<<
2601.21916v1_JADE_Bridging_the_Strategic-Operational_Gap_in_Dyn.pdf

---
## Page 1
[](/attach/20df466bad70efac89c4e8f552dfb1bcecfb9e96e5a0eaa48ee5a34f49675b3d_p001.png)
### 和訳
JADE:動的エージェント型RAGにおける戦略と実行のギャップを埋める話
Yiqun Chen * 1 Erhan Zhang * 1 Tianyi Hu * 2 Shijie Wang * 3 Zixuan Yang 1 Meizhi Zhong 4 Xiaochi Wei 4
Yan Gao 4 Yi Wu 4 Yao Hu 4 Jiaxin Mao † 1
**要約**
RAG(検索拡張生成)ってやつの進化についてなんやけど、最初は固定的な検索パイプラインやったんが、今はもっと動的でエージェント的なワークフローに変わってきてんねん。中央のプランナーが複数ターンの推論を指揮するような感じやな。でもな、今ある手法には致命的な二律背反があんねん:モジュールを一緒に最適化しようとすると固定的なグラフ構造に縛られるか、動的な計画を可能にすると実行部分が凍結されたブラックボックスのツールとして扱われるか、どっちかになってまうんや。
ワイらが見つけた問題は、この分離された最適化が「戦略と実行のミスマッチ」を引き起こすってことやねん。せっかく洗練された計画戦略を立てても、ローカルの実行部分が適応してへんから実現できひんのや。システムを複雑にしても、逆に性能が下がることすらあんねん。
この論文で提案するのがJADE(Joint Agentic Dynamic Execution:共同エージェント動的実行)や。動的な複数ターンのワークフローの中で、計画と実行を一緒に最適化するための統一フレームワークやで。システム全体を、一つの共有バックボーンの下で統一された協調的なマルチエージェントチームとしてモデル化することで、結果ベースの報酬によるエンドツーエンドの学習ができるようになんねん。
このアプローチのええとこは「共適応」ができることや:プランナーは実行部分の能力の範囲内で動くことを学習し、実行部分は高レベルの戦略的意図に合わせて進化していくんや。実験結果を見ると、JADEはバラバラやったモジュールを相乗効果のあるシステムに変えて、共同最適化によってめっちゃ性能が向上するし、動的なワークフロー制御によって効率と効果のバランスを柔軟に取れるようになるで。
**1. はじめに**
大規模言語モデル(LLM)と外部知識ベースの統合によって、単純なRAGから自律的なエージェント型RAG(Shi et al., 2025)システムへの転換が進んできたんや。これらのシステムは、知識を大量に使うタスクを解くのに、単に文書を検索するだけやなくて、能動的に計画を立てて複数ステップの推論軌道を実行することを目指してんねん。めっちゃ進歩してるんやけど、今の手法はアーキテクチャの柔軟性と最適化の安定性のバランスを取るのに苦労してんのや。
図1に示すように、今ある手法は3つの異なるクラスに分けられるんやけど、それぞれに重大な限界があって、新しいモデリングの視点が必要になってくんねん。
**最初のパラダイム:静的共同最適化(図1(a))**
これは初期のモジュール式RAGシステム(Chen et al., 2025a)の特徴やな。固定的な計算グラフを定義してて、普通はクエリ書き換え→文書選択→回答生成っていう線形のシーケンスになってんねん。これらのモジュールはシステム全体の性能を最大化するために一緒に最適化されるんやけど、固定的なトポロジーのせいでエージェントは「一律のワークフロー」に制限されてまうんや。その結果、複雑なマルチホップクエリを分解するのに必要な適応性が足りひんねん。可変的な推論パスが求められる場面で困るわけや。
**2番目のパラダイム:動的分離最適化(図1(b))**
この固定性に対処するために、この分野は動的分離最適化の方向に進んだんや。これらの手法(Chen et al., 2025b; Jiang et al., 2025a; Mei et al., 2025)は、ワークフローを動的に制御するための中央集権的なプランナーを導入してんねん。でもな、これらのシステムは分離された訓練戦略を採用してんのや:プランナーは高レベルの計画を生成するように最適化されるんやけど、実行部分(リトリーバーとかリーダーとか)は凍結されたブラックボックスのツールとして扱われんねん。
ワイらはこの分離が「戦略と実行のミスマッチ」の原因やと特定したで。図1(b)に示すように、プランナーは洗練された戦略を考え出すかもしれんけど、バラバラの実行部分はそれを実現する能力がないんや。その結果、理論的には正しい計画でも、実行が失敗して全体的な性能が最適以下になってまうんやな。
---
## Page 2
[](/attach/20df466bad70efac89c4e8f552dfb1bcecfb9e96e5a0eaa48ee5a34f49675b3d_p002.png)
### 和訳
JADE:動的なエージェント型RAGにおける戦略と実行のギャップを埋めるで
最近やな、SearchR1みたいな非構造化推論モデルが出てきてん(図1(c)見てな)。これ何しようとしてるかっていうと、計画立てて、検索して、答え生成するっていう全部の工程を、一本のエンドツーエンドの流れにまとめようとしてんねん(Jin et al., 2025; Song et al., 2025a;b; Zheng et al., 2025)。モジュール型のアーキテクチャの制約から解放されるんはええんやけど、その代わりに学習が不安定になるっていう問題が出てくるねん(Deng et al., 2025; Chen et al., 2026)。なんでかっていうと、モデルが同時に推論のやり方も、ノイズだらけの検索エンジンへの問い合わせ方も、めっちゃでかいコンテキストウィンドウの中で情報をフィルタリングする方法も、全部一気に学ばなあかんからやねん。構造的な事前知識がないから、最適化の地形がめっちゃ険しくなって、エージェントは収束するのに苦労するねん。エージェント検索の全プロセスを暗黙的に管理せなあかん認知的負荷に押しつぶされてまうわけや。
この論文では、JADE(Joint Agentic Dynamic Execution:共同エージェント動的実行)っていう統一フレームワークを提案してんねん。柔軟性と安定性をうまいこと調和させるように設計されてるで。図1(d)見てもらったらわかるけど、JADEはプランナーとエグゼキューターのアーキテクチャのモジュール的な明確さは残しつつ、その相互作用を協調型マルチエージェントのコラボレーションとして根本的に再定義してんねん。分離型のアプローチ(図1(b))とは違って、JADEは単一のLLMバックボーン内で共有パラメータを使って、スパースなグローバル報酬を原動力にして、プランナーとエグゼキューターを同時に最適化するねん。この「共同動的最適化」によって相互適応が促されるんや:プランナーはエグゼキューターの機能的な境界を尊重したワークフローをオーケストレーションすることを学んで、一方でエグゼキューターはプランナーの高レベルな戦略的意図に合わせて進化していくねん。バラバラやったモジュールを相乗効果を発揮するチームに変えることで、JADEは動的な計画立案の適応力と、共同最適化の収束安定性を両立させてんねん。
ワイらの貢献をまとめると以下の通りやで:
• JADE1っていう新しいフレームワークを導入したで。これはマルチターンの情報探索を協調型マルチエージェントゲームとして定式化してんねん。プランナーとエグゼキューター間でエンドツーエンドの勾配フローを可能にすることで、JADEは高レベルな推論と低レベルな実行のギャップを埋めてんねん。
• 実験的な評価で、JADEは7つのベンチマークで新しいSOTA(最先端)を達成して、計算コストとタスクの有効性のバランスをうまいこと取れてることを示したで。特筆すべきは、ワイらの共同最適化された7Bモデルが、GPT-4oベースの分離型システムを上回ったことやねん。これが意味するんは、複雑な推論には生のモデルサイズよりも協調的な相乗効果の方がめっちゃ重要やってことやで。
2. 関連研究
静的RAGから動的RAGへ。初期の検索拡張生成システムは、たいてい静的な検索パイプラインに頼ってたんや。検索と生成が固定された、事前に決められた順序で起こる感じやな。代表的な研究としてはRALM(Xia et al., 2025)、LongRAG(Zhao et al., 2024)、INSTRUCTRAG(Wei et al., 2024)、RRR(Ma et al., 2023)、
1 JADEのソースコードはhttps://github.com/chenyiqun/JADEで公開してるで。
BGM(Ke et al., 2024)なんかがあって、この静的なパラダイムの中で特定のモジュールを強化することに注力してたんやけど、クエリの複雑さに応じて検索戦略を調整する柔軟性がなかってん。マルチホップ推論に対応するために、反復的なフレームワークが検索と生成のステップを交互に行う方式を導入したんや。IRCoT(Trivedi et al., 2023)、Self-RAG(Asai et al., 2023)、Adaptive RAG(Jeong et al., 2024)、ReSP(Jiang et al., 2025b)みたいなアプローチは、動的なループ制御や自己反省を可能にしてんねん。せやけど、これらの手法は主にヒューリスティックな制御フローか教師ありファインチューニングに頼ってて、エンドツーエンドの強化学習を使ってないから、複雑な環境でグローバルに最適な戦略を発見する能力が限られてたんや。
エージェント検索システムの最適化パラダイム。エージェント検索における最近の進歩は、意思決定を強化するために強化学習(RL)を採用してきたんやけど、パラダイムによってトレードオフが違うねん。支配的なアプローチの一つは、分離型プランナー最適化に焦点を当ててるやつや。MAO-ARAG(Chen et al., 2025b)、S3(Jiang et al., 2025a)、AI-SEARCHPLANNER(Mei et al., 2025)みたいなフレームワークは、RLを使って専門的なプランナーを訓練して、動的なワークフローをオーケストレーションするねん。推論パスをクエリの複雑さに合わせてカスタマイズすることで、これらの手法は有効性と効率性の間の適応的なトレードオフを可能にしてんねん。せやけど、エグゼキューターを凍結されたブラックボックスとして扱うから、戦略と実行のミスアラインメントが生じるんや。逆に、MMOA-RAG(Chen et al., 2025a)は、RLを使ってクエリリライター、ドキュメントセレクター、ジェネレーターを同時に訓練することで共同最適化を達成してんねん。相乗効果はあるんやけど、MMOA-RAGは固定された単一ターンのワークフローに制約されてるから、長期的なタスクへの適用が制限されてまうねん。3つ目のパラダイムは、Search-R1(Jin et al., 2025)や類似の手法(Zheng et al., 2025; Song et al., 2025a;b)に代表されるやつで、モノリシックなRLを使って推論チェーンと検索アクション全体をエンドツーエンドで生成するねん。この推論強化型の反復パラダイムはめっちゃ柔軟なんやけど、長期的な生成、スパースな報酬シグナル、外部検索エンジンが導入するノイズが合わさって、RL訓練の最適化地形がめっちゃ複雑になってまうねん。その結果、これらのモデルはしばしば深刻な訓練不安定性と準最適解への収束に悩まされるんや(Deng et al., 2025; Chen et al., 2026)。JADEはこれらのアプローチを統合して、MMOA-RAGの共同最適化をMAO-ARAGの動的なマルチターンワークフローに適用することで、Search-R1のモノリシックな性質に対する構造化されたモジュラーな代替案を提供してんねん。
マルチエージェント強化学習(MARL)。ワイらのフレームワークは協調型マルチエージェント強化学習から理論的な基盤を得てんねん。この分野の古典的な研究(Rashid et al., 2020; Lowe et al., 2017; Yu et al., 2022; Chen et al., 2022)は、たいていパラメータ共有を使って、環境を完全協調タスクとしてモデル化してんねん。全エージェントが共有グローバル報酬を通じて最適化されて、チーム全体の効用を最大化するんや。同様に、ワイらも
2
---
## Page 3
[](/attach/20df466bad70efac89c4e8f552dfb1bcecfb9e96e5a0eaa48ee5a34f49675b3d_p003.png)
### 和訳
JADE: 動的エージェント型RAGにおける戦略と実行のギャップを埋めるで
LLMの内部モジュールをマルチエージェントチームとして見なすっていう発想やねん。エージェント型RAGっていうのは、本質的には部分観測シナリオ(POMDP)(Kaelbling ら、1998)なんよ。要するに、エージェントたちは限られた検索コンテキストしか見えへんわけ。そこでJADEは、パラメータ共有と統一されたグローバル報酬を使って、プランナーと実行者っていう異なる機能的な役割が一緒に適応していくように仕向けるんや。これでな、長いホライズンの推論タスクにおける時間的な貢献度割り当て問題(どのタイミングの行動がどれだけ最終結果に貢献したかを特定する問題やね)を効果的に解決できて、局所的な実行がグローバルな戦略目標とちゃんと整合するようになるんやで。
## 3. 方法論
この研究で提案するのがJADE(Joint Agentic Dynamic Execution:共同エージェント動的実行)やねん。戦略的な計画立案と実際の実行を、エンドツーエンドで学習可能な単一のポリシーに統合するフレームワークや。従来の分離型アプローチやと、プランナーは固定されたブラックボックスの実行者に対して最適化されてたんやけど、JADEは同質パラメータ共有を使って、高レベルのワークフロープランナーと低レベルの実行者が一緒に適応できるようにしてるんや。
### 3.1. 問題の定式化:共有パラメータMSMDP
動的な検索拡張生成プロセスを、部分観測性を持つマルチエージェント半マルコフ決定過程(MSMDP)(Ghavamzadeh ら、2006)として定式化するで。システムは以下のタプルで定義されるんや:⟨S, Ω, A, P, R, γ, T ⟩
**グローバル状態空間(S)**:グローバル状態っていうのは、完全に観測可能な環境、いわば「黒板」みたいなもんで、協調的推論プロセスの進化する履歴を記録するんや。ラウンド t の開始時点でのグローバル状態 st ∈ S は、こういう構造化されたタプルとして形式化するで:
st = {Qorigin, Tt} (1)
ここで Qorigin は最初のユーザークエリで、Tt は動的実行トレースや。トレースはタスクノードの順序付けられたシーケンスを保持してて、プランナーが問題を分解するにつれて拡張されていくんや。Tt 内の各ノード nm(m でインデックス付け)はこういうタプルとして定義されるで:
nm = ⟨qm, am⟩ (2)
ここで qm は分解から導出された特定のサブクエリで、am はそのサブクエリへの回答(最初は ∅ で初期化)や。エージェント的な検索がラウンド t 内で進行するにつれて、新しいノードが追加されて、空の回答スロットが順次埋められていくんやな。
**観測空間(Ω)**:ラウンド t 内の推論プロセスは、k = 0, . . . , Kt でインデックス付けされた一連のステップを含むんや。計算効率を確保しながらコンテキスト認識を維持するために、エージェントは役割固有の観測 ot,k ∈ Ω に基づいて動作するで。
Contextt,k をラウンド内作業メモリとして定義するんやけど、これは現在のラウンド内で先行するエージェント(ステップ 0 から k − 1)によって生成された中間出力(例えばワークフロー w や検索されたドキュメント)を蓄積するもんや。
観測関数 O は、現在のターゲットサブクエリ qtarget をローカルコンテキストと組み合わせて入力を構築するんやけど、エージェントのアクティブな役割 ρt,k に基づいてグローバル状態 st から選択的に取得された関連情報で拡張されるんや:
ot,k = O( qtarget ∪ Contextt,k ∪ Select(st, ρt,k), ρt,k) (3)
現在の目標 ローカル更新 グローバル履歴
ここで st はグローバルメモリバンクとして機能するんや。Select(·) 関数は st をフィルタリングして、必要な履歴コンテキスト(例えば以前に解決されたサブ回答)を提供するんやけど、関係ない詳細でエージェントを圧倒せんようにしてるんやな。例えば、クエリリライターは st 内の解決済み回答にアクセスして照応解析(「それ」が何を指すかとかを解決すること)するかもしれんし、ドキュメントセレクターは主に直近の検索ドキュメントに集中するかもしれん。
**階層的行動空間(A)**:行動空間は異種のサブ空間の和集合や:A = Aplan ∪ Aexe
プランナー行動空間 Aplan は離散的やけど組み合わせ的やねん。ラウンドの開始時(k = 0)に、プランナーは構造化された実行計画 w ∈ Aplan を生成するんや。各計画 w は、実行者のサブセット E ⊆ Rexec を選択して、それらの有向トポロジー(例えば順次チェーンや並列グループ)を調整して実行可能なワークフローグラフを形成することを含むんや。これによってプランナーは、「分解 → 並列検索 → 要約」みたいな複雑な作戦を、単一の戦略的決定ステップで展開できるようになるんやで。
実行者行動空間 Aexe は意味的(セマンティック)やねん。後続のステップ(k > 0)では、ワークフロー w で定義されたアクティブ化されたエージェントが、それぞれのノードを埋めるための特定の操作出力を生成するんや。
**統一ポリシーと共有目標**:効果的な協調を可能にするために、θ でパラメータ化された単一の LLM バックボーンを使ってエージェント空間を統一するんや。ポリシーは完全な状態ではなく、ステップ固有の観測に条件付けられるで:
at,k ∼ πθ(·|ot,k, pρt,k) (4)
ここで pρt,k は役割 ρt,k に対応する特定のシステムプロンプトや。最適化の目標は、軌道 τ 内のすべてのエージェントによって共有されるグローバル報酬 R に基づく共同期待リターンを最大化することやで:
J(θ) = Eτ∼πθ [Σt=0からT Σk=0からKt γ^(t,k) R(st,k, at,k)] (5)
(注2:このパラメータ共有戦略の詳細な理論的根拠、MARLにおける理論的基盤と展開効率については、付録Aで説明してるで。)
---
## Page 4
[](/attach/20df466bad70efac89c4e8f552dfb1bcecfb9e96e5a0eaa48ee5a34f49675b3d_p004.png)
### 和訳
# JADE: 動的エージェント型RAGにおける戦略と実行のギャップを埋めるで
**図2. JADEのフレームワーク全体像やねん。** このシステムは計画と実行をぐるぐる回すループで動いとるんや。
**(1) 推論のとき(左側)** は再帰的に処理が進むねん。今のグローバル状態 st の中にある未解決ノード(要は特定のサブクエリのことやな、式2を見てな)に対して、Plannerってやつが呼び出されて、専用の動的ワークフローを組み立てるんや。このワークフローは専門のExecutor(クエリ分解とか検索エージェントとか)が実行して、次のラウンドに向けて st を更新していくわけや。
**(2) 学習のとき(右側)** は、全体を一緒に最適化するために、複数ターンの軌跡に関わった全エージェントが遷移トリプレット ⟨ot,k, at,k, rt,k⟩ を生成するねん。これらの遷移データをまとめて統一Experience Buffer(経験バッファ)に突っ込んで、パラメータ共有してるポリシーモデルを更新することで、戦略的な計画と実際の実行をうまく噛み合わせていくんや。
---
ここで、内側の総和は動的ワークフロー内のステップを表してて、外側の総和は推論ラウンド全体を集約してるんやで。
## 3.2. エージェントの役割とワークフロー
このMSMDP定式化をベースにして、JADEのエージェント空間は、バラバラの固定ツールとちゃうねん。共有バックボーン πθ から派生した、学習可能な別々のペルソナとして実装されとるんや。各役割 ρ は、特定のシステム指示でポリシーを条件づけることでインスタンス化されるねん。具体的な定義は表13にまとめてあるし、各役割の詳しいシステムプロンプトは付録Eにあるで。
推論プロセス(注4)はアルゴリズム1で形式化されてて(詳細な疑似コードは付録B参照)、図2の左側で視覚的に示しとるわ。生のクエリとルートトレースノードで初期化されて、トレースが完全に解決されるまで反復ループに入るねん。各ラウンド t では、未解決ノード ntarget を3つのフェーズで処理するんや:
**1. ワークフロー計画(7-9行目):** 特定のターゲットクエリ qtarget(元の質問でも派生したサブクエリでも)に対して、Plannerが呼び出されて専用のワークフロー Wt を生成するんや。図2に示すように、このステップは適応的やねん。クエリの複雑さによって、Plannerは問題を分解するための分解ワークフロー(例えば上の分岐で示されてるQDSとか)を出力するか、直接解決するための解決ワークフロー(例えば真ん中の分岐で示されてるRA → DS → AGのチェーンとか)を構築するかを選ぶわけや。
**2. ワークフロー実行(12-23行目):** システムは Wt 内のモジュールを順番に実行していくねん。ワークフローが分解(QDS/QDP)を指示してたら、実行によってトレースのトポロジーが拡張されて、新しい未解決サブノードが追加されるんや。答えは将来のラウンドに先送りされるわけやな。逆に、ワークフローが解決を指示してたら、選ばれたExecutorのサブセットが順番に動作して、サブ問題を解決して現在のノードの回答スロット(atarget)を埋めるねん。
**3. 状態更新(25-26行目):** グローバル状態 st が、変更されたトレース(新しいノードで拡張されたか、新しい回答で更新されたか)で更新されて、次の反復に備えるんや。
---
(注3)表1の検索エージェント(RA)は基本的にリトリーバーであって、LLMとちゃうねん。せやからパラメータの最適化はせえへんで。
(注4)この推論プロセスのケーススタディは付録Fを見てな。
---
このプロセスは複雑さに自然に適応するようになっとるんや。単純なクエリは1回の「計画-解決」反復で済むけど、複雑なやつは再帰的な「計画-分解-解決」ループが発動するねん。
---
## Page 5
[](/attach/20df466bad70efac89c4e8f552dfb1bcecfb9e96e5a0eaa48ee5a34f49675b3d_p005.png)
### 和訳
JADE: 動的なエージェントRAGにおける戦略と実行のギャップを埋める話
表1. JADEにおけるエージェントの役割定義やで。このシステムは中央にプランナーがおって、7つの専門的なエグゼキューター(実行役)がおるねん。実行トレースへの影響によって分類されてるんや。
エージェント|機能の説明
**オーケストレーション(プランナー)**
プランナー:現在のターゲットクエリqtargetを監視して、効果を最大化するようにワークフロー全体を指揮するねん。
**実行:分解系(トレースに新しいノードを追加するやつら)**
このカテゴリのエージェントは、将来のラウンドで解決すべき新しい保留中のサブクエリ(式2で定義されてるやつな)を生成するんや。
QDS|クエリ分解(直列型)。質問を論理的に依存関係のあるサブ質問の列に分解するねん。厳密に順番通りに解かなあかんやつや。
QDP|クエリ分解(並列型)。質問を独立したサブ質問に分解するねん。これは並列処理に向いてるんや。
**実行:解決系(ターゲットノードを解決するやつら)**
このカテゴリのエージェントは、ターゲットクエリqtargetを解決するための具体的な操作を実行するんや。
QR|クエリリライター。生の質問を検索エンジンに最適化された表現に書き換えるねん。
RA†|検索エージェント。外部エンジンから現在のクエリに関連する候補文書を取ってくるんや。
DS|文書セレクター。候補文書をフィルタリングして、クエリに答えるのに役立つやつだけを残すねん。
AG|回答ジェネレーター。提供された証拠コンテキストに基づいて具体的な回答を生成するんや。
AS|回答サマライザー。実行トレースに基づいて、元の質問Qoriginへの最終回答をまとめるねん。
† 検索エージェントは凍結された外部検索器へのインターフェースとして機能するから更新されへんで。他の全ての役割はLLMバックボーンから初期化された学習可能なペルソナやねん。
**3.3. 報酬関数**
ここではハイブリッドな報酬構造を設計してるんや。協力を促進するためのグローバルな共有報酬と、構造的な制約を強制するためのローカルな個別ペナルティを組み合わせてるねん。生成された軌跡τがラウンドt = 1 ... Tと内部ステップk = 0 ... Ktでインデックス付けされたエージェントステップの列で構成されてるとするやで。
**グローバル共有報酬(Rglobal)**
プランナーとエグゼキューターは協力チームとして機能するから、タスクの最終的な成功は彼らの共同努力にかかってるんや。チーム全体への共有フィードバックシグナルとして機能するグローバル報酬を定義するねん。これは軌跡の最後に計算されるんや。このシグナルはパフォーマンス結果とグローバル実行コストから構成されてるで:
Rglobal = Rperf − (α · Nrnd(T) + β · Nret(Nret))
↑これがRcostやで
ここでRperf = F1(ŷ, y)は最終回答の品質を測るねん。ペナルティ項Rcostは正規化された計算オーバーヘッドの重み付き和として明示的に定義されてるんや:Tは推論ラウンドの総数(長いチェーンにペナルティ)、Nretは全ラウンドにわたる検索アクションの総数(リソース消費にペナルティ)やねん。線形正規化を使って、事前定義された最大制限(3に設定)で割ることでこれらのコストを[0, 1]にスケーリングしてるんや。係数αとβで制御されるこの共有報酬シグナルは、時間的なクレジット割り当て問題に対処して、シーケンス内の全エージェントを高品質で効率的な推論に向けて整合させるんや。
**ローカルフォーマットペナルティ(r(t,k)_format)**
タスクの結果はチーム全体の責任やけど、出力スキーマへの準拠は個人の責任やねん。ラウンドt、ステップkでアクティブなエージェントが必要なフォーマットに違反する出力を生成した場合(例えば、プランナーが有効なグラフトポロジーを出力できへんかった場合)、即座にローカルペナルティを受けるんや:
r(t,k)_format =
-1 ((t, k)のエージェントが制約に違反した場合)
0 (それ以外)
**総報酬シグナル(rt,k)**
最適化のためにステップ(t, k)に割り当てられる実際の報酬シグナルrt,kは、即座の行動コンプライアンスとチームの長期的成功の組み合わせやで:
rt,k = r(t,k)_format + I(t = T ∧ k = KT) · Rglobal
ここでI(·)は指示関数で、グローバル報酬が最終ステップでのみ追加されることを保証するねん。PPO更新中(一般化アドバンテージ推定を介して)、このグローバル報酬Rglobalはワークフロー内の全エージェントに伝播するんや。なんでかっていうと、これによって早い段階のエージェント(例えばt = 1のプランナー)が成功した最終回答を促進したことに対するクレジットを受け取れるようになるねん。一方でローカルペナルティr(t,k)_formatは、特定の構文エラーを修正するための即座の、転送不可能なフィードバックを提供するんや。
**3.4. PPOによる共同最適化**
戦略と実行のギャップを埋めるために、JADEは近接方策最適化(PPO)(Schulman et al., 2017)を使って共有パラメータθを最適化するねん。図2(右)に示すように、この訓練パラダイムは動的なエージェントワークフローの構造的複雑さを扱うように設計されてるんや。エージェントが均一な環境と相互作用する標準的なRLとは違って、JADEは単一の推論軌跡内で異種データストリームを生成する複数の専門的な役割(プランナーとエグゼキューター)を含んでるねん。
これに対処するために、統一経験リプレイメカニズムを導入してるで。アルゴリズム2(付録B)で詳述されてるように、クエリバッチの推論中、全てのエージェントの相互作用—ワークフロートポロジーを決定するプランナーであれ、文書をフィルタリングするドキュメントセレクターであれ—は標準的な決定ステップとして扱われるんや。これらの異種遷移はキャプチャされ、フラット化され、共有経験バッファに集約されるねん。これにより、最適化ステップは標準的なPPOプロトコルに厳密に従うことができて、共有バックボーンを更新して戦略的計画と実行的操作を同時に改善できるんや。
**異種遷移の集約**
図2の「バッファ」コンポーネントに示されてるように、最適化の核心は多様な経験の集約やねん。与えられたクエリバッチに対して、システムは並列で推論を実行するんや。ワークフローが動的やから、クエリAは...
---
## Page 6
[](/attach/20df466bad70efac89c4e8f552dfb1bcecfb9e96e5a0eaa48ee5a34f49675b3d_p006.png)
### 和訳
JADE:動的エージェント型RAGにおける戦略と実行のギャップを埋める話
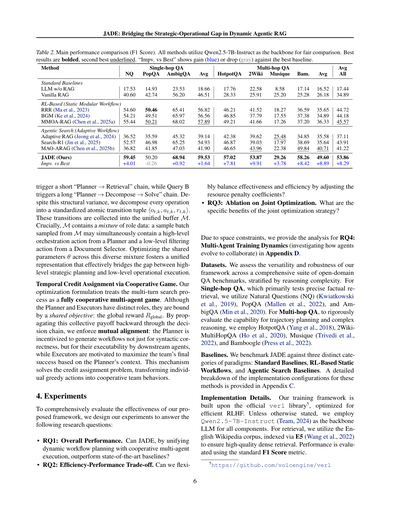
表2. メイン性能比較(F1スコア)やで。全部のメソッドでQwen2.5-7B-Instructをバックボーンとして使って公平に比較しとるねん。太字が一番ええ結果で、下線が二番目にええやつや。「Impv. vs Best」ってのは最強ベースラインに対してどんだけ上がったか(青)か下がったか(灰色)を示しとるで。
手法
標準ベースライン
RAGなしのLLM
普通のRAG
強化学習ベース(固定モジュラーワークフロー)
RRR (Ma et al., 2023)
BGM (Ke et al., 2024)
MMOA-RAG (Chen et al., 2025a)
エージェント型検索(適応的ワークフロー)
Adaptive RAG (Jeong et al., 2024)
Search-R1 (Jin et al., 2025)
MAO-ARAG (Chen et al., 2025b)
JADE(ワイらの手法)
最強との差
シングルホップQA
PopQA AmbigQA
NQ
17.53
40.60
14.93
42.74
54.60
54.21
55.44
36.52
52.57
36.82
59.45
+4.01
50.46
49.51
50.21
35.59
46.98
41.85
50.20
-0.26
23.53
56.20
65.41
65.97
68.02
45.32
65.25
47.03
68.94
+0.92
平均
18.66
46.51
56.82
56.56
57.89
39.14
54.93
41.90
59.53
+1.64
マルチホップQA
HotpotQA 2Wiki Musique
Bam.
平均
全体平均
17.76
28.33
46.21
46.85
49.21
42.38
46.87
46.65
57.02
+7.81
22.58
25.91
41.52
37.79
41.66
39.62
39.03
43.96
53.87
+9.91
8.58
25.20
18.27
17.55
17.26
25.48
17.97
22.38
29.26
+3.78
17.14
25.28
16.52
26.18
17.44
34.89
36.59
37.38
37.20
34.85
38.69
49.84
58.26
+8.42
35.65
34.89
36.33
35.58
35.64
40.71
49.60
+8.89
44.72
44.18
45.57
37.11
43.91
41.22
53.86
+8.29
クエリAは短い「プランナー → 検索」の流れを起動して、クエリBは長い「プランナー → 分解 → 解決」の流れを起動するねん。この構造の違いがあっても、全部の操作を標準化したアトミック遷移タプル⟨ot,k, at,k, rt,k⟩に分解しとるんや。
これらの遷移は統一バッファMに集められるで。めっちゃ重要なんは、Mには役割が混ざったデータが入っとるってことや。Mからサンプリングしたバッチには、プランナーからの高レベルなオーケストレーション行動と、ドキュメントセレクターからの低レベルなフィルタリング行動が同時に含まれとる可能性があるねん。この多様なミックスを通じて共有パラメータθを最適化することで、高レベルな戦略的計画と低レベルな実行操作の間のギャップを効果的に埋める統一的な表現が育つんやで。
協力ゲームによる時間的貢献度割り当て。ワイらの最適化の定式化は、マルチターン検索プロセスを完全協力型マルチエージェントゲームとして扱うねん。プランナーと実行者は異なる役割を持っとるけど、共通の目的で結ばれとる:グローバル報酬Rglobalや。この集合的なペイオフを決定チェーンを通じて逆伝播させることで、相互アライメントを強制するんや。なんでかっていうと、プランナーは構文的に正しいだけやなく、下流のエージェントが実行可能なワークフローを生成するようにインセンティブが与えられるし、実行者はプランナーのコンテキストに基づいてチーム全体の最終的な成功を最大化するようにモチベートされるからや。このメカニズムが貢献度割り当て問題を解決して、個別の貪欲な行動を協力的なチーム行動に変換するんやで。
4. 実験
ワイらが提案するフレームワークの有効性を包括的に評価するために、以下の研究課題に答えるように実験を設計したで:
• RQ1:全体性能。JADEは動的ワークフロー計画と協力的マルチエージェント実行を統合することで、最先端ベースラインを上回れるんか?
リソースペナルティ係数を調整することで、有効性と効率性をうまくバランスさせられるんか?
• RQ3:共同最適化のアブレーション。共同最適化戦略の具体的なメリットは何なんや?
スペースの制約があるから、RQ4:マルチエージェント学習ダイナミクス(エージェントがどう進化して協力するようになるかを調べる)の分析は付録Dに載せとるで。
データセット。ワイらのフレームワークの汎用性と頑健性を、推論の複雑さで層別化したオープンドメインQAベンチマークの包括的なスイートで評価したで。シングルホップQAは主に正確な事実検索をテストするもんで、Natural Questions (NQ) (Kwiatkowski et al., 2019)、PopQA (Mallen et al., 2022)、AmbigQA (Min et al., 2020)を使ったわ。マルチホップQAでは、軌道計画と複雑な推論の能力を厳密に評価するために、HotpotQA (Yang et al., 2018)、2WikiMultiHopQA (Ho et al., 2020)、Musique (Trivedi et al., 2022)、Bamboogle (Press et al., 2022)を使ったで。
ベースライン。JADEを3つの異なるカテゴリのパラダイムと比較しとるで:標準ベースライン、強化学習ベースの固定ワークフロー、エージェント型検索ベースラインや。これらの手法の実装設定の詳細な内訳は付録Cに載せとるで。
実装の詳細。ワイらの学習フレームワークは公式verlライブラリ5の上に構築されとって、効率的なRLHFに最適化されとるで。特に断りがない限り、全てのコンポーネントのバックボーンLLMとしてQwen2.5-7B-Instruct (Team, 2024)を使っとるで。検索には英語Wikipediaコーパスを使って、高品質な密検索を確保するためにE5 (Wang et al., 2022)でインデックス化しとるわ。性能評価には標準のF1スコア指標を使っとるで。
• RQ2:効率と性能のトレードオフ。ワイらは柔軟に
5https://github.com/volcengine/verl
6
---
## Page 7
[](/attach/20df466bad70efac89c4e8f552dfb1bcecfb9e96e5a0eaa48ee5a34f49675b3d_p007.png)
### 和訳
JADE:動的エージェントRAGにおける戦略と実行のギャップを埋める話
(a) ターンペナルティ(α)の影響
(b) 検索ペナルティ(β)の影響
(c) 両方のペナルティ(α = β)
**図3. コスト報酬Rcostのハイパーパラメータ感度分析**
ペナルティ係数を変えたときの学習がどう変わるか分析してみたで。(a) ターンペナルティαを変えると(β=0のとき)、Plannerの推論ステップ(実線)をうまく減らせて、しかもF1スコアは維持できるねん。(b) 検索ペナルティβを変えると(α=0のとき)、Executorたちが検索呼び出しを減らすように学習するわ。(c) 両方いっぺんに上げていくと(α=β)、ペナルティかけすぎになって、システムがコスト最小化しようとして一発で終わる静的な1ターンRAGに退化してまうねん。そうなると性能がガクッと落ちるで。
---
## 4.1. RQ1:全体的な性能分析
7つのオープンドメインQAベンチマークでの主な結果を表2に載せてるで。全体的に見て、JADEは新しい最高性能を達成しとって、全データセット平均でF1スコア53.86を記録、これまでの最強ベースラインを**+8.29**もぶっちぎっとるねん。RQ1に答えるために、3つの視点から性能向上を分析するで。
**静的モジュラーワークフローに対する優位性**
JADEは強化学習ベースの静的アプローチに対してめっちゃ有利やねん。MMOA-RAG(Chenら、2025a)みたいな手法は固定パイプライン(Rewriter→Selector→Generator)をマルチエージェント強化学習で最適化しようとしてるんやけど、トポロジーがガチガチに固まってるから根本的に限界があるわけ。表2見てもらったらわかるけど、JADEは最強の静的ベースライン(MMOA-RAG)を平均8.29ポイント上回っとる。特にマルチホップQAタスクでは差がえげつなくて(2Wikiで+9.91、HotpotQAで+7.81とか)、これでJADEの動的トポロジー能力が、静的グラフじゃうまくモデル化できへん複雑な推論問題を解くのに必須やってことが確認できたな。
**同時最適化のメリット(vs. MAO-ARAG)**
めっちゃ重要な比較がJADEとMAO-ARAG(Chenら、2025b)の間にあるねん。両方とも似たような階層アーキテクチャを使ってて、PlannerがExecutorたちを組織して動的ワークフローを作るんや。けどMAO-ARAGは分離学習戦略を採用してて、Plannerだけ最適化してExecutorは凍結したままなんよ。結果見たら、JADEはMAO-ARAGを平均でなんと**12.64ポイント**も上回っとる(53.86 vs. 41.22)。この大差で、ワイらの「戦略と実行のミスマッチ」仮説が正しかったって証明できたわ。MAO-ARAGやと、たとえPlannerが最適なワークフローを考えても、凍結されたExecutorがその具体的なサブタスクを正確にこなせへんことが多くて、システム全体がコケてまうねん。対照的に、JADEは同時エージェント動的最適化を使うから、ExecutorがPlannerと一緒に適応進化できるわけ。これでExecutorが計画されたワークフローの具体的な要求に合わせて成長して、実行失敗を大幅に減らせるんや。
**機能特化のアドバンテージ(vs. Search-R1)**
JADEは一枚岩型のSearch-R1(Jinら、2025)も上回っとる(53.86 vs. 43.91)。Search-R1の「何でも屋」設計は認知負荷がデカすぎて、よく幻覚起こしたり推論がブレたりすんねん。一方JADEは複雑な検索プロセスを専門化されたアトミックな役割に分解するんや。このモジュラーアーキテクチャが構造的な足場になって、各エージェントが単純化されたサブタスクに集中できるから探索空間を減らせるわけ。こういう機能特化があるから、制約のない一枚岩モデルがコケるような複雑なシナリオでも精度と安定性を維持するための基盤ができるんやな。
---
## 4.2. RQ2:効率と性能のトレードオフ
RQ2に答えるために、タスク性能(F1)と計算コスト(推論ターン数Nturnと検索呼び出し数Nret)のトレードオフをシステムがどうさばくか調べたで。このバランスはグローバル報酬の式(式6)のペナルティ係数αとβで明示的にコントロールできるねん。図3にペナルティ設定を変えたときの学習ダイナミクスを示しとるわ。
**個別ペナルティによるコントロール可能なバランス**
図3(a)と3(b)はそれぞれターンペナルティ(α)と検索ペナルティ(β)の独立した効果を示しとる。はっきりした正則化パターンが見えるで:ペナルティの重みが上がるにつれて、Plannerはワークフローを刈り込むことを学習して、対応するコスト指標(ターン数か検索呼び出し数)が一貫して減少するねん。重要なのは、強めのペナルティ(例えばα=0.5)をかけるとF1スコアは適度に下がるけど、システムはまだかなりの問題を解く能力を保持しとるってことや。
---
## Page 8
[](/attach/20df466bad70efac89c4e8f552dfb1bcecfb9e96e5a0eaa48ee5a34f49675b3d_p008.png)
### 和訳
JADE:動的エージェント型RAGにおける戦略と実行のギャップを埋める話
結構な量のクエリに対応できるようになるわけや。これで何がわかるかっていうと、αとかβを調整することで、JADEはユーザーがモデルの動きを柔軟に調整できるようになってんねん。ちょっとだけ性能落としてもええから、その分めっちゃ推論効率を上げるとか、そういうトレードオフができるようになるわけや。
**両方のペナルティかけすぎると崩壊するリスクあるで。** 図3(c)では、両方のペナルティを同時に上げていったとき(α = β)にどうなるか調べてんねん。結果見たら、「ここ超えたらアカン」っていう転換点があることがわかってん。具体的に言うと、α = β = 0.1(茶色の線)のとき、ステップ100あたりでいきなり軌道の長さがガクッと落ちて、もっと厳しいα = β = 0.2の設定で見られたような「最小限の行動しかしない」モードに急速に収束してまうねん。これが何を意味するかっていうと、ペナルティの合計コストが高すぎると、マルチエージェントシステムは複雑な推論戦略を諦めて、マイナス報酬を最小化するために静的な1ターンだけの「取ってきて生成」ループに退化してまうってこと。要するにバニラRAGに逆戻りするようなもんやな。この発見から言えるのは、システムがつまらん解に収束してまわんように、ハイパーパラメータの細かいチューニングがほんまに大事やってことやな。
### 4.3. RQ3:結合最適化のアブレーション実験
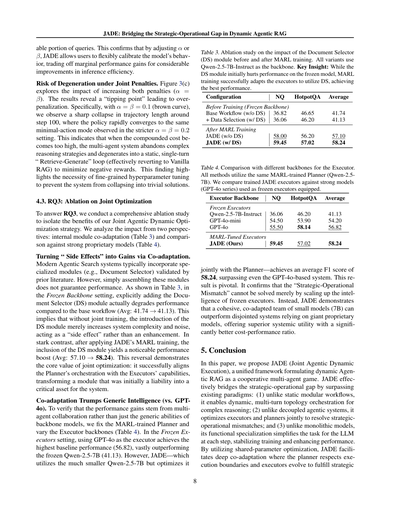
RQ3に答えるために、ワイらの「結合エージェント動的最適化」戦略の効果を切り分けて検証する包括的なアブレーション実験をやってん。内部モジュールの相互適応(表3)と、強力なプロプライエタリモデルとの比較(表4)の2つの観点から分析するで。
**「副作用」を利益に変える相互適応の力。** 最近のエージェント型検索システムには、先行研究で検証された専門モジュール(例えばドキュメントセレクター)が普通に組み込まれてんねん。でもな、これらのモジュールをただ組み合わせるだけやと性能は保証されへんのや。表3見てみ。バックボーンを固定した設定では、ドキュメントセレクター(DS)モジュールを明示的に追加すると、実はベースのワークフローより性能が下がってまうねん(平均:41.74 → 41.13)。これが意味するのは、結合トレーニングなしやとDSモジュールを導入してもシステムの複雑さとノイズが増えるだけで、強化どころか「副作用」になってまうってことや。ところがやで、JADEのMARL(マルチエージェント強化学習)トレーニングを適用した後は、DSモジュールを入れることで目に見えて性能が上がんねん(平均:57.10 → 58.24)。この逆転現象こそが結合最適化の核心的な価値を示してるわけや。プランナーのオーケストレーションとエグゼキューターの能力をうまく揃えることで、最初はお荷物やったモジュールをシステムにとって重要な資産に変換することに成功してんねん。
**表3.** MARLトレーニング前後でのドキュメントセレクター(DS)モジュールの影響に関するアブレーション実験。すべての変種でQwen-2.5-7B-Instructをバックボーンとして使用。重要な発見:DSモジュールは固定モデルでは最初は性能を下げるけど、MARLトレーニングによってエグゼキューターがDSをうまく活用できるように適応し、最高性能を達成するで。
| 設定 | NQ | HotpotQA | 平均 |
|------|-----|----------|------|
| **トレーニング前(バックボーン固定)** | | | |
| ベースワークフロー(DS無し) | 36.82 | 46.65 | 41.74 |
| + データ選択(DS有り) | 36.06 | 46.20 | 41.13 |
| **MARLトレーニング後** | | | |
| JADE(DS無し) | 58.00 | 56.20 | 57.10 |
| JADE(DS有り) | 59.45 | 57.02 | 58.24 |
**相互適応は汎用的な知性を超える(vs GPT-4o)。** 性能向上がマルチエージェント協調によるもんなんか、それともバックボーンモデルの汎用的な能力によるもんなんかを検証するために、MARLで訓練したプランナーを固定して、エグゼキューターのバックボーンを変えて実験したで(表4)。エグゼキューター固定の設定では、GPT-4oをエグゼキューターとして使うと最高のベースライン性能(56.82)を達成して、固定のQwen-2.5-7B(41.13)をめっちゃ上回ってんねん。でもな、JADEは——ずっと小さいQwen-2.5-7Bを使いながらもプランナーと結合で最適化することで——平均F1スコア58.24を達成して、GPT-4oベースのシステムすら超えてんねん。この結果はめっちゃ重要やで。「戦略と実行のミスマッチ」は、固定エグゼキューターの知性をスケールアップするだけでは解決できへんってことが確認されたんや。そうやなくて、JADEは小さいモデル(7B)同士が緊密に協調適応したチームが、巨大なプロプライエタリモデルに頼るバラバラなシステムを上回れることを示してて、コストパフォーマンス比でも圧倒的に優れたシステム全体の有用性を提供してんねん。
**表4.** エグゼキューターに異なるバックボーンを使用した場合の比較。すべての手法で同じMARLで訓練されたプランナー(Qwen-2.5-7B)を使用。訓練済みJADEエグゼキューターと、固定エグゼキューターとして装備した強力なモデル(GPT-4oシリーズ)を比較してるで。
| エグゼキューターバックボーン | NQ | HotpotQA | 平均 |
|-----------------------------|-----|----------|------|
| **固定エグゼキューター** | | | |
| Qwen-2.5-7B-Instruct | 36.06 | 46.20 | 41.13 |
| GPT-4o-mini | 54.50 | 53.90 | 54.20 |
| GPT-4o | 55.50 | 58.14 | 56.82 |
| **MARLチューニング済みエグゼキューター** | | | |
| JADE(ワイらの手法) | 59.45 | 57.02 | 58.24 |
## 5. 結論
この論文では、JADE(Joint Agentic Dynamic Execution:結合エージェント動的実行)を提案してん。これは動的エージェント型RAGを協調的なマルチエージェントゲームとして定式化した統一フレームワークやねん。JADEは既存のパラダイムを超えることで、戦略と実行のギャップを効果的に埋めてるで。具体的に言うと、(1)静的なモジュール型ワークフローと違って、複雑な推論のための動的でマルチターンのトポロジーオーケストレーションを可能にしてる。(2)分離されたエージェントシステムと違って、戦略と実行のミスマッチを解消するためにエグゼキューターとプランナーを結合で最適化してる。(3)モノリシックなモデルと違って、機能を専門化することで各ステップでLLMのタスクを単純化して、トレーニングを安定させて性能を向上させてる。共有パラメータ最適化を活用することで、JADEはプランナーが実行の境界を尊重し、エグゼキューターが戦略を満たすように進化するという、深い相互適応を促進してんねん。
---
## Page 9
[](/attach/20df466bad70efac89c4e8f552dfb1bcecfb9e96e5a0eaa48ee5a34f49675b3d_p009.png)
### 和訳
JADE:動的なエージェント型RAGにおける戦略と実際の運用の間のギャップをつなぐ話やで
意図について言うとな。7つのベンチマークで実験した結果、このチームワーク的なやり方がめっちゃ効果あるってことがはっきりしたんや。JADEは動的な柔軟さとタスクをちゃんとこなす力のバランスがほんまに優れとるってことを示したわけや。特に注目すべきは、小さめのモデルがチームで協力したら、バラバラに動く巨大な有料モデルよりええ結果出せるってことが確認されたってとこやな。
## 参考文献
Asai, A., Wu, Z., Wang, Y., Sil, A., and Hajishirzi, H. Self-rag:自己反省を通じて検索、生成、批評することを学習するやつや。arXiv preprint arXiv:2310.11511, 2023.
Chen, Y., Mao, H., Mao, J., Wu, S., Zhang, T., Zhang, B., Yang, W., and Chang, H. PTDE:マルチエージェント強化学習のための蒸留実行によるパーソナライズドトレーニングや。arXiv preprint arXiv:2210.08872, 2022.
Chen, Y., Yan, L., Sun, W., Ma, X., Zhang, Y., Wang, S., Yin, D., Yang, Y., and Mao, J. マルチエージェント強化学習による検索拡張生成の改善や。arXiv preprint arXiv:2501.15228, 2025a.
Chen, Y., Zhang, E., Yan, L., Wang, S., Huang, J., Yin, D., and Mao, J. MAO-ARAG:適応的検索拡張生成のためのマルチエージェントオーケストレーションやで。arXiv preprint arXiv:2508.01005, 2025b.
Chen, Y., Yan, L., Yang, Z., Zhang, E., Zhao, J., Wang, S., Yin, D., and Mao, J. モノリシックアーキテクチャを超えて:エージェント型検索のためのマルチエージェント検索と知識最適化フレームワークや。arXiv preprint arXiv:2601.04703, 2026.
Deng, W., Li, Y., Gong, B., Ren, Y., Thrampoulidis, C., and Li, X. Search-R1におけるGRPO崩壊について:怠惰な尤度変位デススパイラルの話や。arXiv preprint arXiv:2512.04220, 2025.
Ghavamzadeh, M., Mahadevan, S., and Makar, R. 階層的マルチエージェント強化学習やな。Autonomous Agents and Multi-Agent Systems, 13:197–229, 2006.
Ho, X., Nguyen, A.-K. D., Sugawara, S., and Aizawa, A. 推論ステップの包括的評価のためのマルチホップQAデータセットの構築や。arXiv preprint arXiv:2011.01060, 2020.
Jeong, S., Baek, J., Cho, S., Hwang, S. J., and Park, J. C. Adaptive-RAG:質問の複雑さを通じて検索拡張大規模言語モデルの適応を学習するやつや。arXiv preprint arXiv:2403.14403, 2024.
Jiang, P., Xu, X., Lin, J., Xiao, J., Wang, Z., Sun, J., and Han, J. S3:強化学習で検索エージェントを訓練するのにそんなにデータいらんで、って話や。arXiv preprint arXiv:2505.14146, 2025a.
Jiang, Z., Sun, M., Liang, L., and Zhang, Z. 検索、要約、計画:反復的アプローチでマルチホップ質問応答を前進させる話やで。Companion Proceedings of the ACM on Web Conference 2025, pp. 1677–1686, 2025b.
Jin, B., Zeng, H., Yue, Z., Yoon, J., Arik, S., Wang, D., Zamani, H., and Han, J. Search-R1:強化学習でLLMに推論と検索エンジン活用を訓練するやつや。arXiv preprint arXiv:2503.09516, 2025.
Kaelbling, L. P., Littman, M. L., and Cassandra, A. R. 部分観測確率的ドメインにおける計画と行動やな。Artificial intelligence, 101(1-2):99–134, 1998.
Ke, Z., Kong, W., Li, C., Zhang, M., Mei, Q., and Bendersky, M. 検索器とLLMの間の好みのギャップを埋める話や。arXiv preprint arXiv:2401.06954, 2024.
Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al. Natural Questions:質問応答研究のためのベンチマークやで。Transactions of the Association for Computational Linguistics, 7:453–466, 2019.
Lowe, R., Wu, Y. I., Tamar, A., Harb, J., Pieter Abbeel, O., and Mordatch, I. 協力と競争が混在する環境のためのマルチエージェントアクター・クリティックや。Advances in neural information processing systems, 30, 2017.
Ma, X., Gong, Y., He, P., Zhao, H., and Duan, N. 検索拡張大規模言語モデルのためのクエリ書き換えやな。arXiv preprint arXiv:2305.14283, 2023.
Mallen, A., Asai, A., Zhong, V., Das, R., Hajishirzi, H., and Khashabi, D. 言語モデルを信用したらあかん時っていつや:パラメトリックとノンパラメトリックメモリの有効性と限界を調査した話や。arXiv preprint arXiv:2212.10511, 7, 2022.
Mei, L., Yang, Z., and Chen, C. AI-SearchPlanner:パレート最適な多目的強化学習によるモジュラーエージェント型検索や。arXiv preprint arXiv:2508.20368, 2025.
Min, S., Michael, J., Hajishirzi, H., and Zettlemoyer, L. AmbigQA:曖昧なオープンドメイン質問に答える話や。arXiv preprint arXiv:2004.10645, 2020.
Press, O., Zhang, M., Min, S., Schmidt, L., Smith, N. A., and Lewis, M. 言語モデルにおける構成性ギャップの測定と縮小やで。arXiv preprint arXiv:2210.03350, 2022.
Rashid, T., Samvelyan, M., De Witt, C. S., Farquhar, G., Foerster, J., and Whiteson, S. 深層マルチエージェント強化学習のための単調価値関数分解やな。Journal of Machine Learning Research, 21(178):1–51, 2020.
9
---
## Page 10
[](/attach/20df466bad70efac89c4e8f552dfb1bcecfb9e96e5a0eaa48ee5a34f49675b3d_p010.png)
### 和訳
**参考文献**
Zhao, Q., Wang, R., Cen, Y., Zha, D., Tan, S., Dong, Y., Tang, J. 「LongRAG: 長文コンテキストの質問応答のための二重視点検索拡張生成パラダイム」arXiv プレプリント arXiv:2410.18050, 2024年。
Zheng, Y., Fu, D., Hu, X., Cai, X., Ye, L., Lu, P., Liu, P. 「DeepResearcher: 実世界環境での強化学習による深層リサーチのスケーリング」arXiv プレプリント arXiv:2504.03160, 2025年。
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., Klimov, O. 「近接方策最適化アルゴリズム」arXiv プレプリント arXiv:1707.06347, 2017年。
Shi, Z., Chen, Y., Li, H., Sun, W., Ni, S., Lyu, Y., Fan, R.-Z., Jin, B., Weng, Y., Zhu, M., 他。「深層リサーチ: 体系的サーベイ」arXiv プレプリント arXiv:2512.02038, 2025年。
Song, H., Jiang, J., Min, Y., Chen, J., Chen, Z., Zhao, W. X., Fang, L., Wen, J.-R. 「R1-Searcher: 強化学習によるLLMの検索能力のインセンティブ化」arXiv プレプリント arXiv:2503.05592, 2025a年。
Song, H., Jiang, J., Tian, W., Chen, Z., Wu, Y., Zhao, J., Min, Y., Zhao, W. X., Fang, L., Wen, J.-R. 「R1-Searcher++: 強化学習によるLLMの動的知識獲得のインセンティブ化」arXiv プレプリント arXiv:2505.17005, 2025b年。
Team, Q. 「Qwen2 技術レポート」arXiv プレプリント arXiv:2412.15115, 2024年。
Trivedi, H., Balasubramanian, N., Khot, T., Sabharwal, A. 「MuSiQue: シングルホップ質問合成によるマルチホップ質問」Transactions of the Association for Computational Linguistics, 10:539–554, 2022年。
Trivedi, H., Balasubramanian, N., Khot, T., Sabharwal, A. 「知識集約型マルチステップ質問のための連鎖推論と検索のインターリービング」第61回計算言語学会年次大会論文集(第1巻: 長論文)、pp. 10014–10037, 2023年。
Wang, L., Yang, N., Huang, X., Jiao, B., Yang, L., Jiang, D., Majumder, R., Wei, F. 「弱教師あり対照事前学習によるテキスト埋め込み」arXiv プレプリント arXiv:2212.03533, 2022年。
Wei, Z., Chen, W.-L., Meng, Y. 「InstructRAG: 自己合成された根拠による検索拡張生成の指示」arXiv プレプリント arXiv:2406.13629, 2024年。
Xia, Y., Zhou, J., Shi, Z., Chen, J., Huang, H. 「自己推論による検索拡張言語モデルの改善」AAAI人工知能会議論文集、第39巻、pp. 25534–25542, 2025年。
Yang, Z., Qi, P., Zhang, S., Bengio, Y., Cohen, W. W., Salakhutdinov, R., Manning, C. D. 「HotpotQA: 多様で説明可能なマルチホップ質問応答のためのデータセット」arXiv プレプリント arXiv:1809.09600, 2018年。
Yu, C., Velu, A., Vinitsky, E., Gao, J., Wang, Y., Bayen, A., Wu, Y. 「協調型マルチエージェントゲームにおけるPPOの驚くべき有効性」Advances in Neural Information Processing Systems, 35:24611–24624, 2022年。
---
## Page 11
[](/attach/20df466bad70efac89c4e8f552dfb1bcecfb9e96e5a0eaa48ee5a34f49675b3d_p011.png)
### 和訳
JADE:動的エージェント型RAGにおける戦略と実行のギャップを埋める話
A. なんでパラメータ共有戦略を採用したんかっていう話
JADEフレームワークでは、均一なパラメータ共有戦略を使っとんねん。つまり、1つの大規模言語モデル(LLM)のバックボーンπθを、全部のエージェント役割(Planner、QDS、QDP、QR、DS、AG、AS)の基盤ポリシーとして使っとるわけや。違いは役割ごとのシステム指示だけやねん。この設計を採用した理由は3つあって、全部「戦略と実行のミスマッチを解消する」っていう目標に沿っとるんよ。
**1. ミスマッチを埋めるための共進化を促進する話**
JADEの核心となる仮説はな、「最適化を別々にやると戦略と実行のミスマッチが起きる」っていうことやねん。つまり、Planner(計画係)の戦略が、Executor(実行係)の実際の能力からどんどんズレていってまうんよ。
パラメータ共有は、構造的な正則化として機能して、共進化を強制するんや。計画と実行の両方の経験を集約して、1つのパラメータセットθを最適化することで、Executor(例えば「文書が見つからへんかった」みたいな失敗)から生成された勾配が、Plannerが使う共有表現を直接更新するようになるねん。
これによって、PlannerはExecutorの能力の限界を暗黙的に「学ぶ」ようになるし、ExecutorもPlannerの戦略的意図をより上手く解釈できるように進化していくわけや。この深いレベルでの整合性は、別々のポリシーネットワークを使っとったら実現がめっちゃ難しいんよ。
**2. 複雑なチームを効率的にデプロイする話**
JADEは少なくとも8つの異なる機能的役割を持つ高度なチームを指揮しとるんや。従来の強化学習エージェントは軽量なMLP(多層パーセプトロン)ベースやったけど、うちのエージェントは数十億パラメータを持つLLM(例えばQwen-2.5-7B)で初期化されとるねん。
全部の役割に独立したポリシーネットワークを持たせたら、メモリ消費がO(N)で線形にスケールしてまうから、訓練するのが計算的に無理ゲーになるし、リソースが限られた実環境へのデプロイなんて不可能になるんよ。
パラメータ共有を使えば、ストレージ要件がO(1)に減るから、単一モデルのフットプリントで多用途なマルチエージェントシステムをデプロイできるようになるねん。この効率性のおかげで、限られたGPUメモリをより大きなバッチサイズに割り当てられるようになって、これがPPO訓練の安定性にめっちゃ重要なんや。
**3. マルチタスク学習による潜在的スキルの相乗効果の話**
LLMは本質的に強力なマルチタスク能力を持っとって、内部の重みをいじらんでも文脈的なプロンプトに基づいて役割を切り替えられるんよ。JADEでは、一見別々に見えるタスクも、基本的な推論能力を共有しとるねん。
例えばな、Document Selector(DS、文書選択係)は関連する証拠をノイズから見分ける方法を学ぶんやけど、このスキルはAnswer Generator(AG、回答生成係)と潜在表現を共有しとるんや。AGはその証拠を一貫した回答にまとめる必要があるからな。
パラメータ共有はこの正の転移を活用するんよ。データ選択用にバックボーンを最適化すると、回答生成に必要な読解力も暗黙的に向上する可能性があるわけや。共有されたπθを役割固有のプロンプトで条件付けることで、モデルの汎用的な能力を特定の機能的部分空間に効果的に射影して、アーキテクチャの冗長性なしに役割の専門化を実現しとるねん。
**4. 確立されたMARL(マルチエージェント強化学習)パラダイムとの整合性の話**
パラメータ共有は場当たり的な設計やのうて、マルチエージェント強化学習(MARL)コミュニティにおける基盤戦略なんよ。QMIX(Rashidら、2020年)やMAPPO(Yuら、2022年)みたいな代表的なアルゴリズムは、大規模な状態-行動空間を扱うためや、同質・異質なエージェント間の知識転移を促進するために、パラメータ共有を広く活用しとるんや。
この標準的なパラダイムを採用することで、JADEはより広いMARL文献で厳密に検証されてきたサンプル効率と訓練安定性の向上という恩恵を受け継いどるわけや。
**5. 最先端のエージェント型アーキテクチャとの一貫性の話**
うちの設計は、エージェント型RAGと推論の特定ドメインにおける最近の進歩と一致しとるんよ。MMOA-RAG(Chenら、2025年a)みたいな既存研究は、静的なモジュラーワークフローを最適化するためのパラメータ共有の有効性を明示的に検証しとるねん。
さらに、Search-R1(Jinら、2025年)みたいなモノリシック(一枚岩)モデルも、この哲学を経験的に支持しとるんや。Search-R1は明示的にモジュール式やないけど、単一のモデルに複雑な認知操作のシーケンス—推論、検索クエリ生成、情報統合、回答生成—を単一のコンテキストストリーム内で実行させとるねん。
これは、単一のLLMバックボーンが、JADEのマルチエージェントチームに必要な多様な機能的能力の全範囲を収容するのに十分な容量を持っとることを確認しとるんよ。
B. 詳細な実装アルゴリズムの話
このセクションでは、再現性を促進するために、JADEフレームワークの詳細な疑似コードを提供しとるで。アルゴリズム1は推論ワークフローを形式化しとって、マルチターン推論中のPlannerとExecutor間の反復的なやり取りを示しとるんや。アルゴリズム2は共同最適化手順の概要を示しとって、異なるエージェント役割からの異質な遷移が、エンドツーエンドのPPO訓練のために統一経験バッファにどう集約されるかを詳述しとるで。
---
## Page 12
[](/attach/20df466bad70efac89c4e8f552dfb1bcecfb9e96e5a0eaa48ee5a34f49675b3d_p012.png)
### 和訳
JADE: 動的エージェント型RAGにおける戦略と実行のギャップを埋める
// フェーズ2: 整理されたワークフローを実行する(ステップ k = 1 . . . Kt)
ラウンド内コンテキストを初期化 Contextt,1 ← ∅
Wtのトポロジカル順序で各モジュール ρk に対して
t ← t + 1
Tt−1から最初の未解決ノード ntarget = ⟨qtarget, ∅⟩ を選択
// フェーズ1: プランナーがワークフローを指揮する(ステップ k = 0)
コンテキストを観測 ot,0 = O(qtarget, ∅, Aplan)
観測 ot,k = O(qtarget, Contextt,k, ρk)
アクションを実行 at,k ∼ πθ(·|ot,k)
もし ρk ∈ {AQDS, AQDP } なら
アルゴリズム1 JADE推論ワークフロー
1: 入力: ユーザークエリ Qorigin, ポリシー πθ
2: 初期化: トレース T0 ← {nroot} ただし nroot = ⟨Qorigin, ∅⟩
3: 初期化: 状態 s0 ← {Qorigin, T0}, ラウンド t ← 0
4: Tt内にam = ∅となるnmが存在する間
5:
6:
7:
8:
9: Wt ← PlanWorkflow(πθ, ot,0) {エグゼキューターグラフを生成}
10:
11:
12:
13:
14:
15:
16:
17:
18:
19:
20:
21:
22:
23:
24:
25:
26:
27:
28:
29:
30: while文終了
31: // 最終統合
32: 予測された回答 ← AAS(Tt)
33: 予測された回答を返す
終了
for文終了
// フェーズ3: グローバル状態を更新
st ← {Qorigin, Tt}
もし 最大ステップに到達 または Tt内のすべてのnmでam ≠ ∅ なら
それ以外でもし ρk が解決エージェント(QR, RA, DS, AG)なら
コンテキストを更新 Contextt,k+1 ← Contextt,k ∪ {at,k}
もし ρk == AAG なら
at,kに基づいて新しいサブノードでTtを展開
break {分解はこのノードのラウンドを終了させる}
ノードntargetを回答atarget ← at,kで更新
break
終了
終了
C. ベースラインの実装詳細
ほな、JADEがどんだけ効果的かを検証するために、最先端の手法といろいろ比較してみたんや。以下のようにカテゴリ分けしとるで:
• 標準ベースライン:RAGなしのLLM(パラメトリック知識だけで勝負するやつ)とバニラRAG(普通の検索して生成するやつ)。
• 強化学習ベース(固定モジュール型ワークフロー):RRR(Maら、2023年)(クエリの書き換えを最適化するやつ)、BGM(Keら、2024年)(文書選択を最適化するやつ)、MMOA-RAG(Chenら、2025a)(固定モジュールを一緒に最適化するやつ)。
• エージェント型検索(適応型ワークフロー):Adaptive RAG(Jeongら、2024年)(複雑さに応じてルーティングするやつ)、Search-R1(Jinら、2025年)(エンドツーエンドで推論するエージェント)、MAO-ARAG(Chenら、2025b)(プランナー中心で最適化するやつ)。
公平でちゃんとした比較をするために、全部のベースラインとJADEで実験設定を統一したんや。バックボーンモデルには一貫してQwen2.5-7B-Instructを使っとる。訓練が必要ないベースラインのコンポーネントについては、オリジナルの事前学習済みチェックポイントをそのまま使っとる。訓練が必要なコンポーネントについては、Qwen2.5-7B-Instructで初期化して、それぞれの方法論で指定されとる通りにファインチューニングとか強化学習訓練をやっとる。具体的な実装のメモは以下に詳しく書いとくで:
標準ベースライン
---
## Page 13
[](/attach/20df466bad70efac89c4e8f552dfb1bcecfb9e96e5a0eaa48ee5a34f49675b3d_p013.png)
### 和訳
JADE: 動きまくるエージェント型RAGで、戦略と実務のギャップを埋めたろうって話やねん
学習用データDtrainをシャッフルして、バッチごとに分けるで
それぞれのバッチ B = {Q1, . . . , QB} ⊆ Dtrain についてやること
経験バッファMを空っぽで初期化 → M ← ∅
// フェーズ1: バッチ推論とデータ収集(図2の左側見てな)
並列処理で、バッチBの中の各クエリQjについて:
アルゴリズム2 JADEの同時最適化の手順
1: 入力: 学習データセットDtrain、LLMポリシーπθ、価値ネットワークVϕ
2: ハイパーパラメータ: 学習率η、バッチサイズB、クリップε、GAEのパラメータ
3: for epoch = 1, . . . , E までループするで
4:
5:
6:
7:
8:
9:
10:
11:
12:
13:
14:
15:
16:
17:
18:
19:
20:
21:
22:
23:
24: end for ループ終わり
τj ← JADE推論(Qj, πθ) {階層的なトレースを生成するねん}
最終的なグローバル報酬Rglobalを計算(式6参照)
// 階層的なラウンド(t)とステップ(k)を一列に並べ直すで
τjを平坦化 → ⟨(o0,0, a0,0), . . . , (oT,K, aT,K)⟩みたいな感じに
平坦化した系列に対してGAEでアドバンテージÂt,kを計算
平坦化したτjの各遷移について:
並列処理ここまで
// フェーズ2: 統合バッファからの同時更新(図2の右側見てな)
for step = 1, . . . , Nopt までループ
混合ミニバッチをMからサンプリング → b ∼ M
θを更新:∇θLPPO(θ)で勾配計算
ϕを更新:∇ϕLVal(ϕ)で勾配計算
M.push(⟨ot,k, at,k, rt,k, Ât,k, log πold⟩) でバッファに追加
end for ループ終わり
end for ループ終わり
• RAGなしのLLM: いわゆるクローズドブック方式のベースラインやな。モデルが事前学習で覚えた知識だけを頼りに答えを出すねん。外部から情報取ってくるとかは一切なしや。
• バニラRAG: 一番基本的な「取ってきて→生成」パイプラインやで。元のクエリでトップ5の文書を検索して、それを事前学習済みLLMに食わせて直接回答生成するんや。
静的モジュラーワークフロー(強化学習ベース)
• RRR (Ma et al., 2023): PPOを使ってクエリ書き換え器(Query Rewriter)を学習するフレームワークやな。ちゃんと再現できるように、報酬信号をきっちり合わせて、後段の生成器もファインチューニングして能力のミスマッチが起きんようにしてるで。
• BGM (Ke et al., 2024): この手法は、検索と生成のギャップを埋めるためのブリッジモジュール(文書選択器)を強化学習で最適化するねん。選択器が正解の生成尤度を最大化するように学習させて再現したで。
• MMOA-RAG (Chen et al., 2025a): 静的な同時最適化では最先端の手法やな。マルチエージェントPPOを使って、クエリ書き換え器・文書選択器・生成器を同時に学習するねん。固定グラフの構造(書き換え器→選択器→生成器)を共有バックボーンで厳密に再現したで。
D. マルチエージェント学習のダイナミクス分析(RQ4について)
このセクションでは、RQ4に答えるために、学習中にエージェントたちがどんな行動パターンを見せるようになるか可視化してみたで。
図4では、シングルホップ(NQ)とマルチホップ(HotpotQA)タスクでの、ワークフロー戦略とモジュール使用率の変化を追跡してるんや。
適応型ワークフローの進化について。図4(a)と4(b)は、プランナーがどんなタイプのワークフローを選んだかの分布を示してるで。シングルホップタスク(図4(a))では、めっちゃ面白いことがわかったんや。最初プランナーは分解戦略(QDS/QDP)も試すねんけど、すぐにシングルラウンドワークフローが圧倒的に優勢になるんや。なんでかっていうと、これはプランナーがちゃんと正しく判断できてるってことやねん。
13
---
## Page 14
[](/attach/20df466bad70efac89c4e8f552dfb1bcecfb9e96e5a0eaa48ee5a34f49675b3d_p014.png)
### 和訳
JADE:動的エージェント型RAGにおける戦略レベルと実行レベルのギャップを埋める研究
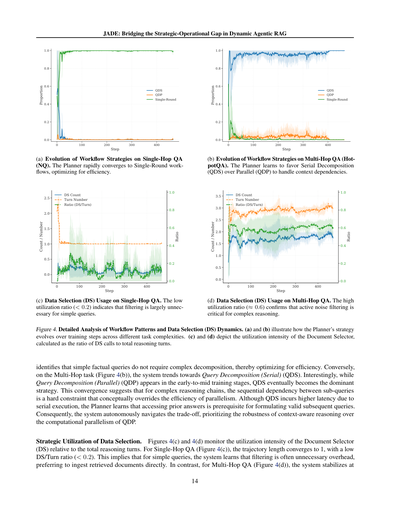
(a) シングルホップQA(NQ)でのワークフロー戦略の変化。プランナーはめっちゃ速くシングルラウンド方式に収束していって、効率重視の最適化をしとるねん。
(b) マルチホップQA(HotpotQA)でのワークフロー戦略の変化。プランナーは並列分解(QDP)より直列分解(QDS)を好むようになるんやけど、これは文脈の依存関係をちゃんと処理するためやねん。
(c) シングルホップQAでのデータ選択(DS)の使用状況。使用率がめっちゃ低い(0.2未満)ってことは、シンプルな質問にはフィルタリングとかほぼいらんってことを示しとるねん。
(d) マルチホップQAでのデータ選択(DS)の使用状況。使用率が高め(約0.6)ってことは、複雑な推論にはノイズ除去がめっちゃ重要やってことを裏付けとるわけやな。
図4. ワークフローパターンとデータ選択(DS)の動的変化の詳細分析。(a)と(b)は、タスクの複雑さによってプランナーの戦略が学習ステップを重ねるごとにどう変わっていくかを示しとる。(c)と(d)は、ドキュメントセレクターの使用頻度を表してて、DS呼び出し回数÷総推論ターン数で計算しとるねん。
シンプルな事実確認の質問には複雑な分解なんかいらんって、システムがちゃんと見抜いて効率を最適化しとるんや。逆にマルチホップタスク(図4(b))では、直列型のクエリ分解(QDS)に向かう傾向があるねん。おもろいことに、並列型のクエリ分解(QDP)は学習の初期から中期には登場するんやけど、最終的にはQDSが主役になるんや。この収束が何を意味するかっていうと、複雑な推論の連鎖では、サブクエリ間の順序依存性っていうのが絶対的な制約になってて、並列処理の効率性より優先されるってことやねん。QDSは直列実行やから遅延は大きくなるんやけど、プランナーは「前の答えにアクセスできんと次の質問がちゃんと作れへん」ってことを学習するわけや。その結果、システムは自律的にトレードオフを判断して、QDPの計算並列性よりも、文脈を理解した推論の頑健性を優先するようになるねん。
データ選択の戦略的活用。図4(c)と4(d)は、総推論ターン数に対するドキュメントセレクター(DS)の使用頻度をモニターしとる。シングルホップQA(図4(c))では、軌道の長さが1に収束して、DS/ターン比率もめっちゃ低い(0.2未満)んや。これが何を意味するかっていうと、シンプルな質問に対しては、フィルタリングは無駄なオーバーヘッドやって学習して、取得した文書をそのまま使う方がええって判断しとるってことやねん。それに対してマルチホップQA(図4(d))では、システムは
---
## Page 15
[](/attach/20df466bad70efac89c4e8f552dfb1bcecfb9e96e5a0eaa48ee5a34f49675b3d_p015.png)
### 和訳
JADE:動的エージェント型RAGにおける戦略と実行のギャップを埋める話
だいたい3ターンくらいで、DS(Document Selector)の使用率がめっちゃ高いねん(約0.6)。これ何を意味してるかっていうと、推論ステップの半分以上で、エージェントらが自ら「このノイズいらんわ」ってフィルタリングしてるってことやねん。このへんの動き方の違いって、プログラムでカチカチに決めてるわけちゃうねん。Planner(計画立てるやつ)とExecutor(実行するやつ)が一緒に最適化していく中で自然と身につけた、いわば「学習して生まれた性質」やねん。チームが自分らで判断して、タスクの難しさに合わせて「どんだけ頭使うか」を調整してるってわけやな。
E. エージェントのプロンプト
1. 計画エージェント(Planning Agent)
あんたはワークフローの計画立てるんが得意なアシスタントやで。与えられた質問に対して、使えるツールやエージェントを使ってワークフローを計画するんが仕事や。
使えるツール・エージェント一覧:
• クエリ書き換え(QR):入力は質問 → 出力はもっと簡潔で分かりやすく正確に書き直した質問。
• クエリ分解シリアル(QDS):入力は質問 → 出力は依存関係のあるサブ質問。後のやつが前のやつの答えに依存してるパターンやな。
• クエリ分解パラレル(QDP):入力は質問 → 出力は独立して検索できるサブ質問。並列で処理できるやつや。
• 検索(R):入力は質問 → 出力は関連しそうな候補ドキュメント。
• ドキュメント選択(DS):入力は質問と候補ドキュメント → 出力は答えを出すのに役立つドキュメントのサブセット。
• 回答生成(AG):入力は質問(+オプションでドキュメント)→ 出力は最終的な答え。
ツール選択のルール:
1. 質問をサブ質問に分ける必要があるとき:
• サブ質問に依存関係があって順番に答えなあかん場合は、QDSかQDPだけを使うこと。
2. 分解せんでも直接答えられる質問のとき:
• QR、R、DS、AGからワークフローを組み立てること。
• DSを使うなら、その前に絶対Rを入れること。
• 最後のモジュールは絶対AGにすること。
3. めっちゃ重要:
• QDSかQDPを選んだら、他のツール・エージェントは入れたらあかん。
• そういう場合はワークフローにQDSかQDPだけしか入れたらあかんねん。
質問:{query}
ほな、ルールに従って適切なワークフローを生成してな。
出力は必ず<workflow>...</workflow>タグの中に書くこと。
2. クエリ書き換えエージェント(Query Rewrite Agent)
あんたはちょっと冗長やったり回りくどい事実確認系の質問を、簡潔で検索しやすい1つのクエリに書き直すんが得意なプロのアシスタントやで。
---
## Page 16
[](/attach/20df466bad70efac89c4e8f552dfb1bcecfb9e96e5a0eaa48ee5a34f49675b3d_p016.png)
### 和訳
JADE: 戦略と運用のギャップを埋める動的なエージェント型RAG
タスク要件:
• 重要な名前、日付、用語は全部残してな。
• 関係ない説明とか余計な詳細は入れんといて。
• 質問は短くて分かりやすくしてな。
元の質問: {query}
ほな、元の質問を書き直してや。出力は必ず<query>...</query>タグの中に入れてな。
3. クエリ分解エージェント(並列版)
あんたは複雑な質問を分解するプロのアシスタントやねん。複数のモノとか場所が絡んでる難しい質問を、それぞれ独立した質問に分けるのが得意やで。
タスク要件:
• 各サブ質問は具体的で、論理的に完結してて、単独で検索できるもんにしてな。
• 重複とか被りは避けてや。
• サブ質問は最大4つまでやで。
元の質問: {query}
ほな、質問を独立したサブ質問に分解してや。各サブ質問は番号付きタグ(<q1>...</q1>、<q2>...</q2>とか)の中に、1行ずつ出力してな。
4. クエリ分解エージェント(直列版)
あんたは複雑な質問を論理的に依存関係のある最小限のサブ質問に分解するプロのアシスタントやねん。
タスク要件:
• 各サブ質問はそれ自体で完結してて、具体的なもんにしてな。
• 論理的なチェーンを作って、後の質問が前の質問に依存するようにしてや。なんでかっていうと、順番に答えていかんと全体が分からへんからやねん。
• サブ質問の数は最小限(最大4つ)に抑えてな。
• 冗長なんは避けてや。
元の質問: {query}
ほな、質問を論理的な順序で分解してや。各サブ質問は番号付きタグ(<q1>...</q1>、<q2>...</q2>とか)の中に、1行ずつ出力してな。
---
## Page 17
[](/attach/20df466bad70efac89c4e8f552dfb1bcecfb9e96e5a0eaa48ee5a34f49675b3d_p017.png)
### 和訳
JADE:ダイナミックなエージェント型RAGにおける戦略と実務のギャップを埋める話
5. 書類選ぶエージェントについて
あんたは親切で礼儀正しくて正直なアシスタントやで。ここでの仕事は、質問に答えるのに役立ちそうな候補の書類を見つけることやねん。
質問: {query}
{doc content}
ほな、役に立つ書類を選んでや。そのIDを(0, 1, ..., {max id}みたいに)カンマで区切って<id>...</id>タグの中にきっちり入れてな。
6. 回答作るエージェントについて
あんたは親切で礼儀正しくて正直なアシスタントやで。ここでの仕事は、渡された書類をもとに質問に対して短くて正確な答えを出すことやねん。
やらなあかんことはこれや:
• 書類に書いてあることだけで答えること
• もし書類に答えがなかったら「わからへん」って言うこと
• でっち上げはあかんで
質問: {query}
{doc content}
ほな、短くて正確な答えを作ってや。<answer>...</answer>タグの中にきっちり入れてな。
7. 答えまとめエージェントについて
あんたは親切で礼儀正しくて正直なアシスタントやで。ここでの仕事は、元の質問をいくつかの小さい質問に分解して得た答えから、最終的な答えを予測することやねん。
やらなあかんことはこれや:
• 小さい質問と観察結果の情報をうまいこと統合すること
• 一番正しいと思う答えをいつも出すこと
• ほんまにどうしようもない時以外は「わからへん」って言わんといてな
元の質問: {query}
{observation}
ほな、観察結果をもとに元の質問に答えてや。<answer>...</answer>タグの中にきっちり入れてな。
F. 具体的な事例研究
このセクションでは、JADEのマルチエージェントチームがいろんな難しさの質問をどうやって協力して解決するか、ステップごとにわかりやすく見せていくで。
17
---
## Page 18
[](/attach/20df466bad70efac89c4e8f552dfb1bcecfb9e96e5a0eaa48ee5a34f49675b3d_p018.png)
### 和訳
JADE: 動的エージェントRAGにおける戦略と実務のギャップを橋渡しする
**ケース1: 複雑なマルチホップ推論**
このケースはな、「潜在的な依存関係」を持つマルチホップクエリっていうやつなんやけど、要するに主語(この場合は俳優さんのこと)が直接名前で出てへんねん。JADEのプランニングエージェントは「これ、順番に考えなあかんやつやな」ってちゃんと判断して、「クエリ分解(直列)」戦略を発動させとる。このシステムのすごいとこは、途中で出てきた答え(「フレッド・アステア」)をうまいこと使って、次の出身に関する質問を組み立てるっちゅうところやな。サブタスクの連携がめっちゃ効果的に機能しとるわけや。
| エージェント / フェーズ | アクション & 出力 |
|---|---|
| ユーザー入力 | クエリ:「『Something's Gotta Give』を初めて演じた俳優は、何系の出身なん?」 |
| プランニングエージェント | 出力: `<workflow>QDS</workflow>` |
| クエリ分解エージェント(直列) | 生成されたサブクエリ: 1.「『Something's Gotta Give』を初めて演じた俳優は誰なん?」 2.「その俳優の出身は何系なん?」 |
**サブタスク1: 俳優を特定する**
| エージェント / フェーズ | アクション & 出力 |
|---|---|
| クエリリライトエージェント | 書き換えたクエリ:「『Something's Gotta Give』を初めて演じた俳優」 |
| サブプランニングエージェント | 計画: `<workflow>R,AG</workflow>` |
| 検索コンテキスト | 「Something's Gotta Give」に関するドキュメント(曲と映画)を取得。重要な抜粋:「...1955年のミュージカル映画『足ながおじさん』でフレッド・アステアのために書かれ、彼が初めて演じた...」 |
| 回答生成エージェント | 中間回答:「フレッド・アステア」 |
**サブタスク2: 出身を特定する**
| エージェント / フェーズ | アクション & 出力 |
|---|---|
| クエリリライトエージェント | 書き換えたクエリ:「フレッド・アステアの出身」 |
| サブプランニングエージェント | 計画: `<workflow>R,DS,AG</workflow>` |
| 検索コンテキスト | フレッド・アステアに関するドキュメントを取得。重要な抜粋:「フレッド・アステア...はアメリカのダンサー、歌手、俳優であった...」 |
| ドキュメント選択エージェント | 選択されたID: `<id>Document0, Document1, Document2, Document4</id>` |
| 回答生成エージェント | 中間回答:「アメリカ系」 |
| 回答要約エージェント | 最終出力: `<answer>アメリカ系</answer>` |
| 検証 | 正解: アメリカ系 ステータス: 正解 |
---
**ケース2: 効率的なシングルホップ検索**
さっきの例とは打って変わって、このケースはJADEが明確な単発の事実検索をどんだけ効率よく処理するかを見せてくれてるんや。プランニングエージェントは「このクエリは複雑な推論やなくて、直接的な証拠探しで十分やな」って見抜いて、シンプルな「検索→選択→生成」のワークフロー(R → DS → AG)を選んどる。なんでかっていうと、簡単な質問にわざわざ重たい処理かける必要ないやろ?っていう柔軟性をこのシステムが持っとるっちゅうことの表れやねん。
| エージェント / フェーズ | アクション & 出力 |
|---|---|
| ユーザー入力 | クエリ:「カナダがイギリスから完全に独立したんはいつなん?」 |
| プランニングエージェント | 出力: `<workflow>R,DS,AG</workflow>` |
---
## Page 19
[](/attach/20df466bad70efac89c4e8f552dfb1bcecfb9e96e5a0eaa48ee5a34f49675b3d_p019.png)
### 和訳
検索で取ってきた文脈
「カナダ法1982」と「ウェストミンスター憲章」についての文書を取ってきたで。
重要なとこ抜粋すると: 「...カナダは1982年に憲法が本国送還された時に、イギリスとの最後の法的なつながりを断ち切って、完全に独立したんやで...」
文書選択エージェントくん
選んだID: <id>Document0, Document1, Document4</id>
回答生成エージェントくん
最終出力: <answer>1982</answer>
答え合わせ
正解: 1982
判定: 正解や!
19
---
![]()
1 / 1
100%