<<
2403.14403v2.pdf

---
## Page 1
[](/attach/12d262c682626c26a98bdafc7ec5dc6af3fae8247d26d4f2c712b1599dafce62_p001.png)
### 和訳
# Adaptive-RAG: 質問の難しさに応じて検索増強型の大規模言語モデルを賢く使い分ける方法を学習するで
ソヨン・ジョン、ジンホン・ベク、スクミン・チョ、ソン・ジュ・ファン、ジョン・C・パク
KAIST(韓国科学技術院)
## 要約
なあなあ、最近めっちゃ話題の検索増強型LLM(大規模言語モデル)って知ってる?これ何かっていうと、LLMに外部の知識ベースから情報を引っ張ってきて組み合わせるやつやねん。質問応答みたいなタスクで、回答の精度をグッと上げられるってことで注目されてんねんな。
せやけどな、ここに問題があんねん。世の中の質問って、簡単なやつから複雑なやつまでいろいろあるやん?今までのアプローチやと、簡単な質問にも無駄に計算パワー使いすぎたり、逆に複雑な質問にはちゃんと対応できへんかったりすんねん。でも実際のユーザーからの質問って、「簡単」か「複雑」かのどっちかだけちゃうやろ?
そこでワイらが提案すんのが、新しい適応型の質問応答フレームワークや!これがめっちゃ賢くてな、質問の複雑さに応じて、一番シンプルな方法から一番凝った方法まで、その場で最適な戦略を選んでくれんねん。
で、この選択をどうやってるかっていうと、小さめの言語モデルを分類器として使ってんねん。この分類器は、入ってきた質問の複雑さレベルを予測するように訓練されてて、そのラベルは自動で集めてんねん。実際にモデルが予測した結果とか、データセットが持ってる特性とかを使ってな。
このアプローチのええとこは、バランスがめっちゃ取れてることやねん。質問の複雑さに応じて、何回も検索するやつ、1回だけ検索するやつ、そもそも検索せえへんやつ、これらをスムーズに切り替えられんねん。
いろんな複雑さの質問が入ったオープンドメインの質問応答データセットで検証したら、ワイらのモデルは他の関連するベースライン(適応型検索のアプローチも含めて)より、効率も精度も両方ええ結果が出たで!コードはGitHubで公開してるから見てみてな。
## 1. はじめに
最近の大規模言語モデル(LLM)、例えばGPT-3とかGPT-4とかLLaMAとかPaLMとかな、これらがいろんなタスクでめっちゃすごい性能出してんのは知ってるやろ?質問応答もその一つやねん。
せやけどな、こいつらにも弱点があんねん。事実と違う答えを平気で出してくることがあんねん。なんでかっていうと、LLMの知識って全部パラメトリックメモリ、つまりモデルの重みに埋め込まれた知識だけに頼ってるからやねん。しかも考えてみ?世界中の知識、しかも日々変わっていく知識を全部記憶するなんて、そもそも無理やろ?
この問題を解決するために出てきたんが、検索増強型LLMってやつや。これは外部の知識ベースから情報を引っ張ってきて、LLMに食わせるんやねん。知識ベースっていうのは、いろんな分野の情報がどっさり入ったデータベースみたいなもんや。ユーザーの質問に関係する情報を検索して、それをLLMに渡すことで、最新の正確な情報に基づいた回答ができるようになるわけや。
特にこの検索増強型LLMが活躍すんのが、質問応答タスクやねん。ユーザーの質問に正しく答えるっていう、特に複雑な質問への対応が求められる場面や。
初期の検索増強型LLMは、主にシングルホップ(1段階)の質問を扱ってたんや。これは答えが1つの文書の中に書いてあるような質問やな。質問に基づいて関連する文書を1つ取ってきて、それをQAモデルに入れて回答を作るっていうシンプルな流れや。
せやけどな、世の中にはそんな単純な質問だけちゃうやろ?複数の文書を繋げたり、情報をまとめたりせなあかん質問もあんねん。
**図1の説明**: 質問応答の性能(F1スコア)と効率(1質問あたりの処理時間)を、いろんな検索増強生成アプローチで比較したグラフやで。ベースのLLMにはGPT-3.5-Turbo-Instructを使ってるねん。見てみ、ワイらのAdaptive-RAGが右上の方にあって、性能も効率もええバランス取れてるやろ?
---
## Page 2
[](/attach/12d262c682626c26a98bdafc7ec5dc6af3fae8247d26d4f2c712b1599dafce62_p002.png)
### 和訳
図2:質問応答における検索拡張型LLMアプローチの概念比較やで。(A)クエリに対して、このシングルステップ方式は関連文書を取ってきて回答を生成するんやけど、複数ステップの推論が必要な複雑なクエリにはちょっと力不足なんよな。(B)このマルチステップ方式は文書取得と中間回答生成を繰り返すから強力なんやけど、シンプルなクエリに対してはLLMと検索システム両方に何回もアクセスせなあかんから、めっちゃ非効率なんや。(C)ウチらの適応型アプローチは、分類器が判定したクエリの複雑さに基づいて、反復型から単発、さらには検索なしまで、検索拡張型LLMに最適な戦略を選べるようになってるねん。
一発の検索して回答するだけじゃ答えられへんクエリって、実際めっちゃ多いんよな。例えば「マラコフを占領した人らが、フィリップスバーグがある地域に来たのはいつ?」みたいなクエリは、解くのに4段階の推論ステップが必要やねん。せやから、こういう複雑なクエリをうまく処理するために、最近の研究はマルチステップ・マルチ推論QAにめっちゃ力入れてて、LLMと検索システム両方に何回も繰り返しアクセスする方式が主流なんや(Press et al., 2023; Trivedi et al., 2023)。ただ、計算コストがえげつないことになるのが難点やねんな。
でもな、ちょっと考え直してみてや:実際の世界で、ユーザーからの質問って全部複雑なんやろか?いや、実際はシンプルで分かりやすい質問が多くて、複雑なんはたまにしか来ーへんのちゃうか。具体的に言うと、「パリはどこの国の首都?」みたいなクエリは、さっき言うたマルチステップクエリよりもずっと頻繁に聞かれるやろし、こういうシンプルな質問はLLM自身が外部知識にアクセスせんでも簡単に答えられる可能性高いねん。つまりな、マルチステップQA方式は複雑なクエリには必須やけど、シンプルなクエリに対しては無駄な計算オーバーヘッドを生んでまうんや(図2(A)参照)。逆に、複雑なクエリをシングルステップ検索や検索なし戦略で処理しようとしたら、全然足りひんねん(図2(B))。これが示唆してるのは、クエリの複雑さに応じて検索拡張型LLMの運用戦略を動的に調整できる適応型QAシステムが必要やってことやな。最近のアプローチで、クエリ内のエンティティの出現頻度に基づいてこれをやるやつ(Mallen et al., 2023)とか、マルチステップQA用モデルの生成出力に基づくやつ(Trivedi et al., 2023)もあるんやけど、まだ最適とは言えへんねん:前者はシンプルすぎてマルチホップクエリを考慮できてへんし、後者は複雑すぎて、モジュールに何回かアクセスした後に回答解決ステップを終了してまうんや。
この研究では、現実世界のクエリには色んな複雑さレベルがあることを踏まえて、従来の「一つのやり方で全部対応」的なアプローチじゃ全部カバーするには不十分やと主張してるねん。代わりに、入力クエリの特定の複雑さに合わせて調整された複数の(検索拡張型)LLMの中から、最適な戦略を選ぶことを提案してるんや。注目すべきは、このプロセスの重要なステップがクエリの複雑さを事前定義することで、これが最適なモデルを決定するのにめっちゃ大事やねん。この研究では、このプロセスを新しい分類器で実現してて、これは入力クエリの複雑さレベルを予測するために訓練された小さいモデルなんや(図2(c)参照)。さらに、この分類器の訓練データセットを人手でラベリングせずに自動収集してるねん。どうやってるかっていうと、予測結果(つまり、どのモデルがどのクエリに正確に答えたか)を活用したり、既存データセットに内在するバイアス(つまり、データセット内のサンプルがシングルステップQA用かマルチステップQA用のどちらかに設計されてること)を利用したりしてるんや。この提案手法は、複雑なクエリ用の反復的LLM拡張手法、シンプルなクエリ用のシングルステップ手法、さらには最も単純なクエリ(LLM自身で答えられるやつ)用の検索拡張なし手法の間で、ええ感じのバランスを提供できるねん。結果として、図1に示すように、全体的な効率と精度がめっちゃ向上するんや。ウチらはこのフレームワークを適応型検索拡張生成(Adaptive-RAG)と呼んでるで。
Adaptive-RAGの有効性は、シングルホップ(Rajpurkar et al., 2016; Joshi et al., 2017; Kwiatkowski et al., 2019)からマルチホップ(Yang et al., 2018; Ho et al., 2020; Trivedi et al., 2022b)まで幅広いクエリ複雑さをカバーするベンチマークのオープンドメインQAデータセットで検証してるねん。実験結果から、ウチらの手法はGPT-3.5(Brown et al., 2020)やFLAN-T5シリーズ(Chung et al., 2022)など複数のLLMにおいて、従来の適応型戦略と比べて全体的な精度と効率を大幅に改善することが分かったんや。
---
## Page 3
[](/attach/12d262c682626c26a98bdafc7ec5dc6af3fae8247d26d4f2c712b1599dafce62_p003.png)
### 和訳
うちらの研究でわかったこととやったことは3つあんねん:
• 現実世界では質問の難しさってバラバラやん?そこに目ぇつけてん。ほんで調べてみたら、今ある検索で強化した文章生成(RAG)のやり方って、シンプルすぎるか複雑すぎるか、どっちかに偏ってまうねん。
• せやから、うちらは質問の難しさを分類器で判定して、その難易度に合わせて検索強化型のLLMを適応させるようにしてん。こうすることで、質問ごとに一番ピッタリな方法を使えるようになるわけや。
• その結果、うちらのAdaptive-RAG(適応型RAG)はめっちゃ効果的で効率もええことがわかってん。いろんな質問に対して、複雑すぎず単純すぎず、ちょうどええバランスが取れるようになったで。
## 2 関連研究
**オープンドメインQA(質問応答)**
オープンドメインQAっていうのは、質問に関係ある文書を探してきて、それを解釈して正確に答えを出すタスクのことやねん(Chenら、2017; Zhuら、2021)。基本的には2つの部品でできてて、文書を探してくる「リトリーバー」(Karpukhinら、2020; Xiongら、2021)と、それを読んで答えを出す「リーダー」(Yangら、2019; IzacardとGrave、2021; Jeongら、2023)があんねん。
ほんで、何十億ものパラメータを持つLLM(大規模言語モデル)が出てきて、めっちゃ賢い推論ができるようになってん(Weiら、2022a)。このLLMとリトリーバーを組み合わせたら、えらい進歩があったわけや(Lazaridouら、2022; Ramら、2023)。
具体的に言うと、この組み合わせによって、リーダーの推論能力が強化されて、外部の文書も活用できるようになったから、LLMの「ハルシネーション」(嘘っぱちを言う問題)を軽減できて、オープンドメインQAの性能が上がったんやで(Choら、2023)。でもな、1回だけ検索する検索強化型LLMでは進歩があったけど、難しい質問にはもっと複雑な戦略が必要やねん。
**マルチホップQA(複数ステップの質問応答)**
マルチホップQAっていうのは、普通のオープンドメインQAの発展版やねん。複数の文書から情報を(繰り返し)集めて文脈を理解して、もっと複雑な質問に答えなあかんのや(Trivediら、2022a; Yangら、2018)。
このマルチホップQAの世界では、LLMと検索モジュールに繰り返しアクセスするアプローチが一般的に使われてるで。具体的には、Khattabら(2022)、Pressら(2023)、Pereiraら(2023)、Khotら(2023)が提案したんやけど、まず複雑なマルチホップの質問をシンプルな1ステップの質問に分解して、LLMとリトリーバーに繰り返しアクセスしてサブ質問を解いて、最後にそれらの答えを合体させて完全な回答を作るんや。
この分解ベースのアプローチとは別に、最近の研究ではYaoら(2023)やTrivediら(2023)が、Chain-of-Thought推論(論理的な思考の連鎖を生成する方法、Weiら、2022b)と文書検索を交互に行う方法を探求してん。推論の連鎖が答えを出すまで、このプロセスを繰り返すんや。
あと、Jiangら(2023)は、生成された文の中のトークン(単語みたいなもん)の確信度が低かったら、新しい文書を繰り返し検索するアプローチを提案してん。
でもな、上で紹介した方法には見落としがあんねん。現実世界では、質問の難しさってめっちゃバラバラやん?せやから、シンプルな質問でも1回の検索だけで十分やったり、LLMだけでも答えられたりするのに、全部の質問に対して繰り返しLLMとリトリーバーにアクセスするのは、ほんまに効率悪いねん。
**適応型検索(Adaptive Retrieval)**
いろんな難易度の質問に対応するために、適応型検索戦略は各質問の複雑さに基づいて、文書を検索するかどうかを動的に決めることを目指してるんや。
この流れで、Mallenら(2023)は、質問に出てくる固有名詞(人名とか地名とか)の出現頻度に基づいて質問の複雑さを判定することを提案してん。頻度がある閾値より低かったら検索モジュールを使う、っていう感じやな。でも、このアプローチは「検索するかしないか」の2択だけに注目してるから、複数の推論ステップが必要なもっと複雑な質問には対応しきれへんかもしれんねん。
あと、Qiら(2021)は、答えが出るまで固定の操作セット(検索、読み取り、再ランキング)を何回も繰り返すアプローチを提案してん。これは従来のBERT系の言語モデルの上に構築されてるで。でも、うちらのAdaptive-RAGは事前に質問の複雑さを判定して、それに応じて既存のLLMの動作を適応させるんやけど、この方法は質問の複雑さに関係なく全部の質問に同じ固定操作を適用するし、言語モデルに追加の特別な訓練も必要やねん。
うちらの研究と同時期に、Asaiら(2024)は、動的に検索して、批評して、テキストを生成する洗練されたモデルを訓練することを提案してん。
でもな、うちらが言いたいのは、こういう単一モデルに頼る適応型検索の方法は、いろんな難易度の質問を扱うには最適やないってことや。なんでかっていうと、どの質問に対してもシンプルすぎるか複雑すぎるかになりがちやから。せやから、質問の複雑さに合わせて検索強化型LLMの一番適した戦略を選べる新しいアプローチが必要やってことやねん。
---
## Page 4
[](/attach/12d262c682626c26a98bdafc7ec5dc6af3fae8247d26d4f2c712b1599dafce62_p004.png)
### 和訳
# 3 方法
このセクションでは、検索拡張型LLM(大規模言語モデル)をどうやって賢く使いこなすかについて説明するで。具体的には、まず質問の難しさを見極めて、それに合った最適な戦略を選ぶっていうアプローチやねん。
## 3.1 準備知識
まずは基礎知識からいこか。検索拡張型LLMの色んな戦略について、ちゃんと説明するわ。
**検索なしの質問応答** まずLLMっていうモデルを定義するで。これは文字の並び x = [x1, x2, ..., xn] を入力として受け取って、別の文字の並び y = [y1, y2, ..., yn] を出力として生成するもんやねん。数式で書くと y = LLM(x) ってなるわけや。ほんで、質問応答の場面では、x がユーザーからの質問(q)になって、y がLLMが生成した回答(ā)になるねん。つまり q = x で ā = y やな。せやから、一番シンプルなLLMベースの質問応答モデルはこう表せるで:ā = LLM(q)。理想的には、生成された回答 ā が正解 a と一致してほしいわけや。この検索なしの方法はめっちゃ効率的で、簡単な質問には結構いけるアプローチやねん。なんでかっていうと、最近のLLMはめちゃくちゃデカくなってきて、大量の知識を内部に溜め込めるようになったからや。せやけど、この方法には大きな問題があってな。特定の人物や出来事、あるいはLLMの内部知識を超えるような話題について、正確な情報や最新の情報が必要な質問には、ほんまに苦戦するねん。
**シングルステップアプローチでの質問応答** さっき言うたみたいに、LLM単体では答えられへん質問に対処するために、外部知識 d を活用できるねん。これは質問に役立つ情報を含んでて、外部の知識ソース D から取ってくるもんや。この D っていうのは、例えばWikipediaみたいな百科事典で、何百万もの文書が入ってるようなもんやな。具体的に言うと、この D から d を取り出すには、特定の検索モデルが必要で、これが質問との関連性に基づいて文書を返してくれるねん。この処理は d = Retriever(q; D) って書けるで。Retriever が検索モデルで、d ∈ D やな。ここでは、既存のどんな検索ツールでも使えるで(Robertson et al., 1994; Karpukhin et al., 2020)。
検索ステップが終わったら、質問 q とそれに関連する文書 d のペアが手に入るわけや。ほんで、この取ってきた外部知識でLLMを強化するために、LLMの入力に組み込むねん。こう表せるで:ā = LLM(q, d)。
この処理によって、LLMは d に含まれる外部情報にアクセスできるようになるねん。これがLLMの内部知識だけでは足りへん補足的な文脈を提供してくれて、結果として質問応答の精度と最新性がめっちゃ向上するわけや。
**マルチステップアプローチでの質問応答** さっきのシングルステップアプローチは、外部知識が必要な質問 q に対して検索なしより大幅に改善できるんやけど、それでも限界があるねん。特に、複数の情報源から情報を統合して、それらを推論せなあかんような複雑な質問を扱うときは厳しいわ。そこで登場するのが、マルチステップアプローチと推論を使った質問応答やねん。
このマルチステップアプローチでは、LLMが Retriever と何回もやり取りして、質問 q への理解を段階的に深めていくねん。最終的な答えを出すまで、複数のステップで集めた発見を積み重ねていくわけや。具体的には、最初の質問 q から始まって、各検索ステップ i で、新しい文書 di が D から取得されて、LLMの入力に組み込まれるねん。こんな感じや:āi = LLM(q, di, ci)。ここで追加の文脈 ci は、それまでの文書と結果(d1, d2, ..., di-1, ā1, ā2, ..., āi-1)で構成されることがあるで。そして di = Retriever(q, ci; D) やな^1。この繰り返しのマルチステッププロセスによって、LLMはより包括的で広範な土台を築いて、質問を効果的に解決できるようになるねん。特に、答えが相互に関連した情報のピースに依存するような、複雑なマルチホップ質問には強いで。せやけど、このマルチステップアプローチは Retriever と LLM に何度もアクセスせなあかんから、計算コストがめっちゃかかることは認識しとかなあかんな。
## 3.2 Adaptive-RAG:適応型検索拡張生成
ここからは、ワイらの適応型検索拡張LLMを紹介するで。これは前のセクションで説明した3つの異なる戦略をベースにしてて、質問の複雑さに応じて最適な戦略を選ぶように設計されてるねん。
**検索拡張型LLMの適応** 現実世界のシナリオでは、ユーザーからの質問 q が全部同じ複雑さってわけやないねんな。せやから、
---
^1 ちなみに言うとくと、LLMと検索モデルの実装は、マルチステップ検索拡張LLMのアプローチによって色々違うねん(Trivedi et al., 2023; Press et al., 2023; Yao et al., 2023)。せやから、文脈 ci には前の文書と回答が全く含まれへんこともあれば、一部だけ、あるいは全部含まれることもあるで。
---
## Page 5
[](/attach/12d262c682626c26a98bdafc7ec5dc6af3fae8247d26d4f2c712b1599dafce62_p005.png)
### 和訳
ほな説明していくでー!
それぞれの質問に合わせた戦略で対応せなあかんねん。どういうことかっていうと、めっちゃ難しい質問qに対して、一番シンプルな「検索なし」のアプローチLLM(q)で答えようとしても、そら無理があるやん(図2のAな)。逆に、簡単な質問qに対して、ごっつい手の込んだ複数ステップのアプローチLLM(q, d, c)を使うのは、効率悪すぎやねん(図2のBな)。やから、ワイらの適応フレームワークは、検索拡張LLMの質問対応戦略を動的に調整できるように設計してんねん。具体的には、答えを出す前に各質問の複雑さを判定するっちゅうわけや。ほんまにええとこついてるのが、このフレームワークは幅広い解決策を提供できる点やねん。一番簡単な質問には一番シンプルなアプローチ、まあまあの質問には1ステップアプローチ、複雑な質問には一番しっかりしたアプローチ、って感じでな。あと、LLMと検索エンジンの処理自体は入力に関係なく一貫してるから、ワイらの手法は複雑さの違う質問間を行ったり来たりしても、内部のモデル構造やパラメータをいじる必要がないねん。めっちゃスムーズやろ?
**質問の複雑さ判定について**
この適応検索拡張LLMフレームワークを実際に動かすには、質問の複雑さを判定せなあかんねん。それを実現するために、「複雑さ分類器」っちゅうもんをモデル化することを提案してんねん。この分類器の目的は、与えられた質問に対して適切な複雑さレベルを返すことや。具体的に言うと、質問qが与えられたら、ワイらの分類器はこんな感じで定式化できんねん:o = Classifier(q)。ここでClassifierは、3つの異なる複雑さレベルのどれかに分類するように訓練された、ちっちゃい言語モデルで、oはそれに対応するクラスラベルやねん。ワイらの分類器の設計では、'A'、'B'、'C'の3つのクラスラベルがあんねん。'A'はqが簡単でLLM(q)だけで答えられることを示してて、'B'はqがまあまあの複雑さで少なくとも1ステップアプローチLLM(q, d)が必要なことを示してて、'C'はqが複雑で一番しっかりした解決策LLM(q, d, c)が必要なことを示してんねん²。
**訓練戦略について**
残りのステップは、与えられた質問qに対して複雑さoを正確に予測できるように、Classifier用のちっちゃい言語モデルを訓練することやねん。でもな、質問と複雑さのペアのアノテーション付きデータセットなんて存在せえへんねん。やから、2つの特別な戦略を使って訓練データセットを自動的に構築することを提案してんねん。
具体的に言うと、まず3つの異なる検索拡張LLM戦略の結果に基づいて質問の複雑さにラベル付けすることを目指してんねん。必要性に応じてラベルを決めるためにな。例えば、一番シンプルな検索なしアプローチで正しく答えが生成できたら、その質問のラベルは'A'になんねん。あと、異なるモデル間で同点になった時にラベルを決めるために、よりシンプルなモデルに高い優先順位を与えてんねん。つまり、1ステップと複数ステップの両方のアプローチが同じ正解を出して、検索なしアプローチだけ失敗した場合は、その質問には'B'を割り当てんねん。
でもな、このラベル付け戦略には限界があんねん。3つの検索拡張アプローチが全部正解を生成できへん場合、ラベルが付かへん質問が出てくるからな。一方で、ベンチマークデータセットには、質問に対する最も適切な検索拡張LLM戦略についての有意義な帰納バイアスがすでに含まれてる可能性があんねん。データセットの作り方を考えたらな(例えば、順序立てた推論が必要なQAデータセットは通常、複数ステップアプローチが必要やし、単一の文書がラベル付けされてる質問は1ステップアプローチで理想的に答えられるやろ)。やから、最初のラベル付けステップの後でラベルが付いてない質問については、単一ホップデータセットの質問には'B'を、複数ホップデータセットの質問には'C'を割り当てんねん。最後に、これらの自動収集された質問-複雑さペアを使って、クロスエントロピー損失を使ってClassifierを訓練すんねん³。ほんで推論時には、質問をClassifierに通すことで、{'A', 'B', 'C'}のどれかの複雑さを判定できんねん:o = Classifier(q)。
## 4 実験セットアップ
このセクションでは、データセット、モデル、評価指標、実装の詳細について説明するでー。追加の詳細は付録Aに載せてんねん。
### 4.1 データセット
異なる質問がいろんな複雑さを持つ現実的なシナリオをシミュレートするために、単一ホップと複数ホップのQAデータセットを同時に使って、統一された実験設定にしてんねん。
**単一ホップQA** より簡単な質問用には、3つのベンチマーク単一ホップQAデータセットを使ってんねん。これらは...
---
²ワイらは質問の複雑さを3段階で考えてんねん。もっと細かい複雑さの探求は将来の研究課題として残しとくわ。
³分類器のラベルを自動で割り当ててるから、ラベル付けにエラーがあるかもしれへんし、もっと高度な自動ラベル付け戦略があるかもしれへんねん。それも将来の研究課題として残しとくわ。
---
## Page 6
[](/attach/12d262c682626c26a98bdafc7ec5dc6af3fae8247d26d4f2c712b1599dafce62_p006.png)
### 和訳
表1: いろんなベンチマークデータセットで平均した結果やねん。オープンドメインの質問応答で、シングルホップとマルチホップのクエリを含んでて、いろんなLLMで試してんで。Self-RAG*は別のベースLLMで学習してんねん、LLaMA2っていうやつや(Touvronら、2023)。せやから、FLAN-T5-XL(3B)の結果はSelf-RAGのLLaMA2(7B)と比べて、他のやつらの結果はSelf-RAGのLLaMA2(13B)と比べてんねん。うちらの結果は太字にしてるから、比較しやすいやろ?
FLAN-T5-XL(3B)
FLAN-T5-XXL(11B)
GPT-3.5(Turbo)
タイプ
手法
EM
F1
Acc
ステップ
時間
EM
F1
Acc
ステップ
時間
EM
F1
Acc
ステップ
時間
シンプル
アダプティブ
検索なし
シングルステップアプローチ
アダプティブ検索
Self-RAG*
Adaptive-RAG(うちらの手法)
複雑 マルチステップアプローチ
オラクル
Adaptive-RAG w/ オラクル
14.87
34.83
23.87
9.90
37.17
39.00
45.00
21.12
44.31
32.24
20.79
46.94
48.85
56.28
15.97
38.87
26.73
31.57
42.10
43.70
49.90
0.00
1.00
0.50
0.72
2.17
4.69
1.28
0.11
1.00
0.56
0.43
3.60
8.81
2.11
17.83
37.87
26.93
10.87
38.90
40.13
47.17
25.14
47.63
35.67
22.98
48.62
50.09
58.60
19.33
41.90
29.73
34.13
43.77
45.20
52.20
0.00
1.00
0.50
0.74
1.35
2.13
0.84
0.08
1.00
0.54
0.23
2.00
3.80
1.10
35.77
34.73
35.90
10.87
37.97
38.13
47.70
48.56
46.99
48.20
22.98
50.91
50.87
62.80
44.27
45.27
45.30
34.13
48.97
49.70
58.57
0.00
1.00
0.50
0.74
1.03
2.81
0.50
0.71
1.00
0.86
1.50
1.46
3.33
1.03
クエリと、その答えが入ってる関連文書のデータセットやねんけど、具体的には、1) SQuAD v1.1(Rajpurkarら、2016)、2) Natural Questions(Kwiatkowskiら、2019)、3) TriviaQA(Joshiら、2017)を使ってんねん。
マルチホップQA もっと複雑なクエリのシナリオも考えなあかんから、3つのベンチマークになるマルチホップQAデータセットも使ってんねん。これは複数の文書をまたいで順番に推論せなあかんやつで、1) MuSiQue(Trivediら、2022a)、2) HotpotQA(Yangら、2018)、3) 2WikiMultiHopQA(Hoら、2020)やねん。
4.2 モデル
うちらのAdaptive-RAGを関連するモデルと比較してんねん。検索で強化されたLLM戦略が3つ(セクション3.1参照)と、アダプティブ検索のアプローチ(Mallenら、2023; Asaiら、2024)があって、これらは3つのカテゴリのどれかに分けられんねん:シンプル、アダプティブ、複雑の3つや。具体的に言うとな、シンプルなアプローチには、1) 検索なしと、2) シングルステップアプローチベースの手法が含まれんねん。アダプティブなアプローチには、3) アダプティブ検索(Mallenら、2023)、4) Self-RAG(Asaiら、2024)、そしてうちらの5) Adaptive-RAGがあって、これらは質問の複雑さに応じてアダプティブに検索できんねん。6) マルチステップアプローチには、めっちゃ洗練された最先端の手法(Trivediら、2023)を使ってて、これは全部のクエリに対して、Chain-of-Thought推論(Weiら、2022b)を使いながら、検索器とLLMの両方に繰り返しアクセスすんねん。ちなみに、違うカテゴリのモデル同士は直接比較でけへんで。けどな、理想的な設定やったら、アダプティブなアプローチはシンプルなカテゴリのやつらより効果的で、同時に複雑なやつより効率的であるべきやねん。せやから、理想的なシナリオでの性能も報告してんねん、7) Adaptive-RAG w/ オラクルっていうて、オラクル分類器をうちらのAdaptive-RAGと一緒に使ったやつや。
4.3 評価指標
アダプティブモデルを評価するときは、タスクの性能と効率の両方を同時に考えて、そのトレードオフも見なあかんねん。せやから、5つの指標で結果を報告してて、そのうち3つが効果を測って、残り2つが効率を測んねん。具体的にはな、効果については、F1、EM、精度(Acc)を使ってて、標準的な評価プロトコル(Mallenら、2023; Baekら、2023; Asaiら、2024)に従ってんねん。F1は予測した答えと正解の間で重複してる単語の数を測って、EMは完全に同じかどうかを測って、Accは予測した答えに正解が含まれてるかを測んねん。効率については、検索と生成のステップ数と、シングルステップアプローチを基準にした各クエリに答えるのにかかる平均時間を測ってんねん。
4.4 実装の詳細
公平に比較するために、Mallenら(2023)とTrivediら(2023)に従って、全部の違うモデルで同じ検索器を使ってんねん。BM25(Robertsonら、1994)っていう、用語ベースのスパース検索モデルやねん。外部の文書コーパスについては、データセットのタイプによって違うソースを使ってて、シングルホップのデータセットにはKarpukhinら(2020)が前処理したWikipediaコーパスを、マルチホップのデータセットにはTrivediら(2023)が前処理したコーパスを使ってんねん。答えを生成するのに使うLLMについては、FLAN-T5シリーズのモデル(Chungら、2022)で、XLが3Bパラメータ、XXLが11Bパラメータのやつと、GPT-3.5モデル(gpt-3.5-turbo-instruct)を使ってんねん。検索強化LLMの設計については、Trivediら(2023)の実装詳細に従ってて、入力プロンプト、指示、評価用のテストサンプル数(例えば、データセットごとに500サンプル)なんかが含まれてんねん。うちらのAdaptive-RAGでは、クエリの複雑さを分類する分類器に、T5-Largeモデル(Raffelら、2020)を使って学習させてんねん。具体的には、この分類器は検証セットから100回の学習イテレーションまでで一番ええ性能を出したエポックを使って学習されてて、学習率は3e-
---
## Page 7
[](/attach/12d262c682626c26a98bdafc7ec5dc6af3fae8247d26d4f2c712b1599dafce62_p007.png)
### 和訳
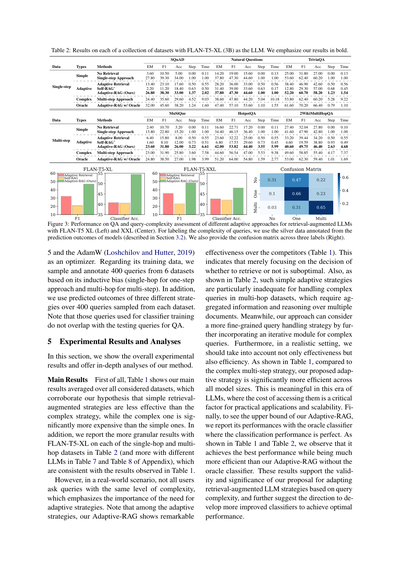
表2: FLAN-T5-XL(30億パラメータ)をLLMとして使ったときの、いろんなデータセットでの結果やで。太字にしてるのがワイらの結果やねん。
SQuAD
Natural Questions
TriviaQA
データの種類 | 手法 | EM | F1 | Acc | Step | Time | EM | F1 | Acc | Step | Time | EM | F1 | Acc | Step | Time
シンプル系
シングルステップ
アダプティブ
検索なし
シングルステップ方式
アダプティブ検索
Self-RAG※
Adaptive-RAG(ワイらの手法)
複雑なマルチステップ方式
オラクル
Adaptive-RAG オラクル付き
[数値データは原文と同じ]
MuSiQue
HotpotQA
2WikiMultiHopQA
[数値データは原文と同じ]
図3: 検索補強型LLMの色んなアダプティブ手法について、QA性能とクエリの複雑さ判定の結果を見せてるで。FLAN-T5 XL(左)とXXL(真ん中)で試してん。クエリの複雑さのラベル付けには、モデルの予測結果からアノテーションしたシルバーデータっていうのを使ってる(これは3.2節で説明してるやつな)。あと、3種類のラベルについての混同行列も右に載せてるで。
学習の最適化には5を使って、オプティマイザーにはAdamW(Loshchilovさんとってるえぇ人たちが2019年に作ったやつ)を使ってん。訓練データについては、6つのデータセットから400個ずつクエリをサンプリングして、そのデータセットの特性に基づいてアノテーションしたで(シングルホップなら1ステップ方式向け、マルチホップならマルチステップ向けってことやな)。さらに、各データセットから400個サンプリングしたクエリに対して、3つの異なる戦略で予測した結果も使ってる。ちなみに、分類器の訓練に使ったクエリと、QAのテストに使ったクエリは全く別もんやで、そこは注意してな。
5 実験結果と分析
このセクションでは、全体的な実験結果を見せて、ワイらの手法の詳しい分析もしていくで。
**メインの結果** まず表1を見てほしいねんけど、これが全データセットの平均結果やねん。ここからワイらの仮説が正しいってことがわかるで。なんでかっていうと、シンプルな検索補強戦略は複雑な戦略より効果が低いんやけど、その複雑な戦略はシンプルなやつよりめっちゃコストがかかるっていうことが確認できたからやねん。あと、表2にはFLAN-T5-XLを使ったときの、シングルホップとマルチホップの各データセットごとのもっと細かい結果を載せてるで(他のLLMでの結果は付録の表7と表8を見てな)。これらも表1で見た結果と一致してるわ。
でもな、現実世界のシナリオでは、ユーザーが聞いてくる質問の複雑さって全部同じちゃうやん?これがめっちゃ大事なポイントで、だからこそアダプティブな戦略が必要やねんって話になるわけや。注目してほしいのは、アダプティブ戦略の中で、ワイらのAdaptive-RAGが他の競合手法をめっちゃ上回ってるってことやねん(表1見てな)。これが何を意味するかっていうと、「検索するかせぇへんか」だけを判断するんじゃ不十分やってことやねん。あと表2を見たらわかるけど、そういうシンプルなアダプティブ戦略は、特にマルチホップデータセットの複雑なクエリを扱うときにイマイチなんよ。なんでかっていうと、マルチホップの問題は複数の文書から情報を集めて推論せなあかんからやねん。一方でワイらの手法は、複雑なクエリ用に反復モジュールを組み込むことで、もっときめ細かいクエリ処理戦略を考えられるようになってるんや。
さらにな、現実的な設定では効果だけやなくて効率も考えなあかんやん。表1を見たらわかるように、複雑なマルチステップ戦略と比べて、ワイらが提案したアダプティブ戦略は全てのモデルサイズでめっちゃ効率ええねん。これはLLMの時代においてはほんまに意味があることやで。だってLLMにアクセスするコストって、実用化とかスケーラビリティを考えたら超重要な要素やからな。最後に、ワイらのAdaptive-RAGの上限を見るために、オラクル分類器(つまり分類性能が完璧なやつ)を使った場合の結果も報告してるで。表1と表2を見たらわかるけど、オラクル分類器なしのAdaptive-RAGよりもめっちゃ効率的でありながら、最高の性能を達成してるんや。この結果が示してるのは、クエリの複雑さに基づいて検索補強型LLMの戦略を適応させるっていうワイらの提案の妥当性と重要性やねん。そしてさらに、最適な性能を達成するためにもっと改良された分類器を開発していくっていう方向性も示唆してるわけや。
---
## Page 8
[](/attach/12d262c682626c26a98bdafc7ec5dc6af3fae8247d26d4f2c712b1599dafce62_p008.png)
### 和訳
表3: 1クエリあたりの正確な処理時間と、分類器から予測されたラベルの全サンプルに対する割合やで。
表4: 分類器の学習における、データアノテーション戦略を変えた場合のQAと複雑度分類の結果や。
| ラベル | 処理時間/クエリ (秒) | 割合 (%) |
|--------|---------------------|----------|
| No (A) | 0.35 | 8.60 |
| One (B) | 3.08 | 53.33 |
| Multi (C) | 27.18 | 38.07 |
| 学習戦略 | QA F1 | Step | 分類器精度 (All / No / One / Multi) |
|----------|-------|------|-------------------------------------|
| Adaptive-RAG (うちらの手法) | 46.94 | 1084 | 54.52 / 30.52 / 66.28 / 65.45 |
| Binary無しバージョン | 43.43 | 640 | 60.30 / 62.19 / 65.70 / 39.55 |
| Silver無しバージョン | 48.79 | 1464 | 40.00 / 0.00 / 53.98 / 75.91 |
**分類器の性能について**
うちらが提案した分類器がどんな感じで動いとるか理解するために、複雑度ラベルごとの性能を分析したんや。図3(左と真ん中)見てもらったらわかるけど、うちらのAdaptive-RAGの分類精度は他の適応的検索のベースラインよりええ結果出とって、これが全体的なQA性能の向上につながっとるねん。つまりな、この結果が示しとるのは、うちらのAdaptive-RAGは複雑度レベルをめっちゃ正確に分類できるってことや。検索せえへんパターン、1回だけ検索するパターン、複数回検索するパターン、色んな粒度でちゃんと見分けられるんやで。
図3(左と真ん中)の3つのラベル全体で平均した真陽性の性能に加えて、図3(右)に混同行列も載せとるで。この混同行列見たらおもろい傾向がわかるねん:「C(複数回)」が「B(1回)」に間違えられることがあって(だいたい31%くらい)、逆に「B(1回)」が「C(複数回)」に間違えられることもある(だいたい23%くらい)。「A(検索なし)」は「B(1回)」によう間違えられて(だいたい47%)、「C(複数回)」にはそこまで間違えられへん(だいたい22%)。まあ図3の全体的な結果見たら、うちらの分類器は3つのラベルをちゃんと分類できとるんやけど、こういう誤分類をもっと改善していくのは今後の研究でおもろいテーマになりそうやな。
**分類器の効率性についての分析**
表1で3つの異なるRAG戦略の相対的な処理時間を見せたけど、表3ではうちらのAdaptive-RAGの1クエリあたりの正確な処理時間と、クエリ複雑度分類器から予測されたラベルの分布をもっと詳しく載せとるで。表1(相対時間)の結果と同じように、表3(正確な時間)でも、シンプルで分かりやすいクエリを見分けることで効率がめっちゃ改善できるってことがわかるねん。
**分類器の学習データについての分析**
分類器が適応的検索においてめっちゃ重要な役割を果たしとることは見せたやん。ここではさらに、分類器を学習するための色んな戦略を分析するで。うちらの完全な学習戦略には2つのアプローチがあるねん:モデルの予測結果からsilverデータを生成する方法と、データセットの帰納的バイアスを活用する方法や(セクション3.2見てな)。
表4見てもらったらわかるけど、帰納的バイアスから得られたデータだけに頼る学習戦略と比べたら、うちらの方法はかなり効率的やねん。なんでかっていうと、うちらの方法は文書を全く考慮せえへんケースも考慮に入れとるからや。これは分類精度からも示唆されとるんやけど、一方で既存のデータセットのクエリには検索が必要かどうかの情報が含まれてへんねん。
逆に、正解した予測からアノテーションしたsilverデータだけを使う場合は、全体的な分類精度は高いんやけど、全体的なQA性能を見たらsilverデータだけに頼るのは最適じゃないかもしれへんことがわかるねん。たぶんこれは、silverデータが間違えた予測のクエリに対する複雑度ラベルをカバーしてへんからやと思うで。それでそういうクエリに関連するものへの汎化効果が低くなってまうんや。一方で、データセットバイアス(シングルホップ vs マルチホップ)からの複雑度ラベルも組み合わせることで、分類器はマルチホップのクエリをより正確に予測できるようになって、性能が向上するんやで。
ちなみに言うとくと、うちらの自動ラベリング戦略は分類器を学習するための2つの特定の実装例であって、他にも色んな実装の仕方がありえるんや。それは今後の研究課題として残しとくで。
**分類器のサイズについての分析**
分類器のサイズを変えた時にどれくらい性能に影響あるか調べるために、追加実験をやったんや。表6に示した通り、小さい分類器で複雑度が減って、パラメータ数が少なくなっても、色んなサイズの分類器間で大きな性能差は見られへんかったで。これが意味するのは、うちらが提案した分類器は、サイズを小さくしても性能を損なわずに、実際の利用場面でリソース効率の良い設定に貢献できるってことやねん。
**ケーススタディ**
うちらのAdaptive-RAGとAdaptive Retrievalを定性的に比較するためにケーススタディをやったで。表5には、シンプルな質問と複雑な質問の両方について、分類された複雑度とクエリの処理パターンを載せとる。まず、シンプルなシングルホップの質問に対しては、うちらのAdaptive-RAGは「Google」についてのLLMのパラメトリック知識だけで答えられると判断しとるねん。一方で、
---
## Page 9
[](/attach/12d262c682626c26a98bdafc7ec5dc6af3fae8247d26d4f2c712b1599dafce62_p009.png)
### 和訳
表5:GPT-3.5(Turbo)使ったケーススタディやで。赤字が事実誤認で、青字が正確な情報やねん。
| データセット | 質問 | Adaptive Retrieval | Adaptive-RAG(ワイらの手法) |
|---|---|---|---|
| NQ(シングルホップ) | 1999年以降初めての大きな変更で、フラットな単色のサンセリフフォントに変わった有名な企業ロゴってどれ? | クエリタイプ:B(シングルステップ方式)<br>推論:1999年以降初の大きな変更でフラットな単色サンセリフフォントに変わった有名な企業ロゴは**マイクロソフト**や。2012年にロゴ変えて、斜体の多色フォントからシンプルでフラットなグレーのフォントになってん。せやから答えは:マイクロソフト。 | クエリタイプ:A(検索なし)<br>推論:1999年以降初の大きな変更でフラットな単色サンセリフフォントに変わった有名な企業ロゴは**Google**や。Googleは2015年にロゴ変えてん。せやから答えは:Google。 |
| MuSiQue(マルチホップ) | セサル・ガイタンが生まれた大陸の東海岸をイギリスのために探検したイタリア人航海士の子供は誰? | クエリタイプ:A(検索なし)<br>推論:セサル・ガイタンは北米大陸で生まれてん。北米東海岸をイギリスのために探検したイタリア人航海士はジョヴァンニ・カボート、ジョン・カボットとも呼ばれる人や。せやから答えは:**ジョヴァンニ・カボート/ジョン・カボット**。 | クエリタイプ:C(マルチステップ方式)<br>推論:セサル・ガイタンはメキシコのハリスコ州グアダラハラで生まれてん。イギリスのために大陸東海岸を探検したイタリア人航海士はジョン・カボットや。ジョン・カボットの息子は**セバスチャン・カボット**やねん。せやから答えは:セバスチャン・カボット。 |
表6:分類器のモデルサイズ変えた時の結果やで。
| サイズ | QA F1 | ステップ All | 分類器(精度)No | One | Multi |
|---|---|---|---|---|---|
| Small(6000万パラメータ) | 45.83 | 964 | 53.48 | 26.65 | 70.62 | 53.18 |
| Base(2億2300万パラメータ) | 45.97 | 983 | 53.41 | 26.42 | 69.46 | 56.82 |
| Large(7億7000万パラメータ) | 46.94 | 1084 | 54.52 | 30.52 | 66.28 | 65.45 |
Adaptive Retrievalは追加の文書取ってくるから、処理時間長くなるし、「マイクロソフト」についての微妙に関係ない情報入ってきて間違った回答出すこともあんねん。一方で、複雑な質問来た時、Adaptive-RAGは「ジョン・カボットの息子」みたいな、LLMに保存されてへんかもしれん関連情報をちゃんと探しに行くねんけど、Adaptive Retrievalは外部ソースにそういう情報取りに行かへんから、不正確な答えになってまうんや。
## 6 結論
この研究でな、ワイらは**Adaptive Retrieval-Augmented Generation**フレームワーク、略して**Adaptive-RAG**を提案したんや。これは色んな複雑さのクエリに対応できるようになってんねん。具体的に言うとな、Adaptive-RAGは統合された検索拡張LLMの中で、遭遇するクエリの複雑さに応じてクエリ処理戦略を動的に調整するように設計されてんねん。めっちゃ簡単なクエリには**検索なしアプローチ**、中程度の複雑さのクエリには**シングルステップアプローチ**、複雑なクエリには**マルチステップアプローチ**って感じで、スペクトラム全体をカバーしてるんや。
Adaptive-RAGの核心はな、与えられたクエリの複雑さを判定するところやねん。これが答えを出すのに最適な戦略を選ぶのにめっちゃ重要なんや。なんでかっていうと、この判定がないと適切な戦略選べへんからや。このプロセスを実現するために、ワイらは**クエリと複雑さのペア**で小さい言語モデルを訓練したんや。このペアは予測結果とデータセットの帰納バイアスから自動的にアノテーションされてんねん。
ワイらはAdaptive-RAGを、シングルホップとマルチホップの質問両方を含む複数のクエリ複雑さをカバーするオープンドメインQAデータセット群で検証したで。結果としてな、ワイらのAdaptive-RAGは**QAシステムの全体的な精度と効率を向上**させることが分かったんや。複雑なクエリにはより多くのリソース割り当てて、シンプルなクエリは効率的に処理するっていう感じやな。これは既存の「一律対応」アプローチ(クエリの複雑さに関係なく最小限主義か最大限主義のどっちかに偏りがち)と比較しての話やで。
## 限界
ワイらのAdaptive-RAGはクエリの複雑さ判定して最適なアプローチ使うことで効果と効率の面で明確なメリット見せてるんやけど、分類器にはまだ改善の余地があることも認識しとかなあかんねん。訓練データセットとアーキテクチャの観点からな。
具体的に言うとな、クエリ複雑さ分類器を訓練するためのデータセットが元々存在してへんから、ワイらはモデルの予測結果とデータセットの帰納バイアスに基づいて新しいデータを自動生成したんや。せやけど、ワイらのラベリングプロセスはクエリ複雑さをラベル付けする一つの具体的な実装方法に過ぎひんくて、効果的ではあるんやけど、クエリを間違ってラベル付けする可能性もあんねん。
せやから、将来の研究では質問-回答ペアのラベルに加えて、**多様なクエリ複雑さでアノテーションされた新しいデータセット**を作成してもええかもしれんな。
あとな、表1の理想的な分類器と図3の現在の分類器の性能差が示すように、分類器の効果にはまだ改善の余地があんねん。言い換えると、ワイらの小さいLMベースの分類器設計は、クエリ複雑さを分類するための最初の、一番シンプルな実装やねん。これをベースにして、将来の研究では分類器のアーキテクチャと性能を改善できるかもしれんし、そうなったら全体的なQA性能にプラスの貢献になるはずやで。
---
## Page 10
[](/attach/12d262c682626c26a98bdafc7ec5dc6af3fae8247d26d4f2c712b1599dafce62_p010.png)
### 和訳
倫理的なことについて
Adaptive-RAGの実験結果見たら、めっちゃいろんなユーザーからの質問が飛んでくる現実的なシナリオでもちゃんと使えることが分かったんやけど、実際の世界ってほんまにいろんな人がおるやん?せやから、攻撃的な内容とか有害な入力が来るケースも考えとかなあかんねん。こういうやばい入力があると、攻撃的な文書を引っ張ってきてまうかもしれんし、検索拡張型のLLMが不適切な回答を生成してまう可能性もあるわけや。この問題に対処するには、検索拡張フレームワークの中で、ユーザーの入力と取得した文書の両方について、攻撃的やったり不適切なコンテンツを検出して管理する方法を開発することがめっちゃ大事やねん。これは今後の研究でほんまに重要な分野やと思ってるで。
謝辞
この研究は、韓国政府が資金提供した情報通信技術振興院(IITP)の助成金(No. 2018-0-00582、言語分析と自動証拠文書収集による信頼性分布の予測と拡張)、教育部が資金提供した韓国研究財団(NRF)を通じた基礎科学研究プログラム(RS-2023-00275747)、そして科学技術情報通信部(MSIT、韓国)と光州広域市が資金提供した人工知能産業融合クラスター開発プロジェクトの支援を受けてるねん。
参考文献
Rohan Anilら(2023年)「Palm 2技術レポート」arXivプレプリント arXiv:2305.10403。
Akari Asaiら(2024年)「Self-RAG:自己省察を通じた検索・生成・批評の学習」第12回国際学習表現会議。
Jinheon Baekら(2023年)「知識拡張型言語モデルの検証」2023年自然言語処理における経験的手法に関する会議論文集、EMNLP 2023、シンガポール、2023年12月6-10日、1720-1736頁、計算言語学会。
Sebastian Borgeaudら(2022年)「数兆トークンからの検索による言語モデルの改善」国際機械学習会議、ICML 2022、2022年7月17-23日、アメリカ・メリーランド州ボルチモア、機械学習研究論文集162巻、2206-2240頁、PMLR。
Tom B. Brownら(2020年)「言語モデルは少数ショット学習者である」ニューラル情報処理システム進歩33:2020年ニューラル情報処理システム年次会議、NeurIPS 2020、2020年12月6-12日、バーチャル開催。
Danqi Chenら(2017年)「オープンドメイン質問応答のためのWikipedia読解」第55回計算言語学会年次総会論文集、ACL 2017、カナダ・バンクーバー、2017年7月30日-8月4日、第1巻:長論文、1870-1879頁、計算言語学会。
Sukmin Choら(2023年)「オープンドメイン質問応答における無関係文書からの妨害を減らすことによるゼロショットリーダーの改善」計算言語学会発見:EMNLP 2023、シンガポール、2023年12月6-10日、3145-3157頁、計算言語学会。
Hyung Won Chungら...
---
## Page 11
[](/attach/12d262c682626c26a98bdafc7ec5dc6af3fae8247d26d4f2c712b1599dafce62_p011.png)
### 和訳
Narang, Gaurav Mishra, Adams Yu, Vincent Y. Zhao,
Yanping Huang, Andrew M. Dai, Hongkun Yu, Slav
Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam
Roberts, Denny Zhou, Quoc V. Le, and Jason Wei.
2022. 指示でファインチューニングした言語モデルのスケーリング。
arXiv preprint arXiv:2210.11416.
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara,
and Akiko Aizawa. 2020. 推論ステップをちゃんと評価できるマルチホップQAデータセット作ったで。第28回国際計算言語学会議の論文集、COLING 2020、バルセロナ、スペイン(オンライン)、2020年12月8-13日、pages 6609–6625. 国際計算言語学委員会。
Gautier Izacard and Edouard Grave. 2021. オープンドメインの質問応答で、生成モデルに文章検索を組み合わせてめっちゃ活用する方法やねん。ヨーロッパ計算言語学会第16回大会メインボリューム論文集、EACL 2021、オンライン、2021年4月19-23日、pages 874–880. 計算言語学会。
Gautier Izacard, Patrick S. H. Lewis, Maria Lomeli,
Lucas Hosseini, Fabio Petroni, Timo Schick, Jane
Dwivedi-Yu, Armand Joulin, Sebastian Riedel, and
Edouard Grave. 2023. Atlas: 検索で強化した言語モデルで少数ショット学習やるで。J. Mach.
Learn. Res., 24:251:1–251:43.
Soyeong Jeong, Jinheon Baek, Sukmin Cho, Sung Ju
Hwang, and Jong Park. 2023. 質問応答のためのテスト時自己適応型小規模言語モデルや。これがほんまにええねん。計算言語学会発見論文集:EMNLP 2023、シンガポール、2023年12月6-10日、pages 15459–15469. 計算言語学会。
Zhengbao Jiang, Frank F. Xu, Luyu Gao, Zhiqing Sun,
Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie
Callan, and Graham Neubig. 2023. アクティブ検索拡張生成や。必要な時だけ検索するってのがミソやねん。EMNLP 2023.
Mandar Joshi, Eunsol Choi, Daniel S. Weld, and Luke
Zettlemoyer. 2017. TriviaQA: 読解力のためのめっちゃでかい遠隔教師ありチャレンジデータセットやで。計算言語学会第55回年次大会論文集、ACL 2017、バンクーバー、カナダ、2017年7月30日-8月4日、第1巻:長編論文、pages 1601–1611. 計算言語学会。
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick
S. H. Lewis, Ledell Wu, Sergey Edunov, Danqi Chen,
and Wen-tau Yih. 2020. オープンドメイン質問応答のための密な文章検索やねん。自然言語処理における経験的手法に関する2020年会議論文集、EMNLP 2020、2020年11月16-20日。計算言語学会。
Jungo Kasai, Keisuke Sakaguchi, Yoichi Takahashi, Ronan Le Bras, Akari Asai, Xinyan Yu, Dragomir R.
Radev, Noah A. Smith, Yejin Choi, and Kentaro Inui.
2022. リアルタイムQA: 今この瞬間の答えは何やねん?arXiv preprint arXiv:2207.13332.
Omar Khattab, Keshav Santhanam, Xiang Lisa
Li, David Hall, Percy Liang, Christopher Potts,
and Matei Zaharia. 2022. Demonstrate-Search-Predict: 知識集約型NLPのために検索と言語モデルを組み合わせるんや。arXiv preprint
arXiv.2212.14024, abs/2212.14024.
Tushar Khot, Harsh Trivedi, Matthew Finlayson, Yao
Fu, Kyle Richardson, Peter Clark, and Ashish Sabharwal. 2023. 分解プロンプティング: 複雑なタスクを解くためのモジュラー式アプローチやで。なんでかっていうと、でかい問題を小さく分けて解くのがコツやねん。第11回国際学習表現会議、ICLR 2023、キガリ、ルワンダ、2023年5月1-5日。OpenReview.net。
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti,
Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew
Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob
Uszkoreit, Quoc Le, and Slav Petrov. 2019. Natural Questions: 質問応答研究のためのベンチマークや。Transactions of the Association for Computational Linguistics, 7:452–466.
Angeliki Lazaridou, Elena Gribovskaya, Wojciech
Stokowiec, and Nikolai Grigorev. 2022. オープンドメイン質問応答のための少数ショットプロンプティングを使ったインターネット拡張言語モデルやねん。ネットから情報引っ張ってきて答えるってことや。arXiv preprint arXiv:2203.05115.
Belinda Z. Li, Sewon Min, Srinivasan Iyer, Yashar
Mehdad, and Wen-tau Yih. 2020. 質問に対する効率的なワンパスのエンドツーエンドエンティティリンキングや。自然言語処理における経験的手法に関する2020年会議論文集、EMNLP 2020、オンライン、2020年11月16-20日、pages 6433–6441. 計算言語学会。
Ilya Loshchilov and Frank Hutter. 2019. 重み減衰正則化の分離や。これがめっちゃ大事でな、AdamWの話やねん。第7回国際学習表現会議、ICLR 2019、ニューオーリンズ、LA、USA、2019年5月6-9日。OpenReview.net。
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das,
Daniel Khashabi, and Hannaneh Hajishirzi. 2023.
言語モデルを信用したらあかん時:パラメトリックメモリと非パラメトリックメモリの有効性を調べたで。計算言語学会第61回年次大会論文集(第1巻:長編論文)、ACL 2023、トロント、カナダ、2023年7月9-14日、pages 9802–9822. 計算言語学会。
OpenAI. 2023. GPT-4のテクニカルレポートや。arXiv preprint arXiv:2303.08774.
Adam Paszke, Sam Gross, Francisco Massa, Adam
Lerer, James Bradbury, Gregory Chanan, Trevor
Killeen, Zeming Lin, Natalia Gimelshein, Luca
Antiga, Alban Desmaison, Andreas Köpf, Edward Z.
---
## Page 12
[](/attach/12d262c682626c26a98bdafc7ec5dc6af3fae8247d26d4f2c712b1599dafce62_p012.png)
### 和訳
Yang、Zachary DeVito、Martin Raison、Alykhan Tejani、Sasank Chilamkurthy、Benoit Steiner、Lu Fang、Junjie Bai、それからSoumith Chintallaさんらが2019年に発表したんがPyTorchや。これ何かっていうと、命令型スタイルで書けるめっちゃ高性能なディープラーニングのライブラリやねん。Neural Information Processing Systems 2019の論文集に載ってて、8024から8035ページに書いてあるで。
Jayr Alencar Pereira、Robson do Nascimento Fidalgo、Roberto de Alencar Lotufo、それからRodrigo Frassetto Nogueiraさんらは2023年にViscondeっちゅうのを発表してん。これはGPT-3とニューラル再ランキングを使った複数文書からの質問応答システムやねん。情報検索の研究を発表するECIRっていうヨーロッパの学会で、2023年4月2日から6日にアイルランドのダブリンで開催されたやつの論文集に入ってるで。Lecture Notes in Computer Scienceのシリーズで13981巻の534から543ページ、Springer出版や。
Ofir Press、Muru Zhang、Sewon Min、Ludwig Schmidt、Noah A. Smith、Mike Lewisさんらは2023年に、言語モデルの「構成性ギャップ」を測定して縮める方法を研究してん。構成性ギャップっていうのは、要するに言語モデルが単純な知識は持ってても、それらを組み合わせた複雑な推論ができへんっていう問題のことやねん。これはEMNLP 2023のFindings部門で発表されとるで。
Peng Qi、Haejun Lee、Tg Sido、Christopher D. Manningさんらは2021年に、いろんな推論ステップが必要なオープンドメインの質問に答える研究をしてん。簡単に言うと、テキストから情報を引っ張ってきて、何段階かの推論を経て答えを出すっていう難しいタスクや。EMNLP 2021で発表されて、2021年11月7日から11日にドミニカ共和国のプンタカナでバーチャル開催されたやつの3599から3614ページに載ってるで。Association for Computational Linguisticsから出てる。
Colin Raffel、Noam Shazeer、Adam Roberts、Katherine Lee、Sharan Narang、Michael Matena、Yanqi Zhou、Wei Li、Peter J. Liuさんらは2020年に、T5っていう統一テキスト間変換モデルで転移学習の限界を探る研究をしたんや。転移学習っていうのは、あるタスクで学習した知識を別のタスクに使い回すことやねん。Journal of Machine Learning Researchの21巻、140:1から140:67に載ってるで。
Pranav Rajpurkar、Jian Zhang、Konstantin Lopyrev、Percy Liangさんらは2016年にSQuADを発表してん。これ何かっていうと、テキストを読んで理解するための10万問以上の質問を集めたデータセットやねん。機械がちゃんと文章を理解できてるか試すためのベンチマークとしてめっちゃ有名やで。EMNLP 2016でテキサス州オースティンにて2016年11月1日から4日に開催された学会の2383から2392ページに載ってる。
Ori Ram、Yoav Levine、Itay Dalmedigos、Dor Muhlgay、Amnon Shashua、Kevin Leyton-Brown、Yoav Shohamさんらは2023年に、文脈内検索で強化した言語モデルの研究をしてん。要するに、言語モデルが答えを出すときにその場で関連情報を検索して使うっていうアプローチやな。Transactions of the Association for Computational Linguisticsに載ってるで。
Stephen E. Robertson、Steve Walker、Susan Jones、Micheline Hancock-Beaulieu、Mike Gatfordさんらは1994年にOkapiシステムをTREC-3で発表してん。TRECっていうのは文書検索の競技会みたいなもんで、1994年11月2日から4日にメリーランド州ゲイザースバーグで開催されたやつや。NIST Special Publicationの500-225巻、109から126ページに載ってるで。
Weijia Shi、Sewon Min、Michihiro Yasunaga、Minjoon Seo、Rich James、Mike Lewis、Luke Zettlemoyer、Wen-tau Yihさんらは2023年にREPLUGを発表してん。これは検索で強化したブラックボックス言語モデルやねん。ブラックボックスっていうのは、中身をいじれへんモデルでも外から検索結果を足して性能を上げるっていうアプローチのことや。arXivのプレプリントで2301.12652として公開されとるで。
Hugo Touvron、Louis Martin、Kevin Stone、Peter Albert、Amjad Almahairi、Yasmine Babaei、Nikolay Bashlykov、Soumya Batra、Prajjwal Bhargava、Shruti Bhosale、Dan Bikel、Lukas Blecher、Cristian Canton-Ferrer、Moya Chen、Guillem Cucurull、David Esiobu、Jude Fernandes、Jeremy Fu、Wenyin Fu、Brian Fuller、Cynthia Gao、Vedanuj Goswami、Naman Goyal、Anthony Hartshorn、Saghar Hosseini、Rui Hou、Hakan Inan、Marcin Kardas、Viktor Kerkez、Madian Khabsa、Isabel Kloumann、Artem Korenev、Punit Singh Koura、Marie-Anne Lachaux、Thibaut Lavril、Jenya Lee、Diana Liskovich、Yinghai Lu、Yuning Mao、Xavier Martinet、Todor Mihaylov、Pushkar Mishra、Igor Molybog、Yixin Nie、Andrew Poulton、Jeremy Reizenstein、Rashi Rungta、Kalyan Saladi、Alan Schelten、Ruan Silva、Eric Michael Smith、Ranjan Subramanian、Xiaoqing Ellen Tan、Binh Tang、Ross Taylor、Adina Williams、Jian Xiang Kuan、Puxin Xu、Zheng Yan、Iliyan Zarov、Yuchen Zhang、Angela Fan、Melanie Kambadur、Sharan Narang、Aurélien Rodriguez、Robert Stojnic、Sergey Edunov、Thomas Scialomさんらは2023年にLlama 2を発表してん。これはオープンな基盤モデルとファインチューニング済みのチャットモデルやねん。誰でも使えるように公開されてるのがめっちゃ画期的やったんや。arXivプレプリントの2307.09288として公開されとるで。
Harsh Trivedi、Niranjan Balasubramanian、Tushar Khot、Ashish Sabharwalさんらは2022年にMuSiQueを発表してん。これは単一ホップの質問を組み合わせてマルチホップの質問を作るっていうデータセットや。マルチホップっていうのは、答えにたどり着くまでに複数の情報を渡り歩かなあかんような質問のことやねん。Transactions of the Association for Computational Linguisticsの10巻、539から554ページに載ってるで。
同じくHarsh Trivedi、Niranjan Balasubramanian、Tushar Khot、Ashish Sabharwalさんらは2022年に♪ MuSiQue(音符マークついてるのがかわいいな)も発表してて、これも単一ホップの質問を組み合わせてマルチホップの質問を作るっていう同じ研究やねん。Transactions of the Association for Computational Linguisticsの10巻、539から554ページや。
さらにHarsh Trivedi、Niranjan Balasubramanian、Tushar Khot、Ashish Sabharwalさんらは2023年に、検索と連鎖的思考推論を交互に使って知識集約型のマルチステップ質問に答える研究を発表してん。なんでかっていうと、一回検索して終わりじゃなくて、推論しながら必要な情報をその都度検索していくっていう賢いやり方やねん。ACL 2023の論文集に入ってて、2023年7月9日から14日にカナダのトロントで開催された学会の10014から10037ページに載ってるで。
Jason Wei、Yi Tay、Rishi Bommasani、Colin Raffel、Barret Zoph、Sebastian Borgeaud、Dani Yogatama、Maarten Bosma、Denny Zhou、Donald Metzler、Ed H. Chi、Tatsunori Hashimoto、Oriol Vinyals、Percy Liang、Jeff Dean、William Fedusさんらは2022年に、大規模言語モデルの「創発的能力」について研究してん。創発的能力っていうのは、モデルがでかくなると突然できるようになる能力のことで、小さいモデルでは全然できへんかったことが急にできるようになるっていうほんまに不思議な現象やねん。Transactions on Machine Learning Researchの2022年版に載ってるで。
Jason Wei、Xuezhi Wang、Dale Schuurmans、Maarten Bosma、Brian Ichter、Fei Xia、Ed H. Chi、Quoc V. Le、Denny Zhouさんらは2022年に、連鎖的思考プロンプティングで大規模言語モデルの推論を引き出す研究をしてん。これめっちゃ有名な研究で、「ステップバイステップで考えてな」って言うだけでAIの推論能力がグンと上がるっていう発見やねん。NeurIPSで発表されとるで。
Thomas Wolf、Lysandre Debut、Victor Sanh、Julien Chaumond、Clement Delangue、Anthony Moi、Pierric Cistac、Tim Rault、Rémi Louf、Morgan Funtowiczさんらの研究は...(ここで文章が切れとるな)
---
## Page 13
[](/attach/12d262c682626c26a98bdafc7ec5dc6af3fae8247d26d4f2c712b1599dafce62_p013.png)
### 和訳
Joe Davison、Sam Shleifer、Patrick von Platen、Clara Ma、Yacine Jernite、Julien Plu、Canwen Xu、Teven Le Scao、Sylvain Gugger、Mariama Drame、Quentin Lhoest、Alexander M. Rush。2020年。Transformers:めっちゃ最先端の自然言語処理やで。2020年の自然言語処理における経験的手法に関する国際会議:システムデモ発表、EMNLP 2020 - Demos、38-45ページ。計算言語学会。
Lee Xiong、Chenyan Xiong、Ye Li、Kwok-Fung Tang、Jialin Liu、Paul N. Bennett、Junaid Ahmed、Arnold Overwijk。2021年。近似最近傍を使った負例対照学習で高密度テキスト検索するねん。なんでかっていうと、文章の意味をベクトルで捉えて、似てるもん同士を近くに、違うもん同士を遠くに配置する学習をするわけや。第9回国際学習表現会議、ICLR 2021、オンライン開催(オーストリア)、2021年5月3-7日。OpenReview.net。
Wei Yang、Yuqing Xie、Aileen Lin、Xingyu Li、Luchen Tan、Kun Xiong、Ming Li、Jimmy Lin。2019年。BERTseriniでエンドツーエンドのオープンドメイン質問応答やるで。要は、どんな分野の質問にも答えられるシステムを最初から最後まで一気通貫で作ったってことやねん。北米計算言語学会:人間言語技術に関する2019年会議予稿集、NAACL-HLT 2019、ミネアポリス、アメリカ、2019年6月2-7日、デモ発表、72-77ページ。計算言語学会。
Zhilin Yang、Peng Qi、Saizheng Zhang、Yoshua Bengio、William Cohen、Ruslan Salakhutdinov、Christopher D. Manning。2018年。HotpotQA:多様で説明可能なマルチホップ質問応答のためのデータセット。マルチホップっていうのはな、1回の検索じゃ答えが出んくて、何回も情報を辿っていかなあかん質問のことやねん。2018年自然言語処理における経験的手法に関する国際会議予稿集、2369-2380ページ、ブリュッセル、ベルギー。計算言語学会。
Shunyu Yao、Jeffrey Zhao、Dian Yu、Nan Du、Izhak Shafran、Karthik R. Narasimhan、Yuan Cao。2023年。ReAct:言語モデルで推論と行動をシナジーさせるねん。ほんまにすごいのが、考えることと実際に動くことを組み合わせて、AIがより賢く問題解決できるようになるってことやな。第11回国際学習表現会議、ICLR 2023、キガリ、ルワンダ、2023年5月1-5日。OpenReview.net。
Fengbin Zhu、Wenqiang Lei、Chao Wang、Jianming Zheng、Soujanya Poria、Tat-Seng Chua。2021年。検索して読む:オープンドメイン質問応答の包括的サーベイ。めっちゃ広い範囲の質問応答研究をまとめた総説論文やで。arXivプレプリント、arXiv:2101.00774。
---
## Page 14
[](/attach/12d262c682626c26a98bdafc7ec5dc6af3fae8247d26d4f2c712b1599dafce62_p014.png)
### 和訳
図4:いろんな検索活用型文章生成アプローチのQA性能(F1スコア)と効率(1クエリあたりの時間)やねん。ベースのLLMにはFLAN-T5-XL(30億パラメータ)を使ってるで。
図5:同じくいろんな検索活用型文章生成アプローチのQA性能(F1スコア)と効率(1クエリあたりの時間)や。こっちはFLAN-T5-XXL(110億パラメータ)をベースLLMにしてるねん。
## A 追加の実験セットアップ
### A.1 データセット
単純な1ホップのQAデータセットと、複数ホップのQAデータセット、両方とも公開されてるやつを使ってんねん。それぞれKarpukhinらの2020年の研究とTrivediらの2023年の研究を参考にしてるで。各データセットの特徴を説明するわな:
1) **SQuAD v1.1**(Rajpurkarら、2016)は、アノテーターさんが文書を読んで、それをもとに質問を作るっていうプロセスで作られたやつやねん。
2) **Natural Questions**(Kwiatkowskiら、2019)は、Google検索での実際のユーザーの検索クエリから作られてんねん。めっちゃリアルな質問が集まってるわけや。
3) **TriviaQA**(Joshiら、2017)は、いろんなクイズサイトから集めてきたトリビア問題で構成されてるで。
4) **MuSiQue**(Trivediら、2022a)は、複数の1ホップクエリを組み合わせて、2〜4ホップにまたがる質問を作ってんねん。なんでかっていうと、複雑な推論が必要な問題を作りたかったからや。
5) **HotpotQA**(Yangら、2018)は、アノテーターさんに複数のWikipedia記事をつなげるような質問を作ってもらって構築されてるねん。
6) **2WikiMultiHopQA**(Hoら、2020)は、Wikipediaとそれに紐づく知識グラフのパスから作られてて、2ホップの推論が必要なやつやで。
### A.2 モデル
使ったモデルの詳細を説明するわな:
1) **検索なし(No Retrieval)**。これはLLMだけを使って、与えられた質問に対する答えを生成するアプローチや。シンプルやけど、知識の限界があるねん。
2) **シングルステップアプローチ**。まず与えられた質問で外部の知識ソースから関連する情報を検索して、その検索結果でLLMを強化して答えを生成するっていう、1回だけの繰り返しで終わるやつや。
3) **適応的検索(Adaptive Retrieval)**。このベースライン(Mallenら、2023)は、質問に出てくるエンティティ(固有名詞とか)があんまり有名やないときだけ、検索モジュールでLLMを強化するねん。エンティティを抽出するのには、BLINKっていう利用可能なエンティティリンキング手法(Liら、2020)を使ってるで。
4) **Self-RAG**。このベースライン(Asaiら、2024)は、LLMをトレーニングして検索と生成を適応的にやらせるねん。特別な検索トークンの予測が一定のしきい値を超えたら検索を実行して、そのあと答えの生成が続くっていう仕組みや。
5) **Adaptive-RAG**。これがワイらのモデルやねん!検索活用型生成戦略を適応的に選択して、検索なし、シングルステップアプローチ、マルチステップアプローチの間をスムーズに行き来するんや。アーキテクチャを変えることなく、分類器が評価したクエリの複雑さに基づいて切り替えるねん。めっちゃ賢いやろ?
6) **マルチステップアプローチ**。このアプローチ(Trivediら、2023)は、マルチステップの検索活用型LLMで、Chain-of-Thought推論(Weiら、2022b)を挟みながら、検索とLLMの両方に繰り返しアクセスして、解決策が出るか最大ステップ数に達するまで続けるねん。
7) **Adaptive-RAG w/ Oracle**。これはワイらのAdaptive-RAGに、クエリの複雑さを完璧に分類できるオラクル分類器を装備した理想的なシナリオや。まあ、上限の性能を見るためのもんやな。
### A.3 実装の詳細
計算リソースとしては、80GBメモリのA100 GPUを使ってるで。あと、検索活用型生成モデルの評価にはめっちゃコストがかかるから、実験は1回だけで行ってんねん。最後に、モデルの実装にはPyTorch(Paszkeら、2019)とTransformersライブラリ(Wolfら、2020)を使ったで。
## B 追加の実験結果
**性能 vs 時間** さらに、FLAN-T5-XLとFLAN-T5-XXLモデルでの異なる検索活用型生成アプローチの比較を、それぞれ図4と図5で示してるねん。性能と効率のトレードオフの観点からの比較やで。図1のGPT-3.5モデルでの観察と同じように、ワイらが提案したAdaptive-RAGは、性能面でもめっちゃ効果的やし、効率面でも優れてるねん。ほんまにええ感じや!
---
4マルチステップアプローチには、IRCoT(Trivediら、2023)の最先端の質問応答戦略を使ってるで。
---
## Page 15
[](/attach/12d262c682626c26a98bdafc7ec5dc6af3fae8247d26d4f2c712b1599dafce62_p015.png)
### 和訳
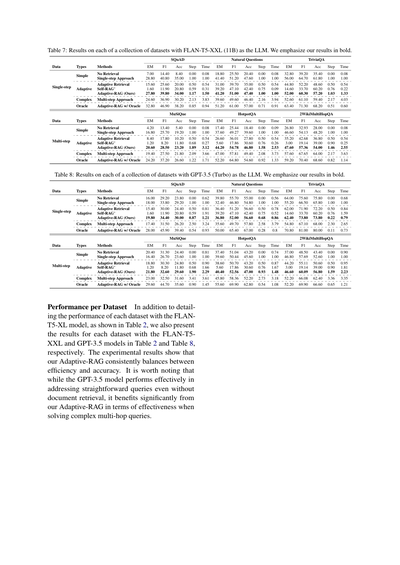
表7:色んなデータセットの結果やねん。FLAN-T5-XXL(110億パラメータ)を大規模言語モデルとして使ったときの話やで。太字にしてるのがワイらの結果な。
SQuAD
Natural Questions
TriviaQA
データの種類とか手法とか、EM(完全一致)、F1スコア、精度、ステップ数、処理時間とか全部載せてるで。
シンプルな質問の場合:
- 検索なしでやると結構キツいねん
- 一発検索でそこそこイケる
- 適応型検索でもっとええ感じになる
- Self-RAGっていう先行研究もあるねんけど
- ワイらのAdaptive-RAGがなかなかの数字出してるやろ?
複雑なマルチステップの手法やと、やっぱりステップ数増えるけど精度も上がってくるねん。
理想的な条件(Oracle)でやったら、Adaptive-RAGはもっとエグい数字叩き出すで。
MuSiQue
HotpotQA
2WikiMultiHopQA
これらは複数の情報を組み合わせなアカン難しめの質問やねんけど、ここでもワイらのAdaptive-RAGはかなりええ線いってるわ。効率と精度のバランスがめっちゃ取れてんねん。
表8:GPT-3.5(Turbo)を使ったときの結果やで。同じく太字がワイらの結果な。
(表の構成は上と一緒やから省略するけど)
データセットごとの性能について
表2でFLAN-T5-XLモデルの各データセットの性能を詳しく説明したけど、ここではFLAN-T5-XXLとGPT-3.5モデルの結果も表2と表8で見せとるで。
実験結果からわかるのは、ワイらのAdaptive-RAGは効率と精度のバランスを常にうまいこと取れてるってことやねん。
特に注目してほしいのがな、GPT-3.5モデルって単純な質問やったら文書検索せんでも結構ちゃんと答えられるねんけど、複雑な複数ホップの質問(いくつかの情報を渡り歩かなアカンやつ)を解くときは、ワイらのAdaptive-RAGのおかげでめっちゃ性能上がってるってことやで。要するに、難しい問題になればなるほど、ワイらの手法が効いてくるってわけや!
---
![]()
1 / 1
100%