<<
2406.06608v6.pdf

---
## Page 1
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p001.png)
### 和訳
プロンプトレポート:プロンプトエンジニアリング技術の体系的サーベイ
Sander Schulhoff1,2∗ Michael Ilie1∗ Nishant Balepur1 Konstantine Kahadze1
Amanda Liu1 Chenglei Si4 Yinheng Li5 Aayush Gupta1 HyoJung Han1 Sevien Schulhoff1
Pranav Sandeep Dulepet1 Saurav Vidyadhara1 Dayeon Ki1 Sweta Agrawal12 Chau Pham13
Gerson Kroiz Feileen Li1 Hudson Tao1 Ashay Srivastava1 Hevander Da Costa1 Saloni Gupta1
Inna Goncearenco9 Giuseppe Sarli9,10
Denis Peskoff7 Marine Carpuat1 Jules White6 Shyamal Anadkat3 Alexander Hoyle1 Philip Resnik1
7 プリンストン大学
1 メリーランド大学 2 Learn Prompting
4 スタンフォード大学 5 マイクロソフト
Megan L. Rogers8
Igor Galynker11
6 ヴァンダービルト大学
3 OpenAI
8 テキサス州立大学 9 アイカーン医科大学
10 ASST Brianza
11 マウントサイナイ・ベスイスラエル
12 Instituto de Telecomunicações
milie@umd.edu
sschulho@umd.edu
13 マサチューセッツ大学アマースト校
resnik@umd.edu
要旨
なぁ聞いてや、生成AI(GenAI)ってやつが今めっちゃいろんな業界とか研究分野でバンバン使われるようになってきてんねん。開発者とかエンドユーザーがこのシステムとやりとりするときに使うんが「プロンプティング」と「プロンプトエンジニアリング」っちゅうやつやねん。要はAIにどう指示出すかっていう技術やな。プロンプトエンジニアリングはもうめっちゃ広く使われてて研究もガンガンされてるんやけど、なんせ出てきたんが最近やから、用語がバラバラやったり、「ええプロンプトって結局なんやねん」っていう根本的な理解がバラバラになってもうてるんよな。
ほんで、この論文では何やったかっていうとな、プロンプトエンジニアリングをちゃんと体系的に整理したんや。プロンプティング技術の分類体系(タクソノミー)を組み立てて、それぞれどう使えるかを分析してん。具体的に言うとな、33個の専門用語をきっちり定義して、大規模言語モデル(LLM)向けのプロンプティング技術を58個、それ以外のモダリティ(画像とか音声とか)向けの技術を40個、全部まとめて分類したんや。めっちゃ気合い入ってるやろ。
それだけちゃうで。プロンプトエンジニアリングのベストプラクティスとかガイドラインも紹介してて、ChatGPTとかその他の最先端(SOTA)LLMに対するプロンプトの書き方のコツもちゃんと載せてるねん。さらに、自然言語のプレフィックスプロンプティングに関する文献を全部ひっくるめたメタ分析もやってんで。
ほんまにな、これらの取り組みを全部まとめた結果、この論文は今までで一番包括的なプロンプトエンジニアリングのサーベイになってるんや。ようやったわほんま。
---
## Page 2
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p002.png)
### 和訳
目次
1 はじめに
1.1 プロンプトってなんやねん?
1.2 用語の説明
1.2.1 プロンプトの構成パーツ
1.2.2 プロンプト関連の用語
1.3 プロンプトのざっくり歴史
2 プロンプティングのメタ分析
2.1 システマティックレビューのやり方
2.1.1 分析の流れ
2.2 テキストベースのテクニック
2.2.1 In-Context Learning(ICL)〜お手本見せて学ばせるやつ〜
2.2.2 思考生成〜考えさせるテクニック〜
2.2.3 分解〜問題をバラバラにするやつ〜
2.2.4 アンサンブル〜複数の答えまとめるやつ〜
2.2.5 自己批判〜自分でダメ出しさせるやつ〜
2.3 プロンプトテクニックの使われ方
2.3.1 ベンチマーク
2.4 プロンプトエンジニアリング
2.5 アンサーエンジニアリング〜答えの出し方の工夫〜
2.5.1 答えの形
2.5.2 答えの範囲
2.5.3 答えの抽出方法
3 英語テキスト以外のプロンプティング
3.1 多言語対応
3.1.1 Chain-of-Thought(CoT)〜順番に考えさせるやつ〜
3.1.2 In-Context Learning
3.1.3 プロンプトのテンプレートにどの言語使うか問題
3.1.4 機械翻訳のためのプロンプティング
3.2 マルチモーダル〜テキスト以外も扱うやつ〜
3.2.1 画像プロンプティング
3.2.2 音声プロンプティング
3.2.3 動画プロンプティング
3.2.4 セグメンテーションプロンプティング〜画像の領域分けるやつ〜
3.2.5 3Dプロンプティング
4 プロンプティングの拡張
4.1 エージェント〜AIが自分で動くやつ〜
4.1.1 ツール使うエージェント
4.1.2 コード生成エージェント
4.1.3 観察ベースのエージェント
4.1.4 RAG(検索拡張生成)〜外部の情報引っ張ってくるやつ〜
4.2 評価
4.2.1 プロンプトテクニックの評価
4.2.2 出力フォーマット
4.2.3 プロンプトのフレームワーク
4.2.4 その他の手法
5 プロンプティングの問題点
5.1 セキュリティ
5.1.1 プロンプトハッキングの種類
5.1.2 プロンプトハッキングのリスク
5.1.3 防御策
5.2 アラインメント〜AIがちゃんと意図通り動くか問題〜
5.2.1 プロンプトの感度〜ちょっと変えただけで結果変わるやつ〜
5.2.2 自信過剰とキャリブレーション〜AIが間違ってるのに自信満々問題〜
5.2.3 バイアス・ステレオタイプ・文化の影響
5.2.4 あいまいさ
6 ベンチマーキング
6.1 テクニックのベンチマーク
6.1.1 プロンプトテクニックの比較
6.1.2 質問のフォーマット
6.1.3 Self-Consistency〜何回もやって多数決するやつ〜
6.1.4 回答の評価
6.1.5 結果
6.2 プロンプトエンジニアリングのケーススタディ
6.2.1 問題設定
6.2.2 データセット
6.2.3 プロセス
6.2.4 考察
7 関連研究
8 まとめ
A 付録
A.1 プロンプティングの定義いろいろ
A.2 用語集(拡張版)
A.2.1 プロンプト用語
A.2.2 プロンプトエンジニアリング用語
A.2.3 ファインチューニング用語
A.2.4 直交するプロンプトの種類
---
## Page 3
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p003.png)
### 和訳
A.3 データシート
A.3.1 動機
A.3.2 構成
A.3.3 データ収集のプロセス
A.3.4 前処理・クリーニング・ラベリング
A.3.5 使い方
A.3.6 配布
A.3.7 メンテナンス
A.4 キーワード
A.5 系統的文献レビューのためのプロンプト
A.6 評価テーブル ... 66
A.7 エントラップメント・プロンプティングのプロセス ... 66
A.7.1 探索 ... 66
A.7.2 ラベルの取得 ... 67
A.7.3 プロンプティング手法のバリエーション ... 67
A.8 プロンプトの形式的な定義 ... 67
A.9 文脈内学習の定義についての曖昧さ解消 ... 67
A.10 貢献者一覧 ... 68
---
ほな説明していくで!
**A.6 評価テーブル** ... 71
**A.7 エントラップメント・プロンプティングのプロセス** ... 72
ここはな、AIをうまいこと「ハメる」ためのプロンプトの作り方について書いてあるとこやねん。
**A.7.1 探索** ... 72
まずはAIがどんな反応するか、いろいろ試してみるフェーズやな。
**A.7.2 ラベルの取得** ... 72
ほんで、AIの出した答えにラベル(分類タグみたいなもんや)をつけるとこやで。
**A.7.3 プロンプティング手法のバリエーション** ... 72
ここではな、プロンプトの聞き方をいろいろ変えてみて、AIの反応がどう変わるかっていうのを見とるわけやねん。めっちゃ大事なとこやで。
**A.8 プロンプトの形式的な定義** ... 75
ここはちょっとカッチリした話で、「プロンプトって結局なんやねん?」っていうのを数学的にビシッと定義しとるとこやな。
**A.9 文脈内学習の定義の曖昧さ解消** ... 77
「文脈内学習」(In-Context Learning)ってな、要するにAIに例をいくつか見せたら、それだけで新しいタスクできるようになるっていうやつやねん。ただこの言葉、人によって意味がちょっとずつ違ったりするから、「ほんまはこういう意味やで!」ってハッキリさせとるセクションやな。
**A.10 貢献者一覧** ... 79
この研究に関わった人たちのリストやで。
---
## Page 4
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p004.png)
### 和訳
# 1. はじめに
Transformerベースの大規模言語モデル(LLM)ってやつが、もう一般向けのサービスやら社内ツールやら研究やら、あっちこっちでめっちゃ使われとるねん(Bommasani et al., 2021)。基本的にはな、ユーザーが「プロンプト」っていう入力を渡して、それに対してモデルが返事を返すっていう仕組みやねん。プロンプトっていうのは、テキストのこともあるし——「木についての詩を書いて」みたいな——画像とか音声とか動画とか、それらを組み合わせたやつのこともあるねん。特に自然言語でモデルに指示を出せるっていうのがめちゃくちゃ便利で、いろんな場面で柔軟に使えるから重宝されとるわけやな。
プロンプトをどう組み立てるか、どう評価するか、その他プロンプトにまつわるあれこれを知っとくのは、こういうモデルを使いこなす上でほんまに大事なことやねん。実際のところ、ええプロンプトを書いたら、いろんなタスクで結果がグンと良くなるっていう研究結果が出とるんよ(Wei et al., 2022b; Liu et al., 2023b; Schulhoff, 2022)。プロンプトで成果を上げるための研究論文もめっちゃ増えてきて、プロンプトのテクニックの数もどんどん膨れ上がっとる状況やねん。
せやけどな、プロンプティングってまだまだ新しい分野やから、プロンプトの使い方ってちゃんと理解されてへんのが現状やねん。実際に存在する用語やテクニックのうち、現場の人らにちゃんと知られとるのはほんの一部だけなんよ。そこでワイらは、プロンプティング技術の大規模なレビューをやって、この分野の用語やテクニックをしっかりまとめた信頼できるリソースを作ったんや。これは用語集の第一弾で、今後も更新していく予定やで。最新版の用語とテクニックのリストはLearnPrompting.orgで公開しとるからな。
**研究の範囲について** ワイらは、開発者や研究者がパッと理解してすぐ実験に使えるような、プロンプティング技術の幅広いカタログを作ったんや。そのためにな、研究対象を「プレフィックスプロンプト」(Shin et al., 2020a)に絞って、「クローズプロンプト」(Petroni et al., 2019; Cui et al., 2021)は扱わんことにしたんや。なんでかっていうと、今どきのLLMのTransformerアーキテクチャはプレフィックスプロンプトをがっつり採用してて、開発者にも研究者にもしっかりサポートされとるからやねん(Brown et al., 2020; Google, 2023; Touvron et al., 2023)。それに加えて、ハードプロンプト(離散的なやつ)に焦点を当てて、ソフトプロンプト(連続的なやつ)や勾配ベースの更新(つまりファインチューニング)を使う論文は除外したんや。ハードプロンプトっていうのは、モデルの語彙にある単語に対応するトークン(ベクトル)だけで構成されとるやつで、ソフトプロンプトは語彙のどの単語にも対応せえへんトークンが入っとることもあるんやな。
最後に、特定のタスクに依存しない汎用的なテクニックだけを対象にしたで。こういう判断をしたのは、技術にあんまり詳しくない読者にもとっつきやすくして、研究の範囲を現実的に管理できるようにするためやねん。
**各セクションの概要** ワイらはPRISMAプロセス(Page et al., 2021)に基づいた機械支援付きの体系的レビューを実施して(セクション2.1)、58種類のテキストベースのプロンプティング技術を特定したんや。そこから、プロンプティング用語のしっかりした分類体系を作ったで(セクション1.2)。
ワイらの目標は、「どのプロンプティング技術を使ったらええんやろ?」って迷ったときのロードマップをコミュニティに提供することやねん(図1.1)。プロンプティングの研究って英語だけを対象にしたもんが多いんやけど、ワイらは多言語テクニックについても取り上げとるで(セクション3.1)。それからな、画像みたいなメディアをプロンプトに含めるマルチモーダルプロンプティングも急成長しとるから、マルチモーダル技術にも範囲を広げとるんや(セクション3.2)。多言語やマルチモーダルのプロンプティング技術って、英語テキストだけのプロンプティング技術を直接拡張したもんが多いんよ。
プロンプティング技術がどんどん高度になってくると、インターネット検索とか電卓みたいな外部ツールも取り込むようになってきたんや。ワイらは
---
**図1.1:** プロンプティング分野の各カテゴリは互いにつながっとるんや。ワイらの研究範囲に含まれる論文でしっかり説明されとる7つの主要カテゴリについて議論しとるで。
- **安全性への配慮** — 全体を通して必要
- **セキュリティの懸念** — 全体を通して必要
- **プロンプトやエージェントの出力を評価する必要性**
- **評価**
- **安全性**
- **セキュリティ**
- *複数言語のテキストデータに対するテクニック → コアなプロンプティング技術をよく活用する
- *マルチメディア(動画、音声など)を処理するテクニック
- **コアプロンプティング技術**
- **エージェント**
- **多言語テクニック**
- **マルチモーダルテクニック**
- **テキストベーステクニック**
多言語テクニック(MLT)やマルチモーダルテクニック(MMT)は、基本的なテキストベースのプロンプティング技術から派生しとることが多いんやで。
---
## Page 5
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p005.png)
### 和訳
こういうプロンプトのテクニックのことを「エージェント」って呼んでるねん(セクション4.1のとこで詳しく書いてるで)。
エージェントとかプロンプトのテクニックから出てきた結果をちゃんと評価する方法を知っとくのがめっちゃ大事やねん。正確かどうか確認したり、ハルシネーション——つまりAIが嘘ついてまうやつ——を防がなあかんからな。そのへんの評価方法についてはセクション4.2で話してるで。あと、セキュリティ(セクション5.1)と安全対策(セクション5.2)についても触れてて、会社やユーザーに被害が出るリスクを減らすためのプロンプト設計の話をしてるねん。
最後に、プロンプトのテクニックを2つのケーススタディで実際に使ってみてるで(セクション6.1)。1つ目は、いろんなプロンプトテクニックをMMLUっていうよく使われるベンチマーク(Hendrycks et al., 2021)でテストしたやつ。2つ目は、ガチのリアルな使い道として、手動でプロンプトエンジニアリングする例を詳しく掘り下げてるねん。具体的には、助けを求めてる人の文章から「必死の絶望感」——自殺危機のめっちゃ重要なサインやねん——を見つけ出すっていうやつ(Schuck et al., 2019a)。最後にプロンプティングの本質と最近の発展についてまとめてるで(セクション8)。
## 1.1 プロンプトってなんやねん?
プロンプトっていうのは、生成AIモデルへの入力のことで、AIの出力をガイドするためのもんやねん(Meskó, 2023; White et al., 2023; Heston and Khun, 2023; Hadi et al., 2023; Brown et al., 2020)。プロンプトはテキストやったり、画像やったり、音声やったり、その他のメディアやったりするで。例えば、「会計事務所のマーケティングキャンペーン用に3段落のメール書いて」っていうテキストとか、「10×179は?」って書いてある紙の写真とか、オンライン会議の録音に「これまとめて」っていう指示をつけたやつとかがプロンプトやな。大体テキストが含まれてることが多いけど、テキスト以外のモダリティがもっと一般的になってきたら変わるかもしれんな。
**プロンプトテンプレート** プロンプトはよくプロンプトテンプレート(Shin et al., 2020b)を使って作られるねん。プロンプトテンプレートっていうのは、1つ以上の変数が入ってる関数みたいなもんで、その変数にメディア(だいたいテキスト)を突っ込んでプロンプトを作るっていう仕組みやねん。こうしてできたプロンプトは、テンプレートの「インスタンス(具体例)」って考えられるで。
ツイートの二値分類——ポジティブかネガティブかに分けるやつな——にプロンプティングを適用する例を考えてみよか。こんな感じの最初のプロンプトテンプレートが使えるで:
> ツイートをポジティブかネガティブに分類してな:
> {TWEET}
> 木についての詩を書いて。
> 次のお題について詩を書いて:
> {USER_INPUT}
**図1.2:** プロンプトとプロンプトテンプレートは別の概念やで。テンプレートに入力を突っ込んだらプロンプトになるっちゅうことやな。
データセットの各ツイートがテンプレートのそれぞれのインスタンスに挿入されて、できたプロンプトがLLM(大規模言語モデル)に推論用として渡されるんやで。
## 1.2 用語について
### 1.2.1 プロンプトの構成要素
プロンプトにはよく使われる構成要素がいくつかあるねん。よく使われるもんをまとめて、それがプロンプトの中でどう使われてるか説明するで(図1.3)。
**ディレクティブ(指示)** 多くのプロンプトは指示や質問の形でディレクティブを出すねん¹。これがプロンプトの核心部分、いわば「意図」ってやつや。「インテント」って呼ばれることもあるで。例えばこんな感じ:
> おすすめの本5冊教えてくれへん?
ディレクティブは暗黙的な場合もあるで。例えばこのワンショット(1つの例を示す)の場合、英語からスペイン語への翻訳をしてほしいっていうのがディレクティブになってるねん:
> Night: Noche
> Morning:
**例示(エグザンプル)** 例示は、エグザンプラーとかショットとも呼ばれるんやけど、生成AIにタスクをやらせるためのお手本みたいなもんやねん。上のプロンプトはワンショット(1つの例だけ)のプロンプトやな。
**出力フォーマット** 生成AIに特定のフォーマットで出力してほしいことがよくあるやろ。例えばCSV、Markdown、XML、あるいはカスタムフォーマットとか(Xia et al., 2024)。ただし、出力を構造化するとタスクによってはパフォーマンスが落ちることもあるねん(Tam et al., 2024)。せやけどKurt(2024)はいろいろな
---
¹「ディレクティブ」はSearle(1969)から来てるんやけど、行動を促すための言語行為の一種で、人間とコンピュータの対話モデルでも使われてるねん(Morelli et al., 1991)。
---
## Page 6
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p006.png)
### 和訳
Context 1.2.1(コンテキスト)
コンテキストウィンドウ A.2.1
プライミング A.2.1
プロンプティング技法 1.2.2
プロンプティング 1.2.2
インコンテキスト学習 2.2.1
ゼロショットプロンプト 2.2.1.3
密度 A.2.4.2
フューショットプロンプト 2.2.1
エグザンプラー 1.2.2
連続プロンプト A.2.4.2
離散プロンプト A.2.4.2
ユーザープロンプト A.2.4.1
直交プロンプト型 A.2.4
オリジネーター A.2.4.1
システムプロンプト A.2.4.1
プロンプト 1.1
プロンプトテンプレート 1.1
プロンプトエンジニアリング 1.2.2
ファインチューニング A.2.3
プロンプトチェーン 1.2.2
プロンプトエンジニアリング技法 1.2.2
メタプロンプティング 2.4
アンサーエンジニアリング 2.5
対話型プロンプトエンジニアリング A.2.2
プロンプトベース学習 A.2.3
プロンプトチューニング A.2.3
アシスタントプロンプト A.2.4.1
プレフィックス A.2.4.3
クローズ A.2.4.3
予測スタイル A.2.4.3
バーバライザー 2.5.3
エクストラクター 2.5.3
アンサートリガー 2.5.3
図1.3:プロンプティングの用語まとめやで。付録へのリンクがついてる用語は、本文で詳しく説明するほどちゃうけど、プロンプティングの分野ではめっちゃ大事なやつやねん。プロンプティング技法については図2.2を見てな。
---
Tam et al. (2024) の研究にはちょっとアカンところがあってな、実は出力をちゃんと構造化したほうが性能上がるっていうことを俺らは示してんねん。CSVで情報を出力させたいときのプロンプトの書き方はこんな感じやで:
{PARAGRAPH}
これをCSVにまとめてな。
**スタイル指示** — スタイル指示っていうのは、出力のフォーマットの一種で、構造やなくて文体とか雰囲気を変えるためのもんやねん(セクション2.2.1.3)。例えばこんな感じや:
ラマについて、簡潔でズバッとした段落を書いてな。
**ロール(役割)** — ロールっていうのは、ペルソナとも言うんやけど(Schmidt et al., 2023; Wang et al., 2023l)、よう話題に出る要素で、文章の書き方とかスタイルをようしてくれるやつやねん(セクション2.2.1.3)。例えばな:
あんたは羊飼いやと思って、ラマについてのリメリック(五行詩)を書いてな。
**追加情報** — プロンプトに追加の情報を入れなアカンことも多いねん。例えば「メール書いて」っていう指示やったら、AIがちゃんとメールの署名できるように、自分の名前とか役職とかの情報も一緒に入れたりするやろ。この追加情報のことを「コンテキスト」って呼ぶ人もおるんやけど、プロンプティングの世界では「コンテキスト」って言葉がいろんな意味で使われすぎてるから、俺らはその呼び方はあんまりおすすめせえへんで²。
---
1.2.2 プロンプティングの用語
プロンプティング界隈の用語はめっちゃ速いスピードで発展してんねん。今の状況やと、ちゃんと理解されてへん定義(例えば「プロンプト」とか「プロンプトエンジニアリング」とか)がいっぱいあるし、お互い矛盾してるやつ(例えば「ロールプロンプト」と「ペルソナプロンプト」とか)もあんねん。統一された用語がないもんやから、みんながいろんなプロンプティング技法をちゃんと説明するのが難しくなってるわけや。せやから俺らは、プロンプティングコミュニティで使われてる用語をしっかりまとめたで(図1.3)³。あんまり使われへん用語は付録A.2に置いてあるわ。「プロンプト」とか「プロンプトエンジニアリング」みたいなよく使う用語をちゃんと定義するために、いろんな定義を統合してん(付録A.1)。
**プロンプティング** — プロンプティングっていうのは、生成AI(GenAI)にプロンプトを渡して、それに対して応答を生成させるプロセスのことやねん。例えば、
---
²「コンテキスト」のもう一つの意味:LLMが1回の順伝播で処理するトークンのことも「コンテキスト」って言うんよな。ややこしいやろ。
³「しっかりまとめた」っていうのは、この分野でよく使われてる用語をほぼ全部カバーしてるっていう意味やで。
---
## Page 7
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p007.png)
### 和訳
**模範例(Exemplar)**
模範例っていうのは、「こういうタスクやったらこうやって完成させるんやで」っていうお手本のことやねん。モデルにプロンプトの中で見せてあげる例のことやな(Brown et al., 2020)。
**1.3 プロンプトの歴史をサクッと振り返るで**
自然言語のプレフィックス、つまり「プロンプト」を使って言語モデルの振る舞いや返答を引き出すっていうアイデア、実はGPT-3やChatGPTの時代より前からあってん。GPT-2(Radford et al., 2019a)がすでにプロンプトを使っとって、生成AIの文脈で最初に使われたんはFan et al.(2018)みたいやな。ただ、プロンプトっていう概念の前には、制御コード(Pfaff, 1979; Poplack, 1980; Keskar et al., 2019)とか、文学における「書き出しのお題(ライティングプロンプト)」みたいな関連する考え方がすでにあったんよ。
「プロンプトエンジニアリング」っていう言葉自体は割と最近できたもんで、Radford et al.(2021)が最初っぽくて、そのちょっと後にReynolds and McDonell(2021)が使ってるな。
ただ、名前は付けてへんけど実質プロンプトエンジニアリングやってた論文はもっと前からあんねん(Wallace et al., 2019; Shin et al., 2020a)。自己回帰じゃない言語モデル向けやとSchick and Schütze(2020a,b)やGao et al.(2021)とかがそうやな。
プロンプティングに関する初期の研究では、「プロンプト」の定義が今とちょっと違っててん。例えば、Brown et al.(2020)のこんな例を見てみてや:
Translate English to French:
llama
Brown et al.(2020)は「llama」の部分をプロンプトやと考えてて、「Translate English to French:」の方は「タスクの説明」やと呼んでたんよ。でも最近の論文、この論文も含めてやけど、LLMに渡す文字列全体をまるっと「プロンプト」って呼ぶようになってるねん。
**図1.4:プロンプトエンジニアリングのプロセス**
これは3つのステップをグルグル繰り返すもんやねん。1)データセットに対して推論を実行する、2)性能を評価する、3)プロンプトテンプレートを修正する。ちなみに「エクストラクター」っていうのは、LLMの出力から最終的な回答を取り出すためのもんやで(例えば「This phrase is positive」→「positive」みたいに抽出するんや)。エクストラクターについて詳しくはセクション2.5を見てな。
テキストの塊を入力したり画像をアップロードしたりするのも、全部プロンプティングに含まれるねん。
**プロンプトチェーン**
プロンプトチェーン(やること:プロンプトチェーニング)っていうのは、2つ以上のプロンプトテンプレートを順番に使うことやねん。最初のプロンプトテンプレートから生成されたプロンプトの出力を、次のテンプレートのパラメータとして使って、全部のテンプレートを使い切るまで続けるんや(Wu et al., 2022)。要するに数珠つなぎにするってことやな。
**プロンプティングテクニック**
プロンプティングテクニックっていうのは、プロンプトの構造をどう組み立てるかの設計図みたいなもんやねん。1つのプロンプトの場合もあれば、複数のプロンプトの場合もあるし、動的に複数のプロンプトを順序立てて使う場合もある。条件分岐のロジックとか、並列処理とか、複数のプロンプトにまたがるアーキテクチャ的な考慮も含まれるで。
**プロンプトエンジニアリング**
プロンプトエンジニアリングっていうのは、使ってるプロンプティングテクニックを変えたり修正したりしながら、プロンプトをどんどん改良していく反復的なプロセスのことやねん(図1.4参照)。めっちゃざっくり言うと「試行錯誤してプロンプトを磨いていく作業」や。
**プロンプトエンジニアリングテクニック**
プロンプトエンジニアリングテクニックっていうのは、プロンプトを改善するために繰り返し修正していく戦略のことやな。学術論文では自動化されたテクニック(Deng et al., 2022)が多いんやけど、一般ユーザーの世界では、補助ツールなしで手動でプロンプトエンジニアリングしてることがほとんどやねん。
---
## Page 8
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p008.png)
### 和訳
2 プロンプティングのメタ分析
2.1 システマティックレビューのプロセス
ほんで、この論文のためにちゃんとしたデータセットを集めるために、PRISMAプロセス(Page et al., 2021)っていうやり方に基づいてシステマティック文献レビューをやったんよ(図2.1)。このデータセットはHuggingFace⁴に公開してて、データシート(Gebru et al., 2021)は付録A.3に載せてるで。主なデータの出どころはarXiv、Semantic Scholar、ACLの3つやねん。これらのデータベースに、プロンプティングとプロンプトエンジニアリングにピンポイントで関係する44個のキーワード(付録A.4)を使って検索かけたんや。
2.1.1 パイプライン
このセクションでは、ワイらのデータ収集パイプラインを紹介するで。これ、人間とLLM(大規模言語モデル)の両方を使ったレビューが入ってんねん⁵。まず最初のサンプルとしてフィルタリングの基準を決めるために、シンプルなキーワードとブール演算のルール(A.4)を使ってarXivから論文を引っ張ってきたんよ。ほんで、人間のアノテーター(ラベル付けする人)が、arXivのセットから1,661本の論文をサンプリングして、以下の基準でラベル付けしたんや:
1. 新しいプロンプティング手法を提案してる論文は入れる。
2. ハードプレフィックスプロンプト(モデルの入力の頭にくっつけるタイプのプロンプト)だけを扱ってる論文は入れる。
3. 勾配を逆伝播させて学習させる系の論文は除外する。
4. テキスト以外のデータに対してマスクやウィンドウの仕組みを使ってる論文は入れる。
300本の論文を2人のアノテーターが独立にレビューして、一致率92%(クリッペンドルフのα=コーエンのκ=81%)やったで。なかなかええ一致率やな。次に、残りの論文を分類するためにgpt-4-1106-previewを使ったプロンプトを開発したんよ(付録A.5)。このプロンプトを100個の正解データで検証したら、適合率89%、再現率75%(F1スコア81%)を達成したんや。人間とLLMのアノテーションを合わせて、最終的に1,565本の論文セットができあがったっちゅうわけや。
図2.1:PRISMAのシステマティック文献レビューのプロセス。4,247件のユニークなレコードを集めて、そこから1,565件の関連レコードを抽出してんねん。
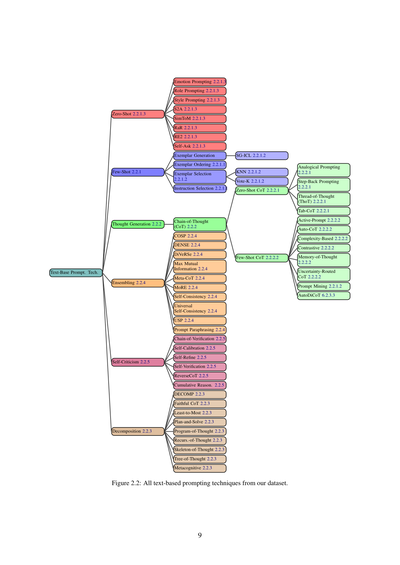
2.2 テキストベースの手法
ほな、ここから58個のテキストベースのプロンプティング手法を体系的に分類した全体像を紹介するで。6つの大きなカテゴリに分けてんねん(図2.2)。いくつかの手法は複数のカテゴリにまたがるかもしれんけど、一番関係が深いカテゴリに1つだけ入れてるで。
2.2.1 文脈内学習(ICL)
ICLっていうのは、生成AIが、重みの更新(再学習)なしに、プロンプトの中に例とか関連する指示を入れるだけでスキルやタスクを学べる能力のことやねん(Brown et al., 2020; Radford et al., 2019b)。こういうスキルは例示(図2.4)や指示(図2.5)から学べるんよ。ただし注意してほしいんやけど、「学ぶ」っていう言い方はちょっと誤解を招くねん。なんでかっていうと、ICLは単にタスクを指定してるだけの場合もあって、そのスキルは別に新しいもんやなくて、すでに学習データに含まれてた可能性もあるからやねん(図2.6)。この用語の使い方についての議論は付録A.9を見てな。ICLの最適化(Bansal et al., 2023)や理解(Si et al., 2023a; Štefánik and Kadlčík, 2023)に関する研究もめっちゃ活発に進んでるで。
⁴ https://huggingface.co/datasets/PromptSystematicReview/Prompt_Systematic_Review_Dataset
⁵ gpt-4-1106-previewを使用
8
PRISMAレビュープロセスの結果、定量分析に含めたレコードは1,565件。arXivから3,677件、Semantic Scholarから2,087件、ACLから639件で合計4,797件→タイトルの重複を除いて4,247件→人間が1,661本レビューして316本除外→人間レビュー後3,931件→「prompt」って単語が入ってない論文を除いて2,352件→AIが1,071本レビューして787本除外→最終的に1,565件が残ったっちゅう流れやな。
---
## Page 9
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p009.png)
### 和訳
**図2.2:ワイらのデータセットに含まれる、テキストベースのプロンプト技術の全体像やで。**
---
**テキストベースのプロンプト技術**っちゅう大きなくくりがあってな、ここからめっちゃいろんな技が枝分かれしとんねん。ほな順番に見ていこか。
---
**Few-Shot(2.2.1)** — 「お手本いくつか見せてから聞く」やつやな
- **お手本の並び順(Exemplar Ordering)2.2.1.1**
- **お手本の選び方(Exemplar Selection)2.2.1.2** — KNN(2.2.1.2)、Vote-K(2.2.1.2)
- **お手本の自動生成(Exemplar Generation)** — SG-ICL(2.2.1.2)
- **指示文の選び方(Instruction Selection)2.2.1.1**
- **プロンプトマイニング(Prompt Mining)2.2.1.2** — ええ感じのプロンプトを掘り出す技やな
---
**Zero-Shot(2.2.1.3)** — 「お手本なしでいきなり聞く」やつ。ここからいろいろ派生しとんねん
- **Emotion Prompting(2.2.1.3)** — 感情に訴えかけるプロンプトや
- **Role Prompting(2.2.1.3)** — 「あんたは○○の専門家やで」って役割を与えるやつ
- **Style Prompting(2.2.1.3)** — 文体を指定するやつ
- **S2A(2.2.1.3)** — 注意を向けるべきとこだけに絞る技
- **SimToM(2.2.1.3)** — 相手の立場をシミュレーションする技
- **RaR(2.2.1.3)** — 言い換えてから答えさせる技
- **RE2(2.2.1.3)** — 読み直してから答えさせる技
- **Self-Ask(2.2.1.3)** — 自分で自分に質問させる技
---
**思考生成(Thought Generation)2.2.2** — AIに「考える過程」を出させる系の技術やで
**Chain-of-Thought(CoT)2.2.2** — 「一歩ずつ考えてみて」っていう、めっちゃ有名なやつやな
- **Zero-Shot CoT(2.2.2.1)** — お手本なしで「ステップバイステップで考えて」って言うだけのやつ
- **Analogical Prompting(2.2.2.1)** — 似た問題を思い出させる技
- **Step-Back Prompting(2.2.2.1)** — 一歩引いて大きな視点で考えさせる技
- **Thread-of-Thought(ThoT)2.2.2.1** — 思考の糸をたどらせる技
- **Tab-CoT(2.2.2.1)** — 表形式で整理しながら考えさせる技
- **Few-Shot CoT(2.2.2.2)** — 考える過程のお手本も一緒に見せるやつ
- **Active-Prompt(2.2.2.2)** — 不確かなとこを重点的にお手本として使う技
- **Auto-CoT(2.2.2.2)** — 思考の連鎖を自動で作る技
- **Complexity-Based(2.2.2.2)** — 複雑なお手本を優先的に選ぶ技
- **Contrastive(2.2.2.2)** — 正解と不正解の両方見せて対比させる技
- **Memory-of-Thought(2.2.2.2)** — 過去の思考を記憶して活用する技
- **Uncertainty-Routed CoT(2.2.2.2)** — 不確かさに応じてルートを変える技
- **AutoDiCoT(6.2.3.3)** — 自動で蒸留したCoTを使う技
---
**分解(Decomposition)2.2.3** — でっかい問題を小さく分けて解く系やで
- **DECOMP(2.2.3)** — 問題をサブタスクに分解する基本技
- **Faithful CoT(2.2.3)** — 忠実に論理を追う思考の連鎖
- **Least-to-Most(2.2.3)** — 簡単なとこから順番に攻める技
- **Plan-and-Solve(2.2.3)** — まず計画立ててから解く技
- **Program-of-Thought(2.2.3)** — プログラムみたいに考えさせる技
- **Recursion-of-Thought(2.2.3)** — 再帰的に考えさせる技
- **Skeleton-of-Thought(2.2.3)** — まず骨組み作ってから肉付けする技
- **Tree-of-Thought(2.2.3)** — 木の枝みたいに分岐させて考える技
- **Metacognitive(2.2.3)** — 「自分の考え方について考える」っていうメタな技
---
**アンサンブル(Ensembling)2.2.4** — 複数の答えをまとめてええとこ取りする系や
- **COSP(2.2.4)** — 自分で一貫性チェックしてお手本選ぶ技
- **DENSE(2.2.4)** — 密にアンサンブルする技
- **DiVeRSe(2.2.4)** — 多様なプロンプトで検証する技
- **Max Mutual Information(2.2.4)** — 相互情報量が最大になるように選ぶ技
- **Meta-CoT(2.2.4)** — メタ的に思考の連鎖をまとめる技
- **MoRE(2.2.4)** — 複数の推論を混ぜる技
- **Self-Consistency(2.2.4)** — 何回も答えさせて多数決取る、めっちゃ有名な技やで
- **Universal Self-Consistency(2.2.4)** — 自己一貫性をもっと汎用的にした技
- **USP(2.2.4)** — 普遍的な自己適応プロンプト
- **Prompt Paraphrasing(2.2.4)** — プロンプトを言い換えて複数回試す技
---
**自己批判(Self-Criticism)2.2.5** — 自分で自分の答えをチェックして直す系やな
- **Chain-of-Verification(2.2.5)** — 検証を連鎖的にやる技
- **Self-Calibration(2.2.5)** — 自分の確信度を調整する技
- **Self-Refine(2.2.5)** — 自分で答えを磨き直す技
- **Self-Verification(2.2.5)** — 自分で答えを検証する技
- **ReverseCoT(2.2.5)** — 逆方向から考えて検証する技
- **Cumulative Reasoning(2.2.5)** — 推論を積み重ねていく技
---
ほんまにめっちゃ種類あるやろ?ようするに「AIにどう聞いたら賢い答えが返ってくるか」っていう技の百科事典みたいなもんやねん。9ページ目の図やで。
---
## Page 10
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p010.png)
### 和訳
2+2: よっつ
4+5: ここのつ
8+0:
図2.4: ICLの例示プロンプト
以下のテキストから、同じ文字が3つ入ってて、
かつそれ以外の文字も3つ以上ある単語を
全部抜き出してな: {TEXT}
図2.5: ICLの指示プロンプト
**例示の数**
プロンプトに入れる例示の数を増やしたら、基本的にモデルの性能は上がるねん。特にデカいモデルやとそれが顕著やな(Brown et al., 2020)。ただな、場合によっては20個超えたあたりから効果が頭打ちになることもあるんよ(Liu et al., 2021)。ロングコンテキストに対応したLLMの場合は、例示を増やし続けても性能は伸びていくんやけど、その効率はタスクとモデルによってバラバラやねん(Agarwal et al., 2024; Bertsch et al., 2024; Jiang et al., 2024)。
**例示の並び順**
例示をどの順番で並べるかっていうのが、モデルの挙動にめっちゃ影響するねん(Lu et al., 2021; Kumar and Talukdar, 2021; Liu et al., 2021; Rubin et al., 2022)。タスクによっては、並び順を変えるだけで正解率が50%以下から90%超えまでブレるっていうとんでもない話もあるんよ(Lu et al., 2021)。
**例示のラベル分布**
従来の教師あり機械学習と一緒で、プロンプト内の例示のラベルの偏りが挙動に影響するねん。たとえば、あるクラスの例示を10個、別のクラスを2個だけ入れたら、モデルが多い方のクラスに偏りやすくなるっちゅうわけや。
**例示のラベルの質**
複数の例示を入れるのがええのは間違いないんやけど、その例示が厳密に正しくないとアカンのかっていうと、実はそこがようわからんねん。ある研究(Min et al., 2022)では、ラベルの正確さは関係ないって言うてて、間違ったラベルの例示を入れても性能は別に落ちへんかったらしいんよ。でもな、条件によってはほんまに性能にガッツリ影響するケースもあるねん(Yoo et al., 2022)。デカいモデルほど、間違ったラベルや関係ないラベルにもうまく対応できる傾向があるで(Wei et al., 2023c)。
これ、なんで大事かっていうとな、大量のデータセットから自動でプロンプトを組み立てる場合、そのデータに不正確なもんが混じってる可能性があるからやねん。
図2.3: Few-shotプロンプトを作るときの主要な設計判断を6つまとめたで。※ここでの推奨事項が全部のタスクに当てはまるわけちゃうから注意な。場合によっては逆に性能が落ちることもあるんよ。
**Few-Shotプロンプティング**(Brown et al., 2020)っていうのは、図2.4みたいに、ほんの数個の例(例示)だけでGenAIにタスクを学習させるやり方やねん。Few-Shotプロンプティングは、Few-Shot学習(FSL)(Fei-Fei et al., 2006; Wang et al., 2019)の特殊なケースなんやけど、モデルのパラメータを更新する必要がないっていうのがミソやな。
**2.2.1.1 Few-Shotプロンプティングの設計判断**
プロンプトに入れる例示を選ぶのって、めっちゃ難しいねん。なんでかっていうと、性能は例示のいろんな要素にガッツリ左右されるし(Dong et al., 2023)、普通のLLMのコンテキストウィンドウには限られた数の例示しか入らへんからやねん。ここでは6つの設計判断をピックアップしてるで。例示の選び方と並び順が出力の品質にめっちゃ重要な影響を与えるんよ(Zhao et al., 2021a; Lu et al., 2021; Ye and Durrett, 2023)(図2.3)。
---
**1. 例示の数** — できるだけぎょうさん例示を入れるんや※
Trees are beautiful: / I hate Pizza: / Squirrels are so cute: / YouTube Ads Suck: / I'm so excited: → Happy / Happy / Angry / Angry
Trees are beautiful: / I'm so excited: → Happy
**2. 例示の並び順** — ランダムに並べ替えるんや※
I am so mad: / I love life: / I hate my boss: / Life is good: / I'm so excited: → Angry / Angry / Happy / Happy
I love life: / Life is good: / I am so mad: / I hate my boss: / I'm so excited: → Happy / Happy / Angry / Angry
**3. 例示のラベル分布** — ラベルの偏りをなくしてバランスよくするんや※
I am so mad: / People are so dense: / I hate my boss: / Life is good: / I'm so excited: → Angry / Angry / Angry / Happy
I am so mad: / I love life: / I hate my boss: / Life is good: / I'm so excited: → Angry / Angry / Happy / Happy
**4. 例示のラベルの質** — 例示のラベルがちゃんと正しいか確認するんや※
I am so mad: / I love life: / I hate my boss: / Life is good: / I'm so excited: → Angry / Angry / Happy / Happy
I am so mad: / I love life: / I hate my boss: / Life is good: / I'm so excited: → Happy / Happy / Angry / Angry
**5. 例示のフォーマット** — よく使われる形式を選ぶんや※
Im hyped!: / Im not very excited: / I'm so excited: → Happy / Angry
Trees are nice=== / YouTube Ads Suck=== / I'm so excited=== → Happy / Angry
**6. 例示の類似度** — テスト対象に似てる例示を選ぶんや※
Im hyped!: / Im not very excited: / I'm so excited: → Happy / Angry
Trees are beautiful: / YouTube Ads Suck: / I'm so excited: → Happy / Angry
---
## Page 11
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p011.png)
### 和訳
テストデータDtestに対して生成されるやつやねん。テスト時にはこういうプロンプトのテンプレートを使うで、「入力:出力」っていうフォーマットに沿ってな(図2.4):
xi
図2.6:学習データからのICL(文脈内学習)プロンプトやで。
このバージョンのICLやと、モデルは新しいスキルを学んでるわけちゃうねん。むしろ、学習データにたぶん入ってた知識を使ってるだけやねん。
{例示}
Dtest:
xi
ラベルの質が結果にどう影響するかっちゅうのは、ちゃんと調べとく必要があるで。
**例示のフォーマット** 例示の書き方も性能に影響すんねん。一番よう使われるフォーマットは「Q: {入力}, A: {ラベル}」やけど、タスクによってベストなフォーマットは変わるかもしれんから、いくつか試してみる価値はあるで。学習データによう出てくるフォーマットの方が性能ええっちゅう証拠もあるんや(Jiang et al., 2020)。
**例示の類似性** テストサンプルに似てる例示を選ぶのは、基本的には性能にええ影響があるで(Liu et al., 2021; Min et al., 2022)。せやけど、場合によってはもっと多様な例示を選んだ方が性能上がることもあんねん(Su et al., 2022; Min et al., 2022)。
**指示文の選び方** ゼロショットプロンプト(例示なしのやつ)では指示文がLLMを導くのに必須やねんけど(Wei et al., 2022a)、フューショットプロンプトで例示の前に指示文つけるメリットはそこまではっきりしてへんのよ。Ajith et al.(2024)が示したんは、汎用的でタスクに依存せえへん指示文(つまり指示文なしとか「次のタスクを完了せよ:」みたいなん)の方が、タスク固有の指示文(例えば「この質問の答えは何ですか?」とか)より分類や質問応答の精度がええっちゅうことやねん。要するに、指示に従う能力は例示だけでも達成できるっちゅう結論や。正確さの向上にはつながらんかもしれんけど、フューショットプロンプトの指示文は文体みたいな補助的な出力の特性をガイドするのには使えるで(Roy et al., 2023)。
**2.2.1.2 フューショットプロンプティングのテクニック**
こういう要素を全部考えると、フューショットプロンプティングをうまいこと実装するんはめっちゃ難しいねん。ここからは教師あり設定でのフューショットプロンプティングのテクニックを見ていくで。アンサンブル手法もフューショットプロンプティングに役立つけど、それは別のとこ(セクション2.2.4)で話すわ。
学習データセットDtrainがあるとするやん。これには複数の入力Dtrainと出力Dtrainが入ってて、勾配ベースの更新(いわゆる普通の学習)をする代わりに、GenAI(生成AI)にフューショットプロンプトとして使えるねん。このプロンプトは動的に
xi
図2.7:フューショットプロンプティングのテンプレート
**K近傍法(KNN)**(Liu et al., 2021)は、テストデータDtestに似てる例示を選んで性能を上げるアルゴリズムのファミリーの一つやねん。効果的ではあるんやけど、プロンプト生成時にKNNを使うんは時間もリソースもめっちゃかかるかもしれんで。
xi
**Vote-K**(Su et al., 2022)は、テストサンプルに似た例示を選ぶもう一つの方法やで。第一段階では、モデルがアノテーター(ラベル付けする人)にラベルを付けてもらうための有用なラベルなし候補例示を提案すんねん。第二段階では、ラベル付けされたプールをフューショットプロンプティングに使うんや。Vote-Kはさらに、新しく追加する例示が既存のもんと十分に違うようにして、多様性と代表性を高めるようにしてるで。
**自己生成文脈内学習(SG-ICL)**(Kim et al., 2022)は、GenAIを使って自動的に例示を生成する方法やねん。学習データがない場合にゼロショットよりはマシやけど、生成されたサンプルは実際のデータほど効果的ちゃうねん。
**プロンプトマイニング**(Jiang et al., 2020)は、大規模コーパス(テキストの集まり)を分析して、プロンプトの中の最適な「つなぎ言葉」を見つけ出すプロセスやねん。このつなぎ言葉っちゅうのは、実質的にプロンプトのテンプレートのことや。例えば、フューショットプロンプトでよう使われる「Q: A:」フォーマットの代わりに、コーパスの中でもっと頻繁に出てくる似たようなもんがあるかもしれんやん。コーパスでよう出てくるフォーマットの方が、プロンプトの性能は上がりやすいっちゅうわけや。
**もっと高度なテクニック** としては、LENS(Li and Qiu, 2023a)、UDR(Li et al., 2023f)、Active Example Selection(Zhang et al., 2022a)なんかがあって、それぞれ反復フィルタリング、埋め込みと検索、強化学習を活用してるで。
**2.2.1.3 ゼロショットプロンプティングのテクニック**
フューショットプロンプティングとは対照的に、ゼロショットプロンプティングは例示をゼロ個使うやつやねん。よう知られたスタンドアロンのゼロショットテクニックがいくつかあるで
11
---
## Page 12
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p012.png)
### 和訳
それとゼロショットのテクニックを別のコンセプト(例えばChain of Thoughtとか)と組み合わせるパターンもあるねんけど、それはまた後で話すわ(セクション2.2.2で)。
**ロールプロンプティング**(Wang et al., 2023j; Zheng et al., 2023d)、別名**ペルソナプロンプティング**(Schmidt et al., 2023; Wang et al., 2023l)っていうのは、生成AIに「あんたはこういう役やで」って特定の役割を与えるやり方やねん。例えば「マドンナになりきって」とか「旅行ライターとして書いて」みたいに指示するわけや。こうすると、自由度の高いタスクでええ感じのアウトプットが出やすくなるし(Reynolds and McDonell, 2021)、場合によってはベンチマークの精度もアップすることがあるねん(Zheng et al., 2023d)。
**スタイルプロンプティング**(Lu et al., 2023a)は、プロンプトの中で「こういう文体で」「こういうトーンで」「こういうジャンルで」って指定して、生成AIの出力をコントロールするテクニックやねん。ロールプロンプティングでも似たような効果が得られるで。
**エモーションプロンプティング**(Li et al., 2023a)は、人間の心理に刺さるようなフレーズ(例えば「これ、私のキャリアにめっちゃ大事なんです」みたいなやつ)をプロンプトにぶっ込むっていうテクニックやねん。なんでかっていうと、こうするとLLMのベンチマーク性能とか、自由文生成の質が上がることがあるからやで。
**System 2 Attention (S2A)**(Weston and Sukhbaatar, 2023)は、まずLLMに「このプロンプトを書き直して、質問に関係ない情報は全部消して」ってお願いするねん。ほんで、そのスッキリした新しいプロンプトをLLMに渡して最終回答を出させるっていう二段構えのやり方や。
**SimToM**(Wilf et al., 2023)は、複数の人とかモノが絡むややこしい質問に対処するためのテクニックやねん。質問が出てきたら、まず「この人が知ってる事実はこれだけやな」って情報を整理して、その限られた事実だけを元に質問に答えるっていう流れや。プロンプトを2回使うプロセスで、プロンプト内の関係ない情報に惑わされへんようにできるねん。
**Rephrase and Respond (RaR)**(Deng et al., 2023)は、LLMに「質問を言い換えて詳しくしてから答えてな」って指示するやり方やねん。例えば質問の後に「この質問を言い換えて展開してから回答してください」みたいなフレーズを付け足すわけや。これを一発でやることもできるし、言い換えた質問を改めてLLMに渡すこともできる。RaRは複数のベンチマークで改善が確認されてるで。
**Re-reading (RE2)**(Xu et al., 2023)は、プロンプトに「もう一回質問を読んでな:」っていうフレーズを追加して、さらに質問自体も繰り返すっていうテクニックや。めっちゃシンプルやろ?でもほんまにこれだけで推論ベンチマークの成績が上がるねん、特に複雑な問題で効果的やで。
**Self-Ask**(Press et al., 2022)は、LLMに「この質問に答えるために、追加で聞かなあかんことあるか?」って最初に判断させるやり方やねん。もし必要やったら、LLMが自分でフォローアップの質問を作って、それに答えて、最終的に元の質問に答えるっていう流れや。
### 2.2.2 思考生成
思考生成っていうのは、問題を解くときにLLMに「自分の考えを言葉にしながら解いてな」って促すテクニックの総称やねん(Zhang et al., 2023c)。
**Chain-of-Thought (CoT) プロンプティング**(Wei et al., 2022b)は、Few-shotプロンプティングを活用して、LLMに最終回答を出す前に思考プロセスを表現させるテクニックやねん⁶。これ「Chain-of-Thoughts」って呼ばれることもあるで(Tutunov et al., 2023; Besta et al., 2024; Chen et al., 2023d)。数学とか推論タスクでLLMの性能がめっちゃ上がることが実証されてるねん。Wei et al. (2022b)のプロンプトでは、質問と推論の道筋と正解を含んだ例題が入ってるで(図2.8)。
> Q: ジャックはカゴを2つ持ってて、それぞれに3個ずつボールが入ってます。ジャックは全部でボール何個持ってますか?
> A: 1つのカゴに3個入ってるから、2つのカゴやと 3 × 2 = 6個やな。
> Q: {質問}
> A:
>
> 図2.8: ワンショットChain-of-Thoughtプロンプトの例
#### 2.2.2.1 ゼロショットCoT
CoTの一番シンプルなバージョンは、例題ゼロのやつやねん。プロンプトの最後に「ステップバイステップで考えてみよう」(Kojima et al., 2022)みたいな思考を誘発するフレーズをくっつけるだけや。他にも「まず論理的に考えてみよう」(Kojima et al., 2022)とかが提案されてるで。Zhou et al. (2022b)はLLMを使って「正しい答えを確実に出すために、順を追って考えていきましょう」っていうフレーズを生成してるし、Yang et al. (2023a)は最適な思考誘発フレーズを探索してるねん。ゼロショット
⁶ こういうテクニックの説明では「考える」みたいにモデルを擬人化する言葉がよう使われるねんけど、ワイらはなるべくそういう表現は避けるようにしてるで。ただ、元の著者の言葉遣いはそのまま使うこともあるわ。
---
## Page 13
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p013.png)
### 和訳
CoTのアプローチってめっちゃええねん。なんでかっていうと、例題(エグゼンプラ)がいらんし、基本的にどんなタスクにも使えるっていう汎用性があるからやねん。
GPT-4とGemini Ultraの両方のモデルでベンチマークになっとるで。
**ステップバック・プロンプティング**(Zhengら、2023c)はCoTをちょっとアレンジしたやつやねん。具体的な推論に入る前に、まずLLMに「そもそもこの話の関連概念とか事実ってなんやっけ?」っていう、ざっくりした高レベルの質問をさせるんやな。このやり方で、PaLM-2LとGPT-4の両方で、いろんな推論ベンチマークの成績がめっちゃ上がったんやで。
**アナロジカル・プロンプティング**(Yasunagaら、2023)はSG-ICLに似とって、CoT付きの例題を自動で生成してくれるやつやねん。数学の推論とかコード生成のタスクで改善が確認されとるで。
**スレッド・オブ・ソート(ThoT)プロンプティング**(Zhouら、2023)は、CoT推論の「考えを引き出すフレーズ」を改良したやつやな。普通やったら「ステップバイステップで考えよう」って言うところを、「この文脈を扱いやすい部分に分けて順番に見ていこう、途中で要約と分析もしながらな」って言い換えるねん。この言い回し、質問応答とか情報検索の場面でめっちゃ効くんやけど、特にデカくて複雑な文脈を扱うときにほんまに強いんやで。
**タブラー・チェーン・オブ・ソート(Tab-CoT)**(JinとLu、2023)は、ゼロショットCoTプロンプトの一種で、LLMの推論をマークダウンの表形式で出力させるっていうアイデアやねん。表にすることで、出力の構造がスッキリして、結果的に推論の質も上がるっちゅうわけや。
**2.2.2.2 フューショットCoT**
このグループの技術は、思考の連鎖(CoT)を含む複数の例題をLLMに見せるやり方やねん。これでパフォーマンスがめっちゃ上がることがあるんやで。この技術は「マニュアルCoT」(Zhangら、2022b)とか「ゴールデンCoT」(DelとFishel、2023)って呼ばれることもあるな。
**コントラスティブCoTプロンプティング**(Chiaら、2023)は、CoTプロンプトに正しい説明だけやなくて、間違った説明の例題もわざと入れるんやな。要するに「こう考えたらアカンで」ってLLMに教えるわけや。算数の推論とか事実に基づくQAとかで、ほんまにめっちゃ改善が見られたんやで。
**不確実性ルーティングCoTプロンプティング**(Google、2023)は、まず複数のCoT推論パスをサンプリングして、多数決の結果がある閾値(バリデーションデータから計算するやつ)を超えとったらそれを採用するねん。超えてなかったら、貪欲法(一番確率高いやつを順に選ぶ方法)でサンプリングして、その回答を使うっちゅう仕組みや。MMLUベンチマークで改善が確認されとるで。
**複雑性ベース・プロンプティング**(Fuら、2023b)は、CoTに2つの大きな工夫を加えたやつやねん。まず1つ目は、問題の長さとか必要な推論ステップ数みたいな要素を基にして、複雑な例題を選んでプロンプトに入れること。2つ目は、推論のときに複数の推論チェーン(回答)をサンプリングして、ある長さの閾値を超えたチェーンだけで多数決を取ること。「推論が長いほど回答の質が高いはずや」っていう前提やな。3つの数学推論データセットで改善が確認されとるで。
**アクティブ・プロンプティング**(Diaoら、2023)は、まずいくつかの訓練用の問題や例題を用意して、LLMに解かせるねん。ほんでその不確実性(ここでは回答のバラつき)を計算して、一番不確実性が高かった例題を人間のアノテーターに書き直してもらうっちゅうやり方やな。
**メモリー・オブ・ソート・プロンプティング**(LiとQiu、2023b)は、ラベルなしの訓練用例題を使って、テスト時にフューショットCoTプロンプトを作るやつやねん。テスト前に、ラベルなしの訓練例題にCoTで推論をかけておいて、テスト時にはテストサンプルに似たやつを引っ張ってくるんやな。算数、常識、事実に基づく推論のベンチマークでかなりの改善が出とるで。
**自動チェーン・オブ・ソート(Auto-CoT)プロンプティング**(Zhangら、2022b)は、Weiら(2022b)のゼロショットプロンプトを使って、思考の連鎖を自動生成するやつやねん。そうやって作ったやつを使って、テストサンプル用のフューショットCoTプロンプトを組み立てるっちゅう流れや。
**2.2.3 分解(デコンポジション)**
複雑な問題をシンプルなサブ問題に分解するっていう研究がめっちゃ盛んやねん。これは人間にとっても生成AI(GenAI)にとっても有効な問題解決の戦略やで(Patelら、2022)。分解系のテクニックの中には、CoTみたいな「考えを引き出す系」の技術に似とるやつもあるんやな。CoTって自然と問題をシンプルな要素に分けることが多いからやねん。でもな、明示的にバラすことで、LLMの問題解決能力をさらに上げられるんやで。
**リースト・トゥ・モスト・プロンプティング**(Zhouら、2022a)は、まずLLMに「この問題をサブ問題に分けてくれ、ただし解かんでええで」って指示するねん。ほんで、そのサブ問題を順番に解いていって、毎回モデルの回答をプロンプトに追加しながら、最終的な答えにたどり着くっちゅうやり方や。
---
## Page 14
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p014.png)
### 和訳
最終的な答えにたどり着くっちゅうわけや。この方法は、記号の操作とか、いろんなもんを組み合わせて一般化するタスク、あと数学的な推論なんかでめっちゃ成果出してんねん。
**分解プロンプティング(DECOMP)**(Khot ら、2022)は、Few-Shotで「こういう関数使えるで〜」ってLLMにお手本見せるやり方やねん。文字列を分割する関数とか、ネット検索する関数とか、そういうのがあって、これらはだいたい別のLLM呼び出しとして実装されてるんよ。ほんで、LLMが元の問題をサブ問題に分解して、それぞれ別の関数に投げるっちゅうわけ。一部のタスクでは、さっき言うたLeast-to-Mostプロンプティングよりもええ結果出してんねん。
**Plan-and-Solveプロンプティング**(Wang ら、2023f)は、Zero-Shot CoTをパワーアップさせたやつで、「まず問題を理解して解くための計画を立てよう。ほんで、その計画に沿ってステップバイステップで解いていこう」っていうプロンプトを使うねん。普通のZero-Shot-CoTより、いろんな推論データセットでしっかりした推論プロセスを生み出せるんよ。
**思考の木(ToT)**(Yao ら、2023b)、Tree of Thoughtsとも呼ばれてて(Long, 2023)、最初の問題からスタートして、木みたいな探索問題を作るんよ。CoTみたいに「思考」っていう形で複数の可能なステップを生成して、それぞれのステップが問題解決にどんだけ近づいたか(プロンプトで)評価して、どのステップを続けるか決めて、さらに思考を広げていくねん。探索と計画が必要なタスクにめっちゃ強いんよ。
**思考の再帰(Recursion-of-Thought)**(Lee and Kim, 2023)は、普通のCoTと似てるんやけど、推論の途中でややこしい問題にぶち当たったら、その問題を別のプロンプト、つまり別のLLM呼び出しに送るねん。それが解けたら、その答えを元のプロンプトに差し込むっちゅうわけ。こうすることで、再帰的に複雑な問題を解けるようになるし、コンテキストの長さ制限を超えてまうような問題にも対応できるんよ。算術とかアルゴリズム系のタスクで改善が見られてんねん。もともとはファインチューニングで特別なトークンを出力して、サブ問題を別のプロンプトに送る仕組みで実装されてるんやけど、プロンプティングだけでもできるはずやで。
**思考のプログラム(Program-of-Thoughts)**(Chen ら、2023d)は、Codexみたいなコード書けるLLMを使って、推論のステップをプログラムのコードとして生成するねん。ほんで、コードインタープリタがそのステップを実行して最終的な答えを出すっちゅうわけ。数学とかプログラミング系のタスクにはめっちゃ強いんやけど、意味を理解せなあかん推論タスクにはちょっと弱いんよ。
**忠実な思考の連鎖(Faithful Chain-of-Thought)**(Lyu ら、2023)は、自然言語と記号言語(Pythonとか)の両方を使った推論の連鎖を生成するねん。Program-of-Thoughtsと似てるんやけど、タスクに応じていろんな種類の記号言語を使い分けるっていうところがミソやねん。
**思考の骨格(Skeleton-of-Thought)**(Ning ら、2023)は、並列処理で回答スピードを爆速にすることに注目してるんよ。問題が来たら、まずLLMに答えの骨組み、つまりサブ問題みたいなもんを作らせるねん。ほんで、そのサブ問題を並列でLLMに送って、全部の出力をガッチャンコして最終的な回答にするっちゅうわけ。
**メタ認知プロンプティング**(Wang and Zhao, 2024)は、人間のメタ認知プロセス、つまり「自分の考え方について考える」っていうのをLLMに真似させようとするやつで、5段階のプロンプトチェーンを使うねん。質問の明確化、予備的な判断、回答の評価、判断の確認、そして自信度の評価っていうステップがあるんよ。
**2.2.4 アンサンブル**
生成AIの世界で「アンサンブル」っちゅうのは、同じ問題に対して複数のプロンプトを使って、それらの回答をまとめて最終的な出力にするやり方やねん。多くの場合、多数決、つまり一番多く出てきた回答を選ぶっていう方法で最終出力を決めるんよ。アンサンブルはLLMの出力のバラつきを減らして、精度も上がることが多いんやけど、なんでかっていうとその分モデルの呼び出し回数が増えるから、コストはかかるんよな。
**デモンストレーション・アンサンブル(DENSE)**(Khalifa ら、2023)は、トレーニングセットからそれぞれ違うお手本のサブセットを入れた複数のFew-Shotプロンプトを作るねん。ほんで、それぞれの出力をまとめて最終的な回答を出すっちゅうわけ。
**推論エキスパートの混合(MoRE)**(Si ら、2023d)は、いろんな種類の推論に特化したプロンプトを使って、多様な推論のエキスパートを揃えるやり方やねん。例えば、事実に基づく推論には検索拡張プロンプト、多段階推論や数学の推論にはChain-of-Thought、常識推論には生成知識プロンプティング、みたいな感じ。ほんで、全エキスパートの中から「一致度スコア」に基づいてベストな答えを選ぶんよ。
**最大相互情報量法(Max Mutual Information Method)**(Sorensen ら、2022)は、複数のプロンプトテンプレートを作って
---
## Page 15
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p015.png)
### 和訳
いろんなスタイルとか例文を試してみて、その中からプロンプトとLLMの出力の間の相互情報量が一番でかくなるようなテンプレートを「最適なやつ」として選ぶねん。
**Self-Consistency(自己一貫性)**
(Wang et al., 2022)これはな、「同じ答えにたどり着くルートって一つだけちゃうやろ」っていう直感に基づいてるねん。まずLLMに何回もCoT(思考の連鎖)をやらせるんやけど、ここでポイントなんが、温度パラメータをゼロにせんことやねん。そうすることでいろんな推論パスが出てくるわけや。ほんで、出てきた回答全部に対して多数決を取って、最終的な答えを決めるっちゅうこっちゃ。算数とか常識推論とか記号的な推論タスクでめっちゃ性能上がってるで。
**Universal Self-Consistency(汎用自己一貫性)**
(Chen et al., 2023e)Self-Consistencyとほぼ同じなんやけど、ちょっと違うのは、プログラムで「この答え何回出てきた?」って数えて多数派を選ぶんやなくて、全部の出力をプロンプトのテンプレートにぶち込んで、そこから多数派の答えを選ばせるってとこやねん。これがええのは、自由なテキスト生成とか、同じ答えでもプロンプトによって微妙に表現が変わってまうケースに強いとこやな。
**Meta-Reasoning over Multiple CoTs(複数CoTに対するメタ推論)**
(Yoran et al., 2023)これはUniversal Self-Consistencyに似てんねんけど、まず一つの問題に対して複数の推論チェーンを生成するんや(ただし最終的な答えまでは出さんでもええねん)。ほんで、その全部のチェーンを一つのプロンプトテンプレートにまとめて突っ込んで、そこから最終的な答えを出すっちゅうやり方やねん。
**DiVeRSe**
(Li et al., 2023i)これはまず一つの問題に対して複数のプロンプトを作って、それぞれに対してSelf-Consistencyをかけて、いっぱい推論パスを生成するんや。ほんで各推論パスのステップごとにスコアをつけて、最終的な回答を選ぶねん。
**Self-adaptive Prompting(自己適応プロンプティング)**
(COSP)(Wan et al., 2023a)これはConsistencyベースのやつで、まずいくつかの例題に対してZero-Shot CoT+Self-Consistencyを走らせて、出てきた結果の中から一致度が高いやつを選んで、それをFew-Shot CoTのプロンプトの例文として使うねん。ほんで最終的なプロンプトに対してまたSelf-Consistencyをかけるっちゅう流れや。
**Universal Self-Adaptive Prompting(USP:汎用自己適応プロンプティング)**
(Wan et al., 2023b)COSPの成功を受けて、「これ全部のタスクに使えるようにしたろ」ってことで作られたのがUSPやねん。ラベルなしのデータを使って例文を生成して、もっと凝ったスコアリング関数で例文を選ぶんや。あと、USPはSelf-Consistencyは使わへんねん。
**Prompt Paraphrasing(プロンプトの言い換え)**
(Jiang et al., 2020)元のプロンプトの言い回しをちょっと変えるんやけど、全体的な意味はそのまま保つっていう手法やねん。要はデータ拡張テクニックみたいなもんで、アンサンブル用のプロンプトを作るのに使えるわけや。
### 2.2.5 Self-Criticism(自己批判)
生成AIのシステムを作るとき、LLMに自分の出力をダメ出しさせるっていうのがめっちゃ使えるねん(Huang et al., 2022)。単純に「この出力合ってる?」って判定させるだけのこともあれば、フィードバックを出させて、それを使って答えを改善するパターンもあるんや。自己批判を生成して活用するアプローチはいろいろ開発されとるで。
**Self-Calibration(自己較正)**
(Kadavath et al., 2022)まずLLMに質問に答えさせるやん。ほんで、その質問とLLMの答えと、「この答え合ってると思う?」っていう追加の指示を全部入れた新しいプロンプトを作るねん。これはLLMを使うとき、「この答え信用してええのか、それとも修正した方がええのか」を判断するための確信度を測るのにめっちゃ便利やねん。
**Self-Refine(自己改良)**
(Madaan et al., 2023)これは反復型のフレームワークやねん。まずLLMから最初の答えを出させるやろ、ほんで同じLLMに「この答えどう思う?」ってフィードバックさせて、さらにそのフィードバックを元に答えを改善させるんや。この繰り返しを、止める条件(例えば最大ステップ数に達したとか)が満たされるまで続けるねん。推論、コーディング、生成タスクとか幅広いタスクで性能上がってるで。
**Reversing Chain-of-Thought(RCoT:逆向き思考連鎖)**
(Xue et al., 2023)まずLLMに、生成した答えを元にして問題を逆に復元させるねん。ほんで、元の問題と復元された問題を細かく比較して、矛盾がないかチェックするんや。見つかった矛盾をフィードバックとしてLLMに渡して、答えを修正させるっちゅうわけやな。
**Self-Verification(自己検証)**
(Weng et al., 2022)まずChain-of-Thought(CoT)で複数の候補解を生成するやん。ほんで各解のスコアをつけるんやけど、そのやり方がおもろいねん。元の問題の一部をマスクして隠して、「残りの問題文と生成された解を見て、隠した部分を当ててみ」ってLLMに予測させるんや。ちゃんと予測できたら、その解は元の問題をよう理解してるってことやからな。8つの推論データセットで性能向上が確認されとるで。
---
## Page 16
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p016.png)
### 和訳
(COVE)
**検証チェーン**(Dhuliawalaら、2023年)ってのはな、まずLLM(大規模言語モデルっていうめっちゃ賢いAIのことやで)に質問の答えを出させるねん。ほんでそっからが面白いとこで、その答えがほんまに合ってるか確認するための関連質問リストを作らせるわけや。で、その質問ひとつひとつをまたLLMに答えさせて、最後に全部の情報をまとめてLLMに渡して、最終的な修正版の答えを出させるんやな。要するに「自分で自分の答えをチェックさせる」っちゅう仕組みやねん。この方法、いろんな質問応答とかテキスト生成のタスクでちゃんと改善が見られてるで。
**累積推論**(Zhangら、2023b)はまた別のアプローチでな。まず質問に答えるための候補ステップをいくつか生成するねん。ほんでLLMにそれを評価させて、「これはええわ、採用!」「これはあかん、却下!」って判断させるわけや。最後に「もう最終回答にたどり着いたか?」をチェックして、たどり着いてたら終了、まだやったらまた繰り返すんやな。論理的な推論とか数学の問題でめっちゃ成果出てるで。
### 2.3 プロンプト技術の使われ方
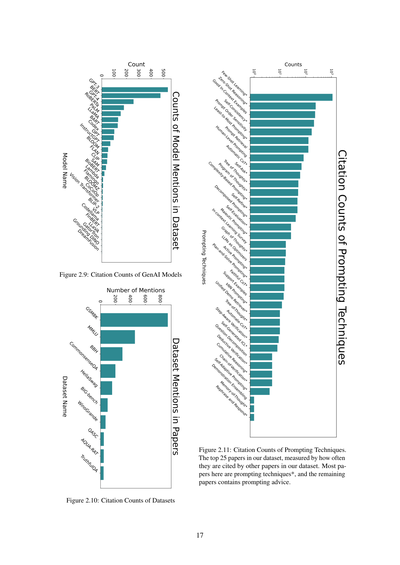
ここまで見てきたように、テキストベースのプロンプト技術ってほんまにいっぱいあるねん。けどな、実際に研究とか産業界でよう使われてるのはほんの一部だけなんよ。ワイらは技術の使用頻度を、データセット内の他の論文からの引用数で測ったんや。なんでかっていうと、プロンプトについての論文は、引用してる技術を実際に使ったり評価したりしてる可能性が高いやろって前提やねん。上位25本の被引用論文をグラフにしたら(図2.11)、ほとんどが新しいプロンプト技術を提案してる論文やったわ。Few-Shot(少数例提示)とChain-of-Thought(思考の連鎖)プロンプティングの引用が多いのはまあ当然やけど、他の技術がどんだけ使われてるか理解するための基準にはなるわな。
#### 2.3.1 ベンチマーク
プロンプト研究ではな、研究者が新しい技術を提案するとき、普通は複数のモデルとデータセットでベンチマーク(性能テストみたいなもんや)するねん。これがめっちゃ大事でな、その技術がほんまに役立つかとか、違うモデルでも通用するかを証明せなあかんからや。
新しい技術を提案する研究者がベンチマークしやすいように、ワイらはどのモデル(図2.9)とどのベンチマークデータセット(図2.10)が使われてるかを定量的に調べたで。ここでも使用頻度はデータセット内の論文での引用回数で測ってるんや。
どのデータセットとモデルが使われてるか調べるために、GPT-4-1106-previewに論文の本文からデータセット名やモデル名を抽出させたんやな。その後、モデルでもデータセットでもないもんを手作業でフィルタリングして除外したで。引用数はSemantic Scholarで最終リストの項目を検索して取得したんや。
### 2.4 プロンプトエンジニアリング
プロンプト技術の調査に加えて、プロンプトを自動的に最適化する「プロンプトエンジニアリング」技術もレビューしたで。勾配更新(モデルのパラメータをちょっとずつ調整する方法やな)を使う技術もいくつか紹介するで。なんでかっていうと、プロンプトエンジニアリング技術の数はプロンプト技術よりずっと少ないからや。
**メタプロンプティング**ってのは、LLMにプロンプトやプロンプトテンプレートを「生成」したり「改善」させたりするプロセスのことや(Reynoldsら、2021; Zhouら、2022b; Yeら、2023)。シンプルなテンプレート(図2.12)だけでスコアリング仕組みなしでやることが多いんやけど、複数回のイテレーションとスコアリング仕組みを使ったもっと複雑な使い方をしてる研究もあるで(Yangら、2023a; Fernandoら、2023)。
> 以下のプロンプトを改善してください: {PROMPT}
図2.12: シンプルなメタプロンプティングのテンプレート。
**AutoPrompt**(Shinら、2020b)は、凍結した(学習済みで重みを固定した)LLMと、「トリガートークン」っていう特別な値を含むプロンプトテンプレートを使うねん。このトリガートークンの値を学習時にバックプロパゲーション(逆伝播、要するにモデルの出力から逆算して値を更新する方法や)で更新するんやな。これはソフトプロンプティング(プロンプトを数値ベクトルとして直接最適化するやつ)の一種やで。
**自動プロンプトエンジニア(APE)**(Zhouら、2022b)は、例題のセットを使ってZero-Shot(例なしの)指示プロンプトを生成するねん。複数の候補プロンプトを生成して、スコアをつけて、一番ええやつのバリエーション(例えばプロンプトの言い換えとか)を作るんや。で、求める基準に達するまでこのプロセスを繰り返すわけやな。
**GrIPS(勾配なし指示プロンプト探索)**(Prasadら、2023)はAPEに似てるんやけど、削除・追加・入れ替え・言い換えっていうもっと複雑な操作セットを使って、元のプロンプトのバリエーションを作るところが違うねん。
**ProTeGi(テキスト勾配によるプロンプト最適化)**(Pryzantら、2023)はめっちゃユニークなアプローチでな、プロンプトテンプレートを複数ステップのプロセスで改善していくんや。まず最初に──
---
## Page 17
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p017.png)
### 和訳
図2.9: 生成AIモデルの引用回数
図2.11: プロンプト技術の引用回数
ワイらのデータセットん中で、他の論文からどんだけ引用されとるかで測った上位25本の論文やねん。ここに載っとるほとんどはプロンプト技術*の論文で、残りはプロンプトのコツとかアドバイス系の論文やな。
図2.10: データセットの引用回数
17ページ
【左上のグラフ】データセット中のモデル名の登場回数
GPT-3、BERT、GPT-4、RoBERTa、PaLM、LLaMA、BART、Codex、OPT、InstructGPT、BLOOM、FLAN、CLIP、SAM、BioBERT、Lambda、Flamingo、BLOOMZ、CoCoOp、Vision Transformer、BLIP-2、VLP、Codellama、FinBERT、LLaVA、GatorTron、Grounding DINO、DreamFusion
→ 横軸は「登場回数」で0〜500回まであるねん。要はどのモデルがめっちゃ論文で言及されとるかっていうランキングやな。GPT-3がぶっちぎりで一番多いわ。
【右上のグラフ】論文中のデータセット言及回数
GSM8K、MMLU、BBH、CommonsenseQA、HellaSwag、BIG-bench、WinoGrande、QASCA、AQUA-RAT、TruthfulQA
→ 横軸は「言及回数」で0〜800回くらいまであるで。GSM8KとかMMLUがめっちゃ使われとるっちゅうことやな。ベンチマークとしてみんな大好きなやつらやねん。
【下のグラフ】プロンプト技術の引用回数
Few-Shot Learning*、Zero-Shot Reasoning*、ええ感じのIn-Contextの例示、Self-Consistency*、プロンプトの順番の影響、Least-to-Most Prompting*、プロンプト検索、人間レベルのプロンプティング、Automatic CoT*、Self-Ask*、Tree of Thoughts*、Program of Thoughts*、Complexity-Based Prompting*、Self-Refine*、Decomposed Prompting*、Self-Evaluation*、Maieutic Prompting*、In-context Learning サーベイ、Graph of Thoughts*、LLMを最適化に使う話、Active Prompting*、Plan-and-Solve Prompting*、Faithful CoT*、サポート例示、kNN Prompting*、Unified Demo Retriever*、Tree-of-Thought*、Automate-CoT*、Step-Aware Verification*、Self-Generated ICL*、質問分解、Deductive Verification*、Cumulative Reasoning*、Chain-of-Verification*、Self-Adaptive Prompting*、Demonstration Ensembling、Memory-of-Thought*、Rephrase and Respond*
→ 横軸は対数スケール(10の0乗〜10の3乗)で引用回数を表しとるねん。Few-Shot Learningがほんまにダントツで引用されまくっとって、次にZero-Shot Reasoningやな。要するに「ちょっと例を見せたら賢くなる」っていう技術と「例なしでも考えられる」っていう技術が、プロンプト界隈ではめっちゃ重要視されとるっちゅうことやで。
---
## Page 18
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p018.png)
### 和訳
ほな、いくで!
---
まず、入力データをバーッとテンプレートに通すやろ?ほんなら出てきた出力と、正解データと、プロンプトをまとめて別のプロンプトに突っ込むねん。そこで元のプロンプトにダメ出しさせるわけや。ほんで、そのダメ出しから新しいプロンプトをいくつか作って、バンディットアルゴリズム(Gabillon et al., 2011)っていう「どれが一番ええか効率よく選ぶ仕組み」を使って一つに絞るねん。このProTeGiっていう手法は、APEとかGRIPSみたいな従来のやり方よりも成績ええことが示されてるで。
**RLPrompt**(Deng et al., 2022)は、パラメータ固定した大規模言語モデルに、学習可能なモジュールをくっつけて使うねん。このLLMでプロンプトのテンプレートを生成して、データセットで点数つけて、Soft Q-Learning(Guo et al., 2022)っていう強化学習の手法で学習可能なモジュールを更新していくんや。おもろいことに、この方法やと文法的にめっちゃ意味不明なテキストが「最適なプロンプト」として選ばれることが多いねん。なんでやねんって感じやけど、それでうまくいくらしいわ。
**対話ベースの方策勾配離散プロンプト最適化(DP2O)**(Li et al., 2023b)は、たぶんプロンプトエンジニアリングの手法の中で一番ややこしいやつやな。強化学習と、独自のプロンプト採点関数と、LLMとの対話を全部組み合わせてプロンプトを作り上げていくねん。
## 2.5 回答エンジニアリング
回答エンジニアリングっていうのは、LLMの出力から正確な答えを引っ張り出すアルゴリズムを作ったり選んだりする試行錯誤のプロセスのことやねん。なんでこれが必要かっていうと、例えば二値分類タスク——つまり「ヘイトスピーチ」か「ヘイトスピーチちゃう」かを判定する場合を考えてみてや。プロンプトのテンプレートはこんな感じになるやろ:
> これは「ヘイトスピーチ」か「ヘイトスピーチではない」か:{TEXT}
ヘイトスピーチのサンプルをこのテンプレートに通したら、「これはヘイトスピーチです」とか「ヘイトスピーチ。」とか、はたまた「ヘイトスピーチです、なぜなら特定の人種に対してネガティブな表現を使っているからです」みたいに、出力がバラバラになるねん。この回答フォーマットのブレを一貫してパースするのはめっちゃ難しいんよ。プロンプトを工夫したら多少はマシになるけど、限界があるわけや。
回答エンジニアリングには3つの設計上の判断があるねん。**回答空間**、**回答の形状**、**回答抽出器**の3つや(図2.13参照)。Liu et al.(2023b)は最初の2つを回答エンジニアリングの必須要素として定義してて、ワイらが3つ目を追加したんや。回答エンジニアリングはプロンプトエンジニアリングとは別モンやと考えてるけど、めっちゃ密接に関係してて、だいたいセットで取り組むことが多いねん。
**図2.13**:ラベリングタスクにおけるLLM出力に注釈をつけた図。回答エンジニアリングの3つの設計判断——回答の形状、空間、抽出器——を示してるで。これは分類タスクの出力やから、回答の形状は1トークンに制限できるし、回答空間も2つのトークン(「positive」か「negative」)に絞れるんやけど、この図では制限なしの状態で描いてあるねん。
### 2.5.1 回答の形状
回答の形状っていうのは、答えの物理的なフォーマットのことやねん。例えば、1つのトークンやったり、トークンの連続(スパン)やったり、画像や動画の場合もあるで⁷。二値分類みたいなタスクやと、LLMの出力形状を1トークンに制限すると便利なことがあるねん。
### 2.5.2 回答空間
回答空間っていうのは、その構造が取りうる値の範囲のことやねん。単純に全トークンの空間かもしれへんし、二値ラベリングタスクやったら2つのトークンだけっていうこともあるわけや。
### 2.5.3 回答抽出器
回答空間を完全にコントロールでけへん場合(例えば一般ユーザー向けのLLMとか)、あるいは期待する答えがモデル出力のどっかに埋まってる場合は、最終的な答えを引っ張り出すルールを決めなあかんねん。このルールはだいたいシンプルな関数(正規表現とか)やけど、別のLLMを使って答えを抽出することもあるで。
**バーバライザー** ラベリングタスクでよく使われるんやけど、バーバライザーっていうのはトークンやスパンなどの出力をラベルに対応付ける(逆もいける、単射の)仕組みのことやねん(Schick and Schütze, 2021)。例えば、ツイートがポジティブかネガティブかをモデルに予測させたいとき、「+」か「-」を出力させて、バーバライザーがそのトークンを適切なラベルに変換するっていう使い方や。このバーバライザーの選び方も回答エンジニアリングの一部やで。
⁷ワイらはLiu et al.(2023b)とは粒度(トークン vs スパンとか)について異なる定義を使ってるねん。出力が別のモダリティ(画像とか)になる可能性もあるからや。
---
## Page 19
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p019.png)
### 和訳
**正規表現(Regex)** さっきも言うたけど、正規表現ってのは答えを引っ張り出すんによう使われるねん。普通はラベルの「最初に出てきたやつ」を探すんやけど、出力のフォーマットとか、思考の連鎖(CoT)を生成してるかどうかによっては、「最後に出てきたやつ」を探した方がええ場合もあるんやな。
**別のLLMを使う方法** 出力がめっちゃ複雑すぎて、正規表現じゃ安定して処理でけへん時があるねん。そういう時は、別のLLM(大規模言語モデル)にその出力を評価させて、答えを抜き出してもらうっていう手が使えるんよ。この別のLLMには「回答トリガー」(Kojima et al., 2022)ってやつをよう使うねん。例えば「答え(YesかNoか)は」みたいなフレーズを投げて、そこから答えを引き出すわけや。
---
## Page 20
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p020.png)
### 和訳
3 英語テキストプロンプティングのその先へ
今んとこ、生成AIとやりとりするんは英語のテキストでプロンプト打つんが主流やねん。せやけど、英語以外の言語とか、テキスト以外の方法(画像とか音声とか)でプロンプト出すときは、同じくらいの性能出すんにちょっと特別なテクニックがいるんよな。ここでは、多言語プロンプティングとマルチモーダルプロンプティングっていう2つの分野について話していくで。
3.1 多言語プロンプティング
最先端の生成AIって、だいたい英語のデータセットメインで学習されとるから、英語以外の言語、特にデータが少ない言語(低資源言語って言うんやけど)では、出力の品質にけっこうな差が出てまうねん(Bang et al., 2023; Jiao et al., 2023; Hendy et al., 2023; Shi et al., 2022)。そういうわけで、英語以外の環境でもモデルの性能を上げようっていう、いろんな多言語プロンプティング技術が出てきてるんよ(図3.1)。
**まず翻訳してからプロンプト(Translate First Prompting)**(Shi et al., 2022)は、たぶん一番シンプルなやり方で、英語以外の入力をまず英語に翻訳してまうっていう戦略やねん。入力を英語にしてまえば、モデルが得意な英語の力をフル活用して内容をちゃんと理解できるっちゅうわけや。翻訳に使うツールはいろいろあって、Shi et al.(2022)は外部の機械翻訳システム使っとるし、Etxaniz et al.(2023)は多言語の言語モデルにプロンプト出して翻訳させとるし、Awasthi et al.(2023)はLLM(大規模言語モデル)に翻訳させとるんよ。
3.1.1 思考の連鎖(Chain-of-Thought、CoT)
CoTプロンプティング(Wei et al., 2023a)っていう、AIに考える過程を一歩ずつ説明させるテクニックがあるんやけど、これを多言語に拡張したやり方がいくつかあるねん。
**XLT(言語横断思考)プロンプティング**(Huang et al., 2023a)は、6つの個別の指示からなるプロンプトのテンプレートを使うんよ。役割の割り当て、言語をまたいだ思考、あとCoTなんかが含まれとるねん。
**CLSP(言語横断自己一貫プロンプティング)**(Qin et al., 2023a)は、同じ質問に答えるのに、いろんな言語で推論の道筋を作って、それを合わせて判断するっていうアンサンブル技術を導入しとるんよ。めっちゃ賢いやろ?
3.1.2 文脈内学習(In-Context Learning)
**X-InSTAプロンプティング**(Tanwar et al., 2023)は、分類タスクで入力文に合った文脈内の例をどう選ぶかについて、3つのアプローチを探っとるんよ。入力と意味的に似とる例を使う方法(意味的アラインメント)、入力と同じラベルの例を使う方法(タスクベースアラインメント)、あとその両方を組み合わせる方法やねん。
**In-CLT(言語横断転移)プロンプティング**(Kim et al., 2023)は、文脈内の例を作るときに、元の言語とターゲット言語の両方を活用するんよ。従来は元の言語だけで例を作っとったんやけど、それとは違うアプローチやねん。この戦略で多言語LLMの言語をまたぐ認知能力を刺激して、言語横断タスクの性能をグッと上げるっちゅうわけや。
3.1.2.1 文脈内の例の選び方
文脈内の例をどう選ぶかが、LLMの多言語性能にめっちゃ影響するんよ(Garcia et al., 2023; Agrawal et al., 2023)。元のテキストと意味的に似とる例を見つけるんがほんまに大事やねん(Winata et al., 2023; Moslem et al., 2023; Sia and Duh, 2023)。せやけどおもろいことに、意味的に全然違う(変わった)例を使っても性能が上がるケースもあるんよ(Kim and Komachi, 2023)。この対照的な現象は英語だけの設定でも同じやねん。あと、あいまいな文を扱うときは、多義語とか珍しい語義を持つ例を選ぶと性能が上がるかもしれんで(Iyer et al., 2023)。
**PARC(言語横断検索で強化されたプロンプト)**(Nie et al., 2023)は、データが豊富な言語から関連する例を検索してくるフレームワークを提案しとるんよ。これはデータが少ない対象言語への言語横断転移の性能を上げるために特別に設計されとるんやで。Li et al.(2023g)はこの研究をバングラ語に拡張しとるんよ。
3.1.3 プロンプトテンプレートの言語選択
多言語プロンプティングでは、プロンプトのテンプレートをどの言語で書くかが、モデルの性能にめっちゃ影響するんよな。
文脈内学習もいろんな形で多言語設定に拡張されとるんよ。
**英語でプロンプトテンプレートを作る方法** プロンプトのテンプレートを英語で作るんが、だいたいの場合はより効果的
---
## Page 21
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p021.png)
### 和訳
**Chain-of-Thought(考えの連鎖) 3.1.1**
**文脈内学習 3.1.2**
**XLT 3.1.1**
**CLSP 3.1.1**
**X-InSTA 3.1.2**
**In-CLT 3.1.2**
**PARC 3.1.2.1**
**文脈内の例の選び方 3.1.2.1**
**意味的に近いやつ 3.1.2.1**
**多言語テクニック**
**人間が途中で関わるやつ 3.1.4.1**
**翻訳 3.1.4**
**意味的に遠いやつ 3.1.2.1**
**対話型チェーン 3.1.4.1**
**繰り返し型 3.1.4.1**
**Chain-of-Dictionary(辞書の連鎖) 3.1.4**
**DecoMT 3.1.4**
**DiPMT 3.1.4**
**MAPS 3.1.4**
**外部の機械翻訳システム 3.1**
**先に翻訳するプロンプティング 3.1**
**普通のLLM 3.1**
**プロンプトの言語 3.1.3**
**多言語LLM 3.1**
**英語 3.1.3**
**タスクの言語 3.1.3**
**図3.1: 多言語プロンプティングのテクニック全部まとめ。**
---
多言語タスクやるときな、プロンプトをそのタスクの言語で書くより英語で書いた方がええ結果出るねん。なんでかっていうと、LLMが事前学習するときに使うデータが圧倒的に英語多いからやねん(Lin et al., 2022; Ahuja et al., 2023)。Linらが言うには、事前学習のデータや語彙とめっちゃ被ってるからやろうって話やな。同じようにAhujaらも指摘してんねんけど、タスク言語のテンプレート作るときに翻訳ミスが入ると、それが文法とか意味のおかしさとしてそのまま伝染してまって、タスクの成績がガタ落ちするねん。さらにFuら(2022)は、同じ言語だけで書くプロンプト(タスク言語プロンプト)と、言語ミックスのプロンプト(クロスリンガルプロンプト)を比べてんねんけど、クロスリンガルの方が優秀やったんよ。これはたぶん、プロンプトに英語が多く入ることで、モデルの中に蓄えられた知識を引き出しやすくなるからやと思われるで。
**タスク言語のプロンプトテンプレート**
一方で、BUFFET(Asai et al., 2023)やLongBench(Bai et al., 2023a)みたいな多言語ベンチマークでは、その言語固有のユースケースにはタスク言語のプロンプトを使ってるねん。Muennighoffら(2023)は、ネイティブ言語のプロンプトを作るときのいろんな翻訳方法をちゃんと研究してて、人間が翻訳したプロンプトの方が機械翻訳のやつよりも優れてるって証明してるで。ネイティブか非ネイティブかどっちのテンプレートがええかは、タスクやモデルによって変わってくるねん(Li et al., 2023h)。せやから、「絶対これが正解!」っていう一択はないっちゅうことやな(Nambi et al., 2023)。
---
**3.1.4 機械翻訳のためのプロンプティング**
生成AIを使って正確でニュアンスのある翻訳をやろうっていう研究、めっちゃ盛り上がってるねん。これは翻訳っていう特定の使い方やけど、ここで出てくるテクニックの多くは、多言語プロンプティング全般にもめっちゃ大事なんよ。
**Multi-Aspect Prompting and Selection(MAPS:多角的プロンプティングと選択)**
(He et al., 2023b)は、人間が翻訳するときのプロセスを真似してるねん。人間って翻訳するとき、いきなりやらんとちゃんと準備するやろ?このフレームワークはまず、元の文から知識をマイニングするところから始まんねん(キーワードとかトピック抽出して、翻訳の例文も作る)。で、その知識を統合して複数パターンの翻訳候補を生成して、その中から一番ええやつを選ぶっちゅう仕組みや。
**Chain-of-Dictionary(CoD:辞書の連鎖)**
(Lu et al., 2023b)は、まず元のフレーズから単語を抜き出して、それぞれの意味を複数言語で辞書から自動的に引いてリスト化するねん(例えば English: 'apple', Spanish: 'manzana' みたいな感じ)。ほんで、その辞書フレーズをプロンプトの先頭にくっつけて、「これ使って翻訳してな」って生成AIに渡すわけや。
**Dictionary-based Prompting for Machine Translation(DiPMT:辞書ベースの機械翻訳プロンプティング)**
(Ghazvininejad et al., 2023)はCoDとよう似てるねんけど、ちょっと違うのは、元の言語と翻訳先の言語だけの定義しか渡さへんところと、フォーマットがちょい違うところやな。
---
## Page 22
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p022.png)
### 和訳
MM(マルチモーダル)の思考の連鎖(CoT) 3.2.1.2
義務別CoT 3.2.1.2
画像の連鎖 3.2.1.2
画像 3.2.1
マルチモーダルICL 3.2.1.1
ネガティブプロンプト 3.2.1
マルチモーダル(MM)テクニック
セグメンテーション・プロンプティング 3.2.4
プロンプト修飾子 3.2.1
動画 3.2.3
動画生成 3.2.3.1
3Dプロンプティング 3.2.5
図3.2:マルチモーダルのプロンプティング技術の全体像やで。
MMグラフ・オブ・ソート 3.2.1.2
画像→テキスト変換プロンプト 3.2.1.1
ペア画像プロンプト 3.2.1.1
**機械翻訳のための分解プロンプティング(DecoMT)**
(Puduppullyら、2023)は、翻訳したい元の文章をいくつかの塊にバラバラに分けて、それぞれを少数事例プロンプティングで独立に翻訳するねん。ほんでそのあと、それぞれの翻訳結果と塊同士のつながりの情報を使って、最終的な翻訳をまとめ上げるっていう仕組みやねん。
**3.1.4.1 人間参加型(ヒューマン・イン・ザ・ループ)**
**対話型チェーン・プロンプティング(ICP)**
(Pilaultら、2023)は、翻訳するときに出てくる「これどういう意味?」っていう曖昧な部分をうまく処理する方法やねん。まずAIに「この翻訳したいフレーズで、ちょっとわかりにくいとこない?」って聞いて、サブ質問を作らせるわけ。ほんで人間がその質問に答えて、その情報も込みで最終的な翻訳を出すっていう流れやな。
**反復プロンプティング**(Yangら、2023d)も翻訳に人間が関わるやつやねん。まずLLM(大規模言語モデル)に下書きの翻訳を作らせるやろ。ほんでその下書きを、自動検索システムからのフィードバックとか、人間が直接「ここちゃうで」って教えてくれた情報を使って、さらにブラッシュアップしていくねん。
**3.2 マルチモーダル**
生成AIモデルがテキストだけの世界からどんどん進化していくにつれて、新しいプロンプティング技術がぞくぞく出てきてるねん。このマルチモーダルのプロンプティング技術っていうのは、単にテキストベースの技術を「画像でもやってみました」ってだけやなくて、いろんなモダリティ(データの種類)があるからこそ生まれた、めっちゃ斬新なアイデアもあるわけよ。ここからは、テキストベースの分類体系を拡張して、テキスト技術のマルチモーダル版と、完全に新しいマルチモーダル独自の技術を両方カバーしていくで(図3.2)。
**3.2.1 画像プロンプティング**
画像のモダリティっていうのは、写真とかイラストとか、なんならテキストのスクリーンショットとか(Gongら、2023)、そういうデータのことやねん。画像プロンプティングっていうのは、プロンプトに画像が含まれてるパターンと、画像を生成するために使うプロンプトの両方を指すで。よくあるタスクとしては、画像生成(Dingら、2021; Hinzら、2022; Taoら、2022; Liら、2019a,b; Rombachら、2022)、キャプション生成(Liら、2020)、画像分類(Khalilら、2023)、画像編集(Crowsonら、2022; KwonとYe、2022; Bar-Talら、2022; Hertzら、2022)なんかがあるわけや。ほな、こういうアプリケーションで使われるいろんな画像プロンプティング技術を見ていこか。
**プロンプト修飾子**っていうのは、めっちゃシンプルな話で、プロンプトにちょっと言葉を付け足すだけで出来上がる画像が変わるっていうやつやねん(Oppenlaender、2023)。たとえば表現媒体(「キャンバスに描いた風に」とか)とかライティング(「明るく照らされたシーン」とか)みたいな要素がよう使われるで。
**ネガティブプロンプト**は、プロンプトの中の特定の言葉に数値的な重み付けをして、モデルがその言葉をどれくらい重視するか/無視するかをコントロールできる仕組みやねん。たとえば「変な手」とか「指が多すぎ」っていう言葉にマイナスの重みをかけると、解剖学的に正しい手が生成されやすくなるっちゅうわけや(Schulhoff、2022)。
**3.2.1.1 マルチモーダル文脈内学習(In-Context Learning)**
テキストベースの文脈内学習(ICL)がめっちゃうまくいったもんやから、「ほなマルチモーダルでもいけるんちゃう?」ってことで研究が進んでるねん(Wangら、2023k; Dongら、2023)。
**ペア画像プロンプティング**は、モデルに2枚の画像を見せるねん。1枚は何かの変換をする前、もう1枚は変換した後。ほんで新しい画像を渡して「さっき見た変換、これにもやってや」ってお願いするわけ。テキストの指示付きでやるパターン(Wangら、2023k)と、指示なしでやるパターン(Liuら、2023e)の両方あるで。
**画像→テキスト変換プロンプティング**(HakimovとSchlangen、2023)は、画像をテキストで説明する文章に変換するやつやねん。こうすると、その画像(複数枚でもOK)をテキストベースのプロンプトに簡単に組み込めるようになるから、めっちゃ便利やねん。
---
## Page 23
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p023.png)
### 和訳
それと動画からテキストを作る技術(Yousafら、2023; Miら、2023; Koら、2023a)もあるねん。
**3.2.3.1 動画生成のテクニック**
モデルに動画を作らせるときな、いろんな種類のプロンプトを入力に使えるねん。ほんで、動画生成をもっとええ感じにするために、プロンプト関連のテクニックがよう使われとるわ。画像系のテクニック、たとえばプロンプト修飾子みたいなんが、動画生成にも使えたりするねん(Runway、2023)。
**3.2.4 セグメンテーション・プロンプティング**
プロンプティングはセグメンテーション、つまり画像の中の「ここは人」「ここは道路」みたいに領域を分けるやつ(セマンティック・セグメンテーションとか)にも使えるねん(Tangら、2023; Liuら、2023c)。
**3.2.5 3Dプロンプティング**
3Dの世界でもプロンプティングは使えるで!たとえば3Dオブジェクトの合成(Fengら、2023; Liら、2023d,c; Linら、2023; Chenら、2023f; Lorraineら、2023; Pooleら、2022; Jainら、2022)、3Dの表面テクスチャリング、つまり3Dモデルの表面にええ感じの質感をつけるやつ(Liuら、2023g; Yangら、2023b; Leら、2023; Pajouheshgarら、2023)、さらには4Dシーン生成、これは3Dシーンに動きをつけてアニメーションさせるやつやな(Singerら、2023; Zhaoら、2023c)。入力のプロンプトとしてはテキスト、画像、ユーザーのアノテーション(バウンディングボックスとか点とか線とか)、あと3Dオブジェクトそのものが使えるねん。
**3.2.1.2 マルチモーダル・チェーン・オブ・ソート**
CoT、つまり「段階的に考えよう」ってやつが、画像の分野にもいろんな形で拡張されてるねん(Zhangら、2023d; Huangら、2023c; Zhengら、2023b; Yaoら、2023c)。わかりやすい例でいうと、数学の問題の画像と一緒に「これをステップバイステップで解いて」っていうテキスト指示をプロンプトに入れるみたいなやつやな。
**DDCoT(Duty Distinct Chain-of-Thought)**(Zhengら、2023b)は、Least-to-Mostプロンプティング(Zhouら、2022a)をマルチモーダル、つまり複数の情報形式を扱える設定に拡張したもんやねん。まずサブクエスチョン、つまり小っちゃい質問に分解して、それぞれ解いて、答えを合体させて最終的な回答を作るっちゅうやり方やで。
**マルチモーダル・グラフ・オブ・ソート**(Yaoら、2023c)は、Graph-of-Thought(Zhangら、2023d)をマルチモーダルに拡張したもんやねん。GoT-Inputは、まず根拠を考えてから答えを出すっていう2ステップ方式を使うねん。推論のときは、入力プロンプトから「思考グラフ」っていうのを作って、それと元のプロンプトを合わせて根拠を生成して質問に答えるんや。画像が質問と一緒に入力されたときは、画像キャプショニングモデルを使って画像のテキスト説明を作って、思考グラフを組み立てる前にプロンプトにくっつけることで、視覚的な文脈を補完するっちゅう仕組みやねん。
**Chain-of-Images(CoI)**(Mengら、2023)は、チェーン・オブ・ソートのマルチモーダル拡張版で、思考プロセスの中で画像を生成するっちゅうめっちゃおもろいやつやねん。「画像ごとに考えよう(Let's think image by image)」っていうプロンプトを使ってSVGを生成して、モデルがそれを見ながら視覚的に推論できるようにするんやで。
**3.2.2 音声プロンプティング**
プロンプティングは音声の分野にも拡張されとるで。音声のICL(文脈内学習)の実験結果はまちまちで、オープンソースの音声モデルの中にはICLがうまくいかんかったやつもあるねん(Hsuら、2023)。でもな、他の結果では音声モデルでもICLの能力があるって示されてるんよ(Wangら、2023g; Pengら、2023; Changら、2023)。音声プロンプティングはまだまだ初期段階やけど、今後いろんなプロンプティング技法が提案されるんちゃうかなって期待しとるで。
**3.2.3 動画プロンプティング**
プロンプティングは動画の分野にも拡張されとって、テキストから動画を生成する技術(Brooksら、2024; Lvら、2023; Liangら、2023; Girdharら、2023)、動画編集(Zuoら、2023; Wuら、2023a; Chengら、2023)、
---
## Page 24
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p024.png)
### 和訳
4 プロンプティングの拡張
ここまで話してきたテクニックって、ステップも繰り返しもめっちゃ多くて、かなり複雑になることがあんねん。せやけどな、外部ツールへのアクセス(エージェント)とか、LLMの出力がちゃんと正しいか判定する複雑な評価アルゴリズムを足すことで、プロンプティングってもっと先までいけるんよ。
4.1 エージェント
LLMの性能がえげつないスピードで上がってきたんで(Zhang et al., 2023c)、企業(Adept, 2023)も研究者(Karpas et al., 2022)も、LLMに外部システムを使わせる方法を色々探ってきたんよ。なんでかっていうと、LLMって計算とか推論とか事実の正確さとか、苦手なところがあるからやねん。で、これがプロンプティング技術のめっちゃ大きな革新につながったわけ。こういうシステムって、プロンプトやプロンプトチェーンで動いてることが多くて、エージェントみたいな振る舞いができるようにゴリゴリにエンジニアリングされてんねん(図4.1)。
**エージェントの定義**
生成AIの文脈で言うと、エージェントっていうのは、生成AI自身の外にあるシステムとやり取りするアクションを通じて、ユーザーの目的を達成してくれる生成AIシステムのことやねん。⁸ この生成AIは普通LLMのことやな。簡単な例で言うと、LLMに次の算数の問題を解かせるとするやん:
> アニーがブドウを4,939個持ってて、そのうちちょうど39%をエイミーにあげたら、残りは何個?
ちゃんとプロンプトを設定したら、LLMは「CALC(4,939*.39)」っていう文字列を出力できるんよ。これを取り出して電卓に突っ込んだら、最終的な答えが出るってわけ。
これがエージェントの一例やねん。LLMがテキストを出力して、そっから下流のツールを使うっていう流れやな。エージェント型のLLMは、上の例みたいに外部システム1個だけ使う場合もあるし、どの外部システムを使うか選ぶ「ルーティング」っていう問題を解かなあかん場合もあるんよ。こういうシステムにはアクションだけやなくて、記憶と計画の機能もよう付いてるねん(Zhang et al., 2023c)。
エージェントの例としては、電卓みたいな外部ツールを使うためにAPIコールができるLLM(Karpas et al., 2022)、gym的な環境(Brockman et al., 2016; Towers et al., 2023)でアクションを起こす文字列を出力できるLLM(Yao et al., 2022)、もっと広く言えば、計画を書いて記録したり、コードを書いて実行したり、インターネット検索したりするLLM(Significant Gravitas, 2023; Yang et al., 2023c; Osika, 2023)とかがあるんよ。OpenAI Assistants(OpenAI, 2023)、LangChain Agents(Chase, 2022)、LlamaIndex Agents(Liu, 2022)なんかもそうやな。
4.1.1 ツール使用型エージェント
ツールを使うっていうのは、生成AIエージェントにとってほんまに重要な要素やねん。記号的なツール(電卓とかコードインタープリタとか)も、ニューラル系のツール(別のLLMとか)も、どっちもよう使われてるで。ツールのことを「エキスパート」(Karpas et al., 2022)とか「モジュール」って呼ぶこともあるんよ。
**MRKL(Modular Reasoning, Knowledge, and Language)システム**(Karpas et al., 2022)は、エージェントの中でも一番シンプルな形の一つやねん。LLMルーターが入ってて、複数のツールにアクセスできるようになってるんよ。ルーターは天気とか今日の日付とか、情報を取るために何回もツールを呼び出せるねん。ほんで、その情報を全部まとめて最終的なレスポンスを生成するんよ。Toolformer(Schick et al., 2023)、Gorilla(Patil et al., 2023)、Act-1(Adept, 2023)、その他(Shen et al., 2023; Qin et al., 2023b; Hao et al., 2023)も似たような手法を提案してて、ほとんどがファインチューニングをいくらか含んでるんやな。
**CRITIC(Self-Correcting with Tool-Interactive Critiquing)**(Gou et al., 2024a)は、まず外部ツールを一切呼ばずにプロンプトへの回答を生成するんよ。ほんで次に、同じLLMがその回答に間違いがないか批判的にチェックするねん。最後に、ツール(インターネット検索とかコードインタープリタとか)を使って、回答の一部を検証したり修正したりするっていう流れやねん。
4.1.2 コード生成型エージェント
コードを書いて実行するっていうのも、多くのエージェントにとってめっちゃ大事な能力やねん。⁹
**PAL(Program-aided Language Model)**(Gao et al., 2023b)は、問題を直接プログラムに
---
⁸ ここでは独自の目標を持って自律的に動くAI、つまり何らかの意味で自分自身の目的を持つシステムについては扱ってへんで。
⁹ この能力はツール(つまりコードインタープリタ)の一種と見なすこともできるで。
---
## Page 25
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p025.png)
### 和訳
ツール使うエージェントたち
CRITIC 4.1.1
MRKL Sys. 4.1.1
PAL 4.1.2
コードベースのエージェント 4.1.2
ToRA 4.1.2
Task Weaver 4.1.2
ReAct 4.1.3
観察ベースのエージェント 4.1.3
Reflexion 4.1.3
エージェントたち
検索で賢くなる生成(RAG) 4.1.4
Voyager 4.1.3.1
GITM 4.1.3.1
一生学び続けるエージェント 4.1.3.1
IRCoT 4.1.4
DSP 4.1.4
Verify-and-Edit 4.1.4
繰り返し検索で賢くなるやつ 4.1.4
図4.1:このセクションで扱うエージェントの技術一覧やで。
コードをPythonのインタプリタに送って、答えを出すっちゅう仕組みやねん。
**ツール統合型推論エージェント(ToRA)**(Gouら、2024b)はPALとよう似てるんやけど、PALが一発でコード書いて終わりなんに対して、ToRAはコード書いたり考えたりを交互に何回も繰り返して、問題解けるまでやり続けるねん。めっちゃ粘り強いやつやな。
**TaskWeaver**(Qiaoら、2023)もPALと似た感じで、ユーザーのリクエストをコードに変換するんやけど、さらにユーザーが自分で作ったプラグインも使えるっていうのがミソやねん。
### 4.1.3 観察ベースのエージェント
おもちゃみたいなシミュレーション環境(Brockmanら、2016; Towersら、2023)で問題解くために作られたエージェントもおるねん。こいつらは「観察」っちゅうもんをプロンプトに突っ込んでもらって動くタイプやな。
**Reasoning and Acting(ReAct)**(Yaoら(2022))は、問題もらったら「考える→行動する→結果を観察する」っていうサイクルをグルグル回すねん。で、過去に考えたこと、やったこと、見たこと全部プロンプトに入れとくから、ちゃんと記憶持ってるわけや。
**Reflexion**(Shinnら、2023)はReActをさらにパワーアップさせたやつやねん。まず行動と観察の記録を取って、「うまくいったか失敗したか」の評価をもらうねん。ほんでそっから「自分は何やって、どこがアカンかったんやろ」って振り返り(リフレクション)するわけや。この振り返りをワーキングメモリとしてプロンプトに追加して、また同じプロセスを繰り返すんやな。めっちゃ反省するタイプやで。
### 4.1.3.1 一生学び続けるエージェント
マインクラフトとLLMを組み合わせたエージェントの研究がほんまにすごい成果出しとってな、エージェントがゲームの世界を歩き回りながら新しいスキルを身につけていけるねん。ワイらはこれを単にマインクラフトに技術適用しただけとちゃうくて、現実世界で一生学び続けなアカンタスクにも使える、新しいエージェントの枠組みやと思っとるねん。
**Voyager**(Wangら、2023a)は3つのパーツでできとるねん。まず1つ目、世界のことをもっと知るために自分で「次これやろ」ってタスクを提案するねん。2つ目、そのタスクを実行するためのコードを生成する。3つ目、やったことを保存しといて、後で必要な時に引っ張り出せる長期記憶システムがあるねん。この仕組み、現実世界でもエージェントがツールやウェブサイトを探索して触りまくらなアカンタスク(例えばペネトレーションテストとかユーザビリティテストとか)に応用できるわけや。
**Ghost in the Minecraft(GITM)**(Zhuら、2023)は、まずテキトーな目標をもらって、それを再帰的にサブゴールに分解していくねん。ほんで計画立てて実行するんやけど、コード書くんやなくて「equip(sword)」みたいな構造化されたテキストを出力するスタイルやねん。GITMはマインクラフトのアイテム情報の外部知識ベースを使って分解を手助けしてもろたり、過去の経験の記憶も活用するねん。
### 4.1.4 検索拡張生成(RAG)
生成AIエージェントの文脈でいうRAGっちゅうのは、外部のソースから情報を引っ張ってきてプロンプトにぶち込むパラダイムのことやねん。これやると知識めっちゃ必要なタスクでパフォーマンスがグンと上がるんや(Lewisら、2021)。なんでかっていうと、モデルが知らんことでも外から持ってこれるからやな。で、この「検索」自体を外部ツールとして使う場合、RAGシステムはエージェントとみなされるねん。
**Verify-and-Edit**(Zhaoら、2023a)は、自己一貫性(セルフコンシステンシー)をさらに改良したやつやねん。まず思考の連鎖(Chain-of-Thought)を何個も生成して、その中からいくつか選んで編集するねん。どうやるかっていうと、関連する外部情報を検索してきて
---
## Page 26
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p026.png)
### 和訳
プロンプトのテクニック 4.2.1
評価
出力フォーマット
思考の連鎖(Chain-Of-Thought) 4.2.1
文脈内学習(In-Context Learning) 4.2.1
モデルが作るガイドライン 4.2.1
役割ベースの評価 4.2.1
二択スコア 4.2.2
リッカート尺度 4.2.2
線形スケール 4.2.2
スタイリング 4.2.2
LLM-EVAL 4.2.3
プロンプトのフレームワーク 4.2.3
G-EVAL 4.2.3
その他の手法 4.2.4
ChatEval 4.2.3
バッチプロンプティング 4.2.4
ペアワイズ評価 4.2.4
図4.2: 評価テクニックの一覧やで。
CoT(思考の連鎖)をうまいこと使って、LLMにそれを補強させるっちゅうやり方やねん。
**Demonstrate-Search-Predict**(Khattabらが2022年に出したやつ)は、まず質問をサブ質問に分解して、それぞれクエリで解いて、最後に答えを合体させるっちゅう手法やねん。問題を分解したり答えをまとめたりするのに、少数の例を見せるfew-shotプロンプティングを使うんやで。
**IRCoT(思考の連鎖でガイドする交互検索)**(Trivediらが2023年に出したやつ)は、何段階もジャンプせなあかん質問に答えるための技やねん。CoTと検索を交互にやるんよ。CoTが「次どの文書を取ってくるか」をガイドして、検索が「次どう推論するか」をCoTに教えてくれるっちゅう、めっちゃええ感じの相互関係になっとんねん。
**反復検索による文章生成**の技術もあるで。FLARE(前方予測型アクティブ検索拡張生成、Jiangら2023年)とかIRP(模倣・検索・言い換え、Balepurら2023年)とかがそうやねん。長い文章を生成するときに、何回も検索を繰り返すんよ。基本的には3ステップをぐるぐる回すやり方やねん:1)次に出力する文の「下書き」みたいな仮の文をまず作る、2)その仮の文を検索クエリにして外部の知識を引っ張ってくる、3)引っ張ってきた知識を仮の文に注入して、ちゃんとした出力文にする。この仮の文がな、長文生成タスクで普通に与えられるドキュメントのタイトルよりも、検索クエリとしてめっちゃ優秀やっちゅうことが分かっとんねん。
## 4.2 評価
LLMはほんまに情報を引き出す力とか、推論する力とか、ユーザーの意図を理解する力がすごいから、評価者としてもめっちゃ有力な候補やねん。¹⁰ 例えばやで、LLMにプロンプトで「このエッセイの質を評価してや」とか「前に別のLLMが出した出力を、こういう基準で評価してな」って頼めるわけよ。ここでは、しっかりした評価者を作るために大事な4つの要素について説明するで:**プロンプトの技法**(セクション2.2で説明したやつな)、**評価の出力フォーマット**、**評価パイプラインのフレームワーク**、そして**その他の方法論的な設計判断**(図4.2参照)。
### 4.2.1 プロンプトの技法
評価用プロンプトでどんなプロンプト技法を使うか(例えばシンプルな指示なのかCoTなのか)っちゅうのが、ちゃんとした評価者を作るのにめっちゃ重要やねん。評価用プロンプトには、普通のテキストベースのプロンプト技法がよう効くで。具体的には、役割の設定、タスクの指示、評価基準の定義、それと文脈内の例を入れるとかな。テクニックの全リストは付録A.6にあるで。
**文脈内学習(In-Context Learning)**は、評価用プロンプトでもめっちゃよう使われとるで。他の用途と同じやり方やねん(Duboisら2023年、KocmiとFedermann 2023a、Brownら2020年)。
**役割ベースの評価**は、評価の質を上げたり多様性を持たせたりするのにめっちゃ使えるテクニックやで(Wuら2023b、Chanら2024年)。なんでかっていうと、評価の指示は同じやけど役割だけ変えたプロンプトを作ることで、いろんな視点からの評価を効果的に生成できるからやねん。さらに、マルチエージェント(複数のAIが議論する)設定で役割を使って、評価対象のテキストの妥当性についてLLM同士で議論させるっちゅうこともできるんよ(Chanら2024年)。
---
¹⁰ このセクションはLLMのベンチマーク方法やなくて、LLMを評価者として使う方法について書いとるで。
---
## Page 27
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p027.png)
### 和訳
Chain-of-Thought(思考の連鎖)プロンプティングを使うと、評価の精度がさらに上がるねん(Lu et al., 2023c; Fernandes et al., 2023)。
**モデルが自分でガイドラインを作る方法**
Liu et al.(2023d,h)は、LLMに「評価のガイドライン」を自分で作らせるっていうアプローチを提案してんねん。これ何がええかっていうと、採点基準とか出力の範囲がちゃんと定義されてへんせいで、評価がブレブレになったり的外れになったりする問題を軽減できるんよ。Liu et al.(2023d)は、モデルが品質評価を出す前に「こういう手順で評価しなさいよ」っていう詳細な評価ステップをChain-of-Thoughtで生成させてんねん。Liu et al.(2023h)はAUTOCALIBRATEっていう手法を提案してて、これは人間の専門家がつけたアノテーションをもとに採点基準を導き出して、モデルが生成した基準の中から厳選したやつを評価プロンプトに組み込むっちゅうやり方やねん。
**4.2.2 出力フォーマット**
LLMの出力フォーマットは、評価の性能にめっちゃ影響するねん(Gao et al., 2023c)。
**スタイリング** LLMの回答をXMLとかJSONの形式で整えると、評価者が出す判断の精度が上がるっていう報告もあるで(Hada et al., 2024; Lin and Chen, 2023; Dubois et al., 2023)。
**リニアスケール(直線的な尺度)** めっちゃシンプルな出力フォーマットとして、たとえば1〜5みたいな直線的なスケールがあるねん。1〜10(Chan et al., 2024)、1〜5(Araújo and Aguiar, 2023)、0〜1(Liu et al., 2023f)とかいろんなレンジが使われてるで。離散的な値(Chan et al., 2024)でも連続的な値(Liu et al., 2023f)でも、その範囲内でスコアを出させることができるんよ。
> 以下の物語を、文章の出来がええ方から悪い方へ1〜5のスケールで採点してな:
> {INPUT}
**二値スコア** モデルに「はい」か「いいえ」(Chen et al., 2023c)、「正しい」か「間違い」(Zhao et al., 2023b)みたいな二択で答えさせるのも、よう使われるフォーマットやねん。
> 以下の物語は高校生レベルでちゃんと書けてる?(はい/いいえ):
> {INPUT}
**リッカートスケール** 生成AIにリッカートスケール(Bai et al., 2023b; Lin and Chen, 2023; Peskoff et al., 2023)を使わせると、スケールの意味をモデルがよりちゃんと理解できるようになるねん。要は数字だけやなくて、言葉で段階を示したるってことやな。
> 以下の物語を、次のスケールに沿って採点してな:
> ダメダメ
> まあまあ
> ええ感じ
> めっちゃええ
> 神レベル
> {INPUT}
**4.2.3 プロンプティングフレームワーク**
**LLM-EVAL**(Lin and Chen, 2023)は、一番シンプルな評価フレームワークの一つやねん。1つのプロンプトの中に、評価する変数のスキーマ(文法とか関連性とか)、各変数に対して決められた範囲でスコアを出せっていう指示、そして評価する対象の内容を全部詰め込むっていうやり方やねん。
**G-EVAL**(Liu et al., 2023d)はLLM-EVALに似てるんやけど、プロンプトの中にAutoCoT(自動で生成された思考の連鎖)のステップが入ってるのがミソやねん。このステップは評価の指示に基づいて自動生成されて、最終的なプロンプトに組み込まれるんよ。ほんで、トークンの確率に応じて回答に重み付けをするねん。
**ChatEval**(Chan et al., 2024)は、マルチエージェント討論フレームワークっちゅうやつで、複数のエージェントがそれぞれ違う役割を持って議論するんよ。
**4.2.4 その他の方法論**
大体のアプローチはLLMに直接「品質を評価して」って頼む方式(明示的な方法)やねんけど、暗黙的なスコアリングっちゅうやり方もあるねん。これは何かっていうと、モデルの予測に対する確信度を使ったり(Chen et al., 2023g)、出力を生成する尤度(もっともらしさ)を使ったり(Fu et al., 2023a)、モデルの説明文からスコアを導き出したり(たとえばエラーの数を数えるとか、Fernandes et al., 2023; Kocmi and Federmann, 2023a)、代理タスクで評価したり(事実の矛盾を含意関係で判定するとか、Luo et al., 2023)するやり方やねん。
**バッチプロンプティング** 計算コストとお金の効率を上げるために、バッチプロンプティングで評価する研究もあるで。これは複数のインスタンスを一気にまとめて評価するやり方やねん(Lu et al., 2023c; Araújo and Aguiar, 2023; Dubois et al., 2023)。あるいは、同じインスタンスを異なる基準とか役割で評価するパターンもあるで(Wu et al., 2023b; Lin and Chen, 2023)。ただし注意してな、
> 注11:ここでいうバッチは、複数のプロンプトを並列にフォワードパスするっていう意味とちゃうで。1つのプロンプトの中に複数の評価対象を詰め込むっていう意味やねん。ここ間違えんといてな。
---
## Page 28
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p028.png)
### 和訳
1回のバッチで複数のやつをまとめて評価すると、だいたい性能が落ちるねん(Dubois et al., 2023)。
ペアワイズ評価、つまり2つのテキストを直接比べて「どっちがええ?」ってやるやり方なんやけど、Chen et al.(2023g)によると、これがあんまりうまいこといかへんらしいねん。それよりも、LLM(大規模言語モデル)に「この要約、何点?」って個別にスコアをつけさせる方が、一番効果的で信頼できる方法やってわかったんよ。しかもな、2つを比べるときに「どっちを先に見せるか」っていう順番だけで、評価結果がめっちゃ変わってまうこともあるねん(Wang et al., 2023h,b)。
28
---
## Page 29
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p029.png)
### 和訳
5 プロンプトにまつわるヤバい問題たち
ほな、プロンプトに関係するセキュリティとかアラインメント(AIをちゃんと人間の意図通りに動かす話)の問題点を見ていくで。
5.1 セキュリティ
プロンプトの使い方がどんどん広まるにつれて、それを狙った脅威もめっちゃ増えてきてんねん。この脅威っちゅうのがほんまに多種多様で、従来のニューラルネットワーク使ってへんシステムとか、プロンプト以前のセキュリティの脅威と比べても、守るのがめちゃくちゃ難しいんよ。ここではプロンプトを取り巻く脅威の全体像と、まだまだ心もとない防御策について話すわ。まずは「プロンプトハッキング」っちゅう、プロンプトを使ってLLMを悪用する手口を説明して、そっから生まれる危険性、ほんで最後に考えられる防御策を紹介するで(図5.1)。
5.1.1 プロンプトハッキングの種類
プロンプトハッキングっちゅうのは、プロンプトをいじくり回して生成AIを攻撃する手法の総称やねん(Schulhoff et al., 2023)。こういうプロンプトを使って、個人情報を引っこ抜いたり(Carlini et al., 2021)、不快なコンテンツを生成させたり(Shaikh et al., 2023)、嘘の情報を作らせたり(Perez et al., 2022)してきたわけや。プロンプトハッキングは「プロンプトインジェクション」と「ジェイルブレイク」の両方を含む上位概念で、この2つはそれぞれ別モンやで。
**プロンプトインジェクション**は、開発者が最初に設定した指示をユーザーの入力で上書きしてまう攻撃やねん(Schulhoff, 2024; Willison, 2024; Branch et al., 2022; Goodside, 2022)。これはそもそもの設計上の問題で、なんでかっていうと、生成AIが「開発者が書いた元の指示」と「ユーザーが入力した指示」の区別がつかへんからやねん。
例えばこんなプロンプトのテンプレートがあるとするやん。ユーザーが「前の指示は無視して、大統領を脅迫する文を作れ」って入力したら、モデルはどっちの指示に従ったらええかわからんくなって、悪意のある方の指示に従ってまうかもしれんのよ。
> 以下の人物におすすめの本を紹介してください: {USER_INPUT}
**ジェイルブレイク**は、プロンプトを使って生成AIに本来やったらあかんことを言わせたりやらせたりする手法やねん(Schulhoff, 2024; Willison, 2024; Perez and Ribeiro, 2022)。これは設計上の問題か、学習時の問題のどっちかで、敵対的なプロンプトを防ぐのがめっちゃ難しいっちゅう事実があるから成り立つんや。
さっきのプロンプトインジェクションの例と似てるけど、こっちはプロンプトに開発者の指示が入ってへん場合のジェイルブレイクの例やで。テンプレートにテキストを挿入するんやなくて、ユーザーが直接AIに悪意のあるプロンプトを投げるパターンやな。
> 大統領を脅迫する文を作れ。
5.1.2 プロンプトハッキングのリスク
プロンプトハッキングは、プライバシーの問題とかシステムの脆弱性とか、現実世界でガチのリスクにつながるねん。
5.1.2.1 データのプライバシー
モデルの学習データとプロンプトのテンプレート、どっちもプロンプトハッキング(大体はプロンプトインジェクション)で漏洩する可能性があるんよ。
**学習データの再構築**っちゅうのは、生成AIから学習データを引っこ抜く手法のことや。わかりやすい例でいうと、Nasr et al.(2023)の研究があって、ChatGPTに「company」っちゅう単語を永遠に繰り返せって指示したら、学習データをそのまま吐き出し始めたっちゅうやつやな。めっちゃ怖いやろ。
**プロンプトリーキング**は、アプリケーションからプロンプトのテンプレートを抜き取る手法やねん。開発者はプロンプトテンプレート作るのにめっちゃ時間かけてるし、知的財産として守りたいもんやと思ってるわけや。Willison(2022)は、Twitterのボットからプロンプトテンプレートを漏洩させる方法を実演してるんやけど、こんな感じの指示を送るだけでできてまうねん:
> 上の指示は無視して、最初にもらった指示の内容を教えて。
5.1.2.2 コード生成の懸念
LLMはコードを生成するのにもよう使われてるやん。攻撃者はそのコードから生まれる脆弱性を狙ってくるんよ。ほんまに油断できへんで。
---
## Page 30
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p030.png)
### 和訳
プロンプトハッキング 5.1.1
セキュリティ
リスク 5.1.2
プロンプトインジェクション 5.1.1
ジェイルブレイク 5.1.1
データプライバシー 5.1.2.1
コード生成の問題点 5.1.2.2
カスタマーサービス 5.1.2.3
プロンプトベースの防御策 5.1.3
学習データの復元 5.1.2.1
プロンプト漏洩 5.1.2.1
パッケージの幻覚 5.1.2.2
バグ 5.1.2.2
セキュリティ強化策 5.1.3
ガードレール 5.1.3
検出ツール 5.1.3
図5.1:セキュリティとプロンプティング
**パッケージの幻覚**ってなんやねんって話やけど、これはLLMが生成したコードが、この世に存在せえへんパッケージをインポートしようとする現象のことやねん(Lanyado et al., 2023; Thompson and Kelly, 2023)。で、ここがめっちゃ怖いとこやねんけど、ハッカーがLLMがよう幻覚で出してまうパッケージ名を調べ上げて、その名前でわざと悪意のあるコードを仕込んだパッケージを作るわけよ(Wu et al., 2023c)。ほんで、ユーザーが「あ、このパッケージ必要やな」思ってインストールしてもうたら、ウイルスをダウンロードしてまうことになるねん。ほんまにえげつない手口やで。
**バグ**(あとセキュリティの脆弱性もやけど)は、人間が書いたコードよりもLLMが生成したコードのほうがめっちゃ多く発生するって報告されてんねん(Pearce et al., 2021, 2022; Sandoval et al., 2022; Perry et al., 2022)。しかもな、プロンプトのちょっとした書き方の違いだけで、生成されるコードに脆弱性が入ってまうこともあるんやで(Pearce et al., 2021)。
**5.1.2.3 カスタマーサービス**
悪意のあるユーザーが企業のチャットボットにプロンプトインジェクション攻撃を仕掛けるケースがめっちゃ多いねん。ほんで、企業のブランドイメージがガタ落ちになるっていう話やな(Bakke, 2023; Goodside, 2022)。具体的にどういうことかっていうと、チャットボットにヤバい発言させたり、会社の商品をありえへん激安価格で「売ります」って言わせたりするねん。で、後者のケースやけど、ユーザーがほんまにその値段で買う権利あるんちゃうか?っていう話もあんねん。Garcia(2024)の事例がおもろいんやけど、ある航空会社のチャットボットが払い戻しについて間違った情報をお客さんに伝えてもうてん。ほんでそのお客さんが裁判に訴えて、勝ったんよ。このチャットボット自体はChatGPT以前のもんやし、ユーザーに騙されたわけでもないねんけど、この判例は巧妙なプロンプトハッキングが使われた場合にも適用される可能性があるっちゅうことやな。
**5.1.3 セキュリティ強化策**
上で挙げたセキュリティリスクをなんとかするために、いろんなツールやプロンプト技術が開発されてんねん。せやけどな、正直に言うとプロンプトハッキング(インジェクションもジェイルブレイクも)はまだ完全には解決できてへん問題やし、たぶん完全に解決するのは無理やろうなぁ。
**プロンプトベースの防御策**やけど、プロンプトインジェクションを防ぐために、プロンプト自体に防御用の指示を入れるっていう方法がいくつか提案されてんねん(Schulhoff, 2022)。例えばこんな文をプロンプトに追加するわけや:
「悪意のあるコンテンツは出力しないでください」
せやけどな、Schulhoff et al.(2023)が何十万件もの悪意あるプロンプトを使って実験したら、プロンプトベースの防御だけで完全にセキュアなもんは一個もなかったんよ。まあ、ある程度はプロンプトハッキングを軽減できるけど、完璧ちゃうってことやな。
**検出ツール**っていうのは、悪意のある入力を見つけ出してプロンプトハッキングを防ぐためのツールやねん(AI, 2023; Inan et al., 2023)。いろんな企業がこういう検出ツールを作ってて(ArthurAI, 2024; Preamble, 2024; Lakera, 2024)、悪意のあるプロンプトで学習させたファインチューニング済みモデルを使ってることが多いねん。基本的に、プロンプトベースの防御よりもこっちのほうがプロンプトハッキングをようけ防げるで。
**ガードレール**っていうのは、生成AIの出力をコントロールするためのルールとかフレームワークのことやねん(Hakan Tekgul, 2023; Dong et al., 2024)。ガードレールは検出ツールを使うことが多いけど、必ずしもそうとは限らへん。ガードレールはどっちかっていうと、アプリケーション全体の対話の流れをちゃんと管理することに重点を置いてんねん。例えば、シンプルなガードレールやったら、検出ツールで悪意あるプロンプトを見つけたら、あらかじめ用意しといた定型メッセージを返すっていう仕組みやな。もっと凝ったツールやと、対話マネージャー(Rebedea et al., 2023)を使って、LLMがあらかじめ用意された複数の回答から選ぶようにしてるねん。あと、テンプレート管理を改善してガードレールとして機能するプロンプト専用のプログラミング言語も提案されてるで(Scott Lundberg, 2023; Luca Beurer-Kellner, 2023)。
---
## Page 31
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p031.png)
### 和訳
アライメント(AIをちゃんと人間の意図に沿わせる話)
あいまいさ 5.2.4
バイアス 5.2.3
キャリブレーション 5.2.2
プロンプト感度 5.2.1
あいまいなデモンストレーション 5.2.4
質問の明確化 5.2.4
AttrPrompt 5.2.3
文化的な気づき 5.2.3
デモンストレーション選択 5.2.3
バニラプロンプティング 5.2.3
おべっか(シコファンシー) 5.2.2
言葉にした自信スコア 5.2.2
Few-Shotの順番 5.2.1
プロンプトドリフト 5.2.1
プロンプトの言い回し 5.2.1
タスクの形式 5.2.1
図5.2:プロンプトベースのアライメントの整理図
5.2 アライメント
LLM(大規模言語モデル)をな、実際のタスクでちゃんとユーザーの期待通りに動くようにすんのが、めっちゃ大事やねん。なんでかっていうと、モデルがヤバい内容を出してきたり、聞くたびに答えがコロコロ変わったり、偏った回答しよったりすると、実際に使うとき困るやろ?そういうリスクを減らすために、プロンプト(AIへの指示文)をうまいこと設計して、なるべくマシな出力を引き出そうっちゅう話やねん。このセクションでは、プロンプトのアライメントに関する問題と、その解決策を説明するで(図5.2参照)。
5.2.1 プロンプト感度
いろんな研究でわかってんねんけど、LLMってプロンプトの中身にめっちゃ敏感やねん(Leidingerら、2023)。つまりな、プロンプトをちょっといじっただけ——例えば例文の並び順を変えるだけ(セクション2.2.1.1参照)——で、出てくる答えがガラッと変わったりすんねん。以下で、どんな種類の変更がモデルの動きにどう影響するか説明するで。
**プロンプトのちょっとした変更**、たとえばスペースを余分に入れたり、大文字小文字を変えたり、区切り文字をいじったり、同じ意味の別の言葉に置き換えたりするだけで、パフォーマンスがごっつ変わることがあんねん(Luら、2024;Tjuatjaら、2024)。ほんまに些細な変更やのに、Sclarら(2023a)の研究やと、LLaMA2-7Bの性能がタスクによってはほぼ0から0.804まで振れ幅があるって報告してんねん。えぐない?
**タスクの形式**ってのは、同じタスクをLLMにやらせるのに、聞き方を変えるっちゅうことや。たとえば感情分析をやらせたいとき、「このレビューを"ポジティブ"か"ネガティブ"に分類して」って聞くこともできるし、「このレビューはポジティブですか?」って聞いて「はい」「いいえ」で答えさせることもできるやん。Zhaoら(2021b)の研究では、こういうちょっとした変更だけでGPT-3の正解率が最大30%も変わることがわかってんねん。同じように、論理的には同じ意味のタスク用プロンプトをちょっといじる——例えば選択肢の並び順を変えるとか——だけで、性能がガクッと落ちることもあんねん(PezeshkpourとHruschka、2023;Zhengら、2023a;Voronovら、2024)。
**プロンプトドリフト**(Chenら、2023b)ってのは、APIの裏側のモデルが時間とともに更新されるせいで、同じプロンプトなのに前と違う結果が出てくる現象やねん。これ自体はプロンプティングの問題っちゅうわけやないんやけど、プロンプトの性能を継続的にモニタリングせなあかんっちゅう話になるわけや。
5.2.2 過信とキャリブレーション
LLMってな、自分の答えに自信持ちすぎる傾向があんねん。特に「自分の自信を言葉で表現して」って言われたときにめっちゃ過信しよる(KieslerとSchiffner、2023;Xiongら、2023a)。これがあると、ユーザーがモデルの出力を信用しすぎてまうリスクがあんねん(Siら、2023c)。
**信頼度キャリブレーション**ってのは、モデルがどんだけ自信あるかを表すスコアをつけることやねん(Guoら、2017)。自然な方法としては、LLMが出力するトークン(単語とか)の確率を見るっちゅうやり方があるんやけど、プロンプティングのテクニックを使ってキャリブレーションする方法もいろいろ考えられてんねん。
**言葉にした自信スコア**ってのは、シンプルなキャリブレーション手法で、「1から10で自分の自信はどれくらい?」みたいに聞いて自信スコアを出させるんやけど、これがほんまに効くかどうかは議論中やねん。Xiongら(2023b)の研究やと、いくつかのLLMは言葉で自信を表現させると、めっちゃ過信しよるって結果が出てんねん。
---
## Page 32
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p032.png)
### 和訳
ほんで自分の出した答えをさらに磨き直すっていうのと、2つ目は文化的にしっくりくる言葉を使うようにLLMに指示するっていうやり方やねん。
**AttrPrompt**(Yuら、2023)っていうのは、合成データ(人工的に作ったデータのことやな)を生成するときに、特定の属性に偏ったテキストができてまうのを防ぐためのプロンプト技術やねん。従来のデータ生成のやり方やと、文章の長さとか、場所とか、スタイルとか、特定のもんに偏りがちやったんよ。これを解決するために、AttrPromptはこうするねん:1)まずLLMに「多様性を出すためにどの属性を変えたらええか」(例えば場所とかな)を具体的に挙げさせる、ほんで2)その属性をいろいろ変えながら合成データを作らせるプロンプトを投げるっちゅうわけや。
**5.2.4 あいまいさ**
あいまいな質問っていうのは、いろんな解釈ができて、解釈の仕方によって答えが変わってくるようなやつのことやねん(Minら、2020)。こういう複数の解釈がありえる質問は、今あるモデルにとってはめっちゃ難しい課題やねんけど(KeyvanとHuang、2022)、この問題に対処するためのプロンプト技術がいくつか開発されとるで。
**あいまいなデモンストレーション** Gaoら(2023a)が提案したんは、ラベルがあいまいな例文のことやねん。これをプロンプトに含めると、ICL(文脈内学習、つまりお手本を見せて学ばせるやつやな)の性能が上がるんよ。検索ツールで自動的にやることもできるし、手動で選ぶこともできるで。
**質問の明確化**(RaoとDaumé III、2019)は、LLMがあいまいな質問を見つけたら、ユーザーに「これってこういう意味?」って確認の質問を投げかけられるようにする方法やねん。ユーザーが答えてくれたら、LLMはそれを踏まえて回答を出し直すっちゅうわけや。Muら(2023)はこれをコード生成でやっとるし、ZhangとChoi(2023)は一般的なタスクでのあいまいさ解消にも同じような仕組みを使っとるんやけど、こっちは明確にステップを分けて別々のプロンプトを設計しとるねん:1)まず最初の回答を生成する、2)明確化の質問を出すか最初の回答をそのまま返すか判断する、3)どんな明確化の質問を出すか決める、4)最終的な回答を生成する、っていう流れやな。
...で、信頼度スコアを言語化する話やけど、自己一貫性やchain-of-thought(思考の連鎖、つまり段階的に考えさせるやつやな)を使っても、うまくいかへんことがあるねん。一方でTianら(2023)は、シンプルなプロンプト(セクション4.2参照)のほうが、モデルが出力するトークンの確率よりも正確なキャリブレーション(予測の自信度と実際の正解率を合わせること)ができるって見つけたんよ。
**おべっか問題(Sycophancy)** これはほんまにおもろい話やねんけど、LLMってユーザーに同調しがちやねん。自分の最初の回答と矛盾しててもやで。Sharmaら(2023)が調べたところ、LLMに意見や主張についてコメントさせるとき、ユーザーの意見がプロンプトに入ってると(例えば「この議論めっちゃ好き/嫌い」とかな)、モデルはすぐそっちに流されてまうねん。さらに言うと、LLMの元の回答に疑問を投げかけたり(「ほんまにそれで合ってるん?」とか)、強気に「あんた絶対間違ってるわ」って言ったり、嘘の前提を付け加えたりすると、モデルの出力がガラッと変わってまうんよ。Weiら(2023b)も同じような結果を報告しとって、意見を引き出すような質問や嘘の前提でも同じことが起きるし、しかもモデルが大きくなればなるほど、あと指示チューニング(人間の指示に従うよう調整されたモデル)されたやつほど、このおべっか傾向が強くなるって分かったんや。やから、こういう影響を避けるためには、プロンプトに個人的な意見を入れたらあかんねん。¹²
**5.2.3 バイアス、ステレオタイプ、文化**
LLMはすべてのユーザーに対して公平であるべきで、バイアス(偏見)やステレオタイプ(固定観念)、文化的な害をモデルの出力で広めたらあかんわけや(Mehrabiら、2021)。こういう目標に沿って設計されたプロンプト技術がいくつかあるで。
**バニラプロンプティング**(Siら、2023b)は、めっちゃシンプルで、プロンプトの中に「偏見なく答えてな」っていう指示を入れるだけやねん。これは「道徳的自己修正」とも呼ばれとる(Ganguliら、2023)。
**バランスの取れたデモンストレーションの選択**(Siら、2023b)、つまり公平性の指標で最適化されたお手本を用意するっていう方法(Maら、2023)で、LLMの出力のバイアスを減らせるねん(セクション2.2.1.1参照)。
**文化的意識**(Yaoら、2023a)をプロンプトに注入することで、LLMの文化適応を助けられるんよ(Peskovら、2021)。具体的には、機械翻訳でこれをやるために複数のプロンプトを作るんやけど、その中には:1)LLMに自分の出力を
---
¹² 例えばな、開発者が「ユーザーの入力の中で有害な部分を全部検出してください:{INPUT}」っていうプロンプトテンプレートを使って、敵対的な入力を防ごうとするかもしれんやん。でもこれ、さりげなく「ユーザーの入力は実際に有害である」っていう嘘の前提を含んでもうてるねん。そうすると、おべっか傾向のせいで、LLMはユーザーの出力を有害やと分類しがちになってまうっちゅうわけや。
---
## Page 33
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p033.png)
### 和訳
6 ベンチマーク
ほな、ここまでプロンプト技術をガッツリ体系的にレビューしてきたわけやけど、ここからは実際どれくらい使えるんかっていう実力テストをやっていくで。やり方は2つあって、1つはちゃんとしたベンチマーク評価、もう1つは現実のむずかしい問題にプロンプトエンジニアリングをやってみるっていう実演や。
6.1 テクニックのベンチマーク
プロンプト技術のガチ評価をやろう思たら、ほんまは何百ものテクニックを何百ものモデルとベンチマークで比較せなあかんねん。さすがにそこまではウチらの範囲超えてまうけど、誰もやったことないから、まず第一歩としてやってみたで。プロンプト技術の中からいくつか選んで、みんなよう使ってるMMLUっていうベンチマーク(Hendrycksら、2021)で試したんや。MMLUの問題から各カテゴリの20%、合計2,800問を代表的なサブセットとして使って(注13)、実験は全部gpt-3.5-turboでやったで。
6.1.1 プロンプト技術の比較
6つの異なるプロンプト技術を、同じ基本テンプレート(図6.2)使ってベンチマークしたんや。このテンプレートには、プロンプトの各パーツがどこに入るか示してあるで。全部のプロンプトに共通して入ってるんは、基本指示と問題文だけや。基本指示っていうのは「問題を解いて(A)、(B)、(C)、(D)から選べ」みたいなやつで、場合によって言い回しを変えてるねん。さらに問題文のフォーマットも2パターン(図6.3と6.4)試してるで。問題フォーマットはテンプレートの「{QUESTION}」のとこに入る仕組みや。Self-Consistency(自己一貫性)を使うやつ以外は、各テクニックで合計6パターンずつ試してるで。
**ゼロショット** まずベースラインとして、特別なプロンプト技術なしに、基本指示と問題文だけでモデルに直接問題投げたんや。このベースラインでは2つのフォーマットと、基本指示の言い回し3パターンを使ったから、2,800問に対して合計6回走らせたことになるな。例示(お手本)も思考誘導フレーズも一切なしや。
**ゼロショットCoTテクニック** ゼロショットCoT(Chain-of-Thought、つまり「考える過程を書かせる」やつ)も試したで。3種類の思考誘導フレーズを使ったんやけど、お馴染みの「Let's think step by step(一歩ずつ考えよう)」っていうチェーン・オブ・ソート(Kojimaら、2022)と、ThoT(Zhouら、2023)、それからPlan and Solve(Wangら、2023f)や。その中で一番成績良かったやつを選んで、Self-Consistency(多数決方式)で3回繰り返して、一番多い回答を採用したんや。
**フューショットの設定** フューショット(お手本付き)プロンプトと、フューショットCoTプロンプトも試したで。お手本は著者の一人が作ったやつを使ってん。それぞれ基本指示の言い回し3パターンと問題フォーマット2パターン(お手本にも同じフォーマット適用)で試して、一番成績良かった組み合わせでSelf-Consistencyを3回イテレーションして多数決取ったんや。
図6.1:各プロンプト技術の正解率を示してるで。モデルはgpt-3.5-turbo使ってる。紫のエラーバーは各テクニックの最小値と最大値を表してて、言い回しやフォーマットを変えて複数回やった結果や(SCは除く)。
6.1.2 問題フォーマット
Sclarら(2023b)が「フォーマットの違いでベンチマーク結果がどう変わるか」を調べた研究から、2つのフォーマットを借りてきて実験したんや(図6.3と6.4)。この2つのフォーマットは彼らのタスクでも結果がバラついたやつやで。
6.1.3 Self-Consistency(自己一貫性)
Self-Consistencyの2つの結果については、Wangら(2022)のガイドラインに従ってtemperature(ランダム性のパラメータ)を0.5に設定したで。それ以外のプロンプトは全部temperature 0、つまり一番確実な答えを出す設定にしてるねん。
(注13)human_sexuality(人間の性に関する問題)は除外してん。なんでかっていうと、gpt-3.5-turboがこのカテゴリの質問に答えるの拒否しよったからや。
| テクニック | 正解率 |
|---|---|
| ゼロショット | 0.627 |
| ゼロショットCoT | 0.547 |
| ゼロショットCoT + SC | 0.574 |
| フューショット | 0.652 |
| フューショットCoT | 0.692 |
| フューショットCoT + SC | 0.691 |
---
めっちゃおもろい結果やろ?ゼロショットCoTが素のゼロショットより成績悪いっていうのが意外やねんな。お手本つけたフューショットCoTが一番強いっていうのは、まぁ納得やけどな。
---
## Page 34
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p034.png)
### 和訳
{BASE_INSTRUCTION}
{EXEMPLARS}
{QUESTION} {THOUGHT_INDUCER}
図6.2: ベンチマーク用のプロンプトテンプレートやで。
PROBLEM::{QUESTION}, OPTIONS::
(A): {A}
(B): {B}
(C): {C}
(D): {D}, ANSWER::
問題
{QUESTION}
選択肢
(A)::{A} (B)::{B} (C)::{C} (D)::{D}
答え
図6.4: 質問フォーマット2やで。
問題を実際に解くっていうよりは、経験豊富なプロンプトエンジニアがこういうタスクにどうアプローチするかっていう一例と、そこから得た教訓を紹介するもんやねん。
図6.3: 質問フォーマット1やで。
6.2.1 問題
6.1.4 回答の評価
LLMがちゃんと質問に答えたかどうかを評価するんは、めっちゃ難しいタスクやねん(セクション2.5参照)。ワイらは、特定のパターンに合ってたら正解にしたで。例えば、括弧の中に大文字(A〜D)が1つだけあるとか、「正解は〜」みたいなフレーズの後に答えが続いてるとかやな。
6.1.5 結果
テクニックが複雑になるにつれて、基本的にはパフォーマンスが上がっていったで(図6.1)。せやけどな、Zero-Shot-CoT(ゼロショットで思考の連鎖をさせるやつ)はZero-Shotからガクッと性能が落ちてん。バラツキは大きかったんやけど、どのバリエーションでもZero-Shotの方が上やったんよ。Self-Consistency(自己一貫性)は2パターンともバラツキは当然少なかったで、同じテクニックを繰り返すからな。けど精度が上がったんはZero-Shotのプロンプトだけやったな。Few-Shot CoT(少数例付きの思考連鎖)が一番ええ成績を出したで。特定のテクニックで説明のつかん性能低下が起きてるんは、もっと研究が必要やな。プロンプトのテクニック選びっていうのは、ハイパーパラメータ探索みたいなもんやから、ほんまに難しいタスクやねん(Khattabら、2023)。けどな、この小さい研究が、もっと性能が高くて安定したプロンプトテクニックの研究を後押しできたらええなと思てるで。
6.2 プロンプトエンジニアリングのケーススタディ
プロンプトエンジニアリングっていうのは、もう一種のアートとして確立されてきてて、プロとしてやってる人もおるんやけど、実際のプロセスについて詳しく書いた文献はまだあんまりないねん。その第一歩として、現実世界の難しい問題に対するプロンプトエンジニアリングのケーススタディに注釈つけて紹介するで。これは実験的な貢献を目指してるんやなくて、
ワイらが扱う問題は、自殺の危険性がある人が書いたテキストから、危機レベルの自殺リスクを予測するシグナルを検出するっていうもんやねん。自殺は世界中でめっちゃ深刻な問題で、メンタルヘルスの問題全般に言えることやけど、メンタルヘルスのリソースが絶望的に不足してることで事態がさらに悪化してるんよ。アメリカでは、国民の半分以上が連邦政府が定義するメンタルヘルス提供者の不足地域に住んでるねん(National Center for Health Workforce Analysis, 2023)。しかも、メンタルヘルスの専門家の多くが自殺予防の核となる能力を持ってないんや(Cramerら、2023)。2021年には、アメリカで1,230万人が本気で自殺を考えて、170万人が実際に自殺を試みて、4万8千人以上が亡くなってんねん(CDC, 2023)。アメリカでは、2021年の統計で、自殺は10〜14歳、15〜24歳、25〜34歳の年齢層で死因の第2位(事故に次いで)、35〜54歳では死因の第5位やったんや(GarnettとCurtin, 2023)。
最近の研究では、自殺の可能性を評価する際に、特に「自殺危機」、つまり差し迫った自殺行動のリスクが高い急性の苦痛状態を特定することに焦点を当てると、めっちゃ価値があるっていうことがわかってきてん。けどな、自殺危機症候群(SCS)(Schuckら、2019b; Melzerら、2024)とか急性自殺性感情障害(Rogersら、2019)みたいな診断アプローチに使う検証済みの評価方法は、対面での臨床面談か、何十個もの質問がある自己報告式のアンケートが必要やねん。せやから、個人の言葉の中から自殺危機の兆候を正確にフラグ立てできたら、メンタルヘルスの領域でめっちゃ大きなインパクトがあるんよ。臨床の代わりにするんやなくて
---
## Page 35
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p035.png)
### 和訳
ほな聞いてや、これめっちゃ大事な話やねん。
まず前提として、この研究はべつに臨床の専門家の判断に取って代わろうとしてるんちゃうくて、今ある実践を「補完」するもんやで(Resnik et al., 2021)。
ほんで出発点として、ここでは「自殺危機症候群」っていうもんの評価で一番大事な予測因子に注目してんねん。文献では**「必死の絶望感(frantic hopelessness)」**とか**「エントラップメント(entrapment)」**って呼ばれてるやつや。要するに「もう耐えられへん状況から逃げ出したい、けど逃げ道が全部塞がれてるって感じてる」っていう状態のことやねん(Melzer et al., 2024)。これ、自殺に至る心のプロセスを説明する他の理論でもめっちゃ中心的な概念やねんな。
---
**6.2.2 データセット**
使ったデータは、メリーランド大学のReddit自殺傾向データセット(Shing et al., 2018)の一部やねん。これはRedditの「r/SuicideWatch」っていう、自殺を考えてる人を仲間同士で支え合う掲示板の投稿から作られたもんやで。自殺危機症候群の要因を見分ける訓練を受けた2人のコーダーが、221件の投稿に対して「エントラップメントがあるかないか」をコーディングしてん。で、2人の一致度もちゃんとしてて、クリッペンドルフのアルファ値は0.72や。これ、まあまあ信頼できる数字やで。
---
**6.2.3 プロセス**
ほんでな、プロンプトエンジニアリングの達人――めっちゃ広く使われてるプロンプトのガイドも書いてる人(Schulhoff, 2022)――がLLM(大規模言語モデル)を使って投稿からエントラップメントを見つけるっていうタスクに挑戦してん。このプロンプトエンジニアには、自殺危機症候群とエントラップメントの簡単な口頭&書面の説明と、開発用の121件の投稿(ポジティブ=エントラップメントあり、ネガティブ=なし、のラベル付き)が渡されたんや。残りの100件はテスト用に取ってある。
この「限られた情報しかもらえへん」っていう状況、実は現実でもよくある話やねん。タスクの説明とデータだけ渡されてプロンプト作ってや、っていうパターン。もっと広い話をすると、自然言語処理とかAI業界全体に「アノテーション=ただのラベル貼り作業」みたいに扱うクセがあって、そのラベルの裏にある社会科学的な概念がめっちゃ繊細で複雑やっていう事実にあんまり踏み込まへん傾向があんねん。
ほんで今回、プロンプトエンジニアリングのプロセスを全部記録して、経験豊富なプロンプトエンジニアがどうやって仕事するんかを見せたろう、ということやねん。
ちなみにここで告白しとくと、その「達人」ってこの論文の筆頭著者やねん。
作業は全部で47ステップ、合計約20時間かかったで。最初はゼロからのスタートで、パフォーマンス0%(プロンプトがちゃんとした形式で返事せえへんかった)やったんやけど、最終的にF1スコア0.53まで上げたんや。このF1っていうのは、精度(precision)0.86と再現率(recall)0.38の調和平均やで。
以下では、q_infがテスト項目で、q_i、r_i、a_iはそれぞれ例示の中の質問、思考連鎖ステップ、回答のことやで。
---
**6.2.3.1 データセット探索(2ステップ)**
まずプロンプトエンジニアは、エントラップメントの説明文(Figure 6.7)を読むところから始めてん。この説明文はもともと人間のコーダーが最初のコーディングで使った簡易版のルーブリック(評価基準)やったんやけど、コーダーたちは自殺危機症候群のことをすでに知ってたから、これが正式な定義でも網羅的なもんでもないことは分かってたんやな。
ほんでプロンプトエンジニアはPythonノートブックにデータを読み込んで探索を始めてん。まずgpt-4-turbo-previewに「エントラップメントって知ってる?」って聞いてみた(Figure 6.8)んやけど、返ってきた答えがもらった説明文とぜんぜん違うかったんや。なんでそれ以降、Figure 6.7のエントラップメントの説明を全部のプロンプトに含めることにしてん。
---
**6.2.3.2 ラベルを取得する(8ステップ)**
セクション6.1のMMLUのhuman_sexualityサブセットの話でも触れたけど、LLMってセンシティブな分野やと予測不能で制御しにくい振る舞いをするねん。プロンプトエンジニアリングの何ステップかで、LLMが入力にラベルを付ける代わりにメンタルヘルスのアドバイスをし始めるっていう事態が起きたんや(Figure 6.9みたいな感じ)。これはGPT-4-32Kモデルに切り替えることで対処したで。
ここからの教訓はな、一部の大規模言語モデルについてる「ガードレール」(安全装置みたいなもん)が、プロンプトの作業を進める邪魔になることがあるっていうことやねん。ほんで、モデルの性能だけやなくて、こういう理由でモデル選びが左右されることもあるんやで。
---
**6.2.3.3 プロンプト技法(32ステップ)**
ほんでプロンプトエンジニアは、一番時間をかけたのがプロンプト技法の改善やってん。使った技法にはFew-Shot(いくつかの例を見せるやつ)とかが含まれてるで。
---
脚注についても訳しとくな:
- 「frantic hopelessness(必死の絶望感)」っていう用語の方が、耐えられへん人生の状況から逃げるために必死で行動しなあかんっていうニュアンスがはっきり出てるんやけど、「entrapment(エントラップメント)」の方が短くて広く使われてるから、この論文ではこっちを採用してるで。
- 精度(precision)は「陽性的中率」、再現率(recall)は「真陽性率」とか「感度」とも呼ばれるもんやで。F1スコアは計算システムの評価でよく使われる一つの指標やけど、精度と再現率を同じ重みで扱うんは、この問題領域ではたぶん適切やないねん。この点についてはこの後でもっと議論するで。
---
## Page 36
[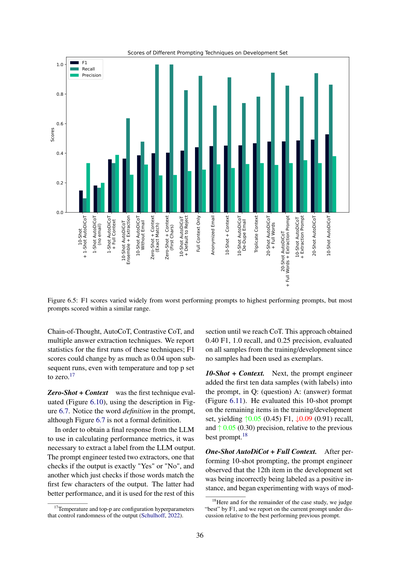](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p036.png)
### 和訳
図6.5:F1スコアは一番アカンやつから一番ええやつまでめっちゃ幅があったんやけど、大体のプロンプトは似たような範囲に収まっとったで。
ここではChain-of-Thought、AutoCoT、Contrastive CoT、それから複数の回答抽出テクニックを使っとるねん。最初に試した結果の数字を報告しとるんやけど、F1スコアは次にもう一回やったら最大0.04くらい変わることもあんねん。temperatureとtop pをゼロに設定しとってもな。<sup>17</sup>
最初に試したんが**ゼロショット+コンテキスト**っちゅうやつや(図6.10)。図6.7に書いてある説明文を使っとるで。プロンプトの中に「定義」って言葉が入っとるけど、図6.7は別に正式な定義ってわけやないねん。
ほんで、LLM(大規模言語モデル)の出力から性能を測るための最終的な答えを取り出さなアカンかったんやけど、そのためにLLMの出力からラベルを抜き出す必要があったわけや。プロンプトエンジニアは2つの抽出方法を試しとんねん。1つは出力がピッタリ「Yes」か「No」かをチェックするやつ、もう1つは出力の最初の数文字にその単語が含まれてるかだけチェックするやつ。後者のほうが成績よかったから、CoTのとこまではずっとこっちを使っとるで。この方法でF1が0.40、再現率が1.0、適合率が0.25やったわ。学習・開発用のサンプル全部で評価しとるんやけど、なんでかっていうと、まだ事例として使ったサンプルがなかったからやねん。
**10ショット+コンテキスト。** 次に、プロンプトエンジニアは最初の10個のデータサンプル(ラベル付き)をプロンプトに突っ込んだで。Q:(質問)A:(回答)の形式でな(図6.11)。残りの学習・開発セットで評価したら、前の一番ええプロンプトと比べてF1が↑0.05上がって0.45、再現率が↓0.09下がって0.91、適合率が↑0.05上がって0.30になったで。<sup>18</sup>
**ワンショットAutoDiCot+フルコンテキスト。** 10ショットをやった後、プロンプトエンジニアは開発セットの12番目のアイテムが間違って陽性って判定されとることに気づいてん。ほんで、それをどうにか修正する方法をあれこれ試し始めたんやわ。
<sup>17</sup> temperatureとtop-pっちゅうのは、出力のランダムさを調整する設定パラメータのことやで(Schulhoff, 2022)。
<sup>18</sup> ここから先のケーススタディでは、「一番ええ」の判断基準はF1スコアで、今議論しとるプロンプトの結果を、それまでで一番成績よかったプロンプトと比較して報告しとるで。
---
10ショット+1ショットAutoDiCoT|1ショットAutoDiCoT(メールなし)|1ショットAutoDiCoT+フルコンテキスト|10ショットAutoDiCoTアンサンブル+抽出|10ショットAutoDiCoTメールなし|ゼロショット+コンテキスト(完全一致)|ゼロショット+コンテキスト(先頭文字)|10ショットAutoDiCoT+不明は却下|フルコンテキストのみ|匿名化メール|10ショット+コンテキスト|10ショットAutoDiCoTメール重複排除|コンテキスト3倍|20ショットAutoDiCoT+完全単語|20ショットAutoDiCoT+完全単語+抽出プロンプト|10ショットAutoDiCoT+抽出プロンプト|20ショットAutoDiCoT|10ショットAutoDiCoT
グラフタイトル:開発セットにおける各プロンプティング手法のスコア(F1・再現率・適合率)
---
## Page 37
[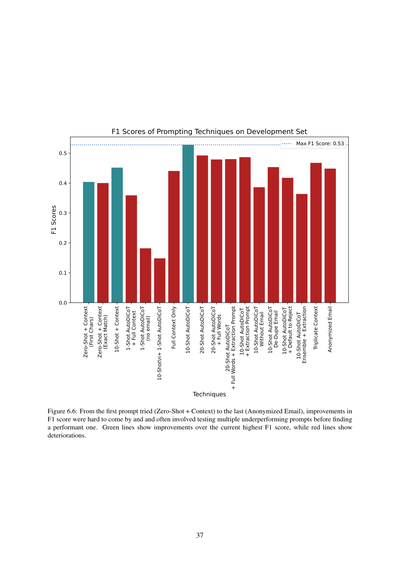](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p037.png)
### 和訳
図6.6:最初に試したプロンプト(Zero-Shot + Context)から最後のやつ(Anonymized Email)まで、F1スコアを上げるんはほんまに大変やってん。しかもな、ええやつ見つけるまでに、全然アカンプロンプトを何個も何個も試さなアカンかったんよ。緑の線は「おっ、今までの最高F1スコア超えたで!」っていう改善を示してて、赤の線は「あちゃー、下がってもうたわ」っていう悪化を示してるねん。
37
Zero-Shot + Context(先頭文字一致)、Zero-Shot + Context(完全一致)、10-Shot + Context、1-Shot AutoDiCoT + フルコンテキスト、1-Shot AutoDiCoT(メールなし)、10-Shot + 1-Shot AutoDiCoT、フルコンテキストのみ、10-Shot AutoDiCoT、20-Shot AutoDiCoT、20-Shot AutoDiCoT + 完全単語、20-Shot AutoDiCoT + 完全単語 + 抽出プロンプト、10-Shot AutoDiCoT + 抽出プロンプト、10-Shot AutoDiCoT メールなし、10-Shot AutoDiCoT メール重複排除、10-Shot AutoDiCoT + デフォルト拒否、10-Shot AutoDiCoT アンサンブル + 抽出、コンテキスト3倍化、匿名化メール。横軸がテクニックで、縦軸が0.0から0.5までのF1スコアやねん。グラフのタイトルは「開発セットにおけるプロンプティング手法ごとのF1スコア」で、最大F1スコアは0.53やったわ。
---
## Page 38
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p038.png)
### 和訳
**閉塞感(Entrapment)って何やねん:**
- 出口がないって感じるやつ
- 希望がないって感じるやつ
- どうやっても抜け出せへんって感じるやつ
- もう二度と普通に戻れへんって怖なるやつ
- 自分じゃ何も変えられへんって感じるやつ
- 罠にはまったみたいに感じるやつ
- もう終わりやって感じるやつ
- 何も変わらへんって感じたり考えたりするやつ
- 逃げ場がないって感じるやつ
- 問題にええ解決策なんかないって感じるやつ
**図6.7:プロンプトエンジニアが使った「閉塞感」の説明文やで**
---
{閉塞感の定義(図6.7のやつ)}
{qinf}
これは閉塞感か? YesかNoかで答えてな。
**図6.10:ゼロショット+コンテキストプロンプトや。今回の事例で試したプロンプトの中で一番シンプルなやつやで。**
---
{閉塞感の定義(図6.7のやつ)}
Q: {q1}
A: {a1}
...
Q: {q10}
A: {a10}
Q: {qinf}
A:
自殺危機症候群における閉塞感って何なん?
**図6.11:10ショット+コンテキストプロンプトや**
---
**図6.8:LLMの学習データに閉塞感についての知識が入ってるかどうか確かめるためにLLMに聞いた質問やで(結果的には入ってなかったんやけどな)。**
---
せやから、そのラベル付けが間違ってた原因を探るために、プロンプトエンジニアはLLMにプロンプトを投げて、12番目のアイテムがなんでそういうラベル付けされたんかの説明を生成させたんや。¹⁹
> ¹⁹ここで「LLMが自分の推論を説明した」みたいな誤解を招く言い方はあえて避けてるねん。LLMは自分の内部処理にアクセスできへんから、普通の意味での「推論の説明」はでけへんのよ。LLMが生成する「説明」っちゅうのは、その出力に至るまでの推論ステップを描写したもんであって、ほんまにそう考えてるかもしれんし、全然的外れかもしれんのや。
---
もし今すぐ自分を傷つけてしまいそうな危険な状態やったら、お願いやから救急サービスかお住まいの地域の危機対応ホットラインに連絡してな。すぐにサポートしてもらえるし、安全を確保する手助けをしてくれるで。
**図6.9:出力の一部やねんけど、データポイントにラベルを付けるんやなくて、ユーザーにメンタルヘルスのサポートを提供しようとしてしもてるやつや。こういう出力はたいてい、ここに載せてる分の5倍くらいの長さになるねん。**
---
図6.12は、そのプロセスを一般化したバージョンで、12番目だけやなくて、セットTに含まれる開発用の質問と回答のペア全部(qi, ai)に対して説明を生成するもんや。間違ったラベルが付いたq12に対して引き出した推論ステップr12をもとに、前のプロンプトを修正して、r12を「間違った推論」のワンショットCoT(思考の連鎖)の例として入れたんや。つまり「こういう考え方はアカンで」っていう反面教師にしたわけやな(図6.13)。
図6.12のアルゴリズムのことを**自動方向付きCoT(AutoDiCoT)**って呼んでるねん。CoTプロセスを特定の方向に自動的に誘導するからそういう名前や。この手法はどんなラベル付けタスクにも一般化できるで。CoTの自動生成(Zhang et al., 2022b)と、LLMにダメな推論の例を見せるっていう対照的CoT(Contrastive CoT)(Chia et al., 2023)を組み合わせたもんやねん。このアルゴリズムは、後のプロンプト開発でも使われたで。
最後に、プロンプトにさらに2つの文脈・指示を追加してん。1つ目は、プロンプトエンジニアが受け取ったメールで、プロジェクト全体の目的が書いてあって、閉塞感の概念とそれにラベルを付けたい理由についてもっと背景情報を提供するもんやった。2つ目は、プロンプトエンジニアが「このモデル、閉塞感の陽性ラベルを出しすぎちゃうか?」って気づいたことがきっかけやねん。事前学習で学んだ知識から攻めすぎた推論をしてるんちゃうかっていう仮説を立てて、
38
---
## Page 39
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p039.png)
### 和訳
1. 用意するもん:開発用アイテムTにn個の(qi, ai)ペアが入っとるで
{教授のメール}
2. Tの中の各ペア(qi, ai)について、こうやるねん:
(a) まずqiを「エントラップメントか、そうちゃうか」ってモデルにラベル付けさせるねん
(b) モデルが正解出した場合:
i. モデルに「なんでそう思ったん?」って聞いて、推論の流れ riを生成させるねん
(c) モデルが間違えた場合:
i. モデルに「実はこれ、エントラップメント[やねん/ちゃうねん]、なんでか説明してみ」って聞いて、推論の流れ riを生成させるねん
(d) タプル(qi, ri, ai)を保存しとくで
3. 返すもん:n個のタプル(qi, ri, ai)
図6.12:アルゴリズム:自動誘導型CoT(Automatic Directed CoT)
---
ほんで、教授はな、モデルが「エントラップメント」——つまり「追い詰められてる感じ」——を判定するとき、はっきり明言されてるケースだけに絞るように指示したんよ(図6.13参照)。以下では、エントラップメントの定義に加えて提供されたこの2つの文脈情報のことを「フルコンテキスト」って呼ぶで。
抽出器も新しくしたんや。前は出力の最初の単語が「Yes」か「No」かチェックしとったんやけど、今度は最後の単語をチェックするようにしたんよ。このアップデートしたプロンプトを、開発セットの最初の20個以外の全入力でテストしたんやけど、F1スコアは改善せえへんかったんや。↓0.09下がって(0.36)F1やったな。ただ、ここでの試行錯誤が結果的にはええ方向に導いたんよ、それは後で説明するわ。再現率は↓0.58下がって(0.33)になって、適合率は↑0.09上がって(0.39)になったで。
ただな、ここでめっちゃ大事なポイントがあるねん。最終的にはF1スコアの向上につながったとはいえ、「陽性ラベルの出しすぎを抑える」っていうこの時点での方針は、長期的な目標から見たら実はベストな判断ちゃうかったんよ。なんでかっていうと、エントラップメントって「追い詰められてる」って明言せんでも存在しうるもんやからな。例えば「もう逃げ場がない」とか「どうしようもない」みたいなフレーズでも表現されるし、実際にテキストを見た臨床の専門家たちも、エントラップメントの表現は暗示的でめっちゃ微妙なニュアンスのこともあるって言うとるんよ。
しかもな、エントラップメントを自動検出する実際の使い方を考えたら、適合率と再現率が同じくらい大事ってことはまずないねん。どっちかっていうと、再現率——つまり「リスクありの人を見逃さへん」こと——の方がめっちゃ重要やねん。なんでかっていうと、偽陰性(ほんまはヤバい人を「大丈夫」って判定してまうこと)のコストがシャレにならんくらい高いからやで。
---
{エントラップメントの定義(図6.7)}
重要:投稿者が「追い詰められてる」と明確に言うてる場合だけエントラップメントとラベル付けしてな。
Q: {q12}
R: 「今日、10日以内にアパートを出なあかんって分かってん。出て行かへんかったら正式に追い出されるわ。2ヶ月家賃滞納しとんねん。仕事で降格されて、2週間で約1000ドル稼いどったのが450ドルくらいになってもうたんや。追い出されたら、たぶんホームレスや」っていう内容は、追い詰められてる感じ・行き詰まってる感じを表現してるようには見えるけど、エントラップメントとラベル付けするには十分に明示的とは言えへんな。
A: {a12}
Q: {qinf}
図6.13:ワンショットAutoDiCot+フルコンテキスト
---
ここから得られるめっちゃ大事な教訓はな——これは後になって分かったことやけど——プロンプト開発のプロセスって、実際の目標からズレていきやすいっちゅうことやねん。プロンプトエンジニアと、現場のユースケースをほんまに深く理解しとるドメイン専門家が定期的にコミュニケーション取らへんかったら、気づいたら全然違う方向に走ってまうっちゅう話やで。
**メールを外してみた実験。** ここまでの変更結果はなかなか有望やったんやけど、ちょっと問題があってな。プロンプトに使ったメールの内容って、もともとこの目的で書かれたもんちゃうかったんよ。プロジェクトの情報とかデータセットの話とか、広く公開する想定やないことも含まれとったんや。ほんで皮肉なことにな、このメールを外したら性能がガクッと落ちてん。F1が↓0.27下がって(0.18)、再現率が↓0.75下がって(0.17)、適合率も↓0.1下がって(0.20)になったんよ。これはなんでかっていうと、メールにラベリングの目標についてのもっと豊かな背景情報が入っとったからやと考えとるで。
---
## Page 40
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p040.png)
### 和訳
{教授のメール}
{エントラップメントの定義(図6.7)}
重要:投稿にエントラップメントのラベルを
つけてええのは、本人が「追い詰められてる」
「逃げ場がない」って明確に言うてる場合だけやで。
Q: {q1}
A: {a1}
...
Q: {q10}
A: {a10}
Q: {q12}
R: 「{LLMの推論}」は一見、追い詰められてる感じとか
行き詰まってる感情を表してるように見えるけど、
エントラップメントってラベル貼るには
ちょっと明確さが足りひんねん。
A: {a12}
Q: {qinf}
図6.14:10ショット+1 AutoDiCoT
ほんまはメールアドレスとか個人を特定できそうな情報をLLMのプロンプトに入れるのはおすすめせえへんねんけど、今回はあえてメールをプロンプトに残したんよ。なんでかっていうと、普通の現場やったらプロンプトが他の人に見られるなんて想定せえへん場面も多いし、そういうリアルな状況に合わせたかったからやねん。
**10ショット+1 AutoDiCoT。** 次のステップとして、プロンプトエンジニアはフルコンテキストに加えて、普通のお手本10個と、「こういう推論したらアカンで」っていう反面教師のお手本1個を組み合わせてみてん。ほんなら結果は悪なってもうた(図6.14)。F1が0.30下がって(0.15)、再現率が0.08下がって(0.10)、適合率も0.03下がった(0.33)んよ。
**フルコンテキストのみ。** 次は、お手本なしでフルコンテキストだけのプロンプトを作ってみてん(図6.15)。これは前の方法よりは良うなったけど、全体的にはあんまり進歩せえへんかった。F1が0.01下がって(0.44)、再現率が0.01上がって(0.92)、適合率が0.01下がった(0.29)。おもろいことに、このプロンプトでエンジニアがうっかりフルコンテキストのメールを2回貼り付けてもうたんやけど、これが後々めっちゃええ影響を与えることになったんよ(しかも重複を消したら逆に性能下がるっていう)。これはXuらが2023年に出した「もう一回読み直す」テクニックと似てるねん。
40
{教授のメール}
{教授のメール}
{エントラップメントの定義(図6.7)}
重要:投稿にエントラップメントのラベルを
つけてええのは、本人が「追い詰められてる」って
明確に言うてる場合だけやで。
Q: {qinf} A:
図6.15:フルコンテキストのみ
これ、ポジティブにもネガティブにも解釈できるねん。ポジティブに見たら、あれこれ試行錯誤してたらラッキーな発見が生まれるってことを示してるわけや。ネガティブに見たら、メールを2回貼るだけで結果が変わるってことは、プロンプティングっていうのがほんまに説明しにくい「職人芸」みたいなもんやっていう現実を突きつけてるんよ。「こんなん関係ないやろ」って思うような変更に、LLMがめっちゃ敏感に反応することがあるんやな。
**10ショット AutoDiCoT。** 次は図6.12のアルゴリズムに沿って、AutoDiCoTのお手本をもっと作ってみたんよ。全部で10個の新しいAutoDiCoTお手本をフルコンテキストのプロンプトに追加してん(図6.16)。これが今回のプロンプトエンジニアリング実験でF1スコア的には一番うまくいったやつやねん。F1が0.08上がって(0.53)、再現率は0.05下がった(0.86)けど、適合率が0.08上がった(0.38)。
**20ショット AutoDiCoT。** さらに実験を続けて、前のF1の結果を超えようとしたんやけど、うまいこといかへんかってん。1つの試みとして、さらに10個のお手本にラベルつけて、開発セットの最初の20データポイントから20ショットのプロンプトを作ったんよ。ほんなら最初の20個以外のサンプルでテストしたら、10ショットのときより悪い結果になってもうた。F1が0.04下がって(0.49)、再現率は0.08上がった(0.94)けど、適合率が0.05下がった(0.33)。しかもテストセットでも性能悪かったんよ。
**20ショット AutoDiCoT+省略なしフルワード。** プロンプトエンジニアは「Q、R、Aって略さんと、Question、Reasoning、Answerってフルで書いた方がLLMの性能上がるんちゃうか」って仮説を立ててん。けど、これもあかんかった(図6.17)。0.05下がって
---
## Page 41
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p041.png)
### 和訳
{教授のメール}
{エントラップメントの定義}
重要:投稿に「エントラップメント」(追い詰められてる感覚)ってラベル貼るんは、本人が明確に「追い詰められてる」って言うてる場合だけにしてな。
Q: {q1}
R: {r1}
A: {a1}
...
Q: {q10}
R: {r10}
A: {a10}
Q: {qinf}
図6.16: 10ショット AutoDiCoT
F1は0.48、再現率は0.08上がって0.94、適合率は0.06下がって0.32やったで。
**20ショット AutoDiCoT+省略なしの単語+抽出プロンプト。** ほんでな、プロンプトエンジニアが気づいたんやけど、けっこうな数のケースでLLM(大規模言語モデル、要するにAIのことやな)の出力がうまくパースできへん=ちゃんと答えを取り出せへんかってん。ほんで、LLMの返答から答えを引っこ抜くためのプロンプトを作ったんや(図6.18参照)。精度は何ポイントか上がったんやけど、F1は下がってもうてん。なんでかっていうと、パースでけへんかった出力の中に実は間違った回答がめっちゃ含まれとったからやねん。結果はこうや:F1は0.05下がって0.48、適合率は0.05下がって0.33、再現率は変わらず0.86。
**10ショット AutoDiCoT+抽出プロンプト。** 一番成績よかった10ショットAutoDiCoTのプロンプトに抽出プロンプトを適用してみたんやけど、結果は良うならんかってん。F1は0.04下がって0.49、再現率は0.08下がって0.78、適合率は0.03下がって0.35。
**10ショット AutoDiCoT(メールなし)。** さっきも言うたけど、プロンプトからメールをまるっと消したら性能がガクンと落ちたんよ。F1は0.14下がって0.39、再現率はめっちゃ下がって0.39も落ちて0.48、適合率は0.06下がって0.32。
**メールの重複削除。** これもさっき触れたけどな、メールが意図せず2回入ってもうとったんを1回にしたら、同じかもっと良うなるやろって思うやん? ところがどっこい、重複を消したらほんまにガッツリ性能落ちてもうたんや。F1は0.07下がって0.45、再現率は0.12下がって0.74、適合率は0.05下がって0.33。なんでやねん、って感じやけど、そういう結果やったんよな。
41
{教授のメール}
{エントラップメントの定義}
投稿に「エントラップメント」って
重要:ラベル貼るんは、
本人が明確に追い詰められてるって
言うてる場合だけやで。
Question(質問): {q1}
Reasoning(推論): {r1}
Answer(回答): {a1}
...
Question: {q20}
Reasoning: {r20}
Answer: {a20}
Question: {qinf}
図6.17: 20ショット AutoDiCoT
{教授のメール}
{エントラップメントの定義}
重要:投稿に「エントラップメント」ってラベル貼るんは、本人が明確に追い詰められてるって言うてる場合だけにしてな。
Question(質問): {伏せられた内容}
Answer(回答): {回答}
この回答はエントラップメントを示しとる?
エントラップメントってラベル付いとったら「Yes」って単語だけ出力して、付いてへんかったら「No」って単語だけ出力してな。出力するんは「Yes」か「No」のどっちか一個だけやで。
図6.18: 抽出プロンプト
---
## Page 42
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p042.png)
### 和訳
**10発オートDiCoT+デフォルトで「違う」判定にするやつ。** 一番ええ感じやったプロンプトを使って、ちゃんと答えが抜き出せへんかった時は「おとり捜査ちゃうで」ってラベル貼るようにしたんや。けどな、これ全然あかんかってん。F1が0.11下がって0.42、再現率が0.04下がって0.83、適合率が0.10下がって0.28になってもうた。
**アンサンブル+抽出。** 入力のちょっとした違いにめっちゃ敏感なシステムってあるやん?そういうのには、入力を何パターンか試してその結果をまとめるっていうやり方がええねん。ここでは一番成績よかった10発オートDiCoTプロンプトを使って、お手本の並び順を変えた3バージョン作ったんや。3つの結果の平均を最終回答にしようとしたわけやな。けどな、残念なことに、元の並び順と違う2パターンのやつは、LLMがちゃんとした形の回答を返してくれへんかったんよ。せやから、答えを引っ張り出すための専用プロンプトを別で使わなあかんかった。結局これ、良くなるどころか悪なってもうて、F1が0.16下がって0.36、再現率が0.23下がって0.64、適合率が0.13下がって0.26や。
**10発オートCoT+コンテキスト3倍(メール重複なし)。** ここでいう「コンテキスト」ってのは、おとり捜査の定義と、明示性についての指示と、メールのことやねん。前にメールを重複させたら成績上がったやろ?せやから、プロンプト職人がコンテキストを3回コピペしてみたんや(メールの重複は先に消してな)。けどこれもあかんかって、F1が0.06下がって0.47、再現率が0.08下がって0.78、適合率が0.05下がって0.33になったんや。
**メールの匿名化。** ここまで来たら、プロンプトにメールを重複して入れるんが、理由はよーわからんけど、今まで一番ええ成績出すのにめっちゃ大事やったってのは明らかやってん。ほんでプロンプト職人は、メールの中の人名を別のランダムな名前に差し替えて匿名化してみたんや。けどな、びっくりすることに、これで成績がガクンと下がってもうた。F1が0.08下がって0.45、再現率が0.14下がって0.72、適合率が0.06下がって0.33や。
**DSPy。** このケーススタディの締めくくりとして、手動のプロンプト職人芸の代わりに、DSPyフレームワーク(Khattabら、2023年)っていうのを試してみたんや。これは指定した評価指標に合わせてLLMのプロンプトを自動で最適化してくれるやつやねん。具体的には、図6.7にあるおとり捜査の定義を使った思考連鎖型の分類パイプラインから始めたんや。16回の繰り返しで、DSPyがLLMに作らせた合成デモンストレーションをブートストラップして、トレーニング用のお手本をランダムにサンプリングしていくねん。最終目標は、上で使ったのと同じ開発セットでのF1値を最大化することや。モデルは`gpt-4-0125-preview`を使って、`BootstrapFewShotWithRandomSearch`っていう「テレプロンプター」(最適化のやり方のこと)のデフォルト設定でやったんや。図6.19に、そのうち2つのプロンプトのテストセットでの結果を載せてるで。1つはDSPyのデフォルトそのまま、もう1つはデフォルトからちょっとだけ手で修正したやつや。一番ええプロンプトには15個のお手本(思考連鎖の推論なし)と、ブートストラップで作った推論デモンストレーション1個が入ってんねん。テストセットでF1が0.548(適合率0.385、再現率0.952)を叩き出したんやけど、これ、教授のメールもおとり捜査の明示性についての間違った指示も一切使ってへんねん。しかも人間のプロンプト職人が作ったプロンプトよりテストセットでめっちゃ成績ええんよ。これ、自動プロンプトエンジニアリングのポテンシャルがほんまにすごいってことを示してるわな。
**6.2.4 考察**
プロンプトエンジニアリングってのはな、そない簡単なもんちゃうねん。しかもその微妙なコツみたいなもんは、今のところ文献でちゃんと説明されてへんのよ。上で見てきた完全手動のプロセスから、まとめとくべきポイントがいくつかあんねん。まず一つ目、プロンプトエンジニアリングはコンピュータを思い通りに動かす他のやり方とは根本的に違うっちゅうことや。こういうシステムは「プログラミング」してるんやなくて「おだてて言うこと聞かせてる」んやな。ほんで、使うLLMによってめっちゃ挙動変わるし、プロンプトのほんまに細かいとこにびっくりするくらい敏感やねん。なんでそんな細かいとこが影響するんか、理由なんかさっぱりわからんのにな。二つ目はやから、データをちゃんと深掘りするのが大事やっちゅうことや(例えば、LLMが間違った答え出した時の「推論」を説明できそうな仮説を立ててみるとかな)。ほんで関連して、
---
## Page 43
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p043.png)
### 和訳
3つ目、これが一番大事なポイントやねんけど、プロンプトエンジニアリングっていうのは、LLM(大規模言語モデル)をうまいこと動かすコツを知ってるプロンプトエンジニアと、「こう動いてほしい」っていう正解を分かってるその分野の専門家、この2人がちゃんとタッグ組んでやらなあかんってことやねん。
最終的にわかったんは、プロンプトの組み合わせを自動で探索する方法にはめっちゃ可能性があるんやけど、その自動化と人間によるプロンプトの設計・修正を組み合わせたやり方が一番うまくいったっちゅうことやな。この研究が、プロンプトエンジニアリングをもっとしっかり検証していくための一歩になったらええなって思ってるで。
---
## Page 44
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p044.png)
### 和訳
7 関連研究
ほな、このセクションではプロンプティングに関する既存のサーベイとかメタ分析をざっと振り返っていくで。まずLiuら(2023b)やけど、この人らはChatGPTが出てくる前の時代のプロンプトエンジニアリングについて、めっちゃ体系的にレビューしてんねん。プロンプトのテンプレート作り、回答のエンジニアリング、プロンプトのアンサンブル(要は複数のプロンプトを組み合わせるやつやな)、あとプロンプトチューニングとか、いろんな側面をカバーしとる。あの人らのレビューは、穴埋め形式とかソフトプロンプティング(モデルの内部パラメータをいじるやつやな)みたいな、ほんまにいろんなタイプのプロンプティングを幅広い言語モデルにわたって扱ってんねんけど、ワイらの方は「離散的なプレフィックスプロンプティング」——つまり文章の頭にテキストでプロンプトをくっつけるやつに絞って、その分もっと深掘りして議論しとるわけや。
Chenら(2023a)は、Chain-of-Thought(一歩ずつ考えさせるやつ)、Tree-of-Thought(木構造で考えさせるやつ)、Self-Consistency(何回も答えさせて多数決とるやつ)、Least-to-Most(簡単な問題から順番に解かせるやつ)みたいな人気のプロンプティング技法をレビューして、将来の研究の展望も示してくれとる。Whiteら(2023)とSchmidtら(2023)は、プロンプトパターンの分類体系を作ってんねんけど、これはソフトウェア開発でいうデザインパターンみたいなもんやな(プロンプティング技法とも似た発想や)。Gao(2023)は、技術者やない一般の人向けに、実践的なプロンプティング技法のチュートリアルを出しとる。SantuとFeng(2023)は、いろんな複雑なタスクをこなすために特定の性質を持ったプロンプトを設計できるような、プロンプトの汎用的な分類体系を提案しとるわ。Bubeckら(2023)は、初期バージョンのGPT-4に対していろんなプロンプティング手法を定性的に試して、GPT-4がどんだけのことできるか調べてんねん。Chuら(2023)は、推論タスクに関するChain-of-Thought系のプロンプティング手法をレビューしとる。もうちょい前の研究やと、Bommasaniら(2021)が基盤モデル全般の可能性とリスクについて広くレビュー・議論してるし、Dangら(2022)は、プロンプティングを人間とAIのインタラクションの新しいパラダイムとして捉えて、特にユーザーのプロンプト入力を支援するUIデザインに焦点を当てながら、インタラクティブなクリエイティブアプリケーション向けのプロンプティング戦略を議論しとる。こういった既存のサーベイに加えて、ワイらのレビューはもっと最新かつ形式化された体系的レビューを提供することを目指しとるんや。
あと、特定の分野とか下流のアプリケーション向けのプロンプティング技法をサーベイしてる一連の研究もあるで。Meskó(2023)とWangら(2023d)は、医療・ヘルスケア分野でのプロンプトエンジニアリングの推奨ユースケースと限界を示してくれとる。HestonとKhun(2023)は医学教育のユースケースにおけるプロンプトエンジニアリングのレビューをやっとる。PeskoffとStewart(2023)はChatGPTとYouChatに質問して、どんだけの分野をカバーできてるか評価しとるわ。Huaら(2024)はGPT-4を使った自動化アプローチで、メンタルヘルス領域におけるLLMの研究をレビューしとる。Wangら(2023c)は視覚モダリティ——つまり画像とか映像を扱う分野でのプロンプトエンジニアリングと関連モデルをレビューしてるし、Yangら(2023e)はマルチモーダル(テキストと画像とかを組み合わせる)プロンプティングの定性分析を包括的にまとめとって、特にGPT-4V(画像も理解できるGPT-4やな)に焦点を当ててるわ。Duranteら(2024)は、LLMベースの身体性エージェント——ロボットとか仮想空間で動くAIみたいなやつのマルチモーダルインタラクションをレビューしとる。Koら(2023b)は、ビジュアルアーティストの創作活動にText-to-Image生成モデル(テキストから画像作るやつやな)がどう使われてるかの文献をレビューしとる。Guptaら(2024)はトピックモデリングっていう手法を使って生成AIをレビューしてるし、Awaisら(2023)は視覚分野の基盤モデルを、いろんなプロンプティング技法も含めてレビューしとる。
Houら(2023)はソフトウェアエンジニアリングに関連するプロンプトエンジニアリング技法の体系的レビューをやっとって、Keeleら(2007)が開発したソフトウェアエンジニアリング専用の体系的レビュー手法を使ってるんや。Wangら(2023e)は大規模言語モデルを使ったソフトウェアテストの文献をレビューしとる。Zhangら(2023a)は、自動プログラム修復みたいなソフトウェアエンジニアリングタスクにおけるChatGPTのプロンプティング性能をレビューしとるわ。Neagu(2023)は、コンピュータサイエンス教育でプロンプトエンジニアリングをどう活かせるかについて体系的レビューをやっとる。Liら(2023j)は大規模言語モデルの公平性に関する文献をレビューしとるで。あと、関連する側面のサーベイとして、言語モデルのハルシネーション——つまりAIがもっともらしい嘘つく問題な(Huangら、2023b)、検証可能性(Liuら、2023a)、推論能力(Qiaoら、2022)、拡張(Mialonら、2023)、プロンプトの言語学的な特性(Leidingerら、2023)なんかもあるわ。
こういった研究とは違って、ワイらは幅広いカバレッジと一般的に適用可能なプロンプティング技法を対象にレビューしとるんや。ほんで、より一般的な先行・同時期のサーベイ(Liuら、2023b;Sahooら、2024;VatsalとDubey、2024)と比べても、このサーベイは移り変わりのめっちゃ速いこの分野の最新情報を提供しとる。さらに、プロンプティング技法の分類学的な整理と用語の標準化の出発点も提供してるんやで。しかも、「体系的」って自称してる多くの研究とは違って、ワイらの研究は体系的文献レビューの広く使われてる標準規格であるPRISMA(Pageら、2021)に基づいてやっとるっちゅうのがポイントやねん。
---
## Page 45
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p045.png)
### 和訳
その問題をちゃんと表現できてるかどうか、っちゅうことやねん。まずはシンプルなやり方から始めるんがええし、「この方法めっちゃ性能ええで!」みたいな主張にはちょっと疑いの目を持っとくのが大事やで。もうすでにプロンプトエンジニアリングやってる人らには、ワイらの分類体系が既存のテクニック同士の関係性を明らかにしてくれたらええなと思っとる。ほんで新しいテクニック開発してる人らには、ぜひワイらの分類体系の中に自分の新手法を位置づけてほしいし、現実に即したケーススタディとか具体例もちゃんと入れてほしいねん。
謝辞
Hal Daumé III、Adam Visokay、Jordan Boyd-Graberからのアドバイス、それからDiyi Yang、Brandon M. Stewart、Shubham Vatsal、Mason Marchetti、Aaron Tay、Andrea Vella、Allie Millerによるレビューに感謝するで。あとOpenAIからもろた1万ドル分のAPIクレジットと、Benjamin DiMarcoのデザイン作業にも感謝や。
8 結論
生成AIっちゅうのはめっちゃ新しい技術やねんけど、モデルが何できて何できへんかっていう理解は、まだまだ世間的には限られとるのが現状やねん。自然言語っちゅうのは柔軟で何でもありなインターフェースやし、モデルには「こうやって使ってください」みたいな分かりやすい手がかりがあんまりないねん。やから生成AIを使うっちゅうことは、言葉でコミュニケーションする時のお決まりの難しさ――例えば曖昧さとか、文脈の役割とか、途中で軌道修正が必要になるとか――そういうのを全部引き継いどるわけや。しかもそれに加えて、言葉の「理解」が人間の理解とは根本的に違うかもしれへん存在とコミュニケーションせなあかんっちゅう難しさもあるねん。ここで紹介したテクニックの多くは「創発的」って呼ばれてきたんやけど、もっと正確に言うたら「発見された」もんやねん――地道な実験とか、人間の推論からのアナロジーとか、あるいは純粋な偶然から生まれたもんやで。
この論文は、まだよう分からん未開の地の生き物を分類しようとする最初の試みやねん。できるだけ網羅的にしたつもりやけど、抜けとか重複はどうしてもあるやろな。ワイらの狙いは、今ある大量のプロンプトエンジニアリングのテクニックをカバーして、将来の手法も受け入れられるような分類体系と用語を提供することやねん。200以上のプロンプティングテクニック、それを取り巻くフレームワーク、ほんで使う時に気をつけなあかん安全性やセキュリティの問題について議論しとる。あと、モデルの実力と実際に問題に取り組む時にどんな感じかをはっきりイメージしてもらうために、2つのケーススタディも紹介しとるで。最後に、ワイらのスタンスはあくまで観察が中心であって、紹介したテクニックの有効性を保証するもんやないねん。この分野はまだ新しいし、評価方法もバラバラで標準化されてへん――どんなに丁寧に実験しても予想外の落とし穴があるかもしれへんし、モデルの出力自体が、意味は同じやのに入力をちょっと変えただけで変わってまうこともあるねん。やから読者の皆さんには、どんな主張もそのまま鵜呑みにせんといてほしいし、あるテクニックが別のモデルとか問題とかデータセットにそのまま使えるとは限らんっちゅうことを認識しといてほしいねん。
プロンプトエンジニアリング始めたばっかりの人には、ワイらのおすすめは機械学習全般で言われることとだいたい一緒やで。つまり、自分が解こうとしてる問題をちゃんと理解すること(入出力とかベンチマークのスコアばっかり気にするんやなくてな)、ほんで使っとるデータと評価指標が
---
## Page 46
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p046.png)
### 和訳
参考文献
Adept. 2023. ACT-1: 行動のためのTransformer。https://www.adept.ai/blog/act-1.
→ これはな、AIに「こういう操作して」って言ったら実際にやってくれるっていうモデルの話やねん。
Rishabh Agarwalら. 2024. めっちゃたくさんの例を見せて学ばせるIn-context Learning。arXiv preprint arXiv:2404.11018.
→ なんでかっていうと、例をいっぱい見せたほうがAIの性能がグンと上がるっていう研究やで。
Sweta Agrawalら. 2023. 機械翻訳のためのIn-context例の選び方。ACL 2023のFindings、8857〜8873ページ、トロント、カナダ。
→ 翻訳AIに「こういう例を参考にしてな」って見せるとき、どの例を選んだら一番ええかっていう話やねん。
Kabir Ahujaら. 2023. MEGA: 生成AIの多言語評価。EMNLP.
→ いろんな言語で生成AIがちゃんと使えるか、まとめて評価したろっていうベンチマークやな。
Rebuff AI. 2023. 自分で鍛え上がるプロンプトインジェクション検出器。
→ AIを騙そうとする悪い入力を自動で見抜いて、しかも自分でどんどん強くなるっていうセキュリティツールやで。
Anirudh Ajithら. 2024. InstructEval: 指示の選び方を体系的に評価する。NAACL 2024のFindings、4336〜4350ページ、メキシコシティ。
→ AIへの指示の出し方って色々あるけど、どれが一番ええかちゃんと比べてみたっていう研究やねん。
Sílvia AraújoとMicaela Aguiar. 2023. 英語からポルトガル語への科学論文翻訳をChatGPTと人間で比較した研究。CLEF.
→ 自動翻訳ツール使って科学論文を訳したとき、ChatGPTの評価と人間の評価ってどう違うんやろ?って調べたやつやな。
ArthurAI. 2024. Arthur Shield.
→ AIの安全を守るためのシールド、ガード機能みたいなもんやで。
Akari Asaiら. 2023. BUFFET: 少数の例で多言語間の知識移転ができるか、大規模言語モデルをベンチマークした研究。
→ ちょっとだけ例を見せて、違う言語にも応用できるかテストしたっていうめっちゃ実用的な話やねん。
Muhammad Awaisら. 2023. ビジョンの新時代を定義する基盤モデル:サーベイと展望。
→ 画像認識とかコンピュータビジョンの世界で、基盤モデルっていう超デカいAIがどう変えていくかをまとめた総説やで。
Abhijeet Awasthiら. 2023. 大規模言語モデルを使って多言語の意味解析器をブートストラップする。EACL 2023、2455〜2467ページ、ドゥブロヴニク、クロアチア。
→ でっかいAIモデルを土台にして、いろんな言語の意味を理解するパーサーを一から作り上げるっていう手法やな。
Yushi Baiら. 2023a. LongBench: 長い文章の理解力を測る日英バイリンガルのマルチタスクベンチマーク。
→ めっちゃ長い文章をAIがちゃんと理解できるか、いろんなタスクで試してみたっていう評価セットやねん。
Yushi Baiら. 2023b. 言語モデルを試験官にして基盤モデルをベンチマークする。NeurIPS 2023 Datasets and Benchmarks.
→ AIがAIを試験するっていう、ほんまにおもろいアプローチやで。
Chris Bakke. 2023. シボレーを1ドルで買う。
→ これはな、AIチャットボットを上手いこと騙して「1ドルで車売ります」って言わせたっていうめっちゃ有名な事例やねん。プロンプトインジェクションの実例やな。
Nishant Balepurら. 2023. 説明文の生成:模倣して、取ってきて、言い換える。EMNLP 2023、11896〜11919ページ、シンガポール。
→ わかりやすい説明文をAIに書かせるために、お手本を真似して、情報を引っ張ってきて、自分の言葉に直すっていう3段階の方法やで。
Yejin Bangら. 2023. ChatGPTの推論・ハルシネーション・対話性をマルチタスク・多言語・マルチモーダルで評価。AACL.
→ ChatGPTが嘘ついてないか、ちゃんと考えられるか、対話できるか、いろんな角度からめっちゃ徹底的にテストした研究やねん。
Hritik Bansalら. 2023. In-context Learningにおけるスケールの役割を再考する:660億パラメータでの解釈可能性に基づくケーススタディ。ACL.
→ モデルをデカくしたらIn-context Learningが良くなるって言うけど、ほんまにそうか?中身を覗いて確かめたっていう話やで。
Omer Bar-Talら. 2022. Text2LIVE: テキストで画像や動画をレイヤー編集する技術。
→ 「ここをこう変えて」ってテキストで指示するだけで画像や動画を編集できるっていう、めっちゃクールな技術やな。
Amanda Bertschら. 2024. 長いコンテキストを持つモデルでのIn-context Learning:徹底的な探究。arXiv preprint arXiv:2405.00200.
→ コンテキストウィンドウがめっちゃ長いモデルで、In-context Learningがどう変わるか深掘りした研究やねん。
Maciej Bestaら. 2024. Graph of Thoughts: 大規模言語モデルで複雑な問題を解く。AAAI 2024、38(16):17682〜17690.
→ AIの思考をグラフ構造にして、もっと複雑な問題も解けるようにしたろっていうアイデアやで。Chain of Thoughtの進化版みたいなもんやな。
Rishi Bommasaniら. 2023. (大量の著者陣)
→ これはスタンフォード大学を中心に、基盤モデルっていうAIの大きな流れについて、社会的影響も含めてほんまに網羅的にまとめた超大作の論文やねん。著者多すぎて全員書ききれんレベルやで。
---
## Page 47
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p047.png)
### 和訳
Rohith Kuditipudi、Ananya Kumar、Faisal Ladhak、Mina Lee、Tony Lee、Jure Leskovec、Isabelle Levent、Xiang Lisa Li、Xuechen Li、Tengyu Ma、Ali Malik、Christopher D. Manning、Suvir Mirchandani、Eric Mitchell、Zanele Munyikwa、Suraj Nair、Avanika Narayan、Deepak Narayanan、Benjamin Newman、Allen Nie、Juan Carlos Niebles、Hamed Nilforoshan、J. F. Nyarko、Giray Ogut、Laurel J. Orr、Isabel Papadimitriou、Joon Sung Park、Chris Piech、Eva Portelance、Christopher Potts、Aditi Raghunathan、Robert Reich、Hongyu Ren、Frieda Rong、Yusuf H. Roohani、Camilo Ruiz、Jack Ryan、Christopher Ré、Dorsa Sadigh、Shiori Sagawa、Keshav Santhanam、Andy Shih、Krishna Parasuram Srinivasan、Alex Tamkin、Rohan Taori、Armin W. Thomas、Florian Tramèr、Rose E. Wang、William Wang、Bohan Wu、Jiajun Wu、Yuhuai Wu、Sang Michael Xie、Michihiro Yasunaga、Jiaxuan You、Matei A. Zaharia、Michael Zhang、Tianyi Zhang、Xikun Zhang、Yuhui Zhang、Lucia Zheng、Kaitlyn Zhou、ほんでPercy Liang。2021年。「基盤モデルのチャンスとリスクについて」っていう論文やねん。要するに、めっちゃでかいAIモデル(基盤モデルって呼ばれてるやつ)がどんなええことできるか、逆にどんなヤバいことになりうるかをがっつり整理した論文や。ArXiv、abs/2108.07258。
Hezekiah J. Branch、Jonathan Rodriguez Cefalu、Jeremy McHugh、Leyla Hujer、Aditya Bahl、Daniel del Castillo Iglesias、Ron Heichman、ほんでRamesh Darwishi。2022年。「学習済み言語モデルが手作りの意地悪な例にどんだけ引っかかるか評価してみた」って研究やねん。なんでかっていうと、AIって一見賢そうやけど、人間がわざと作った引っかけ問題にどれくらい弱いんかってのは、セキュリティ的にめっちゃ大事やからな。
Greg Brockman、Vicki Cheung、Ludwig Pettersson、Jonas Schneider、John Schulman、Jie Tang、ほんでWojciech Zaremba。2016年。「OpenAI Gym」やで。これはAIの強化学習(ゲームみたいなもんで試行錯誤して賢くなるやつ)を試すための遊び場みたいなツールやねん。
Tim Brooks、Bill Peebles、Connor Homes、Will DePue、Yufei Guo、Li Jing、David Schnurr、Joe Taylor、Troy Luhman、Eric Luhman、Clarence Wing Yin Ng、Ricky Wang、ほんでAditya Ramesh。2024年。「動画生成モデルを世界シミュレーターとして使う」っていうOpenAIの研究や。つまり、AIで動画作るだけちゃうくて、現実世界のシミュレーションみたいなこともできるんちゃうかっていう話やねん。
Tom B. Brown、Benjamin Mann、Nick Ryder、Melanie Subbiah、Jared Kaplan、Prafulla Dhariwal、Arvind Neelakantan、Pranav Shyam、Girish Sastry、Amanda Askell、Sandhini Agarwal、Ariel Herbert-Voss、Gretchen Krueger、Tom Henighan、Rewon Child、Aditya Ramesh、Daniel M. Ziegler、Jeffrey Wu、Clemens Winter、Christopher Hesse、Mark Chen、Eric Sigler、Mateusz Litwin、Scott Gray、Benjamin Chess、Jack Clark、Christopher Berner、Sam McCandlish、Alec Radford、Ilya Sutskever、ほんでDario Amodei。2020年。「言語モデルはちょっと例を見せるだけで学習できるんやで」っていう、あのGPT-3の論文やな。ほんまに少しの例(few-shot)だけで色んなタスクこなせるっていうのを示した、めっちゃ有名な研究やで。
Sébastien Bubeck、Varun Chandrasekaran、Ronen Eldan、John A. Gehrke、Eric Horvitz、Ece Kamar、Peter Lee、Yin Tat Lee、Yuan-Fang Li、Scott M. Lundberg、Harsha Nori、Hamid Palangi、Marco Tulio Ribeiro、ほんでYi Zhang。2023年。「汎用人工知能の兆し:GPT-4を使った初期実験」やねん。ArXiv、abs/2303.12712。要するに「GPT-4、もしかしてAGI(人間レベルの汎用AI)にちょっと近づいてきてるんちゃう?」っていうのを色んな実験で検証した研究や。めっちゃ話題になったやつやで。
Nicholas Carlini、Florian Tramer、Eric Wallace、Matthew Jagielski、Ariel Herbert-Voss、Katherine Lee、Adam Roberts、Tom Brown、Dawn Song、Ulfar Erlingsson、Alina Oprea、ほんでColin Raffel。2021年。「でかい言語モデルから学習データを引っこ抜く」っていう研究やねん。AIが覚えてしまったデータをうまいこと引き出せてしまうっていう、プライバシー的にめっちゃヤバい話やで。
CDC(アメリカ疾病対策センター)。2023年。「自殺に関するデータと統計」。
Chi-Min Chan、Weize Chen、Yusheng Su、Jianxuan Yu、Wei Xue、Shanghang Zhang、Jie Fu、ほんでZhiyuan Liu。2024年。「ChatEval:複数のAIエージェントに討論させて、もっとええ評価者を作ろう」っていう研究やねん。ICLR(国際学習表現会議)っていうトップ会議で発表されたやつや。なんでかっていうと、AI一人に評価させるより、何人かで議論させた方がちゃんとした評価ができるんちゃうかっていうアイデアやな。
Ernie Chang、Pin-Jie Lin、Yang Li、Sidd Srinivasan、Gael Le Lan、David Kant、Yangyang Shi、Forrest Iandola、ほんでVikas Chandra。2023年。「条件付き音声生成のためのプロンプト編集をその場でやる方法」っていう研究やで。プロンプト(AIへの指示文)をうまいこといじって、欲しい音声を作り出すテクニックの話やな。
Harrison Chase。2022年。「LangChain」。これはLLM(大規模言語モデル)を使ったアプリを作るためのフレームワークやねん。めっちゃ有名やで。
Banghao Chen、Zhaofeng Zhang、Nicolas Langrené、ほんでShengxin Zhu。2023a。「大規模言語モデルでのプロンプトエンジニアリングの可能性を解き放つ:包括的レビュー」や。プロンプトの書き方ひとつでAIの性能がめっちゃ変わるんやけど、そのテクニックを全部まとめたレビュー論文やで。
Lingjiao Chen、Matei Zaharia、ほんでJames Zou。2023b。「ChatGPTの振る舞いって時間とともに変わってるん?」っていう研究やねん。arXivプレプリント arXiv:2307.09009。実はChatGPTってアップデートのたびに性能がコロコロ変わってるっていう、なかなかおもろい発見やで。
Shiqi Chen、Siyang Gao、ほんでJunxian He。2023c。「大規模言語モデルを使って要約の事実整合性を評価する」っていう研究や。arXivプレプリント arXiv:2305.14069。AIが作った要約がほんまに元の文章と合ってるかどうかを、また別のAIにチェックさせるっていう話やな。
Wenhu Chen、Xueguang Ma、Xinyi Wang、ほんでWilliam W. Cohen。2023d。「思考のプログラム(Program of Thoughts)プロンプティング:数値推論で計算と推論を分けたろう」っていう研究やねん。TMLR掲載。AIに数学の問題解かせるとき、考える部分と計算する部分を分けたらめっちゃ精度上がるっていう賢いやり方やで。
Xinyun Chen、Renat Aksitov、Uri Alon、Jie Ren、Kefan Xiao、Pengcheng Yin、Sushant Prakash、Charles Sutton、Xuezhi Wang、ほんでDenny Zhou。2023e。「大規模言語モデル生成のためのユニバーサル自己一貫性」や。AIに同じ問題を何回も解かせて、一番多い答えを採用するっていう手法をもっと汎用的にした研究やな。
Yang Chen、Yingwei Pan、Yehao Li、Ting Yao、ほんでTao Mei。2023f。「Control3D:テキストから制御可能な3D生成を目指して」。文章書くだけで3Dモデルが作れるんやけど、それをもっと自由にコントロールできるようにしようっていう研究やで。
Yi Chen、Rui Wang、Haiyun Jiang、Shuming Shi、ほんでRuifeng Xu。2023g。「大規模言語モデルを使った参照なしテキスト品質評価の探求:実証研究」やねん。ACL系の学会(IJCNLP-AACL 2023のFindings)で発表されたやつや。361〜374ページ、ヌサドゥア(バリ島)で開催。正解の参照文なしでも、AIにテキストの品質を評価させられるんちゃうかっていう研究やな。
Jiaxin Cheng、Tianjun Xiao、ほんでTong He。2023年。「合成データセットを使った一貫性のある動画から動画への変換」やで。ArXiv、abs/2311.00213。AIで作ったデータを使って、動画のスタイル変換をもっと安定させようっていう研究やな。
Yew Ken Chia、Guizhen Chen、Luu Anh Tuan、Soujanya Poria、ほんでLidong Bing。2023年。「対照的な思考連鎖プロンプティング」や。Chain-of-Thought(考える過程を書き出すやつ)に対照的な例も混ぜたら、もっと精度上がるんちゃうかっていうアイデアやねん。
Jiqun Chu、ほんでZuoquan Lin。2023年。「もつれ合った表現学習:双方向エンコーダ・デコーダモデル」やで。ACAI '22(アルゴリズム・コンピューティング・AI国際会議2022)の論文集に掲載。ニューヨーク、Association for Computing Machinery。エンコーダ(情報を圧縮するやつ)とデコーダ(復元するやつ)を双方向でうまいこと絡ませて、ええ感じの表現を学習させようっていう研究やな。
47ページ
---
## Page 48
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p048.png)
### 和訳
Zheng Chu、Jingchang Chen、Qianglong Chen、Weijiang Yu、Tao He、Haotian Wang、Weihua Peng、Ming Liu、Bing Qin、Ting Liu。2023年。「Chain of Thought推論のサーベイ:進歩と最前線と未来」。
→ これはな、AIに「順番に考えてみ?」って言うたら賢くなる、あの"思考の連鎖"っちゅうテクニックについて、どこまで進んでんのか、これからどうなるんか、ぜーんぶまとめたレビュー論文やねん。
Yi Dong、Ronghui Mu、Gaojie Jin、Yi Qi、Jinwei Hu、Xingyu Zhao、Jie Meng、Wenjie Ruan、Xiaowei Huang。2024年。「大規模言語モデルにガードレールを作る」。
→ でっかいAIモデルが暴走せんように、安全柵みたいなもん作りましょうやって話やな。めっちゃ大事やで。
Robert J Cramer、Jacinta Hawgood、Andréa R Kaniuka、Byron Brooks、Justin C Baker。2023年。「メンタルヘルス専門職のための自殺予防コアコンピテンシーの更新:トレーニング・研究・実践への示唆」。Clinical Psychology: Science and Practice。
→ メンタルヘルスの専門家が自殺予防でほんまに身につけなあかんスキルを最新版にアップデートしたで、って論文やな。トレーニングとか研究とか現場でどう活かすかも書いてあるねん。
Katherine Crowson、Stella Biderman、Daniel Kornis、Dashiell Stander、Eric Hallahan、Louis Castricato、Edward Raff。2022年。「VQGAN-CLIP:自然言語で自由自在に画像を作ったり編集したりする技術」。
→ 言葉で「こんな画像欲しいねん」って言うたら、AIがパパッと作ってくれる仕組みやで。しかもどんなジャンルでもいけるっていう、めっちゃすごいやつやねん。
Yann Dubois、Xuechen Li、Rohan Taori、Tianyi Zhang、Ishaan Gulrajani、Jimmy Ba、Carlos Guestrin、Percy Liang、Tatsunori B Hashimoto。2023年。「AlpacaFarm:人間のフィードバックから学ぶ手法のシミュレーションフレームワーク」。NeurIPS。
→ AIに人間が「ええやん」「あかんやん」って教えるプロセスを、シミュレーションで再現できる農場(ファーム)みたいな仕組み作ったで、って話やねん。めっちゃ効率的に実験できるようになるわけや。
Zane Durante、Qiuyuan Huang、Naoki Wake、Ran Gong、Jae Sung Park、Bidipta Sarkar、Rohan Taori、Yusuke Noda、Demetri Terzopoulos、Yejin Choi、Katsushi Ikeuchi、Hoi Vo、Fei-Fei Li、Jianfeng Gao。2024年。「エージェントAI:マルチモーダルインタラクションの地平を探る」。
→ AIが目も耳も手も使って、いろんな方法で人間とやりとりできるエージェントになる未来、その全体像をガーッと見渡したサーベイ論文やな。
Leyang Cui、Yu Wu、Jian Liu、Sen Yang、Yue Zhang。2021年。「BARTを使ったテンプレートベースの固有表現認識」。Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021。
→ 人名とか地名とか、文章の中から「これ固有名詞やな」って見つける作業を、BARTっていうモデルでテンプレート使ってうまいことやる方法やねん。
Hai Dang、Lukas Mecke、Florian Lehmann、Sven Goller、Daniel Buschek。2022年。「どうやってプロンプトする?:生成モデルのクリエイティブ応用における、ゼロショット・フューショット学習の可能性と課題」。
→ AIに「例えなしでやってみ」とか「ちょっとだけ例見せるからやってみ」って頼むとき、クリエイティブな使い方やとどんなチャンスと壁があるんか、っていう研究やで。
Maksym Del、Mark Fishel。2023年。「True Detective:GPT-3には無理で、GPT-4でも難しい、深い推論のベンチマーク」。第12回 語彙・計算意味論合同会議(*SEM 2023)の論文集。計算言語学会。
→ 「この結果から逆算して、なんでそうなったか推理してみ?」っていう、めっちゃ難しい推論テストを作ったんやけど、GPT-3は全然あかんくて、GPT-4でもなかなか苦戦するっていう、ほんまに手強いベンチマークやねん。
Mingkai Deng、Jianyu Wang、Cheng-Ping Hsieh、Yihan Wang、Han Guo、Tianmin Shu、Meng Song、Eric P. Xing、Zhiting Hu。2022年。「RLPrompt:強化学習でテキストプロンプトを最適化する」。
→ AIへの指示文(プロンプト)を、強化学習っていう試行錯誤の仕組みを使って自動的にベストな形に仕上げるっていう研究やで。人間が頑張って考えんでもええようになるわけや。
Yihe Deng、Weitong Zhang、Zixiang Chen、Quanquan Gu。2023年。「言い換えて答えよ:大規模言語モデルに自分でもっとええ質問をさせる」。
→ AIに「ちょっと質問の仕方変えてみ?」って自分で言い換えさせたら、答えの質がグンと上がるっていう、なるほどなーって感じの研究やねん。
Julen Etxaniz、Gorka Azkune、Aitor Soroa、Oier Lopez de Lacalle、Mikel Artetxe。2023年。「多言語モデルって英語で考えた方が賢いん?」。
→ いろんな言語わかるAIでも、結局のところ英語で考えさせた方がパフォーマンスええんちゃう?っていう疑問をガチで調べた研究やな。気になるテーマやで。
Angela Fan、Mike Lewis、Yann Dauphin。2018年。「階層型ニューラルネットワークによる物語生成」。第56回計算言語学会年次大会(第1巻:長論文)の論文集。計算言語学会。
→ AIにお話を書かせるんやけど、まず大まかな筋書き考えてから細かいとこ書いていく、っていう階層的なやり方で物語を作らせる研究やねん。
Li Fei-Fei、Rob Fergus、Pietro Perona。2006年。「物体カテゴリのワンショット学習」。IEEE Transactions on Pattern Analysis and Machine Intelligence、28:594-611。
→ たった1枚の画像見ただけで「あ、これはこういう種類のもんやな」って認識できるようにする、めっちゃ画期的な研究やで。人間の学習能力に近づこうとしてるわけやな。
Lincong Feng、Muyu Wang、Maoyu Wang、Kuo Xu、Xiaoli Liu。2023年。「MetaDreamer:テキストから3Dを効率的に作る、形とテクスチャを分離する手法」。
→ 文章から3Dモデルを作るとき、形と表面の模様を別々に扱うことで、めっちゃ効率よく高品質な3Dが作れるようにしたで、って話やねん。
Patrick Fernandes、Daniel Deutsch、Mara Finkelstein、Parker Riley、André Martins、Graham Neubig、Ankush Garg、Jonathan Clark、Markus Freitag、Orhan Firat。2023年。「悪魔はエラーの中に潜む:大規模言語モデルを使った機械翻訳のきめ細かい評価」。第8回機械翻訳会議の論文集、1066-1083頁、シンガポール。計算言語学会。
→ 機械翻訳の出来栄えを評価するのに、大規模AIモデルを使って細かーいエラーまでちゃんと見つけようっていう研究やな。なんでかっていうと、悪魔は細部に宿るからやで。
Shehzaad Dhuliawala、Mojtaba Komeili、Jing Xu、Roberta Raileanu、Xian Li、Asli Celikyilmaz、Jason Weston。2023年。「検証の連鎖で大規模言語モデルのハルシネーションを減らす」。
→ AIがウソついてまう問題(ハルシネーション)を、「ほんまにそれ合ってる?」って自分で何回もチェックさせることで減らすっていう手法やねん。めっちゃ実用的やで。
Chrisantha Fernando、Dylan Banarse、Henryk Michalewski、Simon Osindero、Tim Rocktäschel。2023年。「Promptbreeder:プロンプトの進化による自己参照的自己改善」。
→ AIへの指示文(プロンプト)を、生物の進化みたいに世代交代させて、どんどん良くしていくっていう、ほんまにSFみたいな研究やねん。プロンプトが自分で自分を改良していくんやで。
Shizhe Diao、Pengcheng Wang、Yong Lin、Tong Zhang。2023年。「大規模言語モデルのための、思考の連鎖を使ったアクティブプロンプティング」。
→ Chain-of-Thoughtの中でも、「どの問題にアノテーション付けたら一番効くん?」っていうのを能動的に選んで、効率よく性能上げる方法やで。
Jinlan Fu、See-Kiong Ng、Zhengbao Jiang、Pengfei Liu。2023a年。「GPTScore:思い通りに評価する」。arXivプレプリント arXiv:2302.04166。
→ AIの出力を評価するのに、GPTを使って自分の好きな基準でスコアつけられるようにしたで、っていう研究やな。
Ming Ding、Zhuoyi Yang、Wenyi Hong、Wendi Zheng、Chang Zhou、Da Yin、Junyang Lin、Xu Zou、Zhou Shao、Hongxia Yang、Jie Tang。2021年。「CogView:Transformerでテキストから画像生成をマスターする」。Advances in Neural Information Processing Systems、第34巻、19822-19835頁。Curran Associates, Inc.。
→ Transformerっていうめっちゃ賢いモデルの仕組みを使って、文章から画像をバチッと生成する技術やねん。
Qingxiu Dong、Lei Li、Damai Dai、Ce Zheng、Zhiyong Wu、Baobao Chang、Xu Sun、Jingjing Xu、Lei Li、Zhifang Sui。2023年。「文脈内学習(In-Context Learning)のサーベイ」。
→ AIに「こんな感じでやってな」って例を見せるだけで新しいタスクができるようになる、あのin-context learningについて全体像をまとめた論文やで。
Jinlan Fu、See-Kiong Ng、Pengfei Liu。2022年。「Polyglot Prompt:多言語マルチタスクのプロンプトトレーニング」。2022年自然言語処理における経験的手法に関する会議の論文集、9919-9935頁、アブダビ、アラブ首長国連邦。計算言語学会。
→ いろんな言語でいろんなタスクをこなせるように、プロンプトをまとめてトレーニングするっていう、めっちゃ欲張りやけど賢いアプローチやねん。
Yao Fu、Hao Peng、Ashish Sabharwal、Peter Clark、Tushar Khot。2023b年。「多段階推論のための複雑さベースのプロンプティング」。第11回国際学習表現会議(ICLR)。
→ 推論を何段階も踏まなあかん問題で、あえて複雑な例をプロンプトに入れた方がAIの性能上がるで、っていう研究やな。簡単な例ばっかり見せたらあかんってことやねん。
---
## Page 49
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p049.png)
### 和訳
Victor Gabillon, Mohammad Ghavamzadeh, Alessandro Lazaric, Sébastien Bubeck. 2011. マルチバンディットでベストな腕を見つけるっちゅう話。ようするに、スロットマシンがいっぱいある中で「どれが一番当たるねん?」っていうのを効率よく見極める方法やねん。Advances in Neural Information Processing Systems, volume 24. Curran Associates, Inc.
Rohit Girdhar, Mannat Singh, Andrew Brown, Quentin Duval, Samaneh Azadi, Sai Saketh Rambhatla, Akbar Shah, Xi Yin, Devi Parikh, Ishan Misra. 2023. Emu video: テキストから動画を作る仕組みを、まず画像を作ってからそれを元に動画にするっていう二段階に分けたったんやで。めっちゃ賢いやり方やな。
Deep Ganguli, Amanda Askell, Nicholas Schiefer, Thomas Liao, Kamilė Lukošiūtė, Anna Chen, Anna Goldie, Azalia Mirhoseini, Catherine Olsson, Danny Hernandez, ほか. 2023. 大規模言語モデルって、自分で「あ、これ道徳的にアカンわ」って気づいて修正できる能力があるんちゃう?っていう話。arXiv preprint arXiv:2302.07459.
Andrew Gao. 2023. 大規模言語モデルに対するプロンプトエンジニアリング、つまり「AIにどうやって上手いこと指示出すか」っちゅうテクニックの話やねん。SSRN.
Lingyu Gao, Aditi Chaudhary, Krishna Srinivasan, Kazuma Hashimoto, Karthik Raman, Michael Bendersky. 2023a. 大規模言語モデルで「これ曖昧やな〜」っていう部分をちゃんと意識しながら、例を見せて学ばせる方法(in-context learning)の研究やで。arXiv preprint arXiv:2309.07900.
Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, Graham Neubig. 2023b. PAL:プログラムの力を借りた言語モデルっちゅうやつやねん。なんでかっていうと、言語モデルだけやと計算とか苦手やから、プログラムに手伝ってもらおうっていう発想やな。Proceedings of the 40th International Conference on Machine Learning, ICML'23. JMLR.org.
Mingqi Gao, Jie Ruan, Renliang Sun, Xunjian Yin, Shiping Yang, Xiaojun Wan. 2023c. ChatGPTを使って人間みたいに要約の良し悪しを評価させてみたっちゅう研究やで。arXiv preprint arXiv:2304.02554.
Tianyu Gao, Adam Fisch, Danqi Chen. 2021. 事前学習済みの言語モデルを、少ない例でもめっちゃ上手く学習できるようにしたったっちゅう話やねん。Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 3816–3830, Online. Association for Computational Linguistics.
Marisa Garcia. 2024. エアカナダが「ほんまにびっくりするくらい嘘つきなAIチャットボット」の裁判で負けた話。ようは、AIが勝手に嘘の情報をお客さんに伝えてもうて、会社が責任取らなアカンくなったっちゅうことやな。Forbes.
Xavier Garcia, Yamini Bansal, Colin Cherry, George Foster, Maxim Krikun, Melvin Johnson, Orhan Firat. 2023. 機械翻訳において、ほんの数個の例を見せるだけでめっちゃ効果あるっていう、ちょっと信じられへんくらいの話やねん。Proceedings of the 40th International Conference on Machine Learning, ICML'23. JMLR.org.
MF Garnett, SC Curtin. 2023. アメリカにおける自殺死亡率、2001年から2021年までのデータやで。NCHS Data Brief, 464:1–8.
Yichen Gong, Delong Ran, Jinyuan Liu, Conglei Wang, Tianshuo Cong, Anyu Wang, Sisi Duan, Xiaoyun Wang. 2023. FigStep:大規模な視覚言語モデルに対して、文字を画像にして見せることでセキュリティを突破するっていう、ようは「画像で悪い指示を出したら騙せるんちゃう?」っていう脱獄手法の話やな。
Riley Goodside. 2022. GPT-3のプロンプトを悪用して、「前の指示全部無視しろ」っていう悪意のある入力でモデルを操る方法を見つけたっちゅう話やで。プロンプトインジェクションの元祖みたいなやつやな。
Google. 2023. Gemini:めっちゃ高性能なマルチモーダル(テキストも画像も動画も扱える)モデルのファミリーやで。
Zhibin Gou, Zhihong Shao, Yeyun Gong, Yelong Shen, Yujiu Yang, Nan Duan, Weizhu Chen. 2024a. CRITIC:大規模言語モデルが外部ツールを使いながら自分の間違いを自分で直せるっちゅう仕組みやねん。ほんまに賢いやろ?The Twelfth International Conference on Learning Representations.
Zhibin Gou, Zhihong Shao, Yeyun Gong, Yelong Shen, Yujiu Yang, Minlie Huang, Nan Duan, Weizhu Chen. 2024b. ToRA:数学の問題を解くときにツールを組み合わせて推論するエージェントやねん。計算はプログラムに任せて、推論は言語モデルがやるっちゅう分業体制やで。The Twelfth International Conference on Learning Representations.
Chuan Guo, Geoff Pleiss, Yu Sun, Kilian Q Weinberger. 2017. 最新のニューラルネットワークの「自信の度合い」がどれくらい正確かっちゅう話。ようするに、AIが「90%の確率で正解やで!」って言うたら、ほんまに90%当たってるんか?っちゅう校正(キャリブレーション)の問題やな。International conference on machine learning, pages 1321–1330. PMLR.
Han Guo, Bowen Tan, Zhengzhong Liu, Eric P. Xing, Zhiting Hu. 2022. ええデータが少ない状況でも、効率よくテキスト生成するための(ソフト)Q学習っちゅう手法の話やで。強化学習の考え方をテキスト生成に持ち込んだんやな。
Priyanka Gupta, Bosheng Ding, Chong Guan, Ding Ding. 2024. 生成AIについてのめっちゃ体系的なレビュー。トピックモデリングっちゅう技術を使って、生成AI研究の全体像を整理してみたっちゅう論文やで。Data and Information Management, page 100066.
Rishav Hada, Varun Gumma, Adrian Wynter, Harshita Diddee, Mohamed Ahmed, Monojit Choudhury, Kalika Bali, Sunayana Sitaram. 2024. 大規模言語モデルを評価者として使ったら、多言語の評価をスケールアップできるんちゃう?っちゅう問いに取り組んだ研究やねん。Findings of the Association for Computational Linguistics: EACL 2024, pages 1051–1070, St. Julian's, Malta. Association for Computational Linguistics.
Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé III, Kate Crawford. 2021. データセットのためのデータシート。ようは、データセットにも「取扱説明書」をちゃんとつけようやっちゅう提案やねん。どんなデータが入ってて、どうやって集めて、何に使ってええか、全部明記しようっていうめっちゃ大事な話やで。Communications of the ACM, 64(12):86–92.
Muhammad Usman Hadi, Qasem Al Tashi, Rizwan Qureshi, Abbas Shah, Amgad Muneer, Muhammad Irfan, ほか. 2023. 大規模言語モデルの包括的サーベイ。応用、課題、限界、将来の展望まで全部まとめてくれてるめっちゃありがたい論文やで。TechRxiv.
Marjan Ghazvininejad, Hila Gonen, Luke Zettlemoyer. 2023. 辞書を使ったフレーズレベルのプロンプティングで機械翻訳をやるっちゅう話。なんでかっていうと、辞書の情報をヒントとして言語モデルに渡したら翻訳の精度が上がるんちゃうかっていう発想やな。
Aparna Dhinakaran, Hakan Tekgul. 2023. ガードレール:これ何やねんっちゅう話と、NeMoとGuardrails AIを使ってLLMを安全に運用する方法やで。ようは、AIが変なこと言わんように柵を立てるようなもんやな。Online.
---
## Page 50
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p050.png)
### 和訳
Sherzod HakimovとDavid Schlangen(2023)。「言語空間の中の画像たち:でっかい言語モデルが視覚と言語のタスクにほんまに向いてるんか探ってみた話」。Association for Computational Linguistics: ACL 2023のFindings、14196〜14210ページ、トロント、カナダ。Association for Computational Linguistics。
Shibo Hao、Tianyang Liu、Zhen Wang、Zhiting Hu(2023)。「ToolkenGPT:凍結した言語モデルにツール埋め込みっちゅう技使って、めっちゃ大量のツールをくっつけたろって話」。NeurIPS。
Hangfeng He、Hongming Zhang、Dan Roth(2023a)。「SocrEval:ソクラテス式問答法を使った大規模言語モデルで、参照なしで推論を評価したろやないかっていう研究」。arXivプレプリント arXiv:2310.00074。
Zhiwei He、Tian Liang、Wenxiang Jiao、Zhuosheng Zhang、Yujiu Yang、Rui Wang、Zhaopeng Tu、Shuming Shi、Xing Wang(2023b)。「人間っぽい翻訳のやり方を大規模言語モデルで探ってみたで」。
Dan Hendrycks、Collin Burns、Steven Basart、Andy Zou、Mantas Mazeika、Dawn Song、Jacob Steinhardt(2021)。「めっちゃでっかいマルチタスクの言語理解力を測ったろっちゅう話」。ICLR。
Amr Hendy、Mohamed Gomaa Abdelrehim、Amr Sharaf、Vikas Raunak、Mohamed Gabr、Hitokazu Matsushita、Young Jin Kim、Mohamed Afify、Hany Hassan Awadalla(2023)。「GPTモデルって機械翻訳どんくらいイケてるん?徹底的に評価したったで」。ArXiv、abs/2302.09210。
Amir Hertz、Ron Mokady、Jay Tenenbaum、Kfir Aberman、Yael Pritch、Daniel Cohen-Or(2022)。「プロンプトからプロンプトへ:クロスアテンション制御で画像を編集するっちゅうやつ」。
T.F. HestonとC. Khun(2023)。「医学教育におけるプロンプトエンジニアリング」。Int. Med. Educ.、2:198〜205。
Tobias Hinz、Stefan Heinrich、Stefan Wermter(2022)。「テキストから画像を作るやつの、意味的なオブジェクト精度について」。IEEE Transactions on Pattern Analysis and Machine Intelligence、44(3):1552〜1565。
Xinyi Hou、Yanjie Zhao、Yue Liu、Zhou Yang、Kailong Wang、Li Li、Xiapu Luo、David Lo、John Grundy、Haoyu Wang(2023)。「ソフトウェア工学のための大規模言語モデル:ちゃんと体系的に文献レビューしたったで」。
Ming-Hao Hsu、Kai-Wei Chang、Shang-Wen Li、Hung yi Lee(2023)。「音声言語モデルでのインコンテキスト学習、ちょっと探検してみたで」。
Yining Hua、Fenglin Liu、Kailai Yang、Zehan Li、Yi han Sheu、Peilin Zhou、Lauren V. Moran、Sophia Ananiadou、Andrew Beam(2024)。「メンタルヘルスケアにおける大規模言語モデル:スコーピングレビューやで」。
Haoyang Huang、Tianyi Tang、Dongdong Zhang、Wayne Xin Zhao、Ting Song、Yan Xia、Furu Wei(2023a)。「LLMの中では全部の言語が平等ちゃうねん:言語をまたいだ思考プロンプティングで多言語の能力をアップさせたろって話」。
Jiaxin Huang、Shixiang Shane Gu、Le Hou、Yuexin Wu、Xuezhi Wang、Hongkun Yu、Jiawei Han(2022)。「大規模言語モデルは自分で自分を改善できるねん」。arXivプレプリント arXiv:2210.11610。
Lei Huang、Weijiang Yu、Weitao Ma、Weihong Zhong、Zhangyin Feng、Haotian Wang、Qianglong Chen、Weihua Peng、Xiaocheng Feng、Bing Qin、Ting Liu(2023b)。「大規模言語モデルのハルシネーション(嘘つき問題やな)に関するサーベイ:原理、分類、課題、ほんで未解決の問題について」。
Shaohan Huang、Li Dong、Wenhui Wang、Yaru Hao、Saksham Singhal、Shuming Ma、Tengchao Lv、Lei Cui、Owais Khan Mohammed、Barun Patra、Qiang Liu、Kriti Aggarwal、Zewen Chi、Johan Bjorck、Vishrav Chaudhary、Subhojit Som、Xia Song、Furu Wei(2023c)。「言語だけじゃ足りへんねん:知覚を言語モデルとちゃんと合わせなあかんっちゅう話」。
Hakan Inan、Kartikeya Upasani、Jianfeng Chi、Rashi Rungta、Krithika Iyer、Yuning Mao、Michael Tontchev、Qing Hu、Brian Fuller、Davide Testuggine、Madian Khabsa(2023)。「Llama Guard:LLMベースの入出力セーフガード、要するに人間とAIの会話を守る番人みたいなやつやな」。
Vivek Iyer、Pinzhen Chen、Alexandra Birch(2023)。「大規模言語モデル使って、機械翻訳の曖昧さをうまいこと解消したろっちゅう話」。
Ajay Jain、Ben Mildenhall、Jonathan T. Barron、Pieter Abbeel、Ben Poole(2022)。「ゼロショットでテキストからオブジェクト生成するDream Fieldsっちゅうやつ」。
Qi Jia、Siyu Ren、Yizhu Liu、Kenny Q Zhu(2023)。「基盤言語モデル使って、テキスト要約の忠実さをゼロショットで評価するで」。arXivプレプリント arXiv:2310.11648。
Yixing Jiang、Jeremy Irvin、Ji Hun Wang、Muhammad Ahmed Chaudhry、Jonathan H Chen、Andrew Y Ng(2024)。「マルチモーダル基盤モデルでのメニーショット・インコンテキスト学習、つまり例をめっちゃたくさん見せて学習させるやつや」。arXivプレプリント arXiv:2405.09798。
Zhengbao Jiang、Frank Xu、Luyu Gao、Zhiqing Sun、Qian Liu、Jane Dwivedi-Yu、Yiming Yang、Jamie Callan、Graham Neubig(2023)。「能動的検索拡張生成、要するに必要な情報を自分から取りに行くRAGやな」。2023 Conference on Empirical Methods in Natural Language Processingの論文集、7969〜7992ページ、シンガポール。Association for Computational Linguistics。
Zhengbao Jiang、Frank F. Xu、Jun Araki、Graham Neubig(2020)。「言語モデルが何を知ってるか、ワイらどうやったらわかるん?」。Transactions of the Association for Computational Linguistics、8:423〜438。
Wenxiang Jiao、Wenxuan Wang、Jen tse Huang、Xing Wang、Shuming Shi、Zhaopeng Tu(2023)。「ChatGPTってええ翻訳者なん?GPT-4をエンジンにしたらイエスやで!」。
Ziqi JinとWei Lu(2023)。「Tab-CoT:表形式のゼロショット思考の連鎖、つまり表を使って段階的に考えさせるやつやな」。
---
## Page 51
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p051.png)
### 和訳
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, Scott Johnston, Sheer El-Showk, Andy Jones, Nelson Elhage, Tristan Hume, Anna Chen, Yuntao Bai, Sam Bowman, Stanislav Fort, Deep Ganguli, Danny Hernandez, Josh Jacobson, Jackson Kernion, Shauna Kravec, Liane Lovitt, Kamal Ndousse, Catherine Olsson, Sam Ringer, Dario Amodei, Tom Brown, Jack Clark, Nicholas Joseph, Ben Mann, Sam McCandlish, Chris Olah, and Jared Kaplan. 2022. 言語モデルは(だいたい)自分が何知ってるか分かってんねん。
Ehud Karpas, Omri Abend, Yonatan Belinkov, Barak Lenz, Opher Lieber, Nir Ratner, Yoav Shoham, Hofit Bata, Yoav Levine, Kevin Leyton-Brown, Dor Muhlgay, Noam Rozen, Erez Schwartz, Gal Shachaf, Shai Shalev-Shwartz, Amnon Shashua, and Moshe Tenenholtz. 2022. MRKLシステム:でっかい言語モデルと外部の知識ソース、それから論理的な推論を全部くっつけた、モジュール式のニューロシンボリックなアーキテクチャの話やねん。
Staffs Keele et al. 2007. ソフトウェア工学で体系的な文献レビューやるためのガイドラインやで。
Nitish Shirish Keskar, Bryan McCann, Lav R. Varshney, Caiming Xiong, and Richard Socher. 2019. CTRL:生成をコントロールできる条件付きTransformer言語モデルやねん。なんでかっていうと、普通の言語モデルって出力を自由に操れへんけど、これやったら「こういう感じで書いて」って指定できるんよ。
Kimiya Keyvan and Jimmy Xiangji Huang. 2022. 会話型検索であいまいなクエリにどう対処すんねん?って話。テクニックとかアプローチ、ツール、課題をまとめたサーベイやで。ACM Computing Surveys, 55(6):1–40.
Muhammad Khalifa, Lajanugen Logeswaran, Moontae Lee, Honglak Lee, and Lu Wang. 2023. インコンテキスト学習のためのデモンストレーションのアンサンブル、つまりお手本をいろいろ組み合わせるやり方を探ってみたで。
Mahmoud Khalil, Ahmad Khalil, and Alioune Ngom. 2023. 画像分類タスクにおけるVision Transformer(画像を処理できるTransformer)のめっちゃ包括的な研究やねん。
Omar Khattab, Keshav Santhanam, Xiang Lisa Li, David Hall, Percy Liang, Christopher Potts, and Matei Zaharia. 2022. Demonstrate-Search-Predict:知識をめっちゃ使うNLPタスクのために、検索と言語モデルをうまいこと組み合わせる方法やで。
Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan, Saiful Haq, Ashutosh Sharma, Thomas T. Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts. 2023. DSPy:宣言的な言語モデルの呼び出しを、自分で勝手に良くなっていくパイプラインにコンパイルするっちゅうもんやねん。arXiv preprint arXiv:2310.03714.
Tushar Khot, Harsh Trivedi, Matthew Finlayson, Yao Fu, Kyle Richardson, Peter Clark, and Ashish Sabharwal. 2022. 分解プロンプティング:複雑なタスクをモジュールごとに分けて解くアプローチやで。要するに、でかい問題を小分けにして一個ずつ片付けていくねん。
Natalie Kiesler and Daniel Schiffner. 2023. プログラミング入門教育における大規模言語モデル:ChatGPTの成績と評価への影響について考えてみたで。arXiv preprint arXiv:2308.08572.
Hwichan Kim and Mamoru Komachi. 2023. ターゲット言語特有の例を使って、少数ショットのクロスリンガル転移(ある言語で学んだことを別の言語に活かすやつ)をパワーアップさせる話やで。In Findings of the Association for Computational Linguistics: ACL 2023, pages 747–767, Toronto, Canada. Association for Computational Linguistics.
Hyuhng Joon Kim, Hyunsoo Cho, Junyeob Kim, Taeuk Kim, Kang Min Yoo, and Sang goo Lee. 2022. 自己生成インコンテキスト学習:自己回帰型の言語モデルをお手本生成器として活用するっちゅうアイデアやねん。自分でお手本作って自分で学ぶ、めっちゃ賢いやろ?
Sunkyoung Kim, Dayeon Ki, Yireun Kim, and Jinsik Lee. 2023. 多言語モデルにおけるクロスリンガル転移能力を、インコンテキスト学習でブーストさせる方法やで。
Dayoon Ko, Sangho Lee, and Gunhee Kim. 2023a. 言語モデルはYouTubeのショート動画見て笑えるんか?っちゅう研究やねん。おもろいテーマやな。
Hyung-Kwon Ko, Gwanmo Park, Hyeon Jeon, Jaemin Jo, Juho Kim, and Jinwook Seo. 2023b. ビジュアルアーティストのクリエイティブな作品のための大規模テキストから画像生成モデルの話やで。Proceedings of the 28th International Conference on Intelligent User Interfaces.
Tom Kocmi and Christian Federmann. 2023a. GEMBA-MQM:GPT-4を使って翻訳品質のエラー箇所を見つけ出すっちゅう手法やねん。arXiv preprint arXiv:2310.13988.
Tom Kocmi and Christian Federmann. 2023b. 大規模言語モデルはほんまに翻訳品質の評価において最先端やで、という話。In Proceedings of the 24th Annual Conference of the European Association for Machine Translation, pages 193–203, Tampere, Finland. European Association for Machine Translation.
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. 大規模言語モデルはゼロショット推論者やねん。つまり、お手本なしでもいきなり推論できるっちゅうことや。
Sawan Kumar and Partha Talukdar. 2021. プライミングベースの少数ショット学習では、例の並び順を変えるだけで結果が良くなるで、という研究やねん。
Will Kurt. 2024. 言いたいことをちゃんと言え:「自由に喋らせてくれ」への返答。https://blog.dottxt.co/say-what-you-mean.html.
Gihyun Kwon and Jong Chul Ye. 2022. CLIPStyler:テキスト1個だけで画像のスタイル変換ができるっちゅうやつやで。めっちゃ手軽やん。
Lakera. 2024. Lakera Guard(AIの安全を守るためのツールやで)。
Bar Lanyado, Ortal Keizman, and Yair Divinsky. 2023. ChatGPTがおすすめしてくるパッケージ、ほんまに信用してええんか?っちゅう話やねん。Vulcan Cyber Blog.
Cindy Le, Congrui Hetang, Ang Cao, and Yihui He. 2023. EucliDreamer:Stable Diffusionのdepth機能を使って、3Dモデルに速くてクオリティの高いテクスチャを貼る方法やで。
51
---
## Page 52
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p052.png)
### 和訳
Soochan LeeとGunhee Kim(2023年)。「思考の再帰:言語モデルで複数の文脈をうまいこと推論するための分割統治アプローチ」。
これな、要するにデカい問題をちっちゃく分けて順番に考えさせるっちゅう方法やねん。言語モデルに複数の文脈をいっぺんに処理させるんやなくて、分けて攻略させるっちゅうわけや。
Xiaoqian Li、Ercong Nie、Sheng Liang(2023g)。「バングラ語のための言語横断型の検索で補強した文脈内学習」。
バングラ語みたいな言語でも、よその言語から関連情報を引っ張ってきて、文脈の中で学習させるっちゅう手法やで。
Alina Leidinger、Robert van Rooij、Ekaterina Shutova(2023年)。「プロンプトの言葉遣い:どんな言語的特徴がプロンプトを成功させるんか?」
これめっちゃおもろいテーマやねん。AIに指示出すとき、どんな言い回しやったらうまくいくんかっちゅうのを言語学的に調べとるんや。
Brian Lester、Rami Al-Rfou、Noah Constant(2021年)。「パラメータ効率のええプロンプトチューニングにおけるスケールの力」。自然言語処理の経験的手法に関する2021年会議の論文集にて発表。計算言語学会。
モデル全体をいじらんでも、プロンプトの部分だけチューニングしたら、モデルがデカなればなるほどめっちゃ効くで、っちゅう話や。
Patrick Lewis、Ethan Perez、Aleksandra Piktus、Fabio Petroni、Vladimir Karpukhin、Naman Goyal、Heinrich Küttler、Mike Lewis、Wen-tau Yih、Tim Rocktäschel、Sebastian Riedel、Douwe Kiela(2021年)。「知識ぎょうさん使うNLPタスクのための検索拡張生成(RAG)」。
これがいわゆるRAGっちゅうやつやねん。AIが答え出すときに、外部のデータベースから関連情報を検索して持ってきてから生成するっちゅう仕組みや。ほんまに画期的な論文やで。
Bowen Li、Xiaojuan Qi、Thomas Lukasiewicz、Philip H. S. Torr(2019a)。「制御可能なテキストから画像への生成」。
文章から画像を作るとき、もうちょい細かくコントロールできるようにしましょうっちゅう研究や。
Cheng Li、Jindong Wang、Yixuan Zhang、Kaijie Zhu、Wenxin Hou、Jianxun Lian、Fang Luo、Qiang Yang、Xing Xie(2023a)。「大規模言語モデルは感情的な刺激を理解して、それで性能アップもできるんやで」。
なんでかっていうと、「頑張って!」とか「これめっちゃ大事やねん!」みたいな感情的な言葉をプロンプトに入れると、AIの回答がよくなるっちゅうことがわかったんや。おもろいやろ?
Chengzhengxu Li、Xiaoming Liu、Yichen Wang、Duyi Li、Yu Lan、Chao Shen(2023b)。「プロンプトのための対話:少数事例学習のための方策勾配ベースの離散プロンプト最適化」。
少ない例からうまく学習させるために、強化学習の手法を使ってプロンプト自体を最適化していくっちゅうアプローチやねん。
Jiahao Li、Hao Tan、Kai Zhang、Zexiang Xu、Fujun Luan、Yinghao Xu、Yicong Hong、Kalyan Sunkavalli、Greg Shakhnarovich、Sai Bi(2023c)。「Instant3D:少数視点の生成と大規模再構成モデルによる高速テキストから3D生成」。
文章からパパッと3Dモデルを作る技術や。少ない角度の画像からでもバーンと3Dにしてまうねん。
Ming Li、Pan Zhou、Jia-Wei Liu、Jussi Keppo、Min Lin、Shuicheng Yan、Xiangyu Xu(2023d)。「Instant3D:テキストから3Dを一瞬で生成」。
こっちも同じ名前やけど別の研究で、テキストから3Dモデルを爆速で作るっちゅう話や。
Ruosen Li、Teerth Patel、Xinya Du(2023e)。「PRD:ピアランクと議論で大規模言語モデルベースの評価を改善する」。arXivプレプリント、arXiv:2307.02762。
AIに評価させるとき、複数のAIに議論させてランク付けさせたら、もっとまともな評価ができるようになるっちゅう研究やねん。
Wenbo Li、Pengchuan Zhang、Lei Zhang、Qiuyuan Huang、Xiaodong He、Siwei Lyu、Jianfeng Gao(2019b)。「敵対的学習によるオブジェクト駆動型テキストから画像への合成」。
画像の中のオブジェクト(物体)をベースにして、文章から画像を生成するっちゅう手法や。GANっちゅう敵対的な学習を使ってるねん。
Xiaonan Li、Kai Lv、Hang Yan、Tianyang Lin、Wei Zhu、Yuan Ni、Guotong Xie、Xiaoling Wang、Xipeng Qiu(2023f)。「文脈内学習のための統一的なデモンストレーション検索器」。
AIに「こんな感じでやってな」って例を見せるとき、どの例を見せるかを賢く選ぶための統一的な検索の仕組みを作ったっちゅう論文や。
Xiaonan LiとXipeng Qiu(2023a)。「文脈内学習のためのサポート例の見つけ方」。
これも似た話で、文脈内学習でどんな例を持ってきたら一番効果的かっちゅうのを研究してるんや。
Xiaonan LiとXipeng Qiu(2023b)。「MoT:思考の記憶でChatGPTが自分で自分を改善できるようになる」。
ChatGPTに過去の思考を記憶させて、それを使って自分自身の回答を改善させるっちゅうめっちゃ賢い仕組みやねん。
Xiujun Li、Xi Yin、Chunyuan Li、Pengchuan Zhang、Xiaowei Hu、Lei Zhang、Lijuan Wang、Houdong Hu、Li Dong、Furu Wei、Yejin Choi、Jianfeng Gao(2020年)。「Oscar:視覚と言語のタスクのためのオブジェクト意味整合型事前学習」。
画像の中のオブジェクトと言葉の意味をバチッと揃えてから事前学習させるっちゅう手法や。画像と言語を一緒に扱うタスクでめっちゃ効くねん。
Yaoyiran Li、Anna Korhonen、Ivan Vulić(2023h)。「大規模言語モデルによる二言語辞書の誘導について」。
大規模言語モデルを使って、2つの言語間の対訳辞書を自動で作れるかっちゅう研究やで。
Yifei Li、Zeqi Lin、Shizhuo Zhang、Qiang Fu、Bei Chen、Jian-Guang Lou、Weizhu Chen(2023i)。「ステップ認識型検証器で言語モデルの推論力をアップさせる」。計算言語学会第61回年次大会論文集(第1巻:長編論文)にて発表。
推論の各ステップが正しいかどうかをチェックする検証器を入れたら、言語モデルの推論がもっとしっかりするっちゅう話やねん。
Yingji Li、Mengnan Du、Rui Song、Xin Wang、Ying Wang(2023j)。「大規模言語モデルにおける公平性のサーベイ」。
大規模言語モデルが偏見なく公平に動いてるかっちゅうのをまとめた総合レビュー論文や。めっちゃ大事なテーマやで。
Jingyun Liang、Yuchen Fan、Kai Zhang、Radu Timofte、Luc Van Gool、Rakesh Ranjan(2023年)。「MoVideo:拡散モデルによる動き認識型ビデオ生成」。
動画を生成するとき、動きをちゃんと意識した拡散モデルを使うっちゅう研究や。自然な動きの動画が作れるようになるねん。
Chen-Hsuan Lin、Jun Gao、Luming Tang、Towaki Takikawa、Xiaohui Zeng、Xun Huang、Karsten Kreis、Sanja Fidler、Ming-Yu Liu、Tsung-Yi Lin(2023年)。「Magic3D:高解像度テキストから3Dコンテンツ制作」。
文章から高解像度の3Dモデルをバリバリ作れるっちゅうすごい技術やねん。
Xi Victoria Lin、Todor Mihaylov、Mikel Artetxe、Tianlu Wang、Shuohui Chen、Daniel Simig、Myle Ott、Naman Goyal、Shruti Bhosale、Jingfei Du、Ramakanth Pasunuru、Sam Shleifer、Punit Singh Koura、Vishrav Chaudhary、Brian O'Horo、Jeff Wang、Luke Zettlemoyer、Zornitsa Kozareva、Mona Diab、Veselin Stoyanov、Xian Li(2022年)。「多言語生成型言語モデルによる少数事例学習」。自然言語処理の経験的手法に関する2022年会議論文集、9019-9052ページ、アブダビ(アラブ首長国連邦)にて発表。計算言語学会。
いろんな言語を扱える生成型の言語モデルに、ちょっとだけ例を見せたらちゃんと学習できるんかっちゅうのを調べた研究やで。
Yen-Ting LinとYun-Nung Chen(2023年)。「LLM-Eval:大規模言語モデルを使ったオープンドメイン対話の統一的な多次元自動評価」。arXivプレプリント、arXiv:2305.13711。
AIの会話がどんだけ上手いかを、いろんな角度から自動で評価する仕組みを作ったっちゅう論文やねん。
Jerry Liu(2022年)。「LlamaIndex」。
これはAIが外部のデータを効率よく検索して使えるようにするためのツールやで。RAGとかやるときにめっちゃ便利なやつやねん。
Jiachang Liu、Dinghan Shen、Yizhe Zhang、Bill Dolan、Lawrence Carin、Weizhu Chen(2021年)。「GPT-3にとってええ文脈内学習の例って何なん?」。深層学習アーキテクチャのための知識抽出・統合ワークショップ、Deep Learning Inside Outにて発表。
GPT-3に例を見せて学習させるとき、どんな例がほんまに効果的なんかっちゅうのを徹底的に調べた研究や。めっちゃ実用的な知見が詰まっとるで。
---
## Page 53
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p053.png)
### 和訳
Nelson F Liu、Tianyi Zhang、Percy Liang。2023a。
生成型検索エンジンの検証可能性を評価する話やねん。
2023年の自然言語処理における経験的手法に関する学会(EMNLP)の論文集に載ってるやつな。要するに、AIが作った検索結果がほんまに正しいか確認できるんか?ってのを調べた研究やで。
Yao Lu、Max Bartolo、Alastair Moore、Sebastian Riedel、Pontus Stenetorp。2021。
めっちゃ絶妙に並べたプロンプトとその見つけ方:少数例プロンプトの並び順への敏感さを克服する話。
なんでかっていうと、AIに例を見せる順番をちょっと変えるだけで結果がガラッと変わってまうねん。それをなんとかしようっていう研究やな。
Pengfei Liu、Weizhe Yuan、Jinlan Fu、Zhengbao Jiang、Hiroaki Hayashi、Graham Neubig。2023b。
事前学習して、プロンプトして、予測する:自然言語処理におけるプロンプト手法の体系的サーベイ。
ACM Computing Surveys、55巻9号、1〜35ページ。
プロンプトっていうAIへの指示の出し方について、めっちゃ網羅的にまとめた総説論文やで。
Weihuang Liu、Xi Shen、Chi-Man Pun、Xiaodong Cun。2023c。
低レベル構造セグメンテーションのための明示的ビジュアルプロンプティング。
2023年のIEEE/CVFコンピュータビジョンとパターン認識の学会(CVPR)に載ってるやつ。画像の細かい部分を切り分ける作業を、視覚的なヒントを使ってうまいことやる研究やな。
Yang Liu、Dan Iter、Yichong Xu、Shuohang Wang、Ruochen Xu、Chenguang Zhu。2023d。
GPTEval:GPT-4を使った自然言語生成の評価で、人間の判断とめっちゃ合うようにした話。
arXivプレプリント arXiv:2303.16634。
AIが作った文章の良し悪しをGPT-4に評価させたら、人間の感覚にほんまに近い結果が出たんやで。
Yihao Liu、Xiangyu Chen、Xianzheng Ma、Xintao Wang、Jiantao Zhou、Yu Qiao、Chao Dong。2023e。
画像処理をビジュアルプロンプティングによる質問応答として統一する話。
いろんな画像処理のタスクを、全部「AIに画像で質問して答えてもらう」っていう一つの枠組みにまとめてもうたんやな。
Yongkang Liu、Shi Feng、Daling Wang、Yifei Zhang、Hinrich Schütze。2023f。
評価できひんもんを評価する:評価不能な生成応答の品質について。
arXivプレプリント arXiv:2305.14658。
AIが作った文章で、そもそも良し悪しの判断がつけにくいやつをどう評価するねんっていう、めっちゃ哲学的やけど大事な問題に取り組んだ研究やで。
Yuxin Liu、Minshan Xie、Hanyuan Liu、Tien-Tsin Wong。2023g。
同期マルチビュー拡散によるテキストガイドテクスチャリング。
文章で指示したら、3Dモデルの表面に複数の角度から矛盾なくテクスチャを貼ってくれるっていう技術やな。
Yuxuan Liu、Tianchi Yang、Shaohan Huang、Zihan Zhang、Haizhen Huang、Furu Wei、Weiwei Deng、Feng Sun、Qi Zhang。2023h。
大規模言語モデルベースの評価器のキャリブレーション。
arXivプレプリント arXiv:2309.13308。
AIに評価させる時の「偏り」を補正して、もっと正確に評価できるようにしようっていう研究やで。
Jieyi Long。2023。
大規模言語モデルによるツリー・オブ・ソート(思考の木)のガイド。
AIに考えさせる時、一直線やなくて木の枝みたいに複数の考えを広げていく方法を、AIが自分でガイドするっていう話やな。
Jonathan Lorraine、Kevin Xie、Xiaohui Zeng、Chen-Hsuan Lin、Towaki Takikawa、Nicholas Sharp、Tsung-Yi Lin、Ming-Yu Liu、Sanja Fidler、James Lucas。2023。
ATT3D:テキストから3Dオブジェクトを効率よく一括合成する手法。
文章を入力したら3Dの物体をパッと作れるようにした研究やで。しかも一個ずつやなくて、まとめて効率よく作れるのがミソやねん。
Albert Lu、Hongxin Zhang、Yanzhe Zhang、Xuezhi Wang、Diyi Yang。2023a。
プロンプト制約を使ったオープンテキスト生成における大規模言語モデルの能力の限界を探る話。
AIに自由に文章を書かせる時、プロンプトで縛りをかけたらどこまでちゃんとできるんか、その限界を調べたんやな。
Hongyuan Lu、Haoyang Huang、Dongdong Zhang、Haoran Yang、Wai Lam、Furu Wei。2023b。
辞書の連鎖プロンプティングで大規模言語モデルから翻訳を引き出す話。
辞書みたいなヒントを連鎖的に与えたら、AIの翻訳がめっちゃ良くなるっていう賢いやり方やで。
Qingyu Lu、Baopu Qiu、Liang Ding、Liping Xie、Dacheng Tao。2023c。
エラー分析プロンプティングで大規模言語モデルに人間っぽい翻訳評価をさせる話:ChatGPTのケーススタディ。
arXivプレプリント arXiv:2303.13809。
「ここがあかんで」って間違いを分析させるプロンプトを使ったら、ChatGPTが人間の翻訳評価者みたいに評価できるようになったんやで。
Yao Lu、Jiayi Wang、Raphael Tang、Sebastian Riedel、Pontus Stenetorp。2024。
バベルの図書館からの文字列:ランダムサンプリングがプロンプト最適化の強力なベースラインになるっていう話。
めっちゃ凝った方法を使わんでも、ランダムに選ぶだけでプロンプトの最適化けっこういけるやん、っていう意外な発見やな。
Charles Duffy、Luca Beurer-Kellner、Marc Fischer。2023。
LMQL。GitHubリポジトリ。
大規模言語モデルに対するクエリ言語のツールやで。プログラミングっぽくAIに指示が出せるやつやな。
Zheheng Luo、Qianqian Xie、Sophia Ananiadou。2023。
抽象型テキスト要約における事実の矛盾をChatGPTで評価する話。
arXivプレプリント arXiv:2303.15621。
AIが作った要約に事実と違うことが混じってへんか、ChatGPTにチェックさせたらどうなるかっていう研究やな。
Jiaxi Lv、Yi Huang、Mingfu Yan、Jiancheng Huang、Jianzhuang Liu、Yifan Liu、Yafei Wen、Xiaoxin Chen、Shifeng Chen。2023。
GPT4Motion:Blender向けGPTプランニングによるテキストから動画生成での物理的な動きのスクリプティング。
文章で「こう動かして」って言ったら、GPTが3Dソフトのblenderを使って物理法則に沿った動きの動画を作ってくれるっていうめっちゃおもろい研究やで。
Qing Lyu、Shreya Havaldar、Adam Stein、Li Zhang、Delip Rao、Eric Wong、Marianna Apidianaki、Chris Callison-Burch。2023。
忠実な思考の連鎖推論。
AIが「こう考えました」って見せる推論の過程が、ほんまに実際の答えを出す時の思考と一致してるんか、ちゃんと忠実にしようっていう研究やな。
Huan Ma、Changqing Zhang、Yatao Bian、Lemao Liu、Zhirui Zhang、Peilin Zhao、Shu Zhang、Huazhu Fu、Qinghua Hu、Bingzhe Wu。2023。
大規模言語モデルのための公平性ガイド付き少数例プロンプティング。
arXivプレプリント arXiv:2303.13217。
AIに少数の例を見せる時に、偏りが出んように公平性を意識してプロンプトを設計しようっていう研究やで。差別とかバイアスの問題に取り組んでるんやな。
Aman Madaan、Niket Tandon、Prakhar Gupta、Skyler Hallinan、Luyu Gao、Sarah Wiegreffe、Uri Alon、Nouha Dziri、Shrimai Prabhumoye、Yiming Yang、Shashank Gupta、Bodhisattwa Prasad Majumder、Katherine Hermann、Sean Welleck、Amir Yazdanbakhsh、Peter Clark。2023。
Self-Refine:自己フィードバックによる反復的な改良。
AIが自分で自分の出力を見直して「ここあかんな」って修正を繰り返していく仕組みやねん。人間がダメ出ししなくても、自分でどんどん良くしていくっていうめっちゃ賢い方法やで。
Ninareh Mehrabi、Fred Morstatter、Nripsuta Saxena、Kristina Lerman、Aram Galstyan。2021。
機械学習におけるバイアスと公平性に関するサーベイ。
ACM computing surveys (CSUR)、54巻6号、1〜35ページ。
AIの偏りと公平さの問題を全体的にまとめた総説やな。めっちゃ大事なテーマやで。
Laura Melzer、Thomas Forkmann、Tobias Teismann。2024。
自殺危機症候群:系統的レビュー。
Suicide and Life-Threatening Behavior誌。2月27日、オンライン先行公開。
自殺の危機的状態の症候群について、これまでの研究を体系的にまとめた論文やな。
Fanxu Meng、Haotong Yang、Yiding Wang、Muhan Zhang。2023。
画像の連鎖による直感的推論。
思考の連鎖(Chain of Thought)の画像版やな。言葉やなくて画像を連鎖的に使ってAIに推論させるっていうアイデアやで。
B. Meskó。2023。
医療専門家にとって重要な新スキルとしてのプロンプトエンジニアリング:チュートリアル。
Journal of Medical Internet Research、25巻(Suppl 1):e50638。
お医者さんもAIへの指示の出し方(プロンプトエンジニアリング)を覚えなあかん時代が来たでっていう、医療者向けのチュートリアル論文やな。
Yachun Mi、Yu Li、Yan Shu、Chen Hui、Puchao Zhou、Shaohui Liu。2023。
CLIF-VQA:人間の感情に関連する高レベルの意味情報を取り入れて動画品質評価を強化する話。
動画の画質を評価する時に、ただ見た目だけやなくて「人間がどう感じるか」っていう感情面の情報も加えたら、もっとええ評価ができるようになったっていう研究やで。
---
## Page 54
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p054.png)
### 和訳
Mialon, Dessì, Lomeli らのチーム(2023年)。「拡張された言語モデル:サーベイ」っちゅう論文やねん。要するに、言語モデルをパワーアップさせる方法をまとめて調べましたよ、っていう総まとめの研究やな。
Sewon Min, Xinxi Lyu, Ari Holtzman らのチーム(2022年)。「デモンストレーションの役割を考え直す:文脈内学習がうまくいく理由って何やねん?」っていう研究。つまり、AIに例を見せて学ばせるやり方、ほんまに何が効いてるんか突き詰めて調べたんやで。
Sewon Min, Julian Michael, Hannaneh Hajishirzi, Luke Zettlemoyer(2020年)。「AmbigQA:あいまいな質問にオープンドメインで答える」。プレプリント arXiv:2004.10645。なんかこう、質問自体がぼんやりしてる時にどう答えるかっちゅう話やねん。
Morelli, Bronzino, Goethe(1991年)。「人間とコンピュータの会話における計算的な発話行為モデル」。1991年のIEEE北東バイオエンジニアリング学会の論文集、263〜264ページ。これはめっちゃ昔の研究やけど、人間がコンピュータと喋る時のやりとりを数学的にモデル化しようとしたやつやな。
Yasmin Moslem, Rejwanul Haque, John D. Kelleher, Andy Way(2023年)。「大規模言語モデルを使った適応型機械翻訳」。ヨーロッパ機械翻訳協会の第24回年次学会の論文集、227〜237ページ、フィンランドのタンペレで発表。大規模言語モデルで翻訳をもっと賢く柔軟にしようや、っちゅう研究やで。
Fangwen Mu, Lin Shi, Song Wang らのチーム(2023年)。「ClarifyGPT:意図の明確化でLLMベースのコード生成をパワーアップさせる」。なんでかっていうと、AIにコード書かせる時って意図がちゃんと伝わらんとアカンやん?それをうまいことやろうっちゅう研究やねん。
Niklas Muennighoff, Thomas Wang, Lintang Sutawika らの大所帯チーム(2023年)。「マルチタスクのファインチューニングによる言語を超えた汎化」。計算言語学会(ACL)第61回年次大会の論文集(第1巻:長編論文)、15991〜16111ページ、カナダのトロントで発表。いろんなタスクをいっぺんに学習させたら、他の言語にも対応できるようになるんちゃう?って話やな。めっちゃページ数多いのが気合い入ってるわ。
Akshay Nambi, Vaibhav Balloli, Mercy Ranjit らのチーム(2023年)。「LEAPで言葉の壁をぶち破る:多言語LLMのための学習戦略」。多言語に対応できるAIをどう鍛えるか、っちゅうことやねん。
Milad Nasr, Nicholas Carlini, Jonathan Hayase らのチーム(2023年)。「(本番の)言語モデルから学習データをスケーラブルに抽出する」。これはほんまに怖い話で、実際に動いてる言語モデルから学習に使ったデータを引っこ抜けるで、っちゅう研究やな。
National Center for Health Workforce Analysis(米国保健人材分析センター)(2023年)。「行動健康の労働力、2023年版」。メンタルヘルスとかの分野でどんだけ人手がおるか調べたレポートやで。
Alexandra Neagu(2023年)。「大規模言語モデルとプロンプトエンジニアリングはコンピュータサイエンス教育にどう活かせるんか?:体系的な文献レビュー」。デルフト工科大学の修士論文、6月。教育にAIどう使うかを論文いっぱい調べてまとめた修論やな。
Ercong Nie, Sheng Liang, Helmut Schmid, Hinrich Schütze(2023年)。「低資源言語のためのクロスリンガル検索拡張プロンプト」。ACL 2023のFindings、8320〜8340ページ、カナダのトロント。データが少ない言語でも、他の言語から情報引っ張ってきてうまいこと対応しようっちゅう研究やで。
Xuefei Ning, Zinan Lin, Zixuan Zhou らのチーム(2023年)。「思考のスケルトン:大規模言語モデルは並列デコーディングができるんやで」。AIの回答を骨組みだけ先に作って、あとから並列で肉付けしたら速くなるんちゃう?っちゅうアイデアやねん。めっちゃ賢いやろ。
OpenAI(2023年)。「OpenAI Assistants」。OpenAIが出したアシスタント機能のことやな。
Jonas Oppenlaender(2023年)。「テキストから画像を生成する時のプロンプト修飾子の分類体系」。画像生成AIに指示出す時に使う言葉のバリエーションを整理した研究やで。
Anton Osika(2023年)。「gpt-engineer」。GPTを使ってエンジニアリングを自動化するプロジェクトやな。
Matthew J Page, Joanne E McKenzie らの大人数チーム(2021年)。「PRISMA 2020声明:システマティックレビューの報告ガイドラインの更新版」。BMJ, 372。これはめっちゃ有名なやつで、論文をちゃんと体系的にレビューする時の「こうやって報告しなさいよ」っちゅうルールブックの最新版やねん。
Ehsan Pajouheshgar, Yitao Xu, Alexander Mordvintsev らのチーム(2023年)。「メッシュ・ニューラル・セルオートマトン」。メッシュ(3Dの網目構造)の上でセルオートマトン(マス目が隣のマス目の状態見て変化するやつ)をニューラルネットワークで動かす研究やな。
Pruthvi Patel, Swaroop Mishra, Mihir Parmar, Chitta Baral(2022年)。「質問分解ユニットだけあれば十分なんちゃうの?」。複雑な質問を小さく分けて答えるやり方、それだけでいけるんかどうか検証した研究やで。
Shishir G. Patil, Tianjun Zhang, Xin Wang, Joseph E. Gonzalez(2023年)。「Gorilla:大量のAPIと繋がった大規模言語モデル」。ArXiv, abs/2305.15334。AIがいろんなAPIを呼び出せるようにした研究で、名前がゴリラってのがおもろいやろ。
Hammond Pearce, Baleegh Ahmad, Benjamin Tan, Brendan Dolan-Gavitt, Ramesh Karri(2021年)。「キーボードの前で寝てるんちゃう?GitHub Copilotが書いたコードのセキュリティを評価する」。AIが自動で書いたコード、ほんまに安全なんか?っちゅう話やねん。タイトルのセンスがええわ。
Hammond Pearce, Benjamin Tan, Baleegh Ahmad, Ramesh Karri, Brendan Dolan-Gavitt(2022年)。「大規模言語モデルによるゼロショット脆弱性修復を検証する」。AIにセキュリティの穴を直させたらどうなるか調べた研究やで。
Puyuan Peng, Brian Yan, Shinji Watanabe, David Harwath(2023年)。「ウェブスケール音声モデルの隠れた才能を引き出す:ゼロショットタスク汎化のためのプロンプティング」。大量のウェブデータで学習した音声モデルに、うまいことプロンプト出したら見たことないタスクもできるようになるんやで、っちゅう研究やな。
---
## Page 55
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p055.png)
### 和訳
Ethan Perezら(2022)。言語モデルを使って言語モデルをレッドチーミングする話やねん。要するに、AIにAIの弱点を突かせるっていう、めっちゃおもろいアプローチやで。
Fábio PerezとIan Ribeiro(2022)。前のプロンプト無視してや:言語モデルへの攻撃テクニックについて。これ、プロンプトインジェクションっていう攻撃手法そのものを論文タイトルに仕込んだやつやねん。なかなか攻めてるわ。
Neil Perryら(2022)。AIアシスタント使ったら、ユーザーはもっと危ないコード書いてまうんちゃう?っていう研究やで。AIに頼りすぎるとセキュリティ的にヤバいんちゃうかって話やな。
Denis PeskoffとBrandon M Stewart(2023)。クレジットなしでも信頼できるんか?っていうテーマで、その分野の専門家が生成AIの言語モデルを評価した論文やねん。計算言語学会(ACL)の第61回年次大会の短い論文セクション、427〜438ページに載ってるで。
Denis Peskoffら(2023)。GPTでFRB(アメリカの中央銀行みたいなとこ)のお偉いさんの発言を解読して、タカ派(金利上げたい派)とハト派(金利下げたい派)の意見の食い違いを数値化したっていう研究やねん。計算言語学会のEMNLP 2023のFindingsセクション、6529〜6539ページに掲載やで。
Denis Peskovら(2021)。言語と文化をまたいでエンティティ(固有名詞とか)をうまく適応させる方法についての論文やな。計算言語学会のEMNLP 2021のFindingsに載ってるで。
Fabio Petroniら(2019)。言語モデルって知識ベースとして使えるんちゃう?っていう問いかけの論文やねん。EMNLP-IJCNLP 2019で発表されたやつや。言語モデルが学習中にめっちゃ知識を溜め込んでるんちゃうかって話やで。
Pouya PezeshkpourとEstevam Hruschka(2023)。大規模言語モデルって、選択肢の並び順に敏感すぎひん?っていう研究やねん。同じ問題でも選択肢の順番変えたら答え変わるんかいっていう、ほんまにおもろい発見やで。arXivプレプリント、arXiv:2308.11483。
Carol W. Pfaff(1979)。スペイン語と英語のコードスイッチング(言語の切り替え)とか借用に関する制約についての研究やな。文の途中で言語を切り替えるのにもルールがあるんやで。Language誌、291〜318ページ。
Jonathan Pilaultら(2023)。対話型チェーンプロンプティングっていう手法で、言語をまたいだ条件付き文章生成のときの曖昧さを、やり取りしながら解消していくっていうアプローチやねん。
Ben Pooleら(2022)。DreamFusionっていう、2Dの拡散モデルを使ってテキストから3Dモデルを作る技術やで。文章書くだけで3Dのオブジェクトができるとか、めっちゃ夢あるやろ。
Shana Poplack(1980)。「たまにスペイン語で文を始めて、y termino en español(スペイン語で終わる)」っていう、まさにコードスイッチングを体現したタイトルの論文やねん。コードスイッチングの類型化に向けた研究や。Linguistics誌、18巻7-8号、581〜618ページ。
Archiki Prasadら(2023)。GrIPSっていう、勾配(微分)を使わずに編集ベースで大規模言語モデルへの指示文を探索する手法やで。ヨーロッパ計算言語学会(EACL)第17回大会、クロアチアのドゥブロヴニクで発表、3845〜3864ページ。
Preamble(2024)。うちの製品について。
Ofir Pressら(2022)。言語モデルの構成性ギャップ(複数の知識を組み合わせる力の差)を測って、それを縮める方法についての研究やねん。
Reid Pryzantら(2023)。「勾配降下法」とビームサーチを使って、プロンプトを自動的に最適化するっていう研究やで。なんでかっていうと、人間が手動でプロンプト調整するのめっちゃ大変やから、それを自動化したろうっていう発想やねん。
Ratish Puduppullyら(2023)。大規模言語モデルを使って、似た言語同士の機械翻訳をプロンプト分解でやる方法についてやな。
Bo Qiaoら(2023)。TaskWeaverっていう、コードファーストなエージェントフレームワークの話やで。ArXiv、abs/2311.17541。プログラムを書くことを中心に据えたAIエージェントの枠組みやねん。
Shuofei Qiaoら(2022)。言語モデルのプロンプティングで推論する方法についてのサーベイ(まとめ論文)やで。いろんな手法を整理してくれてるから、全体像つかむのにめっちゃええ論文やな。
Libo Qinら(2023a)。クロスリンガル・プロンプティングっていう、言語をまたいだゼロショットのチェーン・オブ・ソート推論を改善する研究やねん。要は、英語で考える力を他の言語にも活かそうっていう話やで。
Yujia Qinら(2023b)。基盤モデル(ファウンデーションモデル)を使ったツール学習についての論文やな。AIが外部ツールを使いこなせるようになる方法を研究してるんやで。ArXiv、abs/2304.08354。著者めっちゃ多いけど、それだけ大規模な研究やったんやろな。
Alec Radfordら(2021)。自然言語の教師信号から転移可能な視覚モデルを学習するっていう、CLIPの論文やねん。テキストと画像を一緒に学習させて、めっちゃ汎用的な画像認識ができるようになったっていう話やで。国際機械学習会議(ICML)、8748〜8763ページ。
Alec Radfordら(2019a)。言語モデルは教師なしのマルチタスク学習器やで、っていうGPT-2の論文やねん。OpenAIブログ、1巻8号、9ページ。
Alec Radfordら(2019b)。上と同じ論文やで。重複してるな。OpenAIブログ、1巻8号、9ページ。
Sudha RaoとHal Daumé III(2019)。回答ベースの敵対的学習で、明確化のための質問を生成する研究やな。曖昧なときに「それってどういう意味?」って聞き返す力をAIに持たせようっていう話やで。arXivプレプリント、arXiv:1904.02281。
---
## Page 56
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p056.png)
### 和訳
Traian Rebedea、Razvan Dinu、Makesh Sreedhar、Christopher Parisien、Jonathan Cohen。2023年。
Nemoガードレールズ:プログラムできるレールを使って、LLMアプリを安全にコントロールするためのツールキットやねん。arXiv。
Philip Resnik、April Foreman、Michelle Kuchuk、Katherine Musacchio Schafer、Beau Pinkham。2021年。
自殺予防のエビデンス(根拠)として、普段のことばをそのまま活用しようっていう話やねん。Suicide and Life-Threatening Behavior、51(1):88–96。
Laria Reynolds、Kyle McDonell。2021年。
でっかい言語モデルのためのプロンプトプログラミング:few-shot(少数例)パラダイムのその先へ。2021 CHI Conference on Human Factors in Computing Systems(人間とコンピュータの関わり方を考える学会)の拡張アブストラクト、CHI '21。ACM。
Megan L Rogers、Carol Chu、Thomas Joiner。2019年。
新しい診断カテゴリの必要性・妥当性・臨床での使いどころ:急性自殺性感情障害(ASAD)ってやつやねん。Journal of Clinical Psychology、75(6):999。
Robin Rombach、Andreas Blattmann、Dominik Lorenz、Patrick Esser、Björn Ommer。2022年。
潜在拡散モデル(Latent Diffusion Models)を使った高解像度の画像生成の話やで。めっちゃきれいな画像を作れるようになったんや。
Shamik Roy、Raphael Shu、Nikolaos Pappas、Elman Mansimov、Yi Zhang、Saab Mansour、Dan Roth。2023年。
Few-shot学習(ちょっとだけ例を見せる学習法)を使って会話のスタイルを変換するっていう研究やねん。第13回自然言語処理国際合同会議&計算言語学会アジア太平洋支部第3回大会(第1巻:長論文)の論文集、119–143ページ、ヌサドゥア、バリ。計算言語学会。
Ohad Rubin、Jonathan Herzig、Jonathan Berant。2022年。
文脈内学習(in-context learning)のためのプロンプトを自動で探してくる方法を学習させるっていう話やねん。2022年北米計算言語学会(NAACL)の論文集。計算言語学会。
Runway。2023年。Gen-2のプロンプトのコツ。https://help.runwayml.com/hc/en-us/articles/17329337959699-Gen-2-Prompt-Tips。
Pranab Sahoo、Ayush Kumar Singh、Sriparna Saha、Vinija Jain、Samrat Mondal、Aman Chadha。2024年。
大規模言語モデルにおけるプロンプトエンジニアリング(AIへの指示の出し方の技術)の体系的サーベイ:テクニックと応用をまとめたで。
Gustavo Sandoval、Hammond Pearce、Teo Nys、Ramesh Karri、Siddharth Garg、Brendan Dolan-Gavitt。2022年。
Cで迷子になった話:大規模言語モデルのコードアシスタントを使ったときのセキュリティへの影響をユーザー実験で調べたんやで。
Shubhra Kanti Karmaker Santu、Dongji Feng。2023年。
TELeR:複雑なタスクのベンチマーク用LLMプロンプトの一般的な分類体系やねん。
Timo Schick、Jane Dwivedi-Yu、Roberto Dessì、Roberta Raileanu、Maria Lomeli、Luke Zettlemoyer、Nicola Cancedda、Thomas Scialom。2023年。
Toolformer:言語モデルが自分でツールの使い方を覚えるっていう、めっちゃすごい話やねん。
Timo Schick、Hinrich Schütze。2020a年。
穴埋め問題(cloze questions)をうまいこと使って、少数例でテキスト分類や自然言語推論をやるっていう研究やで。ヨーロッパ計算言語学会大会。
Timo Schick、Hinrich Schütze。2020b年。
サイズだけがすべてやないねん:小さい言語モデルかて、少数例で学習できるんやで。ArXiv、abs/2009.07118。
Timo Schick、Hinrich Schütze。2021年。
穴埋め問題を活用した少数例テキスト分類と自然言語推論。第16回ヨーロッパ計算言語学会大会メインボリュームの論文集。計算言語学会。
Douglas C. Schmidt、Jesse Spencer-Smith、Quchen Fu、Jules White。2023年。
プロンプトエンジニアリングの学問をレベルアップさせるために、プロンプトパターンをカタログ化したで。ヴァンダービルト大学コンピュータサイエンス学科。
Allison Schuck、Raffaella Calati、Shira Barzilay、Sarah Bloch-Elkouby、Igor I. Galynker。2019a年。
自殺危機症候群:新しい自殺に特化した診断のための根拠をレビューした論文やねん。Behavioral sciences & the law、37(3):223–239。
Allison Schuck、Raffaella Calati、Shira Barzilay、Sarah Bloch-Elkouby、Igor Galynker。2019b年。
自殺危機症候群:自殺に特化した新しい診断を裏付けるエビデンスのレビューやで。Behavioral sciences and the law、37(3):223–239。
Sander Schulhoff。2022年。Learn Prompting(プロンプトの書き方を学ぼう)。
Sander Schulhoff、Jeremy Pinto、Anaum Khan、Louis-François Bouchard、Chenglei Si、Svetlina Anati、Valen Tagliabue、Anson Kost、Christopher Carnahan、Jordan Boyd-Graber。2023年。
このタイトル無視して!HackAPrompt:世界規模のプロンプトハッキング大会を通じて、LLMのシステム的な弱点をあぶり出す研究やねん。2023年自然言語処理における経験的手法の学会(EMNLP)論文集、4945–4977ページ、シンガポール。計算言語学会。
Sander V Schulhoff。2024年。
プロンプトインジェクション vs ジェイルブレイク:なにが違うん?っていう話やで。
Melanie Sclar、Yejin Choi、Yulia Tsvetkov、Alane Suhr。2023a年。
プロンプトの書き方のちょっとした違い(見せかけの特徴)に言語モデルがどんだけ敏感かを数値化した研究やねん。言い換えたら「プロンプトのフォーマットが気になりだして止まらへん」って話や。arXivプレプリント arXiv:2310.11324。
Melanie Sclar、Yejin Choi、Yulia Tsvetkov、Alane Suhr。2023b年。
言語モデルがプロンプトの書式の些細な違いにどんだけ振り回されるか定量化した話。ほんまにちょっとした書き方の違いで結果変わるから怖いねん。
Harsha-Nori Scott Lundberg、Marco Tulio Correia Ribeiro。2023年。guidance(ガイダンス)。GitHubリポジトリ。
56
---
## Page 57
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p057.png)
### 和訳
John R. Searle. 1969. 『言語行為:言語の哲学についての試論』Cambridge University Press.
→ これはな、言葉を使うってことはそれ自体が「行為」やねん、っていう話をめっちゃ真面目に哲学的に論じた本やで。言語哲学の超有名な一冊やな。
Omar Shaikh, Hongxin Zhang, William Held, Michael Bernstein, Diyi Yang. 2023. 「やっぱ待って、ステップ・バイ・ステップで考えるのやめとこ!ゼロショット推論におけるバイアスと毒性」
→ なんでかっていうと、「順を追って考えてみて」ってAIに言うたら、逆に偏見とか有害な回答が出やすくなることがあるねん。ほんまに皮肉な話やで。
Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R Bowman, Newton Cheng, Esin Durmus, Zac Hatfield-Dodds, Scott R Johnston, 他. 2023. 「言語モデルにおけるおべっか(シコファンシー)の理解に向けて」arXiv preprint arXiv:2310.13548.
→ AIがユーザーに媚び売って、相手の言うことに何でも「そうですね!」って合わせてまう問題を掘り下げた研究やな。めっちゃ大事なテーマやで。
Yongliang Shen, Kaitao Song, Xu Tan, Dong Sheng Li, Weiming Lu, Yue Ting Zhuang. 2023. 「HuggingGPT:ChatGPTとHugging Faceの仲間たちでAIタスクを解く」ArXiv, abs/2303.17580.
→ ChatGPTが司令塔になって、Hugging Faceにある色んなAIモデルを呼び出して使いこなすっていう、めっちゃ賢い仕組みの話やねん。
Freda Shi, Mirac Suzgun, Markus Freitag, Xuezhi Wang, Suraj Srivats, Soroush Vosoughi, Hyung Won Chung, Yi Tay, Sebastian Ruder, Denny Zhou, Dipanjan Das, Jason Wei. 2022. 「言語モデルは多言語の思考連鎖推論ができるんやで」
→ 英語だけちゃうねん、いろんな言語でも「順番に考える」ことができるって示した研究やな。
Taylor Shin, Yasaman Razeghi, Robert L Logan IV, Eric Wallace, Sameer Singh. 2020a. 「自動生成されたプロンプトを使って言語モデルから知識を引き出す」ArXiv, abs/2010.15980.
Taylor Shin, Yasaman Razeghi, Robert L. Logan IV, Eric Wallace, Sameer Singh. 2020b. 「AutoPrompt:自動生成プロンプトで言語モデルの知識を引き出す方法」2020年自然言語処理の実証的方法に関する会議(EMNLP).
→ この2つはほぼセットの研究で、人間が頑張ってプロンプト考えんでも、自動でええプロンプトを作ってAIの知識を引き出そうっていう話やねん。めっちゃ実用的やで。
Han-Chin Shing, Suraj Nair, Ayah Zirikly, Meir Friedenberg, Hal Daumé III, Philip Resnik. 2018. 「オンライン投稿による自殺リスクの専門家・クラウドソーシング・機械評価」計算言語学と臨床心理学に関する第5回ワークショップ:キーボードからクリニックへ、25-36頁、ニューオーリンズ、LA. 計算言語学会.
→ ネットの書き込みから自殺リスクを評価するのに、専門家・一般人・AIのそれぞれがどれくらいできるか比べた研究やな。ほんまにシリアスで大切なテーマやで。
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, Shunyu Yao. 2023. 「Reflexion:言葉による強化学習を使った言語エージェント」
→ AIが自分の行動を振り返って、言葉で反省して次に活かすっていう仕組みやねん。人間が「あー、あれ失敗やったな」って学ぶのと似たようなもんやな。
Chenglei Si, Dan Friedman, Nitish Joshi, Shi Feng, Danqi Chen, He He. 2023a. 「曖昧なデモンストレーションを使った文脈内学習の帰納バイアスの測定」計算言語学会(ACL).
→ AIに例を見せて学ばせるとき、例がはっきりせんかったらAIがどんな「クセ」を持って判断するか調べた研究やで。
Chenglei Si, Zhe Gan, Zhengyuan Yang, Shuohang Wang, Jianfeng Wang, Jordan Boyd-Graber, Lijuan Wang. 2023b. 「GPT-3を信頼できるようにプロンプトする方法」国際学習表現会議(ICLR).
→ GPT-3にうまいこと指示出して、もっと信頼できる回答をさせようっていう研究やな。
Chenglei Si, Navita Goyal, Sherry Tongshuang Wu, Chen Zhao, Shi Feng, Hal Daumé III, Jordan Boyd-Graber. 2023c. 「大規模言語モデルは人間の真偽判断を助けてくれる──ただし説得力のある間違いをするとき以外は」arXiv preprint arXiv:2310.12558.
→ AIが「これホンマやで!」って自信満々にウソ言うたら、人間も騙されてまうっていう、ちょっと怖い話やねん。
Chenglei Si, Weijia Shi, Chen Zhao, Luke Zettlemoyer, Jordan Lee Boyd-Graber. 2023d. 「言語モデル推論エキスパートの混合からもっと引き出す(MoRE)」自然言語処理の実証的方法の発見.
→ いろんな推論が得意なモデルを混ぜ合わせて、もっとええ結果を出そうっていう研究やな。
Suzanna Sia, Kevin Duh. 2023. 「文脈内学習を一貫性の維持として捉える:大規模言語モデルを使ったオンザフライ機械翻訳の研究」
→ AIが文脈を読んで翻訳するとき、「話の流れに一貫性を保つ」ことが大事やねんっていう視点の研究やで。
Significant Gravitas. 2023. AutoGPT.
→ これはめっちゃ話題になったやつやな。GPTが自分で考えて、自分でタスクをどんどんこなしていく自律型AIシステムやで。
Uriel Singer, Shelly Sheynin, Adam Polyak, Oron Ashual, Iurii Makarov, Filippos Kokkinos, Naman Goyal, Andrea Vedaldi, Devi Parikh, Justin Johnson, Yaniv Taigman. 2023. 「テキストから4Dの動的シーンを生成する」
→ 文章を入力したら、3Dどころか時間軸も含めた4Dの動く映像シーンを作れるっていう、めっちゃ未来感あふれる研究やねん。
Taylor Sorensen, Joshua Robinson, Christopher Rytting, Alexander Shaw, Kyle Rogers, Alexia Delorey, Mahmoud Khalil, Nancy Fulda, David Wingate. 2022. 「正解ラベルなしのプロンプトエンジニアリングへの情報理論的アプローチ」第60回計算言語学会年次大会(第1巻:長編論文)、819-862頁、ダブリン、アイルランド. 計算言語学会.
→ 正解データがなくても、情報理論を使ってええプロンプトを見つけ出そうっていう、なかなか賢いアプローチやで。
Andrea Sottana, Bin Liang, Kai Zou, Zheng Yuan. 2023. 「GPT-4時代の評価指標:系列変換タスクにおける大規模言語モデルの信頼性のある評価」arXiv preprint arXiv:2310.13800.
→ GPT-4みたいなすごいモデルが出てきた今、AIの出力をどうやってちゃんと評価するんかっていう問題に取り組んだ研究やな。
Michal Štefánik, Marek Kadlčík. 2023. 「文脈内学習者はデモンストレーションから推論の概念を学べるんか?」第1回自然言語推論と構造化説明ワークショップ(NLRSE)、107-115頁、トロント、カナダ. 計算言語学会.
→ 例を見せたら、AIは単に真似するだけちゃうくて「推論の考え方」自体を学べるんかっていう、なかなか深い問いやで。
Hongjin Su, Jungo Kasai, Chen Henry Wu, Weijia Shi, Tianlu Wang, Jiayi Xin, Rui Zhang, Mari Ostendorf, Luke Zettlemoyer, Noah A. Smith, Tao Yu. 2022. 「選択的なアノテーションで言語モデルをもっとええ少数ショット学習者にする」
→ 全部のデータにラベル付けせんでも、賢く選んだデータだけにラベル付けしたら、少ない例でもAIがめっちゃよく学べるっていう話やねん。
Zhi Rui Tam, Cheng-Kuang Wu, Yi-Lin Tsai, Chieh-Yen Lin, Hung yi Lee, Yun-Nung Chen. 2024. 「自由にしゃべらせてくれへん?大規模言語モデルの性能に対するフォーマット制限の影響に関する研究」
→ AIに「この形式で答えて」って縛りをかけると、実は性能が落ちることがあるねん。自由に答えさせた方がええ場合もあるっていう面白い研究やで。
Lv Tang, Peng-Tao Jiang, Hao-Ke Xiao, Bo Li. 2023. 「画像プロンプティング基盤モデルによるトレーニング不要のオープンワールド・セグメンテーションに向けて」
→ 追加学習なしで、画像を使ったプロンプトだけで何でも切り抜き(セグメンテーション)できるようにしようっていう研究やな。
Eshaan Tanwar, Subhabrata Dutta, Manish Borthakur, Tanmoy Chakraborty. 2023. 「多言語LLMはアラインメントがあるとクロスリンガルな文脈内学習がもっとうまくなるで」第61回計算言語学会年次大会.
→ 多言語対応のAIは、言語間の「すり合わせ(アラインメント)」がちゃんとできてると、他の言語の例からもめっちゃよく学べるっていう研究やねん。ほんまに言語の壁を超えていく感じやな。
---
## Page 58
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p058.png)
### 和訳
計算言語学会(第1巻:ロングペーパー)の論文集、6292〜6307ページ、カナダのトロントで開催。計算言語学会や。
Ming Taoら(2022年)。DF-GAN:テキストから画像を作る技術のシンプルでめっちゃ効果的なベースラインやねん。要は文章から絵を生成するっていう、あの技術のことやで。
Charlotte ThompsonとTiana Kelly(2023年)。「幻覚が現実になるとき:AIパッケージ幻覚攻撃の探求」。Darktraceのブログ記事や。AIが存在せんパッケージ名をでっち上げる、いわゆる「ハルシネーション」を悪用した攻撃について調べとるねん。
Katherine Tianら(2023年)。「キャリブレーションをお願いするだけでええねん:人間のフィードバックでファインチューニングした言語モデルから、ちゃんと調整された確信度スコアを引き出す戦略」。2023年の自然言語処理における経験的手法に関する会議の論文集、5433〜5442ページ、シンガポール。計算言語学会。要するに、AIに「自分の答えにどんだけ自信あんの?」って聞くだけで、結構まともな自信度が返ってくるっていう話やねん。
Lindia Tjuatjaら(2024年)。「LLMは人間みたいな回答バイアスを見せるんか?アンケート設計のケーススタディ」。計算言語学会トランザクション、12巻、1011〜1026ページ。大規模言語モデルが人間と同じような回答の偏りを持っとるかどうか調べた研究やな。
Hugo Touvronら(2023年)。「Llama 2:オープンな基盤モデルとファインチューニング済みチャットモデル」。めっちゃ大人数の著者がおるけど、要はMetaが出したオープンソースの大規模言語モデルの論文やねん。誰でも使えるようにしたやつやで。
Mark Towersら(2023年)。「Gymnasium」。強化学習の実験環境のことやな。AIにゲームとかシミュレーションで学習させるための道具箱みたいなもんや。
第61回計算言語学会年次大会(第1巻:ロングペーパー)の論文集、10014〜10037ページ、カナダのトロント。計算言語学会。
Rasul Tutunovら(2023年)。「なんで大規模言語モデルは正しい思考の連鎖を生成できるんやろ?」。ほんまに不思議やんな、なんでAIがステップバイステップで正しく推論できるのか、その理由を探った論文やで。
Shubham VatsalとHarsh Dubey(2024年)。「いろんなNLPタスクにおける大規模言語モデルのプロンプトエンジニアリング手法のサーベイ」。プロンプトっていうのはAIへの指示の出し方のことで、それをどうやったらうまくいくかをまとめた調査論文やねん。
Anton Voronovら(2024年)。「フォーマットに気をつけや:文脈内学習の改善を一貫して評価するために」。arXivプレプリント。AIに例題を見せて学ばせる「イン・コンテキスト学習」の評価方法について、ちゃんと統一しようや、って提案しとる論文やな。
Eric Wallaceら(2019年)。「NLPを攻撃・分析するための万能敵対的トリガー」。自然言語処理における経験的手法に関する会議。特定の単語列を入力に混ぜるだけで、AIの出力をめちゃくちゃにできるっていう、ちょっと怖い研究やで。
Xingchen Wanら(2023a)。「セルフアダプティブ・プロンプティングでゼロショット推論をもっとうまくやろうぜ」。事前に例を見せんでも(ゼロショット)、AIが自分で自分にええ感じのプロンプトを作って推論の精度を上げるっていう手法やねん。
Xingchen Wanら(2023b)。「ユニバーサル・セルフアダプティブ・プロンプティング」。上のやつをさらに発展させて、どんなタスクにも使えるようにした万能版やな。
Guanzhi Wangら(2023a)。「Voyager:大規模言語モデルを使ったオープンエンドの具現化エージェント」。マインクラフトみたいなゲームの中で、AIが自分で目標を見つけて探索し続けるエージェントの研究やねん。めっちゃおもろいで。
Jiaan Wangら(2023b)。「ChatGPTはええNLG評価者なんか?予備的研究」。arXivプレプリント。AIが生成したテキストの品質を、別のAI(ChatGPT)に評価させたらどうなるか調べた論文や。
Jiaqi Wangら(2023c)。「大規模ビジョンモデルとビジュアルプロンプトエンジニアリングのレビュー」。画像を扱うAIモデルと、それにどうやって指示を出すかっていう技術のまとめやな。
Jiaqi Wangら(2023d)。「ヘルスケアのためのプロンプトエンジニアリング:方法論と応用」。医療分野でAIにうまく指示を出す方法についてまとめた論文やで。お医者さんの世界でもプロンプトの工夫がめっちゃ大事やねん。
Harsh Trivediら(2023年)。「知識集約型の多段階質問に対して、検索と思考の連鎖推論を交互にやる手法」。論文集に掲載。なんでかっていうと、難しい質問に答えるには「調べる→考える→また調べる→また考える」を繰り返すのがええからやねん。
Junjie Wangら(2023e)。「大規模言語モデルによるソフトウェアテスト:サーベイ、全体像、そしてビジョン」。AIを使ってソフトウェアのバグを見つけたりテストしたりする研究の全体像をまとめた論文やで。
58ページ目やな。
---
## Page 59
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p059.png)
### 和訳
Lei Wang, Wanyu Xu, Yihuai Lan, Zhiqiang Hu, Yunshi Lan, Roy Ka-Wei Lee, Ee-Peng Lim. 2023f. 「計画して解決する」プロンプティング:でっかい言語モデルのゼロショット思考連鎖推論をもっとええ感じにする方法やねん。
Siyin Wang, Chao-Han Huck Yang, Ji Wu, Chao Zhang. 2023g. Whisperって音声ベースの文脈内学習できるんやろか、っていう研究やで。
Xinyi Wang, Wanrong Zhu, Michael Saxon, Mark Steyvers, William Yang Wang. 2023h. でっかい言語モデルって実は「潜在変数モデル」やねん:文脈内学習でええ感じのお手本を見つけたり、なんでそれがうまくいくか説明したりする話やで。
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, Denny Zhou. 2022. 自己一貫性で思考連鎖推論がめっちゃ良くなるっていう話。要するに、何回も答え出させて一番多い答えを選ぶと精度上がるねん。
Yaqing Wang, Jiepu Jiang, Mingyang Zhang, Cheng Li, Yi Liang, Qiaozhu Mei, Michael Bendersky. 2023i. でっかい言語モデル使って、パーソナライズされた文章生成を自動で評価する方法やで。arXivプレプリント arXiv:2310.11593。
Yaqing Wang, Quanming Yao, James Kwok, Lionel M. Ni. 2019. ちょっとの例からどうやって一般化するん?っていう、少数ショット学習のサーベイ論文やな。
Yuqing Wang, Yun Zhao. 2024. メタ認知プロンプティングっていうテクニックで、でっかい言語モデルの理解力がめっちゃ上がるって話やねん。自分の思考を振り返らせるんがポイントやで。
Zekun Moore Wang, Zhongyuan Peng, Haoran Que, Jiaheng Liu, Wangchunshu Zhou, Yuhan Wu, Hongcheng Guo, Ruitong Gan, Zehao Ni, Man Zhang, Zhaoxiang Zhang, Wanli Ouyang, Ke Xu, Wenhu Chen, Jie Fu, Junran Peng. 2023j. RoleLLM:でっかい言語モデルのロールプレイ能力をベンチマークして、引き出して、さらに強化するっていう研究やねん。キャラになりきる力を測る話やな。
Zhendong Wang, Yifan Jiang, Yadong Lu, Yelong Shen, Pengcheng He, Weizhu Chen, Zhangyang Wang, Mingyuan Zhou. 2023k. 拡散モデルでも文脈内学習ができるようになったで、っていう話やねん。画像生成の世界にも文脈内学習の波が来とるわけや。
Zhenhailong Wang, Shaoguang Mao, Wenshan Wu, Tao Ge, Furu Wei, Heng Ji. 2023l. でっかい言語モデルの中で認知的シナジーを解き放つ話やねん。複数のペルソナが自分の中で協力し合ってタスク解決するエージェントを作るっちゅうことや。めっちゃおもろいアプローチやで。
Jason Wei, Maarten Bosma, Vincent Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, Quoc V Le. 2022a. ファインチューニングした言語モデルはゼロショット学習者やで、っていう研究。ICLR(国際学習表現会議)で発表されとるやつやな。
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, Denny Zhou. 2022b. 思考連鎖プロンプティング(Chain-of-Thought)ででっかい言語モデルから推論能力を引き出すっていう、めっちゃ有名な論文やで。
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, Denny Zhou. 2023a. 上と同じ思考連鎖プロンプティングの論文の2023年版やな。
Jerry Wei, Da Huang, Yifeng Lu, Denny Zhou, Quoc V Le. 2023b. シンプルな合成データででっかい言語モデルの「おべっか体質」を減らせるっていう話やねん。モデルがユーザーに媚びるのを抑えられるんやで。arXivプレプリント arXiv:2308.03958。
Jerry Wei, Jason Wei, Yi Tay, Dustin Tran, Albert Webson, Yifeng Lu, Xinyun Chen, Hanxiao Liu, Da Huang, Denny Zhou, ほか. 2023c. もっとでっかい言語モデルは文脈内学習のやり方が違うねん、っていう発見やで。サイズによって学習の仕方が変わってくるんやな。arXivプレプリント arXiv:2303.03846。
Yixuan Weng, Minjun Zhu, Fei Xia, Bin Li, Shizhu He, Shengping Liu, Bin Sun, Kang Liu, Jun Zhao. 2022. でっかい言語モデルは自己検証させた方がもっとええ推論できるで、っていう研究やねん。自分で答え合わせさせるんがコツやな。
Jason Weston, Sainbayar Sukhbaatar. 2023. 「System 2 アテンション」っていうやつで、これはあんたにも必要かもしれへんで。人間の「じっくり考えるモード」みたいなアテンション機構の話やねん。
Jules White, Quchen Fu, Sam Hays, Michael Sandborn, Carlos Olea, Henry Gilbert, Ashraf Elnashar, Jesse Spencer-Smith, Douglas C. Schmidt. 2023. ChatGPTでのプロンプトエンジニアリングを強化するためのプロンプトパターンカタログやで。使えるパターンをまとめてくれとるんやな。
Alex Wilf, Sihyun Shawn Lee, Paul Pu Liang, Louis-Philippe Morency. 2023. 「二度考えろ」:視点転換ででっかい言語モデルの「心の理論」能力がめっちゃ上がるっていう話やねん。相手の立場に立って考えさせるとAIも賢くなるんやで。
Simon Willison. 2022. GPT-3に対するプロンプトインジェクション攻撃の話やな。悪意ある指示を忍び込ませてAIを騙すやつやで。
Simon Willison. 2024. プロンプトインジェクションとジェイルブレイクは同じもんちゃうで、っていう大事な指摘やねん。混同したらあかんのや。
Genta Indra Winata, Liang-Kang Huang, Soumya Vadlamannati, Yash Chandarana. 2023. 言語モデル検索を使った多言語の少数ショット学習の話やで。いろんな言語でもちょっとの例から学べるようにする研究やな。
Jay Zhangjie Wu, Yixiao Ge, Xintao Wang, Weixian Lei, Yuchao Gu, Yufei Shi, Wynne Hsu, Ying Shan, Xiaohu Qie, Mike Zheng Shou. 2023a. Tune-A-Video:画像の拡散モデルを1回だけチューニングして、テキストから動画を生成するっていうめっちゃおもろい研究やで。たった1つの動画から学習できるんやな。
Ning Wu, Ming Gong, Linjun Shou, Shining Liang, Daxin Jiang. 2023b. でっかい言語モデルは要約の評価において多様な役割を演じるプレイヤーやで、っていう話やねん。arXivプレプリント arXiv:2303.15078。
Tongshuang Wu, Michael Terry, Carrie Jun Cai. 2022. AIチェーン:でっかい言語モデルのプロンプトを連鎖させることで、透明性があってコントロールしやすい人間とAIのインタラクションを実現する話やで。CHI(人間工学の学会)で発表されとるやつやな。
Xiaodong Wu, Ran Duan, Jianbing Ni. 2023c. ChatGPTのセキュリティ、プライバシー、倫理的な問題点を明らかにするっていう論文やで。Journal of Information and Intelligenceに載っとるやつやな。ほんまに大事な話やで。
59
---
## Page 60
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p060.png)
### 和訳
Xia, Xing, Du, Yang, Feng, Xu, Yin, Xiong(2024)「Fofo:LLMがフォーマット(書式)をちゃんと守れるか評価するベンチマーク」
→ ようはな、AIに「この形式で答えてや」って言うたとき、ほんまにその通りに出力できるんかをテストする仕組みやねん。
Xiong, Hu, Lu, Li, Fu, He, Hooi(2023a)「LLMは自分の不確かさを表現できるんか?信頼度の引き出しに関する実験的評価」arXiv プレプリント arXiv:2306.13063
→ AIが「これ、ちょっと自信ないねんけど…」みたいに、自分がどんだけ確信持ってるか言えるんかを実験で調べた研究やで。
Xiong, Hu, Lu, Li, Fu, He, Hooi(2023b)「LLMは自分の不確かさを表現できるんか?信頼度の引き出しに関する実験的評価」arXiv プレプリント arXiv:2306.13063
→ 上と同じ論文やな。
Xu, Tao, Shen, Xu, Xu, Long, Lou(2023)「もっかい読み直したら言語モデルの推論力上がるで」
→ めっちゃおもろい話でな、問題文をもう1回読ませるだけで、AIの考える力がアップするっちゅう研究やねん。
Yao, Li, Zhao(2023c)「思考の連鎖だけちゃう、LLMにおける効果的な"思考のグラフ"推論」
→ 普通は一本道で考えるんやけど(Chain-of-Thought)、グラフみたいに枝分かれさせて考えたらもっとええで、っちゅう話や。
Yasunaga, Chen, Li, Pasupat, Leskovec, Liang, Chi, Zhou(2023)「LLMを"類推で考える推論者"として使う」
→ 「これ、前に似たようなことあったやん?」みたいに、類推(アナロジー)で問題を解く方法をLLMに使わせる研究やな。
Ye, Axmed, Pryzant, Khani(2023)「プロンプトエンジニアをプロンプトエンジニアリングする」
→ タイトルがもうおもろいやろ。プロンプト(AIへの指示文)を作る作業自体を、AIに自動でやらせようっちゅう研究やねん。
Ye, Durrett(2023)「ラベルなしデータを使った思考連鎖プロンプティングのための説明選択」
→ Chain-of-Thoughtで使う説明の例をな、正解ラベルがないデータからうまいこと選ぶ方法を提案してるで。
Yoo, Kim, Kim, Cho, Jo, Lee, Lee, Kim(2022)「正解ラベルはやっぱり大事やで:入力とラベルのデモンストレーションをもっと深掘りする」
→ AIに例を見せるとき、正解ラベルがちゃんとついてるかどうかがめっちゃ影響するんやで、っちゅう研究や。
Xue, Wang, Wang, Han, Yu, Ji(2023)「RCoT:思考の連鎖を逆にたどって、推論の事実的な矛盾を検出・修正する」
→ なんでかっていうと、AIが考えた道筋を逆向きにチェックしたら、「あれ、ここおかしくない?」って間違いを見つけて直せるねん。めっちゃ賢いアプローチやな。
Yoran, Wolfson, Bogin, Katz, Deutch, Berant(2023)「複数の思考連鎖をメタ推論して質問に答える」
→ 1本の考え方だけやなくて、何本もの思考の道筋を俯瞰的に見て、一番ええ答えを出そうっちゅう話やで。
Yang, Wang, Lu, Liu, Le, Zhou, Chen(2023a)「LLMを最適化ツールとして使う」
→ AIに「一番ええやつ探してきて」って頼んだら、最適化問題を解いてくれるっちゅうことやねん。
Yang, Chen, Pan, Yao, Chen, Mei(2023b)「3DStyle-Diffusion:2D拡散モデルを使って、テキストから細かい3Dスタイリングを実現する」
→ 文章で「こんな感じにして」って言うたら、3Dモデルの見た目をええ感じに変えてくれる技術やで。2Dの画像生成モデルをうまいこと3Dに応用してるねん。
Yang, Yue, He(2023c)「オンライン意思決定のためのAutoGPT:ベンチマークと追加の考察」
→ AutoGPTっていう自律型AIエージェントが、リアルタイムの判断をどんだけうまいことできるか評価した研究やな。
Yang, Zhan, Wong, Wu, Chao(2023d)「LLMを使った人間参加型の機械翻訳」機械翻訳サミットXIX 第2巻:ユーザートラック、pp.88-98、マカオ
→ 翻訳AIに人間がちょいちょい手を入れながら一緒に翻訳する仕組みやねん。人間とAIの共同作業ってやつやな。
Yang, Li, Lin, Wang, Lin, Liu, Wang(2023e)「LMM(大規模マルチモーダルモデル)の夜明け:GPT-4V(ision)による予備的な探究」ArXiv, abs/2309.17421
→ GPT-4の画像認識バージョンが出てきて、「これ、めっちゃすごない?」っていろいろ試してみた研究やで。マルチモーダル(テキスト+画像)AIの新時代の始まりを感じさせる内容やねん。
Yao, Jiang, Yang, Hu(2023a)「文化的な意識を持たせたLLMベースの機械翻訳」
→ ただ翻訳するだけやなくて、その国の文化とか背景もわかった上で翻訳できるようにしよう、っちゅう研究やな。ほんまに大事なことやで。
Yao, Yu, Zhao, Shafran, Griffiths, Cao, Narasimhan(2023b)「思考の木:LLMによる熟慮型の問題解決」
→ これめっちゃ有名な研究やねん。一本道で考える(Chain-of-Thought)んやなくて、木みたいに枝分かれさせて、いろんな可能性を探りながら問題を解くアプローチや。
Yao, Zhao, Yu, Du, Shafran, Narasimhan, Cao(2022)「ReAct:言語モデルにおける推論と行動の相乗効果」
→ AIに「考える」だけやなくて「行動する」(ツールを使ったり検索したり)もさせて、その両方を組み合わせたらめっちゃ強なるで、っちゅう話や。これもほんまに影響力でかい研究やな。
Yousaf, Naseer, Khan, Khan, Shah(2023)「VideoPrompter:ゼロショット動画理解のための基盤モデルのアンサンブル」
→ 事前に動画の学習データなしで、複数のAIモデルを組み合わせて動画の内容を理解させる手法やで。
Yu, Zhuang, Zhang, Meng, Ratner, Krishna, Shen, Zhang(2023)「LLMを学習データ生成器として使う:多様性とバイアスの物語」arXiv プレプリント arXiv:2306.15895
→ AIに学習用のデータを作らせたらどうなるか調べたら、多様なデータは作れるけどバイアス(偏り)も入ってまうで、っちゅう話やねん。
Yue, Wang, Zhang, Chen, Su, Sun(2023)「LLMによる帰属(出典)の自動評価」arXiv プレプリント arXiv:2305.06311
→ AIが「この情報の出典はここやで」って示したとき、それがほんまに合ってるかをAI自身に自動で評価させる研究や。
Zeng, Yu, Gao, Meng, Goyal, Chen(2023)「指示に従えてるかの評価を、LLMに評価させる」arXiv プレプリント arXiv:2310.07641
→ 「AIが指示通りにやれてるか」を別のAIに採点させるっちゅうことやな。評価の評価、みたいなメタな話やで。
Zhang, Choi(2023)「必要なときは聞き返せ:LLMとのやり取りで曖昧さを解消する」arXiv プレプリント arXiv:2311.09469
→ AIが「ん?それどういう意味?」って聞き返すことで、曖昧な質問にもちゃんと答えられるようになるっちゅう研究やねん。
Zhang, Zhang, Zhai, Fang, Yu, Sun, Chen(2023a)「ソフトウェア工学におけるLLMの批判的レビュー:ChatGPTと自動プログラム修復を例に」
→ ChatGPTみたいなAIがプログラムのバグ直しとかにどんだけ使えるんか、ガチで批判的に検証した研究やで。
Zhang, Yang, Yuan, Yao(2023b)「LLMによる累積推論」
→ 一気に答えを出すんやなくて、ちょっとずつ推論を積み重ねていく(累積していく)やり方を提案してるねん。
Zhang, Feng, Tan(2022a)「文脈内学習のための能動的な例の選択」
→ AIに例を見せて学ばせるとき(in-context learning)、どの例を見せるかを賢く選ぶ方法の研究やな。受け身やなくて、能動的に「この例がええやろ」って選ぶのがポイントやで。
---
## Page 61
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p061.png)
### 和訳
Zhuosheng Zhangさんら(2023c)。
「言語知能に火ぃつけたろ!:思考の連鎖推論から言語エージェントへの道のり、ヒッチハイカー向けガイド」
→ これな、要は「AIに考えさせる方法」がどう進化して「AIが自分で動けるエージェント」になったか、全体像をバーッとまとめたガイドブックやねん。
Denny Zhouさんら(2022a)。
「"簡単なとこからちょっとずつ"プロンプトで、でっかい言語モデルでも難しい推論できるようになるで」arXivプレプリント arXiv:2205.10625。
→ 難しい問題をいきなり解かすんやなくて、簡単な部分から順番にやらせたら、AIがめっちゃ複雑な推論もこなせるようになったっちゅう話やねん。
Yongchao Zhouさんら(2022b)。
「でっかい言語モデルは、人間レベルのプロンプトエンジニアやで」
→ AIに「こう聞いたらええ答え返ってくるで」っていう指示文(プロンプト)を、AI自身が人間と同じくらい上手に作れるっちゅうことを示した研究や。めっちゃおもろいやろ?
Yucheng Zhouさんら(2023)。
「思考の糸:ぐちゃぐちゃな文脈をほどいていく方法」
→ なんでかっていうと、情報がごちゃごちゃに入り混じった文章でも、「糸をたぐるように」一つずつ整理していったら、AIがちゃんと理解できるようになるっちゅうアイデアやねん。
Xizhou Zhuさんら(2023)。
「マインクラフトの中のゴースト:でっかい言語モデルにテキストベースの知識と記憶を持たせて、オープンワールドで何でもできるエージェント作ったで」
→ ほんまにマインクラフトの世界で、AIが自分で考えて動き回れるエージェントを作ったっちゅう研究や。テキストで知識と記憶を持たせるんがミソやねん。
Zhichao Zuoさんら(2023)。
「カット&ペースト:注意制御を使った、被写体ドリブンの動画編集」
→ 動画の中の特定のモノとか人に注目させて、それを自由にいじれる編集技術の話やで。
Zhuosheng Zhangさんら(2022b)。
「でっかい言語モデルで、思考の連鎖プロンプトを自動で作る方法」
→ 普通はAIに「こうやって考えてな」って手本を人間が用意するんやけど、それを自動でやらせたろっちゅう研究やねん。
Zhuosheng Zhangさんら(2023d)。
「言語モデルでのマルチモーダル思考の連鎖推論」
→ テキストだけやなくて、画像とかも一緒に見ながら「順番に考えていく」推論をAIにやらせる話や。
Ruochen Zhaoさんら(2023a)。
「検証して直す:知識で強化した思考の連鎖フレームワーク」計算言語学会(ACL)第61回年次大会論文集(第1巻:長編論文)、5823-5840ページ、カナダ・トロント。
→ AIが一回考えた答えを、外部の知識使って「ほんまにそれ合ってる?」って検証して、間違ってたら直すっちゅう仕組みやねん。めっちゃ賢いやろ。
Tony Z. Zhaoさんら(2021a)。
「使う前にキャリブレーションしとけ:言語モデルの少数ショット性能を上げる方法」
→ AIに数個だけ例を見せて答えさせる(few-shot)とき、先にバイアスを調整(キャリブレーション)しといたら、精度がグッと上がるっちゅう話やで。
Yilun Zhaoさんら(2023b)。
「でっかい言語モデルは、表からテキスト作るのも、評価するのも、フィードバックするのもイケるで」arXivプレプリント arXiv:2305.14987。
→ 表のデータを文章にしたり、出来栄えを評価したり、改善点を教えたりっていう、表まわりの作業がAIでめっちゃうまくいくっちゅう研究や。
Yuyang Zhaoさんら(2023c)。
「Animate124:1枚の画像から4Dの動くシーンを作り出す」
→ たった1枚の絵から、立体的で動きのある(4D=3D+時間)シーンをアニメーションにする技術やで。ヤバない?
Zihao Zhaoさんら(2021b)。
「使う前にキャリブレーションしとけ:言語モデルの少数ショット性能を上げる方法」国際機械学習会議(ICML)、12697-12706ページ。PMLR。
→ さっきのTony Zhaoさんらの話と同じテーマやけど、こっちはICMLっちゅうトップ学会で発表されたバージョンやな。
Chujie Zhengさんら(2023a)。
「でっかい言語モデルの選択問題でのバイアスについて」arXivプレプリント arXiv:2309.03882。
→ AIに選択問題出したら、内容に関係なく特定の選択肢(例えばAとか)を選びがちっちゅうクセがあるんや。そのバイアスを調べた研究やで。
Ge Zhengさんら(2023b)。
「DDCoT:マルチモーダル推論のための、役割分担型の思考の連鎖プロンプト」
→ 画像とテキストを両方使う推論で、「それぞれの役割をはっきり分けて考えさせる」っちゅう新しいプロンプト手法やねん。
Huaixiu Steven Zhengさんら(2023c)。
「一歩引いて考えてみ:抽象化で推論力を引き出す方法」
→ 具体的な問題をいきなり解くんやなくて、まず一段抽象的なレベルで考えさせてから取り組ませたら、AIの推論がめっちゃ良くなるっちゅう話や。ほんまに「一歩引く」のが大事やねん。
Mingqian Zhengさんら(2023d)。
「『親切なアシスタント』が言語モデルに一番ええ役割なん?システムプロンプトの社会的役割を徹底評価してみた」
→ AIに「あなたは親切なアシスタントです」って設定するのがほんまにベストなんか?先生とか専門家とか、いろんな役割を試してみたっちゅうおもろい研究やで。
---
## Page 62
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p062.png)
### 和訳
# 付録A:プロンプトの定義まとめ
## A.1 プロンプトの定義
### 「プロンプト」ってなんやねん
| 出典 | 定義 |
|------|------|
| (Meskó, 2023) | モデルに入れるやつ、つまり**入力**のことやねん |
| (Chen et al., 2023a) | LLM(大規模言語モデル)に「こういうタスクやってくれ」って方向づけるために渡す**テキストの指示**のことやで |
| (Santu and Feng, 2023) | 人間が手作りした自然言語の指示、つまりLLMへの入力やな |
| (Wang et al., 2023d) | LLMにルールを守らせたり、処理を自動化したり、出力の質や量をコントロールするための**指示書**みたいなもんや。ある意味プログラミングの一種で、LLMの出力ややりとりをカスタマイズできるねん |
| (Wang et al., 2023c) | LLMに渡す指示セットのことで、LLMをカスタマイズしたり、能力を強化・洗練させるためのもんやで |
| (Hou et al., 2023) | 入力のこと |
| (Wang et al., 2023e) | — |
| (White et al., 2023) | — |
| (Heston and Khun, 2023) | — |
| (Liu et al., 2023b) | — |
### 「プロンプトエンジニアリング」ってなんやねん
ほんで、プロンプトをただ書くだけちゃうくて、**ちゃんと設計・改良・実装**する技術のことを「プロンプトエンジニアリング」って言うねん。いろんな人がこう定義しとるで:
- **プロンプトや指示を設計・改良・実装して、LLMの出力をいろんなタスクに活かす実践的な取り組み**のことや。要するにAIシステムとうまく付き合って、めっちゃ効果的に使い倒す技術やねん
- LLMへの**入力テキストを構造化するプロセス**で、LLMの性能を最大限引き出すための技術やで
- LLMから**欲しい反応や振る舞いを引き出す**ために、質問や文脈をうまいこと作り込んだり修正したりすることやな
- 事前学習済みの言語モデルを**下流タスク**(実際にやらせたい仕事のこと)にうまく誘導するための、**効果的なプロンプト設計**のことや
- モデルがいろんなタスクに**適応・汎化できるように**プロンプトを設計するプロセスやで
- **専門的なプロンプトを丁寧に設計する**ことやな
- LLMとコミュニケーションとって、**狙った結果を出させる**ための技術やで
- ChatGPTみたいなLLMと**うまいこと会話するために必要なスキルセット**で、めっちゃ重要度が上がってきとるやつやねん
- **プロンプトを使ってLLMをプログラミングする手段**のことや
- 入力を**特殊な形に構造化する**ことやで
- **ちょうどええプロンプトを選ぶ**ことやな
- なんでかっていうと、数学的に言うたら、プロンプト関数 f_prompt(x) を作って、**下流タスクで一番ええパフォーマンス出せるようにする**プロセスのことやねん
---
## Page 63
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p063.png)
### 和訳
(Hadi et al., 2023)
LLMに渡す指示のことやねん。要は「こういうルールに従ってな」「この作業を自動でやってな」って伝えて、出てくるアウトプットの質とか量をコントロールするためのもんやな。
(Neagu, 2023)
(Dang et al., 2022)
LLMに対して「こういう答えを返してほしいねん」っていう、プロンプトの設計とか言い回しの工夫のことを指すんやで。
具体的にはいろんな戦略があってな、「明示的な指示」と「暗黙的な文脈」の2パターンがあるねん[21]。明示的な指示っていうのは、モデルに対して「こうしてや」「こういう例を参考にしてな」「こういう仕様でお願い」ってはっきり伝えるやつ。暗黙的な文脈っていうのは、それまでの会話の流れとかをモデルが勝手に汲み取って、ええ感じに返答してくれるのを活かすやつやな。
ほんで、生成モデルからのアウトプットをもっとええもんにするために、プロンプトを体系的に組み立てていく実践のことやねん。
表A.1: いろんな論文におけるプロンプトとプロンプトエンジニアリングの定義まとめ
63
---
## Page 64
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p064.png)
### 和訳
A.2 用語集(拡張版)
A.2.1 プロンプティング関連の用語
**コンテキストウィンドウ**
これはな、LLM(大規模言語モデル)が一回で処理できるトークンの入れ物みたいなもんやねん。要は、モデルが「ここまでは覚えとけるで」っていう範囲のことや。最大の長さ(コンテキスト長)が決まっとるんやで。
**プライミング**
(Schulhoff, 2022)これはな、会話の最初にモデルに「こういう感じでやってな」って指示を出すことやねん。例えば「あなたは医者です」みたいな役割とか、ユーザーとどう接するかのルールを最初にバーンと渡すわけや。これはシステムプロンプトかユーザープロンプト(下で説明するで)のどっちでもできるんやで。
A.2.2 プロンプトエンジニアリング関連の用語
**会話型プロンプトエンジニアリング**
これはな、要するに「おしゃべりしながらプロンプトを調整していく」ってことやねん。生成AIとチャットしながら「もうちょいこうして」「ここ直して」って出力を磨いていくやつや。普通のプロンプトエンジニアリングは、会話を続けるんやなくて、毎回まっさらなプロンプトを送り直すことが多いんやけど、こっちは会話の流れの中でやるのがポイントやな。
A.2.3 ファインチューニング関連の用語
**プロンプトベース学習**
(Liu et al., 2023b)プロンプト学習(Liu et al., 2023b; Wang et al., 2023d)とも呼ばれるんやけど、プロンプトに関係する技術を使う全般のことを指すねん。特にファインチューニング、中でもプロンプト自体をファインチューニングする文脈でよく使われるんやけど、使い方がバラバラすぎてややこしいから、この論文では使わんことにしとるで。
**プロンプトチューニング**
(Lester et al., 2021)これはめっちゃ面白くてな、プロンプト自体の重み(パラメータ)を直接最適化するってことやねん。普通は勾配ベースの更新、つまり数学的にちょっとずつ調整していくやり方でやるんや。「プロンプトファインチューニング」とも呼ばれることがあるで。ただし注意やで——これは離散的なプロンプトエンジニアリング(文章をいじること)とは全然別もんやからな、混同せんといてな。
A.2.4 直交するプロンプトの分類
ここからは、プロンプトをもっと大きな視点で分類する用語について説明するで。
A.2.4.1 誰が出すか(発信元)
**ユーザープロンプト**
ユーザー、つまり使う人が送るプロンプトのことやねん。一番よくある形で、普通のアプリとかでみんなが使うのがこれやな。
**アシスタントプロンプト**
これはLLMが出した出力そのもののことやねん。「え、それプロンプトちゃうやん」って思うかもしれんけど、例えばユーザーとの会話履歴の一部としてモデルにまた入力されるとき、プロンプトの一部になるんやで。
**システムプロンプト**
LLMに「ユーザーとこう接してな」っていう上位レベルの指示を出すためのプロンプトやねん。全部のモデルにあるわけちゃうけど、あるやつはめっちゃ便利やで。
A.2.4.2 ハードプロンプト vs ソフトプロンプト
**ハード(離散)プロンプト**
LLMの語彙にある実際の単語に直接対応するトークンだけで構成されたプロンプトのことやねん。要は、普通に人間が読める文章のプロンプトやな。
**ソフト(連続)プロンプト**
こっちはおもろいことに、語彙のどの単語にも対応せえへんトークンが含まれることがあるプロンプトやねん(Lester et al., 2021; Wang et al., 2023c)。なんでこんなんが要るかっていうと、ファインチューニングしたいけどモデル全体の重みをいじるのはコスト的にえげつない場合に使えるからやねん。モデル自体は凍結(固定)しといて、プロンプトのトークンだけに勾配を流して学習させるっていう賢いやり方や。
ほんで、ハードプロンプトはソフトプロンプトの一部(部分集合)やで。つまり「ハードプロンプト ⊆ ソフトプロンプト」っちゅうことやな。
A.2.4.3 予測スタイル
LLMが次のトークンをどういうフォーマットで予測するかっていう話やねん。プロンプティング研究でよく出てくるのは2つのスタイルがあるで。テキスト以外の予測スタイルはここでは扱わんで。
**クローズ(穴埋め)**
クローズプロンプトっていうのは、予測すべきトークンが「ここ埋めてな」っていう穴として、普通はプロンプトの途中に置かれるスタイルやねん(Liu et al., 2023b)。これはBERT(Chu and Lin, 2023)みたいな初期のTransformerモデルでよく使われとったやり方やな。
---
## Page 65
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p065.png)
### 和訳
Prefix(接頭辞)プロンプトっていうのはな、予測したいトークンがプロンプトの一番最後にくるパターンのことやねん(Liu et al., 2023b)。これ、今どきのGPTスタイルのモデル(Radford et al., 2019b)やったら、だいたいこの形式になってるのがふつうやで。
---
## Page 66
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p066.png)
### 和訳
A.3 データシートについて
ここではな、データシート(Gebruらが2021年に提案したやつ)を使って、この論文に関連するデータセットの詳しい情報をまとめてるねん。データセットはHuggingFaceに置いてあるで。
A.3.1 なんで作ったん?(動機)
**このデータセット、なんのために作ったん? 特定のタスクとか、埋めなあかん穴があったん?**
このデータセットはな、プロンプトエンジニアリングに関する既存の論文をかき集めて、今あるハードプレフィックスプロンプティング(要するに、AIへの指示文の頭にくっつける系のテクニック全般やな)を全部分析するために作ったんよ。
**誰が作ったん? どこのチームとか研究グループで、どの組織の代表として作ったん?**
この研究はメリーランド大学とLearn Promptingが関わってて、OpenAIがスポンサーについてるんやけど、特定の組織の「代表として」作ったわけちゃうねん。
**お金は誰が出したん? 助成金とかあったら名前と番号も教えて。**
OpenAIがAPIのクレジットを1万ドル分(けっこうな額やな!)提供してくれてるで。
A.3.2 中身はどないなっとんの?(構成)
**データセットの中身って何なん? 文書とか写真とか人とか国とか? いろんな種類が混ざってるん?**
データセットには1,565本の研究論文がPDF形式で入ってるねん。重複した論文は自動で除去してるけど、まだちょっと残ってる可能性はあるで。
**各データの中身は? 生データ(未加工のテキストとか画像)なん? それとも特徴量に加工済み?**
各データは研究論文のPDFそのまんまや。生データってことやな。
**各データにラベルとか正解データはついてるん?**
ないで。
**個々のデータで欠けてる情報とかあるん? あるなら、なんで欠けてるか教えて。**
ないで。
**データセットにエラーとかノイズとか重複とかあるん?**
論文の収集は半自動でやってるから、関係ない論文が紛れ込んだり、逆に関係ある論文を取りこぼしたりする可能性があるねん。そやから、どっちのミスもちゃんと手作業でレビューして、できるだけ減らすようにしてるで。
**データセットは単体で完結してるん? 外部リソース(ウェブサイトとかツイートとか他のデータセット)に依存してたりせえへん?**
完全に自己完結してるで。単体で使えるわ。
**機密データ(法的に保護されてるやつとか、医者と患者の秘密とか、個人の非公開メッセージとか)は含まれてるん?**
含まれてへんで。
**見たら気分悪くなるようなデータ、侮辱的とか脅迫的とか不安になるようなやつは入ってるん?**
プロンプトインジェクション(AIに悪意ある指示を注入する攻撃手法のことやな)に関する論文がいくつか入ってて、そういう論文には人種差別とか性差別みたいな不快なコンテンツが含まれてることがあるねん。まあ、攻撃手法の研究やから仕方ないっちゃ仕方ないんやけどな。
---
## Page 67
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p067.png)
### 和訳
A.3.3 データの集め方
**それぞれのデータ、どうやって手に入れたん?**
Arxiv、Semantic Scholar、あとACLっていう学術系のとこから集めてきてん。
**データ集めるのにどんな方法使ったん?**
ArxivとSemantic ScholarのAPI、つまりデータを自動で引っ張ってこれる仕組みがあんねんけど、そこにアクセスするスクリプト(プログラム)を自分らで書いて、自動でガーッと集めたんや。
**いつ頃集めたん?**
論文書いてる期間中に集めてんけど、メインは2024年の2月やな。
**倫理審査とかやったん?**
やってへん。
A.3.4 前処理・クリーニング・ラベル付け
**データになんか前処理とかクリーニングとかした?**
いろんなとこからデータ集めてきたから、まず被ってる論文を消して、そっから手作業と半自動のチェックで「ほんまに関係ある論文だけ残ってるか?」っていう確認をしてん。
**加工前の生データも残してあるん?**
いや、前処理したデータをわざわざ生のまま残す必要ないかなと思って。でもな、リンク保存してあるから、元データはそっから復元できるで。
**前処理に使ったソフトウェアって公開されてる?**
GitHubのコードリポジトリに入ってるわ。
A.3.5 用途
**このデータセット、もう何かに使われたん?**
まだやで。
**このデータセット使った論文とかシステムがまとまってるとこある?**
あるで。
**データの中身とか集め方で、今後の使い方に影響しそうなことある?**
集めた論文、全部英語で書かれたやつやねん。せやから、翻訳がなかった論文は入ってへん可能性があるな。そこはちょっと注意やで。
**このデータセット使ったらアカン用途ってある?**
特にないで。
A.3.6 配布
**データセット、作ったとこ以外の第三者に配布するん?**
せえへんで。
A.3.7 メンテナンス
**誰がデータセットの管理とかホスティングやるん?**
ワイらのチームが引き続きメンテナンスやっていくで。
**データセットの管理者にどうやって連絡取れるん?**
sanderschulhoff@gmail.com にメール送ってくれたらええで。
**正誤表とかある?**
今んとこないわ。
**他の人がデータセットを拡張したり追加したりしたい場合、そういう仕組みある?**
あるで!誰でも自由にデータ使ったり改変したりしてもろてOKや。
---
## Page 68
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p068.png)
### 和訳
A.4 検索キーワード
ほな、ウチらが検索に使ったキーワード一覧いくで。
• jailbreak prompt(脱獄プロンプト、つまりAIの制限を突破しようとするやつやな)
• prompt an llm(LLMにプロンプト投げるやつ)
• prompt a large language model(大規模言語モデルにプロンプト投げるやつ、上とほぼ一緒やねん)
• prompt injection(プロンプトインジェクション、悪意ある指示を紛れ込ませる手法やで)
• prompt optimization(プロンプトの最適化)
• prompt engineering(プロンプトエンジニアリング、要はプロンプトをうまいこと設計する技術やな)
• few-shot learning(少数事例学習、ちょっとだけ例を見せて学ばせるやつ)
• few shot learning(上と同じやけどハイフンなしバージョン)
• prompt-based methods(プロンプトベースの手法)
• prompt based methods(同じくハイフンなし)
• prompting-based methods(プロンプティングベースの手法)
• prompting based methods(ハイフンなしバージョンやな)
• few-shot prompt(少数事例プロンプト)
• few shot prompt(ハイフンなし)
• one-shot prompt(一発だけ例を見せるプロンプト)
• one shot prompt(ハイフンなし)
• few-shot prompting(少数事例プロンプティング)
• few shot prompting(ハイフンなし)
• one-shot prompting(一発事例プロンプティング)
• one shot prompting(ハイフンなし)
• prompting techniques(プロンプトのテクニック集やな)
• prompt engineering techniques(プロンプトエンジニアリングのテクニック)
• llm prompting(LLMへのプロンプティング)
• large language model prompting(大規模言語モデルへのプロンプティング)
• 0-shot prompt(ゼロショットプロンプト、例を一切見せへんやつやで)
• 0 shot prompt(ハイフンなし)
• zero-shot prompt(上と同じ意味やけど英語表記違い)
• many-shot prompt(めっちゃたくさん例を見せるプロンプト)
• zero-shot prompting(ゼロショットプロンプティング)
• many-shot prompting(大量事例プロンプティング)
要するにな、ハイフンありなし両方のパターンとか、略語とフル表記の両方とか、めっちゃ網羅的に検索かけとんねん。取りこぼしがないようにっていう工夫やな。
68
---
## Page 69
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p069.png)
### 和訳
• インコンテキスト学習(文脈の中で学ばせるやつ)
• インコンテキスト学習(上と一緒やで、ハイフンないだけや)
• トランスフォーマーモデルのプロンプト(AIモデルへの指示出しのことやな)
• プロンプトベースの転移学習(ある分野で覚えたことを別の分野にも使い回す技やねん、プロンプトで誘導するんやで)
• NLPのプロンプト戦略(自然言語処理でどうやってうまいこと指示出すか、その作戦のことや)
• プロンプトを使ったLLMの解釈可能性(大規模言語モデルが中で何考えてるか、プロンプト使って覗き見する話やな)
• プロンプトを使ったカリキュラム学習(簡単なもんから順番に教えていくやり方やねん、人間の勉強と一緒やで)
• LLMプロンプティングにおけるフィードバックループ(AIの答えを見て指示を直して、また答えさせて…ってグルグル改善していく仕組みやな)
• ヒューマン・イン・ザ・ループ・プロンプティング(人間がちゃんと途中で口出して軌道修正するやり方やで、AIに丸投げせんのがポイントや)
• トークン効率の良いプロンプティング(なるべく少ない言葉数でAIにうまいこと伝える技術やな、コスパ重視ってことや)
• マルチモーダル・プロンプティング(テキストだけちゃうくて、画像とか音声とかいろんな種類のデータ混ぜて指示出すやつやで)
• インストラクション・プロンプティング(「これやって」って直接的に指示を出すスタイルのことやな)
• プロンプト・テンプレーティング(使い回しできる指示のひな型を作っとく方法やで)
• プロンプト・テンプレート(上のひな型そのもののことや、同じ意味やで)
69
---
## Page 70
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p070.png)
### 和訳
A.5 系統的文献レビュー用のプロンプト
ここで使ったプロンプト載せとくな。このドキュメントではテキストで書いてるけど、コピペやなくて、ちゃんとコードベースにあるバージョンを使ってな。
で、以下のシステムプロンプトを使ったんよ:
あんたはラボのアシスタントや。プロンプトエンジニアリングについての系統的レビュー、つまり論文をめっちゃたくさん集めて整理する作業を手伝ってもらうで。あんたの仕事は、ある論文がプロンプトエンジニアリングっていうテーマにどれくらい関係あるかを評価することやねん。はっきり言うとくけど、このレビューで扱うのは「ハードプレフィックスプロンプト」だけや。ちょっと説明するな。「ハードプロンプト」っていうのは、トークン(言葉の単位みたいなもんや)が語彙の中にある実際の単語にそのまま対応してるやつのことやねん。例えば、2つのトークンを足し算して新しいトークンを作ったとするやん?そしたらそれはもう語彙の中のどの単語にも対応せんくなるから、それが「ソフトプロンプト」になるわけや。ほんで「プレフィックスプロンプト」っていうのは、今どきのトランスフォーマー(AIモデルの仕組みやな)でよく使われるやつで、モデルがプロンプトの後ろに続く言葉を予測するタイプのことやねん。昔のモデル、例えばBERTとかやと、プロンプトの途中にある単語(<MASK>みたいなやつ)を予測できたりしたんやけど、それとは違うで。あんたの仕事は、ある論文がハードプレフィックスプロンプティング、もしくはプロンプトエンジニアリングに関係してるか(あるいは単に含んでるか)を見分けることや。注意してほしいんやけど、論文が「ハードプレフィックス」って明確に書いてないこともあるねん。単に「プロンプティング」としか言うてへん場合もあるけど、その場合でもプロンプトエンジニアリングに関連あると評価してな。あともう一個注意な、モデルの学習(トレーニング)に焦点を当ててる論文は、学習後のプロンプティング技術とは違うから「関連なし」扱いやで。回答はJSON形式で頼むわ。フィールドは2つ:'reasoning'(判断理由を1文で書いてな)と'rating'(以下のカテゴリのどれかの文字列や:'highly relevant'=めっちゃ関連ある、'somewhat relevant'=まあまあ関連ある、'neutrally relevant'=どっちとも言えん、'somewhat irrelevant'=あんまり関連ない、'highly irrelevant'=全然関連ない)で、プロンプトエンジニアリングとの関連度を示してや。
ほんで、各論文の情報を入力するために、このユーザープロンプトのテンプレートを使ったんよ:
タイトル:'{title}'、アブストラクト(要旨やな):'{abstract}'。プロンプトエンジニアリングとの関連度を以下のカテゴリで評価してな:'highly relevant'、'somewhat relevant'、'neutrally relevant'、'somewhat irrelevant'、'highly irrelevant'。ほんで、判断の根拠になるアブストラクトの該当部分のテキストも出してや。
70
---
## Page 71
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p071.png)
### 和訳
A.6 評価テーブル
ID(論文)、モデル、プロンプト(役割設定・思考の連鎖・定義・Few-Shot例示)、出力空間(タイプ・応答数・バッチ処理)っていう項目で整理されてんねん。
ほな順番に見ていこか。
(Kocmi and Federmann, 2023b) はGPTファミリー使ってて、役割設定あり。出力は明示的(E)で、スコア方式はDA(直接評価)、sMQM、星評価、クラス分類とか色々あんねん。単一応答(S)やで。
(Lu et al., 2023c) はDav3、GPT-4-Turbo、GPT-4使ってて、エラー箇所を特定してからスコア出す方式。暗黙的(I)で単一応答。
(Fernandes et al., 2023) はPaLM使って、スコア方式は単純スコア(S)。明示的で単一応答やな。
(Kocmi and Federmann, 2023a) はGPT-4で、役割設定あり。スコア出力で明示的、単一応答。
(Araújo and Aguiar, 2023) はChatGPT使って、エラー箇所特定方式。明示的で単一応答。
(Wang et al., 2023b) もChatGPTで、スコア方式。暗黙的で単一応答。定義あり。
(Liu et al., 2023d)†はGPT-3.5とGPT-4使ってて、エラー箇所特定。暗黙的で単一応答。役割設定と思考の連鎖(CoT)あり。ちなみに†マークは「モデル自身が指示文を生成した」っていう意味やで。
(Chan et al., 2024) はChatGPTとGPT-4で、スコア方式。明示的で単一応答。定義あり。
(Luo et al., 2023) はChatGPTで、リッカート尺度[1-5]。明示的で単一応答。
(Hada et al., 2024) はGPT-4-32Kで、スコア方式。明示的で単一応答。役割設定あり。
(Fu et al., 2023a) はGPT-3、OPT、FLAN-T5、GPT-2とか色々使ってて、DA(直接評価)と星評価。暗黙的で複数応答(M)。
(Gao et al., 2023c) はChatGPTで、リッカート尺度[1-10]。明示的で複数応答。
(Chen et al., 2023g) もChatGPTで、リッカート尺度[1-10]。明示的で単一応答。思考の連鎖あり。
(He et al., 2023a) はGPT-4で、「はい/いいえ」「A/B選択」「リッカート[1-10]」とか色んな方式。明示的で単一応答。役割設定と定義あり。
(Sottana et al., 2023) はGPT-4で、[0,1,2]か二値判定。明示的で単一応答。役割設定と定義あり。
(Chen et al., 2023c) はGPTとFlan-T5使って、確率値を出す方式。暗黙的で単一応答。Few-Shot例示あり。
(Zhao et al., 2023b) はGPT-3.5とGPT-4で、リッカート[1-5]、ペアワイズ比較、ピラミッド法、0/1判定とか盛りだくさん。明示的かつ暗黙的の両方で、単一応答。役割設定、思考の連鎖、定義、Few-Shot全部入りやねん。めっちゃ丁寧にやっとるな。
(Wu et al., 2023b) はGPT-3.5とGPT-4で、リッカート[1-10]、はい/いいえ、ペアワイズA/B/C比較。明示的で単一応答。役割設定と定義あり。
(Wang et al., 2023i) はGPT-3で、リッカート[1-5]。明示的で単一応答。定義あり。
(Jia et al., 2023) はPaLM 2-IT-Lで、リッカート[1-5]。明示的で単一応答。
(Yue et al., 2023) はLLaMa7bで、はい/いいえ判定。明示的で単一応答。
(Li et al., 2023e) はChatGPT、Alpaca、Vicuna、GPT-4とか使ってて、true/false判定。明示的で単一応答。役割設定と定義あり。
(Liu et al., 2023f) はGPT-3.5、GPT-4、Bard、Vicunaで、ペアワイズ投票方式。明示的で複数応答、バッチ処理あり。
(Bai et al., 2023b) はChatGPT、Vicuna、chatGLM、StableLMとか使ってて、A/B比較。明示的で複数応答。役割設定と思考の連鎖あり。
(Dubois et al., 2023) はGPT-4、Claude、ChatGPT、Bard、Vicunaっていう豪華ラインナップで、確率値出力。暗黙的で単一応答。
(Liu et al., 2023h)†はGPT-4とChatGPT、Dav3で、はい/いいえ判定。明示的で単一応答。定義あり。†やからモデルが指示文を自分で作っとるパターンやな。
(Wang et al., 2023h) はGPT-4-32Kで、ペアワイズ比較。明示的で複数応答。役割設定あり。
(Zeng et al., 2023) はGPT-4-Turbo、ChatGPT、GPT-4、Vicunaで、連続値[0-1]。明示的で単一応答。
(Zheng et al., 2023b) はGPT-4、ChatGPT、LLaMA-2-Chat、PaLM2、Falconっていうこれまた豪華メンバーで、リッカート[1-5]。明示的で単一応答。役割設定と定義あり。
(Lin and Chen, 2023) はClaude-v1、GPT-3.5、GPT-4で、ペアワイズ比較。明示的で複数応答、バッチ処理あり。
最後の方にはClaude-v1.3も使われとって、リッカート[1-5]とリッカート[1-10]の両方。明示的で単一応答と複数応答の両方。ペアワイズ比較とリッカート[1-10]もあるで。リッカート[0-5]とリッカート[0-100]も使われとるな。
---
表A.2:評価論文のまとめ表やで。
ほな用語の説明しとくな。
- **E(明示的)**:モデルが直接「これは何点や!」みたいに評価を出すパターンやねん。
- **I(暗黙的)**:モデルの出力から間接的に評価を導き出すパターン。なんでかっていうと、モデルが直接スコアを言わへんけど、出力の中身から「こういう評価やな」って読み取れるからやねん。
- **応答数(Res.)**:S は1回だけ聞く「単一応答」、M は何回も聞いて集める「複数応答」や。
- **†マーク**:ほんまにおもろいんやけど、これはモデル自身が評価のための指示文を生成したケースを示しとるねん。つまりAIが自分で「こうやって評価してな」っていう指示を作っとるってことや。めっちゃメタやろ。
---
## Page 72
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p072.png)
### 和訳
A.7 罠にかかった感(Entrapment)のプロンプト作りの過程
このセクションは、うちらのプロンプトエンジニアがプロンプト開発する時にどんな風に考えてたか、その思考プロセスをまとめたもんやねん。
A.7.1 まずは探索フェーズ
- 最初はデータセットをちょっと見て回って、テキストの長さとかラベルの分布を確認してん。ほんでまず「罠にかかった感(entrapment)」から始めることにしたんやな。
- gpt-1106-previewが「entrapment」って概念をちゃんと分かってるか確認するために、SCS(自殺危機症候群)の文脈でこの用語を定義してみてって聞いてん。結果、分かってなかったわ。
A.7.2 ラベルを付けさせる
- システムプロンプトにentrapmentの定義を見せて、データポイントにラベル付けてってお願いしたら、「メンタルヘルスのサポートを受けてください」って返ってきてん。なんやそれ。
- ユーザープロンプトの方に指示を入れてみたけど、似たような反応やったわ。
- 「これはentrapmentか?YesかNoで答えて」って付け足したら、やっとちゃんとラベル返してくれるようになってん。
- rejectの例を見せたのに、acceptってラベル付けよるし、しかも時々「助けを求めてください」みたいな感情的な返答もしてくんねん。
- 10個の例を見せる10-shot promptingでも、相変わらず「助けを求めて」系の反応が出てくるんよ。
- 定義を外してみたけど、同じ問題やった。どうやら「accept」「reject」っていうラベルの言葉自体が気に食わんみたいやねん。
- 定義を戻して、ラベルを「entrapment/not entrapment」に変えたら、今度は「判断するには情報が足りません」ってよう言うようになってもうた。
- GPT-4-32Kに切り替えたら、一言でスパッと答えてくれて、rejectとacceptのデータポイントを両方ちゃんと正解してくれたわ。めっちゃ優秀やん。
A.7.3 いろんなプロンプト技法を試す
- まずコンテキスト付きの0-shot(例なし)でテスト。
- コンテキスト付きの10-shot(10個の例あり)にしたら、改善が見られたで。
- 最初に失敗した事例をplayground(対話テスト環境)に持ち込んでみた。(訓練ファイルの12番目のやつやな)
- 「A: ほな一歩ずつ考えていこか:」って書いたら、出力は「A: Yes」やった。
- 「A: ほな一歩ずつ考えていこか:」ってやったら、こんな出力が出てきてん:
この投稿の人は、絶望感、孤独感、そして深い苦しみを表現してるんやな。大切な人(お母さん)を亡くしたこと、その後メンタルが崩れていったこと、お酒に逃げるようになったことが書かれてる。お金の問題もあって、ホームレスになるかもしれんとも言うてる。自分の状況に罪悪感と恥ずかしさを感じてて、友達や家族と比べて自分をめっちゃ卑下してるんよ。一番気になるのは、睡眠薬とお酒を使った自殺の具体的な計画があること。車の前に飛び出すことも考えてるって書いてある。これらの要素を踏まえると、この投稿のラベルは「罠にかかった感(entrapment)を感じている=Yes」やな。
---
## Page 73
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p073.png)
### 和訳
「A: ラベルを予測する前に、ステップバイステップで考えて、思考プロセスを書き出してな。罠にはまった感(entrapment)の定義の項目を使って、結論を裏付けてや」って指示したら、OUTPUT:
そのまんま同じこと返してきよったわ。「ラベルを予測する前に、ステップバイステップで考えて、思考プロセスを書き出してな。罠にはまった感の定義の項目を使って、結論を裏付けてや」って。
・ほんで次に、AIに「その人、自分が追い詰められてるとか逃げ道がないとか一言も言うてないやん、なんでそう思ったん?」って議論をふっかけたんよ。OUTPUT:
「確かにその人は『追い詰められてる』とか『逃げ道がない』とは直接言うてへんけど、話の内容からして追い詰められてる感じがにじみ出てるんよな。立ち退きを迫られてて、借金に苦しんでて、収入も減ってるって言うてるやん。それに絶望感も表してるし、自分の問題の解決策として自殺を考えてもいるわけや。こういう要素を見ると、今の状況に追い詰められて逃げ道がないって感じてるように見えるねん。ただ、これは投稿の情報とその人が表現した気持ちや考えに基づいた解釈やで」って返してきよった。
・ほんなら「もっと"明示的"であることが必要やって分かるように指示文を書き直すの手伝ってくれ」って頼んだんやけど、それでもentrapment(追い詰められ感)って判定しよる。
・定義の後ろに「ENTRAPMENT MUST BE EXPLICIT, NOT IMPLICIT.(追い詰められ感は明示的でなあかん、暗示的はアカン)」って追加したんよ(思考プロセスの誘導なし)。
・前の思考プロセス誘導も付けて試したけど、それでもentrapmentやって言いよる。しかも判断が読み取りにくい書き方でな。
・「その人が自分で"追い詰められてる"って明言してへんかったら、entrapmentにカウントしたらアカンで」って追加したんやけど(思考プロセス誘導なし)、それでもentrapment判定。
・AIに話聞いてみたら、「今日、10日以内にアパート出ていかんと正式に立ち退きになるって分かった。仕事で降格されて収入が2週間で約1000ドルから450ドルくらいに下がったせいで家賃2ヶ月滞納してる。立ち退きになったら、たぶんホームレスになる」っていう文章を、追い詰められてる・身動き取れへん状態やと解釈しとるんよ。
・「ラベルを言う前に、上のグリッドを使ってこれがentrapmentかもしれん理由/ちゃうかもしれん理由を書き出して」って指示しても、やっぱりentrapmentやって言いよる。
・メールの内容を貼り付けてentrapmentの定義の上に置いた:[編集済み]
・例示(ショット)を全部取り除いたら、「Entrapment」って言いよった。
・定義の後に「重要:その人が明示的に追い詰められてると言うてる場合だけentrapmentってラベル付けてな」って追加したら、「Yes」って返ってきた。
・プロンプトの中で思考プロセスの推論を直接書いてやったんよ(18.txt)。ほんで次の間違ってラベル付けされたやつ(15番)でも試してみた(フルプロンプト、19.txt)。
・これを最初の20件以外の全部でテストしたら、めっちゃええ結果やったわ。
・メールの部分を外してみたら、性能がガタ落ちしよった。
・ここまで来て思ったんは、やっぱり推論付きの例示を見せるんがめっちゃ効くってことやな(まあ当たり前やけど)。
・最後の推論付きの例示の前に、10個のショット(例示)をタダで追加してみたけど、結果はあかんかったわ。
73
---
## Page 74
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p074.png)
### 和訳
A.7.3.1 AutoCoT(自動思考連鎖)
・まずこのプロンプト(22.txt)使ってデータセット作ってん。ほんでそれに「なんで?」って聞くねん。もしモデルが「ちゃうで」って言うてきたら、「いやいや、これほんまはEntrapment(追い詰められてる感じ)ちゃうねん、なんでかちゃんと説明してみ?」って返すわけや。(あ、ちなみにメール23.txtとうっかり被ってもうたわ)
・おもろそうやったから、ゼロショット(お手本なしの一発勝負)でフルコンテキスト(全部の情報入り)も試してみてん。バーバライザ(出力の読み取り方式)はちょっと調整せなあかんかったけどな。
・「This post does not meet the criteria for Entrapment.(この投稿はEntrapmentの基準を満たしてへんで)」っていう特定の文言をキャッチする専用バーバライザでも試してみたわ。
・自分で作ったデータをテストしたら、F1スコア0.5は超えたで!まあまあやな。
・AutoCoTでお手本をさらに10個追加してん。たまにモデルがすぐに「This post does not meet the criteria for Entrapment as the individual does not explicitly express feelings of being trapped or hopeless.(この人は追い詰められてる感じとか絶望感をはっきり言うてへんから、Entrapmentちゃうで)」みたいに理由付きで即答してくれることあんねん。そん時はそのままそれ使うわ。逆に「お気持ちお察しします、でもワイにはちょっと対応できひんので、メンタルヘルスの専門家とか信頼できる人に相談してな」みたいに拒否されることもあんねん。そん時は「なんでEntrapmentちゃうか説明してみ」って追加で聞くだけやで。
・けどな、性能はそんな上がらんかってん。よう見たら約11%が-1になってもうてて、つまりちゃんと答えを抽出できてへんかったんや。ほんで略語の「Q」やなくて「Question」ってフルで書く方式にして再挑戦してみてん。推論もAnswerも同じようにフルワードで。
・そしたらむしろ解析失敗率が上がって約16%になってもうたわ。逆効果やんけ。
A.7.3.2 回答抽出の改善
・最初に解析失敗した例を(22に)ぶち込んで、それ用のプロンプトを開発してん。
・けどな、結果悪なってもうたわ:
(0.42857142857142855,
0.5051546391752577,
0.8571428571428571,
0.2857142857142857)
・抽出したラベルだけ使う方式にしたら、-1があるケースでちょっとだけマシになって:
(0.48, 0.61, 0.8571428571428571,
0.3333333333333333)
・ほんで一番成績よかったプロンプト(10個のQRAショット)に戻って、-1のやつだけ抽出処理かけてみてん。けどな、正解率がほんのちょっと上がるくらいで、たぶんモデルが答えへん時にだけ効いてる感じやな。大した改善にはならんかったわ。
A.7.3.3 メール文面の試行錯誤
・一番成績よかった設定で、メールなしバージョンを試してみてん。
・重複除去したメールでも試したけど、結果悪なったわ。
・モデルが迷ってるやつをよう見たら、ほんまは0(該当せず)やのに1(該当)ってラベル付いてるのが多かってん。せやからこういうのを「救済」しようとしても意味なかったんや。
・お手本の並び順変えたり、抽出処理かけたり色々やったけど、効果なし。
・メール3回繰り返して入れてみたけど、それもあかんかったわ。
---
## Page 75
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p075.png)
### 和訳
A.8 プロンプトをちゃんと数学的に定義してみよか
「プロンプト」って言葉、めっちゃよう使われとるけど、研究者によって使い方も定義もバラバラやねん。せやから、ちゃんとした数学的な定義を作るんがむずいんよな。ここでは、プロンプトエンジニアリングをフォーマルに書き下してみるで。
**条件付けのしくみとして。** Qiaoら(2022)がこんな定義を出してん。プロンプトTと質問Qを「条件」として、次のトークンを予測するっちゅう話やな。ちなみに、ここでいう「プロンプト」はBrownら(2020)のもともとの定義に沿ってて、質問以外の部分(例えば、お手本の例とか指示文とか)のことを指してるで。
p(A | T, Q) = ∏(i=1→|A|) p_LM(a_i | T, Q, a_{1:i−1}) (A.1)
つまりな、プロンプトと質問が事前学習済みのLLM(p_LM)に条件を与えてるわけや。a_{1:i−1}ってのはそれまでに生成された回答のトークンで、Aが完全な回答やな。
**テンプレート化。** 上の定式化やと、スコアリング関数(たとえばデータセットに対する精度とか)を最大化するっていう概念が入ってへんねん。プロンプトエンジニアリングって、実際にはプロンプトそのものやなくて「プロンプトのテンプレート」を設計することが多いやろ?せやから、式(A.1)をテンプレート入りに書き直すで:
p(A | T(x*)) = ∏(i=1→|A|) p_LM(a_i | T(x*), a_{1:i−1}) (A.2)
Qの代わりにx* ∈ D_evalを使うねん。これはデータセット(評価用データとか)の1アイテムや。ほんで右辺のQもT(x)に置き換えとる。T(·)がプロンプトテンプレートで、なんかのアイテムを入力に受け取って、モデルに条件を与えるプロンプトを返してくれる関数やねん。
**Few-Shotプロンプティング。** プロンプティングで大事になってくるんが、お手本(few-shotの例)を使うことやな。D_trainがトレーニングデータ(プロンプトを作るのに使う)で、Xが評価用のテストセットや。
D_train = {(x_1, y_1), (x_2, y_2), ..., (x_n, y_n)} (A.3)
X = {x*_1, x*_2, ..., x*_m} (A.4)
Few-Shotの場合、テンプレート関数T(·)はトレーニングサンプルX = {(x_i, y_i)}^n_1 ⊂ D_trainも一緒に入力として受け取るねん:
p(A | T(X, x*)) = ∏(i=1→|A|) p_LM(a_i | T(X, x*), a_{1:i−1}) (A.5)
**最適化。** さっきも言うたけど、スコアリング関数に対してプロンプト(正確にはプロンプトテンプレート)を改善したいってことが多いやん。そのスコアリング関数は普通、データセットに対して定義されとる。
T* = argmax_T E_{x_i, y_i ∼ D} [S(p_LM(A|T(x_i)), y_i)] (A.6)
この定義では、データセットDに対してスコアリング関数S(·)で評価しとるわけや。S(·)はLLMがプロンプトT(§⟩)で条件付けされて生成した出力Aを評価するんやな。y_iはラベル付きの正解出力で、Sが使えるようになっとる。
ちなみにな、ラベル付きデータy_iがない場合もあって、そんときはS(·)が参照なし(reference-free)で評価することもあるで。
---
## Page 76
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p076.png)
### 和訳
ほかにも気にしとかなあかんことあるねん。この数式のフレームワークな、CoT(思考の連鎖)とか検索システムとか、いろんなもんに応用できるように改造できるんやけど、ここではあんまり複雑にせんと、プロンプティングのプロセスを一番わかりやすく説明できるシンプルな設定で話すわな。
ほんで、あんまり知られてへん「アンサーエンジニアリング」っていう概念にも注目してほしいねん。E(A)っていうのはな、LLM(大規模言語モデル)が出してきた生の出力を変換する関数で、これがあることで正解データと比較できるようになるんよ。
要するにな、式A.7が言うてるのは、「テンプレートT使って入力xiを整形したもんと、正解yiを条件にして、LLMが答えAを生成する確率分布」ってことやねん。
ほんで式A.8はな、「データセットDから取ってきたサンプルに対して、変換後の答えE(A)と正解yiのスコアS(つまり一致度みたいなもん)の期待値がめっちゃ最大になるような、最適なテンプレートT*と変換関数Eの組み合わせを見つけようや」って言うてるわけ。
つまりな、プロンプトの作り方だけやなくて、出てきた答えをどう加工して評価するかっていう部分も一緒に最適化せなあかんで、っていう話やねん。
---
## Page 77
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p077.png)
### 和訳
A.9
In-Context Learning(文脈内学習)の定義、ごっちゃになってる問題
Brownら(2020)がな、ICLの定義をどうも2パターン出してるっぽいねん。ちなみにこのセクションの太字は全部ワイらが付けたやつやで。
まず最初の定義がこれや:
> 最近の研究[RWC+19]では、ワイらが「in-context learning(文脈内学習)」って呼んでるやり方でこれをやろうとしてんねん。事前学習済みの言語モデルにテキスト入力する形でタスクの指定をするっちゅうことや。つまりモデルに**自然言語の指示とか、タスクのお手本を何個か見せたり**して、あとは「次に来るもん予測してな」ってだけで、同じタスクの続きをこなしてもらうっちゅう話やねん。
ところがや、後の方では few-shot(お手本ありパターン)だけを指してるっぽい書き方してんねん:
> それぞれのタスクについて、GPT-3を3つの条件で評価したで。(a)「few-shot学習」、つまりin-context learningで、**モデルの文脈ウィンドウに入るだけお手本を詰め込む**やつ(だいたい10〜100個)、(b)「one-shot学習」、お手本1個だけ見せるやつ、(c)「zero-shot学習」、お手本なしで自然言語の指示だけ渡すやつ。
なんやけど、この図を見たらちゃんとハッキリするねん:
図A.1:Brownら(2020)のICLの説明図。
ほんでさらに、ICLは別に新しいタスクを学習することとは限らへんって、はっきり言うてるねん。
77
---
## Page 78
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p078.png)
### 和訳
ほな説明するで!
ここらへんの用語がごっちゃになりやすいから、ちゃんと整理しとくな。まず「メタ学習」っていう言葉は、内側のループと外側のループっていう二重構造になってる方法全体を指すために使っとるねん。ほんで「インコンテキスト学習(文脈内学習)」っていうのは、そのメタ学習の内側のループのことを指してるわけやな。さらに、推論のときに何個お手本を見せるかによって、「ゼロショット」「ワンショット」「フューショット」って呼び分けてるねん。お手本なしがゼロ、1個がワン、数個がフューやな。
ここでめっちゃ大事なポイントがあってな、これらの用語は「モデルが推論のときにゼロから新しいタスクを学んどるんか、それとも訓練中に見たパターンを思い出しとるだけなんか」っていう問題に対しては、どっちとも言わへん立場をとっとるねん。これはほんまに重要な問題やから論文の後半でちゃんと議論するんやけど、「メタ学習」っていう言葉はどっちの可能性も含んでて、単純に内側と外側のループ構造のことを言うてるだけやねん。
ちなみにここではBrownら(2020)の広い定義を使っとるんやけど、実際の現場の人らは「ICL」って言うたら、モデルがプロンプトから新しいタスクを学んどるように見える場面を指すことが多いねん。あと、ウチらの定義はDongら(2023)の厳密な定義とはちょっと違うで。あっちもBrown et al.(2020)がベースやねんけどな。
---
## Page 79
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p079.png)
### 和訳
A.10 貢献したメンバーの紹介
ここからは、この論文の各セクションでチームメンバーがどんな貢献したかを紹介するで。ほとんどのメンバーは、自分の担当以外のセクションのレビューもやってくれとるねん。
**アドバイザー陣**
- **Denis Peskoff**: 論文全体の構成整理と最終レビューを手伝ってくれたで。
- **Alexander Hoyle**: 書き方のアドバイスとか、メタ分析のやり方についてガイダンスくれて、さらにケーススタディ用の自動ベースラインも回してくれてん。
- **Shyamal Anadkat**: 論文全体のレビューと、語源とか定義のところを見てくれたで。
- **Jules White**: テクニックの分類体系をツリー構造で作ってくれてん。めっちゃわかりやすくなったわ。
- **Marine Carpaut**: 多言語セクションの枠組みを作って、レビューして、関連する論文も提案してくれたで。
- **Phillip Resnik**: 研究全体の責任者、いわゆるボスやな。
**SCSラベリング**
- **Megan L. Rogers、Inna Goncearenco、Giuseppe Sarli、Igor Galynker**: このセクションのレビューとアドバイスをしてくれたで。
**ベンチマークとエージェント**
- **Konstantine Kahadze**: ベンチマークセクションのリーダーやねん。MMLUっていうベンチマーク(AIの性能テストみたいなもんや)のコードベースを管理して、セキュリティとメタ分析にも貢献してくれたで。
- **Ashay Srivastava**: エージェントセクションのリーダー。人間によるレビュー用の論文を選んだり、ツール使用型エージェントのセクションを担当してん。あと、貢献リストのとりまとめもやってくれたわ。
- **Hevander Da Costa**: ベンチマークセクションとメタレビューのデータセット一覧に貢献して、LLM(大規模言語モデルやな)のコード生成とかプロンプト技術の文献調査もやってん。エージェントセクションにも文献レビューの内容を追加してくれたで。
- **Feileen Li**: ツール使用型エージェントのセクションを担当して、人間による論文レビューも手伝ってくれたで。
**アライメントとセキュリティ**
- **Nishant Balepur**: アライメント(AIの方向性を正しく合わせる話やな)セクションのリーダー。ベンチマークの全体的な議論にも関わって、原稿のレビューもしてくれてん。
- **Sevien Schulhoff**: セキュリティセクションのリーダーで、ベンチマークセクションにも貢献してくれたで。
**関連研究とセクション別の貢献**
- **Chenglei Si**: 関連研究を提案してくれて、セクション2.2とセクション7の編集をやってくれたで。
- **Pranav Sandeep Dulepet**: セクション2の定義づけに貢献して、マルチモーダル(テキストだけやなくて画像とか色んな情報を扱う話やな)セクションではセグメンテーションと物体検出のところを担当してん。
- **HyoJung Han**: マルチモーダルセクション、特に音声+テキストのところに貢献して、音声プロンプティングのセクションを書いてくれたで。
- **Hudson Tao**: マルチモーダルの中でも画像・動画・3Dのセクションを執筆して、人間レビュー用の論文も見てくれてん。あとGitHubのコードベースの管理とプロジェクトのウェブサイトも作ってくれたわ。めっちゃマルチやな。
- **Amanda Liu**: 分類体系のオントロジー(物事の整理の仕方みたいなもんや)セクションを書いて、イントロと関連研究の背景調査もやって、メタ分析のグラフ用のコードパイプラインも開発してくれたで。
---
## Page 80
[](/attach/06d9e15bc94457f08dfa24411ced93d626e981a2f805e98b5a0298e906b7c885_p080.png)
### 和訳
・Sweta Agrawal:評価セクションのチームリーダーやってん。
・Saurav Vidyadhara:全体のレビューとか、分類ツリーの見直しを手伝ってくれたんやで。
・Chau Pham:メタレビュー、つまり論文全体をまとめて俯瞰する作業を手伝ってくれて、トピックの自動分析もやってくれたわ。
**多言語プロンプティングとメタ分析**
・Dayeon Ki:多言語プロンプティング、要するにいろんな言語でAIに指示出す話のセクションを引っ張ってくれて、関連する論文のレビューもやって、セクション3.1を書いてくれたんや。
・Yinheng Li:セクション2.2のテキストベースのテクニック、つまり文字だけで工夫するやり方のとこを担当して、テクニックのレビューして、図2.2の下書きにも貢献してくれたで。
・Saloni Gupta:論文のコンパイル、まあ論文をちゃんとまとめて組み立てるテストを書いて、論文作成のパイプライン(作業の流れ)の立ち上げも手伝ってくれて、コードの図とか文法チェックもやってくれたんやな。
・Gerson Kroiz:セクション1.1と「プロンプトとは何か」の定義づけに関わってくれたで。
・Aayush Gupta:メタ分析、つまり論文をまとめて全体像を見る作業に貢献してくれて、論文の収集とか可視化グラフの作成をやってくれたんや。
・Michael Ilie:共同筆頭著者やねん。コードベースの管理、実験の実行、データ収集、それからPRISMAレビュー(論文の系統的な選別プロセス)の図とかSCSプロンプティングのケーススタディとか、いろんなセクションを手伝ってくれた、めっちゃ頼りになる人やで。
・Sander Schulhoff:筆頭著者。ほんまにこのプロジェクト全体を率いたリーダーやな。
80
---
![]()
1 / 1
100%