<<
Structured information extraction from scientific text with large language models

---
## Page 1
[](/attach/06ec2c45959fd0547093ff3776dcc4cd8c38af73884f637a59be6c4a756b61e3_p001.png)
### 和訳
論文
https://doi.org/10.1038/s41467-024-45563-x
大規模言語モデルを使って科学論文から構造化された情報を引っこ抜く話
受付:2023年3月17日
受理:2024年1月22日
John Dagdelen, Alexander Dunn, Sanghoon Lee, Nicholas Walker, Andrew S. Rosen, Gerbrand Ceder, Kristin A. Persson & Anubhav Jain
---
科学論文から整理された知識を引っこ抜くっていうんは、機械学習モデルにとってまだまだムズい課題やねん。ほんでここでは、固有表現認識と関係抽出を一緒にやるシンプルなやり方を提案して、事前学習済みの大規模言語モデル(GPT-3とかLlama-2とか)をファインチューニング——つまり特定の用途向けに追加で学習させることで、複雑な科学知識のレコードをうまいこと抜き出せるっていうのを実証しとるで。材料化学の代表的な3つのタスクで試してんねん:ドーパント(不純物として混ぜるやつ)とホスト材料の紐づけ、金属有機構造体(MOF)のカタログ化、ほんで組成・相・形態・応用情報の一般的な抽出や。1文だけからでもパラグラフ丸ごとからでもレコードを抜き出せるし、出力も普通の英文でもJSONオブジェクトのリストみたいなもっと構造化された形式でも返せるねん。このアプローチは、研究論文から構造化された専門的な科学知識の大規模データベースを作るための、シンプルで誰でも使えて、めっちゃ柔軟な方法やで。
---
固体材料に関する科学知識の大半は、何百万本もある学術論文のテキストとか表とか図の中にバラバラに散らばっとるねん。せやから、研究者が過去の研究全体をちゃんと把握して、実験を設計するときに既存の知識をうまく活かすんがめっちゃ難しいわけや。しかも最近は、材料の発見とか設計のワークフローのスクリーニング(ふるい分け)ステップとして、性質を直接予測する機械学習モデルがどんどん使われるようになっとるんやけど、これはテーブル化されたデータベースにどんだけ学習データがあるかに制限されてまうねん。第一原理シミュレーション——つまりコンピュータ計算から得られた材料の性質データのデータベースは割とあるんやけど、計算でアクセスできる性質にしか使えへんし、実験で測定した性質データとかその他の有用な実験データのデータベースは比較的ちっさい(そもそも存在するかも怪しい)っていう状況やねん。
ここ数年で、研究者らは自然言語処理(NLP)のアルゴリズムを材料科学に適用して、既存のテキストベースの材料科学知識を構造化するっていう面でめっちゃ進歩してきてん。この分野の研究の大半は固有表現認識(NER)に集中しとって、これはテキストの単語に「材料」とか「性質」みたいなエンティティラベルを付ける作業やな。こうやってタグ付けされた単語の列を追加の後処理と組み合わせて使うことで、テキストの記述から集めた材料の性質データの自動生成テーブルデータベースを作れることもあるねん。固体材料の分野でこれまでにやられてきた情報抽出の研究としては、実験方法のセクションのテキストから化学合成パラメータのNERラベリング、バッテリーの充放電実験の定量的結果、UV-Vis実験のピーク吸収波長の抽出とかがあるで。正規表現とか、BiLSTMっていう再帰型ニューラルネットワークとか、BERTみたいな小さめのTransformerベースの言語モデルでこういうタスクは十分対応できるねん。これらの研究では、エンティティ(例えばLiCoO₂とか「350K」とか)が主な抽出ターゲットであって、関係性(例えば「350Kはこの実験でLiCoO₂を合成するときの温度パラメータやで」みたいなん)は主なターゲットちゃうかったんよな。
せやけどな、科学分野の自然言語処理における重要な課題は、固有表現間の関係を正確に抽出するための、頑丈でシンプルで汎用的な関係抽出(RE)技術を開発することやねん。教師あり機械学習とか知識グラフの構築みたいな下流タスクには、構造化されてないテキストを、関心のある意味的エンティティ間の構造化された関係のセットに変換する必要があるわけや。REモデルは、あらかじめ定義された関係のセットによって、どのエンティティ同士がつながっとるかを判定するために使うねん。例えば「LiCoO₂ is studied as a Li-ion battery material」っていう文やったら、材料エンティティの「LiCoO₂」が応用エンティティの「リチウムイオン電池」に紐づけられるっていう具合やな。最近まで、材料科学の分野での関係抽出の研究はあんまり進んでなかってん。
---
1 ローレンスバークレー国立研究所(米カリフォルニア州バークレー)、2 カリフォルニア大学バークレー校 材料科学工学科、3 共同筆頭著者:John Dagdelen, Alexander Dunn
連絡先:ajain@lbl.gov
Nature Communications | (2024) 15:1418
---
## Page 2
[](/attach/06ec2c45959fd0547093ff3776dcc4cd8c38af73884f637a59be6c4a756b61e3_p002.png)
### 和訳
記事
https://doi.org/10.1038/s41467-024-45563-x
材料科学のテキストに関する話なんやけど、実は関係抽出(RE)っていう技術は、もっと一般的なテキスト——つまり人の名前とか組織とか場所とか日付とかを結びつける研究——で、めっちゃ注目されてきてん²⁰'²¹。こういう手法って昔から「パイプライン方式」って呼ばれるやり方が主流やってん。なんでかっていうと、まず最初に「固有表現認識」っていうステップがあって、そのあとにいくつか追加のステップがあって、最後に関係を分類するステップがある、みたいな流れやねん(図1の上の段を見てな)。で、それぞれのステップで別々の機械学習モデルを使うんやけど、モデル同士が重みとか構造を共有してることもあれば、してないこともあるねん。最新のTransformerベースのパイプライン手法は、いろんな一般知識のデータセット²²とか、化学物質と病気の関係²³とか、遺伝子と病気の関係²⁴みたいな専門分野でも、文書レベルの関係抽出をそこそこうまくできることが示されてるで。最近では、こういう2段階のアプローチが、多結晶材料の合成手順を有向グラフとして材料科学のテキストから抜き出すベンチマークデータセットでも実証されてん²⁵。
せやけど、科学の情報って、単純にエンティティ(実体)同士のペアの関係としてモデル化できへんことが多いねん。これが特にはっきりわかるのが無機材料科学の分野で、ある化合物の特性っていうのは、元素の組成、原子の配置、微細構造、形態(例えばナノ粒子とかヘテロ構造とか界面とか)、加工の履歴、それに温度や圧力みたいな環境要因が複雑に絡み合って決まるもんやねん。さらに言うたら、無機材料の知識って本質的にめちゃくちゃ絡み合ってて、ある関係が成り立つのは、ひとつのエンティティの種類と「複合エンティティ」(それ自体がいくつかのエンティティと関係で構成されてるやつ)の間だけ、みたいなこともあるわけよ。例えばな、酸化亜鉛ナノ粒子(組成「ZnO」と形態「ナノ粒子」がくっついたやつ)は触媒やと言えるけど、「ZnO」だけとか「ナノ粒子」だけでは、必ずしも触媒やとは言えへんやろ?こういう複合的な関係の一部が欠けてしもたら、科学的な意味が変わってしまうねん。例えば、HfZrO₄の「エピタキシャルLaドープ薄膜」のサンプルは、HfZrO₄の「Laドープ薄膜」とは物理的特性が違うし、HfZrO₄の「Laドープ」サンプルとも違うわけや。理論的には、n個のエンティティ間の関係はn-タプル(例えば("ZnO", "ナノ粒子", "触媒"))としてモデル化できるんやけど、あらゆるバリエーションを網羅的に列挙するのは現実的やないし、従来の関係抽出手法とも相性が悪いねん。なんでかっていうと、それぞれの関係タイプに対して十分な数の学習例が必要やからや。例えば、10種類のエンティティクラスを抽出するモデルの場合、¹⁰C₃ = 120通りの3-タプルの関係タイプがあって、それぞれに最低でも数個のアノテーション例が要るわけよ。今の関係抽出モデルは、こういうめっちゃ複雑で、入り組んでて、階層的で、しかも任意の数の固有表現の間にある関係を実用的に抽出したり保持したりするようにはできてへんから、もっと柔軟な戦略が必要やねん。
大規模言語モデル(LLM)——GPT-3/4²⁶'²⁷、PaLM²⁸、Megatron²⁹、LLaMA 1/2³⁰'³¹、OPT³²、Gopher³³、FLAN³⁴とか——は、自然言語の中のトークン間の意味的な情報をうまいこと活用する能力がほんまにすごいってことが示されてるねん。特に得意なんが、系列変換(seq2seq)タスクっていうやつで、テキストを入力したら、それをもとにモデルがテキストで返してくれるやつや。この論文では、この入力のことを「プロンプト」、出力のことを「コンプリーション(補完)」って呼ぶで。seq2seqの使い道はめっちゃ幅広くて³⁵、機械翻訳³⁶、一般的な事実の質問に答えること³³'³⁷、簡単な計算³³、言語間の翻訳³⁶'³⁸、テキストの要約²⁸'³⁹、チャットボットの応用²⁶'⁴⁰なんかがあるねん。こう考えたら、こういうモデルが複雑な科学情報の抽出にも使えるんちゃうか、ってなるのは自然な流れやわな。
最近では、単一の機械学習モデルを使ったエンドツーエンド手法が、固有表現認識と
図1 | 従来の関係抽出(RE)手法と本研究の比較の概要図。どの手法も目指してるのは、構造化されてないテキストからエンティティ(色付きのテキスト)とその関係を抽出することやねん。a 複数ステップのパイプラインアプローチの例では、まずエンティティ認識をして、次に共参照解決とかの中間処理をして、最後にエンティティ間のリンクを分類するで。b seq2seqアプローチでは、関係を出力系列の中で2-タプルとしてエンコードするねん。固有表現と関係のリンクには特別な記号(例えば「@FORMULA@」とか「@N2F@」)でタグ付けされるで。c 本研究で示す手法では、エンティティとその関係をJSONドキュメントとかその他の階層構造として出力するねん。
Nature Communications | (2024) 15:1418
2
---
## Page 3
[](/attach/06ec2c45959fd0547093ff3776dcc4cd8c38af73884f637a59be6c4a756b61e3_p003.png)
### 和訳
名前付きエンティティ関係抽出(NERRE)っちゅうもんがあんねん⁴¹⁻⁴³。これはな、sequence-to-sequenceっていうアプローチで、モデルに「2つ以上の名前付きエンティティの組み合わせと、それらの間にある関係のラベル」を出力させるように訓練するやり方やねん(図1の真ん中の行見てな)。関係抽出自体はそこそこうまいこといくんやけど、根本的にはn個の関係を抜き出すシステムのままやから、めっちゃ入り組んだ階層的なNERREには向いてへんのよ。
材料科学の分野ではな、HuangとColeっていう人らが最近、BERTっていうモデルを電池関連の論文で追加学習させて、NLP(自然言語処理)で抜き出した電池データのデータベースを強化するモデルを作ったんや¹¹。彼らのやり方は「質問と回答」(Q/A)方式で、「カソード(正極)は何?」「アノード(負極)は何?」「電解質は何?」みたいな、デバイスレベルの限られた情報を抜き出すもんやってん。従来の情報抽出手法と組み合わせて使うんやけどな¹¹。ただこのやり方、1つの文章に複数のデバイスの情報が入ってると使われへんし、BERTを何十万本もの電池研究論文で事前学習させてからQ/Aタスクでファインチューニングせなあかんかったんよ。もうちょい最近やと、Zhengらが⁴⁴プロンプトエンジニアリング(要はAIへの指示の出し方を工夫するやつ)を使ったChemPromptっちゅうアプローチをChatGPT⁴⁵で設計してんねん。これは科学論文からデータを抜き出すためのもんで、テキストを表形式に整理したり、半構造化された要約を作ったり、事前学習で蓄えた知識をまとめたりするのが目的やな。同じような感じで、Castro NascimentoとPimentel⁴⁶はChatGPTの化学に関する一般知識を調べたんやけど、結果としてわかったんは、めっちゃ工夫したプロンプトエンジニアリング⁴⁷を使う方法とは違って、特に「技」なしのChatGPTは化学の簡単なタスクでもあんまりうまくいかへんっちゅうことやねん。Xieら⁴⁸のアプローチは、大規模で幅広い材料科学のデータでファインチューニングしたLLM(大規模言語モデル)を使って、Q/A、逆設計、分類、回帰なんかいろんなタスクをこなすもんや。これらの方法⁴⁴,⁴⁶⁻⁴⁸はLLMが材料科学の知識エンジンとして使えるかもしれんっていう可能性を示してるんやけど、事前学習データの範囲を超えた複雑な階層的エンティティ関係の構造化表現を抽出できるかどうかはまだ示されてへんのよ。
ほんでこの研究ではな、大規模言語モデルをファインチューニングして、名前付きエンティティとその関係を同時に抽出するっちゅうシンプルなアプローチで複雑な情報抽出に挑んでるねん。この方法のええとこは、複雑な相互関係(情報が複数項目のリストとして存在するケースも含めて)を柔軟に扱えることやな。しかもn個のタプル関係を全部列挙したり、事前にNER(名前付きエンティティ認識)をやったりする必要がないんよ。Jablonkaら⁴⁹,⁵⁰やXieら⁴⁸がやった教師あり学習(化学の回帰や分類とか)や逆設計のアプローチとは違って、ワイらのやり方はLLMで直接設計に影響を与えたり物性を予測したりするんやなくて、下流のモデルで使うための構造化された情報の階層を(正確に)抽出することを目指してるねん。具体的には、事前学習済みの大規模言語モデル(GPT-3²⁶やLlama-2³¹とか)をファインチューニングして、テキスト(例えば研究論文のアブストラクト)を受け取って、プロンプトに含まれる知識を正確にフォーマットされた「要約」として書き出すようにするんや。この出力は英語の文章でもええし、JSONドキュメントのリストみたいなもっと構造化されたスキーマでもええねん。使い方はめっちゃシンプルで、望みの出力構造(例えばあらかじめ決めたキーを持つJSONオブジェクトのリスト)を定義して、100〜500くらいのテキスト段落をそのフォーマットでアノテーション(タグ付け)するだけ。そのデータでLLMをファインチューニングしたら、できたモデルが同じ構造化表現で正確に情報を抽出して出力してくれるっちゅうわけや(図1のフォーマットみたいな感じ)。要するにな、その分野の専門家がLLM-NERREモデルに「何を抽出すべきか」と「その情報をどう表現すべきか」の両方を見せてあげたら、モデルが自分でそのタスクをこなせるようになるっちゅうことやねん。
この方法はOpenAIのGPT-3(非公開ソース)とLlama-2(オープンアクセス)の両方で、文レベルでも文書レベルでも材料情報抽出でめっちゃええ性能を発揮するんや。しかもな、オンラインのLLM APIを活用できるから、LLMの内部の仕組みを詳しく知らんでもカスタムモデルを訓練できるっちゅう利点があるねん。ユーザーからしたら、LLMを「文章を正確にフォーマットされた構造化要約に変換してくれるブラックボックス」として扱えばええだけやから、NLP(自然言語処理)の経験があんまりない研究者でも使えるわけや。あとな、中間モデルを使ってアノテーション用のエンティティを事前に提案させることもできて、これによってドキュメントのアノテーション作業がめっちゃ速く簡単になるから、大きな訓練データセットも比較的短時間で構築できるようになるんよ。例として示してるタスクは材料科学のもんやけど、この方法は汎用的でアクセスしやすいから、化学や健康科学、生物学なんかの他の分野にもすぐ応用できるはずや。特にええのは、以前の方法みたいに大量のドメイン特化データ(何百万ものアブストラクトとかパラグラフとか)でファインチューニングする必要がなさそうやっちゅうとこやな。LLMの包括的な事前学習と、ユーザーが提供するアノテーションだけで、幅広い複雑なタスクをこなせるんや。
**結果**
上で説明したアプローチを、名前付きエンティティ認識と関係抽出を同時にやる(NERRE)材料情報抽出の3つのタスクで試してるで。固体不純物ドーピング、金属有機構造体(MOF)、そして一般的な材料情報抽出の3つや。各データセットの詳細は表1にまとめてあるで。各タスクの詳しい話はMethodsセクションに書いてあるんやけど、ざっくり言うとな、固体不純物ドーピングのタスクは、テキスト(文章)からホスト材料、ドーパント(添加物)、あと関連する追加情報を見つけ出すもんやねん。MOFのタスクは、テキスト(材料科学のアブストラクト)から化学式、用途、ゲスト種(MOFの中に入る分子とか)、あとMOF材料のさらなる記述を特定するもんや。一般材料情報のタスクは、テキスト(材料科学のアブストラクト)から無機材料、化学式、略称、用途、相ラベル、その他の説明的情報を見つけ出すもんやで。一般材料とMOFのモデルは正規化やエラー修正を含むデータで訓練してて、ドーピングのモデルはテキストに書いてある通りにデータを抽出するように訓練してるんや。各ベースLLMモデルは、対象のエンティティ、関連する関係、フォーマットを定義した特定のスキーマに従うように、タスクごとにファインチューニングされてるで。全スキーマは表1に載ってて、詳細はMethodsと補足ノート1を見てな。
**関係抽出の性能**
GPT-3とLlama-2のNERRE精度、再現率、F1スコアを3つのタスクでJSONスキーマ使って比較したのが表2やで。各タスクのJSONスキーマの詳細はMethodsセクションで説明してるわ。性能の計算は単語の完全一致で
表1 | 材料情報抽出の3タスクに対するテストアプローチの概要
| タスク | スキーマ | 訓練サンプル数 | タスクレベル | 出力フォーマット |
|--------|----------|---------------|-------------|----------------|
| ドーピング | Doping-JSON | 413文 | 文 | JSON |
| ドーピング | Doping-English | 413文 | 文 | 英語の文章 |
| ドーピング | DopingExtra-English | 413文 | 文 | 英語の文章 |
| MOF | MOF-JSON | 507アブストラクト | アブストラクト | JSON |
| 一般材料 | General-JSON | 634アブストラクト | アブストラクト | JSON |
3つのタスク全部でJSONスキーマをテストしてて、さらにドーピングタスクでは書き言葉の英語に似た別のスキーマでも追加テストしてるで。MOFと一般材料のモデルはアブストラクトで訓練・評価してて、ドーピングタスクは文単位で評価してるんやな。
Nature Communications | (2024) 15:1418
---
## Page 4
[](/attach/06ec2c45959fd0547093ff3776dcc4cd8c38af73884f637a59be6c4a756b61e3_p004.png)
### 和訳
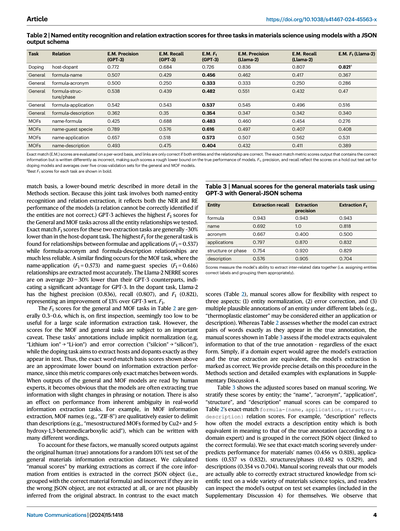
表2|材料科学の3つのタスクにおける固有表現認識と関係抽出のスコア(JSON出力スキーマを使ったモデル)
タスク|関係|完全一致の適合率(GPT-3)|完全一致の再現率(GPT-3)|完全一致のF1(GPT-3)|完全一致の適合率(Llama-2)|完全一致の再現率(Llama-2)|完全一致のF1(Llama-2)
ドーピング|ホスト-ドーパント|0.772|0.684|0.726|0.836|0.807|0.821a
一般|化学式-名前|0.507|0.429|0.456|0.462|0.417|0.367
一般|化学式-略語|0.500|0.250|0.333|0.333|0.250|0.286
一般|化学式-構造/相|0.538|0.439|0.482|0.551|0.432|0.47
一般|化学式-用途|0.542|0.543|0.537|0.545|0.496|0.516
一般|化学式-説明|0.362|0.35|0.354|0.347|0.342|0.340
MOFs|名前-化学式|0.425|0.688|0.483|0.460|0.454|0.276
MOFs|名前-ゲスト種|0.789|0.576|0.616|0.497|0.407|0.408
MOFs|名前-用途|0.657|0.518|0.573|0.507|0.562|0.531
MOFs|名前-説明|0.493|0.475|0.404|0.432|0.411|0.389
完全一致(E.M.)スコアは単語単位で評価してて、リンクが正解になるんは両方のエンティティと関係性が全部合ってる時だけやねん。完全一致の指標って、正しい情報を含んでても書き方がちょっと違うだけで不正解にされてまうから、モデルの本当の実力からしたらだいぶ低めに出る下限値みたいなもんやな。F1、適合率、再現率はドーピングモデルについてはホールドアウトテストセット、一般とMOFモデルについては5分割交差検証の平均値を反映してるで。
a各タスクの最高F1スコアは太字で表示。
完全一致ベースっていう、詳しくは方法のセクションで説明してる下限指標で評価してるんやけどな。この統合タスクは固有表現認識と関係抽出の両方を含んでるから、NERとREの両方の性能を反映してるわけや(エンティティが正しくなかったら関係も正しく識別でけへんからな)。GPT-3は一般タスクとMOFタスクで、ワイらがテストした全てのエンティティ関係において最高のF1スコアを叩き出してるねん。この2つの抽出タスクの完全一致F1スコアは、ホスト-ドーパントタスクと比べてだいたい30%くらい低いな。一般タスクで一番高いF1は化学式と用途の関係で見つかって(F1 = 0.537)、化学式-略語とか化学式-説明の関係はだいぶ信頼性が落ちるねん。MOFタスクでも似たような結果が出てて、名前-用途(F1 = 0.573)と名前-ゲスト種(F1 = 0.616)の関係が一番正確に抽出されてるわ。Llama-2のNERREスコアはGPT-3と比べて平均20〜30%低くて、GPT-3がめっちゃ有利やっていうことを示してるな。ただし!ドーピングタスクではLlama-2が最高の適合率(0.836)、再現率(0.807)、F1(0.821)を出してて、F1に関してはGPT-3を13%も上回っとるんやで。
一般タスクとMOFタスクの表2のF1スコアはだいたい0.3〜0.6の範囲で、パッと見た感じ「大規模な情報抽出タスクに使うには低すぎるんちゃうか?」って思うかもしれんけどな。でもな、MOFと一般タスクのスコアにはめっちゃ重要な注意点があるねん。なんでかっていうと、これらのタスクのアノテーションには暗黙的な正規化(例えば「Lithium ion」→「Li-ion」みたいな変換)やエラー修正(「silcion」→「silicon」みたいなタイポの修正)が含まれてるんやけど、ドーピングタスクの方はテキストに出てきた通りにホストとドーパントをそのまま抽出することを目指してるからな。せやから、上で示した完全一致ベースのスコアは情報抽出性能のだいたいの下限値やねん。この指標は単語同士の完全一致だけを比較してるからな。一般モデルとMOFモデルの出力を人間の専門家が実際に読んでみると、モデルが正しい情報を抽出してるのに言い回しや表記がちょっと違うだけ、っていうケースがめっちゃ多いのがはっきり分かるねん。あと、現実世界の情報抽出タスクに固有のあいまいさからくる性能への影響もあるんよ。例えばMOFの情報抽出やと、MOFの名前(「ZIF-8」とか)は区切りがはっきりしてて比較的簡単やけど、説明文(「Cu2+と5-ヒドロキシ-1,3-ベンゼンジカルボン酸から形成されたメソ構造MOF」みたいなやつ)はいろんな書き方ができるから、めっちゃ難しいわけや。
こういう要因を考慮するために、一般材料情報抽出データセットのランダムな10%テストセットについて、元の人間による(正解)アノテーションと出力を手動でスコアリングしたんや。「手動スコア」は、エンティティの核心的な情報が正しいJSONオブジェクト内に抽出されてたら(つまり正しい材料の化学式とグループ化されてたら)正解、間違ったJSONオブジェクトに入ってたり、全く抽出されてなかったり、元のアブストラクトからもっともらしく推論できひんかったら不正解、っていう基準で計算してるねん。完全一致スコア(表2)と違って、手動スコアは3つの側面について柔軟性を持たせてるんや:(1)エンティティの正規化、(2)エラー修正、(3)異なるラベルでの複数の妥当なアノテーション(例えば「熱可塑性エラストマー」は用途にも説明にもなり得るやん)。表2がモデルが正解アノテーションに出てくる通りの単語ペアをそのまま抽出できるかを評価してるのに対して、表3の手動スコアはモデルが正解アノテーションと同等の情報を抽出してるかどうかを評価してるんや——正確な形式は問わずにな。要するに、その分野の専門家が「モデルの抽出結果と正解の抽出結果は同じ意味やな」って同意するなら、モデルの抽出は正解とみなすっていうことやな。この手順の詳細は方法のセクションに、詳しい例と説明は補足議論4に載せてるで。
表3|GPT-3とGeneral-JSONスキーマを使った一般材料タスクの手動スコア
エンティティ|抽出の再現率|抽出の適合率|抽出のF1
化学式|0.943|0.943|0.943
名前|0.692|1.0|0.818
略語|0.667|0.400|0.500
用途|0.797|0.870|0.832
構造または相|0.754|0.920|0.829
説明|0.576|0.905|0.704
スコアは、モデルが相互に関連するデータをまとめて抽出する能力(つまりエンティティに正しいラベルを付けて適切にグループ化する能力)を測定してるで。
表3は手動スコアリングに基づいた調整後のスコアを示してるんや。エンティティごとに層別化してて、「名前」「略語」「用途」「構造」「説明」の手動スコアは、表2の完全一致の化学式-{名前、用途、構造、説明}の関係スコアと比較できるようになってるで。例えば「説明」は、モデルが抽出した説明エンティティが正解アノテーションと意味的に同等で(分野の専門家の判断による)、かつ正しいJSONオブジェクトにグループ化されてる(正しい化学式にリンクされてる)頻度を反映してるんやな。ほんまにびっくりするんやけど、完全一致スコアリングが性能をめっちゃ過小評価してることが分かるねん:材料名(0.456 vs 0.818)、用途(0.537 vs 0.832)、構造/相(0.482 vs 0.829)、説明(0.354 vs 0.704)。手動スコアリングで明らかになったんは、ワイらのモデルが実はめっちゃ幅広い材料科学のトピックについて、科学論文から構造化された知識をちゃんと正確に抽出できてるっていうことやねん。読者はテストセットの例に対するモデルの出力を補足議論4で自分の目で確認できるで。
Nature Communications | (2024) 15:1418
---
## Page 5
[](/attach/06ec2c45959fd0547093ff3776dcc4cd8c38af73884f637a59be6c4a756b61e3_p005.png)
### 和訳
ほな、翻訳いくで〜!
---
略語(アクロニム)の情報抽出スコアが一番低いんやけど、これにはちゃんと理由があんねん。まず、学習データの中で略語ってめっちゃ少ないねん。データセット全体でたった52個の要約文にしか出てこーへんくて、全文書のだいたい9%くらいしかないんよ。ほんで、モデルが略語と化学式を混同してまうことがあんねん。例えば「AuNP」って金ナノ粒子の略語やねんけど、化学式としても成り立ってまうんよな。こういうケースは普通、文脈の手がかりでしか区別できへんくて、略語を含むデータをもっと増やしたら、略語の抽出スコアも上がるんちゃうかなって思ってるわ。
全体的に見たら、このモデルは文章から材料に関するめっちゃ複雑な知識をちゃんと引っ張り出す能力がかなり高いことがわかるねん。略語以外のカテゴリの適合率(Precision)は全部だいたい0.87以上あって、つまり情報を抽出したときに、デタラメな関係やなくて、ちゃんと文章の中にある本物の関係性を引っ張ってきてるってことやねん。
LLM-NERREっていう手法の強みが、この手動評価のスコアにもバッチリ表れてるんやけど、それは何かっていうと、エラーを自動で直したり、よくある表記パターンを標準化してくれるところやねん。ドーピングモデル(材料に不純物を入れる研究のモデルやで)は、テキストに書いてある通りにそのまんま抜き出すように学習されてたんやけど、General-JSONモデルの学習データには、簡単な正規化とかエラー修正が含まれてたんよ。例えば、化学式の中に余計なスペースが入ってまうのって、元の要約文ではめっちゃよくある話やねん。修正済みの化学式を学習データに入れたら、LLMが抽出した結果を自動的にきれいな形にしてくれるようになったんよ。例えば「Li Co O2」って書いてあっても、モデルが後処理なしで自動的に「LiCoO2」に直してくれるんやで。同じように、学習例が十分にあったら、General-JSONスキーマを使うモデルは「PdO functionalized with platinum(白金で機能化したPdO)」みたいな文を、{formula: "PdO", description: ["Pt-functionalized"]}っていう標準化された形に変換してくれんねん。LLMモデルが持ってるこの正規化・修正能力は、テキストからそのまま引っ張ってきた文字列やなくて、きちんと構造化されたフォーマットが欲しい専門家にはめっちゃ便利やと思うで。だって、抽出した情報の正規化って、普通は後処理でやらなあかん面倒な作業やからな。
**スキーマの違いによる影響**
ホスト-ドーパント(母体材料と添加物)の抽出タスクでは、3つの異なる出力スキーマ(出力フォーマットのことやで)を評価して、どれかが圧倒的に優れてるかどうか調べたんよ。Doping-Englishスキーマを使うモデルは、特定の構造を持った英語の文を出力するねん(例えば「ホスト'〈ホスト名〉'にドーパント'〈ドーパント名〉'をドープした」みたいな感じ)。DopingExtra-Englishモデルも同じく英語の文を出すんやけど、追加情報も含んでるねん(例えば、ホストの一つが固溶体かどうかとか、特定のドーパントの濃度とか)。Doping-JSONスキーマでは、"hosts"、"dopants"、"hosts2dopants"っていうキーを持つJSONオブジェクト形式を使ったんよ(hosts2dopantsの値はまたキーと値のペアになってるねん)。Pythonプログラミング言語を知ってる人向けに言うと、これはキーが文字列で値が文字列か辞書になってるPythonの辞書オブジェクトと全く同じやで。ベースラインとしてseq2relっていう似たような系列変換手法との比較も入れてるし、同じドーピングデータセットで学習させてるで。あと、MatBERT-Dopingっていう約450個の要約文で学習させた固有表現認識モデルとも比較してんねんけど、こっちはホストとドーパントの関係を決めるのに単純なルールを使ってて、同じ文(サンプル)の中にあるホストとドーパントは全部関係あるって判定するやつやねん。これをMatBERT-Proximityって呼んでるわ。全スキーマの詳しい説明と例はMethodsセクションに、seq2relとMatBERT-Proximityの詳細はSupplementary Notes 4-5にあるで。一般的な材料情報の抽出とMOF(金属有機構造体)の情報抽出はもっとずっと複雑やから、JSONやなくて英語文を出力するモデルの学習は試みてへんねん。だって、できた文を構造化データベースに変換するのがめっちゃ難しくなるからな。
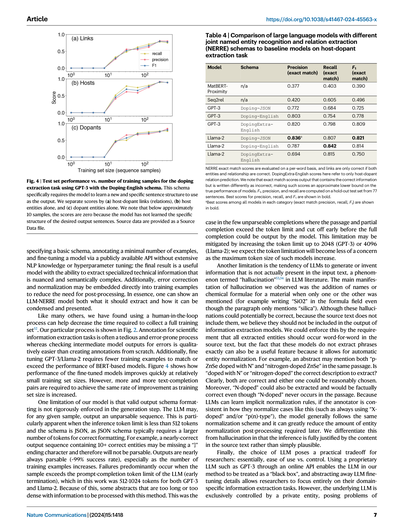
結果としてはな、うちらのLLM-NERREホスト-ドーパント抽出モデル3つとも、MatBERT-Proximityとseq2relのベースラインモデルよりかなり良い性能を出したんよ。2つのベースラインのうちではseq2relの方が適合率(0.420)と再現率(0.605)が高くて、F1スコアは0.496やねん。これはMatBERT-Proximity(0.390)よりちょっと高いけど、LLM-NERREモデルのどれと比べてもだいぶ低いわ。このseq2relベンチマークモデルは、元の実装に従ってPubMedBERTっていう事前学習済みBERTモデルから作ったもんやねんけど、生物医学テキストやなくて材料科学テキストだけで事前学習したBERTモデルを使ったら、seq2rel手法を改善できるかもしれへん。けど、SciBERTとMatBERTの比較で材料NERタスクでの差は比較的小さいことがわかってるから、劇的な改善にはならんと思うわ。ほんで、3つのLLM-NERREモデル全部が、純粋なNER性能でも2つのベースラインを上回ってんねん(Supplementary Discussion 2参照)。しかもMatBERT-NERモデルより少ないテキストで学習してるのにやで(413文 vs 455要約文)。6つのLLMベースモデルの中では、Llama-2のDoping-JSONスキーマが一番ええ成績で(F1=0.821)、GPT-3/Doping-English(F1=0.809)とLlama-2/DopingExtra-English(F1=0.814)も2%以内の差やったわ。両方のLLMの3つのスキーマでの性能と、ベースラインモデルの結果をTable 4にまとめてるで。
GPT-3の結果の中では、DopingExtra-EnglishとDoping-Englishスキーマが一番高いF1やったんよ。特にGPT-3/DopingExtra-Englishは、Doping-EnglishやDoping-JSONモデルと同じ数のサンプルで学習してるのにGPT-3モデルの中でトップやってん。これ注目すべきポイントやで。なんでかっていうと、GPT-3/DopingExtra-Englishは他のスキーマを使ったGPT-3モデルより精度が高いだけやなくて、「結果」や「修飾語」の抽出もできるっていう、より多機能なモデルやからやねん。逆にLlama-2の方は、JSONフォーマットが両方の英語スキーマを上回ってて、DopingExtra-Englishスキーマは適合率が低めやったんよ(0.694)。ざっくり言うと、GPT-3は自然言語っぽいスキーマのときに一番性能が出て、Llama-2はJSONのときに一番ええ感じになるってことやな。
**人間参加型のアノテーション**
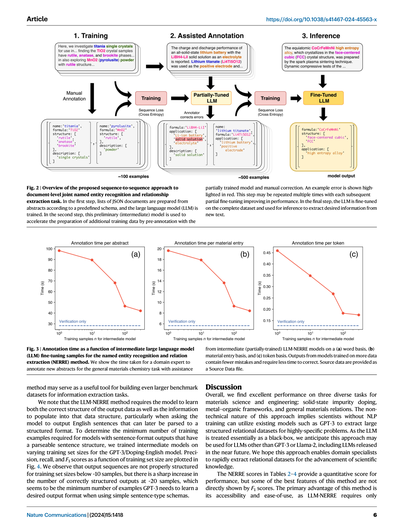
別の実験として、途中まで学習したLLMを「人間参加型(Human-in-the-loop)」のアノテーションプロセスで使うっていうのも評価したんよ。GPT-3/General-JSONでやったんやけど、Fig. 2に載ってるで。実験の各試行では、アノテーター(データにラベル付けする人やな)が10個の要約文と、n個の学習サンプルで学習した中間バージョンのモデルが事前に埋めた10個のスキーマを受け取んねん(n=1, 10, 50, 100, 300)。ゼロからアノテーションするんやなくて、この中間モデルの提案を修正するっていう形で、各アノテーションにかかった時間を記録したんよ。Fig. 3に示されてる通り、中間モデルの学習サンプル数が増えるとアノテーション時間がガクッと減んねん。n=300の中間モデルでは、n=1のモデルと比べて1要約あたりの平均アノテーション時間が57%も減ったんやで。つまりモデルがアノテーションの多くの部分をちゃんと正しくやってくれてたってことやな。
学習サンプルが少ない段階では、モデルの予測が正しいJSONオブジェクトになってへんくて、アノテーターはゼロからやり直さなあかんかったんよ。けど学習サンプルが多くなってきたら、特に50を超えたあたりから、中間モデルの予測はアノテーターがちょっと直すだけでよくなったんよ。下限値として、エントリが完全に正しいかどうかをただ確認するだけの時間(検証時間)も報告してるんやけど、これは完璧なモデルを使った場合のアノテーション速度を反映してて、人間は出力をチェックするだけでええっていう状況やな。3つの指標(1要約あたりの時間、1材料エントリあたりの時間、1プロンプトトークンあたりの時間)全部で、アノテーターは中間モデルの助けがあった方がめっちゃ速くアノテーションできたっていう結果やったで。
---
## Page 6
[](/attach/06ec2c45959fd0547093ff3776dcc4cd8c38af73884f637a59be6c4a756b61e3_p006.png)
### 和訳
図2 | 文書レベルで固有表現認識と関係抽出を同時にやるための、系列変換アプローチの全体像やで。まず最初のステップでは、あらかじめ決めたスキーマ(データの型みたいなもんやな)に従って、論文のアブストラクトからJSONドキュメントのリストを作って、大規模言語モデル(LLM)を学習させるねん。次のステップでは、この途中まで学習させたモデル(中間モデルって呼ぶねんけど)を使って、追加の学習データを作るスピードをめっちゃ上げるんよ。具体的には、この途中段階のモデルに先にアノテーション(ラベル付け)させといて、それを人間が手で直すっていうやり方やねん。赤くハイライトされてるんが間違いの例やで。このステップは何回も繰り返せて、繰り返すたびにファインチューニングの精度がどんどん上がっていくっちゅうわけや。最後のステップでは、全部揃ったデータセットでLLMをファインチューニングして、新しいテキストから欲しい情報を抜き出すのに使うねん。
図3 | 固有表現認識・関係抽出(NERRE)の手法で、中間LLMのファインチューニングに使うサンプル数とアノテーション時間の関係を示したグラフやで。一般的な材料化学のタスクで、専門家が新しいアブストラクトにアノテーションするのにかかった時間を、中間(途中まで学習した)LLM-NERREモデルのアシスト付きで、(a)単語ベース、(b)材料エントリーベース、(c)トークンベースで見せてるねん。ようするに、学習データが多いモデルほど出力の間違いが少なくなるから、修正にかかる時間も減るっちゅうことや。元データはSource Dataファイルとして提供されとるで。
この手法は、情報抽出タスク用のもっとデカいベンチマークデータセットを作るための便利なツールとしても使えるんちゃうかっちゅう話やねん。
ほんで注意しとかなあかんのは、LLM-NERREの手法では、出力データの正しい構造と、その構造に入れるべき情報の両方をモデルに覚えさせなあかんっちゅうことや。特に、後からパース(構造化データに変換)できるような英語の文章を出力させる場合はな。ほんなら、ちゃんとパースできる文構造を持った出力を出すのに最低何個の学習例がいるんか調べるために、GPT-3のドーピング・英語モデルで学習セットのサイズを変えながら中間モデルを学習させてみたんよ。精度(Precision)、再現率(Recall)、F1スコアを学習セットサイズの関数としてプロットしたんが図4やねん。結果を見たら、学習サンプルが10個くらいより少ないと出力の構造がめちゃくちゃになるんやけど、20個くらいになったらいきなり正しい構造の出力がバーッと増えるねん。つまり、シンプルな文型のスキーマを使う場合、GPT-3が望みの出力形式を覚えるのに最低限必要なサンプル数はだいたい20個くらいみたいやな。
考察
全体的に見て、材料科学・工学の3つの多様なタスク——固体への不純物ドーピング、金属有機構造体(MOF)、一般的な材料間の関係——で、めっちゃええ性能が出てるねん。ほんでこのアプローチのすごいとこは、技術的にそんなに難しくないっちゅうことや。なんでかっていうと、自然言語処理(NLP)のトレーニングを受けてない科学者でも、GPT-3みたいな既存のモデルを使って、めちゃくちゃ特化した問題に対する大規模な構造化リレーショナルデータセットを抽出できるっちゅうわけやからな。LLMをほぼブラックボックス(中身を気にせんでええ箱)として扱ってるから、GPT-3やLlama-2以外のLLMでも、今後出てくる新しいLLMでも使えるやろうと見込んでるねん。この手法のおかげで、各分野の専門家がサクッとリレーショナルデータセットを抽出して、科学の発展に役立ててくれたらええなぁと思っとるで。
表2〜4のNERREスコアは性能を定量的に示してくれるんやけど、実はこの手法のほんまにええとこはF1スコアだけでは見えへんねん。一番のメリットは、とにかく使いやすいっちゅうことや。LLM-NERREに必要なんは
Nature Communications | (2024) 15:1418
6
---
## Page 7
[](/attach/06ec2c45959fd0547093ff3776dcc4cd8c38af73884f637a59be6c4a756b61e3_p007.png)
### 和訳
**表4 | 大規模言語モデル(LLM)を使った固体ドーピング材料の抽出タスクで、いろんなNERRE(固有表現認識+関係抽出の同時処理)スキーマとベースラインモデルを比較した結果**
| モデル | スキーマ | 適合率(完全一致) | 再現率(完全一致) | F1(完全一致) |
|--------|----------|-------|------|------|
| MatBERT-Proximity | なし | 0.377 | 0.403 | 0.390 |
| Seq2rel | なし | 0.420 | 0.605 | 0.496 |
| GPT-3 | Doping-JSON | 0.772 | 0.684 | 0.725 |
| GPT-3 | Doping-English | 0.803 | 0.754 | 0.778 |
| GPT-3 | DopingExtra-English | 0.820 | 0.798 | 0.809 |
| Llama-2 | Doping-JSON | **0.836**ᵃ | 0.807 | **0.821** |
| Llama-2 | Doping-English | 0.787 | **0.842** | 0.814 |
| Llama-2 | DopingExtra-English | 0.694 | 0.815 | 0.750 |
NERREの完全一致スコアは単語単位で評価してて、リンクが正解になるには、エンティティ(固有表現)と関係性の両方が合ってなあかんねん。DopingExtra-Englishのスコアはホスト-ドーパント関係の予測だけの話やで。ちなみに完全一致スコアっていうんは、正しい情報が含まれてても書き方がちょっと違うだけで不正解扱いになるから、モデルのほんまの実力の「だいたいこれ以上はあるやろ」っていう下限値みたいなもんやねん。F1、適合率、再現率は77文のテストセットで計算してるで。太字はそのカテゴリで一番ええスコアや。
ᵃ 各カテゴリ(完全一致の適合率、再現率、F1)の中で一番ええスコアを太字にしてるで。
---
パースでけへん(解析不能な)出力がちょっとだけ出るケースってのは、文章と途中までの補完が合わさってトークンの上限超えてまうことがあって、モデルが最後まで出力しきれへんまま途中で切れてまうねん。この問題は、トークンの上限を2048(GPT-3の場合)とか4096(Llama-2の場合)まで上げたら軽減できるし、今後こういうモデルの最大トークン数がどんどん増えていくやろうから、この制限はだんだん気にならんようになるやろなぁ。
もうひとつの限界は、LLMが入力テキストに実際には書いてない情報を勝手に作り出してまう癖があることやねん。これはLLMの研究では「ハルシネーション(幻覚)」⁵³'⁵⁴って呼ばれてるんやけど、ワイらが観察した主なハルシネーションは、名前か化学式のどっちかしか書いてへんのに、もう片方を勝手に付け足してまうパターンやったわ。例えば、段落に「シリカ」としか書いてへんのに、化学式のとこに「SiO₂」って書いてまうみたいなやつやな。こういうハルシネーションは結果的に合ってる可能性もあるんやけど、元のテキストに書いてない以上、情報抽出モデルの出力に含めたらあかんと思うねん。これを防ぐには「抽出したエンティティは全部、元テキストに一字一句そのまま出てこなあかん」ってルールにしたらええんやけど、実はモデルがフレーズを「そのまま」抽出せえへんことが逆にメリットになることもあんねん。なんでかっていうと、自動でエンティティの正規化(表記の統一)ができるからやで。例えば、あるアブストラクトの中に「Nでドープしたp-ZnSe」と「窒素ドープZnSe」の両方が出てくるとするやん。ほんなら「Nでドープした」と「窒素ドープ」のどっちを抽出すんのが正解やねん?って話になるやろ?明らかにどっちも正解やし、どっちを選んでも妥当やねん。しかも「Nドープ」って抽出しても事実としては正しいのに、「Nドープ」って文字列自体は元の文章に一回も出てきてへんわけや。LLMは暗黙的な正規化ルールを学習できるから、アノテーター(ラベル付けする人)がこういうケースの正規化を一貫してやってくれたら(例えば常に「Xドープ」とか「p(n)型」って書くとか)、モデルも大体同じ正規化の仕方に従ってくれるねん。そしたら後処理でエンティティの正規化をゴリゴリやらなあかん手間がめっちゃ減るわけや。これはハルシネーションとは区別せなあかんで。なんでかっていうと、この場合の推論は元テキストの内容から完全に正当化できるもんであって、「まぁありえそうやな」っていう程度のもんとちゃうからやねん。
最後に、どのLLMを使うかっていう選択は研究者にとって実用的なトレードオフになるねん。要するに「使いやすさ」と「コントロールのしやすさ」のバランスやな。GPT-3みたいな企業が持ってるプロプライエタリなLLMをオンラインAPIで使うと、ワイらの手法のLLM部分を「ブラックボックス」として扱えるから、LLMのファインチューニングの細かいこと気にせんでええし、研究者は自分の専門分野の情報抽出タスクだけに集中できるわけや。せやけど、元になるLLMは民間企業が独占的にコントロールしてるから、いろいろ問題が
---
**図4 | GPT-3でDoping-Englishスキーマを使ったドーピング抽出タスクにおける、学習サンプル数に対するテストセットの性能推移。** このスキーマはモデルに特定の新しい文構造を学習させて、それを出力として使わせるもんやねん。スコアを(a)ホスト-ドーパントのリンク(関係)、(b)ホストのエンティティだけ、(c)ドーパントのエンティティだけ、に分けて見てるで。だいたい10サンプル以下やと、モデルが求められてる出力文の構造をまだ学習でけてへんから、スコアはゼロになるんが特徴やな。ソースデータはSource Dataファイルとして提供してるで。
---
基本的なスキーマを決めて、最小限の例をアノテーション(ラベル付け)して、公開APIでモデルをファインチューニングするだけでええねん。NLPの深い知識もハイパーパラメータの細かい調整もいらんのや。ほんで最終的にできるんは、専門的な技術情報を抽出できる実用的なモデルで、ニュアンスがあって意味的にも複雑な情報をちゃんと拾えるやつやねん。さらに、エラーの修正とか正規化を学習データの例の中に直接埋め込めるから、後処理の手間も減らせるんや。要するに、LLM-NERREモデルには「何を抽出すべきか」と「それをどう凝縮して提示するか」の両方を見せたれるっちゅうことやな。
他の研究者もぎょうさん言うてることやけど、ワイらも「ヒューマン・イン・ザ・ループ」(人間が途中でチェックに入るプロセス)を使うと、学習データセット全部を集めるんにかかる時間を短縮でけることがわかったで⁵²。ワイらの具体的なプロセスは図2に示してるわ。科学的な情報抽出タスクのアノテーションってめっちゃ地味でミスも起きやすい作業やねんけど、中間的なモデル出力のエラーをチェックする方が、ゼロからアノテーション作るよりも質的にラクやねん。それに加えて、GPT-3やLlama-2のファインチューニングは、BERT系モデルの性能に追いつくか超えるのに必要な学習例の数がめっちゃ少ないんや。図4を見たらわかるけど、ファインチューニングしたモデルの性能は比較的少ない学習セットサイズでグッと上がるねん。ただし、学習セットのサイズが大きくなるにつれて、同じペースで改善するにはどんどん多くのテキストと補完のペアが必要になってくるけどな。
ワイらのモデルのひとつの限界は、生成ステップで有効な出力スキーマのフォーマットが厳密には強制されてへんことやねん。LLMはどんなサンプルに対しても、パースでけへん(解析不能な)シーケンスを出力してまう可能性があるんや。これが特に目立つんは、推論時のトークン上限が512トークン未満でスキーマがJSONの場合やな。JSONスキーマは正しいフォーマットにするのに普通もっとたくさんのトークンが必要やからやで。例えば、10個以上の正しいエンティティを含むほぼ完璧な出力シーケンスでも、最後の「}」が1個抜けてるだけでパースでけへんようになってまうねん。出力はほぼ確実にパースできる(成功率は約99%)し、特に学習例の数が増えるほど安定するで。失敗が起きるんは主に、サンプルがLLMのプロンプト+補完のトークン上限を超えてまう場合(早期終了)やねん。この研究ではGPT-3もLlama-2も512〜1024トークンやったわ。やから、長すぎたり情報がぎゅうぎゅうに詰まりすぎたりしたアブストラクトは、この方法では処理でけへんこともあるんや。これがまさに
Nature Communications | (2024) 15:1418 7
---
## Page 8
[](/attach/06ec2c45959fd0547093ff3776dcc4cd8c38af73884f637a59be6c4a756b61e3_p008.png)
### 和訳
再現性とセキュリティの話やねんけど、まずセキュリティの面で言うと、ひょっとしたらヤバいかもしれん機密データを処理のために相手先に送らなあかんっていう問題があるねん。再現性の面で言うと、モデルを共有でけへんし、LLMを管理しとる側がいつでもモデルを変えたり、ファインチューニングのやり方をいじったり、最悪モデルへのアクセス自体を取り消したりできるわけや。しかも、学習済みモデルを使ってでっかいデータセットで推論するコストがえげつないことになる可能性もあるねん。一方で、Llama-2とかGPT-NeoX 20Bみたいな自分でホストするモデルを使うと、使いやすさよりもコントロールのしやすさが優先されるんや。モデルの重みとコードが全部見れるし、推論コストはGPUがちゃんと載ったクラスターに対するユーザーの予算次第ってだけやねん。せやけど、Llama-2みたいなLLMをクラスター上で実際に動かしたり、ファインチューニングしたり、デプロイしたりするんは、多くの研究者にとってぶっちゃけそう簡単ちゃうねん。クラウドでホストされたオープンアクセスモデル(例えばマネージドなクラウドインスタンスで動いとるLlama-2とか)は、使いやすさとコントロールのトレードオフをうまいこと解決してくれるかもしれへん。なんでかっていうと、ファインチューニングの技術的な細かいとこはユーザーから隠されとるけど、ファインチューニング済みのモデル自体はオープンアクセスのままにできるからやねん。同じように、ファインチューニングなしのゼロショットアプローチも、精度は犠牲にはなるけど科学的な情報抽出をもっと手軽にできるようにしてくれる可能性があるで(補足議論6参照)。LLMの推論やファインチューニングに必要なパラメータ数を減らす手法も、自前ホスティングの複雑さとコストを下げるめっちゃ有望なアプローチやねん。これらの手法が進歩してLLMのコードベースがもっと成熟していったら、LLM-NERREと互換性のあるファインチューニング可能なモデルが、強力で、自前ホスティングも簡単で、再現性もあって、研究者が完全にコントロールできるっていう全部盛りになると期待しとるで。ワイらがMethodsで公開しとるモデルの重みを使ったファインチューニングと推論実行のコード例が、強力でオープンソースなNERREモデルへの第一歩になったらええなと思っとるわけや。
まとめると、この研究が示しとるんは、数百個の訓練例でファインチューニングされたLLMが、構造化されてないテキストから科学的な情報を抽出して、ユーザーが定義したスキーマ(データの型みたいなもんや)に合わせてフォーマットできるってことやねん。これは今までのモデルとは対照的で、過去のモデルはテキストからエンティティ(要素)を抽出するんは得意やったけど、それらのエンティティ同士の関係を紐づけたり意味のある形に構造化したりするんが苦手やったんや。提案された手法はシンプルで、GPT-3みたいな今あるAPIやインターフェースを使えばめっちゃ幅広く使えるもんやねん。さらに、この論文で示した全モデルのLlama-2 LoRA重みをダウンロードできるようにしとるから(MethodsとCode Availabilityを見てな)、研究者が自分のハードウェアでLLM-NERRE手法を試せるようになっとるで。これらの進歩によって、過去の科学テキストを構造化された形に変換するスピードと精度がめっちゃ上がると期待しとるわけや。
## 手法
### 一般的なsequence-to-sequence NERRE
ワイらはLlama-2とGPT-3モデルをファインチューニングして、NERREタスク(固有表現認識と関係抽出を一緒にやるやつや)を実行させとるねん。使うのは400〜650個の手作業でアノテーション(ラベル付け)されたテキスト抽出のペア(プロンプトと完了文のセットや)。抽出結果には、欲しい情報があらかじめ決められた一貫したスキーマでフォーマットされとるねん。このスキーマは、あらかじめ決まった文の構造を持つ英文から、JSONオブジェクトのリストとか入れ子になったJSONオブジェクトまで、いろんな複雑さのものがあり得るで。原理的には他のスキーマ(YAMLとか疑似コードとか)もいけるかもしれんけど、今回はそこまでは試してへんねん。スキーマに従った十分なデータでファインチューニングしたら、モデルは新しいテキストデータに対しても同じ情報抽出タスクをめっちゃ高い精度でできるようになるんや。モデルの出力は訓練例と同じスキーマで出てくるで。このアプローチ全体を「LLM-NERRE」と呼んどるわけや。
GPT-3とLlama-2をNERREタスク用に訓練する一般的なワークフローは図2にまとめとるで。まず人間の専門家がアノテーションして初期の訓練セットを作って、そっから部分的に訓練されたモデル(GPT-3)を使って追加の訓練例の収集を加速させるんや。ほんでこれらの例でファインチューニングして「部分的に訓練された」モデルを作って、これを使ってアノテーションをあらかじめ埋めておいて、人間のアノテーターがそれを修正してから訓練セットに追加するっちゅう流れやねん。十分な数のアノテーションが完了したら、最終的なファインチューニング済みモデルは人間の修正なしで望みのフォーマットで情報を抽出できるようになるで。オプションとして、図5と図6に示しとるように、構造化された出力をさらにデコードして後処理して、階層的なナレッジグラフにすることもできるんや。
### タスクとスキーマの設計
**固体不純物ドーピングのスキーマ。** Doping-EnglishとDoping-JSONスキーマは、2種類のエンティティ(ホスト材料とドーパント)とそれらの間の関係(ホスト-ドーパント)を抽出することを目指しとるねん。結果は英文かJSONオブジェクトのリストのどっちかで返ってくるで。ホストっていうのは、ホスト結晶とか試料とか材料の種類のことで、その直近の文脈にある重要な説明も含まれるんや(例えば「ZnO2ナノ粒子」とか「LiNbO3」とか「ハーフホイスラー」とかな)。ドーパントは、少量成分の元素やイオン、意図的に加えられた不純物、あるいは特定の点欠陥や電荷キャリアのことや(「ホールドープ」とか「S空孔」とかな)。一つのホストに複数のドーパントがドープされることもあるし(別々の単一ドーピングとか共ドーピングとか)、同じドーパントが複数のホスト材料に紐づくこともあるねん。一つの文の中に独立したドーパント-ホスト関係のペアがいっぱいあったり、関係のないドーパントとホストがぎょうさんあったりすることもあるで。各関係がホストとドーパントを結んどるっていうこと以外には、ドーパント-ホスト関係の数や構造に制限は設けてへんねん。Doping-JSONスキーマは、一つの文の中でのホストとドーパントの関係のグラフを表現しとって、ユニークなキーでドーパントとホストの文字列を識別するんや。モデルはファインチューニング中にこの比較的ゆるいスキーマを学習することを目指すわけや。別のキー「hosts2dopants」で、それらのユニークキーに基づいたペアワイズの関係を記述するねん。Doping-Englishスキーマは、エンティティの関係を準自然言語の要約として表現するで。Doping-EnglishスキーマはDoping-JSONスキーマと同じ情報を表しとるんやけど、ワイらがテストしたLLMの自然言語の事前学習の分布により近い形になっとるんや。同じ文から複数の項目を抽出する場合は、出力文は改行で区切られるで。
**DopingExtra-Englishスキーマ**では、追加で2つのエンティティを導入しとるねん。修飾子(modifiers)と結果(result)や。ただし明示的なリンク付けはなし(つまりNERのみってことや)。結果エンティティは、化学量論係数に代数が入っとる化学式を表すもんで、例えばAlxGa1−xAsみたいなやつやねん。これは組成範囲にわたる実験試料とか結晶固溶体(例:CaCu3−xCoxTi4O12)に使われるんや。代数が代入されとって(つまりxの値が指定されとって)、ドープされた結果が特定の組成になっとるもの(例:CaCu2.99Co0.1Ti4O12)も含むで。修飾子は、ドーパント、ホスト、結果では捉えきれへんドーパント-ホスト関係の他の記述子をざっくりまとめたエンティティやねん。極性(例:「n型」「n-SnSe」)、ドーパント量(例:「5 at.%」「x < 0.3」)、欠陥の種類(例:「置換型」「アンチサイト」「空孔」)、その他ホスト-ドーパント関係の修飾子(例:「高ドーピング」「縮退ドープ」)みたいなもんやね。これらのエンティティ(ホスト、ドーパント、結果、修飾子)は、基本的なドーピング情報を抽出するための最小限で効果的なスキーマを定義するために選ばれたもんやで。
ドーピング関連のモデルは全部、一文だけを対象に動くように訓練されとるねん。この設計にした一番の理由は、ドーパント関連のデータの大半が一文の中に見つかるからで、残りの関係データは人間のアノテーターにとってもモデルにとっても一貫して解決するんがほんまに難しいことが多いからやねん。アノテーションの問題点や曖昧さについては補足議論5で詳しく述べとるし、ドーピングタスクのスキーマについては補足ノート1でさらに説明しとるで。
**一般的な材料情報スキーマ。** ワイらの以前の研究では、特定のエンティティタイプのセットに焦点を当てたNERに取り組んどったんやけど、特に…
---
## Page 9
[](/attach/06ec2c45959fd0547093ff3776dcc4cd8c38af73884f637a59be6c4a756b61e3_p009.png)
### 和訳
**図5 | 大規模言語モデル(LLM)使って固体へのドーピング情報を抜き出す仕組みの図解。名前付きエンティティと関係の同時抽出(NERRE)についてやで。** 3つのパネル全部で、ある決まった出力フォーマット(一番左に書いてあるやつ)を学習したLLMが、生のテキストを読み込んで、そのフォーマットに沿った構造化された出力を返すねん。ほんで、その構造化された出力をパース(読み取り)して、デコード(変換)して、整形したら、関係図(一番右のやつ)ができあがるっちゅうわけや。それぞれのスキーマ(こういう形で出力してほしいっていう構造のこと)について例を見せとるで。パースっちゅうのは構造化された出力を読み取ることで、デコードっちゅうのはプログラム的に(ルールベースで)その出力をJSON形式に変換することやねん。正規化と後処理はプログラム的なステップで、生の文字列(例えば「Co+2」とか)を属性付きの構造化エンティティ(例えば元素:Co、酸化状態:+2みたいな感じ)に変換するもんやな。**a** 生の文章をDoping-Englishスキーマのモデルに渡すと、改行で区切られた構造化文が出力されて、それぞれに1つのホスト(母体材料)と1つ以上のドーパント(添加物)のエンティティが含まれとるねん。**b** 生の文章をDoping-JSONスキーマのモデルに渡すと、入れ子になったJSONオブジェクトが出力されるで。ホストのエンティティにはそれぞれキーと値のペアがあって、ドーパントのエンティティにも同じようにあるねん。さらにhost2dopantっていう関係リストがあって、各ホストのキーに対応するドーパントのキーを紐づけてくれるんや。**c** DopingExtra-Englishスキーマを使ったモデルでの抽出例やで。スキーマの前半部分は**a**と一緒やねんけど、ドーピングの修飾情報が追加で入ってて、さらにスキーマの最後に実験結果を含む文も入っとるんや。
**図6 | 大規模言語モデル(LLM)使った一般的な情報抽出と金属有機構造体(MOF)の情報抽出の図解。名前付きエンティティと関係の同時抽出(NERRE)についてやで。** 両方のパネルで、特定のスキーマ(出力してほしい構造、一番左)で学習されたLLMに生テキストを入力したら、JSON形式の構造化された出力が返ってくるねん。この出力をパースしたら関係図(一番右)が作れるっちゅうわけや。タスクごとに別々のスキーマを使ってて、それぞれLLMに出力してほしいテキストの構造を表してるんやで。**a** 一般的な材料化学の抽出タスクのスキーマとラベリングの例やな。材料科学の研究論文のアブスト(要旨)をGeneral-JSONスキーマのLLMに渡すと、テキストに出てくる順番に並んだJSONオブジェクトのリストが出力されるねん。各材料には名前、化学式、略称、記述子、用途、結晶構造/相の情報なんかが入る可能性があるで。**b** 金属有機構造体(MOF)抽出タスクのスキーマとラベリングの例や。General-JSONモデルと似た感じで、MOF-JSONモデルも材料科学の研究論文のアブスト全文を入力して、JSONオブジェクトのリストを出力するねん。この例やと、文章中にはMOFの名前と用途だけが書かれてて、2つのMOF(LaBTBとZrPDA)が両方とも2つの用途(発光体とVOCセンサー)に紐づけられとるっちゅうことやな。
「エンティティ単体」でバラバラに抜き出すんやなくて、この研究ではLLMに「一般的な材料情報の抽出」タスクをやらせて、エンティティもそれらの間の複雑な関係ネットワークもまとめて捉えられるように訓練してるんや。
このタスク用に設計したスキーマは、固体の化合物とその用途についての重要な情報のサブセットをカプセル化してるねん。リストの各エントリは独立したJSONドキュメントになってて、テキスト中で言及されてる材料と1対1で対応してるで。材料エントリはテキスト中に出てくる順番に並んでるんや。各エントリのルート(一番上の階層)は化合物の名前か化学式、もしくはその両方から始まるねん。もし名前も化学式も書かれてない材料があったら、その材料の情報はテキストから抽出されへんで。略称も抽出するんやけど、略称しか書かれてない場合はその化合物用の材料エントリは作らへんねん。固体やない化合物(イオンとか液体とか溶媒とか溶液とか)は基本的に抽出せえへんで。名前、化学式、略称のフィールドにはJSONドキュメント中で文字列の値だけが入るようになっとるんや。
---
## Page 10
[](/attach/06ec2c45959fd0547093ff3776dcc4cd8c38af73884f637a59be6c4a756b61e3_p010.png)
### 和訳
それぞれの材料に対して、description(説明)、structure_or_phase(構造・相)、applications(用途)っていうフィールドがあんねんけど、これらは任意の数の文字列をリストで持てるようになってんねん。このモデルを「General-JSON」って呼んでて、例は図6(a)に載ってるで。
Descriptionのエンティティっちゅうのは、化合物がどうやって作られたかの履歴とか、欠陥、改変、あとはサンプルの形態に関する詳細情報のことやねん。たとえば「CeO2ナノ粒子に担持されたPt、Nbをドープした...」みたいな仮想的なテキストがあったとするやん。この場合、「Pt」の材料オブジェクトのdescription値は「['supported on CeO2']」って注釈されるし、「CeO2」に対するdescriptionエンティティは「['nanoparticles', 'Nb-doped']」ってなるわけや。
Structure_or_phaseのエンティティは、その化合物の結晶構造とか対称性を直接示す情報のことやねん。「cubic(立方晶)」とか「tetragonal(正方晶)」みたいな結晶系、「rutile(ルチル)」とか「NASICON」みたいな構造名、「Fd3m」とか「空間群No.93」みたいな空間群、こういうのが全部このフィールドで抽出されるんや。あと結晶の単位格子に関する情報、たとえば格子定数とか格子ベクトル間の角度なんかも含まれるで。「Amorphous(アモルファス=非晶質)」も構造/相のラベルとして使えるで。
Applicationsっちゅうのは、その材料のハイレベルな用途とか主要な物性カテゴリのことやねん。たとえば電池の正極材料やったら、applicationsのエントリは「['Li-ion battery', 'cathode']」みたいになるわけや。基本的にはテキストに出てくる順番に記載されるんやけど、バッテリー材料みたいな場合はデバイスの種類が電極タイプより先に書かれるし、触媒の場合は触媒反応が「catalyst」エンティティの後に続く形で書かれることが多いねん(たとえば「['catalyst', 'hydrogenation of citral']」みたいに)。
一般的な材料情報タスクのスキーマについてもっと詳しいことは、Supplementary Discussion 4に書いてあるで。
**金属有機構造体(MOF)スキーマ。** MOFカタログ化タスクに使われるスキーマは、さっき説明した一般的な材料情報スキーマをベースにしてて、MOF研究者のニーズにもっと合うように改変したもんやねん。このスキーマでは、MOFの名前(name)を抽出するんやけど、これには広く認められた標準規格がまだないねん⁶⁰。それと化学式(formula)も抽出して、これがドキュメントのルート(根幹)になるんや。名前も化学式もない場合は、そのインスタンスの情報は抽出されへんで。さらに、MOFをイオンやガスの分離に使うことにめっちゃ注目が集まってるから⁶¹˒⁶²、ゲスト種(guest species)っちゅうのも抽出するねん。これはMOFに取り込まれたり、貯蔵されたり、吸着されたりした化学種のことやで。MOFが研究されてる用途(applications)は文字列のリストとして抽出するし(たとえば「['gas-separation']」とか「['heterogeneous catalyst', 'Diels-Alder reactions']」)、MOFの形態とか処理履歴みたいな関連する説明(description)も、一般情報抽出スキーマと同じ感じで抽出するねん。リストの項目は基本的にテキスト中に材料名とか化学式が出てくる順番に追加されるで。このMOF抽出モデルは「MOF-JSON」って名前がついてて、例は図6(b)に載ってるわ。
**比較ベースラインと評価**
ほんで、うちらのモデルを他のシーケンス・トゥ・シーケンス(入力列から出力列を生成する)方式の情報抽出手法と比較するために、ドーピングタスクで2つの手法をベンチマークして、LLM-NERREモデルと比べてみたんや。1つ目はGiorgiらの⁴¹ seq2rel手法をホスト-ドーパントタスクに使う方法やねん。ホスト-ドーパント関係を@DOPANT@と@BASEMAT@(ベース/ホスト材料)ってタグでフォーマットして、その関係を@DBR@(「ドーパント-ベース材料関係」)で示すようにしたんや。これらの系列はDoping-JSONモデルやDoping-Englishモデルと同じ訓練データから作ったで。seq2relは文レベルの抽出を30エポック、バッチサイズ4、エンコーダ学習率2×10⁻⁵、デコーダ学習率5×10⁻⁴、事前学習済みBiomedNLP BERTトークナイザー⁵¹で訓練したんや(もっと詳しい訓練の話はSupplementary Note 4を見てな)。さらに、以前発表されたMatBERTのドーピングNERモデル⁵と、近接性ベースのヒューリスティクスを使ったリンキングも比較対象にしてるで(Supplementary Note 5参照)。この手法では、約5000万の材料科学パラグラフで事前学習して455個の手動アノテーション付きアブストラクトでファインチューニングしたMatBERT NERモデルが、まずホストとドーパントを抽出して、同じ文中に一緒に出てきたらそれらをリンクするっちゅう仕組みやねん。
**データセット**
データセットは800万件以上の研究論文アブストラクトのデータベースから準備したんや⁶³。アノテーション(ラベル付け)はJupyter⁶⁴を使って作ったGUI(グラフィカルユーザーインターフェース)で人間のアノテーターがやったんやけど、原理的にはシンプルなテキストエディタでもできるで。訓練データの収集を加速するために、「ヒューマン・イン・ザ・ループ」、つまり人間を組み込んだアプローチで新しいアノテーションを集めてんねん。小さなデータセットでモデルを訓練して、その出力を出発点にして人間のアノテーターが修正する(図2参照)。この訓練とアノテーションのプロセスを十分な量の訓練データが集まるまで何回も繰り返すんや。各データセットは1人のドメインエキスパート(専門家)アノテーターが担当したで。各アノテーション済みデータセットのクラスサポートはSupplementary Tables 1-3に載ってるわ。
**ドーピングデータセット。** 訓練・評価データは、論文アブストラクトのデータベースから「n-type」「p-type」「-dop」「-codop」「doped」「doping」「dopant」っていうキーワードで検索して集めたんや(「-dopamine」みたいなよくある無関係キーワードは除外してな)。これで約37万5千件のアブストラクトが引っかかったで。全てのドーピングタスクは、ランダムに選んだ162件のアブストラクトのテキストで訓練して、これが合計1215文あって、正規表現でフィルタリングして関連性のある(ドーピング情報を含む可能性のある)413文だけに絞ったんや。テストは別のホールドアウトテストセット31件のアブストラクトから追加で232文(正規表現で関連ありと判定されたのは77文)を使ったで。
**一般材料データセット。** 訓練・評価データは、アブストラクトのデータベースから材料の様々な物性や用途に関するキーワード(たとえば「magnetic」「laser」「space group」「ceramic」「fuel cell」「electrolytic」とか)で検索して集めたんや。各キーワードについて材料科学のドメインエキスパートが約10〜50件のアブストラクトにアノテーションして、結果として一般材料情報スキーマに従って手動でアノテーションされた約650件のエントリができたで。評価は10%のランダムサンプルをバリデーションに使って、異なるランダムな訓練/バリデーション分割で5回試行して平均を取ったんや。ハイパーパラメータのチューニングはしてへんで。
**金属有機構造体データセット。** 訓練・評価データは、データベースから「MOF」「MOFs」「metal-organic framework」「metal organic framework」「ZIF」「ZIFs」「porous coordination polymer」「framework material」っていうキーワードで選んだんや。これで約6000件のMOF関連情報を含みそうな結果が出てきて、そこからランダムに507件のアブストラクトを選んでMOFのドメインエキスパートがアノテーションしたで。評価は前のセクションの一般材料データセットと同じ、繰り返しランダム分割の手順を使ったわ。
**GPT-3のファインチューニング詳細**
全てのタスクで、GPT-3('davinci'、パラメータ数1750億)²⁶をOpenAI APIを使ってファインチューニングしてんねん。これは予測トークンの交差エントロピー損失を最適化するもんやで。ドーピングモデルは7エポック、バッチサイズ1で訓練して、推論時の温度は0、出力の最大長は512トークン(全ドーピングモデル)か1024トークン(General-JSON、MOF-JSON)に制限したんや。図4に示した中間モデルは、訓練サンプル数tに応じてエポック数を変えてて、20≤t<26の場合は2エポック、26<t≤27の場合は4エポック、t≥28の場合は7エポックやで。MOFと一般材料抽出タスクのモデルは4エポック、バッチサイズ1で訓練したんや。学習率の倍率は0.1、プロンプト損失の重みは0.01を使ってるけど、これらのハイパーパラメータのチューニングはやってへんで。全ての
---
## Page 11
[](/attach/06ec2c45959fd0547093ff3776dcc4cd8c38af73884f637a59be6c4a756b61e3_p011.png)
### 和訳
NERREの性能評価についてやけどな、ここからがほんまに大事なとこやねん。
**Llama-2のファインチューニングの詳細**
Llama-2のファインチューニングはな、Meta Researchが出しとるLlama-2レシピのリポジトリをちょっと改造したやつを使ってやってん。改造版はGitHubに置いてあるで。使ったのは700億パラメータ版のLlama-2(llama-2-70b-hf)で、8ビット精度で量子化しとる。量子化っていうのは、めっちゃデカいモデルをちょっと軽くする技術やな。エポック数(学習データを何周回すかっていう回数やな)はドーピングタスクで7回、MOF(金属有機構造体)と一般タスクで4回に設定しとる。
ファインチューニングにはPEFT(パラメータ効率的ファインチューニング)っていう手法を使っとって、その中でもLoRA(低ランク適応)っていうやり方を採用しとるねん。LoRAのr=8、α=32、ドロップアウト0.05や。なんでかっていうと、全部のパラメータをいじるんやなくて、ちょっとだけ変えるだけで済むから、めっちゃ効率がええねん。ハイパーパラメータのチューニングはそれ以上やってへん。デコード(モデルの出力を生成するとこやな)は、GPT-3の温度パラメータ=0と揃えるために、サンプリングなしの貪欲デコーディングでやっとる。最大トークン数はドーピングタスクで512、一般とMOFタスクで1024や。全部のファインチューニングと推論は、80GBのVRAMを積んだA100(Ampere)テンソルコアGPU1枚でやっとるで。
ファインチューニングした重みは上のリポジトリに全部公開されとって、ダウンロードの仕方とかモデルの立ち上げ方、推論の回し方も書いてあるで。
**評価基準**
前のセクションで説明したエンティティとリレーションシップがな、めっちゃ曖昧で複雑やから、スコアリングには複数の指標を使わなあかんねん。全モデルの性能を2つのレベルで評価しとる:
1. **厳密な完全単語一致ベースの関係F1** — つまり、元のテキストに出てくる通りの単語が、どれだけ正確にリンクされとるかを見るやつ。
2. **専門家による手動検査に基づく、全体的な情報抽出F1** — こっちは単語が完全に一致してなくてもOKなやつ。
あと、系列レベルのエラー分析は補足ノート7と補足議論1に別で載せとるで。
**NERRE性能** — NERREの性能は、モデルがエンティティとそいつらの間の関係性を同時に認識する能力として測っとる。
**厳密単語一致ベースのスコアリング**
名前付きエンティティの関係をな、まず単語ベースでスコアリングするねん。エンティティEをスペースで区切ったk個の単語の集合 E = {w1, w2, w3, …, wk} に変換するんや。化学式を含まない2つのエンティティEtrueとEtestを比べるときは、両方の集合で完全に一致する単語の数を真陽性(Etrue ∩ Etest)、集合の差分を偽陽性(Etest − Etrue)か偽陰性(Etrue − Etest)としてカウントする。
例えばな、正解エンティティが「Bi2Te3 thin film」で予測が「Bi2Te3 film sample」やったら、「Bi2Te3」と「film」の2つが真陽性の完全一致、「thin」が偽陰性(見落とし)、「sample」が偽陽性(余計なやつ)になるわけや。
化学式を含むエンティティはめっちゃ大事やから、特別ルールがあんねん。化学式タイプのエンティティの場合、Etestが化学量論として認識できる全てのwiを含んでへんかったら、どの単語も正解扱いにならへんのや。例えば、正解が「Bi2Te3 thin film」で予測が「thin film」やったら、3つ全部偽陰性になるねん。つまり、化学組成が完全一致してへんかったら丸ごとアウトってことや。
なんでこんな厳しい評価にしたかっていうとな、ミスリーディングな結果を避けるためやねん。例えば「Bi2Te3ナノ粒子」と「Bi2Se3ナノ粒子」は、Jaro-Winkler類似度(0.977)とか文字レベルBLEU-4(0.858)で見たらめっちゃ似とるけど、実際は全然ちゃう物質のことを言うとるやろ?化学組成が間違っとるんやから。うちのスコアリングシステムやと、組成が一致してへんから完全に不正解として記録されるわけや。
**関係性の単語ベーススコアリング**
エンティティ間の関係もな、正しい関係トリプレット(3つ組)の数を調べるために単語ベースでスコアリングするねん。トリプレットっていうのは、エンティティEnの単語wn_jとエンティティEmの単語wm_kを関係rで結んだ3つ組(wn_j, wm_k, r)のことや。テキスト全体の正解関係セットTtrueにはこのトリプレットがいっぱい入っとるわけ。テストセットTtestの評価は、両方に含まれるトリプレット(Ttrue ∩ Ttest)を真陽性、差分を偽陽性(Ttest − Ttrue)か偽陰性(Ttrue − Ttest)としてカウントする。化学式タイプのエンティティに属する単語がトリプレットに含まれとったら、さっきと同じ化学組成の完全一致ルールが適用されるで。
正解・不正解のトリプレットが特定できたら、各関係のF1スコアを以下の式で計算するんや:
適合率 = 正しく取得できた関係の数 ÷ 取得した関係の総数 …(1)
再現率 = 正しく取得できた関係の数 ÷ テストセット中の関係の総数 …(2)
F1 = 2×(適合率×再現率) ÷ (適合率+再現率) …(3)
実際にテストセット全体のトリプレットスコアを計算するときはな、まず評価する関係のサブセットを選ぶねん。これはモデルに学習させとるタスク全体(いろんなエンティティを同時にリンクさせるやつ)の完全な評価やなくて、他のNERRE手法と比べてだいたいどれくらいの性能かを把握するためのもんやで。ドーピングタスクではホスト-ドーパント関係、一般材料とMOFタスクでは化学式フィールド(一般材料ならformula、MOFならmof_formula)と他の全フィールドとの関係を評価しとる。description、structure_or_phase、applicationsフィールドみたいに複数の値を持てるやつは、考えうる全ての化学式-値ペアを評価しとるで。
**手動評価**
上で説明した指標は自動的でかなり厳しいスコアリング方法やけどな、LLMモデルのほんまの実力は手動評価で一番よう分かるねん。特にGeneral-JSONモデルの場合がそうで、エンティティの正確な境界が曖昧やし、定義を統一的に決めるのが難しいし、アノテーションには暗黙的なエンティティの正規化も含まれとるからな。
例えばな、「Pd ions were intercalated into mesoporous silica(パラジウムイオンがメソポーラスシリカにインターカレートされた)」っていうテキストがあったとして、「silica」っていう材料のdescriptionフィールドには、「Pd-intercalated」でも「Pd ion-intercalated」でも「intercalated with Pd ions」でも正解になりうるやろ?どの表現を「正解」にするかなんて、ぶっちゃけ任意やねん。
こういう曖昧なタスクのスコアリングをもっとちゃんとやるために、ドメイン専門家が手動で「抽出された情報が、文章に実際に含まれとる情報の妥当な表現かどうか」を評価する調整スコアを導入しとるんや。これを「手動スコア」って呼んどって、同じ概念を複数の等価な方法で表現できるケースでの、全体的な情報捕捉の質を定量化するための適合率・再現率・F1の基礎になるもんや。このスコアは、実用的な材料情報抽出タスクにおけるモデルの性能をより正確に見積もるために作られたもんやで。
アノテーターが抽出したけどモデルの出力に含まれてへんかったエンティティは偽陰性としてスコアリングするんやけど、妥当なバリエーションが存在する場合は例外や。真陽性の基準は以下の通りやで:
---
## Page 12
[](/attach/06ec2c45959fd0547093ff3776dcc4cd8c38af73884f637a59be6c4a756b61e3_p012.png)
### 和訳
1. そのエンティティ(まあ要は抽出された情報の単位やな)は、元の文章から来てるか、もしくは元の文章のエンティティをちょっと変えたもんやないとアカンねん(例えば「silicon」→「Si」みたいなんはOKや)。モデルが勝手に作ったもんはダメやで。
2. そのエンティティは、ルートエンティティ(一番上の親分みたいなもんや)であるか、ちゃんとしたルートエンティティのグループに入ってなアカンねん。General-JSONモデルの場合やと、ルートエンティティっていうのは材料の化学式か名前のことやねん。両方あるときは化学式の方がルートになるで。
3. そのエンティティが、正しいルートエンティティのグループ(JSONオブジェクト)の中の正しいフィールドに入ってること。これも大事やで。
手動スコアはエンティティごとに、NER(固有表現認識)のスコアみたいな感じで報告されるんやけど、ほんまのところ「正解」って判定されるには関係性の情報も暗黙的に含まれてんねん。なんでかっていうと、正しいルートエンティティと一緒にグループ化されてないとアカンからやな。
**報告のまとめ**
研究デザインについてのもっと詳しい情報は、この論文にリンクされてるNature Portfolioの報告サマリーに載ってるで。
**データの入手方法**
この研究で使ったデータは全部 https://github.com/LBNLP/NERRE と Zenodo65 で手に入るで。アノテーション済みのデータセットとか、テスト用・学習用の分割データが入ってんねん。この論文で報告してるパイプラインの各ステップの中間ファイルも、ちゃんとドキュメント付きでこのリポジトリに保存されとるわ。Llama-2モデルを動かすためのデータは補足リポジトリの https://github.com/lbnlp/nerre-llama66 にあるで。この論文で報告してる全Llama-2モデルのLoRA重み(まあファインチューニングで追加学習した部分のパラメータやな)はFigshare(https://doi.org/10.6084/m9.figshare.24501331.v1)67 から直接ダウンロードできるで。ソースデータはこの論文に付いてるわ。
**コードの入手方法**
この研究で使ったコードは https://github.com/LBNLP/NERRE と Zenodo65 でデータと一緒に手に入るで。アノテーション用のJupyterノートブックとか、アノテーション・前処理・モデルの学習・モデルの評価用のPythonスクリプトが入ってんねん。補足リポジトリの https://github.com/lbnlp/nerre-llama66 には、この研究で学習させたLlama-2モデルのファインチューニングと推論用のコードとデータが入ってて、スクリプト使ったら全部の重みにもアクセスできるようになってるで。
**参考文献**
1. Saal, J. E., Oliynyk, A. O. & Meredig, B. 材料発見における機械学習:確認された予測とその裏にあるアプローチ。Annu. Rev. Mater. Res. 50, 49–69 (2020).
2. Choudhary, K. ほか。材料科学における深層学習の最近の進歩と応用。npj Comput. Mater. 8, 59 (2022).
3. Oliveira, O. N. & Oliveira, M. C. F. 機械学習と知識発見による材料発見。Front. Chem. 10, 930369 (2022).
4. Weston, L. ほか。材料科学文献からの大規模情報抽出に適用した固有表現認識と正規化。J. Chem. Inform. Modeling 59, 3692–3702 (2019).
5. Trewartha, A. ほか。材料科学の固有表現認識タスクにおけるドメイン特化事前学習の優位性の定量化。Patterns 3, 100488 (2022).
6. Isazawa, T. & Cole, J. M. ChemDataExtractorにおける有機・無機化学固有表現認識の単一モデル。J. Chem. Inform. Modeling 62, 1207–1213 (2022).
7. Zhao, X., Greenberg, J., An, Y. & Hu, X. T. 材料固有表現認識のためのBERTモデルのファインチューニング。In: 2021 IEEE International Conference on Big Data (Big Data) (IEEE, 2021).
8. Sierepeklis, O. & Cole, J. M. ChemDataExtractorを使って科学文献から自動生成した熱電材料データベース。Sci. Data 9, 648 (2022).
9. Beard, E. J. & Cole, J. M. ChemDataExtractorを使って自動生成したペロブスカイト型・色素増感型太陽電池デバイスデータベース。Sci. Data 9, 329 (2022).
10. Kumar, P., Kabra, S. & Cole, J. M. ChemDataExtractorを使った降伏強度と結晶粒径のデータベース自動生成。Sci. Data 9, 292 (2022).
11. Huang, S. & Cole, J. M. BatteryBERT:バッテリーデータベース強化のための事前学習済み言語モデル。J. Chem. Inform. Modeling 62, 6365–6377 (2022).
12. Dong, Q. & Cole, J. M. ChemDataExtractorを使った半導体バンドギャップの自動生成データベース。Sci. Data 9, 193 (2022).
13. Kononova, O. ほか。テキストマイニングによる無機材料合成レシピのデータセット。Sci. Data 6, 203 (2019).
14. Huo, H. ほか。固相合成条件の機械学習による合理化と予測。Chem. Mater. 34, 7323–7336 (2022).
15. He, T. ほか。科学文献からテキストマイニングした固相合成における前駆体の類似性。Chem. of Mater. 32, 7861–7873 (2020).
16. Wang, Z. ほか。科学文献から抽出した溶液ベース無機材料合成手順のデータセット。Sci. Data 9, 231 (2022).
17. Huang, S. & Cole, J. M. ChemDataExtractorを使って自動生成したバッテリー材料データベース。Sci. Data 7, 260 (2020).
18. Beard, E. J., Sivaraman, G., Vázquez-Mayagoitia, Á., Vishwanath, V. & Cole, J. M. UV/vis吸収スペクトルの実験値と計算値の比較データセット。Sci. Data 6, 307 (2019).
19. Zhao, J. & Cole, J. M. ChemDataExtractorを使って自動生成した屈折率と誘電率のデータベース。Sci. Data 9, 192 (2022).
20. Bekoulis, G., Deleu, J., Demeester, T. & Develder, C. マルチヘッド選択問題としてのエンティティ認識と関係抽出の同時学習。Expert Syst. Appl. 114, 34–45 (2018).
21. Han, X. ほか。もっとデータを、もっと関係を、もっと文脈を、もっとオープンに:関係抽出のレビューと展望。In: Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing, 745–758 (2020).
22. Yao, Y. ほか。DocRED:大規模文書レベル関係抽出データセット。In: Proc. 57th Annual Meeting of the Association for Computational Linguistics, 764–777 (2019).
23. Li, J. ほか。BioCreative V CDRタスクコーパス:化学物質-疾患関係抽出のためのリソース。Database 2016 (2016).
24. Bravo, Á., Piñero, J., Queralt-Rosinach, N., Rautschka, M. & Furlong, L. I. テキストと大規模データ解析からの遺伝子-疾患間関係の抽出:トランスレーショナルリサーチへの示唆。BMC Bioinformatics 16, 1–17 (2015).
25. Yang, X. ほか。PCMSP:多結晶材料合成手順テキストからの科学的アクショングラフ抽出のためのデータセット。In: Findings of the Association for Computational Linguistics: EMNLP 2022, 6033–6046 (2022).
26. Brown, T. B. ほか。言語モデルはfew-shot学習者である。Preprint at https://browse.arxiv.org/abs/2005.14165 (2020).
27. OpenAI. GPT-4技術レポート。Preprint at https://browse.arxiv.org/abs/2303.08774 (2023).
28. Chowdhery, A. ほか。PaLM:Pathwaysによる言語モデルのスケーリング。Journal of Machine Learning Research 24, 1–113 (2023).
---
## Page 13
[](/attach/06ec2c45959fd0547093ff3776dcc4cd8c38af73884f637a59be6c4a756b61e3_p013.png)
### 和訳
29. Smith, S.ら。DeepSpeedとMegatronを使ってMegatron-Turing NLG 530Bっていうめっちゃでかい文章生成AIモデルを学習させた話。プレプリント、https://arxiv.org/abs/2201.11990 (2022)。
30. Touvron, H.ら。Llama:オープンで効率ええ基盤言語モデルやで。プレプリント、https://arxiv.org/abs/2302.13971 (2023)。
31. Touvron, H.ら。Llama 2:オープンな基盤モデルとチャット用にファインチューニングしたモデルや。プレプリント、https://arxiv.org/abs/2307.09288 (2023)。
32. Zhang, S.ら。OPT:オープンに事前学習したTransformer言語モデルやねん。プレプリント、https://browse.arxiv.org/abs/2205.01068 (2022)。
33. Hoffmann, J.ら。計算コストが最適になるように大規模言語モデルを学習させる方法。プレプリント、http://arxiv.org/abs/2203.15556 (2022)。
34. Wei, J.ら。ファインチューニングした言語モデルはゼロショット、つまり例題なしでもタスクこなせるようになるで、っていう話。国際学習表現会議 (2022)。https://openreview.net/forum?id=gEZrGCozdqR。
35. BIG-benchコラボレーション。模倣ゲームを超えて:言語モデルの能力を測ったり、どこまでいけるか推定したりする話。準備中。https://github.com/google/BIG-bench/ (2021)。
36. Dabre, R.、Chu, C.、Kunchukuttan, A. 多言語ニューラル機械翻訳のサーベイ。要するにAIで色んな言語間の翻訳どうやるかの総まとめやな。ACM Comput. Surv. 53, 1–38 (2020)。
37. Petroni, F.ら。言語モデルって知識ベースとして使えるんちゃう?っていう研究。2019年自然言語処理の実証的手法に関する会議および第9回国際自然言語処理合同会議 (EMNLP-IJCNLP) 論文集, 2463–2473 (計算言語学会, 2019)。https://aclanthology.org/D19-1250。
38. Han, J. M.ら。生成型言語モデルだけで教師なしニューラル機械翻訳をやってまう話。https://openreview.net/forum?id=SVwbKmEg7M (2022)。
39. Zhang, H.、Xu, J.、Wang, J. 事前学習ベースの自然言語生成で文章要約する方法。第23回計算自然言語学習会議 (CoNLL) 論文集, 789–797 (計算言語学会, 2019)。https://aclanthology.org/K19-1074。
40. Liu, Z.ら。知識を使った対話生成のための多段階プロンプティング。計算言語学会:ACL 2022 Findings, 1317–1337 (計算言語学会, 2022)。https://aclanthology.org/2022.findings-acl.104。
41. Giorgi, J.、Bader, G.、Wang, B. 文書レベルの関係抽出に対するsequence-to-sequenceアプローチ。なんでかっていうと、文書全体から情報の関係性を引っ張り出すのにseq2seqが使えるっちゅう話やねん。第21回バイオメディカル言語処理ワークショップ論文集, 10–25 (計算言語学会, 2022)。https://aclanthology.org/2022.bionlp-1.2。
42. Cabot, P.-L. H.、Navigli, R. REBEL:エンドツーエンドの言語生成で関係抽出するやつ。計算言語学会:EMNLP 2021 Findings (計算言語学会, 2021)。https://doi.org/10.18653/v1/2021.findings-emnlp.204。
43. Townsend, B.、Ito-Fisher, E.、Zhang, L.、May, M. Doc2dict:情報抽出をテキスト生成として扱う方法。プレプリント、http://arxiv.org/abs/2105.07510 (2021)。
44. Zheng, Z.、Zhang, O.、Borgs, C.、Chayes, J. T.、Yaghi, O. M. ChatGPTを化学アシスタントとして使って、テキストマイニングとMOF(金属有機構造体)の合成予測に活用した話。めっちゃ実用的やで。J. Am. Chem. Soc. 145, 18048–18062 (2023)。
45. OpenAIら。ChatGPTの紹介。https://openai.com/blog/chatgpt (2022)。
46. Castro Nascimento, C. M.、Pimentel, A. S. 大規模言語モデルってほんまに化学わかってるん?ChatGPTとの会話で検証してみた話。J. Chem. Inform. Modeling 63, 1649–1655 (2023)。
47. White, A. D.ら。コードを生成する大規模言語モデルの化学知識をどこまで持ってるか評価した研究。Digital Discov. 2, 368–376 (2023)。
48. Xie, T.ら。Darwinシリーズ:自然科学に特化した大規模言語モデルやで。プレプリント、https://arxiv.org/abs/2308.13565 (2023)。
49. Jablonka, K. M.、Schwaller, P.、Ortega-Guerrero, A.、Smit, B. 化学でデータ少ない時の発見にGPTだけで十分なんか?っていう検証。https://doi.org/10.26434/chemrxiv-2023-fw8n4-v2 (2023)。
50. Jablonka, K. M.ら。大規模言語モデルが材料科学と化学をどう変えるかの14の具体例:LLMハッカソンを振り返っての考察やねん。Digital Discov. 2, 1233–1250 (2023)。
51. Gu, Y.ら。バイオメディカル自然言語処理のための分野特化型言語モデルの事前学習。要するに医療・生物学に特化させたAIモデルを作ったで、っていう話。ACM Trans. Comput. Healthcare 3, 1 (2021)。
52. Mosqueira-Rey, E.、Hernández-Pereira, E.、Alonso-Ríos, D.、Bobes-Bascarán, J.、Fernández-Leal, Á. ヒューマン・イン・ザ・ループ機械学習の最新動向。これは人間がAIの学習に参加して一緒に精度上げていく仕組みの総まとめやな。Artif. Intel. Rev. 56, 1–50 (2022)。
53. Maynez, J.、Narayan, S.、Bohnet, B.、McDonald, R. 抽象型要約における忠実性と事実性について。ようするにAIが文章まとめる時にほんまのこと言うてるか問題やねん。第58回計算言語学会年次総会論文集 (計算言語学会, 2020)。https://doi.org/10.18653/v1/2020.acl-main.173。
54. Ji, Z.ら。自然言語生成におけるハルシネーション(AIが嘘ついちゃう問題)のサーベイ。めっちゃ重要な問題やで。ACM Comput. Surv. 55, 12 (2023)。
55. Black, S.ら。GPT-NeoX-20B:オープンソースの自己回帰型言語モデル。プレプリント、https://browse.arxiv.org/abs/2204.06745 (2022)。
56. Frantar, E.、Alistarh, D. SparseGPT:めっちゃでかい言語モデルを一発で正確に枝刈り(いらん部分カット)できるで、っていう話。第40回国際機械学習会議論文集, 10323–10337 (JLMR.org, 2023)。https://proceedings.mlr.press/v202/frantar23a/frantar23a.pdf。
57. Sun, M.、Liu, Z.、Bair, A.、Kolter, J. Z. 大規模言語モデルをシンプルかつ効果的に枝刈りするアプローチ。ICML2023基盤モデルのための効率的システムワークショップ。https://openreview.net/forum?id=tz9JV2PRSv (2023)。
58. Hu, E. J.ら。LoRA:大規模言語モデルの低ランク適応。これはモデル全体をいじらんでも、ちょっとした追加パラメータだけで効率よくファインチューニングできるっちゅう画期的な方法やねん。プレプリント、https://arxiv.org/abs/2106.09685 (2021)。
59. Ma, X.、Fang, G.、Wang, X. LLM-Pruner:大規模言語モデルの構造的枝刈りについて。第37回ニューラル情報処理システム会議 (2023)。https://openreview.net/forum?id=J8Ajf9WfXP。
60. Bucior, B. J.ら。金属有機構造体(MOF)の高速検索とケモインフォマティクス解析を可能にする識別スキーム。Cryst. Growth Des. 19, 6682–6697 (2019)。
61. Li, X.、Hill, M. R.、Wang, H.、Zhang, H. 金属有機構造体を使ったイオン選択性膜。Adv. Mater. Technol. 6, 2000790 (2021)。
62. Qian, Q.ら。MOFベースの膜でガス分離する話。ほんまにMOFって色々使えるんやで。Chem. Rev. 120, 8161–8266 (2020)。
63. Tshitoyan, V.ら。教師なし単語埋め込みで材料科学の文献から潜在的な知識を掘り出す話。なんでかっていうと、AIが論文読んで人間がまだ気づいてない材料の関係性見つけてまうねん。めっちゃすごいやろ。Nature 571, 95–98 (2019)。
64. Kluyver, T.ら。Jupyterノートブック—再現可能な計算ワークフローのための出版フォーマット。学術出版における位置づけと影響力:プレイヤー、エージェント、アジェンダ (Loizides, F.、Schmidt, B. 編) 87–90 (IOS Press, 2016)。
65. Dagdelen, J.ら。大規模言語モデルを使った科学テキストからの構造化情報抽出。https://doi.org/10.5281/zenodo.10421174 (2023)。
66. Dagdelen, J.ら。科学テキストからの構造化情報抽出のためのLlama 2コード。https://doi.org/10.5281/zenodo.10421187 (2023)。
67. Dagdelen, J.ら。科学テキストからの構造化情報抽出のためのLlama 2の重みデータ。https://doi.org/10.6084/m9.figshare.24501331.v1 (2023)。
Nature Communications | (2024) 15:1418
13
---
## Page 14
[](/attach/06ec2c45959fd0547093ff3776dcc4cd8c38af73884f637a59be6c4a756b61e3_p014.png)
### 和訳
論文
https://doi.org/10.1038/s41467-024-45563-x
謝辞
この研究はな、トヨタ・リサーチ・インスティテュートの「材料設計・発見を加速させよう!」っていうプログラムから支援してもらってんねん。A.S.R.はカリフォルニア大学バークレー校のミラー基礎科学研究所からミラー・リサーチ・フェローシップっていう研究支援をもろてるで。Llama-2モデル(めっちゃでかいAIモデルやな)のトレーニングと評価のための資金は、アメリカのエネルギー省の科学局、基礎エネルギー科学局の材料科学・工学部門から出てて、契約番号DE-AC02-05CH11231(D2S2プログラム KCD2S2)の下で提供されとるねん。ほんで、この研究ではNERSCっていうアメリカのエネルギー省科学局のスパコン施設を使わせてもろてんねん。これはローレンス・バークレー国立研究所にあって、契約番号DE-AC02-05CH11231のもとで運営されてて、NERSC award BESERCAP0024004を使ってるで。UCバークレーの科学データ・エンジニアリング図書館員のAnna Sackmannさんには、指定した出版社とのテキスト・データマイニング契約の取得を手伝ってもろて、めっちゃ感謝しとるねん。あとJ. MontoyaさんとA. Trewarthaさんにも有益な議論をしてもろたこと感謝するで。
著者の貢献
J.D.、A.D.、N.W.、A.J.がこの論文で紹介してる情報抽出手法を開発して、J.D.とA.D.が使った要約データセットを集めてん。J.D.が最初に実験を考えて実行して、材料科学のテキストから文書レベルの情報抽出にGPT-3を使う「系列から系列へ」っていうアプローチ(要するにテキストを入力して別のテキストを出力する方式やな)がええで!って根拠を示してん。A.D.がJ.D.の最初の実験をさらに発展させてアプローチを磨いたんやで。N.W.とJ.D.が「系列からJSON」っていう方法(テキストを構造化データに変換する方法やな)を開発してん。A.D.はドーピング(材料に少量の不純物を加えて性質を変える技術やな)のスキーマを作って、ドーピング用の「系列から文章」方式を開発して、ドーピングのデータセットにアノテーション(ラベル付け)もしてん。J.D.は一般的な材料情報のスキーマを作って、一般材料データセットにアノテーションして、一般材料の情報抽出モデルをトレーニングして、General-JSONモデルの検証セットの情報抽出結果を手作業でスコアリングしてん。A.D.はドーピング関連のLLM-NERREモデル(大規模言語モデルを使った固有表現認識・関係抽出モデルやな)を全部トレーニングして、MatBERT + Proximityっていうドーピングモデルも実装してん。S.L.はLlama-2とseq2relモデルのトレーニングとデータ収集をやってん。A.D.は学習曲線の実験とアノテーション時間のデータ収集もやったで。A.S.R.とJ.D.が一緒にMOF(金属有機構造体っていう穴ぼこだらけのスポンジみたいな材料やな)のスキーマを作ってMOFデータセットにアノテーションして、J.D.がMOF-JSONモデルをトレーニングしてん。知的リーダーシップと全体的な研究の方向性に加えて、A.J.はタスクの設計とタスクのスコアリング指標にも貢献してんねん。G.C.、K.P.、A.J.がこの研究を監督したで。著者全員が論文の執筆に貢献してるねん。
利益相反
著者らは利益相反はないって宣言してるで。
追加情報
補足情報 オンライン版には補足資料が含まれてて、https://doi.org/10.1038/s41467-024-45563-x で見れるで。
論文に関する連絡や資料の請求はAnubhav Jainまでお願いしますわ。
査読情報 Nature Communicationsは、この論文の査読に貢献してくれた匿名の査読者の皆さんに感謝するで。査読ファイルも公開されとるねん。
転載と許可の情報は http://www.nature.com/reprints で確認できるで。
出版社からの注記 Springer Natureは、出版された地図や所属機関に関する管轄権の主張については中立の立場をとってるで。
オープンアクセス この論文はクリエイティブ・コモンズ 表示4.0国際ライセンスのもとで公開されてんねん。なんでかっていうと、このライセンスがあったら、使用、共有、改変、配布、複製がどんな媒体や形式でもできるからやねん。ただし条件があって、元の著者と出典をちゃんとクレジットして、クリエイティブ・コモンズのライセンスへのリンクを貼って、変更があったら「変更したで」って示さなあかんねん。この論文に含まれる画像やその他の第三者の素材は、素材のクレジット行に別段の記載がない限り、この論文のクリエイティブ・コモンズ・ライセンスに含まれてるで。もし素材がこの論文のクリエイティブ・コモンズ・ライセンスに含まれてなくて、あんたが使いたい用途が法律で認められてへんかったり、許可された使用範囲を超えてたりする場合は、著作権者から直接許可をもらわなあかんで。このライセンスのコピーは http://creativecommons.org/licenses/by/4.0/ で見れるで。
© 著者ら 2024年
Nature Communications | (2024) 15:1418
14
---
![]()
1 / 1
100%