ldc.upenn.edu/LDC2006T06.
→ 自然言語処理の研究でよう使われる多言語のトレーニングデータセットやで。いろんな言語のテキストが入っとって、研究者がモデルの訓練に使うやつやな。
Ben WangとAran Komatsuzaki。GPT-J-6B:60億パラメータの自己回帰型言語モデル、2021.
→ GPT-Jっていう60億個のパラメータを持つオープンソースの言語モデルやねん。自己回帰型ってのは、前の単語から次の単語を予測していく仕組みのことやで。当時としてはオープンで使えるモデルとしてはめっちゃでかかったんや。
---
## Page 17
[](/attach/2d6fc0f85a9a606ac0a2f5fd13c84a1cc99a56765017ca29e32217f9553543b4_p017.png)
### 和訳
ICLR 2024の学会論文として発表されたで
Xiao Wangら(2023a)。InstructUIE:統一的な情報抽出のためのマルチタスク指示チューニング。これはな、いろんな情報を抜き出すタスクをひとまとめにして、指示文で学習させるっていうめっちゃ賢いアプローチやねん。CoRR, abs/2304.08085。
Xingyao Wangら(2023b)。Code4Struct:少数事例でのイベント構造予測のためのコード生成。なんでかっていうと、イベントの構造を予測するんに、コード生成の力を借りるっていう発想やねん。少ない例からでもうまいことやれるようにしてるんやで。ACL 2023(第1巻:長編論文)、トロント、カナダ、pp. 3640–3663。
Xinyu Wangら(2021)。外部コンテキストの取得と協調学習による固有表現認識の改善。要するに、固有表現(人名とか地名とかやな)を見つける精度を上げるために、外から関連情報を引っ張ってきて、さらにモデル同士で協力して学習させるっていう方法やねん。ほんまに賢いやろ。ACL-IJCNLP 2021(第1巻:長編論文)、pp. 1800–1812。
Yizhong Wangら(2022)。Super-NaturalInstructions:1600以上のNLPタスクに対する宣言的指示による汎化。これはめっちゃスケールがデカい話で、1600個以上の自然言語処理タスクに対して「こういう風にやってな」っていう指示文を用意して、それで汎用的に対応できるモデルを作ろうとしてんねん。EMNLP 2022、アブダビ、pp. 5085–5109。
Chih-Hsuan Weiら(2016)。バイオメディカル関係抽出の最先端評価:BioCreative V 化学物質-疾患関係(CDR)タスクの概要。これは生物医学の分野で、化学物質と病気の関係をどんだけうまく抜き出せるかっていうコンテストの話やな。Database誌、2016年。
Renzo M. Rivera Zabalaら(2018)。バイオメディカルテキストからの障害認識のためのハイブリッドBi-LSTM-CRFモデル。医療系の文章から障害に関する表現を見つけ出すんに、Bi-LSTMとCRFを組み合わせたハイブリッドなモデルを使ってるんやで。イベリア言語のための人間言語技術評価に関する第3回ワークショップ。
Mozhi Zhangら(2023a)。PromptNER:k近傍探索を使った少数事例固有表現認識のためのプロンプティング手法。プロンプトを工夫して、似たような例をk近傍法で探してきて、少ないデータでも固有表現をうまいこと認識できるようにしてんねん。めっちゃ実用的やで。CoRR, abs/2305.12217。
Sheng Zhangら(2023b)。対照学習によるバイエンコーダの固有表現認識向け最適化。バイエンコーダっていう二つのエンコーダを使う仕組みを、対照学習(似てるもんは近づけて、違うもんは離す学習法やな)で鍛えて、固有表現認識の性能を上げてるんやで。ICLR 2023。
Susan Zhangら(2022)。OPT:オープンな事前学習済みトランスフォーマー言語モデル。これはMeta(旧Facebook)が出した大規模言語モデルで、GPTみたいなもんをオープンに公開したったで!っていう論文やねん。ほんまにインパクトあったわ。CoRR, abs/2205.01068。
Yuhao Zhangら(2017)。位置認識アテンションと教師ありデータによるスロット充填の改善。スロット充填っていうのは、文章から特定の情報を決まった枠に埋め込むタスクやねんけど、単語の位置を意識したアテンション機構と、ちゃんとしたラベル付きデータを使うことで精度上げてるんやで。EMNLP 2017、コペンハーゲン、デンマーク、pp. 35–45。
---
## Page 18
[](/attach/2d6fc0f85a9a606ac0a2f5fd13c84a1cc99a56765017ca29e32217f9553543b4_p018.png)
### 和訳
ICLR 2024の学会論文として発表済み
Lianmin Zheng、Wei-Lin Chiang、Ying Sheng、Siyuan Zhuang、Zhanghao Wu、Yonghao Zhuang、Zi Lin、Zhuohan Li、Dacheng Li、Eric P. Xing、Hao Zhang、Joseph E. Gonzalez、Ion Stoica。「LLMを審判として使う話:MT-BenchとChatbot Arena」っていう論文やねん。CoRR, abs/2306.05685, 2023年。要するにな、大規模言語モデル(LLM)に「審判役」やらせて、チャットボットの性能をどう評価するかっていう話やで。MT-Benchっていうベンチマークと、Chatbot Arenaっていう対戦形式の評価プラットフォームを提案してんねん。doi: 10.48550/arXiv.2306.05685。URL https://doi.org/10.48550/arXiv.2306.05685。
Wenxuan Zhou、Sheng Zhang、Yu Gu、Muhao Chen、Hoifung Poon。「UniversalNER:大規模言語モデルからのターゲット蒸留でオープンな固有表現認識をやる」っていう論文や。CoRR, abs/2308.03279, 2023年。なんの話かっていうとな、でっかい言語モデルの知識を小さいモデルにギュッと「蒸留」——めっちゃ簡単に言うたら、デカいモデルが持ってる賢さをコンパクトなモデルに移し替えるってことやな——して、固有表現認識(人名とか地名とか組織名とかを文章から見つけ出すタスクのことやで)をオープンにやれるようにしたっていう研究やねん。doi: 10.48550/arXiv.2308.03279。URL https://doi.org/10.48550/arXiv.2308.03279。
18
---
## Page 19
[](/attach/2d6fc0f85a9a606ac0a2f5fd13c84a1cc99a56765017ca29e32217f9553543b4_p019.png)
### 和訳
ICLR 2024の学会論文として発表済みやで
図5:ユーザーが自分で決めたカスタムタスクにもちゃんと対応できるっていう例やな。
## A 具体例たち
図2と図3でそれぞれ見せたNER(固有表現認識)、EE(イベント抽出)、EAE(イベント引数抽出)に加えてな、RE(関係抽出)とSF(スロットフィリング)のデータもモデルに食わせとるねん。REの組み立て方はNERとだいたい一緒やけど、引数の属性が2つあるとこがちゃうねん。せやけどSFタスクはもっとややこしくてな、図6見てもらったらわかるんやけど、入力にいろんな複雑さを足しとるねん。具体的には、ありえる属性(スロット)それぞれに詳しい定義つけたり、任意の引数入れたり、「名前」「値」「文字列」みたいな型の細かい定義もしとるわけや。あと、プロンプトに制約条件も入れて、テキスト中の全テンプレート片っ端から出すんやなくて、こっちが知りたいクエリの情報だけ出すようにモデルを仕向けとるねん。今後はもっと複雑なタスクを学習と評価に追加して、モデルの能力と柔軟性をもっと上げていきたいなって思っとるで。もっと例が見たかったらGitHubリポジトリ見てな。
### A.1 新しいカスタムタスクへの汎化の例
ワイらのモデルはな、ユーザーがPythonコードで自分だけのアノテーションスキーマ(要はデータにラベル付けするルールみたいなもんや)を定義できるようになっとるねん。ここではな、「Launcher(打ち上げ機)」と「Mission(ミッション)」っていう2つの新しいエンティティタイプを定義した例を見せるで。図5を見てもらったらわかるんやけど、LauncherとMissionは単純なエンティティちゃうねん。ワイらが「テンプレート」って呼んどるもんに対応してて、エンティティと似てるけど追加の引数がある、SFタスクみたいなクラスやねん。例えば、打ち上げ機の宇宙企業とか乗組員とかが追加した引数やな。例を見てもらったらわかるけど、モデルの出力(`result = [`の後の部分全部な)がガイドラインで決めた型の制約条件をちゃんと満たしとるんよ。文字列として定義した属性にはちゃんと文字列が入っとるし、リストとして定義した引数(crewみたいなやつな)にはちゃんとリストが入っとるわけや。つまりモデルは、ワイらが新しく作ったアノテーションスキーマを使って、与えられた文をちゃんと正しく分析できとるってことやねん。めっちゃすごない?
19ページ
```python
@dataclass
class Launcher(Template):
"""地球の表面から宇宙にペイロード(荷物)を運ぶために作られた乗り物のことやで。
人工衛星、有人宇宙船、貨物なんかをいろんな軌道に、
場合によっては地球の軌道の外にまで運べるねん。
だいたいロケットエンジンで推進する多段式の乗り物やな。"""
mention: str
"""打ち上げ機の名前やで。
例えば: "Saturn V", "Atlas V", "Soyuz", "Ariane 5"とかな"""
space_company: str # 打ち上げ機を運用してる会社やな。例: "Blue Origin", "ESA", "Boeing"
crew: List[str]
"""打ち上げ機に乗り込む乗組員の名前やで。例: "Neil Armstrong", "Michael Collins", "Buzz Aldrin"とかな"""
@dataclass
class Mission(Template):
"""地球の大気圏の外に出る、特定の目的を持った計画済みまたは達成済みの旅のことやねん。
有人でも無人でもOKやで。人工衛星、国際宇宙ステーション(ISS)、
他の天体、深宇宙へのミッションが含まれるわけや。"""
mention: str
"""ミッションの名前やな。
例えば: "Apollo 11", "Artemis", "Mercury"とかやで"""
date: str # ミッション開始日
departure: str # 打ち上げ場所やな。例: "Florida", "Houston"
destination: str # 打ち上げ機が向かう場所や惑星やで。例: "Moon", "low-orbit"
# これが分析するテキストやで
text = ("Ares 3のミッションは2032年に火星に向けて予定されとるねん。SpaceXが作ったStarshipロケットが"
"Boca Chicaから打ち上がって、宇宙飛行士のMax Rutherford、Elena Soto、Jake Martinezを乗せていくで。")
# テキストの中に出てくるアノテーションのインスタンスがこれやで
result = [
Mission(mention='Ares 3', date='2032', departure='Boca Chica', destination='Mars'),
Launcher(mention='Starship', space_company='SpaceX',
crew=['Max Rutherford', 'Elena Soto', 'Jake Martinez'])
]
```
---
## Page 20
[](/attach/2d6fc0f85a9a606ac0a2f5fd13c84a1cc99a56765017ca29e32217f9553543b4_p020.png)
### 和訳
ICLR 2024の学会論文として発表
図6:TACREDデータセットをスロットフィリングタスクに変換して、コードとして表現した例やで。
B ゼロショットで見たラベルと見てないラベルの性能:もうちょい詳しく分析したで
表6:ゼロショット用のデータセットに含まれるラベルのうち、学習データセットと被ってるやつ(見たことあるやつ)と、学習データセットには全く出てきーへんかったやつ(見たことないやつ)のリストやで
データセット | 見たことあるラベル | 見たことないラベル
BroadTwitter | 場所、組織、人物 | データ漏洩攻撃、フィッシング攻撃、ランサム攻撃、脆弱性の発見、脆弱性のパッチ
CASIE | — | —
AI | — | 分野、タスク、アルゴリズム、研究者、評価指標、大学、プログラミング言語、学会
Literature(文学) | — | 本、作家、賞、詩、雑誌、文学ジャンル
Music(音楽) | — | 音楽ジャンル、曲、バンド、アルバム、ミュージシャン、楽器、賞
Politics(政治) | — | 政治家、政党
Science(科学) | — | 科学者、大学、学問分野、酵素、タンパク質、天体、学術雑誌、理論、賞
E3C | 製品、国、人物、組織、場所、その他 | 臨床エンティティ
FabNER | イベント、人物、場所、組織、国、その他 | 材料、製造プロセス、機械設備、応用、工学的特徴、機械的特性、プロセス特性評価、プロセスパラメータ、要素技術、コンセプト・原理、製造基準
Biomedical(生物医学) | イベント、国、場所、組織、人物、その他 | ポイント、エリア、道路、川
HarveyNER | — | —
Movie(映画) | 人物、組織、場所、選挙、イベント、国、その他 | 俳優、キャラクター、監督、ジャンル、あらすじ、評価、平均評価、レビュー、曲、タイトル、予告編
Year | 人物、組織、国、場所、化学元素、化合物、イベント、その他 | —
Restaurants(レストラン) | 場所、価格、営業時間 | 評価、アメニティ、レストラン名、料理名、料理ジャンル
MultiNERD | 人物、場所、組織、生物、疾患、イベント、時間、乗り物 | 動物、天体、食べ物、楽器、メディア、植物、神話
WikiEventsNER | 商業製品、施設、地政学的実体、場所、医療健康問題、金額、組織、人物、役職、数値、乗り物、兵器 | 抽象概念、身体部位、情報、紛争の当事者
WikiEventsEE | 紛争イベント、連絡イベント、一般犯罪イベント、司法イベント、医療イベント、移動輸送イベント、人事イベント、取引イベント | 人工物存在イベント、認知イベント、制御イベント、災害イベント、人生イベント
表6は、ゼロショットのデータセットごとに、学習データと被ってるラベルと、まったく見たことないラベルを分類したもんやねん。この分類はめっちゃ厳格にやってるで。例えばな、「国(COUNTRY)」っていうラベルは学習データセットには直接出てこーへんねんけど、「地政学的エンティティ(GEOPOLITICAL entity)」みたいな似たようなラベルはあるわけやん。せやから、モデルはこのラベルを学習中にもう見てるやろ、って判断してんねん。
ゼロショットのデータセットにあるラベルの中には学習データと被ってるもんもあるんやけど、ほんまに注意せなあかんのは、同じラベルでもデータセットごとにアノテーションのガイドライン(「こういう場合にこのラベル付けてな」っていうルール)がめっちゃ違うことがあるってことやねん。表7ではマイクロF1を
20
```python
# 以下はタスク定義を説明してるコードやで
@dataclass
class PersonTemplate(Template):
"""人物テンプレートってのは、指定されたクエリの人物エンティティに
関する情報をエンコードするもんやねん。"""
query: str # 人物エンティティのクエリやで
alternate_names: Optional[List[Name]] = None
"""クエリの人物を指すのに使われる別名やな。
「公式」な名前とは違うやつ。エイリアスとか芸名とか略称とか含むで。"""
date_of_birth: Optional[Value] = None
"""クエリの人物が生まれた日付やで。"""
age: Optional[Value] = None
"""クエリの人物について報告されてる年齢やな。"""
city_of_birth: Optional[Name] = None
"""クエリの人物が生まれた自治体レベル(市とか町とか村とか)の
地政学的エンティティやで"""
date_of_death: Optional[Value] = None
"""クエリの人物が亡くなった日付やねん。"""
(あと36個のスロットは折りたたんでるで)
# これが分析対象のテキストやで
text = "モンゴルのエンフボルド首相が、月曜日にここで中国共産党中央委員会の国際部副部長である劉洪才と会談したで。"
# resultっていうリストには、以下のエンティティクエリに対する
# テンプレートのインスタンスが入ってるで:
# - M. Enkhbold: PersonTemplate
result = [
PersonTemplate(
query="M. Enkhbold",
countries_of_residence=[Name("Mongolian")], # 居住国
title=[String("Prime Minister")], # 肩書き
),
]
```
---
## Page 21
[](/attach/2d6fc0f85a9a606ac0a2f5fd13c84a1cc99a56765017ca29e32217f9553543b4_p021.png)
### 和訳
ICLR 2024の学会論文として発表されたで
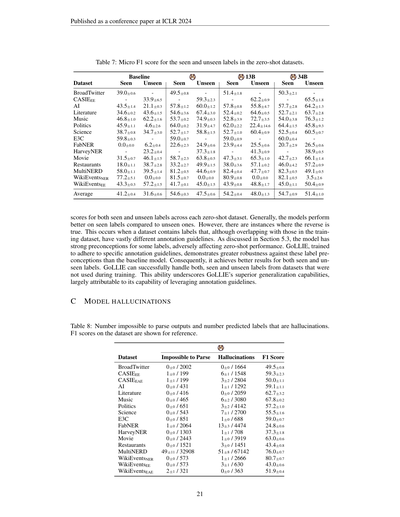
表7:ゼロショットデータセットにおける「見たことあるラベル」と「見たことないラベル」のMicro F1スコアやねん。
データセット|見た|見てない|見た|見てない|見た|見てない|見た|見てない
ベースライン|13B|34B
BroadTwitter 39.0±0.6 33.9±6.5 49.5±0.8 59.3±2.3 51.4±1.8 62.2±0.9 50.3±2.1 65.5±1.8
CASIEEE 43.5±1.4 21.1±0.3 57.8±1.2 60.0±1.2 57.8±0.8 55.8±4.7 57.7±2.8 64.2±1.3
AI 34.6±0.2 43.6±1.5 54.6±3.6 67.4±3.0 52.4±0.2 64.6±0.5 52.7±2.1 63.7±2.8
Literature 46.8±1.0 62.2±1.6 53.7±0.2 74.9±0.3 52.8±3.9 72.7±3.5 54.0±3.8 76.3±1.2
Music 45.9±1.1 4.6±2.6 64.0±0.2 31.9±4.7 62.0±2.2 22.4±14.6 64.4±1.5 45.8±9.3
Politics 38.7±0.8 34.7±3.0 52.7±1.7 58.8±1.5 52.7±1.0 60.4±0.9 52.5±0.4 60.5±0.7
Science 59.8±0.3 6.2±0.4 59.0±0.7 24.9±0.6 59.0±0.9 25.5±0.6 60.0±0.4 26.5±0.6
E3C 0.0±0.0 23.2±0.4 22.6±2.3 37.3±1.8 23.9±4.4 41.3±0.9 20.7±2.9 38.9±0.5
FabNER 31.5±0.7 46.1±1.5 58.7±2.3 63.8±0.5 47.3±3.1 65.3±1.0 42.7±2.3 66.1±1.4
HarveyNER 18.0±1.1 38.7±2.8 33.2±2.7 49.9±1.5 38.0±3.6 57.1±0.2 46.0±4.2 57.2±0.9
Movie 58.0±1.1 39.5±1.4 81.2±0.5 44.6±0.9 82.4±0.4 47.7±0.7 82.3±0.5 49.1±0.5
Restaurants 77.2±5.1 0.0±0.0 81.5±0.7 0.0±0.0 80.9±0.8 0.0±0.0 82.1±0.5 3.5±2.6
MultiNERD 43.3±0.3 57.2±1.5 41.7±0.1 45.0±1.5 43.9±0.8 48.8±1.7 45.0±1.1 50.4±0.9
WikiEventsNER
WikiEventsEE
平均 41.2±0.4 31.6±0.6 54.6±0.3 47.5±0.6 54.2±0.4 48.0±1.3 54.7±0.9 51.4±1.0
ほんで、ここからが面白いとこやねんけどな。「見たことあるラベル」と「見たことないラベル」のスコアを各ゼロショットデータセットで見てみると、だいたいのモデルは「見たことあるラベル」の方が成績ええねん。まあそりゃそうやろって話やな。
せやけどな、逆転してるケースもあんねん。なんでかっていうと、トレーニングデータと同じラベル名やのに、アノテーション(ラベル付け)のルールがめっちゃ違うデータセットがあるからやねん。セクション5.3でも触れてるけど、モデルって一部のラベルに対して「こういうもんやろ」っていう強い思い込みみたいなもんを持ってもうてて、それがゼロショットの成績を悪くしてまうことがあるわけや。
ここでGoLLIEの出番やねん。GoLLIEは「アノテーションガイドライン(ラベル付けのルール)に従え」って訓練されてるから、こういうラベルへの思い込みにめっちゃ強いねん。ベースラインのモデルよりずっとロバスト(頑健)やで。結果として、見たことあるラベルも見たことないラベルも両方ええ成績出せてるわけや。しかもこれ、トレーニングで使ってないデータセットのラベルやで?ほんまにすごいやろ。これはGoLLIEの汎化能力(初めて見るデータにも対応できる力)がめっちゃ優れてることを示してて、その秘密はアノテーションガイドラインを活用できる能力にあるんやな。
## 付録C:モデルのハルシネーション(幻覚)
表8:パースできへんかった出力の数と、モデルが勝手に作り出してもうた(ハルシネーション)ラベルの数やねん。参考としてF1スコアも載せとくで。
データセット|パースできへんかった数|ハルシネーションの数|F1スコア
BroadTwitter 0±0 / 2002 0±0 / 1664 49.5±0.8
CASIEEE 1±0 / 199 6±1 / 1548 59.3±2.3
CASIEEAE 1±1 / 199 3±2 / 2804 50.0±1.1
AI 0±0 / 431 1±1 / 1292 59.1±1.1
Literature 0±0 / 416 0±0 / 2059 62.7±3.2
Music 0±0 / 465 6±2 / 3080 67.8±0.2
Politics 0±0 / 651 3±2 / 4142 57.2±1.0
Science 0±0 / 543 7±1 / 2700 55.5±1.6
E3C 0±0 / 851 1±0 / 688 59.0±0.7
FabNER 1±0 / 2064 13±3 / 4474 24.8±0.6
HarveyNER 0±0 / 1303 1±1 / 708 37.3±1.8
Movie 0±0 / 2443 1±0 / 3919 63.0±0.6
Restaurants 0±0 / 1521 3±0 / 1451 43.4±0.8
MultiNERD 49±11 / 32908 51±8 / 67142 76.0±0.7
WikiEventsNER 0±0 / 573 1±1 / 2666 80.7±0.7
WikiEventsEE 0±0 / 573 3±1 / 630 43.0±0.6
WikiEventsEAE 2±1 / 321 0±0 / 363 51.9±0.4
「パースできへん」っていうのは、モデルが出した答えがフォーマット的に読み取れへんかったやつのことやで。「ハルシネーション」は、モデルが「こんなラベルあるで!」って自信満々に出してきたけど、実際にはそんなラベル定義されてへんかったやつのことやねん。要するにモデルの妄想やな。MultiNERDだけちょっと多いけど、全体的にはめっちゃ少ないから、GoLLIEはかなり信頼できるモデルやってことやで。
---
## Page 22
[](/attach/2d6fc0f85a9a606ac0a2f5fd13c84a1cc99a56765017ca29e32217f9553543b4_p022.png)
### 和訳
ここのセクションではな、モデルが生み出すハルシネーション(でっち上げ)を評価してんねん。2つの違う現象を調べてるで。まず1つ目は、出力がめちゃくちゃに壊れてもうて、パース(解析)すらでけへんケースやねん。こういう場合は、出力を空っぽのリストとして扱うことにしてんねん。2つ目は、モデルが「ハルシネーションラベル」、つまり入力で定義されたクラスにないラベルを勝手に出力してまうケースやな。この場合は、そのラベルを出力からポイッと取り除いてんねん。表8で示されてる通り、ゼロショットの全データセットにおいて、どっちの現象も予測の1%未満しか起きてへんねん。これが何を意味するかっていうと、GoLLIEはハルシネーションにめっちゃ強くて、入力で定義されたクラスにちゃんと忠実に従うってことやねん。
**D 拡張トレーニングの詳細**
**D.1 ロス(損失)の計算**
モデルの学習には標準的な「次のトークン予測(NTP)」のロスを使ってんねん。ただな、モデルに適用したいくつかの正則化のせいで、ガイドラインのトークンに対するロスが、実際の出力トークンに対するロスよりもめっちゃ高くなってもうてん。なんでかっていうと、ガイドラインの順番をランダムにシャッフルしたり、名前をマスクしたり、クラスを丸ごと落としたりしてるから、次に何が来るか予測するんがほぼ不可能になるねん。ガイドライントークンのロスが実際の出力トークンのロスを圧倒してまうのを避けるために、ロスの計算は出力トークンだけに絞ることにしてん。こうすることで、ガイドラインへのオーバーフィッティング(過学習)も防げるんやな。結果として、学習がもっと速くなって、全体的にええ結果が出たわけや。
**D.2 データセットの詳細**
表9は各トレーニング用データセットとゼロショット用データセットのサンプル数を示してるで。OntoNotesは半自動的に生成されたもんで、他のデータセットより桁違いにデカいねん。やから、各トレーニングエポックごとに、トレーニングセットからランダムに30,000個のサンプルを抽出してんねん。モデルは3エポック学習させて、実効バッチサイズは32、学習率は3e-4でコサインスケジューラを使ってるから、合計で15,485ステップのトレーニングを行ってるわけやな。
データの分割についてやけど、すべてのデータセットで標準的なtrain/dev/testの分割を使ってるで。ACEの場合はLin et al.(2020)が提供した分割に従ってて、CASIEの場合は最初の200個をバリデーション用、最後の2000個をテスト用にしてんねん。
表9:各トレーニング用データセットとゼロショット用データセットのサンプル数
| データセット | Train | Dev | Test |
|---|---|---|---|
| ACE05NER | 19217 | 901 | |
| ACE05RE | 19217 | 676 | |
| ACE05EE | 19217 | 901 | |
| ACE05EAE | 3843 | 676 | 397 |
| ACE05RC | 5691 | 4582 | 368 |
| ACE05VER | 19217 | 3250 | 4798 |
| BC5CDR | 4561 | 793 | 3453 |
| CoNLL 2003 | 14041 | 924 | 1309 |
| DIANN | 3976 | 15680 | 941 |
| NCBIDisease | 5433 | 924 | 12217 |
| Ontonotes 5 | 30000 | 3896 | 871 |
| RAMS | 7329 | 1009 | 2311 |
| TACRED | 10027 | | 1287 |
| WNUT 2017 | 3394 | | |
| **合計** | **165163** | **33708** | **30033** |
| データセット | 合計 |
|---|---|
| BroadTwitter | |
| CASIEEE | 2002 |
| CASIEEAE | 199 |
| AI | 199 |
| Literature | 431 |
| Music | 416 |
| Politics | 465 |
| Science | 651 |
| E3C | 543 |
| FabNER | 851 |
| HarveyNER | 2064 |
| Movie | 1303 |
| Restaurants | 2443 |
| MultiNERD | 1521 |
| WikiEventsNER | 32908 |
| WikiEventsEE | 573 |
| WikiEventsEAE | 573 |
| | 321 |
| **合計** | **47463** |
---
## Page 23
[](/attach/2d6fc0f85a9a606ac0a2f5fd13c84a1cc99a56765017ca29e32217f9553543b4_p023.png)
### 和訳
ICLR 2024の学会論文として発表
表10:各モデルの学習に必要なリソースの詳細やで。
モデル | ハードウェア | FLOPs | 時間(h) | CO2排出量(kg)
Baseline | 1xA100 | 4.5e18 | 17.3 | 0.61
GoLLIE | 1xA100 | 11.9e18 | 44.5 | 1.57
13B | 1xA100 | 22.7e18 | 79.5 | 2.80
34B | 2xA100 | 55.8e18 | 94.6 | 6.67
D.3 カーボンフットプリントの話
大規模言語モデルのファインチューニング、つまり追加学習ってやつは、ゼロから学習させるのに比べたらそこまでコストかからへんねん。けどな、ワイらの実験が地球にどんだけ影響あるんかはちゃんと測って記録しとくべきやと思うわけよ。表10に実験1回分に必要なリソースをまとめとるで。全部の実験はワイらの自前のインフラでやったんや。CO2排出量の見積もりは、GPU1台あたり400Wの消費電力で、炭素強度が0.141 kg/kWhっていう数字†を使って計算しとるで。
D.4 LoRAと全パラメータファインチューニングの比較
QLoRA(Huら、2022; Dettmersら、2023)、要するにパラメータの一部だけ学習する方法と、モデルの全パラメータを学習する方法を比べる予備実験をやったんや。この実験にはLLaMA2 7Bモデル(Touvronら、2023b)と初期バージョンのコードを使ったんやけど、両方とも実験の条件は全く同じにしとるで。どっちのやり方もガイドライン付きのプロンプトで動かしたんや。
まず、学習時の損失(ロス)を比べてみたんやけど、図7を見てくれたらわかるように、全パラメータを学習させた場合はロスがめっちゃ早く下がるんやわ。LoRA層だけ学習する場合よりもずっと速くてな、学習の最後にはより低いロスに到達するんや。けどな、ここがおもろいとこやねんけど、1エポック目と3エポック目の終わりにモデルを評価してみたら、全パラメータ学習の方がめっちゃ性能悪いっていう結果が出たんや(表11参照)。
なんでかっていうと、全パラメータを学習させると、モデルがすぐに過学習してしまって(ロスが低いのはそのせいやねん)、学習データを丸暗記しちゃうんやと考えとるわけよ。一方でLoRA層だけの学習は、モデル全体のパラメータのたった0.5%くらいしか動かさへんから、それがボトルネック、つまり「しぼり」みたいな役割を果たして、丸暗記を防いでくれるんやな。
あとこれも注目してほしいんやけど、QLoRAのアプローチは凍結したモデルを4ビットに量子化する技術(Dettmersら、2023)のおかげで、Nvidia A100 80GBのGPUたった1台で学習できたんや。それに対して全パラメータの学習は、モデルをメモリに載せるだけでも最低4台のNvidia A100 80GB GPUが必要やったんやで。学習時には4台のGPUにモデルを分散させるためにDeepSpeed‡を使ったんや。学習コストがめっちゃ高いから、全パラメータモデルのハイパーパラメータ探索は大規模にはやってへんのが正直なところやな。
図7:全パラメータのファインチューニングとLoRA層のみの学習の、学習ロスの比較やで。
†https://app.electricitymaps.com/map から取った統計値や
‡github.com/microsoft/DeepSpeed
23
---
## Page 24
[](/attach/2d6fc0f85a9a606ac0a2f5fd13c84a1cc99a56765017ca29e32217f9553543b4_p024.png)
### 和訳
ICLR 2024の学会論文として発表されたやつやで
表11:モデル全体を学習させた場合と、LoRAレイヤーだけを学習させた場合の、1エポック目と3エポック目終了時点でのF1スコアの比較やねん。
| 学習方法 | エポック | 精度 | 学習率 | HarveyNer | FabNER | Restaurant | Movie | CASIEEE | CoNLL03 |
|---|---|---|---|---|---|---|---|---|---|
| Full | 1 | BF16 | 1e−4 | 0.00 | 0.00 | 0.25 | 4.74 | 0.00 | 85.57 |
| Full | 3 | BF16 | 1e−4 | 3.45 | 0.21 | 46.7 | 16.72 | 0.42 | 84.83 |
| QLoRA | 1 | 4Bit + BF16 | 2e−3 | 34.98 | 20.78 | 45.01 | 51.14 | 55.83 | 91.41 |
| QLoRA | 3 | 4Bit + BF16 | 2e−3 | 35.34 | 16.21 | 39.07 | 44.18 | 57.93 | 93.14 |
## E ラベルが何百個もあるデータセットと、コードスタイルのプロンプトのオーバーヘッドの話
ワイらの研究では、ラベルが20個未満のデータセットに絞って取り組んでんねん。でもな、FIGERみたいなデータセット(Ling & Weld, 2012)やと、めっちゃ細かいラベルが何百個もあるわけよ。ほんで、こういう何百個もラベルがあるデータセットにガイドラインまで入れてしもたら、入力がアホみたいに長くなって、今の大規模言語モデル(LLM)のコンテキストサイズ——つまりモデルが一度に読める文章の長さの上限——を超えてまうねん。これはLLMのよく知られた制約で、最近はコンテキストウィンドウを効率よく広げるアルゴリズムの研究がめっちゃ盛んにやられとる(Press et al., 2022)。将来のLLMやったら、もっとたくさんのラベルだけやなくて、もっと詳しいガイドラインまで余裕で入るぐらいのコンテキストウィンドウを持つようになるやろなぁと期待しとるで。今のところは、ラベルをバッチに分けて複数の入力に振り分けることでこの問題を緩和できるねん。例えばな、100個のラベルを1つの入力にドカッと突っ込むんやなくて、10個ずつに分けて10回入力して、最後にその出力を全部まとめて1つの回答にするっちゅうやり方やな。まぁいずれにしても、ラベル数がめっちゃ多いデータセットの扱いはGoLLIEの限界の一つやねんけどな。
図8:コードスタイルのプロンプトを表現するのに、入力全体の文字数のうち何パーセントが必要かっていうグラフやで。ラベルごとに出してんねん。詳しいガイドラインがある場合は、コード部分の割合はほんまにちょっとやねん。
ワイらのアプローチはPythonベースのコードスタイルのプロンプトを使ってんねんけど、これやとコードの構造を表すためのトークン——要するにプログラムの書き方を示すための余分な文字列やな——を入力に含めなアカンわけよ。図8では、いろんなラベルをワイらのコードスタイルの入力形式で書いたものと、それぞれのガイドラインを一緒に載せてるで。めっちゃざっくりしたガイドラインの場合、例えばOntoNotes 5のPERSON(人物)エンティティみたいなんやと、コード構造が入力の文字数のほぼ半分を占めてまうねん。せやけど、詳しいガイドラインがある場合、例えばHarveyNERのPOINT(地点)エンティティみたいなんやと、コード構造の部分はほんまにちょっとで済むねん。コード構造を表現するためのトークンのオーバーヘッドはあるんやけど、ラベルがめっちゃ大量にあるデータセットを扱う場合の本質的なボトルネックは、Pythonのコード構造を入れるスペースやなくて、ガイドラインの定義そのものをモデルの入力に収めることのほうやねん。
24ページ
```
@dataclass
class Person(Entity):
"""フィクションも含めた人物のことやで。"""
span: str # "Bush", "Clinton", "Barak", "Noriega", "Putin"
@dataclass
class Actor(Entity):
"""映画で役を演じる個人のことを指すねん。主演俳優、脇役、カメオ出演も全部含むで。
テレビとか舞台とか他のメディアで知られてる人でも、映画にも出てたらここではActorに
なるわけやな。"""
span: str # "johnny depp", "brad pitt", "tom hanks", "tom cruise", "clint eastwood"
@dataclass
class Point(Entity):
"""建物、ランドマーク、2つの道路の交差点、川と湖・貯水池・海の合流地点、
もしくは特定の住所のことやで。チェーン店みたいな一般的な企業名は無視してな。
ただし「Kirkwood DriveのHEB」みたいに具体的な場所が付いてたらOKやで。
あと、1店舗しかないような個人経営の店はPointに入れてええで。
Twitterのユーザー名に含まれる場所は無視してな。ただし@がTwitterアカウント名を
指してへん場合は別やで。例えば「I am @ XXX High School」みたいなやつな。"""
span: str # "GRB", "GEORGE R. BROWN", "Lakewood Church", "Bayou Oaks",
# "Northgate Subdivision S of toll road"
Ontonotes 5 - Person → コード比率: 0.43
MIT Movie - Actor → コード比率: 0.13
HarveyNER - Point → コード比率: 0.08
```
---
## Page 25
[](/attach/2d6fc0f85a9a606ac0a2f5fd13c84a1cc99a56765017ca29e32217f9553543b4_p025.png)
### 和訳
ほな、翻訳いくで〜!
---
ICLR 2024の学会論文として発表
**F プロンプト作るのにどんだけ人の手間かかるん?って話**
GoLLIEっていうモデルはな、入力をPythonのコードっぽい形式に整えなあかんねん。これはどうやっとるかっていうと、タスクごと(固有表現認識、イベント抽出、イベント引数抽出、関係抽出、スロットフィリング)にあらかじめ用意したテンプレートを埋めていく方式やねん。このテンプレート一式はコードと一緒に公開するから安心してな。新しいデータセットに対応するときも、ラベルの一覧とそれぞれのラベルのガイドライン(「こういう意味やで」っていう説明書きな)を定義するだけでええねん。しかもそのガイドラインは、データセットの作者さんが元々書いてくれてるやつをそのまま使い回しとるから、ほとんどのデータセットではめっちゃ簡単で、人の手間はほぼかからへんねん。ただし、TACREDみたいにガイドラインがめちゃくちゃ長くて複雑なやつは、人間が手作業で要約せなあかんかったけどな。それでも、その分野の専門家がおらんとあかんってことはないで。あと、入力データはテンプレートから自動生成されるから、新しいデータセット対応するのにPythonのコーディング知識もいらんのや。
一部のデータセットはガイドラインが公開されてへんかったんよ。半自動で作られたやつとか、作者が「公開せーへんで」って決めたやつとかな。そういうデータセットに限っては、開発用データの実例を見ながら人間の専門家がガイドラインを作らなあかんかったわ。ワイらが作ったガイドラインは今後の研究に役立つように公開する予定やで。ガイドラインもアノテーション(正解ラベル付け)もない全く新しいタスクにGoLLIEを適用するには、やっぱり人間の専門家が必要やねん。でもこれはGoLLIEだけの話やなくて、他のどんな情報抽出モデルでも同じ条件やから、しゃーないな。
**G データ汚染についてちゃんと言うとかなあかんこと**
データ汚染ってのはな、要するに「テストに出る問題を事前にカンニングしてもうてるんちゃうか?」って問題やねん。これは最近のNLP(自然言語処理)の評価でめっちゃ深刻な問題になっとって、大規模言語モデル(LLM)が普及してからますますヤバくなってきとるんよ(Dodgeら, 2021; Magar & Schwartz, 2022; Sainzら, 2023b;a)。あるデータセットがLLMの学習データに含まれてたかどうかを見抜くんは、学習データそのものが手元にあっても難しいんやで。ほんで残念なことに、この論文ではワイらのモデルの土台であるCode-LLaMAの学習データにアクセスでけへんのよ。これが特に心配やねんけど、なんでかっていうと、汚染の大きな原因の一つがGitHubとかのコードリポジトリで、そこには評価用のベンチマークデータもアップロードされとるからやねん(Dodgeら, 2021)。Code-LLaMAはコードで学習しとるから、このデータ漏洩が起きとる可能性はあるわけや。せやけどな、ワイらの比較実験は全部、GoLLIEと同じ土台のLLMを使ったベースラインとの比較やねん。仮に結果がデータ汚染の影響を受けてたとしても、ベースラインに対するGoLLIEの改善幅には影響せーへんのよ。なんでかっていうと、両方とも同じ学習データで事前学習されとるから、条件は一緒やねん。将来的にはもっと透明性が高まって、より安全な評価ができるようになることを願っとるわ。
25
---
![]()
1 / 1
100%