<<
Language-Models-as-a-Service Overview of a New Paradigm and its Challenges.pdf

---
## Page 1
[](/attach/2bb7904744e26e395d3db068e172c29038af52b4b45b4500d5111619e4eff7d1_p001.png)
### 和訳
Journal of Artificial Intelligence Research 80 (2024) 1497-1523
2024年1月投稿、2024年8月出版
言語モデル・アズ・ア・サービス:
新しいパラダイムとその課題についての概要
エマヌエーレ・ラ・マルファ
オックスフォード大学 コンピュータサイエンス学科
イギリス オックスフォード OX1 3QG
アラン・チューリング研究所
イギリス ロンドン NW1 2DB
アレクサンダル・ペトロフ
オックスフォード大学 工学部
イギリス オックスフォード OX1 3PJ
サイモン・フリーダー
オックスフォード大学 コンピュータサイエンス学科
イギリス オックスフォード OX1 3QG
ウィーン工科大学 情報学部
オーストリア ウィーン 1040
クリストフ・ヴァインフーバー
オックスフォード大学 コンピュータサイエンス学科
イギリス オックスフォード OX1 3QG
ライアン・バーネル
アラン・チューリング研究所
イギリス ロンドン NW1 2DB
ラザ・ナザール
オックスフォード大学 法学部
イギリス オックスフォード OX1 3UL
アンソニー・G・コーン
リーズ大学 コンピューティング学部
イギリス リーズ LS2 9JT
アラン・チューリング研究所
イギリス ロンドン NW1 2DB
ナイジェル・シャドボルト
マイケル・ウールドリッジ
オックスフォード大学 コンピュータサイエンス学科
イギリス オックスフォード OX1 3QG
アラン・チューリング研究所
イギリス ロンドン NW1 2DB
emanuele.lamalfa@cs.ox.ac.uk
aleksandar.petrov@eng.ox.ac.uk
simon.frieder@cs.ox.ac.uk
christoph.weinhuber@cs.ox.ac.uk
rburnell@turing.ac.uk
razanazar1@gmail.com
a.g.cohn@leeds.ac.uk
nigel.shadbolt@cs.ox.ac.uk
michael.wooldridge@cs.ox.ac.uk
要旨
今一番パワフルな言語モデルって、実はプロプライエタリなシステムが多いねん。ウェブとかプログラミングのインターフェースからしかアクセスできへんし、しかもそれがけっこう制限きついんよ。これが「言語モデル・アズ・ア・サービス」、略してLMaaSっていうパラダイムやねん。オープンソースのモデルみたいにモデル全体にアクセスできる状況とは違って、こういう閉じた言語モデルには、評価したりベンチマークしたりテストしたりするときに独特の難しさがあるんよな。
この論文、目的が2つあんねん。まず1つ目は、さっき言うた課題がLMaaSのアクセシビリティ、再現性、信頼性、そしてトラストワージネスをどう邪魔してるかを明らかにすることやな。言語モデルについての情報が足りへんことで、この4つの側面それぞれにどんな問題が起きるか、体系的に調べてんねん。既存の解決策をめっちゃ詳しく分析して、いくつかの提言を出して、これからどう進めていったらええかも示してるで。2つ目は、人気のLMaaSのライセンスと機能についてまとめた概要としても使えるようになってんねん。
©- 著者ら。AI Access FoundationよりCreative Commons表示ライセンス CC BY 4.0のもとで出版。
---
## Page 2
[](/attach/2bb7904744e26e395d3db068e172c29038af52b4b45b4500d5111619e4eff7d1_p002.png)
### 和訳
La Malfaらの研究チーム
1. はじめに
自然言語処理(NLP)っちゅう分野はな、ここ数年でめっちゃ大きく変わったんやで。なんでかっていうと、Transformerベースの言語モデル(LM)っちゅうのが登場したからやねん(Vaswaniら、2017年;Devlinら、2019年;Radfordら、2019年)。デカいモデルにアクセスしやすくなったんが、研究が進む上でほんまに大事やったんや(Wolfら、2019年)。それを支えたんが、研究機関や企業が使えるデータと計算資源の規模やねん(Kaplanら、2020年)。5年もせんうちに、最先端のモデルはGPU数台でトレーニングできる小さいやつ(Petersら、2018年;Devlinら、2019年)から、専用のデータセンターやスパコンが必要なめっちゃデカくて複雑なやつ(Raffelら、2020年;Raeら、2021年)に進化したんやけど、そういう環境を整えるのはえらいお金かかるねん。商売的なうまみがあるから、高性能なデカい言語モデルが開発されてきたんやけど、これらはサービスとしてだけ使えるようになってて、ユーザーがテキスト入力したら文字列やトークンを返してくれるんやけど、アーキテクチャとか実装方法とか、どうやってトレーニングしたかとか、トレーニングデータの情報は公開されてへんし、中身を覗いたり内部の状態をいじったりもできへんねん。
このやり方は「Language-Models-as-a-Service(LMaaS)」って呼ばれてて(Sunら、2022年)、言語モデルを中央でホストして、だいたいサブスク制か使った分だけ払う方式で提供するライセンスモデルやねん。今どきのLMaaSは、前はバラバラやったいろんなサービスを一つのポータルにまとめてくれてるんや。検索エンジンの領域やった情報へのアクセスから、データ分析とか画像生成とか、めっちゃいろんな分野の問題解決ツールまであるねん(Romera-ParedesとTorr、2015年;Brownら、2020年;Lewisら、2020年;OpenAI、2023年)。こういうサービスはめっちゃ急成長して、今や何億人ものユーザーに使われてるんやで。モデルの性能が上がるんと同時に、悪用されるリスクも高まってて、例えばバイオテクノロジーの兵器化とか大規模監視とかの問題があるねん(Hendrycksら、2023年)。他の最近の研究でも、LMaaSや人間の価値観と合ってへん言語モデルのリスクが指摘されてるんや(Bommasaniら、2021年)。そのせいで、これらのモデルに組み込まれた価値観やバイアスを理解しようっちゅう関心がめっちゃ高まってて、価値観を人間のものと合わせたり、バイアスを軽減したりしようとしてるねん(Ganguliら、2022年;Liuら、2022年;Santurkarら、2023年)。
せやけどな、LMaaSにはアクセス制限があって、しかもブラックボックスやから、一般の人や研究コミュニティがそれらをちゃんと理解して、信頼して、コントロールしたいっちゅうニーズと矛盾してるんや(図1参照)。これは人工知能の核心にある大きな問題を引き起こしてるねん。つまり、一番パワフルで経済的にインパクトがあるけど、同時に一番リスキーなモデルが、一番分析しにくいっちゅうことやねん。言語モデルはいろんなライセンスで公開されてて、オープンソースから「オープンウェイト」みたいなもうちょっと制限のあるやつまであるんや(注1)。でも、一回手に入れたら中身を調べられるし、エンドユーザーが柔軟に動作をコントロールできるねん。一方でLMaaSは商用ライセンスが付いてて、ほとんどクローズドソースで、エンドユーザーがコントロールできる範囲は限られてて、有料サブスクでアクセスすることが多いんや。今、何千ものアプリケーションがLMaaSで動いてて(注2)、その内部パイプラインは生成モデルの出力(または内部表現)に依存してるんやけど、その内部メカニズムは非公開にされてるねん。そういう意味で、LMaaSを信頼するっちゅうのは、それを使った製品を信頼するための必要条件ではあるけど十分条件ではないんや。エンドユーザーにとっても、それを採用する企業にとってもな。こういう問題の一部は言語モデル全般に対する既存の懸念とは別の話やけど、基本的にLMaaSの特殊性がこれらの問題をさらにややこしくしたり、評価や軽減をめっちゃ難しくしたりしてるんや。このパラダイムから生じる困難を、アクセシビリティ、再現性、信頼性、そして信用性の4つのカテゴリに分けてるで。
• アクセシビリティ - セクション3.1。LMaaSはよくAPI(アプリケーションプログラミングインターフェース)やウェブインターフェースを通じてアクセスできるようになってて、無料、従量課金制、またはサブスク制の支払い方法があるねん。使うには、商用
注1: https://github.com/Open-Weights/Definition、2024年6月19日アクセス
注2: https://openai.com/index/gpt-3-apps/、2023年12月29日アクセス
1498
---
## Page 3
[](/attach/2bb7904744e26e395d3db068e172c29038af52b4b45b4500d5111619e4eff7d1_p003.png)
### 和訳
言語モデルのサービス化(LMaaS)について
図1: LMaaSと自分で管理する言語モデルの違いを示した図やねん。
ほとんどの言語モデルって、フルで提供されとる場合は、モデルの中身(重みとかな)にアクセスできるし、どうやって学習させたかとか、自分のパソコンでどう動かすかとかも詳しく書いてくれてるんよ。せやから、モデルの中でなにが起こってるか調べられるし、好きなハードウェアで動かしたり、改造したりもできるわけや。
でもな、LMaaSっていうのは、ウェブサイトかAPIでしかアクセスできへんねん(上の図のAPIの呼び出し方はOpenAIっぽく描いてるで)。裏で動いてる言語モデルは、だいたい他の会社が管理してるサーバーで走ってて、ユーザーに見せてくれる情報って、一般的なレポートとかモデルカード(Wolf et al., 2019)くらいしかないんよ。
それとな、ライセンスの問題もあんねん。企業がユーザーのプロンプト(入力した文章な)を集めてモデル改善に使ってええっていう権利を認めてるライセンスもあるんよ。言語モデル自体は、この論文の最初のセクションで触れるいくつかの例外を除いて、だいたいアクセスしやすくて、緩いライセンスで使えることが多いねん。あと、LMaaSの利用料金って、使いたい人の経済状況とあんまり噛み合ってへんことがあって、特定の層の人らが不利になる可能性もあるんよな。
**再現性について - セクション3.2**
LMaaSって、継続的デリバリー/デプロイメントっていう仕組みで運用されてんねん。なんかっていうと、古いモデルがどんどん新しいのに置き換えられて、前のやつは完全になくなってまうこともあるんよ。しかも事前にあんまり知らせてくれへんこともあるわけや。これがめっちゃ困るんよな。なんでかっていうと、もうなくなったモデルを評価できひんし、バージョン間の比較もできへんようになるからや。しかもな、LMaaSって本質的に結果がランダムに変わることがあるし、サービス提供者が設定できるオプションも限られてるから、再現性がほんまに制限されてまうねん。
**信頼性について - セクション3.3**
言語モデルやLMaaSがいろんなタスクや問題でちゃんと動くかベンチマーク(性能テストみたいなもんや)するのが、モデルの信頼性を確認する方法なんよ。どの言語モデルでもベンチマークするには、めっちゃ計算リソースと人手がかかって、簡単にはいかへんねんけど、LMaaSの場合は、自分で管理するモデルと比べてさらに難しい問題が出てくるんよ。
例えば、データセットの汚染とかユーザーの汚染っていう問題があんねん。これ何かっていうと、モデルがまだ見てへんテスト用のサンプルを作るのがめっちゃ難しいっていうことや。
---
## Page 4
[](/attach/2bb7904744e26e395d3db068e172c29038af52b4b45b4500d5111619e4eff7d1_p004.png)
### 和訳
La Malfaさんたち
分布外テストセット)とか、あと創発性の評価(つまり、言語モデルとかLMaaSの「なんか急に出てきたみたいな能力」がどっから来てんのか突き止めることやな)。
・**信頼性** - セクション3.4やで。基本的な入出力の操作で判断プロセスが見えて理解できるモデルのことを「自己説明型」って呼ぶねんけど、LMaaSはそのカテゴリには入らへんねん。どっちかっていうと説明テクニックの方やな。その説明は条件付きのプロンプトから出てきてて、他のどんなクエリとも同じように処理されるわけや。そういう意味で、モデルの内部にアクセスせなあかん説明テクニックは全部LMaaSには使われへんねん。
これらの問題カテゴリ見てると、LMaaSはSaaS(サービスとしてのソフトウェア)っていう性質があるから慎重に扱わなあかんし、ちゃんとした規制の枠組みと、こういうサービスへのアクセスを提供してる会社が実装するポリシーが必要やってことがわかるわ。この論文はセクション4で締めくくるんやけど、そこではLMaaSが引き起こす一番緊急の問題を軽減するための戦略をいくつか示してるねん。これが研究コミュニティと企業がLMaaSをもっとアクセスしやすく、再現可能で、信頼できて、信用できるもんにするのに役立つことを願ってるわ。企業と研究コミュニティが上記の価値観を植え付けて維持するために、お互い補完し合う役割を果たしてるってことを強調しときたいな。
## 2. 関連研究
言語モデルが成功して、それに伴う商業的な関心とLMaaSパラダイムの登場を支えた要因がいくつかあるねん。このセクションでは、こういう発展についてざっくりレビューするで。
**言語モデル**。自然言語理解に向けた計算モデルとアプローチは、ここ数十年でめっちゃたくさん開発されてきたんや(Goldberg, 2016)。でもな、最近まではパフォーマンスがそこそこやったから、商業的にはあんまりいけてなかったんよ。せやけど、Transformerアーキテクチャ(Vaswani et al., 2017)が登場してな、これは以前のアテンションメカニズムの研究(Bahdanau et al., 2015; Niu et al., 2021)にインスパイアされたもんやねんけど、深層学習ベースの言語モデルをもっと効率的にトレーニングできるようになったんや。大規模なテキストデータをトレーニングに活用できるようになったってことやな。その結果、Transformerベースの言語モデルのパフォーマンスはあっという間に以前のすべての手法を追い抜いたんや(Devlin et al., 2019)。大規模なTransformerベースのモデル、その中でも言語モデルが一番うまくいった実装やねんけど、これらはゼロショットとフューショットの振る舞いも見せるんや。つまり、入力プロンプトの一部として例がゼロ個か数個しか与えられへんでも新しいタスクを解ける能力のことやで(Chang et al., 2008; Brown et al., 2020)。こういう振る舞いはモデルのサイズに比例してスケールするから(Kaplan et al., 2020)、もっとでっかいモデルの開発につながったんや。このスケーリングは、めちゃくちゃ大量のトレーニングデータセットの収集(Shanahan, 2022; Zhao et al., 2023)、新しいトレーニングとファインチューニング技術の開発(Houlsby et al., 2019; Hu et al., 2021; Bai et al., 2022)、あとコンピューティングハードウェアの改善にも支えられてたんやで。
それと並行して、研究コミュニティは言語モデルとそのゼロショット・フューショットの振る舞いの評価(Xian et al., 2018; Chang et al., 2023)、あと組み合わせ推論が必要なタスクを解く能力(と限界)に焦点を当ててきたんや(Dziri et al., 2023; McCoy et al., 2023b)。例えば、最近の研究では、動的ベンチマークのスイート、行動テスト、ドメイン外分析みたいな、未見のデータポイントでの能力をテストする技術が提案されてるんや(Ribeiro et al., 2020; Kiela et al., 2021; Zhou et al., 2022)。めっちゃ印象的なパフォーマンス見せてるにもかかわらず、最先端の言語モデルはまだ感情分析(Barnes et al., 2019; Barnes, 2021; Malfa and Kwiatkowska, 2022)とか数学(Frieder et al., 2023)みたいな低次タスクの一番難しいケースを解くのに苦労してるんや。言語モデルはロバスト性にも欠けることが示されてて、モデルが正しく分類した入力のちょっとした変化に対して間違った応答をすることがあるんや(Sinha et al., 2021; Wang et al., 2023a)。
**Language-Models-as-a-Service**。「Language-Model-as-a-Service」って用語を最初に使った研究として僕らが知ってるのはZhao et al.(2021)やねんけど、多くの論文(Deng et al., 2022; Ding et al., 2022; Dong et al., 2022)はもっと後のSun et al.(2022)の研究を引用してるんや。LMaaSは
1500
---
## Page 5
[](/attach/2bb7904744e26e395d3db068e172c29038af52b4b45b4500d5111619e4eff7d1_p005.png)
### 和訳
言語モデルのサービス化(LMaaS)
ChatGPT(OpenAI, 2023a)が出てきてからめっちゃ注目されるようになってん。GoogleとかMicrosoftも同じような製品出してきてな(Thoppilan et al., 2022)。まあでも、こういうのが成功した背景には、GPT-3(Brown et al., 2020)みたいな昔の言語モデルでの発見とかブレイクスルーがあったんやで。最近は、このLMaaSがちゃんとしたNLPのデータセットとかベンチマークでどんだけ使えるかっていう評価研究がめっちゃされてんねん(Liang et al., 2022; Chang et al., 2023; Laskar et al., 2023)。あと、数学的な推論とか空間認識、記号操作、コード生成みたいな専門的なタスクの評価もな(Chen et al., 2019; Kojima et al., 2022; Cohn and Hernandez-Orallo, 2023; Frieder et al., 2023; Ray, 2023; Rozière et al., 2023; Shen et al., 2023)。こういう評価はどんどん進化してて、NLPの最先端を進めるためにめっちゃ重要な役割果たしてんねん(Wang et al., 2023a; Zhao et al., 2023)。LMaaSは色んなタスクで人間超えの性能出すこともあるんやけど(Bubeck et al., 2023)、人間やったら普通に正解できるようなエッジケースでコケたりすんねん(Berglund et al., 2023; Hao et al., 2023; Kocoń et al., 2023)。あと、言葉の中に隠れたバイアスがあったり(Ahia et al., 2023; Bang et al., 2023; Petrov et al., 2023b)、悪意のあるプロンプトに弱かったりもする(Kocoń et al., 2023; Shen et al., 2023; Schlarmann and Hein, 2023; Zou et al., 2023)。不確実性のモデル化とか曖昧さの扱いもちゃんとできてへんねん(Liu et al., 2023a)。ほんで注意してほしいんやけど、一番性能ええ言語モデルってサービスとしてしか使われへんやつが多いから(OpenAI, 2023)、言語モデルの高度な能力を調べる研究って、提供されてるサービスプラットフォームと切り離して考えられへんねん(Ray, 2023; Shen et al., 2023)。
3. LMaaSパラダイム
ここでは言語モデルの大まかな定義を説明して、それをLMaaSに絞って話すわ。ほんで、LMaaSが普通の言語モデルと4つの重要な点でどう違うかを議論するで。その4つっていうのは、アクセスのしやすさ、再現性、比較可能性、信頼性やねん。
言語モデルっちゅうのは、有限の長さのトークン列に対する確率分布を定義するもんで(Du et al., 2022)、有限の語彙から記号やトークン(文字の並びの一つのインスタンスやな)を予測するように学習されてんねん。次のトークンで一番確率高いやつをそのまま出すんやなくて、ほとんどの言語モデルは非決定的なサンプリング戦略を使って多様性を出してるんや(Holtzman et al., 2020)。決定的なモデルより能力は高いんやけど、非決定的なモデルの振る舞いは温度とかシードみたいなパラメータで変わってくるねん。温度は生成プロセスを決定的にするためのもんやと期待されてて、シードの方は、生成プロセスも含めて全部の不確実性の源を決定的にして、再現可能にする設定のことを指してるねん。
言語モデルはインコンテキスト学習者やねん(Brown et al., 2020; Dong et al., 2022)。これ何かっていうと、モデルの重みを変えずにタスクを解く能力のことで、APIとかウェブインターフェースを通じてサービスとして提供されるモデルにとってめっちゃ理想的な学習アプローチやねん(図1見てな)。一番シンプルな形やと、LMaaSはユーザーのプロンプトに対して応答を返すだけで、どっちもテキストでやり取りするねん。このやり取りの形式やと、モデルの振る舞いを変える方法がかなり限られてまうんやけど、商用サービスやとある程度のファインチューニングはできるようになってるで(OpenAI, 2023b)。
3.1 アクセスのしやすさ
ライセンスっていうのは、ほとんどの言語モデルとかLMaaSについてくる法的な仕組みで、ソフトウェアの使用と配布を規定してるねん。ソフトウェアをどう使っていいか、どう改変していいか、どう配布していいかを定義して、ユーザーとソフトウェア提供者の権利と責任を明確にするもんや。オープンソースとかフリーソフトウェアは広く浸透してる考え方で、透明性、カスタマイズ性、コミュニティ主導の開発を推進してて、ソフトウェア製品のアクセスのしやすさを高めたり制限したりすることがあるねん。言語モデルのライセンスは色々あって、次のセクションと図2で説明するで。一方、LMaaSの方は、会社が商用ライセンスを使うことがほとんどやねん。
3. https://www.microsoft.com/bing、2023年9月26日にアクセス。
---
## Page 6
[](/attach/2bb7904744e26e395d3db068e172c29038af52b4b45b4500d5111619e4eff7d1_p006.png)
### 和訳
La Malfaさんたち
図2:言語モデル(LM)は、https://huggingface.co/models ライブラリから持ってきたやつで、ソフトウェアライセンスごとにグループ分けしてんねん。Huggingfaceにある言語モデルの半分はApache-2.0ライセンスで提供されてて、その次がMITライセンス、ほんでOpenRAILライセンスっていう機械学習専用に新しく作られたライセンスが続いとるねん。最終アクセスは2023年8月1日や。
要はな、サービスとして提供される言語モデル(LMaaS)ってもんがあんねんけど、これがどういうもんかって話をするで。ほんで、従量課金制のサービスとして提供されるLMaaSが、英語みたいなリソースいっぱいある言語と、リソース少ない言語との格差をめっちゃ広げてまうってことも説明するわ。特にトークン化処理とかの部分でな。モデルにプロンプト投げる前の処理のとこや。
**LMaaSと言語モデルのライセンスについて**
一部の言語モデルはローカルで動かすのにめっちゃ計算リソース必要やねんけど(Raeさんたち, 2021; Chowdheryさんたち, 2022)、ほとんどは無料でダウンロードできて、中身見れて、そこそこのスペックのマシンでも動かせるんよ。例えばAlpaca-7B(Taoriさんたち, 2023)とかLLaMA-7B(Touvronさんたち, 2023a,b)は、28GBのRAM積んだGPU1枚でフル精度の推論ができるんやで。さらに、Petal(Borzunovさんたち, 2022)みたいなアプローチを使えば、LLaMAとかFalconみたいな分散型の言語モデルにアクセスしてファインチューニングもできるねん。これはピアツーピアネットワークを使ってて、自分の計算能力をシェアして貢献できる仕組みや。
言語モデルのライセンスはいろいろあって、図2に載せとるで。ほとんどの言語モデルはMITかApacheライセンスで、これらは使ったり、コピーしたり、改変したり、配布したり、ソフトウェアのコピー売ったりしてええねん。ちょっと覚えといてほしいのは、MITライセンスは、ソフトウェア再配布する時にソースコードを公開する必要ないってことや。ただし派生したコードもMITライセンスにする場合は別やけどな。一方でApacheライセンスは、派生物をソースコードで出すにしろバイナリ形式で出すにしろ、ライセンスのコピーとオリジナルに加えた変更のリストを含めなあかんねん。MITライセンスで有名な言語モデルはGPT-2(Radfordさんたち, 2019)で、ApacheライセンスやとBERT(Devlinさんたち, 2019)があるわ。
(Open)RAILファミリーのライセンスってのは、AI搭載ソフトウェア特有のケースに対応するために開発された比較的新しいライセンス方式やねん。ライセンスされた素材や派生物に無料でアクセスして再配布できるんやけど、OpenRAILをクレジットして、新しく作ったもんを同じ条件でライセンスせなあかんねん。その一方で、OpenRAILライセンスは使用ベースの制限条項を設けてて、オープンにライセンスされた言語モデルの有害な使用から生じる潜在的な社会的コストに対応しとるんや。BLOOMってのがOpenRAILライセンスの有名な言語モデルの例やな(Scaoさんたち, 2022)。
もうちょっと広い視点で見ると、言語モデルはHuggingface(Wolfさんたち, 2019)やAllenNLP(Gardnerさんたち, 2018)みたいな機械学習モデルをシェアできる人気ライブラリを通じて公開されとるんやけど、全部がオープンソースとかフリーソフトウェア(Stallman, 2010, 2022)の定義に当てはまるわけちゃうんよ。例えばLLaMAみたいなモデルは「重みは利用可能」っていう位置づけや、
4. https://finbarr.ca/how-is-llama-cpp-possible/、2023年9月26日アクセス。
5. https://www.licenses.ai/ai-licenses
1502
---
## Page 7
[](/attach/2bb7904744e26e395d3db068e172c29038af52b4b45b4500d5111619e4eff7d1_p007.png)
### 和訳
【サービスとしての言語モデル(LMaaS)】
これな、どういうことかっていうと、モデルへのアクセスをお願いして、許可もらったらモデルの重み(パラメータのことやな)を使わせてもらえるっちゅう仕組みやねん。ただ、これがなかなかクセモンで、使い方を制限するオリジナルのライセンスがついてくるんよ。特にLLaMAのライセンスはめっちゃ厳しくて、このモデルが出力したもんを使って他のモデルを学習させたらアカンって決められてんねん。
LMaaS、もっと広く言うたらSaaS(サービスとしてのソフトウェア)全般やけど、計算の重たい作業を提供者側のサーバーでやってくれるんよ。めっちゃ便利やん?でもな、その代わりにユーザーはソフトウェアを直接コントロールでけへんくなってまうんよ。普通の言語モデルよりもかなりすごい能力を持ってることが多いから(Liu et al., 2023b; OpenAI, 2023)、LMaaSは今やユーザーにも研究者にも毎日使われるツールになってんねん。
さっきも言うたけど、フリーソフトウェアっていうのは、ユーザーが実行したり、コピーしたり、配布したり、中身を調べたり、変更したり、改良したりできるソフトウェアのことやねん(Stallman, 2010)。OpenRAILみたいに「責任ある使い方してや」っていう合理的な制限はあるけどな。ところがLMaaSは、サービス提供者によって変わるけど、これらの原則のいくつか、もしくは全部を破ってしまってんねん。ほとんどが商用ライセンスやし(Liesenfeld et al., 2023)、ローカルで動かすこともでけへん。
選択肢は2つしかなくて、APIプロバイダーにお金払うか、フリーミアムサービス(基本は無料で、お金払ったらアップグレードできるやつ)をウェブの画面から使うかやねん。Google Bard(Thoppilan et al., 2022)とかMicrosoft CopilotをBingで使う場合は、この原稿書いてる時点ではAPIでプロンプト送るのが公式にはサポートされてへんねん(表1見てな)。でも裏技みたいなんはあるんよ。ただ、めっちゃ使われてるとはいえ、こういう方法は問題があってな。ソフトウェアの責任の所在とか結果の信頼性とかが怪しくなるんよ。なんでかっていうと、エンドユーザーが守るべき商用ライセンスに違反してまう可能性があるからやねん。結局のところ、ほとんどの商用LMaaSはコピーも、配布も、完全に中身を調べることも、変更することもでけへんっちゅうわけや。
フリーソフトウェアの原則をLMaaSのやり方とすり合わせるには、少なくともソースコードを公開して、学習のやり方も教えなあかんねん。AlpacaとかBLOOMみたいに、いくつかの機関や会社はこういうことをちゃんとやってるLMをリリースしてるんよ(Scao et al., 2022; Taori et al., 2023)。研究コミュニティの一部も、ダウンロードしてローカルで使えるLMの開発に取り組んでてな。LoRAとかその派生技術(Hu et al., 2021; Dettmers et al., 2023)を使えば、本来は大規模な計算施設がないとアカンようなモデルでも、ファインチューニングとか、ある程度の学習ができるようになってんねん。
その一方で、さっき話したLLaMAのケースみたいに批判を受けてるとこもあるんよ。でもな、サービスとしてリリースされる商用製品やと、ライセンスはもっと厳しくなるねん。なんでかっていうと、会社は知的財産とそこから生まれる競争上の優位性を守るために、「隠しとけば安全やろ」っちゅう考え方(セキュリティ・スルー・オブスキュリティ)で、オープンソースのやり方を避けたがるからやねん(Liesenfeld et al., 2023)。
計算パワーがめっちゃ偏って分布してて、ほんの一握りの会社に集中してる状況やから、技術的には優位やけど計算資源では負けてるプレイヤーはジレンマに陥るんよ。自分らのLMaaSをオープンソースにしたら、市場での露出が増えるし、コミュニティがコードベースに貢献してくれるメリットはあるねん。でもな、モデルを動かしてるコードを公開してしまうと、計算資源をいっぱい持ってるプレイヤーに競争優位性をあっという間に持ってかれてまう可能性があるんよ(Henkel, 2009; Heron et al., 2013; Tkacz, 2020)。
**LMaaSへのアクセス障壁**
LMaaSみたいなAI活用ソリューションは、これからの数年でめっちゃ大きな経済成長をもたらすって言われてんねん。例えば、イギリス政府はAIがGDPを10%増加させる可能性があるって予測してるんよ。これだけ経済への影響がでかいとなると、これらのモデルやサービスに広くアクセスできるようにすることがめっちゃ大事になってくるやん。
せやけど、今よくある「みんな同じ料金」っていう価格設定のやり方が壁になってんねん。特に発展途上国や開発途上地域の個人とか組織にとっては、アクセスしにくい状況を作ってしまってるんよ。結果として、LMaaSの有料モデルは、世界のいろんな地域で大きな格差を生んでしまう可能性があるっちゅうわけやねん。
---
## Page 8
[](/attach/2bb7904744e26e395d3db068e172c29038af52b4b45b4500d5111619e4eff7d1_p008.png)
### 和訳
La Malfaら
この技術が世界中の経済にどんな影響を与えてるかっていう話やねん(Zarifhonarvar, 2023)。ほんでな、商売的な理由で、LMaaS(Language Model as a Service、要するにChatGPTみたいな言語モデルをネット経由で使えるサービスのことやで)を開発してる会社らは、お金持ちの市場ばっかり狙ってんねん。このバイアス、めっちゃはっきり見えてんのがマイナー言語のパフォーマンスの差やな。トークン化(文章を細切れにしてAIが処理しやすくする作業のことやで)に関するいろんな研究で指摘されとる(Ahia et al., 2023)。さらにな、トークン数とかUnicode文字数で課金するっていう料金システムが、特定の言語にめっちゃ不利に働いてんねん(Petrov et al., 2023b)。例えばな、英語の最大15倍もの料金がかかる言語もあんねんで。結局のところ、LMaaSのこの排他的で有料っていう仕組みは、「言語モデルは世界の幸福を促進して社会的不平等を減らせますよ」っていう主張と真っ向から矛盾しとるわけや。むしろ僕らの見立てでは、この格差をもっと悪化させる可能性の方が高いと思うわ。
こういう問題を軽減する出発点として、LMaaS、もっと広く言えば従量課金制のAIサービス全般が、単独で存在する、あちこちに浸透した、破壊的な技術としてどんな影響を与えてるか分析することが大事やねん。マイノリティグループ、例えば英語話者以外の人らが不当に高い料金を払わされとるっていう研究に対して、僕らが言いたいのは、料金設定はそれぞれのグループの地理的・経済的な要因を考慮した方がええんちゃうかってことやな(例えば、市場価値の金銭的指標みたいな情報に基づいた指標を使うとかな)。LMaaSみたいな破壊的ソリューションへのアクセス格差を解消するっていうのは、単に技術的な問題を解決するだけやなくて、専用の政策とかガバナンスツールを導入することが必要やねん。
3.2 再現性
再現性っていうのは科学において超基本的な概念で、研究結果の信頼性を確立するための土台みたいなもんやねん。機械学習でいう再現性っていうのは、同じデータセットと同じアルゴリズムを使って同じ結果を得られることを指すんやけど、LMaaSはこの条件をほとんど満たせへんのよ。
なんでかっていうと、まず確率的な性質があるやろ。それに加えて「サービスとして」っていうアクセスポリシーがそれを悪化させとって、さらにモデルをこっそり廃止したり変更したりする慣習があるし、しかも公開通知なしにやるし、本質的に非決定論的(同じ入力でも毎回違う出力が出る可能性があるってことやな)やから、ユーザーが使える乱数のもと全部を固定しても、モデルの挙動に影響が出てまうねん。LMaaSの再現性の問題を掘り下げる前に、MLaaS(機械学習のサービス)製品の中でこいつらがどんだけ特殊なんか話しとくわ。「LMaaSに影響する問題のほとんどは、機械翻訳とか物体認識とか拡散ベースの画像生成とか、他のMLaaSツールでも共通やろ」って言う人もおるかもしれんけど、LMaaS関連の問題には研究コミュニティから前例のない注目が集まっとんねん。2023年には「GPT-4」とか「GPT-3.5」って言葉を含む論文が15,000本以上も発表されとるし(注11)、トップクラスの機械学習学会のほとんどが今や「生成モデル」(つまりLMとかLMaaSを含む)専門のトラックを設けとるわけや。やから僕らは、これらを分析するためのフレームワークとツールを開発することがめっちゃ必要やって強調しとくで。再現性と決定論性は、そういうアプローチの2つの土台やねん。
**LMaaSの廃止を踏まえた再現可能な実験** ソフトウェア開発ではな、継続的デリバリーっていうアプローチがあんねん。これは、すでにデプロイされてるアプリケーションにコード変更を加えて、本番環境にリリースするっていうやり方や。SaaSソリューションの場合、これはどういうことかっていうと、ウェブブラウザのGUIからLMaaSを使っとるユーザーにとって、製品の新バージョンが前のバージョンをシームレスに上書きしてまう可能性があるってことやねん(Hacker News, 2023a,b; OpenAI Community, 2023)。GPT-3.5、GPT-4、Bard、BingのMicrosoft Copilotみたいなサービスは、GUIかAPIでアクセスできるけど、具体的なデプロイ戦略について公開されてる詳細はほとんどあらへん。一方では、継続的デリバリーのおかげで企業はより良いモデルをデプロイしたり、バグや新しく発見された脆弱性を素早く修正したりできるんやけど、他方では、そういうモデル上で行われた実証分析の再現性を損なってまうねん(Chen et al., 2023)。APIアクセスの場合、モデルの変更については明確なドキュメントがあると期待するやろうけど、この場合でさえ、突然の動作変更が報告されとるんよ(Gao, 2023)。
企業がモデルを廃止した場合、実験の妥当性を評価して信頼するかどうかは、過去のデータと研究コミュニティで形成されたコンセンサスだけに依存することになるねん。
---
注11. 出典:Google Scholar、クエリ:"GPT-4" | "GPT-3.5"、2023/12/30にアクセス:https://scholar.google.com/scholar?q=%22GPT-4%22+%7C+%22GPT-3.5%22&hl=en&as_sdt=0%2C5&as_ylo=&as_yhi=2023
1504
---
## Page 9
[](/attach/2bb7904744e26e395d3db068e172c29038af52b4b45b4500d5111619e4eff7d1_p009.png)
### 和訳
Language-Models-as-a-Service(言語モデルをサービスとして提供するやつ)
**図3**: 温度パラメータTをゼロに設定したら、LMaaSは(まあ大体やけど)決定論的になって、次の単語をサンプリングする確率が一個の単語にギュッと集中するねん。逆にT > 0やと、LMaaSはどんどんクリエイティブになっていくんやけど、サンプリングする分布がどんどん平べったくなっていくわけや。
ベンチマーク手法の信頼性についてもちょっと考えなあかんねん。例えばな、2023年の4月から5月の間に、GPT-3.5の性能を(Liang et al., 2022)で書かれてる方法で測定したとするやん。ほんなら2023年5月11日に、OpenAIがGPT-3.5-legacyを利用可能なモデルのリストから削除しよって、新しいモデルにも同じようなポリシーを適用してるねん。12 そうなったらもう、そのモデルでの実験を再現するのは不可能になってしもて、ベンチマーク手法が正しいって信じるしかないわけや。それに対して、LMaaSの形で提供されてへん大半の言語モデルは、サードパーティのサービスに保存されてて、この論文で前に議論したように、寛容なライセンスでダウンロードできるようになってるねん。
LMaaSが更新されたかどうかチェックする方法としては、プロンプトのセットに対する回答をいくつか集めて、そのハッシュを保存して、時間が経ってから比較することでモデルの置き換えが起こったことを証明できるかもしれへんねん。せやけどな、この解決策は完璧やないねん。なんでかっていうと、2つの異なるLMaaSが同じ回答を出力することもあるし、逆に回答が違うのは一方が他方を置き換えたからやなくて、本質的な非決定性のせいかもしれへんからや(次の段落で説明するで)。もう一つの現実的な解決策は、企業にレガシーモデルへのアクセスを長期間サポートするよう求めることやねん。これは廃止直後やなくても、ユーザーが新しいバージョンを採用するのを妨げへん期間が経ってからでもええわけや。でもこれにも欠点があってな、新しいバージョンは安全性や悪用の脆弱性(例えば「ジェイルブレイク」(Chao et al., 2023; Liu et al., 2023c; Yao et al., 2023a))にパッチを当ててるから、「パッチ未適用」のバージョンを維持するのは、悪意のある奴らがシステムを悪用し続ける手段になりかねへんねん。
これらの側面はめっちゃ問題やねん。特にLMaaSがソフトウェアパイプラインの中間ノードとして使われて、LMaaSの上に構築された下流の消費者向けソフトウェアサービスを提供してる場合はな。LMaaSが変わったら、下流のサービスの品質も変わってまうわけや。これらの問題に対処する一つの方法は、審査を受けた個人や組織だけにアクセスを許可することやけど、それやとモデルの監査が制限されてまうねん。あるいは、プロバイダーが研究者向けにベンチマークを登録するインターフェースを提供して、更新のたびにモデルを再評価できるようにする方法もあるわ。公開の継続的インテグレーションテストみたいな感じやな。現状ではAPIの変更がちゃんとドキュメント化されてへんから(Gao, 2023)、一番現実的な(けどコストのかかる)代替手段は、恒久的なリグレッションテストを実行して(Chen et al., 2023)、下流のサービスに関連する指標でモデルの性能を監視して統計的に追跡することやねん。毎日の「GPT-4ユニコーン」(Adam, 2023)みたいな感じやな。
**決定論の神話とプロンプティングの難しさ**。もう一つの懸念は、サービスとしてアクセスできるほとんどのモデルに固有の非決定性やねん。この問題はLMaaSだけに限った話やなくて、サービスとして展開・提供されてる多くの生成AI技術にも及ぶねん。例えば拡散ベースの画像生成器(Rombach et al., 2021)とかな。LMaaSでは、同じプロンプトでも
12. https://openai.com/blog/gpt-4-api-general-availability、2023年9月26日にアクセス。
1505
Prob(word) Prob(word)
---
## Page 10
[](/attach/2bb7904744e26e395d3db068e172c29038af52b4b45b4500d5111619e4eff7d1_p010.png)
### 和訳
La Malfaさんたちの研究やねんけど
モデルがな、1つの質問に対して複数の答えを返してくることがあってん。これが「再現性」っていう研究で大事なもんを、めっちゃ難しくしてまうねん。GPT-3.5とかGPT-4みたいなモデルは、APIとかMicrosoft Azureみたいなクラウドサービスのウェブ画面から使えるんやけど、ユーザーが入力した文章に対してどれくらいバラエティ豊かな回答を生成するか、「temperature(温度)」っていうパラメータで調整できんねん。これは図3に書いてあるわ。
GPT-3.5の場合はな、温度を0にしたら「決定論的」に動くはずやねん。「決定論的」っていうのは、同じ入力したら毎回同じ答えが返ってくるってことやな。せやけどな、実はGPT-3.5とGPT-4は温度を0にしても、なんでか知らんけど毎回違う答え返してくるって報告があんねん(Chann, 2023; Ouyang et al., 2023)。温度が0より大きいと、LMaaS(これは「サービスとしての言語モデル」のことやで)は確率分布に従って出力をサンプリングするから、実行するたびに違う結果が出る可能性があんねん。決定論的なLMaaSが出せる回答の種類は、非決定論的なLMaaSが生成できる回答の一部でしかないわけや。つまり、モデルは非決定論的になることで多様性は増すけど、その代わり生成される回答の一貫性が落ちる可能性があんねん。まとめると、パラメータ制御は間違いなく役立つんやけど、
ランダム性の原因を全部固定(カジュアルに言うたら「シード」を固定)せんと、そのモデルで行った実験を制御したり再現したり信頼したりすることはでけへんねん。せやから、ソースコードへのアクセスを禁止されると、ユーザーの信頼が損なわれるし、LMaaSの制御も弱まる可能性があんねん。あと、関連するリスクで文献でも議論されてんのが、完全に決定論的なモデルを公開したら、他の会社にモデルを真似されるリスクが高まるんちゃうか、っていう話やな。一部の研究論文では、別のモデルの出力とか埋め込み表現だけにアクセスして、競争力のあるレプリカを訓練できるって示されてんねん(Mukherjee et al., 2023; Peng et al., 2023)。せやけど他の研究者は、そういう「模倣」モデルは見かけ上は強力なLMaaSとの差を縮めてるように見えるだけや、って主張してて(Gudibande et al., 2023)、この議論は今んとこ決着ついてへんねん。
透明性に影響するもう一つの問題は、モデルによってアクセス方法が違うってことやねん。ウェブのGUI経由とかAPI経由とか、表1に載ってるで。GPT-3.5と4の場合がわかりやすい例やねんけど、API経由やと温度とか他のパラメータを設定できんねんけど、対応するウェブインターフェースにはそんなオプションがないんや。ちゃんと厳密に評価したいLMaaSやったら、分析を決定論的に再現できるようにパラメータを提供せなあかんねん。それが無理な場合は、ベンチマーク手法の方で非決定論的な振る舞いを考慮に入れなあかんわな。例えば、モデル出力の全体像を頑健に探索するサンプリング戦略を使うとかな。この後者のアプローチやと実験を完全に再現することはでけへんけど、少なくとも信頼できる実験にはなるわけや。
3.3 信頼性
機械学習における信頼性っていうのは、めっちゃ大事な概念やねん。学習モデルの結果がどれだけ一貫してて、頼りになるかってことを意味してんねん。これが基本的な概念やっていうのは、実際の世界のシナリオでモデルの予測や判断をどれだけ信用できるかっていう土台になるからやねん。言語モデル(LM)とLMaaSの文脈では、信頼性っていうのは、メトリクス(評価指標)で性能を数値化できるモデルのことを指すんや。これらのメトリクスは、訓練データの丸暗記とか表面的なパターンへの依存を超えて、ちゃんとタスクをこなせる能力を反映せなあかんねん。
このセクションでは、言語モデルのベンチマーキングに関連する問題を掘り下げていくんやけど、LMaaSの枠組みがこれらの評価の課題をさらにややこしくしてんねん。主な懸念の一つは「データセット汚染」や。これは、訓練データにテストベッド(評価用データセット)で使われるものと似てる、または完全に同じ入力とラベルが含まれてる場合に起こんねん。もう一種類の汚染があって、ワイらはこれを「ユーザー汚染」って呼んでんねんけど、これは企業がユーザーのプロンプトを集めて自分らのモデルの訓練やファインチューニングに使う時に起こんねん。これはLMaaSのパラダイム特有の問題やな。さらに、このセクションではLMaaSの「創発的振る舞い」っていう概念も探っていくで。創発っていうのは、LMaaSが訓練中には出会わなかったタスクに取り組む能力のことやねん。こういう創発的振る舞いを見つけるには、まずそのタスクがほんまに新しい課題なのかどうかを判断せなあかんねん。最後に、ベンチマーキングの実践で進行中の議論の概要を説明するわ。一方では、包括的な
13. https://152334h.github.io/blog/non-determinism-in-gpt-4/、2023年8月24日にアクセス。
1506
---
## Page 11
[](/attach/2bb7904744e26e395d3db068e172c29038af52b4b45b4500d5111619e4eff7d1_p011.png)
### 和訳
言語モデルをサービスとして使う話
いろんなデータセットとか評価指標で実験するのもええし、もう一つのやり方としては、似たようなタスクに対してそのモデルがどんな能力持ってるかをチェックして、それをまとめて評価する方法もあるねん。
**データセット汚染とユーザー汚染の問題**
言語モデルってな、めっちゃでっかいデータセットで事前学習されてんねん。数十億とか、下手したら数兆トークンとかあるやつで、だいたいウェブからスクレイピングしてきた整理されてないテキストやねん(Touvronら、2023b)。これってな、普通の教師あり学習のやり方とは全然違うねん。普通やったら、ちゃんと整理された入力と出力のサンプルで訓練して、見たことないテストデータで評価するやん。でも、めっちゃでっかいデータセットが必要やから、テスト用のデータが足りんくなってくるわけよ(Van、2023)。なんでかっていうと、有名なテストデータってネット上に転がってるから、スクレイピングとかデータ収集のやり方がザルやと、訓練中に食べられてまうねん。これが「データセット汚染」っていう問題や。
こうなると、性能評価がめっちゃ難しなるねん。だって、訓練に使ってないデータで評価せなあかんからな。「暗記」っていう問題もあってな、言語モデルが訓練中に見た文章をそのまんま出力してしまうことがあるねん。これがあるとベンチマークの意味がなくなるし(Ippolitoら、2022)、しかも訓練データに入ってた個人情報がバレてしまうっていうプライバシーの問題もあるねん(Carliniら、2022、2021)。さらにな、ChatGPTとかBardみたいなモデルは、パッと見は正しそうに見えるけど、実は不正確やったり、嘘やったり、でっち上げの情報が入ってる回答を作ってまうことがあるねん(AlkaissiとMcFarlane、2023; Zhangら、2023a)。この現象はほぼ全部のLMaaS(サービスとしての言語モデル)と大半の言語モデルで起きてて(Maynezら、2020a)、各社はこの問題を利用規約に書いてサービス提供してるねん。表1に載ってるとおりや。
もう一つ関連する問題が「ユーザー汚染」やねん。これはな、暗記しやすいLMaaS(Bidermanら、2023a,b)が、ユーザーの入力データでさらに訓練されることで起きるねん。商用ライセンスはこの権利を保持してるって、表1に書いてあるで。データセット汚染はユーザー汚染から引き起こされることもあるねん。最初はデータセット汚染してないモデルでも、新しいテストデータでプロンプトを投げられることがあるやん(テストデータ作成時によくあるパターンやな)。そしたら、そのテストデータがLMaaSに食べられて、ユーザー汚染を通じて、そのLMaaSの将来のベンチマークには使えんくなってまうねん。継続的なデータ収集をオプトアウトできるLMaaSもあるけど、そんなん標準サービスちゃうし、追加料金かかるねん。
人間にとっても難しいタスク(「高次タスク」って呼ばれるやつで、感情分析みたいな「低次タスク」と対比されるもの)については、LMaaSがめっちゃすごい性能を発揮してるっていう実証的な証拠があるねん(Liangら、2022; Wangら、2023b)。人間にとって難しいように設計されたテストでも、専門家レベルの成績を出してるねん(Zhangら、2023b)。最近のディープラーニングの発展で、言語モデルとLMaaSの記号操作能力はめっちゃ上がってんねんけど、データセット汚染があるせいで、実際の性能を過大評価してしまってる可能性があるねん。
分かりやすい例がZhangら(2023b)の研究やねん。GPT-3.5とGPT-4がMITの入学試験を楽勝でパスしたって報告してたんやけど、この論文、後でarXivから取り下げられてん(注14)。データセット汚染の懸念が出てきたからや(他にも問題点はあったけどな)。この論文のメタ分析では、結果が汚染されてた可能性があるって指摘されてるねん(Chowdhuriら、2023)。この問題は上の例だけやなくて、他の研究者もGPT-3.5やGPT-4について明確にデータセット汚染の問題を指摘してるねん(Aiyappaら、2023)。有名なベンチマークは、そのテストセットと正解ラベルがGitHubみたいな共有プラットフォームに置いてあるから(Jacoviら、2023)、モデルの訓練データに含まれてる可能性がめっちゃ高いねん。
データセットを検出して除去しようっていう取り組みは、GPT-2みたいな昔の言語モデルの頃からあるねん(Brownら、2020; Carliniら、2022; McCoyら、2023a)。提案されてる解決策としては、訓練データから、もしくはモデルの出力をテストして、漏れたテストデータのn-gramを全部抽出するっていう方法があるねん(Brownら、2020)。もっと洗練された手法もあるけどな(McCoyら、2023a)。でもな、こういうアプローチは計算コストがめっちゃかかるし、完璧やないねん。見つからんかったからって、モデルがそのデータ(もしくはちょっと変形したバージョン)を食べてないっていう証明にはならへんのよ。
注14: https://arxiv.org/abs/2306.08997、2023年8月19日アクセス。
---
## Page 12
[](/attach/2bb7904744e26e395d3db068e172c29038af52b4b45b4500d5111619e4eff7d1_p012.png)
### 和訳
La Malfaさんら
普通の言語モデルやったら、データセット汚染を見つけたり防いだりするのに、あんまり知られてないベンチマーク選んでモデルの信頼性チェックできるねん。もし事前学習されたモデルを信用でけへんかったら、ちょっと手間かかるけど自分で再学習することもできるわけや。最近出てきた提案で、テスト用データを生テキストでネットにアップするのやめよう、っていうのがあるねん(Jacoviさんら、2023年)。でもな、これだけじゃ足りひんのよ。ネット見れたりコード実行できたりするツール持ってるモデル(GPT-4のプラグインみたいなやつな)やったら、圧縮されたテストデータを自分のコンテキスト内で生テキストに解凍できてまうねん。ほんでそれが将来のモデルの学習に使われる可能性があるってわけ。しかもな、Jacoviさんらの提案って結局「みんな正直にやろうね」っていう名誉システムに頼ってるんよ。うっかりテストセットをモデルに見せてもうたら、それ言うてね、みたいな。でもそんなん、みんながルール知ってるかどうかも、ちゃんと守るかどうかも、確認しようがないやん。
同じようにな、LMaaS(サービスとしての言語モデル)を評価するときも、もしそのモデルがユーザーの入力を学習データに使ってたら、テストサンプルが将来の学習に漏れてまうねん。これがユーザー汚染っていうやつで、実際に起きてることが証明されとるんや。使えるアプローチとしては、プロンプトからデータ集めへんモデルをデプロイして、みんながチェックできるオープンなデータセットでガチガチに学習させる、っていうのがあるわ。
データセット汚染にしてもユーザー汚染にしても、まったく同じテストセットが学習データに入ってなかったらOKってわけちゃうねん。同じ情報が学習データに入ってないことも確認せなあかんのよ。例えばな、足し算の問題を解くための特定のテストセットが取り込まれてなかったとしても、その中の個々の問題が別々に作られてネットに公開されて、学習データセットに取り込まれてへんかも確認せなあかんねん。これめっちゃ大事なんが、2桁の数字の足し算みたいな簡単なタスクな。そんなん、ネット探したらそういう練習問題のシート何百個も見つかるし、ちょっとした手間で生成もできるからな。
やから、汚染が絶対起きひんって保証するのは無理やねん。モデルの能力をテストするために1回だけ使って捨てる手作りのデータ、いわゆるワンショットデータってやつは、実際問題使えへんのよ。なんでかっていうと、人間の専門家か専門的なアルゴリズムが必要やからな。言語的にめっちゃバリエーション豊かで質の高いデータを生成するっていうのは、実はNLPとか計算言語学でまだ解決されてない問題やねん。言語モデルとかLMaaSはそういうデータ生成がかなり上手くなってきてるんやけど(EldanさんとLiさん、2023年; Møllerさんら、2023年)、問題を完全に解決してるわけちゃうねん(Dwivediさんら、2023年)。言語モデルとかLMaaSに内在する生成プロセスをコントロールするのは、言語学的にほんまに難しいんよ。しかもめっちゃリスクあるのが、モデル自身がめっちゃ自信持って生成したデータを使って性能評価すると、そのデータはモデルがすでにかなり正確に分類できるやつかもしれへんってことな。こういうプロセスって、研究コミュニティに新しいデータセットとベンチマークを継続的に開発する負担をかけることにもなるし、そのデータはすぐにLMaaSプロバイダーに取り込まれてまうから、その労力に関する倫理的な問題も出てくるねん。やから、学習セットが独立して同じデータを持ってへんことを確認するのは必須やねん。
というわけで、データセット汚染とユーザー汚染の問題は、モデル開発者が積極的に協力してくれへん限り解決でけへんってうちらは思うてるんや。でもな、おもろいアプローチがいくつか出てきてて、あるサンプルが学習データの一部である確率を推定するやつがあるねん。LMaaSみたいに学習データにアクセスでけへん前提のやつな。例えばShiさんらの研究(2023年)とか見てみて。
そういうアプローチに加えて、モデルとデータセットのレジストリ(登録簿)を作るっていうオプションを調査することを提案するわ。研究者がチェックできるようになるねん、あるモデルの学習データセットにどのテストサンプルが含まれてるか、完全な学習データセットに直接アクセスせんでも。ほんでそのサンプルを評価から除外できるわけや。すでに取り込まれた入力のちょっとした変形バージョンについては、モデルの学習データから似た文を素早く検索するのにベクトルデータベースが使えるねん。ちょっと違う入力間の類似度を計算できるからな(Hanさんら、2023年; Panさんら、2023年)。このアプローチは逆の問題にも対処できるんよ。つまり、ベンチマークや評価のテストセットを避けたいと思ってる良心的なモデル開発者の問題やな。ユーザーがうっかりテストセットをモデルに見せてまうかもしれへんから、これ難しいんやけどな。モデル開発者は自分の学習データセットにレジストリのテストセットが含まれてへんかチェックできるようになるねん。さらに、開発者はユーザー入力を動的にチェックして、そういうテストサンプルを含むデータを将来の学習から除外できるようになるわ。
1508
---
## Page 13
[](/attach/2bb7904744e26e395d3db068e172c29038af52b4b45b4500d5111619e4eff7d1_p013.png)
### 和訳
Language-Models-as-a-Service(サービス型言語モデル)
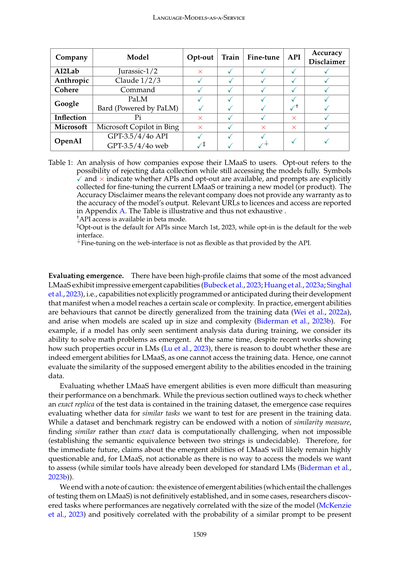
モデル別の対応状況表やで!
| 会社 | モデル | オプトアウト | 学習 | ファインチューン | API |
|---|---|---|---|---|---|
| AI2Lab | | × | ✓ | ✓ | ✓ |
| Anthropic | Claude 1/2/3 | ✓ | ✓ | ✓ | ✓ |
| Cohere | Command | ✓ | ✓ | ✓ | ✓ |
| Google | Jurassic-1/2、PaLM、Bard(PaLM搭載) | ✓ | ✓ | ✓ | ✓ |
| Inflection | Pi | × | ✓ | ✓ | ✓ |
| Microsoft | Microsoft Copilot in Bing | × | ✓ | × | × |
| OpenAI | GPT-3.5/4/4o API、GPT-3.5/4/4o web | ✓‡ | ✓ | ✓∔ | ✓ |
ほんで、全部の会社が「精度の免責事項」ってのを出してるねん。
表1:各社がLMaaS(サービス型言語モデル)をどうユーザーに提供してるかの分析や。「オプトアウト」っていうのは、データ収集を拒否しても全部の機能が使えるかどうかってことやな。✓と×は、APIが使えるかどうか、オプトアウトできるかどうか、入力したプロンプトが今のLMaaSのファインチューニングや新しいモデル(製品)の学習に使われるかどうかを示してるねん。「精度の免責事項」っていうのは、その会社がモデルの出力の正確さについて一切保証してないってことや。ライセンスとアクセスに関するURLは付録Aに載せてるで。この表は説明用やから全部を網羅してるわけちゃうからな。
†APIアクセスはベータ版で提供されてるで。
‡2023年3月1日以降、APIではオプトアウトがデフォルトになってて、ウェブインターフェースではオプトインがデフォルトやねん。
∔ウェブインターフェースでのファインチューニングは、APIで提供されてるほど柔軟ちゃうで。
**創発性の評価について**
最先端のLMaaSのいくつかが、めっちゃすごい「創発的能力」を持ってるって主張があるねん(Bubeck et al., 2023; Huang et al., 2023a; Singhal et al., 2023)。創発的能力っていうのは何かっていうと、開発中に明示的にプログラムされたわけでもないし、予想もされてなかったのに、モデルがある規模や複雑さに達したときに突然現れる能力のことやねん。
実際のところ、創発的能力っていうのは学習データから直接一般化できへん振る舞いのことで(Wei et al., 2022a)、モデルのサイズと複雑さがスケールアップしたときに出てくるもんやねん(Biderman et al., 2023b)。例えばな、モデルが学習中に感情分析のデータしか見てへんかったとして、そのモデルが数学の問題を解けたら、それは創発的やって考えるわけや。
けどな、最近の研究でこういう特性が言語モデルでどう起こるか示されてきてるにもかかわらず(Lu et al., 2023)、LMaaSについてはほんまに創発的能力なんかって疑う理由があるねん。なんでかっていうと、学習データにアクセスできへんからや。せやから、その創発的やって言われてる能力が、学習データにエンコードされてた能力とどんだけ似てるか評価でけへんねん。
LMaaSに創発的能力があるかどうか評価するんは、ベンチマークでの性能を測るよりもっと難しいねん。前のセクションでは、テストデータの完全なコピーが学習データに含まれてるかチェックする方法を説明したけど、創発性の場合は、テストしたいタスクに似たデータが学習データに存在するかどうか評価せなあかんねん。データセットとベンチマークのレジストリに類似度の尺度を持たせることはできるけど、完全一致やなくて類似データを見つけるんは計算的にめっちゃ難しいし、不可能なこともあるねん(2つの文字列の意味的な等価性を確立するんは決定不能問題やからな)。
せやから、当面の間、LMaaSの創発的能力に関する主張はかなり怪しいままやろうし、LMaaSについては実行可能な検証手段がないねん。評価したいモデルにアクセスする方法がないからや(ちなみに、通常の言語モデル用には同様のツールがすでに開発されてるで(Biderman et al., 2023b))。
最後に注意点を言うとくわ:創発的能力の存在自体(それをLMaaSでテストする際の課題を伴うやつな)は確定的に証明されてへんねん。実際、研究者らがモデルのサイズと性能が負の相関を示すタスクを発見したケースもあるし(McKenzie et al., 2023)、似たようなプロンプトが存在する確率と正の相関があるケースもあるねん。
---
## Page 14
[](/attach/2bb7904744e26e395d3db068e172c29038af52b4b45b4500d5111619e4eff7d1_p014.png)
### 和訳
La Malfaらの研究チームの話やねんけどな。
訓練データの中身について言うたら、McCoyらが2023年に指摘してんねんけど、新しい振る舞いをプロンプト(AIへの指示文みたいなもんや)だけで引き出すんはめっちゃ難しいっていう理論的な結果が出てんねん。要するに、モデルがある課題をうまくこなせるってことは、たぶん事前学習の時に似たような課題を見てきたからやろうってPetrovらが2023年に言うてんねんな。
ほんでな、「創発能力」って呼ばれてるやつ、つまりAIが突然できるようになったように見える能力やけど、これ実は評価の仕方がヘタクソやったから起きた見かけ上の現象ちゃうか、ってSchaefferらが2023年に言うてんねん。もっとびっくりする話があってな、Chain-of-Thought(CoT)プロンプティングっていう、AIに段階的に考えさせる手法があんねんけど、これ、論理的に間違った指示を出しても性能上がるの確認されてんねん。えー、おかしくない?って思うやろ?
とはいえや、モデルは単なる「確率的オウム」、つまり見たもんをそのまま繰り返すだけのもんやないってことも、Yuらが2023年に組み合わせ論的な議論で示してんねん。せやから、モデルの本当の能力がなんなんか、創発能力を発揮できるんか、それとも特定の制約があんのか、まだ答え出てへんねん。
**図4の説明**: 上の方に書いてある大規模なベンチマーク手法はな、検査しにくいっていう問題があんねん。なんでかっていうと、モデルの数、データセットの数、評価指標の数に対して計算量が3乗で増えていくからやねん。一方で、下の方の手法は、次元削減とか蒸留した潜在因子(データの本質的な特徴を圧縮したもんやな)を使ってモデルをグループ分けすんねんけど、複数のデータセットや評価指標をまとめる代わりに、解釈しにくいっていう問題があんねん。
**LMaaSの比較について**
データセット汚染とユーザー汚染だけが、汎用LMaaS(Language Model as a Service、要するにAPIで使える言語モデルサービスのことやな)を比較すんのを難しくしてるわけちゃうねん。科学論文の世界ではマルチタスク・マルチモデルの性能評価に向かってて(Liangらが2022年に言うてる)、もっと広範で複雑なベンチマークを目指してんねんけど(Kielaら2021年、Suzgunら2022年)、複数の領域にまたがるタスクで2つのモデルをどう比較すんのかっていう議論はまだ決着ついてへんねん(Changら2023年)。
あるモデルは特定のタスクが得意で、別のタスクは苦手やったりすんねん。せやから、LMaaSの性能に順位つける評価指標を考えるんはめっちゃ難しいわけや。しかもな、BIG-Bench(Srivastavaら2022年)みたいな、だんだん複雑なタスクを追加していくベンチマークは、最初のベンチマークの目的から外れて、モデルが失敗するような想定外のサンプルを含むようになってまうことがあんねん。
言語モデルとLMaaSの評価が難しい理由はめっちゃようさんあんねん。利用可能なモデルは数十個あるし、評価指標は数百個、テスト環境もようさんあるから、全部を徹底的に調べるんはコストかかるし時間もめっちゃかかんねん。LMaaSはさらに複雑で、データ汚染・ユーザー汚染、モデルの入れ替え、非決定性(同じ入力でも毎回違う出力が出ること)の問題があんねん。
汚染があると、テストデータを記憶しちゃってるから性能が不正に上がって結果が台無しになるやろ?それに、違う時期に実験したら現在のモデルの能力を反映してへんねん。なんでかっていうと、その間にモデルが別バージョンに入れ替わってて、性能がガラッと変わってるかもしれへんからや(Chenらが言うてる)。
ちなみにな、脚注15に書いてあんねんけど、Liangらが2022年に報告した実験を、ChatGPT-3.5-turboみたいな従量課金モデルだけでやったとしたら、約18,250ドル(日本円で270万円くらいやな)かかるらしいで。しかもこれ、マシン代とエンジニアの人件費抜きでやで。えぐない?
---
## Page 15
[](/attach/2bb7904744e26e395d3db068e172c29038af52b4b45b4500d5111619e4eff7d1_p015.png)
### 和訳
Language-Models-as-a-Service(サービスとして提供される言語モデル)
2023年)。非決定論的な挙動、これをなんとかせんと(例えば3.2節で提案されてるような方法でな)、一点ずつ比較しようとしても結果が不確かになって、数値的なブレがめっちゃでかくなるねん。
最近の研究見てたら、なんか矛盾した流れがあるなーって気づくねん。一方では、大量のモデルとシナリオを使って一点ずつの指標でベンチマークしまくる派(Liang et al., 2022; Srivastava et al., 2022; Zhong et al., 2023)、もう一方では、似たようなタスクの変動を捉える「潜在因子」ってやつに基づいて、後からモデルをまとめて評価する派(Burnell et al., 2023)がおるんよ。後者の方法は「見せかけの相関」に引っかかりやすいんや。つまり、LMaaSの性能に基づいてタスクをグループ分けするから、「このタスクは似てる」って判断してまうけど、ほんまに似てるかはわからんってことやな。
大規模ベンチマークと潜在因子分析の違いを分かりやすく見せてるのが図4やねん。HELM(Liang et al., 2022)みたいなアプローチは、いろんな指標と設定でLMaaSをめっちゃ細かくベンチマークするんやけど、一方で次元削減手法(図の下の方)は、似たようなパフォーマンスを出したタスクに基づいてLMとかLMaaSをまとめるんや。でもな、計算された潜在因子って解釈しづらいことが多いねん。
まとめるとな、ちゃんとしたベンチマークするには、データやユーザーの汚染、非決定性、それにこの論文で前に言うた大体の問題を軽減せなあかんねん。せやから長期的な課題であって、研究コミュニティとモデル提供者が絶対に協力せなあかんところやな。
3.4 信頼性
図5:LMaaSは説明を生成するのに使えるで。左側は実際のGPT-4とのやり取り(2023年9月21日付け)で、感情分析タスクを解いてもらってるところや。この場合、推論はまともやけど、それが正しいっていう保証はないねん。右側には、同じ感情分析タスクを解くための架空の決定木の仕組みが示されてるんやけど、テキストは2-gram(2つの単語の組み合わせ)として表現されてるねん。この決定木は入力を「ポジティブ」って誤分類することもあるんやけど、入力をベクトルとして表現した後なら、誤分類の理由を「really good」っていう2-gramの存在まで遡って追跡できるんや。この2-gramがいくつかの判断に影響を与えたってわけやな。こういう意味で、決定木みたいな技法は「自己説明型」やねん。モデルの意思決定プロセスを導き出せるような説明が、元から組み込まれてるからな。
言語モデルとLMaaSは、だんだん洗練されてきて、自分の出力の説明を生成するように問い合わせできるレベルにまでなってるねん(Alvarez-Melis and Jaakkola, 2018; Zini and Awad, 2022)。こういうモデルのことを「説明的ニューラルネットワーク」って呼んでるわ(AlRegib and
1511
---
## Page 16
[](/attach/2bb7904744e26e395d3db068e172c29038af52b4b45b4500d5111619e4eff7d1_p016.png)
### 和訳
La Malfaらの論文
Prabhushankar(2022年)は、自己説明って呼ばれる別の説明可能性の手法(Rudin, 2019)と区別するために、こういう言い方してんねん。自己説明っていうのは、モデルがどうやって決定したかをめっちゃ透明にする説明を出す方法やねん。たとえば決定木みたいなやつやと、モデルが判断するときに通った枝から、わかりやすいルールを引っ張り出せるやろ?でもな、LMaaS(サービスとしての言語モデル)に説明を求めても、モデルの判断プロセスの中身は全然見えへんねん。実際のところ、LMaaSの説明って、図5に描いてあるみたいに、前のやり取りを条件にした次のプロンプトでしかないわけや。この問題は普通の言語モデルにもあるんやけど、内部の状態にアクセスできたら、判断プロセスをもっと深く覗き見できるねん(Azaria and Mitchell, 2023)。でもLMaaSはAPIやウェブインターフェースからしか触れへんから、中身が見えへんし、モデルの判断の説明には限界があるわけや。説明を信頼できるかどうかが、モデルを信頼できるかどうかに繋がるねん。たとえば正しさの保証が付いてるとかな。でもLMaaSの説明は前のやり取りに条件付けされたプロンプトでしかないから、信頼する根拠がないねん。
Chain of Thoughts(Wei et al., 2022b)(CoT)とか、その派生形(Zhang et al., 2022; Besta et al., 2023; Paranjape et al., 2023; Yao et al., 2023b)みたいな人気のプロンプト手法があるやん。これらはモデルに「一歩ずつ考えて、考えを書きながら答え出してや」って頼むことで、言語モデルの性能を上げようとしてんねん。このステップバイステップの推論で、LMaaSの性能は上がるし、説明もしやすくなる(Kojima et al., 2022)。でもな、性能が上がるのはモデルの複雑さが増すからかもしれへんし(Feng et al., 2023)、LMaaSが信用できへん理由付けを生成するのを防げるわけでもないねん(Turpin et al., 2023)。しかも、セクション3.3で触れたみたいに、プロンプトが論理的に正しくなくても性能は上がったりするんやで(Schaeffer et al., 2023b参照)。
説明に求められる3つの条件として、明示性・忠実性・安定性ってのがよう言われてんねん(Alvarez Melis and Jaakkola, 2018; Maynez et al., 2020b; Li et al., 2023)。汎用のLMaaSは明示性を最大化する答えを出すから、その意味では説明(LMaaSにとっては条件付きプロンプトやけど)はすぐわかって理解しやすいねん。一方で、忠実性——つまり各入力変数(LMaaSの場合は各トークン)がモデルの判断にどんだけ関係あるかってことと、安定性——入力をちょっと変えても説明が一貫してるかってことは、まだ足りてへんねん。まあ、その方向に進んでる研究もあるけどな(Huang et al., 2023b; Lanham et al., 2023)。
ほんで、忠実な説明ってのは、モデルが特定のプロンプトに対してその答えを出した十分な原因を含むべきやと思うねん(Darwiche and Hirth, 2020)。安定性はロバスト性(頑健性)とめっちゃ関係してるしな。研究の文献では、機械学習モデルの説明はモデルの予測を導くのに十分やないし、入力をちょっと変えただけでめっちゃ敏感に変わってしまうって、圧倒的な証拠が出てんねん(Ignatiev et al., 2019; Marques-Silva and Ignatiev, 2022; Izza et al., 2023)。それを目的に明示的に訓練せん限りはな。安全が重要なアプリケーションに限らず、ロバスト性の保証を明示的に組み込む手法を推してるねん。それはエンドユーザーに安心感を与えるためやし、信頼を損なわんためでもあるわけや。最適性とロバスト性の証明は小規模モデル以上にはスケールせえへん(Malfa et al., 2021)けど、近似的な手法と確率的な保証を推進していきたいねん。こういう性質と、似た入力に対する不変性、さっき言うた明示性(人間のフィードバックを使った強化学習とかその派生アルゴリズム(Bai et al., 2022; Gulcehre et al., 2023)で訓練時に強制できるやつ)を組み合わせたら、本質的に解釈性が低いモデルに対して研究コミュニティが推奨してる説明可能性の条件に、LMaaSを合わせられるはずやねん。LMaaSは他のプロバイダーに対する競争優位を保つためにクローズドソースにされてるけど、出力と一緒に中間表現(内部状態とか出力のロジットとか)を出すのは、クローズドソースと解釈可能性のええ落としどころやと思うねん。企業側も研究者や開発者のチームによるレッドチーミング(脆弱性を探す作業)の恩恵を受けられるしな。他にも追求すべき研究の方向性としては、解釈可能性とモデルの誘導があるねん。企業は検査できへんLMaaSと一緒に、その表現で訓練された代理モデルを公開することもできるわけや。AnthropicがClaude(Templeton et al., 2024; An...)でやってる研究の流れと同じようにな。
1512
---
## Page 17
[](/attach/2bb7904744e26e395d3db068e172c29038af52b4b45b4500d5111619e4eff7d1_p017.png)
### 和訳
LMaaS(Language Models as a Service)について
Anthropicの2024年の話やねんけど、LMaaSの機能がちゃんと解釈できて、出力をコントロールできるようになったら、つまりスパース・オートエンコーダーみたいな代理モデルを使って(Brickenらの2023年の研究参照な)、ユーザーからの信頼がめっちゃ上がるし、今まで誰も手つけてへんかった研究分野がガンガン広がっていくわけよ。
まとめるとな、外部知識を使って説明の根拠を固めようって動きはあるねんけど(Meiらの2023年とかOhmerらの2023年とかな)、再帰的プロンプティングってやり方だけに頼るんじゃなくて、モデルがどう判断してるかをちゃんと形式的に保証されたバイアスのない方法で覗き見できる戦略を作らなあかんねん(Billsらの2023年参照)。ほんで、訓練のプロセス自体に、後から分析しても信頼できる説明手法を組み込んでいく必要があるんよ(Krishnaらの2023年参照)。
## 4. LMaaSの問題をどないかする:とりあえずの作戦
この研究ではな、LMaaSと普通の言語モデル(LM)の違いを4つの観点から見てるねん:アクセスのしやすさ、再現性、信頼性、そして信用できるかどうか。これらの問題は、何億人ものユーザーが毎日使ってるLMaaSの能力と限界を理解するのに影響してくるんよ。やから、研究者も政策立案者も一般の人も、LMaaSを信頼できるようにするための解決策を、コミュニティ全体で見つけていかなあかんねん。以下で、さっき挙げた問題をまとめて、これから取り組むべき課題を強調しながら、前に進む道を示すで。
**アクセシビリティ(アクセスのしやすさ)について**
アクセシビリティを良くするためには、企業がLMaaSの元になってる言語モデルのソースコード(最低でも詳しいモデルカードは)公開すべきやねん。まあ、商用利用を禁止するライセンスだけじゃ、企業の競争優位性を守るには不十分やろな。だって他の企業がその知見を活用して、もっとデカい計算インフラでやっちゃうかもしれんからな。せやから、LMaaSのソースコード(もしくはめっちゃ詳しいモデルカード)は、少なくとも監査する人とか評価する人、レッドチーム(セキュリティテストする人らな)には、共有に制限つけた上で見せるべきやと思うわ。
あと、Alpaca LLaMAとかPythiaみたいに、サイズ違いのモデルを出してくれたら、計算資源が限られてる研究者でも実験できるようになって、アクセシビリティがもっと上がるねん。言語間の不均衡の問題については、公平なトークナイザー(文章を細かく分ける仕組みな)と、トークンごとに課金するポリシーがあれば、経済的に恵まれてない人や、あんまり使われてない言語を話すお客さんにもLMaaSが広がるやろ。それと、テクノロジーへのアクセスが限られてる国や不利な立場のユーザーが、LMaaSにアクセスする時にどんだけ差があるか、ちゃんと評価して数値化する必要があるねん。そうすれば、企業や政策立案者が不公平な扱いを減らすためのヒントとテクニックが得られるわけよ。
**再現性(リプロダクシビリティ)について**
再現性を確保するには、新しいバージョンが出た時に古いLMaaSをオフラインにしたらあかんねん。まあ正直、古いモデルへのアクセスを提供し続けても、企業は儲からへんけどな。さらに言うと、レガシー(古い)LMaaSを寛容なライセンスで、できればオープンソースで公開するのは、商業的な観点からはプロバイダーにダメージを与える可能性が高いねん。ただ、研究コミュニティにバイアスやバグ、脆弱性を見つけて報告してもらえるっていうメリットはあるんやけどな。
研究コミュニティとしては、古いモデルをできるだけ長く研究者に提供してほしいし、アップデートの前にはちゃんと警告して、古いバージョンを廃止する前に十分な時間をくれたら、実験を完了させたり再現の努力ができるんよ。最低限、モデルを構成するすべてのパラメータにハッシュ値(一意の識別子みたいなもんな)をつけて、モデルのメンテナーがアップデートする時に「モデルコミット」のログをユーザーに提供すべきやねん。これのメリットは、ユーザーとモデルのやり取り(特に研究者がやるベンチマークとかな)を、特定のモデルコミットのハッシュと紐づけられることなんよ。
企業は、モデルの動作を完全に決定論的(毎回同じ入力には同じ出力を返すってことな)にするオプションも提供できるやろ。まあこれはモデルのアーキテクチャに対する特定の攻撃を増やすかもしれんけどな。全部のモデルを決定論的にしろとは言うてへんで。ただ、科学的な評価の目的には、非決定論的なやつより決定論的なやつの方がええって言うてるだけや。この意味で、学術誌や学会は、十分な再現性の要件を満たしてないモデルの使用を推奨せんようにすべきやと思うわ。
---
## Page 18
[](/attach/2bb7904744e26e395d3db068e172c29038af52b4b45b4500d5111619e4eff7d1_p018.png)
### 和訳
La Malfa らの研究チーム
**信頼性について**
データセットの汚染問題ってあるやんか、これに対処するには2つのアプローチがあるねん。まず一つ目は、LMaaS(言語モデルのサービス)を提供してる側が、どのデータセットで学習させたかをちゃんと明示すべきやってこと。これって言語モデルの「モデルカード」みたいなもんやな。で、産業界と研究者が協力して、あるモデルが特定の入力データやそのちょっとした変形を学習で取り込んでるかどうかを素早く調べる技術を一緒に開発したらええねん。
ユーザーとのやり取りからプロンプトを収集してるモデルがあるやん?そういうのを全部ダメってことにする必要はないんやけど、研究コミュニティとしては、テストで使うプロンプトが収集されてるかどうかを確認する手段がない状態では、そういうモデルを報告目的(ベンチマークとか)で使うのはやめといた方がええと思うねん。
ベンチマークに関して言うと、タスク間でのパフォーマンスを説明できる「潜在的な要因」を探って検証する方法論を研究・開発すべきやと考えてるねん。ただし、後付けの分析手法は避けて、ある程度の解釈可能性は維持せなあかん。今のところ、HELMとかBIG-Benchみたいな大規模なテスト環境の開発に力が注がれてるけど、これらって中身が見にくいし、学習データとは違う分布のデータでテストしてる可能性もあるわけや。やから、LMaaSや言語モデルを指標やデータセットごとにグループ分けして、解釈しやすいモデル比較ができるような方法論の方向にもっと力を入れるべきやと思ってるねん。
**信用性について**
最後に、忠実性と安定性っていうのは、LMaaSとその振る舞いを分かりやすく説明する「説明可能性ツール」に組み込まれるべきやねん。
忠実性は「グラウンディング」と「充足性」で実現できるんや。言い方は違うけど、どっちもモデルの決定に影響を与えるプロンプトの要素のことを指してるねん。一方で、頑健性とプロンプトのちょっとした変化に対する不変性があれば、安定性が実現できるわけや。形式手法と頑健性の分野では既にめっちゃ豊富な研究蓄積があるから、そこからヒントをもらうべきやな。
長期的な目標としては、安全性が超重要な場面でも使えるようなLMaaSや言語モデルを搭載したアプリケーションを実用化することやねん。そうすれば、モデルがなんでその判断をしたのかっていう理由に対して信頼を持てるようになるし、これは今も続いてる研究課題やで。
**謝辞**
ELMはアラン・チューリング研究所の支援を受けてるねん。APはEPSRC自律知的機械システム博士課程訓練センター(EP/S024050/1)の支援を受けてるわ。AGCは経済社会研究会議(ESRC)の助成金ES/W003473/1と、チューリング防衛・セキュリティプログラム(GCHQとアラン・チューリング研究所間の枠組み協定に基づく英国政府とのパートナーシップを通じて)の支援を受けてるで。
**付録A. 主要なLMaaSの商用ライセンスとオプトアウトフォーム**
以下に、言語モデルをホスティングしてる会社ごとに、主要なリンク(投稿時点のもの)を載せとくで。
AI2Lab
https://www.ai21.com/terms-of-use
https://www.ai21.com/privacy-policy
https://studio.ai21.com/privacy-policy
Anthropic
https://console.anthropic.com/legal/terms
https://console.anthropic.com/legal/privacy
https://support.anthropic.com/en/articles/7996868-i-want-to-opt-out-of-my-prompts-and-results-beingused-for-training-models
Cohere
https://cohere.com/saas-agreement
Google
https://support.google.com/bard/answer/13594961
1514
---
## Page 19
[](/attach/2bb7904744e26e395d3db068e172c29038af52b4b45b4500d5111619e4eff7d1_p019.png)
### 和訳
Language-Models-as-a-Service(言語モデルのサービス化)
https://support.google.com/bard/answer/13594961?hl=en
https://cloud.google.com/vertex-ai/docs/generative-ai/learn/responsible-ai
https://docs.google.com/forms/d/e/1FAIpQLSdUwCF62JRg8rVYh5IaN7VWwIrLtWbxtcQDRC97zbzoq54bfg/viewform
https://blog.google/technology/ai/an-update-on-web-publisher-controls/
Inflection
https://pi.ai/profile/policy - ログインしたらライセンス見れるで。
https://pi.ai/profile/terms - ログインしたらライセンス見れるで。
Microsoft
https://privacy.microsoft.com/privacystatement
OpenAI
https://openai.com/policies/terms-of-use
https://help.openai.com/en/articles/7730893-data-controls-faq
https://platform.openai.com/docs/models/how-we-use-your-data
https://openai.com/index/introducing-gpts/
上に書いてあるURLは全部2023年7月30日に最後にアクセスしたやつやねん。ただし、AnthropicとOpenAIだけは2023年12月29日に最後にアクセスしたで。
参考文献
Dean Adam. 2023. GPT Unicorn: GPT-4の画像生成能力を毎日探ってみたで、っていう研究やな。2023年7月31日にアクセス。
Orevaoghene Ahia, Sachin Kumar, Hila Gonen, Jungo Kasai, David R Mortensen, Noah A Smith, and Yulia Tsvetkov. 2023. 言語によってコストって変わるん?商用言語モデル時代のトークン化について考えてみたで、っていう論文やな。ArXivプレプリント、abs/2305.13707。
Rachith Aiyappa, Jisun An, Haewoon Kwak, and Yong-Yeol Ahn. 2023. ChatGPTの評価ってほんまに信用できるん?っていう疑問を投げかけた論文やで。ArXivプレプリント、abs/2303.12767。
Hussam Alkaissi and Samy I McFarlane. 2023. ChatGPTの人工的なハルシネーション(でっちあげ)について:科学論文書くときにどんな影響あるんか考えたで。Cureus、15(2)。
Ghassan AlRegib and Mohit Prabhushankar. 2022. ニューラルネットワークにおける説明のパラダイムについて語った論文やな。なんでかっていうと、AIがなんでその答え出したんか説明できるようにするのが大事やからやねん。ArXivプレプリント、abs/2202.11838。
David Alvarez-Melis and Tommi S. Jaakkola. 2018. 自己説明型ニューラルネットワークで頑健な解釈可能性を目指すで、っていう研究やな。Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018、NeurIPS 2018、2018年12月3-8日、カナダのモントリオールで発表されて、7786-7795ページに載ってるで。
AI Anthropic. 2024. Claude 3モデルファミリー:Opus、Sonnet、Haikuの紹介やな。Claude-3モデルカード、1。
Amos Azaria and Tom Mitchell. 2023. LLM(大規模言語モデル)の内部状態は嘘ついてるとき自分でわかってるんちゃう?っていうめっちゃおもろい研究やで。arXivプレプリント arXiv:2304.13734。
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. 2015. アテンション機構を使って翻訳と整列を同時に学習するニューラル機械翻訳の研究やな。3rd International Conference on Learning Representations、ICLR 2015、アメリカのサンディエゴで2015年5月7-9日に発表されたカンファレンストラックの論文やで。
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. 2022. 人間のフィードバックからの強化学習(RLHF)を使って、役に立って害のないアシスタントを訓練するで、っていう論文やな。ArXivプレプリント、abs/2204.05862。
Yejin Bang, Samuel Cahyawijaya, Nayeon Lee, Wenliang Dai, Dan Su, Bryan Wilie, Holy Lovenia, Ziwei Ji, Tiezheng Yu, Willy Chung, et al. 2023. ChatGPTの推論能力、ハルシネーション(でっちあげ)、対話性について、いろんなタスク・言語・モダリティで評価してみたで、っていうめっちゃ包括的な研究やな。ArXivプレプリント、abs/2302.04023。
Jeremy Barnes. 2021. もう文分類から先に進む時期ちゃう?っていう問題提起やな。
Jeremy Barnes, Lilja Øvrelid, and Erik Velldal. 2019. 感情分析はまだ解決されてへんで!感情分類を評価して検証してみた、っていう論文やな。Proceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP、イタリアのフィレンツェで発表されて、12-23ページに載ってるで。Association for Computational Linguisticsから出とる。
1515
---
## Page 20
[](/attach/2bb7904744e26e395d3db068e172c29038af52b4b45b4500d5111619e4eff7d1_p020.png)
### 和訳
La Malfaさんたちの論文やけど、
Lukas Berglundさんたち(2023年)がめっちゃおもろい発見したんやで。「逆転の呪い」っていうて、大規模言語モデル(LLM)を「AはBや」って訓練しても、「BはAや」ってことは学習でけへんねんて。arXivのプレプリントで出とるわ。
Maciej Bestaさんたち(2023年)は「思考のグラフ」っていう方法を提案してんねん。これ、LLMで複雑な問題解くときにめっちゃ使えるやつやねんて。
Stella Bidermanさんたち(2023a)が言うてんのは、LLMの記憶ってな、予測できるもんと突然出てくるもんがあるってことやねん。で、別の論文(2023b)では「Pythia」っていうLLMを訓練中とかスケーリングで分析するためのツールセット作ってんねん。機械学習の国際会議で発表しとったわ。
Steven Billsさんたち(2023年)は、なんとLLM使って別のLLMのニューロンを説明できるって言うとんねん。モデルでモデルを説明するって、ちょっとすごない?
Rishi Bommasaniさんたち(2021年)は基盤モデルのチャンスとリスクについて書いてんねん。要するに、でっかいモデルには可能性もあるけど危険もあるで〜って話やな。
Alexander Borzunovさんたち(2022年)は「Petals」っていうシステム作ってん。みんなで協力してでっかいモデルの推論とファインチューニングができるようになるやつやねん。
Trenton Brickenさんたち(2023年)は「単義性に向けて」っていう研究やねん。なんでかっていうと、LLMって一つのニューロンがいろんな意味持っとることが多いんやけど、辞書学習っていう手法でそれをバラバラに分解しようとしてんねん。Transformer Circuits Threadで公開されとるで。
Tom B. Brownさんたち(2020年)の論文はほんまに有名やねん。「言語モデルは少数ショット学習者や」っていうタイトルで、NeurIPS 2020で発表されとる。GPT-3の論文として知られとるやつやな。
Sébastien Bubeckさんたち(2023年)は「汎用人工知能の火花:GPT-4との初期実験」っていう論文出してんねん。GPT-4がどんだけすごいか、でもまだ限界もあるで〜って内容やな。
Ryan Burnellさんたち(2023年)は言語モデルの能力の構造を明らかにしようとしてんねん。モデルが何ができて何があかんのか、体系的に調べとるわけや。
Nicholas Carliniさんは記憶関連でいくつか論文出してんねん。2022年のやつは言語モデルの記憶を定量化する話で、2021年のやつはLLMから訓練データを引っ張り出せてまうっていうセキュリティの問題について書いとる。USENIX Securityで発表されとったで。
Ming-Wei Changさんたち(2008年)は意味表現の重要性について書いてんねん。「データレス分類」っていうて、ラベル付きデータなしでも分類できるって話やな。AAAIで発表されとる。
Yupeng Changさんたち(2023年)はLLMの評価についてのサーベイ論文やねん。どうやってLLMを評価したらええのか、いろんな方法をまとめとるわ。
Sherman Channさん(2023年)は、GPT-4の非決定性はスパースなMoE(専門家混合モデル)のせいやって言うてんねん。同じ入力でも毎回ちょっと違う答えが出るのは、このアーキテクチャが原因やったんやな。
Patrick Chaoさんたち(2023年)は、ブラックボックスのLLMを20回のクエリでジェイルブレイクできるって論文出してんねん。セキュリティ的にはちょっと怖い話やけど、研究としてはめっちゃ重要やで。
---
## Page 21
[](/attach/2bb7904744e26e395d3db068e172c29038af52b4b45b4500d5111619e4eff7d1_p021.png)
### 和訳
言語モデルのサービス化(LMaaS)について
ほな、この参考文献リストを紹介していくで!
Lingjiao Chenさんらが2023年に出した論文「ChatGPTの振る舞いって時間と共にどう変わってんの?」やねん。これめっちゃ気になるテーマやろ?ChatGPTって実は日々アップデートされてて、その変化を追跡した研究やで。
Xinyun Chenさんらの2019年の研究は「実行ガイド付きニューラルプログラム合成」っていうもんで、プログラムを実際に動かしながらAIにコード書かせるっていう賢いアプローチやねん。国際学習表現会議で発表されたやつや。
Aakanksha Chowdheryさんらの2022年の「PaLM」は、Googleが出したでっかい言語モデルやねん。「Pathways」っていう新しいシステム使って、言語モデルのスケールアップに成功したんや。
Raunak Chowdhuriさんらの2023年の論文タイトルがおもろいねん。「いやいや、GPT4はMITの試験満点取れへんで」って。AIの限界をちゃんと示した研究やな。
Anthony Cohnさんらの2023年の研究は、大規模言語モデルの常識的な空間推論能力を「弁証法的」に評価したもんやねん。要するに、AIが「右」とか「上」とかの空間的な概念をどこまで理解できてるかって話や。
Adnan Darwicheさんらの2020年論文は「意思決定の背後にある理由について」や。AIがなんでそういう答え出したんか説明する技術の研究やで。
Mingkai Dengさんらの2022年の「RLPrompt」は強化学習使ってプロンプト(AIへの指示文)を最適化する研究やねん。アブダビで開催された自然言語処理の国際会議で発表されたで。
Tim Dettmersさんらの2023年の「QLoRA」はめっちゃ画期的やねん。大規模言語モデルを効率よくファインチューニング(微調整)する方法で、GPUメモリ少なくても大きいモデル動かせるようになったんや。
Jacob Devlinさんらの2019年の「BERT」は超有名やで!双方向のトランスフォーマーを言語理解の事前学習に使った研究で、ミネアポリスの学会で発表されて、自然言語処理の世界を変えた革命的な論文やねん。
Ning Dingさんらの2022年の「デルタチューニング」は、事前学習済み言語モデルのパラメータを効率よく調整する方法を包括的に調べた研究や。全部のパラメータいじらんでも性能出せるテクニックやで。
Qingxiu Dongさんらの2022年の論文は「文脈内学習」のサーベイや。これって何かっていうと、AIにいくつか例を見せるだけで新しいタスクできるようになる能力のことやねん。めっちゃ便利やろ?
Li Duさんらの2022年の研究は測度論っていう数学を使って「タイトな言語モデル」を特徴づけた論文や。ちょっと難しい数学の話やけど、言語モデルの理論的な基盤を固める重要な研究やで。
Yogesh Dwivediさんらの2023年の論文タイトルも秀逸やねん。「ChatGPTが書いたからってそれがなんやねん?」って感じで、生成AIのチャンスと課題について多角的に論じてるんや。研究・実務・政策への影響を幅広くカバーした国際情報管理ジャーナルの論文や。
Nouha Dziriさんらの2023年「信仰と運命:トランスフォーマーの構成性の限界」は、AIが複雑な組み合わせの推論をどこまでできるかの限界を示した研究やねん。
Ronen Eldanさんらの2023年「TinyStories」は、言語モデルがどこまで小さくなってもちゃんとした英語喋れるかって研究や。ちっちゃいモデルでも意外といけるってことを示したんやで。
Guhao Fengさんらの2023年の論文は「Chain of Thought(思考の連鎖)」の謎を理論的に解明しようとした研究や。なんでAIに「順を追って考えて」って言うと賢くなるんか、その仕組みを数学的に分析しとるねん。
Simon Friederさんらの2023年「ChatGPTの数学的能力」は、ChatGPTが数学どこまでできるかを調べた研究やで。
Deep Ganguliさんらの2022年「レッドチーミング」は、言語モデルの有害な出力を減らすために、わざと悪意ある使い方してテストする方法の研究やねん。攻撃者の視点で穴を探して、先に塞いどこうっていう発想や。
最後にLeo Gaoさんの2023年の記事は「OpenAI APIモデルのサイズについて」で、2023年7月31日にアクセスされたもんやで。
---
## Page 22
[](/attach/2bb7904744e26e395d3db068e172c29038af52b4b45b4500d5111619e4eff7d1_p022.png)
### 和訳
La Malfaさんたち。
Matt Gardnerさんら。2018年。AllenNLP:めっちゃ深い意味を理解する自然言語処理のプラットフォームやねん。NLPのオープンソースソフトウェアのワークショップで発表されたやつで、オーストラリアのメルボルンでやってん。計算言語学会が主催しとったんやで。
Yoav Goldbergさん。2016年。ニューラルネットワークを使った自然言語処理モデルの入門書みたいなやつや。人工知能研究ジャーナルの57巻、345〜420ページに載っとるで。
Arnav Gudibandeさんたち。2023年。有料のでっかい言語モデルを真似したらアカンっていう話やねん。なんでかっていうと、真似してもほんまの実力はつかへんからな。arXivっていう論文サイトに上がっとるプレプリントやで。
Caglar Gulcehreさんたち。2023年。ReST(強化自己学習)っていう言語モデルの訓練方法について書いとるねん。要は、モデルが自分で学んで自分を強化していくっちゅう仕組みやな。arXivのプレプリントや。
Hacker News。2023a。ChatGPTの利用者が「なんか前よりアホになってへん?」って文句言い出して、使う人減ってきたって話や。2023年7月31日にアクセスした情報やで。
Hacker News。2023b。ChatGPT-4の性能が落ちてきたって体感しとる人の話や。これも2023年7月31日にアクセスしたやつやね。
Yikun Hanさんたち。2023年。ベクトルデータベースについてめっちゃ詳しくまとめたサーベイ論文やねん。データの保存方法とか検索技術とか、どんな課題があるかとか全部書いとるで。arXivのプレプリントや。
Shibo Haoさんたち。2023年。言語モデルで推論するってことは、世界モデルを使って計画を立てるってことやねん、っていう話や。ほんまに面白い視点やで。arXivのプレプリントや。
Dan Hendrycksさんたち。2023年。AIがもたらすかもしれへん壊滅的なリスクについてまとめたやつやねん。めっちゃ大事な話やで。arXivのプレプリントや。
Joachim Henkelさん。2009年。オープンソース開発者が企業の中でどんな役割を果たしとるかっていう話や。「公開することのチャンピオン」っていうタイトルやねん。Industrial and Corporate Changeっていう雑誌の18巻3号、435〜471ページや。
Michael Heronさんたち。2013年。オープンソースとアクセシビリティ(みんなが使いやすくする工夫)について、ええところと限界を書いとるねん。Journal of interaction Scienceの1巻1号、1〜10ページや。
Ari Holtzmanさんたち。2020年。ニューラルネットが文章生成するときの不思議な現象について研究したやつやねん。タイトルは「ニューラルテキスト退化の不思議なケース」や。国際学習表現会議で発表されたで。
Neil Houlsbyさんたち。2019年。自然言語処理でパラメータを効率よく転移学習する方法についてやねん。要は、少ないパラメータの調整でモデルを新しいタスクに適応させるって話や。国際機械学習会議の2790〜2799ページに載っとるで。PMLRっていう出版社から出とるねん。
Edward J Huさんたち。2021年。LoRA(ローランク適応)っていう、でっかい言語モデルを効率よく微調整する方法についてやねん。めっちゃ画期的な手法やで。国際学習表現会議で発表されたやつや。
Qiuyuan Huangさんたち。2023a。ArKっていう、知識とインタラクティブにやり取りできる拡張現実の研究やねん。新しい能力が出現するっちゅう話やで。arXivのプレプリントや。
Shiyuan Huangさんたち。2023b。でっかい言語モデルが自分自身を説明できるんかっていう研究やねん。AIが生成した自己説明について調べとるで。arXivのプレプリントや。
Alexey Ignatievさんたち。2019年。機械学習モデルを説明するのにアブダクション(仮説形成推論)を使う方法についてやねん。AAAI会議(人工知能の有名な学会やで)の33巻1号、1511〜1519ページに載っとるわ。
Daphne Ippolitoさんたち。2022年。言語モデルが丸暗記するのを防いでも、プライバシーが守られてるって錯覚しちゃうだけやで、っていう警告の論文やねん。arXivのプレプリントや。
Yacine Izzaさんたち。2023年。「膨らんだ説明を届ける」っていうタイトルの論文やねん。説明がなんか大げさになっちゃう問題についてやな。ArXivのプレプリントで、abs/2306.15272やで。
Alon Jacoviさんたち。2023年。テストデータを平文でアップロードするのやめようやって話やねん。評価用のベンチマークでデータ汚染が起きへんようにする実践的な方法を提案しとるで。なんでかっていうと、モデルがテストデータを学習中に見ちゃったら正確な評価ができへんからな。ArXivのプレプリントで、abs/2305.10160や。
Jared Kaplanさんたち。2020年。ニューラル言語モデルのスケーリング則についてやねん。モデルをでっかくしたり、データ増やしたりしたら、どれくらい賢くなるかっていう法則を見つけたんや。めっちゃ有名な論文やで。ArXivのプレプリントで、abs/2001.08361や。
1518
---
## Page 23
[](/attach/2bb7904744e26e395d3db068e172c29038af52b4b45b4500d5111619e4eff7d1_p023.png)
### 和訳
サービスとしての言語モデル
Douwe Kielaさんらのチームが2021年にめっちゃ面白い研究発表してんねん。「Dynabench: NLPのベンチマーキングを考え直そうや」っていう論文で、北米計算言語学会で発表されたやつやな。要するに、今までのAIの評価方法ちゃうんちゃう?って問題提起してんねん。
Jan Kocoń さんらは2023年に「ChatGPT:なんでもできるけど、どれも中途半端やで」っていう研究出してんねん。まさにタイトル通りで、ChatGPTって色々できるけど、どの分野でもプロには勝てへんって話やな。
Takeshi Kojimaさんらの2022年の研究がほんまにすごくて、「大規模言語モデルってゼロショットで推論できるやん」って発見してんねん。なんでかっていうと、特別な訓練なしでも、ちゃんと考えて答え出せるってことがわかったんやな。
Satyapriya Krishnaさんらは2023年に、「AIの説明を後から付け足したら、そのAI自体がもっと賢くなるで」っていう研究してんねん。これ、めっちゃ画期的やと思わへん?
Tamera Lanhamさんらも2023年に「AIが考える過程ってどれくらい信用できるん?」っていう研究してんねん。Chain-of-thought、つまりAIが段階踏んで考えるやつ、あれがほんまに正しいこと言うてるか調べたんやな。
Md Tahmid Rahman Laskarさんらは2023年に、ChatGPTを色んなテストで徹底的に調べ上げてんねん。まあ健康診断みたいなもんやな。
Patrick Lewisさんらの2020年の研究は「RAG」って呼ばれてて、これがめっちゃ重要やねん。AIが自分で情報検索して、それを元に答えを作るっていう仕組みやな。知識が必要なタスクにめっちゃ効くんやで。
Bo Liさんらは2023年に、ChatGPTの情報抽出能力を調べてんねん。性能だけやなくて、「なんでそう答えたん?」っていう説明能力とか、自信の度合いが正確かとか、ほんまのこと言うてるかとか、色々チェックしてんな。
Percy Liangさんらは2022年に「言語モデルを全方位から評価したろ」っていう研究してんねん。HOLMっていうやつで、一個の側面だけやなくて、総合的に見てみようって話やな。
Andreas Liesenfeld さんらは2023年に「ChatGPTの中身、どれくらいオープンなん?」っていう追跡調査してんねん。透明性とか説明責任とか、そういう社会的な側面も大事やからな。
Alisa Liuさんらは2023年に「言語モデル、あいまいさ苦手やで」っていう研究出してんねん。人間の言葉って結構あいまいやん?それをAIがうまく扱えてへんって指摘してんねん。
Ruibo Liuさんらは2022年に「AIを人間の価値観に合わせようや」っていう研究してんねん。ただ賢いだけやなくて、人間にとって良いことを言うようにするっていう、めっちゃ大事な研究やな。
Xiao Liuさんらは2023年に「AgentBench」っていうのを作ってんねん。AIをエージェント、つまり自分で行動できる存在として評価するためのテストやな。
Yi Liuさんらは2023年に、ChatGPTを騙す方法の研究してんねん。「プロンプトエンジニアリング」っていうテクニックで、AIにルール破らせることができるっていう、ちょっと怖い話やな。セキュリティ的に重要な研究やで。
Sheng Luさんらは2023年に「大規模言語モデルの急に出てくる能力って、実はただのin-context learningちゃうの?」って疑問投げかけてんねん。なんでかっていうと、魔法みたいに見えることにもちゃんと理由があるかもってことやな。
Emanuele La Malfaさんらは2022年のAAAI学会で「NLPの頑健性って何やねん」っていう研究発表してんねん。AIがちょっとした入力の変化で全然違う答え出すの、あかんやろって話やな。
同じくEmanuele La Malfaさんらは2021年に、NLPモデルの説明を数学的にちゃんと保証しようっていう研究もしてんねん。「この説明、絶対正しいで」って言えるようにするための理論的な研究やな。
---
## Page 24
[](/attach/2bb7904744e26e395d3db068e172c29038af52b4b45b4500d5111619e4eff7d1_p024.png)
### 和訳
La Malfaさんたちの研究やな。
Joao Marques-SilvaとAlexey Ignatievが2022年に発表した研究があってな、「形式的な説明可能AI(XAI)で信頼できるAIを届けよう」ってタイトルやねん。AAAIの人工知能カンファレンスの論文集に載ってて、36巻11号の12342ページから12350ページに収録されてるで。
Joshua Maynezらが2020年に出した論文もあるわ(2020a)。これは要約を自動で作るときの「忠実さ」と「事実の正確さ」について書いてんねん。arXivっていうプレプリントサーバーに上がってて、番号はarXiv:2005.00661や。
同じJoshua Maynezらが2020年(2020b)に出したもう一本の論文もあんねん。こっちは計算言語学会(ACL)の第58回年次総会で発表されたやつで、1906ページから1919ページに載ってる。オンライン開催やったみたいやな。
R Thomas McCoyらが2023年(2023a)に発表した研究は、「言語モデルって学習データからどんだけコピーしてんの?」っていう話やねん。RAVENっていう手法を使って、テキスト生成における言語的な新しさを評価してるんや。計算言語学会のトランザクションズっていうジャーナルの11巻、652ページから670ページに載ってるで。
同じMcCoyらが2023年(2023b)に出したもう一本は、「自己回帰の残り火:大規模言語モデルを、解くように訓練された問題を通じて理解する」っていうタイトルや。なんでこんなタイトルかっていうと、大規模言語モデル(LLM)って基本的に「次の単語を予測する」っていう問題を解くように訓練されてるんやけど、そこから生まれる性質を分析してんねん。arXivのプレプリントでarXiv:2309.13638や。
Ian R McKenzieらが2023年に発表した研究は「逆スケーリング:デカけりゃええってもんちゃうで」っていう話やねん。普通、AIモデルって大きくなればなるほど性能上がると思うやん?でもそうじゃないケースがあるって示してんねん。arXivのarXiv:2306.09479に載ってるで。
Alex Meiらが2023年にACLのFindingsで発表した論文は、「注目して、属性を付けて、合理化しよう:物理的に安全で信頼できるAIを目指して」っていう内容や。11021ページから11036ページに収録されてる。
Anders Giovanni Møllerらが2023年に出した論文は、「プロンプトと少数のサンプルだけで十分なん?」っていう疑問を投げかけてんねん。少ないデータしかない分類タスクで、GPT-4を使ってデータを増やす(データ拡張)方法について研究してるわ。ArXivのabs/2304.13861や。
Subhabrata Mukherjeeらが2023年に発表した「Orca」っていう研究もあるで。GPT-4の複雑な説明の流れから段階的に学習していく方法について書いてんねん。ArXivのabs/2306.02707に載ってる。
Zhaoyang Niuらが2021年にNeurocomputingっていうジャーナルに出した論文は、深層学習における「注意機構(アテンション)」についてのレビュー論文や。452巻の48ページから62ページに載ってる。アテンションっていうのは、AIが「ここが大事やで」って特定の部分に注目する仕組みのことやねん。
Xenia Ohmerらが2023年に出した論文は、多言語での一貫性を通じてタスク理解を評価するっていう内容で、ChatGPTを使ったケーススタディやねん。ArXivのabs/2305.11662や。
OpenAIが2023年に出したGPT-4の技術報告書もあるで。ArXivのabs/2303.08774に載ってる。
OpenAIが2023年(2023a)に出した「ChatGPTの紹介」っていう文書もあって、2023年4月11日にアクセスされてるな。
OpenAIが2023年(2023b)に出したOpenAIドキュメントのファインチューニングについての説明もあって、2023年8月7日にアクセスされてる。ファインチューニングっていうのは、既存のAIモデルを特定の用途に合わせて追加学習させることやねん。
OpenAIコミュニティで2023年に上がった投稿で、「ChatGPT-4のパフォーマンスが落ちてる感じがする」っていう報告があって、2023年7月31日にアクセスされてるな。
Shuyin Ouyangらが2023年に出した論文は、「LLMはチョコレートの箱みたいなもんや:コード生成におけるChatGPTの非決定性」っていうタイトルやねん。要するに、同じ質問しても毎回違う答えが返ってくることがあるよって話や。arXivのarXiv:2308.02828に載ってる。
James Jie Panらが2023年に出した論文は、ベクトルデータベース管理システムについてのサーベイ(調査)やねん。ベクトルデータベースっていうのは、AIの埋め込み表現(データを数値のベクトルで表したもの)を効率的に保存・検索するためのデータベースのことや。arXivのarXiv:2310.14021に載ってる。
Bhargavi Paranjapeらが2023年に発表した「ART」っていう研究は、大規模言語モデルのための自動マルチステップ推論とツール使用についてやねん。LLMが複数の手順を踏んで考えたり、外部ツールを使ったりする方法を提案してるんや。arXivのarXiv:2303.09014や。
Wenjun Pengらが2023年に出した論文は、「私のモデルをコピーしてへん?」っていうタイトルで、EaaS(サービスとしての埋め込み)向けに、バックドア透かしを使って大規模言語モデルの著作権を保護する方法について書いてんねん。ArXivのabs/2305.10036や。
Matthew E. Petersらが2018年にNAACL-HLT(北米計算言語学会の人間言語技術カンファレンス)で発表した論文は、「深い文脈化された単語表現」についてやねん。これはELMoっていう有名な手法の論文で、単語の意味を周りの文脈に応じて表現する方法を提案してるんや。ニューオーリンズで開催された第1巻(長い論文)の2227ページから2237ページに載ってる。
Aleksandar Petrovらが2023年(2023a)に出した論文は、「プロンプティングとプレフィックスチューニングはいつ使えるんや?能力と限界についての理論」っていう内容やねん。プロンプティングっていうのはAIへの指示の出し方で、プレフィックスチューニングは特定のタスク用にモデルの入力部分を調整する方法のことや。arXivのarXiv:2310.19698に載ってるで。
1520
---
## Page 25
[](/attach/2bb7904744e26e395d3db068e172c29038af52b4b45b4500d5111619e4eff7d1_p025.png)
### 和訳
**サービスとしての言語モデル**
Aleksandar Petrovら、2023年bの研究やねんけど、「言語モデルのトークナイザーが言語間で不公平を生み出してまうで」っていう話やねん。要するに、英語とかに比べて他の言語は分割の仕方が不利になってもうて、同じ意味でもトークン数が増えたりするっちゅう問題やな。ArXivのプレプリントで、abs/2305.15425やで。
Alec Radfordら、2019年の研究。「言語モデルって教師なしのマルチタスク学習者やねん」っていうOpenAIのブログ記事や。1巻8号の9ページ目。なんでかっていうと、誰も明示的に教えてへんのに色んなタスクこなせるようになるからやねん。めっちゃ賢いやろ?
Jack W Raeら、2021年。「言語モデルのスケーリング:Gopherっていうモデルのトレーニングからわかったメソッドと分析と洞察」っていう論文やな。ArXivのabs/2112.11446。でっかいモデル作ってどうなるか調べましたっていう話。
Colin Raffelら、2020年。「統合テキスト-to-テキスト変換器で転移学習の限界を探る」っちゅう論文。Journal of Machine Learning Research、21巻、140:1から140:67ページ。T5っていうモデルの話で、全部のタスクを「テキストからテキストへの変換」として扱おうっていう発想がめっちゃ画期的やってん。
Partha Pratim Ray、2023年。「ChatGPT徹底レビュー:背景から応用、主要な課題、バイアス、倫理、限界、そして将来展望まで」。Internet of Things and Cyber-Physical Systems誌、3巻121-154ページ。ほんまに全部入りのレビューやな。
Marco Tulio Ribeiroら、2020年。「精度だけやないで:CheckListでNLPモデルの振る舞いをテストしよう」。計算言語学会の第58回年次大会論文集、4902-4912ページ、オンライン開催。精度だけ見てたらあかんで、色んな角度からテストせなっていう大事な指摘やねん。
Robin Rombachら、2021年。「潜在拡散モデルによる高解像度画像合成」。arXivのarXiv:2112.10752。これがStable Diffusionの基礎になった論文やで、めっちゃ重要。
Bernardino Romera-ParedesとPhilip H. S. Torr、2015年。「びっくりするほど単純なゼロショット学習のアプローチ」。第32回国際機械学習会議の論文集、ICML 2015、フランスのリールで7月6-11日開催、JMLR Workshop and Conference Proceedingsの37巻、2152-2161ページ。タイトルからして面白いやろ?シンプルが一番ってことやな。
Baptiste Rozièreら、2023年。「Code Llama:コード用のオープン基盤モデル」。arXivのarXiv:2308.12950。プログラミングに特化したLlamaやねんけど、オープンソースやから誰でも使えるってのがええとこやな。
Cynthia Rudin、2019年。「重要な意思決定でブラックボックス機械学習モデルの説明やめて、解釈可能なモデル使おうや」。Nature machine intelligence、1巻5号206-215ページ。ほんまその通りやねん、命に関わるようなことはちゃんと理由がわかるモデル使わなあかんって話。
Shibani Santurkarら、2023年。「言語モデルって誰の意見を反映してるん?」ArXivのabs/2303.17548。これめっちゃ大事な問いかけやな。学習データの偏りがそのまま出てくるかもしれへんからな。
Teven Le Scaoら、2022年。「BLOOM:1760億パラメータのオープンアクセス多言語言語モデル」。ArXivのabs/2211.05100。オープンソースでめっちゃでっかいモデル作ったで、しかも色んな言語対応やっていう話。
Rylan Schaefferら、2023年aの研究。「大規模言語モデルの創発能力って幻想ちゃうん?」arXivのarXiv:2304.15004。急にできるようになったように見える能力、実は評価の仕方の問題ちゃうかって鋭いツッコミやねん。
Rylan Schaefferら、2023年bの研究。「無効な論理でも同等の成果:言語モデルのプロンプトにおける推論の奇妙さ」。arXivのarXiv:2307.10573。論理的におかしいプロンプトでも結果変わらへんことがあるっていう、なんか不思議な現象の報告やな。
Christian SchlarmannとMatthias Hein、2023年。「マルチモーダル基盤モデルの敵対的頑健性について」。IEEE/CVF国際コンピュータビジョン会議の論文集、3677-3685ページ。画像とテキスト両方扱えるモデルを騙そうとしたらどうなるかって話。
Murray Shanahan、2022年。「大規模言語モデルについて語る」。ArXivのabs/2212.03551。LLMの本質とか、擬人化しすぎたらあかんよって哲学的な考察やねん。
Xinyue Shenら、2023年。「ChatGPT信じてええの?ChatGPTの信頼性を測って特徴づける」。ArXivのabs/2304.08979。ほんまにどこまで信用してええのか、ちゃんと調べましたっていう研究。
Weijia Shiら、2023年。「大規模言語モデルから事前学習データを検出する」。arXivのarXiv:2310.16789。学習に使われたデータかどうかわかるんちゃうかっていう研究で、著作権とかプライバシーの問題に関わってくる話やな。
Karan Singhalら、2023年。「大規模言語モデルは臨床知識をエンコードしてるで」。Nature誌、1-9ページ。医療の知識もちゃんと持ってるっていう、ちょっとすごい発見やねん。
Koustuv Sinhaら、2021年。「マスク言語モデリングと分布仮説:事前学習で単語の順番ってあんまり関係ないねん」。2021年自然言語処理における経験的手法に関する会議の論文集、2888-2913ページ、オンラインとドミニカ共和国のプンタカナで開催。単語の順番シャッフルしてもそこそこ学習できてまうっていう、ちょっと衝撃的な発見やったで。
---
## Page 26
[](/attach/2bb7904744e26e395d3db068e172c29038af52b4b45b4500d5111619e4eff7d1_p026.png)
### 和訳
La Malfa らの論文やねん
Aarohi Srivastavaさんとか、Abhinav Rastogiさんとか、めっちゃ大勢の研究者さんたち(2022年)。「模倣ゲームを超えて:言語モデルの能力を数値化して、どこまでいけるか予測してみよう」っていう研究やねん。ArXivのプレプリントで、番号はabs/2206.04615やで。
Richard Stallmanさん(2010年)。「そのサーバー、ほんまは何のために動いてんの?」っていう話やな。
Richard Stallmanさん(2022年)。「オープンソースって、ちょっと的外れちゃう?」っていう主張やで。
Tianxiang Sunさんたち(2022年)。「言語モデルをサービスとして使うときの、ブラックボックスチューニング」っていう研究やねん。要するに、中身が見えへんモデルでも上手いことチューニングできるで〜っていう話。国際機械学習会議で発表されてて、Proceedings of Machine Learning Researchの162巻、20841〜20855ページに載ってるわ。
Mirac Suzgunさんたち(2022年)。「BIG-Benchのめっちゃ難しいタスクと、Chain-of-Thought(考える過程を書き出す方法)で解けるんかどうか」っていう研究やな。ArXivプレプリントのabs/2210.09261やで。
Rohan Taoriさんたち(2023年)。「Stanford Alpaca:指示に従うLLaMAモデル」やねん。LLaMAっていう言語モデルに指示を理解させるようにしたやつやな。
Adly Templetonさんとか、めっちゃたくさんの人たち(2024年)。「モノセマンティシティのスケーリング:Claude 3 Sonnetから解釈可能な特徴を取り出してみた」っていう研究やねん。Transformer Circuits Threadっていうところで発表されてるで。なんでかっていうと、AIの中で何が起こってるか理解したいからやな。
Romal Thoppilanさんたち(2022年)。「LaMDA:対話アプリケーション用の言語モデル」やねん。要するにチャットボット用のモデルやな。ArXivプレプリントのabs/2201.08239やで。
Nathaniel Tkaczさん(2020年)。『Wikipediaとオープン性の政治学』っていう本やな。シカゴ大学出版から出てるで。
Hugo Touvronさんたち(2023年a)。「LLaMA:オープンで効率的な基盤言語モデル」やねん。誰でも使えるようにした強力な言語モデルやな。ArXivプレプリントのabs/2302.13971やで。
Hugo Touvronさんたち(2023年b)。「LLaMA 2:オープンな基盤モデルと、ファインチューニング済みのチャットモデル」やねん。LLaMAの進化版やな。ArXivプレプリントのabs/2307.09288やで。
Miles Turpinさんたち(2023年)。「言語モデルって、いつも本音言うてるわけちゃうで:Chain-of-Thoughtプロンプティングでの不誠実な説明」っていう研究やねん。要するに、AIが説明してることと、実際に考えてることがズレてることあるで〜っていう話やな。arXivプレプリントのarXiv:2305.04388やで。
Hoang Vanさん(2023年)。「大規模言語モデルのデータ不足問題をなんとかする方法」やねん。学習データが足りひん時どうするか、っていう研究やな。arXivプレプリントのarXiv:2302.01806やで。
Ashish Vaswaniさんたち(2017年)。「Attention is all you need(アテンションさえあればええねん)」っていう、めっちゃ有名な論文やで。今のAIの基礎になってる「Transformer」っていう仕組みを提案した論文やねん。2017年12月4〜9日にカリフォルニアのロングビーチでやったNeural Information Processing Systems 30で発表されて、5998〜6008ページに載ってるわ。
Jindong Wangさんたち(2023年a)。「ChatGPTの頑健性について:敵対的攻撃と、学習データにない状況からの視点」っていう研究やねん。ChatGPTが意地悪な入力とか、見たことない状況にどれだけ強いか調べた話やな。ArXivプレプリントのabs/2302.12095やで。
Zengzhi Wangさんたち(2023年b)。「ChatGPTって感情分析うまいんか?最初の調査してみたで」っていう研究やねん。文章がポジティブかネガティブか判断する能力を調べた話やな。ArXivプレプリントのabs/2304.04339やで。
Jason Weiさんたち(2022年a)。「大規模言語モデルの創発的能力」っていう研究やねん。モデルがデカくなると急に新しい能力が出てくる、っていうめっちゃ面白い現象についての話やな。Transactions on Machine Learning Researchに載ってるで。
Jason Weiさんたち(2022年b)。「Chain-of-Thoughtプロンプティングで大規模言語モデルの推論を引き出す」っていう研究やねん。「考える過程を書いてみて」って言うたら、AIがめっちゃ賢くなるで〜っていう発見やな。ArXivプレプリントのabs/2201.11903やで。
Thomas Wolfさんたち(2019年)。「HuggingFaceのTransformers:最先端の自然言語処理」やねん。今やAI開発者みんなが使ってるライブラリを作った人たちの論文やな。ArXivプレプリントのabs/1910.03771やで。
1522
---
## Page 27
[](/attach/2bb7904744e26e395d3db068e172c29038af52b4b45b4500d5111619e4eff7d1_p027.png)
### 和訳
サービスとしての言語モデル
Yongqin Xianさんら(2018)の研究やけど、「ゼロショット学習のええとこ・あかんとこ・やばいとこを徹底評価したったで」っちゅう論文やねん。IEEE transactions on pattern analysis and machine intelligenceの41巻9号、2251-2265ページに載っとるやつや。ゼロショット学習ってのは、見たことない新しいカテゴリのもんでも認識できるっちゅうめっちゃ便利な技術のことやで。
Dongyu Yaoさんら(2023a)は「FuzzLLM」っちゅうのを提案してんねん。これ何かっていうと、大規模言語モデルの「脱獄」の穴を先に見つけたろうっちゅう汎用的なファジングのフレームワークやねん。ファジングってのは、いろんなデータをぶち込んでバグとか脆弱性を探すテスト手法のことや。arXivのプレプリントarXiv:2309.05274で読めるで。
Shunyu Yaoさんら(2023b)の「Tree of thoughts」っちゅうのがめっちゃおもろいねん。大規模言語モデルでじっくり考えて問題解くっちゅうアプローチやねん。なんでかっていうと、一直線に答え出すんやなくて、木みたいに分岐しながらいろんな考えを試して、ほんまにええ答えに辿り着こうっちゅう発想やねん。arXiv:2305.10601で公開されとるで。
Dingli Yuさんら(2023)は「Skill-mix」っちゅうAIモデルの評価手法を作ったねん。これ、柔軟で拡張しやすい評価の仕組みで、AIがいろんなスキルをどんだけ組み合わせて使えるか見れるようになっとるんや。arXiv:2310.17567やで。
Ali Zarifhonarvarさん(2023)は「ChatGPTの経済学」っちゅうテーマで、AIが仕事にどんな影響与えるか労働市場の観点から分析してはるねん。SSRNの4350925で読めるで。要するに「AIで仕事なくなるんちゃうの?」っちゅう話をちゃんと経済学的に見てんねん。
Muru Zhangさんら(2023a)は、言語モデルのハルシネーション(嘘つき問題やな)がどんどん雪だるま式に膨らんでいくっちゅう現象を研究してんねん。一回嘘ついたら、それに辻褄合わせよとしてもっと嘘重ねてまうっちゅうやっかいな話や。arXiv:2305.13534やで。
Sarah J Zhangさんら(2023b)は、MITの数学と電気工学・コンピュータ科学のカリキュラムを大規模言語モデル使って探索してみたっちゅう研究やねん。AIが大学レベルの問題どんだけ解けるか調べたってことや。ArXivのabs/2306.08997で見れるで。
Zhuosheng Zhangさんら(2022)は「自動Chain of Thought」を提案してんねん。Chain of Thoughtってのは、AIに「考える過程」を出させる技術やねんけど、それを自動でやらせようっちゅうアイデアや。arXiv:2210.03493やで。
Mengjie Zhaoさんら(2021)の「LMTurk」はおもろい発想やで。少数のデータで学習できるAIを、クラウドワーカーみたいに使おうっちゅうフレームワークやねん。「サービスとしての言語モデル」の枠組みで、AIに仕事させるっちゅう感じやな。arXiv:2112.07522で読めるで。
Wayne Xin Zhaoさんら(2023)は大規模言語モデルの総合サーベイ書いてはるねん。今どんなモデルがあって、何ができて、どんな課題があるかまとめてくれとるから、全体像知りたかったらこれ読んだらええで。ArXivのabs/2303.18223や。
Wanjun Zhongさんら(2023)の「AGIEval」は、人間中心のベンチマークやねん。基盤モデル(めっちゃ汎用的なAIのことや)を評価するんやけど、人間にとってどんだけ使えるかっちゅう視点で見てんねん。ArXivのabs/2304.06364やで。
Kaiyang Zhouさんら(2022)は「ドメイン汎化」のサーベイ書いてはるねん。ドメイン汎化ってのは、学習したときと違う状況でもちゃんと動くようにする技術のことや。IEEE Transactions on Pattern Analysis and Machine Intelligenceに載っとるで。
Julia El Ziniさんとワドさん(2022)は、自然言語処理の深層モデルの説明可能性について書いてはるねん。要するに「AIがなんでそう判断したか」を人間にわかるように説明する話や。ACM Computing Surveysの55巻5号、1-31ページやで。
Andy Zouさんら(2023)は、整列された言語モデル(人間の意図に沿うよう訓練されたやつや)に対する汎用的で転用可能な敵対的攻撃について研究してんねん。要するに、いろんなモデルに効く攻撃方法見つけたっちゅう話や。arXiv:2307.15043で公開されとるで。
1523
---
![]()
1 / 1
100%