<<
2410.18908v6.pdf

---
## Page 1
[](/attach/042e1f605bca4d6f13f189f80f11e25db0d1092fe81b61406549f1784ff0fc4a_p001.png)
### 和訳
# 音声理解のための音声大規模言語モデルに関するサーベイ
Jing Peng1,2*、Yucheng Wang3*、Bohan Li1,2、Yiwei Guo1,2、Hankun Wang1,2、YanGui Fang5、Yu Xi1,2、Haoyu Li1,2、Xu Li4、Ke Zhang6、Shuai Wang7、Kai Yu1,2†
1 X-LANCE Lab、コンピュータサイエンス学部、人工知能教育部重点実験室、上海交通大学、中国上海
2 江蘇省言語計算重点実験室、中国蘇州
3 チューリッヒ工科大学、スイス・チューリッヒ
4 AISpeech Co., Ltd.、中国蘇州
5 華中科技大学、中国武漢
6 香港中文大学(深圳)データサイエンス学部、中国深圳
7 南京大学知能科学技術学部、中国蘇州
## 要旨
音声理解ってな、めっちゃ大事なんよ。なんでかっていうと、しゃべり言葉の中には色んな情報が詰まってるねん。言語的な情報はもちろん、準言語的な手がかり(感情とか話し方のニュアンスな)、それに非言語的な手がかり(周りの音とかな)まであって、これ全部、人とコンピュータがうまくやり取りするのにめっちゃ重要やねん。
ほんで最近、大規模言語モデル(LLM)がめっちゃ進化してきて、そこから「音声大規模言語モデル(Speech LLM)」っちゅうもんが出てきたんよ。これがな、汎用的な音声理解システムへの大転換を意味してるわけ。
この論文ではな、タスクの目的をもっとはっきりさせて体系的に整理するために、「音声理解」っていう概念をちゃんと定義して、情報・機能・フォーマットの3つの軸で分類する枠組みを提案してるねん。
この定義の範囲内で、今あるSpeech LLMを包括的にレビューしてるで。アーキテクチャは3段階で抽象化して分析してんねん:モダリティ特徴抽出、モダリティ情報融合、LLM推論の3つや。それに加えて、学習戦略も調べて、代表的なデータセットについて議論して、この分野で使われてる評価手法もレビューしてるで。
実験的な分析と証拠に基づいて、今のSpeech LLMが直面してる2つの重要な課題を特定したんよ。それが「指示への敏感さ」と「意味推論の劣化」やねん。ほんで、これらの問題に対処するための具体的な方向性も提案してるで。
この体系的で詳細なサーベイを通じて、より頑健で、汎用的で、人間に寄り添ったSpeech LLMに向けて研究してる人や実務者のみんなに、基礎的な参考資料を提供できたらええなと思ってるねん。
**キーワード** — 大規模言語モデル、音声理解
## I. はじめに
音声ってな、めっちゃ色んな有用な情報を含んでるんよ。言語的な内容、つまり語彙の意味とか文法とかはもちろん、準言語的な手がかり、例えば感情とか話し方のスタイルとか、さらには非言語的な文脈、背景のノイズとか空間的な手がかりまであるねん。
やから音声を理解するっていうのは、ほんまに大事なタスクなんよ。人と機械の効果的なコミュニケーションを可能にするし、バーチャルアシスタント、自動文字起こし、感情分析、会話AIとか、色んな分野の発展を支えてるんや[1], [2]。
音声理解の研究ってな、長い歴史があって、ずっと進化してきてん。音声処理と自然言語処理(NLP)の交差点に深く根ざしてるんよ。その発展は数十年に及んでて、初期のルールベースや統計的なアプローチから、現代の深層学習や大規模言語モデル(LLM)のパラダイムへと移り変わってきたんや[3]。
「音声理解」っていう言葉はよく使われてるけど、実は普遍的に受け入れられてる定義ってないねん。このサーベイでは、広くてタスクに依存せん定義を採用してるで:音声理解は、話し言葉の知覚と認知を含む統合的なプロセスとして定義できて、最終的にテキストによる解釈を生み出すもんやと。
従来の自然言語理解(NLU)が記号的なテキスト入力だけを扱うのとは違って、音声理解は音響信号のマルチモーダルな解釈を含むねん。語彙内容、韻律、話者の特性、環境の文脈とかな。「何が言われたか」を認識するだけやなくて、「どう言われたか」「誰が話してるか」「どんな状況で話してるか」を知覚する必要があるんよ。
このプロセスには、音声から多様な情報タイプを抽出して、認知的な目標と整合させて、構造化されたまたは生成的な出力を生み出すことが含まれてるねん。低レベルの信号処理と高レベルの言語理解を橋渡しするわけや。
これは話し言葉理解(SLU)とは対照的やで。SLUはもっと狭い範囲に焦点を当ててて、文字起こしされた音声から構造化された意味を抽出することに集中してるんよ[4]。それに比べて、ワイらの定義は、音声を広い理解と推論タスクのためのマルチモーダル信号として扱う、より全体的な見方を反映してるねん。
このイントロでは、音声理解アプローチの歴史的な進化から始めて、その後このサーベイの主な焦点である「理解のための音声大規模言語モデル(Speech LLM)」を紹介していくで。
音声理解は歴史的に、カスケード型のアーキテクチャでアプローチされてきたんよ。個々のサブタスク、例えば自動音声認識(ASR)で音声をテキストに変換したり、意図やエンティティみたいな意味情報を抽出したりするのを、別々のモジュールが順番に処理するパイプラインやな。
この設計は1990年代から2010年代にかけて標準的なパラダイムになって、初期の研究と商用システムの両方のバックボーンを形成してたんや[3], [5]。時間が経つにつれて、ASRと下流の意味タスクはだいたい独立して進化していったで。
ASRの研究は、音響モデリング、言語モデリング、そしてその後の深層学習ベースのエンドツーエンド文字起こしモデルの進歩を通じて、単語誤り率を下げることに焦点を当ててたんよ[6]–[8]。一方、意味理解タスク—しばしば...
---
*この研究は、Jing Peng、Yucheng Wang、Yangui FangがAISpeechでのインターンシップ中に実施されたものです。*
*†Kai Yuが責任著者です。*
---
## Page 2
[](/attach/042e1f605bca4d6f13f189f80f11e25db0d1092fe81b61406549f1784ff0fc4a_p002.png)
### 和訳
SLUっていう名前で呼ばれてた音声言語理解の研究はな、最初はルールベースのシステムからスタートして、そっから意図分類とかスロット埋めのための統計的・ニューラルなアプローチに進化していったんや。テキストベースのNLPから手法借りてくることも多かったで[9]。研究者らはこのモジュール式のセットアップには限界あるなって分かってたんやけど、サブタスクを一緒に最適化しようっていう取り組みはあんまり進まんかったんよな。初期のアプローチやと、ASRの信頼度スコアとかN-best仮説を意味モジュールに渡すってのがあって[10]-[12]、後になると特徴量共有とかマルチタスク学習で共同モデリングを探る研究も出てきた[13]-[15]。せやけど、こういう統合は基本的に浅くて、カチカチのパイプライン構造に縛られてたんや。この時期はずっとこの構造が主流やったわけ。
カスケード型のアーキテクチャはモジュール性と柔軟性があるから広く使われてきたんやけど、研究者らは昔からいくつかの根本的な問題点を指摘しとったんよな。認識エラーが理解コンポーネントに伝播してまうこと[5]、順番に処理するから遅延が増えること[16]、文字起こしの時に貴重な音響情報とか韻律情報が失われること[17]、モジュール間で共同最適化ができへんこと[5]、こんな問題があったんや。こういう限界があったから、もっと統一的なモデリングアプローチに移行しようっていう流れになったんよ。ほんでここ数年で、認識と理解を一つのシステムに統合したエンドツーエンドの音声言語モデルが登場してきたわけや。
統一型音声言語モデルの発展における最初の大きなステージは2010年代後半に出てきて、音声をテキストラベルとか要約とかタスク固有の出力みたいな高レベルの意味表現に直接マッピングするエンドツーエンドシステムが特徴やったんや[5], [15], [18], [19]。こういうモデルは普通、CTCとかRNN-T、アテンションベースのエンコーダ・デコーダモデルみたいなASRモデリングフレームワークを使ってゼロから訓練したエンコーダアーキテクチャ[8], [20]-[22]か、wav2vec 2.0とかHuBERT、WavLMみたいな自己教師あり事前学習エンコーダ[23]-[25]のどっちかを使ってたんや。こういう場合、エンコーダは軽量なデコーダと組み合わせて、タスク固有の意味出力を生成するんよ。カスケードパイプラインと比べると、こういうモデルはエラー伝播が減るし、頑健性が上がるし、アーキテクチャもシンプルになるっていうメリットがあるんや。せやけどな、タスク固有のモデルは個別の音声理解タスクではそこそこ成熟した性能を達成してるけど、一般的な音声理解っていうもっと大きな課題には全然足りてへんのよ。一般的な音声理解には、音声から多様な種類の情報を処理して統合する能力が必要やからな。この段階のモデルの複雑な推論能力とかタスク適応能力はまだまだ限られてて、主な原因はデコーダがシンプルすぎることと、一般的な言語知識が足りてへんことやねん。こういう限界があるから、次のステージのLLM駆動型アプローチが求められるようになったんや。
音声LLMはな、音声理解をエンコーダ・デコーダアーキテクチャから言語モデル中心のフレームワークに移行させたんや。強力な事前学習済みテキストベースLLMを活用して、音声LLMは音声入力(普通は自己教師ありエンコーダで処理される)をテキスト埋め込み空間にマッピングするんよ。これによって言語モデルが音声から直接推論したり、テキスト生成したり、理解したりできるようになるわけや。このアーキテクチャのおかげで、要約とか質問応答とか感情検出とか、柔軟なプロンプティングと指示チューニングを通じて幅広い下流タスクができるようになったんや。SALMONN[26]とかSEED[27]、Listen-Think-Understand[28]、DESTA-2[29]みたいな代表的なモデルがこのパラダイムを体現しとる[30]-[33]。もっと重要なんは、音声LLMが文字起こしと意味解釈と応答生成を統一フレームワークに統合して、ASRとSLUの間の壁をなくして、全体的な音声理解を可能にしたことやねん。一般的な音声理解についての詳しい議論はセクションIIIでやるで。
LLM中心のフレームワークがめっちゃ急速に進歩してるにもかかわらず、音声LLMの定義は今の研究ではまだ標準化されてへんのよな。解釈や研究範囲は色々あるんやけど、このサーベイでは音声LLMを理解指向の音声言語処理として定義するで。具体的には、文字起こしとか意図ラベルとか要約とか回答みたいなテキスト出力を生成する音声LLMに焦点を当てるんや。別の定義やと音声から音声への生成タスクを含む場合もあるんやけど、それはこの論文の範囲外で、他のサーベイでレビューされとる[34], [35]。最近のサーベイでいくつか関連概念を探ってるのはあるんやけど[34], [36]、音声理解の観点から焦点を絞った体系的なレビューを提供してるのはないんよな。音声理解はほとんどの主流音声LLMのコアモジュールとして機能するだけやなくて、それ自体が独立した研究方向として台頭してきてて、理解タスクだけのために専用の音声LLMが開発されるようになってんねん。これは学術界と産業界の両方でめっちゃ注目集めてるトレンドや[26], [28], [32], [37]-[39]。既存のサーベイは主に音声生成とか広いマルチモーダルフレームワークに焦点当ててて、音声LLMを従来の音声理解タスクに結びつける文脈があんまり提供されてへんのよ。このサーベイはそのギャップを埋めて、理解指向タスクのための音声LLMの設計・訓練・評価について、焦点を絞った構造化された概観を提供するで。
俺らの貢献は以下の通りや:
• 音声理解の観点から音声大規模言語モデル(音声LLM)の初めての包括的サーベイを提示するで。音声理解自体の初めての体系的な概念化とタスク指向の定義を提供して、情報的・機能的・フォーマット的次元にまたがる分類法も一緒に示すわ。
• カスケードパイプラインからLLM中心アーキテクチャまでのモデリングアプローチの進化をレビューして、現在のモデル設計・訓練戦略・データセットの構造化された統合を提供するで。音声理解タスク全体での汎化性能の革新的な評価もやるわ。
• 俺ら自身の実験分析に基づいて、現在の音声LLMが直面してる主要な課題を特定するで。指示への敏感性とか、意味推論の限界についての初めての明確化も含めてな。ほんで、より汎化可能で頑健な音声理解に向けた将来の研究の方向性を示すわ。
理解指向タスクに議論を集中させて、概念的な明確さと技術的な深さの両方を提供することで、この論文は基礎的な参考文献として機能するで。音声処理、音声言語理解、マルチモーダルモデリング、会話AIの研究者が現在の状況をよりよく理解して、新しいモデルをその中に位置づけるのに役立つはずや。
---
## Page 3
[](/attach/042e1f605bca4d6f13f189f80f11e25db0d1092fe81b61406549f1784ff0fc4a_p003.png)
### 和訳
ほな、このサーベイ論文の残りの構成を説明するで!
第2章では、音声理解タスクの分類法(タクソノミー)を紹介してるねん。音声理解っていう分野の範囲を定義して、主要なタスクの種類を整理しとるわけや。第3章では、Speech LLM(音声を扱う大規模言語モデル)がどう進化してきたかを追っていくで。従来の「カスケード型パイプライン」、つまり別々のモデルを数珠つなぎにするやり方から、全部まとめた統合モデルへの移行とか、離散的な音声表現と連続的な音声表現でアーキテクチャがどう違うか、そのへんを比較しとるねん。第4章ではSpeech LLMのモデル構造を調べてて、これを3つのステージに分けて説明してるわ。具体的には「モダリティ特徴抽出」「モダリティ情報融合」「LLM推論」の3段階やな。第5章では今あるSpeech LLMの訓練戦略をレビューしてて、第6章では事前学習とか評価に使われる主要なデータセットをまとめとるで。第7章では各種理解タスクでの性能ベンチマークと実験結果を議論してるねん。最後に第8章で、LLMを使った深い音声理解を発展させるための未解決の課題と将来の方向性を示しとるわ。全体の構成は図1を見てもらったらわかるで。
## II. 音声理解タスクの分類法
音声理解っていうのはな、しゃべった入力から意味のある情報を抽出して解釈する「マルチモーダルな認知プロセス」のことやねん。これ、自然言語理解(NLU)とはちょっと違うねん。NLUは主に「言語的な認知」に焦点を当ててて、シンボリックなテキストから意味とか論理とか感情的な意味を推測することが中心やねん。
せやけど音声理解は、めっちゃ重要な「知覚的要素」が加わってくるわけや。なんでかっていうと、しゃべった音声っていうのは言語的な内容だけやなくて、「パラ言語的情報」と「非言語的情報」も一緒に運んでくるからやねん。パラ言語的情報っていうのは、声のトーンとかイントネーションとか感情とか、そういうやつや。非言語的情報は話者の特徴とか環境音とかやな。
せやから音声理解では、意味的な推論をやる前に、時間的に変化する豊かな音響信号をちゃんと知覚して解釈する能力がモデルに求められるねん。つまり音声理解っていうのは、「知覚」と「認知」の両方をやらなあかん共同作業やねんな。知覚の方は、生の多次元信号の土台を提供してくれる。認知の方は、解釈のための目標と戦略を組み立ててくれるわけや。
ほんでここがめっちゃ大事なポイントやねんけど、この2つは相互依存の関係にあるねん。つまり、効果的な認知は正確できめ細かい知覚にかかってるし、意味のある知覚は認知的な事前知識にガイドされなあかんのや。
---
## Page 4
[](/attach/042e1f605bca4d6f13f189f80f11e25db0d1092fe81b61406549f1784ff0fc4a_p004.png)
### 和訳
音声理解システムの設計って、結局このへんの関係性がベースになってんねん。
ほんで、音声理解っちゅう概念をもっとちゃんと整理するために、システム目線で音声理解タスクを3つの切り口で分類してみたで。まず「情報の種類」っていう軸は、音声に含まれてる情報のタイプに注目してて、いわば知覚のフロントエンドやな。次に「機能」っていう軸は、理解の目的に注目してて、システムがどんな認知タスクをやるべきかを決めるもんや。最後に「フォーマット」っていう軸は、入力と出力の構造としてタスクがどう具体化されるかを扱ってて、音声理解システム全体の設計と運用をカバーしてんねん。
## A. 情報の種類による分類:音声に含まれる情報タイプ別
音声信号にはめっちゃいろんな情報が詰まってて、大きく3つに分けられるねん。この軸に基づいて、音声理解タスクは主にどの情報を解釈しようとしてるかで分類できるわけや。
**言語情報**: 音声から単語や文法的な内容を書き起こして理解することに焦点当ててんねん。代表的なタスクは自動音声認識(ASR)と音声言語翻訳(SLT)やな。同音異義語とか方言のバリエーション、書き起こしミスなんかが課題になってくるで。
**パラ言語情報**: 言葉そのものを超えた手がかり、例えば感情とか抑揚、話者の意図を抽出することに関わってんねん。感情認識、話者分離、対話行為分類なんかのタスクがこれに当たって、イントネーションとか話し方のスタイルみたいな特徴に頼ってるんや。
**非言語情報**: やり取りの分析を助ける文脈的な音響の手がかりを含んでんねん。音声区間検出(VAD)、音響イベント分類、音響シーン理解なんかのタスクがこれやな。背景ノイズとか話者の交代、空間的な手がかりに依存してるんや。
この軸は、音声エンコーダーのフロントエンド設計に役立つねん。なんでかっていうと、音声に埋め込まれたいろんな情報タイプを明らかにしてくれるからや。言語・パラ言語・非言語を区別することで、特徴抽出とか表現学習、入力の条件付けに対して狙いを絞ったモデリング戦略が立てられるようになるんや。
## B. 機能による分類:認知目標別
音声理解タスクは、認知的なゴールによって3つの段階に大きく分けられるで。
**知覚タスク**: 音声信号の抽出と操作に焦点当てて、意味的な推論はほとんどいらんやつや。代表例は自動音声認識(ASR)、キーワード検出(KWS)、話者分離(SD)、音声区間検出(VAD)やな。
**浅い認知タスク**: 直感的でパターンベースの理解に頼ってて、素早くてヒューリスティックな推論に対応してんねん。音声翻訳(ST)、感情分類、意図検出、感情認識なんかがその例や。
**深い認知タスク**: 複雑で文脈を考慮した推論が必要で、談話のモデリングとか推論を伴うことが多いんや。複雑な音声質問応答、会話要約、曖昧な状況での話者意図の説明、音声とテキストの文脈に基づくマルチモーダル推論なんかが典型的なタスクやな。
浅い認知と深い認知の区別は、「二重過程理論」っていう認知理論に基づいてんねん。これは2つの相補的な推論モードがあるっていう理論や。システム1は素早く自動的で直感的に動くやつ、システム2はゆっくり慎重で分析的に考えるやつや。このフレームワークでいうと、音声理解の浅い認知タスクはシステム1の処理を反映してて、明示的な多段階推論なしにヒューリスティックやパターンベースの解釈に頼ることが多いんや。それに対して深い認知タスクはシステム2に対応してて、構造化された推論をしたり、複雑な文脈の手がかりを統合したり、曖昧さを解消したりすることがモデルに求められるんやな。
音声理解をこの二重過程の視点で捉えると、タスクの複雑さを階層化してモデル設計を導くための原理的な基盤ができるねん。知覚から深い推論まで、各タスクタイプに必要な認知の深さを明確にすることで、訓練目標の戦略的計画とか、カリキュラム学習の段階設定、意味的複雑さのレベルに応じた評価プロトコルの設計がやりやすくなるんや。
## C. フォーマットによる分類:入出力構造別
情報や機能の軸が「どんな知識を使うか」「なぜタスクを実行するか」を説明するのに対して、フォーマットの軸は「入力がどうパッケージ化されて制約されるか」を規定してんねん。構造は観察しやすくてラベル付けも簡単やから、この軸はメインテーマを薄めることなくスッキリした分類ができるんや。あと、第VII-A節の評価スイートとも整合してるで。
### 1) 入力の定式化
入力条件の構造に基づいて音声理解タスクを区別できるんや。コアの入力には常に音声信号と自然言語の指示が含まれるんやけど、モデルは性能を向上させたり新しい能力を可能にしたりする外部情報源にも条件付けられることがあんねん。これらの入力に符号化される構造と事前知識の程度に基づいて、以下のように分類してるで。
**構造化入力ソース**: 明示的にフォーマットされた信号を提供して、モデルに直接的なガイダンスを与えるもんや。典型例としては:
- ホットワードリスト(例:ASRにバイアスをかけるためのユーザー定義キーワード)
- 話者埋め込み(例:話者のアイデンティティを符号化した固定次元ベクトル)
- 語彙集やドメイン制約(例:タスク固有の語彙や文法規則)
---
## Page 5
[](/attach/042e1f605bca4d6f13f189f80f11e25db0d1092fe81b61406549f1784ff0fc4a_p005.png)
### 和訳
図2: 音声理解タスクの3次元分類体系やで
**構造化された入力ソース**っていうのは、こういうのがあるねん:
- 知識構造(オントロジーとか、文書とか、データベースのスキーマみたいな、外部の専門知識をきっちり形式化して持っとるやつ)
- 感情の記述(微妙な感情の状態を自由形式のテキストで表現するやつ)
- 音声品質の評価(流暢さとか明瞭さを評価するやつ)
**非構造化された入力ソース**は、形式がカッチリ決まってへん、文脈から来る自由なシグナルを提供してくれるねん。こんなのが含まれるで:
- 対話履歴(前の会話のやり取りとか)
- 背景の説明(タスクの指示とか、ユーザーのプロフィールとか、場面の要約とか)
- 長めの文脈要約(前の発話内容とか、意味的な記憶とか)
**2) 出力の形式化**
タスクは出力の構造によっても分類できるねん。以下のタイプがあるで:
**構造化タスク**: きっちりした出力が定義されてて、厳密な方法で評価できるから、正確で客観的な性能指標が計算できるやつや。よくある例としては:
- 自動音声認識(ASR)(音声をそのままのテキストとか正規化したテキストに書き起こすやつ)
- 話者分析(あらかじめ決められたラベルを使った話者識別、検証、ダイアライゼーションとか)
- 感情分類(カテゴリ的な感情ラベルを付けるやつ)
- キーワードスポッティング(KWS)(あらかじめ決められた用語を検出するやつ)
- 音声活動検出(VAD)(音声か非音声かの2値ラベリング)
- タスク指向の構造化タギング(対話行為、ユーザーの意図、ドメインコードを予測するやつ)
**非構造化タスク**: 標準的な答えがない自由形式の出力を生成するから、厳密な評価が難しくて、文脈的・主観的な判断に頼らなあかんやつ。代表的なタスクとしては:
- 話者の記述(年齢とかアクセントみたいな話者の特徴を自然言語で説明するやつ)
- 会話スタイルの分析(丁寧さとか主張の強さを推測するやつ)
- ユーザー意図の説明(曖昧な発話とか情報的な発話を解釈するやつ)
- 自由形式の音声解釈(内容を自由な言葉で要約したり説明したりするやつ)
**弱構造化タスク**: 構造化と非構造化の中間に位置してて、ゆるい正解の制約のもとで複数の許容される答えがあるやつ。こういうタスクは近似的な客観指標をサポートしてて、部分的に厳密な評価ができるねん。典型的な例としては:
- 音声翻訳(ST)(音声をある言語から別の言語に変換するやつで、いろんな有効な出力があって、BLEU [42], [43]で評価される)
- 音声要約(凝縮したコンテンツを生成するやつで、事実のカバー率と一貫性がROUGE [44]を使って評価される)
このフレームワークは、既存のタスクを包括的に分類できるだけやなくて、将来の音声理解システムの設計にもガイダンスを提供してくれるねん。構造化された出力は正確な指標と強い教師信号の恩恵を受けられるし、非構造化された出力は実世界の複雑さと生成的推論の必要性をよりよく反映してるわけや。特に、構造化された出力は下流の計算システムから直接解釈可能やし、信頼できる客観的な評価ができるんやけど、非構造化された出力は生成的な理解が必要で、機械が直接アクションを取るのは簡単やないねん。同様に、構造化と非構造化の入力ソースを統合することで、多様な環境でのモデルの制御性、パーソナライゼーション、適応性が向上するんや。
まとめると、音声LLMの文脈に置いたとき、この分類体系は現在の能力を整理するための原理的なフレームワークを提供するだけやなくて、将来のシステムに対する進化する要求も浮き彫りにしてくれるねん。マルチタスクの汎化、指示追従、文脈を意識した推論への重点が増してきてる中で、音声LLMは柔軟に統合せなあかんわけや。
---
**図の説明**
音声理解タスク
- **情報的次元**: パラ言語的 / 非言語的 / 言語的
- **機能的次元**: 浅い認知 / 深い認知 / 知覚
- **形式次元(出力)**: 弱構造化 / 非構造化 / 構造化
---
## Page 6
[](/attach/042e1f605bca4d6f13f189f80f11e25db0d1092fe81b61406549f1784ff0fc4a_p006.png)
### 和訳
いろんなタイプのインプットに対応できて、構造も具体性もバラバラなアウトプットを出せるようになってきてんねん。せやから、この分類体系があることで、もっと柔軟で解釈しやすくて、ちゃんと目的に沿ったアーキテクチャの開発に役立つんやな。要するに、狭い範囲のASR(音声認識)中心のモデリングから、もっと広い意味での「音声言語を全体的に理解する」っていうパラダイムへの転換を後押ししてくれるわけや。
## III. 汎用的な音声理解に向けて:Speech LLMの登場と進化
Speech LLMの発展の流れをもっと分かりやすく説明するために、このセクションでは2つの視点から話を進めていくで。セクションIII-Aでは時系列での見方、つまり音声理解システムの歴史的な進化をたどって、その中でSpeech LLMがどう登場してきて、なんで重要なんかを説明するわ。それと並行して、セクションIII-Bでは構造的な視点から、Speech LLMが2つの異なるアーキテクチャのパラダイムでどう進歩・発展してきたかを特徴づけていくで。
### A. カスケード型から統合型へ:音声理解のためのSpeech LLMの登場
セクションIIでの音声理解の定義と、セクションII-Bで提案したタスク分類に基づくと、音声理解は大きく2つの視点に分けられるねん。1つは知覚処理に焦点を当てたもの(ASRとか関連タスク)、もう1つは音声入力に対する認知的な推論に焦点を当てたもので、浅い理解から深い理解まで含む目標(SLUとかそれ以上)を扱うんや。歴史的に一貫した用語がないから、このセクションではASRとSLUという代表的な視点からSpeech LLMの進化をたどっていくで。この2つが音声理解の大きな流れを照らし出してくれるからな。網羅的ではないけど、この2つの発展の流れが、この分野の構造的・機能的な進歩を理解するための分かりやすい目印になるねん。
音声理解のためのモデルの発展は、大きく2つの段階に分けられるわ。1つ目は**モジュラーアーキテクチャの時代**で、別々に最適化されたコンポーネントを持つカスケード構造が典型的やった。2つ目は**エンドツーエンド(E2E)アーキテクチャの登場**で、システム全体を一括で訓練してパイプライン全体のパフォーマンスを最適化するようになったんや。E2Eパラダイムの中でも、さらに転換があってん。単一または少数の明確に定義されたタスク向けに設計された**E2E特化型音声理解システム**から、**E2E汎用音声理解システム**へと移行したんや。この汎用システムでは、言語による指示でどんなタスクでも指定できて、あらゆる形式の理解を捉えられるアウトプットをサポートしてるねん。各段階は、モデルの能力とアーキテクチャのマイルストーンを示すだけやなくて、タスク間の収束が進んでいくことも示してて、最終的には汎用的な音声理解を目指した統一モデリング能力に到達してるわけや。この発展プロセスの概要は図3に示してあるで。
#### 1) モジュラーアーキテクチャ
音声処理の初期の取り組みは、主にモジュラーアーキテクチャに従ってたんや。例えばASRでは、パイプラインは通常、別々に訓練された音響モデル(AM)、言語モデル(LM)、デコーダーで構成されてて、重み付き有限状態トランスデューサ(WFST)で統合されてたんや。これらのコンポーネントは独立に最適化されてて、タスクへの適応力がなかったわけや。典型的な実装としては、GMM-HMM(ガウス混合モデル-隠れマルコフモデル)フレームワークや、後のDNN-HMM(ディープニューラルネットワーク-HMM)ハイブリッド[6], [45]があって、これらがKaldi [46]やCMU Sphinx [47]みたいな多くの大規模ASRツールキットの基盤になってたんや。この設計は膨大なエンジニアリング作業が必要で、手作業での設定に大きく依存してて、知識を統合的に組み込んだりマルチタスクの汎化をサポートする能力がなかったんやな。
さらに、SLU(音声言語理解)の分野では、従来、音声言語理解はASRの出力の上に構築されてたんや。初期のSLUシステムは「ASR → NLU」パイプライン[4], [48]を採用してて、自然言語理解モデルが1-bestまたはN-bestのASR仮説に対して動作して、意図分類、スロット埋め、対話状態追跡[49]などのタスクを実行してたんや。でもな、こういうカスケード型システムはエラーの伝播に悩まされて、ノイズの多い音声や曖昧な音声のシナリオでパフォーマンスが落ちてしまうんや。それに加えて、豊かな韻律や音響の手がかりが書き起こし時に失われることが多くて、より深い意味解釈が制限されてたんやな。
感情認識みたいな特定の音声理解タスク向けの他のモデルも、同様にモジュラー開発フェーズを経てきてん。これらのアプローチは強い解釈可能性を提供するけど、パフォーマンス面ではまだまだ改善の余地がめっちゃあるんや。
#### 2) E2E特化型音声理解システム
ディープニューラルネットワークの発展に伴って、特定の音声理解タスク向けに設計されたモデルでは、エンドツーエンドアーキテクチャへのシフトが起きてん。モジュラーパイプラインからエンドツーエンドアーキテクチャへ、カスケード処理から統一モデリングへの移行やな。1つまたは少数の特定タスクをエンドツーエンドで解決することに焦点を当てたこのクラスのモデルを、**E2E特化型音声理解システム**と呼ぶことにするわ。
この転換の最初の大きな段階は、エンドツーエンドASRアーキテクチャの台頭やねん。初期のE2Eシステムは、CTC(Connectionist Temporal Classification)[20]に基づくフレーム同期モデルを採用してて、フレームレベルのアラインメントが不要になることで訓練を簡素化したんや[22]。その後、RNN-T(Recurrent Neural Network Transducer)[21]が登場して、独立性の仮定を緩和してストリーミングアプリケーションをサポートするようになったんや。それと並行して、LAS(Listen, Attend and Spell)[8]、SpeechT5 [50]、Whisper [51]みたいなアテンションベースのエンコーダ・デコーダ(AED)モデルが自己回帰デコーディングを導入して、マルチタスク学習の能力を可能にしたんや。これらのシステムは、音響モデリングと言語モデリングを単一の訓練可能なフレームワークに統合することで、従来のパイプラインから大幅に改善されたんやな。
これらのアーキテクチャの進歩に加えて、E2E時代は自己教師あり学習(SSL)による知覚面での大きな進歩も見られたんや。MFCCみたいな初期の手作り特徴量は、wav2vec 2.0 [23]、HuBERT [24]、WavLM [25]みたいなモデルによって学習された豊かで文脈化された表現に徐々に置き換えられていったんや。これらのSSLベースのエンコーダは、頑健性と汎化性能を大幅に向上させて、多くの最先端E2Eシステムの基盤になったんや[52]。でもな、これらの改善にもかかわらず、従来のE2Eモデルは言語能力が限られた比較的浅いデコーダに依存することが多くて、長距離の推論や豊かな意味解釈を必要とするタスクにはあんまり適してなかったんや。
SLU分野では、エンドツーエンドへの移行には以下のようなモデルが関わっとったんや...
---
## Page 7
[](/attach/042e1f605bca4d6f13f189f80f11e25db0d1092fe81b61406549f1784ff0fc4a_p007.png)
### 和訳
図3: 音声LLM(大規模言語モデル)の構造がどう進化してきたかを示した図やで。モジュール型のアーキテクチャからエンドツーエンド(E2E)のフレームワークへ移り変わっていく様子がわかるねん。
昔のモジュール型システムっていうのは、従来のASR(自動音声認識)パイプラインが代表例やな。その後、エンドツーエンド方式は2つの方向に分かれていくねん:「E2E特化型音声理解システム」と「E2E汎用音声理解システム」や。E2E汎用音声理解システムは「LLM中心型システム」とも呼ばれてて、さらに「離散シーケンスモデリング」(上の図)と「連続シーケンスモデリング」(下の図)に分けられるんや。これは特徴をどう表現するかの戦略の違いを反映してるねん。
---
で、ここからが本題やねんけど、生の音声から直接、意味的な構造——つまり「意図」とか「スロット」って呼ばれるもの——を予測するモデルが出てきたんや。途中で文字起こしを挟まんでええっていうのがポイントやな。Joint SLU [5]とかSLU-Transformer [53]みたいな先駆的な研究で、SSL(自己教師あり学習)で事前学習した音声エンコーダと意味デコーダを組み合わせたら、コンパクトで頑丈なパイプラインが作れるってことが示されたんや。
エンドツーエンドモデルの性能が上がってくると、ターゲットとするタスクもどんどん複合的な目標に進化していったんやで。これらのモデルは汎化性能とタスク特化の性能を向上させたんやけど、データ効率とタスク間の転用性っていう課題はまだ残ってたんや。
**3) E2E汎用音声理解システム**
もっとリッチで汎用的な音声理解タスクへのニーズに応えるために、エンドツーエンドの流れの中で最近出てきたトレンドが「E2E汎用音声理解システム」、別名「LLM中心型システム」やねん。これはLLM(大規模言語モデル)を中核の推論コンポーネントとして統合したシステムのことや。
LLMを中心に据えた音声理解モデルは、「認知主導の知覚」っていうパラダイムシフトを象徴してるんや。これはマルチモーダルシステムの進化において、めっちゃ重要な発展やねん。なんでかっていうと、言語モデルがもはや知覚フロントエンド(音声を受け取る部分)と対等な立場やなくて、解釈全体を司る「中央コントローラー」として機能するようになったからや。この考え方の概念的なルーツは[54]まで遡れるで。
これらのシステムは、従来のE2Eモデルからの構造的・機能的な進化を表してて、焦点が「音響駆動の生成」から「言語モデル駆動の解釈」へとシフトしてるんや。
---
【図の凡例】
- **モジュール型音声システム**(ASRを例として): 音声 → 辞書 → 音響モデル → 言語モデル
- **エンドツーエンドモデル**: Speech-Transformer、Conformer、Hubert、Whisperなど(2018年〜2022年)
- **E2E特化型SUシステム**: 特定タスク向け
- **E2E汎用SUシステム(LLM中心型)**:
- 離散シーケンスモデリング: SpeechGPT、AudioPalm(2023年)、AnyGPT(2024年以降)など
- 連続シーケンスモデリング: LTU、SALMONN、QWEN-AUDIO、WavLLM、Kimi-Audioなど多数
- **テキスト出力のみのLLM** vs **テキストと音声両方出力できるLLM** の区別もあるで
---
## Page 8
[](/attach/042e1f605bca4d6f13f189f80f11e25db0d1092fe81b61406549f1784ff0fc4a_p008.png)
### 和訳
図4:音声とテキストを入力して、テキストを出力する音声LLMの構造の全体像やで。
普通のAED(エンコーダー・アテンション・デコーダー)ベースの構造とちゃうて、LLM中心型のシステムっていうのは、音声の入力をテキストの世界に合わせてあげて、LLMを使ってデコードしたり、文章生成したり、推論したりするねん[26], [27], [30], [31]。このモダリティをまたぐ設計のおかげで、要約とか翻訳とか質問応答みたいないろんなタスクに応用できるようになるし、モジュール性とか解釈しやすさとか、指示に従う能力もめっちゃ上がるんよ[28], [29], [32], [33]。
LLM中心型アーキテクチャの最近の進歩によって、音声理解において今までにないレベルのタスクの汎用性と言語理解力が実現できるようになってきたんや。ここで大事なんは、ほんまもんのLLM中心型アプローチと、単にASR(音声認識)の出力をLLMにつなげただけの従来のカスケード型システムを区別することやねん。そういうパイプラインベースの設計[55], [56]でもテキストを使った下流の推論はできるんやけど、音声をLLMのフレームワークに根本的に統合してるわけちゃうから、ほんまの意味でのLLM中心型モデリングには届いてへんねん。それに対して、Listen-Think-Understand[28]とかSALMONN[26]みたいな最近の指示チューニングされたモデルは、LLM中心型設計のええ例やで。こいつらは生の音声を入力として受け取って、意図推論とか感情検出とか要約とか知識に基づいた質問応答みたいなタスクに対して、意味的に構造化された出力を直接生成するんや。このシステムは音声表現をLLMに埋め込まれた強力なテキストの事前知識と整合させることで、統一された表現空間の中でプロンプティングも解釈も応答生成もできるようになってるねん。このパラダイムは音声理解タスクの中にあった従来の壁をぶち壊して、ほんまに全体的で統合された音声理解システムに向けた転換を示してるんや。
モジュール型パイプラインからエンドツーエンドシステムへ、そしてさらにLLM中心型フレームワークへという進化は、ASRやSLU(音声言語理解)みたいな幅広い音声理解タスクの統一化がどんどん進んでいく軌跡を描いてるんや。ASRは正確な言語変換を重視するし、SLUは意味的な推論を目指すんやけど、両方の視点が音声LLMという傘の下で徐々に収束してきてるねん。これらのモデルは共有された表現空間と統一されたデコーディングの仕組みを提供してくれるから、文字起こしと理解と生成を一貫したフレームワークの中でできるようになるんや。この観点から見ると、LLM中心型音声LLMの登場は、汎用的な音声言語理解の発展における重要な転換点やねん。この能力のことを、この論文ではセクションIIで詳しく説明してるように「音声理解(SU)」って呼んでるで。
B. 音声LLMの構造的進化:離散型 vs 連続型モデリング
音声LLMの発展における重要な違いは、音声とテキストのモダリティをどうやって統合するかっていうところにあるんや。この論文では、現在のアプローチを、音声と言語をつなぐために使われる表現形式に基づいて、2つの主要なパラダイムに分類してるで。1つは音声の離散トークン化に頼るもので、これはLLMがテキストで使ってるトークンベースの処理パラダイムに着想を得てるねん。もう1つは音声モダリティを連続的な埋め込み形式のまま維持するものや。この2つのパラダイムは本質的に直交してて、クロスモーダルアライメントに対する根本的に異なる戦略を反映してるんや(図5を見てな)。
1つ目の離散シーケンスモデリングっていうのは、連続的な音声信号を量子化されたユニットの列、つまりテキストトークンと形式も機能も似てる離散的な音響トークンに変換するパラダイムやねん。これらの離散トークンは通常、教師なしまたは自己教師あり音声表現モデルとその後のベクトル量子化メカニズムによって得られるんや。人気のあるアプローチとしては、HuBERT[24]、w2v-BERT[57]、EnCodec[58]、wav2vec-U[59]があって、これらは重要な音響パターンを学習してキャプチャし、それをトークン語彙に離散化するねん。
音声をトークン化されたシーケンスに変換することで、これらのモデルはテキスト用に設計されたのと同じ自己回帰型やseq2seqフレームワークを使って音声データを処理できるようになるんや。結果として得られる離散ユニットはテキストトークンと整合させることも、生成タスクの入出力として直接使うこともできるで。このトークンレベルでの互換性がモダリティの溝を埋めて、シームレスな音声・テキスト統合を促進するんや。
純粋に離散化された音響トークンを通じて音声をモデル化する代表的な研究には、SpeechGPTやAudioGPT[60], [61]があるで。これらの方法は連続的な波形を離散コードシーケンスに量子化して(例えばニューラルコーデックを使って)、そのトークンストリーム上で生成言語モデルを訓練することで、統一されたテキストみたいなモデリングフレームワーク内で音声理解と合成の両方を可能にしてるんや。
---
## Page 9
[](/attach/042e1f605bca4d6f13f189f80f11e25db0d1092fe81b61406549f1784ff0fc4a_p009.png)
### 和訳
このモデリングのやり方にはええとこがいっぱいあんねん。何がええかっていうと、音声処理がLLM(大規模言語モデル)の事前学習の恩恵をダイレクトに受けられるようになるんよ。なんでかっていうと、問題をLLMが得意な形式に変換するからやねん。しかも、トークンの列を理解することも生成することも、同じ統一されたフレームワークの中でできるようになるんや。せやけどな、音声情報をエンコードするのに離散トークン表現だけに頼ってるモデルは、音声を聞き取る品質がイマイチになりがちやねん。まず、ASR(自動音声認識)みたいな意味情報を認識するタスクの性能が、WhisperとかHuBERTみたいな従来モデルより劣ることが多いんや。ほんで、細かいパラ言語的な手がかり(声のトーンとか感情とか)や音声の微妙な部分を捉える能力も限界があるんよ。こういうことを踏まえて、この研究では純粋な離散系列モデリングのアプローチには主にフォーカスしてへんねん。
2つ目のパラダイムは「連続系列モデリング」っていうて、根本的に違うアプローチを取んねん。音声信号を言語モデルとやり取りする間ずっと、連続的な埋め込み形式のまま保持するんや。音声を離散化する代わりに、事前学習済みのエンコーダー(例えばWavLM、Whisper、Conformerとか)から高次元の特徴を抽出して、それを直接LLMに流し込むんよ。通常は学習された投影層とか軽量なアダプテーション層を通してな。
この戦略のええとこは、音声に本来備わってる豊富な時間情報とスペクトル情報を保持できることやねん。ほんでLLMの入力空間とスムーズに整合させられるんや。特筆すべきは、Pengiっていうモデルが、凍結されたLLMに投影された音声埋め込みを使ってプロンプトを与えることで、いろんなタスクをこなせることを実証したことやな。その後のSALMONN、Qwen-Audio、OSUMみたいな研究は、この設計をさらに拡張して、幅広い音声理解やマルチモーダル推論タスクをサポートできるようにしたんや。
連続モデリングは、細かい音響の違いを識別せなあかんアプリケーションでめっちゃ効果的やって証明されてるんよ。ASRとかST(音声翻訳)とかな。FireRedASRやLLASTみたいなモデルは、最小限のアーキテクチャ変更で最先端の性能を達成できることを示してんねん。多くの場合、シンプルな投影層だけで十分で、限られたファインチューニングと組み合わせるだけでええんや。
ただな、このパラダイムにも課題はあるんよ。訓練データの量やタスクの多様性が限られてると、モデルが過学習しやすいねん。ほんで、生成モジュールと統合するときは、より強力なデータ駆動のサポートか、離散モデリングアプローチからの助けが必要になることが多いんや。とはいえ、スケーラビリティの高さと事前学習済み言語モデルを再利用するトレンドとの整合性を考えると、連続モデリングは最近のSpeech LLM研究でますます重要なアプローチになってきてるんよ。せやから、この論文では主に連続系列モデリングにフォーカスしつつ、離散トークンベースの代替手法との比較も提供するで。
## IV. モデル構造
Speech LLMが音声入力をどうやって処理して推論するんか、もっと深く理解するために、その基盤となるアーキテクチャ設計を調べていくで。特に、Speech LLMの全体構造を調査するんやけど、これは通常、明確な処理段階で構成されるモジュラー式のパイプラインに従ってるんや。
これまでにいろんなSpeech LLMアーキテクチャが開発されてきたけど、全部が3つの基本的な段階を中心に構成されてるんよ。それが「モダリティ特徴抽出」「モダリティ情報融合」「LLM推論」や。図4に示してある通りやで。
全てのSpeech LLMは、モダリティに関係なく、まず入力情報をエンコードすることから始まるんや。通常、これらのSpeech LLMは事前学習済みの音声エンコーダーとテキストエンコーダーを活用して、両方のモダリティの表現を取得するねん。エンコードされた音声埋め込みとテキスト埋め込みは、言語モデルへの入力準備のために融合されるんや。このステップは、特徴抽出プロセスの出力を言語モデルの入力要件と互換性のある形式に変換するんよ。テキスト出力を生成するSpeech LLM(これがこのサーベイの主なフォーカスやねんけど)では、LLM推論プロセスは通常、融合されたマルチモーダル特徴をトークン化された入力として受け取ってテキストを生成するテキストデコーダーを中心に展開されるんや。オプションで音声出力をサポートするモデルでは、LLMデコーダーが音声トークンを生成するように訓練されて、その後ボコーダーを使って音声に変換されるんやけど、このサーベイではテキスト出力のSpeech LLMだけにフォーカスするで。
### A. モダリティ特徴抽出
前のセクションで触れたように、最初の特徴抽出段階では、音声は2つの異なる方法で処理されるんや。これらのアプローチは主に、音声特徴の出力表現形式が違うんよ。「連続系列モデリング」は現在のSpeech LLMでより一般的に採用されてて、事前学習済みでファインチューニングされた音声エンコーダーを使って音声をエンコードし、音声埋め込み Za ∈ R^(B×T×D) を生成するんや。ここでB、T、Dはそれぞれバッチサイズ、フレーム数、埋め込み次元を表すで。一方、「離散系列モデリング」は入力音声信号を離散的な音声トークンの系列に離散化するんや。これは生のテキストから派生したテキストトークンに匹敵するもんで、埋め込み形式では表現されへんねん。このセクションでは、これら2つのアプローチを使って音声特徴を抽出するための一般的なモデルと技術をまとめるで。
#### 1) 連続系列モデリング
連続系列モデリングは一般的により単純明快で、通常は生の音声信号から従来の信号処理ベースの特徴抽出手法を使って抽出された時間-周波数表現の形式で音声をエンコードするんや。音声入力Xaが与えられると、事前学習済みの音声エンコーダーが適用されて音声特徴が生成されるんよ:
Za = g(Xa), (1)
ここでgは音声エンコーディングプロセスを表すで。主流のSpeech LLMで最もよく使われる音声エンコーダーはWhisperとConformerやねん。Whisperは幅広い音声処理タスクで訓練されたシーケンス・トゥ・シーケンスのTransformerモデルで、そのエンコーダーは音声入力処理において最も強力なものの一つとして認められてるんや。Conformerは畳み込み層とTransformerを組み合わせて、音声信号のローカルな依存関係とグローバルな依存関係の両方を効果的にモデル化する、もう一つの広く採用されてるアーキテクチャやで。特に自動音声認識タスクに向いてるんや。主流のSpeech LLMで使われる追加のエンコーダーとしては、予測的な自己教師あり学習(SSL)で事前学習されたモデルのWavLMがあるんよ。この段階では、
---
## Page 10
[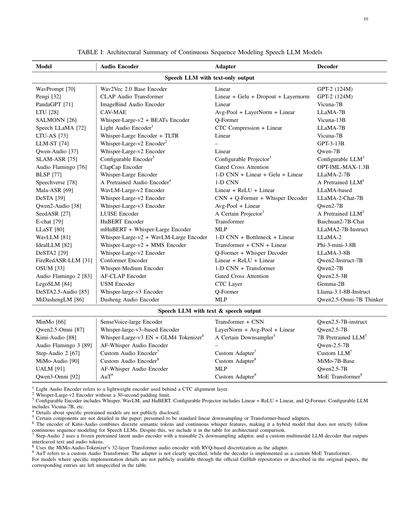](/attach/042e1f605bca4d6f13f189f80f11e25db0d1092fe81b61406549f1784ff0fc4a_p010.png)
### 和訳
# 表I:連続シーケンスモデリング型音声LLMモデルのアーキテクチャまとめ
| モデル | オーディオエンコーダ | アダプタ | デコーダ |
|--------|---------------------|----------|----------|
## テキストだけ出力する音声LLM
| モデル | オーディオエンコーダ | アダプタ | デコーダ |
|--------|---------------------|----------|----------|
| WavPrompt [70] | Wav2Vec 2.0 Base Encoder | GPT-2 (124M) | Vicuna-7B |
| Pengi [32] | CLAP Audio Transformer | Linear | LLaMA-7B |
| PandaGPT [71] | ImageBind Audio Encoder | Linear + Gelu + Dropout + Layernorm | GPT-2 (124M) |
| LTU [28] | CAV-MAE | Linear | Vicuna-13B |
| SALMONN [26] | Whisper-Large-v2 + BEATs Encoder | Avg-Pool + LayerNorm + Linear | LLaMA-7B |
| Speech LLaMA [72] | Light Audio Encoder¹ | Q-Former | Vicuna-7B |
| LTU-AS [73] | Whisper-Large Encoder + TLTR | CTC Compression + Linear | GPT-3-13B |
| LLM-ST [74] | Whisper-Large-v2 Encoder² | Linear | Qwen-7B |
| Qwen-Audio [37] | Whisper-Large-v2 Encoder | – | Configurable LLM³ |
| SLAM-ASR [75] | Configurable Encoder³ | Linear | OPT-IML-MAX-1.3B |
| Audio Flamingo [76] | ClapCap Encoder | Configurable Projector³ | LLaMA-2-7B |
| BLSP [77] | Whisper-Large Encoder | Gated Cross Attention | A Pretrained LLM⁴ |
| Speechverse [78] | A Pretrained Audio Encoder⁴ | 1-D CNN + Linear + Gelu + Linear | LLaMA-based |
| Mala-ASR [69] | WavLM-Large-v2 Encoder | 1-D CNN | LLaMA-2-Chat-7B |
| DeSTA [39] | Whisper-Large-v2 Encoder | Linear + ReLU + Linear | Qwen2-7B |
| Qwen2-Audio [38] | Whisper-Large-v3 Encoder | CNN + Q-Former + Whisper Decoder | A Pretrained LLM³ |
| SeedASR [27] | LUISE Encoder | Avg-Pool + Linear | Baichuan2-7B-Chat |
| E-chat [79] | HuBERT Encoder | A Certain Projector³ | LLaMA2-7B-Instruct |
| LLaST [80] | mHuBERT + Whisper-Large Encoder | Transformer | LLaMA-2 |
| WavLLM [81] | Whisper-Large-v2 + WavLM-Large Encoder | MLP | Phi-3-mini-3.8B |
| IdealLLM [82] | Whisper-Large-v2 + MMS Encoder | 1-D CNN + Bottleneck + Linear | LLaMA-3-8B |
| DeSTA2 [29] | Whisper-Large-v2 Encoder | Transformer + CNN + Linear | Qwen2-Instruct-7B |
| FireRedASR-LLM [31] | Conformer Encoder | Q-Former + Whisper Decoder | Qwen2-7B |
| OSUM [33] | Whisper-Medium Encoder | Linear + ReLU + Linear | Qwen2.5-3B |
| Audio Flamingo 2 [83] | AF-CLAP Encoder | 1-D CNN + Transformer | Gemma-2B |
| LegoSLM [84] | USM Encoder | Gated Cross Attention | Llama-3.1-8B-Instruct |
| DeSTA2.5-Audio [85] | Whisper-large-v3 Encoder | CTC Layer | Qwen2.5-Omni-7B Thinker |
| MiDashengLM [86] | Dasheng Audio Encoder | Q-Former MLP | – |
## テキストと音声の両方出力できる音声LLM
| モデル | オーディオエンコーダ | アダプタ | デコーダ |
|--------|---------------------|----------|----------|
| MinMo [66] | SenseVoice-large Encoder | Transformer + CNN | Qwen2.5-7B-instruct |
| Qwen2.5-Omni [87] | Whisper-large-v3ベースのEncoder | LayerNorm + Avg-Pool + Linear | Qwen2.5-7B |
| Kimi-Audio [88] | Whisper-Large-v3 EN + GLM4 Tokenizer⁶ | A Certain Downsampler⁵ | 7B Pretrained LLM⁵ |
| Audio Flamingo 3 [89] | AF-Whisper Audio Encoder | – | Qwen-2.5-7B |
| Step-Audio 2 [67] | カスタムAudio Encoder⁷ | カスタムAdapter⁷ | カスタムLLM⁷ |
| MiMo-Audio [90] | カスタムAudio Encoder⁸ | カスタムAdapter⁸ | MiMo-7B-Base |
| UALM [91] | AF-Whisper Audio Encoder | MLP | Qwen2.5-7B |
| Qwen3-Omni [92] | AuT⁹ | カスタムAdapter⁹ | MoE Transformer⁹ |
---
## 注釈(ここ大事やで!)
¹ **Light Audio Encoder**っていうのは、CTCアライメント層の後ろで使う軽量なエンコーダのことやねん。要は「軽い版」ってことや。
² Whisper-Large-v2 Encoderやけど、30秒のパディング制限なしバージョンやで。普通は30秒で区切らなあかんねんけど、それ外してるってことやな。
³ **Configurable Encoder**には Whisper、WavLM、HuBERT が含まれてて、**Configurable Projector** には Linear + ReLU + Linear と Q-Former があんねん。**Configurable LLM** は Vicuna-7B とかが入ってる。要するに「好きなの選べるで」ってシステムやな。
⁴ 具体的にどの学習済みモデル使ってるかは公開されてへんねん。秘密主義やな〜。
⁵ 論文に詳しく書いてへん部品があって、たぶん普通の線形ダウンサンプリングかTransformerベースのアダプタやろうって推測されてるわ。
⁶ Kimi-Audioのエンコーダは、離散的なセマンティックトークンと連続的なWhisper特徴量を組み合わせてるハイブリッドモデルやねん。せやから厳密には連続シーケンスモデリングの音声LLMの定義からはちょっと外れるんやけど、アーキテクチャ比較のために表に入れてるで。
⁷ Step-Audio 2は、凍結した学習済み潜在オーディオエンコーダと、学習可能な2倍ダウンサンプリングアダプタを使ってて、デコーダはテキストと音声トークンを交互に出力するカスタムマルチモーダルLLMやねん。めっちゃ凝った作りやな!
⁸ MiMo-Audio-Tokenizerの32層Transformerオーディオエンコーダを使ってて、アダプタにはRVQベースの離散化を採用してるで。
⁹ **AuT**はカスタムのAudio Transformerのことや。アダプタの詳細は明記されてへんけど、デコーダはカスタムのMoE Transformer(Mixture of Expertsの略で、複数の専門家モデルを組み合わせる賢いやつ)で実装されてるねん。
---
公式のGitHubリポジトリや元論文で具体的な実装の詳細が公開されてへんモデルについては、表の該当箇所は未指定のままにしてあるで。「わからんもんはわからん」って正直に書いてるってことやな!
---
## Page 11
[](/attach/042e1f605bca4d6f13f189f80f11e25db0d1092fe81b61406549f1784ff0fc4a_p011.png)
### 和訳
音声エンコーダー自体とは別に、サブサンプリングモジュールっていうのがよく使われてんねん。これ何するかっていうと、入力特徴量の時間解像度を下げるんや。そしたら計算コストが減るし、モデルがもっと高レベルな表現に集中できるようになるわけやな。最終的に出力される音声特徴埋め込みZa ∈ RB×T×Dが、次のステージへの入力になるんや。連続シーケンスモデリングの文脈では、表Iに代表的なモデルのまとめがあって、アーキテクチャの構成要素ごとに整理されとるで。
**2) 離散シーケンスモデリング**: 離散シーケンスモデリングっていうのは、生の音声を離散トークンの列に変換するやり方やねん。このトークンが音響的な中身を表現してて、普通は高品質な音声にデコードして戻せるんや。離散トークンを生成する核心的なアイデアは、ベクトル量子化にあるんや。VQ-VAE [93]っていうのがあってな、これが連続的な音声特徴を学習済みコードブックを使ってシンボリックな表現にエンコードするっていう概念を導入したんやけど、今の主流の離散トークン生成手法には、HuBERT [24]みたいな自己教師あり事前学習型の音声トークナイザーとか、EnCodec [58], [94]みたいなニューラルコーデックモデルがあるんや。一般的な流れとしては、まず連続シーケンスモデリングと同じように、生の音声を潜在表現の列にエンコードするんや:Za = g(Xa)、ここでZa = [z1, z2, . . . , zT]でzt ∈ Rdやな。次に、量子化関数q(·)を適用して最終的な離散音声トークンを得るんや:
ut = q(zt) ここで eut = Q(zt). (2)
ここでQは量子化関数を表してて、連続ベクトルをコードブックベクトルeut ∈ Rdにマッピングするんや。その結果utが得られるんやけど、これは語彙セットからの離散トークンインデックスやねん。最終出力は離散音声トークンインデックスの列になる:U = [u1, u2, . . . , uT]。具体的に言うと、HuBERTみたいな自己教師あり事前学習型音声トークナイザーは、マスク予測タスクを通じて文脈化された音声表現を学習して、k-meansクラスタリングを使って中間特徴を離散化するんや。できあがったクラスタインデックスが、音素っぽい離散トークンとして機能するわけやな。EnCodecみたいなニューラルコーデックモデルは、エンコーダー・量子化器・デコーダーっていうアーキテクチャを採用してて、残差ベクトル量子化を使って音声を離散トークンに圧縮して、後で再構成するんや [95]。これらのモデルはエンドツーエンドで学習されて、生成タスクにめっちゃ適した高忠実度の音声を生成するんやで。できた離散音声トークンは、トークン化されたテキストと一緒に処理されるんやけど、その統合方法は次のセクションで詳しく説明するわ。
## B. モダリティ情報融合
音声特徴抽出のステージが終わったら、音声LLMで一番重要な課題は音声モダリティとテキストモダリティの整合、つまりアラインメントやねん。このセクションでは、連続的な方法と離散的な方法の両方でのアラインメント手法について話すで。前のセクションで紹介したように、この2つの方法は出力フォーマットが違うから、それぞれのケースでモダリティ融合にカスタマイズしたアプローチが必要になるんや。
**1) 連続音声埋め込みのモダリティ融合**:
2種類の情報を効果的に組み合わせる方法を考える前に、重要な検討事項が1つあるんや。それは、音声モダリティのどの部分を使うかを決めることやねん。今の研究者たちは、エンコーダーの最終層からの出力を音声モダリティ情報の主なソースとして使う傾向があるんや。
せやけど、いろんな代替手法もあるんやで。例えば、中間層の出力を使ってもっと細かい特徴を捉えるアプローチもあるし [52]、アテンション機構を適用して音声信号の関連する部分を強調する方法もあるんや [25]。
音声埋め込みが得られたら、2つの主な方法でテキスト埋め込み空間にマージするんや:
1) **デコーダー前アラインメント**: このカテゴリは、LLMデコーダーに入力する前に音声特徴をテキスト埋め込みとアラインメントする方法を指すんや。よくあるアプローチは、コネクターを通じて音声特徴情報をLLMのテキスト特徴空間に射影することやな [26], [30]。具体的には、音声特徴を含むテンソルは普通、独自の特徴次元を持ってるんや。音声特徴埋め込みZaは、射影関数w(·)を使ってテキスト埋め込みと同じ次元のベクトルに射影される:Ha = w(Za)、ここでHaはテキスト埋め込み空間における射影された音声埋め込みを表すんや。これらの音声埋め込みは入力テキスト埋め込みHtと連結されて、音声とテキストの両方の情報を統合した新しい埋め込みシーケンスを形成する:H = [Ha, Ht]。この組み合わされたシーケンスがLLMに入力されるんや。一部の研究者は、元のエンコーダー内に射影ステップを暗黙的に組み込んで、学習中にエンコーダーのパラメータを調整することでモダリティ射影を達成してるんやで [37]。ほとんどのモデルは多層パーセプトロン(MLP)を射影モジュールとして使ってるけど、Q-Formerみたいなもっと複雑な技術を採用してるモデルもあるんや。Q-Formerは学習可能なクエリトークンを導入して、それが音声特徴にアテンションして、LLM入力空間にアラインメントされた固定長の埋め込みを出力するんや [26]。
2) **デコーダー内アラインメント(クロスアテンション)**: 言語モデルに入力する前にモダリティをマージする方法に加えて、クロスアテンションを通じて音声とテキスト特徴の間に双方向の相互作用を確立する方法もあるんや [76]。このアプローチでは、モデルは別々の音声ストリームとテキストストリームを維持して、各モダリティがクロスアテンション層を通じて互いにアテンションできるようにするんや。これによって、トランスフォーマーアーキテクチャ内でより深いマルチモーダル融合が可能になるんやで。
**2) 離散音声トークンのモダリティ融合**: 離散音声トークンについては、普通テキストトークンと同じように扱われるんや。核心的な課題は、テキストベースの語彙だけを使って音声トークンをどう処理するかってことやねん。この問題に対処する方法は基本的に2つあるで:
1) **トークンマッピング**: 一番直感的なアプローチは、音声トークンをLLMが処理できるテキストトークンにマッピングすることやな。Tsunooら [96]は、CTC予測を使って効率的にプロンプトを生成することを提案してるんや——CTCプロンプトって呼ばれてるで。音声特徴がCTCを使ってテキストトークンに変換されたら、これらのトークンはトークン化された入力テキストとマージされて、両方のモダリティを表現する統一されたトークンシーケンスが作られるんや。このシーケンスがLLMに入力されて処理される。このアプローチは音声特徴の意味内容を保持するだけやなくて、LLMの処理パイプラインの一貫性も確保できるんやで。
---
## Page 12
[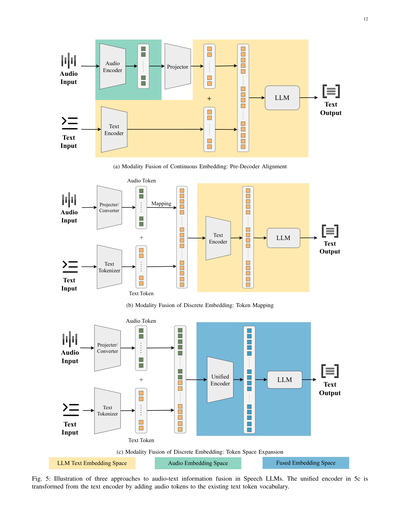](/attach/042e1f605bca4d6f13f189f80f11e25db0d1092fe81b61406549f1784ff0fc4a_p012.png)
### 和訳
12ページ
(a) 連続埋め込みのモダリティ融合:デコーダー前段でのアライメント
(b) 離散埋め込みのモダリティ融合:トークンマッピング
(c) 離散埋め込みのモダリティ融合:トークン空間の拡張
図5:音声LLMにおける音声とテキスト情報を融合させる3つのアプローチを図解したもんやで。5cの統合エンコーダーっちゅうのは、もともとあったテキストエンコーダーに音声トークンを既存のテキストトークン語彙に追加して変換したもんやねん。
---
ほんで図の中身を説明すると:
**上の図(a)**は、音声入力を音声エンコーダーで処理して、プロジェクターで変換してから、テキストエンコーダーからの情報と足し合わせてLLMに突っ込むパターンやな。これが「連続埋め込み」を使った融合方法で、LLMのテキスト埋め込み空間と音声埋め込み空間を合体させて融合埋め込み空間を作るイメージやねん。
**真ん中の図(b)**は、音声トークンとテキストトークンを別々に作っといて、マッピングで対応付けてから足し合わせてLLMに渡すやり方やで。テキストはテキストトークナイザーで、音声はプロジェクター/コンバーターで離散トークンにしてから合体させるねん。
**下の図(c)**は、めっちゃシンプルで、統合エンコーダーっちゅう1個のエンコーダーでテキストも音声も両方処理できるようにしたパターンやな。テキスト入力と音声入力を一緒くたに扱えるから、トークン空間自体を拡張して両方に対応できるようにしてるわけや。
---
## Page 13
[](/attach/042e1f605bca4d6f13f189f80f11e25db0d1092fe81b61406549f1784ff0fc4a_p013.png)
### 和訳
2) トークン空間の拡張について:音声モダリティをテキストモダリティに射影するんは簡単っちゃ簡単やねんけど、これやとほんまの意味でロスレス(情報損失なし)のモダリティ融合にはならへんのよな。モダリティ変換のプロセスで情報が抜け落ちたり、ぶつかり合うことがあるねん(これは後でもっと詳しく説明するわ)。せやから研究者さんたちは別のアプローチを提案してんねん。LLMの入力空間自体をいじって、音声モダリティをネイティブに取り込めるようにする方法や[60], [97], [98]。具体的に言うと、既存のテキストトークンの語彙に音声トークンを追加してトークン空間を拡張して、統一されたトークン空間を作るねん。この新しい音声トークンは、前の段階で抽出した音声特徴から合成されるから、元の音声情報をより多く保持できるっちゅうわけや(図5cを見てな)。
3) モダリティアライメント戦略についての議論:ここまでの話をふまえると、今のSpeech LLMがモダリティを融合させる方法は、(i) 連続的な音声表現を使って、デコーダーの前でアライメントするか、デコーダー内でクロスアテンションを使うパターン、(ii) 離散的な表現を使って、トークンマッピングかトークン空間拡張をするパターン、の2種類があるねん。
実際のシステムでは、いろんな選択肢があってな。融合の話だけやなくて、根本的な設計の選択として「どの音声表現をアライメントするか」っちゅう問題がある。最終層のエンコーディングを使うと意味的な抽象化が最大になるし、中間層の特徴を使うとより細かい韻律とか音素のヒントが見えてくるねん。アテンションベースのプーリング、学習可能なクエリリサンプラー(Q-FormerとかPerceiverスタイルのやつな)、ストライドサブサンプリング、CTCベースの時間圧縮、これ全部LLMに送る音声トークンのレートを制御するのに使われてて、情報の保持と計算量のバランスを取ってるわけや。
注目すべきは、最近の研究で新しいアライメントのパラダイムがいくつか探求されてることやな。例えば、LegoSLM[84]はLLMの単語埋め込みを活用して音声信号の重み付け表現を構築してるし、AlignFormer[99]はCTCの事後分布を直接操作することで音声特徴シーケンスを効果的に簡略化してんねん。同じような発想で、TASU[100]はCTCの事後分布をさらに活用して、音声から意味情報をより効果的に抽出して、音声とテキストのモダリティ間の情報レートのバランスを取ってるわ。
C. LLM推論
LLM推論の段階は主にテキストデコーダーで構成されてて、これは典型的には自己回帰型のトランスフォーマーデコーダーで、入力された音声やテキストに条件づけられてテキストトークンを生成するもんや。アーキテクチャ的にはGPTみたいな標準的な言語モデルと似てるんやけど、マルチモーダル入力を扱えるように特別に設計されたり適応されたりしてんねん。射影された音声埋め込みとか、クロスアテンションされた音声特徴みたいなもんを、テキストトークンと一緒に処理できるようにな。
モダリティ融合に対応するために、デコーダーは特殊トークン(例えば<aud>とか<text>とか)を組み込んだり、プロンプトのフォーマットを使って生成中に異なるモダリティを区別してコンテキスト化したりすることがあるねん。こういう適応があっても、デコーダーは同じ自己回帰目的に従ってる:前のトークンと追加の入力コンテキストが与えられたとき、次のテキストトークンを予測するっちゅうやつや。音声とテキスト両方を出力として生成するモデルでは、デコーダーが離散的な音声トークンの生成もサポートするように拡張されることがあるで。
よくあるアプローチの一つは、VALL-Eで見られるように、音声生成を条件付きコーデック言語モデリングタスクとして扱う方法や。モデルが音素シーケンスと音響プロンプトに条件づけられて音声トークンを生成するねん[101], [102]。もう一つのアプローチはSpeechGPTで使われてて、LLMの語彙をテキストトークンと音声トークン両方を含むように拡張するんや。これでモデルは指示に応じて、テキストと同時に、またはテキストの後に、音声トークンシーケンスを直接生成できるようになる[60]。どっちの場合も、生成された音声トークンはニューラルコーデックデコーダー(EnCodec[58]とかHiFi-GAN[103]とか)を通して最終的な波形に再構成されるねん。
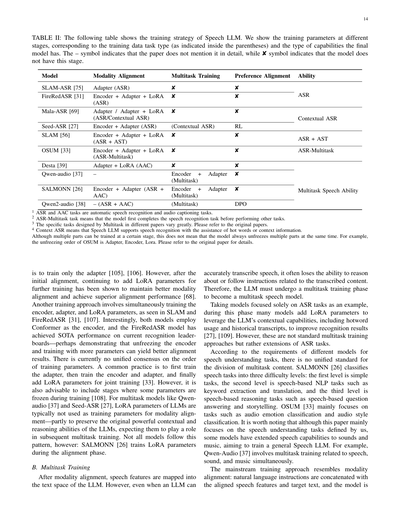
V. 訓練戦略
理解指向の能力の開発をサポートするために、Speech LLMには慎重に設計された訓練戦略が必要やねん。音声理解用に設計されたほとんどのSpeech LLMは連続シーケンスモデリングに依存してるから、このセクションではまず連続埋め込みを使用するモデル専用の訓練戦略について説明するわ。これらのモデルの訓練は通常、3つの主要な段階を経て進むねん:モダリティアライメント、マルチタスク訓練、選好アライメントや(表IIにまとめてあるで)。各段階はモダリティを徐々にアライメントし、タスク能力を拡張し、人間の意図に従うようにモデルを微調整するっていう、それぞれ異なる役割を果たしてんねん。ただし、全部のモデルが必ずしもこの3段階全部を経るわけやないで。実際に使われる訓練段階は、各モデルの意図された能力によって決まるんや。このセクションの構成は、連続シーケンスモデリングを使うSpeech LLMの訓練の3段階に主に沿って進めるわ。セクションの最後で、離散音声トークンに基づくモデルが訓練アプローチでどう違うかを簡単に議論するで。
A. モダリティアライメント
最初に、Speech LLMは音声入力とテキストの間で共有される表現を学習せなあかん。このモダリティアライメント段階では、モデルは通常、膨大な音声データを活用して音声とテキストのギャップを埋めるねん。よくある戦略は、事前学習済みの音声エンコーダーを組み込んで、その音響表現をテキストベースのLLMとアライメントすることや。例えば、Qwen-Audioは事前学習済みのWhisperエンコーダーから始めて、プロジェクターを介してLLMのバックボーンと結合してる[104]。アライメントは、音声とテキストが対応するように強制する教師あり課題によって精緻化されるねん。特筆すべきは、自動音声認識(ASR)と音声キャプショニング(AAC)が通常、基本的なアライメントタスクとして使われることや[27], [29]。
モデルの全パラメータθは、θLLM、θencoder、θadapterで構成されてる。モデルは入力音声シーケンスaをテキスト出力y(書き起こしやキャプション)にマッピングするように訓練されるねん。訓練データは多くの三つ組(a, p, y)で構成されてて:音声入力a、テキストプロンプトまたはタスク記述子p、期待されるテキスト出力yや。モデルはyを予測するように最適化される。この段階では、テキストプロンプトpは通常変更されへんままで、これによってモダリティアライメントの訓練がより簡単になるねん[68], [105]。訓練損失は次のように表せるわ:
Lalign(θ) = − log P (y | θLLM(θadapter(θencoder(a)), p). (3)
訓練目的によって、多くのモデルは音声を完全に理解できるマルチタスク音声モデルを訓練するんやなくて、単一の音声からテキストへのタスク(例えば音声認識)に焦点を当ててるねん。せやから、多くのモデルはモダリティアライメントの1段階だけを持ってるわ。最もよくあるアプローチは
---
## Page 14
[](/attach/042e1f605bca4d6f13f189f80f11e25db0d1092fe81b61406549f1784ff0fc4a_p014.png)
### 和訳
【表II】これはSpeech LLM(音声を理解できる大規模言語モデル)の学習戦略を示した表やねん。各段階でどのパラメータを学習させるか、どんなタスクのデータを使うか(カッコ内に書いてある)、最終的にモデルがどんな能力を持つようになるかを示してるで。「–」は論文に詳しく書いてへんってこと、「✘」はそのモデルにはその段階がないってことやな。
| モデル | モダリティアラインメント | マルチタスク学習 | 好み学習 | 能力 |
|--------|--------------------------|------------------|----------|------|
| SLAM-ASR | アダプター(ASR) | ✘ | ✘ | ASR |
| FireRedASR | エンコーダー+アダプター+LoRA(ASR) | ✘ | ✘ | |
| Mala-ASR | アダプター/アダプター+LoRA(ASR/文脈ASR) | ✘ | ✘ | 文脈ASR |
| Seed-ASR | エンコーダー+アダプター(ASR) | (文脈ASR) | RL | |
| SLAM | エンコーダー+アダプター+LoRA(ASR+AST) | ✘ | ✘ | ASR+AST |
| OSUM | エンコーダー+アダプター+LoRA(ASRマルチタスク) | ✘ | ✘ | ASRマルチタスク |
| Desta | アダプター+LoRA(AAC) | ✘ | ✘ | |
| Qwen-audio | – | エンコーダー+アダプター(マルチタスク) | ✘ | マルチタスク音声能力 |
| SALMONN | エンコーダー+アダプター(ASR+AAC) | エンコーダー+アダプター(マルチタスク) | ✘ | |
| Qwen2-audio | –(ASR+AAC) | (マルチタスク) | DPO | |
1. ASRとAACタスクっていうのは、自動音声認識と音声キャプション生成のことやで。
2. ASRマルチタスクっていうのは、まず音声認識をやってから他のタスクに取り掛かるってやり方やねん。
3. マルチタスクの具体的な中身は論文によってめっちゃ違うから、詳しくは元の論文見てな。
4. 文脈ASRっていうのは、ホットワード(よく出てくる固有名詞とか)や前後の文脈情報を使って音声認識の精度を上げる方法のことやで。
複数の部品を同時に学習できる段階でも、いつも全部同時に解凍して学習させるわけちゃうで。例えばOSUMは、アダプター→エンコーダー→LoRAの順番で解凍していくねん。詳しくは元の論文見てな。
---
まずアダプターだけを学習させるっていうのが基本的なやり方やねん。でもな、最初のアラインメント(音声と言語の対応付け)が終わった後に、LoRAパラメータを追加してさらに学習させると、モダリティのアラインメントがうまく維持できて、もっとええ性能が出ることがわかってるんや。
もう一つのやり方は、エンコーダー、アダプター、LoRAパラメータを全部同時に学習させる方法で、SLAMとかFireRedASRがこれやってるねん。おもろいことに、この2つのモデルはどっちもConformerっていうエンコーダーを使ってて、FireRedASRは今の認識リーダーボードでSOTA(最高性能)を達成してるんや。これ見ると、エンコーダーも解凍してパラメータいっぱい学習させた方がアラインメントの結果がええんかもしれへんな。
学習パラメータの順番については、まだ統一された見解はないねん。よくあるやり方は、まずアダプターを学習させて、次にエンコーダーとアダプターを学習させて、最後にLoRAパラメータを追加して全部一緒に学習させるっていう流れやな。でも、一部のパラメータを凍結したまま学習させる段階を入れるのもええアイデアやで。
Qwen-audioとかSeed-ASRみたいなマルチタスクモデルの場合、モダリティアラインメントの学習パラメータにLLMのLoRAパラメータは普通使わへんねん。なんでかっていうと、LLMが元々持ってるめっちゃ強力な文脈理解能力と推論能力を残しておきたいからや。後のマルチタスク学習でその能力を活かしたいわけやな。でも全部のモデルがこのパターンに従うわけちゃうで。SALMONNはアラインメント段階でLoRAパラメータを学習させとるしな。
---
**B. マルチタスク学習**
モダリティアラインメントが終わると、音声の特徴がLLMのテキスト空間にマッピングされるわけや。でもな、LLMが音声を正確に文字起こしできるようになっても、その内容について推論したり、指示に従ったりする能力がなくなってまうことが多いねん。やから、マルチタスク音声モデルになるためには、マルチタスク学習の段階が必要なんや。
ASRタスクだけに特化したモデルを例にすると、この段階で多くのモデルはLoRAパラメータを追加して、LLMの文脈理解能力を活用するねん。ホットワードとか過去の文字起こし履歴を使って、認識結果を良くするんや。でもこれは標準的なマルチタスク学習というより、ASRタスクの拡張って感じやな。
音声理解タスクに対するモデルごとの要件が違うから、マルチタスクの内容をどう分けるかについて統一された基準はないねん。SALMONNは音声タスクを3つの難易度レベルに分類してるで。第1レベルは簡単なタスク、第2レベルはキーワード抽出とか翻訳みたいな音声ベースのNLPタスク、第3レベルは音声ベースの質問応答とかストーリーテリングみたいな推論タスクやな。OSUMは主に音声の感情分類とかスタイル分類みたいなタスクに注力してるで。
ちなみにこの論文は主にワイらが定義した音声理解タスクに焦点当ててるけど、音声だけやなくて音とか音楽にまで能力を拡張して、汎用的なSpeech LLMを作ろうとしてるモデルもあるねん。例えばQwen-Audioは、音声、音、音楽に関するマルチタスク学習を同時にやってるで。
メインストリームの学習アプローチはモダリティアラインメントと似てるねん。自然言語の指示を、アラインメント済みの音声特徴とターゲットテキストと連結して、モデルを学習させるんや。
---
## Page 15
[](/attach/042e1f605bca4d6f13f189f80f11e25db0d1092fe81b61406549f1784ff0fc4a_p015.png)
### 和訳
なんかな、ここからは「マルチタスク学習」っていうステージの話やねん。クロスエントロピー損失っていう計算方法使って、いろんなタスクを同時に学習させるんやで。普通はここでLoRA(ローラ)っていうパラメータを追加して、LLMをファインチューニングするねん。要するに、LLMに「音声でいろんなことできるようになってや」って能力をつけさせるのが目的やな。
ちなみにな、Qwen-Audioってやつは、Whisperみたいなマルチタスク学習の仕組み使ってて、タスクの頭に「これは○○タスクやで」って印をつける方式やねん。LoRAは使わへんのが特徴や。一方でOSUMってやつは「ASR+X」っていうアプローチやねん。Xってのは他のタスクのことで、つまりOSUMは最初に音声をテキストに書き起こしてから、他の音声タスクをやるっていう順番なんや。
## C. 好み調整(Preference Alignment)
最終段階はな、モデルの振る舞いをユーザーの指示とか好みに合わせることやねん。自然言語のコマンドにちゃんと従って、役に立つ、文脈に合った返答ができるようにするんや。
マルチタスク調整が終わったら、最先端のSpeech LLMの中には、強化学習を使って好み調整するやつもあるねん。このステップで、人間のフィードバックとか学習した報酬関数に基づいて、モデルの返答を最適化すんねん。事実の正確さとか、関連性とか、ユーザー満足度とかを磨き上げるわけや。Seed-ASRとかがその例やな。
有名な方法が「人間フィードバックからの強化学習」、略してRLHFってやつで、PPO(近接方策最適化)っていうアルゴリズムで実装されてるねん。RLHFではな、モデルをπθ(y|X)っていう「方策」として扱うんや。これは入力Xに対して返答yを生成するやつやねん。で、報酬モデルR(X, y)ってのがあって、これは人間の好みランキングから学習したもんで、返答にスコアをつけるんや。
目標は何かっていうと、期待報酬EX [Ey∼πθ [R(X, y)]]を最大化することやねん。ただし、言語モデルの出力分布を事前学習したモデルに近づけとかなあかんのや。なんでかっていうと、流暢さが落ちたらあかんからやで。PPOはθを方策勾配∇θJ ≈ EX,y[R(X, y) ∇θ log πθ(y|X)]の方向に更新して、元の方策からのKLダイバージェンス(どれだけ離れてるかの指標やな)に制約をかけるんや。実際のPPO更新では、クリップされた代理目的関数っていうのを使って、安定した改善を確保するねん。
別のやり方で、もっと軽量なのがDPO(直接好み最適化)やねん。これはQwen2-Audioの最終学習で使われたやつや。報酬モデルを別に学習せなあかん方法と違って、DPOは与えられたプロンプトxに対して、好みのペア(y+, y−)を直接使うんや。好ましい返答y+にはより高い確率を、あんまり好まれへん返答y−には低い確率を割り当てるように方策を最適化するわけや。DPOの損失関数はこんな感じや:
LDPO(θ) = −E(x,y+,y−)∼D [log σ(1/β (log πθ(y+|x) − log πθ(y−|x)))]
ここでσはシグモイド関数で、βは温度ハイパーパラメータやねん。この損失を最小化することで、モデルはy+をy−より好むように促されて、報酬モデルの学習ループの複雑さなしに、人間の好みに合わせられるっちゅうわけや。
この強化学習とか好み調整のフェーズが終わる頃には、Speech LLMは人間好みの指示に従うようにめっちゃチューニングされてるねん。ユーザーの声のリクエストを聞いて、適切な内容で応答するようになるんや。ほんまに重要なのは、このステージで事実性と安全性が改善されることやな。間違った答えとか望ましくない続きにはペナルティを与えるからやねん。
Qwen2-Audioの作者さんたちが言うには、DPOファインチューニング後は、モデルがユーザーの意図にもっと忠実に従って、複雑な音声中心の指示でミスが減るらしいで。指示調整フェーズのええとこは、モデルを「できる」だけやなくて「使える」ようにすることやねん。マルチタスク学習された基盤を、オープンエンドの音声インタラクションを処理できる丁寧な会話エージェントに変えるんや。
ただな、ここは正直に言わなあかんねんけど、このフェーズは音声理解に焦点当てた現在のSpeech LLM研究ではあんまり注目されてへんねん。既存の研究のほとんどは、モダリティ調整とタスク特化のパフォーマンスを重視してて、指示に従う動作とか対話の一貫性とか安全性調整はまだあんまり探求されてへんのや。Speech LLMが汎用音声エージェントに向かって進化し続けるにつれて、指示と好みの調整についてのさらなる研究が、使いやすさ、制御性、ユーザーインタラクションの質を改善するのにめっちゃ重要な役割果たすと期待されてるで。
これらのステージ全部 — モダリティ調整、幅広いマルチタスク学習、そして最終的な好みとの調整 — を組み合わせることで、リッチな文脈で音声を理解して、ユーザーと自然にやり取りできる最先端のSpeech LLMができるんや。話し言葉とテキストベースLLMの強力な推論能力の間のギャップを埋めるっちゅうわけやな。
## D. 離散シーケンスモデリングによるSpeech LLMの学習
連続埋め込みモデルの3段階学習パイプラインとは対照的に、離散音声トークンに基づくSpeech LLMはもっとシンプルで統一された学習戦略を採用してるねん。
こういうモデル(AudioPaLM、SpeechGPT、VALL-Eとか)では、音声表現用の離散トークンを生成した後、そのトークン列はテキストトークンと同じように扱われるんや。これによって、事前学習済みか新しく初期化された言語モデルを、標準的な自己回帰の目的関数で直接学習できるわけやな。
学習は普通、統一されたトークン空間でペアになった音声-テキストデータをファインチューニングすることで進むねん。連続埋め込みモデルでよく使うアダプターみたいな構造的な変更を入れへんから、別個のモダリティ調整ステージは要らんのや。これでパイプラインがシンプルになって、事前学習済みLLMの恩恵を直接受けられるようになるねん。
実際には、モダリティ間の調整はマルチタスクファインチューニングを通じて暗黙的に学習されるんや。モデルは音声トークンとテキストトークンの両方を織り交ぜて推論することを学ぶわけやな。例えばSpeechGPTは「ペア音声-テキスト事前学習」フェーズを導入して、織り交ぜたシーケンスでモデルをウォームアップしてから、合成されたマルチモーダル対話を使った指示ファインチューニングをやるんや。
連続埋め込みSpeech LLMと違って、主流の離散トークンSpeech LLMは明示的な好み調整(RLHFとかDPOとか)をスキップすることが多いねん。学習は音声-テキストデータの教師ありマルチタスクファインチューニングに集中してて、別の報酬モデリングステージはないんや。SpeechAlignみたいな新しい研究がコーデックベース言語モデル向けの好み最適化を探り始めてるけど、こういう方法はまだ実験的で、標準的なspeech-LLM学習ツールボックスの一部にはなってへんねん。
この学習パラダイムは、アーキテクチャのシンプルさと既存LLMインフラの効率的な再利用っていうメリットがあるで。ただな、独自の課題もあるねん。量子化による情報損失とか、音響的な忠実度が下がるとかやな。
---
## Page 16
[](/attach/042e1f605bca4d6f13f189f80f11e25db0d1092fe81b61406549f1784ff0fc4a_p016.png)
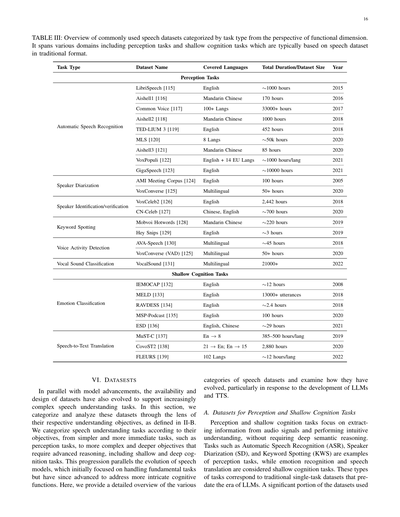
### 和訳
表III: よう使われとる音声データセットを、機能の観点からタスクの種類別にまとめたやつやで。知覚タスクから浅い認知タスクまでいろんな分野をカバーしとって、基本的には従来型フォーマットの音声データセットがベースになっとるねん。
| タスクの種類 | データセット名 | 対応言語 | 総時間/データサイズ | 年 |
|---|---|---|---|---|
| **知覚タスク** | | | | |
| 自動音声認識 | LibriSpeech [115] | 英語 | 約1000時間 | 2015 |
| | Aishell1 [116] | 中国語(普通話) | 170時間 | 2016 |
| | Common Voice [117] | 100以上の言語 | 33000時間以上 | 2017 |
| | Aishell2 [118] | 中国語(普通話) | 1000時間 | 2018 |
| | TED-LIUM 3 [119] | 英語 | 452時間 | 2018 |
| | MLS [120] | 8言語 | 約5万時間 | 2020 |
| | Aishell3 [121] | 中国語(普通話) | 85時間 | 2020 |
| | VoxPopuli [122] | 英語+EU14言語 | 各言語約1000時間 | 2021 |
| | GigaSpeech [123] | 英語 | 約1万時間 | 2021 |
| 話者ダイアライゼーション | AMI Meeting Corpus [124] | 英語 | 100時間 | 2005 |
| | VoxConverse [125] | 多言語 | 50時間以上 | 2020 |
| 話者識別/検証 | VoxCeleb2 [126] | 英語 | 2,442時間 | 2018 |
| | CN-Celeb [127] | 中国語、英語 | 約700時間 | 2020 |
| キーワード検出 | Mobvoi Hotwords [128] | 中国語(普通話) | 約220時間 | 2019 |
| | Hey Snips [129] | 英語 | 約3時間 | 2019 |
| 音声区間検出 | AVA-Speech [130] | 多言語 | 約45時間 | 2018 |
| | VoxConverse (VAD) [125] | 多言語 | 50時間以上 | 2020 |
| 声の音分類 | VocalSound [131] | 多言語 | 21000以上 | 2022 |
| **浅い認知タスク** | | | | |
| 感情分類 | IEMOCAP [132] | 英語 | 約12時間 | 2008 |
| | MELD [133] | 英語 | 13000以上の発話 | 2018 |
| | RAVDESS [134] | 英語 | 約2.4時間 | 2018 |
| | MSP-Podcast [135] | 英語 | 100時間 | 2020 |
| | ESD [136] | 英語、中国語 | 約29時間 | 2021 |
| 音声テキスト翻訳 | MuST-C [137] | 英語→8言語 | 各言語385〜500時間 | 2019 |
| | CovoST2 [138] | 21言語→英語; 英語→15言語 | 2,880時間 | 2020 |
| | FLEURS [139] | 102言語 | 各言語約12時間 | 2022 |
## VI. データセット
モデルがどんどん進化してきたんと同時に、もっと複雑な音声理解タスクに対応できるようにデータセットの種類とか設計もめっちゃ進化してきたんよ。このセクションでは、II-Bで定義した理解の目的っていう視点からデータセットを分類して分析していくで。
音声理解タスクを目的別に分けると、まず一番シンプルですぐできる知覚タスクがあって、そっからもっと複雑で深い推論が必要な浅い認知タスク、さらに深い認知タスクへと進んでいくねん。この流れって、音声モデルの進化とめっちゃ似とるんよ。最初は基本的なタスクをこなすことに集中しとったけど、今ではもっと複雑な認知機能にも対応できるようになったんや。ここでは、いろんな種類の音声データセットを詳しく紹介して、特に大規模言語モデル(LLM)とか音声合成(TTS)の発展に合わせてどう進化してきたかを見ていくで。
### A. 知覚タスクと浅い認知タスク向けのデータセット
知覚タスクと浅い認知タスクっていうのは、音声信号から情報を取り出して直感的に理解するタスクのことやねん。深い意味の推論までは必要あらへんのが特徴や。自動音声認識(ASR)とか話者ダイアライゼーション(SD、誰がいつ喋ったか区別するやつな)、キーワード検出(KWS)なんかが知覚タスクの例で、感情認識とか音声翻訳は浅い認知タスクに分類されるんや。こういうタスクは、LLMが出てくる前からある従来型の単一タスク用データセットに対応しとるねん。使われとるデータセットのかなりの部分が...
---
## Page 17
[](/attach/042e1f605bca4d6f13f189f80f11e25db0d1092fe81b61406549f1784ff0fc4a_p017.png)
### 和訳
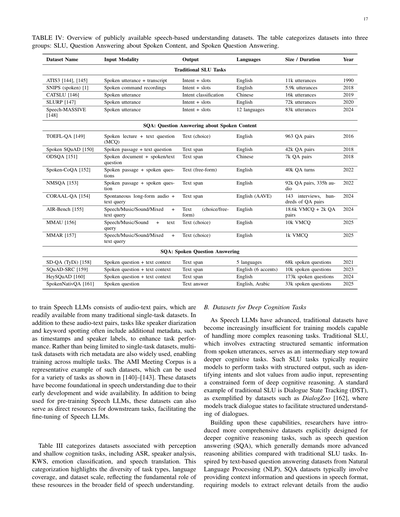
表IV:公開されてる音声理解データセットの一覧やで。このテーブルは3つのグループに分けてあんねん:SLU(音声言語理解)、音声コンテンツに関する質問応答、ほんで音声質問応答やな。
| データセット名 | 入力の種類 | 出力 | 言語 | サイズ/長さ | 年 |
|---|---|---|---|---|---|
| **従来のSLUタスク** |||||
| ATIS3 [144], [145] | 音声発話+書き起こし | 意図+スロット | 英語 | 1万1千発話 | 1990 |
| SNIPS (spoken) [1] | 音声コマンド録音 | 意図+スロット | 英語 | 5,900発話 | 2018 |
| CATSLU [146] | 音声発話 | 意図分類 | 中国語 | 1万6千発話 | 2019 |
| SLURP [147] | 音声発話 | 意図+スロット | 英語 | 7万2千発話 | 2020 |
| Speech-MASSIVE [148] | 音声発話 | 意図+スロット | 12言語 | 8万3千発話 | 2024 |
| **SQA:音声コンテンツに関する質問応答** |||||
| TOEFL-QA [149] | 音声講義+テキスト質問(選択式) | テキスト(選択肢) | 英語 | 963個のQAペア | 2016 |
| Spoken SQuAD [150] | 音声パッセージ+テキスト質問 | テキスト範囲 | 英語 | 4万2千QAペア | 2018 |
| ODSQA [151] | 音声文書+音声/テキスト質問 | テキスト範囲 | 中国語 | 7千QAペア | 2018 |
| Spoken-CoQA [152] | 音声パッセージ+音声質問 | テキスト(自由形式) | 英語 | 4万QAターン | 2022 |
| NMSQA [153] | 音声パッセージ+音声質問 | テキスト範囲 | 英語 | 9万2千QAペア、335時間の音声 | 2022 |
| CORAAL-QA [154] | 自発的な長時間音声+テキストクエリ | テキスト範囲 | 英語(AAVE) | 143件のインタビュー、数百のQAペア | 2024 |
| AIR-Bench [155] | 音声/音楽/環境音/ミックス+テキストクエリ | テキスト(選択式/自由形式) | 英語 | 1万8,600のVMCQ+2千QAペア | 2024 |
| MMAU [156] | 音声/音楽/環境音+テキストクエリ | テキスト(選択肢) | 英語 | 1万VMCQ | 2025 |
| MMAR [157] | 音声/音楽/環境音/ミックス+テキストクエリ | テキスト(選択肢) | 英語 | 1千VMCQ | 2025 |
| **SQA:音声質問応答** |||||
| SD-QA (TyDi) [158] | 音声質問+テキストコンテキスト | テキスト範囲 | 5言語 | 6万8千の音声質問 | 2021 |
| SQuAD-SRC [159] | 音声質問+テキストコンテキスト | テキスト範囲 | 英語(6アクセント) | 1万の音声質問 | 2023 |
| HeySQuAD [160] | 音声質問+テキストコンテキスト | テキスト範囲 | 英語 | 17万3千の音声質問 | 2024 |
| SpokenNativQA [161] | 音声質問 | テキスト回答 | 英語、アラビア語 | 3万3千の音声質問 | 2025 |
音声LLMを訓練するために使われる最も初期のデータセットっていうのは、音声とテキストのペアでできてんねん。これは昔からある単一タスクのデータセットからめっちゃ簡単に手に入るんよ。この音声-テキストペアに加えて、話者ダイアリゼーション(誰がいつ喋ってるか分ける作業やな)とかキーワードスポッティング(特定の言葉を見つけるやつ)みたいなタスクには、タイムスタンプとか話者ラベルみたいな追加のメタデータが含まれてて、タスクの性能をアップさせてんねん。単一タスクのデータセットだけやなくて、豊富なメタデータ付きのマルチタスクデータセットも広く使われてて、複数のタスクをまたいだ訓練ができるようになってんねん。AMI Meeting Corpusがそういうデータセットの代表例で、[140]〜[143]で示されてるように色んなタスクに使えるんよ。これらのデータセットは早い段階で開発されて広く利用できるようになったから、音声理解の基盤になってんねん。音声LLMの事前学習に使われるだけやなくて、下流タスクの直接的なリソースとしても使えて、音声LLMのファインチューニングにも役立つんや。
表IIIでは、知覚と浅い認知タスクに関連するデータセットを分類してんねん。ASR(自動音声認識やな)、話者分析、KWS(キーワードスポッティング)、感情分類、音声翻訳が含まれてるで。この分類は、タスクの種類、言語カバレッジ、データセット規模の多様性を示してて、音声理解のより広い分野におけるこれらのリソースの基本的な役割を反映してんねん。
### B. 深い認知タスク用のデータセット
音声LLMが進歩するにつれて、従来のデータセットだけでは、もっと複雑な推論タスクをこなせるモデルを訓練するには不十分になってきたんよ。従来のSLU、つまり音声発話から構造化された意味情報を抽出するやつは、より深い認知タスクへの中間ステップとして機能してんねん。こういうSLUタスクでは通常、モデルが構造化された出力を持つタスクを実行する必要があんねん。例えば音声入力から意図とスロット値を特定するとかな。これは制約のある形での深い認知推論を表してるんや。従来のSLUの標準的な例は対話状態追跡(DST)で、DialogZoo [162]みたいなデータセットで例示されてるように、モデルが対話状態を追跡して対話の構造化された理解を促進するんやで。
これらの能力を土台にして、研究者たちはより深い認知推論タスク用に明示的に設計された、より包括的なデータセットを導入してきたんよ。例えば音声質問応答(SQA)みたいなやつで、これは一般的に従来のSLUタスクと比べてもっと高度な推論能力が求められんねん。自然言語処理(NLP)のテキストベースの質問応答データセットに触発されて、SQAデータセットでは通常、文脈情報と質問を音声形式で提供して、モデルが音声から関連する詳細を抽出することが求められるんやで。
---
## Page 18
[](/attach/042e1f605bca4d6f13f189f80f11e25db0d1092fe81b61406549f1784ff0fc4a_p018.png)
### 和訳
ほな、この文章を関西弁で説明していくで!
---
で、そっから文字の答えを生成するんやな。こういうSQAデータセットの中には、選択問題形式で出題されるもんもあって、これを「音声ベースの選択問題(VMCQ)」って呼んでんねん。MMAR [157]とかMMAU [157]がその例やねんけど、これらはモデルに対して、音声コンテンツだけを頼りにめっちゃ複雑な推論能力を要求してくるんや。
こういうデータセットはな、モデルが音声入力から関連する情報をちゃんと抜き出すだけやなくて、抜き出した内容を使ってしっかり推論せなあかんねん。これって、深い推論タスクに必要な認知能力とめっちゃ近いもんやで。
表IVでは、音声ベースの理解データセットを統一的にまとめてて、大きく2つに分けてんねん:SLU(音声言語理解)とSQA(音声質問応答)や。SQAの中でも、さらに2種類に分類してて、1つは話された内容(講義とか会話とか)について質問に答えるやつ、もう1つは質問自体が音声で出されるやつやな。この視点から見ると、汎用的な音声言語理解に向かうトレンドがめっちゃ見えてくるし、音声入力をテキストベースの推論で処理できる統合モデルの開発を後押ししてるんやで。
## C. LLMとTTS技術を活用した最近のデータセット開発
最近、LLM(大規模言語モデル)とTTS(テキスト音声合成)技術がめっちゃ進歩してな、マルチモーダルタスク用のデータセット作成とアノテーションが大幅に改善されてきてんねん。研究者たちは、特に音声とテキストを扱うタスクで、データセットのアノテーション作業を自動化したり強化したりする可能性があるから、LLMにどんどん注目するようになってきてんねん。このパートでは、LLMとTTS技術がどうやってよりスケーラブルで多様なデータセットを作るために使われてるか、そしてこのアプローチに関連する課題とチャンスについて見ていくで。
### 1) LLMが参加してアノテーションされたデータセット
LLMの急速な進歩、特にテキストベースの推論能力が人間のパフォーマンスに近づいてきたことで、研究者たちはデータセットのアノテーションにLLMを使う可能性を探り始めてんねん。このアプローチは普通、音声情報をテキスト形式で表現して、タスク固有のプロンプトと組み合わせてLLMに推論を生成させるんや。このプロセスは、SQA形式(音声[テキスト形式] + 質問 + 答え)で行われて、人間の労力を減らしてコストを下げることで、スケーラブルなデータセット作成ができるようになるんやな。さらに、LLMを訓練する新しい方法も提供してくれて、従来の音声データセットだけでは完全には実現できへんかった、音声に関する汎用的な質問応答能力を促進してくれるんや。訓練中は、テキストベースの質問とそれに対応する音声コンテキストが入力として与えられて、モデルはテキスト形式で答えを生成するように訓練されるんやで。
けどな、効率的ではあるんやけど、この方法はLLMの推論能力に制限されてて、多くの場合で最適とは言えへんアノテーションになってまうこともあんねん。LLMが生成するテキストプロンプトや答えは、人間が作った指示に見られるような多様性に欠けることが多いんや。せやから、こういうデータセットは、包括的な音声質問応答タスクをサポートするにはまだ物足りへん部分があるかもしれへんねん。
### 2) TTS技術を使って生成されたデータセット
音声LLM用に特別に設計された音声データセットが不足してて種類も限られてるから、研究者たちは音声とテキストのモダリティをもっと深く統合して、柔軟なミックスモーダル入力を処理できるモデルの能力を実現する革新的なアプローチを提案してんねん。SQAフレームワークをベースにして、このアプローチはテキスト要素の一部(音声/質問)をTTS技術を使って音声に変換し、それによって音声LLMを訓練するための音声-テキストペアを作成するんや。
Pengらは「VoiceTextBlender」を導入して、TTSを使ってミックスモーダルの教師ありファインチューニング(SFT)データを強化する最初の重要な取り組みをしたんや [163]。この方法によって、プロンプトも質問も音声モダリティで表現できるようになって、マルチモーダルタスクの訓練にもっと大きな可能性を提供してくれてんねん。このアプローチは、実際に録音された音声データセットの限界に対処しながら、より深いクロスモーダル統合をサポートするデータセットを作成する新しい可能性を開いてくれてんで。
## VII. 音声タスクにおけるパフォーマンス
### A. 音声理解タスクの評価戦略の分類体系
音声LLMの一貫性があって原則に基づいた評価を促進するために、音声理解タスクの分類体系に沿った既存の評価戦略の構造的な概要を示すで。新しい評価パラダイムを提案するんやなくて、このフレームワークは、セクションII-C2で説明したように、構造化タスク、弱構造化タスク、非構造化タスク全体で広く採用されてる指標と評価技術を統合してんねん。具体的には、評価アプローチを「正確」と「不正確」という2つの主要な区分に分類してて、これはタスク出力の構造化の度合いと、明確な正解データが利用可能かどうかに対応してんねん。
### 1) 正確な評価
決定論的評価っていうのは、出力が離散的で曖昧さがなく、事前定義された参照やラベルセットに対してベンチマークされる構造化された音声理解タスクに関係するもんやねん。このカテゴリは再現可能なテストをサポートして、厳密なモデル比較を容易にしてくれるで。代表的なタスクとその標準的な評価基準を挙げていくな:
- **自動音声認識(ASR)**:単語誤り率(WER)、文字誤り率(CER)、マッチ誤り率(MER)
- **話者識別と検証**:精度、等誤り率(EER)、検出コスト関数(DCF)
- **話者ダイアライゼーション**:ダイアライゼーション誤り率(DER)。これには発話の見逃し、誤警報、話者の混同が含まれるで
- **キーワードスポッティング(KWS)**:適合率、再現率、F1スコア、検出誤りトレードオフ(DET)曲線
- **音声区間検出(VAD)**:フレームレベルの精度、誤受理/誤拒否率
- **感情と意図の分類**:精度、マクロ/ミクロF1スコア、混同行列
- **タスク指向の構造化タグ付け**:スロットF1、意図精度、フレームレベル精度
これらの決定論的指標は、モデルの動作が予測可能で監査可能でなあかん、安全性が重要な場面、リソースが制限された場面、レイテンシに敏感な場面に特に適してるんやで。
---
## Page 19
[](/attach/042e1f605bca4d6f13f189f80f11e25db0d1092fe81b61406549f1784ff0fc4a_p019.png)
### 和訳
2) ちょっと曖昧な評価の話:オープンエンド評価ってのは、構造がゆるいタスクとか、そもそも構造がないタスクに使うもんやねん。正解が柔軟やったり、いろんな答えがあり得たりして、どれも同じくらい正解やったりするんよ。このやり方では、生成の質とか、意味的にちゃんと合ってるかとか、文脈に適切かどうかを、類似度の指標と学習済みの評価モデルを組み合わせて見るんや。
よく使われるアプローチはこんな感じやで:
• 参照ベースの類似度指標:
– BLEU [42]:n-gramの精度を測るやつで、主に翻訳で使うんや。
– ROUGE [44]:要約タスクで再現率を重視するやつやな。
– METEOR [164]:同義語とか語幹とか単語のアラインメントも考慮してくれるねん。
– BERTScore [165]:事前学習モデルで文脈的な埋め込みの類似度を計算するやつやで。
• モデルベースまたは人間による判断:
– LLMベースのスコアリング:事前学習された言語モデルを使って、流暢さとか一貫性とか忠実さを評価するんや [166], [167]。
– 人間による評価:リッカート尺度での評価とか、ペアワイズ比較とか、自然さや適切さをルーブリックで見たりするねん。
– タスク固有のルーブリック:話者の説明とか、トピックの抽象化とか、感情のナレーションみたいな定性的な評価にめっちゃ役立つんや。
これらの方法は、従来の分類では捉えられへん主観的なニュアンスとか、創造性とか、解釈的な推論を捉えるのに欠かせへんもんやねん。
ここで大事なことがあってな、評価のカテゴリ分けはタスクの定義に厳密に従うんやなくて、タスクをどう運用するかによって変わってくるんや。例えば、感情を理解するタスクは:
• 分類問題として設定したら — F1スコアみたいな決定論的な指標で評価するし、
• 自由形式の説明として設定したら — BERTScoreとかLLM評価とか人間の評価で見るんや。
この柔軟性があるから、プロンプトの形式や意図した出力構造に合わせた適応的な評価戦略が必要やってことがわかるやろ。特にSpeech LLMが自然言語の指示ベースのパラダイムを採用してる今はな。
まとめると、このデュアルトラック評価フレームワークは、構造化されたタスク、構造化されてないタスク、弱く構造化されたタスクに対応してて、いろんな音声理解シナリオでSpeech LLMを包括的かつ原則に基づいて分析できるようになってるんや。このフレームワークを実践にもっと根付かせるために、次のセクションでは各カテゴリの代表的なタスクを詳しく分析するで。具体的には、構造化タスクの典型としてのASR、弱く構造化されたタスクの典型としてのST、そして非構造化理解の特徴としてのマルチタスク能力についてや。
B. いろんなタスクでSpeech LLMがどんだけできるかの話
音声理解タスクの評価戦略の分類に続いて、このセクションでは、4つの代表的な音声タスクでSpeech LLMの現在の進捗を定量的に分析するで。
19
これらのタスクは、言語的、パラ言語的、非言語的な側面すべてをカバーしてて、セクションII-Aで示した音声理解の分類の情報次元に対応してるんや。
1) 分析のセットアップ:具体的には、音声理解の幅広さを反映する4つのタスクを選んだで。言語情報を主にターゲットにしたタスクが2つ、パラ言語的な手がかりに焦点を当てたタスクが1つ、非言語的な音響コンテキストを重視したタスクが1つや。
このセクションで評価する言語タスクは:
• 自動音声認識(ASR):話し言葉を書き言葉に書き起こすタスクやな。LibriSpeechデータセットを使うんやけど、これにはtest-cleanとtest-otherっていうめっちゃ有名でよく報告されるサブセットが含まれてるねん。ASRモデルの評価で一番知られてて頻繁に使われるデータセットの一つやで。
• 音声翻訳(ST):モデルが話し言葉をある言語から別の言語に翻訳するタスクや。これにはCoVoST2-En2Zhデータセットを使うんやけど、英語から中国語への音声からテキストへの翻訳のベンチマークやねん。包括的なカバレッジがあって、最近のSpeech LLMの報告でよく使われてるデータセットやで。
評価するパラ言語タスクは:
• 感情認識:モデルが音声から感情を検出して分類するタスクやな。MELDデータセットに焦点を当ててるんやけど、これは対話で表現される感情をキャプチャする人気のデータセットやねん。MELDは感情認識の研究で広く使われてて、Speech LLMの評価の文脈でもよく参照されるんや。
評価する非言語タスクは:
• 人間の音イベント分類:笑い声とかため息とか咳みたいな、いろんな人間の声を識別するタスクやで。このタスクにはVocalSoundデータセットを使うんやけど、非音声の人間の発声を分類するための専門的なコレクションやねん。人間の音イベント分類の報告で最も引用されるデータセットの一つやで。
この4つのデータセット — LibriSpeech、CoVoST2、MELD、VocalSound — は、それぞれのタスクで最も広く使われてて、ワイらがレビューしたSpeech LLMモデルの報告でよく参照されてるんや。これらのデータセットでSpeech LLMを評価することで、いろんな音声理解タスクにおける現在の能力と限界をより明確に理解できるようにしたいんや。
モデルの性能を評価するときは、「最先端(SOTA)と比べてモデルがどんだけ達成できてるか」を定量化する指標を使うで。正式には、この指標はタスクでの最高性能(SOTA)に対するモデルの性能の相対比較を提供するように設計されてるんや。この指標をRPS(State-of-the-Artに対する相対性能)と呼ぶことにするで。
値が大きいほど良い指標(精度とかF1スコアとか)の場合、評価指標はこう定義されるんや:
RPS = モデルスコア / SOTAスコア (5)
---
## Page 20
[](/attach/042e1f605bca4d6f13f189f80f11e25db0d1092fe81b61406549f1784ff0fc4a_p020.png)
### 和訳
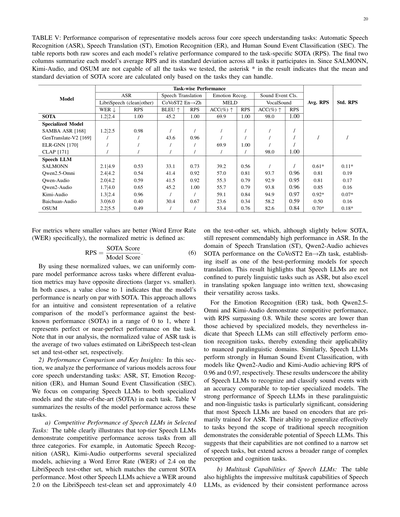
表V:音声理解の4つの基本タスク、自動音声認識(ASR)、音声翻訳(ST)、感情認識(ER)、人間の音声イベント分類(SEC)における代表的なモデルの性能比較やで。この表には生のスコアと、各モデルがそのタスク専用のSOTA(最先端)と比べてどんだけの性能出してるか(RPS)を載せてんねん。右端の2列は、各モデルの平均RPSと、参加した全タスクでの標準偏差をまとめたもんや。SALMONNとKimi-AudioとOSUMはワイらがテストした全タスクに対応してへんから、結果のアスタリスク(*)は、そいつらが対応できるタスクだけで平均と標準偏差を計算してるっちゅうことやで。
[表Vの内容]
タスク別の性能
ASR(自動音声認識): LibriSpeech(クリーン版|その他版) - WER(単語誤り率)↓ 低いほどええ
音声翻訳: CoVoST2 英語→中国語 - BLEU↑ 高いほどええ
感情認識: MELD - 正解率(%)↑
音声イベント分類: VocalSound - 正解率(%)↑
平均RPS、RPS標準偏差
[各モデルのスコアは表の通り]
---
小さい値がええ指標(具体的には単語誤り率WER)の場合、正規化した指標はこう定義すんねん:
RPS = SOTAスコア ÷ モデルスコア (式6)
この正規化した値を使うことで、評価指標の向きが逆(大きいほどええvs小さいほどええ)なタスク間でもモデルの性能を統一的に比較できんねん。どっちの場合も、1に近い値やったら、そのモデルの性能がSOTAとほぼ同等っちゅうことやで。このアプローチやと、0から1の範囲で、最高の性能(SOTA)に対するモデルの相対的な性能を直感的かつ一貫して表現できんねん。1やったら完璧か完璧に近い性能っちゅうことや。ちなみにワイらの分析では、ASRタスクの正規化値はLibriSpeechのtest-cleanセットとtest-otherセットで推定した2つの値の平均やで。
**2) 性能比較と重要な知見**:このセクションでは、4つの基本的な音声理解タスク、つまりASR、ST、感情認識(ER)、人間の音声イベント分類(SEC)における様々なモデルの性能を分析すんで。音声LLMを専門モデルと各タスクのSOTAの両方と比較することに焦点当てとるわ。表Vにこれらのタスクでのモデル性能の結果まとめたで。
**a) 選ばれたタスクでの音声LLMの競争力ある性能**:この表見たら一目瞭然やけど、トップクラスの音声LLMは3つのカテゴリー全部のタスクで競争力ある性能を発揮しとるねん。例えば、自動音声認識(ASR)では、Kimi-Audioが複数の専門モデルを上回って、LibriSpeechのtest-otherセットで単語誤り率(WER)2.4を達成しとって、これは現在のSOTA性能と同等やねん。他のほとんどの音声LLMは、LibriSpeechのtest-cleanセットでWER約2.0、test-otherセットで約4.0を達成しとって、SOTAよりちょっと下やけど、それでもASRとしてめっちゃ高い性能やと言えるで。音声翻訳(ST)の分野では、Qwen2-AudioがCoVoST2の英語→中国語タスクでSOTA性能を達成して、音声翻訳で最高性能のモデルの1つとして確立したんや。この結果が示しとるんは、音声LLMはASRみたいな純粋な言語タスクに限定されへんくて、話し言葉を書き言葉に翻訳することにも優れとるっちゅうことで、タスク間での汎用性の高さを示しとるわけや。
感情認識(ER)タスクでは、Qwen2.5-OmniとKimi-Audioの両方が競争力ある性能を示しとって、RPSが0.8を超えとるねん。これらのスコアは専門モデルが達成したもんより低いけど、それでも音声LLMが感情認識タスクを効果的に実行できることを示しとって、繊細なパラ言語領域への適用可能性を広げとるんや。同様に、人間の音声イベント分類でも音声LLMは強い性能を示しとって、Qwen2-AudioとKimi-Audioはそれぞれ0.96と0.97のRPSを達成しとるで。これらの結果は、音声LLMがトップクラスの専門モデルに匹敵する精度で音声イベントを認識・分類できる能力を強調しとるんや。これらのパラ言語的・非言語的タスクでの音声LLMの強い性能は特に重要やねん。なんでかっていうと、ほとんどの音声LLMは主にASR用に訓練されたエンコーダーをベースにしとるからや。従来の音声認識の範囲を超えたタスクへの効果的な汎化能力は、音声LLMのかなりの可能性を示しとるで。これは、音声LLMの能力が狭い範囲の音声タスクに限定されへんくて、より広範な複雑な知覚・認知タスクにまで及ぶことを示唆しとんねん。
**b) 音声LLMのマルチタスク能力**:この表はまた、音声LLMの印象的なマルチタスク能力も強調しとるで。これは複数タスクでの一貫した性能によって証明されとるんや。
---
## Page 21
[](/attach/042e1f605bca4d6f13f189f80f11e25db0d1092fe81b61406549f1784ff0fc4a_p021.png)
### 和訳
いろんなタスクをこなせるかどうかって話やねん。注目すべきはKimi-Audioっていうモデルで、平均RPSが0.92も出とんねん。これってマルチタスク性能がめっちゃ安定してるってことやで。このモデルがすごいのは、音声認識だけやなくて、パラ言語タスク(声のトーンとか感情とかそういうやつな)とか、非言語タスク(音声以外の音を聞き分けるやつ)でも優秀やってことやねん。ほんまに器用なやつやで。同じように、Qwen-Audioシリーズ、QwenAudioとかQwen2-Audioとかも、平均RPSがそれぞれ0.81と0.85出しとる。これらの結果から分かるのは、音声LLM(音声を扱う大規模言語モデルのことな)は、音声に含まれるいろんな情報に焦点を当てた様々なタスクをちゃんとこなせるってことやねん。
もっとびっくりするのはな、Qwen2.5-Omniっていう、音声だけやなくていろんなモダリティ(画像とか動画とかも含む複数の入力形式のことな)を扱えるように設計されたモデルでも、音声タスクで平均RPS 0.81っていう競争力のある数値を叩き出しとるってことやねん。これが何を意味するかっていうと、Qwen2.5-Omniは広くいろんなものを扱えるようになったからって、音声タスクの性能が落ちてへんってことやねん。実際、他の音声LLMと同等の性能を維持しとって、音声LLMが複数のモダリティに対応できるようにスケールしても、音声固有のタスクで効果を失わへんってことを裏付けとるわけや。これは音声LLMがマルチモーダルLLMに一般化できるってことを示しとって、コアとなる音声理解能力が他のモダリティに拡張されても維持される、むしろ強化されることもあるってことやねん。将来のクロスドメイン(分野横断的な)アプリケーションへの適応力の高さを示しとるわけやで。
こういう観察結果は、音声LLMのマルチタスク能力がどんどん成長しとることを浮き彫りにしとる。これは音声LLMがいろんな分野で汎用的に使えることを強調しとって、特定のタスクだけやなく幅広いアプリケーションでうまくやれることを示しとんねん。音声理解における大きな進歩やで。
**c) タスクによって性能にバラつきがあるって問題**
音声LLMのマルチタスク能力は期待できるもんやけど、タスクによって性能にかなりバラつきがあるんよ。タスク別に見ると、トップモデルは音声翻訳と人間の音イベント分類(拍手とか笑い声とかを分類するやつな)では一貫してRPS 0.9以上を達成しとるんやけど、感情認識(ER)になると性能がイマイチで、RPSが0.8くらいまで落ちるんよ。つまり、音声LLMは特定の分野ではめっちゃ優秀やけど、感情に関するタスクへの一般化はまだ課題があるってことやねん。
さらに、RPSの標準偏差を見ると、性能のバラつきについてもっと深く分かるんよ。Qwen-Audioシリーズみたいなモデルは、タスク間でRPSの標準偏差が0.15〜0.20くらいあって、これは分野によって性能が安定せえへんことを示しとんねん。こういうモデルは多くの分野で強力な候補やけど、このバラつきは音声LLMのマルチタスク能力にまだ限界があることを浮き彫りにしとる。全部のタスクで常に高い性能を維持できてへんからな。この不安定さは、音声LLMを多様なタスクに対して堅牢にするにはまだ課題が残っとることを反映しとるんよ。
さらに重要な点として、全てのモデルがテストされた全タスクを実行できるわけやないってことがあるんよ。例えば、SALMONN、Kimi-Audio、OSUMは表の全タスクについて性能を報告してへんねん。報告されてへんタスクについては、ワイらが独自に実験したんやけど、SALMONNは人間の音イベント分類でめっちゃ性能悪くて、ランダムに当てずっぽうで答えるのとほぼ同じ精度やったんよ。Kimi-AudioとOSUMは音声翻訳ができへんくて、テストすると一貫して文字起こしを出力したり、意味不明なテキストを出したりするんよ。一貫性を保つために、表の平均と標準偏差は、これらのモデルが対応できるタスクだけで計算しとる。Kimi-Audioは訓練されたタスクでは一貫して強い性能を示しとって、高い平均RPSと低い標準偏差に反映されとるんやけど、訓練範囲外のタスクである音声翻訳は処理できへんのよ。この限界は、現在の音声LLMにおけるより広い課題を浮き彫りにしとる:慣れ親しんだ分野ではうまく一般化できるけど、明示的な訓練を受けてへんタスクには自動的に性能が転移せえへんってことやねん。他の関連タスクと類似点があっても、この能力は自動的には一般化せえへんくて、音声LLMの柔軟性と一般化における現在の限界を浮き彫りにしとるわけや。
**d) 深い理解を要するタスクでは性能が限定的って問題**
前のセクションでは情報の観点から現在の音声LLMの能力を体系的に分析したんやけど、主に知覚と浅い認知を中心としたタスクに焦点を当てとったんよ。でもな、セクションII-Bで示したように、認知の深さという観点から見ると、深い推論や複雑な推論を必要とするタスクの評価は限定的やったんよ。このギャップを埋めるために、最近のいくつかの研究では、そういう認知的に難しいタスクを対象とした専用のベンチマークを提案して、主要な音声LLMの包括的な評価を行っとる。これらの評価結果は表VIにまとめとるで。これらのベンチマークは、選択式の質問応答タスクや、選択式と自由回答式が混在した質問応答タスクでモデルを評価しとるんや。
---
**表VI:代表的なモデルの典型的な推論ベンチマークでの性能比較。スコアはLLM審判員によるスコアやで。**
| ベンチマーク | トップモデル | 精度/スコア |
|---|---|---|
| **MMAR** | Gemini 2.0 Flash | 65.60 |
| | GPT-4o Audio | 63.50 |
| | Qwen-2.5-Omni (7B) | 56.70 |
| | Qwen-2.5-Omni (3B) | 53.80 |
| | Baichuan-Omni-1.5 (11B) | 40.70 |
| | Audio-Reasoner (8.4B) | 36.80 |
| | SALMONN (13B) | 33.20 |
| | SALMONN (7B) | 32.80 |
| | Audio-CoT (8.4B) | 31.30 |
| | Qwen2-Audio (7B) | 30.40 |
| | Qwen2-Audio-Instruct (7B) | 30.00 |
| **MMAU** | Gemini 2.0 Flash | 59.93 |
| | Gemini Pro v1.5 | 52.97 |
| | Qwen2-Audio-Instruct (7B) | 52.5 |
| | Qwen2-Audio-Chat (7B) | 41.86 |
| | SALMONN (13B) | 32.77 |
| **AIR-Bench** | Qwen-Audio-Turbo (7B) | 57.8 / 6.34 |
| | Qwen-Audio-Chat (7B) | 54.5 / 6.08 |
| | SALMONN | 36.0 / 6.11 |
---
## Page 22
[](/attach/042e1f605bca4d6f13f189f80f11e25db0d1092fe81b61406549f1784ff0fc4a_p022.png)
### 和訳
音声の内容だけを捉えるタスクとか、単純に意味を推測するようなタスクに加えて、これらのベンチマークはもっと認知的に高度な能力も調べてるねん。例えば、音声から感情の状態をまとめる能力とか、複数の話者の役割を紐づける能力とかな。MMAUベンチマークでいうと、「音声感情状態要約」と「複数話者役割マッピング」っていうトラックがあって、モデルがどれくらいうまいこと抑揚とか声質とか話者固有の手がかりをテキストの推論と組み合わせられるかを評価してるわけや。こういうタスクが示してるのは、音声LLMは細かい音響信号(感情の正負とか、話者の特徴とか、会話の順番交代の構造とかな)とテキストの意味論を同時にモデル化せなあかんっていうことやねん。ほんまの意味での音声認知を達成するにはな。
表VIを見てもらったらわかるけど、今の音声LLMは音声理解のもっと深いレベルが必要なベンチマークでは、まだイマイチな性能しか出せてへんねん。Gemini 2.0 FlashとかGPT-4o Audioみたいなプロプライエタリ(企業が独自開発した非公開の)モデルは精度60〜66%くらいでトップ走ってるけど、ほとんどのオープンソースシステムはかなり悪くて、多くの結果が35%以下やねん[157]。この性能差は、話し言葉の入力から高レベルの意味推論を導き出すのがいかに難しいかを物語ってるわ。知覚タスクとか浅い認知タスクと比べると、これらのベンチマークは文脈に基づく推論とか、談話レベルの理解とか、マルチモーダル統合が必要やねん。今のモデルはまだこの辺の能力が限られてるんやな。
観察されたばらつき、頑健なマルチタスク汎化能力の欠如、深い理解タスクでの性能不足、これらは今の音声LLMが直面してる重大な課題を浮き彫りにしてるわ。次の章では、これらの課題を深掘りしていくで。LLMの休眠問題とか、意味推論能力の限界とか、音響情報の捉え方と推論の不十分さとかに焦点を当てるわ。これらの課題に取り組むことが、音声LLMをさらに発展させて、より幅広い音声理解タスクへの適用可能性を広げるために、めっちゃ重要やねん。
22
表VIIに示すように、こういう設定での多言語音声モデルはまだまだやねん[64], [82], [176]。もう一つの課題はリアルタイムのやり取りや。多くの音声LLMはパラメータ規模がめっちゃでかいから、推論の遅延が大きくなってしまうねん。これが、対話型の音声アシスタントとか、カスタマーサービスのエージェントとか、対話駆動の人間-ロボットインタラクションみたいな、遅延に敏感なアプリケーションで問題になるわけや。量子化とか、モデル蒸留とか、ストリーミングデコーディングアーキテクチャとかを使って遅延を減らす研究は進んでるけど、リアルタイムで完全にマルチモーダルなLLMベースのインタラクションはまだ活発な研究課題のままやねん。
全体的に見ると、音声LLMは制御された評価設定でも実世界のコーパスでもますます競争力のある頑健性を示してるけど、ほんまに多様で、ノイズが多くて、多言語で、低遅延が求められるシナリオでの性能と実用性はまだ限られてるわ。これらの課題に取り組むことが、音声LLMを信頼できる実世界の会話知能に向けて進歩させるために不可欠やねん。
表VII:FLEURSデータセットでの多言語ASR性能の比較(19言語の平均WER)
| カテゴリ | モデル | WER ↓ |
|---------|--------|-------|
| E2E特化モデル | Whisper Large-v2 | 8.86 |
| | Whisper Large-v3 | 6.52 |
| オープンソースSLLM | Qwen2.5-Omni | 14.04 |
| | Qwen3-Omni-30B-A3B-Instruct | 5.33 |
| | Qwen3-Omni-Flash-Instruct | 5.31 |
| プロプライエタリSLLM | GPT-4o-Transcribe | 4.48 |
| | Gemini-2.5-Pro | 5.55 |
対象言語:アラビア語、広東語、中国語、オランダ語、英語、フランス語、ドイツ語、インドネシア語、イタリア語、日本語、韓国語、マレー語、ポルトガル語、ロシア語、スペイン語、タイ語、トルコ語、ウルドゥー語、ベトナム語
C. 実世界シナリオでのモデル性能
前のサブセクションでは音声LLMを標準ベンチマークで評価したけど、実世界での展開となると、きれいに整理されたデータセットでは捉えきれへん追加の考慮事項が出てくるねん。実際には、ユーザーの音声には背景ノイズとか、割り込みとか、カジュアルな言い回しとか、いろんな録音条件が含まれてるわけや。その結果、「野生環境」でのパフォーマンスは、きれいな学術ベンチマークで得られた結果とはずれることがあるねん。例えば、最近のいくつかの音声LLMは、WenetSpeech[175]やGigaSpeech[123]みたいな大規模実世界コーパスで安定した性能を報告してて、頑健な音響フロントエンドと大規模事前学習が制約のない設定でも認識品質を維持するのに役立ってることを示唆してるわ。でもな、統一されて広く受け入れられた実世界評価ベンチマークがないから、実用的なアプリケーション文脈でモデルを直接比較するのは難しいねん。
さらに、実世界のシステムは特定の展開上の制約も満たさなあかんことが多いんや。一つの課題は低リソースと多言語のシナリオで、利用可能な音声データが少なかったり、多様なアクセントや方言をカバーしてたりする場合やな。今の音声LLMは高リソースの事前学習に頼ってることが多いから、従来のASRパイプラインや
VIII. 課題
パフォーマンスセクションで観察された限界をさらに調べるために、僕らは根本的な問題を明らかにして特定するための一連の実験を行ったんや。セクションII-Bで紹介した多次元的な視点に基づいて、2つの主なカテゴリの課題を特定したで。
A. 指示への感度
LLMにおける指示への感度は、自然言語処理(NLP)の分野で広く研究されてきて、モデルの頑健性を示す重要な指標として広く認識されてるねん[177], [178]。頑健性っていうのは、意味的に同等やけど言語的に異なる指示に直面したときに、LLMがタスク性能を維持できる能力のことや。これらのバリエーションには、文字レベルの違い(句読点とか)、同義語の置換、文構造の言い換え、さらには要求される出力形式の違いなんかが含まれるわ。
音声ドメインでは、IFEval-Audioベンチマーク[179]が、音声モダリティを統合したエンドツーエンドまたはカスケード型LLMにおける指示追従性能について6次元の視点を提供してるねん。6つの次元でモデルを評価してて:コンテンツ、大文字化、記号、リスト構造、
---
## Page 23
[](/attach/042e1f605bca4d6f13f189f80f11e25db0d1092fe81b61406549f1784ff0fc4a_p023.png)
### 和訳
表VIII:3つの音声LLMにおけるASR、S2TT、SER、GRタスクでの異なる指示バリエーションに対する感度
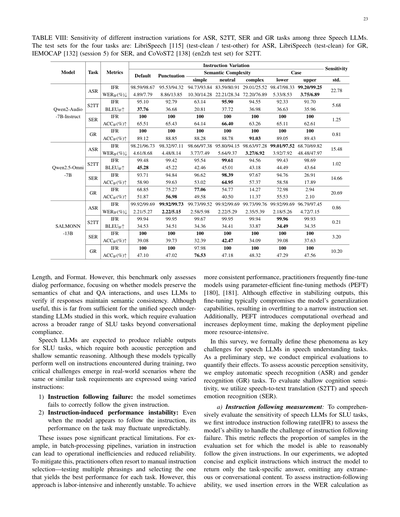
4つのタスクのテストセットは以下の通りやで:ASRにはLibriSpeech [115](test-clean / test-other)、GRにはLibriSpeech(test-clean)、SERにはIEMOCAP [132](セッション5)、S2TTにはCoVoST2 [138](en2zh テストセット)を使っとるねん。
23
[表の内容は数値データのため省略]
長さとかフォーマットとかも見とるんやけどな。ただこのベンチマーク、ダイアログの性能だけしか評価してへんねん。チャットとかQAのやり取りで意味がちゃんと保たれてるかどうかを見て、LLMを使って応答の意味の一貫性を確認しとるだけやねん。まあ便利っちゃ便利やけど、この研究で扱ってる統合型音声理解LLMにはぜんぜん足りへんねん。なんでかっていうと、会話の指示に従えるかどうかだけやなくて、もっと幅広いSLUタスクの評価が必要やからな。
音声LLMには、SLUタスクで信頼できる出力を出してもらわなあかんねん。SLUタスクっていうのは、音響の知覚と浅い意味推論の両方が必要なやつやな。こういうモデルって、学習中に見た指示に対してはだいたいうまくいくんやけど、現実の場面では2つのめっちゃ厄介な問題が出てくるねん。同じような要求を違う言い方で指示したときに起きるやつやで:
1) 指示追従の失敗:モデルが与えられた指示にちゃんと従えへんことがあるねん。
2) 指示による性能の不安定さ:モデルが一見指示に従ってるように見えても、タスクの性能が予測できへん感じで上下するねん。
これらの問題はほんまに実用上キツいねん。例えばバッチ処理のパイプラインでは、指示のバリエーションがあると運用効率が下がって信頼性もガタ落ちするねん。これを何とかするために、実務者は手動で指示を選ぶことが多いねん。いろんな言い回しを試して、各タスクで一番性能が出るやつを選ぶっていうやり方やな。でもこれ、めっちゃ手間かかるし、本質的に不安定やねん。もっと安定した性能を出すために、実務者はパラメータ効率の良いファインチューニング手法(PEFT)[180], [181]を使ってモデルを微調整することが多いねん。これは出力を安定させるには効果的なんやけど、このファインチューニングをすると普通はモデルの汎化能力が落ちてまうねん。結果として、狭い指示セットに過学習してまうわけや。さらにPEFTは計算コストがかかるし、デプロイ時間も増えるから、デプロイのパイプラインがリソース食いまくりになってまうねん。
この調査では、こういう現象を音声LLMの音声理解タスクにおける主要な課題として正式に定義しとるねん。最初のステップとして、その影響を定量化するための実証評価をやっとるで。音響知覚の感度を評価するために、自動音声認識(ASR)と性別認識(GR)タスクを使っとる。浅い認知の感度を評価するために、音声テキスト翻訳(S2TT)と音声感情認識(SER)を使っとるねん。
a) 指示追従の測定:音声LLMのSLUタスクに対する感度を包括的に評価するために、まず指示追従率(IFR)っていうのを導入しとるねん。これは指示追従失敗の課題にモデルがどれだけ対応できるかを評価するための指標やで。この指標は、評価セット中でモデルが与えられた指示にちゃんと合理的に従えたサンプルの割合を表しとるねん。実験では、簡潔で明確な指示を採用したで。タスク固有の回答だけを返すように指示して、余計な内容とか会話っぽい内容は省くようにしたねん。指示追従能力を評価するために、WER計算における挿入エラーを使ったで。
---
## Page 24
[](/attach/042e1f605bca4d6f13f189f80f11e25db0d1092fe81b61406549f1784ff0fc4a_p024.png)
### 和訳
これがその指標やねん。2回以上の挿入がある出力は、だいたい文字起こし以外の余計なもんが入っとって、例えば「文字起こしは」みたいな接頭辞とか、ひどいときはターゲット言語を完全にすっ飛ばしてたりするねん。そういう場合は、指示に従えてへんってことで失敗扱いになるわ。音声から翻訳するタスク(S2TT)では、モデルの出力から特定の接頭辞を直接探して、そんでから正解データと照らし合わせて二次確認して、指示守れてへんかどうか判断したんや。感情認識タスク(SER)では、出力が「Happy」「Sad」「Angry」「Neutral」の4つのカテゴリーのどれかにピッタリ当てはまるかどうかで、指示守れてるか評価してん。同じように、性別認識タスク(GR)では、出力は「Male」か「Female」のどっちかやないとあかんねん。
b) パフォーマンスのブレブレ具合を測る方法:指示のせいでパフォーマンスが不安定になる問題に対処するために、指示に従えてへんサンプルは空っぽの出力として扱って、それでメトリクスを計算するねん。D = (G, H)が評価用のペアデータセットやとして、G = {gi}が正解出力の集合で、H = {hi}がそれに対応するモデル出力やねん。F ⊆ Hは、ちゃんと指示に従えた出力の部分集合や。指示遵守の制約下でのパフォーマンスはこう計算するねん:
MetricIF(D) = (Σhi∈F Metric(gi, hi) + Σhi∉F Metric(gi, ∅)) / |D| (7)
要するに、指示に従えてへんかったら出力は空文字列として扱うってことやな。
元々のメトリクスとしては、音声認識タスクには単語誤り率(WER)、英語から中国語への翻訳タスクにはBLEUスコア、性別認識と感情認識タスクには分類精度(ACC)を使ってるで。
c) 指示への敏感さの評価と分析:
この分析の次元では、まず一般的な指示を作って、そっから6つのバリエーション指示を違う摂動の軸に沿って設計したんや。このバリエーションは、句読点の変更、意味の複雑さ、大文字小文字の区別、フォーマット要件とか、指示の言い回しの変化に対するモデルの敏感さを体系的に調べるためのもんやねん。指示バリエーションの詳細は付録XI-Aに載せてあるで。目標は、同じ音声言語理解タスクの要件を維持しながら、いろんな変換での指示遵守の頑健性と一貫性を評価することや。評価したオープンソースモデルは3つあって、Qwen2-Audio-7B-Instruct、Qwen2.5-Omni-7B、SALMONN-14Bやねん。モデルの指示敏感度は、異なる軸でのMetricIFを含むパフォーマンス不安定性メトリクス集合の標準偏差と正の相関があるねん。つまり、異なる指示間でのパフォーマンスのバラつきが大きいほど、指示の言い回しに対する敏感さが高いってことや:
指示敏感度 ∝ std({MetricIF}) (8)
表VIIIに示してあるように、{MetricIF}の標準誤差を使って指示敏感度を表してるで。程度の差はあるけど、評価した全モデルで観察されてて、これはモデルの基本的な知覚・認知能力に対する潜在的な課題を示唆してるんや。結果を見ると、Qwen2.5-Omni-7Bは比較的高い指示敏感度を示してて、指示遵守率(IFR)が特定のタスクでガクンと落ちてんねん。これは一部、Omniアーキテクチャのせいかもしれへんな。対照的に、SALMONN-13Bはほとんどのタスクで成績悪いんやけど、音声認識だけは例外や。性別認識タスクでは、50%のランダム当てずっぽうより精度が下がることもあるんやけど、これはおそらく同じラベルをずっと出力し続けてるからやな。せやけど、指示敏感度はめっちゃ低くて、指示遵守率はほぼ100%を維持してるねん。俺らの仮説やと、モデルの指示敏感度は、ファインチューニング時に出会った指示の種類と、訓練されたタスク固有データの多様性に密接に関係してると思うねん。
指示敏感度は注目すべき課題で、もっと注目される価値があるで。俺らの実験では指示の言い回しだけを変えたんやけど、指示テンプレートで指定される期待出力フォーマットのバリエーションも同様にモデルの振る舞いに影響する可能性があるんや。これは今後の研究でもっと深く調査・分析する必要があるな。
B. 意味理解能力の劣化
音声LLMは音声表現を理解する能力を獲得する一方で、そのアーキテクチャとパラメータサイズはベースLLMと比べて変わってへんねん。これはつまり、LLMが元々持ってた意味理解やテキスト理解の能力が犠牲になってる可能性があるってことを示唆してるんや。
この仮説を検証するために、音声LLMの意味推論能力を調べたんや。同じ意味入力を与えた条件下で、元のベースLLMとのパフォーマンスを比較したで。公平な比較のために、二つの流れの実験設定を設計したんや。ベースLLMには音声LLMがASRで文字起こししたテキストと同じ指示を与えて、音声LLMには生の音声と同じ指示を与えるねん。
評価したのは2つの代表的な音声LLM—Qwen2.5-Omni [87]とSALMONN [26]—と、それぞれのベースLLM—Qwen2.5-7B-Instruct [104]^1とVicuna-13B-v1.1 [183]—やねん。音声翻訳(ST)タスクと音声言語理解(SLU)タスクの両方でテストしたで。STにはCovost2 [138]データセットの英語から中国語へのサブセットを使ったんや。SU(意味理解)には、MMSU [182]から厳選した433サンプルのサブセットを使ってて、意図検出、因果推論、論理推論、多義語推論の4カテゴリーの意味推論タスクが含まれてるで。MMSUテストには公式プロンプト^2を使ってん。評価メトリクスは、STにはBLEU、SUにはカテゴリー別の精度を使ってるで。このチャレンジではIFRは調べてへんくて、単純にSTタスクでは出力全体を回答として、SLUタスクでは最初の大文字を選択肢として考慮してるんや。
結果は表IXに載せてあるで。詳細なプロンプトはセクションXI-Bにリストアップしてある。STタスクでは、Qwen-Omniの視点から見ると、タスクのファインチューニングが良くなったおかげでInstruct版と比べて全体的な翻訳性能は向上してるんやけど、3つの入力条件(音声、ASRテキスト、正解テキスト)での結果を見ると...
^1 より良い指示遵守のために、ファインチューニング版を選んだで。
^2 https://github.com/dingdongwang/mmsu_bench
---
## Page 25
[](/attach/042e1f605bca4d6f13f189f80f11e25db0d1092fe81b61406549f1784ff0fc4a_p025.png)
### 和訳
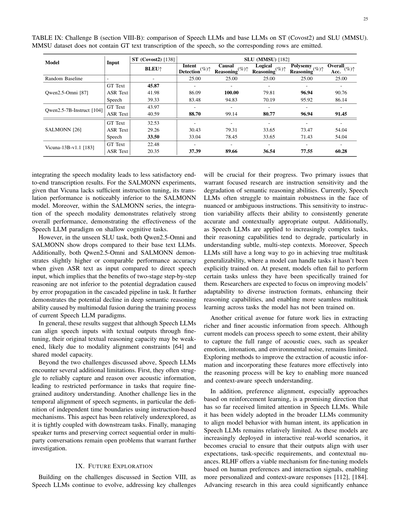
表IXの話やけどな、これはセクションVIII-Bで言うてた「チャレンジB」の結果で、音声LLMと普通のテキストLLMを翻訳タスク(Covost2っていうデータセット使ってる)と音声言語理解タスク(MMSUっていうデータセット)で比べてみた表やねん。ちなみにMMSUには正解のテキスト書き起こしがないから、その行は空欄になっとるで。
表にはQwen2.5-Omni、Qwen2.5-7B-Instruct、SALMONN、Vicuna-13B-v1.1っていうモデルが載ってて、入力の種類(正解テキスト、ASRで書き起こしたテキスト、生の音声)によって成績がどう変わるか見とるわけや。翻訳のBLEUスコアとか、意図検出、因果推論、論理推論、多義語推論の正答率が並んどる。
で、結果を見てみるとな、音声をそのまま入れると翻訳の成績がちょっと下がるんよ。SALMONNの実験では、ベースになってるVicunaは指示チューニングが足りてへんから、翻訳性能がSALMONNより明らかにアカンねん。せやけどSALMONNシリーズの中では、音声を統合したバージョンがそこそこええ成績出してて、「浅い認知タスク」においては音声LLMのやり方がちゃんと効いてるってことがわかるわけや。
ところがやな、初めて見る音声言語理解タスクになると、Qwen2.5-OmniもSALMONNも、ベースのテキストLLMより成績落ちるんよ。しかも両方とも、音声を直接入れるより、ASRで一回テキストに変換してから入れた方がちょっとええか同じくらいの精度が出るねん。これ何を意味するかっていうと、「2段階で順番に推論する」やり方のメリットが、カスケードパイプラインでエラーが伝播するデメリットより劣ってないってことやな。つまり、今の音声LLMの学習方法では、複数のモダリティを融合させる過程で、深い意味推論の能力が落ちてまう可能性があるってことを示しとるわけや。
まとめると、音声LLMはファインチューニングで音声入力とテキスト出力をうまく対応付けられるようになるんやけど、元々持ってたテキストの推論能力が弱まってまう傾向があるねん。なんでかっていうと、モダリティを揃える制約とか、モデルの容量を共有せなアカンっていう問題があるからやと思われるわ。
上で話した2つのチャレンジ以外にも、音声LLMにはまだまだ課題があるんよ。まず、音響情報をちゃんと捉えて推論するのが苦手で、細かい聴覚的な理解が必要なタスクでは性能が制限されがちやねん。もう一つの課題は、音声区間の時間的な位置合わせ、特に指示ベースの仕組みで独立した時間境界をどう定義するかっていう問題や。ここはあんまり研究されてへんのやけど、下流のタスクと密接に関係しとるから難しいんよな。最後に、複数人が喋る会話で話者の交代をうまく扱ったり、正しい順番を保ったりするのもまだ未解決の問題で、もっと調べる価値があるわ。
## IX. 今後の探求
セクションVIIIで議論した課題を踏まえてな、音声LLMがこれから進化していく上で、重要な課題に取り組むことがめっちゃ大事になってくるんよ。特に研究を集中させるべき問題が2つあってな、1つ目は「指示への敏感さ」、2つ目は「意味推論能力の低下」や。今の音声LLMは、微妙な表現とか曖昧な指示に対してロバスト(頑健)でいられへんことが多いねん。指示の言い方がちょっと変わるだけで、正確で文脈に合った出力を安定して生成できへんくなるんよ。それに加えて、音声LLMがどんどん複雑なタスクに使われるようになると、推論能力が落ちる傾向があって、特に微妙なニュアンスとか複数ステップの文脈を理解するのが苦手になるねん。さらに言うと、音声LLMが本当の意味でのマルチタスク汎化、つまり明示的に訓練されてへんタスクもこなせるようになるには、まだまだ道のりが長いんや。今のモデルは、特定のタスク用に訓練されてへん限り、そのタスクができへんことが多いねん。研究者たちには、色んな指示フォーマットへの適応力を上げること、推論能力を強化すること、訓練してへんタスクでもシームレスにマルチタスク学習できるようにすることが期待されとるわけや。
将来の研究でもう一つめっちゃ重要な方向性は、音声からもっと豊かで細かい音響情報を引き出すことやな。今のモデルもある程度は音声を処理できるんやけど、話者の感情、イントネーション、環境ノイズみたいな音響的な手がかりをフルに捉える能力はまだ限られとるんよ。音響情報の抽出を改善する方法を探って、そういう特徴を推論プロセスにもっと効果的に組み込むことが、より繊細で文脈を理解した音声理解を実現するカギになるわけや。
それからな、「選好アライメント」、特に強化学習ベースのアプローチは、めっちゃ有望な方向性なんやけど、音声LLMではまだあんまり注目されてへんねん。広いLLMのコミュニティでは、モデルの振る舞いを人間の意図に合わせるために広く使われとるんやけど、音声LLMでの応用はまだ限定的や。これらのモデルがインタラクティブな実世界のシナリオでどんどん使われるようになると、出力がユーザーの期待、タスク固有の要件、文脈のニュアンスに合ってることを確認するのがめっちゃ重要になってくるんよ。RLHF(人間のフィードバックからの強化学習)は、人間の好みやインタラクションのシグナルに基づいてモデルをファインチューニングする有効な仕組みで、よりパーソナライズされた文脈に沿った応答を可能にするんや。この分野の研究を進めることで、音声LLMの性能が大幅に向上する可能性があるで。
---
## Page 26
[](/attach/042e1f605bca4d6f13f189f80f11e25db0d1092fe81b61406549f1784ff0fc4a_p026.png)
### 和訳
音声LLMの実用場面での信頼性、コントロールのしやすさ、あとユーザーの満足度なんかをガツンと上げていく必要があるねん。
こういう分野を全部まとめると、音声LLMをこれから発展させていく上でめっちゃ大事な方向性を示しとるわけや。この課題らをちゃんと解決していったら、研究者たちは音声ベースのモデルの使い勝手とか適応力、全体的なパフォーマンスをバリバリ改善できるし、ユーザーのことをもっと深く理解して、もっと効果的にやり取りできる、そんな進化したシステムへの道が開けてくるんやで。
## X. まとめ
この論文はな、音声理解っていう視点から音声LLMを包括的にまとめた、ほんまに初めてのサーベイ論文やねん。この視点、実は今まであんまり注目されてこんかったんよ。これまでの研究って、音声を生成する方とか、なんでもできる汎用マルチモーダルモデルの方ばっかり見とったからな。この視点をしっかり固めるために、ワイらは音声理解っていう概念を初めて体系的に整理して、情報的・機能的・フォーマットっていう3つの軸でタスクを分類する仕組みを提案したんや。
この概念的な土台の上に立って、モデリングアプローチがどう進化してきたかを追いかけとるで。最初の頃のモジュール型とかカスケード型のパイプラインから、エンドツーエンドの専門システムへ、ほんでさらに最近では、いろんな音声理解タスクを一つにまとめようとするLLM中心のアーキテクチャへと移り変わってきた流れやな。
今のデザイン空間をはっきりさせるために、モデルのアーキテクチャとか学習戦略、データセットに関する最近の進歩をまとめ上げたし、さらに既存の音声LLMがいろんな音声理解タスクでどんだけ汎化できるかを分析して、実証的な視点も提供しとるで。
ワイらが自分らで実験して調べた結果、2つの切実な課題が見つかったんや。1つ目は指示への敏感さの問題、2つ目は今のシステムの意味的推論能力が劣化してまう問題や。この2つがあるせいで、音声LLMの実世界での応用における頑健性と柔軟性がガッツリ制限されてまうねん。
この分野を体系的にまとめて、重要な課題を特定して、実際に使える方向性を提案することで、このサーベイが概念的な土台としても実践的な参考資料としても役立って、音声LLMの開発をもっと汎用的で適応力があって人間に寄り添った音声理解システムへと進めていく助けになったらええなと思っとるで。
---
## 参考文献
[1] A. Coucke らの研究チームが2018年に発表した「Snips音声プラットフォーム」や。これはな、プライバシー重視で設計された音声インターフェース用の、組み込み型の音声言語理解システムやねん。arXivのプレプリントで公開されとるで。
[2] R. Sarikaya らが2016年のIEEE音声言語技術ワークショップで発表した、パーソナルデジタルアシスタント向けのエンドツーエンド言語理解と対話管理の概要や。
[3] G. Tur と R. De Mori が2011年にJohn Wiley & Sonsから出した本で、音声から意味情報を抽出するシステムについての音声言語理解の教科書やな。
[4] [3]と同じ著者らの同じテーマの本やで。
[5] L. Lugosch らが2019年のInterspeechで発表した、エンドツーエンド音声言語理解のための音声モデル事前学習についての研究や。
[6] G. Hinton らが2012年にIEEE Signal Processing Magazineで発表した、音声認識の音響モデリングにおけるディープニューラルネットワークについての論文や。4つの研究グループの共通見解をまとめたもんやで。
[7] A. Graves と N. Jaitly が2014年の国際機械学習会議(ICML)で発表した、リカレントニューラルネットワークを使ったエンドツーエンド音声認識に向けた研究や。
[8] W. Chan らが2015年に発表した「Listen, Attend and Spell」っていう有名な論文やな。arXivで読めるで。
[9] L. Qin らが2021年にarXivで公開した、音声言語理解に関するサーベイ論文や。最近の進歩と新しいフロンティアについてまとめとる。
[10] X. Yang と J. Liu が2015年のInterspeechで発表した、音声言語理解のスロット埋めに単語混同ネットワークを使う研究や。
[11] G. Tur らが2013年にComputer Speech & Languageで発表した、音声言語理解を改善するためのASRエラー軽減についての論文やな。
[12] F. Ladhak らが2016年のEMNLPで発表した、音声からSQLへの変換におけるラティスリスコアリングの研究や。
[13] P. Haghani らが2018年のIEEE SLTワークショップで発表した、音声から意味へのエンドツーエンド音声言語理解へのアプローチについての論文やで。
[14] S. Kim らが2017年のICASSPで発表した、マルチタスク学習を使った共同CTC-アテンションベースのエンドツーエンド音声認識の研究や。
[15] D. Serdyuk らが2018年のICASSPで発表した、エンドツーエンド音声言語理解に向けた研究やな。
[16] S. Arora らが2022年にarXivで公開した、2パス低遅延エンドツーエンド音声言語理解についての論文や。
[17] Y.-S. Chuang らが2019年にarXivで発表した「SpeechBERT」や。音声とテキストを一緒に学習した言語モデルで、エンドツーエンドの音声質問応答ができるようになったんやで。
[18] S. Shon らが2022年のICASSPで発表した「SLUE」っていう新しいベンチマークや。自然な音声での音声言語理解評価のための新しいタスク群を提案しとる。
[19] J. Seo らが2022年のEMNLPで発表した、事前学習済みTransformerを使ったエンドツーエンド音声質問応答の研究やな。
[20] A. Graves らが2006年の第23回ICML国際会議で発表した、コネクショニスト時系列分類(CTC)についての論文や。リカレントニューラルネットワークでセグメント化されてない系列データにラベル付けする方法やで。
[21] A. Graves が2012年にarXivで発表した、リカレントニューラルネットワークを使った系列変換についての技術レポートやな。
---
## Page 27
[](/attach/042e1f605bca4d6f13f189f80f11e25db0d1092fe81b61406549f1784ff0fc4a_p027.png)
### 和訳
[22] D. Amodeらによる「Deep Speech 2: 英語と中国語のEnd-to-End音声認識」、機械学習国際会議(PMLR, 2016年、pp. 173-182)
[23] A. Baevskiらによる「wav2vec 2.0: 音声表現の自己教師あり学習フレームワーク」、神経情報処理システムの進歩(vol. 33, pp. 12449-12460, 2020年)
[24] W.-N. Hsuらによる「HuBERT: 隠れユニットのマスク予測による自己教師あり音声表現学習」、IEEE音声・言語処理論文誌(2021年)
[25] S. Chenらによる「WavLM: フルスタック音声処理のための大規模自己教師あり事前学習」、神経情報処理システムの進歩(2022年)
[26] C. Tangらによる「SALMONN: 大規模言語モデルに汎用的な聴覚能力をつけようって話やねん」、arXivプレプリント arXiv:2310.13289(2023年)
[27] Y. Baiらによる「SEED-ASR: LLMベースの音声認識で多様な音声とコンテキストを理解するで」、arXivプレプリント arXiv:2407.04675(2024年)
[28] Y. Gongらによる「Listen, Think, and Understand(聴いて、考えて、理解するんや)」(2024年)[オンライン] https://arxiv.org/abs/2305.10790
[29] K.-H. Luらによる「DESTA2: 音声指示チューニングデータなしで指示追従型音声言語モデルを開発する方法」(2025年)[オンライン] https://arxiv.org/abs/2409.20007
[30] Z. Maらによる「LLMに強力なASR能力をつける、めっちゃシンプルなアプローチ」(2024年)[オンライン] https://arxiv.org/abs/2402.08846
[31] K.-T. Xuらによる「FireRedASR: エンコーダ・デコーダからLLM統合まで、オープンソースの産業グレード中国語音声認識モデル」(2025年)[オンライン] https://arxiv.org/abs/2501.14350
[32] S. Deshmukhらによる「Pengi: 音声タスク用の音声言語モデル」、神経情報処理システムの進歩(vol. 36, pp. 18090-18108, 2023年)
[33] X. Gengらによる「OSUM: 学術機関の限られたリソースでオープン音声理解モデルを進化させるで」(2025年)[オンライン] https://arxiv.org/abs/2501.13306
[34] S. Aroraらによる「音声言語モデルの全体像:包括的なサーベイやで」(2025年)[オンライン] https://arxiv.org/abs/2504.08528
[35] S. Jiらによる「WavChat: 音声対話モデルのサーベイ」(2024年)[オンライン] https://arxiv.org/abs/2411.13577
[36] W. Cuiらによる「音声言語モデルの最近の進歩:サーベイ」、arXivプレプリント arXiv:2410.03751(2024年)
[37] Y. Chuらによる「Qwen-Audio: 統一された大規模音声言語モデルで汎用音声理解を進めるんや」、arXivプレプリント arXiv:2311.07919(2023年)
[38] Y. Chuらによる「Qwen2-Audio テクニカルレポート」、arXivプレプリント arXiv:2407.10759(2024年)
[39] K.-H. Luらによる「DESTA: 記述的な音声テキストアライメントで音声言語モデルを強化する」、Interspeech 2024(pp. 4159-4163)
[40] J. S. B. Evansによる「推論・判断・社会的認知の二重処理理論」、Annu. Rev. Psychol.(vol. 59, no. 1, pp. 255-278, 2008年)
[41] D. Kahnemanによる『ファスト&スロー』(macmillan, 2011年)。これめっちゃ有名な本やで、人間の思考には速い思考(システム1)と遅い思考(システム2)があるって話や。
[42] K. Papineniらによる「BLEU: 機械翻訳の自動評価手法」、計算言語学会第40回年次大会論文集(2002年7月、pp. 311-318)[オンライン] https://aclanthology.org/P02-1040/
[43] L. Barraultらによる「SeamlessM4T:めっちゃ多言語・マルチモーダルな機械翻訳」、arXivプレプリント arXiv:2308.11596(2023年)
[44] C.-Y. Linによる「ROUGE: 要約の自動評価パッケージ」、ACL-04ワークショップ論文集(2004年、pp. 74-81)
[45] G. E. Dahlらによる「大語彙音声認識のための文脈依存事前学習済み深層ニューラルネットワーク」、IEEE音声・言語処理論文誌(vol. 20, no. 1, IEEE, 2012年、pp. 30-42)
[46] D. Poveyらによる「Kaldi音声認識ツールキット」、IEEE 2011自動音声認識・理解ワークショップ(IEEE信号処理学会、2011年)
[47] P. Lamereらによる「CMU Sphinx-4音声認識システム」、カーネギーメロン大学技術レポート(2003年)
[48] G. Mesnilらによる「音声言語理解のスロットフィリングにリカレントニューラルネットワークを使う」、IEEE/ACM音声・言語処理論文誌(vol. 23, no. 3, 2014年、pp. 530-539)
[49] D. Hakkani-Türらによる「双方向RNN-LSTMを使ったマルチドメイン統合意味フレーム解析」、INTERSPEECH(2016年、pp. 715-719)
[50] J. Aoらによる「SpeechT5: 音声言語処理のための統一モーダルエンコーダ・デコーダ事前学習」、arXivプレプリント arXiv:2110.07205(2022年)
[51] A. Radfordらによる「大規模弱教師あり学習によるロバストな音声認識」、機械学習国際会議(PMLR, 2023年、pp. 28492-28518)。これがあの有名なWhisperの論文やで!
[52] S.-w. Yangらによる「SUPERB: 音声処理ユニバーサル性能ベンチマーク」、Interspeech(2021年、pp. 1194-1198)
[53] K. Qianらによる「SpeechFormer: End-to-End音声言語理解のためのTransformerアーキテクチャを再設計したで」、Proc. Interspeech(2021年、pp. 2097-2101)
[54] Q. Liuらによる「音響からワードへのモデルのためのモジュール式End-to-End自動音声認識フレームワーク」、IEEE/ACM音声・言語処理論文誌(vol. 28, pp. 2174-2183, 2020年)
[55] J. Huangらによる「SpokenCoT: 音声言語モデルのためのChain-of-Thoughtプロンプティング」、自然言語処理における経験的手法に関する会議(EMNLP)2023年論文集(pp. 12345-12358)[オンライン] https://arxiv.org/abs/2305.12108
[56] A. Bapnaらによる「SLAM: 音声テキスト共同事前学習による音声・言語モデリングの統一エンコーダ」、計算言語学会第60回年次大会(ACL)2022年論文集(pp. 4160-4174)[オンライン] https://arxiv.org/abs/2110.10329
[57] Y.-A. Chungらによる「W2v-BERT: コントラスティブ学習と...」[テキスト省略]
---
## Page 28
[](/attach/042e1f605bca4d6f13f189f80f11e25db0d1092fe81b61406549f1784ff0fc4a_p028.png)
### 和訳
## 参考文献の翻訳(関西弁ver.)
[63] X. Chenらの研究やねんけど、「LLAST」っていう音声翻訳システムの話や。これな、大規模言語モデル(でっかいAIのことやで)を活用して、音声を別の言語に変換する性能をめっちゃ上げたっていう内容やねん。2024年の論文で、arXivで読めるで。
[64] Y. Fangらは「少ないデータでも頑張れる音声AIの適応方法」について書いとるねん。なんでかっていうと、普通は音声データが山ほど必要やねんけど、テキストだけで学習させる方法を見つけたから、データが少ない分野でも使えるようになったんや。2025年の最新研究やで。
[65] S. Kumarらのチームは「SLAM-ASR」っていう音声認識システムの性能評価をしとるねん。タイトルがめっちゃおもろくて「良いとこ、悪いとこ、ヤバいとこ、ほんで今後どないするか」やて。2025年のICASSPワークショップで発表されとる。ほんまに正直なタイトルやな。
[66] Q. Chenらの「Minmo」は、音声でめっちゃスムーズにやり取りできるマルチモーダル大規模言語モデルや。マルチモーダルってのは、テキストも音声も画像も全部扱えるってことやねん。2025年のarXiv論文やで。
[67] B. Wuらの「Step-Audio 2」の技術レポートや。音声AI関連の最新研究で、2025年に出とる。
[68] Y. Fathullahらは、大規模言語モデルに「音声認識能力を持たせる」方法について研究しとるねん。プロンプト(AIへの指示文)を工夫することで、元々テキストしか扱えへんかったモデルでも音声が分かるようになるっていう、めっちゃ賢いアプローチや。2024年のICASSP(音声処理の大きい学会)で発表されとる。
[69] G. Yangらの「MALA-ASR」は、マルチメディア(画像とか動画とか)の情報も使って音声認識の精度を上げようっていう研究や。LLM(大規模言語モデル)ベースの音声認識システムやねん。2024年の論文。
[70] H. Gaoらの「WavPrompt」は、凍結した(学習を止めた)言語モデルを使って、少ないデータでも音声を理解できるようにする研究や。Few-shotっていうのは「ちょっとの例だけで学習する」って意味やねん。2022年の論文。
[71] Y. Suらの「PandaGPT」は、一つのモデルで色んな種類の指示に従えるっていうすごいやつや。2023年の研究やで。
[72] J. Wuらは、音声からテキストへの変換と大規模言語モデルを統合する時に「デコーダーオンリー」っていうアーキテクチャ(設計思想)を使う方法について研究しとる。2023年のASRUワークショップで発表や。
[73] Y. Gongらの「Joint Audio and Speech Understanding」は、音声と音(環境音とか)の両方を理解するっていう研究や。2023年のASRUで発表されとる。
[74] Z. Huangらは、大規模言語モデルを使った音声翻訳の「産業での実践」について書いとるねん。学術研究だけやなくて、実際のビジネスでどう使うかっていう実践的な内容や。2023年の論文。
[75] Z. Maらの研究タイトルがめっちゃおもろいねん。「LLMに強力な音声認識能力を持たせる、めっちゃシンプルな方法」やて。複雑なことせんでも強いASR(自動音声認識)ができるっていう、ある意味革命的な研究や。2024年の論文。
[76] Z. Kongらの「Audio Flamingo」は、音声を理解する言語モデルで、少ないデータでの学習と対話ができるっていうのが特徴や。2024年の研究。
[77] C. Wangらの「BLSP」は、言語と音声の事前学習を「続き書き」の動作を合わせることでブートストラップ(最初の段階を作る)するっていう手法や。2023年の論文やで。
[78] N. Dasらの「SpeechVerse」は、めっちゃ汎用性の高い音声言語モデルや。色んなタスクに使えるように設計されとるねん。2024年の研究。
[79] H. Xueらの「E-chat」は、感情に敏感な音声対話システムや。大規模言語モデルを使って、相手の感情を理解しながら会話できるってのがポイントやねん。2024年のISCSLP(中国語音声処理のシンポジウム)で発表。
[80] X. Chenらの「LLAST」([63]と同じ研究チーム)の詳細論文や。大規模言語モデルを活用した音声翻訳システムの改良版やねん。
[81] S. Huらの「WavLLM」は、頑健で適応力のある音声大規模言語モデルを目指した研究や。ノイズとかにも強くて、色んな状況に対応できるのが売りやねん。2024年のarXiv論文。
[82] H. Xueらの「IDEAL-LLM」は、二つのエンコーダー(音声を処理する部品)と言語に適応したLLMを統合して、多言語の音声からテキストへの変換を実現しとる。2024年の研究。
[83] S. Ghoshらの「Audio Flamingo 2」は、[76]の続編や。長い音声の理解と専門家レベルの推論能力を持っとるねん。2025年の最新研究やで。
[84] R. Maらの「LegoSLM」は、CTCポステリア(音声認識で使う確率情報)を使ってLLMと音声エンコーダーを繋ぐっていう方法や。レゴみたいにパーツを組み合わせるイメージやな。2025年の論文。
[85] K.-H. Luらの「DESTA2.5-Audio」は、自己生成したクロスモーダル(異なる種類のデータ間)のアラインメント(対応付け)を使った汎用音声言語モデルや。2025年の研究。
[86] H. Dinkelらの「MidasHengLLM」は、一般的な音声キャプション(音声の説明文)を使った効率的な音声理解システムや。2025年の論文やで。
[87] J. Xuらの「Qwen2.5-Omni」の技術レポートや。Qwenシリーズの最新版で、音声も扱えるオムニ(全方位)モデルやねん。2025年。
[88] D. Dingらの「Kimi-Audio」の技術レポート。2025年の最新音声AIシステムや。
[89] A. Goelらの「Audio Flamingo 3」は、完全にオープンな大規模音声言語モデルで、音声AI分野を進化させようっていう野心的な研究や。2025年の論文。
[90] Xiaomiの「MiMo-Audio」は、少ないデータでも学習できる音声言語モデルや。GitHubで公開されとるで。2025年。
[91] J. Tianらの「UALM」(Unified Audio Language Model)は、音声の理解・生成・推論を全部統合したモデルや。一つのモデルで全部できるってのがすごいねん。2025年の研究。
[92] J. Xuらの「Qwen3-Omni」の技術レポート。Qwenシリーズのさらに新しいバージョンや。2025年。
[93] Van Den Oordらの「Neural Discrete Representation Learning」は、VQ-VAE(ベクトル量子化変分オートエンコーダー)の元祖論文や。ニューラルネットで離散的な表現を学習する方法を提案しとる。2017年のNeurIPSで発表された重要な研究やねん。
[94] N. Zeghidourらの「SoundStream」は、エンドツーエンド(最初から最後まで一貫した)のニューラル音声コーデックや。音声を効率よく圧縮・復元する技術で、2021年の論文。IEEE/ACMのオーディオ関連のジャーナルに載っとる。
[95] R. Grayの「Vector Quantization」は、ベクトル量子化の基礎理論や。1984年の古典的な論文やけど、今でもめっちゃ重要な概念やねん。
[96] E. Tsunooらは、CTCプロンプトとテキストデータ拡張を使った「デコーダーオンリー」の音声認識アーキテクチャについて研究しとる。2024年の論文。
[97] P. K. Rubensteinら(Googleのチームやな)の「AudioPaLM」は、話すことも聞くこともできる大規模言語モデルや。2023年の研究で、音声AIの大きなブレークスルーやったねん。
[98] J. Zhanらの研究...(以下省略されとる)
---
だいしろーさん!翻訳完了やで!音声AI関連の参考文献、めっちゃ最新の研究が多いな。2024年から2025年の論文がほとんどで、この分野がほんまに急速に発展しとるのがよう分かるわ。
---
## Page 29
[](/attach/042e1f605bca4d6f13f189f80f11e25db0d1092fe81b61406549f1784ff0fc4a_p029.png)
### 和訳
[104] Qwen、ってことで、A. Yangさんとか、B. Yangさんとか、めっちゃ大勢の研究者が集まって書いた「Qwen2.5テクニカルレポート」が2025年に出とるねん。詳しくはhttps://arxiv.org/abs/2412.15115で見れるで。
[105] Y. Liさんらが2024年に出した論文なんやけど、これは「転写プロンプトベースの効率的な音声大規模言語モデル」っちゅうやつで、要は音声認識をめっちゃ頑丈にするための方法やねん。音声をテキストに変換するときに、プロンプトっていう指示文をうまく使って、精度を上げましょうっていう話や。
[106] W. Yuさんらが2024年のICASSPっていう音声信号処理のめっちゃ有名な学会で発表した論文やねん。「音声エンコーダと大規模言語モデルをつなげて音声認識するで」っていう内容や。なんでかっていうと、音声を理解するパーツと、言葉を理解するパーツを上手につなげたら、もっと賢く音声認識できるやろって発想やな。
[107] Z. Chenさんらも2024年のICASSPで発表しとって、「SALM」っていうシステムを提案しとるねん。これは「音声で強化した言語モデル」みたいな意味で、文脈学習っていう技術を使って、音声認識と翻訳を同時にやっちゃおうっていう欲張りなやつや。
[108] T. Xuさんらが2025年に出した論文で、中国の方言の音声認識について調べとるねん。大規模言語モデル(LLM)と自己教師あり学習モデルっていう、自分で勉強するタイプのAIを使って、方言をどれくらい認識できるか比較してみましたっていう内容や。
[109] E. Lakomkinさんらが2024年のICASSPで発表した論文で、「エンドツーエンドの音声認識を大規模言語モデルで文脈化する」っていう話やねん。エンドツーエンドっていうのは、最初から最後まで一気通貫でやるってことで、途中で人間が手を加えんでもええようにするっていう意味やな。
[110] C. Chenさんらが2024年に出した論文で、「人間のフィードバックでゼロショットのテキスト読み上げ合成を強化する」っていう内容や。ゼロショットっていうのは、事前に練習してない声でもいきなり喋れるようにするっていうことで、それを人間の「こっちの方がええな」っていう意見を取り入れて改善しましょうって話やねん。
[111] J. Tianさんらが2024年に出した論文で、「好み調整で言語モデルベースのテキスト読み上げが良くなるで」っていう内容や。AIが作った音声を、人間の好みに合わせてチューニングしていくっていうアプローチやな。
[112] J. Schulmanさんらが2017年に出した論文で、「PPO(近接方策最適化アルゴリズム)」っていうやつやねん。これはAIの強化学習っていう分野でめっちゃ重要な手法で、AIが少しずつ賢くなっていくための学習方法を提案しとるんや。
[113] R. Rafailovさんらが2024年に出した論文で、「直接的な好み最適化:あんたの言語モデル、実は報酬モデルやったんやで」っていうタイトルやねん。これがほんまに面白くて、普通の言語モデルを、人間の好みを理解するモデルとしても使えるっていう発見なんや。詳しくはhttps://arxiv.org/abs/2305.18290で見れるで。
[114] D. Zhangさんらが2024年に出した「SpeechAlign」っていう論文で、音声生成を人間の好みに合わせましょうっていう内容や。AIが作る音声を、人間が「これええな」って思うものに近づけていく手法やねん。
[115] V. Panayotovさんらが2015年のICASSPで発表した「LibriSpeech」っていうデータセットの論文や。これはパブリックドメインのオーディオブック、つまり著作権フリーの朗読音声を使って作った音声認識用のコーパス(データの集まり)やねん。めっちゃ有名で、音声認識の研究では定番中の定番や。
[116] H. Buさんらが2017年に発表した「AISHELL-1」っていうデータセットの論文や。これはオープンソースの中国語音声コーパスで、中国語の音声認識研究のベースラインも一緒に提供しとるねん。
[117] R. Ardilaさんらが2019年に出した「Common Voice」の論文や。これはMozillaがやっとるプロジェクトで、めっちゃたくさんの言語の音声を集めた超多言語の音声コーパスやねん。ボランティアの人らが自分の声を寄付して作られとるんや。
[118] J. Duさんらが2018年に出した「AISHELL-2」の論文で、中国語の音声認識研究を産業規模に持っていこうっていう内容や。AISHELL-1の進化版みたいなもんやな。
[119] F. Hernandezさんらが2018年のSPECOMっていう学会で発表した「TED-LIUM 3」の論文や。これはTEDトークの音声を使ったデータセットで、前のバージョンの2倍のデータ量があるねん。話者適応の実験用にコーパスの分け方も工夫しとるんや。
[120] V. Pratapさんらが2020年に出した「MLS」の論文で、これは音声研究用の大規模多言語データセットやねん。いろんな言語の音声データがどっさり入っとるんや。
[121] Y. Shiさんらが2020年に出した「AISHELL-3」の論文や。これは複数話者の中国語テキスト読み上げ用のコーパスで、ベースラインモデルも一緒に提供しとるねん。
[122] C. Wangさんらが2021年に出した「VoxPopuli」の論文で、これは大規模多言語音声コーパスやねん。表現学習、半教師あり学習、解釈性の研究に使えるように作られとるんや。
[123] G. Chenさんらが2021年に出した「GigaSpeech」の論文や。これは進化し続ける多ドメインの音声認識用コーパスで、なんと1万時間分の書き起こし付き音声が入っとるねん。めっちゃデカいデータセットや。
[124] W. Kraaijさんらが2005年の行動研究の学会で発表した「AMI会議コーパス」の論文や。これは会議の音声を集めたデータセットで、複数の人が喋っとる状況を研究するのに使われとるねん。
[125] J. S. Chungさんらが2020年に出した論文で、「会話を見つけろ:野生環境での話者ダイアリゼーション」っていうタイトルや。話者ダイアリゼーションっていうのは、「この部分は誰が喋っとるか」を自動で判別する技術のことで、「野生環境」っていうのは、きれいなスタジオ収録じゃなくて、実際の雑然とした状況ってことやな。
[126] J. S. Chungさんらが2018年に出した「VoxCeleb2」の論文で、深層学習を使った話者認識のためのデータセットやねん。誰が喋っとるかを声だけで当てる技術の研究に使われとるんや。
[127] Y. Fanさんらが2020年のICASSPで発表した「CN-Celeb」の論文や。これは中国語の話者認識用データセットで、めっちゃ難しい課題を含んどるねん。
[128] J. Houさんらが2019年にIEEE Signal Processing Lettersで発表した論文で、「領域提案ネットワークを使った省フットプリントのキーワードスポッティング」っていう内容や。キーワードスポッティングっていうのは、「OK Google」とか「アレクサ」みたいな特定の言葉を検出する技術のことで、省フットプリントっていうのは、メモリや計算量を節約できるってことやな。
[129] A. Couckeさんらが2019年のICASSPで発表した論文で、「膨張畳み込みとゲーティングを使った効率的なキーワードスポッティング」っていう内容や。膨張畳み込みっていうのは、畳み込みニューラルネットワークの一種で、より広い範囲の情報を効率的に見れるようにした技術やねん。
[130] S. Chaudhuriさんらが2018年に出した「AVA-Speech」の論文や。これは映画の中の発話活動を細かくラベル付けしたデータセットで、「ここで誰かが喋っとる」「ここは無音」みたいな情報がびっしり付いとるねん。
[131] Y. Gongさんらが2022年のICASSPで発表した「VocalSound」の論文や。これは人間の声の音、例えば笑い声とか咳とかくしゃみとかを認識するためのデータセットやねん。
[132] C. Bussoさんらが2008年にLanguage Resources and Evaluationっていう雑誌で発表した「IEMOCAP」の論文や。これは「対話型感情二者間モーションキャプチャデータベース」っていう長い名前で、要は二人が会話しとるときの感情を記録したデータセットやねん。感情認識の研究でめっちゃ使われとる有名なやつや。
[133] S. Poriaさんらが2018年に出した「MELD」の論文で、「マルチモーダル・マルチパーティ会話感情認識データセット」っていうやつや。複数の人が参加する会話の中での感情を、音声だけじゃなくて映像とかも含めて認識するためのデータセットやねん。
[134] S. R. Livingstoneさんらが2018年にPLoS ONEで発表した「RAVDESS」の論文や。これは「ライアソン感情音声・歌唱視聴覚データベース」っていうやつで、北米英語での顔の表情と声の表現がダイナミックに入っとるデータセットやねん。
[135] L. Martinez-Lucasさんらが2020年のInterspeechで発表した「MSP会話コーパス」の論文や。会話中の感情を研究するためのデータセットやねん。
[136] K. Zhouさんらが2022年にSpeech Communicationっていう雑誌で発表した論文で、「感情音声変換:理論、データベース、ESD」っていう内容や。感情音声変換っていうのは、普通の声を嬉しそうな声とか悲しそうな声に変える技術のことで、ESDっていうのはそのためのデータセットやねん。
[137] M. A. Di Gangiさんらが2019年のNAACLっていう自然言語処理の学会で発表した「MuST-C」の論文や。これは多言語の音声翻訳用コーパスで、ある言語で喋った内容を別の言語に翻訳するための研究に使われとるねん。
[138] C. Wangさんらが2021年のInterspeechで発表した「CoVoST 2」の論文で、これも超大規模な多言語音声翻訳のためのデータセットやねん。
---
## Page 30
[](/attach/042e1f605bca4d6f13f189f80f11e25db0d1092fe81b61406549f1784ff0fc4a_p030.png)
### 和訳
[144] C. T. Hemphill, J. J. Godfrey, G. R. Doddington、「ATISの音声言語システムのパイロットコーパス」、Speech and Natural Language: 1990年6月24-27日にペンシルバニア州ヒドゥンバレーで開かれたワークショップの論文集、1990年。
これはな、飛行機の予約とかに関する音声データを集めたやつやねん。音声で「この便予約して」みたいなんを理解するシステムのためのデータセットやで。
[145] D. A. Dahl, M. Bates, M. K. Brown, W. M. Fisher, K. Hunicke-Smith, D. S. Pallett, C. Pao, A. Rudnicky, E. Shriberg、「ATISタスクの範囲拡張:ATIS-3コーパス」、Human Language Technology: 1994年3月8-11日にニュージャージー州プレインズボロで開かれたワークショップの論文集、1994年。
さっきのATISの進化版やな。もっと色んなパターンの音声データを追加して、システムが対応できる範囲を広げたってことやねん。
[146] S. Zhu, Z. Zhao, T. Zhao, C. Zong, K. Yu、「CATSLU:第1回中国語の音声テキスト複合型の音声言語理解チャレンジ」、2019 International Conference on Multimodal Interaction、2019年、pp. 521-525。
中国語版の音声理解コンペティションやな。音声とテキストの両方を使って、コンピュータが中国語をどれだけ理解できるか競い合うやつやで。
[147] E. Bastianelli, A. Vanzo, P. Swietojanski, V. Rieser、「SLURP:音声言語理解のためのリソースパッケージ」、arXivプレプリント arXiv:2011.13205、2020年。
音声言語理解の研究に使えるデータとかツールを一式まとめたパッケージやねん。「はい、これ使ってください」って感じで研究者に提供しとるわけや。
[148] B. Lee, I. Calapodescu, M. Gaido, M. Negri, L. Besacier、「SpeechMASSIVE:音声言語理解とその先のための多言語音声データセット」、arXivプレプリント arXiv:2408.03900、2024年。
めっちゃいろんな言語の音声データを集めたデータセットやで。音声言語理解だけやなくて、もっと幅広い用途にも使えるようになっとるのがポイントやな。
[149] B.-H. Tseng, S.-S. Shen, H.-Y. Lee, L.-S. Lee、「機械による音声内容理解に向けて:TOEFLリスニング理解テストの機械による初挑戦」、arXivプレプリント arXiv:1608.06378、2016年。
ほんまにおもろいやつで、TOEFLのリスニングテストを機械に解かせてみたっていう研究やねん。人間が受ける英語の試験を、AIがどこまでできるかチャレンジしたわけや。
[150] C.-H. Li, S.-L. Wu, C.-L. Liu, H.-y. Lee、「Spoken SQuAD:リスニング理解における音声認識エラーの影響軽減に関する研究」、arXivプレプリント arXiv:1804.00320、2018年。
音声認識って完璧ちゃうやん?聞き間違いとかあるわけや。その聞き間違いがあっても、質問に正しく答えられるようにするにはどうしたらええか、っていう研究やねん。
[151] C.-H. Lee, S.-M. Wang, H.-C. Chang, H.-Y. Lee、「ODSQA:オープンドメイン音声質問応答データセット」、2018 IEEE Spoken Language Technology Workshop (SLT)、IEEE、2018年、pp. 949-956。
テーマを限定せんと、なんでも音声で質問してAIが答えるためのデータセットやで。「今日の天気は?」から「量子力学って何?」まで、幅広い質問に対応するためのもんやな。
[152] C. You, N. Chen, F. Liu, S. Ge, X. Wu, Y. Zou、「エンドツーエンド音声会話型質問応答:タスク・データセット・モデル」、arXivプレプリント arXiv:2204.14272、2022年。
会話の流れの中で音声で質問して音声で答えるっていう、めっちゃ自然なやりとりを最初から最後まで一気に処理するシステムの研究やねん。途中で文字に変換せんと、音声のまま理解するのがミソやで。
[153] G.-T. Lin, Y.-S. Chuang, H.-L. Chung, S.-w. Yang, H.-J. Chen, S. Dong, S.-W. Li, A. Mohamed, H.-y. Lee, L.-s. Lee、「DUAL:テキストなし音声質問応答のための離散音声単位適応学習」、arXivプレプリント arXiv:2203.04911、2022年。
これがまたすごくてな、テキストを一切使わんと、音声だけで質問応答をやるシステムやねん。音声を細かい単位に分解して、それを直接学習するっていうアプローチやで。
[154] N. B. Shankar, A. Johnson, C. Chance, H. Veeramani, A. Alwan、「CORAAL QA:長い音声ファイルからのオープンドメイン自発音声質問応答のためのデータセットとフレームワーク」、ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)、IEEE、2024年、pp. 13371-13375。
長い音声の中から必要な情報を見つけて質問に答えるっていうやつやな。しかも自然な会話音声が対象やから、「えーと」とか「あのー」とかも含まれとって、それでもちゃんと答えなあかんねん。
[155] Q. Yang, J. Xu, W. Liu, Y. Chu, Z. Jiang, X. Zhou, Y. Leng, Y. Lv, Z. Zhao, C. Zhou, J. Zhou、「AIR-Bench:生成的理解による大規模音声言語モデルのベンチマーク」、Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)、L.-W. Ku, A. Martins, V. Srikumar 編、2024年、pp. 1979-1998。
大規模な音声言語モデルがどれだけ賢いか測るためのテストやねん。ただ聞き取るだけやなくて、聞いた内容を理解して新しい文を生成できるかっていう能力を評価するベンチマークやで。
[156] S. Sakshi, U. Tyagi, S. Kumar, A. Seth, R. Selvakumar, O. Nieto, R. Duraiswami, S. Ghosh, D. Manocha、「MMAU:大規模マルチタスク音声理解・推論ベンチマーク」、arXivプレプリント arXiv:2410.19168、2024年。
めっちゃでかい規模のベンチマークで、音声を理解するだけやなくて、そこから推論する能力も測るやつやねん。いろんなタスクを同時に評価できるのがポイントやで。
[157] Z. Ma, Y. Ma, Y. Zhu, C. Yang, Y.-W. Chao, R. Xu, W. Chen, Y. Chen, Z. Chen, J. Cong ら、「MMAR:音声・音響・音楽・ミックスにおける深い推論のための挑戦的ベンチマーク」、arXivプレプリント arXiv:2505.13032、2025年。
これはほんまに難しいベンチマークで、音声だけやなくて、環境音とか音楽とか、それらが混ざったやつまで含めて、深い推論ができるかを試すやつやねん。AIにとってはかなりハードル高いで。
[158] F. Faisal, S. Keshava, A. Anastasopoulos ら、「SD-QA:実世界のための音声方言質問応答」、arXivプレプリント arXiv:2109.12072、2021年。
方言に対応した質問応答やで!標準語だけやなくて、いろんな方言で話しかけられてもちゃんと答えられるかっていう研究やねん。関西弁で質問してもちゃんと答えてくれたら最高やな。
[159] Y. Tang, A. K. Tung、「SQuAD-SRC:多アクセント音声読解理解のためのデータセット」、IJCAI、2023年、pp. 5206-5214。
いろんなアクセント(なまり)で読み上げられた文章を聞いて、質問に答えるためのデータセットやな。アメリカ英語もイギリス英語もインド英語も、全部理解せなあかんわけや。
[160] Y. Wu, S. Rallabandi, R. Srinivasamurthy, P. P. Dakle, A. Gon, P. Raghavan、「HeySQuAD:音声質問応答データセット」、arXivプレプリント arXiv:2304.13689、2023年。
「ヘイ!」って呼びかけて質問するタイプの音声質問応答データセットやねん。スマートスピーカーみたいなシチュエーションを想定しとるんやろな。
[161] F. Alam, M. A. Hasan, S. A. Chowdhury、「SpokenNativQA:大規模言語モデルのための多言語日常音声クエリ」、arXivプレプリント arXiv:2505.19163、2025年。
いろんな言語のネイティブスピーカーが日常的に使う音声での質問を集めたデータセットやで。大規模言語モデル(LLMっていうめっちゃ賢いAI)がこういう自然な質問にどれだけ対応できるか調べるためのもんやねん。
[162] Z. Chen, J. Bao, L. Chen, Y. Liu, D. Ma, B. Chen, M. Wu, S. Zhu, X. Dong, F. Ge ら、「DFM:汎用的な大規模対話指向タスク学習のための対話基盤モデル」、arXivプレプリント arXiv:2205.12662、2022年。
対話に特化した基盤モデルやねん。いろんな種類の対話タスクをまとめて学習できるようにしたモデルで、「一つのモデルで何でもできるようにしよう」っていう発想やな。
[163] Y. Peng, K. C. Puvvada, Z. Chen, P. Zelasko, H. Huang, K. Dhawan, K. Hu, S. Watanabe, J. Balam, B. Ginsburg、「VoiceTextBlender:単一段階の音声テキスト統合教師あり微調整による大規模言語モデルへの音声機能追加」、arXivプレプリント arXiv:2410.17485、2024年。
テキストだけ扱えるLLMに、音声も扱えるようにする研究やねん。しかも一回の学習ステップで音声とテキスト両方を一気に覚えさせるっていう効率的な方法やで。
[164] S. Banerjee, A. Lavie、「METEOR:人間の判断との相関が改善された機械翻訳自動評価指標」、Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization、2005年、pp. 65-72。
機械翻訳の出来栄えを自動で点数つけるための指標やねん。人間が「この翻訳ええやん」って思うかどうかと、もっとよく一致するように作られた評価方法やで。
[165] T. Zhang, V. Kishore, F. Wu, K. Q. Weinberger, Y. Artzi、「BERTScore:BERTを使ったテキスト生成の評価」、2020年。https://arxiv.org/abs/1904.09675 で公開。
BERTっていうめっちゃ賢い言語モデルを使って、AIが生成した文章の品質を評価する方法やねん。単に単語が一致しとるかだけやなくて、意味的に近いかどうかも見てくれるのがええとこやで。
[166] J. Fu, S.-K. Ng, Z. Jiang, P. Liu、「GPTScore:お好みのままに評価」、Proceedings of NAACL 2024 (Long Papers)、2024年、arXivプレプリント arXiv:2302.04166。
GPTを使ってテキストの品質を評価するやつやな。「お好みのままに」ってタイトルがおもろいけど、つまり評価の基準を柔軟にカスタマイズできるっていう意味やねん。
[167] Y. Liu, D. Iter, Y. Xu, S. Wang, R. Xu, C. Zhu、「G-Eval:GPT-4を使った人間との整合性が向上したNLG評価」、Proceedings of EMNLP 2023、Association for Computational Linguistics、2023年、pp. 2511-2522。
GPT-4を使って自然言語生成(NLGって言うんやけど、AIがテキストを作ること)の品質を評価する方法やで。人間が「ええ文章やな」って思うかどうかと、めっちゃよく一致するように工夫されとるねん。
[168] S. A. G. Shakhadri, K. KR, K. B. Angadi、「Samba-ASR:構造化状態空間モデルを活用した最先端の音声認識」、arXivプレプリント arXiv:2501.02832、2025年。
状態空間モデルっていう比較的新しい数学的な仕組みを使って、めっちゃ精度の高い音声認識を実現したっていう研究やで。従来のTransformerとは違うアプローチで攻めとるのが特徴やな。
[169] Y. Hu, C. Chen, C.-H. H. Yang, R. Li, D. Zhang, Z. Chen, E. S. Chng、「GenTranslate:大規模言語モデルは生成的な多言語音声・機械翻訳機」、arXivプレプリント arXiv:2402.06894、2024年。
LLMが実は翻訳もめっちゃ上手にできるっていう研究やねん。音声翻訳も機械翻訳も、いろんな言語間でやれるっていうことを示しとるで。
[170] Y. Shou, W. Ai, J. Du, T. Meng, H. Liu, N. Yin、「会話中のマルチモーダル感情認識のための効率的な長距離潜在関係認識グラフニューラルネットワーク」、arXivプレプリント arXiv:2407.00119、2024年。
会話の中で相手がどんな感情かを、テキストとか音声とか映像とか複数の情報源から読み取るシステムやねん。しかも会話の離れた部分の関係性も考慮するっていう賢いやつやで。グラフニューラルネットワークっていうネットワーク構造を使っとるねん。
[171] B. Elizalde, S. Deshmukh, M. Al Ismail, H. Wang、「CLAP:自然言語の監視による音声概念学習」、ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)、IEEE、2023年、pp. 1-5。
テキストの説明と音声をペアにして学習させることで、「この音は犬の鳴き声やで」みたいに音声の意味を理解できるようにするシステムやねん。画像とテキストをペアにしたCLIPの音声版みたいなもんやな。
[172] Y. Li, J. Liu, T. Zhang, S. Chen, T. Li, Z. Li, L. Liu, L. Ming, G. Dong, D. Pan ら、「Baichuan-Omni-1.5 技術レポート」、arXivプレプリント arXiv:2501.15368、2025年。
Baichuanっていう中国の会社が作ったオムニモデル(テキストも音声も画像も全部扱えるやつ)のバージョン1.5の技術的な詳細レポートやで。
[173] Z. Xie, M. Lin, Z. Liu, P. Wu, S. Yan, C. Miao、「Audio-Reasoner:大規模音声言語モデルの推論能力を向上させる」、arXivプレプリント arXiv:2503.02318、2025年。
音声を聞いて、ただ内容を理解するだけやなくて、「なんでそうなるん?」っていう推論までできるように音声言語モデルの能力を強化する研究やねん。
[174] Z. Ma, Z. Chen, Y. Wang, E. S. Chng, X. Chen、「Audio-CoT:大規模音声言語モデルにおけるチェーン・オブ・ソート推論の探究」、arXivプレプリント arXiv:2501.07246、2025年。
チェーン・オブ・ソート(CoT)っていうのは、「段階的に考える」っていう手法やねん。それを音声モデルにも適用して、音声を聞いた後にステップバイステップで考えて答えを出すようにしたっていう研究やで。
[175] B. Zhang, H. Lv, P. Guo, Q. Shao, C. Yang, L. Xie, X. Xu, H. Bu, X. Chen, C. Zeng ら、「WenetSpeech:音声認識のための10000時間以上の多ドメイン中国語コーパス」、ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)、IEEE、2022年、pp. 6182-6186。
1万時間以上の中国語の音声データを集めたコーパスやで!ニュースとかドラマとかYouTubeとか、いろんなジャンルから集めとるから、音声認識の研究にめっちゃ使えるデータセットやねん。
[176] J. Li, J. Peng, Y. Fang, S. Wang, K. Yu、「MOSA:LLMベースの多言語ASRにおいて、シンプルなアダプタの混合が一体型アプローチを上回る」、2025年。https://arxiv.org/abs/2508.18998 で公開。
多言語の音声認識で、でっかいモデルを丸ごと一つ作るよりも、シンプルなアダプタ(小さな追加モジュール)をいくつか組み合わせた方が性能ええっていう発見やねん。なんでかっていうと、言語ごとに特化した小さなモジュールの方が効率的に学習できるからやで。
[177] N. F. Liu, A. Yu, D. Ju, A. Wong, D. Dohan, M. Bosma, J. Wei, A. M. Dai, Q. V. Le, S. Narang, K. Lee、「途中で迷子になる:言語モデルが長いコンテキストをどう使うか」、Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing、2023年、pp. 11899-11919。
めっちゃおもろい研究やで。長い文章をAIに読ませると、最初と最後の情報はよく覚えてるけど、真ん中辺りの情報は忘れがちやっていうことを発見したんやねん。まるで人間みたいやな。
[178] M. Sclar, Y. Choi, Y. Tsvetkov, A. Suhr、「言語モデルのプロンプト設計における見せかけの特徴への敏感さの定量化、あるいは:私はいかにしてプロンプトの書式を心配するようになったか」、The Twelfth International Conference on Learning Representations、2024年。https://openreview.net/forum?id=RIu5lyNXjT で公開。
タイトルがおもろいんやけど(映画のパロディやな)、要するにプロンプト(AIへの指示文)のちょっとした書き方の違い——スペースの入れ方とか改行の位置とか——でAIの答えがめっちゃ変わってしまうっていう問題を調べた研究やねん。ほんまに些細な違いで結果が変わるから気をつけなあかんで。
[179] C. Xu, Z. Zhang, Y. Tang, J. Li, J.-R. Wen、「IFEval-Audio:音声言語モデルの指示追従評価」
音声で指示を出して、AIがその指示にちゃんと従えるかどうかを評価するためのベンチマークやで。「3つ箇条書きにして」とか「100文字以内で答えて」みたいな指示を音声で出して、ちゃんと守れるか試すんやな。
---
## Page 31
[](/attach/042e1f605bca4d6f13f189f80f11e25db0d1092fe81b61406549f1784ff0fc4a_p031.png)
### 和訳
表X:指示プロンプトのバリエーション内容(指示に対する敏感さ評価用)やで。
ASR(音声認識)
S2TT(英語→中国語の音声翻訳)
SER(感情認識)
GR(性別認識)
31
| 指示のバリエーション | ASR | S2TT (en→zh) | SER | GR |
|---|---|---|---|---|
| デフォルト | 音声を認識して、書き起こしだけ出力してな: | 音声を中国語に翻訳して、翻訳文だけ出力してな: | 感情を認識して、一言で: Happy, Sad, Angry or Neutral: | 話してる人の性別を認識して、一言で: Male or Female: |
| 句読点変更 | 音声を認識して、書き起こしだけ出力してな. | 音声を中国語に翻訳して、翻訳文だけ出力してな. | 感情を認識して、一言で: Happy, Sad, Angry or Neutral. | 話してる人の性別を認識して、一言で: Male or Female. |
| 意味的(シンプル) | ASRやって、書き起こしだけ出力してな: | S2TTをzhにやって、翻訳文だけ出力してな: | SERやって、一言で: Happy, Sad, Angry or Neutral: | 性別認識やって、一言で: Male or Female: |
| 意味的(ニュートラル) | 音声を文字起こしして、書き起こしだけ出力してな: | 話されてる英語を中国語(マンダリン)に変換して、翻訳文だけ出力してな: | 音声の感情を特定して、一言で: Happy, Sad, Angry or Neutral: | 話してる人の性別を特定して、一言で: Male or Female: |
| 意味的(複雑) | 提供された録音の中で話されてるすべての単語を正確に書き起こして、書き起こしだけ出力してな: | 提供された英語の音声録音を流暢な中国語(マンダリン)に翻訳して、翻訳文だけ出力してな: | 提供された音声録音で伝わってくる感情の状態を正確に検出して、一言で: Happy, Sad, Angry or Neutral: | 提供された音声録音の話者の性別を正確に検出して、一言で: Male or Female: |
| 大文字小文字(小文字) | recognize the speech... (全部小文字バージョン) | translate the speech... (全部小文字バージョン) | recognize the emotion... (全部小文字バージョン) | recognize the speaker's gender... (全部小文字バージョン) |
| 大文字小文字(大文字) | RECOGNIZE THE SPEECH... (全部大文字バージョン) | TRANSLATE THE SPEECH... (全部大文字バージョン) | RECOGNIZE THE EMOTION... (全部大文字バージョン) | RECOGNIZE THE SPEAKER'S GENDER... (全部大文字バージョン) |
XI. 付録
A. 指示に対する敏感さ評価用の指示バリエーション
セクションVIII-Aの指示に対する敏感さ評価のためにな、各タスクごとに7種類の指示プロンプトのバリエーションを考えたんよ。デフォルトのプロンプト、句読点を変えたバージョン、意味の複雑さが3段階(シンプル、ニュートラル、複雑)、あと大文字小文字の変換が2種類(全部小文字と全部大文字)やねん。全バリエーションの中身は表Xに載せてるで。
B. チャレンジB:意味理解の劣化に使ったプロンプト
音声LLMとそのベースになってるテキストLLMを公平に比較するためにな、2ストリーム評価っちゅうセットアップを採用してん。要はどっちのモデルにも、それぞれの得意な形式(モダリティ)で同じ意味の入力を渡すっちゅうことやな。音声LLMには音声を入力して、ベースのテキストLLMにはそれに対応するASR(音声認識)の書き起こしか正解のテキストを渡すねん。タスクの指示は両方とも同じやつを使ってるで。
プロンプトのテンプレートはモデルによって違うもん使ってて、それぞれのモデルの公式に報告されてるプロンプト一覧に基づいてるんよ。
1) SALMONN(Vicunaベース):
• 音声入力でのASRタスク:
「音声を文字に書き起こしてください。」
a) 音声翻訳(ST):以下のタスクプロンプトを使ってるで:
• 音声入力での翻訳タスク:
「音声を聞いて中国語に翻訳してください。」
• 正解テキスト/ASRテキスト入力での翻訳タスク:
「テキストを中国語に翻訳してください。」
b) 音声言語理解(SLU):SLUにはな、MMSUベンチマークの公式プロンプトテンプレートを使ってるんよ:
「選択肢A、B、C、Dの中から、次の行の質問に最も適した答えを選んでな。
AかBかCかDだけ選んでくれ。余計な説明とか内容は書かんといてな。
質問: {question}
A. {choice_a}
B. {choice_b}
C. {choice_c}
D. {choice_d}」
評価の時はな、モデルの最終回答はアウトプットの中で最初に出てくる大文字(A、B、C、D)を見つけて抽出するっちゅうやり方やねん。
2) Qwen2.5-Omni(Qwen2.5-Instructベース):Qwen2.5-Omniとそのベースモデルの Qwen2.5-Instruct用に、公式にリリースされてるプロンプトテンプレート(システム入力付き)を採用してるで。モデルカードとデモに報告されてるやつやな。これらのプロンプトは、モダリティとタスクごとにカスタマイズされてるんよ。
• 音声入力でのASRタスク:
「音声を認識して、書き起こしだけ出力してな。他のことは聞かんといて。答えは<ASR_TRANS></ASR_TRANS>の間に書いてな。例:入力音声が"I'm Qwen."やったら、回答:<ASR_TRANS>I'm Qwen.</ASR_TRANS>\n ほな入力された音声を認識してな。」
a) 音声翻訳(ST):
• 音声入力での翻訳タスク:
「音声を直接中国語の書き起こしに翻訳して、翻訳だけ出力してな。他のことは聞かんといて。答えは<translate_to_cn>の間に書いてな。例:入力音声が"I'm Qwen"やったら、回答:<translate_to_cn>我是Qwen</translate_to_cn>.\n ほな入力された音声を認識してな。」
• 正解テキスト/ASRテキスト入力での翻訳タスク:
「テキストを直接中国語に翻訳して、翻訳だけ出力してな。」
---
## Page 32
[](/attach/042e1f605bca4d6f13f189f80f11e25db0d1092fe81b61406549f1784ff0fc4a_p032.png)
### 和訳
ほんで、SALMONN(サルモン)と一緒で、評価するときにはな、モデルが出した答えの中から最初に出てくる大文字のアルファベット(A、B、C、またはD)を見つけて、それを最終的な回答として抜き出すねん。
---
![]()
1 / 1
100%