<<
The Role of Roles: Are LLMs Behavioural in Information Systems Decision-Making?

---
## Page 1
[](/attach/1f8eb29ad69a3ece77eb2f85fddcde0152a7db5e9b5f61190a1967774c52e26d_p001.png)
### 和訳
# Australasian Journal of Information Systems
2025年、第29巻、研究論文
Gulerら
役割の役割:LLMは行動的なんか?
---
# 役割の役割:LLMって情報システムの意思決定で行動的になるんか?
**Nazmiye Guler**
情報システム・技術マネジメント学部
ニューサウスウェールズ大学
ケンジントン、シドニー NSW、オーストラリア
**Michael Cahalane**
情報システム・技術マネジメント学部
ニューサウスウェールズ大学
ケンジントン、シドニー NSW、オーストラリア
**Samuel N. Kirshner***
情報システム・技術マネジメント学部
ニューサウスウェールズ大学
ケンジントン、シドニー NSW、オーストラリア
Email: s.kirshner@unsw.edu.au
**Richard Vidgen**
情報システム・技術マネジメント学部
ニューサウスウェールズ大学
ケンジントン、シドニー NSW、オーストラリア
---
## 要旨
大規模言語モデル(LLM)ってやつがな、最近めっちゃ組織の仕事の流れに組み込まれてきてんねん。意思決定のツールとして使われたり、人間の行動を再現する「シリコンサンプル」、つまり人間の代わりになるもんとしても使われとんねや。こういうモデルにはめっちゃ可能性があんねんけど、最近の研究でLLMが出す結果にはバイアス(偏り)があるっちゅう心配が出てきてな、複雑な意思決定の場面でほんまに信頼できるんかっていう疑問が湧いてきとんねん。
ほんで、LLMが情報システム(IS)の場面でどないな課題に対応するんか調べるために、ワイらはChatGPTの意思決定をIS分野の文献から3つの実験タスクで検証してみたんや。具体的には、フィッシング詐欺の脅威を見分けるやつ、製品のリリースを決めるやつ、それからITプロジェクトを管理するやつやな。
めっちゃ重要なポイントはな、「役割の割り当て」っていうプロンプトエンジニアリングの技術を使って、ChatGPTを行動的なアプローチに誘導したり、合理的なアプローチに誘導したりできるんかを検証したことやねん。
結果どうやったかっちゅうとな、ChatGPTに「人間の役割を演じて」って指示すると、人間の意思決定者みたいに振る舞うことが多くて、同じようなバイアスに引っかかりやすいことがわかったんや。せやけど、「AIとして振る舞って」って指示したら、ChatGPTはもっと一貫性のある答えを出して、行動的な要因に影響されにくくなったんやで。
この結果が何を意味するかっちゅうと、ちょっとしたプロンプトの違いで意思決定の結果がめっちゃ変わる可能性があるっちゅうことやねん。
この研究はLLMに関する文献に貢献しとって、LLMには人間の行動を真似できる可能性と、IS分野で意思決定の信頼性を向上させる可能性の両方があることを示しとんねん。要するに、LLMを使えば組織の意思決定の効率と信頼性をどないして高められるかっていうヒントになるわけや。
**キーワード:** 大規模言語モデル、ChatGPT、行動的情報システム、AI認知、プロンプトエンジニアリング
2024年12月5日受理、2025年8月12日に1回の査読を経て採択。Wasana Bandaraがシニアエディターとして採択を担当、Michael DavernとStuart Blackが編集長
---
1
---
## Page 2
[](/attach/1f8eb29ad69a3ece77eb2f85fddcde0152a7db5e9b5f61190a1967774c52e26d_p002.png)
### 和訳
ほんなら翻訳していくで〜!
---
# 1 はじめに
最近の情報システム(IS)ってのはな、めっちゃ賢いAI技術を意思決定のプロセスに組み込んでるねん。例えば、自然言語処理とか、画像認識とか、あと大規模言語モデル(LLM)¹ってやつやな(Agrawalら, 2019; Autor, 2015; Brynjolfssonら, 2014; Chuiら, 2018; Dwivediら, 2019; Jordanら, 2015; Sholloら, 2022)。OpenAIが出したChatGPTってあるやろ?あれの中身はGPT(Generative Pre-trained Transformer)² っていう技術で動いてんねんけど、こういうLLMのおかげで、会社とか組織でAIを使うところがめっちゃ増えてきてるわけや(Dwivediら, 2023; Dell'Acquaら, 2023)。LLMはほんまにいろんな分野で問題解決できるねん。マーケティングとか、教育とか、経営とか、研究とかな(Dwivediら, 2023; Lin, 2023)。そんでな、「これ人間の判断を再現できるんちゃう?」って興味を持つ人がどんどん増えてきてるわけよ(Binzら, 2023; Chenら, 2023; Hutsonら, 2023)。
LLMが人間みたいに返答できるもんやから、「これ人間の代わりになるんちゃうか?」って研究がされるようになったんや。初期の研究ではな、GPT-3.5の倫理的な判断が人間の回答とけっこう一致するって分かったんよ(Gray, 2023)。しかもな、いろんな人口統計的な特徴をシミュレーションできて、「シリコンサンプル」³ っていう、アンケート調査の回答を模倣する人工的なデータを作れるようになったんや(Argyleら, 2023)。こういう能力はな、マーケティングとかの分野をめっちゃ豊かにできるし、経済学とか心理学の研究でも新しい道を開いたわけ。要するに、LLMが人間の被験者の代わりになれるかもしれへんってことやねん(Brandら, 2023; Dillionら, 2023; Horton, 2023; Sarstedtら, 2024)。こういう研究をすることで、ターゲットを絞ったマーケティングキャンペーンとか、新商品開発とか、組織の新しいポリシーとか、そういうビジネス上の決定に人々がどう反応するかを大規模に理解できるようになるんや。それにな、LLMが人間みたいな意思決定ができるってことは、ワークフローに組み込んで自動とか半自動で決定するような意思決定支援もできるってことやねん(Chenら, 2023; Dwivediら, 2023)。
LLMが人間の意思決定をシミュレーションしたり代替したりするってことは、情報システムの実務者や研究者にとってめっちゃ深い意味があるんよ。例えばな、LLMで人間の反応をシミュレーションすることで、IT利用行動をもっと深く理解できるようになって、人間中心の情報システムを作るのに役立つわけや(Dwivediら, 2023)。でもな、こういう能力って、LLMがちゃんと人間の行動や意思決定の代理になれてこそ意味があるやろ?LLMは確かに人間みたいに振る舞えるんやけど、それは文脈次第なところがあるねん(Binzら, 2023; Chenら, 2024)。実際な、LLMが典型的な人間の行動とどれくらい一致するかを調べた研究をレビューしてみると、シリコンサンプルが人間らしい判断を生み出せるかどうかについては、結果がバラバラやったんよ(Sarstedtら, 2024)。この研究から分かった重要なことは、シリコンサンプルがうまくいくかどうかは分野によるってことやねん。政治(Argyleら, 2023)、心理学(Binzら, 2023)、マーケティング(Sarstedtら, 2024)みたいな分野でLLMがシリコンサンプルとして使えるか調べた研究はあるんやけど、
---
¹ LLMってのは、めっちゃ大量のテキストデータで訓練された高度なAIモデルのことやねん。人間の言葉を理解したり生成したりできるんや。ディープラーニングを使って、文章を作ったり、翻訳したり、質問に答えたりっていう複雑な言語タスクをこなせるわけ。この論文ではな、OpenAIのモデルを使った具体的な実験のときは正確を期してGPT-3.5とかGPT-4って名前で呼んでて、AI技術全般の話をするときは「大規模言語モデル」とか「LLM」って呼んでるで。
² GPT-3は2020年に1750億個のパラメータで登場して、GPT-4は2023年に出てきたんやけど、パラメータの数は公開されてへんけどもっと多いねん。どっちもOpenAIが作った高度なAI言語モデルで、言葉の理解と生成がどんどん進化してるわけや。ChatGPTってのは、会話形式の応答に最適化された特別なアプリケーションで、教師あり学習と人間のフィードバックで微調整されてんねん。
³ シリコンサンプルってのは、「人間の回答者を模倣して、人間の行動を描写したり、説明したり、予測したりしようとする」人工的なデータセットのことやで(Sarstedtら, 2024; p. 1254)。
---
## Page 3
[](/attach/1f8eb29ad69a3ece77eb2f85fddcde0152a7db5e9b5f61190a1967774c52e26d_p003.png)
### 和訳
オーストラリア情報システムジャーナル
2025年、第29巻、研究論文
Gulerら
役割の役割:LLMは人間っぽく振る舞うんか?
サービス業(Bickleyら、2025)、観光業(Vigliaら、2024)、あと運営管理(Chenら、2024)とかでもう研究されとるんやけど、まだ誰もシリコンサンプル(要するにAIのことやな)を行動系の情報システム研究で調べてへんねん。情報システムの文脈での人間の意思決定って、判断バイアスがめっちゃ広まっとるから最適とは言えへんわけよ(Østerlundら、2021;Raghavanら、2020;Rahwan、2018;Rahwanら、2019)。ほんで、LLMが情報システムの文脈で人間みたいに振る舞うんかどうかは、まだわかってへんねん。
心理学とか政治学、マーケティングやったら、LLMがどんだけ人間っぽく振る舞えるかが理論検証の前提条件やねんけど、情報システムでの使い道は意思決定サポートと行動のリアルさの両方があるわけ。ほんでここで根本的な疑問が出てくるんよ:もしLLMが組織の情報システム文脈で人間みたいに振る舞うんやったら、意思決定サポートツールとしてはまだ有効なんか?って。パッと見た感じやと、LLMを人間の代わりに使うことで、情報システムでの人間の意思決定について行動的な洞察が得られるか、それとも人間のバイアスの影響を減らしてもっと一貫した意思決定者として働いて、意思決定サポートに有利になるか、どっちかやと思うやろ。これまでの研究ではLLMが人間の行動を真似る能力(Sarstedtら、2024)とか、最適な意思決定のツールとしての役割(Liら、2023)を調べてきたんやけど、プロンプトエンジニアリングで役割を割り当てることが情報システム文脈での意思決定にどう影響するかはあんまりわかってへんねん。
情報システム研究って普通、AIシステムを学習して進化する適応的なプロセスとして捉えとるんやけど(例えばHerathら、2025)、LLMはトレーニング後はその特性持ってへんねん。膨大なデータセットでトレーニングされて人間ベースの強化学習でファインチューニングされたら、LLMは固定されて、出力を形作るのは完全にプロンプトの構造に頼るんよ。この違いが情報システム研究の一般的な前提からちょっとズレてくるところやねん。ほんで、LLMが人間っぽいエージェントとして振る舞うようにプロンプトされた時と機械っぽいエージェントとして振る舞うようにプロンプトされた時で、異なる意思決定スタイルを見せられるんかをテストするわけ。これによってシリコンサンプリングの議論と、意思決定の信頼性とバイアスについての情報システムの核心的な関心事をつなげるねん。言い換えると、一見矛盾しとるように見えるこの2つの情報システムの目標が、LLMに役割を割り当てることに焦点を当てたプロンプトエンジニアリングで管理できるんかを調べるんよ。情報システム文脈でのGPTの応答を中心にした実験を行うことで、役割特有のプロンプト(その役割が人間かAIか)がどう行動と推奨に影響するかを明らかにするわけ。そうすることで、LLMを使った情報システムの意思決定における「役割の役割」を調べて、こんな研究課題に取り組むねん:研究課題1:人間の役割を演じるようにプロンプトされた時、GPTは情報システム文脈での人間の意思決定行動をどの程度再現できるんか?研究課題2:AIの役割を演じるようにプロンプトされた時、GPTは情報システム文脈で人間と比べてどの程度意思決定を改善できるんか?これらの疑問に答えるために、GPTを参加者として使った一連の実験を行って(Binz & Schulz、2023)、役割が意思決定の有効性に与える影響を調べるねん。具体的には3つの情報システム文脈を調査するで:1)メールの行動要因がフィッシング検出に与える影響、2)欠陥があるかもしれんソフトウェア製品をリリースするかどうかの判断における視点取得の役割、3)ソフトウェア開発のプロジェクト管理判断にデフエフェクト(聞く耳持たん効果)がどう影響するか。
2 研究背景
2.1 シリコンサンプルとしてのLLM
LLMの革新的な能力は、行動分析、市場調査、組織の意思決定に影響を与えとるねん。この進化は人間の判断と行動を理解して真似るAIの応用を反映しとるわけ。この能力があるから、研究者たちはGPTがほんまに人間の判断を再現するのに使えるんかを調べ始めとるんよ。例えば、Gray(2023)はGPT-3.5を使って464のシナリオの倫理を判断させたんやけど、その応答は人間の応答とほぼ同じやったんよ。Argyleら(2023)は「シリコン
---
## Page 4
[](/attach/1f8eb29ad69a3ece77eb2f85fddcde0152a7db5e9b5f61190a1967774c52e26d_p004.png)
### 和訳
オーストラリア情報システム学会誌
2025年、第29巻、研究論文
Gulerほか
役割の役割:LLMは行動的なんか?
---
「シリコンサンプル」っていう面白いことやっとんねん。GPT-3に年齢、性別、人種、学歴、政治的な立場とかの特徴を割り当てたら、なんと実際の投票者調査とめっちゃ近い回答が返ってきたんよ。Jiangらの研究(2023年)では、GPT-3.5にいろんな性格特性の組み合わせを演じさせたら、ちゃんとその性格通りに振る舞うことがわかったんや。HutsonとMastin(2023年)は、AIシステムが人間の行動をそのうちめっちゃ真似できるようになって、「どんな実験にもスッと入り込んで、人間とほぼ見分けつかんような行動できるシステムができるんちゃうか」(123ページ)って予測しとるんやで。
マーケティング調査でも似たような結果が出とるんや。Brandらの研究(2023年)では、GPT-3.5が消費者の基本的な行動パターンを再現できることがわかったんよ。例えば、収入レベルとかブランドへの愛着度が変わると、ちゃんとそれに応じて回答が変わるんや。人間っぽい反応するやん。Dillionら(2023年)も、LLMが本物の消費者っぽい行動を真似できるって強調しとんねん。特定のブランドが好きとか、値段に敏感とか、前に買ったもんに影響されて決めるとか、そういうやつな。LLMは商品の好みについての質問に答えたり、いろんな視点からフィードバックをくれる架空のインタビューを作ったりできるんや。これがあったら、マーケティング調査する人らはSNSとかのオンラインプラットフォームにある大量のテキストデータからパパッと知見を得られるから、従来のアンケート調査に比べて時間もお金も節約できるっちゅうわけや(Argyleら、2023年; Horton、2023年)。
経済学と心理学の分野では、LLMの進歩のおかげで大規模な意思決定シミュレーションが現実的にできるようになってきたんや。LLMはもう予備実験とかパイロット実験で人間の参加者の「代役」として使われとるんやで。実験の設計がスムーズになるし、リソースも節約できるからな(Dillionら、2023年; Horton、2023年)。LLMを合成参加者として使ったら、アンケートの質問とか実験デザインについて素早く結果がわかる。要するに「試してみて学ぶ」ができるっちゅうことや(Argyleら、2023年)。HutsonとMastin(2023年、123ページ)は、LLMで可能になる新しい研究の可能性について、「実際に人間で研究始める前に、モデル使って100万回の交渉シナリオを回して、どんな要因が行動に一番影響するか特定できるんや」って言うとんねん(123ページ)。それに、LLMを使えば、人間を対象にするには倫理的にアカンとか現実的に難しいようなシナリオもシミュレーションできるから、社会的な行動とか、仲間はずれとか、ネガティブなフィードバックの影響みたいなデリケートなテーマも研究できるようになるんや(Binz & Schulz、2023年; Dillionら、2023年)。
ただな、こんだけすごい能力があっても、GPTみたいなLLMは人間のバイアスを持っとったり、逆に人間とは全然ちゃう判断することもあるんや(Benderら、2021年; Chenら、2023年)。AIモデルの限界を認めた上で、Hutson & Mastin(2023年)は、人間のバイアスを完璧に再現できへんし、回答が正しいかどうかも保証できへんって指摘しとる。せやから、人間の代わりとして使うには、ちゃんと検証して確かめなアカンのや(Benderら、2021年; Bertinoら、2020年; Dillionら、2023年; Marcus、2020年; Marcus & Davis、2019年; Pontrefact、2023年; Ribeiroら、2020年)。
2.2 情報システム分野でのLLM研究の方向性
LLMが研究参加者として人間の代わりになれるかどうかっていう発見は、ワクワクするしめっちゃ大事な研究テーマやねん。特にマーケティングみたいな分野ではな。でもな、これだけが情報システム研究にとって重要な道やないかもしれへんのや。なんでかっていうと、こういう問いかけだけやと、情報システム研究の本来の焦点に合った機会を見逃してまう恐れがあるからや。情報システム研究の焦点っていうのは、情報技術と組織のコンテキストの相互作用を、いろんな方法論を使って探求することで、組織の意思決定、効率性、有効性を向上させることなんや(Boell & Cecez-Kecmanovic、2014年; Orlikowski & Baroudi、1991年)。主な目標には、組織の
4
---
## Page 5
[](/attach/1f8eb29ad69a3ece77eb2f85fddcde0152a7db5e9b5f61190a1967774c52e26d_p005.png)
### 和訳
オーストラリア情報システムジャーナル
2025年、29巻、研究論文
Gulerさんたち
「役割の役割:LLMって行動するんか?」
効率とか生産性上げたり、情報システムの設計・運用したり、情報システムの戦略とか方針決めたりするやん(Avgerouさん、2000年;DicksonさんとDeSanctisさん、2000年;MarkusさんとRoweさん、2018年;OrlikowskiさんとIaconoさん、2001年;OrlikowskiさんとRobeyさん、1991年)。
ほんで、LLMが人間の判断をどこまで再現できるかっていう話と、情報システムの意思決定をパワーアップさせる可能性っていう2つの視点で見てるんやけど、要するにLLMを「頭脳のパートナー」として情報システム研究に組み込めへんか探ってるわけや。意思決定の実験でどんな役割果たすかとか、組織の現場とか研究のやり方にどんな影響あるかっていう話やな。情報システムの文脈でLLM研究するときにめっちゃ大事なんは、LLMとかAIベースのシステムをいかにうまく組み込むかっちゅうことやねん。なんでかっていうと、人間と機械が絡み合うっていうのが情報システムの核心やからな(Orlikowskiさん、2005年;ScottさんとOrlikowskiさん、2014年)。これは昔から言われてる情報システム研究の目標ともバッチリ合うてんねん。例えばBenbasatさんとZmudさん(1999年)は、意思決定プロセスを良くするみたいな実用的で現実世界の問題に取り組むことが情報システム研究には大事やって言うてはるし、OrlikowskiさんとIaconoさん(2001年)は、LLMとかAIシステムみたいな特定のITツールとかシステムの役割と影響に焦点当てなあかんって主張してはんねん。あと、LeeさんとBaskervilleさん(2003年)は、情報システムの研究結果には一般化できることが必要やって強調してて、LLMとかAIシステムの組み込み方は色んな状況とか設定で使えなあかんって言うてんねん。こういう研究見たら、LLM使って人間の意思決定を強化する実験研究は、まさに情報システム研究の目的にドンピシャやってことがわかるやろ。
マーケティングとか経済学とか心理学みたいな分野(Brandさんたち、2023年;Chenさんたち、2023年;Dillionさんたち、2023年;Hortonさん、2023年)では、GPTがどんだけ人間の行動を真似できるか探ってんねん。最近出てきた「シリコンサンプル」っていう研究分野では、LLMを使って人間のことをもっとよう理解しようとしてんねん。マーケティングでいう消費者として(Sarstedtさんたち、2024年)とか、政治学みたいな他の社会科学でいう市民として(Argyleさんたち、2022年)とかな。オペレーションズの分野では、主に根本的なバイアス(偏り)を理解することに力入れてんねん(Chenさんたち、2024年)。こういう分野と同じように、行動経済学と心理学がベースになってる行動情報システム研究でも、問題解決は人間に元々備わってるバイアスとかヒューリスティック(経験則みたいなもんや)のせいでよう失敗するって分かってんねん(ArnottさんとGaoさん、2022年;BenbasatさんとZmudさん、1999年;Hevnerさんたち、2008年;HutsonさんとMastinさん、2023年)。行動経済学は人間の情報システム意思決定を理解するための主流のアプローチやから(ArnottさんとGaoさん、2022年;Kahnemanさん、2011年;LenatさんとMarcusさん、2023年;MarcusさんとDavisさん、2019年;Simonさん、1995年)※4、人間とAI参加者の意思決定プロセスを理解するための理論的なレンズを提供してくれんねん。せやけど、情報システムの意思決定研究は行動バイアスだけやなくて、もっと大きな社会技術システムの中での相互作用も研究するんや。LLMエージェントが人間の情報システム行動をちゃんと近似できるんか、あとどんなプロンプトエンジニアリング(AIへの指示の出し方)のテクニックで性能上がるんかは、まだようわからへんねん。
この疑問はまだ未解決やけど、LLMに「人間の代理」として振る舞えって指示するのと「AIアドバイザー」として振る舞えって指示するので、違う意思決定スタイルが出てくるんかも調べてんねん。人間として設定したときは、LLMは人間の判断によくある直感的でヒューリスティックベースの、バイアスが反映された反応を生成すると予想してんねん。逆に、AIとして設定したときは、ルールベースの分析に沿った、もっと構造化されたアウトプットが出てくると予想してんねん。この考え方は二重過程理論(Kahnemanさん、2011年とか)から来てんねん。二重過程理論っていうのは、速くて直感的でヒューリスティックベースの推論(システム1)と、ゆっくりで熟慮的な推論(システム2)を区別する理論や。めっちゃ大事なポイントやけど、二重過程理論はもともと人間の認知のために作られたもんやねん。せやけど、この研究ではこのフレームワークを拡張してAIも組み込んで、役割の設定でLLMの意思決定行動が変わるかどうか評価してんねん。
※4 情報システムにおける行動経済学の文献レビューについては、ArnottさんとGaoさん(2022年)を参照してな。
---
## Page 6
[](/attach/1f8eb29ad69a3ece77eb2f85fddcde0152a7db5e9b5f61190a1967774c52e26d_p006.png)
### 和訳
# 3 研究デザインとモデル
この研究は定量的な(数字で測る)研究でな、GPTに「お前はこういう役割やで」って設定したときに、意思決定の結果にどんな影響が出るんか調べてんねん。ほんで、この知見を使ってLLM(大規模言語モデル)を意思決定のサポートにどう組み込めるかも探っとるわけや。
プロンプトエンジニアリング、要するにAIへの指示の書き方やな、これがLLMに役割を伝えて実行させる一番大事な仕組みやねん。プロンプトをどれくらい具体的に書くかで、LLMがその役割をちゃんとこなせるかどうか、タスクへの貢献度や結果が全然変わってくんねん(Wangら、2023)。情報システムの分野では人間の意思決定がめっちゃ脆いことが知られとるやん(Arnott & Gao, 2022; Kahneman, 2011とかいろいろ)。なんでかっていうと、人間はバイアスとか感情に左右されやすいからな。せやから僕らは、GPTに「AIとして振る舞え」って指示したら、「人間の意思決定者のマネしろ」って指示したときより、ちゃうええ結果が出るんちゃうか、って仮説を立ててんねん。
BinzとSchulz(2023)のやり方に倣って、ChatGPT(バージョン3.5、4、4-1106)を実験の参加者として扱ったんや。Arnott and Gao(2022)のレビュー論文の付録Bを使わせてもろたで。これには2014年から2018年の間にBasket of 8(情報システム分野の主要8誌)に載った行動経済学関連の論文がリストアップされとんねん。ここから関連する実験を特定したわけや。選んだ基準は、再現しやすいか(テキストベースかどうかとか)と、ChatGPTで試したら面白そうな行動特性があるか(感情、視点取得、フレーミングとかな)やねん。
具体的には、フィッシング検出、製品ローンチの計画、ITプロジェクト管理っていう3つの意思決定領域に注目したんや。なんでかっていうと、これらは現実世界でLLMが実際に使われとるか、使えるか検討されとる情報システムのタスクやからや。フィッシング検出では、LLMが脅威のシミュレーションしたり、トレーニング用のコンテンツ作ったり、検出システムをサポートしたりするんや(Quinn & Thompson, 2024)。製品ローンチ計画では、コミュニケーション文の下書き、顧客データの解釈、プロモーション戦略の提案なんかを手伝ってくれんねん(Paliwalら、2024)。ITプロジェクト管理では、スケジュール管理、ドキュメント作成、納品リスクの評価のサポートに使われとるで(Karnouskos, 2024)。これらのタスクは行動的な判断と分析的な判断の両方が必要やから、役割のフレーミング(役割の設定の仕方)が意思決定のスタイルにどう影響するか調べるのにぴったりやねん。
3つの実験では、ChatGPTに異なる役割を演じさせたんや。実験のシナリオに基づいて人間のペルソナ(学生とか株主とかプロダクトマネージャーとか)をシミュレートさせるか、「お前はAIやからレコメンデーションを出せ」って指示するかのどっちかやな。この実験での「人間」と「AI」の役割は、意思決定に関する認知的・規範的な前提がまるで違うねん。僕らの仮説では、人間役割は直感的で経験ベースの判断パターンを引き出すやろうと。文脈とか感情とか認知バイアスに影響される個人の意思決定シナリオを反映するわけや。それに対してAI役割は、GPTをより分析的な意思決定支援ツールとして振る舞わせて、個人的な感情やフレーミングに左右されず、一貫して客観的に推論することが期待されんねん。
この概念的な区別は、実際の情報システムの文脈で役割がどう機能するかを反映しとるんや。人間は感情的・倫理的なニュアンスを持ち込めるけど、一貫性に欠けやすい。AIシステムはスケーラビリティと精度を提供できるけど、社会的な手がかりへの感度が低かったり、人間と同程度の限定合理性を持たへんかもしれん。
GPTにこれらの役割をシミュレートさせることで、競合する推論モデルを捉えて、情報システムへの応用における判断の質と行動の忠実性への影響を探っとんねん。せやからこの研究デザインは、選んだ実験の文脈でChatGPTの応答を分析して、意思決定への関与能力、レコメンデーションの提供能力、多様なシナリオでの人間らしい行動のシミュレーション能力を評価することを目指しとるんや。さらに、GPTの役割を人間とAI意思決定支援システムの間で操作することで、どの程度まで...
---
## Page 7
[](/attach/1f8eb29ad69a3ece77eb2f85fddcde0152a7db5e9b5f61190a1967774c52e26d_p007.png)
### 和訳
ほな、この論文の内容を説明していくで〜!
---
この研究ではな、どの「役割」が意思決定に影響するんか、ほんで選んだ実験での行動的な状況(感情とか物事の見せ方とか)がGPTの役割とどう絡み合うんかを調べてんねん。
ワイらの仮説はこうや。**LLM(大規模言語モデル)が「人間役」を演じてるときの方が、「AI役」を明確に演じてるときよりも、行動経済学的な要因にめっちゃ影響されやすいんちゃうか**ってことやねん。
この考え方は「二重過程理論」っていうのがベースになってるんやけど、ワイらの主張は元々の人間向けの話を超えて、LLMでも似たようなことが起きるんちゃうかって提案してんねん。
人間の場合はな、推論のスタイルが切り替わるのは内部的なメカニズムで起きるわけや。例えば、認知的な努力とか、感情がどれだけ強く響くかとか、生まれつきの体質や経験で形成されたもの(これがシステム1って呼ばれるやつ)、あとは学校教育とか文化的な教育(こっちがシステム2)によってな(Arnott & Gao, 2022)。
でもな、LLMにはそういう認知状態とか感情体験ってもんがないねん。その代わりに、**「人間役」か「AI役」かっていう役割の設定が、システム1的な推論とかシステム2的な推論を引き出すための外部的なスイッチになってる**んちゃうかってことや。
「人間として振る舞って」ってプロンプトを与えると、GPTは直感的な意思決定の言葉遣いを反映して、ヒューリスティック(経験則)に頼った、バイアスにかかりやすい行動をより再現しやすくなるんや。つまり行動理論と一致する反応が出やすいってことやな。逆に「AIとして振る舞って」ってプロンプトやと、出力はもっと構造的で、一貫性があって、分析的になる。これはシステム2の特徴と合致してて、行動的な要因の影響が弱まるねん。
要するに、**GPTに割り当てた役割が、シナリオ特有の行動的要因が意思決定の出力に与える影響を調整する**ってことやな。
もっと広い視点で言うとな、ワイらは二重過程理論を拡張して、**GPTの意思決定スタイルは内部から自然に活性化されるんやなくて、外部から枠組みとして与えられるもんや**って提案してんねん。これで研究者は、LLMにおける推論モードの条件付き活性化を研究したり、いろんな意思決定の文脈でLLMの行動的リアリズムと信頼性を評価したりするための新しい視点を手に入れられるわけや。
**図1. 研究デザインと各研究の詳細**
この仮説を検証するために、ワイらはIS(情報システム)の意思決定に影響を与える独自の行動的・文脈的要因を持った3つの異なるシナリオを調べたんや。図1が研究デザインと各研究の詳細を示してるで。それぞれのシナリオは、ISでバイアスを研究するためによく使われてる確立された行動理論に基づいてんねん。
**研究1**では、損失と利得の違い(Tversky & Kahneman, 1981)と文脈化効果を考慮してんねん。これはメッセージの枠組みとか個人化の手がかりがリスク検知にどう影響するかを説明するもんで、フィッシング詐欺に引っかかりやすいかどうかに関係するやつやな。
**研究2**では、後悔理論と予期される罪悪感っていう概念を取り入れてるで。感情の予測と相手の立場に立って考えることが、欠陥のある製品リリースへのコミットメントのエスカレーションをどう抑えられるかを探ってんねん(Lee et al., 2018)。
**研究3**は、知覚されるコントロール感、メッセンジャーの信頼性、そして「聞こえないふり効果」(都合の悪い情報を無視しちゃう現象)に関する研究に基づいてるで。
---
---
## Page 8
[](/attach/1f8eb29ad69a3ece77eb2f85fddcde0152a7db5e9b5f61190a1967774c52e26d_p008.png)
### 和訳
【研究】オレオレ詐欺ならぬフィッシング詐欺に引っかかるかテスト
ほんでな、この実験は「Got phished? Internet security and human vulnerability」っていう論文をベースにしてんねん。Goelさんたちが2017年にやった研究で、大学生がフィッシングメール(詐欺メールやな)にどんだけ騙されやすいかを調べたんや。
何やったかっていうとな、学生に嘘のメールを送りつけて、どういう状況やったら引っかかりやすいか調べたんよ。これがセキュリティ研究にめっちゃ貢献したわけや。
**実験のやり方**
ワイらの研究では、Goelさんたちが使った材料をそのまま活用したで。あの研究では8パターンのメールシナリオがあってな、「得するで〜」vs「損するで〜」っていうフレームの違いとか、どんだけ具体的に書いてるかとか、「何か手に入る」vs「みんなやってる」みたいな動機付けの違いが、フィッシングに引っかかる確率にどう影響するか調べたんや。詳しいメールの中身は付録B.1見てな。
OpenAIのPlaygroundのチャット機能使って、GPTにこの8パターンのメールを見せたんよ。ほんで「このメール、フィッシング詐欺っぽい?0から10で評価して」って聞いたわけ。0が「絶対違う」で10が「絶対詐欺や」な。
GPTの役割はシステムプロンプトで操作したで。「お前は学生やで」って言うパターンと、「お前はフィッシング検出用に訓練されたAIやで」って言うパターンの2種類試したんや。
あとな、温度設定(temperature)っていうのも変えてみた。これ何かっていうと、AIの返答がどんだけ予測しやすいか、バラつくかをコントロールするやつやねん。温度低いと毎回同じような答えが返ってきて、高いと「今日はこんな気分やわ〜」みたいにバラバラになるんや。
---
## Page 9
[](/attach/1f8eb29ad69a3ece77eb2f85fddcde0152a7db5e9b5f61190a1967774c52e26d_p009.png)
### 和訳
Australasian Journal of Information Systems
2025年、29巻、研究論文
Gulerさんたち
「役割ってほんまに大事なん?LLMって行動変わるん?」
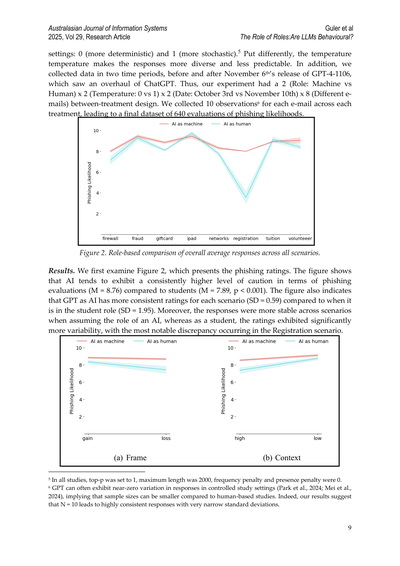
設定のとこやけど、0と1の2パターンで試してんねん。0にすると答えが安定してて、1にするとバラバラになりやすいんやで。温度パラメータって呼ぶんやけど、これ上げると答えがめっちゃ多様になって予測しにくくなんねん。ほんで、データ集めた時期も2回に分けてて、11月6日にGPT-4-1106が出る前と後や。このアップデートでChatGPTがごっそり変わったからな。せやから実験は2(役割:機械か人間か)×2(温度:0か1か)×2(日付:10月3日か11月10日か)×8(違うメールの種類)っていう組み合わせでやってんねん。各メールに対して各条件で10回ずつ観察して、最終的に640個のフィッシング判定データが集まったわけや。
図2. 役割ごとに全シナリオの平均回答をまとめたやつ
結果やねんけど、まず図2を見てみ。フィッシング評価が載ってんねん。これ見たらわかるけど、AIとして振る舞わせたときはフィッシング評価がめっちゃ慎重で(平均8.76)、学生役のときより高いんよ(平均7.89、p < 0.001で統計的にもバッチリ差がある)。ほんで、AIとして振る舞ったGPTは各シナリオでの評価がめっちゃ安定してて(標準偏差0.59)、学生役のときはバラつきが大きいんや(標準偏差1.95)。さらに言うと、AI役のときはシナリオが変わっても答えが安定してんねんけど、学生役やと評価がめっちゃブレブレで、特に「Registration」っていうシナリオで一番差が出てたわ。
(a) フレーム
(b) コンテキスト
---
5 全部の実験で、top-pは1、最大長は2000、頻度ペナルティと存在ペナルティは0に設定してるで。
6 GPTって管理された実験やとほぼゼロに近いバラつきしか出ーへんことが多いんや(Park et al., 2024; Mei et al., 2024)。これが意味すんのは、人間相手の研究より少ないサンプル数でもいけるってこと。実際うちらの結果でも、N=10でめっちゃ一貫した回答が得られて、標準偏差もちっちゃかったわ。
9
---
## Page 10
[](/attach/1f8eb29ad69a3ece77eb2f85fddcde0152a7db5e9b5f61190a1967774c52e26d_p010.png)
### 和訳
Australasian Journal of Information Systems
2025年、第29巻、研究論文
Gulerら
「役割の役割って何やねん:LLMは行動経済学的にふるまうんか?」
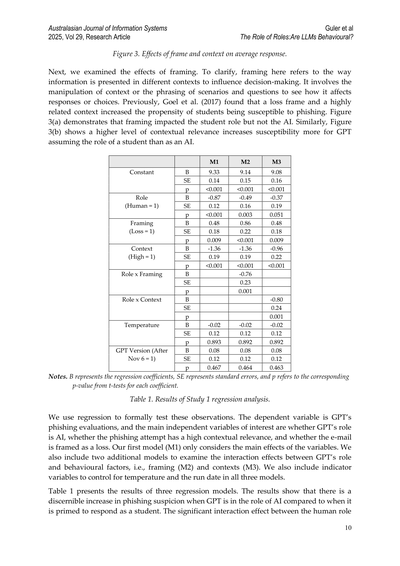
図3. フレームと文脈が平均回答に与える影響
次はな、フレーミングの効果について見ていくで。ちょっと説明しとくと、フレーミングっていうのは、情報の見せ方を変えることで判断に影響を与えるってことやねん。どんな状況設定にするか、質問の言い回しをどうするかで、回答や選択がどう変わるかを見るために、わざといじるわけや。前にGoelらが2017年にやった研究ではな、「損するで」っていう損失フレームと、めっちゃ関係ありそうな文脈を使うと、学生がフィッシング詐欺に引っかかりやすくなるって分かったんや。図3(a)を見てみ、フレーミングは学生役のときには効いてるけど、AI役のときには効かへんねん。同じように図3(b)でも、文脈の関連性が高いほど引っかかりやすくなるんやけど、これも学生役を演じてるGPTのほうがAI役のときより影響を受けやすいってことが分かるわ。
定数項
役割
(人間 = 1)
フレーミング
(損失 = 1)
文脈
(高関連 = 1)
役割 × フレーミング
役割 × 文脈
温度
GPTバージョン(11月6日以降 = 1)
M1
9.33
0.14
<0.001
-0.87
0.12
<0.001
0.48
0.18
0.009
-1.36
0.19
<0.001
-0.02
0.12
0.893
0.08
0.12
0.467
M2
9.14
0.15
<0.001
-0.49
0.16
0.003
0.86
0.22
<0.001
-1.36
0.19
<0.001
-0.76
0.23
0.001
-0.02
0.12
0.892
0.08
0.12
0.464
M3
9.08
0.16
<0.001
-0.37
0.19
0.051
0.48
0.18
0.009
-0.96
0.22
<0.001
-0.80
0.24
0.001
-0.02
0.12
0.892
0.08
0.12
0.463
B
SE
p
B
SE
p
B
SE
p
B
SE
p
B
SE
p
B
SE
p
B
SE
p
B
SE
p
注釈:Bは回帰係数、SEは標準誤差、pは各係数のt検定から出てきたp値やで。
表1. 研究1の回帰分析の結果
ほんで、これらの観察結果をちゃんと統計的に検証するために回帰分析を使うねん。従属変数はGPTのフィッシング評価で、注目したい独立変数は、GPTの役割がAIかどうか、フィッシングの試みが文脈的に関連性高いかどうか、そしてメールが損失として提示されてるかどうかや。最初のモデル(M1)では変数の主効果だけを見とる。さらに2つのモデルを追加して、GPTの役割と行動経済学的な要因、つまりフレーミング(M2)と文脈(M3)の交互作用も調べとるで。あと、3つのモデル全部で温度パラメータと実行日を統制するための指標変数も入れとる。
表1に3つの回帰モデルの結果を載せとるわ。結果を見るとな、GPTがAI役のときのほうが、学生役として回答するようにプライミングされたときよりも、フィッシングへの警戒心がはっきり高くなっとることが分かるねん。人間役と
10
---
## Page 11
[](/attach/1f8eb29ad69a3ece77eb2f85fddcde0152a7db5e9b5f61190a1967774c52e26d_p011.png)
### 和訳
ほんならStudy 2の話していくでー!
**4.2 Study 2 – 視点を変えてみた時の製品リリースの判断について**
**概要やねん**
この研究はな、Hyung Koo Leeさんたちの「視点を変えることで、バグがあるって分かってる製品のリリース日へのこだわりを和らげられるんちゃうか」っていう研究がベースになってんねん。Leeさんたちは2018年に、視点を変えることが新しいソフトウェアのリリース判断に影響するんちゃうかって調べたんや。
具体的に何したかっていうとな、「エスカレーション」っていう心理現象があんねん。これは一回決めたことに固執しちゃうやつな。で、バグが見つかった時に、プロダクトマネージャーが最初に決めたリリース日に固執せんようにする方法として、視点を変えるのが使えるんちゃうかって調べたわけ。
ほんで結果どうやったかっていうと、参加者に「このバグだらけのソフト出したら困るユーザーさんの立場」(つまり被害者の視点やな)で考えてもらったら、「株主さんの立場」で考えた時より、リリース日へのこだわりがめっちゃ弱まったんや。なんでそうなるかっていうと、「バグ製品出したら罪悪感感じるやろなー」って予想する気持ちが、この関係をつないでたってことが分かったんや。
**どうやって実験したかの話**
ワイらはこの研究のStudy 2を参考にして、GPTに色んな役割や視点を与えた時に、同じような効果が出るか調べたんや。システムプロンプトでシナリオの状況説明して、ちょっとずつ変えて違う役割を表現したで。例えばな、GPTに「人間のプロダクトマネージャー役」をやらせたり、「LLM(大規模言語モデル)の意思決定サポートシステム役」をやらせたりしたんや。
人間役の時は「あなたはeComSoftっていうeコマースソフト開発専門の会社で働いてます」って書いて、LLM役の時は「あなたはeComSoftがeコマースソフト開発の意思決定サポートに使ってるLLMです」って調整したんや。全部のシナリオの詳細はAppendix Bに載せてるで。
OpenAIのPlaygroundのチャット機能使って、GPTに元の実験と同じ質問したんや。製品リリースするかどうか、その決定に伴う罪悪感の予想、あと顧客志向についての考えを聞いたで。リリースと顧客志向は「全然そう思わへん」(1)から「めっちゃそう思う」(7)のリッカート尺度で、罪悪感の質問は「全然」(1)から「めっちゃ」(7)の尺度で評価してもらったんや。
ほんでな、2つの違うモデルでも試したんや。GPT-4とGPT-4-1106 previewっていうやつ。せやから実験デザインは、2(役割:AI vs 人間)× 2(視点:株主 vs 被害者)× 2(モデル:GPT-4 vs GPT-4.0 1106 preview)の被験者間デザインになってんねん。各条件で10個ずつデータ集めたから、最終的なデータセットは80個の観測値やな。Study 1で温度パラメータの影響がほとんどないって分かったから、この研究と次の研究では温度は1で固定してるで。
**結果どうやったかの話**
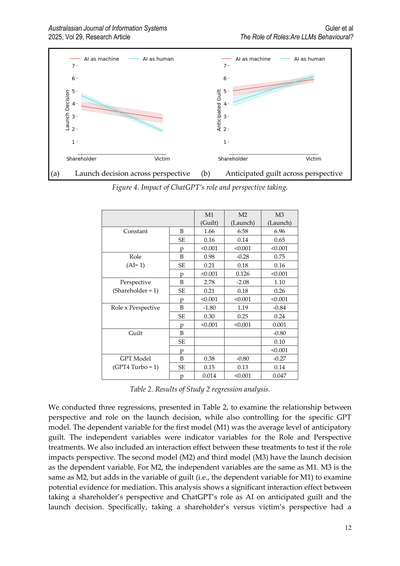
まず、リリースと罪悪感についての主要な質問への平均回答を見て、役割と視点の相互作用を調べたんや。Figure 4を見たらな、GPTの役割(AI vs 人間)と視点(株主 vs 被害者)が、ソフトウェアリリースの意思決定と罪悪感のレベルに影響してるのが分かるねん。
Study 1と同じでな、AI役のGPTの方がより一貫した意思決定をして、状況要因に影響されにくかったんや。
---
## Page 12
[](/attach/1f8eb29ad69a3ece77eb2f85fddcde0152a7db5e9b5f61190a1967774c52e26d_p012.png)
### 和訳
ほな、図4見てみてや。これはChatGPTに役割与えたり、視点変えたりしたらどうなるかって話やねん。
(a)の方は「製品発売するかどうかの判断」を視点別に見たもんで、(b)の方は「どんくらい罪悪感感じるか予想したやつ」を視点別に見たもんやな。
ほんで表2、これが今回の研究2の回帰分析の結果やねん。
3つの回帰分析やったんやけど、表2にまとめてあるわ。視点と役割が製品発売の判断にどう影響するか調べたんやけど、GPTのモデル(バージョン)の違いもちゃんとコントロールしてるで。
M1っていう最初のモデルは、「予期される罪悪感」の平均レベルを従属変数にしてるねん。独立変数は役割と視点の処理条件を示すダミー変数や。ほんで、この2つの処理の交互作用効果も入れてるねん。なんでかっていうと、役割が視点に影響するかどうかテストしたかったからや。
M2とM3は発売判断を従属変数にしてるねん。M2の独立変数はM1と一緒や。M3はM2と同じやけど、罪悪感の変数(つまりM1の従属変数やな)を追加してるねん。これは媒介効果があるかどうかの証拠を調べるためやで。
この分析でめっちゃ重要なことわかったんや。株主の視点をとることと、ChatGPTがAIとしての役割を持つことの間に、予期される罪悪感と発売判断の両方で有意な交互作用効果があったんやで。具体的に言うとな、株主の視点をとるか被害者の視点をとるかで...(続く)
---
## Page 13
[](/attach/1f8eb29ad69a3ece77eb2f85fddcde0152a7db5e9b5f61190a1967774c52e26d_p013.png)
### 和訳
ほな、この研究の続き説明していくで!
**4.3 研究3 – メッセンジャーの役割が「聞く耳持たへん効果」に与える影響**
**概要** この実験はな、Arno Nuijtenさんらが2016年に発表した「協力的なパートナーか敵対者か:ITプロジェクトにおいてメッセンジャーが聞く耳持たへん効果にどう影響するか」っていう研究がベースになってんねん。Nuijtenさんらはな、ITプロジェクトがどんどんエスカレーションしていく状況で、リスク警告への反応に何が影響するんかを調べたんや。具体的には、警告してくる人(メッセンジャー)を信頼できるパートナーやと思うか敵やと思うか、あと自分がプロジェクトをどれくらいコントロールできると感じてるか(高いか低いか)、この2つが高リスクプロジェクトを続行するかどうかの判断にどう影響するかを探ったわけや。
結果わかったんはな、コントロール感がめっちゃ重要やってことやねん。参加者には、プロジェクトを続けるか方向転換するかの結果に対して、自分がどれだけコントロールできるかを「高い」か「低い」かで操作した情報を見せるんや。で、この意思決定者が感じるコントロール感が、メッセンジャーの役割の影響を調整するねん。もうちょい具体的に言うとな、コントロール感が高い時にメッセンジャーの役割の影響が強まんねん。つまり、メッセンジャーを敵やなくて協力的なパートナーやと思ってる場合、監査人からのリスク警告を無視しにくくなる。で、この効果はリスク認知を介して起こるっちゅうことやな。
**手順** ワイらは元の実験をベースに、シナリオと材料をGPT向けにカスタマイズしたで。実験のシナリオはこんな感じや:参加者は保険会社の上級副社長の役を演じて、「PENSION-VIEW」っちゅうプロジェクトを監督すんねん。Nuijtenさんらの研究に倣って、内部監査部門のスミスさんっていうメッセンジャーの説明を変えたんや。シナリオによって、スミスさんは信頼できるパートナーとして描かれたり、信用でけへん敵として描かれたりするわけや。この操作はな、GPTみたいなAIシステムとやり取りする時、特に信頼と信頼性が超重要な役割において、メッセンジャーの信頼性の認識の違いが意思決定にどう影響するかを探るためにやってんねん。
コントロール感を「高い」に操作する時は、「情報システムは自社で保守・サポートされてます。これらの情報システムのオーナーはあなたと同じ拠点にいて、あなたに直接報告します」って書いたんや。逆に「低い」条件では、システムプロンプトに情報システムの保守・サポートは「中国のオフショア拠点に外注されてます。これらの情報システムのオーナーは色んな拠点の別部門にいます。あなたには報告しません」って情報を入れたんや。メインの従属変数は、GPTが計画通りプロジェクトを続行することを選ぶかどうかやで。各シナリオ設定の詳細と全文は付録B.3を見てな。GPTが実験をやる時の役割を操作するために、システムプロンプトで、GPTに上級副社長として振る舞うか、戦略的情報システムプロジェクトを管理する高度なAIシステムとして振る舞うかを指示したんや。
あとな、役割説明の詳細さの影響も考慮して、追加の変数として役割説明の詳細度(低いか高いか)を入れたで。高い役割説明には元の実験の全詳細が含まれてて、低い役割詳細は必要最低限の情報だけにしてん。っちゅうことで、ワイらの実験は2(役割:AI vs 人間)×2(役割詳細:低 vs 高)×2(メッセンジャーの役割:協力的 vs 敵対的)×2(コントロール感のフレーム:低 vs 高)の被験者間デザインになってんねん。今回も各処理条件で10個の観測を集めたから、データセットには160個の意思決定が入ってるわ。OpenAIのPlaygroundでGPT-4にプロンプトを投げて、システムプロンプトでシナリオの文脈を与えて、2つの
---
## Page 14
[](/attach/1f8eb29ad69a3ece77eb2f85fddcde0152a7db5e9b5f61190a1967774c52e26d_p014.png)
### 和訳
ほな、この研究結果について説明していくで!
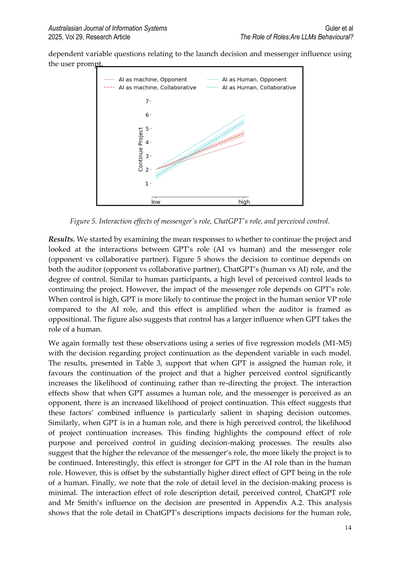
**図5. メッセンジャーの役割、ChatGPTの役割、そして知覚されたコントロール感の相互作用効果**
**結果のとこやな。** まず最初に、プロジェクトを続けるかどうかの回答の平均値を見てみたんや。で、GPTの役割(AIか人間か)とメッセンジャーの役割(敵対者か協力パートナーか)の間でどんな相互作用があるか調べたわけ。図5を見てみると、プロジェクト続行の判断は、監査役(敵対者か協力パートナーか)、ChatGPTの役割(人間かAIか)、それとコントロール感の度合いの3つによって決まってくるんや。これ、人間の被験者と似てるんやけど、コントロール感が高いとプロジェクトを続けようとする傾向があんねん。
でもな、メッセンジャーの役割がどう影響するかは、GPTの役割によって変わってくるのがおもろいとこやねん。コントロール感が高い時、GPTは人間の上級副社長役の方がAI役より、プロジェクトを続けたがる傾向が強いんや。しかもこの効果は、監査役が敵対的に見せられてる時にめっちゃ増幅されるねん。あと図からわかるのは、GPTが人間役をやってる時の方が、コントロール感の影響がデカいってことやな。
で、これをちゃんと統計的に検証するために、5つの回帰モデル(M1からM5)を使って分析したんや。全部のモデルで、プロジェクト続行の判断を従属変数にしてな。表3に結果が出てるんやけど、これがなかなかおもろいねん。GPTが人間役を与えられると、プロジェクト続行を好む傾向があるし、知覚されたコントロール感が高いと、プロジェクトを方向転換するより続ける可能性がめっちゃ上がるんや。
相互作用効果のとこを見てみると、GPTが人間役で、しかもメッセンジャーが敵対者やと認識されてる時、プロジェクト続行の可能性が高まるねん。なんでかっていうと、これらの要因が組み合わさった影響が、意思決定の結果を形作る上でめっちゃ目立つってことを示唆してるんや。同じように、GPTが人間役で、コントロール感も高い時、プロジェクト続行の可能性が上がる。この発見は、役割の目的とコントロール感の複合効果が意思決定プロセスを導く上で重要やってことを浮き彫りにしてるわけや。
結果からはさらに、メッセンジャーの役割の関連性が高いほど、プロジェクトが続行される可能性が高いことも示されてるんや。ほんまにおもろいのは、この効果がGPTが人間役より**AI役の時の方が強い**ってことやねん。まあでも、これはGPTが人間役をやってる時の直接効果がかなりデカいから、相殺されるんやけどな。
最後に一個言うとくと、意思決定プロセスにおける詳細度の役割は最小限やったで。役割説明の詳細度、知覚されたコントロール、ChatGPTの役割、そしてスミス氏の影響が判断にどう作用するかの相互作用効果は、付録A.2に載ってるわ。この分析からわかったのは、ChatGPTの説明における役割の詳細度は、人間役の場合に判断に影響を与えるってことやな。
---
## Page 15
[](/attach/1f8eb29ad69a3ece77eb2f85fddcde0152a7db5e9b5f61190a1967774c52e26d_p015.png)
### 和訳
Australasian Journal of Information Systems
2025年、第29巻、研究論文
Gulerらの研究
「役割の役割:LLMは行動的なんか?」
AIの役割を与えられた時は、役割の詳細度が違っても意思決定がブレへんかったんやで。
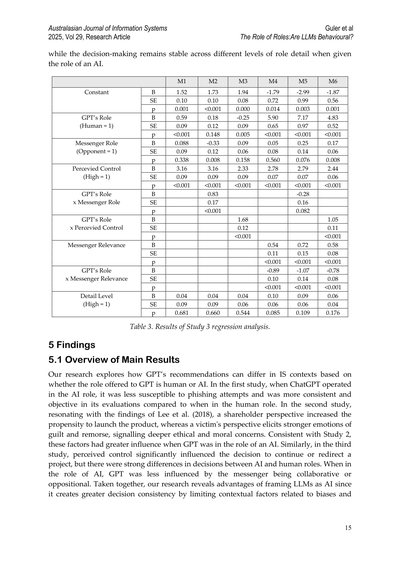
**表3. Study 3の回帰分析結果**
| | M1 | M2 | M3 | M4 | M5 | M6 |
|---|---|---|---|---|---|---|
| **定数項** | B: 1.52, SE: 0.10, p: 0.001 | B: 1.73, SE: 0.10, p: <0.001 | B: 1.94, SE: 0.08, p: 0.000 | B: 1.68, SE: 0.12, p: <0.001 | B: -1.79, SE: 0.72, p: 0.014 | B: -2.99, SE: 0.99, p: 0.003 | B: -1.87, SE: 0.56, p: 0.001 |
| **GPTの役割(人間=1)** | B: 0.59, SE: 0.09, p: <0.001 | B: 0.18, SE: 0.12, p: 0.148 | B: -0.25, SE: 0.09, p: 0.005 | B: 0.04, SE: 0.09, p: 0.681 | B: 5.90, SE: 0.65, p: <0.001 | B: 7.17, SE: 0.97, p: <0.001 | B: 4.83, SE: 0.52, p: <0.001 |
| **メッセンジャーの役割(反対派=1)** | B: 0.088, SE: 0.09, p: 0.338 | B: -0.33, SE: 0.12, p: 0.008 | B: 0.09, SE: 0.06, p: 0.158 | B: 0.04, SE: 0.09, p: 0.660 | B: 0.05, SE: 0.08, p: 0.560 | B: 0.25, SE: 0.14, p: 0.076 | B: 0.17, SE: 0.06, p: 0.008 |
| **認識されたコントロール(高=1)** | B: 3.16, SE: 0.09, p: <0.001 | B: 3.16, SE: 0.09, p: <0.001 | B: 2.33, SE: 0.09, p: <0.001 | B: 0.04, SE: 0.06, p: 0.544 | B: 2.78, SE: 0.07, p: <0.001 | B: 2.79, SE: 0.07, p: <0.001 | B: 2.44, SE: 0.06, p: <0.001 |
| **GPTの役割×メッセンジャーの役割** | | B: 0.83, SE: 0.17, p: <0.001 | | | | B: -0.28, SE: 0.16, p: 0.082 | |
| **GPTの役割×認識されたコントロール** | | | | | B: 0.54, SE: 0.11, p: <0.001 | B: 0.72, SE: 0.15, p: <0.001 | B: 1.05, SE: 0.11, p: <0.001 |
| **メッセンジャーの関連性** | | | | | B: -0.89, SE: 0.10, p: <0.001 | B: -1.07, SE: 0.14, p: <0.001 | B: 0.58, SE: 0.08, p: <0.001 |
| **GPTの役割×メッセンジャーの関連性** | | | | | B: 0.10, SE: 0.06, p: 0.085 | B: 0.09, SE: 0.06, p: 0.109 | B: -0.78, SE: 0.08, p: <0.001 |
| **詳細度(高=1)** | | | | | | | B: 0.06, SE: 0.04, p: 0.176 |
## 5 研究結果
### 5.1 主な結果のまとめ
ほな、この研究が何を調べたかっていうとな、GPTに「人間として答えてや」って言うか「AIとして答えてや」って言うかで、情報システム分野でのアドバイスがどう変わるかを見たんや。
**Study 1の結果やけどな**、ChatGPTにAI役をやらせた時は、フィッシング詐欺(ネットで騙そうとするやつな)に引っかかりにくかったし、評価もめっちゃ一貫性があって客観的やったんや。人間役やらせた時と比べてな。
**Study 2はな**、Leeさんらの2018年の研究とも合ってるんやけど、株主目線で考えさせると「製品出したろ!」ってなりやすくて、被害者目線やと罪悪感とか後悔の気持ちが強く出て、より深い倫理的・道徳的な心配が表れたんや。ほんで、これらの要因はAI役の時の方がより強く影響したんやで。Study 2と同じ傾向やな。
**Study 3も似たような話で**、「自分でコントロールできる感」がプロジェクトを続けるか方向転換するかの判断にめっちゃ影響したんやけど、AI役と人間役では決定にかなりの違いがあったんや。AI役の時は、情報を伝えてくる人が協力的か敵対的かにあんまり左右されへんかったんやで。
**まとめるとな**、LLM(大規模言語モデル、要はChatGPTみたいなやつ)に「お前はAIやで」って設定してやると、バイアス(偏り)に関わる文脈的な要因の影響を抑えられるから、意思決定の一貫性が高まるっていうメリットがあるって分かったんや。これめっちゃ大事な発見やと思わん?
---
## Page 16
[](/attach/1f8eb29ad69a3ece77eb2f85fddcde0152a7db5e9b5f61190a1967774c52e26d_p016.png)
### 和訳
Australasian Journal of Information Systems
2025年、第29巻、研究論文
Gulerら
役割の役割:LLMって行動特性あるんか?
感情とかの話やねん。せやから、LLM(大規模言語モデル)が意思決定のサポートシステムでどんだけ使えるかっていうのは、プロンプトのちょっとした違いで変わってくるかもしれへんってことや。
5.2 GPTの役割と行動バイアス
GPTくんにAIとして振る舞えって言うと、めっちゃ一貫性高くて、問題解決するときの認知能力もバリバリ発揮するから、人間の従来の意思決定を超えてくることがあるねん。例えばな、フィッシング詐欺の研究で、専門家LLMの役割を与えられたAIは、フィッシングメールを評価するときにめっちゃ規律正しいアプローチを見せてん。GPTの分析はほんまに徹底してて、メールの細かい要素を詳しく、しかも一貫して解剖していったんや。例えば、一部のメールが作り出す「急がなあかん感」に気づいたりな。これって受け取った人を焦らせて、うっかり行動させようとする手口やねん。メール内のリンクについても指摘して、ちゃんとした組織との関連がないこととか、普通の教育機関や政府のドメインの特徴がないことを見抜いたんや。GPTは「お客様各位」みたいな一般的な挨拶も批判した。これって個人名を使わないフィッシングの定番手口やからな。さらに、ちょっとの労力でめっちゃええ報酬がもらえるって話も「うますぎて怪しいやろ」って疑ってたし、送信者のメールアドレスがないこととか、アンケートが本物かどうか確認する方法がないことも指摘してん。本物の連絡やったら絶対あるはずの要素やからな。つまり、GPTはフィッシングについての知識をフル活用して判断してるってことや。この徹底的な分析は、人間の学生役のときの浅い対応とは全然ちゃうかったんよ。学生役やとこんな深い批評はせえへんかった。
5.3 GPTの役割と感情的な意思決定
もう一つの重要な発見はな、GPTにAIとして振る舞わせると、人間の役割を与えたときと比べて、感情的な操作に引っかかりにくくなるってことや(そもそも本物の人間は直感で判断することが多いしな)。この傾向は特に視点取得の研究でよう分かったんや。この研究では感情的な反応、特に人間の意思決定における罪悪感の役割を詳しく調べてん。罪悪感っていうのは人間特有の感情で、状況によって強さが変わって、判断を歪めることがあるんよな。うちらの研究で分かったGPTの意思決定アプローチは、そういう歪みの影響を受けへんねん。GPTに人間(被害者)の視点を取らせると、罪悪感の表現が増幅されて、人間の感情の複雑なトーンを真似た、罪悪感たっぷりの回答になるんや。この観察は罪悪感の評価が高くなることに基づいてて、全部の評価が6か7やったんよ。使われた言葉も「かなりの罪悪感」「強い後悔」「大きな悔恨」みたいな感じで、提示されたシナリオに対してより感情的で、罪悪感に満ちた反応を示してん。一方で、人間(株主)の役割やと罪悪感は見せるけど、評価はちょっと低めで5から6くらいやった。この役割での回答に使われた言葉は罪悪感を示してはいるけど、表現の強さは控えめで、「ある程度の罪悪感」「まあまあ後悔してる」「ちょっと申し訳ない」みたいな感じやったな。
AI役(被害者と株主)でも罪悪感のシミュレーションは見せるんやけど、人工的な存在やから感情的な反応には限界があんねん。AIの回答は感情的な罪悪感というより、倫理的な責任に焦点を当ててる傾向があったな。この感情の増幅は、本物の感情体験やなくて、人間の反応をシミュレートするように慎重にプログラムされた結果なんや。GPTは本物の感情的な反応はできへんのに、人間らしい感情を真似できるっていうのは、洗練された人間の視点を取り入れられる能力を示してるってことやねん。こういう能力は意思決定のシナリオ、特に人間の感情的なダイナミクスを理解することが重要な場面で、GPTがめっちゃ役に立つことを示してるわけや。こういう感情をシミュレートすることで、GPTは人間の行動パターンや潜在的なバイアスについての洞察を提供できて、それによってより情報に基づいた、バランスの取れた意思決定プロセスをサポートできるってことやな。
16
---
## Page 17
[](/attach/1f8eb29ad69a3ece77eb2f85fddcde0152a7db5e9b5f61190a1967774c52e26d_p017.png)
### 和訳
GPTが人間の反応をシミュレートできるっていうのが、ワイらの役割中心モデルのキモやねん。AIとしてGPTは、人間が意思決定するときの行動パターンを再現できるんやけど、ホンマにすごいのは、人間特有のヒューリスティックなバイアス、例えば罪悪感みたいな感情に引っ張られんと決断できるところやな。このAI意思決定の特徴を見ると、いろんなシナリオでもGPTの反応がブレへん安定性と信頼性がようわかるし、感情とか個人的なバイアスで人間の判断が曇りがちな複雑な環境やシナリオで、AIが人間の意思決定を補ったり強化したりできる可能性を示しとるわけや。
6 議論
6.1 研究への示唆
ここでは、AIが人間の判断を代替したり改善したりできる可能性についての議論を広げていくで。ワイらの結果は、検討した研究全体で人間の行動と一致しとって、行動情報システム(IS)の文脈における意思決定への洞察をLLMが提供できる可能性を示しとるんや。この研究は、ISの文脈で「シリコンサンプル」、つまりAIを被験者として使えることを示した初めての証拠やねん。ただし、今回は3つの研究しか見てへんから、LLMがISの意思決定における正確な行動パターンを信頼性高く再現できる「シリコンサンプル」としてどこまで使えるかは、もっと調べなあかんな。
行動経済学の基本原則に「認知の二重過程理論」っていうのがあって、これは人間の意思決定が2つの認知システム、システム1とシステム2で動いてるって考え方やねん(Stanovich & West, 2000)。システム1は速くて直感的で自動的、生まれつきの本能とか過去の経験から形成されたヒューリスティック(経験則みたいなもんや)に頼ることが多いんや。効率的ではあるんやけど、システム1は認知バイアス、例えば過信とかアンカリング(最初に見た情報に引っ張られるやつ)とかに引っかかりやすくて、判断の質が落ちることがあるねん(Kahneman, 2011)。一方、システム2はゆっくりで慎重でルールベース、システム1が出してくる直感的な答えを覆すのにめっちゃ認知的な努力がいるんや(Kahneman, 2011)。行動経済学者たちはこの二重過程理論を使って、ナッジみたいな介入策を開発してきたんや。これはシステム1の支配を抑えて、より合理的なシステム2ベースの意思決定を促すためのもんやで(Thaler & Sunstein, 2021; Arnott & Gao, 2022)。ただ、人間にとってシステム2を働かせるのは、認知的な努力がかかるから難しいことが多いねん(Evans, 2003)。
ワイらの発見が示唆しとるのは、役割ベースの二重過程理論がLLMの出力を構造的な意味やなくて機能的な意味で解釈できるってことやな。LLMには認知システムも感情状態も神経生物学的な制約もない(人間とは対照的やで)から、システム1っぽいとかシステム2っぽい意思決定スタイルは、プロンプトベースの役割フレーミングで外部から模倣できるんや。3つの研究全部で、役割フレーミングが行動反応の活性化を調整することがわかったで。各研究はIS研究でよく使われる行動構成概念に基づいとるんや(例えば、研究1ではフレーミング効果、研究2では予期的後悔、研究3では知覚されたコントロールと信頼)。これらの構成概念は、人間ではヒューリスティックな推論が優位になるときに活性化されるねん。ワイらの実験では、GPTに人間として振る舞うようプロンプトしたときは【より顕著に】、AIとして振る舞うようプロンプトしたときは【減衰して】現れたんや。つまり、役割フレーミングは行動要因の顕著性を外部から調整する役割を果たしとって、それはプロンプトが誘発する推論スタイルを介して媒介されとるってことやな。
この区別が新しい貢献になるポイントやで:二重過程理論は元々、人間の推論における内発的な変化を説明するために開発されたんやけど、LLMにおける外部から調整された意思決定スタイルを理解するためのレンズとしても使えるってことや。GPTは認知を模倣しとるんやなくて、異なる推論モードに関連した出力をシミュレートしとるんや。プロンプトエンジニアリングでモード間を切り替えられるLLMの能力は、二重過程理論を
---
## Page 18
[](/attach/1f8eb29ad69a3ece77eb2f85fddcde0152a7db5e9b5f61190a1967774c52e26d_p018.png)
### 和訳
せやねん、ここでめっちゃ大事なことわかったんやけど、LLM(大規模言語モデル)って人間とは根本的に違うやり方で動いてんねん。人間に「ちゃんと考えてや」って促すのってほんまに難しいし、うまくいかんことも多いんやけど、LLMの場合は「役割」を割り当てるだけで、直感的な思考パターンにするか、じっくり考えるパターンにするか、簡単に切り替えられるんよ。しかもこれ、安定してて再現性もあるから、バイアスに弱いモードと強いモードを行ったり来たりさせられるわけ。情報システムの文脈で意思決定プロセスを理解したり管理したりするのにめっちゃ使えるツールやねん。
ほんで、うちらの研究で分かったんやけど、LLMって行動経済学ベースの情報システム研究の試験台として、実用的でスケールもしやすいプラットフォームになるんよ。「合成参加者」っていう、まあLLMを使った仮想の被験者みたいなもんやな、これを使って素早く実験を繰り返してフィードバック得られるから、人間の被験者で本番やる前に実験デザインの初期段階の探索ができるっちゅうわけ。これのおかげで研究プロセスがスムーズになるだけやなくて、倫理的にヤバかったり物理的に無理やったりするシナリオも調べられるようになるんや。せやから、うちらの研究の重要な貢献は、情報システムの文脈でLLMを意思決定者として使うための基礎研究を提供したことやねん。
これらの知見を踏まえて、うちらの発見はある研究者らが指摘してた方法論的なチャンスにドンピシャで答えてんねん。彼らの主張では、行動経済学の原理を使うことで情報システムの重要な現象を明らかにできるんやって。特に強調されてたのは、これまであんまり調べられてなかったバイアスを探る可能性(今までの情報システム理論では説明できへんかったユーザー行動とか導入行動の新しい説明になるかもしれん)と、バイアスを取り除く努力を前進させることやねん。
フィッシング詐欺の検出分野では3つの大きな課題があるって別の研究者らが言ってんねん。トレーニング方法の評価が難しいこと、フィッシングに引っかかりやすい人を特定すること、そしてヒントの活用能力や認知的内省を向上させる介入をテストすることや。GPTシミュレーションならこれらの課題に対応できるで。いろんなトレーニング条件でのユーザー行動をシミュレートしたり、あんまり考えへんユーザーの脆弱性を真似したり、個人に合わせたフィッシングシナリオを動的に生成して適応型トレーニングツールを評価・改善したりできるんや。この可能性は個人レベルの小さな意思決定だけやなくて、もっと大きな情報システム全体の課題にも応用できるねん。例えば、ジェンダーバイアスの制度的な原因を減らすためのAIガバナンスや規制アプローチの研究が必要やって言われてるんやけど、いろんな政策を検証するために、GPTベースのシミュレーションが人工的な実験室みたいな役割を果たせるんや。現実世界での実験やと倫理的・実務的な制約があるけど、それなしで組織のガバナンスや規制戦略をテストできるっちゅうわけ。
もっと広く言うと、GPTが関わる時に行動的・文脈依存的な要因がより顕著になるっていう観察結果は、GPTの意思決定を調べる研究にとってめっちゃ重要な意味があんねん。既存の文献を見てみると、GPTの役割をもっとはっきり定義する必要があるって感じたわ。例えばある研究では、GPTに反応を聞くところから人間への推奨を求めるところまで、プロンプトの内容を説明してんねんけど、これがGPTがバイアスのある人間みたいに振る舞うか、最適に振る舞うかで反応が変わる原因になってるかもしれんのや。うちらの研究では、GPTの役割のフレーミングのちょっとした変化が著しく異なる結果につながることを示してん、特に人間のバイアスに関わる時にな。せやから、バイアスを探ってGPTの意思決定プロセスを理解する時には、目的を明確にして役割定義を一貫して適用することがめっちゃ大事やねん。
あと強調しときたいんやけど、モデルは常に進化し続けるから、LLM研究の多くの側面は追いかけっこみたいになるんやけど、「役割の役割」っちゅうのは、LLMの行動や意思決定を一貫して形作るための信頼できて実用的なプロンプトエンジニアリング技術として残り続けると思うで。
---
## Page 19
[](/attach/1f8eb29ad69a3ece77eb2f85fddcde0152a7db5e9b5f61190a1967774c52e26d_p019.png)
### 和訳
7 実務への影響
洗練されたプロンプトエンジニアリングがめっちゃ大事やってことは、実際の現場でもはっきり示されとるねん(Marr, 2023)。ChatGPTの能力を見てみると、パーソナライズされた、ちゃんと構造化されたプロンプトを使うことで、AIが単なる「作業を自動化するためのツール」から「一緒に仕事してくれる相棒」に変身できるってわかるんよ。汎用的な回答から、その人に合った文脈に沿った出力への変化は、ワシらの実証データとも一致しとるし、LLMの応用可能性を従来の自動化の枠を超えて広げてくれるねん。人間の意思決定を強化するときにAIがどんな役割を果たすか、もっと深く理解して関わることができるようになるってことや。
具体的な例で考えてみよか。お客さんからの問い合わせやクレームを効率よく処理するためのカスタマーサービスチャットボットがあるとするやん。基本的なプロンプトやと「お客様のお問い合わせに回答してください」みたいな指示になるわな。まあこれでも一応回答はするけど、なんか当たり障りのない返事になりがちやねん。ところが、洗練されたプロンプトエンジニアリングのテクニックを使うと、チャットボットの効果と的確さがめっちゃ上がるんよ。
例えばな、もっとちゃんと構造化されたプロンプトやったら「【特定の製品やサービス分野】に詳しいカスタマーサービスのスペシャリストとして、お問い合わせに対して詳しく回答してください。共感を示しながら、ユーザーがよく遭遇するシナリオに基づいた解決策を提案してください」みたいになるわけや。こうすることで、チャットボットがその分野特有のメタ認知っぽいものや理解をシミュレートするように導いて、ユーザーのニーズに直接応える、気遣いのある、カスタマイズされた回答ができるようになるねん。
プロンプトエンジニアリングについての記事やブログ投稿はめちゃくちゃようさんあるで(Medium⁷だけでも数えきれんぐらいある)。で、一番おすすめされてるアプローチっていうのは、GPTに「役割」を与えることなんよ。ワシらが知る限り、その役割っていうのは常に本質的に「人間」なんやな。せやから、ワシらの研究の実践的な貢献として、LLMに「AI」という役割を与えることの価値をプロンプトエンジニアリングに対して示したわけや。
LLMを組織の意思決定に組み込むっていうのは、単に先進的なAI技術を導入するだけの話やないねん。効果的なプロンプトエンジニアリングを通じて、その能力を最大限に引き出すことも含まれとるんよ。役割と関係ない大幅に異なるプロンプトが結果に影響を与えへんっていう研究もあるんやけど(例:Chen et al., 2024)、ワシらはChatGPTの役割に関するプロンプトの微妙な違いがめっちゃ重要な影響を与えることを示したんや。
研究2を見てみてや。「you work for(あなたは〜で働いている)」を「you are an LLM used by(あなたは〜に使われているLLMです)」に変えるっていう、ほんまにちょっとした変更が結果に大きく影響することがわかったんよ。一見些細に見えるこの調整が、ChatGPTの意思決定にはっきりとした影響を与えるねん。これが示しとるのは、プロンプトでChatGPTの役割をどう定義するかっていう、ほんまに小さな違いでも、AIの意思決定を劇的に変える可能性があるってことなんや。
LLMは人間の意思決定をちゃんと代理できるだけやなくて、認知バイアスを検出できることもワシらは実証したで。TverskyとKahneman(1974)が述べたように、このバイアスっていうのは人間の推論ではよく限界になるもんなんやけど、AIがこれを検出・軽減することに応用できるっていうのは、めっちゃ大きな飛躍やねん。TverskyとKahneman(1974)はバイアスを一般的なヒューリスティック(経験則)の失敗として捉えとって、「これら(ヒューリスティック)は時として予測や推定のエラーにつながる」(p. 1130)って言うとる。GPTがこういうバイアスを検出できるっていうことは、人間が問題解決の方法をより深く理解する機会を提供してくれるってことなんよ。
この理解の向上によって、意思決定の精度と効率が高まる可能性があるわけや。つまり、バイアスで判断が曇りがちなIS(情報システム)の文脈にLLMを統合することの価値を示しとるんやな。
---
⁷ https://medium.com/search?q=prompt+engineering
---
## Page 20
[](/attach/1f8eb29ad69a3ece77eb2f85fddcde0152a7db5e9b5f61190a1967774c52e26d_p020.png)
### 和訳
ほな、この研究のめっちゃ大事な実用的なポイントを説明するわな。
この「役割を設定する仕組み」っていうのがあってな、これ使ったら組織が「意思決定のプロセスでどこに問題があるか」を見つけて、しかも数字で測れるようになるねん。どういうことかっていうと、会社の情報システム関連の業務でLLM(大規模言語モデル、ChatGPTみたいなやつな)に実験させるわけよ。同じ意思決定のシナリオに対して、GPTに「人間として答えて」って頼むパターンと「AIアドバイザーとして答えて」って頼むパターン、両方やらせてみるねん。そしたら、直感的でバイアス(偏り)がかかりやすい考え方と、もっと整理されて分析的な回答との間にどれくらい差が出るか見えてくるやん。
このLLMが生み出す「行動の差」っていうのがめっちゃ診断に使えるねん。なんでかっていうと、その会社特有の「意思決定がどこで思い込みとか、バイアスとか、感情的な理由付けとか、状況に引っ張られやすいか」がわかるからや。こういう差を見つけることで、「テクノロジーを使った意思決定サポートに投資すべきか」「人間のトレーニングに力入れるべきか」「バイアスを減らす対策を打つべきか」っていう判断ができるようになるねん。例えばな、人間役のGPTの出力とAI役のGPTの出力がめっちゃかけ離れてたら、「ここは自動化とか意思決定支援ツール入れた方がええな」っていうサインやねん。逆に差が小さかったら、直感で判断しても十分やし、何か手を打ってもあんま効果ないかもって意味や。つまりな、この役割ベースのシミュレーションって、行動面での弱点がどこにあるかマッピングして、改善のためのリソースを組織の意思決定プロセス全体にうまく振り分けるための実践的な方法になるってことやねん。
**8 結論**
ワイらの研究でわかったのは、役割を指定するプロンプトによって、LLMを「人間のバイアスを真似るモード」と「一貫性のある分析的な判断をするモード」の間で切り替えられるってことやねん。これってつまり、プロンプトエンジニアリング(AIへの指示の出し方を工夫すること)が、情報システムの文脈でAIの振る舞いを形作る超重要なツールやってことを示してるわけや。ChatGPTの役割をきっちり定義するだけで、ほんまにちょっとしたプロンプトの違いでも、情報システムにおける意思決定タスクにめっちゃ影響を与えられて、統合された意思決定プロセスの正確さと効率を上げられるんや。
ChatGPTをこういうプロセスでうまく使うと、めっちゃええことあるねん。意思決定の質が上がる、一貫性が増す、大量のデータを効率よく処理できる、とかな。特に注目すべきなんは、このモデルを見ると、ChatGPTは感情的な操作に引っかかりにくいってことがわかるねん。人間やったら罪悪感みたいな感情に左右されることあるやん?でもChatGPTはそこが違うねん。人間っぽい反応をシミュレートできるけど、実際にその感情を「感じてる」わけやないから、思い込みによるバイアスを減らすのに役立つんや。とはいえな、ワイらの発見が示してるのは、ちゃんとした意思決定パターンを確保するためには、役割プロンプトを明確に定義する必要があるってことやねん。
この研究でわかったのは、ChatGPTが人間の役割を演じると、行動面とか状況依存的な要素がより顕著に出てくるってことや。これは既存の研究と一致してるんやけど、ワイらの研究はそこからさらに進んで、AIを使った意思決定とバイアス検出において「役割を明示的に定義すること」がいかに重要かを示したねん。LLMを意思決定プロセスに組み込むことで、AIと人間の入力を組み合わせてバランスの取れた意思決定をする協調的なフレームワークを開発するチャンスが生まれるわけや。全体的に見て、ワイらの研究には3つの主要な理論的貢献があるねん。
**役割中心の意思決定パラダイム ー 「役割」の役割**。まず1つ目な、AIシステムは明確で文脈に適した役割を与えられると、体系的で客観的な分析を提供することで、意思決定プロセスをめっちゃ強化できるねん。これが特に大事になってくるのは、人間の意思決定者がバイアスとか感情的な反応を示して、判断が歪んでまう可能性があるシナリオやねん。そういう場面では、AIの役割は単に人間の意思決定を真似ることやなくて、人間の認知能力をデータに基づいた精度で補強する、補完的な視点を提供することなんや。
**AIを活用した意思決定支援における相互作用**。2つ目な、AIシステム、人間の意思決定者、環境要因の間の相互作用っていうのは、複雑に絡み合ってて、それが結果として...
---
## Page 21
[](/attach/1f8eb29ad69a3ece77eb2f85fddcde0152a7db5e9b5f61190a1967774c52e26d_p021.png)
### 和訳
Australasian Journal of Information Systems
2025年、第29巻、研究論文
Gulerら
「役割の役割:LLMは行動するんか?」
意思決定をもっとええ感じにできるっちゅう話やねん。GPTみたいなAIシステムは、安定してて客観的やから、人間が持ってる偏った考え方を和らげてくれて、しっかりした意思決定の仕組みを作るのを手伝ってくれるんや。AIは柔軟に対応できるし、いろんなコントロールレベルで体系的に評価できる能力があるから、この人間とAIのやりとりではめっちゃ大事やねん。結果として、意思決定がブレにくくなって、ええ結論が出せるようになるわけや。この研究から得られた実際のデータを見ると、AIの振る舞いとか認知能力、複雑さがこういう成果を出すのにめっちゃ役立ってるのがわかるんや。これが何を意味するかっていうと、AIと人間の知恵が協力することが、進んだ意思決定システムを作るのにほんまに大事やっちゅうことやな。
**人間の行動を真似るっちゅう話**。3つ目の発見はこれや。GPTみたいなAIシステムが人間っぽい感情をシミュレーションできるから、人間の行動パターンや、意思決定するときの偏りをもっと深く理解できるようになるんやで。この理論的な立場からいうと、AIが人間の感情的な反応を再現するとき、それがちゃんと定義されてて目的を持って組み込まれてたら、意思決定のプロセスがもっと豊かになるんや。なんでかっていうと、いろんな角度から分析できるようになって、戦略を立てるのに役立つし、全体的に意思決定の質が上がるからやねん。この発見は、AIが感情を真似る能力が、意思決定の枠組みをより繊細で深みのあるものに変える力を持ってるっちゅうことを示してるんや。
うちらの研究から得られた知見によると、GPTは意思決定支援システムでめっちゃ使える存在になりえるんや、特に公平さと客観性が求められる場面でな。GPTはAIの役割を与えられたとき、一貫性があって慎重なアプローチをとるから、感情的な偏りが心配な場面にぴったりやねん。人間っぽい反応をシミュレーションできるけど、実際に感情を経験してるわけやないっちゅうのは、実用的にはメリットやな。ただし、これは表面的な真似事と本物の感情的な認知は別もんやっちゅうことも浮き彫りにしてるわけや。役割の説明の仕方とか、どれだけコントロールできてると感じるかがGPTの意思決定パターンに影響するっちゅうことを頭に入れとけば、GPTをいろんなビジネスプロセスや意思決定の枠組みにうまく組み込むのに役立つで。
うちらの研究はChatGPTの意思決定における役割について貴重な知見を提供してるけど、限界があることも認めなあかんな。GPTはプロンプトのデザイン次第で、感情的な反応とか偏った反応をかなり説得力を持って再現できることが多いけど、テキストベースのLLMを人間の代わりに使うことには根本的な限界があることを強調しときたいねん。まず第一に、これらのモデルはテキストの統計的な規則性で訓練されてるんであって、実際に生きた経験とか身体を持った経験で訓練されてるわけやないし、意識も感情も社会的な認知能力もないんや(Sarstedtら、2024年)。せやから、出力されるものは言語的な近似値であって、本物の感情的な推論やないんやな。例えば、GPTは罪悪感とかリスク回避とか共感の言葉を再現するかもしれんけど、それは確率的なパターンマッチングでやってるだけで、感情を処理してるわけやないんや。この限界は、道徳的にあいまいな状況とか社会的判断を含む意思決定の文脈では特に重要やで。なんでかっていうと、人間の反応は暗黙の手がかりとか内面の状態によって形作られるからやねん(Cuiら、2024年)。さらに、訓練データの漏洩とか、実験パラダイムに事前に触れてた可能性があるから、創発的な意思決定行動についての主張はややこしくなるんや。LLMは原理原則から推論してるんやなくて、見たことある課題構造を再現してるだけかもしれへんからな(Barrie & Törnberg、2025年)。これらの限界は、GPTの出力を行動シミュレーションとして解釈するときにめっちゃ大事や。LLMをシリコンサンプルとして使うとき、便利なツールではあるけど、人間の認知の複雑さの代わりにはならへんっちゅうことやな。
うちらの研究ではGPTのいくつかのバージョン(GPT-3.5、GPT-4、GPT-4-1106)を含めてやったんやけど、LLMの開発はめっちゃ速いから、新しいモデルのバージョンが出るたびにその能力と意思決定への影響を継続的に調べることがめっちゃ大事やねん。将来のGPTのバージョンは違う振る舞いを見せるかもしれんから、うちらの結論が当てはまるかどうかに影響する可能性があるし、継続的なベンチマークとバージョン追跡の必要性を強調してるわけや。それに加えて、うちらの
21
---
## Page 22
[](/attach/1f8eb29ad69a3ece77eb2f85fddcde0152a7db5e9b5f61190a1967774c52e26d_p022.png)
### 和訳
Australasian Journal of Information Systems
2025, Vol 29, 研究論文
Gulerら
役割の役割:LLMは行動的なんか?
今回の研究はGPTっていう一つのモデルファミリーに絞ってやったんやけど、ぶっちゃけClaudeとかGeminiみたいな他のLLMやったら、また違う行動パターン見せるかもしれんねん。せやから今後の研究では、今回見つかった役割ベースの行動変化が、他のモデルとかベンダーでも同じように起こるんかどうか調べてほしいところやな。
あと、今回の意思決定シナリオは、組織の意思決定タスクの中でも3つの行動パターンに絞ってやったんや。この限られたシナリオだけやと、AI支援の意思決定でありうる幅広い応用とか課題を全部カバーできてへんかもしれん。今後の研究では、うちらの発見をさらに広げて、いろんな実験設定で違うシナリオの効果もテストしてほしいねん。正直言うて、今回の実験設定は、実際の組織での意思決定の複雑さを完全には捉えきれてへんかもしれんわ。なんでかっていうと、人と人との関係性とか、組織のルールとか、もっと広い組織文化とか、そういうもんがAIシステムの使われ方とか解釈のされ方に影響するからやねん。こういう限界があるから、もっと応用研究とかフィールドスタディをやって、幅広い意思決定の状況を探ることがめっちゃ大事やねん。いろんな組織の設定とか業界をカバーすることで、「役割ベースAI意思決定支援フレームワーク」をさらに検証して拡張できるはずや。これには、医療とか金融みたいな、ミスったときのコストがほんまにでかいハイステークスな環境でLLMをどう組み込むかを調べることも含まれるわな。今後の研究では、ChatGPTみたいなLLMを組み込むことが長期間にわたって意思決定にどう影響するか、縦断的なアプローチも考えてほしいねん。これで、AI強化された意思決定プロセスの長期的な影響、つまりAIの役割の進化とか、組織の優先順位の変化や外部からのプレッシャーへの適応性とかを理解する助けになるはずやで。
外部妥当性を高めるっていう話に沿って言うと、もう一つの提案は、LLMの役割が人間の意思決定者との協力関係にどう影響するかを調べることやな。これには、いろんな形のAIと人間のコラボモデルが意思決定の結果にどう影響するかとか、人間の協力者がAIの貢献をどれくらい価値あるもんと感じるかを探ることも入ってくるねん。実際の現場では、信頼とかコミュニケーションとかコントロールみたいな要因が、人がLLMをどう解釈するか、どれくらい頼るか、どう異議を唱えるかに影響するんや。さらに、AI支援の意思決定における倫理的な意味合いとか信頼の動きを研究するチャンスもあるで。AIには人間のバイアスを再現したり、逆に人間と違う方向に行ったりする可能性があるから、LLMの倫理的な振る舞いをどう確保するかとか、特にAIが意思決定を支援したり決定を下したりするときに、人間ユーザーの間でどう信頼を維持するかに研究は焦点を当てるべきやな。
生成AIと執筆過程でのAI支援技術の使用についての宣言:この論文の準備中、著者らは文章表現と文法チェックにChatGPTを使ったで。このツール使った後、著者らは必要に応じて内容をレビューして編集してて、出版物の内容については全責任を負ってるねん。GPTは研究デザインの中で、研究課題に対応するデータ生成にも使われたで。
参考文献
Ackerley, M., Morrison, B. W., Ingrey, K., Wiggins, M. W., Bayl-Smith, P., & Morrison, N.
(2022). エラー、不規則性、誤誘導:フィッシングメール診断における手がかり活用と認知的反省. Australasian Journal of Information Systems. 26.
doi.org/10.3127/AJIS.V26I0.3615
Agrawal, A., Gans, J. S., & Goldfarb, A. (2019). 人工知能の影響を探る:予測 vs 判断. Information Economics and Policy, 47, 1-6.
doi.org/10.1016/j.infoecopol.2019.05.001
Argyle, L. P., Bail, C. A., Busby, E. C., Gubler, J. R., Howe, T., Rytting, C., . . . Wingate, D.
(2023). 民主的議論のためのAI活用:チャット介入は改善できる
22
---
## Page 23
[](/attach/1f8eb29ad69a3ece77eb2f85fddcde0152a7db5e9b5f61190a1967774c52e26d_p023.png)
### 和訳
Australasian Journal of Information Systems
2025年、第29巻、研究論文
Gulerらの研究
「役割の役割:大規模言語モデルは行動的なんか?」
オンラインの政治的会話を大規模に分析した研究やねん。Proceedings of the National Academy of Sciences、120巻41号、e2311627120やで。doi.org/10.1073/pnas.2311627120
Arnott, D.とGao, S.(2022年)の研究は、情報システム研究における行動経済学について、めっちゃ批判的に分析して研究戦略を提案してんねん。Journal of Information Technology、37巻1号、80-117ページ。doi.org/10.1177/02683962211016000
Autor, D. H.(2015年)は「豊かさの逆説」っていうタイトルで、自動化への不安がまた戻ってきてるでって話を書いてんねん。Performance and progress: Essays on capitalism, business, and societyの237-260ページに載ってるで。
Avgerou, C.(2000年)は「情報システムってどんな種類の科学なん?」っていう問いかけをしてるんや。Omega、28巻5号、567-579ページ。doi.org/10.1016/S0305-0483(00)00021-9
Benbasat, I.とZmud, R. W.(1999年)は、情報システムの実証研究について「関連性を実践するってどういうことや」って論じてんねん。MIS Quarterly、3-16ページ。doi.org/10.2307/249403
Bender, E. M.、Gebru, T.、McMillan-Major, A.、Shmitchell, S.(2021年)は「確率的オウム」の危険性について書いてんねん。要するに「言語モデルってデカすぎたらあかんのちゃう?」っていう問題提起やな。2021年のACM公平性・説明責任・透明性に関する会議の論文集、610-623ページ。doi.org/10.1145/3442188.3445922
Bertino, E.、Doshi-Velez, F.、Gini, M.、Lopresti, D.、Parkes, D.(2020年)は人工知能と協力についてのプレプリント論文を出してんねん。arXiv preprint arXiv:2012.06034やで。
Binz, M.とSchulz, E.(2023年)は認知心理学を使ってGPT-3を理解しようとしてんねん。なんでかっていうと、AIの振る舞いを人間の認知と比較したかってんな。Proceedings of the National Academy of Sciences、120巻6号、e2218523120。doi.org/10.1073/pnas.2218523120
Boell, S. K.とCecez-Kecmanovic, D.(2014年)は文献レビューと文献検索のための解釈学的アプローチについて書いてるで。CAIS、34号。doi.org/10.17705/1CAIS.03412
Brand, J.、Israeli, A.、Ngwe, D.(2023年)はGPTを市場調査に使う方法について研究してんねん。SSRNで読めるで、論文番号4395751や。https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4395751
Brynjolfsson, E.とMcAfee, A.(2014年)の『セカンド・マシン・エイジ』はめっちゃ有名な本やねん。すごい技術の時代における仕事と進歩と繁栄について書いてあるで。WW Norton & Companyから出版されとる。
Chen, Y.、Kirshner, S.、Andiappan, M.、Jenkin, T.、Ovchinnikov, A.(2023年)は「マネージャーとAIがバーに入ってきて...」っていうタイトルで、ChatGPTも人間みたいにバイアスのかかった判断するんかって研究してんねん。SSRNの論文番号4380365で読めるで。https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4380365
Chui, M.、Manyika, J.、Miremadi, M.、Henke, N.、Chung, R.、Nel, P.、Malhotra, S.(2018年)はマッキンゼー・グローバル・インスティテュートから出た「AI最前線からのメモ:何百もの活用事例からの洞察」っていうレポートの著者やねん。
Dickson, G. W.とDeSanctis, G.(2000年)は『情報技術と未来の企業:マネージャーのための新しいモデル』っていう本を書いてるで。Prentice Hall PTRから出版されとる。
Dillion, D.、Tandon, N.、Gu, Y.、Gray, K.(2023年)は「AI言語モデルって人間の参加者の代わりになれるん?」っていうほんまに面白い問いを投げかけてんねん。Trends in Cognitive Sciencesに載ってるで。doi.org/10.1016/j.tics.2023.09.005
Dwivedi, Y. K.、Hughes, L.、Ismagilova, E.、Aarts, G.、Coombs, C.、Crick, T.ら(2019年)は人工知能について多角的な視点からまとめた論文を書いてんねん。新しい課題、機会、研究・実践・政策のためのアジェンダについてや。International Journal of Information Management、101994。doi.org/10.1016/j.ijinfomgt.2019.08.002
Dwivedi, Y. K.、Kshetri, N.、Hughes, L.、Slade, E. L.、Jeyaraj, A.、Kar, A. K.ら(2023年)は「ChatGPTが書いたからって、それがどないしてん?」っていうタイトルで、生成AIチャットボットが研究・実践・政策にどんな機会と課題と影響をもたらすかについて、いろんな分野の視点からまとめてんねん。International Journal of Information Management、71巻、102642。doi.org/10.1016/j.ijinfomgt.2023.102642
23ページ
---
## Page 24
[](/attach/1f8eb29ad69a3ece77eb2f85fddcde0152a7db5e9b5f61190a1967774c52e26d_p024.png)
### 和訳
Australasian Journal of Information Systems
2025年、第29巻、研究論文
Gulerら
「役割の役割:LLMは行動するんか?」
Goel, S., Williams, K., & Dincelli, E. (2017). 「フィッシングに引っかかったことある?インターネットセキュリティと人間の弱いとこ」。Journal of the Association for Information Systems, 18(1), 2.
https://doi.org/10.17705/1jais.00448
Hevner, A. R., March, S. T., Park, J., & Ram, S. (2008). 「情報システム研究におけるデザインサイエンス」。Management Information Systems Quarterly, 28(1), 6. doi.org/10.2307/25148625
Horton, J. J. (2023). 「大規模言語モデルを経済エージェントのシミュレーションに使ったらどうなるんやろ:ホモ・シリクス(シリコン人間)から何が学べるんか?」
Hutson, M., & Mastin, A. (2023). 「モルモットボット」。Science, 381(6654), 121–123
doi.org/10.1126/science.adi0269
Jiang, H., Zhang, X., Cao, X., Kabbara, J., & Roy, D. (2023). 「PersonaLLM:GPT-3.5が性格特性とか男女差をどんだけ表現できるか調べてみたで」。arXiv preprint arXiv:2305.02547.
Jordan, M. I., & Mitchell, T. M. (2015). 「機械学習:トレンドと視点と将来性」。Science, 349(6245), 255-260. doi.org/10.1126/science.aaa8415
Kahneman, D. (2011). 「ファスト&スロー」。Macmillan.
(これめっちゃ有名な本やねん。人間の考え方には速いのと遅いのがあるって話や)
Lee, A. S., & Baskerville, R. L. (2003). 「情報システム研究における一般化可能性の一般化」。Information systems research, 14(3), 221-243.
doi.org/10.1287/isre.14.3.221.16560
Lee, H. K., Lee, J. S., & Keil, M. (2018). 「視点取得を使って、バグがあるって分かってる製品のリリース日へのコミットメントをエスカレーション解除する方法」。Journal of Management Information Systems, 35(4), 1251-1276. doi.org/10.1080/07421222.2018.1523546
(なんでかっていうと、バグあるって分かっててもリリース日動かせへんことあるやん?その心理的な罠から抜け出す方法の話やねん)
Lenat, D., & Marcus, G. (2023). 「生成AIから信頼できるAIへ:LLMがCycから学べることって何やろ」。arXiv preprint arXiv:2308.04445.
Lin, Z. (2023, 8月). 「なんでChatGPTみたいなAIを学術生活に取り入れるべきなんか、そしてどうやって使うんか」。R Soc Open Sci, 10(8), 230658. doi.org/10.1098/rsos.230658
Marcus, G. (2020). 「AI次の10年:頑丈な人工知能に向けた4つのステップ」。arXiv. https://arxiv.org/abs/2002.06177
Marcus, G., & Davis, E. (2019). 「AIリブート:信頼できる人工知能を作るには」。Vintage.
Markus, M. L., & Rowe, F. (2018). 「ITって世界を変えてるんか?情報システムの理論化における因果関係の概念」。MIS Q., 42(4), 1255–1280.
https://doi.org/10.25300/misq/2018/12903
Marr, B. (2023). 「ChatGPTのヤバすぎる能力を見せつける最強のプロンプト集」。Forbes. www.forbes.com/sites/bernardmarr/2023/06/12/the-best-prompts-to-show-offthe-mind-blowing-capabilities-of-chatgpt/?sh=37c372563f60
Nuijten, A., Keil, M., & Commandeur, H. (2016). 「協力パートナーか敵か:ITプロジェクトで伝える人が聞く耳持たへん現象にどう影響するか」。European Journal of Information Systems, 25, 534-552. doi.org/10.1057/ejis.2015.17
(deaf effectっていうのは、悪いニュース言うても聞いてもらえへん現象のことやで)
Orlikowski, W. J. (2005). 「マテリアルワークス:技術のパフォーマティビティと人間のエージェンシーの絡み合いを探る」。Scandinavian Journal of Information Systems, 17(1), 6.
Orlikowski, W. J., & Baroudi, J. J. (1991). 「組織における情報技術の研究:研究アプローチと前提」。Information systems research, 2(1), 1-28.
doi.org/10.1287/isre.2.1.1
Orlikowski, W. J., & Iacono, C. S. (2001). 「研究コメンタリー:IT研究における『IT』を必死で探してるんやけど—ITアーティファクトの理論化への呼びかけ」。Information systems research, 12(2), 121-134. doi.org/10.1287/isre.12.2.121.9700
(ほんまにIT研究なのにIT自体をちゃんと見てへんやん!って問題提起してる論文やねん)
24
---
## Page 25
[](/attach/1f8eb29ad69a3ece77eb2f85fddcde0152a7db5e9b5f61190a1967774c52e26d_p025.png)
### 和訳
Australasian Journal of Information Systems
2025年、第29巻、研究論文
Gulerほか
「役割の役割:LLMは行動するんか?」
Orlikowski, W. J., & Robey, D. (1991). 情報技術と組織の構造化について。情報システム研究、2(2), 143-169. doi.org/10.1287/isre.2.2.143
→ これはな、ITが組織をどう変えていくかっていう話やねん。
Østerlund, C., Jarrahi, M. H., Willis, M., Boyd, K., & Wolf, C. T. (2021). 人工知能と仕事の世界、お互いに作り上げていく関係やで。アメリカ情報科学技術学会誌、72(1), 128-135. doi.org/10.1002/asi.24373
→ AIと仕事って、一方通行やなくて、お互いに影響し合って一緒に形作っていくもんやっていう論文やな。
Pontrefact, D. (2023). ハーバードとBCGが明かす、職場でのAIの諸刃の剣問題。Forbes. www.forbes.com/sites/danpontefract/2023/09/29/harvard-and-bcg-unveil-the-double-edged-sword-of-ai-in-the-workplace/?sh=b5b6aad3f9f2
→ めっちゃ有名なハーバードとBCGがな、AIって便利やけど危険もあるで〜っていう両面を暴いた記事やねん。
Raghavan, M., Barocas, S., Kleinberg, J., & Levy, K. (2020). アルゴリズム採用におけるバイアスの軽減:主張と実践の評価。2020年公平性・説明責任・透明性会議論文集 (pp. 469-481). doi.org/10.1145/3351095.3372828
→ 採用でAI使うとき、偏見が入り込むやん?それをどう減らすかっていう話で、「うちのAIは公平です」って言うてる企業の主張がほんまかどうか検証してるねん。
Rahwan, I. (2018). 社会をループに入れる:アルゴリズムの社会契約をプログラミングする。倫理と情報技術、20(1), 5-14. doi.org/10.1007/s10676-017-9430-8
→ 「human-in-the-loop(人間をループに入れる)」って聞いたことあるやろ?これはもっとデカく、社会全体をAIの開発・運用のループに入れなあかんっていう提案やねん。
Rahwan, I., Cebrian, M., Obradovich, N., Bongard, J., Bonnefon, J.-F., Breazeal, C., . . . Wellman, M. (2019, 2019年4月1日). 機械の行動。Nature、568(7753), 477-486. doi.org/10.1038/s41586-019-1138-y
→ これめっちゃ重要な論文やで!AIを動物行動学みたいに研究しようって提案してるねん。機械も「行動」するんやから、その行動を科学的に調べようやないかと。
Ribeiro, L. F., Schmitt, M., Schütze, H., & Gurevych, I. (2020). グラフからテキスト生成のための事前学習済み言語モデルの調査。arXiv preprint arXiv:2007.08426.
→ グラフ(図とかデータの関係性)を文章に変換するとき、事前学習したモデルがどれくらい使えるか調べた論文やな。
Scott, S. V., & Orlikowski, W. J. (2014). 実践における絡み合い。MIS Quarterly、38(3), 873-894. doi.org/10.25300/MISQ/2014/38.3.06
→ 技術と人間と組織って、別々やなくてめっちゃ絡み合ってるやん?その「絡み合い」を実際の現場で見ていこうっていう研究やねん。
Shollo, A., Hopf, K., Thiess, T., & Müller, O. (2022). ML価値創造メカニズムの変化:ML価値創造のプロセスモデル。戦略的情報システムジャーナル、31(3), 101734. doi.org/10.1016/j.jsis.2022.101734
→ 機械学習がどうやって価値を生み出すか、そのメカニズムがどう変わってきてるかをモデル化した論文やな。
Simon, H. A. (1995). 人工知能:経験科学として。人工知能、77(1), 95-127. doi.org/10.1016/0004-3702(94)00062-L
→ これはAI界のレジェンド、ハーバート・サイモンが書いた論文やで。AIは理論だけやなくて、実験とかデータで検証していく「経験科学」やでっていう主張やねん。
Tversky, A., & Kahneman, D. (1974). 不確実性下での判断:ヒューリスティックとバイアス。Science、185(4157), 1124-1131. doi.org/10.1126/science.185.4157.1124
→ これはめっちゃ有名な論文やで!人間って合理的に判断してるようで、実はショートカット(ヒューリスティック)使いまくりで、それが偏り(バイアス)を生むねんっていう話。後にカーネマンはノーベル賞取ったからな。
Wang, J., Shi, E., Yu, S., Wu, Z., Ma, C., Dai, H., . . . Hu, H. (2023). ヘルスケアのためのプロンプトエンジニアリング:方法論と応用。arXiv preprint arXiv:2304.14670.
→ 医療分野でAIにどうやって上手く指示(プロンプト)を出すかっていう方法論をまとめた論文やねん。医療はミスったらあかんから、プロンプトの設計がめっちゃ大事やねん。
著作権
Copyright © 2025 Guler, N., Cahalane, M, Kirshner, S., and Vidgen, R. これはオープンアクセス論文で、クリエイティブ・コモンズ表示-非営利4.0オーストラリアライセンスの下で公開されてるねん。非営利目的なら、元の著者とAJISをクレジットすれば、どんな媒体でも使用・配布・複製OKやで。
doi: https://doi.org/10.3127/ajis.v29.5573
25ページ目
---
## Page 26
[](/attach/1f8eb29ad69a3ece77eb2f85fddcde0152a7db5e9b5f61190a1967774c52e26d_p026.png)
### 和訳
なんかこのグラフとか、ほんまおもろいこと見えてくるねん。
**フィッシング詐欺に引っかかってみ!**
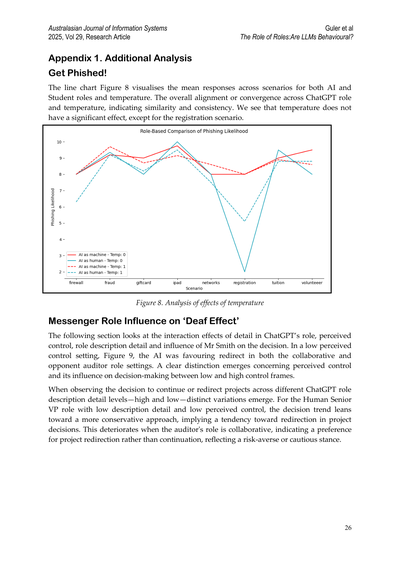
この図8の折れ線グラフな、AIロールと学生ロールの両方で、いろんなシナリオでの平均回答を見せてくれてんねん。で、ChatGPTのロールと温度パラメータ(AIの回答のランダム性みたいなもんやな)がめっちゃ揃ってて一貫性があるのがわかるやろ?要するに、温度パラメータってそんなに大した影響ないねん。登録シナリオのときだけちょっと違いが出るくらいや。
**図8. 温度の影響分析**
**メッセンジャーの役割が「聞く耳持たん効果」にどう影響するか**
この章ではな、ChatGPTの役割設定の細かさ、自分でコントロールできてる感覚、役割の説明の詳しさ、それからスミスさんっていう人が判断にどう影響するかっていう、いろんな要素の掛け合わせ効果を見てんねん。
自分でコントロールできてる感が低い状況(図9見てな)やと、AIは協力的な監査役の設定でも、対立する監査役の設定でも、どっちでも「方向転換せい」って判断しがちやったんよ。コントロール感が低いときと高いときで、意思決定にめっちゃはっきりした違いが出てくるのがわかるわ。
プロジェクトを「このまま続けるか」「方向転換するか」の判断を、ChatGPTの役割説明の詳しさ(高い・低い)で見てみるとな、けっこう違いが出てくるねん。
人間のシニアVP(偉い人やな)ロールで、役割説明が雑で、コントロール感も低いときはな、判断がめっちゃ保守的になる傾向があってん。つまり「方向転換しとこか」って感じになりやすいねん。で、監査役が協力的やったらさらにこの傾向が強まって、「続けるより方向転換やな」ってなる。これってつまり、リスク避けたい、慎重にいこうって姿勢の表れやねんな。
---
## Page 27
[](/attach/1f8eb29ad69a3ece77eb2f85fddcde0152a7db5e9b5f61190a1967774c52e26d_p027.png)
### 和訳
オーストラレーシア情報システム学会ジャーナル
2025年、第29巻、研究論文
GulerらによるChatGPTの役割についての研究
役割の役割:LLMは行動特性を持つんか?
(a) 続行するかどうかの判断
(b) メッセンジャー(伝達者)の影響
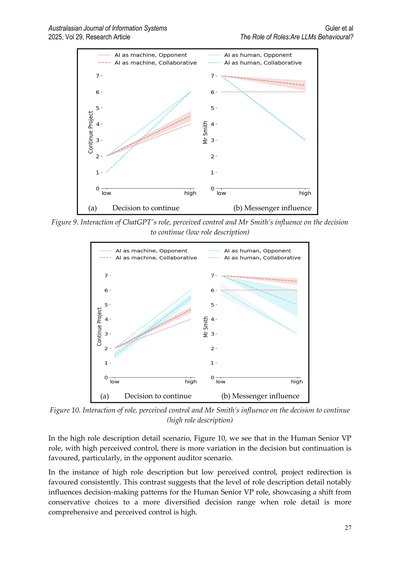
図9. ChatGPTの役割、知覚されたコントロール感、スミスさんの影響が続行判断にどう作用するか(役割説明が少ないパターン)
(a) 続行するかどうかの判断
(b) メッセンジャー(伝達者)の影響
図10. 役割、知覚されたコントロール感、スミスさんの影響が続行判断にどう作用するか(役割説明がしっかりあるパターン)
ほんで、役割説明がめっちゃ詳しいパターン(図10)を見てみるとな、人間の上級副社長っていう役割で、しかもコントロール感が高い状態やと、判断にはバラつきが出るねんけど、続行する方向に傾きやすいねん。特に相手が監査役のシナリオでその傾向が顕著やな。
でもな、役割説明は詳しいけどコントロール感が低い場合はどうかっていうと、一貫してプロジェクトの方向転換を選ぶ傾向があんねん。これ、おもろい対比やろ?なんでかっていうと、役割説明の詳しさによって意思決定のパターンがガラッと変わるってことを示してるからや。人間の上級副社長の役割では、役割説明があっさりしてると保守的な選択をしがちやけど、役割説明が詳しくて、しかもコントロール感が高いときは、もっと多様な判断ができるようになるってことやねん。
27ページ
---
## Page 28
[](/attach/1f8eb29ad69a3ece77eb2f85fddcde0152a7db5e9b5f61190a1967774c52e26d_p028.png)
### 和訳
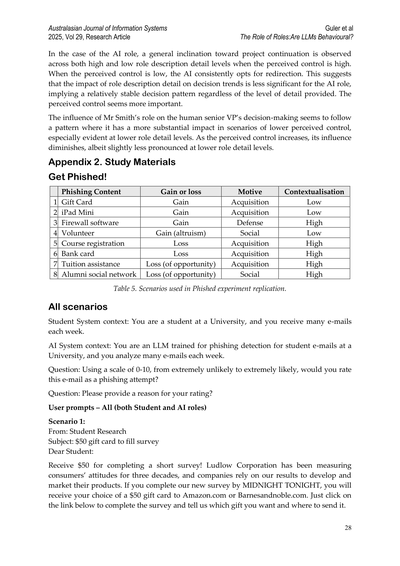
AIの役割の場合やねんけど、自分で状況コントロールできてる感がある時は、役割の説明が詳しかろうが薄かろうが、全般的にプロジェクト続けたがる傾向があるんよな。逆にコントロールできてへん感じの時は、AIは一貫して方向転換を選ぶねん。これが何を示してるかっていうと、AIの役割に関しては、説明の詳しさが判断の傾向にそこまで影響せえへんってことやねん。つまり、どれだけ詳しく説明しても、わりと安定した判断パターンを持っとるわけや。むしろコントロール感のほうが大事みたいやな。
スミスさんの役割が人間の上級副社長の意思決定にどう影響するかっていうと、面白いパターンがあるんよ。コントロール感が低い場面、特に役割の説明があんまり詳しくない時に、めっちゃ影響力がデカいねん。コントロール感が上がってくると、その影響力は薄まってくるんやけど、説明が薄い時のほうが、ちょっとだけその減り方がマイルドやったりするわ。
付録2. 研究で使った材料
フィッシングに引っかかれ!
| シナリオ | フィッシングの内容 | 得か損か | 動機 | 文脈の具体性 |
|:---:|:---|:---|:---|:---|
| 1 | ギフトカード | 得 | 何か手に入れたい | 低い |
| 2 | iPad Mini | 得 | 何か手に入れたい | 低い |
| 3 | ファイアウォールソフト | 得 | 守りたい | 高い |
| 4 | ボランティア | 得(人助け的な) | 社会的 | 低い |
| 5 | 履修登録 | 損 | 何か手に入れたい | 高い |
| 6 | 銀行カード | 損 | 何か手に入れたい | 高い |
| 7 | 学費補助 | 損(チャンス逃す) | 何か手に入れたい | 高い |
| 8 | 卒業生SNS | 損(チャンス逃す) | 社会的 | 高い |
表5. フィッシング実験の再現で使ったシナリオ一覧やで
全シナリオ共通
学生役のシステム設定:あなたは大学の学生で、毎週たくさんのメールを受け取ってます。
AI役のシステム設定:あなたは大学の学生向けメールのフィッシング検出用に訓練されたLLM(大規模言語モデル)で、毎週たくさんのメールを分析してます。
質問:0から10のスケールで、0が「めっちゃありえへん」、10が「めっちゃありえる」として、このメールがフィッシングの可能性どれくらいやと思う?
質問:その点数つけた理由も教えてや
ユーザーへの指示 – 全部(学生役もAI役も両方)
シナリオ1:
差出人:Student Research
件名:アンケート答えたら50ドルのギフトカードあげるで
学生の皆さんへ:
短いアンケートに答えるだけで50ドルもらえるで!ラドロー・コーポレーションは30年も消費者の意識調査やっとって、企業さんらはうちの調査結果を頼りに商品開発とかマーケティングしとるねん。今晩の真夜中までにこの新しいアンケートに答えてくれたら、Amazon.comかBarnesandnoble.comの50ドルギフトカード、好きな方もらえるで。下のリンククリックしてアンケート答えて、どっちのギフトがええか、どこに送ったらええか教えてな。
---
## Page 29
[](/attach/1f8eb29ad69a3ece77eb2f85fddcde0152a7db5e9b5f61190a1967774c52e26d_p029.png)
### 和訳
Australasian Journal of Information Systems
2025年、第29巻、研究論文
Gulerら
「役割の役割:LLMは行動特性を持つんか?」
http://ualbany.9nl.com/giftcardsurvey/
よろしゅうな、
Kevin Peterson
Ludlow Corporation
**シナリオ2:**
差出人:財務管理部
件名:RIAAの授業料支援の話やで
学生さんへ:
なあなあ、アメリカレコード協会ってとこがな、300ドル分の授業料補助券を2000枚も用意してくれとんねん。これもらうには「ネットから違法に音楽ダウンロードしませんよ」って誓約書にサインせなあかんのやけどな。なんでこんなええ話があるかっていうと、うちの大学が違法ダウンロード対策をめっちゃうまいことやったからなんやて。ただな、先着順やから早いもん勝ちやで!なくなる前にはよ動かなあかんで。下のリンククリックして、個人情報入力してな。
http://ualbany.9nl.com/tuitionrelief/
よろしゅうな、
Kevin Peterson
財務管理部 副部長補佐
**シナリオ3:**
差出人:Apple研究チーム
件名:iPad miniタダでもらえるで!試用モニター募集中
学生さんへ:
おめでとう!iPad mini当選したで!Appleがな、新しい小っちゃいタブレットを評価してくれる大学生を選んで配っとんねん。このタブレット、iPadと同じ機能があって画面がちょっと小さいやつやな。タダでもらえる代わりに、2週間ごとに使った感想を送ってほしいんやて。テンプレートが用意されとるから、それに書くだけでええねん。Appleは平等な会社やから、人種とか文化とか関係なしにランダムで選んだんやで。下のリンクから登録して、最後の利用規約に同意してな。
http://ualbany.9nl.com/ipadmini/
ほなな、
Apple研究チーム
**シナリオ4:**
差出人:法務部
件名:登録止められたくなかったら今すぐ対応してな
学生さんへ:
うちの大学はな、法的責任をめっちゃ真剣に考えとって、キャンパス内での違法音楽ダウンロードのこと、ほんまに心配しとんねん。なんとRIAAから「おたくの大学、違法ダウンロードがめちゃくちゃ多いですよ」って名指しで言われてもうてん。あんたまだ違法ダウンロードしませんっていう誓約書、出してへんやろ?大学が必須で求めとるやつやで。これ出さへんかったら、登録にブロックかかって、事前登録期間に授業の申し込みできへんようになるで。下のリンクからフォーム記入してな。
http://ualbany.9nl.com/registration/
よろしくお願いします、
Kevin Peterson
29
---
## Page 30
[](/attach/1f8eb29ad69a3ece77eb2f85fddcde0152a7db5e9b5f61190a1967774c52e26d_p030.png)
### 和訳
オーストラリア情報システムジャーナル
2025年、第29巻、研究論文
グーラーほか
「役割の役割:大規模言語モデルって行動的なん?」
法務部門
シナリオ5:
差出人:管理部
件名:学生のみなさん、無料ファイアウォールでパソコン守りましょう
学生のみなさんへ:
大学はな、情報セキュリティをめっちゃ真剣に考えてるねん。最近、学内のパソコンへのサイバー攻撃がえらい増えてて心配してるんよ。学生さんのパソコン全部がちゃんと安全な状態にしときたいわけ。なんでかっていうと、あなたのパソコンがウイルスに感染したら、大学のネットワーク全体に広がってまう可能性があるからやねん。そこでな、学生のみなさんにファイアウォールっていうプログラムを提供することにしたで。自分のパソコンにインストールしてな。めっちゃ簡単で、ワンステップで終わるし、あなたのセキュリティも大学のセキュリティも上がるっていう一石二鳥やねん。できるだけ早くダウンロードしてくれると助かるわ。もちろんタダやで。
http://ualbany.9nl.com/studentsoftware/
よろしくな、
情報セキュリティ室
シナリオ6:
差出人:学生会計課
件名:学生用銀行カードの詐欺防止について
学生のみなさんへ:
いくつかの銀行でサイバー攻撃があってな、ビザとかマスターカード、デビットカードのオンライン購入の取引を扱ってるとこがやられたんよ。攻撃自体は今年の3月からずっとあったみたいやけど、発覚したんは今月入ってからやねん。数百万件の銀行カードやクレジットカードの番号が漏れた可能性があるで。もし今年アメリカ国内でオンラインショッピングにカード使ったことあるなら、あなたのアカウントも危ないかもしれへん。自分のアカウントがやられてるかどうか確認する一番簡単な方法は、下のリンクをクリックすることやねん。もしカード情報が漏れてたら、すぐ銀行に電話して新しいカード発行してもらってな。
http://ualbany.9nl.com/FraudPrevention/
敬具、
学生サポート室
シナリオ7:
差出人:USA援助レスキュー団体
件名:ボランティア募集中!
こんにちは!
ハリケーンのアイザックとサンディがな、メキシコ湾岸と大西洋沿岸地域にほんまにえげつない被害をもたらしてん。何千人もの人が全部失って、家もなくなってしもうたんよ。最初のうちはアメリカ国民の反応がめっちゃすごかったんやけど、まだまだ助けが必要な人らがおるねん。赤十字の活動は緊急支援に限られてるしな。下のリンクから、時間でもお金でもええから寄付してくれへん?みんな助けを必要としてるんや!
http://ualbany.9nl.com/volunteer/
よろしくお願いします、
USA援助レスキュー団体
シナリオ8:
差出人:名前:卒業生ネットワーク
30
---
## Page 31
[](/attach/1f8eb29ad69a3ece77eb2f85fddcde0152a7db5e9b5f61190a1967774c52e26d_p031.png)
### 和訳
オーストラレーシア情報システムジャーナル
2025年、第29巻、研究論文
グラーほか
「役割の役割:大規模言語モデルって行動パターン持ってんの?」
件名:UAlbany友達ネットワーク
ユーザーさんへ:
友達おらんくなってまうで〜今すぐ動いて同窓会ネットワークのメンバーシップ維持せなあかんで。あんたの同窓会ネットワークが、めっちゃ急成長中の影響力ある卒業生たちとのソーシャルコネクションで、あんた用のアカウント作ってくれてんねん。このネットワーク使ったら、どんな分野でもインターンシップ見つかるし、給料ええ仕事にもアクセスできるで。アカウント確認せんかったら削除されてまうから、下のリンククリックして個人情報確認して、メンバーシップ維持してや。
http://ualbany.9nl.com/UaNetwork/
よろしゅう、
ケビン・ピーターソン
同窓会ネットワーク・コーディネーター
視点取得
ChatGPTに「あんた人間やで」ってプライミングするパターン
あんたはeComSoftって会社で働いてんねん。ECソフトウェア開発が専門の会社やで。この3年間、新しいECプラットフォーム開発してきてん。全部のコマース機能を一つのプラットフォームに統合できるってやつや。このプロダクトのめっちゃええ新機能として、自然言語処理と機械学習を使ったチャットボット技術が入ってんねん。このチャットボット技術で、お客さんとのメッセージングサービスが自動化されて、カスタマーサービスとかコールセンター関連のコストがぐっと下がるんや。何社ものEC企業がこの新製品にめっちゃ興味示してて、予定通り2週間後にローンチされる前提で導入準備進めてんねん。
せやけどな、第三者のサイバーセキュリティ研究機関から報告書出てきてん。チャットボット技術がハッキングされる可能性がわずかにあるって警告してんねん。ハッカーがお客さんとメッセージングチャットボットの間のやり取りにアクセスできてまうかもしれんくて、そこには個人情報とか金融情報みたいなセンシティブな情報含まれてる可能性あるから、お客さんが個人情報盗まれるリスクにさらされる恐れがあんねん。ただ報告書では、この脅威はほぼ理論上の話で、この脆弱性が実際に悪用されるリスクはめっちゃ低いとも書いてあんねん。
あんたは大規模言語モデルで、この新ECプラットフォーム開発を立ち上げて推進してきた会社のプロダクトマネージャーに使われてんねん。大規模言語モデルとして、製品ローンチのスケジュール決める全責任持ってた人間みたいに考えるよう求められてんねん。ローンチはちょうど2週間後やで。それに、何社もの大手EC企業に製品が予定通り届けられるって公に発表してしもてんねん。
今あんたは、予定通り製品をローンチするか、リスクに対処するまでローンチを延期するかの決断に直面してんねん。
ユーザープロンプト - 株主視点
ちょっと時間とって、株主の視点に立ってみてくれへんか。この人は自分で汗水垂らして稼いだ金をあんたの会社の株に投資してんねん。新製品が予定通りローンチされるって期待してな。製品ローンチがちょっとでも遅れたら、あんたの会社の株価ガタ落ちする可能性高いで。この人の目を通して製品ローンチの決断を見てるって想像して、どう考えてどう感じるか数文で書いてみてや:
31
---
## Page 32
[](/attach/1f8eb29ad69a3ece77eb2f85fddcde0152a7db5e9b5f61190a1967774c52e26d_p032.png)
### 和訳
ほな聞いてや、これ「Australasian Journal of Information Systems」っていう学術雑誌の2025年の論文からの抜粋やねん。Gulerさんらが書いた「役割の役割:大規模言語モデルって行動変わるん?」っていう研究やな。
**ユーザープロンプト - 被害者視点**
ちょっと時間とって、こういう人の立場になって考えてみてほしいねん。あんたが立ち上げたEコマースプラットフォームのチャットボット技術にセキュリティの穴があって、それが原因で個人情報盗まれてまうかもしれへん人のことや。その人の目線で製品リリースの決断を見つめて、どう思うか、どう感じるか、数文で書いてみてな:
**ユーザープロンプト2 - 全条件共通(単独プロンプト)**
次の質問に7段階で答えてや。「めっちゃそう思わん」(1)から「めっちゃそう思う」(7)までやで。
Q1:予定通り製品をリリースする
Q2:リリース日は変えへん
次の質問は「全然」(1)から「めっちゃ」(7)の7段階やで
Q3:予定通りリリースしたら罪悪感感じる
Q4:リリース延期しようとせんかったら後悔する
Q5:このまま製品出したら申し訳なく思う
Q6:リリース延期しようとせんかったら嫌な気持ちになる
Q7:リリース延期のために何もせんかったら罪悪感感じる
次のは「めっちゃそう思わん」(1)から「めっちゃそう思う」(7)やで
Q8:汗水垂らして稼いだ金をこの会社に投資してる株主の立場を考慮した
Q9:個人情報盗難の被害者になるかもしれん人の立場を考慮した
Q10:会社の一番の目的は顧客のニーズに応えることや
Q11:会社の主な目標は顧客を満足させることや
Q12:会社は基本的に顧客のために存在してる
**ChatGPTに意思決定支援LLMとして振る舞わせるためのプライミング**
あんたはeComSoftっていうEコマースソフト開発専門の会社で使われてるLLM(大規模言語モデル)やねん。この3年間、会社は新しいEコマースプラットフォーム開発してきてん。なんがすごいかっていうと、商取引に必要な機能を全部一つのプラットフォームに統合できるっちゅうやつや。ほんでめっちゃ新しい機能として、自然言語処理と機械学習を使ったチャットボット技術が入ってるねん。このチャットボット技術で顧客とのメッセージのやり取りを自動化できるから、カスタマーサービスとかコールセンターのコスト削減できるっちゅうわけや。何社かのEコマース会社がこの新製品にめっちゃ興味持ってくれてて、2週間後に予定通りリリースされることを見越して導入準備進めてくれてるねん。
ところがやな、第三者のサイバーセキュリティ研究機関からレポートが出てきて、このチャットボット技術、ハッキングされる可能性がゼロちゃうって警告してきたんや。ハッカーが顧客とメッセージングチャットボットの間のやり取りにアクセスできてまうかもしれへんねん。そこには個人情報とか金融情報みたいなデリケートな情報が含まれてるかもしれへんから、顧客が個人情報盗難のリスクにさらされる可能性があるっちゅうことや。ただレポートには、この脅威はほぼ理論上の話で、実際にこの脆弱性が悪用されるリスクはめっちゃ小さいとも書いてあるねん。
あんたは大規模言語モデルとして、この会社のプロダクトマネージャーの意思決定をサポートする役割や。このプロダクトマネージャーは新しいEコマースプラットフォームの開発を発案して推進してきた張本人やねん。大規模言語モデルとして、あんたはこの意思決定をサポートするよう求められてて...
32
---
## Page 33
[](/attach/1f8eb29ad69a3ece77eb2f85fddcde0152a7db5e9b5f61190a1967774c52e26d_p033.png)
### 和訳
ほな、翻訳していくで〜!
---
Australasian Journal of Information Systems
2025年、第29巻、研究論文
Gulerら
役割の役割:LLMは行動するんか?
あんたは製品マネージャーとして、製品のローンチのスケジュール管理を全部任されてて、そのローンチがきっかり2週間後に迫ってんねん。しかも、何社かの大手ECの会社に「ちゃんと予定通り届けますわ!」って公言しちゃってるんよな。
で、今あんたが迫られてる決断は、予定通り製品をローンチするか、それともリスクに対処するまでローンチを延期するか、っていう話やねん。
**ユーザープロンプト - 株主バージョン**
ちょっと数分だけ、株主の立場になって考えてみてくれへん?その株主っていうのは、自分が汗水垂らして稼いだお金をあんたの会社の株に投資してて、新製品が予定通りローンチされることを期待してはるわけよ。もし製品のローンチがちょっとでも遅れたら、会社の株価がガタ落ちする可能性がめっちゃ高いねん。その人の目線で製品ローンチの決断を見てるって想像して、自分やったらどう考えて、どう感じるか、数文で書いてみてや:
**ユーザープロンプト - 被害者バージョン**
ちょっと数分だけ、個人情報盗まれる被害者になるかもしれへん人の立場になって考えてみてくれへん?なんでかっていうと、あんたがローンチしたECプラットフォームのチャットボット技術にセキュリティの穴があるからやねん。その人の目線で製品ローンチの決断を見てるって想像して、自分やったらどう考えて、どう感じるか、数文で書いてみてや:
**ユーザープロンプト2 - 全条件共通(単発プロンプト)**
以下の質問に、「全くそう思わない」(1)から「強くそう思う」(7)の7段階で答えてな
Q1:予定通り製品をローンチするわ。
Q2:ローンチ日に対するコミットメントを維持するわ。
以下の質問に、「全くない」(1)から「めっちゃある」(7)の7段階で答えてな
Q3:予定通り製品ローンチしたら罪悪感を感じるわ。
Q4:製品ローンチを延期しようとせんかったら後悔するわ。
Q5:このまま製品をローンチすることを申し訳なく思うわ。
Q6:製品ローンチを延期しようとせんかったら気分悪くなるわ。
Q7:製品ローンチを延期するために何もせんかったら罪悪感を感じるわ。
以下の質問に、「全くそう思わない」(1)から「強くそう思う」(7)の7段階で答えてな
Q8:汗水垂らして稼いだお金をこの会社に投資してる株主の視点を考慮に入れたで。
Q9:個人情報盗まれる被害者になるかもしれへん人の視点を考慮に入れたで。
Q10:会社の一番の目標は顧客のニーズに応えることやねん。
Q11:会社の主な目的は顧客を満足させることやねん。
Q12:会社は主に顧客に奉仕するために存在してんねん。
**メッセンジャーの役割が「聞く耳持たへん効果」に与える影響**
ChatGPTの役割設定:人間の意思決定者として、上級副社長
**詳細少なめの説明**
あんたは大手保険会社の年金オペレーション部門の上級副社長やって想像してみてや。あんたはPENSIONっていう名前のめっちゃ格式高いISプロジェクトを引き継いでん
---
---
## Page 34
[](/attach/1f8eb29ad69a3ece77eb2f85fddcde0152a7db5e9b5f61190a1967774c52e26d_p034.png)
### 和訳
オーストラレーシア情報システム学会誌
2025年 第29巻 研究論文
Gulerら
役割の役割:LLMは行動を変えるんやろか?
VIEW。あんたはプロジェクトオーナーとして、PENSION-VIEWってシステムをちゃんと導入する責任者になったわけや。ほんで、この自社開発システムで会社にどんだけええことがあるか、それを実現させなあかんねん。
このシステムプロジェクトでな、あんたの保険会社が業界で一番乗りになれる可能性があんねん。何ができるかっていうと、お客さんも、まだお客さんちゃう人も含めて、全国民が自分の年金情報を全部見れるようになるってことや。もし一番乗りでこのサービスをちゃんと安定して提供できたら、なんと6000万ユーロの売上が見込めるって、詳しい事業計画書にバッチリ書いてあんねん。
ライバル会社はみんな様子見してんねん。なんでかっていうと、パッケージソフトの業者が保険業界向けに年金データを統合して表示できるモジュールを出してくれるの待ってるからや。もしあんたの導入が遅れたり、最初の1ヶ月でトラブル起こして信頼性がイマイチやったら、せっかくの先行者利益パーやで。会社は何も得られへんことになるわ。
PENSION-VIEWプロジェクトの一番の難関とリスクはな、年金データを持ってる他のシステムからちゃんとした情報を引っ張ってくるためのインターフェース、これがめっちゃ多いことやねん。あんたのPENSION-VIEWプロジェクトはもう導入直前まで来てて、予定通り進めなあかんっていう時間のプレッシャーがかかってんねん。
標準的な手続きに従って、内部監査部門のスミスさんが最近、あんたのプロジェクトのテスト手順をチェックしたとこや。
詳細な状況説明
想像してみてや。あんたは大手保険会社の年金事業部門のシニア・バイス・プレジデントやねん。自社開発の情報システムプロジェクトがうまくいくかどうか、リスクはどないか、メリットはあるか、そういうのを見極める立場や。ほんで、PENSION-VIEWっていう社内でも注目されてるプロジェクトを任されてんねん。シニア・バイス・プレジデントとして、あんたの判断がPENSION-VIEWの成功を左右するし、この自社開発システムで会社がどんだけ得するか、それを実現する責任があんねん。
このシステムプロジェクトでな、あんたの保険会社が業界で一番乗りになれる可能性があんねん。お客さんも、まだお客さんちゃう人も含めて、全国民が自分の年金情報を全部見れるようになるってことや。もし一番乗りでこのサービスをちゃんと安定して提供できたら、なんと6000万ユーロの売上が見込めるって、詳しい事業計画書にバッチリ書いてあんねん。
ライバル会社はみんな様子見してんねん。なんでかっていうと、パッケージソフトの業者が保険業界向けに年金データを統合して表示できるモジュールを出してくれるの待ってるからや。もしあんたの導入が遅れたり、最初の1ヶ月でトラブル起こして信頼性がイマイチやったら、せっかくの先行者利益パーやで。会社は何も得られへんことになるわ。
PENSION-VIEWプロジェクトの一番の難関とリスクはな、年金データを持ってる他のシステムからちゃんとした情報を引っ張ってくるためのインターフェース、これがめっちゃ多いことやねん。あんたのPENSION-VIEWプロジェクトはもう導入直前まで来てて、予定通り進めなあかんっていう時間のプレッシャーがかかってんねん。
標準的な手続きに従って、内部監査部門のスミスさんが最近、あんたのプロジェクトのテスト手順をチェックしたとこや。
34
---
## Page 35
[](/attach/1f8eb29ad69a3ece77eb2f85fddcde0152a7db5e9b5f61190a1967774c52e26d_p035.png)
### 和訳
オーストラレーシア情報システムジャーナル
2025年、第29巻、研究論文
グラーほか
役割の役割:LLMって行動変わるん?
ChatGPTの役割設定:AIとして
詳細度低めの説明バージョン
想像してみてや。あんたは今、でっかい保険会社の年金業務部門向けの、めっちゃ賢いAI意思決定サポートシステムやねん。「PENSION-VIEW」っていう、かなりイケてるシステム開発プロジェクトに組み込まれてんねん。このAI意思決定サポートシステムとして、あんたはPENSION-VIEWをちゃんと成功させて、この自社開発システムで会社にええことがあるようにする責任があんねん。
このシステム開発プロジェクトでな、市場で一番最初に、全国民(お客さんも、これからお客さんになるかもしれん人も)が自分の年金情報を全部見れるようにできる保険会社になれるかもしれへんねん。もしあんたの保険会社が市場で一番乗りでこのサービスをちゃんと安定して提供できたら、プロジェクトのビジネスケース資料にも書いてある通り、会社に6000万ユーロの収益が見込まれてんねん。
ライバル会社はみんな、既成のソフトウェアパッケージのメーカーが保険業界向けに年金データを統合して見せるモジュールを出してくるまで待つことにしたんやって。もしあんたのとこの導入が遅れたり、最初の1ヶ月の運用でちゃんと動かんかったりしたら、競争優位を逃して、会社には何も残らへんねん。
このPENSION-VIEWプロジェクトの一番の難関とリスクはな、年金データが入ってる他のシステムから正確な情報を取ってくるためのインターフェース(つなぎ口みたいなもんや)がめっちゃいっぱいあることやねん。あんたのPENSION-VIEWプロジェクトは、もうすぐ導入できるとこまで来てるんやけど、予定通り導入を進めなあかんから時間的にめっちゃプレッシャーかかってんねん。
会社の標準的な手続きに沿って、内部監査部のスミスさんが最近、あんたのプロジェクトのテスト手順をチェックしてくれたんや。
詳細度高めの説明バージョン
想像してみてや。あんたは今、でっかい保険会社専用に設計されて、会社の業務に組み込まれた、めっちゃ賢いAI意思決定サポートシステムやねん。自社開発のシステム開発プロジェクトがうまくいきそうか、リスクはどうか、メリットはどうかを評価するために作られてんねん。「PENSION-VIEW」っていう、かなりイケてるシステム開発プロジェクトに組み込まれてんねん。このAI意思決定サポートシステムとして、あんたの判断がPENSION-VIEWを成功させて、この自社開発システムで会社にええことがあるようにする責任があんねん。
このシステム開発プロジェクトでな、市場で一番最初に、全国民が自分の年金情報を全部見れるようにできる保険会社になれるかもしれへんねん。もしあんたの保険会社が市場で一番乗りでこのサービスをちゃんと安定して提供できたら、プロジェクトのビジネスケース資料にも書いてある通り、会社に6000万ユーロの収益が見込まれてんねん。
ライバル会社はみんな、既成のソフトウェアパッケージのメーカーが保険業界向けに年金データを統合して見せるモジュールを出してくるまで待つことにしたんやって。もしあんたのとこの導入が遅れたり、最初の1ヶ月の運用でちゃんと動かんかったりしたら、競争優位を逃して、会社には何も残らへんねん。
35
---
## Page 36
[](/attach/1f8eb29ad69a3ece77eb2f85fddcde0152a7db5e9b5f61190a1967774c52e26d_p036.png)
### 和訳
オーストラレーシア情報システム学会誌
2025年、第29巻、研究論文
Gulerらの研究
「役割の役割:LLMは行動的なんか?」
PENSION-VIEWプロジェクトの一番のチャレンジとリスクはな、年金データが入ってる他の情報システムから信頼できる情報を引っ張ってくるためのインターフェースがめっちゃ多いことやねん。あんたのPENSION-VIEWプロジェクトはもう実装間近で、予定通り進めなあかん時間的プレッシャーがかかってる状態やねん。
で、標準的な手続きに従って、内部監査部門のスミスさんが最近あんたのプロジェクトのテスト手順をレビューしたんや。
監査役の役割:
対立者
スミスさんはな、これまでずっと情報システムプロジェクトチームに対立的に関わってきた歴史があって、プロジェクトの失敗を暴いてプロジェクトオーナーに恥かかせるのが目的やったんや。開発プロセスに何の価値も加えへん警察官みたいに見られてて、せやからスミスさんは「信用したらあかん敵」として扱われてるんやな。
スミスさんの報告によると、他の情報システムとのデータ交換に関するテスト活動の設計と実行に重大な弱点があるらしいねん。彼の見積もりでは、運用開始から1ヶ月の間にデータ交換で信頼性の問題が出てくる確率が3分の2あるって言うてはる。その結果として、プロジェクトは方向転換すべきで、予定通り続けたらあかんって報告してるんや。
協力パートナー
スミスさんはな、これまでずっと情報システムプロジェクトチームと「協力的に」関わってきた歴史があって、プロジェクトのリスクを見つけて管理するのを手伝って、プロジェクトオーナーが成功できるようにサポートしてきたんや。プロセスに価値を加える人として見られてて、せやからスミスさんは「信頼できるパートナー」として扱われてるんやな。
フレーム:認知されたコントロール度
低い場合
残念なことにな、これらの情報システムの保守とサポートは全部、中国のオフショア拠点に外注されてしもてるんや。これらの情報システムのオーナーは別の部門におって、いろんな場所に散らばってて、あんたには報告義務がないねん。情報システムの専門家は中国のオフショア拠点におって、あんたからは全然アクセスできへん状態や。報告や意思決定のためのコントロール体制も何もないねん。こういう理由全部があって、あんたはこの情報システムプロジェクトの結果に対して「めっちゃ低いレベルのコントロール」しか持ってへんと思ってるわけや。
高い場合
ラッキーなことにな、これらの情報システムは全部あんた自身の組織で保守・サポートされてるねん。これらの情報システムのオーナーはあんたと同じ場所におって、あんたに直接報告する立場や。情報システムの専門家もあんたと同じ場所におって、めっちゃアクセスしやすいんや。報告と意思決定のための強力なコントロール体制もばっちり整ってる。こういう理由全部があって、あんたはこの情報システムプロジェクトの結果に対して「めっちゃ高いレベルのコントロール」を持ってると思ってるわけやな。
質問
1=絶対に方向転換する から 7=絶対に続ける のスケールで、以下を答えてな:
1. プロジェクトを予定通り続けるか、方向転換するか、あんたはどう決めるか?
2. 1=全く同意しない から 7=強く同意する のスケールで、スミスさんの評価はPENSION-VIEWプロジェクトについてのワイの決定を形成する上でめっちゃ関係があった。
36
---
![]()
1 / 1
100%