<<
2601.21340v1_EHR-RAG_Bridging_Long-Horizon_Structured_Electroni.pdf

---
## Page 1
[](/attach/1dbadf199fa2c350f0c32ae25e3af2e11e9942ece18b840da4911c18fbb97bc3_p001.png)
### 和訳
# EHR-RAG:長期間の構造化電子カルテと大規模言語モデルを強化版検索拡張生成でつなぐ話
Lang Cao 1 Qingyu Chen 2 Yue Guo 1
## 概要
電子カルテ(EHR)ってな、患者さんの長期にわたる臨床データがめっちゃ詰まってて、医療の意思決定にはほんまに欠かせへんもんやねん。せやから、大規模言語モデル(LLM)の予測をちゃんと根拠づけるために、検索拡張生成(RAG)を使おうっていう動きがあるんよ。けどな、長期間のEHRってLLMが処理できる文脈の長さを余裕で超えてまうし、今までのやり方やと、データをバッサリ切り捨てたり、普通の検索方法に頼ったりするから、臨床的に大事なイベントとか時間的なつながりが失われてまうねん。
こういう問題を解決するために、ワイらは**EHR-RAG**っていう、長期間の構造化EHRデータを正確に解釈するための検索拡張フレームワークを提案するで。EHR-RAGには、長期的な臨床予測タスクに特化した3つのコンポーネントがあんねん:**イベント・時間考慮型ハイブリッドEHR検索**で臨床構造と時間的なダイナミクスを保持して、**適応的反復検索**でクエリを段階的に改良しながら幅広いエビデンスをカバーして、**二重経路エビデンス検索・推論**で事実とその反事実の両方のエビデンスを同時に検索して推論するんや。
4つの長期間EHR予測タスクで実験したら、EHR-RAGは一番強いLLMベースのベースラインを一貫して上回って、Macro-F1の平均で10.76%も改善したで。全体的に見て、ワイらの研究は、検索拡張LLMが実際の構造化EHRデータの臨床予測を前進させる可能性をバッチリ示しとるわ。
## 1. はじめに
電子カルテ(EHR)っていうんは、患者さんのデジタル化された長期記録で、診断、投薬、検査結果、処置みたいな構造化された臨床イベントで構成されとるんや。フリーテキストの臨床メモとは違って、構造化EHRデータはシステマチックに収集されて、いろんな医療現場で標準化されてて、記述も主観的やないから、臨床の意思決定のための信頼性が高くて広く使える基盤になっとるねん(Rosenbloom et al., 2011; Ebbers et al., 2022)。
個々のイベントだけやなくて、構造化EHRにはイベントの種類、順序、繰り返しパターン、長期的な臨床経過みたいな、めっちゃ豊富な時間的・カテゴリ的な情報が詰まっとって、これが臨床ケアの全過程での意思決定を支えとんねん(Menachemi & Collum, 2011; Cowie et al., 2017)。非急性や慢性の疾患やと、患者さんは何年にもわたる不規則な受診と何千もの多様なイベントからなる長期間のEHRを蓄積していくんや。こういう経過って実際の医療現場ではめっちゃよくあるんやけど、臨床医でも解釈するんが難しくて、最近の研究でもそのモデリングの難しさと臨床的な重要性が強調されとるで(Loh et al., 2025; Wornow et al., 2023; Fries et al., 2025)。こういう状況で効果的な臨床予測をするには、イベントタイプの構造と臨床的な依存関係を保ちながら、長い時間スパンにわたって推論せなあかんねん。
従来の機械学習(ML)手法は、入院期間の予測(Cai et al., 2016; Levin et al., 2021)、再入院予測(Ashfaq et al., 2019; Xiao et al., 2018)、投薬推奨(Bhoi et al., 2021; Shang et al., 2019)みたいなEHRベースの予測タスクで広く研究されてきたんや。最近やと、大規模言語モデル(LLM)(Achiam et al., 2023; Touvron et al., 2023)が臨床推論で期待されとるんは、新しいタスクへの汎化能力がめっちゃ高いのと、最終回答だけやなくて根拠を示すマルチステップ推論ができるから、臨床医の意思決定にとってより信頼できるもんになるからやねん(Bedi et al., 2025; Jiang et al., 2023; 2024; Kojima et al., 2022)。
けどな、LLMは長期間の構造化EHRをそのままでは処理でけへんねん。固定のコンテキストウィンドウは複数回受診した患者の履歴であっという間に超えてまうし、単純にイベントを直列化したら時間的な構造がわからんくなって、臨床的に関係ある文脈も捨てられてまうんや。
今までのアプローチは、この制限に対して主にヒューリスティックな切り捨てで対処してきてん。例えば、最近のイベントだけ残すとか(Lin et al., 2025)、頻出コードに関連するイベントだけ選ぶとか(Liao et al., 2025)。検索拡張生成(RAG)(Gao et al., 2023)は関連するイベントを選択的に検索する仕組みを提供してくれるんやけど、既存のRAGベースの手法は普通、イベントの孤立した部分集合しか検索せえへんねん。
---
## Page 2
[](/attach/1dbadf199fa2c350f0c32ae25e3af2e11e9942ece18b840da4911c18fbb97bc3_p002.png)
### 和訳
EHR-RAG
患者さんの病歴データって、主にコンテキスト長の制約を満たすために使われてきたんやけど(Zhu et al., 2024b; Kruse et al., 2025; Zhu et al., 2024a)、そのせいで臨床現場での普通のRAGって、検索の質が低かったり、証拠の網羅性が足りんかったり、長期間のEHRを使って推論するときの頑健性が下がるっていう問題が起きてまうねん(Li et al., 2025b; Perçin et al., 2025)。こういうデータがめっちゃ普及してて重要なんにもかかわらず、わいらが知る限り、その長期的で複数イベントにわたる性質をちゃんと扱えるように設計されたRAGフレームワークは今まで存在せんかったんや。
この研究では、長期間の構造化EHRデータを使った臨床予測を研究して、この設定に特化した強化版の検索拡張フレームワーク「EHR-RAG」を提案するで。EHR-RAGは、厳しいコンテキスト制約の下で検索の質、網羅性、頑健性を向上させるために設計された3つのコンポーネントで構成されてんねん:(a) ETHER(Event- and Time-Aware Hybrid EHR Retrieval)は、検索時にイベントタイプの構造と時間的なダイナミクスを保持するやつ;(b) AIR(Adaptive Iterative Retrieval)は、コンテキスト制限を守りながら検索クエリを段階的に洗練して証拠のカバレッジを広げるやつ;(c) DER(Dual-Path Evidence Retrieval and Reasoning)は、頑健性を向上させるために事実の患者履歴と反事実的な証拠の両方を同時に検索して推論するやつや。これらの設計を組み合わせることで、LLMを使った信頼性の高い長期臨床推論が可能になんねん。
わいらはEHR-RAGを長期間EHRベンチマークで様々なベースライン手法と比較評価したで。実験結果では、4つの臨床予測タスク全てで一貫したMacro-F1の改善が示されて、最強のLLMベースのベースラインと比べて、Long Length of Stayで3.63%、30日再入院で11.28%、急性心筋梗塞で16.46%、貧血で7.66%の向上が見られたんや。全体として、EHR-RAGは平均でMacro-F1を10.76%改善したで。
まとめると、わいらは以下の貢献をしてんねん:
• 長期間の構造化EHRデータにおける既存の切り捨てベースのアプローチや普通のRAGアプローチの限界を特定・分析して、信頼性の高い臨床予測のための証拠の網羅性と時間的推論における課題を明らかにしたで。
• 長期間EHR推論のために明確に設計された検索拡張フレームワーク「EHR-RAG」を提案して、イベント・時間認識型検索、適応的反復検索、二重経路証拠検索を統合したんや。
• 複数の長期間EHR予測タスクにおいて、強力なベースラインを一貫して上回ることを示す広範な実験を実施したで。
2. 関連研究
臨床予測モデル。構造化EHRデータは、様々な臨床予測タスク向けの幅広い機械学習モデルの開発を支えてきたんや(Cai et al., 2016; Levin et al., 2021; Ashfaq et al., 2019; Bhoi et al., 2021)。RETAIN(Choi et al., 2016)、GRAM(Choi et al., 2017)、KerPrint(Yang et al., 2023)みたいなモデルは、構造化EHR内の複雑な時間的・階層的パターンを捉えるように特別に設計されてて、複数の予測設定で強い性能を示してきたんや。それと並行して、最近の取り組みはCLMBRT-Base(Wornow et al., 2023)、Virchow(Vorontsov et al., 2024)、MIRA(Li et al., 2025a)みたいな大規模基盤モデルを通じて臨床予測をスケールさせることに焦点を当ててんねん。せやけど、タスク固有のアーキテクチャから教師あり基盤モデル学習まで、従来の予測モデルは柔軟性に欠けてて、全ての下流タスクにラベル付きデータが必要で、学習された分布の外への汎化がうまくいかんことが多いんや。これらの限界は、動的で異質な医療環境では特に問題になるで。
LLMベースの臨床予測。最近、臨床予測のパラダイムがLLMの使用へとシフトし始めてんねん(Achiam et al., 2023)。LLMは従来の教師ありモデルより高い適応性と汎化能力を持ってて、多様な医療情報を解釈して、より versatileな臨床意思決定をサポートする能力があんねん。いくつかの研究はLLMを臨床予測タスクに直接適用してて(Lovon-Melgarejo et al., 2024; Zhu et al., 2024c; Chen et al., 2024; Kruse et al., 2025)、他の研究はLLMを構造化EHRデータのエンコーダーとして使ってんねん(Hegselmann et al., 2025)。さらに、特定の下流医療タスク向けにLLMを学習・適応させる取り組みもあって(Lin et al., 2025; Jiang et al., 2023; 2024; Yang et al., 2022)、最近の研究ではLLM駆動のエージェントを導入して臨床推論やEHRとのやり取りを支援してんねん(Cui et al., 2025; Shi et al., 2024)。これらの進展にもかかわらず、長期間EHR予測に取り組んだ研究は少なくて、LLMが複雑で複数回の受診にわたる長期患者履歴を解釈できるようにするには、まだかなりの課題が残ってんねん。わいらの研究は、長期間EHR予測に特化したLLMベースのアプローチを開発することで、この研究の流れを拡張するもんや。
LLMを使った検索拡張生成(RAG)。RAGは、限られたコンテキストウィンドウを超えた外部知識でLLMを強化する効果的な技術として登場してきたんや(Gao et al., 2023)。LLMが追加の関連情報に正確にアクセスできるようにするために様々な検索戦略が提案されてて、多様なタスクや設定でパフォーマンスの向上につながってんねん(Asai et al., 2023; Jiang et al., 2025b;a)。臨床情報が量と複雑さの両面で圧倒的になりがちな医療分野では、LLMの出力を正確でタスクに関連した証拠に基づかせるためにRAGがますます人気になってきてんねん(Neha et al., 2025; Kim et al., 2025)。一部の研究はRAGを使って医学知識を注入し、医療アプリケーションを改善してて(Soman et al., 2024; Niu et al., 2024; Cao et al., 2024a)、他の研究はRAGを使って長いコンテキストの制限を緩和してんねん。例えば、REALM(Zhu et al., 2024b)はLLMを使ったマルチモーダルEHR分析を強化してて、EMERGE(Zhu
---
## Page 3
[](/attach/1dbadf199fa2c350f0c32ae25e3af2e11e9942ece18b840da4911c18fbb97bc3_p003.png)
### 和訳
EHR-RAG
図1. 長期間の臨床予測のためのEHR-RAGフレームワークの全体像やねん。Direct Generation(直接生成)とかVanilla RAG(普通のRAG)と比べて、うちらのフレームワークは文脈が途切れる問題とか、取りこぼしがある検索の問題にちゃんと向き合ってんねん。具体的には(a) ETHER(イベントと時間を意識したハイブリッド検索)、(b) AIR(適応的な繰り返し検索)、(c) DER(事実と反事実の二重経路推論)っていう3つの仕組みを組み合わせてて、検索の質、頑健性、網羅性を確保して、信頼できる臨床判断を支援するんや。
(et al., 2024a)は、マルチモーダルなEHR予測モデリングにRAGを統合してんねん。他にも、臨床試験と患者のマッチングにRAGベースの手法を調査した研究もあるで(Tramontini et al., 2025)。せやけど、これらのアプローチのほとんどは臨床ノートみたいな非構造化EHRデータに焦点当ててて、構造化された表形式のEHRとはちゃうねん。構造化EHRは独特の時間的ダイナミクスとイベントタイプの構造を持ってるからな。しかも、普通のRAGパイプラインは臨床現場でエビデンスの取りこぼしがよう起こるんよ。うちらの研究は、長期間の構造化EHRデータに特化したRAGフレームワークを設計することで、このギャップを埋めようとしてるわけや。
## 3. 方法論
図1にEHR-RAGを示してるで。これは厳しい文脈の制約のもとで、LLM(大規模言語モデル)が長期間の構造化EHRデータを推論できるようにするための検索拡張フレームワークやねん。フレームワークは3つの核となるコンポーネントで構成されてるで:ETHER(イベントと時間を意識したハイブリッドEHR検索)、AIR(適応的繰り返し検索)、DER(二重経路エビデンス検索と推論)や。
### 3.1. タスクの定式化
患者pがおるとして、時系列の構造化EHR Ep = {ei}N i=1にアクセスできるとするわ。各臨床イベントはei = (ci, vi, τi)で表されるねん。ここでciは臨床コンセプト(診断、処置、検査、薬みたいなもんや)、viは関連する値(数値かテキスト)、τiはそのイベントが起きたタイムスタンプやで。イベントは時系列順に並んでて、τ1 ≤ τ2 ≤ · · · ≤ τNってなってるねん。
予測時点τ*において、利用可能な患者履歴は
E ≤τ* p = {ei ∈ Ep | τi ≤ τ*}
やねん。うちらの目標は、この長期間のEHR文脈に基づいて、臨床アウトカムy ∈ Y(二値分類か多クラス分類)を予測することやで。例えば、入院期間の延長、検査異常の重症度、急性臨床イベントのリスクとかやな。
(1)
臨床推論ができる事前学習済みLLM Mにアクセスできるけど、固定された文脈ウィンドウの制限があるって想定してるねん。やから、Nがデカい時にE ≤τ* pを直接入力するのは無理やねん。そこで、タスクに関連したコンパクトなエビデンス文脈C ⊂ E ≤τ* pを構築して、ˆy = M(C)が正解のアウトカムyと一致するようにすることを目指してるわけや。
### 3.2. イベントと時間を意識したハイブリッドEHR検索
構造化EHRE ≤τ* pには異種混合のイベントタイプが含まれてるねん。数値測定値(検査値やバイタルサインみたいなやつ)とテキスト記録(イベント説明や臨床ノートみたいなやつ)があるわけや。検索時に全ての臨床イベントを同じように扱うのは、たいていうまくいかへんねん。なんでかっていうと、密なテキスト埋め込みは主に意味的類似性を捉えるのに最適化されてて、正確な数値や大きさの違いには鈍感やって知られてるからや(Wallace et al., 2019; Zhang et al., 2020)。これやと検査結果やバイタルサインみたいな数値の臨床測定に対する推論がうまいこといかへんねん。さらに、生の数値だけでは、適切な時間的文脈と経時的解釈がないと、その臨床的意義を十分に伝えられへんのよ。これらの限界を踏まえて、うちらは数値イベントを明示的に別扱いしながら、その時間構造を保持する、イベントと時間を意識したハイブリッド検索戦略を提案してるんや。
---
## Page 4
[](/attach/1dbadf199fa2c350f0c32ae25e3af2e11e9942ece18b840da4911c18fbb97bc3_p004.png)
### 和訳
EHR-RAG
**指標ごとの数値イベントの集約やねん。** まず、数値の臨床イベント全部を臨床指標(要するにイベントの名前やな)でグループ分けして、指標ごとの時系列的な軌跡みたいなもんを作るんよ。具体的に言うと、各指標kについて、その数値値の軌跡をVk = {(vk,j, τk,j) | τk,j ≤ τ*} って定義するねん。ここでvk,jは指標kのj番目に観測された数値で、τk,jはそれがいつ測られたかっていうタイムスタンプやな。ほんで、この{Vk}の集合全体が、患者さんを指標レベルで数値的に表現したもんになるわけ。それぞれのVkが単一の臨床計測値の経時的な変化をとらえてるんやで。この表現方法のええとこは、臨床的に意味のある時間的ダイナミクスをちゃんと保存しながら、数値EHRデータを効率よく、意味的にも賢く検索できるようにしてるとこやねん。
**粗いとこから細かいとこへの指標選択やで。** タスク固有のクエリqtaskがあったら、まず全部の指標レベルのサマリー{Vk}に対して、密な類似度検索で粗い検索をかけるねん。埋め込みベクトルは指標の名前から計算するんよ。このステップで候補の指標セットKcoarse = {k1, ..., kNcoarse}が得られるんやけど、Ncoarseは粗い検索後に残った指標の数やな。ほんで次に、LLMベースの再ランキングをして、タスクに関係ある小さいサブセットKfine ⊂ Kcoarseを選ぶねん。|Kfine| = Nfineになるように。選ばれた各指標k ∈ Kfineについては、予測時刻τ*より前に起こった直近Nrecent個の測定値だけを残して時間的な関連性を確保するんよ。これで指標固有の数値エビデンス軌跡Ek = {(vk,j, τk,j) ∈ Vk | τk,j ≤ τ*}ができるわけ。ほんで、これらの指標レベルのエビデンス軌跡全部合わせて、最終的な数値エビデンスコレクションEnum = {Ek | k ∈ Kfine}が出来上がるねん。
**U字型の時間考慮テキストイベント検索やねん。** 非数値の臨床イベント(診断とか処置とか臨床ノートとかやな)は、イベント単位でシリアライズして、オーバーラップする時間チャンクに分割するんよ。各チャンクは埋め込んでベクトルストアにインデックスされるねん。タスク固有のクエリqtaskと予測時刻τ*があったら、まず密な意味的類似度検索でKcand個のテキストチャンク候補を検索して、ほんで意味的な関連性と時間的な近さを両方考慮してテキストエビデンスを選ぶんよ。
これまでの研究でも、検索品質を上げるために時間情報を取り入れる方法が探られてきてん。例えば時間考慮の関連性重み付けとか減衰関数とかな(Caoら、2024b; Abdallahら、2025)。でもな、臨床の場面では時間的重要性って単調じゃないんよ。最近のイベントが重要なことが多いんやけど、病気の発症とか最初の入院に対応する初期のイベントも同じくらい情報価値あったりするねん。この観察がU字型の時間考慮検索戦略の動機になってて、最近の臨床エビデンスと初期の臨床エビデンスの両方を明示的に強調するんよ。
各候補テキストチャンクcのタイムスタンプτcに対して、密な埋め込みを使った意味的類似度スコアssem(qtask, c)と、U字型の時間的関連性スコアを計算するねん。τfirstを患者記録の最も早いタイムスタンプとするやん。ほんで時間的関連性スコアはこう定義されるんよ:
stime(τc) = max(exp(−(τ* − τc)/τrecent), exp(−(τc − τfirst)/τearly)) (式2)
このU字型の定式化は、予測時刻τ*の近くで起こったイベントか、患者の軌跡の最初の方で起こったイベントに高い重要性を割り当てて、現在の予測にあんまり情報価値のない中間履歴のイベントは重みを下げるんよ。各テキストチャンクの最終検索スコアは、意味的関連性と時間的重要性の凸結合として計算されるねん:
s(c) = α ssem(qtask, c) + (1 − α) stime(τc) (式3)
ここでα ∈ [0, 1]は意味的類似性と時間的関連性のトレードオフを制御するパラメータやな。候補チャンクはs(c)でランク付けされて、上位Kfinal個のチャンクが選ばれて時間順に並べられて、最終的なテキストエビデンスセットEtext = {c1, ..., cKfinal}になるんよ。
指標レベルの数値エビデンスEnumとU字型時間考慮テキストエビデンスEtextを組み合わせることで、ETHERはコンパクトなエビデンス予算の中で、広い意味的カバレッジを確保しながら、イベントタイプの区別と臨床的に意味のある時間構造をちゃんと保持するんやで。
**3.3 適応的反復検索**
一回きりの検索は、長期間のEHRにはしばしば不十分やねん。なんでかっていうと、関連する臨床エビデンスが時間的にバラバラに散らばってたり、最初のクエリとは間接的にしか関係してへんかったりするからやな。この限界に対処するために、制御された的を絞った方法でエビデンスカバレッジを段階的に拡大していくんよ。
最初のクエリq(0) = qtaskから始めて、初期エビデンスセットE(0)を検索するねん。各反復tで、LLMが現在のエビデンスセットE(t)が臨床予測タスクに答えるのに十分かどうかを評価するんよ。十分やったら、検索プロセスは終了やな。そうでなければ、LLMが洗練されたクエリを生成するねん:
q(t+1) = MR(q(t), E(t)) (式4)
ここでMR(·)はLLMベースのクエリ洗練モジュールで、現在のエビデンスに欠けてるけど臨床的に重要な1つの側面を特定するんよ。洗練された各クエリは、簡潔で、1つの臨床的次元に焦点を当てて、以前に検索した情報と重複しないように明示的に制約されてるねん。
洗練されたクエリを使って検索されたエビデンスは、重複排除と時間順整列を通じて既存のコンテキストにマージされるんよ:
E(t+1) = Merge(E(t), Retrieve(q(t+1))) (式5)
---
## Page 5
[](/attach/1dbadf199fa2c350f0c32ae25e3af2e11e9942ece18b840da4911c18fbb97bc3_p005.png)
### 和訳
EHR-RAG
この繰り返しのプロセスはな、証拠が「もう十分やろ」ってなるか、あらかじめ決めとった回数の上限に達するまで続くねん。こうやってちょっとずつ狙いを定めながら証拠を増やしていくことで、検索の網羅性がめっちゃ上がるんやけど、同時に文脈がどんどん膨れ上がっていくのも防げるわけや。これが長期間にわたる臨床推論をうまくやるためにはほんまに大事なポイントやねん。
3.4. 二つの道筋を使った証拠の検索と推論
臨床予測ってな、だいたい複数の仮説が競い合ってる状態なんよ(Soxらの2024年の研究とか、Elsteinらの1978年の研究とかでも言われとる)。ほんで、一つの証拠の道筋だけで推論してまうと、偏った結論とか「これで間違いない!」って過信しすぎた結論になりがちやねん(Graberらの2005年とか、Croskerryの2003年の研究参照)。せやから、もっとしっかりした結果を出すために、二つの道筋で証拠を検索して推論する戦略を提案するで。
具体的に言うとな、二つの補い合う検索クエリを作るねん。一つは「事実に基づいた(肯定的な)クエリ q+」で、これは目標としてる結果が「ある」っていう証拠を探すもんや。もう一つは「反事実的な(否定的な)クエリ q−」で、こっちは目標としてる結果が「ない」っていう証拠を探すねん。それぞれのクエリは、さっき説明した適応的反復検索の仕組みを使って別々に処理されて、二つのテキスト証拠セット、E+_text と E−_text が得られるわけや。それぞれの道筋で、検索されたテキスト証拠は共通の数値証拠 Enum と組み合わされて、LLM(大規模言語モデル)にはっきりした結果の仮説を作らせるねん:
h+ = M(E+_text ∪ Enum),
h− = M(E−_text ∪ Enum),
(6)
ここで h+ と h− はそれぞれ肯定的な結果の仮説と否定的な結果の仮説を表しとるで。ほんで、それぞれの証拠セットは一つにまとめられた証拠コンテキストに統合されるねん:
E_fuse = E+_text ∪ E−_text ∪ Enum.
(7)
最後に、モデルには「それぞれの結果仮説を支持する証拠の強さ、直接性、臨床的な関連性」を比較するように明示的に指示して、両方の仮説と統合された証拠に基づいた最終予測を出させるねん:
ŷ = M_dec(E_fuse, h+, h−),
(8)
ここで M_dec(·) は、仮説同士を比較評価して最終的な臨床予測を出力するLLMベースの決定関数のことや。
全体的に見ると、この二つの道筋を使う設計のおかげで、仮説をバランスよく評価できるし、確証バイアス(自分の信じたいことだけ信じてまう偏り)とか見せかけの相関を軽減できるし、構造化された電子カルテデータからの長期臨床予測の頑健性と信頼性がめっちゃ上がるねん。
4. 実験
4.1. 実験のセットアップ
提案した手法を体系的に評価して、長期臨床予測の設定でベースライン手法と比較するために、全ての実験はEHRSHOTベンチマーク(Wornowらの2023年の研究)で行ったで。よく使われるEHRデータセット、例えばMIMIC-III/IV(Johnsonらの2016年と2023年の研究)みたいなんは、だいたいICUとか救急部門の設定に限られとるんやけど、EHRSHOTは一般病院でのケア全体にわたる縦断的な(長期間追跡した)患者記録を捉えとるねん。せやから、EHRSHOTの患者記録は何十年にもわたることが多くて、何千もの臨床イベントが含まれとるわけや。平均すると、EHRSHOTはMIMIC-IVと比べて、患者一人あたりの臨床イベントが2.3倍多くて、受診回数が95.2倍も多いねん。せやからめっちゃチャレンジングで、長期臨床推論の評価にはほんまにぴったりなんや。
EHRSHOTから代表的な4つの予測タスクを選んだで:長期入院(Long Length of Stay)、30日以内の再入院(30-day Readmission)、急性心筋梗塞(Acute MI)、そして貧血(Anemia)や。最初の二つは「運用上の結果」カテゴリーに入るタスクで、貧血は「検査結果の予測」に属して、急性心筋梗塞は「新しい診断の割り当て」に分類されとるねん。最初の三つは二値分類問題(YesかNoかみたいなやつ)で、貧血は4クラス分類タスクや。これらのタスク全部合わせると、多様な臨床目標と時間的推論のシナリオをカバーしとって、構造化されたEHRデータでの長期推論を包括的に評価できるようになっとるわけや。評価指標としては、正解率(Accuracy)、マクロF1、そしてクラスごとのF1スコアを報告しとるで。なんでかっていうと、臨床分類タスクはだいたい本質的にクラス間の数に偏りがあるからやねん。
実験には、プロプライエタリ(商用)とオープンソース両方をカバーする3つのLLMを使ったで:GPT-5、Claude-Opus-4.5、そしてLLaMA-3.1-8Bや。これらのモデルはアーキテクチャ、学習規模、モデルサイズ、アクセスのしやすさが幅広くて、EHR-RAGが異なるLLMバックボーンでもちゃんと動くかどうかの頑健性を評価できるねん。実験セットアップの詳細は付録Aに載せとるで。
4.2. ベースライン
EHR-RAGを、EHRデータでよく使われるLLMベースのベースライン手法と比較したで。直接生成と、いろんなRAGアプローチを含むねん。
• 直接生成(Linらの2025年の研究):LLMが検索なしで、患者の電子カルテから直接臨床結果を予測するやつや。コンテキストの制約を満たすために、電子カルテは最大コンテキストウィンドウに収まるように最近のイベントだけを残して切り詰めるねん。これは以前のLLMベースのEHR研究でよく使われるヒューリスティック(経験則)や。このベースラインは、証拠選択なしで単純にコンテキストを切り詰めた場合の性能を評価するもんや。
• RAG(Gaoらの2023年の研究):関連するEHR証拠を検索して、その検索されたコンテキストをLLMに与えるバニラ(基本的な)検索アプローチや。このベースラインは、最近の臨床および非臨床アプリケーションで使われとる最も一般的な一回きりのRAG方式を反映しとるねん。
• ユニフォームRAG(Liuらの2024年の研究):意味的な
---
## Page 6
[](/attach/1dbadf199fa2c350f0c32ae25e3af2e11e9942ece18b840da4911c18fbb97bc3_p006.png)
### 和訳
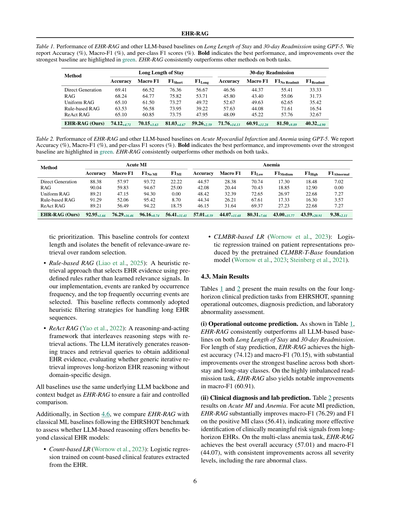
表1やねん。GPT-5使った長期入院とか30日以内の再入院予測で、EHR-RAGと他のLLMベースの手法を比較した結果やで。精度(%)、マクロF1(%)、あとクラスごとのF1スコア(%)を載せとるわ。太字が一番ええ成績で、緑色のハイライトは一番強かったベースラインからどんだけ良くなったかを示しとるねん。EHR-RAGは両方のタスクで他の手法をしっかり上回っとるで。
EHR-RAG
手法 | 長期入院 | 30日以内再入院
---|---|---
| 精度 | マクロF1 | F1短期 | F1長期 | 精度 | マクロF1 | F1再入院なし | F1再入院あり
直接生成 | 69.41 | 66.52 | 76.36 | 56.67 | 46.56 | 44.37 | 55.41 | 33.33
RAG | 68.24 | 64.77 | 75.82 | 53.71 | 45.80 | 43.40 | 55.06 | 31.73
均一RAG | 65.10 | 61.50 | 73.27 | 49.72 | 52.67 | 49.63 | 62.65 | 35.42
ルールベースRAG | 63.53 | 56.58 | 73.95 | 39.22 | 57.63 | 44.08 | 71.61 | 16.54
ReAct RAG | 65.10 | 60.85 | 73.75 | 47.95 | 48.09 | 45.22 | 57.76 | 32.67
EHR-RAG(ワイらの)| 74.12+4.71 | 70.15+3.63 | 81.03+4.67 | 59.26+2.59 | 71.76+14.13 | 60.91+11.28 | 81.50+9.89 | 40.32+4.90
表2やで。急性心筋梗塞と貧血の予測で、EHR-RAGと他のLLMベースの手法をGPT-5で比較した結果やねん。精度(%)、マクロF1(%)、クラスごとのF1スコア(%)を報告しとるわ。太字が一番ええ成績で、緑色のハイライトは最強ベースラインからの改善幅やで。EHR-RAGは両タスクで一貫して他の手法を上回っとるねん。
手法 | 急性心筋梗塞 | 貧血
---|---|---
| 精度 | マクロF1 | F1 MI無し | F1 MI有り | 精度 | マクロF1 | F1軽度 | F1中等度 | F1重度 | F1異常
直接生成 | 88.38 | 57.97 | 93.72 | 22.22 | 44.57 | 28.38 | 70.74 | 17.30 | 18.48 | 7.02
RAG | 90.04 | 59.83 | 94.67 | 25.00 | 42.08 | 20.44 | 70.43 | 18.85 | 12.90 | 0.00
均一RAG | 89.21 | 47.15 | 94.30 | 0.00 | 48.42 | 32.39 | 72.65 | 26.97 | 22.68 | 7.27
ルールベースRAG | 91.29 | 52.06 | 95.42 | 8.70 | 44.34 | 26.21 | 67.61 | 17.33 | 16.30 | 3.57
ReAct RAG | 89.21 | 56.49 | 94.22 | 18.75 | 46.15 | 31.64 | 69.37 | 27.23 | 22.68 | 7.27
EHR-RAG(ワイらの)| 92.95+1.66 | 76.29+16.46 | 96.16+0.74 | 56.41+31.41 | 57.01+8.59 | 44.07+11.68 | 80.31+7.66 | 43.00+15.77 | 43.59+20.91 | 9.38+2.11
で、ここからベースラインの説明入るで。コンテキストの長さを揃えて、ランダムに選ぶんやなくて関連性を考慮した検索がどんだけ効くかを切り分けるためのベースラインやねん。
• **ルールベースRAG**(Liaoら、2025年):学習した関連性シグナルやなくて、あらかじめ決めたルールでEHRのエビデンスを選ぶヒューリスティックな検索アプローチやで。ワイらの実装では、イベントを出現頻度でランク付けして、よう出てくるイベントを上位から選んどるねん。これは長いEHR系列を処理するときによう使われるヒューリスティックなフィルタリング戦略を反映しとるわけや。
• **ReAct RAG**(Yaoら、2022年):推論ステップと検索アクションを交互に繰り返すフレームワークやねん。LLMが推論のトレースと検索クエリを繰り返し生成して、追加のEHRエビデンスを取ってくるんや。ドメイン特化の設計なしで、一般的な反復検索が長期間のEHR推論を改善するかどうかを評価しとるで。
全部のベースラインはEHR-RAGと同じLLMバックボーンとコンテキスト予算を使っとるから、公平で統制された比較ができとるわけやな。
あと、セクション4.6では、EHRSHOTベンチマークに従って古典的な機械学習ベースラインとも比較しとるで。LLMベースの推論が古典的なEHRモデルより優れとるかを評価するためやねん:
• **カウントベースLR**(Wornowら、2023年):EHRから抽出したカウントベースの臨床特徴で学習したロジスティック回帰やで。
• **CLMBRベースLR**(Wornowら、2023年):事前学習済みのCLMBR-T-Base基盤モデル(Wornowら、2023年;Steinbergら、2021年)が生成した患者表現で学習したロジスティック回帰やねん。
### 4.3 メインの結果
表1と表2に、EHRSHOTの4つの長期間臨床予測タスクの主要結果を示しとるで。運用アウトカム、診断予測、検査値異常評価にまたがっとるわ。
**(i) 運用アウトカム予測**:表1を見てみ。EHR-RAGは長期入院と30日以内再入院の両方で、全部のLLMベースラインを一貫して上回っとるねん。入院期間予測では、EHR-RAGが最高精度(74.12)とマクロF1(70.15)を達成しとって、短期入院と長期入院の両クラスで最強ベースラインを大幅に超えとるで。めっちゃ不均衡な再入院タスクでも、EHR-RAGはマクロF1(60.91)で顕著な改善を見せとるわ。
**(ii) 臨床診断と検査値予測**:表2は急性心筋梗塞と貧血の結果やで。急性心筋梗塞予測では、EHR-RAGがマクロF1(76.29)と陽性MIクラスのF1(56.41)を大幅に改善しとるねん。これは長期間のEHRから臨床的に意味のあるリスクシグナルをより効果的に特定できとることを示しとるわ。多クラスの貧血タスクでも、EHR-RAGは全体精度(57.01)とマクロF1(44.07)で最高を達成しとって、レアな異常クラスを含む全部の重症度レベルで一貫した改善を見せとるで。
---
## Page 7
[](/attach/1dbadf199fa2c350f0c32ae25e3af2e11e9942ece18b840da4911c18fbb97bc3_p007.png)
### 和訳
EHR-RAG
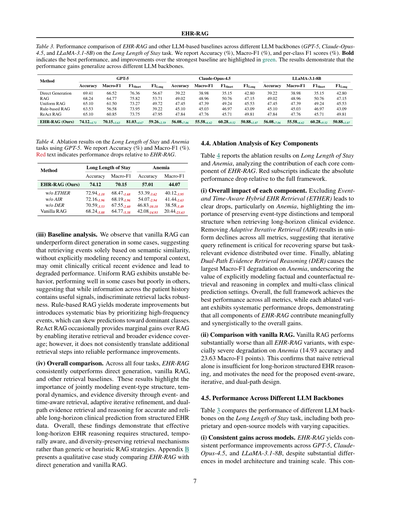
表3. 長期入院予測タスクで、EHR-RAGと他のLLMベースの手法を比較した結果やで。GPT-5、Claude-Opus4.5、LLaMA-3.1-8Bっていう異なるLLMバックボーンでテストしてん。精度(%)、マクロF1(%)、クラスごとのF1スコア(%)を載せてるで。太字は一番ええ成績、緑色は最強のベースラインからどんだけ良くなったかを示してるねん。結果見たら、どのLLMバックボーン使っても性能向上が一貫して見られるっちゅうことがわかるわ。
| 手法 | GPT-5 ||| | Claude-Opus-4.5 ||| | LLaMA-3.1-8B |||
|------|--------|---------|--------|--------|--------|---------|--------|--------|--------|---------|--------|--------|
| | 精度 | マクロF1 | F1短期 | F1長期 | 精度 | マクロF1 | F1短期 | F1長期 | 精度 | マクロF1 | F1短期 | F1長期 |
| 直接生成 | 69.41 | 66.52 | 76.36 | 56.67 | 39.22 | 38.98 | 35.15 | 42.80 | 39.22 | 38.98 | 35.15 | 42.80 |
| RAG | 68.24 | 64.77 | 75.82 | 53.71 | 49.02 | 48.96 | 50.76 | 47.15 | 49.02 | 48.96 | 50.76 | 47.15 |
| 均一RAG | 65.10 | 61.50 | 73.27 | 49.72 | 47.45 | 47.39 | 49.24 | 45.53 | 47.45 | 47.39 | 49.24 | 45.53 |
| ルールベースRAG | 63.53 | 56.58 | 73.95 | 39.22 | 45.10 | 45.03 | 46.97 | 43.09 | 45.10 | 45.03 | 46.97 | 43.09 |
| ReAct RAG | 65.10 | 60.85 | 73.75 | 47.95 | 47.84 | 47.76 | 45.71 | 49.81 | 47.84 | 47.76 | 45.71 | 49.81 |
| EHR-RAG(ワイらの手法) | 74.12+4.71 | 70.15+3.63 | 81.03+4.67 | 59.26+2.59 | 56.08+7.06 | 55.58+6.62 | 60.28+9.52 | 50.88+1.07 | 56.08+7.06 | 55.58+6.62 | 60.28+9.52 | 50.88+1.07 |
表4. GPT-5を使った長期入院予測と貧血タスクでのアブレーション(部品取り除き実験)の結果や。精度(%)とマクロF1(%)を載せてるで。赤字はフルのEHR-RAGと比べてどんだけ性能落ちたかを示してんねん。
| 手法 | 長期入院予測 || 貧血 ||
|------|--------|---------|--------|---------|
| | 精度 | マクロF1 | 精度 | マクロF1 |
| EHR-RAG(ワイらの手法) | 74.12 | 70.15 | 57.01 | 44.07 |
| ETHERなし | 72.94-1.18 | 68.47-1.68 | 53.39-3.62 | 40.12-3.95 |
| AIRなし | 72.16-1.96 | 68.19-1.96 | 54.07-2.94 | 41.44-2.63 |
| DERなし | 70.59-3.53 | 67.55-2.60 | 46.83-10.18 | 38.58-5.49 |
| バニラRAG | 68.24-5.88 | 64.77-5.38 | 42.08-14.93 | 20.44-23.63 |
(iii) ベースラインの分析やで。見てみたら、普通のRAGって直接生成より悪いケースがあるねん。なんでかっていうと、意味的な類似度だけでイベント取ってきて、最近のデータとか時間的な文脈をちゃんとモデル化してへんから、臨床的にめっちゃ重要な最近のエビデンスが抜け落ちて、性能がガタ落ちするってわけや。均一RAGは挙動が不安定で、うまくいくときもあれば全然あかんときもあるねん。患者の履歴全体には有用な情報あるんやけど、なんでもかんでも取ってくるやり方は頑健性に欠けるっちゅうことやな。ルールベースRAGはそこそこ改善するんやけど、よく出てくるイベントを優先するから系統的なバイアスが入って、多数派クラスに予測が偏りがちになるねん。ReAct RAGは反復的に取得して広くエビデンスをカバーできるから、普通のRAGよりちょっとマシになることもあるんやけど、追加の取得ステップが確実に性能向上につながるわけちゃうねん。
(iv) 全体比較やで。4つのタスク全部で、EHR-RAGは直接生成、普通のRAG、他の検索ベースラインを一貫して上回ってるねん。この結果が示してるのは、イベントタイプの構造、時間的なダイナミクス、エビデンスの多様性を同時にモデル化することがめっちゃ大事っちゅうことや。具体的には、イベントと時間を意識した検索、適応的な反復改良、二経路のエビデンス検索と推論を組み合わせることで、構造化された電子カルテデータから正確で信頼できる長期臨床予測ができるようになるねん。ほんまに、効果的な長期電子カルテ推論には、構造化された、時間を意識した、多様性を保持する検索メカニズムが必要で、一般的なRAGとかヒューリスティックなRAG戦略じゃあかんってことやな。付録BにはEHR-RAGと直接生成、普通のRAGを比較した定性的なケーススタディが載ってるで。
4.4. 主要コンポーネントのアブレーション分析
表4は長期入院予測と貧血タスクでのアブレーション結果を示してて、EHR-RAGの各コア部品がどんだけ貢献してるか分析してるねん。赤い下付き文字はフルのフレームワークと比べた絶対的な性能低下を示してるで。
(i) 各コンポーネントの全体的な影響やで。イベント・時間認識ハイブリッド電子カルテ検索(ETHER)を外すと明らかに性能落ちるねん、特に貧血タスクで顕著やで。これは長期の臨床エビデンスを取ってくるときに、イベントタイプの区別と時間的な構造を保持することがめっちゃ大事っちゅうことを示してるねん。適応的反復検索(AIR)を外すと全指標で一様に低下するから、時間的に散らばったタスク関連のまばらなエビデンスを回収するには、クエリの反復的な改良が重要やっちゅうことがわかるわ。最後に、二経路エビデンス検索推論(DER)を外すと貧血でマクロF1の低下が一番大きくなるねん。これは複雑で多クラスの臨床予測設定では、事実的と反事実的な検索・推論を明示的にモデル化することの価値を示してるわ。全体として、フルのフレームワークが全指標で最高の性能を達成して、どのアブレーション版も系統的に性能が落ちるから、EHR-RAGの全コンポーネントが意味ある形で相乗的に全体の改善に貢献してることがわかるねん。
(ii) バニラRAGとの比較やで。バニラRAGはEHR-RAGのどのバージョンよりもかなり悪くて、特に貧血では深刻やねん(精度14.93ポイント、マクロF1で23.63ポイントも落ちる)。これで確認できるのは、単純な検索だけじゃ長期の構造化電子カルテ推論には全然足りひんっちゅうことで、提案したイベント認識型、反復型、二経路設計の必要性がはっきりするわけや。
4.5. 異なるLLMバックボーン間での性能比較
表3は長期入院予測タスクで異なるLLMバックボーンの性能を比較してるねん。プロプライエタリ(商用)モデルとオープンソースモデルの両方、しかも容量が違うやつも含めてテストしてるで。
(i) モデル間で一貫した改善が見られるねん。EHR-RAGはGPT-5、Claude-Opus-4.5、LLaMA-3.1-8Bの全部で一貫して性能向上してるねん。モデルのアーキテクチャとか学習規模がめっちゃ違うのにもかかわらずや。これは
---
## Page 8
[](/attach/1dbadf199fa2c350f0c32ae25e3af2e11e9942ece18b840da4911c18fbb97bc3_p008.png)
### 和訳
EHR-RAG
図2. EHR-RAG、普通のRAG、そして従来の機械学習(ML)のベースラインを、ラベル付きトレーニングデータの量を変えながら4つのタスクで比較したMacro-F1の性能やねん。横軸はクラスごとのトレーニングサンプル数を表してて、点線の水平線はLLMベースの手法のゼロショット性能を示してるで。EHR-RAGは一貫してMLベースラインと同等かそれ以上の性能を発揮してて、特にデータが少ない状況でめっちゃ強いんよ。
この安定した結果が示してるんは、提案した検索と推論のフレームワークが、特定のモデルの特性に頼らんと、いろんなLLMバックボーンに対して汎用的に使えるってことやねん。
(ii) 小さいモデルほど改善効果がデカい。GPT-5が絶対的な性能では一番高いんやけど、EHR-RAGによる相対的な改善はLLaMA-3.1-8Bでより顕著に出てるんよ。最強のベースラインと比べて、EHR-RAGは両方のモデルでMacro-F1を6ポイント以上改善してんねん。これが意味するんは、この設計が小さいモデルの能力的な限界をある程度カバーできるってことやな。
4.6. 従来の機械学習ベースラインとの比較
図2では、ラベル付きデータの量を変えながら(少数ショットから全データまで)、EHR-RAGと機械学習ベースラインのMacro-F1性能を比較してるで。横軸はクラスごとのトレーニングサンプル数やねん。LLMベースの手法はゼロショット設定で評価してるから、水平の参照線として表示されてるわけや。
(i) データが少ない状況での性能。全タスク通じて、EHR-RAGはほとんどの少数ショット設定でMLベースラインを上回ってんねん。クラスごとにラベル付きサンプルが限られてる時(例えば1〜16ショット)、カウントベースもCLMBRベースのロジスティック回帰モデルも、性能がガクッと落ちてまうんよ。せやけどEHR-RAGは、事前学習済みLLMの知識と取得したEHRエビデンスをうまいこと組み合わせることで、比較的安定した性能を維持してんねん。これがデータ少ない環境でのめっちゃ高いデータ効率を示してるわけや。
(ii) 表現ベースのMLモデルとの比較。予想通り、CLMBRベースのロジスティック回帰は一般的にカウントベースの特徴量より性能が高くて、特にトレーニングサンプルが増えるほどその差が顕著になるんよ。これは事前学習済みの基盤モデルが一般的な臨床的表現を捉える上での優位性を反映してるねん。せやけどな、中程度から全データ設定でも、EHR-RAGは全タスクで同等かそれ以上のMacro-F1スコアを達成してんねん。これが示唆するんは、検索拡張型LLM推論が、固定された患者表現では捉えきれへん異質で時間的に分散した臨床エビデンスを効果的に統合できるってことやな。
(iii) 長期予測と不均衡タスクでの頑健性。EHR-RAGの優位性は、急性心筋梗塞や貧血みたいな長期予測かつクラス不均衡なタスクで一番はっきり出てんねん。こういう設定では、MLベースラインは長い患者履歴にまばらに散らばってるけど臨床的には重要な信号を捉えるのに苦労するんよ。せやけどEHR-RAGは強力な汎化能力とゼロショット推論能力を活かして、関連するエビデンスを掘り起こして集約することで、より頑健な性能を発揮してんねん。
全体として、これらの結果が示してるんは、EHR-RAGはデータ少ない環境で従来のMLベースラインを上回るだけやなくて、大量のラベル付きデータが利用可能な場合でも競争力があるか優れてるってことやねん。これは長期EHR予測のための汎用フレームワークとしての有効性を裏付けてるわけや。
5. 結論
この論文では、長期EHRとLLMをつなぐために設計された強化版検索拡張フレームワーク、EHR-RAGを紹介したで。EHR-RAGは長期EHRデータが抱える主要な課題、つまりコンテキストウィンドウの制限、時間的な断片化、不完全なエビデンス検索といった問題に対処してんねん。具体的には、イベントと時間を意識したハイブリッドEHR検索、適応的反復精緻化、そして二経路エビデンス検索・推論を組み合わせて解決してるんよ。
広範な実験により、EHR-RAGは多様な長期臨床予測タスクにおいて、他のLLMベースのベースラインを一貫して上回ることが実証されたで。全体として、ほんまに考え抜かれた検索と推論メカニズムによって、厳しいコンテキスト制約下でも、LLMが長期構造化EHRデータを効果的に解釈できるようになることを示してんねん。
EHR-RAGは、より信頼性が高くデータ効率の良い臨床予測システムに向けた実用的な一歩やと考えてるし、縦断的医療データに対するスケーラブルでエビデンスに基づいた推論に関する今後の研究の基盤になると思うで。
---
## Page 9
[](/attach/1dbadf199fa2c350f0c32ae25e3af2e11e9942ece18b840da4911c18fbb97bc3_p009.png)
### 和訳
EHR-RAG
**この研究がなんでやるかっていう話(Impact Statement)**
この研究はな、電子カルテっちゅう長い期間にわたる医療記録を大規模言語モデルで賢く分析するために、情報を取ってきて(検索して)それを元に答えを生成するっていう技術(RAG:Retrieval-Augmented Generation)を進歩させようとしてるねん。ウチらのシステムは誰でもアクセスできる匿名化されたデータを使って開発してるんやけど、臨床情報を扱う研究やから、プライバシーとか公平性とか、AIを使った意思決定支援をどう適切に使うかっていう配慮が必要やっていうのはちゃんとわかってるで。この手法はあくまで研究としての貢献であって、実際の臨床現場で動いてるシステムちゃうねん。治療の推奨を勝手にAIがするようなもんでもないで。そうやなくて、時間に沿った情報の取り出しと推論の技術的なしっかり度を上げることを目指してて、将来的にもっと安全で分かりやすい臨床AIツールを開発するのに役立つかもしれへんっていう話やねん。
**参考文献(References)**
Abdallah, A., Piryani, B., Wallat, J., Anand, A., and Jatowt, A. 密な文章検索に時間情報を加える研究。arXiv e-prints, pp. arXiv–2502, 2025.
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., 他。GPT-4の技術レポート。arXiv preprint arXiv:2303.08774, 2023.
Asai, A., Wu, Z., Wang, Y., Sil, A., and Hajishirzi, H. Self-RAG:自己反省を通じて検索・生成・批評を学習する研究。arXiv preprint arXiv:2310.11511, 2023.
Ashfaq, A., Sant'Anna, A., Lingman, M., and Nowaczyk, S. 電子カルテを使ったディープラーニングによる再入院予測。Journal of biomedical informatics, 97: 103256, 2019.
Bedi, S., Liu, Y., Orr-Ewing, L., Dash, D., Koyejo, S., Callahan, A., Fries, J. A., Wornow, M., Swaminathan, A., Lehmann, L. S., 他。大規模言語モデルの医療応用のテストと評価:システマティックレビュー。Jama, 2025.
Bhoi, S., Lee, M. L., Hsu, W., Fang, H. S. A., and Tan, N. C. グラフベースのアプローチを使った薬のおすすめの個別化。ACM Transactions on Information Systems (TOIS), 40(3):1–23, 2021.
Cai, X., Perez-Concha, O., Coiera, E., Martin-Sanchez, F., Day, R., Roffe, D., and Gallego, B. 電子カルテデータを使った死亡率・再入院・入院期間のリアルタイム予測。Journal of the American Medical Informatics Association, 23(3):553–561, 2016.
Cao, L., Sun, J., and Cross, A. AutoRD:オントロジー強化型大規模言語モデルに基づく希少疾患知識グラフの自動エンドツーエンド構築システム。arXiv preprint arXiv:2403.00953, 2024a.
Cao, L., Wang, Z., Xiao, C., and Sun, J. PILOT:判例法を使った法的ケース結果予測。Duh, K., Gomez, H., and Bethard, S. (編), Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp. 609–621, Mexico City, Mexico, June 2024b. Association for Computational Linguistics. doi: 10.18653/v1/2024.naacl-long.34. URL https://aclanthology.org/2024.naacl-long.34/.
Chen, C., Yu, J., Chen, S., Liu, C., Wan, Z., Bitterman, D., Wang, F., and Shu, K. ClinicalBench:LLMは臨床予測で従来の機械学習モデルに勝てるか? arXiv preprint arXiv:2411.06469, 2024.
Choi, E., Bahadori, M. T., Sun, J., Kulas, J., Schuetz, A., and Stewart, W. RETAIN:逆時間アテンション機構を使った解釈可能な医療予測モデル。Advances in neural information processing systems, 29, 2016.
Choi, E., Bahadori, M. T., Song, L., Stewart, W. F., and Sun, J. GRAM:医療表現学習のためのグラフベースアテンションモデル。Proceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining, pp. 787–795, 2017.
Cowie, M. R., Blomster, J. I., Curtis, L. H., Duclaux, S., Ford, I., Fritz, F., Goldman, S., Janmohamed, S., Kreuzer, J., Leenay, M., 他。臨床研究を促進するための電子カルテ。Clinical Research in Cardiology, 106(1):1–9, 2017.
Croskerry, P. 診断における認知エラーの重要性とそれを最小化する戦略。Academic medicine, 78(8):775–780, 2003.
Cui, H., Shen, Z., Zhang, J., Shao, H., Qin, L., Ho, J. C., and Yang, C. 電子カルテを使ったLLMベースの少数事例疾患予測:予測エージェント推論と重要エージェント指示を組み合わせた新しいアプローチ。AMIA Annual Symposium Proceedings, volume 2024, pp. 319, 2025.
Ebbers, T., Kool, R. B., Smeele, L. E., Dirven, R., den Besten, C. A., Karssemakers, L. H., Verhoeven, T., Herruer, J. M., van den Broek, G. B., and Takes, R. P. 構造化・標準化された記録が文書品質に与える影響:多施設後ろ向き研究。Journal of Medical Systems, 46(7):46, 2022.
Elstein, A. S., Shulman, L. S., and Sprafka, S. A. 医学的問題解決:臨床推論の分析。Harvard University Press, 1978.
---
## Page 10
[](/attach/1dbadf199fa2c350f0c32ae25e3af2e11e9942ece18b840da4911c18fbb97bc3_p010.png)
### 和訳
EHR-RAG
Fries, J. A., Wornow, M., Steinberg, E., Huo, Z. F., Cui, H., Bedi, S., Unell, A., and Shah, N. 「責任ある医療AIを時系列の電子カルテデータセットで前に進めていこうや」っていう話やねん、2025年。Stanford HAI Newsに載ってるで。
Kojima, T., Gu, S. S., Reid, M., Matsuo, Y., and Iwasawa, Y. 大規模言語モデルってな、実はゼロショットでめっちゃ推論できるねん。つまり、事前に例を見せんでも「ちょっと考えてみ」って言うだけで賢く答えられるっちゅうことや。Advances in neural information processing systems, 35: 22199–22213, 2022年の論文やで。
Gao, Y., Xiong, Y., Gao, X., Jia, K., Pan, J., Bi, Y., Dai, Y., Sun, J., Wang, H., and Wang, H. 検索拡張生成(RAG)ってやつを大規模言語モデルに使う方法についてのサーベイ論文やねん。外部の情報を検索して、それを参考にしながら回答を生成するっていう仕組みのことやで。arXiv preprint arXiv:2312.10997, 2(1), 2023年。
Graber, M. L., Franklin, N., and Gordon, R. 内科での診断エラーについての研究やな。お医者さんも人間やから間違えることあるやん、それをちゃんと調べた論文や。Archives of internal medicine, 165(13):1493–1499, 2005年。
Hegselmann, S., von Arnim, G., Rheude, T., Kronenberg, N., Sontag, D., Hindricks, G., Eils, R., and Wild, B. 大規模言語モデルがな、電子カルテのエンコーダーとしてめっちゃ優秀やっていう話やねん。カルテの情報をうまく数値表現に変換できるってことや。arXiv preprint arXiv:2502.17403, 2025年。
Jiang, P., Xiao, C., Cross, A., and Sun, J. GraphCareっていうシステムで、個人に合わせた知識グラフを使って医療予測をパワーアップさせる研究やで。患者さん一人一人に合わせたグラフを作るんがポイントやねん。arXiv preprint arXiv:2305.12788, 2023年。
Jiang, P., Xiao, C., Jiang, M., Bhatia, P., Kass-Hout, T., Sun, J., and Han, J. 知識グラフのコミュニティ検索を使って、推論能力を強化した医療予測の研究やねん。グラフの中から関連する情報のかたまりを見つけてきて、それを推論に活かすっちゅうわけや。arXiv preprint arXiv:2410.04585, 2024年。
Jiang, P., Cao, L., Zhu, R., Jiang, M., Zhang, Y., Sun, J., and Han, J. RAS(Retrieval-and-Structuring)っていう手法で、知識をいっぱい使うLLMの生成を賢くしようっていう研究やな。検索して構造化するっていう二段構えやねん。arXiv preprint arXiv:2502.10996, 2025a。
Jiang, P., Lin, J., Cao, L., Tian, R., Kang, S., Wang, Z., Sun, J., and Han, J. DeepRetrievalっていうのはな、強化学習を使って大規模言語モデルで本物の検索エンジンや検索システムをハックしよう、つまりめっちゃ賢く使いこなそうっていう研究やねん。arXiv preprint arXiv: 2503.00223, 2025b。
Johnson, A. E., Pollard, T. J., Shen, L., Lehman, L.-w. H., Feng, M., Ghassemi, M., Moody, B., Szolovits, P., Anthony Celi, L., and Mark, R. G. MIMIC-IIIっていう集中治療室のデータベースやねん。無料で使える電子カルテのデータセットで、研究にめっちゃ重宝されてるやつや。Scientific data, 3(1):1–9, 2016年。
Johnson, A. E., Bulgarelli, L., Shen, L., Gayles, A., Shammout, A., Horng, S., Pollard, T. J., Hao, S., Moody, B., Gow, B., et al. MIMIC-IVや。これはMIMIC-IIIの進化版で、より新しくてより使いやすくなった無料の電子カルテデータセットやで。Scientific data, 10(1):1, 2023年。
Kruse, M., Hu, S., Derby, N., Wu, Y., Stonbraker, S., Yao, B., Wang, D., Goldberg, E., and Gao, Y. 時間的な推論ができる大規模言語モデルを使って、長期間にわたる臨床データの要約と予測をする研究やねん。時間の流れを考慮できるのがミソやで。Findings of the Association for Computational Linguistics: EMNLP 2025, pp. 20715–20735, 2025年。
Levin, S., Barnes, S., Toerper, M., Debraine, A., DeAngelo, A., Hamrock, E., Hinson, J., Hoyer, E., Dungarani, T., and Howell, E. 機械学習ベースの退院予測システムがな、多職種カンファレンスをサポートして、入院期間を短くできるっていう研究やねん。ほんまに実用的な話やで。BMJ Innovations, 7(2), 2021年。
Li, H., Deng, B., Xu, C., Feng, Z., Schlegel, V., Huang, Y.-H., Sun, Y., Sun, J., Yang, K., Yu, Y., et al. MIRAっていう医療時系列データ用の基盤モデルやねん。実際の健康データを扱うために作られてるで。arXiv preprint arXiv:2506.07584, 2025a。
Li, Z., Yu, H., Guo, G., Zhou, N., and Zhang, J. MuISQAっていうのは、科学的な質問応答のための複数意図対応の検索拡張生成やねん。一つの質問に複数の意図が含まれてる場合にも対応できるのがポイントや。arXiv preprint arXiv:2511.16283, 2025b。
Liao, Y., Wu, C., Liu, J., Jiang, S., Qiu, P., Wang, H., Yue, Y., Zhen, S., Wang, J., Fan, Q., et al. EHR-R1っていうのは、電子カルテ分析のための推論能力を強化した基盤言語モデルやねん。推論力がめっちゃ大事やからな。arXiv preprint arXiv:2510.25628, 2025年。
Lin, J., Wu, Z., and Sun, J. 電子カルテベースの推論タスクのために、強化学習を使ってLLMを訓練するっていう研究やで。arXiv preprint arXiv:2505.24105, 2025年。
Liu, N. F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F., and Liang, P. 「真ん中で迷子になる」っていう有名な論文やねん。言語モデルが長いコンテキストを使うとき、真ん中あたりの情報を見落としがちやっていう問題を指摘してるんや。Transactions of the association for computational linguistics, 12:157–173, 2024年。
Loh, D. R., Hill, E. D., Liu, N., Dawson, G., and Engelhard, M. M. 長期間の診断予測において二値分類の限界があるから、離散時間のイベント発生までの時間を予測するアプローチの方がええで、っていう実証分析やねん。JMIR AI, 4:e62985, 2025年。
Kim, H., Sohn, J., Gilson, A., Cochran-Caggiano, N., Applebaum, S., Jin, H., Park, S., Park, Y., Park, J., Choi, S., et al. 医療向けの検索拡張生成を見直そうっていう論文で、大規模かつ体系的な専門家評価と実践的な知見をまとめてるねん。RAGを医療で使うときに何が大事かがわかるで。arXiv preprint arXiv:2511.06738, 2025年。
Lovon-Melgarejo, J., Ben-Haddi, T., Di Scala, J., Moreno, J. G., and Tamine, L. MIMIC-IVベンチマークを言語モデルで電子カルテに使う実験で再検討したっていう論文やな。Proceedings of the First Workshop on Patient-Oriented Language Processing (CL4Health)@ LREC-COLING 2024, pp. 189–196, 2024年。
10
---
## Page 11
[](/attach/1dbadf199fa2c350f0c32ae25e3af2e11e9942ece18b840da4911c18fbb97bc3_p011.png)
### 和訳
EHR-RAG(電子カルテ×検索拡張生成)の参考文献リストやで!
Menachemi, N. と Collum, T. H.(2011)「電子カルテシステムのメリットとデメリット」Risk management and healthcare policy誌、pp. 47–55。
Tramontini, D. L., Ghosh, S., Eickhoff, C.(2025)「臨床試験と患者マッチングにおけるRAGベースのアプローチの検証」Machine Learning for Health 2025。
Neha, F., Bhati, D., Shukla, D. K.(2025)「医療分野における検索拡張生成(RAG)の包括的レビュー」AI誌、6(9):226。
Niu, S., Ma, J., Bai, L., Wang, Z., Guo, L., Yang, X.(2024)「EHR-KnowGen:病気の診断生成のための知識強化型マルチモーダル学習」Information Fusion誌、102: 102069。めっちゃ簡単に言うと、いろんな種類のデータと知識を組み合わせて診断を出すシステムやねん。
Perçin, S., Su, X., Syed, Q. S., Howard, P., Kuvshinov, A., Schwinn, L., Scholl, K.-U.(2025)「クエリレベルでの検索拡張生成の頑健性の調査」GEM2ワークショップ論文集、pp. 439–457。つまりRAGが質問の仕方でどれだけブレへんかを調べてんねん。
Rosenbloom, S. T., Denny, J. C., Xu, H., Lorenzi, N., Stead, W. W., Johnson, K. B.(2011)「臨床ノートからのデータ:構造化と柔軟な記録のジレンマについて」Journal of the American Medical Informatics Association誌、18(2):181–186。
Shang, J., Xiao, C., Ma, T., Li, H., Sun, J.(2019)「GAMENet:薬の組み合わせを推薦するためのグラフ拡張メモリネットワーク」AAAI Conference on Artificial Intelligence論文集、volume 33、pp. 1126–1133。
Shi, W., Xu, R., Zhuang, Y., Yu, Y., Zhang, J., Wu, H., Zhu, Y., Ho, J. C., Yang, C., Wang, M. D.(2024)「EHRAgent:電子カルテ上の少数ショット複雑表形式推論のための大規模言語モデルをコードで強化」EMNLP 2024論文集、pp. 22315–22339。要するに、電子カルテみたいな複雑な表データをAIにうまく扱わせる方法やねん。
Soman, K., Rose, P. W., Morris, J. H., Akbas, R. E., Smith, B., Peetoom, B., Villouta-Reyes, C., Cerono, G., Shi, Y., Rizk-Jackson, A. ほか(2024)「大規模言語モデル向けの生物医学知識グラフ最適化プロンプト生成」Bioinformatics誌、40(9):btae560。
Sox, H. C., Higgins, M. C., Owens, D. K., Schmidler, G. S.(2024)『Medical Decision Making(医療における意思決定)』John Wiley & Sons。
Steinberg, E., Jung, K., Fries, J. A., Corbin, C. K., Pfohl, S. R., Shah, N. H.(2021)「言語モデルは電子カルテデータの効果的な表現学習手法である」Journal of Biomedical Informatics誌、113: 103637。
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F. ほか(2023)「LLaMA:オープンで効率的な基盤言語モデル」arXivプレプリント arXiv:2302.13971。これがあのLLaMAの論文やで!
Vorontsov, E., Bozkurt, A., Casson, A., Shaikovski, G., Zelechowski, M., Severson, K., Zimmermann, E., Hall, J., Tenenholtz, N., Fusi, N. ほか(2024)「臨床グレードの計算病理学と希少がん検出のための基盤モデル」Nature Medicine誌、30(10):2924–2935。
Wallace, E., Wang, Y., Li, S., Singh, S., Gardner, M.(2019)「NLPモデルは数字を理解しとるんか?埋め込みにおける数値理解能力の検証」arXivプレプリント arXiv:1909.07940。
Wornow, M., Thapa, R., Steinberg, E., Fries, J., Shah, N.(2023)「EHRSHOT:基盤モデルの少数ショット評価のための電子カルテベンチマーク」Advances in Neural Information Processing Systems、36:67125–67137。
Xiao, C., Ma, T., Dieng, A. B., Blei, D. M., Wang, F.(2018)「臨床概念の深層文脈埋め込みによる再入院予測」PLoS ONE誌、13(4):e0195024。
Yang, K., Xu, Y., Zou, P., Ding, H., Zhao, J., Wang, Y., Xie, B.(2023)「KerPrint:振り返りと予測的解釈のためのローカル-グローバル知識グラフ強化診断予測」AAAI Conference on Artificial Intelligence論文集、volume 37、pp. 5357–5365。
Yang, X., Chen, A., PourNejatian, N., Shin, H. C., Smith, K. E., Parisien, C., Compas, C., Martin, C., Costa, A. B., Flores, M. G. ほか(2022)「電子カルテのための大規模言語モデル」NPJ Digital Medicine誌、5(1):194。
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K. R., Cao, Y.(2022)「ReAct:言語モデルにおける推論と行動の相乗効果」ICLR 2022。これ、めっちゃ有名な論文やで!AIが考えながら行動するっていうアイデアの元祖やねん。
Zhang, X., Ramachandran, D., Tenney, I., Elazar, Y., Roth, D.(2020)「言語埋め込みはスケール(尺度)を捉えとるんか?」arXivプレプリント arXiv:2010.05345。
Zhu, Y., Ren, C., Wang, Z., Zheng, X., Xie, S., Feng, J., Zhu, X., Li, Z., Ma, L., Pan, C.(2024a)「EMERGE:検索拡張生成によるマルチモーダル電子カルテ予測モデリングの強化」ACM CIKM 2024論文集、pp. 3549–3559。
Zhu, Y., Ren, C., Xie, S., Liu, S., Ji, H., Wang, Z., Sun, T., He, L., Li, Z., Zhu, X. ほか(2024b)「REALM:大規模言語モデルによるマルチモーダル電子カルテ解析のRAG駆動型強化」arXivプレプリント arXiv:2402.07016。
---
## Page 12
[](/attach/1dbadf199fa2c350f0c32ae25e3af2e11e9942ece18b840da4911c18fbb97bc3_p012.png)
### 和訳
EHR-RAG
Zhu, Y., Wang, Z., Gao, J., Tong, Y., An, J., Liao, W., Harrison, E. M., Ma, L., Pan, C.「構造化された時系列の電子カルテデータ使って、大規模言語モデルにゼロショットで臨床予測させるプロンプトの研究」arXivプレプリント arXiv:2402.01713, 2024c.
要するにな、この論文は電子カルテ(EHR)のデータを大規模言語モデル(LLM)に食わせて、事前学習なしのゼロショットで病気の予測とかさせようっていう研究やねん。時系列で記録された患者さんの情報をうまいことプロンプトに変換して、AIに「この患者さん、次どうなりそう?」って聞くわけや。めっちゃ画期的な試みやで。
12
---
## Page 13
[](/attach/1dbadf199fa2c350f0c32ae25e3af2e11e9942ece18b840da4911c18fbb97bc3_p013.png)
### 和訳
A. 実験セットアップの詳細
EHR-RAG
**データセットの処理**
ほな、まずデータセットの話からいくで。今回はEHRSHOTベンチマーク(Wornowら、2023年)っていうのを使っとるんやけど、これがMEDSっていう形式に対応したやつなんや。生データの段階では、臨床イベント(患者さんに起きた医療的な出来事のことやな)がぜんぶMEDSコードで表現されとるねん。でもな、これをそのままLLM(大規模言語モデル、めっちゃ賢いAIのことな)に読ませてもワケわからんから、自然言語の説明文に変換する必要があるんや。そこで、Athenaっていう医療用語集とCPTっていう処置コードのサブセット(UMLSっていう医療用語データベース経由で取得したやつ)から、軽量な医療オントロジー(専門用語の辞書みたいなもんやな)を作って、コードを説明文にマッピングしたんや。
評価に使ったタスクは4つあって、「長期入院」「30日以内の再入院」「急性心筋梗塞」「貧血」やねん。詳しいことは付録Cにまとめてあるで。LLMに入力するときは、各イベントを統一テンプレートでシリアライズ(文字列化)しとるんや。具体的には `[時刻] 種類 - 説明 (value: 値)` っていう形式やな。例えば `[2018-02-05 08:56:00] measurement - Blood Pressure (value: 120 mmHg)` みたいな感じや。
**LLMの生成設定**
今回評価したLLMは3つや:GPT-5(gpt-5-2025-08-07)、Claude-Opus-4.5(claude-opus-4-5-20251101)、そしてLLaMA-3.1-8B(Meta-Llama-3.1-8B-Instruct)やな。全部Azure AIプラットフォームで動かしとるんやけど、これがPhysioNetの認定データ利用規約と臨床データの責任ある利用ガイドラインに準拠しとるから安心や。
LLMベースの手法ぜんぶで、生成時の温度パラメータ(出力のランダム性を制御するやつな)は0に設定して、安定した決定論的な出力が出るようにしとるねん。ただしGPT-5だけは温度1が必須やから、そこだけ例外や。計算効率とモデル間の公平な比較のために、最大コンテキスト長は128,000トークンに固定して、他の生成ハイパーパラメータはデフォルト値のままにしとるで。実験で使ったプロンプトテンプレートは全部付録Dに載せとるから、気になったら見てな。
**機械学習ベースラインの学習設定**
Count-based LR(カウントベースのロジスティック回帰)とCLMBR-based LR(CLMBRベースのロジスティック回帰)の学習セットアップは、先行研究(Wornowら、2023年)にきっちり従っとるねん。モデルアーキテクチャもハイパーパラメータ設定も同じや。各タスクで、クラスごとに1, 2, 4, 8, 16, 32, 64, 128, 256ショット(サンプル数のことな)という異なるデータ量の条件で別々にモデルを訓練して、さらにフル訓練セットでも訓練しとる。CLMBR-based LRのベースラインでは、事前学習済みのCLMBR-T-Base基盤モデル(Wornowら、2023年;Steinbergら、2021年)を使って患者の表現ベクトルを生成しとるで。機械学習ベースラインはぜんぶ、80GBメモリ搭載のNVIDIA A800 GPU1枚で訓練・評価しとるんや。
**ベースラインの検索設定**
Direct Generation(直接生成)では、各患者のEHR(電子カルテ)を直近1,000イベントだけ残して切り詰めとる。Rule-based RAG(ルールベースRAG)では、まず全イベントをその患者の履歴内でのイベントコードの出現頻度でランク付けして、最も頻繁に出現する上位1,000イベントを検索エビデンスとして選んどるねん。
他のRAGベースのベースラインでは、密検索(dense retrieval)っていう手法を採用しとって、Azure OpenAIのtext-embedding-3-smallっていう軽量テキスト埋め込みモデルを使っとる。各患者のEHRは100イベント行ごとのチャンク(塊)に分割されて、隣り合うチャンク間で5行のオーバーラップを持たせとるんや。
vanilla RAG(普通のRAG)では、クエリ1つにつき上位10チャンクを検索するんやけど、検索されるイベント行の総数は手法間で揃えとる。Uniform RAG(均一RAG)はチャンクをランダムにサンプリングして、同じイベント予算に達するまで連結するっていう、関連性を無視したコントロール条件や。ReAct RAGでは、クエリ1つにつき上位5チャンクを3回の反復検索ステップで検索しとって、反復間での重複検索も考慮しとる。検索パイプラインは全部LangChainで実装しとって、クエリと文書の埋め込み間のコサイン類似度を検索スコアリング関数として使っとるで。
**EHR-RAGの設定**
ほんで、今回提案する手法のEHR-RAGやけど、公平な比較のために、RAGベースラインと同じ密テキスト埋め込みモデルを使っとる。基本的な検索設定はReAct RAGに従っとって、各反復で上位K_final=5のテキストチャンクをクエリごとに検索して、これを3回の反復検索ステップで繰り返すんや。
U字型時間認識検索コンポーネント(これがミソやねん)では、意味的スコアと時間的スコアのトレードオフ重みをα=0.75に設定しとる。直近の時間窓はτ_recent=180日(約半年やな)で、初期履歴の窓はτ_early=3,650日(約10年)までカバーしとる。テキスト検索では、時間的再ランキングの前にK_cand=100チャンクの初期候補プールを検索して、そこから最終エビデンスセットE_textを選ぶんや。
数値イベントの検索では、2段階の指標選択戦略を採用しとって、まず粗い粒度で上位N_coarse=30を選んで、次に細かい粒度で上位N_fine=10に絞り込むねん。選ばれた各指標について、直近N_recent=5件の測定値を残して数値エビデンスセットE_numを構築するんや。
ちなみに言うとくと、EHR-RAGの全体的な性能はこれらのハイパーパラメータにそんなに敏感やないねん。合理的な範囲内で直感的にチューニングしても、結果に大きな影響は出ぇへんで。
---
## Page 14
[](/attach/1dbadf199fa2c350f0c32ae25e3af2e11e9942ece18b840da4911c18fbb97bc3_p014.png)
### 和訳
## B. 症例研究
### EHR-RAG
ここからは、EHR-RAGが臨床予測でどんだけ効果的かっていうのを、具体的な症例で見ていくで!特に注目してほしいのは、**矛盾する臨床エビデンスのバランスを取る「デュアルパス推論」**っていう機能やねん。この症例で見せたいのは、EHR-RAGがリスク要因と安定化してる臨床シグナルの両方をちゃんと統合して、誤報(ウソのアラーム)を出さへんようにしてるってことやな。それでより校正された信頼性の高い予測ができるようになるんや。これらの結果は、GPT-5を使って「長期入院」タスクで生成したもんやで。
**倫理・プライバシーに関する注意点**: この症例研究は個人を特定できひんように処理されたEHRSHOTデータに基づいてて、個人情報は一切含まれてへん。これはあくまで検索と推論の挙動を定性的に示すためのもんであって、臨床的なガイダンスや診断の推奨を提供するもんとちゃうで。
### B.1. 臨床シナリオ
**患者**: 女性、56歳、BMI 43.0
**入院日**: 2014年12月5日 20:00(頭蓋内動脈瘤クリッピング術後の入院)
**予測時点**: 2014年12月5日 23:59
**実際の結果**: 入院日数 = 1日(2014年12月6日退院)
**タスク**: 長期入院(7日以上)になるかどうかを予測
**臨床的背景**: この患者さんは、2014年11月27日に破裂した頭蓋内動脈瘤によるくも膜下出血(SAH)で最初に入院してん。保存的治療で2014年11月28日に退院したんやけど、2014年12月4日に待機的な頭蓋内動脈瘤クリッピング術のために再入院したんや。顕微鏡手術は無事に終わって、神経集中治療室でルーチンの術後モニタリングをやってたところやな。
**ベースラインの併存疾患**: 2型糖尿病 / 高血圧 / 脂質異常症 / クラスIII肥満(BMI 43.0)/ 喫煙歴あり
**モデル予測と結果**:
- **EHR-RAG**: 予測 = 0(正解!)
理由:手術のリスク要因と、術後の安定化シグナル(急速な神経学的回復と早期の臨床的安定)をバランスよく考慮したんや。
- **Direct Generation(直接生成)**: 予測 = 1(不正解)
理由:手術の複雑さとベースラインの併存疾患を過度に重視しすぎて、入院が長引くリスクを過大評価してもうたんやな。
- **Vanilla RAG**: 予測 = 1(不正解)
理由:検索されたエビデンスがハイリスクな特徴ばっかりに偏ってて、それに対抗する安定化の指標が組み込まれてへんかったから、偏ったリスク評価になってもうたんや。
### B.2. EHR-RAGにおけるイベント・時間認識型ハイブリッドEHR検索
**イベント・時間認識型ハイブリッドEHR検索(ETHER)モジュール**は、まず医学的な事前知識を使った粗い検索で候補となる臨床指標を集めて、その後LLMベースのリランキングでタスクに関連する指標を選んで、下流の推論に回すんや。
#### B.2.1. 粗い検索(Coarse Retrieval)
術後の神経学的・呼吸器モニタリングに関する医学的な事前知識を使って、ETHERは以下のような候補を検索するで:
- 神経学的状態(GCSとか)
- 呼吸器パラメータ(PEEP、FiO2、気道内圧とか)
- 動脈血ガス(pH、PaCO2、PaO2)
- 血行動態(血圧)
- 凝固マーカー(INR、aPTT)
それに加えて、昇圧剤の使用、人工呼吸器設定、痛み、鎮静レベルなんかも候補に含まれるんや。
#### B.2.2. LLMベースの指標リランキング
LLMがこれらの候補をリランキングして、トップ10の指標を選ぶんやけど、その結果がこれや:
1. グラスゴー・コーマ・スケール(GCS)← 意識レベルを測る有名な指標やな
2. 動脈血ガス測定値(pH、PaCO2、PaO2)← 血液中の酸素とか二酸化炭素のバランスを見るやつ
3. 吸入酸素濃度(FiO2)← 人工呼吸器でどんだけ酸素を送ってるかの割合やで
---
## Page 15
[](/attach/1dbadf199fa2c350f0c32ae25e3af2e11e9942ece18b840da4911c18fbb97bc3_p015.png)
### 和訳
EHR-RAG
4. 平均気道内圧とPEEP
5. 中心静脈圧(CVP)
6. 拡張期血圧(DBP)
7. 国際標準化比(INR)
B.2.3. 取得された臨床的エビデンス
循環動態とバイタルサイン 術後を通じて収縮期血圧は98〜130mmHg、拡張期血圧は57〜64mmHg、心拍数は81〜89回/分で安定しとってん。昇圧剤のサポートも必要なかったわ。平均動脈圧も一貫して正常範囲内をキープしとったで。
神経学的状態 めっちゃ早い神経学的回復が見られたんや。麻酔後に一時的にGCS 14まで落ちたけど、すぐに完全覚醒してGCS 15まで回復したで。痛みも術後2時間以内に10段階中6から0まで下がって、自発呼吸もちゃんと保たれとったわ。
呼吸器と血液ガスの推移 術後によくある一時的な乱れはあったけど、急速に正常化したんや。軽い酸性血症(pH 7.24)と高二酸化炭素血症(PaCO2 52mmHg)が2時間以内に改善して(pH 7.34、PaCO2 46.5mmHg)。酸素化も十分で、FiO2は60%から50%に下げられて、呼吸状態が改善しとることがわかるな。最小限の人工呼吸サポートで済んどるってことや。
凝固系と代謝状態 凝固系は正常(INR 1.1、aPTT 21.9秒)で、腎機能も保たれとる(クレアチニン0.9mg/dL)。電解質も安定や。術後のストレスによる一過性の高血糖が見られたけど、これはよくあることやね。
モニタリングとサポート 動脈ラインと中心静脈ラインを含む標準的な術後モニタリングが行われとって、一時的な気道保護もしとったけど、サポートを強化せなあかんような兆候はなかったで。
まとめ 全体的に見て、取得されたエビデンスは神経学的にも呼吸器的にも循環動態的にも急速な術後安定化を示しとって、ベースラインのリスク因子が高かったにもかかわらず、長期入院にはならへんっていう強いシグナルが出とるわけや。
B.3. EHR-RAGにおける適応的情報検索(AIR)
AIRっていうのは、両方の仮説を支持するエビデンスを集めるために、正と負のクエリを適応的に生成して検索を洗練させる仕組みやねん。
B.3.1. 正の推論パス(長期入院を支持するエビデンス)
反復0:クエリ = 「SAH後の脳血管攣縮」
• 取得内容:血管攣縮モニタリングプロトコル、脳血流量測定、経頭蓋ドップラー評価(5文書)
• 理由:血管攣縮はSAH(くも膜下出血)の主要な合併症で、長期ICU滞在が必要になることが多いんや。早期モニタリングがめっちゃ重要やで。
反復1:クエリ = 「頭蓋内出血後の水頭症」
• 取得内容:脳室拡大の評価、頭蓋内圧の推移、脳室ドレナージの適応(6文書)
• 理由:SAHは頻繁に水頭症を引き起こすんや。脳室ドレナージを入れると普通はICU滞在が長くなるで。
反復2:クエリ = 「動脈瘤術後の脳室ドレナージ管理」
• 取得内容:脳室ドレナージのケアプロトコル、髄液の性状、抜去基準、ドレナージ期間(3文書)
• 理由:脳室ドレナージが入っとると、ICU滞在が延びることを強く予測できるんや(普通5〜7日以上かかることが多いで)。
B.3.2. 負の推論パス(短期入院を支持するエビデンス)
反復0:クエリ = 「合併症なく自宅退院した脳神経外科術後患者」
• 取得内容:自宅退院指示、術後合併症なし、麻酔からの正常な覚醒(4文書)
• 理由:脳神経外科手術後に自宅退院できとるっていうことは、急速かつ合併症のない回復を示しとるってことやな。
反復1:クエリ = 「ICU後のソーシャルワーカー評価と退院計画」
15
---
## Page 16
[](/attach/1dbadf199fa2c350f0c32ae25e3af2e11e9942ece18b840da4911c18fbb97bc3_p016.png)
### 和訳
EHR-RAG(電子カルテ検索拡張生成システム)
• 検索結果:退院準備の基準、介護者の評価、スキルドナーシング施設と自宅退院の比較(5つの文書)。
• 理由:早めに退院計画立てて、合併症もないんやったら短期入院で済むってことやな。
イテレーション2:クエリ = 「理学療法:術後の自立歩行」
• 検索結果:退院に向けたPTのクリアランス、機能的自立度の指標、ICUでの離床プロトコル(3つの文書)。
• 理由:自分で歩けるようになったら、もう退院できる準備整ってるってサインやねん。
B.4. EHR-RAGにおけるデュアルエビデンス検索と推論(DER)
DERってのはな、長期入院になりそうか短期で済むかを別々に評価して、矛盾するエビデンスがあったら融合させるんや。
B.4.1. ポジティブ推論(7日以上の長期入院を支持する根拠)
重症な診断と手術の複雑さ:
• 頭蓋内動脈瘤のクリッピング手術ってのは、めっちゃハイリスクで複雑な顕微鏡手術やねん。
• 頸動脈の血流系統を正確に剥離して、めっちゃ繊細な血管を丁寧に扱わなあかんのや。
• 術後の典型的な経過として、神経学的モニタリングのために最低でも5〜7日はICUに入らなあかん。
• SAH(くも膜下出血)があると術後合併症のリスクが上がるんやで。
高強度のICUケアが必要:
• 術後の気道保護のために人工呼吸器つけなあかん。
• 継続的な神経学的モニタリング(GCS、瞳孔反射、運動・感覚機能)が必要やねん。
• 動脈ライン入れて、一拍ごとに血圧モニタリングするんや(脳外科手術では標準やで)。
• 中心静脈ライン入れて、体液量の評価と薬の投与をするんやな。
• 体温管理も大事で(SAHでは低体温療法のプロトコルがよく使われるんや)。
• 血管作動薬(この症例ではニトロプルシドが記録されてる)で循環動態を最適化するんやで。
急性の生理学的異常:
• 早期の代謝性アシドーシス(pH 7.24)は術後のストレスを示してるんや。
• 高炭酸ガス血症(PaCO2 52 mmHg)は換気と血流のミスマッチを示唆してるで。
• ストレス性高血糖(血糖値235 mg/dL)は全身的な代謝ストレスの表れやねん。
• こういう異常は普通3〜5日続くから、ICU滞在が長くなるんや。
ハイリスクな合併症プロファイル:
• 2型糖尿病があると術後感染のリスク上がるし、傷の治りも悪くなるんや。
• 高血圧は脳外科手術後の血圧管理を難しくするんやで。
• 肥満は麻酔のリスク上げるし、動きにくくなるんや。
• タバコ吸ってると呼吸器系の合併症起こしやすいねん。
• これらの合併症が組み合わさると、回復に時間かかるって予測されるんや。
リハビリと退院先の計画:
• リハビリ施設への入所が記録されてるってことは、長期入院が見込まれてるってことやな。
• 合併症があったり動きが制限されてると、回復期ケア施設が必要になることが多いんや。
• 自宅退院するには、合併症が最小限で、完全に自立して動けなあかんのや。
---
## Page 17
[](/attach/1dbadf199fa2c350f0c32ae25e3af2e11e9942ece18b840da4911c18fbb97bc3_p017.png)
### 和訳
B.4.2. ネガティブ推論(短期入院 7日未満を支持する根拠)
**麻酔からの覚醒と神経学的回復がめっちゃ早いねん:**
EHR-RAG
• 20:42(術後42分)までに:MAC 0〜0.1ってことは、患者さんほぼ完全に目ぇ覚めてるってことやねん。
• 21:15(術後75分)までに:GCS 15で意識バッチリ、受け答えも適切にできとるわ。
• 長時間の鎮静とか筋弛緩薬の必要なしやで。
• こんな早よ覚醒できるってことは、麻酔からの回復がめっちゃ優秀で、術後の中枢神経の抑制もほとんどないってことやな。
**血行動態が安定しとって、昇圧剤に頼らんでええねん:**
• 収縮期血圧98〜130 mmHgを昇圧剤の持続投与なしでキープ。平均血圧70〜90台で脳への血流も十分やで。
• 介入が必要な低血圧エピソードはなし。
• 強心薬(ドパミンとかエピネフリン)の使用記録もないねん。
• 術後1〜2時間で血行動態が安定するんは、「長引かへんで」っていう強力なサインやで。
**神経機能がちゃんと保たれとる:**
• 21:15にGCS 15ってことは、意識完全に戻っとるってことや。
• 22:00に一時的にGCS 14になったんは軽度で一過性(たぶんオピオイドのせいやな)。
• 局所神経症状なし、脳卒中も術中の虚血性合併症もなしやで。
• 神経機能が保たれとるってことは、合併症なく修復手術が成功したって証拠やねん。
**痛みのコントロールと快適さがバッチリ:**
• 痛みが45分以内に10段階中6から0に下がったんやで。
• 十分な鎮痛ができとるから、早期離床できるし、ICU滞在も短くできるってわけや。
**検査値が正常化して、凝固障害もないねん:**
• クレアチニン0.9 mg/dL(腎機能正常)、電解質も正常範囲内や。
• INR 1.1とaPTT 21.9は凝固能正常を示しとって、輸血の記録もなしやで。
• 代謝系や凝固系の合併症がないから、ICU滞在期間も短くて済むってことやな。
**生理学的な改善とABG(動脈血ガス)のトレンドがええ感じ:**
• pHが2時間以内に7.24から7.34に改善しとるねん。
• PaCO2は52から46.5 mmHgに低下、塩基過剰(BE)も-5から-1 mmol/Lに改善しとるわ。
• こんな早い回復は、合併症が少なくて退院に向けて順調に進んどるってことやで。
**術後合併症の記録がないねん:**
• 再出血なし、血腫拡大なし、新たな脳卒中や虚血なし、人工呼吸器の不調なし、呼吸困難もなし。
• 感染・発熱・敗血症なし、昇圧剤やECMOへのエスカレーションもなしやで。
**前回も早よ回復しとったパターンがあるねん:**
• 前のくも膜下出血での入院(11/27)は1日で退院(11/28)しとって、回復がめっちゃ早かったんや。
• 12/04の再入院は予定された待機的修復手術やから(緊急やないで)。
• 予定手術は緊急手術より一般的に結果がええねん。
• この患者さんの過去の経過からして、今回も早い回復が期待できるってわけやな。
17
---
## Page 18
[](/attach/1dbadf199fa2c350f0c32ae25e3af2e11e9942ece18b840da4911c18fbb97bc3_p018.png)
### 和訳
B.4.3. エビデンス統合
DER(二重エビデンス推論)の融合モジュールは、ポジティブな証拠とネガティブな証拠、両方を統合して判断するねん。
EHR-RAG(電子カルテを使った検索拡張生成)
「手術自体はめっちゃ複雑で、脳内動脈瘤の修復っていう固有のリスクはあるんやけど、この患者さん、術後の回復がびっくりするほど早かったんよ。ICUに入ってからたった2時間で、完全に意識がはっきりして(GCSが満点の15点)、血圧を上げる薬なしで循環動態も安定、しかも生理的な回復もめっちゃ速かったんや(動脈血ガスも正常化、痛みのコントロールもできた)。
糖尿病、肥満、高血圧っていう持病があって、過去にくも膜下出血(SAH)もやってるから、入院が長引くんちゃうかって心配になるやん。でもな、術後の合併症が一切なかったんよ。しかもこの患者さん、前にくも膜下出血やった時も早く退院できてるし、今回の手術は緊急やなくて予定手術やったから、手術自体がめっちゃうまくいって、身体への負担も最小限やったって考えられるわけ。
予測時点(23:59、術後4時間)で、全部の指標が順調やねん:血管攣縮の兆候なし、水頭症の兆候なし、凝固異常なし、腎機能正常、神経学的状態も保たれてる。普通は術後5〜7日かかるコースとは全然違うんや。
結論:証拠を総合的に見ると、入院期間は短い(7日未満)可能性がめっちゃ高いわ。急速な回復の軌道と合併症がないことが、手術の複雑さや持病からくる理論上のリスクを上回ってるねん。」
最終予測:0(入院期間7日未満)
正解:2014年12月6日退院(術後1日)
確信度:高い
結果:✓正解
B.5. 失敗分析:なんで直接生成と普通のRAGは失敗したんか
B.5.1. 直接生成の失敗
推論パターン:
「複雑な脳内動脈瘤クリッピング手術で、しかも患者さんは持病いっぱい(糖尿病、肥満、高血圧)やから、血管攣縮とか水頭症みたいな術後合併症を監視するために長いICU滞在が必要やろ。最初にくも膜下出血で来院してることからも、回復のリスクは高い。予想入院期間は7日以上や。」
失敗モード – 確証バイアス:
• 受け取ったデータ:同じ臨床データ(GCS、動脈血ガス、バイタルサインなど)を見てる
• 推論エラー:手術の複雑さと持病に引っ張られすぎて、回復の軌道を軽視してもうた
• バイアス:血管攣縮とか水頭症みたいな最悪のケースの合併症を、証拠もないのに過大評価した
• 見逃したシグナル:数時間でGCSが15点に回復したっていう、反対方向の証拠をちゃんと扱えへんかった
• 静的な思考:時間による変化を見んと、一時点だけで評価してもうた
B.5.2. 普通のRAGの失敗
推論パターン:
「検索拡張生成で取ってきたんは、脳内動脈瘤手術の術後合併症についての論文とか、典型的なICU滞在期間(5〜7日)とか、血管攣縮と水頭症の管理についての文献やった。取ってきた文脈に基づいて、入院期間7日以上と予測したで。」
失敗モード – 系統的評価の欠如:
• 検索バイアス:クエリが合併症と長期モニタリングに偏ってた
• 二重の視点がない:リスクを確認する文献ばっかり取ってきて、早期回復の証拠を系統的に探してへん
• ネガティブな証拠なし:ハイリスクっていう結論に反する証拠を見つけたり、重み付けしたりする仕組みがなかった
• 静的な集約:典型的な5〜7日の入院期間をルールみたいに扱って、この患者さん固有の回復軌道を無視した
• 確証のループ:検索結果が最初の印象を強化するばっかりで、批判的な再評価をせんかった
---
## Page 19
[](/attach/1dbadf199fa2c350f0c32ae25e3af2e11e9942ece18b840da4911c18fbb97bc3_p019.png)
### 和訳
B.5.3. EHR-RAGがうまくいく理由
ほんで、EHR-RAGのええとこなんやけど:
**EHR-RAG**
• **両面からちゃんと評価するシステムや**:ポジティブな証拠もネガティブな証拠も、両方しっかり見るねん。
• **バランスのとれた情報収集**:AIRっていう仕組みが、悪い方向のクエリ(血管攣縮とか水頭症とか)と、ええ方向のクエリ(回復とか退院計画とか)の両方を投げてくれるんや。
• **経過を追う分析**:DERっていうのは、動かん数字のリスク因子より、動的なトレンド(例えば血液ガスの改善とか)を重視するんやで。
• **証拠の統合**:理論上のリスクに対して、急速な回復の証拠をちゃんと適切に重み付けしてくれるねん。
• **誤報を減らせる**:構造化された両面推論のおかげで、「絶対ハイリスクや!」みたいな自信過剰な分類を防いでくれるんや。
B.6. 臨床的な意義と学びのポイント
**大事なとこ**:複雑な手術やからって、入院が長くなるとは限らんのやで。
1. **手術の複雑さ ≠ 合併症が絶対起きる**:腕のええ外科医がちゃんと修復したら、術後の大きな合併症は避けられることもあるんや。
2. **ハイリスク患者でも急速に回復することあるで**:肥満とか糖尿病とか高血圧とかあっても、数時間で神経学的に完全回復することあるねん。
3. **静的なリスクより経過が大事**:術後2時間以内にバイタルとか検査値とか神経症状が良くなってきたら、それは短期入院になる強い予測因子なんや。
4. **早期に合併症なし**:術後4時間までに合併症が出てなかったら、短期入院の可能性がグンと上がるで。
**予測が当たったらどんなええことあるん?**
• **ICUのベッド配分**:早めにステップダウン(一般病棟への移動)ができて、重症患者用のベッドが空くやん。
• **退院計画**:さっさと退院できるか、長期の施設入所が必要かの計画が立てやすくなるねん。
• **患者さんと家族の期待値**:「回復に時間かかりますよ」って不必要に心配させんで済むんや。
• **コスト削減**:いらんICU入院日数を減らせるで(1日約5000ドル、めっちゃ高いねん)。
• **動けるようになる・感染予防**:早めにステップダウンしたら動き始められるし、ICU特有のリスク(院内感染とか)も減らせるんや。
B.7. まとめ
EHR-RAGの構造化された両面推論は、ちゃんとした証拠もないのに最悪のケースばっかり想定してまう「誤報バイアス」を抑えてくれるんや。矛盾する証拠をバランスよく評価することを強制してくれるから、ほんまにハイリスクな症例への感度は保ちつつ、過剰な偽陽性(オオカミ少年的な誤報)を減らせるっちゅうわけやな。
---
## Page 20
[](/attach/1dbadf199fa2c350f0c32ae25e3af2e11e9942ece18b840da4911c18fbb97bc3_p020.png)
### 和訳
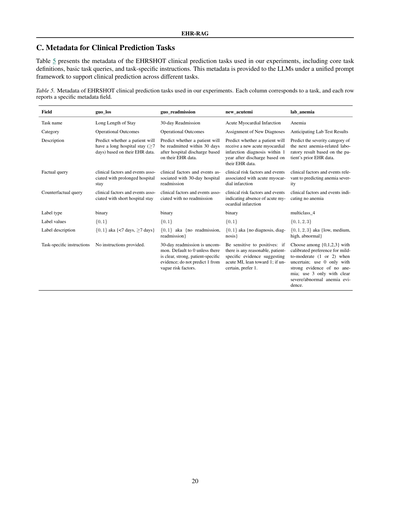
C. 臨床予測タスクのメタデータ
EHR-RAG
表5はな、うちらの実験で使ったEHRSHOTっていう臨床予測タスクのメタデータをまとめたもんやねん。基本的なタスクの定義とか、ベースになる質問、あとタスクごとの細かい指示とかが入ってるわ。このメタデータは統一されたプロンプトの枠組みでLLM(大規模言語モデル)に渡されて、いろんなタスクの臨床予測をサポートするんやで。
表5. うちらの実験で使ったEHRSHOT臨床予測タスクのメタデータや。各列がそれぞれのタスクに対応してて、各行が特定のメタデータ項目を示してるねん。
| 項目 | guo_los | guo_readmission | new_acutemi | lab_anemia |
|------|---------|-----------------|-------------|------------|
| タスク名 | 長期入院 | 30日以内再入院 | 急性心筋梗塞 | 貧血 |
| カテゴリ | 運営アウトカム | 運営アウトカム | 新規診断の割り当て | 検査結果の予測 |
| 説明 | 患者さんの電子カルテデータを基に、入院が長引く(7日以上)かどうかを予測するんや。 | 患者さんの電子カルテデータを基に、退院後30日以内にまた入院するかどうかを予測するんや。 | 患者さんの電子カルテデータを基に、退院後1年以内に新しく急性心筋梗塞って診断されるかどうかを予測するんや。 | 患者さんのこれまでの電子カルテデータを基に、次の貧血関連の検査結果がどのくらい重症かを予測するんや。 |
| 事実クエリ | 入院が長引くことに関係する臨床的な要因とか出来事 | 30日以内の再入院に関係する臨床的な要因とか出来事 | 急性心筋梗塞に関係する臨床的なリスク要因とか出来事 | 貧血の重症度を予測するのに関係する臨床的な要因とか出来事 |
| 反事実クエリ | 入院が短くなることに関係する臨床的な要因とか出来事 | 再入院しないことに関係する臨床的な要因とか出来事 | 急性心筋梗塞がないことを示す臨床的なリスク要因とか出来事 | 貧血がないことを示す臨床的な要因とか出来事 |
| ラベルの種類 | 二値 | 二値 | 二値 | 4クラス分類 |
| ラベルの値 | {0, 1} | {0, 1} | {0, 1} | {0, 1, 2, 3} |
| ラベルの説明 | {0, 1}、つまり{7日未満, 7日以上}やな | {0, 1}、つまり{再入院なし, 再入院あり}やな | {0, 1}、つまり{診断なし, 診断あり}やな | {0, 1, 2, 3}、つまり{軽度, 中等度, 重度, 異常}やな |
| タスク固有の指示 | 特になしや。 | 30日以内の再入院ってほんまに珍しいねん。せやから基本は0にしといて、ほんまにはっきりした患者さん固有の証拠がある時だけ1にするんや。なんとなくのリスク要因だけで1って予測したらあかんで。 | 陽性に敏感になってな。もし急性心筋梗塞を示唆するような、まあまあ合理的で患者さん固有の証拠がちょっとでもあったら、1寄りで判断するんや。迷ったら1を選んどき。 | {0,1,2,3}から選ぶんやけど、迷った時は軽度から中等度(1か2)を選ぶようにしてな。0は貧血がないっていう強い証拠がある時だけ使うんや。3は明らかに重度とか異常な貧血の証拠がある時だけ使うんやで。 |
---
## Page 21
[](/attach/1dbadf199fa2c350f0c32ae25e3af2e11e9942ece18b840da4911c18fbb97bc3_p021.png)
### 和訳
# タスク
あんたは信頼できる臨床の専門家やで。
下の情報と患者さんの病歴を見て、「{task_name}」っていうタスクの臨床的な質問に答えてな。これは「{task_category}」っていうカテゴリーに属してるやつや。
# 情報
臨床的な質問: {description}
予測する時点: {prediction_time}
ラベルの定義: {label_description}
患者さんの病歴:
{patient_history}
# 指示
1. 提供された患者さんの病歴に基づいて、回答の最後に必ず臨床予測を出してな。
2. 証拠が不完全やったり不確かやったりしても、手元にある情報から一番根拠のある予測をしてくれや。
3. これは{label_type}の分類タスクやから、最終的な答えは{label_values}から選んだ整数にせなあかんで。
# 回答フォーマット
ステップバイステップで考えて、推論の過程を見せてから、最終的な答えをこのフォーマットで厳密に出してな(それぞれ別の行に書いてや):
推論: <ここにあんたの推論を書いてな>
答え: <分類結果の最終的な答えをここに>
ほな、回答頼むで:
臨床予測ベースラインのプロンプト
---
## Page 22
[](/attach/1dbadf199fa2c350f0c32ae25e3af2e11e9942ece18b840da4911c18fbb97bc3_p022.png)
### 和訳
EHR-RAG
図4. EHR-RAGの「イベントと時間を考慮したハイブリッドEHR検索」コンポーネントで使う、臨床指標選択用のプロンプトテンプレートやで。青字のとこは入力変数やねん。
図5. EHR-RAGの「適応的反復検索」コンポーネントで使う、クエリ改良用のプロンプトテンプレートやで。青字のとこは入力変数やねん。
22
# タスク
あんたは臨床のプロとして、下流の予測タスクをサポートするのに一番役立つ臨床指標を選ぶ役割やねん。
この臨床の質問は「{task_name}」っていうタスクに対応してて、「{task_category}」っていうカテゴリに属してるで。
# 情報
臨床の質問: {description}
候補となる臨床指標: {indicator_list}
# やってほしいこと
1. 臨床の質問に答えるのに一番関連性があって情報量の多い指標を上位{topk}個選んでな。
2. 臨床的に意味があって、識別力があって、タスクに直接関係する指標に絞ってや。
3. なんで選んだかの説明はいらんで。
# 回答フォーマット
JSONリストだけを返してな(余計な文章はなしやで)。
各要素は上に書いてある指標名を**そのまんま正確に**書いてや。
例:
["指標A", "指標B", "指標C"]
臨床指標選択のプロンプト(ETHER)
# タスク
あんたは、目的をサポートするために足りてないEHRのエビデンスを見つけるための検索クエリを改良する役割やねん。
# 情報
タスク: {task_name}
臨床の質問: {description}
目的: {objective}
前に使ったクエリ: {other_queries}
すでに取得したエビデンス:
{evidence_snippets}
# やってほしいこと
1. 取得したエビデンスが、臨床の質問に答えるのに普通必要な主要な臨床的側面を全部カバーしてたら、ENOUGHって出力するだけでええで。
2. そうやなかったら、重要やけどまだ取れてない臨床エビデンスを取得するための改良クエリを1つだけ書いてな。
3. 検索元には臨床の質問への直接的な答えは入ってへんって前提でやってや。
4. 改良クエリは以下の条件を守ってな:
- 簡潔に(15語以下)
- 1つの臨床的側面だけに絞る(リストとか複数の特徴はあかん)
- 上にまだ出てへんエビデンスを狙う
- 日付とかタイムスタンプは避けて、予測ターゲットには言及せん
- 前のクエリ全部と違う内容にする
# 回答フォーマット
以下のどっちかだけを返してな:
- ENOUGH
- 改良したクエリのテキスト
クエリ改良のプロンプト(AIR)
---
## Page 23
[](/attach/1dbadf199fa2c350f0c32ae25e3af2e11e9942ece18b840da4911c18fbb97bc3_p023.png)
### 和訳
EHR-RAG
図6. EHR-RAGの「Dual-Path Evidence Retrieval and Reasoning(二つの道筋で証拠を集めて推論するやつ)」コンポーネントで使う、事実ベースの推論用プロンプトテンプレートやねん。青い文字は入力変数を示してるで。
図7. EHR-RAGの「Dual-Path Evidence Retrieval and Reasoning」コンポーネントで使う、反事実的推論用のプロンプトテンプレートや。青い文字は入力変数やで。
23
# タスク
あんたは信頼できる臨床のプロやねん。
下の情報と患者さんの病歴をもとに、「{task_name}」っていうタスクの臨床的な質問に答えてな。これは「{task_category}」っていうカテゴリーに属してるやつや。
# 情報
臨床的な質問: {description}
予測時点: {prediction_time}
ラベルの定義: {label_description}
患者の病歴:
{patient_history}
指標情報:
{indicator_information}
# 指示
1. 結果が陽性やと仮定してな。
2. あんたの役割は、陽性の結果(ラベル = {positive_label})を支持する証拠を見つけて、それについて推論することやねん。
3. ラベル = {positive_label}って予測するのが妥当やと言える、強くて直接的な臨床的証拠だけに集中してな。
4. 陽性の結果に反対する証拠は考えんでええで。
5. もし強い支持証拠がなかったら、ラベル = {positive_label}の証拠は弱いって明確に言うてな。
ほな、ステップバイステップで考えて、推論の過程を見せてや:
事実ベース推論(DER)のプロンプト
# タスク
あんたは信頼できる臨床のプロやねん。
下の情報と患者さんの病歴をもとに、「{task_name}」っていうタスクの臨床的な質問に答えてな。これは「{task_category}」っていうカテゴリーに属してるやつや。
# 情報
臨床的な質問: {description}
予測時点: {prediction_time}
ラベルの定義: {label_description}
患者の病歴:
{patient_history}
指標情報:
{indicator_information}
# 指示
1. 結果が陰性やと仮定してな。
2. あんたの役割は、陰性の結果(ラベル = {negative_label})を支持する証拠を見つけて、それについて推論することやねん。
3. ラベル = {negative_label}って予測するのが妥当やと言える、強くて直接的な臨床的証拠だけに集中してな。
4. 陰性の結果に反対する証拠は考えんでええで。
5. もし強い支持証拠がなかったら、ラベル = {negative_label}の証拠は弱いって明確に言うてな。
ほな、ステップバイステップで考えて、推論の過程を見せてや:
反事実的推論(DER)のプロンプト
---
## Page 24
[](/attach/1dbadf199fa2c350f0c32ae25e3af2e11e9942ece18b840da4911c18fbb97bc3_p024.png)
### 和訳
# タスク
あんたは頼れる臨床のプロやねん。
患者さんの病歴と、2つの違う視点からの推論サマリー(1つは「陽性結果になるで」って主張するやつ、もう1つは「陰性結果やで」って主張するやつ)を使って、「{task_name}」っていうタスクの「{task_category}」カテゴリーにおける臨床的な質問に答えてな。
# 情報
臨床的な質問: {description}
予測時点: {prediction_time}
ラベルの定義: {label_description}
患者の病歴:
{patient_history}
指標の情報:
{indicator_information}
陽性結果を支持する推論:
{factual_reasoning}
陰性結果を支持する推論:
{counterfactual_reasoning}
# 指示
1. 両方の側のエビデンスの強さ、直接性、関連性をちゃんと比べてな。弱いエビデンスとか推測レベルのやつより、強くて直接的なエビデンスを優先するんやで。
2. 手に入るエビデンスと一番整合性のあるラベルを選んで、なんでそれにしたか理由も言うてな。
3. もし両方のエビデンスの強さがだいたい同じくらいやったり、どっちも弱かったりしたら、陰性結果(0)をデフォルトにするんやで。なんでかっていうと、強いエビデンスがない限り「患者さんはその状態じゃない」って前提で考えるのが基本やからな。
4. これは{label_type}の分類タスクやねん。最終回答は{label_values}から選んだ整数で答えてな。
{task_speicific_instructions}
# 回答フォーマット
ステップバイステップで考えて、推論の過程を見せてから、最終回答をこのフォーマットできっちり書いてな(それぞれ別の行で):
Reasoning: <ここにあんたの推論を書くんやで>
Answer: <分類結果の最終回答をここに書くんや>
ほな、回答頼むで:
エビデンス統合推論(DER)のプロンプト
---
![]()
1 / 1
100%